Spaces:
Running


title: README
emoji: 🏃
colorFrom: pink
colorTo: red
sdk: static
pinned: false
Knowledge Fusion of Large Language Models
| 📑 FuseLLM Paper @ICLR2024 | 📑 FuseChat Tech Report | 🤗 HuggingFace Repo | 🐱 GitHub Repo |
![]()
News
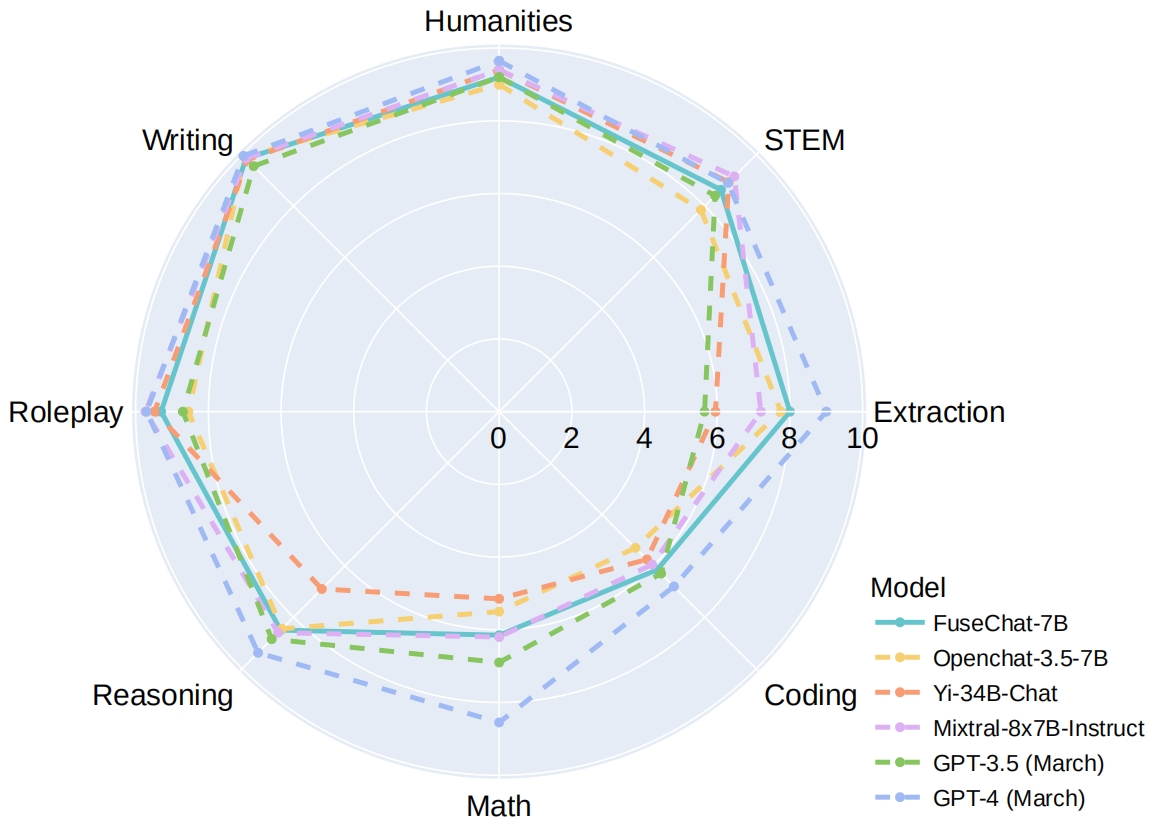
FuseChat [SOTA 7B LLM on MT-Bench]
Feb 26, 2024: 🔥🔥 We release FuseChat-7B-VaRM, which is the fusion of three prominent chat LLMs with diverse architectures and scales, namely NH2-Mixtral-8x7B, NH2-Solar-10.7B, and OpenChat-3.5-7B. FuseChat-7B-VaRM achieves an average performance of 8.22 on MT-Bench, outperforming various powerful chat LLMs like Starling-7B, Yi-34B-Chat, and Tulu-2-DPO-70B, even surpassing GPT-3.5 (March), Claude-2.1, and approaching Mixtral-8x7B-Instruct.
Feb 25, 2024: 🔥 We release FuseChat-Mixture, which is a comprehensive training dataset covers different styles and capabilities, featuring both human-written and model-generated, and spanning general instruction-following and specific skills.
| Proprietary Models | #Params | MT-Bench | Open Source Models | #Params | MT-Bench |
|---|---|---|---|---|---|
| GPT-4-1106-preview | - | 9.32 | Qwen1.5-72B-Chat | 72B | 8.61 |
| GPT-4-0613 | - | 9.18 | Nous-Hermes-2-Mixtral-8x7B-DPO | 8x7B | 8.33 |
| GPT-4-0314 | - | 8.96 | Mixtral-8x7B-Instruct-v0.1 | 8x7B | 8.30 |
| Mistral Medium | - | 8.61 | 🤗 FuseChat-7B-VaRM | 7B | 8.22 |
| GPT-3.5-Turbo-0613 | - | 8.39 | Starling-LM-7B-alpha | 7B | 8.09 |
| GPT-3.5-Turbo-1106 | - | 8.32 | Tulu-2-DPO-70B | 70B | 7.89 |
| 🤗 FuseChat-7B-VaRM | 7B | 8.22 | OpenChat-3.5 | 7B | 7.81 |
| Claude-2.1 | - | 8.18 | OpenChat-3.5-0106 | 7B | 7.80 |
| Claude-2.0 | - | 8.06 | WizardLM-70B-v1.0 | 70B | 7.71 |
| GPT-3.5-Turbo-0314 | - | 7.94 | Yi-34B-Chat | 34B | 7.67 |
| Claude-1 | - | 7.90 | Nous-Hermes-2-SOLAR-10.7B | 10.7B | 7.66 |
FuseLLM
- Jan 22, 2024: 🔥 We release FuseLLM-7B, which is the fusion of three open-source foundation LLMs with distinct architectures, including Llama-2-7B, OpenLLaMA-7B, and MPT-7B.
| Model | BBH | ARC-easy | ARC-challenge | BoolQ | HellaSwag | OpenBookQA |
|---|---|---|---|---|---|---|
| OpenLLaMA-7B | 33.87 | 69.70 | 41.38 | 72.29 | 74.53 | 41.00 |
| MPT-7B | 33.38 | 70.12 | 42.15 | 74.74 | 76.25 | 42.40 |
| Llama-2-7B | 39.70 | 74.58 | 46.33 | 77.71 | 76.00 | 44.20 |
| Llama-2-CLM-7B | 40.44 | 74.54 | 46.50 | 76.88 | 76.57 | 44.80 |
| 🤗 FuseLLM-7B | 41.75 | 75.04 | 47.44 | 78.13 | 76.78 | 45.40 |
| Model | MultiPL-E | TrivialQA | DROP | LAMBADA | IWSLT2017 | SciBench |
|---|---|---|---|---|---|---|
| OpenLLaMA-7B | 18.11 | 39.96 | 22.31 | 70.31 | 5.51 | 0.68 |
| MPT-7B | 17.26 | 28.89 | 23.54 | 70.08 | 5.49 | 0.88 |
| Llama-2-7B | 14.63 | 52.46 | 27.25 | 73.28 | 6.48 | 0.14 |
| Llama-2-CLM-7B | 14.83 | 53.14 | 28.51 | 73.45 | 6.91 | 0.94 |
| 🤗 FuseLLM-7B | 15.56 | 54.49 | 28.97 | 73.72 | 6.75 | 1.65 |
Citation
Please cite the following paper if you reference our model, code, data, or paper related to FuseLLM.
@inproceedings{wan2024knowledge,
title={Knowledge Fusion of Large Language Models},
author={Fanqi Wan and Xinting Huang and Deng Cai and Xiaojun Quan and Wei Bi and Shuming Shi},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/pdf?id=jiDsk12qcz}
}
Please cite the following paper if you reference our model, code, data, or paper related to FuseChat.
@article{wan2024fusechat,
title={FuseChat: Knowledge Fusion of Chat Models},
author={Fanqi Wan and Ziyi Yang and Longguang Zhong and Xiaojun Quan and Xinting Huang and Wei Bi},
journal={arXiv preprint arXiv:2402.16107},
year={2024}
}