

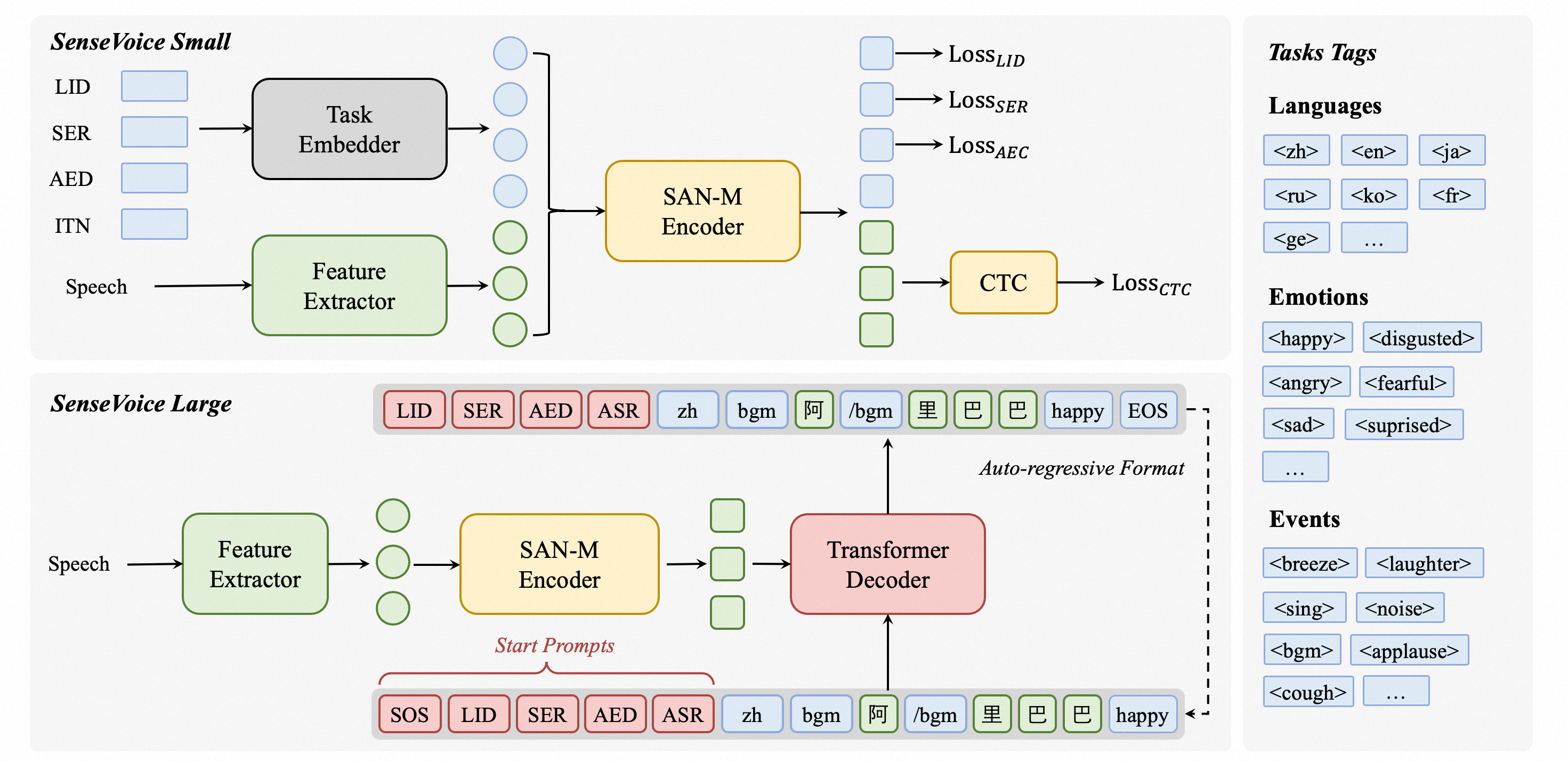
SenseVoice
github repo : https://github.com/FunAudioLLM/SenseVoice
SenseVoiceは、音声認識(ASR)、言語識別(LID)、音声感情認識(SER)、および音響イベント分類(AEC)または音響イベント検出(AED)を含む音声理解能力を備えた音声基盤モデルです。本プロジェクトでは、SenseVoiceモデルの紹介と、複数のタスクテストセットでのベンチマーク、およびモデルの体験に必要な環境のインストールと推論方法を提供します。
ドキュメントホーム | コア機能
最新情報 | ベンチマーク | 環境インストール | 使用方法 | お問い合わせ
モデルリポジトリ:modelscope,huggingface
オンライン体験: modelscope demo, huggingface space
コア機能 🎯
SenseVoiceは、高精度な多言語音声認識、感情認識、および音声イベント検出に焦点を当てています。
- 多言語認識: 40万時間以上のデータを使用してトレーニングされ、50以上の言語をサポートし、認識性能はWhisperモデルを上回ります。
- リッチテキスト認識:
- 優れた感情認識能力を持ち、テストデータで現在の最良の感情認識モデルの効果を達成および上回ります。
- 音声イベント検出能力を提供し、音楽、拍手、笑い声、泣き声、咳、くしゃみなどのさまざまな一般的な人間とコンピュータのインタラクションイベントを検出します。
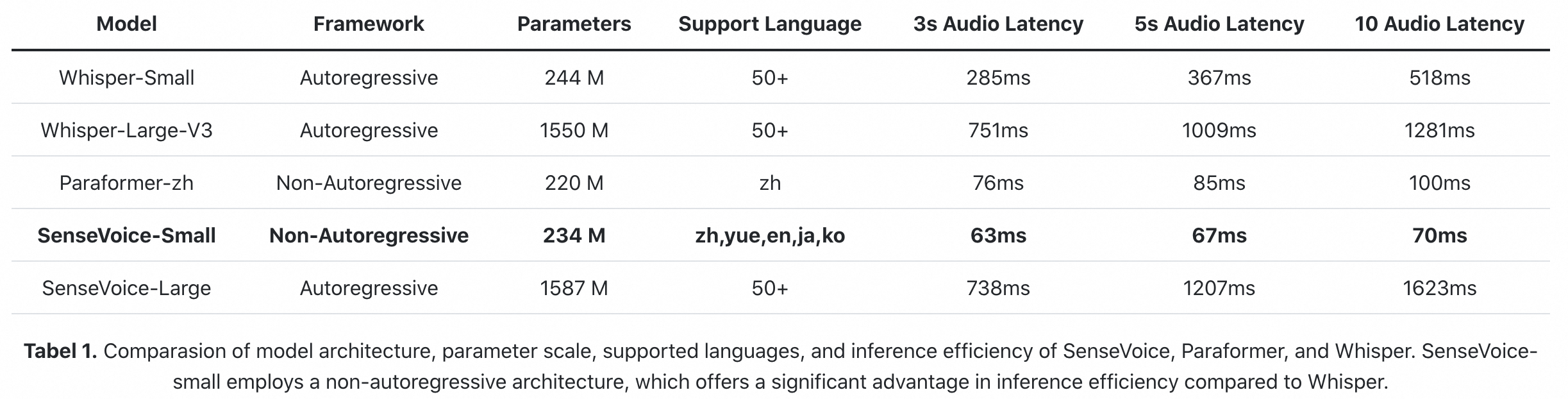
- 効率的な推論: SenseVoice-Smallモデルは非自己回帰エンドツーエンドフレームワークを採用しており、推論遅延が非常に低く、10秒の音声の推論に70msしかかかりません。Whisper-Largeより15倍高速です。
- 簡単な微調整: 便利な微調整スクリプトと戦略を提供し、ユーザーがビジネスシナリオに応じてロングテールサンプルの問題を簡単に解決できるようにします。
- サービス展開: マルチコンカレントリクエストをサポートする完全なサービス展開パイプラインを提供し、クライアントサイドの言語にはPython、C++、HTML、Java、C#などがあります。
最新情報 🔥
- 2024/7:新しくONNXとlibtorchのエクスポート機能を追加し、Pythonバージョンのランタイム:funasr-onnx-0.4.0、funasr-torch-0.1.1も提供開始。
- 2024/7: SenseVoice-Small 多言語音声理解モデルがオープンソース化されました。中国語、広東語、英語、日本語、韓国語の多言語音声認識、感情認識、およびイベント検出能力をサポートし、非常に低い推論遅延を実現しています。
- 2024/7: CosyVoiceは自然な音声生成に取り組んでおり、多言語、音色、感情制御をサポートします。多言語音声生成、ゼロショット音声生成、クロスランゲージ音声クローン、および指示に従う能力に優れています。CosyVoice repo and CosyVoice オンライン体験.
- 2024/7: FunASR は、音声認識(ASR)、音声活動検出(VAD)、句読点復元、言語モデル、話者検証、話者分離、およびマルチトーカーASRなどの機能を提供する基本的な音声認識ツールキットです。
ベンチマーク 📝
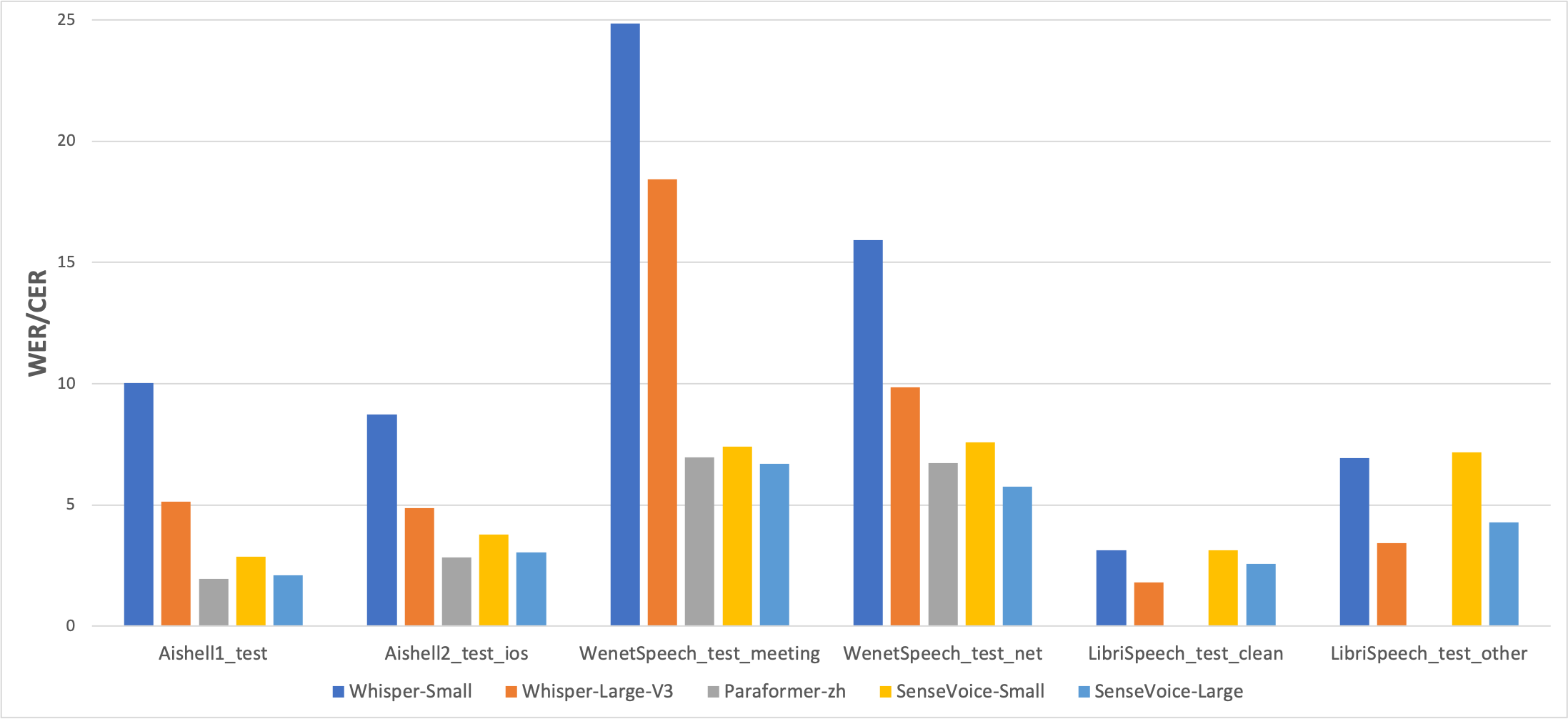
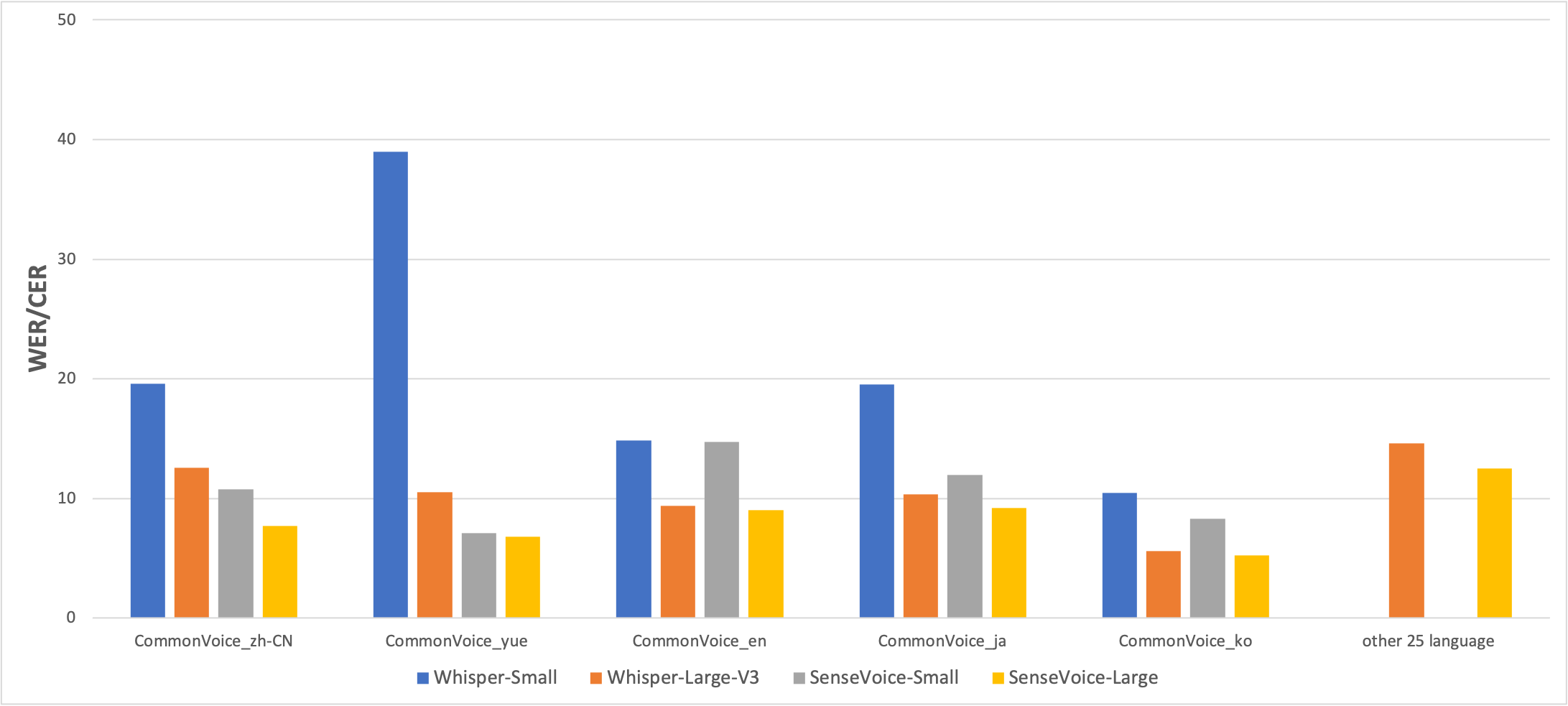
多言語音声認識
オープンソースのベンチマークデータセット(AISHELL-1、AISHELL-2、Wenetspeech、Librispeech、Common Voiceを含む)でSenseVoiceとWhisperの多言語音声認識性能と推論効率を比較しました。中国語と広東語の認識効果において、SenseVoice-Smallモデルは明らかな効果の優位性を持っています。
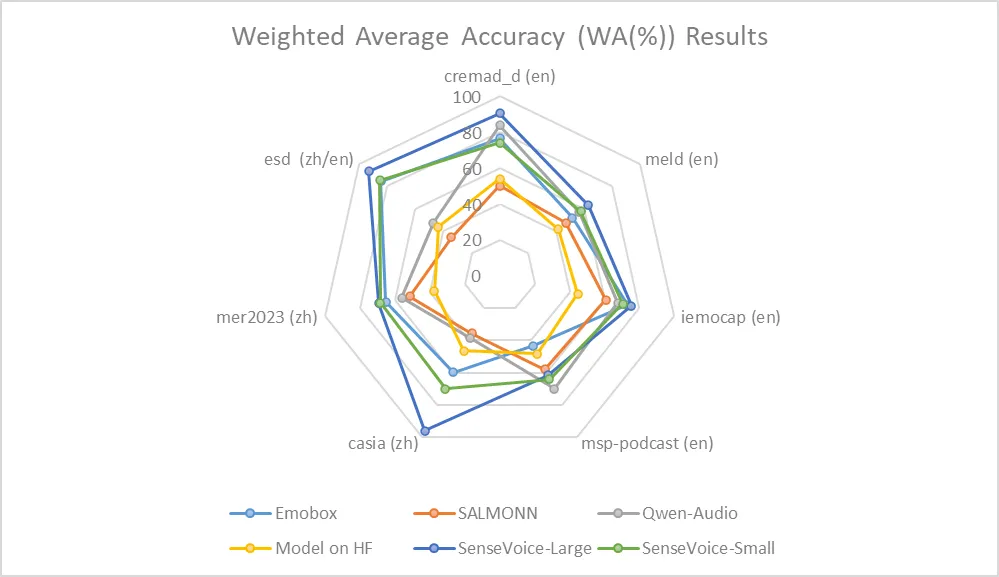
感情認識
現在、広く使用されている感情認識のテスト指標と方法が不足しているため、複数のテストセットでさまざまな指標をテストし、最近のベンチマークの複数の結果と包括的に比較しました。選択されたテストセットには、中国語/英語の両方の言語と、パフォーマンス、映画、自然な会話などのさまざまなスタイルのデータが含まれています。ターゲットデータの微調整を行わない前提で、SenseVoiceはテストデータで現在の最良の感情認識モデルの効果を達成および上回ることができました。

さらに、テストセットで複数のオープンソースの感情認識モデルを比較し、結果はSenseVoice-Largeモデルがほぼすべてのデータで最良の効果を達成し、SenseVoice-Smallモデルも多数のデータセットで他のオープンソースモデルを上回る効果を達成したことを示しています。
イベント検出
SenseVoiceは音声データのみでトレーニングされていますが、イベント検出モデルとして単独で使用することもできます。環境音分類ESC-50データセットで、現在業界で広く使用されているBEATSおよびPANNモデルの効果と比較しました。SenseVoiceモデルはこれらのタスクで良好な効果を達成しましたが、トレーニングデータとトレーニング方法の制約により、イベント分類の効果は専門のイベント検出モデルと比較してまだ一定の差があります。

推論効率
SenseVoice-smallモデルは非自己回帰エンドツーエンドアーキテクチャを採用しており、推論遅延が非常に低いです。Whisper-Smallモデルと同等のパラメータ量で、Whisper-Smallモデルより5倍高速で、Whisper-Largeモデルより15倍高速です。同時に、SenseVoice-smallモデルは音声の長さが増加しても、推論時間に明らかな増加はありません。
環境インストール 🐍
pip install -r requirements.txt
使用方法 🛠️
推論
任意の形式の音声入力をサポートし、任意の長さの入力をサポートします。
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
パラメータの説明:
model_dir:モデル名、またはローカルディスク上のモデルパス。trust_remote_code:vad_model:VAD(音声活動検出)を有効にすることを示します。VADの目的は、長い音声を短いクリップに分割することです。この場合、推論時間にはVADとSenseVoiceの合計消費が含まれ、エンドツーエンドの遅延を表します。SenseVoiceモデルの推論時間を個別にテストする場合は、VADモデルを無効にできます。vad_kwargs:VADモデルの設定を指定します。max_single_segment_time:vad_modelによる音声セグメントの最大長を示し、単位はミリ秒(ms)です。use_itn:出力結果に句読点と逆テキスト正規化が含まれるかどうか。batch_size_s:動的バッチの使用を示し、バッチ内の音声の合計長を秒(s)で測定します。merge_vad:VADモデルによって分割された短い音声フラグメントをマージするかどうか。マージ後の長さはmerge_length_sで、単位は秒(s)です。ban_emo_unk:emo_unkラベルを無効にする。
すべての入力が短い音声(30秒未満)であり、バッチ推論が必要な場合、推論効率を向上させるためにVADモデルを削除し、batch_sizeを設定できます。
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size=64,
)
詳細な使用方法については、ドキュメントを参照してください。
直接推論
任意の形式の音声入力をサポートし、入力音声の長さは30秒以下に制限されます。
from model import SenseVoiceSmall
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir, device="cuda:0")
m.eval()
res = m.inference(
data_in=f"{kwargs['model_path']}/example/en.mp3",
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
**kwargs,
)
text = rich_transcription_postprocess(res[0][0]["text"])
print(text)
サービス展開
未完了
エクスポートとテスト
ONNXとLibtorchのエクスポート
ONNX
# pip3 install -U funasr funasr-onnx
from pathlib import Path
from funasr_onnx import SenseVoiceSmall
from funasr_onnx.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall(model_dir, batch_size=10, quantize=True)
# inference
wav_or_scp = ["{}/.cache/modelscope/hub/{}/example/en.mp3".format(Path.home(), model_dir)]
res = model(wav_or_scp, language="auto", use_itn=True)
print([rich_transcription_postprocess(i) for i in res])
備考:ONNXモデルは元のモデルディレクトリにエクスポートされます。
Libtorch
from pathlib import Path
from funasr_torch import SenseVoiceSmall
from funasr_torch.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall(model_dir, batch_size=10, device="cuda:0")
wav_or_scp = ["{}/.cache/modelscope/hub/{}/example/en.mp3".format(Path.home(), model_dir)]
res = model(wav_or_scp, language="auto", use_itn=True)
print([rich_transcription_postprocess(i) for i in res])
備考:Libtorchモデルは元のモデルディレクトリにエクスポートされます。
展開
未完了
微調整
トレーニング環境のインストール
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./
データ準備
データ形式には以下のフィールドが含まれている必要があります:
{"key": "YOU0000008470_S0000238_punc_itn", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|withitn|>", "target": "Including legal due diligence, subscription agreement, negotiation.", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/YOU0000008470_S0000238.wav", "target_len": 7, "source_len": 140}
{"key": "AUD0000001556_S0007580", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|woitn|>", "target": "there is a tendency to identify the self or take interest in what one has got used to", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/AUD0000001556_S0007580.wav", "target_len": 18, "source_len": 360}
詳細は:data/train_example.jsonlを参照してください。
トレーニングの開始
finetune.shのtrain_toolを、前述のFunASRパス内のfunasr/bin/train_ds.pyの絶対パスに変更することを忘れないでください。
bash finetune.sh
WebUI
python webui.py
お問い合わせ
使用中に問題が発生した場合は、githubページで直接Issuesを提起できます。音声に興味のある方は、以下のDingTalkグループQRコードをスキャンしてコミュニティグループに参加し、交流と議論を行ってください。
| FunAudioLLM | FunASR |
|---|---|
 |
 |