
license: apache-2.0
language:
- en
- zh
pipeline_tag: text-generation
tags:
- ' TransNormerLLM'
TransNormerLLM3 -- A Faster and Better LLM
Introduction
This official repository unveils the TransNormerLLM3 model along with its open-source weights for every 50 billion tokens processed during pre-training.
TransNormerLLM evolving from TransNormer, standing out as the first LLM within the linear transformer architecture. Additionally, it distinguishes itself by being the first non-Transformer LLM to exceed both traditional Transformer and other efficient Transformer models (such as, RetNet and Mamba) in terms of speed and performance.
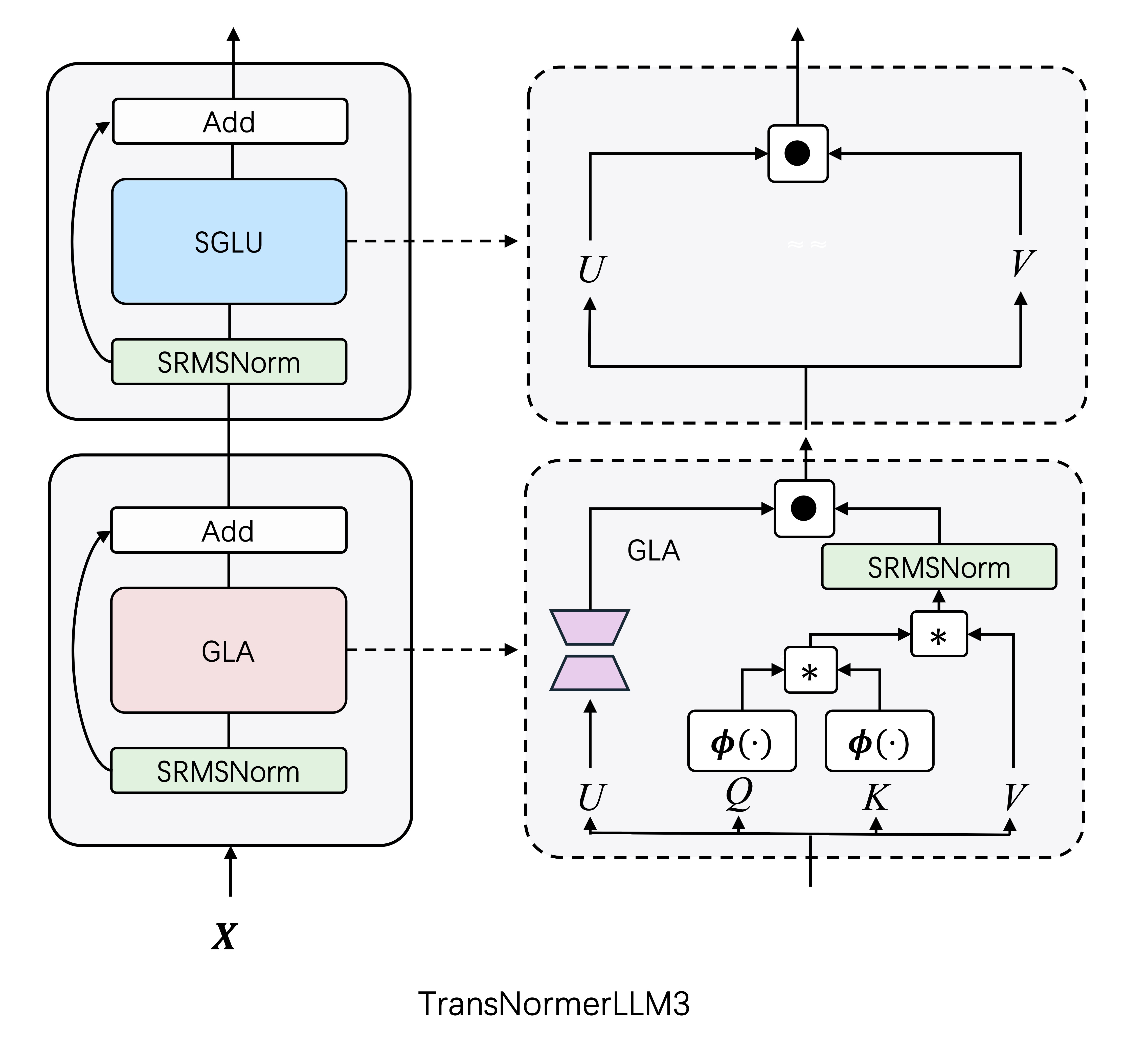
TransNormerLLM3
- TransNormerLLM3-15B features 14.83 billion parameters. It is structured with 42 layers, includes 40 attention heads, and has a total embedding size of 5120.
- TransNormerLLM3-15B is purely intergrated with Lightning Attention-2, which can maintain a stable TGS during training of unlimited sequence lengths, up until encountering firm limitations like GPU memory constraints.
- Titoken tokenizer is used with a total vocabulary size of about 100,000.
Pre-training Logbook
- Realtime Track: https://api.wandb.ai/links/opennlplab/kip314lq
- Join to dicussion: discord <<<>>> wechat group
{kind=link}
--23.12.25-- startup: WeChat - 预训练启航 <<<>>> Twitter - Pre-training Commences <<<>>> YouTube Recording <<<>>> bilibili 回放
--24.01.02-- first week review: WeChat - 第一周概览 <<<>>> Twitter - First Week Review
--24.01.09-- second week review: WeChat - 第二周概览 <<<>>> Twitter - Second Week Review
--24.01.15-- third week review: WeChat - 第三周概览 <<<>>> Twitter - Third Week Review
Released Weights
| param | token | Hugging Face | Model Scope | Wisemodel |
|---|---|---|---|---|
| 15B | 50B | 🤗step13000 | 🤖 | 🐯 |
| 15B | 100B | 🤗step26000 | 🤖 | 🐯 |
| 15B | 150B | 🤗step39000 | 🤖 | 🐯 |
| 15B | 200B | 🤗step52000 | 🤖 | 🐯 |
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("OpenNLPLab/TransNormerLLM3-15B-Intermediate-Checkpoints", revision='step26000-100Btokens', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OpenNLPLab/TransNormerLLM3-15B-Intermediate-Checkpoints", torch_dtype=torch.bfloat16, revision='step26000-100Btokens', device_map="auto", trust_remote_code=True)
Benchmark Results
The evaluations of all models are conducted using the official settings and the lm-evaluation-harness framework.
| Model | P | T | BoolQ | PIQA | HS | WG | ARC-e | ARC-c | OBQA | C-Eval | MMLU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TransNormerLLM3-15B | 15 | 0.05 | 62.08 | 72.52 | 55.55 | 57.14 | 62.12 | 31.14 | 32.40 | 26.18 | 27.50 |
| TransNormerLLM3-15B | 15 | 0.10 | 63.98 | 74.70 | 61.09 | 61.33 | 65.95 | 34.64 | 35.60 | 25.38 | 27.40 |
| TransNormerLLM3-15B | 15 | 0.15 | 60.34 | 75.08 | 63.99 | 62.04 | 64.56 | 34.90 | 35.20 | 22.64 | 26.60 |
| TransNormerLLM3-15B | 15 | 0.20 | 52.05 | 74.48 | 64.72 | 62.75 | 66.16 | 35.15 | 36.80 | 27.25 | 30.80 |
| TransNormerLLM3-15B | 15 | 0.25 | 66.70 | 76.50 | 66.51 | 64.80 | 66.84 | 36.18 | 39.40 | 30.87 | 36.10 |
| TransNormerLLM3-15B | 15 | 0.30 | 67.00 | 76.50 | 67.17 | 64.40 | 66.29 | 36.77 | 38.80 | 33.99 | 37.60 |
P: parameter size (billion). T: tokens (trillion). BoolQ: acc. PIQA: acc. HellaSwag: acc_norm. WinoGrande: acc. ARC-easy: acc. ARC-challenge: acc_norm. OpenBookQA: acc_norm. MMLU: 5-shot acc. C-Eval: 5-shot acc.
# Please configure the following settings when do evaluation
export do_eval=True
export use_triton=False
Acknowledgments and Citation
Acknowledgments
Our project is developed based on the following open source projects:
- tiktoken for the tokenizer.
- metaseq for training.
- lm-evaluation-harness for evaluation.
Citation
If you wish to cite our work, please use the following reference:
@article{qin2023scaling,
title={Scaling transnormer to 175 billion parameters},
author={Qin, Zhen and Li, Dong and Sun, Weigao and Sun, Weixuan and Shen, Xuyang and Han, Xiaodong and Wei, Yunshen and Lv, Baohong and Yuan, Fei and Luo, Xiao and others},
journal={arXiv preprint arXiv:2307.14995},
year={2023}
}
@misc{qin2024lightning,
title={Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models},
author={Zhen Qin and Weigao Sun and Dong Li and Xuyang Shen and Weixuan Sun and Yiran Zhong},
year={2024},
eprint={2401.04658},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
 - OpenNLPLab @2024 -
- OpenNLPLab @2024 -