Quanto
Try Quanto + transformers with this notebook!
🤗 Quanto library is a versatile pytorch quantization toolkit. The quantization method used is the linear quantization. Quanto provides several unique features such as:
- weights quantization (
float8,int8,int4,int2) - activation quantization (
float8,int8) - modality agnostic (e.g CV,LLM)
- device agnostic (e.g CUDA,MPS,CPU)
- compatibility with
torch.compile - easy to add custom kernel for specific device
- supports quantization aware training
Before you begin, make sure the following libraries are installed:
pip install quanto accelerate transformers
Now you can quantize a model by passing QuantoConfig object in the from_pretrained() method. This works for any model in any modality, as long as it contains torch.nn.Linear layers.
The integration with transformers only supports weights quantization. For the more complex use case such as activation quantization, calibration and quantization aware training, you should use quanto library instead.
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0", quantization_config=quantization_config)Note that serialization is not supported yet with transformers but it is coming soon! If you want to save the model, you can use quanto library instead.
Quanto library uses linear quantization algorithm for quantization. Even though this is a basic quantization technique, we get very good results! Have a look at the following benchmark (llama-2-7b on perplexity metric). You can find more benchmarks here
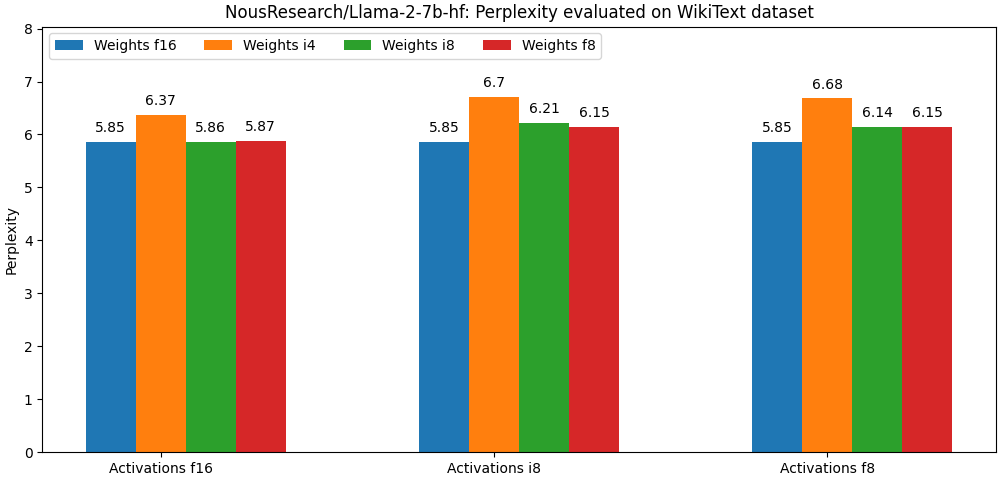
The library is versatile enough to be compatible with most PTQ optimization algorithms. The plan in the future is to integrate the most popular algorithms in the most seamless possible way (AWQ, Smoothquant).
< > Update on GitHub