

pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: stella-large-zh-v3-1792d
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 54.48093298255762
- type: cos_sim_spearman
value: 59.105354109068685
- type: euclidean_pearson
value: 57.761189988643444
- type: euclidean_spearman
value: 59.10537421115596
- type: manhattan_pearson
value: 56.94359297051431
- type: manhattan_spearman
value: 58.37611109821567
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 54.39711127600595
- type: cos_sim_spearman
value: 58.190191920824454
- type: euclidean_pearson
value: 61.80082379352729
- type: euclidean_spearman
value: 58.19018966860797
- type: manhattan_pearson
value: 60.927601060396206
- type: manhattan_spearman
value: 57.78832902694192
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.31600000000001
- type: f1
value: 44.45281663598873
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 69.12211326097868
- type: cos_sim_spearman
value: 71.0741302039443
- type: euclidean_pearson
value: 69.89070483887852
- type: euclidean_spearman
value: 71.07413020351787
- type: manhattan_pearson
value: 69.62345441260962
- type: manhattan_spearman
value: 70.8517591280618
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 41.937723608805314
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 40.34373057675427
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 88.98896401788376
- type: mrr
value: 90.97119047619047
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 89.59718540244556
- type: mrr
value: 91.41246031746032
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.954
- type: map_at_10
value: 40.144999999999996
- type: map_at_100
value: 42.083999999999996
- type: map_at_1000
value: 42.181000000000004
- type: map_at_3
value: 35.709
- type: map_at_5
value: 38.141000000000005
- type: mrr_at_1
value: 40.71
- type: mrr_at_10
value: 48.93
- type: mrr_at_100
value: 49.921
- type: mrr_at_1000
value: 49.958999999999996
- type: mrr_at_3
value: 46.32
- type: mrr_at_5
value: 47.769
- type: ndcg_at_1
value: 40.71
- type: ndcg_at_10
value: 46.869
- type: ndcg_at_100
value: 54.234
- type: ndcg_at_1000
value: 55.854000000000006
- type: ndcg_at_3
value: 41.339
- type: ndcg_at_5
value: 43.594
- type: precision_at_1
value: 40.71
- type: precision_at_10
value: 10.408000000000001
- type: precision_at_100
value: 1.635
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 23.348
- type: precision_at_5
value: 16.929
- type: recall_at_1
value: 26.954
- type: recall_at_10
value: 57.821999999999996
- type: recall_at_100
value: 88.08200000000001
- type: recall_at_1000
value: 98.83800000000001
- type: recall_at_3
value: 41.221999999999994
- type: recall_at_5
value: 48.241
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 83.6680697534576
- type: cos_sim_ap
value: 90.77401562455269
- type: cos_sim_f1
value: 84.68266427450101
- type: cos_sim_precision
value: 81.36177547942253
- type: cos_sim_recall
value: 88.28618190320317
- type: dot_accuracy
value: 83.6680697534576
- type: dot_ap
value: 90.76429465198817
- type: dot_f1
value: 84.68266427450101
- type: dot_precision
value: 81.36177547942253
- type: dot_recall
value: 88.28618190320317
- type: euclidean_accuracy
value: 83.6680697534576
- type: euclidean_ap
value: 90.77401909305344
- type: euclidean_f1
value: 84.68266427450101
- type: euclidean_precision
value: 81.36177547942253
- type: euclidean_recall
value: 88.28618190320317
- type: manhattan_accuracy
value: 83.40348767288035
- type: manhattan_ap
value: 90.57002020310819
- type: manhattan_f1
value: 84.51526032315978
- type: manhattan_precision
value: 81.25134843581445
- type: manhattan_recall
value: 88.05237315875614
- type: max_accuracy
value: 83.6680697534576
- type: max_ap
value: 90.77401909305344
- type: max_f1
value: 84.68266427450101
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 69.705
- type: map_at_10
value: 78.648
- type: map_at_100
value: 78.888
- type: map_at_1000
value: 78.89399999999999
- type: map_at_3
value: 77.151
- type: map_at_5
value: 77.98
- type: mrr_at_1
value: 69.863
- type: mrr_at_10
value: 78.62599999999999
- type: mrr_at_100
value: 78.861
- type: mrr_at_1000
value: 78.867
- type: mrr_at_3
value: 77.204
- type: mrr_at_5
value: 78.005
- type: ndcg_at_1
value: 69.968
- type: ndcg_at_10
value: 82.44399999999999
- type: ndcg_at_100
value: 83.499
- type: ndcg_at_1000
value: 83.647
- type: ndcg_at_3
value: 79.393
- type: ndcg_at_5
value: 80.855
- type: precision_at_1
value: 69.968
- type: precision_at_10
value: 9.515
- type: precision_at_100
value: 0.9990000000000001
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 28.802
- type: precision_at_5
value: 18.019
- type: recall_at_1
value: 69.705
- type: recall_at_10
value: 94.152
- type: recall_at_100
value: 98.84100000000001
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 85.774
- type: recall_at_5
value: 89.252
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.88
- type: map_at_10
value: 79.857
- type: map_at_100
value: 82.636
- type: map_at_1000
value: 82.672
- type: map_at_3
value: 55.184
- type: map_at_5
value: 70.009
- type: mrr_at_1
value: 89.64999999999999
- type: mrr_at_10
value: 92.967
- type: mrr_at_100
value: 93.039
- type: mrr_at_1000
value: 93.041
- type: mrr_at_3
value: 92.65
- type: mrr_at_5
value: 92.86
- type: ndcg_at_1
value: 89.64999999999999
- type: ndcg_at_10
value: 87.126
- type: ndcg_at_100
value: 89.898
- type: ndcg_at_1000
value: 90.253
- type: ndcg_at_3
value: 86.012
- type: ndcg_at_5
value: 85.124
- type: precision_at_1
value: 89.64999999999999
- type: precision_at_10
value: 41.735
- type: precision_at_100
value: 4.797
- type: precision_at_1000
value: 0.488
- type: precision_at_3
value: 77.267
- type: precision_at_5
value: 65.48
- type: recall_at_1
value: 25.88
- type: recall_at_10
value: 88.28399999999999
- type: recall_at_100
value: 97.407
- type: recall_at_1000
value: 99.29299999999999
- type: recall_at_3
value: 57.38799999999999
- type: recall_at_5
value: 74.736
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 53.2
- type: map_at_10
value: 63.556000000000004
- type: map_at_100
value: 64.033
- type: map_at_1000
value: 64.044
- type: map_at_3
value: 60.983
- type: map_at_5
value: 62.588
- type: mrr_at_1
value: 53.2
- type: mrr_at_10
value: 63.556000000000004
- type: mrr_at_100
value: 64.033
- type: mrr_at_1000
value: 64.044
- type: mrr_at_3
value: 60.983
- type: mrr_at_5
value: 62.588
- type: ndcg_at_1
value: 53.2
- type: ndcg_at_10
value: 68.61699999999999
- type: ndcg_at_100
value: 70.88499999999999
- type: ndcg_at_1000
value: 71.15899999999999
- type: ndcg_at_3
value: 63.434000000000005
- type: ndcg_at_5
value: 66.301
- type: precision_at_1
value: 53.2
- type: precision_at_10
value: 8.450000000000001
- type: precision_at_100
value: 0.95
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 23.5
- type: precision_at_5
value: 15.479999999999999
- type: recall_at_1
value: 53.2
- type: recall_at_10
value: 84.5
- type: recall_at_100
value: 95
- type: recall_at_1000
value: 97.1
- type: recall_at_3
value: 70.5
- type: recall_at_5
value: 77.4
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 50.63485956136976
- type: f1
value: 38.286307407751266
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.11632270168855
- type: ap
value: 54.43932599806482
- type: f1
value: 80.85485110996076
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 72.47315152994804
- type: cos_sim_spearman
value: 78.26531600908152
- type: euclidean_pearson
value: 77.8560788714531
- type: euclidean_spearman
value: 78.26531157334841
- type: manhattan_pearson
value: 77.70593783974188
- type: manhattan_spearman
value: 78.13880812439999
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 28.088177976572222
- type: mrr
value: 27.125
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 66.428
- type: map_at_10
value: 75.5
- type: map_at_100
value: 75.82600000000001
- type: map_at_1000
value: 75.837
- type: map_at_3
value: 73.74300000000001
- type: map_at_5
value: 74.87
- type: mrr_at_1
value: 68.754
- type: mrr_at_10
value: 76.145
- type: mrr_at_100
value: 76.432
- type: mrr_at_1000
value: 76.442
- type: mrr_at_3
value: 74.628
- type: mrr_at_5
value: 75.612
- type: ndcg_at_1
value: 68.754
- type: ndcg_at_10
value: 79.144
- type: ndcg_at_100
value: 80.60199999999999
- type: ndcg_at_1000
value: 80.886
- type: ndcg_at_3
value: 75.81599999999999
- type: ndcg_at_5
value: 77.729
- type: precision_at_1
value: 68.754
- type: precision_at_10
value: 9.544
- type: precision_at_100
value: 1.026
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 28.534
- type: precision_at_5
value: 18.138
- type: recall_at_1
value: 66.428
- type: recall_at_10
value: 89.716
- type: recall_at_100
value: 96.313
- type: recall_at_1000
value: 98.541
- type: recall_at_3
value: 80.923
- type: recall_at_5
value: 85.48
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.27841291190316
- type: f1
value: 70.65529957574735
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.30127774041695
- type: f1
value: 76.10358226518304
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 56.3
- type: map_at_10
value: 62.193
- type: map_at_100
value: 62.722
- type: map_at_1000
value: 62.765
- type: map_at_3
value: 60.633
- type: map_at_5
value: 61.617999999999995
- type: mrr_at_1
value: 56.3
- type: mrr_at_10
value: 62.193
- type: mrr_at_100
value: 62.722
- type: mrr_at_1000
value: 62.765
- type: mrr_at_3
value: 60.633
- type: mrr_at_5
value: 61.617999999999995
- type: ndcg_at_1
value: 56.3
- type: ndcg_at_10
value: 65.176
- type: ndcg_at_100
value: 67.989
- type: ndcg_at_1000
value: 69.219
- type: ndcg_at_3
value: 62.014
- type: ndcg_at_5
value: 63.766
- type: precision_at_1
value: 56.3
- type: precision_at_10
value: 7.46
- type: precision_at_100
value: 0.8829999999999999
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 22
- type: precision_at_5
value: 14.04
- type: recall_at_1
value: 56.3
- type: recall_at_10
value: 74.6
- type: recall_at_100
value: 88.3
- type: recall_at_1000
value: 98.1
- type: recall_at_3
value: 66
- type: recall_at_5
value: 70.19999999999999
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 76.44666666666666
- type: f1
value: 76.34548655475949
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 82.34975636166757
- type: cos_sim_ap
value: 85.44149338593267
- type: cos_sim_f1
value: 83.68654509610647
- type: cos_sim_precision
value: 78.46580406654344
- type: cos_sim_recall
value: 89.65153115100317
- type: dot_accuracy
value: 82.34975636166757
- type: dot_ap
value: 85.4415701376729
- type: dot_f1
value: 83.68654509610647
- type: dot_precision
value: 78.46580406654344
- type: dot_recall
value: 89.65153115100317
- type: euclidean_accuracy
value: 82.34975636166757
- type: euclidean_ap
value: 85.4415701376729
- type: euclidean_f1
value: 83.68654509610647
- type: euclidean_precision
value: 78.46580406654344
- type: euclidean_recall
value: 89.65153115100317
- type: manhattan_accuracy
value: 81.97076340010828
- type: manhattan_ap
value: 84.83614660756733
- type: manhattan_f1
value: 83.34167083541772
- type: manhattan_precision
value: 79.18250950570342
- type: manhattan_recall
value: 87.96198521647307
- type: max_accuracy
value: 82.34975636166757
- type: max_ap
value: 85.4415701376729
- type: max_f1
value: 83.68654509610647
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 93.24
- type: ap
value: 91.3586656455605
- type: f1
value: 93.22999314249503
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 39.05676042449009
- type: cos_sim_spearman
value: 44.996534098358545
- type: euclidean_pearson
value: 44.42418609172825
- type: euclidean_spearman
value: 44.995941361058996
- type: manhattan_pearson
value: 43.98118203238076
- type: manhattan_spearman
value: 44.51414152788784
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 36.694269474438045
- type: cos_sim_spearman
value: 38.686738967031616
- type: euclidean_pearson
value: 36.822540068407235
- type: euclidean_spearman
value: 38.68690745429757
- type: manhattan_pearson
value: 36.77180703308932
- type: manhattan_spearman
value: 38.45414914148094
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 65.81209017614124
- type: cos_sim_spearman
value: 66.5255285833172
- type: euclidean_pearson
value: 66.01848701752732
- type: euclidean_spearman
value: 66.5255285833172
- type: manhattan_pearson
value: 66.66433676370542
- type: manhattan_spearman
value: 67.07086311480214
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 80.60785761283502
- type: cos_sim_spearman
value: 82.80278693241074
- type: euclidean_pearson
value: 82.47573315938638
- type: euclidean_spearman
value: 82.80290808593806
- type: manhattan_pearson
value: 82.49682028989669
- type: manhattan_spearman
value: 82.84565039346022
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.37886004738723
- type: mrr
value: 76.08501655006394
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 28.102
- type: map_at_10
value: 78.071
- type: map_at_100
value: 81.71000000000001
- type: map_at_1000
value: 81.773
- type: map_at_3
value: 55.142
- type: map_at_5
value: 67.669
- type: mrr_at_1
value: 90.9
- type: mrr_at_10
value: 93.29499999999999
- type: mrr_at_100
value: 93.377
- type: mrr_at_1000
value: 93.379
- type: mrr_at_3
value: 92.901
- type: mrr_at_5
value: 93.152
- type: ndcg_at_1
value: 90.9
- type: ndcg_at_10
value: 85.564
- type: ndcg_at_100
value: 89.11200000000001
- type: ndcg_at_1000
value: 89.693
- type: ndcg_at_3
value: 87.024
- type: ndcg_at_5
value: 85.66
- type: precision_at_1
value: 90.9
- type: precision_at_10
value: 42.208
- type: precision_at_100
value: 5.027
- type: precision_at_1000
value: 0.517
- type: precision_at_3
value: 75.872
- type: precision_at_5
value: 63.566
- type: recall_at_1
value: 28.102
- type: recall_at_10
value: 84.44500000000001
- type: recall_at_100
value: 95.91300000000001
- type: recall_at_1000
value: 98.80799999999999
- type: recall_at_3
value: 56.772999999999996
- type: recall_at_5
value: 70.99499999999999
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 53.10599999999999
- type: f1
value: 51.40415523558322
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 69.6145576098232
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 63.7129548775017
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 60.199999999999996
- type: map_at_10
value: 69.724
- type: map_at_100
value: 70.185
- type: map_at_1000
value: 70.196
- type: map_at_3
value: 67.95
- type: map_at_5
value: 69.155
- type: mrr_at_1
value: 60.199999999999996
- type: mrr_at_10
value: 69.724
- type: mrr_at_100
value: 70.185
- type: mrr_at_1000
value: 70.196
- type: mrr_at_3
value: 67.95
- type: mrr_at_5
value: 69.155
- type: ndcg_at_1
value: 60.199999999999996
- type: ndcg_at_10
value: 73.888
- type: ndcg_at_100
value: 76.02799999999999
- type: ndcg_at_1000
value: 76.344
- type: ndcg_at_3
value: 70.384
- type: ndcg_at_5
value: 72.541
- type: precision_at_1
value: 60.199999999999996
- type: precision_at_10
value: 8.67
- type: precision_at_100
value: 0.9650000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 25.8
- type: precision_at_5
value: 16.520000000000003
- type: recall_at_1
value: 60.199999999999996
- type: recall_at_10
value: 86.7
- type: recall_at_100
value: 96.5
- type: recall_at_1000
value: 99
- type: recall_at_3
value: 77.4
- type: recall_at_5
value: 82.6
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 88.08
- type: ap
value: 72.66435456846166
- type: f1
value: 86.55995793551286
1 开源清单
本次开源2个通用向量编码模型和一个针对dialogue进行编码的向量模型,同时开源全量160万对话重写数据集和20万的难负例的检索数据集。
开源模型:
| ModelName | ModelSize | MaxTokens | EmbeddingDimensions | Language | Scenario | C-MTEB Score |
|---|---|---|---|---|---|---|
| infgrad/stella-base-zh-v3-1792d | 0.4GB | 512 | 1792 | zh-CN | 通用文本 | 67.96 |
| infgrad/stella-large-zh-v3-1792d | 1.3GB | 512 | 1792 | zh-CN | 通用文本 | 68.48 |
| infgrad/stella-dialogue-large-zh-v3-1792d | 1.3GB | 512 | 1792 | zh-CN | 对话文本 | 不适用 |
开源数据:
- 全量对话重写数据集 约160万
- 部分带有难负例的检索数据集 约20万
上述数据集均使用LLM构造,欢迎各位贡献数据集。
2 使用方法
2.1 通用编码模型使用方法
直接SentenceTransformer加载即可:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("infgrad/stella-base-zh-v3-1792d")
# model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
vectors = model.encode(["text1", "text2"])
2.2 dialogue编码模型使用方法
使用场景: 在一段对话中,需要根据用户语句去检索相关文本,但是对话中的用户语句存在大量的指代和省略,导致直接使用通用编码模型效果不好, 可以使用本项目的专门的dialogue编码模型进行编码
使用要点:
- 对dialogue进行编码时,dialogue中的每个utterance需要是如下格式:
"{ROLE}: {TEXT}",然后使用[SEP]join一下 - 整个对话都要送入模型进行编码,如果长度不够就删掉早期的对话,编码后的向量本质是对话中最后一句话的重写版本的向量!!
- 对话用stella-dialogue-large-zh-v3-1792d编码,被检索文本使用stella-large-zh-v3-1792d进行编码,所以本场景是需要2个编码模型的
如果对使用方法还有疑惑,请到下面章节阅读该模型是如何训练的。
使用示例:
from sentence_transformers import SentenceTransformer
dial_model = SentenceTransformer("infgrad/stella-dialogue-large-zh-v3-1792d")
general_model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
# dialogue = ["张三: 吃饭吗", "李四: 等会去"]
dialogue = ["A: 最近去打篮球了吗", "B: 没有"]
corpus = ["B没打篮球是因为受伤了。", "B没有打乒乓球"]
last_utterance_vector = dial_model.encode(["[SEP]".join(dialogue)], normalize_embeddings=True)
corpus_vectors = general_model.encode(corpus, normalize_embeddings=True)
# 计算相似度
sims = (last_utterance_vector * corpus_vectors).sum(axis=1)
print(sims)
3 通用编码模型训练技巧分享
hard negative
难负例挖掘也是个经典的trick了,几乎总能提升效果
dropout-1d
dropout已经是深度学习的标配,我们可以稍微改造下使其更适合句向量的训练。 我们在训练时会尝试让每一个token-embedding都可以表征整个句子,而在推理时使用mean_pooling从而达到类似模型融合的效果。 具体操作是在mean_pooling时加入dropout_1d,torch代码如下:
vector_dropout = nn.Dropout1d(0.3) # 算力有限,试了0.3和0.5 两个参数,其中0.3更优
last_hidden_state = bert_model(...)[0]
last_hidden = last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
last_hidden = vector_dropout(last_hidden)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
4 dialogue编码模型细节
4.1 为什么需要一个dialogue编码模型?
参见本人历史文章:https://www.zhihu.com/pin/1674913544847077376
4.2 训练数据
单条数据示例:
{
"dialogue": [
"A: 最近去打篮球了吗",
"B: 没有"
],
"last_utterance_rewrite": "B: 我最近没有去打篮球"
}
4.3 训练Loss
loss = cosine_loss( dial_model.encode(dialogue), existing_model.encode(last_utterance_rewrite) )
dial_model就是要被训练的模型,本人是以stella-large-zh-v3-1792d作为base-model进行继续训练的
existing_model就是现有训练好的通用编码模型,本人使用的是stella-large-zh-v3-1792d
已开源dialogue-embedding的全量训练数据,理论上可以复现本模型效果。
Loss下降情况:
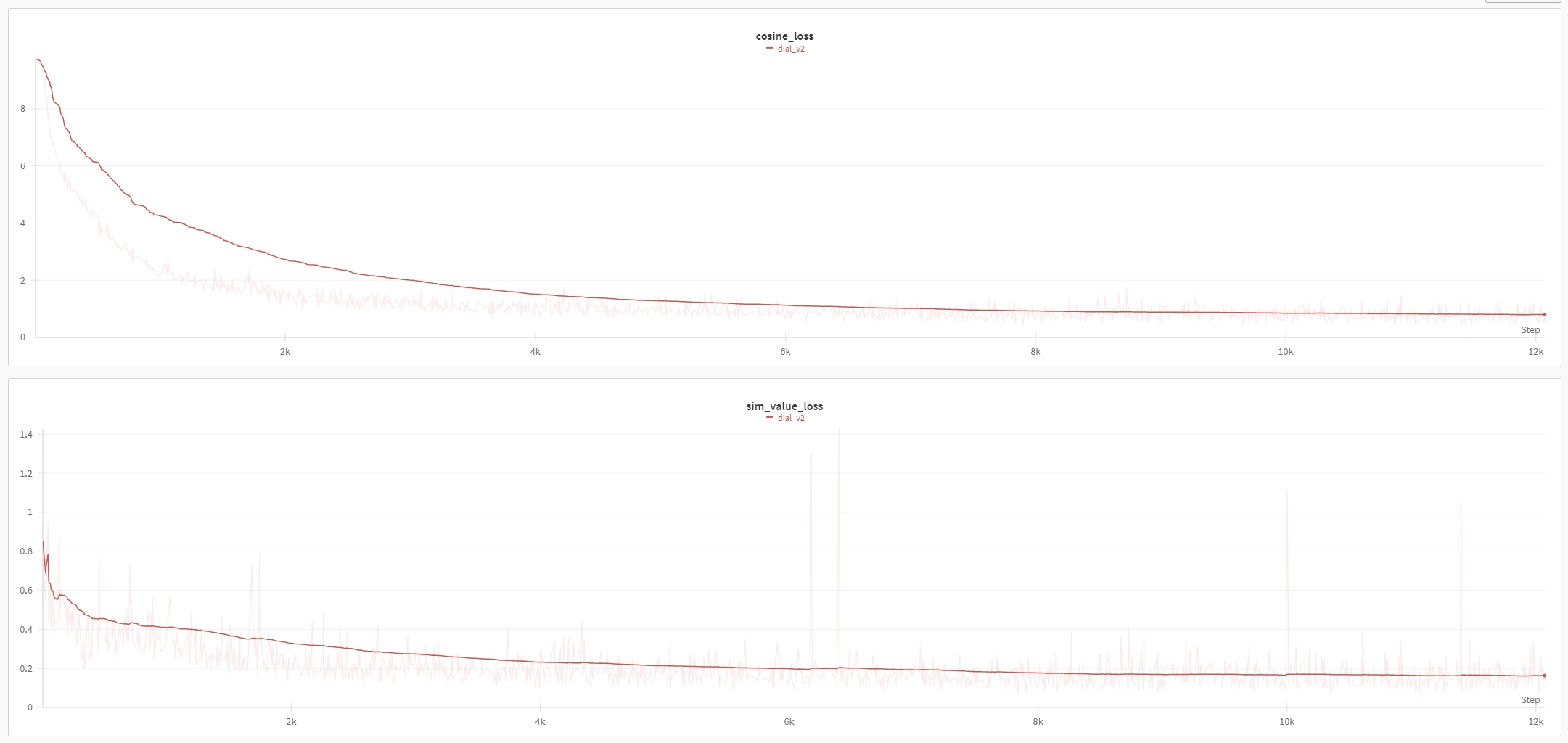
4.4 效果
目前还没有专门测试集,本人简单测试了下是有效果的,部分测试结果见文件dial_retrieval_test.xlsx。
5 后续TODO
- 更多的dial-rewrite数据
- 不同EmbeddingDimensions的编码模型
6 FAQ
Q: 为什么向量维度是1792?
A: 最初考虑发布768、1024,768+768,1024+1024,1024+768维度,但是时间有限,先做了1792就只发布1792维度的模型。理论上维度越高效果越好。
Q: 如何复现CMTEB效果?
A: SentenceTransformer加载后直接用官方评测脚本就行,注意对于Classification任务向量需要先normalize一下
Q: 复现的CMTEB效果和本文不一致?
A: 聚类不一致正常,官方评测代码没有设定seed,其他不一致建议检查代码或联系本人。
Q: 如何选择向量模型?
A: 没有免费的午餐,在自己测试集上试试,本人推荐bge、e5和stella.
Q: 长度为什么只有512,能否更长?
A: 可以但没必要,长了效果普遍不好,这是当前训练方法和数据导致的,几乎无解,建议长文本还是走分块。
Q: 训练资源和算力?
A: 亿级别的数据,单卡A100要一个月起步