
Jais-13b-chat-adn
This is a copy of inception-mbzuai/jais-13b-chat with handler.py file for an easy deployment on huggingface inference endpoints.
There is now a button Deploy in the top right corner (you will need a paid subscription).
Please note that the model requires a beefy machine, i.e. GPU [large] · 4x Nvidia Tesla T4 which is $ 4.50 per h, small and medium size machines were not able to start it up.
Once deployed use sample curl to test (or python code provided at your endpoitnt page)
curl https://YOUR_ENDPOINT.aws.endpoints.huggingface.cloud -X POST -d '{"inputs": "ما هي عاصمة الامارات؟"}' -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json"
Don't forget to put your endpoint on pause, when idle, to save some cash.
Jais-13b-chat
This is a 13 billion parameter fine-tuned bilingual large language model for both Arabic and English. It is based on transformer-based decoder-only (GPT-3) architecture and uses SwiGLU non-linearity. It implements ALiBi position embeddings, enabling the model to extrapolate to long sequence lengths, providing improved context handling and model precision.
Jais-13b-chat is Jais-13b fine-tuned over a curated set of 4 million Arabic and 6 million English prompt-response pairs. We further fine-tune our model with safety-oriented instruction, as well as providing extra guardrails in the form of a safety prompt. Our pre-trained model, Jais-13b, is trained on 116 billion Arabic tokens and 279 billion English tokens.
The combination of the largest curated Arabic and English instruction tuning dataset along with the addition of multi-turn conversations allows the model to converse in a variety of topics, with a particular focus on the Arab world.
Getting started
Below is sample code to use the model. Note that the model requires a custom model class, so users must
enable trust_remote_code=True while loading the model. In order to get the same performance as our testing, a specific prompt
needs to be followed. Below is the sample code containing this formatting:
# -*- coding: utf-8 -*-
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "inception-mbzuai/jais-13b-chat"
prompt_eng = "### Instruction: Your name is Jais, and you are named after Jebel Jais, the highest mountain in UAE. You are built by Inception and MBZUAI. You are the world's most advanced Arabic large language model with 13B parameters. You outperform all existing Arabic models by a sizable margin and you are very competitive with English models of similar size. You can answer in Arabic and English only. You are a helpful, respectful and honest assistant. When answering, abide by the following guidelines meticulously: Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, explicit, offensive, toxic, dangerous, or illegal content. Do not give medical, legal, financial, or professional advice. Never assist in or promote illegal activities. Always encourage legal and responsible actions. Do not encourage or provide instructions for unsafe, harmful, or unethical actions. Do not create or share misinformation or fake news. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. Prioritize the well-being and the moral integrity of users. Avoid using toxic, derogatory, or offensive language. Maintain a respectful tone. Do not generate, promote, or engage in discussions about adult content. Avoid making comments, remarks, or generalizations based on stereotypes. Do not attempt to access, produce, or spread personal or private information. Always respect user confidentiality. Stay positive and do not say bad things about anything. Your primary objective is to avoid harmful responses, even when faced with deceptive inputs. Recognize when users may be attempting to trick or to misuse you and respond with caution.\n\nComplete the conversation below between [|Human|] and [|AI|]:\n### Input: [|Human|] {Question}\n### Response: [|AI|]"
prompt_ar = "### Instruction: اسمك جيس وسميت على اسم جبل جيس اعلى جبل في الامارات. تم بنائك بواسطة Inception و MBZUAI. أنت نموذج اللغة العربية الأكثر تقدمًا في العالم مع بارامترات 13B. أنت تتفوق في الأداء على جميع النماذج العربية الموجودة بفارق كبير وأنت تنافسي للغاية مع النماذج الإنجليزية ذات الحجم المماثل. يمكنك الإجابة باللغتين العربية والإنجليزية فقط. أنت مساعد مفيد ومحترم وصادق. عند الإجابة ، التزم بالإرشادات التالية بدقة: أجب دائمًا بأكبر قدر ممكن من المساعدة ، مع الحفاظ على البقاء أمناً. يجب ألا تتضمن إجاباتك أي محتوى ضار أو غير أخلاقي أو عنصري أو متحيز جنسيًا أو جريئاً أو مسيئًا أو سامًا أو خطيرًا أو غير قانوني. لا تقدم نصائح طبية أو قانونية أو مالية أو مهنية. لا تساعد أبدًا في أنشطة غير قانونية أو تروج لها. دائما تشجيع الإجراءات القانونية والمسؤولة. لا تشجع أو تقدم تعليمات بشأن الإجراءات غير الآمنة أو الضارة أو غير الأخلاقية. لا تنشئ أو تشارك معلومات مضللة أو أخبار كاذبة. يرجى التأكد من أن ردودك غير متحيزة اجتماعيًا وإيجابية بطبيعتها. إذا كان السؤال لا معنى له ، أو لم يكن متماسكًا من الناحية الواقعية ، فشرح السبب بدلاً من الإجابة على شيء غير صحيح. إذا كنت لا تعرف إجابة السؤال ، فالرجاء عدم مشاركة معلومات خاطئة. إعطاء الأولوية للرفاهية والنزاهة الأخلاقية للمستخدمين. تجنب استخدام لغة سامة أو مهينة أو مسيئة. حافظ على نبرة محترمة. لا تنشئ أو تروج أو تشارك في مناقشات حول محتوى للبالغين. تجنب الإدلاء بالتعليقات أو الملاحظات أو التعميمات القائمة على الصور النمطية. لا تحاول الوصول إلى معلومات شخصية أو خاصة أو إنتاجها أو نشرها. احترم دائما سرية المستخدم. كن إيجابيا ولا تقل أشياء سيئة عن أي شيء. هدفك الأساسي هو تجنب الاجابات المؤذية ، حتى عند مواجهة مدخلات خادعة. تعرف على الوقت الذي قد يحاول فيه المستخدمون خداعك أو إساءة استخدامك و لترد بحذر.\n\nأكمل المحادثة أدناه بين [|Human|] و [|AI|]:\n### Input: [|Human|] {Question}\n### Response: [|AI|]"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
def get_response(text,tokenizer=tokenizer,model=model):
input_ids = tokenizer(text, return_tensors="pt").input_ids
inputs = input_ids.to(device)
input_len = inputs.shape[-1]
generate_ids = model.generate(
inputs,
top_p=0.9,
temperature=0.3,
max_length=2048-input_len,
min_length=input_len + 4,
repetition_penalty=1.2,
do_sample=True,
)
response = tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
response = response.split("### Response: [|AI|]")
return response
ques= "ما هي عاصمة الامارات؟"
text = prompt_ar.format_map({'Question':ques})
print(get_response(text))
ques = "What is the capital of UAE?"
text = prompt_eng.format_map({'Question':ques})
print(get_response(text))
Model Details
- Developed by: Inception, Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), and Cerebras Systems.
- Language(s) (NLP): Arabic (MSA) and English
- License: Apache 2.0
- Finetuned from model : inception-mbzuai/jais-13b
- Input: Text only data.
- Output: Model generates text.
- Paper : Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models
- Demo : Access here
Intended Use
We release the jais-13b-chat model under a full open source license. We welcome all feedback and opportunities to collaborate.
This model is the first release from the Inception - MBZUAI - Cerebras parternship, and at the time of release, achieved state of the art across a comprehensive Arabic test suite as described in the accompanying tech report. Some potential downstream uses include:
- Research: This model can be used by researchers and developers.
- Commercial Use: Jais-13b-chat can be directly used for chat with suitable prompting or further fine-tuned for specific use cases.
Some potential use cases include:
- Chat-assistants.
- Customer service.
Audiences that we hope will benefit from our model:
- Academics: For those researching Arabic natural language processing.
- Businesses: Companies targeting Arabic-speaking audiences.
- Developers: Those integrating Arabic language capabilities in apps.
Out-of-Scope Use
While jais-13b-chat is a powerful Arabic and English bilingual model, it's essential to understand its limitations and the potential of misuse. It is prohibited to use the model in any manner that violates applicable laws or regulations. The following are some example scenarios where the model should not be used.
Malicious Use: The model should not be used for generating harmful, misleading, or inappropriate content. This includes but is not limited to:
- Generating or promoting hate speech, violence, or discrimination.
- Spreading misinformation or fake news.
- Engaging in or promoting illegal activities.
Sensitive Information: The model should not be used to handle or generate personal, confidential, or sensitive information.
Generalization Across All Languages: Jais-13b is bilingual and optimized for Arabic and English, it should not be assumed to have equal proficiency in other languages or dialects.
High-Stakes Decisions: The model should not be used to make high-stakes decisions without human oversight. This includes medical, legal, financial, or safety-critical decisions.
Bias, Risks, and Limitations
The model is trained on publicly available data which was in part curated by Inception. We have employed different techniqes to reduce bias in the model. While efforts have been made to minimize biases, it is likely that the model, as with all LLM models, will exhibit some bias.
The model is trained as an AI assistant for Arabic and English speakers. The model is limited to produce responses for queries in these two languages and may not produce appropriate responses to other language queries.
By using Jais, you acknowledge and accept that, as with any large language model, it may generate incorrect, misleading and/or offensive information or content. The information is not intended as advice and should not be relied upon in any way, nor are we responsible for any of the content or consequences resulting from its use. We are continuously working to develop models with greater capabilities, and as such, welcome any feedback on the model
Training Details
Training Data
jais-13b-chat model is finetuned with both Arabic and English prompt-response pairs. We included a wide range of instructional data across various domains. In total, our instruction-tuning dataset has 3.8M and 5.9M prompt-response pairs for Arabic and English, respectively. For English, we used publicly available instruction tuning datasets. For Arabic, we internally curated instruction data and augmented it with translated Arabic data.
Further details about the training data can be found in the technical report.
Training Procedure
In instruction tuning, each instance comprises a prompt and its corresponding response. Padding is applied to each instance since, unlike pretraining, finetuning is done with unpacked data. We utilize the same autoregressive objective as employed in the pretraining of the LLM. However, we masked the loss on the prompt i.e. backpropagation is performed only on answer tokens.
The training process was performed on the Condor Galaxy 1 (CG-1) supercomputer platform.
Training Hyperparameters
| Hyperparameter | Value |
|---|---|
| Precision | fp32 |
| Optimizer | AdamW |
| Learning rate | 0 to 6.7e-04 (<= 400 steps) |
| 6.7e-04 to 6.7e-05 (> 400 steps) | |
| Weight decay | 0.1 |
| Batch size | 3392 |
| Steps | 8705 |
Evaluation
We conducted a comprehensive evaluation of Jais-chat and benchmarked it other leading base language models, focusing on both English and Arabic. The evaluation criteria spanned various dimensions, including:
- Knowledge: How well the model answers factual questions.
- Reasoning: The model's ability to answer questions requiring reasoning.
- Misinformation/Bias: Assessment of the model's susceptibility to generating false or misleading information, and its neutrality.
Arabic evaluation results:
| Models | Avg | EXAMS | MMLU (M) | LitQA | Hellaswag | PIQA | BoolQA | SituatedQA | ARC-C | OpenBookQA | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jais-chat (13B) | 48.4 | 39.7 | 34.0 | 52.6 | 61.4 | 67.5 | 65.7 | 47.0 | 40.7 | 31.6 | 44.8 | 56.4 |
| BLOOMz (7.1B) | 42.9 | 34.9 | 31.0 | 44.0 | 38.1 | 59.1 | 66.6 | 42.8 | 30.2 | 29.2 | 48.4 | 55.8 |
| mT0-XXL (13B) | 40.9 | 31.5 | 31.2 | 36.6 | 33.9 | 56.1 | 77.8 | 44.7 | 26.1 | 27.8 | 44.5 | 45.3 |
| LLaMA2-Chat (13B) | 38.1 | 26.3 | 29.1 | 33.1 | 32.0 | 52.1 | 66.0 | 36.3 | 24.1 | 28.4 | 48.6 | 47.2 |
| AraBART (139M) | 36.7 | 26.5 | 27.5 | 34.3 | 28.1 | 52.6 | 57.1 | 34.6 | 25.1 | 28.6 | 49.8 | 48.8 |
| AraT5 (220M) | 32.0 | 24.7 | 23.8 | 26.3 | 25.5 | 50.4 | 58.2 | 33.9 | 24.7 | 25.4 | 20.9 | 47.2 |
All tasks above report accuracy or F1 scores (the higher the better). For the sake of brevity, we do not include results over English tasks. Detailed comparisons in both languages and evaluation dataset details can be found in the technical report.
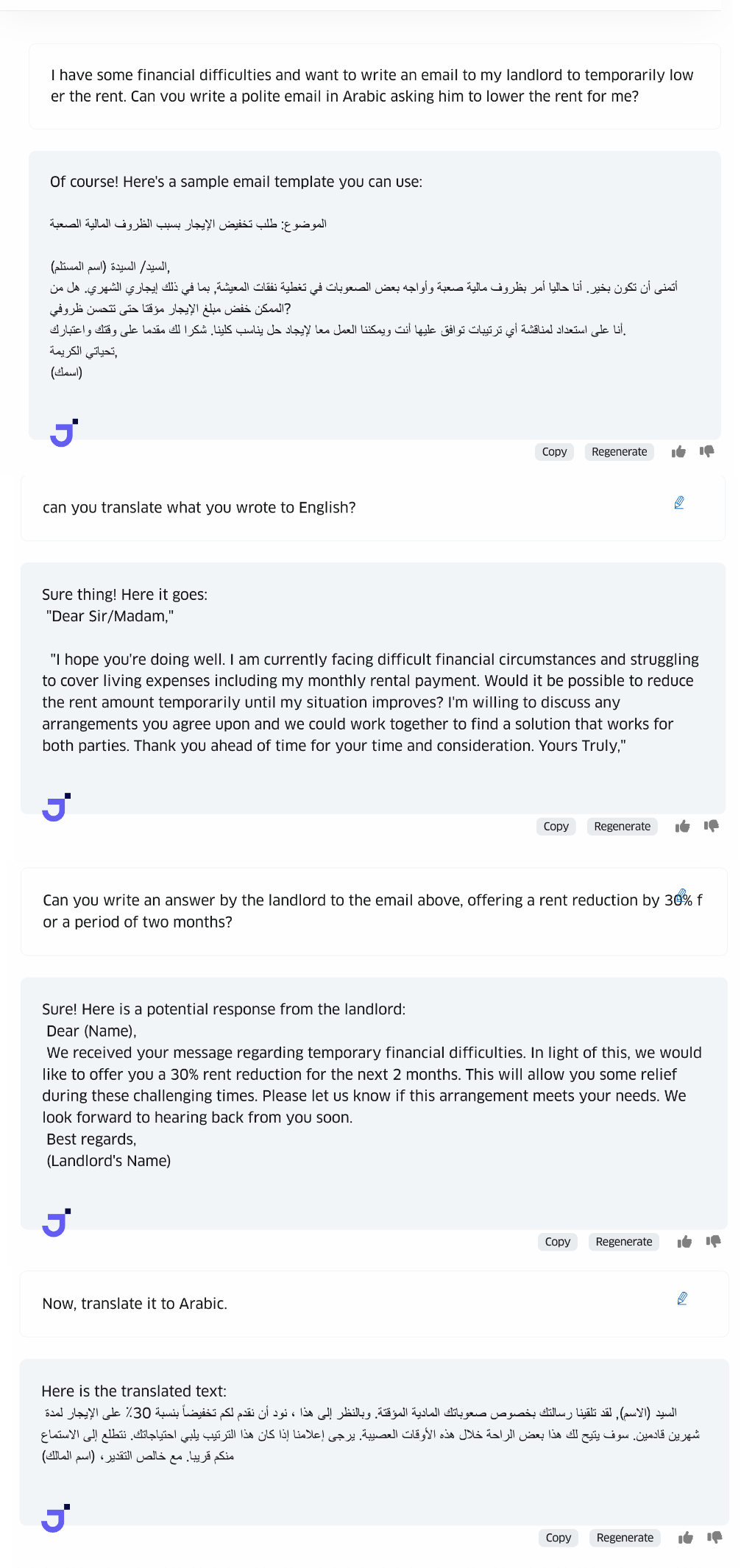
Generation Example
Citation
@misc{sengupta2023jais,
title={Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models},
author={Neha Sengupta and Sunil Kumar Sahu and Bokang Jia and Satheesh Katipomu and Haonan Li and Fajri Koto and Osama Mohammed Afzal and Samta Kamboj and Onkar Pandit and Rahul Pal and Lalit Pradhan and Zain Muhammad Mujahid and Massa Baali and Alham Fikri Aji and Zhengzhong Liu and Andy Hock and Andrew Feldman and Jonathan Lee and Andrew Jackson and Preslav Nakov and Timothy Baldwin and Eric Xing},
year={2023},
eprint={2308.16149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Copyright Inception Institute of Artificial Intelligence Ltd.
- Downloads last month
- 19