|
--- |
|
license: apache-2.0 |
|
language: |
|
- en |
|
- ja |
|
datasets: |
|
- augmxnt/shisa-pretrain-en-ja-v1 |
|
- allenai/MADLAD-400 |
|
base_model: augmxnt/shisa-base-7b-v1 |
|
--- |
|
This is an ExLlamaV2 quantized model in 4bpw of [augmxnt/shisa-base-7b-v1](https://huggingface.co/augmxnt/shisa-base-7b-v1) using the default calibration dataset. |
|
|
|
# Original Model card: |
|
|
|
# shisa-base-7b-v1 |
|
|
|
`shisa-base-7b-v1` takes [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) and adds an additional 8B tokens of primarily Japanese pre-training. Japanese tokens were sourced from [MADLAD-400](https://huggingface.co/datasets/allenai/MADLAD-400), using [DSIR](https://github.com/p-lambda/dsir), along with 10% English tokens sampled from a mix of MADLAD-400 EN and various open datasources added in to prevent catastrophic forgetting. |
|
|
|
We have extended the Mistral tokenizer to 120k tokens to improve Japanese efficiency. Our tokenizer achieves ~2.3 characters per token in JA, versus the base Mistral 7B tokenizer which is <1 character per token. Code for our implementation is available in our [Shisa repo](https://github.com/AUGMXNT/shisa). |
|
|
|
This base model was created for use with [Shisa 7B](https://huggingface.co/augmxnt/shisa-7b-v1), our JA/EN fine-tuned model, but we provide it for the community as we believe the combination of strong performance and efficient bilingual tokenizer could be useful. |
|
|
|
Training took 2,400 A100-40 GPU hours on a single 16 x A100-40 machine with [DeepSpeed](https://github.com/microsoft/DeepSpeed) ZeRO-3. ([WandB logs](https://wandb.ai/jondurbin/mistral-7b-ja-v0.2/runs/rj0lq5v3/overview)) |
|
|
|
## Performance |
|
This base model was able to attain class-leading Japanese performance in standardized benchmarks with significantly less additional pre-training than previously released models. We speculate this may be due to the use of a better-curated pre-training dataset, but ablations at even 2.5B additional JA tokens still showed very strong Japanese performance. |
|
|
|
We used a slightly modified [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) (our base model requires a `bos_token` to be prepended to the prompt; we tested other models with and without the modification and took the higher results for all models tested). Here we validate versus the original Mistral 7B base model as well as [Japanese Stable LM Instruct Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-gamma-7b), which is a Mistral 7B base with an additional 100B tokens of JA/EN pre-training. We also include [Japanese-StableLM-Base-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b), which is a Llama 2 70B that also has an additional 100B tokens of JA/EN pre-training as a reference: |
|
|
|
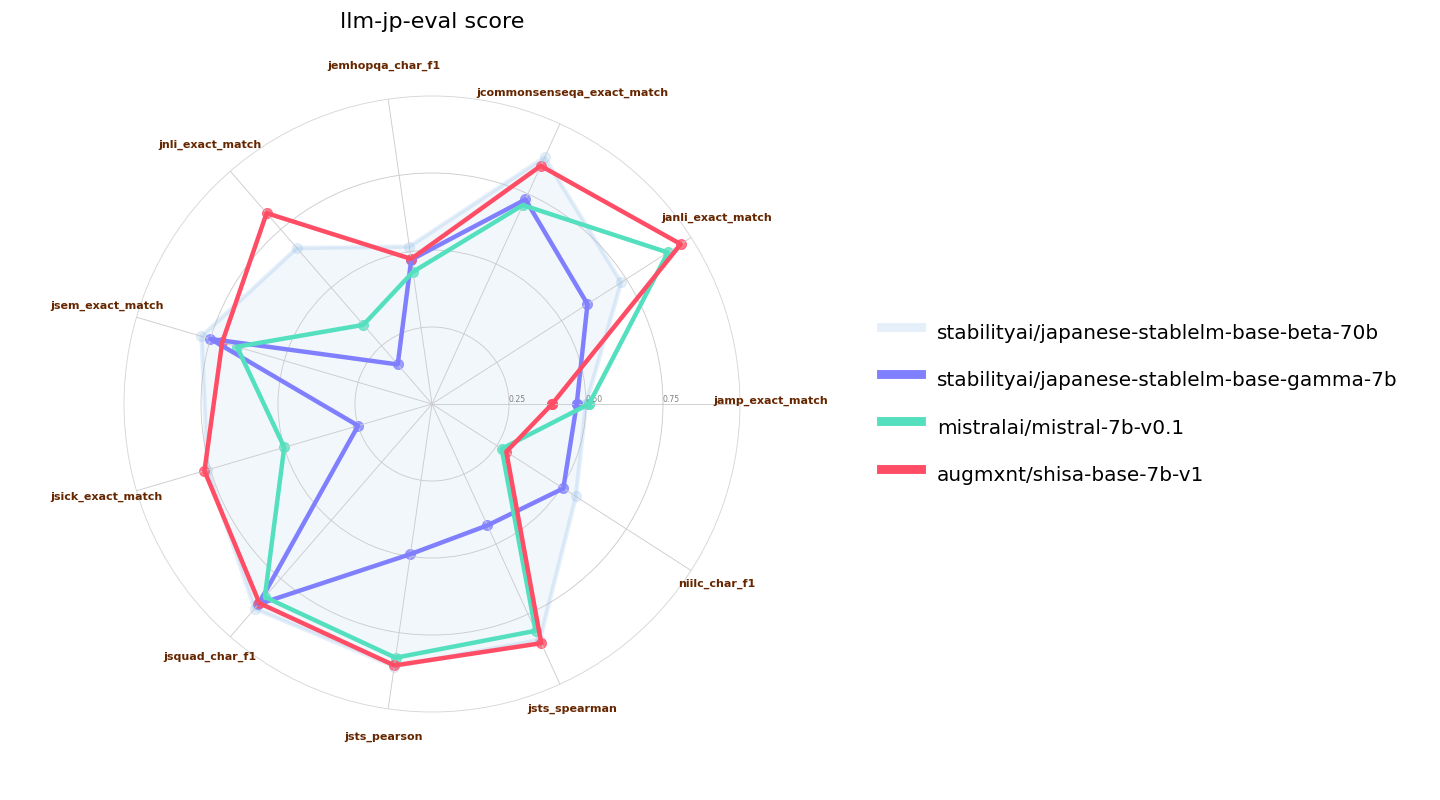 |
|
|
|
Here we also compare `shisa-base-7b-v1` to other recently-released similar classed (7B parameter) Japanese-tuned models. [ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast) and [Youri 7B](https://huggingface.co/rinna/youri-7b) are Llama 2 7B models with 18B and 40B of additional pre-training respectively, and [CALM2-7B](https://huggingface.co/cyberagent/calm2-7b) and [llm-jp-13b]() are pretrained models with 1.3T and 300B JA/EN tokens of pre-training: |
|
|
|
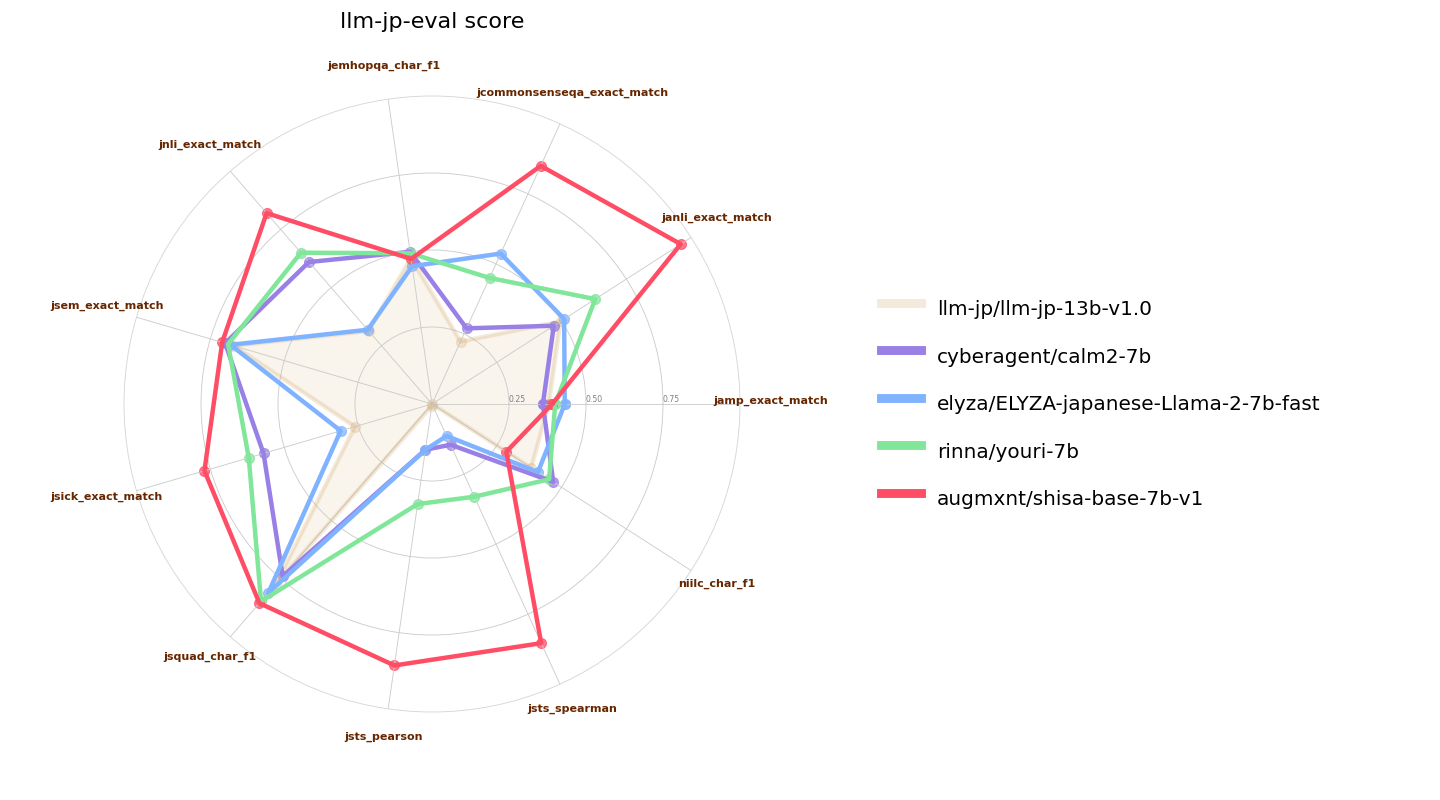 |
|
|
|
## Tokenizer |
|
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 120128 for better performance. The remaining unused tokens are assigned as zero-weighted `<|extra_{idx}|>` tokens. |
|
|
|
We use the "Fast" tokenizer, which should be the default for `AutoTokenizer`, but if you have problems, make sure to check `tokenizer.is_fast` or to initialize with `use_fast=True`. |
|
|
|
Japanese efficiency from sampling 50K items (~85M characters) from the JA subset of the [CulturaX](https://huggingface.co/datasets/uonlp/CulturaX) dataset: |
|
|
|
| LLM | Tokenizer | Vocab Size | Avg Char/Token | |
|
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:| |
|
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *2.31* | |
|
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 | |
|
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 | |
|
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 | |
|
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 1.88 | |
|
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 1.85 | |
|
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 1.83 | |
|
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 1.79 | |
|
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 1.65 | |
|
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 1.53 | |
|
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 1.48 | |
|
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 1.00 | |
|
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 0.95 | |
|
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 0.88 | |
|
|
|
We also test English efficiency using a sampling of 50K items (~177M characters) from the EN subset of the [CulturaX](https://huggingface.co/datasets/uonlp/CulturaX) dataset as a sanity check (and to see how other tokenizers fare): |
|
|
|
| LLM | Tokenizer | Vocab Size | Avg Char/Token | |
|
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:| |
|
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 | |
|
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 | |
|
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 | |
|
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *4.12* | |
|
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 | |
|
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 | |
|
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 | |
|
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 3.86 | |
|
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 3.86 | |
|
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 3.79 | |
|
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.83 | |
|
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.49 | |
|
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 2.42 | |
|
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 2.42 | |
|
|
|
With our extended tokenizer, we are able to achieve class-leading JA token efficiency without any losses in EN performance vs the base tokenizer. This bears out in our testing, and we often see >2X JA inference speedups with our tokenizer. |
|
|
|
## Acknowledgements |
|
Team: [Jon Durbin](https://huggingface.co/jondurbin), [Leonard Lin](https://huggingface.co/leonardlin) |
|
|
|
Compute for this model was generously sponsored by [AKA Virtual](https://akavirtual.com/) (Tokyo, Japan). |
|
|
|
Thanks to the [ELYZA](https://huggingface.co/elyza) team for publishing the details of their [tokenizer extension approach](https://zenn.dev/elyza/articles/2fd451c944649d) which we used as a starting point for our tokenizer. |
|
|
|
And of course, thanks to the [Mistral AI](https://huggingface.co/mistralai) for releasing such a strong base model! |
|
|
|
--- |
|
*(GPT-4によって翻訳されました)* |
|
|
|
# shisa-base-7b-v1 |
|
|
|
`shisa-base-7b-v1`は、[Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1)を基にして、主に日本語の事前トレーニングのために追加で80億トークンを追加しています。日本語トークンは、[MADLAD-400](https://github.com/google-research/google-research/tree/master/madlad_400)から取得し、[DSIR](https://github.com/p-lambda/dsir)を使用しています。さらに、MADLAD-400 ENと様々なオープンデータソースからの英語トークンの10%を追加し、壊滅的忘却を防ぐために組み込んでいます。 |
|
|
|
Mistralのトークン化器を12万トークンまで拡張し、日本語の効率を向上させました。私たちのトークン化器はJAでトークンあたり約2.3文字を実現しており、基本的なMistral 7Bのトークン化器はトークンあたり<1文字です。私たちの実装のコードは、[Shisaリポジトリ](https://github.com/AUGMXNT/shisa)で利用可能です。 |
|
|
|
このベースモデルは、[Shisa 7B](https://huggingface.co/augmxnt/shisa-7b-v1)、私たちのJA/ENファインチューニングモデル用に作成されましたが、強力なパフォーマンスと効率的なバイリンガルトークン化器の組み合わせが有用であると考え、コミュニティに提供しています。 |
|
|
|
トレーニングには、16 x A100-40マシンで2,400 A100-40 GPU時間を使用し、[DeepSpeed](https://github.com/microsoft/DeepSpeed) ZeRO-3で行いました。([WandB ログ](https://wandb.ai/jondurbin/mistral-7b-ja-v0.2/runs/rj0lq5v3/overview)) |
|
|
|
## パフォーマンス |
|
このベースモデルは、以前にリリースされたモデルよりもはるかに少ない追加事前トレーニングで、標準ベンチマークにおいて日本語性能の先頭を切ることができました。これは、より良くキュレーションされた事前トレーニングデータセットの使用によるものかもしれませんが、25億追加JAトークンでのアブレーションでも非常に強力な日本語パフォーマンスを示しました。 |
|
|
|
私たちは、わずかに変更された[llm-jp-eval](https://github.com/llm-jp/llm-jp-eval)を使用しました(私たちのベースモデルは、プロンプトに`bos_token`を追加する必要があります。他のモデルについても、変更の有無にかかわらずテストし、すべてのモデルでテストされた高い結果を取りました)。ここでは、元のMistral 7Bベースモデルおよび[日本語Stable LM Instruct Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-gamma-7b)(これはMistral 7Bベースであり、追加の1000億JA/ENトークンの事前トレーニングが行われています)と比較します。また、[Japanese-StableLM-Base-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b)(これはLlama 2 70Bで、追加の1000億JA/ENトークンの事前トレーニングが行われています)も参考に含まれています。 |
|
|
|
![Mistral llm-jp-eval 比較]() |
|
|
|
ここでは、`shisa-base-7b-v1`を他の最近リリースされた同じクラス(7Bパラメータ)の日本語チューニングモデルとも比較します。[ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast)および[Youri 7B](https://huggingface.co/rinna/youri-7b)はLlama 2 7Bモデルで、それぞれ180億と400億の追加事前トレーニングがあります。また、[CALM2-7B](https://huggingface.co/cyberagent/calm2-7b)と[llm-jp-13b]()は、1.3Tおよび3000億JA/ENトークンの事前トレーニングを行ったプリトレーニングモデルです。 |
|
|
|
![7B llm-jp-eval パフォーマンス]() |
|
|
|
## トークン化器 |
|
序文で触れたように、私たちのトークン化器はMistral 7Bトークン化器の拡張版で、語彙サイズは120073であり、120128に合わせられています。残りの未使用トークンは、ゼロ重み付けされた`<|extra_{idx}|>`トークンとして割り当てられています。 |
|
|
|
私たちは「Fast」トークン化器を使用しており、これは`AutoTokenizer`のデフォルトであるべきですが、問題がある場合は`tokenizer.is_fast`をチェックするか、`use_fast=True`で初期化することを確認してください。 |
|
|
|
[CulturaX](https://huggingface.co/datasets/uonlp/CulturaX)データセットのJAサブセットから50Kアイテム(約8500万文字)をサンプリングした際の日本語効率: |
|
|
|
| LLM | トークン化器 | 語彙サイズ | 1トークンあたりの平均文字数 | |
|
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:| |
|
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *2.31* | |
|
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 | |
|
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 | |
|
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 | |
|
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 1.88 | |
|
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 1.85 | |
|
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 1.83 | |
|
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 1.79 | |
|
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 1.65 | |
|
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 1.53 | |
|
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 1.48 | |
|
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 1.00 | |
|
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 0.95 | |
|
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 0.88 | |
|
|
|
また、[CulturaX](https://huggingface.co/datasets/uonlp/CulturaX)データセットのENサブセットから50Kアイテム(約1億7700万文字)をサンプリングして、英語効率をテストしました。これは健全性チェック(および他のトークン化器のパフォーマンスを確認するため)として行われます: |
|
|
|
| LLM | トークン化器 | 語彙サイズ | 1トークンあたりの平均文字数 | |
|
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:| |
|
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 | |
|
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 | |
|
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 | |
|
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *4.12* | |
|
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 | |
|
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 | |
|
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 | |
|
| Japanese-Llama-2-7b-fast (ELYZA) | elyza/ELYZA-japanese-Llama-2-7b-fast | 45043 | 3.86 | |
|
| Youri 7B (Rinna) | meta-llama/Llama-2-7B | 32000 | 3.86 | |
|
| llm-jp-13b (LLM-jp) | [llm-jp/llm-jp-13b-v1.0](https://github.com/llm-jp/llm-jp-tokenizer) | 50570 | 3.79 | |
|
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.83 | |
|
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.49 | |
|
| Japanese-GPT-NeoX-3.6B (Rinna) | rinna/japanese-gpt-neox-3.6b | 32000 | 2.42 | |
|
| Bilingual-GPT-NeoX-4B (Rinna) | rinna/bilingual-gpt-neox-4b | 65536 | 2.42 | |
|
|
|
私たちの拡張トークン化器を使用することで、基本トークン化器と比較してENパフォーマンスの損失なく、クラス最高のJAトークン効率を実現できました。これは私たちのテストで実証されており、トークン化器を使用することでJA推論速度が2倍以上になることがしばしばあります。 |
|
|
|
## 謝辞 |
|
チーム:[Jon Durbin](https://huggingface.co/jondurbin)、[Leonard Lin](https://huggingface.co/leonardlin) |
|
|
|
このモデルの計算は、[AKA Virtual](https://akavirtual.com/)(日本、東京)によって寛大に提供されました。 |
|
|
|
[ELYZA](https://huggingface.co/elyza)チームが公開した[トークン化器拡張アプローチ](https://zenn.dev/elyza/articles/2fd451c944649d)の詳細に感謝します。これは私たちのトークン化器の出発点として使用されました。 |
|
|
|
もちろん、[Mistral AI](https://huggingface.co/mistralai)による強力なベースモデルのリリースに感謝します! |
