Spaces:
Runtime error

Runtime error

Add GOT
Browse files- pages/29_NVLM.py +2 -2
- pages/30_GOT.py +195 -0
- pages/GOT/image_1.png +0 -0
- pages/GOT/image_2.png +0 -0
- pages/GOT/image_3.png +0 -0
- pages/GOT/image_4.png +0 -0
- pages/GOT/image_5.png +0 -0
pages/29_NVLM.py
CHANGED
|
@@ -161,7 +161,7 @@ with col2:
|
|
| 161 |
with col3:
|
| 162 |
if lang == "en":
|
| 163 |
if st.button("Next paper", use_container_width=True):
|
| 164 |
-
switch_page("
|
| 165 |
else:
|
| 166 |
if st.button("Papier suivant", use_container_width=True):
|
| 167 |
-
switch_page("
|
|
|
|
| 161 |
with col3:
|
| 162 |
if lang == "en":
|
| 163 |
if st.button("Next paper", use_container_width=True):
|
| 164 |
+
switch_page("GOT")
|
| 165 |
else:
|
| 166 |
if st.button("Papier suivant", use_container_width=True):
|
| 167 |
+
switch_page("GOT")
|
pages/30_GOT.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'GOT',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1843278355749065084) (October 7, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
I'm bullish on this foundation OCR model called GOT 📝
|
| 14 |
+
This model can transcribe anything and it's Apache-2.0!
|
| 15 |
+
Keep reading to learn more 🧶
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
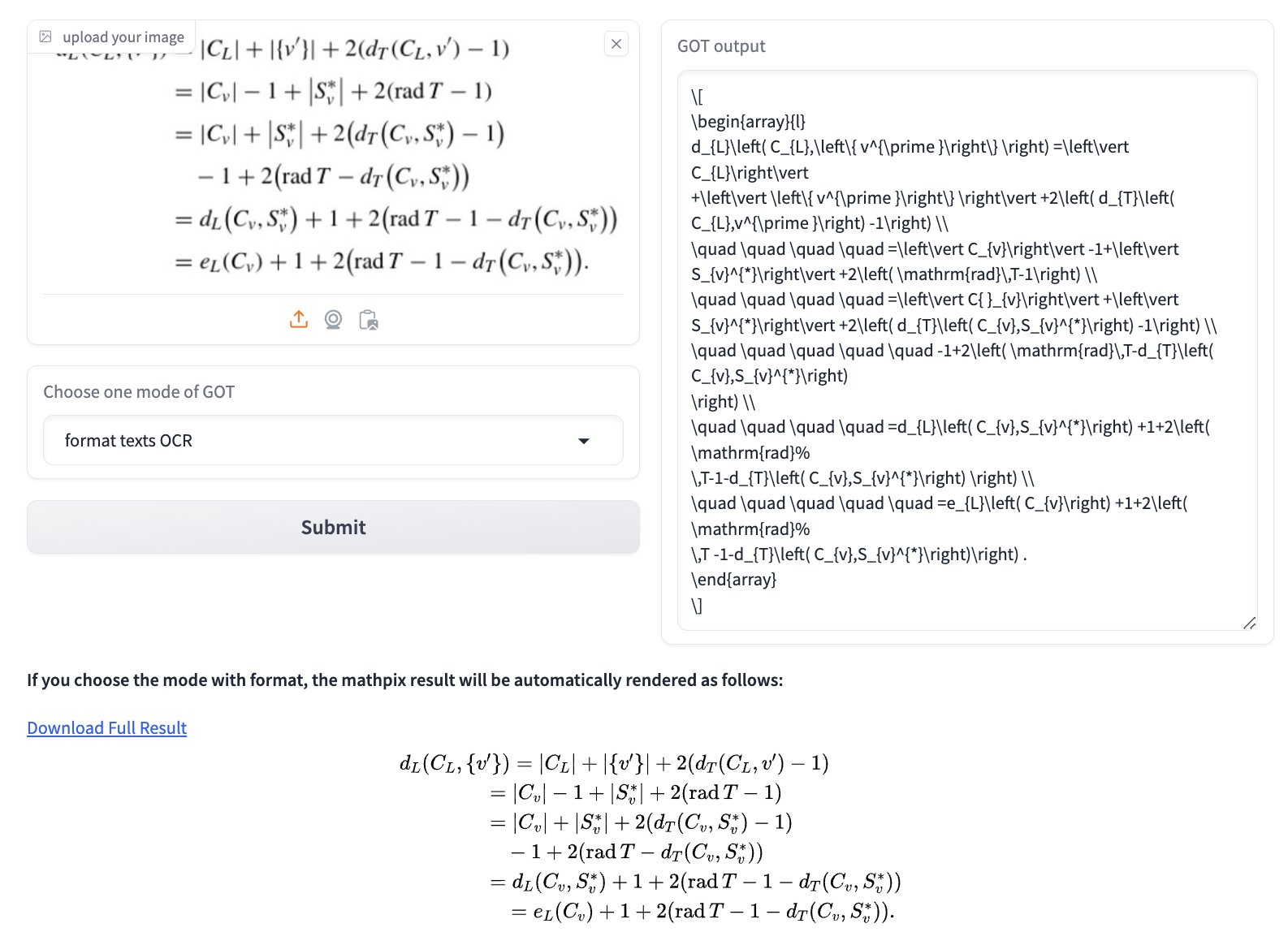
This model can take in screenshots of tables/LaTeX and output formatted text, music sheets, charts, literally anything to meaningful format!
|
| 20 |
+
[Try it](https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo)
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
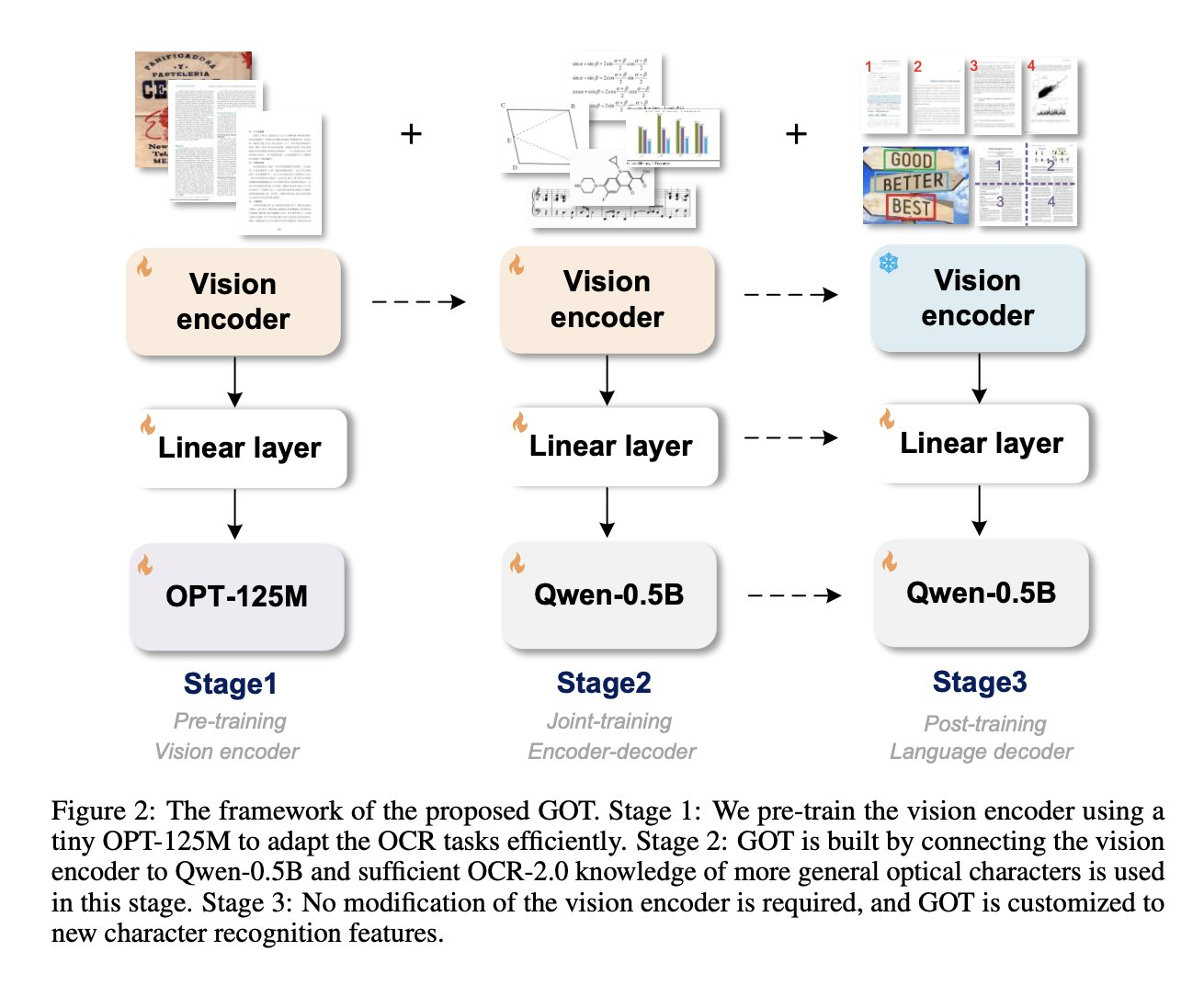
This model has the same architecture as other vision language models 👀 Consists of an image encoder, projector and text decoder.
|
| 25 |
+
<br>
|
| 26 |
+
What makes this model special in my opinion are two things:
|
| 27 |
+
1. Diverse, high quality data mixture (thus data engine)
|
| 28 |
+
2. Alignment technique
|
| 29 |
+
""",
|
| 30 |
+
'tweet_4':
|
| 31 |
+
"""
|
| 32 |
+
Authors followed the following recipe:
|
| 33 |
+
🔥 pre-trained a vision encoder by using OPT-125M
|
| 34 |
+
✨ keep training same encoder, add a new linear layer and Qwen-0.5B and train all the components
|
| 35 |
+
❄️ finally they freeze the encoder and do fine-tuning 👇🏻
|
| 36 |
+
""",
|
| 37 |
+
'tweet_5':
|
| 38 |
+
"""
|
| 39 |
+
Their training data generated with engine consists of:
|
| 40 |
+
📝 plain OCR data
|
| 41 |
+
📑 mathpix markdown (tables, LaTeX formulas etc)
|
| 42 |
+
📊 charts (chart to JSON output)
|
| 43 |
+
📐 geometric shapes (into TikZ)
|
| 44 |
+
🎼 even music sheets
|
| 45 |
+
""",
|
| 46 |
+
'tweet_6':
|
| 47 |
+
"""
|
| 48 |
+
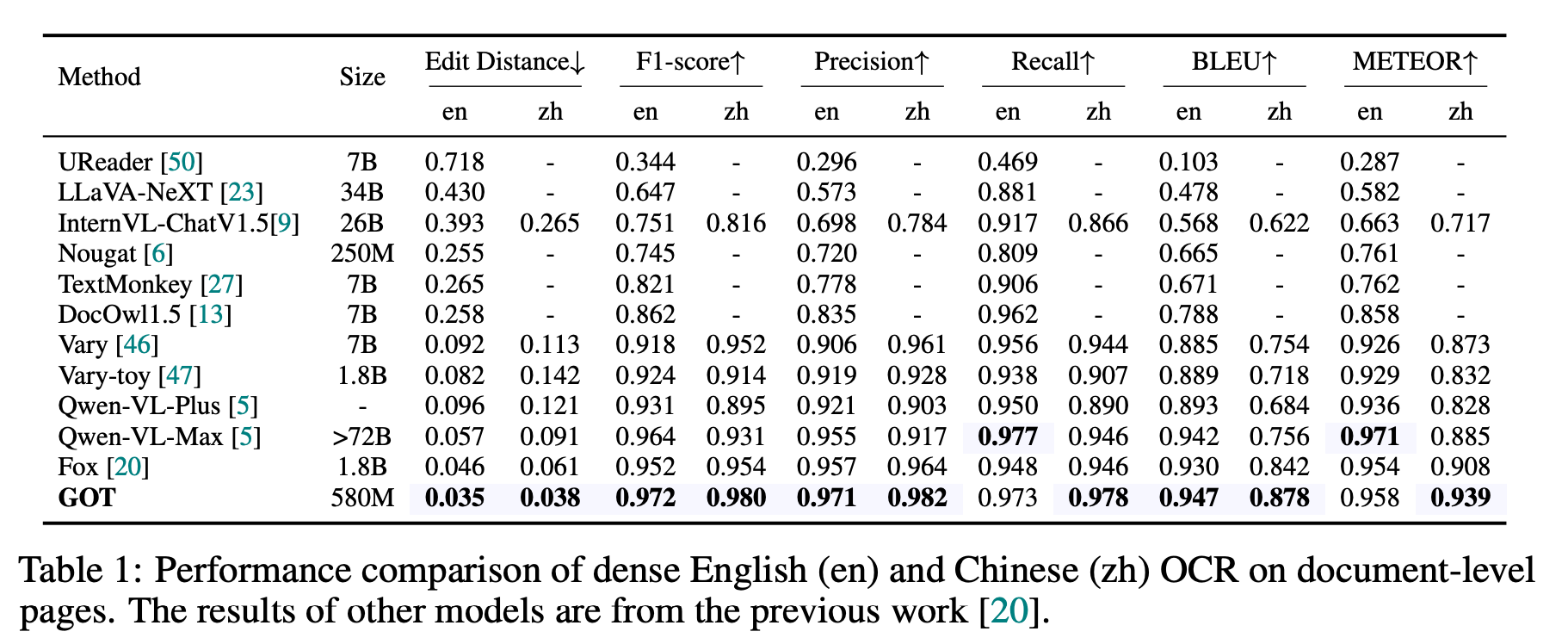
The authors have reported different metrics and it seems despite it's small size, the model seems to be the state-of-the-art in many benchmarks!
|
| 49 |
+
""",
|
| 50 |
+
'ressources':
|
| 51 |
+
"""
|
| 52 |
+
Ressources:
|
| 53 |
+
[General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704)
|
| 54 |
+
by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang (2024)
|
| 55 |
+
[GitHub](https://github.com/Ucas-HaoranWei/GOT-OCR2.0/)
|
| 56 |
+
[Model](https://huggingface.co/stepfun-ai/GOT-OCR2_0)
|
| 57 |
+
"""
|
| 58 |
+
},
|
| 59 |
+
'fr': {
|
| 60 |
+
'title': 'GOT',
|
| 61 |
+
'original_tweet':
|
| 62 |
+
"""
|
| 63 |
+
[Tweet de base](https://x.com/mervenoyann/status/1843278355749065084) (en anglais) (7 ocotbre 2024)
|
| 64 |
+
""",
|
| 65 |
+
'tweet_1':
|
| 66 |
+
"""
|
| 67 |
+
Je suis enthousiaste pour de ce modèle d'OCR appelé GOT 📝
|
| 68 |
+
Ce modèle peut transcrire n'importe quoi et il est Apache-2.0 !
|
| 69 |
+
Continuez à lire pour en savoir plus 🧶
|
| 70 |
+
""",
|
| 71 |
+
'tweet_2':
|
| 72 |
+
"""
|
| 73 |
+
Ce modèle peut recevoir des captures d'écran de tableaux/LaTeX et produire du texte formaté, des partitions, des graphiques, littéralement tout ce qui peut être mis en forme !
|
| 74 |
+
[Essayez-le](https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo)
|
| 75 |
+
""",
|
| 76 |
+
'tweet_3':
|
| 77 |
+
"""
|
| 78 |
+
Ce modèle a la même architecture que d'autres modèles de langage de vision 👀
|
| 79 |
+
Il se compose d'un encodeur d'images, d'un projecteur et d'un décodeur de texte.
|
| 80 |
+
<br>
|
| 81 |
+
Ce qui rend ce modèle spécial à mon avis, ce sont deux choses :
|
| 82 |
+
1. Mélange de données diversifiées et de haute qualité (donc moteur de données).
|
| 83 |
+
2. Technique d'alignement
|
| 84 |
+
""",
|
| 85 |
+
'tweet_4':
|
| 86 |
+
"""
|
| 87 |
+
Les auteurs ont suivi la recette suivante :
|
| 88 |
+
🔥 pré-entraînement d'un encodeur de vision en utilisant OPT-125M
|
| 89 |
+
✨ poursuite de l'entraînement du même encodeur, ajout d'une nouvelle couche linéaire et de Qwen-0.5B et entraînement de tous les composants
|
| 90 |
+
❄️ enfin, ils figent l'encodeur et procèdent à un finetuning 👇🏻
|
| 91 |
+
""",
|
| 92 |
+
'tweet_5':
|
| 93 |
+
"""
|
| 94 |
+
Les données d'entraînement générées par le moteur sont :
|
| 95 |
+
📝 des données OCR simples
|
| 96 |
+
📑 des mathpix markdown (tableaux, formules LaTeX, etc.)
|
| 97 |
+
📊 des graphiques (sortie des graphiques en JSON)
|
| 98 |
+
📐 des formes géométriques (dans TikZ)
|
| 99 |
+
🎼 des partitions de musique
|
| 100 |
+
""",
|
| 101 |
+
'tweet_6':
|
| 102 |
+
"""
|
| 103 |
+
Les auteurs ont rapporté différentes métriques et il semble qu'en dépit de sa petite taille, le modèle soit SOTA dans de nombreux benchmarks !
|
| 104 |
+
""",
|
| 105 |
+
'ressources':
|
| 106 |
+
"""
|
| 107 |
+
Ressources :
|
| 108 |
+
[General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704)
|
| 109 |
+
de Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang (2024)
|
| 110 |
+
[GitHub](https://github.com/Ucas-HaoranWei/GOT-OCR2.0/)
|
| 111 |
+
[Modèle](https://huggingface.co/stepfun-ai/GOT-OCR2_0)
|
| 112 |
+
"""
|
| 113 |
+
}
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def language_selector():
|
| 118 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 119 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 120 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 121 |
+
|
| 122 |
+
left_column, right_column = st.columns([5, 1])
|
| 123 |
+
|
| 124 |
+
# Add a selector to the right column
|
| 125 |
+
with right_column:
|
| 126 |
+
lang = language_selector()
|
| 127 |
+
|
| 128 |
+
# Add a title to the left column
|
| 129 |
+
with left_column:
|
| 130 |
+
st.title(translations[lang]["title"])
|
| 131 |
+
|
| 132 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
|
| 135 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 136 |
+
st.markdown(""" """)
|
| 137 |
+
|
| 138 |
+
st.image("pages/GOT/image_1.png", use_column_width=True)
|
| 139 |
+
st.markdown(""" """)
|
| 140 |
+
|
| 141 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
|
| 144 |
+
st.image("pages/GOT/image_2.png", use_column_width=True)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
|
| 147 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
|
| 150 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 151 |
+
st.markdown(""" """)
|
| 152 |
+
|
| 153 |
+
st.image("pages/GOT/image_3.png", use_column_width=True)
|
| 154 |
+
st.markdown(""" """)
|
| 155 |
+
|
| 156 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 157 |
+
st.markdown(""" """)
|
| 158 |
+
|
| 159 |
+
st.image("pages/GOT/image_4.png", use_column_width=True)
|
| 160 |
+
st.markdown(""" """)
|
| 161 |
+
|
| 162 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
|
| 165 |
+
st.image("pages/GOT/image_5.png", use_column_width=True)
|
| 166 |
+
st.markdown(""" """)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 170 |
+
|
| 171 |
+
st.markdown(""" """)
|
| 172 |
+
st.markdown(""" """)
|
| 173 |
+
st.markdown(""" """)
|
| 174 |
+
col1, col2, col3= st.columns(3)
|
| 175 |
+
with col1:
|
| 176 |
+
if lang == "en":
|
| 177 |
+
if st.button('Previous paper', use_container_width=True):
|
| 178 |
+
switch_page("NVLM")
|
| 179 |
+
else:
|
| 180 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 181 |
+
switch_page("NVLM")
|
| 182 |
+
with col2:
|
| 183 |
+
if lang == "en":
|
| 184 |
+
if st.button("Home", use_container_width=True):
|
| 185 |
+
switch_page("Home")
|
| 186 |
+
else:
|
| 187 |
+
if st.button("Accueil", use_container_width=True):
|
| 188 |
+
switch_page("Home")
|
| 189 |
+
with col3:
|
| 190 |
+
if lang == "en":
|
| 191 |
+
if st.button("Next paper", use_container_width=True):
|
| 192 |
+
switch_page("Home")
|
| 193 |
+
else:
|
| 194 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 195 |
+
switch_page("Home")
|
pages/GOT/image_1.png
ADDED

|
pages/GOT/image_2.png
ADDED
|
pages/GOT/image_3.png
ADDED
|
pages/GOT/image_4.png
ADDED

|
pages/GOT/image_5.png
ADDED
|