
A newer version of the Gradio SDK is available:
5.7.0
title: Qwen-VL
app_file: web_demo_mm.py
sdk: gradio
sdk_version: 3.40.1
![]()
Qwen-VL 🤖 | 🤗 | Qwen-VL-Chat 🤖 | 🤗 | Demo | Report | Discord
中文 | English
Qwen-VL (Qwen Large Vision Language Model) is the multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box. The features of Qwen-VL include:
- Strong performance: It significantly surpasses existing open-source Large Vision Language Models (LVLM) under similar model scale on multiple English evaluation benchmarks (including Zero-shot Captioning, VQA, DocVQA, and Grounding).
- Multi-lingual LVLM supporting text recognition: Qwen-VL naturally supports English, Chinese, and multi-lingual conversation, and it promotes end-to-end recognition of Chinese and English bi-lingual text in images.
- Multi-image interleaved conversations: This feature allows for the input and comparison of multiple images, as well as the ability to specify questions related to the images and engage in multi-image storytelling.
- First generalist model supporting grounding in Chinese: Detecting bounding boxes through open-domain language expression in both Chinese and English.
- Fine-grained recognition and understanding: Compared to the 224*224 resolution currently used by other open-source LVLM, the 448*448 resolution promotes fine-grained text recognition, document QA, and bounding box annotation.

We release two models of the Qwen-VL series:
- Qwen-VL: The pre-trained LVLM model uses Qwen-7B as the initialization of the LLM, and Openclip ViT-bigG as the initialization of the visual encoder. And connects them with a randomly initialized cross-attention layer.
- Qwen-VL-Chat: A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multiple image inputs, multi-round question answering, and creative capabilities.
Evaluation
We evaluated the model's abilities from two perspectives:
Standard Benchmarks: We evaluate the model's basic task capabilities on four major categories of multimodal tasks:
- Zero-shot Captioning: Evaluate model's zero-shot image captioning ability on unseen datasets;
- General VQA: Evaluate the general question-answering ability of pictures, such as the judgment, color, number, category, etc;
- Text-based VQA: Evaluate the model's ability to recognize text in pictures, such as document QA, chart QA, etc;
- Referring Expression Comprehension: Evaluate the ability to localize a target object in an image described by a referring expression.
TouchStone: To evaluate the overall text-image dialogue capability and alignment level with humans, we have constructed a benchmark called TouchStone, which is based on scoring with GPT4 to evaluate the LVLM model.
- The TouchStone benchmark covers a total of 300+ images, 800+ questions, and 27 categories. Such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc;
- In order to break the current limitation of GPT4 in terms of direct image input, TouchStone provides fine-grained image annotations by human labeling. These detailed annotations, along with the questions and the model's output, are then presented to GPT4 for scoring.
- The benchmark includes both English and Chinese versions.
The results of the evaluation are as follows:
Qwen-VL outperforms current SOTA generalist models on multiple VL tasks and has a more comprehensive coverage in terms of capability range.
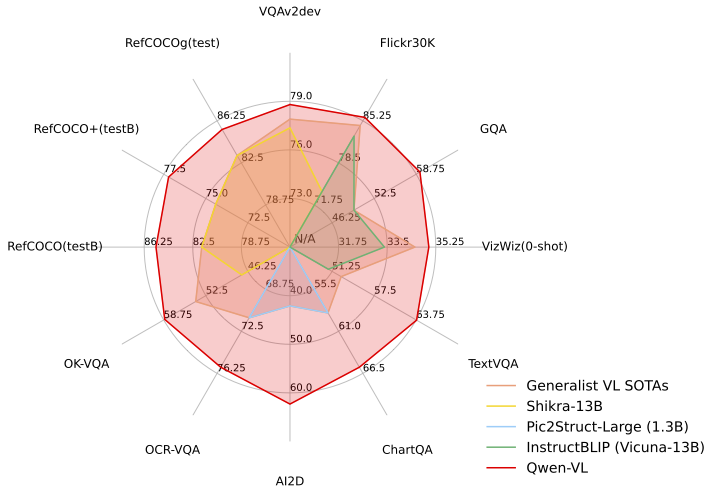
Zero-shot Captioning & General VQA
| Model type | Model | Zero-shot Captioning | General VQA | |||||
|---|---|---|---|---|---|---|---|---|
| NoCaps | Flickr30K | VQAv2dev | OK-VQA | GQA | SciQA-Img (0-shot) |
VizWiz (0-shot) |
||
| Generalist Models |
Flamingo-9B | - | 61.5 | 51.8 | 44.7 | - | - | 28.8 |
| Flamingo-80B | - | 67.2 | 56.3 | 50.6 | - | - | 31.6 | |
| Unified-IO-XL | 100.0 | - | 77.9 | 54.0 | - | - | - | |
| Kosmos-1 | - | 67.1 | 51.0 | - | - | - | 29.2 | |
| Kosmos-2 | - | 66.7 | 45.6 | - | - | - | - | |
| BLIP-2 (Vicuna-13B) | 103.9 | 71.6 | 65.0 | 45.9 | 32.3 | 61.0 | 19.6 | |
| InstructBLIP (Vicuna-13B) | 121.9 | 82.8 | - | - | 49.5 | 63.1 | 33.4 | |
| Shikra (Vicuna-13B) | - | 73.9 | 77.36 | 47.16 | - | - | - | |
| Qwen-VL (Qwen-7B) | 121.4 | 85.8 | 78.8 | 58.6 | 59.3 | 67.1 | 35.2 | |
| Qwen-VL-Chat | 120.2 | 81.0 | 78.2 | 56.6 | 57.5 | 68.2 | 38.9 | |
| Previous SOTA (Per Task Fine-tuning) |
- | 127.0 (PALI-17B) |
84.5 (InstructBLIP -FlanT5-XL) |
86.1 (PALI-X -55B) |
66.1 (PALI-X -55B) |
72.1 (CFR) |
92.53 (LLaVa+ GPT-4) |
70.9 (PALI-X -55B) |
- For zero-shot image captioning, Qwen-VL achieves the SOTA on Flickr30K and competitive results on Nocaps with InstructBlip.
- For general VQA, Qwen-VL achieves the SOTA under the same generalist LVLM scale settings.
Text-oriented VQA (focuse on text understanding capabilities in images)
| Model type | Model | TextVQA | DocVQA | ChartQA | AI2D | OCR-VQA |
|---|---|---|---|---|---|---|
| Generalist Models | BLIP-2 (Vicuna-13B) | 42.4 | - | - | - | - |
| InstructBLIP (Vicuna-13B) | 50.7 | - | - | - | - | |
| mPLUG-DocOwl (LLaMA-7B) | 52.6 | 62.2 | 57.4 | - | - | |
| Pic2Struct-Large (1.3B) | - | 76.6 | 58.6 | 42.1 | 71.3 | |
| Qwen-VL (Qwen-7B) | 63.8 | 65.1 | 65.7 | 62.3 | 75.7 | |
| Specialist SOTAs (Specialist/Finetuned) |
PALI-X-55B (Single-task FT) (Without OCR Pipeline) |
71.44 | 80.0 | 70.0 | 81.2 | 75.0 |
- In text-related recognition/QA evaluation, Qwen-VL achieves the SOTA under the generalist LVLM scale settings.
- Resolution is important for several above evaluations. While most open-source LVLM models with 224 resolution are incapable of these evaluations or can only solve these by cutting images, Qwen-VL scales the resolution to 448 so that it can be evaluated end-to-end. Qwen-VL even outperforms Pic2Struct-Large models of 1024 resolution on some tasks.
Referring Expression Comprehension
| Model type | Model | RefCOCO | RefCOCO+ | RefCOCOg | GRIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| val | test-A | test-B | val | test-A | test-B | val-u | test-u | refexp | ||
| Generalist Models | GPV-2 | - | - | - | - | - | - | - | - | 51.50 |
| OFA-L* | 79.96 | 83.67 | 76.39 | 68.29 | 76.00 | 61.75 | 67.57 | 67.58 | 61.70 | |
| Unified-IO | - | - | - | - | - | - | - | - | 78.61 | |
| VisionLLM-H | 86.70 | - | - | - | - | - | - | - | ||
| Shikra-7B | 87.01 | 90.61 | 80.24 | 81.60 | 87.36 | 72.12 | 82.27 | 82.19 | 69.34 | |
| Shikra-13B | 87.83 | 91.11 | 81.81 | 82.89 | 87.79 | 74.41 | 82.64 | 83.16 | 69.03 | |
| Qwen-VL-7B | 89.36 | 92.26 | 85.34 | 83.12 | 88.25 | 77.21 | 85.58 | 85.48 | 78.22 | |
| Qwen-VL-7B-Chat | 88.55 | 92.27 | 84.51 | 82.82 | 88.59 | 76.79 | 85.96 | 86.32 | - | |
| Specialist SOTAs (Specialist/Finetuned) |
G-DINO-L | 90.56 | 93.19 | 88.24 | 82.75 | 88.95 | 75.92 | 86.13 | 87.02 | - |
| UNINEXT-H | 92.64 | 94.33 | 91.46 | 85.24 | 89.63 | 79.79 | 88.73 | 89.37 | - | |
| ONE-PEACE | 92.58 | 94.18 | 89.26 | 88.77 | 92.21 | 83.23 | 89.22 | 89.27 | - | |
- Qwen-VL achieves the SOTA in all above referring expression comprehension benchmarks.
- Qwen-VL has not been trained on any Chinese grounding data, but it can still generalize to the Chinese Grounding tasks in a zero-shot way by training Chinese Caption data and English Grounding data.
We provide all of the above evaluation scripts for reproducing our experimental results. Please read eval_mm/EVALUATION.md for more information.
Chat evaluation
TouchStone is a benchmark based on scoring with GPT4 to evaluate the abilities of the LVLM model on text-image dialogue and alignment levels with humans. It covers a total of 300+ images, 800+ questions, and 27 categories, such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc. Please read touchstone/README.md for more information.
English evaluation
| Model | Score |
|---|---|
| PandaGPT | 488.5 |
| MiniGPT4 | 531.7 |
| InstructBLIP | 552.4 |
| LLaMA-AdapterV2 | 590.1 |
| mPLUG-Owl | 605.4 |
| LLaVA | 602.7 |
| Qwen-VL-Chat | 645.2 |
Chinese evaluation
| Model | Score |
|---|---|
| VisualGLM | 247.1 |
| Qwen-VL-Chat | 401.2 |
Qwen-VL-Chat has achieved the best results in both Chinese and English alignment evaluation.
Requirements
- python 3.8 and above
- pytorch 1.12 and above, 2.0 and above are recommended
- CUDA 11.4 and above are recommended (this is for GPU users)
Quickstart
Below, we provide simple examples to show how to use Qwen-VL and Qwen-VL-Chat with 🤖 ModelScope and 🤗 Transformers.
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
pip install -r requirements.txt
Now you can start with ModelScope or Transformers. More usage aboue vision encoder, please refer to the tutorial.
🤗 Transformers
To use Qwen-VL-Chat for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, please make sure that you are using the latest code.
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
# 2st dialogue turn
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# <ref>击掌</ref><box>(536,509),(588,602)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('1.jpg')
else:
print("no box")

Running Qwen-VL
Running Qwen-VL pretrained base model is also simple.
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': 'Generate the caption in English with grounding:'},
])
inputs = tokenizer(query, return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
print(response)
# <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>Generate the caption in English with grounding:<ref> Woman</ref><box>(451,379),(731,806)</box> and<ref> her dog</ref><box>(219,424),(576,896)</box> playing on the beach<|endoftext|>
image = tokenizer.draw_bbox_on_latest_picture(response)
if image:
image.save('2.jpg')
else:
print("no box")

🤖 ModelScope
ModelScope is an opensource platform for Model-as-a-Service (MaaS), which provides flexible and cost-effective model service to AI developers. Similarly, you can run the models with ModelScope as shown below:
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
if not hasattr(tokenizer, 'model_dir'):
tokenizer.model_dir = model_dir
# use bf16
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# use auto
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 1st dialogue turn
# Either a local path or an url between <img></img> tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'<img>{image_path}</img>这是什么', history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
# 2st dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# <ref>"击掌"</ref><box>(211,412),(577,891)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('output_chat.jpg')
else:
print("no box")
Demo
Web UI
We provide code for users to build a web UI demo. Before you start, make sure you install the following packages:
pip install -r requirements_web_demo.txt
Then run the command below and click on the generated link:
python web_demo_mm.py
FAQ
If you meet problems, please refer to FAQ and the issues first to search a solution before you launch a new issue.
License Agreement
Researchers and developers are free to use the codes and model weights of both Qwen-VL and Qwen-VL-Chat. We also allow their commercial use. Check our license at LICENSE for more details.
Contact Us
If you are interested to leave a message to either our research team or product team, feel free to send an email to [email protected].