
meta-llama/Llama-3.2-11B-Vision-Instruct
Image-Text-to-Text
•
Updated
•
2.39M
•
•
962
Image-text-to-text models take in an image and text prompt and output text. These models are also called vision-language models, or VLMs. The difference from image-to-text models is that these models take an additional text input, not restricting the model to certain use cases like image captioning, and may also be trained to accept a conversation as input.

Describe the position of the bee in detail.
The bee is sitting on a pink flower, surrounded by other flowers. The bee is positioned in the center of the flower, with its head and front legs sticking out.
Vision language models come in three types:
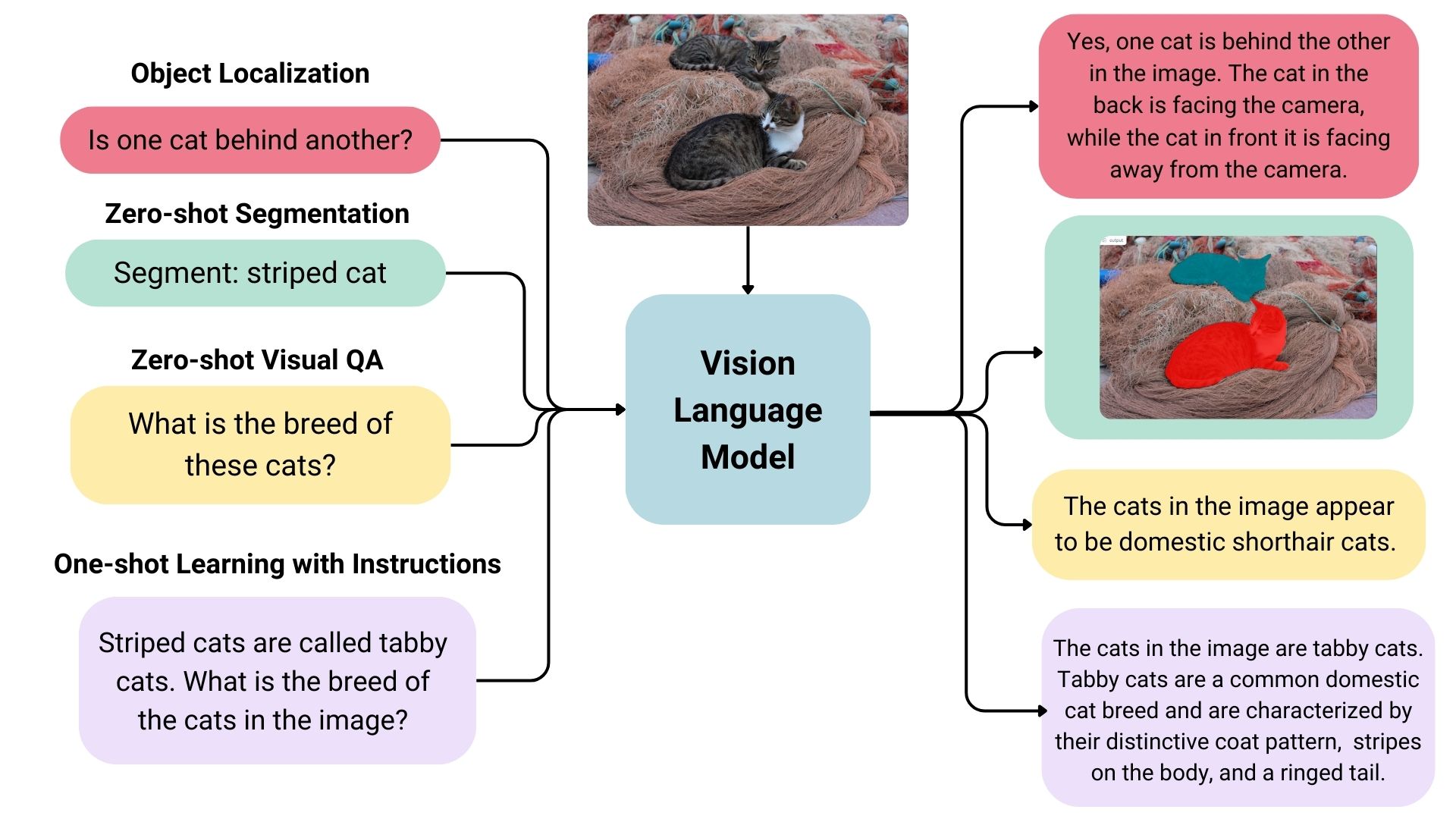
Vision language models can be used as multimodal assistants, keeping context about the conversation and keeping the image to have multiple-turn dialogues.
Some vision language models can detect or segment a set of objects or describe the positions or relative positions of the objects. For example, one could prompt such a model to ask if one object is behind another. Such a model can also output bounding box coordination or segmentation masks directly in the text output, unlike the traditional models explicitly trained on only object detection or image segmentation.
Vision language models trained on image-text pairs can be used for visual question answering and generating captions for images.
Documents often consist of different layouts, charts, tables, images, and more. Vision language models trained on formatted documents can extract information from them. This is an OCR-free approach; the inputs skip OCR, and documents are directly fed to vision language models.
Vision language models can recognize images through descriptions. When given detailed descriptions of specific entities, it can classify the entities in an image.
You can use the Transformers library to interact with vision-language models. You can load the model like below.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16
)
model.to(device)
We can infer by passing image and text dialogues.
from PIL import Image
import requests
# image of a radar chart
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
inputs = processor(prompt, image, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=100)
print(processor.decode(output[0], skip_special_tokens=True))
# The image appears to be a radar chart, which is a type of multivariate chart that displays values for multiple variables represented on axes
# starting from the same point. This particular radar chart is showing the performance of different models or systems across various metrics.
# The axes represent different metrics or benchmarks, such as MM-Vet, MM-Vet, MM-Vet, MM-Vet, MM-Vet, MM-V
Note Powerful vision language model with great visual understanding and reasoning capabilities.
Note Cutting-edge vision language models.
Note Small yet powerful model.
Note Strong image-text-to-text model.
Note Strong image-text-to-text model.
Note Strong image-text-to-text model focused on documents.
Note Instructions composed of image and text.
Note Conversation turns where questions involve image and text.
Note A collection of datasets made for model fine-tuning.
Note Screenshots of websites with their HTML/CSS codes.
Note Leaderboard to evaluate vision language models.
Note Vision language models arena, where models are ranked by votes of users.
Note Powerful vision-language model assistant.
Note An image-text-to-text application focused on documents.
Note An application to compare outputs of different vision language models.
Note An application for chatting with an image-text-to-text model.
No example metric is defined for this task.
Note Contribute by proposing a metric for this task !




