Spaces:
Runtime error

Runtime error
Multilingual version
#1
by
lbourdois
- opened
This view is limited to 50 files because it contains too many changes.
See the raw diff here.
- .gitattributes +3 -0
- Home.py +59 -11
- README.md +1 -1
- Turkish_girl_from_back_sitting_at_a_desk_writing_view_on_an_old_castle_in_a_window_wehre_a_cat_lying_ghibli_anime_like_hd.jpg +0 -0
- pages/0_KOSMOS-2.py +214 -0
- pages/10_LLaVA-NeXT.py +196 -0
- pages/11_Painter.py +129 -0
- pages/12_SegGPT.py +184 -0
- pages/13_Grounding_DINO.py +229 -0
- pages/14_DocOwl_1.5.py +217 -0
- pages/15_MiniGemini.py +165 -0
- pages/16_PLLaVA.py +155 -0
- pages/17_CuMo.py +140 -0
- pages/18_DenseConnector.py +156 -0
- pages/19_Depth_Anything_V2.py +167 -0
- pages/1_MobileSAM.py +134 -41
- pages/20_Florence-2.py +176 -0
- pages/21_4M-21.py +156 -0
- pages/22_RT-DETR.py +156 -0
- pages/23_ColPali.py +186 -0
- pages/24_Llava-NeXT-Interleave.py +208 -0
- pages/25_Chameleon.py +192 -0
- pages/26_Video-LLaVA.py +191 -0
- pages/27_SAMv2.py +187 -0
- pages/28_NVEagle.py +165 -0
- pages/29_NVLM.py +167 -0
- pages/2_Oneformer.py +145 -29
- pages/30_GOT.py +195 -0
- pages/31_Aria.py +187 -0
- pages/3_VITMAE.py +117 -30
- pages/4_DINOv2.py +141 -43
- pages/5_SigLIP.py +155 -41
- pages/6_OWLv2.py +155 -45
- pages/7_Backbone.py +200 -30
- pages/8_Depth_Anything.py +331 -61
- pages/9_UDOP.py +172 -0
- pages/Aria/image_0.png +3 -0
- pages/Aria/image_1.png +0 -0
- pages/Aria/image_2.png +3 -0
- pages/Aria/image_3.png +0 -0
- pages/Aria/image_4.png +0 -0
- pages/Aria/video_1.mp4 +0 -0
- pages/ColPali/image_1.jpg +0 -0
- pages/ColPali/image_2.jpg +0 -0
- pages/ColPali/image_3.jpg +0 -0
- pages/ColPali/image_4.jpg +0 -0
- pages/ColPali/image_5.jpg +0 -0
- pages/GOT/image_1.png +0 -0
- pages/GOT/image_2.png +0 -0
- pages/GOT/image_3.png +0 -0
.gitattributes
CHANGED
|
@@ -36,3 +36,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 36 |
pages/4M-21/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
pages/Depth[[:space:]]Anything/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
pages/RT-DETR/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 36 |
pages/4M-21/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
pages/Depth[[:space:]]Anything/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
pages/RT-DETR/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
pages/KOSMOS-2/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
pages/Aria/image_0.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
pages/Aria/image_2.png filter=lfs diff=lfs merge=lfs -text
|
Home.py
CHANGED
|
@@ -2,17 +2,65 @@ import streamlit as st
|
|
| 2 |
|
| 3 |
st.set_page_config(page_title="Home",page_icon="🏠")
|
| 4 |
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
st.markdown(
|
| 11 |
"""
|
| 12 |
-
This app contains all of my paper posts on X for your convenience!
|
| 13 |
-
|
| 14 |
-
Start browsing papers on the left tab. 🔖
|
| 15 |
-
|
| 16 |
This app is made by an amazing human being called [Loïck Bourdois](https://x.com/BdsLoick) so please show this some love and like the Space if you think it's useful 💖
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
"""
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
st.set_page_config(page_title="Home",page_icon="🏠")
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {
|
| 7 |
+
'title': 'Vision Papers 📚',
|
| 8 |
+
'introduction':
|
|
|
|
|
|
|
| 9 |
"""
|
| 10 |
+
This app contains all of my paper posts on [X](https://x.com/mervenoyann) for your convenience!
|
| 11 |
+
Start browsing papers on the left tab 🔖
|
|
|
|
|
|
|
| 12 |
This app is made by an amazing human being called [Loïck Bourdois](https://x.com/BdsLoick) so please show this some love and like the Space if you think it's useful 💖
|
| 13 |
+
""",
|
| 14 |
+
'extra_content':
|
| 15 |
+
"""
|
| 16 |
+
Beyond this pack of summaries of papers, if you'd like to dig deeper into the subject of vision language models, you can check out some of the other resources I've been working on 👩🔬:
|
| 17 |
+
* This [collection](https://hf.co/collections/merve/vision-language-models-papers-66264531f7152ac0ec80ceca) of papers (listing models which are not summarized in this Space but which may be of interest) 📄
|
| 18 |
+
* Tasks that can be handled by these models, such as [Document Question Answering](https://huggingface.co/tasks/document-question-answering), [Image-Text-to-Text](https://huggingface.co/tasks/image-text-to-text) or [Visual Question Answering](https://huggingface.co/tasks/visual-question-answering)
|
| 19 |
+
* Blog posts on [ConvNets](https://merveenoyan.medium.com/complete-guide-on-deep-learning-architectures-chapter-1-on-convnets-1d3e8086978d), [Autoencoders](https://merveenoyan.medium.com/complete-guide-on-deep-learning-architectures-part-2-autoencoders-293351bbe027), [explaining vision language models](https://huggingface.co/blog/vlms), [finetuning it with TRL](https://huggingface.co/blog/dpo_vlm) and the announcement of certain models such as [PaliGemma](https://huggingface.co/blog/paligemma) ✍️
|
| 20 |
+
* A GitHub repository containing various notebooks taking full advantage of these models (optimizations, quantization, distillation, finetuning, etc.): [smol-vision](https://github.com/merveenoyan/smol-vision) ⭐
|
| 21 |
+
* A 12-minute summary YouTube video 🎥
|
| 22 |
+
"""
|
| 23 |
+
},
|
| 24 |
+
'fr': {
|
| 25 |
+
'title': 'Papiers de vision 📚',
|
| 26 |
+
'introduction':
|
| 27 |
+
"""
|
| 28 |
+
Cette appli contient tous les résumés de papiers que j'ai publiés sur [X](https://x.com/mervenoyann) afin de vous faciliter la tâche !
|
| 29 |
+
Vous avez juste à parcourir l'onglet de gauche 🔖
|
| 30 |
+
Cette application a été créée par un être humain extraordinaire, [Loïck Bourdois](https://x.com/BdsLoick), alors s'il vous plaît montrez-lui un peu d'amour et aimez le Space si vous le pensez utile 💖
|
| 31 |
+
""",
|
| 32 |
+
'extra_content':
|
| 33 |
+
"""
|
| 34 |
+
Au delà de ce pack de résumés de papiers, si vous souhaitez creuser le sujet des modèles de langage/vision, vous pouvez consulter d'autres ressources sur lesquelles j'ai travaillées 👩🔬:
|
| 35 |
+
* Cette [collection](https://hf.co/collections/merve/vision-language-models-papers-66264531f7152ac0ec80ceca) de papiers sur le sujet (listant des modèles non résumés dans ce Space qui pourraient tout de même vous intéresser) 📄
|
| 36 |
+
* Les tâches pouvant être traitées par ces modèles comme le [Document Question Answering](https://huggingface.co/tasks/document-question-answering), l'[Image-Text-to-Text](https://huggingface.co/tasks/image-text-to-text) ou encore le [Visual Question Answering](https://huggingface.co/tasks/visual-question-answering)
|
| 37 |
+
* Des articles de blog portant sur [les ConvNets](https://merveenoyan.medium.com/complete-guide-on-deep-learning-architectures-chapter-1-on-convnets-1d3e8086978d), [les auto-encodeurs](https://merveenoyan.medium.com/complete-guide-on-deep-learning-architectures-part-2-autoencoders-293351bbe027), [l'explication des modèles de langage/vision](https://huggingface.co/blog/vlms), leur [finetuning avec TRL](https://huggingface.co/blog/dpo_vlm) ou encore l'annonce de modèles comme [PaliGemma](https://huggingface.co/blog/paligemma) ✍️
|
| 38 |
+
* Un répertoire GitHub contenant divers notebooks pour tirer le meilleur parti de ces modèles (optimisations, quantization, distillation, finetuning, etc.) : [smol-vision](https://github.com/merveenoyan/smol-vision) ⭐
|
| 39 |
+
* Une vidéo YouTube de synthèse en 12 minutes 🎥
|
| 40 |
"""
|
| 41 |
+
}
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def language_selector():
|
| 46 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 47 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 48 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 49 |
+
|
| 50 |
+
left_column, right_column = st.columns([5, 1])
|
| 51 |
+
|
| 52 |
+
# Add a selector to the right column
|
| 53 |
+
with right_column:
|
| 54 |
+
lang = language_selector()
|
| 55 |
+
|
| 56 |
+
# Add a title to the left column
|
| 57 |
+
with left_column:
|
| 58 |
+
st.title(translations[lang]['title'])
|
| 59 |
+
|
| 60 |
+
# Main app content
|
| 61 |
+
# st.image("Turkish_girl_from_back_sitting_at_a_desk_writing_view_on_an_old_castle_in_a_window_wehre_a_cat_lying_ghibli_anime_like_hd.jpg", use_column_width=True)
|
| 62 |
+
st.markdown(""" """)
|
| 63 |
+
st.write(translations[lang]['introduction'])
|
| 64 |
+
st.markdown(""" """)
|
| 65 |
+
st.write(translations[lang]['extra_content'])
|
| 66 |
+
st.video("https://www.youtube.com/watch?v=IoGaGfU1CIg", format="video/mp4")
|
README.md
CHANGED
|
@@ -6,7 +6,7 @@ colorTo: blue
|
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.37.0
|
| 8 |
app_file: Home.py
|
| 9 |
-
pinned:
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.37.0
|
| 8 |
app_file: Home.py
|
| 9 |
+
pinned: true
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
Turkish_girl_from_back_sitting_at_a_desk_writing_view_on_an_old_castle_in_a_window_wehre_a_cat_lying_ghibli_anime_like_hd.jpg
ADDED

|
pages/0_KOSMOS-2.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'KOSMOS-2',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1720126908384366649) (November 2, 2023)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
New 🤗 Transformers release includes a very powerful Multimodel Large Language Model (MLLM) by @Microsoft called KOSMOS-2! 🤩
|
| 14 |
+
The highlight of KOSMOS-2 is grounding, the model is *incredibly* accurate! 🌎
|
| 15 |
+
Play with the demo [here](https://huggingface.co/spaces/ydshieh/Kosmos-2) by [@ydshieh](https://x.com/ydshieh).
|
| 16 |
+
But how does this model work? Let's take a look! 👀🧶
|
| 17 |
+
""",
|
| 18 |
+
'tweet_2':
|
| 19 |
+
"""
|
| 20 |
+
Grounding helps machine learning models relate to real-world examples. Including grounding makes models more performant by means of accuracy and robustness during inference. It also helps reduce the so-called "hallucinations" in language models.
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
In KOSMOS-2, model is grounded to perform following tasks and is evaluated on 👇
|
| 25 |
+
- multimodal grounding & phrase grounding, e.g. localizing the object through natural language query
|
| 26 |
+
- multimodal referring, e.g. describing object characteristics & location
|
| 27 |
+
- perception-language tasks
|
| 28 |
+
- language understanding and generation
|
| 29 |
+
""",
|
| 30 |
+
'tweet_4':
|
| 31 |
+
"""
|
| 32 |
+
The dataset used for grounding, called GRiT is also available on [Hugging Face Hub](https://huggingface.co/datasets/zzliang/GRIT).
|
| 33 |
+
Thanks to 🤗 Transformers integration, you can use KOSMOS-2 with few lines of code 🤩
|
| 34 |
+
See below! 👇
|
| 35 |
+
""",
|
| 36 |
+
'ressources':
|
| 37 |
+
"""
|
| 38 |
+
Ressources:
|
| 39 |
+
[Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824)
|
| 40 |
+
by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei (2023)
|
| 41 |
+
[GitHub](https://github.com/microsoft/unilm/tree/master/kosmos-2)
|
| 42 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/kosmos-2)
|
| 43 |
+
"""
|
| 44 |
+
},
|
| 45 |
+
'fr': {
|
| 46 |
+
'title': 'KOSMOS-2',
|
| 47 |
+
'original_tweet':
|
| 48 |
+
"""
|
| 49 |
+
[Tweet de base](https://x.com/mervenoyann/status/1720126908384366649) (en anglais) (2 novembre 2023)
|
| 50 |
+
""",
|
| 51 |
+
'tweet_1':
|
| 52 |
+
"""
|
| 53 |
+
La nouvelle version de 🤗 Transformers inclut un très puissant <i>Multimodel Large Language Model</i> (MLLM) de @Microsoft appelé KOSMOS-2 ! 🤩
|
| 54 |
+
Le point fort de KOSMOS-2 est l'ancrage, le modèle est *incroyablement* précis ! 🌎
|
| 55 |
+
Jouez avec la démo [ici](https://huggingface.co/spaces/ydshieh/Kosmos-2) de [@ydshieh](https://x.com/ydshieh).
|
| 56 |
+
Mais comment fonctionne t'il ? Jetons un coup d'œil ! 👀🧶
|
| 57 |
+
""",
|
| 58 |
+
'tweet_2':
|
| 59 |
+
"""
|
| 60 |
+
L'ancrage permet aux modèles d'apprentissage automatique d'être liés à des exemples du monde réel. L'inclusion de l'ancrage rend les modèles plus performants en termes de précision et de robustesse lors de l'inférence. Cela permet également de réduire les « hallucinations » dans les modèles de langage. """,
|
| 61 |
+
'tweet_3':
|
| 62 |
+
"""
|
| 63 |
+
Dans KOSMOS-2, le modèle est ancré pour effectuer les tâches suivantes et est évalué sur 👇
|
| 64 |
+
- l'ancrage multimodal et l'ancrage de phrases, par exemple la localisation de l'objet par le biais d'une requête en langage naturel
|
| 65 |
+
- la référence multimodale, par exemple la description des caractéristiques et de l'emplacement de l'objet
|
| 66 |
+
- tâches de perception-langage
|
| 67 |
+
- compréhension et génération du langage
|
| 68 |
+
""",
|
| 69 |
+
'tweet_4':
|
| 70 |
+
"""
|
| 71 |
+
Le jeu de données utilisé pour l'ancrage, appelé GRiT, est également disponible sur le [Hub d'Hugging Face](https://huggingface.co/datasets/zzliang/GRIT).
|
| 72 |
+
Grâce à l'intégration dans 🤗 Transformers, vous pouvez utiliser KOSMOS-2 avec quelques lignes de code 🤩.
|
| 73 |
+
Voir ci-dessous ! 👇
|
| 74 |
+
""",
|
| 75 |
+
'ressources':
|
| 76 |
+
"""
|
| 77 |
+
Ressources :
|
| 78 |
+
[Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824)
|
| 79 |
+
de Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei (2023)
|
| 80 |
+
[GitHub](https://github.com/microsoft/unilm/tree/master/kosmos-2)
|
| 81 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/kosmos-2)
|
| 82 |
+
"""
|
| 83 |
+
}
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def language_selector():
|
| 88 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 89 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 90 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 91 |
+
|
| 92 |
+
left_column, right_column = st.columns([5, 1])
|
| 93 |
+
|
| 94 |
+
# Add a selector to the right column
|
| 95 |
+
with right_column:
|
| 96 |
+
lang = language_selector()
|
| 97 |
+
|
| 98 |
+
# Add a title to the left column
|
| 99 |
+
with left_column:
|
| 100 |
+
st.title(translations[lang]["title"])
|
| 101 |
+
|
| 102 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 103 |
+
st.markdown(""" """)
|
| 104 |
+
|
| 105 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 106 |
+
st.markdown(""" """)
|
| 107 |
+
|
| 108 |
+
st.video("pages/KOSMOS-2/video_1.mp4", format="video/mp4")
|
| 109 |
+
st.markdown(""" """)
|
| 110 |
+
|
| 111 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 115 |
+
st.markdown(""" """)
|
| 116 |
+
|
| 117 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.image("pages/KOSMOS-2/image_1.jpg", use_column_width=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
with st.expander ("Code"):
|
| 124 |
+
if lang == "en":
|
| 125 |
+
st.code("""
|
| 126 |
+
from transformers import AutoProcessor, AutoModelForVision2Seq
|
| 127 |
+
|
| 128 |
+
model = AutoModelForVision2Seq.from_pretrained("microsoft/kosmos-2-patch14-224").to("cuda")
|
| 129 |
+
processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
|
| 130 |
+
|
| 131 |
+
image_input = Image.open(user_image_path)
|
| 132 |
+
# prepend different preprompts optionally to describe images
|
| 133 |
+
brief_preprompt = "<grounding>An image of"
|
| 134 |
+
detailed_preprompt = "<grounding>Describe this image in detail:"
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
inputs = processor(text=text_input, images=image_input, return_tensors="pt").to("cuda")
|
| 138 |
+
|
| 139 |
+
generated_ids = model.generate(
|
| 140 |
+
pixel_values=inputs["pixel_values"],
|
| 141 |
+
input_ids=inputs["input_ids"],
|
| 142 |
+
attention_mask=inputs["attention_mask"],
|
| 143 |
+
image_embeds=None,
|
| 144 |
+
image_embeds_position_mask=inputs["image_embeds_position_mask"],
|
| 145 |
+
use_cache=True,
|
| 146 |
+
max_new_tokens=128,
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 150 |
+
|
| 151 |
+
processed_text, entities = processor.post_process_generation(generated_text)
|
| 152 |
+
|
| 153 |
+
# check out the Space for inference with bbox drawing
|
| 154 |
+
""")
|
| 155 |
+
else:
|
| 156 |
+
st.code("""
|
| 157 |
+
from transformers import AutoProcessor, AutoModelForVision2Seq
|
| 158 |
+
|
| 159 |
+
model = AutoModelForVision2Seq.from_pretrained("microsoft/kosmos-2-patch14-224").to("cuda")
|
| 160 |
+
processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
|
| 161 |
+
|
| 162 |
+
image_input = Image.open(user_image_path)
|
| 163 |
+
# ajouter différents préprompts facultatifs pour décrire les images
|
| 164 |
+
brief_preprompt = "<grounding>An image of"
|
| 165 |
+
detailed_preprompt = "<grounding>Describe this image in detail:"
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
inputs = processor(text=text_input, images=image_input, return_tensors="pt").to("cuda")
|
| 169 |
+
|
| 170 |
+
generated_ids = model.generate(
|
| 171 |
+
pixel_values=inputs["pixel_values"],
|
| 172 |
+
input_ids=inputs["input_ids"],
|
| 173 |
+
attention_mask=inputs["attention_mask"],
|
| 174 |
+
image_embeds=None,
|
| 175 |
+
image_embeds_position_mask=inputs["image_embeds_position_mask"],
|
| 176 |
+
use_cache=True,
|
| 177 |
+
max_new_tokens=128,
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 181 |
+
|
| 182 |
+
processed_text, entities = processor.post_process_generation(generated_text)
|
| 183 |
+
|
| 184 |
+
# consultez le Space pour l'inférence avec le tracé des bbox
|
| 185 |
+
""")
|
| 186 |
+
st.markdown(""" """)
|
| 187 |
+
|
| 188 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 189 |
+
|
| 190 |
+
st.markdown(""" """)
|
| 191 |
+
st.markdown(""" """)
|
| 192 |
+
st.markdown(""" """)
|
| 193 |
+
col1, col2, col3= st.columns(3)
|
| 194 |
+
with col1:
|
| 195 |
+
if lang == "en":
|
| 196 |
+
if st.button('Previous paper', use_container_width=True):
|
| 197 |
+
switch_page("Home")
|
| 198 |
+
else:
|
| 199 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 200 |
+
switch_page("Home")
|
| 201 |
+
with col2:
|
| 202 |
+
if lang == "en":
|
| 203 |
+
if st.button("Home", use_container_width=True):
|
| 204 |
+
switch_page("Home")
|
| 205 |
+
else:
|
| 206 |
+
if st.button("Accueil", use_container_width=True):
|
| 207 |
+
switch_page("Home")
|
| 208 |
+
with col3:
|
| 209 |
+
if lang == "en":
|
| 210 |
+
if st.button("Next paper", use_container_width=True):
|
| 211 |
+
switch_page("MobileSAM")
|
| 212 |
+
else:
|
| 213 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 214 |
+
switch_page("MobileSAM")
|
pages/10_LLaVA-NeXT.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'LLaVA-NeXT',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1770832875551682563) (March 21, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
LLaVA-NeXT is recently merged to 🤗 Transformers and it outperforms many of the proprietary models like Gemini on various benchmarks!🤩
|
| 14 |
+
For those who don't know LLaVA, it's a language model that can take image 💬
|
| 15 |
+
Let's take a look, demo and more in this.
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
LLaVA is essentially a vision-language model that consists of ViT-based CLIP encoder, a MLP projection and Vicuna as decoder ✨
|
| 20 |
+
LLaVA 1.5 was released with Vicuna, but LLaVA NeXT (1.6) is released with four different LLMs:
|
| 21 |
+
- Nous-Hermes-Yi-34B
|
| 22 |
+
- Mistral-7B
|
| 23 |
+
- Vicuna 7B & 13B
|
| 24 |
+
""",
|
| 25 |
+
'tweet_3':
|
| 26 |
+
"""
|
| 27 |
+
Thanks to 🤗 Transformers integration, it is very easy to use LLaVA NeXT, not only standalone but also with 4-bit loading and Flash Attention 2 💜
|
| 28 |
+
See below on standalone usage 👇
|
| 29 |
+
""",
|
| 30 |
+
'tweet_4':
|
| 31 |
+
"""
|
| 32 |
+
To fit large models and make it even faster and memory efficient, you can enable Flash Attention 2 and load model into 4-bit using bitsandbytes ⚡️ transformers makes it very easy to do this! See below 👇
|
| 33 |
+
""",
|
| 34 |
+
'tweet_5':
|
| 35 |
+
"""
|
| 36 |
+
If you want to try the code right away, here's the [notebook](https://t.co/NvoxvY9z1u).
|
| 37 |
+
Lastly, you can directly play with the LLaVA-NeXT based on Mistral-7B through the demo [here](https://t.co/JTDlqMUwEh) 🤗
|
| 38 |
+
""",
|
| 39 |
+
'ressources':
|
| 40 |
+
"""
|
| 41 |
+
Ressources:
|
| 42 |
+
[LLaVA-NeXT: Improved reasoning, OCR, and world knowledge](https://llava-vl.github.io/blog/2024-01-30-llava-next/)
|
| 43 |
+
by Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee (2024)
|
| 44 |
+
[GitHub](https://github.com/haotian-liu/LLaVA/tree/main)
|
| 45 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/llava_next)
|
| 46 |
+
"""
|
| 47 |
+
},
|
| 48 |
+
'fr': {
|
| 49 |
+
'title': 'LLaVA-NeXT',
|
| 50 |
+
'original_tweet':
|
| 51 |
+
"""
|
| 52 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1770832875551682563) (en anglais) (21 mars 2024)
|
| 53 |
+
""",
|
| 54 |
+
'tweet_1':
|
| 55 |
+
"""
|
| 56 |
+
LLaVA-NeXT a récemment été intégré à 🤗 Transformers et surpasse de nombreux modèles propriétaires comme Gemini sur différents benchmarks !🤩
|
| 57 |
+
Pour ceux qui ne connaissent pas LLaVA, il s'agit d'un modèle de langage qui peut prendre des images 💬.
|
| 58 |
+
""",
|
| 59 |
+
'tweet_2':
|
| 60 |
+
"""
|
| 61 |
+
LLaVA est essentiellement un modèle langage/vision qui se compose d'un encodeur CLIP basé sur ViT, d'une projection MLP et de Vicuna en tant que décodeur ✨.
|
| 62 |
+
LLaVA 1.5 a été publié avec Vicuna, mais LLaVA NeXT (1.6) est publié avec quatre LLM différents :
|
| 63 |
+
- Nous-Hermes-Yi-34B
|
| 64 |
+
- Mistral-7B
|
| 65 |
+
- Vicuna 7B & 13B
|
| 66 |
+
""",
|
| 67 |
+
'tweet_3':
|
| 68 |
+
"""
|
| 69 |
+
Grâce à l'intégration dans 🤗 Transformers, il est très facile d'utiliser LLaVA NeXT, non seulement en mode autonome mais aussi avec un chargement 4 bits et Flash Attention 2 💜.
|
| 70 |
+
Voir ci-dessous pour l'utilisation autonome 👇
|
| 71 |
+
""",
|
| 72 |
+
'tweet_4':
|
| 73 |
+
"""
|
| 74 |
+
Pour entraîner des grands modèles et les rendre encore plus rapides et efficaces en termes de mémoire, vous pouvez activer Flash Attention 2 et charger le modèle en 4 bits à l'aide de bitsandbytes ⚡️ ! Voir ci-dessous 👇 """,
|
| 75 |
+
'tweet_5':
|
| 76 |
+
"""
|
| 77 |
+
Si vous voulez essayer le code tout de suite, voici le [notebook](https://t.co/NvoxvY9z1u).
|
| 78 |
+
Enfin, vous pouvez directement jouer avec le LLaVA-NeXT reposant sur Mistral-7B grâce à cette [démo](https://t.co/JTDlqMUwEh) 🤗
|
| 79 |
+
""",
|
| 80 |
+
'ressources':
|
| 81 |
+
"""
|
| 82 |
+
Ressources :
|
| 83 |
+
[LLaVA-NeXT: Improved reasoning, OCR, and world knowledge](https://llava-vl.github.io/blog/2024-01-30-llava-next/)
|
| 84 |
+
de Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee (2024)
|
| 85 |
+
[GitHub](https://github.com/haotian-liu/LLaVA/tree/main)
|
| 86 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/llava_next)
|
| 87 |
+
"""
|
| 88 |
+
}
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def language_selector():
|
| 93 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 94 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 95 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 96 |
+
|
| 97 |
+
left_column, right_column = st.columns([5, 1])
|
| 98 |
+
|
| 99 |
+
# Add a selector to the right column
|
| 100 |
+
with right_column:
|
| 101 |
+
lang = language_selector()
|
| 102 |
+
|
| 103 |
+
# Add a title to the left column
|
| 104 |
+
with left_column:
|
| 105 |
+
st.title(translations[lang]["title"])
|
| 106 |
+
|
| 107 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 108 |
+
st.markdown(""" """)
|
| 109 |
+
|
| 110 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 111 |
+
st.markdown(""" """)
|
| 112 |
+
|
| 113 |
+
st.image("pages/LLaVA-NeXT/image_1.jpeg", use_column_width=True)
|
| 114 |
+
st.markdown(""" """)
|
| 115 |
+
|
| 116 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 117 |
+
st.markdown(""" """)
|
| 118 |
+
|
| 119 |
+
st.image("pages/LLaVA-NeXT/image_2.jpeg", use_column_width=True)
|
| 120 |
+
st.markdown(""" """)
|
| 121 |
+
|
| 122 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 123 |
+
st.markdown(""" """)
|
| 124 |
+
|
| 125 |
+
st.image("pages/LLaVA-NeXT/image_3.jpeg", use_column_width=True)
|
| 126 |
+
st.markdown(""" """)
|
| 127 |
+
|
| 128 |
+
with st.expander ("Code"):
|
| 129 |
+
st.code("""
|
| 130 |
+
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
|
| 131 |
+
import torch
|
| 132 |
+
|
| 133 |
+
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
|
| 134 |
+
|
| 135 |
+
model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
| 136 |
+
model.to("cuda:0")
|
| 137 |
+
|
| 138 |
+
inputs = processor(prompt, image, return_tensors="pt").to("cuda:0")
|
| 139 |
+
|
| 140 |
+
output = model.generate(**inputs, max_new_tokens=100)
|
| 141 |
+
print(processor.decode(output[0], skip_special_tokens=True))
|
| 142 |
+
""")
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
|
| 145 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 146 |
+
st.markdown(""" """)
|
| 147 |
+
|
| 148 |
+
st.image("pages/LLaVA-NeXT/image_4.jpeg", use_column_width=True)
|
| 149 |
+
st.markdown(""" """)
|
| 150 |
+
|
| 151 |
+
with st.expander ("Code"):
|
| 152 |
+
st.code("""
|
| 153 |
+
from transformers import LlavaNextForConditionalGeneration, BitsandBytesconfig
|
| 154 |
+
|
| 155 |
+
# 4bit
|
| 156 |
+
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtpe="torch.float16")
|
| 157 |
+
model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", quantization_config=quantization_config, device_map="auto")
|
| 158 |
+
|
| 159 |
+
# Flash Attention 2
|
| 160 |
+
model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True, use_flash_attention_2=True).to(0)
|
| 161 |
+
""")
|
| 162 |
+
st.markdown(""" """)
|
| 163 |
+
|
| 164 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 165 |
+
st.markdown(""" """)
|
| 166 |
+
|
| 167 |
+
st.video("pages/LLaVA-NeXT//video_1.mp4", format="video/mp4")
|
| 168 |
+
st.markdown(""" """)
|
| 169 |
+
|
| 170 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 171 |
+
|
| 172 |
+
st.markdown(""" """)
|
| 173 |
+
st.markdown(""" """)
|
| 174 |
+
st.markdown(""" """)
|
| 175 |
+
col1, col2, col3= st.columns(3)
|
| 176 |
+
with col1:
|
| 177 |
+
if lang == "en":
|
| 178 |
+
if st.button('Previous paper', use_container_width=True):
|
| 179 |
+
switch_page("UDOP")
|
| 180 |
+
else:
|
| 181 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 182 |
+
switch_page("UDOP")
|
| 183 |
+
with col2:
|
| 184 |
+
if lang == "en":
|
| 185 |
+
if st.button("Home", use_container_width=True):
|
| 186 |
+
switch_page("Home")
|
| 187 |
+
else:
|
| 188 |
+
if st.button("Accueil", use_container_width=True):
|
| 189 |
+
switch_page("Home")
|
| 190 |
+
with col3:
|
| 191 |
+
if lang == "en":
|
| 192 |
+
if st.button("Next paper", use_container_width=True):
|
| 193 |
+
switch_page("Painter")
|
| 194 |
+
else:
|
| 195 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 196 |
+
switch_page("Painter")
|
pages/11_Painter.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Painter',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1771542172946354643) (March 23, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
I read the Painter [paper](https://t.co/r3aHp29mjf) by [BAAIBeijing](https://x.com/BAAIBeijing) to convert the weights to 🤗 Transformers, and I absolutely loved the approach they took so I wanted to take time to unfold it here!
|
| 14 |
+
""",
|
| 15 |
+
'tweet_2':
|
| 16 |
+
"""
|
| 17 |
+
So essentially this model takes inspiration from in-context learning, as in, in LLMs you give an example input output and give the actual input that you want model to complete (one-shot learning) they adapted this to images, thus the name "images speak in images".
|
| 18 |
+
<br>
|
| 19 |
+
This model doesn't have any multimodal parts, it just has an image encoder and a decoder head (linear layer, conv layer, another linear layer) so it's a single modality.
|
| 20 |
+
<br>
|
| 21 |
+
The magic sauce is the data: they input the task in the form of image and associated transformation and another image they want the transformation to take place and take smooth L2 loss over the predictions and ground truth this is like T5 of image models 😀
|
| 22 |
+
""",
|
| 23 |
+
'tweet_3':
|
| 24 |
+
"""
|
| 25 |
+
What is so cool about it is that it can actually adapt to out of domain tasks, meaning, in below chart, it was trained on the tasks above the dashed line, and the authors found out it generalized to the tasks below the line, image tasks are well generalized 🤯
|
| 26 |
+
""",
|
| 27 |
+
'ressources':
|
| 28 |
+
"""
|
| 29 |
+
Ressources:
|
| 30 |
+
[Images Speak in Images: A Generalist Painter for In-Context Visual Learning](https://arxiv.org/abs/2212.02499)
|
| 31 |
+
by Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, Tiejun Huang (2022)
|
| 32 |
+
[GitHub](https://github.com/baaivision/Painter)
|
| 33 |
+
"""
|
| 34 |
+
},
|
| 35 |
+
'fr': {
|
| 36 |
+
'title': 'Painter',
|
| 37 |
+
'original_tweet':
|
| 38 |
+
"""
|
| 39 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1771542172946354643) (en anglais) (23 mars 2024)
|
| 40 |
+
""",
|
| 41 |
+
'tweet_1':
|
| 42 |
+
"""
|
| 43 |
+
Pour pouvoir convertir les poids du Painter de [BAAIBeijing](https://x.com/BAAIBeijing) dans 🤗 Transformers, j'ai lu le [papier](https://t.co/r3aHp29mjf) et ai absolument adoré l'approche qu'ils ont adoptée. Donc j'ai voulu prendre le temps de l'exposer ici !
|
| 44 |
+
""",
|
| 45 |
+
'tweet_2':
|
| 46 |
+
"""
|
| 47 |
+
Ce modèle s'inspire donc essentiellement de l'apprentissage en contexte, c'est-à-dire que dans les LLM, vous donnez un exemple d'entrée et de sortie et vous donnez l'entrée réelle que vous voulez que le modèle complète (apprentissage 1-shot). Ils ont adapté cette méthode aux images, d'où le nom "images speak in images" (les images parlent en images).
|
| 48 |
+
<br>
|
| 49 |
+
Ce modèle ne comporte aucune partie multimodale, mais seulement un encodeur d'images et une tête de décodage (couche linéaire, couche de convolution et autre couche linéaire), de sorte qu'il s'agit d'une modalité unique.
|
| 50 |
+
<br>
|
| 51 |
+
La sauce magique, ce sont les données : ils introduisent la tâche sous la forme d'une image et d'une transformation associée, ainsi qu'une autre image qu'ils veulent transformer, et prennent une perte L2 lisse sur les prédictions et la vérité de terrain. C'est le T5 des modèles d'image 😀.
|
| 52 |
+
""",
|
| 53 |
+
'tweet_3':
|
| 54 |
+
"""
|
| 55 |
+
Ce qui est particulièrement intéressant, c'est qu'il peut s'adapter à des tâches hors domaine, c'est-à-dire que dans le graphique ci-dessous, il a été entraîné sur les tâches situées au-dessus de la ligne pointillée, et les auteurs ont découvert qu'il s'adaptait aux tâches situées en dessous de la ligne. Les tâches liées à l'image sont bien généralisées 🤯 """,
|
| 56 |
+
'ressources':
|
| 57 |
+
"""
|
| 58 |
+
Ressources :
|
| 59 |
+
[Images Speak in Images: A Generalist Painter for In-Context Visual Learning](https://arxiv.org/abs/2212.02499)
|
| 60 |
+
de Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, Tiejun Huang (2022)
|
| 61 |
+
[GitHub](https://github.com/baaivision/Painter)
|
| 62 |
+
"""
|
| 63 |
+
}
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def language_selector():
|
| 68 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 69 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 70 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 71 |
+
|
| 72 |
+
left_column, right_column = st.columns([5, 1])
|
| 73 |
+
|
| 74 |
+
# Add a selector to the right column
|
| 75 |
+
with right_column:
|
| 76 |
+
lang = language_selector()
|
| 77 |
+
|
| 78 |
+
# Add a title to the left column
|
| 79 |
+
with left_column:
|
| 80 |
+
st.title(translations[lang]["title"])
|
| 81 |
+
|
| 82 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 83 |
+
st.markdown(""" """)
|
| 84 |
+
|
| 85 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 86 |
+
st.markdown(""" """)
|
| 87 |
+
|
| 88 |
+
st.image("pages/Painter/image_1.jpeg", use_column_width=True)
|
| 89 |
+
st.markdown(""" """)
|
| 90 |
+
|
| 91 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 92 |
+
st.markdown(""" """)
|
| 93 |
+
|
| 94 |
+
st.image("pages/Painter/image_2.jpeg", use_column_width=True)
|
| 95 |
+
st.markdown(""" """)
|
| 96 |
+
|
| 97 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 98 |
+
st.markdown(""" """)
|
| 99 |
+
|
| 100 |
+
st.image("pages/Painter/image_3.jpeg", use_column_width=True)
|
| 101 |
+
st.markdown(""" """)
|
| 102 |
+
|
| 103 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 104 |
+
|
| 105 |
+
st.markdown(""" """)
|
| 106 |
+
st.markdown(""" """)
|
| 107 |
+
st.markdown(""" """)
|
| 108 |
+
col1, col2, col3= st.columns(3)
|
| 109 |
+
with col1:
|
| 110 |
+
if lang == "en":
|
| 111 |
+
if st.button('Previous paper', use_container_width=True):
|
| 112 |
+
switch_page("LLaVA-NeXT")
|
| 113 |
+
else:
|
| 114 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 115 |
+
switch_page("LLaVA-NeXT")
|
| 116 |
+
with col2:
|
| 117 |
+
if lang == "en":
|
| 118 |
+
if st.button("Home", use_container_width=True):
|
| 119 |
+
switch_page("Home")
|
| 120 |
+
else:
|
| 121 |
+
if st.button("Accueil", use_container_width=True):
|
| 122 |
+
switch_page("Home")
|
| 123 |
+
with col3:
|
| 124 |
+
if lang == "en":
|
| 125 |
+
if st.button("Next paper", use_container_width=True):
|
| 126 |
+
switch_page("SegGPT")
|
| 127 |
+
else:
|
| 128 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 129 |
+
switch_page("SegGPT")
|
pages/12_SegGPT.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'SegGPT',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1773056450790666568) (March 27, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
SegGPT is a vision generalist on image segmentation, quite like GPT for computer vision ✨
|
| 14 |
+
It comes with the last release of 🤗 Transformers 🎁
|
| 15 |
+
Technical details, demo and how-to's under this!
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
SegGPT is an extension of the <a href='Painter' target='_self'>Painter</a> where you speak to images with images: the model takes in an image prompt, transformed version of the image prompt, the actual image you want to see the same transform, and expected to output the transformed image.
|
| 20 |
+
<br>
|
| 21 |
+
SegGPT consists of a vanilla ViT with a decoder on top (linear, conv, linear). The model is trained on diverse segmentation examples, where they provide example image-mask pairs, the actual input to be segmented, and the decoder head learns to reconstruct the mask output. 👇🏻
|
| 22 |
+
""",
|
| 23 |
+
'tweet_3':
|
| 24 |
+
"""
|
| 25 |
+
This generalizes pretty well!
|
| 26 |
+
The authors do not claim state-of-the-art results as the model is mainly used zero-shot and few-shot inference. They also do prompt tuning, where they freeze the parameters of the model and only optimize the image tensor (the input context).
|
| 27 |
+
""",
|
| 28 |
+
'tweet_4':
|
| 29 |
+
"""
|
| 30 |
+
Thanks to 🤗 Transformers you can use this model easily! See [here](https://t.co/U5pVpBhkfK).
|
| 31 |
+
""",
|
| 32 |
+
'tweet_5':
|
| 33 |
+
"""
|
| 34 |
+
I have built an app for you to try it out. I combined SegGPT with Depth Anything Model, so you don't have to upload image mask prompts in your prompt pair 🤗
|
| 35 |
+
Try it [here](https://t.co/uJIwqJeYUy). Also check out the [collection](https://t.co/HvfjWkAEzP).
|
| 36 |
+
""",
|
| 37 |
+
'ressources':
|
| 38 |
+
"""
|
| 39 |
+
Ressources:
|
| 40 |
+
[SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284)
|
| 41 |
+
by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang (2023)
|
| 42 |
+
[GitHub](https://github.com/baaivision/Painter)
|
| 43 |
+
"""
|
| 44 |
+
},
|
| 45 |
+
'fr': {
|
| 46 |
+
'title': 'SegGPT',
|
| 47 |
+
'original_tweet':
|
| 48 |
+
"""
|
| 49 |
+
[Tweet de base](https://x.com/mervenoyann/status/1773056450790666568) (en anglais) (27 mars 2024)
|
| 50 |
+
""",
|
| 51 |
+
'tweet_1':
|
| 52 |
+
"""
|
| 53 |
+
SegGPT est un modèle généraliste de vision pour la segmentation d'images; c'est un peu comme le GPT pour la vision par ordinateur ✨.
|
| 54 |
+
Il est intégré à la dernière version de 🤗 Transformers 🎁
|
| 55 |
+
Détails techniques, démonstrations et manières de l'utiliser ci-dessous !
|
| 56 |
+
""",
|
| 57 |
+
'tweet_2':
|
| 58 |
+
"""
|
| 59 |
+
SegGPT est une extension de <a href='Painter' target='_self'>Painter</a> où vous parlez aux images avec des images : le modèle reçoit une image, une version transformée de l'image, l'image réelle que vous voulez voir avec la même transformation, et est censé produire l'image transformée.
|
| 60 |
+
<br>
|
| 61 |
+
SegGPT consiste en un ViT standard surmonté d'un décodeur (couche linéaire, convolution, couche linéaire). Le modèle est entraîné sur divers exemples de segmentation, où les auteurs fournissent des paires image-masque, l'entrée réelle à segmenter, et la tête du décodeur apprend à reconstruire la sortie du masque. 👇🏻 """,
|
| 62 |
+
'tweet_3':
|
| 63 |
+
"""
|
| 64 |
+
Cela se généralise assez bien !
|
| 65 |
+
Les auteurs ne prétendent pas obtenir des résultats de pointe, car le modèle est principalement utilisé pour l'inférence zéro-shot et few-shot. Ils effectuent également un prompt tuning, où ils gèlent les paramètres du modèle et optimisent uniquement le tenseur d'image (le contexte d'entrée).
|
| 66 |
+
""",
|
| 67 |
+
'tweet_4':
|
| 68 |
+
"""
|
| 69 |
+
Grâce à 🤗 Transformers, vous pouvez utiliser ce modèle facilement ! Voir [ici] (https://t.co/U5pVpBhkfK).
|
| 70 |
+
""",
|
| 71 |
+
'tweet_5':
|
| 72 |
+
"""
|
| 73 |
+
J'ai créé une application pour que vous puissiez l'essayer. J'ai combiné SegGPT avec Depth Anything Model, de sorte que vous n'avez pas besoin de télécharger des masques d'images dans votre paire de prompt 🤗.
|
| 74 |
+
Essayez-le [ici](https://t.co/uJIwqJeYUy). Consultez également la [collection](https://t.co/HvfjWkAEzP).
|
| 75 |
+
""",
|
| 76 |
+
'ressources':
|
| 77 |
+
"""
|
| 78 |
+
Ressources :
|
| 79 |
+
[SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284)
|
| 80 |
+
de Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang (2023)
|
| 81 |
+
[GitHub](https://github.com/baaivision/Painter)
|
| 82 |
+
"""
|
| 83 |
+
}
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def language_selector():
|
| 88 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 89 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 90 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 91 |
+
|
| 92 |
+
left_column, right_column = st.columns([5, 1])
|
| 93 |
+
|
| 94 |
+
# Add a selector to the right column
|
| 95 |
+
with right_column:
|
| 96 |
+
lang = language_selector()
|
| 97 |
+
|
| 98 |
+
# Add a title to the left column
|
| 99 |
+
with left_column:
|
| 100 |
+
st.title(translations[lang]["title"])
|
| 101 |
+
|
| 102 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 103 |
+
st.markdown(""" """)
|
| 104 |
+
|
| 105 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 106 |
+
st.markdown(""" """)
|
| 107 |
+
|
| 108 |
+
st.image("pages/SegGPT/image_1.jpeg", use_column_width=True)
|
| 109 |
+
st.markdown(""" """)
|
| 110 |
+
|
| 111 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.image("pages/SegGPT/image_2.jpg", use_column_width=True)
|
| 115 |
+
st.markdown(""" """)
|
| 116 |
+
|
| 117 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.image("pages/SegGPT/image_3.jpg", use_column_width=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
st.image("pages/SegGPT/image_4.jpeg", use_column_width=True)
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
with st.expander ("Code"):
|
| 130 |
+
st.code("""
|
| 131 |
+
import torch
|
| 132 |
+
from transformers import SegGptImageProcessor, SegGptForImageSegmentation
|
| 133 |
+
|
| 134 |
+
image_processor = SegGptImageProcessor.from_pretrained("BAAI/seggpt-vit-large")
|
| 135 |
+
model = SegGptForImageSegmentation.from_pretrained("BAAI/seggpt-vit-large")
|
| 136 |
+
|
| 137 |
+
inputs = image_processor(
|
| 138 |
+
images=image_input,
|
| 139 |
+
prompt_images=image_prompt,
|
| 140 |
+
prompt_masks=mask_prompt,
|
| 141 |
+
num_labels=10,
|
| 142 |
+
return_tensors="pt")
|
| 143 |
+
|
| 144 |
+
with torch.no_grad():
|
| 145 |
+
outputs = model(**inputs)
|
| 146 |
+
|
| 147 |
+
target_sizes = [image_input.size[::-1]]
|
| 148 |
+
mask = image_processor.post_process_semantic_segmentation(outputs, target_sizes, num_labels=10)[0]
|
| 149 |
+
""")
|
| 150 |
+
st.markdown(""" """)
|
| 151 |
+
|
| 152 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 153 |
+
st.markdown(""" """)
|
| 154 |
+
|
| 155 |
+
st.image("pages/SegGPT/image_5.jpeg", use_column_width=True)
|
| 156 |
+
st.markdown(""" """)
|
| 157 |
+
|
| 158 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 159 |
+
|
| 160 |
+
st.markdown(""" """)
|
| 161 |
+
st.markdown(""" """)
|
| 162 |
+
st.markdown(""" """)
|
| 163 |
+
col1, col2, col3= st.columns(3)
|
| 164 |
+
with col1:
|
| 165 |
+
if lang == "en":
|
| 166 |
+
if st.button('Previous paper', use_container_width=True):
|
| 167 |
+
switch_page("Painter")
|
| 168 |
+
else:
|
| 169 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 170 |
+
switch_page("Painter")
|
| 171 |
+
with col2:
|
| 172 |
+
if lang == "en":
|
| 173 |
+
if st.button("Home", use_container_width=True):
|
| 174 |
+
switch_page("Home")
|
| 175 |
+
else:
|
| 176 |
+
if st.button("Accueil", use_container_width=True):
|
| 177 |
+
switch_page("Home")
|
| 178 |
+
with col3:
|
| 179 |
+
if lang == "en":
|
| 180 |
+
if st.button("Next paper", use_container_width=True):
|
| 181 |
+
switch_page("Grounding DINO")
|
| 182 |
+
else:
|
| 183 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 184 |
+
switch_page("Grounding DINO")
|
pages/13_Grounding_DINO.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Grounding DINO',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1780558859221733563) (April 17, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
We have merged Grounding DINO in 🤗 Transformers 🦖
|
| 14 |
+
It's an amazing zero-shot object detection model, here's why 🧶
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
There are two zero-shot object detection models as of now, one is OWL series by Google Brain and the other one is Grounding DINO 🦕
|
| 19 |
+
Grounding DINO pays immense attention to detail ⬇️
|
| 20 |
+
Also [try yourself](https://t.co/UI0CMxphE7).
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
I have also built another [application](https://t.co/4EHpOwEpm0) for GroundingSAM, combining GroundingDINO and Segment Anything by Meta for cutting edge zero-shot image segmentation.
|
| 25 |
+
""",
|
| 26 |
+
'tweet_4':
|
| 27 |
+
"""
|
| 28 |
+
Grounding DINO is essentially a model with connected image encoder (Swin transformer), text encoder (BERT) and on top of both, a decoder that outputs bounding boxes 🦖
|
| 29 |
+
This is quite similar to <a href='OWLv2' target='_self'>OWL series</a>, which uses a ViT-based detector on CLIP.
|
| 30 |
+
""",
|
| 31 |
+
'tweet_5':
|
| 32 |
+
"""
|
| 33 |
+
The authors train Swin-L/T with BERT contrastively (not like CLIP where they match the images to texts by means of similarity) where they try to approximate the region outputs to language phrases at the head outputs 🤩
|
| 34 |
+
""",
|
| 35 |
+
'tweet_6':
|
| 36 |
+
"""
|
| 37 |
+
The authors also form the text features on the sub-sentence level.
|
| 38 |
+
This means it extracts certain noun phrases from training data to remove the influence between words while removing fine-grained information.
|
| 39 |
+
""",
|
| 40 |
+
'tweet_7':
|
| 41 |
+
"""
|
| 42 |
+
Thanks to all of this, Grounding DINO has great performance on various REC/object detection benchmarks 🏆📈
|
| 43 |
+
""",
|
| 44 |
+
'tweet_8':
|
| 45 |
+
"""
|
| 46 |
+
Thanks to 🤗 Transformers, you can use Grounding DINO very easily!
|
| 47 |
+
You can also check out [NielsRogge](https://twitter.com/NielsRogge)'s [notebook here](https://t.co/8ADGFdVkta).
|
| 48 |
+
""",
|
| 49 |
+
'ressources':
|
| 50 |
+
"""
|
| 51 |
+
Ressources:
|
| 52 |
+
[Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499)
|
| 53 |
+
by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang (2023)
|
| 54 |
+
[GitHub](https://github.com/IDEA-Research/GroundingDINO)
|
| 55 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/grounding-dino)
|
| 56 |
+
"""
|
| 57 |
+
},
|
| 58 |
+
'fr': {
|
| 59 |
+
'title': 'Grounding DINO',
|
| 60 |
+
'original_tweet':
|
| 61 |
+
"""
|
| 62 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1780558859221733563) (en anglais) (17 avril 2024)
|
| 63 |
+
""",
|
| 64 |
+
'tweet_1':
|
| 65 |
+
"""
|
| 66 |
+
Nous avons ajouté Grounding DINO à 🤗 Transformers 🦖
|
| 67 |
+
C'est un modèle incroyable de détection d'objets en zéro-shot, voici pourquoi 🧶
|
| 68 |
+
""",
|
| 69 |
+
'tweet_2':
|
| 70 |
+
"""
|
| 71 |
+
Il existe actuellement deux modèles de détection d'objets en zero-shot, l'un est la série OWL de Google Brain et l'autre est Grounding DINO 🦕.
|
| 72 |
+
Grounding DINO accorde une grande attention aux détails ⬇️
|
| 73 |
+
[Essayez le vous-même](https://t.co/UI0CMxphE7).
|
| 74 |
+
""",
|
| 75 |
+
'tweet_3':
|
| 76 |
+
"""
|
| 77 |
+
J'ai également créé une autre [application](https://t.co/4EHpOwEpm0) pour GroundingSAM, combinant GroundingDINO et Segment Anything de Meta pour une segmentation d'image en zéro-shot.
|
| 78 |
+
""",
|
| 79 |
+
'tweet_4':
|
| 80 |
+
"""
|
| 81 |
+
Grounding DINO est essentiellement un modèle avec un encodeur d'image (Swin transformer), un encodeur de texte (BERT) et, au-dessus des deux, un décodeur qui produit des boîtes de délimitation 🦖.
|
| 82 |
+
Cela ressemble beaucoup à <a href='OWLv2' target='_self'>OWL</a>, qui utilise un détecteur ViT basé sur CLIP.
|
| 83 |
+
""",
|
| 84 |
+
'tweet_5':
|
| 85 |
+
"""
|
| 86 |
+
Les auteurs entraînent Swin-L/T avec BERT de manière contrastive (pas comme CLIP où ils font correspondre les images aux textes au moyen de la similarité) où ils essaient de faire une approximation entre la région sortie et la phrases sortie 🤩
|
| 87 |
+
""",
|
| 88 |
+
'tweet_6':
|
| 89 |
+
"""
|
| 90 |
+
Les auteurs forment les caractéristiques textuelles au niveau de la sous-phrase.
|
| 91 |
+
Cela signifie qu'ils extraient certaines phrases des données d'apprentissage afin de supprimer l'influence entre les mots tout en supprimant les informations plus fines. """,
|
| 92 |
+
'tweet_7':
|
| 93 |
+
"""
|
| 94 |
+
Grâce à tout cela, Grounding DINO a d'excellentes performances sur divers benchmarks de détection de REC/objets 🏆📈.
|
| 95 |
+
""",
|
| 96 |
+
'tweet_8':
|
| 97 |
+
"""
|
| 98 |
+
Grâce à 🤗 Transformers, vous pouvez utiliser Grounding DINO très facilement !
|
| 99 |
+
Vous pouvez également consulter le [ notebook](https://t.co/8ADGFdVkta) de [NielsRogge](https://twitter.com/NielsRogge).
|
| 100 |
+
""",
|
| 101 |
+
'ressources':
|
| 102 |
+
"""
|
| 103 |
+
Ressources :
|
| 104 |
+
[Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499)
|
| 105 |
+
de Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang (2023)
|
| 106 |
+
[GitHub](https://github.com/IDEA-Research/GroundingDINO)
|
| 107 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/grounding-dino)
|
| 108 |
+
"""
|
| 109 |
+
}
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def language_selector():
|
| 114 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 115 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 116 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 117 |
+
|
| 118 |
+
left_column, right_column = st.columns([5, 1])
|
| 119 |
+
|
| 120 |
+
# Add a selector to the right column
|
| 121 |
+
with right_column:
|
| 122 |
+
lang = language_selector()
|
| 123 |
+
|
| 124 |
+
# Add a title to the left column
|
| 125 |
+
with left_column:
|
| 126 |
+
st.title(translations[lang]["title"])
|
| 127 |
+
|
| 128 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 129 |
+
st.markdown(""" """)
|
| 130 |
+
|
| 131 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 132 |
+
st.markdown(""" """)
|
| 133 |
+
|
| 134 |
+
st.image("pages/Grounding_DINO/image_1.jpeg", use_column_width=True)
|
| 135 |
+
st.markdown(""" """)
|
| 136 |
+
|
| 137 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 138 |
+
st.markdown(""" """)
|
| 139 |
+
|
| 140 |
+
st.image("pages/Grounding_DINO/image_2.jpeg", use_column_width=True)
|
| 141 |
+
st.image("pages/Grounding_DINO/image_3.jpeg", use_column_width=True)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
|
| 144 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
|
| 147 |
+
st.image("pages/Grounding_DINO/image_4.jpeg", use_column_width=True)
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
|
| 150 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 151 |
+
st.markdown(""" """)
|
| 152 |
+
|
| 153 |
+
st.image("pages/Grounding_DINO/image_5.jpeg", use_column_width=True)
|
| 154 |
+
st.markdown(""" """)
|
| 155 |
+
|
| 156 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 157 |
+
st.markdown(""" """)
|
| 158 |
+
|
| 159 |
+
st.image("pages/Grounding_DINO/image_6.jpeg", use_column_width=True)
|
| 160 |
+
st.markdown(""" """)
|
| 161 |
+
|
| 162 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
|
| 165 |
+
st.image("pages/Grounding_DINO/image_7.jpeg", use_column_width=True)
|
| 166 |
+
st.markdown(""" """)
|
| 167 |
+
|
| 168 |
+
st.markdown(translations[lang]["tweet_7"], unsafe_allow_html=True)
|
| 169 |
+
st.markdown(""" """)
|
| 170 |
+
|
| 171 |
+
st.image("pages/Grounding_DINO/image_8.jpeg", use_column_width=True)
|
| 172 |
+
st.markdown(""" """)
|
| 173 |
+
|
| 174 |
+
st.markdown(translations[lang]["tweet_8"], unsafe_allow_html=True)
|
| 175 |
+
st.markdown(""" """)
|
| 176 |
+
|
| 177 |
+
st.image("pages/Grounding_DINO/image_9.jpeg", use_column_width=True)
|
| 178 |
+
st.markdown(""" """)
|
| 179 |
+
|
| 180 |
+
with st.expander ("Code"):
|
| 181 |
+
st.code("""
|
| 182 |
+
import torch
|
| 183 |
+
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
|
| 184 |
+
|
| 185 |
+
model_id = "IDEA-Research/grounding-dino-tiny"
|
| 186 |
+
|
| 187 |
+
processor = AutoProcessor.from_pretrained(model_id)
|
| 188 |
+
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
|
| 189 |
+
|
| 190 |
+
inputs = processor(images=image, text=text, return_tensors="pt").to(device)
|
| 191 |
+
with torch.no_grad():
|
| 192 |
+
outputs = model(**inputs)
|
| 193 |
+
|
| 194 |
+
results = processor.post_process_grounded_object_detection(
|
| 195 |
+
outputs,
|
| 196 |
+
inputs.input_ids,
|
| 197 |
+
box_threshold=0.4,
|
| 198 |
+
text_threshold=0.3,
|
| 199 |
+
target_sizes=[image.size[::-1]])
|
| 200 |
+
""")
|
| 201 |
+
st.markdown(""" """)
|
| 202 |
+
|
| 203 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 204 |
+
|
| 205 |
+
st.markdown(""" """)
|
| 206 |
+
st.markdown(""" """)
|
| 207 |
+
st.markdown(""" """)
|
| 208 |
+
col1, col2, col3= st.columns(3)
|
| 209 |
+
with col1:
|
| 210 |
+
if lang == "en":
|
| 211 |
+
if st.button('Previous paper', use_container_width=True):
|
| 212 |
+
switch_page("SegGPT")
|
| 213 |
+
else:
|
| 214 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 215 |
+
switch_page("SegGPT")
|
| 216 |
+
with col2:
|
| 217 |
+
if lang == "en":
|
| 218 |
+
if st.button("Home", use_container_width=True):
|
| 219 |
+
switch_page("Home")
|
| 220 |
+
else:
|
| 221 |
+
if st.button("Accueil", use_container_width=True):
|
| 222 |
+
switch_page("Home")
|
| 223 |
+
with col3:
|
| 224 |
+
if lang == "en":
|
| 225 |
+
if st.button("Next paper", use_container_width=True):
|
| 226 |
+
switch_page("DocOwl 1.5")
|
| 227 |
+
else:
|
| 228 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 229 |
+
switch_page("DocOwl 1.5")
|
pages/14_DocOwl_1.5.py
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'DocOwl 1.5',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1782421257591357824) (April 22, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
DocOwl 1.5 is the state-of-the-art document understanding model by Alibaba with Apache 2.0 license 😍📝
|
| 14 |
+
Time to dive in and learn more 🧶
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
This model consists of a ViT-based visual encoder part that takes in crops of image and the original image itself.
|
| 19 |
+
Then the outputs of the encoder goes through a convolution based model, after that the outputs are merged with text and then fed to LLM.
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
Initially, the authors only train the convolution based part (called H-Reducer) and vision encoder while keeping LLM frozen.
|
| 24 |
+
Then for fine-tuning (on image captioning, VQA etc), they freeze vision encoder and train H-Reducer and LLM.
|
| 25 |
+
""",
|
| 26 |
+
'tweet_4':
|
| 27 |
+
"""
|
| 28 |
+
Also they use simple linear projection on text and documents. You can see below how they model the text prompts and outputs 🤓
|
| 29 |
+
""",
|
| 30 |
+
'tweet_5':
|
| 31 |
+
"""
|
| 32 |
+
They train the model various downstream tasks including:
|
| 33 |
+
- document understanding (DUE benchmark and more)
|
| 34 |
+
- table parsing (TURL, PubTabNet)
|
| 35 |
+
- chart parsing (PlotQA and more)
|
| 36 |
+
- image parsing (OCR-CC)
|
| 37 |
+
- text localization (DocVQA and more)
|
| 38 |
+
""",
|
| 39 |
+
'tweet_6':
|
| 40 |
+
"""
|
| 41 |
+
They contribute a new model called DocOwl 1.5-Chat by:
|
| 42 |
+
1. creating a new document-chat dataset with questions from document VQA datasets
|
| 43 |
+
2. feeding them to ChatGPT to get long answers
|
| 44 |
+
3. fine-tune the base model with it (which IMO works very well!)
|
| 45 |
+
""",
|
| 46 |
+
'tweet_7':
|
| 47 |
+
"""
|
| 48 |
+
Resulting generalist model and the chat model are pretty much state-of-the-art 😍
|
| 49 |
+
Below you can see how it compares to fine-tuned models.
|
| 50 |
+
""",
|
| 51 |
+
'tweet_8':
|
| 52 |
+
"""
|
| 53 |
+
All the models and the datasets (also some eval datasets on above tasks!) are in this [organization](https://t.co/sJdTw1jWTR).
|
| 54 |
+
The [Space](https://t.co/57E9DbNZXf).
|
| 55 |
+
""",
|
| 56 |
+
'ressources':
|
| 57 |
+
"""
|
| 58 |
+
Ressources:
|
| 59 |
+
[mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding](https://arxiv.org/abs/2403.12895)
|
| 60 |
+
by Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, Jingren Zhou (2024)
|
| 61 |
+
[GitHub](https://github.com/X-PLUG/mPLUG-DocOwl)
|
| 62 |
+
"""
|
| 63 |
+
},
|
| 64 |
+
'fr': {
|
| 65 |
+
'title': 'DocOwl 1.5',
|
| 66 |
+
'original_tweet':
|
| 67 |
+
"""
|
| 68 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1782421257591357824) (en anglais) (22 avril 2024)
|
| 69 |
+
""",
|
| 70 |
+
'tweet_1':
|
| 71 |
+
"""
|
| 72 |
+
DocOwl 1.5 est le modèle de compréhension de documents d'Alibaba sous licence Apache 2.0 😍📝
|
| 73 |
+
Il est temps de découvrir ce modèle 🧶
|
| 74 |
+
""",
|
| 75 |
+
'tweet_2':
|
| 76 |
+
"""
|
| 77 |
+
Ce modèle se compose d'un encodeur visuel basé sur un ViT qui prend en compte les crops de l'image et l'image originale elle-même.
|
| 78 |
+
Les sorties de l'encodeur passent ensuite par un modèle convolutif, après quoi les sorties sont fusionnées avec le texte, puis transmises au LLM.
|
| 79 |
+
""",
|
| 80 |
+
'tweet_3':
|
| 81 |
+
"""
|
| 82 |
+
Au départ, les auteurs n'entraînent que la partie basée sur la convolution (appelée H-Reducer) et l'encodeur de vision tout en gardant le LLM gelé.
|
| 83 |
+
Ensuite, pour le finetuning (légendage d'image, VQA, etc.), ils gèlent l'encodeur de vision et entraînent le H-Reducer et le LLM.
|
| 84 |
+
""",
|
| 85 |
+
'tweet_4':
|
| 86 |
+
"""
|
| 87 |
+
Ils utilisent également une simple projection linéaire sur le texte et les documents. Vous pouvez voir ci-dessous comment ils modélisent les prompts et les sorties textuelles 🤓
|
| 88 |
+
""",
|
| 89 |
+
'tweet_5':
|
| 90 |
+
"""
|
| 91 |
+
Ils entraînent le modèle pour diverses tâches en aval, notamment
|
| 92 |
+
- la compréhension de documents (DUE benchmark et autres)
|
| 93 |
+
- analyse de tableaux (TURL, PubTabNet)
|
| 94 |
+
- analyse de graphiques (PlotQA et autres)
|
| 95 |
+
- analyse d'images (OCR-CC)
|
| 96 |
+
- localisation de textes (DocVQA et autres)
|
| 97 |
+
""",
|
| 98 |
+
'tweet_6':
|
| 99 |
+
"""
|
| 100 |
+
Ils contribuent à un nouveau modèle appelé DocOwl 1.5-Chat en :
|
| 101 |
+
1. créant un nouveau jeu de données document-chat avec des questions provenant de jeux de données VQA
|
| 102 |
+
2. en les envoyant à ChatGPT pour obtenir des réponses longues
|
| 103 |
+
3. en finetunant le modèle de base à l'aide de ce dernier (qui fonctionne très bien selon moi)
|
| 104 |
+
""",
|
| 105 |
+
'tweet_7':
|
| 106 |
+
"""
|
| 107 |
+
Le modèle généraliste qui en résulte et le modèle de chat sont pratiquement à l'état de l'art 😍
|
| 108 |
+
Ci-dessous, vous pouvez voir comment ils se comparent aux modèles finetunés.
|
| 109 |
+
""",
|
| 110 |
+
'tweet_8':
|
| 111 |
+
"""
|
| 112 |
+
Tous les modèles et jeux de données (y compris certains jeux de données d'évaluation sur les tâches susmentionnées !) se trouvent dans cette [organisation](https://t.co/sJdTw1jWTR). Le [Space](https://t.co/57E9DbNZXf).
|
| 113 |
+
""",
|
| 114 |
+
'ressources':
|
| 115 |
+
"""
|
| 116 |
+
Ressources :
|
| 117 |
+
[mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding](https://arxiv.org/abs/2403.12895)
|
| 118 |
+
de Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, Jingren Zhou (2024)
|
| 119 |
+
[GitHub](https://github.com/X-PLUG/mPLUG-DocOwl)
|
| 120 |
+
"""
|
| 121 |
+
}
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def language_selector():
|
| 126 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 127 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 128 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 129 |
+
|
| 130 |
+
left_column, right_column = st.columns([5, 1])
|
| 131 |
+
|
| 132 |
+
# Add a selector to the right column
|
| 133 |
+
with right_column:
|
| 134 |
+
lang = language_selector()
|
| 135 |
+
|
| 136 |
+
# Add a title to the left column
|
| 137 |
+
with left_column:
|
| 138 |
+
st.title(translations[lang]["title"])
|
| 139 |
+
|
| 140 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 141 |
+
st.markdown(""" """)
|
| 142 |
+
|
| 143 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 144 |
+
st.markdown(""" """)
|
| 145 |
+
|
| 146 |
+
st.image("pages/DocOwl_1.5/image_1.jpg", use_column_width=True)
|
| 147 |
+
st.markdown(""" """)
|
| 148 |
+
|
| 149 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 150 |
+
st.markdown(""" """)
|
| 151 |
+
|
| 152 |
+
st.image("pages/DocOwl_1.5/image_2.jpeg", use_column_width=True)
|
| 153 |
+
st.markdown(""" """)
|
| 154 |
+
|
| 155 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 156 |
+
st.markdown(""" """)
|
| 157 |
+
|
| 158 |
+
st.image("pages/DocOwl_1.5/image_3.jpeg", use_column_width=True)
|
| 159 |
+
st.markdown(""" """)
|
| 160 |
+
|
| 161 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 162 |
+
st.markdown(""" """)
|
| 163 |
+
|
| 164 |
+
st.image("pages/DocOwl_1.5/image_4.jpeg", use_column_width=True)
|
| 165 |
+
st.markdown(""" """)
|
| 166 |
+
|
| 167 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 168 |
+
st.markdown(""" """)
|
| 169 |
+
|
| 170 |
+
st.image("pages/DocOwl_1.5/image_5.jpeg", use_column_width=True)
|
| 171 |
+
st.markdown(""" """)
|
| 172 |
+
|
| 173 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 174 |
+
st.markdown(""" """)
|
| 175 |
+
|
| 176 |
+
st.image("pages/DocOwl_1.5/image_6.jpeg", use_column_width=True)
|
| 177 |
+
st.markdown(""" """)
|
| 178 |
+
|
| 179 |
+
st.markdown(translations[lang]["tweet_7"], unsafe_allow_html=True)
|
| 180 |
+
st.markdown(""" """)
|
| 181 |
+
|
| 182 |
+
st.image("pages/DocOwl_1.5/image_7.jpeg", use_column_width=True)
|
| 183 |
+
st.markdown(""" """)
|
| 184 |
+
|
| 185 |
+
st.markdown(translations[lang]["tweet_8"], unsafe_allow_html=True)
|
| 186 |
+
st.markdown(""" """)
|
| 187 |
+
|
| 188 |
+
st.image("pages/DocOwl_1.5/image_8.jpeg", use_column_width=True)
|
| 189 |
+
st.markdown(""" """)
|
| 190 |
+
|
| 191 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 192 |
+
|
| 193 |
+
st.markdown(""" """)
|
| 194 |
+
st.markdown(""" """)
|
| 195 |
+
st.markdown(""" """)
|
| 196 |
+
col1, col2, col3= st.columns(3)
|
| 197 |
+
with col1:
|
| 198 |
+
if lang == "en":
|
| 199 |
+
if st.button('Previous paper', use_container_width=True):
|
| 200 |
+
switch_page("Grounding DINO")
|
| 201 |
+
else:
|
| 202 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 203 |
+
switch_page("Grounding DINO")
|
| 204 |
+
with col2:
|
| 205 |
+
if lang == "en":
|
| 206 |
+
if st.button("Home", use_container_width=True):
|
| 207 |
+
switch_page("Home")
|
| 208 |
+
else:
|
| 209 |
+
if st.button("Accueil", use_container_width=True):
|
| 210 |
+
switch_page("Home")
|
| 211 |
+
with col3:
|
| 212 |
+
if lang == "en":
|
| 213 |
+
if st.button("Next paper", use_container_width=True):
|
| 214 |
+
switch_page("MiniGemini")
|
| 215 |
+
else:
|
| 216 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 217 |
+
switch_page("MiniGemini")
|
pages/15_MiniGemini.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'MiniGemini',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1783864388249694520) (April 26, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
MiniGemini is the coolest VLM, let's explain 🧶
|
| 14 |
+
""",
|
| 15 |
+
'tweet_2':
|
| 16 |
+
"""
|
| 17 |
+
MiniGemini is a vision language model that understands both image and text and also generates text and an image that goes best with the context! 🤯
|
| 18 |
+
""",
|
| 19 |
+
'tweet_3':
|
| 20 |
+
"""
|
| 21 |
+
This model has two image encoders (one CNN and one ViT) in parallel to capture the details in the images.
|
| 22 |
+
I saw the same design in <a href='DocOwl_1.5' target='_self'>DocOwl 1.5</a> then it has a decoder to output text and also a prompt to be sent to SDXL for image generation (which works very well!)
|
| 23 |
+
""",
|
| 24 |
+
'tweet_4':
|
| 25 |
+
"""
|
| 26 |
+
They adopt CLIP's ViT for low resolution visual embedding encoder and a CNN-based one for high resolution image encoding (precisely a pre-trained ConvNeXt).
|
| 27 |
+
""",
|
| 28 |
+
'tweet_5':
|
| 29 |
+
"""
|
| 30 |
+
Thanks to the second encoder it can grasp details in images, which also comes in handy for e.g. document tasks (but see below the examples are mindblowing IMO).
|
| 31 |
+
""",
|
| 32 |
+
'tweet_6':
|
| 33 |
+
"""
|
| 34 |
+
According to their reporting the model performs very well across many benchmarks compared to LLaVA 1.5 and Gemini Pro.
|
| 35 |
+
""",
|
| 36 |
+
'ressources':
|
| 37 |
+
"""
|
| 38 |
+
Resources:
|
| 39 |
+
[Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models](https://huggingface.co/papers/2403.18814)
|
| 40 |
+
by Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, Jiaya Jia (2024)
|
| 41 |
+
[GitHub](https://github.com/dvlab-research/MGM)
|
| 42 |
+
[Model Repository](https://huggingface.co/YanweiLi/MGM-13B-HD)
|
| 43 |
+
"""
|
| 44 |
+
},
|
| 45 |
+
'fr': {
|
| 46 |
+
'title': 'MiniGemini',
|
| 47 |
+
'original_tweet':
|
| 48 |
+
"""
|
| 49 |
+
[Tweet de base](https://x.com/mervenoyann/status/1783864388249694520) (26 avril 2024)
|
| 50 |
+
""",
|
| 51 |
+
'tweet_1':
|
| 52 |
+
"""
|
| 53 |
+
MiniGemini est le VLM le plus cool, voici pourquoi 🧶
|
| 54 |
+
""",
|
| 55 |
+
'tweet_2':
|
| 56 |
+
"""
|
| 57 |
+
MiniGemini est un modèle de langage/vision qui comprend à la fois l'image et le texte et qui génère également le texte et l'image qui s'accordent le mieux avec le contexte ! 🤯 """,
|
| 58 |
+
'tweet_3':
|
| 59 |
+
"""
|
| 60 |
+
Ce modèle possède deux encodeurs d'images (un ConvNet et un ViT) en parallèle pour capturer les détails dans les images.
|
| 61 |
+
J'ai vu la même conception dans <a href='DocOwl 1.5' target='_self'>DocOwl 1.5</a> où il y a un décodeur pour produire du texte et aussi un prompt à envoyer au SDXL pour la génération d'images (qui fonctionne très bien !). """,
|
| 62 |
+
'tweet_4':
|
| 63 |
+
"""
|
| 64 |
+
Les auteurs adoptent le ViT de CLIP pour les enchâssements visuels de basse résolution et un ConvNet pour les images en haute résolution (précisément un ConvNeXt pré-entraîné).
|
| 65 |
+
""",
|
| 66 |
+
'tweet_5':
|
| 67 |
+
"""
|
| 68 |
+
Grâce au second encodeur, il peut saisir des détails dans les images, ce qui s'avère également utile pour les tâches documentaires (voir ci-dessous les exemples époustouflants). """,
|
| 69 |
+
'tweet_6':
|
| 70 |
+
"""
|
| 71 |
+
D'après leur rapport, le modèle est très performant dans de nombreux benchmarks par rapport à LLaVA 1.5 et Gemini Pro.
|
| 72 |
+
""",
|
| 73 |
+
'ressources':
|
| 74 |
+
"""
|
| 75 |
+
Resources :
|
| 76 |
+
[Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models](https://huggingface.co/papers/2403.18814)
|
| 77 |
+
de Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, Jiaya Jia (2024)
|
| 78 |
+
[GitHub](https://github.com/dvlab-research/MGM)
|
| 79 |
+
[Modèle](https://huggingface.co/YanweiLi/MGM-13B-HD)
|
| 80 |
+
"""
|
| 81 |
+
}
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def language_selector():
|
| 86 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 87 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 88 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 89 |
+
|
| 90 |
+
left_column, right_column = st.columns([5, 1])
|
| 91 |
+
|
| 92 |
+
# Add a selector to the right column
|
| 93 |
+
with right_column:
|
| 94 |
+
lang = language_selector()
|
| 95 |
+
|
| 96 |
+
# Add a title to the left column
|
| 97 |
+
with left_column:
|
| 98 |
+
st.title(translations[lang]["title"])
|
| 99 |
+
|
| 100 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 101 |
+
st.markdown(""" """)
|
| 102 |
+
|
| 103 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 104 |
+
st.markdown(""" """)
|
| 105 |
+
|
| 106 |
+
st.image("pages/MiniGemini/image_1.jpg", use_column_width=True)
|
| 107 |
+
st.markdown(""" """)
|
| 108 |
+
|
| 109 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 110 |
+
st.markdown(""" """)
|
| 111 |
+
|
| 112 |
+
st.image("pages/MiniGemini/image_2.jpg", use_column_width=True)
|
| 113 |
+
st.markdown(""" """)
|
| 114 |
+
|
| 115 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
|
| 118 |
+
st.image("pages/MiniGemini/image_3.jpg", use_column_width=True)
|
| 119 |
+
st.markdown(""" """)
|
| 120 |
+
|
| 121 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.image("pages/MiniGemini/image_4.jpg", use_column_width=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.image("pages/MiniGemini/image_5.jpg", use_column_width=True)
|
| 131 |
+
st.markdown(""" """)
|
| 132 |
+
|
| 133 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
|
| 136 |
+
st.image("pages/MiniGemini/image_6.jpg", use_column_width=True)
|
| 137 |
+
st.markdown(""" """)
|
| 138 |
+
|
| 139 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 140 |
+
|
| 141 |
+
st.markdown(""" """)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
col1, col2, col3= st.columns(3)
|
| 145 |
+
with col1:
|
| 146 |
+
if lang == "en":
|
| 147 |
+
if st.button('Previous paper', use_container_width=True):
|
| 148 |
+
switch_page("DocOwl 1.5")
|
| 149 |
+
else:
|
| 150 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 151 |
+
switch_page("DocOwl 1.5")
|
| 152 |
+
with col2:
|
| 153 |
+
if lang == "en":
|
| 154 |
+
if st.button("Home", use_container_width=True):
|
| 155 |
+
switch_page("Home")
|
| 156 |
+
else:
|
| 157 |
+
if st.button("Accueil", use_container_width=True):
|
| 158 |
+
switch_page("Home")
|
| 159 |
+
with col3:
|
| 160 |
+
if lang == "en":
|
| 161 |
+
if st.button("Next paper", use_container_width=True):
|
| 162 |
+
switch_page("CuMo")
|
| 163 |
+
else:
|
| 164 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 165 |
+
switch_page("PLLaVA")
|
pages/16_PLLaVA.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'PLLaVA',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1786336055425138939) (May 3, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Parameter-free LLaVA for video captioning works like magic! 🤩 Let's take a look!
|
| 14 |
+
""",
|
| 15 |
+
'tweet_2':
|
| 16 |
+
"""
|
| 17 |
+
Most of the video captioning models work by downsampling video frames to reduce computational complexity and memory requirements without losing a lot of information in the process.
|
| 18 |
+
PLLaVA on the other hand, uses pooling! 🤩
|
| 19 |
+
<br>
|
| 20 |
+
How? 🧐
|
| 21 |
+
It takes in frames of video, passed to ViT and then projection layer, and then output goes through average pooling where input shape is (# frames, width, height, text decoder input dim) 👇
|
| 22 |
+
""",
|
| 23 |
+
'tweet_3':
|
| 24 |
+
"""
|
| 25 |
+
Pooling operation surprisingly reduces the loss of spatial and temporal information. See below some examples on how it can capture the details 🤗
|
| 26 |
+
""",
|
| 27 |
+
'tweet_4':
|
| 28 |
+
"""
|
| 29 |
+
According to authors' findings, it performs way better than many of the existing models (including proprietary VLMs) and scales very well (on text decoder).
|
| 30 |
+
""",
|
| 31 |
+
'tweet_5':
|
| 32 |
+
"""
|
| 33 |
+
Model repositories 🤗 [7B](https://t.co/AeSdYsz1U7), [13B](https://t.co/GnI1niTxO7), [34B](https://t.co/HWAM0ZzvDc)
|
| 34 |
+
Spaces🤗 [7B](https://t.co/Oms2OLkf7O), [13B](https://t.co/C2RNVNA4uR)
|
| 35 |
+
""",
|
| 36 |
+
'ressources':
|
| 37 |
+
"""
|
| 38 |
+
Ressources:
|
| 39 |
+
[PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning](https://arxiv.org/abs/2404.16994)
|
| 40 |
+
by Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, Jiashi Feng (2024)
|
| 41 |
+
[GitHub](https://github.com/magic-research/PLLaVA)
|
| 42 |
+
"""
|
| 43 |
+
},
|
| 44 |
+
'fr': {
|
| 45 |
+
'title': 'PLLaVA',
|
| 46 |
+
'original_tweet':
|
| 47 |
+
"""
|
| 48 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1786336055425138939) (en anglais) (3 mai 2024)
|
| 49 |
+
""",
|
| 50 |
+
'tweet_1':
|
| 51 |
+
"""
|
| 52 |
+
Parameter-free LLaVA (PLLaVA) pour le sous-titrage vidéo fonctionne comme par magie ! 🤩
|
| 53 |
+
Jetons un coup d'œil !
|
| 54 |
+
""",
|
| 55 |
+
'tweet_2':
|
| 56 |
+
"""
|
| 57 |
+
La plupart des modèles de sous-titrage vidéo fonctionnent par sous-échantillonnage des images vidéo afin de réduire la complexité de calcul et les besoins en mémoire sans perdre beaucoup d'informations au cours du processus.
|
| 58 |
+
PLLaVA, quant à lui, utilise le pooling ! 🤩
|
| 59 |
+
<br>
|
| 60 |
+
Comment ?
|
| 61 |
+
Il prend les images de la vidéo, les passe au ViT puis à la couche de projection, et la sortie passe par un average pooling où la forme d'entrée est (# images, largeur, hauteur, dim d'entrée du décodeur de texte) 👇 """,
|
| 62 |
+
'tweet_3':
|
| 63 |
+
"""
|
| 64 |
+
L'opération de pooling réduit de manière surprenante la perte d'informations spatiales et temporelles. Voir ci-dessous quelques exemples de la façon dont elle peut capturer les détails 🤗 """,
|
| 65 |
+
'tweet_4':
|
| 66 |
+
"""
|
| 67 |
+
Selon les conclusions des auteurs, il est bien plus performant que de nombreux modèles existants (y compris les VLM propriétaires) et passe à l'échelle très bien (sur le décodeur de texte). """,
|
| 68 |
+
'tweet_5':
|
| 69 |
+
"""
|
| 70 |
+
Dépôts des modèles 🤗 [7 Mds](https://t.co/AeSdYsz1U7), [13 Mds](https://t.co/GnI1niTxO7), [34 Mds](https://t.co/HWAM0ZzvDc)
|
| 71 |
+
Spaces🤗 [7 Mds](https://t.co/Oms2OLkf7O), [13 Mds](https://t.co/C2RNVNA4uR)
|
| 72 |
+
""",
|
| 73 |
+
'ressources':
|
| 74 |
+
"""
|
| 75 |
+
Ressources :
|
| 76 |
+
[PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning](https://arxiv.org/abs/2404.16994)
|
| 77 |
+
de Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, Jiashi Feng (2024)
|
| 78 |
+
[GitHub](https://github.com/magic-research/PLLaVA)
|
| 79 |
+
"""
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def language_selector():
|
| 85 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 86 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 87 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 88 |
+
|
| 89 |
+
left_column, right_column = st.columns([5, 1])
|
| 90 |
+
|
| 91 |
+
# Add a selector to the right column
|
| 92 |
+
with right_column:
|
| 93 |
+
lang = language_selector()
|
| 94 |
+
|
| 95 |
+
# Add a title to the left column
|
| 96 |
+
with left_column:
|
| 97 |
+
st.title(translations[lang]["title"])
|
| 98 |
+
|
| 99 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 100 |
+
st.markdown(""" """)
|
| 101 |
+
|
| 102 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 103 |
+
st.markdown(""" """)
|
| 104 |
+
|
| 105 |
+
st.image("pages/PLLaVA/image_1.jpg", use_column_width=True)
|
| 106 |
+
st.markdown(""" """)
|
| 107 |
+
|
| 108 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 109 |
+
st.markdown(""" """)
|
| 110 |
+
|
| 111 |
+
st.image("pages/PLLaVA/image_2.jpeg", use_column_width=True)
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 115 |
+
st.markdown(""" """)
|
| 116 |
+
|
| 117 |
+
st.image("pages/PLLaVA/image_3.jpeg", use_column_width=True)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
st.image("pages/PLLaVA/image_4.jpeg", use_column_width=True)
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 130 |
+
|
| 131 |
+
st.markdown(""" """)
|
| 132 |
+
st.markdown(""" """)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
col1, col2, col3= st.columns(3)
|
| 135 |
+
with col1:
|
| 136 |
+
if lang == "en":
|
| 137 |
+
if st.button('Previous paper', use_container_width=True):
|
| 138 |
+
switch_page("MiniGemini")
|
| 139 |
+
else:
|
| 140 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 141 |
+
switch_page("MiniGemini")
|
| 142 |
+
with col2:
|
| 143 |
+
if lang == "en":
|
| 144 |
+
if st.button("Home", use_container_width=True):
|
| 145 |
+
switch_page("Home")
|
| 146 |
+
else:
|
| 147 |
+
if st.button("Accueil", use_container_width=True):
|
| 148 |
+
switch_page("Home")
|
| 149 |
+
with col3:
|
| 150 |
+
if lang == "en":
|
| 151 |
+
if st.button("Next paper", use_container_width=True):
|
| 152 |
+
switch_page("CuMo")
|
| 153 |
+
else:
|
| 154 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 155 |
+
switch_page("CuMo")
|
pages/17_CuMo.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'CuMo',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1790665706205307191) (May 15, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
It's raining vision language models ☔️
|
| 14 |
+
CuMo is a new vision language model that has MoE in every step of the VLM (image encoder, MLP and text decoder) and uses Mistral-7B for the decoder part 🤓
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
The authors firstly did pre-training of MLP with the by freezing the image encoder and text decoder, then they warmup the whole network by unfreezing and finetuning which they state to stabilize the visual instruction tuning when bringing in the experts.
|
| 19 |
+
""",
|
| 20 |
+
'tweet_3':
|
| 21 |
+
"""
|
| 22 |
+
The mixture of experts MLP blocks above are simply the same MLP blocks initialized from the single MLP that was trained during pre-training and fine-tuned in pre-finetuning 👇
|
| 23 |
+
""",
|
| 24 |
+
'tweet_4':
|
| 25 |
+
"""
|
| 26 |
+
It works very well (also tested myself) that it outperforms the previous SOTA of it's size <a href='LLaVA-NeXT' target='_self'>LLaVA-NeXT</a>! 😍
|
| 27 |
+
I wonder how it would compare to IDEFICS2-8B You can try it yourself [here](https://t.co/MLIYKVh5Ee).
|
| 28 |
+
""",
|
| 29 |
+
'ressources':
|
| 30 |
+
"""
|
| 31 |
+
Ressources:
|
| 32 |
+
[CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts](https://arxiv.org/abs/2405.05949)
|
| 33 |
+
by Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen (2024)
|
| 34 |
+
[GitHub](https://github.com/SHI-Labs/CuMo)
|
| 35 |
+
"""
|
| 36 |
+
},
|
| 37 |
+
'fr': {
|
| 38 |
+
'title': 'CuMo',
|
| 39 |
+
'original_tweet':
|
| 40 |
+
"""
|
| 41 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1790665706205307191) (en anglais) (15 mai 2024)
|
| 42 |
+
""",
|
| 43 |
+
'tweet_1':
|
| 44 |
+
"""
|
| 45 |
+
Il pleut des modèles de langage/vision ☔️
|
| 46 |
+
CuMo est un nouveau modèle de langage/vision qui intègre le MoE à chaque étape du VLM (encodeur d'images, MLP et décodeur de texte) et utilise Mistral-7B pour la partie décodeur 🤓
|
| 47 |
+
""",
|
| 48 |
+
'tweet_2':
|
| 49 |
+
"""
|
| 50 |
+
Les auteurs ont tout d'abord effectué un pré-entraînement du MLP en gelant l'encodeur d'images et le décodeur de texte, puis ils ont réchauffé l'ensemble du réseau en le réglant avec précision, ce qui, selon eux, permet de stabiliser le réglage des instructions visuelles lors de l'intervention des experts.
|
| 51 |
+
""",
|
| 52 |
+
'tweet_3':
|
| 53 |
+
"""
|
| 54 |
+
Le mélange d'experts de blocs MLP ci-dessus est simplement le même bloc MLP initialisé à partir du MLP unique qui a été entraîné pendant le pré-entraînement et finetuné dans le pré-finetuning 👇
|
| 55 |
+
""",
|
| 56 |
+
'tweet_4':
|
| 57 |
+
"""
|
| 58 |
+
Cela fonctionne très bien (je l'ai testé moi-même) et surpasse le précédent SOTA de taille équivalente, <a href='LLaVA-NeXT' target='_self'>LLaVA-NeXT</a> ! 😍
|
| 59 |
+
Je me demande comment il se compare à IDEFICS2-8B. Vous pouvez l'essayer vous-même [ici](https://t.co/MLIYKVh5Ee).
|
| 60 |
+
""",
|
| 61 |
+
'ressources':
|
| 62 |
+
"""
|
| 63 |
+
Ressources :
|
| 64 |
+
[CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts](https://arxiv.org/abs/2405.05949)
|
| 65 |
+
de Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen (2024)
|
| 66 |
+
[GitHub](https://github.com/SHI-Labs/CuMo)
|
| 67 |
+
"""
|
| 68 |
+
}
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def language_selector():
|
| 73 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 74 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 75 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 76 |
+
|
| 77 |
+
left_column, right_column = st.columns([5, 1])
|
| 78 |
+
|
| 79 |
+
# Add a selector to the right column
|
| 80 |
+
with right_column:
|
| 81 |
+
lang = language_selector()
|
| 82 |
+
|
| 83 |
+
# Add a title to the left column
|
| 84 |
+
with left_column:
|
| 85 |
+
st.title(translations[lang]["title"])
|
| 86 |
+
|
| 87 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 88 |
+
st.markdown(""" """)
|
| 89 |
+
|
| 90 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 91 |
+
st.markdown(""" """)
|
| 92 |
+
|
| 93 |
+
st.image("pages/CuMo/image_1.jpg", use_column_width=True)
|
| 94 |
+
st.markdown(""" """)
|
| 95 |
+
|
| 96 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 97 |
+
st.markdown(""" """)
|
| 98 |
+
|
| 99 |
+
st.image("pages/CuMo/image_2.jpg", use_column_width=True)
|
| 100 |
+
st.markdown(""" """)
|
| 101 |
+
|
| 102 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 103 |
+
st.markdown(""" """)
|
| 104 |
+
|
| 105 |
+
st.image("pages/CuMo/image_3.jpg", use_column_width=True)
|
| 106 |
+
st.markdown(""" """)
|
| 107 |
+
|
| 108 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 109 |
+
st.markdown(""" """)
|
| 110 |
+
|
| 111 |
+
st.image("pages/CuMo/image_4.jpg", use_column_width=True)
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 115 |
+
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
st.markdown(""" """)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
col1, col2, col3= st.columns(3)
|
| 120 |
+
with col1:
|
| 121 |
+
if lang == "en":
|
| 122 |
+
if st.button('Previous paper', use_container_width=True):
|
| 123 |
+
switch_page("PLLaVA")
|
| 124 |
+
else:
|
| 125 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 126 |
+
switch_page("PLLaVA")
|
| 127 |
+
with col2:
|
| 128 |
+
if lang == "en":
|
| 129 |
+
if st.button("Home", use_container_width=True):
|
| 130 |
+
switch_page("Home")
|
| 131 |
+
else:
|
| 132 |
+
if st.button("Accueil", use_container_width=True):
|
| 133 |
+
switch_page("Home")
|
| 134 |
+
with col3:
|
| 135 |
+
if lang == "en":
|
| 136 |
+
if st.button("Next paper", use_container_width=True):
|
| 137 |
+
switch_page("DenseConnector")
|
| 138 |
+
else:
|
| 139 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 140 |
+
switch_page("DenseConnector")
|
pages/18_DenseConnector.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'DenseConnector',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1796089181988352216) (May 30, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Do we fully leverage image encoders in vision language models? 👀
|
| 14 |
+
A new paper built a dense connector that does it better! Let's dig in 🧶
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
VLMs consist of an image encoder block, a projection layer that projects image embeddings to text embedding space and then a text decoder sequentially connected 📖
|
| 19 |
+
This [paper](https://t.co/DPQzbj0eWm) explores using intermediate states of image encoder and not a single output 🤩
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
The authors explore three different ways of instantiating dense connector: sparse token integration, sparse channel integration and dense channel integration (each of them just take intermediate outputs and put them together in different ways, see below).
|
| 24 |
+
""",
|
| 25 |
+
'tweet_4':
|
| 26 |
+
"""
|
| 27 |
+
They explore all three of them integrated to LLaVA 1.5 and found out each of the new models are superior to the original LLaVA 1.5.
|
| 28 |
+
""",
|
| 29 |
+
'tweet_5':
|
| 30 |
+
"""
|
| 31 |
+
I tried the [model](https://huggingface.co/spaces/HuanjinYao/DenseConnector-v1.5-8B) and it seems to work very well 🥹
|
| 32 |
+
The authors have released various [checkpoints](https://t.co/iF8zM2qvDa) based on different decoders (Vicuna 7/13B and Llama 3-8B).
|
| 33 |
+
""",
|
| 34 |
+
'ressources':
|
| 35 |
+
"""
|
| 36 |
+
Ressources:
|
| 37 |
+
[Dense Connector for MLLMs](https://arxiv.org/abs/2405.13800)
|
| 38 |
+
by Huanjin Yao, Wenhao Wu, Taojiannan Yang, YuXin Song, Mengxi Zhang, Haocheng Feng, Yifan Sun, Zhiheng Li, Wanli Ouyang, Jingdong Wang (2024)
|
| 39 |
+
[GitHub](https://github.com/HJYao00/DenseConnector)
|
| 40 |
+
"""
|
| 41 |
+
},
|
| 42 |
+
'fr': {
|
| 43 |
+
'title': 'DenseConnector',
|
| 44 |
+
'original_tweet':
|
| 45 |
+
"""
|
| 46 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1796089181988352216) (en anglais) (30 mai 2024)
|
| 47 |
+
""",
|
| 48 |
+
'tweet_1':
|
| 49 |
+
"""
|
| 50 |
+
Exploitons-nous pleinement les encodeurs d'images dans les modèles de langage/vision ? 👀
|
| 51 |
+
Un nouveau papier a construit un connecteur dense qui le fait mieux ! Creusons un peu 🧶
|
| 52 |
+
""",
|
| 53 |
+
'tweet_2':
|
| 54 |
+
"""
|
| 55 |
+
Les VLM se composent d'un bloc encodeur d'images, d'une couche de projection qui projette les enchâssements d'images dans l'espace d'enchâssement du texte, puis d'un décodeur de texte connecté séquentiellement 📖.
|
| 56 |
+
Ce [papier](https://t.co/DPQzbj0eWm) explore l'utilisation d'états intermédiaires de l'encodeur d'images et non d'une sortie unique 🤩
|
| 57 |
+
""",
|
| 58 |
+
'tweet_3':
|
| 59 |
+
"""
|
| 60 |
+
Les auteurs explorent trois manières différentes d'instancier un connecteur dense : l'intégration de tokens épars, l'intégration de canaux épars et l'intégration de canaux denses (chacune d'entre elles prend simplement des sorties intermédiaires et les rassemble de différentes manières, voir ci-dessous).
|
| 61 |
+
""",
|
| 62 |
+
'tweet_4':
|
| 63 |
+
"""
|
| 64 |
+
Ils ont exploré les trois modèles intégrés à LLaVA 1.5 et ont constaté que chacun des nouveaux modèles est supérieur au LLaVA 1.5 original.
|
| 65 |
+
""",
|
| 66 |
+
'tweet_5':
|
| 67 |
+
"""
|
| 68 |
+
J'ai essayé le [modèle](https://huggingface.co/spaces/HuanjinYao/DenseConnector-v1.5-8B) et il semble fonctionner très bien 🥹
|
| 69 |
+
Les auteurs ont publié plusieurs [checkpoints](https://t.co/iF8zM2qvDa) basés sur différents décodeurs (Vicuna 7/13B et Llama 3-8B).
|
| 70 |
+
""",
|
| 71 |
+
'ressources':
|
| 72 |
+
"""
|
| 73 |
+
Ressources :
|
| 74 |
+
[Dense Connector for MLLMs](https://arxiv.org/abs/2405.13800)
|
| 75 |
+
de Huanjin Yao, Wenhao Wu, Taojiannan Yang, YuXin Song, Mengxi Zhang, Haocheng Feng, Yifan Sun, Zhiheng Li, Wanli Ouyang, Jingdong Wang (2024)
|
| 76 |
+
[GitHub](https://github.com/HJYao00/DenseConnector)
|
| 77 |
+
"""
|
| 78 |
+
}
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def language_selector():
|
| 83 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 84 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 85 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 86 |
+
|
| 87 |
+
left_column, right_column = st.columns([5, 1])
|
| 88 |
+
|
| 89 |
+
# Add a selector to the right column
|
| 90 |
+
with right_column:
|
| 91 |
+
lang = language_selector()
|
| 92 |
+
|
| 93 |
+
# Add a title to the left column
|
| 94 |
+
with left_column:
|
| 95 |
+
st.title(translations[lang]["title"])
|
| 96 |
+
|
| 97 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 98 |
+
st.markdown(""" """)
|
| 99 |
+
|
| 100 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 101 |
+
st.markdown(""" """)
|
| 102 |
+
|
| 103 |
+
st.image("pages/DenseConnector/image_1.jpg", use_column_width=True)
|
| 104 |
+
st.markdown(""" """)
|
| 105 |
+
|
| 106 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 107 |
+
st.markdown(""" """)
|
| 108 |
+
|
| 109 |
+
st.image("pages/DenseConnector/image_2.jpg", use_column_width=True)
|
| 110 |
+
st.markdown(""" """)
|
| 111 |
+
|
| 112 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 113 |
+
st.markdown(""" """)
|
| 114 |
+
|
| 115 |
+
st.image("pages/DenseConnector/image_3.jpg", use_column_width=True)
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
|
| 118 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 119 |
+
st.markdown(""" """)
|
| 120 |
+
|
| 121 |
+
st.image("pages/DenseConnector/image_4.jpg", use_column_width=True)
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.image("pages/DenseConnector/image_5.jpg", use_column_width=True)
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 131 |
+
|
| 132 |
+
st.markdown(""" """)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
col1, col2, col3= st.columns(3)
|
| 136 |
+
with col1:
|
| 137 |
+
if lang == "en":
|
| 138 |
+
if st.button('Previous paper', use_container_width=True):
|
| 139 |
+
switch_page("CuMo")
|
| 140 |
+
else:
|
| 141 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 142 |
+
switch_page("CuMo")
|
| 143 |
+
with col2:
|
| 144 |
+
if lang == "en":
|
| 145 |
+
if st.button("Home", use_container_width=True):
|
| 146 |
+
switch_page("Home")
|
| 147 |
+
else:
|
| 148 |
+
if st.button("Accueil", use_container_width=True):
|
| 149 |
+
switch_page("Home")
|
| 150 |
+
with col3:
|
| 151 |
+
if lang == "en":
|
| 152 |
+
if st.button("Next paper", use_container_width=True):
|
| 153 |
+
switch_page("Depth Anything v2")
|
| 154 |
+
else:
|
| 155 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 156 |
+
switch_page("Depth Anything v2")
|
pages/19_Depth_Anything_V2.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Depth Anything V2',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1803063120354492658) (June 18, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
I love Depth Anything V2 😍
|
| 14 |
+
It’s <a href='Depth_Anything' target='_self'>Depth Anything</a>, but scaled with both larger teacher model and a gigantic dataset! Let’s unpack 🤓🧶!
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
The authors have analyzed Marigold, a diffusion based model against Depth Anything and found out what’s up with using synthetic images vs real images for MDE:
|
| 19 |
+
🔖 Real data has a lot of label noise, inaccurate depth maps (caused by depth sensors missing transparent objects etc)
|
| 20 |
+
🔖 Synthetic data have more precise and detailed depth labels and they are truly ground-truth, but there’s a distribution shift between real and synthetic images, and they have restricted scene coverage
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
The authors train different image encoders only on synthetic images and find out unless the encoder is very large the model can’t generalize well (but large models generalize inherently anyway) 🧐
|
| 25 |
+
But they still fail encountering real images that have wide distribution in labels 🥲
|
| 26 |
+
""",
|
| 27 |
+
'tweet_4':
|
| 28 |
+
"""
|
| 29 |
+
Depth Anything v2 framework is to...
|
| 30 |
+
🦖 Train a teacher model based on DINOv2-G based on 595K synthetic images
|
| 31 |
+
🏷️ Label 62M real images using teacher model
|
| 32 |
+
🦕 Train a student model using the real images labelled by teacher
|
| 33 |
+
Result: 10x faster and more accurate than Marigold!
|
| 34 |
+
""",
|
| 35 |
+
'tweet_5':
|
| 36 |
+
"""
|
| 37 |
+
The authors also construct a new benchmark called DA-2K that is less noisy, highly detailed and more diverse!
|
| 38 |
+
I have created a [collection](https://t.co/3fAB9b2sxi) that has the models, the dataset, the demo and CoreML converted model 😚
|
| 39 |
+
""",
|
| 40 |
+
'ressources':
|
| 41 |
+
"""
|
| 42 |
+
Ressources:
|
| 43 |
+
[Depth Anything V2](https://arxiv.org/abs/2406.09414) by Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao (2024)
|
| 44 |
+
[GitHub](https://github.com/DepthAnything/Depth-Anything-V2)
|
| 45 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/depth_anything_v2)
|
| 46 |
+
"""
|
| 47 |
+
},
|
| 48 |
+
'fr': {
|
| 49 |
+
'title': 'Depth Anything V2',
|
| 50 |
+
'original_tweet':
|
| 51 |
+
"""
|
| 52 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1803063120354492658) (en anglais) (18 juin 2024)
|
| 53 |
+
""",
|
| 54 |
+
'tweet_1':
|
| 55 |
+
"""
|
| 56 |
+
J'adore Depth Anything V2 😍
|
| 57 |
+
C'est un <a href='Depth_Anything' target='_self'>Depth Anything</a>, mais passé à l'échelle avec à la fois un modèle enseignant plus grand et un jeu de données gigantesque !
|
| 58 |
+
Décortiquons tout ça 🤓🧶 !
|
| 59 |
+
""",
|
| 60 |
+
'tweet_2':
|
| 61 |
+
"""
|
| 62 |
+
Les auteurs ont analysé Marigold, un modèle de diffusion vs Depth Anything et ont découvert ce qui se passe avec l'utilisation d'images synthétiques par rapport à des images réelles :
|
| 63 |
+
🔖 Les données réelles peuvent être mal étiquettées, les cartes de profondeur peuvent être imprécises (du fait des capteurs de profondeur manquant des objets transparents, etc.)
|
| 64 |
+
🔖 Les données synthétiques ont des étiquettes plus précises ainsi que des cartes de profondeur plus détaillées/véridiques, mais il y a un décalage de distribution entre les images réelles et synthétiques. Les scènes couvertes sont également plus restreintes.
|
| 65 |
+
""",
|
| 66 |
+
'tweet_3':
|
| 67 |
+
"""
|
| 68 |
+
Les auteurs entraînent différents encodeurs d'images uniquement sur des images synthétiques et découvrent qu'à moins que l'encodeur ne soit très grand,
|
| 69 |
+
le modèle ne peut pas bien généraliser (mais les grands modèles généralisent de toute façon de manière inhérente) 🧐
|
| 70 |
+
Mais ils ne parviennent toujours pas à trouver des images réelles ayant une grande diffusion d'étiquettes 🥲
|
| 71 |
+
""",
|
| 72 |
+
'tweet_4':
|
| 73 |
+
"""
|
| 74 |
+
Le framework Depth Anything v2 a pour but...
|
| 75 |
+
🦖 d'entraîner un modèle enseignant basé sur <a href='DINOv2' target='_self'>DINOv2-G</a> à partir de 595K images synthétiques
|
| 76 |
+
🏷️ d'étiqueter 62M d'images réelles à l'aide du modèle enseignant
|
| 77 |
+
🦕 d'entraîner un modèle étudiant en utilisant les images réelles étiquetées par l'enseignant
|
| 78 |
+
Résultat : 10x plus rapide et plus précis que Marigold !
|
| 79 |
+
""",
|
| 80 |
+
'tweet_5':
|
| 81 |
+
"""
|
| 82 |
+
Les auteurs porposent également un nouveau benchmark appelé DA-2K qui est moins bruité, très détaillé et plus diversifié !
|
| 83 |
+
J'ai créé une [collection](https://t.co/3fAB9b2sxi) contenant le modèles le jeu de données, la démo et la convertion en CoreML 😚
|
| 84 |
+
""",
|
| 85 |
+
'ressources':
|
| 86 |
+
"""
|
| 87 |
+
Ressources :
|
| 88 |
+
[Depth Anything V2](https://arxiv.org/abs/2406.09414) de Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao (2024)
|
| 89 |
+
[GitHub](https://github.com/DepthAnything/Depth-Anything-V2)
|
| 90 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/depth_anything_v2)
|
| 91 |
+
"""
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def language_selector():
|
| 97 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 98 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 99 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 100 |
+
|
| 101 |
+
left_column, right_column = st.columns([5, 1])
|
| 102 |
+
|
| 103 |
+
# Add a selector to the right column
|
| 104 |
+
with right_column:
|
| 105 |
+
lang = language_selector()
|
| 106 |
+
|
| 107 |
+
# Add a title to the left column
|
| 108 |
+
with left_column:
|
| 109 |
+
st.title(translations[lang]["title"])
|
| 110 |
+
|
| 111 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 115 |
+
st.markdown(""" """)
|
| 116 |
+
|
| 117 |
+
st.image("pages/Depth_Anything_v2/image_1.jpg", use_column_width=True)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
st.image("pages/Depth_Anything_v2/image_2.jpg", use_column_width=True)
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
st.image("pages/Depth_Anything_v2/image_3.jpg", use_column_width=True)
|
| 130 |
+
st.markdown(""" """)
|
| 131 |
+
|
| 132 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
|
| 135 |
+
st.image("pages/Depth_Anything_v2/image_4.jpg", use_column_width=True)
|
| 136 |
+
st.markdown(""" """)
|
| 137 |
+
|
| 138 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 139 |
+
st.markdown(""" """)
|
| 140 |
+
|
| 141 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 142 |
+
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
st.markdown(""" """)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
col1, col2, col3= st.columns(3)
|
| 147 |
+
with col1:
|
| 148 |
+
if lang == "en":
|
| 149 |
+
if st.button('Previous paper', use_container_width=True):
|
| 150 |
+
switch_page("DenseConnector")
|
| 151 |
+
else:
|
| 152 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 153 |
+
switch_page("DenseConnector")
|
| 154 |
+
with col2:
|
| 155 |
+
if lang == "en":
|
| 156 |
+
if st.button("Home", use_container_width=True):
|
| 157 |
+
switch_page("Home")
|
| 158 |
+
else:
|
| 159 |
+
if st.button("Accueil", use_container_width=True):
|
| 160 |
+
switch_page("Home")
|
| 161 |
+
with col3:
|
| 162 |
+
if lang == "en":
|
| 163 |
+
if st.button("Next paper", use_container_width=True):
|
| 164 |
+
switch_page("Florence-2")
|
| 165 |
+
else:
|
| 166 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 167 |
+
switch_page("Florence-2")
|
pages/1_MobileSAM.py
CHANGED
|
@@ -1,79 +1,172 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
st.markdown(""" """)
|
| 8 |
|
| 9 |
-
st.markdown(""
|
| 10 |
-
The idea 💡: SAM model consist of three parts, a heavy image encoder, a prompt encoder (prompt can be text, bounding box, mask or point) and a mask decoder.
|
| 11 |
-
|
| 12 |
-
To make the SAM model smaller without compromising from the performance, the authors looked into three types of distillation.
|
| 13 |
-
First one is distilling the decoder outputs directly (a more naive approach) with a completely randomly initialized small ViT and randomly initialized mask decoder.
|
| 14 |
-
However, when the ViT and the decoder are both in a bad state, this doesn't work well.
|
| 15 |
-
""")
|
| 16 |
st.markdown(""" """)
|
| 17 |
|
| 18 |
st.image("pages/MobileSAM/image_1.jpeg", use_column_width=True)
|
| 19 |
st.markdown(""" """)
|
| 20 |
|
| 21 |
-
st.markdown(""
|
| 22 |
-
The second type of distillation is called semi-coupled, where the authors only randomly initialized the ViT image encoder and kept the mask decoder.
|
| 23 |
-
This is called semi-coupled because the image encoder distillation still depends on the mask decoder (see below 👇)
|
| 24 |
-
""")
|
| 25 |
st.markdown(""" """)
|
| 26 |
|
| 27 |
st.image("pages/MobileSAM/image_2.jpg", use_column_width=True)
|
| 28 |
st.markdown(""" """)
|
| 29 |
|
| 30 |
-
st.markdown(""
|
| 31 |
-
The last type of distillation, [decoupled distillation](https://openaccess.thecvf.com/content/CVPR2022/papers/Zhao_Decoupled_Knowledge_Distillation_CVPR_2022_paper.pdf), is the most intuitive IMO.
|
| 32 |
-
The authors have "decoupled" image encoder altogether and have frozen the mask decoder and didn't really distill based on generated masks.
|
| 33 |
-
This makes sense as the bottleneck here is the encoder itself and most of the time, distillation works well with encoding.
|
| 34 |
-
""")
|
| 35 |
st.markdown(""" """)
|
| 36 |
|
| 37 |
st.image("pages/MobileSAM/image_3.jpeg", use_column_width=True)
|
| 38 |
st.markdown(""" """)
|
| 39 |
|
| 40 |
-
st.markdown(""
|
| 41 |
-
Finally, they found out that decoupled distillation performs better than coupled distillation by means of mean IoU and requires much less compute! ♥️
|
| 42 |
-
""")
|
| 43 |
st.markdown(""" """)
|
| 44 |
|
| 45 |
st.image("pages/MobileSAM/image_4.jpg", use_column_width=True)
|
| 46 |
st.markdown(""" """)
|
| 47 |
|
| 48 |
-
st.markdown(""
|
| 49 |
-
Wanted to leave some links here if you'd like to try yourself 👇
|
| 50 |
-
- MobileSAM [demo](https://huggingface.co/spaces/dhkim2810/MobileSAMMobileSAM)
|
| 51 |
-
- Model [repository](https://huggingface.co/dhkim2810/MobileSAM)
|
| 52 |
-
|
| 53 |
-
If you'd like to experiment around TinyViT, [timm library](https://huggingface.co/docs/timm/index) ([Ross Wightman](https://x.com/wightmanr)) has a bunch of [checkpoints available](https://huggingface.co/models?sort=trending&search=timm%2Ftinyvit).
|
| 54 |
-
""")
|
| 55 |
st.markdown(""" """)
|
| 56 |
|
| 57 |
st.image("pages/MobileSAM/image_5.jpeg", use_column_width=True)
|
| 58 |
st.markdown(""" """)
|
| 59 |
|
| 60 |
-
|
| 61 |
-
st.info("""
|
| 62 |
-
Ressources:
|
| 63 |
-
[Faster Segment Anything: Towards Lightweight SAM for Mobile Applications](https://arxiv.org/abs/2306.14289)
|
| 64 |
-
by Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, Choong Seon Hong (2023)
|
| 65 |
-
[GitHub](https://github.com/ChaoningZhang/MobileSAM)""", icon="📚")
|
| 66 |
|
| 67 |
st.markdown(""" """)
|
| 68 |
st.markdown(""" """)
|
| 69 |
st.markdown(""" """)
|
| 70 |
col1, col2, col3= st.columns(3)
|
| 71 |
with col1:
|
| 72 |
-
if
|
| 73 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
with col2:
|
| 75 |
-
if
|
| 76 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 77 |
with col3:
|
| 78 |
-
if
|
| 79 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
+
translations = {
|
| 5 |
+
'en': {'title': 'MobileSAM',
|
| 6 |
+
'original_tweet':
|
| 7 |
+
"""
|
| 8 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1738959605542076863) (December 24, 2023)
|
| 9 |
+
""",
|
| 10 |
+
'tweet_1':
|
| 11 |
+
"""Read the MobileSAM paper this weekend 📖 Sharing some insights!
|
| 12 |
+
The idea 💡: SAM model consist of three parts, a heavy image encoder, a prompt encoder (prompt can be text, bounding box, mask or point) and a mask decoder.
|
| 13 |
+
<br>
|
| 14 |
+
To make the SAM model smaller without compromising from the performance, the authors looked into three types of distillation.
|
| 15 |
+
First one is distilling the decoder outputs directly (a more naive approach) with a completely randomly initialized small ViT and randomly initialized mask decoder.
|
| 16 |
+
However, when the ViT and the decoder are both in a bad state, this doesn't work well.
|
| 17 |
+
""",
|
| 18 |
+
'tweet_2':
|
| 19 |
+
"""
|
| 20 |
+
The second type of distillation is called semi-coupled, where the authors only randomly initialized the ViT image encoder and kept the mask decoder.
|
| 21 |
+
This is called semi-coupled because the image encoder distillation still depends on the mask decoder (see below 👇)
|
| 22 |
+
""",
|
| 23 |
+
'tweet_3':
|
| 24 |
+
"""
|
| 25 |
+
The last type of distillation, [decoupled distillation](https://openaccess.thecvf.com/content/CVPR2022/papers/Zhao_Decoupled_Knowledge_Distillation_CVPR_2022_paper.pdf), is the most intuitive IMO.
|
| 26 |
+
The authors have "decoupled" image encoder altogether and have frozen the mask decoder and didn't really distill based on generated masks.
|
| 27 |
+
This makes sense as the bottleneck here is the encoder itself and most of the time, distillation works well with encoding.
|
| 28 |
+
""",
|
| 29 |
+
'tweet_4':
|
| 30 |
+
"""
|
| 31 |
+
Finally, they found out that decoupled distillation performs better than coupled distillation by means of mean IoU and requires much less compute! ♥️
|
| 32 |
+
""",
|
| 33 |
+
'tweet_5':
|
| 34 |
+
"""
|
| 35 |
+
Wanted to leave some links here if you'd like to try yourself 👇
|
| 36 |
+
- MobileSAM [demo](https://huggingface.co/spaces/dhkim2810/MobileSAMMobileSAM)
|
| 37 |
+
- Model [repository](https://huggingface.co/dhkim2810/MobileSAM)
|
| 38 |
+
|
| 39 |
+
If you'd like to experiment around TinyViT, [timm library](https://huggingface.co/docs/timm/index) ([Ross Wightman](https://x.com/wightmanr)) has a bunch of [checkpoints available](https://huggingface.co/models?sort=trending&search=timm%2Ftinyvit).
|
| 40 |
+
""",
|
| 41 |
+
'ressources':
|
| 42 |
+
"""
|
| 43 |
+
Ressources:
|
| 44 |
+
[Faster Segment Anything: Towards Lightweight SAM for Mobile Applications](https://arxiv.org/abs/2306.14289)
|
| 45 |
+
by Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, Choong Seon Hong (2023)
|
| 46 |
+
[GitHub](https://github.com/ChaoningZhang/MobileSAM)"""
|
| 47 |
+
},
|
| 48 |
+
'fr': {
|
| 49 |
+
'title': 'MobileSAM',
|
| 50 |
+
'original_tweet':
|
| 51 |
+
"""
|
| 52 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1738959605542076863) (en anglais) (24 décembre 2023)
|
| 53 |
+
""",
|
| 54 |
+
'tweet_1':
|
| 55 |
+
"""J'ai lu le papier MobileSAM ce week-end 📖 Je vous partage quelques enseignements !
|
| 56 |
+
L'idée 💡 : SAM se compose de trois parties : un gros encodeur pour les images, un encodeur pour le prompt
|
| 57 |
+
(pouvant être un texte, une bounding box, un masque ou un point) et un décodeur pour le masque.
|
| 58 |
+
<br>
|
| 59 |
+
Pour réduire la taille du modèle SAM sans compromettre ses performances, les auteurs ont envisagé trois types de distillation.
|
| 60 |
+
Le premier (naïf) consiste à distiller directement les sorties du décodeur dans un petit ViT et dans un décodeur de masque, tous deux initialisés aléatoirement.
|
| 61 |
+
Cependant, lorsque le ViT et le décodeur sont tous deux dans un mauvais état, cela ne fonctionne pas bien.
|
| 62 |
+
""",
|
| 63 |
+
'tweet_2':
|
| 64 |
+
"""
|
| 65 |
+
Le deuxième type de distillation est appelé semi-couplé, où les auteurs initialisent aléatoirement le ViT de l'encodeur d'image et conservent le décodeur de masque.
|
| 66 |
+
Ce type de distillation est appelé semi-couplé parce que la distillation de l'encodeur d'image dépend toujours du décodeur de masquage (voir ci-dessous 👇).
|
| 67 |
+
""",
|
| 68 |
+
'tweet_3':
|
| 69 |
+
"""
|
| 70 |
+
Le dernier type de distillation, la [distillation découplée](https://openaccess.thecvf.com/content/CVPR2022/papers/Zhao_Decoupled_Knowledge_Distillation_CVPR_2022_paper.pdf), est le plus intuitif selon moi.
|
| 71 |
+
Les auteurs découplent complètement l'encodeur d'image et gèlent le décodeur de masque. Ils ne distillent pas sur les masques générés.
|
| 72 |
+
C'est logique car le goulot d'étranglement ici est l'encodeur lui-même et la plupart du temps la distillation fonctionne bien avec l'encodage.
|
| 73 |
+
""",
|
| 74 |
+
'tweet_4':
|
| 75 |
+
"""
|
| 76 |
+
Finalement, ils observent que la distillation découplée est plus performante que la distillation couplée en termes d'IoU moyen et qu'elle nécessite beaucoup moins de calculs ! ♥️
|
| 77 |
+
""",
|
| 78 |
+
'tweet_5':
|
| 79 |
+
"""
|
| 80 |
+
Quelques liens si vous voulez essayer vous-même 👇
|
| 81 |
+
- La [démo](https://huggingface.co/spaces/dhkim2810/MobileSAMMobileSAM)
|
| 82 |
+
- Le [dépôt Hugging Face du modèle](https://huggingface.co/dhkim2810/MobileSAM)
|
| 83 |
+
|
| 84 |
+
Si vous souhaitez expérimenter avec un TinyViT, la bibliotèque [timm](https://huggingface.co/docs/timm/index) ([Ross Wightman](https://x.com/wightmanr))
|
| 85 |
+
dispose d'un certain nombre de [checkpoints](https://huggingface.co/models?sort=trending&search=timm%2Ftinyvit).
|
| 86 |
+
""",
|
| 87 |
+
'ressources':
|
| 88 |
+
"""
|
| 89 |
+
Ressources :
|
| 90 |
+
[Faster Segment Anything: Towards Lightweight SAM for Mobile Applications](https://arxiv.org/abs/2306.14289)
|
| 91 |
+
de Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, Choong Seon Hong (2023)
|
| 92 |
+
[GitHub](https://github.com/ChaoningZhang/MobileSAM)
|
| 93 |
+
"""
|
| 94 |
+
}
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def language_selector():
|
| 99 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 100 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 101 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 102 |
+
|
| 103 |
+
left_column, right_column = st.columns([5, 1])
|
| 104 |
+
|
| 105 |
+
# Add a selector to the right column
|
| 106 |
+
with right_column:
|
| 107 |
+
lang = language_selector()
|
| 108 |
+
|
| 109 |
+
# Add a title to the left column
|
| 110 |
+
with left_column:
|
| 111 |
+
st.title(translations[lang]["title"])
|
| 112 |
+
|
| 113 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 114 |
st.markdown(""" """)
|
| 115 |
|
| 116 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 117 |
st.markdown(""" """)
|
| 118 |
|
| 119 |
st.image("pages/MobileSAM/image_1.jpeg", use_column_width=True)
|
| 120 |
st.markdown(""" """)
|
| 121 |
|
| 122 |
+
st.markdown(translations[lang]["tweet_2"])
|
|
|
|
|
|
|
|
|
|
| 123 |
st.markdown(""" """)
|
| 124 |
|
| 125 |
st.image("pages/MobileSAM/image_2.jpg", use_column_width=True)
|
| 126 |
st.markdown(""" """)
|
| 127 |
|
| 128 |
+
st.markdown(translations[lang]["tweet_3"])
|
|
|
|
|
|
|
|
|
|
|
|
|
| 129 |
st.markdown(""" """)
|
| 130 |
|
| 131 |
st.image("pages/MobileSAM/image_3.jpeg", use_column_width=True)
|
| 132 |
st.markdown(""" """)
|
| 133 |
|
| 134 |
+
st.markdown(translations[lang]["tweet_4"])
|
|
|
|
|
|
|
| 135 |
st.markdown(""" """)
|
| 136 |
|
| 137 |
st.image("pages/MobileSAM/image_4.jpg", use_column_width=True)
|
| 138 |
st.markdown(""" """)
|
| 139 |
|
| 140 |
+
st.markdown(translations[lang]["tweet_5"])
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 141 |
st.markdown(""" """)
|
| 142 |
|
| 143 |
st.image("pages/MobileSAM/image_5.jpeg", use_column_width=True)
|
| 144 |
st.markdown(""" """)
|
| 145 |
|
| 146 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 147 |
|
| 148 |
st.markdown(""" """)
|
| 149 |
st.markdown(""" """)
|
| 150 |
st.markdown(""" """)
|
| 151 |
col1, col2, col3= st.columns(3)
|
| 152 |
with col1:
|
| 153 |
+
if lang == "en":
|
| 154 |
+
if st.button('Previous paper', use_container_width=True):
|
| 155 |
+
switch_page("KOSMOS-2")
|
| 156 |
+
else:
|
| 157 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 158 |
+
switch_page("KOSMOS-2")
|
| 159 |
with col2:
|
| 160 |
+
if lang == "en":
|
| 161 |
+
if st.button("Home", use_container_width=True):
|
| 162 |
+
switch_page("Home")
|
| 163 |
+
else:
|
| 164 |
+
if st.button("Accueil", use_container_width=True):
|
| 165 |
+
switch_page("Home")
|
| 166 |
with col3:
|
| 167 |
+
if lang == "en":
|
| 168 |
+
if st.button("Next paper", use_container_width=True):
|
| 169 |
+
switch_page("OneFormer")
|
| 170 |
+
else:
|
| 171 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 172 |
+
switch_page("OneFormer")
|
pages/20_Florence-2.py
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Florence-2',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1803769866878623819) (June 20, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Florence-2 is a new vision foundation model by Microsoft capable of a wide variety of tasks 🤯
|
| 14 |
+
Let's unpack! 🧶
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
This model is can handle tasks that vary from document understanding to semantic segmentation 🤩
|
| 19 |
+
[Demo](https://t.co/7YJZvjhw84) | [Collection](https://t.co/Ub7FGazDz1)
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
The difference from previous models is that the authors have compiled a dataset that consists of 126M images with 5.4B annotations labelled with their own data engine ↓↓
|
| 24 |
+
""",
|
| 25 |
+
'tweet_4':
|
| 26 |
+
"""
|
| 27 |
+
The dataset also offers more variety in annotations compared to other datasets, it has region level and image level annotations with more variety in semantic granularity as well!
|
| 28 |
+
""",
|
| 29 |
+
'tweet_5':
|
| 30 |
+
"""
|
| 31 |
+
The model is a similar architecture to previous models, an image encoder, a multimodality encoder with text decoder.
|
| 32 |
+
The authors have compiled the multitask dataset with prompts for each task which makes the model trainable on multiple tasks 🤗
|
| 33 |
+
""",
|
| 34 |
+
'tweet_6':
|
| 35 |
+
"""
|
| 36 |
+
You also fine-tune this model on any task of choice, the authors also released different results on downstream tasks and report their results when un/freezing vision encoder 🤓📉
|
| 37 |
+
They have released fine-tuned models too, you can find them in the collection above 🤗
|
| 38 |
+
""",
|
| 39 |
+
'ressources':
|
| 40 |
+
"""
|
| 41 |
+
Ressources:
|
| 42 |
+
[Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks](https://arxiv.org/abs/2311.06242)
|
| 43 |
+
by Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan (2023)
|
| 44 |
+
[Hugging Face blog post](https://huggingface.co/blog/finetune-florence2)
|
| 45 |
+
[Fine-tuning notebook](https://github.com/merveenoyan/smol-vision/blob/main/Fine_tune_Florence_2.ipynb)
|
| 46 |
+
[Florence-2 fine-tuned](https://huggingface.co/models?search=florence-2)
|
| 47 |
+
"""
|
| 48 |
+
},
|
| 49 |
+
'fr': {
|
| 50 |
+
'title': 'Florence-2',
|
| 51 |
+
'original_tweet':
|
| 52 |
+
"""
|
| 53 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1803769866878623819) (en anglais) (20 juin 2024)
|
| 54 |
+
""",
|
| 55 |
+
'tweet_1':
|
| 56 |
+
"""
|
| 57 |
+
Florence-2 est un nouveau modèle de fondation de vision de Microsoft capable d'une grande variété de tâches 🤯.
|
| 58 |
+
Déballons tout ça ! 🧶
|
| 59 |
+
""",
|
| 60 |
+
'tweet_2':
|
| 61 |
+
"""
|
| 62 |
+
Ce modèle peut traiter des tâches allant de la compréhension de documents à la segmentation sémantique 🤩
|
| 63 |
+
[Demo](https://t.co/7YJZvjhw84) | [Collection](https://t.co/Ub7FGazDz1)
|
| 64 |
+
""",
|
| 65 |
+
'tweet_3':
|
| 66 |
+
"""
|
| 67 |
+
La différence avec les modèles précédents est que les auteurs ont constitué un jeu de données de 126 millions d'images étiquetées avec 5,4 milliards d'annotations via leur propre moteur de données ↓↓
|
| 68 |
+
""",
|
| 69 |
+
'tweet_4':
|
| 70 |
+
"""
|
| 71 |
+
Ce jeu de données offre aussi une plus grande variété d'annotations par rapport aux autres jeux de données, avec des annotations au niveau de la région et de l'image, ainsi qu'une plus grande variété dans la granularité sémantique !
|
| 72 |
+
""",
|
| 73 |
+
'tweet_5':
|
| 74 |
+
"""
|
| 75 |
+
Le modèle a une architecture similaire aux modèles précédents, un encodeur d'image, un encodeur de multimodalité avec un décodeur de texte.
|
| 76 |
+
Les auteurs ont compilé le jeu de données multitâches avec des prompts chaque tâche, ce qui rend le modèle entraînable sur de multiples tâches 🤗
|
| 77 |
+
""",
|
| 78 |
+
'tweet_6':
|
| 79 |
+
"""
|
| 80 |
+
Vous pouvez finetuner ce modèle sur n'importe quelle tâche de votre choix. Les auteurs ont publié différents résultats sur des tâches en aval et rapportent leurs résultats lors qu'ils gèlent/dégelent l'encodeur de vision 🤓📉.
|
| 81 |
+
Ils ont aussi publié des modèles finetunés que vous pouvez trouver dans la collection ci-dessus 🤗
|
| 82 |
+
""",
|
| 83 |
+
'ressources':
|
| 84 |
+
"""
|
| 85 |
+
Ressources :
|
| 86 |
+
[Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks](https://arxiv.org/abs/2311.06242)
|
| 87 |
+
de Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan (2023)
|
| 88 |
+
[Article de blog sur Hugging Face](https://huggingface.co/blog/finetune-florence2)
|
| 89 |
+
[Notebook de finetuning](https://github.com/merveenoyan/smol-vision/blob/main/Fine_tune_Florence_2.ipynb)
|
| 90 |
+
[Les Florence-2 finetunés](https://huggingface.co/models?search=florence-2)
|
| 91 |
+
"""
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def language_selector():
|
| 97 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 98 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 99 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 100 |
+
|
| 101 |
+
left_column, right_column = st.columns([5, 1])
|
| 102 |
+
|
| 103 |
+
# Add a selector to the right column
|
| 104 |
+
with right_column:
|
| 105 |
+
lang = language_selector()
|
| 106 |
+
|
| 107 |
+
# Add a title to the left column
|
| 108 |
+
with left_column:
|
| 109 |
+
st.title(translations[lang]["title"])
|
| 110 |
+
|
| 111 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 115 |
+
st.markdown(""" """)
|
| 116 |
+
|
| 117 |
+
st.image("pages/Florence-2/image_1.jpg", use_column_width=True)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
st.image("pages/Florence-2/image_2.jpg", use_column_width=True)
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
st.image("pages/Florence-2/image_3.jpg", use_column_width=True)
|
| 130 |
+
st.markdown(""" """)
|
| 131 |
+
|
| 132 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
|
| 135 |
+
st.image("pages/Florence-2/image_4.jpg", use_column_width=True)
|
| 136 |
+
st.markdown(""" """)
|
| 137 |
+
|
| 138 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 139 |
+
st.markdown(""" """)
|
| 140 |
+
|
| 141 |
+
st.image("pages/Florence-2/image_5.jpg", use_column_width=True)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
|
| 144 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
|
| 147 |
+
st.image("pages/Florence-2/image_6.jpg", use_column_width=True)
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
|
| 150 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 151 |
+
|
| 152 |
+
st.markdown(""" """)
|
| 153 |
+
st.markdown(""" """)
|
| 154 |
+
st.markdown(""" """)
|
| 155 |
+
col1, col2, col3= st.columns(3)
|
| 156 |
+
with col1:
|
| 157 |
+
if lang == "en":
|
| 158 |
+
if st.button('Previous paper', use_container_width=True):
|
| 159 |
+
switch_page("Depth Anything V2")
|
| 160 |
+
else:
|
| 161 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 162 |
+
switch_page("Depth Anything V2")
|
| 163 |
+
with col2:
|
| 164 |
+
if lang == "en":
|
| 165 |
+
if st.button("Home", use_container_width=True):
|
| 166 |
+
switch_page("Home")
|
| 167 |
+
else:
|
| 168 |
+
if st.button("Accueil", use_container_width=True):
|
| 169 |
+
switch_page("Home")
|
| 170 |
+
with col3:
|
| 171 |
+
if lang == "en":
|
| 172 |
+
if st.button("Next paper", use_container_width=True):
|
| 173 |
+
switch_page("4M-21")
|
| 174 |
+
else:
|
| 175 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 176 |
+
switch_page("4M-21")
|
pages/21_4M-21.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': '4M-21',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1804138208814309626) (June 21, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
EPFL and Apple just released 4M-21: single any-to-any model that can do anything from text-to-image generation to generating depth masks! 🙀
|
| 14 |
+
Let's unpack 🧶
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
4M is a multimodal training [framework](https://t.co/jztLublfSF) introduced by Apple and EPFL.
|
| 19 |
+
Resulting model takes image and text and output image and text 🤩
|
| 20 |
+
[Models](https://t.co/1LC0rAohEl) | [Demo](https://t.co/Ra9qbKcWeY)
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
This model consists of transformer encoder and decoder, where the key to multimodality lies in input and output data:
|
| 25 |
+
input and output tokens are decoded to generate bounding boxes, generated image's pixels, captions and more!
|
| 26 |
+
""",
|
| 27 |
+
'tweet_4':
|
| 28 |
+
"""
|
| 29 |
+
This model also learnt to generate canny maps, SAM edges and other things for steerable text-to-image generation 🖼️
|
| 30 |
+
The authors only added image-to-all capabilities for the demo, but you can try to use this model for text-to-image generation as well ☺️
|
| 31 |
+
""",
|
| 32 |
+
'tweet_5':
|
| 33 |
+
"""
|
| 34 |
+
In the project page you can also see the model's text-to-image and steered generation capabilities with model's own outputs as control masks!
|
| 35 |
+
""",
|
| 36 |
+
'ressources':
|
| 37 |
+
"""
|
| 38 |
+
Ressources
|
| 39 |
+
[4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities](https://arxiv.org/abs/2406.09406) by Roman Bachmann, Oğuzhan Fatih Kar, David Mizrahi, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir (2024)
|
| 40 |
+
[GitHub](https://github.com/apple/ml-4m/)
|
| 41 |
+
"""
|
| 42 |
+
},
|
| 43 |
+
'fr': {
|
| 44 |
+
'title': '4M-21',
|
| 45 |
+
'original_tweet':
|
| 46 |
+
"""
|
| 47 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1804138208814309626) (en anglais) (21 juin 2024)
|
| 48 |
+
""",
|
| 49 |
+
'tweet_1':
|
| 50 |
+
"""
|
| 51 |
+
L'EPFL et Apple viennent de publier 4M-21 : un modèle unique qui peut tout faire, de la génération texte-à-image à la génération de masques de profondeur ! 🙀
|
| 52 |
+
Détaillons tout ça 🧶
|
| 53 |
+
""",
|
| 54 |
+
'tweet_2':
|
| 55 |
+
"""
|
| 56 |
+
4M est un [framework](https://t.co/jztLublfSF) d'entraînement multimodal introduit par Apple et l'EPFL.
|
| 57 |
+
Le modèle résultant prend une image et un texte et produit une image et un texte 🤩
|
| 58 |
+
[Modèles](https://t.co/1LC0rAohEl) | [Demo](https://t.co/Ra9qbKcWeY)
|
| 59 |
+
""",
|
| 60 |
+
'tweet_3':
|
| 61 |
+
"""
|
| 62 |
+
Ce modèle se compose d'un transformer encodeur-décodeur, où la clé de la multimodalité réside dans les données d'entrée et de sortie :
|
| 63 |
+
les tokens d'entrée et de sortie sont décodés pour générer des boîtes de délimitation, les pixels de l'image, les légendes, etc. !
|
| 64 |
+
""",
|
| 65 |
+
'tweet_4':
|
| 66 |
+
"""
|
| 67 |
+
Ce modèle a aussi appris à générer des filtres de Canny, des bordures SAM et pleins d'autres choses pour tout ce qui est pilotage de la génération d'images à partir de textes 🖼️
|
| 68 |
+
Les auteurs n'ont ajouté que des capacités image-vers-tout pour la démo, mais vous pouvez essayer d'utiliser ce modèle pour la génération texte-image également ☺️ """,
|
| 69 |
+
'tweet_5':
|
| 70 |
+
"""
|
| 71 |
+
Dans la page du projet, vous pouvez également voir les capacités du modèle en matière de texte vers image et de génération dirigée avec les propres sorties du modèle en tant que masques de contrôle ! """,
|
| 72 |
+
'ressources':
|
| 73 |
+
"""
|
| 74 |
+
Ressources :
|
| 75 |
+
[4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities](https://arxiv.org/abs/2406.09406) de Roman Bachmann, Oğuzhan Fatih Kar, David Mizrahi, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir (2024)
|
| 76 |
+
[GitHub](https://github.com/apple/ml-4m/)
|
| 77 |
+
"""
|
| 78 |
+
}
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def language_selector():
|
| 83 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 84 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 85 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 86 |
+
|
| 87 |
+
left_column, right_column = st.columns([5, 1])
|
| 88 |
+
|
| 89 |
+
# Add a selector to the right column
|
| 90 |
+
with right_column:
|
| 91 |
+
lang = language_selector()
|
| 92 |
+
|
| 93 |
+
# Add a title to the left column
|
| 94 |
+
with left_column:
|
| 95 |
+
st.title(translations[lang]["title"])
|
| 96 |
+
|
| 97 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 98 |
+
st.markdown(""" """)
|
| 99 |
+
|
| 100 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 101 |
+
st.markdown(""" """)
|
| 102 |
+
|
| 103 |
+
st.image("pages/4M-21/image_1.jpg", use_column_width=True)
|
| 104 |
+
st.markdown(""" """)
|
| 105 |
+
|
| 106 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 107 |
+
st.markdown(""" """)
|
| 108 |
+
|
| 109 |
+
st.video("pages/4M-21/video_1.mp4", format="video/mp4")
|
| 110 |
+
st.markdown(""" """)
|
| 111 |
+
|
| 112 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 113 |
+
st.markdown(""" """)
|
| 114 |
+
|
| 115 |
+
st.image("pages/4M-21/image_2.jpg", use_column_width=True)
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
|
| 118 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 119 |
+
st.markdown(""" """)
|
| 120 |
+
|
| 121 |
+
st.image("pages/4M-21/image_3.jpg", use_column_width=True)
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.video("pages/4M-21/video_2.mp4", format="video/mp4")
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 131 |
+
|
| 132 |
+
st.markdown(""" """)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
col1, col2, col3= st.columns(3)
|
| 136 |
+
with col1:
|
| 137 |
+
if lang == "en":
|
| 138 |
+
if st.button('Previous paper', use_container_width=True):
|
| 139 |
+
switch_page("Florence-2")
|
| 140 |
+
else:
|
| 141 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 142 |
+
switch_page("Florence-2")
|
| 143 |
+
with col2:
|
| 144 |
+
if lang == "en":
|
| 145 |
+
if st.button("Home", use_container_width=True):
|
| 146 |
+
switch_page("Home")
|
| 147 |
+
else:
|
| 148 |
+
if st.button("Accueil", use_container_width=True):
|
| 149 |
+
switch_page("Home")
|
| 150 |
+
with col3:
|
| 151 |
+
if lang == "en":
|
| 152 |
+
if st.button("Next paper", use_container_width=True):
|
| 153 |
+
switch_page("RT-DETR")
|
| 154 |
+
else:
|
| 155 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 156 |
+
switch_page("RT-DETR")
|
pages/22_RT-DETR.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'RT-DETR',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1807790959884665029) (July 1, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Real-time DEtection Transformer (RT-DETR) landed in 🤗 Transformers with Apache 2.0 license 😍
|
| 14 |
+
Do DETRs Beat YOLOs on Real-time Object Detection? Keep reading 👀
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
Short answer, it does! 📖
|
| 19 |
+
[notebook](https://t.co/NNRpG9cAEa), 🔖 [models](https://t.co/ctwWQqNcEt), 🔖 [demo](https://t.co/VrmDDDjoNw)
|
| 20 |
+
|
| 21 |
+
YOLO models are known to be super fast for real-time computer vision, but they have a downside with being volatile to NMS 🥲
|
| 22 |
+
Transformer-based models on the other hand are computationally not as efficient 🥲
|
| 23 |
+
Isn't there something in between? Enter RT-DETR!
|
| 24 |
+
|
| 25 |
+
The authors combined CNN backbone, multi-stage hybrid decoder (combining convs and attn) with a transformer decoder ⇓
|
| 26 |
+
""",
|
| 27 |
+
'tweet_3':
|
| 28 |
+
"""
|
| 29 |
+
In the paper, authors also claim one can adjust speed by changing decoder layers without retraining altogether.
|
| 30 |
+
They also conduct many ablation studies and try different decoders.
|
| 31 |
+
""",
|
| 32 |
+
'tweet_4':
|
| 33 |
+
"""
|
| 34 |
+
The authors find out that the model performs better in terms of speed and accuracy compared to the previous state-of-the-art 🤩
|
| 35 |
+
""",
|
| 36 |
+
'ressources':
|
| 37 |
+
"""
|
| 38 |
+
Ressources:
|
| 39 |
+
[DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069)
|
| 40 |
+
by Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen (2023)
|
| 41 |
+
[GitHub](https://github.com/lyuwenyu/RT-DETR/)
|
| 42 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/main/en/model_doc/rt_detr)
|
| 43 |
+
"""
|
| 44 |
+
},
|
| 45 |
+
'fr': {
|
| 46 |
+
'title': 'RT-DETR',
|
| 47 |
+
'original_tweet':
|
| 48 |
+
"""
|
| 49 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1807790959884665029) (en anglais) (1er juillet 2024)
|
| 50 |
+
""",
|
| 51 |
+
'tweet_1':
|
| 52 |
+
"""
|
| 53 |
+
Real-time DEtection Transformer (RT-DETR) débarque dans 🤗 Transformers avec une licence Apache 2.0 😍
|
| 54 |
+
Les DETR battent-ils les YOLO en matière de détection d'objets en temps réel ? Continuez à lire 👀
|
| 55 |
+
""",
|
| 56 |
+
'tweet_2':
|
| 57 |
+
"""
|
| 58 |
+
Réponse courte, c'est le cas ! 📖
|
| 59 |
+
[notebook](https://t.co/NNRpG9cAEa), 🔖 [models](https://t.co/ctwWQqNcEt), 🔖 [demo](https://t.co/VrmDDDjoNw)
|
| 60 |
+
|
| 61 |
+
Les YOLO sont connus pour être super rapides pour de la vision par ordinateur en temps réel, mais ils ont l'inconvénient d'être volatils pour la suppression non maximale 🥲.
|
| 62 |
+
Les modèles basés sur les transformers quant à eux ne sont pas aussi efficaces sur le plan du calcul 🥲
|
| 63 |
+
N'y a-t-il pas une solution intermédiaire ? C'est là que rentre en jeu RT-DETR !
|
| 64 |
+
|
| 65 |
+
Les auteurs ont combiné un ConvNet, un décodeur hybride à plusieurs étapes (combinant convolution et attention) avec un transformer-décodeur ⇓
|
| 66 |
+
""",
|
| 67 |
+
'tweet_3':
|
| 68 |
+
"""
|
| 69 |
+
Dans le papier, les auteurs affirment qu'il est possible d'ajuster la vitesse en changeant les couches du décodeur sans procéder à un nouvel entraînement.
|
| 70 |
+
Ils mènent également de nombreuses études d'ablation et essaient différents décodeurs.
|
| 71 |
+
""",
|
| 72 |
+
'tweet_4':
|
| 73 |
+
"""
|
| 74 |
+
Les auteurs constatent que le modèle est plus performant en termes de rapidité et de précision que les modèles précédents 🤩
|
| 75 |
+
""",
|
| 76 |
+
'ressources':
|
| 77 |
+
"""
|
| 78 |
+
Ressources :
|
| 79 |
+
[DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069)
|
| 80 |
+
de Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen (2023)
|
| 81 |
+
[GitHub](https://github.com/lyuwenyu/RT-DETR/)
|
| 82 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/main/en/model_doc/rt_detr)
|
| 83 |
+
"""
|
| 84 |
+
}
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def language_selector():
|
| 89 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 90 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 91 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 92 |
+
|
| 93 |
+
left_column, right_column = st.columns([5, 1])
|
| 94 |
+
|
| 95 |
+
# Add a selector to the right column
|
| 96 |
+
with right_column:
|
| 97 |
+
lang = language_selector()
|
| 98 |
+
|
| 99 |
+
# Add a title to the left column
|
| 100 |
+
with left_column:
|
| 101 |
+
st.title(translations[lang]["title"])
|
| 102 |
+
|
| 103 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 104 |
+
st.markdown(""" """)
|
| 105 |
+
|
| 106 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 107 |
+
st.markdown(""" """)
|
| 108 |
+
|
| 109 |
+
st.video("pages/RT-DETR/video_1.mp4", format="video/mp4")
|
| 110 |
+
st.markdown(""" """)
|
| 111 |
+
|
| 112 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 113 |
+
st.markdown(""" """)
|
| 114 |
+
|
| 115 |
+
st.image("pages/RT-DETR/image_1.jpg", use_column_width=True)
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
|
| 118 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 119 |
+
st.markdown(""" """)
|
| 120 |
+
|
| 121 |
+
st.image("pages/RT-DETR/image_2.jpg", use_column_width=True)
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.image("pages/RT-DETR/image_3.jpg", use_column_width=True)
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 131 |
+
|
| 132 |
+
st.markdown(""" """)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
col1, col2, col3= st.columns(3)
|
| 136 |
+
with col1:
|
| 137 |
+
if lang == "en":
|
| 138 |
+
if st.button('Previous paper', use_container_width=True):
|
| 139 |
+
switch_page("4M-21")
|
| 140 |
+
else:
|
| 141 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 142 |
+
switch_page("4M-21")
|
| 143 |
+
with col2:
|
| 144 |
+
if lang == "en":
|
| 145 |
+
if st.button("Home", use_container_width=True):
|
| 146 |
+
switch_page("Home")
|
| 147 |
+
else:
|
| 148 |
+
if st.button("Accueil", use_container_width=True):
|
| 149 |
+
switch_page("Home")
|
| 150 |
+
with col3:
|
| 151 |
+
if lang == "en":
|
| 152 |
+
if st.button("Next paper", use_container_width=True):
|
| 153 |
+
switch_page("ColPali")
|
| 154 |
+
else:
|
| 155 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 156 |
+
switch_page("ColPali")
|
pages/23_ColPali.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'ColPali',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1811003265858912670) (Jul 10, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Forget any document retrievers, use ColPali 💥💥
|
| 14 |
+
<br>
|
| 15 |
+
Document retrieval is done through OCR + layout detection, but it's overkill and doesn't work well! 🤓
|
| 16 |
+
<br>
|
| 17 |
+
ColPali uses a vision language model, which is better in doc understanding 📑
|
| 18 |
+
""",
|
| 19 |
+
'tweet_2':
|
| 20 |
+
"""
|
| 21 |
+
Check out [ColPali model](https://huggingface.co/vidore/colpali) (mit license!)
|
| 22 |
+
Check out the [blog](https://huggingface.co/blog/manu/colpali)
|
| 23 |
+
<br>
|
| 24 |
+
The authors also released a new benchmark for document retrieval, [ViDoRe Leaderboard](https://huggingface.co/spaces/vidore/vidore-leaderboard), submit your model!
|
| 25 |
+
""",
|
| 26 |
+
'tweet_3':
|
| 27 |
+
"""
|
| 28 |
+
Regular document retrieval systems use OCR + layout detection + another model to retrieve information from documents, and then use output representations in applications like RAG 🥲
|
| 29 |
+
<br>
|
| 30 |
+
Meanwhile modern image encoders demonstrate out-of-the-box document understanding capabilities!
|
| 31 |
+
<br>
|
| 32 |
+
ColPali marries the idea of modern vision language models with retrieval 🤝
|
| 33 |
+
<br>
|
| 34 |
+
The authors apply contrastive fine-tuning to <a href='SigLIP' target='_self'>SigLIP</a> on documents, and pool the outputs (they call it BiSigLip). Then they feed the patch embedding outputs to PaliGemma and create BiPali 🖇️
|
| 35 |
+
""",
|
| 36 |
+
'tweet_4':
|
| 37 |
+
"""
|
| 38 |
+
BiPali natively supports image patch embeddings to an LLM, which enables leveraging the ColBERT-like late interaction computations between text tokens and image patches (hence the name ColPali!) 🤩
|
| 39 |
+
<br>
|
| 40 |
+
The authors created the ViDoRe benchmark by collecting PDF documents and generate queries from Claude-3 Sonnet.
|
| 41 |
+
<br>
|
| 42 |
+
See below how every model and ColPali performs on ViDoRe 👇🏻
|
| 43 |
+
""",
|
| 44 |
+
'tweet_5':
|
| 45 |
+
"""
|
| 46 |
+
Aside from performance improvements, ColPali is very fast for offline indexing as well!
|
| 47 |
+
""",
|
| 48 |
+
'ressources':
|
| 49 |
+
"""
|
| 50 |
+
Resources:
|
| 51 |
+
[ColPali: Efficient Document Retrieval with Vision Language Models](https://huggingface.co/papers/2407.01449)
|
| 52 |
+
by Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, Pierre Colombo (2024)
|
| 53 |
+
[GitHub](https://github.com/illuin-tech/colpali)
|
| 54 |
+
[Models](https://huggingface.co/models?search=vidore)
|
| 55 |
+
[Leaderboard](https://huggingface.co/spaces/vidore/vidore-leaderboard)
|
| 56 |
+
"""
|
| 57 |
+
},
|
| 58 |
+
'fr': {
|
| 59 |
+
'title': 'ColPali',
|
| 60 |
+
'original_tweet':
|
| 61 |
+
"""
|
| 62 |
+
[Tweet de base](https://x.com/mervenoyann/status/1811003265858912670) (en anglais) (10 juillet 2024)
|
| 63 |
+
""",
|
| 64 |
+
'tweet_1':
|
| 65 |
+
"""
|
| 66 |
+
Oubliez la recherche de documents, utilisez ColPali 💥💥💥
|
| 67 |
+
|
| 68 |
+
La recherche de documents se fait par OCR + détection de la mise en page, mais c'est exagéré et ça ne fonctionne pas bien ! 🤓
|
| 69 |
+
|
| 70 |
+
ColPali utilise un modèle de langage/vision, qui est meilleur pour la compréhension des documents 📑
|
| 71 |
+
""",
|
| 72 |
+
'tweet_2':
|
| 73 |
+
"""
|
| 74 |
+
Consultez [le modèle](https://huggingface.co/vidore/colpali) (licence mit !) et l'article de [blog](https://huggingface.co/blog/manu/colpali).
|
| 75 |
+
|
| 76 |
+
Les auteurs ont également publié un nouveau benchmark pour la recherche de documents, [ViDoRe Leaderboard](https://huggingface.co/spaces/vidore/vidore-leaderboard), soumettez votre modèle !
|
| 77 |
+
""",
|
| 78 |
+
'tweet_3':
|
| 79 |
+
"""
|
| 80 |
+
Les systèmes de recherche documentaire classiques utilisent l'OCR + la détection de la mise en page + un modèle pour extraire les informations des documents, avant de finalement de fournir les représentations à un système de RAG 🥲.
|
| 81 |
+
|
| 82 |
+
Alors que les encodeurs d'images modernes démontrent des capacités de compréhension de documents prêtes à l'emploi !
|
| 83 |
+
|
| 84 |
+
ColPali combine l'idée de modèles de langage-vision modernes avec la recherche documentaire 🤝
|
| 85 |
+
|
| 86 |
+
Les auteurs procèdent à un finetuningf de <a href='SigLIP' target='_self'>SigLIP</a> sur des documents et font un pooling des sorties (qu'ils appellent BiSigLip). Ils transmettent ensuite des patchs d'enchassements à PaliGemma et créent BiPali 🖇️. """,
|
| 87 |
+
'tweet_4':
|
| 88 |
+
"""
|
| 89 |
+
BiPali supporte nativement les patchs d'enchâssements d'images dans un LLM ce qui permet d'exploiter des interactions de calculs (semblables à ColBERT) entre les tokens de texte et les patchs d'images. D'où le nom de ColPali ! 🤩
|
| 90 |
+
|
| 91 |
+
Les auteurs ont créé le benchmark ViDoRe en collectant des documents PDF et en générant des requêtes à partir de Claude-3 Sonnet.
|
| 92 |
+
|
| 93 |
+
Découvrez ci-dessous les performances de chaque modèle et de ColPali sur ViDoRe 👇🏻
|
| 94 |
+
""",
|
| 95 |
+
'tweet_5':
|
| 96 |
+
"""
|
| 97 |
+
Au-delà des améliorations de performance, ColPali est également très rapide pour l'indexation hors ligne !
|
| 98 |
+
""",
|
| 99 |
+
'ressources':
|
| 100 |
+
"""
|
| 101 |
+
Ressources :
|
| 102 |
+
[ColPali: Efficient Document Retrieval with Vision Language Models](https://huggingface.co/papers/2407.01449)
|
| 103 |
+
de Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, Pierre Colombo (2024)
|
| 104 |
+
[GitHub](https://github.com/illuin-tech/colpali)
|
| 105 |
+
[Modèles](https://huggingface.co/models?search=vidore)
|
| 106 |
+
[Leaderboard](https://huggingface.co/spaces/vidore/vidore-leaderboard)
|
| 107 |
+
"""
|
| 108 |
+
}
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def language_selector():
|
| 113 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 114 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 115 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 116 |
+
|
| 117 |
+
left_column, right_column = st.columns([5, 1])
|
| 118 |
+
|
| 119 |
+
# Add a selector to the right column
|
| 120 |
+
with right_column:
|
| 121 |
+
lang = language_selector()
|
| 122 |
+
|
| 123 |
+
# Add a title to the left column
|
| 124 |
+
with left_column:
|
| 125 |
+
st.title(translations[lang]["title"])
|
| 126 |
+
|
| 127 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 131 |
+
st.markdown(""" """)
|
| 132 |
+
|
| 133 |
+
st.image("pages/ColPali/image_1.jpg", use_column_width=True)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
|
| 136 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 137 |
+
st.markdown(""" """)
|
| 138 |
+
|
| 139 |
+
st.image("pages/ColPali/image_2.jpg", use_column_width=True)
|
| 140 |
+
st.markdown(""" """)
|
| 141 |
+
|
| 142 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
|
| 145 |
+
st.image("pages/ColPali/image_3.jpg", use_column_width=True)
|
| 146 |
+
st.markdown(""" """)
|
| 147 |
+
|
| 148 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 149 |
+
st.markdown(""" """)
|
| 150 |
+
|
| 151 |
+
st.image("pages/ColPali/image_4.jpg", use_column_width=True)
|
| 152 |
+
st.markdown(""" """)
|
| 153 |
+
|
| 154 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 155 |
+
st.markdown(""" """)
|
| 156 |
+
|
| 157 |
+
st.image("pages/ColPali/image_5.jpg", use_column_width=True)
|
| 158 |
+
st.markdown(""" """)
|
| 159 |
+
|
| 160 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 161 |
+
|
| 162 |
+
st.markdown(""" """)
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
st.markdown(""" """)
|
| 165 |
+
col1, col2, col3= st.columns(3)
|
| 166 |
+
with col1:
|
| 167 |
+
if lang == "en":
|
| 168 |
+
if st.button('Previous paper', use_container_width=True):
|
| 169 |
+
switch_page("RT-DETR")
|
| 170 |
+
else:
|
| 171 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 172 |
+
switch_page("RT-DETR")
|
| 173 |
+
with col2:
|
| 174 |
+
if lang == "en":
|
| 175 |
+
if st.button("Home", use_container_width=True):
|
| 176 |
+
switch_page("Home")
|
| 177 |
+
else:
|
| 178 |
+
if st.button("Accueil", use_container_width=True):
|
| 179 |
+
switch_page("Home")
|
| 180 |
+
with col3:
|
| 181 |
+
if lang == "en":
|
| 182 |
+
if st.button("Next paper", use_container_width=True):
|
| 183 |
+
switch_page("Llava-NeXT-Interleave")
|
| 184 |
+
else:
|
| 185 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 186 |
+
switch_page("Llava-NeXT-Interleave")
|
pages/24_Llava-NeXT-Interleave.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Llava-NeXT-Interleave',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1813560292397203630) (July 17, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
The vision language model in this video is 0.5B and can take in image, video and 3D! 🤯
|
| 14 |
+
Llava-NeXT-Interleave is a new vision language model trained on interleaved image, video and 3D data.
|
| 15 |
+
Keep reading ⥥⥥
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
This model comes with 0.5B, 7B and 7B-DPO variants, all can be used with 🤗 Transformers 😍
|
| 20 |
+
[Collection of models](https://t.co/sZsaglSXa3) | [Demo](https://t.co/FbpaMWJY8k)
|
| 21 |
+
See how to use below 👇🏻
|
| 22 |
+
""",
|
| 23 |
+
'tweet_3':
|
| 24 |
+
"""
|
| 25 |
+
Authors of this paper have explored training <a href='LLaVA-NeXT' target='_self'>LLaVA-NeXT</a> on interleaved data where the data consists of multiple modalities, including image(s), video, 3D 📚
|
| 26 |
+
They have discovered that interleaved data increases results across all benchmarks!
|
| 27 |
+
""",
|
| 28 |
+
'tweet_4':
|
| 29 |
+
"""
|
| 30 |
+
The model can do task transfer from single image tasks to multiple images 🤯
|
| 31 |
+
The authors have trained the model on single images and code yet the model can solve coding with multiple images.
|
| 32 |
+
""",
|
| 33 |
+
'tweet_5':
|
| 34 |
+
"""
|
| 35 |
+
Same applies to other modalities, see below for video:
|
| 36 |
+
""",
|
| 37 |
+
'tweet_6':
|
| 38 |
+
"""
|
| 39 |
+
The model also has document understanding capabilities and many real-world application areas.
|
| 40 |
+
""",
|
| 41 |
+
'tweet_7':
|
| 42 |
+
"""
|
| 43 |
+
This release also comes with the dataset this model was fine-tuned on 📖 [M4-Instruct-Data](https://t.co/rutXMtNC0I)
|
| 44 |
+
""",
|
| 45 |
+
'ressources':
|
| 46 |
+
"""
|
| 47 |
+
Ressources:
|
| 48 |
+
[LLaVA-NeXT: Tackling Multi-image, Video, and 3D in Large Multimodal Models](https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/)
|
| 49 |
+
by Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, Chunyuan Li (2024)
|
| 50 |
+
[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT/blob/inference/docs/LLaVA-NeXT-Interleave.md)
|
| 51 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/en/model_doc/llava_next)
|
| 52 |
+
"""
|
| 53 |
+
},
|
| 54 |
+
'fr': {
|
| 55 |
+
'title': 'Llava-NeXT-Interleave',
|
| 56 |
+
'original_tweet':
|
| 57 |
+
"""
|
| 58 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1813560292397203630) (en anglais) (17 juillet 2024)
|
| 59 |
+
""",
|
| 60 |
+
'tweet_1':
|
| 61 |
+
"""
|
| 62 |
+
Le modèle de langage/vision dans cette vidéo est de 500M de parmaètres et peut prendre en charge image, vidéo et 3D ! 🤯
|
| 63 |
+
Llava-NeXT-Interleave est un nouveau modèle entraîné sur des images, des vidéos et des données 3D entrelacées.
|
| 64 |
+
Continuez à lire ⥥⥥⥥
|
| 65 |
+
""",
|
| 66 |
+
'tweet_2':
|
| 67 |
+
"""
|
| 68 |
+
Ce modèle est disponible en versions 0.5B, 7B et 7B-DPO, toutes utilisables avec 🤗 Transformers 😍
|
| 69 |
+
[Les modèles](https://t.co/sZsaglSXa3) | [Demo](https://t.co/FbpaMWJY8k)
|
| 70 |
+
Voir comment les utiliser ci-dessous👇🏻
|
| 71 |
+
""",
|
| 72 |
+
'tweet_3':
|
| 73 |
+
"""
|
| 74 |
+
Les auteurs ont explorer d'entraîner <a href='LLaVA-NeXT' target='_self'>LLaVA-NeXT</a> sur des données entrelacées où les données sont constituées de plusieurs modalités, y compris des images, des vidéos, de la 3D 📚.
|
| 75 |
+
Ils ont découvert que ces données augmentent les résultats de tous les benchmarks !
|
| 76 |
+
""",
|
| 77 |
+
'tweet_4':
|
| 78 |
+
"""
|
| 79 |
+
Le modèle peut transférer des tâches d'une image unique à des images multiples 🤯
|
| 80 |
+
Les auteurs ont entraîné le modèle sur des images et des codes uniques, mais le modèle peut résoudre le codage avec des images multiples.
|
| 81 |
+
""",
|
| 82 |
+
'tweet_5':
|
| 83 |
+
"""
|
| 84 |
+
La même chose s'applique à d'autres modalités, voir ci-dessous pour la vidéo :
|
| 85 |
+
""",
|
| 86 |
+
'tweet_6':
|
| 87 |
+
"""
|
| 88 |
+
Le modèle possède également des capacités de compréhension des documents et a donc de nombreux domaines d'application dans le monde réel.
|
| 89 |
+
""",
|
| 90 |
+
'tweet_7':
|
| 91 |
+
"""
|
| 92 |
+
Les auteurs mettent également en ligne le jeu de données utilisé pour le finetuning : 📖 [M4-Instruct-Data](https://t.co/rutXMtNC0I)
|
| 93 |
+
""",
|
| 94 |
+
'ressources':
|
| 95 |
+
"""
|
| 96 |
+
Ressources :
|
| 97 |
+
[LLaVA-NeXT: Tackling Multi-image, Video, and 3D in Large Multimodal Models](https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/)
|
| 98 |
+
de Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, Chunyuan Li (2024)
|
| 99 |
+
[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT/blob/inference/docs/LLaVA-NeXT-Interleave.md)
|
| 100 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/en/model_doc/llava_next)
|
| 101 |
+
"""
|
| 102 |
+
}
|
| 103 |
+
}
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def language_selector():
|
| 107 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 108 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 109 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 110 |
+
|
| 111 |
+
left_column, right_column = st.columns([5, 1])
|
| 112 |
+
|
| 113 |
+
# Add a selector to the right column
|
| 114 |
+
with right_column:
|
| 115 |
+
lang = language_selector()
|
| 116 |
+
|
| 117 |
+
# Add a title to the left column
|
| 118 |
+
with left_column:
|
| 119 |
+
st.title(translations[lang]["title"])
|
| 120 |
+
|
| 121 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.video("pages/Llava-NeXT-Interleave/video_1.mp4", format="video/mp4")
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 131 |
+
st.markdown(""" """)
|
| 132 |
+
|
| 133 |
+
st.image("pages/Llava-NeXT-Interleave/image_1.jpg", use_column_width=True)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
|
| 136 |
+
with st.expander ("Code"):
|
| 137 |
+
st.code("""
|
| 138 |
+
import torch
|
| 139 |
+
from transformers import AutoProcessor, LlavaForConditionalGeneration
|
| 140 |
+
|
| 141 |
+
model_id = "llava-hf/llava-interleave-qwen-7b-hf"
|
| 142 |
+
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16, low_cpu_mem_usage=True).to("cuda")
|
| 143 |
+
|
| 144 |
+
prompt = "<|im_start|>user <image>\nWhat are these?|im_end|><|im_start|>assistant"
|
| 145 |
+
inputs = processor(prompt, raw_image, return_tensors='pt').to(0, torch.float16)
|
| 146 |
+
|
| 147 |
+
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)
|
| 148 |
+
print(processor.decode(output[0][2:], skip_special_tokens=True))
|
| 149 |
+
""")
|
| 150 |
+
st.markdown(""" """)
|
| 151 |
+
|
| 152 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 153 |
+
st.markdown(""" """)
|
| 154 |
+
|
| 155 |
+
st.image("pages/Llava-NeXT-Interleave/image_2.jpg", use_column_width=True)
|
| 156 |
+
st.markdown(""" """)
|
| 157 |
+
|
| 158 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 159 |
+
st.markdown(""" """)
|
| 160 |
+
|
| 161 |
+
st.image("pages/Llava-NeXT-Interleave/image_3.jpg", use_column_width=True)
|
| 162 |
+
st.markdown(""" """)
|
| 163 |
+
|
| 164 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 165 |
+
st.markdown(""" """)
|
| 166 |
+
|
| 167 |
+
st.image("pages/Llava-NeXT-Interleave/image_4.jpg", use_column_width=True)
|
| 168 |
+
st.markdown(""" """)
|
| 169 |
+
|
| 170 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 171 |
+
st.markdown(""" """)
|
| 172 |
+
|
| 173 |
+
st.image("pages/Llava-NeXT-Interleave/image_5.jpg", use_column_width=True)
|
| 174 |
+
st.markdown(""" """)
|
| 175 |
+
|
| 176 |
+
st.markdown(translations[lang]["tweet_7"], unsafe_allow_html=True)
|
| 177 |
+
st.markdown(""" """)
|
| 178 |
+
|
| 179 |
+
st.image("pages/Llava-NeXT-Interleave/image_6.jpg", use_column_width=True)
|
| 180 |
+
st.markdown(""" """)
|
| 181 |
+
|
| 182 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 183 |
+
|
| 184 |
+
st.markdown(""" """)
|
| 185 |
+
st.markdown(""" """)
|
| 186 |
+
st.markdown(""" """)
|
| 187 |
+
col1, col2, col3= st.columns(3)
|
| 188 |
+
with col1:
|
| 189 |
+
if lang == "en":
|
| 190 |
+
if st.button('Previous paper', use_container_width=True):
|
| 191 |
+
switch_page("ColPali")
|
| 192 |
+
else:
|
| 193 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 194 |
+
switch_page("ColPali")
|
| 195 |
+
with col2:
|
| 196 |
+
if lang == "en":
|
| 197 |
+
if st.button("Home", use_container_width=True):
|
| 198 |
+
switch_page("Home")
|
| 199 |
+
else:
|
| 200 |
+
if st.button("Accueil", use_container_width=True):
|
| 201 |
+
switch_page("Home")
|
| 202 |
+
with col3:
|
| 203 |
+
if lang == "en":
|
| 204 |
+
if st.button("Next paper", use_container_width=True):
|
| 205 |
+
switch_page("Chameleon")
|
| 206 |
+
else:
|
| 207 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 208 |
+
switch_page("Chameleon")
|
pages/25_Chameleon.py
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Chameleon',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1814278511785312320) (July 19, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Chameleon 🦎 by Meta is now available in 🤗 Transformers.
|
| 14 |
+
A multimodal model that comes in 7B and 34B sizes 🤩
|
| 15 |
+
But what makes this model so special? Keep reading ⇣
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
[Demo](https://t.co/GsGE17fSdI) | [Models](https://t.co/cWUiVbsRz6)
|
| 20 |
+
Find below the API to load this model locally use it ⬇️
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
Chameleon is a unique model: it attempts to scale early fusion 🤨
|
| 25 |
+
But what is early fusion?
|
| 26 |
+
Modern vision language models use a vision encoder with a projection layer to project image embeddings so it can be promptable to text decoder.
|
| 27 |
+
""",
|
| 28 |
+
'tweet_4':
|
| 29 |
+
"""
|
| 30 |
+
Early fusion on the other hand attempts to fuse all features together (image patches and text) by using an image tokenizer and all tokens are projected into a shared space, which enables seamless generation 😏
|
| 31 |
+
""",
|
| 32 |
+
'tweet_5':
|
| 33 |
+
"""
|
| 34 |
+
Authors have also introduced different architectural improvements (QK norm and revise placement of layer norms) for scalable and stable training.
|
| 35 |
+
This way they were able to increase the token count (5x tokens compared to Llama 3 which is a must with early-fusion IMO) .
|
| 36 |
+
""",
|
| 37 |
+
'tweet_6':
|
| 38 |
+
"""
|
| 39 |
+
This model is an any-to-any model thanks to early fusion: it can take image and text input and output image and text, but image generation are disabled to prevent malicious use.
|
| 40 |
+
""",
|
| 41 |
+
'tweet_7':
|
| 42 |
+
"""
|
| 43 |
+
One can also do text-only prompting, authors noted the model catches up with larger LLMs, and you can also see how it compares to VLMs with image-text prompting.
|
| 44 |
+
""",
|
| 45 |
+
'ressources':
|
| 46 |
+
"""
|
| 47 |
+
Ressources:
|
| 48 |
+
[Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818)
|
| 49 |
+
by Chameleon Team (2024)
|
| 50 |
+
[GitHub](https://github.com/facebookresearch/chameleon)
|
| 51 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/chameleon)
|
| 52 |
+
"""
|
| 53 |
+
},
|
| 54 |
+
'fr': {
|
| 55 |
+
'title': 'Chameleon',
|
| 56 |
+
'original_tweet':
|
| 57 |
+
"""
|
| 58 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1814278511785312320) (en anglais) (19 juillet 2024)
|
| 59 |
+
""",
|
| 60 |
+
'tweet_1':
|
| 61 |
+
"""
|
| 62 |
+
Chameleon 🦎 de Meta est désormais disponible dans 🤗 Transformers.
|
| 63 |
+
Un modèle multimodal qui se décline en tailles 7 Mds et 34 Mds de paramètres 🤩
|
| 64 |
+
Mais qu'est-ce qui rend ce modèle si particulier ? Continuez à lire ⇣
|
| 65 |
+
""",
|
| 66 |
+
'tweet_2':
|
| 67 |
+
"""
|
| 68 |
+
[Demo](https://t.co/GsGE17fSdI) | [Modèles](https://t.co/cWUiVbsRz6)
|
| 69 |
+
Vous trouverez ci-dessous l'API permettant de charger ce modèle et de l'utiliser localement ⬇️
|
| 70 |
+
""",
|
| 71 |
+
'tweet_3':
|
| 72 |
+
"""
|
| 73 |
+
Chameleon is a unique model: it attempts to scale early fusion 🤨
|
| 74 |
+
But what is early fusion?
|
| 75 |
+
Modern vision language models use a vision encoder with a projection layer to project image embeddings so it can be promptable to text decoder.
|
| 76 |
+
|
| 77 |
+
Chameleon est un modèle unique : il tente de mettre à l'échelle la fusion précoce 🤨
|
| 78 |
+
Mais qu'est-ce que la fusion précoce ?
|
| 79 |
+
Les modèles de langage/vision modernes utilisent un encodeur de vision avec une couche de projection pour projeter des enchâssements d'images de manière à ce qu'ils puissent être transmis au décodeur de texte.
|
| 80 |
+
""",
|
| 81 |
+
'tweet_4':
|
| 82 |
+
"""
|
| 83 |
+
La fusion précoce, quant à elle, tente de fusionner toutes les caractéristiques ensemble (patchs d'image et texte) en utilisant un tokenizer d'image et tous les tokens sont projetés dans un espace partagé, ce qui permet une génération homogène 😏 """,
|
| 84 |
+
'tweet_5':
|
| 85 |
+
"""
|
| 86 |
+
Les auteurs ont également introduit différentes améliorations architecturales (norme QK et modification du placement des normalisations de couches) pour un entraînement passable à l'échelle et stable.
|
| 87 |
+
De cette manière, ils ont pu augmenter le nombre de tokens (5x plus par rapport à Llama 3, ce qui est indispensable avec la fusion précoce selon moi).
|
| 88 |
+
""",
|
| 89 |
+
'tweet_6':
|
| 90 |
+
"""
|
| 91 |
+
Ce modèle est un modèle pouvant tout faire grâce à la fusion précoce : il peut prendre des images et du texte en entrée et produire des images et du texte en sortie, mais la génération d'images est désactivée afin d'éviter toute utilisation malveillante.
|
| 92 |
+
""",
|
| 93 |
+
'tweet_7':
|
| 94 |
+
"""
|
| 95 |
+
Il est également possible d'utiliser des prompts textuels, les auteurs ont noté que le modèle rejoignait les LLM plus grands, et vous pouvez également voir comment il se compare aux VLM avec des prompts image-texte. """,
|
| 96 |
+
'ressources':
|
| 97 |
+
"""
|
| 98 |
+
Ressources :
|
| 99 |
+
[Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818)
|
| 100 |
+
de Chameleon Team (2024)
|
| 101 |
+
[GitHub](https://github.com/facebookresearch/chameleon)
|
| 102 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/chameleon)
|
| 103 |
+
"""
|
| 104 |
+
}
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def language_selector():
|
| 109 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 110 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 111 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 112 |
+
|
| 113 |
+
left_column, right_column = st.columns([5, 1])
|
| 114 |
+
|
| 115 |
+
# Add a selector to the right column
|
| 116 |
+
with right_column:
|
| 117 |
+
lang = language_selector()
|
| 118 |
+
|
| 119 |
+
# Add a title to the left column
|
| 120 |
+
with left_column:
|
| 121 |
+
st.title(translations[lang]["title"])
|
| 122 |
+
|
| 123 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
st.video("pages/Chameleon/video_1.mp4", format="video/mp4")
|
| 130 |
+
st.markdown(""" """)
|
| 131 |
+
|
| 132 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
|
| 135 |
+
st.image("pages/Chameleon/image_1.jpg", use_column_width=True)
|
| 136 |
+
st.markdown(""" """)
|
| 137 |
+
|
| 138 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 139 |
+
st.markdown(""" """)
|
| 140 |
+
|
| 141 |
+
st.image("pages/Chameleon/image_2.jpg", use_column_width=True)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
|
| 144 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
|
| 147 |
+
st.image("pages/Chameleon/image_3.jpg", use_column_width=True)
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
|
| 150 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 151 |
+
st.markdown(""" """)
|
| 152 |
+
|
| 153 |
+
st.image("pages/Chameleon/image_4.jpg", use_column_width=True)
|
| 154 |
+
|
| 155 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 156 |
+
st.markdown(""" """)
|
| 157 |
+
|
| 158 |
+
st.image("pages/Chameleon/image_5.jpg", use_column_width=True)
|
| 159 |
+
|
| 160 |
+
st.markdown(translations[lang]["tweet_7"], unsafe_allow_html=True)
|
| 161 |
+
st.markdown(""" """)
|
| 162 |
+
|
| 163 |
+
st.image("pages/Chameleon/image_6.jpg", use_column_width=True)
|
| 164 |
+
st.image("pages/Chameleon/image_7.jpg", use_column_width=True)
|
| 165 |
+
|
| 166 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 167 |
+
|
| 168 |
+
st.markdown(""" """)
|
| 169 |
+
st.markdown(""" """)
|
| 170 |
+
st.markdown(""" """)
|
| 171 |
+
col1, col2, col3= st.columns(3)
|
| 172 |
+
with col1:
|
| 173 |
+
if lang == "en":
|
| 174 |
+
if st.button('Previous paper', use_container_width=True):
|
| 175 |
+
switch_page("Llava-NeXT-Interleave")
|
| 176 |
+
else:
|
| 177 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 178 |
+
switch_page("Llava-NeXT-Interleave")
|
| 179 |
+
with col2:
|
| 180 |
+
if lang == "en":
|
| 181 |
+
if st.button("Home", use_container_width=True):
|
| 182 |
+
switch_page("Home")
|
| 183 |
+
else:
|
| 184 |
+
if st.button("Accueil", use_container_width=True):
|
| 185 |
+
switch_page("Home")
|
| 186 |
+
with col3:
|
| 187 |
+
if lang == "en":
|
| 188 |
+
if st.button("Next paper", use_container_width=True):
|
| 189 |
+
switch_page("Video-LLaVA")
|
| 190 |
+
else:
|
| 191 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 192 |
+
switch_page("Video-LLaVA")
|
pages/26_Video-LLaVA.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Video-LLaVA',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1816427325073842539) (July 25, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
We have recently merged Video-LLaVA to 🤗 Transformers! 🎞️
|
| 14 |
+
What makes this model different? Keep reading ⇊
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
[Demo](https://t.co/MVP14uEj9e) | [Model](https://t.co/oqSCMUqwJo)
|
| 19 |
+
See below how to initialize the model and processor and infer ⬇️
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
Compared to other models that take image and video input and either project them separately or downsampling video and projecting selected frames, Video-LLaVA is converting images and videos to unified representation and project them using a shared projection layer.
|
| 24 |
+
""",
|
| 25 |
+
'tweet_4':
|
| 26 |
+
"""
|
| 27 |
+
It uses Vicuna 1.5 as the language model and LanguageBind's own encoders that's based on OpenCLIP, these encoders project the modalities to an unified representation before passing to projection layer.
|
| 28 |
+
""",
|
| 29 |
+
'tweet_5':
|
| 30 |
+
"""
|
| 31 |
+
I feel like one of the coolest features of this model is the joint understanding which is also introduced recently with many models.
|
| 32 |
+
It's a relatively older model but ahead of it's time and works very well!
|
| 33 |
+
""",
|
| 34 |
+
'ressources':
|
| 35 |
+
"""
|
| 36 |
+
Ressources:
|
| 37 |
+
[Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122)
|
| 38 |
+
by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan (2023)
|
| 39 |
+
[GitHub](https://github.com/PKU-YuanGroup/Video-LLaVA)
|
| 40 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/main/en/model_doc/video_llava)
|
| 41 |
+
"""
|
| 42 |
+
},
|
| 43 |
+
'fr': {
|
| 44 |
+
'title': 'Video-LLaVA',
|
| 45 |
+
'original_tweet':
|
| 46 |
+
"""
|
| 47 |
+
[Tweet de base](https://x.com/mervenoyann/status/1816427325073842539) (en anglais) (25 juillet 2024)
|
| 48 |
+
""",
|
| 49 |
+
'tweet_1':
|
| 50 |
+
"""
|
| 51 |
+
Nous avons récemment intégré Video-LLaVA dans 🤗 Transformers ! 🎞️
|
| 52 |
+
Qu'est-ce qui rend ce modèle différent ? Continuez à lire ⇊
|
| 53 |
+
""",
|
| 54 |
+
'tweet_2':
|
| 55 |
+
"""
|
| 56 |
+
[Demo](https://t.co/MVP14uEj9e) | [Modèle](https://t.co/oqSCMUqwJo)
|
| 57 |
+
Voir ci-dessous comment initialiser le modèle et le processeur puis inférer ⬇️
|
| 58 |
+
""",
|
| 59 |
+
'tweet_3':
|
| 60 |
+
"""
|
| 61 |
+
Par rapport à d'autres modèles qui prennent des images et des vidéos en entrée et les projettent séparément ou qui réduisent l'échantillonnage vidéo et projettent des images sélectionnées, Video-LLaVA convertit les images et les vidéos en une représentation unifiée et les projette à l'aide d'une couche de projection partagée. """,
|
| 62 |
+
'tweet_4':
|
| 63 |
+
"""
|
| 64 |
+
Il utilise Vicuna 1.5 comme modèle de langage et les encodeurs de LanguageBind basés sur OpenCLIP. Ces encodeurs projettent les modalités vers une représentation unifiée avant de passer à la couche de projection. """,
|
| 65 |
+
'tweet_5':
|
| 66 |
+
"""
|
| 67 |
+
J'ai l'impression que l'une des caractéristiques les plus intéressantes de ce modèle est la compréhension conjointe qui a été introduite récemment dans de nombreux modèles.
|
| 68 |
+
Il s'agit d'un modèle relativement ancien, mais il est en avance sur son temps et fonctionne très bien !
|
| 69 |
+
""",
|
| 70 |
+
'ressources':
|
| 71 |
+
"""
|
| 72 |
+
Ressources :
|
| 73 |
+
[Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122)
|
| 74 |
+
de Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan (2023)
|
| 75 |
+
[GitHub](https://github.com/PKU-YuanGroup/Video-LLaVA)
|
| 76 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/main/en/model_doc/video_llava)
|
| 77 |
+
"""
|
| 78 |
+
}
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def language_selector():
|
| 83 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 84 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 85 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 86 |
+
|
| 87 |
+
left_column, right_column = st.columns([5, 1])
|
| 88 |
+
|
| 89 |
+
# Add a selector to the right column
|
| 90 |
+
with right_column:
|
| 91 |
+
lang = language_selector()
|
| 92 |
+
|
| 93 |
+
# Add a title to the left column
|
| 94 |
+
with left_column:
|
| 95 |
+
st.title(translations[lang]["title"])
|
| 96 |
+
|
| 97 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 98 |
+
st.markdown(""" """)
|
| 99 |
+
|
| 100 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 101 |
+
st.markdown(""" """)
|
| 102 |
+
|
| 103 |
+
st.video("pages/Video-LLaVA/video_1.mp4", format="video/mp4")
|
| 104 |
+
st.markdown(""" """)
|
| 105 |
+
|
| 106 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 107 |
+
st.markdown(""" """)
|
| 108 |
+
|
| 109 |
+
st.image("pages/Video-LLaVA/image_1.jpg", use_column_width=True)
|
| 110 |
+
st.markdown(""" """)
|
| 111 |
+
|
| 112 |
+
with st.expander ("Code"):
|
| 113 |
+
if lang == "en":
|
| 114 |
+
st.code("""
|
| 115 |
+
from transformers import VideoLlavaForConditionalGeneration, VideoLlavaProcessor
|
| 116 |
+
import torch
|
| 117 |
+
|
| 118 |
+
# load the model and processor
|
| 119 |
+
model = VideoLlavaForConditionalGeneration.from_pretrained("LanguageBind/Video-LLaVA-7B-hf", torch_dtype-torch.float16, device_map="cuda")
|
| 120 |
+
processor = VideoLlavaProcessor.from_pretrained("LanguageBind/Video-LLaVA-78-hf")
|
| 121 |
+
|
| 122 |
+
# process inputs and infer
|
| 123 |
+
inputs = processor(text=prompt, videos=sampled_frames, return_tensors="pt")
|
| 124 |
+
generate_ids = model.generate(**inputs, max_tength=80)
|
| 125 |
+
out = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 126 |
+
|
| 127 |
+
# this is a non-exhaustive example to show the API, see model card for full inference
|
| 128 |
+
""")
|
| 129 |
+
else:
|
| 130 |
+
st.code("""
|
| 131 |
+
from transformers import VideoLlavaForConditionalGeneration, VideoLlavaProcessor
|
| 132 |
+
import torch
|
| 133 |
+
|
| 134 |
+
# chargement du modèle et du processeur
|
| 135 |
+
model = VideoLlavaForConditionalGeneration.from_pretrained("LanguageBind/Video-LLaVA-7B-hf", torch_dtype-torch.float16, device_map="cuda")
|
| 136 |
+
processor = VideoLlavaProcessor.from_pretrained("LanguageBind/Video-LLaVA-78-hf")
|
| 137 |
+
|
| 138 |
+
# traiter les entrées et inférer
|
| 139 |
+
inputs = processor(text=prompt, videos=sampled_frames, return_tensors="pt")
|
| 140 |
+
generate_ids = model.generate(**inputs, max_tength=80)
|
| 141 |
+
out = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 142 |
+
|
| 143 |
+
# Il s'agit d'un exemple non exhaustif pour montrer l'API, voir la carte de modèle pour l'inférence complète
|
| 144 |
+
""")
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
|
| 147 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
|
| 150 |
+
st.image("pages/Video-LLaVA/image_2.jpg", use_column_width=True)
|
| 151 |
+
st.markdown(""" """)
|
| 152 |
+
|
| 153 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 154 |
+
st.markdown(""" """)
|
| 155 |
+
|
| 156 |
+
st.image("pages/Video-LLaVA/image_3.jpg", use_column_width=True)
|
| 157 |
+
st.markdown(""" """)
|
| 158 |
+
|
| 159 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 160 |
+
st.markdown(""" """)
|
| 161 |
+
|
| 162 |
+
st.image("pages/Video-LLaVA/image_4.jpg", use_column_width=True)
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
|
| 165 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 166 |
+
|
| 167 |
+
st.markdown(""" """)
|
| 168 |
+
st.markdown(""" """)
|
| 169 |
+
st.markdown(""" """)
|
| 170 |
+
col1, col2, col3= st.columns(3)
|
| 171 |
+
with col1:
|
| 172 |
+
if lang == "en":
|
| 173 |
+
if st.button('Previous paper', use_container_width=True):
|
| 174 |
+
switch_page("Chameleon")
|
| 175 |
+
else:
|
| 176 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 177 |
+
switch_page("Chameleon")
|
| 178 |
+
with col2:
|
| 179 |
+
if lang == "en":
|
| 180 |
+
if st.button("Home", use_container_width=True):
|
| 181 |
+
switch_page("Home")
|
| 182 |
+
else:
|
| 183 |
+
if st.button("Accueil", use_container_width=True):
|
| 184 |
+
switch_page("Home")
|
| 185 |
+
with col3:
|
| 186 |
+
if lang == "en":
|
| 187 |
+
if st.button("Next paper", use_container_width=True):
|
| 188 |
+
switch_page("SAMv2")
|
| 189 |
+
else:
|
| 190 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 191 |
+
switch_page("SAMv2")
|
pages/27_SAMv2.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'SAMv2',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1818675981634109701) (July 31, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
SAMv2 is just mindblowingly good 😍
|
| 14 |
+
Learn what makes this model so good at video segmentation, keep reading 🦆⇓
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
Check out the [demo](https://t.co/35ixEZgPaf) by [skalskip92](https://x.com/skalskip92) to see how to use the model locally.
|
| 19 |
+
Check out Meta's [demo](https://t.co/Bcbli9Cfim) where you can edit segmented instances too!
|
| 20 |
+
<br>
|
| 21 |
+
Segment Anything Model by Meta was released as a universal segmentation model in which you could prompt a box or point prompt to segment the object of interest.
|
| 22 |
+
SAM consists of an image encoder to encode images, a prompt encoder to encode prompts, then outputs of these two are given to a mask decoder to generate masks.
|
| 23 |
+
""",
|
| 24 |
+
'tweet_3':
|
| 25 |
+
"""
|
| 26 |
+
However SAM doesn't naturally track object instances in videos, one needs to make sure to prompt the same mask or point prompt for that instance in each frame and feed each frame, which is infeasible 😔
|
| 27 |
+
But don't fret, that is where SAMv2 comes in with a memory module!
|
| 28 |
+
<br>
|
| 29 |
+
SAMv2 defines a new task called "masklet prediction" here masklet refers to the same mask instance throughout the frames 🎞️
|
| 30 |
+
Unlike SAM, SAM 2 decoder is not fed the image embedding directly from an image encoder, but attention of memories of prompted frames and object pointers.
|
| 31 |
+
""",
|
| 32 |
+
'tweet_4':
|
| 33 |
+
"""
|
| 34 |
+
🖼️ These "memories" are essentially past predictions of object of interest up to a number of recent frames,
|
| 35 |
+
and are in form of feature maps of location info (spatial feature maps).
|
| 36 |
+
👉🏻 The object pointers are high level semantic information of the object of interest based on.
|
| 37 |
+
<br>
|
| 38 |
+
Just like SAM paper SAMv2 depends on a data engine, and the dataset it generated comes with the release: SA-V 🤯
|
| 39 |
+
This dataset is gigantic, it has 190.9K manual masklet annotations and 451.7K automatic masklets!
|
| 40 |
+
""",
|
| 41 |
+
'tweet_5':
|
| 42 |
+
"""
|
| 43 |
+
Initially they apply SAM to each frame to assist human annotators to annotate a video at six FPS for high quality data,
|
| 44 |
+
in the second phase they add SAM and SAM2 to generate masklets across time consistently. Finally they use SAM2 to refine the masklets.
|
| 45 |
+
<br>
|
| 46 |
+
They have evaluated this model on J&F score (Jaccard Index + F-measure for contour acc) which is used to evaluate zero-shot
|
| 47 |
+
video segmentation benchmarks.
|
| 48 |
+
SAMv2 seems to outperform two previously sota models that are built on top of SAM! 🥹
|
| 49 |
+
""",
|
| 50 |
+
'ressources':
|
| 51 |
+
"""
|
| 52 |
+
Ressources:
|
| 53 |
+
[SAM 2: Segment Anything in Images and Videos](https://arxiv.org/abs/2408.00714) by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer (2024)
|
| 54 |
+
[GitHub](https://github.com/facebookresearch/segment-anything-2)
|
| 55 |
+
[Models and Demos Collection](https://huggingface.co/collections/merve/sam2-66ac9deac6fca3bc5482fe30)
|
| 56 |
+
"""
|
| 57 |
+
},
|
| 58 |
+
'fr': {
|
| 59 |
+
'title': 'SAMv2',
|
| 60 |
+
'original_tweet':
|
| 61 |
+
"""
|
| 62 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1818675981634109701) (en anglais) (31 juillet 2024)
|
| 63 |
+
""",
|
| 64 |
+
'tweet_1':
|
| 65 |
+
"""
|
| 66 |
+
SAMv2 est tout simplement époustouflant 😍
|
| 67 |
+
Pour savoir ce qui rend ce modèle si performant en matière de segmentation vidéo, continuez à lire 🦆⇓
|
| 68 |
+
""",
|
| 69 |
+
'tweet_2':
|
| 70 |
+
"""
|
| 71 |
+
Consultez la [demo](https://t.co/35ixEZgPaf) de [skalskip92](https://x.com/skalskip92) pour voir comment utiliser le modèle localement.
|
| 72 |
+
Consultez la [demo](https://t.co/Bcbli9Cfim) de Meta où vous pouvez éditer des instances segmentées !
|
| 73 |
+
|
| 74 |
+
Le modèle Segment Anything de Meta a été lancé en tant que modèle de segmentation universel dans lequel vous pouvez prompter une boîte ou à un point pour segmenter l'objet d'intérêt.
|
| 75 |
+
SAM se compose d'un encodeur d'images pour encoder les images, d'un encodeur de prompt pour encoder les prompts, puis les sorties de ces deux encodeurs sont données à un décodeur masqué pour générer des masques.
|
| 76 |
+
""",
|
| 77 |
+
'tweet_3':
|
| 78 |
+
"""
|
| 79 |
+
Cependant SAM ne traque pas les instances d'objets dans les vidéos, il faut s'assurer de demander le même masque ou le même point pour cette instance dans chaque image, ce qui est infaisable 😔.
|
| 80 |
+
Mais ne vous inquiétez pas, c'est là que SAMv2 intervient avec un module de mémoire !
|
| 81 |
+
|
| 82 |
+
SAMv2 définit une nouvelle tâche appelée "prédiction de masque". Ici le masque se réfère à la même instance de masque à travers les images 🎞️
|
| 83 |
+
Contrairement à SAM, le décodeur SAM 2 n'est pas nourri par l'enchâssement de l'image issu de l'encodeur d'image, mais par l'attention des mémoires des images promptées/pointeurs d'objets.
|
| 84 |
+
""",
|
| 85 |
+
'tweet_4':
|
| 86 |
+
"""
|
| 87 |
+
🖼️ Ces "mémoires" sont essentiellement des prédictions passées de l'objet d'intérêt jusqu'à un certain nombre d'images récentes, et se présentent sous la forme de cartes de caractéristiques d'informations de localisation (cartes de caractéristiques spatiales).
|
| 88 |
+
👉🏻 Les pointeurs d'objets sont des informations sémantiques de haut niveau sur l'objet d'intérêt.
|
| 89 |
+
|
| 90 |
+
Tout comme SAM, SAMv2 dépend d'un moteur de données, et le jeu de données utilisé est fourni : SA-V 🤯
|
| 91 |
+
Il est gigantesque, contenant 190,9K masques annotés manuellement et 451,7K automatiquement !
|
| 92 |
+
""",
|
| 93 |
+
'tweet_5':
|
| 94 |
+
"""
|
| 95 |
+
Dans un premier temps, les auteurs appliquent SAM à chaque image pour aider les annotateurs humains à annoter une vidéo de 6 FPS afin d'obtenir des données de haute qualité. Dans un deuxième temps, ils ajoutent SAM et SAM2 pour générer des masques de manière cohérente dans le temps. Enfin, ils utilisent SAM2 pour affiner les masques.
|
| 96 |
+
|
| 97 |
+
Ils ont évalué ce modèle sur le score J&F (indice de Jaccard et F-mesure pour la précision des contours) qui est utilisé dans les benchmarks de segmentation de vidéos 0-shot.
|
| 98 |
+
SAMv2 semble surpasser deux modèles précédemment à l'état de l'art qui sont construits sur SAM ! 🥹
|
| 99 |
+
""",
|
| 100 |
+
'ressources':
|
| 101 |
+
"""
|
| 102 |
+
Ressources :
|
| 103 |
+
[SAM 2: Segment Anything in Images and Videos](https://arxiv.org/abs/2408.00714) de Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer (2024)
|
| 104 |
+
[GitHub](https://github.com/facebookresearch/segment-anything-2)
|
| 105 |
+
[Collection de modèles et démonstrateurs](https://huggingface.co/collections/merve/sam2-66ac9deac6fca3bc5482fe30)
|
| 106 |
+
"""
|
| 107 |
+
}
|
| 108 |
+
}
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def language_selector():
|
| 112 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 113 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 114 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 115 |
+
|
| 116 |
+
left_column, right_column = st.columns([5, 1])
|
| 117 |
+
|
| 118 |
+
# Add a selector to the right column
|
| 119 |
+
with right_column:
|
| 120 |
+
lang = language_selector()
|
| 121 |
+
|
| 122 |
+
# Add a title to the left column
|
| 123 |
+
with left_column:
|
| 124 |
+
st.title(translations[lang]["title"])
|
| 125 |
+
|
| 126 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 130 |
+
st.markdown(""" """)
|
| 131 |
+
|
| 132 |
+
col1, col2, col3 = st.columns(3)
|
| 133 |
+
with col2:
|
| 134 |
+
st.video("pages/SAMv2/video_1.mp4", format="video/mp4")
|
| 135 |
+
st.markdown(""" """)
|
| 136 |
+
|
| 137 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 138 |
+
st.markdown(""" """)
|
| 139 |
+
|
| 140 |
+
st.image("pages/SAMv2/image_1.jpg", use_column_width=True)
|
| 141 |
+
st.markdown(""" """)
|
| 142 |
+
|
| 143 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 144 |
+
st.markdown(""" """)
|
| 145 |
+
|
| 146 |
+
st.image("pages/SAMv2/image_2.jpg", use_column_width=True)
|
| 147 |
+
st.markdown(""" """)
|
| 148 |
+
|
| 149 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 150 |
+
st.markdown(""" """)
|
| 151 |
+
|
| 152 |
+
st.image("pages/SAMv2/image_3.jpg", use_column_width=True)
|
| 153 |
+
st.markdown(""" """)
|
| 154 |
+
|
| 155 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 156 |
+
st.markdown(""" """)
|
| 157 |
+
|
| 158 |
+
st.image("pages/SAMv2/image_4.jpg", use_column_width=True)
|
| 159 |
+
st.markdown(""" """)
|
| 160 |
+
|
| 161 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 162 |
+
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
st.markdown(""" """)
|
| 165 |
+
st.markdown(""" """)
|
| 166 |
+
col1, col2, col3= st.columns(3)
|
| 167 |
+
with col1:
|
| 168 |
+
if lang == "en":
|
| 169 |
+
if st.button('Previous paper', use_container_width=True):
|
| 170 |
+
switch_page("Video-LLaVA")
|
| 171 |
+
else:
|
| 172 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 173 |
+
switch_page("Video-LLaVA")
|
| 174 |
+
with col2:
|
| 175 |
+
if lang == "en":
|
| 176 |
+
if st.button("Home", use_container_width=True):
|
| 177 |
+
switch_page("Home")
|
| 178 |
+
else:
|
| 179 |
+
if st.button("Accueil", use_container_width=True):
|
| 180 |
+
switch_page("Home")
|
| 181 |
+
with col3:
|
| 182 |
+
if lang == "en":
|
| 183 |
+
if st.button("Next paper", use_container_width=True):
|
| 184 |
+
switch_page("NVEagle")
|
| 185 |
+
else:
|
| 186 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 187 |
+
switch_page("NVEagle")
|
pages/28_NVEagle.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'NVEagle',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1829144958101561681) (August 29, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
NVIDIA just dropped NVEagle 🦅
|
| 14 |
+
Super impressive vision language model that comes in 7B, 13B and 13B fine-tuned on chat, improved visual perception with MoE vision encoders 💬
|
| 15 |
+
Keep reading for details and links ⇓
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
[Model repositories](https://huggingface.co/collections/merve/nveagle-66d0705108582d73bb235c26) | Try it [here](https://huggingface.co/spaces/NVEagle/Eagle-X5-13B-Chat) 💬 (works very well! 🤯)
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
This model essentially explores having different experts (MoE) and fusion strategies for image encoders.
|
| 24 |
+
I have been <a href='MiniGemini' target='_self'>talking</a> about how VLMs improve when using multiple encoders in parallel, so seeing this paper MoE made me happy! 🥲
|
| 25 |
+
""",
|
| 26 |
+
'tweet_4':
|
| 27 |
+
"""
|
| 28 |
+
How? 🧐
|
| 29 |
+
The authors concatenate the vision encoder output tokens together, and they apply "pre-alignment": essentially fine-tune experts with frozen text encoder.
|
| 30 |
+
Rest of the architecture is quite similar to <a href='LLaVA-NeXT' target='_self'>LlaVA</a>.
|
| 31 |
+
""",
|
| 32 |
+
'tweet_5':
|
| 33 |
+
"""
|
| 34 |
+
Then they freeze both experts and the decoder and just train the projection layer, and finally, they unfreeze everything for supervised fine-tuning ✨
|
| 35 |
+
<br>
|
| 36 |
+
They explore different fusion strategies and encoders, extending basic CLIP encoder, and find out that simply concatenating visual tokens works well 🥹
|
| 37 |
+
See below the performances of different experts ⇓⇓
|
| 38 |
+
""",
|
| 39 |
+
'ressources':
|
| 40 |
+
"""
|
| 41 |
+
Ressources:
|
| 42 |
+
[Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders](https://www.arxiv.org/abs/2408.15998)
|
| 43 |
+
by Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, Guilin Liu (2024)
|
| 44 |
+
[GitHub](https://github.com/NVlabs/Eagle)
|
| 45 |
+
[Models and Demos Collection](https://huggingface.co/collections/merve/nveagle-66d0705108582d73bb235c26)
|
| 46 |
+
"""
|
| 47 |
+
},
|
| 48 |
+
'fr': {
|
| 49 |
+
'title': 'NVEagle',
|
| 50 |
+
'original_tweet':
|
| 51 |
+
"""
|
| 52 |
+
[Tweet de base](https://x.com/mervenoyann/status/1829144958101561681) (en anglais) (29 août 2024)
|
| 53 |
+
""",
|
| 54 |
+
'tweet_1':
|
| 55 |
+
"""
|
| 56 |
+
NVIDIA vient de sortir NVEagle 🦅
|
| 57 |
+
Un modèle langage-vision très impressionnant disponible en taille 7B, 13B et 13B, finetuné sur des données de chat.
|
| 58 |
+
Il dispose d'une perception visuelle améliorée via un mélange d'experts (MoE) d'encodeurs de vision 💬
|
| 59 |
+
Continuez à lire pour plus de détails et des liens ⇓
|
| 60 |
+
""",
|
| 61 |
+
'tweet_2':
|
| 62 |
+
"""
|
| 63 |
+
[Répertoire des modèles](https://huggingface.co/collections/merve/nveagle-66d0705108582d73bb235c26) | [Essayez-le ici](https://huggingface.co/spaces/NVEagle/Eagle-X5-13B-Chat) 💬 (fonctionne très bien ! 🤯)
|
| 64 |
+
""",
|
| 65 |
+
'tweet_3':
|
| 66 |
+
"""
|
| 67 |
+
Ce modèle explore le fait d'avoir différents experts et des stratégies de fusion pour les encodeurs d'images.
|
| 68 |
+
J'ai <a href='MiniGemini' target='_self'>parlé</a> de la façon dont les VLM s'améliorent lors de l'utilisation de plusieurs encodeurs en parallèle. Ce papier m'a ainsi rendu heureuse ! 🥲
|
| 69 |
+
""",
|
| 70 |
+
'tweet_4':
|
| 71 |
+
"""
|
| 72 |
+
Comment ? 🧐
|
| 73 |
+
Les auteurs concatènent les tokens de sortie de l'encodeur de vision ensemble, et ils appliquent un « pré-alignement » : ils finetunent les experts avec un encodeur de texte gelé. Le reste de l'architecture est assez similaire à <a href='LLaVA-NeXT' target='_self'>LlaVA</a>.
|
| 74 |
+
""",
|
| 75 |
+
'tweet_5':
|
| 76 |
+
"""
|
| 77 |
+
Ensuite, ils gèlent les experts et le décodeur et entraînent simplement la couche de projection. Finalement, ils dégèlent le tout pour un finetuning supervisé ✨
|
| 78 |
+
<br>
|
| 79 |
+
Ils explorent différentes stratégies de fusion et d'encodeurs, étendant l'encodeur CLIP de base, et découvrent que la simple concaténation de tokens visuels fonctionne bien 🥹
|
| 80 |
+
Voir ci-dessous les performances de différents experts ⇓⇓
|
| 81 |
+
""",
|
| 82 |
+
'ressources':
|
| 83 |
+
"""
|
| 84 |
+
Ressources :
|
| 85 |
+
[Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders](https://www.arxiv.org/abs/2408.15998)
|
| 86 |
+
de Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, Guilin Liu (2024)
|
| 87 |
+
[GitHub](https://github.com/NVlabs/Eagle)
|
| 88 |
+
[Models and Demos Collection](https://huggingface.co/collections/merve/nveagle-66d0705108582d73bb235c26)
|
| 89 |
+
"""
|
| 90 |
+
}
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def language_selector():
|
| 95 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 96 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 97 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 98 |
+
|
| 99 |
+
left_column, right_column = st.columns([5, 1])
|
| 100 |
+
|
| 101 |
+
# Add a selector to the right column
|
| 102 |
+
with right_column:
|
| 103 |
+
lang = language_selector()
|
| 104 |
+
|
| 105 |
+
# Add a title to the left column
|
| 106 |
+
with left_column:
|
| 107 |
+
st.title(translations[lang]["title"])
|
| 108 |
+
|
| 109 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 110 |
+
st.markdown(""" """)
|
| 111 |
+
|
| 112 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 113 |
+
st.markdown(""" """)
|
| 114 |
+
|
| 115 |
+
st.image("pages/NVEagle/image_1.jpg", use_column_width=True)
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
|
| 118 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 119 |
+
st.markdown(""" """)
|
| 120 |
+
|
| 121 |
+
st.image("pages/NVEagle/image_2.jpg", use_column_width=True)
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.image("pages/NVEagle/image_3.jpg", use_column_width=True)
|
| 131 |
+
st.markdown(""" """)
|
| 132 |
+
|
| 133 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
|
| 136 |
+
st.image("pages/NVEagle/image_4.jpg", use_column_width=True)
|
| 137 |
+
st.markdown(""" """)
|
| 138 |
+
|
| 139 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 140 |
+
|
| 141 |
+
st.markdown(""" """)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
col1, col2, col3= st.columns(3)
|
| 145 |
+
with col1:
|
| 146 |
+
if lang == "en":
|
| 147 |
+
if st.button('Previous paper', use_container_width=True):
|
| 148 |
+
switch_page("SAMv2")
|
| 149 |
+
else:
|
| 150 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 151 |
+
switch_page("SAMv2")
|
| 152 |
+
with col2:
|
| 153 |
+
if lang == "en":
|
| 154 |
+
if st.button("Home", use_container_width=True):
|
| 155 |
+
switch_page("Home")
|
| 156 |
+
else:
|
| 157 |
+
if st.button("Accueil", use_container_width=True):
|
| 158 |
+
switch_page("Home")
|
| 159 |
+
with col3:
|
| 160 |
+
if lang == "en":
|
| 161 |
+
if st.button("Next paper", use_container_width=True):
|
| 162 |
+
switch_page("NVLM")
|
| 163 |
+
else:
|
| 164 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 165 |
+
switch_page("NVLM")
|
pages/29_NVLM.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'NVLM',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1841098941900767323) (October 1st, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
NVIDIA just dropped a gigantic multimodal model called NVLM 72B 🦖
|
| 14 |
+
Explaining everything from what I got of reading the paper here 📝
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
The paper contains many ablation studies on various ways to use the LLM backbone 👇🏻
|
| 19 |
+
|
| 20 |
+
🦩 Flamingo-like cross-attention (NVLM-X)
|
| 21 |
+
🌋 Llava-like concatenation of image and text embeddings to a decoder-only model (NVLM-D)
|
| 22 |
+
✨ a hybrid architecture (NVLM-H)
|
| 23 |
+
""",
|
| 24 |
+
'tweet_3':
|
| 25 |
+
"""
|
| 26 |
+
Checking evaluations, NVLM-D and NVLM-H are best or second best compared to other models 👏
|
| 27 |
+
|
| 28 |
+
The released model is NVLM-D based on Qwen-2 Instruct, aligned with InternViT-6B using a huge mixture of different datasets
|
| 29 |
+
""",
|
| 30 |
+
'tweet_4':
|
| 31 |
+
"""
|
| 32 |
+
You can easily use this model by loading it through 🤗 Transformers' AutoModel 😍
|
| 33 |
+
""",
|
| 34 |
+
'ressources':
|
| 35 |
+
"""
|
| 36 |
+
Ressources:
|
| 37 |
+
[NVLM: Open Frontier-Class Multimodal LLMs](https://arxiv.org/abs/2409.11402)
|
| 38 |
+
by Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuoling Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping (2024)
|
| 39 |
+
[GitHub](https://nvlm-project.github.io/)
|
| 40 |
+
[Model](https://huggingface.co/nvidia/NVLM-D-72B)
|
| 41 |
+
"""
|
| 42 |
+
},
|
| 43 |
+
'fr': {
|
| 44 |
+
'title': 'NVLM',
|
| 45 |
+
'original_tweet':
|
| 46 |
+
"""
|
| 47 |
+
[Tweet de base](https://x.com/mervenoyann/status/1841098941900767323) (en anglais) (1er ocotbre 2024)
|
| 48 |
+
""",
|
| 49 |
+
'tweet_1':
|
| 50 |
+
"""
|
| 51 |
+
NVIDIA vient de publier un gigantesque modèle multimodal appelé NVLM 72B 🦖
|
| 52 |
+
J'explique tout ce que j'ai compris suite à la lecture du papier 📝
|
| 53 |
+
""",
|
| 54 |
+
'tweet_2':
|
| 55 |
+
"""
|
| 56 |
+
L'article contient de nombreuses études d'ablation sur les différentes façons d'utiliser le backbone 👇🏻
|
| 57 |
+
|
| 58 |
+
🦩 Attention croisée de type Flamingo (NVLM-X)
|
| 59 |
+
🌋 concaténation de type Llava d'embeddings d'images et de textes à un décodeur (NVLM-D)
|
| 60 |
+
✨ une architecture hybride (NVLM-H)
|
| 61 |
+
""",
|
| 62 |
+
'tweet_3':
|
| 63 |
+
"""
|
| 64 |
+
En vérifiant les évaluations, NVLM-D et NVLM-H sont les meilleurs ou les deuxièmes par rapport aux autres modèles 👏
|
| 65 |
+
|
| 66 |
+
Le modèle publié est NVLM-D basé sur Qwen-2 Instruct, aligné avec InternViT-6B en utilisant un énorme mélange de différents jeux de données.
|
| 67 |
+
""",
|
| 68 |
+
'tweet_4':
|
| 69 |
+
"""
|
| 70 |
+
Vous pouvez facilement utiliser ce modèle en le chargeant via AutoModel de 🤗 Transformers 😍
|
| 71 |
+
""",
|
| 72 |
+
'ressources':
|
| 73 |
+
"""
|
| 74 |
+
Ressources :
|
| 75 |
+
[NVLM: Open Frontier-Class Multimodal LLMs](https://arxiv.org/abs/2409.11402)
|
| 76 |
+
de Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuoling Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping (2024)
|
| 77 |
+
[GitHub](https://nvlm-project.github.io/)
|
| 78 |
+
[Modèle](https://huggingface.co/nvidia/NVLM-D-72B)
|
| 79 |
+
"""
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def language_selector():
|
| 85 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 86 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 87 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 88 |
+
|
| 89 |
+
left_column, right_column = st.columns([5, 1])
|
| 90 |
+
|
| 91 |
+
# Add a selector to the right column
|
| 92 |
+
with right_column:
|
| 93 |
+
lang = language_selector()
|
| 94 |
+
|
| 95 |
+
# Add a title to the left column
|
| 96 |
+
with left_column:
|
| 97 |
+
st.title(translations[lang]["title"])
|
| 98 |
+
|
| 99 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 100 |
+
st.markdown(""" """)
|
| 101 |
+
|
| 102 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 103 |
+
st.markdown(""" """)
|
| 104 |
+
|
| 105 |
+
st.image("pages/NVLM/image_1.png", use_column_width=True)
|
| 106 |
+
st.markdown(""" """)
|
| 107 |
+
|
| 108 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 109 |
+
st.markdown(""" """)
|
| 110 |
+
|
| 111 |
+
st.image("pages/NVLM/image_2.png", use_column_width=True)
|
| 112 |
+
st.markdown(""" """)
|
| 113 |
+
|
| 114 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 115 |
+
st.markdown(""" """)
|
| 116 |
+
|
| 117 |
+
st.image("pages/NVLM/image_3.png", use_column_width=True)
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
st.image("pages/NVLM/image_4.png", use_column_width=True)
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
with st.expander ("Code"):
|
| 127 |
+
st.code("""
|
| 128 |
+
import torch
|
| 129 |
+
from transformers import AutoModel
|
| 130 |
+
|
| 131 |
+
path = "nvidia/NVLM-D-72B"
|
| 132 |
+
|
| 133 |
+
model = AutoModel.from_pretrained(
|
| 134 |
+
path,
|
| 135 |
+
torch_dtype=torch.bfloat16,
|
| 136 |
+
low_cpu_mem_usage=True,
|
| 137 |
+
use_flash_attn=False,
|
| 138 |
+
trust_remote_code=True).eval()
|
| 139 |
+
""")
|
| 140 |
+
|
| 141 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 142 |
+
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
st.markdown(""" """)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
col1, col2, col3= st.columns(3)
|
| 147 |
+
with col1:
|
| 148 |
+
if lang == "en":
|
| 149 |
+
if st.button('Previous paper', use_container_width=True):
|
| 150 |
+
switch_page("NVEagle")
|
| 151 |
+
else:
|
| 152 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 153 |
+
switch_page("NVEagle")
|
| 154 |
+
with col2:
|
| 155 |
+
if lang == "en":
|
| 156 |
+
if st.button("Home", use_container_width=True):
|
| 157 |
+
switch_page("Home")
|
| 158 |
+
else:
|
| 159 |
+
if st.button("Accueil", use_container_width=True):
|
| 160 |
+
switch_page("Home")
|
| 161 |
+
with col3:
|
| 162 |
+
if lang == "en":
|
| 163 |
+
if st.button("Next paper", use_container_width=True):
|
| 164 |
+
switch_page("GOT")
|
| 165 |
+
else:
|
| 166 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 167 |
+
switch_page("GOT")
|
pages/2_Oneformer.py
CHANGED
|
@@ -1,62 +1,178 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("OneFormer")
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
st.markdown(""" """)
|
| 8 |
|
| 9 |
-
st.markdown(""
|
| 10 |
-
OneFormer: one model to segment them all? 🤯
|
| 11 |
-
I was looking into paperswithcode leaderboards when I came across OneFormer for the first time so it was time to dig in!
|
| 12 |
-
""")
|
| 13 |
st.markdown(""" """)
|
| 14 |
|
| 15 |
st.image("pages/OneFormer/image_1.jpeg", use_column_width=True)
|
| 16 |
st.markdown(""" """)
|
| 17 |
|
| 18 |
-
st.markdown(""
|
| 19 |
-
What makes is truly universal is that it's a single model that is trained only once and can be used across all tasks 👇
|
| 20 |
-
""")
|
| 21 |
st.markdown(""" """)
|
| 22 |
|
| 23 |
st.image("pages/OneFormer/image_2.jpeg", use_column_width=True)
|
| 24 |
st.markdown(""" """)
|
| 25 |
|
| 26 |
-
st.markdown(""
|
| 27 |
-
The enabler here is the text conditioning, i.e. the model is given a text query that states task type along with the appropriate input, and using contrastive loss, the model learns the difference between different task types 👇
|
| 28 |
-
""")
|
| 29 |
st.markdown(""" """)
|
| 30 |
|
| 31 |
st.image("pages/OneFormer/image_3.jpeg", use_column_width=True)
|
| 32 |
st.markdown(""" """)
|
| 33 |
|
| 34 |
-
st.markdown(""
|
| 35 |
-
I have drafted a [notebook](https://t.co/cBylk1Uv20) for you to try right away 😊
|
| 36 |
-
You can also check out the [Space](https://t.co/31GxlVo1W5) without checking out the code itself.
|
| 37 |
-
""")
|
| 38 |
st.markdown(""" """)
|
| 39 |
|
| 40 |
st.image("pages/OneFormer/image_4.jpeg", use_column_width=True)
|
| 41 |
st.markdown(""" """)
|
| 42 |
|
| 43 |
-
st.
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
st.markdown(""" """)
|
| 51 |
st.markdown(""" """)
|
| 52 |
st.markdown(""" """)
|
| 53 |
-
col1, col2, col3
|
| 54 |
with col1:
|
| 55 |
-
if
|
| 56 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
with col2:
|
| 58 |
-
if
|
| 59 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 60 |
with col3:
|
| 61 |
-
if
|
| 62 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'OneFormer',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1739707076501221608) (December 26, 2023)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
OneFormer: one model to segment them all? 🤯
|
| 14 |
+
I was looking into paperswithcode leaderboards when I came across OneFormer for the first time so it was time to dig in!
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
OneFormer is a "truly universal" model for semantic, instance and panoptic segmentation tasks ⚔️
|
| 19 |
+
What makes is truly universal is that it's a single model that is trained only once and can be used across all tasks 👇
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
The enabler here is the text conditioning, i.e. the model is given a text query that states task type along with the appropriate input, and using contrastive loss, the model learns the difference between different task types 👇
|
| 24 |
+
|
| 25 |
+
""",
|
| 26 |
+
'tweet_4':
|
| 27 |
+
"""
|
| 28 |
+
Thanks to 🤗 Transformers, you can easily use the model!
|
| 29 |
+
I have drafted a [notebook](https://t.co/cBylk1Uv20) for you to try right away 😊
|
| 30 |
+
You can also check out the [Space](https://t.co/31GxlVo1W5) without checking out the code itself.
|
| 31 |
+
""",
|
| 32 |
+
'ressources':
|
| 33 |
+
"""
|
| 34 |
+
Ressources:
|
| 35 |
+
[OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
|
| 36 |
+
by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi (2022)
|
| 37 |
+
[GitHub](https://github.com/SHI-Labs/OneFormer)
|
| 38 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/oneformer)"""
|
| 39 |
+
},
|
| 40 |
+
'fr': {
|
| 41 |
+
'title': 'OneFormer',
|
| 42 |
+
'original_tweet':
|
| 43 |
+
"""
|
| 44 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1739707076501221608) (en anglais) (26 décembre 2023)
|
| 45 |
+
""",
|
| 46 |
+
'tweet_1':
|
| 47 |
+
"""
|
| 48 |
+
OneFormer : un seul modèle pour tous les segmenter ? 🤯
|
| 49 |
+
Je regardais les classements de paperswithcode quand je suis tombée sur OneFormer pour la première fois. J'ai donc creusé les choses !
|
| 50 |
+
""",
|
| 51 |
+
'tweet_2':
|
| 52 |
+
"""
|
| 53 |
+
OneFormer est un modèle "véritablement universel" pour les tâches de segmentation sémantique, d'instance et panoptique ⚔️
|
| 54 |
+
Ce qui le rend vraiment universel, c'est qu'il s'agit d'un modèle unique qui n'est entraîné qu'une seule fois et qui peut être utilisé pour toutes les tâches 👇
|
| 55 |
+
""",
|
| 56 |
+
'tweet_3':
|
| 57 |
+
"""
|
| 58 |
+
Le catalyseur ici est le conditionnement du texte, c'est-à-dire que le modèle reçoit une requête textuelle indiquant le type de tâche ainsi que l'entrée appropriée, et en utilisant la perte contrastive, le modèle apprend la différence entre les différents types de tâches 👇 """,
|
| 59 |
+
'tweet_4':
|
| 60 |
+
"""
|
| 61 |
+
Grâce à 🤗 Transformers, vous pouvez facilement utiliser ce modèle !
|
| 62 |
+
J'ai rédigé un [notebook](https://t.co/cBylk1Uv20) que vous pouvez essayer sans attendre 😊
|
| 63 |
+
Vous pouvez également consulter le [Space](https://t.co/31GxlVo1W5) sans consulter le code lui-même.
|
| 64 |
+
""",
|
| 65 |
+
'ressources':
|
| 66 |
+
"""
|
| 67 |
+
Ressources :
|
| 68 |
+
[OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
|
| 69 |
+
de Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi (2022)
|
| 70 |
+
[GitHub](https://github.com/SHI-Labs/OneFormer)
|
| 71 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/oneformer)
|
| 72 |
+
"""
|
| 73 |
+
}
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def language_selector():
|
| 78 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 79 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 80 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 81 |
+
|
| 82 |
+
left_column, right_column = st.columns([5, 1])
|
| 83 |
+
|
| 84 |
+
# Add a selector to the right column
|
| 85 |
+
with right_column:
|
| 86 |
+
lang = language_selector()
|
| 87 |
+
|
| 88 |
+
# Add a title to the left column
|
| 89 |
+
with left_column:
|
| 90 |
+
st.title(translations[lang]["title"])
|
| 91 |
+
|
| 92 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 93 |
st.markdown(""" """)
|
| 94 |
|
| 95 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
| 96 |
st.markdown(""" """)
|
| 97 |
|
| 98 |
st.image("pages/OneFormer/image_1.jpeg", use_column_width=True)
|
| 99 |
st.markdown(""" """)
|
| 100 |
|
| 101 |
+
st.markdown(translations[lang]["tweet_2"])
|
|
|
|
|
|
|
| 102 |
st.markdown(""" """)
|
| 103 |
|
| 104 |
st.image("pages/OneFormer/image_2.jpeg", use_column_width=True)
|
| 105 |
st.markdown(""" """)
|
| 106 |
|
| 107 |
+
st.markdown(translations[lang]["tweet_3"])
|
|
|
|
|
|
|
| 108 |
st.markdown(""" """)
|
| 109 |
|
| 110 |
st.image("pages/OneFormer/image_3.jpeg", use_column_width=True)
|
| 111 |
st.markdown(""" """)
|
| 112 |
|
| 113 |
+
st.markdown(translations[lang]["tweet_4"])
|
|
|
|
|
|
|
|
|
|
| 114 |
st.markdown(""" """)
|
| 115 |
|
| 116 |
st.image("pages/OneFormer/image_4.jpeg", use_column_width=True)
|
| 117 |
st.markdown(""" """)
|
| 118 |
|
| 119 |
+
with st.expander ("Code"):
|
| 120 |
+
if lang == "en":
|
| 121 |
+
st.code("""
|
| 122 |
+
from transformers import OneFormerProcessor, OneFormerForUniversalSegmentation
|
| 123 |
+
|
| 124 |
+
# Loading a single model for all three tasks
|
| 125 |
+
processor = OneformerProcessor.from_pretrained("shi-Labs/oneformer_cityscapes_swin_large")
|
| 126 |
+
model = OneFormerForUniversalSegmentation.from_pretrained("shi-labs/oneformer_cityscapes_swin_large")
|
| 127 |
+
|
| 128 |
+
# To get panoptic and instance segmentation results, swap task_inputs with "panoptic" or "instance" and use the appropriate post processing method
|
| 129 |
+
semantic_inputs = processor(images=image, task_inputs=["semantic"], return_tensors="pt")
|
| 130 |
+
semantic_outputs = model(**semantic_inputs)
|
| 131 |
+
|
| 132 |
+
# pass through image_processor for postprocessing
|
| 133 |
+
predicted_semantic_map = processor.post_process_semantic_segmentation(semantic_outputs, target_sizes=[image.size[::-1]])[0]
|
| 134 |
+
""")
|
| 135 |
+
else:
|
| 136 |
+
st.code("""
|
| 137 |
+
from transformers import OneFormerProcessor, OneFormerForUniversalSegmentation
|
| 138 |
+
|
| 139 |
+
# Chargement d'un seul modèle pour les trois tâches
|
| 140 |
+
processor = OneformerProcessor.from_pretrained("shi-Labs/oneformer_cityscapes_swin_large")
|
| 141 |
+
model = OneFormerForUniversalSegmentation.from_pretrained("shi-labs/oneformer_cityscapes_swin_large")
|
| 142 |
+
|
| 143 |
+
# Pour avoir des résultats de segmentation panoptique ou par instance, remplacez task_inputs par "panoptic" ou "instance" et utilisez la méthode de post-traitement appropriée
|
| 144 |
+
semantic_inputs = processor(images=image, task_inputs=["semantic"], return_tensors="pt")
|
| 145 |
+
semantic_outputs = model(**semantic_inputs)
|
| 146 |
+
|
| 147 |
+
# passage par image_processor pour le post-traitement
|
| 148 |
+
predicted_semantic_map = processor.post_process_semantic_segmentation(semantic_outputs, target_sizes=[image.size[::-1]])[0]
|
| 149 |
+
""")
|
| 150 |
+
st.markdown(""" """)
|
| 151 |
+
|
| 152 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 153 |
|
| 154 |
st.markdown(""" """)
|
| 155 |
st.markdown(""" """)
|
| 156 |
st.markdown(""" """)
|
| 157 |
+
col1, col2, col3= st.columns(3)
|
| 158 |
with col1:
|
| 159 |
+
if lang == "en":
|
| 160 |
+
if st.button('Previous paper', use_container_width=True):
|
| 161 |
+
switch_page("MobileSAM")
|
| 162 |
+
else:
|
| 163 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 164 |
+
switch_page("MobileSAM")
|
| 165 |
with col2:
|
| 166 |
+
if lang == "en":
|
| 167 |
+
if st.button("Home", use_container_width=True):
|
| 168 |
+
switch_page("Home")
|
| 169 |
+
else:
|
| 170 |
+
if st.button("Accueil", use_container_width=True):
|
| 171 |
+
switch_page("Home")
|
| 172 |
with col3:
|
| 173 |
+
if lang == "en":
|
| 174 |
+
if st.button("Next paper", use_container_width=True):
|
| 175 |
+
switch_page("VITMAE")
|
| 176 |
+
else:
|
| 177 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 178 |
+
switch_page("VITMAE")
|
pages/30_GOT.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'GOT',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1843278355749065084) (October 7, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
I'm bullish on this foundation OCR model called GOT 📝
|
| 14 |
+
This model can transcribe anything and it's Apache-2.0!
|
| 15 |
+
Keep reading to learn more 🧶
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
This model can take in screenshots of tables/LaTeX and output formatted text, music sheets, charts, literally anything to meaningful format!
|
| 20 |
+
[Try it](https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo)
|
| 21 |
+
""",
|
| 22 |
+
'tweet_3':
|
| 23 |
+
"""
|
| 24 |
+
This model has the same architecture as other vision language models 👀 Consists of an image encoder, projector and text decoder.
|
| 25 |
+
<br>
|
| 26 |
+
What makes this model special in my opinion are two things:
|
| 27 |
+
1. Diverse, high quality data mixture (thus data engine)
|
| 28 |
+
2. Alignment technique
|
| 29 |
+
""",
|
| 30 |
+
'tweet_4':
|
| 31 |
+
"""
|
| 32 |
+
Authors followed the following recipe:
|
| 33 |
+
🔥 pre-trained a vision encoder by using OPT-125M
|
| 34 |
+
✨ keep training same encoder, add a new linear layer and Qwen-0.5B and train all the components
|
| 35 |
+
❄️ finally they freeze the encoder and do fine-tuning 👇🏻
|
| 36 |
+
""",
|
| 37 |
+
'tweet_5':
|
| 38 |
+
"""
|
| 39 |
+
Their training data generated with engine consists of:
|
| 40 |
+
📝 plain OCR data
|
| 41 |
+
📑 mathpix markdown (tables, LaTeX formulas etc)
|
| 42 |
+
📊 charts (chart to JSON output)
|
| 43 |
+
📐 geometric shapes (into TikZ)
|
| 44 |
+
🎼 even music sheets
|
| 45 |
+
""",
|
| 46 |
+
'tweet_6':
|
| 47 |
+
"""
|
| 48 |
+
The authors have reported different metrics and it seems despite it's small size, the model seems to be the state-of-the-art in many benchmarks!
|
| 49 |
+
""",
|
| 50 |
+
'ressources':
|
| 51 |
+
"""
|
| 52 |
+
Ressources:
|
| 53 |
+
[General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704)
|
| 54 |
+
by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang (2024)
|
| 55 |
+
[GitHub](https://github.com/Ucas-HaoranWei/GOT-OCR2.0/)
|
| 56 |
+
[Model](https://huggingface.co/stepfun-ai/GOT-OCR2_0)
|
| 57 |
+
"""
|
| 58 |
+
},
|
| 59 |
+
'fr': {
|
| 60 |
+
'title': 'GOT',
|
| 61 |
+
'original_tweet':
|
| 62 |
+
"""
|
| 63 |
+
[Tweet de base](https://x.com/mervenoyann/status/1843278355749065084) (en anglais) (7 ocotbre 2024)
|
| 64 |
+
""",
|
| 65 |
+
'tweet_1':
|
| 66 |
+
"""
|
| 67 |
+
Je suis enthousiaste pour de ce modèle d'OCR appelé GOT 📝
|
| 68 |
+
Ce modèle peut transcrire n'importe quoi et il est Apache-2.0 !
|
| 69 |
+
Continuez à lire pour en savoir plus 🧶
|
| 70 |
+
""",
|
| 71 |
+
'tweet_2':
|
| 72 |
+
"""
|
| 73 |
+
Ce modèle peut recevoir des captures d'écran de tableaux/LaTeX et produire du texte formaté, des partitions, des graphiques, littéralement tout ce qui peut être mis en forme !
|
| 74 |
+
[Essayez-le](https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo)
|
| 75 |
+
""",
|
| 76 |
+
'tweet_3':
|
| 77 |
+
"""
|
| 78 |
+
Ce modèle a la même architecture que d'autres modèles de langage de vision 👀
|
| 79 |
+
Il se compose d'un encodeur d'images, d'un projecteur et d'un décodeur de texte.
|
| 80 |
+
<br>
|
| 81 |
+
Ce qui rend ce modèle spécial à mon avis, ce sont deux choses :
|
| 82 |
+
1. Mélange de données diversifiées et de haute qualité (donc moteur de données).
|
| 83 |
+
2. Technique d'alignement
|
| 84 |
+
""",
|
| 85 |
+
'tweet_4':
|
| 86 |
+
"""
|
| 87 |
+
Les auteurs ont suivi la recette suivante :
|
| 88 |
+
🔥 pré-entraînement d'un encodeur de vision en utilisant OPT-125M
|
| 89 |
+
✨ poursuite de l'entraînement du même encodeur, ajout d'une nouvelle couche linéaire et de Qwen-0.5B et entraînement de tous les composants
|
| 90 |
+
❄️ enfin, ils figent l'encodeur et procèdent à un finetuning 👇🏻
|
| 91 |
+
""",
|
| 92 |
+
'tweet_5':
|
| 93 |
+
"""
|
| 94 |
+
Les données d'entraînement générées par le moteur sont :
|
| 95 |
+
📝 des données OCR simples
|
| 96 |
+
📑 des mathpix markdown (tableaux, formules LaTeX, etc.)
|
| 97 |
+
📊 des graphiques (sortie des graphiques en JSON)
|
| 98 |
+
📐 des formes géométriques (dans TikZ)
|
| 99 |
+
🎼 des partitions de musique
|
| 100 |
+
""",
|
| 101 |
+
'tweet_6':
|
| 102 |
+
"""
|
| 103 |
+
Les auteurs ont rapporté différentes métriques et il semble qu'en dépit de sa petite taille, le modèle soit SOTA dans de nombreux benchmarks !
|
| 104 |
+
""",
|
| 105 |
+
'ressources':
|
| 106 |
+
"""
|
| 107 |
+
Ressources :
|
| 108 |
+
[General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704)
|
| 109 |
+
de Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang (2024)
|
| 110 |
+
[GitHub](https://github.com/Ucas-HaoranWei/GOT-OCR2.0/)
|
| 111 |
+
[Modèle](https://huggingface.co/stepfun-ai/GOT-OCR2_0)
|
| 112 |
+
"""
|
| 113 |
+
}
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def language_selector():
|
| 118 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 119 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 120 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 121 |
+
|
| 122 |
+
left_column, right_column = st.columns([5, 1])
|
| 123 |
+
|
| 124 |
+
# Add a selector to the right column
|
| 125 |
+
with right_column:
|
| 126 |
+
lang = language_selector()
|
| 127 |
+
|
| 128 |
+
# Add a title to the left column
|
| 129 |
+
with left_column:
|
| 130 |
+
st.title(translations[lang]["title"])
|
| 131 |
+
|
| 132 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 133 |
+
st.markdown(""" """)
|
| 134 |
+
|
| 135 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 136 |
+
st.markdown(""" """)
|
| 137 |
+
|
| 138 |
+
st.image("pages/GOT/image_1.png", use_column_width=True)
|
| 139 |
+
st.markdown(""" """)
|
| 140 |
+
|
| 141 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 142 |
+
st.markdown(""" """)
|
| 143 |
+
|
| 144 |
+
st.image("pages/GOT/image_2.png", use_column_width=True)
|
| 145 |
+
st.markdown(""" """)
|
| 146 |
+
|
| 147 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
|
| 150 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 151 |
+
st.markdown(""" """)
|
| 152 |
+
|
| 153 |
+
st.image("pages/GOT/image_3.png", use_column_width=True)
|
| 154 |
+
st.markdown(""" """)
|
| 155 |
+
|
| 156 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 157 |
+
st.markdown(""" """)
|
| 158 |
+
|
| 159 |
+
st.image("pages/GOT/image_4.png", use_column_width=True)
|
| 160 |
+
st.markdown(""" """)
|
| 161 |
+
|
| 162 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
|
| 165 |
+
st.image("pages/GOT/image_5.png", use_column_width=True)
|
| 166 |
+
st.markdown(""" """)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 170 |
+
|
| 171 |
+
st.markdown(""" """)
|
| 172 |
+
st.markdown(""" """)
|
| 173 |
+
st.markdown(""" """)
|
| 174 |
+
col1, col2, col3= st.columns(3)
|
| 175 |
+
with col1:
|
| 176 |
+
if lang == "en":
|
| 177 |
+
if st.button('Previous paper', use_container_width=True):
|
| 178 |
+
switch_page("NVLM")
|
| 179 |
+
else:
|
| 180 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 181 |
+
switch_page("NVLM")
|
| 182 |
+
with col2:
|
| 183 |
+
if lang == "en":
|
| 184 |
+
if st.button("Home", use_container_width=True):
|
| 185 |
+
switch_page("Home")
|
| 186 |
+
else:
|
| 187 |
+
if st.button("Accueil", use_container_width=True):
|
| 188 |
+
switch_page("Home")
|
| 189 |
+
with col3:
|
| 190 |
+
if lang == "en":
|
| 191 |
+
if st.button("Next paper", use_container_width=True):
|
| 192 |
+
switch_page("Aria")
|
| 193 |
+
else:
|
| 194 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 195 |
+
switch_page("Aria")
|
pages/31_Aria.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Aria',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1844356121370427546) (October 10, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
This is the BEST vision language model I have ever tried!
|
| 14 |
+
<br>
|
| 15 |
+
Aria is a new model by @rhymes_ai_ : a 25.3B multimodal model that can take image/video inputs 🤩
|
| 16 |
+
<br>
|
| 17 |
+
They release the model with Apache-2.0 license and fine-tuning scripts as well 👏
|
| 18 |
+
I tested it extensively, keep reading to learn more 🧶
|
| 19 |
+
""",
|
| 20 |
+
'tweet_2':
|
| 21 |
+
"""
|
| 22 |
+
The model is open-sourced [here](huggingface.co/rhymes-ai/Aria)
|
| 23 |
+
<br>
|
| 24 |
+
The authors have released fine-tuning examples on RefCOCO, NextQA and NLVR and [inference examples](github.com/rhymes-ai/Aria)
|
| 25 |
+
<br>
|
| 26 |
+
Try the demo [here](rhymes.ai)
|
| 27 |
+
<br>
|
| 28 |
+
It's super nice that you can get started with this model using 🤗 Transformers.
|
| 29 |
+
""",
|
| 30 |
+
'tweet_3':
|
| 31 |
+
"""
|
| 32 |
+
I saw on the paper that it can debug screenshot of code??? 🤯
|
| 33 |
+
So I tried it on piece of code that calculates KL-div and it understood very well!
|
| 34 |
+
""",
|
| 35 |
+
'tweet_4':
|
| 36 |
+
"""
|
| 37 |
+
The model has very impressive OCR capabilities even with the bad handwriting 📝
|
| 38 |
+
""",
|
| 39 |
+
'tweet_5':
|
| 40 |
+
"""
|
| 41 |
+
Real world knowledge ⇓
|
| 42 |
+
""",
|
| 43 |
+
'ressources':
|
| 44 |
+
"""
|
| 45 |
+
Ressources:
|
| 46 |
+
[Aria: An Open Multimodal Native Mixture-of-Experts Model](https://arxiv.org/abs/2410.05993)
|
| 47 |
+
by Dongxu Li, Yudong Liu, Haoning Wu, Yue Wang, Zhiqi Shen, Bowen Qu, Xinyao Niu, Guoyin Wang, Bei Chen, Junnan Li (2024)
|
| 48 |
+
[GitHub](https://github.com/rhymes-ai/Aria)
|
| 49 |
+
[Model](https://huggingface.co/rhymes-ai/Aria)
|
| 50 |
+
"""
|
| 51 |
+
},
|
| 52 |
+
'fr': {
|
| 53 |
+
'title': 'Aria',
|
| 54 |
+
'original_tweet':
|
| 55 |
+
"""
|
| 56 |
+
[Tweet de base](https://x.com/mervenoyann/status/1844356121370427546) (en anglais) (10 ocotbre 2024)
|
| 57 |
+
""",
|
| 58 |
+
'tweet_1':
|
| 59 |
+
"""
|
| 60 |
+
C'est le MEILLEUR modèle de langage-vision que j'ai jamais essayé !
|
| 61 |
+
<br>
|
| 62 |
+
Aria est un nouveau modèle de @rhymes_ai_ : de 25,3Mds paramètres ce un modèle multimodal peut prendre des images et des vidéos en entrée 🤩
|
| 63 |
+
<br>
|
| 64 |
+
Ils publient le modèle avec une licence Apache-2.0 et des scripts fine-tuning 👏
|
| 65 |
+
Je l'ai testé en profondeur, continuez à lire pour en savoir plus 🧶
|
| 66 |
+
""",
|
| 67 |
+
'tweet_2':
|
| 68 |
+
"""
|
| 69 |
+
Le modèle est en libre accès [ici](huggingface.co/rhymes-ai/Aria)
|
| 70 |
+
<br>
|
| 71 |
+
Les auteurs ont publié des exemples de finetuning sur RefCOCO, NextQA et NLVR et des [exemples d'inférence](github.com/rhymes-ai/Aria).
|
| 72 |
+
<br>
|
| 73 |
+
Essayez la démo [ici](rhymes.ai)
|
| 74 |
+
<br>
|
| 75 |
+
C'est super sympa de pouvoir utiliser avec ce modèle en utilisant 🤗 Transformers
|
| 76 |
+
""",
|
| 77 |
+
'tweet_3':
|
| 78 |
+
"""
|
| 79 |
+
J'ai vu sur le papier qu'il pouvait déboguer des captures d'écran de code ? ??? 🤯
|
| 80 |
+
J'ai donc essayé sur un bout de code qui calcule la divergence de Kullback-Leibler et il a très bien compris !
|
| 81 |
+
""",
|
| 82 |
+
'tweet_4':
|
| 83 |
+
"""
|
| 84 |
+
Le modèle possède des capacités d'OCR très impressionnantes, même avec une mauvaise écriture. 📝
|
| 85 |
+
""",
|
| 86 |
+
'tweet_5':
|
| 87 |
+
"""
|
| 88 |
+
Connaissance du monde réel ⇓
|
| 89 |
+
""",
|
| 90 |
+
'ressources':
|
| 91 |
+
"""
|
| 92 |
+
Ressources :
|
| 93 |
+
[Aria: An Open Multimodal Native Mixture-of-Experts Model](https://arxiv.org/abs/2410.05993)
|
| 94 |
+
de Dongxu Li, Yudong Liu, Haoning Wu, Yue Wang, Zhiqi Shen, Bowen Qu, Xinyao Niu, Guoyin Wang, Bei Chen, Junnan Li (2024)
|
| 95 |
+
[GitHub](https://github.com/rhymes-ai/Aria)
|
| 96 |
+
[Model](https://huggingface.co/rhymes-ai/Aria)
|
| 97 |
+
"""
|
| 98 |
+
}
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def language_selector():
|
| 103 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 104 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 105 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 106 |
+
|
| 107 |
+
left_column, right_column = st.columns([5, 1])
|
| 108 |
+
|
| 109 |
+
# Add a selector to the right column
|
| 110 |
+
with right_column:
|
| 111 |
+
lang = language_selector()
|
| 112 |
+
|
| 113 |
+
# Add a title to the left column
|
| 114 |
+
with left_column:
|
| 115 |
+
st.title(translations[lang]["title"])
|
| 116 |
+
|
| 117 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 118 |
+
st.markdown(""" """)
|
| 119 |
+
|
| 120 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 121 |
+
st.markdown(""" """)
|
| 122 |
+
|
| 123 |
+
st.video("pages/Aria/video_1.mp4", format="video/mp4")
|
| 124 |
+
st.markdown(""" """)
|
| 125 |
+
|
| 126 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 127 |
+
st.markdown(""" """)
|
| 128 |
+
|
| 129 |
+
st.image("pages/Aria/image_0.png", use_column_width=True)
|
| 130 |
+
st.markdown(""" """)
|
| 131 |
+
with st.expander ("Code"):
|
| 132 |
+
st.code("""
|
| 133 |
+
from transformers import AutoModelForCausalLM, AutoProcessor
|
| 134 |
+
model_id_or_path = "rhymes-ai/Aria"
|
| 135 |
+
|
| 136 |
+
model = AutoModelForCausalLM.from_pretrained(model_id_or_path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
|
| 137 |
+
|
| 138 |
+
processor = AutoProcessor.from_pretrained(model_id_or_path, trust_remote_code=True)
|
| 139 |
+
""")
|
| 140 |
+
st.markdown(""" """)
|
| 141 |
+
|
| 142 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 143 |
+
st.markdown(""" """)
|
| 144 |
+
|
| 145 |
+
st.image("pages/Aria/image_1.png", use_column_width=True)
|
| 146 |
+
st.markdown(""" """)
|
| 147 |
+
|
| 148 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 149 |
+
st.markdown(""" """)
|
| 150 |
+
|
| 151 |
+
st.image("pages/Aria/image_2.png", use_column_width=True)
|
| 152 |
+
st.image("pages/Aria/image_3.png", use_column_width=True)
|
| 153 |
+
st.markdown(""" """)
|
| 154 |
+
|
| 155 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 156 |
+
st.markdown(""" """)
|
| 157 |
+
|
| 158 |
+
st.image("pages/Aria/image_4.png", use_column_width=True)
|
| 159 |
+
st.markdown(""" """)
|
| 160 |
+
|
| 161 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 162 |
+
|
| 163 |
+
st.markdown(""" """)
|
| 164 |
+
st.markdown(""" """)
|
| 165 |
+
st.markdown(""" """)
|
| 166 |
+
col1, col2, col3= st.columns(3)
|
| 167 |
+
with col1:
|
| 168 |
+
if lang == "en":
|
| 169 |
+
if st.button('Previous paper', use_container_width=True):
|
| 170 |
+
switch_page("GOT")
|
| 171 |
+
else:
|
| 172 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 173 |
+
switch_page("GOT")
|
| 174 |
+
with col2:
|
| 175 |
+
if lang == "en":
|
| 176 |
+
if st.button("Home", use_container_width=True):
|
| 177 |
+
switch_page("Home")
|
| 178 |
+
else:
|
| 179 |
+
if st.button("Accueil", use_container_width=True):
|
| 180 |
+
switch_page("Home")
|
| 181 |
+
with col3:
|
| 182 |
+
if lang == "en":
|
| 183 |
+
if st.button("Next paper", use_container_width=True):
|
| 184 |
+
switch_page("Home")
|
| 185 |
+
else:
|
| 186 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 187 |
+
switch_page("Home")
|
pages/3_VITMAE.py
CHANGED
|
@@ -1,63 +1,150 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("VITMAE")
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
st.markdown(""" """)
|
| 8 |
|
| 9 |
-
st.markdown(""
|
| 10 |
-
ViTMAE is a simply yet effective self-supervised pre-training technique, where authors combined vision transformer with masked autoencoder.
|
| 11 |
-
The images are first masked (75 percent of the image!) and then the model tries to learn about the features through trying to reconstruct the original image!
|
| 12 |
-
""")
|
| 13 |
st.markdown(""" """)
|
| 14 |
|
| 15 |
st.image("pages/VITMAE/image_1.jpeg", use_column_width=True)
|
| 16 |
st.markdown(""" """)
|
| 17 |
|
| 18 |
-
st.markdown(""
|
| 19 |
-
Next, a mask token is added to where the masked patches are (a bit like BERT, if you will) and the mask tokens and encoded patches are fed to decoder.
|
| 20 |
-
The decoder then tries to reconstruct the original image.
|
| 21 |
-
""")
|
| 22 |
st.markdown(""" """)
|
| 23 |
|
| 24 |
st.image("pages/VITMAE/image_2.jpeg", use_column_width=True)
|
| 25 |
st.markdown(""" """)
|
| 26 |
|
| 27 |
-
st.markdown(""
|
| 28 |
-
""")
|
| 29 |
st.markdown(""" """)
|
| 30 |
|
| 31 |
st.image("pages/VITMAE/image_3.jpeg", use_column_width=True)
|
| 32 |
st.markdown(""" """)
|
| 33 |
|
| 34 |
-
st.markdown(""
|
| 35 |
-
We've built a [demo](https://t.co/PkuACJiKrB) for you to see the intermediate outputs and reconstruction by VITMAE.
|
| 36 |
-
|
| 37 |
-
Also there's a nice [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb) by [@NielsRogge](https://twitter.com/NielsRogge).
|
| 38 |
-
""")
|
| 39 |
st.markdown(""" """)
|
| 40 |
|
| 41 |
st.image("pages/VITMAE/image_4.jpeg", use_column_width=True)
|
| 42 |
st.markdown(""" """)
|
| 43 |
|
| 44 |
-
st.info("""
|
| 45 |
-
Ressources:
|
| 46 |
-
[Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v3)
|
| 47 |
-
by LKaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick (2021)
|
| 48 |
-
[GitHub](https://github.com/facebookresearch/mae)
|
| 49 |
-
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/vit_mae)""", icon="📚")
|
| 50 |
|
| 51 |
st.markdown(""" """)
|
| 52 |
st.markdown(""" """)
|
| 53 |
st.markdown(""" """)
|
| 54 |
-
col1, col2, col3
|
| 55 |
with col1:
|
| 56 |
-
if
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
with col2:
|
| 59 |
-
if
|
| 60 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
with col3:
|
| 62 |
-
if
|
| 63 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'VITMAE',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1740688304784183664) (December 29, 2023)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Just read ViTMAE paper, sharing some highlights 🧶
|
| 14 |
+
ViTMAE is a simply yet effective self-supervised pre-training technique, where authors combined vision transformer with masked autoencoder.
|
| 15 |
+
The images are first masked (75 percent of the image!) and then the model tries to learn about the features through trying to reconstruct the original image!
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
The image is not masked, but rather only the visible patches are fed to the encoder (and that is the only thing encoder sees!).
|
| 20 |
+
Next, a mask token is added to where the masked patches are (a bit like BERT, if you will) and the mask tokens and encoded patches are fed to decoder.
|
| 21 |
+
The decoder then tries to reconstruct the original image.
|
| 22 |
+
""",
|
| 23 |
+
'tweet_3':
|
| 24 |
+
"""
|
| 25 |
+
As a result, the authors found out that high masking ratio works well in fine-tuning for downstream tasks and linear probing 🤯🤯
|
| 26 |
+
""",
|
| 27 |
+
'tweet_4':
|
| 28 |
+
"""
|
| 29 |
+
If you want to try the model or fine-tune, all the pre-trained VITMAE models released released by Meta are available on [Huggingface](https://t.co/didvTL9Zkm).
|
| 30 |
+
We've built a [demo](https://t.co/PkuACJiKrB) for you to see the intermediate outputs and reconstruction by VITMAE.
|
| 31 |
+
<br>
|
| 32 |
+
Also there's a nice [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb) by [@NielsRogge](https://twitter.com/NielsRogge).
|
| 33 |
+
""",
|
| 34 |
+
'ressources':
|
| 35 |
+
"""
|
| 36 |
+
Ressources:
|
| 37 |
+
[Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v3)
|
| 38 |
+
by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick (2021)
|
| 39 |
+
[GitHub](https://github.com/facebookresearch/mae)
|
| 40 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/vit_mae)"""
|
| 41 |
+
},
|
| 42 |
+
'fr': {
|
| 43 |
+
'title': 'VITMAE',
|
| 44 |
+
'original_tweet':
|
| 45 |
+
"""
|
| 46 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1740688304784183664) (en anglais) (29 décembre 2023)
|
| 47 |
+
""",
|
| 48 |
+
'tweet_1':
|
| 49 |
+
"""
|
| 50 |
+
Je viens de lire le papier du ViTMAE, voici quelques points marquants 🧶
|
| 51 |
+
ViTMAE est une technique de pré-entraînement autosupervisée simple mais efficace, où les auteurs combinent un vision transformer avec un autoencodeur masqué.
|
| 52 |
+
Les images sont d'abord masquées (75 % de l'image !), puis le modèle tente d'apprendre les caractéristiques en reconstruisant l'image originale !
|
| 53 |
+
""",
|
| 54 |
+
'tweet_2':
|
| 55 |
+
"""
|
| 56 |
+
Techniquement l'image n'est pas masquée, seules les parties visibles sont transmises à l'encodeur (et c'est la seule chose qu'il voit !).
|
| 57 |
+
Ensuite, un token de masque est ajouté à l'endroit où se trouvent les patchs masqués (un peu comme BERT) et l'ensemble est transmis au décodeur.
|
| 58 |
+
Le décodeur tente alors de reconstruire l'image originale.
|
| 59 |
+
""",
|
| 60 |
+
'tweet_3':
|
| 61 |
+
"""
|
| 62 |
+
Les auteurs ont constaté qu'un taux de masquage élevé fonctionnait bien pour le finetuning et l'échantillonage linéaire 🤯🤯.
|
| 63 |
+
""",
|
| 64 |
+
'tweet_4':
|
| 65 |
+
"""
|
| 66 |
+
Si vous souhaitez essayer le modèle ou le finetuner, tous les poids pré-entraînés publiés par Meta sont disponibles sur [Huggingface](https://t.co/didvTL9Zkm).
|
| 67 |
+
Nous avons aussi créé une [demo](https://t.co/PkuACJiKrB) pour que vous puissiez voir les sorties intermédiaires et la reconstruction par le VITMAE.
|
| 68 |
+
<br>
|
| 69 |
+
Vous pouvez aussi consulter le [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb) de [@NielsRogge](https://twitter.com/NielsRogge). """,
|
| 70 |
+
'ressources':
|
| 71 |
+
"""
|
| 72 |
+
Ressources :
|
| 73 |
+
[Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v3)
|
| 74 |
+
de Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick (2021)
|
| 75 |
+
[GitHub](https://github.com/facebookresearch/mae)
|
| 76 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/vit_mae)
|
| 77 |
+
"""
|
| 78 |
+
}
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def language_selector():
|
| 83 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 84 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 85 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 86 |
+
|
| 87 |
+
left_column, right_column = st.columns([5, 1])
|
| 88 |
+
|
| 89 |
+
# Add a selector to the right column
|
| 90 |
+
with right_column:
|
| 91 |
+
lang = language_selector()
|
| 92 |
+
|
| 93 |
+
# Add a title to the left column
|
| 94 |
+
with left_column:
|
| 95 |
+
st.title(translations[lang]["title"])
|
| 96 |
+
|
| 97 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 98 |
st.markdown(""" """)
|
| 99 |
|
| 100 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
| 101 |
st.markdown(""" """)
|
| 102 |
|
| 103 |
st.image("pages/VITMAE/image_1.jpeg", use_column_width=True)
|
| 104 |
st.markdown(""" """)
|
| 105 |
|
| 106 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
| 107 |
st.markdown(""" """)
|
| 108 |
|
| 109 |
st.image("pages/VITMAE/image_2.jpeg", use_column_width=True)
|
| 110 |
st.markdown(""" """)
|
| 111 |
|
| 112 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
|
|
|
| 113 |
st.markdown(""" """)
|
| 114 |
|
| 115 |
st.image("pages/VITMAE/image_3.jpeg", use_column_width=True)
|
| 116 |
st.markdown(""" """)
|
| 117 |
|
| 118 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
st.markdown(""" """)
|
| 120 |
|
| 121 |
st.image("pages/VITMAE/image_4.jpeg", use_column_width=True)
|
| 122 |
st.markdown(""" """)
|
| 123 |
|
| 124 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 125 |
|
| 126 |
st.markdown(""" """)
|
| 127 |
st.markdown(""" """)
|
| 128 |
st.markdown(""" """)
|
| 129 |
+
col1, col2, col3= st.columns(3)
|
| 130 |
with col1:
|
| 131 |
+
if lang == "en":
|
| 132 |
+
if st.button('Previous paper', use_container_width=True):
|
| 133 |
+
switch_page("OneFormer")
|
| 134 |
+
else:
|
| 135 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 136 |
+
switch_page("OneFormer")
|
| 137 |
with col2:
|
| 138 |
+
if lang == "en":
|
| 139 |
+
if st.button("Home", use_container_width=True):
|
| 140 |
+
switch_page("Home")
|
| 141 |
+
else:
|
| 142 |
+
if st.button("Accueil", use_container_width=True):
|
| 143 |
+
switch_page("Home")
|
| 144 |
with col3:
|
| 145 |
+
if lang == "en":
|
| 146 |
+
if st.button("Next paper", use_container_width=True):
|
| 147 |
+
switch_page("DINOV2")
|
| 148 |
+
else:
|
| 149 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 150 |
+
switch_page("DINOV2")
|
pages/4_DINOv2.py
CHANGED
|
@@ -1,78 +1,176 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("DINOv2")
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
st.markdown(""" """)
|
| 8 |
|
| 9 |
-
st.markdown(""
|
| 10 |
-
But how does it work? I've tried to explain how it works but let's expand on it 🧶
|
| 11 |
-
""")
|
| 12 |
st.markdown(""" """)
|
| 13 |
|
| 14 |
st.image("pages/DINOv2/image_1.jpeg", use_column_width=True)
|
| 15 |
st.markdown(""" """)
|
| 16 |
|
| 17 |
-
st.markdown(""
|
| 18 |
-
DINOv2 is essentially DINO on steroids, so let's talk about DINOv1 first 🦕
|
| 19 |
-
It's essentially a pre-training technique to train ViTs with self-supervision, that uses an unusual way of distillation 🧟♂️👨🏻🏫.
|
| 20 |
-
Distillation is a technique where there's a large pre-trained model (teacher), and you have a smaller model (student) initialized randomly.
|
| 21 |
-
Then during training the student, you take both models'outputs, calculate divergence between them and then update the loss accordingly.
|
| 22 |
-
In this case, we have no labels! And the teacher is not pretrained!!!! 🤯
|
| 23 |
-
Well, the outputs here are the distributions, and teacher is iteratively updated according to student, which is called exponential moving average.
|
| 24 |
-
""")
|
| 25 |
st.markdown(""" """)
|
| 26 |
|
| 27 |
st.image("pages/DINOv2/image_2.jpg", use_column_width=True)
|
| 28 |
st.markdown(""" """)
|
| 29 |
|
| 30 |
-
st.markdown(""
|
| 31 |
-
DINO doesn't use any contrastive loss or clustering but only cross entropy loss (again, what a paper) which leads the model to collapse.
|
| 32 |
-
This can be avoided by normalizing the teacher output multiple times, but authors center (to squish logits) and sharpen (through temperature) the teacher outputs.
|
| 33 |
-
Finally, local and global crops are given to student and only global crops are given to teacher and this sort of pushes student to identify context from small parts of the image.
|
| 34 |
-
""")
|
| 35 |
st.markdown(""" """)
|
| 36 |
|
| 37 |
st.image("pages/DINOv2/image_3.jpeg", use_column_width=True)
|
| 38 |
st.markdown(""" """)
|
| 39 |
|
| 40 |
-
st.markdown(""
|
| 41 |
-
⚡️ More efficient thanks to FSDP and Flash Attention
|
| 42 |
-
🦖 Has a very efficient data augmentation technique that apparently scales to 100M+ images (put below)
|
| 43 |
-
👨🏻🏫 Uses ViT-g instead of training from scratch
|
| 44 |
-
""")
|
| 45 |
st.markdown(""" """)
|
| 46 |
|
| 47 |
st.image("pages/DINOv2/image_4.jpeg", use_column_width=True)
|
| 48 |
st.markdown(""" """)
|
| 49 |
|
| 50 |
-
st.markdown(""
|
| 51 |
-
The model is so powerful that you can use DINOv2 even with knn or linear classifiers without need to fine-tuning!
|
| 52 |
-
But if you'd like DINOv2 to work even better, [NielsRogge](https://twitter.com/NielsRogge) has built a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Fine\_tune\_DINOv2\_for\_image\_classification\_%5Bminimal%5D.ipynb) to fine-tune it using Trainer 📖
|
| 53 |
-
He also has a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Train\_a\_linear\_classifier\_on\_top\_of\_DINOv2\_for\_semantic\_segmentation.ipynb) if you feel like training a linear classifier only 📔
|
| 54 |
-
All the different DINO/v2 model checkpoints are [here](https://huggingface.co/models?search=dinoLastly).
|
| 55 |
-
Lastly, special thanks to [ykilcher](https://twitter.com/ykilcher) as I couldn't make sense of certain things in the paper and watched his awesome [tutorial](https://youtube.com/watch?v=h3ij3F) 🤩
|
| 56 |
-
""")
|
| 57 |
st.markdown(""" """)
|
| 58 |
|
| 59 |
-
st.info("""
|
| 60 |
-
Ressources:
|
| 61 |
-
[DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)
|
| 62 |
-
by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski (2023)
|
| 63 |
-
[GitHub](https://github.com/facebookresearch/dinov2)
|
| 64 |
-
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/dinov2)""", icon="📚")
|
| 65 |
|
| 66 |
st.markdown(""" """)
|
| 67 |
st.markdown(""" """)
|
| 68 |
st.markdown(""" """)
|
| 69 |
-
col1, col2, col3
|
| 70 |
with col1:
|
| 71 |
-
if
|
| 72 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
with col2:
|
| 74 |
-
if
|
| 75 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 76 |
with col3:
|
| 77 |
-
if
|
| 78 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'DINOv2',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1743290724672495827) (January 5, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
DINOv2 is the king for self-supervised learning in images 🦖🦕
|
| 14 |
+
But how does it work? I've tried to explain how it works but let's expand on it 🧶
|
| 15 |
+
""",
|
| 16 |
+
'tweet_2':
|
| 17 |
+
"""
|
| 18 |
+
DINOv2 is essentially DINO on steroids, so let's talk about DINOv1 first 🦕
|
| 19 |
+
It's essentially a pre-training technique to train ViTs with self-supervision, that uses an unusual way of distillation 🧟♂️👨🏻🏫.
|
| 20 |
+
Distillation is a technique where there's a large pre-trained model (teacher), and you have a smaller model (student) initialized randomly.
|
| 21 |
+
Then during training the student, you take both models'outputs, calculate divergence between them and then update the loss accordingly.
|
| 22 |
+
In this case, we have no labels! And the teacher is not pretrained!!!! 🤯
|
| 23 |
+
Well, the outputs here are the distributions, and teacher is iteratively updated according to student, which is called exponential moving average.
|
| 24 |
+
""",
|
| 25 |
+
'tweet_3':
|
| 26 |
+
"""
|
| 27 |
+
DINO doesn't use any contrastive loss or clustering but only cross entropy loss (again, what a paper) which leads the model to collapse.
|
| 28 |
+
This can be avoided by normalizing the teacher output multiple times, but authors center (to squish logits) and sharpen (through temperature) the teacher outputs.
|
| 29 |
+
Finally, local and global crops are given to student and only global crops are given to teacher and this sort of pushes student to identify context from small parts of the image.
|
| 30 |
+
""",
|
| 31 |
+
'tweet_4':
|
| 32 |
+
"""
|
| 33 |
+
How does DINOv2 improve DINO?
|
| 34 |
+
⚡️ More efficient thanks to FSDP and Flash Attention
|
| 35 |
+
🦖 Has a very efficient data augmentation technique that apparently scales to 100M+ images (put below)
|
| 36 |
+
👨🏻🏫 Uses ViT-g instead of training from scratch
|
| 37 |
+
""",
|
| 38 |
+
'tweet_5':
|
| 39 |
+
"""
|
| 40 |
+
The model is so powerful that you can use DINOv2 even with knn or linear classifiers without need to fine-tuning!
|
| 41 |
+
But if you'd like DINOv2 to work even better, [NielsRogge](https://twitter.com/NielsRogge) has built a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Fine\_tune\_DINOv2\_for\_image\_classification\_%5Bminimal%5D.ipynb) to fine-tune it using Trainer 📖
|
| 42 |
+
He also has a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Train\_a\_linear\_classifier\_on\_top\_of\_DINOv2\_for\_semantic\_segmentation.ipynb) if you feel like training a linear classifier only 📔
|
| 43 |
+
All the different DINO/v2 model checkpoints are [here](https://huggingface.co/models?search=dinoLastly).
|
| 44 |
+
Lastly, special thanks to [ykilcher](https://twitter.com/ykilcher) as I couldn't make sense of certain things in the paper and watched his awesome [tutorial](https://youtube.com/watch?v=h3ij3F) 🤩
|
| 45 |
+
""",
|
| 46 |
+
'ressources':
|
| 47 |
+
"""
|
| 48 |
+
Ressources:
|
| 49 |
+
[DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski (2023)
|
| 50 |
+
[GitHub](https://github.com/facebookresearch/dinov2)
|
| 51 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/dinov2)"""
|
| 52 |
+
},
|
| 53 |
+
'fr': {
|
| 54 |
+
'title': 'DINOv2',
|
| 55 |
+
'original_tweet':
|
| 56 |
+
"""
|
| 57 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1743290724672495827) (en anglais) (5 janvier 2024)
|
| 58 |
+
""",
|
| 59 |
+
'tweet_1':
|
| 60 |
+
"""
|
| 61 |
+
DINOv2 is the king for self-supervised learning in images 🦖🦕
|
| 62 |
+
But how does it work? I've tried to explain how it works but let's expand on it 🧶
|
| 63 |
+
""",
|
| 64 |
+
'tweet_2':
|
| 65 |
+
"""
|
| 66 |
+
DINOv2 is essentially DINO on steroids, so let's talk about DINOv1 first 🦕
|
| 67 |
+
It's essentially a pre-training technique to train ViTs with self-supervision, that uses an unusual way of distillation 🧟♂️👨🏻🏫.
|
| 68 |
+
Distillation is a technique where there's a large pre-trained model (teacher), and you have a smaller model (student) initialized randomly.
|
| 69 |
+
Then during training the student, you take both models'outputs, calculate divergence between them and then update the loss accordingly.
|
| 70 |
+
In this case, we have no labels! And the teacher is not pretrained!!!! 🤯
|
| 71 |
+
Well, the outputs here are the distributions, and teacher is iteratively updated according to student, which is called exponential moving average.
|
| 72 |
+
""",
|
| 73 |
+
'tweet_3':
|
| 74 |
+
"""
|
| 75 |
+
DINO doesn't use any contrastive loss or clustering but only cross entropy loss (again, what a paper) which leads the model to collapse.
|
| 76 |
+
This can be avoided by normalizing the teacher output multiple times, but authors center (to squish logits) and sharpen (through temperature) the teacher outputs.
|
| 77 |
+
Finally, local and global crops are given to student and only global crops are given to teacher and this sort of pushes student to identify context from small parts of the image.
|
| 78 |
+
""",
|
| 79 |
+
'tweet_4':
|
| 80 |
+
"""
|
| 81 |
+
How does DINOv2 improve DINO?
|
| 82 |
+
⚡️ More efficient thanks to FSDP and Flash Attention
|
| 83 |
+
🦖 Has a very efficient data augmentation technique that apparently scales to 100M+ images (put below)
|
| 84 |
+
👨🏻🏫 Uses ViT-g instead of training from scratch
|
| 85 |
+
""",
|
| 86 |
+
'tweet_5':
|
| 87 |
+
"""
|
| 88 |
+
The model is so powerful that you can use DINOv2 even with knn or linear classifiers without need to fine-tuning!
|
| 89 |
+
But if you'd like DINOv2 to work even better, [NielsRogge](https://twitter.com/NielsRogge) has built a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Fine\_tune\_DINOv2\_for\_image\_classification\_%5Bminimal%5D.ipynb) to fine-tune it using Trainer 📖
|
| 90 |
+
He also has a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Train\_a\_linear\_classifier\_on\_top\_of\_DINOv2\_for\_semantic\_segmentation.ipynb) if you feel like training a linear classifier only 📔
|
| 91 |
+
All the different DINO/v2 model checkpoints are [here](https://huggingface.co/models?search=dinoLastly).
|
| 92 |
+
Lastly, special thanks to [ykilcher](https://twitter.com/ykilcher) as I couldn't make sense of certain things in the paper and watched his awesome [tutorial](https://youtube.com/watch?v=h3ij3F) 🤩
|
| 93 |
+
""",
|
| 94 |
+
'ressources':
|
| 95 |
+
"""
|
| 96 |
+
Ressources :
|
| 97 |
+
[DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) de Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski (2023)
|
| 98 |
+
[GitHub](https://github.com/facebookresearch/dinov2)
|
| 99 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/dinov2)
|
| 100 |
+
"""
|
| 101 |
+
}
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def language_selector():
|
| 106 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 107 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 108 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 109 |
+
|
| 110 |
+
left_column, right_column = st.columns([5, 1])
|
| 111 |
+
|
| 112 |
+
# Add a selector to the right column
|
| 113 |
+
with right_column:
|
| 114 |
+
lang = language_selector()
|
| 115 |
+
|
| 116 |
+
# Add a title to the left column
|
| 117 |
+
with left_column:
|
| 118 |
+
st.title(translations[lang]["title"])
|
| 119 |
+
|
| 120 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 121 |
st.markdown(""" """)
|
| 122 |
|
| 123 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
|
|
|
|
|
|
| 124 |
st.markdown(""" """)
|
| 125 |
|
| 126 |
st.image("pages/DINOv2/image_1.jpeg", use_column_width=True)
|
| 127 |
st.markdown(""" """)
|
| 128 |
|
| 129 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 130 |
st.markdown(""" """)
|
| 131 |
|
| 132 |
st.image("pages/DINOv2/image_2.jpg", use_column_width=True)
|
| 133 |
st.markdown(""" """)
|
| 134 |
|
| 135 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 136 |
st.markdown(""" """)
|
| 137 |
|
| 138 |
st.image("pages/DINOv2/image_3.jpeg", use_column_width=True)
|
| 139 |
st.markdown(""" """)
|
| 140 |
|
| 141 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
st.markdown(""" """)
|
| 143 |
|
| 144 |
st.image("pages/DINOv2/image_4.jpeg", use_column_width=True)
|
| 145 |
st.markdown(""" """)
|
| 146 |
|
| 147 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 148 |
st.markdown(""" """)
|
| 149 |
|
| 150 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 151 |
|
| 152 |
st.markdown(""" """)
|
| 153 |
st.markdown(""" """)
|
| 154 |
st.markdown(""" """)
|
| 155 |
+
col1, col2, col3= st.columns(3)
|
| 156 |
with col1:
|
| 157 |
+
if lang == "en":
|
| 158 |
+
if st.button('Previous paper', use_container_width=True):
|
| 159 |
+
switch_page("VITMAE")
|
| 160 |
+
else:
|
| 161 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 162 |
+
switch_page("VITMAE")
|
| 163 |
with col2:
|
| 164 |
+
if lang == "en":
|
| 165 |
+
if st.button("Home", use_container_width=True):
|
| 166 |
+
switch_page("Home")
|
| 167 |
+
else:
|
| 168 |
+
if st.button("Accueil", use_container_width=True):
|
| 169 |
+
switch_page("Home")
|
| 170 |
with col3:
|
| 171 |
+
if lang == "en":
|
| 172 |
+
if st.button("Next paper", use_container_width=True):
|
| 173 |
+
switch_page("SigLIP")
|
| 174 |
+
else:
|
| 175 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 176 |
+
switch_page("SigLIP")
|
pages/5_SigLIP.py
CHANGED
|
@@ -1,78 +1,192 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("SigLIP")
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
st.markdown(""" """)
|
| 8 |
|
| 9 |
-
st.markdown(""
|
| 10 |
-
To celebrate this, I have created a repository on various SigLIP based projects!
|
| 11 |
-
But what is it and how does it work?
|
| 12 |
-
SigLIP an vision-text pre-training technique based on contrastive learning. It jointly trains an image encoder and text encoder such that the dot product of embeddings are most similar for the appropriate text-image pairs.
|
| 13 |
-
The image below is taken from CLIP, where this contrastive pre-training takes place with softmax, but SigLIP replaces softmax with sigmoid. 📎
|
| 14 |
-
""")
|
| 15 |
st.markdown(""" """)
|
| 16 |
|
| 17 |
st.image("pages/SigLIP/image_1.jpg", use_column_width=True)
|
| 18 |
st.markdown(""" """)
|
| 19 |
|
| 20 |
-
st.markdown(""
|
| 21 |
-
Highlights✨
|
| 22 |
-
🖼️📝 Authors used medium sized B/16 ViT for image encoder and B-sized transformer for text encoder
|
| 23 |
-
😍 More performant than CLIP on zero-shot
|
| 24 |
-
🗣️ Authors trained a multilingual model too!
|
| 25 |
-
⚡️ Super efficient, sigmoid is enabling up to 1M items per batch, but the authors chose 32k (see saturation on perf below)
|
| 26 |
-
""")
|
| 27 |
st.markdown(""" """)
|
| 28 |
|
| 29 |
st.image("pages/SigLIP/image_2.jpg", use_column_width=True)
|
| 30 |
st.markdown(""" """)
|
| 31 |
|
| 32 |
-
st.markdown(""
|
| 33 |
-
Below you can find prior CLIP models and SigLIP across different image encoder sizes and their performance on different datasets 👇🏻
|
| 34 |
-
""")
|
| 35 |
st.markdown(""" """)
|
| 36 |
|
| 37 |
st.image("pages/SigLIP/image_3.jpg", use_column_width=True)
|
| 38 |
st.markdown(""" """)
|
| 39 |
|
| 40 |
-
st.markdown(""
|
| 41 |
-
With 🤗 Transformers integration there comes zero-shot-image-classification pipeline, makes SigLIP super easy to use!
|
| 42 |
-
""")
|
| 43 |
st.markdown(""" """)
|
| 44 |
|
| 45 |
st.image("pages/SigLIP/image_4.jpg", use_column_width=True)
|
| 46 |
st.markdown(""" """)
|
| 47 |
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
""")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 55 |
st.markdown(""" """)
|
| 56 |
|
| 57 |
st.image("pages/SigLIP/image_5.jpg", use_column_width=True)
|
| 58 |
st.markdown(""" """)
|
| 59 |
|
| 60 |
-
st.info("""
|
| 61 |
-
|
| 62 |
-
[Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)
|
| 63 |
-
by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer (2023)
|
| 64 |
-
[GitHub](https://github.com/google-research/big_vision)
|
| 65 |
-
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/siglip)""", icon="📚")
|
| 66 |
st.markdown(""" """)
|
| 67 |
st.markdown(""" """)
|
| 68 |
st.markdown(""" """)
|
| 69 |
-
col1, col2, col3
|
| 70 |
with col1:
|
| 71 |
-
if
|
| 72 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
with col2:
|
| 74 |
-
if
|
| 75 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 76 |
with col3:
|
| 77 |
-
if
|
| 78 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'SigLIP',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1745476609686089800) (January 11. 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
SigLIP just got merged to 🤗 Transformers and it's super easy to use!
|
| 14 |
+
To celebrate this, I have created a repository on various SigLIP based projects!
|
| 15 |
+
But what is it and how does it work?
|
| 16 |
+
SigLIP an vision-text pre-training technique based on contrastive learning. It jointly trains an image encoder and text encoder such that the dot product of embeddings are most similar for the appropriate text-image pairs.
|
| 17 |
+
The image below is taken from CLIP, where this contrastive pre-training takes place with softmax, but SigLIP replaces softmax with sigmoid. 📎
|
| 18 |
+
""",
|
| 19 |
+
'tweet_2':
|
| 20 |
+
"""
|
| 21 |
+
Highlights✨
|
| 22 |
+
🖼️📝 Authors used medium sized B/16 ViT for image encoder and B-sized transformer for text encoder
|
| 23 |
+
😍 More performant than CLIP on zero-shot
|
| 24 |
+
🗣️ Authors trained a multilingual model too!
|
| 25 |
+
⚡️ Super efficient, sigmoid is enabling up to 1M items per batch, but the authors chose 32k (see saturation on perf below)
|
| 26 |
+
""",
|
| 27 |
+
'tweet_3':
|
| 28 |
+
"""
|
| 29 |
+
Below you can find prior CLIP models and SigLIP across different image encoder sizes and their performance on different datasets 👇🏻
|
| 30 |
+
""",
|
| 31 |
+
'tweet_4':
|
| 32 |
+
"""
|
| 33 |
+
With 🤗 Transformers integration there comes zero-shot-image-classification pipeline, makes SigLIP super easy to use!
|
| 34 |
+
""",
|
| 35 |
+
'tweet_5':
|
| 36 |
+
"""
|
| 37 |
+
What to use SigLIP for? 🧐
|
| 38 |
+
Honestly the possibilities are endless, but you can use it for image/text retrieval, zero-shot classification, training multimodal models!
|
| 39 |
+
I have made a [GitHub repository](https://t.co/Ah1CrHVuPY) with notebooks and applications that are also hosted on Spaces.
|
| 40 |
+
I have built ["Draw to Search Art"](https://t.co/DcmQWMc1qd) where you can input image (upload one or draw) and search among 10k images in wikiart!
|
| 41 |
+
I've also built apps to [compare](https://t.co/m699TMvuW9) CLIP and SigLIP outputs.
|
| 42 |
+
""",
|
| 43 |
+
'ressources':
|
| 44 |
+
"""
|
| 45 |
+
Ressources:
|
| 46 |
+
[Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer (2023)
|
| 47 |
+
[GitHub](https://github.com/google-research/big_vision)
|
| 48 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/siglip)
|
| 49 |
+
"""
|
| 50 |
+
},
|
| 51 |
+
'fr': {
|
| 52 |
+
'title': 'SigLIP',
|
| 53 |
+
'original_tweet':
|
| 54 |
+
"""
|
| 55 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1745476609686089800) (en anglais) (11 janvier 2024)
|
| 56 |
+
""",
|
| 57 |
+
'tweet_1':
|
| 58 |
+
"""
|
| 59 |
+
SigLIP vient d'être ajouté à 🤗 Transformers et il est super facile à utiliser !
|
| 60 |
+
Pour fêter cela, j'ai créé un dépôt sur différents projets utilisant SigLIP !
|
| 61 |
+
Mais qu'est-ce que c'est et comment ça marche ?
|
| 62 |
+
SigLIP est une technique de pré-entraînement vision-texte basée sur l'apprentissage contrastif. On entraîne conjointement un encodeur d'image et un encodeur de texte de telle sorte que le produit scalaire des enchâssements soit le plus similaire possible pour les paires texte-image liées.
|
| 63 |
+
L'image ci-dessous est tirée de CLIP, où ce pré-entraînement contrastif est effectué avec une fonction Softmax, là où SigLIP utilise à la place une fonction Sigmoïde. 📎
|
| 64 |
+
""",
|
| 65 |
+
'tweet_2':
|
| 66 |
+
"""
|
| 67 |
+
Principaux faits✨
|
| 68 |
+
🖼️📝 Les auteurs ont utilisé un ViT B/16 pour l'encodeur d'images et un transformer B pour l'encodeur de texte
|
| 69 |
+
😍 Plus performant que CLIP en zéro-shot
|
| 70 |
+
🗣️ Les auteurs ont également entraîné un modèle multilingue !
|
| 71 |
+
⚡️ Super efficace, la sigmoïde permet de traiter jusqu'à 1M d'éléments par batch, mais les auteurs ont opté pour 32k (voir la saturation sur les performances ci-dessous)
|
| 72 |
+
""",
|
| 73 |
+
'tweet_3':
|
| 74 |
+
"""
|
| 75 |
+
Vous trouverez ci-dessous les performances des modèles CLIP et SigLIP pour différentes tailles d'encodeurs d'images et leurs performances sur différents jeux de données 👇🏻
|
| 76 |
+
""",
|
| 77 |
+
'tweet_4':
|
| 78 |
+
"""
|
| 79 |
+
Avec l'intégration dans 🤗 Transformers, il est possible d'utiliser SigLIP très simplement via le pipeline de classification d'images en zéro-shot !
|
| 80 |
+
""",
|
| 81 |
+
'tweet_5':
|
| 82 |
+
"""
|
| 83 |
+
Pourquoi utiliser SigLIP ? 🧐
|
| 84 |
+
Honnêtement, les possibilités sont infinies, mais vous pouvez l'utiliser pour la recherche d'images/de textes, la classification zéro-shot, l'entraînement de modèles multimodaux !
|
| 85 |
+
J'ai créé un [dépôt GitHub]((https://t.co/Ah1CrHVuPY)) contenant des notebooks et des applications.
|
| 86 |
+
Par exemple ["Draw to Search Art"](https://t.co/DcmQWMc1qd) où l'on peut saisir une image (en charger une ou bien la dessiner) et effectuer une recherche parmi les 10 000 images de wikiart !
|
| 87 |
+
Ou encore une application pour [comparer](https://t.co/m699TMvuW9) les sorties CLIP et SigLIP.
|
| 88 |
+
""",
|
| 89 |
+
'ressources':
|
| 90 |
+
"""
|
| 91 |
+
Ressources :
|
| 92 |
+
[Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) de Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer (2023)
|
| 93 |
+
[GitHub](https://github.com/google-research/big_vision)
|
| 94 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/siglip)
|
| 95 |
+
"""
|
| 96 |
+
}
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def language_selector():
|
| 101 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 102 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 103 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 104 |
+
|
| 105 |
+
left_column, right_column = st.columns([5, 1])
|
| 106 |
+
|
| 107 |
+
# Add a selector to the right column
|
| 108 |
+
with right_column:
|
| 109 |
+
lang = language_selector()
|
| 110 |
+
|
| 111 |
+
# Add a title to the left column
|
| 112 |
+
with left_column:
|
| 113 |
+
st.title(translations[lang]["title"])
|
| 114 |
+
|
| 115 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 116 |
st.markdown(""" """)
|
| 117 |
|
| 118 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
st.markdown(""" """)
|
| 120 |
|
| 121 |
st.image("pages/SigLIP/image_1.jpg", use_column_width=True)
|
| 122 |
st.markdown(""" """)
|
| 123 |
|
| 124 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 125 |
st.markdown(""" """)
|
| 126 |
|
| 127 |
st.image("pages/SigLIP/image_2.jpg", use_column_width=True)
|
| 128 |
st.markdown(""" """)
|
| 129 |
|
| 130 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
|
|
|
|
|
|
| 131 |
st.markdown(""" """)
|
| 132 |
|
| 133 |
st.image("pages/SigLIP/image_3.jpg", use_column_width=True)
|
| 134 |
st.markdown(""" """)
|
| 135 |
|
| 136 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
|
|
|
|
|
|
| 137 |
st.markdown(""" """)
|
| 138 |
|
| 139 |
st.image("pages/SigLIP/image_4.jpg", use_column_width=True)
|
| 140 |
st.markdown(""" """)
|
| 141 |
|
| 142 |
+
|
| 143 |
+
with st.expander ("Code"):
|
| 144 |
+
st.code("""
|
| 145 |
+
from transformers import pipeline
|
| 146 |
+
|
| 147 |
+
# pipeline
|
| 148 |
+
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-256-multilingual")
|
| 149 |
+
|
| 150 |
+
# inference
|
| 151 |
+
outputs = image_classifier( image, candidate_labels=["2 cats", "a plane", "a remote"])
|
| 152 |
+
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
|
| 153 |
+
print(outputs)
|
| 154 |
+
|
| 155 |
+
# [{'score': 0.2157, 'label': '2 cats'}, {'score': 0.0001, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
|
| 156 |
+
""")
|
| 157 |
+
st.markdown(""" """)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 161 |
st.markdown(""" """)
|
| 162 |
|
| 163 |
st.image("pages/SigLIP/image_5.jpg", use_column_width=True)
|
| 164 |
st.markdown(""" """)
|
| 165 |
|
| 166 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 167 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
| 168 |
st.markdown(""" """)
|
| 169 |
st.markdown(""" """)
|
| 170 |
st.markdown(""" """)
|
| 171 |
+
col1, col2, col3= st.columns(3)
|
| 172 |
with col1:
|
| 173 |
+
if lang == "en":
|
| 174 |
+
if st.button('Previous paper', use_container_width=True):
|
| 175 |
+
switch_page("DINOv2")
|
| 176 |
+
else:
|
| 177 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 178 |
+
switch_page("DINOv2")
|
| 179 |
with col2:
|
| 180 |
+
if lang == "en":
|
| 181 |
+
if st.button("Home", use_container_width=True):
|
| 182 |
+
switch_page("Home")
|
| 183 |
+
else:
|
| 184 |
+
if st.button("Accueil", use_container_width=True):
|
| 185 |
+
switch_page("Home")
|
| 186 |
with col3:
|
| 187 |
+
if lang == "en":
|
| 188 |
+
if st.button("Next paper", use_container_width=True):
|
| 189 |
+
switch_page("OWLv2")
|
| 190 |
+
else:
|
| 191 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 192 |
+
switch_page("OWLv2")
|
pages/6_OWLv2.py
CHANGED
|
@@ -1,87 +1,197 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("OWLv2")
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
st.markdown(""" """)
|
| 11 |
|
| 12 |
st.image("pages/OWLv2/image_1.jpeg", use_column_width=True)
|
| 13 |
st.markdown(""" """)
|
| 14 |
|
| 15 |
-
st.markdown(""
|
| 16 |
-
OWLv2 is scaled version of a model called OWL-ViT, so let's take a look at that first 📝
|
| 17 |
-
OWLViT is an open vocabulary object detector, meaning, it can detect objects it didn't explicitly see during the training 👀
|
| 18 |
-
What's cool is that it can take both image and text queries! This is thanks to how the image and text features aren't fused together.
|
| 19 |
-
""")
|
| 20 |
st.markdown(""" """)
|
| 21 |
|
| 22 |
st.image("pages/OWLv2/image_2.jpeg", use_column_width=True)
|
| 23 |
st.markdown(""" """)
|
| 24 |
|
| 25 |
-
st.markdown(""
|
| 26 |
-
They take that model, remove the final pooling layer and attach a lightweight classification and box detection head and fine-tune.
|
| 27 |
-
""")
|
| 28 |
st.markdown(""" """)
|
| 29 |
|
| 30 |
st.image("pages/OWLv2/image_3.jpeg", use_column_width=True)
|
| 31 |
st.markdown(""" """)
|
| 32 |
|
| 33 |
-
st.markdown(""
|
| 34 |
-
Simply put, loss is calculated over the predicted objects against ground truth objects and the goal is to find a perfect match of these two sets where each object is matched to one object in ground truth.
|
| 35 |
-
|
| 36 |
-
OWL-ViT is very scalable.
|
| 37 |
-
One can easily scale most language models or vision-language models because they require no supervision, but this isn't the case for object detection: you still need supervision.
|
| 38 |
-
Moreover, only scaling the encoders creates a bottleneck after a while.
|
| 39 |
-
""")
|
| 40 |
st.markdown(""" """)
|
| 41 |
|
| 42 |
st.image("pages/OWLv2/image_1.jpeg", use_column_width=True)
|
| 43 |
st.markdown(""" """)
|
| 44 |
|
| 45 |
-
st.markdown(""
|
| 46 |
-
The authors wanted to scale OWL-ViT with more data, so they used OWL-ViT for labelling to train a better detector, "self-train" a new detector on the labels, and fine-tune the model on human-annotated data.
|
| 47 |
-
""")
|
| 48 |
st.markdown(""" """)
|
| 49 |
|
| 50 |
st.image("pages/OWLv2/image_4.jpeg", use_column_width=True)
|
| 51 |
st.markdown(""" """)
|
| 52 |
|
| 53 |
-
st.markdown(""
|
| 54 |
-
Thanks to this, OWLv2 scaled very well and is tops leaderboards on open vocabulary object detection 👑
|
| 55 |
-
""")
|
| 56 |
st.markdown(""" """)
|
| 57 |
|
| 58 |
st.image("pages/OWLv2/image_5.jpeg", use_column_width=True)
|
| 59 |
st.markdown(""" """)
|
| 60 |
|
| 61 |
-
st.markdown(""
|
| 62 |
-
Want to try OWL models?
|
| 63 |
-
I've created a [notebook](https://t.co/ick5tA6nyx) for you to see how to use it with 🤗 Transformers.
|
| 64 |
-
If you want to play with it directly, you can use this [Space](https://t.co/oghdLOtoa5).
|
| 65 |
-
All the models and the applications of OWL-series is in this [collection](https://huggingface.co/collections/merve/owl-series-65aaac3114e6582c300544df).
|
| 66 |
-
""")
|
| 67 |
st.markdown(""" """)
|
| 68 |
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
by Matthias Minderer, Alexey Gritsenko, Neil Houlsby (2023)
|
| 73 |
-
[GitHub](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit)
|
| 74 |
-
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/owlv2)""", icon="📚")
|
| 75 |
st.markdown(""" """)
|
| 76 |
st.markdown(""" """)
|
| 77 |
st.markdown(""" """)
|
| 78 |
-
col1, col2, col3
|
| 79 |
with col1:
|
| 80 |
-
if
|
| 81 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
with col2:
|
| 83 |
-
if
|
| 84 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
with col3:
|
| 86 |
-
if
|
| 87 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'OWLv2',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1748411972675150040) (January 19, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Explaining the 👑 of zero-shot open-vocabulary object detection: OWLv2 🦉🧶
|
| 14 |
+
""",
|
| 15 |
+
'tweet_2':
|
| 16 |
+
"""
|
| 17 |
+
OWLv2 is scaled version of a model called OWL-ViT, so let's take a look at that first 📝
|
| 18 |
+
OWLViT is an open vocabulary object detector, meaning, it can detect objects it didn't explicitly see during the training 👀
|
| 19 |
+
What's cool is that it can take both image and text queries! This is thanks to how the image and text features aren't fused together.
|
| 20 |
+
""",
|
| 21 |
+
'tweet_3':
|
| 22 |
+
"""
|
| 23 |
+
Taking a look at the architecture, the authors firstly do contrastive pre-training of a vision and a text encoder (just like CLIP).
|
| 24 |
+
They take that model, remove the final pooling layer and attach a lightweight classification and box detection head and fine-tune.
|
| 25 |
+
""",
|
| 26 |
+
'tweet_4':
|
| 27 |
+
"""
|
| 28 |
+
During fine-tuning for object detection, they calculate the loss over bipartite matches.
|
| 29 |
+
Simply put, loss is calculated over the predicted objects against ground truth objects and the goal is to find a perfect match of these two sets where each object is matched to one object in ground truth.
|
| 30 |
+
<br>
|
| 31 |
+
OWL-ViT is very scalable.
|
| 32 |
+
One can easily scale most language models or vision-language models because they require no supervision, but this isn't the case for object detection: you still need supervision.
|
| 33 |
+
Moreover, only scaling the encoders creates a bottleneck after a while.
|
| 34 |
+
""",
|
| 35 |
+
'tweet_5':
|
| 36 |
+
"""
|
| 37 |
+
The authors wanted to scale OWL-ViT with more data, so they used OWL-ViT for labelling to train a better detector, "self-train" a new detector on the labels, and fine-tune the model on human-annotated data.
|
| 38 |
+
""",
|
| 39 |
+
'tweet_6':
|
| 40 |
+
"""
|
| 41 |
+
Thanks to this, OWLv2 scaled very well and is tops leaderboards on open vocabulary object detection 👑
|
| 42 |
+
""",
|
| 43 |
+
'tweet_7':
|
| 44 |
+
"""
|
| 45 |
+
Want to try OWL models?
|
| 46 |
+
I've created a [notebook](https://t.co/ick5tA6nyx) for you to see how to use it with 🤗 Transformers.
|
| 47 |
+
If you want to play with it directly, you can use this [Space](https://t.co/oghdLOtoa5).
|
| 48 |
+
All the models and the applications of OWL-series is in this [collection](https://huggingface.co/collections/merve/owl-series-65aaac3114e6582c300544df).
|
| 49 |
+
""",
|
| 50 |
+
'ressources':
|
| 51 |
+
"""
|
| 52 |
+
Ressources:
|
| 53 |
+
[Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby (2023)
|
| 54 |
+
[GitHub](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit)
|
| 55 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/owlv2)
|
| 56 |
+
"""
|
| 57 |
+
},
|
| 58 |
+
'fr': {
|
| 59 |
+
'title': 'OWLv2',
|
| 60 |
+
'original_tweet':
|
| 61 |
+
"""
|
| 62 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1748411972675150040) (en anglais) (19 janvier 2024)
|
| 63 |
+
""",
|
| 64 |
+
'tweet_1':
|
| 65 |
+
"""
|
| 66 |
+
Explication du 👑 de la détection d'objets en zéro-shot à vocabulaire ouvert : OWLv2 🦉🧶
|
| 67 |
+
""",
|
| 68 |
+
'tweet_2':
|
| 69 |
+
"""
|
| 70 |
+
OWLv2 est une version passée à l'échelle d'un modèle appelé OWL-ViT, que nous allons donc examiner d'abord 📝
|
| 71 |
+
OWLViT est un détecteur d'objets à vocabulaire ouvert, ce qui signifie qu'il peut détecter des objets qu'il n'a pas explicitement vus pendant l'entraînement 👀
|
| 72 |
+
Ce qui est génial, c'est qu'il peut répondre à des requêtes d'images et de texte ! Cela est dû au fait que les caractéristiques de l'image et du texte ne sont pas fusionnées.
|
| 73 |
+
""",
|
| 74 |
+
'tweet_3':
|
| 75 |
+
"""
|
| 76 |
+
Si l'on examine l'architecture, les auteurs procèdent tout d'abord à un pré-entraînement contrastif d'encodeurs de vision et de texte (comme pour CLIP).
|
| 77 |
+
Ils prennent ce modèle, suppriment la couche de pooling finale et ajoutent une tête de classification et de détection de boîtes, puis procèdent à un finetuning. """,
|
| 78 |
+
'tweet_4':
|
| 79 |
+
"""
|
| 80 |
+
Lors du finetuning pour la détection d'objets, ils calculent la perte sur les correspondances bipartites.
|
| 81 |
+
Plus simplement, la perte est calculée sur les objets prédits par rapport aux objets de la vérité terrain et l'objectif est de trouver une correspondance parfaite entre ces deux ensembles où chaque objet correspond à un objet de la vérité terrain.
|
| 82 |
+
<br>
|
| 83 |
+
OWL-ViT est fortement passable à l'échelle.
|
| 84 |
+
La plupart des modèles de langage ou des modèles vision-langage sont facilement extensibles car ils ne nécessitent pas de supervision, mais ce n'est pas le cas pour la détection d'objets : une supervision est toujours nécessaire.
|
| 85 |
+
De plus, la seule mise à l'échelle des encodeurs crée un goulot d'étranglement au bout d'un certain temps.
|
| 86 |
+
""",
|
| 87 |
+
'tweet_5':
|
| 88 |
+
"""
|
| 89 |
+
Les auteurs souhaitaient faire passer à l'échelle OWL-ViT avec davantage de données. Ils l'ont donc utilisé pour labéliser des données afin d'entraîner un meilleur détecteur sur ces labels. Puis ils ont finetuné le modèle sur des données annotées par des humains.
|
| 90 |
+
""",
|
| 91 |
+
'tweet_6':
|
| 92 |
+
"""
|
| 93 |
+
Grâce à cela, OWLv2 est en tête des classements sur la détection d'objets à vocabulaire ouvert 👑
|
| 94 |
+
""",
|
| 95 |
+
'tweet_7':
|
| 96 |
+
"""
|
| 97 |
+
Vous voulez essayer les modèles OWL ?
|
| 98 |
+
J'ai créé un [notebook](https://t.co/ick5tA6nyx) pour que vous puissiez voir comment l'utiliser avec 🤗 Transformers.
|
| 99 |
+
Si vous voulez jouer avec directement, vous pouvez utiliser ce [Space](https://t.co/oghdLOtoa5).
|
| 100 |
+
Tous les modèles et les applications de la série OWL se trouvent dans cette [collection](https://huggingface.co/collections/merve/owl-series-65aaac3114e6582c300544df).
|
| 101 |
+
""",
|
| 102 |
+
'ressources' :
|
| 103 |
+
"""
|
| 104 |
+
Ressources:
|
| 105 |
+
[Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) de Matthias Minderer, Alexey Gritsenko, Neil Houlsby (2023)
|
| 106 |
+
[GitHub](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit)
|
| 107 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/owlv2)
|
| 108 |
+
"""
|
| 109 |
+
}
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def language_selector():
|
| 114 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 115 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 116 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 117 |
+
|
| 118 |
+
left_column, right_column = st.columns([5, 1])
|
| 119 |
+
|
| 120 |
+
# Add a selector to the right column
|
| 121 |
+
with right_column:
|
| 122 |
+
lang = language_selector()
|
| 123 |
+
|
| 124 |
+
# Add a title to the left column
|
| 125 |
+
with left_column:
|
| 126 |
+
st.title(translations[lang]["title"])
|
| 127 |
+
|
| 128 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 129 |
+
st.markdown(""" """)
|
| 130 |
+
|
| 131 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 132 |
st.markdown(""" """)
|
| 133 |
|
| 134 |
st.image("pages/OWLv2/image_1.jpeg", use_column_width=True)
|
| 135 |
st.markdown(""" """)
|
| 136 |
|
| 137 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 138 |
st.markdown(""" """)
|
| 139 |
|
| 140 |
st.image("pages/OWLv2/image_2.jpeg", use_column_width=True)
|
| 141 |
st.markdown(""" """)
|
| 142 |
|
| 143 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
|
|
|
|
|
|
| 144 |
st.markdown(""" """)
|
| 145 |
|
| 146 |
st.image("pages/OWLv2/image_3.jpeg", use_column_width=True)
|
| 147 |
st.markdown(""" """)
|
| 148 |
|
| 149 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 150 |
st.markdown(""" """)
|
| 151 |
|
| 152 |
st.image("pages/OWLv2/image_1.jpeg", use_column_width=True)
|
| 153 |
st.markdown(""" """)
|
| 154 |
|
| 155 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
|
|
|
|
|
|
| 156 |
st.markdown(""" """)
|
| 157 |
|
| 158 |
st.image("pages/OWLv2/image_4.jpeg", use_column_width=True)
|
| 159 |
st.markdown(""" """)
|
| 160 |
|
| 161 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
|
|
|
|
|
|
| 162 |
st.markdown(""" """)
|
| 163 |
|
| 164 |
st.image("pages/OWLv2/image_5.jpeg", use_column_width=True)
|
| 165 |
st.markdown(""" """)
|
| 166 |
|
| 167 |
+
st.markdown(translations[lang]["tweet_7"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 168 |
st.markdown(""" """)
|
| 169 |
|
| 170 |
+
|
| 171 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 172 |
+
|
|
|
|
|
|
|
|
|
|
| 173 |
st.markdown(""" """)
|
| 174 |
st.markdown(""" """)
|
| 175 |
st.markdown(""" """)
|
| 176 |
+
col1, col2, col3= st.columns(3)
|
| 177 |
with col1:
|
| 178 |
+
if lang == "en":
|
| 179 |
+
if st.button('Previous paper', use_container_width=True):
|
| 180 |
+
switch_page("SigLIP")
|
| 181 |
+
else:
|
| 182 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 183 |
+
switch_page("SigLIP")
|
| 184 |
with col2:
|
| 185 |
+
if lang == "en":
|
| 186 |
+
if st.button("Home", use_container_width=True):
|
| 187 |
+
switch_page("Home")
|
| 188 |
+
else:
|
| 189 |
+
if st.button("Accueil", use_container_width=True):
|
| 190 |
+
switch_page("Home")
|
| 191 |
with col3:
|
| 192 |
+
if lang == "en":
|
| 193 |
+
if st.button("Next paper", use_container_width=True):
|
| 194 |
+
switch_page("Backbone")
|
| 195 |
+
else:
|
| 196 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 197 |
+
switch_page("Backbone")
|
pages/7_Backbone.py
CHANGED
|
@@ -1,63 +1,233 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("Backbone")
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
st.markdown(""" """)
|
| 8 |
|
| 9 |
-
st.markdown(""
|
| 10 |
-
➰ backbone extracts the features,
|
| 11 |
-
➰ neck refines the features,
|
| 12 |
-
➰ head makes the detection for the task.
|
| 13 |
-
Implementing this is cumbersome, so 🤗 Transformers has an API for this: Backbone!
|
| 14 |
-
""")
|
| 15 |
st.markdown(""" """)
|
| 16 |
|
| 17 |
st.image("pages/Backbone/image_1.jpeg", use_column_width=True)
|
| 18 |
st.markdown(""" """)
|
| 19 |
|
| 20 |
-
st.markdown(""
|
| 21 |
-
Let's see an example of such model.
|
| 22 |
-
Assuming we would like to initialize a multi-stage instance segmentation model with ResNet backbone and MaskFormer neck and a head, you can use the backbone API like following (left comments for clarity) 👇
|
| 23 |
-
""")
|
| 24 |
st.markdown(""" """)
|
| 25 |
|
| 26 |
st.image("pages/Backbone/image_2.jpeg", use_column_width=True)
|
| 27 |
st.markdown(""" """)
|
| 28 |
|
| 29 |
-
st.
|
| 30 |
-
|
| 31 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
st.markdown(""" """)
|
| 33 |
|
| 34 |
st.image("pages/Backbone/image_3.jpeg", use_column_width=True)
|
| 35 |
st.markdown(""" """)
|
| 36 |
|
| 37 |
-
st.
|
| 38 |
-
|
| 39 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
st.markdown(""" """)
|
| 41 |
|
| 42 |
st.image("pages/Backbone/image_4.jpeg", use_column_width=True)
|
| 43 |
st.markdown(""" """)
|
| 44 |
|
| 45 |
-
st.
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
st.markdown(""" """)
|
| 52 |
st.markdown(""" """)
|
| 53 |
st.markdown(""" """)
|
| 54 |
-
col1, col2, col3
|
| 55 |
with col1:
|
| 56 |
-
if
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
with col2:
|
| 59 |
-
if
|
| 60 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
with col3:
|
| 62 |
-
if
|
| 63 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Backbone',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1749841426177810502) (January 23, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Many cutting-edge computer vision models consist of multiple stages:
|
| 14 |
+
➰ backbone extracts the features,
|
| 15 |
+
➰ neck refines the features,
|
| 16 |
+
➰ head makes the detection for the task.
|
| 17 |
+
Implementing this is cumbersome, so 🤗 Transformers has an API for this: Backbone!
|
| 18 |
+
""",
|
| 19 |
+
'tweet_2':
|
| 20 |
+
"""
|
| 21 |
+
Let's see an example of such model.
|
| 22 |
+
Assuming we would like to initialize a multi-stage instance segmentation model with ResNet backbone and MaskFormer neck and a head, you can use the backbone API like following (left comments for clarity) 👇
|
| 23 |
+
""",
|
| 24 |
+
'tweet_3':
|
| 25 |
+
"""
|
| 26 |
+
One can also use a backbone just to get features from any stage. You can initialize any backbone with `AutoBackbone` class.
|
| 27 |
+
See below how to initialize a backbone and getting the feature maps at any stage 👇
|
| 28 |
+
""",
|
| 29 |
+
'tweet_4':
|
| 30 |
+
"""
|
| 31 |
+
Backbone API also supports any timm backbone of your choice! Check out a variation of timm backbones [here](https://t.co/Voiv0QCPB3).
|
| 32 |
+
""",
|
| 33 |
+
'tweet_5':
|
| 34 |
+
"""
|
| 35 |
+
Leaving some links 🔗
|
| 36 |
+
📖 I've created a [notebook](https://t.co/PNfmBvdrtt) for you to play with it
|
| 37 |
+
📒 [Backbone API docs](https://t.co/Yi9F8qAigO)
|
| 38 |
+
📓 [AutoBackbone docs](https://t.co/PGo9oILHDw) (all written with love by me!💜)
|
| 39 |
+
"""
|
| 40 |
+
},
|
| 41 |
+
'fr': {
|
| 42 |
+
'title': 'Backbone',
|
| 43 |
+
'original_tweet':
|
| 44 |
+
"""
|
| 45 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1749841426177810502) (en anglais) (23 janvier 2024)
|
| 46 |
+
""",
|
| 47 |
+
'tweet_1':
|
| 48 |
+
"""
|
| 49 |
+
De nombreux modèles de vision par ordinateur de pointe se composent de plusieurs étapes :
|
| 50 |
+
➰ le backbone extrayant les caractéristiques,
|
| 51 |
+
➰ le cou affinant les caractéristiques,
|
| 52 |
+
➰ la tête effectuant la détection pour la tâche.
|
| 53 |
+
L'implémentation est lourde, c'est pourquoi 🤗 Transformers dispose d'une API pour faire tout cela : Backbone !
|
| 54 |
+
""",
|
| 55 |
+
'tweet_2':
|
| 56 |
+
"""
|
| 57 |
+
Voyons un exemple de ce type de modèle.
|
| 58 |
+
En supposant que nous souhaitions initialiser un modèle de segmentation d'instance à plusieurs étapes avec un ResNet comme backbone et un MaskFormer pour le cou et une tête, vous pouvez utiliser l'API Backbone comme suit (j'ai laissé des commentaires pour plus de clarté) 👇 """,
|
| 59 |
+
'tweet_3':
|
| 60 |
+
"""
|
| 61 |
+
Il est également possible d'utiliser un backbone pour obtenir des fonctionnalités à partir de n'importe quelle étape.
|
| 62 |
+
Vous pouvez initialiser n'importe quel backbone avec la classe `AutoBackbone`.
|
| 63 |
+
Voir ci-dessous comment initialiser un backbone et obtenir les cartes de caractéristiques à n'importe quel étape 👇
|
| 64 |
+
""",
|
| 65 |
+
'tweet_4':
|
| 66 |
+
"""
|
| 67 |
+
L'API Backbone prend également en charge n'importe quel backbone de la bibliotque Timm ! Découvrez la liste des backbones disponibles dans Timm [ici](https://t.co/Voiv0QCPB3). """,
|
| 68 |
+
'tweet_5':
|
| 69 |
+
"""
|
| 70 |
+
Quelques liens utiles (rédigés avec amour par moi !💜) 🔗
|
| 71 |
+
📖 J'ai créé un [notebook](https://t.co/PNfmBvdrtt) pour que vous puissiez jouer avec.
|
| 72 |
+
📒 [La documentation de l'API Backbone API](https://t.co/Yi9F8qAigO)
|
| 73 |
+
📓 [La documentation AutoBackbone](https://t.co/PGo9oILHDw)
|
| 74 |
+
"""
|
| 75 |
+
}
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def language_selector():
|
| 80 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 81 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 82 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 83 |
+
|
| 84 |
+
left_column, right_column = st.columns([5, 1])
|
| 85 |
+
|
| 86 |
+
# Add a selector to the right column
|
| 87 |
+
with right_column:
|
| 88 |
+
lang = language_selector()
|
| 89 |
+
|
| 90 |
+
# Add a title to the left column
|
| 91 |
+
with left_column:
|
| 92 |
+
st.title(translations[lang]["title"])
|
| 93 |
+
|
| 94 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 95 |
st.markdown(""" """)
|
| 96 |
|
| 97 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 98 |
st.markdown(""" """)
|
| 99 |
|
| 100 |
st.image("pages/Backbone/image_1.jpeg", use_column_width=True)
|
| 101 |
st.markdown(""" """)
|
| 102 |
|
| 103 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
| 104 |
st.markdown(""" """)
|
| 105 |
|
| 106 |
st.image("pages/Backbone/image_2.jpeg", use_column_width=True)
|
| 107 |
st.markdown(""" """)
|
| 108 |
|
| 109 |
+
with st.expander ("Code"):
|
| 110 |
+
if lang == "en":
|
| 111 |
+
st.code("""
|
| 112 |
+
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
|
| 113 |
+
|
| 114 |
+
# initialize backbone config
|
| 115 |
+
backbone_config = ResNetConfig. from_pretrained("microsoft/resnet-50")
|
| 116 |
+
|
| 117 |
+
# initialize neck config with backbone config
|
| 118 |
+
config = MaskFormerConfig(backbone_config=backbone_config)
|
| 119 |
+
|
| 120 |
+
# initialize the head using combined config
|
| 121 |
+
model = MaskFormerForInstanceSegmentation(config)
|
| 122 |
+
""")
|
| 123 |
+
else:
|
| 124 |
+
st.code("""
|
| 125 |
+
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
|
| 126 |
+
|
| 127 |
+
# initialiser la configuration du backbone
|
| 128 |
+
backbone_config = ResNetConfig. from_pretrained("microsoft/resnet-50")
|
| 129 |
+
|
| 130 |
+
# initialiser la configuration du cou avec la configuration du backbone
|
| 131 |
+
config = MaskFormerConfig(backbone_config=backbone_config)
|
| 132 |
+
|
| 133 |
+
# initialiser la tête avec la configuration combinée
|
| 134 |
+
model = MaskFormerForInstanceSegmentation(config)
|
| 135 |
+
""")
|
| 136 |
+
st.markdown(""" """)
|
| 137 |
+
|
| 138 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 139 |
st.markdown(""" """)
|
| 140 |
|
| 141 |
st.image("pages/Backbone/image_3.jpeg", use_column_width=True)
|
| 142 |
st.markdown(""" """)
|
| 143 |
|
| 144 |
+
with st.expander ("Code"):
|
| 145 |
+
if lang == "en":
|
| 146 |
+
st.code("""
|
| 147 |
+
from transformers import AutoImageProcessor, AutoBackbone
|
| 148 |
+
import torch
|
| 149 |
+
|
| 150 |
+
# initialize backbone and processor
|
| 151 |
+
processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
|
| 152 |
+
model = AutoBackbone. from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(0,1,2))
|
| 153 |
+
|
| 154 |
+
# pass inputs through the processor and model
|
| 155 |
+
inputs = processor(image, return_tensors="pt")
|
| 156 |
+
outputs = model(**inputs )
|
| 157 |
+
feature_maps = outputs.feature_maps
|
| 158 |
+
|
| 159 |
+
# get feature maps from stem
|
| 160 |
+
list(feature_maps[0].shape)
|
| 161 |
+
# >>> [1, 96, 56, 56]
|
| 162 |
+
|
| 163 |
+
# get feature maps of first stage
|
| 164 |
+
list(feature_maps[1].shape)
|
| 165 |
+
# >>> [1, 96, 56, 56]
|
| 166 |
+
""")
|
| 167 |
+
else:
|
| 168 |
+
st.code("""
|
| 169 |
+
from transformers import AutoImageProcessor, AutoBackbone
|
| 170 |
+
import torch
|
| 171 |
+
|
| 172 |
+
# initialiser le backbone et le processeur
|
| 173 |
+
processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
|
| 174 |
+
model = AutoBackbone. from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(0,1,2))
|
| 175 |
+
|
| 176 |
+
# passer les entrées par le processeur et le modèle
|
| 177 |
+
inputs = processor(image, return_tensors="pt")
|
| 178 |
+
outputs = model(**inputs )
|
| 179 |
+
feature_maps = outputs.feature_maps
|
| 180 |
+
|
| 181 |
+
# obtenir des cartes de caractéristiques [0]
|
| 182 |
+
list(feature_maps[0].shape)
|
| 183 |
+
# >>> [1, 96, 56, 56]
|
| 184 |
+
|
| 185 |
+
# obtenir des cartes de caractéristiques [1]
|
| 186 |
+
list(feature_maps[1].shape)
|
| 187 |
+
# >>> [1, 96, 56, 56]
|
| 188 |
+
""")
|
| 189 |
+
st.markdown(""" """)
|
| 190 |
+
|
| 191 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 192 |
st.markdown(""" """)
|
| 193 |
|
| 194 |
st.image("pages/Backbone/image_4.jpeg", use_column_width=True)
|
| 195 |
st.markdown(""" """)
|
| 196 |
|
| 197 |
+
with st.expander ("Code"):
|
| 198 |
+
st.code("""
|
| 199 |
+
from transformers import TimmBackboneConfig, TimmBackbone
|
| 200 |
+
|
| 201 |
+
backbone_config = TimmBackboneConfig("resnet50")
|
| 202 |
+
model = TimmBackbone(config=backbone_config)
|
| 203 |
+
""")
|
| 204 |
+
st.markdown(""" """)
|
| 205 |
+
|
| 206 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 207 |
+
|
| 208 |
|
| 209 |
st.markdown(""" """)
|
| 210 |
st.markdown(""" """)
|
| 211 |
st.markdown(""" """)
|
| 212 |
+
col1, col2, col3= st.columns(3)
|
| 213 |
with col1:
|
| 214 |
+
if lang == "en":
|
| 215 |
+
if st.button('Previous paper', use_container_width=True):
|
| 216 |
+
switch_page("OWLv2")
|
| 217 |
+
else:
|
| 218 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 219 |
+
switch_page("OWLv2")
|
| 220 |
with col2:
|
| 221 |
+
if lang == "en":
|
| 222 |
+
if st.button("Home", use_container_width=True):
|
| 223 |
+
switch_page("Home")
|
| 224 |
+
else:
|
| 225 |
+
if st.button("Accueil", use_container_width=True):
|
| 226 |
+
switch_page("Home")
|
| 227 |
with col3:
|
| 228 |
+
if lang == "en":
|
| 229 |
+
if st.button("Next paper", use_container_width=True):
|
| 230 |
+
switch_page("Depth Anything")
|
| 231 |
+
else:
|
| 232 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 233 |
+
switch_page("Depth Anything")
|
pages/8_Depth_Anything.py
CHANGED
|
@@ -1,100 +1,370 @@
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
| 4 |
-
st.title("Depth Anything")
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
-
|
| 16 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
-
st.markdown("""
|
| 19 |
-
The paper starts with highlighting previous depth estimation methods and the limitations regarding the data coverage. 👀
|
| 20 |
-
The model's success heavily depends on unlocking the use of unlabeled datasets, although initially the authors used self-training and failed.
|
| 21 |
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
st.markdown(""" """)
|
| 27 |
|
| 28 |
-
st.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
st.markdown(""" """)
|
| 30 |
|
| 31 |
-
st.markdown(""
|
| 32 |
-
|
| 33 |
|
| 34 |
-
|
| 35 |
-
""", unsafe_allow_html=True)
|
| 36 |
|
|
|
|
| 37 |
st.markdown(""" """)
|
| 38 |
|
| 39 |
st.image("pages/Depth Anything/image_1.jpg", use_column_width=True)
|
| 40 |
st.markdown(""" """)
|
| 41 |
|
| 42 |
-
st.markdown(""
|
| 43 |
-
|
| 44 |
-
On T4 GPU, mean of 30 inferences for each. Inferred using `pipeline` (pre-processing and post-processing included with model inference).
|
| 45 |
-
|
| 46 |
-
| Model/Batch Size | 16 | 4 | 1 |
|
| 47 |
-
| ----------------------------- | --------- | -------- | ------- |
|
| 48 |
-
| intel/dpt-large | 2709.652 | 667.799 | 172.617 |
|
| 49 |
-
| facebook/dpt-dinov2-small-nyu | 2534.854 | 654.822 | 159.754 |
|
| 50 |
-
| facebook/dpt-dinov2-base-nyu | 4316.8733 | 1090.824 | 266.699 |
|
| 51 |
-
| Intel/dpt-beit-large-512 | 7961.386 | 2036.743 | 497.656 |
|
| 52 |
-
| depth-anything-small | 1692.368 | 415.915 | 143.379 |
|
| 53 |
|
| 54 |
-
|
|
|
|
| 55 |
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
| intel/dpt-large | 2556.668 | 645.750 | 155.153 |
|
| 59 |
-
| facebook/dpt-dinov2-small-nyu | 2415.25 | 610.967 | 148.526 |
|
| 60 |
-
| facebook/dpt-dinov2-base-nyu | 4057.909 | 1035.672 | 245.692 |
|
| 61 |
-
| Intel/dpt-beit-large-512 | 7417.388 | 1795.882 | 426.546 |
|
| 62 |
-
| depth-anything-small | 1664.025 | 384.688 | 97.865 |
|
| 63 |
|
| 64 |
-
""
|
| 65 |
st.markdown(""" """)
|
| 66 |
|
| 67 |
st.image("pages/Depth Anything/image_2.jpg", use_column_width=True)
|
| 68 |
st.markdown(""" """)
|
| 69 |
|
| 70 |
-
st.markdown(""
|
| 71 |
-
You can use Depth Anything easily thanks to 🤗 Transformers with three lines of code! ✨
|
| 72 |
-
We have also built an app for you to [compare different depth estimation models](https://t.co/6uq4osdwWG) 🐝 🌸
|
| 73 |
-
See all the available Depth Anything checkpoints [here](https://t.co/Ex0IIyx7XC).
|
| 74 |
-
""")
|
| 75 |
st.markdown(""" """)
|
| 76 |
|
| 77 |
st.image("pages/Depth Anything/image_3.jpg", use_column_width=True)
|
| 78 |
st.markdown(""" """)
|
| 79 |
|
| 80 |
-
st.
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
|
|
|
| 86 |
|
| 87 |
|
|
|
|
|
|
|
|
|
|
| 88 |
st.markdown(""" """)
|
| 89 |
st.markdown(""" """)
|
| 90 |
st.markdown(""" """)
|
| 91 |
-
col1, col2, col3
|
| 92 |
with col1:
|
| 93 |
-
if
|
| 94 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
with col2:
|
| 96 |
-
if
|
| 97 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 98 |
with col3:
|
| 99 |
-
if
|
| 100 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'Depth Anything',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1750531698008498431) (January 25. 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
Explaining a new state-of-the-art monocular depth estimation model: Depth Anything ✨🧶
|
| 14 |
+
It has just been integrated in 🤗 Transformers for super-easy use.
|
| 15 |
+
We compared it against DPTs and benchmarked it as well! You can find the usage, benchmark, demos and more below 👇
|
| 16 |
+
""",
|
| 17 |
+
'tweet_2':
|
| 18 |
+
"""
|
| 19 |
+
The paper starts with highlighting previous depth estimation methods and the limitations regarding the data coverage. 👀
|
| 20 |
+
The model's success heavily depends on unlocking the use of unlabeled datasets, although initially the authors used self-training and failed.
|
| 21 |
+
<br>
|
| 22 |
+
What the authors have done:
|
| 23 |
+
➰ Train a teacher model on labelled dataset
|
| 24 |
+
➰ Guide the student using teacher and also use unlabelled datasets pseudolabelled by the teacher. However, this was the cause of the failure, as both architectures were similar, the outputs were the same.
|
| 25 |
+
""",
|
| 26 |
+
'tweet_3':
|
| 27 |
+
"""
|
| 28 |
+
So the authors have added a more difficult optimization target for student to learn additional knowledge on unlabeled images that went through color jittering, distortions, Gaussian blurring and spatial distortion, so it can learn more invariant representations from them.
|
| 29 |
+
<br>
|
| 30 |
+
The architecture consists of <a href='DINOv2' target='_self'>DINOv2</a> encoder to extract the features followed by DPT decoder. At first, they train the teacher model on labelled images, and then they jointly train the student model and add in the dataset pseudo-labelled by ViT-L.
|
| 31 |
+
""",
|
| 32 |
+
'tweet_4':
|
| 33 |
+
"""Thanks to this, Depth Anything performs very well! I have also benchmarked the inference duration of the model against different models here. I also ran `torch.compile` benchmarks across them and got nice speed-ups 🚀
|
| 34 |
+
<br>
|
| 35 |
+
On T4 GPU, mean of 30 inferences for each. Inferred using `pipeline` (pre-processing and post-processing included with model inference).
|
| 36 |
+
<br>
|
| 37 |
+
<table>
|
| 38 |
+
<thead>
|
| 39 |
+
<tr>
|
| 40 |
+
<th>Model/Batch Size</th>
|
| 41 |
+
<th>16</th>
|
| 42 |
+
<th>4</th>
|
| 43 |
+
<th>1</th>
|
| 44 |
+
</tr>
|
| 45 |
+
</thead>
|
| 46 |
+
<tbody>
|
| 47 |
+
<tr>
|
| 48 |
+
<td>intel/dpt-large</td>
|
| 49 |
+
<td>2709.652</td>
|
| 50 |
+
<td>667.799</td>
|
| 51 |
+
<td>172.617</td>
|
| 52 |
+
</tr>
|
| 53 |
+
<tr>
|
| 54 |
+
<td>facebook/dpt-dinov2-small-nyu</td>
|
| 55 |
+
<td>2534.854</td>
|
| 56 |
+
<td>654.822</td>
|
| 57 |
+
<td>159.754</td>
|
| 58 |
+
</tr>
|
| 59 |
+
<tr>
|
| 60 |
+
<td>facebook/dpt-dinov2-base-nyu</td>
|
| 61 |
+
<td>4316.8733</td>
|
| 62 |
+
<td>1090.824</td>
|
| 63 |
+
<td>266.699</td>
|
| 64 |
+
</tr>
|
| 65 |
+
<tr>
|
| 66 |
+
<td>Intel/dpt-beit-large-512</td>
|
| 67 |
+
<td>7961.386</td>
|
| 68 |
+
<td>2036.743</td>
|
| 69 |
+
<td>497.656</td>
|
| 70 |
+
</tr>
|
| 71 |
+
<tr>
|
| 72 |
+
<td>depth-anything-small</td>
|
| 73 |
+
<td>1692.368</td>
|
| 74 |
+
<td>415.915</td>
|
| 75 |
+
<td>143.379</td>
|
| 76 |
+
</tr>
|
| 77 |
+
</tbody>
|
| 78 |
+
</table>
|
| 79 |
+
""",
|
| 80 |
+
'tweet_5':
|
| 81 |
+
"""
|
| 82 |
+
`torch.compile`’s benchmarks with reduce-overhead mode: we have compiled the model and loaded it to the pipeline for the benchmarks to be fair.
|
| 83 |
|
| 84 |
+
<br>
|
| 85 |
+
<table>
|
| 86 |
+
<thead>
|
| 87 |
+
<tr>
|
| 88 |
+
<th>Model/Batch Size</th>
|
| 89 |
+
<th>16</th>
|
| 90 |
+
<th>4</th>
|
| 91 |
+
<th>1</th>
|
| 92 |
+
</tr>
|
| 93 |
+
</thead>
|
| 94 |
+
<tbody>
|
| 95 |
+
<tr>
|
| 96 |
+
<td>intel/dpt-large</td>
|
| 97 |
+
<td>2556.668</td>
|
| 98 |
+
<td>645.750</td>
|
| 99 |
+
<td>155.153</td>
|
| 100 |
+
</tr>
|
| 101 |
+
<tr>
|
| 102 |
+
<td>facebook/dpt-dinov2-small-nyu</td>
|
| 103 |
+
<td>2415.25</td>
|
| 104 |
+
<td>610.967</td>
|
| 105 |
+
<td>148.526</td>
|
| 106 |
+
</tr>
|
| 107 |
+
<tr>
|
| 108 |
+
<td>facebook/dpt-dinov2-base-nyu</td>
|
| 109 |
+
<td>4057.909</td>
|
| 110 |
+
<td>1035.672</td>
|
| 111 |
+
<td>245.692</td>
|
| 112 |
+
</tr>
|
| 113 |
+
<tr>
|
| 114 |
+
<td>Intel/dpt-beit-large-512</td>
|
| 115 |
+
<td>7417.388</td>
|
| 116 |
+
<td>1795.882</td>
|
| 117 |
+
<td>426.546</td>
|
| 118 |
+
</tr>
|
| 119 |
+
<tr>
|
| 120 |
+
<td>depth-anything-small</td>
|
| 121 |
+
<td>1664.025</td>
|
| 122 |
+
<td>384.688</td>
|
| 123 |
+
<td>97.865</td>
|
| 124 |
+
</tr>
|
| 125 |
+
</tbody>
|
| 126 |
+
</table>
|
| 127 |
+
""",
|
| 128 |
+
'tweet_6':
|
| 129 |
+
"""
|
| 130 |
+
You can use Depth Anything easily thanks to 🤗 Transformers with three lines of code! ✨
|
| 131 |
+
We have also built an app for you to [compare different depth estimation models](https://t.co/6uq4osdwWG) 🐝 🌸
|
| 132 |
+
See all the available Depth Anything checkpoints [here](https://t.co/Ex0IIyx7XC).
|
| 133 |
+
""",
|
| 134 |
+
'ressources':
|
| 135 |
+
"""
|
| 136 |
+
Ressources:
|
| 137 |
+
[Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)
|
| 138 |
+
by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao (2024)
|
| 139 |
+
[GitHub](https://github.com/LiheYoung/Depth-Anything)
|
| 140 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/depth_anything)
|
| 141 |
+
"""
|
| 142 |
+
},
|
| 143 |
+
'fr': {
|
| 144 |
+
'title': 'Depth Anything',
|
| 145 |
+
'original_tweet':
|
| 146 |
+
"""
|
| 147 |
+
[Tweet de base](https://twitter.com/mervenoyann/status/1750531698008498431) (en anglais) (25 janvier 2024)
|
| 148 |
+
""",
|
| 149 |
+
'tweet_1':
|
| 150 |
+
"""
|
| 151 |
+
Explication d'un nouveau modèle à l'état de l'art pour l'estimation de la profondeur monoculaire : Depth Anything ✨🧶
|
| 152 |
+
Il vient d'être intégré dans 🤗 Transformers pour une utilisation super-facile.
|
| 153 |
+
Nous l'avons comparé aux DPTs et l'avons benchmarké ! Vous pouvez trouver l'utilisation, le benchmark, les démos et plus encore ci-dessous 👇
|
| 154 |
+
""",
|
| 155 |
+
'tweet_2':
|
| 156 |
+
"""
|
| 157 |
+
Le papier commence par aborder les points forts et faibles des précédentes méthodes d'estimation de la profondeur. 👀
|
| 158 |
+
Le succès du modèle dépend fortement de l'utilisation de jeux de données non étiquetés, bien qu'initialement les auteurs aient utilisé l'auto-apprentissage et aient échoué.
|
| 159 |
+
<br>
|
| 160 |
+
Ce que les auteurs ont fait :
|
| 161 |
+
➰ Entraîner un modèle enseignant sur un jeu de données étiquetées.
|
| 162 |
+
➰ Guider le modèle étudiant à l'aide de l'enseignant ainsi qu'utiliser des jeux de données non étiquetés pseudo-étiquetés par l'enseignant. Cependant, il s'avère que c'est la cause de l'échec, puisque les deux architectures étant similaires, les sorties étaient les mêmes. """,
|
| 163 |
+
'tweet_3':
|
| 164 |
+
"""
|
| 165 |
+
Les auteurs ont donc ajouté un objectif d'optimisation plus difficile pour que l'étudiant apprenne des connaissances supplémentaires sur des images non étiquetées qui ont subi des changements de couleur, des distorsions, un flou gaussien et des distorsions spatiales, afin qu'il puisse apprendre des représentations davantage invariantes à partir de ces images.
|
| 166 |
+
<br>
|
| 167 |
+
L'architecture consiste en un encodeur <a href='DINOv2' target='_self'>DINOv2</a> pour extraire les caractéristiques, suivi d'un décodeur DPT. Dans un premier temps, ils entraînent le modèle enseignant sur des images étiquetées, puis ils entraînent conjointement le modèle de étudiant et ajoutent le jeu de données pseudo-étiqueté par ViT-L.
|
| 168 |
+
""",
|
| 169 |
+
'tweet_4':
|
| 170 |
+
"""
|
| 171 |
+
Grâce à cela, le modèle Depth Anything fonctionne très bien ! J'ai également comparé la durée d'inférence du modèle avec d'autres modèles (avec et sans `torch.compile` qui permet de belles accélérations) 🚀
|
| 172 |
+
<br>
|
| 173 |
+
Sur GPU T4, moyenne de 30 inférences pour chacun. Inféré en utilisant `pipeline` (pré-traitement et post-traitement inclus avec l'inférence du modèle).
|
| 174 |
+
<br>
|
| 175 |
+
<table>
|
| 176 |
+
<thead>
|
| 177 |
+
<tr>
|
| 178 |
+
<th>Modèle/Taille du batch</th>
|
| 179 |
+
<th>16</th>
|
| 180 |
+
<th>4</th>
|
| 181 |
+
<th>1</th>
|
| 182 |
+
</tr>
|
| 183 |
+
</thead>
|
| 184 |
+
<tbody>
|
| 185 |
+
<tr>
|
| 186 |
+
<td>intel/dpt-large</td>
|
| 187 |
+
<td>2709.652</td>
|
| 188 |
+
<td>667.799</td>
|
| 189 |
+
<td>172.617</td>
|
| 190 |
+
</tr>
|
| 191 |
+
<tr>
|
| 192 |
+
<td>facebook/dpt-dinov2-small-nyu</td>
|
| 193 |
+
<td>2534.854</td>
|
| 194 |
+
<td>654.822</td>
|
| 195 |
+
<td>159.754</td>
|
| 196 |
+
</tr>
|
| 197 |
+
<tr>
|
| 198 |
+
<td>facebook/dpt-dinov2-base-nyu</td>
|
| 199 |
+
<td>4316.8733</td>
|
| 200 |
+
<td>1090.824</td>
|
| 201 |
+
<td>266.699</td>
|
| 202 |
+
</tr>
|
| 203 |
+
<tr>
|
| 204 |
+
<td>Intel/dpt-beit-large-512</td>
|
| 205 |
+
<td>7961.386</td>
|
| 206 |
+
<td>2036.743</td>
|
| 207 |
+
<td>497.656</td>
|
| 208 |
+
</tr>
|
| 209 |
+
<tr>
|
| 210 |
+
<td>depth-anything-small</td>
|
| 211 |
+
<td>1692.368</td>
|
| 212 |
+
<td>415.915</td>
|
| 213 |
+
<td>143.379</td>
|
| 214 |
+
</tr>
|
| 215 |
+
</tbody>
|
| 216 |
+
</table>
|
| 217 |
+
""",
|
| 218 |
+
'tweet_5':
|
| 219 |
+
"""
|
| 220 |
+
Les benchmarks de `torch.compile` avec le mode reduce-overhead : nous avons compilé le modèle et l'avons chargé dans le pipeline pour que les benchmarks soient équitables.
|
| 221 |
|
| 222 |
+
<br>
|
| 223 |
+
<table>
|
| 224 |
+
<thead>
|
| 225 |
+
<tr>
|
| 226 |
+
<th>Modèle/Taille du batch</th>
|
| 227 |
+
<th>16</th>
|
| 228 |
+
<th>4</th>
|
| 229 |
+
<th>1</th>
|
| 230 |
+
</tr>
|
| 231 |
+
</thead>
|
| 232 |
+
<tbody>
|
| 233 |
+
<tr>
|
| 234 |
+
<td>intel/dpt-large</td>
|
| 235 |
+
<td>2556.668</td>
|
| 236 |
+
<td>645.750</td>
|
| 237 |
+
<td>155.153</td>
|
| 238 |
+
</tr>
|
| 239 |
+
<tr>
|
| 240 |
+
<td>facebook/dpt-dinov2-small-nyu</td>
|
| 241 |
+
<td>2415.25</td>
|
| 242 |
+
<td>610.967</td>
|
| 243 |
+
<td>148.526</td>
|
| 244 |
+
</tr>
|
| 245 |
+
<tr>
|
| 246 |
+
<td>facebook/dpt-dinov2-base-nyu</td>
|
| 247 |
+
<td>4057.909</td>
|
| 248 |
+
<td>1035.672</td>
|
| 249 |
+
<td>245.692</td>
|
| 250 |
+
</tr>
|
| 251 |
+
<tr>
|
| 252 |
+
<td>Intel/dpt-beit-large-512</td>
|
| 253 |
+
<td>7417.388</td>
|
| 254 |
+
<td>1795.882</td>
|
| 255 |
+
<td>426.546</td>
|
| 256 |
+
</tr>
|
| 257 |
+
<tr>
|
| 258 |
+
<td>depth-anything-small</td>
|
| 259 |
+
<td>1664.025</td>
|
| 260 |
+
<td>384.688</td>
|
| 261 |
+
<td>97.865</td>
|
| 262 |
+
</tr>
|
| 263 |
+
</tbody>
|
| 264 |
+
</table>
|
| 265 |
+
""",
|
| 266 |
+
'tweet_6':
|
| 267 |
+
"""
|
| 268 |
+
Vous pouvez utiliser Depth Anything facilement grâce à 🤗 Transformers avec trois lignes de code ! ✨
|
| 269 |
+
Nous avons également créé une application pour vous permettre de [comparer différents modèles d'estimation de la profondeur](https://t.co/6uq4osdwWG) 🐝 🌸
|
| 270 |
+
Tous les checkpoints de Depth Anything sont disponibles [ici](https://t.co/Ex0IIyx7XC).
|
| 271 |
+
""",
|
| 272 |
+
'ressources':
|
| 273 |
+
"""
|
| 274 |
+
Ressources :
|
| 275 |
+
[Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)
|
| 276 |
+
de Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao (2024)
|
| 277 |
+
[GitHub](https://github.com/LiheYoung/Depth-Anything)
|
| 278 |
+
[Documentation d'Hugging Face](https://huggingface.co/docs/transformers/model_doc/depth_anything)
|
| 279 |
+
"""
|
| 280 |
+
}
|
| 281 |
+
}
|
| 282 |
|
|
|
|
|
|
|
|
|
|
| 283 |
|
| 284 |
+
def language_selector():
|
| 285 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 286 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 287 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
|
|
|
| 288 |
|
| 289 |
+
left_column, right_column = st.columns([5, 1])
|
| 290 |
+
|
| 291 |
+
# Add a selector to the right column
|
| 292 |
+
with right_column:
|
| 293 |
+
lang = language_selector()
|
| 294 |
+
|
| 295 |
+
# Add a title to the left column
|
| 296 |
+
with left_column:
|
| 297 |
+
st.title(translations[lang]["title"])
|
| 298 |
+
|
| 299 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 300 |
st.markdown(""" """)
|
| 301 |
|
| 302 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 303 |
+
st.markdown(""" """)
|
| 304 |
|
| 305 |
+
st.video("pages/Depth Anything/video_1.mp4", format="video/mp4")
|
|
|
|
| 306 |
|
| 307 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 308 |
st.markdown(""" """)
|
| 309 |
|
| 310 |
st.image("pages/Depth Anything/image_1.jpg", use_column_width=True)
|
| 311 |
st.markdown(""" """)
|
| 312 |
|
| 313 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 314 |
+
st.markdown(""" """)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 315 |
|
| 316 |
+
st.image("pages/Depth Anything/image_1.jpg", use_column_width=True)
|
| 317 |
+
st.markdown(""" """)
|
| 318 |
|
| 319 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 320 |
+
st.markdown(""" """)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 321 |
|
| 322 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 323 |
st.markdown(""" """)
|
| 324 |
|
| 325 |
st.image("pages/Depth Anything/image_2.jpg", use_column_width=True)
|
| 326 |
st.markdown(""" """)
|
| 327 |
|
| 328 |
+
st.markdown(translations[lang]["tweet_6"], unsafe_allow_html=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 329 |
st.markdown(""" """)
|
| 330 |
|
| 331 |
st.image("pages/Depth Anything/image_3.jpg", use_column_width=True)
|
| 332 |
st.markdown(""" """)
|
| 333 |
|
| 334 |
+
with st.expander ("Code"):
|
| 335 |
+
st.code("""
|
| 336 |
+
from transformers import pipeline
|
| 337 |
+
|
| 338 |
+
pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
|
| 339 |
+
depth = pipe(image)["depth"]
|
| 340 |
+
""")
|
| 341 |
|
| 342 |
|
| 343 |
+
st.markdown(""" """)
|
| 344 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 345 |
+
|
| 346 |
st.markdown(""" """)
|
| 347 |
st.markdown(""" """)
|
| 348 |
st.markdown(""" """)
|
| 349 |
+
col1, col2, col3= st.columns(3)
|
| 350 |
with col1:
|
| 351 |
+
if lang == "en":
|
| 352 |
+
if st.button('Previous paper', use_container_width=True):
|
| 353 |
+
switch_page("Backbone")
|
| 354 |
+
else:
|
| 355 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 356 |
+
switch_page("Backbone")
|
| 357 |
with col2:
|
| 358 |
+
if lang == "en":
|
| 359 |
+
if st.button("Home", use_container_width=True):
|
| 360 |
+
switch_page("Home")
|
| 361 |
+
else:
|
| 362 |
+
if st.button("Accueil", use_container_width=True):
|
| 363 |
+
switch_page("Home")
|
| 364 |
with col3:
|
| 365 |
+
if lang == "en":
|
| 366 |
+
if st.button("Next paper", use_container_width=True):
|
| 367 |
+
switch_page("UDOP")
|
| 368 |
+
else:
|
| 369 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 370 |
+
switch_page("UDOP")
|
pages/9_UDOP.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
translations = {
|
| 6 |
+
'en': {'title': 'UDOP',
|
| 7 |
+
'original_tweet':
|
| 8 |
+
"""
|
| 9 |
+
[Original tweet](https://x.com/mervenoyann/status/1767200350530859321) (March 11, 2024)
|
| 10 |
+
""",
|
| 11 |
+
'tweet_1':
|
| 12 |
+
"""
|
| 13 |
+
New foundation model on document understanding and generation in 🤗 Transformers 🤩
|
| 14 |
+
UDOP by Microsoft is a bleeding-edge model that is capable of many tasks, including question answering, document editing and more! 🤯
|
| 15 |
+
Check out the [demo](https://huggingface.co/spaces/merve/UDOP).
|
| 16 |
+
Technical details 🧶
|
| 17 |
+
""",
|
| 18 |
+
'tweet_2':
|
| 19 |
+
"""
|
| 20 |
+
UDOP is a model that combines vision, text and layout. 📝
|
| 21 |
+
This model is very interesting because the input representation truly captures the nature of the document modality: text, where the text is, and the layout of the document matters!
|
| 22 |
+
|
| 23 |
+
<br>
|
| 24 |
+
If you know T5, it resembles that: it's pre-trained on both self-supervised and supervised objectives over text, image and layout.
|
| 25 |
+
To switch between tasks, one simply needs to change the task specific prompt at the beginning, e.g. for QA, one prepends with Question answering.
|
| 26 |
+
""",
|
| 27 |
+
'tweet_3':
|
| 28 |
+
"""
|
| 29 |
+
As for the architecture, it's like T5, except it has a single encoder that takes in text, image and layout, and two decoders (text-layout and vision decoders) combined into one.
|
| 30 |
+
The vision decoder is a masked autoencoder (thus the capabilities of document editing).
|
| 31 |
+
""",
|
| 32 |
+
'tweet_4':
|
| 33 |
+
"""
|
| 34 |
+
For me, the most interesting capability is document reconstruction, document editing and layout re-arrangement (see below 👇)
|
| 35 |
+
This decoder isn't released though because it could be used maliciously to fake document editing.
|
| 36 |
+
""",
|
| 37 |
+
'tweet_5':
|
| 38 |
+
"""
|
| 39 |
+
Overall, the model performs very well on document understanding benchmark (DUE) and also information extraction (FUNSD, CORD) and classification (RVL-CDIP) for vision, text, layout modalities 👇
|
| 40 |
+
""",
|
| 41 |
+
'ressources':
|
| 42 |
+
"""
|
| 43 |
+
Resources:
|
| 44 |
+
[Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623)
|
| 45 |
+
by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal (2022)
|
| 46 |
+
[GitHub](https://github.com/microsoft/UDOP)
|
| 47 |
+
[Hugging Face models](https://huggingface.co/microsoft/udop-large)
|
| 48 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/en/model_doc/udop)
|
| 49 |
+
"""
|
| 50 |
+
},
|
| 51 |
+
'fr': {
|
| 52 |
+
'title': 'UDOP',
|
| 53 |
+
'original_tweet':
|
| 54 |
+
"""
|
| 55 |
+
[Tweet de base](https://x.com/mervenoyann/status/1767200350530859321) (en anglais) (11 mars 2024)
|
| 56 |
+
""",
|
| 57 |
+
'tweet_1':
|
| 58 |
+
"""
|
| 59 |
+
Un nouveau modèle de compréhension de documents et de génération est disponible dans 🤗 Transformers 🤩
|
| 60 |
+
UDOP de Microsoft est un modèle de pointe capable d'effectuer de nombreuses tâches, notamment répondre à des questions, éditer des documents et bien plus encore ! 🤯
|
| 61 |
+
Consultez la [démo](https://huggingface.co/spaces/merve/UDOP).
|
| 62 |
+
Détails techniques 🧶
|
| 63 |
+
""",
|
| 64 |
+
'tweet_2':
|
| 65 |
+
"""
|
| 66 |
+
UDOP est un modèle qui combine la vision, le texte et la mise en page. 📝
|
| 67 |
+
Ce modèle est très intéressant car la représentation en entrée capture véritablement la nature de la modalité du document : le texte, l'endroit où se trouve le texte et la mise en page du document comptent ! <br>
|
| 68 |
+
Si vous connaissez le T5, cela y ressemble : il est pré-entraîné sur des objectifs autosupervisés et supervisés sur le texte, l'image et la mise en page.
|
| 69 |
+
Pour passer d'une tâche à l'autre, il suffit de modifier le prompt spécifique à la tâche au début, par exemple, pour le QA, on ajoute "Question answering".
|
| 70 |
+
""",
|
| 71 |
+
'tweet_3':
|
| 72 |
+
"""
|
| 73 |
+
En ce qui concerne l'architecture, elle est similaire à celle du T5, à l'exception d'un seul encodeur qui prend en charge le texte, l'image et la mise en page, et de deux décodeurs (décodeur texte/mise en page et décodeur de vision) combinés en un seul.
|
| 74 |
+
Le décodeur de vision est un autoencodeur masqué (d'où les possibilités d'édition de documents).
|
| 75 |
+
""",
|
| 76 |
+
'tweet_4':
|
| 77 |
+
"""
|
| 78 |
+
Pour moi, la capacité la plus intéressante est la reconstruction de documents, l'édition de documents et le réarrangement de la mise en page (voir ci-dessous 👇).
|
| 79 |
+
Ce décodeur n'est pas publié car il pourrait être utilisé de manière malveillante pour falsifier l'édition d'un document.
|
| 80 |
+
""",
|
| 81 |
+
'tweet_5':
|
| 82 |
+
"""
|
| 83 |
+
Dans l'ensemble, le modèle est très performant pour la compréhension de documents (DUE) ainsi que pour l'extraction d'informations (FUNSD, CORD) et la classification (RVL-CDIP) pour les modalités de vision, de texte et de mise en page 👇 """,
|
| 84 |
+
'ressources':
|
| 85 |
+
"""
|
| 86 |
+
Resources :
|
| 87 |
+
[Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623)
|
| 88 |
+
de Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal (2022)
|
| 89 |
+
[GitHub](https://github.com/microsoft/UDOP)
|
| 90 |
+
[Modèles sur Hugging Face](https://huggingface.co/microsoft/udop-large)
|
| 91 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/en/model_doc/udop)
|
| 92 |
+
"""
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def language_selector():
|
| 98 |
+
languages = {'EN': '🇬🇧', 'FR': '🇫🇷'}
|
| 99 |
+
selected_lang = st.selectbox('', options=list(languages.keys()), format_func=lambda x: languages[x], key='lang_selector')
|
| 100 |
+
return 'en' if selected_lang == 'EN' else 'fr'
|
| 101 |
+
|
| 102 |
+
left_column, right_column = st.columns([5, 1])
|
| 103 |
+
|
| 104 |
+
# Add a selector to the right column
|
| 105 |
+
with right_column:
|
| 106 |
+
lang = language_selector()
|
| 107 |
+
|
| 108 |
+
# Add a title to the left column
|
| 109 |
+
with left_column:
|
| 110 |
+
st.title(translations[lang]["title"])
|
| 111 |
+
|
| 112 |
+
st.success(translations[lang]["original_tweet"], icon="ℹ️")
|
| 113 |
+
st.markdown(""" """)
|
| 114 |
+
|
| 115 |
+
st.markdown(translations[lang]["tweet_1"], unsafe_allow_html=True)
|
| 116 |
+
st.markdown(""" """)
|
| 117 |
+
|
| 118 |
+
st.image("pages/UDOP/image_1.jpg", use_column_width=True)
|
| 119 |
+
st.markdown(""" """)
|
| 120 |
+
|
| 121 |
+
st.markdown(translations[lang]["tweet_2"], unsafe_allow_html=True)
|
| 122 |
+
st.markdown(""" """)
|
| 123 |
+
|
| 124 |
+
st.image("pages/UDOP/image_2.jpg", use_column_width=True)
|
| 125 |
+
st.markdown(""" """)
|
| 126 |
+
|
| 127 |
+
st.markdown(translations[lang]["tweet_3"], unsafe_allow_html=True)
|
| 128 |
+
st.markdown(""" """)
|
| 129 |
+
|
| 130 |
+
st.image("pages/UDOP/image_3.jpg", use_column_width=True)
|
| 131 |
+
st.markdown(""" """)
|
| 132 |
+
|
| 133 |
+
st.markdown(translations[lang]["tweet_4"], unsafe_allow_html=True)
|
| 134 |
+
st.markdown(""" """)
|
| 135 |
+
|
| 136 |
+
st.image("pages/UDOP/image_4.jpg", use_column_width=True)
|
| 137 |
+
st.image("pages/UDOP/image_5.jpg", use_column_width=True)
|
| 138 |
+
st.markdown(""" """)
|
| 139 |
+
|
| 140 |
+
st.markdown(translations[lang]["tweet_5"], unsafe_allow_html=True)
|
| 141 |
+
st.markdown(""" """)
|
| 142 |
+
|
| 143 |
+
st.image("pages/UDOP/image_6.jpg", use_column_width=True)
|
| 144 |
+
st.markdown(""" """)
|
| 145 |
+
|
| 146 |
+
st.info(translations[lang]["ressources"], icon="📚")
|
| 147 |
+
|
| 148 |
+
st.markdown(""" """)
|
| 149 |
+
st.markdown(""" """)
|
| 150 |
+
st.markdown(""" """)
|
| 151 |
+
col1, col2, col3= st.columns(3)
|
| 152 |
+
with col1:
|
| 153 |
+
if lang == "en":
|
| 154 |
+
if st.button('Previous paper', use_container_width=True):
|
| 155 |
+
switch_page("Depth Anything")
|
| 156 |
+
else:
|
| 157 |
+
if st.button('Papier précédent', use_container_width=True):
|
| 158 |
+
switch_page("Depth Anything")
|
| 159 |
+
with col2:
|
| 160 |
+
if lang == "en":
|
| 161 |
+
if st.button("Home", use_container_width=True):
|
| 162 |
+
switch_page("Home")
|
| 163 |
+
else:
|
| 164 |
+
if st.button("Accueil", use_container_width=True):
|
| 165 |
+
switch_page("Home")
|
| 166 |
+
with col3:
|
| 167 |
+
if lang == "en":
|
| 168 |
+
if st.button("Next paper", use_container_width=True):
|
| 169 |
+
switch_page("LLaVA-NeXT")
|
| 170 |
+
else:
|
| 171 |
+
if st.button("Papier suivant", use_container_width=True):
|
| 172 |
+
switch_page("LLaVA-NeXT")
|
pages/Aria/image_0.png
ADDED

|
Git LFS Details
|
pages/Aria/image_1.png
ADDED

|
pages/Aria/image_2.png
ADDED

|
Git LFS Details
|
pages/Aria/image_3.png
ADDED

|
pages/Aria/image_4.png
ADDED

|
pages/Aria/video_1.mp4
ADDED
|
Binary file (655 kB). View file
|
|
|
pages/ColPali/image_1.jpg
ADDED
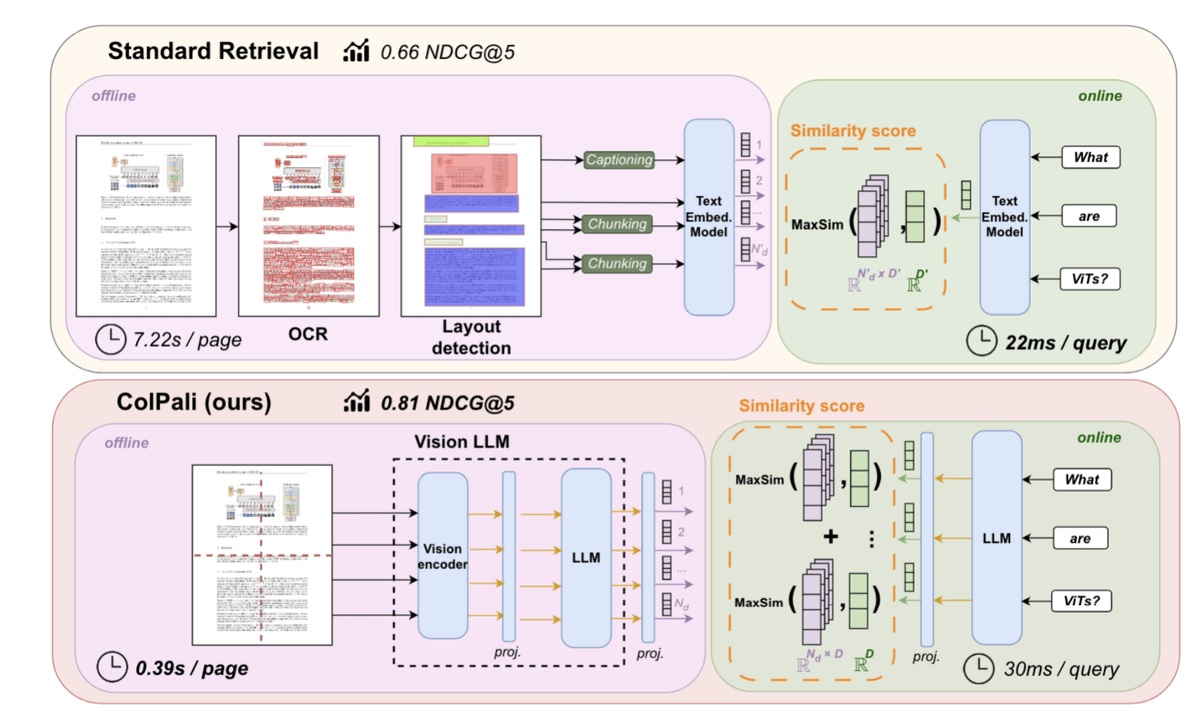
|
pages/ColPali/image_2.jpg
ADDED

|
pages/ColPali/image_3.jpg
ADDED
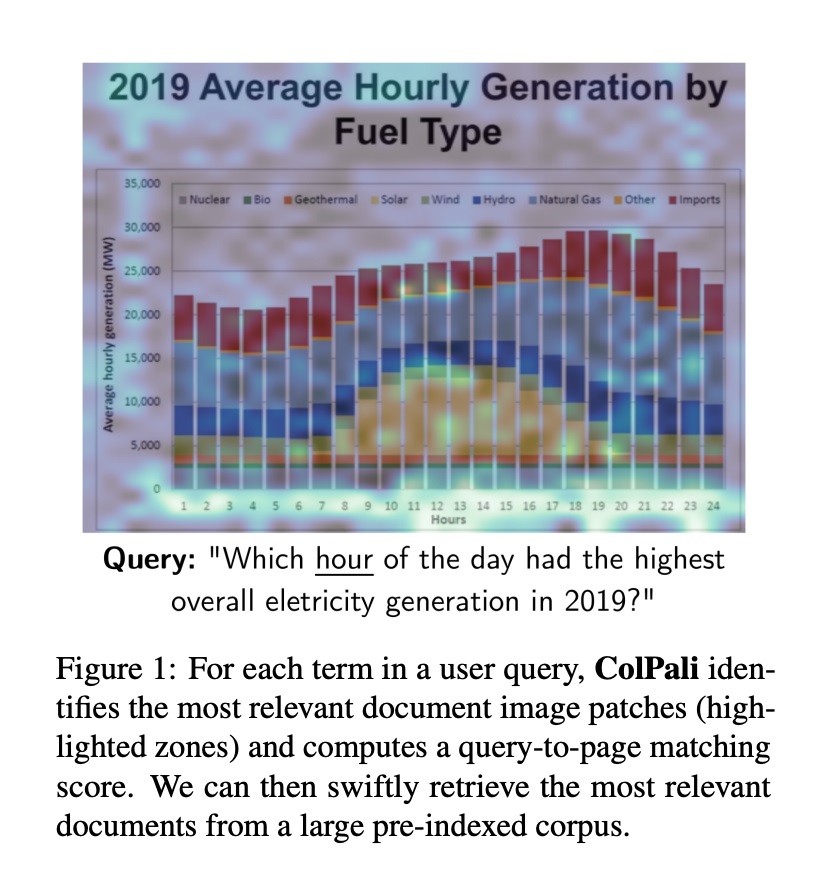
|
pages/ColPali/image_4.jpg
ADDED

|
pages/ColPali/image_5.jpg
ADDED

|
pages/GOT/image_1.png
ADDED

|
pages/GOT/image_2.png
ADDED
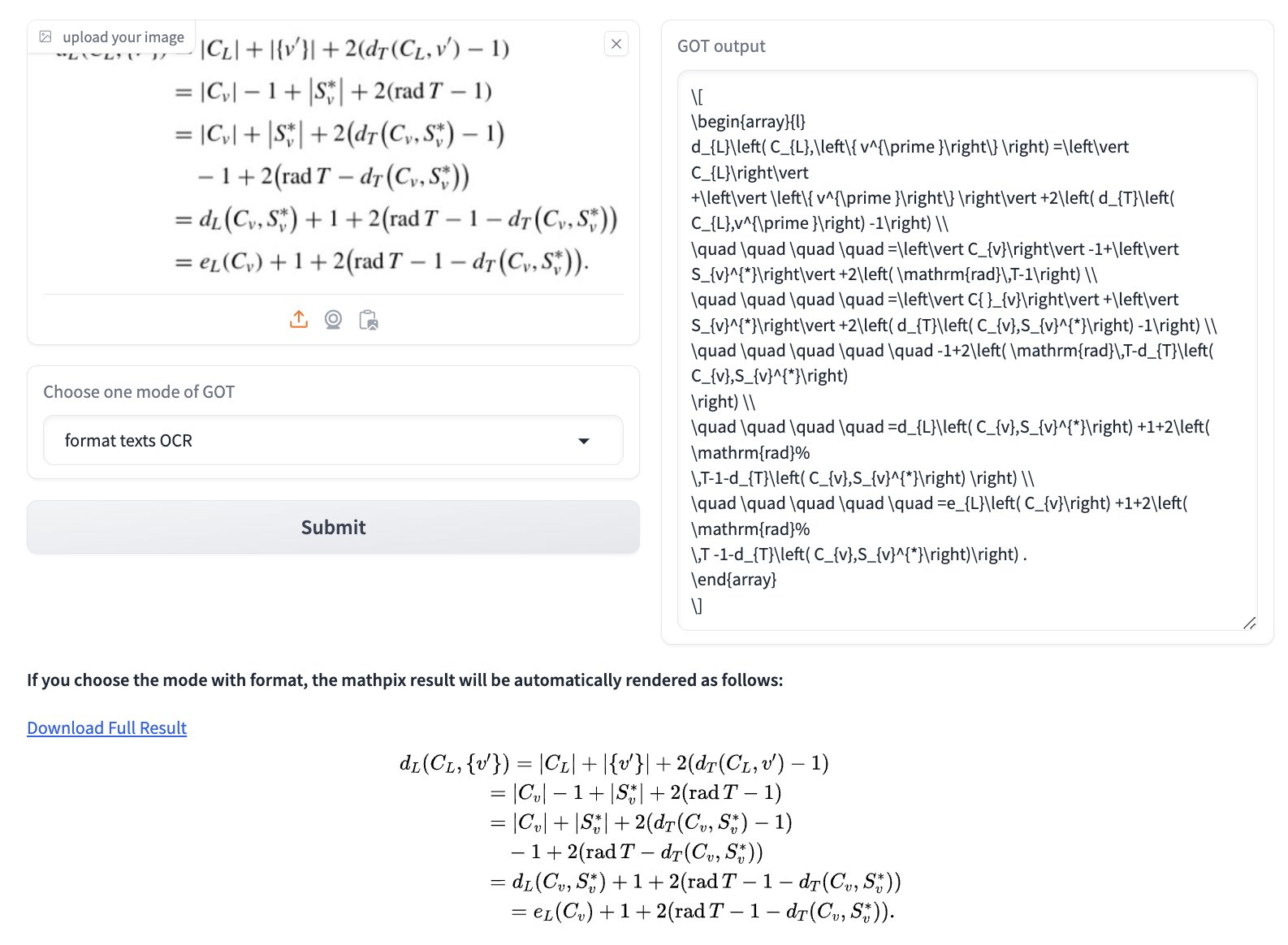
|
pages/GOT/image_3.png
ADDED
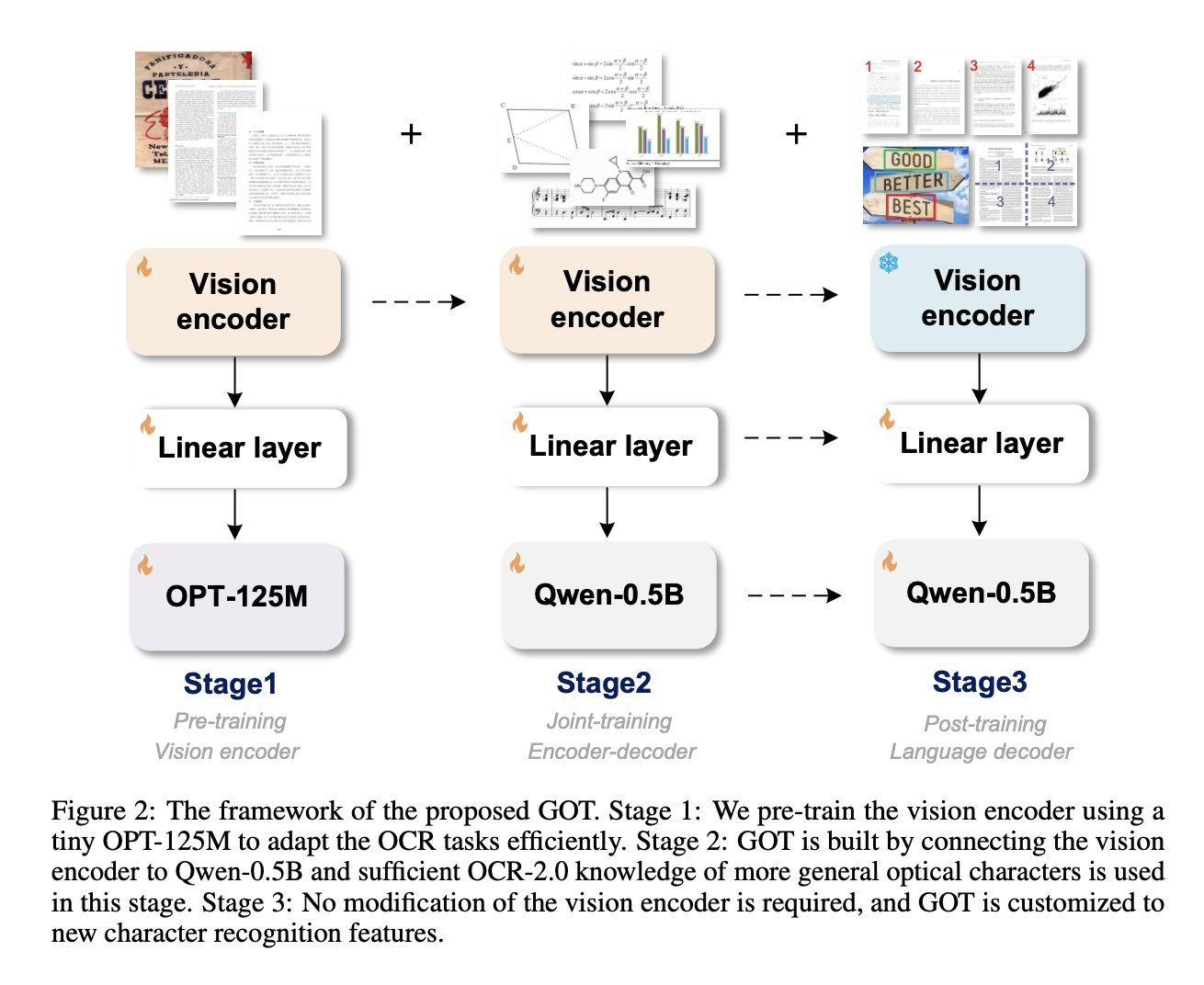
|