
Latent Consistency Models
Official Repository of the paper: Latent Consistency Models.
Project Page: https://latent-consistency-models.github.io
Try our Hugging Face demos:
Model Descriptions:
Distilled from Dreamshaper v7 fine-tune of Stable-Diffusion v1-5 with only 4,000 training iterations (~32 A100 GPU Hours).
Generation Results:

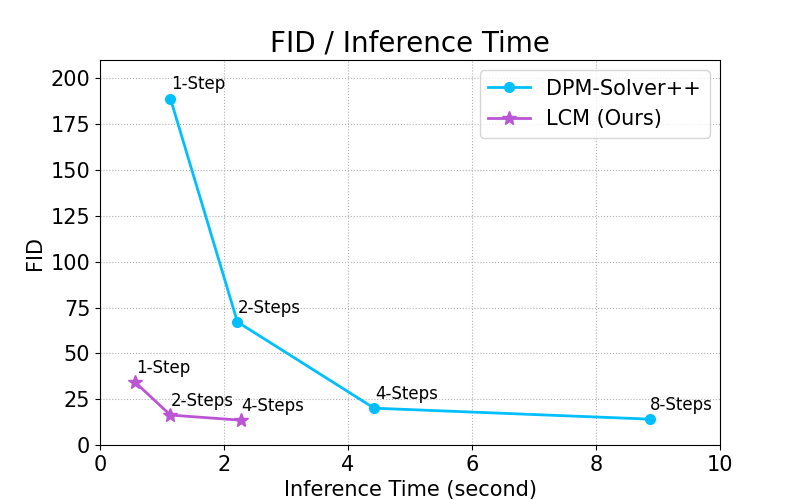
By distilling classifier-free guidance into the model's input, LCM can generate high-quality images in very short inference time. We compare the inference time at the setting of 768 x 768 resolution, CFG scale w=8, batchsize=4, using a A800 GPU.
Usage
You can try out Latency Consistency Models directly on:
To run the model yourself, you can leverage the 🧨 Diffusers library:
- Install the library:
pip install diffusers transformers accelerate
- Run the model:
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_txt2img", custom_revision="main")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
BibTeX
@misc{luo2023latent,
title={Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference},
author={Simian Luo and Yiqin Tan and Longbo Huang and Jian Li and Hang Zhao},
year={2023},
eprint={2310.04378},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
- Downloads last month
- 28
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.