
license: mit
pipeline_tag: any-to-any
library_name: mini-omni2
Mini-Omni2
🤗 Hugging Face | 📖 Github | 📑 Technical report
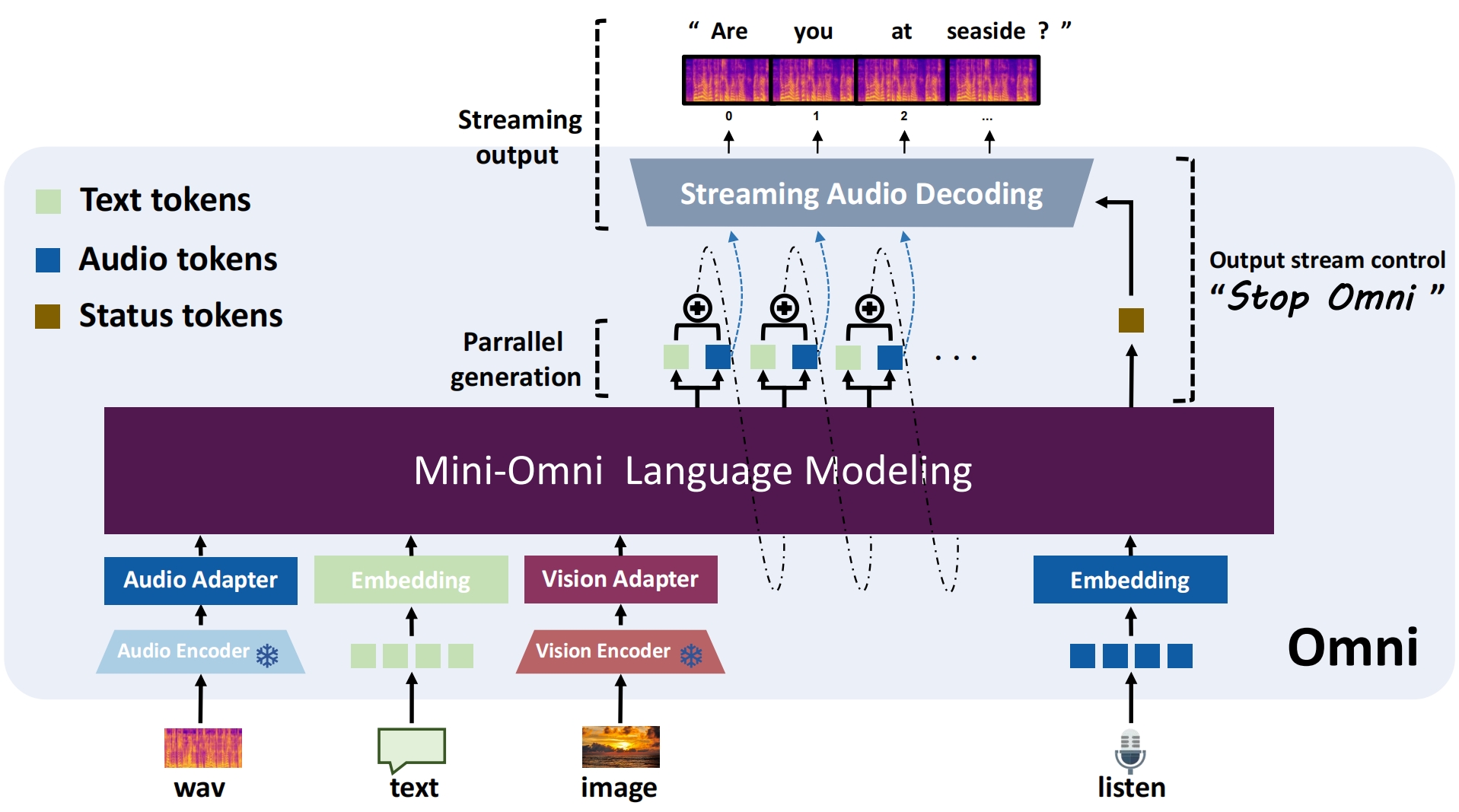
Mini-Omni2 is an omni-interactive model. It can understand image, audio and text inputs and has end-to-end voice conversations with users. Featuring real-time voice output, omni-capable multimodal understanding and flexible interaction ability with interruption mechanism while speaking.
Updates
- 2024.10: Release the model, technical report, inference and chat demo code.
Features
✅ Multimodal interaction: with the ability to understand images, speech and text, just like GPT-4o.
✅ Real-time speech-to-speech conversational capabilities. No extra ASR or TTS models required, just like Mini-Omni.
Demo
NOTE: need to unmute first.
https://github.com/user-attachments/assets/ad97ca7f-f8b4-40c3-a7e8-fa54b4edf155
ToDo
- update interruption mechanism
Install
Create a new conda environment and install the required packages:
conda create -n omni python=3.10
conda activate omni
git clone https://github.com/gpt-omni/mini-omni2.git
cd mini-omni2
pip install -r requirements.txt
Quick start
Interactive demo
- start server
NOTE: you need to start the server before running the streamlit or gradio demo with API_URL set to the server address.
sudo apt-get install ffmpeg
conda activate omni
cd mini-omni2
python3 server.py --ip '0.0.0.0' --port 60808
- run streamlit demo
NOTE: you need to run streamlit locally with PyAudio installed.
pip install PyAudio==0.2.14
API_URL=http://0.0.0.0:60808/chat streamlit run webui/omni_streamlit.py
Local test
conda activate omni
cd mini-omni2
# test run the preset audio samples and questions
python inference_vision.py
Mini-Omni2 Overview
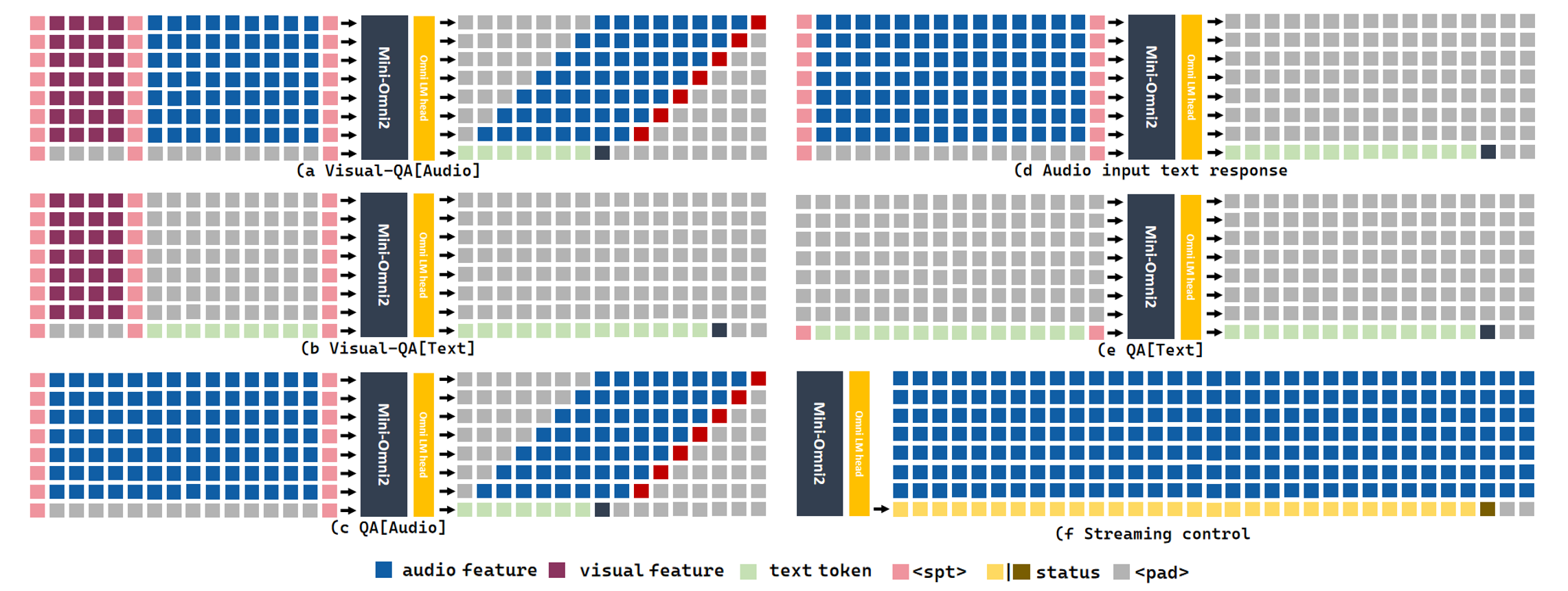
1. Multimodal Modeling: We use multiple sequences as the input and output of the model. In the input part, we will concatenate image, audio and text features to perform a series of comprehensive tasks, as shown in the following figures. In the output part, we use text-guided delayed parallel output to generate real-time speech responses.
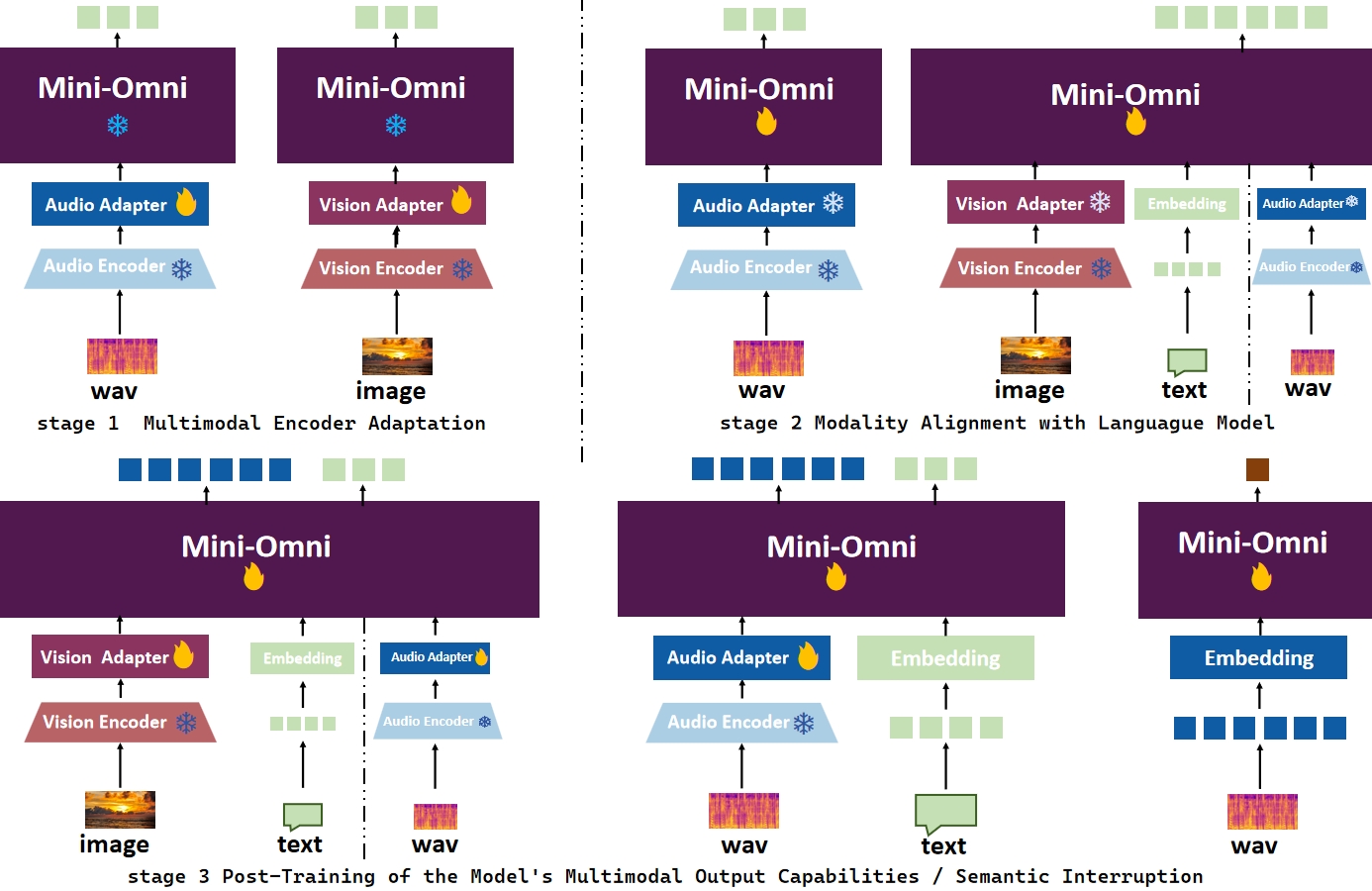
2. Multi-stage Training: We propose an efficient alignment training method and conduct encoder adaptation, modal alignment, and multimodal fine-tuning respectively in the three-stage training.
FAQ
1. Does the model support other languages?
No, the model is only trained on English. However, as we use whisper as the audio encoder, the model can understand other languages which is supported by whisper (like chinese), but the output is only in English.
2. Error: can not run streamlit in local browser, with remote streamlit server
You need start streamlit locally with PyAudio installed.