Spaces:
Running


PromptSource
PromptSource is a toolkit for creating, sharing and using natural language prompts.
Recent work has shown that large language models exhibit the ability to perform reasonable zero-shot generalization to new tasks. For instance, GPT-3 demonstrated that large language models have strong zero- and few-shot abilities. FLAN and T0 then demonstrated that pre-trained language models fine-tuned in a massively multitask fashion yield even stronger zero-shot performance. A common denominator in these works is the use of prompts which have gathered of interest among NLP researchers and engineers. This emphasizes the need for new tools to create, share and use natural language prompts.
Prompts are functions that map an example from a dataset to a natural language input and target output PromptSource contains a growing collection of prompts (which we call P3: Public Pool of Prompts). As of January 20, 2022, there are ~2'000 English prompts for 170+ English datasets in P3.

PromptSource provides the tools to create, and share natural language prompts (see How to create prompts, and then use the thousands of existing and newly created prompts through a simple API (see How to use prompts). Prompts are saved in standalone structured files and are written in a simple templating language called Jinja. An example of prompt availabe in PromptSource for SNLI is:
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[label]}}
You can browse through existing prompts on the hosted version of PromptSource.
Setup
If you do not intend to modify prompts, you can simply run:
pip install promptsource
Otherwise, you need to install the repo locally:
- Download the repo
- Navigate to the root directory of the repo
- Run
pip install -e .to install thepromptsourcemodule
Note: for stability reasons, you will currently need a Python 3.7 environment to run the last step. However, if you only intend to use the prompts, and not create new prompts through the interface, you can remove this constraint in the setup.py and install the package locally.
How to use prompts
You can apply prompts to examples from datasets of the Hugging Face Datasets library.
# Load an example from the datasets ag_news
>>> from datasets import load_dataset
>>> dataset = load_dataset("ag_news", split="train")
>>> example = dataset[1]
# Load prompts for this dataset
>>> from promptsource.templates import DatasetTemplates
>>> ag_news_prompts = DatasetTemplates('ag_news')
# Print all the prompts available for this dataset. The keys of the dict are the uuids the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
>>> print(ag_news_prompts.templates)
{'24e44a81-a18a-42dd-a71c-5b31b2d2cb39': <promptsource.templates.Template object at 0x7fa7aeb20350>, '8fdc1056-1029-41a1-9c67-354fc2b8ceaf': <promptsource.templates.Template object at 0x7fa7aeb17c10>, '918267e0-af68-4117-892d-2dbe66a58ce9': <promptsource.templates.Template object at 0x7fa7ac7a2310>, '9345df33-4f23-4944-a33c-eef94e626862': <promptsource.templates.Template object at 0x7fa7ac7a2050>, '98534347-fff7-4c39-a795-4e69a44791f7': <promptsource.templates.Template object at 0x7fa7ac7a1310>, 'b401b0ee-6ffe-4a91-8e15-77ee073cd858': <promptsource.templates.Template object at 0x7fa7ac7a12d0>, 'cb355f33-7e8c-4455-a72b-48d315bd4f60': <promptsource.templates.Template object at 0x7fa7ac7a1110>}
# Select a prompt by its name
>>> prompt = ag_news_prompts["classify_question_first"]
# Apply the prompt to the example
>>> result = prompt.apply(example)
>>> print("INPUT: ", result[0])
INPUT: What label best describes this news article?
Carlyle Looks Toward Commercial Aerospace (Reuters) Reuters - Private investment firm Carlyle Group,\which has a reputation for making well-timed and occasionally\controversial plays in the defense industry, has quietly placed\its bets on another part of the market.
>>> print("TARGET: ", result[1])
TARGET: Business
In the case that you are looking for the prompts available for a particular subset of a dataset, you should use the following syntax:
dataset_name, subset_name = "super_glue", "rte"
dataset = load_dataset(f"{dataset_name}/{subset_name}", split="train")
example = dataset[0]
prompts = DatasetTemplates(f"{dataset_name}/{subset_name}")
You can also collect all the available prompts for their associated datasets:
>>> from promptsource.templates import TemplateCollection
# Get all the prompts available in PromptSource
>>> collection = TemplateCollection()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
>>> print(collection.datasets_templates)
{('poem_sentiment', None): <promptsource.templates.DatasetTemplates object at 0x7fa7ac7939d0>, ('common_gen', None): <promptsource.templates.DatasetTemplates object at 0x7fa7ac795410>, ('anli', None): <promptsource.templates.DatasetTemplates object at 0x7fa7ac794590>, ('cc_news', None): <promptsource.templates.DatasetTemplates object at 0x7fa7ac798a90>, ('craigslist_bargains', None): <promptsource.templates.DatasetTemplates object at 0x7fa7ac7a2c10>,...}
You can learn more about PromptSource's API to store, manipulate and use prompts in the documentation.
How to create prompts
PromptSource provides a Web-based GUI that enables developers to write prompts in a templating language and immediately view their outputs on different examples.
There are 3 modes in the app:
- Sourcing: create and write new prompts
- Prompted dataset viewer: check the prompts you wrote (or the existing ones) on the entire dataset
- Helicopter view: aggregate high-level metrics on the current state of P3
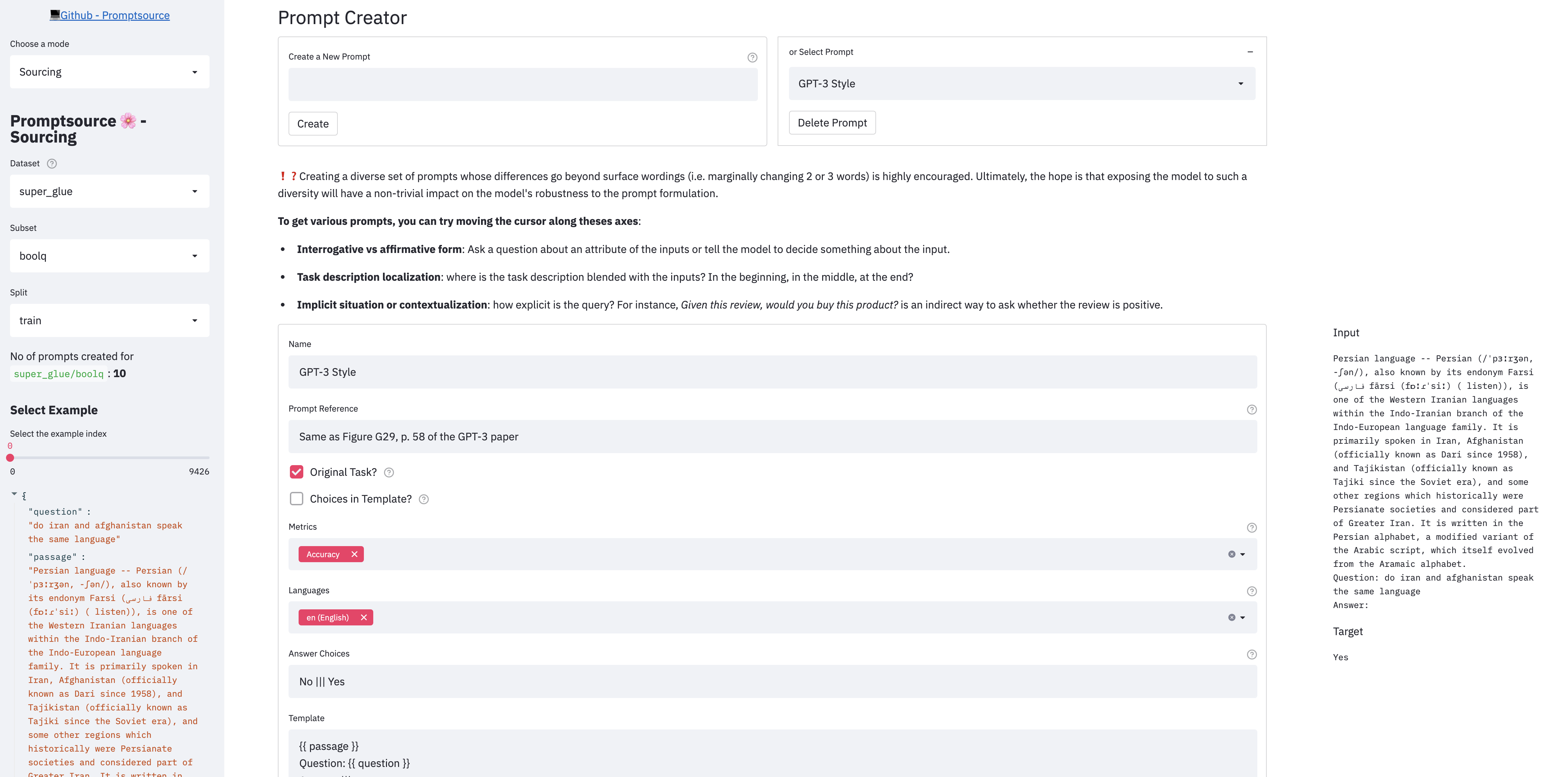
To launch the app locally, please first make sure you have followed the steps in Setup, and from the root directory of the repo, run:
streamlit run promptsource/app.py
You can also browse through existing prompts on the hosted version of PromptSource. Note the hosted version disables the Sourcing mode (streamlit run promptsource/app.py -- --read-only).
Writing prompts
Before creating new prompts, you should read the contribution guidelines which give an step-by-step description of how to contribute to the collection of prompts.
Datasets that require manual downloads
Some datasets are not handled automatically by datasets and require users to download the dataset manually (story_cloze for instance ).
To handle those datasets as well, we require users to download the dataset and put it in ~/.cache/promptsource. This is the root directory containing all manually downloaded datasets.
You can override this default path using PROMPTSOURCE_MANUAL_DATASET_DIR environment variable. This should point to the root directory.
Development structure
PromptSource and P3 were originally developed as part of the BigScience project for open research 🌸, a year-long initiative targeting the study of large models and datasets. The goal of the project is to research language models in a public environment outside large technology companies. The project has 600 researchers from 50 countries and more than 250 institutions.
In particular, PromptSource and P3 were the first steps for the paper Multitask Prompted Training Enables Zero-Shot Task Generalization.
You will find the official repository to reproduce the results of the paper here: https://github.com/bigscience-workshop/t-zero. We also released T0* (pronounce "T Zero"), a series of models trained on P3 and presented in the paper. Checkpoints are available here.
Known Issues
Warning or Error about Darwin on OS X: Try downgrading PyArrow to 3.0.0.
ConnectionRefusedError: [Errno 61] Connection refused: Happens occasionally. Try restarting the app.
Citation
If you find P3 or PromptSource useful, please cite the following reference:
@misc{bach2022promptsource,
title={PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts},
author={Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush},
year={2022},
eprint={2202.01279},
archivePrefix={arXiv},
primaryClass={cs.LG}
}