
Introduction
github repo : https://github.com/FunAudioLLM/SenseVoice
SenseVoice is a speech foundation model with multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language identification (LID), speech emotion recognition (SER), and audio event detection (AED).
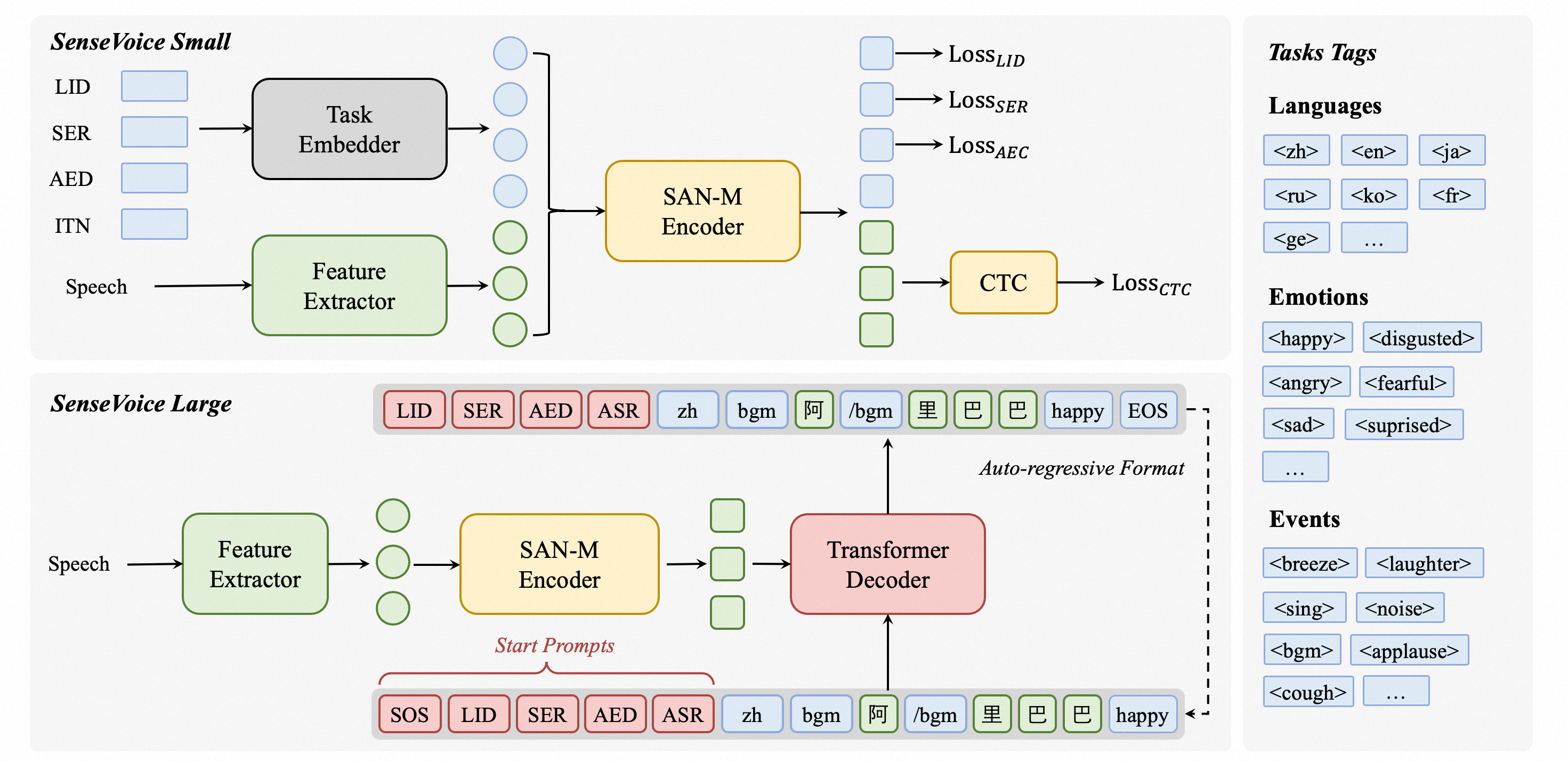
Homepage | What's News | Benchmarks | Install | Usage | Community
Model Zoo: modelscope, huggingface
Online Demo: modelscope demo, huggingface space
Highlights 🎯
SenseVoice focuses on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection.
- Multilingual Speech Recognition: Trained with over 400,000 hours of data, supporting more than 50 languages, the recognition performance surpasses that of the Whisper model.
- Rich transcribe:
- Possess excellent emotion recognition capabilities, achieving and surpassing the effectiveness of the current best emotion recognition models on test data.
- Offer sound event detection capabilities, supporting the detection of various common human-computer interaction events such as bgm, applause, laughter, crying, coughing, and sneezing.
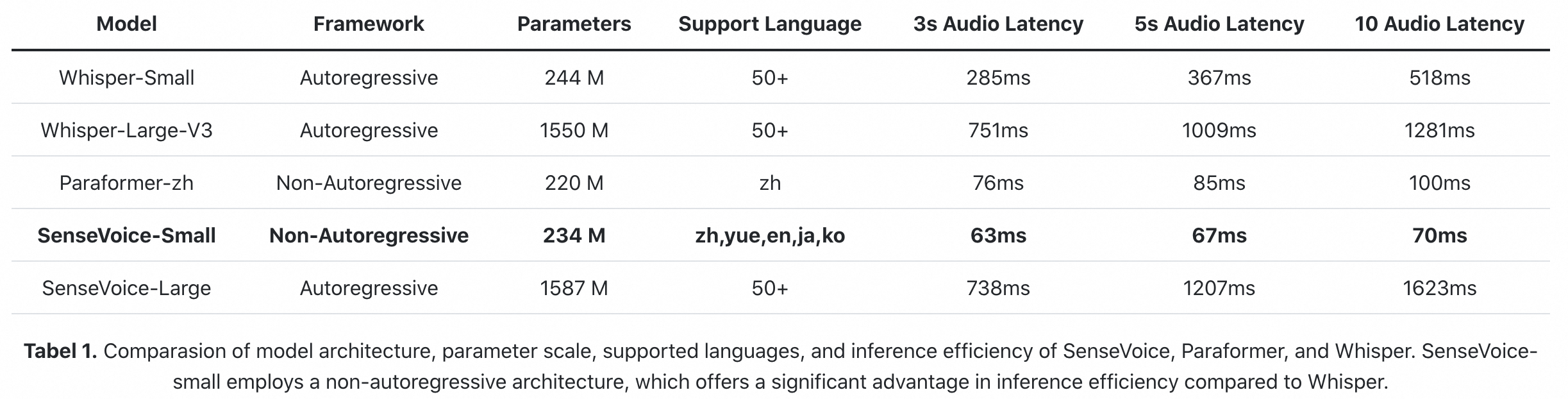
- Efficient Inference: The SenseVoice-Small model utilizes a non-autoregressive end-to-end framework, leading to exceptionally low inference latency. It requires only 70ms to process 10 seconds of audio, which is 15 times faster than Whisper-Large.
- Convenient Finetuning: Provide convenient finetuning scripts and strategies, allowing users to easily address long-tail sample issues according to their business scenarios.
- Service Deployment: Offer service deployment pipeline, supporting multi-concurrent requests, with client-side languages including Python, C++, HTML, Java, and C#, among others.
What's New 🔥
- 2024/7: Added Export Features for ONNX and libtorch, as well as Python Version Runtimes: funasr-onnx-0.4.0, funasr-torch-0.1.1
- 2024/7: The SenseVoice-Small voice understanding model is open-sourced, which offers high-precision multilingual speech recognition, emotion recognition, and audio event detection capabilities for Mandarin, Cantonese, English, Japanese, and Korean and leads to exceptionally low inference latency.
- 2024/7: The CosyVoice for natural speech generation with multi-language, timbre, and emotion control. CosyVoice excels in multi-lingual voice generation, zero-shot voice generation, cross-lingual voice cloning, and instruction-following capabilities. CosyVoice repo and CosyVoice space.
- 2024/7: FunASR is a fundamental speech recognition toolkit that offers a variety of features, including speech recognition (ASR), Voice Activity Detection (VAD), Punctuation Restoration, Language Models, Speaker Verification, Speaker Diarization and multi-talker ASR.
Benchmarks 📝
Multilingual Speech Recognition
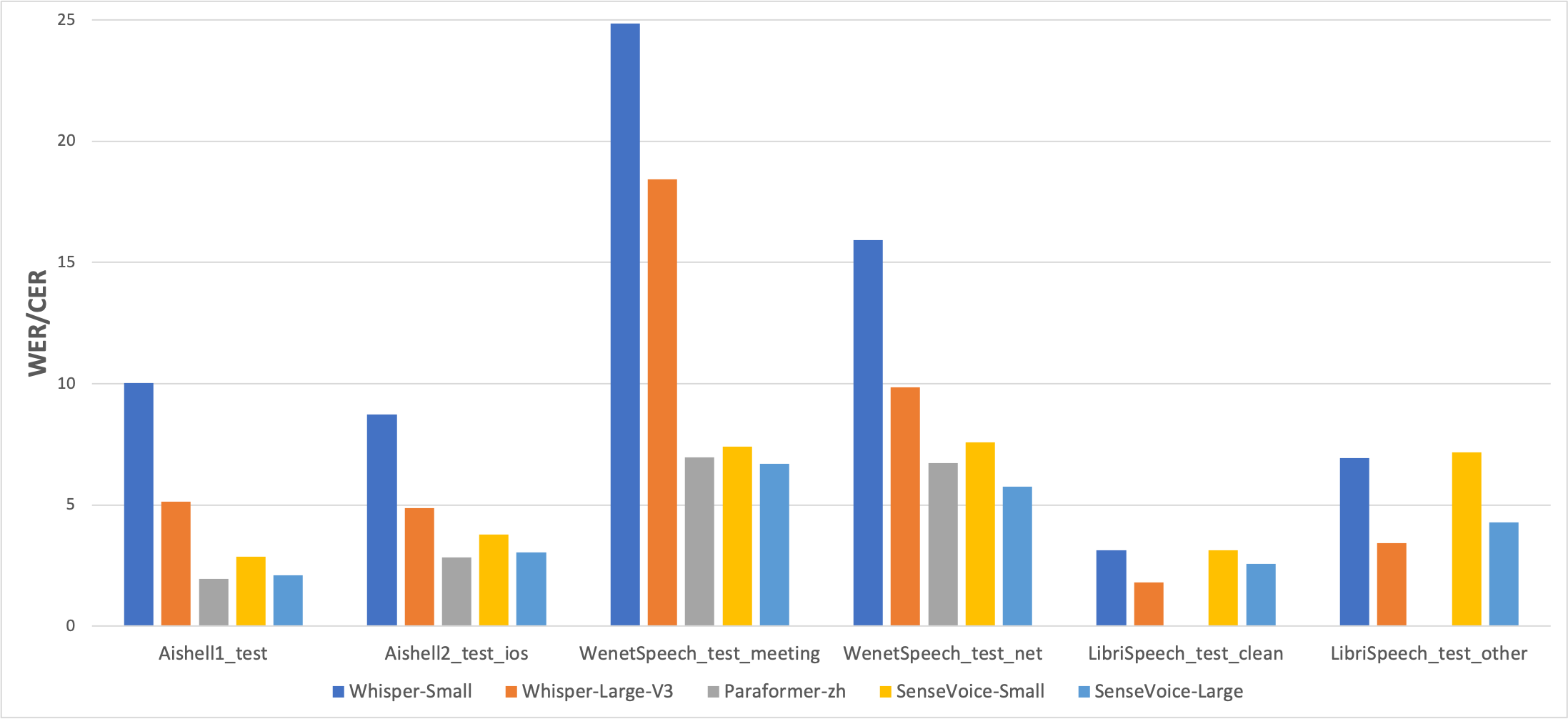
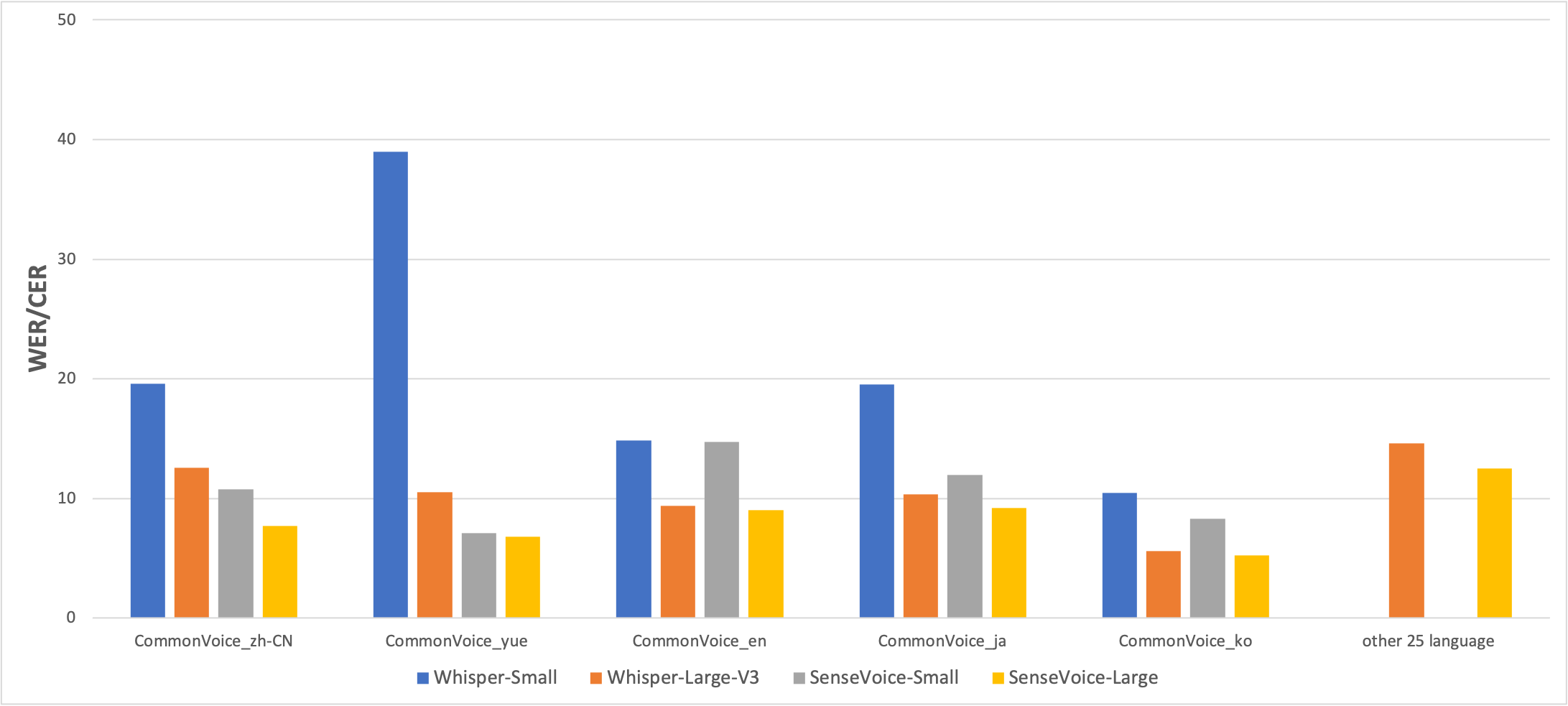
We compared the performance of multilingual speech recognition between SenseVoice and Whisper on open-source benchmark datasets, including AISHELL-1, AISHELL-2, Wenetspeech, LibriSpeech, and Common Voice. In terms of Chinese and Cantonese recognition, the SenseVoice-Small model has advantages.
Speech Emotion Recognition
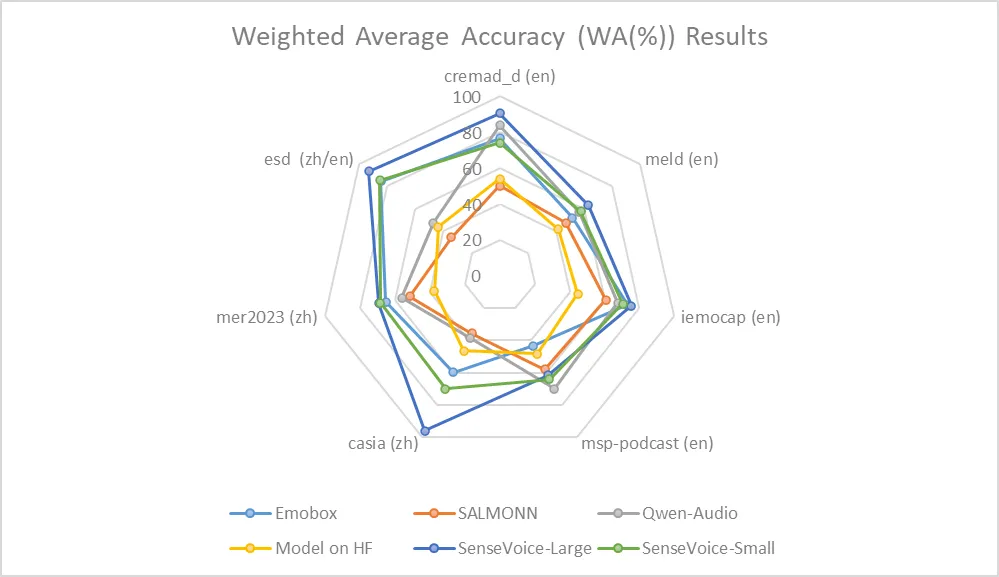
Due to the current lack of widely-used benchmarks and methods for speech emotion recognition, we conducted evaluations across various metrics on multiple test sets and performed a comprehensive comparison with numerous results from recent benchmarks. The selected test sets encompass data in both Chinese and English, and include multiple styles such as performances, films, and natural conversations. Without finetuning on the target data, SenseVoice was able to achieve and exceed the performance of the current best speech emotion recognition models.

Furthermore, we compared multiple open-source speech emotion recognition models on the test sets, and the results indicate that the SenseVoice-Large model achieved the best performance on nearly all datasets, while the SenseVoice-Small model also surpassed other open-source models on the majority of the datasets.
Audio Event Detection
Although trained exclusively on speech data, SenseVoice can still function as a standalone event detection model. We compared its performance on the environmental sound classification ESC-50 dataset against the widely used industry models BEATS and PANN. The SenseVoice model achieved commendable results on these tasks. However, due to limitations in training data and methodology, its event classification performance has some gaps compared to specialized AED models.

Computational Efficiency
The SenseVoice-Small model deploys a non-autoregressive end-to-end architecture, resulting in extremely low inference latency. With a similar number of parameters to the Whisper-Small model, it infers more than 5 times faster than Whisper-Small and 15 times faster than Whisper-Large.
Requirements
pip install -r requirements.txt
Usage
Inference
Supports input of audio in any format and of any duration.
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "FunAudioLLM/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
hub="hf",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
Parameter Description:
model_dir: The name of the model, or the path to the model on the local disk.vad_model: This indicates the activation of VAD (Voice Activity Detection). The purpose of VAD is to split long audio into shorter clips. In this case, the inference time includes both VAD and SenseVoice total consumption, and represents the end-to-end latency. If you wish to test the SenseVoice model's inference time separately, the VAD model can be disabled.vad_kwargs: Specifies the configurations for the VAD model.max_single_segment_time: denotes the maximum duration for audio segmentation by thevad_model, with the unit being milliseconds (ms).use_itn: Whether the output result includes punctuation and inverse text normalization.batch_size_s: Indicates the use of dynamic batching, where the total duration of audio in the batch is measured in seconds (s).merge_vad: Whether to merge short audio fragments segmented by the VAD model, with the merged length beingmerge_length_s, in seconds (s).
If all inputs are short audios (<30s), and batch inference is needed to speed up inference efficiency, the VAD model can be removed, and batch_size can be set accordingly.
model = AutoModel(model=model_dir, device="cuda:0", hub="hf")
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="zh", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size=64,
hub="hf",
)
For more usage, please refer to docs
Inference directly
Supports input of audio in any format, with an input duration limit of 30 seconds or less.
from model import SenseVoiceSmall
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "FunAudioLLM/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir, device="cuda:0", hub="hf")
m.eval()
res = m.inference(
data_in=f"{kwargs['model_path']}/example/en.mp3",
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
**kwargs,
)
text = rich_transcription_postprocess(res[0][0]["text"])
print(text)
Export and Test (On going)
Ref to SenseVoice
Service
Ref to SenseVoice
Finetune
Ref to SenseVoice
WebUI
python webui.py
Community
If you encounter problems in use, you can directly raise Issues on the github page.
You can also scan the following DingTalk group QR code to join the community group for communication and discussion.
| FunAudioLLM | FunASR |
|---|---|
 |
 |
- Downloads last month
- 4,062