
metadata
thumbnail: https://motionbert.github.io/assets/teaser.gif
tags:
- 3D Human Pose Estimation
- Skeleton-based Action Recognition
- Mesh Recovery
arxiv: '2210.06551'
MotionBERT
This is the official PyTorch implementation of the paper "Learning Human Motion Representations: A Unified Perspective".
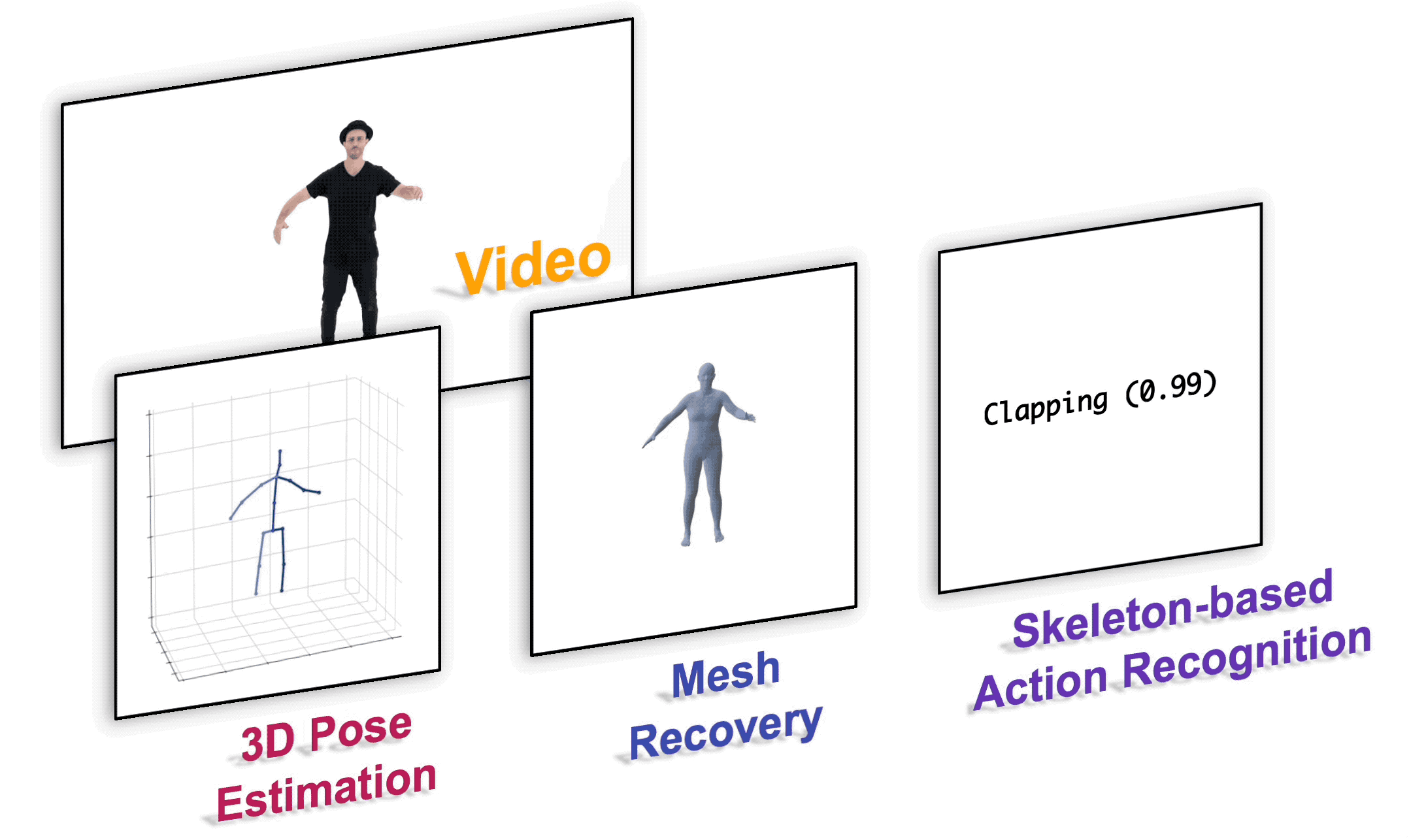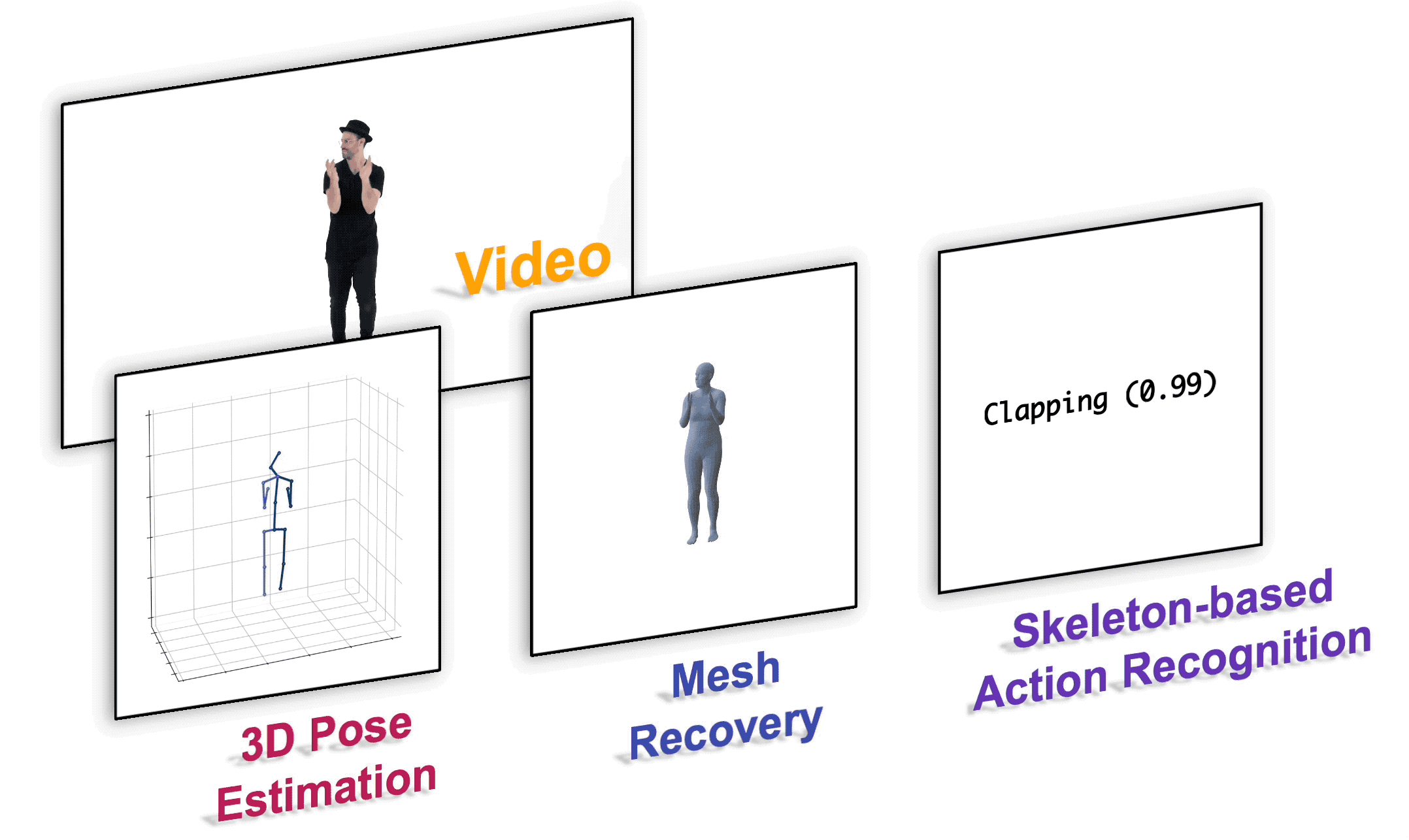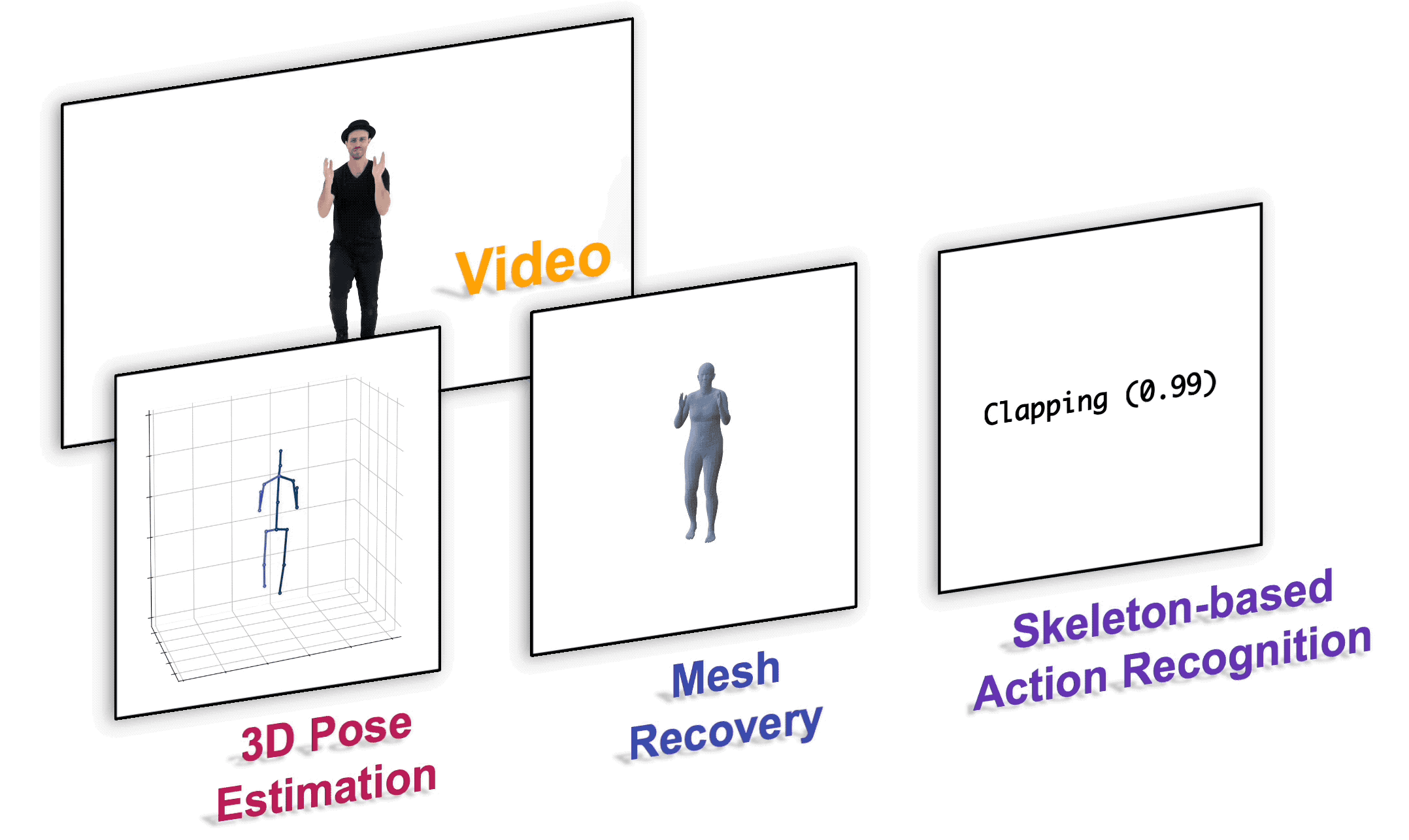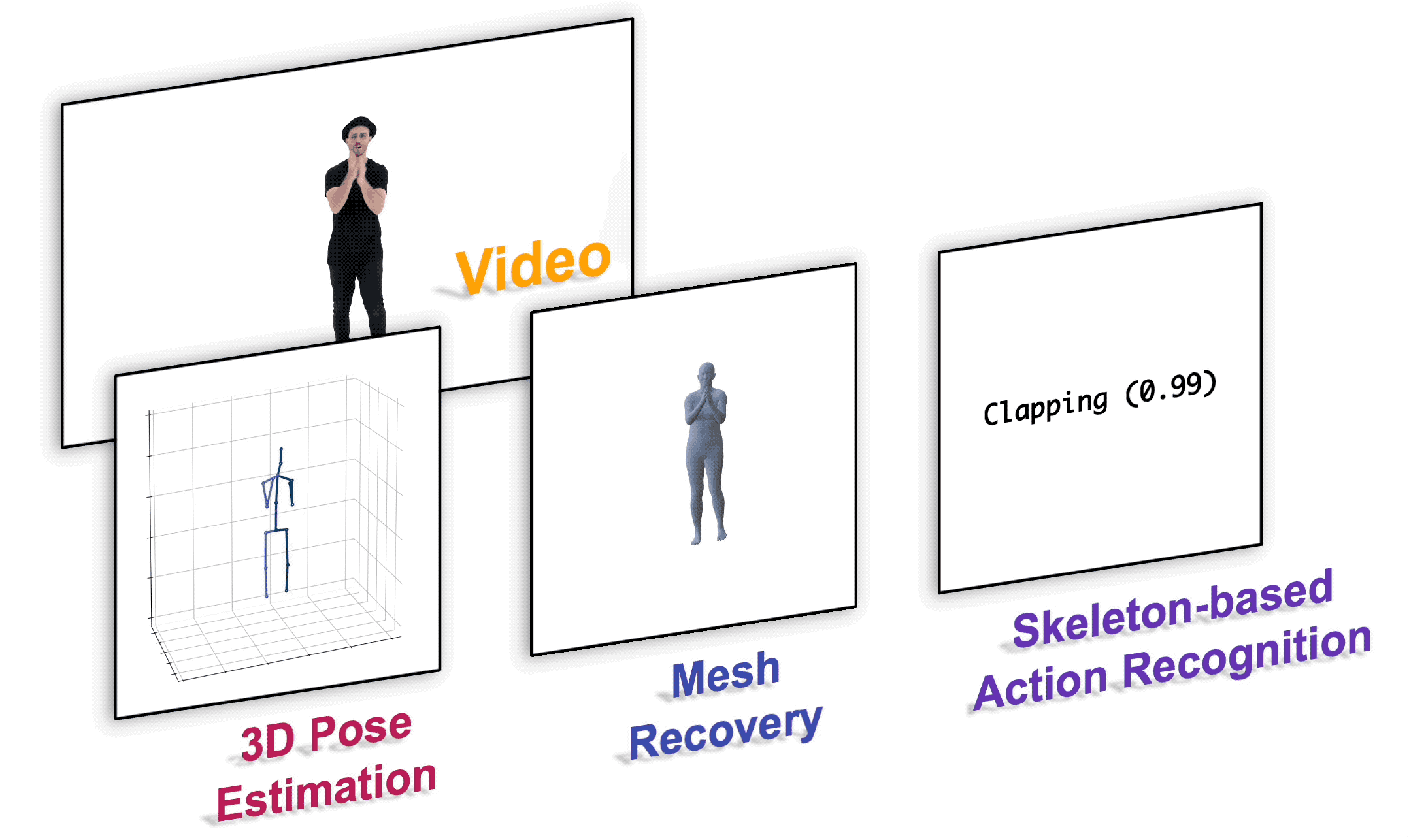
Installation
conda create -n motionbert python=3.7 anaconda
conda activate motionbert
# Please install PyTorch according to your CUDA version.
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
pip install -r requirements.txt
Getting Started
| Task | Document |
|---|---|
| Pretrain | docs/pretrain.md |
| 3D human pose estimation | docs/pose3d.md |
| Skeleton-based action recognition | docs/action.md |
| Mesh recovery | docs/mesh.md |
Applications
In-the-wild inference (for custom videos)
Please refer to docs/inference.md.
Using MotionBERT for human-centric video representations
'''
x: 2D skeletons
type = <class 'torch.Tensor'>
shape = [batch size * frames * joints(17) * channels(3)]
MotionBERT: pretrained human motion encoder
type = <class 'lib.model.DSTformer.DSTformer'>
E: encoded motion representation
type = <class 'torch.Tensor'>
shape = [batch size * frames * joints(17) * channels(512)]
'''
E = MotionBERT.get_representation(x)
Hints
- The model could handle different input lengths (no more than 243 frames). No need to explicitly specify the input length elsewhere.
- The model uses 17 body keypoints (H36M format). If you are using other formats, please convert them before feeding to MotionBERT.
- Please refer to model_action.py and model_mesh.py for examples of (easily) adapting MotionBERT to different downstream tasks.
- For RGB videos, you need to extract 2D poses (inference.md), convert the keypoint format (dataset_wild.py), and then feed to MotionBERT (infer_wild.py).
Model Zoo
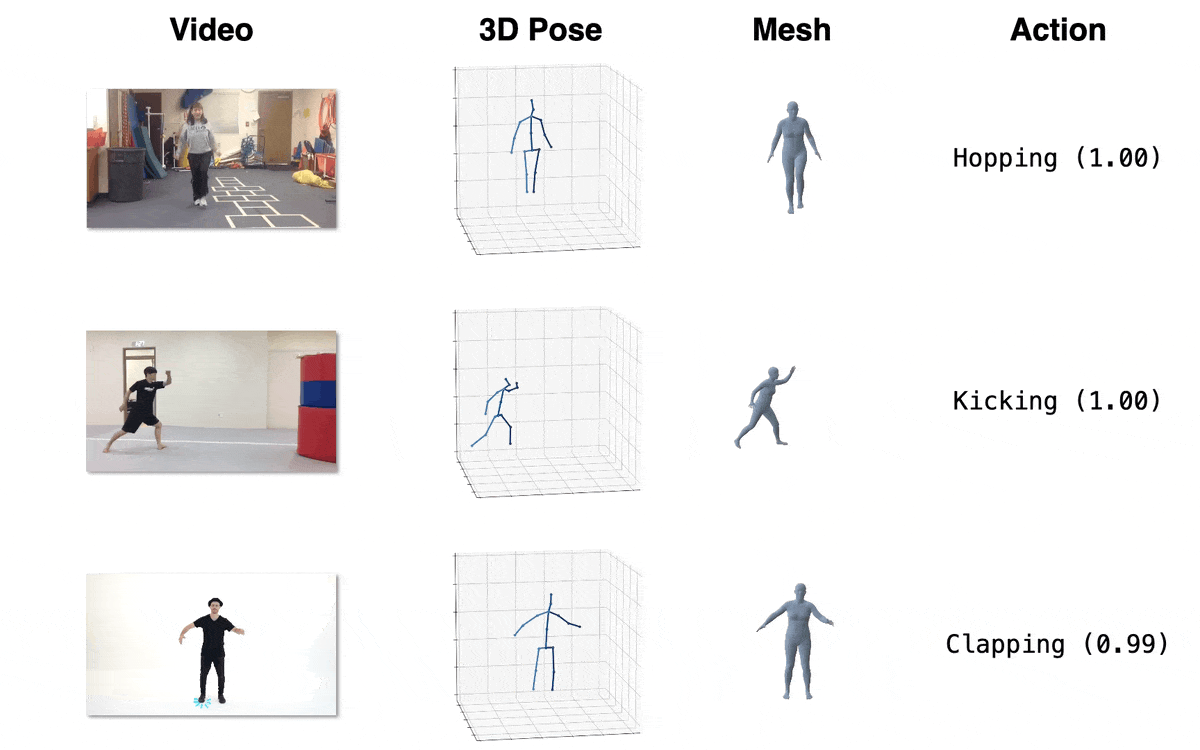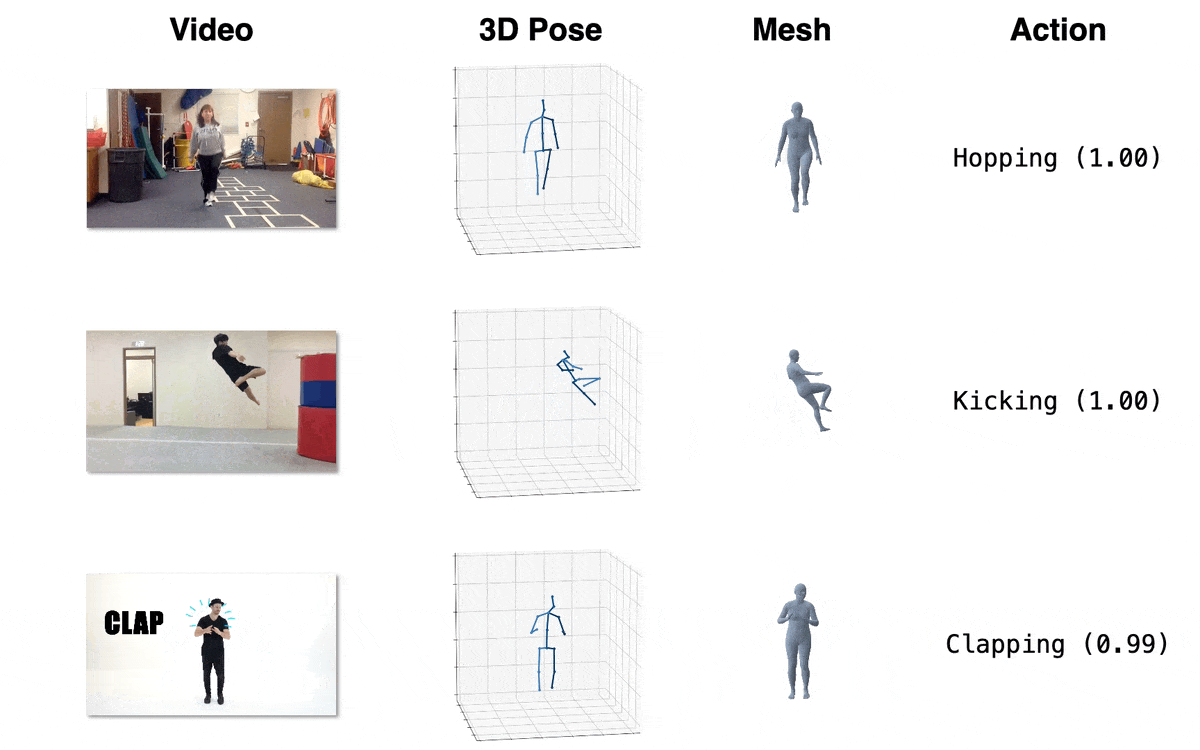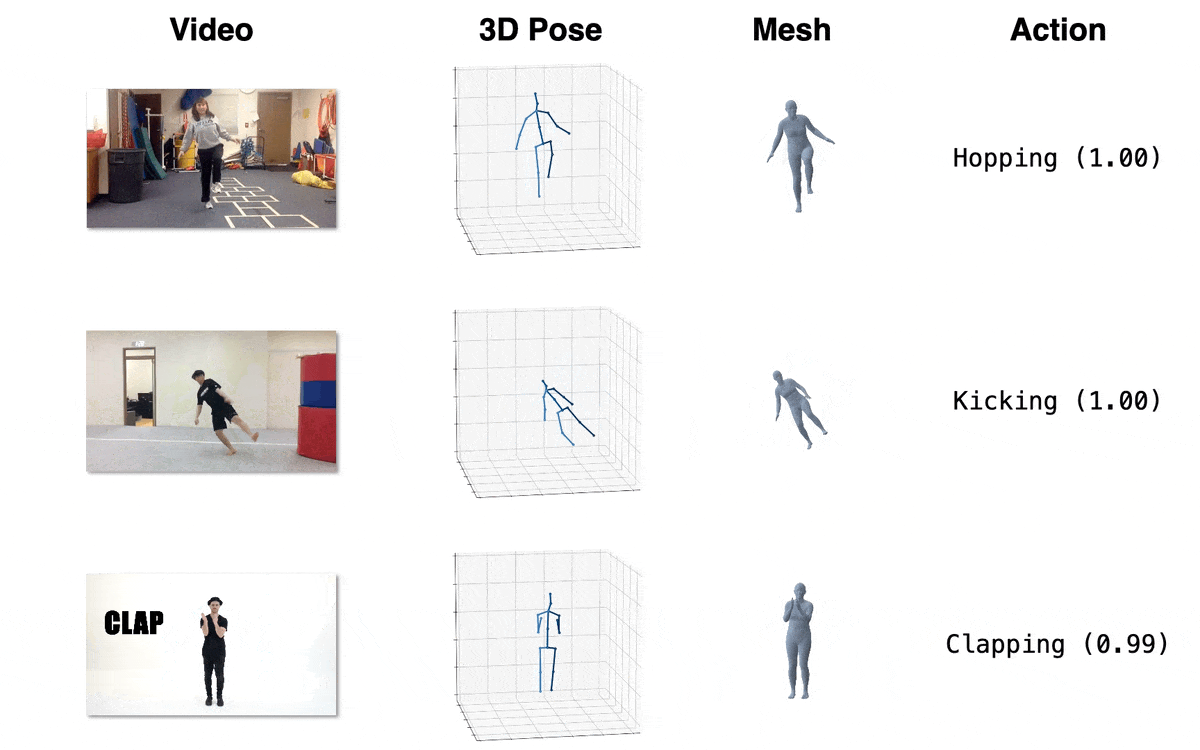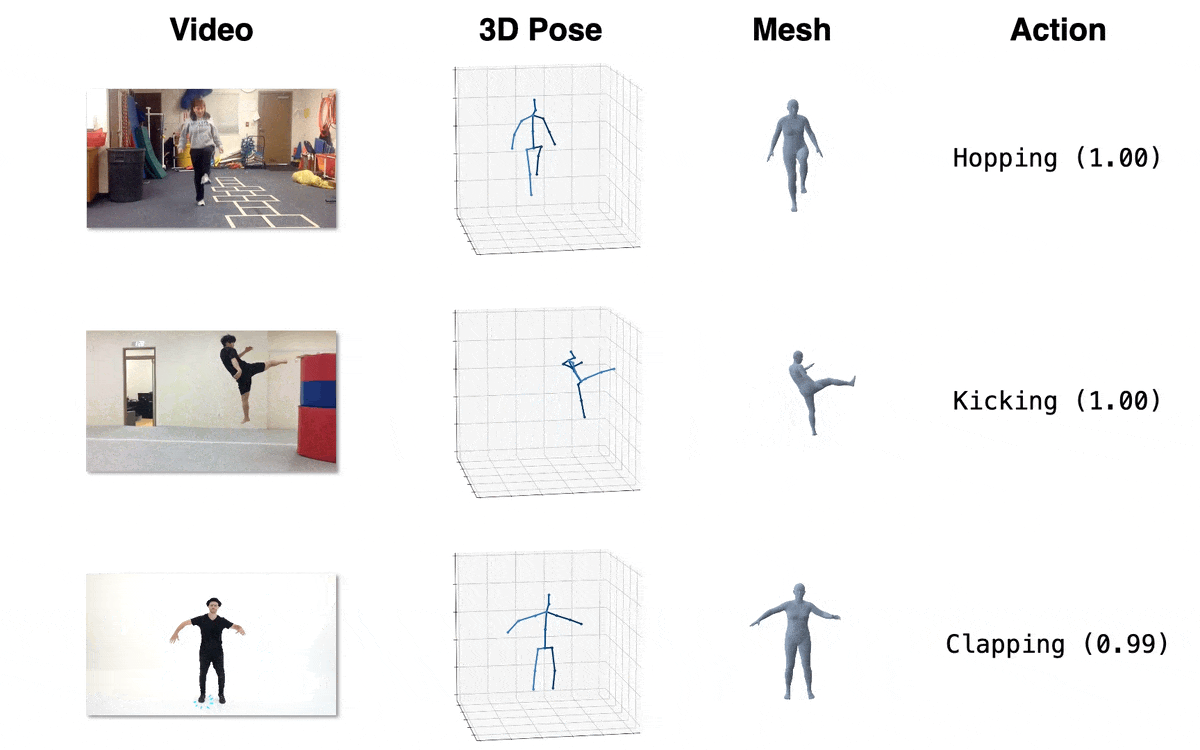
| Model | Download Link | Config | Performance |
|---|---|---|---|
| MotionBERT (162MB) | HuggingFace | pretrain/MB_pretrain.yaml | - |
| MotionBERT-Lite (61MB) | HuggingFace | pretrain/MB_lite.yaml | - |
| 3D Pose (H36M-SH, scratch) | HuggingFace | pose3d/MB_train_h36m.yaml | 39.2mm (MPJPE) |
| 3D Pose (H36M-SH, ft) | HuggingFace | pose3d/MB_ft_h36m.yaml | 37.2mm (MPJPE) |
| Action Recognition (x-sub, ft) | HuggingFace | action/MB_ft_NTU60_xsub.yaml | 97.2% (Top1 Acc) |
| Action Recognition (x-view, ft) | HuggingFace | action/MB_ft_NTU60_xview.yaml | 93.0% (Top1 Acc) |
| Mesh (with 3DPW, ft) | HuggingFace | mesh/MB_ft_pw3d.yaml | 88.1mm (MPVE) |
In most use cases (especially with finetuning), MotionBERT-Lite gives a similar performance with lower computation overhead.
TODO
Scripts and docs for pretraining
Demo for custom videos
Citation
If you find our work useful for your project, please consider citing the paper:
@article{motionbert2022,
title = {Learning Human Motion Representations: A Unified Perspective},
author = {Zhu, Wentao and Ma, Xiaoxuan and Liu, Zhaoyang and Liu, Libin and Wu, Wayne and Wang, Yizhou},
year = {2022},
journal = {arXiv preprint arXiv:2210.06551},
}