Spaces:
Runtime error


Runtime error

A newer version of the Gradio SDK is available:
5.6.0
Amphion Text-to-Audio (TTA) Recipe
Quick Start
We provide a beginner recipe to demonstrate how to train a cutting edge TTA model. Specifically, it is designed as a latent diffusion model like AudioLDM, Make-an-Audio, and AUDIT.
Supported Model Architectures
Until now, Amphion has supported a latent diffusion based text-to-audio model:
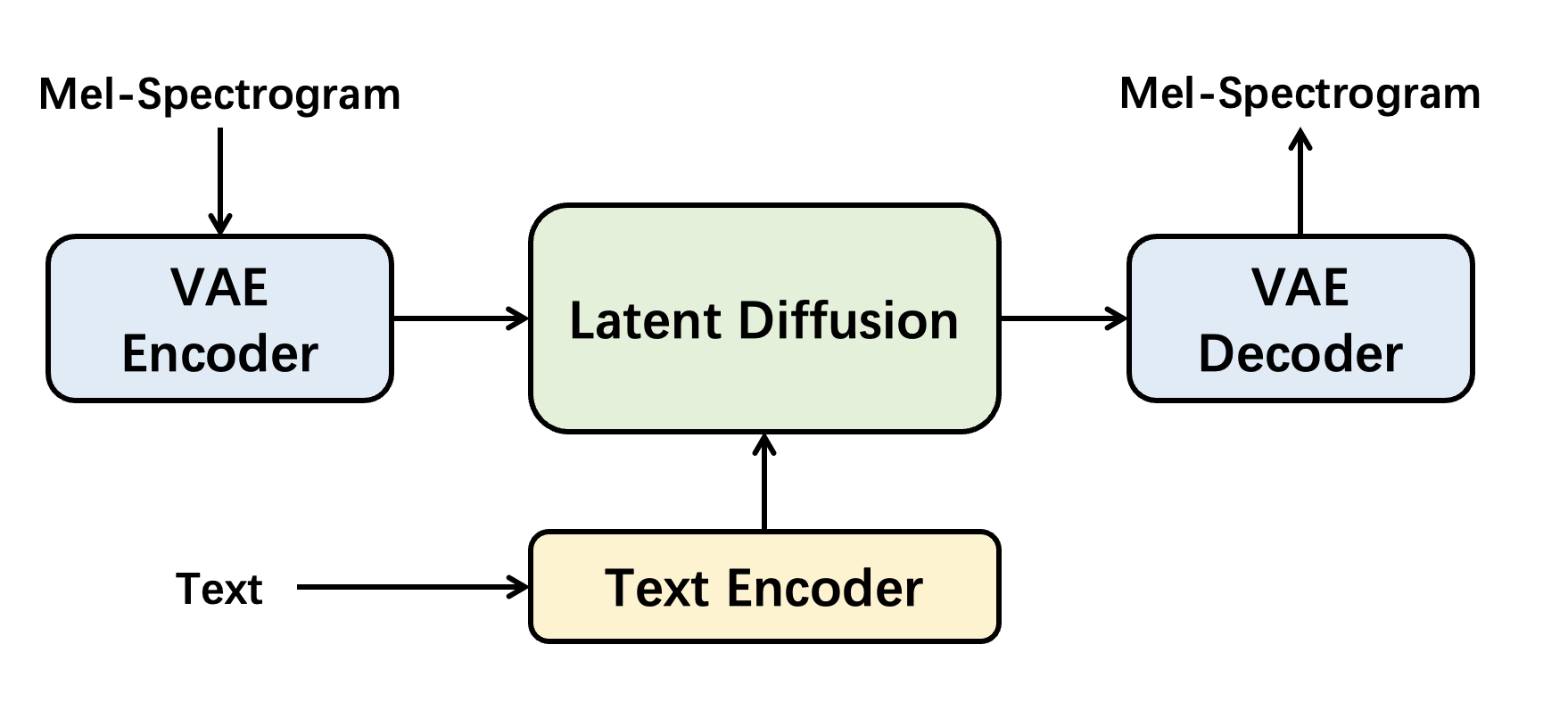
Similar to AUDIT, we implement it in two-stage training:
- Training the VAE which is called
AutoencoderKLin Amphion. - Training the conditional latent diffusion model which is called
AudioLDMin Amphion.