
Update README.md
#1
by
maneprasad1
- opened
README.md
CHANGED
|
@@ -1,201 +1,115 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
library_name: transformers
|
| 3 |
-
|
|
|
|
| 4 |
---
|
| 5 |
|
| 6 |
-
#
|
| 7 |
|
| 8 |
-
|
| 9 |
|
|
|
|
| 10 |
|
|
|
|
| 11 |
|
| 12 |
-
##
|
| 13 |
|
| 14 |
-
|
| 15 |
|
| 16 |
-
<!-- Provide a longer summary of what this model is. -->
|
| 17 |
|
| 18 |
-
|
| 19 |
|
| 20 |
-
|
| 21 |
-
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
-
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
-
- **Model type:** [More Information Needed]
|
| 24 |
-
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
-
- **License:** [More Information Needed]
|
| 26 |
-
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
|
| 28 |
-
|
| 29 |
|
| 30 |
-
|
| 31 |
|
| 32 |
-
|
| 33 |
-
- **Paper [optional]:** [More Information Needed]
|
| 34 |
-
- **Demo [optional]:** [More Information Needed]
|
| 35 |
|
| 36 |
-
|
|
|
|
| 37 |
|
| 38 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 39 |
|
| 40 |
-
|
| 41 |
|
| 42 |
-
|
| 43 |
|
| 44 |
-
|
| 45 |
|
| 46 |
-
###
|
| 47 |
|
| 48 |
-
|
|
|
|
|
|
|
| 49 |
|
| 50 |
-
|
| 51 |
|
| 52 |
-
|
|
|
|
| 53 |
|
| 54 |
-
|
| 55 |
|
| 56 |
-
|
| 57 |
|
| 58 |
-
|
| 59 |
|
| 60 |
-
|
| 61 |
|
| 62 |
-
|
|
|
|
| 63 |
|
| 64 |
-
###
|
| 65 |
|
| 66 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 67 |
|
| 68 |
-
|
| 69 |
|
| 70 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
## Training Details
|
| 77 |
-
|
| 78 |
-
### Training Data
|
| 79 |
-
|
| 80 |
-
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 81 |
-
|
| 82 |
-
[More Information Needed]
|
| 83 |
-
|
| 84 |
-
### Training Procedure
|
| 85 |
-
|
| 86 |
-
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 87 |
-
|
| 88 |
-
#### Preprocessing [optional]
|
| 89 |
-
|
| 90 |
-
[More Information Needed]
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
#### Training Hyperparameters
|
| 94 |
-
|
| 95 |
-
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
-
|
| 97 |
-
#### Speeds, Sizes, Times [optional]
|
| 98 |
-
|
| 99 |
-
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 100 |
-
|
| 101 |
-
[More Information Needed]
|
| 102 |
-
|
| 103 |
-
## Evaluation
|
| 104 |
-
|
| 105 |
-
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 106 |
-
|
| 107 |
-
### Testing Data, Factors & Metrics
|
| 108 |
-
|
| 109 |
-
#### Testing Data
|
| 110 |
-
|
| 111 |
-
<!-- This should link to a Dataset Card if possible. -->
|
| 112 |
-
|
| 113 |
-
[More Information Needed]
|
| 114 |
-
|
| 115 |
-
#### Factors
|
| 116 |
-
|
| 117 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
-
|
| 119 |
-
[More Information Needed]
|
| 120 |
-
|
| 121 |
-
#### Metrics
|
| 122 |
-
|
| 123 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
-
|
| 125 |
-
[More Information Needed]
|
| 126 |
-
|
| 127 |
-
### Results
|
| 128 |
-
|
| 129 |
-
[More Information Needed]
|
| 130 |
-
|
| 131 |
-
#### Summary
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
## Model Examination [optional]
|
| 136 |
-
|
| 137 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 138 |
-
|
| 139 |
-
[More Information Needed]
|
| 140 |
-
|
| 141 |
-
## Environmental Impact
|
| 142 |
-
|
| 143 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 144 |
-
|
| 145 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 146 |
-
|
| 147 |
-
- **Hardware Type:** [More Information Needed]
|
| 148 |
-
- **Hours used:** [More Information Needed]
|
| 149 |
-
- **Cloud Provider:** [More Information Needed]
|
| 150 |
-
- **Compute Region:** [More Information Needed]
|
| 151 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
-
|
| 153 |
-
## Technical Specifications [optional]
|
| 154 |
-
|
| 155 |
-
### Model Architecture and Objective
|
| 156 |
-
|
| 157 |
-
[More Information Needed]
|
| 158 |
-
|
| 159 |
-
### Compute Infrastructure
|
| 160 |
-
|
| 161 |
-
[More Information Needed]
|
| 162 |
-
|
| 163 |
-
#### Hardware
|
| 164 |
-
|
| 165 |
-
[More Information Needed]
|
| 166 |
-
|
| 167 |
-
#### Software
|
| 168 |
-
|
| 169 |
-
[More Information Needed]
|
| 170 |
-
|
| 171 |
-
## Citation [optional]
|
| 172 |
-
|
| 173 |
-
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
-
|
| 175 |
-
**BibTeX:**
|
| 176 |
-
|
| 177 |
-
[More Information Needed]
|
| 178 |
-
|
| 179 |
-
**APA:**
|
| 180 |
-
|
| 181 |
-
[More Information Needed]
|
| 182 |
-
|
| 183 |
-
## Glossary [optional]
|
| 184 |
-
|
| 185 |
-
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 186 |
-
|
| 187 |
-
[More Information Needed]
|
| 188 |
-
|
| 189 |
-
## More Information [optional]
|
| 190 |
-
|
| 191 |
-
[More Information Needed]
|
| 192 |
-
|
| 193 |
-
## Model Card Authors [optional]
|
| 194 |
-
|
| 195 |
-
[More Information Needed]
|
| 196 |
-
|
| 197 |
-
## Model Card Contact
|
| 198 |
-
|
| 199 |
-
[More Information Needed]
|
| 200 |
|
|
|
|
| 201 |
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
datasets:
|
| 3 |
+
- uonlp/CulturaX
|
| 4 |
+
- l3cube-pune/MarathiNLP
|
| 5 |
+
# - https://ai4bharat.iitm.ac.in//samanantar/
|
| 6 |
+
|
| 7 |
+
language:
|
| 8 |
+
- mr
|
| 9 |
+
metrics:
|
| 10 |
+
- accuracy
|
| 11 |
+
tags:
|
| 12 |
+
- marathi
|
| 13 |
+
- sentiment analysis
|
| 14 |
+
- reading comprehension
|
| 15 |
+
- paraphrasing
|
| 16 |
+
- translation
|
| 17 |
library_name: transformers
|
| 18 |
+
pipeline_tag: text-generation
|
| 19 |
+
license: llama2
|
| 20 |
---
|
| 21 |
|
| 22 |
+
# Misal-7B-base-v0.1
|
| 23 |
|
| 24 |
+
Built by - [smallstep.ai](https://smallstep.ai/)
|
| 25 |
|
| 26 |
+
## What is Misal?
|
| 27 |
|
| 28 |
+
Misal 7B, a pretrained and instruction tuned large language model based on Meta’s Llama 7B architecture exclusively for Marathi.
|
| 29 |
|
| 30 |
+
## Making of Misal?
|
| 31 |
|
| 32 |
+
Detailed blog [here](https://smallstep.ai/making-misal).
|
| 33 |
|
|
|
|
| 34 |
|
| 35 |
+
## Pretraining :
|
| 36 |
|
| 37 |
+
During the pretraining phase of our large language model, the model was exposed to a vast corpus of text data comprising approximately 2 billion Marathi tokens. This corpus primarily consisted of newspaper data spanning the years 2016 to 2022, sourced primarily from the CulturaX dataset. In addition to this, we supplemented our training data with additional sources such as l3cube, ai4bharat, and other internet-based datasets.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
+
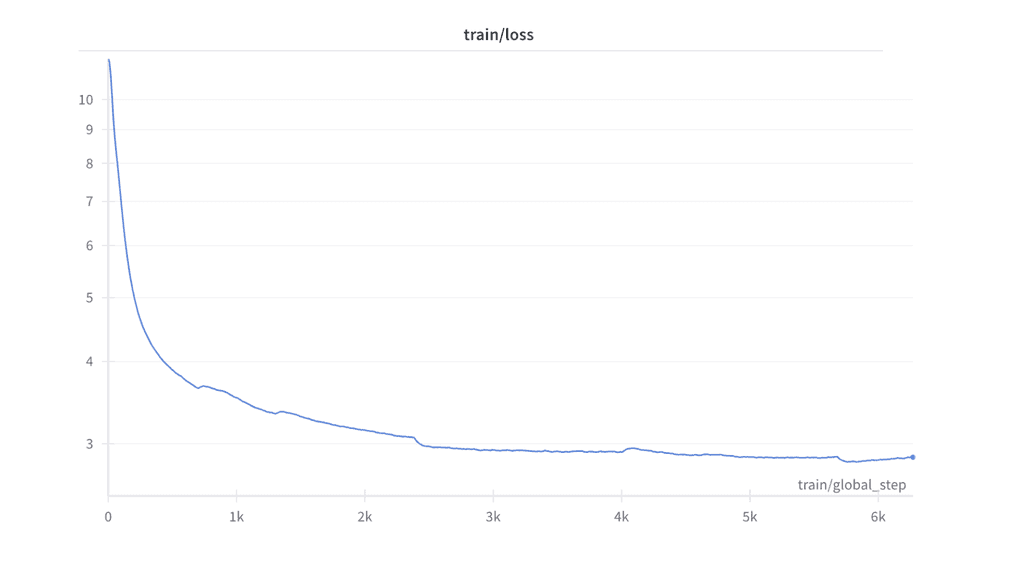
|
| 40 |
|
| 41 |
+
Our model was pretrained using a single A100 80GB GPU on the QBlocks platform. We chose bfloat16 as training precision due to stability issues with float16 precision.
|
| 42 |
|
| 43 |
+
We used Parameter efficient finetuning for pretraining, using Low Rank Adaptation (LoRA), to achieve a training loss of approximately 2.8 after training for almost 2 days.
|
|
|
|
|
|
|
| 44 |
|
| 45 |
+
```python
|
| 46 |
+
# LoRA config
|
| 47 |
|
| 48 |
+
peft:
|
| 49 |
+
r: 64
|
| 50 |
+
lora_alpha: 128
|
| 51 |
+
target_modules:
|
| 52 |
+
[
|
| 53 |
+
"q_proj", "v_proj",
|
| 54 |
+
"k_proj", "o_proj",
|
| 55 |
+
"gate_proj", "up_proj",
|
| 56 |
+
"down_proj",
|
| 57 |
+
]
|
| 58 |
+
lora_dropout: 0.05
|
| 59 |
+
bias: "none"
|
| 60 |
+
task_type: "CAUSAL_LM"
|
| 61 |
+
modules_to_save: ["embed_tokens", "lm_head"]
|
| 62 |
+
```
|
| 63 |
|
| 64 |
+
## License
|
| 65 |
|
| 66 |
+
The model inherits the license from meta-llama/Llama-2-7b.
|
| 67 |
|
| 68 |
+
## Usage
|
| 69 |
|
| 70 |
+
### Installation
|
| 71 |
|
| 72 |
+
```bash
|
| 73 |
+
pip install transformers accelerate
|
| 74 |
+
```
|
| 75 |
|
| 76 |
+
### Prompt
|
| 77 |
|
| 78 |
+
```python
|
| 79 |
+
आपण एक मदतगार, आदरणीय आणि प्रामाणिक सहाय्यक आहात.नेहमी शक्य तितकी उपयुक्त उत्तर द्या. तुमची उत्तरे हानिकारक, अनैतिक, वर्णद्वेषी, लैंगिकतावादी, हानिकारक, धोकादायक किंवा बेकायदेशीर नसावीत. कृपया खात्री करा की तुमची उत्तरे सामाजिक दृष्टिकोनाने निष्पक्ष आणि सकारात्मक स्वरूपाची आहेत. जर एखाद्या प्रश्नाला काही अर्थ नसेल किंवा वस्तुस्थितीशी सुसंगती नसेल, तर उत्तर देण्याऐवजी काहीतरी बरोबर का नाही हे स्पष्ट करा. तुम्हाला एखाद्या प्रश्नाचे उत्तर माहित नसल्यास, कृपया चुकीची माहिती देऊ नये.
|
| 80 |
|
| 81 |
+
### Instruction:
|
| 82 |
|
| 83 |
+
<instruction>
|
| 84 |
|
| 85 |
+
### Input:
|
| 86 |
|
| 87 |
+
<input data>
|
| 88 |
|
| 89 |
+
### Response:
|
| 90 |
+
```
|
| 91 |
|
| 92 |
+
### PyTorch
|
| 93 |
|
| 94 |
+
```python
|
| 95 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 96 |
+
device = "cuda"
|
| 97 |
+
model = AutoModelForCausalLM.from_pretrained("smallstepai/Misal-7B-instruct-v0.1", torch_dtype=torch.bfloat16, device_map='auto')
|
| 98 |
+
tokenizer = AutoTokenizer.from_pretrained("smallstepai/Misal-7B-instruct-v0.1")
|
| 99 |
|
| 100 |
+
def ask_misal(model, tokenizer, instruction, inputs='', system_prompt='', max_new_tokens=200, device='cuda'):
|
| 101 |
|
| 102 |
+
ip = dict(system_prompt=system_prompt, instruction=instruction, inputs=inputs)
|
| 103 |
+
model_inputs = tokenizer.apply_chat_template(ip, return_tensors='pt')
|
| 104 |
+
outputs = model.generate(model_inputs.to(device), max_new_tokens=max_new_tokens)
|
| 105 |
+
response = tokenizer.decode(outputs[0]).split('### Response:')[1].strip()
|
| 106 |
+
return response
|
| 107 |
|
| 108 |
+
instruction="सादरीकरण कसे करावे?"
|
| 109 |
+
resp = ask_misal(model, tokenizer, instruction=instruction, max_new_tokens=1024)
|
| 110 |
+
print(resp)
|
| 111 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 112 |
|
| 113 |
+
### Team
|
| 114 |
|
| 115 |
+
Sagar Sarkale, Abhijeet Katte, Prasad Mane, Shravani Chavan
|