
Real-time Speech Summarization for Medical Conversations
Please cite this paper: https://arxiv.org/abs/2406.15888
@article{VietMed_Sum,
title={Real-time Speech Summarization for Medical Conversations},
author={Le-Duc, Khai and Nguyen, Khai-Nguyen and Vo-Dang, Long and Hy, Truong-Son},
journal={arXiv preprint arXiv:2406.15888},
booktitle={Interspeech 2024},
url = {https://arxiv.org/abs/2406.15888},
year={2024}
}
Model Card for Model ID
Model Details
Model Description
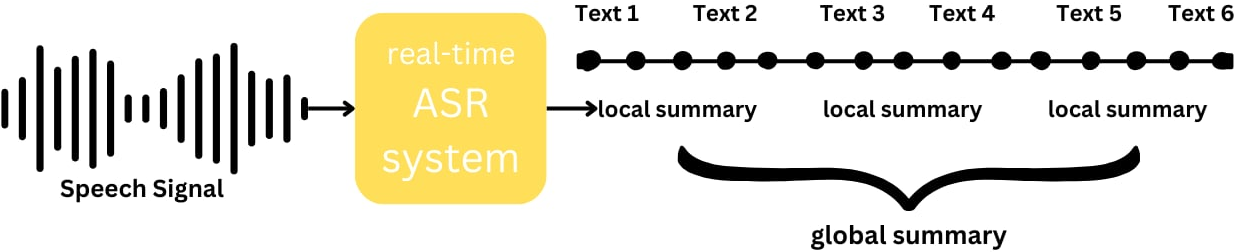
This model summarizes medical dialogues in Vietnamese. It can work in tandem with an ASR system to provide real-time dialogue summary.
- Developed by: Khai-Nguyen Nguyen
- Language(s) (NLP): Vietnamese
- Finetuned from model [optional]: ViT5
How to Get Started with the Model
Install the pre-requisite packages in Python.
pip install transformers
Use the code below to get started with the model.
from transformers import pipeline
# Initialize the pipeline with the ViT5 model, specify the device to use CUDA for GPU acceleration
pipe = pipeline("text2text-generation", model="monishsystem/medisum_vit5", device='cuda')
# Example text in Vietnamese describing a traditional medicine product
example = "Loại thuốc này chứa các thành phần đông y đặc biệt tốt cho sức khoẻ, giúp tăng cường sinh lý và bổ thận tráng dương, đặc biệt tốt cho người cao tuổi và người có bệnh lý nền"
# Generate a summary for the input text with a maximum length of 50 tokens
summary = pipe(example, max_new_tokens=50)
# Print the generated summary
print(summary)
- Downloads last month
- 21
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.