
AudioMAE
This model card provides an easy-to-use API for a pretrained encoder of AudioMAE [1] whose weights are from its original reposotiry. The provided model is specifically designed to easily obtain learned representations given an input audio file. The resulting representation $z$ has a dimension of $(d, h, w)$ for a single audio file, where $d$, $h$, and $w$ denote a latent dimension size, latent frequency dim, and latent temporal dim, respectively. [2] indicates that both frequency and temporal dimensional semantics are preserved in $z$.
Dependency
See requirements.txt
Usage
from transformers import AutoModel
device = 'cpu' # 'cpu' or 'cuda'
model = AutoModel.from_pretrained("hance-ai/audiomae", trust_remote_code=True).to(device) # load the pretrained model
z = model('path/audio_fname.wav') # (768, 8, 64) = (latent_dim_size, latent_freq_dim, latent_temporal_dim)
Depending on a task, a different pooling strategy should be facilitated. For instance, a global average pooling can be used for a classification task. [2] uses an adaptive pooling.
⚠️ AudioMAE accepts audio with maximum length of 10s (as described in [1]). Any audio longer than 10s will be clipped to 10s, meaning the excess beyond 10s will be discarded.
Sanity Check Result
In the following, a spectrogram of an input audio and corresponding $z$ are visualized. The input audio is 10s, containing baby coughing, hiccuping, and adult sneezing. The latent dimension size of $z$ is reduced to 8 using PCA for visualization.
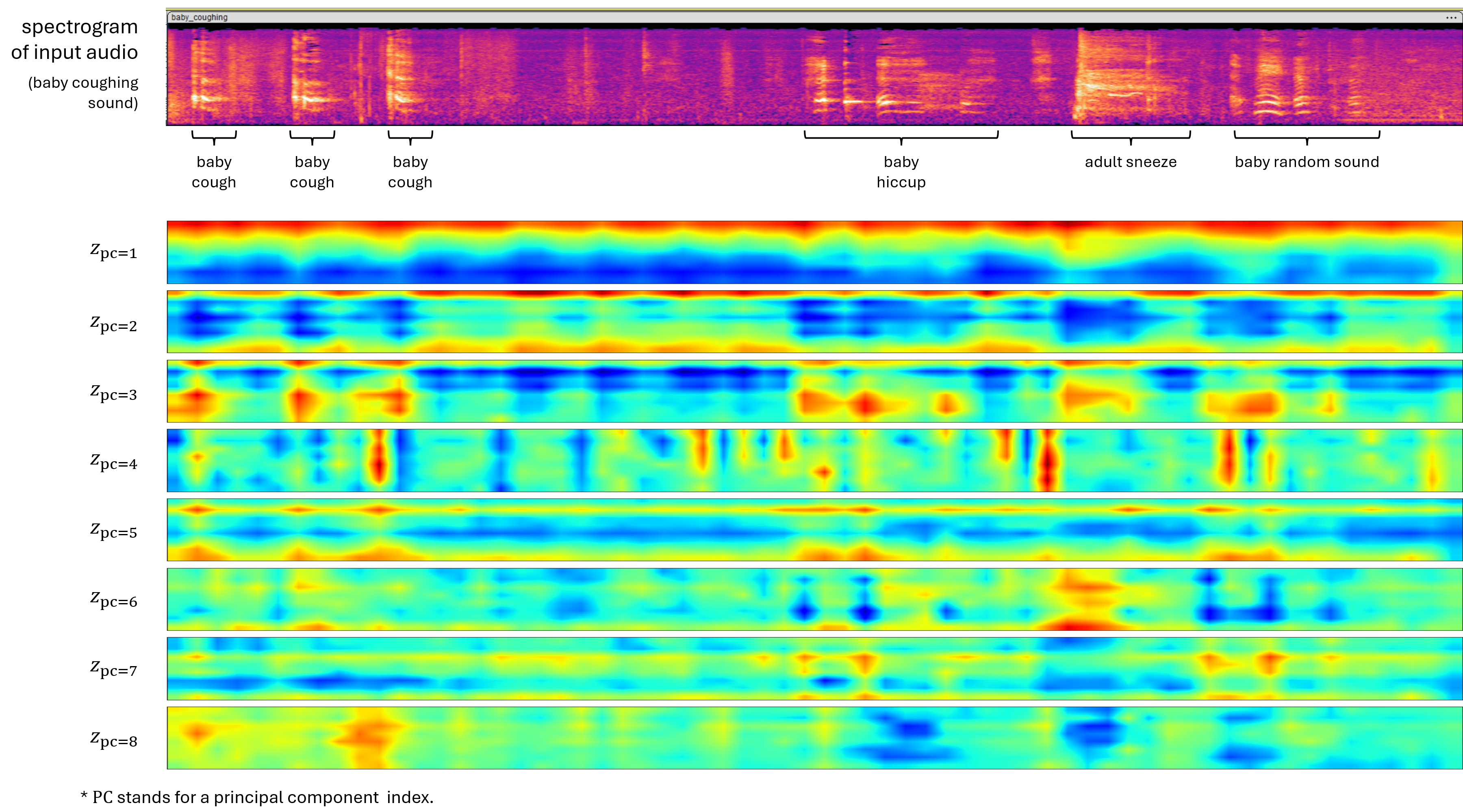
The result shows that the presence of labeled sound is clearly captured in the 3rd principal component (PC). While the baby coughing and hiccuping sounds are not so distinugisable up to the 5th PC, they are in the 6th PC. This result briefly shows the effectiveness of the pretrained AudioMAE.
References
[1] Huang, Po-Yao, et al. "Masked autoencoders that listen." Advances in Neural Information Processing Systems 35 (2022): 28708-28720.
[2] Liu, Haohe, et al. "Audioldm 2: Learning holistic audio generation with self-supervised pretraining." IEEE/ACM Transactions on Audio, Speech, and Language Processing (2024).
- Downloads last month
- 285