

license: mit
language:
- en
metrics:
- accuracy
pipeline_tag: text-generation
🎼 ChatMusician: Understanding and Generating Music Intrinsically with LLM
🌐 DemoPage | 🤗 Dataset | 🤗 Benchmark | 📖 arXiv | 💻 Code | 🤖 Model
🔔News
- 🔥[2024-2-28]: The release of ChatMusician's demo, code, model, data, and benchmark. 😆
- [2023-11-30]: Checkout another awesome project MMMU that includes multimodal music reasoning.
Introduction
While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity’s creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities.
It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. Code, data, model, and benchmark are open-sourced.
Usage
You can use the models through Huggingface's Transformers library. Check our Github repo for more advanced use: https://github.com/hf-lin/ChatMusician
CLI demo
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
from string import Template
prompt_template = Template("Human: ${inst} </s> Assistant: ")
tokenizer = AutoTokenizer.from_pretrained("m-a-p/ChatMusician-v1-sft-78k", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("m-a-p/ChatMusician-v1-sft-78k", trust_remote_code=True).eval()
model.cuda()
generation_config = GenerationConfig(
temperature=0.2,
top_k=40,
top_p=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.1,
min_new_tokens=10,
max_new_tokens=1536
)
instruction = """Using ABC notation, recreate the given text as a musical score.
Meter C
Notes The parts are commonly interchanged.
Transcription 1997 by John Chambers
Key D
Note Length 1/8
Rhythm reel
"""
prompt = prompt_template.safe_substitute({"inst": instruction})
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
response = model.generate(
input_ids=inputs["input_ids"].to(model.device),
attention_mask=inputs['attention_mask'].to(model.device),
eos_token_id=tokenizer.eos_token_id,
generation_config=generation_config,
)
response = tokenizer.decode(response[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(response)
Limitations
- For the music tasks, the model currently only supports strict format and close-ended instructions.
- The model suffers from hallucinations, and shouldn't be used for music education.
- A large proportion of the training data is in the style of Irish music.
- The MusicThoeryBench results reported in the paper are obtained with perplexity mode.
Example Prompts
Our model produces symbolic music(ABC notation) well in the following prompts. Here are some musical tasks.
Function: Text2music
Using ABC notation, recreate the given text as a musical score.
Meter C
Notes The parts are commonly interchanged.
Transcription 1997 by John Chambers
Key D
Note Length 1/8
Rhythm reel
Develop a tune influenced by Bach's compositions.
Function: Melody Harmonization
Construct smooth-flowing chord progressions for the supplied music.
|: BA | G2 g2"^(C)" edeg | B2 BA"^(D7)" BcBA | G2 g2 edeg | dBAG A2 BA |
G2 g2"^(C)" edeg | B2 BA B2 d2 | e2 ef e2 (3def | gedB A2 :: BA | G2 BG dGBe |
dBBA"^(D7)" B3 A | G2 BG dGBe | dBAG A4 | G2 BG dGBe | dBBA B3 d |
e2 ef e2 (3def | gedB A2 :|
Develop a series of chord pairings that amplify the harmonious elements in the given music piece.
E |: EAA ABc | Bee e2 d | cBA ABc | BEE E2 D | EAA ABc | Bee e2 d |
cBA ^GAB |1 A2 A A2 E :|2 A2 A GAB || c3 cdc | Bgg g2 ^g | aed cBA |
^GAB E^F^G | A^GA BAB | cde fed | cBA ^GAB |1 A2 A GAB :|2 \n A3 A2 ||
Function: Chord Conditioned Music Generation
Develop a musical piece using the given chord progression. 'Dm', 'C', 'Dm', 'Dm', 'C', 'Dm', 'C', 'Dm'
Function: Musical Form Conditioned Music Generation
Develop a composition by incorporating elements from the given melodic structure.
Ternary, Sectional: Verse/Chorus/Bridge
Function: Motif and Form Conditioned Music Generation
Create music by incorporating the assigned motif into the predetermined musical arrangement.
Musical Form Input: Only One Section
ABC Notation Music Input:
X:1
L:1/8
M:9/8
K:Emin
vB2 E E2 F G2 A
Function: Music Understanding
Investigate the aspects of this musical work and convey its structural organization using suitable musical words.
X:1
L:1/8
M:2/2
K:G
G2 dG BGdG | G2 dc BAGB | A2 eA cAeA | A2 ed cAFA |
G2 dG BGdG | G2 dc BAGB | ABcd efge |1 aged cAFA :|2
aged ^cdef |: g3 f g2 ef | gedc BA G2 | eaag agea |
aged ^cdef | g3 f g2 ef |gedc BAGB | ABcd efge |1
aged ^cdef :|2 aged cAFA |:"^variations:" G2 BG dGBA |
G2 dG BAGB | A2 cA eAcA | A2 ed cAFA | G2 BG dGBA |
G2 dc BAGB | ABcd efge |1 aged cAFA :|2 aged ^cdef |:
g2 af g2 ef | gedc BAGB | Aaag ageg | aged ^cdef |
gbaf g2 ef | gedc BAGB | ABcd efge |1
aged ^cdef :|2 aged cAFA ||
Analyze the musical work and pinpoint the consistent melodic element in every section.
X:1
L:1/8
M:4/4
K:G
ge | d2 G2 cBAG | d2 G2 cBAG | e2 A2 ABcd | edcB A2 Bc |
d2 cB g2 fe | edcB cBAG | BAGE DEGA | B2 G2 G2 :: ga |
b2 gb a2 fa | g2 eg edcB | e2 A2 ABcd | edcB A2 ga |
b2 gb a2 fa | g2 eg edcB | cBAG DEGA | B2 G2 G2 :|
Training Data
ChatMusician is pretrained on the 🤗 MusicPile, which is the first pretraining corpus for developing musical abilities in large language models. Check out the dataset card for more details. And supervised finetuned on 1.1M samples(2:1 ratio between music scores and music knowledge & music summary data) from MusicPile. Check our paper for more details.
Training Procedure
We initialized a fp16-precision ChatMusician-Base from the LLaMA2-7B-Base weights, and applied a continual pre-training plus fine-tuning pipeline. LoRA adapters were integrated into the attention and MLP layers, with additional training on embeddings and all linear layers. The maximum sequence length was 2048. We utilized 16 80GB-A800 GPUs for one epoch pre-training and 8 32GB-V100 GPUs for two epoch fine-tuning. DeepSpeed was employed for memory efficiency, and the AdamW optimizer was used with a 1e-4 learning rate and a 5% warmup cosine scheduler. Gradient clipping was set at 1.0. The LoRA parameters dimension, alpha, and dropout were set to 64, 16, and 0.1, with a batch size of 8.
Evaluation
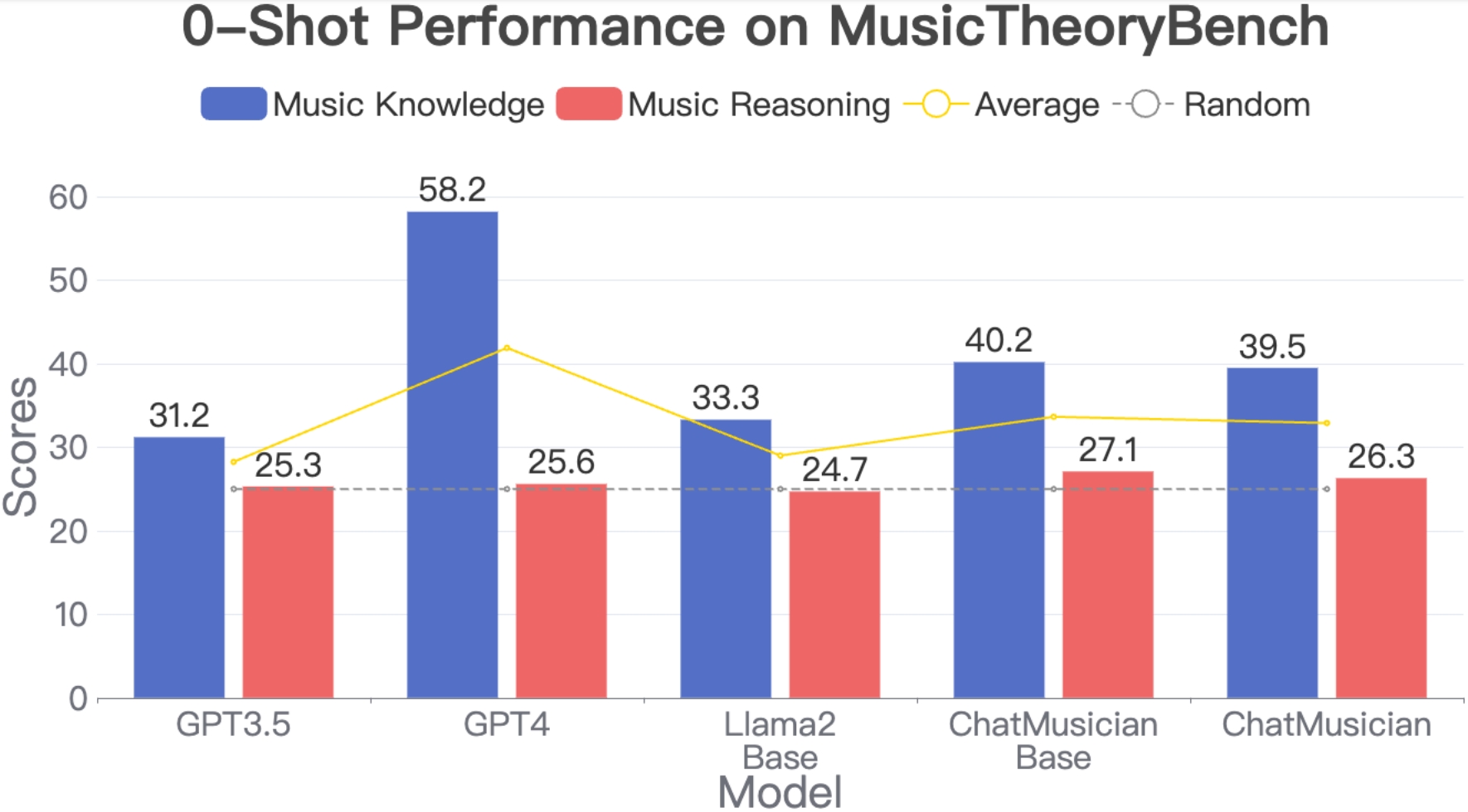
- Music understanding abilities are evaluated on the MusicTheoryBench. The following figure is zero-shot accuracy on MusicTheoryBench.
We included GPT-3.5, GPT-4, LLaMA2-7B-Base, ChatMusician-Base, and ChatMusician. The blue bar represents the performance on the music knowledge metric, and the red bar represents the music reasoning metric. The dashed line corresponds to a random baseline, with a score of 25%.
- General language abilities of ChatMusician are evaluated on the Massive Multitask Language Understanding (MMLU) dataset.

Citation
If you find our work helpful, feel free to give us a cite.
@misc{yuan2024chatmusician,
title={ChatMusician: Understanding and Generating Music Intrinsically with LLM},
author={Ruibin Yuan and Hanfeng Lin and Yi Wang and Zeyue Tian and Shangda Wu and Tianhao Shen and Ge Zhang and Yuhang Wu and Cong Liu and Ziya Zhou and Ziyang Ma and Liumeng Xue and Ziyu Wang and Qin Liu and Tianyu Zheng and Yizhi Li and Yinghao Ma and Yiming Liang and Xiaowei Chi and Ruibo Liu and Zili Wang and Pengfei Li and Jingcheng Wu and Chenghua Lin and Qifeng Liu and Tao Jiang and Wenhao Huang and Wenhu Chen and Emmanouil Benetos and Jie Fu and Gus Xia and Roger Dannenberg and Wei Xue and Shiyin Kang and Yike Guo},
year={2024},
eprint={2402.16153},
archivePrefix={arXiv},
primaryClass={cs.SD}
}