Spaces:
Runtime error

Model Architecture Summary
MMOCR has implemented many models that support various tasks. Depending on the type of tasks, these models have different architectural designs and, therefore, might be a bit confusing for beginners to master. We release a primary design doc to clearly illustrate the basic task-specific architectures and provide quick pointers to docstrings of model components to aid users' understanding.
Text Detection Models
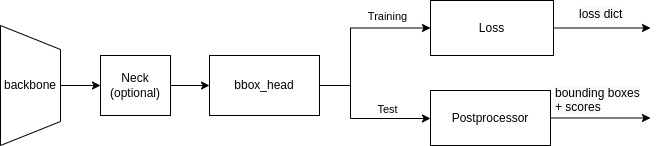
The design of text detectors is similar to SingleStageDetector in MMDetection. The feature of an image was first extracted by backbone (e.g., ResNet), and neck further processes raw features into a head-ready format, where the models in MMOCR usually adapt the variants of FPN to extract finer-grained multi-level features. bbox_head is the core of text detectors, and its implementation varies in different models.
When training, the output of bbox_head is directly fed into the loss module, which compares the output with the ground truth and generates a loss dictionary for optimizer's use. When testing, Postprocessor converts the outputs from bbox_head to bounding boxes, which will be used for evaluation metrics (e.g., hmean-iou) and visualization.
DBNet
- Backbone: mmdet.ResNet
- Neck: FPNC
- Bbox_head: DBHead
- Loss: DBLoss
- Postprocessor: DBPostprocessor
DRRG
- Backbone: mmdet.ResNet
- Neck: FPN_UNet
- Bbox_head: DRRGHead
- Loss: DRRGLoss
- Postprocessor: DRRGPostprocessor
FCENet
- Backbone: mmdet.ResNet
- Neck: mmdet.FPN
- Bbox_head: FCEHead
- Loss: FCELoss
- Postprocessor: FCEPostprocessor
Mask R-CNN
We use the same architecture as in MMDetection. See MMDetection's config documentation for details.
PANet
- Backbone: mmdet.ResNet
- Neck: FPEM_FFM
- Bbox_head: PANHead
- Loss: PANLoss
- Postprocessor: PANPostprocessor
PSENet
- Backbone: mmdet.ResNet
- Neck: FPNF
- Bbox_head: PSEHead
- Loss: PSELoss
- Postprocessor: PSEPostprocessor
Textsnake
- Backbone: mmdet.ResNet
- Neck: FPN_UNet
- Bbox_head: TextSnakeHead
- Loss: TextSnakeLoss
- Postprocessor: TextSnakePostprocessor
Text Recognition Models
Most of the implemented recognizers use the following architecture:
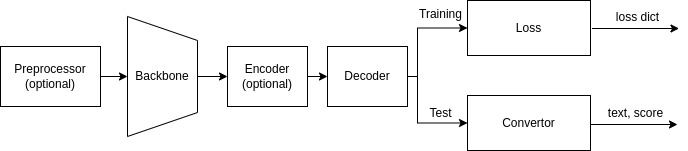
preprocessor refers to any network that processes images before they are fed to backbone. encoder encodes images features into a hidden vector, which is then transcribed into text tokens by decoder.
The architecture diverges at training and test phases. The loss module returns a dictionary during training. In testing, converter is invoked to convert raw features into texts, which are wrapped into a dictionary together with confidence scores. Users can access the dictionary with the text and score keys to query the recognition result.
ABINet
- Preprocessor: None
- Backbone: ResNetABI
- Encoder: ABIVisionModel
- Decoder: ABIVisionDecoder
- Fuser: ABIFuser
- Loss: ABILoss
- Converter: ABIConvertor
:::{note} Fuser fuses the feature output from encoder and decoder before generating the final text outputs and computing the loss in full ABINet. :::
CRNN
- Preprocessor: None
- Backbone: VeryDeepVgg
- Encoder: None
- Decoder: CRNNDecoder
- Loss: CTCLoss
- Converter: CTCConvertor
CRNN with TPS-based STN
- Preprocessor: TPSPreprocessor
- Backbone: VeryDeepVgg
- Encoder: None
- Decoder: CRNNDecoder
- Loss: CTCLoss
- Converter: CTCConvertor
NRTR
- Preprocessor: None
- Backbone: ResNet31OCR
- Encoder: NRTREncoder
- Decoder: NRTRDecoder
- Loss: TFLoss
- Converter: AttnConvertor
RobustScanner
- Preprocessor: None
- Backbone: ResNet31OCR
- Encoder: ChannelReductionEncoder
- Decoder: ChannelReductionEncoder
- Loss: SARLoss
- Converter: AttnConvertor
SAR
- Preprocessor: None
- Backbone: ResNet31OCR
- Encoder: SAREncoder
- Decoder: ParallelSARDecoder
- Loss: SARLoss
- Converter: AttnConvertor
SATRN
- Preprocessor: None
- Backbone: ShallowCNN
- Encoder: SatrnEncoder
- Decoder: NRTRDecoder
- Loss: TFLoss
- Converter: AttnConvertor
SegOCR
- Backbone: ResNet31OCR
- Neck: FPNOCR
- Head: SegHead
- Loss: SegLoss
- Converter: SegConvertor
:::{note} SegOCR's architecture is an exception - it is closer to text detection models. :::
Key Information Extraction Models

The architecture of key information extraction (KIE) models is similar to text detection models, except for the extra feature extractor. As a downstream task of OCR, KIE models are required to run with bounding box annotations indicating the locations of text instances, from which an ROI extractor extracts the cropped features for bbox_head to discover relations among them.
The output containing edges and nodes information from bbox_head is sufficient for test and inference. Computation of loss also relies on such information.
SDMGR
- Backbone: UNet
- Neck: None
- Extractor: mmdet.SingleRoIExtractor
- Bbox_head: SDMGRHead
- Loss: SDMGRLoss