

Bridge Diffusion Model
Official repo for paper "Bridge Diffusion Model: bridge non-English language-native text-to-image diffusion model with English communities"
中文原理解读:解决AI绘画模型的世界观偏见,并无缝兼容SD社区,360人工智能研究院发布中文原生AI绘画模型BDM
Contents
Introduction
BDM (Bridge Diffusion Model) is a generic method for developing non-English language-native TTI (text-to-image) model with compatability with the English Stable Diffusion communities.
Developing non-English language-native TTI model is necessary because all existing (English) models all have language related bias. As pointed out by Stable Bias[1] , English-native Text-to-Image (TTI) models, including but not limited to DALL-E 2[2], Stable Diffusion[3] v1.4, and v2, display a substantial over-representation of attributes associated with white individuals and males. These language-related biases are inherent and pervasive for current TTI models, due to the fact that they are mainly trained with data from English world for example the commonly used LAION dataset, thus resulting in over-representation for English world figures meanwhile inadequate representation for non-English world counter-parts.
Compatability with current English TTI communities is necessary for the thriving of non-English language-native TTI communities. The most straightforward and cheapest choice for non-English language-native TTI model development is to combine SD model with external translation. This however definitely leaves the inherent English model bias entirely untouched. Another line of works involve alignment-based strategies, by aligning the embedding space of different language text encoders with parallel translation text corpus, which is just implicitly another "translation" method. Based on aligned text encoder, Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1[4] further fine-tuned the TTI model with Chinese-native data. This allows the English-native model to assimilate Chinese-native language semantics at low cost while maintain a certain level of compatibility between the English and Chinese TTI communities, though the balance is tricky. To resolve bias inherent in English-native models, the most radical method is to train TTI model from scratch with non-English native data. For instance, ERNIE-ViLG 2.0[5] and Wukong-Huahua[6] are trained with Chinese native data, and capable of generating high-quality images consistent with Chinese language semantics. The fundamental problem of this line of works is that it loses compatibility with its ancestral English-native models, which means it can not utilize progress from the English-native TTI communities directly. This would lead to community isolation and development stagnation for the Chinese-native TTI community in the long run.
Method
BDM entails the utilization of a backbone-branch network architecture akin to ControlNet[7], model structure illustrated in the following
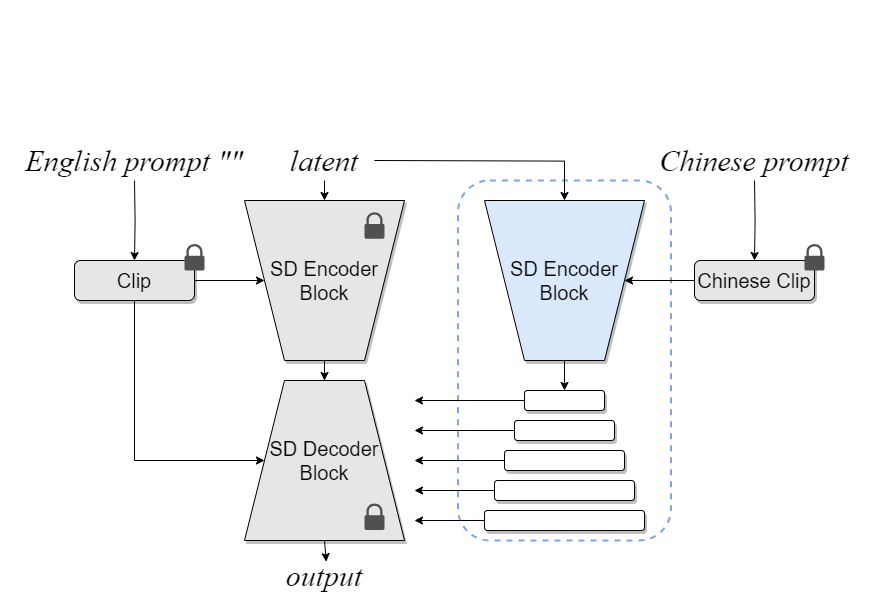
Fig.1 BDM model structure
The backbone part serves as a good diffusion initialization and will be frozen during training, which could be from any pretrained diffusion TTI model. We leverage Stable Diffusion 1.5 in current implementation. The branch part servers as language-native semantics injection module, whose parameters will be trained with language-native text-image pairs. Different from ControlNet, BDM's branch employs a Chinese-native CLIP[8] as the text encoder, where the non-English language-native text prompt is actually processed. The English-native text encoder in the backbone part becomes optional, and will be fed with an empty constant string ("") in our implementation.
For model inference, language-native positive prompts as well as negative ones will be fed through the Chinese text encoder from the BDM's branch part, and we can still plainly feed the English text encoder with empty constant string (""). Since BDM embeds an entire English-native TTI model as its backbone part, existing techniques such as LoRA, ControlNet, Dreambooth, Textual Inversion and even various style fine-tuned checkpoints from English TTI communities (Civitai, Stable Diffusion Online, to name a few) can be directly applied to BDM with minimal cost.
Evaluation
Here are several image generation illustrations for our BDM, with Chinese-native TTI capability and integrated with different English TTI communty techniques.

Fig.2 Chinese unique concepts

Fig.3 Different English branch
For more illustrations and details, please refer to our paper "Bridge Diffusion Model: bridge non-English language-native text-to-image diffusion model with English communities"
Environment
git clone https://github.com/360CVGroup/Bridge_Diffusion_Model.git
cd Bridge_Diffusion_Model
conda env create -f environment.yml
conda activate bdm
pip install -r requirements.txt
cd diffusers
pip install -e .
Model
Running the command sh run.sh will initiate the download of the BDM 1.0 model from Hugging Face.
Download realisticVisionV60B1_v51VAE.safetensors and place it in the model directory.
Running the inference script
cd Bridge_Diffusion_Model
sh run.sh
Citation
If you find this work helpful, please cite us by
@article{liu2023bridge,
title={Bridge Diffusion Model: bridge non-English language-native text-to-image diffusion model with English communities},
author={Liu, Shanyuan and Leng, Dawei and Yin, Yuhui},
journal={arXiv preprint arXiv:2309.00952},
year={2023}
}
References
[1] Luccioni, Alexandra Sasha, et al. "Stable bias: Analyzing societal representations in diffusion models." arXiv preprint arXiv:2303.11408 (2023).
[2] Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
[3] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[4] Zhang, Jiaxing, et al. "Fengshenbang 1.0: Being the foundation of chinese cognitive intelligence." arXiv preprint arXiv:2209.02970 (2022).
[5] Feng, Zhida, et al. "ERNIE-ViLG 2.0: Improving text-to-image diffusion model with knowledge-enhanced mixture-of-denoising-experts." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[6] https://xihe.mindspore.cn/modelzoo/wukong
[7] Zhang, Lvmin, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." arXiv preprint arXiv:2302.05543 (2023).
[8] Yang, An, et al. "Chinese clip: Contrastive vision-language pretraining in chinese." arXiv preprint arXiv:2211.01335 (2022).