
体验
🚀 点击链接,即可体验🔗 http://101.68.79.42:7861/
介绍
- ✅ 对
bloom-7b模型做了sft - 🚀 训练代码和推理代码全部分享,可以查看链接https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chinese_bloom
🚀更新
| 模型链接 | 训练的数据量 | 模型版本 | 备注 |
|---|---|---|---|
| https://huggingface.co/yuanzhoulvpi/chinese_bloom_7b_chat | 15w中文指令数据 | v1 | |
| https://huggingface.co/yuanzhoulvpi/chinese_bloom_7b_chat_v2 | 150w条中文指令数据 | v2 | 目前已经测试过效果,相较于v1,效果有所提升 |
| https://huggingface.co/yuanzhoulvpi/chinese_bloom_7b_chat_v3 | 420w条中文指令数据 | v3 | 目前效果还没测试,欢迎大家测试 |
个人感受
- 🎯
bloom系列的模型,在中文领域,具有极大的潜力,在经过有监督微调训练之后,效果非常惊人! - 🔄
bloom系列的模型,覆盖中文、英文、代码、法语、西班牙语等。即使拿来做翻译、拿来做代码生成,也都没问题!(后期将会分享相关教程) - 😛 当前的这个
bloom-7b模型,我是非常喜欢滴,特地在8xA100机器上训练了部分数据。整体效果非常不错~
如何使用
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "yuanzhoulvpi/chinese_bloom_7b_chat"#"bigscience/bloomz-3b" #"bigscience/bloom-7b1"# "output_dir/checkpoint-8260"#
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).half().cuda()
PROMPT_DICT = {
"prompt_input": (
"Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:"
),
"prompt_no_input": (
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:"
),
}
from typing import Optional
def generate_input(instruction:Optional[str]= None, input_str:Optional[str] = None) -> str:
if input_str is None:
return PROMPT_DICT['prompt_no_input'].format_map({'instruction':instruction})
else:
return PROMPT_DICT['prompt_input'].format_map({'instruction':instruction, 'input':input_str})
for i in range(5):
print("*"*80)
inputs = tokenizer.encode(generate_input(instruction="你是谁"), return_tensors="pt")
outputs = model.generate(inputs,num_beams=3,
max_new_tokens=512,
do_sample=False,
top_k=10,
penalty_alpha=0.6,
temperature=0.8,
repetition_penalty=1.2)
print(tokenizer.decode(outputs[0]))
效果
不管是写代码还是写文案,bloom-7b在中文领域有极大的潜力
- example 1
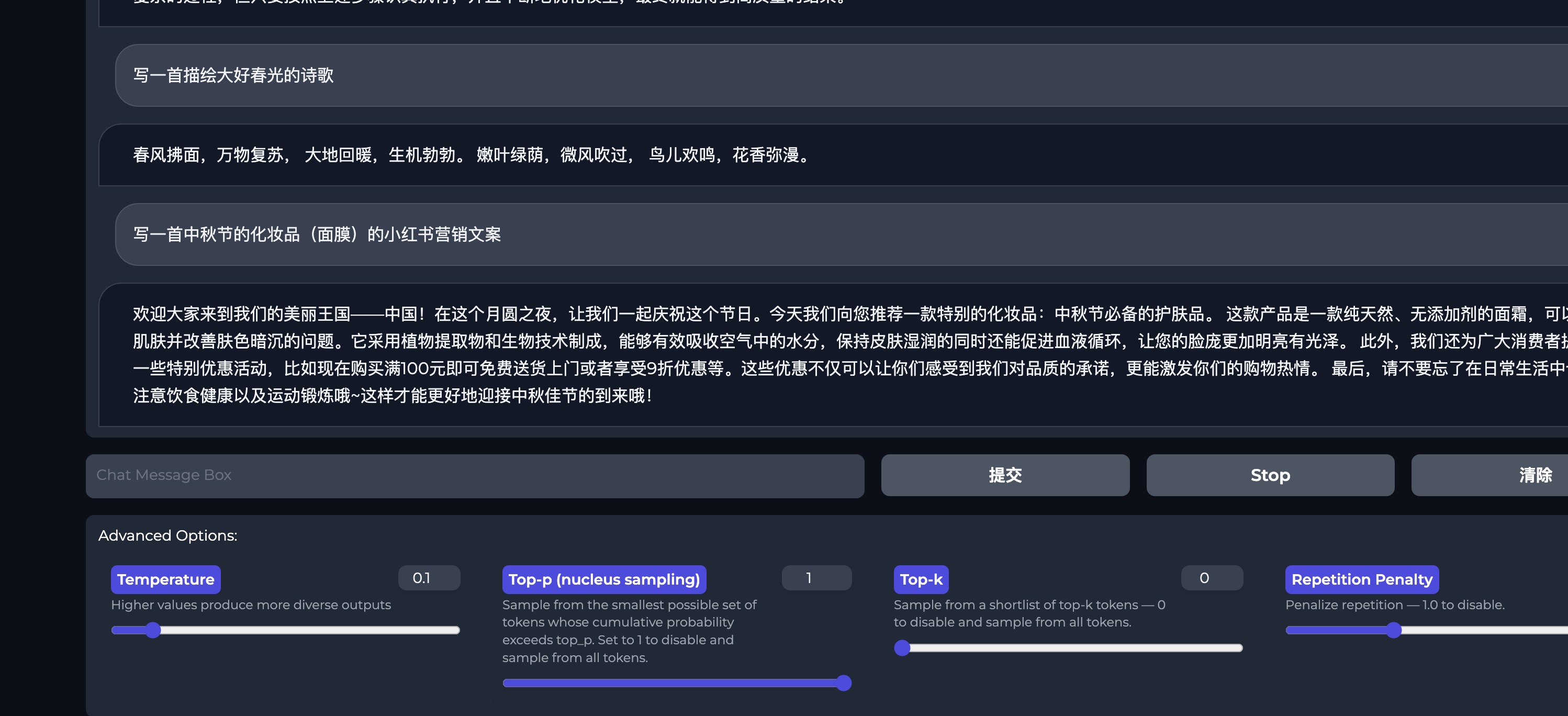
- example 2

- example 3


- example 4

- example 5
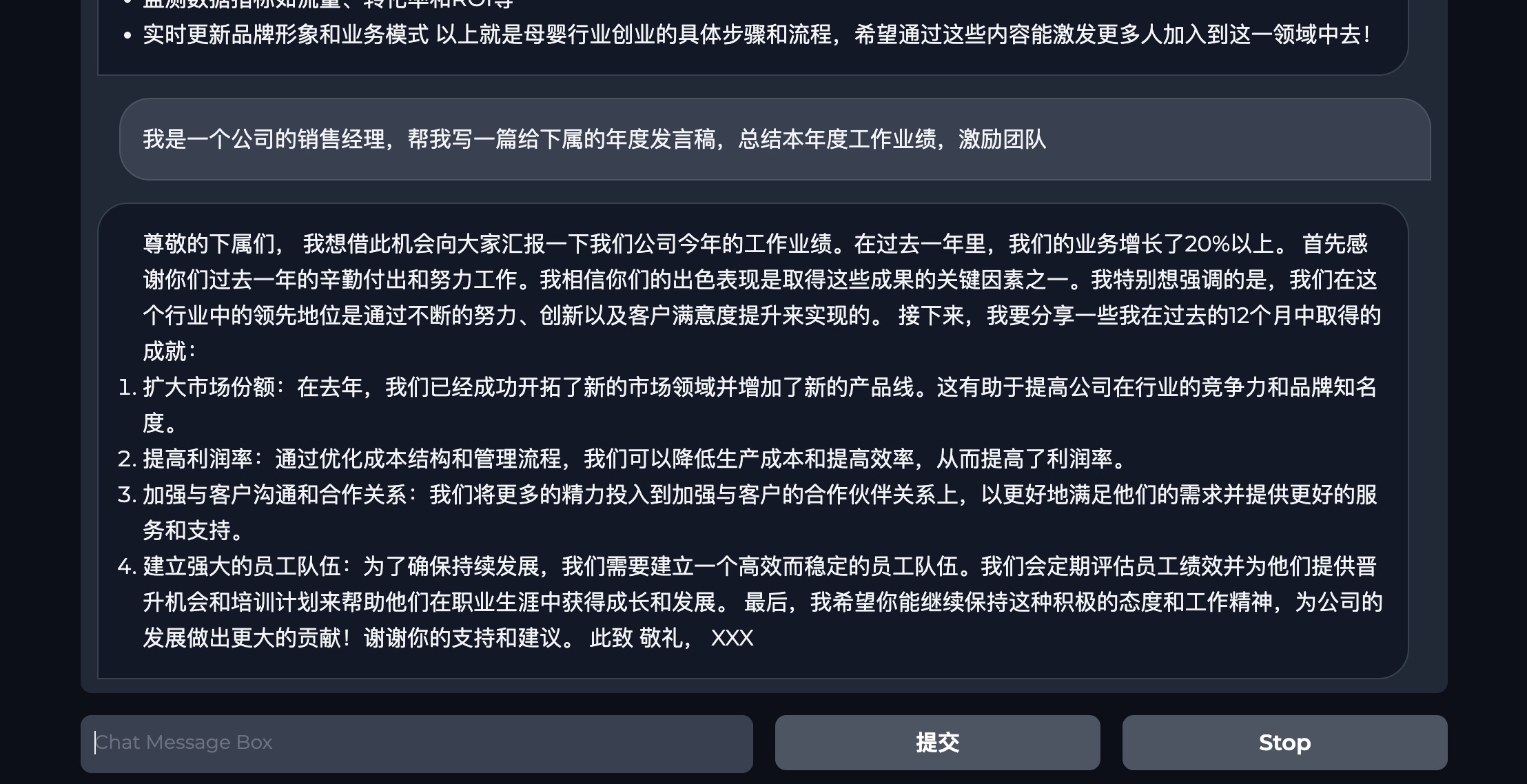






- Downloads last month
- 10
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.