
Model Card for SlimSAM (compressed version of SAM = Segment Anything)
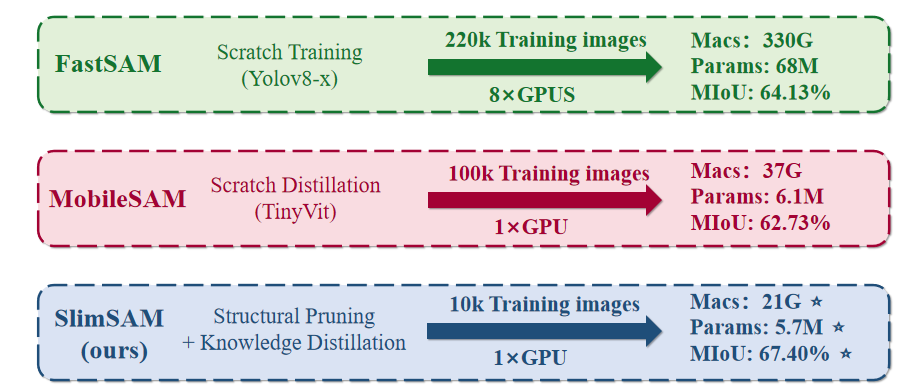 Overview of SlimSAM and its differences to alternatives.
Overview of SlimSAM and its differences to alternatives.
Table of Contents
TL;DR
SlimSAM is a compressed (pruned) version of the Segment Anything (SAM) model, capabling of producing high quality object masks from input prompts such as points or boxes.
The abstract of the paper states:
The formidable model size and demanding computational requirements of Segment Anything Model (SAM) have rendered it cumbersome for deployment on resource-constrained devices. Existing approaches for SAM compression typically involve training a new network from scratch, posing a challenging trade-off between compression costs and model performance. To address this issue, this paper introduces SlimSAM, a novel SAM compression method that achieves superior performance with remarkably low training costs. This is achieved by the efficient reuse of pre-trained SAMs through a unified pruning-distillation framework. To enhance knowledge inheritance from the original SAM, we employ an innovative alternate slimming strategy that partitions the compression process into a progressive procedure. Diverging from prior pruning techniques, we meticulously prune and distill decoupled model structures in an alternating fashion. Furthermore, a novel label-free pruning criterion is also proposed to align the pruning objective with the optimization target, thereby boosting the post-distillation after pruning. SlimSAM yields significant performance improvements while demanding over 10 times less training costs than any other existing methods. Even when compared to the original SAM-H, SlimSAM achieves approaching performance while reducing parameter counts to merely 0.9% (5.7M), MACs to 0.8% (21G), and requiring only 0.1% (10k) of the SAM training data.
Disclaimer: Content from this model card has been written by the Hugging Face team, and parts of it were copy pasted from the original SAM model card.
Model Details
The SAM model is made up of 3 modules:
- The
VisionEncoder: a VIT based image encoder. It computes the image embeddings using attention on patches of the image. Relative Positional Embedding is used. - The
PromptEncoder: generates embeddings for points and bounding boxes - The
MaskDecoder: a two-ways transformer which performs cross attention between the image embedding and the point embeddings (->) and between the point embeddings and the image embeddings. The outputs are fed - The
Neck: predicts the output masks based on the contextualized masks produced by theMaskDecoder.
Usage
Prompted-Mask-Generation
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("nielsr/slimsam-50-uniform")
processor = SamProcessor.from_pretrained("nielsr/slimsam-50-uniform")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D localization of a window
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
Among other arguments to generate masks, you can pass 2D locations on the approximate position of your object of interest, a bounding box wrapping the object of interest (the format should be x, y coordinate of the top right and bottom left point of the bounding box), a segmentation mask. At this time of writing, passing a text as input is not supported by the official model according to the official repository. For more details, refer to this notebook, which shows a walk throught of how to use the model, with a visual example!
Automatic-Mask-Generation
The model can be used for generating segmentation masks in a "zero-shot" fashion, given an input image. The model is automatically prompt with a grid of 1024 points
which are all fed to the model.
The pipeline is made for automatic mask generation. The following snippet demonstrates how easy you can run it (on any device! Simply feed the appropriate points_per_batch argument)
from transformers import pipeline
generator = pipeline(task="mask-generation", model="nielsr/slimsam-50-uniform", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
Now to display the image:
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
Citation
If you use this model, please use the following BibTeX entry.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
@misc{chen202301,
title={0.1% Data Makes Segment Anything Slim},
author={Zigeng Chen and Gongfan Fang and Xinyin Ma and Xinchao Wang},
year={2023},
eprint={2312.05284},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
- Downloads last month
- 85