Spaces:
Running

A newer version of the Gradio SDK is available:
5.6.0
VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Jaehyeon Kim, Jungil Kong, and Juhee Son
In our recent paper, we propose VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech.
Several recent end-to-end text-to-speech (TTS) models enabling single-stage training and parallel sampling have been proposed, but their sample quality does not match that of two-stage TTS systems. In this work, we present a parallel end-to-end TTS method that generates more natural sounding audio than current two-stage models. Our method adopts variational inference augmented with normalizing flows and an adversarial training process, which improves the expressive power of generative modeling. We also propose a stochastic duration predictor to synthesize speech with diverse rhythms from input text. With the uncertainty modeling over latent variables and the stochastic duration predictor, our method expresses the natural one-to-many relationship in which a text input can be spoken in multiple ways with different pitches and rhythms. A subjective human evaluation (mean opinion score, or MOS) on the LJ Speech, a single speaker dataset, shows that our method outperforms the best publicly available TTS systems and achieves a MOS comparable to ground truth.
Visit our demo for audio samples.
We also provide the pretrained models.
** Update note: Thanks to Rishikesh (ऋषिकेश), our interactive TTS demo is now available on Colab Notebook.
| VITS at training | VITS at inference |
|---|---|
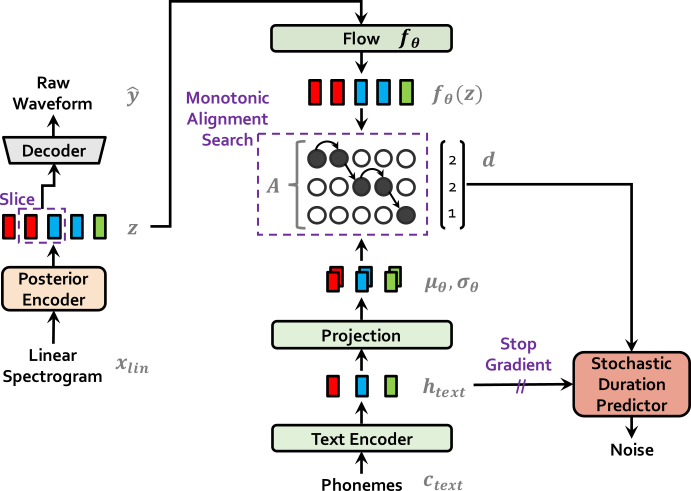 |
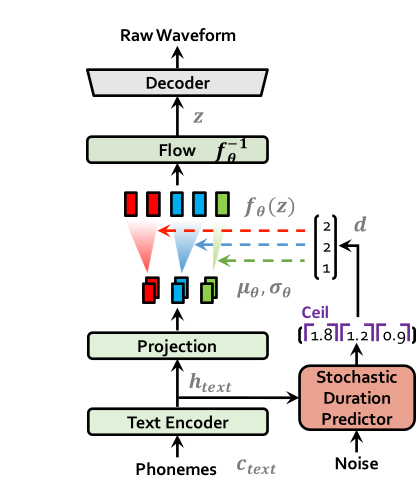 |
Pre-requisites
- Python >= 3.6
- Clone this repository
- Install python requirements. Please refer requirements.txt
- You may need to install espeak first:
apt-get install espeak
- You may need to install espeak first:
- Download datasets
- Download and extract the LJ Speech dataset, then rename or create a link to the dataset folder:
ln -s /path/to/LJSpeech-1.1/wavs DUMMY1 - For mult-speaker setting, download and extract the VCTK dataset, and downsample wav files to 22050 Hz. Then rename or create a link to the dataset folder:
ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2
- Download and extract the LJ Speech dataset, then rename or create a link to the dataset folder:
- Build Monotonic Alignment Search and run preprocessing if you use your own datasets.
# Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt
Training Exmaple
# LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_base
Inference Example
See inference.ipynb