
id
int64 0
3.46k
| description
stringlengths 5
3.38k
| readme
stringlengths 6
512k
⌀ |
|---|---|---|
3,400 | Rails/ActiveRecord support for distributed multi-tenant databases like Postgres+Citus | # activerecord-multi-tenant [ ](https://rubygems.org/gems/activerecord-multi-tenant) [ ](https://rubygems.org/gems/activerecord-multi-tenant)
Introduction Post: https://www.citusdata.com/blog/2017/01/05/easily-scale-out-multi-tenant-apps/
ActiveRecord/Rails integration for multi-tenant databases, in particular the open-source [Citus](https://github.com/citusdata/citus) extension for PostgreSQL.
Enables easy scale-out by adding the tenant context to your queries, enabling the database (e.g. Citus) to efficiently route queries to the right database node.
## Installation
Add the following to your Gemfile:
```ruby
gem 'activerecord-multi-tenant'
```
## Supported Rails versions
All Ruby on Rails versions starting with 6.0 or newer (up to 7.0) are supported.
This gem only supports ActiveRecord (the Rails default ORM), and not alternative ORMs like Sequel.
## Usage
It is required that you add `multi_tenant` definitions to your model in order to have full support for Citus, in particular when updating records.
In the example of an analytics application, sharding on `customer_id`, annotate your models like this:
```ruby
class PageView < ActiveRecord::Base
multi_tenant :customer
belongs_to :site
# ...
end
class Site < ActiveRecord::Base
multi_tenant :customer
has_many :page_views
# ...
end
```
and then wrap all code that runs queries/modifications in blocks like this:
```ruby
customer = Customer.find(session[:current_customer_id])
# ...
MultiTenant.with(customer) do
site = Site.find(params[:site_id])
site.update! last_accessed_at: Time.now
site.page_views.count
end
```
Inside controllers you can use a before_action together with set_current_tenant, to set the tenant for the current request:
```ruby
class ApplicationController < ActionController::Base
set_current_tenant_through_filter # Required to opt into this behavior
before_action :set_customer_as_tenant
def set_customer_as_tenant
customer = Customer.find(session[:current_customer_id])
set_current_tenant(customer)
end
end
```
## Rolling out activerecord-multi-tenant for your application (write-only mode)
The library relies on tenant_id to be present and NOT NULL for all rows. However,
its often useful to have the library set the tenant_id for new records, and then backfilling
tenant_id for existing records as a background task.
To support this, there is a write-only mode, in which tenant_id is not included in queries,
but only set for new records. Include the following in an initializer to enable it:
```ruby
MultiTenant.enable_write_only_mode
```
Once you are ready to enforce tenancy, make your tenant_id column NOT NULL and simply remove that line.
## Frequently Asked Questions
* **What if I have a table that doesn't relate to my tenant?** (e.g. templates that are the same in every account)
We recommend not using activerecord-multi-tenant on these tables. In case only some records in a table are not associated to a tenant (i.e. your templates are in the same table as actual objects), we recommend setting the tenant_id to 0, and then using MultiTenant.with(0) to access these objects.
* **What if my tenant model is not defined in my application?**
The tenant model does not have to be defined. Use the gem as if the model was present. `MultiTenant.with` accepts either a tenant id or model instance.
## Credits
This gem was initially based on [acts_as_tenant](https://github.com/ErwinM/acts_as_tenant), and still shares some code. We thank the authors for their efforts.
## License
Copyright (c) 2018, Citus Data Inc.<br>
Licensed under the MIT license, see LICENSE file for details.
|
3,401 | CSS styled emails without the hassle. | # premailer-rails
CSS styled emails without the hassle.
[![Build Status][build-image]][build-link]
[![Gem Version][gem-image]][gem-link]
[![Code Climate][gpa-image]][gpa-link]
## Introduction
This gem is a drop in solution for styling HTML emails with CSS without having
to do the hard work yourself.
Styling emails is not just a matter of linking to a stylesheet. Most clients,
especially web clients, ignore linked stylesheets or `<style>` tags in the HTML.
The workaround is to write all the CSS rules in the `style` attribute of each
tag inside your email. This is a rather tedious and hard to maintain approach.
Premailer to the rescue! The great [premailer] gem applies all CSS rules to each
matching HTML element by adding them to the `style` attribute. This allows you
to keep HTML and CSS in separate files, just as you're used to from web
development, thus keeping your sanity.
This gem is an adapter for premailer to work with [actionmailer] out of the box.
Actionmailer is the email framework used in Rails, which also works outside of
Rails. Although premailer-rails has certain Rails specific features, **it also
works in the absence of Rails** making it compatible with other frameworks such
as sinatra.
## How It Works
premailer-rails works with actionmailer by registering a delivery hook. This
causes all emails that are delivered to be processed by premailer-rails. This
means that by simply including premailer-rails in your `Gemfile` you'll get
styled emails without having to set anything up.
Whenever premailer-rails processes an email, it collects the URLs of all linked
stylesheets (`<link rel="stylesheet" href="css_url">`). Then, for each of these
URLs, it tries to get the content through a couple of strategies. As long as
a strategy does not return anything, the next one is used. The strategies
available are:
- `:filesystem`: If there's a file inside `public/` with the same path as in
the URL, it is read from disk. E.g. if the URL is
`http://cdn.example.com/assets/email.css` the contents of the file located
at `public/assets/email.css` gets returned if it exists.
- `:asset_pipeline`: If Rails is available and the asset pipeline is enabled,
the file is retrieved through the asset pipeline. E.g. if the URL is
`http://cdn.example.com/assets/email-fingerprint123.css`, the file
`email.css` is requested from the asset pipeline. That is, the fingerprint
and the prefix (in this case `assets` is the prefix) are stripped before
requesting it from the asset pipeline.
- `:network`: As a last resort, the URL is simply requested and the response
body is used. This is useful when the assets are not bundled in the
application and only available on a CDN. On Heroku e.g. you can add assets
to your `.slugignore` causing your assets to not be available to the app
(and thus resulting in a smaller app) and deploy the assets to a CDN such
as S3/CloudFront.
You can configure which strategies you want to use as well as specify their
order. Refer to the *Configuration* section for more on this.
Note that the retrieved CSS is cached when the gem is running with Rails in
production.
## Installation
Simply add the gem to your `Gemfile`:
```ruby
gem 'premailer-rails'
```
premailer-rails and premailer require a gem that is used to parse the email's
HTML. For a list of supported gems and how to select which one to use, please
refer to the [*Adapter*
section](https://github.com/premailer/premailer#adapters) of premailer. Note
that there is no hard dependency from either gem so you should add one yourself.
Also note that this gem is only tested with [nokogiri].
## Configuration
Premailer itself accepts a number of options. In order for premailer-rails to
pass these options on to the underlying premailer instance, specify them
as follows (in Rails you could do that in an initializer such as
`config/initializers/premailer_rails.rb`):
```ruby
Premailer::Rails.config.merge!(preserve_styles: true, remove_ids: true)
```
For a list of options, refer to the [premailer documentation]. The default
configs are:
```ruby
{
input_encoding: 'UTF-8',
generate_text_part: true,
strategies: [:filesystem, :asset_pipeline, :network]
}
```
If you don't want to automatically generate a text part from the html part, set
the config `:generate_text_part` to false.
Note that the options `:with_html_string` and `:css_string` are used internally
by premailer-rails and thus will be overridden.
If you're using this gem outside of Rails, you'll need to call
`Premailer::Rails.register_interceptors` manually in order for it to work. This
is done ideally in some kind of initializer, depending on the framework you're
using.
premailer-rails reads all stylesheet `<link>` tags, inlines the linked CSS
and removes the tags. If you wish to ignore a certain tag, e.g. one that links to
external fonts such as Google Fonts, you can add a `data-premailer="ignore"`
attribute.
## Usage
premailer-rails processes all outgoing emails by default. If you wish to skip
premailer for a certain email, simply set the `:skip_premailer` header:
```ruby
class UserMailer < ActionMailer::Base
def welcome_email(user)
mail to: user.email,
subject: 'Welcome to My Awesome Site',
skip_premailer: true
end
end
```
Note that the mere presence of this header causes premailer to be skipped, i.e.,
even setting `skip_premailer: false` will cause premailer to be skipped. The
reason for that is that the `skip_premailer` is a simple header and the value is
transformed into a string, causing `'false'` to become truthy.
Emails are only processed upon delivery, i.e. when calling `#deliver` on the
email, or when [previewing them in
rails](http://api.rubyonrails.org/v4.1.0/classes/ActionMailer/Base.html#class-ActionMailer::Base-label-Previewing+emails).
If you wish to manually trigger the inlining, you can do so by calling the hook:
```ruby
mail = SomeMailer.some_message(args)
Premailer::Rails::Hook.perform(mail)
```
This will modify the email in place, useful e.g. in tests.
## Supported Rails Versions
This gem is tested on Rails versions 5 through 7.
For Rails 7, it support both the classical Sprockets asset pipeline as well as the new [Propshaft](https://github.com/rails/propshaft) gem.
If you're looking to integrate with Webpacker, check out [these instructions](https://github.com/fphilipe/premailer-rails/issues/232#issuecomment-839819705).
## Small Print
### Author
Philipe Fatio ([@fphilipe][fphilipe twitter])
### License
premailer-rails is released under the MIT license. See the [license file].
[build-image]: https://github.com/fphilipe/premailer-rails/actions/workflows/test.yml/badge.svg
[build-link]: https://github.com/fphilipe/premailer-rails/actions/workflows/test.yml
[gem-image]: https://badge.fury.io/rb/premailer-rails.svg
[gem-link]: https://rubygems.org/gems/premailer-rails
[gpa-image]: https://codeclimate.com/github/fphilipe/premailer-rails.svg
[gpa-link]: https://codeclimate.com/github/fphilipe/premailer-rails
[tip-image]: https://rawgithub.com/twolfson/gittip-badge/0.1.0/dist/gittip.svg
[tip-link]: https://www.gittip.com/fphilipe/
[premailer]: https://github.com/premailer/premailer
[actionmailer]: https://github.com/rails/rails/tree/main/actionmailer
[nokogiri]: https://github.com/sparklemotion/nokogiri
[premailer documentation]: https://www.rubydoc.info/gems/premailer/Premailer:initialize
[fphilipe twitter]: https://twitter.com/fphilipe
[license file]: LICENSE
|
3,402 | Course management service that enables auto-graded programming assignments. | <a href="https://autolabproject.com">
<img src="public/images/autolab_banner.svg" width="380px" height="100px">
</a>
Autolab is a course management service, initially developed by a team of students at Carnegie Mellon University, that enables instructors to offer autograded programming assignments to their students over the Web. The two key ideas in Autolab are *autograding*, that is, programs evaluating other programs, and *scoreboards*.
Autolab also provides other services that instructors expect in a course management system, including gradebooks, rosters, handins/handouts, lab writeups, code annotation, manual grading, late penalties, grace days, cheat checking, meetings, partners, and bulk emails.
Since 2010, Autolab has had a transformative impact on education at CMU. Each semester, it is used by about 5,000 CMU students in courses in Pittsburgh, Silicon Valley, Qatar, and Rwanda. In Fall, 2014, we are releasing Autolab as an open-source system, where it will be available to schools all over the world, and hopefully have the same impact it's had at CMU.
<p>
<a href="https://join.slack.com/t/autolab/shared_invite/zt-1maodn5ti-jdLHUnm5sZkuLn4PJNaTbw" style="float:left">
<img src="public/images/join_slack.svg" width="170px" height="44px">
</a>
<a href="https://docs.autolabproject.com/" style="float:left">
<img src="public/images/read_the_docs.svg" width="170px" height="44px">
</a>
<a href="https://groups.google.com/g/autolabproject" style="float:left">
<img src="public/images/mailing_list.svg" width="170px" height="44px">
</a>
</p>
[](http://autolab-d01.club.cc.cmu.edu:8080/job/autolab%20demosite/)
[](https://betteruptime.com/?utm_source=status_badge)

Subscribe to our [mailing list](https://groups.google.com/g/autolabproject) to receive announcements about major releases and updates to the Autolab Project.
## Try It Out
We have a demo site running at https://nightly.autolabproject.com/. See the [docs](https://docs.autolabproject.com/#demonstration-site) for more information on how to log in and suggestions on things to try.
## Installation
We released new documentation! Check it out [here](https://docs.autolabproject.com).
## Testing
### Setting up Tests
1. Add a test database in `database.yml`
2. Create and migrate the database.
```sh
RAILS_ENV=test bundle exec rails autolab:setup_test_env
```
Do not forget to use `RAILS_ENV=test bundle exec` in front of every rake/rails command.
3. Create necessary directories.
```
mkdir attachments/ tmp/
```
### Running Tests
After setting up the test environment, simply run spec by:
```sh
bundle exec rails spec
```
You may need to run `RAILS_ENV=test bundle exec rails autolab:setup_test_env` when re-running tests as some tests
may create models in the database.
You can also run individual spec files by running:
```sh
rake spec SPEC=./spec/<path_to_spec>/<spec_file>.rb
```
## Rails 5 Support
Autolab is now running on Rails 6. The Rails 5 branch can be found on `master-rails-5`.
We will not be backporting any new features from `master` to `master-rails-5`, and we have discontinued Rails 5 support.
## Updating Docs
To install mkdocs, run
```bash
pip install --user mkdocs
```
We rely on the `mkdocs-material` theme, which can be installed with
```bash
pip install --user mkdocs-material
```
To run and preview this locally, run:
```bash
mkdocs serve
```
Once your updated documentation is in `master`, Jenkins will automatically run a job to update the docs. You can trigger a manual update with
```bash
mkdocs gh-deploy
```
This will build the site using the branch you are currently in (hopefully `master`), place the built HTML files into the `gh-pages` branch, and push them to GitHub. GitHub will then automatically deploy the new content in `gh-pages`.
## Contributing
We encourage you to contribute to Autolab! Please check out the
[Contributing to Autolab Guide](https://github.com/autolab/Autolab/blob/master/CONTRIBUTING.md) for guidelines about how to proceed. You can reach out to us on [Slack](https://join.slack.com/t/autolab/shared_invite/zt-1maodn5ti-jdLHUnm5sZkuLn4PJNaTbw) as well.
## License
Autolab is released under the [Apache License 2.0](http://opensource.org/licenses/Apache-2.0).
## Using Autolab
Please feel free to use Autolab at your school/organization. If you run into any problems, you can reach the core developers at `[email protected]` and we would be happy to help. On a case-by-case basis, we also provide servers for free. (Especially if you are an NGO or small high-school classroom)
## Changelog
### [v2.10.0](https://github.com/autolab/Autolab/releases/tag/v2.10.0) (2023/01/13) LTI Integration, Generalized Feedback, and Streaming Output
- Autolab now supports roster syncing with courses on Canvas and other LTI (Learning Tools Interoperability) services. For full instructions on setup, see the documentation.
- Streaming partial output and new feedback interface
- Generalized annotations
- Numerous UI updates
- Numerous bug fixes and improvements
### [v2.9.0](https://github.com/autolab/Autolab/releases/tag/v2.9.0) (2022/08/08) Metrics Excluded Categories and New Speedgrader Interface
- Instructors can now exclude selected categories of assessments from metrics watchlist calculations
- Introduced new speedgrader interface which utilizes the Golden Layout library, amongst other new features
- Numerous bug fixes and improvements
### [v2.8.0](https://github.com/autolab/Autolab/releases/tag/v2.8.0) (2021/12/20) GitHub Integration and Roster Upload Improvement
- Students can now submit code via GitHub
- Improved Roster Upload with better error reporting
- Numerous bug fixes and improvements
### (2021/10/12) Moved from Uglifier to Terser
- Autolab has migrated from Uglifier to Terser for our Javascript compressor to support the latest Javascript syntax. Please change `Uglifier.new(harmony: true)` to `:terser` in your `production.rb`
### [v2.7.0](https://github.com/autolab/Autolab/releases/tag/v2.7.0) (2021/05/29) Autolab Docker Compose, Student Metrics, Redesigned Documentation
- Integration with new Docker Compose [installation method](https://github.com/autolab/docker)
- Student Metrics Feature, which allows instructors to identify students who may require attention
- Redesigned Autolab documentation
- Numerous bug fixes and improvements
### [v2.6.0](https://github.com/autolab/Autolab/releases/tag/v2.6.0) (2020/10/24) Formatted Feedbacks, Course Dashboard, Accessibility
- Formatted Feedback feature
- Introduction of Course Dashboards
- Numerous bug fixes and improvements
### v2.5.0 (2020/02/22) Upgrade from Rails 4 to Rails 5
- Autolab has been upgraded from Rails 4 to Rails 5 after almost a year of effort! There are still some small
bugs to be fixed, but they should not affect the core functionality of Autolab. Please file an issue if you believe
you have found a bug.
**For older releases, please check out the [releases page](https://github.com/autolab/Autolab/releases).**
|
3,403 | A curated list of awesome things related to Ruby on Rails | # Awesome Rails
> A curated list of awesome things related to Ruby on Rails [](https://github.com/sindresorhus/awesome#readme)

## Table of Contents
- [Resources](#resources)
- [Official Resources](#official-resources)
- [External Resources](#external-resources)
- [Books](#books)
- [Video tutorials](#video-tutorials)
- [Youtube channels](#youtube-channels)
- [Other external resources](#other-external-resources)
- [Jobs](#jobs)
- [Community](#community)
- [Articles](#articles)
- [Open Source Rails Apps](#open-source-rails-apps)
- [Gems](#gems)
- [Starters/Boilerplates](#startersboilerplates)
- [Other Rails Tools](#other-rails-tools)
- [Platforms](#platforms)
- [Generators](#generators)
- [DevTools](#devtools)
## Resources
### Official Resources
- [Rails Official Website](https://rubyonrails.org)
- [Rails Official Guide](https://guides.rubyonrails.org)
- [Rails Official Guide (Edge Guide)](https://edgeguides.rubyonrails.org)
- [Rails API Documentation](https://api.rubyonrails.org)
- [Rails Source Code][link_rails_source]
- [Rails Official Blog](https://rubyonrails.org/blog/)
[Back to top][link_toc]
### External Resources
#### Books
- [Ruby on Rails Tutorial Book](https://www.railstutorial.org/book)
- [Agile Web Development with Rails 6](https://pragprog.com/titles/rails6/agile-web-development-with-rails-6/)
- [Docker for Rails Developers](https://pragprog.com/titles/ridocker/docker-for-rails-developers/)
- [Rails 5 Test Prescriptions](https://pragprog.com/titles/nrtest3/rails-5-test-prescriptions/)
- [Rails, Angular, Postgres, and Bootstrap, Second Edition](https://pragprog.com/titles/dcbang2/rails-angular-postgres-and-bootstrap-second-edition/)
- [Growing Rails Applications in Practice](https://pragprog.com/titles/d-kegrap/growing-rails-applications-in-practice/)
- [Crafting Rails 4 Applications](https://pragprog.com/titles/jvrails2/crafting-rails-4-applications/)
- [The Rails 7 Way](https://leanpub.com/therails7way)
#### Video tutorials
- [RailsCasts](http://railscasts.com) *(inactive since 2013)
- [GoRails](https://gorails.com) *(freemium)
- [Drifting Ruby](https://www.driftingruby.com/) *(freemium)
- [A curated list of Ruby on Rails courses](https://skillcombo.com/topic/ruby-on-rails/)
#### Youtube channels
- [DriftingRuby](https://www.youtube.com/c/DriftingRuby/videos)
- [Gorails](https://www.youtube.com/c/GorailsTV/videos)
- [TechmakerTV](https://www.youtube.com/c/TechmakerTV/videos)
- [Deanin](https://www.youtube.com/c/Deanin/videos)
- [Webcrunch](https://www.youtube.com/c/Webcrunch/videos)
- [CJ Avilla](https://www.youtube.com/playlist?list=PLS6F722u-R6KiuOupokyl8Xnqrot9ukc7)
- [SupeRails](https://www.youtube.com/c/SupeRails/videos)
- [TypeFast](https://www.youtube.com/@typefastco/videos)
- [APPSIMPACT Academy](https://www.youtube.com/@APPSIMPACTAcademy/videos)
- [Mix & Go](https://www.youtube.com/@mixandgo/videos)
- [Phil Smy](https://www.youtube.com/@PhilSmy/videos)
- [David Battersby](https://www.youtube.com/@davidbattersby/videos)
#### Other external resources
- [Learn Ruby on Rails (thoughtbot)](https://thoughtbot.com/upcase/rails)
- [Ruby on Windows Guides](http://rubyonwindowsguides.github.io)
- [Explore Ruby](https://kandi.openweaver.com/explore/ruby) - Discover & find a curated list of popular & new Ruby libraries across all languages, top authors, trending project kits, discussions, tutorials & learning resources.
[Back to top][link_toc]
### Jobs
- [railsjobs on Reddit](https://www.reddit.com/r/railsjobs/)
- [rails jobs on indeed.com](https://www.indeed.com/q-Ruby-On-Rails-jobs.html)
- [rails jobs on glassdoor.com](https://www.glassdoor.com/Job/ruby-on-rails-developer-jobs-SRCH_KO0,23.htm)
- [rails jobs on gorails.com](https://jobs.gorails.com)
- [rails jobs on remoteok.com](https://remoteok.com/remote-ruby-jobs)
- [rails jobs on weworkremotely.com](https://weworkremotely.com/remote-ruby-on-rails-jobs)
- [reverse job board for rails devs - railsdevs.com](https://railsdevs.com)
- [rails jobs on web3.career](https://web3.career/ruby-jobs)
- [rails jobs on rubyonremote.com](https://rubyonremote.com/)
- [rails jobs on Startup Jobs](https://startup.jobs/ruby-jobs)
- [rails jobs on RubyJobBoard](https://www.rubyjobboard.com)
> Tip: You can find list of remote job boards including Rails jobs on [awesome-remote-job](https://github.com/lukasz-madon/awesome-remote-job#job-boards)
[Back to top][link_toc]
### Community
- [rails on Twitter](https://twitter.com/rails)
- [rails on Reddit](https://www.reddit.com/r/rails/)
- [Ruby on Rails Discussions](https://discuss.rubyonrails.org/)
- [Gorails forum](https://gorails.com/forum)
- [WIP Ruby (Telegram group)](https://t.me/wipruby)
- [Ruby on Rails Link (Slack)](https://www.rubyonrails.link/)
[Back to top][link_toc]
### Articles
> from dev.to:
- [More than "Hello World" in Docker: Build Rails + Sidekiq web apps in Docker](https://dev.to/raphael_jambalos/more-than-hello-world-in-docker-run-rails-sidekiq-web-apps-in-docker-1b37)
- [Design Patterns with Ruby on Rails part 1: Introduction and Policy Object](https://dev.to/renatamarques97/design-patterns-with-ruby-on-rails-part-1-introduction-and-policy-object-1c37) - [Part 2](https://dev.to/renatamarques97/design-patterns-with-ruby-on-rails-part-2-query-object-1h65)
- [The Progressive Rails App](https://dev.to/coorasse/the-progressive-rails-app-46ma)
- [Modern Rails flash messages (part 1): ViewComponent, Stimulus & Tailwind CSS](https://dev.to/citronak/modern-rails-flash-messages-part-1-viewcomponent-stimulus-tailwind-css-3alm) - [Part 2](https://dev.to/citronak/modern-rails-flash-messages-part-2-the-undo-action-for-deleted-items-2a50)
- [Building a Rails App With Multiple Subdomains](https://dev.to/appsignal/building-a-rails-app-with-multiple-subdomains-g05)
- [Reactive Rails applications with StimulusReflex](https://dev.to/finiam/reactive-rails-applications-with-stimulusreflex-48kn)
- [1 Backend, 5 Frontends - Todo List with Rails, React, Angular, Vue, Svelte, and jQuery](https://dev.to/alexmercedcoder/1-backend-5-frontends-todo-list-with-rails-react-angular-vue-svelte-and-jquery-18kp)
- [Create a Video Party App With Rails Part 1: Building the Backend](https://dev.to/vonagedev/create-a-video-party-app-with-rails-part-1-building-the-backend-2p4k) - [Part 2](https://dev.to/vonagedev/create-a-video-party-app-with-rails-part-2-building-the-frontend-hfe)
- [The Rails Model Introduction I Wish I Had](https://dev.to/maxwell_dev/the-rails-model-introduction-i-wish-i-had-5h2d)
- [How to create a gem in Ruby on Rails? -From Scratch-](https://dev.to/solutelabs/how-to-create-a-gem-in-ruby-on-rails-fromscratch-3f4p)
- [Multiple Foreign Keys for the Same Relationship in Rails 6](https://dev.to/luchiago/multiple-foreign-keys-for-the-same-model-in-rails-6-7ml)
- [QR Code Reader on Rails](https://dev.to/morinoko/qr-code-reader-on-rails-5816)
- [Magic Links with Ruby On Rails and Devise](https://dev.to/matiascarpintini/magic-links-with-ruby-on-rails-and-devise-4e3o)
- [I created the same application with Rails and no JavaScript](https://dev.to/mario_chavez/i-created-the-same-application-with-rails-and-no-javascript-288o)
- [Instantly speed up your Rails application by self-hosting your fonts](https://dev.to/andrewmcodes/instantly-speed-up-your-rails-application-by-self-hosting-your-fonts-526d)
- [Reactive Map with Rails, Stimulus Reflex and Mapbox](https://dev.to/ilrock__/reactive-map-with-rails-stimulus-reflex-and-mapbox-1po4)
- [A Future for Rails: StimulusReflex](https://dev.to/drews256/a-future-for-rails-stimulusreflex-48kb)
- [Introduction to Ruby on Rails Patterns and Anti-patterns Part 1](https://dev.to/appsignal/introduction-to-ruby-on-rails-patterns-and-anti-patterns-2mhc) - [Part 2](https://dev.to/appsignal/ruby-on-rails-model-patterns-and-anti-patterns-32k9)
- [Rails Concerns: To Concern Or Not To Concern](https://dev.to/appsignal/rails-concerns-to-concern-or-not-to-concern-3n94)
- [Building an Event Sourcing System in Rails, Part 1: What is Event Sourcing?](https://dev.to/isalevine/building-an-event-sourcing-system-in-rails-part-1-what-is-event-sourcing-46db) - [Part 2](https://dev.to/isalevine/building-an-event-sourcing-pattern-in-rails-from-scratch-355h)
- [Real Time Notification System with Sidekiq, Redis and Devise in Rails 6](https://dev.to/matiascarpintini/real-time-notification-system-with-sidekiq-redis-and-devise-in-rails-6-33l9)
- [Deploying Your Rails 6 App](https://dev.to/render/deploying-your-rails-6-app-4an4)
- [What's Cooking in Rails 7?](https://dev.to/hint/what-s-cooking-in-rails-7-a42)
- [Using Hotwire Turbo in Rails with legacy JavaScript](https://dev.to/nejremeslnici/using-hotwire-turbo-in-rails-with-legacy-javascript-17g1)
- [From Rails scaffold listing to Hotwire infinite scroll](https://dev.to/andrzejkrzywda/from-rails-scaffold-listing-to-hotwire-infinite-scroll-3273)
- [Building a Component Library in Rails With Storybook](https://dev.to/orbit/building-a-component-library-in-rails-with-storybook-49m4)
- [How to Speed Up Load Times In A Rails App - What I Wish I Knew Four Months Ago](https://dev.to/nicklevenson/how-to-speed-up-load-times-in-a-rails-app-what-i-wish-i-knew-four-months-ago-28g0)
- [Endless Scroll / Infinite Loading with Turbo Streams & Stimulus](https://dev.to/zealot128/endless-scroll-infinite-loading-with-turbo-streams-stimulus-5d89)
> from shopify.engineering:
- [How to Write Fast Code in Ruby on Rails](https://shopify.engineering/write-fast-code-ruby-rails)
- [How to Introduce Composite Primary Keys in Rails](https://shopify.engineering/how-to-introduce-composite-primary-keys-in-rails)
- [Enforcing Modularity in Rails Apps with Packwerk](https://shopify.engineering/enforcing-modularity-rails-apps-packwerk)
> from blog.planetargon.com:
- [8 Useful Ruby on Rails Gems We Couldn't Live Without](https://blog.planetargon.com/entries/8-useful-ruby-on-rails-gems-we-couldnt-live-without)
- [Ruby on Rails Code Audits: 8 Steps to Review Your App](https://blog.planetargon.com/entries/ruby-on-rails-code-audits-8-steps-to-review-your-app)
- [Rails 6.1 is Out! How to Prepare Your App Now](https://blog.planetargon.com/entries/rails-61-is-coming-soon-how-to-prepare-your-app-now)
- [When Should You Upgrade Your Rails Application?](https://blog.planetargon.com/entries/when-should-you-upgrade-your-rails-application)
- [Helpful Resources for Upgrading Your Rails App Version](https://blog.planetargon.com/entries/helpful-resources-for-your-rails-upgrade)
- [Upgrading Rails: Interview with Eileen Uchitelle](https://blog.planetargon.com/entries/upgrading-rails-an-interview-with-eileen-uchitelle)
> from blog.arkency.com:
- [nil?, empty?, blank? in Ruby on Rails - what's the difference actually?](https://blog.arkency.com/2017/07/nil-empty-blank-ruby-rails-difference/)
- [How well Rails developers actually test their apps](https://blog.arkency.com/how-well-rails-developers-actually-test-their-apps/)
- [Rails multitenancy story in 11 snippets of code](https://blog.arkency.com/rails-multitenancy-story-in-11-snippets-of-code/)
- [Painless Rails upgrades](https://blog.arkency.com/painless-rails-upgrades/)
- [Comparison of approaches to multitenancy in Rails apps](https://blog.arkency.com/comparison-of-approaches-to-multitenancy-in-rails-apps/)
- [Managing Rails Event Store Subscriptions — How To](https://blog.arkency.com/managing-rails-event-store-subscriptions-how-to/)
- [Rails connections, pools and handlers](https://blog.arkency.com/rails-connections-pools-and-handlers/)
- [How to balance the public APIs of an open-source library — practical examples from RailsEventStore](https://blog.arkency.com/how-to-balance-the-public-apis-of-open-source-library-practical-examples-from-railseventstore/)
- [Rack apps mounted in Rails — how to protect access to them?](https://blog.arkency.com/common-authentication-for-mounted-rack-apps-in-rails/)
> from sitepoint.com:
- [10 Ruby on Rails Best Practices](https://www.sitepoint.com/10-ruby-on-rails-best-practices-3/)
- [Building APIs with Ruby on Rails and GraphQL](https://www.sitepoint.com/building-apis-ruby-rails-graphql/)
- [Understanding the Model-View-Controller (MVC) Architecture in Rails](https://www.sitepoint.com/model-view-controller-mvc-architecture-rails/)
- [Beyond Rails Abstractions: A Dive into Database Internals](https://www.sitepoint.com/beyond-rails-abstractions-dive-database-internals/)
- [Search and Autocomplete in Rails Apps](https://www.sitepoint.com/search-autocomplete-rails-apps/)
- [Start Your SEO Right with Sitemaps on Rails](https://www.sitepoint.com/start-your-seo-right-with-sitemaps-on-rails/)
- [Handle Password and Email Changes in Your Rails API](https://www.sitepoint.com/handle-password-and-email-changes-in-your-rails-api/)
- [Master Many-to-Many Associations with ActiveRecord](https://www.sitepoint.com/master-many-to-many-associations-with-activerecord/)
- [Common Rails Security Pitfalls and Their Solutions](https://www.sitepoint.com/common-rails-security-pitfalls-and-their-solutions/)
> from pganalyze.com:
- [Efficient GraphQL queries in Ruby on Rails & Postgres](https://pganalyze.com/blog/efficient-graphql-queries-in-ruby-on-rails-and-postgres)
- [Similarity in Postgres and Rails using Trigrams](https://pganalyze.com/blog/similarity-in-postgres-and-ruby-on-rails-using-trigrams)
- [Effectively Using Materialized Views in Ruby on Rails](https://pganalyze.com/blog/materialized-views-ruby-rails)
- [Full Text Search in Milliseconds with Rails and PostgreSQL](https://pganalyze.com/blog/full-text-search-ruby-rails-postgres)
- [Advanced Active Record: Using Subqueries in Rails](https://pganalyze.com/blog/active-record-subqueries-rails)
- [PostGIS vs. Geocoder in Rails](https://pganalyze.com/blog/postgis-rails-geocoder)
- [Creating Custom Postgres Data Types in Rails](https://pganalyze.com/blog/custom-postgres-data-types-ruby-rails)
> from semaphoreci.com:
- [Integration Testing Ruby on Rails with Minitest and Capybara](https://semaphoreci.com/community/tutorials/integration-testing-ruby-on-rails-with-minitest-and-capybara)
- [Mocking in Ruby with Minitest](https://semaphoreci.com/community/tutorials/mocking-in-ruby-with-minitest)
- [How to Test Rails Models with RSpec](https://semaphoreci.com/community/tutorials/how-to-test-rails-models-with-rspec)
- [Dockerizing a Ruby on Rails Application](https://semaphoreci.com/community/tutorials/dockerizing-a-ruby-on-rails-application)
> from evilmartians.com:
- [Dockerizing Ruby and Rails development](https://evilmartians.com/chronicles/ruby-on-whales-docker-for-ruby-rails-development)
- [How to GraphQL with Ruby, Rails, Active Record, and no N+1](https://evilmartians.com/chronicles/how-to-graphql-with-ruby-rails-active-record-and-no-n-plus-one)
- [Keep up with the Tines: Rails frontend revamp](https://evilmartians.com/chronicles/keep-up-with-the-tines-a-rails-frontend-revamp)
- [Pulling the trigger: How to update counter caches in your Rails app without Active Record callbacks](https://evilmartians.com/chronicles/pulling-the-trigger-how-to-update-counter-caches-in-you-rails-app-without-active-record-callbacks)
- [GraphQL on Rails: On the way to perfection](https://evilmartians.com/chronicles/graphql-on-rails-3-on-the-way-to-perfection)
- [Danger on Rails: make robots do some code review for you!](https://evilmartians.com/chronicles/danger-on-rails-make-robots-do-some-code-review-for-you)
- [GraphQL on Rails: From zero to the first query](https://evilmartians.com/chronicles/graphql-on-rails-1-from-zero-to-the-first-query)
- [A fixture-based approach to interface testing in Rails](https://evilmartians.com/chronicles/a-fixture-based-approach-to-interface-testing-in-rails)
> from digitalocean.com:
- [How To Add Stimulus to a Ruby on Rails Application](https://www.digitalocean.com/community/tutorials/how-to-add-stimulus-to-a-ruby-on-rails-application)
- [Build a RESTful JSON API With Rails 5](https://www.digitalocean.com/community/tutorials/build-a-restful-json-api-with-rails-5-part-one)
> from cloud66.com:
- [Making Hotwire and Devise play nicely](https://blog.cloud66.com/making-hotwire-and-devise-play-nicely-with-viewcomponents)
- [Taking Rails to the next level with Hotwire](https://blog.cloud66.com/taking-rails-to-the-next-level-with-hotwire)
- [Hotwire, ViewComponents and TailwindCSS: The Ultimate Rails Stack](https://blog.cloud66.com/hotwire-viewcomponents-and-tailwindcss-the-ultimate-rails-stack)
- [Adding Super Fast Frontend Search in Rails with Lunr](https://blog.cloud66.com/adding-super-fast-frontend-search-in-rails-with-lunr)
> from not yet classified sources:
- [The 3 Tenets of Service Objects in Ruby on Rails](https://hackernoon.com/the-3-tenets-of-service-objects-c936b891b3c2)
- [Famous Web Apps Built with Ruby on Rails](https://railsware.com/blog/famous-web-apps-built-with-ruby-on-rails/)
- [Building a JSON API with Rails 5](https://www.cloudbees.com/blog/building-a-json-api-with-rails-5)
- [Five Practices for Robust Ruby on Rails Applications](https://www.cloudbees.com/blog/five-practices-for-robust-ruby-on-rails-applications)
- [Crafting APIs With Rails](https://code.tutsplus.com/articles/crafting-apis-with-rails--cms-27695)
- [Working with the SQL ‘time’ type in Ruby on Rails](https://engineering.ezcater.com/youre-not-in-the-zone)
- [Upgrading Rails apps with dual boot](https://medium.com/oreilly-engineering/upgrading-rails-apps-with-dual-boot-e5c271e68a6e)
- [What Are Rails Parameters & How to Use Them Correctly](https://www.rubyguides.com/2019/06/rails-params/)
- [How to Remove Single Table Inheritance from Your Rails Monolith](https://medium.com/flatiron-labs/how-to-remove-single-table-inheritance-from-your-rails-monolith-c6009239defb)
- [Build a Rails application with VueJS using JSX](https://nebulab.com/blog/build-rails-application-vuejs-using-jsx)
- [Implementing Multi-Table Full Text Search with Postgres in Rails](https://thoughtbot.com/blog/implementing-multi-table-full-text-search-with-postgres)
- [Ruby on Rails ActiveRecord PostgreSQL Data Integrity and Validations](https://pawelurbanek.com/rails-postgresql-data-integrity)
- [Programming Community Curated Resources For Learning Ruby on Rails](https://hackr.io/tutorials/learn-ruby-on-rails)
- [Choosing ruby on rails for your next web development project (business guide)](https://www.ideamotive.co/ruby-on-rails/guide)
- [Dockerizing a Rails application](https://iridakos.com/tutorials/2019/04/07/dockerizing-a-rails-application.html)
- [How to painlessly set up your Ruby on Rails dev environment with Docker](https://www.freecodecamp.org/news/painless-rails-development-environment-setup-with-docker/)
- [How I used Docker with Rails](https://admatbandara.medium.com/how-i-used-docker-with-rails-45601c43ed8f)
- [Rails 6 Features: What's New and Why It Matters](https://www.toptal.com/ruby-on-rails/rails-6-features)
- [Containerizing Ruby on Rails Applications](https://technology.doximity.com/articles/containerizing-ruby-on-rails-applications)
- [Behind The Scenes: Rails UJS](https://www.ombulabs.com/blog/learning/javascript/behind-the-scenes-rails-ujs.html)
- [Implement SSR with React + Rails](https://github.com/shakacode/react_on_rails_demo_ssr_hmr)
[Back to top][link_toc]
## Open Source Rails Apps
> Note: Rails versions of these apps are valid as the date of latest commit. They are defined in their Gemfile and/or Gemfile.lock and they might be outdated. If you find it outdated, don't forget to notfiy us by opening a pull request.
- [FAE](https://github.com/wearefine/fae/) - A modern CMS deveveloped by FINE (using Rails 5.2)
- [activeWorkflow](https://github.com/automaticmode/active_workflow) - An intelligent process and workflow automation platform based on software agents (using Rails 6.0).
- [adopt-a-hydrant](https://github.com/codeforamerica/adopt-a-hydrant) - A civic infrastructure detection app (using Rails 4.2).
- [airCasting](https://github.com/HabitatMap/AirCasting) - A platform for recording, mapping, and sharing health and environmental data using your smartphone (using Rails 6.1). - [:earth_africa:](https://www.habitatmap.org/aircasting)
- [alaveteli](https://github.com/mysociety/alaveteli) - A platform for making public freedom of information requests - using Rails 7.0 - [:earth_africa:](https://alaveteli.org)
- [alonetone](https://github.com/sudara/alonetone) - A music hosting, management & distribution app (using Rails 7.0). - [:earth_africa:](https://alonetone.com)
- [api.rss](https://github.com/davidesantangelo/api.rss) - A RSS feed conversion (to API) app (using Rails 6.0).
- [asakusaSatellite](https://github.com/codefirst/AsakusaSatellite) - A realtime chat application for developers (using Rails 6.0). - [:earth_africa:](https://www.codefirst.org/AsakusaSatellite/)
- [askaway](https://github.com/askaway/askaway) - Question & answer app specialized in politics (using Rails 4.1).
- [autolab](https://github.com/autolab/Autolab) - A course management app (using Rails 6.0). - [:earth_africa:](https://autolabproject.com/)
- [beatstream](https://github.com/Darep/Beatstream) - A music streaming app - using Rails 3.2
- [bike_index](https://github.com/bikeindex/bike_index) - A bike registry tracking app (using Rails 6.0). - [:earth_africa:](https://bikeindex.org)
- [blackCandy](https://github.com/blackcandy-org/black_candy) - A music streaming app (using Rails 7.0).
- [brimir](https://github.com/ivaldi/brimir) - An email helpdesk app (using Rails 5.2). (archived).
- [calagator](https://github.com/calagator/calagator) - A community calendaring app (using Rails 5.2).
- [campo](https://github.com/chloerei/campo) - A forum app (using Rails 4.1).
- [canvas-lms](https://github.com/instructure/canvas-lms) - A learning management app (using Rails 5.2).
- [catarse](https://github.com/catarse/catarse) - A crowdfunding platform for creative projects (using Rails 4.2). - [:earth_africa:](https://www.catarse.me/)
- [chatwoot](https://github.com/chatwoot/chatwoot) - A simple and elegant live chat software (using Rails 6.1).
- [ciao](https://github.com/brotandgames/ciao) - A URL status checking app (using Rails 6.0).
- [coRM](https://github.com/SIGIRE/CoRM) - A customer relationship management app - using Rails 3.2 - [:earth_africa:](http://www.corm.fr)
- [coderwall (legacy)](https://github.com/coderwall/coderwall-legacy) - A social network app for software engineers - using Rails 3.2
- [coderwall (next)](https://github.com/coderwall/coderwall-next) - A social network app for software engineers - using Rails 5.0
- [codetriage](https://github.com/codetriage/codetriage) - An open source project finder app (using Rails 7.0). - [:earth_africa:](https://www.codetriage.com/)
- [commudle](https://github.com/commudle/commudle) - A community management app (using Rails 5.2).
- [contribulator](https://github.com/24pullrequests/contribulator) - An open source project finder app - using Rails 5.1
- [coursemology2](https://github.com/Coursemology/coursemology2) - Learning platform app (using Rails 6.0).
- [covoiturage-libre](https://github.com/covoiturage-libre/covoiturage-libre) - A carpooling app - using Rails 5.0 (archived).
- [crabgrass-core](https://0xacab.org/liberate/crabgrass) - A collaboration platform for activist groups (using Rails 5.2).
- [crowdAI](https://github.com/crowdAI/crowdai) - An app for data science challenges (using Rails 5.2). - [:earth_africa:](https://www.aicrowd.com/crowdai.html)
- [crowdtiltOpen](https://github.com/Crowdtilt/CrowdtiltOpen) - A crowdfunding platform - using Rails 6.1
- [cw-ovp](https://github.com/x1wins/CW-OVP) - video packaging to \*.m3u8 for HLS (HTTP Live Streaming) with FFMPEG on website (using Rails 6.0).
- [danbooru](https://github.com/danbooru/danbooru) - A taggable image board app (using Rails 7.0).
- [dcaf_case_management](https://github.com/DARIAEngineering/dcaf_case_management) - A case management app (using Rails 7.0).
- [dgidb](https://github.com/dgidb/dgidb) - A drug gene interaction platform - using Rails 6.0
- [diaspora](https://github.com/diaspora/diaspora) - A social networking app - using Rails 6.1 - [:earth_africa:](https://diasporafoundation.org)
- [discourse](https://github.com/discourse/discourse) - A platform for community discussion (using Rails 7.0). - [:earth_africa:](https://try.discourse.org/)
- [ekylibre](https://github.com/ekylibre/ekylibre) - A farm management app (using Rails 5.0).
- [encrypt.to](https://github.com/encrypt-to/encrypt.to) - A messaging app with encryption support (using Rails 4.2).
- [eol](https://github.com/EOL/deprecated_eol) - An encyclopedia app - using Rails 3.2 - [:earth_africa:](https://eol.org/)
- [expertiza](https://github.com/expertiza/expertiza) - A learning material sharing app (using Rails 5.1).
- [fairmondo](https://github.com/fairmondo/fairmondo) - A marketplace app (using Rails 5.1). - [:earth_africa:](https://www.fairmondo.de)
- [fat-free-crm](https://github.com/fatfreecrm/fat_free_crm) - An open source, Ruby on Rails customer relationship management platform (CRM) (using Rails 6.1). - [:earth_africa:](http://www.fatfreecrm.com/)
- [feedbin](https://github.com/feedbin/feedbin) - A RSS reader app (using Rails 7.0). - [:earth_africa:](https://feedbin.com)
- [follow-all](https://github.com/codeforamerica/follow-all) - A Twitter account management app (using Rails 4.2). (archived).
- [forem](https://github.com/forem/forem) - Social platform app specialized for web development (using Rails 7.0). - [:earth_africa:](https://www.forem.com)
- [fromthepage](https://github.com/benwbrum/fromthepage) - A wiki-like app for crowdsourcing transcription of handwritten documents (using Rails 6.0). - [:earth_africa:](https://www.fromthepage.com/)
- [gitlabhq](https://github.com/gitlabhq/gitlabhq) - A code collaboration app (using Rails 6.1).
- [graff_mags](https://github.com/dankleiman/graff_mags) - A graffiti magazine sharing app (using Rails 4.1).
- [growstuff](https://github.com/Growstuff/growstuff) - A data management app for food gardeners (using Rails 6.1). - [:earth_africa:](https://www.growstuff.org/)
- [hackershare](https://github.com/hackershare/hackershare) - Social bookmarks website for hackers (using Rails 7.0). - [:earth_africa:](https://hackershare.dev/en)
- [hashrobot](https://github.com/rysmith/hashrobot) - A social media management app (using Rails 4.2).
- [helpy](https://github.com/helpyio/helpy) - A customer support app (using Rails 4.2). - [:earth_africa:](https://helpy.io/)
- [hitobito](https://github.com/hitobito/hitobito) - An event organization app (using Rails 6.1). - [:earth_africa:](https://hitobito.com/en)
- [hours](https://github.com/defactosoftware/hours) - A time tracking app (using Rails 4.2).
- [human-essentials](https://github.com/rubyforgood/human-essentials) - An inventory management system for essentials banks (using Rails 7.0). - [:earth_africa:](https://humanessentials.app/)
- [inaturalist](https://github.com/inaturalist/inaturalist) - A community app for nature and related stuff (using Rails 6.1). - [:earth_africa:](https://www.inaturalist.org)
- [intercityup.com](https://github.com/intercity/intercity-next) - A control panel app for app deployment (using Rails 4.1).
- [kanban](https://github.com/seanomlor/kanban) - A Trello clone (using Rails 4.2).
- [kitsu-tools](https://github.com/hummingbird-me/kitsu-tools) - An anime discovery platform (using Rails 4.1).
- [lavish](https://github.com/mquan/lavish) - A color scheme generator (using Rails 4.2).
- [lifeToRemind](https://github.com/eduqg/LifeToRemind) - A career planning app (using Rails 5.2).
- [lobsters](https://github.com/lobsters/lobsters) - A link aggregation app (using Rails 7.0). - [:earth_africa:](https://lobste.rs)
- [loomio](https://github.com/loomio/loomio) - A collaborative decision-making app (using Rails 6.1). - [:earth_africa:](https://www.loomio.com/)
- [mastodon](https://github.com/mastodon/mastodon) - A microblogging app (using Rails 6.1). - [:earth_africa:](https://mastodon.social/about)
- [obtvse2](https://github.com/natew/obtvse2) - A blogging app (using Rails 4.0).
- [onebody](https://github.com/seven1m/onebody) - A social networking app for churches - using Rails 5.1
- [openFarm](https://github.com/openfarmcc/OpenFarm) - A database for information about farming and gardening (using Rails 5.2). -
- [opencongress](https://github.com/sunlightlabs/opencongress) - A website for getting information about US Congress - using Rails 3.0 (archived).
- [openproject](https://github.com/opf/openproject) - A project management app (using Rails 7.0). - [:earth_africa:](https://www.openproject.org)
- [opensourcefriday](https://github.com/github/opensourcefriday) - A project contribution tracking app (using Rails 6.0). - [:earth_africa:](https://opensourcefriday.com)
- [openstreetmap-website](https://github.com/openstreetmap/openstreetmap-website) - A map viewing app (using Rails 7.0). - [:earth_africa:](https://www.openstreetmap.org)
- [otwarchive](https://github.com/otwcode/otwarchive) - A social networking app for fans - using Rails 6.0 - [:earth_africa:](https://archiveofourown.org)
- [passwordPusher](https://github.com/pglombardo/PasswordPusher) - A password delivery app (using Rails 6.1). - [:earth_africa:](https://pwpush.com)
- [peatio](https://github.com/peatio/peatio) - A crypto currency exchange app (using Rails 4.0).
- [planningalerts-app](https://github.com/openaustralia/planningalerts) - A planned applications tracking app (using Rails 6.1). - [:earth_africa:](https://www.planningalerts.org.au)
- [popHealth](https://github.com/pophealth/popHealth) - A population health reporting app (using Rails 4.1).
- [postal](https://github.com/postalserver/postal) - A mail delivery platform (using Rails 5.2).
- [publify](https://github.com/publify/publify) - A blogging app (using Rails 6.1).
- [quant](https://github.com/jdjkelly/quant) - A personal health tracker (using Rails 4.1).
- [racing_on_rails](https://github.com/scottwillson/racing_on_rails) - A bike racing organization app (using Rails 6.1).
- [rapidFTR](https://github.com/rapidftr/RapidFTR) - An information provider app for aid workers (using Rails 4.0).
- [redmine](https://github.com/edavis10/redmine) - A project management app (using Rails 6.1). - [:earth_africa:](http://demo.redmine.org)
- [rentmybikes-rails](https://github.com/balanced/rentmybikes-rails) - A marketplace app - (using Rails 4.0).
- [reservations](https://github.com/YaleSTC/reservations) - An inventory management app (using Rails 6.0). - [:earth_africa:](http://yalestc.github.io/reservations/)
- [retrospring](https://github.com/retrospring/retrospring) - A social network following the Q/A (question and answer) principle - [:earth_africa:](https://retrospring.net)
- [rletters](https://codeberg.org/rletters/rletters) - A frontend for database of journal articles for researchers (using Rails 6.0).
- [rubygems.org](https://github.com/rubygems/rubygems.org) - A gem hosting platform (using Rails 7.0). - [:earth_africa:](https://rubygems.org)
- [sanataro](https://github.com/kaznum/sanataro) - An account tracker (using Rails 4.2).
- [scholarsphere](https://github.com/psu-libraries/scholarsphere) - A digital assets management app - using Rails 6.1
- [selfstarter](https://github.com/apigy/selfstarter) - A crowdfunding app (using Rails 4.0).
- [sharetribe](https://github.com/sharetribe/sharetribe) - A peer-to-peer marketplace platform (using Rails 5.2). - [:earth_africa:](https://www.sharetribe.com)
- [socify](https://github.com/scaffeinate/socify) - A social networking platform - using Rails 5.0
- [splits-io](https://github.com/glacials/splits-io) - A speedrun data store and analysis engine. (using Rails 6.0). - [:earth_africa:](https://splits.io)
- [spokenvote](https://github.com/Spokenvote/spokenvote) - A social voting app (using Rails 4.2).
- [stackneveroverflow](https://github.com/liaoziyang/stackneveroverflow) - A question asking & answering platform - using Rails 5.0
- [teambox](https://github.com/redbooth/teambox) - A collaboration app - using Rails 3.0 - [:earth_africa:](https://redbooth.com) (archived).
- [theodinproject](https://github.com/TheOdinProject/theodinproject) - A teaching & learning platform (using Rails 6.1). - [:earth_africa:](https://www.theodinproject.com/)
- [tracks](https://github.com/TracksApp/tracks) - A goal tracking app (using Rails 6.0). - [:earth_africa:](https://www.getontracks.org)
- [trado](https://github.com/Jellyfishboy/trado) - An e-commerce platform (using Rails 4.2).
- [vglist](https://github.com/connorshea/vglist) - A video game library tracking web app (using Rails 7.0). - [:earth_africa:](https://vglist.co/)
- [websiteOne](https://github.com/AgileVentures/WebsiteOne) - A project tracking app (using Rails 6.1).
- [whitehall](https://github.com/alphagov/whitehall) - A content management app used by UK government - using Rails 7.0
[Back to top][link_toc]
## Gems
> [:red_circle:] : RubyGems link of gems
- [rails][link_rails_source] - A full-stack web development framework [:red_circle:](https://rubygems.org/gems/rails)
> Direct dependencies of the "rails" gem:
- [actioncable](https://github.com/rails/rails/tree/main/actioncable) - A gem to integrate websocket with a Rails app [:red_circle:](https://rubygems.org/gems/actioncable) - [Action Cable Overview](https://guides.rubyonrails.org/action_cable_overview.html)
- [actionmailbox](https://github.com/rails/rails/tree/main/actionmailbox) - A gem to handle incoming emails within a Rails app [:red_circle:](https://rubygems.org/gems/actionmailbox) - [Action Mailbox Basics](https://guides.rubyonrails.org/action_mailbox_basics.html)
- [actionmailer](https://github.com/rails/rails/tree/main/actionmailer) - A gem to compose, deliver & test emails within a Rails app [:red_circle:](https://rubygems.org/gems/actionmailer) - [Action Mailer Basics](https://guides.rubyonrails.org/action_mailer_basics.html)
- [actionpack](https://github.com/rails/rails/tree/main/actionpack) - A gem to manage requests & responses within a Rails app [:red_circle:](https://rubygems.org/gems/actionpack)
- [actiontext](https://github.com/rails/rails/tree/main/actiontext) - A gem to integrate rich text editor into a Rails app [:red_circle:](https://rubygems.org/gems/actiontext) - [Action Text Overview](https://guides.rubyonrails.org/action_text_overview.html)
- [actionview](https://github.com/rails/rails/tree/main/actionview) - A gem to handle view templates within a Rails app [:red_circle:](https://rubygems.org/gems/actionview) - [Action View Overview](https://guides.rubyonrails.org/action_view_overview.html)
- [activejob](https://github.com/rails/rails/tree/main/activejob) - A gem to handle background jobs within a Rails app [:red_circle:](https://rubygems.org/gems/activejob) - [Active Job Basics](https://guides.rubyonrails.org/active_job_basics.html)
- [activemodel](https://github.com/rails/rails/tree/main/activemodel) - A gem to define a set of interfaces to use in model classes within a Rails app [:red_circle:](https://rubygems.org/gems/activemodel) - [Active Model Basics](https://guides.rubyonrails.org/active_model_basics.html)
- [activerecord](https://github.com/rails/rails/tree/main/activerecord) - A gem to connect model classes with relational databases within a Rails app [:red_circle:](https://rubygems.org/gems/activerecord) - [Active Record Basics](https://guides.rubyonrails.org/active_record_basics.html)
- [activestorage](https://github.com/rails/rails/tree/main/activestorage) - A gem to handle file uploads to cloud storage providers within a Rails app [:red_circle:](https://rubygems.org/gems/activestorage) - [Active Storage Overview](https://guides.rubyonrails.org/active_storage_overview.html)
- [activesupport](https://github.com/rails/rails/tree/main/activesupport) - A gem to provide some extensions to support a Rails app [:red_circle:](https://rubygems.org/gems/activesupport) - [Active Support Core Extensions](https://guides.rubyonrails.org/active_support_core_extensions.html)
- [railties](https://github.com/rails/rails/tree/main/railties) - A gem to handle gems & engines used in a Rails app to work together [:red_circle:](https://rubygems.org/gems/railties)
> Other gems that can be used with Rails
- [ace-rails-ap](https://github.com/codykrieger/ace-rails-ap) - A gem to integrate ajax.org cloud9 editor into Rails asset pipeline. [:red_circle:](https://rubygems.org/gems/ace-rails-ap)
- [action_policy](https://github.com/palkan/action_policy) - A tool to handle authorization. [:red_circle:](https://rubygems.org/gems/action_policy)
- [active_decorator](https://github.com/amatsuda/active_decorator) - A gem to keep views & helpers object-oriented. [:red_circle:](https://rubygems.org/gems/active_decorator)
- [active_enum](https://github.com/adzap/active_enum) - A gem to provide enum classes [:red_circle:](https://rubygems.org/gems/active_enum)
- [activeadmin](https://github.com/activeadmin/activeadmin) - A gem to provide admin panel. [:red_circle:](https://rubygems.org/gems/activeadmin)
- [activerecord-analyze](https://github.com/pawurb/activerecord-analyze) - A gem to add EXPLAIN ANALYZE to Rails Active Record query objects. [:red_circle:](https://rubygems.org/gems/activerecord-analyze)
- [activerecord-import](https://github.com/zdennis/activerecord-import) - A gem to handle bulk data insertion using ActiveRecord. [:red_circle:](https://rubygems.org/gems/activerecord-import)
- [activerecord-pg_enum](https://github.com/alassek/activerecord-pg_enum) - A gem to integrate PostgreSQL's enumerated types with the Rails enum feature. [:red_circle:](https://rubygems.org/gems/activerecord-pg_enum)
- [activerecord-postgis-adapter](https://github.com/rgeo/activerecord-postgis-adapter) - ActiveRecord connection adapter for PostGIS. [:red_circle:](https://rubygems.org/gems/activerecord-postgis-adapter)
- [activerecord-postgres_enum](https://github.com/bibendi/activerecord-postgres_enum) - A gem to adds migration and schema.rb support to PostgreSQL enum data types. [:red_circle:](https://rubygems.org/gems/activerecord-postgres_enum)
- [activerecord-sqlserver-adapter](https://github.com/rails-sqlserver/activerecord-sqlserver-adapter) - ActiveRecord connection adapter for the SQL Server. [:red_circle:](https://rubygems.org/gems/activerecord-sqlserver-adapter)
- [activerecord-typedstore](https://github.com/byroot/activerecord-typedstore) - A gem to implement `ActiveRecord::Store` with type definition. [:red_circle:](https://rubygems.org/gems/activerecord-typedstore)
- [activity_notification](https://github.com/simukappu/activity_notification) - A gem to integrate user activity notification. [:red_circle:](https://rubygems.org/gems/activity_notification)
- [aggregate_root](https://github.com/RailsEventStore/rails_event_store/tree/master/aggregate_root) - A gem to handle event sourcing. [:red_circle:](https://rubygems.org/gems/aggregate_root)
- [ahoy_email](https://github.com/ankane/ahoy_email) - A tool to provide mail analytics. [:red_circle:](https://rubygems.org/gems/ahoy_email)
- [algoliasearch-rails](https://github.com/algolia/algoliasearch-rails) - A gem to integrate Algolia search. [:red_circle:](https://rubygems.org/gems/algoliasearch-rails)
- [annotate](https://github.com/ctran/annotate_models) - A gem to annotate rails classes with schema & routes info. [:red_circle:](https://rubygems.org/gems/annotate)
- [anycable-rails](https://github.com/anycable/anycable-rails) - A gem to handle websocket server. [:red_circle:](https://rubygems.org/gems/anycable-rails)
- [apipie-rails](https://github.com/apipie/apipie-rails) - A REST API documentation tool. [:red_circle:](https://rubygems.org/gems/apipie-rails)
- [auther](https://github.com/bkuhlmann/auther) - A gem to provide simple, form-based authentication. [:red_circle:](https://rubygems.org/gems/auther)
- [autoprefixer-rails](https://github.com/ai/autoprefixer-rails) - A gem to add vendor prefixes to stylesheets. [:red_circle:](https://rubygems.org/gems/autoprefixer-rails)
- [avo](https://github.com/avo-hq/avo) - Configuration-based, no-maintenance, extendable Ruby on Rails admin panel. [rubygems](https://rubygems.org/gems/avo)
- [better_errors](https://github.com/BetterErrors/better_errors) - A tool to provide better error page. [:red_circle:](https://rubygems.org/gems/better_errors)
- [brakeman](https://github.com/presidentbeef/brakeman) - A gem to scan code against security vulnerabilities. [:red_circle:](https://rubygems.org/gems/brakeman)
- [breadcrumbs_on_rails](https://github.com/weppos/breadcrumbs_on_rails) - A gem to create & manage breadcrumbs-style navigation. [:red_circle:](https://rubygems.org/gems/breadcrumbs_on_rails)
- [bulma-rails](https://github.com/joshuajansen/bulma-rails) - A wrapper for Bulma, a CSS framework based on flexbox. [:red_circle:](https://rubygems.org/gems/bulma-rails)
- [cancancan](https://github.com/cancancommunity/cancancan) - A gem to handle authorization. [:red_circle:](https://rubygems.org/gems/cancancan)
- [carrierwave](https://github.com/carrierwaveuploader/carrierwave) - A gem to handle file uploads. [:red_circle:](https://rubygems.org/gems/carrierwave)
- [caxlsx_rails](https://github.com/caxlsx/caxlsx_rails) - A gem to generate entity-relationship diagram. [:red_circle:](https://rubygems.org/gems/caxlsx_rails)
- [counter_culture](https://github.com/magnusvk/counter_culture) - A gem to provide counter caches. [:red_circle:](https://rubygems.org/gems/counter_culture)
- [devise](https://github.com/heartcombo/devise) - A gem to provide authentication. [:red_circle:](https://rubygems.org/gems/devise)
- [doorkeeper](https://github.com/doorkeeper-gem/doorkeeper) - A gem to introduce OAuth2 provider functionality. [:red_circle:](https://rubygems.org/gems/doorkeeper)
- [draper](https://github.com/drapergem/draper) - A gem to add presentation logic. [:red_circle:](https://rubygems.org/gems/draper)
- [factory_bot_rails](https://github.com/thoughtbot/factory_bot_rails) - A fixture replacement for testing in Rails [:red_circle:](https://rubygems.org/gems/factory_bot_rails)
- [filestack-rails](https://github.com/filestack/filestack-rails) - A gem to integrate Filestack. [:red_circle:](https://rubygems.org/gems/filestack-rails)
- [formtastic](https://github.com/formtastic/formtastic) - A Rails form builder gem with semantically rich and accessible markup. [:red_circle:](https://rubygems.org/gems/formtastic)
- [friendly_id](https://github.com/norman/friendly_id) - A gem to deal with slugs & permalinks. [:red_circle:](https://rubygems.org/gems/friendly_id)
- [frozen_record](https://github.com/byroot/frozen_record) - A gem to provide ActiveRecord-like interface to query static YAML files. [:red_circle:](https://rubygems.org/gems/frozen_record)
- [geokit-rails](https://github.com/geokit/geokit-rails) - A gem to integrate Geokit in Rails apps. [:red_circle:](https://rubygems.org/gems/geokit-rails)
- [good_job](https://github.com/bensheldon/good_job) - A gem to provide Postgres-based ActiveJob backend. [:red_circle:](https://rubygems.org/gems/good_job)
- [gretel](https://github.com/kzkn/gretel) - A tool to generate breadcrumbs. [:red_circle:](https://rubygems.org/gems/gretel)
- [groupdate](https://github.com/ankane/groupdate) - A gem to manage temporal data. [:red_circle:](https://rubygems.org/gems/groupdate)
- [hotwire-rails](https://github.com/hotwired/hotwire-rails) - A gem to integrate Hotwire in Rails apps. [:red_circle:](https://rubygems.org/gems/hotwire-rails)
- [image_optim_rails](https://github.com/toy/image_optim_rails) - A gem to handle image optimization. [:red_circle:](https://rubygems.org/gems/image_optim_rails)
- [js-routes](https://github.com/railsware/js-routes) - A tool to generate all Rails routes as JavaScript helpers. [:red_circle:](https://rubygems.org/gems/js-routes)
- [kaminari](https://github.com/kaminari/kaminari) - A gem to provide pagination. [:red_circle:](https://rubygems.org/gems/kaminari)
- [kt-paperclip](https://github.com/kreeti/kt-paperclip) - A gem to handle file uploads. [:red_circle:](https://rubygems.org/gems/kt-paperclip)
- [lockbox](https://github.com/ankane/lockbox) - A gem to deal with encryption. [:red_circle:](https://rubygems.org/gems/lockbox)
- [lograge](https://github.com/roidrage/lograge) - A gem to customize logger in Rails apps. [:red_circle:](https://rubygems.org/gems/lograge)
- [mailkick](https://github.com/ankane/mailkick) - A tool to handle mail unsubscriptions. [:red_circle:](https://rubygems.org/gems/mailkick)
- [marginalia](https://github.com/basecamp/marginalia) - A gem to attach comments to ActiveRecord's SQL queries. [:red_circle:](https://rubygems.org/gems/marginalia)
- [metka](https://github.com/jetrockets/metka) - A gem to manage tags using Postgresql array columns. [:red_circle:](https://rubygems.org/gems/metka)
- [money-rails](https://github.com/RubyMoney/money-rails) - A gem to integrate Money gem in Rails apps. [:red_circle:](https://rubygems.org/gems/money-rails)
- [paloma](https://github.com/gnclmorais/paloma) - A gem to manage page-specific JavaScript in Rails apps. [:red_circle:](https://rubygems.org/gems/paloma)
- [pgcli-rails](https://github.com/mattbrictson/pgcli-rails) - A replacement of `rails:dbconsole` command to manage Postgresql. [:red_circle:](https://rubygems.org/gems/pgcli-rails)
- [premailer-rails](https://github.com/fphilipe/premailer-rails) - A gem to handle email styling. [:red_circle:](https://rubygems.org/gems/premailer-rails)
- [prerender_rails](https://github.com/prerender/prerender_rails) - A gem to prerender JavaScript-rendered pages. [:red_circle:](https://rubygems.org/gems/prerender_rails)
- [rails-erd](https://github.com/voormedia/rails-erd) - A gem to generate entity-relationship diagram. [:red_circle:](https://rubygems.org/gems/rails-erd)
- [rails-mermaid_erd](https://github.com/koedame/rails-mermaid_erd) - A gem to interactively generate entity-relationship diagram in image or Markdown format. [:red_circle:](https://rubygems.org/gems/rails-mermaid_erd)
- [rails-settings-cached](https://github.com/huacnlee/rails-settings-cached) - A gem to manage global settings as key-value pairs. [:red_circle:](https://rubygems.org/gems/rails-settings-cached)
- [rails_admin](https://github.com/railsadminteam/rails_admin) - A gem to create & manage admin panel for Rails app. [:red_circle:](https://rubygems.org/gems/rails_admin)
- [rails_event_store](https://github.com/RailsEventStore/rails_event_store) - A gem to implement event store in Rails [:red_circle:](https://rubygems.org/gems/rails_event_store)
- [rails_semantic_logger](https://github.com/reidmorrison/rails_semantic_logger) - A gem to provide alternative logging approach for Rails app. [:red_circle:](https://rubygems.org/gems/rails_semantic_logger)
- [ranked-model](https://github.com/brendon/ranked-model) - A gem to handle sorting for rows. [:red_circle:](https://rubygems.org/gems/ranked-model)
- [ransack](https://github.com/activerecord-hackery/ransack) - A gem to provide search functionality. [:red_circle:](https://rubygems.org/gems/ransack)
- [react-rails](https://github.com/reactjs/react-rails) - A gem to integrate React.js with Rails app. [:red_circle:](https://rubygems.org/gems/react-rails)
- [react_on_rails](https://github.com/shakacode/react_on_rails) - A gem to integrate React.js with Rails app with SSR. [:red_circle:](https://rubygems.org/gems/react_on_rails)
- [redisWebManager](https://github.com/OpenGems/redis_web_manager) - Web interface that allows you to manage easily your Redis instance. [:red_circle:](https://rubygems.org/gems/redis_web_manager)
- [reform-rails](https://github.com/trailblazer/reform-rails) - A gem to wrap Reform gem, a form validation tool, with Rails app. [:red_circle:](https://rubygems.org/gems/reform-rails)
- [rgeo-activerecord](https://github.com/rgeo/rgeo-activerecord) - A gem to provide common tools used by RGeo-based spatial adapters. [:red_circle:](https://rubygems.org/gems/rgeo-activerecord)
- [rodauth-rails](https://github.com/janko/rodauth-rails) - A gem to wrap Rodauth, an authentication handler, for Rails apps. [:red_circle:](https://rubygems.org/gems/rodauth-rails)
- [rollup](https://github.com/ankane/rollup) - A gem to handle time-series data in Rails [:red_circle:](https://rubygems.org/gems/rollups)
- [route_translator](https://github.com/enriclluelles/route_translator) - A tool to handle route translation. [:red_circle:](https://rubygems.org/gems/route_translator)
- [rspec-rails](https://github.com/rspec/rspec-rails) - A testing framework. [:red_circle:](https://rubygems.org/gems/rspec-rails)
- [rubocop-rails](https://github.com/rubocop/rubocop-rails) - A code style checking tool. [:red_circle:](https://rubygems.org/gems/rubocop-rails)
- [scenic](https://github.com/scenic-views/scenic) - A gem to manage database views. [:red_circle:](https://rubygems.org/gems/scenic)
- [searchkick](https://github.com/ankane/searchkick) - A gem to provide search functionality. [:red_circle:](https://rubygems.org/gems/searchkick)
- [select2-rails](https://github.com/argerim/select2-rails) - A gem to integrate Select2 library in Rails apps. [:red_circle:](https://rubygems.org/gems/select2-rails)
- [sequel-activerecord_connection](https://github.com/janko/sequel-activerecord_connection) - A gem to allow Sequel to reuse an ActiveRecord connection. [:red_circle:](https://rubygems.org/gems/sequel-activerecord_connection)
- [shakapacker](https://github.com/shakacode/shakapacker) - A gem to use webpack to manage app-like JavaScript modules in Rails. [:red_circle:](https://rubygems.org/gems/shakapacker)
- [simple_form](https://github.com/heartcombo/simple_form) - A gem to handle forms. [:red_circle:](https://rubygems.org/gems/simple_form)
- [solidus](https://github.com/solidusio/solidus) - A fork of Spree gem, an open source e-commerce platform. [:red_circle:](https://rubygems.org/gems/solidus)
- [sorbet-rails](https://github.com/chanzuckerberg/sorbet-rails) - A gem to integrate Sorbet gem in Rails apps. [:red_circle:](https://rubygems.org/gems/sorbet-rails)
- [spree](https://github.com/spree/spree) - An open source e-commerce platform. [:red_circle:](https://rubygems.org/gems/spree)
- [spring](https://github.com/rails/spring) - A gem to preload Rails app. [:red_circle:](https://rubygems.org/gems/spring)
- [sprockets](https://github.com/rails/sprockets) - A gem to compile & serve web assets. [:red_circle:](https://rubygems.org/gems/sprockets)
- [stimulus-rails](https://github.com/hotwired/stimulus-rails) - A gem to integrate Stimulus.js in Rails apps. [:red_circle:](https://rubygems.org/gems/stimulus-rails)
- [tinymce-rails](https://github.com/spohlenz/tinymce-rails) - A gem to integrate Tinymce in Rails apps. [:red_circle:](https://rubygems.org/gems/tinymce-rails)
- [transloadit-rails](https://github.com/transloadit/rails-sdk) - A gem to integrate Transloadit's file uploading and encoding service. [:red_circle:](https://rubygems.org/gems/transloadit-rails)
- [trove](https://github.com/ankane/trove) - A gem to handle machine learning models deployment. [:red_circle:](https://rubygems.org/gems/trove)
- [turbo-rails](https://github.com/hotwired/turbo-rails) - A gem to integrate Turbo.js in Rails apps. [:red_circle:](https://rubygems.org/gems/turbo-rails)
- [view_component](https://github.com/ViewComponent/view_component) - A gem to introduce view components. [:red_circle:](https://rubygems.org/gems/view_component)
- [webpacker](https://github.com/rails/webpacker) - A gem to bundle web assets using Webpack. [:red_circle:](https://rubygems.org/gems/webpacker)
- [zeitwerk](https://github.com/fxn/zeitwerk) - A gem to handle thread-safe code loading. [:red_circle:](https://rubygems.org/gems/zeitwerk)
[Back to top][link_toc]
## Starters/Boilerplates
- [default_rails_template](https://github.com/infinum/default_rails_template) - Default template for generating new Rails applications.
- [docker-Rails-Template](https://github.com/Ruby-Starter-Kits/Docker-Rails-Template) - A freshly updated version of "rails new", preconfigured to be run with Docker.
- [docker-rails](https://github.com/ledermann/docker-rails)
- [jumpstart(excid3)](https://github.com/excid3/jumpstart) - Easily jumpstart a new Rails application with a bunch of great features by default.
- [jumpstart(thomasvanholder)](https://github.com/thomasvanholder/jumpstart) - Template for set-up of Rails 6, Tailwind 2.0 and Devise.
- [kickoff_tailwind](https://github.com/justalever/kickoff_tailwind) - A rapid Rails 6 application template for personal use bundled with Tailwind CSS.
- [rails-devise-graphql](https://github.com/zauberware/rails-devise-graphql) - A Rails 6 boilerplate to create your next Saas product. Preloaded with graphQL, devise, JWT, CanCanCan, RailsAdmin, Rubocop, Rspec, and more.
- [rails-template(mattbrictson)](https://github.com/mattbrictson/rails-template) - Application template for Rails 6 projects; preloaded with best practices for TDD, security, deployment, and developer productivity.
- [rails-template(TristanToye)](https://github.com/TristanToye/rails-template) - MVP Ready Rails - A Template for Your Next Rails App
- [rails-template(ackama)](https://github.com/ackama/rails-template) - Application template for Rails 6.1 projects; preloaded with best practices for TDD, security, deployment, and developer productivity.
- [rails-template(astrocket)](https://github.com/astrocket/rails-template) - Template for Rails 6.0 + Kubernetes + Webpacker + Stimulus + TailwindCSS + Let's Encrypt.
- [rails-template(dao42)](https://github.com/dao42/rails-template) - A best & newest & fastest rails 6.x template for senior rails developer.
- [rails-templates(lewagon)](https://github.com/lewagon/rails-templates) - Jump start your Rails development with Le Wagon best practices.
- [rails-templates(nimblehq)](https://github.com/nimblehq/rails-templates) - Our optimized Rails templates used in our projects.
- [rails-vue-template](https://github.com/scottrobertson/rails-vue-template) - An example of how to use VueJS as a single page application inside Rails using Webpacker.
- [rails_new](https://github.com/lockstep/rails_new) - A thoughtfully designed template for building modern Rails apps. Get started in minutes instead of hours.
- [suspenders](https://github.com/thoughtbot/suspenders) - A Rails template with our standard defaults, ready to deploy to Heroku.
- [vuejs-rails-starterkit](https://github.com/jetthoughts/vuejs-rails-starterkit) - Vue.js + Rails Starting Kit GitHub Template to develop Hybrid Mobile Application.
- [rails_api_base](https://github.com/rootstrap/rails_api_base) - Rails 6 boilerplate project for JSON RESTful APIs.
- [rails_hotwire_base](https://github.com/rootstrap/rails_hotwire_base) - Rails 6 boilerplate project with Hotwire for full-stack applications with a modern SPA-like experience.
## Other Rails Tools
### Platforms
- [Nanobox](https://github.com/nanobox-io/nanobox) - A micro-PaaS (μPaaS) for creating consistent, isolated, development environments deployable anywhere
[Back to top][link_toc]
### Generators
| Generator | Ready to run | Complex Apps | Sets git | Heroku config |
| --------- | ------------ | ------------ | -------- | ------------- |
| [Rails Composer](https://github.com/RailsApps/rails-composer)| yes, but Stripe needs to be configured | Example apps reaching a SaaS with Stripe. | yes | yes |
[Back to top][link_toc]
### DevTools
- [rails-dashboard](https://github.com/y-takey/rails-dashboard) - A dev-tool to improve your rails log.
- [Optic](https://github.com/opticdev/optic) - Optic automatically documents and tests your APIs.
[Back to top][link_toc]
[link_toc]: #table-of-contents
[link_rails_source]: https://github.com/rails/rails
|
3,404 | Ruby on Rails Custom Error Pages | 
<!-- Intro -->
<div id="intro">
<h4 align="center"><code><strong><a href="https://www.github.com/richpeck/exception_handler">ExceptionHandler</a></strong></code> is presently the MOST POPULAR exceptions gem for <a href="https://medium.com/ruby-on-rails-web-application-development/custom-400-500-error-pages-in-ruby-on-rails-exception-handler-3a04975e4677">CUSTOM Rails error pages</a>.</h4>
<p align="center">
With <strong>290,000+ downloads</strong>, it is the *only* gem to provide <strong>custom 400/500 exception pages for Rails 5 & 6</strong>
</p>
<p><img src="./readme/dev.png" /></p>
<h4 align="center">Current <a href="https://github.com/richpeck/exception_handler/releases"><u>0.8.0.0</u></a> (August 2018)</h4>
</div>
<!-- Badges -->
<p align="center">
<a href="http://badge.fury.io/rb/exception_handler"><img src="https://badge.fury.io/rb/exception_handler.svg" align="absmiddle"></a>
<a href="http://rubygems.org/gems/exception_handler"><img src="http://ruby-gem-downloads-badge.herokuapp.com/exception_handler/0.5.1?type=total&color=brightgreen" align="absmiddle" /></a>
<a href="https://codeclimate.com/github/richpeck/exception_handler"><img src="https://codeclimate.com/github/richpeck/exception_handler/badges/gpa.svg" align="absmiddle"/></a>
<a href='https://coveralls.io/github/richpeck/exception_handler?branch=master'><img src='https://coveralls.io/repos/github/richpeck/exception_handler/badge.svg?branch=master' alt='Coverage Status' align="absmiddle" /></a>
<a href="https://travis-ci.org/richpeck/exception_handler"><img src="https://travis-ci.org/richpeck/exception_handler.svg?branch=master" align="absmiddle"></a>
</p>
<!-- Navigation -->
<div id="navigation">
<p align="center"><img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" /></p>
<p align="center">
<strong>
📝 <a href="#introduction">Introduction</a> -
⚠️ <a href="#installation">Installation</a> -
🔧 <a href="#configuration">Configuration</a> -
☎️ <a href="#support">Support</a> -
⭐ <a href="#changelog">Changelog</a>
</strong>
</p>
<p align="center"><img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" /></p>
</div>
<!-- Introduction -->
<div id="introduction">
<h4>📝 Introduction</h4>
</div>
---
<div>
<p><b><code>ExceptionHandler</b></code> replaces Rails' default error pages with <strong>dynamic views</strong>.</p>
<p>It does this by injecting <a href="https://guides.rubyonrails.org/configuring.html#rails-general-configuration"><code>config.exceptions_app</code></a> with our controller - allowing us to populate erroneous responses with our own HTML. To understand how this works, you need to appreciate how Rails handles errors:</p>
<p align="center"><a href="https://github.com/rails/rails/blob/master/actionpack/lib/action_dispatch/middleware/show_exceptions.rb#L44"><img src="readme/show_exceptions.png" width="550"></a></p>
<p>Rails uses <a href="https://github.com/rails/rails/blob/master/actionpack/lib/action_dispatch/middleware/show_exceptions.rb"><code><strong>ActionDispatch::ShowExceptions</strong></code></a> (above) to generate error responses.</p>
<p>Because web browsers (Rails is a web framework) can only interpret <a href="https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol#Response_message">HTTP responses</a>, Ruby/Rails exceptions have to be translated into something a browser can read. This is done by calling the above middleware.</p>
<p>--</p>
<p>As highlighted, an HTTP response is built independent of the Rails stack. This includes assigning an HTTP status code and HTML response body. It's the response body which <code><strong>ExceptionHandler</strong></code> is designed to override.</p>
</div>
<!-- Sep -->
<p align="center">
<img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" />
</p>
<!-- Installation -->
<div id="installation">
<h4>⚠️ Installation</h4>
</div>
---
<div>
<p>
💎 <u><a href="https://rubygems.org/gems/exception_handler">RubyGems</a></u> (Code) |
💻 <u><a href="https://medium.com/ruby-on-rails-web-application-development/custom-400-500-error-pages-in-ruby-on-rails-exception-handler-3a04975e4677">Medium</a></u> (Tutorial)
</p>
<pre><code># Gemfile
gem 'exception_handler', '~> 0.8.0.0'</code></pre>
<p>Because <b>ExceptionHandler</b> is built around a Rails engine, there is <b>nothing</b> to be done to get it working in production. Installing the Gem <b><i>should</i></b> translate your production 4xx/5xx error pages into dynamic views.</p>
<p>Environments <u>other</u> than production (development/staging) required the <a href="#dev"><code>dev</code></a> variable to be <code>true</code>.</p>
</div>
<!-- Sep -->
<p align="center">
<img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" />
</p>
<!-- configuration -->
<div id="configuration">
<h4>🔧 Configuration</h4>
</div>
---
<p align="center">
<g-emoji class="g-emoji" alias="file_folder" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/1f4c1.png">📁</g-emoji> <a href="#config">Config</a> <g-emoji class="g-emoji" alias="computer" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/1f4bb.png">💻</g-emoji> <a href="#dev" title="Dev Mode">Dev</a> <g-emoji class="g-emoji" alias="floppy_disk" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/1f4be.png">💾</g-emoji> <a href="#db">Database</a> <g-emoji class="g-emoji" alias="email" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/2709.png">✉️</g-emoji> <a href="#email">Email</a> <g-emoji class="g-emoji" alias="eyeglasses" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/1f453.png">👓</g-emoji> <a href="#views">Views</a> <g-emoji class="g-emoji" alias="speech_balloon" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/1f4ac.png">💬</g-emoji> <a href="#locales">Locales</a> <g-emoji class="g-emoji" alias="clipboard" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/1f4cb.png">📋</g-emoji> <a href="#layouts">Layouts</a> <g-emoji class="g-emoji" alias="no_entry" fallback-src="https://github.githubassets.com/images/icons/emoji/unicode/26d4.png">⛔️</g-emoji> <a href="#custom-exceptions">Custom Exceptions</a>
</p>
---
<!-- Config -->
<a name="config"></a>
The **ONLY** thing you need to manage `ExceptionHandler` is its [`config`](https://github.com/richpeck/exception_handler/blob/master/lib/exception_handler/config.rb) settings.
Whilst the gem **works out of the box** (without any configuration), if you want to manage the [`layouts`](#layouts), [`email`](#email), [`dev`](#dev) or the [`database`](#db), you'll need to set the appropriate values in the config hash.
This is done in `config/application.rb` or `config/environments/[env].rb` ↴
```rb
# config/application.rb
module YourApp
class Application < Rails::Application
# => This is an example of ALL available config options
# => You're able to see exactly how it works here:
# => https://github.com/richpeck/exception_handler/blob/master/lib/exception_handler/config.rb
# => Config hash (no initializer required)
config.exception_handler = {
dev: nil, # allows you to turn ExceptionHandler "on" in development
db: nil, # allocates a "table name" into which exceptions are saved (defaults to nil)
email: nil, # sends exception emails to a listed email (string // "[email protected]")
# Custom Exceptions
custom_exceptions: {
#'ActionController::RoutingError' => :not_found # => example
},
# On default 5xx error page, social media links included
social: {
facebook: nil, # Facebook page name
twitter: nil, # Twitter handle
youtube: nil, # Youtube channel name / ID
linkedin: nil, # LinkedIn name
fusion: nil # FL Fusion handle
},
# This is an entirely NEW structure for the "layouts" area
# You're able to define layouts, notifications etc ↴
# All keys interpolated as strings, so you can use symbols, strings or integers where necessary
exceptions: {
:all => {
layout: "exception", # define layout
notification: true, # (false by default)
deliver: #something here to control the type of response
},
:4xx => {
layout: nil, # define layout
notification: true, # (false by default)
deliver: #something here to control the type of response
},
:5xx => {
layout: "exception", # define layout
notification: true, # (false by default)
deliver: #something here to control the type of response
},
500 => {
layout: "exception", # define layout
notification: true, # (false by default)
deliver: #something here to control the type of response
},
# This is the old structure
# Still works but will be deprecated in future versions
501 => "exception",
502 => "exception",
503 => "exception",
504 => "exception",
505 => "exception",
507 => "exception",
510 => "exception"
}
}
end
end
```
For a full retinue of the available options, you'll be best looking at the [`config`](https://github.com/richpeck/exception_handler/blob/master/lib/exception_handler/config.rb) file itself.
--
If using an [`engine`](http://guides.rubyonrails.org/engines.html), you **DON'T need an `initializer`**:
```rb
# lib/engine.rb
module YourModule
class Engine < Rails::Engine
# => ExceptionHandler
# => Works in and out of an initializer
config.exception_handler = {
dev: nil, # => this will not load the gem in development
db: true # => this will use the :errors table to store exceptions
}
end
end
```
The best thing about using a `config` options block is that you are able to only define the options that you require.
If you have particular options you *only* wish to run in `staging`, or have single options for `production` etc, this setup gives you the ability to manage it properly...
---
<!-- Dev -->
<div id="dev">
<h5>💻 Dev</h5>
</div>
As explained, `ExceptionHandler` does *not* work in `development` by default.
This is because it overrides the `exceptions_app` middleware hook - which is *only* invoked in `production` or `staging`.
<p align="center">
<img src="./readme/dev.png" />
</p>
To get it working in `development`, you need to override the [`config.consider_all_requests_local`](http://guides.rubyonrails.org/configuring.html#rails-general-configuration) setting (a standard component of Rails) - setting it to "false" ↴
<p align="center">
<img src="./readme/local_requests.jpg" />
</p>
This is normally done by changing the setting in your Rails config files. However, to make the process simpler for `ExceptionHandler`- we've added a `dev` option which allows you to override the hook through the context of the gem...
```rb
# config/application.rb
config.exception_handler = { dev: true }
```
This disables [`config.consider_all_requests_local`](http://guides.rubyonrails.org/configuring.html#rails-general-configuration), making Rails behave as it would in production.
Whilst simple, it's not recommended for extended use. Very good for testing new ideas etc.
---
<!-- DB -->
<div id="db">
<h5>💾 DB</h5>
</div>
To save exceptions to your database, you're able to set the `db` option.
Because we use a `controller` to manage the underlying way the system works, we're able to invoke the likes of a [`model`](https://github.com/richpeck/exception_handler/blob/master/app/models/exception_handler/exception.rb) with other functionality.
Ths is done automatically with the latest version of `ExceptionHandler`.
To do this, once you've populated the option with either `true` or a `string`, run `rails db:migrate` from your console.
Our new [`migration system`](https://github.com/richpeck/exception_handler/tree/readme#migrations) will automatically run the migration.
```rb
# config/application.rb
config.exception_handler = { db: true }
```
This enables `ActiveRecord::Base` on the [`Exception`](app/models/exception_handler/exception.rb) class, allowing us to save to the database.
In order for this to work, your db needs the correct table.
---
<!-- Email -->
<div id="email">
<h5>✉️ Email</h5>
</div>
`ExceptionHandler` also sends **email notifications**.
If you want to receive emails whenever your application raises an error, you can do so by adding your email to the config:
```rb
# config/application.rb
config.exception_handler = {
email: "[email protected]"
}
```
> **Please Note** this requires [`ActionMailer`](http://guides.rubyonrails.org/action_mailer_basics.html). If you don't have any outbound SMTP server, [`SendGrid`](http://sendgrid.com) is free.
From version [`0.8.0.0`](https://github.com/richpeck/exception_handler/releases/tag/v0.8.0.0), you're able to define whether email notifications are sent on a per-error basis:
```rb
# config/application.rb
config.exception_handlder = {
# This has to be present for any "notification" declarations to work
# Defaults to 'false'
email: "[email protected]",
# Each status code in the new "exceptions" block allows us to define whether email notifications are sent
exceptions: {
:all => { notification: true },
:50x => { notification: false },
500 => { notification: false }
}
}
```
---
<!-- Views -->
<div id="views">
<h5>👓 Views</h5>
</div>
What *most* people want out of the view is to change the way it ***looks***. This can be done without changing the "view" itself.
To better explain, if [`ExceptionsController`](https://github.com/richpeck/exception_handler/blob/master/app/controllers/exception_handler/exceptions_controller.rb) is invoked (by `exceptions_app`), it has **ONE** method ([`show`](https://github.com/richpeck/exception_handler/blob/master/app/controllers/exception_handler/exceptions_controller.rb#L42)).
This method calls the [`show` view](https://github.com/richpeck/exception_handler/blob/master/app/views/exception_handler/exceptions/show.html.erb), which is *entirely* dependent on the locales for content & the layout for the look.
This means that if you wish to change how the view "looks" - you're *either* going to want to change your [layout][layouts] or the [*locales*](#locales). There is NO reason to change the `show` view itself - it's succinct and entirely modular. Whilst you're definitely at liberty to change it, you'll just be making the issue more complicated than it needs to be.
--
We've also included a number of routes which shows in [`dev`](dev) mode (allowing you to test):
<p align="center">
<img src="./readme/routes.jpg" />
</p>
---
<!-- Locales -->
<div id="locales">
<h5>💬 Locales</h5>
</div>
[Locales](https://github.com/richpeck/exception_handler/blob/Readme/config/locales/exception_handler.en.yml) are used to create interchangeable text (translations/internationalization).
--
In `ExceptionHandler`, it provides the wording for each type of error code.
By default, the English name of the error is used (`"404"` will appear as `"Not Found"`) - if you want to create custom messages, you're able to do so by referencing the error's ["status_code"](https://github.com/rack/rack/blob/master/lib/rack/utils.rb#L492) within your locales file:
```yml
# config/locales/en.yml
en:
exception_handler:
not_found: "Your message here" # -> 404 page
unauthorized: "You need to login to continue"
internal_server_error: "This is a test to show the %{status} of the error"
```
You get access to [`%{message}` and `%{status}`](https://github.com/richpeck/exception_handler/blob/master/app/views/exception_handler/exceptions/show.html.erb#L1), both inferring from an [`@exception`](https://github.com/richpeck/exception_handler/blob/master/app/controllers/exception_handler/exceptions_controller.rb#L20) object we invoke in the controller...
- `%{message}` is the error's actual message ("XYZ file could not be shown")
- `%{status}` is the error's status code ("Internal Server Error")
--
By default, only `internal_server_error` is customized by the gem:
```yml
# config/locales/en.yml
en:
exception_handler:
internal_server_error: "<strong>%{status} Error</strong> %{message}"
```
---
<!-- Layouts -->
<div id="layouts">
<h5>📋 Layouts</h5>
</div>
The most attractive feature of `ExceptionHandler` (for most) is its ability to manage [`layouts`](https://guides.rubyonrails.org/layouts_and_rendering.html#structuring-layouts) for HTTP status.
--
The reason for this is due to the way in which Rails works → the "layout" is a "wrapper" for the returned HTML (the "styling" of a page). If you have no layout, it will render the "view" HTML and nothing else.
This means if you want to change the "look" of a Rails action, you simply have to be able to change the `layout`. You should not change the view at all.
To this end, `ExceptionHandler` has been designed around providing a [SINGLE VIEW](app/controllers/exception_handler/exceptions_controller.rb#L44) for exceptions. This view does not need to change (although you're welcome to use a [`generator`][generators] to do so) - the key is the `layout` that's assigned...
- [`4xx`](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors) errors are given a `nil` layout (by default) (inherits from `ApplicationController` in your main app)
- [`5xx`](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#5xx_Server_errors) errors are assigned our own [`exception`](app/views/layouts/exception.html.erb) layout:
```rb
# config/application.rb
config.exception_handler = {
# The new syntax allows us to assign different values to each HTTP status code
# At the moment, only 'layout' & 'notification' are supported
# We plan to include several more in the future...
exceptions: {
all: { layout: nil } # -> this will inherit from ApplicationController's layout
}
}
```
The `layout` system has changed between [`0.7.7.0`](releases/tag/v0.7.7.0) and [`0.8.0.0`](releases/tag/v0.8.0.0).
Building on the former's adoption of HTTP status-centric layouts, it is now the case that we have the `all`, `5xx` and `4xx` options - allowing us to manage the layouts for blocks of HTTP errors respectively:
```rb
# config/application.rb
config.exception_handler = {
# Old (still works)
# No "all" / "4xx"/"5xx" options
layouts: {
500 => 'exception',
501 => 'exception'
},
# New
exceptions: {
:all => { layout: 'exception' },
:4xx => { layout: 'exception' },
:5xx => { layout: 'exception' }, # -> this overrides the :all declaration
500 => { layout: nil } # -> this overrides the 5xx declaration
}
}
```
We've bundled the [`exception`](app/views/layouts/exception.html.erb) layout for `5xx` errors because since these denote internal server errors, it's best to isolate the view system as much as possible. Whilst you're at liberty to change it, we've found it sufficient for most use-cases.
---
<!-- Custom Exceptions -->
<div id="custom-exceptions">
<h5>⛔️ Custom Exceptions</h5>
</div>
As mentioned, Rails' primary role is to convert Ruby exceptions into HTTP errors.
Part of this process involves mapping Ruby/Rails exceptions to the equivalent HTTP status code.
This is done with [`config.action_dispatch.rescue_responses`](https://github.com/rack/rack/blob/master/lib/rack/utils.rb#L492).
<p align="center">
<img src="./readme/custom_exceptions.png" />
</p>
Whilst this works well, it may be the case that you want to map your own classes to an HTTP status code (default is `Internal Server Error`).
If you wanted to keep this functionality inside `ExceptionHandler`, you're able to do it as follows:
```rb
# config/application.rb
config.exception_handler = {
custom_exceptions: {
'CustomClass::Exception' => :not_found
}
}
```
Alternatively, you're able to still do it with the default Rails behaviour:
```rb
# config/application.rb
config.action_dispatch.rescue_responses = { 'CustomClass::Exception' => :not_found }
```
---
<!-- Generators -->
<div id="generators">
<h5>💼 Generators</h5>
</div>
If you want to edit the `controller`, `views`, `model` or `assets`, you're able to invoke them in your own application.
This is done - as with other gems - with a single [`generator`](https://github.com/richpeck/exception_handler/blob/master/lib/generators/exception_handler/views_generator.rb) which takes a series of arguments:
rails g exception_handler:views
rails g exception_handler:views -v views
rails g exception_handler:views -v controllers
rails g exception_handler:views -v models
rails g exception_handler:views -v assets
rails g exception_handler:views -v views controllers models assets
If you don't include any switches, this will copy **all** `ExceptionHandler`'s folders put into your app.
Each switch defines which folders you want (EG `-v views` will only copy `views` dir).
---
<!-- Migrations -->
<div id="migrations">
<h5>✔️ Migrations</h5>
</div>
You **DON'T** need to generate a migration anymore.
From [`0.7.5`](https://github.com/richpeck/exception_handler/releases/tag/0.7.5), the `migration` generator has been removed in favour of our own [migration system](lib/exception_handler/engine.rb#L58).
The reason we did this was so not to pollute your migrations folder with a worthless file. Our migration doesn't need to be changed - we only have to get it into the database and the gem takes care of the rest...
> If you set the [`db`][db] option in config, run `rails db:migrate` and the migration will be run.
To rollback, use the following:
rails db:migrate:down VERSION=000000
The drawback to this is that if you remove `ExceptionHandler` before you rollback the migration, it won't exist anymore.
You can **only** fire the `rollback` when you have `ExceptionHandler` installed.
<!-- Sep -->
<p align="center">
<img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" />
</p>
<!-- Support-->
<div id="support">
<h4>☎️ Support</h4>
</div>
---
<div>
<p>You're welcome to contact me directly at <u><a href="mailto:[email protected]"></a><a href="mailto:[email protected]" ref="nofollow">[email protected]</a></u>.</p>
<p>Alternatively, you may wish to post on our <u><a href="https://github.com/richpeck/exception_handler/issues">GitHub Issues</a></u>, or <u><a href="https://stackoverflow.com/questions/tagged/ruby-on-rails+exceptionhandler" rel="nofollow">StackOverflow</a></u>.</p>
<p>--</p>
<p><a href="https://medium.com/ruby-on-rails-web-application-development/custom-400-500-error-pages-in-ruby-on-rails-exception-handler-3a04975e4677" rel="nofollow"><img src="readme/medium.png" target="_blank" alt="Medium" style="max-width:100%;"></a></p>
</div>
<!-- Sep -->
<p align="center">
<img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" />
</p>
<!-- Changelog -->
<div id="changelog">
<h4>⭐ Changelog</h4>
</div>
---
[**1.0.0.0**](https://github.com/richpeck/exception_handler/releases/tag/v1.0.0.0)
- [ ] TBA
[**0.8.0.0**](https://github.com/richpeck/exception_handler/releases/tag/v0.8.0.0)
- [x] [README](https://github.com/richpeck/exception_handler/issues/52) (focus on utility)
- [x] Introduction of `4xx`,`5xx`,`:all` for layouts config
- [x] Changed `layouts` to `exceptions` in config
- [x] Email improvement
- [x] Streamlined migration
- [x] Updated model
[**0.7.7.0**](https://github.com/richpeck/exception_handler/releases/tag/v0.7.7.0)
- [x] [HTTP status layouts](#layouts)
**0.7.0.0**
- [x] Wildcard mime types
- [x] [Custom exceptions](#custom_exceptions)
- [x] Test suite integration
- [x] [Model backend](#database)
- [x] Sprockets 4+
- [x] New layout
- [x] Readme / wiki overhaul
**0.6.5.0**
- [x] Streamlined interface
- [x] ActiveRecord / Middleware overhaul
- [x] Supports Sprockets 4+ ([`manifest.js`](http://eileencodes.com/posts/the-sprockets-4-manifest/))
- [x] Email integration
- [x] Asset overhaul & improvement
- [x] Removed dependencies
**0.5.0.0**
- [x] Locales
- [x] Email notifications
- [x] Full test suite
- [x] Rails 4.2 & Rails 5.0 native ([`request.env`](https://github.com/rails/rails/commit/05934d24aff62d66fc62621aa38dae6456e276be) fix)
- [x] Controller fixed
- [x] `DB` fixed
- [x] Legacy initializer support ([more](https://github.com/richpeck/exception_handler/wiki/1-Setup))
- [x] Rails asset management improvement
- [x] Reduced gem file size
**0.4.7.0**
- [x] New config system
- [x] Fixed controller layout issues
- [x] Streamlined middleware
- [x] New layout & interface
<!-- Sep -->
<p align="center">
<img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" />
</p>
[![404 + 500 Errors][banner]][rubygems]
<p align="center">
<strong><a href="https://rubygems.org/gems/exception_handler"><code>ExceptionHandler</code></a> provides custom error pages gem for Rails 5+</strong>
<br />
No other gem is as simple or effective at providing branded exception pages in production
</p>
<p align="center">
<a href="http://badge.fury.io/rb/exception_handler"><img src="https://badge.fury.io/rb/exception_handler.svg" align="absmiddle"></a>
<a href="http://rubygems.org/gems/exception_handler"><img src="http://ruby-gem-downloads-badge.herokuapp.com/exception_handler/0.5.1?type=total&color=brightgreen" align="absmiddle" /></a>
<a href="https://codeclimate.com/github/richpeck/exception_handler"><img src="https://codeclimate.com/github/richpeck/exception_handler/badges/gpa.svg" align="absmiddle"/></a>
<a href='https://coveralls.io/github/richpeck/exception_handler?branch=master'><img src='https://coveralls.io/repos/github/richpeck/exception_handler/badge.svg?branch=master' alt='Coverage Status' align="absmiddle" /></a>
<a href="https://travis-ci.org/richpeck/exception_handler"><img src="https://travis-ci.org/richpeck/exception_handler.svg?branch=master" align="absmiddle"></a>
</p>
<p align="center">
<strong>➡️ <a href="https://rubygems.org/gems/exception_handler">Download & Info</a> ⬅️</strong>
</p>
<!-- Sep -->
<p align="center">
<img src="https://cdn-images-1.medium.com/max/800/1*CKyKxRXLovcrUOB-s8_jCw.png" width="100%" />
</p>
:copyright: <a href="http://www.fl.co.uk" align="absmiddle" ><img src="readme/fl.jpg" height="22" align="absmiddle" /></a> <a href="http://stackoverflow.com/users/1143732/richard-peck?tab=profile" align="absmiddle" ><img src="https://avatars0.githubusercontent.com/u/1104431" height="22" align="absmiddle" /></a> <a href="https://github.com/joehilton" align="absmiddle" ><img src="https://avatars2.githubusercontent.com/u/5063592?s=460&v=4" height="22" align="absmiddle" /></a> <a href="https://github.com/toymachiner62" align="absmiddle" ><img src="https://avatars3.githubusercontent.com/u/485782" height="22" align="absmiddle" /></a> <a href="https://github.com/andrewclink" align="absmiddle" ><img src="https://avatars0.githubusercontent.com/u/688916" height="22" align="absmiddle" /></a> <a href="https://github.com/Startouf" align="absmiddle" ><img src="https://avatars2.githubusercontent.com/u/7388889" height="22" align="absmiddle" /></a> <a href="https://github.com/Tonkonozhenko" align="absmiddle" ><img src="https://avatars0.githubusercontent.com/u/1307646" height="22" align="absmiddle" /></a> <a href="https://github.com/mabako" align="absmiddle" ><img src="https://avatars3.githubusercontent.com/u/125113" height="22" align="absmiddle" /></a> <a href="https://github.com/frankzhao" align="absmiddle" ><img src="https://avatars3.githubusercontent.com/u/555499" height="22" align="absmiddle" /></a>
<!-- ################################### -->
<!-- ################################### -->
<!-- Refs -->
<!-- Comments http://stackoverflow.com/a/20885980/1143732 -->
<!-- Images https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet#images -->
<!-- Images -->
[banner]:readme/banner.jpg
<!-- Links -->
[rubygems]: http://rubygems.org/gems/exception_handler
[10x]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#1xx_Informational_responses
[20x]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#2xx_Success
[30x]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#3xx_Redirection
[40x]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors
[50x]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#5xx_Server_errors
<!-- Local Links -->
[db]: #db
[email]: #email
[dev]: #dev
[layouts]: #layouts
[locales]: #locales
[configuration]: #configuration
[generators]: #generators
[custom-exceptions]: #custom-exceptions
<!-- ################################### -->
<!-- ################################### -->
|
3,405 | AlchemyCMS is a Rails CMS engine | # AlchemyCMS
[](http://badge.fury.io/rb/alchemy_cms)
[](https://github.com/AlchemyCMS/alchemy_cms/actions)
[](https://codeclimate.com/github/AlchemyCMS/alchemy_cms/maintainability)
[](https://codeclimate.com/github/AlchemyCMS/alchemy_cms/test_coverage)
[](https://depfu.com/github/AlchemyCMS/alchemy_cms?project_id=4600)
[](https://slackin.alchemy-cms.com)
[](https://houndci.com)
[](#backers)
[](#sponsors)
<img src="./app/assets/images/alchemy/alchemy-logo.svg" width=300>
Alchemy is an open source CMS engine written in Ruby on Rails.
Read more about Alchemy on the [website](https://alchemy-cms.com) and in the [guidelines](https://guides.alchemy-cms.com).
**CAUTION: This main branch is a development branch that *can* contain bugs. For productive environments you should use the [current Ruby gem version](https://rubygems.org/gems/alchemy_cms), or the [latest stable branch (6.0-stable)](https://github.com/AlchemyCMS/alchemy_cms/tree/6.0-stable).**
## ✅ Features
- Flexible templating that separates content from markup
- A rich RESTful API
- Intuitive admin interface with live preview
- Multi language and multi domain
- Page versioning
- SEO friendly urls
- User Access Control
- Build in contact form mailer
- Attachments and downloads
- On-the-fly image cropping and resizing
- Extendable via Rails engines
- Integrates into existing Rails Apps
- Resourceful Rails admin
- Flexible caching
- Hostable on any Server that supports Ruby on Rails, a SQL Database and ImageMagick
## 🎮 Demo
Deploy your own free demo on Heroku
[](https://heroku.com/deploy?template=https://github.com/AlchemyCMS/alchemy-demo)
or visit the existing demo at https://alchemy-demo.herokuapp.com
- Login: `demo`
- Password: `demo123`
## 🚂 Rails Version
**This version of AlchemyCMS runs with Rails 7.0, 6.1 and 6.0**
* For a Rails 5.2 compatible version use the [`5.3-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/5.3-stable).
* For a Rails 5.0 or 5.1 compatible version use the [`4.5-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/4.5-stable).
* For a Rails 4.2 compatible version use the [`3.6-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/3.6-stable).
* For a Rails 4.0/4.1 compatible version use the [`3.1-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/3.1-stable).
* For a Rails 3.2 compatible version use the [`2.8-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/2.8-stable).
* For a Rails 3.1 compatible version use the [`2.1-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/2.1-stable).
* For a Rails 3.0 compatible version use the [`2.0-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/2.0-stable).
* For a Rails 2.3 compatible version use the [`1.6-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/1.6-stable).
## 💎 Ruby Version
Alchemy runs with Ruby >= 2.5.0.
For a Ruby 2.4 compatible version use the [`5.2-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/5.2-stable).
For a Ruby 2.2 compatible version use the [`4.1-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/4.1-stable).
For a Ruby 2.1 compatible version use the [`3.6-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/3.6-stable).
For a Ruby 2.0.0 compatible version use the [`3.2-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/3.2-stable).
For a Ruby 1.9.3 compatible version use the [`3.1-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/3.1-stable).
For a Ruby 1.8.7 compatible version use the [`2.3-stable` branch](https://github.com/AlchemyCMS/alchemy_cms/tree/2.3-stable).
## ⌨️ Installation
### Stand Alone Installation
If you do not have a Rails project yet or just want to check out Alchemy, then use this Rails template.
Make sure you have Rails installed first:
```
$ gem install rails
```
Then create a new Rails project with:
```
$ rails new -m https://raw.githubusercontent.com/AlchemyCMS/rails-templates/master/all.rb <MY-PROJECT-NAME>
```
and follow the on screen instructions.
### Manual Installation
If you want to manually install Alchemy into your Rails project follow these steps.
#### Add the Alchemy gem:
Put Alchemy into your `Gemfile` with:
```
$ bundle add alchemy_cms
```
#### Set the authentication user
Now you have to decide, if you want to use your own user model or if you want to use
the Devise based user model that Alchemy provides and was extracted [into its own gem](https://github.com/AlchemyCMS/alchemy-devise).
##### Use Alchemy user
If you don't have your own user class, you can use the Alchemy user model. Just add the following gem into your `Gemfile`:
```
$ bundle add alchemy-devise
```
Then run the `alchemy-devise` installer:
```bash
$ bin/rails g alchemy:devise:install
```
##### Use your User model
In order to use your own user model you need to tell Alchemy about it.
The best practice is to use an initializer:
```ruby
# config/initializers/alchemy.rb
Alchemy.user_class_name = 'YourUserClass' # Defaults to 'User'
Alchemy.current_user_method = 'current_admin_user' # Defaults to 'current_user'
Alchemy.signup_path = '/your/signup/path' # Defaults to '/signup'
Alchemy.login_path = '/your/login/path' # Defaults to '/login'
Alchemy.logout_path = '/your/logout/path' # Defaults to '/logout'
Alchemy.logout_method = 'http_verb_for_logout' # Defaults to 'delete'
```
The only thing Alchemy needs to know from your user class is the `alchemy_roles` method.
This method has to return an `Array` (or `ActiveRecord::Relation`) with at least one of the following roles: `member`, `author`, `editor`, `admin`.
##### Example
```ruby
# app/models/user.rb
def alchemy_roles
if admin?
%w(admin)
end
end
```
Please follow [this guide](http://guides.alchemy-cms.com/stable/custom_authentication.html) for further instructions on how to customize your user class even more.
#### 4. Install Alchemy into your app:
**After** you set the user model you need to run the Alchemy install task:
```bash
$ bin/rails alchemy:install
```
Now everything should be set up and you should be able to visit the Alchemy Dashboard at:
<http://localhost:3000/admin>
*) Use your custom path if you mounted Alchemy at something else then `'/'`
## 🏗 Customization
Alchemy has very flexible ways to organize and manage content. Please be sure to read [the introduction guide](https://guides.alchemy-cms.com/about.html) in order to understand the basic idea of how Alchemy works.
### Custom Controllers
Beginning with Alchemy 3.1 we do not patch the `ApplicationController` anymore. If you have controllers that loads Alchemy content or uses Alchemy helpers in the views (i.e. `render_menu` or `render_elements`) you can either inherit from `Alchemy::BaseController` or you `include Alchemy::ControllerActions` in your controller (**that's the recommended way**).
### Custom admin interface routing
By default, Alchemy Dashboard is accessible at <http://example.com/admin>. You can change this by setting `Alchemy.admin_path` and `Alchemy.admin_constraints`.
For example, these settings:
```ruby
# config/initializers/alchemy.rb
Alchemy.admin_path = 'backend'
Alchemy.admin_constraints = {subdomain: 'hidden'}
```
will move the dashboard to <http://hidden.example.com/backend>.
### Picture caching
Alchemy uses the Dragonfly gem to render pictures on-the-fly.
To make this as performant as possible the rendered picture gets stored into `public/pictures` so the web server can pick up the file and serve it without hitting the Rails process at all.
This may or may not what you want. Especially for multi server setups you eventually want to use something like S3.
Please follow the guidelines about picture caching on the Dragonfly homepage for further instructions:
http://markevans.github.io/dragonfly/cache
We also provide an [extension for Cloudinary](https://github.com/AlchemyCMS/alchemy_cloudinary)
## 🌍 Localization
Alchemy ships with one default English translation for the admin interface. If you want to use the admin interface in other languages please have a look at the [`alchemy_i18n` project](https://github.com/AlchemyCMS/alchemy_i18n).
## ✨ Upgrading
We, the Alchemy team, take upgrades very seriously and we try to make them as smooth as possible. Therefore we have build an upgrade task, that tries to automate the upgrade procedure as much as possible.
That's why after the Alchemy gem has been updated, with explicit call to:
```bash
$ bundle update alchemy_cms
```
you should **always run the upgrader**:
```bash
$ bin/rake alchemy:upgrade
```
Alchemy will print out useful information after running the automated tasks that help a smooth upgrade path.
So please **take your time and read them**.
Always be sure to keep an eye on the `config/alchemy/config.yml.defaults` file and update your `config/alchemy/config.yml` accordingly.
Also, `git diff` is your friend.
### Customize the upgrade preparation
The Alchemy upgrader comes prepared with several rake tasks in a specific order.
This is sometimes not what you want or could even break upgrades.
In order to customize the upgrade preparation process you can instead run each of the tasks on their own.
```bash
$ bin/rake alchemy:install:migrations
$ bin/rake db:migrate
$ bin/rake alchemy:db:seed
$ bin/rake alchemy:upgrade:config
$ bin/rake alchemy:upgrade:run
```
**WARNING:** This is only recommended, if you have problems with the default `rake alchemy:upgrade` task and need to
repair your data in between. The upgrader depends on these upgrade tasks running in this specific order, otherwise
we can't ensure smooth upgrades for you.
### Run an individual upgrade
You can also run an individual upgrade on its own:
```bash
$ bin/rake -T alchemy:upgrade
```
provides you with a list of each upgrade you can run individually.
#### Example
```bash
$ bin/rake alchemy:upgrade:4.1
```
runs only the Alchemy 4.1 upgrade
## 🚀 Deployment
Alchemy has an official Capistrano extension which takes care of everything you need to deploy an Alchemy site.
Please use [capistrano-alchemy](https://github.com/AlchemyCMS/capistrano-alchemy), if you want to deploy with Capistrano.
### Without Capistrano
If you don't use Capistrano you have to **make sure** that the `uploads`, `tmp/cache/assets`, `public/assets` and `public/pictures` folders get **shared between deployments**, otherwise you **will loose data**. No, not really, but you know, just keep them in sync.
## 🚧 Testing
If you want to contribute to Alchemy ([and we encourage you to do so](CONTRIBUTING.md)) we have a strong test suite that helps you to not break anything.
### Preparation
First of all you need to clone your fork to your local development machine. Then you need to install the dependencies with bundler.
```bash
$ bundle install
```
To prepare the tests of your Alchemy fork please make sure to run the preparation task:
```bash
$ bundle exec rake alchemy:spec:prepare
```
to set up the database for testing.
### Run your tests with:
```bash
$ bundle exec rspec
```
**Alternatively** you can just run*:
```bash
$ bundle exec rake
```
*) This default task executes the database preparations and runs all defined test cases.
### Start the dummy app
You can even start the dummy app and use it to manually test your changes with:
```bash
$ cd spec/dummy
$ bin/setup
$ bin/rails s
```
## 📦 Releasing
### Bump version
Bump the version number in both `lib/alchemy/version.rb` and `./package.json`. Make sure both are exactly the same and follow [SemVer format](https://semver.org/#semantic-versioning-specification-semver).
### Update the changelog
```bash
$ export GITHUB_ACCESS_TOKEN=...
$ PREVIOUS_VERSION=4.1.0 bundle exec rake alchemy:changelog:update
```
### Commit version bump
```bash
$ git commit -am "Bump version to vX.Y.Z"
```
### Release a new version
This task will publish both the ruby gem and the npm package.
It also tags the latest commit.
```bash
$ bundle exec rake alchemy:release
```
## ❓Getting Help
* Read the guidelines: https://guides.alchemy-cms.com.
* Read the documentation: https://www.rubydoc.info/github/AlchemyCMS/alchemy_cms
* If you think you found a bug please use the [issue tracker on Github](https://github.com/AlchemyCMS/alchemy_cms/issues).
* For questions about general usage please use [Stack Overflow](http://stackoverflow.com/questions/tagged/alchemy-cms) or the [Slack](https://slackin.alchemy-cms.com).
* New features should be discussed on our [Trello Board](https://trello.com/alchemycms).
**PLEASE** don't use the Github issues for feature requests. If you want to contribute to Alchemy please [read the contribution guidelines](CONTRIBUTING.md) before doing so.
## 🔗 Resources
* Homepage: <https://alchemy-cms.com>
* Live-Demo: <https://demo.alchemy-cms.com> (user: demo, password: demo123)
* API Documentation: <https://www.rubydoc.info/github/AlchemyCMS/alchemy_cms>
* Issue-Tracker: <https://github.com/AlchemyCMS/alchemy_cms/issues>
* Sourcecode: <https://github.com/AlchemyCMS/alchemy_cms>
* Slack: <https://slackin.alchemy-cms.com>
* Twitter: <https://twitter.com/alchemy_cms>
## ✍️ Authors
* Thomas von Deyen: <https://github.com/tvdeyen>
* Robin Böning: <https://github.com/robinboening>
* Marc Schettke: <https://github.com/masche842>
* Hendrik Mans: <https://github.com/hmans>
* Carsten Fregin: <https://github.com/cfregin>
## 🏅 Contributors
This project exists thanks to all the people who contribute. [[Contribute](CONTRIBUTING.md)].
<a href="https://github.com/undefined/undefinedgraphs/contributors"><img src="https://opencollective.com/alchemy_cms/contributors.svg?width=890&button=false" /></a>
## 💵 Backers
Thank you to all our backers! 🙏 [[Become a backer](https://opencollective.com/alchemy_cms#backer)]
<a href="https://opencollective.com/alchemy_cms#backers" target="_blank"><img src="https://opencollective.com/alchemy_cms/backers.svg?width=890"></a>
## 💰 Sponsors
Support this project by becoming a sponsor. Your logo will show up here with a link to your website. [[Become a sponsor](https://opencollective.com/alchemy_cms#sponsor)]
<a href="https://opencollective.com/alchemy_cms/sponsor/0/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/1/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/2/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/3/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/4/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/5/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/6/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/7/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/8/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/alchemy_cms/sponsor/9/website" target="_blank"><img src="https://opencollective.com/alchemy_cms/sponsor/9/avatar.svg"></a>
## 📜 License
[BSD-3-Clause](LICENSE)
## 📢 Spread the love
If you like Alchemy, please help us to spread the word about Alchemy and star this repo [on GitHub](https://github.com/AlchemyCMS/alchemy_cms), upvote it [on The Ruby Toolbox](https://www.ruby-toolbox.com/projects/alchemy_cms), mention us [on Twitter](https://twitter.com/alchemy_cms).
That will help us to keep Alchemy awesome.
Thank you!
## ❤️
|
3,406 | Pluggable Ruby translation framework | Mobility
========
[][gem]
[][actions]
[][codeclimate]
[](https://gitter.im/mobility-ruby/mobility)
[gem]: https://rubygems.org/gems/mobility
[actions]: https://github.com/shioyama/mobility/actions
[codeclimate]: https://codeclimate.com/github/shioyama/mobility
[docs]: http://www.rubydoc.info/gems/mobility
[wiki]: https://github.com/shioyama/mobility/wiki
**This is the readme for version 1.x of Mobility. If you are using an earlier
version (0.8.x or earlier), you probably want the readme on the [0-8
branch](https://github.com/shioyama/mobility/tree/0-8).**
Mobility is a gem for storing and retrieving translations as attributes on a
class. These translations could be the content of blog posts, captions on
images, tags on bookmarks, or anything else you might want to store in
different languages. For examples of what Mobility can do, see the
<a href="#companies-using-mobility">Companies using Mobility</a> section below.
Storage of translations is handled by customizable "backends" which encapsulate
different storage strategies. The default way to store translations
is to put them all in a set of two shared tables, but many alternatives are
also supported, including [translatable
columns](http://dejimata.com/2017/3/3/translating-with-mobility#strategy-1) and
[model translation
tables](http://dejimata.com/2017/3/3/translating-with-mobility#strategy-2), as
well as database-specific storage solutions such as
[json/jsonb](https://www.postgresql.org/docs/current/static/datatype-json.html) and
[Hstore](https://www.postgresql.org/docs/current/static/hstore.html) (for
PostgreSQL).
Mobility is a cross-platform solution, currently supporting both
[ActiveRecord](http://api.rubyonrails.org/classes/ActiveRecord/Base.html)
and [Sequel](http://sequel.jeremyevans.net/) ORM, with support for other
platforms planned.
For a detailed introduction to Mobility, see [Translating with
Mobility](http://dejimata.com/2017/3/3/translating-with-mobility). See also my
talk at RubyConf 2018, [Building Generic
Software](https://www.youtube.com/watch?v=RZkemV_-__A), where I explain the
thinking behind Mobility's design.
If you're coming from Globalize, be sure to also read the [Migrating from
Globalize](https://github.com/shioyama/mobility/wiki/Migrating-from-Globalize)
section of the wiki.
Installation
------------
Add this line to your application's Gemfile:
```ruby
gem 'mobility', '~> 1.2.9'
```
### ActiveRecord (Rails)
Requirements:
- ActiveRecord >= 5.0 (including 6.x)
(Support for most backends and features is also supported with
ActiveRecord/Rails 4.2, but there are some tests still failing. To see exactly
what might not work, check pending specs in Rails 4.2 builds.)
To translate attributes on a model, extend `Mobility`, then call `translates`
passing in one or more attributes as well as a hash of options (see below).
If using Mobility in a Rails project, you can run the generator to create an
initializer and a migration to create shared translation tables for the
default `KeyValue` backend:
```
rails generate mobility:install
```
(If you do not plan to use the default backend, you may want to use
the `--without_tables` option here to skip the migration generation.)
The generator will create an initializer file `config/initializers/mobility.rb`
which looks something like this:
```ruby
Mobility.configure do
# PLUGINS
plugins do
backend :key_value
active_record
reader
writer
# ...
end
end
```
Each method call inside the block passed to `plugins` declares a plugin, along
with an optional default. To use a different default backend, you can
change the default passed to the `backend` plugin, like this:
```diff
Mobility.configure do
# PLUGINS
plugins do
- backend :key_value
+ backend :table
```
See other possible backends in the [backends section](#backends).
You can also set defaults for backend-specific options. Below, we set the
default `type` option for the KeyValue backend to `:string`.
```diff
Mobility.configure do
# PLUGINS
plugins do
- backend :key_value
+ backend :key_value, type: :string
end
end
```
We will assume the configuration above in the examples that follow.
See [Getting Started](#quickstart) to get started translating your models.
### Sequel
Requirements:
- Sequel >= 4.0
When configuring Mobility, ensure that you include the `sequel` plugin:
```diff
plugins do
backend :key_value
- active_record
+ sequel
```
You can extend `Mobility` just like in ActiveRecord, or you can use the
`mobility` plugin, which does the same thing:
```ruby
class Word < ::Sequel::Model
plugin :mobility
translates :name, :meaning
end
```
Otherwise everything is (almost) identical to AR, with the exception that there
is no equivalent to a Rails generator, so you will need to create the migration
for any translation table(s) yourself, using Rails generators as a reference.
The models in examples below all inherit from `ApplicationRecord`, but
everything works exactly the same if the parent class is `Sequel::Model`.
Usage
-----
### <a name="quickstart"></a>Getting Started
Once the install generator has been run to generate translation tables, using
Mobility is as easy as adding a few lines to any class you want to translate.
Simply pass one or more attribute names to the `translates` method with a hash
of options, like this:
```ruby
class Word < ApplicationRecord
extend Mobility
translates :name, :meaning
end
```
Note: When using the KeyValue backend, use the options hash to pass each attribute's type:
```ruby
class Word < ApplicationRecord
extend Mobility
translates :name, type: :string
translates :meaning, type: :text
end
```
This is important because this is how Mobility knows to which of the [two translation tables](https://github.com/shioyama/mobility/wiki/KeyValue-Backend) it should save your translation.
You now have translated attributes `name` and `meaning` on the model `Word`.
You can set their values like you would any other attribute:
```ruby
word = Word.new
word.name = "mobility"
word.meaning = "(noun): quality of being changeable, adaptable or versatile"
word.name
#=> "mobility"
word.meaning
#=> "(noun): quality of being changeable, adaptable or versatile"
word.save
word = Word.first
word.name
#=> "mobility"
word.meaning
#=> "(noun): quality of being changeable, adaptable or versatile"
```
Presence methods are also supported:
```ruby
word.name?
#=> true
word.name = nil
word.name?
#=> false
word.name = ""
word.name?
#=> false
```
What's different here is that the value of these attributes changes with the
value of `I18n.locale`:
```ruby
I18n.locale = :ja
word.name
#=> nil
word.meaning
#=> nil
```
The `name` and `meaning` of this word are not defined in any locale except
English. Let's define them in Japanese and save the model:
```ruby
word.name = "モビリティ"
word.meaning = "(名詞):動きやすさ、可動性"
word.name
#=> "モビリティ"
word.meaning
#=> "(名詞):動きやすさ、可動性"
word.save
```
Now our word has names and meanings in two different languages:
```ruby
word = Word.first
I18n.locale = :en
word.name
#=> "mobility"
word.meaning
#=> "(noun): quality of being changeable, adaptable or versatile"
I18n.locale = :ja
word.name
#=> "モビリティ"
word.meaning
#=> "(名詞):動きやすさ、可動性"
```
Internally, Mobility is mapping the values in different locales to storage
locations, usually database columns. By default these values are stored as keys
(attribute names) and values (attribute translations) on a set of translation
tables, one for strings and one for text columns, but this can be easily
changed and/or customized (see the [Backends](#backends) section below).
### <a name="getset"></a> Getting and Setting Translations
The easiest way to get or set a translation is to use the getter and setter
methods described above (`word.name` and `word.name=`), enabled by including
the `reader` and `writer` plugins.
You may also want to access the value of an attribute in a specific locale,
independent of the current value of `I18n.locale` (or `Mobility.locale`). There
are a few ways to do this.
The first way is to define locale-specific methods, one for each locale you
want to access directly on a given attribute. These are called "locale
accessors" in Mobility, and can be enabled by including the `locale_accessors`
plugin, with a default set of accessors:
```diff
plugins do
# ...
+ locale_accessors [:en, :ja]
```
You can also override this default from `translates` in any model:
```ruby
class Word < ApplicationRecord
extend Mobility
translates :name, locale_accessors: [:en, :ja]
end
```
Since we have enabled locale accessors for English and Japanese, we can access
translations for these locales with `name_en` and `name_ja`:
```ruby
word.name_en
#=> "mobility"
word.name_ja
#=> "モビリティ"
word.name_en = "foo"
word.name
#=> "foo"
```
Other locales, however, will not work:
```ruby
word.name_ru
#=> NoMethodError: undefined method `name_ru' for #<Word id: ... >
```
With no plugin option (or a default of `true`), Mobility generates methods for
all locales in `I18n.available_locales` at the time the model is first loaded.
An alternative to using the `locale_accessors` plugin is to use the
`fallthrough_accessors` plugin. This uses Ruby's
[`method_missing`](http://apidock.com/ruby/BasicObject/method_missing) method
to implicitly define the same methods as above, but supporting any locale
without any method definitions. (Locale accessors and fallthrough locales can
be used together without conflict, with locale accessors taking precedence if
defined for a given locale.)
Ensure the plugin is enabled:
```diff
plugins do
# ...
+ fallthrough_accessors
```
... then we can access any locale we want, without specifying them upfront:
```ruby
word = Word.new
word.name_fr = "mobilité"
word.name_fr
#=> "mobilité"
word.name_ja = "モビリティ"
word.name_ja
#=> "モビリティ"
```
(Note however that Mobility will complain if you have
`I18n.enforce_available_locales` set to `true` and you try accessing a locale
not present in `I18n.available_locales`; set it to `false` if you want to allow
*any* locale.)
Another way to fetch values in a locale is to pass the `locale` option to the
getter method, like this:
```ruby
word.name(locale: :en)
#=> "mobility"
word.name(locale: :fr)
#=> "mobilité"
```
Note that setting the locale this way will pass an option `locale: true` to the
backend and all plugins. Plugins may use this option to change their behavior
(passing the locale explicitly this way, for example, disables
[fallbacks](#fallbacks), see below for details).
You can also *set* the value of an attribute this way; however, since the
`word.name = <value>` syntax does not accept any options, the only way to do this is to
use `send` (this is included mostly for consistency):
```ruby
word.send(:name=, "mobiliteit", locale: :nl)
word.name_nl
#=> "mobiliteit"
```
Yet another way to get and set translated attributes is to call `read` and
`write` on the storage backend, which can be accessed using the method
`<attribute>_backend`. Without worrying too much about the details of
how this works for now, the syntax for doing this is simple:
```ruby
word.name_backend.read(:en)
#=> "mobility"
word.name_backend.read(:nl)
#=> "mobiliteit"
word.name_backend.write(:en, "foo")
word.name_backend.read(:en)
#=> "foo"
```
Internally, all methods for accessing translated attributes ultimately end up
reading and writing from the backend instance this way. (The `write` methods
do not call underlying backend's methods to persist the change. This is up to
the user, so e.g. with ActiveRecord you should call `save` write the changes to
the database).
Note that accessor methods are defined in an included module, so you can wrap
reads or writes in custom logic:
```ruby
class Post < ApplicationRecord
extend Mobility
translates :title
def title(*)
super.reverse
end
end
```
### Setting the Locale
It may not always be desirable to use `I18n.locale` to set the locale for
content translations. For example, a user whose interface is in English
(`I18n.locale` is `:en`) may want to see content in Japanese. If you use
`I18n.locale` exclusively for the locale, you will have a hard time showing
stored translations in one language while showing the interface in another
language.
For these cases, Mobility also has its own locale, which defaults to
`I18n.locale` but can be set independently:
```ruby
I18n.locale = :en
Mobility.locale #=> :en
Mobility.locale = :fr
Mobility.locale #=> :fr
I18n.locale #=> :en
```
To set the Mobility locale in a block, you can use `Mobility.with_locale` (like
`I18n.with_locale`):
```ruby
Mobility.locale = :en
Mobility.with_locale(:ja) do
Mobility.locale #=> :ja
end
Mobility.locale #=> :en
```
Mobility uses [RequestStore](https://github.com/steveklabnik/request_store) to
reset these global variables after every request, so you don't need to worry
about thread safety. If you're not using Rails, consult RequestStore's
[README](https://github.com/steveklabnik/request_store#no-rails-no-problem) for
details on how to configure it for your use case.
### <a name="fallbacks"></a>Fallbacks
Mobility offers basic support for translation fallbacks. First, enable the
`fallbacks` plugin:
```diff
plugins do
# ...
+ fallbacks
+ locale_accessors
```
Fallbacks will require `fallthrough_accessors` to handle methods like
`title_en`, which are used to track changes. For performance reasons it's
generally best to also enable the `locale_accessors` plugin as shown above.
Now pass a hash with fallbacks for each locale as an option when defining
translated attributes on a class:
```ruby
class Word < ApplicationRecord
extend Mobility
translates :name, fallbacks: { de: :ja, fr: :ja }
translates :meaning, fallbacks: { de: :ja, fr: :ja }
end
```
Internally, Mobility assigns the fallbacks hash to an instance of
`I18n::Locale::Fallbacks.new`.
By setting fallbacks for German and French to Japanese, values will fall
through to the Japanese value if none is present for either of these locales,
but not for other locales:
```ruby
Mobility.locale = :ja
word = Word.create(name: "モビリティ", meaning: "(名詞):動きやすさ、可動性")
Mobility.locale = :de
word.name
#=> "モビリティ"
word.meaning
#=> "(名詞):動きやすさ、可動性"
Mobility.locale = :fr
word.name
#=> "モビリティ"
word.meaning
#=> "(名詞):動きやすさ、可動性"
Mobility.locale = :ru
word.name
#=> nil
word.meaning
#=> nil
```
You can optionally disable fallbacks to get the real value for a given locale
(for example, to check if a value in a particular locale is set or not) by
passing `fallback: false` (*singular*, not plural) to the getter method:
```ruby
Mobility.locale = :de
word.meaning(fallback: false)
#=> nil
Mobility.locale = :fr
word.meaning(fallback: false)
#=> nil
Mobility.locale = :ja
word.meaning(fallback: false)
#=> "(名詞):動きやすさ、可動性"
```
You can also set the fallback locales for a single read by passing one or more
locales:
```ruby
Mobility.with_locale(:fr) do
word.meaning = "(nf): aptitude à bouger, à se déplacer, à changer, à évoluer"
end
word.save
Mobility.locale = :de
word.meaning(fallback: false)
#=> nil
word.meaning(fallback: :fr)
#=> "(nf): aptitude à bouger, à se déplacer, à changer, à évoluer"
word.meaning(fallback: [:ja, :fr])
#=> "(名詞):動きやすさ、可動性"
```
Also note that passing a `locale` option into an attribute reader or writer, or
using [locale accessors or fallthrough accessors](#getset) to get or set
any attribute value, will disable fallbacks (just like `fallback: false`).
(This will take precedence over any value of the `fallback` option.)
Continuing from the last example:
```ruby
word.meaning(locale: :de)
#=> nil
word.meaning_de
#=> nil
Mobility.with_locale(:de) { word.meaning }
#=> "(名詞):動きやすさ、可動性"
```
For more details, see the [API documentation on
fallbacks](http://www.rubydoc.info/gems/mobility/Mobility/Plugins/Fallbacks)
and [this article on I18n
fallbacks](https://github.com/svenfuchs/i18n/wiki/Fallbacks).
### <a name="default"></a>Default values
Another option is to assign a default value, using the `default` plugin:
```diff
plugins do
# ...
+ default 'foo'
```
Here we've set a "default default" of `'foo'`, which will be returned if a fetch would
otherwise return `nil`. This can be overridden from model classes:
```ruby
class Word < ApplicationRecord
extend Mobility
translates :name, default: 'foo'
end
Mobility.locale = :ja
word = Word.create(name: "モビリティ")
word.name
#=> "モビリティ"
Mobility.locale = :de
word.name
#=> "foo"
```
You can override the default by passing a `default` option to the attribute reader:
```ruby
word.name
#=> 'foo'
word.name(default: nil)
#=> nil
word.name(default: 'bar')
#=> 'bar'
```
The default can also be a `Proc`, which will be called with the context as the
model itself, and passed optional arguments (attribute, locale and options
passed to accessor) which can be used to customize behaviour. See the [API
docs][docs] for details.
### <a name="dirty"></a>Dirty Tracking
Dirty tracking (tracking of changed attributes) can be enabled for models which
support it. Currently this is models which include
[ActiveModel::Dirty](http://api.rubyonrails.org/classes/ActiveModel/Dirty.html)
(like `ActiveRecord::Base`) and Sequel models (through the
[dirty](http://sequel.jeremyevans.net/rdoc-plugins/classes/Sequel/Plugins/Dirty.html)
plugin).
First, ensure the `dirty` plugin is enabled in your configuration, and that you
have enabled an ORM plugin (either `active_record` or `sequel`), since the
dirty plugin will depend on one of these being enabled.
```diff
plugins do
# ...
active_record
+ dirty
```
(Once enabled globally, the dirty plugin can be selectively disabled on classes
by passing `dirty: false` to `translates`.)
Take this ActiveRecord class:
```ruby
class Post < ApplicationRecord
extend Mobility
translates :title
end
```
Let's assume we start with a post with a title in English and Japanese:
```ruby
post = Post.create(title: "Introducing Mobility")
Mobility.with_locale(:ja) { post.title = "モビリティの紹介" }
post.save
```
Now let's change the title:
```ruby
post = Post.first
post.title #=> "Introducing Mobility"
post.title = "a new title"
Mobility.with_locale(:ja) do
post.title #=> "モビリティの紹介"
post.title = "新しいタイトル"
post.title #=> "新しいタイトル"
end
```
Now you can use dirty methods as you would any other (untranslated) attribute:
```ruby
post.title_was
#=> "Introducing Mobility"
Mobility.locale = :ja
post.title_was
#=> "モビリティの紹介"
post.changed
["title_en", "title_ja"]
post.save
```
You can also access `previous_changes`:
```ruby
post.previous_changes
#=>
{
"title_en" =>
[
"Introducing Mobility",
"a new title"
],
"title_ja" =>
[
"モビリティの紹介",
"新しいタイトル"
]
}
```
Notice that Mobility uses locale suffixes to indicate which locale has changed;
dirty tracking is implemented this way to ensure that it is clear what
has changed in which locale, avoiding any possible ambiguity.
For performance reasons, it is highly recommended that when using the Dirty
plugin, you also enable [locale accessors](#getset) for all locales which will
be used, so that methods like `title_en` above are defined; otherwise they will
be caught by `method_missing` (using fallthrough accessors), which is much slower.
For more details on dirty tracking, see the [API
documentation](http://www.rubydoc.info/gems/mobility/Mobility/Plugins/Dirty).
### Cache
The Mobility cache caches localized values that have been fetched once so they
can be quickly retrieved again. The cache plugin is included in the default
configuration created by the install generator:
```diff
plugins do
# ...
+ cache
```
It can be disabled selectively per model by passing `cache: false` when
defining an attribute, like this:
```ruby
class Word < ApplicationRecord
extend Mobility
translates :name, cache: false
end
```
You can also turn off the cache for a single fetch by passing `cache: false` to
the getter method, i.e. `post.title(cache: false)`. To remove the cache plugin
entirely, remove the `cache` line from the global plugins configuration.
The cache is normally just a hash with locale keys and string (translation)
values, but some backends (e.g. KeyValue and Table backends) have slightly more
complex implementations.
### <a name="querying"></a>Querying
Mobility backends also support querying on translated attributes. To enable
this feature, include the `query` plugin, and ensure you also have an ORM
plugin enabled (`active_record` or `sequel`):
```diff
plugins do
# ...
active_record
+ query
```
Querying defines a scope or dataset class method, whose default name is `i18n`.
You can override this by passing a default in the configuration, like
`query :t` to use a name `t`.
Querying is supported in two different ways. The first is via query methods
like `where` (and `not` and `find_by` in ActiveRecord, and `except` in Sequel).
So for ActiveRecord, assuming a model using KeyValue as its default backend:
```ruby
class Post < ApplicationRecord
extend Mobility
translates :title, type: :string
translates :content, type: :text
end
```
... we can query for posts with title "foo" and content "bar" just as we would
query on untranslated attributes, and Mobility will convert the queries to
whatever the backend requires to actually return the correct results:
```ruby
Post.i18n.find_by(title: "foo", content: "bar")
```
results in the SQL:
```sql
SELECT "posts".* FROM "posts"
INNER JOIN "mobility_string_translations" "Post_title_en_string_translations"
ON "Post_title_en_string_translations"."key" = 'title'
AND "Post_title_en_string_translations"."locale" = 'en'
AND "Post_title_en_string_translations"."translatable_type" = 'Post'
AND "Post_title_en_string_translations"."translatable_id" = "posts"."id"
INNER JOIN "mobility_text_translations" "Post_content_en_text_translations"
ON "Post_content_en_text_translations"."key" = 'content'
AND "Post_content_en_text_translations"."locale" = 'en'
AND "Post_content_en_text_translations"."translatable_type" = 'Post'
AND "Post_content_en_text_translations"."translatable_id" = "posts"."id"
WHERE "Post_title_en_string_translations"."value" = 'foo'
AND "Post_content_en_text_translations"."value" = 'bar'
```
As can be seen in the query above, behind the scenes Mobility joins two tables,
one with string translations and one with text translations, and aliases the
joins for each attribute so as to match the particular model, attribute(s),
locale(s) and value(s) passed in to the query. Details of how this is done can
be found in the [Wiki page for the KeyValue
backend](https://github.com/shioyama/mobility/wiki/KeyValue-Backend#querying).
You can also use methods like `order`, `select`, `pluck` and `group` on
translated attributes just as you would with normal attributes, and Mobility
will handle generating the appropriate SQL:
```ruby
Post.i18n.pluck(:title)
#=> ["foo", "bar", ...]
```
If you would prefer to avoid the `i18n` scope everywhere, you can define it as
a default scope on your model:
```ruby
class Post < ApplicationRecord
extend Mobility
translates :title, type: :string
translates :content, type: :text
default_scope { i18n }
end
```
Now translated attributes can be queried just like normal attributes:
```ruby
Post.find_by(title: "Introducing Mobility")
#=> finds post with English title "Introducing Mobility"
```
If you want more fine-grained control over your queries, you can alternatively
pass a block to the query method and call attribute names from the block scope
to build Arel predicates:
```ruby
Post.i18n do
title.matches("foo").and(content.matches("bar"))
end
```
which generates the same SQL as above, except the `WHERE` clause becomes:
```sql
SELECT "posts".* FROM "posts"
...
WHERE "Post_title_en_string_translations"."value" ILIKE 'foo'
AND "Post_content_en_text_translations"."value" ILIKE 'bar'
```
The block-format query format is very powerful and allows you to build complex
backend-independent queries on translated and untranslated attributes without
having to deal with the details of how these translations are stored. The same
interface is supported with Sequel to build datasets.
<a name="backends"></a>Backends
--------
Mobility supports different storage strategies, called "backends". The default
backend is the `KeyValue` backend, which stores translations in two tables, by
default named `mobility_text_translations` and `mobility_string_translations`.
You can set the default backend to a different value in the global
configuration, or you can set it explicitly when defining a translated
attribute, like this:
```ruby
class Word < ApplicationRecord
translates :name, backend: :table
end
```
This would set the `name` attribute to use the `Table` backend (see below).
The `type` option (`type: :string` or `type: :text`) is missing here because
this is an option specific to the KeyValue backend (specifying which shared
table to store translations on). Backends have their own specific options; see
the [Wiki][wiki] and [API documentation][docs] for which options are available
for each.
Everything else described above (fallbacks, dirty tracking, locale accessors,
caching, querying, etc) is the same regardless of which backend you use.
### Table Backend (like Globalize)
The `Table` backend stores translations as columns on a model-specific table. If
your model uses the table `posts`, then by default this backend will store an
attribute `title` on a table `post_translations`, and join the table to
retrieve the translated value.
To use the table backend on a model, you will need to first create a
translation table for the model, which (with Rails) you can do using the
`mobility:translations` generator:
```
rails generate mobility:translations post title:string content:text
```
This will generate the `post_translations` table with columns `title` and
`content`, and all other necessary columns and indices. For more details see
the [Table
Backend](https://github.com/shioyama/mobility/wiki/Table-Backend) page of the
wiki and API documentation on the [`Mobility::Backend::Table`
class](http://www.rubydoc.info/gems/mobility/Mobility/Backends/Table).
### Column Backend (like Traco)
The `Column` backend stores translations as columns with locale suffixes on
the model table. For an attribute `title`, these would be of the form
`title_en`, `title_fr`, etc.
Use the `mobility:translations` generator to add columns for locales in
`I18n.available_locales` to your model:
```
rails generate mobility:translations post title:string content:text
```
For more details, see the [Column
Backend](https://github.com/shioyama/mobility/wiki/Column-Backend) page of the
wiki and API documentation on the [`Mobility::Backend::Column`
class](http://www.rubydoc.info/gems/mobility/Mobility/Backends/Column).
### PostgreSQL-specific Backends
Mobility also supports JSON and Hstore storage options, if you are using
PostgreSQL as your database. To use this option, create column(s) on the model
table for each translated attribute, and set your backend to `:json`, `:jsonb`
or `:hstore`. If you are using Sequel, note that you
will need to enable the [pg_json](http://sequel.jeremyevans.net/rdoc-plugins/files/lib/sequel/extensions/pg_json_rb.html)
or
[pg_hstore](http://sequel.jeremyevans.net/rdoc-plugins/files/lib/sequel/extensions/pg_hstore_rb.html)
extensions with `DB.extension :pg_json` or `DB.extension :pg_hstore` (where
`DB` is your database instance).
Another option is to store all your translations on a single jsonb column (one
per model). This is called the "container" backend.
For details on these backends, see the [Postgres
Backend](https://github.com/shioyama/mobility/wiki/Postgres-Backends-%28Column-Attribute%29)
and [Container
Backend](https://github.com/shioyama/mobility/wiki/Container-Backend)
pages of the wiki and in the API documentation
([`Mobility::Backend::Jsonb`](http://www.rubydoc.info/gems/mobility/Mobility/Backends/Jsonb)
and
[`Mobility::Backend::Hstore`](http://www.rubydoc.info/gems/mobility/Mobility/Backends/Hstore)).
*Note: The Json backend (`:json`) may also work with recent versions of MySQL
with JSON column support, although this backend/db combination is not tested.
See [this issue](https://github.com/shioyama/mobility/issues/226) for details.*
Development
-----------
### Custom Backends
Although Mobility is primarily oriented toward storing ActiveRecord model
translations, it can potentially be used to handle storing translations in
other formats. In particular, the features mentioned above (locale accessors,
caching, fallbacks, dirty tracking to some degree) are not specific to database
storage.
To use a custom backend, simply pass the name of a class which includes
`Mobility::Backend` to `translates`:
```ruby
class MyBackend
include Mobility::Backend
# ...
end
class MyClass
extend Mobility
translates :foo, backend: MyBackend
end
```
For details on how to define a backend class, see the [Introduction to Mobility
Backends](https://github.com/shioyama/mobility/wiki/Introduction-to-Mobility-Backends)
page of the wiki and the [API documentation on the `Mobility::Backend`
module](http://www.rubydoc.info/gems/mobility/Mobility/Backend).
### Testing Backends
All included backends are tested against a suite of shared specs which ensure
they conform to the same expected behaviour. These examples can be found in:
- `spec/support/shared_examples/accessor_examples.rb` (minimal specs testing
translation setting/getting)
- `spec/support/shared_examples/querying_examples.rb` (specs for
[querying](#querying))
- `spec/support/shared_examples/serialization_examples.rb` (specialized specs
for backends which store translations as a Hash: `serialized`, `hstore`,
`json` and `jsonb` backends)
A minimal test can simply define a model class and use helpers defined in
`spec/support/helpers.rb` to run these examples, by extending either
`Helpers::ActiveRecord` or `Helpers::Sequel`:
```ruby
describe MyBackend do
extend Helpers::ActiveRecord
before do
stub_const 'MyPost', Class.new(ActiveRecord::Base)
MyPost.extend Mobility
MyPost.translates :title, :content, backend: MyBackend
end
include_accessor_examples 'MyPost'
include_querying_examples 'MyPost'
# ...
end
```
Shared examples expect the model class to have translated attributes `title`
and `content`, and an untranslated boolean column `published`. These defaults
can be changed, see the shared examples for details.
Backends are also each tested against specialized specs targeted at their
particular implementations.
Integrations
------------
* [friendly_id-mobility](https://github.com/shioyama/friendly_id-mobility): Use
Mobility with [FriendlyId](https://github.com/norman/friendly_id).
* [mobility-ransack](https://github.com/shioyama/mobility-ransack): Search
attributes translated by Mobility with
[Ransack](https://github.com/activerecord-hackery/ransack).
* [mobility-actiontext](https://github.com/sedubois/mobility-actiontext): Translate
Rails [Action Text](https://guides.rubyonrails.org/action_text_overview.html) rich text
with Mobility.
Tutorials
---------
- [Polyglot content in a rails
app](https://revs.runtime-revolution.com/polyglot-content-in-a-rails-app-aed823854955)
- [Translating with
Mobility](https://dejimata.com/2017/3/3/translating-with-mobility)
- [JSONify your Ruby
Translations](https://dejimata.com/2018/3/20/jsonify-your-ruby-translations)
More Information
----------------
- [Github repository](https://www.github.com/shioyama/mobility)
- [API documentation][docs]
- [Wiki][wiki]
<a name="#companies-using-mobility"></a>Companies using Mobility
------------------------
<img alt="Logos of companies using Mobility" src="./img/companies-using-mobility.png" style="width: 100%" />
- [Doorkeeper](https://www.doorkeeper.jp/)
- [Oreegano](https://www.oreegano.com/)
- [Venuu](https://venuu.fi)
- ... <sup>✱</sup>
<sup>✱</sup> <small>Post an issue or email me to add your company's name to this list.</small>
License
-------
The gem is available as open source under the terms of the [MIT License](http://opensource.org/licenses/MIT).
|
3,407 | RSpec cheatsheet & Rails app: Learn how to expertly test Rails apps from a model codebase | # RSpec Rails Examples [](https://travis-ci.org/eliotsykes/rspec-rails-examples) [](https://gitter.im/eliotsykes/rspec-rails-examples?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
> An RSpec cheatsheet in the form of a Rails app. Learn how to expertly test Rails apps from a model codebase
A small yet comprehensive reference for developers who want to know how to test Rails apps using RSpec.
Here you'll find in-depth examples with detailed documentation explaining how to test with RSpec and related testing gems, which you can then apply to your own projects.
This application was originally written for the benefit of the developers I coach, who've found it a useful memory aid and catalyst for when they're learning RSpec. Now I'd like to get feedback from the wider community.
The repo contains examples of various spec types such as feature, mailer, and model. See the [spec/](spec/) directory for all the example specs and types.
In the README below, you'll find links to some of the most useful cheatsheets and API documentation available for RSpec users.
See the well-commented files in the [spec/support](spec/support) directory for walkthroughs on how to configure popular testing gems, such as DatabaseCleaner, Capybara, and FactoryGirl.
Hopefully this will be of help to those of you learning RSpec and Rails. If there's anything missing you'd like to see covered in the project, please submit your request via the [issue tracker](https://github.com/eliotsykes/rspec-rails-examples/issues), I'd be happy to help — [_Eliot Sykes_](https://eliotsykes.com)
**PS. Interested in growing your skills *and* supporting this project?** Learn with the [TDD Masterclass](https://eliotsykes.com/#tdd), get [Test Coverage First Aid](https://eliotsykes.com/#coverage) for your app, or grow with [one-to-one coaching for Rails developers](https://eliotsykes.com/#coach).
---
<!-- MarkdownTOC depth=0 autolink=true bracket=round -->
- [Support Configuration](#support-configuration)
- [Run Specs in a Random Order](#run-specs-in-a-random-order)
- [Testing Production Errors](#testing-production-errors)
- [Testing Rake Tasks with RSpec](#testing-rake-tasks-with-rspec)
- [Pry-rescue debugging](#pry-rescue-debugging)
- [Time Travel Examples](#time-travel-examples)
- [ActiveJob Examples](#activejob-examples)
- [Database Cleaner Examples](#database-cleaner-examples)
- [Factory Girl Examples](#factory-girl-examples)
- [VCR Examples](#vcr-examples)
- [Capybara Examples](#capybara-examples)
- [Puffing Billy Examples](#puffing-billy-examples)
- [Shoulda-Matchers Examples](#shoulda-matchers-examples)
- [Email-Spec Examples](#email-spec-examples)
- [Devise Examples](#devise-examples)
- [Custom Matchers](#custom-matchers)
- [RSpec-Expectations Docs](#rspec-expectations-docs)
- [RSpec-Mocks Specs & Docs](#rspec-mocks-specs--docs)
- [RSpec-Rails](#rspec-rails)
- [Matchers](#matchers)
- [Generators](#generators)
- [Feature Specs & Docs](#feature-specs--docs)
- [API Request Specs, Docs, & Helpers](#api-request-specs-docs--helpers)
- [Mailer Specs & Docs](#mailer-specs--docs)
- [Controller Specs & Docs](#controller-specs--docs)
- [View Specs & Docs](#view-specs--docs)
- [Helper Specs & Docs](#helper-specs--docs)
- [Routing Specs & Docs](#routing-specs--docs)
- [Validator Specs](#validator-specs)
- [Enable Spring for RSpec](#enable-spring-for-rspec)
- [Automated Continuous Integration with Travis CI](#automated-continuous-integration-with-travis-ci)
- [Contributors](#contributors)
<!-- /MarkdownTOC -->
# Support Configuration
The tests rely on this configuration being uncommented in `spec/rails_helper.rb`, you probably want it uncommented in your app too:
```ruby
# Loads `.rb` files in `spec/support` and its subdirectories:
Dir[Rails.root.join("spec/support/**/*.rb")].each { |f| require f }
```
(The rspec-rails installer generates this line, but it will be commented out.)
# Run Specs in a Random Order
In a dependable, repeatable automated test suite, data stores (such as database, job queues, and sent email on `ActionMailer::Base.deliveries`) should return to a consistent state between each spec, regardless of the order specs are run in.
For a maintainable, predictable test suite, one spec should not set up data (e.g. creating users) needed by a later spec to pass. Each spec should look after its own test data and clear up after itself. (NB. If there is reference data that all tests need, such as populating a `countries` table, then this can go in `db/seeds.rb` and be run once before the entire suite).
The specs run in a random order each time the test suite is run. This helps prevent the introduction of run order and test data dependencies between tests, which are best avoided.
Random order test runs are configured using the `config.order = :random` and `Kernel.srand config.seed` options in [spec/spec_helper.rb](spec/spec_helper.rb).
# Testing Production Errors
When errors are raised, the Rails test environment may not behave as in production. The test environment may mask the actual error response you want to test. To help with this, you can disable test environment exception handling temporarily, [spec/support/error_responses.rb](spec/support/error_responses.rb) provides `respond_without_detailed_exceptions`. See it in use in [spec/api/v1/token_spec.rb](spec/api/v1/token_spec.rb) to provide production-like error responses in the test environment.
# Testing Rake Tasks with RSpec
RSpec testing Rake task configuration and example:
- [spec/support/tasks.rb](spec/support/tasks.rb) essential to load Rake tasks before specs run
- [spec/tasks/subscription_tasks_spec.rb](spec/tasks/subscription_tasks_spec.rb)
# Pry-rescue debugging
pry-rescue can be used to debug failing specs, by opening pry's debugger whenever a test failure is encountered. For setup and usage see [pry-rescue's README](https://github.com/ConradIrwin/pry-rescue).
# Time Travel Examples
[`ActiveSupport::Testing::TimeHelpers`](http://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html) provides helpers for manipulating and freezing the current time reported within tests. These methods are often enough to replace the time-related testing methods that the `timecop` gem is used for.
`TimeHelpers` configuration how-to and examples:
- [spec/support/time_helpers.rb](spec/support/time_helpers.rb)
- [spec/models/subscription_spec.rb](spec/models/subscription_spec.rb)
- [spec/tasks/subscription_tasks_spec.rb](spec/tasks/subscription_tasks_spec.rb)
- [`travel_to`](http://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html#method-i-travel_to) example: [spec/models/subscription_spec.rb](spec/models/subscription_spec.rb)
- [`ActiveSupport::Testing::TimeHelpers` API documentation](http://api.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html)
# ActiveJob Examples
[`ActiveJob::TestHelper`](http://api.rubyonrails.org/classes/ActiveJob/TestHelper.html) provides help to test ActiveJob jobs.
`ActiveJob::TestHelper` configuration how-to and examples:
- [spec/support/job_helpers.rb](spec/support/job_helpers.rb)
- [spec/jobs/headline_scraper_job_spec.rb](spec/jobs/headline_scraper_job_spec.rb)
- [`ActiveJob::TestHelper` API documentation](http://api.rubyonrails.org/classes/ActiveJob/TestHelper.html)
# Database Cleaner Examples
[Database Cleaner](https://github.com/DatabaseCleaner/database_cleaner) is a set of strategies for cleaning your database in Ruby, to ensure a consistent environment for each test run.
Database Cleaner configuration how-to:
- [spec/support/database_cleaner.rb](spec/support/database_cleaner.rb)
# Factory Girl Examples
[Factory Girl](https://github.com/thoughtbot/factory_girl) is a library to help setup test data. [factory_girl_rails](https://github.com/thoughtbot/factory_girl_rails) integrates Factory Girl with Rails.
Factory Girl configuration how-to and examples:
- [spec/support/factory_girl.rb](spec/support/factory_girl.rb)
- [spec/factories](spec/factories)
- [spec/factories/users.rb](spec/factories/users.rb)
- [spec/models/subscription_spec.rb](spec/models/subscription_spec.rb)
- [spec/tasks/subscription_tasks_spec.rb](spec/tasks/subscription_tasks_spec.rb)
- [spec/features/user_login_and_logout_spec.rb](spec/features/user_login_and_logout_spec.rb)
# VCR Examples
[VCR](https://github.com/vcr/vcr) records your test suite's HTTP interactions and replays them during future test runs. Your tests can run independent of a connection to external URLs. These HTTP interactions are stored in cassette files.
VCR configuration how-to and examples:
- [spec/support/vcr.rb](spec/support/vcr.rb)
- [spec/jobs/headline_scraper_job_spec.rb](spec/jobs/headline_scraper_job_spec.rb)
- [Cassette files in spec/support/http_cache/vcr](spec/support/http_cache/vcr)
- [VCR Relish docs](https://relishapp.com/vcr/vcr/docs)
- [VCR API docs](http://www.rubydoc.info/gems/vcr/frames)
# Capybara Examples
[Capybara](https://github.com/jnicklas/capybara) helps you write feature specs that interact with your app's UI as a user does with a browser.
Capybara configuration how-to and examples:
- [spec/support/capybara.rb](spec/support/capybara.rb)
- [spec/features/home_page_spec.rb](spec/features/home_page_spec.rb)
- [spec/features/subscribe_to_newsletter_spec.rb](spec/features/subscribe_to_newsletter_spec.rb)
- [spec/features/user_login_and_logout_spec.rb](spec/features/user_login_and_logout_spec.rb)
- [spec/features/user_registers_spec.rb](spec/features/user_registers_spec.rb)
- [Capybara cheatsheet](https://gist.github.com/zhengjia/428105)
- [Capybara matchers](http://www.rubydoc.info/github/jnicklas/capybara/master/Capybara/Node/Matchers)
# Puffing Billy Examples
[Puffing Billy](https://github.com/oesmith/puffing-billy) is like VCR for browsers used by feature specs. Puffing Billy is a HTTP proxy between your browser and external sites, including 3rd party JavaScript. If your app depends on JavaScript hosted on another site, then Puffing Billy will keep a copy of that JavaScript and serve it from a local web server during testing. This means tests dependent on that JavaScript will carry on working even if the original host cannot be connected to.
If you need to debug Puffing Billy, refer to its output in `log/test.log`.
Puffing Billy configuration how-to and examples:
- [spec/support/puffing_billy.rb](spec/support/puffing_billy.rb)
- [spec/features/share_page_spec.rb](spec/features/share_page_spec.rb)
- [Cache options](https://github.com/oesmith/puffing-billy#caching)
- [Cached responses in spec/support/http_cache/billy](spec/support/http_cache/billy)
# Shoulda-Matchers Examples
[Shoulda-matchers](https://github.com/thoughtbot/shoulda-matchers) make light work of model specs.
shoulda-matchers configuration how-to and examples:
- [spec/support/shoulda_matchers.rb](spec/support/shoulda_matchers.rb)
- [spec/models/subscription_spec.rb](spec/models/subscription_spec.rb)
# Email-Spec Examples
The "Subscribe to newsletter" feature was developed with help from [email_spec](https://github.com/bmabey/email-spec)
email_spec configuration how-to and examples:
- [spec/support/email_spec.rb](spec/support/email_spec.rb)
- [spec/jobs/headline_scraper_job_spec.rb](spec/jobs/headline_scraper_job_spec.rb)
- [spec/mailers/news_mailer_spec.rb](spec/mailers/news_mailer_spec.rb)
- [spec/mailers/subscription_mailer_spec.rb](spec/mailers/subscription_mailer_spec.rb)
- [spec/features/subscribe_to_newsletter_spec.rb](spec/features/subscribe_to_newsletter_spec.rb)
- [spec/features/user_registers_spec.rb](spec/features/user_registers_spec.rb)
- [`EmailSpec::Helpers` API documentation](http://www.rubydoc.info/gems/email_spec/EmailSpec/Helpers)
- [`EmailSpec::Matchers` API documentation](http://www.rubydoc.info/gems/email_spec/EmailSpec/Matchers)
# Devise Examples
Specs testing registration, sign-in, and other user authentication features provided by Devise:
- [spec/features/user_login_and_logout_spec.rb](spec/features/user_login_and_logout_spec.rb)
- [spec/features/user_registers_spec.rb](spec/features/user_registers_spec.rb)
# Custom Matchers
You can write your own custom RSpec matchers. Custom matchers can help you write more understandable
specs.
Custom matchers configuration how-to and examples:
- [spec/support/matchers.rb](spec/support/matchers.rb)
- [spec/matchers](spec/matchers)
- [spec/matchers/be_pending_subscription_page.rb](spec/matchers/be_pending_subscription_page.rb)
- Chainable matcher: [spec/matchers/be_confirm_subscription_page.rb](spec/matchers/be_confirm_subscription_page.rb)
- [spec/matchers/have_error_messages.rb](spec/matchers/have_error_messages.rb)
- [spec/features/subscribe_to_newsletter_spec.rb](spec/features/subscribe_to_newsletter_spec.rb)
- Lightweight matcher with `satisfy`: [spec/api/v1/token_spec.rb](spec/api/v1/token_spec.rb)
# RSpec-Expectations Docs
- [RSpec-Expectations API](http://www.rubydoc.info/gems/rspec-expectations/frames)
- [RSpec-Expectations matchers](https://www.relishapp.com/rspec/rspec-expectations/docs/built-in-matchers)
- [Expectations matchers cheatsheet](https://gist.github.com/hpjaj/ef5ba70a938a963332d0)
# RSpec-Mocks Specs & Docs
- [spec/controllers/subscriptions_controller_spec.rb](spec/controllers/subscriptions_controller_spec.rb)
- [spec/mailers/subscription_mailer_spec.rb](spec/mailers/subscription_mailer_spec.rb)
- [spec/models/subscription_spec.rb](spec/models/subscription_spec.rb)
- [RSpec Mocks API](https://relishapp.com/rspec/rspec-mocks/docs)
# RSpec-Rails
See [RSpec Rails](https://relishapp.com/rspec/rspec-rails/docs) for installation instructions.
## Matchers
- https://relishapp.com/rspec/rspec-rails/docs/matchers
## Generators
- https://relishapp.com/rspec/rspec-rails/docs/generators
## Feature Specs & Docs
- [spec/features/subscribe_to_newsletter_spec.rb](spec/features/subscribe_to_newsletter_spec.rb)
- [Feature specs API](https://relishapp.com/rspec/rspec-rails/docs/feature-specs/feature-spec)
## API Request Specs, Docs, & Helpers
- [spec/api/v1/token_spec.rb](spec/api/v1/token_spec.rb)
- [spec/support/json_helper.rb](spec/support/json_helper.rb)
- [spec/support/error_responses.rb](spec/support/error_responses.rb)
- [Request specs API](https://relishapp.com/rspec/rspec-rails/docs/request-specs/request-spec)
## Mailer Specs & Docs
- [spec/mailers/subscription_mailer_spec.rb](spec/mailers/subscription_mailer_spec.rb)
- [Mailer specs API](https://relishapp.com/rspec/rspec-rails/docs/mailer-specs/url-helpers-in-mailer-examples)
## Controller Specs & Docs
- [spec/controllers/subscriptions_controller_spec.rb](spec/controllers/subscriptions_controller_spec.rb)
- [Controller specs API](https://relishapp.com/rspec/rspec-rails/docs/controller-specs)
- [Controller specs cheatsheet](https://gist.github.com/eliotsykes/5b71277b0813fbc0df56)
## View Specs & Docs
- [The Big List of View Specs](https://eliotsykes.com/view-specs)
- [View specs API](https://relishapp.com/rspec/rspec-rails/docs/view-specs)
## Helper Specs & Docs
- [spec/helpers/application_helper_spec.rb](spec/helpers/application_helper_spec.rb)
- [Helper specs API](https://relishapp.com/rspec/rspec-rails/docs/helper-specs/helper-spec)
## Routing Specs & Docs
- [spec/routing/subscriptions_routing_spec.rb](spec/routing/subscriptions_routing_spec.rb)
- [Routing specs API](https://relishapp.com/rspec/rspec-rails/docs/routing-specs)
# Validator Specs
To test a custom validator you've written, refer to these validator specs from other Rails projects. These specs each follow a similar pattern where the validator is tested with a dummy model that is defined and used within the spec only. Using a dummy model is usually preferable to writing a validator spec that is dependent on a real model.
- [blacklist_validator_spec.rb](https://github.com/calagator/calagator/blob/b5fb7098fb94627b9791a0e40686be4d80c9c0c9/spec/lib/calagator/blacklist_validator_spec.rb) from Calagator
- [quality_title_validator_spec.rb](https://github.com/discourse/discourse/blob/00342faff9593a78d4c27c774ff75e1dd8819f34/spec/components/validators/quality_title_validator_spec.rb) from Discourse
- [phone_number_validator_spec.rb](https://github.com/netguru/people/blob/410c8f9355b7295af9711aeade8210a1a97e0a0c/spec/validators/phone_number_validator_spec.rb) from Netguru-People
- [no_empty_spaces_validator_spec.rb](https://github.com/danbartlett/opensit/blob/9d434bc6157b470c479f44c87c945c4652d37db1/spec/validators/no_empty_spaces_validator_spec.rb) from OpenSit
Related task: [Demonstrate Validator Specs within rspec-rails-examples](https://github.com/eliotsykes/rspec-rails-examples/issues/106)
# Enable Spring for RSpec
[Spring](https://github.com/rails/spring) is a Rails application preloader. It speeds up development by keeping your application running in the background so you don't need to boot it every time you run a new command.
To take advantage of this boost when you run `bin/rspec`, the `spring-commands-rspec` gem needs to be installed and a new `rspec` binstub needs to be created:
```bash
# 1. Add `spring-commands-rspec` to Gemfile in development and test groups and
# install gem:
bundle install
# 2. Spring-ify the `bin/rspec` binstub:
bundle exec spring binstub rspec
# 3. Stop spring to ensure the changes are picked up:
bin/spring stop
# 4. Check bin/rspec is still working:
bin/rspec
```
See the spring-commands-rspec README for up-to-date installation instructions:
https://github.com/jonleighton/spring-commands-rspec
# Automated Continuous Integration with Travis CI
Continuous Integration (CI) is the practice of integrating new code into the master branch frequently, to help detect merge conflicts, bugs, and improve the quality of the software a development team writes.
CI is usually accompanied by running an application's test suite against the latest code changes, and flagging any test failures that are found. Developers are expected to investigate and fix these failures to maintain a passing test suite and therefore quality.
[Travis CI](https://travis-ci.org) is a build server that helps automate the CI process. Travis CI runs an application's tests against the latest changes pushed to the application's code respository. In this project, Travis CI runs the project's tests (`rake test`) on pull requests and on changes to the master branch.
Travis CI configuration how-to and example:
- [.travis.yml](.travis.yml) - Travis CI's configuration file (with instructions)
- [Our Travis CI build!](https://travis-ci.org/eliotsykes/rspec-rails-examples)
- Our Travis CI badge (hopefully its green): [](https://travis-ci.org/eliotsykes/rspec-rails-examples)
---
# Contributors
- Eliot Sykes https://eliotsykes.com/
- Vitaly Tatarintsev https://github.com/ck3g
- Ryan Wold https://afomi.com/
- Andy Waite http://blog.andywaite.com/
- Alex Birdsall https://github.com/ambirdsall
- Lee Smith https://github.com/leesmith
- Abdullah Alger http://www.abdullahalger.com/
- Your name here, contributions are welcome and easy, just fork the GitHub repo, make your changes, then submit your pull request! Please ask if you'd like some help.
|
3,408 | Dawn is a static analysis security scanner for ruby written web applications. It supports Sinatra, Padrino and Ruby on Rails frameworks. | # Dawnscanner - The raising security scanner for ruby web applications
dawnscanner is a source code scanner designed to review your web applications for
security issues.
dawnscanner is able to scan web applications written in Ruby and it supports all
major MVC (Model View Controller) frameworks, out of the box:
* [Ruby on Rails](http://rubyonrails.org)
* [Sinatra](http://www.sinatrarb.com)
* [Padrino](http://www.padrinorb.com)
## Quick update from April, 2019
We just released version 2.0.0 release candidate 1 with a YAML powered revamped
knowledge base. Please note that dawnscanner will include a telemetry facility
sending a POST on https://dawnscanner.org/telemetry with an application id and
some information about version and knowledge base.
We won't now and ever collect your source code on our side.
## Quick update from November, 2018
As you can see dawnscanner is on hold since more then an year. Sorry for that.
It's life. I was overwhelmed by tons of stuff and I dedicated free time to
Offensive Security certifications. True to be told, I'm starting OSCE journey
really soon.
The dawnscanner project will be updated soon with new security checks and
kickstarted again.
Paolo
---
[](http://badge.fury.io/rb/dawnscanner)
[](https://travis-ci.org/thesp0nge/dawnscanner)
[](https://coveralls.io/r/thesp0nge/dawnscanner)
[](https://www.codetriage.com/thesp0nge/dawnscanner)
[](http://inch-ci.org/github/thesp0nge/dawnscanner)
[](https://gitter.im/thesp0nge/dawnscanner?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
---
dawnscanner version 1.6.6 has 235 security checks loaded in its knowledge
base. Most of them are CVE bulletins applying to gems or the ruby interpreter
itself. There are also some check coming from Owasp Ruby on Rails cheatsheet.
## An overall introduction
When you run dawnscanner on your code it parses your project Gemfile.lock
looking for the gems used and it tries to detect the ruby interpreter version
you are using or you declared in your ruby version management tool you like
most (RVM, rbenv, ...).
Then the tool tries to detect the MVC framework your web application uses and
it applies the security check accordingly. There checks designed to match rails
application or checks that are appliable to any ruby code.
dawnscanner can also understand the code in your views and to backtrack
sinks to spot cross site scripting and sql injections introduced by the code
you actually wrote. In the project roadmap this is the code most of the future
development effort will be focused on.
dawnscanner security scan result is a list of vulnerabilities with some
mitigation actions you want to follow in order to build a stronger web
application.
## Installation
You can install latest dawnscanner version, fetching it from
[Rubygems](https://rubygems.org) by typing:
```
$ gem install dawnscanner
```
If you want to add dawn to your project Gemfile, you must add the following:
group :development do
gem 'dawnscanner', :require=>false
end
And then upgrade your bundle
$ bundle install
You may want to build it from source, so you have to check it out from github first:
$ git clone https://github.com/thesp0nge/dawnscanner.git
$ cd dawnscanner
$ bundle install
$ rake install
And the dawnscanner gem will be built in a pkg directory and then installed
on your system. Please note that you have to manage dependencies on your own
this way. It makes sense only if you want to hack the code or something like
that.
## Usage
You can start your code review with dawnscanner very easily. Simply tell the tool
where the project root directory.
Underlying MVC framework is autodetected by dawnscanner using target Gemfile.lock
file. If autodetect fails for some reason, the tool will complain about it and
you have to specify if it's a rails, sinatra or padrino web application by
hand.
Basic usage is to specify some optional command line option to fit best your
needs, and to specify the target directory where your code is stored.
```
$ dawn [options] target
```
In case of need, there is a quick command line option reference running
```dawn -h``` at your OS prompt.
```
$ dawn -h
Usage: dawn [options] target_directory
Examples:
$ dawn a_sinatra_webapp_directory
$ dawn -C the_rails_blog_engine
$ dawn -C --json a_sinatra_webapp_directory
$ dawn --ascii-tabular-report my_rails_blog_ecommerce
$ dawn --html -F my_report.html my_rails_blog_ecommerce
-G, --gem-lock force dawn to scan only for vulnerabilities affecting dependencies in Gemfile.lock (DEPRECATED)
-d, --dependencies force dawn to scan only for vulnerabilities affecting dependencies in Gemfile.lock
Reporting
-a, --ascii-tabular-report cause dawn to format findings using tables in ascii art (DEPRECATED)
-j, --json cause dawn to format findings using json
-K, --console cause dawn to format findings using plain ascii text
-C, --count-only dawn will only count vulnerabilities (useful for scripts)
-z, --exit-on-warn dawn will return number of found vulnerabilities as exit code
-F, --file filename tells dawn to write output to filename
-c, --config-file filename tells dawn to load configuration from filename
Disable security check family
--disable-cve-bulletins disable all CVE security checks
--disable-code-quality disable all code quality checks
--disable-code-style disable all code style checks
--disable-owasp-ror-cheatsheet disable all Owasp Ruby on Rails cheatsheet checks
--disable-owasp-top-10 disable all Owasp Top 10 checks
Flags useful to query Dawn
-S, --search-knowledge-base [check_name] search check_name in the knowledge base
--list-knowledge-base list knowledge-base content
--list-known-families list security check families contained in dawn's knowledge base
--list-known-framework list ruby MVC frameworks supported by dawn
--list-scan-registry list past scan informations stored in scan registry
Service flags
-D, --debug enters dawn debug mode
-V, --verbose the output will be more verbose
-v, --version show version information
-h, --help show this help
```
### Rake task
To include dawnscanner in your rake task list, you simply have to put this line in
your ```Rakefile```
```
require 'dawn/tasks'
```
Then executing ```$ rake -T``` you will have a ```dawn:run``` task you want to
execute.
```
$ rake -T
...
rake dawn:run # Execute dawnscanner on the current directory
...
```
### Interacting with the knowledge base
You can dump all security checks in the knowledge base this way
```
$ dawn --list-knowledge-base
```
Useful in scripts, you can use ```--search-knowledge-base``` or ```-S``` with
as parameter the check name you want to see if it's implemented as a security
control or not.
```
$ dawn -S CVE-2013-6421
07:59:30 [*] dawn v1.1.0 is starting up
CVE-2013-6421 found in knowledgebase.
$ dawn -S this_test_does_not_exist
08:02:17 [*] dawn v1.1.0 is starting up
this_test_does_not_exist not found in knowledgebase
```
### dawnscanner security scan in action
As output, dawnscanner will put all security checks that are failed during the scan.
This the result of Codedake::dawnscanner running against a
[Sinatra 1.4.2 web application](https://github.com/thesp0nge/railsberry2013) wrote for a talk I
delivered in 2013 at [Railsberry conference](http://www.railsberry.com).
As you may see, dawnscanner first detects MVC running the application by
looking at Gemfile.lock, than it discards all security checks not appliable to
Sinatra (49 security checks, in version 1.0, especially designed for Ruby on
Rails) and it applies them.
```
$ dawn ~/src/hacking/railsberry2013
18:40:27 [*] dawn v1.1.0 is starting up
18:40:27 [$] dawn: scanning /Users/thesp0nge/src/hacking/railsberry2013
18:40:27 [$] dawn: sinatra v1.4.2 detected
18:40:27 [$] dawn: applying all security checks
18:40:27 [$] dawn: 109 security checks applied - 0 security checks skipped
18:40:27 [$] dawn: 1 vulnerabilities found
18:40:27 [!] dawn: CVE-2013-1800 check failed
18:40:27 [$] dawn: Severity: high
18:40:27 [$] dawn: Priority: unknown
18:40:27 [$] dawn: Description: The crack gem 0.3.1 and earlier for Ruby does not properly restrict casts of string values, which might allow remote attackers to conduct object-injection attacks and execute arbitrary code, or cause a denial of service (memory and CPU consumption) by leveraging Action Pack support for (1) YAML type conversion or (2) Symbol type conversion, a similar vulnerability to CVE-2013-0156.
18:40:27 [$] dawn: Solution: Please use crack gem version 0.3.2 or above. Correct your gemfile
18:40:27 [$] dawn: Evidence:
18:40:27 [$] dawn: Vulnerable crack gem version found: 0.3.1
18:40:27 [*] dawn is leaving
```
---
When you run dawnscanner on a web application with up to date dependencies,
it's likely to return a friendly _no vulnerabilities found_ message. Keep it up
working that way!
This is dawnscanner running against a Padrino web application I wrote for [a
scorecard quiz game about application security](http://scorecard.armoredcode.com).
Italian language only. Sorry.
```
18:42:39 [*] dawn v1.1.0 is starting up
18:42:39 [$] dawn: scanning /Users/thesp0nge/src/CORE_PROJECTS/scorecard
18:42:39 [$] dawn: padrino v0.11.2 detected
18:42:39 [$] dawn: applying all security checks
18:42:39 [$] dawn: 109 security checks applied - 0 security checks skipped
18:42:39 [*] dawn: no vulnerabilities found.
18:42:39 [*] dawn is leaving
```
If you need a fancy HTML report about your scan, just ask it to dawnscanner
with the ```--html``` flag used with the ```--file``` since I wanto to save the
HTML to disk.
```
$ dawn /Users/thesp0nge/src/hacking/rt_first_app --html --file report.html
09:00:54 [*] dawn v1.1.0 is starting up
09:00:54 [*] dawn: report.html created (2952 bytes)
09:00:54 [*] dawn is leaving
```
---
## Useful links
Project homepage: [http://dawnscanner.org](http://dawnscanner.org)
Twitter profile: [@dawnscanner](https://twitter.com/dawnscanner)
Github repository: [https://github.com/thesp0nge/dawnscanner](https://github.com/thesp0nge/dawnscanner)
Mailing list: [https://groups.google.com/forum/#!forum/dawnscanner](https://groups.google.com/forum/#!forum/dawnscanner)
## Support us
Feedbacks are great and we really love to hear your voice.
If you're a proud dawnscanner user, if you find it useful, if you integrated
it in your release process and if you want to openly support the project you
can put your reference here. Just open an
[issue](https://github.com/thesp0nge/dawnscanner/issues/new) with a statement saying
how do you feel the tool and your company logo if any.
More easily you can drop an email to
[[email protected]](mailto:[email protected]) sending a statement about your
success story and I'll put on the website.
Thank you.
## Thanks to
[saten](https://github.com/saten): first issue posted about a typo in the README
[presidentbeef](https://github.com/presidentbeef): for his outstanding work that inspired me creating dawn and for double check comparison matrix. Issue #2 is yours :)
[marinerJB](https://github.com/marinerJB): for misc bug reports and further ideas
[Matteo](https://github.com/matteocollina): for ideas on API and their usage with [github.com](https://github.com) hooks
## LICENSE
Copyright (c) 2013-2016 Paolo Perego <[email protected]>
MIT License
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
3,409 | Track changes to your rails models | # PaperTrail
[![Build Status][4]][5]
[![Gem Version][53]][54]
[![SemVer][55]][56]
Track changes to your models, for auditing or versioning. See how a model looked
at any stage in its lifecycle, revert it to any version, or restore it after it
has been destroyed.
## Documentation
This is the _user guide_. See also, the
[API reference](https://www.rubydoc.info/gems/paper_trail).
Choose version:
[Unreleased](https://github.com/paper-trail-gem/paper_trail/blob/master/README.md),
[14.0](https://github.com/paper-trail-gem/paper_trail/blob/v14.0.0/README.md),
[13.0](https://github.com/paper-trail-gem/paper_trail/blob/v13.0.0/README.md),
[12.3](https://github.com/paper-trail-gem/paper_trail/blob/v12.3.0/README.md),
[11.1](https://github.com/paper-trail-gem/paper_trail/blob/v11.1.0/README.md),
[10.3](https://github.com/paper-trail-gem/paper_trail/blob/v10.3.1/README.md),
[9.2](https://github.com/paper-trail-gem/paper_trail/blob/v9.2.0/README.md),
[8.1](https://github.com/paper-trail-gem/paper_trail/blob/v8.1.2/README.md),
[7.1](https://github.com/paper-trail-gem/paper_trail/blob/v7.1.3/README.md),
[6.0](https://github.com/paper-trail-gem/paper_trail/blob/v6.0.2/README.md),
[5.2](https://github.com/paper-trail-gem/paper_trail/blob/v5.2.3/README.md),
[4.2](https://github.com/paper-trail-gem/paper_trail/blob/v4.2.0/README.md),
[3.0](https://github.com/paper-trail-gem/paper_trail/blob/v3.0.9/README.md),
[2.7](https://github.com/paper-trail-gem/paper_trail/blob/v2.7.2/README.md),
[1.6](https://github.com/paper-trail-gem/paper_trail/blob/v1.6.5/README.md)
## Table of Contents
<!-- toc -->
- [1. Introduction](#1-introduction)
- [1.a. Compatibility](#1a-compatibility)
- [1.b. Installation](#1b-installation)
- [1.c. Basic Usage](#1c-basic-usage)
- [1.d. API Summary](#1d-api-summary)
- [1.e. Configuration](#1e-configuration)
- [2. Limiting What is Versioned, and When](#2-limiting-what-is-versioned-and-when)
- [2.a. Choosing Lifecycle Events To Monitor](#2a-choosing-lifecycle-events-to-monitor)
- [2.b. Choosing When To Save New Versions](#2b-choosing-when-to-save-new-versions)
- [2.c. Choosing Attributes To Monitor](#2c-choosing-attributes-to-monitor)
- [2.d. Turning PaperTrail Off](#2d-turning-papertrail-off)
- [2.e. Limiting the Number of Versions Created](#2e-limiting-the-number-of-versions-created)
- [3. Working With Versions](#3-working-with-versions)
- [3.a. Reverting And Undeleting A Model](#3a-reverting-and-undeleting-a-model)
- [3.b. Navigating Versions](#3b-navigating-versions)
- [3.c. Diffing Versions](#3c-diffing-versions)
- [3.d. Deleting Old Versions](#3d-deleting-old-versions)
- [3.e. Queries](#3e-queries)
- [3.f. Defunct `item_id`s](#3f-defunct-item_ids)
- [4. Saving More Information About Versions](#4-saving-more-information-about-versions)
- [4.a. Finding Out Who Was Responsible For A Change](#4a-finding-out-who-was-responsible-for-a-change)
- [4.b. Associations](#4b-associations)
- [4.c. Storing Metadata](#4c-storing-metadata)
- [5. ActiveRecord](#5-activerecord)
- [5.a. Single Table Inheritance (STI)](#5a-single-table-inheritance-sti)
- [5.b. Configuring the `versions` Association](#5b-configuring-the-versions-association)
- [5.c. Generators](#5c-generators)
- [5.d. Protected Attributes](#5d-protected-attributes)
- [6. Extensibility](#6-extensibility)
- [6.a. Custom Version Classes](#6a-custom-version-classes)
- [6.b. Custom Serializer](#6b-custom-serializer)
- [6.c. Custom Object Changes](#6c-custom-object-changes)
- [6.d. Excluding the Object Column](#6d-excluding-the-object-column)
- [7. Testing](#7-testing)
- [7.a. Minitest](#7a-minitest)
- [7.b. RSpec](#7b-rspec)
- [7.c. Cucumber](#7c-cucumber)
- [7.d. Spork](#7d-spork)
- [7.e. Zeus or Spring](#7e-zeus-or-spring)
- [8. PaperTrail Plugins](#8-papertrail-plugins)
- [9. Integration with Other Libraries](#9-integration-with-other-libraries)
- [10. Related Libraries and Ports](#10-related-libraries-and-ports)
- [Articles](#articles)
- [Problems](#problems)
- [Contributors](#contributors)
- [Contributing](#contributing)
- [Inspirations](#inspirations)
- [Intellectual Property](#intellectual-property)
<!-- tocstop -->
## 1. Introduction
### 1.a. Compatibility
| paper_trail | branch | ruby | activerecord |
|-------------|------------|----------|---------------|
| unreleased | master | >= 2.7.0 | >= 6.0, < 7.1 |
| 14 | 14-stable | >= 2.7.0 | >= 6.0, < 7.1 |
| 13 | 13-stable | >= 2.6.0 | >= 5.2, < 7.1 |
| 12 | 12-stable | >= 2.6.0 | >= 5.2, < 7.1 |
| 11 | 11-stable | >= 2.4.0 | >= 5.2, < 6.1 |
| 10 | 10-stable | >= 2.3.0 | >= 4.2, < 6.1 |
| 9 | 9-stable | >= 2.3.0 | >= 4.2, < 5.3 |
| 8 | 8-stable | >= 2.2.0 | >= 4.2, < 5.2 |
| 7 | 7-stable | >= 2.1.0 | >= 4.0, < 5.2 |
| 6 | 6-stable | >= 1.9.3 | >= 4.0, < 5.2 |
| 5 | 5-stable | >= 1.9.3 | >= 3.0, < 5.1 |
| 4 | 4-stable | >= 1.8.7 | >= 3.0, < 5.1 |
| 3 | 3.0-stable | >= 1.8.7 | >= 3.0, < 5 |
| 2 | 2.7-stable | >= 1.8.7 | >= 3.0, < 4 |
| 1 | rails2 | >= 1.8.7 | >= 2.3, < 3 |
Experts: to install incompatible versions of activerecord, see
`paper_trail/compatibility.rb`.
### 1.b. Installation
1. Add PaperTrail to your `Gemfile` and run [`bundle`][57].
`gem 'paper_trail'`
1. Add a `versions` table to your database:
```
bundle exec rails generate paper_trail:install [--with-changes]
```
If tables in your project use `uuid` instead of `integers` for `id`, then use:
```
bundle exec rails generate paper_trail:install [--uuid]
```
See [section 5.c. Generators](#5c-generators) for details.
```
bundle exec rake db:migrate
```
1. Add `has_paper_trail` to the models you want to track.
```ruby
class Widget < ActiveRecord::Base
has_paper_trail
end
```
1. If your controllers have a `current_user` method, you can easily [track who
is responsible for changes](#4a-finding-out-who-was-responsible-for-a-change)
by adding a controller callback.
```ruby
class ApplicationController
before_action :set_paper_trail_whodunnit
end
```
### 1.c. Basic Usage
Your models now have a `versions` method which returns the "paper trail" of
changes to your model.
```ruby
widget = Widget.find 42
widget.versions
# [<PaperTrail::Version>, <PaperTrail::Version>, ...]
```
Once you have a version, you can find out what happened:
```ruby
v = widget.versions.last
v.event # 'update', 'create', 'destroy'. See also: "The versions.event Column"
v.created_at
v.whodunnit # ID of `current_user`. Requires `set_paper_trail_whodunnit` callback.
widget = v.reify # The widget as it was before the update (nil for a create event)
```
PaperTrail stores the pre-change version of the model, unlike some other
auditing/versioning plugins, so you can retrieve the original version. This is
useful when you start keeping a paper trail for models that already have records
in the database.
```ruby
widget = Widget.find 153
widget.name # 'Doobly'
# Add has_paper_trail to Widget model.
widget.versions # []
widget.update name: 'Wotsit'
widget.versions.last.reify.name # 'Doobly'
widget.versions.last.event # 'update'
```
This also means that PaperTrail does not waste space storing a version of the
object as it currently stands. The `versions` method gives you previous
versions; to get the current one just call a finder on your `Widget` model as
usual.
Here's a helpful table showing what PaperTrail stores:
| *Event* | *create* | *update* | *destroy* |
| -------------- | -------- | -------- | --------- |
| *Model Before* | nil | widget | widget |
| *Model After* | widget | widget | nil |
PaperTrail stores the values in the Model Before row. Most other
auditing/versioning plugins store the After row.
### 1.d. API Summary
An introductory sample of common features.
When you declare `has_paper_trail` in your model, you get these methods:
```ruby
class Widget < ActiveRecord::Base
has_paper_trail
end
# Returns this widget's versions. You can customise the name of the
# association, but overriding this method is not supported.
widget.versions
# Return the version this widget was reified from, or nil if it is live.
# You can customise the name of the method.
widget.version
# Returns true if this widget is the current, live one; or false if it is from
# a previous version.
widget.paper_trail.live?
# Returns who put the widget into its current state.
widget.paper_trail.originator
# Returns the widget (not a version) as it looked at the given timestamp.
widget.paper_trail.version_at(timestamp)
# Returns the widget (not a version) as it was most recently.
widget.paper_trail.previous_version
# Returns the widget (not a version) as it became next.
widget.paper_trail.next_version
```
And a `PaperTrail::Version` instance (which is just an ordinary ActiveRecord
instance, with all the usual methods) has methods such as:
```ruby
# Returns the item restored from this version.
version.reify(options = {})
# Return a new item from this version
version.reify(dup: true)
# Returns who put the item into the state stored in this version.
version.paper_trail_originator
# Returns who changed the item from the state it had in this version.
version.terminator
version.whodunnit
version.version_author
# Returns the next version.
version.next
# Returns the previous version.
version.previous
# Returns the index of this version in all the versions.
version.index
# Returns the event that caused this version (create|update|destroy).
version.event
```
This is just a sample of common features. Keep reading for more.
### 1.e. Configuration
Many aspects of PaperTrail are configurable for individual models; typically
this is achieved by passing options to the `has_paper_trail` method within
a given model.
Some aspects of PaperTrail are configured globally for all models. These
settings are assigned directly on the `PaperTrail.config` object.
A common place to put these settings is in a Rails initializer file
such as `config/initializers/paper_trail.rb` or in an environment-specific
configuration file such as `config/environments/test.rb`.
#### 1.e.1 Global
Global configuration options affect all threads.
- association_reify_error_behaviour
- enabled
- has_paper_trail_defaults
- object_changes_adapter
- serializer
- version_limit
Syntax example: (options described in detail later)
```ruby
# config/initializers/paper_trail.rb
PaperTrail.config.enabled = true
PaperTrail.config.has_paper_trail_defaults = {
on: %i[create update destroy]
}
PaperTrail.config.version_limit = 3
````
These options are intended to be set only once, during app initialization (eg.
in `config/initializers`). It is unsafe to change them while the app is running.
In contrast, `PaperTrail.request` has various options that only apply to a
single HTTP request and thus are safe to use while the app is running.
## 2. Limiting What is Versioned, and When
### 2.a. Choosing Lifecycle Events To Monitor
You can choose which events to track with the `on` option. For example, if
you only want to track `update` events:
```ruby
class Article < ActiveRecord::Base
has_paper_trail on: [:update]
end
```
`has_paper_trail` installs [callbacks][52] for the specified lifecycle events.
There are four potential callbacks, and the default is to install all four, ie.
`on: [:create, :destroy, :touch, :update]`.
#### The `versions.event` Column
Your `versions` table has an `event` column with three possible values:
| *event* | *callback* |
| ------- | ------------- |
| create | create |
| destroy | destroy |
| update | touch, update |
You may also have the `PaperTrail::Version` model save a custom string in its
`event` field instead of the typical `create`, `update`, `destroy`. PaperTrail
adds an `attr_accessor` to your model named `paper_trail_event`, and will insert
it, if present, in the `event` column.
```ruby
a = Article.create
a.versions.size # 1
a.versions.last.event # 'create'
a.paper_trail_event = 'update title'
a.update title: 'My Title'
a.versions.size # 2
a.versions.last.event # 'update title'
a.paper_trail_event = nil
a.update title: 'Alternate'
a.versions.size # 3
a.versions.last.event # 'update'
```
#### Controlling the Order of AR Callbacks
If there are other callbacks in your model, their order relative to those
installed by `has_paper_trail` may matter. If you need to control
their order, use the `paper_trail_on_*` methods.
```ruby
class Article < ActiveRecord::Base
# Include PaperTrail, but do not install any callbacks. Passing the
# empty array to `:on` omits callbacks.
has_paper_trail on: []
# Add callbacks in the order you need.
paper_trail.on_destroy # add destroy callback
paper_trail.on_update # etc.
paper_trail.on_create
paper_trail.on_touch
end
```
The `paper_trail.on_destroy` method can be further configured to happen
`:before` or `:after` the destroy event. Until PaperTrail 4, the default was
`:after`. Starting with PaperTrail 5, the default is `:before`, to support
ActiveRecord 5. (see https://github.com/paper-trail-gem/paper_trail/pull/683)
### 2.b. Choosing When To Save New Versions
You can choose the conditions when to add new versions with the `if` and
`unless` options. For example, to save versions only for US non-draft
translations:
```ruby
class Translation < ActiveRecord::Base
has_paper_trail if: Proc.new { |t| t.language_code == 'US' },
unless: Proc.new { |t| t.type == 'DRAFT' }
end
```
#### Choosing Based on Changed Attributes
Starting with PaperTrail 4.0, versions are saved during an after-callback. If
you decide whether to save a new version based on changed attributes,
use attribute_name_was instead of attribute_name.
#### Saving a New Version Manually
You may want to save a new version regardless of options like `:on`, `:if`, or
`:unless`. Or, in rare situations, you may want to save a new version even if
the record has not changed.
```ruby
my_model.paper_trail.save_with_version
```
### 2.c. Choosing Attributes To Monitor
#### Ignore
If you don't want a version created when only a certain attribute changes, you can `ignore` that attribute:
```ruby
class Article < ActiveRecord::Base
has_paper_trail ignore: [:title, :rating]
end
```
Changes to just the `title` or `rating` will not create a version record.
Changes to other attributes will create a version record.
```ruby
a = Article.create
a.versions.length # 1
a.update title: 'My Title', rating: 3
a.versions.length # 1
a.update title: 'Greeting', content: 'Hello'
a.versions.length # 2
a.paper_trail.previous_version.title # 'My Title'
```
Note: ignored fields will be stored in the version records. If you want to keep a field out of the versions table, use [`:skip`](#skip) instead of `:ignore`; skipped fields are also implicitly ignored.
The `:ignore` option can also accept `Hash` arguments that we are considering deprecating.
```ruby
class Article < ActiveRecord::Base
has_paper_trail ignore: [:title, { color: proc { |obj| obj.color == "Yellow" } }]
end
```
#### Only
Or, you can specify a list of the `only` attributes you care about:
```ruby
class Article < ActiveRecord::Base
has_paper_trail only: [:title]
end
```
Only changes to the `title` will create a version record.
```ruby
a = Article.create
a.versions.length # 1
a.update title: 'My Title'
a.versions.length # 2
a.update content: 'Hello'
a.versions.length # 2
a.paper_trail.previous_version.content # nil
```
The `:only` option can also accept `Hash` arguments that we are considering deprecating.
```ruby
class Article < ActiveRecord::Base
has_paper_trail only: [{ title: Proc.new { |obj| !obj.title.blank? } }]
end
```
If the `title` is not blank, then only changes to the `title`
will create a version record.
```ruby
a = Article.create
a.versions.length # 1
a.update content: 'Hello'
a.versions.length # 2
a.update title: 'Title One'
a.versions.length # 3
a.update content: 'Hai'
a.versions.length # 3
a.paper_trail.previous_version.content # "Hello"
a.update title: 'Title Two'
a.versions.length # 4
a.paper_trail.previous_version.content # "Hai"
```
Configuring both `:ignore` and `:only` is not recommended, but it should work as
expected. Passing both `:ignore` and `:only` options will result in the
article being saved if a changed attribute is included in `:only` but not in
`:ignore`.
#### Skip
If you never want a field's values in the versions table, you can `:skip` the attribute. As with `:ignore`,
updates to these attributes will not create a version record. In addition, if a
version record is created for some other reason, these attributes will not be
persisted.
```ruby
class Author < ActiveRecord::Base
has_paper_trail skip: [:social_security_number]
end
```
Author's social security numbers will never appear in the versions log, and if an author updates only their social security number, it won't create a version record.
#### Comparing `:ignore`, `:only`, and `:skip`
- `:only` is basically the same as `:ignore`, but its inverse.
- `:ignore` controls whether paper_trail will create a version record or not.
- `:skip` controls whether paper_trail will save that field with the version record.
- Skipped fields are also implicitly ignored. paper_trail does this internally.
- Ignored fields are not implicitly skipped.
So:
- Ignore a field if you don't want a version record created when it's the only field to change.
- Skip a field if you don't want it to be saved with any version records.
### 2.d. Turning PaperTrail Off
PaperTrail is on by default, but sometimes you don't want to record versions.
#### Per Process
Turn PaperTrail off for **all threads** in a `ruby` process.
```ruby
PaperTrail.enabled = false
```
**Do not use this in production** unless you have a good understanding of
threads vs. processes.
A legitimate use case is to speed up tests. See [Testing](#7-testing) below.
#### Per HTTP Request
```ruby
PaperTrail.request(enabled: false) do
# no versions created
end
```
or,
```ruby
PaperTrail.request.enabled = false
# no versions created
PaperTrail.request.enabled = true
```
#### Per Class
In the rare case that you need to disable versioning for one model while
keeping versioning enabled for other models, use:
```ruby
PaperTrail.request.disable_model(Banana)
# changes to Banana model do not create versions,
# but eg. changes to Kiwi model do.
PaperTrail.request.enable_model(Banana)
PaperTrail.request.enabled_for_model?(Banana) # => true
```
This setting, as with all `PaperTrail.request` settings, affects only the
current request, not all threads.
For this rare use case, there is no convenient way to pass a block.
##### In a Rails Controller Callback (Not Recommended)
PaperTrail installs a callback in your rails controllers. The installed
callback will call `paper_trail_enabled_for_controller`, which you can
override.
```ruby
class ApplicationController < ActionController::Base
def paper_trail_enabled_for_controller
# Don't omit `super` without a good reason.
super && request.user_agent != 'Disable User-Agent'
end
end
```
Because you are unable to control the order of callback execution, this
technique is not recommended, but is preserved for backwards compatibility.
It would be better to install your own callback and use
`PaperTrail.request.enabled=` as you see fit.
#### Per Method (Removed)
The `widget.paper_trail.without_versioning` method was removed in v10, without
an exact replacement. To disable versioning, use the [Per Class](#per-class) or
[Per HTTP Request](#per-http-request) methods.
### 2.e. Limiting the Number of Versions Created
Configure `version_limit` to cap the number of versions saved per record. This
does not apply to `create` events.
```ruby
# Limit: 4 versions per record (3 most recent, plus a `create` event)
PaperTrail.config.version_limit = 3
# Remove the limit
PaperTrail.config.version_limit = nil
```
#### 2.e.1 Per-model limit
Models can override the global `PaperTrail.config.version_limit` setting.
Example:
```
# initializer
PaperTrail.config.version_limit = 10
# At most 10 versions
has_paper_trail
# At most 3 versions (2 updates, 1 create). Overrides global version_limit.
has_paper_trail limit: 2
# Infinite versions
has_paper_trail limit: nil
```
## 3. Working With Versions
### 3.a. Reverting And Undeleting A Model
PaperTrail makes reverting to a previous version easy:
```ruby
widget = Widget.find 42
widget.update name: 'Blah blah'
# Time passes....
widget = widget.paper_trail.previous_version # the widget as it was before the update
widget.save # reverted
```
Alternatively you can find the version at a given time:
```ruby
widget = widget.paper_trail.version_at(1.day.ago) # the widget as it was one day ago
widget.save # reverted
```
Note `version_at` gives you the object, not a version, so you don't need to call
`reify`.
Undeleting is just as simple:
```ruby
widget = Widget.find(42)
widget.destroy
# Time passes....
widget = Widget.new(id:42) # creating a new object with the same id, re-establishes the link
versions = widget.versions # versions ordered by versions.created_at, ascending
widget = versions.last.reify # the widget as it was before destruction
widget.save # the widget lives!
```
You could even use PaperTrail to implement an undo system; [Ryan Bates has!][3]
If your model uses [optimistic locking][1] don't forget to [increment your
`lock_version`][2] before saving or you'll get a `StaleObjectError`.
### 3.b. Navigating Versions
You can call `previous_version` and `next_version` on an item to get it as it
was/became. Note that these methods reify the item for you.
```ruby
live_widget = Widget.find 42
live_widget.versions.length # 4, for example
widget = live_widget.paper_trail.previous_version # => widget == live_widget.versions.last.reify
widget = widget.paper_trail.previous_version # => widget == live_widget.versions[-2].reify
widget = widget.paper_trail.next_version # => widget == live_widget.versions.last.reify
widget.paper_trail.next_version # live_widget
```
If instead you have a particular `version` of an item you can navigate to the
previous and next versions.
```ruby
widget = Widget.find 42
version = widget.versions[-2] # assuming widget has several versions
previous_version = version.previous
next_version = version.next
```
You can find out which of an item's versions yours is:
```ruby
current_version_number = version.index # 0-based
```
If you got an item by reifying one of its versions, you can navigate back to the
version it came from:
```ruby
latest_version = Widget.find(42).versions.last
widget = latest_version.reify
widget.version == latest_version # true
```
You can find out whether a model instance is the current, live one -- or whether
it came instead from a previous version -- with `live?`:
```ruby
widget = Widget.find 42
widget.paper_trail.live? # true
widget = widget.paper_trail.previous_version
widget.paper_trail.live? # false
```
See also: Section 3.e. Queries
### 3.c. Diffing Versions
There are two scenarios: diffing adjacent versions and diffing non-adjacent
versions.
The best way to diff adjacent versions is to get PaperTrail to do it for you. If
you add an `object_changes` column to your `versions` table, PaperTrail will
store the `changes` diff in each version. Ignored attributes are omitted.
```ruby
widget = Widget.create name: 'Bob'
widget.versions.last.changeset # reads object_changes column
# {
# "name"=>[nil, "Bob"],
# "created_at"=>[nil, 2015-08-10 04:10:40 UTC],
# "updated_at"=>[nil, 2015-08-10 04:10:40 UTC],
# "id"=>[nil, 1]
# }
widget.update name: 'Robert'
widget.versions.last.changeset
# {
# "name"=>["Bob", "Robert"],
# "updated_at"=>[2015-08-10 04:13:19 UTC, 2015-08-10 04:13:19 UTC]
# }
widget.destroy
widget.versions.last.changeset
# {}
```
Prior to 10.0.0, the `object_changes` were only stored for create and update
events. As of 10.0.0, they are stored for all three events.
PaperTrail doesn't use diffs internally.
> When I designed PaperTrail I wanted simplicity and robustness so I decided to
> make each version of an object self-contained. A version stores all of its
> object's data, not a diff from the previous version. This means you can
> delete any version without affecting any other. -Andy
To diff non-adjacent versions you'll have to write your own code. These
libraries may help:
For diffing two strings:
* [htmldiff][19]: expects but doesn't require HTML input and produces HTML
output. Works very well but slows down significantly on large (e.g. 5,000
word) inputs.
* [differ][20]: expects plain text input and produces plain
text/coloured/HTML/any output. Can do character-wise, word-wise, line-wise,
or arbitrary-boundary-string-wise diffs. Works very well on non-HTML input.
* [diff-lcs][21]: old-school, line-wise diffs.
Unfortunately, there is no currently widely available and supported library for diffing two ActiveRecord objects.
### 3.d. Deleting Old Versions
Over time your `versions` table will grow to an unwieldy size. Because each
version is self-contained (see the Diffing section above for more) you can
simply delete any records you don't want any more. For example:
```sql
sql> delete from versions where created_at < '2010-06-01';
```
```ruby
PaperTrail::Version.where('created_at < ?', 1.day.ago).delete_all
```
### 3.e. Queries
You can query records in the `versions` table based on their `object` or
`object_changes` columns.
```ruby
# Find versions that meet these criteria.
PaperTrail::Version.where_object(content: 'Hello', title: 'Article')
# Find versions before and after attribute `atr` had value `v`:
PaperTrail::Version.where_object_changes(atr: 'v')
```
See also:
- `where_object_changes_from`
- `where_object_changes_to`
- `where_attribute_changes`
Only `where_object` supports text columns. Your `object_changes` column should
be a `json` or `jsonb` column if possible. If you must use a `text` column,
you'll have to write a [custom
`object_changes_adapter`](#6c-custom-object-changes).
### 3.f. Defunct `item_id`s
The `item_id`s in your `versions` table can become defunct over time,
potentially causing application errors when `id`s in the foreign table are
reused. `id` reuse can be an explicit choice of the application, or implicitly
caused by sequence cycling. The chance of `id` reuse is reduced (but not
eliminated) with `bigint` `id`s or `uuid`s, `no cycle`
[sequences](https://www.postgresql.org/docs/current/sql-createsequence.html),
and/or when `versions` are periodically deleted.
Ideally, a Foreign Key Constraint (FKC) would set `item_id` to null when an item
is deleted. However, `items` is a polymorphic relationship. A partial FKC (e.g.
an FKC with a `where` clause) is possible, but only in Postgres, and it is
impractical to maintain FKCs for every versioned table unless the number of
such tables is very small.
If [per-table `Version`
classes](https://github.com/paper-trail-gem/paper_trail#6a-custom-version-classes)
are used, then a partial FKC is no longer needed. So, a normal FKC can be
written in any RDBMS, but it remains impractical to maintain so many FKCs.
Some applications choose to handle this problem by "soft-deleting" versioned
records, i.e. marking them as deleted instead of actually deleting them. This
completely prevents `id` reuse, but adds complexity to the application. In most
applications, this is the only known practical solution to the `id` reuse
problem.
## 4. Saving More Information About Versions
### 4.a. Finding Out Who Was Responsible For A Change
Set `PaperTrail.request.whodunnit=`, and that value will be stored in the
version's `whodunnit` column.
```ruby
PaperTrail.request.whodunnit = 'Andy Stewart'
widget.update name: 'Wibble'
widget.versions.last.whodunnit # Andy Stewart
```
#### Setting `whodunnit` to a `Proc`
`whodunnit=` also accepts a `Proc`, in the rare case that lazy evaluation is
required.
```ruby
PaperTrail.request.whodunnit = proc do
caller.find { |c| c.starts_with? Rails.root.to_s }
end
```
Because lazy evaluation can be hard to troubleshoot, this is not
recommended for common use.
#### Setting `whodunnit` Temporarily
To set whodunnit temporarily, for the duration of a block, use
`PaperTrail.request`:
```ruby
PaperTrail.request(whodunnit: 'Dorian Marié') do
widget.update name: 'Wibble'
end
```
#### Setting `whodunnit` with a controller callback
If your controller has a `current_user` method, PaperTrail provides a
callback that will assign `current_user.id` to `whodunnit`.
```ruby
class ApplicationController
before_action :set_paper_trail_whodunnit
end
```
You may want `set_paper_trail_whodunnit` to call a different method to find out
who is responsible. To do so, override the `user_for_paper_trail` method in
your controller like this:
```ruby
class ApplicationController
def user_for_paper_trail
logged_in? ? current_member.id : 'Public user' # or whatever
end
end
```
See also: [Setting whodunnit in the rails console][33]
#### Terminator and Originator
A version's `whodunnit` column tells us who changed the object, causing the
`version` to be stored. Because a version stores the object as it looked before
the change (see the table above), `whodunnit` tells us who *stopped* the object
looking like this -- not who made it look like this. Hence `whodunnit` is
aliased as `terminator`.
To find out who made a version's object look that way, use
`version.paper_trail_originator`. And to find out who made a "live" object look
like it does, call `paper_trail_originator` on the object.
```ruby
widget = Widget.find 153 # assume widget has 0 versions
PaperTrail.request.whodunnit = 'Alice'
widget.update name: 'Yankee'
widget.paper_trail.originator # 'Alice'
PaperTrail.request.whodunnit = 'Bob'
widget.update name: 'Zulu'
widget.paper_trail.originator # 'Bob'
first_version, last_version = widget.versions.first, widget.versions.last
first_version.whodunnit # 'Alice'
first_version.paper_trail_originator # nil
first_version.terminator # 'Alice'
last_version.whodunnit # 'Bob'
last_version.paper_trail_originator # 'Alice'
last_version.terminator # 'Bob'
```
#### Storing an ActiveRecord globalid in whodunnit
If you would like `whodunnit` to return an `ActiveRecord` object instead of a
string, please try the [paper_trail-globalid][37] gem.
### 4.b. Associations
To track and reify associations, use [paper_trail-association_tracking][6] (PT-AT).
From 2014 to 2018, association tracking was an experimental feature, but many
issues were discovered. To attract new volunteers to address these issues, PT-AT
was extracted (see https://github.com/paper-trail-gem/paper_trail/issues/1070).
Even though it had always been an experimental feature, we didn't want the
extraction of PT-AT to be a breaking change, so great care was taken to remove
it slowly.
- In PT 9, PT-AT was kept as a runtime dependency.
- In PT 10, it became a development dependency (If you use it you must add it to
your own `Gemfile`) and we kept running all of its tests.
- In PT 11, it will no longer be a development dependency, and it is responsible
for its own tests.
#### 4.b.1 The optional `item_subtype` column
As of PT 10, users may add an `item_subtype` column to their `versions` table.
When storing versions for STI models, rails stores the base class in `item_type`
(that's just how polymorphic associations like `item` work) In addition, PT will
now store the subclass in `item_subtype`. If this column is present PT-AT will
use it to fix a rare issue with reification of STI subclasses.
```ruby
add_column :versions, :item_subtype, :string, null: true
```
So, if you use PT-AT and STI, the addition of this column is recommended.
- https://github.com/paper-trail-gem/paper_trail/issues/594
- https://github.com/paper-trail-gem/paper_trail/pull/1143
- https://github.com/westonganger/paper_trail-association_tracking/pull/5
### 4.c. Storing Metadata
You can add your own custom columns to your `versions` table. Values can be
given using **Model Metadata** or **Controller Metadata**.
#### Model Metadata
You can specify metadata in the model using `has_paper_trail(meta:)`.
```ruby
class Article < ActiveRecord::Base
belongs_to :author
has_paper_trail(
meta: {
author_id: :author_id, # model attribute
word_count: :count_words, # arbitrary model method
answer: 42, # scalar value
editor: proc { |article| article.editor.full_name } # a Proc
}
)
def count_words
153
end
end
```
#### Metadata from Controllers
You can also store any information you like from your controller. Override
the `info_for_paper_trail` method in your controller to return a hash whose keys
correspond to columns in your `versions` table.
```ruby
class ApplicationController
def info_for_paper_trail
{ ip: request.remote_ip, user_agent: request.user_agent }
end
end
```
#### Advantages of Metadata
Why would you do this? In this example, `author_id` is an attribute of
`Article` and PaperTrail will store it anyway in a serialized form in the
`object` column of the `version` record. But let's say you wanted to pull out
all versions for a particular author; without the metadata you would have to
deserialize (reify) each `version` object to see if belonged to the author in
question. Clearly this is inefficient. Using the metadata you can find just
those versions you want:
```ruby
PaperTrail::Version.where(author_id: author_id)
```
#### Metadata can Override PaperTrail Columns
**Experts only**. Metadata will override the normal values that PT would have
inserted into its own columns.
| *PT Column* | *How bad of an idea?* | *Alternative* |
|----------------|-----------------------|-------------------------------|
| created_at | forbidden* | |
| event | meh | paper_trail_event |
| id | forbidden | |
| item_id | forbidden | |
| item_subtype | forbidden | |
| item_type | forbidden | |
| object | a little dangerous | |
| object_changes | a little dangerous | |
| updated_at | forbidden | |
| whodunnit | meh | PaperTrail.request.whodunnit= |
\* forbidden - raises a `PaperTrail::InvalidOption` error as of PT 14
## 5. ActiveRecord
### 5.a. Single Table Inheritance (STI)
PaperTrail supports [Single Table Inheritance][39], and even supports an
un-versioned base model, as of `23ffbdc7e1`.
```ruby
class Fruit < ActiveRecord::Base
# un-versioned base model
end
class Banana < Fruit
has_paper_trail
end
```
However, there is a known issue when reifying [associations](#associations),
see https://github.com/paper-trail-gem/paper_trail/issues/594
### 5.b. Configuring the `versions` Association
#### 5.b.1. `versions` association
You may configure the name of the `versions` association by passing a different
name (default is `:versions`) in the `versions:` options hash:
```ruby
class Post < ActiveRecord::Base
has_paper_trail versions: {
name: :drafts
}
end
Post.new.versions # => NoMethodError
```
You may pass a
[scope](https://api.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many-label-Scopes)
to the `versions` association with the `scope:` option:
```ruby
class Post < ActiveRecord::Base
has_paper_trail versions: {
scope: -> { order("id desc") }
}
# Equivalent to:
has_many :versions,
-> { order("id desc") },
class_name: 'PaperTrail::Version',
as: :item
end
```
Any other [options supported by
`has_many`](https://api.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many-label-Options)
can be passed along to the `has_many` macro via the `versions:` options hash.
```ruby
class Post < ActiveRecord::Base
has_paper_trail versions: {
extend: VersionsExtensions,
autosave: false
}
end
```
Overriding (instead of configuring) the `versions` method is not supported.
Overriding associations is not recommended in general.
#### 5.b.2. `item` association
A `PaperTrail::Version` object `belongs_to` an `item`, the relevant record.
The `item` association is first defined in `PaperTrail::VersionConcern`, but
associations can be redefined.
##### Example: adding a `counter_cache` to `item` association
```ruby
# app/models/paper_trail/version.rb
module PaperTrail
class Version < ActiveRecord::Base
belongs_to :item, polymorphic: true, counter_cache: true
end
end
```
When redefining an association, its options are _replaced_ not _merged_, so
don't forget to specify the options from `PaperTrail::VersionConcern`, like
`polymorphic`.
Be advised that redefining an association is an undocumented feature of Rails.
### 5.c. Generators
PaperTrail has one generator, `paper_trail:install`. It writes, but does not
run, a migration file. The migration creates the `versions` table.
#### Reference
The most up-to-date documentation for this generator can be found by running
`rails generate paper_trail:install --help`, but a copy is included here for
convenience.
```
Usage:
rails generate paper_trail:install [options]
Options:
[--with-changes], [--no-with-changes] # Store changeset (diff) with each version
[--uuid] # To use paper_trail with projects using uuid for id
Runtime options:
-f, [--force] # Overwrite files that already exist
-p, [--pretend], [--no-pretend] # Run but do not make any changes
-q, [--quiet], [--no-quiet] # Suppress status output
-s, [--skip], [--no-skip] # Skip files that already exist
Generates (but does not run) a migration to add a versions table.
```
### 5.d. Protected Attributes
As of version 6, PT no longer supports rails 3 or the [protected_attributes][17]
gem. If you are still using them, you may use PT 5 or lower. We recommend
upgrading to [strong_parameters][18] as soon as possible.
If you must use [protected_attributes][17] for now, and want to use PT > 5, you
can reopen `PaperTrail::Version` and add the following `attr_accessible` fields:
```ruby
# app/models/paper_trail/version.rb
module PaperTrail
class Version < ActiveRecord::Base
include PaperTrail::VersionConcern
attr_accessible :item_type, :item_id, :event, :whodunnit, :object, :object_changes, :created_at
end
end
```
This *unsupported workaround* has been tested with protected_attributes 1.0.9 /
rails 4.2.8 / paper_trail 7.0.3.
## 6. Extensibility
### 6.a. Custom Version Classes
You can specify custom version subclasses with the `:class_name` option:
```ruby
class PostVersion < PaperTrail::Version
# custom behaviour, e.g:
self.table_name = :post_versions
end
class Post < ActiveRecord::Base
has_paper_trail versions: {
class_name: 'PostVersion'
}
end
```
Unlike ActiveRecord's `class_name`, you'll have to supply the complete module
path to the class (e.g. `Foo::BarVersion` if your class is inside the module
`Foo`).
#### Advantages
1. For models which have a lot of versions, storing each model's versions in a
separate table can improve the performance of certain database queries.
1. Store different version [metadata](#4c-storing-metadata) for different models.
#### Configuration
If you are using Postgres, you should also define the sequence that your custom
version class will use:
```ruby
class PostVersion < PaperTrail::Version
self.table_name = :post_versions
self.sequence_name = :post_versions_id_seq
end
```
If you only use custom version classes and don't have a `versions` table, you must
let ActiveRecord know that your base version class (eg. `ApplicationVersion` below)
class is an `abstract_class`.
```ruby
# app/models/application_version.rb
class ApplicationVersion < ActiveRecord::Base
include PaperTrail::VersionConcern
self.abstract_class = true
end
class PostVersion < ApplicationVersion
self.table_name = :post_versions
self.sequence_name = :post_versions_id_seq
end
```
You can also specify custom names for the versions and version associations.
This is useful if you already have `versions` or/and `version` methods on your
model. For example:
```ruby
class Post < ActiveRecord::Base
has_paper_trail versions: { name: :paper_trail_versions },
version: :paper_trail_version
# Existing versions method. We don't want to clash.
def versions
# ...
end
# Existing version method. We don't want to clash.
def version
# ...
end
end
```
### 6.b. Custom Serializer
By default, PaperTrail stores your changes as a `YAML` dump. You can override
this with the serializer config option:
```ruby
PaperTrail.serializer = MyCustomSerializer
```
A valid serializer is a `module` (or `class`) that defines a `load` and `dump`
method. These serializers are included in the gem for your convenience:
* [PaperTrail::Serializers::YAML][24] - Default
* [PaperTrail::Serializers::JSON][25]
#### PostgreSQL JSON column type support
If you use PostgreSQL, and would like to store your `object` (and/or
`object_changes`) data in a column of [type `json` or type `jsonb`][26], specify
`json` instead of `text` for these columns in your migration:
```ruby
create_table :versions do |t|
# ...
t.json :object # Full object changes
t.json :object_changes # Optional column-level changes
# ...
end
```
If you use the PostgreSQL `json` or `jsonb` column type, you do not need
to specify a `PaperTrail.serializer`.
##### Convert existing YAML data to JSON
If you've been using PaperTrail for a while with the default YAML serializer
and you want to switch to JSON or JSONB, you're in a bit of a bind because
there's no automatic way to migrate your data. The first (slow) option is to
loop over every record and parse it in Ruby, then write to a temporary column:
```ruby
add_column :versions, :new_object, :jsonb # or :json
# add_column :versions, :new_object_changes, :jsonb # or :json
# PaperTrail::Version.reset_column_information # needed for rails < 6
PaperTrail::Version.where.not(object: nil).find_each do |version|
version.update_column(:new_object, YAML.load(version.object))
# if version.object_changes
# version.update_column(
# :new_object_changes,
# YAML.load(version.object_changes)
# )
# end
end
remove_column :versions, :object
# remove_column :versions, :object_changes
rename_column :versions, :new_object, :object
# rename_column :versions, :new_object_changes, :object_changes
```
This technique can be very slow if you have a lot of data. Though slow, it is
safe in databases where transactions are protected against DDL, such as
Postgres. In databases without such protection, such as MySQL, a table lock may
be necessary.
If the above technique is too slow for your needs, and you're okay doing without
PaperTrail data temporarily, you can create the new column without converting
the data.
```ruby
rename_column :versions, :object, :old_object
add_column :versions, :object, :jsonb # or :json
```
After that migration, your historical data still exists as YAML, and new data
will be stored as JSON. Next, convert records from YAML to JSON using a
background script.
```ruby
PaperTrail::Version.where.not(old_object: nil).find_each do |version|
version.update_columns old_object: nil, object: YAML.load(version.old_object)
end
```
Finally, in another migration, remove the old column.
```ruby
remove_column :versions, :old_object
```
If you use the optional `object_changes` column, don't forget to convert it
also, using the same technique.
##### Convert a Column from Text to JSON
If your `object` column already contains JSON data, and you want to change its
data type to `json` or `jsonb`, you can use the following [DDL][36]. Of course,
if your `object` column contains YAML, you must first convert the data to JSON
(see above) before you can change the column type.
Using SQL:
```sql
alter table versions
alter column object type jsonb
using object::jsonb;
```
Using ActiveRecord:
```ruby
class ConvertVersionsObjectToJson < ActiveRecord::Migration
def up
change_column :versions, :object, 'jsonb USING object::jsonb'
end
def down
change_column :versions, :object, 'text USING object::text'
end
end
```
### 6.c. Custom Object Changes
To fully control the contents of their `object_changes` column, expert users
can write an adapter.
```ruby
PaperTrail.config.object_changes_adapter = MyObjectChangesAdapter.new
class MyObjectChangesAdapter
# @param changes Hash
# @return Hash
def diff(changes)
# ...
end
end
```
You should only use this feature if you are comfortable reading PT's source to
see exactly how the adapter is used. For example, see how `diff` is used by
reading `::PaperTrail::Events::Base#recordable_object_changes`.
An adapter can implement any or all of the following methods:
1. diff: Returns the changeset in the desired format given the changeset in the
original format
2. load_changeset: Returns the changeset for a given version object
3. where_object_changes: Returns the records resulting from the given hash of
attributes.
4. where_object_changes_from: Returns the records resulting from the given hash
of attributes where the attributes changed *from* the provided value(s).
5. where_object_changes_to: Returns the records resulting from the given hash of
attributes where the attributes changed *to* the provided value(s).
6. where_attribute_changes: Returns the records where the attribute changed to
or from any value.
Depending on your needs, you may choose to implement only a subset of these
methods.
#### Known Adapters
- [paper_trail-hashdiff](https://github.com/hashwin/paper_trail-hashdiff)
### 6.d. Excluding the Object Column
The `object` column ends up storing a lot of duplicate data if you have models that have many columns,
and that are updated many times. You can save ~50% of storage space by removing the column from the
versions table. It's important to note that this will disable `reify` and `where_object`.
## 7. Testing
You may want to turn PaperTrail off to speed up your tests. See [Turning
PaperTrail Off](#2d-turning-papertrail-off) above.
### 7.a. Minitest
First, disable PT for the entire `ruby` process.
```ruby
# in config/environments/test.rb
config.after_initialize do
PaperTrail.enabled = false
end
```
Then, to enable PT for specific tests, you can add a `with_versioning` test
helper method.
```ruby
# in test/test_helper.rb
def with_versioning
was_enabled = PaperTrail.enabled?
was_enabled_for_request = PaperTrail.request.enabled?
PaperTrail.enabled = true
PaperTrail.request.enabled = true
begin
yield
ensure
PaperTrail.enabled = was_enabled
PaperTrail.request.enabled = was_enabled_for_request
end
end
```
Then, use the helper in your tests.
```ruby
test 'something that needs versioning' do
with_versioning do
# your test
end
end
```
### 7.b. RSpec
PaperTrail provides a helper, `paper_trail/frameworks/rspec.rb`, that works with
[RSpec][27] to make it easier to control when `PaperTrail` is enabled during
testing.
```ruby
# spec/rails_helper.rb
ENV["RAILS_ENV"] ||= 'test'
require 'spec_helper'
require File.expand_path("../../config/environment", __FILE__)
require 'rspec/rails'
# ...
require 'paper_trail/frameworks/rspec'
```
With the helper loaded, PaperTrail will be turned off for all tests by
default. To enable PaperTrail for a test you can either wrap the
test in a `with_versioning` block, or pass in `versioning: true` option to a
spec block.
```ruby
describe 'RSpec test group' do
it 'by default, PaperTrail will be turned off' do
expect(PaperTrail).to_not be_enabled
end
with_versioning do
it 'within a `with_versioning` block it will be turned on' do
expect(PaperTrail).to be_enabled
end
end
it 'can be turned on at the `it` or `describe` level', versioning: true do
expect(PaperTrail).to be_enabled
end
end
```
The helper will also reset `whodunnit` to `nil` before each
test to help prevent data spillover between tests. If you are using PaperTrail
with Rails, the helper will automatically set the
`PaperTrail.request.controller_info` value to `{}` as well, again, to help
prevent data spillover between tests.
There is also a `be_versioned` matcher provided by PaperTrail's RSpec helper
which can be leveraged like so:
```ruby
class Widget < ActiveRecord::Base
end
describe Widget do
it 'is not versioned by default' do
is_expected.to_not be_versioned
end
describe 'add versioning to the `Widget` class' do
before(:all) do
class Widget < ActiveRecord::Base
has_paper_trail
end
end
it 'enables paper trail' do
is_expected.to be_versioned
end
end
end
```
#### Matchers
The `have_a_version_with` matcher makes assertions about versions using
`where_object`, based on the `object` column.
```ruby
describe '`have_a_version_with` matcher' do
it 'is possible to do assertions on version attributes' do
widget.update!(name: 'Leonard', an_integer: 1)
widget.update!(name: 'Tom')
widget.update!(name: 'Bob')
expect(widget).to have_a_version_with name: 'Leonard', an_integer: 1
expect(widget).to have_a_version_with an_integer: 1
expect(widget).to have_a_version_with name: 'Tom'
end
end
```
The `have_a_version_with_changes` matcher makes assertions about versions using
`where_object_changes`, based on the optional
[`object_changes` column](#3c-diffing-versions).
```ruby
describe '`have_a_version_with_changes` matcher' do
it 'is possible to do assertions on version changes' do
widget.update!(name: 'Leonard', an_integer: 1)
widget.update!(name: 'Tom')
widget.update!(name: 'Bob')
expect(widget).to have_a_version_with_changes name: 'Leonard', an_integer: 2
expect(widget).to have_a_version_with_changes an_integer: 2
expect(widget).to have_a_version_with_changes name: 'Bob'
end
end
```
For more examples of the RSpec matchers, see the
[Widget spec](https://github.com/paper-trail-gem/paper_trail/blob/master/spec/models/widget_spec.rb)
### 7.c. Cucumber
PaperTrail provides a helper for [Cucumber][28] that works similar to the RSpec
helper. If you want to use the helper, you will need to require in your cucumber
helper like so:
```ruby
# features/support/env.rb
ENV["RAILS_ENV"] ||= 'cucumber'
require File.expand_path(File.dirname(__FILE__) + '/../../config/environment')
# ...
require 'paper_trail/frameworks/cucumber'
```
When the helper is loaded, PaperTrail will be turned off for all scenarios by a
`before` hook added by the helper by default. When you want to enable PaperTrail
for a scenario, you can wrap code in a `with_versioning` block in a step, like
so:
```ruby
Given /I want versioning on my model/ do
with_versioning do
# PaperTrail will be turned on for all code inside of this block
end
end
```
The helper will also reset the `whodunnit` value to `nil` before each
test to help prevent data spillover between tests. If you are using PaperTrail
with Rails, the helper will automatically set the
`PaperTrail.request.controller_info` value to `{}` as well, again, to help
prevent data spillover between tests.
### 7.d. Spork
If you want to use the `RSpec` or `Cucumber` helpers with [Spork][29], you will
need to manually require the helper(s) in your `prefork` block on your test
helper, like so:
```ruby
# spec/rails_helper.rb
require 'spork'
Spork.prefork do
# This file is copied to spec/ when you run 'rails generate rspec:install'
ENV["RAILS_ENV"] ||= 'test'
require 'spec_helper'
require File.expand_path("../../config/environment", __FILE__)
require 'rspec/rails'
require 'paper_trail/frameworks/rspec'
require 'paper_trail/frameworks/cucumber'
# ...
end
```
### 7.e. Zeus or Spring
If you want to use the `RSpec` or `Cucumber` helpers with [Zeus][30] or
[Spring][31], you will need to manually require the helper(s) in your test
helper, like so:
```ruby
# spec/rails_helper.rb
ENV["RAILS_ENV"] ||= 'test'
require 'spec_helper'
require File.expand_path("../../config/environment", __FILE__)
require 'rspec/rails'
require 'paper_trail/frameworks/rspec'
```
## 8. PaperTrail Plugins
- paper_trail-active_record
- [paper_trail-association_tracking][6] - track and reify associations
- paper_trail-audit
- paper_trail-background
- [paper_trail-globalid][49] - enhances whodunnit by adding an `actor`
- paper_trail-hashdiff
- paper_trail-rails
- paper_trail-related_changes
- paper_trail-sinatra
- paper_trail_actor
- paper_trail_changes
- paper_trail_manager
- paper_trail_scrapbook
- paper_trail_ui
- revertible_paper_trail
- rspec-paper_trail
- sequel_paper_trail
## 9. Integration with Other Libraries
- [ActiveAdmin][42]
- [paper_trail_manager][46] - Browse, subscribe, view and revert changes to
records with rails and paper_trail
- [rails_admin_history_rollback][51] - History rollback for rails_admin with PT
- Sinatra - [paper_trail-sinatra][41]
- [globalize][45] - [globalize-versioning][44]
- [solidus_papertrail][47] - PT integration for Solidus
method to instances of PaperTrail::Version that returns the ActiveRecord
object who was responsible for change
## 10. Related Libraries and Ports
- [izelnakri/paper_trail][50] - An Ecto library, inspired by PT.
- [sequelize-paper-trail][48] - A JS library, inspired by PT. A sequelize
plugin for tracking revision history of model instances.
## Articles
* [PaperTrail Gem Tutorial](https://stevepolito.design/blog/paper-trail-gem-tutorial/), 20th April 2020.
* [Jutsu #8 - Version your RoR models with PaperTrail](http://samurails.com/gems/papertrail/),
[Thibault](http://samurails.com/about-me/), 29th September 2014
* [Versioning with PaperTrail](http://www.sitepoint.com/versioning-papertrail),
[Ilya Bodrov](http://www.sitepoint.com/author/ibodrov), 10th April 2014
* [Using PaperTrail to track stack traces](http://web.archive.org/web/20141120233916/http://rubyrailsexpert.com/?p=36),
T James Corcoran's blog, 1st October 2013.
* [RailsCast #255 - Undo with PaperTrail](http://railscasts.com/episodes/255-undo-with-paper-trail),
28th February 2011.
* [Keep a Paper Trail with PaperTrail](http://www.linux-mag.com/id/7528),
Linux Magazine, 16th September 2009.
## Problems
Please use GitHub's [issue tracker](https://github.com/paper-trail-gem/paper_trail/issues).
## Contributors
Created by Andy Stewart in 2010, maintained since 2012 by Ben Atkins, since 2015
by Jared Beck, with contributions by over 150 people.
https://github.com/paper-trail-gem/paper_trail/graphs/contributors
## Contributing
See our [contribution guidelines][43]
## Inspirations
* [Simply Versioned](https://github.com/jerome/simply_versioned)
* [Acts As Audited](https://github.com/collectiveidea/audited)
## Intellectual Property
Copyright (c) 2011 Andy Stewart ([email protected]).
Released under the MIT licence.
[1]: http://api.rubyonrails.org/classes/ActiveRecord/Locking/Optimistic.html
[2]: https://github.com/paper-trail-gem/paper_trail/issues/163
[3]: http://railscasts.com/episodes/255-undo-with-paper-trail
[4]: https://api.travis-ci.org/paper-trail-gem/paper_trail.svg?branch=master
[5]: https://travis-ci.org/paper-trail-gem/paper_trail
[6]: https://github.com/westonganger/paper_trail-association_tracking
[9]: https://github.com/paper-trail-gem/paper_trail/tree/3.0-stable
[10]: https://github.com/paper-trail-gem/paper_trail/tree/2.7-stable
[11]: https://github.com/paper-trail-gem/paper_trail/tree/rails2
[14]: https://raw.github.com/paper-trail-gem/paper_trail/master/lib/generators/paper_trail/templates/create_versions.rb
[16]: https://github.com/paper-trail-gem/paper_trail/issues/113
[17]: https://github.com/rails/protected_attributes
[18]: https://github.com/rails/strong_parameters
[19]: http://github.com/myobie/htmldiff
[20]: http://github.com/pvande/differ
[21]: https://github.com/halostatue/diff-lcs
[24]: https://github.com/paper-trail-gem/paper_trail/blob/master/lib/paper_trail/serializers/yaml.rb
[25]: https://github.com/paper-trail-gem/paper_trail/blob/master/lib/paper_trail/serializers/json.rb
[26]: http://www.postgresql.org/docs/9.4/static/datatype-json.html
[27]: https://github.com/rspec/rspec
[28]: http://cukes.info
[29]: https://github.com/sporkrb/spork
[30]: https://github.com/burke/zeus
[31]: https://github.com/rails/spring
[32]: http://api.rubyonrails.org/classes/ActiveRecord/AutosaveAssociation.html#method-i-mark_for_destruction
[33]: https://github.com/paper-trail-gem/paper_trail/wiki/Setting-whodunnit-in-the-rails-console
[34]: https://github.com/rails/rails/blob/591a0bb87fff7583e01156696fbbf929d48d3e54/activerecord/lib/active_record/fixtures.rb#L142
[35]: https://dev.mysql.com/doc/refman/5.6/en/fractional-seconds.html
[36]: http://www.postgresql.org/docs/9.4/interactive/ddl.html
[37]: https://github.com/ankit1910/paper_trail-globalid
[38]: https://github.com/sferik/rails_admin
[39]: http://api.rubyonrails.org/classes/ActiveRecord/Base.html#class-ActiveRecord::Base-label-Single+table+inheritance
[40]: http://api.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#module-ActiveRecord::Associations::ClassMethods-label-Polymorphic+Associations
[41]: https://github.com/jaredbeck/paper_trail-sinatra
[42]: https://github.com/activeadmin/activeadmin/wiki/Auditing-via-paper_trail-%28change-history%29
[43]: https://github.com/paper-trail-gem/paper_trail/blob/master/.github/CONTRIBUTING.md
[44]: https://github.com/globalize/globalize-versioning
[45]: https://github.com/globalize/globalize
[46]: https://github.com/fusion94/paper_trail_manager
[47]: https://github.com/solidusio-contrib/solidus_papertrail
[48]: https://github.com/nielsgl/sequelize-paper-trail
[49]: https://github.com/ankit1910/paper_trail-globalid
[50]: https://github.com/izelnakri/paper_trail
[51]: https://github.com/rikkipitt/rails_admin_history_rollback
[52]: http://guides.rubyonrails.org/active_record_callbacks.html
[53]: https://badge.fury.io/rb/paper_trail.svg
[54]: https://rubygems.org/gems/paper_trail
[55]: https://api.dependabot.com/badges/compatibility_score?dependency-name=paper_trail&package-manager=bundler&version-scheme=semver
[56]: https://dependabot.com/compatibility-score.html?dependency-name=paper_trail&package-manager=bundler&version-scheme=semver
[57]: https://bundler.io/v2.3/man/bundle-install.1.html
|
3,410 | A community-driven Ruby on Rails style guide | null |
3,411 | 🎓 Sharing machine learning course / lecture notes. | # 🎓 Machine Learning Course Notes
A place to collaborate and share lecture notes on all topics related to machine learning, NLP, and AI.
`WIP` denotes work in progress.
---
### Machine Learning Specialization (2022)
[Website](https://www.coursera.org/specializations/machine-learning-introduction) | Instructor: Andrew Ng
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Introduction to Machine Learning</td>
<td class="tg-yw4l">Supervised Machine Learning: Regression and Classification</td>
<td class="tg-yw4l"><a href="https://www.coursera.org/learn/machine-learning?specialization=machine-learning-introduction">Videos<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Course-1-Supervised-Machine-Learning-3a200719f58145dc8a701a2545bdf9f4">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Advanced Learning Algorithms</td>
<td class="tg-yw4l">Advanced Learning Algorithms</td>
<td class="tg-yw4l"><a href="https://www.coursera.org/learn/advanced-learning-algorithms?specialization=machine-learning-introduction">Videos<a></td>
<td class="tg-yw4l">WIP</td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Unsupervised Learning, Recommenders, Reinforcement Learning</td>
<td class="tg-yw4l">Unsupervised Learning, Recommenders, Reinforcement Learning</td>
<td class="tg-yw4l"><a href="https://www.coursera.org/learn/unsupervised-learning-recommenders-reinforcement-learning?specialization=machine-learning-introduction">Videos<a></td>
<td class="tg-yw4l">WIP</td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### MIT 6.S191 Introduction to Deep Learning (2022)
[Website](http://introtodeeplearning.com/) | Lectures by: Alexander Amini and Ava Soleimany
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Introduction to Deep Learning</td>
<td class="tg-yw4l">Basic fundamentals of neural networks and deep learning.</td>
<td class="tg-yw4l"><a href="https://youtu.be/7sB052Pz0sQ">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-1-Intro-to-DL-d4929997a7a34a33a163cf40ba00360b">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">RNNs and Transformers</td>
<td class="tg-yw4l">Introduction to recurrent neural networks and transformers.</td>
<td class="tg-yw4l"><a href="https://youtu.be/QvkQ1B3FBqA">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-2-Recurrent-Neural-Networks-and-Transformers-71fb3ba2a24f4b6c8cc77281fc19cfab">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Deep Computer Vision</td>
<td class="tg-yw4l">Deep Neural Networks for Computer Vision.</td>
<td class="tg-yw4l"><a href="https://youtu.be/uapdILWYTzE">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-3-Deep-Computer-Vision-e43a17b50f7e4b5f8393c070b22340a3">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Deep Generative Modeling</td>
<td class="tg-yw4l">Autoencoders and GANs.</td>
<td class="tg-yw4l"><a href="https://youtu.be/QcLlc9lj2hk">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-4-Deep-Generative-Modeling-928d24a5764d4bf1bcf5fb4c4234f6ac">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Deep Reinforcement Learning</td>
<td class="tg-yw4l">Deep RL key concepts and DQNs.</td>
<td class="tg-yw4l"><a href="https://youtu.be/-WbN61qtTGQ">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-5-Deep-Reinforcement-Learning-8ecc8b16a5ad4fcc81b5c3ceb21608b5">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Limitations and New Frontiers</td>
<td class="tg-yw4l">Limitations and New Frontiers in Deep Learning.</td>
<td class="tg-yw4l"><a href="https://youtu.be/wySXLRTxAGQ">Video<a></td>
<td class="tg-yw4l">WIP</td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Autonomous Driving with LiDAR</td>
<td class="tg-yw4l">Autonomous Driving with LiDAR.</td>
<td class="tg-yw4l"><a href="https://youtu.be/NHZMfSMAHlo">Video<a></td>
<td class="tg-yw4l">WIP</td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### CMU Neural Nets for NLP (2021)
[Website](http://phontron.com/class/nn4nlp2021/schedule.html) | Instructor: Graham Neubig
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Introduction to Simple Neural Networks for NLP</td>
<td class="tg-yw4l">Provides an introduction to neural networks for NLP covering concepts like BOW, CBOW, and Deep CBOW</td>
<td class="tg-yw4l"><a href="https://www.youtube.com/watch?v=vnx6M7N-ggs&ab_channel=GrahamNeubig">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-1-Introduction-to-Simple-Neural-Networks-for-NLP-b7afa29af56e4d47a75fbcf3b82407db">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### CS224N: Natural Language Processing with Deep Learning (2022)
[Website](https://www.youtube.com/playlist?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ) | Instructor: Christopher Manning
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Introduction and Word Vectors</td>
<td class="tg-yw4l">Introduction to NLP and Word Vectors.</td>
<td class="tg-yw4l"><a href="https://youtu.be/rmVRLeJRkl4">Video<a></td>
<td class="tg-yw4l"><a href="https://dair-ai.notion.site/Lecture-1-Introduction-and-Word-Vectors-afdc392dd83e44faab91f7c1b8f563a0">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Neural Classifiers</td>
<td class="tg-yw4l">Neural Classifiers for NLP.</td>
<td class="tg-yw4l"><a href="https://youtu.be/gqaHkPEZAew">Video<a></td>
<td class="tg-yw4l"><a href="https://github.com/dair-ai/ML-Course-Notes/issues/4">WIP</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### CS25: Transformers United
[Website](https://web.stanford.edu/class/cs25/) | Instructors: Div Garg, Chetanya Rastogi, Advay Pal
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Introduction to Transformers</td>
<td class="tg-yw4l">A short summary of attention and Transformers.</td>
<td class="tg-yw4l"><a href="https://youtu.be/P127jhj-8-Y">Video<a></td>
<td class="tg-yw4l"><a href="https://www.notion.so/dair-ai/Introduction-to-Transformers-4b869c9595b74f72b088e5f2793ece80">Notes</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Transformers in Language: GPT-3, Codex</td>
<td class="tg-yw4l">The development of GPT Models including GPT3.</td>
<td class="tg-yw4l"><a href="https://youtu.be/qGkzHFllWDY">Video<a></td>
<td class="tg-yw4l">WIP</td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### Neural Networks: Zero to Hero
[Lectures](https://www.youtube.com/playlist?list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ) | Instructors: Andrej Karpathy
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Let's build GPT: from scratch, in code, spelled out</td>
<td class="tg-yw4l">Detailed walkthrough of GPT</td>
<td class="tg-yw4l"><a href="https://youtube.com/watch?v=kCc8FmEb1nY&feature=sharesY">Video<a></td>
<td class="tg-yw4l"><a href="">WIP</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### Miscellaneous Lectures
<table class="tg">
<tr>
<th class="tg-yw4l"><b>Lecture</b></th>
<th class="tg-yw4l"><b>Description</b></th>
<th class="tg-yw4l"><b>Video</b></th>
<th class="tg-yw4l"><b>Notes</b></th>
<th class="tg-yw4l"><b>Author</b></th>
</tr>
<tr>
<td class="tg-yw4l">Introduction to Diffusion Models</td>
<td class="tg-yw4l">Technical overview of Diffusion Models</td>
<td class="tg-yw4l"><a href="">Video<a></td>
<td class="tg-yw4l"><a href="">WIP</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
<tr>
<td class="tg-yw4l">Reinforcement Learning from Human Feedback (RLHF)</td>
<td class="tg-yw4l">Overview of RLHF</td>
<td class="tg-yw4l"><a href="">Video<a></td>
<td class="tg-yw4l"><a href="">WIP</a></td>
<td class="tg-yw4l"><a href="https://twitter.com/omarsar0">Elvis<a></td>
</tr>
</table>
---
### How To Contribute
1) Identify a course and lecture from this [list](https://github.com/dair-ai/ML-YouTube-Courses). If you are working on notes for a lecture, please indicate by opening an issue. This avoids duplicate work.
2) Write your notes, preferably in a Google document, Notion document, or GitHub repo.
3) We care about quality, so make sure to revise your notes before submitting.
4) Once you are finished, open a PR here.
If you have any questions, open an issue or reach out to me on [Twitter](https://twitter.com/omarsar0).
Join our [Discord](https://discord.gg/FzNtjEK9dg).
|
3,412 | 《动手学深度学习》:面向中文读者、能运行、可讨论。中英文版被60多个国家的400多所大学用于教学。 | # 动手学深度学习(Dive into Deep Learning,D2L.ai)
[](http://ci.d2l.ai/job/d2l-zh/job/master/)
[第二版:zh.D2L.ai](https://zh.d2l.ai) | [第一版:zh-v1.D2L.ai](https://zh-v1.d2l.ai/) | 安装和使用书中源代码: [第二版](https://zh.d2l.ai/chapter_installation/index.html) [第一版](https://zh-v1.d2l.ai/chapter_prerequisite/install.html)
<h5 align="center"><i>理解深度学习的最佳方法是学以致用。</i></h5>
<p align="center">
<img width="200" src="static/frontpage/_images/eq.jpg">
<img width="200" src="static/frontpage/_images/figure.jpg">
<img width="200" src="static/frontpage/_images/code.jpg">
<img width="200" src="static/frontpage/_images/notebook.gif">
</p>
本开源项目代表了我们的一种尝试:我们将教给读者概念、背景知识和代码;我们将在同一个地方阐述剖析问题所需的批判性思维、解决问题所需的数学知识,以及实现解决方案所需的工程技能。
我们的目标是创建一个为实现以下目标的统一资源:
1. 所有人均可在网上免费获取;
1. 提供足够的技术深度,从而帮助读者实际成为深度学习应用科学家:既理解数学原理,又能够实现并不断改进方法;
1. 包含可运行的代码,为读者展示如何在实际中解决问题。这样不仅直接将数学公式对应成实际代码,而且可以修改代码、观察结果并及时获取经验;
1. 允许我们和整个社区不断快速迭代内容,从而紧跟仍在高速发展的深度学习领域;
1. 由包含有关技术细节问答的论坛作为补充,使大家可以相互答疑并交换经验。
<h5 align="center">将本书(中英文版)用作教材或参考书的大学</h5>
<p align="center">
<img width="400" src="https://d2l.ai/_images/map.png">
</p>
如果本书对你有帮助,请Star (★) 本仓库或引用本书的英文版:
```
@article{zhang2021dive,
title={Dive into Deep Learning},
author={Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J.},
journal={arXiv preprint arXiv:2106.11342},
year={2021}
}
```
## 本书的英文版
虽然纸质书已出版,但深度学习领域依然在迅速发展。为了得到来自更广泛的英文开源社区的帮助,从而提升本书质量,本书的新版将继续用英文编写,并搬回中文版。
欢迎关注本书的[英文开源项目](https://github.com/d2l-ai/d2l-en)。
## 中英文教学资源
加州大学伯克利分校 2019 年春学期 [*Introduction to Deep Learning* 课程](http://courses.d2l.ai/berkeley-stat-157/index.html)教材(同时提供含教学视频地址的[中文版课件](https://github.com/d2l-ai/berkeley-stat-157/tree/master/slides-zh))。
## 学术界推荐
> <p>"Dive into this book if you want to dive into deep learning!"</p>
> <b>— 韩家炜,ACM 院士、IEEE 院士,美国伊利诺伊大学香槟分校计算机系 Michael Aiken Chair 教授</b>
> <p>"This is a highly welcome addition to the machine learning literature."</p>
> <b>— Bernhard Schölkopf,ACM 院士、德国国家科学院院士,德国马克斯•普朗克研究所智能系统院院长</b>
> <p>"书中代码可谓‘所学即所用’。"</p>
> <b>— 周志华,ACM 院士、IEEE 院士、AAAS 院士,南京大学计算机科学与技术系主任</b>
> <p>"这本书可以帮助深度学习实践者快速提升自己的能力。"</p>
> <b>— 张潼,ASA 院士、IMS 院士,香港科技大学计算机系和数学系教授</b>
## 工业界推荐
> <p>"一本优秀的深度学习教材,值得任何想了解深度学习何以引爆人工智能革命的人关注。"</p>
> <b>— 黄仁勋,NVIDIA创始人 & CEO</b>
> <p>"《动手学深度学习》是最适合工业界研发工程师学习的。我毫无保留地向广大的读者们强烈推荐。"</p>
> <b>— 余凯,地平线公司创始人 & CEO</b>
> <p>"强烈推荐这本书!我特别赞赏这种手脑一体的学习方式。"</p>
> <b>— 漆远,复旦大学“浩清”教授、人工智能创新与产业研究院院长</b>
> <p>"《动手学深度学习》是一本很容易让学习者上瘾的书。"</p>
> <b>— 沈强,将门创投创始合伙人</b>
## 贡献
感谢[社区贡献者们](https://github.com/d2l-ai/d2l-zh/graphs/contributors)为每一位读者改进这本开源书。
[如何贡献](https://zh.d2l.ai/chapter_appendix-tools-for-deep-learning/contributing.html) | [致谢](https://zh.d2l.ai/chapter_preface/index.html) | [讨论或报告问题](https://discuss.d2l.ai/c/chinese-version/16) | [其他](INFO.md)
|
3,413 | General Assembly's 2015 Data Science course in Washington, DC | ## DAT8 Course Repository
Course materials for [General Assembly's Data Science course](https://generalassemb.ly/education/data-science/washington-dc/) in Washington, DC (8/18/15 - 10/29/15).
**Instructor:** Kevin Markham ([Data School blog](http://www.dataschool.io/), [email newsletter](http://www.dataschool.io/subscribe/), [YouTube channel](https://www.youtube.com/user/dataschool))
[](http://mybinder.org/repo/justmarkham/DAT8)
Tuesday | Thursday
--- | ---
8/18: [Introduction to Data Science](#class-1-introduction-to-data-science) | 8/20: [Command Line, Version Control](#class-2-command-line-and-version-control)
8/25: [Data Reading and Cleaning](#class-3-data-reading-and-cleaning) | 8/27: [Exploratory Data Analysis](#class-4-exploratory-data-analysis)
9/1: [Visualization](#class-5-visualization) | 9/3: [Machine Learning](#class-6-machine-learning)
9/8: [Getting Data](#class-7-getting-data) | 9/10: [K-Nearest Neighbors](#class-8-k-nearest-neighbors)
9/15: [Basic Model Evaluation](#class-9-basic-model-evaluation) | 9/17: [Linear Regression](#class-10-linear-regression)
9/22: [First Project Presentation](#class-11-first-project-presentation) | 9/24: [Logistic Regression](#class-12-logistic-regression)
9/29: [Advanced Model Evaluation](#class-13-advanced-model-evaluation) | 10/1: [Naive Bayes and Text Data](#class-14-naive-bayes-and-text-data)
10/6: [Natural Language Processing](#class-15-natural-language-processing) | 10/8: [Kaggle Competition](#class-16-kaggle-competition)
10/13: [Decision Trees](#class-17-decision-trees) | 10/15: [Ensembling](#class-18-ensembling)
10/20: [Advanced scikit-learn, Clustering](#class-19-advanced-scikit-learn-and-clustering) | 10/22: [Regularization, Regex](#class-20-regularization-and-regular-expressions)
10/27: [Course Review](#class-21-course-review-and-final-project-presentation) | 10/29: [Final Project Presentation](#class-22-final-project-presentation)
<!--
### Before the Course Begins
* Install [Git](http://git-scm.com/downloads).
* Create an account on the [GitHub](https://github.com/) website.
* It is not necessary to download "GitHub for Windows" or "GitHub for Mac"
* Install the [Anaconda distribution](http://continuum.io/downloads) of Python 2.7x.
* If you choose not to use Anaconda, here is a list of the [Python packages](other/python_packages.md) you will need to install during the course.
* We would like to check the setup of your laptop before the course begins:
* You can have your laptop checked before the intermediate Python workshop on Tuesday 8/11 (5:30pm-6:30pm), at the [15th & K Starbucks](http://www.yelp.com/biz/starbucks-washington-15) on Saturday 8/15 (1pm-3pm), or before class on Tuesday 8/18 (5:30pm-6:30pm).
* Alternatively, you can walk through the [setup checklist](other/setup_checklist.md) yourself.
* Once you receive an email invitation from Slack, join our "DAT8 team" and add your photo.
* Practice Python using the resources below.
-->
### Python Resources
* [Codecademy's Python course](http://www.codecademy.com/en/tracks/python): Good beginner material, including tons of in-browser exercises.
* [Dataquest](https://www.dataquest.io): Uses interactive exercises to teach Python in the context of data science.
* [Google's Python Class](https://developers.google.com/edu/python/): Slightly more advanced, including hours of useful lecture videos and downloadable exercises (with solutions).
* [Introduction to Python](http://introtopython.org/): A series of IPython notebooks that do a great job explaining core Python concepts and data structures.
* [Python for Informatics](http://www.pythonlearn.com/book.php): A very beginner-oriented book, with associated [slides](https://drive.google.com/folderview?id=0B7X1ycQalUnyal9yeUx3VW81VDg&usp=sharing) and [videos](https://www.youtube.com/playlist?list=PLlRFEj9H3Oj4JXIwMwN1_ss1Tk8wZShEJ).
* [A Crash Course in Python for Scientists](http://nbviewer.ipython.org/gist/rpmuller/5920182): Read through the Overview section for a very quick introduction to Python.
* [Python 2.7 Quick Reference](https://github.com/justmarkham/python-reference/blob/master/reference.py): My beginner-oriented guide that demonstrates Python concepts through short, well-commented examples.
* [Beginner](code/00_python_beginner_workshop.py) and [intermediate](code/00_python_intermediate_workshop.py) workshop code: Useful for review and reference.
* [Python Tutor](http://pythontutor.com/): Allows you to visualize the execution of Python code.
<!--
### Submission Forms
* [Feedback form](http://bit.ly/dat8feedback)
* [Homework and project submissions](http://bit.ly/dat8homework)
-->
### [Course project](project/README.md)
### [Comparison of machine learning models](other/model_comparison.md)
### [Comparison of model evaluation procedures and metrics](other/model_evaluation_comparison.md)
### [Advice for getting better at data science](other/advice.md)
### [Additional resources](#additional-resources-1)
-----
### Class 1: Introduction to Data Science
* Course overview ([slides](slides/01_course_overview.pdf))
* Introduction to data science ([slides](slides/01_intro_to_data_science.pdf))
* Discuss the course project: [requirements](project/README.md) and [example projects](https://github.com/justmarkham/DAT-project-examples)
* Types of data ([slides](slides/01_types_of_data.pdf)) and [public data sources](project/public_data.md)
* Welcome from General Assembly staff
**Homework:**
* Work through GA's friendly [command line tutorial](http://generalassembly.github.io/prework/command-line/#/) using Terminal (Linux/Mac) or Git Bash (Windows).
* Read through this [command line reference](code/02_command_line.md), and complete the pre-class exercise at the bottom. (There's nothing you need to submit once you're done.)
* Watch videos 1 through 8 (21 minutes) of [Introduction to Git and GitHub](https://www.youtube.com/playlist?list=PL5-da3qGB5IBLMp7LtN8Nc3Efd4hJq0kD), or read sections 1.1 through 2.2 of [Pro Git](http://git-scm.com/book/en/v2).
* If your laptop has any setup issues, please work with us to resolve them by Thursday. If your laptop has not yet been checked, you should come early on Thursday, or just walk through the [setup checklist](other/setup_checklist.md) yourself (and let us know you have done so).
**Resources:**
* For a useful look at the different types of data scientists, read [Analyzing the Analyzers](http://cdn.oreillystatic.com/oreilly/radarreport/0636920029014/Analyzing_the_Analyzers.pdf) (32 pages).
* For some thoughts on what it's like to be a data scientist, read these short posts from [Win-Vector](http://www.win-vector.com/blog/2012/09/on-being-a-data-scientist/) and [Datascope Analytics](http://datascopeanalytics.com/what-we-think/2014/07/31/six-qualities-of-a-great-data-scientist).
* Quora has a [data science topic FAQ](https://www.quora.com/Data-Science) with lots of interesting Q&A.
* Keep up with local data-related events through the Data Community DC [event calendar](http://www.datacommunitydc.org/calendar) or [weekly newsletter](http://www.datacommunitydc.org/newsletter).
-----
### Class 2: Command Line and Version Control
* Slack tour
* Review the command line pre-class exercise ([code](code/02_command_line.md))
* Git and GitHub ([slides](slides/02_git_github.pdf))
* Intermediate command line
**Homework:**
* Complete the [command line homework assignment](homework/02_command_line_chipotle.md) with the Chipotle data.
* Review the code from the [beginner](code/00_python_beginner_workshop.py) and [intermediate](code/00_python_intermediate_workshop.py) Python workshops. If you don't feel comfortable with any of the content (excluding the "requests" and "APIs" sections), you should spend some time this weekend practicing Python:
* [Introduction to Python](http://introtopython.org/) does a great job explaining Python essentials and includes tons of example code.
* If you like learning from a book, [Python for Informatics](http://www.pythonlearn.com/html-270/) has useful chapters on strings, lists, and dictionaries.
* If you prefer interactive exercises, try these lessons from [Codecademy](http://www.codecademy.com/en/tracks/python): "Python Lists and Dictionaries" and "A Day at the Supermarket".
* If you have more time, try missions 2 and 3 from [DataQuest's Learning Python](https://www.dataquest.io/course/learning-python) course.
* If you've already mastered these topics and want more of a challenge, try solving [Python Challenge](http://www.pythonchallenge.com/) number 1 (decoding a message) and send me your code in Slack.
* To give you a framework for thinking about your project, watch [What is machine learning, and how does it work?](https://www.youtube.com/watch?v=elojMnjn4kk) (10 minutes). (This is the [IPython notebook](https://github.com/justmarkham/scikit-learn-videos/blob/master/01_machine_learning_intro.ipynb) shown in the video.) Alternatively, read [A Visual Introduction to Machine Learning](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/), which focuses on a specific machine learning model called decision trees.
* **Optional:** Browse through some more [example student projects](https://github.com/justmarkham/DAT-project-examples), which may help to inspire your own project!
**Git and Markdown Resources:**
* [Pro Git](http://git-scm.com/book/en/v2) is an excellent book for learning Git. Read the first two chapters to gain a deeper understanding of version control and basic commands.
* If you want to practice a lot of Git (and learn many more commands), [Git Immersion](http://gitimmersion.com/) looks promising.
* If you want to understand how to contribute on GitHub, you first have to understand [forks and pull requests](http://www.dataschool.io/simple-guide-to-forks-in-github-and-git/).
* [GitRef](http://gitref.org/) is my favorite reference guide for Git commands, and [Git quick reference for beginners](http://www.dataschool.io/git-quick-reference-for-beginners/) is a shorter guide with commands grouped by workflow.
* [Cracking the Code to GitHub's Growth](https://growthhackers.com/growth-studies/github) explains why GitHub is so popular among developers.
* [Markdown Cheatsheet](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet) provides a thorough set of Markdown examples with concise explanations. GitHub's [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) is a simpler and more attractive guide, but is less comprehensive.
**Command Line Resources:**
* If you want to go much deeper into the command line, [Data Science at the Command Line](http://shop.oreilly.com/product/0636920032823.do) is a great book. The [companion website](http://datascienceatthecommandline.com/) provides installation instructions for a "data science toolbox" (a virtual machine with many more command line tools), as well as a long reference guide to popular command line tools.
* If you want to do more at the command line with CSV files, try out [csvkit](http://csvkit.readthedocs.org/), which can be installed via `pip`.
-----
### Class 3: Data Reading and Cleaning
* Git and GitHub assorted tips ([slides](slides/02_git_github.pdf))
* Review command line homework ([solution](homework/02_command_line_chipotle.md))
* Python:
* Spyder interface
* Looping exercise
* Lesson on file reading with airline safety data ([code](code/03_file_reading.py), [data](data/airlines.csv), [article](http://fivethirtyeight.com/features/should-travelers-avoid-flying-airlines-that-have-had-crashes-in-the-past/))
* Data cleaning exercise
* Walkthrough of Python homework with Chipotle data ([code](code/03_python_homework_chipotle.py), [data](data/chipotle.tsv), [article](http://www.nytimes.com/interactive/2015/02/17/upshot/what-do-people-actually-order-at-chipotle.html))
**Homework:**
* Complete the [Python homework assignment](code/03_python_homework_chipotle.py) with the Chipotle data, add a commented Python script to your GitHub repo, and submit a link using the homework submission form. You have until Tuesday (9/1) to complete this assignment. (**Note:** Pandas, which is covered in class 4, should not be used for this assignment.)
**Resources:**
* [Want to understand Python's comprehensions? Think in Excel or SQL](http://blog.lerner.co.il/want-to-understand-pythons-comprehensions-think-like-an-accountant/) may be helpful if you are still confused by list comprehensions.
* [My code isn't working](http://www.tecoed.co.uk/uploads/1/4/2/4/14249012/624506_orig.png) is a great flowchart explaining how to debug Python errors.
* [PEP 8](https://www.python.org/dev/peps/pep-0008/) is Python's "classic" style guide, and is worth a read if you want to write readable code that is consistent with the rest of the Python community.
* If you want to understand Python at a deeper level, Ned Batchelder's [Loop Like A Native](http://nedbatchelder.com/text/iter.html) and [Python Names and Values](http://nedbatchelder.com/text/names1.html) are excellent presentations.
-----
### Class 4: Exploratory Data Analysis
* Pandas ([code](code/04_pandas.py)):
* MovieLens 100k movie ratings ([data](data/u.user), [data dictionary](http://files.grouplens.org/datasets/movielens/ml-100k-README.txt), [website](http://grouplens.org/datasets/movielens/))
* Alcohol consumption by country ([data](data/drinks.csv), [article](http://fivethirtyeight.com/datalab/dear-mona-followup-where-do-people-drink-the-most-beer-wine-and-spirits/))
* Reports of UFO sightings ([data](data/ufo.csv), [website](http://www.nuforc.org/webreports.html))
* Project question exercise
**Homework:**
* The deadline for discussing your project ideas with an instructor is Tuesday (9/1), and your project question write-up is due Thursday (9/3).
* Read [How Software in Half of NYC Cabs Generates $5.2 Million a Year in Extra Tips](http://iquantny.tumblr.com/post/107245431809/how-software-in-half-of-nyc-cabs-generates-5-2) for an excellent example of exploratory data analysis.
* Read [Anscombe's Quartet, and Why Summary Statistics Don't Tell the Whole Story](http://data.heapanalytics.com/anscombes-quartet-and-why-summary-statistics-dont-tell-the-whole-story/) for a classic example of why visualization is useful.
**Resources:**
* Browsing or searching the Pandas [API Reference](http://pandas.pydata.org/pandas-docs/stable/api.html) is an excellent way to locate a function even if you don't know its exact name.
* [What I do when I get a new data set as told through tweets](http://simplystatistics.org/2014/06/13/what-i-do-when-i-get-a-new-data-set-as-told-through-tweets/) is a fun (yet enlightening) look at the process of exploratory data analysis.
-----
### Class 5: Visualization
* Python homework with the Chipotle data due ([solution](code/03_python_homework_chipotle.py), [detailed explanation](notebooks/03_python_homework_chipotle_explained.ipynb))
* Part 2 of Exploratory Data Analysis with Pandas ([code](code/04_pandas.py))
* Visualization with Pandas and Matplotlib ([notebook](notebooks/05_pandas_visualization.ipynb))
**Homework:**
* Your project question write-up is due on Thursday.
* Complete the [Pandas homework assignment](code/05_pandas_homework_imdb.py) with the [IMDb data](data/imdb_1000.csv). You have until Tuesday (9/8) to complete this assignment.
* If you're not using Anaconda, install the [Jupyter Notebook](http://jupyter.readthedocs.org/en/latest/install.html) (formerly known as the IPython Notebook) using `pip`. (The Jupyter or IPython Notebook is included with Anaconda.)
**Pandas Resources:**
* To learn more Pandas, read this [three-part tutorial](http://www.gregreda.com/2013/10/26/intro-to-pandas-data-structures/), or review these two excellent (but extremely long) notebooks on Pandas: [introduction](https://github.com/fonnesbeck/Bios8366/blob/master/notebooks/Section2_5-Introduction-to-Pandas.ipynb) and [data wrangling](https://github.com/fonnesbeck/Bios8366/blob/master/notebooks/Section2_6-Data-Wrangling-with-Pandas.ipynb).
* If you want to go really deep into Pandas (and NumPy), read the book [Python for Data Analysis](http://shop.oreilly.com/product/0636920023784.do), written by the creator of Pandas.
* This notebook demonstrates the different types of [joins in Pandas](notebooks/05_pandas_merge.ipynb), for when you need to figure out how to merge two DataFrames.
* This is a nice, short tutorial on [pivot tables](https://beta.oreilly.com/learning/pivot-tables) in Pandas.
* For working with geospatial data in Python, [GeoPandas](http://geopandas.org/index.html) looks promising. This [tutorial](http://michelleful.github.io/code-blog/2015/04/24/sgmap/) uses GeoPandas (and scikit-learn) to build a "linguistic street map" of Singapore.
**Visualization Resources:**
* Watch [Look at Your Data](https://www.youtube.com/watch?v=coNDCIMH8bk) (18 minutes) for an excellent example of why visualization is useful for understanding your data.
* For more on Pandas plotting, read this [notebook](https://github.com/fonnesbeck/Bios8366/blob/master/notebooks/Section2_7-Plotting-with-Pandas.ipynb) or the [visualization page](http://pandas.pydata.org/pandas-docs/stable/visualization.html) from the official Pandas documentation.
* To learn how to customize your plots further, browse through this [notebook on matplotlib](https://github.com/fonnesbeck/Bios8366/blob/master/notebooks/Section2_4-Matplotlib.ipynb) or this [similar notebook](https://github.com/jrjohansson/scientific-python-lectures/blob/master/Lecture-4-Matplotlib.ipynb).
* Read [Overview of Python Visualization Tools](http://pbpython.com/visualization-tools-1.html) for a useful comparison of Matplotlib, Pandas, Seaborn, ggplot, Bokeh, Pygal, and Plotly.
* To explore different types of visualizations and when to use them, [Choosing a Good Chart](http://extremepresentation.typepad.com/files/choosing-a-good-chart-09.pdf) and [The Graphic Continuum](http://www.coolinfographics.com/storage/post-images/The-Graphic-Continuum-POSTER.jpg) are nice one-page references, and the interactive [R Graph Catalog](http://shiny.stat.ubc.ca/r-graph-catalog/) has handy filtering capabilities.
* This [PowerPoint presentation](http://www2.research.att.com/~volinsky/DataMining/Columbia2011/Slides/Topic2-EDAViz.ppt) from Columbia's Data Mining class contains lots of good advice for properly using different types of visualizations.
* [Harvard's Data Science course](http://cs109.github.io/2014/) includes an excellent lecture on [Visualization Goals, Data Types, and Statistical Graphs](http://cm.dce.harvard.edu/2015/01/14328/L03/screen_H264LargeTalkingHead-16x9.shtml) (83 minutes), for which the [slides](https://docs.google.com/file/d/0B7IVstmtIvlHLTdTbXdEVENoRzQ/edit) are also available.
-----
### Class 6: Machine Learning
* Part 2 of Visualization with Pandas and Matplotlib ([notebook](notebooks/05_pandas_visualization.ipynb))
* Brief introduction to the Jupyter/IPython Notebook
* "Human learning" exercise:
* [Iris dataset](http://archive.ics.uci.edu/ml/datasets/Iris) hosted by the UCI Machine Learning Repository
* [Iris photo](http://sebastianraschka.com/Images/2014_python_lda/iris_petal_sepal.png)
* [Notebook](notebooks/06_human_learning_iris.ipynb)
* Introduction to machine learning ([slides](slides/06_machine_learning.pdf))
**Homework:**
* **Optional:** Complete the bonus exercise listed in the [human learning notebook](notebooks/06_human_learning_iris.ipynb). It will take the place of any one homework you miss, past or future! This is due on Tuesday (9/8).
* If you're not using Anaconda, install [requests](http://www.python-requests.org/en/latest/user/install/) and [Beautiful Soup 4](http://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-beautiful-soup) using `pip`. (Both of these packages are included with Anaconda.)
**Machine Learning Resources:**
* For a very quick summary of the key points about machine learning, watch [What is machine learning, and how does it work?](https://www.youtube.com/watch?v=elojMnjn4kk) (10 minutes) or read the [associated notebook](https://github.com/justmarkham/scikit-learn-videos/blob/master/01_machine_learning_intro.ipynb).
* For a more in-depth introduction to machine learning, read section 2.1 (14 pages) of Hastie and Tibshirani's excellent book, [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/). (It's a free PDF download!)
* The [Learning Paradigms](http://work.caltech.edu/library/014.html) video (13 minutes) from [Caltech's Learning From Data course](http://work.caltech.edu/telecourse.html) provides a nice comparison of supervised versus unsupervised learning, as well as an introduction to "reinforcement learning".
* [Real-World Active Learning](https://beta.oreilly.com/ideas/real-world-active-learning) is a readable and thorough introduction to "active learning", a variation of machine learning in which humans label only the most "important" observations.
* For a preview of some of the machine learning content we will cover during the course, read Sebastian Raschka's [overview of the supervised learning process](https://github.com/rasbt/pattern_classification/blob/master/machine_learning/supervised_intro/introduction_to_supervised_machine_learning.md).
* [Data Science, Machine Learning, and Statistics: What is in a Name?](http://www.win-vector.com/blog/2013/04/data-science-machine-learning-and-statistics-what-is-in-a-name/) discusses the differences between these (and other) terms.
* [The Emoji Translation Project](https://www.kickstarter.com/projects/fred/the-emoji-translation-project) is a really fun application of machine learning.
* Look up the [characteristics of your zip code](http://www.esri.com/landing-pages/tapestry/), and then read about the [67 distinct segments](http://doc.arcgis.com/en/esri-demographics/data/tapestry-segmentation.htm) in detail.
**IPython Notebook Resources:**
* For a recap of the IPython Notebook introduction (and a preview of scikit-learn), watch [scikit-learn and the IPython Notebook](https://www.youtube.com/watch?v=IsXXlYVBt1M) (15 minutes) or read the [associated notebook](https://github.com/justmarkham/scikit-learn-videos/blob/master/02_machine_learning_setup.ipynb).
* If you would like to learn the IPython Notebook, the official [Notebook tutorials](https://github.com/jupyter/notebook/blob/master/docs/source/examples/Notebook/Examples%20and%20Tutorials%20Index.ipynb) are useful.
* This [Reddit discussion](https://www.reddit.com/r/Python/comments/3be5z2/do_you_prefer_ipython_notebook_over_ipython/) compares the relative strengths of the IPython Notebook and Spyder.
-----
### Class 7: Getting Data
* Pandas homework with the IMDb data due ([solution](code/05_pandas_homework_imdb.py))
* Optional "human learning" exercise with the iris data due ([solution](notebooks/06_human_learning_iris.ipynb))
* APIs ([code](code/07_api.py))
* [OMDb API](http://www.omdbapi.com/)
* Web scraping ([code](code/07_web_scraping.py))
* [IMDb: robots.txt](http://www.imdb.com/robots.txt)
* [Example web page](data/example.html)
* [IMDb: The Shawshank Redemption](http://www.imdb.com/title/tt0111161/)
**Homework:**
* **Optional:** Complete the homework exercise listed in the [web scraping code](code/07_web_scraping.py). It will take the place of any one homework you miss, past or future! This is due on Tuesday (9/15).
* **Optional:** If you're not using Anaconda, [install Seaborn](http://stanford.edu/~mwaskom/software/seaborn/installing.html) using `pip`. If you're using Anaconda, install Seaborn by running `conda install seaborn` at the command line. (Note that some students in past courses have had problems with Anaconda after installing Seaborn.)
**API Resources:**
* This Python script to [query the U.S. Census API](https://github.com/laurakurup/census-api) was created by a former DAT student. It's a bit more complicated than the example we used in class, it's very well commented, and it may provide a useful framework for writing your own code to query APIs.
* [Mashape](https://www.mashape.com/explore) and [Apigee](https://apigee.com/providers) allow you to explore tons of different APIs. Alternatively, a [Python API wrapper](http://www.pythonforbeginners.com/api/list-of-python-apis) is available for many popular APIs.
* The [Data Science Toolkit](http://www.datasciencetoolkit.org/) is a collection of location-based and text-related APIs.
* [API Integration in Python](https://realpython.com/blog/python/api-integration-in-python/) provides a very readable introduction to REST APIs.
* Microsoft's [Face Detection API](https://www.projectoxford.ai/demo/face#detection), which powers [How-Old.net](http://how-old.net/), is a great example of how a machine learning API can be leveraged to produce a compelling web application.
**Web Scraping Resources:**
* The [Beautiful Soup documentation](http://www.crummy.com/software/BeautifulSoup/bs4/doc/) is incredibly thorough, but is hard to use as a reference guide. However, the section on [specifying a parser](http://www.crummy.com/software/BeautifulSoup/bs4/doc/#specifying-the-parser-to-use) may be helpful if Beautiful Soup appears to be parsing a page incorrectly.
* For more Beautiful Soup examples and tutorials, see [Web Scraping 101 with Python](http://www.gregreda.com/2013/03/03/web-scraping-101-with-python/), a former DAT student's well-commented notebook on [scraping Craigslist](https://github.com/Alexjmsherman/DataScience_GeneralAssembly/blob/master/Final_Project/1.%20Final_Project_Data%20Scraping.ipynb), this [notebook](http://web.stanford.edu/~zlotnick/TextAsData/Web_Scraping_with_Beautiful_Soup.html) from Stanford's Text As Data course, and this [notebook](https://github.com/cs109/2014/blob/master/lectures/2014_09_23-lecture/data_scraping_transcript.ipynb) and associated [video](http://cm.dce.harvard.edu/2015/01/14328/L07/screen_H264LargeTalkingHead-16x9.shtml) from Harvard's Data Science course.
* For a much longer web scraping tutorial covering Beautiful Soup, lxml, XPath, and Selenium, watch [Web Scraping with Python](https://www.youtube.com/watch?v=p1iX0uxM1w8) (3 hours 23 minutes) from PyCon 2014. The [slides](https://docs.google.com/presentation/d/1uHM_esB13VuSf7O1ScGueisnrtu-6usGFD3fs4z5YCE/edit#slide=id.p) and [code](https://github.com/kjam/python-web-scraping-tutorial) are also available.
* For more complex web scraping projects, [Scrapy](http://scrapy.org/) is a popular application framework that works with Python. It has excellent [documentation](http://doc.scrapy.org/en/1.0/index.html), and here's a [tutorial](https://github.com/rdempsey/ddl-data-wrangling) with detailed slides and code.
* [robotstxt.org](http://www.robotstxt.org/robotstxt.html) has a concise explanation of how to write (and read) the `robots.txt` file.
* [import.io](https://import.io/) and [Kimono](https://www.kimonolabs.com/) claim to allow you to scrape websites without writing any code.
* [How a Math Genius Hacked OkCupid to Find True Love](http://www.wired.com/2014/01/how-to-hack-okcupid/all/) and [How Netflix Reverse Engineered Hollywood](http://www.theatlantic.com/technology/archive/2014/01/how-netflix-reverse-engineered-hollywood/282679/?single_page=true) are two fun examples of how web scraping has been used to build interesting datasets.
-----
### Class 8: K-Nearest Neighbors
* Brief review of Pandas ([notebook](notebooks/08_pandas_review.ipynb))
* K-nearest neighbors and scikit-learn ([notebook](notebooks/08_knn_sklearn.ipynb))
* Exercise with NBA player data ([notebook](notebooks/08_nba_knn.ipynb), [data](https://github.com/justmarkham/DAT4-students/blob/master/kerry/Final/NBA_players_2015.csv), [data dictionary](https://github.com/justmarkham/DAT-project-examples/blob/master/pdf/nba_paper.pdf))
* Exploring the bias-variance tradeoff ([notebook](notebooks/08_bias_variance.ipynb))
**Homework:**
* Reading assignment on the [bias-variance tradeoff](homework/09_bias_variance.md)
* Read Kevin's [introduction to reproducibility](http://www.dataschool.io/reproducibility-is-not-just-for-researchers/), read Jeff Leek's [guide to creating a reproducible analysis](https://github.com/jtleek/datasharing), and watch this related [Colbert Report video](http://thecolbertreport.cc.com/videos/dcyvro/austerity-s-spreadsheet-error) (8 minutes).
* Work on your project... your first project presentation is in less than two weeks!
**KNN Resources:**
* For a recap of the key points about KNN and scikit-learn, watch [Getting started in scikit-learn with the famous iris dataset](https://www.youtube.com/watch?v=hd1W4CyPX58) (15 minutes) and [Training a machine learning model with scikit-learn](https://www.youtube.com/watch?v=RlQuVL6-qe8) (20 minutes).
* KNN supports [distance metrics](http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.DistanceMetric.html) other than Euclidean distance, such as [Mahalanobis distance](http://stats.stackexchange.com/questions/62092/bottom-to-top-explanation-of-the-mahalanobis-distance), which [takes the scale of the data into account](http://blogs.sas.com/content/iml/2012/02/15/what-is-mahalanobis-distance.html).
* [A Detailed Introduction to KNN](https://saravananthirumuruganathan.wordpress.com/2010/05/17/a-detailed-introduction-to-k-nearest-neighbor-knn-algorithm/) is a bit dense, but provides a more thorough introduction to KNN and its applications.
* This lecture on [Image Classification](http://cs231n.github.io/classification/) shows how KNN could be used for detecting similar images, and also touches on topics we will cover in future classes (hyperparameter tuning and cross-validation).
* Some applications for which KNN is well-suited are [object recognition](http://vlm1.uta.edu/~athitsos/nearest_neighbors/), [satellite image enhancement](http://land.umn.edu/documents/FS6.pdf), [document categorization](http://www.ceng.metu.edu.tr/~e120321/paper.pdf), and [gene expression analysis](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.208.993).
**Seaborn Resources:**
* To get started with Seaborn for visualization, the official website has a series of [detailed tutorials](http://web.stanford.edu/~mwaskom/software/seaborn/tutorial.html) and an [example gallery](http://web.stanford.edu/~mwaskom/software/seaborn/examples/index.html).
* [Data visualization with Seaborn](https://beta.oreilly.com/learning/data-visualization-with-seaborn) is a quick tour of some of the popular types of Seaborn plots.
* [Visualizing Google Forms Data with Seaborn](http://pbpython.com/pandas-google-forms-part2.html) and [How to Create NBA Shot Charts in Python](http://savvastjortjoglou.com/nba-shot-sharts.html) are both good examples of Seaborn usage on real-world data.
-----
### Class 9: Basic Model Evaluation
* Optional web scraping homework due ([solution](code/07_web_scraping.py#L136))
* Reproducibility
* Discuss assigned readings: [introduction](http://www.dataschool.io/reproducibility-is-not-just-for-researchers/), [Colbert Report video](http://thecolbertreport.cc.com/videos/dcyvro/austerity-s-spreadsheet-error), [cabs article](http://iquantny.tumblr.com/post/107245431809/how-software-in-half-of-nyc-cabs-generates-5-2), [Tweet](https://twitter.com/jakevdp/status/519563939177197571), [creating a reproducible analysis](https://github.com/jtleek/datasharing)
* Examples: [Classic rock](https://github.com/fivethirtyeight/data/tree/master/classic-rock), [student project 1](https://github.com/jwknobloch/DAT4_final_project), [student project 2](https://github.com/justmarkham/DAT4-students/tree/master/Jonathan_Bryan/Project_Files)
* Discuss the reading assignment on the [bias-variance tradeoff](homework/09_bias_variance.md)
* Model evaluation using train/test split ([notebook](notebooks/09_model_evaluation.ipynb))
* Exploring the scikit-learn documentation: [module reference](http://scikit-learn.org/stable/modules/classes.html), [user guide](http://scikit-learn.org/stable/user_guide.html), class and function documentation
**Homework:**
* Watch [Data science in Python](https://www.youtube.com/watch?v=3ZWuPVWq7p4) (35 minutes) for an introduction to linear regression (and a review of other course content), or at the very least, read through the [associated notebook](https://github.com/justmarkham/scikit-learn-videos/blob/master/06_linear_regression.ipynb).
* **Optional:** For another introduction to linear regression, watch [The Easiest Introduction to Regression Analysis](https://www.youtube.com/watch?v=k_OB1tWX9PM) (14 minutes).
**Model Evaluation Resources:**
* For a recap of some of the key points from today's lesson, watch [Comparing machine learning models in scikit-learn](https://www.youtube.com/watch?v=0pP4EwWJgIU) (27 minutes).
* For another explanation of training error versus testing error, the bias-variance tradeoff, and train/test split (also known as the "validation set approach"), watch Hastie and Tibshirani's video on [estimating prediction error](https://www.youtube.com/watch?v=_2ij6eaaSl0&t=2m34s) (12 minutes, starting at 2:34).
* Caltech's Learning From Data course includes a fantastic video on [visualizing bias and variance](http://work.caltech.edu/library/081.html) (15 minutes).
* [Random Test/Train Split is Not Always Enough](http://www.win-vector.com/blog/2015/01/random-testtrain-split-is-not-always-enough/) explains why random train/test split may not be a suitable model evaluation procedure if your data has a significant time element.
**Reproducibility Resources:**
* [What We've Learned About Sharing Our Data Analysis](https://source.opennews.org/en-US/articles/what-weve-learned-about-sharing-our-data-analysis/) includes tips from BuzzFeed News about how to publish a reproducible analysis.
* [Software development skills for data scientists](http://treycausey.com/software_dev_skills.html) discusses the importance of writing functions and proper code comments (among other skills), which are highly useful for creating a reproducible analysis.
* [Data science done well looks easy - and that is a big problem for data scientists](http://simplystatistics.org/2015/03/17/data-science-done-well-looks-easy-and-that-is-a-big-problem-for-data-scientists/) explains how a reproducible analysis demonstrates all of the work that goes into proper data science.
-----
### Class 10: Linear Regression
* Machine learning exercise ([article](http://blog.dominodatalab.com/10-interesting-uses-of-data-science/))
* Linear regression ([notebook](notebooks/10_linear_regression.ipynb))
* [Capital Bikeshare dataset](data/bikeshare.csv) used in a Kaggle competition
* [Data dictionary](https://www.kaggle.com/c/bike-sharing-demand/data)
* Feature engineering example: [Predicting User Engagement in Corporate Collaboration Network](https://github.com/mikeyea/DAT7_project/blob/master/final%20project/Class_Presention_MYea.ipynb)
**Homework:**
* Your first project presentation is on Tuesday (9/22)! Please submit a link to your project repository (with slides, code, data, and visualizations) by 6pm on Tuesday.
* Complete the [homework assignment](homework/10_yelp_votes.md) with the [Yelp data](data/yelp.csv). This is due on Thursday (9/24).
**Linear Regression Resources:**
* To go much more in-depth on linear regression, read Chapter 3 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/). Alternatively, watch the [related videos](http://www.dataschool.io/15-hours-of-expert-machine-learning-videos/) or read my [quick reference guide](http://www.dataschool.io/applying-and-interpreting-linear-regression/) to the key points in that chapter.
* This [introduction to linear regression](http://people.duke.edu/~rnau/regintro.htm) is more detailed and mathematically thorough, and includes lots of good advice.
* This is a relatively quick post on the [assumptions of linear regression](http://pareonline.net/getvn.asp?n=2&v=8).
* Setosa has an [interactive visualization](http://setosa.io/ev/ordinary-least-squares-regression/) of linear regression.
* For a brief introduction to confidence intervals, hypothesis testing, p-values, and R-squared, as well as a comparison between scikit-learn code and [Statsmodels](http://statsmodels.sourceforge.net/) code, read my [DAT7 lesson on linear regression](https://github.com/justmarkham/DAT7/blob/master/notebooks/10_linear_regression.ipynb).
* Here is a useful explanation of [confidence intervals](http://www.quora.com/What-is-a-confidence-interval-in-laymans-terms/answer/Michael-Hochster) from Quora.
* [Hypothesis Testing: The Basics](http://20bits.com/article/hypothesis-testing-the-basics) provides a nice overview of the topic, and John Rauser's talk on [Statistics Without the Agonizing Pain](https://www.youtube.com/watch?v=5Dnw46eC-0o) (12 minutes) gives a great explanation of how the null hypothesis is rejected.
* Earlier this year, a major scientific journal banned the use of p-values:
* Scientific American has a nice [summary](http://www.scientificamerican.com/article/scientists-perturbed-by-loss-of-stat-tools-to-sift-research-fudge-from-fact/) of the ban.
* This [response](http://www.nature.com/news/statistics-p-values-are-just-the-tip-of-the-iceberg-1.17412) to the ban in Nature argues that "decisions that are made earlier in data analysis have a much greater impact on results".
* Andrew Gelman has a readable [paper](http://www.stat.columbia.edu/~gelman/research/unpublished/p_hacking.pdf) in which he argues that "it's easy to find a p < .05 comparison even if nothing is going on, if you look hard enough".
* [Science Isn't Broken](http://fivethirtyeight.com/features/science-isnt-broken/) includes a neat tool that allows you to "p-hack" your way to "statistically significant" results.
* [Accurately Measuring Model Prediction Error](http://scott.fortmann-roe.com/docs/MeasuringError.html) compares adjusted R-squared, AIC and BIC, train/test split, and cross-validation.
**Other Resources:**
* Section 3.3.1 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/) (4 pages) has a great explanation of dummy encoding for categorical features.
* Kaggle has some nice [visualizations of the bikeshare data](https://www.kaggle.com/c/bike-sharing-demand/scripts?outputType=Visualization) we used today.
-----
### Class 11: First Project Presentation
* Project presentations!
**Homework:**
* Watch Rahul Patwari's videos on [probability](https://www.youtube.com/watch?v=o4QmoNfW3bI) (5 minutes) and [odds](https://www.youtube.com/watch?v=GxbXQjX7fC0) (8 minutes) if you're not comfortable with either of those terms.
* Read these excellent articles from BetterExplained: [An Intuitive Guide To Exponential Functions & e](http://betterexplained.com/articles/an-intuitive-guide-to-exponential-functions-e/) and [Demystifying the Natural Logarithm (ln)](http://betterexplained.com/articles/demystifying-the-natural-logarithm-ln/). Then, review this [brief summary](notebooks/12_e_log_examples.ipynb) of exponential functions and logarithms.
-----
### Class 12: Logistic Regression
* Yelp votes homework due ([solution](notebooks/10_yelp_votes_homework.ipynb))
* Logistic regression ([notebook](notebooks/12_logistic_regression.ipynb))
* [Glass identification dataset](https://archive.ics.uci.edu/ml/datasets/Glass+Identification)
* Exercise with Titanic data ([notebook](notebooks/12_titanic_confusion.ipynb), [data](data/titanic.csv), [data dictionary](https://www.kaggle.com/c/titanic/data))
* Confusion matrix ([slides](slides/12_confusion_matrix.pdf), [notebook](notebooks/12_titanic_confusion.ipynb))
**Homework:**
* If you aren't yet comfortable with all of the confusion matrix terminology, watch Rahul Patwari's videos on [Intuitive sensitivity and specificity](https://www.youtube.com/watch?v=U4_3fditnWg) (9 minutes) and [The tradeoff between sensitivity and specificity](https://www.youtube.com/watch?v=vtYDyGGeQyo) (13 minutes).
* Video/reading assignment on [ROC curves and AUC](homework/13_roc_auc.md)
* Video/reading assignment on [cross-validation](homework/13_cross_validation.md)
**Logistic Regression Resources:**
* To go deeper into logistic regression, read the first three sections of Chapter 4 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/), or watch the [first three videos](http://www.dataschool.io/15-hours-of-expert-machine-learning-videos/) (30 minutes) from that chapter.
* For a math-ier explanation of logistic regression, watch the first seven videos (71 minutes) from week 3 of Andrew Ng's [machine learning course](https://www.coursera.org/learn/machine-learning/home/info), or read the [related lecture notes](http://www.holehouse.org/mlclass/06_Logistic_Regression.html) compiled by a student.
* For more on interpreting logistic regression coefficients, read this excellent [guide](http://www.ats.ucla.edu/stat/mult_pkg/faq/general/odds_ratio.htm) by UCLA's IDRE and these [lecture notes](http://www.unm.edu/~schrader/biostat/bio2/Spr06/lec11.pdf) from the University of New Mexico.
* The scikit-learn documentation has a nice [explanation](http://scikit-learn.org/stable/modules/calibration.html) of what it means for a predicted probability to be calibrated.
* [Supervised learning superstitions cheat sheet](http://ryancompton.net/assets/ml_cheat_sheet/supervised_learning.html) is a very nice comparison of four classifiers we cover in the course (logistic regression, decision trees, KNN, Naive Bayes) and one classifier we do not cover (Support Vector Machines).
**Confusion Matrix Resources:**
* My [simple guide to confusion matrix terminology](http://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/) may be useful to you as a reference.
* This blog post about [Amazon Machine Learning](https://aws.amazon.com/blogs/aws/amazon-machine-learning-make-data-driven-decisions-at-scale/) contains a neat [graphic](https://media.amazonwebservices.com/blog/2015/ml_adjust_model_1.png) showing how classification threshold affects different evaluation metrics.
* This notebook (from another DAT course) explains [how to calculate "expected value"](https://github.com/podopie/DAT18NYC/blob/master/classes/13-expected_value_cost_benefit_analysis.ipynb) from a confusion matrix by treating it as a cost-benefit matrix.
-----
### Class 13: Advanced Model Evaluation
* Data preparation ([notebook](notebooks/13_advanced_model_evaluation.ipynb))
* Handling missing values
* Handling categorical features (review)
* ROC curves and AUC
* Discuss the [video/reading assignment](homework/13_roc_auc.md)
* Exercise: drawing an ROC curve ([slides](slides/13_drawing_roc.pdf))
* Return to the main notebook
* Cross-validation
* Discuss the [video/reading assignment](homework/13_cross_validation.md) and associated [notebook](notebooks/13_cross_validation.ipynb)
* Return to the main notebook
* Exercise with bank marketing data ([notebook](notebooks/13_bank_exercise.ipynb), [data](data/bank-additional.csv), [data dictionary](https://archive.ics.uci.edu/ml/datasets/Bank+Marketing))
**Homework:**
* Reading assignment on [spam filtering](homework/14_spam_filtering.md)
* Read these [Introduction to Probability](https://docs.google.com/presentation/d/1cM2dVbJgTWMkHoVNmYlB9df6P2H8BrjaqAcZTaLe9dA/edit#slide=id.gfc3caad2_00) slides, or skim section 2.1 of the [OpenIntro Statistics textbook](https://www.openintro.org/stat/textbook.php?stat_book=os) (12 pages). Pay specific attention to the following terms: probability, mutually exclusive, sample space, independent.
* **Optional:** Try to gain an understanding of conditional probability from this [visualization](http://setosa.io/conditional/).
* **Optional:** For an intuitive introduction to Bayes' theorem, read these posts on [wealth and happiness](http://www.quora.com/What-is-an-intuitive-explanation-of-Bayes-Rule/answer/Michael-Hochster), [ducks](https://planspacedotorg.wordpress.com/2014/02/23/bayes-rule-for-ducks/), or [legos](http://www.countbayesie.com/blog/2015/2/18/bayes-theorem-with-lego).
**ROC Resources:**
* Rahul Patwari has a great video on [ROC Curves](https://www.youtube.com/watch?v=21Igj5Pr6u4) (12 minutes).
* [An introduction to ROC analysis](http://people.inf.elte.hu/kiss/13dwhdm/roc.pdf) is a very readable paper on the topic.
* ROC curves can be used across a wide variety of applications, such as [comparing different feature sets](http://research.microsoft.com/pubs/205472/aisec10-leontjeva.pdf) for detecting fraudulent Skype users, and [comparing different classifiers](http://www.cse.ust.hk/nevinZhangGroup/readings/yi/Bradley_PR97.pdf) on a number of popular datasets.
**Cross-Validation Resources:**
* For more on cross-validation, read section 5.1 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/) (11 pages) or watch the related videos: [K-fold and leave-one-out cross-validation](https://www.youtube.com/watch?v=nZAM5OXrktY) (14 minutes), [cross-validation the right and wrong ways](https://www.youtube.com/watch?v=S06JpVoNaA0) (10 minutes).
* If you want to understand the different variations of cross-validation, this [paper](http://www.jcheminf.com/content/pdf/1758-2946-6-10.pdf) examines and compares them in detail.
* To learn how to use [GridSearchCV and RandomizedSearchCV](http://scikit-learn.org/stable/modules/grid_search.html) for parameter tuning, watch [How to find the best model parameters in scikit-learn](https://www.youtube.com/watch?v=Gol_qOgRqfA) (28 minutes) or read the [associated notebook](https://github.com/justmarkham/scikit-learn-videos/blob/master/08_grid_search.ipynb).
**Other Resources:**
* scikit-learn has extensive documentation on [model evaluation](http://scikit-learn.org/stable/modules/model_evaluation.html).
* [Counterfactual evaluation of machine learning models](https://www.youtube.com/watch?v=QWCSxAKR-h0) (45 minutes) is an excellent talk about the sophisticated way in which Stripe evaluates its fraud detection model. (These are the associated [slides](http://www.slideshare.net/MichaelManapat/counterfactual-evaluation-of-machine-learning-models).)
* [Visualizing Machine Learning Thresholds to Make Better Business Decisions](http://blog.insightdatalabs.com/visualizing-classifier-thresholds/) demonstrates how visualizing precision, recall, and "queue rate" at different thresholds can help you to maximize the business value of your classifier.
-----
### Class 14: Naive Bayes and Text Data
* Conditional probability and Bayes' theorem
* [Slides](slides/14_bayes_theorem.pdf) (adapted from [Visualizing Bayes' theorem](http://oscarbonilla.com/2009/05/visualizing-bayes-theorem/))
* Applying Bayes' theorem to iris classification ([notebook](notebooks/14_bayes_theorem_iris.ipynb))
* Naive Bayes classification
* [Slides](slides/14_naive_bayes.pdf)
* Spam filtering example ([notebook](notebooks/14_naive_bayes_spam.ipynb))
* Applying Naive Bayes to text data in scikit-learn ([notebook](notebooks/14_text_data_sklearn.ipynb))
* [CountVectorizer](http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html) documentation
* SMS messages: [data](data/sms.tsv), [data dictionary](https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection)
**Homework:**
* Complete another [homework assignment](homework/14_yelp_review_text.md) with the [Yelp data](data/yelp.csv). This is due on Tuesday (10/6).
* Confirm that you have [TextBlob](https://textblob.readthedocs.org/) installed by running `import textblob` from within your preferred Python environment. If it's not installed, run `pip install textblob` at the command line (not from within Python).
**Resources:**
* Sebastian Raschka's article on [Naive Bayes and Text Classification](http://sebastianraschka.com/Articles/2014_naive_bayes_1.html) covers the conceptual material from today's class in much more detail.
* For more on conditional probability, read these [slides](https://docs.google.com/presentation/d/1psUIyig6OxHQngGEHr3TMkCvhdLInnKnclQoNUr4G4U/edit#slide=id.gfc69f484_00), or read section 2.2 of the [OpenIntro Statistics textbook](https://www.openintro.org/stat/textbook.php?stat_book=os) (15 pages).
* For an intuitive explanation of Naive Bayes classification, read this post on [airport security](http://www.quora.com/In-laymans-terms-how-does-Naive-Bayes-work/answer/Konstantin-Tt).
* For more details on Naive Bayes classification, Wikipedia has two excellent articles ([Naive Bayes classifier](http://en.wikipedia.org/wiki/Naive_Bayes_classifier) and [Naive Bayes spam filtering](http://en.wikipedia.org/wiki/Naive_Bayes_spam_filtering)), and Cross Validated has a good [Q&A](http://stats.stackexchange.com/questions/21822/understanding-naive-bayes).
* When applying Naive Bayes classification to a dataset with continuous features, it is better to use [GaussianNB](http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html) rather than [MultinomialNB](http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html). This [notebook](notebooks/14_types_of_naive_bayes.ipynb) compares their performances on such a dataset. Wikipedia has a short [description](https://en.wikipedia.org/wiki/Naive_Bayes_classifier#Gaussian_naive_Bayes) of Gaussian Naive Bayes, as well as an excellent [example](https://en.wikipedia.org/wiki/Naive_Bayes_classifier#Sex_classification) of its usage.
* These [slides](http://www.umiacs.umd.edu/~jbg/teaching/DATA_DIGGING/lecture_05.pdf) from the University of Maryland provide more mathematical details on both logistic regression and Naive Bayes, and also explain how Naive Bayes is actually a "special case" of logistic regression.
* Andrew Ng has a [paper](http://ai.stanford.edu/~ang/papers/nips01-discriminativegenerative.pdf) comparing the performance of logistic regression and Naive Bayes across a variety of datasets.
* If you enjoyed Paul Graham's article, you can read [his follow-up article](http://www.paulgraham.com/better.html) on how he improved his spam filter and this [related paper](http://www.merl.com/publications/docs/TR2004-091.pdf) about state-of-the-art spam filtering in 2004.
* Yelp has found that Naive Bayes is more effective than Mechanical Turks at [categorizing businesses](http://engineeringblog.yelp.com/2011/02/towards-building-a-high-quality-workforce-with-mechanical-turk.html).
-----
### Class 15: Natural Language Processing
* Yelp review text homework due ([solution](notebooks/14_yelp_review_text_homework.ipynb))
* Natural language processing ([notebook](notebooks/15_natural_language_processing.ipynb))
* Introduction to our [Kaggle competition](https://inclass.kaggle.com/c/dat8-stack-overflow)
* Create a Kaggle account, join the competition using the invitation link, download the sample submission, and then submit the sample submission (which will require SMS account verification).
**Homework:**
* Your draft paper is due on Thursday (10/8)! Please submit a link to your project repository (with paper, code, data, and visualizations) before class.
* Watch [Kaggle: How it Works](https://www.youtube.com/watch?v=PoD84TVdD-4) (4 minutes) for a brief overview of the Kaggle platform.
* Download the competition files, move them to the `DAT8/data` directory, and make sure you can open the CSV files using Pandas. If you have any problems opening the files, you probably need to turn off real-time virus scanning (especially Microsoft Security Essentials).
* **Optional:** Come up with some theories about which features might be relevant to predicting the response, and then explore the data to see if those theories appear to be true.
* **Optional:** Watch my [project presentation video](https://www.youtube.com/watch?v=HGr1yQV3Um0) (16 minutes) for a tour of the end-to-end machine learning process for a Kaggle competition, including feature engineering. (Or, just read through the [slides](https://speakerdeck.com/justmarkham/allstate-purchase-prediction-challenge-on-kaggle).)
**NLP Resources:**
* If you want to learn a lot more NLP, check out the excellent [video lectures](https://class.coursera.org/nlp/lecture) and [slides](http://web.stanford.edu/~jurafsky/NLPCourseraSlides.html) from this [Coursera course](https://www.coursera.org/course/nlp) (which is no longer being offered).
* This slide deck defines many of the [key NLP terms](https://github.com/ga-students/DAT_SF_9/blob/master/16_Text_Mining/DAT9_lec16_Text_Mining.pdf).
* [Natural Language Processing with Python](http://www.nltk.org/book/) is the most popular book for going in-depth with the [Natural Language Toolkit](http://www.nltk.org/) (NLTK).
* [A Smattering of NLP in Python](https://github.com/charlieg/A-Smattering-of-NLP-in-Python/blob/master/A%20Smattering%20of%20NLP%20in%20Python.ipynb) provides a nice overview of NLTK, as does this [notebook from DAT5](https://github.com/justmarkham/DAT5/blob/master/notebooks/14_nlp.ipynb).
* [spaCy](http://spacy.io/) is a newer Python library for text processing that is focused on performance (unlike NLTK).
* If you want to get serious about NLP, [Stanford CoreNLP](http://nlp.stanford.edu/software/corenlp.shtml) is a suite of tools (written in Java) that is highly regarded.
* When working with a large text corpus in scikit-learn, [HashingVectorizer](http://scikit-learn.org/stable/modules/feature_extraction.html#vectorizing-a-large-text-corpus-with-the-hashing-trick) is a useful alternative to CountVectorizer.
* [Automatically Categorizing Yelp Businesses](http://engineeringblog.yelp.com/2015/09/automatically-categorizing-yelp-businesses.html) discusses how Yelp uses NLP and scikit-learn to solve the problem of uncategorized businesses.
* [Modern Methods for Sentiment Analysis](http://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis) shows how "word vectors" can be used for more accurate sentiment analysis.
* [Identifying Humorous Cartoon Captions](http://www.cs.huji.ac.il/~dshahaf/pHumor.pdf) is a readable paper about identifying funny captions submitted to the New Yorker Caption Contest.
* [DC Natural Language Processing](http://www.meetup.com/DC-NLP/) is an active Meetup group in our local area.
-----
### Class 16: Kaggle Competition
* Overview of how Kaggle works ([slides](slides/16_kaggle.pdf))
* Kaggle In-Class competition: [Predict whether a Stack Overflow question will be closed](https://inclass.kaggle.com/c/dat8-stack-overflow)
* [Complete code file](code/16_kaggle.py)
* [Minimal code file](code/16_kaggle_minimal.py): excludes all exploratory code
* [Explanations of log loss](http://www.quora.com/What-is-an-intuitive-explanation-for-the-log-loss-function)
**Homework:**
* You will be assigned to review the project drafts of two of your peers. You have until Tuesday 10/20 to provide them with feedback, according to the [peer review guidelines](project/peer_review.md).
* Read [A Visual Introduction to Machine Learning](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/) for a brief overview of decision trees.
* Download and install [Graphviz](http://www.graphviz.org/), which will allow you to visualize decision trees in scikit-learn.
* Windows users should also add Graphviz to your path: Go to Control Panel, System, Advanced System Settings, Environment Variables. Under system variables, edit "Path" to include the path to the "bin" folder, such as: `C:\Program Files (x86)\Graphviz2.38\bin`
* **Optional:** Keep working on our Kaggle competition! You can make up to 5 submissions per day, and the competition doesn't close until 6:30pm ET on Tuesday 10/27 (class 21).
**Resources:**
* [Specialist Knowledge Is Useless and Unhelpful](http://www.slate.com/articles/health_and_science/new_scientist/2012/12/kaggle_president_jeremy_howard_amateurs_beat_specialists_in_data_prediction.html) is a brief interview with Jeremy Howard (past president of Kaggle) in which he argues that data science skills are much more important than domain expertise for creating effective predictive models.
* [Getting in Shape for the Sport of Data Science](https://www.youtube.com/watch?v=kwt6XEh7U3g) (74 minutes), also by Jeremy Howard, contains a lot of tips for competitive machine learning.
* [Learning from the best](http://blog.kaggle.com/2014/08/01/learning-from-the-best/) is an excellent blog post covering top tips from Kaggle Masters on how to do well on Kaggle.
* [Feature Engineering Without Domain Expertise](https://www.youtube.com/watch?v=bL4b1sGnILU) (17 minutes), a talk by Kaggle Master Nick Kridler, provides some simple advice about how to iterate quickly and where to spend your time during a Kaggle competition.
* These examples may help you to better understand the process of feature engineering: predicting the number of [passengers at a train station](https://medium.com/@chris_bour/french-largest-data-science-challenge-ever-organized-shows-the-unreasonable-effectiveness-of-open-8399705a20ef), identifying [fraudulent users of an online store](https://docs.google.com/presentation/d/1UdI5NY-mlHyseiRVbpTLyvbrHxY8RciHp5Vc-ZLrwmU/edit#slide=id.p), identifying [bots in an online auction](https://www.kaggle.com/c/facebook-recruiting-iv-human-or-bot/forums/t/14628/share-your-secret-sauce), predicting who will [subscribe to the next season of an orchestra](http://blog.kaggle.com/2015/01/05/kaggle-inclass-stanfords-getting-a-handel-on-data-science-winners-report/), and evaluating the [quality of e-commerce search engine results](http://blog.kaggle.com/2015/07/22/crowdflower-winners-interview-3rd-place-team-quartet/).
* [Our perfect submission](https://www.kaggle.com/c/restaurant-revenue-prediction/forums/t/13950/our-perfect-submission) is a fun read about how great performance on the [public leaderboard](https://www.kaggle.com/c/restaurant-revenue-prediction/leaderboard/public) does not guarantee that a model will generalize to new data.
-----
### Class 17: Decision Trees
* Decision trees ([notebook](notebooks/17_decision_trees.ipynb))
* Exercise with Capital Bikeshare data ([notebook](notebooks/17_bikeshare_exercise.ipynb), [data](data/bikeshare.csv), [data dictionary](https://www.kaggle.com/c/bike-sharing-demand/data))
**Homework:**
* Read the "Wisdom of the crowds" section from MLWave's post on [Human Ensemble Learning](http://mlwave.com/human-ensemble-learning/).
* **Optional:** Read the abstract from [Do We Need Hundreds of Classifiers to Solve Real World Classification Problems?](http://jmlr.csail.mit.edu/papers/volume15/delgado14a/delgado14a.pdf), as well as Kaggle CTO Ben Hamner's [comment](https://news.ycombinator.com/item?id=8719723) about the paper, paying attention to the mentions of "Random Forests".
**Resources:**
* scikit-learn's documentation on [decision trees](http://scikit-learn.org/stable/modules/tree.html) includes a nice overview of trees as well as tips for proper usage.
* For a more thorough introduction to decision trees, read section 4.3 (23 pages) of [Introduction to Data Mining](http://www-users.cs.umn.edu/~kumar/dmbook/index.php). (Chapter 4 is available as a free download.)
* If you want to go deep into the different decision tree algorithms, this slide deck contains [A Brief History of Classification and Regression Trees](https://drive.google.com/file/d/0B-BKohKl-jUYQ3RpMEF0OGRUU3RHVGpHY203NFd3Z19Nc1ZF/view).
* [The Science of Singing Along](http://www.doc.gold.ac.uk/~mas03dm/papers/PawleyMullensiefen_Singalong_2012.pdf) contains a neat regression tree (page 136) for predicting the percentage of an audience at a music venue that will sing along to a pop song.
* Decision trees are common in the medical field for differential diagnosis, such as this classification tree for [identifying psychosis](http://www.psychcongress.com/sites/naccme.com/files/images/pcn/saundras/psychosis_decision_tree.pdf).
-----
### Class 18: Ensembling
* Finish decision trees lesson ([notebook](notebooks/17_decision_trees.ipynb))
* Ensembling ([notebook](notebooks/18_ensembling.ipynb))
* [Major League Baseball player data](data/hitters.csv) from 1986-87
* [Data dictionary](https://cran.r-project.org/web/packages/ISLR/ISLR.pdf) (page 7)
**Resources:**
* scikit-learn's documentation on [ensemble methods](http://scikit-learn.org/stable/modules/ensemble.html) covers both "averaging methods" (such as bagging and Random Forests) as well as "boosting methods" (such as AdaBoost and Gradient Tree Boosting).
* MLWave's [Kaggle Ensembling Guide](http://mlwave.com/kaggle-ensembling-guide/) is very thorough and shows the many different ways that ensembling can take place.
* Browse the excellent [solution paper](https://docs.google.com/viewer?url=https://raw.githubusercontent.com/ChenglongChen/Kaggle_CrowdFlower/master/Doc/Kaggle_CrowdFlower_ChenglongChen.pdf) from the winner of Kaggle's [CrowdFlower competition](https://www.kaggle.com/c/crowdflower-search-relevance) for an example of the work and insight required to win a Kaggle competition.
* [Interpretable vs Powerful Predictive Models: Why We Need Them Both](https://medium.com/@chris_bour/interpretable-vs-powerful-predictive-models-why-we-need-them-both-990340074979) is a short post on how the tactics useful in a Kaggle competition are not always useful in the real world.
* [Not Even the People Who Write Algorithms Really Know How They Work](http://www.theatlantic.com/technology/archive/2015/09/not-even-the-people-who-write-algorithms-really-know-how-they-work/406099/) argues that the decreased interpretability of state-of-the-art machine learning models has a negative impact on society.
* For an intuitive explanation of Random Forests, read Edwin Chen's answer to [How do random forests work in layman's terms?](http://www.quora.com/Random-Forests/How-do-random-forests-work-in-laymans-terms/answer/Edwin-Chen-1)
* [Large Scale Decision Forests: Lessons Learned](http://blog.siftscience.com/blog/2015/large-scale-decision-forests-lessons-learned) is an excellent post from Sift Science about their custom implementation of Random Forests.
* [Unboxing the Random Forest Classifier](http://nerds.airbnb.com/unboxing-the-random-forest-classifier/) describes a way to interpret the inner workings of Random Forests beyond just feature importances.
* [Understanding Random Forests: From Theory to Practice](http://arxiv.org/pdf/1407.7502v3.pdf) is an in-depth academic analysis of Random Forests, including details of its implementation in scikit-learn.
-----
### Class 19: Advanced scikit-learn and Clustering
* Advanced scikit-learn ([notebook](notebooks/19_advanced_sklearn.ipynb))
* [StandardScaler](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html): standardizing features
* [Pipeline](http://scikit-learn.org/stable/modules/pipeline.html): chaining steps
* Clustering ([slides](slides/19_clustering.pdf), [notebook](notebooks/19_clustering.ipynb))
* K-means: [documentation](http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html), [visualization 1](http://tech.nitoyon.com/en/blog/2013/11/07/k-means/), [visualization 2](http://www.naftaliharris.com/blog/visualizing-k-means-clustering/)
* DBSCAN: [documentation](http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html), [visualization](http://www.naftaliharris.com/blog/visualizing-dbscan-clustering/)
**Homework:**
* Reread [Understanding the Bias-Variance Tradeoff](http://scott.fortmann-roe.com/docs/BiasVariance.html). (The "answers" to the [guiding questions](homework/09_bias_variance.md) have been posted and may be helpful to you.)
* **Optional:** Watch these two excellent (and related) videos from Caltech's Learning From Data course: [bias-variance tradeoff](http://work.caltech.edu/library/081.html) (15 minutes) and [regularization](http://work.caltech.edu/library/121.html) (8 minutes).
**scikit-learn Resources:**
* This is a longer example of [feature scaling](https://github.com/rasbt/pattern_classification/blob/master/preprocessing/about_standardization_normalization.ipynb) in scikit-learn, with additional discussion of the types of scaling you can use.
* [Practical Data Science in Python](http://radimrehurek.com/data_science_python/) is a long and well-written notebook that uses a few advanced scikit-learn features: pipelining, plotting a learning curve, and pickling a model.
* To learn how to use [GridSearchCV and RandomizedSearchCV](http://scikit-learn.org/stable/modules/grid_search.html) for parameter tuning, watch [How to find the best model parameters in scikit-learn](https://www.youtube.com/watch?v=Gol_qOgRqfA) (28 minutes) or read the [associated notebook](https://github.com/justmarkham/scikit-learn-videos/blob/master/08_grid_search.ipynb).
* Sebastian Raschka has a number of excellent resources for scikit-learn users, including a repository of [tutorials and examples](https://github.com/rasbt/pattern_classification), a library of machine learning [tools and extensions](http://rasbt.github.io/mlxtend/), a new [book](https://github.com/rasbt/python-machine-learning-book), and a semi-active [blog](http://sebastianraschka.com/blog/).
* scikit-learn has an incredibly active [mailing list](https://www.mail-archive.com/[email protected]/index.html) that is often much more useful than Stack Overflow for researching functions and asking questions.
* If you forget how to use a particular scikit-learn function that we have used in class, don't forget that this repository is fully searchable!
**Clustering Resources:**
* For a very thorough introduction to clustering, read chapter 8 (69 pages) of [Introduction to Data Mining](http://www-users.cs.umn.edu/~kumar/dmbook/index.php) (available as a free download), or browse through the chapter 8 slides.
* scikit-learn's user guide compares many different [types of clustering](http://scikit-learn.org/stable/modules/clustering.html).
* This [PowerPoint presentation](http://www2.research.att.com/~volinsky/DataMining/Columbia2011/Slides/Topic6-Clustering.ppt) from Columbia's Data Mining class provides a good introduction to clustering, including hierarchical clustering and alternative distance metrics.
* An Introduction to Statistical Learning has useful videos on [K-means clustering](https://www.youtube.com/watch?v=aIybuNt9ps4&list=PL5-da3qGB5IBC-MneTc9oBZz0C6kNJ-f2) (17 minutes) and [hierarchical clustering](https://www.youtube.com/watch?v=Tuuc9Y06tAc&list=PL5-da3qGB5IBC-MneTc9oBZz0C6kNJ-f2) (15 minutes).
* This is an excellent interactive visualization of [hierarchical clustering](https://joyofdata.shinyapps.io/hclust-shiny/).
* This is a nice animated explanation of [mean shift clustering](http://spin.atomicobject.com/2015/05/26/mean-shift-clustering/).
* The [K-modes algorithm](http://www.cs.ust.hk/~qyang/Teaching/537/Papers/huang98extensions.pdf) can be used for clustering datasets of categorical features without converting them to numerical values. Here is a [Python implementation](https://github.com/nicodv/kmodes).
* Here are some fun examples of clustering: [A Statistical Analysis of the Work of Bob Ross](http://fivethirtyeight.com/features/a-statistical-analysis-of-the-work-of-bob-ross/) (with [data and Python code](https://github.com/fivethirtyeight/data/tree/master/bob-ross)), [How a Math Genius Hacked OkCupid to Find True Love](http://www.wired.com/2014/01/how-to-hack-okcupid/all/), and [characteristics of your zip code](http://www.esri.com/landing-pages/tapestry/).
-----
### Class 20: Regularization and Regular Expressions
* Regularization ([notebook](notebooks/20_regularization.ipynb))
* Regression: [Ridge](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html), [RidgeCV](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.RidgeCV.html), [Lasso](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html), [LassoCV](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LassoCV.html)
* Classification: [LogisticRegression](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html)
* Helper functions: [Pipeline](http://scikit-learn.org/stable/modules/pipeline.html), [GridSearchCV](http://scikit-learn.org/stable/modules/grid_search.html)
* Regular expressions
* [Baltimore homicide data](data/homicides.txt)
* [Regular expressions 101](https://regex101.com/#python): real-time testing of regular expressions
* [Reference guide](code/20_regex_reference.py)
* [Exercise](code/20_regex_exercise.py)
**Homework:**
* Your final project is due next week!
* **Optional:** Make your final submissions to our Kaggle competition! It closes at 6:30pm ET on Tuesday 10/27.
* **Optional:** Read this classic paper, which may help you to connect many of the topics we have studied throughout the course: [A Few Useful Things to Know about Machine Learning](http://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf).
**Regularization Resources:**
* The scikit-learn user guide for [Generalized Linear Models](http://scikit-learn.org/stable/modules/linear_model.html) explains different variations of regularization.
* Section 6.2 of [An Introduction to Statistical Learning](http://www-bcf.usc.edu/~gareth/ISL/) (14 pages) introduces both lasso and ridge regression. Or, watch the related videos on [ridge regression](https://www.youtube.com/watch?v=cSKzqb0EKS0&list=PL5-da3qGB5IB-Xdpj_uXJpLGiRfv9UVXI&index=6) (13 minutes) and [lasso regression](https://www.youtube.com/watch?v=A5I1G1MfUmA&index=7&list=PL5-da3qGB5IB-Xdpj_uXJpLGiRfv9UVXI) (15 minutes).
* For more details on lasso regression, read Tibshirani's [original paper](http://statweb.stanford.edu/~tibs/lasso/lasso.pdf).
* For a math-ier explanation of regularization, watch the last four videos (30 minutes) from week 3 of Andrew Ng's [machine learning course](https://www.coursera.org/learn/machine-learning/), or read the [related lecture notes](http://www.holehouse.org/mlclass/07_Regularization.html) compiled by a student.
* This [notebook](https://github.com/luispedro/PenalizedRegression/blob/master/PenalizedRegression.ipynb) from chapter 7 of [Building Machine Learning Systems with Python](https://www.packtpub.com/big-data-and-business-intelligence/building-machine-learning-systems-python) has a nice long example of regularized linear regression.
* There are some special considerations when using dummy encoding for categorical features with a regularized model. This [Cross Validated Q&A](https://stats.stackexchange.com/questions/69568/whether-to-rescale-indicator-binary-dummy-predictors-for-lasso) debates whether the dummy variables should be standardized (along with the rest of the features), and a comment on this [blog post](http://appliedpredictivemodeling.com/blog/2013/10/23/the-basics-of-encoding-categorical-data-for-predictive-models) recommends that the baseline level should not be dropped.
**Regular Expressions Resources:**
* Google's Python Class includes an excellent [introductory lesson](https://developers.google.com/edu/python/regular-expressions) on regular expressions (which also has an associated [video](https://www.youtube.com/watch?v=kWyoYtvJpe4&index=4&list=PL5-da3qGB5IA5NwDxcEJ5dvt8F9OQP7q5)).
* Python for Informatics has a nice [chapter](http://www.pythonlearn.com/html-270/book012.html) on regular expressions. (If you want to run the examples, you'll need to download [mbox.txt](http://www.py4inf.com/code/mbox.txt) and [mbox-short.txt](http://www.py4inf.com/code/mbox-short.txt).)
* [Breaking the Ice with Regular Expressions](https://www.codeschool.com/courses/breaking-the-ice-with-regular-expressions/) is an interactive Code School course, though only the first "level" is free.
* If you want to go really deep with regular expressions, [RexEgg](http://www.rexegg.com/) includes endless articles and tutorials.
* [5 Tools You Didn't Know That Use Regular Expressions](http://blog.codeschool.io/2015/07/30/5-tools-you-didnt-know-that-use-regular-expressions/) demonstrates how regular expressions can be used with Excel, Word, Google Spreadsheets, Google Forms, text editors, and other tools.
* [Exploring Expressions of Emotions in GitHub Commit Messages](http://geeksta.net/geeklog/exploring-expressions-emotions-github-commit-messages/) is a fun example of how regular expressions can be used for data analysis, and [Emojineering](http://instagram-engineering.tumblr.com/post/118304328152/emojineering-part-2-implementing-hashtag-emoji) explains how Instagram uses regular expressions to detect emoji in hashtags.
-----
### Class 21: Course Review and Final Project Presentation
* Project presentations!
* [Data science review](https://docs.google.com/document/d/19gBCkmrbMpFFLPX8wa5daMnyl7J5BXhMV8JNJwgp1pk/edit?usp=sharing)
**Resources:**
* scikit-learn's [machine learning map](http://scikit-learn.org/stable/tutorial/machine_learning_map/) may help you to choose the "best" model for your task.
* [Choosing a Machine Learning Classifier](http://blog.echen.me/2011/04/27/choosing-a-machine-learning-classifier/) is a short and highly readable comparison of several classification models, [Classifier comparison](http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html) is scikit-learn's visualization of classifier decision boundaries, [Comparing supervised learning algorithms](http://www.dataschool.io/comparing-supervised-learning-algorithms/) is a model comparison table that I created, and [Supervised learning superstitions cheat sheet](http://ryancompton.net/assets/ml_cheat_sheet/supervised_learning.html) is a more thorough comparison (with links to lots of useful resources).
* [Machine Learning Done Wrong](http://ml.posthaven.com/machine-learning-done-wrong), [Machine Learning Gremlins](https://www.youtube.com/watch?v=tleeC-KlsKA) (31 minutes), [Clever Methods of Overfitting](http://hunch.net/?p=22), and [Common Pitfalls in Machine Learning](http://danielnee.com/?p=155) all offer thoughtful advice on how to avoid common mistakes in machine learning.
* [Practical machine learning tricks from the KDD 2011 best industry paper](http://blog.david-andrzejewski.com/machine-learning/practical-machine-learning-tricks-from-the-kdd-2011-best-industry-paper/) and Andrew Ng's [Advice for applying machine learning](http://cs229.stanford.edu/materials/ML-advice.pdf) include slightly more advanced advice than the resources above.
* [An Empirical Comparison of Supervised Learning Algorithms](http://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml06.pdf) is a readable research paper from 2006, which was also presented as a [talk](http://videolectures.net/solomon_caruana_wslmw/) (77 minutes).
-----
### Class 22: Final Project Presentation
* Project presentations!
* [What's next?](other/advice.md)
-----
## Additional Resources
### Tidy Data
* [Good Data Management Practices for Data Analysis](https://www.prometheusresearch.com/good-data-management-practices-for-data-analysis-tidy-data-part-2/) briefly summarizes the principles of "tidy data".
* [Hadley Wickham's paper](http://www.jstatsoft.org/article/view/v059i10) explains tidy data in detail and includes lots of good examples.
* Example of a tidy dataset: [Bob Ross](https://github.com/fivethirtyeight/data/blob/master/bob-ross/elements-by-episode.csv)
* Examples of untidy datasets: [NFL ticket prices](https://github.com/fivethirtyeight/data/blob/master/nfl-ticket-prices/2014-average-ticket-price.csv), [airline safety](https://github.com/fivethirtyeight/data/blob/master/airline-safety/airline-safety.csv), [Jets ticket prices](https://github.com/fivethirtyeight/data/blob/master/nfl-ticket-prices/jets-buyer.csv), [Chipotle orders](https://github.com/TheUpshot/chipotle/blob/master/orders.tsv)
* If your co-workers tend to create spreadsheets that are [unreadable by computers](https://bosker.wordpress.com/2014/12/05/the-government-statistical-services-terrible-spreadsheet-advice/), they may benefit from reading these [tips for releasing data in spreadsheets](http://www.clean-sheet.org/). (There are some additional suggestions in this [answer](http://stats.stackexchange.com/questions/83614/best-practices-for-creating-tidy-data/83711#83711) from Cross Validated.)
### Databases and SQL
* This [GA slide deck](https://github.com/justmarkham/DAT5/blob/master/slides/20_sql.pdf) provides a brief introduction to databases and SQL. The [Python script](https://github.com/justmarkham/DAT5/blob/master/code/20_sql.py) from that lesson demonstrates basic SQL queries, as well as how to connect to a SQLite database from Python and how to query it using Pandas.
* The repository for this [SQL Bootcamp](https://github.com/brandonmburroughs/sql_bootcamp) contains an extremely well-commented SQL script that is suitable for walking through on your own.
* This [GA notebook](https://github.com/podopie/DAT18NYC/blob/master/classes/17-relational_databases.ipynb) provides a shorter introduction to databases and SQL that helpfully contrasts SQL queries with Pandas syntax.
* [SQLZOO](http://sqlzoo.net/wiki/SQL_Tutorial), [Mode Analytics](http://sqlschool.modeanalytics.com/), [Khan Academy](https://www.khanacademy.org/computing/computer-programming/sql), [Codecademy](https://www.codecademy.com/courses/learn-sql), [Datamonkey](http://datamonkey.pro/guess_sql/lessons/), and [Code School](http://campus.codeschool.com/courses/try-sql/contents) all have online beginner SQL tutorials that look promising. Code School also offers an [advanced tutorial](https://www.codeschool.com/courses/the-sequel-to-sql/), though it's not free.
* [w3schools](http://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all) has a sample database that allows you to practice SQL from your browser. Similarly, Kaggle allows you to query a large SQLite database of [Reddit Comments](https://www.kaggle.com/c/reddit-comments-may-2015/data) using their online "Scripts" application.
* [What Every Data Scientist Needs to Know about SQL](http://joshualande.com/data-science-sql/) is a brief series of posts about SQL basics, and [Introduction to SQL for Data Scientists](http://bensresearch.com/downloads/SQL.pdf) is a paper with similar goals.
* [10 Easy Steps to a Complete Understanding of SQL](https://web.archive.org/web/20150402234726/http://tech.pro/tutorial/1555/10-easy-steps-to-a-complete-understanding-of-sql) is a good article for those who have some SQL experience and want to understand it at a deeper level.
* SQLite's article on [Query Planning](http://www.sqlite.org/queryplanner.html) explains how SQL queries "work".
* [A Comparison Of Relational Database Management Systems](https://www.digitalocean.com/community/tutorials/sqlite-vs-mysql-vs-postgresql-a-comparison-of-relational-database-management-systems) gives the pros and cons of SQLite, MySQL, and PostgreSQL.
* If you want to go deeper into databases and SQL, Stanford has a well-respected series of [14 mini-courses](https://lagunita.stanford.edu/courses/DB/2014/SelfPaced/about).
* [Blaze](http://blaze.pydata.org) is a Python package enabling you to use Pandas-like syntax to query data living in a variety of data storage systems.
### Recommendation Systems
* This [GA slide deck](https://github.com/justmarkham/DAT4/blob/master/slides/18_recommendation_engines.pdf) provides a brief introduction to recommendation systems, and the [Python script](https://github.com/justmarkham/DAT4/blob/master/code/18_recommenders_soutions.py) from that lesson demonstrates how to build a simple recommender.
* Chapter 9 of [Mining of Massive Datasets](http://infolab.stanford.edu/~ullman/mmds/bookL.pdf) (36 pages) is a more thorough introduction to recommendation systems.
* Chapters 2 through 4 of [A Programmer's Guide to Data Mining](http://guidetodatamining.com/) (165 pages) provides a friendlier introduction, with lots of Python code and exercises.
* The Netflix Prize was the famous competition for improving Netflix's recommendation system by 10%. Here are some useful articles about the Netflix Prize:
* [Netflix Recommendations: Beyond the 5 stars](http://techblog.netflix.com/2012/04/netflix-recommendations-beyond-5-stars.html): Two posts from the Netflix blog summarizing the competition and their recommendation system
* [Winning the Netflix Prize: A Summary](http://blog.echen.me/2011/10/24/winning-the-netflix-prize-a-summary/): Overview of the models and techniques that went into the winning solution
* [A Perspective on the Netflix Prize](http://www2.research.att.com/~volinsky/papers/chance.pdf): A summary of the competition by the winning team
* This [paper](http://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf) summarizes how Amazon.com's recommendation system works, and this [Stack Overflow Q&A](http://stackoverflow.com/questions/2323768/how-does-the-amazon-recommendation-feature-work) has some additional thoughts.
* [Facebook](https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/) and [Etsy](https://codeascraft.com/2014/11/17/personalized-recommendations-at-etsy/) have blog posts about how their recommendation systems work.
* [The Global Network of Discovery](http://www.gnod.com/) provides some neat recommenders for music, authors, and movies.
* [The People Inside Your Machine](http://www.npr.org/blogs/money/2015/01/30/382657657/episode-600-the-people-inside-your-machine) (23 minutes) is a Planet Money podcast episode about how Amazon Mechanical Turks can assist with recommendation engines (and machine learning in general).
* Coursera has a [course](https://www.coursera.org/learn/recommender-systems) on recommendation systems, if you want to go even deeper into the material.
|
3,414 | Quiz & Assignment of Coursera | # Coursera Assignments
This repository is aimed to help Coursera learners who have difficulties in their learning process.
The quiz and programming homework is belong to coursera.Please **Do Not** use them for any other purposes.
Please feel free to contact me if you have any problem,my email is [email protected].
* [Bayesian Statistics From Concept to Data Analysis](./Bayesian_Statistics_From_Concept_to_Data_Analysis_UC_Santa_Cruz)
* [Learn to Program: Crafting Quality Code](./Learn_to_Program_Crafting_Quality_Code_University_of_Toronto)
* [Neural Networks for Machine Learning-University of Toronto](./Neural_Networks_for_Machine_Learning_University_of_Toronto)
* Specialization Advanced Machine Learning Higher School of Economics
* Introduction to Deep Learning
* [Specialization Applied Data Science with Python](./Specialization_Applied_Data_Science_with_Python_University_of_Michigan)
* Introduction to Data Science in Python
* Applied Machine Learning in Python
* [Specialization Big Data-UCSD](./Specialization_Big_Data_UC_San_Diego)
* Introduction to Big Data
* Big Data Modeling and Management Systems
* Big Data Interation and Processing
* [Specialization Data Mining-UIUC](./Specialization_Data_Mining_UIUC)
* Text Retrieval and Search Engines
* Text Mining and Analytics
* Pattern Discovery in Data Mining
* Cluster Analysis in Data Mining
* [Specialization Data Science-Johns Hopkins University](./Specialization_Data_Science_Johns_Hopkins_University)
* The Data Scientist’s Toolbox
* R Programming
* Getting and Cleaning Data
* [Specialization Data Structures & Algorithms-UC San Diego](./Specialization_Data_Structures_Algorithms_UC_San_Diego)
* Algorithmic Toolbox
* Data Structures
* Algorithms on Graphs
* Algorithms on Strings
* [Specialization Deep Learning](./Specialization_Deep_Learning_deeplearning.ai)
* Neural Networks and Deep Learning
* Improving Deep Neural Networks Hyperparameter tuning, Regularization and Optimization
* Structuring Machine Learning Projects
* Convolutional Neural Networks
* Sequence Models
* [Specialization Functional Programming in Scala](./Specialization_Functional_Programming_in_Scala)
* Functional Programming Principles in Scala
* Specialization Fundamentals of Computing-Rice University
* Principles of Computing 1
* [Specialization Meachine Learning-University of Washington](./Specialization_Machine_Learning_University_of_Washington)
* Machine Learning Foundations: A Case Study Approach
* Machine Learning: Regression
* Machine Learning: Classification
* Machine Learning: Clustering & Retrieval
* [Specialization Probabilistic Graphical Models-Stanford University](./Specialization_Probabilistic_Graphical_Models_Stanford_University)
* Probabilistic Graphical Models 1: Representation
* Probabilistic Graphical Models 2: Inference
* Probabilistic Graphical Models 3: Learning
* [Specialization 程序设计与算法-Peking University](./Specialization_Program_Design_Algorithm_Peking_University)
* 计算导论与C语言基础
* C程序设计进阶
* C++程序设计
* 算法基础
* 数据结构基础
* [Specialization Recommender System-University of Minnesota](./Specialization_Recommender_System_University_of_Minnesota)
* Introduction to Recommender Systems: Non-Personalized and Content-Based
* Nearest Neighbor Collaborative Filtering
* Recommender Systems:Evaluation and Metrics
* Matrix Factorization and Advanced Techniques
* [Specialization Statistics with R-Duke University](./Specialization_Statistics_with_R_Duke_University)
* Introduction to Probability and Data
* Inferential Statistics
* [The Unix Workbench-Johns Hopkins University](./The_Unix_Workbench_Johns_Hopkins_University)
|
3,415 | All the slides, accompanying code and exercises all stored in this repo. 🎈 | # Data Camp: Data Scientist with Python 🎉🤖
 

# All the slides, accompanying code and exercises are all stored in this repo!
[Sign Up to DataCamp Here!](https://www.datacamp.com)
## 🎮 List of Courses
- [Intro to Python for Data Science](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Intro%20to%20Python%20for%20Data%20Science)
- [Intermediate Python for Data Science](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Intermediate%20Python%20for%20Data%20Science)
- [Python Data Science Toolbox (Part 1)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Python%20Data%20Science%20Toolbox%20pt1)
- [Python Data Science Toolbox (Part 2)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Python%20Data%20Science%20Toolbox%20pt2)
- [Importing Data in Python (Part 1)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Importing%20Data%20in%20Python%20pt1)
- [Importing Data in Python (Part 2)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Importing%20Data%20in%20Python%20pt2)
- [Cleaning Data in Python](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Cleaning%20Data%20in%20Python)
- [Pandas Foundations](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Pandas%20Foundations)
- [Manipulating DataFrames with pandas](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Manipulating%20DataFrames%20with%20pandas)
- [Merging DataFrames with pandas](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Merging%20DataFrames%20with%20pandas)
- [Introduction to Databases in Python](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Introduction%20to%20Databases%20in%20Python)
- [Introduction to Data Visualization with Python](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Introduction%20to%20Data%20Visualizaion%20with%20Python)
- [Interactive Data Visualization with Bokeh](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Interactive%20Data%20Visualization%20with%20Bokeh)
- [Statistical Thinking in Python (Part 1)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Statistical%20Thinking%20in%20Python%20(Part%201))
- [Statistical Thinking in Python (Part 2)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Statistical%20Thinking%20in%20Python%20(Part%202))
- [Supervised Learning with scikit-learn](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Supervised%20Learning%20with%20scikit-learn)
- [Machine Learning with the Experts: School Budgets](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Machine%20Learning%20with%20Experts-School%20Budgets)
- [Unsupervised Learning in Python](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Unsupervised%20Learning%20in%20Python)
- [Deep Learning in Python](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Deep%20Learning%20in%20Python)
- [Network Analysis in Python (Part 1)](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Network%20Analysis%20in%20Python%20(Part%201))
### 💣 Bonus
- [Natural Language Processing Fundamentals in Python](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Natural%20Language%20Processing%20Fundamentals%20in%20Python)
- [Correlation & Regression](https://github.com/AmoDinho/datacamp-python-data-science-track/tree/master/Correlation%20and%20Regression)
## 🍣 Contributions
Anyone is welcome to contribute please check out the issues!
## 📄 License
[MIT License](https://github.com/AmoDinho/datacamp-python-data-science-track/blob/master/LICENSE)
|
3,416 | A collection of notebooks for Natural Language Processing from NLP Town | # nlp-notebooks
A collection of notebooks for Natural Language Processing from NLP Town
## NLP 101
1. [An Introduction to Word Embeddings](https://github.com/nlptown/nlp-notebooks/blob/master/An%20Introduction%20to%20Word%20Embeddings.ipynb)
2. [NLP with Pre-trained models from spaCy and StanfordNLP](https://github.com/nlptown/nlp-notebooks/blob/master/NLP%20with%20pretrained%20models%20-%20spaCy%20and%20StanfordNLP.ipynb)
3. [Discovering and Visualizing Topics in Texts with LDA](https://github.com/nlptown/nlp-notebooks/blob/master/Discovering%20and%20Visualizing%20Topics%20in%20Texts%20with%20LDA.ipynb)
## Named Entity Recognition
1. [Updating spaCy's Named Entity Recognition System](https://github.com/nlptown/nlp-notebooks/blob/master/Updating%20spaCy's%20Named%20Entity%20Recognition%20System.ipynb)
2. [Named Entity Recognition with Conditional Random Fields](https://github.com/nlptown/nlp-notebooks/blob/master/Named%20Entity%20Recognition%20with%20Conditional%20Random%20Fields.ipynb)
3. [Sequence Labelling with a BiLSTM in PyTorch](https://github.com/nlptown/nlp-notebooks/blob/master/Sequence%20Labelling%20with%20a%20BiLSTM%20in%20PyTorch.ipynb)
4. [Medical Entity Recognition with Pretrained Transformers](https://github.com/nlptown/nlp-notebooks/blob/master/Medical%20Entity%20Recognition%20with%20Pretrained%20Transformers.ipynb)
## Text classification
1. ["Traditional" Text Classification with Scikit-learn](https://github.com/nlptown/nlp-notebooks/blob/master/Traditional%20text%20classification%20with%20Scikit-learn.ipynb)
2. [Intent Classification with Smaller Transformers](https://github.com/nlptown/nlp-notebooks/blob/master/Intent%20Classification%20with%20Small%20Transformers.ipynb)
3. [Zero-Shot Text Classification](https://github.com/nlptown/nlp-notebooks/blob/master/Zero-Shot%20Text%20Classification.ipynb)
## Sentence similarity
1. [Simple Sentence Similarity](https://github.com/nlptown/nlp-notebooks/blob/master/Simple%20Sentence%20Similarity.ipynb)
2. [Data Exploration with Sentence Similarity](Data%20exploration%20with%20sentence%20similarity.ipynb)
## Multilingual word embeddings
1. [Introduction](https://github.com/nlptown/nlp-notebooks/blob/master/Multilingual%20Embeddings%20-%201.%20Introduction.ipynb)
2. [Cross-lingual sentence similarity](https://github.com/nlptown/nlp-notebooks/blob/master/Multilingual%20Embeddings%20-%202.%20Cross-lingual%20Sentence%20Similarity.ipynb)
3. [Cross-lingual transfer learning](https://github.com/nlptown/nlp-notebooks/blob/master/Multilingual%20Embeddings%20-%203.%20Transfer%20Learning.ipynb)
## Transfer Learning
1. [Keras sentiment analysis with Elmo Embeddings](https://github.com/nlptown/nlp-notebooks/blob/master/Elmo%20Embeddings.ipynb)
2. [Text classification with BERT in PyTorch](https://github.com/nlptown/nlp-notebooks/blob/master/Text%20classification%20with%20BERT%20in%20PyTorch.ipynb)
3. [Multilingual text classification with BERT](https://github.com/nlptown/nlp-notebooks/blob/master/Multilingual%20text%20classification%20with%20BERT.ipynb)
|
3,417 | Collection of useful data science topics along with articles, videos, and code | [](https://github.com/khuyentran1401/Data-science) [](https://khuyentran1476.medium.com/) [](https://mathdatasimplified.com/) [](https://www.youtube.com/channel/UCNMawpMow-lW5d2svGhOEbw)
# [Data Science Topics](https://github.com/khuyentran1401/Data-science)
Collection of useful data science topics along with articles and videos.
Subscribe to:
- [My YouTube channel](https://www.youtube.com/@datasciencesimplified) for **videos** related to Python and data sience
- [My Medium newsletter](https://khuyentran1476.medium.com/subscribe) for updates of my **blogs** in your mailbox
- [Data Science Simplified](https://mathdatasimplified.com/) for **bite-sized** Python tips in your mailbox
## How to Download the Code in This Repository to Your Local Machine
To download the code in this repo, you can simply use git clone
```bash
git clone https://github.com/khuyentran1401/Data-science
```
# Contents
1. [MLOps](#mlops)
2. [Testing](#testing)
3. [Productive Tools](#productive-tools)
4. [Python Helper Tools](#python-helper-tools)
5. [Tools for Deployment](#tools-for-deployment)
6. [Speed-up Tools](#speed-up-tools)
7. [Math Tools](#math-tools)
8. [Machine Learning](#machine-learning)
9. [Natural Language Processing](#natural-language-processing)
10. [Computer Vision](#computer-vision)
11. [Time Series](#time-series)
12. [Feature Engineering](#feature-engineering)
13. [Visualization](#visualization)
14. [Mathematical Programming](#mathematical-programming)
15. [Scraping](#scraping)
16. [Python](#python)
17. [Terminal](#terminal)
18. [Linear Algebra](#linear-algebra)
19. [Data Structure](#data-structure)
20. [Statistics](#statistics)
21. [Web Applications](#web-applications)
22. [Share Insights](#share-insights)
23. [Cool Tools](#cool-tools)
24. [Learning Tips](#learning-tips)
25. [Productive Tips](#productive-tips)
26. [VSCode](#vscode)
27. [Book Review](#book-review)
28. [Data Science Portfolio](#data-science-portfolio)
# MLOps
| Title | Article | Repository | Video
| ------------- |:-------------:| :-----:| :-----:|
|Introduction to DVC: Data Version Control Tool for Machine Learning Projects | [🔗](https://towardsdatascience.com/introduction-to-dvc-data-version-control-tool-for-machine-learning-projects-7cb49c229fe0) | [🔗](https://github.com/khuyentran1401/Machine-learning-pipeline) | [🔗](https://youtu.be/80s_dbfiqLM)
| Introduction to Hydra.cc: A Powerful Framework to Configure your Data Science Projects | [🔗](https://towardsdatascience.com/introduction-to-hydra-cc-a-powerful-framework-to-configure-your-data-science-projects-ed65713a53c6) | [🔗](https://github.com/khuyentran1401/hydra_demo) | [🔗](https://www.youtube.com/playlist?list=PLnK6m_JBRVNoPnqnVrWaYtZ2G4nFTnGze)
| Introduction to Weight & Biases: Track and Visualize your Machine Learning Experiments in 3 Lines of Code | [🔗](https://towardsdatascience.com/introduction-to-weight-biases-track-and-visualize-your-machine-learning-experiments-in-3-lines-9c9553b0f99d) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/wandb_tracking)
| Kedro — A Python Framework for Reproducible Data Science Project | [🔗](https://towardsdatascience.com/kedro-a-python-framework-for-reproducible-data-science-project-4d44977d4f04) | [🔗](https://github.com/khuyentran1401/kedro_demo)
| Orchestrate a Data Science Project in Python With Prefect | [🔗](https://towardsdatascience.com/orchestrate-a-data-science-project-in-python-with-prefect-e69c61a49074) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/prefect_example)
| Orchestrate Your Data Science Project with Prefect 2.0 | [🔗](https://medium.com/the-prefect-blog/orchestrate-your-data-science-project-with-prefect-2-0-4118418fd7ce) | [🔗](https://github.com/khuyentran1401/prefect2-mlops-demo) | [🔗](https://www.youtube.com/playlist?list=PLnK6m_JBRVNrHeLuMMJGtNLmgn3MpXYvq)
| DagsHub: a GitHub Supplement for Data Scientists and ML Engineers | [🔗](https://towardsdatascience.com/dagshub-a-github-supplement-for-data-scientists-and-ml-engineers-9ecaf49cc505) | [🔗](https://dagshub.com/khuyentran1401/dagshub-demo)
| 4 pre-commit Plugins to Automate Code Reviewing and Formatting in Python | [🔗](https://towardsdatascience.com/4-pre-commit-plugins-to-automate-code-reviewing-and-formatting-in-python-c80c6d2e9f5) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/productive_tools/precommit_examples) | [🔗](https://youtube.com/playlist?list=PLnK6m_JBRVNqskWiXLxx1QRDDng9O8Fsf)
| BentoML: Create an ML Powered Prediction Service in Minutes | [🔗](https://towardsdatascience.com/bentoml-create-an-ml-powered-prediction-service-in-minutes-23d135d6ca76) | [🔗](https://github.com/khuyentran1401/customer_segmentation/tree/bentoml_demo) | [🔗](https://youtu.be/7csscNQnbnI)
| How to Structure a Data Science Project for Readability and Transparency | [🔗](https://towardsdatascience.com/how-to-structure-a-data-science-project-for-readability-and-transparency-360c6716800) | [🔗](https://github.com/khuyentran1401/data-science-template)
| How to Structure an ML Project for Reproducibility and Maintainability | [🔗](https://towardsdatascience.com/how-to-structure-an-ml-project-for-reproducibility-and-maintainability-54d5e53b4c82) | [🔗](https://github.com/khuyentran1401/data-science-template/tree/prefect)
| GitHub Actions in MLOps: Automatically Check and Deploy Your ML Model | [🔗](https://khuyentran1476.medium.com/github-actions-in-mlops-automatically-check-and-deploy-your-ml-model-9a281d7f3c84) | [🔗](https://github.com/khuyentran1401/employee-future-prediction)
| Create Robust Data Pipelines with Prefect, Docker, and GitHub | [🔗](https://towardsdatascience.com/create-robust-data-pipelines-with-prefect-docker-and-github-12b231ca6ed2) | [🔗](https://github.com/khuyentran1401/prefect-docker)
| Create a Maintainable Data Pipeline with Prefect and DVC | [🔗](https://towardsdatascience.com/create-a-maintainable-data-pipeline-with-prefect-and-dvc-1d691ea5bcea) | [🔗](https://github.com/khuyentran1401/prefect-dvc)
| Build a Full-Stack ML Application With Pydantic And Prefect | [🔗](https://towardsdatascience.com/build-a-full-stack-ml-application-with-pydantic-and-prefect-915f00fe0c62) | [🔗](https://github.com/khuyentran1401/iris-prefect) | [🔗](https://youtu.be/c-Bqg7Gbuc8)
| DVC + GitHub Actions: Automatically Rerun Modified Components of a Pipeline | [🔗](https://towardsdatascience.com/dvc-github-actions-automatically-rerun-modified-components-of-a-pipeline-a3632519dc42) | [🔗](https://github.com/khuyentran1401/prefect-dvc/tree/dvc-pipeline) | [🔗](https://youtu.be/jZu7LPKIOlY)
| Create Observable and Reproducible Notebooks with Hex | [🔗](https://towardsdatascience.com/create-observable-and-reproducible-notebooks-with-hex-460e75818a09) | [🔗](https://github.com/khuyentran1401/customer_segmentation/tree/prefect2) | [🔗](https://youtu.be/_BjqCrun4nE)
# Testing
| Title | Article | Repository | Video
| ------------- |:-------------:| :-----:| :-----:|
| Pytest for Data Scientists | [🔗](https://towardsdatascience.com/pytest-for-data-scientists-2990319e55e6) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/pytest) | [🔗](https://www.youtube.com/playlist?list=PLnK6m_JBRVNoYEer9hBmTNwkYB3gmbOPO)
| 4 Lessor-Known Yet Awesome Tips for Pytest | [🔗](https://towardsdatascience.com/4-lessor-known-yet-awesome-tips-for-pytest-2117d8a62d9c) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/advanced_pytest)
| Great Expectations: Always Know What to Expect From Your Data | [🔗](https://towardsdatascience.com/great-expectations-always-know-what-to-expect-from-your-data-51214866c24) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/great_expectations_example)
| Validate Your pandas DataFrame with Pandera | [🔗](https://medium.com/towards-data-science/validate-your-pandas-dataframe-with-pandera-2995910e564) |[🔗](https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/pandera_example/pandera.ipynb) | [🔗](https://youtu.be/CB8D7RUM-lI)
| Introduction to Schema: A Python Libary to Validate your Data | [🔗](https://towardsdatascience.com/introduction-to-schema-a-python-libary-to-validate-your-data-c6d99e06d56a) | [🔗](https://deepnote.com/launch?url=https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/schema.ipynb)
| DeepDiff — Recursively Find and Ignore Trivial Differences Using Python | [🔗](https://towardsdatascience.com/deepdiff-recursively-find-and-ignore-trivial-differences-using-python-231a5524f41d) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/productive_tools/deepdiff_example.ipynb)
| Checklist — Behavioral Testing of NLP Models | [🔗](https://towardsdatascience.com/checklist-behavioral-testing-of-nlp-models-491cf11f0238) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/nlp/checklist/checklist_examples.ipynb)
| How to Create Fake Data with Faker | [🔗](https://towardsdatascience.com/how-to-create-fake-data-with-faker-a835e5b7a9d9) | [🔗](https://deepnote.com/launch?url=https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/faker.ipynb) |
| Detect Defects in a Data Pipeline Early with Validation and Notifications | [🔗](https://towardsdatascience.com/detect-defects-in-a-data-pipeline-early-with-validation-and-notifications-83e9b652e65a) | [🔗](https://github.com/khuyentran1401/prefect2-mlops-demo/tree/deepchecks) | [🔗](https://youtu.be/HdPViOX8Uf8)
| Hypothesis and Pandera: Generate Synthesis Pandas DataFrame for Testing | [🔗](https://towardsdatascience.com/hypothesis-and-pandera-generate-synthesis-pandas-dataframe-for-testing-e5673c7bec2e) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/pandera_hypothesis) | [🔗](https://youtu.be/RbW-x_2dFMQ)
# Productive Tools
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| 3 Tools to Track and Visualize the Execution of your Python Code | [🔗](https://towardsdatascience.com/3-tools-to-track-and-visualize-the-execution-of-your-python-code-666a153e435e) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/debug_tools)
| 2 Tools to Automatically Reload when Python Files Change | [🔗](https://towardsdatascience.com/2-tools-to-automatically-reload-when-python-files-change-90bb28139087) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/terminal/reload_examples)
| 3 Ways to Get Notified with Python | [🔗](https://towardsdatascience.com/how-to-get-a-notification-when-your-training-is-complete-with-python-2d39679d5f0f) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/notification) |
| How to Create Reusable Command-Line | [🔗](https://towardsdatascience.com/how-to-create-reusable-command-line-f9a2bb356bc9) |
| How to Strip Outputs and Execute Interactive Code in a Python Script | [🔗](https://towardsdatascience.com/how-to-strip-outputs-and-execute-interactive-code-in-a-python-script-6d4c5da3beb0) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/strip_interactive_example.py)
| Sending Slack Notifications in Python with Prefect| [🔗](https://medium.com/the-prefect-blog/sending-slack-notifications-in-python-with-prefect-840a895f81c) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/strip_interactive_example.py)
# Python Helper Tools
| Title | Article | Repository | Video
| ------------- |:-------------:| :-----:| :-----:|
| Pydash: A Kitchen Sink of Missing Python Utilities | [🔗](https://towardsdatascience.com/pydash-a-bucket-of-missing-python-utilities-5d10365be4fc) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/python/pydash.ipynb)
| Write Clean Python Code Using Pipes | [🔗](https://towardsdatascience.com/write-clean-python-code-using-pipes-1239a0f3abf5) | [🔗](https://deepnote.com/project/Data-science-hxlyJpi-QrKFJziQgoMSmQ/%2FData-science%2Fproductive_tools%2Fpipe.ipynb) | [🔗](https://youtu.be/K20_eZZGqsc)
| Introducing FugueSQL — SQL for Pandas, Spark, and Dask DataFrames | [🔗](https://towardsdatascience.com/introducing-fuguesql-sql-for-pandas-spark-and-dask-dataframes-63d461a16b27) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/fugueSQL.ipynb)
| Fugue and DuckDB: Fast SQL Code in Python | [🔗](https://towardsdatascience.com/fugue-and-duckdb-fast-sql-code-in-python-e2e2dfc0f8eb) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/productive_tools/Fugue_and_Duckdb/Fugue_and_Duckdb.ipynb)
# Tools for Deployment
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Effortlessly Publish your Python Package to PyPI Using Poetry | [🔗](https://towardsdatascience.com/how-to-effortlessly-publish-your-python-package-to-pypi-using-poetry-44b305362f9f) | [🔗](https://github.com/khuyentran1401/pretty-text)
| Typer: Build Powerful CLIs in One Line of Code using Python | [🔗](https://towardsdatascience.com/typer-build-powerful-clis-in-one-line-of-code-using-python-321d9aef3be8) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/terminal/typer_examples)
# Speed-up Tools
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Cython-A Speed-Up Tool for your Python Function | [🔗](https://towardsdatascience.com/cython-a-speed-up-tool-for-your-python-function-9bab64364bfd) | [🔗](https://github.com/khuyentran1401/Cython) |
| Train your Machine Learning Model 150x Faster with cuML | [🔗](https://towardsdatascience.com/train-your-machine-learning-model-150x-faster-with-cuml-69d0768a047a) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/machine-learning/cuml)
# Math Tools
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| SymPy: Symbolic Computation in Python | [🔗](https://towardsdatascience.com/sympy-symbolic-computation-in-python-f05f1413adb8) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/data_science_tools/sympy_example.ipynb)
# Machine Learning
| Title | Article | Repository | Video
| ------------- |:-------------:| :-----:| :-----:|
| How to Monitor And Log your Machine Learning Experiment Remotely with HyperDash | [🔗](https://towardsdatascience.com/how-to-monitor-and-log-your-machine-learning-experiment-remotely-with-hyperdash-aa7106b15509) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/Hyperdash.ipynb) |
| How to Efficiently Fine-Tune your Machine Learning Models | [🔗](https://towardsdatascience.com/how-to-fine-tune-your-machine-learning-models-with-ease-8ca62d1217b1) | [🔗](https://github.com/khuyentran1401/Machine-learning-pipeline) |
| How to Learn Non-linear Dataset with Support Vector Machines | [🔗](https://towardsdatascience.com/how-to-learn-non-linear-separable-dataset-with-support-vector-machines-a7da21c6d987) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/machine-learning/SVM_Separate_XOR.ipynb) |
| Introduction to IBM Federated Learning: A Collaborative Approach to Train ML Models on Private Data | [🔗](https://towardsdatascience.com/introduction-to-ibm-federated-learning-a-collaborative-approach-to-train-ml-models-on-private-data-2b4221c3839) | [🔗](https://github.com/IBM/federated-learning-lib)
| 3 Steps to Improve your Efficiency when Hypertuning ML Models | [🔗](https://towardsdatascience.com/3-steps-to-improve-your-efficiency-when-hypertuning-ml-models-5a579d57065e)
| human-learn: Create a Human Learning Model by Drawing | [🔗](https://towardsdatascience.com/human-learn-create-rules-by-drawing-on-the-dataset-bcbca229f00) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/machine-learning/human_learn_examples/human-learn%20examples.ipynb)
| Patsy: Build Powerful Features with Arbitrary Python Code | [🔗](https://towardsdatascience.com/patsy-build-powerful-features-with-arbitrary-python-code-bb4bb98db67a#3be4-4bcff97738cd) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/statistics/patsy_example.ipynb)
| SHAP: Explain Any Machine Learning Model in Python | [🔗](https://towardsdatascience.com/shap-explain-any-machine-learning-model-in-python-24207127cad7) | [🔗](https://deepnote.com/project/Data-science-hxlyJpi-QrKFJziQgoMSmQ/%2FData-science%2Fdata_science_tools%2Fshapey_values%2Fshapey_values.ipynb)
| Predict Movie Ratings with User-Based Collaborative Filtering | [🔗](https://towardsdatascience.com/predict-movie-ratings-with-user-based-collaborative-filtering-392304b988af) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/machine-learning/collaborative_filtering/collaborative_filtering.ipynb)
| River: Online Machine Learning in Python | [🔗](https://towardsdatascience.com/river-online-machine-learning-in-python-d0f048120e46) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/machine-learning/river_streaming/streaming.ipynb) | [🔗](https://youtu.be/2PRqU_uC1hk)
| Human-Learn: Rule-Based Learning as an Alternative to Machine Learning | [🔗](https://towardsdatascience.com/human-learn-rule-based-learning-as-an-alternative-to-machine-learning-baf1899ecb3a) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/machine-learning/human_learn_examples/rule_based_model.ipynb) | [🔗](https://youtu.be/JF-bC6JYJsw)
# Natural Language Processing
| Title | Article | Repository | Video
| ------------- |:-------------:| :-----:| :-----:|
| Sentiment Analysis of LinkedIn Messages| [🔗](https://towardsdatascience.com/sentiment-analysis-of-linkedin-messages-3bb152307f84) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/linkedin_analysis) |
| Find Common Words in Article with Python Module Newspaper and NLTK| [🔗](https://towardsdatascience.com/find-common-words-in-article-with-python-module-newspaper-and-nltk-8c7d6c75733) | [🔗](https://github.com/khuyentran1401/Extract-text-from-article) |
| How to Tokenize Tweets with Python | [🔗](https://towardsdatascience.com/an-introduction-to-tweettokenizer-for-processing-tweets-9879389f8fe7) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/tweets_tokenize.ipynb) |
| How to Solve Analogies with Word2Vec | [🔗](https://towardsdatascience.com/how-to-solve-analogies-with-word2vec-6ebaf2354009) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master//nlp/word2vec.ipynb) |
| What is PyTorch | [🔗](https://towardsdatascience.com/what-is-pytorch-a84e4559f0e3) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/PyTorch.ipynb) |
| Convolutional Neural Network in Natural Language Processing | [🔗](https://towardsdatascience.com/convolutional-neural-network-in-natural-language-processing-96d67f91275c) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/nlp/convolutional_neural_network.ipynb) |
| Supercharge your Python String with TextBlob | [🔗](https://towardsdatascience.com/supercharge-your-python-string-with-textblob-2d9c08a8da05) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/nlp/textblob.ipynb) | [🔗](https://youtu.be/V--kSO1vV50)
| pyLDAvis: Topic Modelling Exploration Tool That Every NLP Data Scientist Should Know | [🔗](https://neptune.ai/blog/pyldavis-topic-modelling-exploration-tool-that-every-nlp-data-scientist-should-know) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/pyLDAvis)
| Streamlit and spaCy: Create an App to Predict Sentiment and Word Similarities with Minimal Domain Knowledge | [🔗](https://towardsdatascience.com/streamlit-and-spacy-create-an-app-to-predict-sentiment-and-word-similarities-with-minimal-domain-14085085a5d4) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/spacy_streamlit_app)
| Build a Robust Conversational Assistant with Rasa | [🔗](https://towardsdatascience.com/build-a-conversational-assistant-with-rasa-b410a809572d) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/conversational_rasa)
| I Analyzed 2k Data Scientist and Data Engineer Jobs and This is What I Found | [🔗](https://pub.towardsai.net/i-analyzed-2k-data-scientist-and-data-engineer-jobs-and-this-is-what-i-found-1ed37f98a704) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/diffbot_examples)
| Checklist — Behavioral Testing of NLP Models | [🔗](https://towardsdatascience.com/checklist-behavioral-testing-of-nlp-models-491cf11f0238) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/nlp/checklist/checklist_examples.ipynb)
| PRegEx: Write Human-Readable Regular Expressions in Python | [🔗](https://towardsdatascience.com/pregex-write-human-readable-regular-expressions-in-python-9c87d1b1335) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/productive_tools/pregex.ipynb)
| Texthero: Text Preprocessing, Representation, and Visualization for a pandas DataFrame | [🔗](https://towardsdatascience.com/texthero-text-preprocessing-representation-and-visualization-for-a-pandas-dataframe-525405af16b6) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/texthero)
# Computer Vision
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Create an App to Classify Dogs Using fastai and Streamlit | [🔗](https://towardsdatascience.com/how-to-create-an-app-to-classify-dogs-using-fastai-and-streamlit-af3e75f0ee28) | [🔗](https://github.com/khuyentran1401/dog_classifier)
# Time Series
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Kats: a Generalizable Framework to Analyze Time Series Data in Python | [🔗](https://towardsdatascience.com/kats-a-generalizable-framework-to-analyze-time-series-data-in-python-3c8d21efe057) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/time_series/kats_examples/kats.ipynb)
| How to Detect Seasonality, Outliers, and Changepoints in Your Time Series | [🔗](https://towardsdatascience.com/how-to-detect-seasonality-outliers-and-changepoints-in-your-time-series-5d0901498cff) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/time_series/google_analytics/google-analytics-analysis.ipynb)
| 4 Tools to Automatically Extract Data from Datetime in Python | [🔗](https://towardsdatascience.com/4-tools-to-automatically-extract-data-from-datetime-in-python-9ecf44943f89) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/time_series/extract_date_features.ipynb)
# Feature Engineering
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| 3 Ways to Extract Features from Dates with Python | [🔗](https://towardsdatascience.com/3-ways-to-extract-features-from-dates-927bd89cd5b9) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/time_series/extract_features/extract_features_from_dates.ipynb)
| Similarity Encoding for Dirty Categories Using dirty_cat | [🔗](https://towardsdatascience.com/similarity-encoding-for-dirty-categories-using-dirty-cat-d9f0b581a552) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/feature_engineering/dirty_cat_example/employee_salaries.ipynb)
| Snorkel — A Human-In-The-Loop Platform to Build Training Data | [🔗](https://towardsdatascience.com/snorkel-programmatically-build-training-data-in-python-712fc39649fe) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/feature_engineering/snorkel_example)
# Visualization
| Title | Article | Repository | Video
| ------------- |:-------------:| :-----:| :-----:|
| How to Embed Interactive Charts on your Articles and Personal Website | [🔗](https://towardsdatascience.com/how-to-embed-interactive-charts-on-your-medium-articles-and-website-6987f7b28472) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/embed_charts.ipynb) |
| What I Learned from Scraping 15k Data Science Articles on Medium | [🔗](https://medium.com/@khuyentran1476/what-i-learned-from-scraping-15k-data-science-articles-on-medium-98a5f252d0aa) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/medium_articles) |
| How to Create Interactive Plots with Altair | [🔗](https://towardsdatascience.com/how-to-create-interactive-and-elegant-plot-with-altair-8dd87a890f2a) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/altair/altair.ipynb) |
| How to Create a Drop-Down Menu and a Slide Bar for your Favorite Visualization Tool | [🔗](https://towardsdatascience.com/how-to-create-a-drop-down-menu-and-a-slide-bar-for-your-favorite-visualization-tool-3a50b7c9ea01) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/dropdown/dropdown.ipynb) |
| I Scraped more than 1k Top Machine Learning Github Profiles and this is what I Found | [🔗](https://towardsdatascience.com/i-scraped-more-than-1k-top-machine-learning-github-profiles-and-this-is-what-i-found-1ab4fb0c0474) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/github)
| Top 6 Python Libraries for Visualization: Which one to Use? | [🔗](https://towardsdatascience.com/top-6-python-libraries-for-visualization-which-one-to-use-fe43381cd658) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/top_visualization.ipynb)
| Introduction to Yellowbrick: A Python Library to Visualize the Prediction of your Machine Learning Model | [🔗](https://towardsdatascience.com/introduction-to-yellowbrick-a-python-library-to-explain-the-prediction-of-your-machine-learning-d63ecee10ecc) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/Yellowbrick.ipynb)
| Visualize Gender-Specific Tweets with Scattertext | [🔗](https://medium.com/towards-artificial-intelligence/visualize-gender-specific-tweets-with-scattertext-5167e4600025) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/scattertext)
| Visualize Your Team’s Projects Using Python Gantt Chart | [🔗](https://towardsdatascience.com/visualize-your-teams-projects-using-python-gantt-chart-5a1c1c98ea35) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/gantt_chart/gantt_chart.ipynb)
| How to Create Bindings and Conditions Between Multiple Plots Using Altair | [🔗](https://towardsdatascience.com/how-to-create-bindings-and-conditions-between-multiple-plots-using-altair-4e4fe907de37) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/altair/altair_advanced.ipynb)
| How to Sketch your Data Science Ideas With Excalidraw | [🔗](https://towardsdatascience.com/how-to-sketch-your-data-science-ideas-with-excalidraw-a993d049f55c) |
| Pyvis: Visualize Interactive Network Graphs in Python | [🔗](https://towardsdatascience.com/pyvis-visualize-interactive-network-graphs-in-python-77e059791f01) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/pyvis_examples/pyvis.ipynb) | [🔗](https://youtu.be/6eQOBuvUPeg)
| Build and Analyze Knowledge Graphs with Diffbot | [🔗](https://towardsdatascience.com/build-and-analyze-knowledge-graphs-with-diffbot-2af83065ade0)
| Observe The Friend Paradox in Facebook Data Using Python | [🔗](https://towardsdatascience.com/observe-the-friend-paradox-in-facebook-data-using-python-314c23fd49e4#44e7-514613b6bd18) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/friend_paradox/facebook_network.ipynb)
| What skills and backgrounds do data scientists have in common? | [🔗](https://www.datacamp.com/community/blog/what-skills-and-backgrounds-do-data-scientists-have-in-common) | [🔗](https://deepnote.com/project/Data-science-hxlyJpi-QrKFJziQgoMSmQ/%2FData-science%2Fvisualization%2Fanalyze_data_science_market%2Fanalyze_data_science_market.ipynb)
| Visualize Similarities Between Companies With Graph Database | [🔗](https://khuyentran1476.medium.com/visualize-similarities-between-companies-with-graph-database-212af872fbf6) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/analyze_artificial_intelligence_industry.ipynb)
| Visualize GitHub Social Network with PyGraphistry | [🔗](https://towardsdatascience.com/visualize-github-social-network-with-pygraphistry-dfc23a38ec8d) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/visualize_github_network/github_explore.ipynb)
| Find the Top Bootcamps for Data Professionals From Over 5k Profiles | [🔗](https://khuyentran1476.medium.com/find-the-top-bootcamps-for-data-professionals-from-over-5k-profiles-92c38b10ddb4) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/ds_bootcamps)
| floWeaver — Turn Flow Data Into a Sankey Diagram In Python | [🔗](https://towardsdatascience.com/floweaver-turn-flow-data-into-a-sankey-diagram-in-python-d166e87dbba#2962-71a0f6581d6d) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/floweaver_example/travel.ipynb)
| atoti — Build a BI Platform in Python | [🔗](https://pub.towardsai.net/atoti-build-a-bi-platform-in-python-beea47b92c7b) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/atoti_example/atoti.ipynb)
| Analyze and Visualize URLs with Network Graph | [🔗](https://towardsdatascience.com/analyze-and-visualize-urls-with-network-graph-ee3ad5338b69) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/analyze_URL/analyze_URL.ipynb)
| statsannotations: Add Statistical Significance Annotations on Seaborn Plots | [🔗](https://towardsdatascience.com/statsannotations-add-statistical-significance-annotations-on-seaborn-plots-6b753346a42a) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/visualization/statsannotation_example.ipynb) | [🔗](https://youtu.be/z26I6jsdIno)
# Mathematical Programming
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to choose stocks to invest in with Python | [🔗](https://towardsdatascience.com/choose-stocks-to-invest-with-python-584892e3ad22) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/mathematical_programming/invest_stock/stock_invest.ipynb) |
| Maximize your Productivity with Python | [🔗](https://towardsdatascience.com/maximize-your-productivity-with-python-6110004b45f7) | [🔗](https://github.com/khuyentran1401/Task-scheduler-problem/tree/master)
| How to Find a Good Match with Python | [🔗](https://towardsdatascience.com/how-to-match-two-people-with-python-7583b51ff3f9) | [🔗](https://github.com/khuyentran1401/linear-programming-with-PuLP)
| How to Solve a Staff Scheduling Problem with Python | [🔗](https://towardsdatascience.com/how-to-solve-a-staff-scheduling-problem-with-python-63ae50435ba4) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/mathematical_programming/schedule_workers)
| How to Find Best Locations for your Restaurants with Python | [🔗](https://towardsdatascience.com/how-to-find-best-locations-for-your-restaurants-with-python-b2fadc91c4dd) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/mathematical_programming/locations_of_stores)
| How to Schedule Flights in Python | [🔗](https://towardsdatascience.com/how-to-schedule-flights-in-python-3357b200db9e) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/mathematical_programming/schedule_flight_crew/flight_crew_schedule.ipynb)
| How to Solve a Production Planning and Inventory Problem in Python | [🔗](https://towardsdatascience.com/how-to-solve-a-production-planning-and-inventory-problem-in-python-45c546f4bcf0) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/mathematical_programming/production_and_inventory.ipynb)
# Scraping
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Web Scrape Movie Database with Beautiful Soup | [🔗](https://medium.com/analytics-vidhya/detailed-tutorials-for-beginners-web-scrap-movie-database-from-multiple-pages-with-beautiful-soup-5836828d23) | [🔗](https://github.com/khuyentran1401/Web-scrape-Ghibli-Movie-Database/tree/master) |
| top-github-scraper: Scrape Top Github Users and Repositories Based On a Keyword in One Line of Code | [🔗](https://khuyentran1476.medium.com/top-github-scraper-scrape-top-github-users-and-repositories-based-on-a-keyword-in-one-line-of-code-d48b29954aac) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/scraping/scrape_top_github.ipynb)
# Python
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Numpy Tricks for your Data Science Projects| [🔗](https://medium.com/@khuyentran1476/comprehensive-numpy-tutorials-for-beginners-8b88696bd3a2) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/Numpy_tricks.ipynb) |
| Timing for Efficient Python Code | [🔗](https://towardsdatascience.com/timing-the-performance-to-choose-the-right-python-object-for-your-data-science-project-670db6f11b8e) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master//python/Time.ipynb) |
| How to Use Lambda for Efficient Python Code | [🔗](https://towardsdatascience.com/how-to-use-lambda-for-efficient-python-code-ff950dc8d259) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/lambda.ipynb) |
| Python Tricks for Keeping Track of Your Data | [🔗](https://towardsdatascience.com/python-tricks-for-keeping-track-of-your-data-aef3dc817a4e) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/keep_track.ipynb) |
| Boost Your Efficiency With Specialized Dictionary Implementations in Python | [🔗](https://medium.com/better-programming/boost-your-efficiency-with-specialized-dictionary-implementations-7799ec97d14f) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/python/dictionary.ipynb) |
| Dictionary as an Alternative to If-Else | [🔗](https://towardsdatascience.com/dictionary-as-an-alternative-to-if-else-76fe57a1e4af) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/dictionary_ifelse.ipynb) |
| How to Use Zip to Manipulate a List of Tuples | [🔗](https://levelup.gitconnected.com/how-to-use-zip-to-manipulate-a-list-of-tuples-6ba6e00c02cd) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/zip.ipynb) |
| Get the Most out of Your Array With These Four Numpy Methods | [🔗](https://medium.com/swlh/get-the-most-out-of-your-array-with-these-four-numpy-methods-2fc4a6b04736) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/four_numpy_methods.ipynb)
| 3 Python Tricks to Read, Create, and Run Multiple Files Automatically | [🔗](https://towardsdatascience.com/3-python-tricks-to-read-create-and-run-multiple-files-automatically-5221ebaad2ba) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/python_tricks)
| How to Exclude the Outliers in Pandas DataFrame | [🔗](https://towardsdatascience.com/how-to-exclude-the-outliers-in-pandas-dataframe-c749fca4e091) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/python/4_pandas_lesser_know_tricks.ipynb)
| Python Clean Code: 6 Best Practices to Make Your Python Functions More Readable | [🔗](https://towardsdatascience.com/python-clean-code-6-best-practices-to-make-your-python-functions-more-readable-7ea4c6171d60) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/good_functions)
| 3 Techniques to Effortlessly Import and Execute Python Modules | [🔗](https://towardsdatascience.com/3-advance-techniques-to-effortlessly-import-and-execute-your-python-modules-ccdcba017b0c) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/module_example)
| Simplify Your Functions with Functools’ Partial and Singledispatch | [🔗](https://towardsdatascience.com/simplify-your-functions-with-functools-partial-and-singledispatch-b7071f7543bb) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/python/functools%20example.ipynb)
# Terminal
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Create and View Interactive Cheatsheets on the Command-line | [🔗](https://towardsdatascience.com/how-to-create-and-view-interactive-cheatsheets-on-the-command-line-6578641039ff) |
| Understand CSV Files from your Terminal with XSV | [🔗](https://towardsdatascience.com/understand-your-csv-files-from-your-terminal-with-xsv-65255ae67293)
| Prettify your Terminal Text With Termcolor and Pyfiglet| [🔗](https://towardsdatascience.com/prettify-your-terminal-text-with-termcolor-and-pyfiglet-880de83fda6b) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/python/prettify_terminal_output) |
| Stop Using Print to Debug in Python. Use Icecream Instead | [🔗](https://towardsdatascience.com/stop-using-print-to-debug-in-python-use-icecream-instead-79e17b963fcc)
| Rich: Generate Rich and Beautiful Text in the Terminal with Python | [🔗](https://towardsdatascience.com/rich-generate-rich-and-beautiful-text-in-the-terminal-with-python-541f39abf32e) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/terminal/rich)
| Create a Beautiful Dashboard in your Terminal with Wtfutil | [🔗](https://towardsdatascience.com/create-a-beautiful-dashboard-in-your-terminal-with-wtfutil-573424fe3684) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/terminal/wtf/config.yml)
| 3 Tools to Monitor and Optimize your Linux System | [🔗](https://towardsdatascience.com/3-tools-to-monitor-and-optimize-your-linux-system-c8a46c18d692)
| Ptpython: A Better Python REPL | [🔗](https://towardsdatascience.com/ptpython-a-better-python-repl-6e21df1eb648) | [🔗](https://gist.github.com/khuyentran1401/b5325ff1f3bfe1e36bf9131a0b8cd388)
| fd: a Simple but Powerful Tool to Find and Execute Files on the Command Line | [🔗](https://towardsdatascience.com/fd-a-simple-but-powerful-tool-to-find-and-execute-files-on-the-command-line-602f9af235ad)
| Speed Up your Command-Line Navigation with These 3 Tools | [🔗](https://towardsdatascience.com/speed-up-your-command-line-navigation-with-these-3-tools-f90105c9aa2b)
| Python and Data Science Snippets on the Command Line | [🔗](https://towardsdatascience.com/python-and-data-science-snippets-on-the-command-line-2673d5d9e55d) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/applications/python_snippet_tutorial)
# Statistics
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Can Datasets of a Dinosaur and a Circle have Identical Statistics? | [🔗](https://towardsdatascience.com/how-to-turn-a-dinosaur-dataset-into-a-circle-dataset-with-the-same-statistics-64136c2e2ca0) | [🔗](https://github.com/khuyentran1401/same-stats-different-graphs)
|Introduction to One-Way ANOVA: A Test to Compare the Means between More than Two Groups | [🔗]( https://towardsdatascience.com/introduction-to-one-way-anova-a-test-to-compare-the-means-between-more-than-two-groups-a656cb53b19c)| [🔗](https://github.com/khuyentran1401/Data-science/blob/master/statistics/ANOVA_examples.ipynb)
| Bayes’ Theorem, Clearly Explained with Visualization | [🔗](https://towardsdatascience.com/bayes-theorem-clearly-explained-with-visualization-5083ea5e9b14#5c49-6a7199b5fc13) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/statistics/bayesian_theorem.ipynb)
| Detect Change Points with Bayesian Inference and PyMC3 | [🔗](https://towardsdatascience.com/detect-change-points-with-bayesian-inference-and-pymc3-3b4f3ae6b9bb#9530-e5f3d0f86132) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/statistics/bayesian_example/google%20analytics.ipynb)
| Bayesian Linear Regression with Bambi | [🔗](https://towardsdatascience.com/bayesian-linear-regression-with-bambi-a5e6570f167b) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/statistics/bayes_linear_regression/linear_regression.ipynb)
| Earn More Salary as a Coder — Higher Degree or More Years of Experience? | [🔗](https://towardsdatascience.com/earn-more-salary-as-a-coder-higher-degree-or-more-years-of-experience-68c13f73a557) | [🔗](https://github.com/khuyentran1401/Data-science/blob/master/statistics/stackoverflow_survey/analyze_salary.ipynb)
# Linear Algebra
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Build a Matrix Module from Scratch | [🔗](https://towardsdatascience.com/how-to-build-a-matrix-module-from-scratch-a4f35ec28b56) | [🔗](https://github.com/khuyentran1401/Numerical-Optimization-Machine-learning/tree/master/matrix) |
| Linear Algebra for Machine Learning: Solve a System of Linear Equations | [🔗](https://towardsdatascience.com/linear-algebra-for-machine-learning-solve-a-system-of-linear-equations-3ec7e882e10f) | [🔗](https://github.com/khuyentran1401/Numerical-Optimization-Machine-learning/blob/master/Backward%20substitution%20and%20Gaussian%20Elimiation.ipynb) |
# Data Structure
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Convex Hull: An Innovative Approach to Gift-Wrap your Data | [🔗](https://towardsdatascience.com/convex-hull-an-innovative-approach-to-gift-wrap-your-data-899992881efc) | [🔗](https://github.com/khuyentran1401/Computational-Geometry/blob/master/Graham%20Scan.ipynb) |
| How to Visualize Social Network With Graph Theory | [🔗](https://towardsdatascience.com/how-to-visualize-social-network-with-graph-theory-4b2dc0c8a99f) | [🔗](https://github.com/khuyentran1401/Game-of-Thrones-And-Graph) |
| How to Search Data with KDTree | [🔗](https://towardsdatascience.com/how-to-search-data-with-kdtree-aad5c82ebd99) | [🔗](https://github.com/khuyentran1401/kdtree-implementation) |
| How to Find the Nearest Hospital with a Voronoi Diagram | [🔗](https://towardsdatascience.com/how-to-find-the-nearest-hospital-with-voronoi-diagram-63bd6d0b7b75) | [🔗](https://github.com/khuyentran1401/Voronoi-diagram/)
# Web Applications
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Create an Interactive Startup Growth Calculator with Python | [🔗](https://towardsdatascience.com/how-to-create-an-interactive-startup-growth-calculator-with-python-d224816f29d5) | [🔗](https://github.com/datapane/gallery/tree/master/startup-calculator)
| Streamlit and spaCy: Create an App to Predict Sentiment and Word Similarities with Minimal Domain Knowledge | [🔗](https://towardsdatascience.com/streamlit-and-spacy-create-an-app-to-predict-sentiment-and-word-similarities-with-minimal-domain-14085085a5d4) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/nlp/spacy_streamlit_app)
| PyWebIO: Write Interactive Web App in Script Way Using Python | [🔗](https://towardsdatascience.com/pywebio-write-interactive-web-app-in-script-way-using-python-14f50155af4e) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/applications/pywebio_examples)
| PyWebIO 1.3.0: Add Tabs, Pin Input, and Update an Input Based on Another Input | [🔗](https://towardsdatascience.com/pywebio-1-3-0-add-tabs-pin-input-and-update-an-input-based-on-another-input-e81a139fefcb) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/applications/pywebio_1_3_0)
| Create an App to Deal with Boredom Using PyWebIO | [🔗](https://towardsdatascience.com/create-an-app-to-deal-with-boredom-using-pywebio-d17f3acd1613) | [🔗](https://build.pyweb.io/get/khuyentran1401/bored_app)
| Build a Robust Workflow to Visualize Trending GitHub Repositories in Python | [🔗](https://towardsdatascience.com/build-a-robust-workflow-to-visualize-trending-github-repositories-in-python-98f2fc3e9a86) | [🔗](https://github.com/khuyentran1401/analyze_github_feed)
# Share Insights
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Introduction to Datapane: A Python Library to Build Interactive Reports | [🔗](https://towardsdatascience.com/introduction-to-datapane-a-python-library-to-build-interactive-reports-4593fd3cb9c8) |
| Datapane’s New Features: Create a Beautiful Dashboard in Python in a Few Lines of Code | [🔗](https://towardsdatascience.com/datapanes-new-features-create-a-beautiful-dashboard-in-python-in-a-few-lines-of-code-a3c44523292b) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/Datapane_new_features)
| Introduction to Datasette: Explore and Publish Your Data in One Line of Code | [🔗](https://towardsdatascience.com/introduction-to-datasette-explore-and-publish-your-data-in-one-line-of-code-cbdc40cb4583)
| How to Share your Python Objects Across Different Environments in One Line of Code | [🔗](https://towardsdatascience.com/how-to-share-your-python-objects-across-different-environments-in-one-line-of-code-f30a25e5f50e) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/data_science_tools/blob_datapane.ipynb) |
| How to Share your Jupyter Notebook in 3 Lines of Code with Ngrok | [🔗](https://towardsdatascience.com/how-to-share-your-jupyter-notebook-in-3-lines-of-code-with-ngrok-bfe1495a9c0c) |
| Introduction to Deepnote: Real-time Collaboration on Jupyter Notebook | [🔗](https://pub.towardsai.net/introduction-to-deepnote-real-time-collaboration-on-jupyter-notebook-18509c95d62f)
# Cool Tools
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Simulate Real-life Events in Python Using SimPy | [🔗](https://towardsdatascience.com/simulate-real-life-events-in-python-using-simpy-e6d9152a102f) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/applications/simpy_examples)
| How to Create Mathematical Animations like 3Blue1Brown Using Python |[🔗](https://towardsdatascience.com/how-to-create-mathematical-animations-like-3blue1brown-using-python-f571fb9da3d1) | [🔗](https://github.com/khuyentran1401/Data-science/tree/master/visualization/manim_exp)
# Learning Tips
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Learn Data Science when Life does not Give You a Break | [🔗](https://towardsdatascience.com/how-to-learn-data-science-when-life-does-not-give-you-a-break-a26a6ea328fd) |
| How to Accelerate your Data Science Career by Putting yourself in the Right Environment | [🔗](https://towardsdatascience.com/how-to-accelerate-your-data-science-career-by-putting-yourself-in-the-right-environment-8316f42a476c) |
| To become a Better Data Scientist, you need to Think like a Programmer | [🔗](https://towardsdatascience.com/to-become-a-better-data-scientist-you-need-to-think-like-a-programmer-18d0a00994dc) |
| How not to be Overwhelmed with Data Science | [🔗](https://towardsdatascience.com/how-not-to-be-overwhelmed-with-data-science-5a95ff1618f8)
# Productive Tips
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Organize your Data Science Articles with Github | [🔗](https://towardsdatascience.com/how-to-organize-your-data-science-articles-with-github-b5b9427dad37) | [🔗](https://github.com/khuyentran1401/machine-learning-articles) |
| 5 Reasons why you should Switch from Jupyter Notebook to Scripts | [🔗](https://towardsdatascience.com/5-reasons-why-you-should-switch-from-jupyter-notebook-to-scripts-cb3535ba9c95) |
| 7 Reasons Why you Should Start Documenting your Code | [🔗](https://towardsdatascience.com/7-reasons-why-you-should-start-documenting-your-code-48c2096de6a7)
# VSCode
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Leverage Visual Studio Code for your Data Science Projects | [🔗](https://towardsdatascience.com/how-to-leverage-visual-studio-code-for-your-data-science-projects-7078b70a72f0) |
| Top 4 Code Viewers for Data Scientist in VSCode | [🔗](https://towardsdatascience.com/top-4-code-viewers-for-data-scientist-in-vscode-e275e492350d) |
| Incorporate the Best Practices for Python with These Top 4 VSCode Extensions | [🔗](https://towardsdatascience.com/incorporate-the-best-practices-for-python-with-these-top-4-vscode-extensions-3101177c23a9)
| Boost Your Efficiency with Customized Code Snippets on VSCode | [🔗](https://towardsdatascience.com/how-to-boost-your-efficiency-with-customized-code-snippets-on-vscode-8127781788d7) |
| Top 9 Keyboard Shortcuts in VSCode for Data Scientists | [🔗](https://towardsdatascience.com/top-9-keyboard-shortcuts-in-vscode-for-data-scientists-468691b65ebe) |
# Book Review
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| Python Machine Learning: A Comprehensive Handbook for Machine Learning | [🔗](https://medium.com/analytics-vidhya/python-machine-learning-a-comprehensive-handbook-for-machine-learning-63f024c898d0) |
# Data Science Portfolio
| Title | Article | Repository |
| ------------- |:-------------:| :-----:|
| How to Create an Elegant Website for your Data Science Portfolio in 10 minutes | [🔗](https://towardsdatascience.com/how-to-create-an-elegant-website-for-your-data-science-portfolio-in-10-minutes-577f77d1f693)|
| Build an Impressive Github Profile in 3 Steps | [🔗](https://towardsdatascience.com/build-an-impressive-github-profile-in-3-steps-f1938957d480)
# Supporters
Special thanks to these supporters for supporting this project!
[<img src="img/danny.png" width="100" height="100">](https://github.com/DataWithDanny) [<img src="img/sagar.jpeg" width="100" height="100">](https://www.linkedin.com/in/sagar-ravindra-sonawane/)
|
3,418 | A List of Data Science/Machine Learning Resources (Mostly Free) | # Data Science Resources (Mostly Free)
The first half is more or less my learning path in the past two years while the second half is my plan for this year. I tried to make a balance between comprehension and doability. For more extensive lists, you can check [Github search](https://github.com/search?utf8=%E2%9C%93&q=awesome+machine+learning&type=) or [CS video lectures](https://github.com/Developer-Y/cs-video-courses)
Hope the list is helpful, especially to whom are not in CS major but interested in data science!
***
## Table of Contents
* [One Month Plan](#one-month-plan)
* [Machine Learning](#machine-learning)
* [Natural Language Processing](#natural-language-processing)
* [Deep Learning](#deep-learning)
* [Systems](#systems)
* [Analytics](#analytics)
* [Reinforcement Learning](#reinforcement-learning)
* [Other Courses](#others)
* [Interviews](#interviews)
* [Bayesian](#bayesian)
* [Time series](#time-series)
* [Quant](#quant)
* [More Lists](#more)
***
## One Month Plan:
You may find the list overwhelming. Here is my suggestion if you want to have some basic understanding in one month:
* Learn Python the hard way: [Free book](https://learnpythonthehardway.org/book/)
* Stanford Statistical Learning ([Course page](https://lagunita.stanford.edu/courses/HumanitiesSciences/StatLearning/Winter2016/about)) or Coursera Stanford by Andrew Ng ([Coursera](https://www.coursera.org/learn/machine-learning), [Youtube](https://www.youtube.com/watch?v=PPLop4L2eGk&list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN))
* Ng’s deep learning courses: [Coursera](https://www.coursera.org/specializations/deep-learning)
* Keras in 30 sec: [Link](https://keras.io/#getting-started-30-seconds-to-keras)
* Database by Stanford: [Course](http://online.stanford.edu/course/databases-self-paced)
## Machine Learning:
### - Videos:
* Stanford Statistical Learning: [Course page](https://lagunita.stanford.edu/courses/HumanitiesSciences/StatLearning/Winter2016/about)
* Coursera Stanford by Andrew Ng: [Coursera](https://www.coursera.org/learn/machine-learning), [Youtube](https://www.youtube.com/watch?v=PPLop4L2eGk&list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN)
* Stanford 229: [Youtube](https://www.youtube.com/watch?v=UzxYlbK2c7E&list=PLA89DCFA6ADACE599), [Course page](
http://cs229.stanford.edu/syllabus.html)
* Machine Learning Foundations (機器學習基石): [Coursera](https://www.coursera.org/learn/ntumlone-mathematicalfoundations)
, [Youtube](https://www.youtube.com/playlist?list=PLXVfgk9fNX2I7tB6oIINGBmW50rrmFTqf&disable_polymer=true)
* Machine Learning Techniques (機器學習技法): [Youtube](https://www.youtube.com/playlist?list=PLXVfgk9fNX2IQOYPmqjqWsNUFl2kpk1U2&disable_polymer=true)
* CMU 701 by Tom Mitchell: [Course page](http://www.cs.cmu.edu/~tom/10701_sp11/lectures.shtml)
### - Textbooks:
* Introduction to Statistical Learning: [pdf](http://www-bcf.usc.edu/~gareth/ISL/ISLR%20First%20Printing.pdf)
* Computer Age Statistical Inference: Algorithms, Evidence, and Data Science: [pdf](https://web.stanford.edu/~hastie/CASI_files/PDF/casi.pdf)
* The Elements of Statistical Learning: [pdf](https://web.stanford.edu/~hastie/Papers/ESLII.pdf)
* Machine Learning Yearning: [Website](http://www.mlyearning.org/)
### - Comments:
Statistical Learning is the introduction course. It is free to earn a certificate. It follows Introduction to Statistical Learning book closely. Coursera Stanford by Andrew Ng is another introduction course course and quite popular. Taking either of them is enough for most of data science positions. People want to go deeper can take 229 or 701 and read ESL book.
***
## Natural Language Processing:
### - Videos:
* Stanford - Basic NLP course on Coursera: [Videos](https://www.youtube.com/playlist?list=PLoROMvodv4rOFZnDyrlW3-nI7tMLtmiJZ&disable_polymer=true), [Slides](https://web.stanford.edu/~jurafsky/NLPCourseraSlides.html)
* Stanford - CS224n Natural Language Processing with Deep Learning: [Course web](http://web.stanford.edu/class/cs224n/), [Videos](https://www.youtube.com/playlist?list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6) (2019 winter version: [videos](https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z))
* CMU - Neural Nets for NLP 2017: [Course web](http://www.phontron.com/class/nn4nlp2017/schedule.html), [Videos](https://www.youtube.com/playlist?list=PL8PYTP1V4I8ABXzdqtOpB_eqBlVAz_xPT)
* University of Oxford and DeepMind - Deep Learning for Natural Language Processing: 2016-2017: [Course web](http://www.cs.ox.ac.uk/teaching/courses/2016-2017/dl/), [Videos and slides](https://github.com/oxford-cs-deepnlp-2017/lectures)
* Sequence Models by Andrew Ng on Coursera: [Coursera](https://www.coursera.org/learn/nlp-sequence-models)
### - Books:
* Speech and Language Processing (3rd ed. draft): [Book](https://web.stanford.edu/~jurafsky/slp3/)
* An Introduction to Information Retrieval: [pdf](https://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf)
* Deep Learning (Some chapters or sections): [Book](http://www.deeplearningbook.org)
* A Primer on Neural Network Models for Natural Language Processing: [Paper](http://u.cs.biu.ac.il/~yogo/nnlp.pdf). Goldberg also published a new book this year
* NLP by Jacob Eisenstein: [pdf](https://github.com/jacobeisenstein/gt-nlp-class/tree/master/notes). Free book draft
* Deep Learning in Natural Language Processing by Deng, Li: [Amazon](https://www.springer.com/us/book/9789811052088)
### - Packages:
* NLTK: http://www.nltk.org/
* Standord packages: https://nlp.stanford.edu/software/
### - Comments:
The basic NLP course by Stanford is the fundamental one. SLP 3ed follows this course. After this, feel free to take one of the three NLP+DL courses. They basically cover same topics. The Stanford one have HWs available online. CMU one follows Goldberg's book. Deepmind one is much shorter.
### - More:
Some other people's collections: [NLP](https://github.com/keon/awesome-nlp), [DL-NLP](https://github.com/brianspiering/awesome-dl4nlp), [Speech and NLP](https://github.com/edobashira/speech-language-processing), [Speech](https://github.com/zzw922cn/awesome-speech-recognition-speech-synthesis-papers), [RNN](https://github.com/kjw0612/awesome-rnn)
***
## Deep Learning
### - Videos:
* Ng’s deep learning courses: [Coursera](https://www.coursera.org/specializations/deep-learning). This specialization is so popular. Prof. Ng covers all a lot of details and he is really a good teacher.
* Tensorflow. Stanford CS20SI: [Youtube](https://www.youtube.com/playlist?list=PLQ0sVbIj3URf94DQtGPJV629ctn2c1zN-)
* Stanford 231n: Convolutional Neural Networks for Visual Recognition (Spring 2017): [Youtube](https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv), [Couse page](http://cs231n.stanford.edu/)
* Stanford 224n: Natural Language Processing with Deep Learning (Winter 2017): [Youtube](https://www.youtube.com/playlist?list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6), [Course page](http://web.stanford.edu/class/cs224n/)
* The self-driving car is a really hot topic recently. Take a look at this short course to see how it works. MIT 6.S094: Deep Learning for Self-Driving Cars: [Youtube](https://www.youtube.com/playlist?list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf), [Couse page](http://selfdrivingcars.mit.edu/)
* Neural Networks for Machine Learning by Hinton: [Coursera](https://www.coursera.org/learn/neural-networks). This course is so hard for me but it covers almost everything about neural networks. Prof. Hinton is the hero.
* FAST.ai: [Course](http://www.fast.ai/)
### - Books:
* Deep learning book by Ian Goodfellow: http://www.deeplearningbook.org/. Very detailed reference book.
* ArXiv for research updates: https://arxiv.org/. I found it the mobile version of Feedly is useful to follow ArXiv. Also, try https://deeplearn.org/ or http://www.arxiv-sanity.com/top.
### - Other:
* LSTM: [My collection](https://www.linkedin.com/pulse/ml-4-shujian-liu/)
### - Comments:
Ng's courses are already good enough. Reading Part 2 of Goodfellow's book can also be helpful. Learning one kind of DL packages is important, such as Keras, TF or Pytorch. People may choose a focus, either CV or NLP. People want to have deeper understanding of DL can take Hinton's course and read Part 3 of Goodfellow's book. Fast.ai has very practical courses.
***
## Systems:
* Docker Mastery: [Udemy](https://www.udemy.com/docker-mastery/learn/v4/overview)
* The Ultimate Hands-On Hadoop: [Udemy](https://www.udemy.com/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/v4/overview)
* Spark and Python for Big Data with PySpark: [Udemy](https://www.udemy.com/spark-and-python-for-big-data-with-pyspark/learn/v4)
***
## Analytics:
* Lean Analytics: [Amazon](https://www.amazon.com/Lean-Analytics-Better-Startup-Faster/dp/B00AG66LTM/)
* Data Science for Business: [Amazon](https://www.amazon.com/Data-Science-Business-Data-Analytic-Thinking/dp/1449361323/)
* Data Smart: [Amazon](https://www.amazon.com/Data-Smart-Science-Transform-Information/dp/111866146X/)
* Storytelling with Data: [Amazon](https://www.amazon.com/Storytelling-Data-Visualization-Business-Professionals/dp/1119002257)
***
## Reinforcement Learning:
### - Videos:
* Udacity: [Course](https://www.udacity.com/course/reinforcement-learning--ud600)
* UCL Course on RL by David Silver: [Course page](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html)
* CS 294: Deep Reinforcement Learning by UC Berkeley, Fall 2017: [Course page](http://rll.berkeley.edu/deeprlcourse/)
### - Books:
* Reinforcement Learning: An Introduction (2nd): [pdf](http://incompleteideas.net/book/the-book-2nd.html)
***
## Others:
* Recommender System by UMN: [Coursera](https://www.coursera.org/specializations/recommender-systems)
* Mining Massive Datasets by Stanford: [Free book](http://www.mmds.org/), [Course](http://online.stanford.edu/course/mining-massive-datasets-self-paced)
* Introduction to Algorithms by MIT: [Course page with videos](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-006-introduction-to-algorithms-fall-2011/)
* Database by Stanford: [Course](http://online.stanford.edu/course/databases-self-paced)
* How to Win a Data Science Competition: [Coursera](https://www.coursera.org/learn/competitive-data-science)
* How to finish a Data Challenge: [Kaggle EDA kernels](https://www.kaggle.com/kernels?sortBy=votes&group=everyone&pageSize=20)
***
## Interviews:
### - Lists with Solutions:
* 111 Data Science Interview Questions & Detailed Answers: [Link](https://rpubs.com/JDAHAN/172473?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* 40 Interview Questions asked at Startups in Machine Learning / Data Science [Link](https://www.analyticsvidhya.com/blog/2016/09/40-interview-questions-asked-at-startups-in-machine-learning-data-science/?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* 100 Data Science Interview Questions and Answers (General) for 2017 [Link](https://www.dezyre.com/article/100-data-science-interview-questions-and-answers-general-for-2017/184?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* 21 Must-Know Data Science Interview Questions and Answers [Link](http://www.kdnuggets.com/2016/02/21-data-science-interview-questions-answers.html?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* 45 Questions to test a data scientist on basics of Deep Learning (along with solution) [Link](https://www.analyticsvidhya.com/blog/2017/01/must-know-questions-deep-learning/?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* 30 Questions to test a data scientist on Natural Language Processing [Link](https://www.analyticsvidhya.com/blog/2017/07/30-questions-test-data-scientist-natural-language-processing-solution-skilltest-nlp/?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* Questions on Stackoverflow: [Link](https://stackoverflow.com/questions/tagged/machine-learning?sort=votes&pageSize=15)
* Compare two models: [My collection](https://www.linkedin.com/pulse/ml-2-shujian-liu/)
### - Without Solutions:
* Over 100 Data Science Interview Questions [Link](http://www.learndatasci.com/data-science-interview-questions/?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* 20 questions to detect fake data scientists [Link](https://www.import.io/post/20-questions-to-detect-fake-data-scientists/?lipi=urn%3Ali%3Apage%3Ad_flagship3_pulse_read%3BgFdjeopHQ5C1%2BT367egIug%3D%3D)
* Question on Glassdoor: [link](https://www.glassdoor.com/Interview/data-scientist-interview-questions-SRCH_KO0,14.htm)
***
# Topics to Learn ->
***
## Bayesian:
### - Courses:
* Bayesian Statistics: From Concept to Data Analysis: [Coursera](https://www.coursera.org/learn/bayesian-statistics)
* Bayesian Methods for Machine Learning: [Coursera](https://www.coursera.org/learn/bayesian-methods-in-machine-learning)
* Statistical Rethinking: [Course Page](http://xcelab.net/rm/statistical-rethinking/) (Recorded Lectures: Winter 2015, Fall 2017)
### - Book:
* Bayesian Data Analysis, Third Edition
* Applied Predictive Modeling
***
## Time series:
### - Courses:
* Time Series Forecasting (Udacity): [Udacity](https://www.udacity.com/course/time-series-forecasting--ud980)
* Topics in Mathematics with Applications in Finance (MIT): [Course page](https://ocw.mit.edu/courses/mathematics/18-s096-topics-in-mathematics-with-applications-in-finance-fall-2013/), [Youtube](https://www.youtube.com/playlist?list=PLUl4u3cNGP63ctJIEC1UnZ0btsphnnoHR)
### - Books:
* Time Series Analysis and Its Applications: [Springer](http://www.springer.com/us/book/9783319524511)
### - With LSTM:
* https://machinelearningmastery.com/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
* https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
* More: https://machinelearningmastery.com/?s=Time+Series&submit=Search
***
## Quant:
### - Books:
* Heard on the Street: Quantitative Questions from Wall Street Job Interviews by Timothy Falcon Crack: [Amazon]( https://www.amazon.com/Heard-Street-Quantitative-Questions-Interviews/dp/0994138636/)
* A Practical Guide To Quantitative Finance Interviews by Xinfeng Zhou: [Amazon](https://www.amazon.com/Practical-Guide-Quantitative-Finance-Interviews/dp/1438236662/)
### - Courses:
* Financial Markets with Robert Shiller (Yale): [Youtube](https://www.youtube.com/playlist?list=PL8FB14A2200B87185), [Coursera](https://www.coursera.org/learn/financial-markets-global)
* Topics in Mathematics with Applications in Finance (MIT): [Youtube](https://www.youtube.com/playlist?list=PLUl4u3cNGP63ctJIEC1UnZ0btsphnnoHR), [Course page](https://ocw.mit.edu/courses/mathematics/18-s096-topics-in-mathematics-with-applications-in-finance-fall-2013/)
### - Other:
* A Collection of Dice Problems: [pdf](http://www.madandmoonly.com/doctormatt/mathematics/dice1.pdf)
***
## More:
* Computer Science courses with video lectures: https://github.com/Developer-Y/cs-video-courses
* The Open Source Data Science Masters: http://datasciencemasters.org
|
3,419 | Answers for Quizzes & Assignments that I have taken | # Coursera and edX Assignments
This repository is aimed to help Coursera and edX learners who have difficulties in their learning process.
The quiz and programming homework is belong to coursera and edx and solutions to me.
- #### [EDHEC - Investment Management with Python and Machine Learning Specialization](./EDHEC%20-%20Investment%20Management%20with%20Python%20and%20Machine%20Learning%20Specialization)
1. [EDHEC - Portfolio Construction and Analysis with Python](./EDHEC%20-%20Investment%20Management%20with%20Python%20and%20Machine%20Learning%20Specialization/EDHEC%20-%20Portfolio%20Construction%20and%20Analysis%20with%20Python)
2. [EDHEC - Advanced Portfolio Construction and Analysis with Python](./EDHEC%20-%20Investment%20Management%20with%20Python%20and%20Machine%20Learning%20Specialization/EDHEC%20-%20Advanced%20Portfolio%20Construction%20and%20Analysis%20with%20Python)
- #### [Google Data Analytics Professional Certificate](./Google%20Data%20Analytics%20Professional%20Certificate)
1. [Google - Foundations: Data, Data, Everywhere](./Google%20Data%20Analytics%20Professional%20Certificate/course1-%20Foundations%20Data%2C%20Data%2C%20Everywhere)
2. [Google - Ask Questions to Make Data-Driven Decisions](./Google%20Data%20Analytics%20Professional%20Certificate/course2-%20Ask%20Questions%20to%20Make%20Data-Driven%20Decisions)
3. [Google - Prepare Data for Exploration](./Google%20Data%20Analytics%20Professional%20Certificate/course3-%20Prepare%20Data%20for%20Exploration)
4. [Google - Process Data from Dirty to Clean](./Google%20Data%20Analytics%20Professional%20Certificate/course4-%20Process%20Data%20from%20Dirty%20to%20Clean)
5. [Google - Analyze Data to Answer Questions](./Google%20Data%20Analytics%20Professional%20Certificate/course5-%20Analyze%20Data%20to%20Answer%20Questions)
6. [Google - Share Data Through the Art of Visualization](./Google%20Data%20Analytics%20Professional%20Certificate/course6-%20Share%20Data%20Through%20the%20Art%20of%20Visualization)
7. [Google - Data Analysis with R Programming](./Google%20Data%20Analytics%20Professional%20Certificate/course7-%20Data%20Analysis%20with%20R%20Programming)
8. [Google - Google Data Analytics Capstone: Complete a Case Study](./Google%20Data%20Analytics%20Professional%20Certificate/course8-%20Google%20Data%20Analytics%20Capstone%20Complete%20a%20Case%20Study)
- #### [University of Michigan - PostgreSQL for Everybody Specialization](.//University%20of%20Michigan%20-%20PostgreSQL%20for%20Everybody%20Specialization)
- #### [The University of Melbourne & The Chinese University of Hong Kong - Basic Modeling for Discrete Optimization](./The%20University%20of%20Melbourne%20-%20Basic%20Modeling%20for%20Discrete%20Optimization)
- #### [Stanford University - Machine Learning](./Stanford%20University%20-%20Machine%20Learning)
- #### [Imperial College London - Mathematics for Machine Learning Specialization](./Imperial%20College%20London%20-%20Mathematics%20for%20Machine%20Learning%20Specialization)
1. [Imperial College London - Linear Algebra](./Imperial%20College%20London%20-%20Mathematics%20for%20Machine%20Learning%20Specialization/Imperial%20College%20London%20-%20Mathematics%20for%20Machine%20Learning%20Linear%20Algebra)
2. [Imperial College London - Multivariate Calculus](./Imperial%20College%20London%20-%20Mathematics%20for%20Machine%20Learning%20Specialization/Imperial%20College%20London%20-%20Mathematics%20for%20Machine%20Learning%20Multivariate%20Calculus)
- #### [University of Colorado Boulder - Excel/VBA for Creative Problem Solving Specialization](./CU-Boulder%20-%20Excel%20VBA%20for%20Creative%20Problem%20Solving%20Specialization)
1. [University of Colorado Boulder - Excel/VBA for Creative Problem Solving, Part 1](./CU-Boulder%20-%20Excel%20VBA%20for%20Creative%20Problem%20Solving%20Specialization/CU-Boulder%20-%20Excel%20VBA%20for%20Creative%20Problem%20Solving%2C%20Part%201)
- #### [University of Washington - Machine Learning Specialization](./University%20of%20Washington%20-%20Machine%20Learning%20Specialization)
1. [University of Washington - A Case Study Approach](./University%20of%20Washington%20-%20Machine%20Learning%20Specialization/University%20of%20Washington%20-%20Machine%20Learning%20Foundations%20A%20Case%20Study%20Approach)
2. [University of Washington - Regression](./University%20of%20Washington%20-%20Machine%20Learning%20Specialization/University%20of%20Washington%20-%20Machine%20Learning%20Regression)
- #### [Rice University - Python Data Representations](./Rice-Python-Data-Representations)
- #### [Rice University - Python Data Analysis](./Rice-Python-Data-Analysis)
- #### [Rice University - Python Data Visualization](./Rice-Python-Data-Visualization)
- #### [Johns Hopkins University - Data Science Specialization](./Johns%20Hopkins%20University%20-%20Data%20Science%20Specialization)
1. [Johns Hopkins University - R Programming](./Johns%20Hopkins%20University%20-%20Data%20Science%20Specialization/Johns%20Hopkins%20University%20-%20R%20Programming)
2. [Johns Hopkins University - Getting and Cleaning Data](./Johns%20Hopkins%20University%20-%20Data%20Science%20Specialization/Johns%20Hopkins%20University%20-%20Getting%20and%20Cleaning%20Data)
3. [Johns Hopkins University - Exploratory Data Analysis](./Johns%20Hopkins%20University%20-%20Data%20Science%20Specialization/Johns%20Hopkins%20University%20-%20Exploratory%20Data%20Analysis)
4. [Johns Hopkins University - Reproducible Research](./Johns%20Hopkins%20University%20-%20Data%20Science%20Specialization/Johns%20Hopkins%20University%20-%20Reproducible%20Research)
- #### [Saint Petersburg State University - Competitive Programmer's Core Skills](./Saint%20Petersburg%20State%20University%20-%20Competitive%20Programmer's%20Core%20Skills)
- #### [Rice University - Business Statistics and Analysis Capstone](./Rice%20University%20-%20Business%20Statistics%20and%20Analysis%20Capstone)
- #### [University of California, San Diego - Object Oriented Programming in Java](./UCSD-Object-Oriented-Programming-in-Java)
- #### [University of California, San Diego - Data Structures and Performance](./UCSD-Data-Structures-and-Performance)
- #### [University of California, San Diego - Advanced Data Structures in Java](./UCSD-Advanced-Data-Structures-in-Java)
- #### [IBM: Applied Data Science Specialization](./Applied-Data-Science-Specialization-IBM)
1. [IBM: Open Source tools for Data Science](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Open%20Source%20tools%20for%20Data%20Science)
2. [IBM: Data Science Methodology](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Data%20Science%20Methodology)
3. [IBM: Python for Data Science](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Python%20for%20Data%20Science)
4. [IBM: Databases and SQL for Data Science](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Databases%20and%20SQL%20for%20Data%20Science)
5. [IBM: Data Analysis with Python](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Data%20Analysis%20with%20Python)
6. [IBM: Data Visualization with Python](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Data%20Visualization%20with%20Python)
7. [IBM: Machine Learning with Python](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Machine%20Learning%20with%20Python)
8. [IBM: Applied Data Science Capstone Project](./Applied-Data-Science-Specialization-IBM/IBM%20-%20Applied%20Data%20Science%20Capstone%20Project)
- #### [deeplearning.ai - TensorFlow in Practice Specialization](./deeplearning.ai%20-%20TensorFlow%20in%20Practice%20Specialization)
1. [deeplearning.ai - Introduction to TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning](./deeplearning.ai%20-%20TensorFlow%20in%20Practice%20Specialization/deeplearning.ai%20-%20TensorFlow%20for%20AI%2C%20ML%2C%20and%20Deep%20Learning)
2. [deeplearning.ai - Convolutional Neural Networks in TensorFlow](./deeplearning.ai%20-%20TensorFlow%20in%20Practice%20Specialization/deeplearning.ai%20-%20Convolutional%20Neural%20Networks%20in%20TensorFlow)
3. [deeplearning.ai - Natural Language Processing in TensorFlow](./deeplearning.ai%20-%20TensorFlow%20in%20Practice%20Specialization/deeplearning.ai%20-%20Natural%20Language%20Processing%20in%20TensorFlow)
4. [deeplearning.ai - Sequences, Time Series and Prediction](./deeplearning.ai%20-%20TensorFlow%20in%20Practice%20Specialization/deeplearning.ai%20-%20Sequences%2C%20Time%20Series%20and%20Prediction)
- #### [Alberta Machine Intelligence Institute - Machine Learning Algorithms: Supervised Learning Tip to Tail](./Amii%20-%20Machine%20Learning%20Algorithms)
- #### [University of Helsinki: Object-Oriented Programming with Java, part I](./Object-Oriented-Programming-with-Java-pt1-University-of%20Helsinki-moocfi)
- #### [The Hong Kong University of Science and Technology - Python and Statistics for Financial Analysis](./HKUST%20%20-%20Python%20and%20Statistics%20for%20Financial%20Analysis)
- #### [Google IT Automation with Python Professional Certificate](./Google%20IT%20Automation%20with%20Python)
1. [Google - Crash Course on Python](./Google%20IT%20Automation%20with%20Python/Google%20-%20Crash%20Course%20on%20Python)
2. [Google - Using Python to Interact with the Operating System](./Google%20IT%20Automation%20with%20Python/Google%20-%20Using%20Python%20to%20Interact%20with%20the%20Operating%20System)
- #### [Delft University of Technology - Automated Software Testing](./Delft%20University%20of%20Technology%20-%20Automated%20Software%20Testing)
- #### [University of Maryland, College Park: Cybersecurity Specialization](./University%20of%20Maryland%20-%20Cybersecurity%20Specialization)
1. [University of Maryland, College Park: Software Security](./University%20of%20Maryland%20-%20Cybersecurity%20Specialization/University%20of%20Maryland%20-%20Software%20Security)
2. [University of Maryland, College Park: Usable Security](./University%20of%20Maryland%20-%20Cybersecurity%20Specialization/University%20of%20Maryland%20-%20Usable%20Security)
- #### [University of Maryland, College Park: Programming Mobile Applications for Android Handheld Systems: Part 1](./University%20of%20Maryland%20-%20Programming%20Mobile%20Applications%20for%20Android%20Handheld%20Systems%2C%20Part%20I)
- #### [Harvard University - Introduction to Computer Science CS50x](./Harvard-CS50x)
- #### [Duke University - Java Programming: Principles of Software Design](./Duke-Java-Programming-Principles-of-Software-Design)
- #### [Duke University - Java Programming: Solving Problems with Software](./Duke-Java-Programming-Solving-Problems-with-Software)
- #### [Duke University - Java Programming: Arrays, Lists, and Structured Data](./Duke-Java-Programming-Arrays-Lists-Structured-Data)
- #### [Duke University - Data Science Math Skills](./Duke-University-Data-Science-Math-Skills)
- #### [Massachusetts Institute of Technology - Introduction to Computer Science and Programming Using Python 6.00.1x](./MITx-6.00.1x)
- #### [Massachusetts Institute of Technology - Introduction to Computational Thinking and Data Science 6.00.2x](./MITx-6.00.2x)
- #### [Johns Hopkins University: Ruby on Rails Web Development Specialization](./Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails%20Web%20Development%20Specialization)
1. [Johns Hopkins University - Ruby on Rails](./Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails%20Web%20Development%20Specialization/Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails)
2. [Johns Hopkins University - Rails with Active Record and Action Pack](./Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails%20Web%20Development%20Specialization/Johns%20Hopkins%20University%20-%20Rails%20with%20Active%20Record%20and%20Action%20Pack)
3. [Johns Hopkins University - Ruby on Rails Web Services and Integration with MongoDB](./Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails%20Web%20Development%20Specialization/JHU%20-%20Ruby%20on%20Rails%20Web%20Services%20and%20Integration%20with%20MongoDB)
4. [Johns Hopkins University - HTML, CSS, and Javascript for Web Developers](./Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails%20Web%20Development%20Specialization/Johns%20Hopkins%20University%20-%20HTML%2C%20CSS%2C%20and%20Javascript%20for%20Web%20Developers)
5. [Johns Hopkins University - Single Page Web Applications with AngularJS](./Johns%20Hopkins%20University%20-%20Ruby%20on%20Rails%20Web%20Development%20Specialization/Johns%20Hopkins%20University%20-%20Single%20Page%20Web%20Applications%20with%20AngularJS)
- #### [University of Michigan - Web Design for Everybody: Web Development & Coding Specialization](./University%20of%20Michigan%20-%20Web%20Design%20for%20Everybody)
1. [University of Michigan - HTML5](./University%20of%20Michigan%20-%20Web%20Design%20for%20Everybody/University%20of%20Michigan%20-%20%20HTML5)
2. [University of Michigan - CSS3](./University%20of%20Michigan%20-%20Web%20Design%20for%20Everybody/University%20of%20Michigan%20-%20%20CSS3)
3. [University of Michigan - Interactivity with JavaScript](./University%20of%20Michigan%20-%20Web%20Design%20for%20Everybody/University%20of%20Michigan%20-%20%20Interactivity%20with%20JavaScript)
- #### [Stanford University - Introduction to Mathematical Thinking](./Stanford-University-Introduction-to-Mathematical-Thinking)
- #### [University of London - Responsive Website Development and Design Specialization](./University%20of%20London%20-%20Responsive%20Website%20Development%20and%20Design%20Specialization)
1. [University of London - Responsive Web Design](./University%20of%20London%20-%20Responsive%20Website%20Development%20and%20Design%20Specialization/University%20of%20London%20-%20Responsive%20Web%20Design)
2. [University of London - Web Application Development with JavaScript and MongoDB](./University%20of%20London%20-%20Responsive%20Website%20Development%20and%20Design%20Specialization/University%20of%20London%20-%20Web%20Application%20Development%20with%20JavaScript%20and%20MongoDB)
3. [University of London - Responsive Website Tutorial and Examples](./University%20of%20London%20-%20Responsive%20Website%20Development%20and%20Design%20Specialization/University%20of%20London%20-%20Responsive%20Website%20Tutorial%20and%20Examples)
- #### [University of California, San Diego - Biology Meets Programming: Bioinformatics](./UCSD%20-%20Biology%20Meets%20Programming%20Bioinformatics)
- #### [University of Toronto - Learn to Program: The Fundamentals](./University-of-Toronto-The%20Fundamentals)
- #### [University of Toronto - Learn to Program: Crafting Quality Code](./University-of-Toronto-Crafting-Quality-Code)
- #### [University of British Columbia - How to Code: Simple Data HtC1x](./UBCx-HtC1x)
- #### [University of British Columbia - Software Construction: Data Abstraction](./UBCx-Software-Construction-Data-Abstraction-SoftConst1x)
- #### [University of British Columbia - Software Construction: Object-Oriented Design](./UBCx-Software-Construction-OOP-SoftConst2x)
|
3,420 | Github repo with tutorials to fine tune transformers for diff NLP tasks | # <h1 align="center">PyTorch Transformers Tutorials </h1>
<p align="center">
<img alt="Transformer Tutorials" src="meta/banner.png">
</p>
<p align="center">
<a href="https://github.com/abhimishra91/transformers-tutorials/issues"><img alt="GitHub issues" src="https://img.shields.io/github/issues/abhimishra91/transformers-tutorials"></a>
<a href="https://github.com/abhimishra91/transformers-tutorials/network"><img alt="GitHub forks" src="https://img.shields.io/github/forks/abhimishra91/transformers-tutorials"></a>
<a href="https://github.com/abhimishra91/transformers-tutorials/stargazers"><img alt="Github Stars" src="https://img.shields.io/github/stars/abhimishra91/transformers-tutorials"></a>
<a href="https://github.com/abhimishra91/transformers-tutorials/blob/master/LICENSE"><img alt="GitHub license" src="https://img.shields.io/github/license/abhimishra91/transformers-tutorials"></a>
### Introduction
The field of **NLP** was revolutionized in the year 2018 by introduction of **BERT** and his **Transformer** friends(RoBerta, XLM etc.).
These novel transformer based neural network architectures and new ways to training a neural network on natural language data introduced transfer learning to NLP problems. Transfer learning had been giving out state of the art results in the Computer Vision domain for a few years now and introduction of transformer models for NLP brought about the same paradigm change in NLP.
Companies like [Google](https://github.com/google-research/bert) and [Facebook](https://github.com/pytorch/fairseq/tree/master/examples/roberta) trained their neural networks on large swathes of Natural Language Data to grasp the intricacies of language thereby generating a Language model. Finally these models were fine tuned to specific domain dataset to achieve state of the art results for a specific problem statement. They also published these trained models to open source community. The community members were now able to fine tune these models to their specific use cases.
[Hugging Face](https://github.com/huggingface) made it easier for community to access and fine tune these models using their Python Package: [Transformers](https://github.com/huggingface/transformers).
### Motivation
Despite these amazing technological advancements applying these solutions to business problems is still a challenge given the niche knowledge required to understand and apply these method on specific problem statements. Hence, In the following tutorials i will be demonstrating how a user can leverage technologies along with some other python tools to fine tune these Language models to specific type of tasks.
Before i proceed i will like to mention the following groups for the fantastic work they are doing and sharing which have made these notebooks and tutorials possible:
Please review these amazing sources of information and subscribe to their channels/sources.
- [Hugging Face Team](https://huggingface.co/)
- Abhishek Thakur for his amazing [Youtube videos](https://www.youtube.com/user/abhisheksvnit)
The problem statements that i will be working with are:
| Notebook |Github Link |Colab Link|Kaggle Kernel|
|--|--|--|--|
|Text Classification: Multi-Class| [Github](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|[Kaggle](https://www.kaggle.com/eggwhites2705/transformers-multiclass-classification-ipynb)|
|Text Classification: Multi-Label| [Github](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|[Kaggle](https://www.kaggle.com/eggwhites2705/transformers-multi-label-classification)|
|Sentiment Classification **with Experiment Tracking in [WandB](https://app.wandb.ai/abhimishra-91/transformers_tutorials_sentiment/runs/1zwn4gbg?workspace=user-abhimishra-91)!**|[Github](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_sentiment_wandb.ipynb)|[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_sentiment_wandb.ipynb)||
|Named Entity Recognition: **with TPU processing!**|[Github](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_ner.ipynb)|[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_ner.ipynb)|[Kaggle](https://www.kaggle.com/eggwhites2705/transformers-ner)|
|Question Answering||||
|Summary Writing: **with Experiment Tracking in [WandB](https://app.wandb.ai/abhimishra-91/transformers_tutorials_summarization?workspace=user-abhimishra-91)!**|[Github](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|[Kaggle](https://www.kaggle.com/eggwhites2705/transformers-summarization-t5/output)|
### Directory Structure
1. `data`: This folder contains all the toy data used for fine tuning.
2. `utils`: This folder will contain any miscellaneous script used to prepare for the fine tuning.
3. `models`: Folder to save all the artifacts post fine tuning.
### Further Watching/Reading
I will try to cover the practical and implementation aspects of fine tuning of these language models on various NLP tasks. You can improve your knowledge on this topic by reading/watching the following resources.
- Watching
- [Introduction in Simple terms](https://www.youtube.com/watch?v=gcHkxP9adiM)
- [Transfer Learning in NLP](https://www.youtube.com/watch?v=0T_Qr4qBrqc)
- [BERT Research Series from ChrisMcCormickAI](https://www.youtube.com/playlist?list=PLam9sigHPGwOBuH4_4fr-XvDbe5uneaf6)
- Reading
- [Transformers Documentation](https://huggingface.co/transformers/)
- [Pytorch Documentation](https://pytorch.org/docs/stable/index.html)
- [Google AI Blog](https://ai.googleblog.com/)
|
3,421 | A curated collection of iOS, ML, AR resources sprinkled with some UI additions | # iowncode
The below resources largely pertain to iOS 13. For iOS 14 and above, do check out [this repository](https://github.com/anupamchugh/iOS14-Resources)
## SwiftUI
* [SwiftUI Bar Charts](https://medium.com/better-programming/swiftui-bar-charts-274e9fbc8030?source=friends_link&sk=30da347d33abcfb89cb0eb7a0c7d5d82) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIBarCharts)
* [Gestures in SwiftUI](https://medium.com/better-programming/gestures-in-swiftui-e94b784ecc7?source=friends_link&sk=937a377f00fe038a669a6f16b74a55f2) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIGestures)
* [SwiftUI Line Charts](https://medium.com/better-programming/create-a-line-chart-in-swiftui-using-paths-183d0ddd4578?source=friends_link&sk=d768ace231eecc90028e39d8d2d95111) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUILineChart)
* [SwiftUI UIViewRepresentable](https://medium.com/better-programming/how-to-use-uiviewrepresentable-with-swiftui-7295bfec312b?source=friends_link&sk=c12c8924189352b3e9f381a6aea314ba) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIViewRepresentable)
* [SwiftUI WebSockets](https://medium.com/better-programming/build-a-bitcoin-price-ticker-in-swiftui-b16d9ca566a8?source=friends_link&sk=4ac88d157b3d35feaf8139462b9cb5bf) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIWebSockets)
* [SwiftUI WebView ProgressBar: Modify States During View Updates](https://medium.com/better-programming/how-to-modify-states-during-view-updates-in-swiftui-923bf7cea44f) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIWebViewsProgressBars)
* [SwiftUI Change App Icon](https://medium.com/better-programming/how-to-change-your-apps-icon-in-swiftui-1f2ff3c44344?source=friends_link&sk=687ac692bb6df5ce97669066d799fa2f) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIAlternateIcons)
* [SwiftUI Contact Search](https://medium.com/better-programming/build-a-swiftui-contacts-search-application-d41b414fe046?source=friends_link&sk=38c67b34ada448c52827f5be1f70ada8) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIContactSearch)
* [SwiftUI Pull To Refresh Workaround](https://medium.com/better-programming/pull-to-refresh-in-swiftui-6604f54a01d5) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIPullToRefresh)
* [SwiftUI Alamofire](https://medium.com/better-programming/combine-swiftui-with-alamofire-abb4cd4a0aca?source=friends_link&sk=46215390a2df56654ae240d06755a905) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIAlamofire)
* [SwiftUI COVID-19 Maps Visualisation](https://heartbeat.comet.ml/coronavirus-visualisation-on-maps-with-swiftui-and-combine-on-ios-c3f6e04c2634) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUICoronaMapTracker)
* [SwiftUI Combine URLSession Infinite Scrolling](https://medium.com/better-programming/build-an-endless-scrolling-list-with-swiftui-combine-and-urlsession-8a697a8318cb?source=friends_link&sk=d0ed3a0e29bc59b9faf0176e000dbe68) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUICombineURLSession)
## CoreML and CreateML
* CoreML 3 On Device Training [Part 1: Build Updatable Model](https://medium.com/better-programming/how-to-create-updatable-models-using-core-ml-3-cc7decd517d5?source=friends_link&sk=b34c2f90ec24f355dcad7e0c075e2f5e) | [Part 2: Re-train On Device](https://medium.com/better-programming/how-to-train-a-core-ml-model-on-your-device-cccd0bee19d?source=friends_link&sk=efa2297be5c42ca26c0971f4888f73d1) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSCoreMLOnDeviceTraining)
* [PencilKit Run Core ML Model MNIST](https://medium.com/better-programming/pencilkit-meets-core-ml-aefe3cde6a96?source=friends_link&sk=f3cf758575adb9c6391af3bd18fd65a6) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSPencilKitCoreMLMNIST)
* [Sound Classifier Using CoreML and CreateML](https://betterprogramming.pub/sound-classification-using-core-ml-3-and-create-ml-fc73ca20aff5) | [Code](https://github.com/anupamchugh/iowncode/tree/master/CoreML3SoundClassifier)
* [CoreML CreateML Recommender System](https://betterprogramming.pub/build-a-core-ml-recommender-engine-for-ios-using-create-ml-e8a748d01ba3) | [Code](https://github.com/anupamchugh/iowncode/tree/master/CoreMLRecommender)
* [CoreML NSFW Classifier Using CreateML](https://medium.com/better-programming/nsfw-image-detector-using-create-ml-core-ml-and-vision-79792d805bab?source=friends_link&sk=6b1007eab8dce2aa5079953409b9e63d) | [Code](https://github.com/anupamchugh/iowncode/tree/master/NSFWCreateMLImageClassifier)
* [SwiftUI CoreML Emoji Hunter Game](https://betterprogramming.pub/build-a-swiftui-core-ml-emoji-hunt-game-for-ios-eb4465ec4153) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIVisionEmojiHunt)
* * [CoreML Background Removal](https://betterprogramming.pub/coreml-image-segmentation-background-remove-ca11e6f6a083) | [Code](https://github.com/anupamchugh/iowncode/tree/master/CoreMLBackgroundChangeSwiftUI)
* [Real-time Style Transfer On A Live Camera Feed](https://betterprogramming.pub/train-and-run-a-create-ml-style-transfer-model-in-an-ios-camera-application-84aab3b85458) | [Code](https://github.com/anupamchugh/iOS14-Resources/tree/master/CreateMLVideoStyleTransfer)
## Vision Framework
* [Built-in Animal Classifier](https://medium.com/swlh/ios-vision-cat-vs-dog-image-classifier-in-5-minutes-f9fd6f264762?source=friends_link&sk=2d03ffb703aa0d15415f4690e8d81c3f) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13VisionPetAnimalClassifier)
* [Built-in Text Recognition](https://medium.com/better-programming/ios-vision-text-document-scanner-effc0b7f4635) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13VisionTextRecogniser)
* [Image Similarity](https://betterprogramming.pub/compute-image-similarity-using-computer-vision-in-ios-75b4dcdd095f) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSImageSimilarityUsingVision)
* [Scanning Credit Card Using Rectangle Detection and Text Recognition](https://betterprogramming.pub/scanning-credit-cards-with-computer-vision-on-ios-c3f4d8912de4) | [Code](https://github.com/anupamchugh/iowncode/tree/master/VisionCreditScan)
* [Cropping Using Saliency](https://medium.com/better-programming/cropping-areas-of-interest-using-vision-in-ios-e83b5e53440b?source=friends_link&sk=e14d1979ec429468e5a5f63ec44c5a75) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSVisionCroppingSalientFeatures)
* [Find Best Face Captured In A Live Photo](https://betterprogramming.pub/computer-vision-in-ios-determine-the-best-facial-expression-in-live-photos-452a2eaf6512) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSVisionFaceQualityLivePhoto)
* [Vision Contour Detection](https://betterprogramming.pub/new-in-ios-14-vision-contour-detection-68fd5849816e) | [Code](https://github.com/anupamchugh/iOS14-Resources/tree/master/iOS14VisionContourDetection)
* [Vision Hand Pose Estimation](https://betterprogramming.pub/swipeless-tinder-using-ios-14-vision-hand-pose-estimation-64e5f00ce45c) | [Code](https://github.com/anupamchugh/iOS14-Resources/tree/master/iOS14VisionHandPoseSwipe)
## Natural Language Framework
* [Classify Movie Reviews Using Sentiment Analysis and also CoreML](https://towardsdatascience.com/classifying-movie-reviews-with-natural-language-framework-12dfe2fc3308) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSNLPRottenTomatoes)
* [Sentiment Analysis Of Hacker News Feed Using SwiftUI](https://betterprogramming.pub/sentiment-analysis-on-ios-using-swift-natural-language-and-combine-hacker-news-top-stories-d1b8d8f4f798) | [Code](https://github.com/anupamchugh/iowncode/tree/master/SwiftUIHNSentiments)
## RealityKit
* [Introduction To Entities, Gestures and Raycasting](https://betterprogramming.pub/introduction-to-realitykit-on-ios-entities-gestures-and-ray-casting-8f6633c11877) | [Code](https://github.com/anupamchugh/iowncode/tree/master/RealityKitEntitiesVision)
* [Collisions](https://betterprogramming.pub/realitykit-on-ios-part-2-applying-collision-events-d64b6e10421f) | [Code](https://github.com/anupamchugh/iowncode/tree/master/RealityKitCollisions)
## UIKit and other changes in iOS 13
* [Compositional Layouts](https://medium.com/better-programming/ios-13-compositional-layouts-in-collectionview-90a574b410b8) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13CompostionalLayouts)
* [Diffable Datasources](https://medium.com/better-programming/applying-diffable-data-sources-70ce65b368e4) | [Code](https://github.com/anupamchugh/iowncode/tree/master/DiffableDataSources)
* [ContextMenu and SFSymbols](https://medium.com/better-programming/ios-context-menu-collection-view-a03b032fe330) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13ContextMenu)
* [Multi Selection on TableView and CollectionView](https://medium.com/better-programming/ios-13-multi-selection-gestures-in-tableview-and-collectionview-619d515eef16) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13TableViewAndCollectionView)
* [What's New In MapKit](https://medium.com/better-programming/exploring-mapkit-on-ios-13-1a7a1439e3b6?source=friends_link&sk=5e333f42b70e9adff945a73a2ec922a2) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13MapKit)
* [iOS 13 Location Permissions: CoreLocation](https://medium.com/better-programming/handling-ios-13-location-permissions-5482abc77961) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13CoreLocationChanges)
* [iOS 13 On-Device Speech Recognition](https://medium.com/better-programming/ios-speech-recognition-on-device-e9a54a4468b5) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13OnDeviceSpeechRecognition)
* [Introduction To PencilKit](https://medium.com/better-programming/an-introduction-to-pencilkit-in-ios-4d40aa62ba5b) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOS13OnDeviceSpeechRecognition)
* [PencilKit Meets MapKit](https://medium.com/better-programming/cropping-ios-maps-with-pencilkit-da7f7dd7ec52) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iOSMapAndPencilKit)
* [iPadOS MultiWindow Support](https://medium.com/better-programming/implementing-multiple-window-support-in-ipados-5b9a3ceeac6f?source=friends_link&sk=85b7f435bc341eac7ee420bb0a9da366) | [Code](https://github.com/anupamchugh/iowncode/tree/master/iPadOSMultiWindowExample)
</br>
Let's connect on [Twitter](https://twitter.com/chughanupam)!
</a>
|
3,422 | Machine Learning Open Source University | <p align="center">
<br>
<img src="https://github.com/d0r1h/ML-University/blob/master/ml_logo.png" width="300"/>
<br>
<p>
<p align="center">
<a href="https://hits.seeyoufarm.com"><img src="https://hits.seeyoufarm.com/api/count/incr/badge.svg?url=https%3A%2F%2Fgithub.com%2Fd0r1h%2FML-University&count_bg=%2379C83D&title_bg=%23555555&icon=&icon_color=%23E7E7E7&title=hits&edge_flat=false"/></a>
<a href="https://twitter.com/intent/tweet?text=Checkout this awesome Machine Learning University Repo on Github text:&url=https%3A%2F%2Fgithub.com%2Fd0r1h%2FML-University"><img alt="tweet" src="https://img.shields.io/twitter/url?style=social&url=https%3A%2F%2Fgithub.com%2Fd0r1h%2FML-University">
</a>
</p>
<h3 align="center">
<p>A Free Machine Learning University </p>
</h3>
<br>
Machine Learning Open Source University is an IDEA of free-learning of a ML enthusiast for all other ML enthusiast
**This list is continuously updated** - And if you are a Ml practitioner and have some good suggestions to improve this or have somegood resources to share, you create pull request and contribute.
**Table of Contents**
1. [Getting Started](#getting-started)
2. [Mathematics](#mathematics)
3. [Machine Learning](#machine-learning)
4. [Deep Learning](#deep-learning)
5. [Natural language processing](#natural-language-processing)
6. [Reinforcement learning](#reinforcement-learning)
7. [Books](#books)
8. [ML in Production](#ml-in-production)
9. [Quantum ML](#quantum-ml)
10. [DataSets](#datasets)
11. [Other Useful Websites](#other-useful-websites)
12. [Other Useful GitRrpo](#other-useful-gitrepo)
13. [Blogs and Webinar](#blogs-and-webinar)
14. [Must Read Research Paper](#must-read-research-paper)
15. [Company Tech Blogs](#company-tech-blogs)
## Getting Started
| Title and Source | Link |
|------------------------------------------------------------ | -------------------------------------------------------------|
| Elements of AI : Part-1 | [WebSite](https://course.elementsofai.com/) |
| Elements of AI : Part-2 | [WebSite](https://buildingai.elementsofai.com/) |
| CS50’s Introduction to AI **Harvard** | [Cs50 WebSite](https://cs50.harvard.edu/ai/2020/) |
| Intro to Computational Thinking and Data Science **MIT** | [WebSite](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-0002-introduction-to-computational-thinking-and-data-science-fall-2016/)
| Practical Data Ethics | [fast.ai](https://ethics.fast.ai/)
| Machine learning Mastery Getting Started | [machinelearningmastery](https://machinelearningmastery.com/start-here/)
| Design and Analysis of Algorithms **MIT** | [ocw.mit.edu](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-046j-design-and-analysis-of-algorithms-spring-2015/)
| AI: Principles and Techniques **Stanford** | [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rO1NB9TD4iUZ3qghGEGtqNX)|
| The Private AI Series | [openmined](https://courses.openmined.org/courses)|
## Mathematics
| Title and Source | Link |
|------------------------------------------------------------ | -------------------------------------------------------------
| Statistics in Machine Learning (Krish Naik) | [YouTube](https://www.youtube.com/playlist?list=PLZoTAELRMXVMhVyr3Ri9IQ-t5QPBtxzJO)
| Computational Linear Algebra for Coders | [fast.ai](https://github.com/fastai/numerical-linear-algebra/blob/master/README.md)
| Linear Algebra **MIT** | [WebSite](https://openlearninglibrary.mit.edu/courses/course-v1:OCW+18.06SC+2T2019/course/)|
| Statistics by zstatistics | [WebSite](https://www.zstatistics.com/videos)|
| Essence of linear algebra by 3Blue1Brown | [YouTube](https://www.youtube.com/playlist?list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab)|
| SEEING THEORY (Visual Probability) **brown** | [WebSite](https://seeing-theory.brown.edu/basic-probability/index.html)|
| Matrix Methods in Data Analysis,and Machine Learning **MIT** | [WebSite](https://ocw.mit.edu/courses/mathematics/18-065-matrix-methods-in-data-analysis-signal-processing-and-machine-learning-spring-2018/)
| Math for Machine Learning | [YouTube](https://www.youtube.com/playlist?app=desktop&list=PLD80i8An1OEGZ2tYimemzwC3xqkU0jKUg) |
| Statistics for Applications **MIT** | [YouTube](https://www.youtube.com/playlist?list=PLUl4u3cNGP60uVBMaoNERc6knT_MgPKS0)
## Machine Learning
| Title and Source | Link |
|------------------------------------------------------------ | -------------------------------------------------------------|
| Introduction to Machine Learning with scikit-learn | [dataschool](https://courses.dataschool.io/introduction-to-machine-learning-with-scikit-learn)|
| Introduction to Machine Learning | [sebastianraschka](https://sebastianraschka.com/blog/2021/ml-course.html)
| Open Machine Learning Course | [mlcourse.ai](https://mlcourse.ai/) |
| Machine Learning (CS229) **Stanford** | [WebSite](http://cs229.stanford.edu/syllabus-spring2020.html) [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU)|
| Introduction to Machine Learning **MIT** | [WebSite](https://tinyurl.com/ybl6udcr) |
| Machine Learning Systems Design 2021 (CS329S) **Stanford** | [WebSite](https://stanford-cs329s.github.io/syllabus.html) |
| Applied Machine Learning 2020 (CS5787) **Cornell Tech** | [YouTube](https://www.youtube.com/playlist?list=PL2UML_KCiC0UlY7iCQDSiGDMovaupqc83)
| Machine Learning for Healthcare **MIT** | [WebSite](https://tinyurl.com/yxgeesdf) |
| Machine Learning for Trading **Georgia Tech** | [WebSite](https://lucylabs.gatech.edu/ml4t/) |
| Introduction to Machine Learning for Coders | [fast.ai](https://course18.fast.ai/ml.html)
| Machine Learning Crash Course | [Google AI](https://developers.google.com/machine-learning/crash-course)|
| Machine Learning with Python | [freecodecamp](https://www.freecodecamp.org/learn/machine-learning-with-python/)|
| Deep Reinforcement Learning:CS285 **UC Berkeley** | [YouTube](https://www.youtube.com/playlist?list=PL_iWQOsE6TfURIIhCrlt-wj9ByIVpbfGc)|
| Probabilistic Machine Learning **University of Tübingen** | [YouTube](https://www.youtube.com/playlist?list=PL05umP7R6ij1tHaOFY96m5uX3J21a6yNd)|
| Machine Learning with Graphs(CS224W) **Stanford** | [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn)|
| Machine Learning in Production **CMU** | [WebSite](https://ckaestne.github.io/seai/)|
| Machine Learning & Deep Learning Fundamentals | [deeplizard](https://deeplizard.com/learn/video/gZmobeGL0Yg)|
| Interpretability and Explainability in Machine Learning | [WebSite](https://interpretable-ml-class.github.io/)|
| Practical Machine Learning 2021 **Stanford** | [WebSite](https://c.d2l.ai/stanford-cs329p/index.html#)|
| Machine Learning **VU University** | [WebSite](https://mlvu.github.io/)|
| Machine Learning for Cyber Security **Purdue University** | [YouTube](https://www.youtube.com/playlist?list=PL74sw1ohGx7GHqDHCkXZeqMQBVUTMrVLE)|
| Audio Signal Processing for Machine Learning | [YouTube](https://www.youtube.com/playlist?list=PL-wATfeyAMNqIee7cH3q1bh4QJFAaeNv0)|
| Machine learning & causal inference **Stanford** | [YouTube](https://www.youtube.com/playlist?list=PLxq_lXOUlvQAoWZEqhRqHNezS30lI49G-)|
| Machine learning cs156 **caltech** | [YouTube](https://www.youtube.com/playlist?list=PLD63A284B7615313A) |
| Multimodal machine learning (MMML) **CMU** | [WebSite](https://cmu-multicomp-lab.github.io/mmml-course/fall2020/) [YouTube](https://www.youtube.com/playlist?list=PL-Fhd_vrvisNup9YQs_TdLW7DQz-lda0G) |
## Deep Learning
| Title and Source | Link |
|------------------------------------------------------------ | -------------------------------------------------------------|
| Introduction to Deep Learning(6.S191) **MIT** | [YouTube](https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI) |
| Introduction to Deep Learning | [sebastianraschka](https://sebastianraschka.com/blog/2021/dl-course.html)
| Deep Learning **NYU** | [WebSite](https://atcold.github.io/pytorch-Deep-Learning/) [2021](https://atcold.github.io/NYU-DLSP21/) |
| Deep Learning (CS182) **UC Berkeley** | [YouTube](https://www.youtube.com/playlist?list=PL_iWQOsE6TfVmKkQHucjPAoRtIJYt8a5A)
| Deep Learning Lecture Series **DeepMind x UCL** | [YouTube](https://www.youtube.com/playlist?list=PLqYmG7hTraZCDxZ44o4p3N5Anz3lLRVZF)|
| Deep Learning (CS230) **Stanford** | [WebSite](https://cs230.stanford.edu/lecture/) |
| CNN for Visual Recognition(CS231n) **Stanford** | [WebSite-2020](https://cs231n.github.io/) [YouTube-2017](https://tinyurl.com/y2gghbvs)|
| Full Stack Deep Learning | [WebSite](https://course.fullstackdeeplearning.com/)[2021](https://fullstackdeeplearning.com/spring2021/)|
| Practical Deep Learning for Coders, v3 | [fast.ai](https://course19.fast.ai/index.html) |
| Deep Learning Crash Course 2021 d2l.ai | [YouTube](https://www.youtube.com/playlist?list=PLZSO_6-bSqHQsDaBNtcFwMQuJw_djFnbd)|
| Deep Learning for Computer Vision **Michigan** | [WebSite](https://web.eecs.umich.edu/~justincj/teaching/eecs498/FA2020/)|
| Neural Networks from Scratch in Python by Sentdex | [YouTube](https://www.youtube.com/playlist?app=desktop&list=PLQVvvaa0QuDcjD5BAw2DxE6OF2tius3V3)|
| Keras - Python Deep Learning Neural Network API | [deeplizard](https://deeplizard.com/learn/video/RznKVRTFkBY)|
| Reproducible Deep Learning | [sscardapane.it](https://www.sscardapane.it/teaching/reproducibledl/)|
| PyTorch Fundamentals | [microsoft](https://docs.microsoft.com/en-us/learn/paths/pytorch-fundamentals/)|
| Geometric Deep Learing (GDL100) | [geometricdeeplearning](https://geometricdeeplearning.com/lectures/)|
| Deep learning Neuromatch Academy | [neuromatch](https://deeplearning.neuromatch.io/tutorials/intro.html)
| Deep Learning for Molecules and Materials | [WebSite](https://whitead.github.io/dmol-book/intro.html)|
| Deep Learning course for Vision | [arthurdouillard.com](https://arthurdouillard.com/deepcourse/)|
| Deep Multi-Task and Meta Learning (CS330) **Stanford** | [WebSite](https://cs330.stanford.edu/) [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rMC6zfYmnD7UG3LVvwaITY5)|
| Deep Learning Interviews book | [WebSite](https://github.com/BoltzmannEntropy/interviews.ai)|
| Deep Learning for Computer Vision 2021 | [YouTube](https://www.youtube.com/playlist?list=PL_Z2_U9MIJdNgFM7-f2fZ9ZxjVRP_jhJv)
| Deep Learning 2022 **CMU** | [YouTube](https://www.youtube.com/playlist?list=PLp-0K3kfddPxRmjgjm0P1WT6H-gTqE8j9)
## Natural language processing
| Title and Source | Link |
| ------------------------------------------------------------ | -----------------------------------------------------------|
| Natural Language Processing AWS | [YouTube](https://www.youtube.com/playlist?list=PL8P_Z6C4GcuWfAq8Pt6PBYlck4OprHXsw)
| NLP - Krish Naik | [YouTube](https://www.youtube.com/playlist?list=PLZoTAELRMXVMdJ5sqbCK2LiM0HhQVWNzm)
| NLP with Deep Learning(CS224N) 2019 **Stanford** | [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z) [2021](https://www.youtube.com/playlist?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ)
| A Code-First Introduction to Natural Language Processing | [fast.ai](https://www.fast.ai/2019/07/08/fastai-nlp/)|
| CMU Neural Nets for NLP 2021 **Carnegie Mellon University** | [YouTube](https://www.youtube.com/playlist?list=PL8PYTP1V4I8AkaHEJ7lOOrlex-pcxS-XV)|
| Speech and Language Processing **Stanford** | [WebSite](https://web.stanford.edu/~jurafsky/slp3/) |
| Natural Language Understanding (CS224U) **Stanford** | [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rObpMCir6rNNUlFAn56Js20) [2022](https://web.stanford.edu/class/cs224u/)
| NLP with Dan Jurafsky and Chris Manning, 2012 **Stanford** | [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rOFZnDyrlW3-nI7tMLtmiJZ)|
| Intro to NLP with spaCy | [YouTube](https://www.youtube.com/playlist?list=PLBmcuObd5An559HbDr_alBnwVsGq-7uTF)|
| Advanced NLP with spaCy | [website](https://course.spacy.io/en/) |
| Applied Language Technology | [website](https://applied-language-technology.readthedocs.io/en/latest/)|
| Advanced Natural Language Processing **Umass** | [website](https://people.cs.umass.edu/~miyyer/cs685/schedule.html) [YouTube 2020](https://www.youtube.com/playlist?list=PLWnsVgP6CzadmQX6qevbar3_vDBioWHJL)|
| Huggingface Course | [huggingface.co](https://huggingface.co/course/chapter1?fw=tf)|
| NLP Course **Michigan** | [github](https://github.com/deskool/nlp-class)|
| Multilingual NLP 2020 **CMU** | [YouTube](https://www.youtube.com/playlist?list=PL8PYTP1V4I8CHhppU6n1Q9-04m96D9gt5)|
| Advanced NLP 2021 **CMU** | [YouTube](https://www.youtube.com/playlist?list=PL8PYTP1V4I8AYSXn_GKVgwXVluCT9chJ6)|
| Transformers United **stanford** | [Website](https://web.stanford.edu/class/cs25/) [YouTube](https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM) |
## Reinforcement learning
| Title and Source | Link |
|------------------------------------------------------------ | -----------------------------------------------------------|
| Reinforcement Learning(CS234) **Stanford** | [YouTube-2019](https://www.youtube.com/playlist?list=PLoROMvodv4rOSOPzutgyCTapiGlY2Nd8u)|
| Introduction to reinforcement learning **DeepMind** | [YouTube-2015](https://www.youtube.com/playlist?list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ)|
| Reinforcement Learning Course **DeepMind & UCL** | [YouTube-2018](https://www.youtube.com/playlist?list=PLqYmG7hTraZBKeNJ-JE_eyJHZ7XgBoAyb)|
| Advanced Deep Learning & Reinforcement Learning | [YouTube](https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs)|
| DeepMind x UCL Reinforcement Learning 2021 | [YouTube](https://www.youtube.com/playlist?list=PLqYmG7hTraZDVH599EItlEWsUOsJbAodm)
## Books
| Title and Source | Link |
|------------------------------------------------------------ | -----------------------------------------------------------|
| Scientific Python Lectures | [ScipyLectures](https://scipy-lectures.org/_downloads/ScipyLectures-simple.pdf)|
| Mathematics for Machine Learning | [mml-book](https://mml-book.github.io/book/mml-book.pdf) |
| An Introduction to Statistical Learning | [statlearning](https://www.statlearning.com/) |
| Think Stats | [Think Stats](https://greenteapress.com/wp/think-stats-2e/)|
| Python Data Science Handbook | [Python For DS](https://jakevdp.github.io/PythonDataScienceHandbook/)|
| Natural Language Processing with Python - NLTK | [NLTK](https://www.nltk.org/book/) |
| Deep Learning by Ian Goodfellow | [deeplearningbook](https://www.deeplearningbook.org/) |
| Dive into Deep Learning | [d2l.ai](https://d2l.ai/index.html)
| Approaching (Almost) Any Machine Learning Problem | [AAANLP](https://github.com/abhishekkrthakur/approachingalmost/blob/master/AAAMLP.pdf)|
| Neural networks and Deep learning | [neuralnetworksanddeeplearning](http://neuralnetworksanddeeplearning.com/index.html)|
| AutoML: Methods, Systems, Challenges (first book on AutoML) | [automl](https://www.automl.org/book/)|
| Feature Engineering and Selection | [bookdown.org](https://bookdown.org/max/FES/)|
| Introduction to Machine Learning Interviews Book | [huyenchip.com](https://huyenchip.com/ml-interviews-book/)|
| Hands-On Machine Learning with R | [website](https://bradleyboehmke.github.io/HOML/)|
| Zero to Mastery TensorFlow for Deep Learning Book | [dev.mrdbourke.com/](https://dev.mrdbourke.com/tensorflow-deep-learning/)|
| Introduction to Probability for Data Science | [probability4datascience](https://probability4datascience.com/)|
| Graph Representation Learning Book | [cs.mcgill.ca](https://www.cs.mcgill.ca/~wlh/grl_book/)|
| Interpretable Machine Learning | [christophm](https://christophm.github.io/interpretable-ml-book/)|
| Computer Vision: Algorithms and Applications, 2nd ed. | [szeliski.org](https://szeliski.org/Book/)
## ML in Production
| Title and Source | Link |
|------------------------------------------------------------ | -----------------------------------------------------------|
| Introduction to Docker | [Docker](https://carpentries-incubator.github.io/docker-introduction/)|
| MLOps Basics | [GitHub](https://github.com/graviraja/MLOps-Basics)|
## Quantum ML
| Title and Source | Link |
|------------------------------------------------------------ | -----------------------------------------------------------|
| Quantum machine learning | [pennylane.ai](https://pennylane.ai/qml/)|
## DataSets
| Title and Source | Link |
|------------------------------------------------------------ | -----------------------------------------------------------|
| Yelp Open Dataset | [yelp](https://www.yelp.com/dataset) |
| Machine Translation | [website](https://www.manythings.org/anki/) |
| IndicNLP Corpora (Indian languages) | [ai4bharat](https://indicnlp.ai4bharat.org/explorer/) |
| Amazon product co-purchasing network metadata | [snap.stanford.edu/](https://snap.stanford.edu/data/amazon-meta.html)|
| Stanford Question Answering Dataset (SQuAD) | [website](https://rajpurkar.github.io/SQuAD-explorer/)
## Other Useful Websites
1. [Papers with Code](https://paperswithcode.com/sota)
2. [Two Minute Papers - Youtube](https://www.youtube.com/c/K%C3%A1rolyZsolnai/videos)
3. [The Missing Semester of Your CS Education](https://missing.csail.mit.edu/2020/)
4. [Workera : Measure data-AI skills](https://workera.ai/)
5. [Machine learning mastery](https://machinelearningmastery.com/start-here/)
6. [From Data to viz: Guide for your graph](https://www.data-to-viz.com/)
7. [datatalks club](https://datatalks.club/)
8. [Machine Learning for Art](https://ml4a.net/fundamentals/)
10. [applyingml](https://applyingml.com/)
11. [Deep Learning Drizzle](https://deep-learning-drizzle.github.io/index.html#opt4ml)
12. [The Machine & Deep Learning Compendium](https://book.mlcompendium.com/)
13. [connectedpapers - Research Papers](https://www.connectedpapers.com/)
14. [Papers and Latest Research - deepai](https://deepai.org/)
15. [Tracking Progress in NLP](https://nlpprogress.com/)
16. [NLP Blogs by Sebastian Ruder](https://ruder.io/)
17. [labmlai for papers](https://papers.labml.ai/)
## Other Useful GitRepo
1. [Applied-ml - Papers and blogs by organizations ](https://github.com/eugeneyan/applied-ml)
2. [List Machine learning Python libraries](https://github.com/ml-tooling/best-of-ml-python)
3. [ML From Scratch - Implementations of models/algorithms](https://github.com/eriklindernoren/ML-From-Scratch)
4. [What the f*ck Python?](https://github.com/satwikkansal/wtfpython)
5. [scikit-learn user guide: step-step approach](https://scikit-learn.org/stable/user_guide.html)
6. [NLP Tutorial Code with DL](https://github.com/graykode/nlp-tutorial)
7. [awesome-mlops](https://github.com/visenger/awesome-mlops)
8. [Text Classification Algorithms: A Survey](https://github.com/kk7nc/Text_Classification)
9. [ML use cases by company](https://github.com/khangich/machine-learning-interview/blob/master/appliedml.md)
## Blogs and Webinar
1. [Recommendation algorithms and System design](https://www.theinsaneapp.com/2021/03/system-design-and-recommendation-algorithms.html?m=1)
2. [Machine Learning System Design](https://becominghuman.ai/machine-learning-system-design-f2f4018f2f8?gi=942874b21d0e)
3. [Lil'BLog](https://lilianweng.github.io/lil-log/)
## Must Read Research Paper
**NLP [Text]**
1. [Text Classification Algorithms: A Survey](https://arxiv.org/abs/1904.08067)
2. [Deep Learning Based Text Classification: A Comprehensive Review](https://arxiv.org/abs/2004.03705)
3. [Compression of Deep Learning Models for Text: A Survey](https://arxiv.org/abs/2008.05221)
4. [A Survey on Text Classification: From Shallow to Deep Learning](https://arxiv.org/pdf/2008.00364.pdf)
4. [A Survey of Transformers](https://arxiv.org/abs/2106.04554)
5. [AMMUS : A Survey of Transformer-based Pretrained Models in Natural Language Processing](https://arxiv.org/abs/2108.05542)
6. [Graph Neural Networks for Natural Language Processing: A Survey](https://arxiv.org/abs/2106.06090)
8. [A Survey of Data Augmentation Approaches for NLP](https://arxiv.org/abs/2105.03075)
9. [A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios](https://aclanthology.org/2021.naacl-main.201.pdf)
10. [Evaluation of Text Generation: A Survey](https://arxiv.org/pdf/2006.14799.pdf)
11. [A Survey of Transfer learning In NLP](https://arxiv.org/pdf/2007.04239.pdf)
12. [A Systematic Survey of Prompting Methods in NLP](https://arxiv.org/pdf/2107.13586.pdf)
**OCR [Optical Character Recognition]**
1. [Survey of Post-OCR Processing Approaches](https://dl.acm.org/doi/pdf/10.1145/3453476)
## Company Tech Blogs
1. [AssemblyAI](https://www.assemblyai.com/blog)
2. [Grammarly](https://www.grammarly.com/blog/engineering/)
3. [Huggingface](https://huggingface.co/blog)
4. [Uber](https://eng.uber.com/category/articles/ai/)
5. [Netflix](https://netflixtechblog.com/)
6. [Spotify Research](https://research.atspotify.com/blog/) | [Engineering](https://engineering.atspotify.com/)
|
3,423 | 🧠 A study guide to learn about Transformers | # Transformer Recipe

$$\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V$$
Transformers have accelerated the development of new techniques and models for natural language processing (NLP) tasks. While it has mostly been used for NLP tasks, it is now seeing heavy adoption in other areas such as computer vision and reinforcement learning. That makes it one of the most important modern concepts to understand and be able to apply.
I am aware that a lot of machine learning and NLP students and practitioners are keen on learning about transformers. Therefore, I have prepared a study guide in the form of a list of resources and study materials to help guide students interested in learning about the world of Transformers.
To begin with, I have prepared a few links to materials that I used to better understand and implement transformer models from scratch.
## High-level Introduction
First, try to get a very high-level introduction about transformers. Some references worth looking at:
🔗 [Introduction to Transformer - Lecture Notes](https://www.notion.so/dair-ai/Introduction-to-Transformers-4b869c9595b74f72b088e5f2793ece80) (Elvis Saravia)
🔗 [Transformers From Scratch](https://e2eml.school/transformers.html) (Brandon Rohrer)
🔗 [How Transformers work in deep learning and NLP: an intuitive introduction](https://theaisummer.com/transformer/) (AI Summer)
🔗 [Stanford CS25 - Transformers United](https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM)
🔗 [Deep Learning for Language Understanding](https://youtu.be/8zAP2qWAsKg) (DeepMind)
## The Transformer Explained
Jay Alammar's illustrated explanations are exceptional. Once you get that high-level understanding of transformers, you can jump into this popular detailed and illustrated explanation of transformers:
🔗 [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/)
This next article also breaks down Transformers into its components, explaining and illustrating in detail what each part does:
🔗 [Breaking Down the Transformer](https://aman.ai/primers/ai/transformers/)
## Technical Summary
At this point, you may be looking for a technical summary and overview of transformers. Lilian Weng's blog posts are a gem and provide concise technical explanations/summaries:
🔗 [The Transformer Family](https://lilianweng.github.io/lil-log/2020/04/07/the-transformer-family.html)
🔗 [The Transformer Family Version 2.0](https://lilianweng.github.io/posts/2023-01-27-the-transformer-family-v2/)
## Implementation
After the theory, it's important to test the knowledge. I typically prefer to understand things in more detail so I prefer to implement algorithms from scratch. For implementing transformers, I mainly relied on this tutorial:
🔗 [The Annotated Transformer](https://nlp.seas.harvard.edu/2018/04/03/attention.html) | ([Google Colab](https://colab.research.google.com/drive/1xQXSv6mtAOLXxEMi8RvaW8TW-7bvYBDF) | [GitHub](https://github.com/harvardnlp/annotated-transformer))
🔗 [Language Modeling with nn.Transformer and TorchText](https://pytorch.org/tutorials/beginner/transformer_tutorial.html)
If you are looking for in-depth implementations on some of the latest transformers, you might also find the Papers with Code methods [collection for Transformers](https://paperswithcode.com/methods/category/transformers) useful.
## Attention Is All You Need
This paper by Vaswani et al. introduced the Transformer architecture. Read it after you have a high-level understanding and want to get into the details. Pay attention to other references in the paper for diving deep.
🔗 [Attention Is All You Need](https://arxiv.org/pdf/1706.03762v5.pdf)
## Applying Transformers
After some time studying and understanding the theory behind transformers, you may be interested in applying them to different NLP projects or research. At this time, your best bet is the Transformers library by HuggingFace.
🔗 [Transformers](https://github.com/huggingface/transformers)
The Hugging Face Team has also published a new book on NLP with Transformers, so you might want to check that out [here](https://www.oreilly.com/library/view/natural-language-processing/9781098103231/).
---
Feel free to suggest study material. In the next update, I am looking to add a more comprehensive collection of Transformer applications and papers. In addition, a code implementation for easy experimentation is coming as well. Stay tuned!
*To get regular updates on new ML and NLP resources, [follow me on Twitter](https://twitter.com/omarsar0).*
|
3,424 | Code and data accompanying Natural Language Processing with PyTorch published by O'Reilly Media https://amzn.to/3JUgR2L | # Natural Language Processing with PyTorch
_Build Intelligent Language Applications Using Deep Learning_
<br>By Delip Rao and Brian McMahan
Welcome. This is a companion repository for the book [Natural Language Processing with PyTorch: Build Intelligent Language Applications Using Deep Learning](https://www.amazon.com/Natural-Language-Processing-PyTorch-Applications/dp/1491978236/).
Table of Contents
=================
<!--ts-->
* Get Started!
* [Chapter 1: Introduction](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_1)
* PyTorch Basics
* Chapter 2: A Quick Tour of NLP
* [Chapter 3: Foundational Components of Neural Networks](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_3)
* In-text examples
* Diving deep into supervised training
* Classifying sentiment of restaurant reviews using a Perceptron
* [Chapter 4: Feed-forward Networks for NLP](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_4)
* Limitations of the Perceptron
* Introducing Multi-layer Perceptrons (MLPs)
* Introducing Convolutional Neural Networks (CNNs)
* Surname Classification with an MLP
* Surname Classification with a CNN
* [Chapter 5: Embedding Words and Types](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_5)
* Using Pretrained Embeddings
* Learning Continous Bag-of-words Embeddings (CBOW)
* Transfer Learning using Pre-trained Embeddings
* [Chapter 6: Sequence Modeling for NLP](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_6)
* A sequence representation for Surnames
* [Chapter 7: Intermediate Sequence Modeling for NLP](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_7)
* Generating novel surnames from sequence representations
* Uncondition generation
* Conditioned generation
* [Chapter 8: Advanced Sequence Modeling for NLP](https://github.com/joosthub/PyTorchNLPBook/tree/master/chapters/chapter_8)
* Understanding PackedSequences
* Sequence to Sequence Learning
* Attention
* Neural Machine Translation
* Chapter 9: Classics, Frontiers, Next Steps
<!--te-->
|
3,425 | Drench yourself in Deep Learning, Reinforcement Learning, Machine Learning, Computer Vision, and NLP by learning from these exciting lectures!! | # :balloon: :tada: Deep Learning Drizzle :confetti_ball: :balloon:
:books: [**"Read enough so you start developing intuitions and then trust your intuitions and go for it!"** ](https://www.deeplearning.ai/hodl-geoffrey-hinton/) :books: <br/> Prof. Geoffrey Hinton, University of Toronto
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### Contents
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| | |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| **Deep Learning (Deep Neural Networks)** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#tada-deep-learning-deep-neural-networks-confetti_ball-balloon) | **Probabilistic Graphical Models** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#loudspeaker-probabilistic-graphical-models-sparkles) |
| | |
| **Machine Learning Fundamentals** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#cupid-machine-learning-fundamentals-cyclone-boom) | **Natural Language Processing** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#hibiscus-natural-language-processing-cherry_blossom-sparkling_heart) |
| | |
| **Optimization for Machine Learning** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#cupid-optimization-for-machine-learning-cyclone-boom) | **Automatic Speech Recognition** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#speaking_head-automatic-speech-recognition-speech_balloon-thought_balloon) |
| | |
| **General Machine Learning** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#cupid-general-machine-learning-cyclone-boom) | **Modern Computer Vision** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#fire-modern-computer-vision-camera_flash-movie_camera) |
| | |
| **Reinforcement Learning** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#balloon-reinforcement-learning-hotsprings-video_game) | **Boot Camps or Summer Schools** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#star2-boot-camps-or-summer-schools-maple_leaf) |
| | |
| **Bayesian Deep Learning** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#game_die-bayesian-deep-learning-spades-gem) | **Medical Imaging** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#movie_camera-medical-imaging-camera-video_camera) |
| | |
| **Graph Neural Networks** [:arrow_heading_down: ](https://github.com/kmario23/deep-learning-drizzle#tada-graph-neural-networks-geometric-dl-confetti_ball-balloon) | **Bird's-eye view of Artificial Intelligence** [:arrow_heading_down:](https://github.com/kmario23/deep-learning-drizzle#bird-birds-eye-view-of-agi-eagle) |
| | |
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
## :tada: Deep Learning (Deep Neural Networks) :confetti_ball: :balloon:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ----------------------------------------------------- | ---------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | --------------- |
| 1. | **Neural Networks for Machine Learning** | Geoffrey Hinton, University of Toronto | [Lecture-Slides](http://www.cs.toronto.edu/~hinton/coursera_slides.html) <br/> [CSC321-tijmen](https://www.cs.toronto.edu/~tijmen/csc321/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoRl3Ht4JOcdU872GhiYWf6jwrk_SNhz9) <br/> [UofT-mirror](https://www.cs.toronto.edu/~hinton/coursera_lectures.html) | 2012 <br/> 2014 |
| 2. | **Neural Networks Demystified** | Stephen Welch, Welch Labs | [Suppl. Code](https://github.com/stephencwelch/Neural-Networks-Demystified) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLiaHhY2iBX9hdHaRr6b7XevZtgZRa1PoU) | 2014 |
| 3. | **Deep Learning at Oxford** | Nando de Freitas, Oxford University | [Oxford-ML](http://www.cs.ox.ac.uk/teaching/courses/2014-2015/ml/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLE6Wd9FR--EfW8dtjAuPoTuPcqmOV53Fu) | 2015 |
| 4. | **Deep Learning for Perception** | Dhruv Batra, Virginia Tech | [ECE-6504](https://computing.ece.vt.edu/~f15ece6504/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-fZD610i7yAsfH2eLBiRDa90kL2ML0f7) | 2015 |
| 5. | **Deep Learning** | Ali Ghodsi, University of Waterloo | [STAT-946](https://uwaterloo.ca/data-analytics/deep-learning) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLehuLRPyt1Hyi78UOkMPWCGRxGcA9NVOE) | F2015 |
| 6. | **CS231n: CNNs for Visual Recognition** | Andrej Karpathy, Stanford University | [CS231n](http://cs231n.stanford.edu/2015/) | `None` | 2015 |
| 7. | **CS224d: Deep Learning for NLP** | Richard Socher, Stanford University | [CS224d](http://cs224d.stanford.edu) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLmImxx8Char8dxWB9LRqdpCTmewaml96q) | 2015 |
| 8. | **Bay Area Deep Learning** | Many legends, Stanford | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLrAXtmErZgOfMuxkACrYnD2fTgbzk2THW) | 2016 |
| 9. | **CS231n: CNNs for Visual Recognition** | Andrej Karpathy, Stanford University | [CS231n](http://cs231n.stanford.edu/2016/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC) <br/>[(Academic Torrent)](https://academictorrents.com/details/46c5af9e2075d9af06f280b55b65cf9b44eb9fe7) | 2016 |
| 10. | **Neural Networks** | Hugo Larochelle, Université de Sherbrooke | [Neural-Networks](http://info.usherbrooke.ca/hlarochelle/neural_networks/content.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH) <br/> [(Academic Torrent)](https://academictorrents.com/details/e046bca3bc837053d1609ef33d623ee5c5af7300) | 2016 |
| | | | | | |
| 11. | **CS224d: Deep Learning for NLP** | Richard Socher, Stanford University | [CS224d](http://cs224d.stanford.edu) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLlJy-eBtNFt4CSVWYqscHDdP58M3zFHIG) <br/>[(Academic Torrent)](https://academictorrents.com/details/dd9b74b50a1292b4b154094b7338ec1d66e8894d) | 2016 |
| 12. | **CS224n: NLP with Deep Learning** | Richard Socher, Stanford University | [CS224n](http://web.stanford.edu/class/cs224n/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6) | 2017 |
| 13. | **CS231n: CNNs for Visual Recognition** | Justin Johnson, Stanford University | [CS231n](http://cs231n.stanford.edu/2017/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv) <br/> [(Academic Torrent)](https://academictorrents.com/details/ed8a16ebb346e14119a03371665306609e485f13) | 2017 |
| 14. | **Topics in Deep Learning** | Ruslan Salakhutdinov, CMU | [10707](https://deeplearning-cmu-10707.github.io/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLpIxOj-HnDsOSL__Buy7_UEVQkyfhHapa) | F2017 |
| 15. | **Deep Learning Crash Course** | Leo Isikdogan, UT Austin | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLWKotBjTDoLj3rXBL-nEIPRN9V3a9Cx07) | 2017 |
| 16. | **Deep Learning and its Applications** | François Pitié, Trinity College Dublin | [EE4C16](https://github.com/frcs/4C16-2017) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLIo1iEzl5iB9NkulNR0X5vXN8AaEKglWT) | 2017 |
| 17. | **Deep Learning** | Andrew Ng, Stanford University | [CS230](http://cs230.stanford.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rOABXSygHTsbvUz4G_YQhOb) | 2018 |
| 18. | **UvA Deep Learning** | Efstratios Gavves, University of Amsterdam | [UvA-DLC](https://uvadlc.github.io/) | [Lecture-Videos](https://uvadlc.github.io/lectures-sep2018.html) | 2018 |
| 19. | **Advanced Deep Learning and Reinforcement Learning** | Many legends, DeepMind | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs) | 2018 |
| 20. | **Machine Learning** | Peter Bloem, Vrije Universiteit Amsterdam | [MLVU](https://mlvu.github.io/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLCof9EqayQgsORO3pFzeYZFz6cszYO0VJ) | 2018 |
| | | | | | |
| 21. | **Deep Learning** | Francois Fleuret, EPFL | [EE-59](https://fleuret.org/ee559-2018/dlc) | [Video-Lectures](https://fleuret.org/ee559-2018/dlc/#materials) | 2018 |
| 22. | **Introduction to Deep Learning** | Alexander Amini, Harini Suresh and others, MIT | [6.S191](http://introtodeeplearning.com/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI) <br/> [2017-version](https://www.youtube.com/playlist?list=PLkkuNyzb8LmxFutYuPA7B4oiMn6cjD6Rs) | 2017- 2021 |
| 23. | **Deep Learning for Self-Driving Cars** | Lex Fridman, MIT | [6.S094](https://selfdrivingcars.mit.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf) | 2017-2018 |
| 24. | **Introduction to Deep Learning** | Bhiksha Raj and many others, CMU | [11-485/785](http://deeplearning.cs.cmu.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLp-0K3kfddPwJBJ4Q8We-0yNQEG0fZrSa) | S2018 |
| 25. | **Introduction to Deep Learning** | Bhiksha Raj and many others, CMU | [11-485/785](http://deeplearning.cs.cmu.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLp-0K3kfddPyH44FP0dl0CbYprvTcfgOI) [Recitation-Inclusive](https://www.youtube.com/playlist?list=PLLR0_ZOlbfD6KDBq93G8-guHI-J1ICeFm) | F2018 |
| 26. | **Deep Learning Specialization** | Andrew Ng, Stanford | [DL.AI](https://www.deeplearning.ai/deep-learning-specialization/) | [YouTube-Lectures](https://www.youtube.com/channel/UCcIXc5mJsHVYTZR1maL5l9w/playlists) | 2017-2018 |
| 27. | **Deep Learning** | Ali Ghodsi, University of Waterloo | [STAT-946](https://uwaterloo.ca/data-analytics/teaching/deep-learning-2017) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLehuLRPyt1HxTolYUWeyyIoxDabDmaOSB) | F2017 |
| 28. | **Deep Learning** | Mitesh Khapra, IIT-Madras | [CS7015](https://www.cse.iitm.ac.in/~miteshk/CS7015.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLyqSpQzTE6M9gCgajvQbc68Hk_JKGBAYT) | 2018 |
| 29. | **Deep Learning for AI** | UPC Barcelona | [DLAI-2017](https://telecombcn-dl.github.io/2017-dlai/) <br/> [DLAI-2018](https://telecombcn-dl.github.io/2018-dlai/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-5eMc3HQTBagIUjKefjcTbnXC0wXC_vd) | 2017-2018 |
| 30. | **Deep Learning** | Alex Bronstein and Avi Mendelson, Technion | [CS236605](https://vistalab-technion.github.io/cs236605/info/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM0a6Z788YAZuqg2Ip-_dPLzEd33lZvP2) | 2018 |
| | | | | | |
| 31. | **MIT Deep Learning** | Many Researchers, Lex Fridman, MIT | [6.S094, 6.S091, 6.S093](https://deeplearning.mit.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf) | 2019 |
| 32. | **Deep Learning Book** companion videos | Ian Goodfellow and others | [DL-book slides](https://www.deeplearningbook.org/lecture_slides.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLsXu9MHQGs8df5A4PzQGw-kfviylC-R9b) | 2017 |
| 33. | **Theories of Deep Learning** | Many Legends, Stanford | [Stats-385](https://stats385.github.io/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLwUqqMt5en7fFLwSDa9V3JIkDam-WWgqy) <br/> (first 10 lectures) | F2017 |
| 34. | **Neural Networks** | Grant Sanderson | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi) | 2017-2018 |
| 35. | **CS230: Deep Learning** | Andrew Ng, Kian Katanforoosh, Stanford | [CS230](http://cs230.stanford.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rOABXSygHTsbvUz4G_YQhOb) | A2018 |
| 36. | **Theory of Deep Learning** | Lots of Legends, Canary Islands | [DALI'18](http://dalimeeting.org/dali2018/workshopTheoryDL.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLeCNfJWZKqxtWBnV8gefGqmmPgz9YF4LR) | 2018 |
| 37. | **Introduction to Deep Learning** | Alex Smola, UC Berkeley | [Stat-157](http://courses.d2l.ai/berkeley-stat-157/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZSO_6-bSqHQHBCoGaObUljoXAyyqhpFW) | S2019 |
| 38. | **Deep Unsupervised Learning** | Pieter Abbeel, UC Berkeley | [CS294-158](https://sites.google.com/view/berkeley-cs294-158-sp19/home) | [YouTube-Lectures](https://www.youtube.com/channel/UCf4SX8kAZM_oGcZjMREsU9w/videos) | S2019 |
| 39. | **Machine Learning** | Peter Bloem, Vrije Universiteit Amsterdam | [MLVU](https://mlvu.github.io/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLCof9EqayQgupldnTvqNy_BThTcME5r93) | 2019 |
| 40. | **Deep Learning on Computational Accelerators** | Alex Bronstein and Avi Mendelson, Technion | [CS236605](https://vistalab-technion.github.io/cs236605/lectures/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM0a6Z788YAa_WCy_V-q9NrGm5qQegZR5) | S2019 |
| | | | | | |
| 41. | **Introduction to Deep Learning** | Bhiksha Raj and many others, CMU | [11-785](http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Spring.2019/www) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLp-0K3kfddPzNdZPX4p0lVi6AcDXBofuf) | S2019 |
| 42. | **Introduction to Deep Learning** | Bhiksha Raj and many others, CMU | [11-785](https://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2019/www) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLp-0K3kfddPwz13VqV1PaMXF6V6dYdEsj) <br> [Recitations](https://www.youtube.com/playlist?list=PLp-0K3kfddPxf4T59JEQKv5UanLPVsxzz) | F2019 |
| 43. | **UvA Deep Learning** | Efstratios Gavves, University of Amsterdam | [UvA-DLC](https://uvadlc.github.io/) | [Lecture-Videos](https://uvadlc.github.io/lectures-apr2019.html) | S2019 |
| 44. | **Deep Learning** | Prabir Kumar Biswas, IIT Kgp | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLbRMhDVUMngc7NM-gDwcBzIYZNFSK2N1a) | 2019 |
| 45. | **Deep Learning and its Applications** | Aditya Nigam, IIT Mandi | [CS-671](http://faculty.iitmandi.ac.in/~aditya/cs671/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLKvX2d3IUq586Ic9gIhZj6ubpWV-OJfl4) | 2019 |
| 46. | **Neural Networks** | Neil Rhodes, Harvey Mudd College | [CS-152](https://www.cs.hmc.edu/~rhodes/cs152/schedule.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgEuVSRbAI9UIQSHGy4l01laA_12YOqEj) | F2019 |
| 47. | **Deep Learning** | Thomas Hofmann, ETH Zürich | [DAL-DL](http://www.da.inf.ethz.ch/teaching/2019/DeepLearning) | [Lecture-Videos](https://video.ethz.ch/lectures/d-infk/2019/autumn/263-3210-00L.html) | F2019 |
| 48. | **Deep Learning** | Milan Straka, Charles University | [NPFL114](https://ufal.mff.cuni.cz/courses/npfl114) | [Lecture-Videos](https://ufal.mff.cuni.cz/courses/npfl114/1718-summer) | S2019 |
| 49. | **UvA Deep Learning** | Efstratios Gavves, University of Amsterdam | [UvA-DLC-19](https://uvadlc.github.io/#lectures) | [Lecture-Videos](https://uvadlc.github.io/#lectures) | F2019 |
| 50. | **Artificial Intelligence: Principles and Techniques** | Percy Liang and Dorsa Sadigh, Stanford University | [CS221](https://stanford-cs221.github.io/autumn2019/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rO1NB9TD4iUZ3qghGEGtqNX) | F2019 |
| | | | | | |
| 51. | **Analyses of Deep Learning** | Lots of Legends, Stanford University | [STATS-385](https://stats385.github.io/) | [YouTube-Lectures](https://stats385.github.io/lecture_videos) | 2017-2019 |
| 52. | **Deep Learning Foundations and Applications** | Debdoot Sheet and Sudeshna Sarkar, IIT-Kgp | [AI61002](http://www.facweb.iitkgp.ac.in/~debdoot/courses/AI61002/Spr2020) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_AdDfjIMo6pZfwjZ0rJlkE_MIsmRW7Mh) | S2020 |
| 53. | **Designing, Visualizing, and Understanding Deep Neural Networks** | John Canny, UC Berkeley | [CS 182/282A](https://bcourses.berkeley.edu/courses/1487769/pages/cs-l-w-182-slash-282a-designing-visualizing-and-understanding-deep-neural-networks-spring-2020) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkFD6_40KJIwaO6Eca8kzsEFBob0nFvwm) | S2020 |
| 54. | **Deep Learning** | Yann LeCun and Alfredo Canziani, NYU | [DS-GA 1008](https://atcold.github.io/pytorch-Deep-Learning/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLLHTzKZzVU9eaEyErdV26ikyolxOsz6mq) | S2020 |
| 55. | **Introduction to Deep Learning** | Bhiksha Raj, CMU | [11-785](https://deeplearning.cs.cmu.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLp-0K3kfddPzCnS4CqKphh-zT3aDwybDe) | S2020 |
| 56. | **Deep Unsupervised Learning** | Pieter Abbeel, UC Berkeley | [CS294-158](https://sites.google.com/view/berkeley-cs294-158-sp20) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLwRJQ4m4UJjPiJP3691u-qWwPGVKzSlNP) | S2020 |
| 57. | **Machine Learning** | Peter Bloem, Vrije Universiteit Amsterdam | [VUML](https://mlvu.github.io/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLCof9EqayQgthR7IViXkAkUwel_rhxGYM) | S2020 |
| 58. | **Deep Learning (with PyTorch)** | Alfredo Canziani and Yann LeCun, NYU | [DS-GA 1008](https://atcold.github.io/pytorch-Deep-Learning/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLLHTzKZzVU9eaEyErdV26ikyolxOsz6mq) | S2020 |
| 59. | **Introduction to Deep Learning and Generative Models** | Sebastian Raschka, UW-Madison | [Stat453](http://pages.stat.wisc.edu/~sraschka/teaching/stat453-ss2020/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTKMiZHVd_2JkR6QtQEnml7swCnFBtq4P) | S2020 |
| 60. | **Deep Learning** | Andreas Maier, FAU Erlangen-Nürnberg | [DL-2020](https://www.video.uni-erlangen.de/course/id/925) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLpOGQvPCDQzvgpD3S0vTy7bJe2pf_yJFj) <br/>[Lecture-Videos](https://www.video.uni-erlangen.de/course/id/925) | SS2020 |
| | | | | | |
| 61. | **Introduction to Deep Learning** | Laura Leal-Taixé and Matthias Niessner, TU-München | [I2DL-IN2346](https://dvl.in.tum.de/teaching/i2dl-ss20/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLQ8Y4kIIbzy_OaXv86lfbQwPHSomk2o2e) | SS2020 |
| 62. | **Deep Learning** | Sargur Srihari, SUNY-Buffalo | [CSE676](https://cedar.buffalo.edu/~srihari/CSE676/) | [YouTube-Lectures-P1](https://www.youtube.com/playlist?list=PLmx4utxjUQD70k_NzeiSIXf30m54T_e1h) <br/>[YouTube-Lectures-P2](https://www.youtube.com/channel/UCUm7yUmVJyAbYh_0ppJ4H-g/videos) | 2020 |
| 63. | **Deep Learning Lecture Series** | Lots of Legends, DeepMind x UCL, London | [DLLS-20](https://deepmind.com/learning-resources/deep-learning-lecture-series-2020) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqYmG7hTraZCDxZ44o4p3N5Anz3lLRVZF) | 2020 |
| 64. | **MultiModal Machine Learning** | Louis-Philippe Morency & others, Carnegie Mellon University | [11-777 MMML-20](https://cmu-multicomp-lab.github.io/mmml-course/fall2020) | [YouTube-Lectures](https://www.youtube.com/channel/UCqlHIJTGYhiwQpNuPU5e2gg/videos) | F2020 |
| 65. | **Reliable and Interpretable Artificial Intelligence** | Martin Vechev, ETH Zürich | [RIAI-20](https://www.sri.inf.ethz.ch/teaching/riai2020) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLWjm4hHpaNg6c-W7JjNYDEC_kJK9oSp0Y) | F2020 |
| 66. | **Fundamentals of Deep Learning** | David McAllester, Toyota Technological Institute, Chicago | [TTIC-31230](https://mcallester.github.io/ttic-31230/Fall2020) | [YouTube-Lectures](https://www.youtube.com/channel/UCciVrtrRR3bQdaGbti9-hVQ/videos) | F2020 |
| 67. | **Foundations of Deep Learning** | Soheil Feize, University of Maryland, College Park | [CMSC 828W](http://www.cs.umd.edu/class/fall2020/cmsc828W) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLHgjs9ncvHi80UCSlSvQe-TK_uOyDv_Jf) | F2020 |
| 68. | **Deep Learning** | Andreas Geiger, Universität Tübingen | [DL-UT](https://uni-tuebingen.de/fakultaeten/mathematisch-naturwissenschaftliche-fakultaet/fachbereiche/informatik/lehrstuehle/autonomous-vision/teaching/lecture-deep-learning/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij3NTWIdtMbfvX7Z-4WEXRqD) | W20/21 |
| 69. | **Deep Learning** | Andreas Maier, FAU Erlangen-Nürnberg | [DL-FAU](https://www.fau.tv/course/id/1599) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLpOGQvPCDQzvJEPFUQ3mJz72GJ95jyZTh) | W20/21 |
| 70. | **Fundamentals of Deep Learning** | Terence Parr and Yannet Interian, University of San Francisco | [DL-Fundamentals](https://github.com/parrt/fundamentals-of-deep-learning) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLFCc_Fc116ikeol9CZcWWKqmrJljxhE4N) | S2021 |
| | | | | | |
| 71. | **Full Stack Deep Learning** | Pieter Abbeel, Sergey Karayev, UC Berkeley | [FS-DL](https://fullstackdeeplearning.com/spring2021) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL1T8fO7ArWlcWg04OgNiJy91PywMKT2lv) | S2021 |
| 72. | **Deep Learning: Designing, Visualizing, and Understanding DNNs** | Sergey Levine, UC Berkeley | [CS 182](https://cs182sp21.github.io) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_iWQOsE6TfVmKkQHucjPAoRtIJYt8a5A) | S2021 |
| 73. | **Deep Learning in the Life Sciences** | Manolis Kellis, MIT | [6.874](https://mit6874.github.io) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLypiXJdtIca5sxV7aE3-PS9fYX3vUdIOX) | S2021 |
| 74. | **Introduction to Deep Learning and Generative Models** | Sebastian Raschka, University of Wisconsin-Madison | [Stat 453](http://pages.stat.wisc.edu/~sraschka/teaching/stat453-ss2021) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTKMiZHVd_2KJtIXOW0zFhFfBaJJilH51) | S2021 |
| 75. | **Deep Learning** | Alfredo Canziani and Yann LeCun, NYU | [NYU-DLSP21](https://atcold.github.io/NYU-DLSP21) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLLHTzKZzVU9e6xUfG10TkTWApKSZCzuBI) | S2021 |
| 76. | **Applied Deep Learning** | Alexander Pacha, TU Wien | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLNsFwZQ_pkE8xNYTEyorbaWPN7nvbWyk1) | 2020-2021 |
| 77. | **Machine Learning** | Hung-yi Lee, National Taiwan University | [ML'21](https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLJV_el3uVTsNxV_IGauQZBHjBKZ26JHjd) | S2021 |
| 78. | **Mathematics of Deep Learning** | Lots of legends, FAU | [MoDL](https://www.fau.tv/course/id/878) | [Lecture-Videos](https://www.fau.tv/course/id/878) | 2019-21 |
| 79. | **Deep Learning** | Peter Bloem, Michael Cochez, and Jakub Tomczak, VU-Amsterdam | [DL](https://dlvu.github.io/) | [YouTube-Lectures](https://www.youtube.com/channel/UCYh1zKnwzrSjrO2Ae-akfTg/playlists) | 2020-21 |
| 80. | **Applied Deep Learning** | Maziar Raissi, UC Boulder | [ADL'21](https://github.com/maziarraissi/Applied-Deep-Learning) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoEMreTa9CNmuxQeIKWaz7AVFd_ZeAcy4) | 2021 |
| | | | | | |
| 81. | **An Introduction to Group Equivariant Deep Learning** | Erik J. Bekkers, Universiteit van Amsterdam | [UvAGEDL](https://uvagedl.github.io) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8FnQMH2k7jzPrxqdYufoiYVHim8PyZWd) | 2022 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :cupid: Machine Learning Fundamentals :cyclone: :boom:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course Webpage | Video Lectures | Year |
| ---- | ------------------------------------------------------------ | ------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ---------- |
| 1. | **Linear Algebra** | Gilbert Strang, MIT | [18.06 SC](http://ocw.mit.edu/18-06SCF11) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL221E2BBF13BECF6C) | 2011 |
| 2. | **Probability Primer** | Jeffrey Miller, Brown University | `mathematical monk` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL17567A1A3F5DB5E4) | 2011 |
| 3. | **Information Theory, Pattern Recognition, and Neural Networks** | David Mackay, University of Cambridge | [ITPRNN](http://www.inference.org.uk/mackay/itprnn) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLruBu5BI5n4aFpG32iMbdWoRVAA-Vcso6) | 2012 |
| 4. | **Linear Algebra Review** | Zico Kolter, CMU | [LinAlg](http://www.cs.cmu.edu/~zkolter/course/linalg/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGzL5ay6dmpyzRnbzQ__8v_t) | 2013 |
| 5. | **Probability and Statistics** | Michel van Biezen | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLX2gX-ftPVXUWwTzAkOhBdhplvz0fByqV) | 2015 |
| 6. | **Linear Algebra: An in-depth Introduction** | Pavel Grinfeld | `None` | [Part-1](https://www.youtube.com/playlist?list=PLlXfTHzgMRUKXD88IdzS14F4NxAZudSmv) <br/> [Part-2](https://www.youtube.com/playlist?list=PLlXfTHzgMRULWJYthculb2QWEiZOkwTSU) <br/> [Part-3](https://www.youtube.com/playlist?list=PLlXfTHzgMRUIqYrutsFXCOmiqKUgOgGJ5) <br/> [Part-4](https://www.youtube.com/playlist?list=PLlXfTHzgMRULZfrNCrrJ7xDcTjGr633mm) | 2015- 2017 |
| 7. | **Multivariable Calculus** | Grant Sanderson, Khan Academy | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLSQl0a2vh4HC5feHa6Rc5c0wbRTx56nF7) | 2016 |
| 8. | **Essence of Linear Algebra** | Grant Sanderson | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab) | 2016 |
| 9. | **Essence of Calculus** | Grant Sanderson | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZHQObOWTQDMsr9K-rj53DwVRMYO3t5Yr) | 2017-2018 |
| 10. | **Math Background for Machine Learning** | Geoff Gordon, CMU | [10-606](https://canvas.cmu.edu/courses/603/assignments/syllabus), [10-607](https://piazza.com/cmu/fall2017/1060610607/home) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL7y-1rk2cCsAqRtWoZ95z-GMcecVG5mzA) | F2017 |
| | | | | | |
| 11. | **Mathematics for Machine Learning** (Linear Algebra, Calculus) | David Dye, Samuel Cooper, and Freddie Page, IC-London | [MML](https://www.coursera.org/learn/linear-algebra-machine-learning) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLmAuaUS7wSOP-iTNDivR0ANKuTUhEzMe4) | 2018 |
| 12. | **Multivariable Calculus** | S.K. Gupta and Sanjeev Kumar, IIT-Roorkee | [MVC](https://nptel.ac.in/syllabus/111107108/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLq-Gm0yRYwTiQtK374NzhFOcQkWmJ71vx) | 2018 |
| 13. | **Engineering Probability** | Rich Radke, Rensselaer Polytechnic Institute | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuh62Q4Sv7BU1dN2G6ncyiMbML7OXh_Jx) | 2018 |
| 14. | **Matrix Methods in Data Analysis, Signal Processing, and Machine Learning** | Gilbert Strang, MIT | [18.065](https://ocw.mit.edu/courses/mathematics/18-065-matrix-methods-in-data-analysis-signal-processing-and-machine-learning-spring-2018) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLUl4u3cNGP63oMNUHXqIUcrkS2PivhN3k) | S2018 |
| 15. | **Information Theory** | Himanshu Tyagi, IISC, Bengaluru | [E2 201](https://ece.iisc.ac.in/~htyagi/course-E2201-2020.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgMDNELGJ1CYS-8dlMGPIaowVfeda4nUj) | 2018-20 |
| 16. | **Math Camp** | Mark Walker, University of Arizona | [UAMathCamp / Econ-519](http://www.u.arizona.edu/~mwalker/MathCamp2019.htm) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLcjqUUQt__ZGLhwUacPm7_RKs2eJNFwco) | 2019 |
| 17. | **A 2020 Vision of Linear Algebra** | Gilbert Strang, MIT | [VoLA](https://ocw.mit.edu/resources/res-18-010-a-2020-vision-of-linear-algebra-spring-2020/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLUl4u3cNGP61iQEFiWLE21EJCxwmWvvek) | S2020 |
| 18. | **Mathematics for Numerical Computing and Machine Learning** | Szymon Rusinkiewicz, Princeton University | [COS-302](https://www.cs.princeton.edu/courses/archive/fall20/cos302/outline.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL88aSuXxl_dSjC5pIG8bGkC5wsUPyW_Hh) | F2020 |
| 19. | **Essential Statistics for Neuroscientists** | Philipp Berens, Universität Klinikum Tübingen | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij0Gw5SLIrOA1dMYScCx4oXT) | 2020 |
| 20. | **Mathematics for Machine Learning** | Ulrike von Luxburg, Eberhard Karls Universität Tübingen | [Math4ML](https://www.tml.cs.uni-tuebingen.de/teaching/2020_maths_for_ml) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij1a6KdEy8PVE9zoCv6SlHRS) | W2020 |
| 21. | **Introduction to Causal Inference** | Brady Neal, Mila, Montréal | [CausalInf](https://www.bradyneal.com/causal-inference-course) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoazKTcS0Rzb6bb9L508cyJ1z-U9iWkA0) | F2020 |
| 22. | **Applied Linear Algebra** | Andrew Thangaraj, IIT Madras | [EE5120](http://www.ee.iitm.ac.in/~andrew/EE5120) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLyqSpQzTE6M-CHZU5RGfamcXOnuFyTOpm) | 2021 |
| 23. | **Mathematical Tools for Data Science** | Carlos Fernandez-Granda, New York University | [DS-GA 1013/Math-GA 2824](https://cds.nyu.edu/math-tools) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLBEf5mJtE6KtU6YlXFZD6lyYcHhW5pIlc) | 2021 |
| 24. | **Mathematics for Numerical Computing and Machine Learning** | Ryan Adams, Princeton University | [COS 302 / SML 305](https://www.cs.princeton.edu/courses/archive/spring21/cos302) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLCO4cUaBLHFEHo42HVIVWaSOvbAiH30uc) | 2021 |
| | | | | | |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :cupid: Optimization for Machine Learning :cyclone: :boom:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course Webpage | Video Lectures | Year |
| ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ---------- |
| 1. | **Convex Optimization** | Stephen Boyd, Stanford University | [ee364a](http://web.stanford.edu/class/ee364a/lectures.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL3940DD956CDF0622) | 2008 |
| 2. | **Introduction to Optimization** | Michael Zibulevsky, Technion | [CS-236330](https://sites.google.com/site/michaelzibulevsky/optimization-course) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLDFB2EEF4DDAFE30B) | 2009 |
| 3. | **Optimization for Machine Learning** | S V N Vishwanathan, Purdue University | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL09B0E8AFC69BE108) | 2011 |
| 4. | **Optimization** | Geoff Gordon & Ryan Tibshirani, CMU | [10-725](https://www.cs.cmu.edu/~ggordon/10725-F12/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL7y-1rk2cCsDOv91McLOnV4kExFfTB7dU) | 2012 |
| 5. | **Convex Optimization** | Joydeep Dutta, IIT-Kanpur | [cvx-nptel](https://nptel.ac.in/courses/111/104/111104068) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLbMVogVj5nJQHFqfiSdgaLCCWvDcm1W4l) | 2013 |
| 6. | **Foundations of Optimization** | Joydeep Dutta, IIT-Kanpur | [fop-nptel](https://nptel.ac.in/courses/111/104/111104071) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLbMVogVj5nJRRbofh3Qm3P6_NVyevDGD_) | 2014 |
| 7. | **Algorithmic Aspects of Machine Learning** | Ankur Moitra, MIT | [18.409-AAML](http://people.csail.mit.edu/moitra/409.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLB3sDpSRdrOvI1hYXNsa6Lety7K8FhPpx) | S2015 |
| 8. | **Numerical Optimization** | Shirish K. Shevade, IISC | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL6EA0722B99332589) | 2015 |
| 9. | **Convex Optimization** | Ryan Tibshirani, CMU | [10-725](https://www.stat.cmu.edu/~ryantibs/convexopt-S15/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLjbUi5mgii6BZBhJ9nW7eydgycyCOYeZ6) | S2015 |
| 10. | **Convex Optimization** | Ryan Tibshirani, CMU | [10-725](http://stat.cmu.edu/~ryantibs/convexopt-F15/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLjbUi5mgii6AGJW3La3BpEXe27n8v3biT) | F2015 |
| 11. | **Advanced Algorithms** | Ankur Moitra, MIT | [6.854-AA](http://people.csail.mit.edu/moitra/854.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL6ogFv-ieghdoGKGg2Bik3Gl1glBTEu8c) | S2016 |
| 12. | **Introduction to Optimization** | Michael Zibulevsky, Technion | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLBD31626529B0AC2A) | 2016 |
| 13. | **Convex Optimization** | Javier Peña & Ryan Tibshirani | [10-725/36-725](https://www.stat.cmu.edu/~ryantibs/convexopt-F16) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLjbUi5mgii6AVdvImLB9-Hako68p9MpIC) | F2016 |
| 14. | **Convex Optimization** | Ryan Tibshirani, CMU | [10-725](https://www.stat.cmu.edu/~ryantibs/convexopt-F18/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLpIxOj-HnDsMM7BCNGC3hPFU3DfCWfVIw) <br/> [Lecture-Videos](https://www.stat.cmu.edu/~ryantibs/convexopt-F18/) | F2018 |
| 15. | **Modern Algorithmic Optimization** | Yurii Nesterov, UCLouvain | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLEqoHzpnmTfAoUDqnmMly-KgyJ6ZM_axf) | 2018 |
| 16. | **Optimization, Foundations of Optimization** | Mark Walker, University of Arizona | [MathCamp-20](http://www.u.arizona.edu/~mwalker/MathCamp2020/MathCamp2020LectureNotes.htm) | [YouTube-Lectures-Found.](https://www.youtube.com/playlist?list=PLcjqUUQt__ZE6wp_c4-FcRdmzBvx8VN7O) <br/> [YouTube-Lectures-Opt](https://www.youtube.com/playlist?list=PLcjqUUQt__ZE0ZSTNRyBIgLJ5obPHdmxC) | 2019 - now |
| 17. | **Optimization: Principles and Algorithms** | Michel Bierlaire, École polytechnique fédérale de Lausanne (EPFL) | [opt-algo](https://transp-or.epfl.ch/books/optimization/html/about_book.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGzOpWwsaV6GgllT6njsi1G-) | 2019 |
| 18. | **Optimization and Simulation** | Michel Bierlaire, École polytechnique fédérale de Lausanne (EPFL) | [opt-sim](https://transp-or.epfl.ch/courses/OptSim2019/slides.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL10NOnsbP5Q5NlJ-Y6Eiup6RTSfkuj1TR) | S2019 |
| 19. | **Brazilian Workshop on Continuous Optimization** | Lots of Legends, Instituto Nacional de Matemática Pura e Aplicada, Rio de Janeiro | [cont. opt.](https://impa.br/eventos-do-impa/eventos-2019/xiii-brazilian-workshop-on-continuous-optimization) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLo4jXE-LdDTQVZhnLPq2W31vJ1fq1VSp6) | 2019 |
| 20. | **One World Optimization Seminar** | Lots of Legends, Universität Wien | [1W-OPT](https://owos.univie.ac.at) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLBQo-yZOMzLWEcAptzTYOnwXo9hhXrAa2) | 2020- |
| | | | | | |
| 21. | **Convex Optimization II** | Constantine Caramanis, UT Austin | [CVX-Optim-II](http://users.ece.utexas.edu/~cmcaram/constantine_caramanis/Announcements.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLXsmhnDvpjORzPelSDs0LSDrfJcqyLlZc) | S2020 |
| 22. | **Combinatorial Optimization** | Constantine Caramanis, UT Austin | [comb-op](https://caramanis.github.io/teaching/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLXsmhnDvpjORcTRFMVF3aUgyYlHsxfhNL) | F2020 |
| 23. | **Optimization Methods for Machine Learning and Engineering** | Julius Pfrommer, Jürgen Beyerer, Karlsruher Institut für Technologie (KIT) | [Optim-MLE](https://ies.anthropomatik.kit.edu/lehre_1487.php), [slides](https://drive.google.com/drive/folders/1WWVWV4vDBIOkjZc6uFY3nfXvpaOUHcfb) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdkTDauaUnQpzuOCZyUUZc0lxf4-PXNR5) | W2020-21 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :cupid: General Machine Learning :cyclone: :boom:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course Webpage | Video Lectures | Year |
| ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | --------- |
| 1. | **CS229: Machine Learning** | Andrew Ng, Stanford University | [CS229-old](https://see.stanford.edu/Course/CS229/) <br/> [CS229-new](http://cs229.stanford.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLA89DCFA6ADACE599) | 2007 |
| 2. | **Machine Learning** | Jeffrey Miller, Brown University | `mathematical monk` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLD0F06AA0D2E8FFBA) | 2011 |
| 3. | **Machine Learning** | Tom Mitchell, CMU | [10-701](http://www.cs.cmu.edu/~tom/10701_sp11/) | [Lecture-Videos](http://www.cs.cmu.edu/~tom/10701_sp11/lectures.shtml) | 2011 |
| 4. | **Machine Learning and Data Mining** | Nando de Freitas, University of British Columbia | [CPSC-340](https://www.cs.ubc.ca/~nando/340-2012/index.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLE6Wd9FR--Ecf_5nCbnSQMHqORpiChfJf) | 2012 |
| 5. | **Learning from Data** | Yaser Abu-Mostafa, CalTech | [CS156](http://work.caltech.edu/telecourse.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLD63A284B7615313A) | 2012 |
| 6. | **Machine Learning** | Rudolph Triebel, Technische Universität München | [Machine Learning](https://vision.in.tum.de/teaching/ws2013/ml_ws13) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTBdjV_4f-EIiongKlS9OKrBEp8QR47Wl) | 2013 |
| 7. | **Introduction to Machine Learning** | Alex Smola, CMU | [10-701](http://alex.smola.org/teaching/cmu2013-10-701/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZSO_6-bSqHQmMKwWVvYwKreGu4b4kMU9) | 2013 |
| 8. | **Introduction to Machine Learning** | Alex Smola and Geoffrey Gordon, CMU | [10-701x](http://alex.smola.org/teaching/cmu2013-10-701x/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZSO_6-bSqHR7NPk4k0zqdm2dPdraQZ_B) | 2013 |
| 9. | **Pattern Recognition** | Sukhendu Das, IIT-M and C.A. Murthy, ISI-Calcutta | [PR-NPTEL](https://nptel.ac.in/syllabus/106106046/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLbMVogVj5nJQJMLb2CYw9rry0d5s0TQRp) | 2014 |
| 10. | **An Introduction to Statistical Learning with Applications in R** | Trevor Hastie and Robert Tibshirani, Stanford | [stat-learn](https://lagunita.stanford.edu/courses/HumanitiesandScience/StatLearning/Winter2015/about) <br/> [R-bloggers](https://www.r-bloggers.com/in-depth-introduction-to-machine-learning-in-15-hours-of-expert-videos/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLOg0ngHtcqbPTlZzRHA2ocQZqB1D_qZ5V) | 2014 |
| | | | | | |
| 11. | **Introduction to Machine Learning** | Katie Malone, Sebastian Thrun, Udacity | [ML-Udacity](https://www.udacity.com/course/ud120) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLAwxTw4SYaPkQXg8TkVdIvYv4HfLG7SiH) | 2015 |
| 12. | **Introduction to Machine Learning** | Dhruv Batra, Virginia Tech | [ECE-5984](https://filebox.ece.vt.edu/~s15ece5984/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-fZD610i7yDUiNTFy-tEOxkTwg4mHZHu) | 2015 |
| 13. | **Statistical Learning - Classification** | Ali Ghodsi, University of Waterloo | [STAT-441](https://uwaterloo.ca/data-analytics/statistical-learning-classification) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLehuLRPyt1Hy-4ObWBK4Ab0xk97s6imfC) | 2015 |
| 14. | **Machine Learning Theory** | Shai Ben-David, University of Waterloo | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLPW2keNyw-usgvmR7FTQ3ZRjfLs5jT4BO) | 2015 |
| 15. | **Introduction to Machine Learning** | Alex Smola, CMU | [10-701](http://alex.smola.org/teaching/10-701-15/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZSO_6-bSqHTTV7w9u7grTXBHMH-mw3qn) | S2015 |
| 16. | **Statistical Machine Learning** | Larry Wasserman, CMU | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLjbUi5mgii6BWEUZf7He6nowWvGne_Y8r) | S2015 |
| 17. | **ML: Supervised Learning** | Michael Littman, Charles Isbell, Pushkar Kolhe, GaTech | [ML-Udacity](https://eu.udacity.com/course/machine-learning--ud262) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLAwxTw4SYaPl0N6-e1GvyLp5-MUMUjOKo) | 2015 |
| 18. | **ML: Unsupervised Learning** | Michael Littman, Charles Isbell, Pushkar Kolhe, GaTech | [ML-Udacity](https://eu.udacity.com/course/machine-learning-unsupervised-learning--ud741) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLAwxTw4SYaPmaHhu-Lz3mhLSj-YH-JnG7) | 2015 |
| 19. | **Advanced Introduction to Machine Learning** | Barnabas Poczos and Alex Smola | [10-715](https://www.cs.cmu.edu/~bapoczos/Classes/ML10715_2015Fall/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL4YhK0pT0ZhWBzSBkMGzpnPw6sf6Ma0IX) | F2015 |
| 20. | **Machine Learning** | Pedro Domingos, UWashington | [CSEP-546](https://courses.cs.washington.edu/courses/csep546/16sp/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTPQEx-31JXgtDaC6-3HxWcp7fq4N8YGr) | S2016 |
| | | | | | |
| 21. | **Statistical Machine Learning** | Larry Wasserman, CMU | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTB9VQq8WiaCBK2XrtYn5t9uuPdsNm7YE) | S2016 |
| 22. | **Machine Learning with Large Datasets** | William Cohen, CMU | [10-605](http://curtis.ml.cmu.edu/w/courses/index.php/Machine_Learning_with_Large_Datasets_10-605_in_Fall_2016) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLnfBqXRW5MRhPtfkadfwQ0VcuSi2IwEcW) | F2016 |
| 23. | **Math Background for Machine Learning** | Geoffrey Gordon, CMU | `10-600` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL7y-1rk2cCsA339crwXMWUaBRuLBvPBCg) | F2016 |
| 24. | **Statistical Learning - Classification** | Ali Ghodsi, University of Waterloo | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLehuLRPyt1HzXDemu7K4ETcF0Ld_B5adG) | 2017 |
| 25. | **Machine Learning** | Andrew Ng, Stanford University | [Coursera-ML](https://www.coursera.org/learn/machine-learning) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN) | 2017 |
| 26. | **Machine Learning** | Roni Rosenfield, CMU | [10-601](http://www.cs.cmu.edu/~roni/10601-f17/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL7k0r4t5c10-g7CWCnHfZOAxLaiNinChk) | 2017 |
| 27. | **Statistical Machine Learning** | Ryan Tibshirani, Larry Wasserman, CMU | [10-702](http://www.stat.cmu.edu/~ryantibs/statml/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLjbUi5mgii6B7A0nM74zHTOVQtTC9DaCv) | S2017 |
| 28. | **Machine Learning for Computer Vision** | Fred Hamprecht, Heidelberg University | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuRaSnb3n4kSQFyt8VBldsQ9pO9Xtu8rY) | F2017 |
| 29. | **Math Background for Machine Learning** | Geoffrey Gordon, CMU | [10-606 / 10-607](https://canvas.cmu.edu/courses/603/assignments/syllabus) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL7y-1rk2cCsAqRtWoZ95z-GMcecVG5mzA) | F2017 |
| 30. | **Data Visualization** | Ali Ghodsi, University of Waterloo | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLehuLRPyt1HzQoXEhtNuYTmd0aNQvtyAK) | 2017 |
| | | | | | |
| 31. | **Machine Learning for Physicists** | Florian Marquardt, Uni Erlangen-Nürnberg | [ML4Phy-17](http://www.thp2.nat.uni-erlangen.de/index.php/2017_Machine_Learning_for_Physicists,_by_Florian_Marquardt) | [Lecture-Videos](https://www.video.uni-erlangen.de/course/id/574) | 2017 |
| 32. | **Machine Learning for Intelligent Systems** | Kilian Weinberger, Cornell University | [CS4780](http://www.cs.cornell.edu/courses/cs4780/2018fa/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLl8OlHZGYOQ7bkVbuRthEsaLr7bONzbXS) | F2018 |
| 33. | **Statistical Learning Theory and Applications** | Tomaso Poggio, Lorenzo Rosasco, Sasha Rakhlin | [9.520/6.860](https://cbmm.mit.edu/lh-9-520) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLyGKBDfnk-iAtLO6oLW4swMiQGz4f2OPY) | F2018 |
| 34. | **Machine Learning and Data Mining** | Mike Gelbart, University of British Columbia | [CPSC-340](https://ubc-cs.github.io/cpsc340/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLWmXHcz_53Q02ZLeAxigki1JZFfCO6M-b) | 2018 |
| 35. | **Foundations of Machine Learning** | David Rosenberg, Bloomberg | [FOML](https://bloomberg.github.io/foml/#home) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLnZuxOufsXnvftwTB1HL6mel1V32w0ThI) | 2018 |
| 36. | **Introduction to Machine Learning** | Andreas Krause, ETH Zürich | [IntroML](https://las.inf.ethz.ch/teaching/introml-s18) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLzn6LN6WhlN273tsqyfdrBUsA-o5nUESV) | 2018 |
| 37. | **Machine Learning Fundamentals** | Sanjoy Dasgupta, UC-San Diego | [MLF-slides](https://drive.google.com/drive/folders/1l1rwv-jMihLZIpW0zTgGN9-snWOsA3M9) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_onPhFCkVQhUzcTVgQiC8W2ShZKWlm0s) | 2018 |
| 38. | **Machine Learning** | Jordan Boyd-Graber, University of Maryland | [CMSC-726](http://users.umiacs.umd.edu/~jbg/teaching/CMSC_726/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLegWUnz91WfsELyRcZ7d1GwAVifDaZmgo) | 2015-2018 |
| 39. | **Machine Learning** | Andrew Ng, Stanford University | [CS229](http://cs229.stanford.edu/syllabus-autumn2018.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU) | 2018 |
| 40. | **Machine Intelligence** | H.R.Tizhoosh, UWaterloo | [SYDE-522](https://kimialab.uwaterloo.ca/kimia/index.php/teaching/syde-522-machine-intelligence-2) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL4upCU5bnihwCX93Gv6AQnKmVMwx4AZoT) | 2019 |
| | | | | | |
| 41. | **Introduction to Machine Learning** | Pascal Poupart, University of Waterloo | [CS480/680](https://cs.uwaterloo.ca/~ppoupart/teaching/cs480-spring19) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdAoL1zKcqTW-uzoSVBNEecKHsnug_M0k) | S2019 |
| 42. | **Advanced Machine Learning** | Thorsten Joachims, Cornell University | [CS-6780](https://www.cs.cornell.edu/courses/cs6780/2019sp) | [Lecture-Videos](https://cornell.mediasite.com/Mediasite/Catalog/Full/f5d1cd3323f746cca80b2468bf97efd421) | S2019 |
| 43. | **Machine Learning for Structured Data** | Matt Gormley, Carnegie Mellon University | [10-418/10-618](http://www.cs.cmu.edu/~mgormley/courses/10418/schedule.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL4CxkUJbvNVihRKP4bXufvRLIWzeS-ieP) | F2019 |
| 44. | **Advanced Machine Learning** | Joachim Buhmann, ETH Zürich | [ML2-AML](https://ml2.inf.ethz.ch/courses/aml/) | [Lecture-Videos](https://video.ethz.ch/lectures/d-infk/2019/autumn/252-0535-00L.html) | F2019 |
| 45. | **Machine Learning for Signal Processing** | Vipul Arora, IIT-Kanpur | [MLSP](http://home.iitk.ac.in/~vipular/stuff/2019_MLSP.html) | [Lecture-Videos](https://iitk-my.sharepoint.com/:f:/g/personal/vipular_iitk_ac_in/Enf97NZfsoVBiyclC6yHfe4BlUv6CA4U8LPQQ4vtsDo_Xg) | F2019 |
| 46. | **Foundations of Machine Learning** | Animashree Anandkumar, CalTech | [CMS-165](http://tensorlab.cms.caltech.edu/users/anima/cms165-2019.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLVNifWxslHCA5GUh0o92neMiWiQiGVFqp) | 2019 |
| 47. | **Machine Learning for Physicists** | Florian Marquardt, Uni Erlangen-Nürnberg | `None` | [Lecture-Videos](https://www.video.uni-erlangen.de/course/id/778) | 2019 |
| 48. | **Applied Machine Learning** | Andreas Müller, Columbia University | [COMS-W4995](https://www.cs.columbia.edu/~amueller/comsw4995s19/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_pVmAaAnxIQGzQS2oI3OWEPT-dpmwTfA) | 2019 |
| 49. | **Fundamentals of Machine Learning over Networks** | Hossein Shokri-Ghadikolaei, KTH, Sweden | [MLoNs](https://sites.google.com/view/mlons/course-materials) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLWoZTd81WFCEBFrxDfNUrDnt3ABdLfg80) | 2019 |
| 50. | **Foundations of Machine Learning and Statistical Inference** | Animashree Anandkumar, CalTech | [CMS-165](http://tensorlab.cms.caltech.edu/users/anima/cms165-2020.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLVNifWxslHCDlbyitaLLYBOAEPbmF1AHg) | 2020 |
| | | | | | |
| 51. | **Machine Learning** | Rebecca Willett and Yuxin Chen, University of Chicago | [STAT 37710 / CMSC 35400](https://voices.uchicago.edu/willett/teaching/stats37710-cmsc35400-s20) | [Lecture-Videos](https://voices.uchicago.edu/willett/teaching/stats37710-cmsc35400-s20) | S2020 |
| 52. | **Introduction to Machine Learning** | Sanjay Lall and Stephen Boyd, Stanford University | [EE104/CME107](http://ee104.stanford.edu) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rN_Uy7_wmS051_q1d6akXmK) | S2020 |
| 53. | **Applied Machine Learning** | Andreas Müller, Columbia University | [COMS-W4995](https://www.cs.columbia.edu/~amueller/comsw4995s20/schedule/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_pVmAaAnxIRnSw6wiCpSvshFyCREZmlM) | S2020 |
| 54. | **Statistical Machine Learning** | Ulrike von Luxburg, Eberhard Karls Universität Tübingen | [Stat-ML](https://www.tml.cs.uni-tuebingen.de/teaching/2020_statistical_learning/index.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij2XCvrRzLokX6EoHWaGA2cC) | SS2020 |
| 55. | **Probabilistic Machine Learning** | Philipp Hennig, Eberhard Karls Universität Tübingen | [Prob-ML](https://uni-tuebingen.de/en/180804) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij1tHaOFY96m5uX3J21a6yNd) | SS2020 |
| 56. | **Machine Learning** | Sarath Chandar, PolyMTL, UdeM, Mila | [INF8953CE](http://sarathchandar.in/teaching/ml/fall2020) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLImtCgowF_ET0mi-AmmqQ0SIJUpWYaIOr) | F2020 |
| 57. | **Machine Learning** | Erik Bekkers, Universiteit van Amsterdam | [UvA-ML](https://uvaml1.github.io/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8FnQMH2k7jzhtVYbKmvrMyXDYMmgjj_n) | F2020 |
| 58. | **Neural Networks for Signal Processing** | Shayan Srinivasa Garani, Indian Institute of Science | [NN4SP](https://labs.dese.iisc.ac.in/pnsil/neural-networks-and-learning-systems-i-fall-2020/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgMDNELGJ1CZn1399dV7_U4VBNJflRsua) | F2020 |
| 59. | **Introduction to Machine Learning** | Dmitry Kobak, Universität Klinikum Tübingen | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij35ShKLDqccJSDntugY4FQT) | 2020 |
| 60. | **Machine Learning (PRML)** | Erik J. Bekkers, Universiteit van Amsterdam | [UvAML-1](https://uvaml1.github.io) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8FnQMH2k7jzhtVYbKmvrMyXDYMmgjj_n) | 2020 |
| | | | | | |
| 61. | **Machine Learning with Kernel Methods** | Julien Mairal and Jean-Philippe Vert, Inria/ENS Paris-Saclay, Google | [ML-Kernels](http://members.cbio.mines-paristech.fr/~jvert/svn/kernelcourse/course/2021mva/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLD93kGj6_EdrkNj27AZMecbRlQ1SMkp_o) | S2021 |
| 62. | **Continual Learning** | Vincenzo Lomonaco, Università di Pisa | [ContLearn'21](https://course.continualai.org/background/details) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLm6QXeaB-XkBfM5RgQP6wCR7Jegdg51Px) | 2021 |
| 63. | **Causality** | Christina Heinze-Deml, ETH Zurich | [Causal'21](https://stat.ethz.ch/lectures/ss21/causality.php#course_materials) | [YouTube-Lectures](https://stat.ethz.ch/lectures/ss21/causality.php#course_materials) | 2021 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :balloon: Reinforcement Learning :hotsprings: :video_game:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course Webpage | Video Lectures | Year |
| ---- | -------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------ |
| 1. | **A Short Course on Reinforcement Learning** | Satinder Singh, UMichigan | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGy4cIFQ5C36-1jMNLab80Ky) | 2011 |
| 2. | **Approximate Dynamic Programming** | Dimitri P. Bertsekas, MIT | [Lecture-Slides](http://adpthu2014.weebly.com/slides--materials.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLiCLbsFQNFAxOmVeqPhI5er1LGf2-L9I4) | 2014 |
| 3. | **Introduction to Reinforcement Learning** | David Silver, DeepMind | [UCL-RL](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ) | 2015 |
| 4. | **Reinforcement Learning** | Charles Isbell, Chris Pryby, GaTech; Michael Littman, Brown | [RL-Udacity](https://eu.udacity.com/course/reinforcement-learning--ud600) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLAwxTw4SYaPnidDwo9e2c7ixIsu_pdSNp) | 2015 |
| 5. | **Reinforcement Learning** | Balaraman Ravindran, IIT Madras | [RL-IITM](https://www.cse.iitm.ac.in/~ravi/courses/Reinforcement%20Learning.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLNdWVHi37UggQIVcaZcmtGGEQHY9W7d9D) | 2016 |
| 6. | **Deep Reinforcement Learning** | Sergey Levine, UC Berkeley | [CS-294](http://rail.eecs.berkeley.edu/deeprlcoursesp17/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkFD6_40KJIwTmSbCv9OVJB3YaO4sFwkX) | S2017 |
| 7. | **Deep Reinforcement Learning** | Sergey Levine, UC Berkeley | [CS-294](http://rail.eecs.berkeley.edu/deeprlcourse-fa17/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkFD6_40KJIznC9CDbVTjAF2oyt8_VAe3) | F2017 |
| 8. | **Deep RL Bootcamp** | Many legends, UC Berkeley | [Deep-RL](https://sites.google.com/view/deep-rl-bootcamp/lectures) | [YouTube-Lectures](https://www.youtube.com/channel/UCTgM-VlXKuylPrZ_YGAJHOw/videos) | 2017 |
| 9 | **Data Efficient Reinforcement Learning** | Lots of Legends, Canary Islands | [DERL-17](http://dalimeeting.org/dali2017/data-efficient-reinforcement-learning.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-tWvTpyd1VAvDpxukup6w-SuZQQ7e8K8) | 2017 |
| 10. | **Deep Reinforcement Learning** | Sergey Levine, UC Berkeley | [CS-294-112](http://rail.eecs.berkeley.edu/deeprlcourse-fa18/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkFD6_40KJIxJMR-j5A1mkxK26gh_qg37) | 2018 |
| | | | | | |
| 11. | **Reinforcement Learning** | Pascal Poupart, University of Waterloo | [CS-885](https://cs.uwaterloo.ca/~ppoupart/teaching/cs885-spring18/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdAoL1zKcqTXFJniO3Tqqn6xMBBL07EDc) | 2018 |
| 12. | **Deep Reinforcement Learning and Control** | Katerina Fragkiadaki and Tom Mitchell, CMU | [10-703](http://www.andrew.cmu.edu/course/10-703/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLpIxOj-HnDsNfvOwRKLsUobmnF2J1l5oV) | 2018 |
| 13. | **Reinforcement Learning and Optimal Control** | Dimitri Bertsekas, Arizona State University | [RLOC](http://web.mit.edu/dimitrib/www/RLbook.html) | [Lecture-Videos](http://web.mit.edu/dimitrib/www/RLbook.html) | 2019 |
| 14. | **Reinforcement Learning** | Emma Brunskill, Stanford University | [CS 234](http://web.stanford.edu/class/cs234/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rOSOPzutgyCTapiGlY2Nd8u) | 2019 |
| 15. | **Reinforcement Learning Day** | Lots of Legends, Microsoft Research, New York | [RLD-19](https://www.microsoft.com/en-us/research/event/reinforcement-learning-day-2019/#!agenda) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLD7HFcN7LXRe9nWEX3Up-RiCDi6-0mqVC) | 2019 |
| 16. | **New Directions in Reinforcement Learning and Control** | Lots of Legends, IAS, Princeton University | [NDRLC-19](https://www.math.ias.edu/ndrlc) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdDZb3TwJPZ61sGqd6cbWCmTc275NrKu3) | 2019 |
| 17. | **Deep Reinforcement Learning** | Sergey Levine, UC Berkeley | [CS 285](http://rail.eecs.berkeley.edu/deeprlcourse-fa19) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkFD6_40KJIwhWJpGazJ9VSj9CFMkb79A) | F2019 |
| 18. | **Deep Multi-Task and Meta Learning** | Chelsea Finn, Stanford University | [CS 330](https://cs330.stanford.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rMC6zfYmnD7UG3LVvwaITY5) | F2019 |
| 19. | **RL-Theory Seminars** | Lots of Legends, Earth | [RL-theory-sem](https://sites.google.com/view/rltheoryseminars/past-seminars) | [YouTube-Lectures](https://www.youtube.com/channel/UCfBFutC9RbKK6p--B4R9ebA/videos) | 2020 - |
| 20. | **Deep Reinforcement Learning** | Sergey Levine, UC Berkeley | [CS 285](http://rail.eecs.berkeley.edu/deeprlcourse-fa20) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_iWQOsE6TfURIIhCrlt-wj9ByIVpbfGc) | F2020 |
| | | | | | |
| 21. | **Introduction to Reinforcement Learning** | Amir-massoud Farahmand, Vector Institute, University of Toronto | [RL-intro](https://amfarahmand.github.io/IntroRL) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLCveiXxL2xNbiDq51a8iJwPRq2aO0ykrq) | S2021 |
| 22. | **Reinforcement Learning** | Antonio Celani and Emanuele Panizon, International Centre for Theoretical Physics | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLp0hSY2uBeP8q2G3mfHGVGvQFEMX0QRWM) | 2021 |
| 23. | **Computational Sensorimotor Learning** | Pulkit Agrawal, MIT-CSAIL | [6.884-CSL](https://pulkitag.github.io/6.884/lectures) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLwNwxAG-kBxPMTIs2fKWSsf7HqL2TcC78) | S2021 |
| 24. | **Reinforcement Learning** | Dimitri P. Bertsekas, ASU/MIT | [RL-21](http://web.mit.edu/dimitrib/www/RLbook.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLmH30BG15SIp79JRJ-MVF12uvB1qPtPzn) | S2021 |
| 25. | **Reinforcement Learning** | Sarath Chandar, École Polytechnique de Montréal | [INF8953DE](https://chandar-lab.github.io/INF8953DE) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLImtCgowF_ES_JdF_UcM60EXTcGZg67Ua) | F2021 |
| 26. | **Deep Reinforcement Learning** | Sergey Levine, UC Berkeley | [CS 285](http://rail.eecs.berkeley.edu/deeprlcourse) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_iWQOsE6TfXxKgI1GgyV1B_Xa0DxE5eH) | F2021 |
| 27. | **Reinforcement Learning Lecture Series** | Lots of Legends, DeepMind & UC London | [RL-series](https://deepmind.com/learning-resources/reinforcement-learning-series-2021) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqYmG7hTraZDVH599EItlEWsUOsJbAodm) | 2021 |
| 28. | **Reinforcement Learning** | Dimitri P. Bertsekas, ASU/MIT | [RL-22](http://web.mit.edu/dimitrib/www/RLbook.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLmH30BG15SIoXhxLldoio0BhsIY84YMDj) | S2022 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :loudspeaker: Probabilistic Graphical Models :sparkles:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ------------------------------------------------------------ | --------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------- |
| 1. | **Probabilistic Graphical Models** | Many Legends, MPI-IS | [MLSS-Tuebingen](http://mlss.tuebingen.mpg.de/2013/2013/speakers.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLL0GjJzXhAWTRiW_ynFswMaiLSa0hjCZ3) | 2013 |
| 2. | **Probabilistic Modeling and Machine Learning** | Zoubin Ghahramani, University of Cambridge | [WUST-Wroclaw](https://www.ii.pwr.edu.pl/~gonczarek/zoubin.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLwUOK5j_XOsdfVAGKErx9HqnrVZIuRbZ2) | 2013 |
| 3. | **Probabilistic Graphical Models** | Eric Xing, CMU | [10-708](http://www.cs.cmu.edu/~epxing/Class/10708/lecture.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLI3nIOD-p5aoXrOzTd1P6CcLavu9rNtC-) | 2014 |
| 4. | **Learning with Structured Data: An Introduction to Probabilistic Graphical Models** | Christoph Lampert, IST Austria | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLEqoHzpnmTfA0wc1JxjoVVOrJlx8W0rGf) | 2016 |
| 5. | **Probabilistic Graphical Models** | Nicholas Zabaras, University of Notre Dame | [PGM](https://www.zabaras.com/probabilistic-graphical-models) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLd-PuDzW85AcV4bgdu7wHPL37hm60W4RM) | 2018 |
| 6. | **Probabilistic Graphical Models** | Eric Xing, CMU | [10-708](https://sailinglab.github.io/pgm-spring-2019/) | [Lecture-Videos](https://sailinglab.github.io/pgm-spring-2019/lectures) <br> [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoZgVqqHOumTY2CAQHL45tQp6kmDnDcqn) | S2019 |
| 7. | **Probabilistic Graphical Models** | Eric Xing, CMU | [10-708](https://www.cs.cmu.edu/~epxing/Class/10708-20/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoZgVqqHOumTqxIhcdcpOAJOOimrRCGZn) | S2020 |
| 8. | **Uncertainty Modeling in AI** | Gim Hee Lee, National University of Singapura (NUS) | [CS 5340 - CH](https://www.coursehero.com/sitemap/schools/2652-National-University-of-Singapore/courses/7821096-CS5340/), [CS 5340-NB](https://github.com/clear-nus/CS5340-notebooks) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLxg0CGqViygOb9Eyc8IXM27doxjp2SK0H) | 2020-21 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
## :game_die: Bayesian Deep Learning :spades: :gem:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | --------------------------------------------------- | --------------------------------- | -------------------------------------------------------- | ------------------------------------------------------------ | -------- |
| 1. | **Bayesian Neural Networks, Variational Inference** | Lots of Legends | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGwUB4bFy183hwGhpL9ytvA1) | 2014-now |
| 2. | **Variational Inference** | Chieh Wu, Northeastern University | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdk2fd27CQzSd1sQ3kBYL4vtv6GjXvPsE) | 2015 |
| 3. | **Deep Learning and Bayesian Methods** | Lots of Legends, HSE Moscow | [DLBM-SS](http://deepbayes.ru/2018) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLe5rNUydzV9Q01vWCP9BV7NhJG3j7mz62) | 2018 |
| 4. | **Deep Learning and Bayesian Methods** | Lots of Legends, HSE Moscow | [DLBM-SS](http://deepbayes.ru/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLe5rNUydzV9QHe8VDStpU0o8Yp63OecdW) | 2019 |
| 5. | **Nordic Probabilistic AI** | Lots of Legends, NTNU, Trondheim | [ProbAI](https://github.com/probabilisticai/probai-2019) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLRy-VW__9hV8s--JkHXZvnd26KgjRP2ik) | 2019 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
## :movie_camera: Medical Imaging :camera: :video_camera:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ------------------------------------------------------------ | ------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ----- |
| 1. | **Medical Imaging Summer School** | Lots of Legends, Sicily | [MISS-14](http://iplab.dmi.unict.it/miss14/programme.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_VeUGLULXQtvcCdAgmvKoJ1k0Ajhz-Qu) | 2014 |
| 2. | **Biomedical Image Analysis Summer School** | Lots of Legends, Paris | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgSHH6boFf5uJAUT4ZRiAZc_ofXolkAGK) | 2015 |
| 3. | **Medical Imaging Summer School** | Lots of Legends, Sicily | [MISS-16](http://iplab.dmi.unict.it/miss16/programme.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTRCr47yTx5iXIYSneX3LKf16upaw59wa) | 2016 |
| 4. | **OPtical and UltraSound imaging - OPUS** | Lots of Legends, Université de Lyon, France | [OPUS'16](https://opus2016lyon.sciencesconf.org/resource/page/id/2) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL95ayoVLX8GdUKbxu-R9WqRWwzdWcKjti) | 2016 |
| 5. | **Medical Imaging Summer School** | Lots of Legends, Sicily | [MISS-18](http://iplab.dmi.unict.it/miss/programme.htm) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_VeUGLULXQux1dV4iA3XuMX6AueJmGGa) | 2018 |
| 6. | **Seminar on AI in Healthcare** | Lots of Legends, Stanford | [CS 522](http://cs522.stanford.edu/2018/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLYn-ZmPR1DtNQJ-ot-L2V2EgUEH6OH_7w) | 2018 |
| 7. | **Machine Learning for Healthcare** | David Sontag, Peter Szolovits, CSAIL MIT | [MLHC-19](https://mlhc19mit.github.io/) <br/>[MIT 6.S897](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-s897-machine-learning-for-healthcare-spring-2019/lecture-notes/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLUl4u3cNGP60B0PQXVQyGNdCyCTDU1Q5j) | S2019 |
| 8. | **Deep Learning and Medical Applications** | Lots of Legends, IPAM, UCLA | [DLM-20](https://www.ipam.ucla.edu/programs/workshops/deep-learning-and-medical-applications/?tab=schedule) | [Lecture-Videos](https://www.ipam.ucla.edu/programs/workshops/deep-learning-and-medical-applications/?tab=schedule) | 2020 |
| 9. | **Stanford Symposium on Artificial Intelligence in Medicine and Imaging** | Lots of Legends, Stanford AIMI | [AIMI-20](https://aimi.stanford.edu/news-events/aimi-symposium/agenda) | [YouTube-Lectures](https://www.youtube.com/watch?v=tR2ObiL4il8&list=PLe6zdIMe5B7IR0oDOobXBDBlYY1eqLYPx) | 2020 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
## :tada: Graph Neural Networks (Geometric DL) :confetti_ball: :balloon:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ------------------------------------------------------------ | ------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ----- |
| 1. | **Deep learning on graphs and manifolds** | Michael Bronstein, Technion | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLH39kM3nuavcVOUIIBraBNHjv-CwEd1uV) | 2017 |
| 2. | **Geometric Deep Learning on Graphs and Manifolds** | Michael Bronstein, Technische Universität München | `None` | [Lec-part1](https://streams.tum.de/Mediasite/Play/1f3b894e78f6400daa7885c886b936fb1d), <br/>[Lec-part2](https://streams.tum.de/Mediasite/Play/6039c846b2f84e7a806024c06e3f5c5c1d) | 2017 |
| 3. | **Eurographics Symposium on Geometry Processing - Graduate School** | Lots of Legends, SIGGRAPH, London | [SGP-2017](http://geometry.cs.ucl.ac.uk/SGP2017/?p=gradschool) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLOp-ngXvomHArqntgLVNzuJNdzNx3rDjZ) | 2017 |
| 4. | **Eurographics Symposium on Geometry Processing - Graduate School** | Lots of Legends, SIGGRAPH, Paris | [SGP-2018](https://sgp2018.sciencesconf.org/resource/page/id/7) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLvcoRb-DvAmgpp8LYw7dUvLxh-1Vrrm-v) | 2018 |
| 5. | **Analysis of Networks: Mining and Learning with Graphs** | Jure Leskovec, Stanford University | [CS224W](http://snap.stanford.edu/class/cs224w-2018/) | [Lecture-Videos](http://snap.stanford.edu/class/cs224w-2018/) | 2018 |
| 6. | **Machine Learning with Graphs** | Jure Leskovec, Stanford University | [CS224W](http://snap.stanford.edu/class/cs224w-2019/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-Y8zK4dwCrQyASidb2mjj_itW2-YYx6-) | 2019 |
| 7. | Geometry and Learning from Data in 3D and Beyond -**Geometry and Learning from Data Tutorials** | Lots of Legends, IPAM UCLA | [GLDT](http://www.ipam.ucla.edu/programs/workshops/geometry-and-learning-from-data-tutorials) | [Lecture-Videos](http://www.ipam.ucla.edu/programs/workshops/geometry-and-learning-from-data-tutorials/?tab=schedule) | 2019 |
| 8. | Geometry and Learning from Data in 3D and Beyond - **Geometric Processing** | Lots of Legends, IPAM UCLA | [GeoPro](http://www.ipam.ucla.edu/programs/workshops/workshop-i-geometric-processing/) | [Lecture-Videos](http://www.ipam.ucla.edu/programs/workshops/workshop-i-geometric-processing/?tab=schedule) | 2019 |
| 9. | Geometry and Learning from Data in 3D and Beyond - **Shape Analysis** | Lots of Legends, IPAM UCLA | [Shape-Analysis](http://www.ipam.ucla.edu/programs/workshops/workshop-ii-shape-analysis/) | [Lecture-Videos](http://www.ipam.ucla.edu/programs/workshops/workshop-ii-shape-analysis/?tab=schedule) | 2019 |
| 10. | Geometry and Learning from Data in 3D and Beyond - **Geometry of Big Data** | Lots of Legends, IPAM UCLA | [Geo-BData](http://www.ipam.ucla.edu/programs/workshops/workshop-iii-geometry-of-big-data) | [Lecture-Videos](http://www.ipam.ucla.edu/programs/workshops/workshop-iii-geometry-of-big-data/?tab=schedule) | 2019 |
| | | | | | |
| 11. | Geometry and Learning from Data in 3D and Beyond - **Deep Geometric Learning of Big Data and Applications** | Lots of Legends, IPAM UCLA | [DGL-BData](http://www.ipam.ucla.edu/programs/workshops/workshop-iv-deep-geometric-learning-of-big-data-and-applications) | [Lecture-Videos](http://www.ipam.ucla.edu/programs/workshops/workshop-iv-deep-geometric-learning-of-big-data-and-applications/?tab=schedule) | 2019 |
| 12. | **Israeli Geometric Deep Learning** | Lots of Legends, Israel | [iGDL-20](https://gdl-israel.github.io/schedule.html) | [Lecture-Videos](https://www.youtube.com/watch?v=c8_32IVn-sg) | 2020 |
| 13. | **Machine Learning for Graphs and Sequential Data** | Stephan Günnemann, Technische Universität München (TUM) | [MLGS-20](https://www.in.tum.de/en/daml/teaching/summer-term-2020/machine-learning-for-graphs-and-sequential-data/) | [Lecture-Videos](https://www.in.tum.de/daml/teaching/mlgs/) | S2020 |
| 14. | **Machine Learning with Graphs** | Jure Leskovec, Stanford | [CS224W](http://web.stanford.edu/class/cs224w) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn) | W2021 |
| 15. | **Geometric Deep Learning** - AMMI | Lots of Legends, Virtual | [GDL-AMMI](https://geometricdeeplearning.com/lectures) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLn2-dEmQeTfQ8YVuHBOvAhUlnIPYxkeu3) | 2021 |
| 16. | **Summer School on Geometric Deep Learning** - | Lots of Legends, DTU, DIKU & AAU | [GDL- DTU, DIKU & AAU](https://geometric-deep-learning.compute.dtu.dk) | [Lecture-Videos](https://geometric-deep-learning.compute.dtu.dk/talks-and-materials) | 2021 |
| 17. | **Graph Neural Networks** | Alejandro Ribeiro, University of Pennsylvania | [ESE 514](https://gnn.seas.upenn.edu) | [YouTube-Lectures](https://www.youtube.com/channel/UC_YPrqpiEqkeGOG1TCt0giQ/playlists) | F2021 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :hibiscus: Natural Language Processing :cherry_blossom: :sparkling_heart:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | --------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | --------- |
| 1. | **Computational Linguistics I** | Jordan Boyd-Graber, University of Maryland | [CMS-723](http://users.umiacs.umd.edu/~jbg/teaching/CMSC_723/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLegWUnz91WfuPebLI97-WueAP90JO-15i) | 2013-2018 |
| 2. | **Deep Learning for Natural Language Processing** | Nils Reimers, TU Darmstadt | [DL4NLP](https://github.com/UKPLab/deeplearning4nlp-tutorial) | [YouTube-Lectures](https://www.youtube.com/channel/UC1zCuTrfpjT6Sv2kJk-JkvA/videos) | 2015-2017 |
| 3. | **Deep Learning for Natural Language Processing** | Many Legends, DeepMind-Oxford | [DL-NLP](http://www.cs.ox.ac.uk/teaching/courses/2016-2017/dl/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL613dYIGMXoZBtZhbyiBqb0QtgK6oJbpm) | 2017 |
| 4. | **Deep Learning for Speech & Language** | UPC Barcelona | [DL-SL](https://telecombcn-dl.github.io/2017-dlsl/) | [Lecture-Videos](https://telecombcn-dl.github.io/2017-dlsl/) | 2017 |
| 5. | **Neural Networks for Natural Language Processing** | Graham Neubig, CMU | [NN4NLP](http://www.phontron.com/class/nn4nlp2017/) [Code](https://github.com/neubig/nn4nlp-code) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8PYTP1V4I8ABXzdqtOpB_eqBlVAz_xPT) | 2017 |
| 6. | **Neural Networks for Natural Language Processing** | Graham Neubig, CMU | [NN4-NLP](http://www.phontron.com/class/nn4nlp2018/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8PYTP1V4I8Ba7-rY4FoB4-jfuJ7VDKEE) | 2018 |
| 7. | **Deep Learning for NLP** | Min-Yen Kan, NUS | [CS-6101](https://www.comp.nus.edu.sg/~kanmy/courses/6101_1810/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLllwxvcS7ca5eD44KTCiT7Rmu_hFAafXB) | 2018 |
| 8. | **Neural Networks for Natural Language Processing** | Graham Neubig, CMU | [NN4NLP](http://www.phontron.com/class/nn4nlp2019/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8PYTP1V4I8Ajj7sY6sdtmjgkt7eo2VMs) | 2019 |
| 9. | **Natural Language Processing with Deep Learning** | Abigail See, Chris Manning, Richard Socher, Stanford University | [CS224n](http://web.stanford.edu/class/cs224n/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z) | 2019 |
| 10. | **Natural Language Understanding** | Bill MacCartney and Christopher Potts | [CS224U](https://web.stanford.edu/class/cs224u) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rObpMCir6rNNUlFAn56Js20) | S2019 |
| | | | | | |
| 11. | **Neural Networks for Natural Language Processing** | Graham Neubig, Carnegie Mellon University | [CS 11-747](http://www.phontron.com/class/nn4nlp2020/schedule.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8PYTP1V4I8CJ7nMxMC8aXv8WqKYwj-aJ) | S2020 |
| 12. | **Advanced Natural Language Processing** | Mohit Iyyer, UMass Amherst | [CS 685](https://people.cs.umass.edu/~miyyer/cs685) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLWnsVgP6CzadmQX6qevbar3_vDBioWHJL) | F2020 |
| 13. | **Machine Translation** | Philipp Koehn, Johns Hopkins University | [EN 601.468/668](http://mt-class.org/jhu/syllabus.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLQrCiUDqDLG0lQX54o9jB4phJ-SLI6ZBQ) | F2020 |
| 14. | **Neural Networks for NLP** | Graham Neubig, Carnegie Mellon University | [CS 11-747](http://www.phontron.com/class/nn4nlp2021) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL8PYTP1V4I8AkaHEJ7lOOrlex-pcxS-XV) | 2021 |
| 15. | **Deep Learning for Natural Language Processing** | Kyunghyun Cho, New York University | [DS-GA 1011](https://drive.google.com/drive/folders/1ykXBtophaY_65VHK_8yDzZQJwfJDD5Ve) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdH9u0f1XKW_s-c8EcgJpn_HJz5Jj1IRf) | F2021 |
| 16. | **Natural Language Processing with Deep Learning** | Chris Manning, Stanford University | [CS224n](https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1214/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ) | 2021 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :speaking_head: Automatic Speech Recognition :speech_balloon: :thought_balloon:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ---------------------------------------- | ------------------------------ | --------------------------------------------------- | ------------------------------------------------------------ | --------- |
| 1. | **Deep Learning for Speech & Language** | UPC Barcelona | [DL-SL](https://telecombcn-dl.github.io/2017-dlsl/) | [Lecture-Videos](https://telecombcn-dl.github.io/2017-dlsl/) <br/> [YouTube-Videos](https://www.youtube.com/playlist?list=PL-5DCZHuHZkWeF9ljIjoC_X5gHRLNtIkU) | 2017 |
| 2. | **Speech and Audio in the Northeast** | Many Legends, Google NYC | [SANE-15](http://www.saneworkshop.org/sane2015/) | [YouTube-Videos](https://www.youtube.com/playlist?list=PLBJWRPcgwk7sZOB4UTVilWWnRg84L9o5i) | 2015 |
| 3. | **Automatic Speech Recognition** | Samudra Vijaya K, TIFR | `None` | [YouTube-Videos](https://www.youtube.com/channel/UCHk6uq1Cr9J3k5KNmIsYUNw/videos) | 2016 |
| 4. | **Speech and Audio in the Northeast** | Many Legends, Google NYC | [SANE-17](http://www.saneworkshop.org/sane2017/) | [YouTube-Videos](https://www.youtube.com/playlist?list=PLBJWRPcgwk7tNLaBVu_S90ZQSblO3bwjg) | 2017 |
| 5. | **Speech and Audio in the Northeast** | Many Legends, Google Cambridge | [SANE-18](http://www.saneworkshop.org/sane2018/) | [YouTube-Videos](https://www.youtube.com/playlist?list=PLBJWRPcgwk7sjMANn8jqosyHIMe6DJhmn) | 2018 |
| | | | | | |
| -1. | **Deep Learning for Speech Recognition** | Many Legends, AoE | `None` | [YouTube-Videos](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGyFYCXV6YPWAKVOR2gmHnQd) | 2015-2018 |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :fire: Modern Computer Vision :camera_flash: :movie_camera:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ------------------------------------------------------------ | ------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ---------- |
| 1. | **Microsoft Computer Vision Summer School** - (classical) | Lots of Legends, Lomonosov Moscow State University | `None` | [YouTube-Videos](https://www.youtube.com/playlist?list=PLbwKcm5vdiSYU54xFUG1zoxQTulqvIcJu) <br> [Russian-mirror](https://www.youtube.com/playlist?list=PL-_cKNuVAYAUp0eCL7KO8QY4ETY3tIDFH) | 2011 |
| 2. | **Computer Vision** - (classical) | Mubarak Shah, UCF | [CAP-5415](http://crcv.ucf.edu/courses/CAP5415/Fall2012/index.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLd3hlSJsX_Imk_BPmB_H3AQjFKZS9XgZm) | 2012 |
| 3. | **Image and Multidimensional Signal Processing** - (classical) | William Hoff, Colorado School of Mines | [CSCI 510/EENG 510](http://inside.mines.edu/~whoff/courses/EENG510) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLyED3W677ALNv8Htn0f9Xh-AHe1aZPftv) | 2012 |
| 4. | **Computer Vision** - (classical) | William Hoff, Colorado School of Mines | [CSCI 512/EENG 512](http://inside.mines.edu/~whoff/courses/EENG512/index.htm) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL4B3F8D4A5CAD8DA3) | 2012 |
| 5. | **Image and Video Processing: From Mars to Hollywood with a Stop at the Hospital** | Guillermo Sapiro, Duke University | `None` | [YouTube-Videos](https://www.youtube.com/playlist?list=PLZ9qNFMHZ-A79y1StvUUqgyL-O0fZh2rs) | 2013 |
| 6. | **Multiple View Geometry** (classical) | Daniel Cremers, Technische Universität München | [mvg](https://vision.in.tum.de/teaching/ss2014/mvg2014) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTBdjV_4f-EJn6udZ34tht9EVIW7lbeo4) | 2013 |
| 7. | **Mathematical Methods for Robotics, Vision, and Graphics** | Justin Solomon, Stanford University | [CS-205A](http://graphics.stanford.edu/courses/cs205a/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLQ3UicqQtfNvQ_VzflHYKhAqZiTxOkSwi) | 2013 |
| 8. | **Computer Vision** - (classical) | Mubarak Shah, UCF | [CAP-5415](http://crcv.ucf.edu/courses/CAP5415/Fall2014/index.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLd3hlSJsX_ImKP68wfKZJVIPTd8Ie5u-9) | 2014 |
| 9. | **Computer Vision for Visual Effects** (classical) | Rich Radke, Rensselaer Polytechnic Institute | [ECSE-6969](https://www.ecse.rpi.edu/~rjradke/cvfxcourse.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuh62Q4Sv7BUJlKlt84HFqSWfW36MDd5a) | S2014 |
| 10. | **Autonomous Navigation for Flying Robots** | Juergen Sturm, Technische Universität München | [Autonavx](https://jsturm.de/wp/teaching/autonavx-slides/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTBdjV_4f-EKBCUs1HmMtsnXv4JUoFrzg) | 2014 |
| | | | | | |
| 11. | **SLAM - Mobile Robotics** | Cyrill Stachniss, Universitaet Freiburg | [RobotMapping](http://ais.informatik.uni-freiburg.de/teaching/ws13/mapping/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgnQpQtFTOGQrZ4O5QzbIHgl3b1JHimN_) | 2014 |
| 12. | **Computational Photography** | Irfan Essa, David Joyner, Arpan Chakraborty | [CP-Udacity](https://eu.udacity.com/course/computational-photography--ud955) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLAwxTw4SYaPn-unAWtRMleY4peSe4OzIY) | 2015 |
| 13. | **Introduction to Digital Image Processing** | Rich Radke, Rensselaer Polytechnic Institute | [ECSE-4540](https://www.ecse.rpi.edu/~rjradke/improccourse.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuh62Q4Sv7BUf60vkjePfcOQc8sHxmnDX) | S2015 |
| 14. | **Lectures on Digital Photography** | Marc Levoy, Stanford/Google Research | [LoDP](https://sites.google.com/site/marclevoylectures/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL7ddpXYvFXspUN0N-gObF1GXoCA-DA-7i) | 2016 |
| 15. | **Introduction to Computer Vision** (foundation) | Aaron Bobick, Irfan Essa, Arpan Chakraborty | [CV-Udacity](https://eu.udacity.com/course/introduction-to-computer-vision--ud810) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLAwxTw4SYaPnbDacyrK_kB_RUkuxQBlCm) | 2016 |
| 16. | **Computer Vision** | Syed Afaq Ali Shah, University of Western Australia | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLvqB6_mDBCdlnT84LK_NvbOqcXLlOTR8j) | 2016 |
| 17. | **Photogrammetry I & II** | Cyrill Stachniss, University of Bonn | [PG-I&II](https://www.ipb.uni-bonn.de/photogrammetry-i-ii/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgnQpQtFTOGRsi5vzy9PiQpNWHjq-bKN1) | 2016 |
| 18. | **Deep Learning for Computer Vision** | UPC Barcelona | [DLCV-16](http://imatge-upc.github.io/telecombcn-2016-dlcv/) <br/> [DLCV-17](https://telecombcn-dl.github.io/2017-dlcv/) <br/> [DLCV-18](https://telecombcn-dl.github.io/2018-dlcv/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-5eMc3HQTBbuaTFP4wsfD2Y2VqEfQcaP) | 2016-2018 |
| 19. | **Convolutional Neural Networks** | Andrew Ng, Stanford University | [DeepLearning.AI](https://www.deeplearning.ai/deep-learning-specialization/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLkDaE6sCZn6Gl29AoE31iwdVwSG-KnDzF) | 2017 |
| 20. | **Variational Methods for Computer Vision** | Daniel Cremers, Technische Universität München | [VMCV](https://vision.in.tum.de/teaching/ws2016/vmcv2016) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTBdjV_4f-EJ7A2iIH5L5ztqqrWYjP2RI) | 2017 |
| | | | | | |
| 21. | **Winter School on Computer Vision** | Lots of Legends, Israel Institute for Advanced Studies | [WS-CV](http://www.as.huji.ac.il/cse) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTn74Qx5mPsSniA5tt6W-o0OGYEeKScug) | 2017 |
| 22. | **Deep Learning for Visual Computing** | Debdoot Sheet, IIT-Kgp | [Nptel](https://onlinecourses.nptel.ac.in/noc18_ee08/preview) [Notebooks](https://github.com/iitkliv/dlvcnptel) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuv3GM6-gsE1Biyakccxb3FAn4wBLyfWf) | 2018 |
| 23. | **The Ancient Secrets of Computer Vision** | Joseph Redmon, Ali Farhadi | [TASCV](https://pjreddie.com/courses/computer-vision/) ; [TASCV-UW](https://courses.cs.washington.edu/courses/cse455/18sp/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLjMXczUzEYcHvw5YYSU92WrY8IwhTuq7p) | 2018 |
| 24. | **Modern Robotics** | Kevin Lynch, Northwestern Robotics | [modern-robot](http://hades.mech.northwestern.edu/index.php/Modern_Robotics) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLggLP4f-rq02vX0OQQ5vrCxbJrzamYDfx) | 2018 |
| 25. | **Digial Image Processing** | Alex Bronstein, Technion | [CS236860](https://vistalab-technion.github.io/cs236860/info/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM0a6Z788YAZOxUyWda9y3N_i2upIj1Ep) | 2018 |
| 26. | **Mathematics of Imaging** - Variational Methods and Optimization in Imaging | Lots of Legends, Institut Henri Poincaré | [Workshop-1](http://www.ihp.fr/sites/default/files/conf1-04_au_08_fevr-imaging2019.pdf) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL9kd4mpdvWcAzD5Aq-P1TrLLiYckrloxw) | 2019 |
| 27. | **Deep Learning for Video** | Xavier Giró, UPC Barcelona | [deepvideo](https://mcv-m6-video.github.io/deepvideo-2019/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL-5eMc3HQTBbPY-627Gornj09pZrNQgPD) | 2019 |
| 28. | **Statistical modeling for shapes and imaging** | Lots of Legends, Institut Henri Poincaré, Paris | [workshop-2](https://imaging-in-paris.github.io/semester2019/workshop2prog) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL9kd4mpdvWcAzD5Aq-P1TrLLiYckrloxw) | 2019 |
| 29. | **Imaging and machine learning** | Lots of Legends, Institut Henri Poincaré, Paris | [workshop-3](https://imaging-in-paris.github.io/semester2019/workshop3prog) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL9kd4mpdvWcAzD5Aq-P1TrLLiYckrloxw) | 2019 |
| 30. | **Computer Vision** | Jayanta Mukhopadhyay, IIT Kgp | [CV-nptel](https://nptel.ac.in/courses/106/105/106105216/) | [YouTube-Lectures](https://nptel.ac.in/courses/106/105/106105216/) | 2019 |
| | | | | | |
| 31. | **Deep Learning for Computer Vision** | Justin Johnson, UMichigan | [EECS 498-007](https://web.eecs.umich.edu/~justincj/teaching/eecs498/) | [Lecture-Videos](http://leccap.engin.umich.edu/leccap/site/jhygcph151x25gjj1f0) <br/> [YouTube-Lectures](https://www.youtube.com/playlist?list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r) | 2019 |
| 32. | **Sensors and State Estimation 2** | Cyrill Stachniss, University of Bonn | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgnQpQtFTOGQh_J16IMwDlji18SWQ2PZ6) | S2020 |
| 33. | **Computer Vision III: Detection, Segmentation and Tracking** | Laura Leal-Taixé, TU München | [CV3DST](https://dvl.in.tum.de/teaching/cv3dst-ss20/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLog3nOPCjKBneGyffEktlXXMfv1OtKmCs) | S2020 |
| 34. | **Advanced Deep Learning for Computer Vision** | Laura Leal-Taixé and Matthias Nießner, TU München | [ADL4CV](https://dvl.in.tum.de/teaching/adl4cv-ss20) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLog3nOPCjKBnjhuHMIXu4ISE4Z4f2jm39) | S2020 |
| 35. | **Computer Vision: Foundations** | Fred Hamprecht, Universität Heidelberg | [CVF](https://hci.iwr.uni-heidelberg.de/ial/cvf) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuRaSnb3n4kRAbnmiyGd77hyoGzO9wPde) | SS2020 |
| 36. | **MIT Vision Seminar** | Lots of Legends, MIT | [MIT-Vision](https://sites.google.com/view/visionseminar/past-talks) | [YouTube-Lectures](https://www.youtube.com/channel/UCLMiFkFyfcNnZs6iwYLPI9g/videos) | 2015-now |
| 37. | **TUM AI Guest Lectures** | Lots of Legends, Technische Universität München | [TUM-AI](https://niessner.github.io/TUM-AI-Lecture-Series) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLQ8Y4kIIbzy8kMlz7cRqz-BjbdyWsfLXt) | 2020 - now |
| 38. | **Seminar on 3D Geometry & Vision** | Lots of Legends, Virtual | [3DGV seminar](https://3dgv.github.io) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZk0jtN0g8e-xVTfsiV67q8Iz1cZO_FpV) | 2020 - now |
| 39. | **Event-based Robot Vision** | Guillermo Gallego, Technische Universität Berlin | [EVIS-SS20](https://sites.google.com/view/guillermogallego/teaching/event-based-robot-vision) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL03Gm3nZjVgUFYUh3v5x8jVonjrGfcal8) | 2020 - now |
| 40. | **Deep Learning for Computer Vision** | Vineeth Balasubramanian, IIT Hyderabad | [DL-CV'20](https://onlinecourses.nptel.ac.in/noc20_cs88/preview) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLyqSpQzTE6M_PI-rIz4O1jEgffhJU9GgG) | 2020 |
| | | | | | |
| 41. | **Deep Learning for Visual Computing** | Peter Wonka, KAUST, SA | `NOne` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLMpQLEui13s2DHbw6kTTxwQma8rehlfZE) | 2020 |
| 42. | **Computer Vision** | Yogesh Rawat, University of Central Florida | [CAP5415-CV](https://www.crcv.ucf.edu/courses/cap5415-fall-2020/schedule/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLd3hlSJsX_Ikm5il1HgmDB_z62BeoikFX) | F2020 |
| 43. | **Multimedia Signal Processing** | Mark Hasegawa-Johnson, UIUC | [ECE-417 MSP](https://courses.engr.illinois.edu/ece417/fa2020/) | [Lecture Videos](https://mediaspace.illinois.edu/channel/ECE%20417/26816181) | F2020 |
| 44. | **Computer Vision** | Andreas Geiger, Universität Tübingen | [Comp.Vis](https://uni-tuebingen.de/fakultaeten/mathematisch-naturwissenschaftliche-fakultaet/fachbereiche/informatik/lehrstuehle/autonomous-vision/lectures/computer-vision/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij35L2MHGzis8AEHz7mg381_) | S2021 |
| 45. | **3D Computer Vision** | Lee Gim Hee, National Univeristy of Singapura | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLxg0CGqViygP47ERvqHw_v7FVnUovJeaz) | 2021 |
| 46. | **Deep Learning for Computer Vision: Fundamentals and Applications** | T. Dekel et al., Weizmann Institute of Science | [DL4CV](https://dl4cv.github.io/schedule.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL_Z2_U9MIJdNgFM7-f2fZ9ZxjVRP_jhJv) | S2021 |
| 47. | **Current Topics in ML Methods in 3D and Geometric Deep Learning** | Animesh Garg & others, University of Toronto | [CSC 2547](http://www.pair.toronto.edu/csc2547-w21) | [YouTube-Lectures](https://www.youtube.com/channel/UCrsmAXnwu6sgccWevW12Dfg/videos) | 2021 |
| 48. | **First Principles of Computer Vision** | Shree K. Nayar, Columbia University | [FPCV](https://fpcv.cs.columbia.edu) | [YouTube-Lectures](https://www.youtube.com/channel/UCf0WB91t8Ky6AuYcQV0CcLw/videos) | 2021 |
| 49. | **Self-Driving Cars** | Andreas Geiger, Universität Tübingen | [SDC'21](https://uni-tuebingen.de/de/123611) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL05umP7R6ij321zzKXK6XCQXAaaYjQbzr) | W2021 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :star2: Boot Camps or Summer Schools :maple_leaf:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | ------------------------------------------------------- | -------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | --------- |
| 1. | **Deep Learning, Feature Learning** | Lots of Legends, IPAM UCLA | [GSS-2012](https://www.ipam.ucla.edu/programs/summer-schools/graduate-summer-school-deep-learning-feature-learning/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLHyI3Fbmv0SdzMHAy0aN59oYnLy5vyyTA) | 2012 |
| 2. | **Big Data Boot Camp** | Lots of Legends, Simons Institute | [Big Data](https://simons.berkeley.edu/workshops/schedule/316) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre13RmUC2AybRvVAxO5DEMIBH) | 2013 |
| 3. | **Machine Learning Summer School** | Lots of Legends, MPI-IS Tübingen | [MLSS-13](http://mlss.tuebingen.mpg.de/2013/2013/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqJm7Rc5-EXFv6RXaPZzzlzo93Hl0v91E) | 2013 |
| 4 | **Graduate Summer School: Computer Vision** | Lots of Legends, IPAM-UCLA | [GSS-CV](http://www.ipam.ucla.edu/programs/summer-schools/graduate-summer-school-computer-vision/) | [Video-Lectures](http://www.ipam.ucla.edu/programs/summer-schools/graduate-summer-school-computer-vision/?tab=schedule) | 2013 |
| 5. | **Machine Learning Summer School** | Lots of Legends, Reykjavik University | [MLSS-14](http://mlss2014.hiit.fi/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqdbxUnkqOw2nKn7VxYqIrKWcqRkQYOsF) | 2014 |
| 6. | **Machine Learning Summer School** | Lots of Legends, Pittsburgh | [MLSS-14](http://www.mlss2014.com) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLZSO_6-bSqHQCIYxE3ycGLXHMjK3XV7Iz) | 2014 |
| 7. | **Deep Learning Summer School** | Lots of Legends, Université de Montréal | [DLSS-15](https://sites.google.com/site/deeplearningsummerschool/home) | [YouTube-Lectures](http://videolectures.net/deeplearning2015_montreal/) | 2015 |
| 8. | **Biomedical Image Analysis Summer School** | Lots of Legends, CentraleSupelec, Paris | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgSHH6boFf5uJAUT4ZRiAZc_ofXolkAGK) | 2015 |
| 9. | **Mathematics of Signal Processing** | Lots of Legends, Hausdorff Institute for Mathematics | [SigProc](http://www.him.uni-bonn.de/signal-processing-2016/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLul8LCT3AJqSQo3lr5RbwxJ92RsgRuDtx) | 2016 |
| 10. | **Microsoft Research - Machine Learning Course** | S V N Vishwanathan and Prateek Jain MS-Research | `None` | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL34iyE0uXtxo7vPXGFkmm6KbgZQwjf9Kf) | 2016 |
| | | | | | |
| 11. | **Deep Learning Summer School** | Lots of Legends, Université de Montréal | [DL-SS-16](https://sites.google.com/site/deeplearningsummerschool2016/home) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL5bqIc6XopCbb-FvnHmD1neVlQKwGzQyR) | 2016 |
| 12. | **Lisbon Machine Learning School** | Lots of Legends, Instituto Superior Técnico, Portugal | [LxMLS-16](http://lxmls.it.pt/2016/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLToLj8M4ao-fymxXBIOU6sF1NGFLb5EiX) | 2016 |
| 13. | **Machine Learning Advances and Applications Seminar** | Lots of Legends, Fields Institute, University of Toronto | [MLAAS-16](http://www.fields.utoronto.ca/activities/16-17/machine-learning) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLfsVAYSMwskuQcRkuDApP40lX_i08d0QK) <br/> [Video-Lectures](http://www.fields.utoronto.ca/video-archive/event/2267) | 2016-2017 |
| 14. | **Machine Learning Advances and Applications Seminar** | Lots of Legends, Fields Institute, University of Toronto | [MLAAS-17](http://www.fields.utoronto.ca/activities/17-18/machine-learning) | [Video Lectures](http://www.fields.utoronto.ca/video-archive/event/2487) | 2017-2018 |
| 15. | **Machine Learning Summer School** | Lots of Legends, MPI-IS Tübingen | [MLSS-17](http://mlss.tuebingen.mpg.de/2017/index.html) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLqJm7Rc5-EXFUOvoYCdKikfck8YeUCnl9) | 2017 |
| 16. | **Representation Learning** | Lots of Legends, Simons Institute | [RepLearn](https://simons.berkeley.edu/workshops/abstracts/3750) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre13UNV4ztsWUXciUZ7x_ZDHz) | 2017 |
| 17. | **Foundations of Machine Learning** | Lots of Legends, Simons Institute | [ML-BootCamp](https://simons.berkeley.edu/workshops/abstracts/3748) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre11GbZWneln-VZDLHyejO7YD) | 2017 |
| 18. | **Optimization, Statistics, and Uncertainty** | Lots of Legends, Simons Institute | [Optim-Stats](https://simons.berkeley.edu/workshops/abstracts/4795) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre13ACD44z2FH-IVP1e8ip5JO) | 2017 |
| 19. | **Deep Learning: Theory, Algorithms, and Applications** | Lots of Legends, TU-Berlin | [DL: TAA](http://doc.ml.tu-berlin.de/dlworkshop2017/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLJOzdkh8T5kqCNV_v1w2tapvtJDZYiohW) | 2017 |
| 20. | **Deep Learning and Reinforcement Learning Summer School** | Lots of Legends, Université de Montréal | [DLRL-2017](https://mila.quebec/en/cours/deep-learning-summer-school-2017/) | [Lecture-videos](http://videolectures.net/deeplearning2017_montreal/) | 2017 |
| | | | | | |
| 21. | **Statistical Physics Methods in Machine Learning** | Lots of Legends, International Centre for Theoretical Sciences, TIFR | [SPMML](https://www.icts.res.in/discussion-meeting/SPMML2017) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL04QVxpjcnjhtL3IIVyFRMOgdhWtPn7YJ) | 2017 |
| 22. | **Lisbon Machine Learning School** | Lots of Legends, Instituto Superior Técnico, Portugal | [LxMLS-17](http://lxmls.it.pt/2017/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLToLj8M4ao-fuRfnzEJCCnvuW2_FeJ73N) | 2017 |
| 23. | **Interactive Learning** | Lots of Legends, Simons Institute, Berkeley | [IL-2017](https://simons.berkeley.edu/workshops/schedule/3749) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre10T2POF-WzXh0ckdpyvANUx) | 2017 |
| 24. | **Computational Challenges in Machine Learning** | Lots of Legends, Simons Institute, Berkeley | [CCML-17](https://simons.berkeley.edu/workshops/schedule/3751) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre12eXz4dnvc8oervo2_Af4iU) | 2017 |
| 25. | **Foundations of Data Science** | Lots of Legends, Simons Institute | [DS-BootCamp](https://simons.berkeley.edu/workshops/abstracts/6680) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre13r1Qrnrejj3f498-NurSf3) | 2018 |
| 26. | **Deep Learning and Bayesian Methods** | Lots of Legends, HSE Moscow | [DLBM-SS](http://deepbayes.ru/2018/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLe5rNUydzV9Q01vWCP9BV7NhJG3j7mz62) | 2018 |
| 27. | **New Deep Learning Techniques** | Lots of Legends, IPAM UCLA | [IPAM-Workshop](https://www.ipam.ucla.edu/programs/workshops/new-deep-learning-techniques/?tab=schedule) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLHyI3Fbmv0SdM0zXj31HWjG9t9Q0v2xYN) | 2018 |
| 28. | **Deep Learning and Reinforcement Learning Summer School** | Lots of Legends, University of Toronto | [DLRL-2018](https://dlrlsummerschool.ca/2018-event/) | [Lecture-videos](http://videolectures.net/DLRLsummerschool2018_toronto/) | 2018 |
| 29. | **Machine Learning Summer School** | Lots of Legends, Universidad Autónoma de Madrid, Spain | [MLSS-18](http://mlss.ii.uam.es/mlss2018/index.html) | [YouTube-Lectures](https://www.youtube.com/channel/UCbPJHr__eIor_7jFH3HmVHQ/videos) <br/> [Course-videos](http://mlss.ii.uam.es/mlss2018/speakers.html) | 2018 |
| 30. | **Theoretical Basis of Machine Learning** | Lots of Legends, International Centre for Theoretical Sciences, TIFR | [TBML-18](https://www.icts.res.in/discussion-meeting/tbml2018) | [Lecture-Videos](https://www.icts.res.in/discussion-meeting/tbml2018/talks) <br/> [YouTube-Videos](https://www.youtube.com/playlist?list=PL04QVxpjcnjj1DgnXxFBo2fkSju4r-ggr) | 2018 |
| | | | | | |
| 31. | **Polish View on Machine Learning** | Lots of Legends, Warsaw | [PLinML-18](https://plinml.mimuw.edu.pl/) | [YouTube-Videos](https://www.youtube.com/playlist?list=PLoaWrlj9TDhPcA6N9dZQ6GPXboYuumDRp) | 2018 |
| 32. | **Big Data Analysis in Astronomy** | Lots of Legends, Tenerife | [BDAA-18](http://research.iac.es/winterschool/2018/pages/book-ws2018.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGx42W5pSp3Itetp0u-PENtI) | 2018 |
| 33. | **Machine Learning Advances and Applications Seminar** | Lots of Legends, Fields Institute, University of Toronto | [MLASS](http://www.fields.utoronto.ca/activities/18-19/machine-learning) | [Video Lectures](http://www.fields.utoronto.ca/video-archive/event/2681) | 2018-2019 |
| 34. | **MIFODS- ML, Stats, ToC seminar** | Lots of Legends, MIT | [MIFODS-seminar](http://mifods.mit.edu/seminar.php) | [Lecture-videos](http://mifods.mit.edu/seminar.php) | 2018-2019 |
| 35. | **Learning Machines Seminar Series** | Lots of Legends, Cornell Tech | [LMSS](https://lmss.tech.cornell.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLycW2Yy79JuxbQZ9uHEu_NS3cGNomhL2A) | 2018-now |
| 36. | **Machine Learning Summer School** | Lots of Legends, South Africa | [MLSS'19](https://mlssafrica.com/programme-schedule/) | [YouTube-Lectures](https://www.youtube.com/channel/UC722CmQVgcLtxt_jXr3RyWg/videos) | 2019 |
| 37. | **Deep Learning Boot Camp** | Lots of Legends, Simons Institute, Berkeley | [DLBC-19](https://simons.berkeley.edu/workshops/schedule/10624) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre12c2Il9mNX0Cmp9Z4oFNrQh) | 2019 |
| 38. | **Frontiers of Deep Learning** | Lots of Legends, Simons Institute, Berkeley | [FoDL-19](https://simons.berkeley.edu/workshops/schedule/10627) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre11ekU7g-Z_qsvjDD8cT-hi9) | 2019 |
| 39. | **Mathematics of data: Structured representations for sensing, approximation and learning** | Lots of Legends, The Alan Turing Institute, London | [MoD-19](https://www.turing.ac.uk/sites/default/files/2019-05/agenda_9_3.pdf) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLuD_SqLtxSdX_w1Ztexpzl_EJgFQSkWez) | 2019 |
| 40. | **Deep Learning and Bayesian Methods** | Lots of Legends, HSE Moscow | [DLBM-SS](http://deepbayes.ru/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLe5rNUydzV9QHe8VDStpU0o8Yp63OecdW) | 2019 |
| | | | | | |
| 41. | **The Mathematics of Deep Learning and Data Science** | Lots of Legends, Isaac Newton Institute, Cambridge | [MoDL-DS](https://gateway.newton.ac.uk/event/ofbw46) | [Lecture-Videos](https://gateway.newton.ac.uk/event/ofbw46/programme) | 2019 |
| 42. | **Geometry of Deep Learning** | Lots of Legends, MSR Redmond | [GoDL](https://www.microsoft.com/en-us/research/event/ai-institute-2019) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLD7HFcN7LXRe30qq36It2XCljxc340O_d) | 2019 |
| 43. | **Deep Learning for Science School** | Many folks, LBNL, Berkeley | [DLfSS](https://dl4sci-school.lbl.gov/agenda) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL20S5EeApOSvfvEyhCPOUzU7zkBcR5-eL) | 2019 |
| 44. | **Emerging Challenges in Deep Learning** | Lots of Legends, Simons Institute, Berkeley | [ECDL](https://simons.berkeley.edu/workshops/schedule/10629) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLgKuh-lKre10BpafDrv0fg2VNUweWXWVd) | 2019 |
| 45. | **Full Stack Deep Learning** | Pieter Abbeel and many others, UC Berkeley | [FSDL-M19](https://fullstackdeeplearning.com/march2019) | [YouTube-Lectures-Day-1](https://www.youtube.com/playlist?list=PL1T8fO7ArWlcf3Hc4VMEVBlH8HZm_NbeB) <br/> [Day-2](https://www.youtube.com/playlist?list=PL1T8fO7ArWlf6TWwdstb-PcwlubnlrKrm) | 2019 |
| 46. | **Algorithmic and Theoretical aspects of Machine Learning** | Lots of legends, IIIT-Bengaluru | [ACM-ML](https://india.acm.org/education/machine-learning) <br/> [nptel](https://nptel.ac.in/courses/128/106/128106011/) | [YouTube-Lectures](https://nptel.ac.in/courses/128/106/128106011) | 2019 |
| 47. | **Deep Learning and Reinforcement Learning Summer School** | Lots of Legends, AMII, Edmonton, Canada | [DLRL-2019](https://dlrlsummerschool.ca/past-years) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLKlhhkvvU8-aXmPQZNYG_e-2nTd0tJE8v) | 2019 |
| 48. | **Mathematics of Machine Learning** - Summer Graduate School | Lots of Legends, University of Washington | [MoML-SGS](http://www.msri.org/summer_schools/866#schedule), [MoML-SS](http://mathofml.cs.washington.edu/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLTPQEx-31JXhguCush5J7OGnEORofoCW9) | 2019 |
| 49. | **Workshop on Theory of Deep Learning: Where next?** | Lots of Legends, IAS, Princeton University | [WTDL](https://www.math.ias.edu/wtdl) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdDZb3TwJPZ5dqqg_S-rgJqSFeH4DQqFQ) | 2019 |
| 50. | **Computational Vision Summer School** | Lots of Legends, Black Forest, Germany | [CVSS-2019](http://orga.cvss.cc/program-cvss-2019/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLeCNfJWZKqxsvidOlVLtWq9s7sIsX1QTC) | 2019 |
| | | | | | |
| 51. | **Learning under complex structure** | Lots of Legends, MIT | [LUCS](https://mifods.mit.edu/complex.php) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLM4Pv4KYYzGwhIHcaY6zYR7M9hhFO4Vud) | 2020 |
| 52. | **Machine Learning Summer School** | Lots of Legends, MPI-IS Tübingen (virtual) | [MLSS](http://mlss.tuebingen.mpg.de/2020/schedule.html) | [YouTube-Lectures](https://www.youtube.com/channel/UCBOgpkDhQuYeVVjuzS5Wtxw/videos) | SS2020 |
| 53. | **Eastern European Machine Learning Summer School** | Lots of Legends, Kraków, Poland (virtual) | [EEML](https://www.eeml.eu/program) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLaKY4p4V3gE1j01FOY2FeglV4jRntQj84) | S2020 |
| 54. | **Lisbon Machine Learning Summer School** | Lots of Legends, Lisbon, Portugal (virtual) | [LxMLS](http://lxmls.it.pt/2020/?page_id=19) | [YouTube-Lectures](https://www.youtube.com/channel/UCkVFZWgT1jR75UvSLGP9_mw) | S2020 |
| 55. | **Workshop on New Directions in Optimization, Statistics and Machine Learning** | Lots of Legends, Institute of Advanced Study, Princeton | [ML-Opt new dir.](https://www.ias.edu/video/workshop/2020/0415-16) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdDZb3TwJPZ4Ri6i0MIdesIEpYK4lx17Q) | 2020 |
| 56. | **Mediterranean Machine Learning School** | Lots of Legends, Italy (virtual) | [M2L-school](https://www.m2lschool.org/talks) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLF-wkqRv4u1YRbfnwN8cXXyrmXld-sked) | 2021 |
| 57. | **Mathematics of Machine Learning - One World Seminar** | Lots of Legends, Virtual | [1W-ML](https://sites.google.com/view/oneworldml/past-events) | [YouTube-Lectures](https://www.youtube.com/channel/UCz7WlgXs20CzugkfxhFCNFg/videos) | 2020 - now |
| 58. | **Deep Learning Theory Summer School** | Lots of Legends, Princeton University (virtual) | [DLT'21](https://deep-learning-summer-school.princeton.edu) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PL2mB9GGlueJj_FNjJ8RWgz4Nc_hCSXfMU) | 2021 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :bird: Bird's Eye view of A(G)I :eagle:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
| S.No | Course Name | University/Instructor(s) | Course WebPage | Lecture Videos | Year |
| ---- | -------------------------------------- | -------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | --------- |
| 1. | **Artificial General Intelligence** | Lots of Legends, MIT | [6.S099-AGI](https://agi.mit.edu/) | [Lecture-Videos](https://agi.mit.edu/) | 2018-2019 |
| 2. | **AI Podcast** | Lots of Legends, MIT | [AI-Pod](https://lexfridman.com/ai/) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLrAXtmErZgOdP_8GztsuKi9nrraNbKKp4) | 2018-2019 |
| 3. | **NYU - AI Seminars** | Lots of Legends, NYU | [modern-AI](https://engineering.nyu.edu/academics/departments/electrical-and-computer-engineering/ece-seminar-series/modern-artificial) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLhwo5ntex8iY9xhpSwWas451NgVuqBE7U) | 2017-now |
| 4. | **Deep Learning: Alchemy or Science?** | Lots of Legends, Institute for Advanced Study, Princeton | [DLAS](https://video.ias.edu/deeplearning/2019/0222) <br/> [Agenda](https://www.math.ias.edu/tml/dlasagenda) | [YouTube-Lectures](https://www.youtube.com/playlist?list=PLdDZb3TwJPZ7aAxhIHALBoh8l6-UxmMNP) | 2019 |
| | | | | | |
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### To-Do :running:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
:white_large_square: Optimization courses which form the foundation for ML, DL, RL
:white_large_square: Computer Vision courses which are DL & ML heavy
:white_large_square: Speech recognition courses which are DL heavy
:white_large_square: Structured Courses on Geometric, Graph Neural Networks
:white_large_square: Section on Autonomous Vehicles
:white_large_square: Section on Computer Graphics with ML/DL focus
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
[Go to Contents :arrow_heading_up:](https://github.com/kmario23/deep-learning-drizzle#contents)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### Around the Web :earth_asia:
- [Montreal.AI](http://www.montreal.ai/ai4all.pdf)
- [UPC-DLAI-2018](https://telecombcn-dl.github.io/2018-dlai/)
- [UPC-DLAI-2019](https://telecombcn-dl.github.io/dlai-2019/)
- [www.hashtagtechgeek.com](https://www.hashtagtechgeek.com/2019/10/250-machine-learning-deep-learning-videos-courseware.html)
- [UPC-Barcelona, IDL-2020](https://telecombcn-dl.github.io/idl-2020/)
- [UPC-DLAI-2020](https://telecombcn-dl.github.io/dlai-2020)
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### Contributions :pray:
If you find a course that fits in any of the above categories (i.e. DL, ML, RL, CV, NLP), **and** the course has lecture videos (with slides being optional), then please raise an issue or send a PR by updating the course according to the above format.
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### Support :moneybag:
**Optional:** If you're a kind Samaritan and want to support me, please do so if possible, for which I would eternally be thankful and, most importantly, your contribution imbues me with greater motivation to work, particularly in hard times :pray:
[](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=NT3EATS5N35WU)
Vielen lieben Dank! :blue_heart:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
### :gift_heart: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board::mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board::mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :mortar_board: :gift_heart:
:heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign::heavy_minus_sign:
|
3,426 | An NLP library for building bots, with entity extraction, sentiment analysis, automatic language identify, and so more | 
# NLP.js
[](https://github.com/axa-group/nlp.js/actions/workflows/node.js.yml)
[](https://coveralls.io/github/axa-group/nlp.js?branch=master)
[](https://www.npmjs.com/package/node-nlp)
[](https://www.npmjs.com/package/node-nlp)
[](https://sonarcloud.io/dashboard?id=axa-group_nlp.js)
[](https://sonarcloud.io/dashboard?id=axa-group_nlp.js)
[](https://sonarcloud.io/dashboard?id=axa-group_nlp.js)
[](https://sonarcloud.io/dashboard?id=axa-group_nlp.js)
*If you're looking for the version 3 docs, you can find them here* [Version 3](docs/v3/README.md)
"NLP.js" is a general natural language utility for nodejs. Currently supporting:
- Guess the language of a phrase
- Fast _Levenshtein_ distance of two strings
- Search the best substring of a string with less _Levenshtein_ distance to a given pattern.
- Get stemmers and tokenizers for several languages.
- Sentiment Analysis for phrases (with negation support).
- Named Entity Recognition and management, multi-language support, and acceptance of similar strings, so the introduced text does not need to be exact.
- Natural Language Processing Classifier, to classify an utterance into intents.
- NLP Manager: a tool able to manage several languages, the Named Entities for each language, the utterances, and intents for the training of the classifier, and for a given utterance return the entity extraction, the intent classification and the sentiment analysis. Also, it is able to maintain a Natural Language Generation Manager for the answers.
- 40 languages natively supported, 104 languages supported with BERT integration
- Any other language is supported through tokenization, even fantasy languages

## New in version 4`!`
Version 4 is very different from previous versions. Before this version, NLP.js was a monolithic library. The big changes:
- Now the library is split into small independent packages.
- So every language has its own package
- It provides a plugin system, so you can provide your own plugins or replace the existing ones.
- It provides a container system for the plugins, settings for the plugins and also pipelines
- A pipeline is code defining how the plugins interact. Usually it is linear: there is an input into the plugin, and this generates the input for the next one. As an example, the preparation of a utterance (the process to convert the utterance to a hashmap of stemmed features) is now a pipeline like this: `normalize -> tokenize -> removeStopwords -> stem -> arrToObj`
- There is a simple compiler for the pipelines, but they can also be built using a modified version of javascript and python (compilers are also included as plugins, so other languages can be added as a plugin).
- NLP.js now includes connectors, a connector is understood to be something that has at least 2 methods: `hear` and `say`. Examples of connectors included: Console Connector, Microsoft Bot Framework Connector and a Direct Line Offline Connector (this one allows you to build a web chatbot using the Microsoft Webchat, but without having to deploy anything in Azure).
- Some plugins can be registered by language, so for different languages different plugins will be used. Also some plugins, like NLU, can be registered not only by language but also by domain (a functional set of intents that can be trained separately)
- As an example of per-language/domain plugins, a Microsoft LUIS NLU plugin is provided. You can configure your chatbot to use the NLU from NLP.js for some languages/domains, and LUIS for other languages/domains.
- Having plugins and pipelines makes it possible to write chatbots by only modifying the configuration and the pipelines file, without modifying the code.
### TABLE OF CONTENTS
<!--ts-->
- [Installation](#installation)
- [QuickStart](docs/v4/quickstart.md)
- [Install the library](docs/v4/quickstart.md#install-the-library)
- [Create the code](docs/v4/quickstart.md#create-the-code)
- [Extracting the corpus into a file](docs/v4/quickstart.md#extracting-the-corpus-into-a-file)
- [Extracting the configuration into a file](docs/v4/quickstart.md#extracting-the-configuration-into-a-file)
- [Creating your first pipeline](docs/v4/quickstart.md#creating-your-first-pipeline)
- [Console Connector](docs/v4/quickstart.md#adding-your-first-connector)
- [Extending your bot with the pipeline](docs/v4/quickstart.md#extending-your-bot-with-the-pipeline)
- [Adding multiple languages](docs/v4/quickstart.md#adding-multilanguage)
- [Adding API and WebChat](docs/v4/quickstart.md#adding-api-and-webchat)
- [Using Microsoft Bot Framework](docs/v4/quickstart.md#using-microsoft-bot-framework)
- [Recognizing the bot name and the channel](docs/v4/quickstart.md#recognizing-the-bot-name-and-the-channel)
- [One bot per connector](docs/v4/quickstart.md#one-bot-per-connector)
- [Different port for Microsoft Bot Framework and Webchat](docs/v4/quickstart.md#different-port-for-microsoft-bot-framework-and-webchat)
- [Adding logic to an intent](docs/v4/quickstart.md#adding-logic-to-an-intent)
- [Mini FAQ](docs/v4/mini-faq.md)
- [Web and React Native](docs/v4/webandreact.md)
- [Preparing to generate a bundle](docs/v4/webandreact.md#preparing-to-generate-a-bundle)
- [Your first web NLP](docs/v4/webandreact.md#your-first-web-nlp)
- [Creating a distributable version](docs/v4/webandreact.md#creating-a-distributable-version)
- [Load corpus from URL](docs/v4/webandreact.md#load-corpus-from-url)
- [QnA](docs/v4/qna.md)
- [Install the library and the qna plugin](docs/v4/qna.md#install-the-library-and-the-qna-plugin)
- [Train and test a QnA file](docs/v4/qna.md#train-and-test-a-qna-file)
- [Extracting the configuration into a file](docs/v4/qna.md#extracting-the-configuration-into-a-file)
- [Exposing the bot with a Web and API](docs/v4/qna.md#exposing-the-bot-with-a-web-and-api)
- [NER Quickstart](docs/v4/ner-quickstart.md)
- [Install the needed packages](docs/v4/ner-quickstart.md#install-the-needed-packages)
- [Create the conf.json](docs/v4/ner-quickstart.md#create-the-confjson)
- [Create the corpus.json](docs/v4/ner-quickstart.md#create-the-corpusjson)
- [Create the heros.json](docs/v4/ner-quickstart.md#create-the-herosjson)
- [Create the index.js](docs/v4/ner-quickstart.md#create-the-indexjs)
- [Start the application](docs/v4/ner-quickstart.md#start-the-application)
- [Stored context](docs/v4/ner-quickstart.md#stored-context)
- [NeuralNetwork](docs/v4/neural.md)
- [Introduction](docs/v4/neural.md#introduction)
- [Installing](docs/v4/neural.md#installing)
- [Corpus Format](docs/v4/neural.md#corpus-format)
- [Example of use](docs/v4/neural.md#example-of-use)
- [Exporting trained model to JSON and importing](docs/v4/neural.md#exporting-trained-model-to-json-and-importing)
- [Options](docs/v4/neural.md#options)
- [Logger](docs/v4/logger.md)
- [Introduction](docs/v4/logger.md#introduction)
- [Default logger in @nlpjs/core](docs/v4/logger.md#default-logger-in-nlpjscore)
- [Default logger in @nlpjs/basic](docs/v4/logger.md#default-logger-in-nlpjsbasic)
- [Adding your own logger to the container](docs/v4/logger.md#adding-your-own-logger-to-the-container)
- [@nlpjs/emoji](docs/v4/emoji.md)
- [Introduction](docs/v4/emoji.md#introduction)
- [Installing](docs/v4/emoji.md#installing)
- [Example of use](docs/v4/emoji.md#example-of-use)
- [@nlpjs/console-connector](docs/v4/console-connector.md)
- [Installation](docs/v4/console-connector.md#installation)
- [Example of use inside NLP.js](docs/v4/console-connector.md#example-of-use-inside-nlpjs)
- [Example of use of the package](docs/v4/console-connector.md#example-of-use-of-the-package)
- [Example of use with @nlpjs/basic](docs/v4/console-connector.md#example-of-use-with-nlpjsbasic)
- [@nlpjs/similarity](docs/v4/similarity.md)
- [Installation](docs/v4/similarity.md#installation)
- [leven](docs/v4/similarity.md#leven)
- [similarity](docs/v4/similarity.md#similarity)
- [SpellCheck](docs/v4/similarity.md#spellcheck)
- [SpellCheck trained with words trained from a text](docs/v4/similarity.md#spellcheck-trained-with-words-trained-from-a-text)
- [@nlpjs/nlu](docs/v4/nlu.md)
- [Installation](docs/v4/nlu.md#installation)
- [NluNeural](docs/v4/nlu.md#nluneural)
- [DomainManager](docs/v4/nlu.md#domainmanager)
- [NluManager](docs/v4/nlu.md#nlumanager)
- [React Native](#react-native)
- [Example of use](#example-of-use)
- [False Positives](#false-positives)
- [Log Training Progress](#log-training-progress)
- [Benchmarking](docs/v3/benchmarking.md)
- [Language Support](docs/v4/language-support.md)
- [Supported languages](docs/v4/language-support.md#supported-languages)
- [Sentiment Analysis](docs/v4/language-support.md#sentiment-analysis)
- [Comparision with other NLP products](docs/v4/language-support.md#comparision-with-other-nlp-products)
- [Example with several languages](docs/v4/language-support.md#example-with-several-languages)
- [Language Guesser](docs/v3/language-guesser.md)
- [Similar Search](docs/v3/similar-search.md)
- [NLU](docs/v3/nlu-manager.md)
- [NLU Manager](docs/v3/nlu-manager.md)
- [Brain NLU](docs/v3/brain-nlu.md)
- [Bayes NLU](docs/v3/bayes-nlu.md)
- [Binary Relevance NLU](docs/v3/binary-relevance-nlu.md)
- [Logistic Regression NLU](docs/v3/logistic-regression-nlu.md)
- [NER Manager](docs/v4/ner-manager.md)
- [Enum Named Entities](docs/v4/ner-manager.md#enum-entities)
- [Regular Expression Named Entities](docs/v4/ner-manager.md#regex-entities)
- [Trim Named Entities](docs/v4/ner-manager.md#trim-entities)
- [Utterances with duplicated Entities](docs/v4/ner-manager.md#enum-entities)
- [Integration with Duckling](docs/v3/builtin-duckling.md)
- [Language support](docs/v3/builtin-duckling.md#language-support)
- [How to integrate with duckling](docs/v3/builtin-duckling.md#how-to-integrate-with-duckling)
- [Email Extraction](docs/v3/builtin-duckling.md#email-extraction)
- [Phone Number Extraction](docs/v3/builtin-duckling.md#phone-number-extraction)
- [URL Extraction](docs/v3/builtin-duckling.md#url-extraction)
- [Number Extraction](docs/v3/builtin-duckling.md#number-extraction)
- [Ordinal Extraction](docs/v3/builtin-duckling.md#ordinal-extraction)
- [Dimension Extraction](docs/v3/builtin-duckling.md#dimension-extraction)
- [Quantity Extraction](docs/v3/builtin-duckling.md#quantity-extraction)
- [Amount of Money Extraction](docs/v3/builtin-duckling.md#amount-of-money-extraction)
- [Date Extraction](docs/v3/builtin-duckling.md#date-extraction)
- [Builtin Entity Extraction](docs/v3/builtin-entity-extraction.md)
- [Email Extraction](docs/v3/builtin-entity-extraction.md#email-extraction)
- [IP Extraction](docs/v3/builtin-entity-extraction.md#ip-extraction)
- [Hashtag Extraction](docs/v3/builtin-entity-extraction.md#hashtag-extraction)
- [Phone Number Extraction](docs/v3/builtin-entity-extraction.md#phone-number-extraction)
- [URL Extraction](docs/v3/builtin-entity-extraction.md#url-extraction)
- [Number Extraction](docs/v3/builtin-entity-extraction.md#number-extraction)
- [Ordinal Extraction](docs/v3/builtin-entity-extraction.md#ordinal-extraction)
- [Percentage Extraction](docs/v3/builtin-entity-extraction.md#percentage-extraction)
- [Age Extraction](docs/v3/builtin-entity-extraction.md#age-extraction)
- [Currency Extraction](docs/v3/builtin-entity-extraction.md#currency-extraction)
- [Date Extraction](docs/v3/builtin-entity-extraction.md#date-extraction)
- [Duration Extraction](docs/v3/builtin-entity-extraction.md#duration-extraction)
- [Sentiment Analysis](docs/v3/sentiment-analysis.md)
- [NLP Manager](docs/v4/nlp-manager.md)
- [Load/Save](docs/v4/nlp-manager.md#loadsave)
- [Import/Export](docs/v4/nlp-manager.md#importexport)
- [Context](docs/v4/nlp-manager.md#context)
- [Intent Logic (Actions, Pipelines)](docs/v4/nlp-intent-logics.md)
- [Slot Filling](docs/v4/slot-filling.md)
- [Loading from Excel](docs/v3/loading-from-excel.md)
- [Microsoft Bot Framework](docs/v3/microsoft-bot-framework.md)
- [Introduction](docs/v3/microsoft-bot-framework.md#introduction)
- [Example of use](docs/v3/microsoft-bot-framework.md#example-of-use)
- [Recognizer and Slot filling](docs/v3/microsoft-bot-framework.md#recognizer-and-slot-filling)
- Languages
- [English](https://github.com/axa-group/nlp.js/blob/master/packages/lang-en/README.md)
- [Indonesian](https://github.com/axa-group/nlp.js/blob/master/packages/lang-id/README.md)
- [Italian](https://github.com/axa-group/nlp.js/blob/master/packages/lang-it/README.md)
- [Spanish](https://github.com/axa-group/nlp.js/blob/master/packages/lang-es/README.md)
- [Contributing](#contributing)
- [Contributors](#contributors)
- [Code of Conduct](#code-of-conduct)
- [Who is behind it](#who-is-behind-it)
- [License](#license)
<!--te-->
## Installation
If you're looking to use NLP.js in your Node application, you can install via NPM like so:
```bash
npm install node-nlp
```
## React Native
There is a version of NLP.js that works in React Native, so you can build chatbots that can be trained and executed on the mobile even without the internet. You can install it via NPM:
```bash
npm install node-nlp-rn
```
Some limitations:
- No Chinese
- The Japanese stemmer is not the complete one
- No Excel import
- No loading from a file, or saving to a file, but it can still import from JSON and export to JSON.
## Example of use
You can see a great example of use in the folder [`/examples/02-qna-classic`](https://github.com/axa-group/nlp.js/tree/master/examples/02-qna-classic). This example is able to train the bot and save the model to a file, so when the bot is started again, the model is loaded instead of being trained again.
You can start to build your NLP from scratch with a few lines:
```javascript
const { NlpManager } = require('node-nlp');
const manager = new NlpManager({ languages: ['en'], forceNER: true });
// Adds the utterances and intents for the NLP
manager.addDocument('en', 'goodbye for now', 'greetings.bye');
manager.addDocument('en', 'bye bye take care', 'greetings.bye');
manager.addDocument('en', 'okay see you later', 'greetings.bye');
manager.addDocument('en', 'bye for now', 'greetings.bye');
manager.addDocument('en', 'i must go', 'greetings.bye');
manager.addDocument('en', 'hello', 'greetings.hello');
manager.addDocument('en', 'hi', 'greetings.hello');
manager.addDocument('en', 'howdy', 'greetings.hello');
// Train also the NLG
manager.addAnswer('en', 'greetings.bye', 'Till next time');
manager.addAnswer('en', 'greetings.bye', 'see you soon!');
manager.addAnswer('en', 'greetings.hello', 'Hey there!');
manager.addAnswer('en', 'greetings.hello', 'Greetings!');
// Train and save the model.
(async() => {
await manager.train();
manager.save();
const response = await manager.process('en', 'I should go now');
console.log(response);
})();
```
This produces the following result in a console:
```bash
{ utterance: 'I should go now',
locale: 'en',
languageGuessed: false,
localeIso2: 'en',
language: 'English',
domain: 'default',
classifications:
[ { label: 'greetings.bye', value: 0.698219120207268 },
{ label: 'None', value: 0.30178087979273216 },
{ label: 'greetings.hello', value: 0 } ],
intent: 'greetings.bye',
score: 0.698219120207268,
entities:
[ { start: 12,
end: 14,
len: 3,
accuracy: 0.95,
sourceText: 'now',
utteranceText: 'now',
entity: 'datetime',
resolution: [Object] } ],
sentiment:
{ score: 1,
comparative: 0.25,
vote: 'positive',
numWords: 4,
numHits: 2,
type: 'senticon',
language: 'en' },
actions: [],
srcAnswer: 'Till next time',
answer: 'Till next time' }
```
## False Positives
By default, the neural network tries to avoid false positives. To achieve that, one of the internal processes is that words never seen by the network are represented as a feature that gives some weight to the `None` intent. So, if you try the previous example with "_I have to go_" it will return the `None` intent because 2 of the 4 words have never been seen while training.
If you don't want to avoid those false positives, and you feel more comfortable with classifications into the intents that you declare, then you can disable this behavior by setting the `useNoneFeature` to false:
```javascript
const manager = new NlpManager({ languages: ['en'], nlu: { useNoneFeature: false } });
```
## Log Training Progress
You can also add a log progress, so you can trace what is happening during the training.
You can log the progress to the console:
```javascript
const nlpManager = new NlpManager({ languages: ['en'], nlu: { log: true } });
```
Or you can provide your own log function:
```javascript
const logfn = (status, time) => console.log(status, time);
const nlpManager = new NlpManager({ languages: ['en'], nlu: { log: logfn } });
```
## Contributing
You can read the guide for how to contribute at [Contributing](CONTRIBUTING.md).
## Contributors
[](https://github.com/axa-group/nlp.js/graphs/contributors)
Made with [contributors-img](https://contributors-img.firebaseapp.com).
## Code of Conduct
You can read the Code of Conduct at [Code of Conduct](CODE_OF_CONDUCT.md).
## Who is behind it`?`
This project is developed by AXA Group Operations Spain S.A.
If you need to contact us, you can do it at the email [email protected]
## License
Copyright (c) AXA Group Operations Spain S.A.
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
3,427 | 💁♀️Your new best friend powered by an artificial neural network | <h1 align="center">
<br>
<img src="https://olivia-ai.org/img/icons/olivia-with-text.png" alt="Olivia's character" width="300">
<br>
</h1>
<h4 align="center">💁♀️ Your new best friend</h4>
<p align="center">
<a href="https://goreportcard.com/report/github.com/olivia-ai/olivia"><img src="https://goreportcard.com/badge/github.com/olivia-ai/olivia"></a>
<a href="https://godoc.org/github.com/olivia-ai/olivia"><img src="https://godoc.org/github.com/olivia-ai/olivia?status.svg" alt="GoDoc"></a>
<a href="https://app.fossa.io/projects/git%2Bgithub.com%2Folivia-ai%2Folivia?ref=badge_shield"><img src="https://app.fossa.io/api/projects/git%2Bgithub.com%2Folivia-ai%2Folivia.svg?type=shield"></a>
<a href="https://codecov.io/gh/olivia-ai/olivia"><img src="https://codecov.io/gh/olivia-ai/olivia/branch/master/graph/badge.svg" /></a>
<br>
<img src="https://github.com/olivia-ai/olivia/workflows/Code%20coverage/badge.svg">
<img src="https://github.com/olivia-ai/olivia/workflows/Docker%20CI/badge.svg">
<img src="https://github.com/olivia-ai/olivia/workflows/Format%20checker/badge.svg">
</p>
<p align="center">
<a href="https://twitter.com/oliv_ai"><img alt="Twitter Follow" src="https://img.shields.io/twitter/follow/oliv_ai"></a>
<a href="https://discord.gg/wXDwTdy"><img src="https://img.shields.io/discord/699567909235720224?label=Discord&style=social"></a>
</p>
<p align="center">
<a href="https://www.youtube.com/watch?v=JRSNnW05suo"><img width="250" src="https://i.imgur.com/kEKJjJn.png"></a>
</p>
<p align="center">
<a href="https://olivia-ai.org">Website</a> —
<a href="https://docs.olivia-ai.org">Documentation</a> —
<a href="#getting-started">Getting started</a> —
<a href="#introduction">Introduction</a> —
<a href="#translations">Translations</a> —
<a href="#contributors">Contributors</a> —
<a href="#license">License</a>
</p>
<p align="center">
⚠️ Please check the <strong><a href="https://github.com/olivia-ai/olivia/issues">Call for contributors</a></strong>
</p>
## Introduction
<p align="center">
<img alt="introduction" height="100" src="https://i.imgur.com/Ygm9CMc.png">
</p>
### Description
Olivia is an open-source chatbot built in Golang using Machine Learning technologies.
Its goal is to provide a free and open-source alternative to big services like DialogFlow.
You can chat with her by speaking (STT) or writing, she replies with a text message but you can enable her voice (TTS).
You can clone the project and customize it as you want using [GitHub](https://github.com/olivia-ai/olivia)
Try it on [her website!](https://olivia-ai.org)
### Why Olivia?
- The only chatbot project in Go that could be modulable and customizable.
- Using daily a privacy-friendly chatbot is great.
- The Website is a Progressive Web Application, which means you can add it to your phone and it seems like a native app!
## Getting started
### Installation
#### Login to Github
To get a personal access token from Github go to `Setings > Developer settings > Personal Access Tokens`
Click on Generate new Token and name it you MUST have read and write packages ticked on.
Then click Generate new token
Replace `TOKEN` with the Token that you just made.
```bash
$ export PAT=TOKEN
```
Login to Github (Note: change USERNAME to Gthub username)
```bash
$ echo $PAT | docker login docker.pkg.github.com -u USERNAME --password-stdin
```
#### Docker
<p align="center">
<img alt="docker installation" height="100" src="https://i.imgur.com/5NDCfF3.png">
</p>
Pull the image from GitHub Packages
```bash
$ docker pull docker.pkg.github.com/olivia-ai/olivia/olivia:latest
```
Then start it
```bash
$ docker run -d -e PORT=8080 -p 8080:8080 docker.pkg.github.com/olivia-ai/olivia/olivia:latest
```
You can just use the websocket of Olivia now.
To stop it, get the container id:
```bash
$ docker container ls
```
```bash
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
311b3abb963a olivia "./main" 7 minutes ago Up 7 minutes 0.0.0.0:8080->8080/tcp quizzical_mayer
```
and stop it
```bash
$ docker container stop 311b3abb963a
```
The app will automatically check for `res/datasets/training.json` file which contains the save of the neural network.
By default when you clone the repository from Github you have a stable save.
If you want to train a new model just delete this file and rerun the app.
#### GitHub
<p align="center">
<img height="100" src="https://i.imgur.com/RRPoP69.png">
</p>
Clone the project via GitHub:
```bash
$ git clone [email protected]:olivia-ai/olivia.git
```
Then download the dependencies
```bash
$ go mod download
```
And run it
```bash
$ go run main.go
```
### Frontend and Backend
To install the frontend and the backend together, please use the `docker-compose.yml` file:
```bash
$ docker-compose up
```
And all done!
## Architecture
<p align="center">
<img alt="architecture" height="85" src="https://i.imgur.com/95h8WIU.png">
<br>
<img src="https://i.imgur.com/G9BYf4Y.png">
</p>
## Translations
<p align="center">
<img alt="introduction" height="130" src="https://i.imgur.com/MDKbP0R.png">
</p>
### Languages supported
- <img src="https://i.imgur.com/URqxsb0.png" width="25"> English
- <img src="https://i.imgur.com/Oo5BNk0.png" width="25"> Spanish
- <img src="https://i.imgur.com/2DWxeF9.png" width="25"> Catalan
- <img src="https://i.imgur.com/0dVqbjf.png" width="25"> French
- <img src="https://i.imgur.com/sXLQp8e.png" width="25"> German
- <img src="https://i.imgur.com/DGNcrRF.png" width="25"> Italian
- <img src="https://i.imgur.com/kB0RoFZ.png" width="25"> Brazilian portuguese - not completed
### Coverage
The coverage of the translations is given [here](https://olivia-ai.org/dashboard/language).
To add a language please read [the documentation for that](https://docs.olivia-ai.org/translations.html).
## Contributors
<p align="center">
<img alt="docker installation" height="85" src="https://i.imgur.com/6xr2zdp.png">
</p>
### Contributing
Please refer to the [contributing file](.github/CONTRIBUTING.md)
### Code Contributors
Thanks to the people who contribute to Olivia.
[Contribute](.github/CONTRIBUTING.md)
<a href="https://github.com/olivia-ai/olivia/graphs/contributors"><img src="https://opencollective.com/olivia-ai/contributors.svg?width=950&button=false" /></a>
### Financial Contributors
Become a financial contributor and help Olivia growth.
Contribute on the GitHub page of [hugolgst](https://github.com/sponsors/hugolgst) ❤️
## License
<p align="center">
<img src="https://i.imgur.com/9Xxtchv.png" height="90">
</p>
[](https://app.fossa.io/projects/git%2Bgithub.com%2Folivia-ai%2Folivia?ref=badge_large)
<p align="center">
<img width="60" src="https://olivia-ai.org/img/icons/olivia.png">
<p>
<p align="center">
Made with ❤️ by <a href="https://github.com/hugolgst">Hugo Lageneste</a>
</p>

|
3,428 | This repositary is a combination of different resources lying scattered all over the internet. The reason for making such an repositary is to combine all the valuable resources in a sequential manner, so that it helps every beginners who are in a search of free and structured learning resource for Data Science. For Constant Updates Follow me in Twitter. | This Repository Consists of Free Resources needed for a person to learn Datascience from the beginning to end. This repository is divided into Four main Parts. They are
Part 1:- [Roadmap]
Part 2:- [Free Online Courses]
Part 3:- [500 Datascience Projects]
Part 4:- [100+ Free Machine Learning Books]
This repository is a combination of different resources lying scattered all over the internet. The reason for making such an repository is to combine all the valuable resources in a sequential manner, so that it helps every beginners who are in a search of free and structured learning resource for Datascience. I hope it helps many people who could not afford a large fee for their education. This repository shall be constantly updated on the basics of availability of new free resources.
If you guys like this Repo, please SHARE with everyone who are in need of these materials.
For Constant Updates, Follow me on [Twitter](https://twitter.com/therealsreehari)
Give a 🌟 if it's Useful and Share with other Datascience Enthusiasts.
# Data-Scientist-Roadmap (2021)
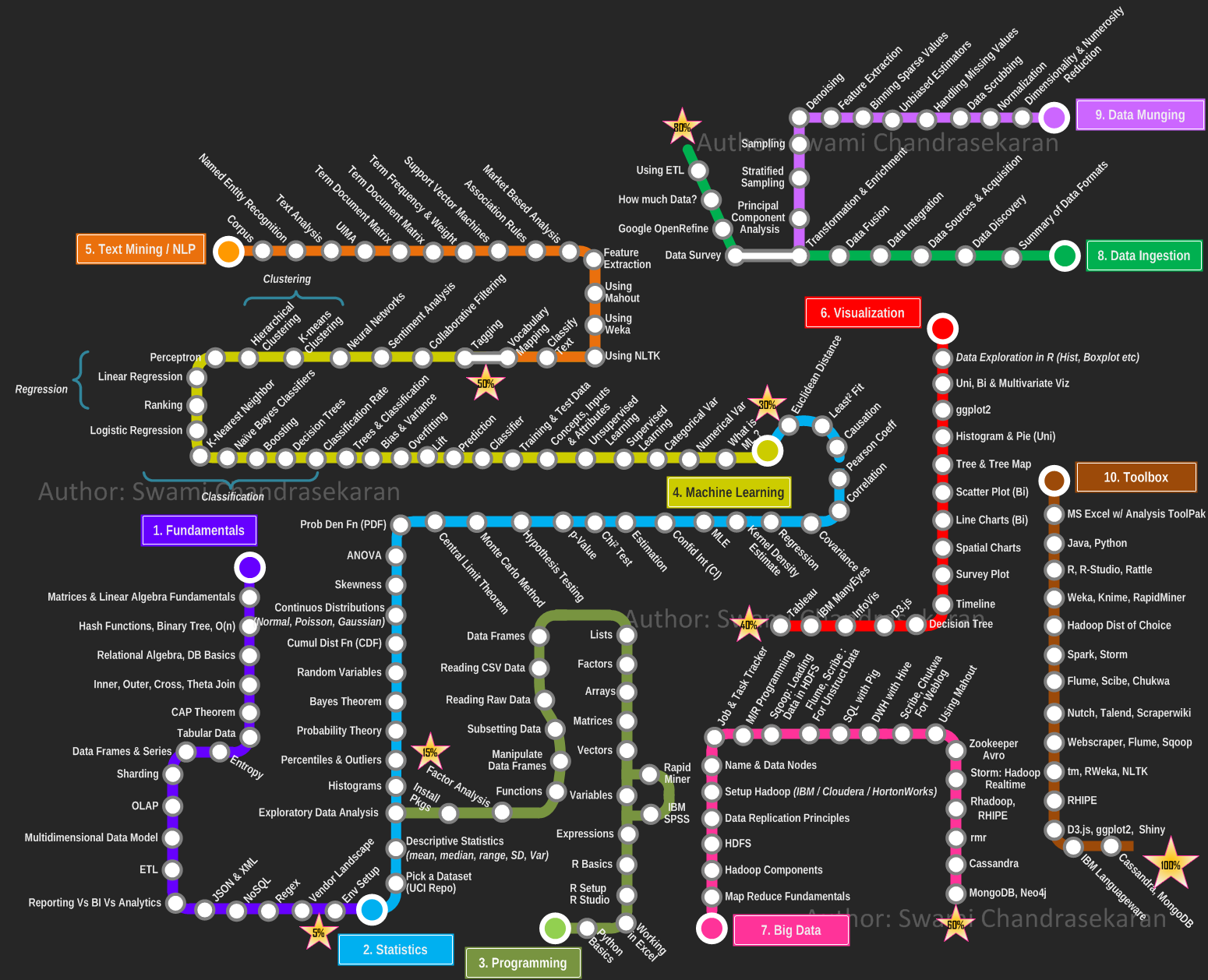
****
# 1_ Fundamentals
## 1_ Matrices & Algebra fundamentals
### About
In mathematics, a matrix is a __rectangular array of numbers, symbols, or expressions, arranged in rows and columns__. A matrix could be reduced as a submatrix of a matrix by deleting any collection of rows and/or columns.

### Operations
There are a number of basic operations that can be applied to modify matrices:
* [Addition](https://en.wikipedia.org/wiki/Matrix_addition)
* [Scalar Multiplication](https://en.wikipedia.org/wiki/Scalar_multiplication)
* [Transposition](https://en.wikipedia.org/wiki/Transpose)
* [Multiplication](https://en.wikipedia.org/wiki/Matrix_multiplication)
## 2_ Hash function, binary tree, O(n)
### Hash function
#### Definition
A hash function is __any function that can be used to map data of arbitrary size to data of fixed size__. One use is a data structure called a hash table, widely used in computer software for rapid data lookup. Hash functions accelerate table or database lookup by detecting duplicated records in a large file.

### Binary tree
#### Definition
In computer science, a binary tree is __a tree data structure in which each node has at most two children__, which are referred to as the left child and the right child.

### O(n)
#### Definition
In computer science, big O notation is used to __classify algorithms according to how their running time or space requirements grow as the input size grows__. In analytic number theory, big O notation is often used to __express a bound on the difference between an arithmetical function and a better understood approximation__.
## 3_ Relational algebra, DB basics
### Definition
Relational algebra is a family of algebras with a __well-founded semantics used for modelling the data stored in relational databases__, and defining queries on it.
The main application of relational algebra is providing a theoretical foundation for __relational databases__, particularly query languages for such databases, chief among which is SQL.
### Natural join
#### About
In SQL language, a natural junction between two tables will be done if :
* At least one column has the same name in both tables
* Theses two columns have the same data type
* CHAR (character)
* INT (integer)
* FLOAT (floating point numeric data)
* VARCHAR (long character chain)
#### mySQL request
SELECT <COLUMNS>
FROM <TABLE_1>
NATURAL JOIN <TABLE_2>
SELECT <COLUMNS>
FROM <TABLE_1>, <TABLE_2>
WHERE TABLE_1.ID = TABLE_2.ID
## 4_ Inner, Outer, Cross, theta-join
### Inner join
The INNER JOIN keyword selects records that have matching values in both tables.
#### Request
SELECT column_name(s)
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;
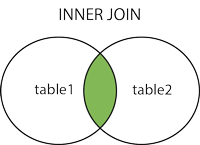
### Outer join
The FULL OUTER JOIN keyword return all records when there is a match in either left (table1) or right (table2) table records.
#### Request
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2 ON table1.column_name = table2.column_name;
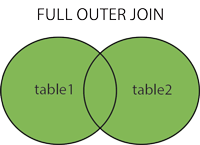
### Left join
The LEFT JOIN keyword returns all records from the left table (table1), and the matched records from the right table (table2). The result is NULL from the right side, if there is no match.
#### Request
SELECT column_name(s)
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;
### Right join
The RIGHT JOIN keyword returns all records from the right table (table2), and the matched records from the left table (table1). The result is NULL from the left side, when there is no match.
#### Request
SELECT column_name(s)
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;
## 5_ CAP theorem
It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
* Every read receives the most recent write or an error.
* Every request receives a (non-error) response – without guarantee that it contains the most recent write.
* The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
In other words, the CAP Theorem states that in the presence of a network partition, one has to choose between consistency and availability. Note that consistency as defined in the CAP Theorem is quite different from the consistency guaranteed in ACID database transactions.
## 6_ Tabular data
Tabular data are __opposed to relational__ data, like SQL database.
In tabular data, __everything is arranged in columns and rows__. Every row have the same number of column (except for missing value, which could be substituted by "N/A".
The __first line__ of tabular data is most of the time a __header__, describing the content of each column.
The most used format of tabular data in data science is __CSV___. Every column is surrounded by a character (a tabulation, a coma ..), delimiting this column from its two neighbours.
## 7_ Entropy
Entropy is a __measure of uncertainty__. High entropy means the data has high variance and thus contains a lot of information and/or noise.
For instance, __a constant function where f(x) = 4 for all x has no entropy and is easily predictable__, has little information, has no noise and can be succinctly represented . Similarly, f(x) = ~4 has some entropy while f(x) = random number is very high entropy due to noise.
## 8_ Data frames & series
A data frame is used for storing data tables. It is a list of vectors of equal length.
A series is a series of data points ordered.
## 9_ Sharding
*Sharding* is **horizontal(row wise) database partitioning** as opposed to **vertical(column wise) partitioning** which is *Normalization*
Why use Sharding?
1. Database systems with large data sets or high throughput applications can challenge the capacity of a single server.
2. Two methods to address the growth : Vertical Scaling and Horizontal Scaling
3. Vertical Scaling
* Involves increasing the capacity of a single server
* But due to technological and economical restrictions, a single machine may not be sufficient for the given workload.
4. Horizontal Scaling
* Involves dividing the dataset and load over multiple servers, adding additional servers to increase capacity as required
* While the overall speed or capacity of a single machine may not be high, each machine handles a subset of the overall workload, potentially providing better efficiency than a single high-speed high-capacity server.
* Idea is to use concepts of Distributed systems to achieve scale
* But it comes with same tradeoffs of increased complexity that comes hand in hand with distributed systems.
* Many Database systems provide Horizontal scaling via Sharding the datasets.
## 10_ OLAP
Online analytical processing, or OLAP, is an approach to answering multi-dimensional analytical (MDA) queries swiftly in computing.
OLAP is part of the __broader category of business intelligence__, which also encompasses relational database, report writing and data mining. Typical applications of OLAP include ___business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas, with new applications coming up, such as agriculture__.
The term OLAP was created as a slight modification of the traditional database term online transaction processing (OLTP).
## 11_ Multidimensional Data model
## 12_ ETL
* Extract
* extracting the data from the multiple heterogenous source system(s)
* data validation to confirm whether the data pulled has the correct/expected values in a given domain
* Transform
* extracted data is fed into a pipeline which applies multiple functions on top of data
* these functions intend to convert the data into the format which is accepted by the end system
* involves cleaning the data to remove noise, anamolies and redudant data
* Load
* loads the transformed data into the end target
## 13_ Reporting vs BI vs Analytics
## 14_ JSON and XML
### JSON
JSON is a language-independent data format. Example describing a person:
{
"firstName": "John",
"lastName": "Smith",
"isAlive": true,
"age": 25,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021-3100"
},
"phoneNumbers": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "office",
"number": "646 555-4567"
},
{
"type": "mobile",
"number": "123 456-7890"
}
],
"children": [],
"spouse": null
}
## XML
Extensible Markup Language (XML) is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
<CATALOG>
<PLANT>
<COMMON>Bloodroot</COMMON>
<BOTANICAL>Sanguinaria canadensis</BOTANICAL>
<ZONE>4</ZONE>
<LIGHT>Mostly Shady</LIGHT>
<PRICE>$2.44</PRICE>
<AVAILABILITY>031599</AVAILABILITY>
</PLANT>
<PLANT>
<COMMON>Columbine</COMMON>
<BOTANICAL>Aquilegia canadensis</BOTANICAL>
<ZONE>3</ZONE>
<LIGHT>Mostly Shady</LIGHT>
<PRICE>$9.37</PRICE>
<AVAILABILITY>030699</AVAILABILITY>
</PLANT>
<PLANT>
<COMMON>Marsh Marigold</COMMON>
<BOTANICAL>Caltha palustris</BOTANICAL>
<ZONE>4</ZONE>
<LIGHT>Mostly Sunny</LIGHT>
<PRICE>$6.81</PRICE>
<AVAILABILITY>051799</AVAILABILITY>
</PLANT>
</CATALOG>
## 15_ NoSQL
noSQL is oppsed to relationnal databases (stand for __N__ot __O__nly __SQL__). Data are not structured and there's no notion of keys between tables.
Any kind of data can be stored in a noSQL database (JSON, CSV, ...) whithout thinking about a complex relationnal scheme.
__Commonly used noSQL stacks__: Cassandra, MongoDB, Redis, Oracle noSQL ...
## 16_ Regex
### About
__Reg__ ular __ex__ pressions (__regex__) are commonly used in informatics.
It can be used in a wide range of possibilities :
* Text replacing
* Extract information in a text (email, phone number, etc)
* List files with the .txt extension ..
http://regexr.com/ is a good website for experimenting on Regex.
### Utilisation
To use them in [Python](https://docs.python.org/3/library/re.html), just import:
import re
## 17_ Vendor landscape
## 18_ Env Setup
# 2_ Statistics
[Statistics-101 for data noobs](https://medium.com/@debuggermalhotra/statistics-101-for-data-noobs-2e2a0e23a5dc)
## 1_ Pick a dataset
### Datasets repositories
#### Generalists
- [KAGGLE](https://www.kaggle.com/datasets)
- [Google](https://toolbox.google.com/datasetsearch)
#### Medical
- [PMC](https://www.ncbi.nlm.nih.gov/pmc/)
#### Other languages
##### French
- [DATAGOUV](https://www.data.gouv.fr/fr/)
## 2_ Descriptive statistics
### Mean
In probability and statistics, population mean and expected value are used synonymously to refer to one __measure of the central tendency either of a probability distribution or of the random variable__ characterized by that distribution.
For a data set, the terms arithmetic mean, mathematical expectation, and sometimes average are used synonymously to refer to a central value of a discrete set of numbers: specifically, the __sum of the values divided by the number of values__.

### Median
The median is the value __separating the higher half of a data sample, a population, or a probability distribution, from the lower half__. In simple terms, it may be thought of as the "middle" value of a data set.
### Descriptive statistics in Python
[Numpy](http://www.numpy.org/) is a python library widely used for statistical analysis.
#### Installation
pip3 install numpy
#### Utilization
import numpy
## 3_ Exploratory data analysis
The step includes visualization and analysis of data.
Raw data may possess improper distributions of data which may lead to issues moving forward.
Again, during applications we must also know the distribution of data, for instance, the fact whether the data is linear or spirally distributed.
[Guide to EDA in Python](https://towardsdatascience.com/data-preprocessing-and-interpreting-results-the-heart-of-machine-learning-part-1-eda-49ce99e36655)
##### Libraries in Python
[Matplotlib](https://matplotlib.org/)
Library used to plot graphs in Python
__Installation__:
pip3 install matplotlib
__Utilization__:
import matplotlib.pyplot as plt
[Pandas](https://pandas.pydata.org/)
Library used to large datasets in python
__Installation__:
pip3 install pandas
__Utilization__:
import pandas as pd
[Seaborn](https://seaborn.pydata.org/)
Yet another Graph Plotting Library in Python.
__Installation__:
pip3 install seaborn
__Utilization__:
import seaborn as sns
#### PCA
PCA stands for principle component analysis.
We often require to shape of the data distribution as we have seen previously. We need to plot the data for the same.
Data can be Multidimensional, that is, a dataset can have multiple features.
We can plot only two dimensional data, so, for multidimensional data, we project the multidimensional distribution in two dimensions, preserving the principle components of the distribution, in order to get an idea of the actual distribution through the 2D plot.
It is used for dimensionality reduction also. Often it is seen that several features do not significantly contribute any important insight to the data distribution. Such features creates complexity and increase dimensionality of the data. Such features are not considered which results in decrease of the dimensionality of the data.
[Mathematical Explanation](https://medium.com/towards-artificial-intelligence/demystifying-principal-component-analysis-9f13f6f681e6)
[Application in Python](https://towardsdatascience.com/data-preprocessing-and-interpreting-results-the-heart-of-machine-learning-part-2-pca-feature-92f8f6ec8c8)
## 4_ Histograms
Histograms are representation of distribution of numerical data. The procedure consists of binnng the numeric values using range divisions i.e, the entire range in which the data varies is split into several fixed intervals. Count or frequency of occurences of the numbers in the range of the bins are represented.
[Histograms](https://en.wikipedia.org/wiki/Histogram)
In python, __Pandas__,__Matplotlib__,__Seaborn__ can be used to create Histograms.
## 5_ Percentiles & outliers
### Percentiles
Percentiles are numberical measures in statistics, which represents how much or what percentage of data falls below a given number or instance in a numerical data distribution.
For instance, if we say 70 percentile, it represents, 70% of the data in the ditribution are below the given numerical value.
[Percentiles](https://en.wikipedia.org/wiki/Percentile)
### Outliers
Outliers are data points(numerical) which have significant differences with other data points. They differ from majority of points in the distribution. Such points may cause the central measures of distribution, like mean, and median. So, they need to be detected and removed.
[Outliers](https://www.itl.nist.gov/div898/handbook/prc/section1/prc16.htm)
__Box Plots__ can be used detect Outliers in the data. They can be created using __Seaborn__ library
## 6_ Probability theory
__Probability__ is the likelihood of an event in a Random experiment. For instance, if a coin is tossed, the chance of getting a head is 50% so, probability is 0.5.
__Sample Space__: It is the set of all possible outcomes of a Random Experiment.
__Favourable Outcomes__: The set of outcomes we are looking for in a Random Experiment
__Probability = (Number of Favourable Outcomes) / (Sample Space)__
__Probability theory__ is a branch of mathematics that is associated with the concept of probability.
[Basics of Probability](https://towardsdatascience.com/basic-probability-theory-and-statistics-3105ab637213)
## 7_ Bayes theorem
### Conditional Probability:
It is the probability of one event occurring, given that another event has already occurred. So, it gives a sense of relationship between two events and the probabilities of the occurences of those events.
It is given by:
__P( A | B )__ : Probability of occurence of A, after B occured.
The formula is given by:

So, P(A|B) is equal to Probablity of occurence of A and B, divided by Probability of occurence of B.
[Guide to Conditional Probability](https://en.wikipedia.org/wiki/Conditional_probability)
### Bayes Theorem
Bayes theorem provides a way to calculate conditional probability. Bayes theorem is widely used in machine learning most in Bayesian Classifiers.
According to Bayes theorem the probability of A, given that B has already occurred is given by Probability of A multiplied by the probability of B given A has already occurred divided by the probability of B.
__P(A|B) = P(A).P(B|A) / P(B)__
[Guide to Bayes Theorem](https://machinelearningmastery.com/bayes-theorem-for-machine-learning/)
## 8_ Random variables
Random variable are the numeric outcome of an experiment or random events. They are normally a set of values.
There are two main types of Random Variables:
__Discrete Random Variables__: Such variables take only a finite number of distinct values
__Continous Random Variables__: Such variables can take an infinite number of possible values.
## 9_ Cumul Dist Fn (CDF)
In probability theory and statistics, the cumulative distribution function (CDF) of a real-valued random variable __X__, or just distribution function of __X__, evaluated at __x__, is the probability that __X__ will take a value less than or equal to __x__.
The cumulative distribution function of a real-valued random variable X is the function given by:

Resource:
[Wikipedia](https://en.wikipedia.org/wiki/Cumulative_distribution_function)
## 10_ Continuous distributions
A continuous distribution describes the probabilities of the possible values of a continuous random variable. A continuous random variable is a random variable with a set of possible values (known as the range) that is infinite and uncountable.
## 11_ Skewness
Skewness is the measure of assymetry in the data distribution or a random variable distribution about its mean.
Skewness can be positive, negative or zero.
__Negative skew__: Distribution Concentrated in the right, left tail is longer.
__Positive skew__: Distribution Concentrated in the left, right tail is longer.
Variation of central tendency measures are shown below.

Data Distribution are often Skewed which may cause trouble during processing the data. __Skewed Distribution can be converted to Symmetric Distribution, taking Log of the distribution__.
##### Skew Distribution
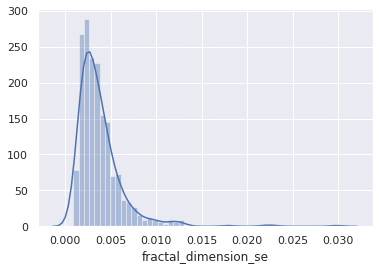
##### Log of the Skew Distribution.
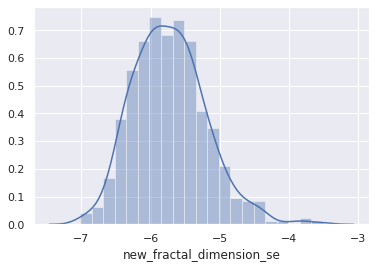
[Guide to Skewness](https://en.wikipedia.org/wiki/Skewness)
## 12_ ANOVA
ANOVA stands for __analysis of variance__.
It is used to compare among groups of data distributions.
Often we are provided with huge data. They are too huge to work with. The total data is called the __Population__.
In order to work with them, we pick random smaller groups of data. They are called __Samples__.
ANOVA is used to compare the variance among these groups or samples.
Variance of group is given by:
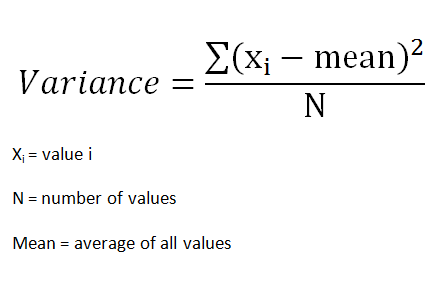
The differences in the collected samples are observed using the differences between the means of the groups. We often use the __t-test__ to compare the means and also to check if the samples belong to the same population,
Now, t-test can only be possible among two groups. But, often we get more groups or samples.
If we try to use t-test for more than two groups we have to perform t-tests multiple times, once for each pair. This is where ANOVA is used.
ANOVA has two components:
__1.Variation within each group__
__2.Variation between groups__
It works on a ratio called the __F-Ratio__
It is given by:
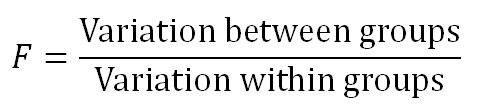
F ratio shows how much of the total variation comes from the variation between groups and how much comes from the variation within groups. If much of the variation comes from the variation between groups, it is more likely that the mean of groups are different. However, if most of the variation comes from the variation within groups, then we can conclude the elements in a group are different rather than entire groups. The larger the F ratio, the more likely that the groups have different means.
Resources:
[Defnition](https://statistics.laerd.com/statistical-guides/one-way-anova-statistical-guide.php)
[GUIDE 1](https://towardsdatascience.com/anova-analysis-of-variance-explained-b48fee6380af)
[Details](https://medium.com/@StepUpAnalytics/anova-one-way-vs-two-way-6b3ff87d3a94)
## 13_ Prob Den Fn (PDF)
It stands for probability density function.
__In probability theory, a probability density function (PDF), or density of a continuous random variable, is a function whose value at any given sample (or point) in the sample space (the set of possible values taken by the random variable) can be interpreted as providing a relative likelihood that the value of the random variable would equal that sample.__
The probability density function (PDF) P(x) of a continuous distribution is defined as the derivative of the (cumulative) distribution function D(x).
It is given by the integral of the function over a given range.

## 14_ Central Limit theorem
## 15_ Monte Carlo method
## 16_ Hypothesis Testing
### Types of curves
We need to know about two distribution curves first.
Distribution curves reflect the probabilty of finding an instance or a sample of a population at a certain value of the distribution.
__Normal Distribution__
The normal distribution represents how the data is distributed. In this case, most of the data samples in the distribution are scattered at and around the mean of the distribution. A few instances are scattered or present at the long tail ends of the distribution.
Few points about Normal Distributions are:
1. The curve is always Bell-shaped. This is because most of the data is found around the mean, so the proababilty of finding a sample at the mean or central value is more.
2. The curve is symmetric
3. The area under the curve is always 1. This is because all the points of the distribution must be present under the curve
4. For Normal Distribution, Mean and Median lie on the same line in the distribution.
__Standard Normal Distribution__
This type of distribution are normal distributions which following conditions.
1. Mean of the distribution is 0
2. The Standard Deviation of the distribution is equal to 1.
The idea of Hypothesis Testing works completely on the data distributions.
### Hypothesis Testing
Hypothesis testing is a statistical method that is used in making statistical decisions using experimental data. Hypothesis Testing is basically an assumption that we make about the population parameter.
For example, say, we take the hypothesis that boys in a class are taller than girls.
The above statement is just an assumption on the population of the class.
__Hypothesis__ is just an assumptive proposal or statement made on the basis of observations made on a set of information or data.
We initially propose two mutually exclusive statements based on the population of the sample data.
The initial one is called __NULL HYPOTHESIS__. It is denoted by H0.
The second one is called __ALTERNATE HYPOTHESIS__. It is denoted by H1 or Ha. It is used as a contrary to Null Hypothesis.
Based on the instances of the population we accept or reject the NULL Hypothesis and correspondingly we reject or accept the ALTERNATE Hypothesis.
#### Level of Significance
It is the degree which we consider to decide whether to accept or reject the NULL hypothesis. When we consider a hypothesis on a population, it is not the case that 100% or all instances of the population abides the assumption, so we decide a __level of significance as a cutoff degree, i.e, if our level of significance is 5%, and (100-5)% = 95% of the data abides by the assumption, we accept the Hypothesis.__
__It is said with 95% confidence, the hypothesis is accepted__
The non-reject region is called __acceptance region or beta region__. The rejection regions are called __critical or alpha regions__. __alpha__ denotes the __level of significance__.
If level of significance is 5%. the two alpha regions have (2.5+2.5)% of the population and the beta region has the 95%.
The acceptance and rejection gives rise to two kinds of errors:
__Type-I Error:__ NULL Hypothesis is true, but wrongly Rejected.
__Type-II Error:__ NULL Hypothesis if false but is wrongly accepted.
### Tests for Hypothesis
__One Tailed Test__:
This is a test for Hypothesis, where the rejection region is only one side of the sampling distribution. The rejection region may be in right tail end or in the left tail end.
The idea is if we say our level of significance is 5% and we consider a hypothesis "Hieght of Boys in a class is <=6 ft". We consider the hypothesis true if atmost 5% of our population are more than 6 feet. So, this will be one-tailed as the test condition only restricts one tail end, the end with hieght > 6ft.
In this case, the rejection region extends at both tail ends of the distribution.
The idea is if we say our level of significance is 5% and we consider a hypothesis "Hieght of Boys in a class is !=6 ft".
Here, we can accept the NULL hyposthesis iff atmost 5% of the population is less than or greater than 6 feet. So, it is evident that the crirtical region will be at both tail ends and the region is 5% / 2 = 2.5% at both ends of the distribution.
## 17_ p-Value
Before we jump into P-values we need to look at another important topic in the context: Z-test.
### Z-test
We need to know two terms: __Population and Sample.__
__Population__ describes the entire available data distributed. So, it refers to all records provided in the dataset.
__Sample__ is said to be a group of data points randomly picked from a population or a given distribution. The size of the sample can be any number of data points, given by __sample size.__
__Z-test__ is simply used to determine if a given sample distribution belongs to a given population.
Now,for Z-test we have to use __Standard Normal Form__ for the standardized comparison measures.
As we already have seen, standard normal form is a normal form with mean=0 and standard deviation=1.
The __Standard Deviation__ is a measure of how much differently the points are distributed around the mean.
It states that approximately 68% , 95% and 99.7% of the data lies within 1, 2 and 3 standard deviations of a normal distribution respectively.
Now, to convert the normal distribution to standard normal distribution we need a standard score called Z-Score.
It is given by:
x = value that we want to standardize
µ = mean of the distribution of x
σ = standard deviation of the distribution of x
We need to know another concept __Central Limit Theorem__.
##### Central Limit Theorem
_The theorem states that the mean of the sampling distribution of the sample means is equal to the population mean irrespective if the distribution of population where sample size is greater than 30._
And
_The sampling distribution of sampling mean will also follow the normal distribution._
So, it states, if we pick several samples from a distribution with the size above 30, and pick the static sample means and use the sample means to create a distribution, the mean of the newly created sampling distribution is equal to the original population mean.
According to the theorem, if we draw samples of size N, from a population with population mean μ and population standard deviation σ, the condition stands:
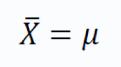
i.e, mean of the distribution of sample means is equal to the sample means.
The standard deviation of the sample means is give by:
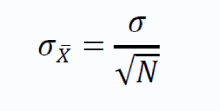
The above term is also called standard error.
We use the theory discussed above for Z-test. If the sample mean lies close to the population mean, we say that the sample belongs to the population and if it lies at a distance from the population mean, we say the sample is taken from a different population.
To do this we use a formula and check if the z statistic is greater than or less than 1.96 (considering two tailed test, level of significance = 5%)
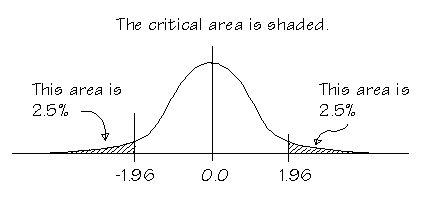
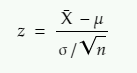
The above formula gives Z-static
z = z statistic
X̄ = sample mean
μ = population mean
σ = population standard deviation
n = sample size
Now, as the Z-score is used to standardize the distribution, it gives us an idea how the data is distributed overall.
### P-values
It is used to check if the results are statistically significant based on the significance level.
Say, we perform an experiment and collect observations or data. Now, we make a hypothesis (NULL hypothesis) primary, and a second hypothesis, contradictory to the first one called the alternative hypothesis.
Then we decide a level of significance which serve as a threshold for our null hypothesis. The P value actually gives the probability of the statement. Say, the p-value of our alternative hypothesis is 0.02, it means the probability of alternate hypothesis happenning is 2%.
Now, the level of significance into play to decide if we can allow 2% or p-value of 0.02. It can be said as a level of endurance of the null hypothesis. If our level of significance is 5% using a two tailed test, we can allow 2.5% on both ends of the distribution, we accept the NULL hypothesis, as level of significance > p-value of alternate hypothesis.
But if the p-value is greater than level of significance, we tell that the result is __statistically significant, and we reject NULL hypothesis.__ .
Resources:
1. https://medium.com/analytics-vidhya/everything-you-should-know-about-p-value-from-scratch-for-data-science-f3c0bfa3c4cc
2. https://towardsdatascience.com/p-values-explained-by-data-scientist-f40a746cfc8
3.https://medium.com/analytics-vidhya/z-test-demystified-f745c57c324c
## 18_ Chi2 test
Chi2 test is extensively used in data science and machine learning problems for feature selection.
A chi-square test is used in statistics to test the independence of two events. So, it is used to check for independence of features used. Often dependent features are used which do not convey a lot of information but adds dimensionality to a feature space.
It is one of the most common ways to examine relationships between two or more categorical variables.
It involves calculating a number, called the chi-square statistic - χ2. Which follows a chi-square distribution.
It is given as the summation of the difference of the expected values and observed value divided by the observed value.

Resources:
[Definitions](investopedia.com/terms/c/chi-square-statistic.asp)
[Guide 1](https://towardsdatascience.com/chi-square-test-for-feature-selection-in-machine-learning-206b1f0b8223)
[Guide 2](https://medium.com/swlh/what-is-chi-square-test-how-does-it-work-3b7f22c03b01)
[Example of Operation](https://medium.com/@kuldeepnpatel/chi-square-test-of-independence-bafd14028250)
## 19_ Estimation
## 20_ Confid Int (CI)
## 21_ MLE
## 22_ Kernel Density estimate
In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable. Kernel density estimation is a fundamental data smoothing problem where inferences about the population are made, based on a finite data sample.
Kernel Density estimate can be regarded as another way to represent the probability distribution.

It consists of choosing a kernel function. There are mostly three used.
1. Gaussian
2. Box
3. Tri
The kernel function depicts the probability of finding a data point. So, it is highest at the centre and decreases as we move away from the point.
We assign a kernel function over all the data points and finally calculate the density of the functions, to get the density estimate of the distibuted data points. It practically adds up the Kernel function values at a particular point on the axis. It is as shown below.

Now, the kernel function is given by:

where K is the kernel — a non-negative function — and h > 0 is a smoothing parameter called the bandwidth.
The 'h' or the bandwidth is the parameter, on which the curve varies.

Kernel density estimate (KDE) with different bandwidths of a random sample of 100 points from a standard normal distribution. Grey: true density (standard normal). Red: KDE with h=0.05. Black: KDE with h=0.337. Green: KDE with h=2.
Resources:
[Basics](https://www.youtube.com/watch?v=x5zLaWT5KPs)
[Advanced](https://jakevdp.github.io/PythonDataScienceHandbook/05.13-kernel-density-estimation.html)
## 23_ Regression
Regression tasks deal with predicting the value of a __dependent variable__ from a set of __independent variables.__
Say, we want to predict the price of a car. So, it becomes a dependent variable say Y, and the features like engine capacity, top speed, class, and company become the independent variables, which helps to frame the equation to obtain the price.
If there is one feature say x. If the dependent variable y is linearly dependent on x, then it can be given by __y=mx+c__, where the m is the coefficient of the independent in the equation, c is the intercept or bias.
The image shows the types of regression
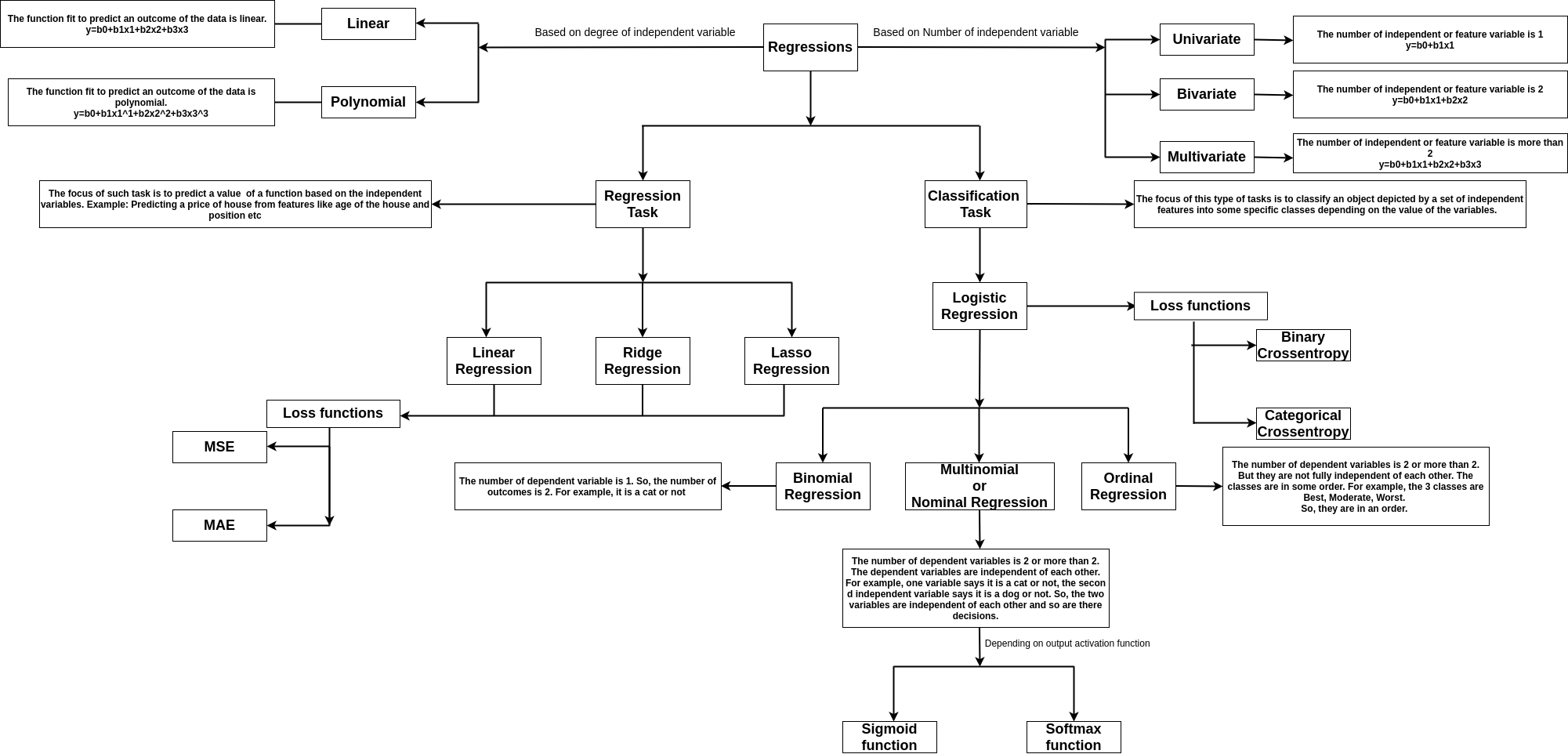
[Guide to Regression](https://towardsdatascience.com/a-deep-dive-into-the-concept-of-regression-fb912d427a2e)
## 24_ Covariance
### Variance
The variance is a measure of how dispersed or spread out the set is. If it is said that the variance is zero, it means all the elements in the dataset are same. If the variance is low, it means the data are slightly dissimilar. If the variance is very high, it means the data in the dataset are largely dissimilar.
Mathematically, it is a measure of how far each value in the data set is from the mean.
Variance (sigma^2) is given by summation of the square of distances of each point from the mean, divided by the number of points

### Covariance
Covariance gives us an idea about the degree of association between two considered random variables. Now, we know random variables create distributions. Distribution are a set of values or data points which the variable takes and we can easily represent as vectors in the vector space.
For vectors covariance is defined as the dot product of two vectors. The value of covariance can vary from positive infinity to negative infinity. If the two distributions or vectors grow in the same direction the covariance is positive and vice versa. The Sign gives the direction of variation and the Magnitude gives the amount of variation.
Covariance is given by:
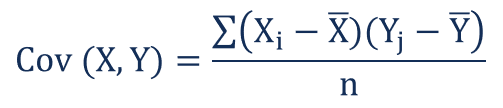
where Xi and Yi denotes the i-th point of the two distributions and X-bar and Y-bar represent the mean values of both the distributions, and n represents the number of values or data points in the distribution.
## 25_ Correlation
Covariance measures the total relation of the variables namely both direction and magnitude. Correlation is a scaled measure of covariance. It is dimensionless and independent of scale. It just shows the strength of variation for both the variables.
Mathematically, if we represent the distribution using vectors, correlation is said to be the cosine angle between the vectors. The value of correlation varies from +1 to -1. +1 is said to be a strong positive correlation and -1 is said to be a strong negative correlation. 0 implies no correlation, or the two variables are independent of each other.
Correlation is given by:
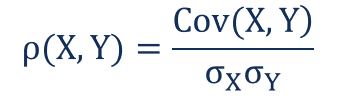
Where:
ρ(X,Y) – the correlation between the variables X and Y
Cov(X,Y) – the covariance between the variables X and Y
σX – the standard deviation of the X-variable
σY – the standard deviation of the Y-variable
Standard deviation is given by square roo of variance.
## 26_ Pearson coeff
## 27_ Causation
## 28_ Least2-fit
## 29_ Euclidian Distance
__Eucladian Distance is the most used and standard measure for the distance between two points.__
It is given as the square root of sum of squares of the difference between coordinates of two points.
__The Euclidean distance between two points in Euclidean space is a number, the length of a line segment between the two points. It can be calculated from the Cartesian coordinates of the points using the Pythagorean theorem, and is occasionally called the Pythagorean distance.__
__In the Euclidean plane, let point p have Cartesian coordinates (p_{1},p_{2}) and let point q have coordinates (q_{1},q_{2}). Then the distance between p and q is given by:__

# 3_ Programming
## 1_ Python Basics
### About
Python is a high-level programming langage. I can be used in a wide range of works.
Commonly used in data-science, [Python](https://www.python.org/) has a huge set of libraries, helpful to quickly do something.
Most of informatics systems already support Python, without installing anything.
### Execute a script
* Download the .py file on your computer
* Make it executable (_chmod +x file.py_ on Linux)
* Open a terminal and go to the directory containing the python file
* _python file.py_ to run with Python2 or _python3 file.py_ with Python3
## 2_ Working in excel
## 3_ R setup / R studio
### About
R is a programming language specialized in statistics and mathematical visualizations.
It can be used with manually created scripts using the terminal, or directly in the R console.
### Installation
#### Linux
sudo apt-get install r-base
sudo apt-get install r-base-dev
#### Windows
Download the .exe setup available on [CRAN](https://cran.rstudio.com/bin/windows/base/) website.
### R-studio
Rstudio is a graphical interface for R. It is available for free on [their website](https://www.rstudio.com/products/rstudio/download/).
This interface is divided in 4 main areas :

* The top left is the script you are working on (highlight code you want to execute and press Ctrl + Enter)
* The bottom left is the console to instant-execute some lines of codes
* The top right is showing your environment (variables, history, ...)
* The bottom right show figures you plotted, packages, help ... The result of code execution
## 4_ R basics
R is an open source programming language and software environment for statistical computing and graphics that is supported by the R Foundation for Statistical Computing.
The R language is widely used among statisticians and data miners for developing statistical software and data analysis.
Polls, surveys of data miners, and studies of scholarly literature databases show that R's popularity has increased substantially in recent years.
## 5_ Expressions
## 6_ Variables
## 7_ IBM SPSS
## 8_ Rapid Miner
## 9_ Vectors
## 10_ Matrices
## 11_ Arrays
## 12_ Factors
## 13_ Lists
## 14_ Data frames
## 15_ Reading CSV data
CSV is a format of __tabular data__ comonly used in data science. Most of structured data will come in such a format.
To __open a CSV file__ in Python, just open the file as usual :
raw_file = open('file.csv', 'r')
* 'r': Reading, no modification on the file is possible
* 'w': Writing, every modification will erease the file
* 'a': Adding, every modification will be made at the end of the file
### How to read it ?
Most of the time, you will parse this file line by line and do whatever you want on this line. If you want to store data to use them later, build lists or dictionnaries.
To read such a file row by row, you can use :
* Python [library csv](https://docs.python.org/3/library/csv.html)
* Python [function open](https://docs.python.org/2/library/functions.html#open)
## 16_ Reading raw data
## 17_ Subsetting data
## 18_ Manipulate data frames
## 19_ Functions
A function is helpful to execute redondant actions.
First, define the function:
def MyFunction(number):
"""This function will multiply a number by 9"""
number = number * 9
return number
## 20_ Factor analysis
## 21_ Install PKGS
Python actually has two mainly used distributions. Python2 and python3.
### Install pip
Pip is a library manager for Python. Thus, you can easily install most of the packages with a one-line command. To install pip, just go to a terminal and do:
# __python2__
sudo apt-get install python-pip
# __python3__
sudo apt-get install python3-pip
You can then install a library with [pip](https://pypi.python.org/pypi/pip?) via a terminal doing:
# __python2__
sudo pip install [PCKG_NAME]
# __python3__
sudo pip3 install [PCKG_NAME]
You also can install it directly from the core (see 21_install_pkgs.py)
# 4_ Machine learning
## 1_ What is ML ?
### Definition
Machine Learning is part of the Artificial Intelligences study. It concerns the conception, devloppement and implementation of sophisticated methods, allowing a machine to achieve really hard tasks, nearly impossible to solve with classic algorithms.
Machine learning mostly consists of three algorithms:
### Utilisation examples
* Computer vision
* Search engines
* Financial analysis
* Documents classification
* Music generation
* Robotics ...
## 2_ Numerical var
Variables which can take continous integer or real values. They can take infinite values.
These types of variables are mostly used for features which involves measurements. For example, hieghts of all students in a class.
## 3_ Categorical var
Variables that take finite discrete values. They take a fixed set of values, in order to classify a data item.
They act like assigned labels. For example: Labelling the students of a class according to gender: 'Male' and 'Female'
## 4_ Supervised learning
Supervised learning is the machine learning task of inferring a function from __labeled training data__.
The training data consist of a __set of training examples__.
In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal).
A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples.
In other words:
Supervised Learning learns from a set of labeled examples. From the instances and the labels, supervised learning models try to find the correlation among the features, used to describe an instance, and learn how each feature contributes to the label corresponding to an instance. On receiving an unseen instance, the goal of supervised learning is to label the instance based on its feature correctly.
__An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances__.
## 5_ Unsupervised learning
Unsupervised machine learning is the machine learning task of inferring a function to describe hidden structure __from "unlabeled" data__ (a classification or categorization is not included in the observations).
Since the examples given to the learner are unlabeled, there is no evaluation of the accuracy of the structure that is output by the relevant algorithm—which is one way of distinguishing unsupervised learning from supervised learning and reinforcement learning.
Unsupervised learning deals with data instances only. This approach tries to group data and form clusters based on the similarity of features. If two instances have similar features and placed in close proximity in feature space, there are high chances the two instances will belong to the same cluster. On getting an unseen instance, the algorithm will try to find, to which cluster the instance should belong based on its feature.
Resource:
[Guide to unsupervised learning](https://towardsdatascience.com/a-dive-into-unsupervised-learning-bf1d6b5f02a7)
## 6_ Concepts, inputs and attributes
A machine learning problem takes in the features of a dataset as input.
For supervised learning, the model trains on the data and then it is ready to perform. So, for supervised learning, apart from the features we also need to input the corresponding labels of the data points to let the model train on them.
For unsupervised learning, the models simply perform by just citing complex relations among data items and grouping them accordingly. So, unsupervised learning do not need a labelled dataset. The input is only the feature section of the dataset.
## 7_ Training and test data
If we train a supervised machine learning model using a dataset, the model captures the dependencies of that particular data set very deeply. So, the model will always perform well on the data and it won't be proper measure of how well the model performs.
To know how well the model performs, we must train and test the model on different datasets. The dataset we train the model on is called Training set, and the dataset we test the model on is called the test set.
We normally split the provided dataset to create the training and test set. The ratio of splitting is majorly: 3:7 or 2:8 depending on the data, larger being the trining data.
#### sklearn.model_selection.train_test_split is used for splitting the data.
Syntax:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
[Sklearn docs](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html)
## 8_ Classifiers
Classification is the most important and most common machine learning problem. Classification problems can be both suprvised and unsupervised problems.
The classification problems involve labelling data points to belong to a particular class based on the feature set corresponding to the particluar data point.
Classification tasks can be performed using both machine learning and deep learning techniques.
Machine learning classification techniques involve: Logistic Regressions, SVMs, and Classification trees. The models used to perform the classification are called classifiers.
## 9_ Prediction
The output generated by a machine learning models for a particuolar problem is called its prediction.
There are majorly two kinds of predictions corresponding to two types of problen:
1. Classification
2. Regression
In classiication, the prediction is mostly a class or label, to which a data points belong
In regression, the prediction is a number, a continous a numeric value, because regression problems deal with predicting the value. For example, predicting the price of a house.
## 10_ Lift
## 11_ Overfitting
Often we train our model so much or make our model so complex that our model fits too tghtly with the training data.
The training data often contains outliers or represents misleading patterns in the data. Fitting the training data with such irregularities to deeply cause the model to lose its generalization. The model performs very well on the training set but not so good on the test set.
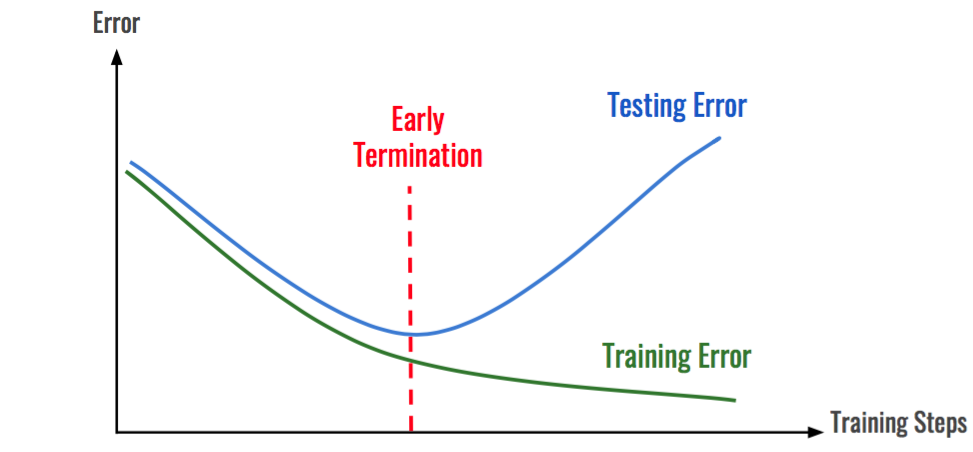
As we can see on training further a point the training error decreases and testing error increases.
A hypothesis h1 is said to overfit iff there exists another hypothesis h where h gives more error than h1 on training data and less error than h1 on the test data
## 12_ Bias & variance
Bias is the difference between the average prediction of our model and the correct value which we are trying to predict. Model with high bias pays very little attention to the training data and oversimplifies the model. It always leads to high error on training and test data.
Variance is the variability of model prediction for a given data point or a value which tells us spread of our data. Model with high variance pays a lot of attention to training data and does not generalize on the data which it hasn’t seen before. As a result, such models perform very well on training data but has high error rates on test data.
Basically High variance causes overfitting and high bias causes underfitting. We want our model to have low bias and low variance to perform perfectly. We need to avoid a model with higher variance and high bias
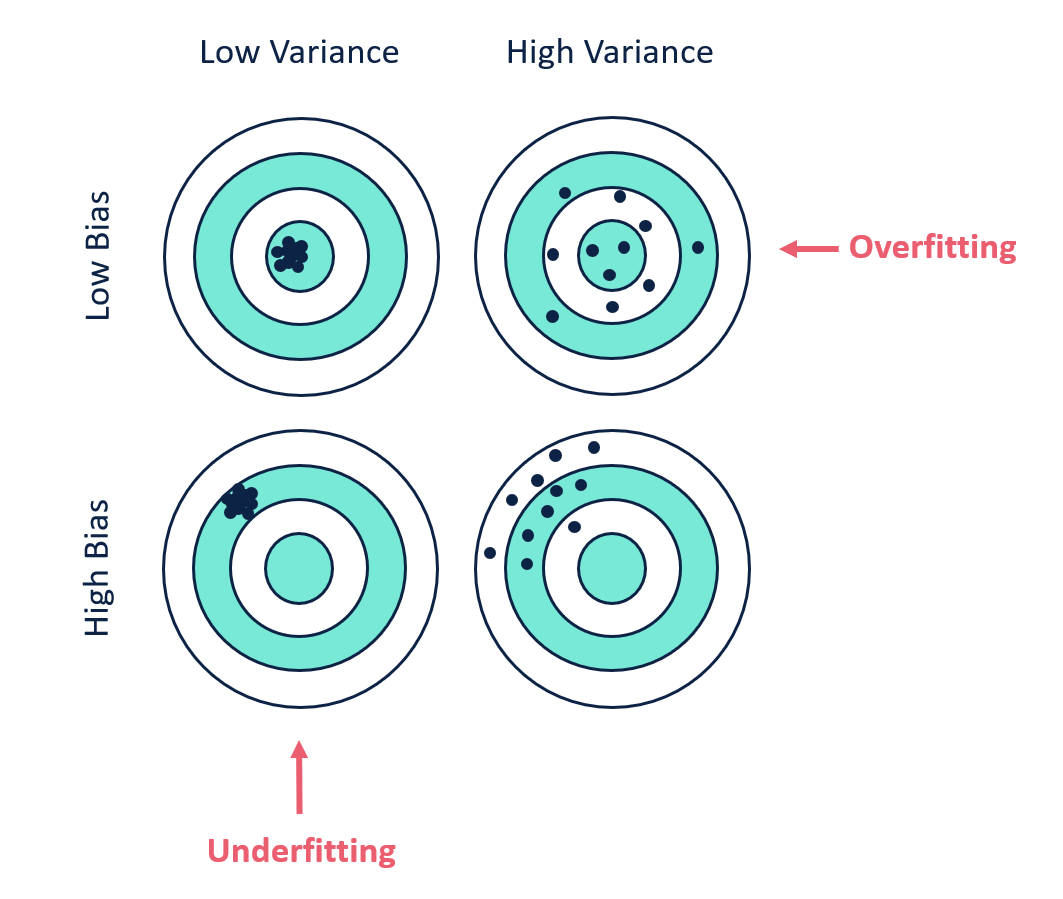
We can see that for Low bias and Low Variance our model predicts all the data points correctly. Again in the last image having high bias and high variance the model predicts no data point correctly.

We can see from the graph that rge Error increases when the complex is either too complex or the model is too simple. The bias increases with simpler model and Variance increases with complex models.
This is one of the most important tradeoffs in machine learning
## 13_ Tree and classification
We have previously talked about classificaion. We have seen the most used methods are Logistic Regression, SVMs and decision trees. Now, if the decision boundary is linear the methods like logistic regression and SVM serves best, but its a complete scenerio when the decision boundary is non linear, this is where decision tree is used.

The first image shows linear decision boundary and second image shows non linear decision boundary.
Ih the cases, for non linear boundaries, the decision trees condition based approach work very well for classification problems. The algorithm creates conditions on features to drive and reach a decision, so is independent of functions.
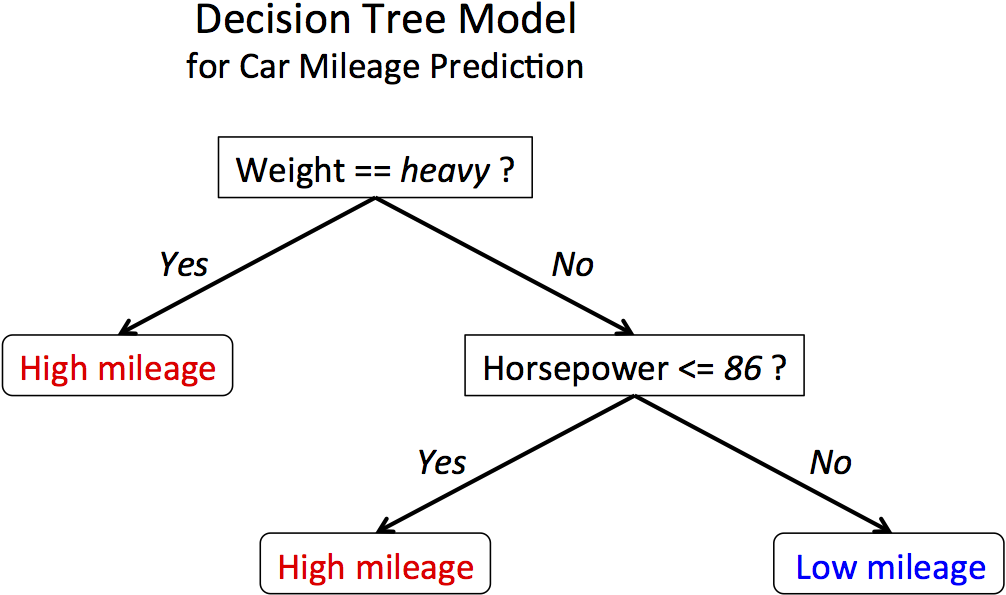
Decision tree approach for classification
## 14_ Classification rate
## 15_ Decision tree
Decision Trees are some of the most used machine learning algorithms. They are used for both classification and Regression. They can be used for both linear and non-linear data, but they are mostly used for non-linear data. Decision Trees as the name suggests works on a set of decisions derived from the data and its behavior. It does not use a linear classifier or regressor, so its performance is independent of the linear nature of the data.
One of the other most important reasons to use tree models is that they are very easy to interpret.
Decision Trees can be used for both classification and regression. The methodologies are a bit different, though principles are the same. The decision trees use the CART algorithm (Classification and Regression Trees)
Resource:
[Guide to Decision Tree](https://towardsdatascience.com/a-dive-into-decision-trees-a128923c9298)
## 16_ Boosting
#### Ensemble Learning
It is the method used to enhance the performance of the Machine learning models by combining several number of models or weak learners. They provide improved efficiency.
There are two types of ensemble learning:
__1. Parallel ensemble learning or bagging method__
__2. Sequential ensemble learning or boosting method__
In parallel method or bagging technique, several weak classifiers are created in parallel. The training datasets are created randomly on a bootstrapping basis from the original dataset. The datasets used for the training and creation phases are weak classifiers. Later during predictions, the reults from all the classifiers are bagged together to provide the final results.
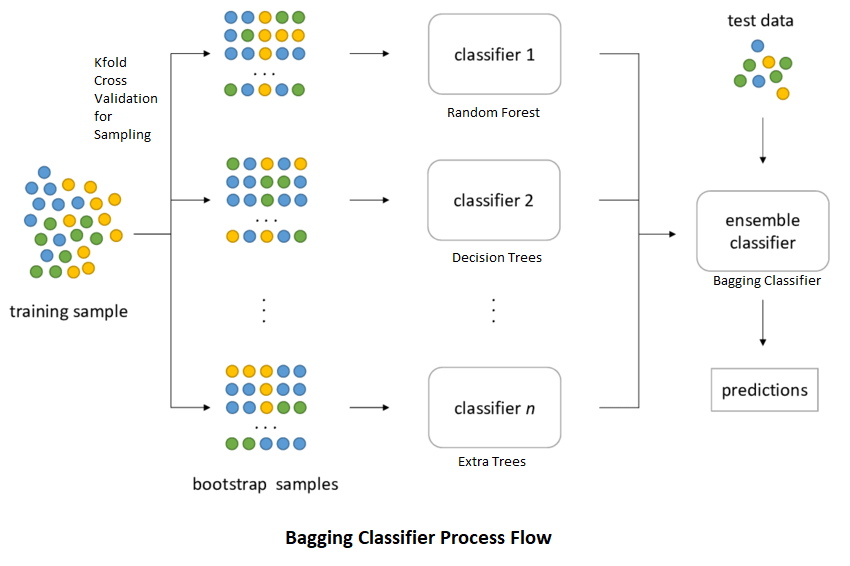
Ex: Random Forests
In sequential learning or boosting weak learners are created one after another and the data sample set are weighted in such a manner that during creation, the next learner focuses on the samples that were wrongly predicted by the previous classifier. So, at each step, the classifier improves and learns from its previous mistakes or misclassifications.
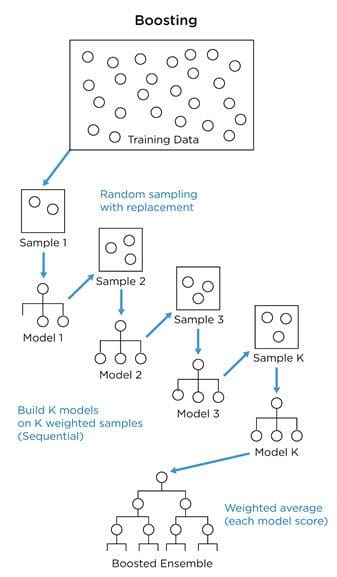
There are mostly three types of boosting algorithm:
__1. Adaboost__
__2. Gradient Boosting__
__3. XGBoost__
__Adaboost__ algorithm works in the exact way describe. It creates a weak learner, also known as stumps, they are not full grown trees, but contain a single node based on which the classification is done. The misclassifications are observed and they are weighted more than the correctly classified ones while training the next weak learner.
__sklearn.ensemble.AdaBoostClassifier__ is used for the application of the classifier on real data in python.

Reources:
[Understanding](https://blog.paperspace.com/adaboost-optimizer/#:~:text=AdaBoost%20is%20an%20ensemble%20learning,turn%20them%20into%20strong%20ones.)
__Gradient Boosting__ algorithm starts with a node giving 0.5 as output for both classification and regression. It serves as the first stump or weak learner. We then observe the Errors in predictions. Now, we create other learners or decision trees to actually predict the errors based on the conditions. The errors are called Residuals. Our final output is:
__0.5 (Provided by the first learner) + The error provided by the second tree or learner.__
Now, if we use this method, it learns the predictions too tightly, and loses generalization. In order to avoid that gradient boosting uses a learning parameter _alpha_.
So, the final results after two learners is obtained as:
__0.5 (Provided by the first learner) + _alpha_ X (The error provided by the second tree or learner.)__
We can see that using the added portion we take a small leap towards the correct results. We continue adding learners until the point we are very close to the actual value given by the training set.
Overall the equation becomes:
__0.5 (Provided by the first learner) + _alpha_ X (The error provided by the second tree or learner.)+ _alpha_ X (The error provided by the third tree or learner.)+.............__
__sklearn.ensemble.GradientBoostingClassifier__ used to apply gradient boosting in python

Resource:
[Guide](https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d)
## 17_ Naïves Bayes classifiers
The Naive Bayes classifiers are a collection of classification algorithms based on __Bayes’ Theorem.__
Bayes theorem describes the probability of an event, based on prior knowledge of conditions that might be related to the event. It is given by:

Where P(A|B) is the probabaility of occurrence of A knowing B already occurred and P(B|A) is the probability of occurrence of B knowing A occurred.
[Scikit-learn Guide](https://github.com/abr-98/data-scientist-roadmap/edit/master/04_Machine-Learning/README.md)
There are mostly two types of Naive Bayes:
__1. Gaussian Naive Bayes__
__2. Multinomial Naive Bayes.__
#### Multinomial Naive Bayes
The method is used mostly for document classification. For example, classifying an article as sports article or say film magazine. It is also used for differentiating actual mails from spam mails. It uses the frequency of words used in different magazine to make a decision.
For example, the word "Dear" and "friends" are used a lot in actual mails and "offer" and "money" are used a lot in "Spam" mails. It calculates the prorbability of the occurrence of the words in case of actual mails and spam mails using the training examples. So, the probability of occurrence of "money" is much higher in case of spam mails and so on.
Now, we calculate the probability of a mail being a spam mail using the occurrence of words in it.
#### Gaussian Naive Bayes
When the predictors take up a continuous value and are not discrete, we assume that these values are sampled from a gaussian distribution.
It links guassian distribution and Bayes theorem.
Resources:
[GUIDE](https://youtu.be/H3EjCKtlVog)
## 18_ K-Nearest neighbor
K-nearest neighbour algorithm is the most basic and still essential algorithm. It is a memory based approach and not a model based one.
KNN is used in both supervised and unsupervised learning. It simply locates the data points across the feature space and used distance as a similarity metrics.
Lesser the distance between two data points, more similar the points are.
In K-NN classification algorithm, the point to classify is plotted on the feature space and classified as the class of its nearest K-neighbours. K is the user parameter. It gives the measure of how many points we should consider while deciding the label of the point concerned. If K is more than 1 we consider the label that is in majority.
If the dataset is very large, we can use a large k. The large k is less effected by noise and generates smooth boundaries. For small dataset, a small k must be used. A small k helps to notice the variation in boundaries better.

Resource:
[GUIDE](https://towardsdatascience.com/machine-learning-basics-with-the-k-nearest-neighbors-algorithm-6a6e71d01761)
## 19_ Logistic regression
Regression is one of the most important concepts used in machine learning.
[Guide to regression](https://towardsdatascience.com/a-deep-dive-into-the-concept-of-regression-fb912d427a2e)
Logistic Regression is the most used classification algorithm for linearly seperable datapoints. Logistic Regression is used when the dependent variable is categorical.
It uses the linear regression equation:
__Y= w1x1+w2x2+w3x3……..wkxk__
in a modified format:
__Y= 1/ 1+e^-(w1x1+w2x2+w3x3……..wkxk)__
This modification ensures the value always stays between 0 and 1. Thus, making it feasible to be used for classification.
The above equation is called __Sigmoid__ function. The function looks like:
The loss fucnction used is called logloss or binary cross-entropy.
__Loss= —Y_actual. log(h(x)) —(1 — Y_actual.log(1 — h(x)))__
If Y_actual=1, the first part gives the error, else the second part.
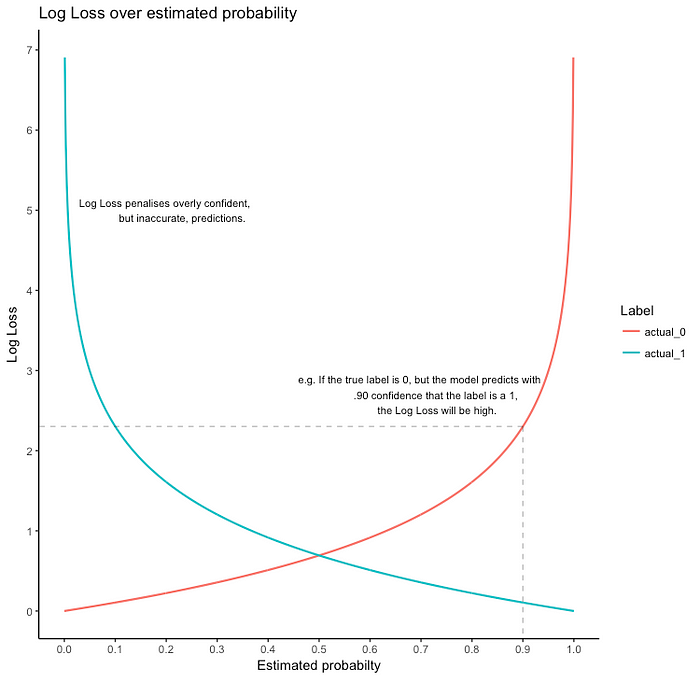
Logistic Regression is used for multiclass classification also. It uses softmax regresssion or One-vs-all logistic regression.
[Guide to logistic Regression](https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc)
__sklearn.linear_model.LogisticRegression__ is used to apply logistic Regression in python.
## 20_ Ranking
## 21_ Linear regression
Regression tasks deal with predicting the value of a dependent variable from a set of independent variables i.e, the provided features. Say, we want to predict the price of a car. So, it becomes a dependent variable say Y, and the features like engine capacity, top speed, class, and company become the independent variables, which helps to frame the equation to obtain the price.
Now, if there is one feature say x. If the dependent variable y is linearly dependent on x, then it can be given by y=mx+c, where the m is the coefficient of the feature in the equation, c is the intercept or bias. Both M and C are the model parameters.
We use a loss function or cost function called Mean Square error of (MSE). It is given by the square of the difference between the actual and the predicted value of the dependent variable.
__MSE=1/2m * (Y_actual — Y_pred)²__
If we observe the function we will see its a parabola, i.e, the function is convex in nature. This convex function is the principle used in Gradient Descent to obtain the value of the model parameters
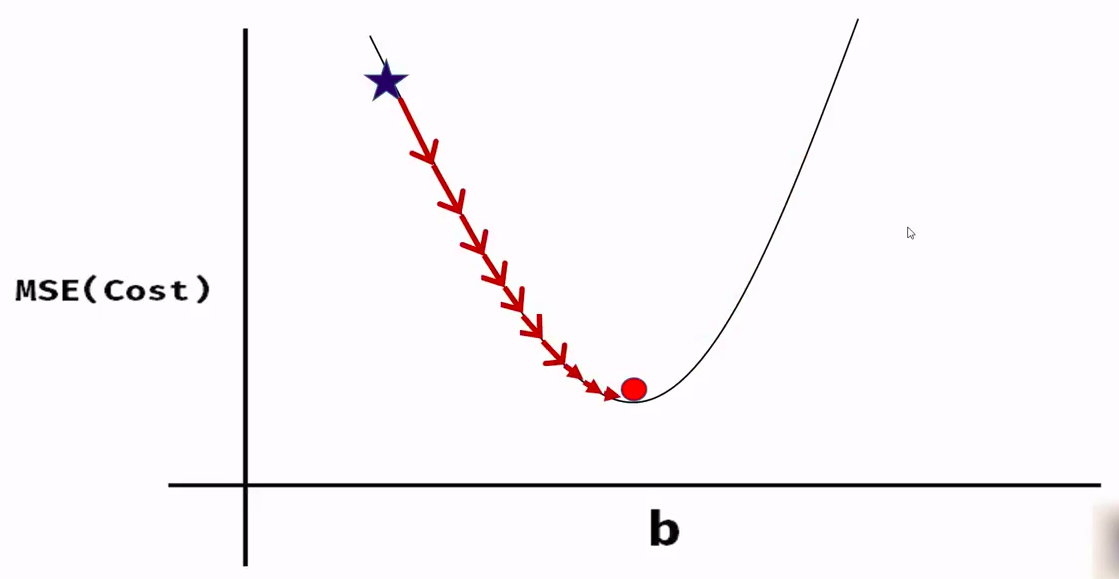
The image shows the loss function.
To get the correct estimate of the model parameters we use the method of __Gradient Descent__
[Guide to Gradient Descent](https://towardsdatascience.com/an-introduction-to-gradient-descent-and-backpropagation-81648bdb19b2)
[Guide to linear Regression](https://towardsdatascience.com/linear-regression-detailed-view-ea73175f6e86)
__sklearn.linear_model.LinearRegression__ is used to apply linear regression in python
## 22_ Perceptron
The perceptron has been the first model described in the 50ies.
This is a __binary classifier__, ie it can't separate more than 2 groups, and thoses groups have to be __linearly separable__.
The perceptron __works like a biological neuron__. It calculate an activation value, and if this value if positive, it returns 1, 0 otherwise.
## 23_ Hierarchical clustering
The hierarchical algorithms are so-called because they create tree-like structures to create clusters. These algorithms also use a distance-based approach for cluster creation.
The most popular algorithms are:
__Agglomerative Hierarchical clustering__
__Divisive Hierarchical clustering__
__Agglomerative Hierarchical clustering__: In this type of hierarchical clustering, each point initially starts as a cluster, and slowly the nearest or similar most clusters merge to create one cluster.
__Divisive Hierarchical Clustering__: The type of hierarchical clustering is just the opposite of Agglomerative clustering. In this type, all the points start as one large cluster and slowly the clusters get divided into smaller clusters based on how large the distance or less similarity is between the two clusters. We keep on dividing the clusters until all the points become individual clusters.
For agglomerative clustering, we keep on merging the clusters which are nearest or have a high similarity score to one cluster. So, if we define a cut-off or threshold score for the merging we will get multiple clusters instead of a single one. For instance, if we say the threshold similarity metrics score is 0.5, it means the algorithm will stop merging the clusters if no two clusters are found with a similarity score less than 0.5, and the number of clusters present at that step will give the final number of clusters that need to be created to the clusters.
Similarly, for divisive clustering, we divide the clusters based on the least similarity scores. So, if we define a score of 0.5, it will stop dividing or splitting if the similarity score between two clusters is less than or equal to 0.5. We will be left with a number of clusters and it won’t reduce to every point of the distribution.
The process is as shown below:
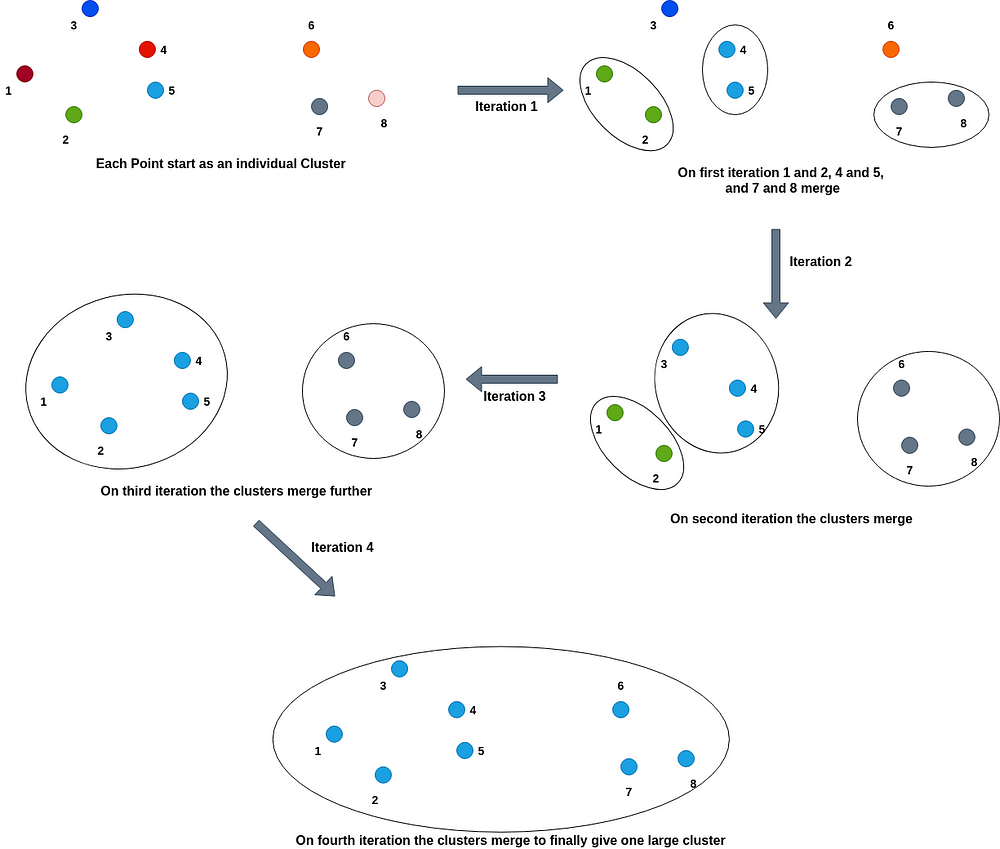
One of the most used methods for the measuring distance and applying cutoff is the dendrogram method.
The dendogram for above clustering is:
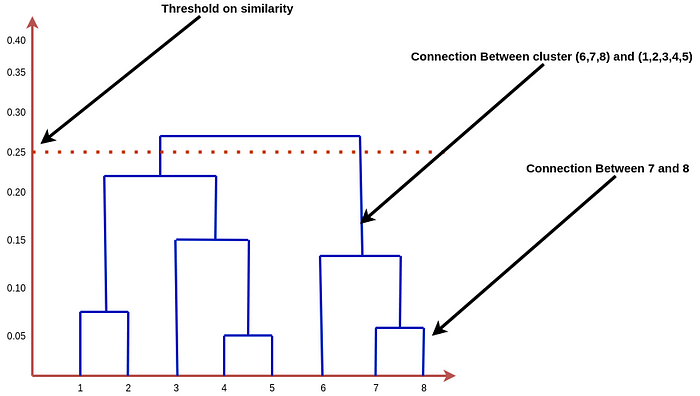
[Guide](https://towardsdatascience.com/understanding-the-concept-of-hierarchical-clustering-technique-c6e8243758ec)
## 24_ K-means clustering
The algorithm initially creates K clusters randomly using N data points and finds the mean of all the point values in a cluster for each cluster. So, for each cluster we find a central point or centroid calculating the mean of the values of the cluster. Then the algorithm calculates the sum of squared error (SSE) for each cluster. SSE is used to measure the quality of clusters. If a cluster has large distances between the points and the center, then the SSE will be high and if we check the interpretation it allows only points in the close vicinity to create clusters.
The algorithm works on the principle that the points lying close to a center of a cluster should be in that cluster. So, if a point x is closer to the center of cluster A than cluster B, then x will belong to cluster A. Thus a point enters a cluster and as even a single point moves from one cluster to another, the centroid changes and so does the SSE. We keep doing this until the SSE decreases and the centroid does not change anymore. After a certain number of shifts, the optimal clusters are found and the shifting stops as the centroids don’t change any more.
The initial number of clusters ‘K’ is a user parameter.
The image shows the method
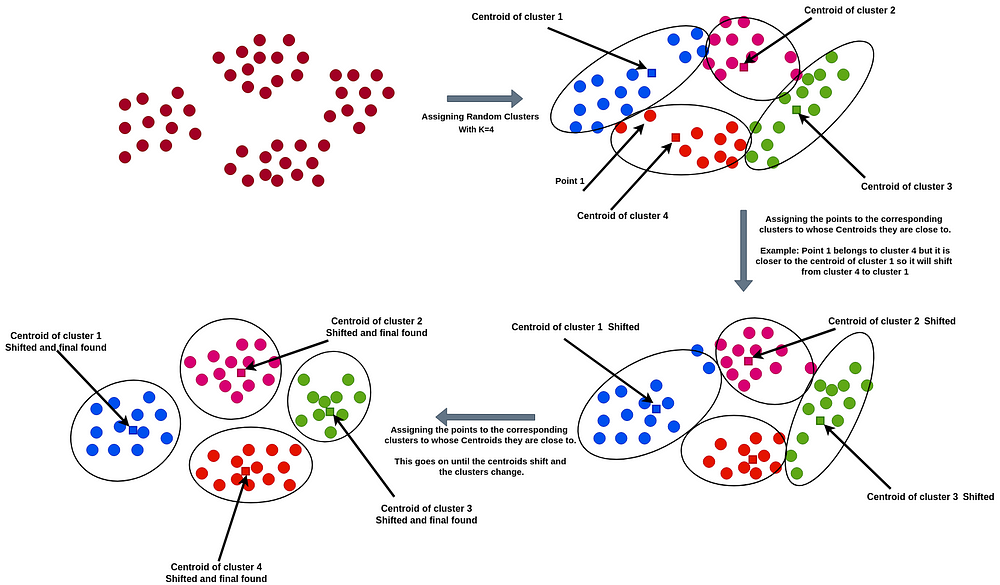
We have seen that for this type of clustering technique we need a user-defined parameter ‘K’ which defines the number of clusters that need to be created. Now, this is a very important parameter. To, find this parameter a number of methods are used. The most important and used method is the elbow method.
For smaller datasets, k=(N/2)^(1/2) or the square root of half of the number of points in the distribution.
[Guide](https://towardsdatascience.com/understanding-k-means-clustering-in-machine-learning-6a6e67336aa1)
## 25_ Neural networks
Neural Networks are a set of interconnected layers of artificial neurons or nodes. They are frameworks that are modeled keeping in mind, the structure and working of the human brain. They are meant for predictive modeling and applications where they can be trained via a dataset. They are based on self-learning algorithms and predict based on conclusions and complex relations derived from their training sets of information.
A typical Neural Network has a number of layers. The First Layer is called the Input Layer and The Last layer is called the Output Layer. The layers between the Input and Output layers are called Hidden Layers. It basically functions like a Black Box for prediction and classification. All the layers are interconnected and consist of numerous artificial neurons called Nodes.
[Guide to nueral Networks](https://medium.com/ai-in-plain-english/neural-networks-overview-e6ea484a474e)
Neural networks are too complex to work on Gradient Descent algorithms, so it works on the principles of Backproapagations and Optimizers.
[Guide to Backpropagation](https://towardsdatascience.com/an-introduction-to-gradient-descent-and-backpropagation-81648bdb19b2)
[Guide to optimizers](https://towardsdatascience.com/introduction-to-gradient-descent-weight-initiation-and-optimizers-ee9ae212723f)
## 26_ Sentiment analysis
Text Classification and sentiment analysis is a very common machine learning problem and is used in a lot of activities like product predictions, movie recommendations, and several others.
Text classification problems like sentimental analysis can be achieved in a number of ways using a number of algorithms. These are majorly divided into two main categories:
A bag of Word model: In this case, all the sentences in our dataset are tokenized to form a bag of words that denotes our vocabulary. Now each individual sentence or sample in our dataset is represented by that bag of words vector. This vector is called the feature vector. For example, ‘It is a sunny day’, and ‘The Sun rises in east’ are two sentences. The bag of words would be all the words in both the sentences uniquely.
The second method is based on a time series approach: Here each word is represented by an Individual vector. So, a sentence is represented as a vector of vectors.
[Guide to sentimental analysis](https://towardsdatascience.com/a-guide-to-text-classification-and-sentiment-analysis-2ab021796317)
## 27_ Collaborative filtering
We all have used services like Netflix, Amazon, and Youtube. These services use very sophisticated systems to recommend the best items to their users to make their experiences great.
Recommenders mostly have 3 components mainly, out of which, one of the main component is Candidate generation. This method is responsible for generating smaller subsets of candidates to recommend to a user, given a huge pool of thousands of items.
Types of Candidate Generation Systems:
__Content-based filtering System__
__Collaborative filtering System__
__Content-based filtering system__: Content-Based recommender system tries to guess the features or behavior of a user given the item’s features, he/she reacts positively to.
__Collaborative filtering System__: Collaborative does not need the features of the items to be given. Every user and item is described by a feature vector or embedding.
It creates embedding for both users and items on its own. It embeds both users and items in the same embedding space.
It considers other users’ reactions while recommending a particular user. It notes which items a particular user likes and also the items that the users with behavior and likings like him/her likes, to recommend items to that user.
It collects user feedbacks on different items and uses them for recommendations.
[Guide to collaborative filtering](https://towardsdatascience.com/introduction-to-recommender-systems-1-971bd274f421)
## 28_ Tagging
## 29_ Support Vector Machine
Support vector machines are used for both Classification and Regressions.
SVM uses a margin around its classifier or regressor. The margin provides an extra robustness and accuracy to the model and its performance.

The above image describes a SVM classifier. The Red line is the actual classifier and the dotted lines show the boundary. The points that lie on the boundary actually decide the Margins. They support the classifier margins, so they are called __Support Vectors__.
The distance between the classifier and the nearest points is called __Marginal Distance__.
There can be several classifiers possible but we choose the one with the maximum marginal distance. So, the marginal distance and the support vectors help to choose the best classifier.
[Official Documentation from Sklearn](https://scikit-learn.org/stable/modules/svm.html)
[Guide to SVM](https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47)
## 30_Reinforcement Learning
“Reinforcement learning (RL) is an area of machine learning concerned with how software agents ought to take actions in an environment in order to maximize the notion of cumulative reward.”
To play a game, we need to make multiple choices and predictions during the course of the game to achieve success, so they can be called a multiple decision processes. This is where we need a type of algorithm called reinforcement learning algorithms. The class of algorithm is based on decision-making chains which let such algorithms to support multiple decision processes.
The reinforcement algorithm can be used to reach a goal state from a starting state making decisions accordingly.
The reinforcement learning involves an agent which learns on its own. If it makes a correct or good move that takes it towards the goal, it is positively rewarded, else not. This way the agent learns.
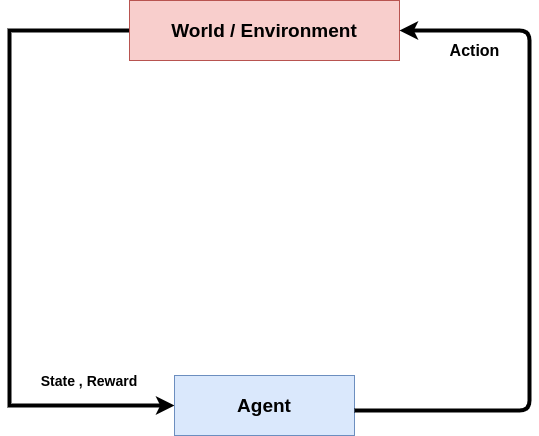
The above image shows reinforcement learning setup.
[WIKI](https://en.wikipedia.org/wiki/Reinforcement_learning#:~:text=Reinforcement%20learning%20(RL)%20is%20an,supervised%20learning%20and%20unsupervised%20learning.)
# 5_ Text Mining
## 1_ Corpus
## 2_ Named Entity Recognition
## 3_ Text Analysis
## 4_ UIMA
## 5_ Term Document matrix
## 6_ Term frequency and Weight
## 7_ Support Vector Machines (SVM)
## 8_ Association rules
## 9_ Market based analysis
## 10_ Feature extraction
## 11_ Using mahout
## 12_ Using Weka
## 13_ Using NLTK
## 14_ Classify text
## 15_ Vocabulary mapping
# 6_ Data Visualization
Open .R scripts in Rstudio for line-by-line execution.
See [10_ Toolbox/3_ R, Rstudio, Rattle](https://github.com/MrMimic/data-scientist-roadmap/tree/master/10_Toolbox#3_-r-rstudio-rattle) for installation.
## 1_ Data exploration in R
In mathematics, the graph of a function f is the collection of all ordered pairs (x, f(x)). If the function input x is a scalar, the graph is a two-dimensional graph, and for a continuous function is a curve. If the function input x is an ordered pair (x1, x2) of real numbers, the graph is the collection of all ordered triples (x1, x2, f(x1, x2)), and for a continuous function is a surface.
## 2_ Uni, bi and multivariate viz
### Univariate
The term is commonly used in statistics to distinguish a distribution of one variable from a distribution of several variables, although it can be applied in other ways as well. For example, univariate data are composed of a single scalar component. In time series analysis, the term is applied with a whole time series as the object referred to: thus a univariate time series refers to the set of values over time of a single quantity.
### Bivariate
Bivariate analysis is one of the simplest forms of quantitative (statistical) analysis.[1] It involves the analysis of two variables (often denoted as X, Y), for the purpose of determining the empirical relationship between them.
### Multivariate
Multivariate analysis (MVA) is based on the statistical principle of multivariate statistics, which involves observation and analysis of more than one statistical outcome variable at a time. In design and analysis, the technique is used to perform trade studies across multiple dimensions while taking into account the effects of all variables on the responses of interest.
## 3_ ggplot2
### About
ggplot2 is a plotting system for R, based on the grammar of graphics, which tries to take the good parts of base and lattice graphics and none of the bad parts. It takes care of many of the fiddly details that make plotting a hassle (like drawing legends) as well as providing a powerful model of graphics that makes it easy to produce complex multi-layered graphics.
[http://ggplot2.org/](http://ggplot2.org/)
### Documentation
### Examples
[http://r4stats.com/examples/graphics-ggplot2/](http://r4stats.com/examples/graphics-ggplot2/)
## 4_ Histogram and pie (Uni)
### About
Histograms and pie are 2 types of graphes used to visualize frequencies.
Histogram is showing the distribution of these frequencies over classes, and pie the relative proportion of this frequencies in a 100% circle.
## 5_ Tree & tree map
### About
[Treemaps](https://en.wikipedia.org/wiki/Treemapping) display hierarchical (tree-structured) data as a set of nested rectangles.
Each branch of the tree is given a rectangle, which is then tiled with smaller rectangles representing sub-branches.
A leaf node’s rectangle has an area proportional to a specified dimension of the data.
Often the leaf nodes are colored to show a separate dimension of the data.
### When to use it ?
- Less than 10 branches.
- Positive values.
- Space for visualisation is limited.
### Example
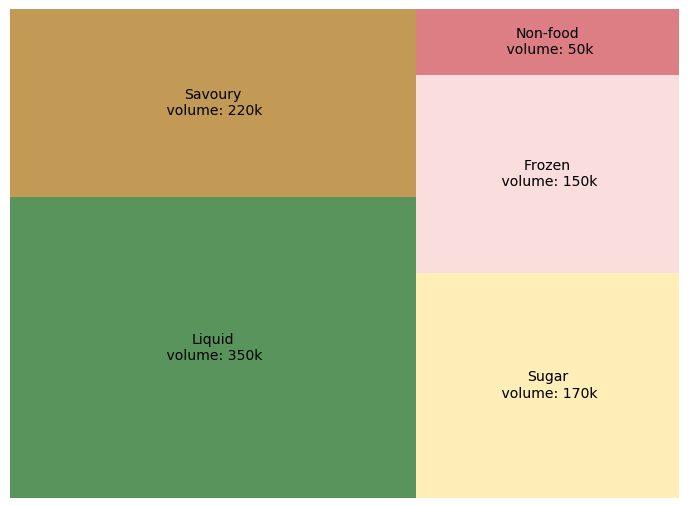
This treemap describes volume for each product universe with corresponding surface. Liquid products are more sold than others.
If you want to explore more, we can go into products “liquid” and find which shelves are prefered by clients.
### More information
[Matplotlib Series 5: Treemap](https://jingwen-z.github.io/data-viz-with-matplotlib-series5-treemap/)
## 6_ Scatter plot
### About
A [scatter plot](https://en.wikipedia.org/wiki/Scatter_plot) (also called a scatter graph, scatter chart, scattergram, or scatter diagram) is a type of plot or mathematical diagram using Cartesian coordinates to display values for typically two variables for a set of data.
### When to use it ?
Scatter plots are used when you want to show the relationship between two variables.
Scatter plots are sometimes called correlation plots because they show how two variables are correlated.
### Example
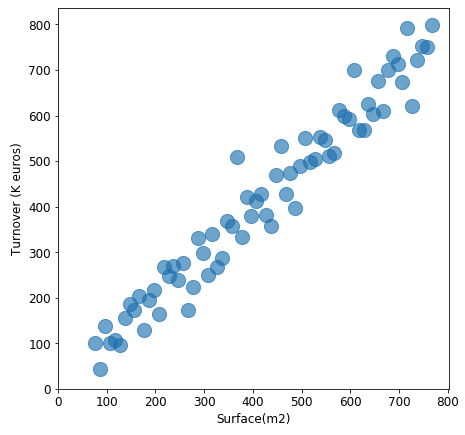
This plot describes the positive relation between store’s surface and its turnover(k euros), which is reasonable: for stores, the larger it is, more clients it can accept, more turnover it will generate.
### More information
[Matplotlib Series 4: Scatter plot](https://jingwen-z.github.io/data-viz-with-matplotlib-series4-scatter-plot/)
## 7_ Line chart
### About
A [line chart](https://en.wikipedia.org/wiki/Line_chart) or line graph is a type of chart which displays information as a series of data points called ‘markers’ connected by straight line segments. A line chart is often used to visualize a trend in data over intervals of time – a time series – thus the line is often drawn chronologically.
### When to use it ?
- Track changes over time.
- X-axis displays continuous variables.
- Y-axis displays measurement.
### Example
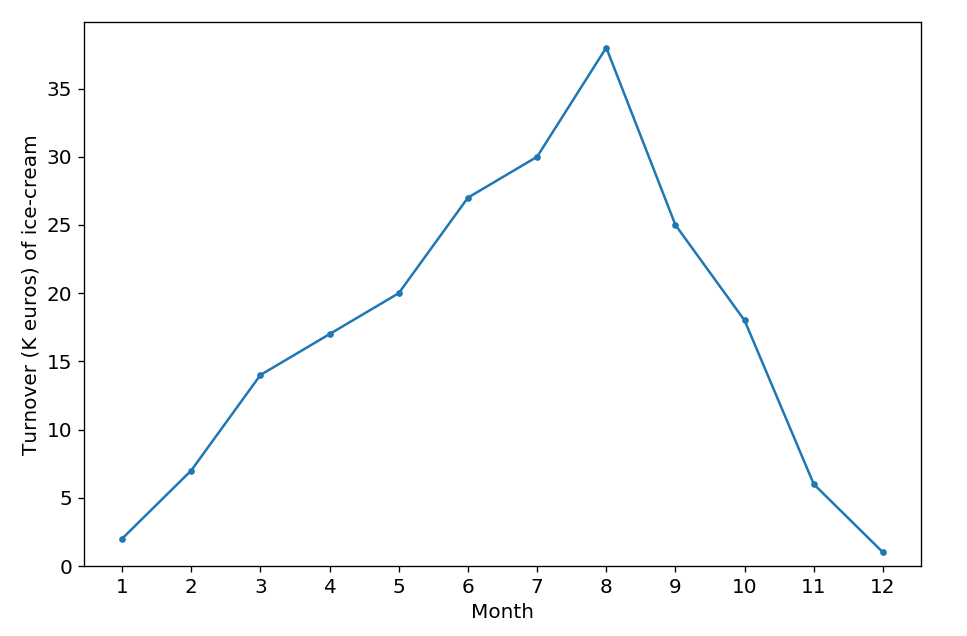
Suppose that the plot above describes the turnover(k euros) of ice-cream’s sales during one year.
According to the plot, we can clearly find that the sales reach a peak in summer, then fall from autumn to winter, which is logical.
### More information
[Matplotlib Series 2: Line chart](https://jingwen-z.github.io/data-viz-with-matplotlib-series2-line-chart/)
## 8_ Spatial charts
## 9_ Survey plot
## 10_ Timeline
## 11_ Decision tree
## 12_ D3.js
### About
This is a JavaScript library, allowing you to create a huge number of different figure easily.
https://d3js.org/
D3.js is a JavaScript library for manipulating documents based on data.
D3 helps you bring data to life using HTML, SVG, and CSS.
D3’s emphasis on web standards gives you the full capabilities of modern browsers without tying yourself to a proprietary framework, combining powerful visualization components and a data-driven approach to DOM manipulation.
### Examples
There is many examples of chars using D3.js on [D3's Github](https://github.com/d3/d3/wiki/Gallery).
## 13_ InfoVis
## 14_ IBM ManyEyes
## 15_ Tableau
## 16_ Venn diagram
### About
A [venn diagram](https://en.wikipedia.org/wiki/Venn_diagram) (also called primary diagram, set diagram or logic diagram) is a diagram that shows all possible logical relations between a finite collection of different sets.
### When to use it ?
Show logical relations between different groups (intersection, difference, union).
### Example
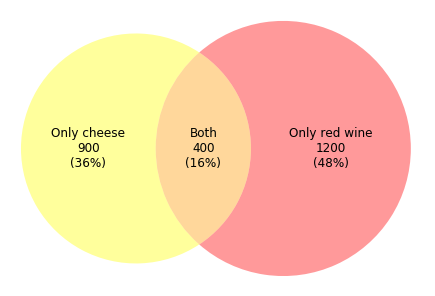
This kind of venn diagram can usually be used in retail trading.
Assuming that we need to study the popularity of cheese and red wine, and 2500 clients answered our questionnaire.
According to the diagram above, we find that among 2500 clients, 900 clients(36%) prefer cheese, 1200 clients(48%) prefer red wine, and 400 clients(16%) favor both product.
### More information
[Matplotlib Series 6: Venn diagram](https://jingwen-z.github.io/data-viz-with-matplotlib-series6-venn-diagram/)
## 17_ Area chart
### About
An [area chart](https://en.wikipedia.org/wiki/Area_chart) or area graph displays graphically quantitative data.
It is based on the line chart. The area between axis and line are commonly emphasized with colors, textures and hatchings.
### When to use it ?
Show or compare a quantitative progression over time.
### Example
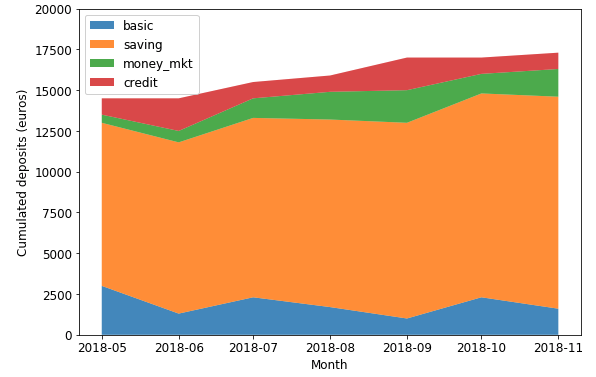
This stacked area chart displays the amounts’ changes in each account, their contribution to total amount (in term of value) as well.
### More information
[Matplotlib Series 7: Area chart](https://jingwen-z.github.io/data-viz-with-matplotlib-series7-area-chart/)
## 18_ Radar chart
### About
The [radar chart](https://en.wikipedia.org/wiki/Radar_chart) is a chart and/or plot that consists of a sequence of equi-angular spokes, called radii, with each spoke representing one of the variables. The data length of a spoke is proportional to the magnitude of the variable for the data point relative to the maximum magnitude of the variable across all data points. A line is drawn connecting the data values for each spoke. This gives the plot a star-like appearance and the origin of one of the popular names for this plot.
### When to use it ?
- Comparing two or more items or groups on various features or characteristics.
- Examining the relative values for a single data point.
- Displaying less than ten factors on one radar chart.
### Example
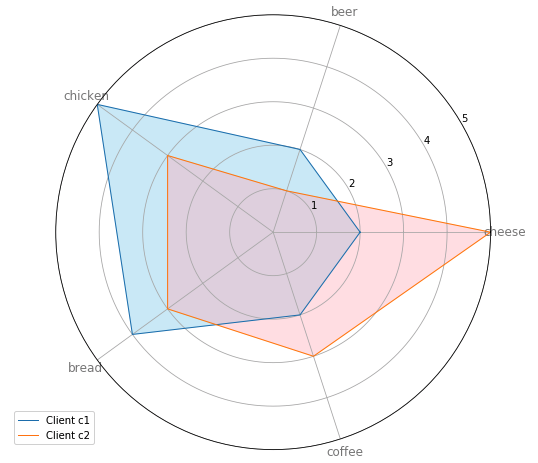
This radar chart displays the preference of 2 clients among 4.
Client c1 favors chicken and bread, and doesn’t like cheese that much.
Nevertheless, client c2 prefers cheese to other 4 products and doesn’t like beer.
We can have an interview with these 2 clients, in order to find the weakness of products which are out of preference.
### More information
[Matplotlib Series 8: Radar chart](https://jingwen-z.github.io/data-viz-with-matplotlib-series8-radar-chart/)
## 19_ Word cloud
### About
A [word cloud](https://en.wikipedia.org/wiki/Tag_cloud) (tag cloud, or weighted list in visual design) is a novelty visual representation of text data. Tags are usually single words, and the importance of each tag is shown with font size or color. This format is useful for quickly perceiving the most prominent terms and for locating a term alphabetically to determine its relative prominence.
### When to use it ?
- Depicting keyword metadata (tags) on websites.
- Delighting and provide emotional connection.
### Example

According to this word cloud, we can globally know that data science employs techniques and theories drawn from many fields within the context of mathematics, statistics, information science, and computer science. It can be used for business analysis, and called “The Sexiest Job of the 21st Century”.
### More information
[Matplotlib Series 9: Word cloud](https://jingwen-z.github.io/data-viz-with-matplotlib-series9-word-cloud/)
# 7_ Big Data
## 1_ Map Reduce fundamentals
## 2_ Hadoop Ecosystem
## 3_ HDFS
## 4_ Data replications Principles
## 5_ Setup Hadoop
## 6_ Name & data nodes
## 7_ Job & task tracker
## 8_ M/R/SAS programming
## 9_ Sqop: Loading data in HDFS
## 10_ Flume, Scribe
## 11_ SQL with Pig
## 12_ DWH with Hive
## 13_ Scribe, Chukwa for Weblog
## 14_ Using Mahout
## 15_ Zookeeper Avro
## 16_ Lambda Architecture
## 17_ Storm: Hadoop Realtime
## 18_ Rhadoop, RHIPE
## 19_ RMR
## 20_ NoSQL Databases (MongoDB, Neo4j)
## 21_ Distributed Databases and Systems (Cassandra)
# 8_ Data Ingestion
## 1_ Summary of data formats
## 2_ Data discovery
## 3_ Data sources & Acquisition
## 4_ Data integration
## 5_ Data fusion
## 6_ Transformation & enrichment
## 7_ Data survey
## 8_ Google OpenRefine
## 9_ How much data ?
## 10_ Using ETL
# 9_ Data Munging
## 1_ Dim. and num. reduction
## 2_ Normalization
## 3_ Data scrubbing
## 4_ Handling missing Values
## 5_ Unbiased estimators
## 6_ Binning Sparse Values
## 7_ Feature extraction
## 8_ Denoising
## 9_ Sampling
## 10_ Stratified sampling
## 11_ PCA
# 10_ Toolbox
## 1_ MS Excel with Analysis toolpack
## 2_ Java, Python
## 3_ R, Rstudio, Rattle
## 4_ Weka, Knime, RapidMiner
## 5_ Hadoop dist of choice
## 6_ Spark, Storm
## 7_ Flume, Scibe, Chukwa
## 8_ Nutch, Talend, Scraperwiki
## 9_ Webscraper, Flume, Sqoop
## 10_ tm, RWeka, NLTK
## 11_ RHIPE
## 12_ D3.js, ggplot2, Shiny
## 13_ IBM Languageware
## 14_ Cassandra, MongoDB
## 13_ Microsoft Azure, AWS, Google Cloud
## 14_ Microsoft Cognitive API
## 15_ Tensorflow
https://www.tensorflow.org/
TensorFlow is an open source software library for numerical computation using data flow graphs.
Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them.
The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.
TensorFlow was originally developed by researchers and engineers working on the Google Brain Team within Google's Machine Intelligence research organization for the purposes of conducting machine learning and deep neural networks research, but the system is general enough to be applicable in a wide variety of other domains as well.
# OTHER FREE COURSES
### Artificial Intelligence
- [CS 188 - Introduction to Artificial Intelligence, UC Berkeley - Spring 2015](http://www.infocobuild.com/education/audio-video-courses/computer-science/cs188-spring2015-berkeley.html)
- [6.034 Artificial Intelligence, MIT OCW](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/lecture-videos/)
- [CS221: Artificial Intelligence: Principles and Techniques - Autumn 2019 - Stanford University](https://www.youtube.com/playlist?list=PLoROMvodv4rO1NB9TD4iUZ3qghGEGtqNX)
- [15-780 - Graduate Artificial Intelligence, Spring 14, CMU](http://www.cs.cmu.edu/~zkolter/course/15-780-s14/lectures.html)
- [CSE 592 Applications of Artificial Intelligence, Winter 2003 - University of Washington](https://courses.cs.washington.edu/courses/csep573/03wi/lectures/index.htm)
- [CS322 - Introduction to Artificial Intelligence, Winter 2012-13 - UBC](http://www.cs.ubc.ca/~mack/CS322/) ([YouTube](https://www.youtube.com/playlist?list=PLDPnGbm0sUmpzvcGvktbz446SLdFbfZVU))
- [CS 4804: Introduction to Artificial Intelligence, Fall 2016](https://www.youtube.com/playlist?list=PLUenpfvlyoa1iiSbGy9BBewgiXjzxVgBd)
- [CS 5804: Introduction to Artificial Intelligence, Spring 2015](https://www.youtube.com/playlist?list=PLUenpfvlyoa0PB6_kqJ9WU7m6i6z1RhfJ)
- [Artificial Intelligence - IIT Kharagpur](https://nptel.ac.in/courses/106105077/)
- [Artificial Intelligence - IIT Madras](https://nptel.ac.in/courses/106106126/)
- [Artificial Intelligence(Prof.P.Dasgupta) - IIT Kharagpur](https://nptel.ac.in/courses/106105079/)
- [MOOC - Intro to Artificial Intelligence - Udacity](https://www.youtube.com/playlist?list=PLAwxTw4SYaPlqMkzr4xyuD6cXTIgPuzgn)
- [MOOC - Artificial Intelligence for Robotics - Udacity](https://www.youtube.com/playlist?list=PLAwxTw4SYaPkCSYXw6-a_aAoXVKLDwnHK)
- [Graduate Course in Artificial Intelligence, Autumn 2012 - University of Washington](https://www.youtube.com/playlist?list=PLbQ3Aya0VERDoDdbMogU9EASJGWris9qG)
- [Agent-Based Systems 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/abs.htm)
- [Informatics 2D - Reasoning and Agents 2014/15- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2014/inf2d.htm)
- [Artificial Intelligence - Hochschule Ravensburg-Weingarten](https://www.youtube.com/playlist?list=PL39B5D3AFC249556A)
- [Deductive Databases and Knowledge-Based Systems - Technische Universität Braunschweig, Germany](http://www.ifis.cs.tu-bs.de/teaching/ws-1516/KBS)
- [Artificial Intelligence: Knowledge Representation and Reasoning - IIT Madras](https://nptel.ac.in/courses/106106140/)
- [Semantic Web Technologies by Dr. Harald Sack - HPI](https://www.youtube.com/playlist?list=PLoOmvuyo5UAeihlKcWpzVzB51rr014TwD)
- [Knowledge Engineering with Semantic Web Technologies by Dr. Harald Sack - HPI](https://www.youtube.com/playlist?list=PLoOmvuyo5UAcBXlhTti7kzetSsi1PpJGR)
--------------
### Machine Learning
- **Introduction to Machine Learning**
- [MOOC Machine Learning Andrew Ng - Coursera/Stanford](https://www.youtube.com/playlist?list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN) ([Notes](http://www.holehouse.org/mlclass/))
- [Introduction to Machine Learning for Coders](https://course.fast.ai/ml.html)
- [MOOC - Statistical Learning, Stanford University](http://www.dataschool.io/15-hours-of-expert-machine-learning-videos/)
- [Foundations of Machine Learning Boot Camp, Berkeley Simons Institute](https://www.youtube.com/playlist?list=PLgKuh-lKre11GbZWneln-VZDLHyejO7YD)
- [CS155 - Machine Learning & Data Mining, 2017 - Caltech](https://www.youtube.com/playlist?list=PLuz4CTPOUNi6BfMrltePqMAHdl5W33-bC) ([Notes](http://www.yisongyue.com/courses/cs155/2017_winter/)) ([2016](https://www.youtube.com/playlist?list=PL5HdMttxBY0BVTP9y7qQtzTgmcjQ3P0mb))
- [CS 156 - Learning from Data, Caltech](https://work.caltech.edu/lectures.html)
- [10-601 - Introduction to Machine Learning (MS) - Tom Mitchell - 2015, CMU](http://www.cs.cmu.edu/~ninamf/courses/601sp15/lectures.shtml) ([YouTube](https://www.youtube.com/playlist?list=PLAJ0alZrN8rD63LD0FkzKFiFgkOmEtltQ))
- [10-601 Machine Learning | CMU | Fall 2017](https://www.youtube.com/playlist?list=PL7k0r4t5c10-g7CWCnHfZOAxLaiNinChk)
- [10-701 - Introduction to Machine Learning (PhD) - Tom Mitchell, Spring 2011, CMU](http://www.cs.cmu.edu/~tom/10701_sp11/lectures.shtml) ([Fall 2014](https://www.youtube.com/playlist?list=PL7y-1rk2cCsDZCVz2xS7LrExqidHpJM3B)) ([Spring 2015 by Alex Smola](https://www.youtube.com/playlist?list=PLZSO_6-bSqHTTV7w9u7grTXBHMH-mw3qn))
- [10 - 301/601 - Introduction to Machine Learning - Spring 2020 - CMU](https://www.youtube.com/playlist?list=PLpqQKYIU-snAPM89YPPwyQ9xdaiAdoouk)
- [CMS 165 Foundations of Machine Learning and Statistical Inference - 2020 - Caltech](https://www.youtube.com/playlist?list=PLVNifWxslHCDlbyitaLLYBOAEPbmF1AHg)
- [Microsoft Research - Machine Learning Course](https://www.youtube.com/playlist?list=PL34iyE0uXtxo7vPXGFkmm6KbgZQwjf9Kf)
- [CS 446 - Machine Learning, Spring 2019, UIUC](https://courses.engr.illinois.edu/cs446/sp2019/AGS/_site/)([ Fall 2016 Lectures](https://www.youtube.com/playlist?list=PLQcasX5-oG91TgY6A_gz-IW7YSpwdnD2O))
- [undergraduate machine learning at UBC 2012, Nando de Freitas](https://www.youtube.com/playlist?list=PLE6Wd9FR--Ecf_5nCbnSQMHqORpiChfJf)
- [CS 229 - Machine Learning - Stanford University](https://see.stanford.edu/Course/CS229) ([Autumn 2018](https://www.youtube.com/playlist?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU))
- [CS 189/289A Introduction to Machine Learning, Prof Jonathan Shewchuk - UCBerkeley](https://people.eecs.berkeley.edu/~jrs/189/)
- [CPSC 340: Machine Learning and Data Mining (2018) - UBC](https://www.youtube.com/playlist?list=PLWmXHcz_53Q02ZLeAxigki1JZFfCO6M-b)
- [CS4780/5780 Machine Learning, Fall 2013 - Cornell University](http://www.cs.cornell.edu/courses/cs4780/2013fa/)
- [CS4780/5780 Machine Learning, Fall 2018 - Cornell University](http://www.cs.cornell.edu/courses/cs4780/2018fa/page18/index.html) ([Youtube](https://www.youtube.com/playlist?list=PLl8OlHZGYOQ7bkVbuRthEsaLr7bONzbXS))
- [CSE474/574 Introduction to Machine Learning - SUNY University at Buffalo](https://www.youtube.com/playlist?list=PLEQDy5tl3xkMzk_zlo2DPzXteCquHA8bQ)
- [CS 5350/6350 - Machine Learning, Fall 2016, University of Utah](https://www.youtube.com/playlist?list=PLbuogVdPnkCozRSsdueVwX7CF9N4QWL0B)
- [ECE 5984 Introduction to Machine Learning, Spring 2015 - Virginia Tech](https://filebox.ece.vt.edu/~s15ece5984/)
- [CSx824/ECEx242 Machine Learning, Bert Huang, Fall 2015 - Virginia Tech](https://www.youtube.com/playlist?list=PLUenpfvlyoa0rMoE5nXA8kdctBKE9eSob)
- [STA 4273H - Large Scale Machine Learning, Winter 2015 - University of Toronto](http://www.cs.toronto.edu/~rsalakhu/STA4273_2015/lectures.html)
- [CS 485/685 Machine Learning, Shai Ben-David, University of Waterloo](https://www.youtube.com/channel/UCR4_akQ1HYMUcDszPQ6jh8Q/videos)
- [STAT 441/841 Classification Winter 2017 , Waterloo](https://www.youtube.com/playlist?list=PLehuLRPyt1HzXDemu7K4ETcF0Ld_B5adG)
- [10-605 - Machine Learning with Large Datasets, Fall 2016 - CMU](https://www.youtube.com/channel/UCIE4UdPoCJZMAZrTLuq-CPQ/videos)
- [Information Theory, Pattern Recognition, and Neural Networks - University of Cambridge](https://www.youtube.com/playlist?list=PLruBu5BI5n4aFpG32iMbdWoRVAA-Vcso6)
- [Python and machine learning - Stanford Crowd Course Initiative](https://www.youtube.com/playlist?list=PLVxFQjPUB2cnYGZPAGG52OQc9SpWVKjjB)
- [MOOC - Machine Learning Part 1a - Udacity/Georgia Tech](https://www.youtube.com/playlist?list=PLAwxTw4SYaPl0N6-e1GvyLp5-MUMUjOKo) ([Part 1b](https://www.youtube.com/playlist?list=PLAwxTw4SYaPlkESDcHD-0oqVx5sAIgz7O) [Part 2](https://www.youtube.com/playlist?list=PLAwxTw4SYaPmaHhu-Lz3mhLSj-YH-JnG7) [Part 3](https://www.youtube.com/playlist?list=PLAwxTw4SYaPnidDwo9e2c7ixIsu_pdSNp))
- [Machine Learning and Pattern Recognition 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/mlpr.htm)
- [Introductory Applied Machine Learning 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/iaml.htm)
- [Pattern Recognition Class (2012)- Universität Heidelberg](https://www.youtube.com/playlist?list=PLuRaSnb3n4kRDZVU6wxPzGdx1CN12fn0w)
- [Introduction to Machine Learning and Pattern Recognition - CBCSL OSU](https://www.youtube.com/playlist?list=PLcXJymqaE9PPGGtFsTNoDWKl-VNVX5d6b)
- [Introduction to Machine Learning - IIT Kharagpur](https://nptel.ac.in/courses/106105152/)
- [Introduction to Machine Learning - IIT Madras](https://nptel.ac.in/courses/106106139/)
- [Pattern Recognition - IISC Bangalore](https://nptel.ac.in/courses/117108048/)
- [Pattern Recognition and Application - IIT Kharagpur](https://nptel.ac.in/courses/117105101/)
- [Pattern Recognition - IIT Madras](https://nptel.ac.in/courses/106106046/)
- [Machine Learning Summer School 2013 - Max Planck Institute for Intelligent Systems Tübingen](https://www.youtube.com/playlist?list=PLqJm7Rc5-EXFv6RXaPZzzlzo93Hl0v91E)
- [Machine Learning - Professor Kogan (Spring 2016) - Rutgers](https://www.youtube.com/playlist?list=PLauepKFT6DK_1_plY78bXMDj-bshv7UsQ)
- [CS273a: Introduction to Machine Learning](http://sli.ics.uci.edu/Classes/2015W-273a) ([YouTube](https://www.youtube.com/playlist?list=PLkWzaBlA7utJMRi89i9FAKMopL0h0LBMk))
- [Machine Learning Crash Course 2015](https://www.youtube.com/playlist?list=PLyGKBDfnk-iD5dK8N7UBUFVVDBBtznenR)
- [COM4509/COM6509 Machine Learning and Adaptive Intelligence 2015-16](http://inverseprobability.com/mlai2015/)
- [10715 Advanced Introduction to Machine Learning](https://sites.google.com/site/10715advancedmlintro2017f/lectures)
- [Introduction to Machine Learning - Spring 2018 - ETH Zurich](https://www.youtube.com/playlist?list=PLzn6LN6WhlN273tsqyfdrBUsA-o5nUESV)
- [Machine Learning - Pedro Domingos- University of Washington](https://www.youtube.com/user/UWCSE/playlists?view=50&sort=dd&shelf_id=16)
- [Advanced Machine Learning - 2019 - ETH Zürich](https://www.youtube.com/playlist?list=PLY-OA_xnxFwSe98pzMGVR4bjAZZYrNT7L)
- [Machine Learning (COMP09012)](https://www.youtube.com/playlist?list=PLyH-5mHPFffFwz7Twap0XuVeUJ8vuco9t)
- [Probabilistic Machine Learning 2020 - University of Tübingen](https://www.youtube.com/playlist?list=PL05umP7R6ij1tHaOFY96m5uX3J21a6yNd)
- [Statistical Machine Learning 2020 - Ulrike von Luxburg - University of Tübingen](https://www.youtube.com/playlist?list=PL05umP7R6ij2XCvrRzLokX6EoHWaGA2cC)
- [COMS W4995 - Applied Machine Learning - Spring 2020 - Columbia University](https://www.cs.columbia.edu/~amueller/comsw4995s20/schedule/)
- **Data Mining**
- [CSEP 546, Data Mining - Pedro Domingos, Sp 2016 - University of Washington](https://courses.cs.washington.edu/courses/csep546/16sp/) ([YouTube](https://www.youtube.com/playlist?list=PLTPQEx-31JXgtDaC6-3HxWcp7fq4N8YGr))
- [CS 5140/6140 - Data Mining, Spring 2016, University of Utah](https://www.cs.utah.edu/~jeffp/teaching/cs5140.html) ([Youtube](https://www.youtube.com/playlist?list=PLbuogVdPnkCpXfb43Wvc7s5fXWzedwTPB))
- [CS 5955/6955 - Data Mining, University of Utah](http://www.cs.utah.edu/~jeffp/teaching/cs5955.html) ([YouTube](https://www.youtube.com/channel/UCcrlwW88yMcXujhGjSP2WBg/videos))
- [Statistics 202 - Statistical Aspects of Data Mining, Summer 2007 - Google](http://www.stats202.com/original_index.html) ([YouTube](https://www.youtube.com/playlist?list=PLFE776F2C513A744E))
- [MOOC - Text Mining and Analytics by ChengXiang Zhai](https://www.youtube.com/playlist?list=PLLssT5z_DsK8Xwnh_0bjN4KNT81bekvtt)
- [Information Retrieval SS 2014, iTunes - HPI](https://itunes.apple.com/us/itunes-u/information-retrieval-ss-2014/id874200291)
- [MOOC - Data Mining with Weka](https://www.youtube.com/playlist?list=PLm4W7_iX_v4NqPUjceOGd-OKNVO4c_cPD)
- [CS 290 DataMining Lectures](https://www.youtube.com/playlist?list=PLB4CCA346A5741C4C)
- [CS246 - Mining Massive Data Sets, Winter 2016, Stanford University](https://web.stanford.edu/class/cs246/) ([YouTube](https://www.youtube.com/channel/UC_Oao2FYkLAUlUVkBfze4jg/videos))
- [Data Mining: Learning From Large Datasets - Fall 2017 - ETH Zurich](https://www.youtube.com/playlist?list=PLY-OA_xnxFwRHZO6L6yT253VPgrZazQs6)
- [Information Retrieval - Spring 2018 - ETH Zurich](https://www.youtube.com/playlist?list=PLzn6LN6WhlN1ktkDvNurPSDwTQ_oGQisn)
- [CAP6673 - Data Mining and Machine Learning - FAU](http://www.cse.fau.edu/~taghi/classes/cap6673/)([Video lectures](https://vimeo.com/album/1505953))
- [Data Warehousing and Data Mining Techniques - Technische Universität Braunschweig, Germany](http://www.ifis.cs.tu-bs.de/teaching/ws-1617/dwh)
- **Data Science**
- [Data 8: The Foundations of Data Science - UC Berkeley](http://data8.org/) ([Summer 17](http://data8.org/su17/))
- [CSE519 - Data Science Fall 2016 - Skiena, SBU](https://www.youtube.com/playlist?list=PLOtl7M3yp-DVBdLYatrltDJr56AKZ1qXo)
- [CS 109 Data Science, Harvard University](http://cs109.github.io/2015/pages/videos.html) ([YouTube](https://www.youtube.com/playlist?list=PLb4G5axmLqiuneCqlJD2bYFkBwHuOzKus))
- [6.0002 Introduction to Computational Thinking and Data Science - MIT OCW](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-0002-introduction-to-computational-thinking-and-data-science-fall-2016/lecture-videos/)
- [Data 100 - Summer 19- UC Berkeley](https://www.youtube.com/playlist?list=PLPHXc20GewP8J56CisONS_mFZWZAfa7jR)
- [Distributed Data Analytics (WT 2017/18) - HPI University of Potsdam](https://www.tele-task.de/series/1179/)
- [Statistics 133 - Concepts in Computing with Data, Fall 2013 - UC Berkeley](https://www.youtube.com/playlist?list=PL-XXv-cvA_iDsSPnMJlnhIyADGUmikoIO)
- [Data Profiling and Data Cleansing (WS 2014/15) - HPI University of Potsdam](https://www.tele-task.de/series/1027/)
- [AM 207 - Stochastic Methods for Data Analysis, Inference and Optimization, Harvard University](http://am207.github.io/2016/index.html)
- [CS 229r - Algorithms for Big Data, Harvard University](http://people.seas.harvard.edu/~minilek/cs229r/fall15/lec.html) ([Youtube](https://www.youtube.com/playlist?list=PL2SOU6wwxB0v1kQTpqpuu5kEJo2i-iUyf))
- [Algorithms for Big Data - IIT Madras](https://nptel.ac.in/courses/106106142/)
- **Probabilistic Graphical Modeling**
- [MOOC - Probabilistic Graphical Models - Coursera](https://www.youtube.com/playlist?list=PLvfF4UFg6Ejj6SX-ffw-O4--SPbB9P7eP)
- [CS 6190 - Probabilistic Modeling, Spring 2016, University of Utah](https://www.youtube.com/playlist?list=PLbuogVdPnkCpvxdF-Gy3gwaBObx7AnQut)
- [10-708 - Probabilistic Graphical Models, Carnegie Mellon University](https://www.cs.cmu.edu/~epxing/Class/10708-20/lectures.html)
- [Probabilistic Graphical Models, Daphne Koller, Stanford University](http://openclassroom.stanford.edu/MainFolder/CoursePage.php?course=ProbabilisticGraphicalModels)
- [Probabilistic Models - UNIVERSITY OF HELSINKI](https://www.cs.helsinki.fi/en/courses/582636/2015/K/K/1)
- [Probabilistic Modelling and Reasoning 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/pmr.htm)
- [Probabilistic Graphical Models, Spring 2018 - Notre Dame](https://www.youtube.com/playlist?list=PLd-PuDzW85AcV4bgdu7wHPL37hm60W4RM)
- **Deep Learning**
- [6.S191: Introduction to Deep Learning - MIT](http://introtodeeplearning.com/)
- [Deep Learning CMU](https://www.youtube.com/channel/UC8hYZGEkI2dDO8scT8C5UQA/videos)
- [Part 1: Practical Deep Learning for Coders, v3 - fast.ai](https://course.fast.ai/)
- [Part 2: Deep Learning from the Foundations - fast.ai](https://course.fast.ai/part2)
- [Deep learning at Oxford 2015 - Nando de Freitas](https://www.youtube.com/playlist?list=PLE6Wd9FR--EfW8dtjAuPoTuPcqmOV53Fu)
- [6.S094: Deep Learning for Self-Driving Cars - MIT](https://www.youtube.com/playlist?list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf)
- [CS294-129 Designing, Visualizing and Understanding Deep Neural Networks](https://bcourses.berkeley.edu/courses/1453965/pages/cs294-129-designing-visualizing-and-understanding-deep-neural-networks) ([YouTube](https://www.youtube.com/playlist?list=PLkFD6_40KJIxopmdJF_CLNqG3QuDFHQUm))
- [CS230: Deep Learning - Autumn 2018 - Stanford University](https://www.youtube.com/playlist?list=PLoROMvodv4rOABXSygHTsbvUz4G_YQhOb)
- [STAT-157 Deep Learning 2019 - UC Berkeley ](https://www.youtube.com/playlist?list=PLZSO_6-bSqHQHBCoGaObUljoXAyyqhpFW)
- [Full Stack DL Bootcamp 2019 - UC Berkeley](https://www.youtube.com/playlist?list=PL_Ig1a5kxu5645uORPL8xyvHr91Lg8G1l)
- [Deep Learning, Stanford University](http://openclassroom.stanford.edu/MainFolder/CoursePage.php?course=DeepLearning)
- [MOOC - Neural Networks for Machine Learning, Geoffrey Hinton 2016 - Coursera](https://www.youtube.com/playlist?list=PLoRl3Ht4JOcdU872GhiYWf6jwrk_SNhz9)
- [Deep Unsupervised Learning -- Berkeley Spring 2020](https://www.youtube.com/playlist?list=PLwRJQ4m4UJjPiJP3691u-qWwPGVKzSlNP)
- [Stat 946 Deep Learning - University of Waterloo](https://www.youtube.com/playlist?list=PLehuLRPyt1Hyi78UOkMPWCGRxGcA9NVOE)
- [Neural networks class - Université de Sherbrooke](http://info.usherbrooke.ca/hlarochelle/neural_networks/content.html) ([YouTube](https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH))
- [CS294-158 Deep Unsupervised Learning SP19](https://www.youtube.com/channel/UCf4SX8kAZM_oGcZjMREsU9w/videos)
- [DLCV - Deep Learning for Computer Vision - UPC Barcelona](https://www.youtube.com/playlist?list=PL-5eMc3HQTBavDoZpFcX-bff5WgQqSLzR)
- [DLAI - Deep Learning for Artificial Intelligence @ UPC Barcelona](https://www.youtube.com/playlist?list=PL-5eMc3HQTBagIUjKefjcTbnXC0wXC_vd)
- [Neural Networks and Applications - IIT Kharagpur](https://nptel.ac.in/courses/117105084/)
- [UVA DEEP LEARNING COURSE](http://uvadlc.github.io/#lecture)
- [Nvidia Machine Learning Class](https://www.youtube.com/playlist?list=PLTIkHmXc-7an8xbwhAJX-LQ4D4Uf-ar5I)
- [Deep Learning - Winter 2020-21 - Tübingen Machine Learning](https://www.youtube.com/playlist?list=PL05umP7R6ij3NTWIdtMbfvX7Z-4WEXRqD)
- **Reinforcement Learning**
- [CS234: Reinforcement Learning - Winter 2019 - Stanford University](https://www.youtube.com/playlist?list=PLoROMvodv4rOSOPzutgyCTapiGlY2Nd8u)
- [Introduction to reinforcement learning - UCL](https://www.youtube.com/playlist?list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ)
- [Advanced Deep Learning & Reinforcement Learning - UCL](https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs)
- [Reinforcement Learning - IIT Madras](https://www.youtube.com/playlist?list=PLyqSpQzTE6M_FwzHFAyf4LSkz_IjMyjD9)
- [CS885 Reinforcement Learning - Spring 2018 - University of Waterloo](https://www.youtube.com/playlist?list=PLdAoL1zKcqTXFJniO3Tqqn6xMBBL07EDc)
- [CS 285 - Deep Reinforcement Learning- UC Berkeley](https://www.youtube.com/playlist?list=PLkFD6_40KJIwhWJpGazJ9VSj9CFMkb79A)
- [CS 294 112 - Reinforcement Learning](https://www.youtube.com/playlist?list=PLkFD6_40KJIxJMR-j5A1mkxK26gh_qg37)
- [NUS CS 6101 - Deep Reinforcement Learning](https://www.youtube.com/playlist?list=PLllwxvcS7ca5wOmRLKm6ri-OaC0INYehv)
- [ECE 8851: Reinforcement Learning](https://www.youtube.com/playlist?list=PL_Nk3YvgORJs1tCLQnlnSRsOJArj_cP9u)
- [CS294-112, Deep Reinforcement Learning Sp17](http://rll.berkeley.edu/deeprlcourse/) ([YouTube](https://www.youtube.com/playlist?list=PLkFD6_40KJIwTmSbCv9OVJB3YaO4sFwkX))
- [UCL Course 2015 on Reinforcement Learning by David Silver from DeepMind](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html) ([YouTube](https://www.youtube.com/watch?v=2pWv7GOvuf0))
- [Deep RL Bootcamp - Berkeley Aug 2017](https://sites.google.com/view/deep-rl-bootcamp/lectures)
- [Reinforcement Learning - IIT Madras](https://www.youtube.com/playlist?list=PLyqSpQzTE6M_FwzHFAyf4LSkz_IjMyjD9)
- **Advanced Machine Learning**
- [Machine Learning 2013 - Nando de Freitas, UBC](https://www.youtube.com/playlist?list=PLE6Wd9FR--EdyJ5lbFl8UuGjecvVw66F6)
- [Machine Learning, 2014-2015, University of Oxford](https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/)
- [10-702/36-702 - Statistical Machine Learning - Larry Wasserman, Spring 2016, CMU](https://www.stat.cmu.edu/~ryantibs/statml/) ([Spring 2015](https://www.youtube.com/playlist?list=PLjbUi5mgii6BWEUZf7He6nowWvGne_Y8r))
- [10-715 Advanced Introduction to Machine Learning - CMU](http://www.cs.cmu.edu/~bapoczos/Classes/ML10715_2015Fall/) ([YouTube](https://www.youtube.com/playlist?list=PL4DwY1suLMkcu-wytRDbvBNmx57CdQ2pJ))
- [CS 281B - Scalable Machine Learning, Alex Smola, UC Berkeley](http://alex.smola.org/teaching/berkeley2012/syllabus.html)
- [18.409 Algorithmic Aspects of Machine Learning Spring 2015 - MIT](https://www.youtube.com/playlist?list=PLB3sDpSRdrOvI1hYXNsa6Lety7K8FhPpx)
- [CS 330 - Deep Multi-Task and Meta Learning - Fall 2019 - Stanford University](https://cs330.stanford.edu/) ([Youtube](https://www.youtube.com/playlist?list=PLoROMvodv4rMC6zfYmnD7UG3LVvwaITY5))
- **ML based Natural Language Processing and Computer Vision**
- [CS 224d - Deep Learning for Natural Language Processing, Stanford University](http://cs224d.stanford.edu/syllabus.html) ([Lectures - Youtube](https://www.youtube.com/playlist?list=PLCJlDcMjVoEdtem5GaohTC1o9HTTFtK7_))
- [CS 224N - Natural Language Processing, Stanford University](http://web.stanford.edu/class/cs224n/) ([Lecture videos](https://www.youtube.com/playlist?list=PLgtM85Maly3n2Fp1gJVvqb0bTC39CPn1N))
- [CS 124 - From Languages to Information - Stanford University](https://www.youtube.com/channel/UC_48v322owNVtORXuMeRmpA/playlists?view=50&sort=dd&shelf_id=2)
- [MOOC - Natural Language Processing, Dan Jurafsky & Chris Manning - Coursera](https://www.youtube.com/playlist?list=PL6397E4B26D00A269)
- [fast.ai Code-First Intro to Natural Language Processing](https://www.youtube.com/playlist?list=PLtmWHNX-gukKocXQOkQjuVxglSDYWsSh9) ([Github](https://github.com/fastai/course-nlp))
- [MOOC - Natural Language Processing - Coursera, University of Michigan](https://www.youtube.com/playlist?list=PLLssT5z_DsK8BdawOVCCaTCO99Ya58ryR)
- [CS 231n - Convolutional Neural Networks for Visual Recognition, Stanford University](https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv)
- [CS224U: Natural Language Understanding - Spring 2019 - Stanford University](https://www.youtube.com/playlist?list=PLoROMvodv4rObpMCir6rNNUlFAn56Js20)
- [Deep Learning for Natural Language Processing, 2017 - Oxford University](https://github.com/oxford-cs-deepnlp-2017/lectures)
- [Machine Learning for Robotics and Computer Vision, WS 2013/2014 - TU München](https://vision.in.tum.de/teaching/ws2013/ml_ws13) ([YouTube](https://www.youtube.com/playlist?list=PLTBdjV_4f-EIiongKlS9OKrBEp8QR47Wl))
- [Informatics 1 - Cognitive Science 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/inf1cs.htm)
- [Informatics 2A - Processing Formal and Natural Languages 2016-17 - University of Edinburgh](http://www.inf.ed.ac.uk/teaching/courses/inf2a/schedule.html)
- [Computational Cognitive Science 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/ccs.htm)
- [Accelerated Natural Language Processing 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/anlp.htm)
- [Natural Language Processing - IIT Bombay](https://nptel.ac.in/courses/106101007/)
- [NOC:Deep Learning For Visual Computing - IIT Kharagpur](https://nptel.ac.in/courses/108/105/108105103/)
- [CS 11-747 - Neural Nets for NLP - 2019 - CMU](https://www.youtube.com/playlist?list=PL8PYTP1V4I8Ajj7sY6sdtmjgkt7eo2VMs)
- [Natural Language Processing - Michael Collins - Columbia University](https://www.youtube.com/playlist?list=PLA212ij5XG8OTDRl8IWFiJgHR9Ve2k9pv)
- [Deep Learning for Computer Vision - University of Michigan](https://www.youtube.com/playlist?list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r)
- [CMU CS11-737 - Multilingual Natural Language Processing](https://www.youtube.com/playlist?list=PL8PYTP1V4I8CHhppU6n1Q9-04m96D9gt5)
- **Time Series Analysis**
- [02417 Time Series Analysis](https://www.youtube.com/playlist?list=PLtiTxpFJ4k6TZ0g496fVcQpt_-XJRNkbi)
- [Applied Time Series Analysis](https://www.youtube.com/playlist?list=PLl0FT6O_WWDBm-4W-eoK34omYmEMseQDX)
- **Misc Machine Learning Topics**
- [EE364a: Convex Optimization I - Stanford University](http://web.stanford.edu/class/ee364a/videos.html)
- [CS 6955 - Clustering, Spring 2015, University of Utah](https://www.youtube.com/playlist?list=PLbuogVdPnkCpRvi-qSMCdOwyn4UYoPxTI)
- [Info 290 - Analyzing Big Data with Twitter, UC Berkeley school of information](http://blogs.ischool.berkeley.edu/i290-abdt-s12/) ([YouTube](https://www.youtube.com/playlist?list=PLE8C1256A28C1487F))
- [10-725 Convex Optimization, Spring 2015 - CMU](http://www.stat.cmu.edu/~ryantibs/convexopt-S15/)
- [10-725 Convex Optimization: Fall 2016 - CMU](http://www.stat.cmu.edu/~ryantibs/convexopt/)
- [CAM 383M - Statistical and Discrete Methods for Scientific Computing, University of Texas](http://granite.ices.utexas.edu/coursewiki/index.php/Main_Page)
- [9.520 - Statistical Learning Theory and Applications, Fall 2015 - MIT](https://www.youtube.com/playlist?list=PLyGKBDfnk-iDj3FBd0Avr_dLbrU8VG73O)
- [Reinforcement Learning - UCL](https://www.youtube.com/playlist?list=PLacBNHqv7n9gp9cBMrA6oDbzz_8JqhSKo)
- [Regularization Methods for Machine Learning 2016](http://academictorrents.com/details/493251615310f9b6ae1f483126292378137074cd) ([YouTube](https://www.youtube.com/playlist?list=PLbF0BXX_6CPJ20Gf_KbLFnPWjFTvvRwCO))
- [Statistical Inference in Big Data - University of Toronto](http://fields2015bigdata2inference.weebly.com/materials.html)
- [10-725 Optimization Fall 2012 - CMU](http://www.cs.cmu.edu/~ggordon/10725-F12/schedule.html)
- [10-801 Advanced Optimization and Randomized Methods - CMU](http://www.cs.cmu.edu/~suvrit/teach/aopt.html) ([YouTube](https://www.youtube.com/playlist?list=PLjTcdlvIS6cjdA8WVXNIk56X_SjICxt0d))
- [Reinforcement Learning 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/rl.htm)
- [Reinforcement Learning - IIT Madras](https://nptel.ac.in/courses/106106143/)
- [Statistical Rethinking Winter 2015 - Richard McElreath](https://www.youtube.com/playlist?list=PLDcUM9US4XdMdZOhJWJJD4mDBMnbTWw_z)
- [Music Information Retrieval - University of Victoria, 2014](http://marsyas.cs.uvic.ca/mirBook/course/)
- [PURDUE Machine Learning Summer School 2011](https://www.youtube.com/playlist?list=PL2A65507F7D725EFB)
- [Foundations of Machine Learning - Blmmoberg Edu](https://bloomberg.github.io/foml/#home)
- [Introduction to reinforcement learning - UCL](https://www.youtube.com/playlist?list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ)
- [Advanced Deep Learning & Reinforcement Learning - UCL](https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs)
- [Web Information Retrieval (Proff. L. Becchetti - A. Vitaletti)](https://www.youtube.com/playlist?list=PLAQopGWlIcya-9yzQ8c8UtPOuCv0mFZkr)
- [Big Data Systems (WT 2019/20) - Prof. Dr. Tilmann Rabl - HPI](https://www.tele-task.de/series/1286/)
- [Distributed Data Analytics (WT 2017/18) - Dr. Thorsten Papenbrock - HPI](https://www.tele-task.de/series/1179/)
- **Probability & Statistics**
- [6.041 Probabilistic Systems Analysis and Applied Probability - MIT OCW](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-041sc-probabilistic-systems-analysis-and-applied-probability-fall-2013/)
- [Statistics 110 - Probability - Harvard University](https://www.youtube.com/playlist?list=PL2SOU6wwxB0uwwH80KTQ6ht66KWxbzTIo)
- [STAT 2.1x: Descriptive Statistics | UC Berkeley](https://www.youtube.com/playlist?list=PL_Ig1a5kxu56TfFnGlRlH2YpOBWGiYsQD)
- [STAT 2.2x: Probability | UC Berkeley](https://www.youtube.com/playlist?list=PL_Ig1a5kxu57qPZnHm-ie-D7vs9g7U-Cl)
- [MOOC - Statistics: Making Sense of Data, Coursera](http://academictorrents.com/details/a0cbaf3e03e0893085b6fbdc97cb6220896dddf2)
- [MOOC - Statistics One - Coursera](https://www.youtube.com/playlist?list=PLycnP7USbo1V3jlyjAzWUB201cLxPq4NP)
- [Probability and Random Processes - IIT Kharagpur](https://nptel.ac.in/courses/117105085/)
- [MOOC - Statistical Inference - Coursera](https://www.youtube.com/playlist?list=PLgIPpm6tJZoSvrYM54BUqJJ4CWrYeGO40)
- [131B - Introduction to Probability and Statistics, UCI](https://www.youtube.com/playlist?list=PLqOZ6FD_RQ7k-j-86QUC2_0nEu0QOP-Wy)
- [STATS 250 - Introduction to Statistics and Data Analysis, UMichigan](https://www.youtube.com/playlist?list=PL432AB57AF9F43D4F)
- [Sets, Counting and Probability - Harvard](http://matterhorn.dce.harvard.edu/engage/ui/index.html#/1999/01/82347)
- [Opinionated Lessons in Statistics](http://www.opinionatedlessons.org/) ([Youtube](https://www.youtube.com/playlist?list=PLUAHeOPjkJseXJKbuk9-hlOfZU9Wd6pS0))
- [Statistics - Brandon Foltz](https://www.youtube.com/user/BCFoltz/playlists)
- [Statistical Rethinking: A Bayesian Course Using R and Stan](https://github.com/rmcelreath/statrethinking_winter2019) ([Lectures - Aalto University](https://aalto.cloud.panopto.eu/Panopto/Pages/Sessions/List.aspx#folderID=%22f0ec3a25-9e23-4935-873b-a9f401646812%22)) ([Book](http://www.stat.columbia.edu/~gelman/book/))
- [02402 Introduction to Statistics E12 - Technical University of Denmark](https://www.youtube.com/playlist?list=PLMn2aW3wpAtPC8tZHQy6nwWsFG7P6sPqw) ([F17](https://www.youtube.com/playlist?list=PLgowegO9Se58_BnUNnaARajEE_bX-GJEz))
- **Linear Algebra**
- [18.06 - Linear Algebra, Prof. Gilbert Strang, MIT OCW](https://ocw.mit.edu/courses/mathematics/18-06sc-linear-algebra-fall-2011/)
- [18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine Learning - MIT OCW](https://ocw.mit.edu/courses/mathematics/18-065-matrix-methods-in-data-analysis-signal-processing-and-machine-learning-spring-2018/video-lectures/)
- [Linear Algebra (Princeton University)](https://www.youtube.com/playlist?list=PLGqzsq0erqU7w7ZrTZ-pWWk4-AOkiGEGp)
- [MOOC: Coding the Matrix: Linear Algebra through Computer Science Applications - Coursera](http://academictorrents.com/details/54cd86f3038dfd446b037891406ba4e0b1200d5a)
- [CS 053 - Coding the Matrix - Brown University](http://cs.brown.edu/courses/cs053/current/lectures.htm) ([Fall 14 videos](https://cs.brown.edu/video/channels/coding-matrix-fall-2014/))
- [Linear Algebra Review - CMU](http://www.cs.cmu.edu/~zkolter/course/linalg/outline.html)
- [A first course in Linear Algebra - N J Wildberger - UNSW](https://www.youtube.com/playlist?list=PL44B6B54CBF6A72DF)
- [INTRODUCTION TO MATRIX ALGEBRA](http://ma.mathforcollege.com/youtube/index.html)
- [Computational Linear Algebra - fast.ai](https://www.youtube.com/playlist?list=PLtmWHNX-gukIc92m1K0P6bIOnZb-mg0hY) ([Github](https://github.com/fastai/numerical-linear-algebra))
- [10-600 Math Background for ML - CMU](https://www.youtube.com/playlist?list=PL7y-1rk2cCsA339crwXMWUaBRuLBvPBCg)
- [MIT 18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine Learning](https://ocw.mit.edu/courses/mathematics/18-065-matrix-methods-in-data-analysis-signal-processing-and-machine-learning-spring-2018/video-lectures/)
- [36-705 - Intermediate Statistics - Larry Wasserman, CMU](http://www.stat.cmu.edu/~larry/=stat705/) ([YouTube](https://www.youtube.com/playlist?list=PLcW8xNfZoh7eI7KSWneVWq-7wr8ffRtHF))
- [Combinatorics - IISC Bangalore](https://nptel.ac.in/courses/106108051/)
- [Advanced Engineering Mathematics - Notre Dame](https://www.youtube.com/playlist?list=PLd-PuDzW85Ae4pzlylMLzq_a-RHPx8ryA)
- [Statistical Computing for Scientists and Engineers - Notre Dame](https://www.youtube.com/playlist?list=PLd-PuDzW85AeltIRcjDY7Z4q49NEAuMcA)
- [Statistical Computing, Fall 2017 - Notre Dame](https://www.youtube.com/playlist?list=PLd-PuDzW85AcSgNGnT5TUHt85SrCljT3V)
- [Mathematics for Machine Learning, Lectures by Ulrike von Luxburg - Tübingen Machine Learning](https://www.youtube.com/playlist?list=PL05umP7R6ij1a6KdEy8PVE9zoCv6SlHRS)
-------------------------
### Robotics
- [CS 223A - Introduction to Robotics, Stanford University](https://see.stanford.edu/Course/CS223A)
- [6.832 Underactuated Robotics - MIT OCW](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-832-underactuated-robotics-spring-2009/)
- [CS287 Advanced Robotics at UC Berkeley Fall 2019 -- Instructor: Pieter Abbeel](https://www.youtube.com/playlist?list=PLwRJQ4m4UJjNBPJdt8WamRAt4XKc639wF)
- [CS 287 - Advanced Robotics, Fall 2011, UC Berkeley](https://people.eecs.berkeley.edu/~pabbeel/cs287-fa11/) ([Videos](http://rll.berkeley.edu/cs287/lecture_videos/))
- [CS235 - Applied Robot Design for Non-Robot-Designers - Stanford University](https://www.youtube.com/user/StanfordCS235/videos)
- [Lecture: Visual Navigation for Flying Robots](https://vision.in.tum.de/teaching/ss2012/visnav2012) ([YouTube](https://www.youtube.com/playlist?list=PLTBdjV_4f-EKeki5ps2WHqJqyQvxls4ha))
- [CS 205A: Mathematical Methods for Robotics, Vision, and Graphics (Fall 2013)](https://www.youtube.com/playlist?list=PLQ3UicqQtfNvQ_VzflHYKhAqZiTxOkSwi)
- [Robotics 1, Prof. De Luca, Università di Roma](http://www.dis.uniroma1.it/~deluca/rob1_en/material_rob1_en_2014-15.html) ([YouTube](https://www.youtube.com/playlist?list=PLAQopGWlIcyaqDBW1zSKx7lHfVcOmWSWt))
- [Robotics 2, Prof. De Luca, Università di Roma](http://www.diag.uniroma1.it/~deluca/rob2_en/material_rob2_en.html) ([YouTube](https://www.youtube.com/playlist?list=PLAQopGWlIcya6LnIF83QlJTqvpYmJXnDm))
- [Robot Mechanics and Control, SNU](https://www.youtube.com/playlist?list=PLkjy3Accn-E7mlbuSF4aajcMMckG4wLvW)
- [Introduction to Robotics Course - UNCC](https://www.youtube.com/playlist?list=PL4847E1D1C121292F)
- [SLAM Lectures](https://www.youtube.com/playlist?list=PLpUPoM7Rgzi_7YWn14Va2FODh7LzADBSm)
- [Introduction to Vision and Robotics 2015/16- University of Edinburgh](http://groups.inf.ed.ac.uk/vision/VIDEO/2015/ivr.htm)
- [ME 597 – Autonomous Mobile Robotics – Fall 2014](http://wavelab.uwaterloo.ca/index6ea9.html?page_id=267)
- [ME 780 – Perception For Autonomous Driving – Spring 2017](http://wavelab.uwaterloo.ca/indexaef8.html?page_id=481)
- [ME780 – Nonlinear State Estimation for Robotics and Computer Vision – Spring 2017](http://wavelab.uwaterloo.ca/indexe9a5.html?page_id=533)
- [METR 4202/7202 -- Robotics & Automation - University of Queensland](http://robotics.itee.uq.edu.au/~metr4202/lectures.html)
- [Robotics - IIT Bombay](https://nptel.ac.in/courses/112101099/)
- [Introduction to Machine Vision](https://www.youtube.com/playlist?list=PL1pxneANaikCO1-Z0XTaljLR3SE8tgRXY)
- [6.834J Cognitive Robotics - MIT OCW ](https://ocw.mit.edu/courses/aeronautics-and-astronautics/16-412j-cognitive-robotics-spring-2016/)
- [Hello (Real) World with ROS – Robot Operating System - TU Delft](https://ocw.tudelft.nl/courses/hello-real-world-ros-robot-operating-system/)
- [Programming for Robotics (ROS) - ETH Zurich](https://www.youtube.com/playlist?list=PLE-BQwvVGf8HOvwXPgtDfWoxd4Cc6ghiP)
- [Mechatronic System Design - TU Delft](https://ocw.tudelft.nl/courses/mechatronic-system-design/)
- [CS 206 Evolutionary Robotics Course Spring 2020](https://www.youtube.com/playlist?list=PLAuiGdPEdw0inlKisMbjDypCbvcb_GBN9)
- [Foundations of Robotics - UTEC 2018-I](https://www.youtube.com/playlist?list=PLoWGuY2dW-Acmc8V5NYSAXBxADMm1rE4p)
- [Robotics - Youtube](https://www.youtube.com/playlist?list=PL_onPhFCkVQhuPiUxUW2lFHB39QsavEEA)
- [Robotics and Control: Theory and Practice IIT Roorkee](https://www.youtube.com/playlist?list=PLLy_2iUCG87AjAXKbNMiKJZ2T9vvGpMB0)
- [Mechatronics](https://www.youtube.com/playlist?list=PLtuwVtW88fOeTFS_szBWif0Mcc0lfNWaz)
- [ME142 - Mechatronics Spring 2020 - UC Merced](https://www.youtube.com/playlist?list=PL-euleXgwWUNQ80DGq6qopHBmHcQyEyNQ)
- [Mobile Sensing and Robotics - Bonn University](https://www.youtube.com/playlist?list=PLgnQpQtFTOGQJXx-x0t23RmRbjp_yMb4v)
- [MSR2 - Sensors and State Estimation Course (2020) - Bonn University](https://www.youtube.com/playlist?list=PLgnQpQtFTOGQh_J16IMwDlji18SWQ2PZ6)
- [SLAM Course (2013) - Bonn University](https://www.youtube.com/playlist?list=PLgnQpQtFTOGQrZ4O5QzbIHgl3b1JHimN_)
- [ENGR486 Robot Modeling and Control (2014W)](https://www.youtube.com/playlist?list=PLJzZfbLAMTelwaLxFXteeblbY2ytU2AxX)
- [Robotics by Prof. D K Pratihar - IIT Kharagpur](https://www.youtube.com/playlist?list=PLbRMhDVUMngcdUbBySzyzcPiFTYWr4rV_)
- [Introduction to Mobile Robotics - SS 2019 - Universität Freiburg](http://ais.informatik.uni-freiburg.de/teaching/ss19/robotics/)
- [Robot Mapping - WS 2018/19 - Universität Freiburg](http://ais.informatik.uni-freiburg.de/teaching/ws18/mapping/)
- [Mechanism and Robot Kinematics - IIT Kharagpur](https://nptel.ac.in/courses/112/105/112105236/)
- [Self-Driving Cars - Cyrill Stachniss - Winter 2020/21 - University of Bonn) ](https://www.youtube.com/playlist?list=PLgnQpQtFTOGQo2Z_ogbonywTg8jxCI9pD)
- [Mobile Sensing and Robotics 1 – Part Stachniss (Jointly taught with PhoRS) - University of Bonn](https://www.ipb.uni-bonn.de/msr1-2020/)
- [Mobile Sensing and Robotics 2 – Stachniss & Klingbeil/Holst - University of Bonn](https://www.ipb.uni-bonn.de/msr2-2020/)
----------------------------------
## 500 + 𝗔𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 𝗣𝗿𝗼𝗷𝗲𝗰𝘁 𝗟𝗶𝘀𝘁 𝘄𝗶𝘁𝗵 𝗰𝗼𝗱𝗲
*500 AI Machine learning Deep learning Computer vision NLP Projects with code*
***This list is continuously updated.*** - You can take pull request and contribute.
| Sr No | Name | Link |
| ----- | --------------------------------------------------------------------- | ----------------------------------- |
| 1 | 180 Machine learning Project | [is.gd/MLtyGk](http://is.gd/MLtyGk) |
| 2 | 12 Machine learning Object Detection | [is.gd/jZMP1A](http://is.gd/jZMP1A) |
| 3 | 20 NLP Project with Python | [is.gd/jcMvjB](http://is.gd/jcMvjB) |
| 4 | 10 Machine Learning Projects on Time Series Forecasting | [is.gd/dOR66m](http://is.gd/dOR66m) |
| 5 | 20 Deep Learning Projects Solved and Explained with Python | [is.gd/8Cv5EP](http://is.gd/8Cv5EP) |
| 6 | 20 Machine learning Project | [is.gd/LZTF0J](http://is.gd/LZTF0J) |
| 7 | 30 Python Project Solved and Explained | [is.gd/xhT36v](http://is.gd/xhT36v) |
| 8 | Machine learning Course for Free | https://lnkd.in/ekCY8xw |
| 9 | 5 Web Scraping Projects with Python | [is.gd/6XOTSn](http://is.gd/6XOTSn) |
| 10 | 20 Machine Learning Projects on Future Prediction with Python | [is.gd/xDKDkl](http://is.gd/xDKDkl) |
| 11 | 4 Chatbot Project With Python | [is.gd/LyZfXv](http://is.gd/LyZfXv) |
| 12 | 7 Python Gui project | [is.gd/0KPBvP](http://is.gd/0KPBvP) |
| 13 | All Unsupervised learning Projects | [is.gd/cz11Kv](http://is.gd/cz11Kv) |
| 14 | 10 Machine learning Projects for Regression Analysis | [is.gd/k8faV1](http://is.gd/k8faV1) |
| 15 | 10 Machine learning Project for Classification with Python | [is.gd/BJQjMN](http://is.gd/BJQjMN) |
| 16 | 6 Sentimental Analysis Projects with python | [is.gd/WeiE5p](http://is.gd/WeiE5p) |
| 17 | 4 Recommendations Projects with Python | [is.gd/pPHAP8](http://is.gd/pPHAP8) |
| 18 | 20 Deep learning Project with python | [is.gd/l3OCJs](http://is.gd/l3OCJs) |
| 19 | 5 COVID19 Projects with Python | [is.gd/xFCnYi](http://is.gd/xFCnYi) |
| 20 | 9 Computer Vision Project with python | [is.gd/lrNybj](http://is.gd/lrNybj) |
| 21 | 8 Neural Network Project with python | [is.gd/FCyOOf](is.gd/FCyOOf) |
| 22 | 5 Machine learning Project for healthcare | https://bit.ly/3b86bOH |
| 23 | 5 NLP Project with Python | https://bit.ly/3hExtNS |
| 24 | 47 Machine Learning Projects for 2021 | https://bit.ly/356bjiC |
| 25 | 19 Artificial Intelligence Projects for 2021 | https://bit.ly/38aLgsg |
| 26 | 28 Machine learning Projects for 2021 | https://bit.ly/3bguRF1 |
| 27 | 16 Data Science Projects with Source Code for 2021 | https://bit.ly/3oa4zYD |
| 28 | 24 Deep learning Projects with Source Code for 2021 | https://bit.ly/3rQrOsU |
| 29 | 25 Computer Vision Projects with Source Code for 2021 | https://bit.ly/2JDMO4I |
| 30 | 23 Iot Projects with Source Code for 2021 | https://bit.ly/354gT53 |
| 31 | 27 Django Projects with Source Code for 2021 | https://bit.ly/2LdRPRZ |
| 32 | 37 Python Fun Projects with Code for 2021 | https://bit.ly/3hBHzz4 |
| 33 | 500 + Top Deep learning Codes | https://bit.ly/3n7AkAc |
| 34 | 500 + Machine learning Codes | https://bit.ly/3b32n13 |
| 35 | 20+ Machine Learning Datasets & Project Ideas | https://bit.ly/3b2J48c |
| 36 | 1000+ Computer vision codes | https://bit.ly/2LiX1nv |
| 37 | 300 + Industry wise Real world projects with code | https://bit.ly/3rN7lVR |
| 38 | 1000 + Python Project Codes | https://bit.ly/3oca2xM |
| 39 | 363 + NLP Project with Code | https://bit.ly/3b442DO |
| 40 | 50 + Code ML Models (For iOS 11) Projects | https://bit.ly/389dB2s |
| 41 | 180 + Pretrained Model Projects for Image, text, Audio and Video | https://bit.ly/3hFyQMw |
| 42 | 50 + Graph Classification Project List | https://bit.ly/3rOYFhH |
| 43 | 100 + Sentence Embedding(NLP Resources) | https://bit.ly/355aS8c |
| 44 | 100 + Production Machine learning Projects | https://bit.ly/353ckI0 |
| 45 | 300 + Machine Learning Resources Collection | https://bit.ly/3b2LjIE |
| 46 | 70 + Awesome AI | https://bit.ly/3hDIXkD |
| 47 | 150 + Machine learning Project Ideas with code | https://bit.ly/38bfpbg |
| 48 | 100 + AutoML Projects with code | https://bit.ly/356zxZX |
| 49 | 100 + Machine Learning Model Interpretability Code Frameworks | https://bit.ly/3n7FaNB |
| 50 | 120 + Multi Model Machine learning Code Projects | https://bit.ly/38QRI76 |
| 51 | Awesome Chatbot Projects | https://bit.ly/3rQyxmE |
| 52 | Awesome ML Demo Project with iOS | https://bit.ly/389hZOY |
| 53 | 100 + Python based Machine learning Application Projects | https://bit.ly/3n9zLWv |
| 54 | 100 + Reproducible Research Projects of ML and DL | https://bit.ly/2KQ0J8C |
| 55 | 25 + Python Projects | https://bit.ly/353fRpK |
| 56 | 8 + OpenCV Projects | https://bit.ly/389mj0B |
| 57 | 1000 + Awesome Deep learning Collection | https://bit.ly/3b0a9Jj |
| 58 | 200 + Awesome NLP learning Collection | https://bit.ly/3b74b9o |
| 59 | 200 + The Super Duper NLP Repo | https://bit.ly/3hDNnbd |
| 60 | 100 + NLP dataset for your Projects | https://bit.ly/353h2Wc |
| 61 | 364 + Machine Learning Projects definition | https://bit.ly/2X5QRdb |
| 62 | 300+ Google Earth Engine Jupyter Notebooks to Analyze Geospatial Data | https://bit.ly/387JwjC |
| 63 | 1000 + Machine learning Projects Information | https://bit.ly/3rMGk4N |
| 64. | 11 Computer Vision Projects with code | https://bit.ly/38gz2OR |
| 65. | 13 Computer Vision Projects with Code | https://bit.ly/3hMJdhh |
| 66. | 13 Cool Computer Vision GitHub Projects To Inspire You | https://bit.ly/2LrSv6d |
| 67. | Open-Source Computer Vision Projects (With Tutorials) | https://bit.ly/3pUss6U |
| 68. | OpenCV Computer Vision Projects with Python | https://bit.ly/38jmGpn |
| 69. | 100 + Computer vision Algorithm Implementation | https://bit.ly/3rWgrzF |
| 70. | 80 + Computer vision Learning code | https://bit.ly/3hKCpkm |
| 71. | Deep learning Treasure | https://bit.ly/359zLQb |
[#100+ Free Machine Learning Books](https://www.theinsaneapp.com/2020/12/download-free-machine-learning-books.html)
#ALL THE CREDITS GOES TO THE RESPECTIVE CREATORS AND THESE RESOURCES ARE COMBINED TOGETHER TO MAKE A WONDERFUL AND COMPACT LEARNING RESOURCE FOR THE DATASCIENCE ENTHUSIASTS
Part 1:- [Roadmap](https://github.com/MrMimic/data-scientist-roadmap)
Part 2:- [Free Online Courses](https://github.com/Developer-Y)
Part 3:- [500 Datascience Projects](https://github.com/ashishpatel26/500-AI-Machine-learning-Deep-learning-Computer-vision-NLP-Projects-with-code)
Part 4:- [100+ Free Machine Learning Books](https://www.theinsaneapp.com/2020/12/download-free-machine-learning-books.html)
|
3,429 | Go to https://github.com/pytorch/tutorials - this repo is deprecated and no longer maintained | **These tutorials have been merged into [the official PyTorch tutorials](https://github.com/pytorch/tutorials). Please go there for better maintained versions of these tutorials compatible with newer versions of PyTorch.**
---

Learn PyTorch with project-based tutorials. These tutorials demonstrate modern techniques with readable code and use regular data from the internet.
## Tutorials
#### Series 1: RNNs for NLP
Applying recurrent neural networks to natural language tasks, from classification to generation.
* [Classifying Names with a Character-Level RNN](https://github.com/spro/practical-pytorch/blob/master/char-rnn-classification/char-rnn-classification.ipynb)
* [Generating Shakespeare with a Character-Level RNN](https://github.com/spro/practical-pytorch/blob/master/char-rnn-generation/char-rnn-generation.ipynb)
* [Generating Names with a Conditional Character-Level RNN](https://github.com/spro/practical-pytorch/blob/master/conditional-char-rnn/conditional-char-rnn.ipynb)
* [Translation with a Sequence to Sequence Network and Attention](https://github.com/spro/practical-pytorch/blob/master/seq2seq-translation/seq2seq-translation.ipynb)
* [Exploring Word Vectors with GloVe](https://github.com/spro/practical-pytorch/blob/master/glove-word-vectors/glove-word-vectors.ipynb)
* *WIP* Sentiment Analysis with a Word-Level RNN and GloVe Embeddings
#### Series 2: RNNs for timeseries data
* *WIP* Predicting discrete events with an RNN
## Get Started
The quickest way to run these on a fresh Linux or Mac machine is to install [Anaconda](https://www.continuum.io/anaconda-overview):
```
curl -LO https://repo.continuum.io/archive/Anaconda3-4.3.0-Linux-x86_64.sh
bash Anaconda3-4.3.0-Linux-x86_64.sh
```
Then install PyTorch:
```
conda install pytorch -c soumith
```
Then clone this repo and start Jupyter Notebook:
```
git clone http://github.com/spro/practical-pytorch
cd practical-pytorch
jupyter notebook
```
## Recommended Reading
### PyTorch basics
* http://pytorch.org/ For installation instructions
* [Offical PyTorch tutorials](http://pytorch.org/tutorials/) for more tutorials (some of these tutorials are included there)
* [Deep Learning with PyTorch: A 60-minute Blitz](http://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html) to get started with PyTorch in general
* [Introduction to PyTorch for former Torchies](https://github.com/pytorch/tutorials/blob/master/Introduction%20to%20PyTorch%20for%20former%20Torchies.ipynb) if you are a former Lua Torch user
* [jcjohnson's PyTorch examples](https://github.com/jcjohnson/pytorch-examples) for a more in depth overview (including custom modules and autograd functions)
### Recurrent Neural Networks
* [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/) shows a bunch of real life examples
* [Deep Learning, NLP, and Representations](http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/) for an overview on word embeddings and RNNs for NLP
* [Understanding LSTM Networks](http://colah.github.io/posts/2015-08-Understanding-LSTMs/) is about LSTMs work specifically, but also informative about RNNs in general
### Machine translation
* [Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation](http://arxiv.org/abs/1406.1078)
* [Sequence to Sequence Learning with Neural Networks](http://arxiv.org/abs/1409.3215)
### Attention models
* [Neural Machine Translation by Jointly Learning to Align and Translate](https://arxiv.org/abs/1409.0473)
* [Effective Approaches to Attention-based Neural Machine Translation](https://arxiv.org/abs/1508.04025)
### Other RNN uses
* [A Neural Conversational Model](http://arxiv.org/abs/1506.05869)
### Other PyTorch tutorials
* [Deep Learning For NLP In PyTorch](https://github.com/rguthrie3/DeepLearningForNLPInPytorch)
## Feedback
If you have ideas or find mistakes [please leave a note](https://github.com/spro/practical-pytorch/issues/new).
|
3,430 | Huggingface Transformers + Adapters = ❤️ | <!---
Copyright 2020 The AdapterHub Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<p align="center">
<img style="vertical-align:middle" src="https://raw.githubusercontent.com/Adapter-Hub/adapter-transformers/master/adapter_docs/logo.png" />
</p>
<h1 align="center">
<span>adapter-transformers</span>
</h1>
<h3 align="center">
A friendly fork of HuggingFace's <i>Transformers</i>, adding Adapters to PyTorch language models
</h3>

[](https://github.com/adapter-hub/adapter-transformers/blob/master/LICENSE)
[](https://pypi.org/project/adapter-transformers/)
`adapter-transformers` is an extension of [HuggingFace's Transformers](https://github.com/huggingface/transformers) library, integrating adapters into state-of-the-art language models by incorporating **[AdapterHub](https://adapterhub.ml)**, a central repository for pre-trained adapter modules.
_💡 Important: This library can be used as a drop-in replacement for HuggingFace Transformers and regularly synchronizes new upstream changes.
Thus, most files in this repository are direct copies from the HuggingFace Transformers source, modified only with changes required for the adapter implementations._
## Installation
`adapter-transformers` currently supports **Python 3.7+** and **PyTorch 1.3.1+**.
After [installing PyTorch](https://pytorch.org/get-started/locally/), you can install `adapter-transformers` from PyPI ...
```
pip install -U adapter-transformers
```
... or from source by cloning the repository:
```
git clone https://github.com/adapter-hub/adapter-transformers.git
cd adapter-transformers
pip install .
```
## Getting Started
HuggingFace's great documentation on getting started with _Transformers_ can be found [here](https://huggingface.co/transformers/index.html). `adapter-transformers` is fully compatible with _Transformers_.
To get started with adapters, refer to these locations:
- **[Colab notebook tutorials](https://github.com/Adapter-Hub/adapter-transformers/tree/master/notebooks)**, a series notebooks providing an introduction to all the main concepts of (adapter-)transformers and AdapterHub
- **https://docs.adapterhub.ml**, our documentation on training and using adapters with _adapter-transformers_
- **https://adapterhub.ml** to explore available pre-trained adapter modules and share your own adapters
- **[Examples folder](https://github.com/Adapter-Hub/adapter-transformers/tree/master/examples/pytorch)** of this repository containing HuggingFace's example training scripts, many adapted for training adapters
## Implemented Methods
Currently, adapter-transformers integrates all architectures and methods listed below:
| Method | Paper(s) | Quick Links |
| --- | --- | --- |
| Bottleneck adapters | [Houlsby et al. (2019)](https://arxiv.org/pdf/1902.00751.pdf)<br> [Bapna and Firat (2019)](https://arxiv.org/pdf/1909.08478.pdf) | [Quickstart](https://docs.adapterhub.ml/quickstart.html), [Notebook](https://colab.research.google.com/github/Adapter-Hub/adapter-transformers/blob/master/notebooks/01_Adapter_Training.ipynb) |
| AdapterFusion | [Pfeiffer et al. (2021)](https://aclanthology.org/2021.eacl-main.39.pdf) | [Docs: Training](https://docs.adapterhub.ml/training.html#train-adapterfusion), [Notebook](https://colab.research.google.com/github/Adapter-Hub/adapter-transformers/blob/master/notebooks/03_Adapter_Fusion.ipynb) |
| MAD-X,<br> Invertible adapters | [Pfeiffer et al. (2020)](https://aclanthology.org/2020.emnlp-main.617/) | [Notebook](https://colab.research.google.com/github/Adapter-Hub/adapter-transformers/blob/master/notebooks/04_Cross_Lingual_Transfer.ipynb) |
| AdapterDrop | [Rücklé et al. (2021)](https://arxiv.org/pdf/2010.11918.pdf) | [Notebook](https://colab.research.google.com/github/Adapter-Hub/adapter-transformers/blob/master/notebooks/05_Adapter_Drop_Training.ipynb) |
| MAD-X 2.0,<br> Embedding training | [Pfeiffer et al. (2021)](https://arxiv.org/pdf/2012.15562.pdf) | [Docs: Embeddings](https://docs.adapterhub.ml/embeddings.html), [Notebook](https://colab.research.google.com/github/Adapter-Hub/adapter-transformers/blob/master/notebooks/08_NER_Wikiann.ipynb) |
| Prefix Tuning | [Li and Liang (2021)](https://arxiv.org/pdf/2101.00190.pdf) | [Docs](https://docs.adapterhub.ml/overview.html#prefix-tuning) |
| Parallel adapters,<br> Mix-and-Match adapters | [He et al. (2021)](https://arxiv.org/pdf/2110.04366.pdf) | [Docs](https://docs.adapterhub.ml/overview.html#mix-and-match-adapters) |
| Compacter | [Mahabadi et al. (2021)](https://arxiv.org/pdf/2106.04647.pdf) | [Docs](https://docs.adapterhub.ml/overview.html#compacter) |
| LoRA | [Hu et al. (2021)](https://arxiv.org/pdf/2106.09685.pdf) | [Docs](https://docs.adapterhub.ml/overview.html#lora) |
| (IA)^3 | [Liu et al. (2022)](https://arxiv.org/pdf/2205.05638.pdf) | [Docs](https://docs.adapterhub.ml/overview.html#ia-3) |
| UniPELT | [Mao et al. (2022)](https://arxiv.org/pdf/2110.07577.pdf) | [Docs](https://docs.adapterhub.ml/overview.html#unipelt) |
## Supported Models
We currently support the PyTorch versions of all models listed on the **[Model Overview](https://docs.adapterhub.ml/model_overview.html) page** in our documentation.
## Citation
If you use this library for your work, please consider citing our paper [AdapterHub: A Framework for Adapting Transformers](https://arxiv.org/abs/2007.07779):
```
@inproceedings{pfeiffer2020AdapterHub,
title={AdapterHub: A Framework for Adapting Transformers},
author={Pfeiffer, Jonas and
R{\"u}ckl{\'e}, Andreas and
Poth, Clifton and
Kamath, Aishwarya and
Vuli{\'c}, Ivan and
Ruder, Sebastian and
Cho, Kyunghyun and
Gurevych, Iryna},
booktitle={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages={46--54},
year={2020}
}
```
|
3,431 | NLP in Python with Deep Learning | Natural Language Processing Notebooks
--
# Available as a Book: [NLP in Python - Quickstart Guide](https://www.amazon.in/dp/B07L3PLQS1)
### Written for Practicing Engineers
This work builds on the outstanding work which exists on Natural Language Processing. These range from classics like Jurafsky's Speech and Language Processing to rather modern work in The Deep Learning Book by Ian Goodfellow et al.
While they are great as introductory textbooks for college students - this is intended for practitioners to quickly read, skim, select what is useful and then proceed. There are several notebooks divided into 7 logical themes.
Each section builds on ideas and code from previous notebooks, but you can fill in the gaps mentally and jump directly to what interests you.
## Chapter 01
[Introduction To Text Processing, with Text Classification](https://github.com/NirantK/nlp-python-deep-learning/blob/master/Part-01.ipynb)
- Perfect for Getting Started! We learn better with code-first approaches
## Chapter 02
- [Text Cleaning](https://github.com/NirantK/nlp-python-deep-learning/blob/master/02-A.ipynb) notebook, code-first approaches with supporting explanation. Covers some simple ideas like:
- Stop words removal
- Lemmatization
- [Spell Correction](https://github.com/NirantK/nlp-python-deep-learning/blob/master/02-B.ipynb) covers **almost everything** that you will ever need to get started with spell correction, similar words problems and so on
## Chapter 03
[Leveraging Linguistics](https://github.com/NirantK/nlp-python-deep-learning/blob/master/Part-03%20NLP%20with%20spaCy%20and%20Textacy.ipynb) is an important toolkit in any practitioners toolkit. Using **spaCy** and textacy we look at two interesting challenges and how to tackle them:
- Redacting names
- Named Entity Recognition
- Question and Answer Generation
- Part of Speech Tagging
- Dependency Parsing
## Chapter 04
[Text Representations](https://github.com/NirantK/nlp-python-deep-learning/blob/master/Part-04%20Text%20Representations.ipynb) is about converting text to numerical representations aka vectors
- Covers popular celebrities: word2vec, fasttext and doc2vec - document similarity using the same
- Programmer's Guide to **gensim**
## Chapter 05
[Modern Methods for Text Classification](https://github.com/NirantK/nlp-python-deep-learning/blob/master/Part-05%20Modern%20Text%20Classification.ipynb) is simple, exploratory and talks about:
- Simple Classifiers and How to Optimize Them from **scikit-learn**
- How to combine and **ensemble** them for increased performance
- Builds intuition for ensembling - so that you can write your own ensembling techniques
## Chapter 06
[Deep Learning for NLP](https://github.com/NirantK/nlp-python-deep-learning/blob/master/Part-06%20Deep%20Learning%20for%20NLP.ipynb) is less about fancy data modeling, and more engineering for Deep Learning
- From scratch code tutorial with Text Classification as an example
- Using **PyTorch** and *torchtext*
- Write our own data loaders, pre-processing, training loop and other utilities
## Chapter 07
[Building your own Chatbot](https://github.com/NirantK/nlp-python-deep-learning/blob/master/Part-07%20Building%20your%20own%20Chatbot%20in%2030%20minutes.ipynb) from scratch in 30 minutes. We use this to explore unsupervised learning and put together several of the ideas we have already seen.
- simpler, direct problem formulation instead of complicated chatbot tutorials commonly seen
- intents, responses and templates in chat bot parlance
- hacking word based similarity engine to work with little to no training samples
|
3,432 | A high-level machine learning and deep learning library for the PHP language. | # Rubix ML
[](https://www.php.net/) [](https://packagist.org/packages/rubix/ml) [](https://packagist.org/packages/rubix/ml) [](https://github.com/RubixML/ML/actions/workflows/ci.yml) [](https://github.com/RubixML/ML/blob/master/LICENSE.md)
A high-level machine learning and deep learning library for the [PHP](https://php.net) language.
- **Developer-friendly** API is delightful to use
- **40+** supervised and unsupervised learning algorithms
- **Support** for ETL, preprocessing, and cross-validation
- **Open source** and free to use commercially
## Installation
Install Rubix ML into your project using [Composer](https://getcomposer.org/):
```sh
$ composer require rubix/ml
```
### Requirements
- [PHP](https://php.net/manual/en/install.php) 7.4 or above
#### Recommended
- [Tensor extension](https://github.com/Scien-ide/Tensor) for fast Matrix/Vector computing
#### Optional
- [Extras Package](https://github.com/RubixML/Extras) for experimental features
- [GD extension](https://php.net/manual/en/book.image.php) for image support
- [Mbstring extension](https://www.php.net/manual/en/book.mbstring.php) for fast multibyte string manipulation
- [SVM extension](https://php.net/manual/en/book.svm.php) for Support Vector Machine engine (libsvm)
- [PDO extension](https://www.php.net/manual/en/book.pdo.php) for relational database support
- [GraphViz](https://graphviz.org/) for graph visualization
## Documentation
Read the latest docs [here](https://docs.rubixml.com).
## What is Rubix ML?
Rubix ML is a free open-source machine learning (ML) library that allows you to build programs that learn from your data using the PHP language. We provide tools for the entire machine learning life cycle from ETL to training, cross-validation, and production with over 40 supervised and unsupervised learning algorithms. In addition, we provide tutorials and other educational content to help you get started using ML in your projects.
## Getting Started
If you are new to machine learning, we recommend taking a look at the [What is Machine Learning?](https://docs.rubixml.com/latest/what-is-machine-learning.html) section to get started. If you are already familiar with basic ML concepts, you can browse the [basic introduction](https://docs.rubixml.com/latest/basic-introduction.html) for a brief look at a typical Rubix ML project. From there, you can browse the official tutorials below which range from beginner to advanced skill level.
### Tutorials & Example Projects
Check out these example projects using the Rubix ML library. Many come with instructions and a pre-cleaned dataset.
- [CIFAR-10 Image Recognizer](https://github.com/RubixML/CIFAR-10)
- [Color Clusterer](https://github.com/RubixML/Colors)
- [Credit Default Risk Predictor](https://github.com/RubixML/Credit)
- [Divorce Predictor](https://github.com/RubixML/Divorce)
- [DNA Taxonomer](https://github.com/RubixML/DNA)
- [Dota 2 Game Outcome Predictor](https://github.com/RubixML/Dota2)
- [Human Activity Recognizer](https://github.com/RubixML/HAR)
- [Housing Price Predictor](https://github.com/RubixML/Housing)
- [Iris Flower Classifier](https://github.com/RubixML/Iris)
- [MNIST Handwritten Digit Recognizer](https://github.com/RubixML/MNIST)
- [Text Sentiment Analyzer](https://github.com/RubixML/Sentiment)
## Interact With The Community
- [Join Our Telegram Channel](https://t.me/RubixML)
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
The code is licensed [MIT](LICENSE) and the documentation is licensed [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/).
|
3,433 | Data augmentation for NLP | <p align="center">
<br>
<img src="https://github.com/makcedward/nlpaug/blob/master/res/logo_small.png"/>
<br>
<p>
<p align="center">
<a href="https://travis-ci.org/makcedward/nlpaug">
<img alt="Build" src="https://travis-ci.org/makcedward/nlpaug.svg?branch=master">
</a>
<a href="https://www.codacy.com/app/makcedward/nlpaug?utm_source=github.com&utm_medium=referral&utm_content=makcedward/nlpaug&utm_campaign=Badge_Grade">
<img alt="Code Quality" src="https://api.codacy.com/project/badge/Grade/2d6d1d08016a4f78818161a89a2dfbfb">
</a>
<a href="https://pepy.tech/badge/nlpaug">
<img alt="Downloads" src="https://pepy.tech/badge/nlpaug">
</a>
</p>
# nlpaug
This python library helps you with augmenting nlp for your machine learning projects. Visit this introduction to understand about [Data Augmentation in NLP](https://towardsdatascience.com/data-augmentation-in-nlp-2801a34dfc28). `Augmenter` is the basic element of augmentation while `Flow` is a pipeline to orchestra multi augmenter together.
## Features
* Generate synthetic data for improving model performance without manual effort
* Simple, easy-to-use and lightweight library. Augment data in 3 lines of code
* Plug and play to any machine leanring/ neural network frameworks (e.g. scikit-learn, PyTorch, TensorFlow)
* Support textual and audio input
<h3 align="center">Textual Data Augmentation Example</h3>
<br><p align="center"><img src="https://github.com/makcedward/nlpaug/blob/master/res/textual_example.png"/></p>
<h3 align="center">Acoustic Data Augmentation Example</h3>
<br><p align="center"><img src="https://github.com/makcedward/nlpaug/blob/master/res/audio_example.png"/></p>
| Section | Description |
|:---:|:---:|
| [Quick Demo](https://github.com/makcedward/nlpaug#quick-demo) | How to use this library |
| [Augmenter](https://github.com/makcedward/nlpaug#augmenter) | Introduce all available augmentation methods |
| [Installation](https://github.com/makcedward/nlpaug#installation) | How to install this library |
| [Recent Changes](https://github.com/makcedward/nlpaug#recent-changes) | Latest enhancement |
| [Extension Reading](https://github.com/makcedward/nlpaug#extension-reading) | More real life examples or researchs |
| [Reference](https://github.com/makcedward/nlpaug#reference) | Reference of external resources such as data or model |
## Quick Demo
* [Quick Example](https://github.com/makcedward/nlpaug/blob/master/example/quick_example.ipynb)
* [Example of Augmentation for Textual Inputs](https://github.com/makcedward/nlpaug/blob/master/example/textual_augmenter.ipynb)
* [Example of Augmentation for Multilingual Textual Inputs ](https://github.com/makcedward/nlpaug/blob/master/example/textual_language_augmenter.ipynb)
* [Example of Augmentation for Spectrogram Inputs](https://github.com/makcedward/nlpaug/blob/master/example/spectrogram_augmenter.ipynb)
* [Example of Augmentation for Audio Inputs](https://github.com/makcedward/nlpaug/blob/master/example/audio_augmenter.ipynb)
* [Example of Orchestra Multiple Augmenters](https://github.com/makcedward/nlpaug/blob/master/example/flow.ipynb)
* [Example of Showing Augmentation History](https://github.com/makcedward/nlpaug/blob/master/example/change_log.ipynb)
* How to train [TF-IDF model](https://github.com/makcedward/nlpaug/blob/master/example/tfidf-train_model.ipynb)
* How to train [LAMBADA model](https://github.com/makcedward/nlpaug/blob/master/example/lambada-train_model.ipynb)
* How to create [custom augmentation](https://github.com/makcedward/nlpaug/blob/master/example/custom_augmenter.ipynb)
* [API Documentation](https://nlpaug.readthedocs.io/en/latest/)
## Augmenter
| Augmenter | Target | Augmenter | Action | Description |
|:---:|:---:|:---:|:---:|:---:|
|Textual| Character | KeyboardAug | substitute | Simulate keyboard distance error |
|Textual| | OcrAug | substitute | Simulate OCR engine error |
|Textual| | [RandomAug](https://medium.com/hackernoon/does-your-nlp-model-able-to-prevent-adversarial-attack-45b5ab75129c) | insert, substitute, swap, delete | Apply augmentation randomly |
|Textual| Word | AntonymAug | substitute | Substitute opposite meaning word according to WordNet antonym|
|Textual| | ContextualWordEmbsAug | insert, substitute | Feeding surroundings word to [BERT](https://towardsdatascience.com/how-bert-leverage-attention-mechanism-and-transformer-to-learn-word-contextual-relations-5bbee1b6dbdb), DistilBERT, [RoBERTa](https://medium.com/towards-artificial-intelligence/a-robustly-optimized-bert-pretraining-approach-f6b6e537e6a6) or [XLNet](https://medium.com/dataseries/why-does-xlnet-outperform-bert-da98a8503d5b) language model to find out the most suitlabe word for augmentation|
|Textual| | RandomWordAug | swap, crop, delete | Apply augmentation randomly |
|Textual| | SpellingAug | substitute | Substitute word according to spelling mistake dictionary |
|Textual| | SplitAug | split | Split one word to two words randomly|
|Textual| | SynonymAug | substitute | Substitute similar word according to WordNet/ PPDB synonym |
|Textual| | [TfIdfAug](https://medium.com/towards-artificial-intelligence/unsupervised-data-augmentation-6760456db143) | insert, substitute | Use TF-IDF to find out how word should be augmented |
|Textual| | WordEmbsAug | insert, substitute | Leverage [word2vec](https://towardsdatascience.com/3-silver-bullets-of-word-embedding-in-nlp-10fa8f50cc5a), [GloVe](https://towardsdatascience.com/3-silver-bullets-of-word-embedding-in-nlp-10fa8f50cc5a) or [fasttext](https://towardsdatascience.com/3-silver-bullets-of-word-embedding-in-nlp-10fa8f50cc5a) embeddings to apply augmentation|
|Textual| | [BackTranslationAug](https://towardsdatascience.com/data-augmentation-in-nlp-2801a34dfc28) | substitute | Leverage two translation models for augmentation |
|Textual| | ReservedAug | substitute | Replace reserved words |
|Textual| Sentence | ContextualWordEmbsForSentenceAug | insert | Insert sentence according to [XLNet](https://medium.com/dataseries/why-does-xlnet-outperform-bert-da98a8503d5b), [GPT2](https://towardsdatascience.com/too-powerful-nlp-model-generative-pre-training-2-4cc6afb6655) or DistilGPT2 prediction |
|Textual| | AbstSummAug | substitute | Summarize article by abstractive summarization method |
|Textual| | LambadaAug | substitute | Using language model to generate text and then using classification model to retain high quality results |
|Signal| Audio | CropAug | delete | Delete audio's segment |
|Signal| | LoudnessAug|substitute | Adjust audio's volume |
|Signal| | MaskAug | substitute | Mask audio's segment |
|Signal| | NoiseAug | substitute | Inject noise |
|Signal| | PitchAug | substitute | Adjust audio's pitch |
|Signal| | ShiftAug | substitute | Shift time dimension forward/ backward |
|Signal| | SpeedAug | substitute | Adjust audio's speed |
|Signal| | VtlpAug | substitute | Change vocal tract |
|Signal| | NormalizeAug | substitute | Normalize audio |
|Signal| | PolarityInverseAug | substitute | Swap positive and negative for audio |
|Signal| Spectrogram | FrequencyMaskingAug | substitute | Set block of values to zero according to frequency dimension |
|Signal| | TimeMaskingAug | substitute | Set block of values to zero according to time dimension |
|Signal| | LoudnessAug | substitute | Adjust volume |
## Flow
| Augmenter | Augmenter | Description |
|:---:|:---:|:---:|
|Pipeline| Sequential | Apply list of augmentation functions sequentially |
|Pipeline| Sometimes | Apply some augmentation functions randomly |
## Installation
The library supports python 3.5+ in linux and window platform.
To install the library:
```bash
pip install numpy requests nlpaug
```
or install the latest version (include BETA features) from github directly
```bash
pip install numpy git+https://github.com/makcedward/nlpaug.git
```
or install over conda
```bash
conda install -c makcedward nlpaug
```
If you use BackTranslationAug, ContextualWordEmbsAug, ContextualWordEmbsForSentenceAug and AbstSummAug, installing the following dependencies as well
```bash
pip install torch>=1.6.0 transformers>=4.11.3 sentencepiece
```
If you use LambadaAug, installing the following dependencies as well
```bash
pip install simpletransformers>=0.61.10
```
If you use AntonymAug, SynonymAug, installing the following dependencies as well
```bash
pip install nltk>=3.4.5
```
If you use WordEmbsAug (word2vec, glove or fasttext), downloading pre-trained model first and installing the following dependencies as well
```bash
from nlpaug.util.file.download import DownloadUtil
DownloadUtil.download_word2vec(dest_dir='.') # Download word2vec model
DownloadUtil.download_glove(model_name='glove.6B', dest_dir='.') # Download GloVe model
DownloadUtil.download_fasttext(model_name='wiki-news-300d-1M', dest_dir='.') # Download fasttext model
pip install gensim>=4.1.2
```
If you use SynonymAug (PPDB), downloading file from the following URI. You may not able to run the augmenter if you get PPDB file from other website
```bash
http://paraphrase.org/#/download
```
If you use PitchAug, SpeedAug and VtlpAug, installing the following dependencies as well
```bash
pip install librosa>=0.9.1 matplotlib
```
## Recent Changes
### 1.1.11 Jul 6, 2022
* [Return list of output](https://github.com/makcedward/nlpaug/issues/302)
* [Fix download util](https://github.com/makcedward/nlpaug/issues/301)
* [Fix lambda label misalignment](https://github.com/makcedward/nlpaug/issues/295)
* [Add language pack reference link for SynonymAug](https://github.com/makcedward/nlpaug/issues/289)
See [changelog](https://github.com/makcedward/nlpaug/blob/master/CHANGE.md) for more details.
## Extension Reading
* [Data Augmentation library for Text](https://towardsdatascience.com/data-augmentation-library-for-text-9661736b13ff)
* [Does your NLP model able to prevent adversarial attack?](https://medium.com/hackernoon/does-your-nlp-model-able-to-prevent-adversarial-attack-45b5ab75129c)
* [How does Data Noising Help to Improve your NLP Model?](https://medium.com/towards-artificial-intelligence/how-does-data-noising-help-to-improve-your-nlp-model-480619f9fb10)
* [Data Augmentation library for Speech Recognition](https://towardsdatascience.com/data-augmentation-for-speech-recognition-e7c607482e78)
* [Data Augmentation library for Audio](https://towardsdatascience.com/data-augmentation-for-audio-76912b01fdf6)
* [Unsupervied Data Augmentation](https://medium.com/towards-artificial-intelligence/unsupervised-data-augmentation-6760456db143)
* [A Visual Survey of Data Augmentation in NLP](https://amitness.com/2020/05/data-augmentation-for-nlp/)
## Reference
This library uses data (e.g. capturing from internet), research (e.g. following augmenter idea), model (e.g. using pre-trained model) See [data source](https://github.com/makcedward/nlpaug/blob/master/SOURCE.md) for more details.
## Citation
```latex
@misc{ma2019nlpaug,
title={NLP Augmentation},
author={Edward Ma},
howpublished={https://github.com/makcedward/nlpaug},
year={2019}
}
```
This package is cited by many books, workshop and academic research papers (70+). Here are some of examples and you may visit [here](https://github.com/makcedward/nlpaug/blob/master/CITED.md) to get the full list.
### Workshops cited nlpaug
* S. Vajjala. [NLP without a readymade labeled dataset](https://rpubs.com/vbsowmya/tmls2021) at [Toronto Machine Learning Summit, 2021](https://www.torontomachinelearning.com/). 2021
### Book cited nlpaug
* S. Vajjala, B. Majumder, A. Gupta and H. Surana. [Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems](https://www.amazon.com/Practical-Natural-Language-Processing-Pragmatic/dp/1492054054). 2020
* A. Bartoli and A. Fusiello. [Computer Vision–ECCV 2020 Workshops](https://books.google.com/books?hl=en&lr=lang_en&id=0rYREAAAQBAJ&oi=fnd&pg=PR7&dq=nlpaug&ots=88bPp5rhnY&sig=C2ue8Xxbu09l59nAMOcVxWYvvWM#v=onepage&q=nlpaug&f=false). 2020
* L. Werra, L. Tunstall, and T. Wolf [Natural Language Processing with Transformers](https://www.amazon.com/Natural-Language-Processing-Transformers-Applications/dp/1098103246/ref=sr_1_3?crid=2CWBPA8QG0TRU&keywords=Natural+Language+Processing+with+Transformers&qid=1645646312&sprefix=natural+language+processing+with+transformers%2Caps%2C111&sr=8-3). 2022
### Research paper cited nlpaug
* Google: M. Raghu and E. Schmidt. [A Survey of Deep Learning for Scientific Discovery](https://arxiv.org/pdf/2003.11755.pdf). 2020
* Sirius XM: E. Jing, K. Schneck, D. Egan and S. A. Waterman. [Identifying Introductions in Podcast Episodes from Automatically Generated Transcripts](https://arxiv.org/pdf/2110.07096.pdf). 2021
* Salesforce Research: B. Newman, P. K. Choubey and N. Rajani. [P-adapters: Robustly Extracting Factual Information from Language Modesl with Diverse Prompts](https://arxiv.org/pdf/2110.07280.pdf). 2021
* Salesforce Research: L. Xue, M. Gao, Z. Chen, C. Xiong and R. Xu. [Robustness Evaluation of Transformer-based Form Field Extractors via Form Attacks](https://arxiv.org/pdf/2110.04413.pdf). 2021
## Contributions
<table>
<tr>
<td align="center"><a href="https://github.com/sakares"><img src="https://avatars.githubusercontent.com/u/1306031" width="100px;" alt=""/><br /><sub><b>sakares saengkaew</b></sub></a><br /></td>
<td align="center"><a href="https://github.com/bdalal"><img src="https://avatars.githubusercontent.com/u/3478378?s=400&v=4" width="100px;" alt=""/><br /><sub><b>Binoy Dalal</b></sub></a><br /></td>
<td align="center"><a href="https://github.com/emrecncelik"><img src="https://avatars.githubusercontent.com/u/20845117?v=4" width="100px;" alt=""/><br /><sub><b>Emrecan Çelik</b></sub></a><br /></td>
</tr>
</table> |
3,434 | 🌊HMTL: Hierarchical Multi-Task Learning - A State-of-the-Art neural network model for several NLP tasks based on PyTorch and AllenNLP | # HMTL (Hierarchical Multi-Task Learning model)
**\*\*\*\*\* New November 20th, 2018: Online web demo is available \*\*\*\*\***
We released an [online demo](https://huggingface.co/hmtl/) (along with pre-trained weights) so that you can play yourself with the model. The code for the web interface is also available in the `demo` folder.
To download the pre-trained models, please install [git lfs](https://git-lfs.github.com/) and do a `git lfs pull`. The weights of the model will be saved in the model_dumps folder.
[__A Hierarchical Multi-Task Approach for Learning Embeddings from Semantic Tasks__](https://arxiv.org/abs/1811.06031)\
Victor SANH, Thomas WOLF, Sebastian RUDER\
Accepted at AAAI 2019
<img src="https://github.com/huggingface/hmtl/blob/master/HMTL_architecture.png" alt="HMTL Architecture" width="350"/>
## About
HMTL is a Hierarchical Multi-Task Learning model which combines a set of four carefully selected semantic tasks (namely Named Entity Recoginition, Entity Mention Detection, Relation Extraction and Coreference Resolution). The model achieves state-of-the-art results on Named Entity Recognition, Entity Mention Detection and Relation Extraction. Using [SentEval](https://github.com/facebookresearch/SentEval), we show that as we move from the bottom to the top layers of the model, the model tend to learn more complex semantic representation.
For further details on the results, please refer to our [paper](https://arxiv.org/abs/1811.06031).
We released the code for _training_, _fine tuning_ and _evaluating_ HMTL. We hope that this code will be useful for building your own Multi-Task models (hierarchical or not). The code is written in __Python__ and powered by __Pytorch__.
## Dependecies and installation
The main dependencies are:
- [AllenNLP](https://github.com/allenai/allennlp)
- [PyTorch](https://pytorch.org/)
- [SentEval](https://github.com/facebookresearch/SentEval) (only for evaluating the embeddings)
The code works with __Python 3.6__. A stable version of the dependencies is listed in `requirements.txt`.
You can quickly setup a working environment by calling the script `./script/machine_setup.sh`. It installs Python 3.6, creates a clean virtual environment, and installs all the required dependencies (listed in `requirements.txt`). Please adapt the script depending on your needs.
## Example usage
We based our implementation on the [AllenNLP library](https://github.com/allenai/allennlp). For an introduction to this library, you should check [these tutorials](https://allennlp.org/tutorials).
An experiment is defined in a _json_ configuration file (see `configs/*.json` for examples). The configuration file mainly describes the datasets to load, the model to create along with all the hyper-parameters of the model.
Once you have set up your configuration file (and defined custom classes such `DatasetReaders` if needed), you can simply launch a training with the following command and arguments:
```bash
python train.py --config_file_path configs/hmtl_coref_conll.json --serialization_dir my_first_training
```
Once the training has started, you can simply follow the training in the terminal or open a [Tensorboard](https://www.tensorflow.org/guide/summaries_and_tensorboard) (please make sure you have installed Tensorboard and its Tensorflow dependecy before):
```bash
tensorboard --logdir my_first_training/log
```
## Evaluating the embeddings with SentEval
We used [SentEval](https://github.com/facebookresearch/SentEval) to assess the linguistic properties learned by the model. `hmtl_senteval.py` gives an example of how we can create an interface between SentEval and HMTL. It evaluates the linguistic properties learned by every layer of the hiearchy (shared based word embeddings and encoders).
## Data
To download the pre-trained embeddings we used in HMTL, you can simply launch the script `./script/data_setup.sh`.
We did not attach the datasets used to train HMTL for licensing reasons, but we invite you to collect them by yourself: [OntoNotes 5.0](https://catalog.ldc.upenn.edu/LDC2013T19), [CoNLL2003](https://www.clips.uantwerpen.be/conll2003/ner/), and [ACE2005](https://catalog.ldc.upenn.edu/LDC2006T06). The configuration files expect the datasets to be placed in the `data/` folder.
## References
Please consider citing the following paper if you find this repository useful.
```
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}
```
|
3,435 | The codes of paper "Long Text Generation via Adversarial Training with Leaked Information" on AAAI 2018. Text generation using GAN and Hierarchical Reinforcement Learning. | # LeakGAN
The code of research paper [Long Text Generation via Adversarial Training with Leaked Information](https://arxiv.org/abs/1709.08624).
This paper has been accepted at the Thirty-Second AAAI Conference on Artificial Intelligence ([AAAI-18](https://aaai.org/Conferences/AAAI-18/)).
## Requirements
* **Tensorflow r1.2.1**
* Python 2.7
* CUDA 7.5+ (For GPU)
## Introduction
Automatically generating coherent and semantically meaningful text has many applications in machine translation, dialogue systems, image captioning, etc. Recently, by combining with policy gradient, Generative Adversarial Nets (GAN) that use a discriminative model to guide the training of the generative model as a reinforcement learning policy has shown promising results in text generation. However, the scalar guiding signal is only available after the entire text has been generated and lacks intermediate information about text structure during the generative process. As such, it limits its success when the length of the generated text samples is long (more than 20 words). In this project, we propose a new framework, called LeakGAN, to address the problem for long text generation. We allow the discriminative net to leak its own high-level extracted features to the generative net to further help the guidance. The generator incorporates such informative signals into all generation steps through an additional Manager module, which takes the extracted features of current generated words and outputs a latent vector to guide the Worker module for next-word generation. Our extensive experiments on synthetic data and various real-world tasks with Turing test demonstrate that LeakGAN is highly effective in long text generation and also improves the performance in short text generation scenarios. More importantly, without any supervision, LeakGAN would be able to implicitly learn sentence structures only through the interaction between Manager and Worker.

As the illustration of LeakGAN. We specifically introduce a hierarchical generator G, which consists of a high-level MANAGER module and a low-level WORKER module. The MANAGER is a long short term memory network (LSTM) and serves as a mediator. In each step, it receives generator D’s high-level feature representation, e.g., the feature map of the CNN, and uses it to form the guiding goal for the WORKER module in that timestep. As the information from D is internally-maintained and in an adversarial game it is not supposed to provide G with such information. We thus call it a leakage of information from D.
Next, given the goal embedding produced by the MANAGER, the WORKER firstly encodes current generated words with another LSTM, then combines the output of the LSTM and the goal embedding to take a final action at current state. As such, the guiding signals from D are not only available to G at the end in terms of the scalar reward signals, but also available in terms of a goal embedding vector during the generation process to guide G how to get improved.
## Reference
```bash
@article{guo2017long,
title={Long Text Generation via Adversarial Training with Leaked Information},
author={Guo, Jiaxian and Lu, Sidi and Cai, Han and Zhang, Weinan and Yu, Yong and Wang, Jun},
journal={arXiv preprint arXiv:1709.08624},
year={2017}
}
```
You can get the code and run the experiments in follow folders.
## Folder
Synthetic Data: synthetic data experiment
Image COCO: a real text example for our model using dataset Image COCO (http://cocodataset.org/#download)
Note: this code is based on the [previous work by LantaoYu](https://github.com/LantaoYu/SeqGAN). Many thanks to [LantaoYu](https://github.com/LantaoYu).
|
3,436 | 🤗 The largest hub of ready-to-use datasets for ML models with fast, easy-to-use and efficient data manipulation tools | <p align="center">
<br>
<img src="https://raw.githubusercontent.com/huggingface/datasets/main/docs/source/imgs/datasets_logo_name.jpg" width="400"/>
<br>
<p>
<p align="center">
<a href="https://github.com/huggingface/datasets/actions/workflows/ci.yml?query=branch%3Amain">
<img alt="Build" src="https://github.com/huggingface/datasets/actions/workflows/ci.yml/badge.svg?branch=main">
</a>
<a href="https://github.com/huggingface/datasets/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue">
</a>
<a href="https://huggingface.co/docs/datasets/index.html">
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/datasets/index.html.svg?down_color=red&down_message=offline&up_message=online">
</a>
<a href="https://github.com/huggingface/datasets/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/datasets.svg">
</a>
<a href="https://huggingface.co/datasets/">
<img alt="Number of datasets" src="https://img.shields.io/endpoint?url=https://huggingface.co/api/shields/datasets&color=brightgreen">
</a>
<a href="CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.0-4baaaa.svg">
</a>
<a href="https://zenodo.org/badge/latestdoi/250213286"><img src="https://zenodo.org/badge/250213286.svg" alt="DOI"></a>
</p>
🤗 Datasets is a lightweight library providing **two** main features:
- **one-line dataloaders for many public datasets**: one-liners to download and pre-process any of the  major public datasets (image datasets, audio datasets, text datasets in 467 languages and dialects, etc.) provided on the [HuggingFace Datasets Hub](https://huggingface.co/datasets). With a simple command like `squad_dataset = load_dataset("squad")`, get any of these datasets ready to use in a dataloader for training/evaluating a ML model (Numpy/Pandas/PyTorch/TensorFlow/JAX),
- **efficient data pre-processing**: simple, fast and reproducible data pre-processing for the public datasets as well as your own local datasets in CSV, JSON, text, PNG, JPEG, WAV, MP3, Parquet, etc. With simple commands like `processed_dataset = dataset.map(process_example)`, efficiently prepare the dataset for inspection and ML model evaluation and training.
[🎓 **Documentation**](https://huggingface.co/docs/datasets/) [🕹 **Colab tutorial**](https://colab.research.google.com/github/huggingface/datasets/blob/main/notebooks/Overview.ipynb)
[🔎 **Find a dataset in the Hub**](https://huggingface.co/datasets) [🌟 **Add a new dataset to the Hub**](https://huggingface.co/docs/datasets/share.html)
<h3 align="center">
<a href="https://hf.co/course"><img src="https://raw.githubusercontent.com/huggingface/datasets/main/docs/source/imgs/course_banner.png"></a>
</h3>
🤗 Datasets is designed to let the community easily add and share new datasets.
🤗 Datasets has many additional interesting features:
- Thrive on large datasets: 🤗 Datasets naturally frees the user from RAM memory limitation, all datasets are memory-mapped using an efficient zero-serialization cost backend (Apache Arrow).
- Smart caching: never wait for your data to process several times.
- Lightweight and fast with a transparent and pythonic API (multi-processing/caching/memory-mapping).
- Built-in interoperability with NumPy, pandas, PyTorch, Tensorflow 2 and JAX.
- Native support for audio and image data
- Enable streaming mode to save disk space and start iterating over the dataset immediately.
🤗 Datasets originated from a fork of the awesome [TensorFlow Datasets](https://github.com/tensorflow/datasets) and the HuggingFace team want to deeply thank the TensorFlow Datasets team for building this amazing library. More details on the differences between 🤗 Datasets and `tfds` can be found in the section [Main differences between 🤗 Datasets and `tfds`](#main-differences-between--datasets-and-tfds).
# Installation
## With pip
🤗 Datasets can be installed from PyPi and has to be installed in a virtual environment (venv or conda for instance)
```bash
pip install datasets
```
## With conda
🤗 Datasets can be installed using conda as follows:
```bash
conda install -c huggingface -c conda-forge datasets
```
Follow the installation pages of TensorFlow and PyTorch to see how to install them with conda.
For more details on installation, check the installation page in the documentation: https://huggingface.co/docs/datasets/installation
## Installation to use with PyTorch/TensorFlow/pandas
If you plan to use 🤗 Datasets with PyTorch (1.0+), TensorFlow (2.2+) or pandas, you should also install PyTorch, TensorFlow or pandas.
For more details on using the library with NumPy, pandas, PyTorch or TensorFlow, check the quick start page in the documentation: https://huggingface.co/docs/datasets/quickstart
# Usage
🤗 Datasets is made to be very simple to use. The main methods are:
- `datasets.list_datasets()` to list the available datasets
- `datasets.load_dataset(dataset_name, **kwargs)` to instantiate a dataset
This library can be used for text/image/audio/etc. datasets. Here is an example to load a text dataset:
Here is a quick example:
```python
from datasets import list_datasets, load_dataset
# Print all the available datasets
print(list_datasets())
# Load a dataset and print the first example in the training set
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
# Process the dataset - add a column with the length of the context texts
dataset_with_length = squad_dataset.map(lambda x: {"length": len(x["context"])})
# Process the dataset - tokenize the context texts (using a tokenizer from the 🤗 Transformers library)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
tokenized_dataset = squad_dataset.map(lambda x: tokenizer(x['context']), batched=True)
```
If your dataset is bigger than your disk or if you don't want to wait to download the data, you can use streaming:
```python
# If you want to use the dataset immediately and efficiently stream the data as you iterate over the dataset
image_dataset = load_dataset('cifar100', streaming=True)
for example in image_dataset["train"]:
break
```
For more details on using the library, check the quick start page in the documentation: https://huggingface.co/docs/datasets/quickstart.html and the specific pages on:
- Loading a dataset: https://huggingface.co/docs/datasets/loading
- What's in a Dataset: https://huggingface.co/docs/datasets/access
- Processing data with 🤗 Datasets: https://huggingface.co/docs/datasets/process
- Processing audio data: https://huggingface.co/docs/datasets/audio_process
- Processing image data: https://huggingface.co/docs/datasets/image_process
- Processing text data: https://huggingface.co/docs/datasets/nlp_process
- Streaming a dataset: https://huggingface.co/docs/datasets/stream
- Writing your own dataset loading script: https://huggingface.co/docs/datasets/dataset_script
- etc.
Another introduction to 🤗 Datasets is the tutorial on Google Colab here:
[](https://colab.research.google.com/github/huggingface/datasets/blob/main/notebooks/Overview.ipynb)
# Add a new dataset to the Hub
We have a very detailed step-by-step guide to add a new dataset to the  datasets already provided on the [HuggingFace Datasets Hub](https://huggingface.co/datasets).
You can find:
- [how to upload a dataset to the Hub using your web browser or Python](https://huggingface.co/docs/datasets/upload_dataset) and also
- [how to upload it using Git](https://huggingface.co/docs/datasets/share).
# Main differences between 🤗 Datasets and `tfds`
If you are familiar with the great TensorFlow Datasets, here are the main differences between 🤗 Datasets and `tfds`:
- the scripts in 🤗 Datasets are not provided within the library but are queried, downloaded/cached and dynamically loaded upon request
- 🤗 Datasets also provides evaluation metrics in a similar fashion to the datasets, i.e. as dynamically installed scripts with a unified API. This gives access to the pair of a benchmark dataset and a benchmark metric for instance for benchmarks like [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) or [GLUE](https://gluebenchmark.com/).
- the backend serialization of 🤗 Datasets is based on [Apache Arrow](https://arrow.apache.org/) instead of TF Records and leverage python dataclasses for info and features with some diverging features (we mostly don't do encoding and store the raw data as much as possible in the backend serialization cache).
- the user-facing dataset object of 🤗 Datasets is not a `tf.data.Dataset` but a built-in framework-agnostic dataset class with methods inspired by what we like in `tf.data` (like a `map()` method). It basically wraps a memory-mapped Arrow table cache.
# Disclaimers
Similar to TensorFlow Datasets, 🤗 Datasets is a utility library that downloads and prepares public datasets. We do not host or distribute most of these datasets, vouch for their quality or fairness, or claim that you have license to use them. It is your responsibility to determine whether you have permission to use the dataset under the dataset's license.
Moreover 🤗 Datasets may run Python code defined by the dataset authors to parse certain data formats or structures. For security reasons, we ask users to:
- check the dataset scripts they're going to run beforehand and
- pin the `revision` of the repositories they use.
If you're a dataset owner and wish to update any part of it (description, citation, license, etc.), or do not want your dataset to be included in the Hugging Face Hub, please get in touch by opening a discussion or a pull request in the Community tab of the dataset page. Thanks for your contribution to the ML community!
## BibTeX
If you want to cite our 🤗 Datasets library, you can use our [paper](https://arxiv.org/abs/2109.02846):
```bibtex
@inproceedings{lhoest-etal-2021-datasets,
title = "Datasets: A Community Library for Natural Language Processing",
author = "Lhoest, Quentin and
Villanova del Moral, Albert and
Jernite, Yacine and
Thakur, Abhishek and
von Platen, Patrick and
Patil, Suraj and
Chaumond, Julien and
Drame, Mariama and
Plu, Julien and
Tunstall, Lewis and
Davison, Joe and
{\v{S}}a{\v{s}}ko, Mario and
Chhablani, Gunjan and
Malik, Bhavitvya and
Brandeis, Simon and
Le Scao, Teven and
Sanh, Victor and
Xu, Canwen and
Patry, Nicolas and
McMillan-Major, Angelina and
Schmid, Philipp and
Gugger, Sylvain and
Delangue, Cl{\'e}ment and
Matussi{\`e}re, Th{\'e}o and
Debut, Lysandre and
Bekman, Stas and
Cistac, Pierric and
Goehringer, Thibault and
Mustar, Victor and
Lagunas, Fran{\c{c}}ois and
Rush, Alexander and
Wolf, Thomas",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.21",
pages = "175--184",
abstract = "The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.",
eprint={2109.02846},
archivePrefix={arXiv},
primaryClass={cs.CL},
}
```
If you need to cite a specific version of our 🤗 Datasets library for reproducibility, you can use the corresponding version Zenodo DOI from this [list](https://zenodo.org/search?q=conceptrecid:%224817768%22&sort=-version&all_versions=True).
|
3,437 | An evolving guide to learning Deep Learning effectively. | # The Incomplete Deep Learning Guide
From Self-Driving Cars to Alpha Go to Language Translation, Deep Learning seems to be everywhere nowadays. While the debate whether the hype is justified or not continues, Deep Learning has seen a rapid surge of interest across academia and industry over the past years.
With so much attention on the topic, more and more information has been recently published, from various MOOCs to books to YouTube Channels. With such a vast amount of resources at hand, there has never been a better time to learn Deep Learning.
Yet a side effect of such an influx of readily available material is choice overload. With thousands and thousands of resources, which are the ones worth looking at?
Inspired by Haseeb Qureshi's excellent [Guide on Learning Blockchain Development](https://medium.freecodecamp.org/the-authoritative-guide-to-blockchain-development-855ab65b58bc), this is my try to share the resources that I have found throughout my journey. As I am planning on continuously updating this guide with updated and better information, I deemed this work in progress an _incomplete guide_.
As of now, all the resources in this guide are all free thanks to their authors.
The link to my original blog post can be found [here](https://medium.freecodecamp.org/the-incomplete-deep-learning-guide-2cc510cb23ee).
**Target Audience**
- Anybody who wants to dive deeper into the topic, seeks a career in this field or aspires to gain a theoretical understanding of Deep Learning
**Goals of this Guide**
- Give an overview and a sense of direction within the ocean of resources
- Give a clear and useful path towards learning Deep Learning Theory and Development
- Give some practical tips along the way on how to maximize your learning experience
**Outline**
This guide is structured in the following way:
- **Phase 1** : Prerequisites
- **Phase 2** : Deep Learning Fundamentals
- **Phase 3** : Create Something
- **Phase 4** : Dive Deeper
- **Phase X** : Keep Learning
How long your learning will take depends on numerous factors such as your dedication, background and time-commitment. And depending on your background and the things you want to learn, feel free to skip to any part of this guide. The linear progression I outline below is just the path I found to be useful for myself.
**Phase 1: Pre-Requisites**
Let me be clear from the beginning. The prerequisites you need depend on the objectives you intend to pursue. The foundations you need to conduct research in Deep Learning will differ from the things you need to become a Practitioner (both are of course not mutually exclusive).
Whether you don't have any knowledge of coding yet or you are already an expert in R, I would still recommend acquiring a working knowledge of Python as most of the resources on Deep Learning out there will require you to know Python.
**Coding**
While Codecademy is a great way to start coding from the beginning, MIT's 6.0001 lectures are an incredible introduction to the world of computer science. So, is CS50, Harvard's infamous CS intro course, but CS50 has less of a focus on Python. For people who prefer reading, the interactive online book _How To Think Like A Computer Scientist_ is the way to go.
- [MIT Lecture 6.0001](https://www.youtube.com/watch?v=ytpJdnlu9ug&list=PLUl4u3cNGP63WbdFxL8giv4yhgdMGaZNA)
- [CodeCademy](https://www.codecademy.com/learn/learn-python)
- [How to think like a Computer Scientist](http://interactivepython.org/runestone/static/thinkcspy/index.html)
- [Harvard CS50](https://www.edx.org/course/cs50s-introduction-computer-science-harvardx-cs50x)
**Math**
If you simply want to apply Deep Learning techniques to a problem you face or gain a high-level understanding of Deep Learning, it is not necessary to know its mathematical underpinnings. But, in my experience, it has been significantly easier to understand and even more rewarding to use Deep Learning frameworks after getting familiar with its theoretical foundations. For such intentions, the basics of Calculus, Linear Algebra and Statistics are extremely useful. Fortunately, there are plenty of great Math resources online.
Here are the most important concepts you should know:
1. Multivariable Calculus
- Differentiation
- Chain Rule
- Partial Derivatives
2. Linear Algebra
- Definition of Vectors & Matrices
- Matrix Operations and Transformations: Addition, Subtraction, Multiplication, Transpose, Inverse
3. Statistics & Probability
- Basic ideas like mean and standard deviation
- Distributions
- Sampling
- Bayes Theorem
That being said, it is also possible to learn these concepts concurrently with Phase 2, looking up the Math whenever you need it.
If you want to dive right into the Matrix Calculus that is used in Deep Learning, take a look at [The Matrix Calculus You Need For Deep Learning](https://arxiv.org/abs/1802.01528) by Terence Parr and Jeremy Howard.
For lectures, Gilbert Strang's recorded videos of his course [MIT 18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine Learning (2018)](https://www.youtube.com/playlist?list=PLUl4u3cNGP63oMNUHXqIUcrkS2PivhN3k) are on YouTube and covers Linear Algebra, Probability and Optimization in the context of Deep Learning.
**Calculus**
For Calculus, I would choose between the MIT OCW Lectures, Prof. Leonard's Lectures and Khan Academy. The MIT Lectures are great for people who are comfortable with Math and seek a fast-paced yet rigorous introduction to Calculus. Prof. Leonard Lectures are perfect for anybody who is not too familiar with Math as he takes the time to explain everything in a very understandable manner. Lastly, I would recommend Khan Academy for people who just need a refresher or want to get an overview as fast as possible.
- [MIT 18.01 Single Variable Calculus](https://www.youtube.com/watch?v=jbIQW0gkgxo&t=1s)
- [Prof Leonard Calculus 1](https://www.youtube.com/watch?v=fYyARMqiaag&list=PLF797E961509B4EB5)
- [Khan Academy Calculus 1](https://www.khanacademy.org/math/calculus-1)
**Linear Algebra**
For Linear Algebra, I really enjoyed Professor Strang's Lecture Series and its accompanying book on Linear Algebra (MIT OCW). If you are interested in spending more time on Linear Algebra, I would recommend the MIT lectures, but if you just want to learn the basics quickly or get a refresher, Khan Academy is perfect for that.
For a more hands-on coding approach, check out Rachel Thomas' (from fast.ai) Computational Linear Algebra Course.
- [MIT 18.06 Linear Algebra](https://www.youtube.com/watch?v=ZK3O402wf1c&list=PLE7DDD91010BC51F8)
- [Khan Academy Linear Algebra](https://www.khanacademy.org/math/linear-algebra)
- [Rachel Thomas' Computational Linear Algebra](https://www.youtube.com/watch?v=8iGzBMboA0I&index=1&list=PLtmWHNX-gukIc92m1K0P6bIOnZb-mg0hY)
At last, this [review](http://cs229.stanford.edu/section/cs229-linalg.pdf) from Stanford's CS229 course offers a nice reference you can always come back to.
For both Calculus and Linear Algebra, 3Blue1Brown's Essence of Calculus and Linear Algebra series are beautiful complementary materials to gain a more intuitive and visual understanding of the subject.
- [3Blue1Brown Essence of Calculus](https://www.youtube.com/watch?v=WUvTyaaNkzM&list=PLZHQObOWTQDMsr9K-rj53DwVRMYO3t5Yr)
- [3Blue1Brown Essence of Linear Algebra](https://www.youtube.com/watch?v=kjBOesZCoqc&list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab)
**Statistics and Probability**
Harvard has all its Stats 110 lectures, which is taught by Prof. Joe Blitzstein, on YouTube. It starts off with Probability and covers a wide range of Intro to Statistics topics. The practice problems and content can be challenging at times, but it is one of the most interesting courses out there.
Beyond Harvard's course, Khan Academy and Brandon Foltz also have some high-quality material on YouTube.
- [Harvard Statistics 110](https://www.youtube.com/watch?v=KbB0FjPg0mw&list=PL2SOU6wwxB0uwwH80KTQ6ht66KWxbzTIo)
- [Khan Academy Statistics & Probability](https://www.khanacademy.org/math/statistics-probability)
- [Brandon Foltz' Statistics 101](https://www.youtube.com/user/BCFoltz/videos)
Similarly to Linear Algebra, Stanford's CS229 course also offers a nice [review](http://cs229.stanford.edu/section/cs229-prob.pdf) of Probability Theory that you can use as a point of reference.
**Phase 2: Deep Learning Fundamentals**
With the plethora of free deep learning resources online, the paradox of choice becomes particularly apparent. Which ones should I choose, which ones are the right fit for me, where can I learn the most?
**MOOCs**
Just as important as learning theory is practicing your newfound knowledge, which is why my favorite choice of MOOCs would be a mix of Andrew Ng's [_deeplearning.ai_](https://www.coursera.org/specializations/deep-learning) (more theoretical) and Jeremy Howard's and Rachel Thomas' [_fast.ai_](http://course.fast.ai/) (more practical). Andrew Ng is excellent at explaining the basic theory behind Deep Learning, while fast.ai is a lot more focused on hands-on coding. With the theoretical foundations of deeplearning.ai, Jeremy Howard's code and explanations become a lot more intuitive, while the coding part of fast.ai is super helpful to ingrain your theoretical knowledge into practical understanding.
fast.ai Part I
Since deeplearning.ai consists of five courses and fast.ai consists of two parts, I would structure my learning in the following way:
1. Watch Deep Learning.ai's Course Lectures I, II, IV and V
2. Take Fast.ai Part I
3. Watch Deeplearning.ai Course III
4. Optional: Take deeplearning.ai assignments
5. Repeat Steps 1–4 or Go to Phase III
The reason I would first skip the deeplearning.ai assignments is that I found fast.ai's coding examples and assignments to be a lot more practical than the deeplearning.ai assignments. If you want to reiterate the deeplearning.ai course material (i.e. repetition to strengthen your memory), then give the assignments a try. Unlike fast.ai, which uses PyTorch and its own fastai library, they primarily use Keras. So, it's a good opportunity to get familiar with another Deep Learning Framework.
Fast.ai Part 2 deals with quite advanced topics and requires a good grasp of theory as wells as the coding aspects of Deep Learning, which is why I would put that one in Phase IV of this guide.
**Tip:** You can freely watch deeplearning.ai videos on Coursera, but you need to purchase the specialization to do the assignments. If you can't afford the coursera specialization fee, apply for a [scholarship](https://learner.coursera.help/hc/en-us/articles/209819033-Apply-for-Financial-Aid)!
For people who prefer reading books, Michael Nielsen published a free [Intro book on Deep Learning](http://neuralnetworksanddeeplearning.com/) that also incorporates coding examples in Python.
To really take advantage of fast.ai, you will need a GPU. But lucky us, Google offers an environment similar to Jupyter Notebooks called [_Google Colaboratory_](https://colab.research.google.com/) that comes with free GPU access. Somebody already made a tutorial on how to use Colab for Fast.ai. So, check that out [here](https://towardsdatascience.com/fast-ai-lesson-1-on-google-colab-free-gpu-d2af89f53604). Kaggle has also started providing accessto a free Nvidia K80 GPU on their [_Kernels_](https://www.kaggle.com/dansbecker/running-kaggle-kernels-with-a-gpu).
AWS also provides students with up to 100$ in credits (depending on whether your college is part of their program), which you can use for their GPU instances.
**Complementary Non-Mooc Material**
Do not solely rely on one means of information, combine watching videos with coding and reading.
**YouTube**
Just like in his series on Calculus and Linear Algebra, 3Blue1Brown gives one of the most intuitive explanations on Neural Networks. Computer Phile and Brandon also offer great explanations of Deep Learning, each from a slightly different perspective. Lastly, sentdex can be helpful as he instantly puts concepts into code.
- [3Blue1Brown Neural Networks](https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi)
- [Computer Phile Neural Networks](https://www.youtube.com/playlist?list=PLzH6n4zXuckoezZuZPnXXbvN-9jMFV0qh)
- [Brandon Rohrer Neural Networks](https://www.youtube.com/watch?v=ILsA4nyG7I0)
- [Practical Machine Learning sentdex](https://www.youtube.com/watch?v=OGxgnH8y2NM&list=PLQVvvaa0QuDfKTOs3Keq_kaG2P55YRn5v)
**Beginner-Friendly Blogs**
Blogs are also a phenomenal way of reiterating over newly acquired knowledge, exploring new ideas or going in-depth into a topic.
[Distill.pub](https://distill.pub/) is one of the best blogs I know in the Deep Learning space and beyond. The way its editors approach topics like [Feature Visualization](https://distill.pub/2017/feature-visualization/) or [Momentum](https://distill.pub/2017/momentum/) is simply clear, dynamic and engaging.
Although not updated anymore, [Andrej Karpathy's old Blog](http://karpathy.github.io/) has some classic articles on things such as [RNNs](http://karpathy.github.io/2015/05/21/rnn-effectiveness/) that are worth checking out.
Finally, Medium Publications like FreeCodeCamp and Towards Data Science regularly publish interesting posts from [Reinforcement Learning](https://simoninithomas.github.io/Deep_reinforcement_learning_Course/) to [Objection Detection](https://towardsdatascience.com/deep-learning-for-object-detection-a-comprehensive-review-73930816d8d9).
**Coding**
Get familiar with code! Knowing how to graph plots, deal with messy data and do scientific computing is crucial in Deep Learning, which is why libraries such as Numpy or Matplotlib are ubiquitously used. So, practicing and using these tools will definitely help you along the way.
Jupyter Notebook
- [Introduction, Setup and Walkthrough](https://www.youtube.com/watch?v=HW29067qVWk)
- [DataCamp Comprehensive Jupyter Notebook Tutorial](https://www.datacamp.com/community/tutorials/tutorial-jupyter-notebook?utm_source=adwords_ppc&utm_campaignid=1366776656&utm_adgroupid=57448230227&utm_device=c&utm_keyword=&utm_matchtype=b&utm_network=g&utm_adpostion=1t1&utm_creative=265681164941&utm_targetid=aud-364780883969:dsa-429603003980&utm_loc_interest_ms=&utm_loc_physical_ms=9042585&gclid=Cj0KCQjwxtPYBRD6ARIsAKs1XJ4XsOoAhoDXVUIxahP5aX2Ign1X8w1IKQ3RSAvfwnzh9m6rSPLMX1waAs3NEALw_wcB)
Jupyter Notebooks can be a great tool but definitely carry some drawbacks. Take a look at Joel Grus' informative and meme-filled presentation [_I don't Like Notebooks_](https://docs.google.com/presentation/d/1n2RlMdmv1p25Xy5thJUhkKGvjtV-dkAIsUXP-AL4ffI/preview?slide=id.g362da58057_0_1) to be aware of those pitfalls.
Numpy
- [Stanford CS231 Numpy Tutorial](http://cs231n.github.io/python-numpy-tutorial/)
- [DataCamp Numpy Tutorial](https://www.datacamp.com/community/tutorials/python-numpy-tutorial)
Pandas
- [Data School Comprehensive Tutorial Series on Data Analysis Pandas](https://www.youtube.com/watch?v=yzIMircGU5I&list=PL5-da3qGB5ICCsgW1MxlZ0Hq8LL5U3u9y)
- [Code Basics Short Tutorial Series on Pandas](https://www.youtube.com/watch?v=CmorAWRsCAw&list=PLeo1K3hjS3uuASpe-1LjfG5f14Bnozjwy)
Scikit-learn
- [Data School scikit-learn Tutorial Series](https://www.youtube.com/watch?v=elojMnjn4kk&list=PL5-da3qGB5ICeMbQuqbbCOQWcS6OYBr5A)
Matplotlib
- [Sentdex Matplotlib Series](https://www.youtube.com/watch?v=q7Bo_J8x_dw&list=PLQVvvaa0QuDfefDfXb9Yf0la1fPDKluPF)
- [Matplotlib Video Tutorials](https://www.youtube.com/watch?v=b3lK639ymu4&list=PLNmACol6lYY5aGQtxghQTq0bHXYoIMORy)
And if you ever get stuck with a concept or code snippet, google it! The quality of the answers will be highly variable, but sites such as Quora, Stackoverflow or PyTorch's excellent Forum are certainly sources you can leverage. Reddit can sometimes offer nice explanations as well, in formats such as [ELI5](https://www.reddit.com/r/explainlikeimfive/) (Explain Me Like I'm Five) when you're completely perplexed by a new topic.
**Phase 3: Create Something**
While you should definitely play around with code and use it with external datasets/problems while taking the fast.ai course, I think it's crucial to implement your own project as well. The deeplearning.ai course III is an excellent guide on how to structure and execute a Machine Learning Project.
**Brainstorm Ideas**
Start with brainstorming ideas that seem feasible to you with the knowledge you just acquired, look at openly available datasets and think about problems you might want to solve with Deep Learning. Take a look at these [Projects](https://github.com/NirantK/awesome-project-ideas) to get some inspiration!
**Or Use Kaggle**
Otherwise, an easy way to start with a project is participating in a [Kaggle competition](https://www.kaggle.com/competitions) (current or past) or exploring their vast amount of [open datasets](https://www.kaggle.com/datasets). Kaggle offers an excellent gateway into the ML community. People share Kernels (their walkthrough of a given problem) and actively discuss ideas, which you can learn from. It becomes especially interesting after the end of a competition, when teams start to post their solutions in the Discussion Forums, which often involves creative approaches to the competition.
**Choose a framework**
Whatever Deep Learning Framework you feel most comfortable, choose one! I would go for either PyTorch or Keras as they are both relatively easy to pick up and have a very active community.
**Reflect**
After completing your project, take a day or so to reflect on what you have achieved, what you have learned and what you could improve upon in the future. This is also the perfect time to write your first blog post! It's one thing to think that you understand something and another to convey it to other people. Quincy Larson, the founder of FreeCodeCamp, gave a really helpful presentation on how to write a technical blog post [here](https://www.youtube.com/watch?v=YODPgBadj80).
**Phase 4: Dive Deeper**
Now that you built some fundamental Deep Learning knowledge and went through your first Practical Experience, it's time to go deeper!
From here on, there are tons of things you can do. But the first thing I would do is go through Fast.ai Part 2 [Cutting Edge Deep Learning For Coders](http://course.fast.ai/part2.html). As the name suggests, you'll learn some of the cutting edge stuff in Deep Learning: from GANs to Neural Translation to Super Resolution! The course will give you an overview of some of the hottest topics in Deep Learning right now with a strong focus on Computer Vision and Natural Language Processing (NLP). I particularly appreciate the course as Jeremy Howard not only gives very clear explanations but also really goes into the code that is needed to enable these ideas.
After fast.ai, here are some of the things you can do:
- Take a deep dive into one topic such as Computer Vision, NLP or Reinforcement Learning
- Read papers and/or reimplement ideas from a paper
- Do more projects and/or gain work experience in Deep Learning
- Follow blogs, listen to podcasts and stay up to date
**Deep Dives**
**Computer Vision**
The best place to continue your Computer Vision path is definitely Stanford's CS231n Course, also called _Convolutional Neural Networks for Visual Recognition_. They not only have all their lecture videos online, but their website also offers [course notes](http://cs231n.github.io/) and [assignments](http://cs231n.stanford.edu/2017/syllabus.html)! Fast.ai Part 2 and deeplearning.ai will give you a good foundation for the course as CS231n will go a a lot further in terms of the theory behind CNNs and related topics.
While both versions cover mostly the same topics, which also means _choose whichever version's teaching style you like better_, the final lectures differ slightly. For example, 2017 incorporates a Lecture on Generative Models and 2016 has a guest lecture by Jeff Dean on Deep Learning at Google. If you want to see how Computer Vision was before Deep Learning took off, the University of Central Florida (UCF) has a Computer Vision course from 2012 teaching about concepts such as SIFT features.
CS231n is still one of the best resources for learning Computer Vision, but if you want to combine old-school computer vision techniques such as edge detection and stereo in combination with more recent Machine Learning approaches, check out the course "The Ancient Secrets of Computer Vision" by the authors of YOLO.
- [UW's The Ancient Secrets of Computer Vision (2018)](https://pjreddie.com/courses/computer-vision/)
- [Stanford CS231n (2017)](https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk)
- [Stanford CS231n (2016)](https://www.youtube.com/watch?v=NfnWJUyUJYU&list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC)
- [UCF Computer Vision (2012](https://www.youtube.com/watch?v=715uLCHt4jE&list=PLd3hlSJsX_ImKP68wfKZJVIPTd8Ie5u-9))
**Natural Language Processing**
Stanford has quite an extensive course called CS224n _Natural Language Processing with Deep Learning_, which similarly to CS231n not only uploaded its lecture videos but also hosts a handy website with [lecture slides, assignments, assignment solutions](http://web.stanford.edu/class/cs224n/syllabus.html) and even students' [Class Projects](http://web.stanford.edu/class/cs224n/reports.html)!
Oxford also has a very nice lecture series on NLP in cooperation with DeepMind. While it does have a helpful [GitHub repository](https://github.com/oxford-cs-deepnlp-2017/lectures) with slides and pointers to further readings, it lacks the assignment part of Stanford's CS224. The courses overlap to some extent, but not to the extent that it's not worth looking at both courses. CS224N currently has a 2017 and 2019 version available. I would highly recommend watching the 2019 lectures, as they contain many more new topics such as the Transformer architecture and Contextual Word Embeddings. CMU also recently published a 2019 version of their Neural Nets for NLP course, which is slightly broader than CS224N. And a recent update: take a look Stanford's CS224u course, which is focused on Natural Language Understanding.
- [Stanford CS224N NLP with Deep Learning (2019)](https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z)
- [Stanford CS224u NLU (2019)](https://www.youtube.com/watch?v=tZ_Jrc_nRJY&list=PLoROMvodv4rObpMCir6rNNUlFAn56Js20&index=2&t=0s)
- [Stanford CS224N NLP with Deep Learning (2017)](https://www.youtube.com/watch?v=OQQ-W_63UgQ&list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6)
- [CMU Neural Nets for NLP (2019)](https://www.youtube.com/playlist?list=PL8PYTP1V4I8Ajj7sY6sdtmjgkt7eo2VMs)
- [Oxford Deep Learning for NLP with DeepMind (2017)](https://www.youtube.com/watch?v=RP3tZFcC2e8&list=PL613dYIGMXoZBtZhbyiBqb0QtgK6oJbpm)
**General Deep Learning**
For people who are still unsure about what in Deep Learning excites them the most, Carnegie Mellon University (CMU) has a course on _Topics in Deep Learning_, which introduces a broad range of topics from Restricted Boltzmann Machines to Deep Reinforcement Learning. Oxford also has a Deep Learning Course, which can give you a firmer mathematical grasp of concepts you learned in deeplearning.ai and fast.ai, meaning things such as Regularization or Optimization. Andrew Ng, the creator of deeplearning.ai also published his 2018 CS230 lectures at Stanford online, which give a general overview of Deep Learning.
A book that could help you in any Deep Learning field is _The Deep Learning Book_ byIan Goodfellow et al., which is the most comprehensive book on Deep Learning theory I know of. Classes such as Oxford's NLP course also use this book as complementary material. A currently very hot topic is Unsupervised Learning and Berkeley recently published their new course on Deep Unsupervised Learning CS294-158, which covers an excellent set of topics in that area.
Noteworthy as well is that top-tier research conferences such as NIPS or ICML, which disseminate the state-of-the-art Deep Learning papers, regularly publish their keynote talks and tutorial videos. Lastly, the 2019 version of Fullstack Deep Learning Bootcamp led by Pieter Abbeel has all its course material online and is an excellent resource for anybody who wants to receive tips and tricks on putting Deep Learning into practice.
- [Fullstack Deep Learning Bootcamp (2019)](https://fullstackdeeplearning.com/march2019)
- [Berkeley CS294 Deep Unsupervised Learning (2019)](https://sites.google.com/view/berkeley-cs294-158-sp19/home)
- [Stanford CS230 Deep Learning (2018)](https://www.youtube.com/playlist?list=PLoROMvodv4rOABXSygHTsbvUz4G_YQhOb)
- [CMU Topics in Deep Learning Course (2017)](https://www.youtube.com/watch?v=fDlOQrLX8Hs&list=PLpIxOj-HnDsOSL__Buy7_UEVQkyfhHapa)
- [Oxford Deep Learning Course (2015)](https://www.youtube.com/watch?v=PlhFWT7vAEw&list=PLjK8ddCbDMphIMSXn-w1IjyYpHU3DaUYw)
- [Deep Learning Book by Ian Goodfellow et al.](https://www.deeplearningbook.org/)
- [NeurIPS](https://nips.cc/Conferences/2017/Videos) (2018), [ICML](https://icml.cc/Conferences/2017/Videos) (2018), [ICLR](https://www.facebook.com/pg/iclr.cc/videos/) (2019), [CVPR](https://www.youtube.com/channel/UC0n76gicaarsN_Y9YShWwhw/videos) (2018) Conference Videos
**Reinforcement Learning**
As Reinforcement Learning (RL) is neither covered by deeplearning.ai nor fast.ai, I would first watch Arxiv Insight's Intro to RL and Jacob Schrum's RL videos, which are extremely understandable explanations of the topic. Then head to Andrej Karpathy's blog post on Deep Reinforcement Learning and read Chapter 1–2 of Andrew Ng's PhD Thesis (as suggested by[Berkeley's CS 294 website](http://rll.berkeley.edu/deeprlcoursesp17/#prerequisites)) to get a primer on Markov Decision Processes. Afterwards, David Silver's (Deep Mind) Course on RL will give you a strong foundation to transition to Berkeley's CS294 Course on Deep RL. Alternatively, Stanford made their 2019 version of CS234 Reinforcement Learning course available. One last foundational RL course I want to mention is UWaterloo's 885 course, which goes into more depth on topics such as MDPs and bandits. In addition to any primary resource, I would suggest using OpenAI's "Spinning up in Deep RL" website, which was built with the aim to take people with little or no background in RL to RL practitioners.
There are also recorded sessions of a Deep RL Bootcamp at Berkeley and an RL Summer School at the Montreal Institute for Learning Algorithms with speakers like Pieter Abbeel and Richard Sutton. The latter also co-authored an introductory textbook on RL, which currently can be accessed openly in its 2nd edition as a draft (chapter 3 & 4 are pre-readings for CS294). Additionally, Udacity has a fabulous [GitHub repo](https://github.com/udacity/deep-reinforcement-learning) with tutorials, projects and a cheatsheet from their _paid_ Deep RL course. Another resource that was published recently is Thomas Simonini's ongoing Deep RL course that is very easy to follow and hands-on in its coding methodology. One paradigm that has influenced RL in particular over the last years is Meta Learning. Stanford's CS330 class is a great overview of this topic taught by Chelsea Finn.
- [Arxiv Insight's Intro To RL Video](https://www.youtube.com/watch?v=JgvyzIkgxF0)
- [Jacob Schrum's Intro To RL](https://www.youtube.com/watch?v=3T5eCou2erg&list=PLWi7UcbOD_0u1eUjmF59XW2TGHWdkHjnS)
- [Andrej Karpathy's Blog Post on Deep Reinforcement Learning](http://karpathy.github.io/2016/05/31/rl/)
- [Chapter 1–2 of Andrew Ng's PhD Thesis on Markov Decision Processes](http://rll.berkeley.edu/deeprlcoursesp17/docs/ng-thesis.pdf)
- [Stanford CS234 Reinforcement Learning (2019)](https://www.youtube.com/playlist?list=PLoROMvodv4rOSOPzutgyCTapiGlY2Nd8u)
- [UWaterloo CS885 Reinforcement Learning (2018)](https://www.youtube.com/playlist?list=PLdAoL1zKcqTXFJniO3Tqqn6xMBBL07EDc)
- [OpenAI Spinning up in Deep RL (2018)](https://spinningup.openai.com/)
- [DeepMind's Advanced Deep Learning & Reinforcement Learning (2018)](https://www.youtube.com/watch?v=iOh7QUZGyiU&list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs)
- [David Silver's Course on Reinforcement Learning](https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLzuuYNsE1EZAXYR4FJ75jcJseBmo4KQ9-)
- [Berkeley CS294 Deep Reinforcement Learning Course(2017)](http://rll.berkeley.edu/deeprlcoursesp17/))
- [Berkeley CS294 Deep Reinforcement Learning (2018, ongoing session)](http://rail.eecs.berkeley.edu/deeprlcourse/)
- [Reinforcement Learning: An Introduction (Final Version, 2018)](https://drive.google.com/file/d/1opPSz5AZ_kVa1uWOdOiveNiBFiEOHjkG/view)
- [Berkeley Deep RL Bootcamp (2017)](https://www.youtube.com/watch?v=qaMdN6LS9rA&list=PLAdk-EyP1ND8MqJEJnSvaoUShrAWYe51U)
- [MILA Reinforcement Learning Summer School (2017](https://mila.quebec/en/cours/deep-learning-summer-school-2017/))
- [Udacity Deep RL GitHub Repo](https://github.com/udacity/deep-reinforcement-learning)
- [Thomas Simonini's Deep RL Course](https://simoninithomas.github.io/Deep_reinforcement_learning_Course/)
- [Stanford CS330 Deep Multi-Task and Meta Learning (2019)](https://www.youtube.com/watch?v=0rZtSwNOTQo&list=PLoROMvodv4rMC6zfYmnD7UG3LVvwaITY5&index=1)
**Machine Learning and AI (that is not necessarily Deep Learning)**
There is certainly value to knowing various Machine Learning and AI ideas that came before Deep Learning. Whether Logistic Regression or Anomaly Detection, Andrew Ng's classic Machine Learning Course is a great starting point. If you want a more mathematically rigorous course, Caltech has a superb MOOC that is more theoretically grounded. Professor Ng is also writing a book with ML best practices, for which you can access the first chapters of his draft. Lastly, Stanford and Berkeley both have excellent Introduction to AI courses that cover topics such as search and game playing.
- [Stanford CS221 (2019)](https://www.youtube.com/playlist?list=PLoROMvodv4rO1NB9TD4iUZ3qghGEGtqNX)
- [Berkeley CS188 (2018)](https://www.youtube.com/playlist?list=PL7k0r4t5c108AZRwfW-FhnkZ0sCKBChLH)
- [Andrew Ng's Machine Learning course (2012)](https://www.coursera.org/learn/machine-learning)
- [Andrew Ng's Machine Learning course (2012)](https://www.coursera.org/learn/machine-learning)
- [Caltech CS156 Machine Learning course (2012)](http://work.caltech.edu/telecourse.html)
- [Christopher Bishop's Pattern Recognition and Machine Learning Book (2006)](https://www.microsoft.com/en-us/research/uploads/prod/2006/01/Bishop-Pattern-Recognition-and-Machine-Learning-2006.pdf)
- [Machine Learning Yearning Book by Andrew Ng](http://www.mlyearning.org/)
**Self-Driving Cars**
Self-Driving Cars are one of the most interesting areas of application for Deep Learning. So, it's quite amazing that MIT offers its own course on that topic. The course will give you a breadth of introductions to topics such as perception and motion planning as well as provide you with insights from industry experts such as the Co-Founder of Aurora. If you're further interested in the Computer Vision part of Autonomous Driving, a few researchers from ETH Zurich and the Max Planck Institute for Intelligent Systems have written an extensive survey on the subject matter. Moreover, ICCV uploaded the slides from an 8-Part Tutorial Series, which have some useful information on Sensor Fusion and Localization. Regarding projects I would take a look at projects from Udacity's _paid_ Self-Driving Car Nanodegree, which you can _freely_ find on GitHub. Udacity does consistently offer scholarships. For instance, [last year](https://www.udacity.com/scholarships/lyft) in cooperation with Lyft for its Self-Driving Cars Intro Course. So, be on the lookout for that as well!
- [MIT Self-Driving Cars Course (2018)](https://www.youtube.com/watch?v=-6INDaLcuJY&list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf)
- [Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art (2017)](https://arxiv.org/pdf/1704.05519.pdf)
- [ICCV Tutorial on Computer Vision for Autonomous Driving (2015)](https://sites.google.com/site/cvadtutorial15/materials)
- [Udacity Self-Driving Car Project Ideas](https://github.com/ndrplz/self-driving-car)
**Strengthen your understanding of Fundamental Concepts**
You will keep encountering fundamental concepts such as Losses, Regularizations, Optimizers, Activation Functions and Gradient Descent, so gaining an Intuition for them is crucial. Two posts that expound Gradient Descent and Backpropagation very well:
- [Sebastian Ruder Gradient Descent Blog Post](http://ruder.io/optimizing-gradient-descent/)
- [CS231n Backpropagation](http://cs231n.github.io/optimization-2/)
**Read Papers**
While Arxiv is of paramount importance in the fast and open dissemination of Deep Learning research ideas, it can get overwhelming very quickly with the influx of papers on the platform. For that reason, Andrej Karpathy built [_Arxiv Sanity_](http://www.arxiv-sanity.com/), a tool that lets you filter and track papers according to your preferences. Here are just a few seminal papers from recent years, starting with the ImageNet Papers (AlexNet, VGG, InceptionNet, ResNet) that have had a tremendous influence on the trajectory of Deep Learning. A great way to look into papers is through reading groups. And thanks to the internet, reading groups such as AISC stream all their sessions online. Furthermore, Kaggle has an online reading group for NLP papers and Microsoft records their paper review calls. All three discuss a variety of different papers, so it's worth taking a look at all of them, but AISC in particular has a vast library of previously recorded sessions.
- [AlexNet](https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf) (2012), [VGG](https://arxiv.org/abs/1409.1556) (2014), [InceptionNet](https://arxiv.org/pdf/1409.4842.pdf) (2014), [ResNet](https://arxiv.org/abs/1512.03385) (2015)
- [Generative Adversarial Networks (2014)](https://arxiv.org/abs/1406.2661)
- [Yolo Object Detection Paper (2015)](https://arxiv.org/abs/1506.02640)
- [Playing Atari with Deep Reinforcement Learning (2013)](https://arxiv.org/pdf/1312.5602.pdf)
- [AISC YouTube Channel](https://www.youtube.com/user/amirfzpr/videos)
- [Kaggle Reading Group](https://www.youtube.com/playlist?list=PLqFaTIg4myu8t5ycqvp7I07jTjol3RCl9)
- [Microsoft Paper Review Calls](https://www.youtube.com/playlist?list=PLNe3Jh7xEi2Pv6Z33r2ZNpO8MIMr5ElWI)
**YouTube Channels**
_Arxiv Insights_,_CodeEmperium_ and _Yannic Kilcher_ are the most under-appreciated YouTube Channels on Deep Learning with some of the clearest explanations on Autoencoders and Attention. Another YouTube Channel that should be mentioned is _Lex Fridman, who_ is the main instructor MIT's Self-Driving Course, but also taught MIT's course on Artificial General Intelligence, which has some fascinating lectures on Meta-Learning, Consciousness and Intelligence.
- [Arxiv Insights](https://www.youtube.com/channel/UCNIkB2IeJ-6AmZv7bQ1oBYg/videos)
- [CodeEmperium](https://www.youtube.com/channel/UC5_6ZD6s8klmMu9TXEB_1IA/videos)
- [Yannic Kilcher](https://www.youtube.com/channel/UCZHmQk67mSJgfCCTn7xBfew/videos)
- [Lex Fridman](https://www.youtube.com/user/lexfridman)
**Podcasts**
Podcasts are quite a nice way to hear from various people on a diverse range of topics. Two of my favorite podcasts, which produce a lot of Deep Learning related content, are T_alking Machines_ and _This Week in ML & AI_ (TWiML&AI). For example, listen to Talking Machine's recent [podcast](https://www.thetalkingmachines.com/episodes/icml-2018-jennifer-dy) at ICML 2018 or TWiML's [podcast](https://twimlai.com/twiml-talk-176-openai-five-with-christy-dennison/) with OpenAI Five's Christy Dennison!
- [This Week in ML & AI](https://twimlai.com/)
- [Lex Fridman's AI Podcast](https://www.youtube.com/playlist?list=PLrAXtmErZgOdP_8GztsuKi9nrraNbKKp4)
- [Mind the Machines](https://www.youtube.com/channel/UCDK-mgQqtgLDtmsZZ651pNg/videos)
- [Talking Machines](https://www.thetalkingmachines.com/)
**Blogs**
As mentioned previously, I am a huge fan of _Distill.pub,_ and _o_ne of its Editors, _Chris Olah_, has some other high-quality posts on his personal blog as well. Another really promising blog is _The Gradient_, which provides well-written and clear overviews of the newest research findings as well as perspectives on the future of the field. Sebastian Ruder is one of the contributing authors of The Gradient and like Chris Olah, his blog has some awesome content as well, in particular for NLP-related topics. The last blog is not really a blog, but rather a hub for study plans to specific papers such as AlphaGo Zero or InfoGans. For each of these topics, _Depth First Learning_ publishes curriculums that allow you to learn the ideas of the papers at their cores.
- [pub](https://distill.pub/)
- [Chris Olah](http://colah.github.io/)
- [The Gradient](https://thegradient.pub/)
- [Sebastian Ruder](http://ruder.io/#open)
- [Depth First Learning](http://www.depthfirstlearning.com/)
**Cheatsheets**
Cheatsheets are awesome. After learning new concepts or programming commands, you can always refer back to them in case you forget, for example, how to retrieve array dimensions in Numpy.
- [Deep Learning](https://stanford.edu/~shervine/teaching/cs-229/cheatsheet-deep-learning)
- [PyTorch](https://www.sznajdman.com/pytorch-cheat-sheet/)
- [Numpy](https://www.datacamp.com/community/blog/python-numpy-cheat-sheet)
- [Pandas](https://www.datacamp.com/community/blog/python-pandas-cheat-sheet)
- [Matplotlib](https://www.datacamp.com/community/blog/python-matplotlib-cheat-sheet)
- [Scikit-Learn](https://www.datacamp.com/community/blog/scikit-learn-cheat-sheet)
- [Jupyter Notebook](https://www.datacamp.com/community/blog/jupyter-notebook-cheat-sheet)
**Requests for Research**
In case you want to get started with your own research, here are some pointers to topics other people have requested for research.
- [Sebastian Ruder NLP](http://ruder.io/requests-for-research/)
- [OpenAI Reinforcement Learning](https://blog.openai.com/requests-for-research-2/)
- [AI Open Network](https://ai-on.org/)
**Stay Up to Date**
Believe it or not, but one of the best ways to stay updated on the progress of Deep Learning is Twitter. Tons of researchers use the platform to share their publications, discuss ideas and interact with the community.
Some of the people worth following on Twitter:
- [hardmaru](https://twitter.com/hardmaru)
- [Jeremy Howard](https://twitter.com/jeremyphoward)
- [Rachel Thomas](https://twitter.com/math_rachel)
- [Sebastian Ruder](https://twitter.com/seb_ruder)
- [Fei Fei Li](https://twitter.com/drfeifei)
- [Smerity](https://twitter.com/Smerity)
- [François Chollet](https://twitter.com/fchollet)
**Phase X: Keep Learning**
The field is changing rapidly, so keep learning and enjoy the ride.
|
3,438 | 🔮 A refreshing functional take on deep learning, compatible with your favorite libraries | <a href="https://explosion.ai"><img src="https://explosion.ai/assets/img/logo.svg" width="125" height="125" align="right" /></a>
# Thinc: A refreshing functional take on deep learning, compatible with your favorite libraries
### From the makers of [spaCy](https://spacy.io) and [Prodigy](https://prodi.gy)
[Thinc](https://thinc.ai) is a **lightweight deep learning library** that offers an elegant,
type-checked, functional-programming API for **composing models**, with support
for layers defined in other frameworks such as **PyTorch, TensorFlow and MXNet**. You
can use Thinc as an interface layer, a standalone toolkit or a flexible way to
develop new models. Previous versions of Thinc have been running quietly in
production in thousands of companies, via both [spaCy](https://spacy.io) and
[Prodigy](https://prodi.gy). We wrote the new version to let users **compose,
configure and deploy custom models** built with their favorite framework.
[](https://dev.azure.com/explosion-ai/public/_build?definitionId=7)
[](https://github.com/explosion/thinc/releases)
[](https://pypi.python.org/pypi/thinc)
[](https://anaconda.org/conda-forge/thinc)
[](https://github.com/explosion/wheelwright/releases)
[](https://github.com/ambv/black)
[![Open demo in Colab][colab]][intro_to_thinc_colab]
## 🔥 Features
- **Type-check** your model definitions with custom types and [`mypy`](https://mypy.readthedocs.io/en/latest/) plugin.
- Wrap **PyTorch**, **TensorFlow** and **MXNet** models for use in your network.
- Concise **functional-programming** approach to model definition, using composition rather than inheritance.
- Optional custom infix notation via **operator overloading**.
- Integrated **config system** to describe trees of objects and hyperparameters.
- Choice of **extensible backends**.
- **[Read more →](https://thinc.ai/docs)**
## 🚀 Quickstart
Thinc is compatible with **Python 3.6+** and runs on **Linux**,
**macOS** and **Windows**. The latest releases with binary wheels are available from
[pip](https://pypi.python.org/pypi/thinc). Before you install Thinc and its
dependencies, make sure that your `pip`, `setuptools` and `wheel` are up to
date. For the most recent releases, pip 19.3 or newer is recommended.
```bash
pip install -U pip setuptools wheel
pip install thinc
```
See the [extended installation docs](https://thinc.ai/docs/install#extended) for details on optional dependencies for different backends and GPU. You might also want to [set up static type checking](https://thinc.ai/docs/install#type-checking) to take advantage of Thinc's type system.
> ⚠️ If you have installed PyTorch and you are using Python 3.7+, uninstall the
> package `dataclasses` with `pip uninstall dataclasses`, since it may have
> been installed by PyTorch and is incompatible with Python 3.7+.
### 📓 Selected examples and notebooks
Also see the [`/examples`](examples) directory and [usage documentation](https://thinc.ai/docs) for more examples. Most examples are Jupyter notebooks – to launch them on [Google Colab](https://colab.research.google.com) (with GPU support!) click on the button next to the notebook name.
| Notebook | Description |
| --------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [`intro_to_thinc`][intro_to_thinc]<br />[![Open in Colab][colab]][intro_to_thinc_colab] | Everything you need to know to get started. Composing and training a model on the MNIST data, using config files, registering custom functions and wrapping PyTorch, TensorFlow and MXNet models. |
| [`transformers_tagger_bert`][transformers_tagger_bert]<br />[![Open in Colab][colab]][transformers_tagger_bert_colab] | How to use Thinc, `transformers` and PyTorch to train a part-of-speech tagger. From model definition and config to the training loop. |
| [`pos_tagger_basic_cnn`][pos_tagger_basic_cnn]<br />[![Open in Colab][colab]][pos_tagger_basic_cnn_colab] | Implementing and training a basic CNN for part-of-speech tagging model without external dependencies and using different levels of Thinc's config system. |
| [`parallel_training_ray`][parallel_training_ray]<br />[![Open in Colab][colab]][parallel_training_ray_colab] | How to set up synchronous and asynchronous parameter server training with Thinc and [Ray](https://ray.readthedocs.io/en/latest/). |
**[View more →](examples)**
[colab]: https://gistcdn.githack.com/ines/dcf354aa71a7665ae19871d7fd14a4e0/raw/461fc1f61a7bc5860f943cd4b6bcfabb8c8906e7/colab-badge.svg
[intro_to_thinc]: examples/00_intro_to_thinc.ipynb
[intro_to_thinc_colab]: https://colab.research.google.com/github/explosion/thinc/blob/master/examples/00_intro_to_thinc.ipynb
[transformers_tagger_bert]: examples/02_transformers_tagger_bert.ipynb
[transformers_tagger_bert_colab]: https://colab.research.google.com/github/explosion/thinc/blob/master/examples/02_transformers_tagger_bert.ipynb
[pos_tagger_basic_cnn]: examples/03_pos_tagger_basic_cnn.ipynb
[pos_tagger_basic_cnn_colab]: https://colab.research.google.com/github/explosion/thinc/blob/master/examples/03_pos_tagger_basic_cnn.ipynb
[parallel_training_ray]: examples/04_parallel_training_ray.ipynb
[parallel_training_ray_colab]: https://colab.research.google.com/github/explosion/thinc/blob/master/examples/04_parallel_training_ray.ipynb
### 📖 Documentation & usage guides
| Documentation | Description |
| --------------------------------------------------------------------------------- | ----------------------------------------------------- |
| [Introduction](https://thinc.ai/docs) | Everything you need to know. |
| [Concept & Design](https://thinc.ai/docs/concept) | Thinc's conceptual model and how it works. |
| [Defining and using models](https://thinc.ai/docs/usage-models) | How to compose models and update state. |
| [Configuration system](https://thinc.ai/docs/usage-config) | Thinc's config system and function registry. |
| [Integrating PyTorch, TensorFlow & MXNet](https://thinc.ai/docs/usage-frameworks) | Interoperability with machine learning frameworks |
| [Layers API](https://thinc.ai/docs/api-layers) | Weights layers, transforms, combinators and wrappers. |
| [Type Checking](https://thinc.ai/docs/usage-type-checking) | Type-check your model definitions and more. |
## 🗺 What's where
| Module | Description |
| ----------------------------------------- | --------------------------------------------------------------------------------- |
| [`thinc.api`](thinc/api.py) | **User-facing API.** All classes and functions should be imported from here. |
| [`thinc.types`](thinc/types.py) | Custom [types and dataclasses](https://thinc.ai/docs/api-types). |
| [`thinc.model`](thinc/model.py) | The `Model` class. All Thinc models are an instance (not a subclass) of `Model`. |
| [`thinc.layers`](thinc/layers) | The layers. Each layer is implemented in its own module. |
| [`thinc.shims`](thinc/shims) | Interface for external models implemented in PyTorch, TensorFlow etc. |
| [`thinc.loss`](thinc/loss.py) | Functions to calculate losses. |
| [`thinc.optimizers`](thinc/optimizers.py) | Functions to create optimizers. Currently supports "vanilla" SGD, Adam and RAdam. |
| [`thinc.schedules`](thinc/schedules.py) | Generators for different rates, schedules, decays or series. |
| [`thinc.backends`](thinc/backends) | Backends for `numpy` and `cupy`. |
| [`thinc.config`](thinc/config.py) | Config parsing and validation and function registry system. |
| [`thinc.util`](thinc/util.py) | Utilities and helper functions. |
## 🐍 Development notes
Thinc uses [`black`](https://github.com/psf/black) for auto-formatting, [`flake8`](http://flake8.pycqa.org/en/latest/) for linting and [`mypy`](https://mypy.readthedocs.io/en/latest/) for type checking. All code is written compatible with **Python 3.6+**, with type hints wherever possible. See the [type reference](https://thinc.ai/docs/api-types) for more details on Thinc's custom types.
### 👷♀️ Building Thinc from source
Building Thinc from source requires the full dependencies listed in
[`requirements.txt`](requirements.txt) to be installed. You'll also need a
compiler to build the C extensions.
```bash
git clone https://github.com/explosion/thinc
cd thinc
python -m venv .env
source .env/bin/activate
pip install -U pip setuptools wheel
pip install -r requirements.txt
pip install --no-build-isolation .
```
Alternatively, install in editable mode:
```bash
pip install -r requirements.txt
pip install --no-build-isolation --editable .
```
Or by setting `PYTHONPATH`:
```bash
export PYTHONPATH=`pwd`
pip install -r requirements.txt
python setup.py build_ext --inplace
```
### 🚦 Running tests
Thinc comes with an [extensive test suite](thinc/tests). The following should all pass and not report any warnings or errors:
```bash
python -m pytest thinc # test suite
python -m mypy thinc # type checks
python -m flake8 thinc # linting
```
To view test coverage, you can run `python -m pytest thinc --cov=thinc`. We aim for a 100% test coverage. This doesn't mean that we meticulously write tests for every single line – we ignore blocks that are not relevant or difficult to test and make sure that the tests execute all code paths.
|
3,439 | Natural Language Processing Best Practices & Examples | <img src="NLP-Logo.png" align="right" alt="" width="300"/>
# NLP Best Practices
In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive business adoption of artificial intelligence (AI) solutions. In the last few years, researchers have been applying newer deep learning methods to NLP. Data scientists started moving from traditional methods to state-of-the-art (SOTA) deep neural network (DNN) algorithms which use language models pretrained on large text corpora.
This repository contains examples and best practices for building NLP systems, provided as [Jupyter notebooks](examples) and [utility functions](utils_nlp). The focus of the repository is on state-of-the-art methods and common scenarios that are popular among researchers and practitioners working on problems involving text and language.
## Overview
The goal of this repository is to build a comprehensive set of tools and examples that leverage recent advances in NLP algorithms, neural architectures, and distributed machine learning systems.
The content is based on our past and potential future engagements with customers as well as collaboration with partners, researchers, and the open source community.
We hope that the tools can significantly reduce the “time to market” by simplifying the experience from defining the business problem to development of solution by orders of magnitude. In addition, the example notebooks would serve as guidelines and showcase best practices and usage of the tools in a wide variety of languages.
In an era of transfer learning, transformers, and deep architectures, we believe that pretrained models provide a unified solution to many real-world problems and allow handling different tasks and languages easily. We will, therefore, prioritize such models, as they achieve state-of-the-art results on several NLP benchmarks like [*GLUE*](https://gluebenchmark.com/leaderboard) and [*SQuAD*](https://rajpurkar.github.io/SQuAD-explorer/) leaderboards. The models can be used in a number of applications ranging from simple text classification to sophisticated intelligent chat bots.
Note that for certain kind of NLP problems, you may not need to build your own models. Instead, pre-built or easily customizable solutions exist which do not require any custom coding or machine learning expertise. We strongly recommend evaluating if these can sufficiently solve your problem. If these solutions are not applicable, or the accuracy of these solutions is not sufficient, then resorting to more complex and time-consuming custom approaches may be necessary. The following cognitive services offer simple solutions to address common NLP tasks:
<br><br><b>[Text Analytics](https://azure.microsoft.com/en-us/services/cognitive-services/text-analytics/) </b> are a set of pre-trained REST APIs which can be called for Sentiment Analysis, Key phrase extraction, Language detection and Named Entity Detection and more. These APIs work out of the box and require minimal expertise in machine learning, but have limited customization capabilities.
<br><br><b>[QnA Maker](https://azure.microsoft.com/en-us/services/cognitive-services/qna-maker/) </b>is a cloud-based API service that lets you create a conversational question-and-answer layer over your existing data. Use it to build a knowledge base by extracting questions and answers from your semi-structured content, including FAQs, manuals, and documents.
<br><br><b>[Language Understanding](https://azure.microsoft.com/en-us/services/cognitive-services/language-understanding-intelligent-service/)</b> is a SaaS service to train and deploy a model as a REST API given a user-provided training set. You could do Intent Classification as well as Named Entity Extraction by performing simple steps of providing example utterances and labelling them. It supports Active Learning, so your model always keeps learning and improving.
## Target Audience
For this repository our target audience includes data scientists and machine learning engineers with varying levels of NLP knowledge as our content is source-only and targets custom machine learning modelling. The utilities and examples provided are intended to be solution accelerators for real-world NLP problems.
## Focus Areas
The repository aims to expand NLP capabilities along three separate dimensions
### Scenarios
We aim to have end-to-end examples of common tasks and scenarios such as text classification, named entity recognition etc.
### Algorithms
We aim to support multiple models for each of the supported scenarios. Currently, transformer-based models are supported across most scenarios. We have been working on integrating the [transformers package](https://github.com/huggingface/transformers) from [Hugging Face](https://huggingface.co/) which allows users to easily load pretrained models and fine-tune them for different tasks.
### Languages
We strongly subscribe to the multi-language principles laid down by ["Emily Bender"](http://faculty.washington.edu/ebender/papers/Bender-SDSS-2019.pdf)
* "Natural language is not a synonym for English"
* "English isn't generic for language, despite what NLP papers might lead you to believe"
* "Always name the language you are working on" ([Bender rule](https://www.aclweb.org/anthology/Q18-1041/))
The repository aims to support non-English languages across all the scenarios. Pre-trained models used in the repository such as BERT, FastText support 100+ languages out of the box. Our goal is to provide end-to-end examples in as many languages as possible. We encourage community contributions in this area.
## Content
The following is a summary of the commonly used NLP scenarios covered in the repository. Each scenario is demonstrated in one or more [Jupyter notebook examples](examples) that make use of the core code base of models and repository utilities.
| Scenario | Models | Description|Languages|
|-------------------------| ------------------- |-------|---|
|Text Classification |BERT, DistillBERT, XLNet, RoBERTa, ALBERT, XLM| Text classification is a supervised learning method of learning and predicting the category or the class of a document given its text content. |English, Chinese, Hindi, Arabic, German, French, Japanese, Spanish, Dutch|
|Named Entity Recognition |BERT| Named entity recognition (NER) is the task of classifying words or key phrases of a text into predefined entities of interest. |English|
|Text Summarization|BERTSumExt <br> BERTSumAbs <br> UniLM (s2s-ft) <br> MiniLM |Text summarization is a language generation task of summarizing the input text into a shorter paragraph of text.|English
|Entailment |BERT, XLNet, RoBERTa| Textual entailment is the task of classifying the binary relation between two natural-language texts, *text* and *hypothesis*, to determine if the *text* agrees with the *hypothesis* or not. |English|
|Question Answering |BiDAF, BERT, XLNet| Question answering (QA) is the task of retrieving or generating a valid answer for a given query in natural language, provided with a passage related to the query. |English|
|Sentence Similarity |BERT, GenSen| Sentence similarity is the process of computing a similarity score given a pair of text documents. |English|
|Embeddings| Word2Vec<br>fastText<br>GloVe| Embedding is the process of converting a word or a piece of text to a continuous vector space of real number, usually, in low dimension.|English|
|Sentiment Analysis| Dependency Parser <br>GloVe| Provides an example of train and use Aspect Based Sentiment Analysis with Azure ML and [Intel NLP Architect](http://nlp_architect.nervanasys.com/absa.html) .|English|
## Getting Started
While solving NLP problems, it is always good to start with the prebuilt [Cognitive Services](https://azure.microsoft.com/en-us/services/cognitive-services/directory/lang/). When the needs are beyond the bounds of the prebuilt cognitive service and when you want to search for custom machine learning methods, you will find this repository very useful. To get started, navigate to the [Setup Guide](SETUP.md), which lists instructions on how to setup your environment and dependencies.
## Azure Machine Learning Service
[Azure Machine Learning service](https://azure.microsoft.com/en-us/services/machine-learning-service/) is a cloud service used to train, deploy, automate, and manage machine learning models, all at the broad scale that the cloud provides. AzureML is presented in notebooks across different scenarios to enhance the efficiency of developing Natural Language systems at scale and for various AI model development related tasks like:
* [**Accessing Datastores**](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-access-data) to easily read and write your data in Azure storage services such as blob storage or file share.
* Scaling up and out on [**Azure Machine Learning Compute**](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-set-up-training-targets#amlcompute).
* [**Automated Machine Learning**](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-configure-auto-train) which builds high quality machine learning models by automating model and hyperparameter selection. AutoML explores BERT, BiLSTM, bag-of-words, and word embeddings on the user's dataset to handle text columns.
* [**Tracking experiments and monitoring metrics**](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-track-experiments) to enhance the model creation process.
* [**Distributed Training**](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-train-ml-models#distributed-training-and-custom-docker-images)
* [**Hyperparameter tuning**](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-tune-hyperparameters)
* Deploying the trained machine learning model as a web service to [**Azure Container Instance**](https://azure.microsoft.com/en-us/services/container-instances/) for deveopment and test, or for low scale, CPU-based workloads.
* Deploying the trained machine learning model as a web service to [**Azure Kubernetes Service**](https://azure.microsoft.com/en-us/services/kubernetes-service/) for high-scale production deployments and provides autoscaling, and fast response times.
To successfully run these notebooks, you will need an [**Azure subscription**](https://azure.microsoft.com/en-us/) or can [**try Azure for free**](https://azure.microsoft.com/en-us/free/). There may be other Azure services or products used in the notebooks. Introduction and/or reference of those will be provided in the notebooks themselves.
## Contributing
We hope that the open source community would contribute to the content and bring in the latest SOTA algorithm. This project welcomes contributions and suggestions. Before contributing, please see our [contribution guidelines](CONTRIBUTING.md).
## Blog Posts
- [Bootstrap Your Text Summarization Solution with the Latest Release from NLP-Recipes](https://techcommunity.microsoft.com/t5/ai-customer-engineering-team/bootstrap-your-text-summarization-solution-with-the-latest/ba-p/1268809)
- [Text Annotation made easy with Doccano](https://techcommunity.microsoft.com/t5/ai-customer-engineering-team/text-annotation-made-easy-with-doccano/ba-p/1242612)
- [Jumpstart Analyzing your Hindi Text Data using the NLP Repository](https://techcommunity.microsoft.com/t5/ai-customer-engineering-team/jumpstart-analyzing-your-hindi-text-data-using-the-nlp/ba-p/1087851)
- [Speeding up the Development of Natural Language Processing Solutions with Azure Machine Learning](https://techcommunity.microsoft.com/t5/ai-customer-engineering-team/speeding-up-the-development-of-natural-language-processing/ba-p/1042577)
## References
The following is a list of related repositories that we like and think are useful for NLP tasks.
|Repository|Description|
|---|---|
|[Transformers](https://github.com/huggingface/transformers)|A great PyTorch library from Hugging Face with implementations of popular transformer-based models. We've been using their package extensively in this repo and greatly appreciate their effort.|
|[Azure Machine Learning Notebooks](https://github.com/Azure/MachineLearningNotebooks/)|ML and deep learning examples with Azure Machine Learning.|
|[AzureML-BERT](https://github.com/Microsoft/AzureML-BERT)|End-to-end recipes for pre-training and fine-tuning BERT using Azure Machine Learning service.|
|[MASS](https://github.com/microsoft/MASS)|MASS: Masked Sequence to Sequence Pre-training for Language Generation.|
|[MT-DNN](https://github.com/microsoft/mt-dnn)|Multi-Task Deep Neural Networks for Natural Language Understanding.|
|[UniLM](https://github.com/microsoft/unilm)|Unified Language Model Pre-training.|
|[DialoGPT](https://github.com/microsoft/DialoGPT)|DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation|
## Build Status
| Build | Branch | Status |
| --- | --- | --- |
| **Linux CPU** | master | [](https://dev.azure.com/best-practices/nlp/_build/latest?definitionId=50&branchName=master) |
| **Linux CPU** | staging | [](https://dev.azure.com/best-practices/nlp/_build/latest?definitionId=50&branchName=staging) |
| **Linux GPU** | master | [](https://dev.azure.com/best-practices/nlp/_build/latest?definitionId=51&branchName=master) |
| **Linux GPU** | staging | [](https://dev.azure.com/best-practices/nlp/_build/latest?definitionId=51&branchName=staging) |
|
3,440 | A Unified Semi-Supervised Learning Codebase (NeurIPS'22) | <div id="top"></div>
<!--
*** Thanks for checking out the Best-README-Template. If you have a suggestion
*** that would make this better, please fork the repo and create a pull request
*** or simply open an issue with the tag "enhancement".
*** Don't forget to give the project a star!
*** Thanks again! Now go create something AMAZING! :D
-->
<!-- PROJECT SHIELDS -->
<!--
*** I'm using markdown "reference style" links for readability.
*** Reference links are enclosed in brackets [ ] instead of parentheses ( ).
*** See the bottom of this document for the declaration of the reference variables
*** for contributors-url, forks-url, etc. This is an optional, concise syntax you may use.
*** https://www.markdownguide.org/basic-syntax/#reference-style-links
-->
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]
<!--
***[![MIT License][license-shield]][license-url]
-->
<!-- PROJECT LOGO -->
<br />
<div align="center">
<a href="https://github.com/microsoft/Semi-supervised-learning">
<img src="figures/logo.png" alt="Logo" width="400">
</a>
<!-- <h3 align="center">USB</h3> -->
<p align="center">
<strong>USB</strong>: A Unified Semi-supervised learning Benchmark for CV, NLP, and Audio Classification
<!-- <br />
<a href="https://github.com/microsoft/Semi-supervised-learning"><strong>Explore the docs »</strong></a>
<br /> -->
<br />
<a href="https://arxiv.org/abs/2208.07204">Paper</a>
·
<a href="https://github.com/microsoft/Semi-supervised-learning/tree/main/results">Benchmark</a>
·
<a href="https://colab.research.google.com/drive/1lFygK31jWyTH88ktao6Ow-5nny5-B7v5">Demo</a>
·
<a href="https://usb.readthedocs.io/en/main/">Docs</a>
·
<a href="https://github.com/microsoft/Semi-supervised-learning/issues">Issue</a>
·
<a href="https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/pushing-the-limit-of-semi-supervised-learning-with-the-unified-semi-supervised-learning-benchmark/">Blog</a>
·
<a href="https://zhuanlan.zhihu.com/p/566055279">Blog (Chinese)</a>
·
<a href="https://nips.cc/virtual/2022/poster/55710">Video</a>
·
<a href="https://www.bilibili.com/video/av474982872/">Video (Chinese)</a>
</p>
</div>
<!-- TABLE OF CONTENTS -->
<details>
<summary>Table of Contents</summary>
<ol>
<li><a href="#news-and-updates">News and Updates</a></li>
<li><a href="#intro">Introduction</a></li>
<li>
<a href="#getting-started">Getting Started</a>
<ul>
<li><a href="#prerequisites">Prerequisites</a></li>
<li><a href="#installation">Installation</a></li>
</ul>
</li>
<li><a href="#usage">Usage</a></li>
<li><a href="#benchmark-results">Benchmark Results</a></li>
<li><a href="#model-zoo">Model Zoo</a></li>
<li><a href="#contributing">Community</a></li>
<li><a href="#license">License</a></li>
<li><a href="#acknowledgments">Acknowledgments</a></li>
</ol>
</details>
<!-- News and Updates -->
## News and Updates
- [01/30/2023] Update semilearn==0.3.0. Add [FreeMatch](https://arxiv.org/abs/2205.07246) and [SoftMatch](https://arxiv.org/abs/2301.10921). Add imbalanced algorithms. Update results and add wandb support. Refer [CHANGE_LOG](CHANGE_LOG.md) for details. [[Results]](https://github.com/microsoft/Semi-supervised-learning/tree/main/results)[[Logs]](https://drive.google.com/drive/folders/1bRSqrRyyuDafgOI3VAuqqiuzHG6CexHF?usp=sharing)[[Wandb]](https://wandb.ai/usb). Older classic logs can be found here: [[TorchSSL Log]](https://1drv.ms/u/s!AlpW9hcyb0KvmyCfsCjGvhDXG5Nb?e=Xc6amH).
- [10/16/2022] Dataset download link and process instructions released! [[Datasets](https://github.com/microsoft/Semi-supervised-learning/tree/main/preprocess)]
- [10/13/2022] We have finished the camera ready version with updated [[Results](https://github.com/microsoft/Semi-supervised-learning/tree/main/results)]. [[Openreview](https://openreview.net/forum?id=QeuwINa96C)]
- [10/06/2022] Training logs and results of USB has been updated! Available dataset will be uploaded soon. [[Logs](https://drive.google.com/drive/folders/1fg3Fxem_UNWhfN5-4x2lRI3mluGxqD4N?usp=sharing)] [[Results](https://github.com/microsoft/Semi-supervised-learning/tree/main/results)]
- [09/17/2022] The USB paper has been accepted by NeurIPS 2022 Dataset and Benchmark Track! [[Openreview](https://openreview.net/forum?id=QeuwINa96C)]
- [08/21/2022] USB has been released!
<!-- Introduction -->
## Introduction
**USB** is a Pytorch-based Python package for Semi-Supervised Learning (SSL). It is easy-to-use/extend, *affordable* to small groups, and comprehensive for developing and evaluating SSL algorithms. USB provides the implementation of 14 SSL algorithms based on Consistency Regularization, and 15 tasks for evaluation from CV, NLP, and Audio domain.

<p align="right">(<a href="#top">back to top</a>)</p>
<!-- GETTING STARTED -->
## Getting Started
This is an example of how to set up USB locally.
To get a local copy up, running follow these simple example steps.
### Prerequisites
USB is built on pytorch, with torchvision, torchaudio, and transformers.
To install the required packages, you can create a conda environment:
```sh
conda create --name usb python=3.8
```
then use pip to install required packages:
```sh
pip install -r requirements.txt
```
### Installation
We provide a Python package *semilearn* of USB for users who want to start training/testing the supported SSL algorithms on their data quickly:
```sh
pip install semilearn
```
<p align="right">(<a href="#top">back to top</a>)</p>
### Development
You can also develop your own SSL algorithm and evaluate it by cloning USB:
```sh
git clone https://github.com/microsoft/Semi-supervised-learning.git
```
<p align="right">(<a href="#top">back to top</a>)</p>
### Prepare Datasets
The detailed instructions for downloading and processing are shown in [Dataset Download](./preprocess/). Please follow it to download datasets before running or developing algorithms.
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- USAGE EXAMPLES -->
## Usage
USB is easy to use and extend. Going through the belowing examples will help you faimiliar with USB for quick use, evaluate an exsiting SSL algorithm on your own dataset, or developing new SSL algorithms.
### Quick Start with USB package
<!-- TODO: add quick start example and refer lighting notebook -->
Please see [Installation](#installation) to install USB first. We provide colab tutorials for:
- [Beginning example](https://colab.research.google.com/drive/1lFygK31jWyTH88ktao6Ow-5nny5-B7v5)
- [Customize datasets](https://colab.research.google.com/drive/1zbswPm1sM8j0fndUQOeqX2HADdYq-wOw)
### Start with Docker
**Step1: Check your environment**
You need to properly install Docker and nvidia driver first. To use GPU in a docker container
You also need to install nvidia-docker2 ([Installation Guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker)).
Then, Please check your CUDA version via `nvidia-smi`
**Step2: Clone the project**
```shell
git clone https://github.com/microsoft/Semi-supervised-learning.git
```
**Step3: Build the Docker image**
Before building the image, you may modify the [Dockerfile](Dockerfile) according to your CUDA version.
The CUDA version we use is 11.6. You can change the base image tag according to [this site](https://hub.docker.com/r/nvidia/cuda/tags).
You also need to change the `--extra-index-url` according to your CUDA version in order to install the correct version of Pytorch.
You can check the url through [Pytorch website](https://pytorch.org).
Use this command to build the image
```shell
cd Semi-supervised-learning && docker build -t semilearn .
```
Job done. You can use the image you just built for your own project. Don't forget to use the argument `--gpu` when you want
to use GPU in a container.
### Training
Here is an example to train FixMatch on CIFAR-100 with 200 labels. Trianing other supported algorithms (on other datasets with different label settings) can be specified by a config file:
```sh
python train.py --c config/usb_cv/fixmatch/fixmatch_cifar100_200_0.yaml
```
### Evaluation
After trianing, you can check the evaluation performance on training logs, or running evaluation script:
```
python eval.py --dataset cifar100 --num_classes 100 --load_path /PATH/TO/CHECKPOINT
```
### Develop
Check the developing documentation for creating your own SSL algorithm!
_For more examples, please refer to the [Documentation](https://example.com)_
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- BENCHMARK RESULTS -->
## Benchmark Results
Please refer to [Results](./results) for benchmark results on different tasks.
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- MODEL ZOO -->
## Model Zoo
TODO: add pre-trained models.
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- ROADMAP -->
## TODO
- [ ] Finish Readme
- [ ] Updating SUPPORT.MD with content about this project's support experience
- [ ] Multi-language Support
- [ ] Chinese
See the [open issues](https://github.com/microsoft/Semi-supervised-learning/issues) for a full list of proposed features (and known issues).
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- CONTRIBUTING -->
## Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a
Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide
a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
contact [[email protected]](mailto:[email protected]) with any additional questions or comments.
If you have a suggestion that would make USB better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
Don't forget to give the project a star! Thanks again!
1. Fork the project
2. Create your branch (`git checkout -b your_name/your_branch`)
3. Commit your changes (`git commit -m 'Add some features'`)
4. Push to the branch (`git push origin your_name/your_branch`)
5. Open a Pull Request
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- TRADEMARKS -->
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft
trademarks or logos is subject to and must follow
[Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general).
Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship.
Any use of third-party trademarks or logos are subject to those third-party's policies.
<!-- LICENSE -->
## License
Distributed under the MIT License. See `LICENSE.txt` for more information.
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- CONTACT -->
## Community and Contact
The USB comunity is maintained by:
- Yidong Wang ([email protected]), Tokyo Institute of Technology
- Hao Chen ([email protected]), Carnegie Mellon University
- Yue Fan ([email protected]), Max Planck Institute for Informatics
- Wenxin Hou ([email protected]), Microsoft STCA
- Ran Tao ([email protected]), Carnegie Mellon University
- Jindong Wang ([email protected]), Microsoft Research Asia
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- CITE -->
## Citing USB
Please cite us if you fine this project helpful for your project/paper:
```
@inproceedings{usb2022,
doi = {10.48550/ARXIV.2208.07204},
url = {https://arxiv.org/abs/2208.07204},
author = {Wang, Yidong and Chen, Hao and Fan, Yue and Sun, Wang and Tao, Ran and Hou, Wenxin and Wang, Renjie and Yang, Linyi and Zhou, Zhi and Guo, Lan-Zhe and Qi, Heli and Wu, Zhen and Li, Yu-Feng and Nakamura, Satoshi and Ye, Wei and Savvides, Marios and Raj, Bhiksha and Shinozaki, Takahiro and Schiele, Bernt and Wang, Jindong and Xie, Xing and Zhang, Yue},
title = {USB: A Unified Semi-supervised Learning Benchmark for Classification},
booktitle = {Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track}
year = {2022}
}
@article{wang2023freematch},
title={FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning},
author={Wang, Yidong and Chen, Hao and Heng, Qiang and Hou, Wenxin and Fan, Yue and and Wu, Zhen and Wang, Jindong and Savvides, Marios and Shinozaki, Takahiro and Raj, Bhiksha and Schiele, Bernt and Xie, Xing},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}
@article{chen2023softmatch},
title={SoftMatch: Addressing the Quantity-Quality Trade-off in Semi-supervised Learning},
author={Chen, Hao and Tao, Ran and Fan, Yue and Wang, Yidong and Wang, Jindong and Schiele, Bernt and Xie, Xing and Raj, Bhiksha and Savvides, Marios},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}
@article{zhang2021flexmatch},
title={FlexMatch: Boosting Semi-supervised Learning with Curriculum Pseudo Labeling},
author={Zhang, Bowen and Wang, Yidong and Hou, Wenxin and Wu, Hao and Wang, Jindong and Okumura, Manabu and Shinozaki, Takahiro},
booktitle={Neural Information Processing Systems (NeurIPS)},
year={2021}
}
```
<!-- ACKNOWLEDGMENTS -->
## Acknowledgments
We thanks the following projects for reference of creating USB:
- [TorchSSL](https://github.com/TorchSSL/TorchSSL)
- [FixMatch](https://github.com/google-research/fixmatch)
- [CoMatch](https://github.com/salesforce/CoMatch)
- [SimMatch](https://github.com/KyleZheng1997/simmatch)
- [HuggingFace](https://huggingface.co/docs/transformers/index)
- [Pytorch Lighting](https://github.com/Lightning-AI/lightning)
- [README Template](https://github.com/othneildrew/Best-README-Template)
<p align="right">(<a href="#top">back to top</a>)</p>
<!-- MARKDOWN LINKS & IMAGES -->
<!-- https://www.markdownguide.org/basic-syntax/#reference-style-links -->
[contributors-shield]: https://img.shields.io/github/contributors/microsoft/Semi-supervised-learning.svg?style=for-the-badge
[contributors-url]: https://github.com/microsoft/Semi-supervised-learning/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/microsoft/Semi-supervised-learning.svg?style=for-the-badge
[forks-url]: https://github.com/microsoft/Semi-supervised-learning/network/members
[stars-shield]: https://img.shields.io/github/stars/microsoft/Semi-supervised-learning.svg?style=for-the-badge
[stars-url]: https://github.com/microsoft/Semi-supervised-learning/stargazers
[issues-shield]: https://img.shields.io/github/issues/microsoft/Semi-supervised-learning.svg?style=for-the-badge
[issues-url]: https://github.com/microsoft/Semi-supervised-learning/issues
[license-shield]: https://img.shields.io/github/license/microsoft/Semi-supervised-learning.svg?style=for-the-badge
[license-url]: https://github.com/microsoft/Semi-supervised-learning/blob/main/LICENSE.txt
|
3,441 | 👩🏫 Advanced NLP with spaCy: A free online course | # Advanced NLP with spaCy: A free online course
This repo contains both an [**online course**](https://course.spacy.io), as well
as its modern open-source web framework. In the course, you'll learn how to use
[spaCy](https://spacy.io) to build advanced natural language understanding
systems, using both rule-based and machine learning approaches. The front-end is
powered by [Gatsby](http://gatsbyjs.org/), [Reveal.js](https://revealjs.com) and
[Plyr](https://github.com/sampotts/plyr), and the back-end code execution uses
[Binder](https://mybinder.org) 💖 It's all open-source and published under the
MIT license (code and framework) and CC BY-NC (spaCy course materials).
_This course is mostly intended for **self-study**. Yes, you can cheat – the
solutions are all in this repo, there's no penalty for clicking "Show hints" or
"Show solution", and you can mark an exercise as done when you think it's done._
[](https://dev.azure.com/explosion-ai/public/_build?definitionId=10)

[](https://mybinder.org/v2/gh/explosion/spacy-course/master)
## 💬 Languages and Translations
| Language | Text Examples<sup>1</sup> | Source | Authors |
| -------------------------------------------- | ------------------------- | ------------------------------------------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **[English](https://course.spacy.io/en)** | English | [`chapters/en`](chapters/en), [`exercises/en`](exercises/en) | [@ines](https://github.com/ines) |
| **[German](https://course.spacy.io/de)** | German | [`chapters/de`](chapters/de), [`exercises/de`](exercises/de) | [@ines](https://github.com/ines), [@Jette16](https://github.com/Jette16) |
| **[Spanish](https://course.spacy.io/es)** | Spanish | [`chapters/es`](chapters/es), [`exercises/es`](exercises/es) | [@mariacamilagl](https://github.com/mariacamilagl), [@damian-romero](https://github.com/damian-romero) |
| **[French](https://course.spacy.io/fr)** | French | [`chapters/fr`](chapters/fr), [`exercises/fr`](exercises/fr) | [@datakime](https://github.com/datakime) |
| **[Japanese](https://course.spacy.io/ja)** | Japanese | [`chapters/ja`](chapters/ja), [`exercises/ja`](exercises/ja) | [@tamuhey](https://github.com/tamuhey), [@hiroshi-matsuda-rit](https://github.com/hiroshi-matsuda-rit), [@icoxfog417](https://github.com/icoxfog417), [@akirakubo](https://github.com/akirakubo), [@forest1988](https://github.com/forest1988), [@ao9mame](https://github.com/ao9mame), [@matsurih](https://github.com/matsurih), [@HiromuHota](https://github.com/HiromuHota), [@mei28](https://github.com/mei28), [@polm](https://github.com/polm) |
| **[Chinese](https://course.spacy.io/zh)** | Chinese | [`chapters/zh`](chapters/zh), [`exercises/zh`](exercises/zh) | [@crownpku](https://github.com/crownpku) |
| **[Portuguese](https://course.spacy.io/pt)** | English | [`chapters/pt`](chapters/pt), [`exercises/pt`](exercises/pt) | [@Cristianasp](https://github.com/Cristianasp) |
If you spot a mistake, I always appreciate
[pull requests](https://github.com/explosion/spacy-course/pulls)!
**1.** This is the language used for the text examples and resources used in the
exercises. For example, the German version of the course also uses German text
examples and models. It's not always possible to translate all code examples, so
some translations may still use and analyze English text as part of the course.
### Related resources
- 📚 **Prefer notebooks?** Check out
[the Jupyter notebook version](https://github.com/cristianasp/spacy) of this
course, put together by [@cristianasp](https://github.com/cristianasp).
## 💁 FAQ
#### Is this related to the spaCy course on DataCamp?
I originally developed the content for DataCamp, but I wanted to make a free
version to make it available to more people, and so you don't have to sign up
for their service. As a weekend project, I ended up putting together my own
little app to present the exercises and content in a fun and interactive way.
#### Can I use this to build my own course?
Probably, yes! If you've been looking for a DIY way to publish your materials, I
hope that my little framework can be useful. Because so many people expressed
interest in this, I put together some starter repos that you can fork and adapt:
- 🐍 Python:
[`ines/course-starter-python`](https://github.com/ines/course-starter-python)
- 🇷 R: [`ines/course-starter-r`](https://github.com/ines/course-starter-r)
#### Why the different licenses?
The source of the app, UI components and Gatsby framework for building
interactive courses is licensed as MIT, like pretty much all of my open-source
software. The course materials themselves (slides and chapters), are licensed
under CC BY-NC. This means that you can use them freely – you just can't make
money off them.
#### I want to help translate this course into my language. How can I contribute?
First, thanks so much, this is really cool and valuable to the community 🙌 I've
tried to set up the course structure so it's easy to add different languages:
language-specific files are organized into directories in
[`exercises`](exercises) and [`chapters`](chapters), and other language specific
texts are available in [`locale.json`](locale.json). If you want to contribute,
there are two different ways to get involved:
1. Start a community translation project. This is the easiest,
no-strings-attached way. You can fork the repo, copy-paste the English
version, change the
[language code](https://www.loc.gov/standards/iso639-2/php/code_list.php),
start translating and invite others to contribute (if you like). If you're
looking for contributors, feel free to open an issue here or tag
[@spacy_io](https://twitter.com/spacy_io) on Twitter so we can help get the
word out. We're also happy to answer your questions on the issue tracker.
2. Make us an offer. We're open to commissioning translations for different
languages, so if you're interested, email us at
[[email protected]](mailto:[email protected]) and include your offer,
estimated time schedule and a bit about you and your background (and any
technical writing or translation work you've done in the past, if available).
It doesn't matter where you're based, but you should be able to issue
invoices as a freelancer or similar, depending on your country.
#### I want to help create an audio/video tutorial for an existing translation. How can I get involved?
Again, thanks, this is super cool! While the
[English](https://www.youtube.com/watch?v=THduWAnG97k) and
[German](https://www.youtube.com/watch?v=K1elwpgDdls) videos also include a
video recording, it's not a requirement and we'd be happy to just provide an
audio track alongside the slides. We'd take care of the postprocessing and video
editing, so all we need is the audio recording. If you feel comfortable
recording yourself reading out the slide notes in your language, email us at
[[email protected]](mailto:[email protected]) and make us an offer and
include a bit about you and similar work you've done in the past, if available.
## 🎛 Usage & API
### Running the app
To start the local development server, install [Gatsby](https://gatsbyjs.org)
and then all other dependencies, then use `npm run dev` to start the development
server. Make sure you have at least Node 10.15 installed.
```bash
npm install -g gatsby-cli # Install Gatsby globally
npm install # Install dependencies
npm run dev # Run the development server
```
If running with docker just run `make build` and then `make gatsby-dev`
### How it works
When building the site, Gatsby will look for `.py` files and make their contents
available to query via GraphQL. This lets us use the raw code within the app.
Under the hood, the app uses [Binder](https://mybinder.org) to serve up an image
with the package dependencies, including the spaCy models. By calling into
[JupyterLab](https://jupyterlab.readthedocs.io/en/stable/), we can then execute
code using the active kernel. This lets you edit the code in the browser and see
the live results. Also see my [`juniper`](https://github.com/ines/juniper) repo
for more details on the implementation.
To validate the code when the user hits "Submit", I'm currently using a slightly
hacky trick. Since the Python code is sent back to the kernel as a string, we
can manipulate it and add tests – for example, exercise `exc_01_02_01.py` will
be validated using `test_01_02_01.py` (if available). The user code and test are
combined using a string template. At the moment, the `testTemplate` in the
`meta.json` looks like this:
```
from wasabi import msg
__msg__ = msg
__solution__ = """${solution}"""
${solution}
${test}
try:
test()
except AssertionError as e:
__msg__.fail(e)
```
If present, `${solution}` will be replaced with the string value of the
submitted user code. In this case, we're inserting it twice: once as a string so
we can check whether the submission includes something, and once as the code, so
we can actually run it and check the objects it creates. `${test}` is replaced
by the contents of the test file. I'm also making
[`wasabi`](https://github.com/ines/wasabi)'s printer available as `__msg__`, so
we can easily print pretty messages in the tests. Finally, the `try`/`accept`
block checks if the test function raises an `AssertionError` and if so, displays
the error message. This also hides the full error traceback (which can easily
leak the correct answers).
A test file could then look like this:
```python
def test():
assert "spacy.load" in __solution__, "Are you calling spacy.load?"
assert nlp.meta["lang"] == "en", "Are you loading the correct model?"
assert nlp.meta["name"] == "core_web_sm", "Are you loading the correct model?"
assert "nlp(text)" in __solution__, "Are you processing the text correctly?"
assert "print(doc.text)" in __solution__, "Are you printing the Doc's text?"
__msg__.good(
"Well done! Now that you've practiced loading models, let's look at "
"some of their predictions."
)
```
With this approach, it's not _always_ possible to validate the input perfectly –
there are too many options and we want to avoid false positives.
#### Running automated tests
The automated tests make sure that the provided solution code is compatible with
the test file that's used to validate submissions. The test suite is powered by
the [`pytest`](https://docs.pytest.org/en/latest/) framework and runnable test
files are generated automatically in a directory `__tests__` before the test
session starts. See the [`conftest.py`](conftest.py) for implementation details.
```bash
# Install requirements
pip install -r binder/requirements.txt
# Run the tests (will generate the files automatically)
python -m pytest __tests__
```
If running with docker just run `make build` and then `make pytest`
### Directory Structure
```yaml
├── binder
| └── requirements.txt # Python dependency requirements for Binder
├── chapters # chapters, grouped by language
| ├── en # English chapters, one Markdown file per language
| | └── slides # English slides, one Markdown file per presentation
| └── ... # other languages
├── exercises # code files, tests and assets for exercises
| ├── en # English exercises, solutions, tests and data
| └── ... # other languages
├── public # compiled site
├── src # Gatsby/React source, independent from content
├── static # static assets like images, available in slides/chapters
├── locale.json # translations of meta and UI text
├── meta.json # course metadata
└── theme.sass # UI theme colors and settings
```
### Setting up Binder
The [`requirements.txt`](binder/requirements.txt) in the repository defines the
packages that are installed when building it with Binder. For this course, I'm
using the source repo as the Binder repo, as it allows to keep everything in one
place. It also lets the exercises reference and load other files (e.g. JSON),
which will be copied over into the Python environment. I build the binder from a
branch `binder`, though, which I only update if Binder-relevant files change.
Otherwise, every update to `master` would trigger an image rebuild.
You can specify the binder settings like repo, branch and kernel type in the
`"juniper"` section of the `meta.json`. I'd recommend running the very first
build via the interface on the [Binder website](https://mybinder.org), as this
gives you a detailed build log and feedback on whether everything worked as
expected. Enter your repository URL, click "launch" and wait for it to install
the dependencies and build the image.
### File formats
#### Chapters
Chapters are placed in [`/chapters`](/chapters) and are Markdown files
consisting of `<exercise>` components. They'll be turned into pages, e.g.
`/chapter1`. In their frontmatter block at the top of the file, they need to
specify `type: chapter`, as well as the following meta:
```yaml
---
title: The chapter title
description: The chapter description
prev: /chapter1 # exact path to previous chapter or null to not show a link
next: /chapter3 # exact path to next chapter or null to not show a link
id: 2 # unique identifier for chapter
type: chapter # important: this creates a standalone page from the chapter
---
```
#### Slides
Slides are placed in [`/slides`](/slides) and are markdown files consisting of
slide content, separated by `---`. They need to specify the following
frontmatter block at the top of the file:
```yaml
---
type: slides
---
```
The **first and last slide** use a special layout and will display the headline
in the center of the slide. **Speaker notes** (in this case, the script) can be
added at the end of a slide, prefixed by `Notes:`. They'll then be shown on the
right next to the slides. Here's an example slides file:
```markdown
---
type: slide
---
# Processing pipelines
Notes: This is a slide deck about processing pipelines.
---
# Next slide
- Some bullet points here
- And another bullet point
<img src="/image.jpg" alt="An image located in /static" />
```
### Custom Elements
When using custom elements, make sure to place a newline between the
opening/closing tags and the children. Otherwise, Markdown content may not
render correctly.
#### `<exercise>`
Container of a single exercise.
| Argument | Type | Description |
| ------------ | --------------- | -------------------------------------------------------------- |
| `id` | number / string | Unique exercise ID within chapter. |
| `title` | string | Exercise title. |
| `type` | string | Optional type. `"slides"` makes container wider and adds icon. |
| **children** | - | The contents of the exercise. |
```markdown
<exercise id="1" title="Introduction to spaCy">
Content goes here...
</exercise>
```
#### `<codeblock>`
| Argument | Type | Description |
| ------------ | --------------- | -------------------------------------------------------------------------------------------- |
| `id` | number / string | Unique identifier of the code exercise. |
| `source` | string | Name of the source file (without file extension). Defaults to `exc_${id}` if not set. |
| `solution` | string | Name of the solution file (without file extension). Defaults to `solution_${id}` if not set. |
| `test` | string | Name of the test file (without file extension). Defaults to `test_${id}` if not set. |
| **children** | string | Optional hints displayed when the user clicks "Show hints". |
```markdown
<codeblock id="02_03">
This is a hint!
</codeblock>
```
#### `<slides>`
Container to display slides interactively using Reveal.js and a Markdown file.
| Argument | Type | Description |
| -------- | ------ | --------------------------------------------- |
| `source` | string | Name of slides file (without file extension). |
```markdown
<slides source="chapter1_01_introduction-to-spacy">
</slides>
```
#### `<choice>`
Container for multiple-choice question.
| Argument | Type | Description |
| ------------ | --------------- | -------------------------------------------------------------------------------------------- |
| `id` | string / number | Optional unique ID. Can be used if more than one choice question is present in one exercise. |
| **children** | nodes | Only `<opt>` components for the options. |
```markdown
<choice>
<opt text="Option one">You have selected option one! This is not good.</opt>
<opt text="Option two" correct="true">Yay! </opt>
</choice>
```
#### `<opt>`
A multiple-choice option.
| Argument | Type | Description |
| ------------ | ------ | ---------------------------------------------------------------------------------------------- |
| `text` | string | The option text to be displayed. Supports inline HTML. |
| `correct` | string | `"true"` if the option is the correct answer. |
| **children** | string | The text to be displayed if the option is selected (explaining why it's correct or incorrect). |
|
3,442 | An Open-Source Framework for Prompt-Learning. |
<div align="center">
<img src="https://z3.ax1x.com/2021/11/11/IwED0K.png" width="350px">
**An Open-Source Framework for Prompt-learning.**
------
<p align="center">
<a href="#Overview">Overview</a> •
<a href="#installation">Installation</a> •
<a href="#use-openprompt">How To Use</a> •
<a href="https://thunlp.github.io/OpenPrompt/">Docs</a> •
<a href="https://arxiv.org/abs/2111.01998">Paper</a> •
<a href="#citation">Citation</a> •
<a href="https://github.com/thunlp/OpenPrompt/tree/main/results/">Performance</a> •
</p>
</div>

## What's New?
- Aug 2022: Thanks to contributor [zhiyongLiu1114](https://github.com/zhiyongLiu1114), OpenPrompt now supports [ERNIE 1.0](https://github.com/thunlp/OpenPrompt/tree/main/tutorial/7_ernie_paddlepaddle) in PaddlePaddle.
- July 2022: OpenPrompt supports OPT now.
- June 2022: OpenPrompt wins ACL 2022 Best Demo Paper Award.
- Mar 2022: We add a [tutorial](https://github.com/thunlp/OpenPrompt/blob/main/tutorial/6.1_chinese_dataset_uer_t5.py) as the response to [issue 124](https://github.com/thunlp/OpenPrompt/issues/124), which uses a customized tokenizer_wrapper to perform tasks that are not in the default configuration of OpenPrompt (e.g., Bert tokenizer+T5 model).
- Feb 2022: Check out our sister repo [OpenDelta](https://github.com/thunlp/OpenDelta)!
- Dec 2021: `pip install openprompt`
- Dec 2021: [SuperGLUE performance](https://github.com/thunlp/OpenPrompt/tree/main/results) are added
- Dec 2021: We support **generation paradigm for all tasks** by adding a new verbalizer:[GenerationVerbalizer](https://github.com/thunlp/OpenPrompt/blob/main/openprompt/prompts/generation_verbalizer.py) and a [tutorial: 4.1_all_tasks_are_generation.py](https://github.com/thunlp/OpenPrompt/blob/main/tutorial/4.1_all_tasks_are_generation.py)
- Nov 2021: Now we have released a paper [OpenPrompt: An Open-source Framework for Prompt-learning](https://arxiv.org/abs/2111.01998).
- Nov 2021 PrefixTuning supports t5 now.
- Nov 2021: We made some major changes from the last version, where a flexible template language is newly introduced! Part of the docs is outdated and we will fix it soon.
## Overview
**Prompt-learning** is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from [huggingface transformers](https://github.com/huggingface/transformers). In the future, we will also support PLMs implemented by other libraries. For more resources about prompt-learning, please check our [paper list](https://github.com/thunlp/PromptPapers).
<div align="center">
<img src="https://z3.ax1x.com/2021/11/03/IAdT3D.png" width="85%" align="center"/>
</div>
## What Can You Do via OpenPrompt?

- Use the implementations of current prompt-learning approaches.* We have implemented various of prompting methods, including templating, verbalizing and optimization strategies under a unified standard. You can easily call and understand these methods.
- *Design your own prompt-learning work.* With the extensibility of OpenPrompt, you can quickly practice your prompt-learning ideas.
## Installation
**Note: Please use Python 3.8+ for OpenPrompt**
### Using Pip
Our repo is tested on Python **3.8+** and PyTorch **1.8.1+**, install OpenPrompt using pip as follows:
```shell
pip install openprompt
```
To play with the latest features, you can also install OpenPrompt from the source.
### Using Git
Clone the repository from github:
```shell
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install
```
Modify the code
```
python setup.py develop
```
## Use OpenPrompt
### Base Concepts
A `PromptModel` object contains a `PLM`, a (or multiple) `Template` and a (or multiple) `Verbalizer`, where the `Template` class is defined to wrap the original input with templates, and the `Verbalizer` class is to construct a projection between labels and target words in the current vocabulary. And a `PromptModel` object practically participates in training and inference.
### Introduction by a Simple Example
With the modularity and flexibility of OpenPrompt, you can easily develop a prompt-learning pipeline.
#### Step 1: Define a task
The first step is to determine the current NLP task, think about what’s your data looks like and what do you want from the data! That is, the essence of this step is to determine the `classses` and the `InputExample` of the task. For simplicity, we use Sentiment Analysis as an example. tutorial_task.
```python
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
```
#### Step 2: Define a Pre-trained Language Models (PLMs) as backbone.
Choose a PLM to support your task. Different models have different attributes, we encourge you to use OpenPrompt to explore the potential of various PLMs. OpenPrompt is compatible with models on [huggingface](https://huggingface.co/transformers/).
```python
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
```
#### Step 3: Define a Template.
A `Template` is a modifier of the original input text, which is also one of the most important modules in prompt-learning.
We have defined `text_a` in Step 1.
```python
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
```
#### Step 4: Define a Verbalizer
A `Verbalizer` is another important (but not necessary) in prompt-learning,which projects the original labels (we have defined them as `classes`, remember?) to a set of label words. Here is an example that we project the `negative` class to the word bad, and project the `positive` class to the words good, wonderful, great.
```python
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
```
#### Step 5: Combine them into a PromptModel
Given the task, now we have a `PLM`, a `Template` and a `Verbalizer`, we combine them into a `PromptModel`. Note that although the example naively combine the three modules, you can actually define some complicated interactions among them.
```python
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
```
#### Step 6: Define a DataLoader
A ``PromptDataLoader`` is basically a prompt version of pytorch Dataloader, which also includes a ``Tokenizer``, a ``Template`` and a ``TokenizerWrapper``.
```python
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
```
#### Step 7: Train and inference
Done! We can conduct training and inference the same as other processes in Pytorch.
```python
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
```
Please refer to our [tutorial scripts](https://github.com/thunlp/OpenPrompt/tree/main/tutorial), and [documentation](https://thunlp.github.io/OpenPrompt/) for more details.
## Datasets
We provide a series of download scripts in the `dataset/` folder, feel free to use them to download benchmarks.
## Performance Report
There are too many possible combinations powered by OpenPrompt. We are trying our best
to test the performance of different methods as soon as possible. The performance will be constantly updated into the [Tables](https://github.com/thunlp/OpenPrompt/tree/main/results/).
We also encourage the users to find the best hyper-parameters for their own tasks and report the results by making pull request.
## Known Issues
Major improvement/enhancement in future.
- We made some major changes from the last version, so part of the docs is outdated. We will fix it soon.
## Citation
Please cite our paper if you use OpenPrompt in your work
```bibtex
@article{ding2021openprompt,
title={OpenPrompt: An Open-source Framework for Prompt-learning},
author={Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong},
journal={arXiv preprint arXiv:2111.01998},
year={2021}
}
```
## Contributors
<!-- Copy-paste in your Readme.md file -->
<a href="https://github.com/thunlp/OpenPrompt/graphs/contributors">
<img src="https://contrib.rocks/image?repo=thunlp/OpenPrompt" />
</a>
We thank all the contributors to this project, more contributors are welcome!
|
3,443 | Curated List: Practical Natural Language Processing done in Ruby | null |
3,444 | Oxford Deep NLP 2017 course | # Preamble
This repository contains the lecture slides and course description for the [Deep Natural Language Processing](http://www.cs.ox.ac.uk/teaching/courses/2016-2017/dl/) course offered in Hilary Term 2017 at the University of Oxford.
This is an advanced course on natural language processing. Automatically processing natural language inputs and producing language outputs is a key component of Artificial General Intelligence. The ambiguities and noise inherent in human communication render traditional symbolic AI techniques ineffective for representing and analysing language data. Recently statistical techniques based on neural networks have achieved a number of remarkable successes in natural language processing leading to a great deal of commercial and academic interest in the field
This is an applied course focussing on recent advances in analysing and generating speech and text using recurrent neural networks. We introduce the mathematical definitions of the relevant machine learning models and derive their associated optimisation algorithms. The course covers a range of applications of neural networks in NLP including analysing latent dimensions in text, transcribing speech to text, translating between languages, and answering questions. These topics are organised into three high level themes forming a progression from understanding the use of neural networks for sequential language modelling, to understanding their use as conditional language models for transduction tasks, and finally to approaches employing these techniques in combination with other mechanisms for advanced applications. Throughout the course the practical implementation of such models on CPU and GPU hardware is also discussed.
This course is organised by Phil Blunsom and delivered in partnership with the DeepMind Natural Language Research Group.
# Lecturers
* Phil Blunsom (Oxford University and DeepMind)
* Chris Dyer (Carnegie Mellon University and DeepMind)
* Edward Grefenstette (DeepMind)
* Karl Moritz Hermann (DeepMind)
* Andrew Senior (DeepMind)
* Wang Ling (DeepMind)
* Jeremy Appleyard (NVIDIA)
# TAs
* Yannis Assael
* Yishu Miao
* Brendan Shillingford
* Jan Buys
# Timetable
## Practicals
* Group 1 - Monday, 9:00-11:00 (Weeks 2-8), 60.05 Thom Building
* Group 2 - Friday, 16:00-18:00 (Weeks 2-8), Room 379
1. [Practical 1: word2vec](https://github.com/oxford-cs-deepnlp-2017/practical-1)
2. [Practical 2: text classification](https://github.com/oxford-cs-deepnlp-2017/practical-2)
3. [Practical 3: recurrent neural networks for text classification and language modelling](https://github.com/oxford-cs-deepnlp-2017/practical-3)
4. [Practical 4: open practical](https://github.com/oxford-cs-deepnlp-2017/practical-open)
## Lectures
Public Lectures are held in Lecture Theatre 1 of the Maths Institute, on Tuesdays and Thursdays (except week 8), 16:00-18:00 (Hilary Term Weeks 1,3-8).
# Lecture Materials
## 1. Lecture 1a - Introduction [Phil Blunsom]
This lecture introduces the course and motivates why it is interesting to study language processing using Deep Learning techniques.
[[slides]](Lecture%201a%20-%20Introduction.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_1a_intro.mp4)
## 2. Lecture 1b - Deep Neural Networks Are Our Friends [Wang Ling]
This lecture revises basic machine learning concepts that students should know before embarking on this course.
[[slides]](Lecture%201b%20-%20Deep%20Neural%20Networks%20Are%20Our%20Friends.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_1b_friends.mp4)
## 3. Lecture 2a- Word Level Semantics [Ed Grefenstette]
Words are the core meaning bearing units in language. Representing and learning the meanings of words is a fundamental task in NLP and in this lecture the concept of a word embedding is introduced as a practical and scalable solution.
[[slides]](Lecture%202a-%20Word%20Level%20Semantics.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_2a_lexical_semantics.mp4)
### Reading
#### Embeddings Basics
* [Firth, John R. "A synopsis of linguistic theory, 1930-1955." (1957): 1-32.](http://annabellelukin.edublogs.org/files/2013/08/Firth-JR-1962-A-Synopsis-of-Linguistic-Theory-wfihi5.pdf)
* [Curran, James Richard. "From distributional to semantic similarity." (2004).](https://www.era.lib.ed.ac.uk/bitstream/handle/1842/563/IP030023.pdf?sequence=2&isAllowed=y)
* [Collobert, Ronan, et al. "Natural language processing (almost) from scratch." Journal of Machine Learning Research 12. Aug (2011): 2493-2537.](http://www.jmlr.org/papers/volume12/collobert11a/collobert11a.pdf)
* [Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf)
#### Datasets and Visualisation
* [Finkelstein, Lev, et al. "Placing search in context: The concept revisited." Proceedings of the 10th international conference on World Wide Web. ACM, 2001.](http://www.iicm.tugraz.at/thesis/cguetl_diss/literatur/Kapitel07/References/Finkelstein_et_al._2002/p116-finkelstein.pdf)
* [Hill, Felix, Roi Reichart, and Anna Korhonen. "Simlex-999: Evaluating semantic models with (genuine) similarity estimation." Computational Linguistics (2016).](http://www.aclweb.org/website/old_anthology/J/J15/J15-4004.pdf)
* [Maaten, Laurens van der, and Geoffrey Hinton. "Visualizing data using t-SNE." Journal of Machine Learning Research 9.Nov (2008): 2579-2605.](http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf)
#### Blog posts
* [Deep Learning, NLP, and Representations](http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/), Christopher Olah.
* [Visualizing Top Tweeps with t-SNE, in Javascript](http://karpathy.github.io/2014/07/02/visualizing-top-tweeps-with-t-sne-in-Javascript/), Andrej Karpathy.
#### Further Reading
* [Hermann, Karl Moritz, and Phil Blunsom. "Multilingual models for compositional distributed semantics." arXiv preprint arXiv:1404.4641 (2014).](https://arxiv.org/pdf/1404.4641.pdf)
* [Levy, Omer, and Yoav Goldberg. "Neural word embedding as implicit matrix factorization." Advances in neural information processing systems. 2014.](http://u.cs.biu.ac.il/~nlp/wp-content/uploads/Neural-Word-Embeddings-as-Implicit-Matrix-Factorization-NIPS-2014.pdf)
* [Levy, Omer, Yoav Goldberg, and Ido Dagan. "Improving distributional similarity with lessons learned from word embeddings." Transactions of the Association for Computational Linguistics 3 (2015): 211-225.](https://www.transacl.org/ojs/index.php/tacl/article/view/570/124)
* [Ling, Wang, et al. "Two/Too Simple Adaptations of Word2Vec for Syntax Problems." HLT-NAACL. 2015.](https://www.aclweb.org/anthology/N/N15/N15-1142.pdf)
## 4. Lecture 2b - Overview of the Practicals [Chris Dyer]
This lecture motivates the practical segment of the course.
[[slides]](Lecture%202b%20-%20Overview%20of%20the%20Practicals.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_2b_practicals.mp4)
## 5. Lecture 3 - Language Modelling and RNNs Part 1 [Phil Blunsom]
Language modelling is important task of great practical use in many NLP applications. This lecture introduces language modelling, including traditional n-gram based approaches and more contemporary neural approaches. In particular the popular Recurrent Neural Network (RNN) language model is introduced and its basic training and evaluation algorithms described.
[[slides]](Lecture%203%20-%20Language%20Modelling%20and%20RNNs%20Part%201.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_3_modelling_1.mp4)
### Reading
#### Textbook
* [Deep Learning, Chapter 10](http://www.deeplearningbook.org/contents/rnn.html).
#### Blogs
* [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/), Andrej Karpathy.
* [The unreasonable effectiveness of Character-level Language Models](http://nbviewer.jupyter.org/gist/yoavg/d76121dfde2618422139), Yoav Goldberg.
* [Explaining and illustrating orthogonal initialization for recurrent neural networks](http://smerity.com/articles/2016/orthogonal_init.html), Stephen Merity.
## 6. Lecture 4 - Language Modelling and RNNs Part 2 [Phil Blunsom]
This lecture continues on from the previous one and considers some of the issues involved in producing an effective implementation of an RNN language model. The vanishing and exploding gradient problem is described and architectural solutions, such as Long Short Term Memory (LSTM), are introduced.
[[slides]](Lecture%204%20-%20Language%20Modelling%20and%20RNNs%20Part%202.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_4_modelling_2.mp4)
### Reading
#### Textbook
* [Deep Learning, Chapter 10](http://www.deeplearningbook.org/contents/rnn.html).
#### Vanishing gradients, LSTMs etc.
* [On the difficulty of training recurrent neural networks. Pascanu et al., ICML 2013.](http://jmlr.csail.mit.edu/proceedings/papers/v28/pascanu13.pdf)
* [Long Short-Term Memory. Hochreiter and Schmidhuber, Neural Computation 1997.](http://dl.acm.org/citation.cfm?id=1246450)
* [Learning Phrase Representations using RNN EncoderDecoder for Statistical Machine Translation. Cho et al, EMNLP 2014.](https://arxiv.org/abs/1406.1078)
* Blog: [Understanding LSTM Networks](http://colah.github.io/posts/2015-08-Understanding-LSTMs/), Christopher Olah.
#### Dealing with large vocabularies
* [A scalable hierarchical distributed language model. Mnih and Hinton, NIPS 2009.](https://papers.nips.cc/paper/3583-a-scalable-hierarchical-distributed-language-model.pdf)
* [A fast and simple algorithm for training neural probabilistic language models. Mnih and Teh, ICML 2012.](https://www.cs.toronto.edu/~amnih/papers/ncelm.pdf)
* [On Using Very Large Target Vocabulary for Neural Machine Translation. Jean et al., ACL 2015.](http://www.aclweb.org/anthology/P15-1001)
* [Exploring the Limits of Language Modeling. Jozefowicz et al., arXiv 2016.](https://arxiv.org/abs/1602.02410)
* [Efficient softmax approximation for GPUs. Grave et al., arXiv 2016.](https://arxiv.org/abs/1609.04309)
* [Notes on Noise Contrastive Estimation and Negative Sampling. Dyer, arXiv 2014.](https://arxiv.org/abs/1410.8251)
* [Pragmatic Neural Language Modelling in Machine Translation. Baltescu and Blunsom, NAACL 2015](http://www.aclweb.org/anthology/N15-1083)
#### Regularisation and dropout
* [A Theoretically Grounded Application of Dropout in Recurrent Neural Networks. Gal and Ghahramani, NIPS 2016.](https://arxiv.org/abs/1512.05287)
* Blog: [Uncertainty in Deep Learning](http://mlg.eng.cam.ac.uk/yarin/blog_2248.html), Yarin Gal.
#### Other stuff
* [Recurrent Highway Networks. Zilly et al., arXiv 2016.](https://arxiv.org/abs/1607.03474)
* [Capacity and Trainability in Recurrent Neural Networks. Collins et al., arXiv 2016.](https://arxiv.org/abs/1611.09913)
## 7. Lecture 5 - Text Classification [Karl Moritz Hermann]
This lecture discusses text classification, beginning with basic classifiers, such as Naive Bayes, and progressing through to RNNs and Convolution Networks.
[[slides]](Lecture%205%20-%20Text%20Classification.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_5_text_classification.mp4)
### Reading
* [Recurrent Convolutional Neural Networks for Text Classification. Lai et al. AAAI 2015.](http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552)
* [A Convolutional Neural Network for Modelling Sentences, Kalchbrenner et al. ACL 2014.](http://www.aclweb.org/anthology/P14-1062)
* [Semantic compositionality through recursive matrix-vector, Socher et al. EMNLP 2012.](http://nlp.stanford.edu/pubs/SocherHuvalManningNg_EMNLP2012.pdf)
* Blog: [Understanding Convolution Neural Networks For NLP](http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/), Denny Britz.
* Thesis: [Distributional Representations for Compositional Semantics, Hermann (2014).](https://arxiv.org/abs/1411.3146)
## 8. Lecture 6 - Deep NLP on Nvidia GPUs [Jeremy Appleyard]
This lecture introduces Graphical Processing Units (GPUs) as an alternative to CPUs for executing Deep Learning algorithms. The strengths and weaknesses of GPUs are discussed as well as the importance of understanding how memory bandwidth and computation impact throughput for RNNs.
[[slides]](Lecture%206%20-%20Nvidia%20RNNs%20and%20GPUs.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_6_nvidia_gpus.mp4)
### Reading
* [Optimizing Performance of Recurrent Neural Networks on GPUs. Appleyard et al., arXiv 2016.](https://arxiv.org/abs/1604.01946)
* [Persistent RNNs: Stashing Recurrent Weights On-Chip, Diamos et al., ICML 2016](http://jmlr.org/proceedings/papers/v48/diamos16.pdf)
* [Efficient softmax approximation for GPUs. Grave et al., arXiv 2016.](https://arxiv.org/abs/1609.04309)
## 9. Lecture 7 - Conditional Language Models [Chris Dyer]
In this lecture we extend the concept of language modelling to incorporate prior information. By conditioning an RNN language model on an input representation we can generate contextually relevant language. This very general idea can be applied to transduce sequences into new sequences for tasks such as translation and summarisation, or images into captions describing their content.
[[slides]](Lecture%207%20-%20Conditional%20Language%20Modeling.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_7_conditional_lang_mod.mp4)
### Reading
* [Recurrent Continuous Translation Models. Kalchbrenner and Blunsom, EMNLP 2013](http://anthology.aclweb.org/D/D13/D13-1176.pdf)
* [Sequence to Sequence Learning with Neural Networks. Sutskever et al., NIPS 2014](https://arxiv.org/abs/1409.3215)
* [Multimodal Neural Language Models. Kiros et al., ICML 2014](http://www.cs.toronto.edu/~rkiros/papers/mnlm2014.pdf)
* [Show and Tell: A Neural Image Caption Generator. Vinyals et al., CVPR 2015](https://arxiv.org/abs/1411.4555)
## 10. Lecture 8 - Generating Language with Attention [Chris Dyer]
This lecture introduces one of the most important and influencial mechanisms employed in Deep Neural Networks: Attention. Attention augments recurrent networks with the ability to condition on specific parts of the input and is key to achieving high performance in tasks such as Machine Translation and Image Captioning.
[[slides]](Lecture%208%20-%20Conditional%20Language%20Modeling%20with%20Attention.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_8_conditional_lang_mod_att.mp4)
### Reading
* [Neural Machine Translation by Jointly Learning to Align and Translate. Bahdanau et al., ICLR 2015](https://arxiv.org/abs/1409.0473)
* [Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention. Xu et al., ICML 2015](https://arxiv.org/pdf/1502.03044.pdf)
* [Incorporating structural alignment biases into an attentional neural translation model. Cohn et al., NAACL 2016](http://www.aclweb.org/anthology/N16-1102)
* [BLEU: a Method for Automatic Evaluation of Machine Translation. Papineni et al, ACL 2002](http://www.aclweb.org/anthology/P02-1040.pdf)
## 11. Lecture 9 - Speech Recognition (ASR) [Andrew Senior]
Automatic Speech Recognition (ASR) is the task of transducing raw audio signals of spoken language into text transcriptions. This talk covers the history of ASR models, from Gaussian Mixtures to attention augmented RNNs, the basic linguistics of speech, and the various input and output representations frequently employed.
[[slides]](Lecture%209%20-%20Speech%20Recognition.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_9_speech_recognition.mp4)
## 12. Lecture 10 - Text to Speech (TTS) [Andrew Senior]
This lecture introduces algorithms for converting written language into spoken language (Text to Speech). TTS is the inverse process to ASR, but there are some important differences in the models applied. Here we review traditional TTS models, and then cover more recent neural approaches such as DeepMind's WaveNet model.
[[slides]](Lecture%2010%20-%20Text%20to%20Speech.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_10_text_speech.mp4)
## 13. Lecture 11 - Question Answering [Karl Moritz Hermann]
[[slides]](Lecture%2011%20-%20Question%20Answering.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_11_question_answering.mp4)
### Reading
* [Teaching machines to read and comprehend. Hermann et al., NIPS 2015](http://papers.nips.cc/paper/5945-teaching-machines-to-read-and-comprehend)
* [Deep Learning for Answer Sentence Selection. Yu et al., NIPS Deep Learning Workshop 2014](https://arxiv.org/abs/1412.1632)
## 14. Lecture 12 - Memory [Ed Grefenstette]
[[slides]](Lecture%2012-%20Memory%20Lecture.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_12_memory.mp4)
### Reading
* [Hybrid computing using a neural network with dynamic external memory. Graves et al., Nature 2016](http://www.nature.com/nature/journal/v538/n7626/abs/nature20101.html)
* [Reasoning about Entailment with Neural Attention. Rocktäschel et al., ICLR 2016](https://arxiv.org/abs/1509.06664)
* [Learning to transduce with unbounded memory. Grefenstette et al., NIPS 2015](http://papers.nips.cc/paper/5648-learning-to-transduce-with-unbounded-memory)
* [End-to-End Memory Networks. Sukhbaatar et al., NIPS 2015](https://arxiv.org/abs/1503.08895)
## 15. Lecture 13 - Linguistic Knowledge in Neural Networks
[[slides]](Lecture%2013%20-%20Linguistics.pdf)
[[video]](http://media.podcasts.ox.ac.uk/comlab/deep_learning_NLP/2017-01_deep_NLP_13_linguistic_knowledge_neural.mp4)
# Piazza
We will be using Piazza to facilitate class discussion during the course. Rather than emailing questions directly, I encourage you to post your questions on Piazza to be answered by your fellow students, instructors, and lecturers. However do please do note that all the lecturers for this course are volunteering their time and may not always be available to give a response.
Find our class page at: https://piazza.com/ox.ac.uk/winter2017/dnlpht2017/home
# Assessment
The primary assessment for this course will be a take-home assignment issued at the end of the term. This assignment will ask questions drawing on the concepts and models discussed in the course, as well as from selected research publications. The nature of the questions will include analysing mathematical descriptions of models and proposing extensions, improvements, or evaluations to such models. The assignment may also ask students to read specific research publications and discuss their proposed algorithms in the context of the course. In answering questions students will be expected to both present coherent written arguments and use appropriate mathematical formulae, and possibly pseudo-code, to illustrate answers.
The practical component of the course will be assessed in the usual way.
# Acknowledgements
This course would not have been possible without the support of [DeepMind](http://www.deepmind.com), [The University of Oxford Department of Computer Science](http://www.cs.ox.ac.uk/), [Nvidia](http://www.nvidia.com), and the generous donation of GPU resources from [Microsoft Azure](https://azure.microsoft.com).
|
3,445 | A comprehensive list of pytorch related content on github,such as different models,implementations,helper libraries,tutorials etc. | Awesome-Pytorch-list
========================

<p align="center">
<img src="https://img.shields.io/badge/stars-12400+-brightgreen.svg?style=flat"/>
<img src="https://img.shields.io/badge/contributions-welcome-brightgreen.svg?style=flat">
</p>
## Contents
- [Pytorch & related libraries](#pytorch--related-libraries)
- [NLP & Speech Processing](#nlp--Speech-Processing)
- [Computer Vision](#cv)
- [Probabilistic/Generative Libraries](#probabilisticgenerative-libraries)
- [Other libraries](#other-libraries)
- [Tutorials, books & examples](#tutorials-books--examples)
- [Paper implementations](#paper-implementations)
- [Talks & Conferences](#talks--conferences)
- [Pytorch elsewhere](#pytorch-elsewhere)
## Pytorch & related libraries
1. [pytorch](http://pytorch.org): Tensors and Dynamic neural networks in Python with strong GPU acceleration.
2. [Captum](https://github.com/pytorch/captum): Model interpretability and understanding for PyTorch.
### NLP & Speech Processing:
1. [pytorch text](https://github.com/pytorch/text): Torch text related contents.
2. [pytorch-seq2seq](https://github.com/IBM/pytorch-seq2seq): A framework for sequence-to-sequence (seq2seq) models implemented in PyTorch.
3. [anuvada](https://github.com/Sandeep42/anuvada): Interpretable Models for NLP using PyTorch.
4. [audio](https://github.com/pytorch/audio): simple audio I/O for pytorch.
5. [loop](https://github.com/facebookresearch/loop): A method to generate speech across multiple speakers
6. [fairseq-py](https://github.com/facebookresearch/fairseq-py): Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
7. [speech](https://github.com/awni/speech): PyTorch ASR Implementation.
8. [OpenNMT-py](https://github.com/OpenNMT/OpenNMT-py): Open-Source Neural Machine Translation in PyTorch http://opennmt.net
9. [neuralcoref](https://github.com/huggingface/neuralcoref): State-of-the-art coreference resolution based on neural nets and spaCy huggingface.co/coref
10. [sentiment-discovery](https://github.com/NVIDIA/sentiment-discovery): Unsupervised Language Modeling at scale for robust sentiment classification.
11. [MUSE](https://github.com/facebookresearch/MUSE): A library for Multilingual Unsupervised or Supervised word Embeddings
12. [nmtpytorch](https://github.com/lium-lst/nmtpytorch): Neural Machine Translation Framework in PyTorch.
13. [pytorch-wavenet](https://github.com/vincentherrmann/pytorch-wavenet): An implementation of WaveNet with fast generation
14. [Tacotron-pytorch](https://github.com/soobinseo/Tacotron-pytorch): Tacotron: Towards End-to-End Speech Synthesis.
15. [AllenNLP](https://github.com/allenai/allennlp): An open-source NLP research library, built on PyTorch.
16. [PyTorch-NLP](https://github.com/PetrochukM/PyTorch-NLP): Text utilities and datasets for PyTorch pytorchnlp.readthedocs.io
17. [quick-nlp](https://github.com/outcastofmusic/quick-nlp): Pytorch NLP library based on FastAI.
18. [TTS](https://github.com/mozilla/TTS): Deep learning for Text2Speech
19. [LASER](https://github.com/facebookresearch/LASER): Language-Agnostic SEntence Representations
20. [pyannote-audio](https://github.com/pyannote/pyannote-audio): Neural building blocks for speaker diarization: speech activity detection, speaker change detection, speaker embedding
21. [gensen](https://github.com/Maluuba/gensen): Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning.
22. [translate](https://github.com/pytorch/translate): Translate - a PyTorch Language Library.
23. [espnet](https://github.com/espnet/espnet): End-to-End Speech Processing Toolkit espnet.github.io/espnet
24. [pythia](https://github.com/facebookresearch/pythia): A software suite for Visual Question Answering
25. [UnsupervisedMT](https://github.com/facebookresearch/UnsupervisedMT): Phrase-Based & Neural Unsupervised Machine Translation.
26. [jiant](https://github.com/jsalt18-sentence-repl/jiant): The jiant sentence representation learning toolkit.
27. [BERT-PyTorch](https://github.com/codertimo/BERT-pytorch): Pytorch implementation of Google AI's 2018 BERT, with simple annotation
28. [InferSent](https://github.com/facebookresearch/InferSent): Sentence embeddings (InferSent) and training code for NLI.
29. [uis-rnn](https://github.com/google/uis-rnn):This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization. arxiv.org/abs/1810.04719
30. [flair](https://github.com/zalandoresearch/flair): A very simple framework for state-of-the-art Natural Language Processing (NLP)
31. [pytext](https://github.com/facebookresearch/pytext): A natural language modeling framework based on PyTorch fb.me/pytextdocs
32. [voicefilter](https://github.com/mindslab-ai/voicefilter): Unofficial PyTorch implementation of Google AI's VoiceFilter system http://swpark.me/voicefilter
33. [BERT-NER](https://github.com/kamalkraj/BERT-NER): Pytorch-Named-Entity-Recognition-with-BERT.
34. [transfer-nlp](https://github.com/feedly/transfer-nlp): NLP library designed for flexible research and development
35. [texar-pytorch](https://github.com/asyml/texar-pytorch): Toolkit for Machine Learning and Text Generation, in PyTorch texar.io
36. [pytorch-kaldi](https://github.com/mravanelli/pytorch-kaldi): pytorch-kaldi is a project for developing state-of-the-art DNN/RNN hybrid speech recognition systems. The DNN part is managed by pytorch, while feature extraction, label computation, and decoding are performed with the kaldi toolkit.
37. [NeMo](https://github.com/NVIDIA/NeMo): Neural Modules: a toolkit for conversational AI nvidia.github.io/NeMo
38. [pytorch-struct](https://github.com/harvardnlp/pytorch-struct): A library of vectorized implementations of core structured prediction algorithms (HMM, Dep Trees, CKY, ..,)
39. [espresso](https://github.com/freewym/espresso): Espresso: A Fast End-to-End Neural Speech Recognition Toolkit
40. [transformers](https://github.com/huggingface/transformers): huggingface Transformers: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch. huggingface.co/transformers
41. [reformer-pytorch](https://github.com/lucidrains/reformer-pytorch): Reformer, the efficient Transformer, in Pytorch
42. [torch-metrics](https://github.com/enochkan/torch-metrics): Metrics for model evaluation in pytorch
43. [speechbrain](https://github.com/speechbrain/speechbrain): SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
44. [Backprop](https://github.com/backprop-ai/backprop): Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models.
### CV:
1. [pytorch vision](https://github.com/pytorch/vision): Datasets, Transforms and Models specific to Computer Vision.
2. [pt-styletransfer](https://github.com/tymokvo/pt-styletransfer): Neural style transfer as a class in PyTorch.
3. [OpenFacePytorch](https://github.com/thnkim/OpenFacePytorch): PyTorch module to use OpenFace's nn4.small2.v1.t7 model
4. [img_classification_pk_pytorch](https://github.com/felixgwu/img_classification_pk_pytorch): Quickly comparing your image classification models with the state-of-the-art models (such as DenseNet, ResNet, ...)
5. [SparseConvNet](https://github.com/facebookresearch/SparseConvNet): Submanifold sparse convolutional networks.
6. [Convolution_LSTM_pytorch](https://github.com/automan000/Convolution_LSTM_pytorch): A multi-layer convolution LSTM module
7. [face-alignment](https://github.com/1adrianb/face-alignment): :fire: 2D and 3D Face alignment library build using pytorch adrianbulat.com
8. [pytorch-semantic-segmentation](https://github.com/ZijunDeng/pytorch-semantic-segmentation): PyTorch for Semantic Segmentation.
9. [RoIAlign.pytorch](https://github.com/longcw/RoIAlign.pytorch): This is a PyTorch version of RoIAlign. This implementation is based on crop_and_resize and supports both forward and backward on CPU and GPU.
10. [pytorch-cnn-finetune](https://github.com/creafz/pytorch-cnn-finetune): Fine-tune pretrained Convolutional Neural Networks with PyTorch.
11. [detectorch](https://github.com/ignacio-rocco/detectorch): Detectorch - detectron for PyTorch
12. [Augmentor](https://github.com/mdbloice/Augmentor): Image augmentation library in Python for machine learning. http://augmentor.readthedocs.io
13. [s2cnn](https://github.com/jonas-koehler/s2cnn):
This library contains a PyTorch implementation of the SO(3) equivariant CNNs for spherical signals (e.g. omnidirectional cameras, signals on the globe)
14. [TorchCV](https://github.com/donnyyou/torchcv): A PyTorch-Based Framework for Deep Learning in Computer Vision.
15. [maskrcnn-benchmark](https://github.com/facebookresearch/maskrcnn-benchmark): Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch.
16. [image-classification-mobile](https://github.com/osmr/imgclsmob): Collection of classification models pretrained on the ImageNet-1K.
17. [medicaltorch](https://github.com/perone/medicaltorch): A medical imaging framework for Pytorch http://medicaltorch.readthedocs.io
18. [albumentations](https://github.com/albu/albumentations): Fast image augmentation library.
19. [kornia](https://github.com/arraiyopensource/kornia): Differentiable computer vision library.
20. [pytorch-text-recognition](https://github.com/s3nh/pytorch-text-recognition): Text recognition combo - CRAFT + CRNN.
21. [facenet-pytorch](https://github.com/timesler/facenet-pytorch): Pretrained Pytorch face detection and recognition models ported from davidsandberg/facenet.
22. [detectron2](https://github.com/facebookresearch/detectron2): Detectron2 is FAIR's next-generation research platform for object detection and segmentation.
23. [vedaseg](https://github.com/Media-Smart/vedaseg): A semantic segmentation framework by pyotrch
24. [ClassyVision](https://github.com/facebookresearch/ClassyVision): An end-to-end PyTorch framework for image and video classification.
25. [detecto](https://github.com/alankbi/detecto):Computer vision in Python with less than 10 lines of code
26. [pytorch3d](https://github.com/facebookresearch/pytorch3d): PyTorch3D is FAIR's library of reusable components for deep learning with 3D data pytorch3d.org
27. [MMDetection](https://github.com/open-mmlab/mmdetection): MMDetection is an open source object detection toolbox, a part of the [OpenMMLab project](https://open-mmlab.github.io/).
28. [neural-dream](https://github.com/ProGamerGov/neural-dream): A PyTorch implementation of the DeepDream algorithm. Creates dream-like hallucinogenic visuals.
29. [FlashTorch](https://github.com/MisaOgura/flashtorch): Visualization toolkit for neural networks in PyTorch!
30. [Lucent](https://github.com/greentfrapp/lucent): Tensorflow and OpenAI Clarity's Lucid adapted for PyTorch.
31. [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): MMDetection3D is OpenMMLab's next-generation platform for general 3D object detection, a part of the [OpenMMLab project](https://open-mmlab.github.io/).
32. [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): MMSegmentation is a semantic segmentation toolbox and benchmark, a part of the [OpenMMLab project](https://open-mmlab.github.io/).
33. [MMEditing](https://github.com/open-mmlab/mmediting): MMEditing is a image and video editing toolbox, a part of the [OpenMMLab project](https://open-mmlab.github.io/).
34. [MMAction2](https://github.com/open-mmlab/mmaction2): MMAction2 is OpenMMLab's next generation action understanding toolbox and benchmark, a part of the [OpenMMLab project](https://open-mmlab.github.io/).
35. [MMPose](https://github.com/open-mmlab/mmpose): MMPose is a pose estimation toolbox and benchmark, a part of the [OpenMMLab project](https://open-mmlab.github.io/).
36. [lightly](https://github.com/lightly-ai/lightly) - Lightly is a computer vision framework for self-supervised learning.
37. [RoMa](https://naver.github.io/roma/): a lightweight and efficient library to deal with 3D rotations.
### Probabilistic/Generative Libraries:
1. [ptstat](https://github.com/stepelu/ptstat): Probabilistic Programming and Statistical Inference in PyTorch
2. [pyro](https://github.com/uber/pyro): Deep universal probabilistic programming with Python and PyTorch http://pyro.ai
3. [probtorch](https://github.com/probtorch/probtorch): Probabilistic Torch is library for deep generative models that extends PyTorch.
4. [paysage](https://github.com/drckf/paysage): Unsupervised learning and generative models in python/pytorch.
5. [pyvarinf](https://github.com/ctallec/pyvarinf): Python package facilitating the use of Bayesian Deep Learning methods with Variational Inference for PyTorch.
6. [pyprob](https://github.com/probprog/pyprob): A PyTorch-based library for probabilistic programming and inference compilation.
7. [mia](https://github.com/spring-epfl/mia): A library for running membership inference attacks against ML models.
8. [pro_gan_pytorch](https://github.com/akanimax/pro_gan_pytorch): ProGAN package implemented as an extension of PyTorch nn.Module.
9. [botorch](https://github.com/pytorch/botorch): Bayesian optimization in PyTorch
### Other libraries:
1. [pytorch extras](https://github.com/mrdrozdov/pytorch-extras): Some extra features for pytorch.
2. [functional zoo](https://github.com/szagoruyko/functional-zoo): PyTorch, unlike lua torch, has autograd in it's core, so using modular structure of torch.nn modules is not necessary, one can easily allocate needed Variables and write a function that utilizes them, which is sometimes more convenient. This repo contains model definitions in this functional way, with pretrained weights for some models.
3. [torch-sampling](https://github.com/ncullen93/torchsample): This package provides a set of transforms and data structures for sampling from in-memory or out-of-memory data.
4. [torchcraft-py](https://github.com/deepcraft/torchcraft-py): Python wrapper for TorchCraft, a bridge between Torch and StarCraft for AI research.
5. [aorun](https://github.com/ramon-oliveira/aorun): Aorun intend to be a Keras with PyTorch as backend.
6. [logger](https://github.com/oval-group/logger): A simple logger for experiments.
7. [PyTorch-docset](https://github.com/iamaziz/PyTorch-docset): PyTorch docset! use with Dash, Zeal, Velocity, or LovelyDocs.
8. [convert_torch_to_pytorch](https://github.com/clcarwin/convert_torch_to_pytorch): Convert torch t7 model to pytorch model and source.
9. [pretrained-models.pytorch](https://github.com/Cadene/pretrained-models.pytorch): The goal of this repo is to help to reproduce research papers results.
10. [pytorch_fft](https://github.com/locuslab/pytorch_fft): PyTorch wrapper for FFTs
11. [caffe_to_torch_to_pytorch](https://github.com/fanq15/caffe_to_torch_to_pytorch)
12. [pytorch-extension](https://github.com/sniklaus/pytorch-extension): This is a CUDA extension for PyTorch which computes the Hadamard product of two tensors.
13. [tensorboard-pytorch](https://github.com/lanpa/tensorboard-pytorch): This module saves PyTorch tensors in tensorboard format for inspection. Currently supports scalar, image, audio, histogram features in tensorboard.
14. [gpytorch](https://github.com/jrg365/gpytorch): GPyTorch is a Gaussian Process library, implemented using PyTorch. It is designed for creating flexible and modular Gaussian Process models with ease, so that you don't have to be an expert to use GPs.
15. [spotlight](https://github.com/maciejkula/spotlight): Deep recommender models using PyTorch.
16. [pytorch-cns](https://github.com/awentzonline/pytorch-cns): Compressed Network Search with PyTorch
17. [pyinn](https://github.com/szagoruyko/pyinn): CuPy fused PyTorch neural networks ops
18. [inferno](https://github.com/nasimrahaman/inferno): A utility library around PyTorch
19. [pytorch-fitmodule](https://github.com/henryre/pytorch-fitmodule): Super simple fit method for PyTorch modules
20. [inferno-sklearn](https://github.com/dnouri/inferno): A scikit-learn compatible neural network library that wraps pytorch.
21. [pytorch-caffe-darknet-convert](https://github.com/marvis/pytorch-caffe-darknet-convert): convert between pytorch, caffe prototxt/weights and darknet cfg/weights
22. [pytorch2caffe](https://github.com/longcw/pytorch2caffe): Convert PyTorch model to Caffemodel
23. [pytorch-tools](https://github.com/nearai/pytorch-tools): Tools for PyTorch
24. [sru](https://github.com/taolei87/sru): Training RNNs as Fast as CNNs (arxiv.org/abs/1709.02755)
25. [torch2coreml](https://github.com/prisma-ai/torch2coreml): Torch7 -> CoreML
26. [PyTorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding): PyTorch Deep Texture Encoding Network http://hangzh.com/PyTorch-Encoding
27. [pytorch-ctc](https://github.com/ryanleary/pytorch-ctc): PyTorch-CTC is an implementation of CTC (Connectionist Temporal Classification) beam search decoding for PyTorch. C++ code borrowed liberally from TensorFlow with some improvements to increase flexibility.
28. [candlegp](https://github.com/t-vi/candlegp): Gaussian Processes in Pytorch.
29. [dpwa](https://github.com/loudinthecloud/dpwa): Distributed Learning by Pair-Wise Averaging.
30. [dni-pytorch](https://github.com/koz4k/dni-pytorch): Decoupled Neural Interfaces using Synthetic Gradients for PyTorch.
31. [skorch](https://github.com/dnouri/skorch): A scikit-learn compatible neural network library that wraps pytorch
32. [ignite](https://github.com/pytorch/ignite): Ignite is a high-level library to help with training neural networks in PyTorch.
33. [Arnold](https://github.com/glample/Arnold): Arnold - DOOM Agent
34. [pytorch-mcn](https://github.com/albanie/pytorch-mcn): Convert models from MatConvNet to PyTorch
35. [simple-faster-rcnn-pytorch](https://github.com/chenyuntc/simple-faster-rcnn-pytorch): A simplified implemention of Faster R-CNN with competitive performance.
36. [generative_zoo](https://github.com/DL-IT/generative_zoo): generative_zoo is a repository that provides working implementations of some generative models in PyTorch.
37. [pytorchviz](https://github.com/szagoruyko/pytorchviz): A small package to create visualizations of PyTorch execution graphs.
38. [cogitare](https://github.com/cogitare-ai/cogitare): Cogitare - A Modern, Fast, and Modular Deep Learning and Machine Learning framework in Python.
39. [pydlt](https://github.com/dmarnerides/pydlt): PyTorch based Deep Learning Toolbox
40. [semi-supervised-pytorch](https://github.com/wohlert/semi-supervised-pytorch): Implementations of different VAE-based semi-supervised and generative models in PyTorch.
41. [pytorch_cluster](https://github.com/rusty1s/pytorch_cluster): PyTorch Extension Library of Optimised Graph Cluster Algorithms.
42. [neural-assembly-compiler](https://github.com/aditya-khant/neural-assembly-compiler): A neural assembly compiler for pyTorch based on adaptive-neural-compilation.
43. [caffemodel2pytorch](https://github.com/vadimkantorov/caffemodel2pytorch): Convert Caffe models to PyTorch.
44. [extension-cpp](https://github.com/pytorch/extension-cpp): C++ extensions in PyTorch
45. [pytoune](https://github.com/GRAAL-Research/pytoune): A Keras-like framework and utilities for PyTorch
46. [jetson-reinforcement](https://github.com/dusty-nv/jetson-reinforcement): Deep reinforcement learning libraries for NVIDIA Jetson TX1/TX2 with PyTorch, OpenAI Gym, and Gazebo robotics simulator.
47. [matchbox](https://github.com/salesforce/matchbox): Write PyTorch code at the level of individual examples, then run it efficiently on minibatches.
48. [torch-two-sample](https://github.com/josipd/torch-two-sample): A PyTorch library for two-sample tests
49. [pytorch-summary](https://github.com/sksq96/pytorch-summary): Model summary in PyTorch similar to `model.summary()` in Keras
50. [mpl.pytorch](https://github.com/BelBES/mpl.pytorch): Pytorch implementation of MaxPoolingLoss.
51. [scVI-dev](https://github.com/YosefLab/scVI-dev): Development branch of the scVI project in PyTorch
52. [apex](https://github.com/NVIDIA/apex): An Experimental PyTorch Extension(will be deprecated at a later point)
53. [ELF](https://github.com/pytorch/ELF): ELF: a platform for game research.
54. [Torchlite](https://github.com/EKami/Torchlite): A high level library on top of(not only) Pytorch
55. [joint-vae](https://github.com/Schlumberger/joint-vae): Pytorch implementation of JointVAE, a framework for disentangling continuous and discrete factors of variation star2
56. [SLM-Lab](https://github.com/kengz/SLM-Lab): Modular Deep Reinforcement Learning framework in PyTorch.
57. [bindsnet](https://github.com/Hananel-Hazan/bindsnet): A Python package used for simulating spiking neural networks (SNNs) on CPUs or GPUs using PyTorch
58. [pro_gan_pytorch](https://github.com/akanimax/pro_gan_pytorch): ProGAN package implemented as an extension of PyTorch nn.Module
59. [pytorch_geometric](https://github.com/rusty1s/pytorch_geometric): Geometric Deep Learning Extension Library for PyTorch
60. [torchplus](https://github.com/knighton/torchplus): Implements the + operator on PyTorch modules, returning sequences.
61. [lagom](https://github.com/zuoxingdong/lagom): lagom: A light PyTorch infrastructure to quickly prototype reinforcement learning algorithms.
62. [torchbearer](https://github.com/ecs-vlc/torchbearer): torchbearer: A model training library for researchers using PyTorch.
63. [pytorch-maml-rl](https://github.com/tristandeleu/pytorch-maml-rl): Reinforcement Learning with Model-Agnostic Meta-Learning in Pytorch.
64. [NALU](https://github.com/bharathgs/NALU): Basic pytorch implementation of NAC/NALU from Neural Arithmetic Logic Units paper by trask et.al arxiv.org/pdf/1808.00508.pdf
66. [QuCumber](https://github.com/PIQuIL/QuCumber): Neural Network Many-Body Wavefunction Reconstruction
67. [magnet](https://github.com/MagNet-DL/magnet): Deep Learning Projects that Build Themselves http://magnet-dl.readthedocs.io/
68. [opencv_transforms](https://github.com/jbohnslav/opencv_transforms): OpenCV implementation of Torchvision's image augmentations
69. [fastai](https://github.com/fastai/fastai): The fast.ai deep learning library, lessons, and tutorials
70. [pytorch-dense-correspondence](https://github.com/RobotLocomotion/pytorch-dense-correspondence): Code for "Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation" arxiv.org/pdf/1806.08756.pdf
71. [colorization-pytorch](https://github.com/richzhang/colorization-pytorch): PyTorch reimplementation of Interactive Deep Colorization richzhang.github.io/ideepcolor
72. [beauty-net](https://github.com/cms-flash/beauty-net): A simple, flexible, and extensible template for PyTorch. It's beautiful.
73. [OpenChem](https://github.com/Mariewelt/OpenChem): OpenChem: Deep Learning toolkit for Computational Chemistry and Drug Design Research mariewelt.github.io/OpenChem
74. [torchani](https://github.com/aiqm/torchani): Accurate Neural Network Potential on PyTorch aiqm.github.io/torchani
75. [PyTorch-LBFGS](https://github.com/hjmshi/PyTorch-LBFGS): A PyTorch implementation of L-BFGS.
76. [gpytorch](https://github.com/cornellius-gp/gpytorch): A highly efficient and modular implementation of Gaussian Processes in PyTorch.
77. [hessian](https://github.com/mariogeiger/hessian): hessian in pytorch.
78. [vel](https://github.com/MillionIntegrals/vel): Velocity in deep-learning research.
79. [nonechucks](https://github.com/msamogh/nonechucks): Skip bad items in your PyTorch DataLoader, use Transforms as Filters, and more!
80. [torchstat](https://github.com/Swall0w/torchstat): Model analyzer in PyTorch.
81. [QNNPACK](https://github.com/pytorch/QNNPACK): Quantized Neural Network PACKage - mobile-optimized implementation of quantized neural network operators.
82. [torchdiffeq](https://github.com/rtqichen/torchdiffeq): Differentiable ODE solvers with full GPU support and O(1)-memory backpropagation.
83. [redner](https://github.com/BachiLi/redner): A differentiable Monte Carlo path tracer
84. [pixyz](https://github.com/masa-su/pixyz): a library for developing deep generative models in a more concise, intuitive and extendable way.
85. [euclidesdb](https://github.com/perone/euclidesdb): A multi-model machine learning feature embedding database http://euclidesdb.readthedocs.io
86. [pytorch2keras](https://github.com/nerox8664/pytorch2keras): Convert PyTorch dynamic graph to Keras model.
87. [salad](https://github.com/domainadaptation/salad): Semi-Supervised Learning and Domain Adaptation.
88. [netharn](https://github.com/Erotemic/netharn): Parameterized fit and prediction harnesses for pytorch.
89. [dgl](https://github.com/dmlc/dgl): Python package built to ease deep learning on graph, on top of existing DL frameworks. http://dgl.ai.
90. [gandissect](https://github.com/CSAILVision/gandissect): Pytorch-based tools for visualizing and understanding the neurons of a GAN. gandissect.csail.mit.edu
91. [delira](https://github.com/justusschock/delira): Lightweight framework for fast prototyping and training deep neural networks in medical imaging delira.rtfd.io
92. [mushroom](https://github.com/AIRLab-POLIMI/mushroom): Python library for Reinforcement Learning experiments.
93. [Xlearn](https://github.com/thuml/Xlearn): Transfer Learning Library
94. [geoopt](https://github.com/ferrine/geoopt): Riemannian Adaptive Optimization Methods with pytorch optim
95. [vegans](https://github.com/unit8co/vegans): A library providing various existing GANs in PyTorch.
96. [torchgeometry](https://github.com/arraiyopensource/torchgeometry): TGM: PyTorch Geometry
97. [AdverTorch](https://github.com/BorealisAI/advertorch): A Toolbox for Adversarial Robustness (attack/defense/training) Research
98. [AdaBound](https://github.com/Luolc/AdaBound): An optimizer that trains as fast as Adam and as good as SGD.a
99. [fenchel-young-losses](https://github.com/mblondel/fenchel-young-losses): Probabilistic classification in PyTorch/TensorFlow/scikit-learn with Fenchel-Young losses
100. [pytorch-OpCounter](https://github.com/Lyken17/pytorch-OpCounter): Count the FLOPs of your PyTorch model.
101. [Tor10](https://github.com/kaihsin/Tor10): A Generic Tensor-Network library that is designed for quantum simulation, base on the pytorch.
102. [Catalyst](https://github.com/catalyst-team/catalyst): High-level utils for PyTorch DL & RL research. It was developed with a focus on reproducibility, fast experimentation and code/ideas reusing. Being able to research/develop something new, rather than write another regular train loop.
103. [Ax](https://github.com/facebook/Ax): Adaptive Experimentation Platform
104. [pywick](https://github.com/achaiah/pywick): High-level batteries-included neural network training library for Pytorch
105. [torchgpipe](https://github.com/kakaobrain/torchgpipe): A GPipe implementation in PyTorch torchgpipe.readthedocs.io
106. [hub](https://github.com/pytorch/hub): Pytorch Hub is a pre-trained model repository designed to facilitate research reproducibility.
107. [pytorch-lightning](https://github.com/williamFalcon/pytorch-lightning): Rapid research framework for Pytorch. The researcher's version of keras.
108. [Tor10](https://github.com/kaihsin/Tor10): A Generic Tensor-Network library that is designed for quantum simulation, base on the pytorch.
109. [tensorwatch](https://github.com/microsoft/tensorwatch): Debugging, monitoring and visualization for Deep Learning and Reinforcement Learning from Microsoft Research.
110. [wavetorch](https://github.com/fancompute/wavetorch): Numerically solving and backpropagating through the wave equation arxiv.org/abs/1904.12831
111. [diffdist](https://github.com/ag14774/diffdist): diffdist is a python library for pytorch. It extends the default functionality of torch.autograd and adds support for differentiable communication between processes.
112. [torchprof](https://github.com/awwong1/torchprof): A minimal dependency library for layer-by-layer profiling of Pytorch models.
113. [osqpth](https://github.com/oxfordcontrol/osqpth): The differentiable OSQP solver layer for PyTorch.
114. [mctorch](https://github.com/mctorch/mctorch): A manifold optimization library for deep learning.
115. [pytorch-hessian-eigenthings](https://github.com/noahgolmant/pytorch-hessian-eigenthings): Efficient PyTorch Hessian eigendecomposition using the Hessian-vector product and stochastic power iteration.
116. [MinkowskiEngine](https://github.com/StanfordVL/MinkowskiEngine): Minkowski Engine is an auto-diff library for generalized sparse convolutions and high-dimensional sparse tensors.
117. [pytorch-cpp-rl](https://github.com/Omegastick/pytorch-cpp-rl): PyTorch C++ Reinforcement Learning
118. [pytorch-toolbelt](https://github.com/BloodAxe/pytorch-toolbelt): PyTorch extensions for fast R&D prototyping and Kaggle farming
119. [argus-tensor-stream](https://github.com/Fonbet/argus-tensor-stream): A library for real-time video stream decoding to CUDA memory tensorstream.argus-ai.com
120. [macarico](https://github.com/hal3/macarico): learning to search in pytorch
121. [rlpyt](https://github.com/astooke/rlpyt): Reinforcement Learning in PyTorch
122. [pywarm](https://github.com/blue-season/pywarm): A cleaner way to build neural networks for PyTorch. blue-season.github.io/pywarm
123. [learn2learn](https://github.com/learnables/learn2learn): PyTorch Meta-learning Framework for Researchers http://learn2learn.net
124. [torchbeast](https://github.com/facebookresearch/torchbeast): A PyTorch Platform for Distributed RL
125. [higher](https://github.com/facebookresearch/higher): higher is a pytorch library allowing users to obtain higher order gradients over losses spanning training loops rather than individual training steps.
126. [Torchelie](https://github.com/Vermeille/Torchelie/): Torchélie is a set of utility functions, layers, losses, models, trainers and other things for PyTorch. torchelie.readthedocs.org
127. [CrypTen](https://github.com/facebookresearch/CrypTen): CrypTen is a Privacy Preserving Machine Learning framework written using PyTorch that allows researchers and developers to train models using encrypted data. CrypTen currently supports Secure multi-party computation as its encryption mechanism.
128. [cvxpylayers](https://github.com/cvxgrp/cvxpylayers): cvxpylayers is a Python library for constructing differentiable convex optimization layers in PyTorch
129. [RepDistiller](https://github.com/HobbitLong/RepDistiller): Contrastive Representation Distillation (CRD), and benchmark of recent knowledge distillation methods
130. [kaolin](https://github.com/NVIDIAGameWorks/kaolin): PyTorch library aimed at accelerating 3D deep learning research
131. [PySNN](https://github.com/BasBuller/PySNN): Efficient Spiking Neural Network framework, built on top of PyTorch for GPU acceleration.
132. [sparktorch](https://github.com/dmmiller612/sparktorch): Train and run Pytorch models on Apache Spark.
133. [pytorch-metric-learning](https://github.com/KevinMusgrave/pytorch-metric-learning): The easiest way to use metric learning in your application. Modular, flexible, and extensible. Written in PyTorch.
134. [autonomous-learning-library](https://github.com/cpnota/autonomous-learning-library): A PyTorch library for building deep reinforcement learning agents.
135. [flambe](https://github.com/asappresearch/flambe): An ML framework to accelerate research and its path to production. flambe.ai
136. [pytorch-optimizer](https://github.com/jettify/pytorch-optimizer): Collections of modern optimization algorithms for PyTorch, includes: AccSGD, AdaBound, AdaMod, DiffGrad, Lamb, RAdam, RAdam, Yogi.
137. [PyTorch-VAE](https://github.com/AntixK/PyTorch-VAE): A Collection of Variational Autoencoders (VAE) in PyTorch.
138. [ray](https://github.com/ray-project/ray): A fast and simple framework for building and running distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library. ray.io
139. [Pytorch Geometric Temporal](https://github.com/benedekrozemberczki/pytorch_geometric_temporal): A temporal extension library for PyTorch Geometric
140. [Poutyne](https://github.com/GRAAL-Research/poutyne): A Keras-like framework for PyTorch that handles much of the boilerplating code needed to train neural networks.
141. [Pytorch-Toolbox](https://github.com/PistonY/torch-toolbox): This is toolbox project for Pytorch. Aiming to make you write Pytorch code more easier, readable and concise.
142. [Pytorch-contrib](https://github.com/pytorch/contrib): It contains reviewed implementations of ideas from recent machine learning papers.
143. [EfficientNet PyTorch](https://github.com/lukemelas/EfficientNet-PyTorch): It contains an op-for-op PyTorch reimplementation of EfficientNet, along with pre-trained models and examples.
144. [PyTorch/XLA](https://github.com/pytorch/xla): PyTorch/XLA is a Python package that uses the XLA deep learning compiler to connect the PyTorch deep learning framework and Cloud TPUs.
145. [webdataset](https://github.com/tmbdev/webdataset): WebDataset is a PyTorch Dataset (IterableDataset) implementation providing efficient access to datasets stored in POSIX tar archives.
146. [volksdep](https://github.com/Media-Smart/volksdep): volksdep is an open-source toolbox for deploying and accelerating PyTorch, Onnx and Tensorflow models with TensorRT.
147. [PyTorch-StudioGAN](https://github.com/POSTECH-CVLab/PyTorch-StudioGAN): StudioGAN is a Pytorch library providing implementations of representative Generative Adversarial Networks (GANs) for conditional/unconditional image generation. StudioGAN aims to offer an identical playground for modern GANs so that machine learning researchers can readily compare and analyze a new idea.
148. [torchdrift](https://github.com/torchdrift/torchdrift/): drift detection library
149. [accelerate](https://github.com/huggingface/accelerate) : A simple way to train and use PyTorch models with multi-GPU, TPU, mixed-precision
150. [lightning-transformers](https://github.com/PyTorchLightning/lightning-transformers): Flexible interface for high-performance research using SOTA Transformers leveraging Pytorch Lightning, Transformers, and Hydra.
151. [Flower](https://flower.dev/) A unified approach to federated learning, analytics, and evaluation. It allows to federated any machine learning workload.
152. [lightning-flash](https://github.com/PyTorchLightning/lightning-flash): Flash is a collection of tasks for fast prototyping, baselining and fine-tuning scalable Deep Learning models, built on PyTorch Lightning.
153. [Pytorch Geometric Signed Directed](https://github.com/SherylHYX/pytorch_geometric_signed_directed): A signed and directed extension library for PyTorch Geometric.
154. [Koila](https://github.com/rentruewang/koila): A simple wrapper around pytorch that prevents CUDA out of memory issues.
155. [Renate](https://github.com/awslabs/renate): A library for real-world continual learning.
## Tutorials, books, & examples
1. **[Practical Pytorch](https://github.com/spro/practical-pytorch)**: Tutorials explaining different RNN models
2. [DeepLearningForNLPInPytorch](https://pytorch.org/tutorials/beginner/deep_learning_nlp_tutorial.html): An IPython Notebook tutorial on deep learning, with an emphasis on Natural Language Processing.
3. [pytorch-tutorial](https://github.com/yunjey/pytorch-tutorial): tutorial for researchers to learn deep learning with pytorch.
4. [pytorch-exercises](https://github.com/keon/pytorch-exercises): pytorch-exercises collection.
5. [pytorch tutorials](https://github.com/pytorch/tutorials): Various pytorch tutorials.
6. [pytorch examples](https://github.com/pytorch/examples): A repository showcasing examples of using pytorch
7. [pytorch practice](https://github.com/napsternxg/pytorch-practice): Some example scripts on pytorch.
8. [pytorch mini tutorials](https://github.com/vinhkhuc/PyTorch-Mini-Tutorials): Minimal tutorials for PyTorch adapted from Alec Radford's Theano tutorials.
9. [pytorch text classification](https://github.com/xiayandi/Pytorch_text_classification): A simple implementation of CNN based text classification in Pytorch
10. [cats vs dogs](https://github.com/desimone/pytorch-cat-vs-dogs): Example of network fine-tuning in pytorch for the kaggle competition Dogs vs. Cats Redux: Kernels Edition. Currently #27 (0.05074) on the leaderboard.
11. [convnet](https://github.com/eladhoffer/convNet.pytorch): This is a complete training example for Deep Convolutional Networks on various datasets (ImageNet, Cifar10, Cifar100, MNIST).
12. [pytorch-generative-adversarial-networks](https://github.com/mailmahee/pytorch-generative-adversarial-networks): simple generative adversarial network (GAN) using PyTorch.
13. [pytorch containers](https://github.com/amdegroot/pytorch-containers): This repository aims to help former Torchies more seamlessly transition to the "Containerless" world of PyTorch by providing a list of PyTorch implementations of Torch Table Layers.
14. [T-SNE in pytorch](https://github.com/cemoody/topicsne): t-SNE experiments in pytorch
15. [AAE_pytorch](https://github.com/fducau/AAE_pytorch): Adversarial Autoencoders (with Pytorch).
16. [Kind_PyTorch_Tutorial](https://github.com/GunhoChoi/Kind_PyTorch_Tutorial): Kind PyTorch Tutorial for beginners.
17. [pytorch-poetry-gen](https://github.com/justdark/pytorch-poetry-gen): a char-RNN based on pytorch.
18. [pytorch-REINFORCE](https://github.com/JamesChuanggg/pytorch-REINFORCE): PyTorch implementation of REINFORCE, This repo supports both continuous and discrete environments in OpenAI gym.
19. **[PyTorch-Tutorial](https://github.com/MorvanZhou/PyTorch-Tutorial)**: Build your neural network easy and fast https://morvanzhou.github.io/tutorials/
20. [pytorch-intro](https://github.com/joansj/pytorch-intro): A couple of scripts to illustrate how to do CNNs and RNNs in PyTorch
21. [pytorch-classification](https://github.com/bearpaw/pytorch-classification): A unified framework for the image classification task on CIFAR-10/100 and ImageNet.
22. [pytorch_notebooks - hardmaru](https://github.com/hardmaru/pytorch_notebooks): Random tutorials created in NumPy and PyTorch.
23. [pytorch_tutoria-quick](https://github.com/soravux/pytorch_tutorial): Quick PyTorch introduction and tutorial. Targets computer vision, graphics and machine learning researchers eager to try a new framework.
24. [Pytorch_fine_tuning_Tutorial](https://github.com/Spandan-Madan/Pytorch_fine_tuning_Tutorial): A short tutorial on performing fine tuning or transfer learning in PyTorch.
25. [pytorch_exercises](https://github.com/Kyubyong/pytorch_exercises): pytorch-exercises
26. [traffic-sign-detection](https://github.com/soumith/traffic-sign-detection-homework): nyu-cv-fall-2017 example
27. [mss_pytorch](https://github.com/Js-Mim/mss_pytorch): Singing Voice Separation via Recurrent Inference and Skip-Filtering Connections - PyTorch Implementation. Demo: js-mim.github.io/mss_pytorch
28. [DeepNLP-models-Pytorch](https://github.com/DSKSD/DeepNLP-models-Pytorch) Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ: NLP with Deep Learning)
29. [Mila introductory tutorials](https://github.com/mila-udem/welcome_tutorials): Various tutorials given for welcoming new students at MILA.
30. [pytorch.rl.learning](https://github.com/moskomule/pytorch.rl.learning): for learning reinforcement learning using PyTorch.
31. [minimal-seq2seq](https://github.com/keon/seq2seq): Minimal Seq2Seq model with Attention for Neural Machine Translation in PyTorch
32. [tensorly-notebooks](https://github.com/JeanKossaifi/tensorly-notebooks): Tensor methods in Python with TensorLy tensorly.github.io/dev
33. [pytorch_bits](https://github.com/jpeg729/pytorch_bits): time-series prediction related examples.
34. [skip-thoughts](https://github.com/sanyam5/skip-thoughts): An implementation of Skip-Thought Vectors in PyTorch.
35. [video-caption-pytorch](https://github.com/xiadingZ/video-caption-pytorch): pytorch code for video captioning.
36. [Capsule-Network-Tutorial](https://github.com/higgsfield/Capsule-Network-Tutorial): Pytorch easy-to-follow Capsule Network tutorial.
37. [code-of-learn-deep-learning-with-pytorch](https://github.com/SherlockLiao/code-of-learn-deep-learning-with-pytorch): This is code of book "Learn Deep Learning with PyTorch" item.jd.com/17915495606.html
38. [RL-Adventure](https://github.com/higgsfield/RL-Adventure): Pytorch easy-to-follow step-by-step Deep Q Learning tutorial with clean readable code.
39. [accelerated_dl_pytorch](https://github.com/hpcgarage/accelerated_dl_pytorch): Accelerated Deep Learning with PyTorch at Jupyter Day Atlanta II.
40. [RL-Adventure-2](https://github.com/higgsfield/RL-Adventure-2): PyTorch4 tutorial of: actor critic / proximal policy optimization / acer / ddpg / twin dueling ddpg / soft actor critic / generative adversarial imitation learning / hindsight experience replay
41. [Generative Adversarial Networks (GANs) in 50 lines of code (PyTorch)](https://medium.com/@devnag/generative-adversarial-networks-gans-in-50-lines-of-code-pytorch-e81b79659e3f)
42. [adversarial-autoencoders-with-pytorch](https://blog.paperspace.com/adversarial-autoencoders-with-pytorch/)
43. [transfer learning using pytorch](https://medium.com/@vishnuvig/transfer-learning-using-pytorch-4c3475f4495)
44. [how-to-implement-a-yolo-object-detector-in-pytorch](https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/)
45. [pytorch-for-recommenders-101](http://blog.fastforwardlabs.com/2018/04/10/pytorch-for-recommenders-101.html)
46. [pytorch-for-numpy-users](https://github.com/wkentaro/pytorch-for-numpy-users)
47. [PyTorch Tutorial](http://www.pytorchtutorial.com/): PyTorch Tutorials in Chinese.
48. [grokking-pytorch](https://github.com/Kaixhin/grokking-pytorch): The Hitchiker's Guide to PyTorch
49. [PyTorch-Deep-Learning-Minicourse](https://github.com/Atcold/PyTorch-Deep-Learning-Minicourse): Minicourse in Deep Learning with PyTorch.
50. [pytorch-custom-dataset-examples](https://github.com/utkuozbulak/pytorch-custom-dataset-examples): Some custom dataset examples for PyTorch
51. [Multiplicative LSTM for sequence-based Recommenders](https://florianwilhelm.info/2018/08/multiplicative_LSTM_for_sequence_based_recos/)
52. [deeplearning.ai-pytorch](https://github.com/furkanu/deeplearning.ai-pytorch): PyTorch Implementations of Coursera's Deep Learning(deeplearning.ai) Specialization.
53. [MNIST_Pytorch_python_and_capi](https://github.com/tobiascz/MNIST_Pytorch_python_and_capi): This is an example of how to train a MNIST network in Python and run it in c++ with pytorch 1.0
54. [torch_light](https://github.com/ne7ermore/torch_light): Tutorials and examples include Reinforcement Training, NLP, CV
55. [portrain-gan](https://github.com/dribnet/portrain-gan): torch code to decode (and almost encode) latents from art-DCGAN's Portrait GAN.
56. [mri-analysis-pytorch](https://github.com/omarsar/mri-analysis-pytorch): MRI analysis using PyTorch and MedicalTorch
57. [cifar10-fast](https://github.com/davidcpage/cifar10-fast):
Demonstration of training a small ResNet on CIFAR10 to 94% test accuracy in 79 seconds as described in this [blog series](https://www.myrtle.ai/2018/09/24/how_to_train_your_resnet/).
58. [Intro to Deep Learning with PyTorch](https://in.udacity.com/course/deep-learning-pytorch--ud188): A free course by Udacity and facebook, with a good intro to PyTorch, and an interview with Soumith Chintala, one of the original authors of PyTorch.
59. [pytorch-sentiment-analysis](https://github.com/bentrevett/pytorch-sentiment-analysis): Tutorials on getting started with PyTorch and TorchText for sentiment analysis.
60. [pytorch-image-models](https://github.com/rwightman/pytorch-image-models): PyTorch image models, scripts, pretrained weights -- (SE)ResNet/ResNeXT, DPN, EfficientNet, MobileNet-V3/V2/V1, MNASNet, Single-Path NAS, FBNet, and more.
61. [CIFAR-ZOO](https://github.com/BIGBALLON/CIFAR-ZOO): Pytorch implementation for multiple CNN architectures and improve methods with state-of-the-art results.
62. [d2l-pytorch](https://github.com/dsgiitr/d2l-pytorch): This is an attempt to modify Dive into Deep Learning, Berkeley STAT 157 (Spring 2019) textbook's code into PyTorch.
63. [thinking-in-tensors-writing-in-pytorch](https://github.com/stared/thinking-in-tensors-writing-in-pytorch): Thinking in tensors, writing in PyTorch (a hands-on deep learning intro).
64. [NER-BERT-pytorch](https://github.com/lemonhu/NER-BERT-pytorch): PyTorch solution of named entity recognition task Using Google AI's pre-trained BERT model.
65. [pytorch-sync-batchnorm-example](https://github.com/dougsouza/pytorch-sync-batchnorm-example): How to use Cross Replica / Synchronized Batchnorm in Pytorch.
66. [SentimentAnalysis](https://github.com/barissayil/SentimentAnalysis): Sentiment analysis neural network trained by fine tuning BERT on the Stanford Sentiment Treebank, thanks to [Hugging Face](https://huggingface.co/transformers/)'s Transformers library.
67. [pytorch-cpp](https://github.com/prabhuomkar/pytorch-cpp): C++ implementations of PyTorch tutorials for deep learning researchers (based on the Python tutorials from [pytorch-tutorial](https://github.com/yunjey/pytorch-tutorial)).
68. [Deep Learning with PyTorch: Zero to GANs](https://jovian.ml/aakashns/collections/deep-learning-with-pytorch): Interactive and coding-focused tutorial series on introduction to Deep Learning with PyTorch ([video](https://www.youtube.com/watch?v=GIsg-ZUy0MY)).
69. [Deep Learning with PyTorch](https://www.manning.com/books/deep-learning-with-pytorch): Deep Learning with PyTorch teaches you how to implement deep learning algorithms with Python and PyTorch, the book includes a case study: building an algorithm capable of detecting malignant lung tumors using CT scans.
70. [Serverless Machine Learning in Action with PyTorch and AWS](https://www.manning.com/books/serverless-machine-learning-in-action): Serverless Machine Learning in Action is a guide to bringing your experimental PyTorch machine learning code to production using serverless capabilities from major cloud providers like AWS, Azure, or GCP.
71. [LabML NN](https://github.com/lab-ml/nn): A collection of PyTorch implementations of neural networks architectures and algorithms with side-by-side notes.
72. [Run your PyTorch Example Fedarated with Flower](https://github.com/adap/flower/tree/main/examples/pytorch_from_centralized_to_federated): This example demonstrates how an already existing centralized PyTorch machine learning project can be federated with Flower. A Cifar-10 dataset is used together with a convolutional neural network (CNN).
## Paper implementations
1. [google_evolution](https://github.com/neuralix/google_evolution): This implements one of result networks from Large-scale evolution of image classifiers by Esteban Real, et. al.
2. [pyscatwave](https://github.com/edouardoyallon/pyscatwave): Fast Scattering Transform with CuPy/PyTorch,read the paper [here](https://arxiv.org/abs/1703.08961)
3. [scalingscattering](https://github.com/edouardoyallon/scalingscattering): Scaling The Scattering Transform : Deep Hybrid Networks.
4. [deep-auto-punctuation](https://github.com/episodeyang/deep-auto-punctuation): a pytorch implementation of auto-punctuation learned character by character.
5. [Realtime_Multi-Person_Pose_Estimation](https://github.com/tensorboy/pytorch_Realtime_Multi-Person_Pose_Estimation): This is a pytorch version of Realtime_Multi-Person_Pose_Estimation, origin code is [here](https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation) .
6. [PyTorch-value-iteration-networks](https://github.com/onlytailei/PyTorch-value-iteration-networks): PyTorch implementation of the Value Iteration Networks (NIPS '16) paper
7. [pytorch_Highway](https://github.com/analvikingur/pytorch_Highway): Highway network implemented in pytorch.
8. [pytorch_NEG_loss](https://github.com/analvikingur/pytorch_NEG_loss): NEG loss implemented in pytorch.
9. [pytorch_RVAE](https://github.com/analvikingur/pytorch_RVAE): Recurrent Variational Autoencoder that generates sequential data implemented in pytorch.
10. [pytorch_TDNN](https://github.com/analvikingur/pytorch_TDNN): Time Delayed NN implemented in pytorch.
11. [eve.pytorch](https://github.com/moskomule/eve.pytorch): An implementation of Eve Optimizer, proposed in Imploving Stochastic Gradient Descent with Feedback, Koushik and Hayashi, 2016.
12. [e2e-model-learning](https://github.com/locuslab/e2e-model-learning): Task-based end-to-end model learning.
13. [pix2pix-pytorch](https://github.com/mrzhu-cool/pix2pix-pytorch): PyTorch implementation of "Image-to-Image Translation Using Conditional Adversarial Networks".
14. [Single Shot MultiBox Detector](https://github.com/amdegroot/ssd.pytorch): A PyTorch Implementation of Single Shot MultiBox Detector.
15. [DiscoGAN](https://github.com/carpedm20/DiscoGAN-pytorch): PyTorch implementation of "Learning to Discover Cross-Domain Relations with Generative Adversarial Networks"
16. [official DiscoGAN implementation](https://github.com/SKTBrain/DiscoGAN): Official implementation of "Learning to Discover Cross-Domain Relations with Generative Adversarial Networks".
17. [pytorch-es](https://github.com/atgambardella/pytorch-es): This is a PyTorch implementation of [Evolution Strategies](https://arxiv.org/abs/1703.03864) .
18. [piwise](https://github.com/bodokaiser/piwise): Pixel-wise segmentation on VOC2012 dataset using pytorch.
19. [pytorch-dqn](https://github.com/transedward/pytorch-dqn): Deep Q-Learning Network in pytorch.
20. [neuraltalk2-pytorch](https://github.com/ruotianluo/neuraltalk2.pytorch): image captioning model in pytorch(finetunable cnn in branch with_finetune)
21. [vnet.pytorch](https://github.com/mattmacy/vnet.pytorch): A Pytorch implementation for V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation.
22. [pytorch-fcn](https://github.com/wkentaro/pytorch-fcn): PyTorch implementation of Fully Convolutional Networks.
23. [WideResNets](https://github.com/xternalz/WideResNet-pytorch): WideResNets for CIFAR10/100 implemented in PyTorch. This implementation requires less GPU memory than what is required by the official Torch implementation: https://github.com/szagoruyko/wide-residual-networks .
24. [pytorch_highway_networks](https://github.com/c0nn3r/pytorch_highway_networks): Highway networks implemented in PyTorch.
25. [pytorch-NeuCom](https://github.com/ypxie/pytorch-NeuCom): Pytorch implementation of DeepMind's differentiable neural computer paper.
26. [captionGen](https://github.com/eladhoffer/captionGen): Generate captions for an image using PyTorch.
27. [AnimeGAN](https://github.com/jayleicn/animeGAN): A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing.
28. [Cnn-text classification](https://github.com/Shawn1993/cnn-text-classification-pytorch): This is the implementation of Kim's Convolutional Neural Networks for Sentence Classification paper in PyTorch.
29. [deepspeech2](https://github.com/SeanNaren/deepspeech.pytorch): Implementation of DeepSpeech2 using Baidu Warp-CTC. Creates a network based on the DeepSpeech2 architecture, trained with the CTC activation function.
30. [seq2seq](https://github.com/MaximumEntropy/Seq2Seq-PyTorch): This repository contains implementations of Sequence to Sequence (Seq2Seq) models in PyTorch
31. [Asynchronous Advantage Actor-Critic in PyTorch](https://github.com/rarilurelo/pytorch_a3c): This is PyTorch implementation of A3C as described in Asynchronous Methods for Deep Reinforcement Learning. Since PyTorch has a easy method to control shared memory within multiprocess, we can easily implement asynchronous method like A3C.
32. [densenet](https://github.com/bamos/densenet.pytorch): This is a PyTorch implementation of the DenseNet-BC architecture as described in the paper Densely Connected Convolutional Networks by G. Huang, Z. Liu, K. Weinberger, and L. van der Maaten. This implementation gets a CIFAR-10+ error rate of 4.77 with a 100-layer DenseNet-BC with a growth rate of 12. Their official implementation and links to many other third-party implementations are available in the liuzhuang13/DenseNet repo on GitHub.
33. [nninit](https://github.com/alykhantejani/nninit): Weight initialization schemes for PyTorch nn.Modules. This is a port of the popular nninit for Torch7 by @kaixhin.
34. [faster rcnn](https://github.com/longcw/faster_rcnn_pytorch): This is a PyTorch implementation of Faster RCNN. This project is mainly based on py-faster-rcnn and TFFRCNN.For details about R-CNN please refer to the paper Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks by Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun.
35. [doomnet](https://github.com/akolishchak/doom-net-pytorch): PyTorch's version of Doom-net implementing some RL models in ViZDoom environment.
36. [flownet](https://github.com/ClementPinard/FlowNetPytorch): Pytorch implementation of FlowNet by Dosovitskiy et al.
37. [sqeezenet](https://github.com/gsp-27/pytorch_Squeezenet): Implementation of Squeezenet in pytorch, #### pretrained models on CIFAR10 data to come Plan to train the model on cifar 10 and add block connections too.
38. [WassersteinGAN](https://github.com/martinarjovsky/WassersteinGAN): wassersteinGAN in pytorch.
39. [optnet](https://github.com/locuslab/optnet): This repository is by Brandon Amos and J. Zico Kolter and contains the PyTorch source code to reproduce the experiments in our paper OptNet: Differentiable Optimization as a Layer in Neural Networks.
40. [qp solver](https://github.com/locuslab/qpth): A fast and differentiable QP solver for PyTorch. Crafted by Brandon Amos and J. Zico Kolter.
41. [Continuous Deep Q-Learning with Model-based Acceleration ](https://github.com/ikostrikov/pytorch-naf): Reimplementation of Continuous Deep Q-Learning with Model-based Acceleration.
42. [Learning to learn by gradient descent by gradient descent](https://github.com/ikostrikov/pytorch-meta-optimizer): PyTorch implementation of Learning to learn by gradient descent by gradient descent.
43. [fast-neural-style](https://github.com/darkstar112358/fast-neural-style): pytorch implementation of fast-neural-style, The model uses the method described in [Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/abs/1603.08155) along with Instance Normalization.
44. [PytorchNeuralStyleTransfer](https://github.com/leongatys/PytorchNeuralStyleTransfer): Implementation of Neural Style Transfer in Pytorch.
45. [Fast Neural Style for Image Style Transform by Pytorch](https://github.com/bengxy/FastNeuralStyle): Fast Neural Style for Image Style Transform by Pytorch .
46. [neural style transfer](https://github.com/alexis-jacq/Pytorch-Tutorials): An introduction to PyTorch through the Neural-Style algorithm (https://arxiv.org/abs/1508.06576) developed by Leon A. Gatys, Alexander S. Ecker and Matthias Bethge.
47. [VIN_PyTorch_Visdom](https://github.com/zuoxingdong/VIN_PyTorch_Visdom): PyTorch implementation of Value Iteration Networks (VIN): Clean, Simple and Modular. Visualization in Visdom.
48. [YOLO2](https://github.com/longcw/yolo2-pytorch): YOLOv2 in PyTorch.
49. [attention-transfer](https://github.com/szagoruyko/attention-transfer): Attention transfer in pytorch, read the paper [here](https://arxiv.org/abs/1612.03928).
50. [SVHNClassifier](https://github.com/potterhsu/SVHNClassifier-PyTorch): A PyTorch implementation of [Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks](https://arxiv.org/pdf/1312.6082.pdf).
51. [pytorch-deform-conv](https://github.com/oeway/pytorch-deform-conv): PyTorch implementation of Deformable Convolution.
52. [BEGAN-pytorch](https://github.com/carpedm20/BEGAN-pytorch): PyTorch implementation of [BEGAN](https://arxiv.org/abs/1703.10717): Boundary Equilibrium Generative Adversarial Networks.
53. [treelstm.pytorch](https://github.com/dasguptar/treelstm.pytorch): Tree LSTM implementation in PyTorch.
54. [AGE](https://github.com/DmitryUlyanov/AGE): Code for paper "Adversarial Generator-Encoder Networks" by Dmitry Ulyanov, Andrea Vedaldi and Victor Lempitsky which can be found [here](http://sites.skoltech.ru/app/data/uploads/sites/25/2017/04/AGE.pdf)
55. [ResNeXt.pytorch](https://github.com/prlz77/ResNeXt.pytorch): Reproduces ResNet-V3 (Aggregated Residual Transformations for Deep Neural Networks) with pytorch.
56. [pytorch-rl](https://github.com/jingweiz/pytorch-rl): Deep Reinforcement Learning with pytorch & visdom
57. [Deep-Leafsnap](https://github.com/sujithv28/Deep-Leafsnap): LeafSnap replicated using deep neural networks to test accuracy compared to traditional computer vision methods.
58. [pytorch-CycleGAN-and-pix2pix](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix): PyTorch implementation for both unpaired and paired image-to-image translation.
59. [A3C-PyTorch](https://github.com/onlytailei/A3C-PyTorch):PyTorch implementation of Advantage async actor-critic Algorithms (A3C) in PyTorch
60. [pytorch-value-iteration-networks](https://github.com/kentsommer/pytorch-value-iteration-networks): Pytorch implementation of Value Iteration Networks (NIPS 2016 best paper)
61. [PyTorch-Style-Transfer](https://github.com/zhanghang1989/PyTorch-Style-Transfer): PyTorch Implementation of Multi-style Generative Network for Real-time Transfer
62. [pytorch-deeplab-resnet](https://github.com/isht7/pytorch-deeplab-resnet): pytorch-deeplab-resnet-model.
63. [pointnet.pytorch](https://github.com/fxia22/pointnet.pytorch): pytorch implementation for "PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation" https://arxiv.org/abs/1612.00593
64. **[pytorch-playground](https://github.com/aaron-xichen/pytorch-playground): Base pretrained models and datasets in pytorch (MNIST, SVHN, CIFAR10, CIFAR100, STL10, AlexNet, VGG16, VGG19, ResNet, Inception, SqueezeNet)**.
65. [pytorch-dnc](https://github.com/jingweiz/pytorch-dnc): Neural Turing Machine (NTM) & Differentiable Neural Computer (DNC) with pytorch & visdom.
66. [pytorch_image_classifier](https://github.com/jinfagang/pytorch_image_classifier): Minimal But Practical Image Classifier Pipline Using Pytorch, Finetune on ResNet18, Got 99% Accuracy on Own Small Datasets.
67. [mnist-svhn-transfer](https://github.com/yunjey/mnist-svhn-transfer): PyTorch Implementation of CycleGAN and SGAN for Domain Transfer (Minimal).
68. [pytorch-yolo2](https://github.com/marvis/pytorch-yolo2): pytorch-yolo2
69. [dni](https://github.com/andrewliao11/dni.pytorch): Implement Decoupled Neural Interfaces using Synthetic Gradients in Pytorch
70. [wgan-gp](https://github.com/caogang/wgan-gp): A pytorch implementation of Paper "Improved Training of Wasserstein GANs".
71. [pytorch-seq2seq-intent-parsing](https://github.com/spro/pytorch-seq2seq-intent-parsing): Intent parsing and slot filling in PyTorch with seq2seq + attention
72. [pyTorch_NCE](https://github.com/demelin/pyTorch_NCE): An implementation of the Noise Contrastive Estimation algorithm for pyTorch. Working, yet not very efficient.
73. [molencoder](https://github.com/cxhernandez/molencoder): Molecular AutoEncoder in PyTorch
74. [GAN-weight-norm](https://github.com/stormraiser/GAN-weight-norm): Code for "On the Effects of Batch and Weight Normalization in Generative Adversarial Networks"
75. [lgamma](https://github.com/rachtsingh/lgamma): Implementations of polygamma, lgamma, and beta functions for PyTorch
76. [bigBatch](https://github.com/eladhoffer/bigBatch): Code used to generate the results appearing in "Train longer, generalize better: closing the generalization gap in large batch training of neural networks"
77. [rl_a3c_pytorch](https://github.com/dgriff777/rl_a3c_pytorch): Reinforcement learning with implementation of A3C LSTM for Atari 2600.
78. [pytorch-retraining](https://github.com/ahirner/pytorch-retraining): Transfer Learning Shootout for PyTorch's model zoo (torchvision)
79. [nmp_qc](https://github.com/priba/nmp_qc): Neural Message Passing for Computer Vision
80. [grad-cam](https://github.com/jacobgil/pytorch-grad-cam): Pytorch implementation of Grad-CAM
81. [pytorch-trpo](https://github.com/mjacar/pytorch-trpo): PyTorch Implementation of Trust Region Policy Optimization (TRPO)
82. [pytorch-explain-black-box](https://github.com/jacobgil/pytorch-explain-black-box): PyTorch implementation of Interpretable Explanations of Black Boxes by Meaningful Perturbation
83. [vae_vpflows](https://github.com/jmtomczak/vae_vpflows): Code in PyTorch for the convex combination linear IAF and the Householder Flow, J.M. Tomczak & M. Welling https://jmtomczak.github.io/deebmed.html
84. [relational-networks](https://github.com/kimhc6028/relational-networks): Pytorch implementation of "A simple neural network module for relational reasoning" (Relational Networks) https://arxiv.org/pdf/1706.01427.pdf
85. [vqa.pytorch](https://github.com/Cadene/vqa.pytorch): Visual Question Answering in Pytorch
86. [end-to-end-negotiator](https://github.com/facebookresearch/end-to-end-negotiator): Deal or No Deal? End-to-End Learning for Negotiation Dialogues
87. [odin-pytorch](https://github.com/ShiyuLiang/odin-pytorch): Principled Detection of Out-of-Distribution Examples in Neural Networks.
88. [FreezeOut](https://github.com/ajbrock/FreezeOut): Accelerate Neural Net Training by Progressively Freezing Layers.
89. [ARAE](https://github.com/jakezhaojb/ARAE): Code for the paper "Adversarially Regularized Autoencoders for Generating Discrete Structures" by Zhao, Kim, Zhang, Rush and LeCun.
90. [forward-thinking-pytorch](https://github.com/kimhc6028/forward-thinking-pytorch): Pytorch implementation of "Forward Thinking: Building and Training Neural Networks One Layer at a Time" https://arxiv.org/pdf/1706.02480.pdf
91. [context_encoder_pytorch](https://github.com/BoyuanJiang/context_encoder_pytorch): PyTorch Implement of Context Encoders
92. [attention-is-all-you-need-pytorch](https://github.com/jadore801120/attention-is-all-you-need-pytorch): A PyTorch implementation of the Transformer model in "Attention is All You Need".https://github.com/thnkim/OpenFacePytorch
93. [OpenFacePytorch](https://github.com/thnkim/OpenFacePytorch): PyTorch module to use OpenFace's nn4.small2.v1.t7 model
94. [neural-combinatorial-rl-pytorch](https://github.com/pemami4911/neural-combinatorial-rl-pytorch): PyTorch implementation of Neural Combinatorial Optimization with Reinforcement Learning.
95. [pytorch-nec](https://github.com/mjacar/pytorch-nec): PyTorch Implementation of Neural Episodic Control (NEC)
96. [seq2seq.pytorch](https://github.com/eladhoffer/seq2seq.pytorch): Sequence-to-Sequence learning using PyTorch
97. [Pytorch-Sketch-RNN](https://github.com/alexis-jacq/Pytorch-Sketch-RNN): a pytorch implementation of arxiv.org/abs/1704.03477
98. [pytorch-pruning](https://github.com/jacobgil/pytorch-pruning): PyTorch Implementation of [1611.06440] Pruning Convolutional Neural Networks for Resource Efficient Inference
99. [DrQA](https://github.com/hitvoice/DrQA): A pytorch implementation of Reading Wikipedia to Answer Open-Domain Questions.
100. [YellowFin_Pytorch](https://github.com/JianGoForIt/YellowFin_Pytorch): auto-tuning momentum SGD optimizer
101. [samplernn-pytorch](https://github.com/deepsound-project/samplernn-pytorch): PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model.
102. [AEGeAN](https://github.com/tymokvo/AEGeAN): Deeper DCGAN with AE stabilization
103. [/pytorch-SRResNet](https://github.com/twtygqyy/pytorch-SRResNet): pytorch implementation for Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network arXiv:1609.04802v2
104. [vsepp](https://github.com/fartashf/vsepp): Code for the paper "VSE++: Improved Visual Semantic Embeddings"
105. [Pytorch-DPPO](https://github.com/alexis-jacq/Pytorch-DPPO): Pytorch implementation of Distributed Proximal Policy Optimization: arxiv.org/abs/1707.02286
106. [UNIT](https://github.com/mingyuliutw/UNIT): PyTorch Implementation of our Coupled VAE-GAN algorithm for Unsupervised Image-to-Image Translation
107. [efficient_densenet_pytorch](https://github.com/gpleiss/efficient_densenet_pytorch): A memory-efficient implementation of DenseNets
108. [tsn-pytorch](https://github.com/yjxiong/tsn-pytorch): Temporal Segment Networks (TSN) in PyTorch.
109. [SMASH](https://github.com/ajbrock/SMASH): An experimental technique for efficiently exploring neural architectures.
110. [pytorch-retinanet](https://github.com/kuangliu/pytorch-retinanet): RetinaNet in PyTorch
111. [biogans](https://github.com/aosokin/biogans): Implementation supporting the ICCV 2017 paper "GANs for Biological Image Synthesis".
112. [Semantic Image Synthesis via Adversarial Learning]( https://github.com/woozzu/dong_iccv_2017): A PyTorch implementation of the paper "Semantic Image Synthesis via Adversarial Learning" in ICCV 2017.
113. [fmpytorch](https://github.com/jmhessel/fmpytorch): A PyTorch implementation of a Factorization Machine module in cython.
114. [ORN](https://github.com/ZhouYanzhao/ORN): A PyTorch implementation of the paper "Oriented Response Networks" in CVPR 2017.
115. [pytorch-maml](https://github.com/katerakelly/pytorch-maml): PyTorch implementation of MAML: arxiv.org/abs/1703.03400
116. [pytorch-generative-model-collections](https://github.com/znxlwm/pytorch-generative-model-collections): Collection of generative models in Pytorch version.
117. [vqa-winner-cvprw-2017](https://github.com/markdtw/vqa-winner-cvprw-2017): Pytorch Implementation of winner from VQA Chllange Workshop in CVPR'17.
118. [tacotron_pytorch](https://github.com/r9y9/tacotron_pytorch): PyTorch implementation of Tacotron speech synthesis model.
119. [pspnet-pytorch](https://github.com/Lextal/pspnet-pytorch): PyTorch implementation of PSPNet segmentation network
120. [LM-LSTM-CRF](https://github.com/LiyuanLucasLiu/LM-LSTM-CRF): Empower Sequence Labeling with Task-Aware Language Model http://arxiv.org/abs/1709.04109
121. [face-alignment](https://github.com/1adrianb/face-alignment): Pytorch implementation of the paper "How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)", ICCV 2017
122. [DepthNet](https://github.com/ClementPinard/DepthNet): PyTorch DepthNet Training on Still Box dataset.
123. [EDSR-PyTorch](https://github.com/thstkdgus35/EDSR-PyTorch): PyTorch version of the paper 'Enhanced Deep Residual Networks for Single Image Super-Resolution' (CVPRW 2017)
124. [e2c-pytorch](https://github.com/ethanluoyc/e2c-pytorch): Embed to Control implementation in PyTorch.
125. [3D-ResNets-PyTorch](https://github.com/kenshohara/3D-ResNets-PyTorch): 3D ResNets for Action Recognition.
126. [bandit-nmt](https://github.com/khanhptnk/bandit-nmt): This is code repo for our EMNLP 2017 paper "Reinforcement Learning for Bandit Neural Machine Translation with Simulated Human Feedback", which implements the A2C algorithm on top of a neural encoder-decoder model and benchmarks the combination under simulated noisy rewards.
127. [pytorch-a2c-ppo-acktr](https://github.com/ikostrikov/pytorch-a2c-ppo-acktr): PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO) and Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR).
128. [zalando-pytorch](https://github.com/baldassarreFe/zalando-pytorch): Various experiments on the [Fashion-MNIST](zalandoresearch/fashion-mnist) dataset from Zalando.
129. [sphereface_pytorch](https://github.com/clcarwin/sphereface_pytorch): A PyTorch Implementation of SphereFace.
130. [Categorical DQN](https://github.com/floringogianu/categorical-dqn): A PyTorch Implementation of Categorical DQN from [A Distributional Perspective on Reinforcement Learning](https://arxiv.org/abs/1707.06887).
131. [pytorch-ntm](https://github.com/loudinthecloud/pytorch-ntm): pytorch ntm implementation.
132. [mask_rcnn_pytorch](https://github.com/felixgwu/mask_rcnn_pytorch): Mask RCNN in PyTorch.
133. [graph_convnets_pytorch](https://github.com/xbresson/graph_convnets_pytorch): PyTorch implementation of graph ConvNets, NIPS’16
134. [pytorch-faster-rcnn](https://github.com/ruotianluo/pytorch-faster-rcnn): A pytorch implementation of faster RCNN detection framework based on Xinlei Chen's tf-faster-rcnn.
135. [torchMoji](https://github.com/huggingface/torchMoji): A pyTorch implementation of the DeepMoji model: state-of-the-art deep learning model for analyzing sentiment, emotion, sarcasm etc.
136. [semantic-segmentation-pytorch](https://github.com/hangzhaomit/semantic-segmentation-pytorch): Pytorch implementation for Semantic Segmentation/Scene Parsing on [MIT ADE20K dataset](http://sceneparsing.csail.mit.edu)
137. [pytorch-qrnn](https://github.com/salesforce/pytorch-qrnn): PyTorch implementation of the Quasi-Recurrent Neural Network - up to 16 times faster than NVIDIA's cuDNN LSTM
138. [pytorch-sgns](https://github.com/theeluwin/pytorch-sgns): Skipgram Negative Sampling in PyTorch.
139. [SfmLearner-Pytorch ](https://github.com/ClementPinard/SfmLearner-Pytorch): Pytorch version of SfmLearner from Tinghui Zhou et al.
140. [deformable-convolution-pytorch](https://github.com/1zb/deformable-convolution-pytorch): PyTorch implementation of Deformable Convolution.
141. [skip-gram-pytorch](https://github.com/fanglanting/skip-gram-pytorch): A complete pytorch implementation of skipgram model (with subsampling and negative sampling). The embedding result is tested with Spearman's rank correlation.
142. [stackGAN-v2](https://github.com/hanzhanggit/StackGAN-v2): Pytorch implementation for reproducing StackGAN_v2 results in the paper StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks by Han Zhang*, Tao Xu*, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas.
143. [self-critical.pytorch](https://github.com/ruotianluo/self-critical.pytorch): Unofficial pytorch implementation for Self-critical Sequence Training for Image Captioning.
144. [pygcn](https://github.com/tkipf/pygcn): Graph Convolutional Networks in PyTorch.
145. [dnc](https://github.com/ixaxaar/pytorch-dnc): Differentiable Neural Computers, for Pytorch
146. [prog_gans_pytorch_inference](https://github.com/ptrblck/prog_gans_pytorch_inference): PyTorch inference for "Progressive Growing of GANs" with CelebA snapshot.
147. [pytorch-capsule](https://github.com/timomernick/pytorch-capsule): Pytorch implementation of Hinton's Dynamic Routing Between Capsules.
148. [PyramidNet-PyTorch](https://github.com/dyhan0920/PyramidNet-PyTorch): A PyTorch implementation for PyramidNets (Deep Pyramidal Residual Networks, arxiv.org/abs/1610.02915)
149. [radio-transformer-networks](https://github.com/gram-ai/radio-transformer-networks): A PyTorch implementation of Radio Transformer Networks from the paper "An Introduction to Deep Learning for the Physical Layer". arxiv.org/abs/1702.00832
150. [honk](https://github.com/castorini/honk): PyTorch reimplementation of Google's TensorFlow CNNs for keyword spotting.
151. [DeepCORAL](https://github.com/SSARCandy/DeepCORAL): A PyTorch implementation of 'Deep CORAL: Correlation Alignment for Deep Domain Adaptation.', ECCV 2016
152. [pytorch-pose](https://github.com/bearpaw/pytorch-pose): A PyTorch toolkit for 2D Human Pose Estimation.
153. [lang-emerge-parlai](https://github.com/karandesai-96/lang-emerge-parlai): Implementation of EMNLP 2017 Paper "Natural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog" using PyTorch and ParlAI
154. [Rainbow](https://github.com/Kaixhin/Rainbow): Rainbow: Combining Improvements in Deep Reinforcement Learning
155. [pytorch_compact_bilinear_pooling v1](https://github.com/gdlg/pytorch_compact_bilinear_pooling): This repository has a pure Python implementation of Compact Bilinear Pooling and Count Sketch for PyTorch.
156. [CompactBilinearPooling-Pytorch v2](https://github.com/DeepInsight-PCALab/CompactBilinearPooling-Pytorch): (Yang Gao, et al.) A Pytorch Implementation for Compact Bilinear Pooling.
157. [FewShotLearning](https://github.com/gitabcworld/FewShotLearning): Pytorch implementation of the paper "Optimization as a Model for Few-Shot Learning"
158. [meProp](https://github.com/jklj077/meProp): Codes for "meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting".
159. [SFD_pytorch](https://github.com/clcarwin/SFD_pytorch): A PyTorch Implementation of Single Shot Scale-invariant Face Detector.
160. [GradientEpisodicMemory](https://github.com/facebookresearch/GradientEpisodicMemory): Continuum Learning with GEM: Gradient Episodic Memory. https://arxiv.org/abs/1706.08840
161. [DeblurGAN](https://github.com/KupynOrest/DeblurGAN): Pytorch implementation of the paper DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks.
162. [StarGAN](https://github.com/yunjey/StarGAN): StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Tranlsation.
163. [CapsNet-pytorch](https://github.com/adambielski/CapsNet-pytorch): PyTorch implementation of NIPS 2017 paper Dynamic Routing Between Capsules.
164. [CondenseNet](https://github.com/ShichenLiu/CondenseNet): CondenseNet: An Efficient DenseNet using Learned Group Convolutions.
165. [deep-image-prior](https://github.com/DmitryUlyanov/deep-image-prior): Image restoration with neural networks but without learning.
166. [deep-head-pose](https://github.com/natanielruiz/deep-head-pose): Deep Learning Head Pose Estimation using PyTorch.
167. [Random-Erasing](https://github.com/zhunzhong07/Random-Erasing): This code has the source code for the paper "Random Erasing Data Augmentation".
168. [FaderNetworks](https://github.com/facebookresearch/FaderNetworks): Fader Networks: Manipulating Images by Sliding Attributes - NIPS 2017
169. [FlowNet 2.0](https://github.com/NVIDIA/flownet2-pytorch): FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
170. [pix2pixHD](https://github.com/NVIDIA/pix2pixHD): Synthesizing and manipulating 2048x1024 images with conditional GANs tcwang0509.github.io/pix2pixHD
171. [pytorch-smoothgrad](https://github.com/pkdn/pytorch-smoothgrad): SmoothGrad implementation in PyTorch
172. [RetinaNet](https://github.com/c0nn3r/RetinaNet): An implementation of RetinaNet in PyTorch.
173. [faster-rcnn.pytorch](https://github.com/jwyang/faster-rcnn.pytorch): This project is a faster faster R-CNN implementation, aimed to accelerating the training of faster R-CNN object detection models.
174. [mixup_pytorch](https://github.com/leehomyc/mixup_pytorch): A PyTorch implementation of the paper Mixup: Beyond Empirical Risk Minimization in PyTorch.
175. [inplace_abn](https://github.com/mapillary/inplace_abn): In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
176. [pytorch-pose-hg-3d](https://github.com/xingyizhou/pytorch-pose-hg-3d): PyTorch implementation for 3D human pose estimation
177. [nmn-pytorch](https://github.com/HarshTrivedi/nmn-pytorch): Neural Module Network for VQA in Pytorch.
178. [bytenet](https://github.com/kefirski/bytenet): Pytorch implementation of bytenet from "Neural Machine Translation in Linear Time" paper
179. [bottom-up-attention-vqa](https://github.com/hengyuan-hu/bottom-up-attention-vqa): vqa, bottom-up-attention, pytorch
180. [yolo2-pytorch](https://github.com/ruiminshen/yolo2-pytorch): The YOLOv2 is one of the most popular one-stage object detector. This project adopts PyTorch as the developing framework to increase productivity, and utilize ONNX to convert models into Caffe 2 to benifit engineering deployment.
181. [reseg-pytorch](https://github.com/Wizaron/reseg-pytorch): PyTorch Implementation of ReSeg (arxiv.org/pdf/1511.07053.pdf)
182. [binary-stochastic-neurons](https://github.com/Wizaron/binary-stochastic-neurons): Binary Stochastic Neurons in PyTorch.
183. [pytorch-pose-estimation](https://github.com/DavexPro/pytorch-pose-estimation): PyTorch Implementation of Realtime Multi-Person Pose Estimation project.
184. [interaction_network_pytorch](https://github.com/higgsfield/interaction_network_pytorch): Pytorch Implementation of Interaction Networks for Learning about Objects, Relations and Physics.
185. [NoisyNaturalGradient](https://github.com/wlwkgus/NoisyNaturalGradient): Pytorch Implementation of paper "Noisy Natural Gradient as Variational Inference".
186. [ewc.pytorch](https://github.com/moskomule/ewc.pytorch): An implementation of Elastic Weight Consolidation (EWC), proposed in James Kirkpatrick et al. Overcoming catastrophic forgetting in neural networks 2016(10.1073/pnas.1611835114).
187. [pytorch-zssr](https://github.com/jacobgil/pytorch-zssr): PyTorch implementation of 1712.06087 "Zero-Shot" Super-Resolution using Deep Internal Learning
188. [deep_image_prior](https://github.com/atiyo/deep_image_prior): An implementation of image reconstruction methods from Deep Image Prior (Ulyanov et al., 2017) in PyTorch.
189. [pytorch-transformer](https://github.com/leviswind/pytorch-transformer): pytorch implementation of Attention is all you need.
190. [DeepRL-Grounding](https://github.com/devendrachaplot/DeepRL-Grounding): This is a PyTorch implementation of the AAAI-18 paper Gated-Attention Architectures for Task-Oriented Language Grounding
191. [deep-forecast-pytorch](https://github.com/Wizaron/deep-forecast-pytorch): Wind Speed Prediction using LSTMs in PyTorch (arxiv.org/pdf/1707.08110.pdf)
192. [cat-net](https://github.com/utiasSTARS/cat-net): Canonical Appearance Transformations
193. [minimal_glo](https://github.com/tneumann/minimal_glo): Minimal PyTorch implementation of Generative Latent Optimization from the paper "Optimizing the Latent Space of Generative Networks"
194. [LearningToCompare-Pytorch](https://github.com/dragen1860/LearningToCompare-Pytorch): Pytorch Implementation for Paper: Learning to Compare: Relation Network for Few-Shot Learning.
195. [poincare-embeddings](https://github.com/facebookresearch/poincare-embeddings): PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations".
196. [pytorch-trpo(Hessian-vector product version)](https://github.com/ikostrikov/pytorch-trpo): This is a PyTorch implementation of "Trust Region Policy Optimization (TRPO)" with exact Hessian-vector product instead of finite differences approximation.
197. [ggnn.pytorch](https://github.com/JamesChuanggg/ggnn.pytorch): A PyTorch Implementation of Gated Graph Sequence Neural Networks (GGNN).
198. [visual-interaction-networks-pytorch](https://github.com/Mrgemy95/visual-interaction-networks-pytorch): This's an implementation of deepmind Visual Interaction Networks paper using pytorch
199. [adversarial-patch](https://github.com/jhayes14/adversarial-patch): PyTorch implementation of adversarial patch.
200. [Prototypical-Networks-for-Few-shot-Learning-PyTorch](https://github.com/orobix/Prototypical-Networks-for-Few-shot-Learning-PyTorch): Implementation of Prototypical Networks for Few Shot Learning (arxiv.org/abs/1703.05175) in Pytorch
201. [Visual-Feature-Attribution-Using-Wasserstein-GANs-Pytorch](https://github.com/orobix/Visual-Feature-Attribution-Using-Wasserstein-GANs-Pytorch): Implementation of Visual Feature Attribution using Wasserstein GANs (arxiv.org/abs/1711.08998) in PyTorch.
202. [PhotographicImageSynthesiswithCascadedRefinementNetworks-Pytorch](https://github.com/Blade6570/PhotographicImageSynthesiswithCascadedRefinementNetworks-Pytorch): Photographic Image Synthesis with Cascaded Refinement Networks - Pytorch Implementation
203. [ENAS-pytorch](https://github.com/carpedm20/ENAS-pytorch): PyTorch implementation of "Efficient Neural Architecture Search via Parameters Sharing".
204. [Neural-IMage-Assessment](https://github.com/kentsyx/Neural-IMage-Assessment): A PyTorch Implementation of Neural IMage Assessment.
205. [proxprop](https://github.com/tfrerix/proxprop): Proximal Backpropagation - a neural network training algorithm that takes implicit instead of explicit gradient steps.
206. [FastPhotoStyle](https://github.com/NVIDIA/FastPhotoStyle): A Closed-form Solution to Photorealistic Image Stylization
207. [Deep-Image-Analogy-PyTorch](https://github.com/Ben-Louis/Deep-Image-Analogy-PyTorch): A python implementation of Deep-Image-Analogy based on pytorch.
208. [Person-reID_pytorch](https://github.com/layumi/Person_reID_baseline_pytorch): PyTorch for Person re-ID.
209. [pt-dilate-rnn](https://github.com/zalandoresearch/pt-dilate-rnn): Dilated RNNs in pytorch.
210. [pytorch-i-revnet](https://github.com/jhjacobsen/pytorch-i-revnet): Pytorch implementation of i-RevNets.
211. [OrthNet](https://github.com/Orcuslc/OrthNet): TensorFlow and PyTorch layers for generating Orthogonal Polynomials.
212. [DRRN-pytorch](https://github.com/jt827859032/DRRN-pytorch): An implementation of Deep Recursive Residual Network for Super Resolution (DRRN), CVPR 2017
213. [shampoo.pytorch](https://github.com/moskomule/shampoo.pytorch): An implementation of shampoo.
214. [Neural-IMage-Assessment 2](https://github.com/truskovskiyk/nima.pytorch): A PyTorch Implementation of Neural IMage Assessment.
215. [TCN](https://github.com/locuslab/TCN): Sequence modeling benchmarks and temporal convolutional networks locuslab/TCN
216. [DCC](https://github.com/shahsohil/DCC): This repository contains the source code and data for reproducing results of Deep Continuous Clustering paper.
217. [packnet](https://github.com/arunmallya/packnet): Code for PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning arxiv.org/abs/1711.05769
218. [PyTorch-progressive_growing_of_gans](https://github.com/github-pengge/PyTorch-progressive_growing_of_gans): PyTorch implementation of Progressive Growing of GANs for Improved Quality, Stability, and Variation.
219. [nonauto-nmt](https://github.com/salesforce/nonauto-nmt): PyTorch Implementation of "Non-Autoregressive Neural Machine Translation"
220. [PyTorch-GAN](https://github.com/eriklindernoren/PyTorch-GAN): PyTorch implementations of Generative Adversarial Networks.
221. [PyTorchWavelets](https://github.com/tomrunia/PyTorchWavelets): PyTorch implementation of the wavelet analysis found in Torrence and Compo (1998)
222. [pytorch-made](https://github.com/karpathy/pytorch-made): MADE (Masked Autoencoder Density Estimation) implementation in PyTorch
223. [VRNN](https://github.com/emited/VariationalRecurrentNeuralNetwork): Pytorch implementation of the Variational RNN (VRNN), from A Recurrent Latent Variable Model for Sequential Data.
224. [flow](https://github.com/emited/flow): Pytorch implementation of ICLR 2018 paper Deep Learning for Physical Processes: Integrating Prior Scientific Knowledge.
225. [deepvoice3_pytorch](https://github.com/r9y9/deepvoice3_pytorch): PyTorch implementation of convolutional networks-based text-to-speech synthesis models
226. [psmm](https://github.com/elanmart/psmm): imlementation of the the Pointer Sentinel Mixture Model, as described in the paper by Stephen Merity et al.
227. [tacotron2](https://github.com/NVIDIA/tacotron2): Tacotron 2 - PyTorch implementation with faster-than-realtime inference.
228. [AccSGD](https://github.com/rahulkidambi/AccSGD): Implements pytorch code for the Accelerated SGD algorithm.
229. [QANet-pytorch](https://github.com/hengruo/QANet-pytorch): an implementation of QANet with PyTorch (EM/F1 = 70.5/77.2 after 20 epoches for about 20 hours on one 1080Ti card.)
230. [ConvE](https://github.com/TimDettmers/ConvE): Convolutional 2D Knowledge Graph Embeddings
231. [Structured-Self-Attention](https://github.com/kaushalshetty/Structured-Self-Attention): Implementation for the paper A Structured Self-Attentive Sentence Embedding, which is published in ICLR 2017: arxiv.org/abs/1703.03130 .
232. [graphsage-simple](https://github.com/williamleif/graphsage-simple): Simple reference implementation of GraphSAGE.
233. [Detectron.pytorch](https://github.com/roytseng-tw/Detectron.pytorch): A pytorch implementation of Detectron. Both training from scratch and inferring directly from pretrained Detectron weights are available.
234. [R2Plus1D-PyTorch](https://github.com/irhumshafkat/R2Plus1D-PyTorch): PyTorch implementation of the R2Plus1D convolution based ResNet architecture described in the paper "A Closer Look at Spatiotemporal Convolutions for Action Recognition"
235. [StackNN](https://github.com/viking-sudo-rm/StackNN): A PyTorch implementation of differentiable stacks for use in neural networks.
236. [translagent](https://github.com/facebookresearch/translagent): Code for Emergent Translation in Multi-Agent Communication.
237. [ban-vqa](https://github.com/jnhwkim/ban-vqa): Bilinear attention networks for visual question answering.
238. [pytorch-openai-transformer-lm](https://github.com/huggingface/pytorch-openai-transformer-lm): This is a PyTorch implementation of the TensorFlow code provided with OpenAI's paper "Improving Language Understanding by Generative Pre-Training" by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
239. [T2F](https://github.com/akanimax/T2F): Text-to-Face generation using Deep Learning. This project combines two of the recent architectures StackGAN and ProGAN for synthesizing faces from textual descriptions.
240. [pytorch - fid](https://github.com/mseitzer/pytorch-fid): A Port of Fréchet Inception Distance (FID score) to PyTorch
241. [vae_vpflows](https://github.com/jmtomczak/vae_vpflows):Code in PyTorch for the convex combination linear IAF and the Householder Flow, J.M. Tomczak & M. Welling jmtomczak.github.io/deebmed.html
242. [CoordConv-pytorch](https://github.com/mkocabas/CoordConv-pytorch): Pytorch implementation of CoordConv introduced in 'An intriguing failing of convolutional neural networks and the CoordConv solution' paper. (arxiv.org/pdf/1807.03247.pdf)
243. [SDPoint](https://github.com/xternalz/SDPoint): Implementation of "Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks", published in CVPR 2018.
244. [SRDenseNet-pytorch](https://github.com/wxywhu/SRDenseNet-pytorch): SRDenseNet-pytorch(ICCV_2017)
245. [GAN_stability](https://github.com/LMescheder/GAN_stability): Code for paper "Which Training Methods for GANs do actually Converge? (ICML 2018)"
246. [Mask-RCNN](https://github.com/wannabeOG/Mask-RCNN): A PyTorch implementation of the architecture of Mask RCNN, serves as an introduction to working with PyTorch
247. [pytorch-coviar](https://github.com/chaoyuaw/pytorch-coviar): Compressed Video Action Recognition
248. [PNASNet.pytorch](https://github.com/chenxi116/PNASNet.pytorch): PyTorch implementation of PNASNet-5 on ImageNet.
249. [NALU-pytorch](https://github.com/kevinzakka/NALU-pytorch): Basic pytorch implementation of NAC/NALU from Neural Arithmetic Logic Units arxiv.org/pdf/1808.00508.pdf
250. [LOLA_DiCE](https://github.com/alexis-jacq/LOLA_DiCE): Pytorch implementation of LOLA (arxiv.org/abs/1709.04326) using DiCE (arxiv.org/abs/1802.05098)
251. [generative-query-network-pytorch](https://github.com/wohlert/generative-query-network-pytorch): Generative Query Network (GQN) in PyTorch as described in "Neural Scene Representation and Rendering"
252. [pytorch_hmax](https://github.com/wmvanvliet/pytorch_hmax): Implementation of the HMAX model of vision in PyTorch.
253. [FCN-pytorch-easiest](https://github.com/yunlongdong/FCN-pytorch-easiest): trying to be the most easiest and just get-to-use pytorch implementation of FCN (Fully Convolotional Networks)
254. [transducer](https://github.com/awni/transducer): A Fast Sequence Transducer Implementation with PyTorch Bindings.
255. [AVO-pytorch](https://github.com/artix41/AVO-pytorch): Implementation of Adversarial Variational Optimization in PyTorch.
256. [HCN-pytorch](https://github.com/huguyuehuhu/HCN-pytorch): A pytorch reimplementation of { Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation }.
257. [binary-wide-resnet](https://github.com/szagoruyko/binary-wide-resnet): PyTorch implementation of Wide Residual Networks with 1-bit weights by McDonnel (ICLR 2018)
258. [piggyback](https://github.com/arunmallya/piggyback): Code for Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights arxiv.org/abs/1801.06519
259. [vid2vid](https://github.com/NVIDIA/vid2vid): Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic video-to-video translation.
260. [poisson-convolution-sum](https://github.com/cranmer/poisson-convolution-sum): Implements an infinite sum of poisson-weighted convolutions
261. [tbd-nets](https://github.com/davidmascharka/tbd-nets): PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning" arxiv.org/abs/1803.05268
262. [attn2d](https://github.com/elbayadm/attn2d): Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
263. [yolov3](https://github.com/ultralytics/yolov3): YOLOv3: Training and inference in PyTorch pjreddie.com/darknet/yolo
264. [deep-dream-in-pytorch](https://github.com/duc0/deep-dream-in-pytorch): Pytorch implementation of the DeepDream computer vision algorithm.
265. [pytorch-flows](https://github.com/ikostrikov/pytorch-flows): PyTorch implementations of algorithms for density estimation
266. [quantile-regression-dqn-pytorch](https://github.com/ars-ashuha/quantile-regression-dqn-pytorch): Quantile Regression DQN a Minimal Working Example
267. [relational-rnn-pytorch](https://github.com/L0SG/relational-rnn-pytorch): An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
268. [DEXTR-PyTorch](https://github.com/scaelles/DEXTR-PyTorch): Deep Extreme Cut http://www.vision.ee.ethz.ch/~cvlsegmentation/dextr
269. [PyTorch_GBW_LM](https://github.com/rdspring1/PyTorch_GBW_LM): PyTorch Language Model for Google Billion Word Dataset.
270. [Pytorch-NCE](https://github.com/Stonesjtu/Pytorch-NCE): The Noise Contrastive Estimation for softmax output written in Pytorch
271. [generative-models](https://github.com/shayneobrien/generative-models): Annotated, understandable, and visually interpretable PyTorch implementations of: VAE, BIRVAE, NSGAN, MMGAN, WGAN, WGANGP, LSGAN, DRAGAN, BEGAN, RaGAN, InfoGAN, fGAN, FisherGAN.
272. [convnet-aig](https://github.com/andreasveit/convnet-aig): PyTorch implementation for Convolutional Networks with Adaptive Inference Graphs.
273. [integrated-gradient-pytorch](https://github.com/TianhongDai/integrated-gradient-pytorch): This is the pytorch implementation of the paper - Axiomatic Attribution for Deep Networks.
274. [MalConv-Pytorch](https://github.com/Alexander-H-Liu/MalConv-Pytorch): Pytorch implementation of MalConv.
275. [trellisnet](https://github.com/locuslab/trellisnet): Trellis Networks for Sequence Modeling
276. [Learning to Communicate with Deep Multi-Agent Reinforcement Learning](https://github.com/minqi/learning-to-communicate-pytorch): pytorch implementation of Learning to Communicate with Deep Multi-Agent Reinforcement Learning paper.
277. [pnn.pytorch](https://github.com/michaelklachko/pnn.pytorch): PyTorch implementation of CVPR'18 - Perturbative Neural Networks http://xujuefei.com/pnn.html.
278. [Face_Attention_Network](https://github.com/rainofmine/Face_Attention_Network): Pytorch implementation of face attention network as described in Face Attention Network: An Effective Face Detector for the Occluded Faces.
279. [waveglow](https://github.com/NVIDIA/waveglow): A Flow-based Generative Network for Speech Synthesis.
280. [deepfloat](https://github.com/facebookresearch/deepfloat): This repository contains the SystemVerilog RTL, C++, HLS (Intel FPGA OpenCL to wrap RTL code) and Python needed to reproduce the numerical results in "Rethinking floating point for deep learning"
281. [EPSR](https://github.com/subeeshvasu/2018_subeesh_epsr_eccvw): Pytorch implementation of [Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network](https://arxiv.org/pdf/1811.00344.pdf). This work has won the first place in PIRM2018-SR competition (region 1) held as part of the ECCV 2018.
282. [ClariNet](https://github.com/ksw0306/ClariNet): A Pytorch Implementation of ClariNet arxiv.org/abs/1807.07281
283. [pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT): PyTorch version of Google AI's BERT model with script to load Google's pre-trained models
284. [torch_waveglow](https://github.com/npuichigo/waveglow): A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis.
285. [3DDFA](https://github.com/cleardusk/3DDFA): The pytorch improved re-implementation of TPAMI 2017 paper: Face Alignment in Full Pose Range: A 3D Total Solution.
286. [loss-landscape](https://github.com/tomgoldstein/loss-landscape): loss-landscape Code for visualizing the loss landscape of neural nets.
287. [famos](https://github.com/zalandoresearch/famos):
Pytorch implementation of the paper "Copy the Old or Paint Anew? An Adversarial Framework for (non-) Parametric Image Stylization" available at http://arxiv.org/abs/1811.09236.
288. [back2future.pytorch](https://github.com/anuragranj/back2future.pytorch): This is a Pytorch implementation of
Janai, J., Güney, F., Ranjan, A., Black, M. and Geiger, A., Unsupervised Learning of Multi-Frame Optical Flow with Occlusions. ECCV 2018.
289. [FFTNet](https://github.com/mozilla/FFTNet): Unofficial Implementation of FFTNet vocode paper.
290. [FaceBoxes.PyTorch](https://github.com/zisianw/FaceBoxes.PyTorch): A PyTorch Implementation of FaceBoxes.
291. [Transformer-XL](https://github.com/kimiyoung/transformer-xl): Transformer-XL: Attentive Language Models Beyond a Fixed-Length Contexthttps://github.com/kimiyoung/transformer-xl
292. [associative_compression_networks](https://github.com/jalexvig/associative_compression_networks): Associative Compression Networks for Representation Learning.
293. [fluidnet_cxx](https://github.com/jolibrain/fluidnet_cxx): FluidNet re-written with ATen tensor lib.
294. [Deep-Reinforcement-Learning-Algorithms-with-PyTorch](https://github.com/p-christ/Deep-Reinforcement-Learning-Algorithms-with-PyTorch): This repository contains PyTorch implementations of deep reinforcement learning algorithms.
295. [Shufflenet-v2-Pytorch](https://github.com/ericsun99/Shufflenet-v2-Pytorch): This is a Pytorch implementation of faceplusplus's ShuffleNet-v2.
296. [GraphWaveletNeuralNetwork](https://github.com/benedekrozemberczki/GraphWaveletNeuralNetwork): This is a Pytorch implementation of Graph Wavelet Neural Network. ICLR 2019.
297. [AttentionWalk](https://github.com/benedekrozemberczki/AttentionWalk): This is a Pytorch implementation of Watch Your Step: Learning Node Embeddings via Graph Attention. NIPS 2018.
298. [SGCN](https://github.com/benedekrozemberczki/SGCN): This is a Pytorch implementation of Signed Graph Convolutional Network. ICDM 2018.
299. [SINE](https://github.com/benedekrozemberczki/SINE): This is a Pytorch implementation of SINE: Scalable Incomplete Network Embedding. ICDM 2018.
300. [GAM](https://github.com/benedekrozemberczki/GAM): This is a Pytorch implementation of Graph Classification using Structural Attention. KDD 2018.
301. [neural-style-pt](https://github.com/ProGamerGov/neural-style-pt): A PyTorch implementation of Justin Johnson's Neural-style.
302. [TuckER](https://github.com/ibalazevic/TuckER): TuckER: Tensor Factorization for Knowledge Graph Completion.
303. [pytorch-prunes](https://github.com/BayesWatch/pytorch-prunes): Pruning neural networks: is it time to nip it in the bud?
304. [SimGNN](https://github.com/benedekrozemberczki/SimGNN): SimGNN: A Neural Network Approach to Fast Graph Similarity Computation.
305. [Character CNN](https://github.com/ahmedbesbes/character-based-cnn): PyTorch implementation of the Character-level Convolutional Networks for Text Classification paper.
306. [XLM](https://github.com/facebookresearch/XLM): PyTorch original implementation of Cross-lingual Language Model Pretraining.
307. [DiffAI](https://github.com/eth-sri/diffai): A provable defense against adversarial examples and library for building compatible PyTorch models.
308. [APPNP](https://github.com/benedekrozemberczki/APPNP): Combining Neural Networks with Personalized PageRank for Classification on Graphs. ICLR 2019.
309. [NGCN](https://github.com/benedekrozemberczki/MixHop-and-N-GCN): A Higher-Order Graph Convolutional Layer. NeurIPS 2018.
310. [gpt-2-Pytorch](https://github.com/graykode/gpt-2-Pytorch): Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
311. [Splitter](https://github.com/benedekrozemberczki/Splitter): Splitter: Learning Node Representations that Capture Multiple Social Contexts. (WWW 2019).
312. [CapsGNN](https://github.com/benedekrozemberczki/CapsGNN): Capsule Graph Neural Network. (ICLR 2019).
313. [BigGAN-PyTorch](https://github.com/ajbrock/BigGAN-PyTorch): The author's officially unofficial PyTorch BigGAN implementation.
314. [ppo_pytorch_cpp](https://github.com/mhubii/ppo_pytorch_cpp): This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch.
315. [RandWireNN](https://github.com/seungwonpark/RandWireNN): Implementation of: "Exploring Randomly Wired Neural Networks for Image Recognition".
316. [Zero-shot Intent CapsNet](https://github.com/joel-huang/zeroshot-capsnet-pytorch): GPU-accelerated PyTorch implementation of "Zero-shot User Intent Detection via Capsule Neural Networks".
317. [SEAL-CI](https://github.com/benedekrozemberczki/SEAL-CI) Semi-Supervised Graph Classification: A Hierarchical Graph Perspective. (WWW 2019).
318. [MixHop](https://github.com/benedekrozemberczki/MixHop-and-N-GCN): MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing. ICML 2019.
319. [densebody_pytorch](https://github.com/Lotayou/densebody_pytorch): PyTorch implementation of CloudWalk's recent paper DenseBody.
320. [voicefilter](https://github.com/mindslab-ai/voicefilter): Unofficial PyTorch implementation of Google AI's VoiceFilter system http://swpark.me/voicefilter.
321. [NVIDIA/semantic-segmentation](https://github.com/NVIDIA/semantic-segmentation): A PyTorch Implementation of [Improving Semantic Segmentation via Video Propagation and Label Relaxation](https://arxiv.org/abs/1812.01593), In CVPR2019.
322. [ClusterGCN](https://github.com/benedekrozemberczki/ClusterGCN): A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019).
323. [NVlabs/DG-Net](https://github.com/NVlabs/DG-Net): A PyTorch implementation of "Joint Discriminative and Generative Learning for Person Re-identification" (CVPR19 Oral).
324. [NCRF](https://github.com/baidu-research/NCRF): Cancer metastasis detection with neural conditional random field (NCRF)
325. [pytorch-sift](https://github.com/ducha-aiki/pytorch-sift): PyTorch implementation of SIFT descriptor.
326. [brain-segmentation-pytorch](https://github.com/mateuszbuda/brain-segmentation-pytorch): U-Net implementation in PyTorch for FLAIR abnormality segmentation in brain MRI.
327. [glow-pytorch](https://github.com/rosinality/glow-pytorch): PyTorch implementation of Glow, Generative Flow with Invertible 1x1 Convolutions (arxiv.org/abs/1807.03039)
328. [EfficientNets-PyTorch](https://github.com/zsef123/EfficientNets-PyTorch): A PyTorch implementation of EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.
329. [STEAL](https://github.com/nv-tlabs/STEAL): STEAL - Learning Semantic Boundaries from Noisy Annotations nv-tlabs.github.io/STEAL
330. [EigenDamage-Pytorch](https://github.com/alecwangcq/EigenDamage-Pytorch): Official implementation of the ICML'19 paper "EigenDamage: Structured Pruning in the Kronecker-Factored Eigenbasis".
331. [Aspect-level-sentiment](https://github.com/ruidan/Aspect-level-sentiment): Code and dataset for ACL2018 paper "Exploiting Document Knowledge for Aspect-level Sentiment Classification"
332. [breast_cancer_classifier](https://github.com/nyukat/breast_cancer_classifier): Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening arxiv.org/abs/1903.08297
333. [DGC-Net](https://github.com/AaltoVision/DGC-Net): A PyTorch implementation of "DGC-Net: Dense Geometric Correspondence Network".
334. [universal-triggers](https://github.com/Eric-Wallace/universal-triggers): Universal Adversarial Triggers for Attacking and Analyzing NLP (EMNLP 2019)
335. [Deep-Reinforcement-Learning-Algorithms-with-PyTorch](https://github.com/p-christ/Deep-Reinforcement-Learning-Algorithms-with-PyTorch): PyTorch implementations of deep reinforcement learning algorithms and environments.
336. [simple-effective-text-matching-pytorch](https://github.com/alibaba-edu/simple-effective-text-matching-pytorch): A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
336. [Adaptive-segmentation-mask-attack (ASMA)](https://github.com/utkuozbulak/adaptive-segmentation-mask-attack): A pytorch implementation of the MICCAI2019 paper "Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation".
337. [NVIDIA/unsupervised-video-interpolation](https://github.com/NVIDIA/unsupervised-video-interpolation): A PyTorch Implementation of [Unsupervised Video Interpolation Using Cycle Consistency](https://arxiv.org/abs/1906.05928), In ICCV 2019.
338. [Seg-Uncertainty](https://github.com/layumi/Seg-Uncertainty): Unsupervised Scene Adaptation with Memory Regularization in vivo, In IJCAI 2020.
339. [pulse](https://github.com/adamian98/pulse): Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
340. [distance-encoding](https://github.com/snap-stanford/distance-encoding): Distance-Encoding - Design Provably More PowerfulGNNs for Structural Representation Learning.
341. [Pathfinder Discovery Networks](https://github.com/benedekrozemberczki/PDN): Pathfinder Discovery Networks for Neural Message Passing.
342. [PyKEEN](https://github.com/pykeen/pykeen): A Python library for learning and evaluating knowledge graph embeddings.
343. [SSSNET](https://github.com/SherylHYX/SSSNET_Signed_Clustering): Official implementation of the SDM2022 paper "SSSNET: Semi-Supervised Signed Network Clustering".
344. [MagNet](https://github.com/matthew-hirn/magnet): Official implementation of the NeurIPS2021 paper "MagNet: A Neural Network for Directed Graphs".
345. [Semantic Search](https://github.com/kuutsav/information-retrieval): Latest in the field of neural information retrieval / semantic search.
## Talks & conferences
1. [PyTorch Conference 2018](https://developers.facebook.com/videos/2018/pytorch-developer-conference/): First PyTorch developer conference at 2018.
## Pytorch elsewhere
1. **[the-incredible-pytorch](https://github.com/ritchieng/the-incredible-pytorch)**: The Incredible PyTorch: a curated list of tutorials, papers, projects, communities and more relating to PyTorch.
2. [generative models](https://github.com/wiseodd/generative-models): Collection of generative models, e.g. GAN, VAE in Tensorflow, Keras, and Pytorch. http://wiseodd.github.io
3. [pytorch vs tensorflow](https://www.reddit.com/r/MachineLearning/comments/5w3q74/d_so_pytorch_vs_tensorflow_whats_the_verdict_on/): an informative thread on reddit.
4. [Pytorch discussion forum](https://discuss.pytorch.org/)
5. [pytorch notebook: docker-stack](https://hub.docker.com/r/escong/pytorch-notebook/): A project similar to [Jupyter Notebook Scientific Python Stack](https://github.com/jupyter/docker-stacks/tree/master/scipy-notebook)
6. [drawlikebobross](https://github.com/kendricktan/drawlikebobross): Draw like Bob Ross using the power of Neural Networks (With PyTorch)!
7. [pytorch-tvmisc](https://github.com/t-vi/pytorch-tvmisc): Totally Versatile Miscellanea for Pytorch
8. [pytorch-a3c-mujoco](https://github.com/andrewliao11/pytorch-a3c-mujoco): Implement A3C for Mujoco gym envs.
9. [PyTorch in 5 Minutes](https://www.youtube.com/watch?v=nbJ-2G2GXL0&list=WL&index=9).
10. [pytorch_chatbot](https://github.com/jinfagang/pytorch_chatbot): A Marvelous ChatBot implemented using PyTorch.
11. [malmo-challenge](https://github.com/Kaixhin/malmo-challenge): Malmo Collaborative AI Challenge - Team Pig Catcher
12. [sketchnet](https://github.com/jtoy/sketchnet): A model that takes an image and generates Processing source code to regenerate that image
13. [Deep-Learning-Boot-Camp](https://github.com/QuantScientist/Deep-Learning-Boot-Camp): A nonprofit community run, 5-day Deep Learning Bootcamp http://deep-ml.com.
14. [Amazon_Forest_Computer_Vision](https://github.com/mratsim/Amazon_Forest_Computer_Vision): Satellite Image tagging code using PyTorch / Keras with lots of PyTorch tricks. kaggle competition.
15. [AlphaZero_Gomoku](https://github.com/junxiaosong/AlphaZero_Gomoku): An implementation of the AlphaZero algorithm for Gomoku (also called Gobang or Five in a Row)
16. [pytorch-cv](https://github.com/youansheng/pytorch-cv): Repo for Object Detection, Segmentation & Pose Estimation.
17. [deep-person-reid](https://github.com/KaiyangZhou/deep-person-reid): Pytorch implementation of deep person re-identification approaches.
18. [pytorch-template](https://github.com/victoresque/pytorch-template): PyTorch template project
19. [Deep Learning With Pytorch TextBook](https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-pytorch) A practical guide to build neural network models in text and vision using PyTorch. [Purchase on Amazon ](https://www.amazon.in/Deep-Learning-PyTorch-practical-approach/dp/1788624335/ref=tmm_pap_swatch_0?_encoding=UTF8&qid=1523853954&sr=8-1) [github code repo](https://github.com/svishnu88/DLwithPyTorch)
20. [compare-tensorflow-pytorch](https://github.com/jalola/compare-tensorflow-pytorch): Compare outputs between layers written in Tensorflow and layers written in Pytorch.
21. [hasktorch](https://github.com/hasktorch/hasktorch): Tensors and neural networks in Haskell
22. [Deep Learning With Pytorch](https://www.manning.com/books/deep-learning-with-pytorch) Deep Learning with PyTorch teaches you how to implement deep learning algorithms with Python and PyTorch.
23. [nimtorch](https://github.com/fragcolor-xyz/nimtorch): PyTorch - Python + Nim
24. [derplearning](https://github.com/John-Ellis/derplearning): Self Driving RC Car Code.
25. [pytorch-saltnet](https://github.com/tugstugi/pytorch-saltnet): Kaggle | 9th place single model solution for TGS Salt Identification Challenge.
26. [pytorch-scripts](https://github.com/peterjc123/pytorch-scripts): A few Windows specific scripts for PyTorch.
27. [pytorch_misc](https://github.com/ptrblck/pytorch_misc): Code snippets created for the PyTorch discussion board.
28. [awesome-pytorch-scholarship](https://github.com/arnas/awesome-pytorch-scholarship): A list of awesome PyTorch scholarship articles, guides, blogs, courses and other resources.
29. [MentisOculi](https://github.com/mmirman/MentisOculi): A raytracer written in PyTorch (raynet?)
30. [DoodleMaster](https://github.com/karanchahal/DoodleMaster): "Don't code your UI, Draw it !"
31. [ocaml-torch](https://github.com/LaurentMazare/ocaml-torch): OCaml bindings for PyTorch.
32. [extension-script](https://github.com/pytorch/extension-script): Example repository for custom C++/CUDA operators for TorchScript.
33. [pytorch-inference](https://github.com/zccyman/pytorch-inference): PyTorch 1.0 inference in C++ on Windows10 platforms.
34. [pytorch-cpp-inference](https://github.com/Wizaron/pytorch-cpp-inference): Serving PyTorch 1.0 Models as a Web Server in C++.
35. [tch-rs](https://github.com/LaurentMazare/tch-rs): Rust bindings for PyTorch.
36. [TorchSharp](https://github.com/interesaaat/TorchSharp): .NET bindings for the Pytorch engine
37. [ML Workspace](https://github.com/ml-tooling/ml-workspace): All-in-one web IDE for machine learning and data science. Combines Jupyter, VS Code, PyTorch, and many other tools/libraries into one Docker image.
38. [PyTorch Style Guide](https://github.com/IgorSusmelj/pytorch-styleguide) Style guide for PyTorch code. Consistent and good code style helps collaboration and prevents errors!
##### Feedback: If you have any ideas or you want any other content to be added to this list, feel free to contribute.
|
3,446 | Awesome Search - this is all about the (e-commerce, but not only) search and its awesomeness | # Awesome Search
<p align="center"> <a href="https://how-to-help-ukraine-now.super.site" target="_blank"> <img src="https://emojipedia-us.s3.dualstack.us-west-1.amazonaws.com/thumbs/120/google/313/flag-ukraine_1f1fa-1f1e6.png" alt="Ukraine" width="50" height="50"/> </a>
[RUSSIAN WARSHIP, GO F*CK YOURSELF](https://en.wikipedia.org/wiki/Russian_warship,_go_fuck_yourself!)
I've been building e-commerce search applications for almost ten years. Below you can find a list of (some) publications, conferences and books that inspire me. Grouped by topic (If an article fits into multiple topics - it goes into multiple sections).
:star: Star us on GitHub — it helps!
Also check my other collections [awesome e-commerce](https://github.com/frutik/awesome-e-commerce), [awesome knowledge graphs](https://github.com/frutik/awesome-knowledge-graphs), [awesome cloud apps](https://github.com/frutik/awesome-cloud-apps)
### Topics
- [General, fun, philosophy](#general-fun-philosophy)
- [Types of search](#types-of-search)
- [Classic search](#classic-search)
- [Hybrid search](#hybrid-search)
- [Multimodal search](#multimodal-search)
- [Search Results](#search-results)
- [Relevance](#relevance)
- [Relevance Algorithms](#relevance-algorithms)
- [Learning to Rank](#learning-to-rank)
- [Click models for search](#click-models-for-search)
- [Bias](#bias)
- [Diversification](#diversification)
- [Personalisation](#personalisation)
- [Search UX](#search-ux)
- [Baymard Institute](#baymard-institute)
- [Nielsen Norman Group](#nielsen-norman-group)
- [Enterprise Knowledge LLC](#enterprise-knowledge-llc)
- [Facets](#facets)
- [Accidental Taxonomist](#accidental-taxonomist)
- [Other](#other)
- [Spelling correction](#spelling-correction)
- [Suggestions](#suggestions)
- [Synonyms](#synonyms)
- [Stopwords](#stopwords)
- [Graphs/Taxonomies/Knowledge Graph](#graphstaxonomiesknowledge-graph)
- Integrating Search and Knowledge Graphs (by Enterprise Knowledge)
- [Query expansion](#query-expansion)
- [Query understanding](#query-understanding)
- [Search Intent](#search-intent)
- [Query segmentation](#query-segmentation)
- [Algorithms](#algorithms)
- [BERT](#bert)
- [Collocations, common phrases](#collocations-common-phrases)
- [Other Algorithms](#other-algorithms)
- [Tracking, profiling, GDPR, Analysis](#tracking-profiling-gdpr-analysis)
- [Testing, metrics, KPIs](#testing-metrics-kpis)
- Metrics
- KPIs
- A/B testing, MABs
- Evaluating Search (by Daniel Tunkelang)
- Measuring Search (by James Rubinstein)
- Three Pillars of Search Relevancy (by Andreas Wagner)
- [Architecture](#architecture)
- [Vectors search](#vectors-search)
- [Education and networking](#education-and-networking)
- [Conferences](#conferences)
- [Trainings and courses](#trainings-and-courses)
- [Books](#books)
- [Blogs and Portals, News](#blogs-and-portals)
- [Papers](#papers)
- [Management, Search Team](#management-search-team)
- Job Interviews
- [Industry players](#industry-players)
- Personalies and influencers
- Search Engines
- Products and services
- Consulting companies
- [Blogposts series](#blogposts-series)
- Search Optimization 101 (by Charlie Hull)
- Query Understanding (by Daniel Tunkelang)
- Grid Dynamics
- Considering Search: Search Topics (by Derek Sisson)
- [Videos](#videos)
- Channels
- Featured
- [Case studies](#case-studies)
- [General search](#general-search)
- [Multisided markets](#multisided-markets)
- [E-commerce](#e-commerce)
- [Tools](#tools)
## Unsorted
- [sandbox Jun 2021](https://github.com/frutik/awesome-search/issues/19)
- [sandbox May 2021](https://github.com/frutik/awesome-search/issues/18)
- [sandbox April 2021](https://github.com/frutik/awesome-search/issues/17)
- [sandbox Dec 2020](https://github.com/frutik/awesome-search/issues/10)
- [sandbox Jan 2020](https://github.com/frutik/awesome-search/issues/1)
## General, fun, philosophy
* [Falsehoods Programmers Believe About Search](https://opensourceconnections.com/blog/2019/05/29/falsehoods-programmers-believe-about-search/)
* [Ethical Search: Designing an irresistible journey with a positive impact](https://medium.com/empathyco/fooddiscovery-2-ethical-search-designing-an-irresistible-journey-with-a-positive-impact-cc921c07a5a8)
* [On Semantic Search](https://medium.com/modern-nlp/semantic-search-fuck-yeah-e371c0f639d)
* [Feedback debt: what the segway teaches search teams](https://opensourceconnections.com/blog/2020/03/19/feedback-debt/)
* [Supporting the Searcher’s Journey: When and How](https://medium.com/@dtunkelang/supporting-the-searchers-journey-when-and-how-568e9b68fe02)
* [Shopping is Hard, Let’s go Searching!](https://medium.com/@dtunkelang/shopping-is-hard-lets-go-searching-f61f3d5764d3)
* [An Introduction to Search Quality](https://opensourceconnections.com/blog/2018/11/19/an-introduction-to-search-quality/)
* [On-Site Search Design Patterns for E-Commerce: Schema Structure, Data Driven Ranking & More](https://project-a.github.io/on-site-search-design-patterns-for-e-commerce/)
* [In Search of Recall](https://www.linkedin.com/pulse/search-recall-daniel-tunkelang/)
* [Balance Your Search Budget!](https://www.linkedin.com/pulse/balance-your-search-budget-daniel-tunkelang/)
## Types of search
### Classic search
* Etsy. [Targeting Broad Queries in Search](https://codeascraft.com/2015/07/29/targeting-broad-queries-in-search/)
* [How Etsy Uses Thermodynamics to Help You Search for “Geeky”](https://codeascraft.com/2015/08/31/how-etsy-uses-thermodynamics-to-help-you-search-for-geeky/)
* [Broad and Ambiguous Search Queries](https://medium.com/@dtunkelang/broad-and-ambiguous-search-queries-1bbbe417dcc)
* [Deconstructing E-Commerce Search: The 12 Query Types](https://baymard.com/blog/ecommerce-search-query-types)
### Hybrid search
* [Hybrid search > sum of its parts?](https://pretalx.com/bbuzz22/talk/YEHRTE/)
### Multimodal search
* [Muves: Multimodal & multilingual vector search w/ Hardware Acceleration](https://www.youtube.com/watch?v=9OS8cMf2rwY)
## Search Results
### Relevance
* [Humans Search for Things not for Strings](https://www.linkedin.com/pulse/humans-search-things-strings-andreas-wagner/)
* [What is a ‘Relevant’ Search Result?](https://opensourceconnections.com/blog/2019/12/11/what-is-a-relevant-search-result/)
* [How to Achieve Ecommerce Search Relevance](https://blog.searchhub.io/how-to-achieve-ecommerce-search-relevance?cn-reloaded=1&cn-reloaded=1)
* [Setting up a relevance evaluation program](https://medium.com/@jamesrubinstein/setting-up-a-relevance-evaluation-program-c955d32fba0e)
#### Relevance Algorithms
* Practical BM25: [How Shards Affect Relevance Scoring in Elasticsearch](https://www.elastic.co/blog/practical-bm25-part-1-how-shards-affect-relevance-scoring-in-elasticsearch), [The BM25 Algorithm and its Variables](https://www.elastic.co/blog/practical-bm25-part-2-the-bm25-algorithm-and-its-variables)
* [The influence of TF-IDF algorithms in eCommerce search](https://medium.com/empathyco/the-influence-of-tf-idf-algorithms-in-ecommerce-search-e7cb9ab8e662)
* [BM25 The Next Generation of Lucene Relevance](https://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/)
* [Lucene Similarities (BM25, DFR, DFI, IB, LM) Explained](https://sematext.com/blog/search-relevance-solr-elasticsearch-similarity/)
#### Learning to Rank
* [How is search different than other machine learning problems?](https://opensourceconnections.com/blog/2017/08/03/search-as-machine-learning-prob/)
* [Reinforcement learning assisted search ranking](https://medium.com/sajari/reinforcement-learning-assisted-search-ranking-a594cdc36c29)
* [E-commerce Search Re-Ranking as a Reinforcement Learning Problem](https://towardsdatascience.com/e-commerce-search-re-ranking-as-a-reinforcement-learning-problem-a9d1561edbd0)
* [When to use a machine learned vs. score-based search ranker](https://towardsdatascience.com/when-to-use-a-machine-learned-vs-score-based-search-ranker-aa8762cd9aa9)
* [What is Learning To Rank?](https://opensourceconnections.com/blog/2017/02/24/what-is-learning-to-rank/)
* [Using AI and Machine Learning to Overcome Position Bias within Adobe Stock Search](https://medium.com/adobetech/evaluating-addressing-position-bias-in-adobe-stock-search-9807b11ee268)
* [Train and Test Sets Split for Evaluating Learning To Rank Models](https://sease.io/2022/07/how-to-split-your-dataset-into-train-and-test-sets-for-evaluating-learning-to-rank-models.html)
##### Click models for search
* [Click models](https://github.com/filipecasal/knowledge-repo/blob/master/click_models.md)
* [Click Modeling for eCommerce](https://tech.ebayinc.com/engineering/click-modeling-for-ecommerce/)
* [Using Behavioral Data to Improve Search](https://tech.ebayinc.com/engineering/using-behavioral-data-to-improve-search/)
### Bias
* [What is Presentation Bias in search?](https://softwaredoug.com/blog/2022/07/16/what-is-presentation-bias-in-search.html)
### Diversification
* [Search Result Diversification using Causal Language Models](https://arxiv.org/pdf/2108.04026.pdf)
* [Learning to Diversify for E-commerce Search with Multi-Armed Bandit](http://ceur-ws.org/Vol-2410/paper18.pdf)
* [Search Quality for Discovery & Inspiration](https://blog.searchhub.io/three-pillars-of-search-quality-in-ecommerce-part-2-discovery-inspiration)
* [How to measure Diversity of Search Results](https://2021.berlinbuzzwords.de/session/how-measure-diversity-search-results)
* [Searching for Goldilocks](https://dtunkelang.medium.com/searching-for-goldilocks-12cb21c7d036)
* [Broad and Ambiguous Search Queries - Recognizing When Search Results Need Diversification](https://dtunkelang.medium.com/broad-and-ambiguous-search-queries-1bbbe417dcc)
* [Thoughts on Search Result Diversity](https://dtunkelang.medium.com/thoughts-on-search-result-diversity-1df54cb5bf4a)
### Personalisation
* [Patterns for Personalization in Recommendations and Search](https://eugeneyan.com/writing/patterns-for-personalization/)
* Daniel Tunkelang [Personalization](https://queryunderstanding.com/personalization-3ed715e05ef)
* Airbnb - [Real-time personalization in search](https://medium.com/airbnb-engineering/listing-embeddings-for-similar-listing-recommendations-and-real-time-personalization-in-search-601172f7603e)
* [98 personal data points that facebook uses to target ads to you](https://www.washingtonpost.com/news/the-intersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-to-you/)
* [Architecture of real world recommendation systems](https://fennel.ai/blog/real-world-recommendation-system/)
* [Feature engineering for personalized search](https://fennel.ai/blog/feature-engineering-for-personalized-search/)
## Search UX
### Baymard Institute
* [Deconstructing E-Commerce Search: The 12 Query Types](https://baymard.com/blog/ecommerce-search-query-types)
* [Autodirect or Guide Users to Matching Category](https://baymard.com/blog/autodirect-searches-matching-category-scopes)
* [13 Design Patterns for Autocomplete Suggestions (27% Get it Wrong)](https://baymard.com/blog/autocomplete-design)
* [E-Commerce Search Needs to Support Users’ Non-Product Search Queries (15% Don’t)](https://baymard.com/blog/support-non-product-search)
* [Search UX: 6 Essential Elements for ‘No Results’ Pages](https://baymard.com/blog/no-results-page)
* [Product Thumbnails Should Dynamically Update to Match the Variation Searched For (54% Don’t)](https://baymard.com/blog/color-and-variation-searches)
* [Faceted Sorting - A New Method for Sorting Search Results](https://baymard.com/blog/faceted-sorting)
* [The Current State of E-Commerce Search](https://baymard.com/blog/external-article-state-of-ecommerce-search)
* [E-Commerce Sites Need Multiple of These 5 ‘Search Scope’ Features](https://baymard.com/blog/search-scope)
* [E-Commerce Search Field Design and Its Implications](https://baymard.com/blog/search-field-design)
* [E-Commerce Sites Should Include Contextual Search Snippets (96% Get it Wrong)](https://baymard.com/blog/search-snippets)
* [E-Commerce Search Usability: Report & Benchmark](https://baymard.com/blog/ecommerce-search-report-and-benchmark)
* [Six ‘COVID-19’ Related E-Commerce UX Improvements to Make](https://baymard.com/blog/covid-19-ux-improvements)
### Nielsen Norman Group
* [The Love-at-First-Sight Gaze Pattern on Search-Results Pages](https://www.nngroup.com/articles/love-at-first-sight-pattern/)
* [Good Abandonment on Search Results Pages](https://www.nngroup.com/articles/good-abandonment/)
* [Complex Search-Results Pages Change Search Behavior: The Pinball Pattern](https://www.nngroup.com/articles/pinball-pattern-search-behavior/)
* [Site Search Suggestions](https://www.nngroup.com/articles/site-search-suggestions/)
* [Search-Log Analysis: The Most Overlooked Opportunity in Web UX Research](https://www.nngroup.com/articles/search-log-analysis/)
* [Scoped Search: Dangerous, but Sometimes Useful](https://www.nngroup.com/articles/scoped-search/)
* [3 Guidelines for Search Engine "No Results" Pages](https://www.nngroup.com/articles/search-no-results-serp/)
### Enterprise Knowledge LLC
* [Optimizing Your Search Experience: A Human-Centered Approach to Search Design](https://enterprise-knowledge.com/optimizing-your-search-experience-a-human-centered-approach-to-search-design/)
### Facets
* [Facets of Faceted Search](https://medium.com/@dtunkelang/facets-of-faceted-search-38c3e1043592)
* [Coffee, Coffee, Coffee!](https://medium.com/@dtunkelang/coffee-coffee-coffee-de3121b797d1)
* [Faceted Search](https://queryunderstanding.com/faceted-search-7d053cc4fada) (start here!)
* [How to implement faceted search the right way](https://medium.com/empathyco/how-to-implement-faceted-search-the-right-way-4bfba2bd2adc)
* [Metadata and Faceted Search](https://medium.com/searchblox/metadata-and-faceted-search-62ec6e4de353)
* [Metacrap: Putting the torch to seven straw-men of the meta-utopia](https://people.well.com/user/doctorow/metacrap.htm)
* [7 Filtering Implementations That Make Macy’s Best-in-Class](https://baymard.com/blog/macys-filtering-experience)
* [Facet Search: The Most Comprehensive Guide. Best Practices, Design Patterns, Hidden Caveats, And Workarounds](https://hybrismart.com/2019/02/13/facet-search-the-most-comprehensible-guide-best-practices-design-patterns/#d5)
#### Accidental Taxonomist
* [How Many Facets Should a Taxonomy Have](http://accidental-taxonomist.blogspot.com/2020/07/how-many-facets-in-taxonomy.html)
* [When a Taxonomy Should not be Hierarchical](https://accidental-taxonomist.blogspot.com/2020/06/when-taxonomy-should-not-be-hierarchical.html)
* [Customizing Taxonomy Facets](http://accidental-taxonomist.blogspot.com/2020/10/customizing-taxonomy-facets.html)
### Other
* [Learning from Friction to Improve the Search Experience](https://medium.com/@dtunkelang/learning-from-friction-to-improve-the-search-experience-8937c71ec97a)
* [Why is it so hard to sort by price?](https://medium.com/@dtunkelang/why-is-it-so-hard-to-sort-by-price-2a5e63899233)
* [Faceted Sorting](https://baymard.com/blog/faceted-sorting)
* [Google kills Instant Search](https://www.904labs.com/en/blog-google-kills-instant-search.html)
## Spelling correction
* Peter Norvig. ["How to Write a Spelling Corrector"](http://norvig.com/spell-correct.html). Classic publication.
* Daniel Tunkelang. ["Spelling Correction"](https://queryunderstanding.com/spelling-correction-471f71b19880)
* [A simple spell checker built from word vectors](https://blog.usejournal.com/a-simple-spell-checker-built-from-word-vectors-9f28452b6f26)
* A closer look into the spell correction problem: [1](https://medium.com/@searchhub.io/a-closer-look-into-the-spell-correction-problem-part-1-a6795bbf7112), [2](https://medium.com/@searchhub.io/a-closer-look-into-the-spell-correction-problem-part-2-introducing-predict-8993ecab7226), [3](https://medium.com/@searchhub.io/a-closer-look-into-the-spell-correction-problem-part-3-the-bells-and-whistles-19697a34011b), [preDict](https://github.com/searchhub/preDict)
* [Deep Spelling](https://machinelearnings.co/deep-spelling-9ffef96a24f6)
* [Modeling Spelling Correction for Search at Etsy](https://codeascraft.com/2017/05/01/modeling-spelling-correction-for-search-at-etsy/)
* Wolf Garbe. Author of [Sympell](https://github.com/wolfgarbe/symspell). [1000x Faster Spelling Correction algorithm](https://medium.com/@wolfgarbe/1000x-faster-spelling-correction-algorithm-2012-8701fcd87a5f), [Top highlight SymSpell vs. BK-tree: 100x faster fuzzy string search & spell checking](https://towardsdatascience.com/symspell-vs-bk-tree-100x-faster-fuzzy-string-search-spell-checking-c4f10d80a078), [Fast Word Segmentation of Noisy Text](https://towardsdatascience.com/fast-word-segmentation-for-noisy-text-2c2c41f9e8da)
* [Chars2vec: character-based language model for handling real world texts with spelling errors and](https://hackernoon.com/chars2vec-character-based-language-model-for-handling-real-world-texts-with-spelling-errors-and-a3e4053a147d)
* JamSpell, spelling correction taking into account surrounding context - [library](https://github.com/bakwc/JamSpell), (in russian) [Исправляем опечатки с учётом контекста](https://habr.com/ru/post/346618/)
* [Embedding for spelling correction](https://towardsdatascience.com/embedding-for-spelling-correction-92c93f835d79)
* [A simple spell checker built from word vectors](https://blog.usejournal.com/a-simple-spell-checker-built-from-word-vectors-9f28452b6f26)
* [What are some algorithms of spelling correction that are used by search engines?](https://www.quora.com/String-Searching-Algorithms/What-are-some-algorithms-of-spelling-correction-that-are-used-by-search-engines-For-example-when-I-used-Google-to-search-Google-imeges-it-prompted-me-Did-you-mean-Google-images/answer/Wolf-Garbe)
* [Moman](https://github.com/jpbarrette/moman) - lucene/solr/elasticsearch spell correction/autocorrect is (was?) actually powered by this library.
* [Query Segmentation and Spelling Correction](https://towardsdatascience.com/query-segmentation-and-spelling-correction-483173008981)
* [Applying Context Aware Spell Checking in Spark NLP](https://medium.com/spark-nlp/applying-context-aware-spell-checking-in-spark-nlp-3c29c46963bc)
* [Autocorrect in Google, Amazon and Pinterest and how to write your own one](https://towardsdatascience.com/autocorrect-in-google-amazon-and-pinterest-and-how-to-write-your-own-one-6d23bc927c81)
## Synonyms
* [Boosting the power of Elasticsearch with synonyms](https://www.elastic.co/blog/boosting-the-power-of-elasticsearch-with-synonyms)
* [Real Talk About Synonyms and Search](https://medium.com/@dtunkelang/real-talk-about-synonyms-and-search-bb5cf41a8741)
* [Synonyms in Solr I — The good, the bad and the ugly](https://medium.com/empathyco/synonyms-in-solr-i-the-good-the-bad-and-the-ugly-efe8e437a940)
* [Synonyms and Antonyms from WordNet](https://medium.com/@tameremil/synonyms-and-antonyms-from-wordnet-778f6274fb09)
* [Synonyms and Antonyms in Python](https://towardsdatascience.com/synonyms-and-antonyms-in-python-a865a5e14ce8)
* [Dive into WordNet with NLTK](https://medium.com/parrot-prediction/dive-into-wordnet-with-nltk-b313c480e788)
* [Creating Better Searches Through Automatic Synonym Detection](https://lucidworks.com/post/search-automatic-synonym-detection/)
* [Multiword synonyms in search using Querqy](https://sharing.luminis.eu/blog/multiword-synonyms-in-search-using-querqy/)
* [How to Build a Smart Synonyms Model](https://blog.kensho.com/how-to-build-a-smart-synonyms-model-1d525971a4ee)
* [The importance of Synonyms in eCommerce Search](https://blog.searchhub.io/the-importance-of-synonyms-in-ecommerce-search)
## Stopwords
- [Do all-stopword queries matter?](https://observer.wunderwood.org/2007/05/31/do-all-stopword-queries-matter/)
## Suggestions
Synonyms: autocomplete, search as you type, suggestions
* Giovanni Fernandez-Kincade.
[Bootstrapping Autosuggest](https://medium.com/related-works-inc/bootstrapping-autosuggest-c1ca3edaf1eb), [Building an Autosuggest Corpus, Part 1](https://medium.com/related-works-inc/building-an-autosuggest-corpus-part-1-3acd26056708), [Building an Autosuggest Corpus, Part 2](https://medium.com/related-works-inc/building-an-autosuggest-corpus-nlp-d21b0f25c31b), [Autosuggest Retrieval Data Structures & Algorithms](https://medium.com/related-works-inc/autosuggest-retrieval-data-structures-algorithms-3a902c74ffc8), [Autosuggest Ranking](https://medium.com/related-works-inc/autosuggest-ranking-d8a3242c2837)
* [On two types of suggestions](https://web.archive.org/web/20181207194952/https://www.searchblox.com/autosuggest-search-query-based-vs-content-based)
* [Improving Search Suggestions for eCommerce](https://medium.com/empathyco/improving-search-suggestions-for-ecommerce-cb1bc2946021)
* [Autocomplete Search Best Practices to Increase Conversions](https://lucidworks.com/post/autocomplete-search-increase-conversions/)
* [Why we’ve developed the searchhub smartSuggest module and why it might matter to you](https://www.linkedin.com/pulse/why-weve-developed-searchhub-smartsuggest-module-might-andreas-wagner/)
* Nielsen Norman Group: [Site Search Suggestions](https://www.nngroup.com/articles/site-search-suggestions/)
* [13 Design Patterns for Autocomplete Suggestions](https://baymard.com/blog/autocomplete-design)
* [Autocomplete](https://queryunderstanding.com/autocomplete-69ed81bba245)
* [Autocomplete and User Experience](https://queryunderstanding.com/autocomplete-and-user-experience-421df6ab3000)
* [IMPLEMENTING A LINKEDIN LIKE SEARCH AS YOU TYPE WITH ELASTICSEARCH](https://spinscale.de/posts/2020-05-29-implementing-a-linkedin-like-search-as-you-type-with-elasticsearch.html)
* [Smart autocomplete best practices: improve search relevance and sales](https://blog.griddynamics.com/smart-autocomplete-best-practices/)
* OLX: [Building Corpus for AutoSuggest (Part 1)](https://tech.olx.com/building-corpus-for-autosuggest-part-1-4f63512b1ea1), [AutoSuggest Retrieval & Ranking (Part 2)](https://tech.olx.com/autosuggest-retrieval-ranking-part-2-14a8f50fef34)
* [Autocomplete, Live Search Suggestions, and Autocorrection: Best Practice Design Patterns](https://hybrismart.com/2019/01/08/autocomplete-live-search-suggestions-autocorrection-best-practice-design-patterns/)
* [Mirror, Mirror, What Am I Typing Next? All About Search Suggestions](https://spinscale.de/posts/2023-01-18-mirror-mirror-what-am-i-typing-next.html)
## Graphs/Taxonomies/Knowledge Graph
* [Knowledge graphs applied in the retail industry](https://towardsdatascience.com/knowledge-graphs-applied-in-the-retail-industry-ecac4e7baf8)
Knowledge graphs are becoming increasingly popular in tech. We explore how they can be used in the retail industry to enrich data, widen search results and add value to a retail company.
* [Awesome Knowledge Graphs](https://github.com/frutik/awesome-knowledge-graphs)
### Integrating Search and Knowledge Graphs (by Enterprise Knowledge)
* [Part 1: Displaying Relationships](https://enterprise-knowledge.com/integrating-search-and-knowledge-graphs-series-part-1-displaying-relationships/)
* [Search query expansion with query embeddings](https://bytes.grubhub.com/search-query-embeddings-using-query2vec-f5931df27d79)
## Query expansion
- [Fundamentals of query rewriting (part 1): introduction to query expansion](https://opensourceconnections.com/blog/2021/10/19/fundamentals-of-query-rewriting-part-1-introduction-to-query-expansion/?utm_source=dlvr.it&utm_medium=linkedin)
## Query understanding
* Daniel Tunkelang [Query Understanding](https://queryunderstanding.com/introduction-c98740502103).
* [Query Understanding, Divided into Three Parts](https://medium.com/@dtunkelang/query-understanding-divided-into-three-parts-d9cbc81a5d09)
* [Search for Things not for Strings](https://blog.searchhub.io/humans-search-for-things-not-for-strings-2?cn-reloaded=1)
* Understanding the Search Query. [Part 1](https://towardsdatascience.com/understanding-the-search-query-part-i-632d1b323b50), [Part 2](https://medium.com/analytics-vidhya/understanding-the-search-query-part-ii-44d18892283f), [Part 3](https://medium.com/@sonusharma.mnnit/understanding-the-search-query-part-iii-a0c5637a639)
* [Food Discovery with Uber Eats: Building a Query Understanding Engine](https://eng.uber.com/uber-eats-query-understanding/)
* [AI for Query Understanding](https://www.linkedin.com/pulse/ai-query-understanding-daniel-tunkelang)
### Search Intent
* [Mapping Search Queries To Search Intents](https://medium.com/@dtunkelang/search-queries-and-search-intent-1dec79ad155f)
* [Search: Intent, Not Inventory](https://medium.com/@dtunkelang/search-intent-not-inventory-289386f28a21)
### Query segmentation
* Paper [Unsupervised Query Segmentation Using only Query Logs ](https://www.microsoft.com/en-us/research/wp-content/uploads/2011/01/pp0295-mishra.pdf)
* Paper [Towards Semantic Query Segmentation](https://arxiv.org/pdf/1707.07835.pdf)
## Algorithms
### BERT
* [Understanding BERT and Search Relevance](https://opensourceconnections.com/blog/2019/11/05/understanding-bert-and-search-relevance/)
* [Google is improving web search with BERT – can we use it for enterprise search too?](https://www.linkedin.com/pulse/google-improving-web-search-bert-can-we-use-too-mickel-gr%C3%B6nroos/)
### Collocations, common phrases
* [Automatically detect common phrases – multi-word expressions / word n-grams – from a stream of sentences.]( https://radimrehurek.com/gensim/models/phrases.html)
* [The Unreasonable Effectiveness of Collocations](https://opensourceconnections.com/blog/2019/05/16/unreasonable-effectiveness-of-collocations/)
### Other Algorithms
* [Locality Sensitive Hashing](https://towardsdatascience.com/understanding-locality-sensitive-hashing-49f6d1f6134)
* [Locality Sensitive Hashing (LSH): The Practical and Illustrated Guide](https://www.pinecone.io/learn/locality-sensitive-hashing/)
* [Minhash](http://ekzhu.com/datasketch/minhash.html)
* [Better than Average: Sort by Best Rating](https://www.elastic.co/blog/better-than-average-sort-by-best-rating-with-elasticsearch)
* [How Not To Sort By Average Rating](https://www.evanmiller.org/how-not-to-sort-by-average-rating.html)
* [One hot encoding](https://medium.com/fintechexplained/nlp-text-data-to-numbers-d28d32294d2e)
* [Keyword Extraction using RAKE](https://codelingo.wordpress.com/2017/05/26/keyword-extraction-using-rake/)
* [Yet Another Keyword Extractor (Yake)](https://github.com/LIAAD/yake)
* [Writing a full-text search engine using Bloom filters](https://www.stavros.io/posts/bloom-filter-search-engine/)
## Tracking, profiling, GDPR, Analysis
* [Anonymisation: managing data protection risk (code of practice)](https://ico.org.uk/media/1061/anonymisation-code.pdf)
* [The Anonymisation Decision-Making Framework](https://ukanon.net/wp-content/uploads/2015/05/The-Anonymisation-Decision-making-Framework.pdf)
* [98 personal data points that facebook uses to target ads to you](https://www.washingtonpost.com/news/the-intersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-to-you/)
* [Opportunity Analysis for Search](https://www.linkedin.com/pulse/opportunity-analysis-search-daniel-tunkelang/)
* [A Face Is Exposed for AOL Searcher No. 4417749](https://www.nytimes.com/2006/08/09/technology/09aol.html)
* [AOL search data leak](https://en.wikipedia.org/wiki/AOL_search_data_leak)
* [Personal data](https://en.wikipedia.org/wiki/Personal_data)
## Testing, metrics, KPIs
### Metrics
* [Discounted cumulative gain](https://en.wikipedia.org/wiki/Discounted_cumulative_gain)
* [Mean reciprocal rank](https://en.wikipedia.org/wiki/Mean_reciprocal_rank)
* [P@k](https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)#Precision_at_K)
* [Demystifying nDCG and ERR](https://opensourceconnections.com/blog/2019/12/09/demystifying-ndcg-and-err/)
* [Choosing your search relevance evaluation metric](https://opensourceconnections.com/blog/2020/02/28/choosing-your-search-relevance-metric/)
* [How to Implement a Normalized Discounted Cumulative Gain (NDCG) Ranking Quality Scorer in Quepid](https://opensourceconnections.com/blog/2018/02/26/ndcg-scorer-in-quepid/)
* https://en.wikipedia.org/wiki/Precision_and_recall
* https://en.wikipedia.org/wiki/F1_score
* [Visualizing search metrics](https://nathanday.shinyapps.io/rank-algo-app/)
* [Choosing your search relevance evaluation metric](https://opensourceconnections.com/blog/2020/02/28/choosing-your-search-relevance-metric/)
* [Compute Mean Reciprocal Rank (MRR) using Pandas](https://softwaredoug.com/blog/2021/04/21/compute-mrr-using-pandas.html)
* [Recommender Systems: Machine Learning Metrics and Business Metrics](https://neptune.ai/blog/recommender-systems-metrics)
### KPIs
* [5 Right Ways to Measure How Search Is Performing](https://opensourceconnections.com/blog/2020/05/11/5-right-ways-to-measure-search/)
* E-commerce Site-Search KPIs. [Part 1 – Customers](https://opensourceconnections.com/blog/2020/08/28/e-commerce-site-search-kpis/), [Part 2 – Products](https://opensourceconnections.com/blog/2020/09/10/e-commerce-site-search-kpis-part-2/), [Part 3 - Queries](https://opensourceconnections.com/blog/2020/09/24/e-commerce-site-search-kpis-part-3-queries/)
* [Learning from Friction to Improve the Search Experience](https://medium.com/@dtunkelang/learning-from-friction-to-improve-the-search-experience-8937c71ec97a)
* [Behind the Wizardry of a Seamless Search Experience](https://enterprise-knowledge.com/if-i-only-had-an-enterprise-search-brain-behind-the-wizardry-of-a-seamless-search-experience/)
* [Analyzing online search relevance metrics with the Elastic Stack](https://www.elastic.co/blog/analyzing-online-search-relevance-metrics-with-the-elastic-stack)
* [How to Gain Insight From Search Analytics](https://www.searchblox.com/how-to-gain-insight-from-search-analytics/)
### A/B testing, MABs
* [A/B Testing for Search is Different](https://medium.com/@dtunkelang/a-b-testing-for-search-is-different-f6b0f6f4d0f5)
* [A/B Testing Search: thinking like a scientist](https://medium.com/@jamesrubinstein/a-b-testing-search-thinking-like-a-scientist-1cc34b88392e)
### Evaluating Search (by Daniel Tunkelang)
* [Measure It](https://medium.com/@dtunkelang/evaluating-good-search-part-i-measure-it-5507b2dbf4f6)
* [Measuring Searcher Behavior](https://medium.com/@dtunkelang/evaluating-search-measuring-searcher-behavior-5f8347619eb0)
* [Using Human Judgement](https://medium.com/@dtunkelang/evaluating-search-using-human-judgement-fbb2eeba37d9)
* [When There’s No Conversion Rate](https://medium.com/@dtunkelang/when-theres-no-conversion-rate-67a372666fed)
### Measuring Search (by James Rubinstein)
* [Statistical and human-centered approaches to search engine improvement](https://medium.com/@jamesrubinstein/statistical-and-human-centered-approaches-to-search-engine-improvement-52af0e98f38f)
* [A Human Approach](https://medium.com/@jamesrubinstein/measuring-search-a-human-approach-acf54e2cf33d)
* [Setting up a relevance evaluation program](https://medium.com/@jamesrubinstein/setting-up-a-relevance-evaluation-program-c955d32fba0e)
* [Metrics Matter](https://medium.com/@jamesrubinstein/measuring-search-metrics-matter-de124c2f6f8c)
* [A/B Testing Search: thinking like a scientist](https://medium.com/@jamesrubinstein/a-b-testing-search-thinking-like-a-scientist-1cc34b88392e)
* [Query Triage: The Secret Weapon for Search Relevance](https://medium.com/@jamesrubinstein/query-triage-the-secret-weapon-for-search-relevance-1a02cdd297ed)
* [The Launch Review: bringing it all together…](https://medium.com/@jamesrubinstein/the-launch-review-bringing-it-all-together-2f7e4cfbf86e)
### Three Pillars of Search Relevancy (by Andreas Wagner)
* [Part 1: Findability](https://blog.searchhub.io/three-pillars-of-search-quality-in-ecommerce-part-1-findability)
* [part 2: Search Quality For Discovery & Inspiration](https://blog.searchhub.io/three-pillars-of-search-quality-in-ecommerce-part-2-discovery-inspiration)
## Architecture
* [The Art Of Abstraction – Revisiting Webshop Architecture](https://blog.searchhub.io/the-art-of-abstraction-revisting-webshop-architecture)
* Canva - Search Pipeline
* [Part One](https://canvatechblog.com/search-pipeline-part-i-faa6c543aef1) outline of the challenges faced
* [Part Two](https://canvatechblog.com/search-pipeline-part-ii-3b43978607cd) new search arcthitecture
## Vectors search
* [Nearest Neighbor Indexes for Similarity Search](https://www.pinecone.io/learn/vector-indexes/)
* [The Missing WHERE Clause in Vector Search](https://www.pinecone.io/learn/vector-search-filtering/)
* [Migrating to Elasticsearch with dense vector for Carousell Spotlight search engine](https://medium.com/carousell-insider/migrating-to-elasticsearch-with-dense-vector-for-carousell-spotlight-search-engine-e328b16155fc)
## Education and networking
### Conferences
* [Activate](https://www.activate-conf.com/)
* [Berlin buzzword](berlinbuzzwords.de)
* [Haystack](https://haystackconf.com/)
* [Elastic{ON}](https://www.elastic.co/elasticon/)
* [MIX-CAMP E-COMMERCE SEARCH](http://www.mices.co)
* [SIGIR eCommerce](https://sigir-ecom.github.io/index.html)
- [2019](https://sigir-ecom.github.io/ecom2019/index.html)
- [2018](https://sigir-ecom.github.io/ecom2018/index.html)
- [2017](http://sigir-ecom.weebly.com/)
### Trainings and courses
* [Machine Learning Powered Search. Doug Turnbull](https://www.getsphere.com/cohorts/machine-learning-powered-search) Next: Jan 24, 2023
* OpenSource Connections
- [Elasticsearch "Think Like a Relevance Engineer"](https://opensourceconnections.com/training/elasticsearch-think-like-a-relevance-engineer-tlre/)
- [Solr "Think Like a Relevance Engingeer"](https://opensourceconnections.com/training/solr-think-like-a-relevance-engineer-tlre/)
- [Hello LTR](https://opensourceconnections.com/training/hello-ltr-learning-to-rank/)
* [Sease's trainings](https://sease.io/training)
* [Search Fundamentals. Daniel Tunkelang, Grant Ingersoll](https://corise.com/course/search-fundamentals) Next: Feb 6, 2023
* [Search with Machine Learning. Daniel Tunkelang, Grant Ingersoll](https://corise.com/course/search-with-machine-learning) Next: Feb 27, 2023
* [Search for Product Managers. Daniel Tunkelang](https://corise.com/course/search-for-product-managers) Next: Apr 3, 2023
* [Sematext trainings](https://sematext.com/training/)
### Books
* [AI-powered search](https://www.manning.com/books/ai-powered-search)
* [Relevant Search](https://www.manning.com/books/relevant-search)
* [Deep Learning for search](https://www.manning.com/books/deep-learning-for-search)
* [Interactions with search systems](https://www.cambridge.org/core/books/interactions-with-search-systems/5B3CF5920355A8B09088F2C409FFABDC)
* [Embeddings in Natural Language Processing. Theory and Advances in Vector Representation of Meaning](http://josecamachocollados.com/book_embNLP_draft.pdf)
* [Search User Interfaces](http://www.searchuserinterfaces.com)
* [Search Patterns](https://searchpatterns.org/)
* [Search Analytics for Your Site: Conversations with Your Customers](https://www.amazon.com/Search-Analytics-Your-Site-Conversations/dp/1933820209)
* [Click Models for Web Search](https://www.amazon.com/Synthesis-Lectures-Information-Concepts-Retrieval/dp/1627056475/)
* [Optimization Algorithms](https://www.manning.com/books/optimization-algorithms)
### Blogs and Portals
* [Searchnews](http://searchnews.org/)
### Papers
* [List of papers](PAPERS.md)
## Management, Search Team
* [Search is a Team Sport](https://medium.com/search-in-21st-century/search-is-a-team-sport-400eecdfe736)
* [Thoughts about Managing Search Teams](https://medium.com/@dtunkelang/thoughts-about-managing-search-teams-f8d2f54fbed7)
* [On Search Leadership](https://dtunkelang.medium.com/on-search-leadership-815b36c15df1)
* [Building an Effective Search Team: the key to great search & relevancy](https://opensourceconnections.com/blog/2020/05/14/building-an-effective-search-team-the-key-to-great-search-relevancy/)
* [Query Triage: The Secret Weapon for Search Relevance](https://medium.com/@jamesrubinstein/query-triage-the-secret-weapon-for-search-relevance-1a02cdd297ed)
* [The Launch Review: bringing it all together ](https://medium.com/@jamesrubinstein/the-launch-review-bringing-it-all-together-2f7e4cfbf86e)
* [The Role of Search Product Owners](https://enterprise-knowledge.com/the-role-of-search-product-owners/)
* [Search Product Management: The Most Misunderstood Role in Search?](https://jamesrubinstein.medium.com/search-product-management-the-most-misunderstood-role-in-search-2b7569058638)
### Job Interviews
* [Interview Questions for Search Relevance Engineers, Data Scientists, and Product Managers](https://medium.com/@dtunkelang/interview-questions-for-search-relevance-engineers-and-product-managers-7a1b6b8cacea)
* [Data Science Interviews: Ranking and search](https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md#ranking-andsearch)
## Blogposts series
### Search Optimization 101 (by Charlie Hull)
* [How do I know that my search is broken?](https://blog.supahands.com/2020/07/08/how-do-i-know-that-my-search-is-broken/)
* [What does it mean if my search is ‘broken’?](https://blog.supahands.com/2020/07/20/search-optimization-101-what-does-it-mean-if-my-search-is-broken/)
* [How do you fix a broken search?](https://blog.supahands.com/2020/08/04/search-optimization-101-how-do-you-fix-a-broken-search/)
* [Reducing business risk by optimizing search
](https://blog.supahands.com/2020/09/02/reducing-business-risks-by-optimizing-search/)
### Query Understanding (by Daniel Tunkelang)
Better search through query understanding.
* [An Introduction](https://queryunderstanding.com/introduction-c98740502103)
* [Language Identification](https://queryunderstanding.com/language-identification-c1d2a072eda)
* [Character Filtering](https://queryunderstanding.com/character-filtering-76ede1cf1a97)
* [Tokenization](https://queryunderstanding.com/tokenization-c8cdd6aef7ff)
* [Spelling Correction](https://queryunderstanding.com/spelling-correction-471f71b19880)
* [Stemming and Lemmatization](https://queryunderstanding.com/stemming-and-lemmatization-6c086742fe45)
* [Query Rewriting: An Overview](https://queryunderstanding.com/query-rewriting-an-overview-d7916eb94b83)
* [Query Expansion](https://queryunderstanding.com/query-expansion-2d68d47cf9c8)
* [Query Relaxation](https://queryunderstanding.com/query-relaxation-342bc37ad425)
* [Query Segmentation](https://queryunderstanding.com/query-segmentation-2cf860ade503)
* [Query Scoping](https://queryunderstanding.com/query-scoping-ed61b5ec8753)
* [Entity Recognition](https://queryunderstanding.com/entity-recognition-763cae840a20)
* [Taxonomies and Ontologies](https://queryunderstanding.com/taxonomies-and-ontologies-8e4812a79cb2)
* [Autocomplete](https://queryunderstanding.com/autocomplete-69ed81bba245)
* [Autocomplete and User Experience](https://queryunderstanding.com/autocomplete-and-user-experience-421df6ab3000)
* [Contextual Query Understanding: An Overview](https://queryunderstanding.com/contextual-query-understanding-65c78d792dd8)
* [Session Context](https://queryunderstanding.com/session-context-4af0a355c94a)
* [Location as Context](https://queryunderstanding.com/geographical-context-77ce4c773dc7)
* [Seasonality](https://queryunderstanding.com/seasonality-5eef79d8bf1c)
* [Personalization](https://queryunderstanding.com/personalization-3ed715e05ef)
* [Search as a Conversation](https://queryunderstanding.com/search-as-a-conversation-bafa7cd0c9a5)
* [Clarification Dialogues](https://queryunderstanding.com/clarification-dialogues-69420432f451)
* [Relevance Feedback](https://queryunderstanding.com/relevance-feedback-c6999529b92c)
* [Faceted Search](https://queryunderstanding.com/faceted-search-7d053cc4fada)
* [Search Results Presentation](https://queryunderstanding.com/search-results-presentation-7d6c6c384ec1)
* [Search Result Snippets](https://queryunderstanding.com/search-result-snippets-e8c447950219)
* [Search Results Clustering](https://queryunderstanding.com/search-results-clustering-b2fa64c6c809)
* [Question Answering](https://queryunderstanding.com/question-answering-94984185c203)
* [Query Understanding and Voice Interfaces](https://queryunderstanding.com/query-understanding-and-voice-interfaces-6cd60d063fca)
* [Query Understanding and Chatbots](https://queryunderstanding.com/query-understanding-and-chatbots-5fa0c154f)
### Grid Dynamics
* [Not your father’s search engine: a brief history of retail search](https://blog.griddynamics.com/not-your-fathers-search-engine-a-brief-history-of-retail-search/)
* [Semantic vector search: the new frontier in product discovery](https://blog.griddynamics.com/semantic-vector-search-the-new-frontier-in-product-discovery/)
* [Boosting product discovery with semantic search](https://blog.griddynamics.com/boosting-product-discovery-with-semantic-search/)
* [Semantic query parsing blueprint](https://blog.griddynamics.com/semantic-query-parsing-blueprint/)
### Considering Search: Search Topics (by Derek Sisson)
* [Intro](https://www.philosophe.com/archived_content/search_topics/search_topics.html)
* [Assumptions About Search](https://www.philosophe.com/archived_content/search_topics/search_assumptions.html)
* [Assumptions About User Search Behavior](https://www.philosophe.com/archived_content/search_topics/user_behavior.html)
* [Types of Information Collections](https://www.philosophe.com/archived_content/search_topics/collections.html)
* [A Structural Look at Search](https://www.philosophe.com/archived_content/search_topics/structure.html)
* [Users and the Task of Information Retrieval](https://www.philosophe.com/archived_content/search_topics/search_tasks.html)
* [Testing Search](https://www.philosophe.com/archived_content/search_topics/search_tests.html)
* [Useful Search Links and References](https://www.philosophe.com/archived_content/search_topics/search_links.html)
## Industry players
### Personalies and influencers
* [Daniel Tunkelang (he is God of Search)](https://medium.com/@dtunkelang)
* [Max Irwin](https://twitter.com/binarymax)
* [Doug Turnbull](https://twitter.com/softwaredoug)
* [Baymard’s Institute](https://baymard.com/blog)
### Search Engines
* Google
* Bing
* Yandex
* Amazon
* eBay
### Products and services
* [Algolia](https://www.algolia.com/)
* Vespa
* Elastic
* Solr
* [Fess Enterprise Search Server](https://github.com/codelibs/fess)
* [Typesense](https://github.com/typesense/typesense) - an opensource alternative to Algolia.
* [SearchHub.io](https://www.searchhub.io/)
* [Datafari](https://www.datafari.com/en/index.html) - an open source enterprise search solution.
* [Qdrant](https://qdrant.tech/) - an open source vector database.
### Consulting companies
* [OpenSource Connections](https://www.opensourceconnections.com)
* https://sease.io/
## Case studies
* Airbnb - [Machine Learning-Powered Search Ranking of Airbnb Experiences](https://medium.com/airbnb-engineering/machine-learning-powered-search-ranking-of-airbnb-experiences-110b4b1a0789)
* Airbnb - [Listing Embeddings in Search Ranking](https://medium.com/airbnb-engineering/listing-embeddings-for-similar-listing-recommendations-and-real-time-personalization-in-search-601172f7603e)
* Algolia - [The Architecture Of Algolia’s Distributed Search Network](http://highscalability.com/blog/2015/3/9/the-architecture-of-algolias-distributed-search-network.html)
* Meituan - Exploration and practice of BERT in the core ranking of Meituan search (🇨🇳 [BERT在美团搜索核心排序的探索和实践](https://tech.meituan.com/2020/07/09/bert-in-meituan-search.html))
* Netflix - How Netflix Content Engineering makes a federated graph searchable ([Part 1](https://netflixtechblog.com/how-netflix-content-engineering-makes-a-federated-graph-searchable-5c0c1c7d7eaf), [Part 2](https://netflixtechblog.com/how-netflix-content-engineering-makes-a-federated-graph-searchable-part-2-49348511c06c))
* Netflix - [Elasticsearch Indexing Strategy in Asset Management Platform (AMP)](https://netflixtechblog.medium.com/elasticsearch-indexing-strategy-in-asset-management-platform-amp-99332231e541)
* Skyscanner - [Learning to Rank for Flight Itinerary Search](https://hackernoon.com/learning-to-rank-for-flight-itinerary-search-8594761eb867)
* Slack - [Search at Slack](https://slack.engineering/search-at-slack-431f8c80619e)
* Twitter - [Stability and scalability for search](https://blog.twitter.com/engineering/en_us/topics/infrastructure/2022/stability-and-scalability-for-search)
* [Amazon SEO Explained: How to Rank Your Products #1 in Amazon Search Results in 2020](https://crazylister.com/blog/amazon-seo-ultimate-guide/)
* [Building a Better Search Engine for Semantic Scholar](https://medium.com/ai2-blog/building-a-better-search-engine-for-semantic-scholar-ea23a0b661e7)
### General search
* [How Bing Ranks Search Results: Core Algorithm & Blue Links](https://www.searchenginejournal.com/how-bing-ranks-search-results/357804/)
* [How Google Search Ranking Works – Darwinism in Search](https://www.searchenginejournal.com/how-google-search-ranking-works/307591/)
### E-commerce
* [Searchandising](https://searchanise.io/blog/searchandising/)
### Multisided markets
* [Discover How Cassini (The eBay Search Engine) Works and Rank](https://crazylister.com/blog/ebay-search-engine-cassini/)
## Videos
### Channels
* [Lucid Thoughts](https://www.youtube.com/c/LucidThoughts)
* [Lucidworks](https://www.youtube.com/user/LucidWorksSearch)
* [MIx-Camp E-commerce Search](https://www.youtube.com/channel/UCCxvMykUdtFFc1O_tIr9oxA)
* [OpenSource Connections](https://www.youtube.com/channel/UCiuXt-f2Faan4Es37nADUdQ)
* [SIGIR eCom](https://www.youtube.com/channel/UCd6PyC_9zrxgA7vmT05Mx4Q)
### Featured
* [Relevant Facets](https://www.youtube.com/watch?v=W8DJYfAKKLA)
## Tools
### Spacy
[Awesome Spacy](https://github.com/frutik/awesome-spacy) - Natural language upderstanding, content enrichment etc.
### Word2Vec
* [Word2Vec For Phrases — Learning Embeddings For More Than One Word](https://towardsdatascience.com/word2vec-for-phrases-learning-embeddings-for-more-than-one-word-727b6cf723cf)
* [Gensim Word2Vec Tutorial](http://kavita-ganesan.com/gensim-word2vec-tutorial-starter-code/#.XV-wnJMzbUL)
* [How to incorporate phrases into Word2Vec – a text mining approach](http://kavita-ganesan.com/how-to-incorporate-phrases-into-word2vec-a-text-mining-approach/#.XV-wnJMzbUL)
* [Word2Vec — a baby step in Deep Learning but a giant leap towards Natural Language Processing](https://medium.com/explore-artificial-intelligence/word2vec-a-baby-step-in-deep-learning-but-a-giant-leap-towards-natural-language-processing-40fe4e8602ba)
* [How to Develop Word Embeddings in Python with Gensim](https://machinelearningmastery.com/develop-word-embeddings-python-gensim/)
### Libs
* [Query Segmenter](https://github.com/soumyaxyz/query-segmenter)
* https://github.com/zentity-io/zentity
* https://github.com/mammothb/symspellpy
* https://github.com/searchhub/search-collector
* [Kiri](https://github.com/kiri-ai/kiri) - State-of-the-art semantic search made easy.
* [Haystack](https://github.com/deepset-ai/haystack) - End-to-end Python framework for building natural language search interfaces to data.
* https://github.com/castorini/docTTTTTquery
### Other
* [Chorus](https://github.com/querqy/chorus), [Smui](https://github.com/querqy/smui), [Querqy](https://github.com/querqy/querqy)
* [Quepid](https://github.com/o19s/quepid)
* [Rated Ranking Evaluator](https://github.com/SeaseLtd/rated-ranking-evaluator)
* [Jina AI](https://github.com/jina-ai/jina) - A neural search framework
## Other awesome stuff
* [Awesome Knowledge Graphs](https://github.com/frutik/awesome-knowledge-graphs)
* [Awesome time series](https://github.com/frutik/awesome-timeseries)
* [Awesome Spacy](https://github.com/frutik/awesome-spacy)
* [Query-Understanding](https://github.com/sanazb/Query-Understanding)
* [Click models](https://github.com/filipecasal/knowledge-repo/blob/master/click_models.md)
|
3,447 | This repository is a list of machine learning libraries written in Rust. It's a compilation of GitHub repositories, blogs, books, movies, discussions, papers, etc. 🦀 | 
This repository is a list of machine learning libraries written in Rust.
It's a compilation of GitHub repositories, blogs, books, movies, discussions, papers.
This repository is targeted at people who are thinking of migrating from Python. 🦀🐍
It is divided into several basic library and algorithm categories.
And it also contains libraries that are no longer maintained and small libraries.
It has commented on the helpful parts of the code.
It also commented on good libraries within each category.
We can find a better way to use Rust for Machine Learning.
- [Website (en)](https://vaaaaanquish.github.io/Awesome-Rust-MachineLearning)
- [GitHub (en)](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning/blob/main/README.md)
- [GitHub (ja)](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning/blob/main/README.ja.md)
# ToC
- [Support Tools](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#support-tools)
- [Jupyter Notebook](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#jupyter-notebook)
- [Graph Plot](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#graph-plot)
- [Vector](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#vector)
- [Dataframe](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#dataframe)
- [Image Processing](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#image-processing)
- [Natural Language Processing (preprocessing)](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#natural-language-processing-preprocessing)
- [Graphical Modeling](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#graphical-modeling)
- [Interface & Pipeline & AutoML](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#interface--pipeline--automl)
- [Workflow](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#workflow)
- [GPU](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#gpu)
- [Comprehensive (like sklearn)](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#comprehensive-like-sklearn)
- [Comprehensive (statistics)](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#comprehensive-statistics)
- [Gradient Boosting](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#gradient-boosting)
- [Deep Neural Network](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#deep-neural-network)
- [Graph Model](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#graph-model)
- [Natural Language Processing (model)](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#natural-language-processing-model)
- [Recommendation](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#recommendation)
- [Information Retrieval](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#information-retrieval)
- [Full Text Search](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#full-text-search)
- [Nearest Neighbor Search](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#nearest-neighbor-search)
- [Reinforcement Learning](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#reinforcement-learning)
- [Supervised Learning](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#supervised-learning-model)
- [Unsupervised Learning & Clustering Model](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#unsupervised-learning--clustering-model)
- [Statistical Model](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#statistical-model)
- [Evolutionary Algorithm](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#evolutionary-algorithm)
- [Reference](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#reference)
- [Nearby Projects](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#nearby-projects)
- [Blogs](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#blogs)
- [Introduction](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#introduction)
- [Tutorial](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#tutorial)
- [Apply](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#apply)
- [Case Study](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#case-study)
- [Discussion](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#discussion)
- [Books](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#books)
- [Movie](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#movie)
- [PodCast](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#podcast)
- [Paper](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#paper)
- [Thanks](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning#thanks)
# Support Tools
## Jupyter Notebook
`evcxr` can be handled as Jupyter Kernel or REPL. It is helpful for learning and validation.
- [google/evcxr](https://github.com/google/evcxr) - An evaluation context for Rust.
- [emakryo/rustdef](https://github.com/emakryo/rustdef) - Jupyter extension for rust.
- [murarth/rusti](https://github.com/murarth/rusti) - REPL for the Rust programming language
## Graph Plot
It might want to try `plotters` for now.
- [38/plotters](https://github.com/38/plotters) - A rust drawing library for high quality data plotting for both WASM and native, statically and realtimely 🦀 📈🚀
- [igiagkiozis/plotly](https://github.com/igiagkiozis/plotly) - Plotly for Rust
- [milliams/plotlib](https://github.com/milliams/plotlib) - Data plotting library for Rust
- [tiby312/poloto](https://github.com/tiby312/poloto) - A simple 2D plotting library that outputs graphs to SVG that can be styled using CSS.
- [askanium/rustplotlib](https://github.com/askanium/rustplotlib) - A pure Rust visualization library inspired by D3.js
- [SiegeLord/RustGnuplot](https://github.com/SiegeLord/RustGnuplot) - A Rust library for drawing plots, powered by Gnuplot.
- [saona-raimundo/preexplorer](https://github.com/saona-raimundo/preexplorer) - Externalize easily the plotting process from Rust to gnuplot.
- [procyon-rs/vega_lite_4.rs](https://github.com/procyon-rs/vega_lite_4.rs) - rust api for vega-lite v4
- [procyon-rs/showata](https://github.com/procyon-rs/showata) - A library of to show data (in browser, evcxr_jupyter) as table, chart...
- [coder543/dataplotlib](https://github.com/coder543/dataplotlib) - Scientific plotting library for Rust
- [shahinrostami/chord_rs](https://github.com/shahinrostami/chord_rs) - Rust crate for creating beautiful interactive Chord Diagrams. Pro version available at https://m8.fyi/chord
ASCII line graph:
- [loony-bean/textplots-rs](https://github.com/loony-bean/textplots-rs) Terminal plotting library for Rust
- [orhanbalci/rasciigraph](https://github.com/orhanbalci/rasciigraph) Zero dependency Rust crate to make lightweight ASCII line graph ╭┈╯ in command line apps with no other dependencies.
- [jakobhellermann/piechart](https://github.com/jakobhellermann/piechart) a rust crate for drawing fancy pie charts in the terminal
- [milliams/plot](https://github.com/milliams/plot) Command-line plotting tool written in Rust
Examples:
- Plotters Developer's Guide - Plotter Developer's Guide [https://plotters-rs.github.io/book/intro/introduction.html](https://plotters-rs.github.io/book/intro/introduction.html)
- Plotly.rs - Plotly.rs Book [https://igiagkiozis.github.io/plotly/content/plotly_rs.html](https://igiagkiozis.github.io/plotly/content/plotly_rs.html)
- petgraph_review [https://timothy.hobbs.cz/rust-play/petgraph_review.html](https://timothy.hobbs.cz/rust-play/petgraph_review.html)
- evcxr-jupyter-integration [https://plotters-rs.github.io/plotters-doc-data/evcxr-jupyter-integration.html](https://plotters-rs.github.io/plotters-doc-data/evcxr-jupyter-integration.html)
- Rust for Data Science: Tutorial 1 - DEV Community [https://dev.to/davidedelpapa/rust-for-data-science-tutorial-1-4g5j](https://dev.to/davidedelpapa/rust-for-data-science-tutorial-1-4g5j)
- Preface | Data Crayon [https://datacrayon.com/posts/programming/rust-notebooks/preface/](https://datacrayon.com/posts/programming/rust-notebooks/preface/)
- Drawing SVG Graphs with Rust [https://cetra3.github.io/blog/drawing-svg-graphs-rust/](Drawing SVG Graphs with Rust https://cetra3.github.io/blog/drawing-svg-graphs-rust/)
## Vector
Most things use `ndarray` or `std::vec`.
Also, look at `nalgebra`. When the size of the matrix is known, it is valid.
See also: [ndarray vs nalgebra - reddit](https://www.reddit.com/r/rust/comments/btn1cz/ndarray_vs_nalgebra/)
- [dimforge/nalgebra](https://github.com/dimforge/nalgebra) - Linear algebra library for Rust.
- [rust-ndarray/ndarray](https://github.com/rust-ndarray/ndarray) - ndarray: an N-dimensional array with array views, multidimensional slicing, and efficient operations
- [AtheMathmo/rulinalg](https://github.com/AtheMathmo/rulinalg) - A linear algebra library written in Rust
- [arrayfire/arrayfire-rust](https://github.com/arrayfire/arrayfire-rust) - Rust wrapper for ArrayFire
- [bluss/arrayvec](https://github.com/bluss/arrayvec) - A vector with a fixed capacity. (Rust)
- [vbarrielle/sprs](https://github.com/vbarrielle/sprs) - sparse linear algebra library for rust
- [liborty/rstats](https://github.com/liborty/rstats) - Rust Statistics and Vector Algebra Library
- [PyO3/rust-numpy](https://github.com/PyO3/rust-numpy) - PyO3-based Rust binding of NumPy C-API
## Dataframe
It might want to try `polars` for now. `datafusion` looks good too.
- [ritchie46/polars](https://github.com/ritchie46/polars) - Rust DataFrame library
- [apache/arrow](https://github.com/apache/arrow-rs) - In-memory columnar format, in Rust.
- [apache/arrow-datafusion](https://github.com/apache/arrow-datafusion) - Apache Arrow DataFusion and Ballista query engines
- [milesgranger/black-jack](https://github.com/milesgranger/black-jack) - DataFrame / Series data processing in Rust
- [nevi-me/rust-dataframe](https://github.com/nevi-me/rust-dataframe) - A Rust DataFrame implementation, built on Apache Arrow
- [kernelmachine/utah](https://github.com/kernelmachine/utah) - Dataframe structure and operations in Rust
- [sinhrks/brassfibre](https://github.com/sinhrks/brassfibre) - Provides multiple-dtype columner storage, known as DataFrame in pandas/R
## Image Processing
It might want to try `image-rs` for now. Algorithms such as linear transformations are implemented in other libraries as well.
- [image-rs/image](https://github.com/image-rs/image) - Encoding and decoding images in Rust
- [image-rs/imageproc](https://github.com/image-rs/imageproc) - Image processing operations
- [rust-cv/ndarray-image](https://github.com/rust-cv/ndarray-image) - Allows conversion between ndarray's types and image's types
- [rust-cv/cv](https://github.com/rust-cv/cv) - Rust CV mono-repo. Contains pure-Rust dependencies which attempt to encapsulate the capability of OpenCV, OpenMVG, and vSLAM frameworks in a cohesive set of APIs.
- [twistedfall/opencv-rust](https://github.com/twistedfall/opencv-rust) - Rust bindings for OpenCV 3 & 4
- [rustgd/cgmath](https://github.com/rustgd/cgmath) - A linear algebra and mathematics library for computer graphics.
- [atomashpolskiy/rustface](https://github.com/atomashpolskiy/rustface) - Face detection library for the Rust programming language
## Natural Language Processing (preprocessing)
- [google-research/deduplicate-text-datasets](https://github.com/google-research/deduplicate-text-datasets) - This repository contains code to deduplicate language model datasets as descrbed in the paper "Deduplicating Training Data Makes Language Models Better" by Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch and Nicholas Carlini. This repository contains both the ExactSubstr deduplication implementation (written in Rust) along with the scripts we used in the paper to perform deduplication and inspect the results (written in Python). In an upcoming update, we will add files to reproduce the NearDup-deduplicated versions of the C4, RealNews, LM1B, and Wiki-40B-en datasets.
- [pemistahl/lingua-rs](https://github.com/pemistahl/lingua-rs) - 👄 The most accurate natural language detection library in the Rust ecosystem, suitable for long and short text alike
- [usamec/cntk-rs](https://github.com/usamec/cntk-rs) - Wrapper around Microsoft CNTK library
- [stickeritis/sticker](https://github.com/stickeritis/sticker) - A LSTM/Transformer/dilated convolution sequence labeler
- [tensordot/syntaxdot](https://github.com/tensordot/syntaxdot) - Neural syntax annotator, supporting sequence labeling, lemmatization, and dependency parsing.
- [christophertrml/rs-natural](https://github.com/christophertrml/rs-natural) - Natural Language Processing for Rust
- [bminixhofer/nnsplit](https://github.com/bminixhofer/nnsplit) - Semantic text segmentation. For sentence boundary detection, compound splitting and more.
- [greyblake/whatlang-rs](https://github.com/greyblake/whatlang-rs) - Natural language detection library for Rust.
- [finalfusion/finalfrontier](https://github.com/finalfusion/finalfrontier) - Context-sensitive word embeddings with subwords. In Rust.
- [bminixhofer/nlprule](https://github.com/bminixhofer/nlprule) - A fast, low-resource Natural Language Processing and Error Correction library written in Rust.
- [rth/vtext](https://github.com/rth/vtext) - Simple NLP in Rust with Python bindings
- [tamuhey/tokenizations](https://github.com/tamuhey/tokenizations) - Robust and Fast tokenizations alignment library for Rust and Python
- [vgel/treebender](https://github.com/vgel/treebender) - A HDPSG-inspired symbolic natural language parser written in Rust
- [reinfer/blingfire-rs](https://github.com/reinfer/blingfire-rs) - Rust wrapper for the BlingFire tokenization library
- [CurrySoftware/rust-stemmers](https://github.com/CurrySoftware/rust-stemmers) - Common stop words in a variety of languages
- [cmccomb/rust-stop-words](https://github.com/cmccomb/rust-stop-words) - Common stop words in a variety of languages
- [Freyskeyd/nlp](https://github.com/Freyskeyd/nlp) - Rust-nlp is a library to use Natural Language Processing algorithm with RUST
- [Daniel-Liu-c0deb0t/uwu](https://github.com/Daniel-Liu-c0deb0t/uwu) - fastest text uwuifier in the west
## Graphical Modeling
- [alibaba/GraphScope](https://github.com/alibaba/GraphScope) - GraphScope: A One-Stop Large-Scale Graph Computing System from Alibaba
- [petgraph/petgraph](https://github.com/petgraph/petgraph) - Graph data structure library for Rust.
- [rs-graph/rs-graph](https://chiselapp.com/user/fifr/repository/rs-graph/doc/release/README.md) - rs-graph is a library for graph algorithms and combinatorial optimization
- [metamolecular/gamma](https://github.com/metamolecular/gamma) - A graph library for Rust.
- [purpleprotocol/graphlib](https://github.com/purpleprotocol/graphlib) - Simple but powerful graph library for Rust
- [yamafaktory/hypergraph](https://github.com/yamafaktory/hypergraph) - Hypergraph is a data structure library to generate directed hypergraphs
## Interface & Pipeline & AutoML
- [modelfoxdotdev/modelfox](https://github.com/modelfoxdotdev/modelfox) - Modelfox is an all-in-one automated machine learning framework. https://github.com/modelfoxdotdev/modelfox
- [datafuselabs/datafuse](https://github.com/datafuselabs/datafuse) - A Modern Real-Time Data Processing & Analytics DBMS with Cloud-Native Architecture, written in Rust
- [mstallmo/tensorrt-rs](https://github.com/mstallmo/tensorrt-rs) - Rust library for running TensorRT accelerated deep learning models
- [pipehappy1/tensorboard-rs](https://github.com/pipehappy1/tensorboard-rs) - Write TensorBoard events in Rust.
- [ehsanmok/tvm-rust](https://github.com/ehsanmok/tvm-rust) - Rust bindings for TVM runtime
- [vertexclique/orkhon](https://github.com/vertexclique/orkhon) - Orkhon: ML Inference Framework and Server Runtime
- [xaynetwork/xaynet](https://github.com/xaynetwork/xaynet) - Xaynet represents an agnostic Federated Machine Learning framework to build privacy-preserving AI applications
- [webonnx/wonnx](https://github.com/webonnx/wonnx) - A GPU-accelerated ONNX inference run-time written 100% in Rust, ready for the web
- [sonos/tract](https://github.com/sonos/tract) - Tiny, no-nonsense, self-contained, Tensorflow and ONNX inference
- [MegEngine/MegFlow](https://github.com/MegEngine/MegFlow) - Efficient ML solutions for long-tailed demands.
## Workflow
- [substantic/rain](https://github.com/substantic/rain) - Framework for large distributed pipelines
- [timberio/vector](https://github.com/timberio/vector) - A high-performance, highly reliable, observability data pipeline
## GPU
- [Rust-GPU/Rust-CUDA](https://github.com/Rust-GPU/Rust-CUDA) - Ecosystem of libraries and tools for writing and executing extremely fast GPU code fully in Rust.
- [EmbarkStudios/rust-gpu](https://github.com/EmbarkStudios/rust-gpu) - 🐉 Making Rust a first-class language and ecosystem for GPU code 🚧
- [termoshtt/accel](https://github.com/termoshtt/accel) - GPGPU Framework for Rust
- [kmcallister/glassful](https://github.com/kmcallister/glassful) - Rust-like syntax for OpenGL Shading Language
- [MaikKlein/rlsl](https://github.com/MaikKlein/rlsl) - Rust to SPIR-V compiler
- [japaric-archived/nvptx](https://github.com/japaric-archived/nvptx) - How to: Run Rust code on your NVIDIA GPU
- [msiglreith/inspirv-rust](https://github.com/msiglreith/inspirv-rust) - Rust (MIR) → SPIR-V (Shader) compiler
# Comprehensive (like sklearn)
All libraries support the following algorithms.
- Linear Regression
- Logistic Regression
- K-Means Clustering
- Neural Networks
- Gaussian Process Regression
- Support Vector Machines
- kGaussian Mixture Models
- Naive Bayes Classifiers
- DBSCAN
- k-Nearest Neighbor Classifiers
- Principal Component Analysis
- Decision Tree
- Support Vector Machines
- Naive Bayes
- Elastic Net
It might want to try `smartcore` or `linfa` for now.
- [smartcorelib/smartcore](https://github.com/smartcorelib/smartcore) - SmartCore is a comprehensive library for machine learning and numerical computing. The library provides a set of tools for linear algebra, numerical computing, optimization, and enables a generic, powerful yet still efficient approach to machine learning.
- LASSO, Ridge, Random Forest, LU, QR, SVD, EVD, and more metrics
- https://smartcorelib.org/user_guide/quick_start.html
- [rust-ml/linfa](https://github.com/rust-ml/linfa) - A Rust machine learning framework.
- Gaussian Mixture Model Clustering, Agglomerative Hierarchical Clustering, ICA
- https://github.com/rust-ml/linfa#current-state
- [maciejkula/rustlearn](https://github.com/maciejkula/rustlearn) - Machine learning crate for Rust
- factorization machines, k-fold cross-validation, ndcg
- https://github.com/maciejkula/rustlearn#features
- [AtheMathmo/rusty-machine](https://github.com/AtheMathmo/rusty-machine) - Machine Learning library for Rust
- Confusion Matrix, Cross Varidation, Accuracy, F1 Score, MSE
- https://github.com/AtheMathmo/rusty-machine#machine-learning
- [benjarison/eval-metrics](https://github.com/benjarison/eval-metrics) - Evaluation metrics for machine learning
- Many evaluation functions
- [blue-yonder/vikos](https://github.com/blue-yonder/vikos) - A machine learning library for supervised training of parametrized models
- [mbillingr/openml-rust](https://github.com/mbillingr/openml-rust) - A rust interface to http://openml.org/
# Comprehensive (Statistics)
- [statrs-dev/statrs](https://github.com/statrs-dev/statrs) - Statistical computation library for Rust
- [rust-ndarray/ndarray-stats](https://github.com/rust-ndarray/ndarray-stats) - Statistical routines for ndarray
- [Axect/Peroxide](https://github.com/Axect/Peroxide) - Rust numeric library with R, MATLAB & Python syntax
- Linear Algebra, Functional Programming, Automatic Differentiation, Numerical Analysis, Statistics, Special functions, Plotting, Dataframe
- [tarcieri/micromath](https://github.com/tarcieri/micromath) - Embedded Rust arithmetic, 2D/3D vector, and statistics library
# Gradient Boosting
- [mesalock-linux/gbdt-rs](https://github.com/mesalock-linux/gbdt-rs) - MesaTEE GBDT-RS : a fast and secure GBDT library, supporting TEEs such as Intel SGX and ARM TrustZone
- [davechallis/rust-xgboost](https://github.com/davechallis/rust-xgboost) - Rust bindings for XGBoost.
- [vaaaaanquish/lightgbm-rs](https://github.com/vaaaaanquish/lightgbm-rs) - LightGBM Rust binding
- [catboost/catboost](https://github.com/catboost/catboost/tree/master/catboost/rust-package) - A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks (predict only)
- [Entscheider/stamm](https://github.com/entscheider/stamm) - Generic decision trees for rust
# Deep Neural Network
`Tensorflow bindings` and `PyTorch bindings` are the most common.
`tch-rs` also has torch vision, which is useful.
- [tensorflow/rust](https://github.com/tensorflow/rust) - Rust language bindings for TensorFlow
- [LaurentMazare/tch-rs](https://github.com/LaurentMazare/tch-rs) - Rust bindings for the C++ api of PyTorch.
- [VasanthakumarV/einops](https://github.com/vasanthakumarv/einops) - Simplistic API for deep learning tensor operations
- [spearow/juice](https://github.com/spearow/juice) - The Hacker's Machine Learning Engine
- [neuronika/neuronika](https://github.com/neuronika/neuronika) - Tensors and dynamic neural networks in pure Rust.
- [bilal2vec/L2](https://github.com/bilal2vec/L2) - l2 is a fast, Pytorch-style Tensor+Autograd library written in Rust
- [raskr/rust-autograd](https://github.com/raskr/rust-autograd) - Tensors and differentiable operations (like TensorFlow) in Rust
- [charles-r-earp/autograph](https://github.com/charles-r-earp/autograph) - Machine Learning Library for Rust
- [patricksongzy/corgi](https://github.com/patricksongzy/corgi) - A neural network, and tensor dynamic automatic differentiation implementation for Rust.
- [JonathanWoollett-Light/cogent](https://github.com/JonathanWoollett-Light/cogent) - Simple neural network library for classification written in Rust.
- [oliverfunk/darknet-rs](https://github.com/oliverfunk/darknet-rs) - Rust bindings for darknet
- [jakelee8/mxnet-rs](https://github.com/jakelee8/mxnet-rs) - mxnet for Rust
- [jramapuram/hal](https://github.com/jramapuram/hal) - Rust based Cross-GPU Machine Learning
- [primitiv/primitiv-rust](https://github.com/primitiv/primitiv-rust) - Rust binding of primitiv
- [chantera/dynet-rs](https://github.com/chantera/dynet-rs) - The Rust Language Bindings for DyNet
- [millardjn/alumina](https://github.com/millardjn/alumina) - A deep learning library for rust
- [jramapuram/hal](https://github.com/jramapuram/hal) - Rust based Cross-GPU Machine Learning
- [afck/fann-rs](https://github.com/afck/fann-rs) - Rust wrapper for the Fast Artificial Neural Network library
- [autumnai/leaf](https://github.com/autumnai/leaf) - Open Machine Intelligence Framework for Hackers. (GPU/CPU)
- [c0dearm/mushin](https://github.com/c0dearm/mushin) - Compile-time creation of neural networks
- [tedsta/deeplearn-rs](https://github.com/tedsta/deeplearn-rs) - Neural networks in Rust
- [sakex/neat-gru-rust](https://github.com/sakex/neat-gru-rust) - neat-gru
- [nerosnm/n2](https://github.com/nerosnm/n2) - (Work-in-progress) library implementation of a feedforward, backpropagation artificial neural network
- [Wuelle/deep_thought](https://github.com/Wuelle/deep_thought) - Neural Networks in Rust
- [MikhailKravets/NeuroFlow](https://github.com/MikhailKravets/NeuroFlow) - Awesome deep learning crate
- [dvigneshwer/deeprust](https://github.com/dvigneshwer/deeprust) - Machine learning crate in Rust
- [millardjn/rusty_sr](https://github.com/millardjn/rusty_sr) - Deep learning superresolution in pure rust
- [coreylowman/dfdx](https://github.com/coreylowman/dfdx) - Strongly typed Deep Learning in Rust
# Graph Model
- [Synerise/cleora](https://github.com/Synerise/cleora) - Cleora AI is a general-purpose model for efficient, scalable learning of stable and inductive entity embeddings for heterogeneous relational data.
- [Pardoxa/net_ensembles](https://github.com/Pardoxa/net_ensembles) - Rust library for random graph ensembles
# Natural Language Processing (model)
- [huggingface/tokenizers](https://github.com/huggingface/tokenizers/tree/master/tokenizers) - The core of tokenizers, written in Rust. Provides an implementation of today's most used tokenizers, with a focus on performance and versatility.
- [guillaume-be/rust-tokenizers](https://github.com/guillaume-be/rust-tokenizers) - Rust-tokenizer offers high-performance tokenizers for modern language models, including WordPiece, Byte-Pair Encoding (BPE) and Unigram (SentencePiece) models
- [guillaume-be/rust-bert](https://github.com/guillaume-be/rust-bert) - Rust native ready-to-use NLP pipelines and transformer-based models (BERT, DistilBERT, GPT2,...)
- [sno2/bertml](https://github.com/sno2/bertml) - Use common pre-trained ML models in Deno!
- [cpcdoy/rust-sbert](https://github.com/cpcdoy/rust-sbert) - Rust port of sentence-transformers (https://github.com/UKPLab/sentence-transformers)
- [vongaisberg/gpt3_macro](https://github.com/vongaisberg/gpt3_macro) - Rust macro that uses GPT3 codex to generate code at compiletime
- [proycon/deepfrog](https://github.com/proycon/deepfrog) - An NLP-suite powered by deep learning
- [ferristseng/rust-tfidf](https://github.com/ferristseng/rust-tfidf) - Library to calculate TF-IDF
- [messense/fasttext-rs](https://github.com/messense/fasttext-rs) - fastText Rust binding
- [mklf/word2vec-rs](https://github.com/mklf/word2vec-rs) - pure rust implementation of word2vec
- [DimaKudosh/word2vec](https://github.com/DimaKudosh/word2vec) - Rust interface to word2vec.
- [lloydmeta/sloword2vec-rs](https://github.com/lloydmeta/sloword2vec-rs) - A naive (read: slow) implementation of Word2Vec. Uses BLAS behind the scenes for speed.
# Recommendation
- [PersiaML/PERSIA](https://github.com/PersiaML/PERSIA) - High performance distributed framework for training deep learning recommendation models based on PyTorch.
- [jackgerrits/vowpalwabbit-rs](https://github.com/jackgerrits/vowpalwabbit-rs) - 🦀🐇 Rusty VowpalWabbit
- [outbrain/fwumious_wabbit](https://github.com/outbrain/fwumious_wabbit) - Fwumious Wabbit, fast on-line machine learning toolkit written in Rust
- [hja22/rucommender](https://github.com/hja22/rucommender) - Rust implementation of user-based collaborative filtering
- [maciejkula/sbr-rs](https://github.com/maciejkula/sbr-rs) - Deep recommender systems for Rust
- [chrisvittal/quackin](https://github.com/chrisvittal/quackin) - A recommender systems framework for Rust
- [snd/onmf](https://github.com/snd/onmf) - fast rust implementation of online nonnegative matrix factorization as laid out in the paper "detect and track latent factors with online nonnegative matrix factorization"
- [rhysnewell/nymph](https://github.com/rhysnewell/nymph) - Non-Negative Matrix Factorization in Rust
# Information Retrieval
## Full Text Search
- [quickwit-inc/quickwit](https://github.com/quickwit-inc/quickwit) - Quickwit is a big data search engine.
- [bayard-search/bayard](https://github.com/bayard-search/bayard) - A full-text search and indexing server written in Rust.
- [neuml/txtai.rs](https://github.com/neuml/txtai.rs) - AI-powered search engine for Rust
- [meilisearch/MeiliSearch](https://github.com/meilisearch/MeiliSearch) - Lightning Fast, Ultra Relevant, and Typo-Tolerant Search Engine
- [toshi-search/Toshi](https://github.com/toshi-search/Toshi) - A full-text search engine in rust
- [BurntSushi/fst](https://github.com/BurntSushi/fst) - Represent large sets and maps compactly with finite state transducers.
- [tantivy-search/tantivy](https://github.com/tantivy-search/tantivy) - Tantivy is a full-text search engine library inspired by Apache Lucene and written in Rust
- [tinysearch/tinysearch](https://github.com/tinysearch/tinysearch) - 🔍 Tiny, full-text search engine for static websites built with Rust and Wasm
- [quantleaf/probly-search](https://github.com/quantleaf/probly-search) - A lightweight full-text search library that provides full control over the scoring calculations
- [https://github.com/andylokandy/simsearch-rs](https://github.com/andylokandy/simsearch-rs) - A simple and lightweight fuzzy search engine that works in memory, searching for similar strings
- [jameslittle230/stork](https://github.com/jameslittle230/stork) - 🔎 Impossibly fast web search, made for static sites.
- [elastic/elasticsearch-rs](https://github.com/elastic/elasticsearch-rs) - Official Elasticsearch Rust Client
## Nearest Neighbor Search
- [Enet4/faiss-rs](https://github.com/Enet4/faiss-rs) - Rust language bindings for Faiss
- [rust-cv/hnsw](https://github.com/rust-cv/hnsw) - HNSW ANN from the paper "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs"
- [hora-search/hora](https://github.com/hora-search/hora) - 🚀 efficient approximate nearest neighbor search algorithm collections library, which implemented with Rust 🦀. horasearch.com
- [InstantDomain/instant-distance](https://github.com/InstantDomain/instant-distance) - Fast approximate nearest neighbor searching in Rust, based on HNSW index
- [lerouxrgd/ngt-rs](https://github.com/lerouxrgd/ngt-rs) - Rust wrappers for NGT approximate nearest neighbor search
- [granne/granne](https://github.com/granne/granne) - Graph-based Approximate Nearest Neighbor Search
- [u1roh/kd-tree](https://github.com/u1roh/kd-tree) - k-dimensional tree in Rust. Fast, simple, and easy to use.
- [qdrant/qdrant](https://github.com/qdrant/qdrant) - Qdrant - vector similarity search engine with extended filtering support
- [rust-cv/hwt](https://github.com/rust-cv/hwt) - Hamming Weight Tree from the paper "Online Nearest Neighbor Search in Hamming Space"
- [fulara/kdtree-rust](https://github.com/fulara/kdtree-rust) - kdtree implementation for rust.
- [mrhooray/kdtree-rs](https://github.com/mrhooray/kdtree-rs) - K-dimensional tree in Rust for fast geospatial indexing and lookup
- [kornelski/vpsearch](https://github.com/kornelski/vpsearch) - C library for finding nearest (most similar) element in a set
- [petabi/petal-neighbors](https://github.com/petabi/petal-neighbors) - Nearest neighbor search algorithms including a ball tree and a vantage point tree.
- [ritchie46/lsh-rs](https://github.com/ritchie46/lsh-rs) - Locality Sensitive Hashing in Rust with Python bindings
- [kampersanda/mih-rs](https://github.com/kampersanda/mih-rs) - Rust implementation of multi-index hashing for neighbor searches on 64-bit codes in the Hamming space
# Reinforcement Learning
- [taku-y/border](https://github.com/taku-y/border) - Border is a reinforcement learning library in Rust.
- [NivenT/REnforce](https://github.com/NivenT/REnforce) - Reinforcement learning library written in Rust
- [edlanglois/relearn](https://github.com/edlanglois/relearn) - Reinforcement learning with Rust
- [tspooner/rsrl](https://github.com/tspooner/rsrl) - A fast, safe and easy to use reinforcement learning framework in Rust.
- [milanboers/rurel](https://github.com/milanboers/rurel) - Flexible, reusable reinforcement learning (Q learning) implementation in Rust
- [Ragnaroek/bandit](https://github.com/Ragnaroek/bandit) - Bandit Algorithms in Rust
- [MrRobb/gym-rs](https://github.com/mrrobb/gym-rs) - OpenAI Gym bindings for Rust
# Supervised Learning Model
- [tomtung/omikuji](https://github.com/tomtung/omikuji) - An efficient implementation of Partitioned Label Trees & its variations for extreme multi-label classification
- [shadeMe/liblinear-rs](https://github.com/shademe/liblinear-rs) - Rust language bindings for the LIBLINEAR C/C++ library.
- [messense/crfsuite-rs](https://github.com/messense/crfsuite-rs) - Rust binding to crfsuite
- [ralfbiedert/ffsvm-rust](https://github.com/ralfbiedert/ffsvm-rust) - FFSVM stands for "Really Fast Support Vector Machine"
- [zenoxygen/bayespam](https://github.com/zenoxygen/bayespam) - A simple bayesian spam classifier written in Rust.
- [Rui_Vieira/naive-bayesnaive-bayes](https://gitlab.com/ruivieira/naive-bayes) - A Naive Bayes classifier written in Rust.
- [Rui_Vieira/random-forests](https://gitlab.com/ruivieira/random-forests) - A Rust library for Random Forests.
- [sile/randomforest](https://github.com/sile/randomforest) - A random forest implementation in Rust
- [tomtung/craftml-rs](https://github.com/tomtung/craftml-rs) - A Rust🦀 implementation of CRAFTML, an Efficient Clustering-based Random Forest for Extreme Multi-label Learning
- [nkaush/naive-bayes-rs](https://github.com/nkaush/naive-bayes-rs) - A Rust library with homemade machine learning models to classify the MNIST dataset. Built in an attempt to get familiar with advanced Rust concepts.
# Unsupervised Learning & Clustering Model
- [frjnn/bhtsne](https://github.com/frjnn/bhtsne) - Barnes-Hut t-SNE implementation written in Rust.
- [vaaaaanquish/label-propagation-rs](https://github.com/vaaaaanquish/label-propagation-rs) - Label Propagation Algorithm by Rust. Label propagation (LP) is graph-based semi-supervised learning (SSL). LGC and CAMLP have been implemented.
- [nmandery/extended-isolation-forest](https://github.com/nmandery/extended-isolation-forest) - Rust port of the extended isolation forest algorithm for anomaly detection
- [avinashshenoy97/RusticSOM](https://github.com/avinashshenoy97/RusticSOM) - Rust library for Self Organising Maps (SOM).
- [diffeo/kodama](https://github.com/diffeo/kodama) - Fast hierarchical agglomerative clustering in Rust.
- [kno10/rust-kmedoids](https://github.com/kno10/rust-kmedoids) - k-Medoids clustering in Rust with the FasterPAM algorithm
- [petabi/petal-clustering](https://github.com/petabi/petal-clustering) - DBSCAN and OPTICS clustering algorithms.
- [savish/dbscan](https://github.com/savish/dbscan) - A naive DBSCAN implementation in Rust
- [gu18168/DBSCANSD](https://github.com/gu18168/DBSCANSD) - Rust implementation for DBSCANSD, a trajectory clustering algorithm.
- [lazear/dbscan](https://github.com/lazear/dbscan) - Dependency free implementation of DBSCAN clustering in Rust
- [whizsid/kddbscan-rs](https://github.com/whizsid/kddbscan-rs) - A rust library inspired by kDDBSCAN clustering algorithm
- [Sauro98/appr_dbscan_rust](https://github.com/Sauro98/appr_dbscan_rust) - Program implementing the approximate version of DBSCAN introduced by Gan and Tao
- [quietlychris/density_clusters](https://github.com/quietlychris/density_clusters) - A naive density-based clustering algorithm written in Rust
- [milesgranger/gap_statistic](https://github.com/milesgranger/gap_statistic) - Dynamically get the suggested clusters in the data for unsupervised learning.
- [genbattle/rkm](https://github.com/genbattle/rkm) - Generic k-means implementation written in Rust
- [selforgmap/som-rust](https://github.com/selforgmap/som-rust) - Self Organizing Map (SOM) is a type of Artificial Neural Network (ANN) that is trained using an unsupervised, competitive learning to produce a low dimensional, discretized representation (feature map) of higher dimensional data.
# Statistical Model
- [Redpoll/changepoint](https://gitlab.com/Redpoll/changepoint) - Includes the following change point detection algorithms: Bocpd -- Online Bayesian Change Point Detection Reference. BocpdTruncated -- Same as Bocpd but truncated the run-length distribution when those lengths are unlikely.
- [krfricke/arima](https://github.com/krfricke/arima) - ARIMA modelling for Rust
- [Daingun/automatica](https://gitlab.com/daingun/automatica) - Automatic Control Systems Library
- [rbagd/rust-linearkalman](https://github.com/rbagd/rust-linearkalman) - Kalman filtering and smoothing in Rust
- [sanity/pair_adjacent_violators](https://github.com/sanity/pair_adjacent_violators) - An implementation of the Pair Adjacent Violators algorithm for isotonic regression in Rust
# Evolutionary Algorithm
- [martinus/differential-evolution-rs](https://github.com/martinus/differential-evolution-rs) - Generic Differential Evolution for Rust
- [innoave/genevo](https://github.com/innoave/genevo) - Execute genetic algorithm (GA) simulations in a customizable and extensible way.
- [Jeffail/spiril](https://github.com/Jeffail/spiril) - Rust library for genetic algorithms
- [sotrh/rust-genetic-algorithm](https://github.com/sotrh/rust-genetic-algorithm) - Example of a genetic algorithm in Rust and Python
- [willi-kappler/darwin-rs](https://github.com/willi-kappler/darwin-rs) - darwin-rs, evolutionary algorithms with rust
# Reference
## Nearby Projects
- [Are we learning yet?](http://www.arewelearningyet.com/), A work-in-progress to catalog the state of machine learning in Rust
- [e-tony/best-of-ml-rust](https://github.com/e-tony/best-of-ml-rust), A ranked list of awesome machine learning Rust libraries
- [The Best 51 Rust Machine learning Libraries](https://rustrepo.com/catalog/rust-machine-learning_newest_1), RustRepo
- [rust-unofficial/awesome-rust](https://github.com/rust-unofficial/awesome-rust), A curated list of Rust code and resources
- [Top 16 Rust Machine learning Projects](https://www.libhunt.com/l/rust/t/machine-learning), Open-source Rust projects categorized as Machine learning
- [39+ Best Rust Machine learning frameworks, libraries, software and resourcese](https://reposhub.com/rust/machine-learning), ReposHub
## Blogs
### Introduction
- [About Rust’s Machine Learning Community](https://medium.com/@autumn_eng/about-rust-s-machine-learning-community-4cda5ec8a790#.hvkp56j3f), Medium, 2016/1/6, Autumn Engineering
- [Rust vs Python: Technology And Business Comparison](https://www.ideamotive.co/blog/rust-vs-python-technology-and-business-comparison), 2021/3/4, Miłosz Kaczorowski
- [I wrote one of the fastest DataFrame libraries](https://www.ritchievink.com/blog/2021/02/28/i-wrote-one-of-the-fastest-dataframe-libraries), 2021/2/28, Ritchie Vink
- [Polars: The fastest DataFrame library you've never heard of](https://www.analyticsvidhya.com/blog/2021/06/polars-the-fastest-dataframe-library-youve-never-heard-of) 2021/1/19, Analytics Vidhya
- [Data Manipulation: Polars vs Rust](https://able.bio/haixuanTao/data-manipulation-polars-vs-rust--3def44c8), 2021/3/13, Xavier Tao
- [State of Machine Learning in Rust – Ehsan's Blog](https://ehsanmkermani.com/2019/05/13/state-of-machine-learning-in-rust/), 2019/5/13, Published by Ehsan
- [Ritchie Vink, Machine Learning Engineer, writes Polars, one of the fastest DataFrame libraries in Python and Rust](https://www.xomnia.com/post/ritchie-vink-writes-polars-one-of-the-fastest-dataframe-libraries-in-python-and-rust/), Xomnia, 2021/5/11
- [Quickwit: A highly cost-efficient search engine in Rust](https://quickwit.io/blog/quickwit-first-release/), 2021/7/13, quickwit, PAUL MASUREL
- [Data Manipulation: Polars vs Rust](https://able.bio/haixuanTao/data-manipulation-polars-vs-rust--3def44c8), 2021/3/13, Xavier Tao
- [Check out Rust in Production](https://serokell.io/blog/rust-in-production-qovery), 2021/8/10, Qovery, @serokell
- [Why I started Rust instead of stick to Python](https://medium.com/geekculture/why-i-started-rust-instead-of-stick-to-python-626bab07479a), 2021/9/26, Medium, Geek Culture, Marshal SHI
### Tutorial
- [Rust Machine Learning Book](https://rust-ml.github.io/book/chapter_1.html), Examples of KMeans and DBSCAN with linfa-clustering
- [Artificial Intelligence and Machine Learning – Practical Rust Projects: Building Game, Physical Computing, and Machine Learning Applications – Dev Guis ](http://devguis.com/6-artificial-intelligence-and-machine-learning-practical-rust-projects-building-game-physical-computing-and-machine-learning-applications.html), 2021/5/19
- [Machine learning in Rust using Linfa](https://blog.logrocket.com/machine-learning-in-rust-using-linfa/), LogRocket Blog, 2021/4/30, Timeular, Mario Zupan, Examples of LogisticRegression
- [Machine Learning in Rust, Smartcore](https://medium.com/swlh/machine-learning-in-rust-smartcore-2f472d1ce83), Medium, The Startup, 2021/1/15, [Vlad Orlov](https://volodymyr-orlov.medium.com/), Examples of LinerRegression, Random Forest Regressor, and K-Fold
- [Machine Learning in Rust, Logistic Regression](https://medium.com/swlh/machine-learning-in-rust-logistic-regression-74d6743df161), Medium, The Startup, 2021/1/6, [Vlad Orlov](https://volodymyr-orlov.medium.com/)
- [Machine Learning in Rust, Linear Regression](https://medium.com/swlh/machine-learning-in-rust-linear-regression-edef3fb65f93), Medium, The Startup, 2020/12/16, [Vlad Orlov](https://volodymyr-orlov.medium.com/)
- [Machine Learning in Rust](https://athemathmo.github.io/2016/03/07/rusty-machine.html), 2016/3/7, James, Examples of LogisticRegressor
- [Machine Learning and Rust (Part 1): Getting Started!](https://levelup.gitconnected.com/machine-learning-and-rust-part-1-getting-started-745885771bc2), Level Up Coding, 2021/1/9, Stefano Bosisio
- [Machine Learning and Rust (Part 2): Linear Regression](https://levelup.gitconnected.com/machine-learning-and-rust-part-2-linear-regression-d3b820ed28f9), Level Up Coding, 2021/6/15, Stefano Bosisio
- [Machine Learning and Rust (Part 3): Smartcore, Dataframe, and Linear Regression](https://levelup.gitconnected.com/machine-learning-and-rust-part-3-smartcore-dataframe-and-linear-regression-10451fdc2e60), Level Up Coding, 2021/7/1, Stefano Bosisio
- [Tensorflow Rust Practical Part 1](https://www.programmersought.com/article/18696273900/), Programmer Sought, 2018
- [A Machine Learning introduction to ndarray](https://barcelona.rustfest.eu/sessions/machine-learning-ndarray), RustFest 2019, 2019/11/12, [Luca Palmieri](https://github.com/LukeMathWalker)
- [Simple Linear Regression from scratch in Rust](https://cheesyprogrammer.com/2018/12/13/simple-linear-regression-from-scratch-in-rust/), Web Development, Software Architecture, Algorithms and more, 2018/12/13, philipp
- [Interactive Rust in a REPL and Jupyter Notebook with EVCXR](https://depth-first.com/articles/2020/09/21/interactive-rust-in-a-repl-and-jupyter-notebook-with-evcxr/), Depth-First, 2020/9/21, Richard L. Apodaca
- [Rust for Data Science: Tutorial 1](https://dev.to/davidedelpapa/rust-for-data-science-tutorial-1-4g5j), dev, 2021/8/25, Davide Del Papa
- [petgraph_review](https://timothy.hobbs.cz/rust-play/petgraph_review.html), 2019/10/11, Timothy Hobbs
- [Rust for ML. Rust](https://medium.com/tempus-ex/rust-for-ml-fba0421b0959), Medium, Tempus Ex, 2021/8/1, Michael Naquin
- [Adventures in Drone Photogrammetry Using Rust and Machine Learning (Image Segmentation with linfa and DBSCAN)](http://cmoran.xyz/writing/adventures_in_photogrammetry), 2021/11/14, CHRISTOPHER MORAN
### Apply
- [Deep Learning in Rust: baby steps](https://medium.com/@tedsta/deep-learning-in-rust-7e228107cccc), Medium, 2016/2/2, Theodore DeRego
- [A Rust SentencePiece implementation](https://guillaume-be.github.io/2020-05-30/sentence_piece), Rust NLP tales, 2020/5/30
- [Accelerating text generation with Rust](https://guillaume-be.github.io/2020-11-21/generation_benchmarks), Rust NLP tales, 2020/11/21
- [A Simple Text Summarizer written in Rust](https://towardsdatascience.com/a-simple-text-summarizer-written-in-rust-4df05f9327a5), Towards Data Science, 2020/11/24, [Charles Chan](https://chancharles.medium.com/), Examples of Text Sentence Vector, Cosine Distance and PageRank
- [Extracting deep learning image embeddings in Rust](https://logicai.io/blog/extracting-image-embeddings/), RecoAI, 2021/6/1, Paweł Jankiewic, Examples of ONNX
- [Deep Learning in Rust with GPU](https://able.bio/haixuanTao/deep-learning-in-rust-with-gpu--26c53a7f), 2021/7/30, Xavier Tao
- [tch-rs pretrain example - Docker for PyTorch rust bindings tch-rs. Example of pretrain model](https://github.com/vaaaaanquish/tch-rs-pretrain-example-docker), 2021/8/15, vaaaaanquish
- [Rust ANN search Example - Image search example by approximate nearest-neighbor library In Rust](https://github.com/vaaaaanquish/rust-ann-search-example), 2021/8/15, vaaaaanquish
- [dzamkov/deep-learning-test - Implementing deep learning in Rust using just a linear algebra library (nalgebra)](https://github.com/dzamkov/deep-learning-test), 2021/8/30, dzamkov
- [vaaaaanquish/rust-machine-learning-api-example - The axum example that uses resnet224 to infer images received in base64 and returns the results.](https://github.com/vaaaaanquish/rust-machine-learning-api-example), 2021/9/7, vaaaaanquish
- [Rust for Machine Learning: Benchmarking Performance in One-shot - A Rust implementation of Siamese Neural Networks for One-shot Image Recognition for benchmarking performance and results](https://utmist.gitlab.io/projects/rust-ml-oneshot/), UofT Machine Intelligence Student Team
- [Why Wallaroo Moved From Pony To Rust](https://wallarooai.medium.com/why-wallaroo-moved-from-pony-to-rust-292e7339fc34), 2021/8/19, Wallaroo.ai
- [epwalsh/rust-dl-webserver - Example of serving deep learning models in Rust with batched prediction](https://github.com/epwalsh/rust-dl-webserver), 2021/11/16, epwalsh
### Case study
- [Production users - Rust Programming Language](https://www.rust-lang.org/production/users), by rust-lang.org
- [Taking ML to production with Rust: a 25x speedup](https://www.lpalmieri.com/posts/2019-12-01-taking-ml-to-production-with-rust-a-25x-speedup/), A LEARNING JOURNAL, 2019/12/1, [@algo_luca](https://twitter.com/algo_luca)
- [9 Companies That Use Rust in Production](https://serokell.io/blog/rust-companies), serokell, 2020/11/18, Gints Dreimanis
- [Masked Language Model on Wasm, BERT on flontend examples](https://github.com/optim-corp/masked-lm-wasm/), optim-corp/masked-lm-wasm, 2021/8/27, Optim
- [Serving TensorFlow with Actix-Web](https://github.com/kykosic/actix-tensorflow-example), kykosic/actix-tensorflow-example
- [Serving PyTorch with Actix-Web](https://github.com/kykosic/actix-pytorch-example), kykosic/actix-pytorch-example
## Discussion
- [Natural Language Processing in Rust : rust](https://www.reddit.com/r/rust/comments/5jj8vr/natural_language_processing_in_rust), 2016/12/6
- [Future prospect of Machine Learning in Rust Programming Language : MachineLearning](https://www.reddit.com/r/MachineLearning/comments/7iz51p/d_future_prospect_of_machine_learning_in_rust/), 2017/11/11
- [Interest for NLP in Rust? - The Rust Programming Language Forum](https://users.rust-lang.org/t/interest-for-nlp-in-rust/15331), 2018/1/19
- [Is Rust good for deep learning and artificial intelligence? - The Rust Programming Language Forum](https://users.rust-lang.org/t/is-rust-good-for-deep-learning-and-artificial-intelligence/22866), 2018/11/18
- [ndarray vs nalgebra : rust](https://www.reddit.com/r/rust/comments/btn1cz/ndarray_vs_nalgebra/), 2019/5/28
- [Taking ML to production with Rust | Hacker News](https://news.ycombinator.com/item?id=21680965), 2019/12/2
- [Who is using Rust for Machine learning in production/research? : rust](https://www.reddit.com/r/rust/comments/fvehyq/d_who_is_using_rust_for_machine_learning_in/), 2020/4/5
- [Deep Learning in Rust](https://www.reddit.com/r/rust/comments/igz8iv/deep_learning_in_rust/), 2020/8/26
- [SmartCore, fast and comprehensive machine learning library for Rust! : rust](https://www.reddit.com/r/rust/comments/j1mj1g/smartcore_fast_and_comprehensive_machine_learning/), 2020/9/29
- [Deep Learning in Rust with GPU on ONNX](https://www.reddit.com/r/MachineLearning/comments/ouul33/d_p_deep_learning_in_rust_with_gpu_on_onnx/), 2021/7/31
- [Rust vs. C++ the main differences between these popular programming languages](https://codilime.com/blog/rust-vs-cpp-the-main-differences-between-these-popular-programming-languages/), 2021/8/25
- [I wanted to share my experience of Rust as a deep learning researcher](https://www.reddit.com/r/rust/comments/pft9n9/i_wanted_to_share_my_experience_of_rust_as_a_deep/), 2021/9/2
- [How far along is the ML ecosystem with Rust?](https://www.reddit.com/r/rust/comments/poglgg/how_far_along_is_the_ml_ecosystem_with_rust/), 2021/9/15
## Books
- [Practical Machine Learning with Rust: Creating Intelligent Applications in Rust (English Edition)](https://amzn.to/3h7JV8U), 2019/12/10, Joydeep Bhattacharjee
- Write machine learning algorithms in Rust
- Use Rust libraries for different tasks in machine learning
- Create concise Rust packages for your machine learning applications
- Implement NLP and computer vision in Rust
- Deploy your code in the cloud and on bare metal servers
- source code: [Apress/practical-machine-learning-w-rust](https://github.com/Apress/practical-machine-learning-w-rust)
- [DATA ANALYSIS WITH RUST NOTEBOOKS](https://datacrayon.com/shop/product/data-analysis-with-rust-notebooks/), 2021/9/3, Shahin Rostami
- Plotting with Plotters and Plotly
- Operations with ndarray
- Descriptive Statistics
- Interactive Diagram
- Visualisation of Co-occurring Types
- download source code and dataset
- full text
- [https://datacrayon.com/posts/programming/rust-notebooks/preface/](https://datacrayon.com/posts/programming/rust-notebooks/preface/)
## Movie
- [The /r/playrust Classifier: Real World Rust Data Science](https://www.youtube.com/watch?v=lY10kTcM8ek), RustConf 2016, 2016/10/05, Suchin Gururangan & Colin O'Brien
- [Building AI Units in Rust](https://www.youtube.com/watch?v=UHFlKAmANJg), FOSSASIA 2018, 2018/3/25, Vigneshwer Dhinakaran
- [Python vs Rust for Simulation](https://www.youtube.com/watch?v=kytvDxxedWY), EuroPython 2019, 2019/7/10, Alisa Dammer
- [Machine Learning is changing - is Rust the right tool for the job?](https://www.youtube.com/watch?v=odI_LY8AIqo), RustLab 2019, 2019/10/31, Luca Palmieri
- [Using TensorFlow in Embedded Rust](https://www.youtube.com/watch?v=DUVE86yTfKU), 2020/09/29, Ferrous Systems GmbH, Richard Meadows
- [Writing the Fastest GBDT Library in Rust](https://www.youtube.com/watch?v=D1NAREuicNs), 2021/09/16, RustConf 2021, Isabella Tromba
## PodCast
- DATA SCIENCE AT HOME
- [Rust and machine learning #1 (Ep. 107)](https://datascienceathome.com/rust-and-machine-learning-1-ep-107/)
- [Rust and machine learning #2 with Luca Palmieri (Ep. 108)](https://datascienceathome.com/rust-and-machine-learning-2-with-luca-palmieri-ep-108/)
- [Rust and machine learning #3 with Alec Mocatta (Ep. 109)](https://datascienceathome.com/rust-and-machine-learning-3-with-alec-mocatta-ep-109/)
- [Rust and machine learning #4: practical tools (Ep. 110)](https://datascienceathome.com/rust-and-machine-learning-4-practical-tools-ep-110/)
- [Machine Learning in Rust: Amadeus with Alec Mocatta (Ep. 127)](https://datascienceathome.com/machine-learning-in-rust-amadeus-with-alec-mocatta-rb-ep-127/)
- [Rust and deep learning with Daniel McKenna (Ep. 135)](https://datascienceathome.com/rust-and-deep-learning/)
- [Is Rust flexible enough for a flexible data model? (Ep. 137)](https://datascienceathome.com/is-rust-flexible-enough-for-a-flexible-data-model-ep-137/)
- [Pandas vs Rust (Ep. 144)](https://datascienceathome.com/pandas-vs-rust-ep-144/)
- [Apache Arrow, Ballista and Big Data in Rust with Andy Grove (Ep. 145)](https://datascienceathome.com/apache-arrow-ballista-and-big-data-in-rust-with-andy-grove-ep-145/)
- [Polars: the fastest dataframe crate in Rust (Ep. 146)](https://datascienceathome.com/polars-the-fastest-dataframe-crate-in-rust-ep-146/)
- [Apache Arrow, Ballista and Big Data in Rust with Andy Grove RB (Ep. 160)](https://datascienceathome.com/apache-arrow-ballista-and-big-data-in-rust-with-andy-grove-rb-ep-160/)
## Paper
- [End-to-end NLP Pipelines in Rust](https://www.aclweb.org/anthology/2020.nlposs-1.4.pdf), Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS), pages 20–25 Virtual Conference, 2020/11/19, Guillaume Becquin
# How to contribute
Please just update the README.md.
If you update this README.md, CI will be executed automatically.
And the website will also be updated.
# Thanks
Thanks for all the projects.
[https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning](https://github.com/vaaaaanquish/Awesome-Rust-MachineLearning)
|
3,448 | Open Source Pre-training Model Framework in PyTorch & Pre-trained Model Zoo | [**English**](https://github.com/dbiir/UER-py) | [**中文**](https://github.com/dbiir/UER-py/blob/master/README_ZH.md)
[](https://github.com/dbiir/UER-py/actions/workflows/github-actions.yml)
[](https://codebeat.co/projects/github-com-dbiir-uer-py-master)

[](https://arxiv.org/abs/1909.05658)
<img src="logo.jpg" width="390" hegiht="390" align=left />
Pre-training has become an essential part for NLP tasks. UER-py (Universal Encoder Representations) is a toolkit for pre-training on general-domain corpus and fine-tuning on downstream task. UER-py maintains model modularity and supports research extensibility. It facilitates the use of existing pre-training models, and provides interfaces for users to further extend upon. With UER-py, we build a model zoo which contains pre-trained models of different properties. **See the Wiki for [Full Documentation](https://github.com/dbiir/UER-py/wiki)**.
<br/>
Table of Contents
=================
* [Features](#features)
* [Requirements](#requirements)
* [Quickstart](#quickstart)
* [Datasets](#datasets)
* [Modelzoo](#modelzoo)
* [Instructions](#instructions)
* [Competition solutions](#competition-solutions)
* [Citation](#citation)
* [Contact information](#contact-information)
<br/>
## Features
UER-py has the following features:
- __Reproducibility__ UER-py has been tested on many datasets and should match the performances of the original pre-training model implementations such as BERT, GPT-2, ELMo, and T5.
- __Model modularity__ UER-py is divided into the following components: embedding, encoder, target embedding (optional), decoder (optional), and target. Ample modules are implemented in each component. Clear and robust interface allows users to combine modules to construct pre-training models with as few restrictions as possible.
- __Model training__ UER-py supports CPU mode, single GPU mode, distributed training mode, and gigantic model training with DeepSpeed.
- __Model zoo__ With the help of UER-py, we pre-train and release models of different properties. Proper selection of pre-trained models is important to the performances of downstream tasks.
- __SOTA results__ UER-py supports comprehensive downstream tasks (e.g. classification and machine reading comprehension) and provides winning solutions of many NLP competitions.
- __Abundant functions__ UER-py provides abundant functions related with pre-training, such as feature extractor and text generation.
<br/>
## Requirements
* Python >= 3.6
* torch >= 1.1
* six >= 1.12.0
* argparse
* packaging
* regex
* For the mixed precision training you will need apex from NVIDIA
* For the pre-trained model conversion (related with TensorFlow) you will need TensorFlow
* For the tokenization with sentencepiece model you will need [SentencePiece](https://github.com/google/sentencepiece)
* For developing a stacking model you will need LightGBM and [BayesianOptimization](https://github.com/fmfn/BayesianOptimization)
* For the pre-training with whole word masking you will need word segmentation tool such as [jieba](https://github.com/fxsjy/jieba)
* For the use of CRF in sequence labeling downstream task you will need [pytorch-crf](https://github.com/kmkurn/pytorch-crf)
* For the gigantic model training you will need [DeepSpeed](https://github.com/microsoft/DeepSpeed)
<br/>
## Quickstart
This section uses several commonly-used examples to demonstrate how to use UER-py. More details are discussed in Instructions section. We firstly use BERT model on Douban book review classification dataset. We pre-train model on book review corpus and then fine-tune it on book review classification dataset. There are three input files: book review corpus, book review classification dataset, and vocabulary. All files are encoded in UTF-8 and included in this project.
The format of the corpus for BERT is as follows (one sentence per line and documents are delimited by empty lines):
```
doc1-sent1
doc1-sent2
doc1-sent3
doc2-sent1
doc3-sent1
doc3-sent2
```
The book review corpus is obtained from book review classification dataset. We remove labels and split a review into two parts from the middle to construct a document with two sentences (see *book_review_bert.txt* in *corpora* folder).
The format of the classification dataset is as follows:
```
label text_a
1 instance1
0 instance2
1 instance3
```
Label and instance are separated by \t . The first row is a list of column names. The label ID should be an integer between (and including) 0 and n-1 for n-way classification.
We use Google's Chinese vocabulary file *models/google_zh_vocab.txt*, which contains 21128 Chinese characters.
We firstly pre-process the book review corpus. In the pre-processing stage, the corpus needs to be processed into the format required by the specified pre-training model (*--data_processor*):
```
python3 preprocess.py --corpus_path corpora/book_review_bert.txt --vocab_path models/google_zh_vocab.txt \
--dataset_path dataset.pt --processes_num 8 --data_processor bert
```
Notice that *six>=1.12.0* is required.
Pre-processing is time-consuming. Using multiple processes can largely accelerate the pre-processing speed (*--processes_num*). BERT tokenizer is used in default (*--tokenizer bert*). After pre-processing, the raw text is converted to *dataset.pt*, which is the input of *pretrain.py*. Then we download Google's pre-trained Chinese BERT model [*google_zh_model.bin*](https://share.weiyun.com/A1C49VPb) (in UER format and the original model is from [here](https://github.com/google-research/bert)), and put it in *models* folder. We load the pre-trained Chinese BERT model and further pre-train it on book review corpus. Pre-training model is usually composed of embedding, encoder, and target layers. To build a pre-training model, we should provide related information. Configuration file (*--config_path*) specifies the modules and hyper-parameters used by pre-training models. More details can be found in *models/bert/base_config.json*. Suppose we have a machine with 8 GPUs:
```
python3 pretrain.py --dataset_path dataset.pt --vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/google_zh_model.bin \
--config_path models/bert/base_config.json \
--output_model_path models/book_review_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 5000 --save_checkpoint_steps 1000 --batch_size 32
mv models/book_review_model.bin-5000 models/book_review_model.bin
```
Notice that the model trained by *pretrain.py* is attacted with the suffix which records the training step (*--total_steps*). We could remove the suffix for ease of use.
Then we fine-tune the pre-trained model on downstream classification dataset. We use embedding and encoder layers of [*book_review_model.bin*](https://share.weiyun.com/wDzMu0Rb), which is the output of *pretrain.py*:
```
python3 finetune/run_classifier.py --pretrained_model_path models/book_review_model.bin \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/base_config.json \
--train_path datasets/douban_book_review/train.tsv \
--dev_path datasets/douban_book_review/dev.tsv \
--test_path datasets/douban_book_review/test.tsv \
--epochs_num 3 --batch_size 32
```
The default path of the fine-tuned classifier model is *models/finetuned_model.bin* . It is noticeable that the actual batch size of pre-training is *--batch_size* times *--world_size* ; The actual batch size of downstream task (e.g. classification) is *--batch_size* .
Then we do inference with the fine-tuned model.
```
python3 inference/run_classifier_infer.py --load_model_path models/finetuned_model.bin \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/base_config.json \
--test_path datasets/douban_book_review/test_nolabel.tsv \
--prediction_path datasets/douban_book_review/prediction.tsv \
--labels_num 2
```
*--test_path* specifies the path of the file to be predicted. The file should contain text_a column.
*--prediction_path* specifies the path of the file with prediction results.
We need to explicitly specify the number of labels by *--labels_num*. Douban book review is a two-way classification dataset.
<br>
The above content provides basic ways of using UER-py to pre-process, pre-train, fine-tune, and do inference. More use cases can be found in complete :arrow_right: [__quickstart__](https://github.com/dbiir/UER-py/wiki/Quickstart) :arrow_left: . The complete quickstart contains abundant use cases, covering most of the pre-training related application scenarios. It is recommended that users read the complete quickstart in order to use the project reasonably.
<br/>
## Datasets
We collected a range of :arrow_right: [__downstream datasets__](https://github.com/dbiir/UER-py/wiki/Datasets) :arrow_left: and converted them into the format that UER can load directly.
<br/>
## Modelzoo
With the help of UER, we pre-trained models of different properties (e.g. models based on different corpora, encoders, and targets). Detailed introduction of pre-trained models and their download links can be found in :arrow_right: [__modelzoo__](https://github.com/dbiir/UER-py/wiki/Modelzoo) :arrow_left: . All pre-trained models can be loaded by UER directly. More pre-trained models will be released in the future.
<br/>
## Instructions
UER-py is organized as follows:
```
UER-py/
|--uer/
| |--embeddings/ # contains embeddings
| |--encoders/ # contains encoders such as RNN, CNN,
| |--decoders/ # contains decoders
| |--targets/ # contains targets such as language modeling, masked language modeling
| |--layers/ # contains frequently-used NN layers, such as embedding layer, normalization layer
| |--models/ # contains model.py, which combines embedding, encoder, and target modules
| |--utils/ # contains frequently-used utilities
| |--model_builder.py
| |--model_loader.py
| |--model_saver.py
| |--trainer.py
|
|--corpora/ # contains corpora for pre-training
|--datasets/ # contains downstream tasks
|--models/ # contains pre-trained models, vocabularies, and configuration files
|--scripts/ # contains useful scripts for pre-training models
|--finetune/ # contains fine-tuning scripts for downstream tasks
|--inference/ # contains inference scripts for downstream tasks
|
|--preprocess.py
|--pretrain.py
|--README.md
|--README_ZH.md
|--requirements.txt
|--logo.jpg
```
The code is well-organized. Users can use and extend upon it with little efforts.
Comprehensive examples of using UER can be found in :arrow_right: [__instructions__](https://github.com/dbiir/UER-py/wiki/Instructions) :arrow_left: , which help users quickly implement pre-training models such as BERT, GPT-2, ELMo, T5 and fine-tune pre-trained models on a range of downstream tasks.
<br/>
## Competition solutions
UER-py has been used in winning solutions of many NLP competitions. In this section, we provide some examples of using UER-py to achieve SOTA results on NLP competitions, such as CLUE. See :arrow_right: [__competition solutions__](https://github.com/dbiir/UER-py/wiki/Competition-solutions) :arrow_left: for more detailed information.
<br/>
## Citation
#### If you are using the work (e.g. pre-trained models) in UER-py for academic work, please cite the [system paper](https://arxiv.org/pdf/1909.05658.pdf) published in EMNLP 2019:
```
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
<br/>
## Contact information
For communication related to this project, please contact Zhe Zhao ([email protected]; [email protected]) or Yudong Li ([email protected]) or Cheng Hou ([email protected]) or Wenhang Shi ([email protected]).
This work is instructed by my enterprise mentors __Qi Ju__, __Xuefeng Yang__, __Haotang Deng__ and school mentors __Tao Liu__, __Xiaoyong Du__.
We also got a lot of help from Weijie Liu, Lusheng Zhang, Jianwei Cui, Xiayu Li, Weiquan Mao, Xin Zhao, Hui Chen, Jinbin Zhang, Zhiruo Wang, Peng Zhou, Haixiao Liu, and Weijian Wu.
|
3,449 | A curated list of resources for Document Understanding (DU) topic | # Awesome Document Understanding [](https://awesome.re)
A curated list of resources for Document Understanding (DU) topic related to Intelligent Document Processing (IDP), which is relative to Robotic Process Automation (RPA) from unstructured data, especially form Visually Rich Documents (VRDs).
**Note 1: bolded positions are more important then others.**
**Note 2: due to the novelty of the field, this list is under construction - contributions are welcome (thank you in advance!).** Please remember to use following convention:
* [Title of a publication / dataset / resource title](https://arxiv.org), \[[code/data/Website](https://github.com/example/test) \]
<details>
<summary> List of authors <em>Conference/Journal name</em> Year </summary>
Dataset size: Train(no of examples), Dev(no of examples), Test(no of examples) [Optional for dataset papers/resources]; Abstract/short description ...
</details>
<br/><br/>
<p align="center">
<a href="https://openreview.net/forum?id=rNs2FvJGDK">
<img src="images/du_example.png">
</a>
</p>
<br/><br/>
# Table of contents
1. [Introduction](#introduction)
1. [Research topics](#research-topics)
1. [Key Information Extraction (KIE)](topics/kie/README.md)
1. [Document Layout Analysis (DLA)](topics/dla/README.md)
1. [Document Question Answering (DQA)](topics/dqa/README.md)
1. [Scientific Document Understanding (SDU)](topics/sdu/README.md)
1. [Optical Character Recognition (OCR)](topics/ocr/README.md)
1. [Related](topics/related/README.md)
1. [General](topics/related/README.md#general)
1. [Tabular Data Comprehension (TDC)](topics/related/README.md#tabular-data-comprehension)
1. [Robotic Process Automation (RPA)](topics/related/README.md#robotic-process-automation)
1. [Others](#others)
1. [Resources](#resources)
1. [Datasets for Pre-training Language Models](#datasets-for-pre-training-language-models)
1. [PDF processing tools](#pdf-processing-tools)
1. [Conferences / workshops](#conferences-workshops)
1. [Blogs](#blogs)
1. [Solutions](#solutions)
1. [Examples](#examples)
1. [Visually Rich Documents (VRDs)](#visually-rich-documents)
1. [Key Information Extraction (KIE)](#key-information-extraction)
1. [Document Layout Analysis (DLA)](#document-layout-analysis)
1. [Document Question Answering (DQA)](#document-question-answering)
1. [Inspirations](#inspirations)
# Introduction
Documents are a core part of many businesses in many fields such as law, finance, and technology among others. Automatic understanding of documents such as invoices, contracts, and resumes is lucrative, opening up many new avenues of business. The fields of natural language processing and computer vision have seen tremendous progress through the development of deep learning such that these methods have started to become infused in contemporary document understanding systems. [source](https://arxiv.org/abs/2011.13534)
### Papers
#### 2022
* [Business Document Information Extraction: Towards Practical Benchmarks](https://arxiv.org/abs/2206.11229)
<details>
<summary> Matyáš Skalický, Štěpán Šimsa, Michal Uřičář, Milan Šulc <em>CLEF</em> 2022 </summary>
Information extraction from semi-structured documents is crucial for frictionless business-to-business (B2B) communication. While machine learning problems related to Document Information Extraction (IE) have been studied for decades, many common problem definitions and benchmarks do not reflect domain-specific aspects and practical needs for automating B2B document communication. We review the landscape of Document IE problems, datasets and benchmarks. We highlight the practical aspects missing in the common definitions and define the Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) problems. There is a lack of relevant datasets and benchmarks for Document IE on semi-structured business documents as their content is typically legally protected or sensitive. We discuss potential sources of available documents including synthetic data.
</details>
#### 2021
* [Document AI: Benchmarks, Models and Applications](https://arxiv.org/abs/2111.08609)
<details>
<summary> Lei Cui, Yiheng Xu, Tengchao Lv, Furu Wei <em>arxiv</em> 2021 </summary>
Document AI, or Document Intelligence, is a relatively new research topic that refers to the techniques for automatically reading, understanding, and analyzing business documents. It is an important research direction for natural language processing and computer vision. In recent years, the popularity of deep learning technology has greatly advanced the development of Document AI, such as document layout analysis, visual information extraction, document visual question answering, document image classification, etc. This paper briefly reviews some of the representative models, tasks, and benchmark datasets. Furthermore, we also introduce early-stage heuristic rule-based document analysis, statistical machine learning algorithms, and deep learning approaches especially pre-training methods. Finally, we look into future directions for Document AI research.
</details>
* **[Efficient Automated Processing of the Unstructured Documents using Artificial Intelligence: A Systematic Literature Review and Future Directions](https://ieeexplore.ieee.org/abstract/document/9402739)**
<details>
<summary> Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, Ketan Kotecha <em>IEEE Access</em> 2021 </summary>
The unstructured data impacts 95% of the organizations and costs them millions of dollars annually. If managed well, it can significantly improve business productivity. The traditional information extraction techniques are limited in their functionality, but AI-based techniques can provide a better solution. A thorough investigation of AI-based techniques for automatic information extraction from unstructured documents is missing in the literature. The purpose of this Systematic Literature Review (SLR) is to recognize, and analyze research on the techniques used for automatic information extraction from unstructured documents and to provide directions for future research. The SLR guidelines proposed by Kitchenham and Charters were adhered to conduct a literature search on various databases between 2010 and 2020. We found that: 1. The existing information extraction techniques are template-based or rule-based, 2. The existing methods lack the capability to tackle complex document layouts in real-time situations such as invoices and purchase orders, 3.The datasets available publicly are task-specific and of low quality. Hence, there is a need to develop a new dataset that reflects real-world problems. Our SLR discovered that AI-based approaches have a strong potential to extract useful information from unstructured documents automatically. However, they face certain challenges in processing multiple layouts of the unstructured documents. Our SLR brings out conceptualization of a framework for construction of high-quality unstructured documents dataset with strong data validation techniques for automated information extraction. Our SLR also reveals a need for a close association between the businesses and researchers to handle various challenges of the unstructured data analysis.
</details>
#### 2020
* **[A Survey of Deep Learning Approaches for OCR and Document Understanding](https://arxiv.org/abs/2011.13534)**
<details>
<summary> Nishant Subramani, Alexandre Matton, Malcolm Greaves, Adrian Lam <em>ML-RSA Workshop at NeurIPS</em> 2020 </summary>
Documents are a core part of many businesses in many fields such as law, finance, and technology among others. Automatic understanding of documents such as invoices, contracts, and resumes is lucrative, opening up many new avenues of business. The fields of natural language processing and computer vision have seen tremendous progress through the development of deep learning such that these methods have started to become infused in contemporary document understanding systems. In this survey paper, we review different techniques for document understanding for documents written in English and consolidate methodologies present in literature to act as a jumping-off point for researchers exploring this area.
</details>
* **[Conversations with Documents. An Exploration of Document-Centered Assistance](https://arxiv.org/pdf/2002.00747.pdf)**
<details>
<summary> Maartje ter Hoeve, Robert Sim, Elnaz Nouri, Adam Fourney, Maarten de Rijke, Ryen W. White <em>CHIIR</em> 2020 </summary>
The role of conversational assistants has become more prevalent in helping people increase their productivity. Document-centered assistance, for example to help an individual quickly review a document, has seen less significant progress, even though it has the potential to tremendously increase a user's productivity. This type of document-centered assistance is the focus of this paper. Our contributions are three-fold: (1) We first present a survey to understand the space of document-centered assistance and the capabilities people expect in this scenario. (2) We investigate the types of queries that users will pose while seeking assistance with documents, and show that document-centered questions form the majority of these queries. (3) We present a set of initial machine learned models that show that (a) we can accurately detect document-centered questions, and (b) we can build reasonably accurate models for answering such questions. These positive results are encouraging, and suggest that even greater results may be attained with continued study of this interesting and novel problem space. Our findings have implications for the design of intelligent systems to support task completion via natural interactions with documents.
</details>
#### 2018
* [Future paradigms of automated processing of business documents](https://www.sciencedirect.com/science/article/pii/S0268401217309994)
<details>
<summary> Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia <em>International Journal of Information Management</em> 2018 </summary>
In this paper we summarize the results obtained so far in the communities interested in the development of automated processing techniques as applied to business documents, and devise a few evolutions that are demanded by the current stage of either those techniques by themselves or by collateral sector advancements. It emerges a clear picture of a field that has put an enormous effort in solving problems that changed a lot during the last 30 years, and is now rapidly evolving to incorporate document processing into workflow management systems on one side and to include features derived by the introduction of cloud computing technologies on the other side. We propose an architectural schema for business document processing that comes from the two above evolution lines.
</details>
#### Older
* [Machine Learning for Intelligent Processing of Printed Documents](https://www.semanticscholar.org/paper/Machine-Learning-for-Intelligent-Processing-of-Esposito-Malerba/1f23b61f04d450ffc49ec6371bb5b30d198cdc5b)
<details>
<summary> F. Esposito, D. Malerba, F. Lisi <em>-</em> 2004 </summary>
A paper document processing system is an information system component which transforms information on printed or handwritten documents into a computer-revisable form. In intelligent systems for paper document processing this information capture process is based on knowledge of the specific layout and logical structures of the documents. This article proposes the application of machine learning techniques to acquire the specific knowledge required by an intelligent document processing system, named WISDOM++, that manages printed documents, such as letters and journals. Knowledge is represented by means of decision trees and first-order rules automatically generated from a set of training documents. In particular, an incremental decision tree learning system is applied for the acquisition of decision trees used for the classification of segmented blocks, while a first-order learning system is applied for the induction of rules used for the layout-based classification and understanding of documents. Issues concerning the incremental induction of decision trees and the handling of both numeric and symbolic data in first-order rule learning are discussed, and the validity of the proposed solutions is empirically evaluated by processing a set of real printed documents.
</details>
* [Document Understanding: Research Directions](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.40.9880&rep=rep1&type=pdf)
<details>
<summary> S. Srihari, S. Lam, V. Govindaraju, R. Srihari, J. Hull <em>-</em> 1994 </summary>
A document image is a visual representation of a printed page such as a journal article page, a facsimile cover page, a technical document, an office letter, etc. Document understanding as a research endeavor consists of studying all processes involved in taking a document through various representations: from a scanned physical document to high-level semantic descriptions of the document. Some of the types of representation that are useful are: editable descriptions, descriptions that enable exact reproductions and high-level semantic descriptions about document content. This report is a definition of five research subdomains within document understanding as pertaining to predominantly printed documents. The topics described are: modular architectures for document understanding; decomposition and structural analysis of documents; model-based OCR; table, diagram and image understanding; and performance evaluation under distortion and noise.
</details>
# Research topics
* [Key Information Extraction (KIE)](topics/kie/README.md)
* [Document Layout Analysis (DLA)](topics/dla/README.md)
* [Document Question Answering (DQA)](topics/dqa/README.md)
* [Scientific Document Understanding (SDU)](topics/sdu/README.md)
* [Optical Character Recogtion (OCR)](topics/ocr/README.md)
* [Related](topics/related/README.md)
* [General](topics/related/README.md#general)
* [Tabular Data Comprehension (TDC)](topics/related/README.md#tabular-data-comprehension)
* [Robotic Process Automation (RPA)](topics/related/README.md#robotic-process-automation)
# Others
## Resources
[Back to top](#table-of-contents)
#### Datasets for Pre-training Language Models
1. [The RVL-CDIP Dataset](https://adamharley.com/rvl-cdip/) - dataset consists of 400,000 grayscale images in 16 classes, with 25,000 images per class
1. [The Industry Documents Library](https://www.industrydocuments.ucsf.edu/) - a portal to millions of documents created by industries that influence public health, hosted by the UCSF Library
1. [Color Document Dataset](https://ivi.fnwi.uva.nl/isis/UvA-CDD/) - from the Intelligent Sensory Information Systems, University of Amsterdam
1. [The IIT CDIP Collection](https://data.nist.gov/od/id/mds2-2531) - dataset consists of documents from the states' lawsuit against the tobacco industry in the 1990s, consists of around 7 million documents
#### PDF processing tools
1. [borb](https://github.com/jorisschellekens/borb)  - is a pure python library to read, write and manipulate PDF documents. It represents a PDF document as a JSON-like datastructure of nested lists, dictionaries and primitives (numbers, string, booleans, etc).
1. [pawls](https://github.com/allenai/pawls)  - PDF Annotations with Labels and Structure is software that makes it easy to collect a series of annotations associated with a PDF document
1. [pdfplumber](https://github.com/jsvine/pdfplumber)  - Plumb a PDF for detailed information about each text character, rectangle, and line. Plus: Table extraction and visual debugging
1. [Pdfminer.six](https://github.com/pdfminer/pdfminer.six)  - Pdfminer.six is a community maintained fork of the original PDFMiner. It is a tool for extracting information from PDF documents. It focuses on getting and analyzing text data
1. [Layout Parser](https://github.com/Layout-Parser/layout-parser)  - Layout Parser is a deep learning based tool for document image layout analysis tasks
1. [Tabulo](https://github.com/interviewBubble/Tabulo)  - Table extraction from images
1. [OCRmyPDF](https://github.com/jbarlow83/OCRmyPDF)  - OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted
1. [PDFBox](https://github.com/apache/pdfbox)  - The Apache PDFBox library is an open source Java tool for working with PDF documents. This project allows creation of new PDF documents, manipulation of existing documents and the ability to extract content from documents
1. [PdfPig](https://github.com/UglyToad/PdfPig)  - This project allows users to read and extract text and other content from PDF files. In addition the library can be used to create simple PDF documents containing text and geometrical shapes. This project aims to port PDFBox to C#
1. [parsing-prickly-pdfs](https://porter.io/github.com/jsfenfen/parsing-prickly-pdfs)  - Resources and worksheet for the NICAR 2016 workshop of the same name
1. [pdf-text-extraction-benchmark](https://github.com/ckorzen/pdf-text-extraction-benchmark)  - PDF tools benchmark
1. [Born digital pdf scanner](https://github.com/applicaai/digital-born-pdf-scanner)  - checking if pdf is born-digital
1. [OpenContracts](https://github.com/JSv4/OpenContracts)  Apache2-licensed, PDF annotating platform for visually-rich documents that preserves the original layout and exports x,y positional data for tokens as well as span starts and stops. Based on PAWLs, but with a Python-based backend and readily deployable on your local machine, company intranet or the web via Docker Compose.
1. [deepdoctection](https://github.com/deepdoctection/deepdoctection)  **deep**doctection is a Python library that orchestrates document extraction and document layout analysis tasks for images and pdf documents using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models.
## Conferences, workshops
[Back to top](#table-of-contents)
#### General/ Business / Finance
1. **International Conference on Document Analysis and Recognition (ICDAR)** [[2021](https://icdar2021.org/), [2019](http://icdar2019.org/), [2017](http://u-pat.org/ICDAR2017/index.php)]
1. Workshop on Document Intelligence (DI) [[2021](https://document-intelligence.github.io/DI-2021/), [2019](https://sites.google.com/view/di2019)]
1. Financial Narrative Processing Workshop (FNP) [[2021](http://wp.lancs.ac.uk/cfie/fnp2021/), [2020](http://wp.lancs.ac.uk/cfie/fincausal2020/), [2019](https://www.aclweb.org/anthology/volumes/W19-64/) ]
1. Workshop on Economics and Natural Language Processing (ECONLP) [[2021](https://julielab.de/econlp/2021/), [2019](https://sites.google.com/view/econlp-2019), [2018](https://www.aclweb.org/anthology/W18-31.pdf) ]
1. INTERNATIONAL WORKSHOP ON DOCUMENT ANALYSIS SYSTEMS (DAS) [[2020](https://www.vlrlab.net/das2020/), [2018](https://das2018.cvl.tuwien.ac.at/en/), [2016](https://www.primaresearch.org/das2016/)]
1. [ACM International Conference on AI in Finance (ICAIF)](https://ai-finance.org/)
1. [The AAAI-21 Workshop on Knowledge Discovery from Unstructured Data in Financial Services](https://aaai-kdf.github.io/kdf2021/)
1. [CVPR 2020 Workshop on Text and Documents in the Deep Learning Era](https://cvpr2020text.wordpress.com/accepted-papers/)
1. [KDD Workshop on Machine Learning in Finance (KDD MLF 2020)](https://sites.google.com/view/kdd-mlf-2020)
1. [FinIR 2020: The First Workshop on Information Retrieval in Finance](https://finir2020.github.io/)
1. [2nd KDD Workshop on Anomaly Detection in Finance (KDD 2019)](https://sites.google.com/view/kdd-adf-2019)
1. [Document Understanding Conference (DUC 2007)](https://duc.nist.gov/pubs.html)
#### Scientific Document Understanding
1. [The AAAI-21 Workshop on Scientific Document Understanding (SDU 2021)](https://sites.google.com/view/sdu-aaai21/home)
1. [First Workshop on Scholarly Document Processing (SDProc 2020)](https://ornlcda.github.io/SDProc/)
1. International Workshop on SCIentific DOCument Analysis (SCIDOCA) [[2020](http://research.nii.ac.jp/SCIDOCA2020/), [2018](http://www.jaist.ac.jp/event/SCIDOCA/2018/), [2017](https://aclweb.org/portal/content/second-international-workshop-scientific-document-analysis) ]
## Blogs
[Back to top](#table-of-contents)
1. [A Survey of Document Understanding Models](https://www.pragmatic.ml/a-survey-of-document-understanding-models/), 2021
1. [Document Form Extraction](https://www.crosstab.io/product-comparisons/document-form-extraction), 2021
1. [How to automate processes with unstructured data](https://levity.ai/blog/automate-processes-with-unstructured-data), 2021
1. [A Comprehensive Guide to OCR with RPA and Document Understanding](https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/), 2021
1. [Information Extraction from Receipts with Graph Convolutional Networks](https://nanonets.com/blog/information-extraction-graph-convolutional-networks/), 2021
1. [How to extract structured data from invoices](https://nanonets.com/blog/extract-structured-data-from-invoice/), 2021
1. [Extracting Structured Data from Templatic Documents](https://ai.googleblog.com/2020/06/extracting-structured-data-from.html), 2020
1. [To apply AI for good, think form extraction](http://jonathanstray.com/to-apply-ai-for-good-think-form-extraction), 2020
1. [UiPath Document Understanding Solution Architecture and Approach](https://medium.com/@lahirufernando90/uipath-document-understanding-solution-architecture-and-approach-934a9a26630a), 2020
1. [How Can I Automate Data Extraction from Complex Documents?](https://www.infrrd.ai/blog/how-can-i-automate-data-extraction-from-complex-documents), 2020
1. [LegalTech: Information Extraction in legal documents](https://naturaltech.medium.com/legaltech-information-extraction-in-legal-documents-e1843a60bc8d), 2020
## Solutions
[Back to top](#table-of-contents)
Big companies:
1. [Abby](https://www.abbyy.com/flexicapture/)
1. [Accenture](https://www.accenture.com/us-en/services/applied-intelligence/document-understanding-solutions)
1. [Amazon](https://aws.amazon.com/about-aws/whats-new/2020/11/introducing-document-understanding-solution/)
1. [Google](https://cloud.google.com/document-ai)
1. [Microsoft](https://azure.microsoft.com/en-us/services/cognitive-services/)
1. [Uipath](https://www.uipath.com/product/document-understanding)
Smaller:
1. [Applica.ai](https://applica.ai/)
1. [Base64.ai](https://base64.ai)
1. [Docstack](https://www.docstack.com/ai-document-understanding)
1. [Element AI](https://www.elementai.com/products/document-intelligence)
1. [Indico](https://indico.io)
1. [Instabase](https://instabase.com/)
1. [Konfuzio](https://konfuzio.com/en/)
1. [Metamaze](https://metamaze.eu)
1. [Nanonets](https://nanonets.com)
1. [Rossum](https://rossum.ai/)
1. [Silo](https://silo.ai/how-document-understanding-improves-invoice-contract-and-resume-processing/)
# Examples
## Visually Rich Documents
[Back to top](#table-of-contents)
In VRDs the importance of the layout information is crucial to understand the whole document correctly (this is the case with almost all business documents). For humans spatial information improves readability and speeds document understanding.
#### Invoice / Resume / Job Ad
<p align="center">
<a href="https://arxiv.org/pdf/2005.11017.pdf">
<img src="images/vrd_examples_2v2.png">
</a>
</p>
<br/><br/>
#### NDA / Annual reports
<p align="center">
<a href="https://arxiv.org/abs/2003.02356">
<img src="images/vrd_examples_1.png">
</a>
</p>
<br/><br/>
## Key Information Extraction
[Back to top](#table-of-contents)
The aim of this task is to extract texts of a number of key fields from a given collection of documents containing similar key entities.
<br/>
#### Scanned Receipts
<p align="center">
<a href="https://medium.com/analytics-vidhya/extracting-structured-data-from-invoice-96cf5e548e40">
<img src="images/kie_examples_1.png">
</a>
</p>
<br/><br/>
#### NDA / Annual reports
Examples of a real business applications and data for Kleister datasets (The key entities are in blue)
<p align="center">
<a href="https://arxiv.org/abs/2003.02356">
<img src="images/kie_examples_2.png">
</a>
</p>
<br/><br/>
#### Multimedia Online Flyers
An example of a commercial real estate flyer and manually entered listing information © ProMaker Commercial Real Estate LLC, © BrokerSavant Inc.
<p align="center">
<a href="https://www.aclweb.org/anthology/N15-1032.pdf">
<img src="images/kie_examples_3.png">
</a>
</p>
<br/><br/>
#### Value-added tax invoice
<p align="center">
<a href="https://arxiv.org/pdf/1903.11279.pdf">
<img src="images/kie_examples_4.png">
</a>
</p>
<br/><br/>
#### Webpages
<p align="center">
<a href="https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/StructedDataExtraction_SIGIR2011.pdf">
<img src="images/kie_examples_5.png">
</a>
</p>
<br/><br/>
## Document Layout Analysis
[Back to top](#table-of-contents)
In computer vision or natural language processing, document layout analysis is the process of identifying and categorizing the regions of interest in the scanned image of a text document. A reading system requires the segmentation of text zones from non-textual ones and the arrangement in their correct reading order. Detection and labeling of the different zones (or blocks) as text body, illustrations, math symbols, and tables embedded in a document is called geometric layout analysis. But text zones play different logical roles inside the document (titles, captions, footnotes, etc.) and this kind of semantic labeling is the scope of the logical layout analysis. (https://en.wikipedia.org/wiki/Document_layout_analysis)
#### Scientific publication
<p align="center">
<a href="https://arxiv.org/pdf/1908.07836.pdf">
<img src="images/dla_examples_1.png">
</a>
</p>
<br/><br/>
<p align="center">
<a href="https://arxiv.org/pdf/2006.01038.pdf">
<img src="images/dla_examples_2.png">
</a>
</p>
<br/><br/>
#### Historical newspapers
<p align="center">
<a href="https://primaresearch.org/www/assets/papers/ICDAR2015_Clausner_ENPDataset.pdf">
<img src="images/dla_examples_3.png">
</a>
</p>
<br/><br/>
#### Business documents
Red: text block, Blue: figure.
<p align="center">
<a href="http://personal.psu.edu/duh188/papers/ICDAR2017_DAFANG.pdf">
<img src="images/dla_examples_4.png">
</a>
</p>
<br/><br/>
## Document Question Answering
[Back to top](#table-of-contents)
#### DocVQA example
<p align="center">
<a href="https://arxiv.org/pdf/2007.00398.pdf">
<img src="images/dqa_example_2.png">
</a>
</p>
<br/><br/>
#### [Tilt model](https://arxiv.org/pdf/2102.09550.pdf) demo
<p align="center">
<a href="https://arxiv.org/pdf/2102.09550.pdf">
<img src="images/dqa_example_1.gif">
</a>
</p>
<br/><br/>
# Inspirations
[Back to top](#table-of-contents)
**Domain**
1. https://github.com/kba/awesome-ocr 
1. https://github.com/Liquid-Legal-Institute/Legal-Text-Analytics 
1. https://github.com/icoxfog417/awesome-financial-nlp 
1. https://github.com/BobLd/DocumentLayoutAnalysis 
1. https://github.com/bikash/DocumentUnderstanding 
1. https://github.com/harpribot/awesome-information-retrieval 
1. https://github.com/roomylee/awesome-relation-extraction 
1. https://github.com/caufieldjh/awesome-bioie 
1. https://github.com/HelloRusk/entity-related-papers 
1. https://github.com/pliang279/awesome-multimodal-ml 
1. https://github.com/thunlp/LegalPapers 
1. https://github.com/heartexlabs/awesome-data-labeling 
**General AI/DL/ML**
1. https://github.com/jsbroks/awesome-dataset-tools 
1. https://github.com/EthicalML/awesome-production-machine-learning 
1. https://github.com/eugeneyan/applied-ml 
1. https://github.com/awesomedata/awesome-public-datasets 
1. https://github.com/keon/awesome-nlp 
1. https://github.com/thunlp/PLMpapers 
1. https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists 
1. https://github.com/papers-we-love/papers-we-love 
1. https://github.com/BAILOOL/DoYouEvenLearn 
1. https://github.com/hibayesian/awesome-automl-papers 
|
3,450 | An open-source NLP research library, built on PyTorch. | <div align="center">
<br>
<img src="https://raw.githubusercontent.com/allenai/allennlp/main/docs/img/allennlp-logo-dark.png" width="400"/>
<p>
An Apache 2.0 NLP research library, built on PyTorch, for developing state-of-the-art deep learning models on a wide variety of linguistic tasks.
</p>
<hr/>
</div>
<p align="center">
<a href="https://github.com/allenai/allennlp/actions">
<img alt="CI" src="https://github.com/allenai/allennlp/workflows/CI/badge.svg?event=push&branch=main">
</a>
<a href="https://pypi.org/project/allennlp/">
<img alt="PyPI" src="https://img.shields.io/pypi/v/allennlp">
</a>
<a href="https://github.com/allenai/allennlp/blob/main/LICENSE">
<img alt="License" src="https://img.shields.io/github/license/allenai/allennlp.svg?color=blue&cachedrop">
</a>
<a href="https://codecov.io/gh/allenai/allennlp">
<img alt="Codecov" src="https://codecov.io/gh/allenai/allennlp/branch/main/graph/badge.svg">
</a>
<a href="https://optuna.org">
<img alt="Optuna" src="https://img.shields.io/badge/Optuna-integrated-blue">
</a>
<br/>
</p>
⚠️ **NOTICE:** The AllenNLP library is now in maintenance mode. That means we are no longer adding new features or upgrading dependencies. We will still respond to questions and address bugs as they arise up until December 16th, 2022. If you have any concerns or are interested in maintaining AllenNLP going forward, please open an issue on this repository.
AllenNLP has been a big success, but as the field is advancing quickly it's time to focus on new initiatives. We're working hard to make [AI2 Tango](https://github.com/allenai/tango) the best way to organize research codebases. If you are an active user of AllenNLP, here are some suggested alternatives:
* If you like the trainer, the configuration language, or are simply looking for a better way to manage your experiments, check out [AI2 Tango](https://github.com/allenai/tango).
* If you like AllenNLP's `modules` and `nn` packages, check out [delmaksym/allennlp-light](https://github.com/delmaksym/allennlp-light). It's even compatible with [AI2 Tango](https://github.com/allenai/tango)!
* If you like the framework aspect of AllenNLP, check out [flair](https://github.com/flairNLP/flair). It has multiple state-of-art NLP models and allows you to easily use pretrained embeddings such as those from transformers.
* If you like the AllenNLP metrics package, check out [torchmetrics](https://torchmetrics.readthedocs.io/en/stable/). It has the same API as AllenNLP, so it should be a quick learning curve to make the switch.
* If you want to vectorize text, try [the transformers library](https://github.com/huggingface/transformers).
* If you want to maintain the AllenNLP Fairness or Interpret components, please get in touch. There is no alternative to it, so we are looking for a dedicated maintainer.
* If you are concerned about other AllenNLP functionality, please create an issue. Maybe we can find another way to continue supporting your use case.
## Quick Links
- ↗️ [Website](https://allennlp.org/)
- 🔦 [Guide](https://guide.allennlp.org/)
- 🖼 [Gallery](https://gallery.allennlp.org)
- 💻 [Demo](https://demo.allennlp.org)
- 📓 [Documentation](https://docs.allennlp.org/) ( [latest](https://docs.allennlp.org/latest/) | [stable](https://docs.allennlp.org/stable/) | [commit](https://docs.allennlp.org/main/) )
- ⬆️ [Upgrade Guide from 1.x to 2.0](https://github.com/allenai/allennlp/discussions/4933)
- ❓ [Stack Overflow](https://stackoverflow.com/questions/tagged/allennlp)
- ✋ [Contributing Guidelines](CONTRIBUTING.md)
- 🤖 [Officially Supported Models](https://github.com/allenai/allennlp-models)
- [Pretrained Models](https://github.com/allenai/allennlp-models/blob/main/allennlp_models/pretrained.py)
- [Documentation](https://docs.allennlp.org/models/) ( [latest](https://docs.allennlp.org/models/latest/) | [stable](https://docs.allennlp.org/models/stable/) | [commit](https://docs.allennlp.org/models/main/) )
- ⚙️ [Continuous Build](https://github.com/allenai/allennlp/actions)
- 🌙 [Nightly Releases](https://pypi.org/project/allennlp/#history)
## In this README
- [Getting Started Using the Library](#getting-started-using-the-library)
- [Plugins](#plugins)
- [Package Overview](#package-overview)
- [Installation](#installation)
- [Installing via pip](#installing-via-pip)
- [Installing using Docker](#installing-using-docker)
- [Installing from source](#installing-from-source)
- [Running AllenNLP](#running-allennlp)
- [Issues](#issues)
- [Contributions](#contributions)
- [Citing](#citing)
- [Team](#team)
## Getting Started Using the Library
If you're interested in using AllenNLP for model development, we recommend you check out the
[AllenNLP Guide](https://guide.allennlp.org) for a thorough introduction to the library, followed by our more advanced guides
on [GitHub Discussions](https://github.com/allenai/allennlp/discussions/categories/guides).
When you're ready to start your project, we've created a couple of template repositories that you can use as a starting place:
* If you want to use `allennlp train` and config files to specify experiments, use [this
template](https://github.com/allenai/allennlp-template-config-files). We recommend this approach.
* If you'd prefer to use python code to configure your experiments and run your training loop, use
[this template](https://github.com/allenai/allennlp-template-python-script). There are a few
things that are currently a little harder in this setup (loading a saved model, and using
distributed training), but otherwise it's functionality equivalent to the config files
setup.
In addition, there are external tutorials:
* [Hyperparameter optimization for AllenNLP using Optuna](https://medium.com/optuna/hyperparameter-optimization-for-allennlp-using-optuna-54b4bfecd78b)
* [Training with multiple GPUs in AllenNLP](https://medium.com/ai2-blog/tutorial-how-to-train-with-multiple-gpus-in-allennlp-c4d7c17eb6d6)
* [Training on larger batches with less memory in AllenNLP](https://medium.com/ai2-blog/tutorial-training-on-larger-batches-with-less-memory-in-allennlp-1cd2047d92ad)
* [How to upload transformer weights and tokenizers from AllenNLP to HuggingFace](https://medium.com/ai2-blog/tutorial-how-to-upload-transformer-weights-and-tokenizers-from-allennlp-to-huggingface-ecf6c0249bf)
And others on the [AI2 AllenNLP blog](https://medium.com/ai2-blog/allennlp/home).
## Plugins
AllenNLP supports loading "plugins" dynamically. A plugin is just a Python package that
provides custom registered classes or additional `allennlp` subcommands.
There is ecosystem of open source plugins, some of which are maintained by the AllenNLP
team here at AI2, and some of which are maintained by the broader community.
<table>
<tr>
<td><b> Plugin </b></td>
<td><b> Maintainer </b></td>
<td><b> CLI </b></td>
<td><b> Description </b></td>
</tr>
<tr>
<td> <a href="https://github.com/allenai/allennlp-models"><b>allennlp-models</b></a> </td>
<td> AI2 </td>
<td> No </td>
<td> A collection of state-of-the-art models </td>
</tr>
<tr>
<td> <a href="https://github.com/allenai/allennlp-semparse"><b>allennlp-semparse</b></a> </td>
<td> AI2 </td>
<td> No </td>
<td> A framework for building semantic parsers </td>
</tr>
<tr>
<td> <a href="https://github.com/allenai/allennlp-server"><b>allennlp-server</b></a> </td>
<td> AI2 </td>
<td> Yes </td>
<td> A simple demo server for serving models </td>
</tr>
<tr>
<td> <a href="https://github.com/himkt/allennlp-optuna"><b>allennlp-optuna</b></a> </td>
<td> <a href="https://himkt.github.io/profile/">Makoto Hiramatsu</a> </td>
<td> Yes </td>
<td> <a href="https://optuna.org/">Optuna</a> integration for hyperparameter optimization </td>
</tr>
</table>
AllenNLP will automatically find any official AI2-maintained plugins that you have installed,
but for AllenNLP to find personal or third-party plugins you've installed,
you also have to create either a local plugins file named `.allennlp_plugins`
in the directory where you run the `allennlp` command, or a global plugins file at `~/.allennlp/plugins`.
The file should list the plugin modules that you want to be loaded, one per line.
To test that your plugins can be found and imported by AllenNLP, you can run the `allennlp test-install` command.
Each discovered plugin will be logged to the terminal.
For more information about plugins, see the [plugins API docs](https://docs.allennlp.org/main/api/common/plugins/). And for information on how to create a custom subcommand
to distribute as a plugin, see the [subcommand API docs](https://docs.allennlp.org/main/api/commands/subcommand/).
## Package Overview
<table>
<tr>
<td><b> allennlp </b></td>
<td> An open-source NLP research library, built on PyTorch </td>
</tr>
<tr>
<td><b> allennlp.commands </b></td>
<td> Functionality for the CLI </td>
</tr>
<tr>
<td><b> allennlp.common </b></td>
<td> Utility modules that are used across the library </td>
</tr>
<tr>
<td><b> allennlp.data </b></td>
<td> A data processing module for loading datasets and encoding strings as integers for representation in matrices </td>
</tr>
<tr>
<td><b> allennlp.fairness </b></td>
<td> A module for bias mitigation and fairness algorithms and metrics </td>
</tr>
<tr>
<td><b> allennlp.modules </b></td>
<td> A collection of PyTorch modules for use with text </td>
</tr>
<tr>
<td><b> allennlp.nn </b></td>
<td> Tensor utility functions, such as initializers and activation functions </td>
</tr>
<tr>
<td><b> allennlp.training </b></td>
<td> Functionality for training models </td>
</tr>
</table>
## Installation
AllenNLP requires Python 3.6.1 or later and [PyTorch](https://pytorch.org/).
We support AllenNLP on Mac and Linux environments. We presently do not support Windows but are open to contributions.
### Installing via conda-forge
The simplest way to install AllenNLP is using conda (you can choose a different python version):
```
conda install -c conda-forge python=3.8 allennlp
```
To install optional packages, such as `checklist`, use
```
conda install -c conda-forge allennlp-checklist
```
or simply install `allennlp-all` directly. The plugins mentioned above are similarly installable, e.g.
```
conda install -c conda-forge allennlp-models allennlp-semparse allennlp-server allennlp-optuna
```
### Installing via pip
It's recommended that you install the PyTorch ecosystem **before** installing AllenNLP by following the instructions on [pytorch.org](https://pytorch.org/).
After that, just run `pip install allennlp`.
> ⚠️ If you're using Python 3.7 or greater, you should ensure that you don't have the PyPI version of `dataclasses` installed after running the above command, as this could cause issues on certain platforms. You can quickly check this by running `pip freeze | grep dataclasses`. If you see something like `dataclasses=0.6` in the output, then just run `pip uninstall -y dataclasses`.
If you need pointers on setting up an appropriate Python environment or would like to install AllenNLP using a different method, see below.
#### Setting up a virtual environment
[Conda](https://conda.io/) can be used set up a virtual environment with the
version of Python required for AllenNLP. If you already have a Python 3
environment you want to use, you can skip to the 'installing via pip' section.
1. [Download and install Conda](https://conda.io/projects/conda/en/latest/user-guide/install/index.html).
2. Create a Conda environment with Python 3.8 (3.7 or 3.9 would work as well):
```
conda create -n allennlp_env python=3.8
```
3. Activate the Conda environment. You will need to activate the Conda environment in each terminal in which you want to use AllenNLP:
```
conda activate allennlp_env
```
#### Installing the library and dependencies
Installing the library and dependencies is simple using `pip`.
```bash
pip install allennlp
```
To install the optional dependencies, such as `checklist`, run
```bash
pip install allennlp[checklist]
```
Or you can just install all optional dependencies with `pip install allennlp[all]`.
*Looking for bleeding edge features? You can install nightly releases directly from [pypi](https://pypi.org/project/allennlp/#history)*
AllenNLP installs a script when you install the python package, so you can run allennlp commands just by typing `allennlp` into a terminal. For example, you can now test your installation with `allennlp test-install`.
You may also want to install `allennlp-models`, which contains the NLP constructs to train and run our officially
supported models, many of which are hosted at [https://demo.allennlp.org](https://demo.allennlp.org).
```bash
pip install allennlp-models
```
### Installing using Docker
Docker provides a virtual machine with everything set up to run AllenNLP--
whether you will leverage a GPU or just run on a CPU. Docker provides more
isolation and consistency, and also makes it easy to distribute your
environment to a compute cluster.
AllenNLP provides [official Docker images](https://hub.docker.com/r/allennlp/allennlp) with the library and all of its dependencies installed.
Once you have [installed Docker](https://docs.docker.com/engine/installation/),
you should also install the [NVIDIA Container Toolkit](https://github.com/NVIDIA/nvidia-docker)
if you have GPUs available.
Then run the following command to get an environment that will run on GPU:
```bash
mkdir -p $HOME/.allennlp/
docker run --rm --gpus all -v $HOME/.allennlp:/root/.allennlp allennlp/allennlp:latest
```
You can test the Docker environment with
```bash
docker run --rm --gpus all -v $HOME/.allennlp:/root/.allennlp allennlp/allennlp:latest test-install
```
If you don't have GPUs available, just omit the `--gpus all` flag.
#### Building your own Docker image
For various reasons you may need to create your own AllenNLP Docker image, such as if you need a different version
of PyTorch. To do so, just run `make docker-image` from the root of your local clone of AllenNLP.
By default this builds an image with the tag `allennlp/allennlp`, but you can change this to anything you want
by setting the `DOCKER_IMAGE_NAME` flag when you call `make`. For example,
`make docker-image DOCKER_IMAGE_NAME=my-allennlp`.
If you want to use a different version of Python or PyTorch, set the flags `DOCKER_PYTHON_VERSION` and `DOCKER_TORCH_VERSION` to something like
`3.9` and `1.9.0-cuda10.2`, respectively. These flags together determine the base image that is used. You can see the list of valid
combinations in this GitHub Container Registry: [github.com/allenai/docker-images/pkgs/container/pytorch](https://github.com/allenai/docker-images/pkgs/container/pytorch).
After building the image you should be able to see it listed by running `docker images allennlp`.
```
REPOSITORY TAG IMAGE ID CREATED SIZE
allennlp/allennlp latest b66aee6cb593 5 minutes ago 2.38GB
```
### Installing from source
You can also install AllenNLP by cloning our git repository:
```bash
git clone https://github.com/allenai/allennlp.git
```
Create a Python 3.7 or 3.8 virtual environment, and install AllenNLP in `editable` mode by running:
```bash
pip install -U pip setuptools wheel
pip install --editable .[dev,all]
```
This will make `allennlp` available on your system but it will use the sources from the local clone
you made of the source repository.
You can test your installation with `allennlp test-install`.
See [https://github.com/allenai/allennlp-models](https://github.com/allenai/allennlp-models)
for instructions on installing `allennlp-models` from source.
## Running AllenNLP
Once you've installed AllenNLP, you can run the command-line interface
with the `allennlp` command (whether you installed from `pip` or from source).
`allennlp` has various subcommands such as `train`, `evaluate`, and `predict`.
To see the full usage information, run `allennlp --help`.
You can test your installation by running `allennlp test-install`.
## Issues
Everyone is welcome to file issues with either feature requests, bug reports, or general questions. As a small team with our own internal goals, we may ask for contributions if a prompt fix doesn't fit into our roadmap. To keep things tidy we will often close issues we think are answered, but don't hesitate to follow up if further discussion is needed.
## Contributions
The AllenNLP team at AI2 ([@allenai](https://github.com/allenai)) welcomes contributions from the community.
If you're a first time contributor, we recommend you start by reading our [CONTRIBUTING.md](https://github.com/allenai/allennlp/blob/main/CONTRIBUTING.md) guide.
Then have a look at our issues with the tag [**`Good First Issue`**](https://github.com/allenai/allennlp/issues?q=is%3Aissue+is%3Aopen+label%3A%22Good+First+Issue%22).
If you would like to contribute a larger feature, we recommend first creating an issue with a proposed design for discussion. This will prevent you from spending significant time on an implementation which has a technical limitation someone could have pointed out early on. Small contributions can be made directly in a pull request.
Pull requests (PRs) must have one approving review and no requested changes before they are merged. As AllenNLP is primarily driven by AI2 we reserve the right to reject or revert contributions that we don't think are good additions.
## Citing
If you use AllenNLP in your research, please cite [AllenNLP: A Deep Semantic Natural Language Processing Platform](https://www.semanticscholar.org/paper/AllenNLP%3A-A-Deep-Semantic-Natural-Language-Platform-Gardner-Grus/a5502187140cdd98d76ae711973dbcdaf1fef46d).
```bibtex
@inproceedings{Gardner2017AllenNLP,
title={AllenNLP: A Deep Semantic Natural Language Processing Platform},
author={Matt Gardner and Joel Grus and Mark Neumann and Oyvind Tafjord
and Pradeep Dasigi and Nelson F. Liu and Matthew Peters and
Michael Schmitz and Luke S. Zettlemoyer},
year={2017},
Eprint = {arXiv:1803.07640},
}
```
## Team
AllenNLP is an open-source project backed by [the Allen Institute for Artificial Intelligence (AI2)](https://allenai.org/).
AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering.
To learn more about who specifically contributed to this codebase, see [our contributors](https://github.com/allenai/allennlp/graphs/contributors) page.
|
3,451 | Unsupervised text tokenizer for Neural Network-based text generation. | # SentencePiece
[](https://github.com/google/sentencepiece/actions/workflows/cmake.yml)
[](https://github.com/google/sentencepiece/actions/workflows/wheel.yml)
[](https://github.com/google/sentencepiece/issues)
[](https://badge.fury.io/py/sentencepiece)
[](https://pypi.org/project/sentencepiece/)
[](CONTRIBUTING.md)
[](https://opensource.org/licenses/Apache-2.0)
[](https://slsa.dev)
SentencePiece is an unsupervised text tokenizer and detokenizer mainly for
Neural Network-based text generation systems where the vocabulary size
is predetermined prior to the neural model training. SentencePiece implements
**subword units** (e.g., **byte-pair-encoding (BPE)** [[Sennrich et al.](https://www.aclweb.org/anthology/P16-1162)]) and
**unigram language model** [[Kudo.](https://arxiv.org/abs/1804.10959)])
with the extension of direct training from raw sentences. SentencePiece allows us to make a purely end-to-end system that does not depend on language-specific pre/postprocessing.
**This is not an official Google product.**
## Technical highlights
- **Purely data driven**: SentencePiece trains tokenization and detokenization
models from sentences. Pre-tokenization ([Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)/[MeCab](http://taku910.github.io/mecab/)/[KyTea](http://www.phontron.com/kytea/)) is not always required.
- **Language independent**: SentencePiece treats the sentences just as sequences of Unicode characters. There is no language-dependent logic.
- **Multiple subword algorithms**: **BPE** [[Sennrich et al.](https://www.aclweb.org/anthology/P16-1162)] and **unigram language model** [[Kudo.](https://arxiv.org/abs/1804.10959)] are supported.
- **Subword regularization**: SentencePiece implements subword sampling for [subword regularization](https://arxiv.org/abs/1804.10959) and [BPE-dropout](https://arxiv.org/abs/1910.13267) which help to improve the robustness and accuracy of NMT models.
- **Fast and lightweight**: Segmentation speed is around 50k sentences/sec, and memory footprint is around 6MB.
- **Self-contained**: The same tokenization/detokenization is obtained as long as the same model file is used.
- **Direct vocabulary id generation**: SentencePiece manages vocabulary to id mapping and can directly generate vocabulary id sequences from raw sentences.
- **NFKC-based normalization**: SentencePiece performs NFKC-based text normalization.
For those unfamiliar with SentencePiece as a software/algorithm, one can read [a gentle introduction here](https://medium.com/@jacky2wong/understanding-sentencepiece-under-standing-sentence-piece-ac8da59f6b08).
## Comparisons with other implementations
|Feature|SentencePiece|[subword-nmt](https://github.com/rsennrich/subword-nmt)|[WordPiece](https://arxiv.org/pdf/1609.08144.pdf)|
|:---|:---:|:---:|:---:|
|Supported algorithm|BPE, unigram, char, word|BPE|BPE*|
|OSS?|Yes|Yes|Google internal|
|Subword regularization|[Yes](#subword-regularization-and-bpe-dropout)|No|No|
|Python Library (pip)|[Yes](python/README.md)|No|N/A|
|C++ Library|[Yes](doc/api.md)|No|N/A|
|Pre-segmentation required?|[No](#whitespace-is-treated-as-a-basic-symbol)|Yes|Yes|
|Customizable normalization (e.g., NFKC)|[Yes](doc/normalization.md)|No|N/A|
|Direct id generation|[Yes](#end-to-end-example)|No|N/A|
Note that BPE algorithm used in WordPiece is slightly different from the original BPE.
## Overview
### What is SentencePiece?
SentencePiece is a re-implementation of **sub-word units**, an effective way to alleviate the open vocabulary
problems in neural machine translation. SentencePiece supports two segmentation algorithms, **byte-pair-encoding (BPE)** [[Sennrich et al.](http://www.aclweb.org/anthology/P16-1162)] and **unigram language model** [[Kudo.](https://arxiv.org/abs/1804.10959)]. Here are the high level differences from other implementations.
#### The number of unique tokens is predetermined
Neural Machine Translation models typically operate with a fixed
vocabulary. Unlike most unsupervised word segmentation algorithms, which
assume an infinite vocabulary, SentencePiece trains the segmentation model such
that the final vocabulary size is fixed, e.g., 8k, 16k, or 32k.
Note that SentencePiece specifies the final vocabulary size for training, which is different from
[subword-nmt](https://github.com/rsennrich/subword-nmt) that uses the number of merge operations.
The number of merge operations is a BPE-specific parameter and not applicable to other segmentation algorithms, including unigram, word and character.
#### Trains from raw sentences
Previous sub-word implementations assume that the input sentences are pre-tokenized. This constraint was required for efficient training, but makes the preprocessing complicated as we have to run language dependent tokenizers in advance.
The implementation of SentencePiece is fast enough to train the model from raw sentences. This is useful for training the tokenizer and detokenizer for Chinese and Japanese where no explicit spaces exist between words.
#### Whitespace is treated as a basic symbol
The first step of Natural Language processing is text tokenization. For
example, a standard English tokenizer would segment the text "Hello world." into the
following three tokens.
> [Hello] [World] [.]
One observation is that the original input and tokenized sequence are **NOT
reversibly convertible**. For instance, the information that is no space between
“World” and “.” is dropped from the tokenized sequence, since e.g., `Tokenize(“World.”) == Tokenize(“World .”)`
SentencePiece treats the input text just as a sequence of Unicode characters. Whitespace is also handled as a normal symbol. To handle the whitespace as a basic token explicitly, SentencePiece first escapes the whitespace with a meta symbol "▁" (U+2581) as follows.
> Hello▁World.
Then, this text is segmented into small pieces, for example:
> [Hello] [▁Wor] [ld] [.]
Since the whitespace is preserved in the segmented text, we can detokenize the text without any ambiguities.
```
detokenized = ''.join(pieces).replace('▁', ' ')
```
This feature makes it possible to perform detokenization without relying on language-specific resources.
Note that we cannot apply the same lossless conversions when splitting the
sentence with standard word segmenters, since they treat the whitespace as a
special symbol. Tokenized sequences do not preserve the necessary information to restore the original sentence.
* (en) Hello world. → [Hello] [World] [.] \(A space between Hello and World\)
* (ja) こんにちは世界。 → [こんにちは] [世界] [。] \(No space between こんにちは and 世界\)
#### Subword regularization and BPE-dropout
Subword regularization [[Kudo.](https://arxiv.org/abs/1804.10959)] and BPE-dropout [Provilkov et al](https://arxiv.org/abs/1910.13267) are simple regularization methods
that virtually augment training data with on-the-fly subword sampling, which helps to improve the accuracy as well as robustness of NMT models.
To enable subword regularization, you would like to integrate SentencePiece library
([C++](doc/api.md#sampling-subword-regularization)/[Python](python/README.md)) into the NMT system to sample one segmentation for each parameter update, which is different from the standard off-line data preparations. Here's the example of [Python library](python/README.md). You can find that 'New York' is segmented differently on each ``SampleEncode (C++)`` or ``encode with enable_sampling=True (Python)`` calls. The details of sampling parameters are found in [sentencepiece_processor.h](src/sentencepiece_processor.h).
```
>>> import sentencepiece as spm
>>> s = spm.SentencePieceProcessor(model_file='spm.model')
>>> for n in range(5):
... s.encode('New York', out_type=str, enable_sampling=True, alpha=0.1, nbest_size=-1)
...
['▁', 'N', 'e', 'w', '▁York']
['▁', 'New', '▁York']
['▁', 'New', '▁Y', 'o', 'r', 'k']
['▁', 'New', '▁York']
['▁', 'New', '▁York']
```
## Installation
### Python module
SentencePiece provides Python wrapper that supports both SentencePiece training and segmentation.
You can install Python binary package of SentencePiece with.
```
pip install sentencepiece
```
For more detail, see [Python module](python/README.md)
### Build and install SentencePiece command line tools from C++ source
The following tools and libraries are required to build SentencePiece:
* [cmake](https://cmake.org/)
* C++11 compiler
* [gperftools](https://github.com/gperftools/gperftools) library (optional, 10-40% performance improvement can be obtained.)
On Ubuntu, the build tools can be installed with apt-get:
```
% sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
```
Then, you can build and install command line tools as follows.
```
% git clone https://github.com/google/sentencepiece.git
% cd sentencepiece
% mkdir build
% cd build
% cmake ..
% make -j $(nproc)
% sudo make install
% sudo ldconfig -v
```
On OSX/macOS, replace the last command with `sudo update_dyld_shared_cache`
### Build and install using vcpkg
You can download and install sentencepiece using the [vcpkg](https://github.com/Microsoft/vcpkg) dependency manager:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install sentencepiece
The sentencepiece port in vcpkg is kept up to date by Microsoft team members and community contributors. If the version is out of date, please [create an issue or pull request](https://github.com/Microsoft/vcpkg) on the vcpkg repository.
### Download and install SentencePiece from signed released wheels
You can download the wheel from the [GitHub releases page](https://github.com/google/sentencepiece/releases/latest).
We generate [SLSA3 signatures](slsa.dev) using the OpenSSF's [slsa-framework/slsa-github-generator](https://github.com/slsa-framework/slsa-github-generator) during the release process. To verify a release binary:
1. Install the verification tool from [slsa-framework/slsa-verifier#installation](https://github.com/slsa-framework/slsa-verifier#installation).
2. Download the provenance file `attestation.intoto.jsonl` from the [GitHub releases page](https://github.com/google/sentencepiece/releases/latest).
3. Run the verifier:
```shell
slsa-verifier -artifact-path <the-wheel> -provenance attestation.intoto.jsonl -source github.com/google/sentencepiece -tag <the-tag>
```
pip install wheel_file.whl
## Usage instructions
### Train SentencePiece Model
```
% spm_train --input=<input> --model_prefix=<model_name> --vocab_size=8000 --character_coverage=1.0 --model_type=<type>
```
* `--input`: one-sentence-per-line **raw** corpus file. No need to run
tokenizer, normalizer or preprocessor. By default, SentencePiece normalizes
the input with Unicode NFKC. You can pass a comma-separated list of files.
* `--model_prefix`: output model name prefix. `<model_name>.model` and `<model_name>.vocab` are generated.
* `--vocab_size`: vocabulary size, e.g., 8000, 16000, or 32000
* `--character_coverage`: amount of characters covered by the model, good defaults are: `0.9995` for languages with rich character set like Japanese or Chinese and `1.0` for other languages with small character set.
* `--model_type`: model type. Choose from `unigram` (default), `bpe`, `char`, or `word`. The input sentence must be pretokenized when using `word` type.
Use `--help` flag to display all parameters for training, or see [here](doc/options.md) for an overview.
### Encode raw text into sentence pieces/ids
```
% spm_encode --model=<model_file> --output_format=piece < input > output
% spm_encode --model=<model_file> --output_format=id < input > output
```
Use `--extra_options` flag to insert the BOS/EOS markers or reverse the input sequence.
```
% spm_encode --extra_options=eos (add </s> only)
% spm_encode --extra_options=bos:eos (add <s> and </s>)
% spm_encode --extra_options=reverse:bos:eos (reverse input and add <s> and </s>)
```
SentencePiece supports nbest segmentation and segmentation sampling with `--output_format=(nbest|sample)_(piece|id)` flags.
```
% spm_encode --model=<model_file> --output_format=sample_piece --nbest_size=-1 --alpha=0.5 < input > output
% spm_encode --model=<model_file> --output_format=nbest_id --nbest_size=10 < input > output
```
### Decode sentence pieces/ids into raw text
```
% spm_decode --model=<model_file> --input_format=piece < input > output
% spm_decode --model=<model_file> --input_format=id < input > output
```
Use `--extra_options` flag to decode the text in reverse order.
```
% spm_decode --extra_options=reverse < input > output
```
### End-to-End Example
```
% spm_train --input=data/botchan.txt --model_prefix=m --vocab_size=1000
unigram_model_trainer.cc(494) LOG(INFO) Starts training with :
input: "../data/botchan.txt"
... <snip>
unigram_model_trainer.cc(529) LOG(INFO) EM sub_iter=1 size=1100 obj=10.4973 num_tokens=37630 num_tokens/piece=34.2091
trainer_interface.cc(272) LOG(INFO) Saving model: m.model
trainer_interface.cc(281) LOG(INFO) Saving vocabs: m.vocab
% echo "I saw a girl with a telescope." | spm_encode --model=m.model
▁I ▁saw ▁a ▁girl ▁with ▁a ▁ te le s c o pe .
% echo "I saw a girl with a telescope." | spm_encode --model=m.model --output_format=id
9 459 11 939 44 11 4 142 82 8 28 21 132 6
% echo "9 459 11 939 44 11 4 142 82 8 28 21 132 6" | spm_decode --model=m.model --input_format=id
I saw a girl with a telescope.
```
You can find that the original input sentence is restored from the vocabulary id sequence.
### Export vocabulary list
```
% spm_export_vocab --model=<model_file> --output=<output file>
```
```<output file>``` stores a list of vocabulary and emission log probabilities. The vocabulary id corresponds to the line number in this file.
### Redefine special meta tokens
By default, SentencePiece uses Unknown (<unk>), BOS (<s>) and EOS (</s>) tokens which have the ids of 0, 1, and 2 respectively. We can redefine this mapping in the training phase as follows.
```
% spm_train --bos_id=0 --eos_id=1 --unk_id=5 --input=... --model_prefix=... --character_coverage=...
```
When setting -1 id e.g., ```bos_id=-1```, this special token is disabled. Note that the unknown id cannot be disabled. We can define an id for padding (<pad>) as ```--pad_id=3```.
If you want to assign another special tokens, please see [Use custom symbols](doc/special_symbols.md).
### Vocabulary restriction
```spm_encode``` accepts a ```--vocabulary``` and a ```--vocabulary_threshold``` option so that ```spm_encode``` will only produce symbols which also appear in the vocabulary (with at least some frequency). The background of this feature is described in [subword-nmt page](https://github.com/rsennrich/subword-nmt#best-practice-advice-for-byte-pair-encoding-in-nmt).
The usage is basically the same as that of ```subword-nmt```. Assuming that L1 and L2 are the two languages (source/target languages), train the shared spm model, and get resulting vocabulary for each:
```
% cat {train_file}.L1 {train_file}.L2 | shuffle > train
% spm_train --input=train --model_prefix=spm --vocab_size=8000 --character_coverage=0.9995
% spm_encode --model=spm.model --generate_vocabulary < {train_file}.L1 > {vocab_file}.L1
% spm_encode --model=spm.model --generate_vocabulary < {train_file}.L2 > {vocab_file}.L2
```
```shuffle``` command is used just in case because ```spm_train``` loads the first 10M lines of corpus by default.
Then segment train/test corpus with ```--vocabulary``` option
```
% spm_encode --model=spm.model --vocabulary={vocab_file}.L1 --vocabulary_threshold=50 < {test_file}.L1 > {test_file}.seg.L1
% spm_encode --model=spm.model --vocabulary={vocab_file}.L2 --vocabulary_threshold=50 < {test_file}.L2 > {test_file}.seg.L2
```
## Advanced topics
* [SentencePiece Experiments](doc/experiments.md)
* [SentencePieceProcessor C++ API](doc/api.md)
* [Use custom text normalization rules](doc/normalization.md)
* [Use custom symbols](doc/special_symbols.md)
* [Python Module](python/README.md)
* [Segmentation and training algorithms in detail]
|
3,452 | The Python Code Tutorials | 
# Python Code Tutorials
This is a repository of all the tutorials of [The Python Code](https://www.thepythoncode.com) website.
## List of Tutorials
- ### [Ethical Hacking](https://www.thepythoncode.com/topic/ethical-hacking)
- ### [Scapy](https://www.thepythoncode.com/topic/scapy)
- [Getting Started With Scapy: Python Network Manipulation Tool](https://www.thepythoncode.com/article/getting-started-with-scapy)
- [Building an ARP Spoofer](https://www.thepythoncode.com/article/building-arp-spoofer-using-scapy). ([code](scapy/arp-spoofer))
- [Detecting ARP Spoof attacks](https://www.thepythoncode.com/article/detecting-arp-spoof-attacks-using-scapy). ([code](scapy/arp-spoof-detector))
- [How to Make a DHCP Listener using Scapy in Python](https://www.thepythoncode.com/article/dhcp-listener-using-scapy-in-python). ([code](scapy/dhcp_listener))
- [Fake Access Point Generator](https://www.thepythoncode.com/article/create-fake-access-points-scapy). ([code](scapy/fake-access-point))
- [Forcing a device to disconnect using scapy in Python](https://www.thepythoncode.com/article/force-a-device-to-disconnect-scapy). ([code](scapy/network-kicker))
- [Simple Network Scanner](https://www.thepythoncode.com/article/building-network-scanner-using-scapy). ([code](scapy/network-scanner))
- [Writing a DNS Spoofer](https://www.thepythoncode.com/article/make-dns-spoof-python). ([code](scapy/dns-spoof))
- [How to Sniff HTTP Packets in the Network using Scapy in Python](https://www.thepythoncode.com/article/sniff-http-packets-scapy-python). ([code](scapy/http-sniffer))
- [How to Build a WiFi Scanner in Python using Scapy](https://www.thepythoncode.com/article/building-wifi-scanner-in-python-scapy). ([code](scapy/wifi-scanner))
- [How to Make a SYN Flooding Attack in Python](https://www.thepythoncode.com/article/syn-flooding-attack-using-scapy-in-python). ([code](scapy/syn-flood))
- [How to Inject Code into HTTP Responses in the Network in Python](https://www.thepythoncode.com/article/injecting-code-to-html-in-a-network-scapy-python). ([code](scapy/http-code-injector/))
- [Writing a Keylogger in Python from Scratch](https://www.thepythoncode.com/article/write-a-keylogger-python). ([code](ethical-hacking/keylogger))
- [Making a Port Scanner using sockets in Python](https://www.thepythoncode.com/article/make-port-scanner-python). ([code](ethical-hacking/port_scanner))
- [How to Create a Reverse Shell in Python](https://www.thepythoncode.com/article/create-reverse-shell-python). ([code](ethical-hacking/reverse_shell))
- [How to Encrypt and Decrypt Files in Python](https://www.thepythoncode.com/article/encrypt-decrypt-files-symmetric-python). ([code](ethical-hacking/file-encryption))
- [How to Make a Subdomain Scanner in Python](https://www.thepythoncode.com/article/make-subdomain-scanner-python). ([code](ethical-hacking/subdomain-scanner))
- [How to Use Steganography to Hide Secret Data in Images in Python](https://www.thepythoncode.com/article/hide-secret-data-in-images-using-steganography-python). ([code](ethical-hacking/steganography))
- [How to Brute-Force SSH Servers in Python](https://www.thepythoncode.com/article/brute-force-ssh-servers-using-paramiko-in-python). ([code](ethical-hacking/bruteforce-ssh))
- [How to Build a XSS Vulnerability Scanner in Python](https://www.thepythoncode.com/article/make-a-xss-vulnerability-scanner-in-python). ([code](ethical-hacking/xss-vulnerability-scanner))
- [How to Use Hash Algorithms in Python using hashlib](https://www.thepythoncode.com/article/hashing-functions-in-python-using-hashlib). ([code](ethical-hacking/hashing-functions/))
- [How to Brute Force FTP Servers in Python](https://www.thepythoncode.com/article/brute-force-attack-ftp-servers-using-ftplib-in-python). ([code](ethical-hacking/ftp-cracker))
- [How to Extract Image Metadata in Python](https://www.thepythoncode.com/article/extracting-image-metadata-in-python). ([code](ethical-hacking/image-metadata-extractor))
- [How to Crack Zip File Passwords in Python](https://www.thepythoncode.com/article/crack-zip-file-password-in-python). ([code](ethical-hacking/zipfile-cracker))
- [How to Crack PDF Files in Python](https://www.thepythoncode.com/article/crack-pdf-file-password-in-python). ([code](ethical-hacking/pdf-cracker))
- [How to Build a SQL Injection Scanner in Python](https://www.thepythoncode.com/code/sql-injection-vulnerability-detector-in-python). ([code](ethical-hacking/sql-injection-detector))
- [How to Extract Chrome Passwords in Python](https://www.thepythoncode.com/article/extract-chrome-passwords-python). ([code](ethical-hacking/chrome-password-extractor))
- [How to Use Shodan API in Python](https://www.thepythoncode.com/article/using-shodan-api-in-python). ([code](ethical-hacking/shodan-api))
- [How to Make an HTTP Proxy in Python](https://www.thepythoncode.com/article/writing-http-proxy-in-python-with-mitmproxy). ([code](ethical-hacking/http-mitm-proxy))
- [How to Extract Chrome Cookies in Python](https://www.thepythoncode.com/article/extract-chrome-cookies-python). ([code](ethical-hacking/chrome-cookie-extractor))
- [How to Extract Saved WiFi Passwords in Python](https://www.thepythoncode.com/article/extract-saved-wifi-passwords-in-python). ([code](ethical-hacking/get-wifi-passwords))
- [How to Make a MAC Address Changer in Python](https://www.thepythoncode.com/article/make-a-mac-address-changer-in-python). ([code](ethical-hacking/mac-address-changer))
- [How to Make a Password Generator in Python](https://www.thepythoncode.com/article/make-a-password-generator-in-python). ([code](ethical-hacking/password-generator))
- [How to Make a Ransomware in Python](https://www.thepythoncode.com/article/make-a-ransomware-in-python). ([code](ethical-hacking/ransomware))
- [How to Perform DNS Enumeration in Python](https://www.thepythoncode.com/article/dns-enumeration-with-python). ([code](ethical-hacking/dns-enumeration))
- [How to Geolocate IP addresses in Python](https://www.thepythoncode.com/article/geolocate-ip-addresses-with-ipinfo-in-python). ([code](ethical-hacking/geolocating-ip-addresses))
- ### [Machine Learning](https://www.thepythoncode.com/topic/machine-learning)
- ### [Natural Language Processing](https://www.thepythoncode.com/topic/nlp)
- [How to Build a Spam Classifier using Keras in Python](https://www.thepythoncode.com/article/build-spam-classifier-keras-python). ([code](machine-learning/nlp/spam-classifier))
- [How to Build a Text Generator using TensorFlow and Keras in Python](https://www.thepythoncode.com/article/text-generation-keras-python). ([code](machine-learning/nlp/text-generator))
- [How to Perform Text Classification in Python using Tensorflow 2 and Keras](https://www.thepythoncode.com/article/text-classification-using-tensorflow-2-and-keras-in-python). ([code](machine-learning/nlp/text-classification))
- [Sentiment Analysis using Vader in Python](https://www.thepythoncode.com/article/vaderSentiment-tool-to-extract-sentimental-values-in-texts-using-python). ([code](machine-learning/nlp/sentiment-analysis-vader))
- [How to Perform Text Summarization using Transformers in Python](https://www.thepythoncode.com/article/text-summarization-using-huggingface-transformers-python). ([code](machine-learning/nlp/text-summarization))
- [How to Fine Tune BERT for Text Classification using Transformers in Python](https://www.thepythoncode.com/article/finetuning-bert-using-huggingface-transformers-python). ([code](machine-learning/nlp/bert-text-classification))
- [Conversational AI Chatbot with Transformers in Python](https://www.thepythoncode.com/article/conversational-ai-chatbot-with-huggingface-transformers-in-python). ([code](machine-learning/nlp/chatbot-transformers))
- [How to Train BERT from Scratch using Transformers in Python](https://www.thepythoncode.com/article/pretraining-bert-huggingface-transformers-in-python). ([code](machine-learning/nlp/pretraining-bert))
- [How to Perform Machine Translation using Transformers in Python](https://www.thepythoncode.com/article/machine-translation-using-huggingface-transformers-in-python). ([code](machine-learning/nlp/machine-translation))
- [Speech Recognition using Transformers in Python](https://www.thepythoncode.com/article/speech-recognition-using-huggingface-transformers-in-python). ([code](machine-learning/nlp/speech-recognition-transformers))
- [Text Generation with Transformers in Python](https://www.thepythoncode.com/article/text-generation-with-transformers-in-python). ([code](machine-learning/nlp/text-generation-transformers))
- [How to Paraphrase Text using Transformers in Python](https://www.thepythoncode.com/article/paraphrase-text-using-transformers-in-python). ([code](machine-learning/nlp/text-paraphrasing))
- [Fake News Detection using Transformers in Python](https://www.thepythoncode.com/article/fake-news-classification-in-python). ([code](machine-learning/nlp/fake-news-classification))
- [Named Entity Recognition using Transformers and Spacy in Python](https://www.thepythoncode.com/article/named-entity-recognition-using-transformers-and-spacy). ([code](machine-learning/nlp/named-entity-recognition))
- [Tokenization, Stemming, and Lemmatization in Python](https://www.thepythoncode.com/article/tokenization-stemming-and-lemmatization-in-python). ([code](machine-learning/nlp/tokenization-stemming-lemmatization))
- ### [Computer Vision](https://www.thepythoncode.com/topic/computer-vision)
- [How to Detect Human Faces in Python using OpenCV](https://www.thepythoncode.com/article/detect-faces-opencv-python). ([code](machine-learning/face_detection))
- [How to Make an Image Classifier in Python using TensorFlow and Keras](https://www.thepythoncode.com/article/image-classification-keras-python). ([code](machine-learning/image-classifier))
- [How to Use Transfer Learning for Image Classification using Keras in Python](https://www.thepythoncode.com/article/use-transfer-learning-for-image-flower-classification-keras-python). ([code](machine-learning/image-classifier-using-transfer-learning))
- [How to Perform Edge Detection in Python using OpenCV](https://www.thepythoncode.com/article/canny-edge-detection-opencv-python). ([code](machine-learning/edge-detection))
- [How to Detect Shapes in Images in Python](https://www.thepythoncode.com/article/detect-shapes-hough-transform-opencv-python). ([code](machine-learning/shape-detection))
- [How to Detect Contours in Images using OpenCV in Python](https://www.thepythoncode.com/article/contour-detection-opencv-python). ([code](machine-learning/contour-detection))
- [How to Recognize Optical Characters in Images in Python](https://www.thepythoncode.com/article/optical-character-recognition-pytesseract-python). ([code](machine-learning/optical-character-recognition))
- [How to Use K-Means Clustering for Image Segmentation using OpenCV in Python](https://www.thepythoncode.com/article/kmeans-for-image-segmentation-opencv-python). ([code](machine-learning/kmeans-image-segmentation))
- [How to Perform YOLO Object Detection using OpenCV and PyTorch in Python](https://www.thepythoncode.com/article/yolo-object-detection-with-opencv-and-pytorch-in-python). ([code](machine-learning/object-detection))
- [How to Blur Faces in Images using OpenCV in Python](https://www.thepythoncode.com/article/blur-faces-in-images-using-opencv-in-python). ([code](machine-learning/blur-faces))
- [Skin Cancer Detection using TensorFlow in Python](https://www.thepythoncode.com/article/skin-cancer-detection-using-tensorflow-in-python). ([code](machine-learning/skin-cancer-detection))
- [How to Perform Malaria Cells Classification using TensorFlow 2 and Keras in Python](https://www.thepythoncode.com/article/malaria-cells-classification). ([code](machine-learning/malaria-classification))
- [Image Transformations using OpenCV in Python](https://www.thepythoncode.com/article/image-transformations-using-opencv-in-python). ([code](machine-learning/image-transformation))
- [How to Apply HOG Feature Extraction in Python](https://www.thepythoncode.com/article/hog-feature-extraction-in-python). ([code](machine-learning/hog-feature-extraction))
- [SIFT Feature Extraction using OpenCV in Python](https://www.thepythoncode.com/article/sift-feature-extraction-using-opencv-in-python). ([code](machine-learning/sift))
- [Age Prediction using OpenCV in Python](https://www.thepythoncode.com/article/predict-age-using-opencv). ([code](machine-learning/face-age-prediction))
- [Gender Detection using OpenCV in Python](https://www.thepythoncode.com/article/gender-detection-using-opencv-in-python). ([code](machine-learning/face-gender-detection))
- [Age and Gender Detection using OpenCV in Python](https://www.thepythoncode.com/article/gender-and-age-detection-using-opencv-python). ([code](machine-learning/age-and-gender-detection))
- [Satellite Image Classification using TensorFlow in Python](https://www.thepythoncode.com/article/satellite-image-classification-using-tensorflow-python). ([code](machine-learning/satellite-image-classification))
- [Building a Speech Emotion Recognizer using Scikit-learn](https://www.thepythoncode.com/article/building-a-speech-emotion-recognizer-using-sklearn). ([code](machine-learning/speech-emotion-recognition))
- [How to Convert Speech to Text in Python](https://www.thepythoncode.com/article/using-speech-recognition-to-convert-speech-to-text-python). ([code](machine-learning/speech-recognition))
- [Top 8 Python Libraries For Data Scientists and Machine Learning Engineers](https://www.thepythoncode.com/article/top-python-libraries-for-data-scientists).
- [How to Predict Stock Prices in Python using TensorFlow 2 and Keras](https://www.thepythoncode.com/article/stock-price-prediction-in-python-using-tensorflow-2-and-keras). ([code](machine-learning/stock-prediction))
- [How to Convert Text to Speech in Python](https://www.thepythoncode.com/article/convert-text-to-speech-in-python). ([code](machine-learning/text-to-speech))
- [How to Perform Voice Gender Recognition using TensorFlow in Python](https://www.thepythoncode.com/article/gender-recognition-by-voice-using-tensorflow-in-python). ([code](https://github.com/x4nth055/gender-recognition-by-voice))
- [Introduction to Finance and Technical Indicators with Python](https://www.thepythoncode.com/article/introduction-to-finance-and-technical-indicators-with-python). ([code](machine-learning/technical-indicators))
- [Algorithmic Trading with FXCM Broker in Python](https://www.thepythoncode.com/article/trading-with-fxcm-broker-using-fxcmpy-library-in-python). ([code](machine-learning/trading-with-fxcm))
- [How to Create Plots With Plotly In Python](https://www.thepythoncode.com/article/creating-dynamic-plots-with-plotly-visualization-tool-in-python). ([code](machine-learning/plotly-visualization))
- [Feature Selection using Scikit-Learn in Python](https://www.thepythoncode.com/article/feature-selection-and-feature-engineering-using-python). ([code](machine-learning/feature-selection))
- [Imbalance Learning With Imblearn and Smote Variants Libraries in Python](https://www.thepythoncode.com/article/handling-imbalance-data-imblearn-smote-variants-python). ([code](machine-learning/imbalance-learning))
- [Credit Card Fraud Detection in Python](https://www.thepythoncode.com/article/credit-card-fraud-detection-using-sklearn-in-python#near-miss). ([code](machine-learning/credit-card-fraud-detection))
- [Customer Churn Prediction in Python](https://www.thepythoncode.com/article/customer-churn-detection-using-sklearn-in-python). ([code](machine-learning/customer-churn-detection))
- [Recommender Systems using Association Rules Mining in Python](https://www.thepythoncode.com/article/build-a-recommender-system-with-association-rule-mining-in-python). ([code](machine-learning/recommender-system-using-association-rules))
- [Handling Imbalanced Datasets: A Case Study with Customer Churn](https://www.thepythoncode.com/article/handling-imbalanced-datasets-sklearn-in-python). ([code](machine-learning/handling-inbalance-churn-data))
- [Logistic Regression using PyTorch in Python](https://www.thepythoncode.com/article/logistic-regression-using-pytorch). ([code](machine-learning/logistic-regression-in-pytorch))
- [Dropout Regularization using PyTorch in Python](https://www.thepythoncode.com/article/dropout-regularization-in-pytorch). ([code](machine-learning/dropout-in-pytorch))
- [K-Fold Cross Validation using Scikit-Learn in Python](https://www.thepythoncode.com/article/kfold-cross-validation-using-sklearn-in-python). ([code](machine-learning/k-fold-cross-validation-sklearn))
- [Dimensionality Reduction: Feature Extraction using Scikit-learn in Python](https://www.thepythoncode.com/article/dimensionality-reduction-using-feature-extraction-sklearn). ([code](machine-learning/dimensionality-reduction-feature-extraction))
- [Dimensionality Reduction: Using Feature Selection in Python](https://www.thepythoncode.com/article/dimensionality-reduction-feature-selection). ([code](machine-learning/dimensionality-reduction-feature-selection))
- [A Guide to Explainable AI Using Python](https://www.thepythoncode.com/article/explainable-ai-model-python). ([code](machine-learning/explainable-ai))
- [Autoencoders for Dimensionality Reduction using TensorFlow in Python](https://www.thepythoncode.com/article/feature-extraction-dimensionality-reduction-autoencoders-python-keras). ([code](machine-learning/feature-extraction-autoencoders))
- [Exploring the Different Types of Clustering Algorithms in Machine Learning with Python](https://www.thepythoncode.com/article/clustering-algorithms-in-machine-learning-with-python). ([code](machine-learning/clustering-algorithms))
- [Image Captioning using PyTorch and Transformers](https://www.thepythoncode.com/article/image-captioning-with-pytorch-and-transformers-in-python). ([code](machine-learning/image-captioning))
- ### [General Python Topics](https://www.thepythoncode.com/topic/general-python-topics)
- [How to Make Facebook Messenger bot in Python](https://www.thepythoncode.com/article/make-bot-fbchat-python). ([code](general/messenger-bot))
- [How to Get Hardware and System Information in Python](https://www.thepythoncode.com/article/get-hardware-system-information-python). ([code](general/sys-info))
- [How to Control your Mouse in Python](https://www.thepythoncode.com/article/control-mouse-python). ([code](general/mouse-controller))
- [How to Control your Keyboard in Python](https://www.thepythoncode.com/article/control-keyboard-python). ([code](general/keyboard-controller))
- [How to Make a Process Monitor in Python](https://www.thepythoncode.com/article/make-process-monitor-python). ([code](general/process-monitor))
- [How to Download Files in Python](https://www.thepythoncode.com/article/download-files-python). ([code](general/file-downloader))
- [How to Execute BASH Commands in a Remote Machine in Python](https://www.thepythoncode.com/article/executing-bash-commands-remotely-in-python). ([code](general/execute-ssh-commands))
- [How to Convert Python Files into Executables](https://www.thepythoncode.com/article/building-python-files-into-stand-alone-executables-using-pyinstaller)
- [How to Get the Size of Directories in Python](https://www.thepythoncode.com/article/get-directory-size-in-bytes-using-python). ([code](general/calculate-directory-size))
- [How to Get Geographic Locations in Python](https://www.thepythoncode.com/article/get-geolocation-in-python). ([code](general/geolocation))
- [How to Assembly, Disassembly and Emulate Machine Code using Python](https://www.thepythoncode.com/article/arm-x86-64-assembly-disassembly-and-emulation-in-python). ([code](general/assembly-code))
- [How to Change Text Color in Python](https://www.thepythoncode.com/article/change-text-color-in-python). ([code](general/printing-in-colors))
- [How to Create a Watchdog in Python](https://www.thepythoncode.com/article/create-a-watchdog-in-python). ([code](general/directory-watcher))
- [How to Convert Pandas Dataframes to HTML Tables in Python](https://www.thepythoncode.com/article/convert-pandas-dataframe-to-html-table-python). ([code](general/dataframe-to-html))
- [How to Make a Simple Math Quiz Game in Python](https://www.thepythoncode.com/article/make-a-simple-math-quiz-game-in-python). ([code](general/simple-math-game))
- [How to Make a Network Usage Monitor in Python](https://www.thepythoncode.com/article/make-a-network-usage-monitor-in-python). ([code](general/network-usage))
- [How to Replace Text in Docx Files in Python](https://www.thepythoncode.com/article/replace-text-in-docx-files-using-python). ([code](general/docx-file-replacer))
- [How to Make a Text Adventure Game in Python](https://www.thepythoncode.com/article/make-a-text-adventure-game-with-python). ([code](general/text-adventure-game))
- [Zipf's Word Frequency Plot with Python](https://www.thepythoncode.com/article/plot-zipfs-law-using-matplotlib-python). ([code](general/zipf-curve))
- [How to Plot Weather Temperature in Python](https://www.thepythoncode.com/article/interactive-weather-plot-with-matplotlib-and-requests). ([code](general/interactive-weather-plot/))
- [How to Generate SVG Country Maps in Python](https://www.thepythoncode.com/article/generate-svg-country-maps-python). ([code](general/generate-svg-country-map))
- [How to Query the Ethereum Blockchain with Python](https://www.thepythoncode.com/article/query-ethereum-blockchain-with-python). ([code](general/query-ethereum))
- [Data Cleaning with Pandas in Python](https://www.thepythoncode.com/article/data-cleaning-using-pandas-in-python). ([code](general/data-cleaning-pandas))
- [How to Minify CSS with Python](https://www.thepythoncode.com/article/minimize-css-files-in-python). ([code](general/minify-css))
- ### [Web Scraping](https://www.thepythoncode.com/topic/web-scraping)
- [How to Access Wikipedia in Python](https://www.thepythoncode.com/article/access-wikipedia-python). ([code](web-scraping/wikipedia-extractor))
- [How to Extract YouTube Data in Python](https://www.thepythoncode.com/article/get-youtube-data-python). ([code](web-scraping/youtube-extractor))
- [How to Extract Weather Data from Google in Python](https://www.thepythoncode.com/article/extract-weather-data-python). ([code](web-scraping/weather-extractor))
- [How to Download All Images from a Web Page in Python](https://www.thepythoncode.com/article/download-web-page-images-python). ([code](web-scraping/download-images))
- [How to Extract All Website Links in Python](https://www.thepythoncode.com/article/extract-all-website-links-python). ([code](web-scraping/link-extractor))
- [How to Make an Email Extractor in Python](https://www.thepythoncode.com/article/extracting-email-addresses-from-web-pages-using-python). ([code](web-scraping/email-extractor))
- [How to Convert HTML Tables into CSV Files in Python](https://www.thepythoncode.com/article/convert-html-tables-into-csv-files-in-python). ([code](web-scraping/html-table-extractor))
- [How to Use Proxies to Anonymize your Browsing and Scraping using Python](https://www.thepythoncode.com/article/using-proxies-using-requests-in-python). ([code](web-scraping/using-proxies))
- [How to Extract Script and CSS Files from Web Pages in Python](https://www.thepythoncode.com/article/extract-web-page-script-and-css-files-in-python). ([code](web-scraping/webpage-js-css-extractor))
- [How to Extract and Submit Web Forms from a URL using Python](https://www.thepythoncode.com/article/extracting-and-submitting-web-page-forms-in-python). ([code](web-scraping/extract-and-fill-forms))
- [How to Get Domain Name Information in Python](https://www.thepythoncode.com/article/extracting-domain-name-information-in-python). ([code](web-scraping/get-domain-info))
- [How to Extract YouTube Comments in Python](https://www.thepythoncode.com/article/extract-youtube-comments-in-python). ([code](web-scraping/youtube-comments-extractor))
- [Automated Browser Testing with Edge and Selenium in Python](https://www.thepythoncode.com/article/automated-browser-testing-with-edge-and-selenium-in-python). ([code](web-scraping/selenium-edge-browser))
- [How to Automate Login using Selenium in Python](https://www.thepythoncode.com/article/automate-login-to-websites-using-selenium-in-python). ([code](web-scraping/automate-login))
- [How to Make a Currency Converter in Python](https://www.thepythoncode.com/article/make-a-currency-converter-in-python). ([code](web-scraping/currency-converter))
- [How to Extract Google Trends Data in Python](https://www.thepythoncode.com/article/extract-google-trends-data-in-python). ([code](web-scraping/extract-google-trends-data))
- [How to Make a YouTube Video Downloader in Python](https://www.thepythoncode.com/article/make-a-youtube-video-downloader-in-python). ([code](web-scraping/youtube-video-downloader))
- [How to Build a YouTube Audio Downloader in Python](https://www.thepythoncode.com/article/build-a-youtube-mp3-downloader-tkinter-python). ([code](web-scraping/youtube-mp3-downloader))
- ### [Python Standard Library](https://www.thepythoncode.com/topic/python-standard-library)
- [How to Transfer Files in the Network using Sockets in Python](https://www.thepythoncode.com/article/send-receive-files-using-sockets-python). ([code](general/transfer-files/))
- [How to Compress and Decompress Files in Python](https://www.thepythoncode.com/article/compress-decompress-files-tarfile-python). ([code](general/compressing-files))
- [How to Use Pickle for Object Serialization in Python](https://www.thepythoncode.com/article/object-serialization-saving-and-loading-objects-using-pickle-python). ([code](general/object-serialization))
- [How to Manipulate IP Addresses in Python using ipaddress module](https://www.thepythoncode.com/article/manipulate-ip-addresses-using-ipaddress-module-in-python). ([code](general/ipaddress-module))
- [How to Send Emails in Python using smtplib Module](https://www.thepythoncode.com/article/sending-emails-in-python-smtplib). ([code](general/email-sender))
- [How to Handle Files in Python using OS Module](https://www.thepythoncode.com/article/file-handling-in-python-using-os-module). ([code](python-standard-library/handling-files))
- [How to Generate Random Data in Python](https://www.thepythoncode.com/article/generate-random-data-in-python). ([code](python-standard-library/generating-random-data))
- [How to Use Threads to Speed Up your IO Tasks in Python](https://www.thepythoncode.com/article/using-threads-in-python). ([code](python-standard-library/using-threads))
- [How to List all Files and Directories in FTP Server using Python](https://www.thepythoncode.com/article/list-files-and-directories-in-ftp-server-in-python). ([code](python-standard-library/listing-files-in-ftp-server))
- [How to Read Emails in Python](https://www.thepythoncode.com/article/reading-emails-in-python). ([code](python-standard-library/reading-email-messages))
- [How to Download and Upload Files in FTP Server using Python](https://www.thepythoncode.com/article/download-and-upload-files-in-ftp-server-using-python). ([code](python-standard-library/download-and-upload-files-in-ftp))
- [How to Work with JSON Files in Python](https://www.thepythoncode.com/article/working-with-json-files-in-python). ([code](python-standard-library/working-with-json))
- [How to Use Regular Expressions in Python](https://www.thepythoncode.com/article/work-with-regular-expressions-in-python). ([code](python-standard-library/regular-expressions))
- [Logging in Python](https://www.thepythoncode.com/article/logging-in-python). ([code](python-standard-library/logging))
- [How to Make a Chat Application in Python](https://www.thepythoncode.com/article/make-a-chat-room-application-in-python). ([code](python-standard-library/chat-application))
- [How to Delete Emails in Python](https://www.thepythoncode.com/article/deleting-emails-in-python). ([code](python-standard-library/deleting-emails))
- [Daemon Threads in Python](https://www.thepythoncode.com/article/daemon-threads-in-python). ([code](python-standard-library/daemon-thread))
- [How to Organize Files by Extension in Python](https://www.thepythoncode.com/article/organize-files-by-extension-with-python). ([code](python-standard-library/extension-separator))
- [How to Split a String In Python](https://www.thepythoncode.com/article/split-a-string-in-python). ([code](python-standard-library/split-string))
- [How to Print Variable Name and Value in Python](https://www.thepythoncode.com/article/print-variable-name-and-value-in-python). ([code](python-standard-library/print-variable-name-and-value))
- ### [Using APIs](https://www.thepythoncode.com/topic/using-apis-in-python)
- [How to Automate your VPS or Dedicated Server Management in Python](https://www.thepythoncode.com/article/automate-veesp-server-management-in-python). ([code](general/automating-server-management))
- [How to Download Torrent Files in Python](https://www.thepythoncode.com/article/download-torrent-files-in-python). ([code](general/torrent-downloader))
- [How to Use Google Custom Search Engine API in Python](https://www.thepythoncode.com/article/use-google-custom-search-engine-api-in-python). ([code](general/using-custom-search-engine-api))
- [How to Use Github API in Python](https://www.thepythoncode.com/article/using-github-api-in-python). ([code](general/github-api))
- [How to Use Google Drive API in Python](https://www.thepythoncode.com/article/using-google-drive--api-in-python). ([code](general/using-google-drive-api))
- [How to Translate Text in Python](https://www.thepythoncode.com/article/translate-text-in-python). ([code](general/using-google-translate-api))
- [How to Make a URL Shortener in Python](https://www.thepythoncode.com/article/make-url-shortener-in-python). ([code](general/url-shortener))
- [How to Get Google Page Ranking in Python](https://www.thepythoncode.com/article/get-google-page-ranking-by-keyword-in-python). ([code](general/getting-google-page-ranking))
- [How to Make a Telegram Bot in Python](https://www.thepythoncode.com/article/make-a-telegram-bot-in-python). ([code](general/telegram-bot))
- [How to Use Gmail API in Python](https://www.thepythoncode.com/article/use-gmail-api-in-python). ([code](general/gmail-api))
- [How to Use YouTube API in Python](https://www.thepythoncode.com/article/using-youtube-api-in-python). ([code](general/youtube-api))
- [Webhooks in Python with Flask](https://www.thepythoncode.com/article/webhooks-in-python-with-flask). ([code](https://github.com/bassemmarji/Flask_Webhook))
- [How to Make a Language Detector in Python](https://www.thepythoncode.com/article/language-detector-in-python). ([code](general/language-detector))
- ### [Database](https://www.thepythoncode.com/topic/using-databases-in-python)
- [How to Use MySQL Database in Python](https://www.thepythoncode.com/article/using-mysql-database-in-python). ([code](database/mysql-connector))
- [How to Connect to a Remote MySQL Database in Python](https://www.thepythoncode.com/article/connect-to-a-remote-mysql-server-in-python). ([code](database/connect-to-remote-mysql-server))
- [How to Use MongoDB Database in Python](https://www.thepythoncode.com/article/introduction-to-mongodb-in-python). ([code](database/mongodb-client))
- ### [Handling PDF Files](https://www.thepythoncode.com/topic/handling-pdf-files)
- [How to Extract All PDF Links in Python](https://www.thepythoncode.com/article/extract-pdf-links-with-python). ([code](web-scraping/pdf-url-extractor))
- [How to Extract PDF Tables in Python](https://www.thepythoncode.com/article/extract-pdf-tables-in-python-camelot). ([code](general/pdf-table-extractor))
- [How to Extract Images from PDF in Python](https://www.thepythoncode.com/article/extract-pdf-images-in-python). ([code](web-scraping/pdf-image-extractor))
- [How to Watermark PDF Files in Python](https://www.thepythoncode.com/article/watermark-in-pdf-using-python). ([code](general/add-watermark-pdf))
- [Highlighting Text in PDF with Python](https://www.thepythoncode.com/article/redact-and-highlight-text-in-pdf-with-python). ([code](handling-pdf-files/highlight-redact-text))
- [How to Extract Text from Images in PDF Files with Python](https://www.thepythoncode.com/article/extract-text-from-images-or-scanned-pdf-python). ([code](handling-pdf-files/pdf-ocr))
- [How to Convert PDF to Docx in Python](https://www.thepythoncode.com/article/convert-pdf-files-to-docx-in-python). ([code](handling-pdf-files/convert-pdf-to-docx))
- [How to Convert PDF to Images in Python](https://www.thepythoncode.com/article/convert-pdf-files-to-images-in-python). ([code](handling-pdf-files/convert-pdf-to-image))
- [How to Compress PDF Files in Python](https://www.thepythoncode.com/article/compress-pdf-files-in-python). ([code](handling-pdf-files/pdf-compressor))
- [How to Encrypt and Decrypt PDF Files in Python](https://www.thepythoncode.com/article/encrypt-pdf-files-in-python). ([code](handling-pdf-files/encrypt-pdf))
- [How to Merge PDF Files in Python](https://www.thepythoncode.com/article/merge-pdf-files-in-python). ([code](handling-pdf-files/pdf-merger))
- [How to Sign PDF Files in Python](https://www.thepythoncode.com/article/sign-pdf-files-in-python). ([code](handling-pdf-files/pdf-signer))
- [How to Extract PDF Metadata in Python](https://www.thepythoncode.com/article/extract-pdf-metadata-in-python). ([code](handling-pdf-files/extract-pdf-metadata))
- [How to Split PDF Files in Python](https://www.thepythoncode.com/article/split-pdf-files-in-python). ([code](handling-pdf-files/split-pdf))
- [How to Extract Text from PDF in Python](https://www.thepythoncode.com/article/extract-text-from-pdf-in-python). ([code](handling-pdf-files/extract-text-from-pdf))
- [How to Convert HTML to PDF in Python](https://www.thepythoncode.com/article/convert-html-to-pdf-in-python). ([code](handling-pdf-files/convert-html-to-pdf))
- ### [Python for Multimedia](https://www.thepythoncode.com/topic/python-for-multimedia)
- [How to Make a Screen Recorder in Python](https://www.thepythoncode.com/article/make-screen-recorder-python). ([code](general/screen-recorder))
- [How to Generate and Read QR Code in Python](https://www.thepythoncode.com/article/generate-read-qr-code-python). ([code](general/generating-reading-qrcode))
- [How to Play and Record Audio in Python](https://www.thepythoncode.com/article/play-and-record-audio-sound-in-python). ([code](general/recording-and-playing-audio))
- [How to Make a Barcode Reader in Python](https://www.thepythoncode.com/article/making-a-barcode-scanner-in-python). ([code](general/barcode-reader))
- [How to Extract Audio from Video in Python](https://www.thepythoncode.com/article/extract-audio-from-video-in-python). ([code](general/video-to-audio-converter))
- [How to Combine a Static Image with Audio in Python](https://www.thepythoncode.com/article/add-static-image-to-audio-in-python). ([code](python-for-multimedia/add-photo-to-audio))
- [How to Concatenate Video Files in Python](https://www.thepythoncode.com/article/concatenate-video-files-in-python). ([code](python-for-multimedia/combine-video))
- [How to Concatenate Audio Files in Python](https://www.thepythoncode.com/article/concatenate-audio-files-in-python). ([code](python-for-multimedia/combine-audio))
- [How to Extract Frames from Video in Python](https://www.thepythoncode.com/article/extract-frames-from-videos-in-python). ([code](python-for-multimedia/extract-frames-from-video))
- [How to Reverse Videos in Python](https://www.thepythoncode.com/article/reverse-video-in-python). ([code](python-for-multimedia/reverse-video))
- [How to Extract Video Metadata in Python](https://www.thepythoncode.com/article/extract-media-metadata-in-python). ([code](python-for-multimedia/extract-video-metadata))
- [How to Record a Specific Window in Python](https://www.thepythoncode.com/article/record-a-specific-window-in-python). ([code](python-for-multimedia/record-specific-window))
- [How to Add Audio to Video in Python](https://www.thepythoncode.com/article/add-audio-to-video-in-python). ([code](python-for-multimedia/add-audio-to-video))
- [How to Compress Images in Python](https://www.thepythoncode.com/article/compress-images-in-python). ([code](python-for-multimedia/compress-image))
- ### [Web Programming](https://www.thepythoncode.com/topic/web-programming)
- [Detecting Fraudulent Transactions in a Streaming Application using Kafka in Python](https://www.thepythoncode.com/article/detect-fraudulent-transactions-with-apache-kafka-in-python). ([code](general/detect-fraudulent-transactions))
- [Asynchronous Tasks with Celery in Python](https://www.thepythoncode.com/article/async-tasks-with-celery-redis-and-flask-in-python). ([code](https://github.com/bassemmarji/flask_sync_async))
- [How to Build a CRUD App with Flask and SQLAlchemy in Python](https://www.thepythoncode.com/article/building-crud-app-with-flask-and-sqlalchemy). ([code](web-programming/bookshop-crud-app-flask))
- [How to Build an English Dictionary App with Django in Python](https://www.thepythoncode.com/article/build-dictionary-app-with-django-and-pydictionary-api-python). ([code](web-programming/djangodictionary))
- [How to Build a CRUD Application using Django in Python](https://www.thepythoncode.com/article/build-bookstore-app-with-django-backend-python). ([code](web-programming/bookshop-crud-app-django))
- [How to Build a Weather App using Django in Python](https://www.thepythoncode.com/article/weather-app-django-openweather-api-using-python). ([code](web-programming/django-weather-app))
- [How to Build an Authentication System in Django](https://www.thepythoncode.com/article/authentication-system-in-django-python). ([code](web-programming/django-authentication))
- [How to Make a Blog using Django in Python](https://www.thepythoncode.com/article/create-a-blog-using-django-in-python). ([code](https://github.com/chepkiruidorothy/simple-blog-site))
- [How to Make a Todo App using Django in Python](https://www.thepythoncode.com/article/build-a-todo-app-with-django-in-python). ([code](https://github.com/chepkiruidorothy/todo-app-simple/tree/master))
- [How to Build an Email Address Verifier App using Django in Python](https://www.thepythoncode.com/article/build-an-email-verifier-app-using-django-in-python). ([code](web-programming/webbased-emailverifier))
- [How to Build a Web Assistant Using Django and OpenAI GPT-3.5 API in Python](https://www.thepythoncode.com/article/web-assistant-django-with-gpt3-api-python). ([code](web-programming/webassistant))
- ### [GUI Programming](https://www.thepythoncode.com/topic/gui-programming)
- [How to Make a Text Editor using Tkinter in Python](https://www.thepythoncode.com/article/text-editor-using-tkinter-python). ([code](gui-programming/text-editor))
- [How to Make a Button using PyGame in Python](https://www.thepythoncode.com/article/make-a-button-using-pygame-in-python). ([code](gui-programming/button-in-pygame))
- [How to Make a Drawing Program in Python](https://www.thepythoncode.com/article/make-a-drawing-program-with-python). ([code](gui-programming/drawing-tool-in-pygame))
- [How to Make a File Explorer using Tkinter in Python](https://www.thepythoncode.com/article/create-a-simple-file-explorer-using-tkinter-in-python). ([code](gui-programming/file-explorer))
- [How to Make a Calculator with Tkinter in Python](https://www.thepythoncode.com/article/make-a-calculator-app-using-tkinter-in-python). ([code](gui-programming/calculator-app))
- [How to Make a Typing Speed Tester with Tkinter in Python](https://www.thepythoncode.com/article/how-to-make-typing-speed-tester-in-python-using-tkinter). ([code](gui-programming/type-speed-tester))
- [How to Make a Planet Simulator with PyGame in Python](https://www.thepythoncode.com/article/make-a-planet-simulator-using-pygame-in-python). ([code](gui-programming/planet-simulator))
- [How to Make a Markdown Editor using Tkinter in Python](https://www.thepythoncode.com/article/markdown-editor-with-tkinter-in-python). ([code](gui-programming/markdown-editor))
- [How to Build a GUI Currency Converter using Tkinter in Python](https://www.thepythoncode.com/article/currency-converter-gui-using-tkinter-python). ([code](gui-programming/currency-converter-gui/))
- [How to Detect Gender by Name using Python](https://www.thepythoncode.com/article/gender-predictor-gui-app-tkinter-genderize-api-python). ([code](gui-programming/genderize-app))
- [How to Build a Spreadsheet App with Tkinter in Python](https://www.thepythoncode.com/article/spreadsheet-app-using-tkinter-in-python). ([code](gui-programming/spreadsheet-app))
- [How to Make a Rich Text Editor with Tkinter in Python](https://www.thepythoncode.com/article/create-rich-text-editor-with-tkinter-python). ([code](gui-programming/rich-text-editor))
- [How to Make a Python Code Editor using Tkinter in Python](https://www.thepythoncode.com/article/python-code-editor-using-tkinter-python). ([code](gui-programming/python-code-editor/))
- [How to Make an Age Calculator in Python](https://www.thepythoncode.com/article/age-calculator-using-tkinter-python). ([code](gui-programming/age-calculator))
- [How to Create an Alarm Clock App using Tkinter in Python](https://www.thepythoncode.com/article/build-an-alarm-clock-app-using-tkinter-python). ([code](gui-programming/alarm-clock-app))
- [How to Build a GUI Voice Recorder App in Python](https://www.thepythoncode.com/article/make-a-gui-voice-recorder-python). ([code](gui-programming/voice-recorder-app))
- [How to Make a Chess Game with Pygame in Python](https://www.thepythoncode.com/article/make-a-chess-game-using-pygame-in-python). ([code](gui-programming/chess-game))
- [How to Build a GUI QR Code Generator and Detector Using Python](https://www.thepythoncode.com/article/make-a-qr-code-generator-and-reader-tkinter-python). ([code](gui-programming/qrcode-generator-reader-gui))
- [How to Build a GUI Dictionary App with Tkinter in Python](https://www.thepythoncode.com/article/make-a-gui-audio-dictionary-python). ([code](gui-programming/word-dictionary-with-audio))
For any feedback, please consider pulling requests.
|
3,453 | Accelerated deep learning R&D | <div align="center">
[](https://github.com/catalyst-team/catalyst)
**Accelerated Deep Learning R&D**
[](https://www.codefactor.io/repository/github/catalyst-team/catalyst)
[](https://pypi.org/project/catalyst/)
[](https://catalyst-team.github.io/catalyst/index.html)
[](https://hub.docker.com/r/catalystteam/catalyst/tags)
[](https://pepy.tech/project/catalyst)
[](https://twitter.com/CatalystTeam)
[](https://t.me/catalyst_team)
[](https://join.slack.com/t/catalyst-team-devs/shared_invite/zt-d9miirnn-z86oKDzFMKlMG4fgFdZafw)
[](https://github.com/catalyst-team/catalyst/graphs/contributors)




[](https://github.com/catalyst-team/catalyst/workflows/catalyst/badge.svg?branch=master&event=push)
[](https://github.com/catalyst-team/catalyst/workflows/catalyst/badge.svg?branch=master&event=push)
[](https://github.com/catalyst-team/catalyst/workflows/catalyst/badge.svg?branch=master&event=push)
[](https://github.com/catalyst-team/catalyst/workflows/catalyst/badge.svg?branch=master&event=push)
[](https://github.com/catalyst-team/catalyst/workflows/catalyst/badge.svg?branch=master&event=push)
[](https://github.com/catalyst-team/catalyst/workflows/catalyst/badge.svg?branch=master&event=push)
</div>
Catalyst is a PyTorch framework for Deep Learning Research and Development.
It focuses on reproducibility, rapid experimentation, and codebase reuse
so you can create something new rather than write yet another train loop.
<br/> Break the cycle – use the Catalyst!
- [Project Manifest](https://github.com/catalyst-team/catalyst/blob/master/MANIFEST.md)
- [Framework architecture](https://miro.com/app/board/o9J_lxBO-2k=/)
- [Catalyst at AI Landscape](https://landscape.lfai.foundation/selected=catalyst)
- Part of the [PyTorch Ecosystem](https://pytorch.org/ecosystem/)
<details>
<summary>Catalyst at PyTorch Ecosystem Day 2021</summary>
<p>
[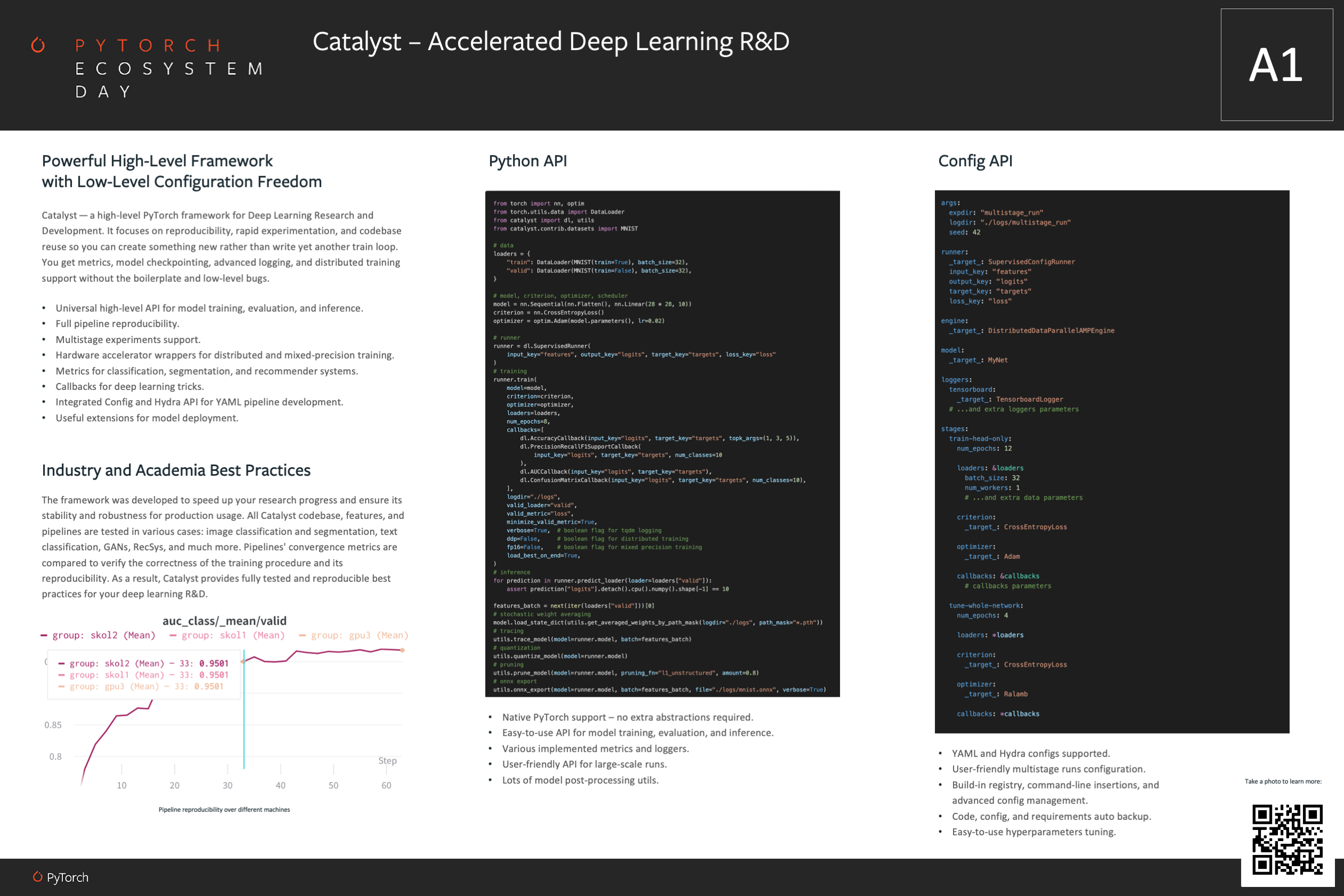](https://github.com/catalyst-team/catalyst)
</p>
</details>
<details>
<summary>Catalyst at PyTorch Developer Day 2021</summary>
<p>
[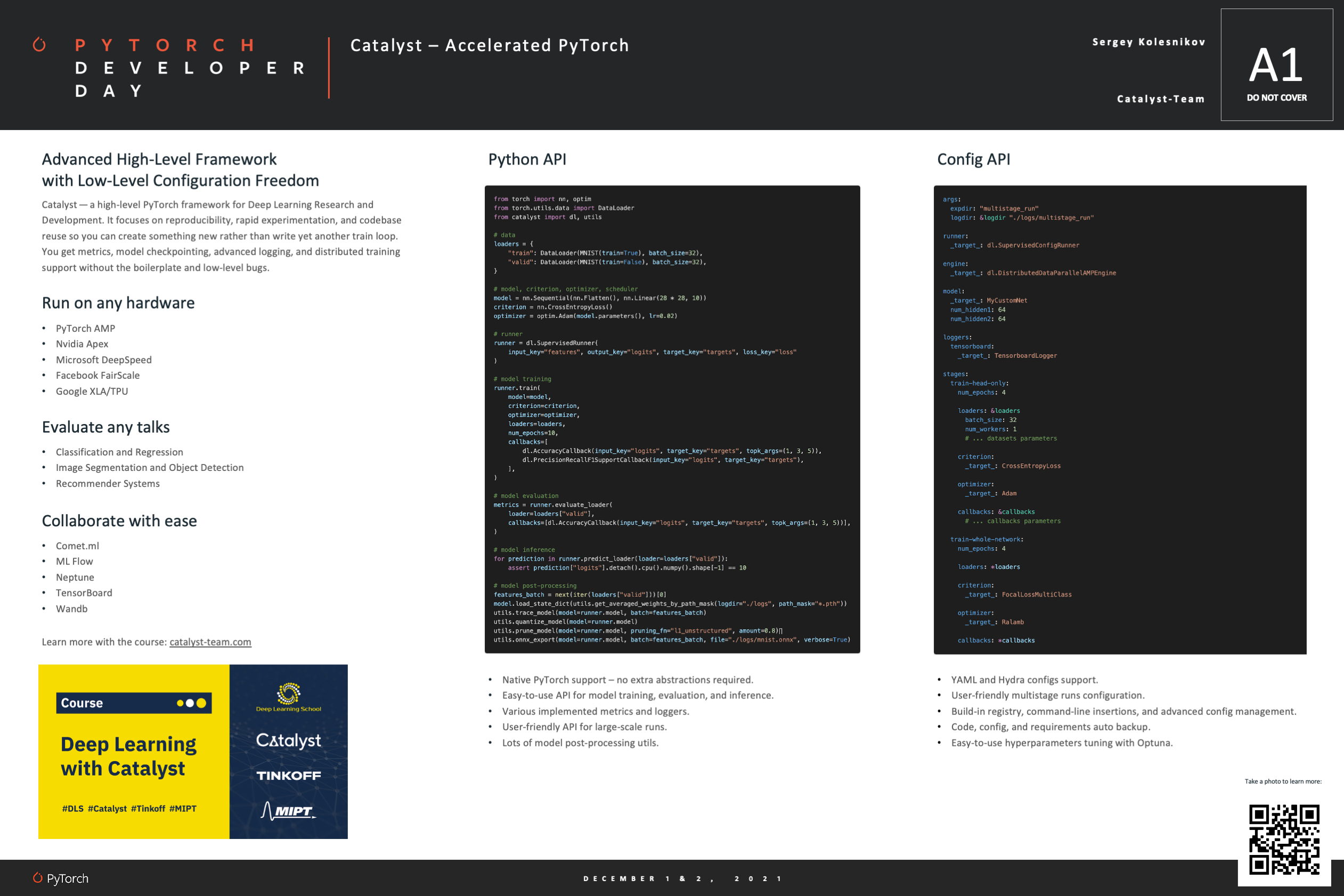](https://github.com/catalyst-team/catalyst)
</p>
</details>
----
## Getting started
```bash
pip install -U catalyst
```
```python
import os
from torch import nn, optim
from torch.utils.data import DataLoader
from catalyst import dl, utils
from catalyst.contrib.datasets import MNIST
model = nn.Sequential(nn.Flatten(), nn.Linear(28 * 28, 10))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.02)
loaders = {
"train": DataLoader(MNIST(os.getcwd(), train=True), batch_size=32),
"valid": DataLoader(MNIST(os.getcwd(), train=False), batch_size=32),
}
runner = dl.SupervisedRunner(
input_key="features", output_key="logits", target_key="targets", loss_key="loss"
)
# model training
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
loaders=loaders,
num_epochs=1,
callbacks=[
dl.AccuracyCallback(input_key="logits", target_key="targets", topk=(1, 3, 5)),
dl.PrecisionRecallF1SupportCallback(input_key="logits", target_key="targets"),
],
logdir="./logs",
valid_loader="valid",
valid_metric="loss",
minimize_valid_metric=True,
verbose=True,
)
# model evaluation
metrics = runner.evaluate_loader(
loader=loaders["valid"],
callbacks=[dl.AccuracyCallback(input_key="logits", target_key="targets", topk=(1, 3, 5))],
)
# model inference
for prediction in runner.predict_loader(loader=loaders["valid"]):
assert prediction["logits"].detach().cpu().numpy().shape[-1] == 10
# model post-processing
model = runner.model.cpu()
batch = next(iter(loaders["valid"]))[0]
utils.trace_model(model=model, batch=batch)
utils.quantize_model(model=model)
utils.prune_model(model=model, pruning_fn="l1_unstructured", amount=0.8)
utils.onnx_export(model=model, batch=batch, file="./logs/mnist.onnx", verbose=True)
```
### Step-by-step Guide
1. Start with [Catalyst — A PyTorch Framework for Accelerated Deep Learning R&D](https://medium.com/pytorch/catalyst-a-pytorch-framework-for-accelerated-deep-learning-r-d-ad9621e4ca88?source=friends_link&sk=885b4409aecab505db0a63b06f19dcef) introduction.
1. Try [notebook tutorials](#minimal-examples) or check [minimal examples](#minimal-examples) for first deep dive.
1. Read [blog posts](https://catalyst-team.com/post/) with use-cases and guides.
1. Learn machine learning with our ["Deep Learning with Catalyst" course](https://catalyst-team.com/#course).
1. And finally, [join our slack](https://join.slack.com/t/catalyst-team-core/shared_invite/zt-d9miirnn-z86oKDzFMKlMG4fgFdZafw) if you want to chat with the team and contributors.
## Table of Contents
- [Getting started](#getting-started)
- [Step-by-step Guide](#step-by-step-guide)
- [Table of Contents](#table-of-contents)
- [Overview](#overview)
- [Installation](#installation)
- [Documentation](#documentation)
- [Minimal Examples](#minimal-examples)
- [Tests](#tests)
- [Blog Posts](#blog-posts)
- [Talks](#talks)
- [Community](#community)
- [Contribution Guide](#contribution-guide)
- [User Feedback](#user-feedback)
- [Acknowledgments](#acknowledgments)
- [Trusted by](#trusted-by)
- [Citation](#citation)
## Overview
Catalyst helps you implement compact
but full-featured Deep Learning pipelines with just a few lines of code.
You get a training loop with metrics, early-stopping, model checkpointing,
and other features without the boilerplate.
### Installation
Generic installation:
```bash
pip install -U catalyst
```
<details>
<summary>Specialized versions, extra requirements might apply</summary>
<p>
```bash
pip install catalyst[ml] # installs ML-based Catalyst
pip install catalyst[cv] # installs CV-based Catalyst
# master version installation
pip install git+https://github.com/catalyst-team/catalyst@master --upgrade
# all available extensions are listed here:
# https://github.com/catalyst-team/catalyst/blob/master/setup.py
```
</p>
</details>
Catalyst is compatible with: Python 3.7+. PyTorch 1.4+. <br/>
Tested on Ubuntu 16.04/18.04/20.04, macOS 10.15, Windows 10, and Windows Subsystem for Linux.
### Documentation
- [master](https://catalyst-team.github.io/catalyst/)
- [22.02](https://catalyst-team.github.io/catalyst/v22.02/index.html)
- <details>
<summary>2021 edition</summary>
<p>
- [21.12](https://catalyst-team.github.io/catalyst/v21.12/index.html)
- [21.11](https://catalyst-team.github.io/catalyst/v21.11/index.html)
- [21.10](https://catalyst-team.github.io/catalyst/v21.10/index.html)
- [21.09](https://catalyst-team.github.io/catalyst/v21.09/index.html)
- [21.08](https://catalyst-team.github.io/catalyst/v21.08/index.html)
- [21.07](https://catalyst-team.github.io/catalyst/v21.07/index.html)
- [21.06](https://catalyst-team.github.io/catalyst/v21.06/index.html)
- [21.05](https://catalyst-team.github.io/catalyst/v21.05/index.html) ([Catalyst — A PyTorch Framework for Accelerated Deep Learning R&D](https://medium.com/pytorch/catalyst-a-pytorch-framework-for-accelerated-deep-learning-r-d-ad9621e4ca88?source=friends_link&sk=885b4409aecab505db0a63b06f19dcef))
- [21.04/21.04.1](https://catalyst-team.github.io/catalyst/v21.04/index.html), [21.04.2](https://catalyst-team.github.io/catalyst/v21.04.2/index.html)
- [21.03](https://catalyst-team.github.io/catalyst/v21.03/index.html), [21.03.1/21.03.2](https://catalyst-team.github.io/catalyst/v21.03.1/index.html)
</p>
</details>
- <details>
<summary>2020 edition</summary>
<p>
- [20.12](https://catalyst-team.github.io/catalyst/v20.12/index.html)
- [20.11](https://catalyst-team.github.io/catalyst/v20.11/index.html)
- [20.10](https://catalyst-team.github.io/catalyst/v20.10/index.html)
- [20.09](https://catalyst-team.github.io/catalyst/v20.09/index.html)
- [20.08.2](https://catalyst-team.github.io/catalyst/v20.08.2/index.html)
- [20.07](https://catalyst-team.github.io/catalyst/v20.07/index.html) ([dev blog: 20.07 release](https://medium.com/pytorch/catalyst-dev-blog-20-07-release-fb489cd23e14?source=friends_link&sk=7ab92169658fe9a9e1c44068f28cc36c))
- [20.06](https://catalyst-team.github.io/catalyst/v20.06/index.html)
- [20.05](https://catalyst-team.github.io/catalyst/v20.05/index.html), [20.05.1](https://catalyst-team.github.io/catalyst/v20.05.1/index.html)
- [20.04](https://catalyst-team.github.io/catalyst/v20.04/index.html), [20.04.1](https://catalyst-team.github.io/catalyst/v20.04.1/index.html), [20.04.2](https://catalyst-team.github.io/catalyst/v20.04.2/index.html)
</p>
</details>
### Minimal Examples
- [](https://colab.research.google.com/github/catalyst-team/catalyst/blob/master/examples/notebooks/customizing_what_happens_in_train.ipynb) Introduction tutorial "[Customizing what happens in `train`](./examples/notebooks/customizing_what_happens_in_train.ipynb)"
- [](https://colab.research.google.com/github/catalyst-team/catalyst/blob/master/examples/notebooks/customization_tutorial.ipynb) Demo with [customization examples](./examples/notebooks/customization_tutorial.ipynb)
- [](https://colab.research.google.com/github/catalyst-team/catalyst/blob/master/examples/notebooks/reinforcement_learning.ipynb) [Reinforcement Learning with Catalyst](./examples/notebooks/reinforcement_learning.ipynb)
- [And more](./examples/)
<details>
<summary>CustomRunner – PyTorch for-loop decomposition</summary>
<p>
```python
import os
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from catalyst import dl, metrics
from catalyst.contrib.datasets import MNIST
model = nn.Sequential(nn.Flatten(), nn.Linear(28 * 28, 10))
optimizer = optim.Adam(model.parameters(), lr=0.02)
train_data = MNIST(os.getcwd(), train=True)
valid_data = MNIST(os.getcwd(), train=False)
loaders = {
"train": DataLoader(train_data, batch_size=32),
"valid": DataLoader(valid_data, batch_size=32),
}
class CustomRunner(dl.Runner):
def predict_batch(self, batch):
# model inference step
return self.model(batch[0].to(self.engine.device))
def on_loader_start(self, runner):
super().on_loader_start(runner)
self.meters = {
key: metrics.AdditiveMetric(compute_on_call=False)
for key in ["loss", "accuracy01", "accuracy03"]
}
def handle_batch(self, batch):
# model train/valid step
# unpack the batch
x, y = batch
# run model forward pass
logits = self.model(x)
# compute the loss
loss = F.cross_entropy(logits, y)
# compute the metrics
accuracy01, accuracy03 = metrics.accuracy(logits, y, topk=(1, 3))
# log metrics
self.batch_metrics.update(
{"loss": loss, "accuracy01": accuracy01, "accuracy03": accuracy03}
)
for key in ["loss", "accuracy01", "accuracy03"]:
self.meters[key].update(self.batch_metrics[key].item(), self.batch_size)
# run model backward pass
if self.is_train_loader:
self.engine.backward(loss)
self.optimizer.step()
self.optimizer.zero_grad()
def on_loader_end(self, runner):
for key in ["loss", "accuracy01", "accuracy03"]:
self.loader_metrics[key] = self.meters[key].compute()[0]
super().on_loader_end(runner)
runner = CustomRunner()
# model training
runner.train(
model=model,
optimizer=optimizer,
loaders=loaders,
logdir="./logs",
num_epochs=5,
verbose=True,
valid_loader="valid",
valid_metric="loss",
minimize_valid_metric=True,
)
# model inference
for logits in runner.predict_loader(loader=loaders["valid"]):
assert logits.detach().cpu().numpy().shape[-1] == 10
```
</p>
</details>
<details>
<summary>ML - linear regression</summary>
<p>
```python
import torch
from torch.utils.data import DataLoader, TensorDataset
from catalyst import dl
# data
num_samples, num_features = int(1e4), int(1e1)
X, y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=32, num_workers=1)
loaders = {"train": loader, "valid": loader}
# model, criterion, optimizer, scheduler
model = torch.nn.Linear(num_features, 1)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [3, 6])
# model training
runner = dl.SupervisedRunner()
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
logdir="./logdir",
valid_loader="valid",
valid_metric="loss",
minimize_valid_metric=True,
num_epochs=8,
verbose=True,
)
```
</p>
</details>
<details>
<summary>ML - multiclass classification</summary>
<p>
```python
import torch
from torch.utils.data import DataLoader, TensorDataset
from catalyst import dl
# sample data
num_samples, num_features, num_classes = int(1e4), int(1e1), 4
X = torch.rand(num_samples, num_features)
y = (torch.rand(num_samples,) * num_classes).to(torch.int64)
# pytorch loaders
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=32, num_workers=1)
loaders = {"train": loader, "valid": loader}
# model, criterion, optimizer, scheduler
model = torch.nn.Linear(num_features, num_classes)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [2])
# model training
runner = dl.SupervisedRunner(
input_key="features", output_key="logits", target_key="targets", loss_key="loss"
)
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
logdir="./logdir",
num_epochs=3,
valid_loader="valid",
valid_metric="accuracy03",
minimize_valid_metric=False,
verbose=True,
callbacks=[
dl.AccuracyCallback(input_key="logits", target_key="targets", num_classes=num_classes),
# uncomment for extra metrics:
# dl.PrecisionRecallF1SupportCallback(
# input_key="logits", target_key="targets", num_classes=num_classes
# ),
# dl.AUCCallback(input_key="logits", target_key="targets"),
# catalyst[ml] required ``pip install catalyst[ml]``
# dl.ConfusionMatrixCallback(
# input_key="logits", target_key="targets", num_classes=num_classes
# ),
],
)
```
</p>
</details>
<details>
<summary>ML - multilabel classification</summary>
<p>
```python
import torch
from torch.utils.data import DataLoader, TensorDataset
from catalyst import dl
# sample data
num_samples, num_features, num_classes = int(1e4), int(1e1), 4
X = torch.rand(num_samples, num_features)
y = (torch.rand(num_samples, num_classes) > 0.5).to(torch.float32)
# pytorch loaders
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=32, num_workers=1)
loaders = {"train": loader, "valid": loader}
# model, criterion, optimizer, scheduler
model = torch.nn.Linear(num_features, num_classes)
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters())
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [2])
# model training
runner = dl.SupervisedRunner(
input_key="features", output_key="logits", target_key="targets", loss_key="loss"
)
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
logdir="./logdir",
num_epochs=3,
valid_loader="valid",
valid_metric="accuracy01",
minimize_valid_metric=False,
verbose=True,
callbacks=[
dl.BatchTransformCallback(
transform=torch.sigmoid,
scope="on_batch_end",
input_key="logits",
output_key="scores"
),
dl.AUCCallback(input_key="scores", target_key="targets"),
# uncomment for extra metrics:
# dl.MultilabelAccuracyCallback(input_key="scores", target_key="targets", threshold=0.5),
# dl.MultilabelPrecisionRecallF1SupportCallback(
# input_key="scores", target_key="targets", threshold=0.5
# ),
]
)
```
</p>
</details>
<details>
<summary>ML - multihead classification</summary>
<p>
```python
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, TensorDataset
from catalyst import dl
# sample data
num_samples, num_features, num_classes1, num_classes2 = int(1e4), int(1e1), 4, 10
X = torch.rand(num_samples, num_features)
y1 = (torch.rand(num_samples,) * num_classes1).to(torch.int64)
y2 = (torch.rand(num_samples,) * num_classes2).to(torch.int64)
# pytorch loaders
dataset = TensorDataset(X, y1, y2)
loader = DataLoader(dataset, batch_size=32, num_workers=1)
loaders = {"train": loader, "valid": loader}
class CustomModule(nn.Module):
def __init__(self, in_features: int, out_features1: int, out_features2: int):
super().__init__()
self.shared = nn.Linear(in_features, 128)
self.head1 = nn.Linear(128, out_features1)
self.head2 = nn.Linear(128, out_features2)
def forward(self, x):
x = self.shared(x)
y1 = self.head1(x)
y2 = self.head2(x)
return y1, y2
# model, criterion, optimizer, scheduler
model = CustomModule(num_features, num_classes1, num_classes2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, [2])
class CustomRunner(dl.Runner):
def handle_batch(self, batch):
x, y1, y2 = batch
y1_hat, y2_hat = self.model(x)
self.batch = {
"features": x,
"logits1": y1_hat,
"logits2": y2_hat,
"targets1": y1,
"targets2": y2,
}
# model training
runner = CustomRunner()
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
num_epochs=3,
verbose=True,
callbacks=[
dl.CriterionCallback(metric_key="loss1", input_key="logits1", target_key="targets1"),
dl.CriterionCallback(metric_key="loss2", input_key="logits2", target_key="targets2"),
dl.MetricAggregationCallback(metric_key="loss", metrics=["loss1", "loss2"], mode="mean"),
dl.BackwardCallback(metric_key="loss"),
dl.OptimizerCallback(metric_key="loss"),
dl.SchedulerCallback(),
dl.AccuracyCallback(
input_key="logits1", target_key="targets1", num_classes=num_classes1, prefix="one_"
),
dl.AccuracyCallback(
input_key="logits2", target_key="targets2", num_classes=num_classes2, prefix="two_"
),
# catalyst[ml] required ``pip install catalyst[ml]``
# dl.ConfusionMatrixCallback(
# input_key="logits1", target_key="targets1", num_classes=num_classes1, prefix="one_cm"
# ),
# dl.ConfusionMatrixCallback(
# input_key="logits2", target_key="targets2", num_classes=num_classes2, prefix="two_cm"
# ),
dl.CheckpointCallback(
logdir="./logs/one",
loader_key="valid", metric_key="one_accuracy01", minimize=False, topk=1
),
dl.CheckpointCallback(
logdir="./logs/two",
loader_key="valid", metric_key="two_accuracy03", minimize=False, topk=3
),
],
loggers={"console": dl.ConsoleLogger(), "tb": dl.TensorboardLogger("./logs/tb")},
)
```
</p>
</details>
<details>
<summary>ML – RecSys</summary>
<p>
```python
import torch
from torch.utils.data import DataLoader, TensorDataset
from catalyst import dl
# sample data
num_users, num_features, num_items = int(1e4), int(1e1), 10
X = torch.rand(num_users, num_features)
y = (torch.rand(num_users, num_items) > 0.5).to(torch.float32)
# pytorch loaders
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=32, num_workers=1)
loaders = {"train": loader, "valid": loader}
# model, criterion, optimizer, scheduler
model = torch.nn.Linear(num_features, num_items)
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters())
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [2])
# model training
runner = dl.SupervisedRunner(
input_key="features", output_key="logits", target_key="targets", loss_key="loss"
)
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
num_epochs=3,
verbose=True,
callbacks=[
dl.BatchTransformCallback(
transform=torch.sigmoid,
scope="on_batch_end",
input_key="logits",
output_key="scores"
),
dl.CriterionCallback(input_key="logits", target_key="targets", metric_key="loss"),
# uncomment for extra metrics:
# dl.AUCCallback(input_key="scores", target_key="targets"),
# dl.HitrateCallback(input_key="scores", target_key="targets", topk=(1, 3, 5)),
# dl.MRRCallback(input_key="scores", target_key="targets", topk=(1, 3, 5)),
# dl.MAPCallback(input_key="scores", target_key="targets", topk=(1, 3, 5)),
# dl.NDCGCallback(input_key="scores", target_key="targets", topk=(1, 3, 5)),
dl.BackwardCallback(metric_key="loss"),
dl.OptimizerCallback(metric_key="loss"),
dl.SchedulerCallback(),
dl.CheckpointCallback(
logdir="./logs", loader_key="valid", metric_key="loss", minimize=True
),
]
)
```
</p>
</details>
<details>
<summary>CV - MNIST classification</summary>
<p>
```python
import os
from torch import nn, optim
from torch.utils.data import DataLoader
from catalyst import dl
from catalyst.contrib.datasets import MNIST
model = nn.Sequential(nn.Flatten(), nn.Linear(28 * 28, 10))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.02)
train_data = MNIST(os.getcwd(), train=True)
valid_data = MNIST(os.getcwd(), train=False)
loaders = {
"train": DataLoader(train_data, batch_size=32),
"valid": DataLoader(valid_data, batch_size=32),
}
runner = dl.SupervisedRunner()
# model training
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
loaders=loaders,
num_epochs=1,
logdir="./logs",
valid_loader="valid",
valid_metric="loss",
minimize_valid_metric=True,
verbose=True,
# uncomment for extra metrics:
# callbacks=[
# dl.AccuracyCallback(input_key="logits", target_key="targets", num_classes=10),
# dl.PrecisionRecallF1SupportCallback(
# input_key="logits", target_key="targets", num_classes=10
# ),
# dl.AUCCallback(input_key="logits", target_key="targets"),
# # catalyst[ml] required ``pip install catalyst[ml]``
# dl.ConfusionMatrixCallback(
# input_key="logits", target_key="targets", num_classes=num_classes
# ),
# ]
)
```
</p>
</details>
<details>
<summary>CV - MNIST segmentation</summary>
<p>
```python
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from catalyst import dl
from catalyst.contrib.datasets import MNIST
from catalyst.contrib.losses import IoULoss
model = nn.Sequential(
nn.Conv2d(1, 1, 3, 1, 1), nn.ReLU(),
nn.Conv2d(1, 1, 3, 1, 1), nn.Sigmoid(),
)
criterion = IoULoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
train_data = MNIST(os.getcwd(), train=True)
valid_data = MNIST(os.getcwd(), train=False)
loaders = {
"train": DataLoader(train_data, batch_size=32),
"valid": DataLoader(valid_data, batch_size=32),
}
class CustomRunner(dl.SupervisedRunner):
def handle_batch(self, batch):
x = batch[self._input_key]
x_noise = (x + torch.rand_like(x)).clamp_(0, 1)
x_ = self.model(x_noise)
self.batch = {self._input_key: x, self._output_key: x_, self._target_key: x}
runner = CustomRunner(
input_key="features", output_key="scores", target_key="targets", loss_key="loss"
)
# model training
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
loaders=loaders,
num_epochs=1,
callbacks=[
dl.IOUCallback(input_key="scores", target_key="targets"),
dl.DiceCallback(input_key="scores", target_key="targets"),
dl.TrevskyCallback(input_key="scores", target_key="targets", alpha=0.2),
],
logdir="./logdir",
valid_loader="valid",
valid_metric="loss",
minimize_valid_metric=True,
verbose=True,
)
```
</p>
</details>
<details>
<summary>CV - MNIST metric learning</summary>
<p>
```python
import os
from torch.optim import Adam
from torch.utils.data import DataLoader
from catalyst import dl
from catalyst.contrib.data import HardTripletsSampler
from catalyst.contrib.datasets import MnistMLDataset, MnistQGDataset
from catalyst.contrib.losses import TripletMarginLossWithSampler
from catalyst.contrib.models import MnistSimpleNet
from catalyst.data.sampler import BatchBalanceClassSampler
# 1. train and valid loaders
train_dataset = MnistMLDataset(root=os.getcwd())
sampler = BatchBalanceClassSampler(
labels=train_dataset.get_labels(), num_classes=5, num_samples=10, num_batches=10
)
train_loader = DataLoader(dataset=train_dataset, batch_sampler=sampler)
valid_dataset = MnistQGDataset(root=os.getcwd(), gallery_fraq=0.2)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=1024)
# 2. model and optimizer
model = MnistSimpleNet(out_features=16)
optimizer = Adam(model.parameters(), lr=0.001)
# 3. criterion with triplets sampling
sampler_inbatch = HardTripletsSampler(norm_required=False)
criterion = TripletMarginLossWithSampler(margin=0.5, sampler_inbatch=sampler_inbatch)
# 4. training with catalyst Runner
class CustomRunner(dl.SupervisedRunner):
def handle_batch(self, batch) -> None:
if self.is_train_loader:
images, targets = batch["features"].float(), batch["targets"].long()
features = self.model(images)
self.batch = {"embeddings": features, "targets": targets,}
else:
images, targets, is_query = \
batch["features"].float(), batch["targets"].long(), batch["is_query"].bool()
features = self.model(images)
self.batch = {"embeddings": features, "targets": targets, "is_query": is_query}
callbacks = [
dl.ControlFlowCallbackWrapper(
dl.CriterionCallback(input_key="embeddings", target_key="targets", metric_key="loss"),
loaders="train",
),
dl.ControlFlowCallbackWrapper(
dl.CMCScoreCallback(
embeddings_key="embeddings",
labels_key="targets",
is_query_key="is_query",
topk=[1],
),
loaders="valid",
),
dl.PeriodicLoaderCallback(
valid_loader_key="valid", valid_metric_key="cmc01", minimize=False, valid=2
),
]
runner = CustomRunner(input_key="features", output_key="embeddings")
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
callbacks=callbacks,
loaders={"train": train_loader, "valid": valid_loader},
verbose=False,
logdir="./logs",
valid_loader="valid",
valid_metric="cmc01",
minimize_valid_metric=False,
num_epochs=10,
)
```
</p>
</details>
<details>
<summary>CV - MNIST GAN</summary>
<p>
```python
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from catalyst import dl
from catalyst.contrib.datasets import MNIST
from catalyst.contrib.layers import GlobalMaxPool2d, Lambda
latent_dim = 128
generator = nn.Sequential(
# We want to generate 128 coefficients to reshape into a 7x7x128 map
nn.Linear(128, 128 * 7 * 7),
nn.LeakyReLU(0.2, inplace=True),
Lambda(lambda x: x.view(x.size(0), 128, 7, 7)),
nn.ConvTranspose2d(128, 128, (4, 4), stride=(2, 2), padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(128, 128, (4, 4), stride=(2, 2), padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 1, (7, 7), padding=3),
nn.Sigmoid(),
)
discriminator = nn.Sequential(
nn.Conv2d(1, 64, (3, 3), stride=(2, 2), padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, (3, 3), stride=(2, 2), padding=1),
nn.LeakyReLU(0.2, inplace=True),
GlobalMaxPool2d(),
nn.Flatten(),
nn.Linear(128, 1),
)
model = nn.ModuleDict({"generator": generator, "discriminator": discriminator})
criterion = {"generator": nn.BCEWithLogitsLoss(), "discriminator": nn.BCEWithLogitsLoss()}
optimizer = {
"generator": torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.5, 0.999)),
"discriminator": torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.5, 0.999)),
}
train_data = MNIST(os.getcwd(), train=False)
loaders = {"train": DataLoader(train_data, batch_size=32)}
class CustomRunner(dl.Runner):
def predict_batch(self, batch):
batch_size = 1
# Sample random points in the latent space
random_latent_vectors = torch.randn(batch_size, latent_dim).to(self.engine.device)
# Decode them to fake images
generated_images = self.model["generator"](random_latent_vectors).detach()
return generated_images
def handle_batch(self, batch):
real_images, _ = batch
batch_size = real_images.shape[0]
# Sample random points in the latent space
random_latent_vectors = torch.randn(batch_size, latent_dim).to(self.engine.device)
# Decode them to fake images
generated_images = self.model["generator"](random_latent_vectors).detach()
# Combine them with real images
combined_images = torch.cat([generated_images, real_images])
# Assemble labels discriminating real from fake images
labels = \
torch.cat([torch.ones((batch_size, 1)), torch.zeros((batch_size, 1))]).to(self.engine.device)
# Add random noise to the labels - important trick!
labels += 0.05 * torch.rand(labels.shape).to(self.engine.device)
# Discriminator forward
combined_predictions = self.model["discriminator"](combined_images)
# Sample random points in the latent space
random_latent_vectors = torch.randn(batch_size, latent_dim).to(self.engine.device)
# Assemble labels that say "all real images"
misleading_labels = torch.zeros((batch_size, 1)).to(self.engine.device)
# Generator forward
generated_images = self.model["generator"](random_latent_vectors)
generated_predictions = self.model["discriminator"](generated_images)
self.batch = {
"combined_predictions": combined_predictions,
"labels": labels,
"generated_predictions": generated_predictions,
"misleading_labels": misleading_labels,
}
runner = CustomRunner()
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
loaders=loaders,
callbacks=[
dl.CriterionCallback(
input_key="combined_predictions",
target_key="labels",
metric_key="loss_discriminator",
criterion_key="discriminator",
),
dl.BackwardCallback(metric_key="loss_discriminator"),
dl.OptimizerCallback(
optimizer_key="discriminator",
metric_key="loss_discriminator",
),
dl.CriterionCallback(
input_key="generated_predictions",
target_key="misleading_labels",
metric_key="loss_generator",
criterion_key="generator",
),
dl.BackwardCallback(metric_key="loss_generator"),
dl.OptimizerCallback(
optimizer_key="generator",
metric_key="loss_generator",
),
],
valid_loader="train",
valid_metric="loss_generator",
minimize_valid_metric=True,
num_epochs=20,
verbose=True,
logdir="./logs_gan",
)
# visualization (matplotlib required):
# import matplotlib.pyplot as plt
# %matplotlib inline
# plt.imshow(runner.predict_batch(None)[0, 0].cpu().numpy())
```
</p>
</details>
<details>
<summary>CV - MNIST VAE</summary>
<p>
```python
import os
import torch
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from catalyst import dl, metrics
from catalyst.contrib.datasets import MNIST
LOG_SCALE_MAX = 2
LOG_SCALE_MIN = -10
def normal_sample(loc, log_scale):
scale = torch.exp(0.5 * log_scale)
return loc + scale * torch.randn_like(scale)
class VAE(nn.Module):
def __init__(self, in_features, hid_features):
super().__init__()
self.hid_features = hid_features
self.encoder = nn.Linear(in_features, hid_features * 2)
self.decoder = nn.Sequential(nn.Linear(hid_features, in_features), nn.Sigmoid())
def forward(self, x, deterministic=False):
z = self.encoder(x)
bs, z_dim = z.shape
loc, log_scale = z[:, : z_dim // 2], z[:, z_dim // 2 :]
log_scale = torch.clamp(log_scale, LOG_SCALE_MIN, LOG_SCALE_MAX)
z_ = loc if deterministic else normal_sample(loc, log_scale)
z_ = z_.view(bs, -1)
x_ = self.decoder(z_)
return x_, loc, log_scale
class CustomRunner(dl.IRunner):
def __init__(self, hid_features, logdir, engine):
super().__init__()
self.hid_features = hid_features
self._logdir = logdir
self._engine = engine
def get_engine(self):
return self._engine
def get_loggers(self):
return {
"console": dl.ConsoleLogger(),
"csv": dl.CSVLogger(logdir=self._logdir),
"tensorboard": dl.TensorboardLogger(logdir=self._logdir),
}
@property
def num_epochs(self) -> int:
return 1
def get_loaders(self):
loaders = {
"train": DataLoader(MNIST(os.getcwd(), train=False), batch_size=32),
"valid": DataLoader(MNIST(os.getcwd(), train=False), batch_size=32),
}
return loaders
def get_model(self):
model = self.model if self.model is not None else VAE(28 * 28, self.hid_features)
return model
def get_optimizer(self, model):
return optim.Adam(model.parameters(), lr=0.02)
def get_callbacks(self):
return {
"backward": dl.BackwardCallback(metric_key="loss"),
"optimizer": dl.OptimizerCallback(metric_key="loss"),
"checkpoint": dl.CheckpointCallback(
self._logdir,
loader_key="valid",
metric_key="loss",
minimize=True,
topk=3,
),
}
def on_loader_start(self, runner):
super().on_loader_start(runner)
self.meters = {
key: metrics.AdditiveMetric(compute_on_call=False)
for key in ["loss_ae", "loss_kld", "loss"]
}
def handle_batch(self, batch):
x, _ = batch
x = x.view(x.size(0), -1)
x_, loc, log_scale = self.model(x, deterministic=not self.is_train_loader)
loss_ae = F.mse_loss(x_, x)
loss_kld = (
-0.5 * torch.sum(1 + log_scale - loc.pow(2) - log_scale.exp(), dim=1)
).mean()
loss = loss_ae + loss_kld * 0.01
self.batch_metrics = {"loss_ae": loss_ae, "loss_kld": loss_kld, "loss": loss}
for key in ["loss_ae", "loss_kld", "loss"]:
self.meters[key].update(self.batch_metrics[key].item(), self.batch_size)
def on_loader_end(self, runner):
for key in ["loss_ae", "loss_kld", "loss"]:
self.loader_metrics[key] = self.meters[key].compute()[0]
super().on_loader_end(runner)
def predict_batch(self, batch):
random_latent_vectors = torch.randn(1, self.hid_features).to(self.engine.device)
generated_images = self.model.decoder(random_latent_vectors).detach()
return generated_images
runner = CustomRunner(128, "./logs", dl.CPUEngine())
runner.run()
# visualization (matplotlib required):
# import matplotlib.pyplot as plt
# %matplotlib inline
# plt.imshow(runner.predict_batch(None)[0].cpu().numpy().reshape(28, 28))
```
</p>
</details>
<details>
<summary>AutoML - hyperparameters optimization with Optuna</summary>
<p>
```python
import os
import optuna
import torch
from torch import nn
from torch.utils.data import DataLoader
from catalyst import dl
from catalyst.contrib.datasets import MNIST
def objective(trial):
lr = trial.suggest_loguniform("lr", 1e-3, 1e-1)
num_hidden = int(trial.suggest_loguniform("num_hidden", 32, 128))
train_data = MNIST(os.getcwd(), train=True)
valid_data = MNIST(os.getcwd(), train=False)
loaders = {
"train": DataLoader(train_data, batch_size=32),
"valid": DataLoader(valid_data, batch_size=32),
}
model = nn.Sequential(
nn.Flatten(), nn.Linear(784, num_hidden), nn.ReLU(), nn.Linear(num_hidden, 10)
)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
runner = dl.SupervisedRunner(input_key="features", output_key="logits", target_key="targets")
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
loaders=loaders,
callbacks={
"accuracy": dl.AccuracyCallback(
input_key="logits", target_key="targets", num_classes=10
),
# catalyst[optuna] required ``pip install catalyst[optuna]``
"optuna": dl.OptunaPruningCallback(
loader_key="valid", metric_key="accuracy01", minimize=False, trial=trial
),
},
num_epochs=3,
)
score = trial.best_score
return score
study = optuna.create_study(
direction="maximize",
pruner=optuna.pruners.MedianPruner(
n_startup_trials=1, n_warmup_steps=0, interval_steps=1
),
)
study.optimize(objective, n_trials=3, timeout=300)
print(study.best_value, study.best_params)
```
</p>
</details>
<details>
<summary>Config API - minimal example</summary>
<p>
```yaml title="example.yaml"
runner:
_target_: catalyst.runners.SupervisedRunner
model:
_var_: model
_target_: torch.nn.Sequential
args:
- _target_: torch.nn.Flatten
- _target_: torch.nn.Linear
in_features: 784 # 28 * 28
out_features: 10
input_key: features
output_key: &output_key logits
target_key: &target_key targets
loss_key: &loss_key loss
run:
# ≈ stage 1
- _call_: train # runner.train(...)
criterion:
_target_: torch.nn.CrossEntropyLoss
optimizer:
_target_: torch.optim.Adam
params: # model.parameters()
_var_: model.parameters
lr: 0.02
loaders:
train:
_target_: torch.utils.data.DataLoader
dataset:
_target_: catalyst.contrib.datasets.MNIST
root: data
train: y
batch_size: 32
&valid_loader_key valid:
&valid_loader
_target_: torch.utils.data.DataLoader
dataset:
_target_: catalyst.contrib.datasets.MNIST
root: data
train: n
batch_size: 32
callbacks:
- &accuracy_metric
_target_: catalyst.callbacks.AccuracyCallback
input_key: *output_key
target_key: *target_key
topk: [1,3,5]
- _target_: catalyst.callbacks.PrecisionRecallF1SupportCallback
input_key: *output_key
target_key: *target_key
num_epochs: 1
logdir: logs
valid_loader: *valid_loader_key
valid_metric: *loss_key
minimize_valid_metric: y
verbose: y
# ≈ stage 2
- _call_: evaluate_loader # runner.evaluate_loader(...)
loader: *valid_loader
callbacks:
- *accuracy_metric
```
```sh
catalyst-run --config example.yaml
```
</p>
</details>
### Tests
All Catalyst code, features, and pipelines [are fully tested](./tests).
We also have our own [catalyst-codestyle](https://github.com/catalyst-team/codestyle) and a corresponding pre-commit hook.
During testing, we train a variety of different models: image classification,
image segmentation, text classification, GANs, and much more.
We then compare their convergence metrics in order to verify
the correctness of the training procedure and its reproducibility.
As a result, Catalyst provides fully tested and reproducible
best practices for your deep learning research and development.
### [Blog Posts](https://catalyst-team.com/post/)
### [Talks](https://catalyst-team.com/talk/)
## Community
### Accelerated with Catalyst
<details>
<summary>Research Papers</summary>
<p>
- [Hierarchical Attention for Sentiment Classification with Visualization](https://github.com/neuromation/ml-recipe-hier-attention)
- [Pediatric Bone Age Assessment](https://github.com/neuromation/ml-recipe-bone-age)
- [Implementation of the paper "Tell Me Where to Look: Guided Attention Inference Network"](https://github.com/ngxbac/GAIN)
- [Implementation of the paper "Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks"](https://github.com/yukkyo/PyTorch-FilterResponseNormalizationLayer)
- [Implementation of the paper "Utterance-level Aggregation For Speaker Recognition In The Wild"](https://github.com/ptJexio/Speaker-Recognition)
- [Implementation of the paper "Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation"](https://github.com/vitrioil/Speech-Separation)
- [Implementation of the paper "ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks"](https://github.com/leverxgroup/esrgan)
</p>
</details>
<details>
<summary>Blog Posts</summary>
<p>
- [Solving the Cocktail Party Problem using PyTorch](https://medium.com/pytorch/addressing-the-cocktail-party-problem-using-pytorch-305fb74560ea)
- [Beyond fashion: Deep Learning with Catalyst (Config API)](https://evilmartians.com/chronicles/beyond-fashion-deep-learning-with-catalyst)
- [Tutorial from Notebook API to Config API (RU)](https://github.com/Bekovmi/Segmentation_tutorial)
</p>
</details>
<details>
<summary>Competitions</summary>
<p>
- [Kaggle Quick, Draw! Doodle Recognition Challenge](https://github.com/ngxbac/Kaggle-QuickDraw) - 11th place
- [Catalyst.RL - NeurIPS 2018: AI for Prosthetics Challenge](https://github.com/Scitator/neurips-18-prosthetics-challenge) – 3rd place
- [Kaggle Google Landmark 2019](https://github.com/ngxbac/Kaggle-Google-Landmark-2019) - 30th place
- [iMet Collection 2019 - FGVC6](https://github.com/ngxbac/Kaggle-iMet) - 24th place
- [ID R&D Anti-spoofing Challenge](https://github.com/bagxi/idrnd-anti-spoofing-challenge-solution) - 14th place
- [NeurIPS 2019: Recursion Cellular Image Classification](https://github.com/ngxbac/Kaggle-Recursion-Cellular) - 4th place
- [MICCAI 2019: Automatic Structure Segmentation for Radiotherapy Planning Challenge 2019](https://github.com/ngxbac/StructSeg2019)
* 3rd place solution for `Task 3: Organ-at-risk segmentation from chest CT scans`
* and 4th place solution for `Task 4: Gross Target Volume segmentation of lung cancer`
- [Kaggle Seversteal steel detection](https://github.com/bamps53/kaggle-severstal) - 5th place
- [RSNA Intracranial Hemorrhage Detection](https://github.com/ngxbac/Kaggle-RSNA) - 5th place
- [APTOS 2019 Blindness Detection](https://github.com/BloodAxe/Kaggle-2019-Blindness-Detection) – 7th place
- [Catalyst.RL - NeurIPS 2019: Learn to Move - Walk Around](https://github.com/Scitator/run-skeleton-run-in-3d) – 2nd place
- [xView2 Damage Assessment Challenge](https://github.com/BloodAxe/xView2-Solution) - 3rd place
</p>
</details>
<details>
<summary>Toolkits</summary>
<p>
- [Catalyst.RL](https://github.com/Scitator/catalyst-rl-framework) – A Distributed Framework for Reproducible RL Research by [Scitator](https://github.com/Scitator)
- [Catalyst.Classification](https://github.com/catalyst-team/classification) - Comprehensive classification pipeline with Pseudo-Labeling by [Bagxi](https://github.com/bagxi) and [Pdanilov](https://github.com/pdanilov)
- [Catalyst.Segmentation](https://github.com/catalyst-team/segmentation) - Segmentation pipelines - binary, semantic and instance, by [Bagxi](https://github.com/bagxi)
- [Catalyst.Detection](https://github.com/catalyst-team/detection) - Anchor-free detection pipeline by [Avi2011class](https://github.com/Avi2011class) and [TezRomacH](https://github.com/TezRomacH)
- [Catalyst.GAN](https://github.com/catalyst-team/gan) - Reproducible GANs pipelines by [Asmekal](https://github.com/asmekal)
- [Catalyst.Neuro](https://github.com/catalyst-team/neuro) - Brain image analysis project, in collaboration with [TReNDS Center](https://trendscenter.org)
- [MLComp](https://github.com/catalyst-team/mlcomp) – Distributed DAG framework for machine learning with UI by [Lightforever](https://github.com/lightforever)
- [Pytorch toolbelt](https://github.com/BloodAxe/pytorch-toolbelt) - PyTorch extensions for fast R&D prototyping and Kaggle farming by [BloodAxe](https://github.com/BloodAxe)
- [Helper functions](https://github.com/ternaus/iglovikov_helper_functions) - An assorted collection of helper functions by [Ternaus](https://github.com/ternaus)
- [BERT Distillation with Catalyst](https://github.com/elephantmipt/bert-distillation) by [elephantmipt](https://github.com/elephantmipt)
</p>
</details>
<details>
<summary>Other</summary>
<p>
- [CamVid Segmentation Example](https://github.com/BloodAxe/Catalyst-CamVid-Segmentation-Example) - Example of semantic segmentation for CamVid dataset
- [Notebook API tutorial for segmentation in Understanding Clouds from Satellite Images Competition](https://www.kaggle.com/artgor/segmentation-in-pytorch-using-convenient-tools/)
- [Catalyst.RL - NeurIPS 2019: Learn to Move - Walk Around](https://github.com/Scitator/learning-to-move-starter-kit) – starter kit
- [Catalyst.RL - NeurIPS 2019: Animal-AI Olympics](https://github.com/Scitator/animal-olympics-starter-kit) - starter kit
- [Inria Segmentation Example](https://github.com/BloodAxe/Catalyst-Inria-Segmentation-Example) - An example of training segmentation model for Inria Sattelite Segmentation Challenge
- [iglovikov_segmentation](https://github.com/ternaus/iglovikov_segmentation) - Semantic segmentation pipeline using Catalyst
- [Logging Catalyst Runs to Comet](https://colab.research.google.com/drive/1TaG27HcMh2jyRKBGsqRXLiGUfsHVyCq6?usp=sharing) - An example of how to log metrics, hyperparameters and more from Catalyst runs to [Comet](https://www.comet.ml/site/data-scientists/)
</p>
</details>
See other projects at [the GitHub dependency graph](https://github.com/catalyst-team/catalyst/network/dependents).
If your project implements a paper,
a notable use-case/tutorial, or a Kaggle competition solution, or
if your code simply presents interesting results and uses Catalyst,
we would be happy to add your project to the list above!
Do not hesitate to send us a PR with a brief description of the project similar to the above.
### Contribution Guide
We appreciate all contributions.
If you are planning to contribute back bug-fixes, there is no need to run that by us; just send a PR.
If you plan to contribute new features, new utility functions, or extensions,
please open an issue first and discuss it with us.
- Please see the [Contribution Guide](CONTRIBUTING.md) for more information.
- By participating in this project, you agree to abide by its [Code of Conduct](CODE_OF_CONDUCT.md).
### User Feedback
We've created `[email protected]` as an additional channel for user feedback.
- If you like the project and want to thank us, this is the right place.
- If you would like to start a collaboration between your team and Catalyst team to improve Deep Learning R&D, you are always welcome.
- If you don't like Github Issues and prefer email, feel free to email us.
- Finally, if you do not like something, please, share it with us, and we can see how to improve it.
We appreciate any type of feedback. Thank you!
### Acknowledgments
Since the beginning of the Сatalyst development, a lot of people have influenced it in a lot of different ways.
#### Catalyst.Team
- [Dmytro Doroshenko](https://www.linkedin.com/in/dmytro-doroshenko-05671112a/) ([ditwoo](https://github.com/Ditwoo))
- [Eugene Kachan](https://www.linkedin.com/in/yauheni-kachan/) ([bagxi](https://github.com/bagxi))
- [Nikita Balagansky](https://www.linkedin.com/in/nikita-balagansky-50414a19a/) ([elephantmipt](https://github.com/elephantmipt))
- [Sergey Kolesnikov](https://www.scitator.com/) ([scitator](https://github.com/Scitator))
#### Catalyst.Contributors
- [Aleksey Grinchuk](https://www.facebook.com/grinchuk.alexey) ([alexgrinch](https://github.com/AlexGrinch))
- [Aleksey Shabanov](https://linkedin.com/in/aleksey-shabanov-96b351189) ([AlekseySh](https://github.com/AlekseySh))
- [Alex Gaziev](https://www.linkedin.com/in/alexgaziev/) ([gazay](https://github.com/gazay))
- [Andrey Zharkov](https://www.linkedin.com/in/andrey-zharkov-8554a1153/) ([asmekal](https://github.com/asmekal))
- [Artem Zolkin](https://www.linkedin.com/in/artem-zolkin-b5155571/) ([arquestro](https://github.com/Arquestro))
- [David Kuryakin](https://www.linkedin.com/in/dkuryakin/) ([dkuryakin](https://github.com/dkuryakin))
- [Evgeny Semyonov](https://www.linkedin.com/in/ewan-semyonov/) ([lightforever](https://github.com/lightforever))
- [Eugene Khvedchenya](https://www.linkedin.com/in/cvtalks/) ([bloodaxe](https://github.com/BloodAxe))
- [Ivan Stepanenko](https://www.facebook.com/istepanenko)
- [Julia Shenshina](https://github.com/julia-shenshina) ([julia-shenshina](https://github.com/julia-shenshina))
- [Nguyen Xuan Bac](https://www.linkedin.com/in/bac-nguyen-xuan-70340b66/) ([ngxbac](https://github.com/ngxbac))
- [Roman Tezikov](http://linkedin.com/in/roman-tezikov/) ([TezRomacH](https://github.com/TezRomacH))
- [Valentin Khrulkov](https://www.linkedin.com/in/vkhrulkov/) ([khrulkovv](https://github.com/KhrulkovV))
- [Vladimir Iglovikov](https://www.linkedin.com/in/iglovikov/) ([ternaus](https://github.com/ternaus))
- [Vsevolod Poletaev](https://linkedin.com/in/vsevolod-poletaev-468071165) ([hexfaker](https://github.com/hexfaker))
- [Yury Kashnitsky](https://www.linkedin.com/in/kashnitskiy/) ([yorko](https://github.com/Yorko))
### Trusted by
- [Awecom](https://www.awecom.com)
- Researchers at the [Center for Translational Research in Neuroimaging and Data Science (TReNDS)](https://trendscenter.org)
- [Deep Learning School](https://en.dlschool.org)
- Researchers at [Emory University](https://www.emory.edu)
- [Evil Martians](https://evilmartians.com)
- Researchers at the [Georgia Institute of Technology](https://www.gatech.edu)
- Researchers at [Georgia State University](https://www.gsu.edu)
- [Helios](http://helios.to)
- [HPCD Lab](https://www.hpcdlab.com)
- [iFarm](https://ifarmproject.com)
- [Kinoplan](http://kinoplan.io/)
- Researchers at the [Moscow Institute of Physics and Technology](https://mipt.ru/english/)
- [Neuromation](https://neuromation.io)
- [Poteha Labs](https://potehalabs.com/en/)
- [Provectus](https://provectus.com)
- Researchers at the [Skolkovo Institute of Science and Technology](https://www.skoltech.ru/en)
- [SoftConstruct](https://www.softconstruct.io/)
- Researchers at [Tinkoff](https://www.tinkoff.ru/eng/)
- Researchers at [Yandex.Research](https://research.yandex.com)
### Citation
Please use this bibtex if you want to cite this repository in your publications:
@misc{catalyst,
author = {Kolesnikov, Sergey},
title = {Catalyst - Accelerated deep learning R&D},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/catalyst-team/catalyst}},
}
|
3,454 | The Natural Language Decathlon: A Multitask Challenge for NLP | 
--------------------------------------------------------------------------------
[](https://travis-ci.org/salesforce/decaNLP)
The Natural Language Decathlon is a multitask challenge that spans ten tasks:
question answering ([SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)), machine translation ([IWSLT](https://wit3.fbk.eu/mt.php?release=2016-01)), summarization ([CNN/DM](https://cs.nyu.edu/~kcho/DMQA/)), natural language inference ([MNLI](https://www.nyu.edu/projects/bowman/multinli/)), sentiment analysis ([SST](https://nlp.stanford.edu/sentiment/treebank.html)), semantic role labeling([QA‑SRL](https://dada.cs.washington.edu/qasrl/)), zero-shot relation extraction ([QA‑ZRE](http://nlp.cs.washington.edu/zeroshot/)), goal-oriented dialogue ([WOZ](https://github.com/nmrksic/neural-belief-tracker/tree/master/data/woz), semantic parsing ([WikiSQL](https://github.com/salesforce/WikiSQL)), and commonsense reasoning ([MWSC](https://s3.amazonaws.com/research.metamind.io/decaNLP/data/schema.txt)).
Each task is cast as question answering, which makes it possible to use our new Multitask Question Answering Network ([MQAN](https://github.com/salesforce/decaNLP/blob/d594b2bf127e13d0e61151b6a2af3bf63612f380/models/multitask_question_answering_network.py)).
This model jointly learns all tasks in decaNLP without any task-specific modules or parameters in the multitask setting. For a more thorough introduction to decaNLP and the tasks, see the main [website](http://decanlp.com/), our [blog post](https://einstein.ai/research/the-natural-language-decathlon), or the [paper](https://arxiv.org/abs/1806.08730).
While the research direction associated with this repository focused on multitask learning, the framework itself is designed in a way that should make single-task training, transfer learning, and zero-shot evaluation simple. Similarly, the [paper](https://arxiv.org/abs/1806.08730) focused on multitask learning as a form of question answering, but this framework can be easily adapted for different approaches to single-task or multitask learning.
## Leaderboard
| Model | decaNLP | [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) | [IWSLT](https://wit3.fbk.eu/mt.php?release=2016-01) | [CNN/DM](https://cs.nyu.edu/~kcho/DMQA/) | [MNLI](https://www.nyu.edu/projects/bowman/multinli/) | [SST](https://nlp.stanford.edu/sentiment/treebank.html) | [QA‑SRL](https://dada.cs.washington.edu/qasrl/) | [QA‑ZRE](http://nlp.cs.washington.edu/zeroshot/) | [WOZ](https://github.com/nmrksic/neural-belief-tracker/tree/master/data/woz) | [WikiSQL](https://github.com/salesforce/WikiSQL) | [MWSC](https://s3.amazonaws.com/research.metamind.io/decaNLP/data/schema.txt) |
| --- | --- | --- | --- | --- | --- | --- | ---- | ---- | --- | --- |--- |
| [MQAN](https://arxiv.org/abs/1806.08730)(Sampling+[CoVe](http://papers.nips.cc/paper/7209-learned-in-translation-contextualized-word-vectors)) | 609.0 | 77.0 | 21.4 | 24.4 | 74.0 | 86.5 | 80.9 | 40.9 | 84.8 | 70.2 | 48.8 |
| [MQAN](https://arxiv.org/abs/1806.08730)(QA‑first+[CoVe](http://papers.nips.cc/paper/7209-learned-in-translation-contextualized-word-vectors)) | 599.9 | 75.5 | 18.9 | 24.4 | 73.6 | 86.4 | 80.8 | 37.4 | 85.8 | 68.5 | 48.8 |
| [MQAN](https://arxiv.org/abs/1806.08730)(QA‑first) | 590.5 | 74.4 | 18.6 | 24.3 | 71.5 | 87.4 | 78.4 | 37.6 | 84.8 | 64.8 | 48.7 |
| [S2S](https://arxiv.org/abs/1806.08730) | 513.6 | 47.5 | 14.2 | 25.7 | 60.9 | 85.9 | 68.7 | 28.5 | 84.0 | 45.8 | 52.4 |
## Getting Started
### GPU vs. CPU
The `devices` argument can be used to specify the devices for training. For CPU training, specify `--devices -1`; for GPU training, specify `--devices DEVICEID`. Note that Multi-GPU training is currently a WIP, so `--device` is sufficient for commands below. The default will be to train on GPU 0 as training on CPU will be quite time-consuming to train on all ten tasks in decaNLP.
If you want to use CPU, then remove the `nvidia-` and the `cuda9_` prefixes from the default commands listed in sections below. This will allow you to use Docker without CUDA.
For example, if you have CUDA and all the necessary drivers and GPUs, you you can run a command inside the CUDA Docker image using:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "COMMAND --device 0"
```
If you want to run the same command without CUDA:
```bash
docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:torch041 bash -c "COMMAND --device -1"
```
For those in the Docker know, you can look at the Dockerfiles used to build these two images in `dockerfiles/`.
### PyTorch Version
The research associated with the original paper was done using Pytorch 0.3, but we have since migrated to 0.4. If you want to replicate results from the paper, then to be safe, you should use the code at a commit on or before 3c4f94b88768f4c3efc2fd4f015fed2f5453ebce. You should also replace `toch041` with `torch03` in the commands below to access a Docker image with the older version of PyTorch.
## Training
For example, to train a Multitask Question Answering Network (MQAN) on the Stanford Question Answering Dataset (SQuAD) on GPU 0:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --train_tasks squad --device 0"
```
To multitask with the fully joint, round-robin training described in the paper, you can add multiple tasks:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --train_tasks squad iwslt.en.de --train_iterations 1 --device 0"
```
To train on the entire Natural Language Decathlon:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --train_tasks squad iwslt.en.de cnn_dailymail multinli.in.out sst srl zre woz.en wikisql schema --train_iterations 1 --device 0"
```
To pretrain on `n_jump_start=1` tasks for `jump_start=75000` iterations before switching to round-robin sampling of all tasks in the Natural Language Decathlon:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --n_jump_start 1 --jump_start 75000 --train_tasks squad iwslt.en.de cnn_dailymail multinli.in.out sst srl zre woz.en wikisql schema --train_iterations 1 --device 0"
```
This jump starting (or pretraining) on a subset of tasks can be done for any set of tasks, not only the entirety of decaNLP.
### Tensorboard
If you would like to make use of tensorboard, you can add the `--tensorboard` flag to your training runs. This will log things in the format that Tensorboard expects.
To read those files and run the Tensorboard server, run (typically in a `tmux` pane or equivalent so that the process is not killed when you shut your laptop) the following command:
```bash
docker run -it --rm -p 0.0.0.0:6006:6006 -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "tensorboard --logdir /decaNLP/results"
```
If you are running the server on a remote machine, you can run the following on your local machine to forward to http://localhost:6006/:
```bash
ssh -4 -N -f -L 6006:127.0.0.1:6006 YOUR_REMOTE_IP
```
If you are having trouble with the specified port on either machine, run `lsof -if:6006` and kill the process if it is unnecessary. Otherwise, try changing the port numbers in the commands above. The first port number is the port the local machine tries to bind to, and and the second port is the one exposed by the remote machine (or docker container).
### Notes on Training
- On a single NVIDIA Volta GPU, the code should take about 3 days to complete 500k iterations. These should be sufficient to approximately reproduce the experiments in the paper. Training for about 7 days should be enough to fully replicate those scores, which should be only a few points higher than what is achieved by 500k iterations.
- The model can be resumed using stored checkpoints using `--load <PATH_TO_CHECKPOINT>` and `--resume`. By default, models are stored every `--save_every` iterations in the `results/` folder tree.
- During training, validation can be slow! Especially when computing ROUGE scores. Use the `--val_every` flag to change the frequency of validation.
- If you run out of GPU memory, reduce `--train_batch_tokens` and `--val_batch_size`.
- If you run out of CPU memory, make sure that you are running the most recent version of the code that interns strings; if you are still running out of CPU memory, post an issue with the command you ran and your peak memory usage.
- The first time you run, the code will download and cache all considered datasets. Please be advised that this might take a while, especially for some of the larger datasets.
### Notes on Cached Data
- In order to make data loading much quicker for repeated experiments, datasets are cached using code in `text/torchtext/datasets/generic.py`.
- If there is an update to this repository that touches any files in `text/`, then it might have changed the way a dataset is cached. If this is the case, then you'll need to delete all relevant cached files or you will not see the changes.
- Paths to cached files should be printed out when a dataset is loaded, either in training or in prediction. Search the text logged to stdout for `Loading cached data from` or `Caching data to` in order to locate the relevant path names for data caches.
## Evaluation
You can evaluate a model for a specific task with `EVALUATION_TYPE` as `validation` or `test`:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate EVALUATION_TYPE --path PATH_TO_CHECKPOINT_DIRECTORY --device 0 --tasks squad"
```
or evaluate on the entire decathlon by removing any task specification:
```bash
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate EVALUATION_TYPE --path PATH_TO_CHECKPOINT_DIRECTORY --device 0"
```
For test performance, please use the original [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/), and [WikiSQL](https://github.com/salesforce/WikiSQL) evaluation systems. For WikiSQL, there is a detailed walk-through of how to get test numbers in the section of this document concerning [pretrained models](https://github.com/salesforce/decaNLP#pretrained-models).
## Pretrained Models
This model is the best MQAN trained on decaNLP so far. It was trained first on SQuAD and then on all of decaNLP. It uses [CoVe](http://papers.nips.cc/paper/7209-learned-in-translation-contextualized-word-vectors.pdf) as well. You can obtain this model and run it on the validation sets with the following.
```bash
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/mqan_decanlp_better_sampling_cove_cpu.tgz
tar -xvzf mqan_decanlp_better_sampling_cove_cpu.tgz
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate validation --path /decaNLP/mqan_decanlp_better_sampling_cove_cpu/ --checkpoint_name iteration_560000.pth --device 0 --silent"
```
This model is the best MQAN trained on WikiSQL alone, which established [a new state-of-the-art performance by several points on that task](https://github.com/salesforce/WikiSQL): 73.2 / 75.4 / 81.4 (ordered test logical form accuracy, unordered test logical form accuracy, test execution accuracy).
```bash
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/mqan_wikisql_cpu.tar.gz
tar -xvzf mqan_wikisql_cpu.tar.gz
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ bmccann/decanlp:cuda9_torch041 -c "python /decaNLP/predict.py --evaluate validation --path /decaNLP/mqan_wikisql_cpu --checkpoint_name iteration_57000.pth --device 0 --tasks wikisql"
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate test --path /decaNLP/mqan_wikisql_cpu --checkpoint_name iteration_57000.pth --device 0 --tasks wikisql"
docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/convert_to_logical_forms.py /decaNLP/.data/ /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql.ids.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql_logical_forms.jsonl valid"
docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/convert_to_logical_forms.py /decaNLP/.data/ /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql.ids.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql_logical_forms.jsonl test"
git clone https://github.com/salesforce/WikiSQL.git #[email protected]:salesforce/WikiSQL.git for ssh
docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/WikiSQL/evaluate.py /decaNLP/.data/wikisql/data/dev.jsonl /decaNLP/.data/wikisql/data/dev.db /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql_logical_forms.jsonl" # assumes that you have data stored in .data
docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/WikiSQL/evaluate.py /decaNLP/.data/wikisql/data/test.jsonl /decaNLP/.data/wikisql/data/test.db /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql_logical_forms.jsonl" # assumes that you have data stored in .data
```
You can similarly follow the instructions above for downloading, decompressing, and loading in pretrained models for other indivual tasks (single-task models):
```bash
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/squad_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/cnn_dailymail_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/iwslt.en.de_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/sst_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/multinli.in.out_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/woz.en_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/srl_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/zre_mqan_cove_cpu.tgz
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/schema_mqan_cove_cpu.tgz
```
## Inference on a Custom Dataset
Using a pretrained model or a model you have trained yourself, you can run on new, custom datasets easily by following the instructions below. In this example, we use the checkpoint for the best MQAN trained on the entirety of decaNLP (see the section on Pretrained Models to see how to get this checkpoint) to run on `my_custom_dataset`.
```bash
mkdir -p .data/my_custom_dataset/
touch .data/my_custom_dataset/val.jsonl
echo '{"context": "The answer is answer.", "question": "What is the answer?", "answer": "answer"}' >> .data/my_custom_dataset/val.jsonl
# TODO add your own examples line by line to val.jsonl in the form of a JSON dictionary, as demonstrated above.
# Make sure to delete the first line if you don't want the demonstrated example.
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate valid --path /decaNLP/mqan_decanlp_qa_first_cpu --checkpoint_name iteration_1140000.pth --tasks my_custom_dataset"
```
You should get output that ends with something like this:
```
** /decaNLP/mqan_decanlp_qa_first_cpu/iteration_1140000/valid/my_custom_dataset.txt already exists -- this is where predictions are stored **
** /decaNLP/mqan_decanlp_qa_first_cpu/modeltion_1140000/valid/my_custom_dataset.gold.txt already exists -- this is where ground truth answers are stored **
** /decaNLP/mqan_decanlp_qa_first_cpu/modeltion_1140000/valid/my_custom_dataset.results.txt already exists -- this is where metrics are stored **
{"em":0.0,"nf1":100.0,"nem":100.0}
{'em': 0.0, 'nf1': 100.0, 'nem': 100.0}
Prediction: the answer
Answer: answer
```
From this output, you can see where predictions are stored along with ground truth outputs and metrics. If you want to rerun using this model checkpoint on this particular dataset, you'll need to pass the `--overwrite_predictions` argument to `predict.py`. If you do not want predictions and answers printed to stdout, then pass the `--silent` argument to `predict.py`.
The metrics dictionary should have printed something like `{'em': 0.0, 'nf1': 100.0, 'nem': 100.0}`. Here `em` stands for exact match. This is the percentage of predictions that had every token match the ground truth answer exactly. The normalized version, `nem`, lowercases and strips punctuation -- all of our models are trained on lowercased data, so `nem` is a more accurate representation of performance than `em` for our models. For tasks that are typically treated as classification problems, these exact match scores should correspond to accuracy. `nf1` is a normalized (lowercased; punctuation stripped) [F1 score](https://en.wikipedia.org/wiki/F1_score) over the predicted and ground truth sequences. If you would like to add additional metrics that are already implemented you can try adding `--bleu` (the typical metric for machine translation) and `--rouge` (the typical metric for summarization). Other metrics can be implemented following the patterns in `metrics.py`.
## Citation
If you use this in your work, please cite [*The Natural Language Decathlon: Multitask Learning as Question Answering*](https://arxiv.org/abs/1806.08730).
```
@article{McCann2018decaNLP,
title={The Natural Language Decathlon: Multitask Learning as Question Answering},
author={Bryan McCann and Nitish Shirish Keskar and Caiming Xiong and Richard Socher},
journal={arXiv preprint arXiv:1806.08730},
year={2018}
}
```
## Contact
Contact: [[email protected]](mailto:[email protected]) and [[email protected]](mailto:[email protected])
|
3,455 | 📖 A curated list of awesome resources dedicated to Relation Extraction, one of the most important tasks in Natural Language Processing (NLP). | # Awesome Relation Extraction [](https://awesome.re)

A curated list of awesome resources dedicated to Relation Extraction, inspired by [awesome-nlp](https://github.com/keon/awesome-nlp) and [awesome-deep-vision](https://github.com/kjw0612/awesome-deep-vision).
**Contributing**: Please feel free to make *[pull requests](https://github.com/roomylee/awesome-relation-extraction/pulls)*.
## Contents
* [Research Trends and Surveys](#research-trends-and-surveys)
* [Papers](#papers)
* [Supervised Approaches](#supervised-approaches)
* [Distant Supervision Approaches](#distant-supervision-approaches)
* [GNN-based Models](#gnn-based-models)
* [Language Models](#language-models)
* [Encoder Representation from Transformer](#encoder-representation-from-transformer)
* [Decoder Representation from Transformer](#decoder-representation-from-transformer)
* [Knowledge Graph Based Approaches](#knowledge-graph-based-approaches)
* [Few-Shot Learning Approaches](#few-shot-learning-approaches)
* [Datasets](#datasets)
* [Videos and Lectures](#videos-and-lectures)
* [Systems](#systems)
* [Frameworks](#frameworks)
## Research Trends and Surveys
* [NLP progress: Relationship Extraction](https://nlpprogress.com/english/relationship_extraction.html)
* [Named Entity Recognition and Relation Extraction:State-of-the-Art](https://www.researchgate.net/profile/Syed-Waqar-Jaffry/publication/345315661_Named_Entity_Recognition_and_Relation_Extraction_State_of_the_Art/links/603015aaa6fdcc37a83aafd5/Named-Entity-Recognition-and-Relation-Extraction-State-of-the-Art.pdf) (Nasar et al., 2021)
* [A Survey of Deep Learning Methods for Relation Extraction](https://arxiv.org/abs/1705.03645) (Kumar, 2017)
* [A Survey on Relation Extraction](https://www.cs.cmu.edu/~nbach/papers/A-survey-on-Relation-Extraction.pdf) (Bach and Badaskar, 2017)
* [Relation Extraction: A Survey](https://arxiv.org/abs/1712.05191) (Pawar et al., 2017)
* [A Review on Entity Relation Extraction](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8269916) (Zhang et al., 2017)
* [Review of Relation Extraction Methods: What is New Out There?](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.727.1005&rep=rep1&type=pdf) (Konstantinova et al., 2014)
* [100 Best Github: Relation Extraction](http://meta-guide.com/software-meta-guide/100-best-github-relation-extraction)
## Papers
### Supervised Approaches
#### CNN-based Models
* Convolution Neural Network for Relation Extraction [[paper]](https://link.springer.com/chapter/10.1007/978-3-642-53917-6_21) [[code]](https://github.com/roomylee/cnn-relation-extraction) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Convolution%20Neural%20Network%20for%20Relation%20Extraction/review.md)
* ChunYang Liu, WenBo Sun, WenHan Chao and WanXiang Che
* ADMA 2013
* Relation Classification via Convolutional Deep Neural Network [[paper]](http://www.aclweb.org/anthology/C14-1220) [[code]](https://github.com/roomylee/cnn-relation-extraction) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Relation_Classification_via_Convolutional_Deep_Neural_Network/review.md)
* Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou and Jun Zhao
* COLING 2014
* Relation Extraction: Perspective from Convolutional Neural Networks [[paper]](http://www.cs.nyu.edu/~thien/pubs/vector15.pdf) [[code]](https://github.com/roomylee/cnn-relation-extraction) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Relation_Extraction-Perspective_from_Convolutional_Neural_Networks/review.md)
* Thien Huu Nguyen and Ralph Grishman
* NAACL 2015
* Classifying Relations by Ranking with Convolutional Neural Networks [[paper]](https://arxiv.org/abs/1504.06580) [[code]](https://github.com/pratapbhanu/CRCNN)
* Cicero Nogueira dos Santos, Bing Xiang and Bowen Zhou
* ACL 2015
* Attention-Based Convolutional Neural Network for Semantic Relation Extraction [[paper]](http://www.aclweb.org/anthology/C16-1238) [[code]](https://github.com/nicolay-r/mlp-attention)
* Yatian Shen and Xuanjing Huang
* COLING 2016
* Relation Classification via Multi-Level Attention CNNs [[paper]](http://aclweb.org/anthology/P16-1123) [[code]](https://github.com/lawlietAi/relation-classification-via-attention-model)
* Linlin Wang, Zhu Cao, Gerard de Melo and Zhiyuan Liu
* ACL 2016
* MIT at SemEval-2017 Task 10: Relation Extraction with Convolutional Neural Networks [[paper]](https://aclanthology.info/pdf/S/S17/S17-2171.pdf)
* Ji Young Lee, Franck Dernoncourt and Peter Szolovits
* SemEval 2017
#### RNN-based Models
* Relation Classification via Recurrent Neural Network [[paper]](https://arxiv.org/abs/1508.01006)
* Dongxu Zhang and Dong Wang
* arXiv 2015
* Bidirectional Long Short-Term Memory Networks for Relation Classification [[paper]](http://www.aclweb.org/anthology/Y15-1009)
* Shu Zhang, Dequan Zheng, Xinchen Hu and Ming Yang
* PACLIC 2015
* End-to-End Relation Extraction using LSTMs on Sequences and Tree Structure [[paper]](https://arxiv.org/abs/1601.00770)
* Makoto Miwa and Mohit Bansal
* ACL 2016
* Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification [[paper]](http://anthology.aclweb.org/P16-2034) [[code]](https://github.com/SeoSangwoo/Attention-Based-BiLSTM-relation-extraction)
* Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao and Bo Xu
* ACL 2016
* Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention [[paper]](http://www.aclweb.org/anthology/C16-1119)
* Minguang Xiao and Cong Liu
* COLING 2016
* Semantic Relation Classification via Bidirectional LSTM Networks with Entity-aware Attention using Latent Entity Typing [[paper]](https://arxiv.org/abs/1901.08163) [[code]](https://github.com/roomylee/entity-aware-relation-classification)
* Joohong Lee, Sangwoo Seo and Yong Suk Choi
* arXiv 2019
#### Dependency-based Models
* Semantic Compositionality through Recursive Matrix-Vector Spaces [[paper]](http://aclweb.org/anthology/D12-1110) [[code]](https://github.com/pratapbhanu/MVRNN)
* Richard Socher, Brody Huval, Christopher D. Manning and Andrew Y. Ng
* EMNLP-CoNLL 2012
* Factor-based Compositional Embedding Models [[paper]](https://www.cs.cmu.edu/~mgormley/papers/yu+gormley+dredze.nipsw.2014.pdf)
* Mo Yu, Matthw R. Gormley and Mark Dredze
* NIPS Workshop on Learning Semantics 2014
* A Dependency-Based Neural Network for Relation Classification [[paper]](http://www.aclweb.org/anthology/P15-2047)
* Yang Liu, Furu Wei, Sujian Li, Heng Ji, Ming Zhou and Houfeng Wang
* ACL 2015
* Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Path [[paper]](https://arxiv.org/abs/1508.03720) [[code]](https://github.com/Sshanu/Relation-Classification)
* Xu Yan, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng and Zhi Jin
* EMNLP 2015
* Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling [[paper]](https://www.aclweb.org/anthology/D/D15/D15-1062.pdf)
* Kun Xu, Yansong Feng, Songfang Huang and Dongyan Zhao
* EMNLP 2015
* Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation [[paper]](https://arxiv.org/abs/1601.03651)
* Yan Xu, Ran Jia, Lili Mou, Ge Li, Yunchuan Chen, Yangyang Lu and Zhi Jin
* COLING 2016
* Bidirectional Recurrent Convolutional Neural Network for Relation Classification [[paper]](http://www.aclweb.org/anthology/P16-1072)
* Rui Cai, Xiaodong Zhang and Houfeng Wang
* ACL 2016
* Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning [[paper]](https://arxiv.org/abs/1808.06738)
* Tianyi Liu, Xinsong Zhang, Wanhao Zhou, Weijia Jia
* EMNLP 2018
#### GNN-based Models
* Matching the Blanks: Distributional Similarity for Relation Learning [[paper]](https://arxiv.org/abs/1906.03158)
* Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, Tom Kwiatkowski
* ACL 2019
* Relation of the Relations: A New Paradigm of the Relation Extraction Problem [[paper]](https://arxiv.org/abs/2006.03719)
* Zhijing Jin, Yongyi Yang, Xipeng Qiu, Zheng Zhang
* EMNLP 2020
* GDPNet: Refining Latent Multi-View Graph for Relation Extraction
[[paper]](https://arxiv.org/abs/2012.06780.pdf)
[[code]](https://github.com/XueFuzhao/GDPNet)
* Fuzhao Xue, Aixin Sun, Hao Zhang, Eng Siong Chng
* AAAI 21
* RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network
[[parer]](https://arxiv.org/abs/2009.08694.pdf)
[[code]](https://github.com/ansonb/RECON)
* Anson Bastos, Abhishek Nadgeri, Kuldeep Singh, Isaiah Onando Mulang', Saeedeh Shekarpour, Johannes Hoffart, Manohar Kaul
* WWW'21
### Distant Supervision Approaches
* Distant supervision for relation extraction without labeled data [[paper]](https://web.stanford.edu/~jurafsky/mintz.pdf) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Distant_supervision_for_relation_extraction_without_labeled_data/review.md)
* Mike Mintz, Steven Bills, Rion Snow and Dan Jurafsky
* ACL 2009
* Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations [[paper]](http://www.aclweb.org/anthology/P11-1055) [[code]](http://aiweb.cs.washington.edu/ai/raphaelh/mr/)
* Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer and Daniel S. Weld
* ACL 2011
* Multi-instance Multi-label Learning for Relation Extraction [[paper]](http://www.aclweb.org/anthology/D12-1042) [[code]](https://nlp.stanford.edu/software/mimlre.shtml)
* Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati and Christopher D. Manning
* EMNLP-CoNLL 2012
* Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks [[paper]](http://www.emnlp2015.org/proceedings/EMNLP/pdf/EMNLP203.pdf) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Distant_Supervision_for_Relation_Extraction_via_Piecewise_Convolutional_Neural_Networks/review.md) [[code]](https://github.com/nicolay-r/sentiment-pcnn)
* Daojian Zeng, Kang Liu, Yubo Chen and Jun Zhao
* EMNLP 2015
* Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks [[paper]](https://pdfs.semanticscholar.org/8731/369a707046f3f8dd463d1fd107de31d40a24.pdf) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Relation_Extraction_with_Multi-instance_Multi-label_Convolutional_Neural_Networks/review.md) [[code]](https://github.com/may-/cnn-re-tf)
* Xiaotian Jiang, Quan Wang, Peng Li, Bin Wang
* COLING 2016
* Incorporating Relation Paths in Neural Relation Extraction [[paper]](http://aclweb.org/anthology/D17-1186) [[review]](https://github.com/roomylee/paper-review/blob/master/relation_extraction/Incorporating_Relation_Paths_in_Neural_Relation_Extraction/review.md)
* Wenyuan Zeng, Yankai Lin, Zhiyuan Liu and Maosong Sun
* EMNLP 2017
* Neural Relation Extraction with Selective Attention over Instances [[paper]](http://www.aclweb.org/anthology/P16-1200) [[code]](https://github.com/thunlp/OpenNRE/)
* Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan and Maosong Sun
* ACL 2017
* Learning local and global contexts using a convolutional recurrent network model for relation classification in biomedical text [[paper]](http://www.aclweb.org/anthology/K17-1032) [[code]](https://github.com/desh2608/crnn-relation-classification) [[code]](https://github.com/kwonmha/Convolutional-Recurrent-Neural-Networks-for-Relation-Extraction)
* Desh Raj, Sunil Kumar Sahu and Ashish Anan
* CoNLL 2017
* Hierarchical Relation Extraction with Coarse-to-Fine Grained Attention[[paper]](https://aclweb.org/anthology/D18-1247)[[code]](https://github.com/thunlp/HNRE)
* Xu Han, Pengfei Yu∗, Zhiyuan Liu, Maosong Sun, Peng Li
* EMNLP 2018
* RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information [[paper]](http://malllabiisc.github.io/publications/papers/reside_emnlp18.pdf) [[code]](https://github.com/malllabiisc/RESIDE)
* Shikhar Vashishth, Rishabh Joshi, Sai Suman Prayaga, Chiranjib Bhattacharyya and Partha Talukdar
* EMNLP 2018
* Distant Supervision Relation Extraction with Intra-Bag and Inter-Bag Attentions
[[paper]](https://arxiv.org/abs/1904.00143.pdf)
[[code]](https://github.com/ZhixiuYe/Intra-Bag-and-Inter-Bag-Attentions)
* Zhi-Xiu Ye, Zhen-Hua Ling
* NAACL 2019
### Language Models
#### Encoder Representation from Transformer
* Enriching Pre-trained Language Model with Entity Information for Relation Classification [[paper]](https://arxiv.org/abs/1905.08284.pdf)
* Shanchan Wu, Yifan He
* arXiv 2019
* LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
[[paper]](https://www.aclweb.org/anthology/2020.emnlp-main.523/)
[[code]](https://github.com/studio-ousia/luke)
* Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto
* EMNLP 2020
* SpanBERT: Improving pre-training by representing and predicting spans [[paper]](https://arxiv.org/abs/1907.10529.pdf) [[code]](https://github.com/facebookresearch/SpanBERT)
* Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer and Omer Levy
* TACL 2020 (Transactions of the Association for Computational Linguistics)
* Efficient long-distance relation extraction with DG-SpanBERT
[[paper]](https://arxiv.org/abs/2004.03636)
* Jun Chen, Robert Hoehndorf, Mohamed Elhoseiny, Xiangliang Zhang
#### Decoder Representation from Transformer
* Improving Relation Extraction by Pretrained Language Representations
[[paper]](https://arxiv.org/abs/1906.03088)
[[review]](https://openreview.net/forum?id=BJgrxbqp67)
[[code]](https://github.com/DFKI-NLP/TRE)
* Christoph Alt, Marc Hübner, Leonhard Hennig
* AKBC 19
### Knowledge Graph Based Approaches
* KGPool: Dynamic Knowledge Graph Context Selection for Relation Extraction
[[paper]](https://arxiv.org/pdf/2106.00459.pdf)
[[code]](https://github.com/nadgeri14/KGPool)
* Abhishek Nadgeri, Anson Bastos, Kuldeep Singh, Isaiah Onando Mulang, Johannes Hoffart, Saeedeh Shekarpour, and Vijay Saraswat
* ACL 2021 (findings)
### Few-Shot Learning Approaches
* FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation [[paper]](https://arxiv.org/abs/1810.10147) [[website]](http://zhuhao.me/fewrel) [[code]](https://github.com/ProKil/FewRel)
* Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, Maosong Sun
* EMNLP 2018
### Miscellaneous
* Jointly Extracting Relations with Class Ties via Effective Deep Ranking [[paper]](http://aclweb.org/anthology/P17-1166)
* Hai Ye, Wenhan Chao, Zhunchen Luo and Zhoujun Li
* ACL 2017
* End-to-End Neural Relation Extraction with Global Optimization [[paper]](http://aclweb.org/anthology/D17-1182)
* Meishan Zhang, Yue Zhang and Guohong Fu
* EMNLP 2017
* Adversarial Training for Relation Extraction [[paper]](https://people.eecs.berkeley.edu/~russell/papers/emnlp17-relation.pdf)
* Yi Wu, David Bamman and Stuart Russell
* EMNLP 2017
* A neural joint model for entity and relation extraction from biomedical text[[paper]](https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-017-1609-9)
* Fei Li, Meishan Zhang, Guohong Fu and Donghong Ji
* BMC bioinformatics 2017
* Joint Extraction of Entities and Relations Using Reinforcement Learning and Deep Learning [[paper]](https://www.hindawi.com/journals/cin/2017/7643065/)
* Yuntian Feng, Hongjun Zhang, Wenning Hao, and Gang Chen
* Journal of Computational Intelligence and Neuroscience 2017
* TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations [[paper]](https://aclanthology.org/2021.emnlp-main.635/) [[code]](https://github.com/4ai/tdeer)
* Xianming Li, Xiaotian Luo, Chenghao Dong, Daichuan Yang, Beidi Luan and Zhen He
* EMNLP 2021
[Back to Top](#contents)
## Datasets
* SemEval-2010 Task 8 [[paper]](http://www.aclweb.org/anthology/S10-1006) [[download]](https://docs.google.com/leaf?id=0B_jQiLugGTAkMDQ5ZjZiMTUtMzQ1Yy00YWNmLWJlZDYtOWY1ZDMwY2U4YjFk&sort=name&layout=list&num=50)
* Multi-Way Classification of Semantic Relations Between Pairs of Nominals
* New York Times (NYT) Corpus [[paper]](http://www.riedelcastro.org//publications/papers/riedel10modeling.pdf) [[download]](https://catalog.ldc.upenn.edu/LDC2008T19)
* This dataset was generated by aligning *Freebase* relations with the NYT corpus, with sentences from the years 2005-2006 used as the training corpus and sentences from 2007 used as the testing corpus.
* FewRel: Few-Shot Relation Classification Dataset [[paper]](https://arxiv.org/abs/1810.10147) [[Website]](http://zhuhao.me/fewrel)
* This dataset is a supervised few-shot relation classification dataset. The corpus is Wikipedia and the knowledge base used to annotate the corpus is Wikidata.
* TACRED: The TAC Relation Extraction Dataset
[[paper]](https://www.aclweb.org/anthology/D17-1004.pdf)
[[Website]](https://nlp.stanford.edu/projects/tacred/)
[[download]](https://catalog.ldc.upenn.edu/LDC2018T24)
* Is a large-scale relation extraction dataset with built over newswire and web text from the corpus used in the yearly TAC Knowledge Base Population (TAC KBP) challenges.
* ACE05:
[[Website]](https://catalog.ldc.upenn.edu/LDC2006T06)
[[download-info]](https://www.ldc.upenn.edu/language-resources/data/obtaining)
* This dataset represent texts extracted from a variety of sources: broadcast conversation, broadcast news, newsgroups, weblogs. The
6 relation types between 7 types on entities: acility (FAC), Geo-PoliticalEntity (GPE), Location (LOC), Organization (ORG),
Person (PER), Vehicle (VEH), Weapon (WEA).
* SemEval-2018 Task 7
[[paper]](https://www.aclweb.org/anthology/S18-1111.pdf)
[[Website]](https://competitions.codalab.org/competitions/17422)
[[download]](https://lipn.univ-paris13.fr/~gabor/semeval2018task7/)
* The corpus is collected from abstracts and introductions of scientific papers, and
there are six types of semantic relations in total.
There are three subtasks of it: Subtask
1.1 and Subtask 1.2 are relation classification on
clean and noisy data, respectively; Subtask 2 is
the standard relation extraction.
For state of the art results check out [nlpprogress.com on relation extraction](https://nlpprogress.com/english/relationship_extraction.html)
[Back to Top](#contents)
## Videos and Lectures
* [Stanford University: CS124](https://web.stanford.edu/class/cs124/), Dan Jurafsky
* (Video) [Week 5: Relation Extraction and Question](https://www.youtube.com/watch?v=5SUzf6252_0&list=PLaZQkZp6WhWyszpcteV4LFgJ8lQJ5WIxK&ab_channel=FromLanguagestoInformation)
* [Washington University: CSE517](https://courses.cs.washington.edu/courses/cse517/), Luke Zettlemoyer
* (Slide) [Relation Extraction 1](https://courses.cs.washington.edu/courses/cse517/13wi/slides/cse517wi13-RelationExtraction.pdf)
* (Slide) [Relation Extraction 2](https://courses.cs.washington.edu/courses/cse517/13wi/slides/cse517wi13-RelationExtractionII.pdf)
* [New York University: CSCI-GA.2590](https://cs.nyu.edu/courses/spring17/CSCI-GA.2590-001/), Ralph Grishman
* (Slide) [Relation Extraction: Rule-based Approaches](https://cs.nyu.edu/courses/spring17/CSCI-GA.2590-001/DependencyPaths.pdf)
* [Michigan University: Coursera](https://ai.umich.edu/portfolio/natural-language-processing/), Dragomir R. Radev
* (Video) [Lecture 48: Relation Extraction](https://www.youtube.com/watch?v=TbrlRei_0h8&ab_channel=ArtificialIntelligence-AllinOne)
* [Virginia University: CS6501-NLP](http://web.cs.ucla.edu/~kwchang/teaching/NLP16/), Kai-Wei Chang
* (Slide) [Lecture 24: Relation Extraction](http://web.cs.ucla.edu/~kwchang/teaching/NLP16/slides/24-relation.pdf)
[Back to Top](#contents)
## Systems
* [DeepDive](http://deepdive.stanford.edu/)
* [Stanford Relation Extractor](https://nlp.stanford.edu/software/relationExtractor.html)
[Back to Top](#contents)
## Frameworks
* **OpenNRE** [[github]](https://github.com/thunlp/OpenNRE) [[paper]](https://aclanthology.org/D19-3029.pdf)
* Is an open-source and extensible toolkit that provides a unified framework to implement neural models for relation extraction (RE) between named entities.
It is designed for various scenarios for RE, including sentence-level RE, bag-level RE, document-level RE, and few-shot RE.
It provides various functional RE modules based on both TensorFlow and PyTorch to maintain sufficient modularity and extensibility, making it becomes easy to incorporate new models into the framework.
* **AREkit** [[github]](https://github.com/nicolay-r/AREkit) [[research-applicable-paper]](https://arxiv.org/pdf/2006.13730.pdf)
* Is an open-source and extensible toolkit focused on data preparation for document-level relation extraction organization.
It complements the OpenNRE functionality, as in terms of the latter, *document-level RE setting is not widely explored* (2.4 [[paper]](https://aclanthology.org/D19-3029.pdf)).
The core functionality includes
(1) API for document presentation with EL (Entity Linking, i.e. Object Synonymy) support
for sentence level relations preparation (dubbed as contexts)
(2) API for contexts extraction
(3) relations transferring from sentence-level onto document-level, etc.
It provides
[neural networks](https://github.com/nicolay-r/AREkit/tree/0.21.0-rc/contrib/networks) (like OpenNRE)
and
[BERT](https://github.com/nicolay-r/AREkit/tree/0.21.0-rc/contrib/bert) modules,
both applicable for sentiment attitude extraction task.
* **DeRE** [[github]](https://github.com/ims-tcl/DeRE) [[paper]](https://aclanthology.org/D18-2008/)
* Is an open-source framework for **de**claritive **r**elation **e**xtraction, and therefore allows to declare your own task (using XML schemas) and apply manually implemented models towards it (using a provided API).
The task declaration builds on top of the *spans* and *relations between spans*. In terms of the latter, authors propose *frames*, where every frame yelds of: (1) *trigger* (span) and (2) *n*-slots, where every slot
may refer to *frame* or *span*.
The framework poses no theoretical restrictions to the window from which frames are extracted.
Thus, this concept may cover sentence-level, document-level and multi-document RE tasks.
[Back to Top](#contents)
## License
[](https://creativecommons.org/publicdomain/zero/1.0/)
To the extent possible under law, [Joohong Lee](https://roomylee.github.io/) has waived all copyright and related or neighboring rights to this work.
|
3,456 | TensorFlow code and pre-trained models for BERT | # BERT
**\*\*\*\*\* New March 11th, 2020: Smaller BERT Models \*\*\*\*\***
This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download all 24 from [here][all], or individually from the table below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-2_H-128_A-2.zip
[2_256]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-2_H-256_A-4.zip
[2_512]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-2_H-512_A-8.zip
[2_768]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-2_H-768_A-12.zip
[4_128]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-4_H-128_A-2.zip
[4_256]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-4_H-256_A-4.zip
[4_512]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-4_H-512_A-8.zip
[4_768]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-4_H-768_A-12.zip
[6_128]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-6_H-128_A-2.zip
[6_256]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-6_H-256_A-4.zip
[6_512]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-6_H-512_A-8.zip
[6_768]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-6_H-768_A-12.zip
[8_128]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-8_H-128_A-2.zip
[8_256]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-8_H-256_A-4.zip
[8_512]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-8_H-512_A-8.zip
[8_768]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-8_H-768_A-12.zip
[10_128]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-10_H-128_A-2.zip
[10_256]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-10_H-256_A-4.zip
[10_512]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-10_H-512_A-8.zip
[10_768]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-10_H-768_A-12.zip
[12_128]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-128_A-2.zip
[12_256]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-256_A-4.zip
[12_512]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-512_A-8.zip
[12_768]: https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-768_A-12.zip
[all]: https://storage.googleapis.com/bert_models/2020_02_20/all_bert_models.zip
**\*\*\*\*\* New May 31st, 2019: Whole Word Masking Models \*\*\*\*\***
This is a release of several new models which were the result of an improvement
the pre-processing code.
In the original pre-processing code, we randomly select WordPiece tokens to
mask. For example:
`Input Text: the man jumped up , put his basket on phil ##am ##mon ' s head`
`Original Masked Input: [MASK] man [MASK] up , put his [MASK] on phil
[MASK] ##mon ' s head`
The new technique is called Whole Word Masking. In this case, we always mask
*all* of the the tokens corresponding to a word at once. The overall masking
rate remains the same.
`Whole Word Masked Input: the man [MASK] up , put his basket on [MASK] [MASK]
[MASK] ' s head`
The training is identical -- we still predict each masked WordPiece token
independently. The improvement comes from the fact that the original prediction
task was too 'easy' for words that had been split into multiple WordPieces.
This can be enabled during data generation by passing the flag
`--do_whole_word_mask=True` to `create_pretraining_data.py`.
Pre-trained models with Whole Word Masking are linked below. The data and
training were otherwise identical, and the models have identical structure and
vocab to the original models. We only include BERT-Large models. When using
these models, please make it clear in the paper that you are using the Whole
Word Masking variant of BERT-Large.
* **[`BERT-Large, Uncased (Whole Word Masking)`](https://storage.googleapis.com/bert_models/2019_05_30/wwm_uncased_L-24_H-1024_A-16.zip)**:
24-layer, 1024-hidden, 16-heads, 340M parameters
* **[`BERT-Large, Cased (Whole Word Masking)`](https://storage.googleapis.com/bert_models/2019_05_30/wwm_cased_L-24_H-1024_A-16.zip)**:
24-layer, 1024-hidden, 16-heads, 340M parameters
Model | SQUAD 1.1 F1/EM | Multi NLI Accuracy
---------------------------------------- | :-------------: | :----------------:
BERT-Large, Uncased (Original) | 91.0/84.3 | 86.05
BERT-Large, Uncased (Whole Word Masking) | 92.8/86.7 | 87.07
BERT-Large, Cased (Original) | 91.5/84.8 | 86.09
BERT-Large, Cased (Whole Word Masking) | 92.9/86.7 | 86.46
**\*\*\*\*\* New February 7th, 2019: TfHub Module \*\*\*\*\***
BERT has been uploaded to [TensorFlow Hub](https://tfhub.dev). See
`run_classifier_with_tfhub.py` for an example of how to use the TF Hub module,
or run an example in the browser on
[Colab](https://colab.sandbox.google.com/github/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb).
**\*\*\*\*\* New November 23rd, 2018: Un-normalized multilingual model + Thai +
Mongolian \*\*\*\*\***
We uploaded a new multilingual model which does *not* perform any normalization
on the input (no lower casing, accent stripping, or Unicode normalization), and
additionally inclues Thai and Mongolian.
**It is recommended to use this version for developing multilingual models,
especially on languages with non-Latin alphabets.**
This does not require any code changes, and can be downloaded here:
* **[`BERT-Base, Multilingual Cased`](https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H-768_A-12.zip)**:
104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
**\*\*\*\*\* New November 15th, 2018: SOTA SQuAD 2.0 System \*\*\*\*\***
We released code changes to reproduce our 83% F1 SQuAD 2.0 system, which is
currently 1st place on the leaderboard by 3%. See the SQuAD 2.0 section of the
README for details.
**\*\*\*\*\* New November 5th, 2018: Third-party PyTorch and Chainer versions of
BERT available \*\*\*\*\***
NLP researchers from HuggingFace made a
[PyTorch version of BERT available](https://github.com/huggingface/pytorch-pretrained-BERT)
which is compatible with our pre-trained checkpoints and is able to reproduce
our results. Sosuke Kobayashi also made a
[Chainer version of BERT available](https://github.com/soskek/bert-chainer)
(Thanks!) We were not involved in the creation or maintenance of the PyTorch
implementation so please direct any questions towards the authors of that
repository.
**\*\*\*\*\* New November 3rd, 2018: Multilingual and Chinese models available
\*\*\*\*\***
We have made two new BERT models available:
* **[`BERT-Base, Multilingual`](https://storage.googleapis.com/bert_models/2018_11_03/multilingual_L-12_H-768_A-12.zip)
(Not recommended, use `Multilingual Cased` instead)**: 102 languages,
12-layer, 768-hidden, 12-heads, 110M parameters
* **[`BERT-Base, Chinese`](https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip)**:
Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M
parameters
We use character-based tokenization for Chinese, and WordPiece tokenization for
all other languages. Both models should work out-of-the-box without any code
changes. We did update the implementation of `BasicTokenizer` in
`tokenization.py` to support Chinese character tokenization, so please update if
you forked it. However, we did not change the tokenization API.
For more, see the
[Multilingual README](https://github.com/google-research/bert/blob/master/multilingual.md).
**\*\*\*\*\* End new information \*\*\*\*\***
## Introduction
**BERT**, or **B**idirectional **E**ncoder **R**epresentations from
**T**ransformers, is a new method of pre-training language representations which
obtains state-of-the-art results on a wide array of Natural Language Processing
(NLP) tasks.
Our academic paper which describes BERT in detail and provides full results on a
number of tasks can be found here:
[https://arxiv.org/abs/1810.04805](https://arxiv.org/abs/1810.04805).
To give a few numbers, here are the results on the
[SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/) question answering
task:
SQuAD v1.1 Leaderboard (Oct 8th 2018) | Test EM | Test F1
------------------------------------- | :------: | :------:
1st Place Ensemble - BERT | **87.4** | **93.2**
2nd Place Ensemble - nlnet | 86.0 | 91.7
1st Place Single Model - BERT | **85.1** | **91.8**
2nd Place Single Model - nlnet | 83.5 | 90.1
And several natural language inference tasks:
System | MultiNLI | Question NLI | SWAG
----------------------- | :------: | :----------: | :------:
BERT | **86.7** | **91.1** | **86.3**
OpenAI GPT (Prev. SOTA) | 82.2 | 88.1 | 75.0
Plus many other tasks.
Moreover, these results were all obtained with almost no task-specific neural
network architecture design.
If you already know what BERT is and you just want to get started, you can
[download the pre-trained models](#pre-trained-models) and
[run a state-of-the-art fine-tuning](#fine-tuning-with-bert) in only a few
minutes.
## What is BERT?
BERT is a method of pre-training language representations, meaning that we train
a general-purpose "language understanding" model on a large text corpus (like
Wikipedia), and then use that model for downstream NLP tasks that we care about
(like question answering). BERT outperforms previous methods because it is the
first *unsupervised*, *deeply bidirectional* system for pre-training NLP.
*Unsupervised* means that BERT was trained using only a plain text corpus, which
is important because an enormous amount of plain text data is publicly available
on the web in many languages.
Pre-trained representations can also either be *context-free* or *contextual*,
and contextual representations can further be *unidirectional* or
*bidirectional*. Context-free models such as
[word2vec](https://www.tensorflow.org/tutorials/representation/word2vec) or
[GloVe](https://nlp.stanford.edu/projects/glove/) generate a single "word
embedding" representation for each word in the vocabulary, so `bank` would have
the same representation in `bank deposit` and `river bank`. Contextual models
instead generate a representation of each word that is based on the other words
in the sentence.
BERT was built upon recent work in pre-training contextual representations —
including [Semi-supervised Sequence Learning](https://arxiv.org/abs/1511.01432),
[Generative Pre-Training](https://blog.openai.com/language-unsupervised/),
[ELMo](https://allennlp.org/elmo), and
[ULMFit](http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html)
— but crucially these models are all *unidirectional* or *shallowly
bidirectional*. This means that each word is only contextualized using the words
to its left (or right). For example, in the sentence `I made a bank deposit` the
unidirectional representation of `bank` is only based on `I made a` but not
`deposit`. Some previous work does combine the representations from separate
left-context and right-context models, but only in a "shallow" manner. BERT
represents "bank" using both its left and right context — `I made a ... deposit`
— starting from the very bottom of a deep neural network, so it is *deeply
bidirectional*.
BERT uses a simple approach for this: We mask out 15% of the words in the input,
run the entire sequence through a deep bidirectional
[Transformer](https://arxiv.org/abs/1706.03762) encoder, and then predict only
the masked words. For example:
```
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
```
In order to learn relationships between sentences, we also train on a simple
task which can be generated from any monolingual corpus: Given two sentences `A`
and `B`, is `B` the actual next sentence that comes after `A`, or just a random
sentence from the corpus?
```
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
```
```
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
```
We then train a large model (12-layer to 24-layer Transformer) on a large corpus
(Wikipedia + [BookCorpus](http://yknzhu.wixsite.com/mbweb)) for a long time (1M
update steps), and that's BERT.
Using BERT has two stages: *Pre-training* and *fine-tuning*.
**Pre-training** is fairly expensive (four days on 4 to 16 Cloud TPUs), but is a
one-time procedure for each language (current models are English-only, but
multilingual models will be released in the near future). We are releasing a
number of pre-trained models from the paper which were pre-trained at Google.
Most NLP researchers will never need to pre-train their own model from scratch.
**Fine-tuning** is inexpensive. All of the results in the paper can be
replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU,
starting from the exact same pre-trained model. SQuAD, for example, can be
trained in around 30 minutes on a single Cloud TPU to achieve a Dev F1 score of
91.0%, which is the single system state-of-the-art.
The other important aspect of BERT is that it can be adapted to many types of
NLP tasks very easily. In the paper, we demonstrate state-of-the-art results on
sentence-level (e.g., SST-2), sentence-pair-level (e.g., MultiNLI), word-level
(e.g., NER), and span-level (e.g., SQuAD) tasks with almost no task-specific
modifications.
## What has been released in this repository?
We are releasing the following:
* TensorFlow code for the BERT model architecture (which is mostly a standard
[Transformer](https://arxiv.org/abs/1706.03762) architecture).
* Pre-trained checkpoints for both the lowercase and cased version of
`BERT-Base` and `BERT-Large` from the paper.
* TensorFlow code for push-button replication of the most important
fine-tuning experiments from the paper, including SQuAD, MultiNLI, and MRPC.
All of the code in this repository works out-of-the-box with CPU, GPU, and Cloud
TPU.
## Pre-trained models
We are releasing the `BERT-Base` and `BERT-Large` models from the paper.
`Uncased` means that the text has been lowercased before WordPiece tokenization,
e.g., `John Smith` becomes `john smith`. The `Uncased` model also strips out any
accent markers. `Cased` means that the true case and accent markers are
preserved. Typically, the `Uncased` model is better unless you know that case
information is important for your task (e.g., Named Entity Recognition or
Part-of-Speech tagging).
These models are all released under the same license as the source code (Apache
2.0).
For information about the Multilingual and Chinese model, see the
[Multilingual README](https://github.com/google-research/bert/blob/master/multilingual.md).
**When using a cased model, make sure to pass `--do_lower=False` to the training
scripts. (Or pass `do_lower_case=False` directly to `FullTokenizer` if you're
using your own script.)**
The links to the models are here (right-click, 'Save link as...' on the name):
* **[`BERT-Large, Uncased (Whole Word Masking)`](https://storage.googleapis.com/bert_models/2019_05_30/wwm_uncased_L-24_H-1024_A-16.zip)**:
24-layer, 1024-hidden, 16-heads, 340M parameters
* **[`BERT-Large, Cased (Whole Word Masking)`](https://storage.googleapis.com/bert_models/2019_05_30/wwm_cased_L-24_H-1024_A-16.zip)**:
24-layer, 1024-hidden, 16-heads, 340M parameters
* **[`BERT-Base, Uncased`](https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip)**:
12-layer, 768-hidden, 12-heads, 110M parameters
* **[`BERT-Large, Uncased`](https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-24_H-1024_A-16.zip)**:
24-layer, 1024-hidden, 16-heads, 340M parameters
* **[`BERT-Base, Cased`](https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip)**:
12-layer, 768-hidden, 12-heads , 110M parameters
* **[`BERT-Large, Cased`](https://storage.googleapis.com/bert_models/2018_10_18/cased_L-24_H-1024_A-16.zip)**:
24-layer, 1024-hidden, 16-heads, 340M parameters
* **[`BERT-Base, Multilingual Cased (New, recommended)`](https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H-768_A-12.zip)**:
104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
* **[`BERT-Base, Multilingual Uncased (Orig, not recommended)`](https://storage.googleapis.com/bert_models/2018_11_03/multilingual_L-12_H-768_A-12.zip)
(Not recommended, use `Multilingual Cased` instead)**: 102 languages,
12-layer, 768-hidden, 12-heads, 110M parameters
* **[`BERT-Base, Chinese`](https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip)**:
Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M
parameters
Each .zip file contains three items:
* A TensorFlow checkpoint (`bert_model.ckpt`) containing the pre-trained
weights (which is actually 3 files).
* A vocab file (`vocab.txt`) to map WordPiece to word id.
* A config file (`bert_config.json`) which specifies the hyperparameters of
the model.
## Fine-tuning with BERT
**Important**: All results on the paper were fine-tuned on a single Cloud TPU,
which has 64GB of RAM. It is currently not possible to re-produce most of the
`BERT-Large` results on the paper using a GPU with 12GB - 16GB of RAM, because
the maximum batch size that can fit in memory is too small. We are working on
adding code to this repository which allows for much larger effective batch size
on the GPU. See the section on [out-of-memory issues](#out-of-memory-issues) for
more details.
This code was tested with TensorFlow 1.11.0. It was tested with Python2 and
Python3 (but more thoroughly with Python2, since this is what's used internally
in Google).
The fine-tuning examples which use `BERT-Base` should be able to run on a GPU
that has at least 12GB of RAM using the hyperparameters given.
### Fine-tuning with Cloud TPUs
Most of the examples below assumes that you will be running training/evaluation
on your local machine, using a GPU like a Titan X or GTX 1080.
However, if you have access to a Cloud TPU that you want to train on, just add
the following flags to `run_classifier.py` or `run_squad.py`:
```
--use_tpu=True \
--tpu_name=$TPU_NAME
```
Please see the
[Google Cloud TPU tutorial](https://cloud.google.com/tpu/docs/tutorials/mnist)
for how to use Cloud TPUs. Alternatively, you can use the Google Colab notebook
"[BERT FineTuning with Cloud TPUs](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb)".
On Cloud TPUs, the pretrained model and the output directory will need to be on
Google Cloud Storage. For example, if you have a bucket named `some_bucket`, you
might use the following flags instead:
```
--output_dir=gs://some_bucket/my_output_dir/
```
The unzipped pre-trained model files can also be found in the Google Cloud
Storage folder `gs://bert_models/2018_10_18`. For example:
```
export BERT_BASE_DIR=gs://bert_models/2018_10_18/uncased_L-12_H-768_A-12
```
### Sentence (and sentence-pair) classification tasks
Before running this example you must download the
[GLUE data](https://gluebenchmark.com/tasks) by running
[this script](https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e)
and unpack it to some directory `$GLUE_DIR`. Next, download the `BERT-Base`
checkpoint and unzip it to some directory `$BERT_BASE_DIR`.
This example code fine-tunes `BERT-Base` on the Microsoft Research Paraphrase
Corpus (MRPC) corpus, which only contains 3,600 examples and can fine-tune in a
few minutes on most GPUs.
```shell
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
python run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/
```
You should see output like this:
```
***** Eval results *****
eval_accuracy = 0.845588
eval_loss = 0.505248
global_step = 343
loss = 0.505248
```
This means that the Dev set accuracy was 84.55%. Small sets like MRPC have a
high variance in the Dev set accuracy, even when starting from the same
pre-training checkpoint. If you re-run multiple times (making sure to point to
different `output_dir`), you should see results between 84% and 88%.
A few other pre-trained models are implemented off-the-shelf in
`run_classifier.py`, so it should be straightforward to follow those examples to
use BERT for any single-sentence or sentence-pair classification task.
Note: You might see a message `Running train on CPU`. This really just means
that it's running on something other than a Cloud TPU, which includes a GPU.
#### Prediction from classifier
Once you have trained your classifier you can use it in inference mode by using
the --do_predict=true command. You need to have a file named test.tsv in the
input folder. Output will be created in file called test_results.tsv in the
output folder. Each line will contain output for each sample, columns are the
class probabilities.
```shell
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
export TRAINED_CLASSIFIER=/path/to/fine/tuned/classifier
python run_classifier.py \
--task_name=MRPC \
--do_predict=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$TRAINED_CLASSIFIER \
--max_seq_length=128 \
--output_dir=/tmp/mrpc_output/
```
### SQuAD 1.1
The Stanford Question Answering Dataset (SQuAD) is a popular question answering
benchmark dataset. BERT (at the time of the release) obtains state-of-the-art
results on SQuAD with almost no task-specific network architecture modifications
or data augmentation. However, it does require semi-complex data pre-processing
and post-processing to deal with (a) the variable-length nature of SQuAD context
paragraphs, and (b) the character-level answer annotations which are used for
SQuAD training. This processing is implemented and documented in `run_squad.py`.
To run on SQuAD, you will first need to download the dataset. The
[SQuAD website](https://rajpurkar.github.io/SQuAD-explorer/) does not seem to
link to the v1.1 datasets any longer, but the necessary files can be found here:
* [train-v1.1.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json)
* [dev-v1.1.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json)
* [evaluate-v1.1.py](https://github.com/allenai/bi-att-flow/blob/master/squad/evaluate-v1.1.py)
Download these to some directory `$SQUAD_DIR`.
The state-of-the-art SQuAD results from the paper currently cannot be reproduced
on a 12GB-16GB GPU due to memory constraints (in fact, even batch size 1 does
not seem to fit on a 12GB GPU using `BERT-Large`). However, a reasonably strong
`BERT-Base` model can be trained on the GPU with these hyperparameters:
```shell
python run_squad.py \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=/tmp/squad_base/
```
The dev set predictions will be saved into a file called `predictions.json` in
the `output_dir`:
```shell
python $SQUAD_DIR/evaluate-v1.1.py $SQUAD_DIR/dev-v1.1.json ./squad/predictions.json
```
Which should produce an output like this:
```shell
{"f1": 88.41249612335034, "exact_match": 81.2488174077578}
```
You should see a result similar to the 88.5% reported in the paper for
`BERT-Base`.
If you have access to a Cloud TPU, you can train with `BERT-Large`. Here is a
set of hyperparameters (slightly different than the paper) which consistently
obtain around 90.5%-91.0% F1 single-system trained only on SQuAD:
```shell
python run_squad.py \
--vocab_file=$BERT_LARGE_DIR/vocab.txt \
--bert_config_file=$BERT_LARGE_DIR/bert_config.json \
--init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=24 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=gs://some_bucket/squad_large/ \
--use_tpu=True \
--tpu_name=$TPU_NAME
```
For example, one random run with these parameters produces the following Dev
scores:
```shell
{"f1": 90.87081895814865, "exact_match": 84.38978240302744}
```
If you fine-tune for one epoch on
[TriviaQA](http://nlp.cs.washington.edu/triviaqa/) before this the results will
be even better, but you will need to convert TriviaQA into the SQuAD json
format.
### SQuAD 2.0
This model is also implemented and documented in `run_squad.py`.
To run on SQuAD 2.0, you will first need to download the dataset. The necessary
files can be found here:
* [train-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json)
* [dev-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json)
* [evaluate-v2.0.py](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/)
Download these to some directory `$SQUAD_DIR`.
On Cloud TPU you can run with BERT-Large as follows:
```shell
python run_squad.py \
--vocab_file=$BERT_LARGE_DIR/vocab.txt \
--bert_config_file=$BERT_LARGE_DIR/bert_config.json \
--init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v2.0.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v2.0.json \
--train_batch_size=24 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=gs://some_bucket/squad_large/ \
--use_tpu=True \
--tpu_name=$TPU_NAME \
--version_2_with_negative=True
```
We assume you have copied everything from the output directory to a local
directory called ./squad/. The initial dev set predictions will be at
./squad/predictions.json and the differences between the score of no answer ("")
and the best non-null answer for each question will be in the file
./squad/null_odds.json
Run this script to tune a threshold for predicting null versus non-null answers:
python $SQUAD_DIR/evaluate-v2.0.py $SQUAD_DIR/dev-v2.0.json
./squad/predictions.json --na-prob-file ./squad/null_odds.json
Assume the script outputs "best_f1_thresh" THRESH. (Typical values are between
-1.0 and -5.0). You can now re-run the model to generate predictions with the
derived threshold or alternatively you can extract the appropriate answers from
./squad/nbest_predictions.json.
```shell
python run_squad.py \
--vocab_file=$BERT_LARGE_DIR/vocab.txt \
--bert_config_file=$BERT_LARGE_DIR/bert_config.json \
--init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \
--do_train=False \
--train_file=$SQUAD_DIR/train-v2.0.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v2.0.json \
--train_batch_size=24 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=gs://some_bucket/squad_large/ \
--use_tpu=True \
--tpu_name=$TPU_NAME \
--version_2_with_negative=True \
--null_score_diff_threshold=$THRESH
```
### Out-of-memory issues
All experiments in the paper were fine-tuned on a Cloud TPU, which has 64GB of
device RAM. Therefore, when using a GPU with 12GB - 16GB of RAM, you are likely
to encounter out-of-memory issues if you use the same hyperparameters described
in the paper.
The factors that affect memory usage are:
* **`max_seq_length`**: The released models were trained with sequence lengths
up to 512, but you can fine-tune with a shorter max sequence length to save
substantial memory. This is controlled by the `max_seq_length` flag in our
example code.
* **`train_batch_size`**: The memory usage is also directly proportional to
the batch size.
* **Model type, `BERT-Base` vs. `BERT-Large`**: The `BERT-Large` model
requires significantly more memory than `BERT-Base`.
* **Optimizer**: The default optimizer for BERT is Adam, which requires a lot
of extra memory to store the `m` and `v` vectors. Switching to a more memory
efficient optimizer can reduce memory usage, but can also affect the
results. We have not experimented with other optimizers for fine-tuning.
Using the default training scripts (`run_classifier.py` and `run_squad.py`), we
benchmarked the maximum batch size on single Titan X GPU (12GB RAM) with
TensorFlow 1.11.0:
System | Seq Length | Max Batch Size
------------ | ---------- | --------------
`BERT-Base` | 64 | 64
... | 128 | 32
... | 256 | 16
... | 320 | 14
... | 384 | 12
... | 512 | 6
`BERT-Large` | 64 | 12
... | 128 | 6
... | 256 | 2
... | 320 | 1
... | 384 | 0
... | 512 | 0
Unfortunately, these max batch sizes for `BERT-Large` are so small that they
will actually harm the model accuracy, regardless of the learning rate used. We
are working on adding code to this repository which will allow much larger
effective batch sizes to be used on the GPU. The code will be based on one (or
both) of the following techniques:
* **Gradient accumulation**: The samples in a minibatch are typically
independent with respect to gradient computation (excluding batch
normalization, which is not used here). This means that the gradients of
multiple smaller minibatches can be accumulated before performing the weight
update, and this will be exactly equivalent to a single larger update.
* [**Gradient checkpointing**](https://github.com/openai/gradient-checkpointing):
The major use of GPU/TPU memory during DNN training is caching the
intermediate activations in the forward pass that are necessary for
efficient computation in the backward pass. "Gradient checkpointing" trades
memory for compute time by re-computing the activations in an intelligent
way.
**However, this is not implemented in the current release.**
## Using BERT to extract fixed feature vectors (like ELMo)
In certain cases, rather than fine-tuning the entire pre-trained model
end-to-end, it can be beneficial to obtained *pre-trained contextual
embeddings*, which are fixed contextual representations of each input token
generated from the hidden layers of the pre-trained model. This should also
mitigate most of the out-of-memory issues.
As an example, we include the script `extract_features.py` which can be used
like this:
```shell
# Sentence A and Sentence B are separated by the ||| delimiter for sentence
# pair tasks like question answering and entailment.
# For single sentence inputs, put one sentence per line and DON'T use the
# delimiter.
echo 'Who was Jim Henson ? ||| Jim Henson was a puppeteer' > /tmp/input.txt
python extract_features.py \
--input_file=/tmp/input.txt \
--output_file=/tmp/output.jsonl \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--layers=-1,-2,-3,-4 \
--max_seq_length=128 \
--batch_size=8
```
This will create a JSON file (one line per line of input) containing the BERT
activations from each Transformer layer specified by `layers` (-1 is the final
hidden layer of the Transformer, etc.)
Note that this script will produce very large output files (by default, around
15kb for every input token).
If you need to maintain alignment between the original and tokenized words (for
projecting training labels), see the [Tokenization](#tokenization) section
below.
**Note:** You may see a message like `Could not find trained model in model_dir:
/tmp/tmpuB5g5c, running initialization to predict.` This message is expected, it
just means that we are using the `init_from_checkpoint()` API rather than the
saved model API. If you don't specify a checkpoint or specify an invalid
checkpoint, this script will complain.
## Tokenization
For sentence-level tasks (or sentence-pair) tasks, tokenization is very simple.
Just follow the example code in `run_classifier.py` and `extract_features.py`.
The basic procedure for sentence-level tasks is:
1. Instantiate an instance of `tokenizer = tokenization.FullTokenizer`
2. Tokenize the raw text with `tokens = tokenizer.tokenize(raw_text)`.
3. Truncate to the maximum sequence length. (You can use up to 512, but you
probably want to use shorter if possible for memory and speed reasons.)
4. Add the `[CLS]` and `[SEP]` tokens in the right place.
Word-level and span-level tasks (e.g., SQuAD and NER) are more complex, since
you need to maintain alignment between your input text and output text so that
you can project your training labels. SQuAD is a particularly complex example
because the input labels are *character*-based, and SQuAD paragraphs are often
longer than our maximum sequence length. See the code in `run_squad.py` to show
how we handle this.
Before we describe the general recipe for handling word-level tasks, it's
important to understand what exactly our tokenizer is doing. It has three main
steps:
1. **Text normalization**: Convert all whitespace characters to spaces, and
(for the `Uncased` model) lowercase the input and strip out accent markers.
E.g., `John Johanson's, → john johanson's,`.
2. **Punctuation splitting**: Split *all* punctuation characters on both sides
(i.e., add whitespace around all punctuation characters). Punctuation
characters are defined as (a) Anything with a `P*` Unicode class, (b) any
non-letter/number/space ASCII character (e.g., characters like `$` which are
technically not punctuation). E.g., `john johanson's, → john johanson ' s ,`
3. **WordPiece tokenization**: Apply whitespace tokenization to the output of
the above procedure, and apply
[WordPiece](https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/data_generators/text_encoder.py)
tokenization to each token separately. (Our implementation is directly based
on the one from `tensor2tensor`, which is linked). E.g., `john johanson ' s
, → john johan ##son ' s ,`
The advantage of this scheme is that it is "compatible" with most existing
English tokenizers. For example, imagine that you have a part-of-speech tagging
task which looks like this:
```
Input: John Johanson 's house
Labels: NNP NNP POS NN
```
The tokenized output will look like this:
```
Tokens: john johan ##son ' s house
```
Crucially, this would be the same output as if the raw text were `John
Johanson's house` (with no space before the `'s`).
If you have a pre-tokenized representation with word-level annotations, you can
simply tokenize each input word independently, and deterministically maintain an
original-to-tokenized alignment:
```python
### Input
orig_tokens = ["John", "Johanson", "'s", "house"]
labels = ["NNP", "NNP", "POS", "NN"]
### Output
bert_tokens = []
# Token map will be an int -> int mapping between the `orig_tokens` index and
# the `bert_tokens` index.
orig_to_tok_map = []
tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=True)
bert_tokens.append("[CLS]")
for orig_token in orig_tokens:
orig_to_tok_map.append(len(bert_tokens))
bert_tokens.extend(tokenizer.tokenize(orig_token))
bert_tokens.append("[SEP]")
# bert_tokens == ["[CLS]", "john", "johan", "##son", "'", "s", "house", "[SEP]"]
# orig_to_tok_map == [1, 2, 4, 6]
```
Now `orig_to_tok_map` can be used to project `labels` to the tokenized
representation.
There are common English tokenization schemes which will cause a slight mismatch
between how BERT was pre-trained. For example, if your input tokenization splits
off contractions like `do n't`, this will cause a mismatch. If it is possible to
do so, you should pre-process your data to convert these back to raw-looking
text, but if it's not possible, this mismatch is likely not a big deal.
## Pre-training with BERT
We are releasing code to do "masked LM" and "next sentence prediction" on an
arbitrary text corpus. Note that this is *not* the exact code that was used for
the paper (the original code was written in C++, and had some additional
complexity), but this code does generate pre-training data as described in the
paper.
Here's how to run the data generation. The input is a plain text file, with one
sentence per line. (It is important that these be actual sentences for the "next
sentence prediction" task). Documents are delimited by empty lines. The output
is a set of `tf.train.Example`s serialized into `TFRecord` file format.
You can perform sentence segmentation with an off-the-shelf NLP toolkit such as
[spaCy](https://spacy.io/). The `create_pretraining_data.py` script will
concatenate segments until they reach the maximum sequence length to minimize
computational waste from padding (see the script for more details). However, you
may want to intentionally add a slight amount of noise to your input data (e.g.,
randomly truncate 2% of input segments) to make it more robust to non-sentential
input during fine-tuning.
This script stores all of the examples for the entire input file in memory, so
for large data files you should shard the input file and call the script
multiple times. (You can pass in a file glob to `run_pretraining.py`, e.g.,
`tf_examples.tf_record*`.)
The `max_predictions_per_seq` is the maximum number of masked LM predictions per
sequence. You should set this to around `max_seq_length` * `masked_lm_prob` (the
script doesn't do that automatically because the exact value needs to be passed
to both scripts).
```shell
python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
```
Here's how to run the pre-training. Do not include `init_checkpoint` if you are
pre-training from scratch. The model configuration (including vocab size) is
specified in `bert_config_file`. This demo code only pre-trains for a small
number of steps (20), but in practice you will probably want to set
`num_train_steps` to 10000 steps or more. The `max_seq_length` and
`max_predictions_per_seq` parameters passed to `run_pretraining.py` must be the
same as `create_pretraining_data.py`.
```shell
python run_pretraining.py \
--input_file=/tmp/tf_examples.tfrecord \
--output_dir=/tmp/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5
```
This will produce an output like this:
```
***** Eval results *****
global_step = 20
loss = 0.0979674
masked_lm_accuracy = 0.985479
masked_lm_loss = 0.0979328
next_sentence_accuracy = 1.0
next_sentence_loss = 3.45724e-05
```
Note that since our `sample_text.txt` file is very small, this example training
will overfit that data in only a few steps and produce unrealistically high
accuracy numbers.
### Pre-training tips and caveats
* **If using your own vocabulary, make sure to change `vocab_size` in
`bert_config.json`. If you use a larger vocabulary without changing this,
you will likely get NaNs when training on GPU or TPU due to unchecked
out-of-bounds access.**
* If your task has a large domain-specific corpus available (e.g., "movie
reviews" or "scientific papers"), it will likely be beneficial to run
additional steps of pre-training on your corpus, starting from the BERT
checkpoint.
* The learning rate we used in the paper was 1e-4. However, if you are doing
additional steps of pre-training starting from an existing BERT checkpoint,
you should use a smaller learning rate (e.g., 2e-5).
* Current BERT models are English-only, but we do plan to release a
multilingual model which has been pre-trained on a lot of languages in the
near future (hopefully by the end of November 2018).
* Longer sequences are disproportionately expensive because attention is
quadratic to the sequence length. In other words, a batch of 64 sequences of
length 512 is much more expensive than a batch of 256 sequences of
length 128. The fully-connected/convolutional cost is the same, but the
attention cost is far greater for the 512-length sequences. Therefore, one
good recipe is to pre-train for, say, 90,000 steps with a sequence length of
128 and then for 10,000 additional steps with a sequence length of 512. The
very long sequences are mostly needed to learn positional embeddings, which
can be learned fairly quickly. Note that this does require generating the
data twice with different values of `max_seq_length`.
* If you are pre-training from scratch, be prepared that pre-training is
computationally expensive, especially on GPUs. If you are pre-training from
scratch, our recommended recipe is to pre-train a `BERT-Base` on a single
[preemptible Cloud TPU v2](https://cloud.google.com/tpu/docs/pricing), which
takes about 2 weeks at a cost of about $500 USD (based on the pricing in
October 2018). You will have to scale down the batch size when only training
on a single Cloud TPU, compared to what was used in the paper. It is
recommended to use the largest batch size that fits into TPU memory.
### Pre-training data
We will **not** be able to release the pre-processed datasets used in the paper.
For Wikipedia, the recommended pre-processing is to download
[the latest dump](https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2),
extract the text with
[`WikiExtractor.py`](https://github.com/attardi/wikiextractor), and then apply
any necessary cleanup to convert it into plain text.
Unfortunately the researchers who collected the
[BookCorpus](http://yknzhu.wixsite.com/mbweb) no longer have it available for
public download. The
[Project Guttenberg Dataset](https://web.eecs.umich.edu/~lahiri/gutenberg_dataset.html)
is a somewhat smaller (200M word) collection of older books that are public
domain.
[Common Crawl](http://commoncrawl.org/) is another very large collection of
text, but you will likely have to do substantial pre-processing and cleanup to
extract a usable corpus for pre-training BERT.
### Learning a new WordPiece vocabulary
This repository does not include code for *learning* a new WordPiece vocabulary.
The reason is that the code used in the paper was implemented in C++ with
dependencies on Google's internal libraries. For English, it is almost always
better to just start with our vocabulary and pre-trained models. For learning
vocabularies of other languages, there are a number of open source options
available. However, keep in mind that these are not compatible with our
`tokenization.py` library:
* [Google's SentencePiece library](https://github.com/google/sentencepiece)
* [tensor2tensor's WordPiece generation script](https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/data_generators/text_encoder_build_subword.py)
* [Rico Sennrich's Byte Pair Encoding library](https://github.com/rsennrich/subword-nmt)
## Using BERT in Colab
If you want to use BERT with [Colab](https://colab.research.google.com), you can
get started with the notebook
"[BERT FineTuning with Cloud TPUs](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb)".
**At the time of this writing (October 31st, 2018), Colab users can access a
Cloud TPU completely for free.** Note: One per user, availability limited,
requires a Google Cloud Platform account with storage (although storage may be
purchased with free credit for signing up with GCP), and this capability may not
longer be available in the future. Click on the BERT Colab that was just linked
for more information.
## FAQ
#### Is this code compatible with Cloud TPUs? What about GPUs?
Yes, all of the code in this repository works out-of-the-box with CPU, GPU, and
Cloud TPU. However, GPU training is single-GPU only.
#### I am getting out-of-memory errors, what is wrong?
See the section on [out-of-memory issues](#out-of-memory-issues) for more
information.
#### Is there a PyTorch version available?
There is no official PyTorch implementation. However, NLP researchers from
HuggingFace made a
[PyTorch version of BERT available](https://github.com/huggingface/pytorch-pretrained-BERT)
which is compatible with our pre-trained checkpoints and is able to reproduce
our results. We were not involved in the creation or maintenance of the PyTorch
implementation so please direct any questions towards the authors of that
repository.
#### Is there a Chainer version available?
There is no official Chainer implementation. However, Sosuke Kobayashi made a
[Chainer version of BERT available](https://github.com/soskek/bert-chainer)
which is compatible with our pre-trained checkpoints and is able to reproduce
our results. We were not involved in the creation or maintenance of the Chainer
implementation so please direct any questions towards the authors of that
repository.
#### Will models in other languages be released?
Yes, we plan to release a multi-lingual BERT model in the near future. We cannot
make promises about exactly which languages will be included, but it will likely
be a single model which includes *most* of the languages which have a
significantly-sized Wikipedia.
#### Will models larger than `BERT-Large` be released?
So far we have not attempted to train anything larger than `BERT-Large`. It is
possible that we will release larger models if we are able to obtain significant
improvements.
#### What license is this library released under?
All code *and* models are released under the Apache 2.0 license. See the
`LICENSE` file for more information.
#### How do I cite BERT?
For now, cite [the Arxiv paper](https://arxiv.org/abs/1810.04805):
```
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
```
If we submit the paper to a conference or journal, we will update the BibTeX.
## Disclaimer
This is not an official Google product.
## Contact information
For help or issues using BERT, please submit a GitHub issue.
For personal communication related to BERT, please contact Jacob Devlin
(`[email protected]`), Ming-Wei Chang (`[email protected]`), or
Kenton Lee (`[email protected]`).
|
3,457 | A comprehensive reference for all topics related to Natural Language Processing | 
<p align="center">
This pandect (πανδέκτης is Ancient Greek for encyclopedia) was created to help you find almost anything related to Natural Language Processing that is available online.
</p>
<p align="center"> <img src="https://emojipedia-us.s3.dualstack.us-west-1.amazonaws.com/thumbs/120/google/313/flag-ukraine_1f1fa-1f1e6.png" alt="Ukraine" width="50" height="50"/>
> __Note__
> Quick legend on available resource types:
>
> ⭐ - open source project, usually a GitHub repository with its number of stars
>
> 📙 - resource you can read, usually a blog post or a paper
>
> 🗂️ - a collection of additional resources
>
> 🔱 - non-open source tool, framework or paid service
>
> 🎥️ - a resource you can watch
>
> 🎙️ - a resource you can listen to
### <p align="center"><b>Table of Contents</b></p>
| 📇 Main Section | 🗃️ Sub-sections Sample |
| ------------- | ------------- |
| [NLP Resources](https://github.com/ivan-bilan/The-NLP-Pandect#) | [Paper Summaries](https://github.com/ivan-bilan/The-NLP-Pandect#papers-and-paper-summaries), [Conference Summaries](https://github.com/ivan-bilan/The-NLP-Pandect#conference-summaries), [NLP Datasets](https://github.com/ivan-bilan/The-NLP-Pandect#nlp-datasets) |
| [NLP Podcasts](https://github.com/ivan-bilan/The-NLP-Pandect#-1) | [NLP-only Podcasts](https://github.com/ivan-bilan/The-NLP-Pandect#nlp-only-podcasts), [Podcasts with many NLP Episodes](https://github.com/ivan-bilan/The-NLP-Pandect#many-nlp-episodes) |
| [NLP Newsletters](https://github.com/ivan-bilan/The-NLP-Pandect#-2) | - |
| [NLP Meetups](https://github.com/ivan-bilan/The-NLP-Pandect#-3) | - |
| [NLP YouTube Channels](https://github.com/ivan-bilan/The-NLP-Pandect#-4) | - |
| [NLP Benchmarks](https://github.com/ivan-bilan/The-NLP-Pandect#-5) | [General NLU](https://github.com/ivan-bilan/The-NLP-Pandect#general-nlu), [Question Answering](https://github.com/ivan-bilan/The-NLP-Pandect#question-answering), [Multilingual](https://github.com/ivan-bilan/The-NLP-Pandect#multilingual-and-non-english-benchmarks) |
| [Research Resources](https://github.com/ivan-bilan/The-NLP-Pandect#-6) | [Resource on Transformer Models](https://github.com/ivan-bilan/The-NLP-Pandect#transformer-based-architectures), [Distillation and Pruning](https://github.com/ivan-bilan/The-NLP-Pandect#distillation-pruning-and-quantization), [Automated Summarization](https://github.com/ivan-bilan/The-NLP-Pandect#automated-summarization) |
| [Industry Resources](https://github.com/ivan-bilan/The-NLP-Pandect#-7) | [Best Practices for NLP Systems](https://github.com/ivan-bilan/The-NLP-Pandect#best-practices-for-nlp), [MLOps for NLP](https://github.com/ivan-bilan/The-NLP-Pandect#mlops-for-nlp) |
| [Speech Recognition](https://github.com/ivan-bilan/The-NLP-Pandect#-8) | [General Resources](https://github.com/ivan-bilan/The-NLP-Pandect#general-speech-recognition), [Text to Speech](https://github.com/ivan-bilan/The-NLP-Pandect#text-to-speech), [Speech to Text](https://github.com/ivan-bilan/The-NLP-Pandect#speech-to-text), [Datasets](https://github.com/ivan-bilan/The-NLP-Pandect#datasets) |
| [Topic Modeling](https://github.com/ivan-bilan/The-NLP-Pandect#-9) | [Blogs](https://github.com/ivan-bilan/The-NLP-Pandect#blogs-1), [Frameworks](https://github.com/ivan-bilan/The-NLP-Pandect#frameworks-for-topic-modeling), [Repositories and Projects](https://github.com/ivan-bilan/The-NLP-Pandect#repositories-1) |
| [Keyword Extraction](https://github.com/ivan-bilan/The-NLP-Pandect#-10) | [Text Rank](https://github.com/ivan-bilan/The-NLP-Pandect#text-rank), [Rake](https://github.com/ivan-bilan/The-NLP-Pandect#rake---rapid-automatic-keyword-extraction), [Other Approaches](https://github.com/ivan-bilan/The-NLP-Pandect#other-approaches) |
| [Responsible NLP](https://github.com/ivan-bilan/The-NLP-Pandect#-11) | [NLP and ML Interpretability](https://github.com/ivan-bilan/The-NLP-Pandect#nlp-and-ml-interpretability), [Ethics, Bias, and Equality in NLP](https://github.com/ivan-bilan/The-NLP-Pandect#ethics-bias-and-equality-in-nlp), [Adversarial Attacks for NLP](https://github.com/ivan-bilan/The-NLP-Pandect#adversarial-attacks-for-nlp) |
| [NLP Frameworks](https://github.com/ivan-bilan/The-NLP-Pandect#-12) | [General Purpose](https://github.com/ivan-bilan/The-NLP-Pandect#general-purpose), [Data Augmentation](https://github.com/ivan-bilan/The-NLP-Pandect#data-augmentation), [Machine Translation](https://github.com/ivan-bilan/The-NLP-Pandect#machine-translation), [Adversarial Attacks](https://github.com/ivan-bilan/The-NLP-Pandect#adversarial-nlp-attacks--behavioral-testing), [Dialog Systems & Speech](https://github.com/ivan-bilan/The-NLP-Pandect#dialog-systems-and-speech), [Entity and String Matching](https://github.com/ivan-bilan/The-NLP-Pandect#entity-and-string-matching), [Non-English Frameworks](https://github.com/ivan-bilan/The-NLP-Pandect#non-english-oriented), [Text Annotation](https://github.com/ivan-bilan/The-NLP-Pandect#text-data-labelling) |
| [Learning NLP](https://github.com/ivan-bilan/The-NLP-Pandect#-13) | [Courses](https://github.com/ivan-bilan/The-NLP-Pandect#courses), [Books](https://github.com/ivan-bilan/The-NLP-Pandect#books), [Tutorials](https://github.com/ivan-bilan/The-NLP-Pandect#tutorials) |
| [NLP Communities](https://github.com/ivan-bilan/The-NLP-Pandect#-14) | - |
| [Other NLP Topics](https://github.com/ivan-bilan/The-NLP-Pandect#-15) | [Tokenization](https://github.com/ivan-bilan/The-NLP-Pandect#tokenization), [Data Augmentation](https://github.com/ivan-bilan/The-NLP-Pandect#data-augmentation-and-weak-supervision), [Named Entity Recognition](https://github.com/ivan-bilan/The-NLP-Pandect#named-entity-recognition-ner), [Error Correction](https://github.com/ivan-bilan/The-NLP-Pandect#spell-correction--error-correction), [AutoML/AutoNLP](https://github.com/ivan-bilan/The-NLP-Pandect#automl--autonlp), [Text Generation](https://github.com/ivan-bilan/The-NLP-Pandect#text-generation) |

-----
> __Note__
> Section keywords: paper summaries, compendium, awesome list
#### Compendiums and awesome lists on the topic of NLP:
* 🗂️ [The NLP Index](https://index.quantumstat.com) - Searchable Index of NLP Papers by Quantum Stat / NLP Cypher
* ⭐ [Awesome NLP](https://github.com/keon/awesome-nlp) by [keon](https://github.com/keon) [GitHub, 13963 stars]
* ⭐ [Speech and Natural Language Processing Awesome List](https://github.com/edobashira/speech-language-processing#readme) by [elaboshira](https://github.com/edobashira) [GitHub, 2121 stars]
* ⭐ [Awesome Deep Learning for Natural Language Processing (NLP)](https://github.com/brianspiering/awesome-dl4nlp) [GitHub, 1094 stars]
* ⭐ [Text Mining and Natural Language Processing Resources](https://github.com/stepthom/text_mining_resources) by [stepthom](https://github.com/stepthom) [GitHub, 505 stars]
* 🗂️ [Made with ML List](https://madewithml.com/topics/#nlp) by [madewithml.com](https://madewithml.com)
* 🗂️ [Brainsources for #NLP enthusiasts](https://www.notion.so/634eba1a37d34e2baec1bb574a8a5482) by [Philip Vollet](https://www.linkedin.com/in/philipvollet/)
* ⭐ [Awesome AI/ML/DL - NLP Section](https://github.com/neomatrix369/awesome-ai-ml-dl/tree/master/natural-language-processing#natural-language-processing-nlp) [GitHub, 1142 stars]
* 🗂️ [Resources on various machine learning topics](https://www.backprop.org) by Backprop
* 🗂️ [NLP articles](https://devopedia.org/site-map/browse-articles/natural+language+processing) by [Devopedia](https://devopedia.org)
#### NLP Conferences, Paper Summaries and Paper Compendiums:
##### Papers and Paper Summaries
* ⭐ [100 Must-Read NLP Papers](https://github.com/mhagiwara/100-nlp-papers) 100 Must-Read NLP Papers [GitHub, 3446 stars]
* ⭐ [NLP Paper Summaries](https://github.com/dair-ai/nlp_paper_summaries) by [dair-ai](https://github.com/dair-ai) [GitHub, 1431 stars]
* ⭐ [Curated collection of papers for the NLP practitioner](https://github.com/mihail911/nlp-library) [GitHub, 1059 stars]
* ⭐ [Papers on Textual Adversarial Attack and Defense](https://github.com/thunlp/TAADpapers) [GitHub, 1182 stars]
* ⭐ [Recent Deep Learning papers in NLU and RL](https://github.com/madrugado/deep-learning-nlp-rl-papers) by Valentin Malykh [GitHub, 291 stars]
* ⭐ [A Survey of Surveys (NLP & ML): Collection of NLP Survey Papers](https://github.com/NiuTrans/ABigSurvey) [GitHub, 1713 stars]
* ⭐ [A Paper List for Style Transfer in Text](https://github.com/fuzhenxin/Style-Transfer-in-Text) [GitHub, 1456 stars]
* 🎥 [Video recordings index for papers](https://papertalk.org/index)
##### Conference Summaries
* ⭐ [NLP top 10 conferences Compendium](https://github.com/soulbliss/NLP-conference-compendium) by [soulbliss](https://github.com/soulbliss) [GitHub, 439 stars]
* 📙 [ICLR 2020 Trends](https://gsarti.com/post/iclr2020-transformers/)
* 📙 [SpacyIRL 2019 Conference in Overview](https://www.linkedin.com/pulse/spacyirl-2019-conference-overview-ivan-bilan/)
* 📙 [Paper Digest](https://www.paperdigest.org/category/nlp/) - Conferences and Papers in Overview
* 🎥 [Video Recordings from Conferences](https://crossminds.ai/explore/)
#### NLP Progress and NLP Tasks:
* ⭐ [NLP Progress](https://github.com/sebastianruder/NLP-progress) by [sebastianruder](https://github.com/sebastianruder) [GitHub, 21123 stars]
* ⭐ [NLP Tasks](https://github.com/Kyubyong/nlp_tasks) by [Kyubyong](https://github.com/Kyubyong) [GitHub, 2984 stars]
#### NLP Datasets:
* ⭐ [NLP Datasets](https://github.com/niderhoff/nlp-datasets) by [niderhoff](https://github.com/niderhoff) [GitHub, 5225 stars]
* ⭐ [Datasets](https://github.com/huggingface/datasets) by Huggingface [GitHub, 14838 stars]
* 🗂️ [Big Bad NLP Database](https://datasets.quantumstat.com)
* ⭐ [UWA Unambiguous Word Annotations](http://danlou.github.io/uwa/) - Word Sense Disambiguation Dataset
* ⭐ [MLDoc](https://github.com/facebookresearch/MLDoc) - Corpus for Multilingual Document Classification in Eight Language [GitHub, 145 stars]
#### Word and Sentence embeddings:
* ⭐ [Awesome Embedding Models](https://github.com/Hironsan/awesome-embedding-models) by [Hironsan](https://github.com/Hironsan) [GitHub, 1544 stars]
* ⭐ [Awesome list of Sentence Embeddings](https://github.com/Separius/awesome-sentence-embedding) by [Separius](https://github.com/Separius) [GitHub, 2086 stars]
* ⭐ [Awesome BERT](https://github.com/Jiakui/awesome-bert) by [Jiakui](https://github.com/Jiakui) [GitHub, 1797 stars]
#### Notebooks, Scripts and Repositories
* ⭐ [The Super Duper NLP Repo](https://notebooks.quantumstat.com) [Website, 2020]
#### Non-English resources and Compendiums
* ⭐ [NLP Resources for Bahasa Indonesian](https://github.com/louisowen6/NLP_bahasa_resources) [GitHub, 329 stars]
* ⭐ [Indic NLP Catalog](https://github.com/AI4Bharat/indicnlp_catalog) [GitHub, 381 stars]
* ⭐ [Pre-trained language models for Vietnamese](https://github.com/VinAIResearch/PhoBERT) [GitHub, 491 stars]
* ⭐ [Natural Language Toolkit for Indic Languages (iNLTK)](https://github.com/goru001/inltk) [GitHub, 773 stars]
* ⭐ [Indic NLP Library](https://github.com/anoopkunchukuttan/indic_nlp_library) [GitHub, 448 stars]
* ⭐ [AI4Bharat-IndicNLP Portal](https://indicnlp.ai4bharat.org)
* ⭐ [ARBML](https://github.com/ARBML/ARBML) - Implementation of many Arabic NLP and ML projects [GitHub, 284 stars]
* ⭐ [zemberek-nlp](https://github.com/ahmetaa/zemberek-nlp) - NLP tools for Turkish [GitHub, 1021 stars]
* ⭐ [TDD AI](https://tdd.ai) - An open-source platform for all Turkish datasets, language models, and NLP tools.
* ⭐ [KLUE](https://github.com/KLUE-benchmark/KLUE) - Korean Language Understanding Evaluation [GitHub, 468 stars]
* ⭐ [Persian NLP Benchmark](https://github.com/Mofid-AI/persian-nlp-benchmark) - benchmark for evaluation and comparison of various NLP tasks in Persian language [GitHub, 69 stars]
* ⭐ [nlp-greek](https://github.com/Yuliya-HV/nlp-greek) - Greek language sources [GitHub, 5 stars]
* ⭐ [Awesome NLP Resources for Hungarian](https://github.com/oroszgy/awesome-hungarian-nlp) [GitHub, 160 stars]
#### Pre-trained NLP models
* ⭐ [List of pre-trained NLP models](https://github.com/balavenkatesh3322/NLP-pretrained-model) [GitHub, 163 stars]
* 📙 [General Pretrained Language Models](https://mr-nlp.github.io/posts/2022/07/general-tptlms-list/) [Blog, July 2022]
* ⭐ [Pretrained language models developed by Huawei Noah's Ark Lab](https://github.com/huawei-noah/Pretrained-Language-Model) [GitHub, 2547 stars]
* ⭐ [Spanish Language Models and resources](https://github.com/PlanTL-GOB-ES/lm-spanish) [GitHub, 202 stars]
* 🗂 [Monolingual Pretrained Language Models](https://mr-nlp.github.io/posts/2022/07/monolingual-tptlms-list/) - collection of available pre-trained models [Blog, July 2022]
#### NLP History
##### General
* ⭐ [Modern Deep Learning Techniques Applied to Natural Language Processing](https://github.com/omarsar/nlp_overview) [GitHub, 1269 stars]
* 📙 [A Review of the Neural History of Natural Language Processing](https://aylien.com/blog/a-review-of-the-recent-history-of-natural-language-processing) [Blog, October 2018]
##### 2020 Year in Review
* 📙 [Natural Language Processing in 2020: The Year In Review](https://www.linkedin.com/pulse/natural-language-processing-2020-year-review-ivan-bilan/) [Blog, December 2020]
* 📙 [ML and NLP Research Highlights of 2020](https://ruder.io/research-highlights-2020/) [Blog, January 2021]

-----
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
#### NLP-only podcasts
* 🎙️ [NLP Highlights](https://soundcloud.com/nlp-highlights) [Years: 2017 - now, Status: active]
* 🎙️ [The NLP Zone](https://de.player.fm/series/the-nlp-zone) [Episodes](https://player.captivate.fm/episode/e2f87641-1421-4729-a2b5-d64951c845c6) [Years: 2021 - now, Status: active]
#### Many NLP episodes
* 🎙️ [TWIML AI](https://twimlai.com) [Years: 2016 - now, Status: active]
* 🎙️ [Practical AI](https://changelog.com/practicalai) [Years: 2018 - now, Status: active]
* 🎙️ [The Data Exchange](https://thedataexchange.media) [Years: 2019 - now, Status: active]
* 🎙️ [Gradient Dissent](https://www.wandb.com/podcast) [Years: 2020 - now, Status: active]
* 🎙️ [Machine Learning Street Talk](https://open.spotify.com/show/02e6PZeIOdpmBGT9THuzwR) [Years: 2020 - now, Status: active]
* 🎙️ [DataFramed](https://www.datacamp.com/community/podcast) - latest trends and insights on how to scale the impact of data science in organizations [Years: 2019 - now, Status: active]
#### Some NLP episodes
* 🎙️ [The Super Data Science Podcast](https://www.superdatascience.com/podcast) [Years: 2016 - now, Status: active]
* 🎙️ [Data Hack Radio](https://soundcloud.com/datahack-radio) [Years: 2018 - now, Status: active]
* 🎙️ [AI Game Changers](https://podcasts.apple.com/de/podcast/ai-game-changers/id1512574291) [Years: 2020 - now, Status: active]
* 🎙️ [The Analytics Show](https://anchor.fm/analyticsshow) [Years: 2019 - now, Status: active]

-----
* 📙 [NLP News](https://ruder.io/nlp-news/) by [Sebastian Ruder](https://ruder.io)
* 📙 [dair.ai Newsletter](https://dair.ai/newsletter/) by [dair.ai](dair.ai)
* 📙 [This Week in NLP by Robert Dale](https://www.language-technology.com/twin)
* 📙 [Papers with Code](https://paperswithcode.com)
* 📙 [The Batch](https://www.deeplearning.ai/thebatch/) by [deeplearning.ai](https://www.deeplearning.ai/thebatch/)
* 📙 [Paper Digest](https://www.paperdigest.org/2020/04/recent-papers-on-question-answering/) by [PaperDigest](https://www.paperdigest.org/daily-paper-digest/)
* 📙 [NLP Cypher](https://medium.com/@quantumstat) by [QuantumStat](https://quantumstat.com)

-----
* 🎥 [NLP Zurich](https://www.linkedin.com/company/nlp-zurich/) [[YouTube Recordings](https://www.youtube.com/channel/UCLLX-5j9UNYassOwS0nveDQ)]
* 🎥 [Hacking-Machine-Learning](https://www.meetup.com/Hacking-Machine-Learning) [[YouTube Recordings](https://www.youtube.com/channel/UCt5RvrC-_3X7FNAWhORVn7Q)]
* 🎥 [NY-NLP (New York)](https://www.meetup.com/NY-NLP/)

-----
* 🎥 [Yannic Kilcher](https://www.youtube.com/channel/UCZHmQk67mSJgfCCTn7xBfew)
* 🎥 [HuggingFace](https://www.youtube.com/channel/UCHlNU7kIZhRgSbhHvFoy72w)
* 🎥 [Kaggle Reading Group](https://www.youtube.com/watch?v=PhTF7yJNR70&list=PLqFaTIg4myu8t5ycqvp7I07jTjol3RCl9)
* 🎥 [Rasa Paper Reading](https://www.youtube.com/channel/UCJ0V6493mLvqdiVwOKWBODQ/playlists)
* 🎥 [Stanford CS224N: NLP with Deep Learning](https://www.youtube.com/watch?v=8rXD5-xhemo&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z)
* 🎥 [NLPxing](https://www.youtube.com/channel/UCuGC1JusVvbOGa__qMtH3QA/videos)
* 🎥 [ML Explained - A.I. Socratic Circles - AISC](https://www.youtube.com/channel/UCfk3pS8cCPxOgoleriIufyg)
* 🎥 [Deeplearning.ai](https://www.youtube.com/channel/UCcIXc5mJsHVYTZR1maL5l9w/featured)
* 🎥 [Machine Learning Street Talk](https://www.youtube.com/channel/UCMLtBahI5DMrt0NPvDSoIRQ/featured)

-----
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### General NLU
* ⭐ [GLUE](https://gluebenchmark.com) - General Language Understanding Evaluation (GLUE) benchmark
* ⭐ [SuperGLUE](https://super.gluebenchmark.com) - benchmark styled after GLUE with a new set of more difficult language understanding tasks
* ⭐ [decaNLP](https://decanlp.com) - The Natural Language Decathlon (decaNLP) for studying general NLP models
* ⭐ [dialoglue](https://github.com/alexa/dialoglue) - DialoGLUE: A Natural Language Understanding Benchmark for Task-Oriented Dialogue [GitHub, 235 stars]
* ⭐ [DynaBench](https://dynabench.org/) - Dynabench is a research platform for dynamic data collection and benchmarking
* ⭐ [Big-Bench](https://github.com/google/BIG-bench) - collaborative benchmark for measuring and extrapolating the capabilities of language models [GitHub, 1228 stars]
### Summarization
* ⭐ [WikiAsp](https://github.com/neulab/wikiasp) - WikiAsp: Multi-document aspect-based summarization Dataset
* ⭐ [WikiLingua](https://github.com/esdurmus/Wikilingua) - A Multilingual Abstractive Summarization Dataset
### Question Answering
* ⭐ [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) - Stanford Question Answering Dataset (SQuAD)
* ⭐ [XQuad](https://github.com/deepmind/xquad) - XQuAD (Cross-lingual Question Answering Dataset) for cross-lingual question answering
* ⭐ [GrailQA](https://dki-lab.github.io/GrailQA/) - Strongly Generalizable Question Answering (GrailQA)
* ⭐ [CSQA](https://amritasaha1812.github.io/CSQA/) - Complex Sequential Question Answering
### Multilingual and Non-English Benchmarks
* 📙 [XTREME](https://arxiv.org/abs/2003.11080) - Massively Multilingual Multi-task Benchmark
* ⭐ [GLUECoS](https://github.com/microsoft/GLUECoS) - A benchmark for code-switched NLP
* ⭐ [IndicGLUE](https://indicnlp.ai4bharat.org/indic-glue/) - Natural Language Understanding Benchmark for Indic Languages
* ⭐ [LinCE](https://ritual.uh.edu/lince/) - Linguistic Code-Switching Evaluation Benchmark
* ⭐ [Russian SuperGlue](https://russiansuperglue.com) - Russian SuperGlue Benchmark
### Bio, Law, and other scientific domains
* ⭐ [BLURB](https://microsoft.github.io/BLURB/) - Biomedical Language Understanding and Reasoning Benchmark
* ⭐ [BLUE](https://github.com/ncbi-nlp/BLUE_Benchmark) - Biomedical Language Understanding Evaluation benchmark
* ⭐ [LexGLUE](https://github.com/coastalcph/lex-glue) - A Benchmark Dataset for Legal Language Understanding in English
### Transformer Efficiency
* ⭐ [Long-Range Arena](https://github.com/google-research/long-range-arena) - Long Range Arena for Benchmarking Efficient Transformers ([Pre-print](https://arxiv.org/abs/2011.04006)) [GitHub, 481 stars]
### Speech Processing
* ⭐ [SUPERB](http://superbbenchmark.org/) - Speech processing Universal PERformance Benchmark
### Other
* ⭐ [CodeXGLUE](https://www.microsoft.com/en-us/research/blog/codexglue-a-benchmark-dataset-and-open-challenge-for-code-intelligence/) - A benchmark dataset for code intelligence
* ⭐ [CrossNER](https://github.com/zliucr/CrossNER) - CrossNER: Evaluating Cross-Domain Named Entity Recognition
* ⭐ [MultiNLI](cims.nyu.edu/~sbowman/multinli/) - Multi-Genre Natural Language Inference corpus
* ⭐ [iSarcasm: A Dataset of Intended Sarcasm](https://github.com/silviu-oprea/iSarcasm) - iSarcasm is a dataset of tweets, each labelled as either sarcastic or non_sarcastic

-----
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### General
* 📙 [A Recipe for Training Neural Networks](https://karpathy.github.io/2019/04/25/recipe/) by Andrej Karpathy [Keywords: research, training, 2019]
* 📙 [Recent Advances in NLP via Large Pre-Trained Language Models: A Survey](https://arxiv.org/abs/2111.01243) [Paper, November 2021]
### Embeddings
#### Repositories
* ⭐ [Pre-trained ELMo Representations for Many Languages](https://github.com/HIT-SCIR/ELMoForManyLangs) [GitHub, 1413 stars]
* ⭐ [sense2vec](https://github.com/explosion/sense2vec) - Contextually-keyed word vectors [GitHub, 1449 stars]
* ⭐ [wikipedia2vec](https://github.com/wikipedia2vec/wikipedia2vec) [GitHub, 831 stars]
* ⭐ [StarSpace](https://github.com/facebookresearch/StarSpace) [GitHub, 3809 stars]
* ⭐ [fastText](https://github.com/facebookresearch/fastText) [GitHub, 24067 stars]
#### Blogs
* 📙 [Language Models and Contextualised Word Embeddings](http://www.davidsbatista.net/blog/2018/12/06/Word_Embeddings/) by David S. Batista [Blog, 2018]
* 📙 [An Essential Guide to Pretrained Word Embeddings for NLP Practitioners](https://www.analyticsvidhya.com/blog/2020/03/pretrained-word-embeddings-nlp/?utm_source=AVLinkedin&utm_medium=post&utm_campaign=22_may_new_article) by AnalyticsVidhya [Blog, 2020]
* 📙 [Polyglot Word Embeddings Discover Language Clusters](http://blog.shriphani.com/2020/02/03/polyglot-word-embeddings-discover-language-clusters/) [Blog, 2020]
* 📙 [The Illustrated Word2vec](https://jalammar.github.io/illustrated-word2vec/) by Jay Alammar [Blog, 2019]
#### Cross-lingual Word and Sentence Embeddings
* ⭐ [vecmap](https://github.com/artetxem/vecmap) - VecMap (cross-lingual word embedding mappings) [GitHub, 604 stars]
* ⭐ [sentence-transformers](https://github.com/UKPLab/sentence-transformers) - Multilingual Sentence & Image Embeddings with BERT [GitHub, 8944 stars]
#### Byte Pair Encoding
* ⭐ [bpemb](https://github.com/bheinzerling/bpemb) - Pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) [GitHub, 1081 stars]
* ⭐ [subword-nmt](https://github.com/rsennrich/subword-nmt) - Unsupervised Word Segmentation for Neural Machine Translation and Text Generation [GitHub, 1972 stars]
* ⭐ [python-bpe](https://github.com/soaxelbrooke/python-bpe) - Byte Pair Encoding for Python [GitHub, 188 stars]
### Transformer-based Architectures
#### General
* 📙 [The Transformer Family](https://lilianweng.github.io/lil-log/2020/04/07/the-transformer-family.html) by Lilian Weng [Blog, 2020]
* 📙 [Playing the lottery with rewards and multiple languages](https://arxiv.org/abs/1906.02768) - about the effect of random initialization [ICLR 2020 Paper]
* 📙 [Attention? Attention!](https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html) by Lilian Weng [Blog, 2018]
* 📙 [the transformer … “explained”?](https://nostalgebraist.tumblr.com/post/185326092369/the-transformer-explained) [Blog, 2019]
* 🎥️ [Attention is all you need; Attentional Neural Network Models](https://www.youtube.com/watch?v=rBCqOTEfxvg) by Łukasz Kaiser [Talk, 2017]
* 🎥️ [Understanding and Applying Self-Attention for NLP](https://www.youtube.com/watch?v=OYygPG4d9H0) [Talk, 2018]
* 📙 [The NLP Cookbook: Modern Recipes for Transformer based Deep Learning Architectures](https://arxiv.org/abs/2104.10640) [Paper, April 2021]
* 📙 [Pre-Trained Models: Past, Present and Future](https://arxiv.org/abs/2106.07139) [Paper, June 2021]
* 📙 [A Survey of Transformers](https://arxiv.org/abs/2106.04554) [Paper, June 2021]
#### Transformer
* 📙 [The Annotated Transformer](https://nlp.seas.harvard.edu/2018/04/03/attention.html) by Harvard NLP [Blog, 2018]
* 📙 [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/) by Jay Alammar [Blog, 2018]
* 📙 [Illustrated Guide to Transformers](https://towardsdatascience.com/illustrated-guide-to-transformer-cf6969ffa067) by Hong Jing [Blog, 2020]
* 📙 [Sequential Transformer with Adaptive Attention Span](https://github.com/facebookresearch/adaptive-span) by Facebook. [Blog](https://ai.facebook.com/blog/making-transformer-networks-simpler-and-more-efficient/) [Blog, 2019]
* 📙 [Evolution of Representations in the Transformer](https://lena-voita.github.io/posts/emnlp19_evolution.html) by Lena Voita [Blog, 2019]
* 📙 [Reformer: The Efficient Transformer](https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html) [Blog, 2020]
* 📙 [Longformer — The Long-Document Transformer](https://medium.com/dair-ai/longformer-what-bert-should-have-been-78f4cd595be9) by Viktor Karlsson [Blog, 2020]
* 📙 [TRANSFORMERS FROM SCRATCH](http://www.peterbloem.nl/blog/transformers) [Blog, 2019]
* 📙 [Universal Transformers](https://mostafadehghani.com/2019/05/05/universal-transformers/) by Mostafa Dehghani [Blog, 2019]
* 📙 [Transformers in Natural Language Processing — A Brief Survey](https://eigenfoo.xyz/transformers-in-nlp/) by George Ho [Blog, May 2020]
* ⭐ [Lite Transformer](https://github.com/mit-han-lab/lite-transformer) - Lite Transformer with Long-Short Range Attention [GitHub, 550 stars]
* 📙 [Transformers from Scratch](https://e2eml.school/transformers.html) [Blog, Oct 2021]
#### BERT
* 📙 [A Visual Guide to Using BERT for the First Time](https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/) by Jay Alammar [Blog, 2019]
* 📙 [The Dark Secrets of BERT](https://text-machine-lab.github.io/blog/2020/bert-secrets/) by Anna Rogers [Blog, 2020]
* 📙 [Understanding searches better than ever before](https://www.blog.google/products/search/search-language-understanding-bert/) [Blog, 2019]
* 📙 [Demystifying BERT: A Comprehensive Guide to the Groundbreaking NLP Framework](https://www.analyticsvidhya.com/blog/2019/09/demystifying-bert-groundbreaking-nlp-framework/) [Blog, 2019]
* ⭐ [SemBERT](https://github.com/cooelf/SemBERT) - Semantics-aware BERT for Language Understanding [GitHub, 278 stars]
* ⭐ [BERTweet](https://github.com/VinAIResearch/BERTweet) - BERTweet: A pre-trained language model for English Tweets [GitHub, 487 stars]
* ⭐ [Optimal Subarchitecture Extraction for BERT](https://github.com/alexa/bort) [GitHub, 461 stars]
* ⭐ [CharacterBERT: Reconciling ELMo and BERT](https://github.com/helboukkouri/character-bert) [GitHub, 163 stars]
* 📙 [When BERT Plays The Lottery, All Tickets Are Winning](https://thegradient.pub/when-bert-plays-the-lottery-all-tickets-are-winning/) [Blog, Dec 2020]
* ⭐ [BERT-related Papers](https://github.com/tomohideshibata/BERT-related-papers) a list of BERT-related papers [GitHub, 1933 stars]
#### Other Transformer Variants
##### T5
* 📙 [T5 Understanding Transformer-Based Self-Supervised Architectures](https://medium.com/@rojagtap/t5-text-to-text-transfer-transformer-643f89e8905e) [Blog, August 2020]
* 📙 [T5: the Text-To-Text Transfer Transformer](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) [Blog, 2020]
* ⭐ [multilingual-t5](https://github.com/google-research/multilingual-t5) - Multilingual T5 (mT5) is a massively multilingual pretrained text-to-text transformer model [GitHub, 956 stars]
##### BigBird
* 📙 [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) original paper by Google Research [Paper, July 2020]
##### Reformer / Linformer / Longformer / Performers
* 🎥️ [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) - [Paper, February 2020] [[Video](https://www.youtube.com/watch?v=xJrKIPwVwGM), October 2020]
* 🎥️ [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) - [Paper, April 2020] [[Video](https://www.youtube.com/watch?v=_8KNb5iqblE), April 2020]
* 🎥️ [Linformer: Self-Attention with Linear Complexity](https://arxiv.org/abs/2006.04768) - [Paper, June 2020] [[Video](https://www.youtube.com/watch?v=-_2AF9Lhweo), June 2020]
* 🎥️ [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794) - [Paper, September 2020] [[Video](https://www.youtube.com/watch?v=0eTULzrOztQ), September 2020]
* ⭐ [performer-pytorch](https://github.com/lucidrains/performer-pytorch) - An implementation of Performer, a linear attention-based transformer, in Pytorch [GitHub, 898 stars]
##### Switch Transformer
* 📙 [Switch Transformers: Scaling to Trillion Parameter Models](https://arxiv.org/abs/2101.03961) original paper by Google Research [Paper, January 2021]
#### GPT-family
##### General
* 📙 [The Illustrated GPT-2](http://jalammar.github.io/illustrated-gpt2/) by Jay Alammar [Blog, 2019]
* 📙 [The Annotated GPT-2](https://amaarora.github.io/2020/02/18/annotatedGPT2.html) by Aman Arora
* 📙 [OpenAI’s GPT-2: the model, the hype, and the controversy](https://towardsdatascience.com/openais-gpt-2-the-model-the-hype-and-the-controversy-1109f4bfd5e8) by Ryan Lowe [Blog, 2019]
* 📙 [How to generate text](https://huggingface.co/blog/how-to-generate) by Patrick von Platen [Blog, 2020]
##### GPT-3
###### Learning Resources
* 📙 [Zero Shot Learning for Text Classification](https://amitness.com/2020/05/zero-shot-text-classification/) by Amit Chaudhary [Blog, 2020]
* 📙 [GPT-3 A Brief Summary](https://leogao.dev/2020/05/29/GPT-3-A-Brief-Summary/) by Leo Gao [Blog, 2020]
* 📙 [GPT-3, a Giant Step for Deep Learning And NLP](https://anotherdatum.com/gpt-3.html) by Yoel Zeldes [Blog, June 2020]
* 📙 [GPT-3 Language Model: A Technical Overview](https://lambdalabs.com/blog/demystifying-gpt-3/) by Chuan Li [Blog, June 2020]
* 📙 [Is it possible for language models to achieve language understanding?](https://medium.com/@ChrisGPotts/is-it-possible-for-language-models-to-achieve-language-understanding-81df45082ee2) by Christopher Potts
###### Applications
* ⭐ [Awesome GPT-3](https://github.com/elyase/awesome-gpt3) - list of all resources related to GPT-3 [GitHub, 3773 stars]
* 🗂️ [GPT-3 Projects](https://airtable.com/shrndwzEx01al2jHM/tblYMAiGeDLXe35jC) - a map of all GPT-3 start-ups and commercial projects
* 🗂️ [GPT-3 Demo Showcase](https://gpt3demo.com/) - GPT-3 Demo Showcase, 180+ Apps, Examples, & Resources
* 🔱 [OpenAI API](https://beta.openai.com) - API Demo to use GPT-3 for commercial applications
###### Open-source Efforts
* 📙 [GPT-Neo](https://eleuther.ai/projects/gpt-neo/) - in-progress GPT-3 open source replication [HuggingFace Hub](https://huggingface.co/EleutherAI)
* ⭐ [GPT-J](https://github.com/kingoflolz/mesh-transformer-jax/#gpt-j-6b) - A 6 billion parameter, autoregressive text generation model trained on The Pile
* 📙 [Effectively using GPT-J with few-shot learning](https://nlpcloud.io/effectively-using-gpt-j-gpt-neo-gpt-3-alternatives-few-shot-learning.html) [Blog, July 2021]
#### Other
* 📙 [What is Two-Stream Self-Attention in XLNet](https://towardsdatascience.com/what-is-two-stream-self-attention-in-xlnet-ebfe013a0cf3) by Xu LIANG [Blog, 2019]
* 📙 [Visual Paper Summary: ALBERT (A Lite BERT)](https://amitness.com/2020/02/albert-visual-summary/) by Amit Chaudhary [Blog, 2020]
* 📙 [Turing NLG](https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/) by Microsoft
* 📙 [Multi-Label Text Classification with XLNet](https://towardsdatascience.com/multi-label-text-classification-with-xlnet-b5f5755302df) by Josh Xin Jie Lee [Blog, 2019]
* ⭐ [ELECTRA](https://github.com/google-research/electra) [GitHub, 2095 stars]
* ⭐ [Performer](https://github.com/lucidrains/performer-pytorch) implementation of Performer, a linear attention-based transformer, in Pytorch [GitHub, 898 stars]
#### Distillation, Pruning and Quantization
##### Reading Material
* 📙 [Distilling knowledge from Neural Networks to build smaller and faster models](https://blog.floydhub.com/knowledge-distillation/) by FloydHub [Blog, 2019]
* 📙 [Compression of Deep Learning Models for Text: A Survey](https://arxiv.org/abs/2008.05221) [Paper, April 2021]
##### Tools
* ⭐ [Bert-squeeze](https://github.com/JulesBelveze/bert-squeeze) - code to reduce the size of Transformer-based models or decrease their latency at inference time [GitHub, 65 stars]
* ⭐ [XtremeDistil ](https://github.com/microsoft/xtreme-distil-transformers) - XtremeDistilTransformers for Distilling Massive Multilingual Neural Networks [GitHub, 122 stars]
### Automated Summarization
* 📙 [PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization](https://ai.googleblog.com/2020/06/pegasus-state-of-art-model-for.html) by Google AI [Blog, June 2020]
* ⭐ [CTRLsum](https://github.com/salesforce/ctrl-sum) - CTRLsum: Towards Generic Controllable Text Summarization [GitHub, 128 stars]
* ⭐ [XL-Sum](https://github.com/csebuetnlp/xl-sum) - XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages [GitHub, 186 stars]
* ⭐ [SummerTime](https://github.com/Yale-LILY/SummerTime) - an open-source text summarization toolkit for non-experts [GitHub, 211 stars]
* ⭐ [PRIMER](https://github.com/allenai/PRIMER) - PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization [GitHub, 107 stars]
* ⭐ [summarus](https://github.com/IlyaGusev/summarus) - Models for automatic abstractive summarization [GitHub, 145 stars]
### Knowledge Graphs and NLP
* 📙 [Fusing Knowledge into Language Model](https://drive.google.com/file/d/1Zgijg9RPxF-tIGWU9nt9rBcryOIB4lOk/view) [Presentation, Oct 2021]

-----
> __Note__
> Section keywords: best practices, MLOps
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### Best Practices for building NLP Projects
* 🎥 [In Search of Best Practices for NLP Projects](https://www.youtube.com/watch?v=0S9iai4Ld4I) [[Slides](https://www.dropbox.com/s/4fymdzz4yh3mlyz/NLP_Best_Practices_Bilan.pdf?dl=0), Dec. 2020]
* 🎥 [EMNLP 2020: High Performance Natural Language Processing](https://slideslive.com/38940826) by Google Research, [Recording](https://slideslive.com/38940826), Nov. 2020]
* 📙 [Practical Natural Language Processing](https://www.amazon.com/Practical-Natural-Language-Processing-Pragmatic/dp/1492054054) - A Comprehensive Guide to Building Real-World NLP Systems [Book, June 2020]
* 📙 [How to Structure and Manage NLP Projects](https://neptune.ai/blog/how-to-structure-and-manage-nlp-projects-templates) [Blog, May 2021]
* 📙 [Applied NLP Thinking](https://explosion.ai/blog/applied-nlp-thinking) - Applied NLP Thinking: How to Translate Problems into Solutions [Blog, June 2021]
* 🎥 [Introduction to NLP for Industry Use](https://www.youtube.com/watch?v=VRur3xey31s) - DataTalksClub presentation on Introduction to NLP for Industry Use [Recording, December 2021]
* 📙 [Measuring Embedding Drift](https://arize.com/blog/embedding-drift/) - Best practices for monitoring drift of NLP models [Blog, December 2022]
### MLOps for NLP
MLOps, especially when applied to NLP, is a set of best practices around automating various parts of the workflow when building and deploying NLP pipelines.
In general, MLOps for NLP includes having the following processes in place:
- **Data Versioning** - make sure your training, annotation and other types of data are versioned and tracked
- **Experiment Tracking** - make sure that all of your experiments are automatically tracked and saved where they can be easily replicated or retraced
- **Model Registry** - make sure any neural models you train are versioned and tracked and it is easy to roll back to any of them
- **Automated Testing and Behavioral Testing** - besides regular unit and integration tests, you want to have behavioral tests that check for bias or potential adversarial attacks
- **Model Deployment and Serving** - automate model deployment, ideally also with zero-downtime deploys like Blue/Green, Canary deploys etc.
- **Data and Model Observability** - track data drift, model accuracy drift etc.
Additionally, there are two more components that are not as prevalent for NLP and are mostly used for Computer Vision and other sub-fields of AI:
- **Feature Store** - centralized storage of all features developed for ML models than can be easily reused by any other ML project
- **Metadata Management** - storage for all information related to the usage of ML models, mainly for reproducing behavior of deployed ML models, artifact tracking etc.
#### MLOps Compilations & Awesome Lists
* ⭐ [awesome-mlops](https://github.com/visenger/awesome-mlops) [GitHub, 8929 stars]
* ⭐ [best-of-ml-python](https://github.com/ml-tooling/best-of-ml-python) [GitHub, 12011 stars]
* 🗂️ [MLOps.Toys](https://mlops.toys) - a curated list of MLOps projects
#### Reading Material
* 📙 [Machine Learning Operations (MLOps): Overview, Definition, and Architecture](https://arxiv.org/abs/2205.02302) [Paper, May 2022]
* 📙 [Requirements and Reference Architecture for MLOps:Insights from Industry](https://www.techrxiv.org/articles/preprint/Requirements_and_Reference_Architecture_for_MLOps_Insights_from_Industry/21397413) [Paper, Oct 2022]
* 📙 [MLOps: What It Is, Why it Matters, and How To Implement It](https://neptune.ai/blog/mlops-what-it-is-why-it-matters-and-how-to-implement-it-from-a-data-scientist-perspective) by Neptune AI [Blog, July 2021]
* 📙 [Best MLOps Tools You Need to Know as a Data Scientist](https://neptune.ai/blog/best-mlops-tools) by Neptune AI [Blog, July 2021]
* 📙 [Robust MLOps](https://blog.verta.ai/blog/robust-mlops-with-open-source-modeldb-docker-jenkins-and-prometheus) - Robust MLOps with Open-Source: ModelDB, Docker, Jenkins and Prometheus [Blog, May 2021]
* 📙 [State of MLOps 2021](https://valohai.com/state-of-mlops/#introduction) by Valohai [Blog, August 2021]
* 📙 [The MLOps Stack](https://valohai.com/blog/the-mlops-stack/) by Valohai [Blog, October 2020]
* 📙 [Data Version Control for Machine Learning Applications](https://megagon.ai/blog/data-version-control-for-machine-learning-applications/) by Megagon AI [Blog, July 2021]
* 📙 [The Rapid Evolution of the Canonical Stack for Machine Learning](https://medium.com/@ODSC/the-rapid-evolution-of-the-canonical-stack-for-machine-learning-21b37af9c3b5) [Blog, July 2021]
* 📙 [MLOps: Comprehensive Beginner’s Guide](https://medium.com/sciforce/mlops-comprehensive-beginners-guide-c235c77f407f) [Blog, March 2021]
* 📙 [What I’ve learned about MLOps from speaking with 100+ ML practitioners](https://veselinastaneva.medium.com/what-ive-learned-about-mlops-from-speaking-with-100-ml-practitioners-3025e33458ad) [Blog, May 2021]
* 📙 [DataRobot Challenger Models](https://www.datarobot.com/blog/introducing-mlops-champion-challenger-models) - MLOps Champion/Challenger Models
* 📙 [State of MLOps Blog](https://www.stateofmlops.com/) by Dr. Ori Cohen
* 📙 [MLOps Ecosystem Overview](https://arize.com/wp-content/uploads/2021/04/Arize-AI-Ecosystem-White-Paper.pdf) [Blog, 2021]
#### Learning Material
* 🗂 [MLOps cource](https://madewithml.com/#mlops) by Made With ML
* 🗂 [GitHub MLOps](https://mlops.githubapp.com) - collection of resources on how to facilitate Machine Learning Ops with GitHub
* 🗂 [ML Observability Fundamentals Course](https://arize.com/ml-observability-fundamentals/) Learn how to monitor and root-cause issues with production NLP models
#### MLOps Communities
* [The MLOps Community](https://mlops.community/) - blogs, slack group, newsletter and more all about MLOps
#### Data Versioning
* ⭐ [DVC](https://dvc.org/) - Data Version Control (DVC) tracks ML models and data sets [Free and Open Source] [Link to GitHub](https://github.com/iterative/dvc)
* 🔱 [Weights & Biases](https://wandb.ai/site) - tools for experiment tracking and dataset versioning [Paid Service]
* 🔱 [Pachyderm](https://www.pachyderm.com/) - version control for data with the tools to build scalable end-to-end ML/AI pipelines [Paid Service with Free Tier]
#### Experiment Tracking
* ⭐ [mlflow](https://mlflow.org/) - open source platform for the machine learning lifecycle [Free and Open Source] [Link to GitHub](https://github.com/mlflow/mlflow/)
* 🔱 [Weights & Biases](https://wandb.ai/site) - tools for experiment tracking and dataset versioning [Paid Service]
* 🔱 [Neptune AI](https://neptune.ai/) - experiment tracking and model registry built for research and production teams [Paid Service]
* 🔱 [Comet ML](https://www.comet.ml/site/) - enables data scientists and teams to track, compare, explain and optimize experiments and models [Paid Service]
* 🔱 [SigOpt](https://sigopt.com/) - automate training & tuning, visualize & compare runs [Paid Service]
* ⭐ [Optuna](https://github.com/optuna/optuna) - hyperparameter optimization framework [GitHub, 7255 stars]
* ⭐ [Clear ML](https://clear.ml/) - experiment, orchestrate, deploy, and build data stores, all in one place [Free and Open Source] [Link to GitHub](https://github.com/allegroai/clearml/)
* ⭐ [Metaflow](https://github.com/Netflix/metaflow) - human-friendly Python/R library that helps scientists and engineers build and manage real-life data science projects [GitHub, 6187 stars]
##### Model Registry
* ⭐ [DVC](https://dvc.org/) - Data Version Control (DVC) tracks ML models and data sets [Free and Open Source] [Link to GitHub](https://github.com/iterative/dvc)
* ⭐ [mlflow](https://mlflow.org/) - open source platform for the machine learning lifecycle [Free and Open Source] [Link to GitHub](https://github.com/mlflow/mlflow/)
* ⭐ [ModelDB](https://github.com/VertaAI/modeldb) - open-source system for Machine Learning model versioning, metadata, and experiment management [GitHub, 1530 stars]
* 🔱 [Neptune AI](https://neptune.ai/) - experiment tracking and model registry built for research and production teams [Paid Service]
* 🔱 [Valohai](https://valohai.com/) - End-to-end ML pipelines [Paid Service]
* 🔱 [Pachyderm](https://www.pachyderm.com/) - version control for data with the tools to build scalable end-to-end ML/AI pipelines [Paid Service with Free Tier]
* 🔱 [polyaxon](https://polyaxon.com/) - reproduce, automate, and scale your data science workflows with production-grade MLOps tools [Paid Service]
* 🔱 [Comet ML](https://www.comet.ml/site/) - enables data scientists and teams to track, compare, explain and optimize experiments and models [Paid Service]
#### Automated Testing and Behavioral Testing
* ⭐ [CheckList](https://github.com/marcotcr/checklist) - Beyond Accuracy: Behavioral Testing of NLP models [GitHub, 1806 stars]
* ⭐ [TextAttack](https://github.com/QData/TextAttack) - framework for adversarial attacks, data augmentation, and model training in NLP [GitHub, 2161 stars]
* ⭐ [WildNLP](https://github.com/MI2DataLab/WildNLP) - Corrupt an input text to test NLP models' robustness [GitHub, 74 stars]
* ⭐ [Great Expectations](https://github.com/great-expectations/great_expectations) - Write tests for your data [GitHub, 7703 stars]
* ⭐ [Deepchecks](https://github.com/deepchecks/deepchecks) - Python package for comprehensively validating your machine learning models and data [GitHub, 2254 stars]
#### Model Deployability and Serving
* ⭐ [mlflow](https://mlflow.org/) - open source platform for the machine learning lifecycle [Free and Open Source] [Link to GitHub](https://github.com/mlflow/mlflow/)
* 🔱 [Amazon SageMaker](https://aws.amazon.com/de/sagemaker/) [Paid Service]
* 🔱 [Valohai](https://valohai.com/) - End-to-end ML pipelines [Paid Service]
* 🔱 [NLP Cloud](https://nlpcloud.io/) - Production-ready NLP API [Paid Service]
* 🔱 [Saturn Cloud](https://saturncloud.io/) [Paid Service]
* 🔱 [SELDON](https://www.seldon.io/tech/) - machine learning deployment for enterprise [Paid Service]
* 🔱 [Comet ML](https://www.comet.ml/site/) - enables data scientists and teams to track, compare, explain and optimize experiments and models [Paid Service]
* 🔱 [polyaxon](https://polyaxon.com/) - reproduce, automate, and scale your data science workflows with production-grade MLOps tools [Paid Service]
* ⭐ [TorchServe](https://github.com/pytorch/serve) - flexible and easy to use tool for serving PyTorch models [GitHub, 3008 stars]
* 🔱 [Kubeflow](https://www.kubeflow.org/) - The Machine Learning Toolkit for Kubernetes [GitHub, 10600 stars]
* ⭐ [KFServing](https://github.com/kubeflow/kfserving) - Serverless Inferencing on Kubernetes [GitHub, 1841 stars]
* 🔱 [TFX](https://www.tensorflow.org/tfx) - TensorFlow Extended - end-to-end platform for deploying production ML pipelines [Paid Service]
* 🔱 [Pachyderm](https://www.pachyderm.com/) - version control for data with the tools to build scalable end-to-end ML/AI pipelines [Paid Service with Free Tier]
* 🔱 [Cortex](https://www.cortex.dev/) - containers as a service on AWS [Paid Service]
* 🔱 [Azure Machine Learning](https://azure.microsoft.com/en-us/services/machine-learning/#features) - end-to-end machine learning lifecycle [Paid Service]
* ⭐ [End2End Serverless Transformers On AWS Lambda](https://github.com/bhavsarpratik/serverless-transformers-on-aws-lambda) [GitHub, 110 stars]
* ⭐ [NLP-Service](https://github.com/karndeb/NLP-Service) - sample demo of NLP as a service platform built using FastAPI and Hugging Face [GitHub, 13 stars]
* 🔱 [Dagster](https://dagster.io/) - data orchestrator for machine learning [Free and Open Source]
* 🔱 [Verta](https://www.verta.ai/) - AI and machine learning deployment and operations [Paid Service]
* ⭐ [Metaflow](https://github.com/Netflix/metaflow) - human-friendly Python/R library that helps scientists and engineers build and manage real-life data science projects [GitHub, 6187 stars]
* ⭐ [flyte](https://github.com/flyteorg/flyte) - workflow automation platform for complex, mission-critical data and ML processes at scale [GitHub, 2887 stars]
* ⭐ [MLRun](https://github.com/mlrun/mlrun) - Machine Learning automation and tracking [GitHub, 856 stars]
* 🔱 [DataRobot MLOps](https://www.datarobot.com/platform/mlops/) - DataRobot MLOps provides a center of excellence for your production AI
#### Model Debugging
* ⭐ [imodels](https://github.com/csinva/imodels) - package for concise, transparent, and accurate predictive modeling [GitHub, 971 stars]
* ⭐ [Cockpit](https://github.com/f-dangel/cockpit) - A Practical Debugging Tool for Training Deep Neural Networks [GitHub, 416 stars]
#### Model Accuracy Prediction
* ⭐ [WeightWatcher](https://github.com/CalculatedContent/WeightWatcher) - WeightWatcher tool for predicting the accuracy of Deep Neural Networks [GitHub, 1028 stars]
#### Data and Model Observability
##### General
* ⭐ [Arize AI](https://arize.com/) - embedding drift monitoring for NLP models
* ⭐ [whylogs](https://github.com/whylabs/whylogs) - open source standard for data and ML logging [GitHub, 1907 stars]
* ⭐ [Rubrix](https://github.com/recognai/rubrix) - open-source tool for exploring and iterating on data for artificial intelligence projects [GitHub, 1450 stars]
* ⭐ [MLRun](https://github.com/mlrun/mlrun) - Machine Learning automation and tracking [GitHub, 856 stars]
* 🔱 [DataRobot MLOps](https://www.datarobot.com/platform/mlops/) - DataRobot MLOps provides a center of excellence for your production AI
* 🔱 [Cortex](https://www.cortex.dev/) - containers as a service on AWS [Paid Service]
##### Model Centric
* 🔱 [Algorithmia](https://algorithmia.com/) - minimize risk with advanced reporting and enterprise-grade security and governance across all data, models, and infrastructure [Paid Service]
* 🔱 [Dataiku](https://www.dataiku.com/) - dataiku is for teams who want to deliver advanced analytics using the latest techniques at big data scale [Paid Service]
* ⭐ [Evidently AI](https://evidentlyai.com/) - tools to analyze and monitor machine learning models [Free and Open Source] [Link to GitHub](https://github.com/evidentlyai/evidently)
* 🔱 [Fiddler](https://www.fiddler.ai/) - ML Model Performance Management Tool [Paid Service]
* 🔱 [Hydrosphere](https://hydrosphere.io/) - open-source platform for managing ML models [Paid Service]
* 🔱 [Verta](https://www.verta.ai/) - AI and machine learning deployment and operations [Paid Service]
* 🔱 [Domino Model Ops](https://www.dominodatalab.com/product/model-ops/) - Deploy and Manage Models to Drive Business Impact [Paid Service]
* 🔱 [iguazio](https://www.iguazio.com/) - deployment and management of your AI applications with MLOps and end-to-end automation of machine learning pipelines [Paid Service]
##### Data Centric
* 🔱 [Datafold](https://www.datafold.com/) - data quality through diffs, profiling, and anomaly detection [Paid Service]
* 🔱 [acceldata](https://www.acceldata.io/) - improve reliability, accelerate scale, and reduce costs across all data pipelines [Paid Service]
* 🔱 [Bigeye](https://www.bigeye.com/) - monitoring and alerting to your datasets in minutes [Paid Service]
* 🔱 [datakin](https://datakin.com/product/) - end-to-end, real-time data lineage solution [Paid Service]
* 🔱 [Monte Carlo](https://www.montecarlodata.com/) - data integrity, drifts, schema, lineage [Paid Service]
* 🔱 [SODA](https://www.soda.io/) - data monitoring, testing and validation [Paid Service]
* 🔱 [whatify](https://whatify.ai/) - data quality and action recommendation on it [Paid Service]
#### Feature Stores
* 🔱 [Tecton](https://www.tecton.ai/) - enterprise feature store for machine learning [Paid Service]
* ⭐ [FEAST](https://github.com/feast-dev/feast) - open source feature store for machine learning [Website](https://feast.dev/) [GitHub, 3792 stars]
* 🔱 [Hopsworks Feature Store](https://www.hopsworks.ai/feature-store) - data management system for managing machine learning features [Paid Service]
#### Metadata Management
* ⭐ [ML Metadata](https://github.com/google/ml-metadata) - a library for recording and retrieving metadata associated with ML developer and data scientist workflows [GitHub, 500 stars]
* 🔱 [Neptune AI](https://neptune.ai/) - experiment tracking and model registry built for research and production teams [Paid Service]
#### MLOps Frameworks
* ⭐ [Metaflow](https://github.com/Netflix/metaflow) - human-friendly Python/R library that helps scientists and engineers build and manage real-life data science projects [GitHub, 6187 stars]
* ⭐ [kedro](https://github.com/quantumblacklabs/kedro) - Python framework for creating reproducible, maintainable and modular data science code [GitHub, 7865 stars]
* ⭐ [Seldon Core](https://github.com/SeldonIO/seldon-core) - MLOps framework to package, deploy, monitor and manage thousands of production machine learning models [GitHub, 3503 stars]
* ⭐ [ZenML](https://github.com/maiot-io/zenml) - MLOps framework to create reproducible ML pipelines for production machine learning [GitHub, 2549 stars]
* 🔱 [Google Vertex AI](https://cloud.google.com/vertex-ai) - build, deploy, and scale ML models faster, with pre-trained and custom tooling within a unified AI platform [Paid Service]
* ⭐ [Diffgram](https://github.com/diffgram/diffgram) - Complete training data platform for machine learning delivered as a single application [GitHub, 1583 stars]
* 🔱 [Continual.ai](https://continual.ai/) - build, deploy, and operationalize ML models easier and faster with a declarative interface on cloud data warehouses like Snowflake, BigQuery, RedShift, and Databricks. [Paid Service]
### Transformer-based Architectures
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
#### General
* 📙 [Why BERT Fails in Commercial Environments](https://www.intel.com/content/www/us/en/artificial-intelligence/posts/bert-commercial-environments.html) by Intel AI [Blog, 2020]
* 📙 [Fine Tuning BERT for Text Classification with FARM](https://towardsdatascience.com/fine-tuning-bert-for-text-classification-with-farm-2880665065e2) by Sebastian Guggisberg [Blog, 2020]
* ⭐ [Pretrain Transformers Models in PyTorch using Hugging Face Transformers](https://github.com/gmihaila/ml_things/blob/master/notebooks/pytorch/pretrain_transformers_pytorch.ipynb) [GitHub, 186 stars]
* 🎥️ [Practical NLP for the Real World](https://www.infoq.com/presentations/practical-nlp/) [Presentation, 2019]
* 🎥️ [From Paper to Product – How we implemented BERT](https://www.youtube.com/watch?v=VnmKDPBQjJk) by Christoph Henkelmann [Talk, 2020]
##### Multi-GPU Transformers
* ⭐ [Parallelformers: An Efficient Model Parallelization Toolkit for Deployment](https://github.com/tunib-ai/parallelformers) [GitHub, 548 stars]
##### Training Transformers Effectively
* ⭐ [Training BERT with Compute/Time (Academic) Budget](https://github.com/IntelLabs/academic-budget-bert) [GitHub, 256 stars]
### Embeddings as a Service
* ⭐ [embedding-as-service](https://github.com/amansrivastava17/embedding-as-service) [GitHub, 176 stars]
* ⭐ [Bert-as-service](https://github.com/hanxiao/bert-as-service) [GitHub, 11035 stars]
### NLP Recipes Industrial Applications:
* ⭐ [NLP Recipes](https://github.com/microsoft/nlp-recipes) by [microsoft](https://github.com/microsoft) [GitHub, 6048 stars]
* ⭐ [NLP with Python](https://github.com/susanli2016/NLP-with-Python) by [susanli2016](https://github.com/susanli2016) [GitHub, 2454 stars]
* ⭐ [Basic Utilities for PyTorch NLP](https://github.com/PetrochukM/PyTorch-NLP) by [PetrochukM](https://github.com/PetrochukM) [GitHub, 2127 stars]
### NLP Applications in Bio, Finance, Legal and other industries
* ⭐ [Blackstone](https://github.com/ICLRandD/Blackstone) - A spaCy pipeline and model for NLP on unstructured legal text [GitHub, 573 stars]
* ⭐ [Sci spaCy](https://github.com/allenai/scispacy) - spaCy pipeline and models for scientific/biomedical documents [GitHub, 1279 stars]
* ⭐ [FinBERT: Pre-Trained on SEC Filings for Financial NLP Tasks](https://github.com/psnonis/FinBERT) [GitHub, 165 stars]
* ⭐ [LexNLP](https://github.com/LexPredict/lexpredict-lexnlp) - Information retrieval and extraction for real, unstructured legal text [GitHub, 555 stars]
* ⭐ [NerDL and NerCRF](https://github.com/JohnSnowLabs/spark-nlp-workshop/blob/master/tutorials/blogposts/data_prep.ipynb) - Tutorial on Named Entity Recognition for Healthcare with SparkNLP
* ⭐ [Legal Text Analytics](https://github.com/Liquid-Legal-Institute/Legal-Text-Analytics) - A list of selected resources dedicated to Legal Text Analytics [GitHub, 410 stars]
* ⭐ [BioIE](https://github.com/caufieldjh/awesome-bioie) - A curated list of resources relevant to doing Biomedical Information Extraction [GitHub, 222 stars]

-----
> __Note__
> Section keywords: speech recognition
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### General Speech Recognition
* ⭐ [wav2letter](https://github.com/facebookresearch/wav2letter) - Automatic Speech Recognition Toolkit [GitHub, 6149 stars]
* ⭐ [DeepSpeech](https://github.com/mozilla/DeepSpeech) - Baidu's DeepSpeech architecture [GitHub, 20639 stars]
* 📙 [Acoustic Word Embeddings](https://medium.com/@maobedkova/acoustic-word-embeddings-fc3f1a8f0519) by Maria Obedkova [Blog, 2020]
* ⭐ [kaldi](https://github.com/kaldi-asr/kaldi) - Kaldi is a toolkit for speech recognition [GitHub, 12177 stars]
* ⭐ [awesome-kaldi](https://github.com/YoavRamon/awesome-kaldi) - resources for using Kaldi [GitHub, 510 stars]
* ⭐ [ESPnet](https://github.com/espnet/espnet) - End-to-End Speech Processing Toolkit [GitHub, 5791 stars]
* 📙 [HuBERT](https://ai.facebook.com/blog/hubert-self-supervised-representation-learning-for-speech-recognition-generation-and-compression) - Self-supervised representation learning for speech recognition, generation, and compression [Blog, June 2021]
### Text to Speech
* ⭐ [FastSpeech](https://github.com/xcmyz/FastSpeech) - The Implementation of FastSpeech based on pytorch [GitHub, 746 stars]
* ⭐ [TTS](https://github.com/coqui-ai/TTS) - a deep learning toolkit for Text-to-Speech [GitHub, 7214 stars]
### Speech to Text
* ⭐ [whisper](https://github.com/openai/whisper) - Robust Speech Recognition via Large-Scale Weak Supervision, by OpenAI [GitHub, 17097 stars]
### Datasets
* ⭐ [VoxPopuli](https://github.com/facebookresearch/voxpopuli) - large-scale multilingual speech corpus for representation learning [GitHub, 392 stars]

-----
> __Note__
> Section keywords: topic modeling
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### Blogs
* 📙 [Topic Modelling with PySpark and Spark NLP](https://medium.com/trustyou-engineering/topic-modelling-with-pyspark-and-spark-nlp-a99d063f1a6e) by Maria Obedkova [Spark, Blog, 2020]
* 📙 [A Unique Approach to Short Text Clustering (Algorithmic Theory)](https://towardsdatascience.com/a-unique-approach-to-short-text-clustering-part-1-algorithmic-theory-4d4fad0882e1) by Brittany Bowers [Blog, 2020]
### Frameworks for Topic Modeling
* ⭐ [gensim](https://github.com/RaRe-Technologies/gensim) - framework for topic modeling [GitHub, 13760 stars]
* ⭐ [Spark NLP](https://github.com/JohnSnowLabs/spark-nlp) [GitHub, 3018 stars]
### Repositories
* ⭐ [Top2Vec](https://github.com/ddangelov/Top2Vec) [GitHub, 2325 stars]
* ⭐ [Anchored Correlation Explanation Topic Modeling](https://github.com/gregversteeg/CorEx) [GitHub, 289 stars]
* ⭐ [Topic Modeling in Embedding Spaces](https://github.com/adjidieng/ETM) [GitHub, 480 stars] [Paper](https://arxiv.org/abs/1907.04907)
* ⭐ [TopicNet](https://github.com/machine-intelligence-laboratory/TopicNet) - A high-level interface for BigARTM library [GitHub, 128 stars]
* ⭐ [BERTopic](https://github.com/MaartenGr/BERTopic) - Leveraging BERT and a class-based TF-IDF to create easily interpretable topics [GitHub, 3426 stars]
* ⭐ [OCTIS](https://github.com/MIND-Lab/OCTIS) - A python package to optimize and evaluate topic models [GitHub, 457 stars]
* ⭐ [Contextualized Topic Models](https://github.com/MilaNLProc/contextualized-topic-models) [GitHub, 968 stars]
* ⭐ [GSDMM](https://github.com/rwalk/gsdmm) - GSDMM: Short text clustering [GitHub, 305 stars]

-----
> __Note__
> Section keywords: keyword extraction
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### Text Rank
* ⭐ [PyTextRank](https://github.com/DerwenAI/pytextrank) - PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension [GitHub, 1933 stars]
* ⭐ [textrank](https://github.com/summanlp/textrank) - TextRank implementation for Python 3 [GitHub, 1158 stars]
### RAKE - Rapid Automatic Keyword Extraction
* ⭐ [rake-nltk](https://github.com/csurfer/rake-nltk) - Rapid Automatic Keyword Extraction algorithm using NLTK [GitHub, 956 stars]
* ⭐ [yake](https://github.com/LIAAD/yake) - Single-document unsupervised keyword extraction [GitHub, 1238 stars]
* ⭐ [RAKE-tutorial](https://github.com/zelandiya/RAKE-tutorial) - A python implementation of the Rapid Automatic Keyword Extraction [GitHub, 369 stars]
* ⭐ [rake-nltk](https://github.com/csurfer/rake-nltk) - Rapid Automatic Keyword Extraction algorithm using NLTK [GitHub, 956 stars]
### Other Approaches
* ⭐ [flashtext](https://github.com/vi3k6i5/flashtext) - Extract Keywords from sentence or Replace keywords in sentences [GitHub, 5318 stars]
* ⭐ [BERT-Keyword-Extractor](https://github.com/ibatra/BERT-Keyword-Extractor) - Deep Keyphrase Extraction using BERT [GitHub, 225 stars]
* ⭐ [keyBERT](https://github.com/MaartenGr/KeyBERT) - Minimal keyword extraction with BERT [GitHub, 1998 stars]
* ⭐ [KeyphraseVectorizers](https://github.com/TimSchopf/KeyphraseVectorizers) - vectorizers that extract keyphrases with part-of-speech patterns [GitHub, 117 stars]
### Further Reading
* 📙 [Adding a custom tokenizer to spaCy and extracting keywords from Chinese texts](https://howard-haowen.github.io/blog.ai/keyword-extraction/spacy/textacy/ckip-transformers/jieba/textrank/rake/2021/02/16/Adding-a-custom-tokenizer-to-spaCy-and-extracting-keywords.html) by Haowen Jiang [Blog, Feb 2021]
* 📙 [How to Extract Relevant Keywords with KeyBERT](https://towardsdatascience.com/how-to-extract-relevant-keywords-with-keybert-6e7b3cf889ae) [Blog, June 2021]

-----
> __Note__
> Section keywords: ethics, responsible NLP
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### NLP and ML Interpretability
#### NLP-centric
* [Explainability for Natural Language Processing - KDD'2021 Tutorial](https://www.youtube.com/watch?v=PvKOSYGclPk&t=2s) [Slides](https://www.slideshare.net/YunyaoLi/explainability-for-natural-language-processing-249992241) [Presentation, August 2021]
* ⭐ [ecco](https://github.com/jalammar/ecco) - Tools to visuals and explore NLP language models [GitHub, 1548 stars]
* ⭐ [NLP Profiler](https://github.com/neomatrix369/nlp_profiler) - A simple NLP library allows profiling datasets with text columns [GitHub, 223 stars]
* ⭐ [transformers-interpret](https://github.com/cdpierse/transformers-interpret) - Model explainability that works seamlessly with transformers [GitHub, 905 stars]
* ⭐ [Awesome-explainable-AI](https://github.com/wangyongjie-ntu/Awesome-explainable-AI) - collection of research materials on explainable AI/ML [GitHub, 780 stars]
* ⭐ [LAMA](https://github.com/facebookresearch/LAMA) - LAMA is a probe for analyzing the factual and commonsense knowledge contained in pretrained language models [GitHub, 956 stars]
#### General
* ⭐ [Language Interpretability Tool (LIT)](https://github.com/PAIR-code/lit) [GitHub, 3020 stars]
* ⭐ [WhatLies](https://github.com/RasaHQ/whatlies) - Toolkit to help visualise - what lies in word embeddings [GitHub, 435 stars]
* ⭐ [Interpret-Text](https://github.com/interpretml/interpret-text) - Interpretability techniques and visualization dashboards for NLP models [GitHub, 340 stars]
* ⭐ [InterpretML](https://github.com/interpretml/interpret) - Fit interpretable models. Explain blackbox machine learning [GitHub, 5155 stars]
* ⭐ [thermostat](https://github.com/DFKI-NLP/thermostat) - Collection of NLP model explanations and accompanying analysis tools [GitHub, 126 stars]
* ⭐ [Dodrio](https://github.com/poloclub/dodrio) - Exploring attention weights in transformer-based models with linguistic knowledge [GitHub, 245 stars]
* ⭐ [imodels](https://github.com/csinva/imodels) - package for concise, transparent, and accurate predictive modeling [GitHub, 971 stars]
### Ethics, Bias, and Equality in NLP
* 📙 [Bias in Natural Language Processing @EMNLP 2020](https://gaurav-maheshwari.medium.com/bias-in-natural-language-processing-emnlp-2020-8f1cb2806fcc#cc1a) [Blog, Nov 2020]
* 🎥️ [Machine Learning as a Software Engineering Enterprise](https://nips.cc/virtual/2020/public/invited_16166.html) - NeurIPS 2020 Keynote [Presentation, Dec 2020]
* 📙 [Computational Ethics for NLP](http://demo.clab.cs.cmu.edu/ethical_nlp/) - course resources from the Carnegie Mellon University [Lecture Notes, Spring 2020]
* 🗂️ [Ethics in NLP](https://aclweb.org/aclwiki/Ethics_in_NLP) - resources from ACLs Ethics in NLP track
* 🗂️ [The Institute for Ethical AI & Machine Learning](https://ethical.institute)
* 📙 [Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models](https://arxiv.org/abs/2102.02503) [Paper, Feb 2021]
* ⭐ [Fairness-in-AI](https://github.com/dreji18/Fairness-in-AI) - this package is used to detect and mitigate biases in NLP tasks [GitHub, 24 stars]
* ⭐ [nlg-bias](https://github.com/ewsheng/nlg-bias) - dataset + classifier tools to study social perception biases in natural language generation [GitHub, 46 stars]
* 🗂️ [bias-in-nlp](https://github.com/cisnlp/bias-in-nlp) - list of papers related to bias in NLP [GitHub, 9 stars]
### Adversarial Attacks for NLP
* 📙 [Privacy Considerations in Large Language Models](https://ai.googleblog.com/2020/12/privacy-considerations-in-large.html?m=1) [Blog, Dec 2020]
* ⭐ [DeepWordBug](https://github.com/QData/deepWordBug) - Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers [GitHub, 57 stars]
* ⭐ [Adversarial-Misspellings](https://github.com/danishpruthi/Adversarial-Misspellings) - Combating Adversarial Misspellings with Robust Word Recognition [GitHub, 57 stars]
### Hate Speech Analysis
* ⭐ [HateXplain](https://github.com/hate-alert/HateXplain) - BERT for detecting abusive language [GitHub, 135 stars]

-----
> __Note__
> Section keywords: frameworks
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
### General Purpose
* ⭐ [spaCy](https://github.com/explosion/spaCy) by Explosion AI [GitHub, 24708 stars]
* ⭐ [flair](https://github.com/flairNLP/flair) by Zalando [GitHub, 12278 stars]
* ⭐ [AllenNLP](https://github.com/allenai/allennlp) by AI2 [GitHub, 11314 stars]
* ⭐ [stanza](https://github.com/stanfordnlp/stanza) (former Stanford NLP) [GitHub, 6413 stars]
* ⭐ [spaCy stanza](https://github.com/explosion/spacy-stanza) [GitHub, 660 stars]
* ⭐ [nltk](https://github.com/nltk/nltk) [GitHub, 11280 stars]
* ⭐ [gensim](https://github.com/RaRe-Technologies/gensim) - framework for topic modeling [GitHub, 13760 stars]
* ⭐ [pororo](https://github.com/kakaobrain/pororo) - Platform of neural models for natural language processing [GitHub, 1164 stars]
* ⭐ [NLP Architect](https://github.com/NervanaSystems/nlp-architect) - A Deep Learning NLP/NLU library by Intel® AI Lab [GitHub, 2883 stars]
* ⭐ [FARM](https://github.com/deepset-ai/FARM) [GitHub, 1597 stars]
* ⭐ [gobbli](https://github.com/RTIInternational/gobbli) by RTI International [GitHub, 268 stars]
* ⭐ [headliner](https://github.com/as-ideas/headliner) - training and deployment of seq2seq models [GitHub, 231 stars]
* ⭐ [SyferText](https://github.com/OpenMined/SyferText) - A privacy preserving NLP framework [GitHub, 190 stars]
* ⭐ [DeText](https://github.com/linkedin/detext) - Text Understanding Framework for Ranking and Classification Tasks [GitHub, 1230 stars]
* ⭐ [TextHero](https://github.com/jbesomi/texthero) - Text preprocessing, representation and visualization [GitHub, 2635 stars]
* ⭐ [textblob](https://github.com/sloria/textblob) - TextBlob: Simplified Text Processing [GitHub, 8373 stars]
* ⭐ [AdaptNLP](https://github.com/Novetta/adaptnlp) - A high level framework and library for NLP [GitHub, 407 stars]
* ⭐ [textacy](https://github.com/chartbeat-labs/textacy) - NLP, before and after spaCy [GitHub, 1999 stars]
* ⭐ [texar](https://github.com/asyml/texar) - Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow [GitHub, 2323 stars]
* ⭐ [jiant](https://github.com/nyu-mll/jiant) - jiant is an NLP toolkit [GitHub, 1449 stars]
### Data Augmentation
* ⭐ [WildNLP](https://github.com/MI2DataLab/WildNLP) Text manipulation library to test NLP models [GitHub, 74 stars]
* ⭐ [snorkel](https://github.com/snorkel-team/snorkel) Framework to generate training data [GitHub, 5338 stars]
* ⭐ [NLPAug](https://github.com/makcedward/nlpaug) Data augmentation for NLP [GitHub, 3665 stars]
* ⭐ [SentAugment](https://github.com/facebookresearch/SentAugment) Data augmentation by retrieving similar sentences from larger datasets [GitHub, 361 stars]
* ⭐ [faker](https://github.com/joke2k/faker) - Python package that generates fake data for you [GitHub, 15129 stars]
* ⭐ [textflint](https://github.com/textflint/textflint) - Unified Multilingual Robustness Evaluation Toolkit for NLP [GitHub, 585 stars]
* ⭐ [Parrot](https://github.com/PrithivirajDamodaran/Parrot_Paraphraser) - Practical and feature-rich paraphrasing framework [GitHub, 636 stars]
* ⭐ [AugLy](https://github.com/facebookresearch/AugLy) - data augmentations library for audio, image, text, and video [GitHub, 4616 stars]
* ⭐ [TextAugment](https://github.com/dsfsi/textaugment) - Python 3 library for augmenting text for natural language processing applications [GitHub, 290 stars]
### Adversarial NLP Attacks & Behavioral Testing
* ⭐ [TextAttack](https://github.com/QData/TextAttack) - framework for adversarial attacks, data augmentation, and model training in NLP [GitHub, 2161 stars]
* ⭐ [CleverHans](https://github.com/tensorflow/cleverhans) - adversarial example library for constructing NLP attacks and building defenses [GitHub, 5660 stars]
* ⭐ [CheckList](https://github.com/marcotcr/checklist) - Beyond Accuracy: Behavioral Testing of NLP models [GitHub, 1806 stars]
### Transformer-oriented
* ⭐ [transformers](https://github.com/huggingface/transformers) by HuggingFace [GitHub, 75428 stars]
* ⭐ [Adapter Hub](https://github.com/Adapter-Hub/adapter-transformers) and its [documentation](https://docs.adapterhub.ml/index.html) - Adapter modules for Transformers [GitHub, 1110 stars]
* ⭐ [haystack](https://github.com/deepset-ai/haystack) - Transformers at scale for question answering & neural search. [GitHub, 6147 stars]
### Dialog Systems and Speech
* ⭐ [DeepPavlov](https://github.com/deepmipt/DeepPavlov) by MIPT [GitHub, 5933 stars]
* ⭐ [ParlAI](https://github.com/facebookresearch/ParlAI) by FAIR [GitHub, 9640 stars]
* ⭐ [rasa](https://github.com/RasaHQ/rasa) - Framework for Conversational Agents [GitHub, 15150 stars]
* ⭐ [wav2letter](https://github.com/facebookresearch/wav2letter) - Automatic Speech Recognition Toolkit [GitHub, 6149 stars]
* ⭐ [ChatterBot](https://github.com/gunthercox/ChatterBot) - conversational dialog engine for creating chat bots [GitHub, 12696 stars]
* ⭐ [SpeechBrain](https://github.com/speechbrain/speechbrain) - open-source and all-in-one speech toolkit based on PyTorch [GitHub, 4935 stars]
### Word/Sentence-embeddings oriented
* ⭐ [MUSE](https://github.com/facebookresearch/MUSE) A library for Multilingual Unsupervised or Supervised word Embeddings [GitHub, 3021 stars]
* ⭐ [vecmap](https://github.com/artetxem/vecmap) A framework to learn cross-lingual word embedding mappings [GitHub, 604 stars]
* ⭐ [sentence-transformers](https://github.com/UKPLab/sentence-transformers) - Multilingual Sentence & Image Embeddings with BERT [GitHub, 8944 stars]
### Social Media Oriented
* ⭐ [Ekphrasis](https://github.com/cbaziotis/ekphrasis) - text processing tool, geared towards text from social networks [GitHub, 592 stars]
### Phonetics
* ⭐ [DeepPhonemizer](https://github.com/as-ideas/DeepPhonemizer) - grapheme to phoneme conversion with deep learning [GitHub, 197 stars]
### Morphology
* ⭐ [LemmInflect](https://github.com/bjascob/LemmInflect) - python module for English lemmatization and inflection [GitHub, 186 stars]
* ⭐ [Inflect](https://github.com/jaraco/inflect) - generate plurals, ordinals, indefinite articles [GitHub, 757 stars]
* ⭐ [simplemma](https://github.com/jaraco/inflect) - simple multilingual lemmatizer for Python [GitHub, 757 stars]
### Multi-lingual tools
* ⭐ [polyglot](https://github.com/aboSamoor/polyglot) - Multi-lingual NLP Framework [GitHub, 2086 stars]
* ⭐ [trankit](https://github.com/nlp-uoregon/trankit) - Light-Weight Transformer-based Python Toolkit for Multilingual NLP [GitHub, 649 stars]
### Distributed NLP / Multi-GPU NLP
* ⭐ [Spark NLP](https://github.com/JohnSnowLabs/spark-nlp) [GitHub, 3018 stars]
* ⭐ [Parallelformers: An Efficient Model Parallelization Toolkit for Deployment](https://github.com/tunib-ai/parallelformers) [GitHub, 548 stars]
### Machine Translation
* ⭐ [COMET](https://github.com/Unbabel/COMET) -A Neural Framework for MT Evaluation [GitHub, 191 stars]
* ⭐ [marian-nmt](https://github.com/marian-nmt/marian) - Fast Neural Machine Translation in C++ [GitHub, 974 stars]
* ⭐ [argos-translate](https://github.com/argosopentech/argos-translate) - Open source neural machine translation in Python [GitHub, 1535 stars]
* ⭐ [Opus-MT](https://github.com/Helsinki-NLP/Opus-MT) - Open neural machine translation models and web services [GitHub, 257 stars]
* ⭐ [dl-translate](https://github.com/xhlulu/dl-translate) - A deep learning-based translation library built on Huggingface transformers [GitHub, 241 stars]
### Entity and String Matching
* ⭐ [PolyFuzz](https://github.com/MaartenGr/PolyFuzz) - Fuzzy string matching, grouping, and evaluation [GitHub, 589 stars]
* ⭐ [pyahocorasick](https://github.com/WojciechMula/pyahocorasick) - Python module implementing Aho-Corasick algorithm for string matching [GitHub, 757 stars]
* ⭐ [fuzzywuzzy](https://github.com/seatgeek/fuzzywuzzy) - Fuzzy String Matching in Python [GitHub, 8776 stars]
* ⭐ [jellyfish](https://github.com/jamesturk/jellyfish) - approximate and phonetic matching of strings [GitHub, 1759 stars]
* ⭐ [textdistance](https://github.com/life4/textdistance) - Compute distance between sequences [GitHub, 3000 stars]
* ⭐ [DeepMatcher](https://github.com/anhaidgroup/deepmatcher) - Compute distance between sequences [GitHub, 457 stars]
* ⭐ [RE2](https://github.com/alibaba-edu/simple-effective-text-matching) - Simple and Effective Text Matching with Richer Alignment Features [GitHub, 336 stars]
* ⭐ [Machamp](https://github.com/megagonlabs/machamp) - Machamp: A Generalized Entity Matching Benchmark [GitHub, 9 stars]
### Discourse Analysis
* ⭐ [ConvoKit](https://github.com/CornellNLP/Cornell-Conversational-Analysis-Toolkit) - Cornell Conversational Analysis Toolkit [GitHub, 399 stars]
### PII scrubbing
* ⭐ [scrubadub](https://github.com/LeapBeyond/scrubadub) - Clean personally identifiable information from dirty dirty text [GitHub, 309 stars]
### Hastag Segmentation
* ⭐ [hashformers](https://github.com/ruanchaves/hashformers) - automatically inserting the missing spaces between the words in a hashtag [GitHub, 41 stars]
### Books Analysis / Literary Analysis
* ⭐ [booknlp](https://github.com/booknlp/booknlp) - a natural language processing pipeline that scales to books and other long documents (in English) [GitHub, 647 stars]
* ⭐ [bookworm](https://github.com/harrisonpim/bookworm) - ingests novels, builds an implicit character network and a deeply analysable graph [GitHub, 73 stars]
### Non-English oriented
#### Japanese
* ⭐ [fugashi](https://github.com/polm/fugashi) - Cython MeCab wrapper for fast, pythonic Japanese tokenization and morphological analysis [GitHub, 268 stars]
* ⭐ [SudachiPy](https://github.com/WorksApplications/SudachiPy) - SudachiPy is a Python version of Sudachi, a Japanese morphological analyzer [GitHub, 330 stars]
* ⭐ [Konoha](https://github.com/himkt/konoha) - easy-to-use Japanese Text Processing tool, which makes it possible to switch tokenizers with small changes of code [GitHub, 182 stars]
* ⭐ [jProcessing](https://github.com/kevincobain2000/jProcessing) - Japanese Natural Langauge Processing Libraries [GitHub, 142 stars]
* ⭐ [Ginza](https://github.com/megagonlabs/ginza) - Japanese NLP Library using spaCy as framework based on Universal Dependencies [GitHub, 620 stars]
* ⭐ [kuromoji](https://github.com/atilika/kuromoji) - self-contained and very easy to use Japanese morphological analyzer designed for search [GitHub, 847 stars]
* ⭐ [nagisa](https://github.com/taishi-i/nagisa) - Japanese tokenizer based on recurrent neural networks [GitHub, 321 stars]
* ⭐ [KyTea](https://github.com/neubig/kytea) - Kyoto Text Analysis Toolkit for word segmentation and pronunciation estimation [GitHub, 190 stars]
* ⭐ [Jigg](https://github.com/mynlp/jigg) - Pipeline framework for easy natural language processing [GitHub, 72 stars]
* ⭐ [Juman++](https://github.com/ku-nlp/jumanpp) - Juman++ (a Morphological Analyzer Toolkit) [GitHub, 321 stars]
* ⭐ [RakutenMA](https://github.com/rakuten-nlp/rakutenma) - morphological analyzer (word segmentor + PoS Tagger) for Chinese and Japanese written purely in JavaScript [GitHub, 447 stars]
* ⭐ [toiro](https://github.com/taishi-i/toiro) - a comparison tool of Japanese tokenizers [GitHub, 105 stars]
#### Thai
* ⭐ [AttaCut](https://github.com/PyThaiNLP/attacut) - Fast and Reasonably Accurate Word Tokenizer for Thai [GitHub, 68 stars]
* ⭐ [ThaiLMCut](https://github.com/meanna/ThaiLMCUT) - Word Tokenizer for Thai Language [GitHub, 15 stars]
#### Chinese
* ⭐ [Spacy-pkuseg](https://github.com/explosion/spacy-pkuseg) - The pkuseg toolkit for multi-domain Chinese word segmentation [GitHub, 20 stars]
#### Other
* ⭐ [textblob-de](https://github.com/markuskiller/textblob-de) - TextBlob: Simplified Text Processing for German [GitHub, 95 stars]
* ⭐ [Kashgari](https://github.com/BrikerMan/Kashgari) Transfer Learning with focus on Chinese [GitHub, 2333 stars]
* ⭐ [Underthesea](https://github.com/undertheseanlp/underthesea) - Vietnamese NLP Toolkit [GitHub, 1057 stars]
* ⭐ [PTT5](https://github.com/unicamp-dl/PTT5) - Pretraining and validating the T5 model on Brazilian Portuguese data [GitHub, 62 stars]
### Text Data Labelling
* ⭐ [Small-Text](https://github.com/webis-de/small-text) - Active Learning for Text Classifcation in Python [GitHub, 369 stars]
* ⭐ [Doccano](https://github.com/doccano/doccano) - open source annotation tool for machine learning practitioners [GitHub, 7005 stars]
* 🔱 [Prodigy](https://prodi.gy/) - annotation tool powered by active learning [Paid Service]

-----
> __Note__
> Section keywords: learn NLP
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
#### General
* 📙 [Learn NLP the practical way](https://towardsdatascience.com/learn-nlp-the-practical-way-b854ce1035c4) [Blog, Nov. 2019]
* 📙 [Learn NLP the Stanford way](https://towardsdatascience.com/learn-nlp-the-stanford-way-lesson-1-3f1844265760) ([+Part 2](https://towardsdatascience.com/learn-nlp-the-stanford-way-lesson-2-7447f2c12b36)) [Blog, Nov 2020]
* 📙 [Choosing the right course for a Practical NLP Engineer](https://airev.us/ultimate-guide-to-natural-language-processing-courses/)
* 📙 [12 Best Natural Language Processing Courses & Tutorials to Learn Online](https://blog.coursesity.com/best-natural-language-processing-courses/)
* ⭐ [Treasure of Transformers](https://github.com/ashishpatel26/Treasure-of-Transformers) - Natural Language processing papers, videos, blogs, official repos along with colab Notebooks [GitHub, 563 stars]
* 🎥️ [Rasa Algorithm Whiteboard](https://www.youtube.com/playlist?list=PL75e0qA87dlG-za8eLI6t0_Pbxafk-cxb) - YouTube series by Rasa explaining various Data Science and NLP Algorithms
* 🎥️ [ExplosionAI Videos](https://www.youtube.com/c/ExplosionAI/videos) - YouTube series by ExplosionAI teaching you how to use spacy and apply it for NLP
#### Courses
* 🎥️ [CS25: Transformers United Stanford - Fall 2021](https://web.stanford.edu/class/cs25/) [Course, Fall 2021]
* 📙 [NLP Course | For You](https://lena-voita.github.io/nlp_course.html) - Great and interactive course on NLP
* 📙 [OpenClass NLP](https://openclass.ai/catalog/nlp) - Natural language processing (NLP) assignments
* 📙 [Advanced NLP with spaCy](https://course.spacy.io/en/) - how to use spaCy to build advanced natural language understanding systems
* 📙 [Transformer models for NLP](https://huggingface.co/course/chapter1) by HuggingFace
* 🎥️ [Stanford NLP Seminar](https://nlp.stanford.edu/seminar/) - slides from the Stanford NLP course
#### Books
* 📙 [Natural Language Processing with Transformers](https://www.buecher.de/shop/maschinelles-lernen/natural-language-processing-with-transformers/tunstall-lewis-von-werra-leandro-wolf-thomas/products_products/detail/prod_id/64140211/) - [Book, February 2022]
* 📙 [Applied Natural Language Processing in the Enterprise](https://www.oreilly.com/library/view/applied-natural-language/9781492062561/) - [Book, May 2021]
* 📙 [Practical Natural Language Processing](https://www.oreilly.com/library/view/practical-natural-language/9781492054047/) - [Book, June 2020]
* 📙 [Dive into Deep Learning](https://d2l.ai/index.html) - An interactive deep learning book with code, math, and discussions
* 📙 [Natural Language Processing and Computational Linguistics](https://www.amazon.de/Natural-Language-Processing-Computational-Linguistics/dp/1848218486) - Speech, Morphology and Syntax (Cognitive Science)
* 📙 [Top NLP Books to Read 2020](https://towardsdatascience.com/top-nlp-books-to-read-2020-12012ef41dc1) - Blog post by Raymong Cheng [Blog, Sep 2020]
#### Tutorials
* ⭐ [nlp-tutorial](https://github.com/lyeoni/nlp-tutorial) - A list of NLP(Natural Language Processing) tutorials built on PyTorch [GitHub, 1324 stars]
* ⭐ [nlp-tutorial](https://github.com/graykode/nlp-tutorial) - Natural Language Processing Tutorial for Deep Learning Researchers [GitHub, 11796 stars]
* ⭐ [Hands-On NLTK Tutorial](https://github.com/hb20007/hands-on-nltk-tutorial) [GitHub, 506 stars]
* ⭐ [Modern Practical Natural Language Processing](https://github.com/jmugan/modern_practical_nlp) [GitHub, 260 stars]
* ⭐ [Transformers-Tutorials](https://github.com/NielsRogge/Transformers-Tutorials) - demos with the Transformers library by HuggingFace [GitHub, 3408 stars]
* 🗂️ [CalmCode Tutorials](https://calmcode.io/#science) - Set of Python Data Science Tutorials

-----
* [r/LanguageTechnology](https://www.reddit.com/r/LanguageTechnology/) - NLP Reddit forum

-----
[🔙 Back to the Table of Contents](https://github.com/ivan-bilan/The-NLP-Pandect#table-of-contents)
#### Tokenization
* ⭐ [tokenizers](https://github.com/huggingface/tokenizers) - Fast State-of-the-Art Tokenizers optimized for Research and Production [GitHub, 6064 stars]
* ⭐ [SentencePiece](https://github.com/google/sentencepiece) - Unsupervised text tokenizer for Neural Network-based text generation [GitHub, 6316 stars]
* ⭐ [SoMaJo](https://github.com/tsproisl/SoMaJo) - A tokenizer and sentence splitter for German and English web and social media texts [GitHub, 108 stars]
#### Data Augmentation and Weak Supervision
##### Libraries and Frameworks
* ⭐ [WildNLP](https://github.com/MI2DataLab/WildNLP) Text manipulation library to test NLP models [GitHub, 74 stars]
* ⭐ [NLPAug](https://github.com/makcedward/nlpaug) Data augmentation for NLP [GitHub, 3665 stars]
* ⭐ [SentAugment](https://github.com/facebookresearch/SentAugment) Data augmentation by retrieving similar sentences from larger datasets [GitHub, 361 stars]
* ⭐ [TextAttack](https://github.com/QData/TextAttack) - framework for adversarial attacks, data augmentation, and model training in NLP [GitHub, 2161 stars]
* ⭐ [skweak](https://github.com/NorskRegnesentral/skweak) - software toolkit for weak supervision applied to NLP tasks [GitHub, 843 stars]
* ⭐ [NL-Augmenter](https://github.com/GEM-benchmark/NL-Augmenter) - Collaborative Repository of Natural Language Transformations [GitHub, 679 stars]
* ⭐ [EDA](https://github.com/jasonwei20/eda_nlp) - Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks [GitHub, 1356 stars]
* ⭐ [snorkel](https://github.com/snorkel-team/snorkel) Framework to generate training data [GitHub, 5338 stars]
##### Reading Material and Tutorials
* ⭐ [A Survey of Data Augmentation Approaches for NLP](https://arxiv.org/abs/2105.03075) [Paper, May 2021] [GitHub Link](https://github.com/styfeng/DataAug4NLP)
* 📙 [A Visual Survey of Data Augmentation in NLP](https://amitness.com/2020/05/data-augmentation-for-nlp/) [Blog, 2020]
* 📙 [Weak Supervision: A New Programming Paradigm for Machine Learning](http://ai.stanford.edu/blog/weak-supervision/) [Blog, March 2019]
#### Named Entity Recognition (NER)
* ⭐ [Datasets for Entity Recognition](https://github.com/juand-r/entity-recognition-datasets) [GitHub, 1255 stars]
* ⭐ [Datasets to train supervised classifiers for Named-Entity Recognition](https://github.com/davidsbatista/NER-datasets) [GitHub, 297 stars]
* ⭐ [Bootleg](https://github.com/HazyResearch/bootleg) - Self-Supervision for Named Entity Disambiguation at the Tail [GitHub, 189 stars]
* ⭐ [Few-NERD](https://github.com/thunlp/Few-NERD) - Large-scale, fine-grained manually annotated named entity recognition dataset [GitHub, 318 stars]
#### Relation Extraction
* ⭐ [tacred-relation](https://github.com/yuhaozhang/tacred-relation) TACRED: position-aware attention model for relation extraction [GitHub, 336 stars]
* ⭐ [tacrev](https://github.com/DFKI-NLP/tacrev) TACRED Revisited: A Thorough Evaluation of the TACRED Relation Extraction Task [GitHub, 55 stars]
* ⭐ [tac-self-attention](https://github.com/ivan-bilan/tac-self-attention) Relation extraction with position-aware self-attention [GitHub, 64 stars]
* ⭐ [Re-TACRED](https://github.com/gstoica27/Re-TACRED) Re-TACRED: Addressing Shortcomings of the TACRED Dataset [GitHub, 39 stars]
#### Coreference Resolution
* ⭐ [NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks](https://github.com/huggingface/neuralcoref) by HuggingFace [GitHub, 2627 stars]
* ⭐ [coref](https://github.com/mandarjoshi90/coref) - BERT and SpanBERT for Coreference Resolution [GitHub, 399 stars]
#### Sentiment Analysis
* ⭐ [Reading list for Awesome Sentiment Analysis papers](https://github.com/declare-lab/awesome-sentiment-analysis) by [declare-lab](https://github.com/declare-lab) [GitHub, 475 stars]
* ⭐ [Awesome Sentiment Analysis](https://github.com/xiamx/awesome-sentiment-analysis) by [xiamx](https://github.com/xiamx) [GitHub, 884 stars]
#### Domain Adaptation
* ⭐ [Neural Adaptation in Natural Language Processing - curated list](https://github.com/bplank/awesome-neural-adaptation-in-NLP) [GitHub, 246 stars]
#### Low Resource NLP
* ⭐ [CMU LTI Low Resource NLP Bootcamp 2020](https://github.com/neubig/lowresource-nlp-bootcamp-2020) - CMU Language Technologies Institute low resource NLP bootcamp 2020 [GitHub, 555 stars]
#### Spell Correction / Error Correction
* ⭐ [Gramformer](https://github.com/PrithivirajDamodaran/Gramformer) - ramework for detecting, highlighting and correcting grammatical errors [GitHub, 1244 stars]
* ⭐ [NeuSpell](https://github.com/neuspell/neuspell) - A Neural Spelling Correction Toolkit [GitHub, 515 stars]
* ⭐ [SymSpellPy](https://github.com/mammothb/symspellpy) - Python port of SymSpell [GitHub, 641 stars]
* 📙 [Speller100](https://www.microsoft.com/en-us/research/blog/speller100-zero-shot-spelling-correction-at-scale-for-100-plus-languages/) by Microsoft [Blog, Feb 2021]
* ⭐ [JamSpell](https://github.com/bakwc/JamSpell) - spell checking library - accurate, fast, multi-language [GitHub, 527 stars]
* ⭐ [pycorrector](https://github.com/shibing624/pycorrector) - spell correction for Chinese [GitHub, 3714 stars]
* ⭐ [contractions](https://github.com/kootenpv/contractions) - Fixes contractions such as `you're` to you `are` [GitHub, 262 stars]
#### Style Transfer for NLP
* ⭐ [Styleformer](https://github.com/PrithivirajDamodaran/Styleformer) - Neural Language Style Transfer framework [GitHub, 427 stars]
* ⭐ [StylePTB](https://github.com/lvyiwei1/StylePTB) - A Compositional Benchmark for Fine-grained Controllable Text Style Transfer [GitHub, 51 stars]
#### Automata Theory for NLP
* ⭐ [pyahocorasick](https://github.com/WojciechMula/pyahocorasick) - Python module implementing Aho-Corasick algorithm for string matching [GitHub, 757 stars]
#### Obscene words detection
* ⭐ [LDNOOBW](https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words) - List of Dirty, Naughty, Obscene, and Otherwise Bad Words [GitHub, 1988 stars]
#### Reddit Analysis
* ⭐ [Subreddit Analyzer](https://github.com/PhantomInsights/subreddit-analyzer) - comprehensive Data and Text Mining workflow for submissions and comments from any given public subreddit [GitHub, 483 stars]
#### Skill Detection
* ⭐ [SkillNER](https://github.com/AnasAito/SkillNER) - rule based NLP module to extract job skills from text [GitHub, 71 stars]
#### Reinforcement Learning for NLP
* ⭐ [nlp-gym](https://github.com/rajcscw/nlp-gym) - NLPGym - A toolkit to develop RL agents to solve NLP tasks [GitHub, 132 stars]
#### AutoML / AutoNLP
* ⭐ [AutoNLP](https://github.com/huggingface/autonlp) - Faster and easier training and deployments of SOTA NLP models [GitHub, 689 stars]
* ⭐ [TPOT](https://github.com/EpistasisLab/tpot) - Python Automated Machine Learning tool [GitHub, 8826 stars]
* ⭐ [Auto-PyTorch](https://github.com/automl/Auto-PyTorch) - Automatic architecture search and hyperparameter optimization for PyTorch [GitHub, 1862 stars]
* ⭐ [HungaBunga](https://github.com/ypeleg/HungaBunga) - Brute-Force all sklearn models with all parameters using .fit .predict [GitHub, 674 stars]
* 🔱 [AutoML Natural Language](https://cloud.google.com/natural-language/automl/docs) - Google's paid AutoML NLP service
* ⭐ [Optuna](https://github.com/optuna/optuna) - hyperparameter optimization framework [GitHub, 7255 stars]
* ⭐ [FLAML](https://github.com/microsoft/FLAML) - fast and lightweight AutoML library [GitHub, 2154 stars]
* ⭐ [Gradsflow](https://github.com/gradsflow/gradsflow) - open-source AutoML & PyTorch Model Training Library [GitHub, 289 stars]
#### OCR - Optical Character Recognition
* 🎥️ [A framework for designing document processing solutions](https://ljvmiranda921.github.io/notebook/2022/06/19/document-processing-framework/) [Blog, June 2022]
#### Document AI
* 📙 [Table Transformer](https://huggingface.co/docs/transformers/main/model_doc/table-transformer) + [HuggingFace Models](https://huggingface.co/models?other=table-transformer)
#### Text Generation
* ⭐ [keytotext](https://github.com/gagan3012/keytotext) - a model which will take keywords as inputs and generate sentences as outputs [GitHub, 353 stars]
* 📙 [Controllable Neural Text Generation](https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html) [Blog, Jan 2021]
* ⭐ [BARTScore](https://github.com/neulab/BARTScore) Evaluating Generated Text as Text Generation [GitHub, 192 stars]
#### Title / Headlines Generation
* ⭐ [TitleStylist](https://github.com/jind11/TitleStylist) Learning to Generate Headlines with Controlled Styles [GitHub, 72 stars]
#### NLP research reproducibility
* 📙 [A Systematic Review of Reproducibility Research in Natural Language Processing](https://arxiv.org/abs/2103.07929) [Paper, March 2021]
## License [CC0](./LICENSE)
## Attributions
#### Resources
* All linked resources belong to original authors
#### Icons
* [Akropolis](https://thenounproject.com/search/?q=ancient%20greek&i=403786) by parkjisun from the [Noun Project](https://thenounproject.com)
* [Book](https://thenounproject.com/icon/304884/) of Ester by Gilad Sotil from the [Noun Project](https://thenounproject.com)
* [quill](https://thenounproject.com/term/quill/17013/) by Juan Pablo Bravo from the [Noun Project](https://thenounproject.com)
* [acting](https://thenounproject.com/term/acting/2369397/) by Flatart from the [Noun Project](https://thenounproject.com)
* [olympic](https://thenounproject.com/term/olympic/1870751/) by supalerk laipawat from the [Noun Project](https://thenounproject.com)
* [aristocracy](https://thenounproject.com/eucalyp/collection/ancient-greece-line/?i=3156156) by Eucalyp from the [Noun Project](https://thenounproject.com)
* [Horn](https://thenounproject.com/eucalyp/collection/ancient-greece-line/?i=3156640) by Eucalyp from the [Noun Project](https://thenounproject.com)
* [temple](https://thenounproject.com/eucalyp/collection/ancient-greece-line/?i=3156638) by Eucalyp from the [Noun Project](https://thenounproject.com)
* [constellation](https://thenounproject.com/eucalyp/collection/ancient-greece-glyph/?i=3156142) by Eucalyp from the [Noun Project](https://thenounproject.com)
* [ancient greek round pattern](https://thenounproject.com/term/ancient-greek-round-pattern/2048889/) by Olena Panasovska from the [Noun Project](https://thenounproject.com)
* Harp by Vectors Point from the [Noun Project](https://thenounproject.com)
* [Atlas](https://thenounproject.com/naripuru/collection/ancient-gods/?i=2225785) by parkjisun from the [Noun Project](https://thenounproject.com)
* [Parthenon](https://thenounproject.com/eucalyp/collection/ancient-greece-line/?i=3158942) by Eucalyp from the [Noun Project](https://thenounproject.com)
* [papyrus](https://thenounproject.com/iconmark/collection/greek-mythology/?i=3515982) by IconMark from the [Noun Project](https://thenounproject.com)
* [papyrus](https://thenounproject.com/search/?q=papyrus&i=2239368) by Smalllike from the [Noun Project](https://thenounproject.com)
* [pegasus](https://thenounproject.com/search/?q=pegasus&i=2266449) by Saeful Muslim from the [Noun Project](https://thenounproject.com)
#### Fonts
* [Dalek Font](https://www.dafont.com/dalek.font)
-----
<h3 align="center">The Pandect Series also includes</h3>
<p align="middle">
<a href="https://github.com/ivan-bilan/The-Microservices-Pandect">
<img src="https://raw.githubusercontent.com/ivan-bilan/The-Engineering-Manager-Pandect/main/Resources/Images/microservices_pandect_promo.png" width="390" />
</a>
<a href="https://github.com/ivan-bilan/The-Engineering-Manager-Pandect">
<img src="https://raw.githubusercontent.com/ivan-bilan/The-Engineering-Manager-Pandect/main/Resources/Images/em_pandect_promo.png" width="370" />
</a>
</p>
|
3,458 | A collection of 700+ survey papers on Natural Language Processing (NLP) and Machine Learning (ML) | # A Survey of Surveys (NLP & ML)
In this document, we survey hundreds of survey papers on Natural Language Processing (NLP) and Machine Learning (ML). We categorize these papers into popular topics and do simple counting for some interesting problems. In addition, we show the list of the papers with urls (813 papers).
## Categorization
We follow the ACL and ICML submission guideline of recent years, covering a broad range of areas in NLP and ML. The categorization is as follows:
+ Natural Language Processing
+ <a href="#computational-social-science-and-social-media">Computational Social Science and Social Media</a>
+ <a href="#dialogue-and-interactive-systems">Dialogue and Interactive Systems</a>
+ <a href="#generation">Generation</a>
+ <a href="#information-extraction">Information Extraction</a>
+ <a href="#information-retrieval-and-text-mining">Information Retrieval and Text Mining</a>
+ <a href="#interpretability-and-analysis-of-models-for-nLP">Interpretability and Analysis of Models for NLP</a>
+ <a href="#knowledge-graph">Knowledge Graph</a>
+ <a href="#language-grounding-to-vision-robotics-and-beyond">Language Grounding to Vision, Robotics and Beyond</a>
+ <a href="#linguistic-theories-cognitive-modeling-and-psycholinguistics">Linguistic Theories, Cognitive Modeling and Psycholinguistics</a>
+ <a href="#machine-learning-for-nlp">Machine Learning for NLP</a>
+ <a href="#machine-translation">Machine Translation</a>
+ <a href="#named-entity-recognition">Named Entity Recognition</a>
+ <a href="#natural-language-inference">Natural Language Inference</a>
+ <a href="#natural-language-processing">Natural Language Processing</a>
+ <a href="#nlp-applications">NLP Applications</a>
+ <a href="#pre-training">Pre-training</a>
+ <a href="#question-answering">Question Answering</a>
+ <a href="#reading-comprehension">Reading Comprehension</a>
+ <a href="#recommender-systems">Recommender Systems</a>
+ <a href="#resources-and-evaluation">Resources and Evaluation</a>
+ <a href="#semantics">Semantics</a>
+ <a href="#sentiment-analysis-stylistic-analysis-and-argument-mining">Sentiment Analysis, Stylistic Analysis and Argument Mining</a>
+ <a href="#speech-and-multimodality">Speech and Multimodality</a>
+ <a href="#summarization">Summarization</a>
+ <a href="#tagging-chunking-syntax-and-parsing">Tagging, Chunking, Syntax and Parsing</a>
+ <a href="#text-classification">Text Classification</a>
+ Machine Learning
+ <a href="#architectures">Architectures</a>
+ <a href="#automl">AutoML</a>
+ <a href="#bayesian-methods">Bayesian Methods</a>
+ <a href="#classification-clustering-and-regression">Classification, Clustering and Regression</a>
+ <a href="#computer-vision">Computer Vision</a>
+ <a href="#contrastive-learning">Contrastive Learning</a>
+ <a href="#curriculum-learning">Curriculum Learning</a>
+ <a href="#data-augmentation">Data Augmentation</a>
+ <a href="#deep-learning-general-methods">Deep Learning General Methods</a>
+ <a href="#deep-reinforcement-learning">Deep Reinforcement Learning</a>
+ <a href="#federated-learning">Federated Learning</a>
+ <a href="#few-shot-and-zero-shot-learning">Few-Shot and Zero-Shot Learning</a>
+ <a href="#general-machine-learning">General Machine Learning</a>
+ <a href="#generative-adversarial-networks">Generative Adversarial Networks</a>
+ <a href="#graph-neural-networks">Graph Neural Networks</a>
+ <a href="#interpretability-and-analysis">Interpretability and Analysis</a>
+ <a href="#knowledge-distillation">Knowledge Distillation</a>
+ <a href="#meta-learning">Meta Learning</a>
+ <a href="#metric-learning">Metric Learning</a>
+ <a href="#ml-and-dl-applications">ML and DL Applications</a>
+ <a href="#model-compression-and-acceleration">Model Compression and Acceleration</a>
+ <a href="#multi-label-learning">Multi-Label Learning</a>
+ <a href="#multi-task-and-multi-view-learning">Multi-Task and Multi-View Learning</a>
+ <a href="#online-learning">Online Learning</a>
+ <a href="#optimization">Optimization</a>
+ <a href="#semi-supervised-weakly-supervised-and-unsupervised-learning">Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning</a>
+ <a href="#transfer-learning">Transfer Learning</a>
+ <a href="#trustworthy-machine-learning">Trustworthy Machine Learning</a>
To reduce class imbalance, we separate some of the hot sub-topics from the original categorization of ACL and ICML submissions. E.g., Named Entity Recognition is a first-level area in our categorization because it is the focus of several surveys.
## Statistics
We show the number of paper in each area in Figures 1-2.
<p align="center"><img src="https://i.loli.net/2020/12/13/uN2IiLQVXMZ9vm3.png" width="70%" height="70%" /></p>
<p align="center">Figure 1: # of papers in each NLP area.</p>
<p align="center"><img src="https://i.loli.net/2020/12/13/AdhCzxSsQFZ6pNO.png" width="70%" height="70%" /></p>
<p align="center">Figure 2: # of papers in each ML area..</p>
Also, we plot paper number as a function of publication year (see Figure 3).
<p align="center"><img src="https://i.loli.net/2020/12/13/FlDJGP2pbLKy8xn.png" width="70%" height="70%"/></p>
<p align="center">Figure 3: # of papers vs publication year.</p>
In addition, we generate word clouds to show hot topics in these surveys (see Figures 4-5).
<p align="center"><img src="https://i.loli.net/2020/07/15/Iywg9lxEGYRvpHO.png" width="70%" height="70%" /></p>
<p align="center">Figure 4: The word cloud for NLP.</p>
<p align="center"><img src="https://i.loli.net/2020/07/15/VYgHR6dhQc2J7Wx.png" width="70%" height="70%" /></p>
<p align="center">Figure 5: The word cloud for ML.</p>
## The NLP Paper List
#### [Computational Social Science and Social Media](#content)
1. **A Comprehensive Survey on Community Detection with Deep Learning.** arXiv 2021 [paper](https://arxiv.org/pdf/2105.12584.pdf) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Su2021A.md)
*Xing Su, Shan Xue, Fanzhen Liu, Jia Wu, Jian Yang, Chuan Zhou, Wenbin Hu, Cécile Paris, Surya Nepal, Di Jin, Quan Z. Sheng, Philip S. Yu*
2. **A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities.** ACM Comput. Surv. 2020 [paper](https://arxiv.org/abs/1812.00315) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Zhou2020A.md)
*Xinyi Zhou, Reza Zafarani*
3. **A Survey of Race, Racism, and Anti-Racism in NLP.** ACL 2021 [paper](https://arxiv.org/abs/2106.11410) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Field2021A.md)
*Anjalie Field, Su Lin Blodgett, Zeerak Waseem, Yulia Tsvetkov*
4. **A Survey on Computational Propaganda Detection.** IJCAI 2020 [paper](https://arxiv.org/pdf/2007.08024.pdf) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Martino2020A.md)
*Giovanni Da San Martino, Stefano Cresci, Alberto Barrón-Cedeño, Seunghak Yu, Roberto Di Pietro, Preslav Nakov*
5. **Computational Sociolinguistics: A Survey.** Comput. Linguistics 2016 [paper](https://arxiv.org/abs/1508.07544) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Nguyen2016Computational.md)
*Dong Nguyen, A. Seza Dogruöz, Carolyn Penstein Rosé, Franciska de Jong*
6. **Confronting Abusive Language Online: A Survey from the Ethical and Human Rights Perspective.** J. Artif. Intell. Res. 2021 [paper](https://arxiv.org/abs/2012.12305) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Kiritchenko2021Confronting.md)
*Svetlana Kiritchenko, Isar Nejadgholi, Kathleen C. Fraser*
7. **From Symbols to Embeddings: A Tale of Two Representations in Computational Social Science.** J. Soc. Comput. 2021 [paper](https://arxiv.org/pdf/2106.14198) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Chen2021From.md)
*Huimin Chen, Cheng Yang, Xuanming Zhang, Zhiyuan Liu, Maosong Sun, Jianbin Jin*
8. **Language (Technology) is Power: A Critical Survey of "Bias" in NLP.** ACL 2020 [paper](https://arxiv.org/abs/2005.14050) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Blodgett2020Language.md)
*Su Lin Blodgett, Solon Barocas, Hal Daumé III, Hanna M. Wallach*
9. **Societal Biases in Language Generation: Progress and Challenges.** ACL 2021 [paper](https://arxiv.org/pdf/2105.04054.pdf) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Sheng2021Societal.md)
*Emily Sheng, Kai-Wei Chang, Prem Natarajan, Nanyun Peng*
10. **Tackling Online Abuse: A Survey of Automated Abuse Detection Methods.** arXiv 2019 [paper](https://arxiv.org/pdf/1908.06024.pdf) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Mishra2019Tackling.md)
*Pushkar Mishra, Helen Yannakoudakis, Ekaterina Shutova*
11. **When do Word Embeddings Accurately Reflect Surveys on our Beliefs About People?.** ACL 2020 [paper](https://arxiv.org/abs/2004.12043) [bib](/bib/Natural-Language-Processing/Computational-Social-Science-and-Social-Media/Joseph2020When.md)
*Kenneth Joseph, Jonathan H. Morgan*
#### [Dialogue and Interactive Systems](#content)
1. **A Survey of Arabic Dialogues Understanding for Spontaneous Dialogues and Instant Message.** IJNLC 2015 [paper](https://arxiv.org/abs/1505.03084) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Elmadany2015A.md)
*AbdelRahim A. Elmadany, Sherif M. Abdou, Mervat Gheith*
2. **A Survey of Available Corpora For Building Data-Driven Dialogue Systems: The Journal Version.** Dialogue Discourse 2018 [paper](https://journals.uic.edu/ojs/index.php/dad/article/view/10733/9501) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Serban2018A.md)
*Iulian Vlad Serban, Ryan Lowe, Peter Henderson, Laurent Charlin, Joelle Pineau*
3. **A Survey of Document Grounded Dialogue Systems (DGDS).** arXiv 2020 [paper](https://arxiv.org/abs/2004.13818) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Ma2020A.md)
*Longxuan Ma, Wei-Nan Zhang, Mingda Li, Ting Liu*
4. **A Survey of Natural Language Generation Techniques with a Focus on Dialogue Systems - Past, Present and Future Directions.** arXiv 2019 [paper](https://arxiv.org/abs/1906.00500) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Santhanam2019A.md)
*Sashank Santhanam, Samira Shaikh*
5. **A Survey on Dialog Management: Recent Advances and Challenges.** arXiv 2020 [paper](https://arxiv.org/abs/2005.02233) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Dai2020A.md)
*Yinpei Dai, Huihua Yu, Yixuan Jiang, Chengguang Tang, Yongbin Li, Jian Sun*
6. **A Survey on Dialogue Systems: Recent Advances and New Frontiers.** SIGKDD Explor. 2017 [paper](https://arxiv.org/abs/1711.01731) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Chen2017A.md)
*Hongshen Chen, Xiaorui Liu, Dawei Yin, Jiliang Tang*
7. **Advances in Multi-turn Dialogue Comprehension: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.03125) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Zhang2021Advances.md)
*Zhuosheng Zhang, Hai Zhao*
8. **Challenges in Building Intelligent Open-domain Dialog Systems.** ACM Trans. Inf. Syst. 2020 [paper](https://arxiv.org/abs/1905.05709) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Huang2020Challenges.md)
*Minlie Huang, Xiaoyan Zhu, Jianfeng Gao*
9. **Conversational Machine Comprehension: a Literature Review.** COLING 2020 [paper](https://arxiv.org/abs/2006.00671) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Gupta2020Conversational.md)
*Somil Gupta, Bhanu Pratap Singh Rawat, Hong Yu*
10. **Neural Approaches to Conversational AI.** ACL 2018 [paper](https://arxiv.org/pdf/1809.08267) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Gao2018Neural.md)
*Jianfeng Gao, Michel Galley, Lihong Li*
11. **Neural Approaches to Conversational AI: Question Answering, Task-oriented Dialogues and Social Chatbots.** Now Foundations and Trends 2019 [paper](https://ieeexplore.ieee.org/document/8649787) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Gao2019Neural.md)
*Jianfeng Gao, Michel Galley, Lihong Li*
12. **POMDP-Based Statistical Spoken Dialog Systems: A Review.** Proc. IEEE 2013 [paper](https://ieeexplore.ieee.org/document/6407655/) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Young2013POMDP-Based.md)
*Steve J. Young, Milica Gasic, Blaise Thomson, Jason D. Williams*
13. **Recent Advances and Challenges in Task-oriented Dialog System.** arXiv 2020 [paper](https://arxiv.org/pdf/2003.07490) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Zhang2020Recent.md)
*Zheng Zhang, Ryuichi Takanobu, Minlie Huang, Xiaoyan Zhu*
14. **Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2105.04387.pdf) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Ni2021Recent.md)
*Jinjie Ni, Tom Young, Vlad Pandelea, Fuzhao Xue, Vinay Adiga, Erik Cambria*
15. **Utterance-level Dialogue Understanding: An Empirical Study.** arXiv 2020 [paper](https://arxiv.org/abs/2009.13902) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Ghosal2020Utterance-level.md)
*Deepanway Ghosal, Navonil Majumder, Rada Mihalcea, Soujanya Poria*
16. **How to Evaluate Your Dialogue Models: A Review of Approaches.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.01369.pdf) [bib](/bib/Natural-Language-Processing/Dialogue-and-Interactive-Systems/Li2021How.md)
*Xinmeng Li, Wansen Wu, Long Qin, Quanjun Yin*
#### [Generation](#content)
1. **A Survey of Knowledge-Enhanced Text Generation.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.04389.pdf) [bib](/bib/Natural-Language-Processing/Generation/Yu2020A.md)
*Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang*
2. **A Survey on Text Simplification.** arXiv 2020 [paper](https://arxiv.org/abs/2008.08612) [bib](/bib/Natural-Language-Processing/Generation/Sikka2020A.md)
*Punardeep Sikka, Vijay Mago*
3. **Automatic Detection of Machine Generated Text: A Critical Survey.** COLING 2020 [paper](https://arxiv.org/pdf/2011.01314.pdf) [bib](/bib/Natural-Language-Processing/Generation/Jawahar2020Automatic.md)
*Ganesh Jawahar, Muhammad Abdul-Mageed, Laks V. S. Lakshmanan*
4. **Automatic Story Generation: Challenges and Attempts.** arXiv 2021 [paper](https://arxiv.org/abs/2102.12634) [bib](/bib/Natural-Language-Processing/Generation/Alabdulkarim2021Automatic.md)
*Amal Alabdulkarim, Siyan Li, Xiangyu Peng*
5. **Content Selection in Data-to-Text Systems: A Survey.** arXiv 2016 [paper](https://arxiv.org/abs/1610.08375) [bib](/bib/Natural-Language-Processing/Generation/Gkatzia2016Content.md)
*Dimitra Gkatzia*
6. **Data-Driven Sentence Simplification: Survey and Benchmark.** Comput. Linguistics 2020 [paper](https://www.mitpressjournals.org/doi/pdf/10.1162/COLI_a_00370) [bib](/bib/Natural-Language-Processing/Generation/Alva2020Data-Driven.md)
*Fernando Alva-Manchego, Carolina Scarton, Lucia Specia*
7. **Deep Learning for Text Style Transfer: A Survey.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.00416.pdf) [bib](/bib/Natural-Language-Processing/Generation/Jin2020Deep.md)
*Di Jin, Zhijing Jin, Zhiting Hu, Olga Vechtomova, Rada Mihalcea*
8. **Evaluation of Text Generation: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2006.14799) [bib](/bib/Natural-Language-Processing/Generation/Celikyilmaz2020Evaluation.md)
*Asli Celikyilmaz, Elizabeth Clark, Jianfeng Gao*
9. **Human Evaluation of Creative NLG Systems: An Interdisciplinary Survey on Recent Papers.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.00308.pdf) [bib](/bib/Natural-Language-Processing/Generation/Hämäläinen2021Human.md)
*Mika Hämäläinen, Khalid Al-Najjar*
10. **Keyphrase Generation: A Multi-Aspect Survey.** FRUCT 2019 [paper](https://arxiv.org/abs/1910.05059) [bib](/bib/Natural-Language-Processing/Generation/Çano2019Keyphrase.md)
*Erion Çano, Ondrej Bojar*
11. **Neural Language Generation: Formulation, Methods, and Evaluation.** arXiv 2020 [paper](https://arxiv.org/pdf/2007.15780.pdf) [bib](/bib/Natural-Language-Processing/Generation/Garbacea2020Neural.md)
*Cristina Garbacea, Qiaozhu Mei*
12. **Neural Text Generation: Past, Present and Beyond.** arXiv 2018 [paper](https://arxiv.org/pdf/1803.07133.pdf) [bib](/bib/Natural-Language-Processing/Generation/Lu2018Neural.md)
*Sidi Lu, Yaoming Zhu, Weinan Zhang, Jun Wang, Yong Yu*
13. **Quiz-Style Question Generation for News Stories.** WWW 2021 [paper](https://arxiv.org/abs/2102.09094) [bib](/bib/Natural-Language-Processing/Generation/Lelkes2021Quiz-Style.md)
*Ádám D. Lelkes, Vinh Q. Tran, Cong Yu*
14. **Recent Advances in Neural Question Generation.** arXiv 2019 [paper](https://arxiv.org/abs/1905.08949) [bib](/bib/Natural-Language-Processing/Generation/Pan2019Recent.md)
*Liangming Pan, Wenqiang Lei, Tat-Seng Chua, Min-Yen Kan*
15. **Recent Advances in SQL Query Generation: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2005.07667) [bib](/bib/Natural-Language-Processing/Generation/Kalajdjieski2020Recent.md)
*Jovan Kalajdjieski, Martina Toshevska, Frosina Stojanovska*
16. **Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation.** J. Artif. Intell. Res. 2018 [paper](https://arxiv.org/abs/1703.09902) [bib](/bib/Natural-Language-Processing/Generation/Gatt2018Survey.md)
*Albert Gatt, Emiel Krahmer*
#### [Information Extraction](#content)
1. **A Compact Survey on Event Extraction: Approaches and Applications.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.02126.pdf) [bib](/bib/Natural-Language-Processing/Information-Extraction/Li2021A.md)
*Qian Li, Hao Peng, Jianxin Li, Yiming Hei, Rui Sun, Jiawei Sheng, Shu Guo, Lihong Wang, Philip S. Yu*
2. **A Review on Fact Extraction and Verification.** arXiv 2020 [paper](http://arxiv.org/abs/2010.03001) [bib](/bib/Natural-Language-Processing/Information-Extraction/Bekoulis2020A.md)
*Giannis Bekoulis, Christina Papagiannopoulou, Nikos Deligiannis*
3. **A Survey of Deep Learning Methods for Relation Extraction.** arXiv 2017 [paper](https://arxiv.org/abs/1705.03645) [bib](/bib/Natural-Language-Processing/Information-Extraction/Kumar2017A.md)
*Shantanu Kumar*
4. **A Survey of Event Extraction From Text.** IEEE Access 2019 [paper](https://ieeexplore.ieee.org/document/8918013) [bib](/bib/Natural-Language-Processing/Information-Extraction/Xiang2019A.md)
*Wei Xiang, Bang Wang*
5. **A Survey of event extraction methods from text for decision support systems.** Decis. Support Syst. 2016 [paper](https://www.sciencedirect.com/science/article/abs/pii/S0167923616300173) [bib](/bib/Natural-Language-Processing/Information-Extraction/Hogenboom2016A.md)
*Frederik Hogenboom, Flavius Frasincar, Uzay Kaymak, Franciska de Jong, Emiel Caron*
6. **A survey of joint intent detection and slot-filling models in natural language understanding.** arXiv 2021 [paper](https://arxiv.org/abs/2101.08091) [bib](/bib/Natural-Language-Processing/Information-Extraction/Weld2021A.md)
*Henry Weld, Xiaoqi Huang, Siqi Long, Josiah Poon, Soyeon Caren Han*
7. **A Survey of Textual Event Extraction from Social Networks.** LPKM 2017 [paper](http://ceur-ws.org/Vol-1988/LPKM2017_paper_15.pdf) [bib](/bib/Natural-Language-Processing/Information-Extraction/Mejri2017A.md)
*Mohamed Mejri, Jalel Akaichi*
8. **A Survey on Open Information Extraction.** COLING 2018 [paper](https://arxiv.org/abs/1806.05599) [bib](/bib/Natural-Language-Processing/Information-Extraction/Niklaus2018A.md)
*Christina Niklaus, Matthias Cetto, André Freitas, Siegfried Handschuh*
9. **A Survey on Temporal Reasoning for Temporal Information Extraction from Text (Extended Abstract).** IJCAI 2020 [paper](https://arxiv.org/abs/2005.06527) [bib](/bib/Natural-Language-Processing/Information-Extraction/Leeuwenberg2020A.md)
*Artuur Leeuwenberg, Marie-Francine Moens*
10. **An Overview of Event Extraction from Text.** DeRiVE@ISWC 2011 [paper](http://ceur-ws.org/Vol-779/derive2011_submission_1.pdf) [bib](/bib/Natural-Language-Processing/Information-Extraction/Hogenboom2011An.md)
*Frederik Hogenboom, Flavius Frasincar, Uzay Kaymak, Franciska de Jong*
11. **Automatic Extraction of Causal Relations from Natural Language Texts: A Comprehensive Survey.** arXiv 2016 [paper](https://arxiv.org/abs/1605.07895) [bib](/bib/Natural-Language-Processing/Information-Extraction/Asghar2016Automatic.md)
*Nabiha Asghar*
12. **Complex Relation Extraction: Challenges and Opportunities.** arXiv 2020 [paper](https://arxiv.org/pdf/2012.04821.pdf) [bib](/bib/Natural-Language-Processing/Information-Extraction/Jiang2020Complex.md)
*Haiyun Jiang, Qiaoben Bao, Qiao Cheng, Deqing Yang, Li Wang, Yanghua Xiao*
13. **Extracting Events and Their Relations from Texts: A Survey on Recent Research Progress and Challenges.** AI Open 2020 [paper](https://www.sciencedirect.com/science/article/pii/S266665102100005X/pdfft?md5=3983861e9ae91ce7b45f0c5533071077&pid=1-s2.0-S266665102100005X-main.pdf) [bib](/bib/Natural-Language-Processing/Information-Extraction/Liu2020Extracting.md)
*Kang Liu, Yubo Chen, Jian Liu, Xinyu Zuo, Jun Zhao*
14. **More Data, More Relations, More Context and More Openness: A Review and Outlook for Relation Extraction.** AACL 2020 [paper](https://arxiv.org/abs/2004.03186) [bib](/bib/Natural-Language-Processing/Information-Extraction/Han2020More.md)
*Xu Han, Tianyu Gao, Yankai Lin, Hao Peng, Yaoliang Yang, Chaojun Xiao, Zhiyuan Liu, Peng Li, Jie Zhou, Maosong Sun*
15. **Neural relation extraction: a survey.** arXiv 2020 [paper](https://arxiv.org/abs/2007.04247) [bib](/bib/Natural-Language-Processing/Information-Extraction/Aydar2020Neural.md)
*Mehmet Aydar, Ozge Bozal, Furkan Özbay*
16. **Recent Neural Methods on Slot Filling and Intent Classification for Task-Oriented Dialogue Systems: A Survey.** COLING 2020 [paper](https://arxiv.org/abs/2011.00564) [bib](/bib/Natural-Language-Processing/Information-Extraction/Louvan2020Recent.md)
*Samuel Louvan, Bernardo Magnini*
17. **Relation Extraction : A Survey.** arXiv 2017 [paper](https://arxiv.org/abs/1712.05191) [bib](/bib/Natural-Language-Processing/Information-Extraction/Pawar2017Relation.md)
*Sachin Pawar, Girish K. Palshikar, Pushpak Bhattacharyya*
18. **Techniques for Jointly Extracting Entities and Relations: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.06118) [bib](/bib/Natural-Language-Processing/Information-Extraction/Pawar2021Techniques.md)
*Sachin Pawar, Pushpak Bhattacharyya, Girish K. Palshikar*
#### [Information Retrieval and Text Mining](#content)
1. **A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques.** arXiv 2017 [paper](https://arxiv.org/abs/1707.02919) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Allahyari2017A.md)
*Mehdi Allahyari, Seyed Amin Pouriyeh, Mehdi Assefi, Saied Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, Krys J. Kochut*
2. **A survey of methods to ease the development of highly multilingual text mining applications.** Lang. Resour. Evaluation 2012 [paper](https://arxiv.org/abs/1401.2937) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Steinberger2012A.md)
*Ralf Steinberger*
3. **Data Mining and Information Retrieval in the 21st century: A bibliographic review.** Comput. Sci. Rev. 2019 [paper](https://www.sciencedirect.com/science/article/abs/pii/S1574013719301297) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Liu2019Data.md)
*Jiaying Liu, Xiangjie Kong, Xinyu Zhou, Lei Wang, Da Zhang, Ivan Lee, Bo Xu, Feng Xia*
4. **Neural Entity Linking: A Survey of Models Based on Deep Learning.** arXiv 2020 [paper](https://arxiv.org/abs/2006.00575) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Sevgili2020Neural.md)
*Özge Sevgili, Artem Shelmanov, Mikhail Y. Arkhipov, Alexander Panchenko, Chris Biemann*
5. **Neural Models for Information Retrieval.** arXiv 2017 [paper](https://arxiv.org/pdf/1705.01509.pdf) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Mitra2017Neural.md)
*Bhaskar Mitra, Nick Craswell*
6. **Opinion Mining and Analysis: A survey.** IJNLC 2013 [paper](https://arxiv.org/abs/1307.3336) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Buche2013Opinion.md)
*Arti Buche, M. B. Chandak, Akshay Zadgaonkar*
7. **Relational World Knowledge Representation in Contextual Language Models: A Review.** EMNLP 2021 [paper](https://arxiv.org/abs/2104.05837) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Safavi2021Relational.md)
*Tara Safavi, Danai Koutra*
8. **Short Text Topic Modeling Techniques, Applications, and Performance: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1904.07695) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Qiang2019Short.md)
*Jipeng Qiang, Zhenyu Qian, Yun Li, Yunhao Yuan, Xindong Wu*
9. **Topic Modelling Meets Deep Neural Networks: A Survey.** IJCAI 2021 [paper](https://arxiv.org/abs/2103.00498) [bib](/bib/Natural-Language-Processing/Information-Retrieval-and-Text-Mining/Zhao2021Topic.md)
*He Zhao, Dinh Q. Phung, Viet Huynh, Yuan Jin, Lan Du, Wray L. Buntine*
#### [Interpretability and Analysis of Models for NLP](#content)
1. **A Primer in BERTology: What we know about how BERT works.** Trans. Assoc. Comput. Linguistics 2020 [paper](https://arxiv.org/pdf/2002.12327.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Rogers2020A.md)
*Anna Rogers, Olga Kovaleva, Anna Rumshisky*
2. **A Survey of the State of Explainable AI for Natural Language Processing.** AACL 2020 [paper](https://arxiv.org/pdf/2010.00711.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Danilevsky2020A.md)
*Marina Danilevsky, Kun Qian, Ranit Aharonov, Yannis Katsis, Ban Kawas, Prithviraj Sen*
3. **A Survey on Deep Learning and Explainability for Automatic Report Generation from Medical Images.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.10563.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Messina2020A.md)
*Pablo Messina, Pablo Pino, Denis Parra, Alvaro Soto, Cecilia Besa, Sergio Uribe, Marcelo andía, Cristian Tejos, Claudia Prieto, Daniel Capurro*
4. **A Survey on Explainability in Machine Reading Comprehension.** arXiv 2020 [paper](http://arxiv.org/pdf/2010.00389.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Thayaparan2020A.md)
*Mokanarangan Thayaparan, Marco Valentino, André Freitas*
5. **Analysis Methods in Neural Language Processing: A Survey.** Trans. Assoc. Comput. Linguistics 2019 [paper](https://arxiv.org/abs/1812.08951) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Belinkov2019Analysis.md)
*Yonatan Belinkov, James R. Glass*
6. **Analyzing and Interpreting Neural Networks for NLP: A Report on the First BlackboxNLP Workshop.** Nat. Lang. Eng. 2019 [paper](http://arxiv.org/pdf/1904.04063.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Alishahi2019Analyzing.md)
*Afra Alishahi, Grzegorz Chrupala, Tal Linzen*
7. **Post-hoc Interpretability for Neural NLP: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04840.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Madsen2021Post-hoc.md)
*Andreas Madsen, Siva Reddy, Sarath Chandar*
8. **Teach Me to Explain: A Review of Datasets for Explainable Natural Language Processing.** arXiv 2021 [paper](https://arxiv.org/pdf/2102.12060) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Wiegreffe2021Teach.md)
*Sarah Wiegreffe, Ana Marasović*
9. **Which *BERT? A Survey Organizing Contextualized Encoders.** EMNLP 2020 [paper](https://arxiv.org/pdf/2010.00854.pdf) [bib](/bib/Natural-Language-Processing/Interpretability-and-Analysis-of-Models-for-NLP/Xia2020Which.md)
*Patrick Xia, Shijie Wu, Benjamin Van Durme*
#### [Knowledge Graph](#content)
1. **A Review of Relational Machine Learning for Knowledge Graphs.** Proc. IEEE 2016 [paper](https://arxiv.org/pdf/1503.00759) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Nickel2016A.md)
*Maximilian Nickel, Kevin Murphy, Volker Tresp, Evgeniy Gabrilovich*
2. **A survey of embedding models of entities and relationships for knowledge graph completion.** arXiv 2017 [paper](https://arxiv.org/pdf/1703.08098.pdf) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Nguyen2017A.md)
*Dat Quoc Nguyen*
3. **A Survey of Embedding Space Alignment Methods for Language and Knowledge Graphs.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.13688.pdf) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Kalinowski2020A.md)
*Alexander Kalinowski, Yuan An*
4. **A Survey of Techniques for Constructing Chinese Knowledge Graphs and Their Applications.** Sustainability 2018 [paper](https://www.mdpi.com/2071-1050/10/9/3245/htm) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Wu2018A.md)
*Tianxing Wu, Guilin Qi, Cheng Li, Meng Wang*
5. **A Survey on Graph Neural Networks for Knowledge Graph Completion.** arXiv 2020 [paper](https://arxiv.org/abs/2007.12374) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Arora2020A.md)
*Siddhant Arora*
6. **A Survey on Knowledge Graphs: Representation, Acquisition and Applications.** arXiv 2020 [paper](https://arxiv.org/abs/2002.00388) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Ji2020A.md)
*Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, Philip S. Yu*
7. **Introduction to neural network-based question answering over knowledge graphs.** WIREs Data Mining Knowl. Discov. 2021 [paper](https://onlinelibrary.wiley.com/doi/epdf/10.1002/widm.1389) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Chakraborty2021Introduction.md)
*Nilesh Chakraborty, Denis Lukovnikov, Gaurav Maheshwari, Priyansh Trivedi, Jens Lehmann, Asja Fischer*
8. **Knowledge Graph Embedding for Link Prediction: A Comparative Analysis.** ACM Trans. Knowl. Discov. Data 2021 [paper](https://arxiv.org/abs/2002.00819) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Rossi2021Knowledge.md)
*Andrea Rossi, Denilson Barbosa, Donatella Firmani, Antonio Matinata, Paolo Merialdo*
9. **Knowledge Graph Embedding: A Survey of Approaches and Applications.** IEEE Trans. Knowl. Data Eng. 2017 [paper](https://ieeexplore.ieee.org/document/8047276) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Wang2017Knowledge.md)
*Quan Wang, Zhendong Mao, Bin Wang, Li Guo*
10. **Knowledge Graph Refinement: A Survey of Approaches and Evaluation Methods.** Semantic Web 2017 [paper](http://www.semantic-web-journal.net/system/files/swj1167.pdf) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Paulheim2017Knowledge.md)
*Heiko Paulheim*
11. **Knowledge Graphs.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2003.02320) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Hogan2021Knowledge.md)
*Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d'Amato, Gerard de Melo, Claudio Gutiérrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, Axel-Cyrille Ngonga Ngomo, Axel Polleres, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, Antoine Zimmermann*
12. **Knowledge Graphs: An Information Retrieval Perspective.** Found. Trends Inf. Retr. 2020 [paper](https://www.nowpublishers.com/article/Details/INR-063) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Reinanda2020Knowledge.md)
*Ridho Reinanda, Edgar Meij, Maarten de Rijke*
13. **知识表示学习研究进展.** 计算机研究与发展 2016 [paper](https://crad.ict.ac.cn/EN/Y2016/V53/I2/247) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Liu2016Knowledge.md)
*刘知远, 孙茂松, 林衍凯, 谢若冰*
14. **Neural, Symbolic and Neural-symbolic Reasoning on Knowledge Graphs.** AI Open 2021 [paper](https://www.sciencedirect.com/science/article/pii/S2666651021000061/pdfft?md5=41dae412c5802b063f8ff0615ba12622&pid=1-s2.0-S2666651021000061-main.pdf) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Zhang2021Neural.md)
*Jing Zhang, Bo Chen, Lingxi Zhang, Xirui Ke, Haipeng Ding*
15. **Survey and Open Problems in Privacy Preserving Knowledge Graph: Merging, Query, Representation, Completion and Applications.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.10180.pdf) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Chen2020Survey.md)
*Chaochao Chen, Jamie Cui, Guanfeng Liu, Jia Wu, Li Wang*
16. **领域知识图谱研究综述.** 计算机系统应用 2020 [paper](http://www.c-s-a.org.cn/html/2020/6/7431.html#top) [bib](/bib/Natural-Language-Processing/Knowledge-Graph/Liu2020Survey.md)
*刘烨宸, 李华昱*
#### [Language Grounding to Vision, Robotics and Beyond](#content)
1. **A comprehensive survey of mostly textual document segmentation algorithms since 2008.** Pattern Recognit. 2017 [paper](https://www.sciencedirect.com/science/article/abs/pii/S0031320316303399) [bib](/bib/Natural-Language-Processing/Language-Grounding-to-Vision,-Robotics-and-Beyond/Eskenazi2017A.md)
*Sébastien Eskenazi, Petra Gomez-Krämer, Jean-Marc Ogier*
2. **Emotionally-Aware Chatbots: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1906.09774) [bib](/bib/Natural-Language-Processing/Language-Grounding-to-Vision,-Robotics-and-Beyond/Pamungkas2019Emotionally-Aware.md)
*Endang Wahyu Pamungkas*
3. **From Show to Tell: A Survey on Deep Learning-based Image Captioning.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.06912.pdf) [bib](/bib/Natural-Language-Processing/Language-Grounding-to-Vision,-Robotics-and-Beyond/Stefanini2021From.md)
*Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Silvia Cascianelli, Giuseppe Fiameni, Rita Cucchiara*
4. **Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods.** arXiv 2019 [paper](https://arxiv.org/abs/1907.09358) [bib](/bib/Natural-Language-Processing/Language-Grounding-to-Vision,-Robotics-and-Beyond/Mogadala2019Trends.md)
*Aditya Mogadala, Marimuthu Kalimuthu, Dietrich Klakow*
#### [Linguistic Theories, Cognitive Modeling and Psycholinguistics](#content)
1. **A Survey of Code-switching: Linguistic and Social Perspectives for Language Technologies.** ACL 2021 [paper](https://aclanthology.org/2021.acl-long.131.pdf) [bib](/bib/Natural-Language-Processing/Linguistic-Theories,-Cognitive-Modeling-and-Psycholinguistics/Dogruöz2021A.md)
*A. Seza Dogruöz, Sunayana Sitaram, Barbara E. Bullock, Almeida Jacqueline Toribio*
2. **Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing.** Comput. Linguistics 2019 [paper](https://arxiv.org/abs/1807.00914) [bib](/bib/Natural-Language-Processing/Linguistic-Theories,-Cognitive-Modeling-and-Psycholinguistics/Ponti2019Modeling.md)
*Edoardo Maria Ponti, Helen O'Horan, Yevgeni Berzak, Ivan Vulic, Roi Reichart, Thierry Poibeau, Ekaterina Shutova, Anna Korhonen*
3. **Survey on the Use of Typological Information in Natural Language Processing.** COLING 2016 [paper](https://arxiv.org/abs/1610.03349) [bib](/bib/Natural-Language-Processing/Linguistic-Theories,-Cognitive-Modeling-and-Psycholinguistics/Horan2016Survey.md)
*Helen O'Horan, Yevgeni Berzak, Ivan Vulic, Roi Reichart, Anna Korhonen*
#### [Machine Learning for NLP](#content)
1. **A Comprehensive Survey on Word Representation Models: From Classical to State-Of-The-Art Word Representation Language Models.** ACM Trans. Asian Low Resour. Lang. Inf. Process. 2021 [paper](https://arxiv.org/pdf/2010.15036.pdf) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Naseem2021A.md)
*Usman Naseem, Imran Razzak, Shah Khalid Khan, Mukesh Prasad*
2. **A Survey Of Cross-lingual Word Embedding Models.** J. Artif. Intell. Res. 2019 [paper](https://arxiv.org/abs/1706.04902) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Ruder2019A.md)
*Sebastian Ruder, Ivan Vulic, Anders Søgaard*
3. **A Survey of Data Augmentation Approaches for NLP.** ACL 2021 [paper](https://arxiv.org/pdf/2105.03075) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Feng2021A.md)
*Steven Y. Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush Vosoughi, Teruko Mitamura, Eduard H. Hovy*
4. **A Survey of Neural Network Techniques for Feature Extraction from Text.** arXiv 2017 [paper](https://arxiv.org/abs/1704.08531) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/John2017A.md)
*Vineet John*
5. **A Survey of Neural Networks and Formal Languages.** arXiv 2020 [paper](https://arxiv.org/abs/2006.01338) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Ackerman2020A.md)
*Joshua Ackerman, George Cybenko*
6. **A Survey of the Usages of Deep Learning in Natural Language Processing.** arXiv 2018 [paper](https://arxiv.org/pdf/1807.10854) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Otter2018A.md)
*Daniel W. Otter, Julian R. Medina, Jugal K. Kalita*
7. **A Survey on Contextual Embeddings.** arXiv 2020 [paper](https://arxiv.org/abs/2003.07278) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Liu2020A.md)
*Qi Liu, Matt J. Kusner, Phil Blunsom*
8. **A Survey on Transfer Learning in Natural Language Processing.** arXiv 2020 [paper](https://arxiv.org/abs/2007.04239) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Alyafeai2020A.md)
*Zaid Alyafeai, Maged Saeed AlShaibani, Irfan Ahmad*
9. **Adversarial Attacks and Defense on Texts: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2005.14108) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Huq2020Adversarial.md)
*Aminul Huq, Mst. Tasnim Pervin*
10. **Adversarial Attacks on Deep-Learning Models in Natural Language Processing: A Survey.** ACM Trans. Intell. Syst. Technol. 2020 [paper](https://dl.acm.org/doi/pdf/10.1145/3374217) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Zhang2020Adversarial.md)
*Wei Emma Zhang, Quan Z. Sheng, Ahoud Abdulrahmn F. Alhazmi, Chenliang Li*
11. **An Empirical Survey of Unsupervised Text Representation Methods on Twitter Data.** W-NUT@EMNLP 2020 [paper](https://www.aclweb.org/anthology/2020.wnut-1.27/) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Wang2020An.md)
*Lili Wang, Chongyang Gao, Jason Wei, Weicheng Ma, Ruibo Liu, Soroush Vosoughi*
12. **Bangla Natural Language Processing: A Comprehensive Review of Classical, Machine Learning, and Deep Learning Based Methods.** arXiv 2021 [paper](https://arxiv.org/abs/2105.14875) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Sen2021Bangla.md)
*Ovishake Sen, Mohtasim Fuad, Md. Nazrul Islam, Jakaria Rabbi, Md. Kamrul Hasan, Awal Ahmed Fime, Md. Tahmid Hasan Fuad, Delowar Sikder, Md. Akil Raihan Iftee*
13. **Federated Learning Meets Natural Language Processing: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.12603.pdf) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Liu2021Federated.md)
*Ming Liu, Stella Ho, Mengqi Wang, Longxiang Gao, Yuan Jin, He Zhang*
14. **From static to dynamic word representations: a survey.** Int. J. Mach. Learn. Cybern. 2020 [paper](http://ir.hit.edu.cn/~car/papers/icmlc2020-wang.pdf) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Wang2020From.md)
*Yuxuan Wang, Yutai Hou, Wanxiang Che, Ting Liu*
15. **From Word to Sense Embeddings: A Survey on Vector Representations of Meaning.** J. Artif. Intell. Res. 2018 [paper](https://arxiv.org/abs/1805.04032) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Camacho2018From.md)
*José Camacho-Collados, Mohammad Taher Pilehvar*
16. **Graph Neural Networks for Natural Language Processing: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.06090.pdf) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Wu2021Graph.md)
*Lingfei Wu, Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Jian Pei, Bo Long*
17. **Informed Machine Learning -- A Taxonomy and Survey of Integrating Knowledge into Learning Systems.** arXiv 2019 [paper](https://arxiv.org/abs/1903.12394) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Rueden2019Informed.md)
*Laura von Rueden, Sebastian Mayer, Katharina Beckh, Bogdan Georgiev, Sven Giesselbach, Raoul Heese, Birgit Kirsch, Julius Pfrommer, Annika Pick, Rajkumar Ramamurthy, Michal Walczak, Jochen Garcke, Christian Bauckhage, Jannis Schuecker*
18. **Narrative Science Systems: A Review.** International Journal of Research in Computer Science 2015 [paper](https://arxiv.org/abs/1510.04420) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Sarao2015Narrative.md)
*Paramjot Kaur Sarao, Puneet Mittal, Rupinder Kaur*
19. **Natural Language Processing Advancements By Deep Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2003.01200) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Torfi2020Natural.md)
*Amirsina Torfi, Rouzbeh A. Shirvani, Yaser Keneshloo, Nader Tavaf, Edward A. Fox*
20. **Recent Trends in Deep Learning Based Natural Language Processing [Review Article].** IEEE Comput. Intell. Mag. 2018 [paper](https://ieeexplore.ieee.org/document/8416973) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Young2018Recent.md)
*Tom Young, Devamanyu Hazarika, Soujanya Poria, Erik Cambria*
21. **网络表示学习算法综述.** 计算机科学 2020 [paper](http://www.jsjkx.com/CN/10.11896/jsjkx.190300004) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Yu2020Survey.md)
*丁钰, 魏浩, 潘志松, 刘鑫*
22. **Symbolic, Distributed, and Distributional Representations for Natural Language Processing in the Era of Deep Learning: A Survey.** Frontiers Robotics AI 2019 [paper](https://arxiv.org/abs/1702.00764) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Ferrone2019Symbolic.md)
*Lorenzo Ferrone, Fabio Massimo Zanzotto*
23. **Token-Modification Adversarial Attacks for Natural Language Processing: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.00676) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Roth2021Token-Modification.md)
*Tom Roth, Yansong Gao, Alsharif Abuadbba, Surya Nepal, Wei Liu*
24. **Towards a Robust Deep Neural Network in Texts: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1902.07285) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Wang2019Towards.md)
*Wenqi Wang, Lina Wang, Run Wang, Zhibo Wang, Aoshuang Ye*
25. **Word Embeddings: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1901.09069) [bib](/bib/Natural-Language-Processing/Machine-Learning-for-NLP/Almeida2019Word.md)
*Felipe Almeida, Geraldo Xexéo*
#### [Machine Translation](#content)
1. **A Comprehensive Survey of Multilingual Neural Machine Translation.** arXiv 2020 [paper](https://arxiv.org/abs/2001.01115) [bib](/bib/Natural-Language-Processing/Machine-Translation/Dabre2020A.md)
*Raj Dabre, Chenhui Chu, Anoop Kunchukuttan*
2. **A Survey of Deep Learning Techniques for Neural Machine Translation.** arXiv 2020 [paper](https://arxiv.org/abs/2002.07526) [bib](/bib/Natural-Language-Processing/Machine-Translation/Yang2020A.md)
*Shuoheng Yang, Yuxin Wang, Xiaowen Chu*
3. **A Survey of Domain Adaptation for Neural Machine Translation.** COLING 2018 [paper](https://arxiv.org/abs/1806.00258) [bib](/bib/Natural-Language-Processing/Machine-Translation/Chu2018A.md)
*Chenhui Chu, Rui Wang*
4. **A Survey of Methods to Leverage Monolingual Data in Low-resource Neural Machine Translation.** arXiv 2019 [paper](https://arxiv.org/abs/1910.00373) [bib](/bib/Natural-Language-Processing/Machine-Translation/Gibadullin2019A.md)
*Ilshat Gibadullin, Aidar Valeev, Albina Khusainova, Adil Khan*
5. **A Survey of Orthographic Information in Machine Translation.** SN Comput. Sci. 2021 [paper](https://arxiv.org/abs/2008.01391) [bib](/bib/Natural-Language-Processing/Machine-Translation/Chakravarthi2021A.md)
*Bharathi Raja Chakravarthi, Priya Rani, Mihael Arcan, John P. McCrae*
6. **A Survey of Word Reordering in Statistical Machine Translation: Computational Models and Language Phenomena.** Comput. Linguistics 2016 [paper](https://arxiv.org/abs/1502.04938) [bib](/bib/Natural-Language-Processing/Machine-Translation/Bisazza2016A.md)
*Arianna Bisazza, Marcello Federico*
7. **A Survey on Document-level Neural Machine Translation: Methods and Evaluation.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/1912.08494) [bib](/bib/Natural-Language-Processing/Machine-Translation/Maruf2021A.md)
*Sameen Maruf, Fahimeh Saleh, Gholamreza Haffari*
8. **A Survey on Low-Resource Neural Machine Translation.** IJCAI 2021 [paper](https://arxiv.org/pdf/2107.04239.pdf) [bib](/bib/Natural-Language-Processing/Machine-Translation/Wang2021A.md)
*Rui Wang, Xu Tan, Renqian Luo, Tao Qin, Tie-Yan Liu*
9. **Domain Adaptation and Multi-Domain Adaptation for Neural Machine Translation: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2104.06951) [bib](/bib/Natural-Language-Processing/Machine-Translation/Saunders2021Domain.md)
*Danielle Saunders*
10. **Gender Bias in Machine Translation.** arXiv 2021 [paper](https://arxiv.org/abs/2104.06001) [bib](/bib/Natural-Language-Processing/Machine-Translation/Savoldi2021Gender.md)
*Beatrice Savoldi, Marco Gaido, Luisa Bentivogli, Matteo Negri, Marco Turchi*
11. **Machine Translation Approaches and Survey for Indian Languages.** Int. J. Comput. Linguistics Chin. Lang. Process. 2013 [paper](http://www.aclclp.org.tw/clclp/v18n1/v18n1a3.pdf) [bib](/bib/Natural-Language-Processing/Machine-Translation/Antony2013Machine.md)
*P. J. Antony*
12. **Machine Translation Approaches and Survey for Indian Languages.** arXiv 2017 [paper](https://arxiv.org/abs/1701.04290) [bib](/bib/Natural-Language-Processing/Machine-Translation/Khan2017Machine.md)
*Nadeem Jadoon Khan, Waqas Anwar, Nadir Durrani*
13. **Machine Translation Evaluation Resources and Methods: A Survey.** Ireland Postgraduate Research Conference 2018 [paper](https://arxiv.org/abs/1605.04515) [bib](/bib/Natural-Language-Processing/Machine-Translation/Han2018Machine.md)
*Lifeng Han*
14. **Machine Translation using Semantic Web Technologies: A Survey.** J. Web Semant. 2018 [paper](https://arxiv.org/abs/1711.09476) [bib](/bib/Natural-Language-Processing/Machine-Translation/Moussallem2018Machine.md)
*Diego Moussallem, Matthias Wauer, Axel-Cyrille Ngonga Ngomo*
15. **Machine-Translation History and Evolution: Survey for Arabic-English Translations.** CJAST 2017 [paper](https://arxiv.org/abs/1709.04685) [bib](/bib/Natural-Language-Processing/Machine-Translation/Alsohybe2017Machine-Translation.md)
*Nabeel T. Alsohybe, Neama Abdulaziz Dahan, Fadl Mutaher Ba-Alwi*
16. **Multimodal Machine Translation through Visuals and Speech.** Mach. Transl. 2020 [paper](https://arxiv.org/abs/1911.12798) [bib](/bib/Natural-Language-Processing/Machine-Translation/Sulubacak2020Multimodal.md)
*Umut Sulubacak, Ozan Caglayan, Stig-Arne Grönroos, Aku Rouhe, Desmond Elliott, Lucia Specia, Jörg Tiedemann*
17. **Neural Machine Translation and Sequence-to-sequence Models: A Tutorial.** arXiv 2017 [paper](https://arxiv.org/abs/1703.01619) [bib](/bib/Natural-Language-Processing/Machine-Translation/Neubig2017Neural.md)
*Graham Neubig*
18. **Neural Machine Translation for Low-Resource Languages: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2106.15115 ) [bib](/bib/Natural-Language-Processing/Machine-Translation/Ranathunga2021Neural.md)
*Surangika Ranathunga, En-Shiun Annie Lee, Marjana Prifti Skenduli, Ravi Shekhar, Mehreen Alam, Rishemjit Kaur*
19. **Neural Machine Translation: A Review.** J. Artif. Intell. Res. 2020 [paper](https://arxiv.org/abs/1912.02047) [bib](/bib/Natural-Language-Processing/Machine-Translation/Stahlberg2020Neural.md)
*Felix Stahlberg*
20. **Neural machine translation: A review of methods, resources, and tools.** AI Open 2020 [paper](https://www.sciencedirect.com/science/article/pii/S2666651020300024) [bib](/bib/Natural-Language-Processing/Machine-Translation/Tan2020Neural.md)
*Zhixing Tan, Shuo Wang, Zonghan Yang, Gang Chen, Xuancheng Huang, Maosong Sun, Yang Liu*
21. **Neural Machine Translation: Challenges, Progress and Future.** Science China Technological Sciences 2020 [paper](https://arxiv.org/abs/2004.05809) [bib](/bib/Natural-Language-Processing/Machine-Translation/Zhang2020Neural.md)
*Jiajun Zhang, Chengqing Zong*
22. **Survey of Low-Resource Machine Translation.** arXiv 2021 [paper](https://export.arxiv.org/pdf/2109.00486) [bib](/bib/Natural-Language-Processing/Machine-Translation/Haddow2021Survey.md)
*Barry Haddow, Rachel Bawden, Antonio Valerio Miceli Barone, Jindrich Helcl, Alexandra Birch*
23. **The Query Translation Landscape: a Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1910.03118) [bib](/bib/Natural-Language-Processing/Machine-Translation/Mami2019The.md)
*Mohamed Nadjib Mami, Damien Graux, Harsh Thakkar, Simon Scerri, Sören Auer, Jens Lehmann*
24. **神经机器翻译前沿综述.** 中文信息学报 2020 [paper](http://www.cnki.com.cn/Article/CJFDTotal-MESS202007002.htm) [bib](/bib/Natural-Language-Processing/Machine-Translation/Feng2020Survey.md)
*冯洋, 邵晨泽*
#### [Named Entity Recognition](#content)
1. **A Survey of Arabic Named Entity Recognition and Classification.** Comput. Linguistics 2014 [paper](https://direct.mit.edu/coli/article/40/2/469/1475/A-Survey-of-Arabic-Named-Entity-Recognition-and) [bib](/bib/Natural-Language-Processing/Named-Entity-Recognition/Shaalan2014A.md)
*Khaled Shaalan*
2. **A survey of named entity recognition and classification.** Lingvisticae Investigationes 2007 [paper](https://nlp.cs.nyu.edu/sekine/papers/li07.pdf) [bib](/bib/Natural-Language-Processing/Named-Entity-Recognition/Nadeau2007A.md)
*David Nadeau, Satoshi Sekine*
3. **A Survey of Named Entity Recognition in Assamese and other Indian Languages.** arXiv 2014 [paper](https://arxiv.org/abs/1407.2918) [bib](/bib/Natural-Language-Processing/Named-Entity-Recognition/Talukdar2014A.md)
*Gitimoni Talukdar, Pranjal Protim Borah, Arup Baruah*
4. **A Survey on Deep Learning for Named Entity Recognition.** IEEE Trans. Knowl. Data Eng. 2022 [paper](https://arxiv.org/abs/1812.09449) [bib](/bib/Natural-Language-Processing/Named-Entity-Recognition/Li2022A.md)
*Jing Li, Aixin Sun, Jianglei Han, Chenliang Li*
5. **A Survey on Recent Advances in Named Entity Recognition from Deep Learning models.** COLING 2018 [paper](https://arxiv.org/abs/1910.11470) [bib](/bib/Natural-Language-Processing/Named-Entity-Recognition/Yadav2018A.md)
*Vikas Yadav, Steven Bethard*
6. **Design Challenges and Misconceptions in Neural Sequence Labeling.** COLING 2018 [paper](https://arxiv.org/abs/1806.04470) [bib](/bib/Natural-Language-Processing/Named-Entity-Recognition/Yang2018Design.md)
*Jie Yang, Shuailong Liang, Yue Zhang*
#### [Natural Language Inference](#content)
1. **A Comparative Survey of Recent Natural Language Interfaces for Databases.** VLDB J. 2019 [paper](https://arxiv.org/abs/1906.08990) [bib](/bib/Natural-Language-Processing/Natural-Language-Inference/Affolter2019A.md)
*Katrin Affolter, Kurt Stockinger, Abraham Bernstein*
2. **Beyond Leaderboards: A survey of methods for revealing weaknesses in Natural Language Inference data and models.** arXiv 2020 [paper](https://arxiv.org/abs/2005.14709) [bib](/bib/Natural-Language-Processing/Natural-Language-Inference/Schlegel2020Beyond.md)
*Viktor Schlegel, Goran Nenadic, Riza Batista-Navarro*
3. **Recent Advances in Natural Language Inference: A Survey of Benchmarks, Resources, and Approaches.** arXiv 2019 [paper](https://arxiv.org/pdf/1904.01172) [bib](/bib/Natural-Language-Processing/Natural-Language-Inference/Storks2019Recent.md)
*Shane Storks, Qiaozi Gao, Joyce Y Chai*
#### [Natural Language Processing](#content)
1. **A bit of progress in language modeling.** Comput. Speech Lang. 2001 [paper](https://www.sciencedirect.com/science/article/pii/S0885230801901743) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Goodman2001A.md)
*Joshua T. Goodman*
2. **A Brief Survey and Comparative Study of Recent Development of Pronoun Coreference Resolution.** arXiv 2020 [paper](https://arxiv.org/pdf/2009.12721.pdf) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Zhang2020A.md)
*Hongming Zhang, Xinran Zhao, Yangqiu Song*
3. **A Comprehensive Survey of Grammar Error Correction.** arXiv 2020 [paper](https://arxiv.org/abs/2005.06600) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Wang2020A.md)
*Yu Wang, Yuelin Wang, Jie Liu, Zhuo Liu*
4. **A Neural Entity Coreference Resolution Review.** Expert Syst. Appl. 2021 [paper](https://arxiv.org/abs/1910.09329) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Stylianou2021A.md)
*Nikolaos Stylianou, Ioannis P. Vlahavas*
5. **A Primer on Neural Network Models for Natural Language Processing.** J. Artif. Intell. Res. 2016 [paper](https://arxiv.org/abs/1510.00726) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Goldberg2016A.md)
*Yoav Goldberg*
6. **A Review of Bangla Natural Language Processing Tasks and the Utility of Transformer Models.** arXiv 2021 [paper](https://arxiv.org/abs/2107.03844 ) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Alam2021A.md)
*Firoj Alam, Md. Arid Hasan, Tanvirul Alam, Akib Khan, Jannatul Tajrin, Naira Khan, Shammur Absar Chowdhury*
7. **A Survey and Classification of Controlled Natural Languages.** Comput. Linguistics 2014 [paper](https://arxiv.org/abs/1507.01701) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Kuhn2014A.md)
*Tobias Kuhn*
8. **A Survey on Neural Network Language Models.** arXiv 2019 [paper](https://arxiv.org/abs/1906.03591) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Jing2019A.md)
*Kun Jing, Jungang Xu*
9. **A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios.** NAACL-HLT 2021 [paper](https://arxiv.org/pdf/2010.12309.pdf) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Hedderich2021A.md)
*Michael A. Hedderich, Lukas Lange, Heike Adel, Jannik Strötgen, Dietrich Klakow*
10. **An Introductory Survey on Attention Mechanisms in NLP Problems.** IntelliSys 2019 [paper](https://arxiv.org/pdf/1811.05544.pdf) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Hu2019An.md)
*Dichao Hu*
11. **Attention in Natural Language Processing.** IEEE Trans. Neural Networks Learn. Syst. 2021 [paper](https://paper.idea.edu.cn/paper/3031696893) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Galassi2021Attention.md)
*Andrea Galassi, Marco Lippi, Paolo Torroni*
12. **Automatic Arabic Dialect Identification Systems for Written Texts: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.12622) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Althobaiti2020Automatic.md)
*Maha J. Althobaiti*
13. **Chinese Word Segmentation: A Decade Review.** Journal of Chinese Information Processing 2007 [paper](https://en.cnki.com.cn/Article_en/CJFDTotal-MESS200703001.htm) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Huang2007Chinese.md)
*Changning Huang, Hai Zhao*
14. **Continual Lifelong Learning in Natural Language Processing: A Survey.** COLING 2020 [paper](https://www.aclweb.org/anthology/2020.coling-main.574/) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Biesialska2020Continual.md)
*Magdalena Biesialska, Katarzyna Biesialska, Marta R. Costa-jussà*
15. **Experience Grounds Language.** EMNLP 2020 [paper](https://arxiv.org/abs/2004.10151) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Bisk2020Experience.md)
*Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, Angeliki Lazaridou, Jonathan May, Aleksandr Nisnevich, Nicolas Pinto, Joseph P. Turian*
16. **How Commonsense Knowledge Helps with Natural Language Tasks: A Survey of Recent Resources and Methodologies.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04674.pdf) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Xie2021How.md)
*Yubo Xie, Pearl Pu*
17. **Jumping NLP curves: A review of natural language processing research [Review Article].** IEEE Comput. Intell. Mag. 2014 [paper](http://krchowdhary.com/ai/ai14/lects/nlp-research-com-intlg-ieee.pdf) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Cambria2014Jumping.md)
*Erik Cambria, Bebo White*
18. **Natural Language Processing - A Survey.** arXiv 2012 [paper](https://arxiv.org/abs/1209.6238) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Mote2012Natural.md)
*Kevin Mote*
19. **Natural Language Processing: State of The Art, Current Trends and Challenges.** arXiv 2017 [paper](https://arxiv.org/abs/1708.05148) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Khurana2017Natural.md)
*Diksha Khurana, Aditya Koli, Kiran Khatter, Sukhdev Singh*
20. **Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering.** COLING 2018 [paper](https://arxiv.org/pdf/1806.04330.pdf) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Lan2018Neural.md)
*Wuwei Lan, Wei Xu*
21. **Overview of the Transformer-based Models for NLP Tasks.** FedCSIS 2020 [paper](https://ieeexplore.ieee.org/document/9222960) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Gillioz2020Overview.md)
*Anthony Gillioz, Jacky Casas, Elena Mugellini, Omar Abou Khaled*
22. **Progress in Neural NLP: Modeling, Learning, and Reasoning.** Engineering 2020 [paper](https://www.sciencedirect.com/science/article/pii/S2095809919304928) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Zhou2020Progress.md)
*Ming Zhou, Nan Duan, Shujie Liu, Heung-Yeung Shum*
23. **Putting Humans in the Natural Language Processing Loop: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.04044) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Wang2021Putting.md)
*Zijie J. Wang, Dongjin Choi, Shenyu Xu, Diyi Yang*
24. **Survey on Publicly Available Sinhala Natural Language Processing Tools and Research.** arXiv 2019 [paper](https://arxiv.org/abs/1906.02358) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Silva2019Survey.md)
*Nisansa de Silva*
25. **Visualizing Natural Language Descriptions: A Survey.** ACM Comput. Surv. 2016 [paper](https://arxiv.org/abs/1607.00623) [bib](/bib/Natural-Language-Processing/Natural-Language-Processing/Hassani2016Visualizing.md)
*Kaveh Hassani, Won-Sook Lee*
#### [NLP Applications](#content)
1. **A Short Survey of Biomedical Relation Extraction Techniques.** arXiv 2017 [paper](https://arxiv.org/abs/1707.05850) [bib](/bib/Natural-Language-Processing/NLP-Applications/Shahab2017A.md)
*Elham Shahab*
2. **A survey on natural language processing (nlp) and applications in insurance.** arXiv 2020 [paper](http://arxiv.org/pdf/2010.00462.pdf) [bib](/bib/Natural-Language-Processing/NLP-Applications/Ly2020A.md)
*Antoine Ly, Benno Uthayasooriyar, Tingting Wang*
3. **Android Security using NLP Techniques: A Review.** arXiv 2021 [paper](https://arxiv.org/abs/2107.03072 ) [bib](/bib/Natural-Language-Processing/NLP-Applications/Sen2021Android.md)
*Sevil Sen, Burcu Can*
4. **Disinformation Detection: A review of linguistic feature selection and classification models in news veracity assessments.** arXiv 2019 [paper](https://arxiv.org/abs/1910.12073) [bib](/bib/Natural-Language-Processing/NLP-Applications/Tompkins2019Disinformation.md)
*Jillian Tompkins*
5. **Extraction and Analysis of Fictional Character Networks: A Survey.** ACM Comput. Surv. 2019 [paper](https://arxiv.org/abs/1907.02704) [bib](/bib/Natural-Language-Processing/NLP-Applications/Labatut2019Extraction.md)
*Vincent Labatut, Xavier Bost*
6. **How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence.** ACL 2020 [paper](https://arxiv.org/pdf/2004.12158) [bib](/bib/Natural-Language-Processing/NLP-Applications/Zhong2020How.md)
*Haoxi Zhong, Chaojun Xiao, Cunchao Tu, Tianyang Zhang, Zhiyuan Liu, Maosong Sun*
7. **Natural Language Based Financial Forecasting: A Survey.** Artif. Intell. Rev. 2018 [paper](https://dspace.mit.edu/bitstream/handle/1721.1/116314/10462_2017_9588_ReferencePDF.pdf?sequence=2&isAllowed=y) [bib](/bib/Natural-Language-Processing/NLP-Applications/Xing2018Natural.md)
*Frank Z. Xing, Erik Cambria, Roy E. Welsch*
8. **Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review.** arXiv 2021 [paper]( https://arxiv.org/abs/2107.02975 ) [bib](/bib/Natural-Language-Processing/NLP-Applications/Li2021Neural.md)
*Irene Li, Jessica Pan, Jeremy Goldwasser, Neha Verma, Wai Pan Wong, Muhammed Yavuz Nuzumlali, Benjamin Rosand, Yixin Li, Matthew Zhang, David Chang, Richard Andrew Taylor, Harlan M. Krumholz, Dragomir R. Radev*
9. **SECNLP: A survey of embeddings in clinical natural language processing.** J. Biomed. Informatics 2020 [paper](https://www.sciencedirect.com/science/article/pii/S1532046419302436) [bib](/bib/Natural-Language-Processing/NLP-Applications/Kalyan2020SECNLP.md)
*Katikapalli Subramanyam Kalyan, Sivanesan Sangeetha*
10. **Survey of Natural Language Processing Techniques in Bioinformatics.** Comput. Math. Methods Medicine 2015 [paper](https://pdfs.semanticscholar.org/7013/479be7dda124750aa22fb6231eea2671f630.pdf) [bib](/bib/Natural-Language-Processing/NLP-Applications/Zeng2015Survey.md)
*Zhiqiang Zeng, Hua Shi, Yun Wu, Zhiling Hong*
11. **Survey of Text-based Epidemic Intelligence: A Computational Linguistics Perspective.** ACM Comput. Surv. 2020 [paper](https://dl.acm.org/doi/10.1145/3361141) [bib](/bib/Natural-Language-Processing/NLP-Applications/Joshi2020Survey.md)
*Aditya Joshi, Sarvnaz Karimi, Ross Sparks, Cécile Paris, C. Raina MacIntyre*
12. **The Potential of Machine Learning and NLP for Handling Students' Feedback (A Short Survey).** arXiv 2020 [paper](https://arxiv.org/pdf/2011.05806) [bib](/bib/Natural-Language-Processing/NLP-Applications/Edalati2020The.md)
*Maryam Edalati*
13. **Towards Improved Model Design for Authorship Identification: A Survey on Writing Style Understanding.** arXiv 2020 [paper](https://arxiv.org/pdf/2009.14445.pdf) [bib](/bib/Natural-Language-Processing/NLP-Applications/Ma2020Towards.md)
*Weicheng Ma, Ruibo Liu, Lili Wang, Soroush Vosoughi*
#### [Pre-training](#content)
1. **A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives.** arXiv 2021 [paper](https://arxiv.org/abs/2102.12982) [bib](/bib/Natural-Language-Processing/Pre-training/Rethmeier2021A.md)
*Nils Rethmeier, Isabelle Augenstein*
2. **A Short Survey of Pre-trained Language Models for Conversational AI-A NewAge in NLP.** arXiv 2021 [paper](https://arxiv.org/abs/2104.10810) [bib](/bib/Natural-Language-Processing/Pre-training/Zaib2021A.md)
*Munazza Zaib, Quan Z. Sheng, Wei Emma Zhang*
3. **AMMUS : A Survey of Transformer-based Pretrained Models in Natural Language Processing.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.05542.pdf) [bib](/bib/Natural-Language-Processing/Pre-training/Kalyan2021AMMUS.md)
*Katikapalli Subramanyam Kalyan, Ajit Rajasekharan, Sivanesan Sangeetha*
4. **Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.13586.pdf) [bib](/bib/Natural-Language-Processing/Pre-training/Liu2021Pre-train.md)
*Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig*
5. **Pretrained Language Models for Text Generation: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2105.10311.pdf) [bib](/bib/Natural-Language-Processing/Pre-training/Li2021Pretrained.md)
*Junyi Li, Tianyi Tang, Wayne Xin Zhao, Ji-Rong Wen*
6. **Pre-trained models for natural language processing: A survey.** Science China Technological Sciences 2020 [paper](https://link.springer.com/content/pdf/10.1007/s11431-020-1647-3.pdf) [bib](/bib/Natural-Language-Processing/Pre-training/Qiu2020Pre-trained.md)
*Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, Xuanjing Huang*
7. **Pre-Trained Models: Past, Present and Future.** arXiv 2021 [paper](https://arxiv.org/abs/2106.07139) [bib](/bib/Natural-Language-Processing/Pre-training/Han2021Pre-Trained.md)
*Xu Han, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, Liang Zhang, Wentao Han, Minlie Huang, Qin Jin, Yanyan Lan, Yang Liu, Zhiyuan Liu, Zhiwu Lu, Xipeng Qiu, Ruihua Song, Jie Tang, Ji-Rong Wen, Jinhui Yuan, Wayne Xin Zhao, Jun Zhu*
8. **Pretrained Transformers for Text Ranking: BERT and Beyond.** WSDM 2021 [paper](https://dl.acm.org/doi/pdf/10.1145/3437963.3441667) [bib](/bib/Natural-Language-Processing/Pre-training/Yates2021Pretrained.md)
*Andrew Yates, Rodrigo Nogueira, Jimmy Lin*
#### [Question Answering](#content)
1. **A Survey of Question Answering over Knowledge Base.** CCKS 2019 [paper](https://link.springer.com/chapter/10.1007%2F978-981-15-1956-7_8) [bib](/bib/Natural-Language-Processing/Question-Answering/Wu2019A.md)
*Peiyun Wu, Xiaowang Zhang, Zhiyong Feng*
2. **A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions.** IJCAI 2021 [paper](https://arxiv.org/abs/2105.11644) [bib](/bib/Natural-Language-Processing/Question-Answering/Lan2021A.md)
*Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, Ji-Rong Wen*
3. **A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges.** arXiv 2020 [paper](https://arxiv.org/abs/2007.13069) [bib](/bib/Natural-Language-Processing/Question-Answering/Fu2020A.md)
*Bin Fu, Yunqi Qiu, Chengguang Tang, Yang Li, Haiyang Yu, Jian Sun*
4. **A survey on question answering technology from an information retrieval perspective.** Inf. Sci. 2011 [paper](https://www.sciencedirect.com/science/article/pii/S0020025511003860) [bib](/bib/Natural-Language-Processing/Question-Answering/Kolomiyets2011A.md)
*Oleksandr Kolomiyets, Marie-Francine Moens*
5. **A Survey on Why-Type Question Answering Systems.** arXiv 2019 [paper](https://arxiv.org/abs/1911.04879) [bib](/bib/Natural-Language-Processing/Question-Answering/Breja2019A.md)
*Manvi Breja, Sanjay Kumar Jain*
6. **Complex Knowledge Base Question Answering: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.06688.pdf) [bib](/bib/Natural-Language-Processing/Question-Answering/Lan2021Complex.md)
*Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, Ji-Rong Wen*
7. **Core techniques of question answering systems over knowledge bases: a survey.** Knowl. Inf. Syst. 2018 [paper](https://link.springer.com/article/10.1007/s10115-017-1100-y) [bib](/bib/Natural-Language-Processing/Question-Answering/Diefenbach2018Core.md)
*Dennis Diefenbach, Vanessa López, Kamal Deep Singh, Pierre Maret*
8. **Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs.** arXiv 2019 [paper](https://arxiv.org/abs/1907.09361) [bib](/bib/Natural-Language-Processing/Question-Answering/Chakraborty2019Introduction.md)
*Nilesh Chakraborty, Denis Lukovnikov, Gaurav Maheshwari, Priyansh Trivedi, Jens Lehmann, Asja Fischer*
9. **Narrative Question Answering with Cutting-Edge Open-Domain QA Techniques: A Comprehensive Study.** arXiv 2021 [paper](https://arxiv.org/abs/2106.03826) [bib](/bib/Natural-Language-Processing/Question-Answering/Mou2021Narrative.md)
*Xiangyang Mou, Chenghao Yang, Mo Yu, Bingsheng Yao, Xiaoxiao Guo, Saloni Potdar, Hui Su*
10. **Question Answering Systems: Survey and Trends.** Procedia Computer Science 2015 [paper](https://www.sciencedirect.com/science/article/pii/S1877050915034663) [bib](/bib/Natural-Language-Processing/Question-Answering/Bouziane2015Question.md)
*Abdelghani Bouziane, Djelloul Bouchiha, Noureddine Doumi, Mimoun Malki*
11. **Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering.** arXiv 2021 [paper](http://arxiv.org/pdf/2101.00774.pdf) [bib](/bib/Natural-Language-Processing/Question-Answering/Zhu2021Retrieving.md)
*Fengbin Zhu, Wenqiang Lei, Chao Wang, Jianming Zheng, Soujanya Poria, Tat-Seng Chua*
12. **Survey of Visual Question Answering: Datasets and Techniques.** arXiv 2017 [paper](https://arxiv.org/abs/1705.03865) [bib](/bib/Natural-Language-Processing/Question-Answering/Gupta2017Survey.md)
*Akshay Kumar Gupta*
13. **Text-based Question Answering from Information Retrieval and Deep Neural Network Perspectives: A Survey.** WIREs Data Mining Knowl. Discov. 2021 [paper](https://arxiv.org/abs/2002.06612) [bib](/bib/Natural-Language-Processing/Question-Answering/Abbasiantaeb2021Text-based.md)
*Zahra Abbasiantaeb, Saeedeh Momtazi*
14. **Tutorial on Answering Questions about Images with Deep Learning.** arXiv 2016 [paper](https://arxiv.org/abs/1610.01076) [bib](/bib/Natural-Language-Processing/Question-Answering/Malinowski2016Tutorial.md)
*Mateusz Malinowski, Mario Fritz*
15. **Visual Question Answering using Deep Learning: A Survey and Performance Analysis.** CVIP 2020 [paper](https://arxiv.org/abs/1909.01860) [bib](/bib/Natural-Language-Processing/Question-Answering/Srivastava2020Visual.md)
*Yash Srivastava, Vaishnav Murali, Shiv Ram Dubey, Snehasis Mukherjee*
#### [Reading Comprehension](#content)
1. **A Survey on Explainability in Machine Reading Comprehension.** arXiv 2020 [paper](http://arxiv.org/pdf/2010.00389.pdf) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Thayaparan2020A.md)
*Mokanarangan Thayaparan, Marco Valentino, André Freitas*
2. **A Survey on Machine Reading Comprehension Systems.** arXiv 2020 [paper](https://arxiv.org/abs/2001.01582) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Baradaran2020A.md)
*Razieh Baradaran, Razieh Ghiasi, Hossein Amirkhani*
3. **A Survey on Machine Reading Comprehension—Tasks, Evaluation Metrics and Benchmark Datasets.** Applied Sciences 2020 [paper](https://www.mdpi.com/2076-3417/10/21/7640/html) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Zeng2020A.md)
*Chengchang Zeng, Shaobo Li, Qin Li, Jie Hu, Jianjun Hu*
4. **A Survey on Neural Machine Reading Comprehension.** arXiv 2019 [paper](https://arxiv.org/abs/1906.03824) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Qiu2019A.md)
*Boyu Qiu, Xu Chen, Jungang Xu, Yingfei Sun*
5. **English Machine Reading Comprehension Datasets: A Survey.** EMNLP 2021 [paper](https://arxiv.org/abs/2101.10421) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Dzendzik2021English.md)
*Daria Dzendzik, Jennifer Foster, Carl Vogel*
6. **Machine Reading Comprehension: a Literature Review.** arXiv 2019 [paper](https://arxiv.org/abs/1907.01686) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Zhang2019Machine.md)
*Xin Zhang, An Yang, Sujian Li, Yizhong Wang*
7. **Machine Reading Comprehension: The Role of Contextualized Language Models and Beyond.** arXiv 2020 [paper](https://arxiv.org/abs/2005.06249) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Zhang2020Machine.md)
*Zhuosheng Zhang, Hai Zhao, Rui Wang*
8. **Neural Machine Reading Comprehension: Methods and Trends.** Applied Surface Science 2019 [paper](https://arxiv.org/abs/1907.01118) [bib](/bib/Natural-Language-Processing/Reading-Comprehension/Liu2019Neural.md)
*Shanshan Liu, Xin Zhang, Sheng Zhang, Hui Wang, Weiming Zhang*
#### [Recommender Systems](#content)
1. **A review on deep learning for recommender systems: challenges and remedies.** Artif. Intell. Rev. 2019 [paper](https://link.springer.com/article/10.1007/s10462-018-9654-y) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Batmaz2019A.md)
*Zeynep Batmaz, Ali Yürekli, Alper Bilge, Cihan Kaleli*
2. **A Survey of Explanations in Recommender Systems.** ICDE Workshops 2007 [paper](https://ieeexplore.ieee.org/document/4401070) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Tintarev2007A.md)
*Nava Tintarev, Judith Masthoff*
3. **A survey on Adversarial Recommender Systems: from Attack/Defense strategies to Generative Adversarial Networks.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2005.10322) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Deldjoo2021A.md)
*Yashar Deldjoo, Tommaso Di Noia, Felice Antonio Merra*
4. **A Survey on Conversational Recommender Systems.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2004.00646) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Jannach2021A.md)
*Dietmar Jannach, Ahtsham Manzoor, Wanling Cai, Li Chen*
5. **A Survey on Knowledge Graph-Based Recommender Systems.** arXiv 2020 [paper](https://arxiv.org/abs/2003.00911) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Guo2020A.md)
*Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, Qing He*
6. **A Survey on Personality-Aware Recommendation Systems.** arXiv 2021 [paper](http://arxiv.org/pdf/2101.12153.pdf) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Dhelim2021A.md)
*Sahraoui Dhelim, Nyothiri Aung, Mohammed Amine Bouras, Huansheng Ning, Erik Cambria*
7. **A Survey on Session-based Recommender Systems.** ACM Comput. Surv. 2022 [paper](https://arxiv.org/pdf/1902.04864.pdf) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Wang2022A.md)
*Shoujin Wang, Longbing Cao, Yan Wang, Quan Z. Sheng, Mehmet A. Orgun, Defu Lian*
8. **Advances and Challenges in Conversational Recommender Systems: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2101.09459) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Gao2021Advances.md)
*Chongming Gao, Wenqiang Lei, Xiangnan He, Maarten de Rijke, Tat-Seng Chua*
9. **Are we really making much progress? A worrying analysis of recent neural recommendation approaches.** RecSys 2019 [paper](https://dl.acm.org/doi/10.1145/3298689.3347058) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Dacrema2019Are.md)
*Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach*
10. **Bias and Debias in Recommender System: A Survey and Future Directions.** arXiv 2020 [paper](https://arxiv.org/abs/2010.03240) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Chen2020Bias.md)
*Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, Xiangnan He*
11. **Content-based Recommender Systems: State of the Art and Trends.** Recommender Systems Handbook 2011 [paper](https://link.springer.com/chapter/10.1007/978-0-387-85820-3_3) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Lops2011Content-based.md)
*Pasquale Lops, Marco de Gemmis, Giovanni Semeraro*
12. **Cross Domain Recommender Systems: A Systematic Literature Review.** ACM Comput. Surv. 2017 [paper](https://dl.acm.org/doi/10.1145/3073565) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Khan2017Cross.md)
*Muhammad Murad Khan, Roliana Ibrahim, Imran Ghani*
13. **Deep Conversational Recommender Systems: A New Frontier for Goal-Oriented Dialogue Systems.** arXiv 2020 [paper](https://arxiv.org/abs/2004.13245) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Tran2020Deep.md)
*Dai Hoang Tran, Quan Z. Sheng, Wei Emma Zhang, Salma Abdalla Hamad, Munazza Zaib, Nguyen H. Tran, Lina Yao, Nguyen Lu Dang Khoa*
14. **Deep Learning based Recommender System: A Survey and New Perspectives.** ACM Comput. Surv. 2019 [paper](https://arxiv.org/abs/1707.07435) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Zhang2019Deep.md)
*Shuai Zhang, Lina Yao, Aixin Sun, Yi Tay*
15. **Deep Learning for Matching in Search and Recommendation.** Found. Trends Inf. Retr. 2020 [paper](http://staff.ustc.edu.cn/~hexn/papers/www18-tutorial-deep-matching-paper.pdf) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Xu2020Deep.md)
*Jun Xu, Xiangnan He, Hang Li*
16. **Deep Learning on Knowledge Graph for Recommender System: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2004.00387) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Gao2020Deep.md)
*Yang Gao, Yi-Fan Li, Yu Lin, Hang Gao, Latifur Khan*
17. **Diversity in recommender systems – A survey.** Knowledge-Based Systems 2017 [paper](https://www.sciencedirect.com/science/article/abs/pii/S0950705117300680) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Kunavera2017Diversity.md)
*Matevž Kunavera, Tomaž Požrl*
18. **Explainable Recommendation: A Survey and New Perspectives.** Found. Trends Inf. Retr. 2020 [paper](https://arxiv.org/abs/1804.11192) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Zhang2020Explainable.md)
*Yongfeng Zhang, Xu Chen*
19. **Graph Learning based Recommender Systems: A Review.** IJCAI 2021 [paper](https://arxiv.org/pdf/2105.06339.pdf) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Wang2021Graph.md)
*Shoujin Wang, Liang Hu, Yan Wang, Xiangnan He, Quan Z. Sheng, Mehmet A. Orgun, Longbing Cao, Francesco Ricci, Philip S. Yu*
20. **Graph Neural Networks in Recommender Systems: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2011.02260) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Wu2020Graph.md)
*Shiwen Wu, Wentao Zhang, Fei Sun, Bin Cui*
21. **Hybrid Recommender Systems: Survey and Experiments.** User Model. User Adapt. Interact. 2002 [paper](https://link.springer.com/article/10.1023/A:1021240730564) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Burke2002Hybrid.md)
*Robin D. Burke*
22. **Knowledge Transfer via Pre-training for Recommendation: A Review and Prospect.** Frontiers Big Data 2021 [paper](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8013982/) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Zeng2021Knowledge.md)
*Zheni Zeng, Chaojun Xiao, Yuan Yao, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun*
23. **Recommender systems survey.** Knowledge-Based Systems 2013 [paper](https://www.sciencedirect.com/science/article/abs/pii/S0950705113001044) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Bobadilla2013Recommender.md)
*Bobadilla J., Ortega F., Hernando A., Gutiérrez A.*
24. **Sequence-Aware Recommender Systems.** ACM Comput. Surv. 2018 [paper](https://arxiv.org/abs/1802.08452) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Quadrana2018Sequence-Aware.md)
*Massimo Quadrana, Paolo Cremonesi, Dietmar Jannach*
25. **Survey for Trust-aware Recommender Systems: A Deep Learning Perspective.** arXiv 2020 [paper](http://arxiv.org/abs/2004.03774) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Dong2020Survey.md)
*Manqing Dong, Feng Yuan, Lina Yao, Xianzhi Wang, Xiwei Xu, Liming Zhu*
26. **Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions.** IEEE Trans. Knowl. Data Eng. 2005 [paper](https://ieeexplore.ieee.org/abstract/document/1423975) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Adomavicius2005Toward.md)
*Gediminas Adomavicius, Alexander Tuzhilin*
27. **Use of Deep Learning in Modern Recommendation System: A Summary of Recent Works.** arXiv 2017 [paper](https://arxiv.org/abs/1712.07525) [bib](/bib/Natural-Language-Processing/Recommender-Systems/Singhal2017Use.md)
*Ayush Singhal, Pradeep Sinha, Rakesh Pant*
#### [Resources and Evaluation](#content)
1. **A Review of Human Evaluation for Style Transfer.** arXiv 2021 [paper](https://arxiv.org/abs/2106.04747 ) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Briakou2021A.md)
*Eleftheria Briakou, Sweta Agrawal, Ke Zhang, Joel R. Tetreault, Marine Carpuat*
2. **A Short Survey on Sense-Annotated Corpora.** LREC 2020 [paper](https://arxiv.org/abs/1802.04744) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Pasini2020A.md)
*Tommaso Pasini, José Camacho-Collados*
3. **A Survey of Current Datasets for Vision and Language Research.** EMNLP 2015 [paper](https://arxiv.org/abs/1506.06833) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Ferraro2015A.md)
*Francis Ferraro, Nasrin Mostafazadeh, Ting-Hao (Kenneth) Huang, Lucy Vanderwende, Jacob Devlin, Michel Galley, Margaret Mitchell*
4. **A Survey of Evaluation Metrics Used for NLG Systems.** arXiv 2020 [paper](https://arxiv.org/abs/2008.12009) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Sai2020A.md)
*Ananya B. Sai, Akash Kumar Mohankumar, Mitesh M. Khapra*
5. **A Survey of Word Embeddings Evaluation Methods.** arXiv 2018 [paper](https://arxiv.org/abs/1801.09536) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Bakarov2018A.md)
*Amir Bakarov*
6. **A Survey on Recognizing Textual Entailment as an NLP Evaluation.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.03061.pdf) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Poliak2020A.md)
*Adam Poliak*
7. **Corpora Annotated with Negation: An Overview.** Comput. Linguistics 2020 [paper](https://watermark.silverchair.com/coli_a_00371.pdf?token=AQECAHi208BE49Ooan9kkhW_Ercy7Dm3ZL_9Cf3qfKAc485ysgAAAqUwggKhBgkqhkiG9w0BBwagggKSMIICjgIBADCCAocGCSqGSIb3DQEHATAeBglghkgBZQMEAS4wEQQMwFfpYsXe-j1WZLOYAgEQgIICWK8_os-_3bOw2Egxl-QP8k6_eaUBXbfLcdwSiN1AKd2RyuDFyjIlDYSZ5NTAAsDgDlMCD3TrhPG0ikKF7P7kuegNT5PvSubob_GmEmkrscxcBW6EJJepel-bEup-_A22uwRLCznueNRO_TIF1YCNc5jsTEopV_PzSEeI-vqG3BTbc_EtWxty9udu1sZYsHmXO2i8h7_m5MGt3nCX8aXXNkRPhrmNZ4IHU2moi76_JOuBQb6U6n6SItsdwObWewSPB3eGmx4DmUboNcB-Dv7OJAS9jmWHgsNzsSiRw9lRBcsf1O_0Nkv5YkFSkVNTiCldQ3B1fWgjDN0GWSOTsMS-6Je6keFnovcc8nQnxw-ubXQ57UZYQjZHa8jg6Ea1kOUHJem8uRdc4IMJuKCunIKRJLT1SSLFGYDgehwxQfOQk-H6LOIsbWOaiXwP9aDDqG4a6Pxl_bwnpi8JUp5dQYvqLNteQ-rjGS8FbRvlaV34wL49UAEBwa2DFlkTVhebzCkrzuzN-H3obLkhqnR-LDXbjSQhYOzROGh74Gq-beWVM7boVegN49iq-El7CzRqnoTIzVjtBrp3b-tnaevilOo05l0s2rhFLr-46GRyXgD11UTbz0tCy892aJACw6XYCsRvx2veM2tzBxg5D6a65ev1F3ViYbOlyz99M11QLllIMdoRT1R5fkdEyFrDQh-Q6VCJT3tJAOdlhWCc6kpie4jME3xACsVXSKXIW4q7OCXDHtdvmQnUWWJURJAYZ2Rwfvc9JwQ20jY37wr5ZyyQ8VuiRXwkiiOK4EScHg) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Zafra2020Corpora.md)
*Salud María Jiménez Zafra, Roser Morante, María Teresa Martín-Valdivia, Luis Alfonso Ureña López*
8. **Critical Survey of the Freely Available Arabic Corpora.** arXiv 2017 [paper](https://arxiv.org/abs/1702.07835) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Zaghouani2017Critical.md)
*Wajdi Zaghouani*
9. **Recent Advances in Natural Language Inference: A Survey of Benchmarks, Resources, and Approaches.** arXiv 2019 [paper](https://arxiv.org/abs/1904.01172) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Storks2019Recent.md)
*Shane Storks, Qiaozi Gao, Joyce Y. Chai*
10. **Survey on Evaluation Methods for Dialogue Systems.** Artif. Intell. Rev. 2021 [paper](https://arxiv.org/abs/1905.04071) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Deriu2021Survey.md)
*Jan Deriu, Álvaro Rodrigo, Arantxa Otegi, Guillermo Echegoyen, Sophie Rosset, Eneko Agirre, Mark Cieliebak*
11. **Survey on Publicly Available Sinhala Natural Language Processing Tools and Research.** arXiv 2019 [paper](https://arxiv.org/abs/1906.02358) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Silva2019Survey.md)
*Nisansa de Silva*
12. **The Great Misalignment Problem in Human Evaluation of NLP Methods.** arXiv 2021 [paper](https://arxiv.org/abs/2104.05361) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Hämäläinen2021The.md)
*Mika Hämäläinen, Khalid Al-Najjar*
13. **Towards Standard Criteria for human evaluation of Chatbots: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2105.11197) [bib](/bib/Natural-Language-Processing/Resources-and-Evaluation/Liang2021Towards.md)
*Hongru Liang, Huaqing Li*
#### [Semantics](#content)
1. **A reproducible survey on word embeddings and ontology-based methods for word similarity: Linear combinations outperform the state of the art.** Eng. Appl. Artif. Intell. 2019 [paper](https://www.sciencedirect.com/science/article/pii/S0952197619301745) [bib](/bib/Natural-Language-Processing/Semantics/Lastra2019A.md)
*Juan J. Lastra-Díaz, Josu Goikoetxea, Mohamed Ali Hadj Taieb, Ana García-Serrano, Mohamed Ben Aouicha, Eneko Agirre*
2. **A survey of loss functions for semantic segmentation.** CIBCB 2020 [paper](https://arxiv.org/abs/2006.14822) [bib](/bib/Natural-Language-Processing/Semantics/Jadon2020A.md)
*Shruti Jadon*
3. **A Survey of Paraphrasing and Textual Entailment Methods.** J. Artif. Intell. Res. 2010 [paper](https://arxiv.org/abs/0912.3747) [bib](/bib/Natural-Language-Processing/Semantics/Androutsopoulos2010A.md)
*Ion Androutsopoulos, Prodromos Malakasiotis*
4. **A Survey of Syntactic-Semantic Parsing Based on Constituent and Dependency Structures.** arXiv 2020 [paper](http://arxiv.org/pdf/2006.11056.pdf) [bib](/bib/Natural-Language-Processing/Semantics/Zhang2020A.md)
*Meishan Zhang*
5. **A Survey on Semantic Parsing.** AKBC 2019 [paper](https://arxiv.org/pdf/1812.00978) [bib](/bib/Natural-Language-Processing/Semantics/Kamath2019A.md)
*Aishwarya Kamath, Rajarshi Das*
6. **Argument Linking: A Survey and Forecast.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.08523.pdf) [bib](/bib/Natural-Language-Processing/Semantics/Gantt2021Argument.md)
*William Gantt*
7. **Corpus-Based Paraphrase Detection Experiments and Review.** Inf. 2020 [paper](https://arxiv.org/abs/2106.00145) [bib](/bib/Natural-Language-Processing/Semantics/Vrbanec2020Corpus-Based.md)
*Tedo Vrbanec, Ana Mestrovic*
8. **Diachronic word embeddings and semantic shifts: a survey.** COLING 2018 [paper](https://arxiv.org/abs/1806.03537) [bib](/bib/Natural-Language-Processing/Semantics/Kutuzov2018Diachronic.md)
*Andrey Kutuzov, Lilja Øvrelid, Terrence Szymanski, Erik Velldal*
9. **Distributional Measures of Semantic Distance: A Survey.** arXiv 2012 [paper](https://arxiv.org/abs/1203.1858) [bib](/bib/Natural-Language-Processing/Semantics/Mohammad2012Distributional.md)
*Saif Mohammad, Graeme Hirst*
10. **Evolution of Semantic Similarity - A Survey.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2004.13820) [bib](/bib/Natural-Language-Processing/Semantics/Chandrasekaran2021Evolution.md)
*Dhivya Chandrasekaran, Vijay Mago*
11. **Measuring Sentences Similarity: A Survey.** Indian Journal of Science and Technology 2019 [paper](https://arxiv.org/abs/1910.03940) [bib](/bib/Natural-Language-Processing/Semantics/Farouk2019Measuring.md)
*Mamdouh Farouk*
12. **Semantic search on text and knowledge bases.** Found. Trends Inf. Retr. 2016 [paper](http://ceur-ws.org/Vol-1883/invited6.pdf) [bib](/bib/Natural-Language-Processing/Semantics/Bast2016Semantic.md)
*Hannah Bast, Björn Buchhold, Elmar Haussmann*
13. **Semantics, Modelling, and the Problem of Representation of Meaning - a Brief Survey of Recent Literature.** arXiv 2014 [paper](https://arxiv.org/abs/1402.7265) [bib](/bib/Natural-Language-Processing/Semantics/Gal2014Semantics.md)
*Yarin Gal*
14. **Survey of Computational Approaches to Lexical Semantic Change.** arXiv 2018 [paper](https://arxiv.org/abs/1811.06278) [bib](/bib/Natural-Language-Processing/Semantics/Tahmasebi2018Survey.md)
*Nina Tahmasebi, Lars Borin, Adam Jatowt*
15. **The Knowledge Acquisition Bottleneck Problem in Multilingual Word Sense Disambiguation.** IJCAI 2020 [paper](https://www.ijcai.org/Proceedings/2020/687) [bib](/bib/Natural-Language-Processing/Semantics/Pasini2020The.md)
*Tommaso Pasini*
16. **Word Sense disambiguation: A Survey.** ACM Comput. Surv. 2009 [paper](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.153.8457&rep=rep1&type=pdf) [bib](/bib/Natural-Language-Processing/Semantics/Navigli2009Word.md)
*Roberto Navigli*
17. **Word sense disambiguation: a survey.** IJCTCM 2015 [paper](https://arxiv.org/abs/1508.01346) [bib](/bib/Natural-Language-Processing/Semantics/Pal2015Word.md)
*Alok Ranjan Pal, Diganta Saha*
#### [Sentiment Analysis, Stylistic Analysis and Argument Mining](#content)
1. **360 degree view of cross-domain opinion classification: a survey.** Artif. Intell. Rev. 2021 [paper](https://link.springer.com/article/10.1007/s10462-020-09884-9) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Singh2021360.md)
*Rahul Kumar Singh, Manoj Kumar Sachan, R. B. Patel*
2. **A Comprehensive Survey on Aspect Based Sentiment Analysis.** arXiv 2020 [paper](https://arxiv.org/abs/2006.04611) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Yadav2020A.md)
*Kaustubh Yadav*
3. **A Survey of Sentiment Analysis in Social Media.** Knowl. Inf. Syst. 2019 [paper](http://cse.iitkgp.ac.in/~saptarshi/courses/socomp2020a/sentiment-analysis-survey-yue2019.pdf) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Yue2019A.md)
*Lin Yue, Weitong Chen, Xue Li, Wanli Zuo, Minghao Yin*
4. **A Survey on Sentiment and Emotion Analysis for Computational Literary Studies.** ZFDG 2019 [paper](https://arxiv.org/abs/1808.03137) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Kim2019A.md)
*Evgeny Kim, Roman Klinger*
5. **Beneath the Tip of the Iceberg: Current Challenges and New Directions in Sentiment Analysis Research.** arXiv 2020 [paper](https://arxiv.org/abs/2005.00357) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Poria2020Beneath.md)
*Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Rada Mihalcea*
6. **Deep Learning for Aspect-Level Sentiment Classification: Survey, Vision, and Challenges.** IEEE Access 2019 [paper](https://ieeexplore.ieee.org/document/8726353) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Zhou2019Deep.md)
*Jie Zhou, Jimmy Xiangji Huang, Qin Chen, Qinmin Vivian Hu, Tingting Wang, Liang He*
7. **Deep Learning for Sentiment Analysis : A Survey.** arXiv 2018 [paper](https://arxiv.org/abs/1801.07883) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Zhang2018Deep.md)
*Lei Zhang, Shuai Wang, Bing Liu*
8. **Emotion Recognition in Conversation: Research Challenges, Datasets, and Recent Advances.** IEEE Access 2019 [paper](https://ieeexplore.ieee.org/abstract/document/8764449) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Poria2019Emotion.md)
*Soujanya Poria, Navonil Majumder, Rada Mihalcea, Eduard H. Hovy*
9. **Fine-grained Financial Opinion Mining: A Survey and Research Agenda.** arXiv 2020 [paper](https://arxiv.org/pdf/2005.01897.pdf) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Chen2020Fine-grained.md)
*Chung-Chi Chen, Hen-Hsen Huang, Hsin-Hsi Chen*
10. **On Positivity Bias in Negative Reviews.** ACL 2021 [paper](https://arxiv.org/abs/2106.12056) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Aithal2021On.md)
*Madhusudhan Aithal, Chenhao Tan*
11. **Sarcasm Detection: A Comparative Study.** arXiv 2021 [paper](https://arxiv.org/abs/2107.02276) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Yaghoobian2021Sarcasm.md)
*Hamed Yaghoobian, Hamid R. Arabnia, Khaled Rasheed*
12. **Sentiment analysis algorithms and applications: A survey.** Ain Shams Engineering Journal 2014 [paper](https://www.sciencedirect.com/science/article/pii/S2090447914000550) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Medhat2014Sentiment.md)
*Walaa Medhat, Ahmed Hassan, Hoda Korashy*
13. **Sentiment analysis for Arabic language: A brief survey of approaches and techniques.** arXiv 2018 [paper](https://arxiv.org/abs/1809.02782) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Alrefai2018Sentiment.md)
*Mo'ath Alrefai, Hossam Faris, Ibrahim Aljarah*
14. **Sentiment Analysis of Czech Texts: An Algorithmic Survey.** ICAART 2019 [paper](https://arxiv.org/abs/1901.02780) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Çano2019Sentiment.md)
*Erion Çano, Ondrej Bojar*
15. **Sentiment Analysis of Twitter Data: A Survey of Techniques.** IJCAI 2016 [paper](https://arxiv.org/abs/1601.06971) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Kharde2016Sentiment.md)
*Vishal.A.Kharde, Prof. Sheetal.Sonawane*
16. **Sentiment Analysis on YouTube: A Brief Survey.** arXiv 2015 [paper](https://arxiv.org/abs/1511.09142) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Asghar2015Sentiment.md)
*Muhammad Zubair Asghar, Shakeel Ahmad, Afsana Marwat, Fazal Masood Kundi*
17. **Sentiment/Subjectivity Analysis Survey for Languages other than English.** Soc. Netw. Anal. Min. 2016 [paper](https://arxiv.org/abs/1601.00087) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Korayem2016SentimentSubjectivity.md)
*Mohammed Korayem, Khalifeh AlJadda, David J. Crandall*
18. **Towards Argument Mining for Social Good: A Survey.** ACL 2021 [paper](https://aclanthology.org/2021.acl-long.107.pdf) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Vecchi2021Towards.md)
*Eva Maria Vecchi, Neele Falk, Iman Jundi, Gabriella Lapesa*
19. **Word Embeddings for Sentiment Analysis: A Comprehensive Empirical Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1902.00753) [bib](/bib/Natural-Language-Processing/Sentiment-Analysis,-Stylistic-Analysis-and-Argument-Mining/Çano2019Word.md)
*Erion Çano, Maurizio Morisio*
#### [Speech and Multimodality](#content)
1. **A Comprehensive Survey on Cross-modal Retrieval.** arXiv 2016 [paper](https://arxiv.org/abs/1607.06215) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Wang2016A.md)
*Kaiye Wang, Qiyue Yin, Wei Wang, Shu Wu, Liang Wang*
2. **A Multimodal Memes Classification: A Survey and Open Research Issues.** arXiv 2020 [paper](https://arxiv.org/abs/2009.08395) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Afridi2020A.md)
*Tariq Habib Afridi, Aftab Alam, Muhammad Numan Khan, Jawad Khan, Young-Koo Lee*
3. **A Survey and Taxonomy of Adversarial Neural Networks for Text-to-Image Synthesis.** WIREs Data Mining Knowl. Discov. 2020 [paper](https://arxiv.org/abs/1910.09399) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Agnese2020A.md)
*Jorge Agnese, Jonathan Herrera, Haicheng Tao, Xingquan Zhu*
4. **A Survey of Code-switched Speech and Language Processing.** arXiv 2019 [paper](https://arxiv.org/abs/1904.00784) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Sitaram2019A.md)
*Sunayana Sitaram, Khyathi Raghavi Chandu, Sai Krishna Rallabandi, Alan W. Black*
5. **A Survey of Deep Learning Approaches for OCR and Document Understanding.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.13534.pdf) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Subramani2020A.md)
*Nishant Subramani, Alexandre Matton, Malcolm Greaves, Adrian Lam*
6. **A Survey of Recent DNN Architectures on the TIMIT Phone Recognition Task.** TSD 2018 [paper](https://arxiv.org/abs/1806.07974) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Michálek2018A.md)
*Josef Michálek, Jan Vanek*
7. **A Survey of Voice Translation Methodologies - Acoustic Dialect Decoder.** ICICES 2016 [paper](https://arxiv.org/abs/1610.03934) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Krupakar2016A.md)
*Hans Krupakar, Keerthika Rajvel, Bharathi B, Angel Deborah S, Vallidevi Krishnamurthy*
8. **A Survey on Neural Speech Synthesis.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.15561.pdf) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Tan2021A.md)
*Xu Tan, Tao Qin, Frank K. Soong, Tie-Yan Liu*
9. **A Survey on Spoken Language Understanding: Recent Advances and New Frontiers.** IJCAI 2021 [paper](https://arxiv.org/abs/2103.03095) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Qin2021A.md)
*Libo Qin, Tianbao Xie, Wanxiang Che, Ting Liu*
10. **A Thorough Review on Recent Deep Learning Methodologies for Image Captioning.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.13114.pdf) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Elhagry2021A.md)
*Ahmed Elhagry, Karima Kadaoui*
11. **Accented Speech Recognition: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2104.10747) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Hinsvark2021Accented.md)
*Arthur Hinsvark, Natalie Delworth, Miguel Del Rio, Quinten McNamara, Joshua Dong, Ryan Westerman, Michelle Huang, Joseph Palakapilly, Jennifer Drexler, Ilya Pirkin, Nishchal Bhandari, Miguel Jette*
12. **Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures.** J. Artif. Intell. Res. 2016 [paper](https://arxiv.org/abs/1601.03896) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Bernardi2016Automatic.md)
*Raffaella Bernardi, Ruket Çakici, Desmond Elliott, Aykut Erdem, Erkut Erdem, Nazli Ikizler-Cinbis, Frank Keller, Adrian Muscat, Barbara Plank*
13. **Automatic Speech Recognition using limited vocabulary: A survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.10254.pdf) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Fendji2021Automatic.md)
*Jean Louis Ebongue Kedieng Fendji, Diane M. Tala, Blaise Omer Yenke, Marcellin Atemkeng*
14. **Deep Emotion Recognition in Dynamic Data using Facial, Speech and Textual Cues: A Survey.** TechRxiv 2021 [paper](https://www.techrxiv.org/articles/preprint/Deep_Emotion_Recognition_in_Dynamic_Data_using_Facial_Speech_and_Textual_Cues_A_Survey/15184302/1) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Zhang2021Deep.md)
*Tao ZhangTao Zhang, Zhenhua Tan*
15. **Image Captioning based on Deep Learning Methods: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1905.08110) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Wang2019Image.md)
*Yiyu Wang, Jungang Xu, Yingfei Sun, Ben He*
16. **Multimodal Intelligence: Representation Learning, Information Fusion, and Applications.** IEEE J. Sel. Top. Signal Process. 2020 [paper](https://ieeexplore.ieee.org/abstract/document/9068414) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Zhang2020Multimodal.md)
*Chao Zhang, Zichao Yang, Xiaodong He, Li Deng*
17. **Multimodal Machine Learning: A Survey and Taxonomy.** IEEE Trans. Pattern Anal. Mach. Intell. 2019 [paper](https://arxiv.org/abs/1705.09406) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Baltrusaitis2019Multimodal.md)
*Tadas Baltrusaitis, Chaitanya Ahuja, Louis-Philippe Morency*
18. **Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision.** arXiv 2021 [paper](https://arxiv.org/abs/2103.04037) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Shin2021Perspectives.md)
*Andrew Shin, Masato Ishii, Takuya Narihira*
19. **Recent Advances and Trends in Multimodal Deep Learning: A Review.** arXiv 2021 [paper](https://arxiv.org/pdf/2105.11087.pdf) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Summaira2021Recent.md)
*Jabeen Summaira, Xi Li, Amin Muhammad Shoib, Songyuan Li, Jabbar Abdul*
20. **Referring Expression Comprehension: A Survey of Methods and Datasets.** IEEE Trans. Multim. 2021 [paper](https://arxiv.org/abs/2007.09554) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Qiao2021Referring.md)
*Yanyuan Qiao, Chaorui Deng, Qi Wu*
21. **Review of end-to-end speech synthesis technology based on deep learning.** arXiv 2021 [paper](https://arxiv.org/abs/2104.09995) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Mu2021Review.md)
*Zhaoxi Mu, Xinyu Yang, Yizhuo Dong*
22. **Speech and Language Processing.** Stanford 2019 [paper](http://web.stanford.edu/~jurafsky/slp3/) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Jurafsky2019Speech.md)
*Dan Jurafsky, James H. Martin*
23. **Text Detection and Recognition in the Wild: A Review.** arXiv 2020 [paper](https://arxiv.org/abs/2006.04305) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Raisi2020Text.md)
*Zobeir Raisi, Mohamed A. Naiel, Paul W. Fieguth, Steven Wardell, John S. Zelek*
24. **Text Recognition in the Wild: A Survey.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2005.03492) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Chen2021Text.md)
*Xiaoxue Chen, Lianwen Jin, Yuanzhi Zhu, Canjie Luo, Tianwei Wang*
25. **Thank you for Attention: A survey on Attention-based Artificial Neural Networks for Automatic Speech Recognition.** arXiv 2021 [paper](https://arxiv.org/abs/2102.07259) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Karmakar2021Thank.md)
*Priyabrata Karmakar, Shyh Wei Teng, Guojun Lu*
26. **Unsupervised Automatic Speech Recognition: A Review.** arXiv 2021 [paper](https://arxiv.org/abs/2106.04897 ) [bib](/bib/Natural-Language-Processing/Speech-and-Multimodality/Aldarmaki2021Unsupervised.md)
*Hanan Aldarmaki, Asad Ullah, Nazar Zaki*
#### [Summarization](#content)
1. **A Survey of the State-of-the-Art Models in Neural Abstractive Text Summarization.** IEEE Access 2021 [paper](https://ieeexplore.ieee.org/abstract/document/9328413/) [bib](/bib/Natural-Language-Processing/Summarization/Syed2021A.md)
*Ayesha Ayub Syed, Ford Lumban Gaol, Tokuro Matsuo*
2. **A Survey on Dialogue Summarization: Recent Advances and New Frontiers.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.03175) [bib](/bib/Natural-Language-Processing/Summarization/Feng2021A.md)
*Xiachong Feng, Xiaocheng Feng, Bing Qin*
3. **A Survey on Neural Network-Based Summarization Methods.** arXiv 2018 [paper](https://arxiv.org/abs/1804.04589) [bib](/bib/Natural-Language-Processing/Summarization/Dong2018A.md)
*Yue Dong*
4. **Abstractive Summarization: A Survey of the State of the Art.** AAAI 2019 [paper](https://aaai.org/ojs/index.php/AAAI/article/view/5056) [bib](/bib/Natural-Language-Processing/Summarization/Lin2019Abstractive.md)
*Hui Lin, Vincent Ng*
5. **Automated text summarisation and evidence-based medicine: A survey of two domains.** arXiv 2017 [paper](https://arxiv.org/abs/1706.08162) [bib](/bib/Natural-Language-Processing/Summarization/Sarker2017Automated.md)
*Abeed Sarker, Diego Mollá Aliod, Cécile Paris*
6. **Automatic Keyword Extraction for Text Summarization: A Survey.** arXiv 2017 [paper](https://arxiv.org/abs/1704.03242) [bib](/bib/Natural-Language-Processing/Summarization/Bharti2017Automatic.md)
*Santosh Kumar Bharti, Korra Sathya Babu*
7. **Automatic summarization of scientific articles: A survey.** Journal of King Saud University - Computer and Information Sciences 2020 [paper](https://www.sciencedirect.com/science/article/pii/S1319157820303554) [bib](/bib/Natural-Language-Processing/Summarization/Altmami2020Automatic.md)
*Nouf Ibrahim Altmami, Mohamed El Bachir Menai*
8. **Deep Learning Based Abstractive Text Summarization: Approaches, Datasets, Evaluation Measures, and Challenges.** Mathematical Problems in Engineering 2020 [paper](https://www.hindawi.com/journals/mpe/2020/9365340/) [bib](/bib/Natural-Language-Processing/Summarization/Suleiman2020Deep.md)
*Dima Suleiman, Arafat Awajan*
9. **From Standard Summarization to New Tasks and Beyond: Summarization with Manifold Information.** IJCAI 2020 [paper](https://arxiv.org/abs/2005.04684) [bib](/bib/Natural-Language-Processing/Summarization/Gao2020From.md)
*Shen Gao, Xiuying Chen, Zhaochun Ren, Dongyan Zhao, Rui Yan*
10. **How to Evaluate a Summarizer: Study Design and Statistical Analysis for Manual Linguistic Quality Evaluation.** EACL 2021 [paper](https://aclanthology.org/2021.eacl-main.160.pdf) [bib](/bib/Natural-Language-Processing/Summarization/Steen2021How.md)
*Julius Steen, Katja Markert*
11. **Neural Abstractive Text Summarization with Sequence-to-Sequence Models.** Trans. Data Sci. 2021 [paper](https://arxiv.org/abs/1812.02303) [bib](/bib/Natural-Language-Processing/Summarization/Shi2021Neural.md)
*Tian Shi, Yaser Keneshloo, Naren Ramakrishnan, Chandan K. Reddy*
12. **Recent automatic text summarization techniques: a survey.** Artif. Intell. Rev. 2017 [paper](https://link.springer.com/article/10.1007%2Fs10462-016-9475-9) [bib](/bib/Natural-Language-Processing/Summarization/Gambhir2017Recent.md)
*Mahak Gambhir, Vishal Gupta*
13. **Text Summarization Techniques: A Brief Survey.** arXiv 2017 [paper](https://arxiv.org/abs/1707.02268) [bib](/bib/Natural-Language-Processing/Summarization/Allahyari2017Text.md)
*Mehdi Allahyari, Seyed Amin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, Krys J. Kochut*
14. **The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2104.14839) [bib](/bib/Natural-Language-Processing/Summarization/Huang2021The.md)
*Yi-Chong Huang, Xia-Chong Feng, Xiao-Cheng Feng, Bing Qin*
15. **What Have We Achieved on Text Summarization?.** EMNLP 2020 [paper](https://aclanthology.org/2020.emnlp-main.33.pdf) [bib](/bib/Natural-Language-Processing/Summarization/Huang2020What.md)
*Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang*
16. **Multi-document Summarization via Deep Learning Techniques: A Survey.** arXiv 2020 [paper](http://arxiv.org/pdf/2011.04843.pdf) [bib](/bib/Natural-Language-Processing/Summarization/Ma2020Multi-document.md)
*Congbo Ma, Wei Emma Zhang, Mingyu Guo, Hu Wang, Quan Z. Sheng*
#### [Tagging, Chunking, Syntax and Parsing](#content)
1. **A survey of cross-lingual features for zero-shot cross-lingual semantic parsing.** arXiv 2019 [paper](https://arxiv.org/abs/1908.10461) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Yang2019A.md)
*Jingfeng Yang, Federico Fancellu, Bonnie L. Webber*
2. **A Survey of Syntactic-Semantic Parsing Based on Constituent and Dependency Structures.** arXiv 2020 [paper](http://arxiv.org/pdf/2006.11056.pdf) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Zhang2020A.md)
*Meishan Zhang*
3. **A Survey on Recent Advances in Sequence Labeling from Deep Learning Models.** arXiv 2020 [paper](https://arxiv.org/abs/2011.06727) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/He2020A.md)
*Zhiyong He, Zanbo Wang, Wei Wei, Shanshan Feng, Xianling Mao, Sheng Jiang*
4. **A Survey on Semantic Parsing.** AKBC 2019 [paper](https://arxiv.org/abs/1812.00978) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Kamath2019A.md)
*Aishwarya Kamath, Rajarshi Das*
5. **A Survey on Semantic Parsing from the perspective of Compositionality.** arXiv 2020 [paper](https://arxiv.org/pdf/2009.14116.pdf) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Kumar2020A.md)
*Pawan Kumar, Srikanta Bedathur*
6. **Context Dependent Semantic Parsing: A Survey.** COLING 2020 [paper](https://arxiv.org/pdf/2011.00797.pdf) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Li2020Context.md)
*Zhuang Li, Lizhen Qu, Gholamreza Haffari*
7. **Design Challenges and Misconceptions in Neural Sequence Labeling.** COLING 2018 [paper](https://arxiv.org/abs/1806.04470) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Yang2018Design.md)
*Jie Yang, Shuailong Liang, Yue Zhang*
8. **Part‐of‐speech tagging.** Wiley Interdisciplinary Reviews: Computational Statistics 2011 [paper](https://wires.onlinelibrary.wiley.com/doi/epdf/10.1002/wics.195) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Martinez2011Part‐of‐speech.md)
*Angel R. Martinez*
9. **Sememe knowledge computation: a review of recent advances in application and expansion of sememe knowledge bases.** Frontiers Comput. Sci. 2021 [paper](https://link.springer.com/article/10.1007/s11704-020-0002-4) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Qi2021Sememe.md)
*Fanchao Qi, Ruobing Xie, Yuan Zang, Zhiyuan Liu, Maosong Sun*
10. **Syntactic Parsing: A Survey.** Computers and the Humanities 1989 [paper](https://link.springer.com/article/10.1007/BF00058766) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Sanders1989Syntactic.md)
*Alton F. Sanders and Ruth H. Sanders*
11. **Syntax Representation in Word Embeddings and Neural Networks - A Survey.** ITAT 2020 [paper](http://arxiv.org/pdf/2010.01063.pdf) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Limisiewicz2020Syntax.md)
*Tomasz Limisiewicz, David Marecek*
12. **The Gap of Semantic Parsing: A Survey on Automatic Math Word Problem Solvers.** IEEE Trans. Pattern Anal. Mach. Intell. 2020 [paper](https://arxiv.org/abs/1808.07290) [bib](/bib/Natural-Language-Processing/Tagging,-Chunking,-Syntax-and-Parsing/Zhang2020The.md)
*Dongxiang Zhang, Lei Wang, Luming Zhang, Bing Tian Dai, Heng Tao Shen*
#### [Text Classification](#content)
1. **A Survey of Active Learning for Text Classification using Deep Neural Networks.** arXiv 2020 [paper](https://arxiv.org/abs/2008.07267) [bib](/bib/Natural-Language-Processing/Text-Classification/Schröder2020A.md)
*Christopher Schröder, Andreas Niekler*
2. **A Survey of Naïve Bayes Machine Learning approach in Text Document Classification.** IJCSIS 2010 [paper](https://arxiv.org/abs/1003.1795) [bib](/bib/Natural-Language-Processing/Text-Classification/Vidhya2010A.md)
*K. A. Vidhya, G. Aghila*
3. **A Survey on Data Augmentation for Text Classification.** arXiv 2021 [paper](https://arxiv.org/abs/2107.03158) [bib](/bib/Natural-Language-Processing/Text-Classification/Bayer2021A.md)
*Markus Bayer, Marc-André Kaufhold, Christian Reuter*
4. **A Survey on Natural Language Processing for Fake News Detection.** LREC 2020 [paper](https://arxiv.org/abs/1811.00770) [bib](/bib/Natural-Language-Processing/Text-Classification/Oshikawa2020A.md)
*Ray Oshikawa, Jing Qian, William Yang Wang*
5. **A survey on phrase structure learning methods for text classification.** IJNLC 2014 [paper](https://arxiv.org/abs/1406.5598) [bib](/bib/Natural-Language-Processing/Text-Classification/Prasad2014A.md)
*Reshma Prasad, Mary Priya Sebastian*
6. **A Survey on Stance Detection for Mis- and Disinformation Identification.** arXiv 2021 [paper](https://arxiv.org/abs/2103.00242) [bib](/bib/Natural-Language-Processing/Text-Classification/Hardalov2021A.md)
*Momchil Hardalov, Arnav Arora, Preslav Nakov, Isabelle Augenstein*
7. **A Survey on Text Classification: From Shallow to Deep Learning.** arXiv 2020 [paper](https://arxiv.org/pdf/2008.00364.pdf) [bib](/bib/Natural-Language-Processing/Text-Classification/Li2020A.md)
*Qian Li, Hao Peng, Jianxin Li, Congying Xia, Renyu Yang, Lichao Sun, Philip S. Yu, Lifang He*
8. **Automatic Language Identification in Texts: A Survey.** J. Artif. Intell. Res. 2019 [paper](https://arxiv.org/abs/1804.08186) [bib](/bib/Natural-Language-Processing/Text-Classification/Jauhiainen2019Automatic.md)
*Tommi Jauhiainen, Marco Lui, Marcos Zampieri, Timothy Baldwin, Krister Lindén*
9. **Deep Learning-based Text Classification: A Comprehensive Review.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2004.03705) [bib](/bib/Natural-Language-Processing/Text-Classification/Minaee2021Deep.md)
*Shervin Minaee, Nal Kalchbrenner, Erik Cambria, Narjes Nikzad, Meysam Chenaghlu, Jianfeng Gao*
10. **Fake News Detection using Stance Classification: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1907.00181) [bib](/bib/Natural-Language-Processing/Text-Classification/Lillie2019Fake.md)
*Anders Edelbo Lillie, Emil Refsgaard Middelboe*
11. **Semantic text classification: A survey of past and recent advances.** Inf. Process. Manag. 2018 [paper](https://www.sciencedirect.com/science/article/abs/pii/S0306457317305757) [bib](/bib/Natural-Language-Processing/Text-Classification/Altinel2018Semantic.md)
*Berna Altinel, Murat Can Ganiz*
12. **Text Classification Algorithms: A Survey.** Inf. 2019 [paper](https://arxiv.org/abs/1904.08067) [bib](/bib/Natural-Language-Processing/Text-Classification/Kowsari2019Text.md)
*Kamran Kowsari, Kiana Jafari Meimandi, Mojtaba Heidarysafa, Sanjana Mendu, Laura E. Barnes, Donald E. Brown*
#### [Architectures](#content)
1. **A Practical Survey on Faster and Lighter Transformers.** arXiv 2021 [paper](https://arxiv.org/pdf/2103.14636.pdf) [bib](/bib/Machine-Learning/Architectures/Fournier2021A.md)
*Quentin Fournier, Gaétan Marceau Caron, Daniel Aloise*
2. **A Review of Binarized Neural Networks.** Electronics 2019 [paper](http://www.socolar.com/Article/Index?aid=100010075063&jid=100000022108) [bib](/bib/Machine-Learning/Architectures/Simons2019A.md)
*Taylor Simons, Dah-Jye Lee*
3. **A State-of-the-Art Survey on Deep Learning Theory and Architectures.** Electronics 2019 [paper](https://www.mdpi.com/2079-9292/8/3/292) [bib](/bib/Machine-Learning/Architectures/Alom2019A.md)
*Md Zahangir Alom, Tarek M. Taha, Chris Yakopcic, Stefan Westberg, Paheding Sidike, Mst Shamima Nasrin, Mahmudul Hasan, Brian C. Van Essen, Abdul A. S. Awwal and Vijayan K. Asari*
4. **A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects.** arXiv 2020 [paper](https://arxiv.org/abs/2004.02806) [bib](/bib/Machine-Learning/Architectures/Li2020A.md)
*Zewen Li, Wenjie Yang, Shouheng Peng, Fan Liu*
5. **A Survey of End-to-End Driving: Architectures and Training Methods.** arXiv 2020 [paper](https://arxiv.org/abs/2003.06404) [bib](/bib/Machine-Learning/Architectures/Tampuu2020A.md)
*Ardi Tampuu, Maksym Semikin, Naveed Muhammad, Dmytro Fishman, Tambet Matiisen*
6. **A Survey of Transformers.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.04554.pdf) [bib](/bib/Machine-Learning/Architectures/Lin2021A.md)
*Tianyang Lin, Yuxin Wang, Xiangyang Liu, Xipeng Qiu*
7. **A Survey on Activation Functions and their relation with Xavier and He Normal Initialization.** arXiv 2020 [paper](https://arxiv.org/abs/2004.06632) [bib](/bib/Machine-Learning/Architectures/Datta2020A.md)
*Leonid Datta*
8. **A Survey on Latent Tree Models and Applications.** J. Artif. Intell. Res. 2013 [paper](https://arxiv.org/abs/1402.0577) [bib](/bib/Machine-Learning/Architectures/Mourad2013A.md)
*Raphaël Mourad, Christine Sinoquet, Nevin Lianwen Zhang, Tengfei Liu, Philippe Leray*
9. **A survey on modern trainable activation functions.** Neural Networks 2021 [paper](https://arxiv.org/abs/2005.00817) [bib](/bib/Machine-Learning/Architectures/Apicella2021A.md)
*Andrea Apicella, Francesco Donnarumma, Francesco Isgrò, Roberto Prevete*
10. **A Survey on Vision Transformer.** arXiv 2020 [paper](https://arxiv.org/abs/2012.12556) [bib](/bib/Machine-Learning/Architectures/Han2020A.md)
*Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, Zhaohui Yang, Yiman Zhang, Dacheng Tao*
11. **An Attentive Survey of Attention Models.** ACM Trans. Intell. Syst. Technol. 2021 [paper](https://arxiv.org/abs/1904.02874) [bib](/bib/Machine-Learning/Architectures/Chaudhari2021An.md)
*Sneha Chaudhari, Varun Mithal, Gungor Polatkan, Rohan Ramanath*
12. **Attention mechanisms and deep learning for machine vision: A survey of the state of the art.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.07550.pdf) [bib](/bib/Machine-Learning/Architectures/Hafiz2021Attention.md)
*Abdul Mueed Hafiz, Shabir Ahmad Parah, Rouf Ul Alam Bhat*
13. **Big Networks: A Survey.** Comput. Sci. Rev. 2020 [paper](https://arxiv.org/abs/2008.03638) [bib](/bib/Machine-Learning/Architectures/Bedru2020Big.md)
*Hayat Dino Bedru, Shuo Yu, Xinru Xiao, Da Zhang, Liangtian Wan, He Guo, Feng Xia*
14. **Binary Neural Networks: A Survey.** Pattern Recognit. 2020 [paper](https://arxiv.org/abs/2004.03333) [bib](/bib/Machine-Learning/Architectures/Qin2020Binary.md)
*Haotong Qin, Ruihao Gong, Xianglong Liu, Xiao Bai, Jingkuan Song, Nicu Sebe*
15. **Deep Echo State Network (DeepESN): A Brief Survey.** arXiv 2017 [paper](https://arxiv.org/abs/1712.04323) [bib](/bib/Machine-Learning/Architectures/Gallicchio2017Deep.md)
*Claudio Gallicchio, Alessio Micheli*
16. **Deep Tree Transductions - A Short Survey.** INNSBDDL 2019 [paper](https://arxiv.org/abs/1902.01737) [bib](/bib/Machine-Learning/Architectures/Bacciu2019Deep.md)
*Davide Bacciu, Antonio Bruno*
17. **Efficient Transformers: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.06732) [bib](/bib/Machine-Learning/Architectures/Tay2020Efficient.md)
*Yi Tay, Mostafa Dehghani, Dara Bahri, Donald Metzler*
18. **Pooling Methods in Deep Neural Networks, a Review.** arXiv 2020 [paper](https://arxiv.org/abs/2009.07485) [bib](/bib/Machine-Learning/Architectures/Gholamalinezhad2020Pooling.md)
*Hossein Gholamalinezhad, Hossein Khosravi*
19. **Position Information in Transformers: An Overview.** arXiv 2021 [paper](https://arxiv.org/abs/2102.11090) [bib](/bib/Machine-Learning/Architectures/Dufter2021Position.md)
*Philipp Dufter, Martin Schmitt, Hinrich Schütze*
20. **Recent Advances in Convolutional Neural Networks.** Pattern Recognit. 2018 [paper](https://arxiv.org/abs/1512.07108) [bib](/bib/Machine-Learning/Architectures/Gu2018Recent.md)
*Jiuxiang Gu, Zhenhua Wang, Jason Kuen, Lianyang Ma, Amir Shahroudy, Bing Shuai, Ting Liu, Xingxing Wang, Gang Wang, Jianfei Cai, Tsuhan Chen*
21. **Sum-product networks: A survey.** arXiv 2020 [paper](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9363463) [bib](/bib/Machine-Learning/Architectures/París2020Sum-product.md)
*Iago París, Raquel Sánchez-Cauce, Francisco Javier Díez*
22. **Survey of Dropout Methods for Deep Neural Networks.** arXiv 2019 [paper](https://arxiv.org/abs/1904.13310) [bib](/bib/Machine-Learning/Architectures/Labach2019Survey.md)
*Alex Labach, Hojjat Salehinejad, Shahrokh Valaee*
23. **Survey on the attention based RNN model and its applications in computer vision.** arXiv 2016 [paper](https://arxiv.org/abs/1601.06823) [bib](/bib/Machine-Learning/Architectures/Wang2016Survey.md)
*Feng Wang, David M. J. Tax*
24. **The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches.** arXiv 2018 [paper](https://arxiv.org/abs/1803.01164) [bib](/bib/Machine-Learning/Architectures/Alom2018The.md)
*Md. Zahangir Alom, Tarek M. Taha, Christopher Yakopcic, Stefan Westberg, Paheding Sidike, Mst Shamima Nasrin, Brian C. Van Essen, Abdul A. S. Awwal, Vijayan K. Asari*
25. **The NLP Cookbook: Modern Recipes for Transformer based Deep Learning Architectures.** IEEE Access 2021 [paper](https://arxiv.org/pdf/2104.10640.pdf) [bib](/bib/Machine-Learning/Architectures/Singh2021The.md)
*Sushant Singh, Ausif Mahmood*
26. **Transformers in Vision: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2101.01169) [bib](/bib/Machine-Learning/Architectures/Khan2021Transformers.md)
*Salman H. Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, Mubarak Shah*
27. **Understanding LSTM - a tutorial into Long Short-Term Memory Recurrent Neural Networks.** arXiv 2019 [paper](https://arxiv.org/abs/1909.09586) [bib](/bib/Machine-Learning/Architectures/Staudemeyer2019Understanding.md)
*Ralf C. Staudemeyer, Eric Rothstein Morris*
#### [AutoML](#content)
1. **A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2006.02903) [bib](/bib/Machine-Learning/AutoML/Ren2021A.md)
*Pengzhen Ren, Yun Xiao, Xiaojun Chang, Poyao Huang, Zhihui Li, Xiaojiang Chen, Xin Wang*
2. **A Comprehensive Survey on Hardware-Aware Neural Architecture Search.** arXiv 2021 [paper](https://arxiv.org/abs/2101.09336) [bib](/bib/Machine-Learning/AutoML/Benmeziane2021A.md)
*Hadjer Benmeziane, Kaoutar El Maghraoui, Hamza Ouarnoughi, Smaïl Niar, Martin Wistuba, Naigang Wang*
3. **A Review of Meta-Reinforcement Learning for Deep Neural Networks Architecture Search.** arXiv 2018 [paper](https://arxiv.org/pdf/1812.07995.pdf) [bib](/bib/Machine-Learning/AutoML/Jaâfra2018A.md)
*Yesmina Jaâfra, Jean Luc Laurent, Aline Deruyver, Mohamed Saber Naceur*
4. **A Survey on Neural Architecture Search.** arXiv 2019 [paper](https://arxiv.org/abs/1905.01392) [bib](/bib/Machine-Learning/AutoML/Wistuba2019A.md)
*Martin Wistuba, Ambrish Rawat, Tejaswini Pedapati*
5. **Automated Machine Learning on Graphs: A Survey.** IJCAI 2021 [paper](https://arxiv.org/abs/2103.00742) [bib](/bib/Machine-Learning/AutoML/Zhang2021Automated.md)
*Ziwei Zhang, Xin Wang, Wenwu Zhu*
6. **AutoML: A Survey of the State-of-the-Art.** Knowl. Based Syst. 2021 [paper](https://arxiv.org/abs/1908.00709) [bib](/bib/Machine-Learning/AutoML/He2021AutoML.md)
*Xin He, Kaiyong Zhao, Xiaowen Chu*
7. **Benchmark and Survey of Automated Machine Learning Frameworks.** J. Artif. Intell. Res. 2021 [paper](https://www.jair.org/index.php/jair/article/view/11854) [bib](/bib/Machine-Learning/AutoML/Zöller2021Benchmark.md)
*Marc-André Zöller, Marco F. Huber*
8. **Neural Architecture Search: A Survey.** J. Mach. Learn. Res. 2019 [paper](https://arxiv.org/abs/1808.05377) [bib](/bib/Machine-Learning/AutoML/Elsken2019Neural.md)
*Thomas Elsken, Jan Hendrik Metzen, Frank Hutter*
9. **Reinforcement learning for neural architecture search: A review.** Image Vis. Comput. 2019 [paper](https://www.sciencedirect.com/science/article/abs/pii/S0262885619300885?via%3Dihub) [bib](/bib/Machine-Learning/AutoML/Jaâfra2019Reinforcement.md)
*Yesmina Jaâfra, Jean Luc Laurent, Aline Deruyver, Mohamed Saber Naceur*
#### [Bayesian Methods](#content)
1. **A survey of non-exchangeable priors for Bayesian nonparametric models.** IEEE Trans. Pattern Anal. Mach. Intell. 2015 [paper](https://arxiv.org/abs/1211.4798) [bib](/bib/Machine-Learning/Bayesian-Methods/Foti2015A.md)
*Nicholas J. Foti, Sinead A. Williamson*
2. **A Survey on Bayesian Deep Learning.** ACM Comput. Surv. 2020 [paper](http://arxiv.org/abs/1604.01662) [bib](/bib/Machine-Learning/Bayesian-Methods/Wang2020A.md)
*Hao Wang, Dit-Yan Yeung*
3. **Bayesian Neural Networks: An Introduction and Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2006.12024) [bib](/bib/Machine-Learning/Bayesian-Methods/Goan2020Bayesian.md)
*Ethan Goan, Clinton Fookes*
4. **Bayesian Nonparametric Space Partitions: A Survey.** IJCAI 2021 [paper](https://arxiv.org/abs/2002.11394) [bib](/bib/Machine-Learning/Bayesian-Methods/Fan2021Bayesian.md)
*Xuhui Fan, Bin Li, Ling Luo, Scott A. Sisson*
5. **Deep Bayesian Active Learning, A Brief Survey on Recent Advances.** arXiv 2020 [paper](http://arxiv.org/pdf/2012.08044.pdf) [bib](/bib/Machine-Learning/Bayesian-Methods/Mohamadi2020Deep.md)
*Salman Mohamadi, Hamidreza Amindavar*
6. **Hands-on Bayesian Neural Networks - a Tutorial for Deep Learning Users.** arXiv 2020 [paper](https://arxiv.org/abs/2007.06823) [bib](/bib/Machine-Learning/Bayesian-Methods/Jospin2020Hands-on.md)
*Laurent Valentin Jospin, Wray L. Buntine, Farid Boussaïd, Hamid Laga, Mohammed Bennamoun*
7. **Taking the Human Out of the Loop: A Review of Bayesian Optimization.** Proc. IEEE 2016 [paper](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7352306) [bib](/bib/Machine-Learning/Bayesian-Methods/Shahriari2016Taking.md)
*Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, Nando de Freitas*
#### [Classification, Clustering and Regression](#content)
1. **A continual learning survey: Defying forgetting in classification tasks.** TPAMI 2021 [paper](https://arxiv.org/pdf/1909.08383.pdf) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Lange2021A.md)
*Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Ales Leonardis, Gregory Slabaugh, Tinne Tuytelaars*
2. **A Survey of Classification Techniques in the Area of Big Data.** arXiv 2015 [paper](https://arxiv.org/abs/1503.07477) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Koturwar2015A.md)
*Praful Koturwar, Sheetal Girase, Debajyoti Mukhopadhyay*
3. **A Survey of Constrained Gaussian Process Regression: Approaches and Implementation Challenges.** arXiv 2020 [paper](https://arxiv.org/abs/2006.09319) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Swiler2020A.md)
*Laura P. Swiler, Mamikon Gulian, Ari Frankel, Cosmin Safta, John D. Jakeman*
4. **A Survey of Machine Learning Methods and Challenges for Windows Malware Classification.** arXiv 2020 [paper](https://arxiv.org/abs/2006.09271) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Raff2020A.md)
*Edward Raff, Charles Nicholas*
5. **A Survey of Methods for Managing the Classification and Solution of Data Imbalance Problem.** arXiv 2020 [paper](https://arxiv.org/abs/2012.11870) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Hasib2020A.md)
*Khan Md. Hasib, Md. Sadiq Iqbal, Faisal Muhammad Shah, Jubayer Al Mahmud, Mahmudul Hasan Popel, Md. Imran Hossain Showrov, Shakil Ahmed, Obaidur Rahman*
6. **A Survey of Techniques All Classifiers Can Learn from Deep Networks: Models, Optimizations, and Regularization.** arXiv 2019 [paper](https://arxiv.org/pdf/1909.04791.pdf) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Ghods2019A.md)
*Alireza Ghods, Diane J. Cook*
7. **A Survey on Multi-View Clustering.** arXiv 2017 [paper](https://arxiv.org/abs/1712.06246) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Chao2017A.md)
*Guoqing Chao, Shiliang Sun, Jinbo Bi*
8. **Comprehensive Comparative Study of Multi-Label Classification Methods.** arXiv 2021 [paper](https://arxiv.org/abs/2102.07113) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Bogatinovski2021Comprehensive.md)
*Jasmin Bogatinovski, Ljupco Todorovski, Saso Dzeroski, Dragi Kocev*
9. **Deep learning for time series classification: a review.** Data Min. Knowl. Discov. 2019 [paper](https://arxiv.org/abs/1809.04356) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Fawaz2019Deep.md)
*Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, Pierre-Alain Muller*
10. **How Complex is your classification problem?: A survey on measuring classification complexity.** ACM Comput. Surv. 2019 [paper](https://arxiv.org/abs/1808.03591) [bib](/bib/Machine-Learning/Classification,-Clustering-and-Regression/Lorena2019How.md)
*Ana Carolina Lorena, Luís Paulo F. Garcia, Jens Lehmann, Marcílio Carlos Pereira de Souto, Tin Kam Ho*
#### [Computer Vision](#content)
1. **3D Object Detection for Autonomous Driving: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.10823.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Qian20213D.md)
*Rui Qian, Xin Lai, Xirong Li*
2. **A Survey of Black-Box Adversarial Attacks on Computer Vision Models.** arXiv 2019 [paper](https://arxiv.org/pdf/1912.01667.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Bhambri2019A.md)
*Siddhant Bhambri, Sumanyu Muku, Avinash Tulasi, Arun Balaji Buduru*
3. **A survey of loss functions for semantic segmentation.** CIBCB 2020 [paper](https://arxiv.org/pdf/2006.14822.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Jadon2020A.md)
*Shruti Jadon*
4. **A Survey of Modern Deep Learning based Object Detection Models.** arXiv 2021 [paper](https://arxiv.org/pdf/2104.11892.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Zaidi2021A.md)
*Syed Sahil Abbas Zaidi, Mohammad Samar Ansari, Asra Aslam, Nadia Kanwal, Mamoona Naveed Asghar, Brian Lee*
5. **A survey on applications of augmented, mixed and virtual reality for nature and environment.** HCI 2021 [paper](https://arxiv.org/abs/2008.12024) [bib](/bib/Machine-Learning/Computer-Vision/Rambach2021A.md)
*Jason R. Rambach, Gergana Lilligreen, Alexander Schäfer, Ramya Bankanal, Alexander Wiebel, Didier Stricker*
6. **A survey on deep hashing for image retrieval.** arXiv 2020 [paper](https://arxiv.org/abs/2006.05627) [bib](/bib/Machine-Learning/Computer-Vision/Zhang2020A.md)
*Xiaopeng Zhang*
7. **A Survey on Deep Learning in Medical Image Analysis.** Medical Image Anal. 2017 [paper](https://arxiv.org/abs/1702.05747) [bib](/bib/Machine-Learning/Computer-Vision/Litjens2017A.md)
*Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Arnaud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A. W. M. van der Laak, Bram van Ginneken, Clara I. Sánchez*
8. **A Survey on Deep Learning Technique for Video Segmentation.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.01153.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Wang2021A.md)
*Wenguan Wang, Tianfei Zhou, Fatih Porikli, David J. Crandall, Luc Van Gool*
9. **A Technical Survey and Evaluation of Traditional Point Cloud Clustering Methods for LiDAR Panoptic Segmentation.** ICCVW 2021 [paper](https://arxiv.org/pdf/2108.09522.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Zhao2021A.md)
*Yiming Zhao, Xiao Zhang, Xinming Huang*
10. **Advances in adversarial attacks and defenses in computer vision: A survey.** IEEE Access 2021 [paper](https://arxiv.org/pdf/2108.00401.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Akhtar2021Advances.md)
*Naveed Akhtar, Ajmal Mian, Navid Kardan, Mubarak Shah*
11. **Adversarial Examples on Object Recognition: A Comprehensive Survey.** ACM Comput. Surv. 2020 [paper](https://arxiv.org/abs/2008.04094) [bib](/bib/Machine-Learning/Computer-Vision/Serban2020Adversarial.md)
*Alexandru Constantin Serban, Erik Poll, Joost Visser*
12. **Adversarial Machine Learning in Image Classification: A Survey Towards the Defender's Perspective.** arXiv 2020 [paper](https://arxiv.org/pdf/2009.03728.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Machado2020Adversarial.md)
*Gabriel Resende Machado, Eugênio Silva, Ronaldo Ribeiro Goldschmidt*
13. **Affective Image Content Analysis: Two Decades Review and New Perspectives.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.16125.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Zhao2021Affective.md)
*Sicheng Zhao, Xingxu Yao, Jufeng Yang, Guoli Jia, Guiguang Ding, Tat-Seng Chua, Björn W. Schuller, Kurt Keutzer*
14. **Applications of Artificial Neural Networks in Microorganism Image Analysis: A Comprehensive Review from Conventional Multilayer Perceptron to Popular Convolutional Neural Network and Potential Visual Transformer.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.00358.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Zhang2021Applications.md)
*Jinghua Zhang, Chen Li, Marcin Grzegorzek*
15. **Automatic Gaze Analysis: A Survey of Deep Learning based Approaches.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.05479.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Ghosh2021Automatic.md)
*Shreya Ghosh, Abhinav Dhall, Munawar Hayat, Jarrod Knibbe, Qiang Ji*
16. **Bridging Gap between Image Pixels and Semantics via Supervision: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.13757.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Duan2021Bridging.md)
*Jiali Duan, C.-C. Jay Kuo*
17. **Deep Learning for 3D Point Cloud Understanding: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.08920) [bib](/bib/Machine-Learning/Computer-Vision/Lu2020Deep.md)
*Haoming Lu, Humphrey Shi*
18. **Deep Learning for Embodied Vision Navigation: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04097.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Zhu2021Deep.md)
*Fengda Zhu, Yi Zhu, Xiaodan Liang, Xiaojun Chang*
19. **Deep Learning for Image Super-resolution: A Survey.** IEEE Trans. Pattern Anal. Mach. Intell. 2021 [paper](https://arxiv.org/abs/1902.06068) [bib](/bib/Machine-Learning/Computer-Vision/Wang2021Deep.md)
*Zhihao Wang, Jian Chen, Steven C. H. Hoi*
20. **Deep Learning for Instance Retrieval: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2101.11282.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Chen2021Deep.md)
*Wei Chen, Yu Liu, Weiping Wang, Erwin Bakker, Theodoros Georgiou, Paul Fieguth, Li Liu, Michael S. Lew*
21. **Deep Learning for Scene Classification: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2101.10531) [bib](/bib/Machine-Learning/Computer-Vision/Zeng2021Deep.md)
*Delu Zeng, Minyu Liao, Mohammad Tavakolian, Yulan Guo, Bolei Zhou, Dewen Hu, Matti Pietikäinen, Li Liu*
22. **Image/Video Deep Anomaly Detection: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.01739) [bib](/bib/Machine-Learning/Computer-Vision/Mohammadi2021Image.md)
*Bahram Mohammadi, Mahmood Fathy, Mohammad Sabokrou*
23. **Image-to-Image Translation: Methods and Applications.** arXiv 2021 [paper](https://arxiv.org/abs/2101.08629) [bib](/bib/Machine-Learning/Computer-Vision/Pang2021Image-to-Image.md)
*Yingxue Pang, Jianxin Lin, Tao Qin, Zhibo Chen*
24. **Imbalance Problems in Object Detection: A Review.** IEEE Trans. Pattern Anal. Mach. Intell. 2021 [paper](https://arxiv.org/abs/1909.00169) [bib](/bib/Machine-Learning/Computer-Vision/Oksuz2021Imbalance.md)
*Kemal Oksuz, Baris Can Cam, Sinan Kalkan, Emre Akbas*
25. **MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.03004.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Wei2021MmWave.md)
*Zhiqing Wei, Fengkai Zhang, Shuo Chang, Yangyang Liu, Huici Wu, Zhiyong Feng*
26. **Object Detection in 20 Years: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1905.05055) [bib](/bib/Machine-Learning/Computer-Vision/Zou2019Object.md)
*Zhengxia Zou, Zhenwei Shi, Yuhong Guo, Jieping Ye*
27. **The Impact of Machine Learning on 2D/3D Registration for Image-guided Interventions: A Systematic Review and Perspective.** Frontiers Robotics AI 2021 [paper](https://arxiv.org/pdf/2108.02238.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Unberath2021The.md)
*Mathias Unberath, Cong Gao, Yicheng Hu, Max Judish, Russell H. Taylor, Mehran Armand, Robert B. Grupp*
28. **The Need and Status of Sea Turtle Conservation and Survey of Associated Computer Vision Advances.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.14061.pdf) [bib](/bib/Machine-Learning/Computer-Vision/Paul2021The.md)
*Aditya Jyoti Paul*
#### [Contrastive Learning](#content)
1. **A Survey on Contrastive Self-supervised Learning.** arXiv 2020 [paper](https://arxiv.org/abs/2011.00362) [bib](/bib/Machine-Learning/Contrastive-Learning/Jaiswal2020A.md)
*Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, Fillia Makedon*
2. **Contrastive Representation Learning: A Framework and Review.** IEEE Access 2020 [paper](http://doras.dcu.ie/25121/1/ACCESS3031549.pdf) [bib](/bib/Machine-Learning/Contrastive-Learning/Le-Khac2020Contrastive.md)
*Phuc H. Le-Khac, Graham Healy, Alan F. Smeaton*
3. **Self-supervised Learning: Generative or Contrastive.** arXiv 2020 [paper](https://arxiv.org/abs/2006.08218) [bib](/bib/Machine-Learning/Contrastive-Learning/Liu2020Self-supervised.md)
*Xiao Liu, Fanjin Zhang, Zhenyu Hou, Zhaoyu Wang, Li Mian, Jing Zhang, Jie Tang*
#### [Curriculum Learning](#content)
1. **A Survey on Curriculum Learning.** TPAMI 2021 [paper](https://arxiv.org/abs/2010.13166) [bib](/bib/Machine-Learning/Curriculum-Learning/Wang2021A.md)
*Xin Wang, Yudong Chen, Wenwu Zhu*
2. **Automatic Curriculum Learning For Deep RL: A Short Survey.** IJCAI 2020 [paper](https://arxiv.org/abs/2003.04664) [bib](/bib/Machine-Learning/Curriculum-Learning/Portelas2020Automatic.md)
*Rémy Portelas, Cédric Colas, Lilian Weng, Katja Hofmann, Pierre-Yves Oudeyer*
3. **Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey.** J. Mach. Learn. Res. 2020 [paper](https://arxiv.org/abs/2003.04960) [bib](/bib/Machine-Learning/Curriculum-Learning/Narvekar2020Curriculum.md)
*Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E. Taylor, Peter Stone*
4. **Curriculum Learning: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2101.10382) [bib](/bib/Machine-Learning/Curriculum-Learning/Soviany2021Curriculum.md)
*Petru Soviany, Radu Tudor Ionescu, Paolo Rota, Nicu Sebe*
#### [Data Augmentation](#content)
1. **A survey on Image Data Augmentation for Deep Learning.** J. Big Data 2019 [paper](https://link.springer.com/article/10.1186/s40537-019-0197-0) [bib](/bib/Machine-Learning/Data-Augmentation/Shorten2019A.md)
*Connor Shorten, Taghi M. Khoshgoftaar*
2. **An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks.** arXiv 2020 [paper](https://arxiv.org/abs/2007.15951) [bib](/bib/Machine-Learning/Data-Augmentation/Iwana2020An.md)
*Brian Kenji Iwana, Seiichi Uchida*
3. **Time Series Data Augmentation for Deep Learning: A Survey.** IJCAI 2021 [paper](https://arxiv.org/abs/2002.12478) [bib](/bib/Machine-Learning/Data-Augmentation/Wen2021Time.md)
*Qingsong Wen, Liang Sun, Fan Yang, Xiaomin Song, Jingkun Gao, Xue Wang, Huan Xu*
#### [Deep Learning General Methods](#content)
1. **A Survey of Deep Active Learning.** ACM Comput. Surv. 2022 [paper](https://arxiv.org/abs/2009.00236) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Ren2022A.md)
*Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B. Gupta, Xiaojiang Chen, Xin Wang*
2. **A Survey of Deep Learning for Data Caching in Edge Network.** Informatics 2020 [paper](https://arxiv.org/abs/2008.07235) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Wang2020A.md)
*Yantong Wang, Vasilis Friderikos*
3. **A Survey of Deep Learning for Scientific Discovery.** arXiv 2020 [paper](https://arxiv.org/pdf/2003.11755.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Raghu2020A.md)
*Maithra Raghu, Eric Schmidt*
4. **A Survey of Label-noise Representation Learning: Past, Present and Future.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.04406.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Han2020A.md)
*Bo Han, Quanming Yao, Tongliang Liu, Gang Niu, Ivor W. Tsang, James T. Kwok, Masashi Sugiyama*
5. **A Survey of Neuromorphic Computing and Neural Networks in Hardware.** arXiv 2017 [paper](https://arxiv.org/abs/1705.06963) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Schuman2017A.md)
*Catherine D. Schuman, Thomas E. Potok, Robert M. Patton, J. Douglas Birdwell, Mark E. Dean, Garrett S. Rose, James S. Plank*
6. **A Survey of Uncertainty in Deep Neural Networks.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.03342.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Gawlikowski2021A.md)
*Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna M. Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, Muhammad Shahzad, Wen Yang, Richard Bamler, Xiao Xiang Zhu*
7. **A Survey on Active Deep Learning: From Model-driven to Data-driven.** arXiv 2021 [paper](https://arxiv.org/abs/2101.09933) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Liu2021A.md)
*Peng Liu, Lizhe Wang, Guojin He, Lei Zhao*
8. **A Survey on Assessing the Generalization Envelope of Deep Neural Networks: Predictive Uncertainty, Out-of-distribution and Adversarial Samples.** arXiv 2020 [paper](https://arxiv.org/abs/2008.09381) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Lust2020A.md)
*Julia Lust, Alexandru Paul Condurache*
9. **A Survey on Concept Factorization: From Shallow to Deep Representation Learning.** Inf. Process. Manag. 2021 [paper](https://arxiv.org/abs/2007.15840) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Zhang2021A.md)
*Zhao Zhang, Yan Zhang, Mingliang Xu, Li Zhang, Yi Yang, Shuicheng Yan*
10. **A Survey on Deep Hashing Methods.** arXiv 2020 [paper](https://arxiv.org/abs/2003.03369) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Luo2020A.md)
*Xiao Luo, Chong Chen, Huasong Zhong, Hao Zhang, Minghua Deng, Jianqiang Huang, Xiansheng Hua*
11. **A Survey on Deep Learning with Noisy Labels: How to train your model when you cannot trust on the annotations?.** SIBGRAPI 2020 [paper](https://arxiv.org/pdf/2012.03061.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Cordeiro2020A.md)
*Filipe R. Cordeiro, Gustavo Carneiro*
12. **A Survey on Dynamic Network Embedding.** arXiv 2020 [paper](https://arxiv.org/pdf/2006.08093.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Xie2020A.md)
*Yu Xie, Chunyi Li, Bin Yu, Chen Zhang, Zhouhua Tang*
13. **A Survey on Network Embedding.** IEEE Trans. Knowl. Data Eng. 2019 [paper](https://arxiv.org/pdf/1711.08752) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Cui2019A.md)
*Peng Cui, Xiao Wang, Jian Pei, Wenwu Zhu*
14. **A Tutorial on Network Embeddings.** arXiv 2018 [paper](https://arxiv.org/abs/1808.02590) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Chen2018A.md)
*Haochen Chen, Bryan Perozzi, Rami Al-Rfou, Steven Skiena*
15. **Continual Lifelong Learning with Neural Networks: A Review.** Neural Networks 2019 [paper](https://arxiv.org/pdf/1802.07569.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Parisi2019Continual.md)
*German Ignacio Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, Stefan Wermter*
16. **Convergence of Edge Computing and Deep Learning: A Comprehensive Survey.** IEEE Commun. Surv. Tutorials 2020 [paper](https://ieeexplore.ieee.org/document/8976180) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Wang2020Convergence.md)
*Xiaofei Wang, Yiwen Han, Victor C. M. Leung, Dusit Niyato, Xueqiang Yan, Xu Chen*
17. **Deep learning.** Nat. 2015 [paper](https://www.nature.com/articles/nature14539) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/LeCun2015Deep.md)
*Yann LeCun, Yoshua Bengio, Geoffrey Hinton*
18. **Deep Learning for Matching in Search and Recommendation.** SIGIR 2018 [paper](https://dl.acm.org/doi/abs/10.1145/3209978.3210181) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Xu2018Deep.md)
*Jun Xu, Xiangnan He, Hang Li*
19. **Deep Learning Theory Review: An Optimal Control and Dynamical Systems Perspective.** arXiv 2019 [paper](https://arxiv.org/abs/1908.10920) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Liu2019Deep.md)
*Guan-Horng Liu, Evangelos A. Theodorou*
20. **Dynamic Neural Networks: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2102.04906) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Han2021Dynamic.md)
*Yizeng Han, Gao Huang, Shiji Song, Le Yang, Honghui Wang, Yulin Wang*
21. **Embracing Change: Continual Learning in Deep Neural Networks.** Trends in Cognitive Sciences 2020 [paper](https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(20)30219-9?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS1364661320302199%3Fshowall%3Dtrue) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Hadsell2020Embracing.md)
*Raia Hadsell, Dushyant Rao, Andrei A. Rusu, Razvan Pascanu*
22. **Geometric deep learning: going beyond Euclidean data.** IEEE Signal Process. Mag. 2017 [paper](https://arxiv.org/abs/1611.08097) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Bronstein2017Geometric.md)
*Michael M. Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, Pierre Vandergheynst*
23. **Heuristic design of fuzzy inference systems: A review of three decades of research.** Eng. Appl. Artif. Intell. 2019 [paper](https://arxiv.org/abs/1908.10122) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Ojha2019Heuristic.md)
*Varun Ojha, Ajith Abraham, Václav Snásel*
24. **Imitation Learning: Progress, Taxonomies and Opportunities.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.12177.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Zheng2021Imitation.md)
*Boyuan Zheng, Sunny Verma, Jianlong Zhou, Ivor W. Tsang, Fang Chen*
25. **Improving Deep Learning Models via Constraint-Based Domain Knowledge: a Brief Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2005.10691) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Borghesi2020Improving.md)
*Andrea Borghesi, Federico Baldo, Michela Milano*
26. **Learning from Noisy Labels with Deep Neural Networks: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2007.08199) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Song2020Learning.md)
*Hwanjun Song, Minseok Kim, Dongmin Park, Jae-Gil Lee*
27. **Model Complexity of Deep Learning: A Survey.** Knowl. Inf. Syst. 2021 [paper](https://arxiv.org/abs/2103.05127) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Hu2021Model.md)
*Xia Hu, Lingyang Chu, Jian Pei, Weiqing Liu, Jiang Bian*
28. **Network representation learning: A macro and micro view.** AI Open 2021 [paper](https://www.sciencedirect.com/science/article/pii/S2666651021000024) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Liu2021Network.md)
*Xueyi Liu, Jie Tang*
29. **Network Representation Learning: A Survey.** IEEE Trans. Big Data 2020 [paper](https://ieeexplore.ieee.org/document/8395024) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Zhang2020Network.md)
*Daokun Zhang, Jie Yin, Xingquan Zhu, Chengqi Zhang*
30. **Network representation learning: an overview.** SCIENTIA SINICA Informationis 2017 [paper](http://engine.scichina.com/publisher/scp/journal/SSI/47/8/10.1360/N112017-00145) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/TU2017Network.md)
*Cunchao TU, Cheng YANG, Zhiyuan LIU, Maosong SUN*
31. **Opportunities and Challenges in Deep Learning Adversarial Robustness: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2007.00753) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Silva2020Opportunities.md)
*Samuel Henrique Silva, Peyman Najafirad*
32. **Recent advances in deep learning theory.** arXiv 2020 [paper](https://arxiv.org/pdf/2012.10931.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/He2020Recent.md)
*Fengxiang He, Dacheng Tao*
33. **Relational inductive biases, deep learning, and graph networks.** arXiv 2018 [paper](http://arxiv.org/abs/1806.01261) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Battaglia2018Relational.md)
*Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinícius Flores Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, Çaglar Gülçehre, H. Francis Song, Andrew J. Ballard, Justin Gilmer, George E. Dahl, Ashish Vaswani, Kelsey R. Allen, Charles Nash, Victoria Langston, Chris Dyer, Nicolas Heess, Daan Wierstra, Pushmeet Kohli, Matthew Botvinick, Oriol Vinyals, Yujia Li, Razvan Pascanu*
34. **Representation Learning: A Review and New Perspectives.** IEEE Trans. Pattern Anal. Mach. Intell. 2013 [paper](https://arxiv.org/pdf/1206.5538) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Bengio2013Representation.md)
*Yoshua Bengio, Aaron C. Courville, Pascal Vincent*
35. **Review: Ordinary Differential Equations For Deep Learning.** arXiv 2019 [paper](https://arxiv.org/abs/1911.00502) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Chen2019Review.md)
*Xinshi Chen*
36. **Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks.** J. Mach. Learn. Res. 2021 [paper](https://arxiv.org/abs/2102.00554) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Hoefler2021Sparsity.md)
*Torsten Hoefler, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, Alexandra Peste*
37. **Survey of Expressivity in Deep Neural Networks.** NIPS 2016 [paper](https://arxiv.org/abs/1611.08083) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Raghu2016Survey.md)
*Maithra Raghu, Ben Poole, Jon Kleinberg, Surya Ganguli, Jascha Sohl-Dickstein*
38. **Survey of reasoning using Neural networks.** arXiv 2017 [paper](https://arxiv.org/abs/1702.06186) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Sahu2017Survey.md)
*Amit Sahu*
39. **The Deep Learning Compiler: A Comprehensive Survey.** IEEE Trans. Parallel Distributed Syst. 2021 [paper](https://arxiv.org/abs/2002.03794) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Li2021The.md)
*Mingzhen Li, Yi Liu, Xiaoyan Liu, Qingxiao Sun, Xin You, Hailong Yang, Zhongzhi Luan, Lin Gan, Guangwen Yang, Depei Qian*
40. **The Modern Mathematics of Deep Learning.** arXiv 2021 [paper](https://arxiv.org/pdf/2105.04026.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Berner2021The.md)
*Julius Berner, Philipp Grohs, Gitta Kutyniok, Philipp Petersen*
41. **Time Series Data Imputation: A Survey on Deep Learning Approaches.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.11347.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Fang2020Time.md)
*Chenguang Fang, Chen Wang*
42. **Time-series forecasting with deep learning: a survey.** Philosophical Transactions of the Royal Society A 2021 [paper](https://royalsocietypublishing.org/doi/10.1098/rsta.2020.0209) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Lim2021Time-series.md)
*Bryan Lim, Stefan Zohren*
43. **Tutorial on Variational Autoencoders.** arXiv 2016 [paper](https://arxiv.org/pdf/1606.05908.pdf) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Doersch2016Tutorial.md)
*Carl Doersch*
44. **网络表示学习算法综述.** 计算机科学 2020 [paper](http://www.jsjkx.com/CN/10.11896/jsjkx.190300004) [bib](/bib/Machine-Learning/Deep-Learning-General-Methods/Ding2020Survey.md)
*丁钰, 魏浩, 潘志松, 刘鑫*
#### [Deep Reinforcement Learning](#content)
1. **A Short Survey On Memory Based Reinforcement Learning.** arXiv 2019 [paper](https://arxiv.org/abs/1904.06736) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Ramani2019A.md)
*Dhruv Ramani*
2. **A Short Survey on Probabilistic Reinforcement Learning.** arXiv 2019 [paper](https://arxiv.org/abs/1901.07010) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Russel2019A.md)
*Reazul Hasan Russel*
3. **A survey of benchmarking frameworks for reinforcement learning.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.13577.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Stapelberg2020A.md)
*Belinda Stapelberg, Katherine M. Malan*
4. **A Survey of Exploration Strategies in Reinforcement Learning.** McGill University 2003 [paper](https://www.semanticscholar.org/paper/A-Survey-of-Exploration-Strategies-in-Reinforcement-McFarlane/02761533d794ed9ed5dfd0295f2577e1e98c4fe2?p2df) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/McFarlane2003A.md)
*R. McFarlane*
5. **A Survey of Inverse Reinforcement Learning: Challenges, Methods and Progress.** Artif. Intell. 2021 [paper](https://arxiv.org/abs/1806.06877) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Arora2021A.md)
*Saurabh Arora, Prashant Doshi*
6. **A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2005.10619) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Padakandla2021A.md)
*Sindhu Padakandla*
7. **A Survey of Reinforcement Learning Informed by Natural Language.** IJCAI 2019 [paper](https://arxiv.org/abs/1906.03926) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Luketina2019A.md)
*Jelena Luketina, Nantas Nardelli, Gregory Farquhar, Jakob N. Foerster, Jacob Andreas, Edward Grefenstette, Shimon Whiteson, Tim Rocktäschel*
8. **A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions.** arXiv 2020 [paper](https://arxiv.org/abs/2001.06921) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Mondal2020A.md)
*Amit Kumar Mondal*
9. **A Survey on Deep Reinforcement Learning for Audio-Based Applications.** arXiv 2021 [paper](http://arxiv.org/pdf/2101.00240.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Latif2021A.md)
*Siddique Latif, Heriberto Cuayáhuitl, Farrukh Pervez, Fahad Shamshad, Hafiz Shehbaz Ali, Erik Cambria*
10. **A Survey on Deep Reinforcement Learning for Data Processing and Analytics.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04526.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Cai2021A.md)
*Qingpeng Cai, Can Cui, Yiyuan Xiong, Wei Wang, Zhongle Xie, Meihui Zhang*
11. **A survey on intrinsic motivation in reinforcement learning.** arXiv 2019 [paper](https://arxiv.org/abs/1908.06976) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Aubret2019A.md)
*Arthur Aubret, Laëtitia Matignon, Salima Hassas*
12. **A Survey on Reinforcement Learning for Combinatorial Optimization.** arXiv 2020 [paper](https://arxiv.org/pdf/2008.12248.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Yang2020A.md)
*Yunhao Yang, Andrew B. Whinston*
13. **A Survey on Reproducibility by Evaluating Deep Reinforcement Learning Algorithms on Real-World Robots.** CoRL 2019 [paper](https://arxiv.org/abs/1909.03772) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Lynnerup2019A.md)
*Nicolai A. Lynnerup, Laura Nolling, Rasmus Hasle, John Hallam*
14. **Adapting Behaviour via Intrinsic Reward: A Survey and Empirical Study.** arXiv 2019 [paper](https://arxiv.org/pdf/1906.07865.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Linke2019Adapting.md)
*Cam Linke, Nadia M. Ady, Martha White, Thomas Degris, Adam White*
15. **Comprehensive Review of Deep Reinforcement Learning Methods and Applications in Economics.** Mathematics 2020 [paper](https://www.mdpi.com/2227-7390/8/10/1640) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Mosavi2020Comprehensive.md)
*Amirhosein Mosavi, Yaser Faghan, Pedram Ghamisi, Puhong Duan, Sina Faizollahzadeh Ardabili, Ely Salwana, Shahab S. Band*
16. **Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey.** J. Mach. Learn. Res. 2020 [paper](https://arxiv.org/pdf/2003.04960.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Narvekar2020Curriculum.md)
*Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E. Taylor, Peter Stone*
17. **Deep Model-Based Reinforcement Learning for High-Dimensional Problems, a Survey.** arXiv 2020 [paper](http://arxiv.org/pdf/2008.05598.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Plaat2020Deep.md)
*Aske Plaat, Walter Kosters, Mike Preuss*
18. **Deep Reinforcement Learning for Clinical Decision Support: A Brief Survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1907.09475.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Liu2019Deep.md)
*Siqi Liu, Kee Yuan Ngiam, Mengling Feng*
19. **Deep Reinforcement Learning for Demand Driven Services in Logistics and Transportation Systems: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04462.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Zong2021Deep.md)
*Zefang Zong, Tao Feng, Tong Xia, Depeng Jin, Yong Li*
20. **Deep Reinforcement Learning for Intelligent Transportation Systems: A Survey.** IEEE Trans. Intell. Transp. Syst. 2022 [paper](https://arxiv.org/pdf/2005.00935.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Haydari2022Deep.md)
*Ammar Haydari, Yasin Yilmaz*
21. **Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.00123.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Pricope2021Deep.md)
*Tidor-Vlad Pricope*
22. **Deep Reinforcement Learning: A Brief Survey.** IEEE Signal Process. Mag. 2017 [paper](https://ieeexplore.ieee.org/document/8103164) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Arulkumaran2017Deep.md)
*Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, Anil Anthony Bharath*
23. **Deep Reinforcement Learning: An Overview.** arXiv 2017 [paper](https://arxiv.org/abs/1701.07274) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Li2017Deep.md)
*Yuxi Li*
24. **Derivative-Free Reinforcement Learning: A Review.** Frontiers Comput. Sci. 2021 [paper](https://arxiv.org/abs/2102.05710) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Qian2021Derivative-Free.md)
*Hong Qian, Yang Yu*
25. **Explainable Reinforcement Learning for Broad-XAI: A Conceptual Framework and Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.09003.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Dazeley2021Explainable.md)
*Richard Dazeley, Peter Vamplew, Francisco Cruz*
26. **Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations.** IEEE CAA J. Autom. Sinica 2019 [paper](https://arxiv.org/abs/1804.04577) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Bertsekas2019Feature-Based.md)
*Dimitri P. Bertsekas*
27. **Model-based Reinforcement Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2006.16712) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Moerland2020Model-based.md)
*Thomas M. Moerland, Joost Broekens, Catholijn M. Jonker*
28. **Reinforcement Learning for Combinatorial Optimization: A Survey.** Comput. Oper. Res. 2021 [paper](https://arxiv.org/abs/2003.03600) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Mazyavkina2021Reinforcement.md)
*Nina Mazyavkina, Sergey Sviridov, Sergei Ivanov, Evgeny Burnaev*
29. **Reinforcement Learning in Healthcare: A Survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1908.08796.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Yu2019Reinforcement.md)
*Chao Yu, Jiming Liu, Shamim Nemati*
30. **Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: a Survey.** SSCI 2020 [paper](https://arxiv.org/pdf/2009.13303.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Zhao2020Sim-to-Real.md)
*Wenshuai Zhao, Jorge Peña Queralta, Tomi Westerlund*
31. **Survey on reinforcement learning for language processing.** arXiv 2021 [paper](https://arxiv.org/abs/2104.05565) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Uc-Cetina2021Survey.md)
*Víctor Uc-Cetina, Nicolás Navarro-Guerrero, Anabel Martín-González, Cornelius Weber, Stefan Wermter*
32. **Tutorial and Survey on Probabilistic Graphical Model and Variational Inference in Deep Reinforcement Learning.** SSCI 2019 [paper](https://arxiv.org/pdf/1908.09381.pdf) [bib](/bib/Machine-Learning/Deep-Reinforcement-Learning/Sun2019Tutorial.md)
*Xudong Sun, Bernd Bischl*
#### [Federated Learning](#content)
1. **A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection.** arXiv 2019 [paper](http://arxiv.org/pdf/1907.09693.pdf) [bib](/bib/Machine-Learning/Federated-Learning/Li2019A.md)
*Qinbin Li, Zeyi Wen, Zhaomin Wu, Sixu Hu, Naibo Wang, Xu Liu, Bingsheng He*
2. **Achieving Security and Privacy in Federated Learning Systems: Survey, Research Challenges and Future Directions.** Eng. Appl. Artif. Intell. 2021 [paper](http://arxiv.org/pdf/2012.06810.pdf) [bib](/bib/Machine-Learning/Federated-Learning/Blanco-Justicia2021Achieving.md)
*Alberto Blanco-Justicia, Josep Domingo-Ferrer, Sergio Martínez, David Sánchez, Adrian Flanagan, Kuan Eeik Tan*
3. **Advances and Open Problems in Federated Learning.** Found. Trends Mach. Learn. 2021 [paper](https://arxiv.org/abs/1912.04977) [bib](/bib/Machine-Learning/Federated-Learning/Kairouz2021Advances.md)
*Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista A. Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, Rafael G. L. D'Oliveira, Hubert Eichner, Salim El Rouayheb, David Evans, Josh Gardner, Zachary Garrett, Adrià Gascón, Badih Ghazi, Phillip B. Gibbons, Marco Gruteser, Zaïd Harchaoui, Chaoyang He, Lie He, Zhouyuan Huo, Ben Hutchinson, Justin Hsu, Martin Jaggi, Tara Javidi, Gauri Joshi, Mikhail Khodak, Jakub Konecný, Aleksandra Korolova, Farinaz Koushanfar, Sanmi Koyejo, Tancrède Lepoint, Yang Liu, Prateek Mittal, Mehryar Mohri, Richard Nock, Ayfer Özgür, Rasmus Pagh, Hang Qi, Daniel Ramage, Ramesh Raskar, Mariana Raykova, Dawn Song, Weikang Song, Sebastian U. Stich, Ziteng Sun, Ananda Theertha Suresh, Florian Tramèr, Praneeth Vepakomma, Jianyu Wang, Li Xiong, Zheng Xu, Qiang Yang, Felix X. Yu, Han Yu, Sen Zhao*
4. **Fusion of Federated Learning and Industrial Internet of Things: A Survey.** arXiv 2021 [paper](http://arxiv.org/pdf/2101.00798.pdf) [bib](/bib/Machine-Learning/Federated-Learning/Parimala2021Fusion.md)
*Parimala M., R. M. Swarna Priya, Quoc-Viet Pham, Kapal Dev, Praveen Kumar Reddy Maddikunta, Thippa Reddy Gadekallu, Thien Huynh-The*
5. **Privacy and Robustness in Federated Learning: Attacks and Defenses.** arXiv 2020 [paper](https://arxiv.org/abs/2012.06337) [bib](/bib/Machine-Learning/Federated-Learning/Lyu2020Privacy.md)
*Lingjuan Lyu, Han Yu, Xingjun Ma, Lichao Sun, Jun Zhao, Qiang Yang, Philip S. Yu*
6. **Threats to Federated Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2003.02133) [bib](/bib/Machine-Learning/Federated-Learning/Lyu2020Threats.md)
*Lingjuan Lyu, Han Yu, Qiang Yang*
7. **Towards Utilizing Unlabeled Data in Federated Learning: A Survey and Prospective.** arXiv 2020 [paper](https://arxiv.org/abs/2002.11545) [bib](/bib/Machine-Learning/Federated-Learning/Jin2020Towards.md)
*Yilun Jin, Xiguang Wei, Yang Liu, Qiang Yang*
#### [Few-Shot and Zero-Shot Learning](#content)
1. **A Survey of Zero-Shot Learning: Settings, Methods, and Applications.** ACM Trans. Intell. Syst. Technol. 2019 [paper](https://dl.acm.org/doi/10.1145/3293318) [bib](/bib/Machine-Learning/Few-Shot-and-Zero-Shot-Learning/Wang2019A.md)
*Wei Wang, Vincent W. Zheng, Han Yu, Chunyan Miao*
2. **Generalizing from a Few Examples: A Survey on Few-Shot Learning.** ACM Comput. Surv. 2020 [paper](https://arxiv.org/abs/1904.05046) [bib](/bib/Machine-Learning/Few-Shot-and-Zero-Shot-Learning/Wang2020Generalizing.md)
*Yaqing Wang, Quanming Yao, James T. Kwok, Lionel M. Ni*
3. **Learning from Few Samples: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2007.15484) [bib](/bib/Machine-Learning/Few-Shot-and-Zero-Shot-Learning/Bendre2020Learning.md)
*Nihar Bendre, Hugo Terashima-Marín, Peyman Najafirad*
4. **Learning from Very Few Samples: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.02653) [bib](/bib/Machine-Learning/Few-Shot-and-Zero-Shot-Learning/Lu2020Learning.md)
*Jiang Lu, Pinghua Gong, Jieping Ye, Changshui Zhang*
#### [General Machine Learning](#content)
1. **A Comprehensive Survey on Outlying Aspect Mining Methods.** arXiv 2020 [paper](https://arxiv.org/pdf/2005.02637.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Samariya2020A.md)
*Durgesh Samariya, Jiangang Ma, Sunil Aryal*
2. **A Survey of Adaptive Resonance Theory Neural Network Models for Engineering Applications.** Neural Networks 2019 [paper](https://arxiv.org/abs/1905.11437) [bib](/bib/Machine-Learning/General-Machine-Learning/Silva2019A.md)
*Leonardo Enzo Brito da Silva, Islam Elnabarawy, Donald C. Wunsch II*
3. **A survey of dimensionality reduction techniques.** arXiv 2014 [paper](https://arxiv.org/abs/1403.2877) [bib](/bib/Machine-Learning/General-Machine-Learning/Sorzano2014A.md)
*Carlos Oscar Sánchez Sorzano, Javier Vargas, Alberto Domingo Pascual-Montano*
4. **A Survey of Human-in-the-loop for Machine Learning.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.00941) [bib](/bib/Machine-Learning/General-Machine-Learning/Wu2021A.md)
*Xingjiao Wu, Luwei Xiao, Yixuan Sun, Junhang Zhang, Tianlong Ma, Liang He*
5. **A Survey of Learning Causality with Data: Problems and Methods.** ACM Comput. Surv. 2020 [paper](https://arxiv.org/pdf/1809.09337.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Guo2020A.md)
*Ruocheng Guo, Lu Cheng, Jundong Li, P. Richard Hahn, Huan Liu*
6. **A Survey of Predictive Modelling under Imbalanced Distributions.** arXiv 2015 [paper](https://arxiv.org/abs/1505.01658) [bib](/bib/Machine-Learning/General-Machine-Learning/Branco2015A.md)
*Paula Branco, Luís Torgo, Rita P. Ribeiro*
7. **A Survey On (Stochastic Fractal Search) Algorithm.** arXiv 2021 [paper](https://arxiv.org/abs/2102.01503) [bib](/bib/Machine-Learning/General-Machine-Learning/ElKomy2021A.md)
*Mohammed ElKomy*
8. **A Survey on Data Collection for Machine Learning: a Big Data - AI Integration Perspective.** IEEE Trans. Knowl. Data Eng. 2021 [paper](https://arxiv.org/abs/1811.03402) [bib](/bib/Machine-Learning/General-Machine-Learning/Roh2021A.md)
*Yuji Roh, Geon Heo, Steven Euijong Whang*
9. **A Survey on Distributed Machine Learning.** ACM Comput. Surv. 2020 [paper](https://arxiv.org/abs/1912.09789) [bib](/bib/Machine-Learning/General-Machine-Learning/Verbraeken2020A.md)
*Joost Verbraeken, Matthijs Wolting, Jonathan Katzy, Jeroen Kloppenburg, Tim Verbelen, Jan S. Rellermeyer*
10. **A survey on feature weighting based K-Means algorithms.** J. Classif. 2016 [paper](https://arxiv.org/abs/1601.03483) [bib](/bib/Machine-Learning/General-Machine-Learning/Amorim2016A.md)
*Renato Cordeiro de Amorim*
11. **A survey on graph kernels.** Appl. Netw. Sci. 2020 [paper](https://appliednetsci.springeropen.com/articles/10.1007/s41109-019-0195-3) [bib](/bib/Machine-Learning/General-Machine-Learning/Kriege2020A.md)
*Nils M. Kriege, Fredrik D. Johansson, Christopher Morris*
12. **A Survey on Large-scale Machine Learning.** arXiv 2020 [paper](https://arxiv.org/abs/2008.03911) [bib](/bib/Machine-Learning/General-Machine-Learning/Wang2020A.md)
*Meng Wang, Weijie Fu, Xiangnan He, Shijie Hao, Xindong Wu*
13. **A Survey on Optimal Transport for Machine Learning: Theory and Applications.** arXiv 2021 [paper](https://arxiv.org/abs/2106.01963) [bib](/bib/Machine-Learning/General-Machine-Learning/Torres2021A.md)
*Luis Caicedo Torres, Luiz Manella Pereira, M. Hadi Amini*
14. **A Survey on Resilient Machine Learning.** arXiv 2017 [paper](https://arxiv.org/abs/1707.03184) [bib](/bib/Machine-Learning/General-Machine-Learning/Kumar2017A.md)
*Atul Kumar, Sameep Mehta*
15. **A Survey on Surrogate Approaches to Non-negative Matrix Factorization.** Vietnam journal of mathematics 2018 [paper](https://link.springer.com/content/pdf/10.1007/s10013-018-0315-x.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Fernsel2018A.md)
*Pascal Fernsel, Peter Maass*
16. **Adversarial Examples in Modern Machine Learning: A Review.** arXiv 2019 [paper](https://arxiv.org/abs/1911.05268) [bib](/bib/Machine-Learning/General-Machine-Learning/Wiyatno2019Adversarial.md)
*Rey Reza Wiyatno, Anqi Xu, Ousmane Dia, Archy de Berker*
17. **Algorithms Inspired by Nature: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1903.01893) [bib](/bib/Machine-Learning/General-Machine-Learning/Gupta2019Algorithms.md)
*Pranshu Gupta*
18. **An Overview of Privacy in Machine Learning.** arXiv 2020 [paper](https://arxiv.org/pdf/2005.08679.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Cristofaro2020An.md)
*Emiliano De Cristofaro*
19. **Are deep learning models superior for missing data imputation in large surveys? Evidence from an empirical comparison.** arXiv 2021 [paper](https://arxiv.org/abs/2103.09316) [bib](/bib/Machine-Learning/General-Machine-Learning/Wang2021Are.md)
*Zhenhua Wang, Olanrewaju Akande, Jason Poulos, Fan Li*
20. **Certification of embedded systems based on Machine Learning: A survey.** arXiv 2021 [paper](https://arxiv.org/abs/2106.07221) [bib](/bib/Machine-Learning/General-Machine-Learning/Vidot2021Certification.md)
*Guillaume Vidot, Christophe Gabreau, Ileana Ober, Iulian Ober*
21. **Class-incremental learning: survey and performance evaluation.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.15277.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Masana2020Class-incremental.md)
*Marc Masana, Xialei Liu, Bartlomiej Twardowski, Mikel Menta, Andrew D. Bagdanov, Joost van de Weijer*
22. **Data and its (dis)contents: A survey of dataset development and use in machine learning research.** Patterns 2021 [paper](https://arxiv.org/pdf/2012.05345.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Paullada2021Data.md)
*Amandalynne Paullada, Inioluwa Deborah Raji, Emily M. Bender, Emily Denton, Alex Hanna*
23. **Generating Artificial Outliers in the Absence of Genuine Ones - a Survey.** ACM Trans. Knowl. Discov. Data 2021 [paper](https://arxiv.org/pdf/2006.03646.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Steinbuss2021Generating.md)
*Georg Steinbuss, Klemens Böhm*
24. **Hierarchical Mixtures-of-Experts for Exponential Family Regression Models with Generalized Linear Mean Functions: A Survey of Approximation and Consistency Results.** UAI 1998 [paper](https://arxiv.org/abs/1301.7390) [bib](/bib/Machine-Learning/General-Machine-Learning/Jiang1998Hierarchical.md)
*Wenxin Jiang, Martin A. Tanner*
25. **Hyperbox-based machine learning algorithms: A comprehensive survey.** Soft Comput. 2021 [paper](https://arxiv.org/abs/1901.11303) [bib](/bib/Machine-Learning/General-Machine-Learning/Khuat2021Hyperbox-based.md)
*Thanh Tung Khuat, Dymitr Ruta, Bogdan Gabrys*
26. **Introduction to Core-sets: an Updated Survey.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.09384.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Feldman2020Introduction.md)
*Dan Feldman*
27. **Laplacian-Based Dimensionality Reduction Including Spectral Clustering, Laplacian Eigenmap, Locality Preserving Projection, Graph Embedding, and Diffusion Map: Tutorial and Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2106.02154) [bib](/bib/Machine-Learning/General-Machine-Learning/Ghojogh2021Laplacian-Based.md)
*Benyamin Ghojogh, Ali Ghodsi, Fakhri Karray, Mark Crowley*
28. **Logic Locking at the Frontiers of Machine Learning: A Survey on Developments and Opportunities.** VLSI-SoC 2021 [paper](https://arxiv.org/abs/2107.01915) [bib](/bib/Machine-Learning/General-Machine-Learning/Sisejkovic2021Logic.md)
*Dominik Sisejkovic, Lennart M. Reimann, Elmira Moussavi, Farhad Merchant, Rainer Leupers*
29. **Machine Learning at the Network Edge: A Survey.** ACM Comput. Surv. 2022 [paper](https://arxiv.org/abs/1908.00080) [bib](/bib/Machine-Learning/General-Machine-Learning/Murshed2022Machine.md)
*M. G. Sarwar Murshed, Christopher Murphy, Daqing Hou, Nazar Khan, Ganesh Ananthanarayanan, Faraz Hussain*
30. **Machine Learning for Spatiotemporal Sequence Forecasting: A Survey.** arXiv 2018 [paper](https://arxiv.org/abs/1808.06865) [bib](/bib/Machine-Learning/General-Machine-Learning/Shi2018Machine.md)
*Xingjian Shi, Dit-Yan Yeung*
31. **Machine Learning in Network Centrality Measures: Tutorial and Outlook.** ACM Comput. Surv. 2019 [paper](https://dl.acm.org/doi/10.1145/3237192) [bib](/bib/Machine-Learning/General-Machine-Learning/Grando2019Machine.md)
*Felipe Grando, Lisandro Zambenedetti Granville, Luís C. Lamb*
32. **Machine Learning Testing: Survey, Landscapes and Horizons.** IEEE Trans. Software Eng. 2022 [paper](https://arxiv.org/abs/1906.10742) [bib](/bib/Machine-Learning/General-Machine-Learning/Zhang2022Machine.md)
*Jie M. Zhang, Mark Harman, Lei Ma, Yang Liu*
33. **Machine Learning that Matters.** ICML 2012 [paper](https://arxiv.org/abs/1206.4656) [bib](/bib/Machine-Learning/General-Machine-Learning/Wagstaff2012Machine.md)
*Kiri Wagstaff*
34. **Machine Learning with World Knowledge: The Position and Survey.** arXiv 2017 [paper](https://arxiv.org/abs/1705.02908) [bib](/bib/Machine-Learning/General-Machine-Learning/Song2017Machine.md)
*Yangqiu Song, Dan Roth*
35. **Mean-Field Learning: a Survey.** arXiv 2012 [paper](https://arxiv.org/abs/1210.4657) [bib](/bib/Machine-Learning/General-Machine-Learning/Tembine2012Mean-Field.md)
*Hamidou Tembine, Raúl Tempone, Pedro Vilanova*
36. **Multidimensional Scaling, Sammon Mapping, and Isomap: Tutorial and Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.08136) [bib](/bib/Machine-Learning/General-Machine-Learning/Ghojogh2020Multidimensional.md)
*Benyamin Ghojogh, Ali Ghodsi, Fakhri Karray, Mark Crowley*
37. **Multimodal Machine Learning: A Survey and Taxonomy.** IEEE Trans. Pattern Anal. Mach. Intell. 2019 [paper](https://arxiv.org/abs/1705.09406) [bib](/bib/Machine-Learning/General-Machine-Learning/Baltrusaitis2019Multimodal.md)
*Tadas Baltrusaitis, Chaitanya Ahuja, Louis-Philippe Morency*
38. **Multi-Objective Multi-Agent Decision Making: A Utility-based Analysis and Survey.** AAMAS 2020 [paper](https://link.springer.com/content/pdf/10.1007/s10458-019-09433-x.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Radulescu2020Multi-Objective.md)
*Roxana Radulescu, Patrick Mannion, Diederik M. Roijers, Ann Nowé*
39. **Rational Kernels: A survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1910.13800.pdf) [bib](/bib/Machine-Learning/General-Machine-Learning/Ghose2019Rational.md)
*Abhishek Ghose*
40. **Statistical Queries and Statistical Algorithms: Foundations and Applications.** arXiv 2020 [paper](https://arxiv.org/abs/2004.00557) [bib](/bib/Machine-Learning/General-Machine-Learning/Reyzin2020Statistical.md)
*Lev Reyzin*
41. **Structure Learning of Probabilistic Graphical Models: A Comprehensive Survey.** arXiv 2011 [paper](https://arxiv.org/abs/1111.6925) [bib](/bib/Machine-Learning/General-Machine-Learning/Zhou2011Structure.md)
*Yang Zhou*
42. **Survey & Experiment: Towards the Learning Accuracy.** arXiv 2010 [paper](https://arxiv.org/abs/1012.4051) [bib](/bib/Machine-Learning/General-Machine-Learning/Zhu2010Survey.md)
*Zeyuan Allen Zhu*
43. **Survey on Feature Selection.** arXiv 2015 [paper](https://arxiv.org/abs/1510.02892) [bib](/bib/Machine-Learning/General-Machine-Learning/Abdallah2015Survey.md)
*Tarek Amr Abdallah, Beatriz de la Iglesia*
44. **Survey on Multi-output Learning.** IEEE Trans. Neural Networks Learn. Syst. 2020 [paper](https://arxiv.org/abs/1901.00248) [bib](/bib/Machine-Learning/General-Machine-Learning/Xu2020Survey.md)
*Donna Xu, Yaxin Shi, Ivor W. Tsang, Yew-Soon Ong, Chen Gong, Xiaobo Shen*
45. **Survey: Machine Learning in Production Rendering.** arXiv 2020 [paper](https://arxiv.org/abs/2005.12518) [bib](/bib/Machine-Learning/General-Machine-Learning/Zhu2020Survey.md)
*Shilin Zhu*
46. **The Benefits of Population Diversity in Evolutionary Algorithms: A Survey of Rigorous Runtime Analyses.** arXiv 2018 [paper](https://arxiv.org/abs/1801.10087) [bib](/bib/Machine-Learning/General-Machine-Learning/Sudholt2018The.md)
*Dirk Sudholt*
47. **Towards Causal Representation Learning.** arXiv 2021 [paper](https://arxiv.org/abs/2102.11107) [bib](/bib/Machine-Learning/General-Machine-Learning/Schölkopf2021Towards.md)
*Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, Yoshua Bengio*
48. **Verification for Machine Learning, Autonomy, and Neural Networks Survey.** arXiv 2018 [paper](https://arxiv.org/abs/1810.01989) [bib](/bib/Machine-Learning/General-Machine-Learning/Xiang2018Verification.md)
*Weiming Xiang, Patrick Musau, Ayana A. Wild, Diego Manzanas Lopez, Nathaniel Hamilton, Xiaodong Yang, Joel A. Rosenfeld, Taylor T. Johnson*
49. **What Can Knowledge Bring to Machine Learning? - A Survey of Low-shot Learning for Structured Data.** arXiv 2021 [paper](https://arxiv.org/abs/2106.06410) [bib](/bib/Machine-Learning/General-Machine-Learning/Hu2021What.md)
*Yang Hu, Adriane Chapman, Guihua Wen, Wendy Hall*
50. **机器学习的五大类别及其主要算法综述.** 软件导刊 2019 [paper](http://www.rjdk.org/thesisDetails#10.11907/rjdk.182932&lang=zh) [bib](/bib/Machine-Learning/General-Machine-Learning/Li2019Survey.md)
*李旭然, 丁晓红*
#### [Generative Adversarial Networks](#content)
1. **A Review of Generative Adversarial Networks in Cancer Imaging: New Applications, New Solutions.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.09543.pdf) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Osuala2021A.md)
*Richard Osuala, Kaisar Kushibar, Lidia Garrucho, Akis Linardos, Zuzanna Szafranowska, Stefan Klein, Ben Glocker, Oliver Díaz, Karim Lekadir*
2. **A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications.** arXiv 2020 [paper](https://arxiv.org/abs/2001.06937) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Gui2020A.md)
*Jie Gui, Zhenan Sun, Yonggang Wen, Dacheng Tao, Jieping Ye*
3. **A Survey on Generative Adversarial Networks: Variants, Applications, and Training.** ACM Comput. Surv. 2022 [paper](https://arxiv.org/abs/2006.05132) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Jabbar2022A.md)
*Abdul Jabbar, Xi Li, Bourahla Omar*
4. **Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models.** arXiv 2021 [paper](https://arxiv.org/abs/2103.04922) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Bond-Taylor2021Deep.md)
*Sam Bond-Taylor, Adam Leach, Yang Long, Chris G. Willcocks*
5. **GAN Computers Generate Arts? A Survey on Visual Arts, Music, and Literary Text Generation using Generative Adversarial Network.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.03857.pdf) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Shahriar2021GAN.md)
*Sakib Shahriar*
6. **GAN Inversion: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2101.05278.pdf) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Xia2021GAN.md)
*Weihao Xia, Yulun Zhang, Yujiu Yang, Jing-Hao Xue, Bolei Zhou, Ming-Hsuan Yang*
7. **Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/1906.01529) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Wang2021Generative.md)
*Zhengwei Wang, Qi She, Tomás E. Ward*
8. **Generative Adversarial Networks in Human Emotion Synthesis: A Review.** IEEE Access 2020 [paper](https://ieeexplore.ieee.org/document/9279199) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Hajarolasvadi2020Generative.md)
*Noushin Hajarolasvadi, Miguel Arjona Ramírez, Wesley Beccaro, Hasan Demirel*
9. **Generative Adversarial Networks: A Survey Towards Private and Secure Applications.** arXiv 2021 [paper](https://arxiv.org/abs/2106.03785) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Cai2021Generative.md)
*Zhipeng Cai, Zuobin Xiong, Honghui Xu, Peng Wang, Wei Li, Yi Pan*
10. **Generative Adversarial Networks: An Overview.** IEEE Signal Process. Mag. 2018 [paper](https://arxiv.org/abs/1710.07035) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Creswell2018Generative.md)
*Antonia Creswell, Tom White, Vincent Dumoulin, Kai Arulkumaran, Biswa Sengupta, Anil A. Bharath*
11. **How Generative Adversarial Networks and Their Variants Work: An Overview.** ACM Comput. Surv. 2019 [paper](https://arxiv.org/abs/1711.05914) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Hong2019How.md)
*Yongjun Hong, Uiwon Hwang, Jaeyoon Yoo, Sungroh Yoon*
12. **Stabilizing Generative Adversarial Networks: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1910.00927) [bib](/bib/Machine-Learning/Generative-Adversarial-Networks/Wiatrak2019Stabilizing.md)
*Maciej Wiatrak, Stefano V. Albrecht, Andrew Nystrom*
#### [Graph Neural Networks](#content)
1. **A Comprehensive Survey of Graph Embedding: Problems, Techniques, and Applications.** IEEE Trans. Knowl. Data Eng. 2018 [paper](https://ieeexplore.ieee.org/abstract/document/8294302) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Cai2018A.md)
*Hongyun Cai, Vincent W. Zheng, Kevin Chen-Chuan Chang*
2. **A Comprehensive Survey on Graph Neural Networks.** IEEE Trans. Neural Networks Learn. Syst. 2021 [paper](https://arxiv.org/abs/1901.00596) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Wu2021A.md)
*Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, Philip S. Yu*
3. **A Survey on Graph Neural Networks for Knowledge Graph Completion.** arXiv 2020 [paper](http://arxiv.org/pdf/2007.12374.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Arora2020A.md)
*Siddhant Arora*
4. **A Survey on Graph Structure Learning: Progress and Opportunities.** arXiv 2021 [paper](https://arxiv.org/abs/2103.03036) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Zhu2021A.md)
*Yanqiao Zhu, Weizhi Xu, Jinghao Zhang, Yuanqi Du, Jieyu Zhang, Qiang Liu, Carl Yang, Shu Wu*
5. **A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.14867.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Wang2020A.md)
*Xiao Wang, Deyu Bo, Chuan Shi, Shaohua Fan, Yanfang Ye, Philip S. Yu*
6. **A Survey on The Expressive Power of Graph Neural Networks.** arXiv 2020 [paper](https://arxiv.org/abs/2003.04078) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Sato2020A.md)
*Ryoma Sato*
7. **A Systematic Survey on Deep Generative Models for Graph Generation.** arXiv 2020 [paper](https://arxiv.org/pdf/2007.06686.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Guo2020A.md)
*Xiaojie Guo, Liang Zhao*
8. **Adversarial Attack and Defense on Graph Data: A Survey.** arXiv 2018 [paper](https://arxiv.org/abs/1812.10528) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Sun2018Adversarial.md)
*Lichao Sun, Ji Wang, Philip S. Yu, Bo Li*
9. **Bridging the Gap between Spatial and Spectral Domains: A Survey on Graph Neural Networks.** arXiv 2020 [paper](https://arxiv.org/abs/2002.11867) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Chen2020Bridging.md)
*Zhiqian Chen, Fanglan Chen, Lei Zhang, Taoran Ji, Kaiqun Fu, Liang Zhao, Feng Chen, Chang-Tien Lu*
10. **Computing Graph Neural Networks: A Survey from Algorithms to Accelerators.** ACM Comput. Surv. 2022 [paper](http://arxiv.org/pdf/2010.00130.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Abadal2022Computing.md)
*Sergi Abadal, Akshay Jain, Robert Guirado, Jorge López-Alonso, Eduard Alarcón*
11. **Deep Graph Similarity Learning: A Survey.** Data Min. Knowl. Discov. 2021 [paper](https://arxiv.org/pdf/1912.11615.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Ma2021Deep.md)
*Guixiang Ma, Nesreen K. Ahmed, Theodore L. Willke, Philip S. Yu*
12. **Deep Learning on Graphs: A Survey.** IEEE Trans. Knowl. Data Eng. 2022 [paper](https://arxiv.org/abs/1812.04202) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Zhang2022Deep.md)
*Ziwei Zhang, Peng Cui, Wenwu Zhu*
13. **Explainability in Graph Neural Networks: A Taxonomic Survey.** arXiv 2020 [paper](http://arxiv.org/pdf/2012.15445.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Yuan2020Explainability.md)
*Hao Yuan, Haiyang Yu, Shurui Gui, Shuiwang Ji*
14. **Foundations and modelling of dynamic networks using Dynamic Graph Neural Networks: A survey.** arXiv 2020 [paper](https://arxiv.org/abs/2005.07496) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Skarding2020Foundations.md)
*Joakim Skarding, Bogdan Gabrys, Katarzyna Musial*
15. **Graph Embedding Techniques, Applications, and Performance: A Survey.** Knowl. Based Syst. 2018 [paper](https://arxiv.org/abs/1705.02801) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Goyal2018Graph.md)
*Palash Goyal, Emilio Ferrara*
16. **Graph Learning for Combinatorial Optimization: A Survey of State-of-the-Art.** Data Sci. Eng. 2021 [paper](https://arxiv.org/pdf/2008.12646.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Peng2021Graph.md)
*Yun Peng, Byron Choi, Jianliang Xu*
17. **Graph Learning: A Survey.** IEEE Trans. Artif. Intell. 2021 [paper](https://arxiv.org/pdf/2105.00696.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Xia2021Graph.md)
*Feng Xia, Ke Sun, Shuo Yu, Abdul Aziz, Liangtian Wan, Shirui Pan, Huan Liu*
18. **Graph Neural Network for Traffic Forecasting: A Survey.** arXiv 2021 [paper](http://arxiv.org/pdf/2101.11174.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Jiang2021Graph.md)
*Weiwei Jiang, Jiayun Luo*
19. **Graph Neural Networks for Natural Language Processing: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.06090.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Wu2021Graph.md)
*Lingfei Wu, Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Jian Pei, Bo Long*
20. **Graph Neural Networks Meet Neural-Symbolic Computing: A Survey and Perspective.** IJCAI 2020 [paper](https://arxiv.org/abs/2003.00330) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Lamb2020Graph.md)
*Luís C. Lamb, Artur S. d'Avila Garcez, Marco Gori, Marcelo O. R. Prates, Pedro H. C. Avelar, Moshe Y. Vardi*
21. **Graph Neural Networks: A Review of Methods and Applications.** AI Open 2020 [paper](https://arxiv.org/abs/1812.08434) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Zhou2020Graph1.md)
*Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, Maosong Sun*
22. **Graph Neural Networks: Methods, Applications, and Opportunities.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.10733.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Waikhom2021Graph.md)
*Lilapati Waikhom, Ripon Patgiri*
23. **Graph Neural Networks: Taxonomy, Advances and Trends.** arXiv 2020 [paper](https://arxiv.org/pdf/2012.08752.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Zhou2020Graph.md)
*Yu Zhou, Haixia Zheng, Xin Huang*
24. **Graph Representation Learning: A Survey.** APSIPA Transactions on Signal and Information Processing 2020 [paper](https://arxiv.org/abs/1909.00958) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Chen2020Graph.md)
*Fenxiao Chen, Yuncheng Wang, Bin Wang, C.-C. Jay Kuo*
25. **Graph Self-Supervised Learning: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.00111) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Liu2021Graph.md)
*Yixin Liu, Shirui Pan, Ming Jin, Chuan Zhou, Feng Xia, Philip S. Yu*
26. **Graph-Based Deep Learning for Medical Diagnosis and Analysis: Past, Present and Future.** Sensors 2021 [paper](https://arxiv.org/pdf/2105.13137.pdf) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Ahmedt-Aristizabal2021Graph-Based.md)
*David Ahmedt-Aristizabal, Mohammad Ali Armin, Simon Denman, Clinton Fookes, Lars Petersson*
27. **Introduction to Graph Neural Networks.** Synthesis Lectures on Artificial Intelligence and Machine Learning 2020 [paper](https://ieeexplore.ieee.org/document/9048171) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Liu2020Introduction.md)
*Zhiyuan Liu, Jie Zhou*
28. **Learning Representations of Graph Data - A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1906.02989) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Kinderkhedia2019Learning.md)
*Mital Kinderkhedia*
29. **Meta-Learning with Graph Neural Networks: Methods and Applications.** arXiv 2021 [paper](https://arxiv.org/abs/2103.00137) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Mandal2021Meta-Learning.md)
*Debmalya Mandal, Sourav Medya, Brian Uzzi, Charu Aggarwal*
30. **Representation Learning for Dynamic Graphs: A Survey.** J. Mach. Learn. Res. 2020 [paper](https://arxiv.org/abs/1905.11485) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Kazemi2020Representation.md)
*Seyed Mehran Kazemi, Rishab Goel, Kshitij Jain, Ivan Kobyzev, Akshay Sethi, Peter Forsyth, Pascal Poupart*
31. **Robustness of deep learning models on graphs: A survey.** AI Open 2021 [paper](https://www.sciencedirect.com/science/article/pii/S2666651021000139) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Xu2021Robustness.md)
*Jiarong Xu, Junru Chen, Siqi You, Zhiqing Xiao, Yang Yang, Jiangang Lu*
32. **Self-Supervised Learning of Graph Neural Networks: A Unified Review.** arXiv 2021 [paper](https://arxiv.org/abs/2102.10757) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Xie2021Self-Supervised.md)
*Yaochen Xie, Zhao Xu, Zhengyang Wang, Shuiwang Ji*
33. **Survey of Image Based Graph Neural Networks.** arXiv 2021 [paper](https://arxiv.org/abs/2106.06307) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Nazir2021Survey.md)
*Usman Nazir, He Wang, Murtaza Taj*
34. **Tackling Graphical NLP problems with Graph Recurrent Networks.** arXiv 2019 [paper](https://arxiv.org/abs/1907.06142) [bib](/bib/Machine-Learning/Graph-Neural-Networks/Song2019Tackling.md)
*Linfeng Song*
#### [Interpretability and Analysis](#content)
1. **A brief survey of visualization methods for deep learning models from the perspective of Explainable AI.** macs.hw.ac.uk 2018 [paper](http://www.macs.hw.ac.uk/~ic14/IoannisChalkiadakis_RRR.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Chalkiadakis2018A.md)
*Ioannis Chalkiadakis*
2. **A Survey of Methods for Explaining Black Box Models.** ACM Comput. Surv. 2019 [paper](https://dl.acm.org/doi/10.1145/3236009) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Guidotti2019A.md)
*Riccardo Guidotti, Anna Monreale, Salvatore Ruggieri, Franco Turini, Fosca Giannotti, Dino Pedreschi*
3. **A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI.** IEEE Trans. Neural Networks Learn. Syst. 2021 [paper](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9233366) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Tjoa2021A.md)
*Erico Tjoa, Cuntai Guan*
4. **A Survey on Knowledge integration techniques with Artificial Neural Networks for seq-2-seq/time series models.** arXiv 2020 [paper](https://arxiv.org/pdf/2008.05972.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Vadiraja2020A.md)
*Pramod Vadiraja, Muhammad Ali Chattha*
5. **A Survey on Neural Network Interpretability.** IEEE Trans. Emerg. Top. Comput. Intell. 2021 [paper](https://arxiv.org/pdf/2012.14261.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Zhang2021A.md)
*Yu Zhang, Peter Tiño, Ales Leonardis, Ke Tang*
6. **A Survey on the Explainability of Supervised Machine Learning.** J. Artif. Intell. Res. 2021 [paper](https://arxiv.org/abs/2011.07876) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Burkart2021A.md)
*Nadia Burkart, Marco F. Huber*
7. **A Survey on Understanding, Visualizations, and Explanation of Deep Neural Networks.** arXiv 2021 [paper](https://arxiv.org/abs/2102.01792) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Shahroudnejad2021A.md)
*Atefeh Shahroudnejad*
8. **Benchmarking and Survey of Explanation Methods for Black Box Models.** arXiv 2021 [paper](https://arxiv.org/pdf/2102.13076.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Bodria2021Benchmarking.md)
*Francesco Bodria, Fosca Giannotti, Riccardo Guidotti, Francesca Naretto, Dino Pedreschi, Salvatore Rinzivillo*
9. **Causal Interpretability for Machine Learning - Problems, Methods and Evaluation.** SIGKDD Explor. 2020 [paper](https://arxiv.org/abs/2003.03934) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Moraffah2020Causal.md)
*Raha Moraffah, Mansooreh Karami, Ruocheng Guo, Adrienne Raglin, Huan Liu*
10. **Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI.** Inf. Fusion 2020 [paper](https://arxiv.org/abs/1910.10045) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Arrieta2020Explainable.md)
*Alejandro Barredo Arrieta, Natalia Díaz Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, Francisco Herrera*
11. **Explainable Artificial Intelligence Approaches: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2101.09429) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Islam2021Explainable.md)
*Sheikh Rabiul Islam, William Eberle, Sheikh Khaled Ghafoor, Mohiuddin Ahmed*
12. **Explainable artificial intelligence: A survey.** MIPRO 2018 [paper](https://ieeexplore.ieee.org/document/8400040) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Dosilovic2018Explainable.md)
*Filip Karlo Dosilovic, Mario Brcic, Nikica Hlupic*
13. **Explainable Automated Fact-Checking: A Survey.** COLING 2020 [paper](https://arxiv.org/pdf/2011.03870.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Kotonya2020Explainable.md)
*Neema Kotonya, Francesca Toni*
14. **Explainable Reinforcement Learning: A Survey.** CD-MAKE 2020 [paper](https://arxiv.org/abs/2005.06247) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Puiutta2020Explainable.md)
*Erika Puiutta, Eric M. S. P. Veith*
15. **Foundations of Explainable Knowledge-Enabled Systems.** Knowledge Graphs for eXplainable Artificial Intelligence 2020 [paper](https://arxiv.org/abs/2003.07520) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Chari2020Foundations.md)
*Shruthi Chari, Daniel M. Gruen, Oshani Seneviratne, Deborah L. McGuinness*
16. **How convolutional neural networks see the world - A survey of convolutional neural network visualization methods.** Math. Found. Comput. 2018 [paper](https://arxiv.org/abs/1804.11191) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Qin2018How.md)
*Zhuwei Qin, Fuxun Yu, Chenchen Liu, Xiang Chen*
17. **Interpretable Machine Learning - A Brief History, State-of-the-Art and Challenges.** PKDD/ECML Workshops 2020 [paper](https://arxiv.org/abs/2010.09337) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Molnar2020Interpretable.md)
*Christoph Molnar, Giuseppe Casalicchio, Bernd Bischl*
18. **Machine Learning Interpretability: A Survey on Methods and Metrics.** Electronics 2019 [paper](http://www.socolar.com/Article/Index?aid=100018215892&jid=100000022108) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Carvalho2019Machine.md)
*Diogo V. Carvalho, Eduardo M. Pereira, Jaime S. Cardoso*
19. **On Interpretability of Artificial Neural Networks: A Survey.** IEEE Transactions on Radiation and Plasma Medical Sciences 2021 [paper](https://arxiv.org/pdf/2001.02522) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Fan2021On.md)
*Feng-Lei Fan, Jinjun Xiong, Mengzhou Li, Ge Wang*
20. **On the computation of counterfactual explanations - A survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1911.07749.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Artelt2019On.md)
*André Artelt, Barbara Hammer*
21. **Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2006.11371) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Das2020Opportunities.md)
*Arun Das, Paul Rad*
22. **Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI).** IEEE Access 2018 [paper](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8466590) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Adadi2018Peeking.md)
*Amina Adadi, Mohammed Berrada*
23. **Survey of explainable machine learning with visual and granular methods beyond quasi-explanations.** arXiv 2020 [paper](https://arxiv.org/abs/2009.10221) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Kovalerchuk2020Survey.md)
*Boris Kovalerchuk, Muhammad Aurangzeb Ahmad, Ankur Teredesai*
24. **Understanding Neural Networks via Feature Visualization: A survey.** Explainable AI 2019 [paper](https://arxiv.org/abs/1904.08939) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Nguyen2019Understanding.md)
*Anh Nguyen, Jason Yosinski, Jeff Clune*
25. **Visual Analytics in Deep Learning: An Interrogative Survey for the Next Frontiers.** IEEE Trans. Vis. Comput. Graph. 2019 [paper](https://arxiv.org/abs/1801.06889) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Hohman2019Visual.md)
*Fred Hohman, Minsuk Kahng, Robert Pienta, Duen Horng Chau*
26. **Visual Interpretability for Deep Learning: a Survey.** Frontiers Inf. Technol. Electron. Eng. 2018 [paper](https://arxiv.org/abs/1802.00614) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Zhang2018Visual.md)
*Quanshi Zhang, Song-Chun Zhu*
27. **Visualisation of Pareto Front Approximation: A Short Survey and Empirical Comparisons.** CEC 2019 [paper](https://arxiv.org/abs/1903.01768) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Gao2019Visualisation.md)
*Huiru Gao, Haifeng Nie, Ke Li*
28. **When will the mist clear? On the Interpretability of Machine Learning for Medical Applications: a survey.** arXiv 2020 [paper](https://arxiv.org/abs/2010.00353) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Banegas-Luna2020When.md)
*Antonio-Jesús Banegas-Luna, Jorge Peña-García, Adrian Iftene, Fiorella Guadagni, Patrizia Ferroni, Noemi Scarpato, Fabio Massimo Zanzotto, Andrés Bueno-Crespo, Horacio Pérez Sánchez*
29. **XAI Methods for Neural Time Series Classification: A Brief Review.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.08009.pdf) [bib](/bib/Machine-Learning/Interpretability-and-Analysis/Simic2021XAI.md)
*Ilija Simic, Vedran Sabol, Eduardo E. Veas*
#### [Knowledge Distillation](#content)
1. **A Selective Survey on Versatile Knowledge Distillation Paradigm for Neural Network Models.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.14554.pdf) [bib](/bib/Machine-Learning/Knowledge-Distillation/Ku2020A.md)
*Jeong-Hoe Ku, Jihun Oh, Young-Yoon Lee, Gaurav Pooniwala, SangJeong Lee*
2. **Knowledge Distillation: A Survey.** Int. J. Comput. Vis. 2021 [paper](https://arxiv.org/abs/2006.05525) [bib](/bib/Machine-Learning/Knowledge-Distillation/Gou2021Knowledge.md)
*Jianping Gou, Baosheng Yu, Stephen J. Maybank, Dacheng Tao*
#### [Meta Learning](#content)
1. **A Comprehensive Overview and Survey of Recent Advances in Meta-Learning.** arXiv 2020 [paper](https://arxiv.org/abs/2004.11149) [bib](/bib/Machine-Learning/Meta-Learning/Peng2020A.md)
*Huimin Peng*
2. **A Survey of Deep Meta-Learning.** Artif. Intell. Rev. 2021 [paper](https://arxiv.org/pdf/2010.03522.pdf) [bib](/bib/Machine-Learning/Meta-Learning/Huisman2021A.md)
*Mike Huisman, Jan N. van Rijn, Aske Plaat*
3. **Meta-learning for Few-shot Natural Language Processing: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2007.09604) [bib](/bib/Machine-Learning/Meta-Learning/Yin2020Meta-learning.md)
*Wenpeng Yin*
4. **Meta-Learning in Neural Networks: A Survey.** TPAMI 2021 [paper](https://arxiv.org/abs/2004.05439) [bib](/bib/Machine-Learning/Meta-Learning/Hospedales2021Meta-Learning.md)
*Timothy Hospedales, Antreas Antoniou, Paul Micaelli, Amos Storkey*
5. **Meta-Learning: A Survey.** arXiv 2018 [paper](https://arxiv.org/abs/1810.03548) [bib](/bib/Machine-Learning/Meta-Learning/Vanschoren2018Meta-Learning.md)
*Joaquin Vanschoren*
#### [Metric Learning](#content)
1. **A Survey on Metric Learning for Feature Vectors and Structured Data.** arXiv 2013 [paper](https://arxiv.org/abs/1306.6709) [bib](/bib/Machine-Learning/Metric-Learning/Bellet2013A.md)
*Aurélien Bellet, Amaury Habrard, Marc Sebban*
2. **A Tutorial on Distance Metric Learning: Mathematical Foundations, Algorithms, Experimental Analysis, Prospects and Challenges.** Neurocomputing 2021 [paper](https://arxiv.org/abs/1812.05944) [bib](/bib/Machine-Learning/Metric-Learning/Suárez2021A.md)
*Juan-Luis Suárez, Salvador García, Francisco Herrera*
#### [ML and DL Applications](#content)
1. **A Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.06801.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Ji2020A.md)
*Shulei Ji, Jing Luo, Xinyu Yang*
2. **A Comprehensive Survey on Graph Anomaly Detection with Deep Learning.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.07178.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Ma2021A.md)
*Xiaoxiao Ma, Jia Wu, Shan Xue, Jian Yang, Quan Z. Sheng, Hui Xiong*
3. **A Comprehensive Survey on Machine Learning Techniques and User Authentication Approaches for Credit Card Fraud Detection.** arXiv 2019 [paper](https://arxiv.org/pdf/1912.02629.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Yousefi2019A.md)
*Niloofar Yousefi, Marie Alaghband, Ivan Garibay*
4. **A guide to deep learning in healthcare.** Nature Medicine 2019 [paper](https://www.nature.com/articles/s41591-018-0316-z) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Esteva2019A.md)
*Andre Esteva, Alexandre Robicquet, Bharath Ramsundar, Volodymyr Kuleshov, Mark DePristo, Katherine Chou, Claire Cui, Greg Corrado, Sebastian Thrun, Jeff Dean*
5. **A Survey of Deep Learning Applications to Autonomous Vehicle Control.** IEEE Trans. Intell. Transp. Syst. 2021 [paper](https://arxiv.org/pdf/1912.10773.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Kuutti2021A.md)
*Sampo Kuutti, Richard Bowden, Yaochu Jin, Phil Barber, Saber Fallah*
6. **A Survey of Deep Learning Techniques for Autonomous Driving.** J. Field Robotics 2020 [paper](https://arxiv.org/pdf/1910.07738.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Grigorescu2020A.md)
*Sorin Mihai Grigorescu, Bogdan Trasnea, Tiberiu T. Cocias, Gigel Macesanu*
7. **A Survey of Machine Learning for Computer Architecture and Systems.** arXiv 2021 [paper](https://arxiv.org/abs/2102.07952) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Wu2021A.md)
*Nan Wu, Yuan Xie*
8. **A Survey of Machine Learning Techniques for Detecting and Diagnosing COVID-19 from Imaging.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04344.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Panday2021A.md)
*Aishwarza Panday, Muhammad Ashad Kabir, Nihad Karim Chowdhury*
9. **A Survey on Anomaly Detection for Technical Systems using LSTM Networks.** Comput. Ind. 2021 [paper](https://arxiv.org/abs/2105.13810) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Lindemann2021A.md)
*Benjamin Lindemann, Benjamin Maschler, Nada Sahlab, Michael Weyrich*
10. **A Survey on Deep Learning-based Non-Invasive Brain Signals:Recent Advances and New Frontiers.** Journal of Neural Engineering 2021 [paper](https://arxiv.org/abs/1905.04149) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Zhang2021A.md)
*Xiang Zhang, Lina Yao, Xianzhi Wang, Jessica Monaghan, David McAlpine, Yu Zhang*
11. **A Survey on Machine Learning Applied to Dynamic Physical Systems.** arXiv 2020 [paper](https://arxiv.org/pdf/2009.09719.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Verma2020A.md)
*Sagar Verma*
12. **A Survey on Practical Applications of Multi-Armed and Contextual Bandits.** arXiv 2019 [paper](https://arxiv.org/pdf/1904.10040.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Bouneffouf2019A.md)
*Djallel Bouneffouf, Irina Rish*
13. **A Survey on Spatial and Spatiotemporal Prediction Methods.** arXiv 2020 [paper](https://arxiv.org/pdf/2012.13384.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Jiang2020A.md)
*Zhe Jiang*
14. **A Survey on the Use of AI and ML for Fighting the COVID-19 Pandemic.** arXiv 2020 [paper](https://arxiv.org/pdf/2008.07449.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Islam2020A.md)
*Muhammad Nazrul Islam, Toki Tahmid Inan, Suzzana Rafi, Syeda Sabrina Akter, Iqbal H. Sarker, A. K. M. Najmul Islam*
15. **A Survey on Traffic Signal Control Methods.** arXiv 2019 [paper](https://arxiv.org/pdf/1904.08117.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Wei2019A.md)
*Hua Wei, Guanjie Zheng, Vikash V. Gayah, Zhenhui Li*
16. **Aesthetics, Personalization and Recommendation: A survey on Deep Learning in Fashion.** arXiv 2021 [paper](https://arxiv.org/abs/2101.08301) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Gong2021Aesthetics.md)
*Wei Gong, Laila Khalid*
17. **Artificial Neural Networks-Based Machine Learning for Wireless Networks: A Tutorial.** IEEE Commun. Surv. Tutorials 2019 [paper](https://ieeexplore.ieee.org/document/8755300) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Chen2019Artificial.md)
*Mingzhe Chen, Ursula Challita, Walid Saad, Changchuan Yin, Mérouane Debbah*
18. **Classification of Pathological and Normal Gait: A Survey.** arXiv 2020 [paper](https://arxiv.org/pdf/2012.14465.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Saxe2020Classification.md)
*Ryan C. Saxe, Samantha Kappagoda, David K. A. Mordecai*
19. **Classification supporting COVID-19 diagnostics based on patient survey data.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.12247.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Henzel2020Classification.md)
*Joanna Henzel, Joanna Tobiasz, Michal Kozielski, Malgorzata Bach, Pawel Foszner, Aleksandra Gruca, Mateusz Kania, Justyna Mika, Anna Papiez, Aleksandra Werner, Joanna Zyla, Jerzy Jaroszewicz, Joanna Polanska, Marek Sikora*
20. **Credit card fraud detection using machine learning: A survey.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.06479.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Lucas2020Credit.md)
*Yvan Lucas, Johannes Jurgovsky*
21. **Deep Learning for Click-Through Rate Estimation.** IJCAI 2021 [paper](https://arxiv.org/pdf/2104.10584.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Zhang2021Deep.md)
*Weinan Zhang, Jiarui Qin, Wei Guo, Ruiming Tang, Xiuqiang He*
22. **Deep Learning for Spatio-Temporal Data Mining: A Survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1906.04928.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Wang2019Deep.md)
*Senzhang Wang, Jiannong Cao, Philip S. Yu*
23. **Deep learning models for predictive maintenance: a survey, comparison, challenges and prospect.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.03207.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Serradilla2020Deep.md)
*Oscar Serradilla, Ekhi Zugasti, Urko Zurutuza*
24. **Deep Learning-based Spacecraft Relative Navigation Methods: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.08876.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Song2021Deep.md)
*Jianing Song, Duarte Rondao, Nabil Aouf*
25. **DL-Traff: Survey and Benchmark of Deep Learning Models for Urban Traffic Prediction.** CIKM 2021 [paper](https://arxiv.org/pdf/2108.09091.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Jiang2021DL-Traff.md)
*Renhe Jiang, Du Yin, Zhaonan Wang, Yizhuo Wang, Jiewen Deng, Hangchen Liu, Zekun Cai, Jinliang Deng, Xuan Song, Ryosuke Shibasaki*
26. **Event Prediction in the Big Data Era: A Systematic Survey.** ACM Comput. Surv. 2021 [paper](https://dl.acm.org/doi/10.1145/3450287) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Zhao2021Event.md)
*Liang Zhao*
27. **Fashion Meets Computer Vision: A Survey.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2003.13988) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Cheng2021Fashion.md)
*Wen-Huang Cheng, Sijie Song, Chieh-Yun Chen, Shintami Chusnul Hidayati, Jiaying Liu*
28. **Going Deeper Into Face Detection: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2103.14983) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Minaee2021Going.md)
*Shervin Minaee, Ping Luo, Zhe Lin, Kevin W. Bowyer*
29. **Graph Representation Learning in Biomedicine.** arXiv 2021 [paper](http://arxiv.org/abs/2104.04883) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Li2021Graph.md)
*Michelle M. Li, Kexin Huang, Marinka Zitnik*
30. **Graph-based Deep Learning for Communication Networks: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2106.02533) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Jiang2021Graph-based.md)
*Weiwei Jiang*
31. **How Developers Iterate on Machine Learning Workflows - A Survey of the Applied Machine Learning Literature.** arXiv 2018 [paper](https://arxiv.org/abs/1803.10311) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Xin2018How.md)
*Doris Xin, Litian Ma, Shuchen Song, Aditya G. Parameswaran*
32. **Known Operator Learning and Hybrid Machine Learning in Medical Imaging - A Review of the Past, the Present, and the Future.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04543.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Maier2021Known.md)
*Andreas Maier, Harald Köstler, Marco Heisig, Patrick Krauss, Seung Hee Yang*
33. **Machine Learning Aided Static Malware Analysis: A Survey and Tutorial.** arXiv 2018 [paper](https://arxiv.org/abs/1808.01201) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Shalaginov2018Machine.md)
*Andrii Shalaginov, Sergii Banin, Ali Dehghantanha, Katrin Franke*
34. **Machine Learning for Cataract Classification and Grading on Ophthalmic Imaging Modalities: A Survey.** arXiv 2020 [paper](http://arxiv.org/pdf/2012.04830.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Zhang2020Machine.md)
*Xiaoqing Zhang, Jiansheng Fang, Yan Hu, Yanwu Xu, Risa Higashita, Jiang Liu*
35. **Machine Learning for Electronic Design Automation: A Survey.** ACM Trans. Design Autom. Electr. Syst. 2021 [paper](https://arxiv.org/abs/2102.03357) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Huang2021Machine.md)
*Guyue Huang, Jingbo Hu, Yifan He, Jialong Liu, Mingyuan Ma, Zhaoyang Shen, Juejian Wu, Yuanfan Xu, Hengrui Zhang, Kai Zhong, Xuefei Ning, Yuzhe Ma, Haoyu Yang, Bei Yu, Huazhong Yang, Yu Wang*
36. **Machine Learning for Survival Analysis: A Survey.** ACM Comput. Surv. 2019 [paper](https://arxiv.org/abs/1708.04649) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Wang2019Machine.md)
*Ping Wang, Yan Li, Chandan K. Reddy*
37. **Medical Image Segmentation using 3D Convolutional Neural Networks: A Review.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.08467.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Niyas2021Medical.md)
*S. Niyas, S. J. Pawan, M. Anand Kumar, Jeny Rajan*
38. **Physics-Guided Deep Learning for Dynamical Systems: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2107.01272) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Wang2021Physics-Guided.md)
*Rui Wang*
39. **Predicting the Future from First Person (Egocentric) Vision: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2107.13411.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Rodin2021Predicting.md)
*Ivan Rodin, Antonino Furnari, Dimitrios Mavroedis, Giovanni Maria Farinella*
40. **Prediction of neonatal mortality in Sub-Saharan African countries using data-level linkage of multiple surveys.** arXiv 2020 [paper](https://arxiv.org/pdf/2011.12707.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Tadesse2020Prediction.md)
*Girmaw Abebe Tadesse, Celia Cintas, Skyler Speakman, Komminist Weldemariam*
41. **Requirement Engineering Challenges for AI-intense Systems Development.** WAIN@ICSE 2021 [paper](https://arxiv.org/pdf/2103.10270.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Heyn2021Requirement.md)
*Hans-Martin Heyn, Eric Knauss, Amna Pir Muhammad, Olof Eriksson, Jennifer Linder, Padmini Subbiah, Shameer Kumar Pradhan, Sagar Tungal*
42. **Short-term Traffic Prediction with Deep Neural Networks: A Survey.** IEEE Access 2021 [paper](https://arxiv.org/abs/2009.00712) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Lee2021Short-term.md)
*Kyungeun Lee, Moonjung Eo, Euna Jung, Yoonjin Yoon, Wonjong Rhee*
43. **Should I Raise The Red Flag? A comprehensive survey of anomaly scoring methods toward mitigating false alarms.** arXiv 2019 [paper](https://arxiv.org/pdf/1904.06646.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Zohrevand2019Should.md)
*Zahra Zohrevand, Uwe Glässer*
44. **The Threat of Adversarial Attacks on Machine Learning in Network Security - A Survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1911.02621.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Ibitoye2019The.md)
*Olakunle Ibitoye, Rana Abou Khamis, Ashraf Matrawy, M. Omair Shafiq*
45. **Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey.** IEEE Access 2018 [paper](https://ieeexplore.ieee.org/abstract/document/8294186) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Akhtar2018Threat.md)
*Naveed Akhtar, Ajmal S. Mian*
46. **Understanding racial bias in health using the Medical Expenditure Panel Survey data.** arXiv 2019 [paper](https://arxiv.org/pdf/1911.01509.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Singh2019Understanding.md)
*Moninder Singh, Karthikeyan Natesan Ramamurthy*
47. **Urban flows prediction from spatial-temporal data using machine learning: A survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1908.10218.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Xie2019Urban.md)
*Peng Xie, Tianrui Li, Jia Liu, Shengdong Du, Xin Yang, Junbo Zhang*
48. **Using Deep Learning for Visual Decoding and Reconstruction from Brain Activity: A Review.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.04169.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Horn2021Using.md)
*Madison Van Horn*
49. **Utilising Graph Machine Learning within Drug Discovery and Development.** arXiv 2020 [paper](https://arxiv.org/pdf/2012.05716.pdf) [bib](/bib/Machine-Learning/ML-and-DL-Applications/Gaudelet2020Utilising.md)
*Thomas Gaudelet, Ben Day, Arian R. Jamasb, Jyothish Soman, Cristian Regep, Gertrude Liu, Jeremy B. R. Hayter, Richard Vickers, Charles Roberts, Jian Tang, David Roblin, Tom L. Blundell, Michael M. Bronstein, Jake P. Taylor-King*
#### [Model Compression and Acceleration](#content)
1. **A Survey of Model Compression and Acceleration for Deep Neural Networks.** arXiv 2017 [paper](https://arxiv.org/abs/1710.09282) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Cheng2017A.md)
*Yu Cheng, Duo Wang, Pan Zhou, Tao Zhang*
2. **A Survey of Quantization Methods for Efficient Neural Network Inference.** arXiv 2021 [paper](https://arxiv.org/pdf/2103.13630.pdf) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Gholami2021A.md)
*Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer*
3. **A Survey on Deep Neural Network Compression: Challenges, Overview, and Solutions.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.03954.pdf) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Mishra2020A.md)
*Rahul Mishra, Hari Prabhat Gupta, Tanima Dutta*
4. **A Survey on GAN Acceleration Using Memory Compression Technique.** arXiv 2021 [paper](https://arxiv.org/pdf/2108.06626.pdf) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Tantawy2021A.md)
*Dina Tantawy, Mohamed Zahran, Amr Wassal*
5. **A Survey on Methods and Theories of Quantized Neural Networks.** arXiv 2018 [paper](https://arxiv.org/abs/1808.04752) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Guo2018A.md)
*Yunhui Guo*
6. **An Overview of Neural Network Compression.** arXiv 2020 [paper](https://arxiv.org/abs/2006.03669) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Neill2020An.md)
*James O'Neill*
7. **Compression of Deep Learning Models for Text: A Survey.** ACM Trans. Knowl. Discov. Data 2022 [paper](https://arxiv.org/abs/2008.05221) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Gupta2022Compression.md)
*Manish Gupta, Puneet Agrawal*
8. **Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better.** arXiv 2021 [paper](https://arxiv.org/pdf/2106.08962.pdf) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Menghani2021Efficient.md)
*Gaurav Menghani*
9. **Pruning Algorithms to Accelerate Convolutional Neural Networks for Edge Applications: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2005.04275) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Liu2020Pruning.md)
*Jiayi Liu, Samarth Tripathi, Unmesh Kurup, Mohak Shah*
10. **Pruning and Quantization for Deep Neural Network Acceleration: A Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2101.09671) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Liang2021Pruning.md)
*Tailin Liang, John Glossner, Lei Wang, Shaobo Shi*
11. **Survey of Machine Learning Accelerators.** HPEC 2020 [paper](http://arxiv.org/pdf/2009.00993.pdf) [bib](/bib/Machine-Learning/Model-Compression-and-Acceleration/Reuther2020Survey.md)
*Albert Reuther, Peter Michaleas, Michael Jones, Vijay Gadepally, Siddharth Samsi, Jeremy Kepner*
#### [Multi-Label Learning](#content)
1. **A Review on Multi-Label Learning Algorithms.** IEEE Trans. Knowl. Data Eng. 2014 [paper](https://ieeexplore.ieee.org/abstract/document/6471714) [bib](/bib/Machine-Learning/Multi-Label-Learning/Zhang2014A.md)
*Min-Ling Zhang, Zhi-Hua Zhou*
2. **Multi-Label Classification: An Overview.** Int. J. Data Warehous. Min. 2007 [paper](https://www.igi-global.com/article/multi-label-classification/1786) [bib](/bib/Machine-Learning/Multi-Label-Learning/Tsoumakas2007Multi-Label.md)
*Grigorios Tsoumakas, Ioannis Katakis*
3. **Multi-label learning: a review of the state of the art and ongoing research.** WIREs Data Mining Knowl. Discov. 2014 [paper](https://wires.onlinelibrary.wiley.com/doi/abs/10.1002/widm.1139) [bib](/bib/Machine-Learning/Multi-Label-Learning/Galindo2014Multi-label.md)
*Eva Lucrecia Gibaja Galindo, Sebastián Ventura*
4. **The Emerging Trends of Multi-Label Learning.** arXiv 2020 [paper](https://arxiv.org/abs/2011.11197) [bib](/bib/Machine-Learning/Multi-Label-Learning/Liu2020The.md)
*Weiwei Liu, Xiaobo Shen, Haobo Wang, Ivor W. Tsang*
#### [Multi-Task and Multi-View Learning](#content)
1. **A brief review on multi-task learning.** Multim. Tools Appl. 2018 [paper](https://link.springer.com/article/10.1007/s11042-018-6463-x) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Thung2018A.md)
*Kim-Han Thung, Chong-Yaw Wee*
2. **A Survey on Multi-Task Learning.** IEEE Trans. Knowl. Data Eng. 2021 [paper](https://arxiv.org/abs/1707.08114) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Zhang2021A.md)
*Yu Zhang, Qiang Yang*
3. **A Survey on Multi-view Learning.** arXiv 2013 [paper](https://arxiv.org/abs/1304.5634) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Xu2013A.md)
*Chang Xu, Dacheng Tao, Chao Xu*
4. **An overview of multi-task learning.** National Science Review 2017 [paper](https://academic.oup.com/nsr/article/5/1/30/4101432) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Zhang2017An.md)
*Yu Zhang, Qiang Yang*
5. **An Overview of Multi-Task Learning in Deep Neural Networks.** arXiv 2017 [paper](https://arxiv.org/abs/1706.05098) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Ruder2017An.md)
*Sebastian Ruder*
6. **Multi-Task Learning for Dense Prediction Tasks: A Survey.** TPAMI 2021 [paper](https://arxiv.org/pdf/2004.13379.pdf) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Vandenhende2021Multi-Task.md)
*Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proesmans, Dengxin Dai, Luc Van Gool*
7. **Multi-task learning for natural language processing in the 2020s: where are we going?.** Pattern Recognit. Lett. 2020 [paper](https://arxiv.org/pdf/2007.16008) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Worsham2020Multi-task.md)
*Joseph Worsham, Jugal Kalita*
8. **Multi-Task Learning with Deep Neural Networks: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.09796) [bib](/bib/Machine-Learning/Multi-Task-and-Multi-View-Learning/Crawshaw2020Multi-Task.md)
*Michael Crawshaw*
#### [Online Learning](#content)
1. **A Survey of Algorithms and Analysis for Adaptive Online Learning.** J. Mach. Learn. Res. 2017 [paper](https://arxiv.org/abs/1403.3465) [bib](/bib/Machine-Learning/Online-Learning/McMahan2017A.md)
*H. Brendan McMahan*
2. **Online Continual Learning in Image Classification: An Empirical Survey.** Neurocomputing 2022 [paper](http://arxiv.org/pdf/2101.10423.pdf) [bib](/bib/Machine-Learning/Online-Learning/Mai2022Online.md)
*Zheda Mai, Ruiwen Li, Jihwan Jeong, David Quispe, Hyunwoo Kim, Scott Sanner*
3. **Online Learning: A Comprehensive Survey.** Neurocomputing 2021 [paper](https://arxiv.org/abs/1802.02871) [bib](/bib/Machine-Learning/Online-Learning/Hoi2021Online.md)
*Steven C. H. Hoi, Doyen Sahoo, Jing Lu, Peilin Zhao*
4. **Preference-based Online Learning with Dueling Bandits: A Survey.** J. Mach. Learn. Res. 2021 [paper](https://jmlr.org/papers/v22/18-546.html) [bib](/bib/Machine-Learning/Online-Learning/Bengs2021Preference-based.md)
*Viktor Bengs, Róbert Busa-Fekete, Adil El Mesaoudi-Paul, Eyke Hüllermeier*
#### [Optimization](#content)
1. **A Survey of Optimization Methods from a Machine Learning Perspective.** IEEE Trans. Cybern. 2020 [paper](https://arxiv.org/abs/1906.06821) [bib](/bib/Machine-Learning/Optimization/Sun2020A.md)
*Shiliang Sun, Zehui Cao, Han Zhu, Jing Zhao*
2. **A Systematic and Meta-analysis Survey of Whale Optimization Algorithm.** Comput. Intell. Neurosci. 2019 [paper](https://arxiv.org/abs/1903.08763) [bib](/bib/Machine-Learning/Optimization/Mohammed2019A.md)
*Hardi M. Mohammed, Shahla U. Umar, Tarik A. Rashid*
3. **An overview of gradient descent optimization algorithms.** arXiv 2016 [paper](https://arxiv.org/abs/1609.04747) [bib](/bib/Machine-Learning/Optimization/Ruder2016An.md)
*Sebastian Ruder*
4. **Convex Optimization Overview.** citeseerx 2008 [paper](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.142.6470) [bib](/bib/Machine-Learning/Optimization/Kolter2008Convex.md)
*Zico Kolter, Honglak Lee*
5. **Evolutionary Multitask Optimization: a Methodological Overview, Challenges and Future Research Directions.** arXiv 2021 [paper](https://arxiv.org/abs/2102.02558) [bib](/bib/Machine-Learning/Optimization/Osaba2021Evolutionary.md)
*Eneko Osaba, Aritz D. Martinez, Javier Del Ser*
6. **Gradient Boosting Machine: A Survey.** arXiv 2019 [paper](https://arxiv.org/abs/1908.06951) [bib](/bib/Machine-Learning/Optimization/He2019Gradient.md)
*Zhiyuan He, Danchen Lin, Thomas Lau, Mike Wu*
7. **Investigating Bi-Level Optimization for Learning and Vision from a Unified Perspective: A Survey and Beyond.** arXiv 2021 [paper](https://arxiv.org/abs/2101.11517) [bib](/bib/Machine-Learning/Optimization/Liu2021Investigating.md)
*Risheng Liu, Jiaxin Gao, Jin Zhang, Deyu Meng, Zhouchen Lin*
8. **Learning Combinatorial Optimization on Graphs: A Survey with Applications to Networking.** IEEE Access 2020 [paper](https://arxiv.org/pdf/2005.11081.pdf) [bib](/bib/Machine-Learning/Optimization/Vesselinova2020Learning.md)
*Natalia Vesselinova, Rebecca Steinert, Daniel F. Perez-Ramirez, Magnus Boman*
9. **Nature-Inspired Optimization Algorithms: Research Direction and Survey.** arXiv 2021 [paper](https://arxiv.org/abs/2102.04013) [bib](/bib/Machine-Learning/Optimization/Sachan2021Nature-Inspired.md)
*Rohit Kumar Sachan, Dharmender Singh Kushwaha*
10. **Optimization for deep learning: theory and algorithms.** arXiv 2019 [paper](https://arxiv.org/abs/1912.08957) [bib](/bib/Machine-Learning/Optimization/Sun2019Optimization.md)
*Ruoyu Sun*
11. **Optimization Problems for Machine Learning: A Survey.** Eur. J. Oper. Res. 2021 [paper](https://arxiv.org/abs/1901.05331) [bib](/bib/Machine-Learning/Optimization/Gambella2021Optimization.md)
*Claudio Gambella, Bissan Ghaddar, Joe Naoum-Sawaya*
12. **Particle Swarm Optimization: A survey of historical and recent developments with hybridization perspectives.** Mach. Learn. Knowl. Extr. 2019 [paper](https://arxiv.org/abs/1804.05319) [bib](/bib/Machine-Learning/Optimization/Sengupta2019Particle.md)
*Saptarshi Sengupta, Sanchita Basak, Richard A. Peters*
13. **Why Do Local Methods Solve Nonconvex Problems?.** Beyond the Worst-Case Analysis of Algorithms 2020 [paper](https://arxiv.org/pdf/2103.13462.pdf) [bib](/bib/Machine-Learning/Optimization/Ma2020Why.md)
*Tengyu Ma*
#### [Semi-Supervised, Weakly-Supervised and Unsupervised Learning](#content)
1. **A brief introduction to weakly supervised learning.** National Science Review 2017 [paper](https://cs.nju.edu.cn/_upload/tpl/01/0b/267/template267/zhouzh.files/publication/nsr18.pdf) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Zhou2017A.md)
*Zhi-Hua Zhou*
2. **A Survey of Unsupervised Dependency Parsing.** COLING 2020 [paper](https://arxiv.org/pdf/2010.01535.pdf) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Han2020A.md)
*Wenjuan Han, Yong Jiang, Hwee Tou Ng, Kewei Tu*
3. **A Survey on Deep Semi-supervised Learning.** arXiv 2021 [paper](https://arxiv.org/abs/2103.00550) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Yang2021A.md)
*Xiangli Yang, Zixing Song, Irwin King, Zenglin Xu*
4. **A survey on Semi-, Self- and Unsupervised Learning for Image Classification.** IEEE Access 2021 [paper](https://arxiv.org/abs/2002.08721) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Schmarje2021A.md)
*Lars Schmarje, Monty Santarossa, Simon-Martin Schröder, Reinhard Koch*
5. **A Survey on Semi-Supervised Learning Techniques.** IJCTT 2014 [paper](https://arxiv.org/abs/1402.4645) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Prakash2014A.md)
*V. Jothi Prakash, Dr. L.M. Nithya*
6. **Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey.** arXiv 2021 [paper](https://arxiv.org/pdf/2105.12694.pdf) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Shao2021Deep.md)
*Feifei Shao, Long Chen, Jian Shao, Wei Ji, Shaoning Xiao, Lu Ye, Yueting Zhuang, Jun Xiao*
7. **Graph-based Semi-supervised Learning: A Comprehensive Review.** arXiv 2021 [paper](https://arxiv.org/abs/2102.13303) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Song2021Graph-based.md)
*Zixing Song, Xiangli Yang, Zenglin Xu, Irwin King*
8. **Improvability Through Semi-Supervised Learning: A Survey of Theoretical Results.** arXiv 2019 [paper](https://arxiv.org/abs/1908.09574) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Mey2019Improvability.md)
*Alexander Mey, Marco Loog*
9. **Learning from positive and unlabeled data: a survey.** Mach. Learn. 2020 [paper](https://arxiv.org/abs/1811.04820) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Bekker2020Learning.md)
*Jessa Bekker, Jesse Davis*
10. **Unsupervised Cross-Lingual Representation Learning.** ACL 2019 [paper](https://www.aclweb.org/anthology/P19-4007.pdf) [bib](/bib/Machine-Learning/Semi-Supervised,-Weakly-Supervised-and-Unsupervised-Learning/Ruder2019Unsupervised.md)
*Sebastian Ruder, Anders Søgaard, Ivan Vulic*
#### [Transfer Learning](#content)
1. **A Comprehensive Survey on Transfer Learning.** Proc. IEEE 2021 [paper](https://arxiv.org/abs/1911.02685) [bib](/bib/Machine-Learning/Transfer-Learning/Zhuang2021A.md)
*Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, Qing He*
2. **A Survey of Unsupervised Deep Domain Adaptation.** ACM Trans. Intell. Syst. Technol. 2020 [paper](https://arxiv.org/abs/1812.02849) [bib](/bib/Machine-Learning/Transfer-Learning/Wilson2020A.md)
*Garrett Wilson, Diane J. Cook*
3. **A Survey on Deep Transfer Learning.** ICANN 2018 [paper](https://arxiv.org/abs/1808.01974) [bib](/bib/Machine-Learning/Transfer-Learning/Tan2018A.md)
*Chuanqi Tan, Fuchun Sun, Tao Kong, Wenchang Zhang, Chao Yang, Chunfang Liu*
4. **A survey on domain adaptation theory: learning bounds and theoretical guarantees.** arXiv 2020 [paper](https://arxiv.org/abs/2004.11829) [bib](/bib/Machine-Learning/Transfer-Learning/Redko2020A.md)
*Ievgen Redko, Emilie Morvant, Amaury Habrard, Marc Sebban, Younès Bennani*
5. **A Survey on Negative Transfer.** arXiv 2020 [paper](http://arxiv.org/pdf/2009.00909.pdf) [bib](/bib/Machine-Learning/Transfer-Learning/Zhang2020A.md)
*Wen Zhang, Lingfei Deng, Lei Zhang, Dongrui Wu*
6. **A Survey on Transfer Learning.** IEEE Trans. Knowl. Data Eng. 2010 [paper](https://ieeexplore.ieee.org/abstract/document/5288526) [bib](/bib/Machine-Learning/Transfer-Learning/Pan2010A.md)
*Sinno Jialin Pan, Qiang Yang*
7. **A Survey on Transfer Learning in Natural Language Processing.** arXiv 2020 [paper](https://arxiv.org/abs/2007.04239) [bib](/bib/Machine-Learning/Transfer-Learning/Alyafeai2020A.md)
*Zaid Alyafeai, Maged Saeed AlShaibani, Irfan Ahmad*
8. **Evolution of transfer learning in natural language processing.** arXiv 2019 [paper](https://arxiv.org/abs/1910.07370) [bib](/bib/Machine-Learning/Transfer-Learning/Malte2019Evolution.md)
*Aditya Malte, Pratik Ratadiya*
9. **Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.** J. Mach. Learn. Res. 2020 [paper](https://arxiv.org/pdf/1910.10683.pdf) [bib](/bib/Machine-Learning/Transfer-Learning/Raffel2020Exploring.md)
*Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*
10. **Neural Unsupervised Domain Adaptation in NLP - A Survey.** COLING 2020 [paper](https://arxiv.org/abs/2006.00632) [bib](/bib/Machine-Learning/Transfer-Learning/Ramponi2020Neural.md)
*Alan Ramponi, Barbara Plank*
11. **Transfer Adaptation Learning: A Decade Survey.** arXiv 2019 [paper](https://arxiv.org/pdf/1903.04687.pdf) [bib](/bib/Machine-Learning/Transfer-Learning/Zhang2019Transfer.md)
*Lei Zhang, Xinbo Gao*
12. **Transfer Learning for Reinforcement Learning Domains: A Survey.** J. Mach. Learn. Res. 2009 [paper](https://jmlr.csail.mit.edu/papers/v10/taylor09a.html#:~:text=Transfer%20Learning%20for%20Reinforcement%20Learning%20Domains%3A%20A%20Survey,as%20is%20common%20in%20other%20machine%20learning%20contexts.) [bib](/bib/Machine-Learning/Transfer-Learning/Taylor2009Transfer.md)
*Matthew E. Taylor, Peter Stone*
13. **Transfer Learning in Deep Reinforcement Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2009.07888) [bib](/bib/Machine-Learning/Transfer-Learning/Zhu2020Transfer.md)
*Zhuangdi Zhu, Kaixiang Lin, Jiayu Zhou*
#### [Trustworthy Machine Learning](#content)
1. **A Survey of Privacy Attacks in Machine Learning.** arXiv 2020 [paper](https://arxiv.org/pdf/2007.07646) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Rigaki2020A.md)
*Maria Rigaki, Sebastian Garcia*
2. **A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversarial attack and defence, and interpretability.** Comput. Sci. Rev. 2020 [paper](https://www.sciencedirect.com/science/article/abs/pii/S1574013719302527?via%3Dihub) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Huang2020A.md)
*Xiaowei Huang, Daniel Kroening, Wenjie Ruan, James Sharp, Youcheng Sun, Emese Thamo, Min Wu, Xinping Yi*
3. **A Survey on Bias and Fairness in Machine Learning.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/1908.09635) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Mehrabi2021A.md)
*Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, Aram Galstyan*
4. **Backdoor Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2007.08745) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Li2020Backdoor.md)
*Yiming Li, Baoyuan Wu, Yong Jiang, Zhifeng Li, Shu-Tao Xia*
5. **Differential Privacy and Machine Learning: a Survey and Review.** arXiv 2014 [paper](https://arxiv.org/abs/1412.7584) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Ji2014Differential.md)
*Zhanglong Ji, Zachary Chase Lipton, Charles Elkan*
6. **Fairness in Machine Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/pdf/2010.04053.pdf) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Caton2020Fairness.md)
*Simon Caton, Christian Haas*
7. **Local Differential Privacy and Its Applications: A Comprehensive Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2008.03686) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Yang2020Local.md)
*Mengmeng Yang, Lingjuan Lyu, Jun Zhao, Tianqing Zhu, Kwok-Yan Lam*
8. **Practical Machine Learning Safety: A Survey and Primer.** arXiv 2021 [paper](https://arxiv.org/abs/2106.04823) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Mohseni2021Practical.md)
*Sina Mohseni, Haotao Wang, Zhiding Yu, Chaowei Xiao, Zhangyang Wang, Jay Yadawa*
9. **Privacy in Deep Learning: A Survey.** arXiv 2020 [paper](https://arxiv.org/abs/2004.12254) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Mireshghallah2020Privacy.md)
*Fatemehsadat Mireshghallah, Mohammadkazem Taram, Praneeth Vepakomma, Abhishek Singh, Ramesh Raskar, Hadi Esmaeilzadeh*
10. **Technology Readiness Levels for Machine Learning Systems.** arXiv 2021 [paper](https://arxiv.org/pdf/2101.03989.pdf) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Lavin2021Technology.md)
*Alexander Lavin, Ciarán M. Gilligan-Lee, Alessya Visnjic, Siddha Ganju, Dava Newman, Sujoy Ganguly, Danny Lange, Atilim Günes Baydin, Amit Sharma, Adam Gibson, Yarin Gal, Eric P. Xing, Chris Mattmann, James Parr*
11. **The Creation and Detection of Deepfakes: A Survey.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/abs/2004.11138) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Mirsky2021The.md)
*Yisroel Mirsky, Wenke Lee*
12. **Tutorial: Safe and Reliable Machine Learning.** arXiv 2019 [paper](https://arxiv.org/abs/1904.07204) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Saria2019Tutorial.md)
*Suchi Saria, Adarsh Subbaswamy*
13. **When Machine Learning Meets Privacy: A Survey and Outlook.** ACM Comput. Surv. 2021 [paper](https://arxiv.org/pdf/2011.11819.pdf) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Liu2021When.md)
*Bo Liu, Ming Ding, Sina Shaham, Wenny Rahayu, Farhad Farokhi, Zihuai Lin*
14. **机器学习模型安全与隐私研究综述.** 软件学报 2021 [paper](http://www.jos.org.cn/jos/ch/reader/view_abstract.aspx?file_no=6131&flag=1) [bib](/bib/Machine-Learning/Trustworthy-Machine-Learning/Ji2021Security.md)
*纪守领, 杜天宇, 李进锋, 沈超, 李博*
## Team Members
The project is maintained by
*Ziyang Wang, Shuhan Zhou, Nuo Xu, Bei Li, Yinqiao Li, Quan Du, Tong Xiao, and Jingbo Zhu*
*Natural Language Processing Lab., School of Computer Science and Engineering, Northeastern University*
*NiuTrans Research*
Please feel free to contact us if you have any questions (wangziyang [at] stumail.neu.edu.cn or libei_neu [at] outlook.com).
## Acknowledge
We would like to thank the people who have contributed to this project. They are
*Xin Zeng, Laohu Wang, Chenglong Wang, Xiaoqian Liu, Xuanjun Zhou, Jingnan Zhang, Yongyu Mu, Zefan Zhou, Yanhong Jiang, Xinyang Zhu, Xingyu Liu, Dong Bi, Ping Xu, Zijian Li, Fengning Tian, Hui Liu, Kai Feng, Yuhao Zhang, Chi Hu, Di Yang, Lei Zheng, Hexuan Chen, Zeyang Wang, Tengbo Liu, Xia Meng, Weiqiao Shan, Tao Zhou, Runzhe Cao, Yingfeng Luo, Binghao Wei, Wandi Xu, Yan Zhang, Yichao Wang, Mengyu Ma, Zihao Liu*
|
3,459 | Natural Language Processing Tasks and References | # Natural Language Processing Tasks and Selected References
I've been working on several natural language processing tasks for a long time. One day, I felt like drawing a map of the NLP field where I earn a living. I'm sure I'm not the only person who wants to see at a glance which tasks are in NLP.
I did my best to cover as many as possible tasks in NLP, but admittedly this is far from exhaustive purely due to my lack of knowledge. And selected references are biased towards recent deep learning accomplishments. I expect these serve as a starting point when you're about to dig into the task. I'll keep updating this repo myself, but what I really hope is you collaborate on this work. Don't hesitate to send me a pull request!
Oct. 13, 2017.<br/>
by Kyubyong
Reviewed and updated by [YJ Choe](https://github.com/yjchoe) on Oct. 18, 2017.
## Anaphora Resolution
* See [Coreference Resolution](#coreference-resolution)
## Automated Essay Scoring
* ****`PAPER`**** [Automatic Text Scoring Using Neural Networks](https://arxiv.org/abs/1606.04289)
* ****`PAPER`**** [A Neural Approach to Automated Essay Scoring](http://www.aclweb.org/old_anthology/D/D16/D16-1193.pdf)
* ****`CHALLENGE`**** [Kaggle: The Hewlett Foundation: Automated Essay Scoring](https://www.kaggle.com/c/asap-aes)
* ****`PROJECT`**** [EASE (Enhanced AI Scoring Engine)](https://github.com/edx/ease)
## Automatic Speech Recognition
* ****`WIKI`**** [Speech recognition](https://en.wikipedia.org/wiki/Speech_recognition)
* ****`PAPER`**** [Deep Speech 2: End-to-End Speech Recognition in English and Mandarin](https://arxiv.org/abs/1512.02595)
* ****`PAPER`**** [WaveNet: A Generative Model for Raw Audio](https://arxiv.org/abs/1609.03499)
* ****`PROJECT`**** [A TensorFlow implementation of Baidu's DeepSpeech architecture](https://github.com/mozilla/DeepSpeech)
* ****`PROJECT`**** [Speech-to-Text-WaveNet : End-to-end sentence level English speech recognition using DeepMind's WaveNet](https://github.com/buriburisuri/speech-to-text-wavenet)
* ****`CHALLENGE`**** [The 5th CHiME Speech Separation and Recognition Challenge](http://spandh.dcs.shef.ac.uk/chime_challenge/)
* ****`DATA`**** [The 5th CHiME Speech Separation and Recognition Challenge](http://spandh.dcs.shef.ac.uk/chime_challenge/download.html)
* ****`DATA`**** [CSTR VCTK Corpus](http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html)
* ****`DATA`**** [LibriSpeech ASR corpus](http://www.openslr.org/12/)
* ****`DATA`**** [Switchboard-1 Telephone Speech Corpus](https://catalog.ldc.upenn.edu/ldc97s62)
* ****`DATA`**** [TED-LIUM Corpus](http://www-lium.univ-lemans.fr/en/content/ted-lium-corpus)
* ****`DATA`**** [Open Speech and Language Resources](http://www.openslr.org/)
* ****`DATA`**** [Common Voice](https://voice.mozilla.org/en/data)
## Automatic Summarisation
* ****`WIKI`**** [Automatic summarization](https://en.wikipedia.org/wiki/Automatic_summarization)
* ****`BOOK`**** [Automatic Text Summarization](https://www.amazon.com/Automatic-Text-Summarization-Juan-Manuel-Torres-Moreno/dp/1848216688/ref=sr_1_1?s=books&ie=UTF8&qid=1507782304&sr=1-1&keywords=Automatic+Text+Summarization)
* ****`PAPER`**** [Text Summarization Using Neural Networks](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.823.8025&rep=rep1&type=pdf)
* ****`PAPER`**** [Ranking with Recursive Neural Networks and Its Application to Multi-Document Summarization](https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/viewFile/9414/9520)
* ****`DATA`**** [Text Analytics Conferences (TAC)](https://tac.nist.gov/data/index.html)
* ****`DATA`**** [Document Understanding Conferences (DUC)](http://www-nlpir.nist.gov/projects/duc/data.html)
## Coreference Resolution
* ****`INFO`**** [Coreference Resolution](https://nlp.stanford.edu/projects/coref.shtml)
* ****`PAPER`**** [Deep Reinforcement Learning for Mention-Ranking Coreference Models](https://arxiv.org/abs/1609.08667)
* ****`PAPER`**** [Improving Coreference Resolution by Learning Entity-Level Distributed Representations](https://arxiv.org/abs/1606.01323)
* ****`CHALLENGE`**** [CoNLL 2012 Shared Task: Modeling Multilingual Unrestricted Coreference in OntoNotes](http://conll.cemantix.org/2012/task-description.html)
* ****`CHALLENGE`**** [CoNLL 2011 Shared Task: Modeling Unrestricted Coreference in OntoNotes](http://conll.cemantix.org/2011/task-description.html)
* ****`CHALLENGE`**** [SemEval 2018 Task 4: Character Identification on Multiparty Dialogues](https://competitions.codalab.org/competitions/17310)
## Entity Linking
* See [Named Entity Disambiguation](#named-entity-disambiguation)
## Grammatical Error Correction
* ****`PAPER`**** [A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction](https://arxiv.org/abs/1801.08831)
* ****`PAPER`**** [Neural Network Translation Models for Grammatical Error Correction](https://arxiv.org/abs/1606.00189)
* ****`PAPER`**** [Adapting Sequence Models for Sentence Correction](http://aclweb.org/anthology/D17-1297)
* ****`CHALLENGE`**** [CoNLL-2013 Shared Task: Grammatical Error Correction](http://www.comp.nus.edu.sg/~nlp/conll13st.html)
* ****`CHALLENGE`**** [CoNLL-2014 Shared Task: Grammatical Error Correction](http://www.comp.nus.edu.sg/~nlp/conll14st.html)
* ****`DATA`**** [NUS Non-commercial research/trial corpus license](http://www.comp.nus.edu.sg/~nlp/conll14st/nucle_license.pdf)
* ****`DATA`**** [Lang-8 Learner Corpora](http://cl.naist.jp/nldata/lang-8/)
* ****`DATA`**** [Cornell Movie--Dialogs Corpus](http://www.cs.cornell.edu/%7Ecristian/Cornell_Movie-Dialogs_Corpus.html)
* ****`PROJECT`**** [Deep Text Corrector](https://github.com/atpaino/deep-text-corrector)
* ****`PRODUCT`**** [deep grammar](http://deepgrammar.com/)
## Grapheme To Phoneme Conversion
* ****`PAPER`**** [Grapheme-to-Phoneme Models for (Almost) Any Language](https://pdfs.semanticscholar.org/b9c8/fef9b6f16b92c6859f6106524fdb053e9577.pdf)
* ****`PAPER`**** [Polyglot Neural Language Models: A Case Study in Cross-Lingual Phonetic Representation Learning](https://arxiv.org/pdf/1605.03832.pdf)
* ****`PAPER`**** [Multitask Sequence-to-Sequence Models for Grapheme-to-Phoneme Conversion](https://pdfs.semanticscholar.org/26d0/09959fa2b2e18cddb5783493738a1c1ede2f.pdf)
* ****`PROJECT`**** [Sequence-to-Sequence G2P toolkit](https://github.com/cmusphinx/g2p-seq2seq)
* ****`PROJECT`**** [g2p_en: A Simple Python Module for English Grapheme To Phoneme Conversion](https://github.com/kyubyong/g2p)
* ****`DATA`**** [Multilingual Pronunciation Data](https://drive.google.com/drive/folders/0B7R_gATfZJ2aWkpSWHpXUklWUmM)
## Humor and Sarcasm Detection
* ****`PAPER`**** [Automatic Sarcasm Detection: A Survey](https://arxiv.org/abs/1602.03426)
* ****`PAPER`**** [Magnets for Sarcasm: Making Sarcasm Detection Timely, Contextual and Very Personal](http://aclweb.org/anthology/D17-1051)
* ****`PAPER`**** [Sarcasm Detection on Twitter: A Behavioral Modeling Approach](http://ai2-s2-pdfs.s3.amazonaws.com/67b5/9db00c29152d8e738f693f153e1ab9b43466.pdf)
* ****`CHALLENGE`**** [SemEval-2017 Task 6: #HashtagWars: Learning a Sense of Humor](http://alt.qcri.org/semeval2017/task6/)
* ****`CHALLENGE`**** [SemEval-2017 Task 7: Detection and Interpretation of English Puns](http://alt.qcri.org/semeval2017/task7/)
* ****`DATA`**** [Sarcastic comments from Reddit](https://www.kaggle.com/danofer/sarcasm/)
* ****`DATA`**** [Sarcasm Corpus V2](https://nlds.soe.ucsc.edu/sarcasm2)
* ****`DATA`**** [Sarcasm Amazon Reviews Corpus](https://github.com/ef2020/SarcasmAmazonReviewsCorpus)
## Language Grounding
* ****`WIKI`**** [Symbol grounding problem](https://en.wikipedia.org/wiki/Symbol_grounding_problem)
* ****`PAPER`**** [The Symbol Grounding Problem](http://courses.media.mit.edu/2004spring/mas966/Harnad%20symbol%20grounding.pdf)
* ****`PAPER`**** [From phonemes to images: levels of representation in a recurrent neural model of visually-grounded language learning](https://arxiv.org/abs/1610.03342)
* ****`PAPER`**** [Encoding of phonology in a recurrent neural model of grounded speech](https://arxiv.org/abs/1706.03815)
* ****`PAPER`**** [Gated-Attention Architectures for Task-Oriented Language Grounding](https://arxiv.org/abs/1706.07230)
* ****`PAPER`**** [Sound-Word2Vec: Learning Word Representations Grounded in Sounds](https://arxiv.org/abs/1703.01720)
* ****`COURSE`**** [Language Grounding to Vision and Control](https://www.cs.cmu.edu/~katef/808/)
* ****`WORKSHOP`**** [Language Grounding for Robotics](https://robonlp2017.github.io/)
## Language Guessing
* See [Language Identification](#language-identification)
## Language Identification
* ****`WIKI`**** [Language identification](https://en.wikipedia.org/wiki/Language_identification)
* ****`PAPER`**** [AUTOMATIC LANGUAGE IDENTIFICATION USING DEEP NEURAL NETWORKS](https://repositorio.uam.es/bitstream/handle/10486/666848/automatic_lopez-moreno_ICASSP_2014_ps.pdf?sequence=1)
* ****`PAPER`**** [Natural Language Processing with Small Feed-Forward Networks](http://aclweb.org/anthology/D17-1308)
* ****`CHALLENGE`**** [2015 Language Recognition Evaluation](https://www.nist.gov/itl/iad/mig/2015-language-recognition-evaluation)
## Language Modeling
* ****`WIKI`**** [Language model](https://en.wikipedia.org/wiki/Language_model)
* ****`TOOLKIT`**** [KenLM Language Model Toolkit](http://kheafield.com/code/kenlm/)
* ****`PAPER`**** [Distributed Representations of Words and Phrases and their Compositionality](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf)
* ****`PAPER`**** [Generating Sequences with Recurrent Neural Networks](https://arxiv.org/pdf/1308.0850.pdf)
* ****`PAPER`**** [Character-Aware Neural Language Models](https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/viewFile/12489/12017)
* ****`THESIS`**** [Statistical Language Models Based on Neural Networks](http://www.fit.vutbr.cz/~imikolov/rnnlm/thesis.pdf)
* ****`DATA`**** [Penn Treebank](https://github.com/townie/PTB-dataset-from-Tomas-Mikolov-s-webpage/tree/master/data)
* ****`TUTORIAL`**** [TensorFlow Tutorial on Language Modeling with Recurrent Neural Networks](https://www.tensorflow.org/tutorials/recurrent#language_modeling)
## Language Recognition
* See [Language Identification](#language-identification)
## Lemmatisation
* ****`WIKI`**** [Lemmatisation](https://en.wikipedia.org/wiki/Lemmatisation)
* ****`PAPER`**** [Joint Lemmatization and Morphological Tagging with LEMMING](http://www.cis.lmu.de/~muellets/pdf/emnlp_2015.pdf)
* ****`TOOLKIT`**** [WordNet Lemmatizer](http://www.nltk.org/api/nltk.stem.html#nltk.stem.wordnet.WordNetLemmatizer.lemmatize)
* ****`DATA`**** [Treebank-3](https://catalog.ldc.upenn.edu/ldc99t42)
## Lip-reading
* ****`WIKI`**** [Lip reading](https://en.wikipedia.org/wiki/Lip_reading)
* ****`PAPER`**** [LipNet: End-to-End Sentence-level Lipreading](https://arxiv.org/abs/1611.01599)
* ****`PAPER`**** [Lip Reading Sentences in the Wild](https://arxiv.org/abs/1611.05358)
* ****`PAPER`**** [Large-Scale Visual Speech Recognition](https://arxiv.org/abs/1807.05162)
* ****`PROJECT`**** [Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks](https://github.com/astorfi/lip-reading-deeplearning)
* ****`PRODUCT`**** [Liopa](http://www.liopa.co.uk/)
* ****`DATA`**** [The GRID audiovisual sentence corpus](http://spandh.dcs.shef.ac.uk/gridcorpus/)
* ****`DATA`**** [The BBC-Oxford 'Multi-View Lip Reading Sentences' (MV-LRS) Dataset](http://www.robots.ox.ac.uk/~vgg/data/lip_reading_sentences/)
## Machine Translation
* ****`PAPER`**** [Neural Machine Translation by Jointly Learning to Align and Translate](https://arxiv.org/abs/1409.0473)
* ****`PAPER`**** [Neural Machine Translation in Linear Time](https://arxiv.org/abs/1610.10099)
* ****`PAPER`**** [Attention Is All You Need](https://arxiv.org/abs/1706.03762)
* ****`PAPER`**** [Six Challenges for Neural Machine Translation](http://aclweb.org/anthology/W/W17/W17-3204.pdf)
* ****`PAPER`**** [Phrase-Based & Neural Unsupervised Machine Translation](https://arxiv.org/abs/1804.07755)
* ****`CHALLENGE`**** [ACL 2014 NINTH WORKSHOP ON STATISTICAL MACHINE TRANSLATION](http://www.statmt.org/wmt14/translation-task.html#download)
* ****`CHALLENGE`**** [EMNLP 2017 SECOND CONFERENCE ON MACHINE TRANSLATION (WMT17) ](http://www.statmt.org/wmt17/translation-task.html)
* ****`DATA`**** [OpenSubtitles2016](http://opus.lingfil.uu.se/OpenSubtitles2016.php)
* ****`DATA`**** [WIT3: Web Inventory of Transcribed and Translated Talks](https://wit3.fbk.eu/)
* ****`DATA`**** [The QCRI Educational Domain (QED) Corpus](http://alt.qcri.org/resources/qedcorpus/)
* ****`PAPER`**** [Multi-task Sequence to Sequence Learning](https://arxiv.org/abs/1511.06114)
* ****`PAPER`**** [Unsupervised Pretraining for Sequence to Sequence Learning](http://aclweb.org/anthology/D17-1039)
* ****`PAPER`**** [Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation](https://arxiv.org/abs/1611.04558)
* ****`TOOLKIT`**** [Subword Neural Machine Translation with Byte Pair Encoding (BPE)](https://github.com/rsennrich/subword-nmt)
* ****`TOOLKIT`**** [Multi-Way Neural Machine Translation](https://github.com/nyu-dl/dl4mt-multi)
* ****`TOOLKIT`**** [OpenNMT: Open-Source Toolkit for Neural Machine Translation](http://opennmt.net/)
## Morphological Inflection Generation
* ****`WIKI`**** [Inflection](https://en.wikipedia.org/wiki/Inflection)
* ****`PAPER`**** [Morphological Inflection Generation Using Character Sequence to Sequence Learning](https://arxiv.org/abs/1512.06110)
* ****`CHALLENGE`**** [SIGMORPHON 2016 Shared Task: Morphological Reinflection](http://ryancotterell.github.io/sigmorphon2016/)
* ****`DATA`**** [sigmorphon2016](https://github.com/ryancotterell/sigmorphon2016)
## Named Entity Disambiguation
* ****`WIKI`**** [Entity linking](https://en.wikipedia.org/wiki/Entity_linking)
* ****`PAPER`**** [Robust and Collective Entity Disambiguation through Semantic Embeddings](http://www.stefanzwicklbauer.info/pdf/Sigir_2016.pdf)
## Named Entity Recognition
* ****`WIKI`**** [Named-entity recognition](https://en.wikipedia.org/wiki/Named-entity_recognition)
* ****`PAPER`**** [Neural Architectures for Named Entity Recognition](https://arxiv.org/abs/1603.01360)
* ****`PROJECT`**** [OSU Twitter NLP Tools](https://github.com/aritter/twitter_nlp)
* ****`CHALLENGE`**** [Named Entity Recognition in Twitter](https://noisy-text.github.io/2016/ner-shared-task.html)
* ****`CHALLENGE`**** [CoNLL 2002 Language-Independent Named Entity Recognition](https://www.clips.uantwerpen.be/conll2002/ner/)
* ****`CHALLENGE`**** [Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition](http://aclweb.org/anthology/W03-0419)
* ****`DATA`**** [CoNLL-2002 NER corpus](https://github.com/teropa/nlp/tree/master/resources/corpora/conll2002)
* ****`DATA`**** [CoNLL-2003 NER corpus](https://github.com/synalp/NER/tree/master/corpus/CoNLL-2003)
* ****`DATA`**** [NUT Named Entity Recognition in Twitter Shared task](https://github.com/aritter/twitter_nlp/tree/master/data/annotated/wnut16)
* ****`TOOLKIT`**** [Stanford Named Entity Recognizer](https://nlp.stanford.edu/software/CRF-NER.shtml)
## Paraphrase Detection
* ****`PAPER`**** [Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.650.7199&rep=rep1&type=pdf)
* ****`PROJECT`**** [Paralex: Paraphrase-Driven Learning for Open Question Answering](http://knowitall.cs.washington.edu/paralex/)
* ****`CHALLENGE`**** [SemEval-2015 Task 1: Paraphrase and Semantic Similarity in Twitter](http://alt.qcri.org/semeval2015/task1/)
* ****`DATA`**** [Microsoft Research Paraphrase Corpus](https://www.microsoft.com/en-us/download/details.aspx?id=52398)
* ****`DATA`**** [Microsoft Research Video Description Corpus](https://www.microsoft.com/en-us/download/details.aspx?id=52422&from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fdownloads%2F38cf15fd-b8df-477e-a4e4-a4680caa75af%2F)
* ****`DATA`**** [Pascal Dataset](http://nlp.cs.illinois.edu/HockenmaierGroup/pascal-sentences/index.html)
* ****`DATA`**** [Flickr Dataset](http://nlp.cs.illinois.edu/HockenmaierGroup/8k-pictures.html)
* ****`DATA`**** [The SICK data set](http://clic.cimec.unitn.it/composes/sick.html)
* ****`DATA`**** [PPDB: The Paraphrase Database](http://www.cis.upenn.edu/%7Eccb/ppdb/)
* ****`DATA`**** [WikiAnswers Paraphrase Corpus](http://knowitall.cs.washington.edu/paralex/wikianswers-paraphrases-1.0.tar.gz)
## Paraphrase Generation
* ****`PAPER`**** [Neural Paraphrase Generation with Stacked Residual LSTM Networks](https://arxiv.org/pdf/1610.03098.pdf)
* ****`DATA`**** [Neural Paraphrase Generation with Stacked Residual LSTM Networks](https://github.com/iamaaditya/neural-paraphrase-generation/tree/master/data)
* ****`CODE`**** [Neural Paraphrase Generation with Stacked Residual LSTM Networks](https://github.com/iamaaditya/neural-paraphrase-generation)
* ****`PAPER`**** [A Deep Generative Framework for Paraphrase Generation](https://arxiv.org/pdf/1709.05074.pdf)
* ****`PAPER`**** [Paraphrasing Revisited with Neural Machine Translation](http://www.research.ed.ac.uk/portal/files/34902784/document.pdf)
## Parsing
* ****`WIKI`**** [Parsing](https://en.wikipedia.org/wiki/Parsing)
* ****`TOOLKIT`**** [The Stanford Parser: A statistical parser](https://nlp.stanford.edu/software/lex-parser.shtml)
* ****`TOOLKIT`**** [spaCy parser](https://spacy.io/docs/usage/dependency-parse)
* ****`PAPER`**** [Grammar as a Foreign Language](https://papers.nips.cc/paper/5635-grammar-as-a-foreign-language.pdf)
* ****`PAPER`**** [A fast and accurate dependency parser using neural networks](http://www.aclweb.org/anthology/D14-1082)
* ****`PAPER`**** [Universal Semantic Parsing](https://aclanthology.info/pdf/D/D17/D17-1009.pdf)
* ****`CHALLENGE`**** [CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies](http://universaldependencies.org/conll17/)
* ****`CHALLENGE`**** [CoNLL 2016 Shared Task: Multilingual Shallow Discourse Parsing](http://www.cs.brandeis.edu/~clp/conll16st/)
* ****`CHALLENGE`**** [CoNLL 2015 Shared Task: Shallow Discourse Parsing](http://www.cs.brandeis.edu/~clp/conll15st/)
* ****`CHALLENGE`**** [SemEval-2016 Task 8: The meaning representations may be abstract, but this task is concrete!](http://alt.qcri.org/semeval2016/task8/)
## Part-of-speech Tagging
* ****`WIKI`**** [Part-of-speech tagging](https://en.wikipedia.org/wiki/Part-of-speech_tagging)
* ****`PAPER`**** [Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss](https://arxiv.org/pdf/1604.05529.pdf)
* ****`PAPER`**** [Unsupervised Part-Of-Speech Tagging with Anchor Hidden Markov Models](https://transacl.org/ojs/index.php/tacl/article/viewFile/837/192)
* ****`DATA`**** [Treebank-3](https://catalog.ldc.upenn.edu/ldc99t42)
* ****`TOOLKIT`**** [nltk.tag package](http://www.nltk.org/api/nltk.tag.html)
## Pinyin-To-Chinese Conversion
* ****`WIKI`**** [Pinyin input method](https://en.wikipedia.org/wiki/Pinyin_input_method)
* ****`PAPER`**** [Neural Network Language Model for Chinese Pinyin Input Method Engine](http://aclweb.org/anthology/Y15-1052)
* ****`PROJECT`**** [Neural Chinese Transliterator](https://github.com/Kyubyong/neural_chinese_transliterator)
## Question Answering
* ****`WIKI`**** [Question answering](https://en.wikipedia.org/wiki/Question_answering)
* ****`PAPER`**** [Ask Me Anything: Dynamic Memory Networks for Natural Language Processing](http://www.thespermwhale.com/jaseweston/ram/papers/paper_21.pdf)
* ****`PAPER`**** [Dynamic Memory Networks for Visual and Textual Question Answering](http://proceedings.mlr.press/v48/xiong16.pdf)
* ****`CHALLENGE`**** [TREC Question Answering Task](http://trec.nist.gov/data/qamain.html)
* ****`CHALLENGE`**** [NTCIR-8: Advanced Cross-lingual Information Access (ACLIA)](http://aclia.lti.cs.cmu.edu/ntcir8/Home)
* ****`CHALLENGE`**** [CLEF Question Answering Track](http://nlp.uned.es/clef-qa/)
* ****`CHALLENGE`**** [SemEval-2017 Task 3: Community Question Answering](http://alt.qcri.org/semeval2017/task3/)
* ****`CHALLENGE`**** [SemEval-2018 Task 11: Machine Comprehension using Commonsense Knowledge](https://competitions.codalab.org/competitions/17184)
* ****`DATA`**** [MS MARCO: Microsoft MAchine Reading COmprehension Dataset](http://www.msmarco.org/)
* ****`DATA`**** [Maluuba NewsQA](https://github.com/Maluuba/newsqa)
* ****`DATA`**** [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://rajpurkar.github.io/SQuAD-explorer/)
* ****`DATA`**** [GraphQuestions: A Characteristic-rich Question Answering Dataset](https://github.com/ysu1989/GraphQuestions)
* ****`DATA`**** [Story Cloze Test and ROCStories Corpora](http://cs.rochester.edu/nlp/rocstories/)
* ****`DATA`**** [Microsoft Research WikiQA Corpus](https://www.microsoft.com/en-us/download/details.aspx?id=52419&from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fdownloads%2F4495da01-db8c-4041-a7f6-7984a4f6a905%2Fdefault.aspx)
* ****`DATA`**** [DeepMind Q&A Dataset](http://cs.nyu.edu/%7Ekcho/DMQA/)
* ****`DATA`**** [QASent](http://cs.stanford.edu/people/mengqiu/data/qg-emnlp07-data.tgz)
* ****`DATA`**** [Textbook Question Answering](http://textbookqa.org/)
## Relationship Extraction
* ****`WIKI`**** [Relationship extraction](https://en.wikipedia.org/wiki/Relationship_extraction)
* ****`PAPER`**** [A deep learning approach for relationship extraction from interaction context in social manufacturing paradigm](http://www.sciencedirect.com/science/article/pii/S0950705116001210)
* ****`CHALLENGE`**** [SemEval-2018 task 7 Semantic Relation Extraction and Classification in Scientific Papers](https://competitions.codalab.org/competitions/17422)
## Semantic Role Labeling
* ****`WIKI`**** [Semantic role labeling](https://en.wikipedia.org/wiki/Semantic_role_labeling)
* ****`BOOK`**** [Semantic Role Labeling](https://www.amazon.com/Semantic-Labeling-Synthesis-Lectures-Technologies/dp/1598298313/ref=sr_1_1?s=books&ie=UTF8&qid=1507776173&sr=1-1&keywords=Semantic+Role+Labeling)
* ****`PAPER`**** [End-to-end Learning of Semantic Role Labeling Using Recurrent Neural Networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)
* ****`PAPER`**** [Neural Semantic Role Labeling with Dependency Path Embeddings](https://arxiv.org/abs/1605.07515)
* ****`PAPER`**** [Deep Semantic Role Labeling: What Works and What's Next](https://homes.cs.washington.edu/~luheng/files/acl2017_hllz.pdf)
* ****`CHALLENGE`**** [CoNLL-2005 Shared Task: Semantic Role Labeling](http://www.cs.upc.edu/~srlconll/st05/st05.html)
* ****`CHALLENGE`**** [CoNLL-2004 Shared Task: Semantic Role Labeling](http://www.cs.upc.edu/~srlconll/st04/st04.html)
* ****`TOOLKIT`**** [Illinois Semantic Role Labeler (SRL)](http://cogcomp.org/page/software_view/SRL)
* ****`DATA`**** [CoNLL-2005 Shared Task: Semantic Role Labeling](http://www.cs.upc.edu/~srlconll/soft.html)
## Sentence Boundary Disambiguation
* ****`WIKI`**** [Sentence boundary disambiguation](https://en.wikipedia.org/wiki/Sentence_boundary_disambiguation)
* ****`PAPER`**** [A Quantitative and Qualitative Evaluation of Sentence Boundary Detection for the Clinical Domain](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5001746/)
* ****`TOOLKIT`**** [NLTK Tokenizers](http://www.nltk.org/_modules/nltk/tokenize.html)
* ****`DATA`**** [The British National Corpus](http://www.natcorp.ox.ac.uk/)
* ****`DATA`**** [Switchboard-1 Telephone Speech Corpus](https://catalog.ldc.upenn.edu/ldc97s62)
## Sentiment Analysis
* ****`WIKI`**** [Sentiment analysis](https://en.wikipedia.org/wiki/Sentiment_analysis)
* ****`INFO`**** [Awesome Sentiment Analysis](https://github.com/xiamx/awesome-sentiment-analysis)
* ****`CHALLENGE`**** [Kaggle: UMICH SI650 - Sentiment Classification](https://www.kaggle.com/c/si650winter11#description)
* ****`CHALLENGE`**** [SemEval-2017 Task 4: Sentiment Analysis in Twitter](http://alt.qcri.org/semeval2017/task4/)
* ****`CHALLENGE`**** [SemEval-2017 Task 5: Fine-Grained Sentiment Analysis on Financial Microblogs and News](http://alt.qcri.org/semeval2017/task5/)
* ****`PROJECT`**** [SenticNet](http://sentic.net/about/)
* ****`PROJECT`**** [Stanford NLP Group Sentiment Analysis](https://nlp.stanford.edu/sentiment/)
* ****`DATA`**** [Multi-Domain Sentiment Dataset (version 2.0)](http://www.cs.jhu.edu/%7Emdredze/datasets/sentiment/)
* ****`DATA`**** [Stanford Sentiment Treebank](https://nlp.stanford.edu/sentiment/code.html)
* ****`DATA`**** [Twitter Sentiment Corpus](http://www.sananalytics.com/lab/twitter-sentiment/)
* ****`DATA`**** [Twitter Sentiment Analysis Training Corpus](http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/)
* ****`DATA`**** [AFINN: List of English words rated for valence](http://www2.imm.dtu.dk/pubdb/views/publication_details.php?id=6010)
## Sign Language Recognition/Translation
* ****`PAPER`**** [Video-based Sign Language Recognition without Temporal Segmentation](https://arxiv.org/pdf/1801.10111.pdf)
* ****`PAPER`**** [SubUNets: End-to-end Hand Shape and Continuous Sign Language Recognition](http://openaccess.thecvf.com/content_ICCV_2017/papers/Camgoz_SubUNets_End-To-End_Hand_ICCV_2017_paper.pdf)
* ****`DATA`**** [RWTH-PHOENIX-Weather](https://www-i6.informatik.rwth-aachen.de/~forster/database-rwth-phoenix.php)
* ****`DATA`**** [ASLLRP](http://www.bu.edu/asllrp/)
* ****`PROJECT`**** [SignAll](http://www.signall.us/)
## Singing Voice Synthesis
* ****`PAPER`**** [Singing voice synthesis based on deep neural networks](https://pdfs.semanticscholar.org/9a8e/b69480eead85f32ee4b92fa2563dd5f83401.pdf)
* ****`PAPER`**** [A Neural Parametric Singing Synthesizer Modeling Timbre and Expression from Natural Songs](http://www.mdpi.com/2076-3417/7/12/1313)
* ****`PRODUCT`**** [VOCALOID: voice synthesis technology and software developed by Yamaha](https://www.vocaloid.com/en)
* ****`CHALLENGE`**** [Special Session Interspeech 2016 Singing synthesis challenge "Fill-in the Gap"](https://chanter.limsi.fr/doku.php?id=description:start)
## Social Science Applications
* ****`WORKSHOP`**** [NLP+CSS: Workshops on Natural Language Processing and Computational Social Science](https://sites.google.com/site/nlpandcss/)
* ****`TOOLKIT`**** [Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints](https://github.com/uclanlp/reducingbias)
* ****`TOOLKIT`**** [Online Variational Bayes for Latent Dirichlet Allocation (LDA)](https://github.com/blei-lab/onlineldavb)
* ****`GROUP`**** [The University of Chicago Knowledge Lab](http://www.knowledgelab.org/)
## Source Separation
* ****`WIKI`**** [Source separation](https://en.wikipedia.org/wiki/Source_separation)
* ****`PAPER`**** [From Blind to Guided Audio Source Separation](https://hal-univ-rennes1.archives-ouvertes.fr/hal-00922378/document)
* ****`PAPER`**** [Joint Optimization of Masks and Deep Recurrent Neural Networks for Monaural Source Separation](https://arxiv.org/abs/1502.04149)
* ****`CHALLENGE`**** [Signal Separation Evaluation Campaign (SiSEC)](https://sisec.inria.fr/)
* ****`CHALLENGE`**** [CHiME Speech Separation and Recognition Challenge](http://spandh.dcs.shef.ac.uk/chime_challenge/)
## Speaker Authentication
* See [Speaker Verification](#speaker-verification)
## Speaker Diarisation
* ****`WIKI`**** [Speaker diarisation](https://en.wikipedia.org/wiki/Speaker_diarisation)
* ****`PAPER`**** [DNN-based speaker clustering for speaker diarisation](http://eprints.whiterose.ac.uk/109281/1/milner_is16.pdf)
* ****`PAPER`**** [Unsupervised Methods for Speaker Diarization: An Integrated and Iterative Approach](http://groups.csail.mit.edu/sls/publications/2013/Shum_IEEE_Oct-2013.pdf)
* ****`PAPER`**** [Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion](https://arxiv.org/pdf/1603.09725.pdf)
* ****`CHALLENGE`**** [Rich Transcription Evaluation](https://www.nist.gov/itl/iad/mig/rich-transcription-evaluation)
## Speaker Recognition
* ****`WIKI`**** [Speaker recognition](https://en.wikipedia.org/wiki/Speaker_recognition)
* ****`PAPER`**** [A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK](https://pdfs.semanticscholar.org/204a/ff8e21791c0a4113a3f75d0e6424a003c321.pdf)
* ****`PAPER`**** [DEEP NEURAL NETWORKS FOR SMALL FOOTPRINT TEXT-DEPENDENT SPEAKER VERIFICATION](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41939.pdf)
* ****`PAPER`**** [Deep Speaker: an End-to-End Neural Speaker Embedding System](https://arxiv.org/abs/1705.02304)
* ****`PROJECT`**** [Voice Vector: which of the Hollywood stars is most similar to my voice?](https://github.com/andabi/voice-vector)
* ****`CHALLENGE`**** [NIST Speaker Recognition Evaluation (SRE)](https://www.nist.gov/itl/iad/mig/speaker-recognition)
* ****`INFO`**** [Are there any suggestions for free databases for speaker recognition?](https://www.researchgate.net/post/Are_there_any_suggestions_for_free_databases_for_speaker_recognition)
* ****`DATA`**** [VoxCeleb2: Deep Speaker Recognition](http://www.robots.ox.ac.uk/~vgg/data/voxceleb2/)
## Speech Reading
* See [Lip-reading](#lip-reading)
## Speech Recognition
* See [Automatic Speech Recognition](#automatic-speech-recognition)
## Speech Segmentation
* ****`WIKI`**** [Speech_segmentation](https://en.wikipedia.org/wiki/Speech_segmentation)
* ****`PAPER`**** [Word Segmentation by 8-Month-Olds: When Speech Cues Count More Than Statistics](http://www.utm.toronto.edu/infant-child-centre/sites/files/infant-child-centre/public/shared/elizabeth-johnson/Johnson_Jusczyk.pdf)
* ****`PAPER`**** [Unsupervised Word Segmentation and Lexicon Discovery Using Acoustic Word Embeddings](https://arxiv.org/abs/1603.02845)
* ****`PAPER`**** [Unsupervised Lexicon Discovery from Acoustic Input](http://www.aclweb.org/old_anthology/Q/Q15/Q15-1028.pdf)
* ****`PAPER`**** [Weakly supervised spoken term discovery using cross-lingual side information](http://www.research.ed.ac.uk/portal/files/29957958/1609.06530v1.pdf)
* ****`DATA`**** [CALLHOME Spanish Speech](https://catalog.ldc.upenn.edu/ldc96s35)
## Speech Synthesis
* ****`WIKI`**** [Speech synthesis](https://en.wikipedia.org/wiki/Speech_synthesis)
* ****`PAPER`**** [Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions](https://arxiv.org/abs/1712.05884)
* ****`PAPER`**** [WaveNet: A Generative Model for Raw Audio](https://arxiv.org/abs/1609.03499)
* ****`PAPER`**** [Tacotron: Towards End-to-End Speech Synthesis](https://arxiv.org/abs/1703.10135)
* ****`PAPER`**** [Deep Voice 3: 2000-Speaker Neural Text-to-Speech](https://arxiv.org/abs/1710.07654)
* ****`PAPER`**** [Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention](https://arxiv.org/abs/1710.08969)
* ****`DATA`**** [The World English Bible](https://github.com/Kyubyong/tacotron)
* ****`DATA`**** [LJ Speech Dataset](https://github.com/keithito/tacotron)
* ****`DATA`**** [Lessac Data](http://www.cstr.ed.ac.uk/projects/blizzard/2011/lessac_blizzard2011/)
* ****`CHALLENGE`**** [Blizzard Challenge 2017](https://synsig.org/index.php/Blizzard_Challenge_2017)
* ****`PRODUCT`**** [Lyrebird](https://lyrebird.ai/)
* ****`PROJECT`**** [The Festvox project](http://www.festvox.org/index.html)
* ****`TOOLKIT`**** [Merlin: The Neural Network (NN) based Speech Synthesis System](https://github.com/CSTR-Edinburgh/merlin)
## Speech Enhancement
* ****`WIKI`**** [Speech enhancement](https://en.wikipedia.org/wiki/Speech_enhancement)
* ****`BOOK`**** [Speech enhancement: theory and practice](https://www.amazon.com/Speech-Enhancement-Theory-Practice-Second/dp/1466504218/ref=sr_1_1?ie=UTF8&qid=1507874199&sr=8-1&keywords=Speech+enhancement%3A+theory+and+practice)
* ****`PAPER`**** [An Experimental Study on Speech Enhancement BasedonDeepNeuralNetwork](http://staff.ustc.edu.cn/~jundu/Speech%20signal%20processing/publications/SPL2014_Xu.pdf)
* ****`PAPER`**** [A Regression Approach to Speech Enhancement BasedonDeepNeuralNetworks](https://www.researchgate.net/profile/Yong_Xu63/publication/272436458_A_Regression_Approach_to_Speech_Enhancement_Based_on_Deep_Neural_Networks/links/57fdfdda08aeaf819a5bdd97.pdf)
* ****`PAPER`**** [Speech Enhancement Based on Deep Denoising Autoencoder](https://www.researchgate.net/profile/Yu_Tsao/publication/283600839_Speech_enhancement_based_on_deep_denoising_Auto-Encoder/links/577b486108ae213761c9c7f8/Speech-enhancement-based-on-deep-denoising-Auto-Encoder.pdf)
## Speech-To-Text
* See [Automatic Speech Recognition](#automatic-speech-recognition)
## Spoken Term Detection
* See [Speech Segmentation](#speech-segmentation)
## Stemming
* ****`WIKI`**** [Stemming](https://en.wikipedia.org/wiki/Stemming)
* ****`PAPER`**** [A BACKPROPAGATION NEURAL NETWORK TO IMPROVE ARABIC STEMMING](http://www.jatit.org/volumes/Vol82No3/7Vol82No3.pdf)
* ****`TOOLKIT`**** [NLTK Stemmers](http://www.nltk.org/howto/stem.html)
## Term Extraction
* ****`WIKI`**** [Terminology extraction](https://en.wikipedia.org/wiki/Terminology_extraction)
* ****`PAPER`**** [Neural Attention Models for Sequence Classification: Analysis and Application to Key Term Extraction and Dialogue Act Detection](https://arxiv.org/pdf/1604.00077.pdf)
## Text Similarity
* ****`WIKI`**** [Semantic similarity](https://en.wikipedia.org/wiki/Semantic_similarity)
* ****`PAPER`**** [A Survey of Text Similarity Approaches](https://pdfs.semanticscholar.org/5b5c/a878c534aee3882a038ef9e82f46e102131b.pdf)
* ****`PAPER`**** [Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks](http://casa.disi.unitn.it/~moschitt/since2013/2015_SIGIR_Severyn_LearningRankShort.pdf)
* ****`PAPER`**** [Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks](https://nlp.stanford.edu/pubs/tai-socher-manning-acl2015.pdf)
* ****`CHALLENGE`**** [SemEval-2014 Task 3: Cross-Level Semantic Similarity](http://alt.qcri.org/semeval2014/task3/)
* ****`CHALLENGE`**** [SemEval-2014 Task 10: Multilingual Semantic Textual Similarity](http://alt.qcri.org/semeval2014/task10/)
* ****`CHALLENGE`**** [SemEval-2017 Task 1: Semantic Textual Similarity](http://alt.qcri.org/semeval2017/task1/)
* ****`WIKI`**** [Semantic Textual Similarity Wiki](http://ixa2.si.ehu.es/stswiki/index.php/Main_Page)
## Text Simplification
* ****`WIKI`**** [Text simplification](https://en.wikipedia.org/wiki/Text_simplification)
* ****`PAPER`**** [Aligning Sentences from Standard Wikipedia to Simple Wikipedia](https://ssli.ee.washington.edu/~hannaneh/papers/simplification.pdf)
* ****`PAPER`**** [Problems in Current Text Simplification Research: New Data Can Help](https://pdfs.semanticscholar.org/2b8d/a013966c0c5e020ebc842d49d8ed166c8783.pdf)
* ****`DATA`**** [Newsela Data](https://newsela.com/data/)
## Text-To-Speech
* See [Speech Synthesis](#speech-synthesis)
## Textual Entailment
* ****`WIKI`**** [Textual entailment](https://en.wikipedia.org/wiki/Textual_entailment)
* ****`PROJECT`**** [Textual Entailment with TensorFlow](https://github.com/Steven-Hewitt/Entailment-with-Tensorflow)
* ****`PAPER`**** [Textual Entailment with Structured Attentions and Composition](https://arxiv.org/pdf/1701.01126.pdf)
* ****`CHALLENGE`**** [SemEval-2014 Task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment](http://alt.qcri.org/semeval2014/task1/)
* ****`CHALLENGE`**** [SemEval-2013 Task 7: The Joint Student Response Analysis and 8th Recognizing Textual Entailment Challenge](https://www.cs.york.ac.uk/semeval-2013/task7.html)
## Transliteration
* ****`WIKI`**** [Transliteration](https://en.wikipedia.org/wiki/Transliteration)
* ****`INFO`**** [Transliteration of Non-Latin scripts](http://transliteration.eki.ee/)
* ****`PAPER`**** [A Deep Learning Approach to Machine Transliteration](https://pdfs.semanticscholar.org/54f1/23122b8dd1f1d3067cf348cfea1276914377.pdf)
* ****`CHALLENGE`**** [NEWS 2016 Shared Task on Transliteration of Named Entities](http://workshop.colips.org/news2016/index.html)
* ****`PROJECT`**** [Neural Japanese Transliteration—can you do better than SwiftKey™ Keyboard?](https://github.com/Kyubyong/neural_japanese_transliterator)
## Voice Conversion
* ****`PAPER`**** [PHONETIC POSTERIORGRAMS FOR MANY-TO-ONE VOICE CONVERSION WITHOUT PARALLEL DATA TRAINING](http://www1.se.cuhk.edu.hk/~hccl/publications/pub/2016_paper_297.pdf)
* ****`PROJECT`**** [Deep neural networks for voice conversion (voice style transfer) in Tensorflow](https://github.com/andabi/deep-voice-conversion)
* ****`PROJECT`**** [An implementation of voice conversion system utilizing phonetic posteriorgrams](https://github.com/sesenosannko/ppg_vc)
* ****`CHALLENGE`**** [Voice Conversion Challenge 2016](http://www.vc-challenge.org/vcc2016/index.html)
* ****`CHALLENGE`**** [Voice Conversion Challenge 2018](http://www.vc-challenge.org/)
* ****`DATA`**** [CMU_ARCTIC speech synthesis databases](http://festvox.org/cmu_arctic/)
* ****`DATA`**** [TIMIT Acoustic-Phonetic Continuous Speech Corpus](https://catalog.ldc.upenn.edu/ldc93s1)
## Voice Recognition
* See [Speaker recognition](#speaker-recognition)
## Word Embeddings
* ****`WIKI`**** [Word embedding](https://en.wikipedia.org/wiki/Word_embedding)
* ****`TOOLKIT`**** [Gensim: word2vec](https://radimrehurek.com/gensim/models/word2vec.html)
* ****`TOOLKIT`**** [fastText](https://github.com/facebookresearch/fastText)
* ****`TOOLKIT`**** [GloVe: Global Vectors for Word Representation](https://nlp.stanford.edu/projects/glove/)
* ****`INFO`**** [Where to get a pretrained model](https://github.com/3Top/word2vec-api)
* ****`PROJECT`**** [Pre-trained word vectors](https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md)
* ****`PROJECT`**** [Pre-trained word vectors of 30+ languages](https://github.com/Kyubyong/wordvectors)
* ****`PROJECT`**** [Polyglot: Distributed word representations for multilingual NLP](https://sites.google.com/site/rmyeid/projects/polyglot)
* ****`PROJECT`**** [BPEmb: a collection of pre-trained subword embeddings in 275 languages](https://github.com/bheinzerling/bpemb)
* ****`CHALLENGE`**** [SemEval 2018 Task 10 Capturing Discriminative Attributes](https://competitions.codalab.org/competitions/17326)
* ****`PAPER`**** [Bilingual Word Embeddings for Phrase-Based Machine Translation](https://ai.stanford.edu/~wzou/emnlp2013_ZouSocherCerManning.pdf)
* ****`PAPER`**** [A Survey of Cross-Lingual Embedding Models](https://arxiv.org/abs/1706.04902)
## Word Prediction
* ****`INFO`**** [What is Word Prediction?](http://www2.edc.org/ncip/library/wp/what_is.htm)
* ****`PAPER`**** [The prediction of character based on recurrent neural network language model](http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7960065)
* ****`PAPER`**** [An Embedded Deep Learning based Word Prediction](https://arxiv.org/abs/1707.01662)
* ****`PAPER`**** [Evaluating Word Prediction: Framing Keystroke Savings](http://aclweb.org/anthology/P08-2066)
* ****`DATA`**** [An Embedded Deep Learning based Word Prediction](https://github.com/Meinwerk/WordPrediction/master.zip)
* ****`PROJECT`**** [Word Prediction using Convolutional Neural Networks—can you do better than iPhone™ Keyboard?](https://github.com/Kyubyong/word_prediction)
* ****`CHALLENGE`**** [SemEval-2018 Task 2, Multilingual Emoji Prediction](https://competitions.codalab.org/competitions/17344)
## Word Segmentation
* ****`WIKI`**** [Word segmentation](https://en.wikipedia.org/wiki/Text_segmentation#Segmentation_problems)
* ****`PAPER`**** [Neural Word Segmentation Learning for Chinese](https://arxiv.org/abs/1606.04300)
* ****`PROJECT`**** [Convolutional neural network for Chinese word segmentation](https://github.com/chqiwang/convseg)
* ****`TOOLKIT`**** [Stanford Word Segmenter](https://nlp.stanford.edu/software/segmenter.html)
* ****`TOOLKIT`**** [NLTK Tokenizers](http://www.nltk.org/_modules/nltk/tokenize.html)
## Word Sense Disambiguation
* ****`DATA`**** [Word-sense disambiguation](https://en.wikipedia.org/wiki/Word-sense_disambiguation)
* ****`PAPER`**** [Train-O-Matic: Large-Scale Supervised Word Sense Disambiguation in Multiple Languages without Manual Training Data](http://www.aclweb.org/anthology/D17-1008)
* ****`DATA`**** [Train-O-Matic Data](http://trainomatic.org/data/train-o-matic-data.zip)
* ****`DATA`**** [BabelNet](http://babelnet.org/)
|
3,460 | List of Machine Learning, AI, NLP solutions for iOS. The most recent version of this article can be found on my blog. | # Machine Learning for iOS
**Last Update: January 12, 2018.**
Curated list of resources for iOS developers in following topics:
- [Core ML](#coreml)
- [Machine Learning Libraries](#gpmll)
- [Deep Learning Libraries](#dll)
- [Deep Learning: Model Compression](#dlmc)
- [Computer Vision](#cv)
- [Natural Language Processing](#nlp)
- [Speech Recognition (TTS) and Generation (STT)](#tts)
- [Text Recognition (OCR)](#ocr)
- [Other AI](#ai)
- [Machine Learning Web APIs](#web)
- [Opensource ML Applications](#mlapps)
- [Game AI](#gameai)
- Other related staff
- [Linear algebra](#la)
- [Statistics, random numbers](#stat)
- [Mathematical optimization](#mo)
- [Feature extraction](#fe)
- [Data Visualization](#dv)
- [Bioinformatics (kinda)](#bio)
- [Big Data (not really)](#bd)
- [iOS ML Blogs](#blogs)
- [Mobile ML books](#books)
- [GPU Computing Blogs](#gpublogs)
- [Learn Machine Learning](#learn)
- [Other Lists](#lists)
Most of the de-facto standard tools in AI-related domains are written in iOS-unfriendly languages (Python/Java/R/Matlab) so finding something appropriate for your iOS application may be a challenging task.
This list consists mainly of libraries written in Objective-C, Swift, C, C++, JavaScript and some other languages that can be easily ported to iOS. Also, I included links to some relevant web APIs, blog posts, videos and learning materials.
Resources are sorted alphabetically or randomly. The order doesn't reflect my personal preferences or anything else. Some of the resources are awesome, some are great, some are fun, and some can serve as an inspiration.
Have fun!
**Pull-requests are welcome [here](https://github.com/alexsosn/iOS_ML)**.
# <a name="coreml"/>Core ML
* [coremltools](https://pypi.python.org/pypi/coremltools) is a Python package. It contains converters from some popular machine learning libraries to the Apple format.
* [Core ML](https://developer.apple.com/documentation/coreml) is an Apple framework to run inference on device. It is highly optimized to Apple hardware.
Currently CoreML is compatible (partially) with the following machine learning packages via [coremltools python package](https://apple.github.io/coremltools/):
- [Caffe](http://caffe.berkeleyvision.org)
- [Keras](https://keras.io/)
- [libSVM](https://www.csie.ntu.edu.tw/~cjlin/libsvm/)
- [scikit-learn](http://scikit-learn.org/)
- [XGBoost](https://xgboost.readthedocs.io/en/latest/)
Third-party converters to [CoreML format](https://apple.github.io/coremltools/coremlspecification/) are also available for some models from:
- [Turicreate](https://github.com/apple/turicreate)
- [TensorFlow](https://github.com/tf-coreml/tf-coreml)
- [MXNet](https://github.com/apache/incubator-mxnet/tree/master/tools/coreml)
- [Torch7](https://github.com/prisma-ai/torch2coreml)
- [CatBoost](https://tech.yandex.com/catboost/doc/dg/features/export-model-to-core-ml-docpage/)
There are many curated lists of pre-trained neural networks in Core ML format: [\[1\]](https://github.com/SwiftBrain/awesome-CoreML-models), [\[2\]](https://github.com/cocoa-ai/ModelZoo), [\[3\]](https://github.com/likedan/Awesome-CoreML-Models).
Core ML currently doesn't support training models, but still, you can replace model by downloading a new one from a server in runtime. [Here is a demo](https://github.com/zedge/DynamicCoreML) of how to do it. It uses generator part of MNIST GAN as Core ML model.
# <a name="gpmll"/>General-Purpose Machine Learning Libraries
<p></p>
<table rules="groups">
<thead>
<tr>
<th style="text-align: center">Library</th>
<th style="text-align: center">Algorithms</th>
<th style="text-align: center">Language</th>
<th style="text-align: center">License</th>
<th style="text-align: center">Code</th>
<th style="text-align: center">Dependency manager</th>
</tr>
</thead>
<tr>
<td style="text-align: center"><a href="https://github.com/KevinCoble/AIToolbox">AIToolbox</a></td>
<td>
<ul>
<li>Graphs/Trees</li>
<ul>
<li>Depth-first search</li>
<li>Breadth-first search</li>
<li>Hill-climb search</li>
<li>Beam Search</li>
<li>Optimal Path search</li>
</ul>
<li>Alpha-Beta (game tree)</li>
<li>Genetic Algorithms</li>
<li>Constraint Propogation</li>
<li>Linear Regression</li>
<li>Non-Linear Regression</li>
<ul>
<li>parameter-delta</li>
<li>Gradient-Descent</li>
<li>Gauss-Newton</li>
</ul>
<li>Logistic Regression</li>
<li>Neural Networks</li>
<ul>
<li>multiple layers, several non-linearity models</li>
<li>on-line and batch training</li>
<li>feed-forward or simple recurrent layers can be mixed in one network</li>
<li>LSTM network layer implemented - needs more testing</li>
<li>gradient check routines</li>
</ul>
<li>Support Vector Machine</li>
<li>K-Means</li>
<li>Principal Component Analysis</li>
<li>Markov Decision Process</li>
<ul>
<li>Monte-Carlo (every-visit, and first-visit)</li>
<li>SARSA</li>
</ul>
<li>Single and Multivariate Gaussians</li>
<li>Mixture Of Gaussians</li>
<li>Model validation</li>
<li>Deep Network</li>
<ul>
<li>Convolution layers</li>
<li>Pooling layers</li>
<li>Fully-connected NN layers</li>
</ul>
</ul>
</td>
<td>Swift</td>
<td>Apache 2.0</td>
<td><p><a href="https://github.com/KevinCoble/AIToolbox">GitHub</a></p></td>
<td> </td>
</tr>
<tr>
<td style="text-align: center">
<a href="http://dlib.net/">
<img src="http://dlib.net/dlib-logo.png" width="100" >
<br>dlib</a>
</td>
<td>
<ul>
<li>Deep Learning</li>
<li>Support Vector Machines</li>
<li>Reduced-rank methods for large-scale classification and regression</li>
<li>Relevance vector machines for classification and regression</li>
<li>A Multiclass SVM</li>
<li>Structural SVM</li>
<li>A large-scale SVM-Rank</li>
<li>An online kernel RLS regression</li>
<li>An online SVM classification algorithm</li>
<li>Semidefinite Metric Learning</li>
<li>An online kernelized centroid estimator/novelty detector and offline support vector one-class classification</li>
<li>Clustering algorithms: linear or kernel k-means, Chinese Whispers, and Newman clustering</li>
<li>Radial Basis Function Networks</li>
<li>Multi layer perceptrons</li>
</ul>
</td>
<td>C++</td>
<td>Boost</td>
<td><a href="https://github.com/davisking/dlib">GitHub</a></td>
<td></td>
</tr>
<tr>
<td style="text-align: center"><a href="http://leenissen.dk/fann/wp/">FANN</a></td>
<td>
<ul>
<li>Multilayer Artificial Neural Network</li>
<li>Backpropagation (RPROP, Quickprop, Batch, Incremental)</li>
<li>Evolving topology training</li>
</ul>
</td>
<td>C++</td>
<td>GNU LGPL 2.1</td>
<td><a href="https://github.com/libfann/fann">GitHub</a></td>
<td><a href="https://cocoapods.org/pods/FANN">Cocoa Pods</a></td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/lemire/lbimproved">lbimproved</a></td>
<td>k-nearest neighbors and Dynamic Time Warping</td>
<td>C++</td>
<td>Apache 2.0</td>
<td><a href="https://github.com/lemire/lbimproved">GitHub</a> </td>
<td> </td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/gianlucabertani/MAChineLearning">MAChineLearning</a></td>
<td>
<ul>
<li>Neural Networks</li>
<ul>
<li>Activation functions: Linear, ReLU, Step, sigmoid, TanH</li>
<li>Cost functions: Squared error, Cross entropy</li>
<li>Backpropagation: Standard, Resilient (a.k.a. RPROP).</li>
<li>Training by sample or by batch.</li>
</ul>
<li>Bag of Words</li>
<li>Word Vectors</li>
</ul>
</td>
<td>Objective-C</td>
<td>BSD 3-clause</td>
<td><a href="https://github.com/gianlucabertani/MAChineLearning">GitHub</a> </td>
<td> </td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/Somnibyte/MLKit"><img width="100" src="https://github.com/Somnibyte/MLKit/raw/master/MLKitSmallerLogo.png"><br>MLKit</a></td>
<td>
<ul>
<li>Linear Regression: simple, ridge, polynomial</li>
<li>Multi-Layer Perceptron, & Adaline ANN Architectures</li>
<li>K-Means Clustering</li>
<li>Genetic Algorithms</li>
</ul>
</td>
<td>Swift</td>
<td>MIT</td>
<td><a href="https://github.com/Somnibyte/MLKit">GitHub</a></td>
<td><a href="https://cocoapods.org/pods/MachineLearningKit">Cocoa Pods</a></td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/saniul/Mendel"><img width="100" src="https://github.com/saniul/Mendel/raw/master/[email protected]"><br>Mendel</a></td>
<td>Evolutionary/genetic algorithms</td>
<td>Swift</td>
<td>?</td>
<td><a href="https://github.com/saniul/Mendel">GitHub</a></td>
<td></td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/vincentherrmann/multilinear-math">multilinear-math</a></td>
<td>
<ul>
<li>Linear algebra and tensors</li>
<li>Principal component analysis</li>
<li>Multilinear subspace learning algorithms for dimensionality reduction</li>
<li>Linear and logistic regression</li>
<li>Stochastic gradient descent</li>
<li>Feedforward neural networks</li>
<ul>
<li>Sigmoid</li>
<li>ReLU</li>
<li>Softplus activation functions</li>
</ul>
</ul>
</td>
<td>Swift</td>
<td>Apache 2.0</td>
<td><a href="https://github.com/vincentherrmann/multilinear-math">GitHub</a> </td>
<td>Swift Package Manager</td>
</tr>
<tr>
<td style="text-align: center"><a href="http://opencv.org/"><img width="100" src="http://opencv.org/assets/theme/logo.png">OpenCV</a></td>
<td>
<ul>
<li>Multi-Layer Perceptrons</li>
<li>Boosted tree classifier</li>
<li>decision tree</li>
<li>Expectation Maximization</li>
<li>K-Nearest Neighbors</li>
<li>Logistic Regression</li>
<li>Bayes classifier</li>
<li>Random forest</li>
<li>Support Vector Machines</li>
<li>Stochastic Gradient Descent SVM classifier</li>
<li>Grid search</li>
<li>Hierarchical k-means</li>
<li>Deep neural networks</li>
</ul>
</td>
<td>C++</td>
<td>3-clause BSD</td>
<td><a href="https://github.com/opencv">GitHub</a> </td>
<td> <a href="https://cocoapods.org/pods/OpenCV">Cocoa Pods</a></td>
</tr>
<tr>
<td style="text-align: center"><a href="http://image.diku.dk/shark/sphinx_pages/build/html/index.html"><img width="100" src="http://image.diku.dk/shark/sphinx_pages/build/html/_static/SharkLogo.png"><br>Shark</a></td>
<td>
<ul>
<li><b>Supervised:</b> </li>
<ul>
<li>Linear discriminant analysis (LDA)</li>
<li>Fisher–LDA</li>
<li>Linear regression</li>
<li>SVMs</li>
<li>FF NN</li>
<li>RNN</li>
<li>Radial basis function networks</li>
<li>Regularization networks</li>
<li>Gaussian processes for regression</li>
<li>Iterative nearest neighbor classification and regression</li>
<li>Decision trees</li>
<li>Random forest</li>
</ul>
<li><b>Unsupervised:</b> </li>
<ul>
<li>PCA</li>
<li>Restricted Boltzmann machines</li>
<li>Hierarchical clustering</li>
<li>Data structures for efficient distance-based clustering</li>
</ul>
<li><b>Optimization:</b> </li>
<ul>
<li>Evolutionary algorithms</li>
<li>Single-objective optimization (e.g., CMA–ES)</li>
<li>Multi-objective optimization</li>
<li>Basic linear algebra and optimization algorithms</li>
</ul>
</ul>
</td>
<td>C++</td>
<td>GNU LGPL</td>
<td><a href="https://github.com/lemire/lbimproved">GitHub</a> </td>
<td><a href="https://cocoapods.org/pods/Shark-SDK">Cocoa Pods</a></td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/yconst/YCML"><img width="100" src="https://raw.githubusercontent.com/yconst/YCML/master/Logo.png"><br>YCML</a></td>
<td>
<ul>
<li>Gradient Descent Backpropagation</li>
<li>Resilient Backpropagation (RProp)</li>
<li>Extreme Learning Machines (ELM)</li>
<li>Forward Selection using Orthogonal Least Squares (for RBF Net), also with the PRESS statistic</li>
<li>Binary Restricted Boltzmann Machines (CD & PCD)</li>
<li><b>Optimization algorithms</b>: </li>
<ul>
<li>Gradient Descent (Single-Objective, Unconstrained)</li>
<li>RProp Gradient Descent (Single-Objective, Unconstrained)</li>
<li>NSGA-II (Multi-Objective, Constrained)</li>
</ul>
</ul>
</td>
<td>Objective-C</td>
<td>GNU GPL 3.0</td>
<td><a href="https://github.com/yconst/ycml/">GitHub</a> </td>
<td> </td>
</tr>
<tr>
<td style="text-align: center"><a href="https://github.com/Kalvar"><img width="100" src="https://avatars2.githubusercontent.com/u/1835631?v=4&s=460"><br>Kalvar Lin's libraries</a></td>
<td>
<ul>
<li><a href="https://github.com/Kalvar/ios-KRHebbian-Algorithm">ios-KRHebbian-Algorithm</a> - <a href="https://en.wikipedia.org/wiki/Hebbian_theory">Hebbian Theory</a></li>
<li><a href="https://github.com/Kalvar/ios-KRKmeans-Algorithm">ios-KRKmeans-Algorithm</a> - <a href="https://en.wikipedia.org/wiki/K-means_clustering">K-Means</a> clustering method.</li>
<li><a href="https://github.com/Kalvar/ios-KRFuzzyCMeans-Algorithm">ios-KRFuzzyCMeans-Algorithm</a> - <a href="https://en.wikipedia.org/wiki/Fuzzy_clustering">Fuzzy C-Means</a>, the fuzzy clustering algorithm.</li>
<li><a href="https://github.com/Kalvar/ios-KRGreyTheory">ios-KRGreyTheory</a> - <a href="http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.678.3477&rep=rep1&type=pdf">Grey Theory</a> / <a href="http://www.mecha.ee.boun.edu.tr/Prof.%20Dr.%20Okyay%20Kaynak%20Publications/c%20Journal%20Papers(appearing%20in%20SCI%20or%20SCIE%20or%20CompuMath)/62.pdf">Grey system theory-based models in time series prediction</a></li>
<li><a href="https://github.com/Kalvar/ios-KRSVM">ios-KRSVM</a> - Support Vector Machine and SMO.</li>
<li><a href="https://github.com/Kalvar/ios-KRKNN">ios-KRKNN</a> - kNN implementation.</li>
<li><a href="https://github.com/Kalvar/ios-KRRBFNN">ios-KRRBFNN</a> - Radial basis function neural network and OLS.</li>
</ul>
</td>
<td>Objective-C</td>
<td>MIT</td>
<td><a href="https://github.com/Kalvar">GitHub</a></td>
<td></td>
</tr>
</table>
**Multilayer perceptron implementations:**
- [Brain.js](https://github.com/harthur/brain) - JS
- [SNNeuralNet](https://github.com/devongovett/SNNeuralNet) - Objective-C port of brain.js
- [MLPNeuralNet](https://github.com/nikolaypavlov/MLPNeuralNet) - Objective-C, Accelerate
- [Swift-AI](https://github.com/Swift-AI/Swift-AI) - Swift
- [SwiftSimpleNeuralNetwork](https://github.com/davecom/SwiftSimpleNeuralNetwork) - Swift
- <a href="https://github.com/Kalvar/ios-BPN-NeuralNetwork">ios-BPN-NeuralNetwork</a> - Objective-C
- <a href="https://github.com/Kalvar/ios-Multi-Perceptron-NeuralNetwork">ios-Multi-Perceptron-NeuralNetwork</a>- Objective-C
- <a href="https://github.com/Kalvar/ios-KRDelta">ios-KRDelta</a> - Objective-C
- [ios-KRPerceptron](https://github.com/Kalvar/ios-KRPerceptron) - Objective-C
# <a name="dll"/>Deep Learning Libraries:
### On-Device training and inference
* [Birdbrain](https://github.com/jordenhill/Birdbrain) - RNNs and FF NNs on top of Metal and Accelerate. Not ready for production.
* [BrainCore](https://github.com/aleph7/BrainCore) - simple but fast neural network framework written in Swift. It uses Metal framework to be as fast as possible. ReLU, LSTM, L2 ...
* [Caffe](http://caffe.berkeleyvision.org) - A deep learning framework developed with cleanliness, readability, and speed in mind. [GitHub](https://github.com/BVLC/caffe). [BSD]
* [iOS port](https://github.com/aleph7/caffe)
* [caffe-mobile](https://github.com/solrex/caffe-mobile) - another iOS port.
* C++ examples: [Classifying ImageNet](http://caffe.berkeleyvision.org/gathered/examples/cpp_classification.html), [Extracting Features](http://caffe.berkeleyvision.org/gathered/examples/feature_extraction.html)
* [Caffe iOS sample](https://github.com/noradaiko/caffe-ios-sample)
* [Caffe2](https://caffe2.ai/) - a cross-platform framework made with expression, speed, and modularity in mind.
* [Cocoa Pod](https://github.com/RobertBiehl/caffe2-ios)
* [iOS demo app](https://github.com/KleinYuan/Caffe2-iOS)
* [Convnet.js](http://cs.stanford.edu/people/karpathy/convnetjs/) - ConvNetJS is a Javascript library for training Deep Learning models by [Andrej Karpathy](https://twitter.com/karpathy). [GitHub](https://github.com/karpathy/convnetjs)
* [ConvNetSwift](https://github.com/alexsosn/ConvNetSwift) - Swift port [work in progress].
* [Deep Belief SDK](https://github.com/jetpacapp/DeepBeliefSDK) - The SDK for Jetpac's iOS Deep Belief image recognition framework
* [TensorFlow](http://www.tensorflow.org/) - an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.
* [iOS examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/ios_examples)
* [another example](https://github.com/hollance/TensorFlow-iOS-Example)
* [Perfect-TensorFlow](https://github.com/PerfectlySoft/Perfect-TensorFlow) - TensorFlow binding for [Perfect](http://perfect.org/) (server-side Swift framework). Includes only C TF API.
* [tiny-dnn](https://github.com/tiny-dnn/tiny-dnn) - header only, dependency-free deep learning framework in C++11.
* [iOS example](https://github.com/tiny-dnn/tiny-dnn/tree/d4fff53fa0d01f59eb162de2ec32c652a1f6f467/examples/ios)
* [Torch](http://torch.ch/) is a scientific computing framework with wide support for machine learning algorithms.
* [Torch4iOS](https://github.com/jhondge/torch4ios)
* [Torch-iOS](https://github.com/clementfarabet/torch-ios)
### Deep Learning: Running pre-trained models on device
These libraries doesn't support training, so you need to pre-train models in some ML framework.
* [Bender](https://github.com/xmartlabs/Bender) - Framework for building fast NNs. Supports TensorFlow models. It uses Metal under the hood.
* [Core ML](#coreml)
* [DeepLearningKit](http://deeplearningkit.org/) - Open Source Deep Learning Framework from Memkite for Apple's tvOS, iOS and OS X.
* [Espresso](https://github.com/codinfox/espresso) - A minimal high performance parallel neural network framework running on iOS.
* [Forge](https://github.com/hollance/Forge) - A neural network toolkit for Metal.
* [Keras.js](https://transcranial.github.io/keras-js/#/) - run [Keras](https://keras.io/) models in a web view.
* [KSJNeuralNetwork](https://github.com/woffle/KSJNeuralNetwork) - A Neural Network Inference Library Built atop BNNS and MPS
* [Converter for Torch models](https://github.com/woffle/torch2ios)
* [MXNet](https://mxnet.incubator.apache.org/) - MXNet is a deep learning framework designed for both efficiency and flexibility.
* [Deploying pre-trained mxnet model to a smartphone](https://mxnet.incubator.apache.org/how_to/smart_device.html)
* [Quantized-CNN](https://github.com/jiaxiang-wu/quantized-cnn) - compressed convolutional neural networks for Mobile Devices
* [WebDNN](https://mil-tokyo.github.io/webdnn/) - You can run deep learning model in a web view if you want. Three modes: WebGPU acceleration, WebAssembly acceleration and pure JS (on CPU). No training, inference only.
### Deep Learning: Low-level routines libraries
* [BNNS](https://developer.apple.com/reference/accelerate/1912851-bnns) - Apple Basic neural network subroutines (BNNS) is a collection of functions that you use to implement and run neural networks, using previously obtained training data.
* [BNNS usage examples](https://github.com/shu223/iOS-10-Sampler) in iOS 10 sampler.
* [An example](https://github.com/bignerdranch/bnns-cocoa-example) of a neural network trained by tensorflow and executed using BNNS
* [MetalPerformanceShaders](https://developer.apple.com/reference/metalperformanceshaders) - CNNs on GPU from Apple.
* [MetalCNNWeights](https://github.com/kakugawa/MetalCNNWeights) - a Python script to convert Inception v3 for MPS.
* [MPSCNNfeeder](https://github.com/kazoo-kmt/MPSCNNfeeder) - Keras to MPS models conversion.
* [NNPACK](https://github.com/Maratyszcza/NNPACK) - Acceleration package for neural networks on multi-core CPUs. Prisma [uses](http://prisma-ai.com/libraries.html) this library in the mobile app.
* [STEM](https://github.com/abeschneider/stem) - Swift Tensor Engine for Machine-learning
* [Documentation](http://stem.readthedocs.io/en/latest/)
### <a name="dlmc"/>Deep Learning: Model Compression
* TensorFlow implementation of [knowledge distilling](https://github.com/chengshengchan/model_compression) method
* [MobileNet-Caffe](https://github.com/shicai/MobileNet-Caffe) - Caffe Implementation of Google's MobileNets
* [keras-surgeon](https://github.com/BenWhetton/keras-surgeon) - Pruning for trained Keras models.
# <a name="cv"/>Computer Vision
* [ccv](http://libccv.org) - C-based/Cached/Core Computer Vision Library, A Modern Computer Vision Library
* [iOS demo app](https://github.com/liuliu/klaus)
* [OpenCV](http://opencv.org) – Open Source Computer Vision Library. [BSD]
* [OpenCV crash course](http://www.pyimagesearch.com/free-opencv-crash-course/)
* [OpenCVSwiftStitch](https://github.com/foundry/OpenCVSwiftStitch)
* [Tutorial: using and building openCV on iOS devices](http://maniacdev.com/2011/07/tutorial-using-and-building-opencv-open-computer-vision-on-ios-devices)
* [A Collection of OpenCV Samples For iOS](https://github.com/woffle/OpenCV-iOS-Demos)
* [OpenFace](https://github.com/TadasBaltrusaitis/OpenFace) – a state-of-the art open source tool intended for facial landmark detection, head pose estimation, facial action unit recognition, and eye-gaze estimation.
* [iOS port](https://github.com/FaceAR/OpenFaceIOS)
* [iOS demo](https://github.com/FaceAR/OpenFaceIOS)
* [trackingjs](http://trackingjs.com/) – Object tracking in JS
* [Vision](https://developer.apple.com/documentation/vision) is an Apple framework for computer vision.
# <a name="nlp"/>Natural Language Processing
* [CoreLinguistics](https://github.com/rxwei/CoreLinguistics) - POS tagging (HMM), ngrams, Naive Bayes, IBM alignment models.
* [GloVe](https://github.com/rxwei/GloVe-swift) Swift package. Vector words representations.
* [NSLinguisticTagger](http://nshipster.com/nslinguistictagger/)
* [Parsimmon](https://github.com/ayanonagon/Parsimmon)
* [Twitter text](https://github.com/twitter/twitter-text-objc) -
An Objective-C implementation of Twitter's text processing library. The library includes methods for extracting user names, mentions headers, hashtags, and more – all the tweet specific language syntax you could ever want.
* [Verbal expressions for Swift](https://github.com/VerbalExpressions/SwiftVerbalExpressions), like regexps for humans.
* [Word2Vec](https://code.google.com/p/word2vec/) - Original C implementation of Word2Vec Deep Learning algorithm. Works on iPhone like a charm.
# <a name="tts"/>Speech Recognition (TTS) and Generation (STT)
* [Kaldi-iOS framework](http://keenresearch.com/) - on-device speech recognition using deep learning.
* [Proof of concept app](https://github.com/keenresearch/kaldi-ios-poc)
* [MVSpeechSynthesizer](https://github.com/vimalmurugan89/MVSpeechSynthesizer)
* [OpenEars™: free speech recognition and speech synthesis for the iPhone](http://www.politepix.com/openears/) - OpenEars™ makes it simple for you to add offline speech recognition and synthesized speech/TTS to your iPhone app quickly and easily. It lets everyone get the great results of using advanced speech UI concepts like statistical language models and finite state grammars in their app, but with no more effort than creating an NSArray or NSDictionary.
* [Tutorial (Russian)](http://habrahabr.ru/post/237589/)
* [TLSphinx](https://github.com/tryolabs/TLSphinx), [Tutorial](http://blog.tryolabs.com/2015/06/15/tlsphinx-automatic-speech-recognition-asr-in-swift/)
# <a name="ocr"/>Text Recognition (OCR)
* [ocrad.js](https://github.com/antimatter15/ocrad.js) - JS OCR
* **Tesseract**
* [Install and Use Tesseract on iOS](http://lois.di-qual.net/blog/install-and-use-tesseract-on-ios-with-tesseract-ios/)
* [tesseract-ios-lib](https://github.com/ldiqual/tesseract-ios-lib)
* [tesseract-ios](https://github.com/ldiqual/tesseract-ios)
* [Tesseract-OCR-iOS](https://github.com/gali8/Tesseract-OCR-iOS)
* [OCR-iOS-Example](https://github.com/robmathews/OCR-iOS-Example)
# <a name="ai"/>Other AI
* [Axiomatic](https://github.com/JadenGeller/Axiomatic) - Swift unification framework for logic programming.
* [Build Your Own Lisp In Swift](https://github.com/hollance/BuildYourOwnLispInSwift)
* [Logician](https://github.com/mdiep/Logician) - Logic programming in Swift
* [Swiftlog](https://github.com/JadenGeller/Swiftlog) - A simple Prolog-like language implemented entirely in Swift.
# <a name="web"/>Machine Learning Web APIs
* [**IBM** Watson](http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/) - Enable Cognitive Computing Features In Your App Using IBM Watson's Language, Vision, Speech and Data APIs.
* [Introducing the (beta) IBM Watson iOS SDK](https://developer.ibm.com/swift/2015/12/18/introducing-the-new-watson-sdk-for-ios-beta/)
* [AlchemyAPI](http://www.alchemyapi.com/) - Semantic Text Analysis APIs Using Natural Language Processing. Now part of IBM Watson.
* [**Microsoft** Project Oxford](https://www.projectoxford.ai/)
* [**Google** Prediction engine](https://cloud.google.com/prediction/docs)
* [Objective-C API](https://code.google.com/p/google-api-objectivec-client/wiki/Introduction)
* [Google Translate API](https://cloud.google.com/translate/docs)
* [Google Cloud Vision API](https://cloud.google.com/vision/)
* [**Amazon** Machine Learning](http://aws.amazon.com/documentation/machine-learning/) - Amazon ML is a cloud-based service for developers. It provides visualization tools to create machine learning models. Obtain predictions for application using APIs.
* [iOS developer guide](https://docs.aws.amazon.com/mobile/sdkforios/developerguide/getting-started-machine-learning.html).
* [iOS SDK](https://github.com/aws/aws-sdk-ios)
* [**PredictionIO**](https://prediction.io/) - opensource machine learning server for developers and ML engineers. Built on Apache Spark, HBase and Spray.
* [Swift SDK](https://github.com/minhtule/PredictionIO-Swift-SDK)
* [Tapster iOS Demo](https://github.com/minhtule/Tapster-iOS-Demo) - This demo demonstrates how to use the PredictionIO Swift SDK to integrate an iOS app with a PredictionIO engine to make your mobile app more interesting.
* [Tutorial](https://github.com/minhtule/Tapster-iOS-Demo/blob/master/TUTORIAL.md) on using Swift with PredictionIO.
* [**Wit.AI**](https://wit.ai/) - NLP API
* [**Yandex** SpeechKit](https://tech.yandex.com/speechkit/mobilesdk/) Text-to-speech and speech-to-text for Russian language. iOS SDK available.
* [**Abbyy** OCR SDK](http://www.abbyy.com/mobile-ocr/iphone-ocr/)
* [**Clarifai**](http://www.clarifai.com/#) - deep learning web api for image captioning. [iOS starter project](https://github.com/Clarifai/clarifai-ios-starter)
* [**MetaMind**](https://www.metamind.io/) - deep learning web api for image captioning.
* [Api.AI](https://api.ai/) - Build intelligent speech interfaces
for apps, devices, and web
* [**CloudSight.ai**](https://cloudsight.ai/) - deep learning web API for fine grained object detection or whole screen description, including natural language object captions. [Objective-C](https://github.com/cloudsight/cloudsight-objc) API client is available.
# <a name="mlapps"/>Opensource ML Applications
### Deep Learning
* [DeepDreamer](https://github.com/johndpope/deepdreamer) - Deep Dream application
* [DeepDreamApp](https://github.com/johndpope/DeepDreamApp) - Deep Dream Cordova app.
* [Texture Networks](https://github.com/DmitryUlyanov/texture_nets), Lua implementation
* [Feedforward style transfer](https://github.com/jcjohnson/fast-neural-style), Lua implementation
* [TensorFlow implementation of Neural Style](https://github.com/cysmith/neural-style-tf)
* [Corrosion detection app](https://github.com/jmolayem/corrosionapp)
* [ios_camera_object_detection](https://github.com/yjmade/ios_camera_object_detection) - Realtime mobile visualize based Object Detection based on TensorFlow and YOLO model
* [TensorFlow MNIST iOS demo](https://github.com/mattrajca/MNIST) - Getting Started with Deep MNIST and TensorFlow on iOS
* [Drummer App](https://github.com/hollance/RNN-Drummer-Swift) with RNN and Swift
* [What'sThis](https://github.com/pppoe/WhatsThis-iOS)
* [enVision](https://github.com/IDLabs-Gate/enVision) - Deep Learning Models for Vision Tasks on iOS\
* [GoogLeNet on iOS demo](https://github.com/krasin/MetalDetector)
* [Neural style in Android](https://github.com/naman14/Arcade)
* [mnist-bnns](https://github.com/paiv/mnist-bnns) - TensorFlow MNIST demo port to BNNS
* [Benchmark of BNNS vs. MPS](https://github.com/hollance/BNNS-vs-MPSCNN)
* [VGGNet on Metal](https://github.com/hollance/VGGNet-Metal)
* A [Sudoku Solver](https://github.com/waitingcheung/deep-sudoku-solver) that leverages TensorFlow and iOS BNNS for deep learning.
* [HED CoreML Implementation](https://github.com/s1ddok/HED-CoreML) is a demo with tutorial on how to use Holistically-Nested Edge Detection on iOS with CoreML and Swift
### Traditional Computer Vision
* [SwiftOCR](https://github.com/garnele007/SwiftOCR)
* [GrabCutIOS](https://github.com/naver/grabcutios) - Image segmentation using GrabCut algorithm for iOS
### NLP
* [Classical ELIZA chatbot in Swift](https://gist.github.com/hollance/be70d0d7952066cb3160d36f33e5636f)
* [InfiniteMonkeys](https://github.com/craigomac/InfiniteMonkeys) - A Keras-trained RNN to emulate the works of a famous poet, powered by BrainCore
### Other
* [Swift implementation of Joel Grus's "Data Science from Scratch"](https://github.com/graceavery/LearningMachineLearning)
* [Neural Network built in Apple Playground using Swift](https://github.com/Luubra/EmojiIntelligence)
# <a name="gameai"/>Game AI
* [Introduction to AI Programming for Games](http://www.raywenderlich.com/24824/introduction-to-ai-programming-for-games)
* [dlib](http://dlib.net/) is a library which has many useful tools including machine learning.
* [MicroPather](http://www.grinninglizard.com/MicroPather/) is a path finder and A* solver (astar or a-star) written in platform independent C++ that can be easily integrated into existing code.
* Here is a [list](http://www.ogre3d.org/tikiwiki/List+Of+Libraries#Artificial_intelligence) of some AI libraries suggested on OGRE3D website. Seems they are mostly written in C++.
* [GameplayKit Programming Guide](https://developer.apple.com/library/content/documentation/General/Conceptual/GameplayKit_Guide/)
# Other related staff
### <a name="la"/>Linear algebra
* [Accelerate-in-Swift](https://github.com/hyperjeff/Accelerate-in-Swift) - Swift example codes for the Accelerate.framework
* [cuda-swift](https://github.com/rxwei/cuda-swift) - Swift binding to CUDA. Not iOS, but still interesting.
* [Dimensional](https://github.com/JadenGeller/Dimensional) - Swift matrices with friendly semantics and a familiar interface.
* [Eigen](http://eigen.tuxfamily.org/) - A high-level C++ library of template headers for linear algebra, matrix and vector operations, numerical solvers and related algorithms. [MPL2]
* [Matrix](https://github.com/hollance/Matrix) - convenient matrix type with different types of subscripts, custom operators and predefined matrices. A fork of Surge.
* [NDArray](https://github.com/t-ae/ndarray) - Float library for Swift, accelerated with Accelerate Framework.
* [Swift-MathEagle](https://github.com/rugheid/Swift-MathEagle) - A general math framework to make using math easy. Currently supports function solving and optimisation, matrix and vector algebra, complex numbers, big int, big frac, big rational, graphs and general handy extensions and functions.
* [SwiftNum](https://github.com/donald-pinckney/SwiftNum) - linear algebra, fft, gradient descent, conjugate GD, plotting.
* [Swix](https://github.com/scottsievert/swix) - Swift implementation of NumPy and OpenCV wrapper.
* [Surge](https://github.com/mattt/Surge) from Mattt
* [Upsurge](https://github.com/aleph7/Upsurge) - generic tensors, matrices on top of Accelerate. A fork of Surge.
* [YCMatrix](https://github.com/yconst/YCMatrix) - A flexible Matrix library for Objective-C and Swift (OS X / iOS)
### <a name="stat"/>Statistics, random numbers
* [SigmaSwiftStatistics](https://github.com/evgenyneu/SigmaSwiftStatistics) - A collection of functions for statistical calculation written in Swift.
* [SORandom](https://github.com/SebastianOsinski/SORandom) - Collection of functions for generating psuedorandom variables from various distributions
* [RandKit](https://github.com/aidangomez/RandKit) - Swift framework for random numbers & distributions.
### <a name="mo"/>Mathematical optimization
* [fmincg-c](https://github.com/gautambhatrcb/fmincg-c) - Conjugate gradient implementation in C
* [libLBFGS](https://github.com/chokkan/liblbfgs) - a C library of Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS)
* [SwiftOptimizer](https://github.com/haginile/SwiftOptimizer) - QuantLib Swift port.
### <a name="fe"/>Feature extraction
* [IntuneFeatures](https://github.com/venturemedia/intune-features) framework contains code to generate features from audio files and feature labels from the respective MIDI files.
* [matchbox](https://github.com/hfink/matchbox) - Mel-Frequency-Cepstral-Coefficients and Dynamic-Time-Warping for iOS/OSX. **Warning: the library was updated last time when iOS 4 was still hot.**
* [LibXtract](https://github.com/jamiebullock/LibXtract) is a simple, portable, lightweight library of audio feature extraction functions.
### <a name="dv"/>Data Visualization
* [Charts](https://github.com/danielgindi/Charts) - The Swift port of the MPAndroidChart.
* [iOS-Charts](https://github.com/danielgindi/ios-charts)
* [Core Plot](https://github.com/core-plot/core-plot)
* [Awesome iOS charts](https://github.com/sxyx2008/awesome-ios-chart)
* [JTChartView](https://github.com/kubatru/JTChartView)
* [VTK](http://www.vtk.org/gallery/)
* [VTK in action](http://www.vtk.org/vtk-in-action/)
* [D3.js iOS binding](https://github.com/lee-leonardo/iOS-D3)
### <a name="bio"/>Bioinformatics (kinda)
* [BioJS](http://biojs.net/) - a set of tools for bioinformatics in the browser. BioJS builds a infrastructure, guidelines and tools to avoid the reinvention of the wheel in life sciences. Community builds modules than can be reused by anyone.
* [BioCocoa](http://www.bioinformatics.org/biococoa/wiki/pmwiki.php) - BioCocoa is an open source OpenStep (GNUstep/Cocoa) framework for bioinformatics written in Objective-C. [Dead project].
* [iBio](https://github.com/Lizhen0909/iBio) - A Bioinformatics App for iPhone.
### <a name="bd"/>Big Data (not really)
* [HDF5Kit](https://github.com/aleph7/HDF5Kit) - This is a Swift wrapper for the HDF5 file format. HDF5 is used in the scientific comunity for managing large volumes of data. The objective is to make it easy to read and write HDF5 files from Swift, including playgrounds.
### <a name="ip"/>IPython + Swift
* [iSwift](https://github.com/KelvinJin/iSwift) - Swift kernel for IPython notebook.
# <a name="blogs"/>iOS ML Blogs
### Regular mobile ML
* **[The "Machine, think!" blog](http://machinethink.net/blog/) by Matthijs Hollemans**
* [The “hello world” of neural networks](http://matthijshollemans.com/2016/08/24/neural-network-hello-world/) - Swift and BNNS
* [Convolutional neural networks on the iPhone with VGGNet](http://matthijshollemans.com/2016/08/30/vggnet-convolutional-neural-network-iphone/)
* **[Pete Warden's blog](https://petewarden.com/)**
* [How to Quantize Neural Networks with TensorFlow](https://petewarden.com/2016/05/03/how-to-quantize-neural-networks-with-tensorflow/)
### Accidental mobile ML
* **[Google research blog](https://research.googleblog.com)**
* **[Apple Machine Learning Journal](https://machinelearning.apple.com/)**
* **[Invasive Code](https://www.invasivecode.com/weblog/) blog**
* [Machine Learning for iOS](https://www.invasivecode.com/weblog/machine-learning-swift-ios/)
* [Convolutional Neural Networks in iOS 10 and macOS](https://www.invasivecode.com/weblog/convolutional-neural-networks-ios-10-macos-sierra/)
* **Big Nerd Ranch** - [Use TensorFlow and BNNS to Add Machine Learning to your Mac or iOS App](https://www.bignerdranch.com/blog/use-tensorflow-and-bnns-to-add-machine-learning-to-your-mac-or-ios-app/)
### Other
* [Intelligence in Mobile Applications](https://medium.com/@sadmansamee/intelligence-in-mobile-applications-ca3be3c0e773#.lgk2gt6ik)
* [An exclusive inside look at how artificial intelligence and machine learning work at Apple](https://backchannel.com/an-exclusive-look-at-how-ai-and-machine-learning-work-at-apple-8dbfb131932b)
* [Presentation on squeezing DNNs for mobile](https://www.slideshare.net/mobile/anirudhkoul/squeezing-deep-learning-into-mobile-phones)
* [Curated list of papers on deep learning models compression and acceleration](https://handong1587.github.io/deep_learning/2015/10/09/acceleration-model-compression.html)
# <a name="gpublogs"/>GPU Computing Blogs
* [OpenCL for iOS](https://github.com/linusyang/opencl-test-ios) - just a test.
* Exploring GPGPU on iOS.
* [Article](http://ciechanowski.me/blog/2014/01/05/exploring_gpgpu_on_ios/)
* [Code](https://github.com/Ciechan/Exploring-GPGPU-on-iOS)
* GPU-accelerated video processing for Mac and iOS. [Article](http://www.sunsetlakesoftware.com/2010/10/22/gpu-accelerated-video-processing-mac-and-ios0).
* [Concurrency and OpenGL ES](https://developer.apple.com/library/ios/documentation/3ddrawing/conceptual/opengles_programmingguide/ConcurrencyandOpenGLES/ConcurrencyandOpenGLES.html) - Apple programming guide.
* [OpenCV on iOS GPU usage](http://stackoverflow.com/questions/10704916/opencv-on-ios-gpu-usage) - SO discussion.
### Metal
* Simon's Gladman \(aka flexmonkey\) [blog](http://flexmonkey.blogspot.com/)
* [Talk on iOS GPU programming](https://realm.io/news/altconf-simon-gladman-ios-gpu-programming-with-swift-metal/) with Swift and Metal at Realm Altconf.
* [The Supercomputer In Your Pocket:
Metal & Swift](https://realm.io/news/swift-summit-simon-gladman-metal/) - a video from the Swift Summit Conference 2015
* https://github.com/FlexMonkey/MetalReactionDiffusion
* https://github.com/FlexMonkey/ParticleLab
* [Memkite blog](http://memkite.com/) - startup intended to create deep learning library for iOS.
* [Swift and Metal example for General Purpose GPU Processing on Apple TVOS 9.0](https://github.com/memkite/MetalForTVOS)
* [Data Parallel Processing with Swift and Metal on GPU for iOS8](https://github.com/memkite/SwiftMetalGPUParallelProcessing)
* [Example of Sharing Memory between GPU and CPU with Swift and Metal for iOS8](http://memkite.com/blog/2014/12/30/example-of-sharing-memory-between-gpu-and-cpu-with-swift-and-metal-for-ios8/)
* [Metal by Example blog](http://metalbyexample.com/)
* [objc-io article on Metal](https://www.objc.io/issues/18-games/metal/)
# <a name="books"/>Mobile ML Books
* <b>Building Mobile Applications with TensorFlow</b> by Pete Warden. [Book page](http://www.oreilly.com/data/free/building-mobile-applications-with-tensorflow.csp). <b>[Free download](http://www.oreilly.com/data/free/building-mobile-applications-with-tensorflow.csp?download=true)</b>
# <a name="learn"/>Learn Machine Learning
<i>Please note that in this section, I'm not trying to collect another list of ALL machine learning study resources, but only composing a list of things that I found useful.</i>
* <b>[Academic Torrents](http://academictorrents.com/browse.php?cat=7)</b>. Sometimes awesome courses or datasets got deleted from their sites. But this doesn't mean, that they are lost.
* [Arxiv Sanity Preserver](http://www.arxiv-sanity.com/) - a tool to keep pace with the ML research progress.
## Free Books
* Immersive Linear Algebra [interactive book](http://immersivemath.com/ila/index.html) by J. Ström, K. Åström, and T. Akenine-Möller.
* ["Natural Language Processing with Python"](http://www.nltk.org/book/) - free online book.
* [Probabilistic Programming & Bayesian Methods for Hackers](http://camdavidsonpilon.github.io/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/) - An intro to Bayesian methods and probabilistic programming from a computation/understanding-first, mathematics-second point of view.
* ["Deep learning"](http://www.deeplearningbook.org/) - the book by Ian Goodfellow and Yoshua Bengio and Aaron Courville
## Free Courses
* [Original Machine Learning Coursera course](https://www.coursera.org/learn/machine-learning/home/info) by Andrew Ng.
* [Machine learning playlist on Youtube](https://www.youtube.com/playlist?list=PLD0F06AA0D2E8FFBA).
* Free online interactive book ["Neural Networks and Deep Learning"](http://neuralnetworksanddeeplearning.com/).
* [Heterogeneous Parallel Programming](https://www.coursera.org/course/hetero) course.
* [Deep Learning for Perception](https://computing.ece.vt.edu/~f15ece6504/) by Virginia Tech, Electrical and Computer Engineering, Fall 2015: ECE 6504
* [CAP 5415 - Computer Vision](http://crcv.ucf.edu/courses/CAP5415/Fall2014/index.php) by UCF
* [CS224d: Deep Learning for Natural Language Processing](http://cs224d.stanford.edu/syllabus.html) by Stanford
* [Machine Learning: 2014-2015 Course materials](https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/) by Oxford
* [Stanford CS class CS231n: Convolutional Neural Networks for Visual Recognition.](http://cs231n.stanford.edu/)
* [Deep Learning for Natural Language Processing \(without Magic\)](http://nlp.stanford.edu/courses/NAACL2013/)
* [Videos](http://videolectures.net/deeplearning2015_montreal/) from Deep Learning Summer School, Montreal 2015.
* [Deep Learning Summer School, Montreal 2016](http://videolectures.net/deeplearning2016_montreal/)
# <a name="lists"/>Other Lists
* [Awesome Machine Learning](https://github.com/josephmisiti/awesome-machine-learning)
* [Machine Learning Courses](https://github.com/prakhar1989/awesome-courses#machine-learning)
* [Awesome Data Science](https://github.com/okulbilisim/awesome-datascience)
* [Awesome Computer Vision](https://github.com/jbhuang0604/awesome-computer-vision)
* [Speech and language processing](https://github.com/edobashira/speech-language-processing)
* [The Rise of Chat Bots:](https://stanfy.com/blog/the-rise-of-chat-bots-useful-links-articles-libraries-and-platforms/) Useful Links, Articles, Libraries and Platforms by Pavlo Bashmakov.
* [Awesome Machine Learning for Cyber Security](https://github.com/jivoi/awesome-ml-for-cybersecurity)
|
3,461 | Federated learning on graph and tabular data related papers, frameworks, and datasets. | # Federated-Learning-on-Graph-and-Tabular-Data
[](https://github.com/youngfish42/Awesome-Federated-Learning-on-Graph-and-Tabular-Data/stargazers) [](https://awesome.re) [](https://github.com/youngfish42/image-registration-resources/blob/master/LICENSE) 
---
**Table of Contents**
- [Papers](#papers)
- [FL on Graph Data and Graph Neural Networks](#fl-on-graph-data-and-graph-neural-networks) [](https://dblp.uni-trier.de/search?q=Federated%20graph%7Csubgraph%7Cgnn)
- [FL on Tabular Data](#fl-on-tabular-data) [](https://dblp.org/search?q=federate%20tree%7Cboost%7Cbagging%7Cgbdt%7Ctabular%7Cforest%7CXGBoost)
- [FL in top-tier journal](#fl-in-top-tier-journal)
- FL in top-tier conference and journal by category
- [AI](#fl-in-top-ai-conference-and-journal) [ML](#fl-in-top-ml-conference-and-journal) [DM](#fl-in-top-dm-conference-and-journal) [Secure](#fl-in-top-secure-conference-and-journal) [CV](#fl-in-top-cv-conference-and-journal) [NLP](#fl-in-top-nlp-conference-and-journal) [IR](#fl-in-top-ir-conference-and-journal) [DB](#fl-in-top-db-conference-and-journal) [Network](#fl-in-top-network-conference-and-journal) [System](#fl-in-top-system-conference-and-journal)
- [Framework](#framework)
- [Datasets](#datasets)
- [Surveys](#surveys)
- [Tutorials and Courses](#tutorials-and-courses)
- Key Conferences/Workshops/Journals
- [Workshops](#workshops) [Special Issues](#journal-special-issues) [Special Tracks](#conference-special-tracks)
- [Update log](#update-log)
- [How to contact us](#how-to-contact-us)
- [Acknowledgments](#acknowledgments)
- [Citation](#citation)
# papers
**categories**
- Artificial Intelligence (IJCAI, AAAI, AISTATS, AI)
- Machine Learning (NeurIPS, ICML, ICLR, COLT, UAI, JMLR, TPAMI)
- Data Mining (KDD, WSDM)
- Secure (S&P, CCS, USENIX Security, NDSS)
- Computer Vision (ICCV, CVPR, ECCV, MM, IJCV)
- Natural Language Processing (ACL, EMNLP, NAACL, COLING)
- Information Retrieval (SIGIR)
- Database (SIGMOD, ICDE, VLDB)
- Network (SIGCOMM, INFOCOM, MOBICOM, NSDI, WWW)
- System (OSDI, SOSP, ISCA, MLSys, TPDS, DAC, TOCS, TOS, TCAD, TC)
**keywords**
Statistics: :fire: code is available & stars >= 100 | :star: citation >= 50 | :mortar_board: Top-tier venue
**`kg.`**: Knowledge Graph | **`data.`**: dataset | **`surv.`**: survey
## fl on graph data and graph neural networks
[](https://dblp.uni-trier.de/search?q=Federated%20graph%7Csubgraph%7Cgnn)
This section partially refers to [DBLP](https://dblp.uni-trier.de/search?q=Federated%20graph%7Csubgraph%7Cgnn) search engine and repositories [Awesome-Federated-Learning-on-Graph-and-GNN-papers](https://github.com/huweibo/Awesome-Federated-Learning-on-Graph-and-GNN-papers) and [Awesome-Federated-Machine-Learning](https://github.com/innovation-cat/Awesome-Federated-Machine-Learning#16-graph-neural-networks).
<!-- START:fl-on-graph-data-and-graph-neural-network -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ---------------------- | ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| HetVis: A Visual Analysis Approach for Identifying Data Heterogeneity in Horizontal Federated Learning | Nankai University | IEEE Trans. Vis. Comput. Graph. :mortar_board: | 2023 | HetVis[^HetVis] | [[PUB](https://ieeexplore.ieee.org/document/9912364)] [[PDF](https://arxiv.org/abs/2208.07491)] |
| Federated Learning on Non-IID Graphs via Structural Knowledge Sharing | UTS | AAAI :mortar_board: | 2023 | FedStar[^FedStar] | [[PDF](https://arxiv.org/abs/2211.13009)] [[CODE](https://github.com/yuetan031/fedstar)] |
| FedGS: Federated Graph-based Sampling with Arbitrary Client Availability | XMU | AAAI :mortar_board: | 2023 | FedGS[^FedGS] | [[PDF](https://arxiv.org/abs/2211.13975)] [[CODE](https://github.com/wwzzz/fedgs)] |
| Federated Learning-Based Cross-Enterprise Recommendation With Graph Neural | | IEEE Trans. Ind. Informatics | 2023 | FL-GMT[^FL-GMT] | [[PUB](https://ieeexplore.ieee.org/document/9873989)] |
| FedWalk: Communication Efficient Federated Unsupervised Node Embedding with Differential Privacy | SJTU | KDD :mortar_board: | 2022 | FedWalk[^FedWalk] | [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539308)] [[PDF](https://arxiv.org/abs/2205.15896)] |
| FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Platform for Federated Graph Learning :fire: | Alibaba | KDD (Best Paper Award) :mortar_board: | 2022 | FederatedScope-GNN[^FederatedScope-GNN] | [[PDF](https://arxiv.org/abs/2204.05562)] [[CODE](https://github.com/alibaba/FederatedScope)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539112)] |
| Deep Neural Network Fusion via Graph Matching with Applications to Model Ensemble and Federated Learning | SJTU | ICML :mortar_board: | 2022 | GAMF[^GAMF] | [[PUB](https://proceedings.mlr.press/v162/liu22k/liu22k.pdf)] [[CODE](https://github.com/Thinklab-SJTU/GAMF)] |
| Meta-Learning Based Knowledge Extrapolation for Knowledge Graphs in the Federated Setting **`kg.`** | ZJU | IJCAI :mortar_board: | 2022 | MaKEr[^MaKEr] | [[PUB](https://www.ijcai.org/proceedings/2022/273)] [[PDF](https://doi.org/10.48550/arXiv.2205.04692)] [[CODE](https://github.com/zjukg/maker)] |
| Personalized Federated Learning With a Graph | UTS | IJCAI :mortar_board: | 2022 | SFL[^SFL] | [[PUB](https://www.ijcai.org/proceedings/2022/357)] [[PDF](https://arxiv.org/abs/2203.00829)] [[CODE](https://github.com/dawenzi098/SFL-Structural-Federated-Learning)] |
| Vertically Federated Graph Neural Network for Privacy-Preserving Node Classification | ZJU | IJCAI :mortar_board: | 2022 | VFGNN[^VFGNN] | [[PUB](https://www.ijcai.org/proceedings/2022/272)] [[PDF](https://arxiv.org/abs/2005.11903)] |
| SpreadGNN: Decentralized Multi-Task Federated Learning for Graph Neural Networks on Molecular Data | USC | AAAI:mortar_board: | 2022 | SpreadGNN[^SpreadGNN] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20643)] [[PDF](https://arxiv.org/abs/2106.02743)] [[CODE](https://github.com/FedML-AI/SpreadGNN)] [[解读](https://zhuanlan.zhihu.com/p/429720860)] |
| FedGraph: Federated Graph Learning with Intelligent Sampling | UoA | TPDS :mortar_board: | 2022 | FedGraph[^FedGraph] | [[PUB](https://ieeexplore.ieee.org/abstract/document/9606516/)] [[CODE](https://github.com/cfh19980612/FedGraph)] [[解读](https://zhuanlan.zhihu.com/p/442233479)] |
| Federated Graph Machine Learning: A Survey of Concepts, Techniques, and Applications **`surv.`** | University of Virginia | SIGKDD Explor. | 2022 | FGML[^FGML] | [[PUB](https://dl.acm.org/doi/10.1145/3575637.3575644)] [[PDF](https://arxiv.org/abs/2207.11812)] |
| More is Better (Mostly): On the Backdoor Attacks in Federated Graph Neural Networks | TU Delft | ACSAC | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3564625.3567999)] [[PDF](https://arxiv.org/abs/2202.03195)] |
| FedNI: Federated Graph Learning with Network Inpainting for Population-Based Disease Prediction | UESTC | TMI | 2022 | FedNI[^FedNI] | [[PUB](https://ieeexplore.ieee.org/document/9815303)] [[PDF](https://arxiv.org/abs/2112.10166)] |
| SemiGraphFL: Semi-supervised Graph Federated Learning for Graph Classification. | PKU | PPSN | 2022 | SemiGraphFL[^SemiGraphFL] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-031-14714-2_33)] |
| A federated graph neural network framework for privacy-preserving personalization | THU | Nature Communications | 2022 | FedPerGNN[^FedPerGNN] | [[PUB](https://www.nature.com/articles/s41467-022-30714-9)] [[CODE](https://github.com/wuch15/FedPerGNN)] [[解读](https://zhuanlan.zhihu.com/p/487383715)] |
| Malicious Transaction Identification in Digital Currency via Federated Graph Deep Learning | BIT | INFOCOM Workshops | 2022 | GraphSniffer[^GraphSniffer] | [[PUB](https://ieeexplore.ieee.org/document/9797992/)] |
| Efficient Federated Learning on Knowledge Graphs via Privacy-preserving Relation Embedding Aggregation **`kg.`** | Lehigh University | EMNLP | 2022 | FedR[^FedR] | [[PDF](https://arxiv.org/abs/2203.09553)] [[CODE](https://github.com/taokz/FedR)] |
| FedGCN: Convergence and Communication Tradeoffs in Federated Training of Graph Convolutional Networks | CMU | CIKM Workshop (Oral) | 2022 | FedGCN[^FedGCN] | [[PDF](https://arxiv.org/abs/2201.12433)] [[CODE](https://github.com/yh-yao/FedGCN)] |
| Investigating the Predictive Reproducibility of Federated Graph Neural Networks using Medical Datasets. | | MICCAI Workshop | 2022 | | [[PDF](https://arxiv.org/abs/2209.06032)] [[CODE](https://github.com/basiralab/reproducibleFedGNN)] |
| Power Allocation for Wireless Federated Learning using Graph Neural Networks | Rice University | ICASSP | 2022 | wirelessfl-pdgnet[^wirelessfl-pdgnet] | [[PUB](https://ieeexplore.ieee.org/document/9747764)] [[PDF](https://arxiv.org/abs/2111.07480)] [[CODE](https://github.com/bl166/wirelessfl-pdgnet)] |
| Privacy-Preserving Federated Multi-Task Linear Regression: A One-Shot Linear Mixing Approach Inspired By Graph Regularization | UC | ICASSP | 2022 | multitask-fusion[^multitask-fusion] | [[PUB](https://ieeexplore.ieee.org/document/9746007)] [[PDF](https://www.math.ucla.edu/~harlin/papers/mtl.pdf)] [[CODE](https://github.com/HarlinLee/multitask-fusion)] |
| Graph-regularized federated learning with shareable side information | NWPU | Knowl. Based Syst. | 2022 | | [[PUB](https://www.sciencedirect.com/science/article/pii/S095070512201053X)] |
| Federated knowledge graph completion via embedding-contrastive learning **`kg.`** | ZJU | Knowl. Based Syst. | 2022 | FedEC[^FedEC] | [[PUB](https://www.sciencedirect.com/science/article/abs/pii/S0950705122007316?via%3Dihub)] |
| Federated Graph Learning with Periodic Neighbour Sampling | HKU | IWQoS | 2022 | PNS-FGL[^PNS-FGL] | [[PUB](https://ieeexplore.ieee.org/document/9812908)] |
| Domain-Aware Federated Social Bot Detection with Multi-Relational Graph Neural Networks. | UCAS; CAS | IJCNN | 2022 | DA-MRG[^DA-MRG] | [[PUB](https://ieeexplore.ieee.org/document/9892366)] |
| A Privacy-Preserving Subgraph-Level Federated Graph Neural Network via Differential Privacy | Ping An Technology | KSEM | 2022 | DP-FedRec[^DP-FedRec] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-031-10989-8_14)] [[PDF](https://arxiv.org/abs/2206.03492)] |
| Peer-to-Peer Variational Federated Learning Over Arbitrary Graphs | UCSD | Int. J. Bio Inspired Comput. | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9825726/)] |
| Federated Multi-task Graph Learning | ZJU | ACM Trans. Intell. Syst. Technol. | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3527622)] |
| Graph-Based Traffic Forecasting via Communication-Efficient Federated Learning | SUSTech | WCNC | 2022 | CTFL[^CTFL] | [[PUB](https://ieeexplore.ieee.org/document/9771883)] |
| Federated meta-learning for spatial-temporal prediction | NEU | Neural Comput. Appl. | 2022 | FML-ST[^FML-ST] | [[PUB](https://link.springer.com/article/10.1007/s00521-021-06861-3)] [[CODE](https://github.com/lwz001/FML-ST)] |
| BiG-Fed: Bilevel Optimization Enhanced Graph-Aided Federated Learning | NTU | IEEE Transactions on Big Data | 2022 | BiG-Fed[^BiG-Fed] | [[PUB](https://ieeexplore.ieee.org/abstract/document/9832778)] [[PDF](https://fl-icml.github.io/2021/papers/FL-ICML21_paper_74.pdf)] |
| Leveraging Spanning Tree to Detect Colluding Attackers in Federated Learning | Missouri S&T | INFCOM Workshops | 2022 | FL-ST[^FL-ST] | [[PUB](https://ieeexplore.ieee.org/document/9798077)] |
| Federated learning of molecular properties with graph neural networks in a heterogeneous setting | University of Rochester | Patterns | 2022 | FLIT+[^FLITplus] | [[PUB](https://linkinghub.elsevier.com/retrieve/pii/S2666389922001180)] [[PDF](https://arxiv.org/abs/2109.07258)] [[CODE](https://doi.org/10.5281/zenodo.6485682)] |
| Graph Federated Learning for CIoT Devices in Smart Home Applications | University of Toronto | IEEE Internet Things J. | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9983539)] [[PDF](https://arxiv.org/abs/2212.14395)] [[CODE](https://github.com/FL-HAR/Graph-Federated-Learning-for-CIoT-Devices.git)] |
| Multi-Level Federated Graph Learning and Self-Attention Based Personalized Wi-Fi Indoor Fingerprint Localization | SYSU | IEEE Commun. Lett. | 2022 | ML-FGL[^ML-FGL] | [[PUB](https://ieeexplore.ieee.org/document/9734052)] |
| Graph-Assisted Communication-Efficient Ensemble Federated Learning | UC | EUSIPCO | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9909826)] [[PDF](https://arxiv.org/abs/2202.13447)] |
| Decentralized Graph Federated Multitask Learning for Streaming Data | NTNU | CISS | 2022 | PSO-GFML[^PSO-GFML] | [[PUB](https://doi.org/10.1109/CISS53076.2022.9751160)] |
| Neural graph collaborative filtering for privacy preservation based on federated transfer learning | | Electron. Libr. | 2022 | FTL-NGCF[^FTL-NGCF] | [[PUB](https://www.emerald.com/insight/content/doi/10.1108/EL-06-2022-0141/full/html)] |
| Dynamic Neural Graphs Based Federated Reptile for Semi-Supervised Multi-Tasking in Healthcare Applications | Oxford | JBHI | 2022 | DNG-FR[^DNG-FR] | [[PUB](https://ieeexplore.ieee.org/document/9648036)] |
| FedGCN: Federated Learning-Based Graph Convolutional Networks for Non-Euclidean Spatial Data | NUIST | Mathematics | 2022 | FedGCN-NES[^FedGCN-NES] | [[PUB](https://www.mdpi.com/2227-7390/10/6/1000)] |
| Federated Dynamic Graph Neural Networks with Secure Aggregation for Video-based Distributed Surveillance | ND | ACM Trans. Intell. Syst. Technol. | 2022 | Feddy[^Feddy] | [[PUB](https://dl.acm.org/doi/10.1145/3501808)] [[PDF](https://arxiv.org/abs/2009.07351)] [[解读](https://zhuanlan.zhihu.com/p/441686576)] |
| Device Sampling for Heterogeneous Federated Learning: Theory, Algorithms, and Implementation. | Purdue | INFOCOM :mortar_board: | 2021 | D2D-FedL[^D2D-FedL] | [[PUB](https://ieeexplore.ieee.org/document/9488906)] [[PDF](https://arxiv.org/abs/2101.00787)] |
| Federated Graph Classification over Non-IID Graphs | Emory | NeurIPS :mortar_board: | 2021 | GCFL[^GCFL] | [[PUB](https://papers.nips.cc/paper/2021/hash/9c6947bd95ae487c81d4e19d3ed8cd6f-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.13423)] [[CODE](https://github.com/Oxfordblue7/GCFL)] [[解读](https://zhuanlan.zhihu.com/p/430623053)] |
| Subgraph Federated Learning with Missing Neighbor Generation | Emory; UBC; Lehigh University | NeurIPS :mortar_board: | 2021 | FedSage[^FedSage] | [[PUB](https://papers.neurips.cc/paper/2021/hash/34adeb8e3242824038aa65460a47c29e-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.13430)] |
| Cross-Node Federated Graph Neural Network for Spatio-Temporal Data Modeling | USC | KDD :mortar_board: | 2021 | CNFGNN[^CNFGNN] | [[PUB](https://dl.acm.org/doi/10.1145/3447548.3467371)] [[PDF](https://arxiv.org/abs/2106.05223)] [[CODE](https://github.com/mengcz13/KDD2021_CNFGNN)] [[解读](https://zhuanlan.zhihu.com/p/434839878)] |
| Differentially Private Federated Knowledge Graphs Embedding **`kg.`** | BUAA | CIKM | 2021 | FKGE[^FKGE] | [[PUB](https://dl.acm.org/doi/10.1145/3459637.3482252)] [[PDF](https://arxiv.org/abs/2105.07615)] [[CODE](https://github.com/HKUST-KnowComp/FKGE)] [[解读](https://zhuanlan.zhihu.com/p/437895959)] |
| Decentralized Federated Graph Neural Networks | Blue Elephant Tech | IJCAI Workshop | 2021 | D-FedGNN[^D-FedGNN] | [[PDF](https://federated-learning.org/fl-ijcai-2021/FTL-IJCAI21_paper_20.pdf)] |
| FedSGC: Federated Simple Graph Convolution for Node Classification | HKUST | IJCAI Workshop | 2021 | FedSGC[^FedSGC] | [[PDF](https://federated-learning.org/fl-ijcai-2021/FTL-IJCAI21_paper_5.pdf)] |
| FL-DISCO: Federated Generative Adversarial Network for Graph-based Molecule Drug Discovery: Special Session Paper | UNM | ICCAD | 2021 | FL-DISCO[^FL-DISCO] | [[PUB](https://doi.org/10.1109/ICCAD51958.2021.9643440)] |
| FASTGNN: A Topological Information Protected Federated Learning Approach for Traffic Speed Forecasting | UTS | IEEE Trans. Ind. Informatics | 2021 | FASTGNN[^FASTGNN] | [[PUB](https://ieeexplore.ieee.org/document/9340313)] |
| DAG-FL: Direct Acyclic Graph-based Blockchain Empowers On-Device Federated Learning | BUPT; UESTC | ICC | 2021 | DAG-FL[^DAG-FL] | [[PUB](https://doi.org/10.1109/ICC42927.2021.9500737)] [[PDF](https://arxiv.org/abs/2104.13092)] |
| FedE: Embedding Knowledge Graphs in Federated Setting **`kg.`** | ZJU | IJCKG | 2021 | FedE[^FedE] | [[PUB](https://doi.org/10.1145/3502223.3502233)] [[PDF](https://arxiv.org/abs/2010.12882)] [[CODE](https://github.com/AnselCmy/FedE)] |
| Federated Knowledge Graph Embeddings with Heterogeneous Data **`kg.`** | TJU | CCKS | 2021 | FKE[^FKE] | [[PUB](https://doi.org/10.1007/978-981-16-6471-7_2)] |
| A Graph Federated Architecture with Privacy Preserving Learning | EPFL | SPAWC | 2021 | GFL[^GFL] | [[PUB](https://doi.org/10.1109/SPAWC51858.2021.9593148)] [[PDF](https://arxiv.org/abs/2104.13215)] [[解读](https://zhuanlan.zhihu.com/p/440809332)] |
| Federated Social Recommendation with Graph Neural Network | UIC | ACM TIST | 2021 | FeSoG[^FeSoG] | [[PUB](https://dl.acm.org/doi/abs/10.1145/3501815)] [[PDF](https://arxiv.org/abs/2111.10778)] [[CODE](https://github.com/YangLiangwei/FeSoG)] |
| FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks :fire: **`surv.`** | USC | ICLR Workshop / MLSys Workshop | 2021 | FedGraphNN[^FedGraphNN] | [[PDF](https://arxiv.org/abs/2104.07145)] [[CODE](https://github.com/FedML-AI/FedGraphNN)] [[解读](https://zhuanlan.zhihu.com/p/429220636)] |
| A Federated Multigraph Integration Approach for Connectional Brain Template Learning | Istanbul Technical University | MICCAI Workshop | 2021 | Fed-CBT[^Fed-CBT] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-89847-2_4)] [[CODE](https://github.com/basiralab/Fed-CBT)] |
| Cluster-driven Graph Federated Learning over Multiple Domains | Politecnico di Torino | CVPR Workshop | 2021 | FedCG-MD[^FedCG-MD] | [[PDF](https://arxiv.org/abs/2104.14628)] [[解读](https://zhuanlan.zhihu.com/p/440527314)] |
| FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation | THU | ICML workshop | 2021 | FedGNN[^FedGNN] | [[PDF](https://arxiv.org/abs/2102.04925)] [[解读](https://zhuanlan.zhihu.com/p/428783383)] |
| Decentralized federated learning of deep neural networks on non-iid data | RISE; Chalmers University of Technology | ICML workshop | 2021 | DFL-PENS[^DFL-PENS] | [[PDF](https://arxiv.org/abs/2107.08517)] [[CODE](https://github.com/guskarls/dfl-pens)] |
| Glint: Decentralized Federated Graph Learning with Traffic Throttling and Flow Scheduling | The University of Aizu | IWQoS | 2021 | Glint[^Glint] | [[PUB](https://doi.org/10.1109/IWQOS52092.2021.9521331)] |
| Federated Graph Neural Network for Cross-graph Node Classification | BUPT | CCIS | 2021 | FGNN[^FGNN] | [[PUB](https://doi.org/10.1109/CCIS53392.2021.9754598)] |
| GraFeHTy: Graph Neural Network using Federated Learning for Human Activity Recognition | Lead Data Scientist Ericsson Digital Services | ICMLA | 2021 | GraFeHTy[^GraFeHTy] | [[PUB](https://doi.org/10.1109/ICMLA52953.2021.00184)] |
| Distributed Training of Graph Convolutional Networks | Sapienza University of Rome | TSIPN | 2021 | D-GCN[^D-GCN] | [[PUB](https://ieeexplore.ieee.org/document/9303371)] [[PDF](https://arxiv.org/abs/2007.06281)] [[解读](https://zhuanlan.zhihu.com/p/433329525)] |
| Decentralized federated learning for electronic health records | UMN | NeurIPS Workshop / CISS | 2020 | FL-DSGD[^FL-DSGD] | [[PUB](https://ieeexplore.ieee.org/abstract/document/9086196#:~:text=Decentralized%20Federated%20Learning%20for%20Electronic%20Health%20Records%20Abstract:,in%20distributed%20training%20problems%20within%20a%20star%20network.)] [[PDF](https://arxiv.org/abs/1912.01792)] [[解读](https://zhuanlan.zhihu.com/p/448738120)] |
| ASFGNN: Automated Separated-Federated Graph Neural Network | Ant Group | PPNA | 2020 | ASFGNN[^ASFGNN] | [[PUB](https://doi.org/10.1007/s12083-021-01074-w)] [[PDF](https://arxiv.org/abs/2011.03248)] [[解读](https://zhuanlan.zhihu.com/p/431283541)] |
| Decentralized federated learning via sgd over wireless d2d networks | SZU | SPAWC | 2020 | DSGD[^DSGD] | [[PUB](https://ieeexplore.ieee.org/document/9154332)] [[PDF](https://arxiv.org/abs/2002.12507)] |
| SGNN: A Graph Neural Network Based Federated Learning Approach by Hiding Structure | SDU | BigData | 2019 | SGNN[^SGNN] | [[PUB](https://ieeexplore.ieee.org/document/9005983)] [[PDF](https://www.researchgate.net/profile/Shijun_Liu3/publication/339482514_SGNN_A_Graph_Neural_Network_Based_Federated_Learning_Approach_by_Hiding_Structure/links/5f48365d458515a88b790595/SGNN-A-Graph-Neural-Network-Based-Federated-Learning-Approach-by-Hiding-Structure.pdf)] |
| Towards Federated Graph Learning for Collaborative Financial Crimes Detection | IBM | NeurIPS Workshop | 2019 | FGL-DFC[^FGL-DFC] | [[PDF](https://arxiv.org/abs/1909.12946)] |
| Federated learning of predictive models from federated Electronic Health Records :star: | BU | Int. J. Medical Informatics | 2018 | cPDS[^cPDS] | [[PUB](https://www.sciencedirect.com/science/article/abs/pii/S138650561830008X?via%3Dihub)] |
| Federated Learning over Coupled Graphs | | preprint | 2023 | | [[PDF](https://arxiv.org/abs/2301.11099)] |
| Uplink Scheduling in Federated Learning: an Importance-Aware Approach via Graph Representation Learning | | preprint | 2023 | | [[PDF](https://arxiv.org/abs/2301.11903)] |
| Graph Federated Learning with Hidden Representation Sharing | UCLA | preprint | 2022 | GFL-APPNP[^GFL-APPNP] | [[PDF](https://arxiv.org/abs/2212.12158)] |
| FedRule: Federated Rule Recommendation System with Graph Neural Networks | CMU | preprint | 2022 | FedRule[^FedRule] | [[PDF](https://arxiv.org/abs/2211.06812)] |
| M3FGM:a node masking and multi-granularity message passing-based federated graph model for spatial-temporal data prediction | Xidian University | preprint | 2022 | M3FGM[^M3FGM] | [[PDF](https://arxiv.org/abs/2210.16193)] |
| Federated Graph-based Networks with Shared Embedding | BUCEA | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2210.01803)] |
| Privacy-preserving Decentralized Federated Learning over Time-varying Communication Graph | Lancaster University | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2210.00325)] |
| Heterogeneous Federated Learning on a Graph. | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2209.08737)] |
| FedEgo: Privacy-preserving Personalized Federated Graph Learning with Ego-graphs | SYSU | preprint | 2022 | FedEgo[^FedEgo] | [[PDF](https://arxiv.org/abs/2208.13685)] [[CODE](https://github.com/fedego/fedego)] |
| Federated Graph Contrastive Learning | UTS | preprint | 2022 | FGCL[^FGCL] | [[PDF](https://arxiv.org/abs/2207.11836)] |
| FD-GATDR: A Federated-Decentralized-Learning Graph Attention Network for Doctor Recommendation Using EHR | | preprint | 2022 | FD-GATDR[^FD-GATDR] | [[PDF](https://arxiv.org/abs/2207.05750)] |
| Privacy-preserving Graph Analytics: Secure Generation and Federated Learning | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2207.00048)] |
| Personalized Subgraph Federated Learning | | preprint | 2022 | FED-PUB[^FED-PUB] | [[PDF](https://arxiv.org/abs/2206.10206)] |
| Federated Graph Attention Network for Rumor Detection | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2206.05713)] [[CODE](https://github.com/baichuanzheng1/fedgat)] |
| FedRel: An Adaptive Federated Relevance Framework for Spatial Temporal Graph Learning | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2206.03420)] |
| Privatized Graph Federated Learning | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2203.07105)] |
| Federated Graph Neural Networks: Overview, Techniques and Challenges **`surv.`** | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2202.07256)] |
| Decentralized event-triggered federated learning with heterogeneous communication thresholds. | | preprint | 2022 | EF-HC[^EF-HC] | [[PDF](https://github.com/ShahryarBQ/EF_HC)] |
| Federated Learning with Heterogeneous Architectures using Graph HyperNetworks | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2201.08459)] |
| STFL: A Temporal-Spatial Federated Learning Framework for Graph Neural Networks | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2111.06750)] [[CODE](https://github.com/jw9msjwjnpdrlfw/tsfl)] |
| Graph-Fraudster: Adversarial Attacks on Graph Neural Network Based Vertical Federated Learning | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2110.06468)] [[CODE](https://github.com/hgh0545/graph-fraudster)] |
| PPSGCN: A Privacy-Preserving Subgraph Sampling Based Distributed GCN Training Method | | preprint | 2021 | PPSGCN[^PPSGCN] | [[PDF](https://arxiv.org/abs/2110.12906)] |
| Leveraging a Federation of Knowledge Graphs to Improve Faceted Search in Digital Libraries **`kg.`** | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2107.05447)] |
| Federated Myopic Community Detection with One-shot Communication | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2106.07255)] |
| Federated Graph Learning -- A Position Paper **`surv.`** | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2105.11099)] |
| A Vertical Federated Learning Framework for Graph Convolutional Network | | preprint | 2021 | FedVGCN[^FedVGCN] | [[PDF](https://arxiv.org/abs/2106.11593)] |
| FedGL: Federated Graph Learning Framework with Global Self-Supervision | | preprint | 2021 | FedGL[^FedGL] | [[PDF](https://arxiv.org/abs/2105.03170)] |
| FL-AGCNS: Federated Learning Framework for Automatic Graph Convolutional Network Search | | preprint | 2021 | FL-AGCNS[^FL-AGCNS] | [[PDF](https://arxiv.org/abs/2104.04141)] |
| Towards On-Device Federated Learning: A Direct Acyclic Graph-based Blockchain Approach | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2104.13092)] |
| A New Look and Convergence Rate of Federated Multi-Task Learning with Laplacian Regularization | | preprint | 2021 | dFedU[^dFedU] | [[PDF](https://arxiv.org/abs/2102.07148)] [[CODE](https://github.com/dual-grp/fedu_fmtl)] |
| GraphFL: A Federated Learning Framework for Semi-Supervised Node Classification on Graphs | | preprint | 2020 | GraphFL[^GraphFL] | [[PDF](https://arxiv.org/abs/2012.04187)] [[解读](https://zhuanlan.zhihu.com/p/431479904)] |
| Improving Federated Relational Data Modeling via Basis Alignment and Weight Penalty **`kg.`** | | preprint | 2020 | FedAlign-KG[^FedAlign-KG] | [[PDF](https://arxiv.org/abs/2011.11369)] |
| GraphFederator: Federated Visual Analysis for Multi-party Graphs | | preprint | 2020 | | [[PDF](https://arxiv.org/abs/2008.11989)] |
| Privacy-Preserving Graph Neural Network for Node Classification | | preprint | 2020 | | [[PDF](https://arxiv.org/abs/2005.11903)] |
| Peer-to-peer federated learning on graphs | UC | preprint | 2019 | P2P-FLG[^P2P-FLG] | [[PDF](https://arxiv.org/abs/1901.11173)] [[解读](https://zhuanlan.zhihu.com/p/441944011)] |
<!-- END:fl-on-graph-data-and-graph-neural-network -->
### Private Graph Neural Networks (todo)
- [Arxiv 2021] Privacy-Preserving Graph Convolutional Networks for Text Classification. [[PDF]](https://arxiv.org/abs/2102.09604)
- [Arxiv 2021] GraphMI: Extracting Private Graph Data from Graph Neural Networks. [[PDF]](https://arxiv.org/abs/2106.02820)
- [Arxiv 2021] Towards Representation Identical Privacy-Preserving Graph Neural Network via Split Learning. [[PDF]](https://arxiv.org/abs/2107.05917)
- [Arxiv 2020] Locally Private Graph Neural Networks. [[PDF]](https://arxiv.org/abs/2006.05535)
<!-- START:private-graph-neural-networks -->
<!-- END:private-graph-neural-networks -->
## fl on tabular data
[](https://dblp.org/search?q=federate%20tree%7Cboost%7Cbagging%7Cgbdt%7Ctabular%7Cforest%7CXGBoost)
This section refers to [DBLP](https://dblp.org/search?q=federate%20tree%7Cboost%7Cbagging%7Cgbdt%7Ctabular%7Cforest) search engine.
<!-- START:fl-on-tabular-data -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | --------------------------------- | --------------------------- | ---- | --------------------------- | ------------------------------------------------------------ |
| SGBoost: An Efficient and Privacy-Preserving Vertical Federated Tree Boosting Framework | Xidian University | IEEE Trans. Inf. Forensics Secur. :mortar_board: | 2023 | SGBoost[^SGBoost] | [[PUB](https://ieeexplore.ieee.org/document/10002374)] [[CODE](https://github.com/nds2022/SGBoost)] |
| Incentive-boosted Federated Crowdsourcing | SDU | AAAI :mortar_board: | 2023 | iFedCrowd[^iFedCrowd] | [[PDF](https://arxiv.org/abs/2211.14439)] |
| Explaining predictions and attacks in federated learning via random forests | Universitat Rovira i Virgili | Appl. Intell. | 2023 | | [[PUB](https://link.springer.com/article/10.1007/s10489-022-03435-1)] [[CODE](https://github.com/RamiHaf/Explainable-Federated-Learning-via-Random-Forests)] |
| Boosting Accuracy of Differentially Private Federated Learning in Industrial IoT With Sparse Responses | | IEEE Trans. Ind. Informatics | 2023 | | [[PUB](https://ieeexplore.ieee.org/document/9743613)] |
| OpBoost: A Vertical Federated Tree Boosting Framework Based on Order-Preserving Desensitization | ZJU | Proc. VLDB Endow. :mortar_board: | 2022 | OpBoost[^OpBoost] | [[PUB](https://www.vldb.org/pvldb/volumes/16/paper/OpBoost%3A%20A%20Vertical%20Federated%20Tree%20Boosting%20Framework%20Based%20on%20Order-Preserving%20Desensitization)] [[PDF](https://arxiv.org/abs/2210.01318)] [[CODE](https://github.com/alibaba-edu/mpc4j/tree/main/mpc4j-sml-opboost)] |
| RevFRF: Enabling Cross-Domain Random Forest Training With Revocable Federated Learning | XIDIAN UNIVERSITY | IEEE Trans. Dependable Secur. Comput. :mortar_board: | 2022 | RevFRF[^RevFRF] | [[PUB](https://ieeexplore.ieee.org/document/9514457)] [[PDF](https://arxiv.org/abs/1911.03242)] |
| A Tree-based Model Averaging Approach for Personalized Treatment Effect Estimation from Heterogeneous Data Sources | University of Pittsburgh | ICML :mortar_board: | 2022 | | [[PUB](https://proceedings.mlr.press/v162/tan22a.html)] [[PDF](https://arxiv.org/abs/2103.06261)] [[CODE](https://github.com/ellenxtan/ifedtree)] |
| Federated Boosted Decision Trees with Differential Privacy | University of Warwick | CCS :mortar_board: | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3548606.3560687)] [[PDF](https://arxiv.org/abs/2210.02910)] [[CODE](https://github.com/Samuel-Maddock/federated-boosted-dp-trees)] |
| Federated Functional Gradient Boosting | University of Pennsylvania | AISTATS :mortar_board: | 2022 | FFGB[^FFGB] | [[PUB](https://proceedings.mlr.press/v151/shen22a.html)] [[PDF](https://arxiv.org/abs/2103.06972)] [[CODE](https://github.com/shenzebang/Federated-Learning-Pytorch)] |
| Federated Learning for Tabular Data: Exploring Potential Risk to Privacy | Newcastle University | ISSRE | 2022 | | [[PDF](https://arxiv.org/abs/2210.06856)] |
| Federated Random Forests can improve local performance of predictive models for various healthcare applications | University of Marburg | Bioinform. | 2022 | FRF[^FRF] | [[PUB](https://academic.oup.com/bioinformatics/article-abstract/38/8/2278/6525214)] [[CODE](https://featurecloud.ai/)] |
| Boosting the Federation: Cross-Silo Federated Learning without Gradient Descent. | unito | IJCNN | 2022 | federation-boosting[^federation-boosting] | [[PUB](https://ieeexplore.ieee.org/document/9892284)] [[CODE](https://github.com/ml-unito/federation_boosting)] |
| Federated Forest | JD | TBD | 2022 | FF[^FF] | [[PUB](https://ieeexplore.ieee.org/document/9088965)] [[PDF](https://arxiv.org/abs/1905.10053)] |
| Fed-GBM: a cost-effective federated gradient boosting tree for non-intrusive load monitoring | The University of Sydney | e-Energy | 2022 | Fed-GBM[^Fed-GBM] | [[PUB](https://dl.acm.org/doi/10.1145/3538637.3538840)] |
| Verifiable Privacy-Preserving Scheme Based on Vertical Federated Random Forest | NUST | IEEE Internet Things J. | 2022 | VPRF[^VPRF] | [[PUB](https://ieeexplore.ieee.org/document/9461157)] |
| Statistical Detection of Adversarial examples in Blockchain-based Federated Forest In-vehicle Network Intrusion Detection Systems | CNU | IEEE Access | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9912427)] [[PDF](https://arxiv.org/abs/2207.04843)] |
| BOFRF: A Novel Boosting-Based Federated Random Forest Algorithm on Horizontally Partitioned Data | METU | IEEE Access | 2022 | BOFRF[^BOFRF] | [[PUB](https://ieeexplore.ieee.org/document/9867984/)] |
| eFL-Boost: Efficient Federated Learning for Gradient Boosting Decision Trees | kobe-u | IEEE Access | 2022 | eFL-Boost[^eFL-Boost] | [[PUB](https://ieeexplore.ieee.org/document/9761890)] |
| An Efficient Learning Framework for Federated XGBoost Using Secret Sharing and Distributed Optimization | TJU | ACM Trans. Intell. Syst. Technol. | 2022 | MP-FedXGB[^MP-FedXGB] | [[PUB](https://dl.acm.org/doi/10.1145/3523061)] [[PDF](https://arxiv.org/abs/2105.05717)] [[CODE](https://github.com/HikariX/MP-FedXGB)] |
| An optional splitting extraction based gain-AUPRC balanced strategy in federated XGBoost for mitigating imbalanced credit card fraud detection | Swinburne University of Technology | Int. J. Bio Inspired Comput. | 2022 | | [[PUB](https://www.inderscience.com/offer.php?id=126793)] |
| Random Forest Based on Federated Learning for Intrusion Detection | Malardalen University | AIAI | 2022 | FL-RF[^FL-RF] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-031-08333-4_11)] |
| Cross-silo federated learning based decision trees | ETH Zürich | SAC | 2022 | FL-DT[^FL-DT] | [[PUB](https://dl.acm.org/doi/10.1145/3477314.3507149)] |
| Leveraging Spanning Tree to Detect Colluding Attackers in Federated Learning | Missouri S&T | INFCOM Workshops | 2022 | FL-ST[^FL-ST] | [[PUB](https://ieeexplore.ieee.org/document/9798077)] |
| VF2Boost: Very Fast Vertical Federated Gradient Boosting for Cross-Enterprise Learning | PKU | SIGMOD :mortar_board: | 2021 | VF2Boost[^VF2Boost] | [[PUB](https://dl.acm.org/doi/10.1145/3448016.3457241)] |
| Boosting with Multiple Sources | Google | NeurIPS:mortar_board: | 2021 | | [[PUB](https://openreview.net/forum?id=1oP1duoZxx)] |
| SecureBoost: A Lossless Federated Learning Framework :fire: | UC | IEEE Intell. Syst. | 2021 | SecureBoost[^SecureBoost] | [[PUB](https://ieeexplore.ieee.org/document/9440789/)] [[PDF](https://arxiv.org/abs/1901.08755)] [[SLIDE](https://fate.readthedocs.io/en/latest/resources/SecureBoost-ijcai2019-workshop.pdf)] [[CODE](https://github.com/FederatedAI/FATE/tree/master/python/federatedml/ensemble/secureboost)] [[解读](https://zhuanlan.zhihu.com/p/545739311)] [[UC](https://github.com/Koukyosyumei/AIJack)] |
| A Blockchain-Based Federated Forest for SDN-Enabled In-Vehicle Network Intrusion Detection System | CNU | IEEE Access | 2021 | BFF-IDS[^BFF-IDS] | [[PUB](https://ieeexplore.ieee.org/document/9471858)] |
| Research on privacy protection of multi source data based on improved gbdt federated ensemble method with different metrics | NCUT | Phys. Commun. | 2021 | I-GBDT[^I-GBDT] | [[PUB](https://www.sciencedirect.com/science/article/pii/S1874490721000847)] |
| Fed-EINI: An Efficient and Interpretable Inference Framework for Decision Tree Ensembles in Vertical Federated Learning | UCAS; CAS | IEEE BigData | 2021 | Fed-EINI[^Fed-EINI] | [[PUB](https://ieeexplore.ieee.org/document/9671749)] [[PDF](https://arxiv.org/abs/2105.09540)] |
| Gradient Boosting Forest: a Two-Stage Ensemble Method Enabling Federated Learning of GBDTs | THU | ICONIP | 2021 | GBF-Cen[^GBF-Cen] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-92270-2_7)] |
| A k-Anonymised Federated Learning Framework with Decision Trees | Umeå University | DPM/CBT @ESORICS | 2021 | KA-FL[^KA-FL] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-93944-1_7)] |
| AF-DNDF: Asynchronous Federated Learning of Deep Neural Decision Forests | Chalmers | SEAA | 2021 | AF-DNDF[^AF-DNDF] | [[PUB](https://ieeexplore.ieee.org/document/9582575)] |
| Compression Boosts Differentially Private Federated Learning | Univ. Grenoble Alpes | EuroS&P | 2021 | CB-DP[^CB-DP] | [[PUB](https://ieeexplore.ieee.org/document/9581200)] [[PDF](https://arxiv.org/abs/2011.05578)] |
| Practical Federated Gradient Boosting Decision Trees | NUS; UWA | AAAI :mortar_board: | 2020 | SimFL[^SimFL] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/5895)] [[PDF](https://arxiv.org/abs/1911.04206)] [[CODE](https://github.com/Xtra-Computing/SimFL)] |
| Privacy Preserving Vertical Federated Learning for Tree-based Models | NUS | VLDB :mortar_board: | 2020 | Pivot-DT[^Pivot-DT] | [[PUB](http://vldb.org/pvldb/vol13/p2090-wu.pdf)] [[PDF](https://arxiv.org/abs/2008.06170)] [[VIDEO](https://www.youtube.com/watch?v=sjii8oVCqiY)] [[CODE](https://github.com/nusdbsystem/pivot)] |
| Boosting Privately: Federated Extreme Gradient Boosting for Mobile Crowdsensing | Xidian University | ICDCS | 2020 | FEDXGB[^FEDXGB] | [[PUB](https://ieeexplore.ieee.org/document/9355600)] [[PDF](https://arxiv.org/abs/1907.10218)] |
| FedCluster: Boosting the Convergence of Federated Learning via Cluster-Cycling | University of Utah | IEEE BigData | 2020 | FedCluster[^FedCluster] | [[PUB](https://ieeexplore.ieee.org/document/9377960)] [[PDF](https://arxiv.org/abs/2009.10748)] |
| New Approaches to Federated XGBoost Learning for Privacy-Preserving Data Analysis | kobe-u | ICONIP | 2020 | FL-XGBoost[^FL-XGBoost] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-63833-7_47)] |
| Bandwidth Slicing to Boost Federated Learning Over Passive Optical Networks | Chalmers University of Technology | IEEE Communications Letters | 2020 | FL-PON[^FL-PON] | [[PUB](https://ieeexplore.ieee.org/document/9044640)] |
| DFedForest: Decentralized Federated Forest | UFRJ | Blockchain | 2020 | DFedForest[^DFedForest] | [[PUB](https://ieeexplore.ieee.org/document/9284805/)] |
| Straggler Remission for Federated Learning via Decentralized Redundant Cayley Tree | Stevens Institute of Technology | LATINCOM | 2020 | DRC-tree[^DRC-tree] | [[PUB](https://ieeexplore.ieee.org/document/9282334)] |
| Federated Soft Gradient Boosting Machine for Streaming Data | Sinovation Ventures AI Institute | Federated Learning | 2020 | Fed-sGBM[^Fed-sGBM] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-63076-8_7)] [[解读](https://www.leiphone.com/category/academic/4tVdYDuYTA293NCy.html)] |
| Federated Learning of Deep Neural Decision Forests | Fraunhofer-Chalmers Centre | LOD | 2019 | FL-DNDF[^FL-DNDF] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-37599-7_58)] |
| Fed-TDA: Federated Tabular Data Augmentation on Non-IID Data | HIT | preprint | 2022 | Fed-TDA[^Fed-TDA] | [[PDF](https://arxiv.org/abs/2211.13116)] |
| Data Leakage in Tabular Federated Learning | ETH Zurich | preprint | 2022 | TabLeak[^TabLeak] | [[PDF](https://arxiv.org/abs/2210.01785)] |
| Boost Decentralized Federated Learning in Vehicular Networks by Diversifying Data Sources | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2209.01750)] |
| Federated XGBoost on Sample-Wise Non-IID Data | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2209.01340)] |
| Hercules: Boosting the Performance of Privacy-preserving Federated Learning | | preprint | 2022 | Hercules[^Hercules] | [[PDF](https://arxiv.org/abs/2207.04620)] |
| FedGBF: An efficient vertical federated learning framework via gradient boosting and bagging | | preprint | 2022 | FedGBF[^FedGBF] | [[PDF](https://arxiv.org/abs/2204.00976)] |
| A Fair and Efficient Hybrid Federated Learning Framework based on XGBoost for Distributed Power Prediction. | THU | preprint | 2022 | HFL-XGBoost[^HFL-XGBoost] | [[PDF](https://arxiv.org/abs/2201.02783)] |
| An Efficient and Robust System for Vertically Federated Random Forest | | preprint | 2022 | | [[PDF](https://arxiv.org/abs/2201.10761)] |
| Efficient Batch Homomorphic Encryption for Vertically Federated XGBoost. | BUAA | preprint | 2021 | EBHE-VFXGB[^EBHE-VFXGB] | [[PDF](https://arxiv.org/abs/2112.04261)] |
| Guess what? You can boost Federated Learning for free | | preprint | 2021 | | [[PDF](https://arxiv.org/abs/2110.11486)] |
| SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning :fire: | | preprint | 2021 | SecureBoost+[^SecureBoostplus] | [[PDF](https://arxiv.org/abs/2110.10927)] [[CODE](https://github.com/FederatedAI/FATE)] |
| Fed-TGAN: Federated Learning Framework for Synthesizing Tabular Data | | preprint | 2021 | Fed-TGAN[^Fed-TGAN] | [[PDF](https://arxiv.org/abs/2108.07927)] |
| FedXGBoost: Privacy-Preserving XGBoost for Federated Learning | TUM | preprint | 2021 | FedXGBoost[^FedXGBoost] | [[PDF](https://arxiv.org/abs/2106.10662)] |
| Adaptive Histogram-Based Gradient Boosted Trees for Federated Learning | | preprint | 2020 | | [[PDF](https://arxiv.org/abs/2012.06670)] |
| FederBoost: Private Federated Learning for GBDT | ZJU | preprint | 2020 | FederBoost[^FederBoost] | [[PDF](https://arxiv.org/abs/2011.02796)] |
| Privacy Preserving Text Recognition with Gradient-Boosting for Federated Learning | | preprint | 2020 | | [[PDF](https://arxiv.org/abs/2007.07296)] [[CODE](https://github.com/rand2ai/fedboost)] |
| Cloud-based Federated Boosting for Mobile Crowdsensing | | preprint | 2020 | | [[ARXIV](https://arxiv.org/abs/2005.05304)] |
| Federated Extra-Trees with Privacy Preserving | | preprint | 2020 | | [[PDF](https://arxiv.org/abs/2002.07323.pdf)] |
| Bandwidth Slicing to Boost Federated Learning in Edge Computing | | preprint | 2019 | | [[PDF](https://arxiv.org/abs/1911.07615)] |
| Revocable Federated Learning: A Benchmark of Federated Forest | | preprint | 2019 | | [[PDF](https://arxiv.org/abs/1911.03242)] |
| The Tradeoff Between Privacy and Accuracy in Anomaly Detection Using Federated XGBoost | CUHK | preprint | 2019 | F-XGBoost[^F-XGBoost] | [[PDF](https://arxiv.org/abs/1907.07157)] [[CODE](https://github.com/Raymw/Federated-XGBoost)] |
<!-- END:fl-on-tabular-data -->
## fl in top-tier journal
List of papers in the field of federated learning in Nature(and its sub-journals), Cell, Science(and Science Advances) and PANS refers to [WOS](https://www.webofscience.com/wos/woscc/summary/ed3f4552-5450-4de7-bf2c-55d01e20d5de-4301299e/relevance/1) search engine.
<!-- START:fl-in-top-tier-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ----------- | --------------------- | ---- | --------------------- | ------------------------------------------------------------ |
| Federated learning for predicting histological response to neoadjuvant chemotherapy in triple-negative breast cancer | Owkin | Nat. Med. | 2023 | | [[PUB](https://www.nature.com/articles/s41591-022-02155-w)] [[CODE](https://github.com/Substra/substra)] |
| Federated learning enables big data for rare cancer boundary detection | University of Pennsylvania | Nat. Commun. | 2022 | | [[PUB](https://www.nature.com/articles/s41467-022-33407-5)] [[PDF](https://arxiv.org/abs/2204.10836)] [[CODE](https://github.com/FETS-AI/Front-End)] |
| Federated learning and Indigenous genomic data sovereignty | Hugging Face | Nat. Mach. Intell. | 2022 | | [[PUB](https://www.nature.com/articles/s42256-022-00551-y)] |
| Federated disentangled representation learning for unsupervised brain anomaly detection | TUM | Nat. Mach. Intell. | 2022 | FedDis[^FedDis] | [[PUB](https://www.nature.com/articles/s42256-022-00515-2)] [[PDF](https://doi.org/https://doi.org/10.21203/rs.3.rs-722389/v1)] [[CODE](https://doi.org/10.5281/zenodo.6604161)] |
| Shifting machine learning for healthcare from development to deployment and from models to data | | Nat. Biomed. Eng. | 2022 | FL-healthy[^FL-healthy] | [[PUB](https://www.nature.com/articles/s41551-022-00898-y)] |
| A federated graph neural network framework for privacy-preserving personalization | THU | Nat. Commun. | 2022 | FedPerGNN[^FedPerGNN] | [[PUB](https://www.nature.com/articles/s41467-022-30714-9)] [[CODE](https://github.com/wuch15/FedPerGNN)] [[解读](https://zhuanlan.zhihu.com/p/487383715)] |
| Communication-efficient federated learning via knowledge distillation | | Nat. Commun. | 2022 | | [[PUB](https://www.nature.com/articles/s41467-022-29763-x)] [[PDF](https://arxiv.org/abs/2108.13323)] [[CODE](https://zenodo.org/record/6383473)] |
| Lead federated neuromorphic learning for wireless edge artificial intelligence | | Nat. Commun. | 2022 | | [[PUB](https://www.nature.com/articles/s41467-022-32020-w)] [[CODE](https://github.com/GOGODD/FL-EDGE-COMPUTING/releases/tag/federated_learning)] [[解读](https://zhuanlan.zhihu.com/p/549087420)] |
| Advancing COVID-19 diagnosis with privacy-preserving collaboration in artificial intelligence | | Nat. Mach. Intell. | 2021 | | [[PUB](https://www.nature.com/articles/s42256-021-00421-z)] [[PDF](https://arxiv.org/abs/2111.09461)] [[CODE](https://github.com/HUST-EIC-AI-LAB/UCADI)] |
| Federated learning for predicting clinical outcomes in patients with COVID-19 | | Nat. Med. | 2021 | | [[PUB](https://www.nature.com/articles/s41591-021-01506-3)] [[CODE](https://www.nature.com/articles/s41591-021-01506-3#code-availability)] |
| Adversarial interference and its mitigations in privacy-preserving collaborative machine learning | | Nat. Mach. Intell. | 2021 | | [[PUB](https://www.nature.com/articles/s42256-021-00390-3)] |
| Swarm Learning for decentralized and confidential clinical machine learning :star: | | Nature :mortar_board: | 2021 | | [[PUB](https://www.nature.com/articles/s41586-021-03583-3)] [[CODE](https://github.com/HewlettPackard/swarm-learning)] [[SOFTWARE](https://myenterpriselicense.hpe.com)] [[解读](https://zhuanlan.zhihu.com/p/379434722)] |
| End-to-end privacy preserving deep learning on multi-institutional medical imaging | | Nat. Mach. Intell. | 2021 | | [[PUB](https://www.nature.com/articles/s42256-021-00337-8)] [[CODE](https://doi.org/10.5281/zenodo.4545599)] [[解读](https://zhuanlan.zhihu.com/p/484801505)] |
| Communication-efficient federated learning | | PANS. | 2021 | | [[PUB](https://www.pnas.org/doi/full/10.1073/pnas.2024789118)] [[CODE](https://code.ihub.org.cn/projects/4394/repository/revisions/master/show/PNAS)] |
| Breaking medical data sharing boundaries by using synthesized radiographs | | Science. Advances. | 2020 | | [[PUB](https://www.science.org/doi/10.1126/sciadv.abb7973)] [[CODE](https://github.com/peterhan91/Thorax_GAN)] |
| Secure, privacy-preserving and federated machine learning in medical imaging :star: | | Nat. Mach. Intell. | 2020 | | [[PUB](https://www.nature.com/articles/s42256-020-0186-1)] |
<!-- END:fl-in-top-tier-journal -->
## fl in top ai conference and journal
In this section, we will summarize Federated Learning papers accepted by top AI(Artificial Intelligence) conference and journal, Including [IJCAI](https://dblp.org/db/conf/ijcai/index.html)(International Joint Conference on Artificial Intelligence), [AAAI](https://dblp.uni-trier.de/db/conf/aaai/index.html)(AAAI Conference on Artificial Intelligence), [AISTATS](https://dblp.uni-trier.de/db/conf/aistats/index.html)(Artificial Intelligence and Statistics), [AI](https://dblp.uni-trier.de/db/journals/ai/index.html)(Artificial Intelligence).
- [IJCAI](https://dblp.uni-trier.de/search?q=federate%20venue%3AIJCAI%3A) [2022](https://ijcai-22.org/main-track-accepted-papers/),[2021](https://ijcai-21.org/program-main-track/#),[2020](https://static.ijcai.org/2020-accepted_papers.html),[2019](https://www.ijcai19.org/accepted-papers.html)
- [AAAI](https://dblp.uni-trier.de/search?q=federate%20venue%3AAAAI%3A) 2023, [2022](https://aaai.org/Conferences/AAAI-22/wp-content/uploads/2021/12/AAAI-22_Accepted_Paper_List_Main_Technical_Track.pdf),[2021](https://aaai.org/Conferences/AAAI-21/wp-content/uploads/2020/12/AAAI-21_Accepted-Paper-List.Main_.Technical.Track_.pdf),[2020](https://aaai.org/Conferences/AAAI-20/wp-content/uploads/2020/01/AAAI-20-Accepted-Paper-List.pdf)
- [AISTATS](https://dblp.uni-trier.de/search?q=federate%20venue%3AAISTATS%3A) [2022](http://proceedings.mlr.press/v151/), [2021](http://proceedings.mlr.press/v130/),[2020](http://proceedings.mlr.press/v108/)
- [AI](https://dblp.uni-trier.de/search?q=federate%20venue%3AArtif%20Intell%3A) NULL
<!-- START:fl-in-top-ai-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------- | ---- | ------------------------- | ------------------------------------------------------------ |
| Federated Learning on Non-IID Graphs via Structural Knowledge Sharing | UTS | AAAI | 2023 | FedStar[^FedStar] | [[PDF](https://arxiv.org/abs/2211.13009)] [[CODE](https://github.com/yuetan031/fedstar)] |
| FedGS: Federated Graph-based Sampling with Arbitrary Client Availability | XMU | AAAI | 2023 | FedGS[^FedGS] | [[PDF](https://arxiv.org/abs/2211.13975)] [[CODE](https://github.com/wwzzz/fedgs)] |
| Incentive-boosted Federated Crowdsourcing | SDU | AAAI | 2023 | iFedCrowd[^iFedCrowd] | [[PDF](https://arxiv.org/abs/2211.14439)] |
| Towards Understanding Biased Client Selection in Federated Learning. | CMU | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/jee-cho22a.html)] [[CODE](https://proceedings.mlr.press/v151/jee-cho22a/jee-cho22a-supp.zip)] |
| FLIX: A Simple and Communication-Efficient Alternative to Local Methods in Federated Learning | KAUST | AISTATS | 2022 | FLIX[^FLIX] | [[PUB](https://proceedings.mlr.press/v151/gasanov22a.html)] [[PDF](https://arxiv.org/abs/2111.11556)] [[CODE](https://proceedings.mlr.press/v151/gasanov22a/gasanov22a-supp.zip)] |
| Sharp Bounds for Federated Averaging (Local SGD) and Continuous Perspective. | Stanford | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/glasgow22a.html)] [[PDF](https://arxiv.org/abs/2111.03741)] [[CODE](https://github.com/hongliny/sharp-bounds-for-fedavg-and-continuous-perspective)] |
| Federated Reinforcement Learning with Environment Heterogeneity. | PKU | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/jin22a.html)] [[PDF](https://arxiv.org/abs/2204.02634)] [[CODE](https://github.com/pengyang7881187/fedrl)] |
| Federated Myopic Community Detection with One-shot Communication | Purdue | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/ke22a.html)] [[PDF](https://arxiv.org/abs/2106.07255)] |
| Asynchronous Upper Confidence Bound Algorithms for Federated Linear Bandits. | University of Virginia | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/li22e.html)] [[PDF](https://arxiv.org/abs/2110.01463)] [[CODE](https://github.com/cyrilli/Async-LinUCB)] |
| Towards Federated Bayesian Network Structure Learning with Continuous Optimization. | CMU | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/ng22a.html)] [[PDF](https://arxiv.org/abs/2110.09356)] [[CODE](https://github.com/ignavierng/notears-admm)] |
| Federated Learning with Buffered Asynchronous Aggregation | Meta AI | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/nguyen22b.html)] [[PDF](https://arxiv.org/abs/2106.06639)] [[VIDEO](https://www.youtube.com/watch?v=Ui-OGUAieNY&ab_channel=FederatedLearningOneWorldSeminar)] |
| Differentially Private Federated Learning on Heterogeneous Data. | Stanford | AISTATS | 2022 | DP-SCAFFOLD[^DP-SCAFFOLD] | [[PUB](https://proceedings.mlr.press/v151/noble22a.html)] [[PDF](https://arxiv.org/abs/2111.09278)] [[CODE](https://github.com/maxencenoble/Differential-Privacy-for-Heterogeneous-Federated-Learning)] |
| SparseFed: Mitigating Model Poisoning Attacks in Federated Learning with Sparsification | Princeton | AISTATS | 2022 | SparseFed[^SparseFed] | [[PUB](https://proceedings.mlr.press/v151/panda22a.html)] [[PDF](https://arxiv.org/abs/2112.06274)] [[CODE](https://github.com/sparsefed/sparsefed)] [[VIDEO](https://www.youtube.com/watch?v=TXG7ZScheas&ab_channel=GoogleTechTalks)] |
| Basis Matters: Better Communication-Efficient Second Order Methods for Federated Learning | KAUST | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/qian22a.html)] [[PDF](https://arxiv.org/abs/2111.01847)] |
| Federated Functional Gradient Boosting. | University of Pennsylvania | AISTATS | 2022 | | [[PUB](https://proceedings.mlr.press/v151/shen22a.html)] [[PDF](https://arxiv.org/abs/2103.06972)] [[CODE](https://github.com/shenzebang/Federated-Learning-Pytorch)] |
| QLSD: Quantised Langevin Stochastic Dynamics for Bayesian Federated Learning. | Criteo AI Lab | AISTATS | 2022 | QLSD[^QLSD] | [[PUB](https://proceedings.mlr.press/v151/vono22a.html)] [[PDF](https://arxiv.org/abs/2106.00797)] [[CODE](https://proceedings.mlr.press/v151/vono22a/vono22a-supp.zip)] [[VIDEO](https://www.youtube.com/watch?v=fY8V184It1g&ab_channel=FederatedLearningOneWorldSeminar)] |
| Meta-Learning Based Knowledge Extrapolation for Knowledge Graphs in the Federated Setting **`kg.`** | ZJU | IJCAI | 2022 | MaKEr[^MaKEr] | [[PUB](https://www.ijcai.org/proceedings/2022/273)] [[PDF](https://doi.org/10.48550/arXiv.2205.04692)] [[CODE](https://github.com/zjukg/maker)] |
| Personalized Federated Learning With a Graph | UTS | IJCAI | 2022 | SFL[^SFL] | [[PUB](https://www.ijcai.org/proceedings/2022/357)] [[PDF](https://arxiv.org/abs/2203.00829)] [[CODE](https://github.com/dawenzi098/SFL-Structural-Federated-Learning)] |
| Vertically Federated Graph Neural Network for Privacy-Preserving Node Classification | ZJU | IJCAI | 2022 | VFGNN[^VFGNN] | [[PUB](https://www.ijcai.org/proceedings/2022/272)] [[PDF](https://arxiv.org/abs/2005.11903)] |
| Adapt to Adaptation: Learning Personalization for Cross-Silo Federated Learning | | IJCAI | 2022 | | [[PUB](https://www.ijcai.org/proceedings/2022/301)] [[PDF](https://arxiv.org/abs/2110.08394)] [[CODE](https://github.com/ljaiverson/pFL-APPLE)] |
| Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning | | IJCAI | 2022 | Fed-ET[^Fed-ET] | [[PUB](https://www.ijcai.org/proceedings/2022/399)] [[PDF](https://arxiv.org/abs/2204.12703)] |
| Private Semi-Supervised Federated Learning. | | IJCAI | 2022 | | [[PUB](https://www.ijcai.org/proceedings/2022/279)] |
| Continual Federated Learning Based on Knowledge Distillation. | | IJCAI | 2022 | | [[PUB](https://doi.org/10.24963/ijcai.2022/306)] |
| Federated Learning on Heterogeneous and Long-Tailed Data via Classifier Re-Training with Federated Features | | IJCAI | 2022 | CReFF[^CReFF] | [[PUB](https://www.ijcai.org/proceedings/2022/308)] [[PDF](https://arxiv.org/abs/2204.13399)] [[CODE](https://github.com/shangxinyi/CReFF-FL)] |
| Federated Multi-Task Attention for Cross-Individual Human Activity Recognition | | IJCAI | 2022 | | [[PUB](https://www.ijcai.org/proceedings/2022/475)] |
| Personalized Federated Learning with Contextualized Generalization. | | IJCAI | 2022 | | [[PUB](https://www.ijcai.org/proceedings/2022/311)] [[PDF](https://arxiv.org/abs/2106.13044)] |
| Shielding Federated Learning: Robust Aggregation with Adaptive Client Selection. | | IJCAI | 2022 | | [[PUB](https://www.ijcai.org/proceedings/2022/106)] [[PDF](https://arxiv.org/abs/2204.13256)] |
| FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning | | IJCAI | 2022 | FedCG[^FedCG] | [[PUB](https://www.ijcai.org/proceedings/2022/324)] [[PDF](https://arxiv.org/abs/2111.08211)] [[CODE](https://github.com/FederatedAI/research/tree/main/publications/FedCG)] |
| FedDUAP: Federated Learning with Dynamic Update and Adaptive Pruning Using Shared Data on the Server. | | IJCAI | 2022 | FedDUAP[^FedDUAP] | [[PUB](https://www.ijcai.org/proceedings/2022/385)] [[PDF](https://arxiv.org/abs/2204.11536)] |
| Towards Verifiable Federated Learning **`surv.`** | | IJCAI | 2022 | | [[PUB](https://www.ijcai.org/proceedings/2022/792)] [[PDF](https://arxiv.org/abs/2202.08310)] |
| HarmoFL: Harmonizing Local and Global Drifts in Federated Learning on Heterogeneous Medical Images | CUHK; BUAA | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/19993)] [[PDF](https://arxiv.org/abs/2112.10775)] [[CODE](https://github.com/med-air/HarmoFL)] [[解读](https://zhuanlan.zhihu.com/p/472555067)] |
| Federated Learning for Face Recognition with Gradient Correction | BUPT | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20095)] [[PDF](https://arxiv.org/abs/2112.07246)] |
| SpreadGNN: Decentralized Multi-Task Federated Learning for Graph Neural Networks on Molecular Data | USC | AAAI | 2022 | SpreadGNN[^SpreadGNN] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20643)] [[PDF](https://arxiv.org/abs/2106.02743)] [[CODE](https://github.com/FedML-AI/SpreadGNN)] [[解读](https://zhuanlan.zhihu.com/p/429720860)] |
| SmartIdx: Reducing Communication Cost in Federated Learning by Exploiting the CNNs Structures | HIT; PCL | AAAI | 2022 | SmartIdx[^SmartIdx] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20345)] [[CODE](https://github.com/wudonglei99/smartidx)] |
| Bridging between Cognitive Processing Signals and Linguistic Features via a Unified Attentional Network | TJU | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/19878)] [[PDF](https://arxiv.org/abs/2112.08831)] |
| Seizing Critical Learning Periods in Federated Learning | SUNY-Binghamton University | AAAI | 2022 | FedFIM[^FedFIM] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20859)] [[PDF](https://arxiv.org/abs/2109.05613)] |
| Coordinating Momenta for Cross-silo Federated Learning | University of Pittsburgh | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20853)] [[PDF](https://arxiv.org/abs/2102.03970)] |
| FedProto: Federated Prototype Learning over Heterogeneous Devices | UTS | AAAI | 2022 | FedProto[^FedProto] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20819)] [[PDF](https://arxiv.org/abs/2105.00243)] [[CODE](https://github.com/yuetan031/fedproto)] |
| FedSoft: Soft Clustered Federated Learning with Proximal Local Updating | CMU | AAAI | 2022 | FedSoft[^FedSoft] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20785)] [[PDF](https://arxiv.org/abs/2112.06053)] [[CODE](https://github.com/ycruan/FedSoft)] |
| Federated Dynamic Sparse Training: Computing Less, Communicating Less, Yet Learning Better | The University of Texas at Austin | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20555)] [[PDF](https://arxiv.org/abs/2112.09824)] [[CODE](https://github.com/bibikar/feddst)] |
| FedFR: Joint Optimization Federated Framework for Generic and Personalized Face Recognition | National Taiwan University | AAAI | 2022 | FedFR[^FedFR] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20057)] [[PDF](https://arxiv.org/abs/2112.12496)] [[CODE](https://github.com/jackie840129/fedfr)] |
| SplitFed: When Federated Learning Meets Split Learning | CSIRO | AAAI | 2022 | SplitFed[^SplitFed] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20825)] [[PDF](https://arxiv.org/abs/2004.12088)] [[CODE](https://github.com/chandra2thapa/SplitFed-When-Federated-Learning-Meets-Split-Learning)] |
| Efficient Device Scheduling with Multi-Job Federated Learning | Soochow University | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/21235)] [[PDF](https://arxiv.org/abs/2112.05928)] |
| Implicit Gradient Alignment in Distributed and Federated Learning | IIT Kanpur | AAAI | 2022 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20597)] [[PDF](https://arxiv.org/abs/2106.13897)] |
| Federated Nearest Neighbor Classification with a Colony of Fruit-Flies | IBM Research | AAAI | 2022 | FlyNNFL[^FlyNNFL] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/20775)] [[PDF](https://arxiv.org/abs/2112.07157)] [[CODE](https://github.com/rithram/flynn)] |
| Federated Learning with Sparsification-Amplified Privacy and Adaptive Optimization | | IJCAI | 2021 | | [[PUB](https://www.ijcai.org/proceedings/2021/202)] [[PDF](https://arxiv.org/abs/2008.01558)] [[VIDEO](https://papertalk.org/papertalks/35198)] |
| Behavior Mimics Distribution: Combining Individual and Group Behaviors for Federated Learning | | IJCAI | 2021 | | [[PUB](https://www.ijcai.org/proceedings/2021/352)] [[PDF](https://arxiv.org/abs/2106.12300)] |
| FedSpeech: Federated Text-to-Speech with Continual Learning | | IJCAI | 2021 | FedSpeech[^FedSpeech] | [[PUB](https://www.ijcai.org/proceedings/2021/527)] [[PDF](https://arxiv.org/abs/2110.07216)] |
| Practical One-Shot Federated Learning for Cross-Silo Setting | | IJCAI | 2021 | FedKT[^FedKT] | [[PUB](https://www.ijcai.org/proceedings/2021/205)] [[PDF](https://arxiv.org/abs/2010.01017)] [[CODE](https://github.com/QinbinLi/FedKT)] |
| Federated Model Distillation with Noise-Free Differential Privacy | | IJCAI | 2021 | FEDMD-NFDP[^FEDMD-NFDP] | [[PUB](https://www.ijcai.org/proceedings/2021/216)] [[PDF](https://arxiv.org/abs/2202.08310)] [[VIDEO](https://papertalk.org/papertalks/35184)] |
| LDP-FL: Practical Private Aggregation in Federated Learning with Local Differential Privacy | | IJCAI | 2021 | LDP-FL[^LDP-FL] | [[PUB](https://www.ijcai.org/proceedings/2021/217)] [[PDF](https://arxiv.org/abs/2007.15789)] |
| Federated Learning with Fair Averaging. :fire: | | IJCAI | 2021 | FedFV[^FedFV] | [[PUB](https://www.ijcai.org/proceedings/2021/223)] [[PDF](https://arxiv.org/abs/2104.14937)] [[CODE](https://github.com/WwZzz/easyFL)] |
| H-FL: A Hierarchical Communication-Efficient and Privacy-Protected Architecture for Federated Learning. | | IJCAI | 2021 | H-FL[^H-FL] | [[PUB](https://www.ijcai.org/proceedings/2021/67)] [[PDF](https://arxiv.org/abs/2106.00275)] |
| Communication-efficient and Scalable Decentralized Federated Edge Learning. | | IJCAI | 2021 | | [[PUB](https://www.ijcai.org/proceedings/2021/720)] |
| Secure Bilevel Asynchronous Vertical Federated Learning with Backward Updating | Xidian University; JD Tech | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17301)] [[PDF](https://arxiv.org/abs/2103.00958)] [[VIDEO](https://slideslive.com/38947765/secure-bilevel-asynchronous-vertical-federated-learning-with-backward-updating)] |
| FedRec++: Lossless Federated Recommendation with Explicit Feedback | SZU | AAAI | 2021 | FedRec++[^FedRecplusplus] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/16546)] [[VIDEO](https://slideslive.com/38947798/fedrec-lossless-federated-recommendation-with-explicit-feedback)] |
| Federated Multi-Armed Bandits | University of Virginia | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17156)] [[PDF](https://arxiv.org/abs/2101.12204)] [[CODE](https://github.com/ShenGroup/FMAB)] [[VIDEO](https://slideslive.com/38947985/federated-multiarmed-bandits)] |
| On the Convergence of Communication-Efficient Local SGD for Federated Learning | Temple University; University of Pittsburgh | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/16920)] [[VIDEO](https://slideslive.com/38948341/on-the-convergence-of-communicationefficient-local-sgd-for-federated-learning)] |
| FLAME: Differentially Private Federated Learning in the Shuffle Model | Renmin University of China; Kyoto University | AAAI | 2021 | FLAME_D[^FLAME_D] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17053)] [[PDF](https://arxiv.org/abs/2009.08063)] [[VIDEO](https://slideslive.com/38948496/flame-differentially-private-federated-learning-in-the-shuffle-model)] [[CODE](https://github.com/Rachelxuan11/FLAME)] |
| Toward Understanding the Influence of Individual Clients in Federated Learning | SJTU; The University of Texas at Dallas | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17263)] [[PDF](https://arxiv.org/abs/2012.10936)] [[VIDEO](https://slideslive.com/38948549/toward-understanding-the-influence-of-individual-clients-in-federated-learning)] |
| Provably Secure Federated Learning against Malicious Clients | Duke University | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/16849)] [[PDF](https://arxiv.org/abs/2102.01854)] [[VIDEO](https://www.youtube.com/watch?v=LP4uqW18yA0&ab_channel=PurdueCERIAS)] [[SLIDE](https://people.duke.edu/~zg70/code/Secure_Federated_Learning.pdf)] |
| Personalized Cross-Silo Federated Learning on Non-IID Data | Simon Fraser University; McMaster University | AAAI | 2021 | FedAMP[^FedAMP] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/16960)] [[PDF](https://arxiv.org/abs/2007.03797)] [[VIDEO](https://slideslive.com/38948676/personalized-crosssilo-federated-learning-on-noniid-data)] [[UC.](https://github.com/TsingZ0/PFL-Non-IID)] |
| Model-Sharing Games: Analyzing Federated Learning under Voluntary Participation | Cornell University | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/16669)] [[PDF](https://arxiv.org/abs/2010.00753)] [[CODE](https://github.com/kpdonahue/model_sharing_games)] [[VIDEO](https://slideslive.com/38948684/modelsharing-games-analyzing-federated-learning-under-voluntary-participation)] |
| Curse or Redemption? How Data Heterogeneity Affects the Robustness of Federated Learning | University of Nevada; IBM Research | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17291)] [[PDF](https://arxiv.org/abs/2102.00655)] [[VIDEO](https://slideslive.com/38949098/curse-or-redemption-how-data-heterogeneity-affects-the-robustness-of-federated-learning)] |
| Game of Gradients: Mitigating Irrelevant Clients in Federated Learning | IIT Bombay; IBM Research | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17093)] [[PDF](https://arxiv.org/abs/2110.12257)] [[CODE](https://github.com/nlokeshiisc/sfedavg-aaai21)] [[VIDEO](https://slideslive.com/38949109/game-of-gradients-mitigating-irrelevant-clients-in-federated-learning)] [[SUPPLEMENTARY](https://github.com/nlokeshiisc/SFedAvg-AAAI21)] |
| Federated Block Coordinate Descent Scheme for Learning Global and Personalized Models | CUHK; Arizona State University | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17240)] [[PDF](https://arxiv.org/abs/2012.13900)] [[VIDEO](https://slideslive.com/38949195/federated-block-coordinate-descent-scheme-for-learning-global-and-personalized-models)] [[CODE](https://github.com/REIYANG/FedBCD)] |
| Addressing Class Imbalance in Federated Learning | Northwestern University | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17219)] [[PDF](https://arxiv.org/abs/2008.06217)] [[VIDEO](https://slideslive.com/38949283/adressing-class-imbalance-in-federated-learning)] [[CODE](https://github.com/balanced-fl/Addressing-Class-Imbalance-FL)] [[解读](https://zhuanlan.zhihu.com/p/443009189)] |
| Defending against Backdoors in Federated Learning with Robust Learning Rate | The University of Texas at Dallas | AAAI | 2021 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/17118)] [[PDF](https://arxiv.org/abs/2007.03767)] [[VIDEO](https://slideslive.com/38949344/defending-against-backdoors-in-federated-learning-with-robust-learning-rate)] [[CODE](https://github.com/TinfoilHat0/Defending-Against-Backdoors-with-Robust-Learning-Rate)] |
| Free-rider Attacks on Model Aggregation in Federated Learning | Accenture Labs | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/fraboni21a/fraboni21a.pdf)] [[PDF](https://arxiv.org/abs/2006.11901)] [[CODE](https://github.com/Accenture/Labs-Federated-Learning)] [[VIDEO](https://papertalk.org/papertalks/27640)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/fraboni21a/fraboni21a-supp.pdf)] |
| Federated f-differential privacy | University of Pennsylvania | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/zheng21a/zheng21a.pdf)] [[CODE](https://github.com/enosair/federated-fdp)] [[VIDEO](https://papertalk.org/papertalks/27595)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/zheng21a/zheng21a-supp.pdf)] |
| Federated learning with compression: Unified analysis and sharp guarantees :fire: | The Pennsylvania State University; The University of Texas at Austin | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/haddadpour21a/haddadpour21a.pdf)] [[PDF](https://arxiv.org/abs/2007.01154)] [[CODE](https://github.com/MLOPTPSU/FedTorch)] [[VIDEO](https://papertalk.org/papertalks/27584)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/haddadpour21a/haddadpour21a-supp.pdf)] |
| Shuffled Model of Differential Privacy in Federated Learning | UCLA; Google | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/girgis21a/girgis21a.pdf)] [[VIDEO](https://papertalk.org/papertalks/27565)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/girgis21a/girgis21a-supp.pdf)] |
| Convergence and Accuracy Trade-Offs in Federated Learning and Meta-Learning | Google | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/charles21a/charles21a.pdf)] [[PDF](https://arxiv.org/abs/2103.05032)] [[VIDEO](https://papertalk.org/papertalks/27559)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/charles21a/charles21a-supp.pdf)] |
| Federated Multi-armed Bandits with Personalization | University of Virginia; The Pennsylvania State University | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/shi21c/shi21c.pdf)] [[PDF](https://arxiv.org/abs/2102.13101)] [[CODE](https://github.com/ShenGroup/PF_MAB)] [[VIDEO](https://papertalk.org/papertalks/27521)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/shi21c/shi21c-supp.pdf)] |
| Towards Flexible Device Participation in Federated Learning | CMU; SYSU | AISTAT | 2021 | | [[PUB](http://proceedings.mlr.press/v130/ruan21a/ruan21a.pdf)] [[PDF](https://arxiv.org/abs/2006.06954)] [[VIDEO](https://papertalk.org/papertalks/27467)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v130/ruan21a/ruan21a-supp.pdf)] |
| Federated Meta-Learning for Fraudulent Credit Card Detection | | IJCAI | 2020 | | [[PUB](https://www.ijcai.org/proceedings/2020/642)] [[VIDEO](https://www.ijcai.org/proceedings/2020/video/23994)] |
| A Multi-player Game for Studying Federated Learning Incentive Schemes | | IJCAI | 2020 | FedGame[^FedGame] | [[PUB](https://www.ijcai.org/proceedings/2020/769)] [[CODE](https://github.com/benggggggggg/fedgame)] [[解读](https://zhuanlan.zhihu.com/p/353868739)] |
| Practical Federated Gradient Boosting Decision Trees | NUS; UWA | AAAI | 2020 | SimFL[^SimFL] | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/5895)] [[PDF](https://arxiv.org/abs/1911.04206)] [[CODE](https://github.com/Xtra-Computing/PrivML)] |
| Federated Learning for Vision-and-Language Grounding Problems | PKU; Tencent | AAAI | 2020 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/6824)] |
| Federated Latent Dirichlet Allocation: A Local Differential Privacy Based Framework | BUAA | AAAI | 2020 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/6096)] |
| Federated Patient Hashing | Cornell University | AAAI | 2020 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/6121)] |
| Robust Federated Learning via Collaborative Machine Teaching | Symantec Research Labs; KAUST | AAAI | 2020 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/5826)] [[PDF](https://arxiv.org/abs/1905.02941)] |
| FedVision: An Online Visual Object Detection Platform Powered by Federated Learning | WeBank | AAAI | 2020 | | [[PUB](https://ojs.aaai.org/index.php/AAAI/article/view/7021)] [[PDF](https://arxiv.org/abs/2001.06202)] [[CODE](https://github.com/FederatedAI/FedVision)] |
| FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization | UC Santa Barbara; UT Austin | AISTAT | 2020 | | [[PUB](http://proceedings.mlr.press/v108/reisizadeh20a/reisizadeh20a.pdf)] [[PDF](https://arxiv.org/abs/1909.13014)] [[VIDEO](https://papertalk.org/papertalks/7961)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v108/reisizadeh20a/reisizadeh20a-supp.pdf)] |
| How To Backdoor Federated Learning :fire: | Cornell Tech | AISTAT | 2020 | | [[PUB](http://proceedings.mlr.press/v108/bagdasaryan20a/bagdasaryan20a.pdf)] [[PDF](https://arxiv.org/abs/1807.00459)] [[VIDEO](https://papertalk.org/papertalks/8046)] [[CODE](https://github.com/ebagdasa/backdoor_federated_learning)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v108/bagdasaryan20a/bagdasaryan20a-supp.pdf)] |
| Federated Heavy Hitters Discovery with Differential Privacy | RPI; Google | AISTAT | 2020 | | [[PUB](http://proceedings.mlr.press/v108/zhu20a/zhu20a.pdf)] [[PDF](https://arxiv.org/abs/1902.08534)] [[VIDEO](https://papertalk.org/papertalks/8129)] [[SUPPLEMENTARY](http://proceedings.mlr.press/v108/zhu20a/zhu20a-supp.pdf)] |
| Multi-Agent Visualization for Explaining Federated Learning | WeBank | IJCAI | 2019 | | [[PUB](https://www.ijcai.org/proceedings/2019/960)] [[VIDEO](https://youtu.be/NPGf_OJrzOg)] |
<!-- END:fl-in-top-ai-conference-and-journal -->
## fl in top ml conference and journal
In this section, we will summarize Federated Learning papers accepted by top ML(machine learning) conference and journal, Including [NeurIPS](https://dblp.uni-trier.de/db/conf/nips/index.html)(Annual Conference on Neural Information Processing Systems), [ICML](https://dblp.uni-trier.de/db/conf/icml/index.html)(International Conference on Machine Learning), [ICLR](https://dblp.uni-trier.de/db/conf/iclr/index.html)(International Conference on Learning Representations), [COLT](https://dblp.org/db/conf/colt/index.html)(Annual Conference Computational Learning Theory) , [UAI](https://dblp.org/db/conf/uai/index.html)(Conference on Uncertainty in Artificial Intelligence), [JMLR](https://dblp.uni-trier.de/db/journals/jmlr/index.html)(Journal of Machine Learning Research), [TPAMI](https://dblp.uni-trier.de/db/journals/pami/index.html)(IEEE Transactions on Pattern Analysis and Machine Intelligence).
- [NeurIPS](https://dblp.uni-trier.de/search?q=federate%20venue%3ANeurIPS%3A) 2022([OpenReview](https://openreview.net/group?id=NeurIPS.cc/2022/Conference)), [2021](https://papers.nips.cc/paper/2021)([OpenReview](https://openreview.net/group?id=NeurIPS.cc/2021/Conference)), [2020](https://papers.nips.cc/paper/2020), [2018](https://papers.nips.cc/paper/2018), [2017](https://papers.nips.cc/paper/2017)
- [ICML](https://dblp.uni-trier.de/search?q=federate%20venue%3AICML%3A) [2022](https://icml.cc/Conferences/2022/Schedule?type=Poster), [2021](https://icml.cc/Conferences/2021/Schedule?type=Poster), [2020](https://icml.cc/Conferences/2020/Schedule?type=Poster), [2019](https://icml.cc/Conferences/2019/Schedule?type=Poster)
- [ICLR](https://dblp.uni-trier.de/search?q=federate%20venue%3AICLR%3A) [2022](https://openreview.net/group?id=ICLR.cc/2022/Conference)([OpenReview](https://openreview.net/group?id=ICLR.cc/2022/Conference)),[2021](https://openreview.net/group?id=ICLR.cc/2021/Conference), [2020](https://openreview.net/group?id=ICLR.cc/2020/Conference)
- [COLT](https://dblp.org/search?q=federated%20venue%3ACOLT%3A) NULL
- [UAI](https://dblp.org/search?q=federated%20venue%3AUAI%3A) [2022](https://www.auai.org/uai2022/accepted_papers), [2021](https://www.auai.org/uai2021/accepted_papers)
- [JMLR](https://dblp.uni-trier.de/search?q=federate%20venue%3AJ%20Mach%20Learn%20Res%3A) 2021
- [TPAMI](https://dblp.uni-trier.de/search?q=federate%20venue%3ATrans%20Pattern%20Anal%20Mach%20Intell%3A) 2022
<!-- START:fl-in-top-ml-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------------------------------------ | -------------- | ---- | --------------------------- | ------------------------------------------------------------ |
| Federated online clustering of bandits. | CUHK | UAI | 2022 | | [[PUB](https://openreview.net/forum?id=rKUgiU8iqeq)] [[PDF](https://arxiv.org/abs/2208.14865)] [[CODE](https://github.com/zhaohaoru/federated-clustering-of-bandits)] |
| Privacy-aware compression for federated data analysis. | Meta AI | UAI | 2022 | | [[PUB](https://openreview.net/forum?id=BqUdRP8i9e9)] [[PDF](https://arxiv.org/abs/2203.08134)] [[CODE](https://github.com/facebookresearch/dp_compression)] |
| Faster non-convex federated learning via global and local momentum. | UTEXAS | UAI | 2022 | | [[PUB](https://openreview.net/forum?id=SSlLRUIs9e9)] [[PDF](https://arxiv.org/abs/2012.04061)] |
| Fedvarp: Tackling the variance due to partial client participation in federated learning. | CMU | UAI | 2022 | | [[PUB](https://openreview.net/forum?id=HlWLLdUocx5)] [[PDF](https://arxiv.org/abs/2207.14130)] |
| SASH: Efficient secure aggregation based on SHPRG for federated learning | CAS; CASTEST | UAI | 2022 | | [[PUB](https://openreview.net/forum?id=HSleBPIoql9)] [[PDF](https://arxiv.org/abs/2111.12321)] |
| Bayesian federated estimation of causal effects from observational data | NUS | UAI | 2022 | | [[PUB](https://openreview.net/forum?id=BEl3vP8sqlc)] [[PDF](https://arxiv.org/abs/2106.00456)] |
| Communication-Efficient Randomized Algorithm for Multi-Kernel Online Federated Learning | Hanyang University | TPAMI | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9625795)] |
| Lazily Aggregated Quantized Gradient Innovation for Communication-Efficient Federated Learning | ZJU | TPAMI | 2022 | TPAMI-LAQ[^TPAMI-LAQ] | [[PUB](https://ieeexplore.ieee.org/document/9238427)] [[CODE](https://github.com/sunjunaimer/TPAMI-LAQ)] |
| Communication Acceleration of Local Gradient Methods via an Accelerated Primal-Dual Algorithm with an Inexact Prox | Moscow Institute of Physics and Technology | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=W72rB0wwLVu)] [[PDF](https://arxiv.org/abs/2207.03957)] |
| LAMP: Extracting Text from Gradients with Language Model Priors | ETHZ | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=6iqd9JAVR1z)] [[CODE](https://openreview.net/attachment?id=6iqd9JAVR1z&name=supplementary_material)] |
| FedAvg with Fine Tuning: Local Updates Lead to Representation Learning | utexas | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=G3fswMh9P8y)] [[PDF](https://arxiv.org/abs/2205.13692)] |
| On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond | NUIST | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=_33ynl9VgCX)] [[PDF](https://arxiv.org/abs/2206.05187)] |
| Improved Differential Privacy for SGD via Optimal Private Linear Operators on Adaptive Streams | WISC | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=i9XrHJoyLqJ)] [[CODE](https://openreview.net/attachment?id=i9XrHJoyLqJ&name=supplementary_material)] |
| Decentralized Gossip-Based Stochastic Bilevel Optimization over Communication Networks | Columbia University | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=Vj-jYs47cx)] [[PDF](https://arxiv.org/abs/2206.10870)] |
| Asymptotic Behaviors of Projected Stochastic Approximation: A Jump Diffusion Perspective | PKU | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=wo-a8Ji6s3A)] |
| Subspace Recovery from Heterogeneous Data with Non-isotropic Noise | Stanford | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=mUeMOdJ2IJp)] [[PDF](https://arxiv.org/abs/2210.13497)] |
| EF-BV: A Unified Theory of Error Feedback and Variance Reduction Mechanisms for Biased and Unbiased Compression in Distributed Optimization | KAUST | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=PeJO709WUup)] [[PDF](https://arxiv.org/abs/2205.04180)] |
| On-Demand Sampling: Learning Optimally from Multiple Distributions | UC Berkeley | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=FR289LMkmxZ)] [[CODE](https://openreview.net/attachment?id=FR289LMkmxZ&name=supplementary_material)] |
| Improved Utility Analysis of Private CountSketch | ITU | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=XFCirHGr4Cs)] [[PDF](https://arxiv.org/abs/2205.08397)] [[CODE](https://github.com/rasmus-pagh/private-countsketch)] |
| Rate-Distortion Theoretic Bounds on Generalization Error for Distributed Learning | HUAWEI | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=APXedc0hgdT)] [[CODE](https://openreview.net/attachment?id=APXedc0hgdT&name=supplementary_material)] |
| Decentralized Local Stochastic Extra-Gradient for Variational Inequalities | phystech | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=Y4vT7m4e3d)] [[PDF](https://arxiv.org/abs/2106.08315)] |
| BEER: Fast O(1/T) Rate for Decentralized Nonconvex Optimization with Communication Compression | Princeton | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=I47eFCKa1f3)] [[PDF](https://arxiv.org/abs/2201.13320)] [[CODE](https://github.com/liboyue/beer)] |
| Escaping Saddle Points with Bias-Variance Reduced Local Perturbed SGD for Communication Efficient Nonconvex Distributed Learning | The University of Tokyo | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=KOHC_CYEIuP)] [[PDF](https://arxiv.org/abs/2202.06083)] |
| Near-Optimal Collaborative Learning in Bandits | INRIA; Inserm | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=2xfJ26BuFP)] [[PDF](https://arxiv.org/abs/2206.00121)] [[CODE](https://github.com/clreda/near-optimal-federated)] |
| Distributed Methods with Compressed Communication for Solving Variational Inequalities, with Theoretical Guarantees | phystech | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=J0nhRuMkdGf)] [[PDF](https://arxiv.org/abs/2110.03313)] |
| Towards Optimal Communication Complexity in Distributed Non-Convex Optimization | TTIC | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=SNElc7QmMDe)] [[CODE](https://openreview.net/attachment?id=SNElc7QmMDe&name=supplementary_material)] |
| FedPop: A Bayesian Approach for Personalised Federated Learning | Skoltech | NeurIPS | 2022 | FedPop[^FedPop] | [[PUB](https://openreview.net/forum?id=KETwimTQexH)] [[PDF](https://arxiv.org/abs/2206.03611)] |
| Fairness in Federated Learning via Core-Stability | UIUC | NeurIPS | 2022 | CoreFed[^CoreFed] | [[PUB](https://openreview.net/forum?id=lKULHf7oFDo)] [[CODE](https://openreview.net/attachment?id=lKULHf7oFDo&name=supplementary_material)] |
| SecureFedYJ: a safe feature Gaussianization protocol for Federated Learning | Sorbonne Université | NeurIPS | 2022 | SecureFedYJ[^SecureFedYJ] | [[PUB](https://openreview.net/forum?id=25XIE30VHZE)] [[PDF](https://arxiv.org/abs/2210.01639)] |
| FedRolex: Model-Heterogeneous Federated Learning with Rolling Submodel Extraction | MSU | NeurIPS | 2022 | FedRolex[^FedRolex] | [[PUB](https://openreview.net/forum?id=OtxyysUdBE)] [[CODE](https://github.com/MSU-MLSys-Lab/FedRolex)] |
| On Sample Optimality in Personalized Collaborative and Federated Learning | INRIA | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=7EP90NMAoK)] |
| DReS-FL: Dropout-Resilient Secure Federated Learning for Non-IID Clients via Secret Data Sharing | HKUST | NeurIPS | 2022 | DReS-FL[^DReS-FL] | [[PUB](https://openreview.net/forum?id=hPkGV4BPsmv)] [[PDF](https://arxiv.org/abs/2210.02680)] |
| FairVFL: A Fair Vertical Federated Learning Framework with Contrastive Adversarial Learning | THU | NeurIPS | 2022 | FairVFL[^FairVFL] | [[PUB](https://openreview.net/forum?id=5vVSA_cdRqe)] |
| Variance Reduced ProxSkip: Algorithm, Theory and Application to Federated Learning | KAUST | NeurIPS | 2022 | VR-ProxSkip[^VR-ProxSkip] | [[PUB](https://openreview.net/forum?id=edkno3SvKo)] [[PDF](https://arxiv.org/abs/2207.04338)] |
| VF-PS: How to Select Important Participants in Vertical Federated Learning, Efficiently and Securely? | WHU | NeurIPS | 2022 | VF-PS[^VF-PS] | [[PUB](https://openreview.net/forum?id=vNrSXIFJ9wz)] [[CODE](https://openreview.net/attachment?id=edkno3SvKo&name=supplementary_material)] |
| DENSE: Data-Free One-Shot Federated Learning | ZJU | NeurIPS | 2022 | DENSE[^DENSE] | [[PUB](https://openreview.net/forum?id=QFQoxCFYEkA)] [[PDF](https://arxiv.org/abs/2112.12371)] |
| CalFAT: Calibrated Federated Adversarial Training with Label Skewness | ZJU | NeurIPS | 2022 | CalFAT[^CalFAT] | [[PUB](https://openreview.net/forum?id=8N1NDRGQSQ)] [[PDF](https://arxiv.org/abs/2205.14926)] |
| SAGDA: Achieving O(ϵ−2) Communication Complexity in Federated Min-Max Learning | OSU | NeurIPS | 2022 | SAGDA[^SAGDA] | [[PUB](https://openreview.net/forum?id=wTp4KgVIJ5)] [[PDF](https://arxiv.org/abs/2210.00611)] |
| Taming Fat-Tailed (“Heavier-Tailed” with Potentially Infinite Variance) Noise in Federated Learning | OSU | NeurIPS | 2022 | FAT-Clipping[^FAT-Clipping] | [[PUB](https://openreview.net/forum?id=8SilFGuXgmk)] [[PDF](https://arxiv.org/abs/2210.00690)] |
| Personalized Federated Learning towards Communication Efficiency, Robustness and Fairness | PKU | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=wFymjzZEEkH)] |
| Federated Submodel Optimization for Hot and Cold Data Features | SJTU | NeurIPS | 2022 | FedSubAvg[^FedSubAvg] | [[PUB](https://openreview.net/forum?id=sj9l1JCrAk6)] |
| BooNTK: Convexifying Federated Learning using Bootstrapped Neural Tangent Kernels | UC Berkeley | NeurIPS | 2022 | BooNTK[^BooNTK] | [[PUB](https://openreview.net/forum?id=jzd2bE5MxW)] [[PDF](https://arxiv.org/abs/2207.06343)] |
| Byzantine-tolerant federated Gaussian process regression for streaming data | PSU | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=Nx4gNemvNvx)] [[CODE](https://openreview.net/attachment?id=Nx4gNemvNvx&name=supplementary_material)] |
| SoteriaFL: A Unified Framework for Private Federated Learning with Communication Compression | CMU | NeurIPS | 2022 | SoteriaFL[^SoteriaFL] | [[PUB](https://openreview.net/forum?id=tz1PRT6lfLe)] [[PDF](https://arxiv.org/abs/2206.09888)] |
| Coresets for Vertical Federated Learning: Regularized Linear Regression and K-Means Clustering | Yale | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=N0tKCpMhA2)] [[PDF](https://arxiv.org/abs/2210.14664)] [[CODE](https://github.com/haoyuzhao123/coreset-vfl-codes)] |
| Communication Efficient Federated Learning for Generalized Linear Bandits | University of Virginia | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=Xwz9B6LDM5c)] [[CODE](https://openreview.net/attachment?id=Xwz9B6LDM5c&name=supplementary_material)] |
| Recovering Private Text in Federated Learning of Language Models | Princeton | NeurIPS | 2022 | FILM[^FILM] | [[PUB](https://openreview.net/forum?id=dqgzfhHd2-)] [[PDF](https://arxiv.org/abs/2205.08514)] [[CODE](https://github.com/Princeton-SysML/FILM)] |
| Federated Learning from Pre-Trained Models: A Contrastive Learning Approach | UTS | NeurIPS | 2022 | FedPCL[^FedPCL] | [[PUB](https://openreview.net/forum?id=mhQLcMjWw75)] [[PDF](https://arxiv.org/abs/2209.10083)] |
| Global Convergence of Federated Learning for Mixed Regression | Northeastern University | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=DdxNka9tMRd)] [[PDF](https://arxiv.org/abs/2206.07279)] |
| Resource-Adaptive Federated Learning with All-In-One Neural Composition | JHU | NeurIPS | 2022 | FLANC[^FLANC] | [[PUB](https://openreview.net/forum?id=wfel7CjOYk)] |
| Self-Aware Personalized Federated Learning | Amazon | NeurIPS | 2022 | Self-FL[^Self-FL] | [[PUB](https://openreview.net/forum?id=EqJ5_hZSqgy)] [[PDF](https://arxiv.org/abs/2204.08069)] |
| A Communication-efficient Algorithm with Linear Convergence for Federated Minimax Learning | Northeastern University | NeurIPS | 2022 | FedGDA-GT[^FedGDA-GT] | [[PUB](https://openreview.net/forum?id=TATzsweWfof)] [[PDF](https://arxiv.org/abs/2206.01132)] |
| An Adaptive Kernel Approach to Federated Learning of Heterogeneous Causal Effects | NUS | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=fJt2KFnRqZ)] |
| Sharper Convergence Guarantees for Asynchronous SGD for Distributed and Federated Learning | EPFL | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=4_oCZgBIVI)] [[PDF](https://arxiv.org/abs/2206.08307)] |
| Personalized Online Federated Multi-Kernel Learning | UCI | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=wUctlvhsNWg)] |
| SemiFL: Semi-Supervised Federated Learning for Unlabeled Clients with Alternate Training | Duke University | NeurIPS | 2022 | SemiFL[^SemiFL] | [[PUB](https://openreview.net/forum?id=1GAjC_FauE)] [[PDF](https://arxiv.org/abs/2106.01432)] [[CODE](https://openreview.net/attachment?id=1GAjC_FauE&name=supplementary_material)] |
| A Unified Analysis of Federated Learning with Arbitrary Client Participation | IBM | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=qSs7C7c4G8D)] [[PDF](https://arxiv.org/abs/2205.13648)] |
| Preservation of the Global Knowledge by Not-True Distillation in Federated Learning | KAIST | NeurIPS | 2022 | FedNTD[^FedNTD] | [[PUB](https://openreview.net/forum?id=qw3MZb1Juo)] [[PDF](https://arxiv.org/abs/2106.03097)] [[CODE](https://openreview.net/attachment?id=qw3MZb1Juo&name=supplementary_material)] |
| FedSR: A Simple and Effective Domain Generalization Method for Federated Learning | University of Oxford | NeurIPS | 2022 | FedSR[^FedSR] | [[PUB](https://openreview.net/forum?id=mrt90D00aQX)] [[CODE](https://openreview.net/attachment?id=mrt90D00aQX&name=supplementary_material)] |
| Factorized-FL: Personalized Federated Learning with Parameter Factorization & Similarity Matching | KAIST | NeurIPS | 2022 | Factorized-FL[^Factorized-FL] | [[PUB](https://openreview.net/forum?id=Ql75oqz1npy)] [[PDF](https://arxiv.org/abs/2202.00270)] [[CODE](https://openreview.net/attachment?id=Ql75oqz1npy&name=supplementary_material)] |
| A Simple and Provably Efficient Algorithm for Asynchronous Federated Contextual Linear Bandits | UC | NeurIPS | 2022 | FedLinUCB[^FedLinUCB] | [[PUB](https://openreview.net/forum?id=Fx7oXUVEPW)] [[PDF](https://arxiv.org/abs/2207.03106)] |
| Learning to Attack Federated Learning: A Model-based Reinforcement Learning Attack Framework | Tulane University | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=4OHRr7gmhd4)] |
| On Privacy and Personalization in Cross-Silo Federated Learning | CMU | NeurIPS | 2022 | | [[PUB](https://openreview.net/forum?id=Oq2bdIQQOIZ)] [[PDF](https://arxiv.org/abs/2206.07902)] |
| A Coupled Design of Exploiting Record Similarity for Practical Vertical Federated Learning | NUS | NeurIPS | 2022 | FedSim[^FedSim] | [[PUB](https://openreview.net/forum?id=fiBnhdazkyx)] [[PDF](https://arxiv.org/abs/2106.06312)] [[CODE](https://github.com/Xtra-Computing/FedSim)] |
| FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings | Owkin | NeurIPS Datasets and Benchmarks | 2022 | | [[PUB](https://openreview.net/forum?id=GgM5DiAb6A2)] [[CODE](https://github.com/owkin/FLamby)] |
| A Tree-based Model Averaging Approach for Personalized Treatment Effect Estimation from Heterogeneous Data Sources | University of Pittsburgh | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/tan22a.html)] [[PDF](https://arxiv.org/abs/2103.06261)] [[CODE](https://github.com/ellenxtan/ifedtree)] |
| Fast Composite Optimization and Statistical Recovery in Federated Learning | SJTU | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/bao22b.html)] [[PDF](https://arxiv.org/abs/2207.08204)] [[CODE](https://github.com/MingruiLiu-ML-Lab/Federated-Sparse-Learning)] |
| Personalization Improves Privacy-Accuracy Tradeoffs in Federated Learning | NYU | ICML | 2022 | PPSGD[^PPSGD] | [[PUB](https://proceedings.mlr.press/v162/bietti22a.html)] [[PDF](https://arxiv.org/abs/2202.05318)] [[CODE](https://github.com/albietz/ppsgd)] |
| The Fundamental Price of Secure Aggregation in Differentially Private Federated Learning :fire: | Stanford; Google Research | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/chen22c.html)] [[PDF](https://arxiv.org/abs/2203.03761)] [[CODE](https://github.com/google-research/federated/tree/master/private_linear_compression)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/17529.pdf)] |
| The Poisson Binomial Mechanism for Unbiased Federated Learning with Secure Aggregation | Stanford; Google Research | ICML | 2022 | PBM[^PBM] | [[PUB](https://proceedings.mlr.press/v162/chen22s.html)] [[PDF](https://arxiv.org/abs/2207.09916)] [[CODE](https://github.com/WeiNingChen/pbm)] |
| DisPFL: Towards Communication-Efficient Personalized Federated Learning via Decentralized Sparse Training | USTC | ICML | 2022 | DisPFL[^DisPFL] | [[PUB](https://proceedings.mlr.press/v162/dai22b.html)] [[PDF](https://arxiv.org/abs/2206.00187)] [[CODE](https://github.com/rong-dai/DisPFL)] |
| FedNew: A Communication-Efficient and Privacy-Preserving Newton-Type Method for Federated Learning | University of Oulu | ICML | 2022 | FedNew[^FedNew] | [[PUB](https://proceedings.mlr.press/v162/elgabli22a.html)] [[PDF](https://arxiv.org/abs/2206.08829)] [[CODE](https://github.com/aelgabli/FedNew)] |
| DAdaQuant: Doubly-adaptive quantization for communication-efficient Federated Learning | University of Cambridge | ICML | 2022 | DAdaQuant[^DAdaQuant] | [[PUB](https://proceedings.mlr.press/v162/honig22a.html)] [[PDF](https://arxiv.org/abs/2111.00465)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/16009.pdf)] [[CODE](https://media.icml.cc/Conferences/ICML2022/supplementary/honig22a-supp.zip)] |
| Accelerated Federated Learning with Decoupled Adaptive Optimization | Auburn University | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/jin22e.html)] [[PDF](https://arxiv.org/abs/2207.07223)] |
| Federated Reinforcement Learning: Linear Speedup Under Markovian Sampling | Georgia Tech | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/khodadadian22a.html)] [[PDF](https://arxiv.org/abs/2206.10185)] |
| Multi-Level Branched Regularization for Federated Learning | Seoul National University | ICML | 2022 | FedMLB[^FedMLB] | [[PUB](https://proceedings.mlr.press/v162/kim22a.html)] [[PDF](https://arxiv.org/abs/2207.06936)] [[CODE](https://github.com/jinkyu032/FedMLB)] [[PAGE](http://cvlab.snu.ac.kr/research/FedMLB/)] |
| FedScale: Benchmarking Model and System Performance of Federated Learning at Scale :fire: | University of Michigan | ICML | 2022 | FedScale[^FedScale] | [[PUB](https://proceedings.mlr.press/v162/lai22a.html)] [[PDF](https://arxiv.org/abs/2105.11367)] [[CODE](https://github.com/SymbioticLab/FedScale)] |
| Federated Learning with Positive and Unlabeled Data | XJTU | ICML | 2022 | FedPU[^FedPU] | [[PUB](https://proceedings.mlr.press/v162/lin22b.html)] [[PDF](https://arxiv.org/abs/2106.10904)] [[CODE](https://github.com/littlesunlxy/fedpu-torch)] |
| Deep Neural Network Fusion via Graph Matching with Applications to Model Ensemble and Federated Learning | SJTU | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/liu22k.html)] [[CODE](https://github.com/Thinklab-SJTU/GAMF)] |
| Orchestra: Unsupervised Federated Learning via Globally Consistent Clustering | University of Michigan | ICML | 2022 | Orchestra[^Orchestra] | [[PUB](https://proceedings.mlr.press/v162/lubana22a.html)] [[PDF](https://arxiv.org/abs/2205.11506)] [[CODE](https://github.com/akhilmathurs/orchestra)] |
| Disentangled Federated Learning for Tackling Attributes Skew via Invariant Aggregation and Diversity Transferring | USTC | ICML | 2022 | DFL[^DFL] | [[PUB](https://proceedings.mlr.press/v162/luo22b.html)] [[PDF](https://arxiv.org/abs/2206.06818)] [[CODE](https://github.com/luozhengquan/DFL)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/16881.pdf)] [[解读](https://www.bilibili.com/read/cv17092678)] |
| Architecture Agnostic Federated Learning for Neural Networks | The University of Texas at Austin | ICML | 2022 | FedHeNN[^FedHeNN] | [[PUB](https://proceedings.mlr.press/v162/makhija22a.html)] [[PDF](https://proceedings.mlr.press/v162/zhang22p.html)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/16926.pdf)] |
| Personalized Federated Learning through Local Memorization | Inria | ICML | 2022 | KNN-PER[^KNN-PER] | [[PUB](https://proceedings.mlr.press/v162/marfoq22a.html)] [[PDF](https://arxiv.org/abs/2111.09360)] [[CODE](https://github.com/omarfoq/knn-per)] |
| Proximal and Federated Random Reshuffling | KAUST | ICML | 2022 | ProxRR[^ProxRR] | [[PUB](https://proceedings.mlr.press/v162/mishchenko22a.html)] [[PDF](https://arxiv.org/abs/2102.06704)] [[CODE](https://github.com/konstmish/rr_prox_fed)] |
| Federated Learning with Partial Model Personalization | University of Washington | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/pillutla22a.html)] [[PDF](https://arxiv.org/abs/2204.03809)] [[CODE](https://github.com/krishnap25/FL_partial_personalization)] |
| Generalized Federated Learning via Sharpness Aware Minimization | University of South Florida | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/qu22a.html)] [[PDF](https://arxiv.org/abs/2206.02618)] |
| FedNL: Making Newton-Type Methods Applicable to Federated Learning | KAUST | ICML | 2022 | FedNL[^FedNL] | [[PUB](https://proceedings.mlr.press/v162/safaryan22a.html)] [[PDF](https://arxiv.org/abs/2106.02969)] [[VIDEO](https://www.youtube.com/watch?v=_VYCEWT17R0&ab_channel=FederatedLearningOneWorldSeminar)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/17084.pdf)] |
| Federated Minimax Optimization: Improved Convergence Analyses and Algorithms | CMU | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/sharma22c.html)] [[PDF](https://arxiv.org/abs/2203.04850)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/17435.pdf)] |
| Virtual Homogeneity Learning: Defending against Data Heterogeneity in Federated Learning | Hong Kong Baptist University | ICML | 2022 | VFL[^VFL] | [[PUB](https://proceedings.mlr.press/v162/tang22d.html)] [[PDF](https://arxiv.org/abs/2206.02465)] [[CODE](https://github.com/wizard1203/VHL)] [[解读](https://zhuanlan.zhihu.com/p/548508633)] |
| FedNest: Federated Bilevel, Minimax, and Compositional Optimization | University of Michigan | ICML | 2022 | FedNest[^FedNest] | [[PUB](https://proceedings.mlr.press/v162/tarzanagh22a.html)] [[PDF](https://arxiv.org/abs/2205.02215)] [[CODE](https://github.com/mc-nya/FedNest)] |
| EDEN: Communication-Efficient and Robust Distributed Mean Estimation for Federated Learning | VMware Research | ICML | 2022 | EDEN[^EDEN] | [[PUB](https://proceedings.mlr.press/v162/vargaftik22a.html)] [[PDF](https://arxiv.org/abs/2108.08842)] [[CODE](https://github.com/amitport/EDEN-Distributed-Mean-Estimation)] |
| Communication-Efficient Adaptive Federated Learning | Pennsylvania State University | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/wang22o.html)] [[PDF](https://arxiv.org/abs/2205.02719)] |
| ProgFed: Effective, Communication, and Computation Efficient Federated Learning by Progressive Training | CISPA Helmholz Center for Information Security | ICML | 2022 | ProgFed[^ProgFed] | [[PUB](https://proceedings.mlr.press/v162/wang22y.html)] [[PDF](https://arxiv.org/abs/2110.05323)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/16194_hmjFNsN.pdf)] [[CODE](https://github.com/a514514772/ProgFed)] |
| Fishing for User Data in Large-Batch Federated Learning via Gradient Magnification :fire: | University of Maryland | ICML | 2022 | breaching[^breaching] | [[PUB](https://proceedings.mlr.press/v162/wen22a.html)] [[PDF](https://arxiv.org/abs/2202.00580)] [[CODE](https://github.com/JonasGeiping/breaching)] |
| Anarchic Federated Learning | The Ohio State University | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/yang22r.html)] [[PDF](https://arxiv.org/abs/2108.09875)] |
| QSFL: A Two-Level Uplink Communication Optimization Framework for Federated Learning | Nankai University | ICML | 2022 | QSFL[^QSFL] | [[PUB](https://proceedings.mlr.press/v162/yi22a.html)] [[CODE](https://github.com/LipingYi/QSFL)] |
| Bitwidth Heterogeneous Federated Learning with Progressive Weight Dequantization | KAIST | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/yoon22a.html)] [[PDF](https://arxiv.org/abs/2202.11453)] |
| Neural Tangent Kernel Empowered Federated Learning | NC State University | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/yue22a.html)] [[PDF](https://arxiv.org/abs/2110.03681)] [[CODE](https://github.com/KAI-YUE/ntk-fed)] |
| Understanding Clipping for Federated Learning: Convergence and Client-Level Differential Privacy | UMN | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/zhang22b.html)] [[PDF](https://arxiv.org/abs/2106.13673)] |
| Personalized Federated Learning via Variational Bayesian Inference | CAS | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/zhang22o.html)] [[PDF](https://arxiv.org/abs/2206.07977)] [[SLIDE](https://icml.cc/media/icml-2022/Slides/17302.pdf)] [[UC.](https://github.com/AllenBeau/pFedBayes)] |
| Federated Learning with Label Distribution Skew via Logits Calibration | ZJU | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/zhang22p.html)] |
| Neurotoxin: Durable Backdoors in Federated Learning | Southeast University;Princeton | ICML | 2022 | Neurotoxin[^Neurotoxin] | [[PUB](https://proceedings.mlr.press/v162/zhang22w.html)] [[PDF](https://arxiv.org/abs/2206.10341)] [[CODE](https://github.com/jhcknzzm/Federated-Learning-Backdoor/)] |
| Resilient and Communication Efficient Learning for Heterogeneous Federated Systems | Michigan State University | ICML | 2022 | | [[PUB](https://proceedings.mlr.press/v162/zhu22e.html)] |
| Minibatch vs Local SGD with Shuffling: Tight Convergence Bounds and Beyond | KAIST | ICLR (oral) | 2022 | | [[PUB](https://openreview.net/forum?id=LdlwbBP2mlq)] [[CODE](https://openreview.net/attachment?id=LdlwbBP2mlq&name=supplementary_material)] |
| Bayesian Framework for Gradient Leakage | ETH Zurich | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=f2lrIbGx3x7)] [[PDF](https://arxiv.org/abs/2111.04706)] [[CODE](https://github.com/eth-sri/bayes-framework-leakage)] |
| Federated Learning from only unlabeled data with class-conditional-sharing clients | The University of Tokyo; CUHK | ICLR | 2022 | FedUL[^FedUL] | [[PUB](https://openreview.net/forum?id=WHA8009laxu)] [[CODE](https://github.com/lunanbit/FedUL)] |
| FedChain: Chained Algorithms for Near-Optimal Communication Cost in Federated Learning | CMU; University of Illinois at Urbana-Champaign; University of Washington | ICLR | 2022 | FedChain[^FedChain] | [[PUB](https://openreview.net/forum?id=ZaVVVlcdaN)] [[PDF](https://arxiv.org/abs/2108.06869.)] |
| Acceleration of Federated Learning with Alleviated Forgetting in Local Training | THU | ICLR | 2022 | FedReg[^FedReg] | [[PUB](https://openreview.net/forum?id=541PxiEKN3F)] [[PDF](https://arxiv.org/abs/2203.02645)] [[CODE](https://github.com/Zoesgithub/FedReg)] |
| FedPara: Low-rank Hadamard Product for Communicatkion-Efficient Federated Learning | POSTECH | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=d71n4ftoCBy)] [[PDF](https://arxiv.org/abs/2108.06098)] [[CODE](https://github.com/South-hw/FedPara_ICLR22)] |
| An Agnostic Approach to Federated Learning with Class Imbalance | University of Pennsylvania | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=Xo0lbDt975)] [[CODE](https://github.com/shenzebang/Federated-Learning-Pytorch)] |
| Efficient Split-Mix Federated Learning for On-Demand and In-Situ Customization | Michigan State University; The University of Texas at Austin | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=_QLmakITKg)] [[PDF](https://arxiv.org/abs/2203.09747)] [[CODE](https://github.com/illidanlab/SplitMix)] |
| Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models :fire: | University of Maryland; NYU | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=fwzUgo0FM9v)] [[PDF](https://arxiv.org/abs/2110.13057)] [[CODE](https://github.com/JonasGeiping/breaching)] |
| ZeroFL: Efficient On-Device Training for Federated Learning with Local Sparsity | University of Cambridge; University of Oxford | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=2sDQwC_hmnM)] [[PDF](https://arxiv.org/abs/2208.02507)] |
| Diverse Client Selection for Federated Learning via Submodular Maximization | Intel; CMU | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=nwKXyFvaUm)] [[CODE](https://github.com/melodi-lab/divfl)] |
| Recycling Model Updates in Federated Learning: Are Gradient Subspaces Low-Rank? | Purdue | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=B7ZbqNLDn-_)] [[PDF](https://arxiv.org/abs/2202.00280)] [[CODE](https://github.com/shams-sam/FedOptim)] |
| Diurnal or Nocturnal? Federated Learning of Multi-branch Networks from Periodically Shifting Distributions :fire: | University of Maryland; Google | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=E4EE_ohFGz)] [[CODE](https://github.com/google-research/federated/tree/7525c36324cb022bc05c3fce88ef01147cae9740/periodic_distribution_shift)] |
| Towards Model Agnostic Federated Learning Using Knowledge Distillation | EPFL | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=lQI_mZjvBxj)] [[PDF](https://arxiv.org/abs/2110.15210)] [[CODE](https://github.com/AfoninAndrei/ICLR2022)] |
| Divergence-aware Federated Self-Supervised Learning | NTU; SenseTime | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=oVE1z8NlNe)] [[PDF](https://arxiv.org/abs/2204.04385)] [[CODE](https://github.com/EasyFL-AI/EasyFL)] |
| What Do We Mean by Generalization in Federated Learning? :fire: | Stanford; Google | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=VimqQq-i_Q)] [[PDF](https://arxiv.org/abs/2110.14216)] [[CODE](https://github.com/google-research/federated/tree/master/generalization)] |
| FedBABU: Toward Enhanced Representation for Federated Image Classification | KAIST | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=HuaYQfggn5u)] [[PDF](https://arxiv.org/abs/2106.06042)] [[CODE](https://github.com/jhoon-oh/FedBABU)] |
| Byzantine-Robust Learning on Heterogeneous Datasets via Bucketing | EPFL | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=jXKKDEi5vJt)] [[PDF](https://arxiv.org/abs/2006.09365)] [[CODE](https://github.com/liehe/byzantine-robust-noniid-optimizer)] |
| Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters | Aibee | ICLR Spotlight | 2022 | | [[PUB](https://openreview.net/forum?id=7l1IjZVddDW)] [[PDF](https://arxiv.org/abs/2201.12467)] [[PAGE](https://irvingmeng.github.io/projects/privacyface/)] [[解读](https://zhuanlan.zhihu.com/p/484920301)] |
| Hybrid Local SGD for Federated Learning with Heterogeneous Communications | University of Texas; Pennsylvania State University | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=H0oaWl6THa)] |
| On Bridging Generic and Personalized Federated Learning for Image Classification | The Ohio State University | ICLR | 2022 | Fed-RoD[^Fed-RoD] | [[PUB](https://openreview.net/forum?id=I1hQbx10Kxn)] [[PDF](https://arxiv.org/abs/2107.00778)] [[CODE](https://github.com/hongyouc/Fed-RoD)] |
| Minibatch vs Local SGD with Shuffling: Tight Convergence Bounds and Beyond | KAIST; MIT | ICLR | 2022 | | [[PUB](https://openreview.net/forum?id=LdlwbBP2mlq)] [[PDF](https://arxiv.org/abs/2110.10342)] |
| One-Shot Federated Learning: Theoretical Limits and Algorithms to Achieve Them. | | JMLR | 2021 | | [[PUB](http://jmlr.org/papers/v22/19-1048.html)] [[CODE](https://github.com/sabersalehk/MRE_C)] |
| Constrained differentially private federated learning for low-bandwidth devices | | UAI | 2021 | | [[PUB](https://proceedings.mlr.press/v161/kerkouche21a.html)] [[PDF](https://arxiv.org/abs/2103.00342)] |
| Federated stochastic gradient Langevin dynamics | | UAI | 2021 | | [[PUB](https://proceedings.mlr.press/v161/mekkaoui21a.html)] [[PDF](https://arxiv.org/abs/2004.11231)] |
| Federated Learning Based on Dynamic Regularization | BU; ARM | ICLR | 2021 | | [[PUB](https://openreview.net/forum?id=B7v4QMR6Z9w)] [[PDF](https://arxiv.org/abs/2111.04263)] [[CODE](https://github.com/AntixK/FedDyn)] |
| Achieving Linear Speedup with Partial Worker Participation in Non-IID Federated Learning | The Ohio State University | ICLR | 2021 | | [[PUB](https://openreview.net/forum?id=jDdzh5ul-d)] [[PDF](https://arxiv.org/abs/2101.11203)] |
| HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients | Duke University | ICLR | 2021 | HeteroFL[^HeteroFL] | [[PUB](https://openreview.net/forum?id=TNkPBBYFkXg)] [[PDF](https://arxiv.org/abs/2010.01264)] [[CODE](https://github.com/dem123456789/HeteroFL-Computation-and-Communication-Efficient-Federated-Learning-for-Heterogeneous-Clients)] |
| FedMix: Approximation of Mixup under Mean Augmented Federated Learning | KAIST | ICLR | 2021 | FedMix[^FedMix] | [[PUB](https://openreview.net/forum?id=Ogga20D2HO-)] [[PDF](https://arxiv.org/abs/2107.00233)] |
| Federated Learning via Posterior Averaging: A New Perspective and Practical Algorithms :fire: | CMU; Google | ICLR | 2021 | | [[PUB](https://openreview.net/forum?id=GFsU8a0sGB)] [[PDF](https://arxiv.org/abs/2010.05273)] [[CODE](https://github.com/alshedivat/fedpa)] |
| Adaptive Federated Optimization :fire: | Google | ICLR | 2021 | | [[PUB](https://openreview.net/forum?id=LkFG3lB13U5)] [[PDF](https://arxiv.org/abs/2003.00295)] [[CODE](https://github.com/google-research/federated/tree/master/optimization)] |
| Personalized Federated Learning with First Order Model Optimization | Stanford; NVIDIA | ICLR | 2021 | FedFomo[^FedFomo] | [[PUB](https://openreview.net/forum?id=ehJqJQk9cw)] [[PDF](https://arxiv.org/abs/2012.08565)] [[CODE](https://github.com/NVlabs/FedFomo)] [[UC.](https://github.com/TsingZ0/PFL-Non-IID)] |
| FedBN: Federated Learning on Non-IID Features via Local Batch Normalization :fire: | Princeton | ICLR | 2021 | FedBN[^FedBN] | [[PUB](https://openreview.net/forum?id=6YEQUn0QICG)] [[PDF](https://arxiv.org/abs/2102.07623)] [[CODE](https://github.com/med-air/FedBN)] |
| FedBE: Making Bayesian Model Ensemble Applicable to Federated Learning | The Ohio State University | ICLR | 2021 | FedBE[^FedBE] | [[PUB](https://openreview.net/forum?id=dgtpE6gKjHn)] [[PDF](https://arxiv.org/abs/2009.01974)] [[CODE](https://github.com/hongyouc/fedbe)] |
| Federated Semi-Supervised Learning with Inter-Client Consistency & Disjoint Learning | KAIST | ICLR | 2021 | | [[PUB](https://openreview.net/forum?id=ce6CFXBh30h)] [[PDF](https://arxiv.org/abs/2006.12097)] [[CODE](https://github.com/wyjeong/FedMatch)] |
| KD3A: Unsupervised Multi-Source Decentralized Domain Adaptation via Knowledge Distillation | ZJU | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/feng21f.html)] [[PDF](https://arxiv.org/abs/2011.09757)] [[CODE](https://github.com/FengHZ/KD3A)] [[解读](https://mp.weixin.qq.com/s/gItgiZmKUxg0ltaeOVdnRw)] |
| Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix | Harvard University | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/lam21b.html)] [[PDF](https://arxiv.org/abs/2106.06089)] [[VIDEO](https://slideslive.com/38958558/gradient-disaggregation-breaking-privacy-in-federated-learning-by-reconstructing-the-user-participant-matrix)] [[CODE](https://github.com/gdisag/gradient_disaggregation)] |
| FL-NTK: A Neural Tangent Kernel-based Framework for Federated Learning Analysis | PKU; Princeton | ICML | 2021 | FL-NTK[^FL-NTK] | [[PUB](http://proceedings.mlr.press/v139/huang21c.html)] [[PDF](https://arxiv.org/abs/2105.05001)] [[VIDEO](https://slideslive.com/38959650/flntk-a-neural-tangent-kernelbased-framework-for-federated-learning-analysis)] |
| Personalized Federated Learning using Hypernetworks :fire: | Bar-Ilan University; NVIDIA | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/shamsian21a.html)] [[PDF](https://arxiv.org/abs/2103.04628)] [[CODE](https://github.com/AvivSham/pFedHN)] [[PAGE](https://avivsham.github.io/pfedhn/)] [[VIDEO](https://slideslive.com/38959583/personalized-federated-learning-using-hypernetworks)] [[解读](https://zhuanlan.zhihu.com/p/431130945)] |
| Federated Composite Optimization | Stanford; Google | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/yuan21d.html)] [[PDF](https://arxiv.org/abs/2011.08474)] [[CODE](https://github.com/hongliny/FCO-ICML21)] [[VIDEO](https://www.youtube.com/watch?v=tKDbc60XJks&ab_channel=FederatedLearningOneWorldSeminar)] [[SLIDE](https://hongliny.github.io/files/FCO_ICML21/FCO_ICML21_slides.pdf)] |
| Exploiting Shared Representations for Personalized Federated Learning | University of Texas at Austin; University of Pennsylvania | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/collins21a.html)] [[PDF](https://arxiv.org/abs/2102.07078)] [[CODE](https://github.com/lgcollins/FedRep)] [[VIDEO](https://slideslive.com/38959519/exploiting-shared-representations-for-personalized-federated-learning)] |
| Data-Free Knowledge Distillation for Heterogeneous Federated Learning :fire: | Michigan State University | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/zhu21b.html)] [[PDF](https://arxiv.org/abs/2105.10056)] [[CODE](https://github.com/zhuangdizhu/FedGen)] [[VIDEO](https://slideslive.com/38959429/datafree-knowledge-distillation-for-heterogeneous-federated-learning)] |
| Federated Continual Learning with Weighted Inter-client Transfer | KAIST | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/yoon21b.html)] [[PDF](https://arxiv.org/abs/2003.03196)] [[CODE](https://github.com/wyjeong/FedWeIT)] [[VIDEO](https://slideslive.com/38959323/federated-continual-learning-with-weighted-interclient-transfer)] |
| Federated Deep AUC Maximization for Hetergeneous Data with a Constant Communication Complexity | The University of Iowa | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/yuan21a.html)] [[PDF](https://arxiv.org/abs/2102.04635)] [[CODE](https://libauc.org/)] [[VIDEO](https://slideslive.com/38959235/federated-deep-auc-maximization-for-hetergeneous-data-with-a-constant-communication-complexity)] |
| Bias-Variance Reduced Local SGD for Less Heterogeneous Federated Learning | The University of Tokyo | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/murata21a.html)] [[PDF](https://arxiv.org/abs/2102.03198)] [[VIDEO](https://slideslive.com/38959169/biasvariance-reduced-local-sgd-for-less-heterogeneous-federated-learning)] |
| Federated Learning of User Verification Models Without Sharing Embeddings | Qualcomm | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/hosseini21a.html)] [[PDF](https://arxiv.org/abs/2104.08776)] [[VIDEO](https://slideslive.com/38958858/federated-learning-of-user-verification-models-without-sharing-embeddings)] |
| Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning | Accenture | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/fraboni21a.html)] [[PDF](https://arxiv.org/abs/2105.05883)] [[CODE](https://github.com/Accenture//Labs-Federated-Learning/tree/clustered_sampling)] [[VIDEO](https://slideslive.com/38959618/clustered-sampling-lowvariance-and-improved-representativity-for-clients-selection-in-federated-learning)] |
| Ditto: Fair and Robust Federated Learning Through Personalization | CMU; Facebook AI | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/li21h.html)] [[PDF](https://arxiv.org/abs/2012.04221)] [[CODE](https://github.com/litian96/ditto)] [[VIDEO](https://slideslive.com/38955195/ditto-fair-and-robust-federated-learning-through-personalization)] |
| Heterogeneity for the Win: One-Shot Federated Clustering | CMU | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/dennis21a.html)] [[PDF](https://arxiv.org/abs/2103.00697)] [[VIDEO](https://slideslive.com/38959380/heterogeneity-for-the-win-oneshot-federated-clustering)] |
| The Distributed Discrete Gaussian Mechanism for Federated Learning with Secure Aggregation :fire: | Google | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/kairouz21a.html)] [[PDF](https://arxiv.org/abs/2102.06387)] [[CODE](https://github.com/google-research/federated/tree/master/distributed_dp)] [[VIDEO](https://slideslive.com/38959306/the-distributed-discrete-gaussian-mechanism-for-federated-learning-with-secure-aggregation)] |
| Debiasing Model Updates for Improving Personalized Federated Training | BU; Arm | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/acar21a.html)] [[CODE](https://github.com/venkatesh-saligrama/Personalized-Federated-Learning)] [[VIDEO](https://slideslive.com/38959212/debiasing-model-updates-for-improving-personalized-federated-training)] |
| One for One, or All for All: Equilibria and Optimality of Collaboration in Federated Learning | Toyota; Berkeley; Cornell University | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/blum21a.html)] [[PDF](https://arxiv.org/abs/2103.03228)] [[CODE](https://github.com/rlphilli/Collaborative-Incentives)] [[VIDEO](https://slideslive.com/38959135/one-for-one-or-all-for-all-equilibria-and-optimality-of-collaboration-in-federated-learning)] |
| CRFL: Certifiably Robust Federated Learning against Backdoor Attacks | UIUC; IBM | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/xie21a.html)] [[PDF](https://arxiv.org/abs/2106.08283)] [[CODE](https://github.com/AI-secure/CRFL)] [[VIDEO](https://slideslive.com/38959047/crfl-certifiably-robust-federated-learning-against-backdoor-attacks)] |
| Federated Learning under Arbitrary Communication Patterns | Indiana University; Amazon | ICML | 2021 | | [[PUB](http://proceedings.mlr.press/v139/avdiukhin21a.html)] [[VIDEO](https://slideslive.com/38959048/federated-learning-under-arbitrary-communication-patterns)] |
| CANITA: Faster Rates for Distributed Convex Optimization with Communication Compression | CMU | NeurIPS | 2021 | | [[PUB](https://openreview.net/forum?id=eNB4WXnNczJ)] [[PDF](https://arxiv.org/abs/2107.09461)] |
| Boosting with Multiple Sources | Google | NeurIPS | 2021 | | [[PUB](https://openreview.net/forum?id=1oP1duoZxx)] |
| DRIVE: One-bit Distributed Mean Estimation | VMware | NeurIPS | 2021 | | [[PUB](https://openreview.net/forum?id=KXRTmcv3dQ8)] [[CODE](https://github.com/amitport/DRIVE-One-bit-Distributed-Mean-Estimation)] |
| Gradient Driven Rewards to Guarantee Fairness in Collaborative Machine Learning | NUS | NeurIPS | 2021 | | [[PUB](https://openreview.net/forum?id=yRfsADObu18)] [[CODE](https://github.com/XinyiYS/Gradient-Driven-Rewards-to-Guarantee-Fairness-in-Collaborative-Machine-Learning)] |
| Gradient Inversion with Generative Image Prior | POSTECH | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/fa84632d742f2729dc32ce8cb5d49733-Abstract.html)] [[PDF](https://arxiv.org/abs/2110.14962)] [[CODE](https://github.com/ml-postech/gradient-inversion-generative-image-prior)] |
| Distributed Machine Learning with Sparse Heterogeneous Data | University of Oxford | NeurIPS | 2021 | | [[PUB](https://openreview.net/forum?id=F9HNBbytcqT)] [[PDF](https://arxiv.org/abs/1912.01417)] |
| Renyi Differential Privacy of The Subsampled Shuffle Model In Distributed Learning | UCLA | NeurIPS | 2021 | | [[PUB](https://openreview.net/forum?id=SPrVNsXnGd)] [[PDF](https://arxiv.org/abs/2107.08763)] |
| Sageflow: Robust Federated Learning against Both Stragglers and Adversaries | KAIST | NeurIPS | 2021 | Sageflow[^Sageflow] | [[PUB](https://proceedings.neurips.cc/paper/2021/hash/076a8133735eb5d7552dc195b125a454-Abstract.html)] |
| CAFE: Catastrophic Data Leakage in Vertical Federated Learning | Rensselaer Polytechnic Institute; IBM Research | NeurIPS | 2021 | CAFE[^CAFE] | [[PUB](https://papers.nips.cc/paper/2021/hash/08040837089cdf46631a10aca5258e16-Abstract.html)] [[CODE](https://github.com/DeRafael/CAFE)] |
| Fault-Tolerant Federated Reinforcement Learning with Theoretical Guarantee | NUS | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/080acdcce72c06873a773c4311c2e464-Abstract.html)] [[PDF](https://arxiv.org/abs/2110.14074)] [[CODE](https://github.com/flint-xf-fan/Byzantine-Federeated-RL)] |
| Optimality and Stability in Federated Learning: A Game-theoretic Approach | Cornell University | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/09a5e2a11bea20817477e0b1dfe2cc21-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.09580)] [[CODE](https://github.com/kpdonahue/model_sharing_games)] |
| QuPeD: Quantized Personalization via Distillation with Applications to Federated Learning | UCLA | NeurIPS | 2021 | QuPeD[^QuPeD] | [[PUB](https://papers.nips.cc/paper/2021/hash/1dba3025b159cd9354da65e2d0436a31-Abstract.html)] [[PDF](https://arxiv.org/abs/2107.13892)] [[CODE](https://github.com/zkhku/fedsage)] [[解读](https://zhuanlan.zhihu.com/p/430789355)] |
| The Skellam Mechanism for Differentially Private Federated Learning :fire: | Google Research; CMU | NeurIPS | 2021 | | [[PUB](https://papers.neurips.cc/paper/2021/hash/285baacbdf8fda1de94b19282acd23e2-Abstract.html)] [[PDF](https://arxiv.org/abs/2110.04995)] [[CODE](https://github.com/google-research/federated/tree/master/distributed_dp)] |
| No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data | NUS; Huawei | NeurIPS | 2021 | | [[PUB](https://papers.neurips.cc/paper/2021/hash/2f2b265625d76a6704b08093c652fd79-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.05001)] |
| STEM: A Stochastic Two-Sided Momentum Algorithm Achieving Near-Optimal Sample and Communication Complexities for Federated Learning | UMN | NeurIPS | 2021 | | [[PUB](https://papers.neurips.cc/paper/2021/hash/3016a447172f3045b65f5fc83e04b554-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.10435)] |
| Subgraph Federated Learning with Missing Neighbor Generation | Emory; UBC; Lehigh University | NeurIPS | 2021 | FedSage[^FedSage] | [[PUB](https://papers.neurips.cc/paper/2021/hash/34adeb8e3242824038aa65460a47c29e-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.13430)] [[CODE](https://github.com/zkhku/fedsage)] [[解读](https://zhuanlan.zhihu.com/p/423555171)] |
| Evaluating Gradient Inversion Attacks and Defenses in Federated Learning :fire: | Princeton | NeurIPS | 2021 | GradAttack[^GradAttack] | [[PUB](https://papers.neurips.cc/paper/2021/hash/3b3fff6463464959dcd1b68d0320f781-Abstract.html)] [[PDF](https://arxiv.org/abs/2112.00059)] [[CODE](https://github.com/Princeton-SysML/GradAttack)] |
| Personalized Federated Learning With Gaussian Processes | Bar-Ilan University | NeurIPS | 2021 | | [[PUB](https://proceedings.neurips.cc/paper/2021/hash/46d0671dd4117ea366031f87f3aa0093-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.15482)] [[CODE](https://github.com/IdanAchituve/pFedGP)] |
| Differentially Private Federated Bayesian Optimization with Distributed Exploration | MIT; NUS | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/4c27cea8526af8cfee3be5e183ac9605-Abstract.html)] [[PDF](https://arxiv.org/abs/2110.14153)] [[CODE](https://github.com/daizhongxiang/Differentially-Private-Federated-Bayesian-Optimization)] |
| Parameterized Knowledge Transfer for Personalized Federated Learning | PolyU | NeurIPS | 2021 | KT-pFL[^KT-pFL] | [[PUB](https://papers.nips.cc/paper/2021/hash/5383c7318a3158b9bc261d0b6996f7c2-Abstract.html)] [[PDF](https://arxiv.org/abs/2111.02862)] [[CODE](https://github.com/cugzj/KT-pFL)] |
| Federated Reconstruction: Partially Local Federated Learning :fire: | Google Research | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/5d44a2b0d85aa1a4dd3f218be6422c66-Abstract.html)] [[PDF](https://arxiv.org/abs/2102.03448)] [[CODE](https://github.com/google-research/federated/tree/master/reconstruction)] [[UC.](https://github.com/KarhouTam/FedRecon)] |
| Fast Federated Learning in the Presence of Arbitrary Device Unavailability | THU; Princeton; MIT | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/64be20f6dd1dd46adf110cf871e3ed35-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.04159)] [[CODE](https://github.com/hmgxr128/MIFA_code/)] |
| FL-WBC: Enhancing Robustness against Model Poisoning Attacks in Federated Learning from a Client Perspective | Duke University; Accenture Labs | NeurIPS | 2021 | FL-WBC[^FL-WBC] | [[PUB](https://papers.nips.cc/paper/2021/hash/692baebec3bb4b53d7ebc3b9fabac31b-Abstract.html)] [[PDF](https://arxiv.org/abs/2110.13864)] [[CODE](https://github.com/jeremy313/FL-WBC)] |
| FjORD: Fair and Accurate Federated Learning under heterogeneous targets with Ordered Dropout | KAUST; Samsung AI Center | NeurIPS | 2021 | FjORD[^FjORD] | [[PUB](https://papers.nips.cc/paper/2021/hash/6aed000af86a084f9cb0264161e29dd3-Abstract.html)] [[PDF](https://arxiv.org/abs/2102.13451)] |
| Linear Convergence in Federated Learning: Tackling Client Heterogeneity and Sparse Gradients | University of Pennsylvania | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/7a6bda9ad6ffdac035c752743b7e9d0e-Abstract.html)] [[PDF](https://arxiv.org/abs/2102.07053)] [[VIDEO](https://papertalk.org/papertalks/35898)] |
| Federated Multi-Task Learning under a Mixture of Distributions | INRIA; Accenture Labs | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/82599a4ec94aca066873c99b4c741ed8-Abstract.html)] [[PDF](https://arxiv.org/abs/2108.10252)] [[CODE](https://github.com/omarfoq/FedEM)] |
| Federated Graph Classification over Non-IID Graphs | Emory | NeurIPS | 2021 | GCFL[^GCFL] | [[PUB](https://papers.nips.cc/paper/2021/hash/9c6947bd95ae487c81d4e19d3ed8cd6f-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.13423)] [[CODE](https://github.com/Oxfordblue7/GCFL)] [[解读](https://zhuanlan.zhihu.com/p/430718887)] |
| Federated Hyperparameter Tuning: Challenges, Baselines, and Connections to Weight-Sharing | CMU; Hewlett Packard Enterprise | NeurIPS | 2021 | FedEx[^FedEx] | [[PUB](https://papers.nips.cc/paper/2021/hash/a0205b87490c847182672e8d371e9948-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.04502)] [[CODE](https://github.com/mkhodak/fedex)] |
| On Large-Cohort Training for Federated Learning :fire: | Google; CMU | NeurIPS | 2021 | Large-Cohort[^Large-Cohort] | [[PUB](https://papers.nips.cc/paper/2021/hash/ab9ebd57177b5106ad7879f0896685d4-Abstract.html)] [[PDF](https://arxiv.org/abs/2106.07820)] [[CODE](https://github.com/google-research/federated/tree/f4e26c1b9b47ac320e520a8b9943ea2c5324b8c2/large_cohort)] |
| DeepReduce: A Sparse-tensor Communication Framework for Federated Deep Learning | KAUST; Columbia University; University of Central Florida | NeurIPS | 2021 | DeepReduce[^DeepReduce] | [[PUB](https://papers.nips.cc/paper/2021/hash/b0ab42fcb7133122b38521d13da7120b-Abstract.html)] [[PDF](https://arxiv.org/abs/2102.03112)] [[CODE](https://github.com/hangxu0304/DeepReduce)] |
| PartialFed: Cross-Domain Personalized Federated Learning via Partial Initialization | Huawei | NeurIPS | 2021 | PartialFed[^PartialFed] | [[PUB](https://papers.nips.cc/paper/2021/hash/c429429bf1f2af051f2021dc92a8ebea-Abstract.html)] [[VIDEO](https://papertalk.org/papertalks/37327)] |
| Federated Split Task-Agnostic Vision Transformer for COVID-19 CXR Diagnosis | KAIST | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/ceb0595112db2513b9325a85761b7310-Abstract.html)] [[PDF](https://arxiv.org/abs/2111.01338)] |
| Addressing Algorithmic Disparity and Performance Inconsistency in Federated Learning | THU; Alibaba; Weill Cornell Medicine | NeurIPS | 2021 | FCFL[^FCFL] | [[PUB](https://papers.nips.cc/paper/2021/hash/db8e1af0cb3aca1ae2d0018624204529-Abstract.html)] [[PDF](https://arxiv.org/abs/2108.08435)] [[CODE](https://github.com/cuis15/FCFL)] |
| Federated Linear Contextual Bandits | The Pennsylvania State University; Facebook; University of Virginia | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/e347c51419ffb23ca3fd5050202f9c3d-Abstract.html)] [[PDF](https://arxiv.org/abs/2110.14177)] [[CODE](https://github.com/Ruiquan5514/Federated-Linear-Contextual-Bandits)] |
| Few-Round Learning for Federated Learning | KAIST | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/f065d878ccfb4cc4f4265a4ff8bafa9a-Abstract.html)] |
| Breaking the centralized barrier for cross-device federated learning | EPFL; Google Research | NeurIPS | 2021 | | [[PUB](https://papers.nips.cc/paper/2021/hash/f0e6be4ce76ccfa73c5a540d992d0756-Abstract.html)] [[CODE](https://fedjax.readthedocs.io/en/latest/fedjax.algorithms.html#module-fedjax.algorithms.mime)] [[VIDEO](https://papertalk.org/papertalks/37564)] |
| Federated-EM with heterogeneity mitigation and variance reduction | Ecole Polytechnique; Google Research | NeurIPS | 2021 | Federated-EM[^Federated-EM] | [[PUB](https://papers.nips.cc/paper/2021/hash/f740c8d9c193f16d8a07d3a8a751d13f-Abstract.html)] [[PDF](https://arxiv.org/abs/2111.02083)] |
| Delayed Gradient Averaging: Tolerate the Communication Latency for Federated Learning | MIT; Amazon; Google | NeurIPS | 2021 | | [[PUB](https://proceedings.neurips.cc/paper/2021/hash/fc03d48253286a798f5116ec00e99b2b-Abstract.html)] [[PAGE](https://dga.hanlab.ai/)] [[SLIDE](https://dga.hanlab.ai/assets/dga_slides.pdf)] |
| FedDR – Randomized Douglas-Rachford Splitting Algorithms for Nonconvex Federated Composite Optimization | University of North Carolina at Chapel Hill; IBM Research | NeurIPS | 2021 | FedDR[^FedDR] | [[PUB](https://papers.nips.cc/paper/2021/hash/fe7ee8fc1959cc7214fa21c4840dff0a-Abstract.html)] [[PDF](https://arxiv.org/abs/2103.03452)] [[CODE](https://github.com/unc-optimization/FedDR)] |
| Federated Adversarial Domain Adaptation | BU; Columbia University; Rutgers University | ICLR | 2020 | | [[PUB](https://openreview.net/forum?id=HJezF3VYPB)] [[PDF](https://arxiv.org/abs/1911.02054)] [[CODE](https://drive.google.com/file/d/1OekTpqB6qLfjlE2XUjQPm3F110KDMFc0/view?usp=sharing)] |
| DBA: Distributed Backdoor Attacks against Federated Learning | ZJU; IBM Research | ICLR | 2020 | | [[PUB](https://openreview.net/forum?id=rkgyS0VFvr)] [[CODE](https://github.com/AI-secure/DBA)] |
| Fair Resource Allocation in Federated Learning :fire: | CMU; Facebook AI | ICLR | 2020 | fair-flearn[^fair-flearn] | [[PUB](https://openreview.net/forum?id=ByexElSYDr)] [[PDF](https://arxiv.org/abs/1905.10497)] [[CODE](https://github.com/litian96/fair_flearn)] |
| Federated Learning with Matched Averaging :fire: | University of Wisconsin-Madison; IBM Research | ICLR | 2020 | FedMA[^FedMA] | [[PUB](https://openreview.net/forum?id=BkluqlSFDS)] [[PDF](https://arxiv.org/abs/2002.06440)] [[CODE](https://github.com/IBM/FedMA)] |
| Differentially Private Meta-Learning | CMU | ICLR | 2020 | | [[PUB](https://openreview.net/forum?id=rJgqMRVYvr)] [[PDF](https://proceedings.mlr.press/v162/zhang22p.html)] |
| Generative Models for Effective ML on Private, Decentralized Datasets :fire: | Google | ICLR | 2020 | | [[PUB](https://openreview.net/forum?id=SJgaRA4FPH)] [[PDF](https://arxiv.org/abs/1911.06679)] [[CODE](https://github.com/google-research/federated/tree/master/gans)] |
| On the Convergence of FedAvg on Non-IID Data :fire: | PKU | ICLR | 2020 | | [[PUB](https://openreview.net/forum?id=HJxNAnVtDS)] [[PDF](https://arxiv.org/abs/1907.02189#:~:text=%EE%80%80On%20the%20Convergence%20of%20FedAvg%20on%20Non-IID%20Data%EE%80%81.,of%20the%20total%20devices%20and%20averages%20the%20)] [[CODE](https://github.com/lx10077/fedavgpy)] [[解读](https://zhuanlan.zhihu.com/p/500005337)] |
| FedBoost: A Communication-Efficient Algorithm for Federated Learning | Google | ICML | 2020 | FedBoost[^FedBoost] | [[PUB](http://proceedings.mlr.press/v119/hamer20a.html)] [[VIDEO](https://slideslive.com/38928463/fedboost-a-communicationefficient-algorithm-for-federated-learning?ref=speaker-16993-latest)] |
| FetchSGD: Communication-Efficient Federated Learning with Sketching | UC Berkeley; Johns Hopkins University; Amazon | ICML | 2020 | FetchSGD[^FetchSGD] | [[PUB](http://proceedings.mlr.press/v119/rothchild20a.html)] [[PDF](https://arxiv.org/abs/2007.07682)] [[VIDEO](https://slideslive.com/38928454/fetchsgd-communicationefficient-federated-learning-with-sketching)] [[CODE](https://github.com/kiddyboots216/CommEfficient)] |
| SCAFFOLD: Stochastic Controlled Averaging for Federated Learning | EPFL; Google | ICML | 2020 | SCAFFOLD[^SCAFFOLD] | [[PUB](http://proceedings.mlr.press/v119/karimireddy20a.html)] [[PDF](https://arxiv.org/abs/1910.06378)] [[VIDEO](https://slideslive.com/38927610/scaffold-stochastic-controlled-averaging-for-federated-learning)] [[UC.](https://github.com/ramshi236/Accelerated-Federated-Learning-Over-MAC-in-Heterogeneous-Networks)] [[解读](https://zhuanlan.zhihu.com/p/538941775)] |
| Federated Learning with Only Positive Labels | Google | ICML | 2020 | | [[PUB](http://proceedings.mlr.press/v119/yu20f.html)] [[PDF](https://arxiv.org/abs/2004.10342)] [[VIDEO](https://slideslive.com/38928322/federated-learning-with-only-positive-labels)] |
| From Local SGD to Local Fixed-Point Methods for Federated Learning | Moscow Institute of Physics and Technology; KAUST | ICML | 2020 | | [[PUB](http://proceedings.mlr.press/v119/malinovskiy20a.html)] [[PDF](https://arxiv.org/abs/2004.01442)] [[SLIDE](https://icml.cc/media/Slides/icml/2020/virtual)] [[VIDEO](https://slideslive.com/38928320/from-local-sgd-to-local-fixed-point-methods-for-federated-learning)] |
| Acceleration for Compressed Gradient Descent in Distributed and Federated Optimization | KAUST | ICML | 2020 | | [[PUB](http://proceedings.mlr.press/v119/li20g.html)] [[PDF](https://arxiv.org/abs/2002.11364)] [[SLIDE](https://icml.cc/media/Slides/icml/2020/virtual)] [[VIDEO](https://slideslive.com/38927921/acceleration-for-compressed-gradient-descent-in-distributed-optimization)] |
| Differentially-Private Federated Linear Bandits | MIT | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/47a658229eb2368a99f1d032c8848542-Abstract.html)] [[PDF](https://arxiv.org/abs/2010.11425)] [[CODE](https://github.com/abhimanyudubey/private_federated_linear_bandits)] |
| Federated Principal Component Analysis | University of Cambridge; Quine Technologies | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/47a658229eb2368a99f1d032c8848542-Abstract.html)] [[PDF](https://arxiv.org/abs/1907.08059)] [[CODE](https://github.com/andylamp/federated_pca)] |
| FedSplit: an algorithmic framework for fast federated optimization | UC Berkeley | NeurIPS | 2020 | FedSplit[^FedSplit] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/4ebd440d99504722d80de606ea8507da-Abstract.html)] [[PDF](https://arxiv.org/abs/2005.05238)] |
| Federated Bayesian Optimization via Thompson Sampling | NUS; MIT | NeurIPS | 2020 | fbo[^fbo] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/6dfe08eda761bd321f8a9b239f6f4ec3-Abstract.html)] [[PDF](https://arxiv.org/abs/2010.10154)] [[CODE](https://github.com/daizhongxiang/Federated_Bayesian_Optimization)] |
| Lower Bounds and Optimal Algorithms for Personalized Federated Learning | KAUST | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/187acf7982f3c169b3075132380986e4-Abstract.html)] [[PDF](https://arxiv.org/abs/2010.02372)] |
| Robust Federated Learning: The Case of Affine Distribution Shifts | UC Santa Barbara; MIT | NeurIPS | 2020 | RobustFL[^RobustFL] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/f5e536083a438cec5b64a4954abc17f1-Abstract.html)] [[PDF](https://arxiv.org/abs/2006.08907)] [[CODE](https://github.com/farzanfarnia/RobustFL)] |
| An Efficient Framework for Clustered Federated Learning | UC Berkeley; DeepMind | NeurIPS | 2020 | ifca[^ifca] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/e32cc80bf07915058ce90722ee17bb71-Abstract.html)] [[PDF](https://arxiv.org/abs/2006.04088)] [[CODE](https://github.com/jichan3751/ifca)] |
| Distributionally Robust Federated Averaging :fire: | Pennsylvania State University | NeurIPS | 2020 | DRFA[^DRFA] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/ac450d10e166657ec8f93a1b65ca1b14-Abstract.html)] [[PDF](https://arxiv.org/abs/2102.12660)] [[CODE](https://github.com/MLOPTPSU/FedTorch)] |
| Personalized Federated Learning with Moreau Envelopes :fire: | The University of Sydney | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/f4f1f13c8289ac1b1ee0ff176b56fc60-Abstract.html)] [[PDF](https://arxiv.org/abs/2006.08848)] [[CODE](https://github.com/CharlieDinh/pFedMe)] |
| Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach | MIT; UT Austin | NeurIPS | 2020 | Per-FedAvg[^Per-FedAvg] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/24389bfe4fe2eba8bf9aa9203a44cdad-Abstract.html)] [[PDF](https://arxiv.org/abs/2002.07948)] [[UC.](https://github.com/KarhouTam/Per-FedAvg)] |
| Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge | USC | NeurIPS | 2020 | FedGKT[^FedGKT] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/a1d4c20b182ad7137ab3606f0e3fc8a4-Abstract.html)] [[PDF](https://arxiv.org/abs/2007.14513)] [[CODE](https://github.com/FedML-AI/FedML/tree/master/fedml_experiments/distributed/fedgkt)] [[解读](https://zhuanlan.zhihu.com/p/536901871)] |
| Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization :fire: | CMU; Princeton | NeurIPS | 2020 | FedNova[^FedNova] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/564127c03caab942e503ee6f810f54fd-Abstract.html)] [[PDF](https://arxiv.org/abs/2007.07481)] [[CODE](https://github.com/JYWa/FedNova)] [[UC.](https://github.com/carbonati/fl-zoo)] |
| Attack of the Tails: Yes, You Really Can Backdoor Federated Learning | University of Wisconsin-Madison | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/b8ffa41d4e492f0fad2f13e29e1762eb-Abstract.html)] [[PDF](https://arxiv.org/abs/2007.05084)] |
| Federated Accelerated Stochastic Gradient Descent | Stanford | NeurIPS | 2020 | FedAc[^FedAc] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/39d0a8908fbe6c18039ea8227f827023-Abstract.html)] [[PDF](https://arxiv.org/abs/2006.08950)] [[CODE](https://github.com/hongliny/FedAc-NeurIPS20)] [[VIDEO](https://youtu.be/K28zpAgg3HM)] |
| Inverting Gradients - How easy is it to break privacy in federated learning? :fire: | University of Siegen | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/c4ede56bbd98819ae6112b20ac6bf145-Abstract.html)] [[PDF](https://arxiv.org/abs/2003.14053)] [[CODE](https://github.com/JonasGeiping/invertinggradients)] |
| Ensemble Distillation for Robust Model Fusion in Federated Learning | EPFL | NeurIPS | 2020 | FedDF[^FedDF] | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/18df51b97ccd68128e994804f3eccc87-Abstract.html)] [[PDF](https://arxiv.org/abs/2006.07242)] [[CODE](https://github.com/epfml/federated-learning-public-code/tree/master/codes/FedDF-code)] |
| Throughput-Optimal Topology Design for Cross-Silo Federated Learning | INRIA | NeurIPS | 2020 | | [[PUB](https://proceedings.neurips.cc/paper/2020/hash/e29b722e35040b88678e25a1ec032a21-Abstract.html)] [[PDF](https://arxiv.org/abs/2010.12229)] [[CODE](https://github.com/omarfoq/communication-in-cross-silo-fl)] |
| Bayesian Nonparametric Federated Learning of Neural Networks :fire: | IBM | ICML | 2019 | | [[PUB](http://proceedings.mlr.press/v97/yurochkin19a.html)] [[PDF](https://arxiv.org/abs/1905.12022)] [[CODE](https://github.com/IBM/probabilistic-federated-neural-matching)] |
| Analyzing Federated Learning through an Adversarial Lens :fire: | Princeton; IBM | ICML | 2019 | | [[PUB](http://proceedings.mlr.press/v97/bhagoji19a.html)] [[PDF](https://arxiv.org/abs/1811.12470)] [[CODE](https://github.com/inspire-group/ModelPoisoning)] |
| Agnostic Federated Learning | Google | ICML | 2019 | | [[PUB](http://proceedings.mlr.press/v97/mohri19a.html)] [[PDF](https://arxiv.org/abs/1902.00146)] |
| cpSGD: Communication-efficient and differentially-private distributed SGD | Princeton; Google | NeurIPS | 2018 | | [[PUB](https://papers.nips.cc/paper/2018/hash/21ce689121e39821d07d04faab328370-Abstract.html)] [[PDF](https://arxiv.org/abs/1805.10559)] |
| Federated Multi-Task Learning :fire: | Stanford; USC; CMU | NeurIPS | 2017 | | [[PUB](https://papers.nips.cc/paper/2017/hash/6211080fa89981f66b1a0c9d55c61d0f-Abstract.html)] [[PDF](https://arxiv.org/abs/1705.10467)] [[CODE](https://github.com/gingsmith/fmtl)] |
<!-- END:fl-in-top-ml-conference-and-journal -->
## fl in top dm conference and journal
In this section, we will summarize Federated Learning papers accepted by top DM(Data Mining) conference and journal, Including [KDD](https://dblp.uni-trier.de/db/conf/kdd/index.html)(ACM SIGKDD Conference on Knowledge Discovery and Data Mining) and [WSDM](https://dblp.uni-trier.de/db/conf/wsdm/index.html)(Web Search and Data Mining).
- [KDD](https://dblp.uni-trier.de/search?q=federate%20venue%3AKDD%3A) 2022([Research Track](https://kdd.org/kdd2022/paperRT.html), [Applied Data Science track](https://kdd.org/kdd2022/paperADS.html)) , [2021](https://kdd.org/kdd2021/accepted-papers/index),[2020](https://www.kdd.org/kdd2020/accepted-papers)
- [WSDM](https://dblp.uni-trier.de/search?q=federate%20venue%3AWSDM%3A) [2023](https://www.wsdm-conference.org/2023/program/accepted-papers), [2022](https://www.wsdm-conference.org/2022/accepted-papers/), [2021](https://www.wsdm-conference.org/2021/accepted-papers.php), [2019](https://www.wsdm-conference.org/2019/accepted-papers.php)
<!-- START:fl-in-top-dm-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ---------------------------------------------------------- | ---------------------- | ---- | ----------------------------------------------------- | ------------------------------------------------------------ |
| Federated Unlearning for On-Device Recommendation | UQ | WSDM | 2023 | | [[PDF](https://arxiv.org/abs/2210.10958)] |
| Collaboration Equilibrium in Federated Learning | THU | KDD | 2022 | CE[^CE] | [[PDF](https://arxiv.org/abs/2108.07926)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539237)] [[CODE](https://github.com/cuis15/learning-to-collaborate)] |
| Connected Low-Loss Subspace Learning for a Personalization in Federated Learning | Ulsan National Institute of Science and Technology | KDD | 2022 | SuPerFed[^SuPerFed] | [[PDF](https://arxiv.org/abs/2109.07628)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539254)] [[CODE](https://github.com/vaseline555/superfed)] |
| FedMSplit: Correlation-Adaptive Federated Multi-Task Learning across Multimodal Split Networks | University of Virginia | KDD | 2022 | FedMSplit[^FedMSplit] | [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539384)] |
| Communication-Efficient Robust Federated Learning with Noisy Labels | University of Pittsburgh | KDD | 2022 | Comm-FedBiO[^Comm-FedBiO] | [[PDF](https://arxiv.org/abs/2206.05558)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539328)] |
| FLDetector: Detecting Malicious Clients in Federated Learning via Checking Model-Updates Consistency | USTC | KDD | 2022 | FLDetector[^FLDetector] | [[PDF](https://arxiv.org/abs/2207.09209)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539231)] [[CODE](https://github.com/zaixizhang/FLDetector)] |
| Practical Lossless Federated Singular Vector Decomposition Over Billion-Scale Data | HKUST | KDD | 2022 | FedSVD[^FedSVD] | [[PDF](https://arxiv.org/abs/2105.08925)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539402)] [[CODE](https://github.com/Di-Chai/FedEval)] |
| FedWalk: Communication Efficient Federated Unsupervised Node Embedding with Differential Privacy | SJTU | KDD | 2022 | FedWalk[^FedWalk] | [[PDF](https://arxiv.org/abs/2205.15896)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539308)] |
| FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Platform for Federated Graph Learning :fire: | Alibaba | KDD (Best Paper Award) | 2022 | FederatedScope-GNN[^FederatedScope-GNN] | [[PDF](https://arxiv.org/abs/2204.05562)] [[CODE](https://github.com/alibaba/FederatedScope)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539112)] |
| Fed-LTD: Towards Cross-Platform Ride Hailing via Federated Learning to Dispatch | BUAA | KDD | 2022 | Fed-LTD[^Fed-LTD] | [[PDF](https://hufudb.com/static/paper/2022/SIGKDD2022_Fed-LTD%20Towards%20Cross-Platform%20Ride%20Hailing%20via.pdf)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539047)] [[解读](https://zhuanlan.zhihu.com/p/544183874)] |
| Felicitas: Federated Learning in Distributed Cross Device Collaborative Frameworks | USTC | KDD | 2022 | Felicitas[^Felicitas] | [[PDF](https://arxiv.org/abs/2202.08036)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539039)] |
| No One Left Behind: Inclusive Federated Learning over Heterogeneous Devices | Renmin University of China | KDD | 2022 | InclusiveFL[^InclusiveFL] | [[PDF](https://arxiv.org/abs/2202.08036)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539086)] |
| FedAttack: Effective and Covert Poisoning Attack on Federated Recommendation via Hard Sampling | THU | KDD | 2022 | FedAttack[^FedAttack] | [[PDF](https://arxiv.org/abs/2202.04975)] [[PUB](https://dl.acm.org/doi/10.1145/3534678.3539119)] [[CODE](https://github.com/wuch15/FedAttack)] |
| PipAttack: Poisoning Federated Recommender Systems for Manipulating Item Promotion | The University of Queensland | WSDM | 2022 | PipAttack[^PipAttack] | [[PDF](https://arxiv.org/abs/2110.10926)] [[PUB](https://dl.acm.org/doi/10.1145/3488560.3498386)] |
| Fed2: Feature-Aligned Federated Learning | George Mason University; Microsoft; University of Maryland | KDD | 2021 | Fed2[^Fed2] | [[PDF](https://arxiv.org/abs/2111.14248)] [[PUB](https://dl.acm.org/doi/10.1145/3447548.3467309)] |
| FedRS: Federated Learning with Restricted Softmax for Label Distribution Non-IID Data | Nanjing University | KDD | 2021 | FedRS[^FedRS] | [[CODE](https://github.com/lxcnju/FedRepo)] [[PUB](https://dl.acm.org/doi/10.1145/3447548.3467254)] |
| Federated Adversarial Debiasing for Fair and Trasnferable Representations | Michigan State University | KDD | 2021 | FADE[^FADE] | [[PAGE](https://jyhong.gitlab.io/publication/fade2021kdd/)] [[CODE](https://github.com/illidanlab/FADE)] [[SLIDE](https://jyhong.gitlab.io/publication/fade2021kdd/slides.pdf)] [[PUB](https://dl.acm.org/doi/10.1145/3447548.3467281)] |
| Cross-Node Federated Graph Neural Network for Spatio-Temporal Data Modeling | USC | KDD | 2021 | CNFGNN[^CNFGNN] | [[PUB](https://dl.acm.org/doi/pdf/10.1145/3447548.3467371)] [[CODE](https://github.com/mengcz13/KDD2021_CNFGNN)] [[解读](https://zhuanlan.zhihu.com/p/434839878)] |
| AsySQN: Faster Vertical Federated Learning Algorithms with Better Computation Resource Utilization | Xidian University;JD Tech | KDD | 2021 | AsySQN[^AsySQN] | [[PDF](https://arxiv.org/abs/2109.12519)] [[PUB](https://dl.acm.org/doi/10.1145/3447548.3467169)] |
| FLOP: Federated Learning on Medical Datasets using Partial Networks | Duke University | KDD | 2021 | FLOP[^FLOP] | [[PDF](https://arxiv.org/abs/2102.05218.pdf)] [[PUB](https://dl.acm.org/doi/10.1145/3447548.3467185)] [[CODE](https://github.com/jianyizhang123/FLOP)] |
| A Practical Federated Learning Framework for Small Number of Stakeholders | ETH Zürich | WSDM | 2021 | Federated-Learning-source[^Federated-Learning-source] | [[PUB](https://dl.acm.org/doi/10.1145/3437963.3441702)] [[CODE](https://github.com/MTC-ETH/Federated-Learning-source)] |
| Federated Deep Knowledge Tracing | USTC | WSDM | 2021 | FDKT[^FDKT] | [[PUB](https://dl.acm.org/doi/10.1145/3437963.3441747)] [[CODE](https://github.com/hxwujinze/federated-deep-knowledge-tracing)] |
| FedFast: Going Beyond Average for Faster Training of Federated Recommender Systems | University College Dublin | KDD | 2020 | FedFast[^FedFast] | [[PUB](https://dl.acm.org/doi/10.1145/3394486.3403176)] [[VIDEO](https://papertalk.org/papertalks/23422)] |
| Federated Doubly Stochastic Kernel Learning for Vertically Partitioned Data | JD Tech | KDD | 2020 | FDSKL[^FDSKL] | [[PUB](https://dl.acm.org/doi/10.1145/3394486.3403298)] [[PDF](https://arxiv.org/abs/2008.06197)] [[VIDEO](https://papertalk.org/papertalks/23301)] |
| Federated Online Learning to Rank with Evolution Strategies | Facebook AI Research | WSDM | 2019 | FOLtR-ES[^FOLtR-ES] | [[PUB](https://dl.acm.org/doi/10.1145/3289600.3290968)] [[CODE](http://github.com/facebookresearch/foltr-es)] |
<!-- END:fl-in-top-dm-conference-and-journal -->
## fl in top secure conference and journal
In this section, we will summarize Federated Learning papers accepted by top Secure conference and journal, Including [S&P](https://dblp.uni-trier.de/db/conf/sp/index.html)(IEEE Symposium on Security and Privacy), [CCS](https://dblp.uni-trier.de/db/conf/ccs/index.html)(Conference on Computer and Communications Security), [USENIX Security](https://dblp.uni-trier.de/db/conf/uss/index.html)(Usenix Security Symposium) and [NDSS](https://dblp.uni-trier.de/db/conf/ndss/index.html)(Network and Distributed System Security Symposium).
- [S&P](https://dblp.uni-trier.de/search?q=federate%20venue%3AIEEE%20Symposium%20on%20Security%20and%20Privacy%3A) [2023](https://sp2023.ieee-security.org/program-papers.html), [2022](https://www.ieee-security.org/TC/SP2022/program-papers.html), [2019](https://www.ieee-security.org/TC/SP2019/program-papers.html)
- [CCS](https://dblp.uni-trier.de/search?q=federate%20venue%3ACCS%3A) [2022](https://www.sigsac.org/ccs/CCS2022/program/accepted-papers.html), [2021](https://sigsac.org/ccs/CCS2021/accepted-papers.html), [2019](https://www.sigsac.org/ccs/CCS2019/index.php/program/accepted-papers/), [2017](https://acmccs.github.io/papers/)
- [USENIX Security](https://dblp.uni-trier.de/search?q=federate%20venue%3AUSENIX%20Security%20Symposium%3A) [2022](https://www.usenix.org/conference/usenixsecurity22/technical-sessions), [2020](https://www.usenix.org/conference/usenixsecurity20/technical-sessions)
- [NDSS](https://dblp.uni-trier.de/search?q=federate%20venue%3ANDSS%3A) [2022](https://www.ndss-symposium.org/ndss2022/accepted-papers/), [2021](https://www.ndss-symposium.org/ndss2021/accepted-papers/)
<!-- START:fl-in-top-secure-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------------------------------------ | ----- | ---- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| CERBERUS: Exploring Federated Prediction of Security Events | UCL London | CCS | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3548606.3560580)] [[PDF](https://arxiv.org/abs/2209.03050)] |
| EIFFeL: Ensuring Integrity for Federated Learning | UW-Madison | CCS | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3548606.3560611)] [[PDF](https://arxiv.org/abs/2112.12727)] |
| Eluding Secure Aggregation in Federated Learning via Model Inconsistency | SPRING Lab; EPFL | CCS | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3548606.3560557)] [[PDF](https://arxiv.org/abs/2111.07380)] [[CODE](https://github.com/pasquini-dario/eludingsecureaggregation)] |
| Federated Boosted Decision Trees with Differential Privacy | University of Warwick | CCS | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3548606.3560687)] [[PDF](https://arxiv.org/abs/2210.02910)] [[CODE](https://github.com/Samuel-Maddock/federated-boosted-dp-trees)] |
| FedRecover: Recovering from Poisoning Attacks in Federated Learning using Historical Information | Duke University | S&P | 2023 | FedRecover[^FedRecover] | [[PUB](https://www.computer.org/csdl/proceedings-article/sp/2023/933600a326/1He7Y3q8FMY)] [[PDF](https://arxiv.org/abs/2210.10936)] |
| Private, Efficient, and Accurate: Protecting Models Trained by Multi-party Learning with Differential Privacy | Fudan University | S&P | 2023 | PEA[^PEA] | [[PUB](https://www.computer.org/csdl/proceedings-article/sp/2023/933600a076/1He7XMLcnsc)] [[PDF](https://arxiv.org/abs/2208.08662)] |
| Back to the Drawing Board: A Critical Evaluation of Poisoning Attacks on Production Federated Learning | University of Massachusetts | S&P | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9833647/)] [[VIDEO](https://www.youtube.com/watch?v=tQv3CpxIyvs)] |
| SIMC: ML Inference Secure Against Malicious Clients at Semi-Honest Cost | Microsoft Research | USENIX Security | 2022 | SIMC[^SIMC] | [[PUB](https://www.usenix.org/conference/usenixsecurity22/presentation/chandran)] [[PDF](https://eprint.iacr.org/2021/1538)] [[CODE](https://github.com/shahakash28/simc)] |
| Efficient Differentially Private Secure Aggregation for Federated Learning via Hardness of Learning with Errors | University of Vermont | USENIX Security | 2022 | | [[PUB](https://www.usenix.org/conference/usenixsecurity22/presentation/stevens)] [[SLIDE](https://www.usenix.org/system/files/sec22_slides-stevens.pdf)] |
| Label Inference Attacks Against Vertical Federated Learning | ZJU | USENIX Security | 2022 | | [[PUB](https://www.usenix.org/conference/usenixsecurity22/presentation/fu-chong)] [[SLIDE](https://www.usenix.org/system/files/sec22_slides-fu-chong.pdf)] [[CODE](https://github.com/FuChong-cyber/label-inference-attacks)] |
| FLAME: Taming Backdoors in Federated Learning | Technical University of Darmstadt | USENIX Security | 2022 | FLAME[^FLAME] | [[PUB](https://www.usenix.org/conference/usenixsecurity22/presentation/nguyen)] [[SLIDE](https://www.usenix.org/system/files/sec22_slides-nguyen.pdf)] [[PDF](https://arxiv.org/abs/2101.02281)] |
| Local and Central Differential Privacy for Robustness and Privacy in Federated Learning | University at Buffalo, SUNY | NDSS | 2022 | | [[PUB](https://www.ndss-symposium.org/ndss-paper/auto-draft-204/)] [[PDF](https://arxiv.org/abs/2009.03561)] [[UC.](https://github.com/wenzhu23333/Differential-Privacy-Based-Federated-Learning)] |
| Interpretable Federated Transformer Log Learning for Cloud Threat Forensics | University of the Incarnate Word | NDSS | 2022 | | [[PUB](https://www.ndss-symposium.org/ndss-paper/auto-draft-236/)] [[UC.](https://github.com/cyberthreat-datasets/ctdd-2021-os-syslogs)] |
| FedCRI: Federated Mobile Cyber-Risk Intelligence | Technical University of Darmstadt | NDSS | 2022 | FedCRI[^FedCRI] | [[PUB](https://www.ndss-symposium.org/ndss-paper/auto-draft-229/)] |
| DeepSight: Mitigating Backdoor Attacks in Federated Learning Through Deep Model Inspection | Technical University of Darmstadt | NDSS | 2022 | DeepSight[^DeepSight] | [[PUB](https://www.ndss-symposium.org/ndss-paper/auto-draft-205/)] [[PDF](https://arxiv.org/abs/2201.00763)] |
| Private Hierarchical Clustering in Federated Networks | NUS | CCS | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3460120.3484822)] [[PDF](https://arxiv.org/abs/2105.09057)] |
| FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping | Duke University | NDSS | 2021 | | [[PUB](https://www.ndss-symposium.org/ndss-paper/fltrust-byzantine-robust-federated-learning-via-trust-bootstrapping/)] [[PDF](https://arxiv.org/abs/2012.13995)] [[CODE](https://people.duke.edu/~zg70/code/fltrust.zip)] [[VIDEO](https://www.youtube.com/watch?v=zhhdPgKPCN0&list=PLfUWWM-POgQvaqlGPwlOa0JR3bryB1KCS&index=2)] [[SLIDE](https://people.duke.edu/~zg70/code/Secure_Federated_Learning.pdf)] |
| POSEIDON: Privacy-Preserving Federated Neural Network Learning | EPFL | NDSS | 2021 | | [[PUB](https://www.ndss-symposium.org/ndss-paper/poseidon-privacy-preserving-federated-neural-network-learning/)] [[VIDEO](https://www.youtube.com/watch?v=kX6-PMzxZ3c&list=PLfUWWM-POgQvaqlGPwlOa0JR3bryB1KCS&index=1)] |
| Manipulating the Byzantine: Optimizing Model Poisoning Attacks and Defenses for Federated Learning | University of Massachusetts Amherst | NDSS | 2021 | | [[PUB](https://www.ndss-symposium.org/ndss-paper/manipulating-the-byzantine-optimizing-model-poisoning-attacks-and-defenses-for-federated-learning/)] [[CODE](https://github.com/vrt1shjwlkr/NDSS21-Model-Poisoning)] [[VIDEO](https://www.youtube.com/watch?v=G2VYRnLqAXE&list=PLfUWWM-POgQvaqlGPwlOa0JR3bryB1KCS&index=3)] |
| Local Model Poisoning Attacks to Byzantine-Robust Federated Learning | The Ohio State University | USENIX Security | 2020 | | [[PUB](https://www.usenix.org/conference/usenixsecurity20/presentation/fang)] [[PDF](https://arxiv.org/abs/1911.11815)] [[CODE](https://people.duke.edu/~zg70/code/fltrust.zip)] [[VIDEO](https://www.youtube.com/watch?v=SQ12UpYrUVU&feature=emb_imp_woyt)] [[SLIDE](https://www.usenix.org/system/files/sec20_slides_fang.pdf)] |
| A Reliable and Accountable Privacy-Preserving Federated Learning Framework using the Blockchain | University of Kansas | CCS (Poster) | 2019 | | [[PUB](https://dl.acm.org/doi/10.1145/3319535.3363256)] |
| IOTFLA : A Secured and Privacy-Preserving Smart Home Architecture Implementing Federated Learning | Université du Québéc á Montréal | S&P (Workshop) | 2019 | | [[PUB](https://ieeexplore.ieee.org/document/8844592)] |
| Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning :fire: | University of Massachusetts Amherst | S&P | 2019 | | [[PUB](https://www.computer.org/csdl/proceedings-article/sp/2019/666000a739/1dlwhtj4r7O)] [[VIDEO](https://youtu.be/lzJY4BjCxTc)] [[SLIDE](https://www.ieee-security.org/TC/SP2019/SP19-Slides-pdfs/Milad_Nasr_-_08-Milad_Nasr-Comprehensive_Privacy_Analysis_of_Deep_Learning_)] [[CODE](https://github.com/privacytrustlab/ml_privacy_meter)] |
| Practical Secure Aggregation for Privacy Preserving Machine Learning | Google | CCS | 2017 | | [[PUB](https://dl.acm.org/doi/10.1145/3133956.3133982)] [[PDF](https://eprint.iacr.org/2017/281)] [[解读](https://zhuanlan.zhihu.com/p/445656765)] [[UC.](https://github.com/Chen-Junbao/SecureAggregation)] [[UC](https://github.com/corentingiraud/federated-learning-secure-aggregation)] |
<!-- END:fl-in-top-secure-conference-and-journal -->
## fl in top cv conference and journal
In this section, we will summarize Federated Learning papers accepted by top CV(computer vision) conference and journal, Including [CVPR](https://dblp.uni-trier.de/db/conf/cvpr/index.html)(Computer Vision and Pattern Recognition), [ICCV](https://dblp.uni-trier.de/db/conf/iccv/index.html)(IEEE International Conference on Computer Vision), [ECCV](https://dblp.uni-trier.de/db/conf/eccv/index.html)(European Conference on Computer Vision), [MM](https://dblp.org/db/conf/mm/index.html)(ACM International Conference on Multimedia), [IJCV](https://dblp.uni-trier.de/db/journals/ijcv/index.html)(International Journal of Computer Vision).
- [CVPR](https://dblp.uni-trier.de/search?q=federate%20venue%3ACVPR%3A) [2022](https://openaccess.thecvf.com/CVPR2022), [2021](https://openaccess.thecvf.com/CVPR2021?day=all)
- [ICCV](https://dblp.uni-trier.de/search?q=federate%20venue%3AICCV%3A) [2021](https://openaccess.thecvf.com/ICCV2021?day=all)
- [ECCV](https://dblp.uni-trier.de/search?q=federate%20venue%3AECCV%3A) [2022](https://www.ecva.net/papers.php), [2020](https://www.ecva.net/papers.php)
- [MM](https://dblp.uni-trier.de/search?q=federate%20venue%3AACM%20Multimedia%3A) [2022](https://dblp.uni-trier.de/db/conf/mm/mm2022.html), [2021](https://2021.acmmm.org/main-track-list), [2020](https://2020.acmmm.org/main-track-list.html)
- [IJCV](https://dblp.uni-trier.de/search?q=federate%20venue%3AInt%20J%20Comput%20Vis%3A) NULL
<!-- START:fl-in-top-cv-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------------------------------------ | ----- | ---- | ------------------------------------------- | ------------------------------------------------------------ |
| Confederated Learning: Going Beyond Centralization | CAS; UCAS | MM | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3503161.3548157)] |
| Few-Shot Model Agnostic Federated Learning | WHU | MM | 2022 | FSMAFL[^FSMAFL] | [[PUB](https://dl.acm.org/doi/10.1145/3503161.3548764)] [[CODE](https://github.com/WenkeHuang/FSMAFL)] |
| Feeling Without Sharing: A Federated Video Emotion Recognition Framework Via Privacy-Agnostic Hybrid Aggregation | TJUT | MM | 2022 | EmoFed[^EmoFed] | [[PUB](https://dl.acm.org/doi/10.1145/3503161.3548278)] |
| FedLTN: Federated Learning for Sparse and Personalized Lottery Ticket Networks | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/6634_ECCV_2022_paper.php)] |
| Auto-FedRL: Federated Hyperparameter Optimization for Multi-Institutional Medical Image Segmentation | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/1129_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2203.06338)] [[CODE](https://github.com/guopengf/Auto-FedRL)] |
| Improving Generalization in Federated Learning by Seeking Flat Minima | Politecnico di Torino | ECCV | 2022 | FedSAM[^FedSAM] | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/7093_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2203.11834)] [[CODE](https://github.com/debcaldarola/fedsam)] |
| AdaBest: Minimizing Client Drift in Federated Learning via Adaptive Bias Estimation | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/8092_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2204.13170)] [[CODE](https://github.com/varnio/fedsim)] [[PAGE](https://fedsim.varnio.com/en/latest/)] |
| SphereFed: Hyperspherical Federated Learning | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/2255_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2207.09413)] |
| Federated Self-Supervised Learning for Video Understanding | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/7693_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2207.01975)] [[CODE](https://github.com/yasar-rehman/fedvssl)] |
| FedVLN: Privacy-Preserving Federated Vision-and-Language Navigation | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/6298_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2203.14936)] [[CODE](https://github.com/eric-ai-lab/FedVLN)] |
| Addressing Heterogeneity in Federated Learning via Distributional Transformation | | ECCV | 2022 | | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/6551_ECCV_2022_paper.php)] [[CODE](https://github.com/hyhmia/DisTrans)] |
| FedX: Unsupervised Federated Learning with Cross Knowledge Distillation | KAIST | ECCV | 2022 | FedX[^FedX] | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/3932_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2207.09158)] [[CODE](https://github.com/sungwon-han/fedx)] |
| Personalizing Federated Medical Image Segmentation via Local Calibration | Xiamen University | ECCV | 2022 | LC-Fed[^LC-Fed] | [[PUB](https://www.ecva.net/papers/eccv_2022/papers_ECCV/html/1626_ECCV_2022_paper.php)] [[PDF](https://arxiv.org/abs/2207.04655)] [[CODE](https://github.com/jcwang123/fedlc)] |
| ATPFL: Automatic Trajectory Prediction Model Design Under Federated Learning Framework | HIT | CVPR | 2022 | ATPFL[^ATPFL] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Wang_ATPFL_Automatic_Trajectory_Prediction_Model_Design_Under_Federated_Learning_Framework_CVPR_2022_paper.html)] |
| Rethinking Architecture Design for Tackling Data Heterogeneity in Federated Learning | Stanford | CVPR | 2022 | ViT-FL[^ViT-FL] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Qu_Rethinking_Architecture_Design_for_Tackling_Data_Heterogeneity_in_Federated_Learning_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Qu_Rethinking_Architecture_Design_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2106.06047)] [[CODE](https://github.com/Liangqiong/ViT-FL-main)] [[VIDEO](https://www.youtube.com/watch?v=Ae1CDi0_Nok&ab_channel=StanfordMedAI)] |
| FedCorr: Multi-Stage Federated Learning for Label Noise Correction | Singapore University of Technology and Design | CVPR | 2022 | FedCorr[^FedCorr] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Xu_FedCorr_Multi-Stage_Federated_Learning_for_Label_Noise_Correction_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Xu_FedCorr_Multi-Stage_Federated_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2204.04677)] [[CODE](https://github.com/xu-jingyi/fedcorr)] [[VIDEO](https://www.youtube.com/watch?v=GA22ct1LgRA&ab_channel=ZihanChen)] |
| FedCor: Correlation-Based Active Client Selection Strategy for Heterogeneous Federated Learning | Duke University | CVPR | 2022 | FedCor[^FedCor] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Tang_FedCor_Correlation-Based_Active_Client_Selection_Strategy_for_Heterogeneous_Federated_Learning_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Tang_FedCor_Correlation-Based_Active_CVPR_2022_supplemental.zip)] [[PDF](http://arxiv.org/abs/2103.13822)] |
| Layer-Wised Model Aggregation for Personalized Federated Learning | PolyU | CVPR | 2022 | pFedLA[^pFedLA] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Ma_Layer-Wised_Model_Aggregation_for_Personalized_Federated_Learning_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Ma_Layer-Wised_Model_Aggregation_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2205.03993)] |
| Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning | University of Central Florida | CVPR | 2022 | FedAlign[^FedAlign] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Mendieta_Local_Learning_Matters_Rethinking_Data_Heterogeneity_in_Federated_Learning_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Mendieta_Local_Learning_Matters_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2111.14213)] [[CODE](https://github.com/mmendiet/FedAlign)] |
| Federated Learning With Position-Aware Neurons | Nanjing University | CVPR | 2022 | PANs[^PANs] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Li_Federated_Learning_With_Position-Aware_Neurons_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Li_Federated_Learning_With_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2203.14666)] |
| RSCFed: Random Sampling Consensus Federated Semi-Supervised Learning | HKUST | CVPR | 2022 | RSCFed[^RSCFed] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Liang_RSCFed_Random_Sampling_Consensus_Federated_Semi-Supervised_Learning_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Liang_RSCFed_Random_Sampling_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2203.13993)] [[CODE](https://github.com/xmed-lab/rscfed)] |
| Learn From Others and Be Yourself in Heterogeneous Federated Learning | Wuhan University | CVPR | 2022 | FCCL[^FCCL] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Huang_Learn_From_Others_and_Be_Yourself_in_Heterogeneous_Federated_Learning_CVPR_2022_paper.html)] [[CODE](https://github.com/wenkehuang/fccl)] [[VIDEO](https://www.youtube.com/watch?v=zZoASA71qwQ&ab_channel=HuangWenke)] |
| Robust Federated Learning With Noisy and Heterogeneous Clients | Wuhan University | CVPR | 2022 | RHFL[^RHFL] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Fang_Robust_Federated_Learning_With_Noisy_and_Heterogeneous_Clients_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Fang_Robust_Federated_Learning_CVPR_2022_supplemental.pdf)] [[CODE](https://github.com/FangXiuwen/Robust_FL)] |
| ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning | Arizona State University | CVPR | 2022 | ResSFL[^ResSFL] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Li_ResSFL_A_Resistance_Transfer_Framework_for_Defending_Model_Inversion_Attack_CVPR_2022_paper.html)] [[SUPP](https://openaccess.thecvf.com/content/CVPR2022/supplemental/Li_ResSFL_A_Resistance_CVPR_2022_supplemental.pdf)] [[PDF](http://arxiv.org/abs/2205.04007)] [[CODE](https://github.com/zlijingtao/ResSFL)] |
| FedDC: Federated Learning With Non-IID Data via Local Drift Decoupling and Correction | National University of Defense Technology | CVPR | 2022 | FedDC[^FedDC] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Gao_FedDC_Federated_Learning_With_Non-IID_Data_via_Local_Drift_Decoupling_CVPR_2022_paper.html)] [[PDF](http://arxiv.org/abs/2203.11751)] [[CODE](https://github.com/gaoliang13/FedDC)] [[解读](https://zhuanlan.zhihu.com/p/505889549)] |
| Federated Class-Incremental Learning | CAS; Northwestern University; UTS | CVPR | 2022 | GLFC[^GLFC] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Dong_Federated_Class-Incremental_Learning_CVPR_2022_paper.html)] [[PDF](http://arxiv.org/abs/2203.11473)] [[CODE](https://github.com/conditionWang/FCIL)] |
| Fine-Tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning | PKU; JD Explore Academy; The University of Sydney | CVPR | 2022 | FedFTG[^FedFTG] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Zhang_Fine-Tuning_Global_Model_via_Data-Free_Knowledge_Distillation_for_Non-IID_Federated_CVPR_2022_paper.html)] [[PDF](http://arxiv.org/abs/2203.09249)] |
| Differentially Private Federated Learning With Local Regularization and Sparsification | CAS | CVPR | 2022 | DP-FedAvg+BLUR+LUS[^DP-FedAvgplusBLURplusLUS] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Cheng_Differentially_Private_Federated_Learning_With_Local_Regularization_and_Sparsification_CVPR_2022_paper.html)] [[PDF](http://arxiv.org/abs/2203.03106)] |
| Auditing Privacy Defenses in Federated Learning via Generative Gradient Leakage | University of Tennessee; Oak Ridge National Laboratory; Google Research | CVPR | 2022 | GGL[^GGL] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Li_Auditing_Privacy_Defenses_in_Federated_Learning_via_Generative_Gradient_Leakage_CVPR_2022_paper.html)] [[PDF](http://arxiv.org/abs/2203.15696)] [[CODE](https://github.com/zhuohangli/GGL)] [[VIDEO](https://www.youtube.com/watch?v=rphFSGDlGPY&ab_channel=MoSISLab)] |
| CD2-pFed: Cyclic Distillation-Guided Channel Decoupling for Model Personalization in Federated Learning | SJTU | CVPR | 2022 | CD2-pFed[^CD2-pFed] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Shen_CD2-pFed_Cyclic_Distillation-Guided_Channel_Decoupling_for_Model_Personalization_in_Federated_CVPR_2022_paper.html)] [[PDF](https://arxiv.org/abs/2204.03880)] |
| Closing the Generalization Gap of Cross-Silo Federated Medical Image Segmentation | Univ. of Pittsburgh; NVIDIA | CVPR | 2022 | FedSM[^FedSM] | [[PUB](https://openaccess.thecvf.com/content/CVPR2022/html/Xu_Closing_the_Generalization_Gap_of_Cross-Silo_Federated_Medical_Image_Segmentation_CVPR_2022_paper.html)] [[PDF](http://arxiv.org/abs/2203.10144)] |
| Multi-Institutional Collaborations for Improving Deep Learning-Based Magnetic Resonance Image Reconstruction Using Federated Learning | Johns Hopkins University | CVPR | 2021 | FL-MRCM[^FL-MRCM] | [[PUB](https://ieeexplore.ieee.org/document/9578476)] [[PDF](https://arxiv.org/abs/2103.02148)] [[CODE](https://github.com/guopengf/FL-MRCM)] |
| Model-Contrastive Federated Learning :fire: | NUS; UC Berkeley | CVPR | 2021 | MOON[^MOON] | [[PUB](https://ieeexplore.ieee.org/document/9578660)] [[PDF](https://arxiv.org/abs/2103.16257)] [[CODE](https://github.com/QinbinLi/MOON)] [[解读](https://weisenhui.top/posts/17666.html)] |
| FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space :fire: | CUHK | CVPR | 2021 | FedDG-ELCFS[^FedDG-ELCFS] | [[PUB](https://ieeexplore.ieee.org/document/9577482)] [[PDF](https://arxiv.org/abs/2103.06030)] [[CODE](https://github.com/liuquande/FedDG-ELCFS)] |
| Soteria: Provable Defense Against Privacy Leakage in Federated Learning From Representation Perspective | Duke University | CVPR | 2021 | Soteria[^Soteria] | [[PUB](https://ieeexplore.ieee.org/document/9578192)] [[PDF](https://arxiv.org/abs/2012.06043)] [[CODE](https://github.com/jeremy313/Soteria)] |
| Federated Learning for Non-IID Data via Unified Feature Learning and Optimization Objective Alignment | PKU | ICCV | 2021 | FedUFO[^FedUFO] | [[PUB](https://ieeexplore.ieee.org/document/9710573)] |
| Ensemble Attention Distillation for Privacy-Preserving Federated Learning | University at Buffalo | ICCV | 2021 | FedAD[^FedAD] | [[PUB](https://ieeexplore.ieee.org/document/9710586)] [[PDF](https://openaccess.thecvf.com/content/ICCV2021/papers/Gong_Ensemble_Attention_Distillation_for_Privacy-Preserving_Federated_Learning_ICCV_2021_paper.pdf)] |
| Collaborative Unsupervised Visual Representation Learning from Decentralized Data | NTU; SenseTime | ICCV | 2021 | FedU[^FedU] | [[PUB](https://ieeexplore.ieee.org/document/9710366)] [[PDF](https://arxiv.org/abs/2108.06492)] |
| Joint Optimization in Edge-Cloud Continuum for Federated Unsupervised Person Re-identification | NTU | MM | 2021 | FedUReID[^FedUReID] | [[PUB](https://dl.acm.org/doi/10.1145/3474085.3475182)] [[PDF](https://arxiv.org/abs/2108.06493)] |
| Federated Visual Classification with Real-World Data Distribution | MIT; Google | ECCV | 2020 | FedVC+FedIR[^FedVCplusFedIR] | [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-58607-2_5)] [[PDF](https://arxiv.org/abs/2003.08082)] [[VIDEO](https://www.youtube.com/watch?v=Rc67rZzPDDY&ab_channel=TzuMingHsu)] |
| InvisibleFL: Federated Learning over Non-Informative Intermediate Updates against Multimedia Privacy Leakages | | MM | 2020 | InvisibleFL[^InvisibleFL] | [[PUB](https://dl.acm.org/doi/10.1145/3394171.3413923)] |
| Performance Optimization of Federated Person Re-identification via Benchmark Analysis **`data.`** | NTU | MM | 2020 | FedReID[^FedReID] | [[PUB](https://dl.acm.org/doi/10.1145/3394171.3413814)] [[PDF](https://arxiv.org/abs/2008.11560)] [[CODE](https://github.com/cap-ntu/FedReID)] [[解读](https://zhuanlan.zhihu.com/p/265987079)] |
<!-- END:fl-in-top-cv-conference-and-journal -->
## fl in top nlp conference and journal
In this section, we will summarize Federated Learning papers accepted by top AI and NLP conference and journal, including [ACL](https://dblp.uni-trier.de/db/conf/acl/index.html)(Annual Meeting of the Association for Computational Linguistics), [NAACL](https://dblp.uni-trier.de/db/conf/naacl/index.html)(North American Chapter of the Association for Computational Linguistics), [EMNLP](https://dblp.uni-trier.de/db/conf/emnlp/index.html)(Conference on Empirical Methods in Natural Language Processing) and [COLING](https://dblp.uni-trier.de/db/conf/coling/index.html)(International Conference on Computational Linguistics).
- [ACL](https://dblp.uni-trier.de/search?q=federate%20venue%3AACL%3A) [2022](https://aclanthology.org/events/acl-2022/), [2021](https://aclanthology.org/events/acl-2021/), [2019](https://aclanthology.org/events/acl-2019/)
- [NAACL](https://dblp.uni-trier.de/search?q=federate%20venue%3ANAACL-HLT%3A) [2022](https://aclanthology.org/events/naacl-2022/), [2021](https://aclanthology.org/events/naacl-2021/)
- [EMNLP](https://dblp.uni-trier.de/search?q=federate%20venue%3AEMNLP%3A) 2022, [2021](https://aclanthology.org/events/emnlp-2021/), [2020](https://aclanthology.org/events/emnlp-2020/)
- [COLING](https://dblp.uni-trier.de/search?q=federate%20venue%3ACOLING%3A) [2020](https://aclanthology.org/events/coling-2020/)
<!-- START:fl-in-top-nlp-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------------------------- | -------------- | ---- | ----------------------------------- | ------------------------------------------------------------ |
| Dim-Krum: Backdoor-Resistant Federated Learning for NLP with Dimension-wise Krum-Based Aggregation | | EMNLP | 2022 | | [[PDF](https://arxiv.org/abs/2210.06894)] |
| Efficient Federated Learning on Knowledge Graphs via Privacy-preserving Relation Embedding Aggregation **`kg.`** | Lehigh University | EMNLP | 2022 | FedR[^FedR] | [[PDF](https://arxiv.org/abs/2203.09553)] [[CODE](https://github.com/taokz/FedR)] |
| Federated Continual Learning for Text Classification via Selective Inter-client Transfer | | EMNLP | 2022 | | [[PDF](https://arxiv.org/abs/2210.06101)] [[CODE](https://github.com/raipranav/fcl-fedseit)] |
| Backdoor Attacks in Federated Learning by Rare Embeddings and Gradient Ensembling | | EMNLP | 2022 | | [[PDF](https://arxiv.org/abs/2204.14017)] |
| Federated Model Decomposition with Private Vocabulary for Text Classification | | EMNLP | 2022 | | [[CODE](https://github.com/SMILELab-FL/FedVocab)] |
| Federated Meta-Learning for Emotion and Sentiment Aware Multi-modal Complaint Identification | | EMNLP | 2022 | | [[PUB](https://openreview.net/forum?id=rVgVJ9eWxM9)] |
| A Federated Approach to Predicting Emojis in Hindi Tweets | | EMNLP | 2022 | | |
| Fair NLP Models with Differentially Private Text Encoders | | EMNLP | 2022 | | [[PUB](https://openreview.net/forum?id=BVgNSki6q1c)] [[PDF](https://arxiv.org/abs/2205.06135)] [[CODE](https://github.com/saist1993/dpnlp)] |
| Scaling Language Model Size in Cross-Device Federated Learning | Google | ACL workshop | 2022 | SLM-FL[^SLM-FL] | [[PUB](https://aclanthology.org/2022.fl4nlp-1.2/)] [[PDF](https://arxiv.org/abs/2204.09715)] |
| Intrinsic Gradient Compression for Scalable and Efficient Federated Learning | Oxford | ACL workshop | 2022 | IGC-FL[^IGC-FL] | [[PUB](https://aclanthology.org/2022.fl4nlp-1.4/)] [[PDF](https://arxiv.org/abs/2112.02656)] |
| ActPerFL: Active Personalized Federated Learning | Amazon | ACL workshop | 2022 | ActPerFL[^ActPerFL] | [[PUB](https://aclanthology.org/2022.fl4nlp-1.1)] [[PAGE](https://www.amazon.science/publications/actperfl-active-personalized-federated-learning)] |
| FedNLP: Benchmarking Federated Learning Methods for Natural Language Processing Tasks :fire: | USC | NAACL | 2022 | FedNLP[^FedNLP] | [[PUB](https://aclanthology.org/2022.findings-naacl.13/)] [[PDF](https://arxiv.org/abs/2104.08815)] [[CODE](https://github.com/FedML-AI/FedNLP)] |
| Federated Learning with Noisy User Feedback | USC; Amazon | NAACL | 2022 | FedNoisy[^FedNoisy] | [[PUB](https://aclanthology.org/2022.naacl-main.196/)] [[PDF](https://arxiv.org/abs/2205.03092)] |
| Training Mixed-Domain Translation Models via Federated Learning | Amazon | NAACL | 2022 | FedMDT[^FedMDT] | [[PUB](https://aclanthology.org/2022.naacl-main.186)] [[PAGE](https://www.amazon.science/publications/training-mixed-domain-translation-models-via-federated-learning)] [[PDF](https://arxiv.org/abs/2205.01557)] |
| Pretrained Models for Multilingual Federated Learning | Johns Hopkins University | NAACL | 2022 | | [[PUB](https://aclanthology.org/2022.naacl-main.101)] [[PDF](https://arxiv.org/abs/2206.02291)] [[CODE](https://github.com/orionw/multilingual-federated-learning)] |
| Training Mixed-Domain Translation Models via Federated Learning | Amazon | NAACL | 2022 | | [[PUB](https://aclanthology.org/2022.naacl-main.186/)] [[PAGE](https://www.amazon.science/publications/training-mixed-domain-translation-models-via-federated-learning)] [[PDF](https://arxiv.org/abs/2205.01557)] |
| Federated Chinese Word Segmentation with Global Character Associations | University of Washington | ACL workshop | 2021 | | [[PUB](https://aclanthology.org/2021.findings-acl.376)] [[CODE](https://github.com/cuhksz-nlp/GCASeg)] |
| Efficient-FedRec: Efficient Federated Learning Framework for Privacy-Preserving News Recommendation | USTC | EMNLP | 2021 | Efficient-FedRec[^Efficient-FedRec] | [[PUB](https://aclanthology.org/2021.emnlp-main.223)] [[PDF](https://arxiv.org/abs/2109.05446)] [[CODE](https://github.com/yjw1029/Efficient-FedRec)] [[VIDEO](https://aclanthology.org/2021.emnlp-main.223.mp4)] |
| Improving Federated Learning for Aspect-based Sentiment Analysis via Topic Memories | CUHK (Shenzhen) | EMNLP | 2021 | | [[PUB](https://aclanthology.org/2021.emnlp-main.321/)] [[CODE](https://github.com/cuhksz-nlp/ASA-TM)] [[VIDEO](https://aclanthology.org/2021.emnlp-main.321.mp4)] |
| A Secure and Efficient Federated Learning Framework for NLP | University of Connecticut | EMNLP | 2021 | | [[PUB](https://aclanthology.org/2021.emnlp-main.606)] [[PDF](https://arxiv.org/abs/2201.11934)] [[VIDEO](https://aclanthology.org/2021.emnlp-main.606.mp4)] |
| Distantly Supervised Relation Extraction in Federated Settings | UCAS | EMNLP workshop | 2021 | | [[PUB](https://aclanthology.org/2021.findings-emnlp.52)] [[PDF](https://arxiv.org/abs/2008.05049)] [[CODE](https://github.com/DianboWork/FedDS)] |
| Federated Learning with Noisy User Feedback | USC; Amazon | NAACL workshop | 2021 | | [[PUB](https://aclanthology.org/2022.naacl-main.196)] [[PDF](https://arxiv.org/abs/2205.03092)] |
| An Investigation towards Differentially Private Sequence Tagging in a Federated Framework | Universität Hamburg | NAACL workshop | 2021 | | [[PUB](https://aclanthology.org/2021.privatenlp-1.4)] |
| Understanding Unintended Memorization in Language Models Under Federated Learning | Google | NAACL workshop | 2021 | | [[PUB](https://aclanthology.org/2021.privatenlp-1.1)] [[PDF](https://arxiv.org/abs/2006.07490)] |
| FedED: Federated Learning via Ensemble Distillation for Medical Relation Extraction | CAS | EMNLP | 2020 | | [[PUB](https://aclanthology.org/2020.emnlp-main.165)] [[VIDEO](https://slideslive.com/38939230)] [[解读](https://zhuanlan.zhihu.com/p/539347225)] |
| Empirical Studies of Institutional Federated Learning For Natural Language Processing | Ping An Technology | EMNLP workshop | 2020 | | [[PUB](https://aclanthology.org/2020.findings-emnlp.55)] |
| Federated Learning for Spoken Language Understanding | PKU | COLING | 2020 | | [[PUB](https://aclanthology.org/2020.coling-main.310/)] |
| Two-stage Federated Phenotyping and Patient Representation Learning | Boston Children’s Hospital Harvard Medical School | ACL workshop | 2019 | | [[PUB](https://aclanthology.org/W19-5030)] [[PDF](https://arxiv.org/abs/1908.05596)] [[CODE](https://github.com/kaiyuanmifen/FederatedNLP)] [[UC.](https://github.com/MarcioPorto/federated-phenotyping)] |
<!-- END:fl-in-top-nlp-conference-and-journal -->
## fl in top ir conference and journal
In this section, we will summarize Federated Learning papers accepted by top Information Retrieval conference and journal, including [SIGIR](https://dblp.org/db/conf/sigir/index.html)(Annual International ACM SIGIR Conference on Research and Development in Information Retrieval).
- [SIGIR](https://dblp.uni-trier.de/search?q=federate%20venue%3ASIGIR%3A) [2022](https://dl.acm.org/doi/proceedings/10.1145/3477495), [2021](https://dl.acm.org/doi/proceedings/10.1145/3404835), [2020](https://dl.acm.org/doi/proceedings/10.1145/3397271)
<!-- START:fl-in-top-ir-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------- | ----- | ---- | --------------------------- | ------------------------------------------------------------ |
| Is Non-IID Data a Threat in Federated Online Learning to Rank? | The University of Queensland | SIGIR | 2022 | noniid-foltr[^noniid-foltr] | [[PUB](https://dl.acm.org/doi/10.1145/3477495.3531709)] [[CODE](https://github.com/ielab/2022-SIGIR-noniid-foltr)] |
| FedCT: Federated Collaborative Transfer for Recommendation | Rutgers University | SIGIR | 2021 | FedCT[^FedCT] | [[PUB](https://dl.acm.org/doi/10.1145/3404835.3462825)] [[PDF](http://yongfeng.me/attach/liu-sigir2021.pdf)] [[CODE](https://github.com/CharlieMat/EdgeCDR)] |
| On the Privacy of Federated Pipelines | Technical University of Munich | SIGIR | 2021 | FedGWAS[^FedGWAS] | [[PUB](https://dl.acm.org/doi/10.1145/3404835.3462996)] |
| FedCMR: Federated Cross-Modal Retrieval. | Dalian University of Technology | SIGIR | 2021 | FedCMR[^FedCMR] | [[PUB](https://dl.acm.org/doi/10.1145/3404835.3462989)] [[CODE](https://github.com/hasakiXie123/FedCMR)] |
| Meta Matrix Factorization for Federated Rating Predictions. | SDU | SIGIR | 2020 | MetaMF[^MetaMF] | [[PUB](https://dl.acm.org/doi/10.1145/3397271.3401081)] [[PDF](https://arxiv.org/abs/1910.10086)] |
<!-- END:fl-in-top-ir-conference-and-journal -->
## fl in top db conference and journal
In this section, we will summarize Federated Learning papers accepted by top Database conference and journal, including [SIGMOD](https://dblp.uni-trier.de/db/conf/sigmod/index.html)(ACM SIGMOD Conference) , [ICDE](https://dblp.uni-trier.de/db/conf/icde/index.html)(IEEE International Conference on Data Engineering) and [VLDB](https://dblp.uni-trier.de/db/conf/vldb/index.html)(Very Large Data Bases Conference).
- [SIGMOD](https://dblp.uni-trier.de/search?q=federate%20venue%3ASIGMOD%20Conference%3A) [2022](https://2022.sigmod.org/sigmod_research_list.shtml), [2021](https://2021.sigmod.org/sigmod_research_list.shtml)
- [ICDE](https://dblp.uni-trier.de/search?q=federate%20venue%3AICDE%3A) [2022](https://icde2022.ieeecomputer.my/accepted-research-track/), [2021](https://ieeexplore.ieee.org/xpl/conhome/9458599/proceeding)
- [VLDB](https://dblp.org/search?q=federate%20venue%3AProc%20VLDB%20Endow%3A) [2022](https://vldb.org/pvldb/vol16-volume-info/), [2021](https://vldb.org/pvldb/vol15-volume-info/), [2021](http://www.vldb.org/pvldb/vol14/), [2020](http://vldb.org/pvldb/vol13-volume-info/)
<!-- START:fl-in-top-db-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------- | --------------- | ---- | ----------------------------------------- | ------------------------------------------------------------ |
| Skellam Mixture Mechanism: a Novel Approach to Federated Learning with Differential Privacy. | NUS | VLDB | 2022 | SMM[^SMM] | [[PUB](https://www.vldb.org/pvldb/vol15/p2348-bao.pdf)] [[CODE](https://github.com/SkellamMixtureMechanism/SMM)] |
| Towards Communication-efficient Vertical Federated Learning Training via Cache-enabled Local Update | PKU | VLDB | 2022 | CELU-VFL[^CELU-VFL] | [[PUB](https://dl.acm.org/doi/10.14778/3547305.3547316)] [[PDF](https://arxiv.org/abs/2207.14628)] [[CODE](https://github.com/ccchengff/FDL/tree/main/playground/celu_vfl)] |
| FedTSC: A Secure Federated Learning System for Interpretable Time Series Classification. | HIT | VLDB | 2022 | FedTSC[^FedTSC] | [[PUB](https://www.vldb.org/pvldb/vol15/p3686-wang.pdf)] [[CODE](https://github.com/hit-mdc/FedTSC-FedST)] |
| Improving Fairness for Data Valuation in Horizontal Federated Learning | The UBC | ICDE | 2022 | CSFV[^CSFV] | [[PUB](https://ieeexplore.ieee.org/document/9835382)] [[PDF](https://arxiv.org/abs/2109.09046)] |
| FedADMM: A Robust Federated Deep Learning Framework with Adaptivity to System Heterogeneity | USTC | ICDE | 2022 | FedADMM[^FedADMM] | [[PUB](https://ieeexplore.ieee.org/document/9835545)] [[PDF](https://arxiv.org/abs/2204.03529)] [[CODE](https://github.com/YonghaiGong/FedADMM)] |
| FedMP: Federated Learning through Adaptive Model Pruning in Heterogeneous Edge Computing. | USTC | ICDE | 2022 | FedMP[^FedMP] | [[PUB](https://ieeexplore.ieee.org/document/9835327)] |
| Federated Learning on Non-IID Data Silos: An Experimental Study. :fire: | NUS | ICDE | 2022 | ESND[^ESND] | [[PUB](https://ieeexplore.ieee.org/document/9835537)] [[PDF](https://arxiv.org/abs/2102.02079)] [[CODE](https://github.com/Xtra-Computing/NIID-Bench)] |
| Enhancing Federated Learning with Intelligent Model Migration in Heterogeneous Edge Computing | USTC | ICDE | 2022 | FedMigr[^FedMigr] | [[PUB](https://ieeexplore.ieee.org/document/9835657)] |
| Samba: A System for Secure Federated Multi-Armed Bandits | Univ. Clermont Auvergne | ICDE | 2022 | Samba[^Samba] | [[PUB](https://ieeexplore.ieee.org/document/9835585)] [[CODE](https://github.com/gamarcad/samba-demo)] |
| FedRecAttack: Model Poisoning Attack to Federated Recommendation | ZJU | ICDE | 2022 | FedRecAttack[^FedRecAttack] | [[PUB](https://ieeexplore.ieee.org/document/9835228)] [[PDF](https://arxiv.org/abs/2204.01499)] [[CODE](https://github.com/rdz98/fedrecattack)] |
| Enhancing Federated Learning with In-Cloud Unlabeled Data | USTC | ICDE | 2022 | Ada-FedSemi[^Ada-FedSemi] | [[PUB](https://ieeexplore.ieee.org/document/9835163)] |
| Efficient Participant Contribution Evaluation for Horizontal and Vertical Federated Learning | USTC | ICDE | 2022 | DIG-FL[^DIG-FL] | [[PUB](https://ieeexplore.ieee.org/document/9835159)] |
| An Introduction to Federated Computation | University of Warwick; Facebook | SIGMOD Tutorial | 2022 | FCT[^FCT] | [[PUB](https://dl.acm.org/doi/10.1145/3514221.3522561)] |
| BlindFL: Vertical Federated Machine Learning without Peeking into Your Data | PKU; Tencent | SIGMOD | 2022 | BlindFL[^BlindFL] | [[PUB](https://dl.acm.org/doi/10.1145/3514221.3526127)] [[PDF](https://arxiv.org/abs/2206.07975)] |
| An Efficient Approach for Cross-Silo Federated Learning to Rank | BUAA | ICDE | 2021 | CS-F-LTR[^CS-F-LTR] | [[PUB](https://ieeexplore.ieee.org/document/9458704)] [[RELATED PAPER(ZH)](https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.13328/j.cnki.jos.006174)] |
| Feature Inference Attack on Model Predictions in Vertical Federated Learning | NUS | ICDE | 2021 | FIA[^FIA] | [[PUB](https://ieeexplore.ieee.org/document/9458672/)] [[PDF](https://arxiv.org/abs/2010.10152)] [[CODE](https://github.com/xj231/featureinference-vfl)] |
| Efficient Federated-Learning Model Debugging | USTC | ICDE | 2021 | FLDebugger[^FLDebugger] | [[PUB](https://ieeexplore.ieee.org/document/9458829)] |
| Federated Matrix Factorization with Privacy Guarantee | Purdue | VLDB | 2021 | FMFPG[^FMFPG] | [[PUB](https://www.vldb.org/pvldb/vol15/p900-li.pdf)] |
| Projected Federated Averaging with Heterogeneous Differential Privacy. | Renmin University of China | VLDB | 2021 | PFA-DB[^PFA-DB] | [[PUB](https://dl.acm.org/doi/10.14778/3503585.3503592)] [[CODE](https://github.com/Emory-AIMS/PFA)] |
| Enabling SQL-based Training Data Debugging for Federated Learning | Simon Fraser University | VLDB | 2021 | FedRain-and-Frog[^FedRain-and-Frog] | [[PUB](http://www.vldb.org/pvldb/vol15/p388-wu.pdf)] [[PDF](https://arxiv.org/abs/2108.11884)] [[CODE](https://github.com/sfu-db/FedRain-and-Frog)] |
| Refiner: A Reliable Incentive-Driven Federated Learning System Powered by Blockchain | ZJU | VLDB | 2021 | Refiner[^Refiner] | [[PUB](http://vldb.org/pvldb/vol14/p2659-jiang.pdf)] |
| Tanium Reveal: A Federated Search Engine for Querying Unstructured File Data on Large Enterprise Networks | Tanium Inc. | VLDB | 2021 | TaniumReveal[^TaniumReveal] | [[PUB](http://www.vldb.org/pvldb/vol14/p3096-stoddard.pdf)] [[VIDEO](https://www.bilibili.com/video/BV1Wg411j7aA)] |
| VF2Boost: Very Fast Vertical Federated Gradient Boosting for Cross-Enterprise Learning | PKU | SIGMOD | 2021 | VF2Boost[^VF2Boost] | [[PUB](https://dl.acm.org/doi/10.1145/3448016.3457241)] |
| ExDRa: Exploratory Data Science on Federated Raw Data | SIEMENS | SIGMOD | 2021 | ExDRa[^ExDRa] | [[PUB](https://dl.acm.org/doi/10.1145/3448016.3457549)] |
| Joint blockchain and federated learning-based offloading in harsh edge computing environments | TJU | SIGMOD workshop | 2021 | FLoffloading[^FLoffloading] | [[PUB](https://dl.acm.org/doi/10.1145/3460866.3461765)] |
| Privacy Preserving Vertical Federated Learning for Tree-based Models | NUS | VLDB | 2020 | Pivot-DT[^Pivot-DT] | [[PUB](http://vldb.org/pvldb/vol13/p2090-wu.pdf)] [[PDF](https://arxiv.org/abs/2008.06170)] [[VIDEO](https://www.youtube.com/watch?v=sjii8oVCqiY)] [[CODE](https://github.com/nusdbsystem/pivot)] |
<!-- END:fl-in-top-db-conference-and-journal -->
## fl in top network conference and journal
In this section, we will summarize Federated Learning papers accepted by top Database conference and journal, including [SIGCOMM](https://dblp.org/db/conf/sigcomm/index.html)(Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication), [INFOCOM](https://dblp.org/db/conf/infocom/index.html)(IEEE Conference on Computer Communications), [MobiCom](https://dblp.org/db/conf/mobicom/index.html)(ACM/IEEE International Conference on Mobile Computing and Networking), [NSDI](https://dblp.org/db/conf/nsdi/index.html)(Symposium on Networked Systems Design and Implementation) and [WWW](https://dblp.org/db/conf/www/index.html)(The Web Conference).
- [SIGCOMM](https://dblp.uni-trier.de/search?q=federate%20venue%3ASIGCOMM%3A) NULL
- [INFOCOM](https://dblp.uni-trier.de/search?q=federate%20venue%3AINFOCOM%3A) [2022](https://infocom2022.ieee-infocom.org/program/accepted-paper-list-main-conference)([Page](https://infocom.info/day/3/track/Track%20B#B-7)), [2021](https://infocom2021.ieee-infocom.org/accepted-paper-list-main-conference.html)([Page](https://duetone.org/infocom21)), [2020](https://infocom2020.ieee-infocom.org/accepted-paper-list-main-conference.html)([Page](https://duetone.org/infocom20)), [2019](https://infocom2019.ieee-infocom.org/accepted-paper-list-main-conference.html), 2018
- [MobiCom](https://dblp.uni-trier.de/search?q=federate%20venue%3AMobiCom%3A) [2022](https://www.sigmobile.org/mobicom/2022/accepted.html), [2021](https://www.sigmobile.org/mobicom/2021/accepted.html), [2020](https://www.sigmobile.org/mobicom/2020/accepted.php)
- [NSDI](https://dblp.uni-trier.de/search?q=federate%20venue%3ANSDI%3A) NULL
- [WWW](https://dblp.uni-trier.de/search?q=federate%20venue%3AWWW%3A) [2022](https://www2022.thewebconf.org/accepted-papers/), [2021](https://www2021.thewebconf.org/program/papers-program/links/index.html)
<!-- START:fl-in-top-network-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------------------------------------------ | ---------- | ---- | ----------------------------------------- | ------------------------------------------------------------ |
| PyramidFL: Fine-grained Data and System Heterogeneity-aware Client Selection for Efficient Federated Learning | MSU | MobiCom | 2022 | PyramidFL[^PyramidFL] | [[PUB](https://dl.acm.org/doi/10.1145/3495243.3517017)] [[PDF](https://www.egr.msu.edu/~mizhang/papers/2022_MobiCom_PyramidFL.pdf)] [[CODE](https://github.com/liecn/PyramidFL)] |
| NestFL: efficient federated learning through progressive model pruning in heterogeneous edge computing | pmlabs | MobiCom(Poster) | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3495243.3558248)] |
| Federated learning-based air quality prediction for smart cities using BGRU model | IITM | MobiCom(Poster) | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3495243.3558267)] |
| FedHD: federated learning with hyperdimensional computing | UCSD | MobiCom(Demo) | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3495243.3558757)] [[CODE](https://github.com/QuanlingZhao/FedHD)] |
| Joint Superposition Coding and Training for Federated Learning over Multi-Width Neural Networks | Korea University | INFOCOM | 2022 | SlimFL[^SlimFL] | [[PUB](https://ieeexplore.ieee.org/document/9796733)] |
| Towards Optimal Multi-Modal Federated Learning on Non-IID Data with Hierarchical Gradient Blending | University of Toronto | INFOCOM | 2022 | HGBFL[^HGBFL] | [[PUB](https://ieeexplore.ieee.org/document/9796724)] |
| Optimal Rate Adaption in Federated Learning with Compressed Communications | SZU | INFOCOM | 2022 | ORAFL[^ORAFL] | [[PUB](https://ieeexplore.ieee.org/document/9796982)] [[PDF](https://arxiv.org/abs/2112.06694)] |
| The Right to be Forgotten in Federated Learning: An Efficient Realization with Rapid Retraining. | CityU | INFOCOM | 2022 | RFFL[^RFFL] | [[PUB](https://ieeexplore.ieee.org/document/9796721)] [[PDF](https://arxiv.org/abs/2203.07320)] |
| Tackling System and Statistical Heterogeneity for Federated Learning with Adaptive Client Sampling. | CUHK; AIRS ;Yale University | INFOCOM | 2022 | FLACS[^FLACS] | [[PUB](https://ieeexplore.ieee.org/document/9796935)] [[PDF](https://arxiv.org/abs/2112.11256)] |
| Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization | Army Research Laboratory, Adelphi | INFOCOM | 2022 | CEDSFL[^CEDSFL] | [[PUB](https://ieeexplore.ieee.org/document/9796818)] [[PDF](https://arxiv.org/abs/2201.07912)] |
| FLASH: Federated Learning for Automated Selection of High-band mmWave Sectors | NEU | INFOCOM | 2022 | FLASH[^FLASH] | [[PUB](https://ieeexplore.ieee.org/document/9796865)] [[CODE](https://github.com/Batool-Salehi/FL-based-Sector-Selection)] |
| A Profit-Maximizing Model Marketplace with Differentially Private Federated Learning | CUHK; AIRS | INFOCOM | 2022 | PMDPFL[^PMDPFL] | [[PUB](https://ieeexplore.ieee.org/document/9796833)] |
| Protect Privacy from Gradient Leakage Attack in Federated Learning | PolyU | INFOCOM | 2022 | PPGLFL[^PPGLFL] | [[PUB](https://ieeexplore.ieee.org/document/9796841/)] [[SLIDE](https://jxiao.wang/slides/INFOCOM22.pdf)] |
| FedFPM: A Unified Federated Analytics Framework for Collaborative Frequent Pattern Mining. | SJTU | INFOCOM | 2022 | FedFPM[^FedFPM] | [[PUB](https://ieeexplore.ieee.org/document/9796719)] [[CODE](https://github.com/HuskyW/FFPA)] |
| An Accuracy-Lossless Perturbation Method for Defending Privacy Attacks in Federated Learning | SWJTU;THU | WWW | 2022 | PBPFL[^PBPFL] | [[PUB](https://dl.acm.org/doi/10.1145/3485447.3512233)] [[PDF](https://arxiv.org/abs/2002.09843)] [[CODE](https://github.com/Kira0096/PBPFL)] |
| LocFedMix-SL: Localize, Federate, and Mix for Improved Scalability, Convergence, and Latency in Split Learning | Yonsei University | WWW | 2022 | LocFedMix-SL[^LocFedMix-SL] | [[PUB](https://dl.acm.org/doi/10.1145/3485447.3512153)] |
| Federated Unlearning via Class-Discriminative Pruning | PolyU | WWW | 2022 | | [[PUB](https://dl.acm.org/doi/10.1145/3485447.3512222)] [[PDF](https://arxiv.org/abs/2110.11794)] [[CODE](https://github.com/MoonkeyBoy/Federated-Unlearning-via-Class-Discriminative-Pruning)] |
| FedKC: Federated Knowledge Composition for Multilingual Natural Language Understanding | Purdue | WWW | 2022 | FedKC[^FedKC] | [[PUB](https://dl.acm.org/doi/10.1145/3485447.3511988)] |
| Federated Bandit: A Gossiping Approach | University of California | SIGMETRICS | 2021 | Federated-Bandit[^Federated-Bandit] | [[PUB](https://dl.acm.org/doi/10.1145/3447380)] [[PDF](https://arxiv.org/abs/2010.12763)] |
| Hermes: an efficient federated learning framework for heterogeneous mobile clients | Duke University | MobiCom | 2021 | Hermes[^Hermes] | [[PUB](https://dl.acm.org/doi/10.1145/3447993.3483278)] |
| Federated mobile sensing for activity recognition | Samsung AI Center | MobiCom | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3447993.3488031)] [[PAGE](https://federatedsensing.gitlab.io/)] [[TALKS](https://federatedsensing.gitlab.io/talks/)] [[VIDEO](https://federatedsensing.gitlab.io/program/)] |
| Learning for Learning: Predictive Online Control of Federated Learning with Edge Provisioning. | Nanjing University | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488733/)] |
| Device Sampling for Heterogeneous Federated Learning: Theory, Algorithms, and Implementation. | Purdue | INFOCOM | 2021 | D2D-FedL[^D2D-FedL] | [[PUB](https://ieeexplore.ieee.org/document/9488906)] [[PDF](https://arxiv.org/abs/2101.00787)] |
| FAIR: Quality-Aware Federated Learning with Precise User Incentive and Model Aggregation | THU | INFOCOM | 2021 | FAIR[^FAIR] | [[PUB](https://ieeexplore.ieee.org/document/9488743)] |
| Sample-level Data Selection for Federated Learning | USTC | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488723)] |
| To Talk or to Work: Flexible Communication Compression for Energy Efficient Federated Learning over Heterogeneous Mobile Edge Devices | Xidian University; CAS | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488839)] [[PDF](https://arxiv.org/abs/2012.11804)] |
| Cost-Effective Federated Learning Design | CUHK; AIRS; Yale University | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488679)] [[PDF](https://arxiv.org/abs/2012.08336)] |
| An Incentive Mechanism for Cross-Silo Federated Learning: A Public Goods Perspective | The UBC | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488705)] |
| Resource-Efficient Federated Learning with Hierarchical Aggregation in Edge Computing | USTC | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488756/)] |
| FedServing: A Federated Prediction Serving Framework Based on Incentive Mechanism. | Jinan University; CityU | INFOCOM | 2021 | FedServing[^FedServing] | [[PUB](https://ieeexplore.ieee.org/document/9488807)] [[PDF](https://arxiv.org/abs/2012.10566)] |
| Federated Learning over Wireless Networks: A Band-limited Coordinated Descent Approach | Arizona State University | INFOCOM | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9488818)] [[PDF](https://arxiv.org/abs/2102.07972)] |
| Dual Attention-Based Federated Learning for Wireless Traffic Prediction | King Abdullah University of Science and Technology | INFOCOM | 2021 | FedDA[^FedDA] | [[PUB](https://ieeexplore.ieee.org/document/9488883)] [[PDF](https://arxiv.org/abs/2110.05183)] [[CODE](https://github.com/chuanting/fedda)] |
| FedSens: A Federated Learning Approach for Smart Health Sensing with Class Imbalance in Resource Constrained Edge Computing | University of Notre Dame | INFOCOM | 2021 | FedSens[^FedSens] | [[PUB](https://ieeexplore.ieee.org/document/9488776/)] |
| P-FedAvg: Parallelizing Federated Learning with Theoretical Guarantees | SYSU; Guangdong Key Laboratory of Big Data Analysis and Processing | INFOCOM | 2021 | P-FedAvg[^P-FedAvg] | [[PUB](https://ieeexplore.ieee.org/document/9488877)] |
| Meta-HAR: Federated Representation Learning for Human Activity Recognition. | University of Alberta | WWW | 2021 | Meta-HAR[^Meta-HAR] | [[PUB](https://dl.acm.org/doi/10.1145/3442381.3450006)] [[PDF](https://arxiv.org/abs/2106.00615)] [[CODE](https://github.com/Chain123/Meta-HAR)] |
| PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization | PKU | WWW | 2021 | PFA[^PFA] | [[PUB](https://dl.acm.org/doi/10.1145/3442381.3449847)] [[PDF](https://arxiv.org/abs/2103.01548)] [[CODE](https://github.com/lebyni/PFA)] |
| Communication Efficient Federated Generalized Tensor Factorization for Collaborative Health Data Analytics | Emory | WWW | 2021 | FedGTF-EF-PC[^FedGTF-EF-PC] | [[PUB](https://dl.acm.org/doi/10.1145/3442381.3449832)] [[CODE](https://github.com/jma78/FedGTF-EF)] |
| Hierarchical Personalized Federated Learning for User Modeling | USTC | WWW | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3442381.3449926)] |
| Characterizing Impacts of Heterogeneity in Federated Learning upon Large-Scale Smartphone Data | PKU | WWW | 2021 | Heter-aware[^Heter-aware] | [[PUB](https://dl.acm.org/doi/10.1145/3442381.3449851)] [[PDF](https://arxiv.org/abs/2006.06983)] [[SLIDE](https://qipengwang.github.io/files/www21.slides.pdf)] [[CODE](https://github.com/PKU-Chengxu/FLASH)] |
| Incentive Mechanism for Horizontal Federated Learning Based on Reputation and Reverse Auction | SYSU | WWW | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3442381.3449888)] |
| Physical-Layer Arithmetic for Federated Learning in Uplink MU-MIMO Enabled Wireless Networks. | Nanjing University | INFOCOM | 2020 | | [[PUB](https://ieeexplore.ieee.org/document/9155479)] |
| Optimizing Federated Learning on Non-IID Data with Reinforcement Learning :fire: | University of Toronto | INFOCOM | 2020 | | [[PUB](https://ieeexplore.ieee.org/document/9155494)] [[SLIDE](https://workshoputrgv.github.io/slides/hao_wang.pdf)] [[CODE](https://github.com/iQua/flsim)] [[解读](https://zhuanlan.zhihu.com/p/458716656)] |
| Enabling Execution Assurance of Federated Learning at Untrusted Participants | THU | INFOCOM | 2020 | | [[PUB](https://ieeexplore.ieee.org/document/9155414)] [[CODE](https://github.com/zeyu-zh/TrustFL)] |
| Billion-scale federated learning on mobile clients: a submodel design with tunable privacy | SJTU | MobiCom | 2020 | | [[PUB](https://dl.acm.org/doi/10.1145/3372224.3419188)] |
| Federated Learning over Wireless Networks: Optimization Model Design and Analysis | The University of Sydney | INFOCOM | 2019 | | [[PUB](https://ieeexplore.ieee.org/document/8737464)] [[CODE](https://github.com/nhatminh/FEDL-INFOCOM)] |
| Beyond Inferring Class Representatives: User-Level Privacy Leakage From Federated Learning | Wuhan University | INFOCOM | 2019 | | [[PUB](https://ieeexplore.ieee.org/document/8737416)] [[PDF](https://arxiv.org/abs/1812.00535)] [[UC.](https://github.com/JonasGeiping/breaching)] |
| InPrivate Digging: Enabling Tree-based Distributed Data Mining with Differential Privacy | Collaborative Innovation Center of Geospatial Technology | INFOCOM | 2018 | TFL[^TFL] | [[PUB](https://ieeexplore.ieee.org/document/8486352)] |
<!-- END:fl-in-top-network-conference-and-journal -->
## fl in top system conference and journal
In this section, we will summarize Federated Learning papers accepted by top Database conference and journal, including [OSDI](https://dblp.org/db/conf/osdi/index.html)(USENIX Symposium on Operating Systems Design and Implementation), [SOSP](https://dblp.org/db/conf/sosp/index.html)(Symposium on Operating Systems Principles), [ISCA](https://dblp.org/db/conf/isca/index.html)(International Symposium on Computer Architecture), [MLSys](https://dblp.org/db/conf/mlsys/index.html)(Conference on Machine Learning and Systems), [TPDS](https://dblp.uni-trier.de/db/journals/tpds/index.html)(IEEE Transactions on Parallel and Distributed Systems), [DAC](https://dblp.uni-trier.de/db/conf/dac/index.html)(Design Automation Conference), [TOCS](https://dblp.uni-trier.de/db/journals/tocs/index.html)(ACM Transactions on Computer Systems), [TOS](https://dblp.uni-trier.de/db/journals/tos/index.html)(ACM Transactions on Storage), [TCAD](https://dblp.uni-trier.de/db/journals/tcad/index.html)(IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems), [TC](https://dblp.uni-trier.de/db/journals/tc/index.html)(IEEE Transactions on Computers).
- [OSDI](https://dblp.org/search?q=federated%20venue%3AOSDI%3A) 2021
- [SOSP](https://dblp.org/search?q=federated%20venue%3ASOSP%3A) 2021
- [ISCA](https://dblp.org/search?q=federated%20venue%3AISCA%3A) NULL
- [MLSys](https://dblp.org/search?q=federated%20venue%3AMLSys%3A) 2022, 2020, 2019
- [TPDS](https://dblp.uni-trier.de/search?q=federate%20venue%3AIEEE%20Trans.%20Parallel%20Distributed%20Syst.%3A) 2023, 2022, 2021, 2020
- [DAC](https://dblp.uni-trier.de/search?q=federate%20venue%3ADAC%3A) 2022, 2021
- [TOCS](https://dblp.uni-trier.de/search?q=federate%20venue%3AACM%20Trans%20Comput%20Syst%3A) NULL
- [TOS](https://dblp.uni-trier.de/search?q=federate%20venue%3A%20ACM%20Trans%20Storage%3A) NULL
- [TCAD](https://dblp.uni-trier.de/search?q=federate%20venue%3AIEEE%20Trans%20Comput%20Aided%20Des%20Integr%20Circuits%20Syst%3A) 2022, 2021
- [TC](https://dblp.uni-trier.de/search?q=federate%20venue%3AIEEE%20Trans.%20Computers%3A) 2022, 2021
<!-- START:fl-in-top-system-conference-and-journal -->
|Title | Affiliation | Venue | Year | TL;DR | Materials|
| ------------------------------------------------------------ | ------------------------- | ------------------------- | ---- | ----------------------------------- | ------------------------------------------------------------ |
| HierFedML: Aggregator Placement and UE Assignment for Hierarchical Federated Learning in Mobile Edge Computing. | DUT | TPDS | 2023 | | [[PUB](https://ieeexplore.ieee.org/document/9935309)] |
| BAFL: A Blockchain-Based Asynchronous Federated Learning Framework | | TC | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9399813/)] [[CODE](https://github.com/xuchenhao001/AFL)] |
| L4L: Experience-Driven Computational Resource Control in Federated Learning | | TC | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9384231)] |
| Adaptive Federated Learning on Non-IID Data With Resource Constraint | | TC | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9496155)] |
| Client Scheduling and Resource Management for Efficient Training in Heterogeneous IoT-Edge Federated Learning | ECNU | TCAD | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9530450)] |
| PervasiveFL: Pervasive Federated Learning for Heterogeneous IoT Systems. | ECNU | TCAD | 2022 | PervasiveFL[^PervasiveFL] | [[PUB](https://ieeexplore.ieee.org/document/9925684)] |
| FHDnn: communication efficient and robust federated learning for AIoT networks | UC San Diego | DAC | 2022 | FHDnn[^FHDnn] | [[PUB](https://dl.acm.org/doi/10.1145/3489517.3530394)] |
| A Decentralized Federated Learning Framework via Committee Mechanism With Convergence Guarantee | SYSU | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9870745)] [[PDF](https://arxiv.org/abs/2108.00365)] |
| Improving Federated Learning With Quality-Aware User Incentive and Auto-Weighted Model Aggregation | THU | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9847055)] |
| $f$funcX: Federated Function as a Service for Science. | SUST | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9899739)] [[PDF](https://arxiv.org/abs/2209.11631)] |
| Blockchain Assisted Decentralized Federated Learning (BLADE-FL): Performance Analysis and Resource Allocation | NUST | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9664296)] [[PDF](https://arxiv.org/abs/2101.06905)] [[CODE](https://github.com/ElvisShaoYumeng/BLADE-FL)] |
| Adaptive Federated Deep Reinforcement Learning for Proactive Content Caching in Edge Computing. | CQU | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9868114)] |
| TDFL: Truth Discovery Based Byzantine Robust Federated Learning | BIT | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9887909)] |
| Federated Learning With Nesterov Accelerated Gradient | The University of Sydney | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9891808)] [[PDF](https://arxiv.org/abs/2009.08716)] |
| FedGraph: Federated Graph Learning with Intelligent Sampling | UoA | TPDS | 2022 | FedGraph[^FedGraph] | [[PUB](https://ieeexplore.ieee.org/abstract/document/9606516/)] [[CODE](https://github.com/cfh19980612/FedGraph)] [[解读](https://zhuanlan.zhihu.com/p/442233479)] |
| AUCTION: Automated and Quality-Aware Client Selection Framework for Efficient Federated Learning. | THU | TPDS | 2022 | AUCTION[^AUCTION] | [[PUB](https://ieeexplore.ieee.org/document/9647925)] |
| DONE: Distributed Approximate Newton-type Method for Federated Edge Learning. | University of Sydney | TPDS | 2022 | DONE[^DONE] | [[PUB](https://ieeexplore.ieee.org/document/9695269)] [[PDF](https://arxiv.org/abs/2012.05625)] [[CODE](https://github.com/dual-grp/DONE)] |
| Flexible Clustered Federated Learning for Client-Level Data Distribution Shift. | CQU | TPDS | 2022 | FlexCFL[^FlexCFL] | [[PUB](https://ieeexplore.ieee.org/document/9647969)] [[PDF](https://arxiv.org/abs/2108.09749)] [[CODE](https://github.com/morningd/flexcfl)] |
| Min-Max Cost Optimization for Efficient Hierarchical Federated Learning in Wireless Edge Networks. | Xidian University | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9629331)] |
| LightFed: An Efficient and Secure Federated Edge Learning System on Model Splitting. | CSU | TPDS | 2022 | LightFed[^LightFed] | [[PUB](https://ieeexplore.ieee.org/document/9613755)] |
| On the Benefits of Multiple Gossip Steps in Communication-Constrained Decentralized Federated Learning. | Purdue | TPDS | 2022 | Deli-CoCo[^Deli-CoCo] | [[PUB](https://ieeexplore.ieee.org/document/9664349)] [[PDF](https://arxiv.org/abs/2011.10643)] [[CODE](https://github.com/anishacharya/DeLiCoCo)] |
| Incentive-Aware Autonomous Client Participation in Federated Learning. | Sun Yat-sen University | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9705080)] |
| Communicational and Computational Efficient Federated Domain Adaptation. | HKUST | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9757821)] |
| Decentralized Edge Intelligence: A Dynamic Resource Allocation Framework for Hierarchical Federated Learning. | NTU | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9479786)] |
| Differentially Private Byzantine-Robust Federated Learning. | Qufu Normal University | TPDS | 2022 | DPBFL[^DPBFL] | [[PUB](https://ieeexplore.ieee.org/document/9757841)] |
| Multi-Task Federated Learning for Personalised Deep Neural Networks in Edge Computing. | University of Exeter | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9492755)] [[PDF](https://arxiv.org/abs/2007.09236)] [[CODE](https://github.com/JedMills/MTFL-For-Personalised-DNNs)] |
| Reputation-Aware Hedonic Coalition Formation for Efficient Serverless Hierarchical Federated Learning. | BUAA | TPDS | 2022 | SHFL[^SHFL] | [[PUB](https://ieeexplore.ieee.org/document/9665214)] |
| Differentially Private Federated Temporal Difference Learning. | Stony Brook University | TPDS | 2022 | | [[PUB](https://ieeexplore.ieee.org/document/9645233)] |
| Towards Efficient and Stable K-Asynchronous Federated Learning With Unbounded Stale Gradients on Non-IID Data. | XJTU | TPDS | 2022 | WKAFL[^WKAFL] | [[PUB](https://ieeexplore.ieee.org/document/9712243)] [[PDF](https://arxiv.org/abs/2203.01214)] |
| Communication-Efficient Federated Learning With Compensated Overlap-FedAvg. | SCU | TPDS | 2022 | Overlap-FedAvg[^Overlap-FedAvg] | [[PUB](https://ieeexplore.ieee.org/document/9459540)] [[PDF](https://arxiv.org/abs/2012.06706)] [[CODE](https://github.com/Soptq/Overlap-FedAvg)] |
| PAPAYA: Practical, Private, and Scalable Federated Learning. | Meta AI | MLSys | 2022 | PAPAYA[^PAPAYA] | [[PDF](https://arxiv.org/abs/2111.04877)] [[PUB](https://proceedings.mlsys.org/paper/2022/hash/f340f1b1f65b6df5b5e3f94d95b11daf-Abstract.html)] |
| LightSecAgg: a Lightweight and Versatile Design for Secure Aggregation in Federated Learning | USC | MLSys | 2022 | LightSecAgg[^LightSecAgg] | [[PDF](https://arxiv.org/abs/2109.14236)] [[PUB](https://proceedings.mlsys.org/paper/2022/hash/d2ddea18f00665ce8623e36bd4e3c7c5-Abstract.html)] [[CODE](https://github.com/LightSecAgg/MLSys2022_anonymous)] |
| SAFA: A Semi-Asynchronous Protocol for Fast Federated Learning With Low Overhead | University of Warwick | TC | 2021 | SAFA[^SAFA] | [[PDF](https://arxiv.org/abs/1910.01355)] [[PUB](https://ieeexplore.ieee.org/document/9093123)] [[CODE](https://github.com/wingter562/SAFA)] |
| Efficient Federated Learning for Cloud-Based AIoT Applications | ECNU | TCAD | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9302596)] |
| HADFL: Heterogeneity-aware Decentralized Federated Learning Framework | USTC | DAC | 2021 | HADFL[^HADFL] | [[PDF](https://arxiv.org/abs/2111.08274)] [[PUB](https://ieeexplore.ieee.org/document/9586101)] |
| Helios: Heterogeneity-Aware Federated Learning with Dynamically Balanced Collaboration. | GMU | DAC | 2021 | Helios[^Helios] | [[PDF](https://arxiv.org/abs/1912.01684)] [[PUB](https://ieeexplore.ieee.org/document/9586241)] |
| FedLight: Federated Reinforcement Learning for Autonomous Multi-Intersection Traffic Signal Control. | ECNU | DAC | 2021 | FedLight[^FedLight] | [[PUB](https://ieeexplore.ieee.org/document/9586175)] |
| Oort: Efficient Federated Learning via Guided Participant Selection | University of Michigan | OSDI | 2021 | Oort[^Oort] | [[PUB](https://www.usenix.org/conference/osdi21/presentation/lai)] [[PDF](https://arxiv.org/abs/2010.06081)] [[CODE](https://github.com/SymbioticLab/Oort)] [[SLIDES](https://www.usenix.org/system/files/osdi21_slides_lai.pdf)] [[VIDEO](https://www.youtube.com/watch?v=5npOel4T4Mw)] |
| Towards Efficient Scheduling of Federated Mobile Devices Under Computational and Statistical Heterogeneity. | Old Dominion University | TPDS | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9195793)] [[PDF](https://arxiv.org/abs/2005.12326)] |
| Self-Balancing Federated Learning With Global Imbalanced Data in Mobile Systems. | CQU | TPDS | 2021 | Astraea[^Astraea] | [[PUB](https://ieeexplore.ieee.org/document/9141436)] [[CODE](https://github.com/mtang724/Self-Balancing-Federated-Learning)] |
| An Efficiency-Boosting Client Selection Scheme for Federated Learning With Fairness Guarantee | SCUT | TPDS | 2021 | RBCS-F[^RBCS-F] | [[PUB](https://ieeexplore.ieee.org/document/9272649/)] [[PDF](https://arxiv.org/abs/2011.01783)] [[解读](https://zhuanlan.zhihu.com/p/456101770)] |
| Proof of Federated Learning: A Novel Energy-Recycling Consensus Algorithm. | Beijing Normal University | TPDS | 2021 | PoFL[^PoFL] | [[PUB](https://ieeexplore.ieee.org/document/9347812)] [[PDF](https://arxiv.org/abs/1912.11745)] |
| Biscotti: A Blockchain System for Private and Secure Federated Learning. | UBC | TPDS | 2021 | Biscotti[^Biscotti] | [[PUB](https://ieeexplore.ieee.org/document/9292450)] |
| Mutual Information Driven Federated Learning. | Deakin University | TPDS | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9272656)] |
| Accelerating Federated Learning Over Reliability-Agnostic Clients in Mobile Edge Computing Systems. | University of Warwick | TPDS | 2021 | | [[PUB](https://ieeexplore.ieee.org/document/9272671)] [[PDF](https://arxiv.org/abs/2007.14374)] |
| FedSCR: Structure-Based Communication Reduction for Federated Learning. | HKU | TPDS | 2021 | FedSCR[^FedSCR] | [[PUB](https://ieeexplore.ieee.org/document/9303442)] |
| FedScale: Benchmarking Model and System Performance of Federated Learning :fire: | University of Michigan | SOSP workshop / ICML 2022 | 2021 | FedScale[^FedScale] | [[PUB](https://proceedings.mlr.press/v162/lai22a.html)] [[PDF](https://arxiv.org/abs/2105.11367)] [[CODE](https://github.com/SymbioticLab/FedScale)] [[解读](https://zhuanlan.zhihu.com/p/520020117)] |
| Redundancy in cost functions for Byzantine fault-tolerant federated learning | | SOSP workshop | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3477114.3488761)] |
| Towards an Efficient System for Differentially-private, Cross-device Federated Learning | | SOSP workshop | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3477114.3488762)] |
| GradSec: a TEE-based Scheme Against Federated Learning Inference Attacks | | SOSP workshop | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3477114.3488763)] |
| Community-Structured Decentralized Learning for Resilient EI. | | SOSP workshop | 2021 | | [[PUB](https://dl.acm.org/doi/10.1145/3477114.3488764)] |
| Separation of Powers in Federated Learning (Poster Paper) | IBM Research | SOSP workshop | 2021 | TRUDA[^TRUDA] | [[PUB](https://dl.acm.org/doi/10.1145/3477114.3488765)] [[PDF](https://arxiv.org/abs/2105.09400)] |
| Accelerating Federated Learning via Momentum Gradient Descent. | USTC | TPDS | 2020 | MFL[^MFL] | [[PUB](https://ieeexplore.ieee.org/document/9003425)] [[PDF](https://arxiv.org/abs/1910.03197)] |
| Towards Fair and Privacy-Preserving Federated Deep Models. | NUS | TPDS | 2020 | FPPDL[^FPPDL] | [[PUB](https://ieeexplore.ieee.org/document/9098045)] [[PDF](https://arxiv.org/abs/1906.01167)] [[CODE](https://github.com/lingjuanlv/FPPDL)] |
| Federated Optimization in Heterogeneous Networks :fire: | CMU | MLSys | 2020 | FedProx[^FedProx] | [[PUB](https://proceedings.mlsys.org/paper/2020/hash/38af86134b65d0f10fe33d30dd76442e-Abstract.html)] [[PDF](https://arxiv.org/abs/1812.06127)] [[CODE](https://github.com/litian96/FedProx)] |
| Towards Federated Learning at Scale: System Design | Google | MLSys | 2019 | System_Design[^System_Design] | [[PUB](https://proceedings.mlsys.org/paper/2019/hash/bd686fd640be98efaae0091fa301e613-Abstract.html)] [[PDF](https://arxiv.org/abs/1902.01046)] [[解读](https://zhuanlan.zhihu.com/p/450993635)] |
<!-- END:fl-in-top-system-conference-and-journal -->
# framework
## federated learning framework
### table
*Note: **SG** means Support for Graph data and algorithms, **ST** means Support for Tabular data and algorithms.*
<!-- START:federated-learning-framework -->
|Platform | Papers | Affiliations | SG | ST | Materials|
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------ | ------------------------------------ | ------------------------------------------------------------ |
| [PySyft](https://github.com/OpenMined/PySyft)<br />[](https://github.com/OpenMined/PySyft/stargazers)<br /> | [A generic framework for privacy preserving deep learning](https://arxiv.org/abs/1811.04017) | [OpenMined](https://www.openmined.org/) | | | [[DOC](https://pysyft.readthedocs.io/en/latest/installing.html)] |
| [FATE](https://github.com/FederatedAI/FATE)<br />[](https://github.com/FederatedAI/FATE/stargazers)<br /> | [FATE: An Industrial Grade Platform for Collaborative Learning With Data Protection](https://www.jmlr.org/papers/volume22/20-815/20-815.pdf) | [WeBank](https://fedai.org/) | | :white_check_mark::white_check_mark: | [[DOC](https://fate.readthedocs.io/en/latest/)] [[DOC(ZH)](https://fate.readthedocs.io/en/latest/zh/)] |
| [MindSpore Federated](https://github.com/mindspore-ai/mindspore/tree/master/tests/st/fl)<br />[](https://github.com/mindspore-ai/mindspore/stargazers)<br /> | | HUAWEI | | | [[DOC](https://mindspore.cn/federated/docs/zh-CN/r1.6/index.html)] [[PAGE](https://mindspore.cn/federated)] |
| [FedML](https://github.com/FedML-AI/FedML)<br />[](https://github.com/FedML-AI/FedML/stargazers)<br /> | [FedML: A Research Library and Benchmark for Federated Machine Learning](https://arxiv.org/abs/2007.13518) | [FedML](https://fedml.ai/) | :white_check_mark::white_check_mark: | :white_check_mark: | [[DOC](https://doc.fedml.ai/)] |
| [TFF(Tensorflow-Federated)](https://github.com/tensorflow/federated) <br />[](https://github.com/tensorflow/federated/stargazers)<br /> | [Towards Federated Learning at Scale: System Design](https://arxiv.org/abs/1902.01046) | Google | | | [[DOC](https://www.tensorflow.org/federated)] [[PAGE](https://www.tensorflow.org/federated)] |
| [Flower](https://github.com/adap/flower)<br />[](https://github.com/adap/flower/stargazers)<br /> | [Flower: A Friendly Federated Learning Research Framework](https://arxiv.org/abs/2104.03042.pdf) | [flower.dev](https://flower.dev/) [adap](https://adap.com/en) | | | [[DOC](https://flower.dev/docs/)] |
| [SecretFlow](https://github.com/secretflow/secretflow) <br />[](https://github.com/secretflow/secretflow/stargazers)<br /> | | [Ant group](https://www.antgroup.com/) | | :white_check_mark: | [[DOC](https://secretflow.readthedocs.io/en/latest/getting_started/index.html)] |
| [Fedlearner](https://github.com/bytedance/fedlearner)<br />[](https://github.com/bytedance/fedlearner/stargazers)<br /> | | [Bytedance](https://github.com/bytedance) | | | |
| [FederatedScope](https://github.com/alibaba/FederatedScope)<br />[](https://github.com/alibaba/FederatedScope/stargazers)<br /> | [FederatedScope: A Flexible Federated Learning Platform for Heterogeneity](https://arxiv.org/abs/2204.05011) | [Alibaba DAMO Academy](https://damo.alibaba.com/labs/data-analytics-and-intelligence) | :white_check_mark::white_check_mark: | | [[DOC](https://federatedscope.io/refs/index)] [[PAGE](https://federatedscope.io/)] |
| [LEAF](https://github.com/TalwalkarLab/leaf)<br />[](https://github.com/TalwalkarLab/leaf/stargazers)<br /> | [LEAF: A Benchmark for Federated Settings](https://arxiv.org/abs/1812.01097.pdf) | [CMU](https://leaf.cmu.edu/) | | | |
| [Rosetta](https://github.com/LatticeX-Foundation/Rosetta)<br />[](https://github.com/LatticeX-Foundation/Rosetta/stargazers)<br /> | | [matrixelements](https://www.matrixelements.com/product/rosetta) | | | [[DOC](https://github.com/LatticeX-Foundation/Rosetta/blob/master/doc/DEPLOYMENT.md)] [[PAGE](https://github.com/LatticeX-Foundation/Rosetta)] |
| [PaddleFL](https://github.com/PaddlePaddle/PaddleFL)<br />[](https://github.com/PaddlePaddle/PaddleFL/stargazers)<br /> | | Baidu | | | [[DOC](https://paddlefl.readthedocs.io/en/latest/index.html)] |
| [OpenFL](https://github.com/intel/openfl)<br />[](https://github.com/intel/openfl/stargazers)<br /> | [OpenFL: An open-source framework for Federated Learning](https://arxiv.org/abs/2105.06413) | [Intel](https://github.com/intel) | | | [[DOC](https://openfl.readthedocs.io/en/latest/install.html)] |
| [IBM Federated Learning](https://github.com/IBM/federated-learning-lib)<br />[](https://github.com/IBM/federated-learning-lib/stargazers)<br /> | [IBM Federated Learning: an Enterprise Framework White Paper](https://arxiv.org/abs/2007.10987.pdf) | [IBM](https://github.com/IBM) | | :white_check_mark: | [[PAPERS](https://github.com/IBM/federated-learning-lib/blob/main/docs/papers.md)] |
| [PFL-Non-IID](https://github.com/TsingZ0/PFL-Non-IID)<br />[](https://github.com/TsingZ0/PFL-Non-IID/stargazers)<br /> | | SJTU | | | |
| [KubeFATE](https://github.com/FederatedAI/KubeFATE)<br />[](https://github.com/FederatedAI/KubeFATE/stargazers)<br /> | | [WeBank](https://fedai.org/) | | | [[WIKI](https://github.com/FederatedAI/KubeFATE/wiki/#faqs)] |
| [Fedlab](https://github.com/SMILELab-FL/FedLab)<br />[](https://github.com/SMILELab-FL/FedLab/stargazers)<br /> | [FedLab: A Flexible Federated Learning Framework](https://arxiv.org/abs/2107.11621) | [SMILELab](https://github.com/SMILELab-FL/) | | | [[DOC](https://fedlab.readthedocs.io/en/master/)] [[DOC(ZH)](https://fedlab.readthedocs.io/zh_CN/latest/)] [[PAGE](https://github.com/SMILELab-FL/FedLab-benchmarks)] |
| [Privacy Meter](https://github.com/privacytrustlab/ml_privacy_meter)<br />[](https://github.com/PaddlePaddle/privacytrustlab/ml_privacy_meter)<br /> | [Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning](https://ieeexplore.ieee.org/document/8835245) | University of Massachusetts Amherst | | | |
| [Primihub](https://github.com/primihub/primihub)<br />[](https://github.com/primihub/primihub/stargazers)<br /> | | [primihub](https://github.com/primihub) | | | [[DOC]()] |
| [NVFlare](https://github.com/NVIDIA/NVFlare)<br />[](https://github.com/NVIDIA/NVFlare/stargazers)<br /> | | [NVIDIA](https://github.com/NVIDIA) | | | [[DOC](https://nvflare.readthedocs.io/en/2.1.1/)] |
| [NIID-Bench](https://github.com/Xtra-Computing/NIID-Bench)<br />[](https://github.com/Xtra-Computing/NIID-Bench/stargazers)<br /> | [Federated Learning on Non-IID Data Silos: An Experimental Study](https://arxiv.org/abs/2102.02079.pdf) | [Xtra Computing Group](https://github.com/Xtra-Computing) | | | |
| [Differentially Private Federated Learning: A Client-level Perspective](https://github.com/SAP-samples/machine-learning-diff-private-federated-learning) <br />[](https://github.comSAP-samples/machine-learning-diff-private-federated-learning/stargazers)<br /> | [Differentially Private Federated Learning: A Client Level Perspective](https://arxiv.org/abs/1712.07557) | [SAP-samples](https://github.com/SAP-samples) | | | |
| [FedScale](https://github.com/SymbioticLab/FedScale)<br />[](https://github.com/SymbioticLab/FedScale/stargazers)<br /> | [FedScale: Benchmarking Model and System Performance of Federated Learning at Scale](https://arxiv.org/abs/2105.11367.pdf) | [SymbioticLab(U-M)](https://symbioticlab.org/) | | | |
| [easyFL](https://github.com/WwZzz/easyFL)<br />[](https://github.com/WwZzz/easyFL/stargazers)<br /> | [Federated Learning with Fair Averaging](https://www.ijcai.org/proceedings/2021/223) | XMU | | | |
| [Backdoors 101](https://github.com/ebagdasa/backdoors101)<br />[](https://github.com/ebagdasa/backdoors101/stargazers)<br /> | [Blind Backdoors in Deep Learning Models](https://arxiv.org/abs/2005.03823) | Cornell Tech | | | |
| [FedNLP](https://github.com/FedML-AI/FedNLP)<br />[](https://github.com/FedML-AI/FedNLP/stargazers)<br /> | [FedNLP: Benchmarking Federated Learning Methods for Natural Language Processing Tasks](https://arxiv.org/abs/2104.08815) | [FedML](https://fedml.ai/) | | | |
| [SWARM LEARNING](https://github.com/HewlettPackard/swarm-learning) <br />[](https://github.com/HewlettPackard/swarm-learning/stargazers)<br /> | [Swarm Learning for decentralized and confidential clinical machine learning](https://www.nature.com/articles/s41586-021-03583-3) | | | | [[VIDEO](https://github.com/HewlettPackard/swarm-learning/blob/master/docs/videos.md)] |
| [substra](https://github.com/Substra/substra) <br />[](https://github.com/Substra/substra/stargazers)<br /> | | [Substra](https://github.com/Substra) | | | [[DOC](https://doc.substra.ai/index.html)] |
| [FedJAX](https://github.com/google/fedjax)<br />[](https://github.com/google/fedjax/stargazers)<br /> | [FEDJAX: Federated learning simulation with JAX](https://arxiv.org/abs/2108.02117.pdf) | [Google](https://ai.googleblog.com/2021/10/fedjax-federated-learning-simulation.html) | | | |
| [plato](https://github.com/TL-System/plato)<br />[](https://github.com/TL-System/plato/stargazers)<br /> | | UofT | | | |
| [Xaynet](https://github.com/xaynetwork/xaynet)<br />[](https://github.com/xaynetwork/xaynet/stargazers)<br /> | | [XayNet](https://www.xayn.com/) | | | [[PAGE](https://www.xaynet.dev/)] [[DOC](https://docs.rs/xaynet)] [[WHITEPAPER](https://uploads-ssl.webflow.com/5f0c5c0bb18a279f0a62919e/5f157004da6585f299fa542b_XayNet%20Whitepaper%202.1.pdf)] [[LEGAL REVIEW](https://uploads-ssl.webflow.com/5f0c5c0bb18a279f0a62919e/5fcfa8e3389ecc84a9309513_XAIN%20Legal%20Review%202020%20v1.pdf)] |
| [SyferText](https://github.com/OpenMined/SyferText)<br />[](https://github.com/OpenMined/SyferText/stargazers)<br /> | | [OpenMined](https://www.openmined.org/) | | | |
| [Galaxy Federated Learning](https://github.com/GalaxyLearning/GFL)<br />[](https://github.com/GalaxyLearning/GFL/stargazers)<br /> | [GFL: A Decentralized Federated Learning Framework Based On Blockchain](https://arxiv.org/abs/2010.10996.pdf) | ZJU | | | [[DOC](http://galaxylearning.github.io/)] |
| [FedGraphNN](https://github.com/FedML-AI/FedGraphNN)<br />[](https://github.com/FedML-AI/FedGraphNN/stargazers)<br /> | [FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks](https://arxiv.org/abs/2104.07145) | [FedML](https://fedml.ai/) | :white_check_mark::white_check_mark: | | |
| [FLSim](https://github.com/facebookresearch/FLSim)<br />[](https://github.com/facebookresearch/FLSim/stargazers)<br /> | | [facebook research ](https://github.com/facebookresearch) | | | |
| [PyVertical ](https://github.com/OpenMined/PyVertical)<br />[](https://github.com/OpenMined/PyVertical/stargazers)<br /> | [PyVertical: A Vertical Federated Learning Framework for Multi-headed SplitNN](https://arxiv.org/abs/2104.00489.pdf) | [OpenMined](https://www.openmined.org/) | | | |
| [Breaching](https://github.com/JonasGeiping/breaching)<br />[](https://github.com/JonasGeiping/breaching/stargazers)<br /> | A Framework for Attacks against Privacy in Federated Learning ([papers](https://github.com/JonasGeiping/breaching)) | | | | |
| [FedTorch](https://github.com/MLOPTPSU/FedTorch) <br />[](https://github.com/MLOPTPSU/FedTorch/stargazers)<br /> | [Distributionally Robust Federated Averaging](https://papers.nips.cc/paper/2020/file/ac450d10e166657ec8f93a1b65ca1b14-Paper.pdf) | Penn State | | | |
| [EasyFL](https://github.com/EasyFL-AI/EasyFL)<br />[](https://github.com/EasyFL-AI/EasyFL/stargazers)<br /> | [EasyFL: A Low-code Federated Learning Platform For Dummies](https://ieeexplore.ieee.org/abstract/document/9684558) | NTU | | | |
| [PhotoLabeller](https://github.com/mccorby/PhotoLabeller)<br />[](https://github.com/mccorby/PhotoLabeller/stargazers)<br /> | | | | | [[BLOG](https://proandroiddev.com/federated-learning-e79e054c33ef)] |
| [FLUTE](https://github.com/microsoft/msrflute)<br />[](https://github.com/microsoft/msrflute/stargazers)<br /> | [FLUTE: A Scalable, Extensible Framework for High-Performance Federated Learning Simulations](https://arxiv.org/abs/2203.13789) | microsoft | | | [[DOC](https://microsoft.github.io/msrflute/)] |
| [FATE-Serving](https://github.com/FederatedAI/FATE-Serving) <br />[](https://github.com/FederatedAI/FATE-Serving/stargazers)<br /> | | [WeBank](https://fedai.org/) | | | [[DOC](https://fate-serving.readthedocs.io/en/develop/)] |
| [FLSim](https://github.com/iQua/flsim) <br />[](https://github.com/iQua/flsim/stargazers)<br /> | [Optimizing Federated Learning on Non-IID Data with Reinforcement Learning](https://ieeexplore.ieee.org/document/9155494/) | University of Toronto | | | |
| [PriMIA](https://github.com/gkaissis/PriMIA)<br />[](https://github.com/gkaissis/PriMIA/stargazers)<br /> | [End-to-end privacy preserving deep learning on multi-institutional medical imaging](https://www.nature.com/articles/s42256-021-00337-8) | [TUM](https://www.tum.de/en/); Imperial College London; [OpenMined](https://www.openmined.org) | | | [[DOC](https://g-k.ai/PriMIA/)] |
| [9nfl](https://github.com/jd-9n/9nfl)<br />[](https://github.com/jd-9n/9nfl/stargazers)<br /> | | JD | | | |
| [FedLearn](https://github.com/fedlearnAI/fedlearn-algo)<br />[](https://github.com/fedlearnAI/fedlearn-algo/stargazers)<br /> | [Fedlearn-Algo: A flexible open-source privacy-preserving machine learning platform](https://arxiv.org/abs/2107.04129) | JD | | | |
| [FedTree](https://github.com/Xtra-Computing/FedTree)<br />[](https://github.com/Xtra-Computing/FedTree/stargazers)<br /> | | [Xtra Computing Group](https://github.com/Xtra-Computing) | | :white_check_mark::white_check_mark: | [[DOC](https://fedtree.readthedocs.io/en/latest/index.html)] |
| [FEDn](https://github.com/scaleoutsystems/fedn)<br />[](https://github.com/scaleoutsystems/fedn/stargazers)<br /> | [Scalable federated machine learning with FEDn](https://arxiv.org/abs/2103.00148) | [scaleoutsystems](http://www.scaleoutsystems.com) | | | [[DOC](https://scaleoutsystems.github.io/fedn/)] |
| [FedCV](https://github.com/FedML-AI/FedCV)<br />[](https://github.com/FedML-AI/FedCV/stargazers)<br /> | [FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks](https://arxiv.org/abs/2111.11066) | FedML | | | |
| [MPLC](https://github.com/LabeliaLabs/distributed-learning-contributivity)<br />[](https://github.com/LabeliaLabs/distributed-learning-contributivity/stargazers)<br /> | | [LabeliaLabs](https://github.com/LabeliaLabs) | | | [[PAGE](https://www.labelia.org)] |
| [FeTS](https://github.com/FETS-AI/Front-End)<br />[](https://github.com/FETS-AI/Front-End/stargazers)<br /> | [The federated tumor segmentation (FeTS) tool: an open-source solution to further solid tumor research](http://iopscience.iop.org/article/10.1088/1361-6560/ac9449) | [Federated Tumor Segmentation (FeTS) initiative](https://www.med.upenn.edu/cbica/fets/) | | | [[DOC](https://fets-ai.github.io/Front-End/)] |
| [OpenHealth](https://github.com/QibingLee/OpenHealth) <br />[](https://github.com/QibingLee/OpenHealth/stargazers)<br /> | | ZJU | | | |
| [UCADI](https://github.com/HUST-EIC-AI-LAB/UCADI) <br />[](https://github.com/HUST-EIC-AI-LAB/UCADI/stargazers)<br /> | [Advancing COVID-19 diagnosis with privacy-preserving collaboration in artificial intelligence](https://www.nature.com/articles/s42256-021-00421-z) | Huazhong University of Science and Technology | | | |
| [OpenFed](https://github.com/FederalLab/OpenFed/)<br />[](https://github.com/FederalLab/OpenFed/stargazers)<br /> | [OpenFed: A Comprehensive and Versatile Open-Source Federated Learning Framework](https://arxiv.org/abs/2109.07852) | | | | [[DOC](https://openfed.readthedocs.io/README.html)] |
| [APPFL](https://github.com/APPFL/APPFL)<br />[](https://github.com/APPFL/APPFL/stargazers)<br /> | | | | | [[DOC](https://appfl.readthedocs.io/en/stable/)] |
| [FedGroup](https://github.com/morningD/GrouProx)<br />[](https://github.com/morningD/GrouProx/stargazers)<br /> | [FedGroup: Efficient Clustered Federated Learning via Decomposed Data-Driven Measure](https://arxiv.org/abs/2010.06870) | Chongqing University | | | |
| [Flame](https://github.com/cisco-open/flame)<br />[](https://github.com/cisco-open/flame/stargazers)<br /> | | Cisco | | | [[DOC](https://fedsim.varnio.com/en/latest/)] |
| [FlexCFL](https://github.com/morningD/FlexCFL)<br />[](https://github.com/morningD/FlexCFL/stargazers)<br /> | [Flexible Clustered Federated Learning for Client-Level Data Distribution Shift](https://arxiv.org/abs/2108.09749) | Chongqing University | | | |
| [FedEval](https://github.com/Di-Chai/FedEval)<br />[](https://github.com/Di-Chai/FedEval/stargazers)<br /> | [FedEval: A Benchmark System with a Comprehensive Evaluation Model for Federated Learning](https://arxiv.org/abs/2011.09655) | HKU | | | [[DOC](https://di-chai.github.io/FedEval/)] |
| [FedSim](https://github.com/varnio/fedsim)<br />[](https://github.com/varnio/fedsim/stargazers)<br /> | | | | | |
| [Federated-Learning-source](https://github.com/MTC-ETH/Federated-Learning-source) <br />[](https://github.com/MTC-ETH/Federated-Learning-source/stargazers)<br /> | [A Practical Federated Learning Framework for Small Number of Stakeholders](https://dl.acm.org/doi/10.1145/3437963.3441702) | ETH Zürich | | | [[DOC](https://github.com/MTC-ETH/Federated-Learning-source/blob/master/dashboard/README.md)] |
| [Clara](https://developer.nvidia.com/clara) | | NVIDIA | | | |
<!-- END:federated-learning-framework -->
### benchmark
- UniFed leaderboard
Here's a really great Benchmark for the federated learning open source framework :+1: [UniFed leaderboard](https://unifedbenchmark.github.io/leaderboard/index.html), which present both qualitative and quantitative evaluation results of existing popular open-sourced FL frameworks, from the perspectives of **functionality, usability, and system performance**.
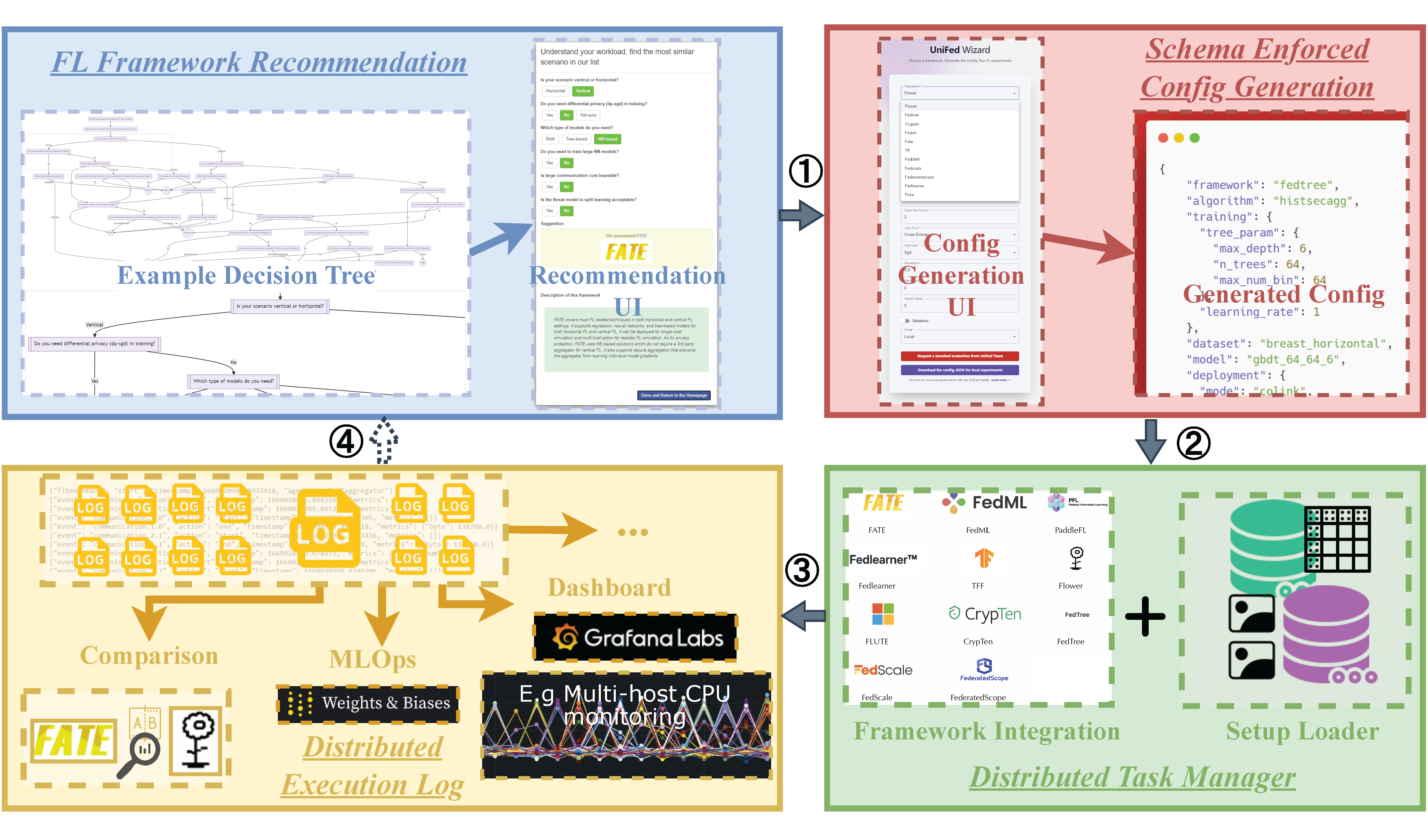

For more results, please refer to [Framework Functionality Support](https://unifedbenchmark.github.io/leaderboard/index.html)
# datasets
## graph datasets
## tabular datasets
## fl datasets
- [LEAF](https://leaf.cmu.edu/)
- [Federated AI Dataset](https://dataset.fedai.org/#/)
# surveys
This section partially refers to repository [Federated-Learning](https://github.com/lokinko/Federated-Learning) and [FederatedAI research](https://github.com/FederatedAI/research#survey) , the order of the surveys is arranged in reverse order according to the time of first submission (the latest being placed at the top)
- [SIGKDD Explor. 2022] Federated Graph Machine Learning: A Survey of Concepts, Techniques, and Applications [PUB](https://dl.acm.org/doi/10.1145/3575637.3575644) [PDF](https://arxiv.org/abs/2207.11812)
- [ACM Trans. Interact. Intell. Syst.] Toward Responsible AI: An Overview of Federated Learning for User-centered Privacy-preserving Computing [[PUB](https://dl.acm.org/doi/abs/10.1145/3485875)]
- [ICML Workshop 2020] SECure: A Social and Environmental Certificate for AI Systems [PDF](https://arxiv.org/abs/2006.06217)
- [IEEE Commun. Mag. 2020] From Federated Learning to Fog Learning: Towards Large-Scale Distributed Machine Learning in Heterogeneous Wireless Networks [PDF](https://arxiv.org/abs/2006.03594) [[PUB](https://ieeexplore.ieee.org/document/9311906)]
- [China Communications 2020] Federated Learning for 6G Communications: Challenges, Methods, and Future Directions [PDF](https://arxiv.org/abs/2006.02931) [[PUB](https://ieeexplore.ieee.org/document/9205981).]
- [Federated Learning Systems] A Review of Privacy Preserving Federated Learning for Private IoT Analytics [PDF](https://arxiv.org/abs/2004.11794) [[PUB](https://link.springer.com/chapter/10.1007/978-3-030-70604-3_2)]
- [WorldS4 2020] Survey of Personalization Techniques for Federated Learning [PDF](https://arxiv.org/abs/2003.08673) [[PUB](https://ieeexplore.ieee.org/document/9210355)]
- Towards Utilizing Unlabeled Data in Federated Learning: A Survey and Prospective [PDF](https://arxiv.org/abs/2002.11545)
- [IEEE Internet Things J. 2022] A Survey on Federated Learning for Resource-Constrained IoT Devices [PDF](https://arxiv.org/abs/2002.10610) [[PUB](https://ieeexplore.ieee.org/document/9475501/)]
- [IEEE Communications Surveys & Tutorials 2020] Communication-Efficient Edge AI: Algorithms and Systems [PDF](http://arxiv.org/abs/2002.09668) [[PUB](https://ieeexplore.ieee.org/document/9134426)]
- [IEEE Communications Surveys & Tutorials 2020] Federated Learning in Mobile Edge Networks: A Comprehensive Survey [PDF](https://arxiv.org/abs/1909.11875) [[PUB](https://ieeexplore.ieee.org/document/9060868)]
- [IEEE Signal Process. Mag. 2020] Federated Learning: Challenges, Methods, and Future Directions [PDF](https://arxiv.org/abs/1908.07873) [[PUB](https://ieeexplore.ieee.org/document/9084352)]
- [IEEE Commun. Mag. 2020] Federated Learning for Wireless Communications: Motivation, Opportunities and Challenges [PDF](https://arxiv.org/abs/1908.06847) [[PUB](https://ieeexplore.ieee.org/document/9141214)]
- [IEEE TKDE 2021] A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection [PDF](https://arxiv.org/abs/1907.09693) [[PUB](https://ieeexplore.ieee.org/document/9599369)]
- [IJCAI Workshop 2020] Threats to Federated Learning: A Survey [PDF](https://arxiv.org/abs/2003.02133)
- [Foundations and Trends in Machine Learning 2021] Advances and Open Problems in Federated Learning [PDF](https://arxiv.org/abs/1912.04977) [[PUB](https://www.nowpublishers.com/article/Details/MAL-083)]
- Privacy-Preserving Blockchain Based Federated Learning with Differential Data Sharing [PDF](https://arxiv.org/abs/1912.04859)
- An Introduction to Communication Efficient Edge Machine Learning [PDF](https://arxiv.org/abs/1912.01554)
- [IEEE Communications Surveys & Tutorials 2020] Convergence of Edge Computing and Deep Learning: A Comprehensive Survey [PDF](https://arxiv.org/abs/1907.08349) [[PUB](https://ieeexplore.ieee.org/document/8976180)]
- [IEEE TIST 2019] Federated Machine Learning: Concept and Applications [PDF](https://arxiv.org/abs/1902.04885) [[PUB](https://dl.acm.org/doi/10.1145/3298981)]
- [J. Heal. Informatics Res. 2021] Federated Learning for Healthcare Informatics [PDF](https://arxiv.org/abs/1911.06270) [[PUB](https://link.springer.com/article/10.1007/s41666-020-00082-4)]
- Federated Learning for Coalition Operations [PDF](https://arxiv.org/abs/1910.06799)
- No Peek: A Survey of private distributed deep learning [PDF](https://arxiv.org/abs/1812.03288)
# tutorials and courses
## tutorials
- [联邦学习入门教程参考](https://docs.qq.com/doc/DVUxDVkd4b0FXdUpK)
- [NeurIPS 2020] Federated Learning Tutorial [[Web\]](https://sites.google.com/view/fl-tutorial/) [[Slides\]](https://drive.google.com/file/d/1QGY2Zytp9XRSu95fX2lCld8DwfEdcHCG/view) [[Video\]](https://slideslive.com/38935813/federated-learning-tutorial)
- [Federated Learning on MNIST using a CNN](https://colab.research.google.com/drive/1dRG3yNAlDar3tll4VOkmoU-aLslhUS8d), AI6101, 2020 ([Demo Video](https://www.youtube.com/watch?v=XKQi-CUqCsM))
- [AAAI 2019] [Federated Learning: User Privacy, Data Security and Confidentiality in Machine Learning](https://aaai.org/Conferences/AAAI-19/aaai19tutorials/)
- [Applied Cryptography](https://www.udacity.com/course/applied-cryptography--cs387)
- [A Brief Introduction to Differential Privacy](https://medium.com/georgian-impact-blog/a-brief-introduction-to-differential-privacy-eacf8722283b)
- [Deep Learning with Differential Privacy.](http://doi.acm.org/10.1145/2976749.2978318)
- [Building Safe A.I.](http://iamtrask.github.io/2017/03/17/safe-ai/)
* A Tutorial for Encrypted Deep Learning
* Use Homomorphic Encryption (HE)
- [Private Image Analysis with MPC](https://mortendahl.github.io/2017/09/19/private-image-analysis-with-mpc/)
* Training CNNs on Sensitive Data
* Use SPDZ as MPC protocol
- [Private Deep Learning with MPC](https://mortendahl.github.io/2017/04/17/private-deep-learning-with-mpc/)
* A Simple Tutorial from Scratch
* Use Multiparty Compuation (MPC)
## course
### secret sharing
* [Simple Introduction to Sharmir's Secret Sharing and Lagrange Interpolation](https://www.youtube.com/watch?v=kkMps3X_tEE)
* Secret Sharing
* [ Part 1](https://mortendahl.github.io/2017/06/04/secret-sharing-part1/): Shamir's Secret Sharing & Packed Variant
* [Part 2](https://mortendahl.github.io/2017/06/24/secret-sharing-part2/): Improve efficiency
* [Part 3](https://mortendahl.github.io/2017/08/13/secret-sharing-part3/): Robust Reconstruction
# key conferences/workshops/journals
This section partially refers to [The Federated Learning Portal](https://federated-learning.org/).
## workshops
- [[CIKM'22](https://sites.google.com/view/fedgraph2022/home)] The 1st International Workshop on Federated Learning with Graph Data (FedGraph), Atlanta, GA, USA
- [[AI Technology School 2022](https://aitechnologyschool.github.io/)] Trustable, Verifiable and Auditable Artificial Intelligence, Singapore
- [[FL-NeurIPS'22](http://federated-learning.org/fl-neurips-2022/)] International Workshop on Federated Learning: Recent Advances and New Challenges in Conjunction with NeurIPS 2022 , New Orleans, LA, USA
- [[FL-IJCAI'22](http://federated-learning.org/fl-ijcai-2022/)] International Workshop on Trustworthy Federated Learning in Conjunction with IJCAI 2022, Vienna, Austria
- [[FL-AAAI-22](http://federated-learning.org/fl-aaai-2022/)] International Workshop on Trustable, Verifiable and Auditable Federated Learning in Conjunction with AAAI 2022, Vancouver, BC, Canada (Virtual)
- [[FL-NeurIPS'21](https://neurips2021workshopfl.github.io/NFFL-2021/)] New Frontiers in Federated Learning: Privacy, Fairness, Robustness, Personalization and Data Ownership, (Virtual)
- [[The Federated Learning Workshop, 2021](https://sites.google.com/view/federatedlearning-workshop/home)] , Paris, France (Hybrid)
- [[PDFL-EMNLP'21](https://pdfl.iais.fraunhofer.de/)] Workshop on Parallel, Distributed, and Federated Learning, Bilbao, Spain (Virtual)
- [[FTL-IJCAI'21](https://federated-learning.org/fl-ijcai-2021/)] International Workshop on Federated and Transfer Learning for Data Sparsity and Confidentiality in Conjunction with IJCAI 2021, Montreal, QB, Canada (Virtual)
- [[DeepIPR-IJCAI'21](http://federated-learning.org/DeepIPR-IJCAI-2021/)] Toward Intellectual Property Protection on Deep Learning as a Services, Montreal, QB, Canada (Virtual)
- [[FL-ICML'21](http://federated-learning.org/fl-icml-2021/)] International Workshop on Federated Learning for User Privacy and Data Confidentiality, (Virtual)
- [[RSEML-AAAI-21](http://federated-learning.org/rseml2021)] Towards Robust, Secure and Efficient Machine Learning, (Virtual)
- [[NeurIPS-SpicyFL'20](http://icfl.cc/SpicyFL/2020)] Workshop on Scalability, Privacy, and Security in Federated Learning, Vancouver, BC, Canada (Virtual)
- [[FL-IJCAI'20](http://fl-ijcai20.federated-learning.org/)] International Workshop on Federated Learning for User Privacy and Data Confidentiality, Yokohama, Japan (Virtual)
- [[FL-ICML'20](http://federated-learning.org/fl-icml-2020/)] International Workshop on Federated Learning for User Privacy and Data Confidentiality, Vienna, Austria (Virtual)
- [[FL-IBM'20](https://federated-learning.bitbucket.io/ibm2020/)] Workshop on Federated Learning and Analytics, New York, NY, USA
- [[FL-NeurIPS'19](http://federated-learning.org/fl-neurips-2019/)] Workshop on Federated Learning for Data Privacy and Confidentiality (in Conjunction with NeurIPS 2019), Vancouver, BC, Canada
- [[FL-IJCAI'19](http://federated-learning.org/fl-ijcai-2019/)] International Workshop on Federated Learning for User Privacy and Data Confidentiality
in Conjunction with IJCAI 2019, Macau
- [[FL-Google'19](https://sites.google.com/view/federated-learning-2019/home)] Workshop on Federated Learning and Analytics, Seattle, WA, USA
## journal special issues
- [Special Issue on Trustable, Verifiable, and Auditable Federated Learning](https://www.computer.org/digital-library/journals/bd/call-for-papers-special-issue-on-trustable-verifiable-and-auditable-federated-learning), *IEEE Transactions on Big Data (TBD)*, 2022.
- [Special Issue on Federated Learning: Algorithms, Systems, and Applications](https://dl.acm.org/pb-assets/static_journal_pages/tist/cfps/tist-si-cfp-12-2020-federated-learning-extended2-1617161513293.pdf), *ACM Transactions on Intelligent Systems and Technology (TIST)*, 2021.
- [Special Issue on Federated Machine Learning](https://www.computer.org/digital-library/magazines/ex/call-for-papers-federated-machine-learning), *IEEE Intelligent Systems (IS)*, 2019.
## conference special tracks
- "Federated Learning" included as a new keyword in [IJCAI'20](https://ijcai20.org/), Yokohama, Japan
- [Special Track on Federated Machine Learning](http://federated-learning.org/fl-ieeebigdata-2019/), *IEEE BigData'19*, Los Angeles, CA, USA
## update log

- *2023/01/14 - add UAI 2022 papers, refresh system (TCAD +1, TPDS+8), ML (TPAMI +1,UAI +6), network(MobiCom +3) fields papers*
- *2022/11/24 - refresh NeurIPS 2022,2021 and ICLR 2022 papers*
- *2022/11/06- add S&P 2023 papers*
- *2022/10/29 - add WSDM 2023 paper*
- *2022/10/20 - add CCS, MM, ECCV 2022 papers*
- *2022/10/16 - add AI, JMLR, TPAMI, IJCV, TOCS, TOS, TCAD, TC papers*
- *2022/10/13 - add DAC papers*
- *2022/10/09 - add MobiCom 2022 paper*
- *2022/09/19 - add NeurIPS 2022 papers*
- *2022/09/16 - repository is online with [Github Pages](https://youngfish42.github.io/Awesome-Federated-Learning-on-Graph-and-Tabular-Data/)*
- *2022/09/06 - add information about FL on Tabular and Graph data*
- *2022/09/05 - add some information about top journals and add TPDS papers*
- *2022/08/31 - all papers (including 400+ papers from top conferences and top journals and 100+ papers with graph and tabular data) have been comprehensively sorted out, and information such as publication addresses, links to preprints and source codes of these papers have been compiled. The source code of 280+ papers has been obtained. We hope it can help those who use this project.* :smiley:
- *2022/07/31 - add VLDB papers*
- *2022/07/30 - add top-tier system conferences papers and add COLT,UAI,OSDI, SOSP, ISCA, MLSys, AISTATS,WSDM papers*
- *2022/07/28 - add a list of top-tier conferences papers and add IJCAI,SIGIR,SIGMOD,ICDE,WWW,SIGCOMM.INFOCOM,WWW papers*
- *2022/07/27 - add some ECCV 2022 papers*
- *2022/07/22 - add CVPR 2022 and MM 2020,2021 papers*
- *2022/07/21 - give TL;DR and interpret information(解读) of papers. And add KDD 2022 papers*
- *2022/07/15 - give a list of papers in the field of federated learning in top NLP/Secure conferences. And add ICML 2022 papers*
- *2022/07/14 - give a list of papers in the field of federated learning in top ML/CV/AI/DM conferences from [innovation-cat](https://github.com/innovation-cat)‘s [Awesome-Federated-Machine-Learning](https://github.com/innovation-cat/Awesome-Federated-Machine-Learning) and find :fire: papers(code is available & stars >= 100)*
- *2022/07/12 - added information about the last commit time of the federated learning open source framework (can be used to determine the maintenance of the code base)*
- *2022/07/12 - give a list of papers in the field of federated learning in top journals*
- *2022/05/25 - complete the paper and code lists of FL on tabular data and Tree algorithms*
- *2022/05/25 - add the paper list of FL on tabular data and Tree algorithms*
- *2022/05/24 - complete the paper and code lists of FL on graph data and Graph Neural Networks*
- *2022/05/23 - add the paper list of FL on graph data and Graph Neural Networks*
- *2022/05/21 - update all of Federated Learning Framework*
## how to contact us
**More items will be added to the repository**. Please feel free to suggest other key resources by opening an [issue](https://github.com/youngfish42/Awesome-Federated-Learning-on-Graph-and-Tabular-Data/issues) report, submitting a pull request, or dropping me an email @ ([[email protected]](mailto:[email protected])). Enjoy reading!
## acknowledgments
Many thanks :heart: to the other awesome list:
- Federated Learning
- [Awesome-Federated-Learning-on-Graph-and-GNN-papers](https://github.com/huweibo/Awesome-Federated-Learning-on-Graph-and-GNN-papers)
- [Awesome-GNN-Research](https://github.com/XunKaiLi/Awesome-GNN-Research)
- [Awesome-Federated-Machine-Learning](https://github.com/innovation-cat/Awesome-Federated-Machine-Learning)
- [Awesome-Federated-Learning](https://github.com/chaoyanghe/Awesome-Federated-Learning)
- [awesome-federated-learning](https://github.com/weimingwill/awesome-federated-learning)
- [Federated-Learning](https://github.com/lokinko/Federated-Learning)
- [FederatedAI research](https://github.com/FederatedAI/research)
- [FLsystem-paper](https://github.com/AmberLJC/FLsystem-paper)
- [Federated Learning Framework Benchmark (UniFed)](https://github.com/AI-secure/FLBenchmark-toolkit)
- [awesome-privacy-chinese](https://github.com/international-explore/awesome-privacy-chinese)
- Other fields
- [anomaly-detection-resources](https://github.com/yzhao062/anomaly-detection-resources)
- [awesome-image-registration](https://github.com/Awesome-Image-Registration-Organization/awesome-image-registration)
## citation
```text
@misc{awesomeflGTD,
title = {Awesome-Federated-Learning-on-Graph-and-Tabular-Data},
author = {Yuwen Yang, Bingjie Yan, Xuefeng Jiang, Hongcheng Li, Jian Wang, Jiao Chen, Xiangmou Qu, Chang Liu and others},
year = {2022},
howpublished = {\\url{https://github.com/youngfish42/Awesome-Federated-Learning-on-Graph-and-Tabular-Data}
}
```
[<img src="https://rf.revolvermaps.com/h/m/a/0/ff0000/80/35/5zw06d5f905.png" alt="map" style="zoom:1%;" />](https://www.revolvermaps.com/livestats/5zw06d5f905/)
<script type="text/javascript" src="//rf.revolvermaps.com/0/0/8.js?i=5zw06d5f905&m=6&c=ff0000&cr1=ffffff&f=arial&l=33" async="async"></script>
<!-- START:reference-section -->
[^HetVis]: A visual analytics tool, HetVis, for participating clients to explore data heterogeneity. We identify data heterogeneity through comparing prediction behaviors of the global federated model and the stand-alone model trained with local data. Then, a context-aware clustering of the inconsistent records is done, to provide a summary of data heterogeneity. Combining with the proposed comparison techniques, we develop a novel set of visualizations to identify heterogeneity issues in HFL(Horizontal federated learning). 可视化分析工具Het Vis,用于参与客户探索数据异质性。我们通过比较全局联邦模型和使用本地数据训练的单机模型的预测行为来识别数据异构性。然后,对不一致记录进行上下文感知的聚类,以提供数据异质性的总结。结合所提出的比较技术,我们开发了一套新颖的可视化来识别HFL(横向联邦学习)中的异质性问题。
[^FedStar]: From real-world graph datasets, we observe that some structural properties are shared by various domains, presenting great potential for sharing structural knowledge in FGL. Inspired by this, we propose FedStar, an FGL framework that extracts and shares the common underlying structure information for inter-graph federated learning tasks. To explicitly extract the structure information rather than encoding them along with the node features, we define structure embeddings and encode them with an independent structure encoder. Then, the structure encoder is shared across clients while the feature-based knowledge is learned in a personalized way, making FedStar capable of capturing more structure-based domain-invariant information and avoiding feature misalignment issues. We perform extensive experiments over both cross-dataset and cross-domain non-IID FGL settings. 从现实世界的图数据集中,我们观察到一些结构属性被不同的领域所共享,这为联邦图机器学习中共享结构知识提供了巨大的潜力。受此启发,我们提出了FedStar,一个为图间联合学习任务提取和分享共同基础结构信息的FGL框架。为了明确地提取结构信息,而不是将其与节点特征一起编码,我们定义了结构嵌入,并用一个独立的结构编码器对其进行编码。然后,结构编码器在客户之间共享,而基于特征的知识则以个性化的方式学习,这使得FedStar能够捕获更多基于结构的领域变量信息,并避免了特征错位问题。我们在跨数据集和跨域的非IID FGL设置上进行了广泛的实验。
[^FedGS]: Federated Graph-based Sampling (FedGS) to stabilize the global model update and mitigate the long-term bias given arbitrary client availability simultaneously. First, we model the data correlations of clients with a Data-Distribution-Dependency Graph (3DG) that helps keep the sampled clients data apart from each other, which is theoretically shown to improve the approximation to the optimal model update. Second, constrained by the far-distance in data distribution of the sampled clients, we further minimize the variance of the numbers of times that the clients are sampled, to mitigate long-term bias. 基于图的联合采样(Federated Graph-based Sampling,FedGS)稳定了全局模型的更新,并同时减轻了任意客户端可用性的长期偏差。首先,我们用数据分布-依赖图(3DG)对客户的数据相关性进行建模,这有助于使被采样的客户数据相互分离,理论上证明这可以提高对最佳模型更新的近似度。其次,受制于被抽样客户数据分布的远距离,我们进一步将客户被抽样次数的方差降到最低,以减轻长期偏差。
[^FL-GMT]: TBC
[^FedWalk]: FedWalk, a random-walk-based unsupervised node embedding algorithm that operates in such a node-level visibility graph with raw graph information remaining locally. FedWalk,一个基于随机行走的无监督节点嵌入算法,在这样一个节点级可见度图中操作,原始图信息保留在本地。
[^FederatedScope-GNN]: FederatedScope-GNN present an easy-to-use FGL (federated graph learning) package. FederatedScope-GNN提出了一个易于使用的FGL(联邦图学习)软件包。
[^GAMF]: GAMF formulate the model fusion problem as a graph matching task, considering the second-order similarity of model weights instead of previous work merely formulating model fusion as a linear assignment problem. For the rising problem scale and multi-model consistency issues, GAMF propose an efficient graduated assignment-based model fusion method, iteratively updates the matchings in a consistency-maintaining manner. GAMF将模型融合问题表述为图形匹配任务,考虑了模型权重的二阶相似性,而不是之前的工作仅仅将模型融合表述为一个线性赋值问题。针对问题规模的扩大和多模型的一致性问题,GAMF提出了一种高效的基于分级赋值的模型融合方法,以保持一致性的方式迭代更新匹配结果。
[^MaKEr]: We study the knowledge extrapolation problem to embed new components (i.e., entities and relations) that come with emerging knowledge graphs (KGs) in the federated setting. In this problem, a model trained on an existing KG needs to embed an emerging KG with unseen entities and relations. To solve this problem, we introduce the meta-learning setting, where a set of tasks are sampled on the existing KG to mimic the link prediction task on the emerging KG. Based on sampled tasks, we meta-train a graph neural network framework that can construct features for unseen components based on structural information and output embeddings for them. 我们研究了知识外推问题,以嵌入新的组件(即实体和关系),这些组件来自于联邦设置的新兴知识图(KGs)。在这个问题上,一个在现有KG上训练的模型需要嵌入一个带有未见过的实体和关系的新兴KG。为了解决这个问题,我们引入了元学习设置,在这个设置中,一组任务在现有的KG上被抽样,以模拟新兴KG上的链接预测任务。基于抽样任务,我们对图神经网络框架进行元训练,该框架可以根据结构信息为未见过的组件构建特征,并为其输出嵌入。
[^SFL]: A novel structured federated learning (SFL) framework to enhance the knowledge-sharing process in PFL by leveraging the graph-based structural information among clients and learn both the global and personalized models simultaneously using client-wise relation graphs and clients' private data. We cast SFL with graph into a novel optimization problem that can model the client-wise complex relations and graph-based structural topology by a unified framework. Moreover, in addition to using an existing relation graph, SFL could be expanded to learn the hidden relations among clients. 一个新的结构化联邦学习(SFL)框架通过利用客户之间基于图的结构信息来加强PFL中的知识共享过程,并使用客户的关系图和客户的私人数据同时学习全局和个性化的模型。我们把带图的SFL变成一个新的优化问题,它可以通过一个统一的框架对客户的复杂关系和基于图的结构拓扑进行建模。此外,除了使用现有的关系图之外,SFL还可以扩展到学习客户之间的隐藏关系。
[^VFGNN]: VFGNN, a federated GNN learning paradigm for privacy-preserving node classification task under data vertically partitioned setting, which can be generalized to existing GNN models. Specifically, we split the computation graph into two parts. We leave the private data (i.e., features, edges, and labels) related computations on data holders, and delegate the rest of computations to a semi-honest server. We also propose to apply differential privacy to prevent potential information leakage from the server. VFGNN是一种联邦的GNN学习范式,适用于数据纵向分割情况下的隐私保护节点分类任务,它可以被推广到现有的GNN模型。具体来说,我们将计算图分成两部分。我们将私有数据(即特征、边和标签)相关的计算留给数据持有者,并将其余的计算委托给半诚实的服务器。我们还提议应用差分隐私来防止服务器的潜在信息泄露。
[^SpreadGNN]: SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. We provide convergence guarantees and empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. SpreadGNN首次提出一个新颖的多任务联邦训练框架,能够在存在部分标签和没有中央服务器的情况下运行。我们提供了收敛保证,并在各种具有部分标签的非I.I.D.分布式图级分子特性预测数据集上实证了我们框架的功效。我们的研究结果表明,SpreadGNN优于通过依赖中央服务器的联邦学习系统训练的GNN模型,即使在受限的拓扑结构中也是如此。
[^FedGraph]: FedGraph for federated graph learning among multiple computing clients, each of which holds a subgraph. FedGraph provides strong graph learning capability across clients by addressing two unique challenges. First, traditional GCN training needs feature data sharing among clients, leading to risk of privacy leakage. FedGraph solves this issue using a novel cross-client convolution operation. The second challenge is high GCN training overhead incurred by large graph size. We propose an intelligent graph sampling algorithm based on deep reinforcement learning, which can automatically converge to the optimal sampling policies that balance training speed and accuracy. FedGraph 用于多个计算客户端之间的联邦图学习,每个客户端都有一个子图。FedGraph通过解决两个独特的挑战,跨客户端提供了强大的图形学习能力。首先,传统的GCN训练需要在客户之间进行功能数据共享,从而导致隐私泄露的风险。FedGraph使用一种新的跨客户端卷积操作来解决了这个问题。第二个挑战是大图所产生的高GCN训练开销。提出了一种基于深度强化学习的智能图采样算法,该算法可以自动收敛到最优的平衡训练速度和精度的采样策略。
[^FGML]: FGML a comprehensive review of the literature in Federated Graph Machine Learning. FGML 对图联邦机器学习的文献进行了全面回顾的综述文章。
[^FedNI]: FedNI, to leverage network inpainting and inter-institutional data via FL. Specifically, we first federatively train missing node and edge predictor using a graph generative adversarial network (GAN) to complete the missing information of local networks. Then we train a global GCN node classifier across institutions using a federated graph learning platform. The novel design enables us to build more accurate machine learning models by leveraging federated learning and also graph learning approaches. FedNI,通过 FL 来利用网络补全和机构间数据。 具体来说,我们首先使用图生成对抗网络(GAN)对缺失节点和边缘预测器进行联邦训练,以完成局部网络的缺失信息。 然后,我们使用联邦图学习平台跨机构训练全局 GCN 节点分类器。 新颖的设计使我们能够通过利用联邦学习和图学习方法来构建更准确的机器学习模型。
[^SemiGraphFL]: This work focuses on the graph classification task with partially labeled data. (1) Enhancing the collaboration processes: We propose a new personalized FL framework to deal with Non-IID data. Clients with more similar data have greater mutual influence, where the similarities can be evaluated via unlabeled data. (2) Enhancing the local training process: We introduce auxiliary loss for unlabeled data that restrict the training process. We propose a new pseudo-label strategy for our SemiGraphFL framework to make more effective predictions. 这项工作专注于具有部分标记数据的图分类任务。(1) 加强合作过程。我们提出了一个新的个性化的FL框架来处理非IID数据。拥有更多相似数据的客户有更大的相互影响,其中的相似性可以通过未标记的数据进行评估。(2) 加强本地训练过程。我们为未标记的数据引入了辅助损失,限制了训练过程。我们为我们的SemiGraphFL框架提出了一个新的伪标签策略,以做出更有效的预测。
[^FedPerGNN]: FedPerGNN, a federated GNN framework for both effective and privacy-preserving personalization. Through a privacy-preserving model update method, we can collaboratively train GNN models based on decentralized graphs inferred from local data. To further exploit graph information beyond local interactions, we introduce a privacy-preserving graph expansion protocol to incorporate high-order information under privacy protection. FedPerGNN是一个既有效又保护隐私的GNN联盟框架。通过一个保护隐私的模型更新方法,我们可以根据从本地数据推断出的分散图来协作训练GNN模型。为了进一步利用本地互动以外的图信息,我们引入了一个保护隐私的图扩展协议,在保护隐私的前提下纳入高阶信息。
[^GraphSniffer]: A graph neural network model based on federated learning named GraphSniffer to identify malicious transactions in the digital currency market. GraphSniffer leverages federated learning and graph neural networks to model graph-structured Bitcoin transaction data distributed at different worker nodes, and transmits the gradients of the local model to the server node for aggregation to update the parameters of the global model. GraphSniffer 一种基于联邦学习的图神经网络模型来识别数字货币市场中的恶意交易。GraphSniffer 利用联邦学习和图神经网络对分布在不同工作节点的图结构比特币交易数据进行建模,并将局部模型的梯度传递到服务器节点进行聚合,更新全局模型的参数。
[^FedR]: In this paper, we first develop a novel attack that aims to recover the original data based on embedding information, which is further used to evaluate the vulnerabilities of FedE. Furthermore, we propose a Federated learning paradigm with privacy-preserving Relation embedding aggregation (FedR) to tackle the privacy issue in FedE. Compared to entity embedding sharing, relation embedding sharing policy can significantly reduce the communication cost due to its smaller size of queries. 在本文中,我们首先开发了一个新颖的攻击,旨在基于嵌入信息恢复原始数据,并进一步用于评估FedE的漏洞。此外,我们提出了一种带有隐私保护的关系嵌入聚合(FedR)的联邦学习范式,以解决FedE的隐私问题。与实体嵌入共享相比,关系嵌入共享策略由于其较小的查询规模,可以大大降低通信成本。
[^FedGCN]: TBC
[^wirelessfl-pdgnet]: A data-driven approach for power allocation in the context of federated learning (FL) over interference-limited wireless networks. The power policy is designed to maximize the transmitted information during the FL process under communication constraints, with the ultimate objective of improving the accuracy and efficiency of the global FL model being trained. The proposed power allocation policy is parameterized using a graph convolutional network and the associated constrained optimization problem is solved through a primal-dual algorithm. 在干扰有限的无线网络上联邦学习(FL)的背景下,一种数据驱动的功率分配方法。功率策略的设计是为了在通信约束下的联邦学习过程中最大化传输信息,其最终目的是提高正在训练的全局联邦学习模型的准确性和效率。所提出的功率分配策略使用图卷积网络进行参数化,相关的约束性优化问题通过原始-双重算法进行解决。
[^multitask-fusion]: We investigate multi-task learning (MTL), where multiple learning tasks are performed jointly rather than separately to leverage their similarities and improve performance. We focus on the federated multi-task linear regression setting, where each machine possesses its own data for individual tasks and sharing the full local data between machines is prohibited. Motivated by graph regularization, we propose a novel fusion framework that only requires a one-shot communication of local estimates. Our method linearly combines the local estimates to produce an improved estimate for each task, and we show that the ideal mixing weight for fusion is a function of task similarity and task difficulty. 我们研究了多任务学习(MTL),其中多个学习任务被关联而不是单独执行,以利用它们的相似性并提高性能。我们专注于联邦多任务线性回归的设置,其中每台机器拥有自己的个别任务的数据,并且禁止在机器之间共享完整的本地数据。在图正则化的启发下,我们提出了一个新的融合框架,只需要一次本地估计的交流。我们的方法线性地结合本地估计,为每个任务产生一个改进的估计,我们表明,融合的理想混合权重是任务相似性和任务难度的函数。
[^FedEC]: FedEC framework, a local training procedure is responsible for learning knowledge graph embeddings on each client based on a specific embedding learner. We apply embedding-contrastive learning to limit the embedding update for tackling data heterogeneity. Moreover, a global update procedure is used for sharing and averaging entity embeddings on the master server. 在FedEC框架中,一个本地训练程序负责在每个客户端上基于特定的嵌入学习者学习知识图的嵌入。我们应用嵌入对比学习来限制嵌入的更新,以解决数据的异质性问题。此外,全局更新程序被用于共享和平均主服务器上的实体嵌入。
[^PNS-FGL]: Existing FL paradigms are inefficient for geo-distributed GCN training since neighbour sampling across geo-locations will soon dominate the whole training process and consume large WAN bandwidth. We derive a practical federated graph learning algorithm, carefully striking the trade-off among GCN convergence error, wall-clock runtime, and neighbour sampling interval. Our analysis is divided into two cases according to the budget for neighbour sampling. In the unconstrained case, we obtain the optimal neighbour sampling interval, that achieves the best trade-off between convergence and runtime; in the constrained case, we show that determining the optimal sampling interval is actually an online problem and we propose a novel online algorithm with bounded competitive ratio to solve it. Combining the two cases, we propose a unified algorithm to decide the neighbour sampling interval in federated graph learning, and demonstrate its effectiveness with extensive simulation over graph datasets. 现有的FL范式对于地理分布式的GCN训练是低效的,因为跨地理位置的近邻采样很快将主导整个训练过程,并消耗大量的广域网带宽。我们推导了一个实用的联邦图学习算法,仔细权衡了GCN收敛误差、wall - clock运行时间和近邻采样间隔。我们的分析根据邻居抽样的预算分为两种情况。在无约束的情况下,我们得到了最优的近邻采样间隔,实现了收敛性和运行时间的最佳折衷;在有约束的情况下,我们证明了确定最优采样间隔实际上是一个在线问题,并提出了一个新的有界竞争比的在线算法来解决这个问题。结合这两种情况,我们提出了一个统一的算法来决定联邦图学习中的近邻采样间隔,并通过在图数据集上的大量仿真证明了其有效性
[^DA-MRG]: Social bot detection is essential for the social network's security. Existing methods almost ignore the differences in bot behaviors in multiple domains. Thus, we first propose a DomainAware detection method with Multi-Relational Graph neural networks (DA-MRG) to improve detection performance. Specifically, DA-MRG constructs multi-relational graphs with users' features and relationships, obtains the user presentations with graph embedding and distinguishes bots from humans with domainaware classifiers. Meanwhile, considering the similarity between bot behaviors in different social networks, we believe that sharing data among them could boost detection performance. However, the data privacy of users needs to be strictly protected. To overcome the problem, we implement a study of federated learning framework for DA-MRG to achieve data sharing between different social networks and protect data privacy simultaneously. 社交机器人检测对于社交网络的安全至关重要。现有方法几乎忽略了多个域中机器人行为的差异。因此,本文首先提出一种基于多关系图神经网络(DA-MRG)的Domain Aware检测方法,以提高检测性能。具体来说,DA-MRG利用用户的特征和关系构建多关系图,通过图嵌入获得用户表示,并通过领域感知分类器区分机器人和人类。同时,考虑到不同社交网络中机器人行为之间的相似性,我们认为在它们之间共享数据可以提高检测性能。然而,用户的数据隐私需要严格保护。为了克服这个问题,我们实现了一个面向DA-MRG的联邦学习框架研究,以实现不同社交网络之间的数据共享,同时保护数据隐私。
[^DP-FedRec]: The DP-based federated GNN has not been well investigated, especially in the sub-graph-level setting, such as the scenario of recommendation system. DP-FedRec, a DP-based federated GNN to fill the gap. Private Set Intersection (PSI) is leveraged to extend the local graph for each client, and thus solve the non-IID problem. Most importantly, DP(differential privacy) is applied not only on the weights but also on the edges of the intersection graph from PSI to fully protect the privacy of clients. 基于DP的联邦GNN还没有得到很好的研究,特别是在子图层面的设置,如推荐系统的场景。DP-FedRec,一个基于DP的联盟式GNN来填补这一空白。隐私集合求交(PSI)被用来扩展每个客户端的本地图,从而解决非IID问题。最重要的是,DP(差分隐私)不仅适用于权重,也适用于PSI中交集图的边,以充分保护客户的隐私。
[^CTFL]: C lustering-based hierarchical and T wo-step- optimized FL (CTFL) employs a divide-and-conquer strategy, clustering clients based on the closeness of their local model parameters. Furthermore, we incorporate the particle swarm optimization algorithm in CTFL, which employs a two-step strategy for optimizing local models. This technique enables the central server to upload only one representative local model update from each cluster, thus reducing the communication overhead associated with model update transmission in the FL. 基于聚类的层次化和两步优化的FL ( CTFL )采用分治策略,根据本地模型参数的接近程度对客户端进行聚类。此外,我们将粒子群优化算法集成到CTFL中,该算法采用两步策略优化局部模型。此技术使中心服务器能够仅从每个集群上载一个有代表性的本地模型更新,从而减少与FL中模型更新传输相关的通信开销。
[^FML-ST]: A privacy-preserving spatial-temporal prediction technique via federated learning (FL). Due to inherent non-independent identically distributed (non-IID) characteristic of spatial-temporal data, the basic FL-based method cannot deal with this data heterogeneity well by sharing global model; furthermore, we propose the personalized federated learning methods based on meta-learning. We automatically construct the global spatial-temporal pattern graph under a data federation. This global pattern graph incorporates and memorizes the local learned patterns of all of the clients, and each client leverages those global patterns to customize its own model by evaluating the difference between global and local pattern graph. Then, each client could use this customized parameters as its model initialization parameters for spatial-temporal prediction tasks. 一种通过联邦学习(FL)保护隐私的时空预测技术。由于时空数据固有的非独立同分布(non-IID)特性,基本的基于FL的方法无法通过共享全局模型很好地处理这种数据异构性;此外,我们提出了基于元学习的个性化联邦学习方法。我们在数据联邦下自动构建全局时空模式图。这个全局模式图包含并记忆了所有客户机的本地学习模式,每个客户机利用这些全局模式通过评估全局模式图和本地模式图之间的差异来定制自己的模型。然后,每个客户端可以使用这个定制的参数作为其时空预测任务的模型初始化参数。
[^BiG-Fed]: We investigate FL scenarios in which data owners are related by a network topology (e.g., traffic prediction based on sensor networks). Existing personalized FL approaches cannot take this information into account. To address this limitation, we propose the Bilevel Optimization enhanced Graph-aided Federated Learning (BiG-Fed) approach. The inner weights enable local tasks to evolve towards personalization, and the outer shared weights on the server side target the non-i.i.d problem enabling individual tasks to evolve towards a global constraint space. To the best of our knowledge, BiG-Fed is the first bilevel optimization technique to enable FL approaches to cope with two nested optimization tasks at the FL server and FL clients simultaneously. 我们研究了数据所有者与网络拓扑相关的 FL 场景(例如,基于传感器网络的流量预测)。 现有的个性化 FL 方法无法将这些信息考虑在内。 为了解决这个限制,我们提出了双层优化增强的图形辅助联邦学习(BiG-Fed)方法。 内部权重使本地任务向个性化发展,而服务器端的外部共享权重针对非独立同分布问题,使单个任务向全局约束空间发展。 据我们所知,BiG-Fed 是第一个使 FL 方法能够同时处理 FL 服务器和 FL 客户端的两个嵌套优化任务的双层优化技术。
[^FL-ST]: We explore the threat of collusion attacks from multiple malicious clients who pose targeted attacks (e.g., label flipping) in a federated learning configuration. By leveraging client weights and the correlation among them, we develop a graph-based algorithm to detect malicious clients. 我们探讨了来自多个恶意客户的串通攻击的威胁,这些客户在联邦学习配置中提出了有针对性的攻击(例如,标签翻转)。通过利用客户端的权重和它们之间的关联性,我们开发了一种基于图的算法来检测恶意客户端。
[^FLITplus]: Federated learning allows end users to build a global model collaboratively while keeping their training data isolated. We first simulate a heterogeneous federated-learning benchmark (FedChem) by jointly performing scaffold splitting and latent Dirichlet allocation on existing datasets. Our results on FedChem show that significant learning challenges arise when working with heterogeneous molecules across clients. We then propose a method to alleviate the problem: Federated Learning by Instance reweighTing (FLIT+). FLIT+ can align local training across clients. Experiments conducted on FedChem validate the advantages of this method. 联邦学习允许最终用户协同构建全局模型,同时保持他们的训练数据是孤立的。我们首先通过在现有数据集上联邦执行支架拆分和隐狄利克雷分配来模拟一个异构的联邦学习基准FedChem 。我们在FedChem上的研究结果表明,在跨客户端处理异构分子时,会出现显著的学习挑战。然后,我们提出了一种缓解该问题的方法:实例重加权联邦学习FLIT + 。FLIT+可以跨客户对齐本地训练。在FedChem上进行的实验验证了这种方法的优势。
[^ML-FGL]: Deep learning-based Wi-Fi indoor fingerprint localization, which requires a large received signal strength (RSS) dataset for training. A multi-level federated graph learning and self-attention based personalized indoor localization method is proposed to further capture the intrinsic features of RSS(received signal strength), and learn the aggregation manner of shared information uploaded by clients, with better personalization accuracy. 基于深度学习的Wi-Fi室内指纹定位,需要一个大的接收信号强度( RSS )数据集进行训练。为了进一步捕获RSS(接收信号强度)的内在特征,学习客户端上传的共享信息的聚合方式,具有更好的个性化精度,提出了一种基于多级联邦图学习和自注意力机制的个性化室内定位方法。
[^PSO-GFML]: This paper proposes a decentralized online multitask learning algorithm based on GFL (O-GFML). Clients update their local models using continuous streaming data while clients and multiple servers can train different but related models simul-taneously. Furthermore, to enhance the communication efficiency of O-GFML, we develop a partial-sharing-based O-GFML (PSO-GFML). The PSO-GFML allows participating clients to exchange only a portion of model parameters with their respective servers during a global iteration, while non-participating clients update their local models if they have access to new data. 本文提出了一种基于GFL (O-GFML)的去中心化在线多任务学习算法。客户端使用连续的流数据更新本地模型,而客户端和多个服务器可以同时训练不同但相关的模型。此外,为了提高O-GFML的通信效率,我们开发了一种基于部分共享的O-GFML (PSO-GFML)。PSO-GFML允许参与的客户端在全局迭代过程中只与各自的服务器交换部分模型参数,而非参与的客户端在有机会获得新数据的情况下更新本地模型。
[^FTL-NGCF]: TBC
[^DNG-FR]: AI healthcare applications rely on sensitive electronic healthcare records (EHRs) that are scarcely labelled and are often distributed across a network of the symbiont institutions. In this work, we propose dynamic neural graphs based federated learning framework to address these challenges. The proposed framework extends Reptile , a model agnostic meta-learning (MAML) algorithm, to a federated setting. However, unlike the existing MAML algorithms, this paper proposes a dynamic variant of neural graph learning (NGL) to incorporate unlabelled examples in the supervised training setup. Dynamic NGL computes a meta-learning update by performing supervised learning on a labelled training example while performing metric learning on its labelled or unlabelled neighbourhood. This neighbourhood of a labelled example is established dynamically using local graphs built over the batches of training examples. Each local graph is constructed by comparing the similarity between embedding generated by the current state of the model. The introduction of metric learning on the neighbourhood makes this framework semi-supervised in nature. The experimental results on the publicly available MIMIC-III dataset highlight the effectiveness of the proposed framework for both single and multi-task settings under data decentralisation constraints and limited supervision. 人工智能医疗应用依赖于敏感的电子医疗记录( EHR ),这些记录几乎没有标签,而且往往分布在共生体机构的网络中。在这项工作中,我们提出了基于动态神经图的联邦学习框架来解决这些挑战。提出的框架将模型不可知元学习(MAML)算法Reptile扩展到联邦环境。然而,与现有的MAML算法不同,本文提出了神经图学习(Neural Graph Learning,NGL 的动态变体,以在有监督的训练设置中纳入未标记的示例。动态NGL通过对带标签的训练示例执行监督学习,同时对其带标签或未带标签的邻域执行度量学习来计算元学习更新。标记样本的这个邻域是使用在批量训练样本上建立的局部图动态建立的。通过比较由模型的当前状态生成的嵌入之间的相似性来构造每个局部图。在邻域上引入度量学习使得这个框架具有半监督的性质。
[^FedGCN-NES]: A Federated Learning-Based Graph Convolutional Network (FedGCN). First, we propose a Graph Convolutional Network (GCN) as a local model of FL. Based on the classical graph convolutional neural network, TopK pooling layers and full connection layers are added to this model to improve the feature extraction ability. Furthermore, to prevent pooling layers from losing information, cross-layer fusion is used in the GCN, giving FL an excellent ability to process non-Euclidean spatial data. Second, in this paper, a federated aggregation algorithm based on an online adjustable attention mechanism is proposed. The trainable parameter ρ is introduced into the attention mechanism. The aggregation method assigns the corresponding attention coefficient to each local model, which reduces the damage caused by the inefficient local model parameters to the global model and improves the fault tolerance and accuracy of the FL algorithm. 基于联邦学习的图卷积网络(Fedgcn)。首先,我们提出了一个图卷积网络(GCN)作为FL的局部模型。该模型在经典图卷积神经网络的基础上,增加了Top K池化层和全连接层,提高了特征提取能力。此外,为了防止池化层丢失信息,在GCN中使用跨层融合,使FL具有处理非欧几里得空间数据的出色能力。其次,本文提出了一种基于在线可调注意力机制的联邦聚合算法。可训练参数ρ被引入注意力机制。聚合方法为每个局部模型分配相应的注意力系数,减少了低效的局部模型参数对全局模型造成的破坏,提高了FL算法的容错性和准确性。
[^Feddy]: Distributed surveillance systems have the ability to detect, track, and snapshot objects moving around in a certain space. The systems generate video data from multiple personal devices or street cameras. Intelligent video-analysis models are needed to learn dynamic representation of the objects for detection and tracking. In this work, we introduce Federated Dynamic Graph Neural Network (Feddy), a distributed and secured framework to learn the object representations from graph sequences: (1) It aggregates structural information from nearby objects in the current graph as well as dynamic information from those in the previous graph. It uses a self-supervised loss of predicting the trajectories of objects. (2) It is trained in a federated learning manner. The centrally located server sends the model to user devices. Local models on the respective user devices learn and periodically send their learning to the central server without ever exposing the user’s data to server. (3) Studies showed that the aggregated parameters could be inspected though decrypted when broadcast to clients for model synchronizing, after the server performed a weighted average. 分布式监控系统有能力检测、跟踪和抓拍在一定空间内移动的物体。这些系统从多个个人设备或街道摄像机产生视频数据。需要智能视频分析模型来学习物体的动态表示,以便进行检测和跟踪。在这项工作中,我们引入了联邦动态图谱神经网络(Feddy),这是一个分布式的安全框架,用于从图谱序列中学习物体的表征。(1) 它聚集了来自当前图中附近物体的结构信息,以及来自前一个图中物体的动态信息。它使用自监督的方法来预测物体的运动轨迹。(2) 它是以联邦学习的方式进行训练的。位于中心的服务器将模型发送给用户设备。各个用户设备上的本地模型进行学习,并定期将它们的学习结果发送到中央服务器,而不需要将用户的数据暴露给服务器。(3) 研究表明,在服务器进行加权平均后,广播给客户进行模型同步时,聚集的参数可以被检查,尽管是解密的。
[^D2D-FedL]: Two important characteristics of contemporary wireless networks: (i) the network may contain heterogeneous communication/computation resources, while (ii) there may be significant overlaps in devices' local data distributions. In this work, we develop a novel optimization methodology that jointly accounts for these factors via intelligent device sampling complemented by device-to-device (D2D) offloading. Our optimization aims to select the best combination of sampled nodes and data offloading configuration to maximize FedL training accuracy subject to realistic constraints on the network topology and device capabilities. Theoretical analysis of the D2D offloading subproblem leads to new FedL convergence bounds and an efficient sequential convex optimizer. Using this result, we develop a sampling methodology based on graph convolutional networks (GCNs) which learns the relationship between network attributes, sampled nodes, and resulting offloading that maximizes FedL accuracy. 当代无线网络的两个重要特征:( i )网络中可能包含异构的通信/计算资源( ii )设备的本地数据分布可能存在显著的重叠。在这项工作中,我们开发了一种新的优化方法,通过智能设备采样和设备到设备(D2D)卸载来共同考虑这些因素。我们的优化目标是在网络拓扑和设备能力的现实约束下,选择采样节点和数据卸载配置的最佳组合,以最大化FedL训练精度。对D2D卸载子问题的理论分析得到了新的FedL收敛界和一个有效的序列凸优化器。利用这一结果,我们开发了一种基于图卷积网络(GCN)的采样方法,该方法学习网络属性、采样节点和结果卸载之间的关系,从而最大化FedL的准确性。
[^GCFL]: Graphs can also be regarded as a special type of data samples. We analyze real-world graphs from different domains to confirm that they indeed share certain graph properties that are statistically significant compared with random graphs. However, we also find that different sets of graphs, even from the same domain or same dataset, are non-IID regarding both graph structures and node features. A graph clustered federated learning (GCFL) framework that dynamically finds clusters of local systems based on the gradients of GNNs, and theoretically justify that such clusters can reduce the structure and feature heterogeneity among graphs owned by the local systems. Moreover, we observe the gradients of GNNs to be rather fluctuating in GCFL which impedes high-quality clustering, and design a gradient sequence-based clustering mechanism based on dynamic time warping (GCFL+). 图也可以看作是一种特殊类型的数据样本。我们分析来自不同领域的真实图,以确认它们确实共享某些与随机图形相比具有统计意义的图属性。然而,我们也发现不同的图集,即使来自相同的域或相同的数据集,在图结构和节点特性方面都是非IID的。图聚类联邦学习(GCFL)框架,基于GNNs的梯度动态地找到本地系统的集群,并从理论上证明这样的集群可以减少本地系统所拥有的图之间的结构和特征异构性。此外,我们观察到GNNs的梯度在GCFL中波动较大,阻碍了高质量的聚类,并设计了基于动态时间规整的梯度序列聚类机制(GCFL+)。
[^FedSage]: In this work, towards the novel yet realistic setting of subgraph federated learning, we propose two major techniques: (1) FedSage, which trains a GraphSage model based on FedAvg to integrate node features, link structures, and task labels on multiple local subgraphs; (2) FedSage+, which trains a missing neighbor generator along FedSage to deal with missing links across local subgraphs. 在本工作中,针对子图联邦学习的新颖而现实的设置,我们提出了两个主要技术:(1) FedSage,它基于FedAvg训练一个GraphSage模型,以整合多个局部子图上的节点特征、链接结构和任务标签;(2) FedSage +,它沿着FedSage训练一个缺失的邻居生成器,以处理跨本地子图的缺失链接。
[^CNFGNN]: Cross-Node Federated Graph Neural Network (CNFGNN) , a federated spatio-temporal model, which explicitly encodes the underlying graph structure using graph neural network (GNN)-based architecture under the constraint of cross-node federated learning, which requires that data in a network of nodes is generated locally on each node and remains decentralized. CNFGNN operates by disentangling the temporal dynamics modeling on devices and spatial dynamics on the server, utilizing alternating optimization to reduce the communication cost, facilitating computations on the edge devices. 跨节点联邦图神经网络(CNFGNN),是一个联邦时空模型,在跨节点联邦学习的约束下,使用基于图神经网络(GNN)的架构对底层图结构进行显式编码,这要求节点网络中的数据是在每个节点上本地生成的,并保持分散。CNFGNN通过分解设备上的时间动态建模和服务器上的空间动态来运作,利用交替优化来降低通信成本,促进边缘设备的计算。
[^FKGE]: A novel decentralized scalable learning framework, Federated Knowledge Graphs Embedding (FKGE), where embeddings from different knowledge graphs can be learnt in an asynchronous and peer-to-peer manner while being privacy-preserving. FKGE exploits adversarial generation between pairs of knowledge graphs to translate identical entities and relations of different domains into near embedding spaces. In order to protect the privacy of the training data, FKGE further implements a privacy-preserving neural network structure to guarantee no raw data leakage. 一种新颖的去中心化可扩展学习框架,联邦知识图谱嵌入(FKGE),其中来自不同知识图谱的嵌入可以以异步和对等的方式学习,同时保持隐私。FKGE利用成对知识图谱之间的对抗生成,将不同领域的相同实体和关系转换到临近嵌入空间。为了保护训练数据的隐私,FKGE进一步实现了一个保护隐私的神经网络结构,以保证原始数据不会泄露。
[^D-FedGNN]: A new Decentralized Federated Graph Neural Network (D-FedGNN for short) which allows multiple participants to train a graph neural network model without a centralized server. Specifically, D-FedGNN uses a decentralized parallel stochastic gradient descent algorithm DP-SGD to train the graph neural network model in a peer-to-peer network structure. To protect privacy during model aggregation, D-FedGNN introduces the Diffie-Hellman key exchange method to achieve secure model aggregation between clients. 一个新的去中心化的联邦图神经网络(简称D-FedGNN)允许多个参与者在没有中心化服务器的情况下训练一个图神经网络模型。具体地,D-FedGNN采用去中心化的并行随机梯度下降算法DP-SGD在对等网络结构中训练图神经网络模型。为了保护模型聚合过程中的隐私,D-FedGNN引入了Diffie-Hellman密钥交换方法来实现客户端之间的安全模型聚合。
[^FedSGC]: We study the vertical and horizontal settings for federated learning on graph data. We propose FedSGC to train the Simple Graph Convolution model under three data split scenarios. 我们研究了图数据上联邦学习的横向和纵向设置。我们提出FedSGC在三种数据分割场景下训练简单图卷积模型。
[^FL-DISCO]: A holistic collaborative and privacy-preserving FL framework, namely FL-DISCO, which integrates GAN and GNN to generate molecular graphs. 集成GAN和GNN生成分子图的整体协作和隐私保护FL框架FL-DISCO。
[^FASTGNN]: We introduce a differential privacy-based adjacency matrix preserving approach for protecting the topological information. We also propose an adjacency matrix aggregation approach to allow local GNN-based models to access the global network for a better training effect. Furthermore, we propose a GNN-based model named attention-based spatial-temporal graph neural networks (ASTGNN) for traffic speed forecasting. We integrate the proposed federated learning framework and ASTGNN as FASTGNN for traffic speed forecasting. 我们提出了一种基于差分隐私的邻接矩阵保护方法来保护拓扑信息。我们还提出了一种邻接矩阵聚合方法,允许基于局部GNN的模型访问全局网络,以获得更好的训练效果。此外,我们提出了一个基于GNN的模型,称为基于注意力的时空图神经网络(ASTGNN)的交通速度预测。我们将提出的联邦学习框架和ASTGNN集成为FASTGNN用于交通速度预测。
[^DAG-FL]: In order to address device asynchrony and anomaly detection in FL while avoiding the extra resource consumption caused by blockchain, this paper introduces a framework for empowering FL using Direct Acyclic Graph (DAG)-based blockchain systematically (DAG-FL). 为了解决FL中的设备不同步和异常检测问题,同时避免区块链带来的额外资源消耗,本文提出了一种基于直接无环图(DAG, Direct Acyclic Graph)的区块链系统为FL赋能的框架(DAG-FL)。
[^FedE]: In this paper, we introduce federated setting to keep Multi-Source KGs' privacy without triple transferring between KGs(Knowledge graphs) and apply it in embedding knowledge graph, a typical method which have proven effective for KGC(Knowledge Graph Completion) in the past decade. We propose a Federated Knowledge Graph Embedding framework FedE, focusing on learning knowledge graph embeddings by aggregating locally-computed updates. 在本文中,我们引入联邦设置来保持多源KGs的隐私,而不需要在KGs (知识图谱)之间传输三元组,并将其应用于知识图谱嵌入(这是一个典型的方法,在过去的十年中已证明对KGC(知识图谱补全)有效)。我们提出了一个联邦知识图谱嵌入框架FedE,重点是通过聚合本地计算的更新来学习知识图谱嵌入。
[^FKE]: A new federated framework FKE for representation learning of knowledge graphs to deal with the problem of privacy protection and heterogeneous data. 一种新的联邦框架 FKE,用于知识图谱的表示学习,以处理隐私保护和异构数据的问题。
[^GFL]: GFL, A private multi-server federated learning scheme, which we call graph federated learning. We use cryptographic and differential privacy concepts to privatize the federated learning algorithm over a graph structure. We further show under convexity and Lipschitz conditions, that the privatized process matches the performance of the non-private algorithm. GFL,一种私有的多服务器联邦学习方案,我们称之为图联邦学习。 我们使用密码学和差分隐私概念将联邦学习算法私有化在图结构上。 我们进一步表明在凸性和 Lipschitz 条件下,私有化过程与非私有算法的性能相匹配。
[^FeSoG]: A novel framework Fedrated Social recommendation with Graph neural network (FeSoG). Firstly, FeSoG adopts relational attention and aggregation to handle heterogeneity. Secondly, FeSoG infers user embeddings using local data to retain personalization.The proposed model employs pseudo-labeling techniques with item sampling to protect the privacy and enhance training. 一种带有图神经网络 (FeSoG) 的新框架联邦社交推荐。 首先,FeSoG 采用关系注意力和聚合来处理异质性。 其次,FeSoG 使用本地数据推断用户嵌入以保留个性化。所提出的模型采用带有项目采样的伪标签技术来保护隐私并增强训练。
[^FedGraphNN]: FedGraphNN, an open FL benchmark system that can facilitate research on federated GNNs. FedGraphNN is built on a unified formulation of graph FL and contains a wide range of datasets from different domains, popular GNN models, and FL algorithms, with secure and efficient system support. FedGraphNN是一个开放的FL基准系统,可以方便地进行联邦GNN的研究。FedGraphNN建立在图FL的统一提法之上,包含来自不同领域的广泛数据集、流行的GNN模型和FL算法,具有安全高效的系统支持。
[^Fed-CBT]: The connectional brain template (CBT) is a compact representation (i.e., a single connectivity matrix) multi-view brain networks of a given population. CBTs are especially very powerful tools in brain dysconnectivity diagnosis as well as holistic brain mapping if they are learned properly – i.e., occupy the center of the given population. We propose the first federated connectional brain template learning (Fed-CBT) framework to learn how to integrate multi-view brain connectomic datasets collected by different hospitals into a single representative connectivity map. First, we choose a random fraction of hospitals to train our global model. Next, all hospitals send their model weights to the server to aggregate them. We also introduce a weighting method for aggregating model weights to take full benefit from all hospitals. Our model to the best of our knowledge is the first and only federated pipeline to estimate connectional brain templates using graph neural networks. 连接脑模板(CBT)是一个给定人群的紧凑表示(即,单个连接矩阵)多视图脑网络。CBTs在大脑障碍诊断和整体大脑映射中特别是非常强大的工具,如果它们被正确地学习- -即占据给定人群的中心。我们提出了第一个联邦连接脑模板学习( Fed-CBT )框架来学习如何将不同医院收集的多视角脑连接组学数据集整合成一个单一的代表性连接图。首先,我们随机选择一部分医院来训练我们的全球模型。接下来,所有医院将其模型权重发送给服务器进行聚合。我们还介绍了一种加权方法,用于聚合模型权重,以充分受益于所有医院。据我们所知,我们的模型是第一个也是唯一一个使用图神经网络来估计连接大脑模板的联邦管道。
[^FedCG-MD]: A novel Cluster-driven Graph Federated Learning (FedCG). In FedCG, clustering serves to address statistical heterogeneity, while Graph Convolutional Networks (GCNs) enable sharing knowledge across them. FedCG: i) identifies the domains via an FL-compliant clustering and instantiates domain-specific modules (residual branches) for each domain; ii) connects the domain-specific modules through a GCN at training to learn the interactions among domains and share knowledge; and iii) learns to cluster unsupervised via teacher-student classifier-training iterations and to address novel unseen test domains via their domain soft-assignment scores. 一种新颖的集群驱动的图联邦学习(FedCG)。 在 FedCG 中,聚类用于解决统计异质性,而图卷积网络 (GCN) 可以在它们之间共享知识。 FedCG:i)通过符合 FL 的集群识别域,并为每个域实例化特定于域的模块(剩余分支); ii) 在训练时通过 GCN 连接特定领域的模块,以学习领域之间的交互并共享知识; iii)通过教师-学生分类器训练迭代学习无监督聚类,并通过其域软分配分数解决新的未知测试域。
[^FedGNN]: Graph neural network (GNN) is widely used for recommendation to model high-order interactions between users and items.We propose a federated framework for privacy-preserving GNN-based recommendation, which can collectively train GNN models from decentralized user data and meanwhile exploit high-order user-item interaction information with privacy well protected. 图神经网络(GNN)被广泛用于推荐,以对用户和项目之间的高阶交互进行建模。我们提出了一种基于隐私保护的基于 GNN 的推荐的联邦框架,它可以从分散的用户数据集中训练 GNN 模型,同时利用高阶 - 订购用户-项目交互信息,隐私得到很好的保护。
[^DFL-PENS]: We study the problem of how to efficiently learn a model in a peer-to-peer system with non-iid client data. We propose a method named Performance-Based Neighbor Selection (PENS) where clients with similar data distributions detect each other and cooperate by evaluating their training losses on each other's data to learn a model suitable for the local data distribution. 我们研究如何在具有非独立同分布客户端数据的对等系统中高效地学习模型的问题。我们提出了一种名为基于性能的邻居选择(Performance-Based Neighbor Selection,PENS)的方法,具有相似数据分布的客户端通过评估彼此数据的训练损失来相互检测和合作,从而学习适合本地数据分布的模型。
[^Glint]: We study federated graph learning (FGL) under the cross-silo setting where several servers are connected by a wide-area network, with the objective of improving the Quality-of-Service (QoS) of graph learning tasks. Glint, a decentralized federated graph learning system with two novel designs: network traffic throttling and priority-based flows scheduling. 我们研究了跨孤岛设置下的联邦图学习(FGL),其中多台服务器通过广域网连接,目的是提高图学习任务的服务质量(QoS)。 Glint,一个分散的联邦图学习系统,具有两种新颖的设计:网络流量节流和基于优先级的流调度。
[^FGNN]: A novel distributed scalable federated graph neural network (FGNN) to solve the cross-graph node classification problem. We add PATE mechanism into the domain adversarial neural network (DANN) to construct a cross-network node classification model, and extract effective information from node features of source and target graphs for encryption and spatial alignment. Moreover, we use a one-to-one approach to construct cross-graph node classification models for multiple source graphs and the target graph. Federated learning is used to train the model jointly through multi-party cooperation to complete the target graph node classification task. 一种新颖的分布式可扩展联邦图神经网络 (FGNN),用于解决跨图节点分类问题。 我们在域对抗神经网络(DANN)中加入PATE机制,构建跨网络节点分类模型,从源图和目标图的节点特征中提取有效信息进行加密和空间对齐。 此外,我们使用一对一的方法为多个源图和目标图构建跨图节点分类模型。 联邦学习用于通过多方合作共同训练模型,完成目标图节点分类任务。
[^GraFeHTy]: Human Activity Recognition (HAR) from sensor measurements is still challenging due to noisy or lack of la-belled examples and issues concerning data privacy. We propose a novel algorithm GraFeHTy, a Graph Convolution Network (GCN) trained in a federated setting. We construct a similarity graph from sensor measurements for each user and apply a GCN to perform semi-supervised classification of human activities by leveraging inter-relatedness and closeness of activities. 由于噪声或缺乏标记示例以及有关数据隐私的问题,来自传感器测量的人类活动识别 (HAR) 仍然具有挑战性。 我们提出了一种新的算法 GraFeHTy,一种在联邦设置中训练的图卷积网络 (GCN)。 我们从每个用户的传感器测量中构建相似图,并应用 GCN 通过利用活动的相互关联性和密切性来执行人类活动的半监督分类。
[^D-GCN]: The aim of this work is to develop a fully-distributed algorithmic framework for training graph convolutional networks (GCNs). The proposed method is able to exploit the meaningful relational structure of the input data, which are collected by a set of agents that communicate over a sparse network topology. After formulating the centralized GCN training problem, we first show how to make inference in a distributed scenario where the underlying data graph is split among different agents. Then, we propose a distributed gradient descent procedure to solve the GCN training problem. The resulting model distributes computation along three lines: during inference, during back-propagation, and during optimization. Convergence to stationary solutions of the GCN training problem is also established under mild conditions. Finally, we propose an optimization criterion to design the communication topology between agents in order to match with the graph describing data relationships. 这项工作的目的是开发一个用于训练图卷积网络(GCN)的完全分布式算法框架。 所提出的方法能够利用输入数据的有意义的关系结构,这些数据由一组通过稀疏网络拓扑进行通信的代理收集。 在制定了集中式 GCN 训练问题之后,我们首先展示了如何在底层数据图在不同代理之间拆分的分布式场景中进行推理。 然后,我们提出了一种分布式梯度下降程序来解决 GCN 训练问题。 生成的模型沿三条线分布计算:推理期间、反向传播期间和优化期间。 GCN 训练问题的平稳解的收敛性也在温和条件下建立。 最后,我们提出了一种优化标准来设计代理之间的通信拓扑,以便与描述数据关系的图相匹配。
[^FL-DSGD]: We focus on improving the communication efficiency for fully decentralized federated learning (DFL) over a graph, where the algorithm performs local updates for several iterations and then enables communications among the nodes. 我们专注于提高图上完全分散的联邦学习(DFL)的通信效率,其中算法执行多次迭代的本地更新,然后实现节点之间的通信。
[^ASFGNN]: An Automated Separated-Federated Graph Neural Network (ASFGNN) learning paradigm. ASFGNN consists of two main components, i.e., the training of GNN and the tuning of hyper-parameters. Specifically, to solve the data Non-IID problem, we first propose a separated-federated GNN learning model, which decouples the training of GNN into two parts: the message passing part that is done by clients separately, and the loss computing part that is learnt by clients federally. To handle the time-consuming parameter tuning problem, we leverage Bayesian optimization technique to automatically tune the hyper-parameters of all the clients. 自动分离联邦图神经网络( ASFGNN )学习范式。ASFGNN由两个主要部分组成,即GNN的训练和超参数的调整。具体来说,为了解决数据Non - IID问题,我们首先提出了分离联邦GNN学习模型,将GNN的训练解耦为两个部分:由客户端单独完成的消息传递部分和由客户端联邦学习的损失计算部分。为了处理耗时的参数调优问题,我们利用贝叶斯优化技术自动调优所有客户端的超参数。
[^DSGD]: Communication is a critical enabler of large-scale FL due to significant amount of model information exchanged among edge devices. In this paper, we consider a network of wireless devices sharing a common fading wireless channel for the deployment of FL. Each device holds a generally distinct training set, and communication typically takes place in a Device-to-Device (D2D) manner. In the ideal case in which all devices within communication range can communicate simultaneously and noiselessly, a standard protocol that is guaranteed to converge to an optimal solution of the global empirical risk minimization problem under convexity and connectivity assumptions is Decentralized Stochastic Gradient Descent (DSGD). DSGD integrates local SGD steps with periodic consensus averages that require communication between neighboring devices. In this paper, wireless protocols are proposed that implement DSGD by accounting for the presence of path loss, fading, blockages, and mutual interference. The proposed protocols are based on graph coloring for scheduling and on both digital and analog transmission strategies at the physical layer, with the latter leveraging over-the-air computing via sparsity-based recovery. 由于边缘设备之间交换了大量模型信息,因此通信是大规模 FL 的关键推动力。在本文中,我们考虑了一个无线设备网络,该网络共享一个共同的衰落无线信道来部署 FL。每个设备都拥有一个通常不同的训练集,并且通信通常以设备到设备 (D2D) 的方式进行。在通信范围内的所有设备可以同时无噪声地通信的理想情况下,保证在凸性和连通性假设下收敛到全局经验风险最小化问题的最优解的标准协议是分散随机梯度下降(DSGD)。 DSGD 将本地 SGD 步骤与需要相邻设备之间通信的周期性共识平均值集成在一起。在本文中,提出了通过考虑路径损耗、衰落、阻塞和相互干扰的存在来实现 DSGD 的无线协议。所提出的协议基于用于调度的图形着色以及物理层的数字和模拟传输策略,后者通过基于稀疏性的恢复利用空中计算。
[^SGNN]: We propose a similarity-based graph neural network model, SGNN, which captures the structure information of nodes precisely in node classification tasks. It also takes advantage of the thought of federated learning to hide the original information from different data sources to protect users' privacy. We use deep graph neural network with convolutional layers and dense layers to classify the nodes based on their structures and features. 我们提出了一种基于相似度的图神经网络模型 SGNN,它在节点分类任务中精确地捕获节点的结构信息。 它还利用联邦学习的思想,对不同数据源隐藏原始信息,保护用户隐私。 我们使用具有卷积层和密集层的深度图神经网络根据节点的结构和特征对节点进行分类。
[^FGL-DFC]: To detect financial misconduct, A methodology to share key information across institutions by using a federated graph learning platform that enables us to build more accurate machine learning models by leveraging federated learning and also graph learning approaches. We demonstrated that our federated model outperforms local model by 20% with the UK FCA TechSprint data set. 为了检测财务不当行为,一种通过使用联邦图学习平台在机构间共享关键信息的方法,使我们能够通过利用联邦学习和图学习方法来构建更准确的机器学习模型。 我们证明了我们的联邦模型在英国 FCA TechSprint 数据集上的性能优于本地模型 20%。
[^cPDS]: We aim at solving a binary supervised classification problem to predict hospitalizations for cardiac events using a distributed algorithm. We focus on the soft-margin l1-regularized sparse Support Vector Machine (sSVM) classifier. We develop an iterative cluster Primal Dual Splitting (cPDS) algorithm for solving the large-scale sSVM problem in a decentralized fashion. 我们的目标是解决一个二元监督分类问题,以使用分布式算法预测心脏事件的住院情况。 我们专注于软边距 l1 正则化稀疏支持向量机 (sSVM) 分类器。 我们开发了一种迭代集群 Primal Dual Splitting (cPDS) 算法,用于以分散的方式解决大规模 sSVM 问题。
[^GFL-APPNP]: We first formulate the Graph Federated Learning (GFL) problem that unifies LoG(Learning on Graphs) and FL(Federated Learning) in multi-client systems and then propose sharing hidden representation instead of the raw data of neighbors to protect data privacy as a solution. To overcome the biased gradient problem in GFL, we provide a gradient estimation method and its convergence analysis under the non-convex objective. 我们首先在多客户机系统中统一LoG(在图上学习)和FL (Federation Learning)的图联邦学习(Graph Federation Learning,GFL)问题,然后提出共享隐藏表示代替邻居的原始数据以保护数据隐私作为解决方案。为了克服GFL中的有偏梯度问题,我们给出了非凸目标下的梯度估计方法及其收敛性分析。
[^FedRule]: TBC
[^M3FGM]: TBC
[^FedEgo]: FedEgo, a federated graph learning framework based on ego-graphs, where each client will train their local models while also contributing to the training of a global model. FedEgo applies GraphSAGE over ego-graphs to make full use of the structure information and utilizes Mixup for privacy concerns. To deal with the statistical heterogeneity, we integrate personalization into learning and propose an adaptive mixing coefficient strategy that enables clients to achieve their optimal personalization. FedEgo是一个基于自中心图的联邦图学习框架,每个客户端将训练他们的本地模型,同时也为全局模型的训练作出贡献。FedEgo在自中心图上应用GraphSAGE来充分利用结构信息,并利用Mixup来解决隐私问题。为了处理统计上的异质性,我们将个性化整合到学习中,并提出了一个自适应混合系数策略,使客户能够实现其最佳的个性化。
[^FGCL]: TBC
[^FD-GATDR]: TBC
[^FED-PUB]: TBC
[^EF-HC]: TBC
[^PPSGCN]: TBC
[^FedVGCN]: TBC
[^FedGL]: TBC
[^FL-AGCNS]: TBC
[^dFedU]: TBC
[^GraphFL]: TBC
[^FedAlign-KG]: TBC
[^P2P-FLG]: TBC
[^SGBoost]: An efficient and privacy-preserving vertical federated tree boosting framework, namely SGBoost, where multiple participants can collaboratively perform model training and query without staying online all the time. Specifically, we first design secure bucket sharing and best split finding algorithms, with which the global tree model can be constructed over vertically partitioned data; meanwhile, the privacy of training data can be well guaranteed. Then, we design an oblivious query algorithm to utilize the trained model without leaking any query data or results. Moreover, SGBoost does not require multi-round interactions between participants, significantly improving the system efficiency. Detailed security analysis shows that SGBoost can well guarantee the privacy of raw data, weights, buckets, and split information. 一个高效且保护隐私的纵向联邦树提升框架,即SGBoost,多个参与者可以协同进行模型训练和查询,而无需一直保持在线。具体来说,我们首先设计了安全的桶共享和最佳分割寻找算法,通过这些算法可以在垂直分割的数据上构建全局树模型;同时,训练数据的隐私可以得到很好的保证。然后,我们设计了一个遗忘查询算法来利用训练好的模型,而不泄露任何查询数据或结果。此外,SGBoost不需要参与者之间的多轮互动,大大提高了系统的效率。详细的安全分析表明,SGBoost可以很好地保证原始数据、权重、桶和分割信息的隐私。
[^iFedCrowd]: iFedCrowd (incentive-boosted Federated Crowdsourcing), to manage the privacy and quality of crowdsourcing projects. iFedCrowd allows participants to locally process sensitive data and only upload encrypted training models, and then aggregates the model parameters to build a shared server model to protect data privacy. To motivate workers to build a high-quality global model in an efficacy way, we introduce an incentive mechanism that encourages workers to constantly collect fresh data to train accurate client models and boosts the global model training. We model the incentive-based interaction between the crowdsourcing platform and participating workers as a Stackelberg game, in which each side maximizes its own profit. We derive the Nash Equilibrium of the game to find the optimal solutions for the two sides. iFedCrowd(激励促进的联合众包),管理众包项目的隐私和质量。iFedCrowd允许参与者在本地处理敏感数据,只上传加密的训练模型,然后汇总模型参数,建立一个共享的服务器模型,保护数据隐私。为了激励工人以效能的方式建立高质量的全局模型,我们引入了一种激励机制,鼓励工人不断收集新鲜数据来训练准确的客户模型,并促进全局模型的训练。我们将众包平台和参与工人之间基于激励的互动建模为Stackelberg博弈,其中每一方都最大化自己的利润。我们推导出博弈的纳什均衡,以找到双方的最佳解决方案。
[^OpBoost]: OpBoost. Three order-preserving desensitization algorithms satisfying a variant of LDP called distance-based LDP (dLDP) are designed to desensitize the training data. In particular, we optimize the dLDP definition and study efficient sampling distributions to further improve the accuracy and efficiency of the proposed algorithms. The proposed algorithms provide a trade-off between the privacy of pairs with large distance and the utility of desensitized values. OpBoost。设计了三种满足LDP变体的保序脱敏算法,称为基于距离的LDP(dLDP),以使训练数据脱敏。特别是,我们优化了dLDP的定义,并研究了有效的采样分布,以进一步提高拟议算法的准确性和效率。所提出的算法在大距离的配对隐私和脱敏值的效用之间进行了权衡。
[^RevFRF]: TBC
[^FFGB]: Federated functional gradient boosting (FFGB). Under appropriate assumptions on the weak learning oracle, the FFGB algorithm is proved to efficiently converge to certain neighborhoods of the global optimum. The radii of these neighborhoods depend upon the level of heterogeneity measured via the total variation distance and the much tighter Wasserstein-1 distance, and diminish to zero as the setting becomes more homogeneous.
[^FRF]: Federated Random Forests (FRF) models, focusing particularly on the heterogeneity within and between datasets. 联邦随机森林(FRF)模型,特别关注数据集内部和之间的异质性。
[^federation-boosting]: This paper proposes FL algorithms that build federated models without relying on gradient descent-based methods. Specifically, we leverage distributed versions of the AdaBoost algorithm to acquire strong federated models. In contrast with previous approaches, our proposal does not put any constraint on the client-side learning models. 不依赖基于梯度下降的方法建立联邦模型的FL算法。具体来说,我们利用AdaBoost算法的分布式版本来获得强大的联邦模型。与之前的方法相比,我们没有对客户端的学习模型施加任何约束。
[^FF]: Federated Forest , which is a lossless learning model of the traditional random forest method, i.e., achieving the same level of accuracy as the non-privacy-preserving approach. Based on it, we developed a secure cross-regional machine learning system that allows a learning process to be jointly trained over different regions’ clients with the same user samples but different attribute sets, processing the data stored in each of them without exchanging their raw data. A novel prediction algorithm was also proposed which could largely reduce the communication overhead. Federated Forest ,是传统随机森林方法的无损学习模型,即达到与非隐私保护方法相同的准确度。在此基础上,我们开发了一个安全的跨区域机器学习系统,允许在具有相同用户样本但不同属性集的不同区域的客户端上联邦训练一个学习过程,处理存储在每个客户端的数据,而不交换其原始数据。还提出了一种新的预测算法,可以在很大程度上减少通信开销。
[^Fed-GBM]: Fed-GBM (Federated Gradient Boosting Machines), a cost-effective collaborative learning framework, consisting of two-stage voting and node-level parallelism, to address the problems in co-modelling for Non-intrusive load monitoring (NILM). Fed-GBM(联邦梯度提升)是一个具有成本效益的协作学习框架,由两阶段投票和节点级并行组成,用于解决非侵入式负载监测(NILM)中的协同建模问题。
[^VPRF]: A verifiable privacy-preserving scheme (VPRF) based on vertical federated Random forest, in which the users are dynamic change. First, we design homomorphic comparison and voting statistics algorithms based on multikey homomorphic encryption for privacy preservation. Then, we propose a multiclient delegated computing verification algorithm to make up for the disadvantage that the above algorithms cannot verify data integrity. 一个基于纵向联邦随机森林的可验证的隐私保护方案(VPRF),其中的用户是动态变化的。首先,我们设计了基于多键同态加密的同态比较和投票统计算法来保护隐私。然后,我们提出了一种多客户委托计算验证算法,以弥补上述算法不能验证数据完整性的缺点。
[^BOFRF]: A novel federated ensemble classification algorithm for horizontally partitioned data, namely Boosting-based Federated Random Forest (BOFRF), which not only increases the predictive power of all participating sites, but also provides significantly high improvement on the predictive power of sites having unsuccessful local models. We implement a federated version of random forest, which is a well-known bagging algorithm, by adapting the idea of boosting to it. We introduce a novel aggregation and weight calculation methodology that assigns weights to local classifiers based on their classification performance at each site without increasing the communication or computation cost. 一种针对横向划分数据的新型联邦集成分类算法,即基于 Boosting 的联邦随机森林 (BOFRF),它不仅提高了所有参与站点的预测能力,而且显着提高了局部模型不成功的站点的预测能力 . 我们通过采用 boosting 的思想来实现一个联邦版本的随机森林,这是一种众所周知的 bagging 算法。 我们引入了一种新颖的聚合和权重计算方法,该方法根据本地分类器在每个站点的分类性能为它们分配权重,而不会增加通信或计算成本。
[^eFL-Boost]: Efficient FL for GBDT (eFL-Boost), which minimizes accuracy loss, communication costs, and information leakage. The proposed scheme focuses on appropriate allocation of local computation (performed individually by each organization) and global computation (performed cooperatively by all organizations) when updating a model. A tree structure is determined locally at one of the organizations, and leaf weights are calculated globally by aggregating the local gradients of all organizations. Specifically, eFL-Boost requires only three communications per update, and only statistical information that has low privacy risk is leaked to other organizations. 针对GBDT的高效FL(eFL-Boost),将精度损失、通信成本和信息泄露降到最低。该方案的重点是在更新模型时适当分配局部计算(由每个组织单独执行)和全局计算(由所有组织合作执行)。树状结构由其中一个组织在本地确定,而叶子的权重则由所有组织的本地梯度汇总后在全局计算。具体来说,eFL-Boost每次更新只需要三次通信,而且只有具有低隐私风险的统计信息才会泄露给其他组织。
[^MP-FedXGB]: MP-FedXGB, a lossless multi-party federated XGB learning framework is proposed with a security guarantee, which reshapes the XGBoost's split criterion calculation process under a secret sharing setting and solves the leaf weight calculation problem by leveraging distributed optimization. MP-FedXGB是一个无损的多方联邦XGB学习框架,它在秘密共享的环境下重塑了XGBoost的分割准则计算过程,并通过利用分布式优化解决了叶子权重计算问题。
[^FL-RF]: Random Forest Based on Federated Learning for Intrusion Detection 使用联邦随机森林做入侵检测
[^FL-DT]: A federated decision tree-based random forest algorithm where a small number of organizations or industry companies collaboratively build models. 一个基于联邦决策树的随机森林算法,由少数组织或行业公司合作建立模型。
[^FL-ST]: We explore the threat of collusion attacks from multiple malicious clients who pose targeted attacks (e.g., label flipping) in a federated learning configuration. By leveraging client weights and the correlation among them, we develop a graph-based algorithm to detect malicious clients. 我们探讨了来自多个恶意客户的串通攻击的威胁,这些客户在联邦学习配置中提出了有针对性的攻击(例如,标签翻转)。通过利用客户端的权重和它们之间的关联性,我们开发了一种基于图的算法来检测恶意客户端。
[^VF2Boost]: VF2Boost, a novel and efficient vertical federated GBDT system. First, to handle the deficiency caused by frequent mutual-waiting in federated training, we propose a concurrent training protocol to reduce the idle periods. Second, to speed up the cryptography operations, we analyze the characteristics of the algorithm and propose customized operations. Empirical results show that our system can be 12.8-18.9 times faster than the existing vertical federated implementations and support much larger datasets. VF2Boost,一个新颖而高效的纵向联邦GBDT系统。首先,为了处理联邦训练中频繁的相互等待造成的缺陷,我们提出了一个并发训练协议来减少空闲期。第二,为了加快密码学操作,我们分析了算法的特点,并提出了定制的操作。经验结果表明,我们的系统可以比现有的纵向联邦实现快12.8-18.9倍,并支持更大的数据集。我们将保证公平性的客户选择建模为一个Lyapunov优化问题,然后提出一个基于C2MAB的方法来估计每个客户和服务器之间的模型交换时间,在此基础上,我们设计了一个保证公平性的算法,即RBCS-F来解决问题。
[^SecureBoost]: SecureBoost, a novel lossless privacy-preserving tree-boosting system. SecureBoost first conducts entity alignment under a privacy-preserving protocol and then constructs boosting trees across multiple parties with a carefully designed encryption strategy. This federated learning system allows the learning process to be jointly conducted over multiple parties with common user samples but different feature sets, which corresponds to a vertically partitioned data set. SecureBoost是一种新型的无损隐私保护的提升树系统。SecureBoost首先在一个保护隐私的协议下进行实体对齐,然后通过精心设计的加密策略在多方之间构建提升树。这种联邦学习系统允许学习过程在具有共同用户样本但不同特征集的多方联邦进行,这相当于一个纵向分割的数据集。
[^BFF-IDS]: A Blockchain-Based Federated Forest for SDN-Enabled In-Vehicle Network Intrusion Detection System 基于区块链的联邦森林用于支持SDN的车载网络入侵检测系统
[^I-GBDT]: An improved gradient boosting decision tree (GBDT) federated ensemble learning method is proposed, which takes the average gradient of similar samples and its own gradient as a new gradient to improve the accuracy of the local model. Different ensemble learning methods are used to integrate the parameters of the local model, thus improving the accuracy of the updated global model. 提出了一种改进的梯度提升决策树(GBDT)联邦集合学习方法,该方法将相似样本的平均梯度和自身的梯度作为新的梯度来提高局部模型的精度。采用不同的集合学习方法来整合局部模型的参数,从而提高更新的全局模型的精度。
[^Fed-EINI]: Decision tree ensembles such as gradient boosting decision trees (GBDT) and random forest are widely applied powerful models with high interpretability and modeling efficiency. However, state-of-art framework for decision tree ensembles in vertical federated learning frameworks adapt anonymous features to avoid possible data breaches, makes the interpretability of the model compromised. Fed-EINI make a problem analysis about the necessity of disclosure meanings of feature to Guest Party in vertical federated learning. Fed-EINI protect data privacy and allow the disclosure of feature meaning by concealing decision paths and adapt a communication-efficient secure computation method for inference outputs. 集成决策树,如梯度提升决策树(GBDT)和随机森林,是被广泛应用的强大模型,具有较高的可解释性和建模效率。然而,纵向联邦学习框架中的决策树群的先进框架适应匿名特征以避免可能的数据泄露,使得模型的可解释性受到影响。Fed-EINI对纵向联邦学习中向客人方披露特征含义的必要性进行了问题分析。Fed-EINI通过隐藏决策路径来保护数据隐私,并允许披露特征含义,同时为推理输出适应一种通信效率高的安全计算方法。
[^GBF-Cen]: Propose a new tree-boosting method, named Gradient Boosting Forest (GBF), where the single decision tree in each gradient boosting round of GBDT is replaced by a set of trees trained from different subsets of the training data (referred to as a forest), which enables training GBDT in Federated Learning scenarios. We empirically prove that GBF outperforms the existing GBDT methods in both centralized (GBF-Cen) and federated (GBF-Fed) cases. 我们提出了一种新的提升树方法,即梯度提升森林(GBF),在GBDT的每一轮梯度提升中,单一的决策树被一组从训练数据的不同子集训练出来的树(称为森林)所取代,这使得在联邦学习场景中可以训练GBDT。我们通过经验证明,GBF在集中式(GBF-Cen)和联邦式(GBF-Fed)情况下都优于现有的GBDT方法。
[^KA-FL]: A privacy-preserving framework using Mondrian k-anonymity with decision trees for the horizontally partitioned data. 使用Mondrian K-匿名化的隐私保护框架,对横向分割的数据使用决策树建模。
[^AF-DNDF]: AF-DNDF which extends DNDF (Deep Neural Decision Forests, which unites classification trees with the representation learning functionality from deep convolutional neural networks) with an asynchronous federated aggregation protocol. Based on the local quality of each classification tree, our architecture can select and combine the optimal groups of decision trees from multiple local devices. AF-DNDF,它将DNDF(深度神经决策森林,它将分类树与深度卷积神经网络的表征学习功能结合起来)与一个异步的联邦聚合协议进行了扩展。基于每个分类树的本地质量,我们的架构可以选择和组合来自多个本地设备的最佳决策树组。
[^CB-DP]: Differential Privacy is used to obtain theoretically sound privacy guarantees against such inference attacks by noising the exchanged update vectors. However, the added noise is proportional to the model size which can be very large with modern neural networks. This can result in poor model quality. Compressive sensing is used to reduce the model size and hence increase model quality without sacrificing privacy. 差分隐私是通过对交换的更新向量进行噪声处理来获得理论上合理的隐私保证,以抵御这种推断攻击。然而,增加的噪声与模型大小成正比,而现代神经网络的模型大小可能非常大。这可能会导致模型质量不佳。压缩感知被用来减少模型大小,从而在不牺牲隐私的情况下提高模型质量。
[^SimFL]: A practical horizontal federated environment with relaxed privacy constraints. In this environment, a dishonest party might obtain some information about the other parties' data, but it is still impossible for the dishonest party to derive the actual raw data of other parties. Specifically, each party boosts a number of trees by exploiting similarity information based on locality-sensitive hashing. 一个具有宽松隐私约束的实用横向联邦环境。在这种环境中,不诚实的一方可能会获得其他方数据的一些信息,但不诚实的一方仍然不可能得出其他方的实际原始数据。具体来说,每一方通过利用基于位置敏感散列的相似性信息来提升一些树。
[^Pivot-DT]: Pivot, a novel solution for privacy preserving vertical decision tree training and prediction, ensuring that no intermediate information is disclosed other than those the clients have agreed to release (i.e., the final tree model and the prediction output). Pivot does not rely on any trusted third party and provides protection against a semi-honest adversary that may compromise m - 1 out of m clients. We further identify two privacy leakages when the trained decision tree model is released in plain-text and propose an enhanced protocol to mitigate them. The proposed solution can also be extended to tree ensemble models, e.g., random forest (RF) and gradient boosting decision tree (GBDT) by treating single decision trees as building blocks. Pivot,一个用于保护隐私的纵向决策树训练和预测的新颖解决方案,确保除了客户同意发布的信息(即最终的树模型和预测输出)外,没有任何中间信息被披露。Pivot不依赖任何受信任的第三方,并提供保护,防止半诚实的对手可能损害m个客户中的m-1。我们进一步确定了当训练好的决策树模型以明文形式发布时的两个隐私泄漏,并提出了一个增强的协议来缓解这些泄漏。通过将单个决策树作为构建块,所提出的解决方案也可以扩展到集成树模型,如随机森林(RF)和梯度提升决策树(GBDT)。
[^FEDXGB]: FEDXGB, a federated extreme gradient boosting (XGBoost) scheme supporting forced aggregation. First, FEDXGB involves a new HE(homomorphic encryption) based secure aggregation scheme for FL. Then, FEDXGB extends FL to a new machine learning model by applying the secure aggregation scheme to the classification and regression tree building of XGBoost. FEDXGB,一个支持强制聚合的联邦极端梯度提升(XGBoost)方案。首先,FEDXGB涉及一个新的基于HE(同态加密)的FL的安全聚合方案。然后,FEDXGB通过将安全聚合方案应用于XGBoost的分类和回归树构建,将FL扩展到一个新的机器学习模型。
[^FedCluster]: FedCluster, a novel federated learning framework with improved optimization efficiency, and investigate its theoretical convergence properties. The FedCluster groups the devices into multiple clusters that perform federated learning cyclically in each learning round. FedCluster是一个具有改进的优化效率的新型联邦学习框架,并研究其理论收敛特性。FedCluster将设备分成多个集群,在每一轮学习中循环进行联邦学习。
[^FL-XGBoost]: The proposed FL-XGBoost can train a sensitive task to be solved among different entities without revealing their own data. The proposed FL-XGBoost can achieve significant reduction in the number of communications between entities by exchanging decision tree models. FL-XGBoost可以训练一个敏感的任务,在不同的实体之间解决,而不透露他们自己的数据。所提出的FL-XGBoost可以通过交换决策树模型实现实体之间通信数量的大幅减少。
[^FL-PON]: A bandwidth slicing algorithm in PONs(passive optical network) is introduced for efficient FL, in which bandwidth is reserved for the involved ONUs(optical network units) collaboratively and mapped into each polling cycle. 在PONs(无源光网络)中引入了一种高效的FL算法,即为参与的ONU(光网络单元)协同保留带宽并映射到每个轮询周期。
[^DFedForest]: A distributed machine learning system based on local random forest algorithms created with shared decision trees through the blockchain. 一个基于本地随机森林算法的分布式机器学习系统通过区块链创建了共享决策树。
[^DRC-tree]: A decentralized redundant n-Cayley tree (DRC-tree) for federated learning. Explore the hierarchical structure of the n-Cayley tree to enhance the redundancy rate in federated learning to mitigate the impact of stragglers. In the DRC- tree structure, the fusion node serves as the root node, while all the worker devices are the intermediate tree nodes and leaves that formulated through a distributed message passing interface. the redundancy of workers is constructed layer by layer with a given redundancy branch degree. 用于联邦学习的分散冗余n-Cayley树(DRC-tree)。探索n-Cayley树的分层结构,提高联邦学习中的冗余率,以减轻散兵游勇的影响。在DRC-树结构中,融合节点作为根节点,而所有客户端设备是通过分布式消息传递接口制定的中间树节点和叶子。客户端的冗余度是以给定的冗余分支度逐层构建的。
[^Fed-sGBM]: Fed-sGBM, a federated soft gradient boosting machine framework applicable on the streaming data. Compared with traditional gradient boosting methods, where base learners are trained sequentially, each base learner in the proposed framework can be efficiently trained in a parallel and distributed fashion. Fed-sGBM是一个适用于流数据的联邦软梯度提升机框架。与传统的梯度提升方法相比,传统的梯度提升方法中的基础学习器是按顺序训练的,而拟议的框架中的每个基础学习器可以以平行和分布的方式有效地训练。
[^FL-DNDF]: Deep neural decision forests (DNDF), combine the divide-and-conquer principle together with the property representation learning. By parameterizing the probability distributions in the prediction nodes of the forest, and include all trees of the forest in the loss function, a gradient of the whole forest can be computed which some/several federated learning algorithms utilize. 深度神经决策森林(DNDF),将分治策略与属性表示学习结合起来。通过对森林预测节点的概率分布进行参数化,并将森林中的所有树木纳入损失函数中,可以计算出整个森林的梯度,一些/一些联邦学习算法利用了这一梯度。
[^Fed-TDA]: A federated tabular data augmentation method, named Fed-TDA. The core idea of Fed-TDA is to synthesize tabular data for data augmentation using some simple statistics (e.g., distributions of each column and global covariance). Specifically, we propose the multimodal distribution transformation and inverse cumulative distribution mapping respectively synthesize continuous and discrete columns in tabular data from a noise according to the pre-learned statistics. Furthermore, we theoretically analyze that our Fed-TDA not only preserves data privacy but also maintains the distribution of the original data and the correlation between columns. 一种名为Fed-TDA的联合表格式数据扩充方法。Fed-TDA的核心思想是利用一些简单的统计数据(如每一列的分布和全局协方差)来合成表格数据进行数据扩增。具体来说,我们提出了多模态分布变换和反累积分布映射,分别根据预先学习的统计数据从噪声中合成表格数据的连续和离散列。此外,我们从理论上分析,我们的Fed-TDA不仅保留了数据隐私,而且还保持了原始数据的分布和列之间的相关性。
[^TabLeak]: Most high-stakes applications of FL (e.g., legal and financial) use tabular data. Compared to the NLP and image domains, reconstruction of tabular data poses several unique challenges: (i) categorical features introduce a significantly more difficult mixed discrete-continuous optimization problem, (ii) the mix of categorical and continuous features causes high variance in the final reconstructions, and (iii) structured data makes it difficult for the adversary to judge reconstruction quality. In this work, we tackle these challenges and propose the first comprehensive reconstruction attack on tabular data, called TabLeak. TabLeak is based on three key ingredients: (i) a softmax structural prior, implicitly converting the mixed discrete-continuous optimization problem into an easier fully continuous one, (ii) a way to reduce the variance of our reconstructions through a pooled ensembling scheme exploiting the structure of tabular data, and (iii) an entropy measure which can successfully assess reconstruction quality. 大多数高风险的FL应用(例如,法律和金融)都使用表格数据。与NLP和图像领域相比,表格数据的重建带来了几个独特的挑战:(i)分类特征引入了一个明显更困难的混合离散-连续优化问题,(ii)分类和连续特征的混合导致最终重建的高差异,以及(iii)结构化数据使得对手很难判断重建质量。在这项工作中,我们解决了这些挑战,并提出了第一个针对表格数据的全面重建攻击,称为TabLeak。TabLeak是基于三个关键因素。(i) 一个softmax结构先验,隐含地将混合的离散-连续优化问题转换为一个更容易的完全连续问题,(ii) 一个通过利用表格数据结构的集合方案来减少我们重建的方差的方法,以及(iii) 一个可以成功评估重建质量的熵测量。
[^Hercules]: TBC
[^FedGBF]: TBC
[^HFL-XGBoost]: A hybrid federated learning framework based on XGBoost, for distributed power prediction from real-time external features. In addition to introducing boosted trees to improve accuracy and interpretability, we combine horizontal and vertical federated learning, to address the scenario where features are scattered in local heterogeneous parties and samples are scattered in various local districts. Moreover, we design a dynamic task allocation scheme such that each party gets a fair share of information, and the computing power of each party can be fully leveraged to boost training efficiency. 一个基于XGBoost的混合联邦学习框架,用于从实时外部特征进行分布式电力预测。除了引入提升树来提高准确性和可解释性,我们还结合了横向和纵向的联邦学习,以解决特征分散在本地异质方和样本分散在不同本地区的情况。此外,我们设计了一个动态的任务分配方案,使每一方都能获得公平的信息份额,并能充分利用每一方的计算能力来提高训练效率。
[^EBHE-VFXGB]: Efficient XGBoost vertical federated learning. we proposed a novel batch homomorphic encryption method to cut the cost of encryption-related computation and transmission in nearly half. This is achieved by encoding the first-order derivative and the second-order derivative into a single number for encryption, ciphertext transmission, and homomorphic addition operations. The sum of multiple first-order derivatives and second-order derivatives can be simultaneously decoded from the sum of encoded values. 高效的XGBoost纵向联邦学习。我们提出了一种新颖的批量同态加密方法,将加密相关的计算和传输成本减少了近一半。这是通过将一阶导数和二阶导数编码为一个数字来实现的,用于加密、密码文本传输和同态加法操作。多个一阶导数和二阶导数的总和可以同时从编码值的总和中解密。
[^SecureBoostplus]: TBC
[^Fed-TGAN]: TBC
[^FedXGBoost]: Two variants of federated XGBoost with privacy guarantee: FedXGBoost-SMM and FedXGBoost-LDP. Our first protocol FedXGBoost-SMM deploys enhanced secure matrix multiplication method to preserve privacy with lossless accuracy and lower overhead than encryption-based techniques. Developed independently, the second protocol FedXGBoost-LDP is heuristically designed with noise perturbation for local differential privacy. 两种具有隐私保护的联邦XGBoost的变体:FedXGBoost-SMM和FedXGBoost-LDP。FedXGBoost-SMM部署了增强的安全矩阵乘法,以无损的精度和低于基于加密的技术的开销来保护隐私。第二个协议FedXGBoost-LDP以启发式方法设计的,带有噪声扰动,用于保护局部差分隐私。
[^FederBoost]: FederBoost for private federated learning of gradient boosting decision trees (GBDT). It supports running GBDT over both horizontally and vertically partitioned data. The key observation for designing FederBoost is that the whole training process of GBDT relies on the order of the data instead of the values. Consequently, vertical FederBoost does not require any cryptographic operation and horizontal FederBoost only requires lightweight secure aggregation. FederBoost用于梯度提升决策树(GBDT)的私有联邦学习。它支持在横向和纵向分区的数据上运行GBDT。设计FederBoost的关键是,GBDT的整个训练过程依赖于数据的顺序而不是数值。因此,纵向FederBoost不需要任何加密操作,横向FederBoost只需要轻量级的安全聚合。
[^F-XGBoost]: A horizontal federated XGBoost algorithm to solve the federated anomaly detection problem, where the anomaly detection aims to identify abnormalities from extremely unbalanced datasets and can be considered as a special classification problem. Our proposed federated XGBoost algorithm incorporates data aggregation and sparse federated update processes to balance the tradeoff between privacy and learning performance. In particular, we introduce the virtual data sample by aggregating a group of users' data together at a single distributed node. 一个横向联邦XGBoost算法来解决联邦异常检测问题,其中异常检测的目的是从极不平衡的数据集中识别异常,可以被视为一个特殊的分类问题。我们提出的联邦XGBoost算法包含了数据聚合和稀疏的联邦更新过程,以平衡隐私和学习性能之间的权衡。特别是,我们通过将一组用户的数据聚集在一个分布式节点上,引入虚拟数据样本。
[^FedDis]: With the advent of deep learning and increasing use of brain MRIs, a great amount of interest has arisen in automated anomaly segmentation to improve clinical workflows; however, it is time-consuming and expensive to curate medical imaging. FedDis to collaboratively train an unsupervised deep convolutional autoencoder on 1,532 healthy magnetic resonance scans from four different institutions, and evaluate its performance in identifying pathologies such as multiple sclerosis, vascular lesions, and low- and high-grade tumours/glioblastoma on a total of 538 volumes from six different institutions. To mitigate the statistical heterogeneity among different institutions, we disentangle the parameter space into global (shape) and local (appearance). Four institutes jointly train shape parameters to model healthy brain anatomical structures. Every institute trains appearance parameters locally to allow for client-specific personalization of the global domain-invariant features. 随着深度学习的出现和脑 MRI 的使用越来越多,人们对自动异常分割以改善临床工作流程产生了极大的兴趣。然而,管理医学成像既耗时又昂贵。 FedDis 将在来自四个不同机构的 1,532 次健康磁共振扫描上协作训练一个无监督的深度卷积自动编码器,并评估其在总共 538 个机构中识别多发性硬化症、血管病变以及低级别和高级别肿瘤/胶质母细胞瘤等病理的性能来自六个不同机构的卷。为了减轻不同机构之间的统计异质性,我们将参数空间分解为全局(形状)和局部(外观)。四个研究所联邦训练形状参数来模拟健康的大脑解剖结构。每个机构都在本地训练外观参数,以允许对全局域不变特征进行客户特定的个性化。
[^FL-healthy]: This progress has emphasized that, from model development to model deployment, data play central roles. In this Review, we provide a data-centric view of the innovations and challenges that are defining ML for healthcare. We discuss deep generative models and federated learning as strategies to augment datasets for improved model performance, as well as the use of the more recent transformer models for handling larger datasets and enhancing the modelling of clinical text. We also discuss data-focused problems in the deployment of ML, emphasizing the need to efficiently deliver data to ML models for timely clinical predictions and to account for natural data shifts that can deteriorate model performance. 这一进展强调,从模型开发到模型部署,数据发挥着核心作用。在这篇评论中,我们提供了一个以数据为中心的观点,即定义医疗保健的ML的创新和挑战。我们讨论了深度生成模型和联邦学习,作为增强数据集以提高模型性能的策略,以及使用最近的转化器模型来处理更大的数据集和加强临床文本的建模。我们还讨论了ML部署中以数据为重点的问题,强调需要有效地将数据交付给ML模型,以便及时进行临床预测,并考虑到可能恶化模型性能的自然数据转移。
[^FedPerGNN]: FedPerGNN, a federated GNN framework for both effective and privacy-preserving personalization. Through a privacy-preserving model update method, we can collaboratively train GNN models based on decentralized graphs inferred from local data. To further exploit graph information beyond local interactions, we introduce a privacy-preserving graph expansion protocol to incorporate high-order information under privacy protection. FedPerGNN是一个既有效又保护隐私的GNN联盟框架。通过一个保护隐私的模型更新方法,我们可以根据从本地数据推断出的分散图来协作训练GNN模型。为了进一步利用本地互动以外的图信息,我们引入了一个保护隐私的图扩展协议,在保护隐私的前提下纳入高阶信息。
[^FedStar]: From real-world graph datasets, we observe that some structural properties are shared by various domains, presenting great potential for sharing structural knowledge in FGL. Inspired by this, we propose FedStar, an FGL framework that extracts and shares the common underlying structure information for inter-graph federated learning tasks. To explicitly extract the structure information rather than encoding them along with the node features, we define structure embeddings and encode them with an independent structure encoder. Then, the structure encoder is shared across clients while the feature-based knowledge is learned in a personalized way, making FedStar capable of capturing more structure-based domain-invariant information and avoiding feature misalignment issues. We perform extensive experiments over both cross-dataset and cross-domain non-IID FGL settings. 从现实世界的图数据集中,我们观察到一些结构属性被不同的领域所共享,这为联邦图机器学习中共享结构知识提供了巨大的潜力。受此启发,我们提出了FedStar,一个为图间联合学习任务提取和分享共同基础结构信息的FGL框架。为了明确地提取结构信息,而不是将其与节点特征一起编码,我们定义了结构嵌入,并用一个独立的结构编码器对其进行编码。然后,结构编码器在客户之间共享,而基于特征的知识则以个性化的方式学习,这使得FedStar能够捕获更多基于结构的领域变量信息,并避免了特征错位问题。我们在跨数据集和跨域的非IID FGL设置上进行了广泛的实验。
[^FedGS]: Federated Graph-based Sampling (FedGS) to stabilize the global model update and mitigate the long-term bias given arbitrary client availability simultaneously. First, we model the data correlations of clients with a Data-Distribution-Dependency Graph (3DG) that helps keep the sampled clients data apart from each other, which is theoretically shown to improve the approximation to the optimal model update. Second, constrained by the far-distance in data distribution of the sampled clients, we further minimize the variance of the numbers of times that the clients are sampled, to mitigate long-term bias. 基于图的联合采样(Federated Graph-based Sampling,FedGS)稳定了全局模型的更新,并同时减轻了任意客户端可用性的长期偏差。首先,我们用数据分布-依赖图(3DG)对客户的数据相关性进行建模,这有助于使被采样的客户数据相互分离,理论上证明这可以提高对最佳模型更新的近似度。其次,受制于被抽样客户数据分布的远距离,我们进一步将客户被抽样次数的方差降到最低,以减轻长期偏差。
[^iFedCrowd]: iFedCrowd (incentive-boosted Federated Crowdsourcing), to manage the privacy and quality of crowdsourcing projects. iFedCrowd allows participants to locally process sensitive data and only upload encrypted training models, and then aggregates the model parameters to build a shared server model to protect data privacy. To motivate workers to build a high-quality global model in an efficacy way, we introduce an incentive mechanism that encourages workers to constantly collect fresh data to train accurate client models and boosts the global model training. We model the incentive-based interaction between the crowdsourcing platform and participating workers as a Stackelberg game, in which each side maximizes its own profit. We derive the Nash Equilibrium of the game to find the optimal solutions for the two sides. iFedCrowd(激励促进的联合众包),管理众包项目的隐私和质量。iFedCrowd允许参与者在本地处理敏感数据,只上传加密的训练模型,然后汇总模型参数,建立一个共享的服务器模型,保护数据隐私。为了激励工人以效能的方式建立高质量的全局模型,我们引入了一种激励机制,鼓励工人不断收集新鲜数据来训练准确的客户模型,并促进全局模型的训练。我们将众包平台和参与工人之间基于激励的互动建模为Stackelberg博弈,其中每一方都最大化自己的利润。我们推导出博弈的纳什均衡,以找到双方的最佳解决方案。
[^FLIX]: TBC
[^DP-SCAFFOLD]: TBC
[^SparseFed]: TBC
[^QLSD]: TBC
[^MaKEr]: We study the knowledge extrapolation problem to embed new components (i.e., entities and relations) that come with emerging knowledge graphs (KGs) in the federated setting. In this problem, a model trained on an existing KG needs to embed an emerging KG with unseen entities and relations. To solve this problem, we introduce the meta-learning setting, where a set of tasks are sampled on the existing KG to mimic the link prediction task on the emerging KG. Based on sampled tasks, we meta-train a graph neural network framework that can construct features for unseen components based on structural information and output embeddings for them. 我们研究了知识外推问题,以嵌入新的组件(即实体和关系),这些组件来自于联邦设置的新兴知识图(KGs)。在这个问题上,一个在现有KG上训练的模型需要嵌入一个带有未见过的实体和关系的新兴KG。为了解决这个问题,我们引入了元学习设置,在这个设置中,一组任务在现有的KG上被抽样,以模拟新兴KG上的链接预测任务。基于抽样任务,我们对图神经网络框架进行元训练,该框架可以根据结构信息为未见过的组件构建特征,并为其输出嵌入。
[^SFL]: A novel structured federated learning (SFL) framework to enhance the knowledge-sharing process in PFL by leveraging the graph-based structural information among clients and learn both the global and personalized models simultaneously using client-wise relation graphs and clients' private data. We cast SFL with graph into a novel optimization problem that can model the client-wise complex relations and graph-based structural topology by a unified framework. Moreover, in addition to using an existing relation graph, SFL could be expanded to learn the hidden relations among clients. 一个新的结构化联邦学习(SFL)框架通过利用客户之间基于图的结构信息来加强PFL中的知识共享过程,并使用客户的关系图和客户的私人数据同时学习全局和个性化的模型。我们把带图的SFL变成一个新的优化问题,它可以通过一个统一的框架对客户的复杂关系和基于图的结构拓扑进行建模。此外,除了使用现有的关系图之外,SFL还可以扩展到学习客户之间的隐藏关系。
[^VFGNN]: VFGNN, a federated GNN learning paradigm for privacy-preserving node classification task under data vertically partitioned setting, which can be generalized to existing GNN models. Specifically, we split the computation graph into two parts. We leave the private data (i.e., features, edges, and labels) related computations on data holders, and delegate the rest of computations to a semi-honest server. We also propose to apply differential privacy to prevent potential information leakage from the server. VFGNN是一种联邦的GNN学习范式,适用于数据纵向分割情况下的隐私保护节点分类任务,它可以被推广到现有的GNN模型。具体来说,我们将计算图分成两部分。我们将私有数据(即特征、边和标签)相关的计算留给数据持有者,并将其余的计算委托给半诚实的服务器。我们还提议应用差分隐私来防止服务器的潜在信息泄露。
[^Fed-ET]: TBC
[^CReFF]: TBC
[^FedCG]: TBC
[^FedDUAP]: TBC
[^SpreadGNN]: SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. We provide convergence guarantees and empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. SpreadGNN首次提出一个新颖的多任务联邦训练框架,能够在存在部分标签和没有中央服务器的情况下运行。我们提供了收敛保证,并在各种具有部分标签的非I.I.D.分布式图级分子特性预测数据集上实证了我们框架的功效。我们的研究结果表明,SpreadGNN优于通过依赖中央服务器的联邦学习系统训练的GNN模型,即使在受限的拓扑结构中也是如此。
[^SmartIdx]: TBC
[^FedFIM]: TBC
[^FedProto]: TBC
[^FedSoft]: TBC
[^FedFR]: TBC
[^SplitFed]: TBC
[^FlyNNFL]: TBC
[^FedSpeech]: TBC
[^FedKT]: TBC
[^FEDMD-NFDP]: TBC
[^LDP-FL]: TBC
[^FedFV]: TBC
[^H-FL]: TBC
[^FedRecplusplus]: TBC
[^FLAME_D]: TBC
[^FedAMP]: TBC
[^FedGame]: TBC
[^SimFL]: A practical horizontal federated environment with relaxed privacy constraints. In this environment, a dishonest party might obtain some information about the other parties' data, but it is still impossible for the dishonest party to derive the actual raw data of other parties. Specifically, each party boosts a number of trees by exploiting similarity information based on locality-sensitive hashing. 一个具有宽松隐私约束的实用横向联邦环境。在这种环境中,不诚实的一方可能会获得其他方数据的一些信息,但不诚实的一方仍然不可能得出其他方的实际原始数据。具体来说,每一方通过利用基于位置敏感散列的相似性信息来提升一些树。
[^TPAMI-LAQ]: This paper focuses on communication-efficient federated learning problem, and develops a novel distributed quantized gradient approach, which is characterized by adaptive communications of the quantized gradients. The key idea to save communications from the worker to the server is to quantize gradients as well as skip less informative quantized gradient communications by reusing previous gradients. Quantizing and skipping result in ‘lazy’ worker-server communications, which justifies the term Lazily Aggregated Quantized (LAQ) gradient. Theoretically, the LAQ algorithm achieves the same linear convergence as the gradient descent in the strongly convex case, while effecting major savings in the communication in terms of transmitted bits and communication rounds . 本文围绕通信高效的联邦学习问题,发展了一种新的分布式量化梯度方法,其特点是量化梯度的自适应通信。保存工作者到服务器之间的通信的关键思想是量化梯度,并通过重用先前的梯度跳过信息量较少的量化梯度通信。量化和跳过会导致"懒惰"的工作者-服务器通信,这就证明了Lazily Aggregate Quantized (LAQ)梯度一词的合理性。理论上,LAQ算法在强凸的情况下实现了与梯度下降相同的线性收敛,同时在传输比特数和通信轮数方面大大节省了通信开销。
[^FedPop]: A novel methodology coined FedPop by recasting personalised FL into the population modeling paradigm where clients' models involve fixed common population parameters and random individual ones, aiming at explaining data heterogeneity. To derive convergence guarantees for our scheme, we introduce a new class of federated stochastic optimisation algorithms which relies on Markov chain Monte Carlo methods. Compared to existing personalised FL methods, the proposed methodology has important benefits: it is robust to client drift, practical for inference on new clients, and above all, enables **uncertainty quantification** under mild computational and memory overheads. We provide non-asymptotic convergence guarantees for the proposed algorithms. 一种新的方法被称为FedPop,它将个性化的FL重塑为群体建模范式,客户的模型涉及固定的共同群体参数和随机的个体参数,旨在解释数据的异质性。为了得出我们方案的收敛保证,我们引入了一类新的联邦随机优化算法,该算法依赖于马尔科夫链蒙特卡洛方法。与现有的个性化FL方法相比,所提出的方法具有重要的优势:它对客户的漂移是稳健的,对新客户的推断是实用的,最重要的是,在温和的计算和内存开销下,可以进行**不确定性量化**。我们为提议的算法提供了非渐进收敛保证。
[^CoreFed]: We aim to formally represent this problem and address these fairness issues using concepts from co-operative game theory and social choice theory. We model the task of learning a shared predictor in the federated setting as a fair public decision making problem, and then define the notion of core-stable fairness: Given N agents, there is no subset of agents S that can benefit significantly by forming a coalition among themselves based on their utilities UN and US. Core-stable predictors are robust to low quality local data from some agents, and additionally they satisfy Proportionality (each agent gets at least 1/n fraction of the best utility that she can get from any predictor) and Pareto-optimality (there exists no model that can increase the utility of an agent without decreasing the utility of another), two well sought-after fairness and efficiency notions within social choice. We then propose an efficient federated learning protocol CoreFed to optimize a core stable predictor. CoreFed determines a core-stable predictor when the loss functions of the agents are convex. CoreFed also determines approximate core-stable predictors when the loss functions are not convex, like mooth neural networks. We further show the existence of core-stable predictors in more general settings using Kakutani's fixed point theorema. 我们旨在利用合作博弈理论和社会选择理论的概念来正式表示这个问题并解决这些公平性问题。我们把在联盟环境中学习共享预测器的任务建模为一个公平的公共决策问题,然后定义核心稳定的公平概念。给定N个代理人,没有一个代理人的子集S可以通过在他们之间形成一个基于他们的效用UN和US的联盟而显著受益。核心稳定的预测器对一些代理人的低质量本地数据具有鲁棒性,此外,它们还满足Proportionality(每个代理人从任何预测器中得到的最佳效用的至少1/n部分)和Pareto-optimality(不存在任何模型可以在增加一个代理人的效用的同时不减少另一个代理人的效用),这是社会选择中两个广受欢迎的公平和效率概念。然后,我们提出了一个高效的联邦学习协议CoreFed来优化一个核心稳定的预测器。当代理人的损失函数是凸的时候,CoreFed确定了一个核心稳定的预测器。当损失函数不是凸的时候,CoreFed也能确定近似的核心稳定预测器,比如摩斯神经网络。我们利用Kakutani的固定点定理,进一步证明了在更一般的情况下核心稳定预测器的存在。
[^SecureFedYJ]: The Yeo-Johnson (YJ) transformation is a standard parametrized per-feature unidimensional transformation often used to Gaussianize features in machine learning. In this paper, we investigate the problem of applying the YJ transformation in a cross-silo Federated Learning setting under privacy constraints. For the first time, we prove that the YJ negative log-likelihood is in fact convex, which allows us to optimize it with exponential search. We numerically show that the resulting algorithm is more stable than the state-of-the-art approach based on the Brent minimization method. Building on this simple algorithm and Secure Multiparty Computation routines, we propose SECUREFEDYJ, a federated algorithm that performs a pooled-equivalent YJ transformation without leaking more information than the final fitted parameters do. Quantitative experiments on real data demonstrate that, in addition to being secure, our approach reliably normalizes features across silos as well as if data were pooled, making it a viable approach for safe federated feature Gaussianization. Yeo-Johnson(YJ)变换是一个标准的参数化的每特征单维变换,通常用于机器学习的高斯化特征。在本文中,我们研究了在隐私约束下,在跨语境的联邦学习环境中应用YJ转换的问题。我们首次证明了YJ负对数可能性实际上是凸的,这使我们能够用指数搜索来优化它。我们在数值上表明,所得到的算法比基于布伦特最小化方法的最先进的方法更稳定。在这个简单的算法和安全多方计算程序的基础上,我们提出了SECUREFEDYJ,这是一个联邦算法,在不泄露比最终拟合参数更多信息的情况下执行集合等效的YJ转换。在真实数据上的定量实验表明,除了安全之外,我们的方法还能可靠地将不同筒仓的特征归一化,就像数据被汇集起来一样,这使得它成为安全联邦特征高斯化的可行方法。
[^FedRolex]: A simple yet effective model-heterogeneous FL method named FedRolex to tackle this constraint. Unlike the model-homogeneous scenario, the fundamental challenge of model heterogeneity in FL is that different parameters of the global model are trained on heterogeneous data distributions. FedRolex addresses this challenge by rolling the submodel in each federated iteration so that the parameters of the global model are evenly trained on the global data distribution across all devices, making it more akin to model-homogeneous training. 一个名为FedRolex的简单而有效的模型-异质性FL方法来解决这一约束。与模型同质化的情况不同,FL中模型异质化的根本挑战是全局模型的不同参数是在异质的数据分布上训练的。FedRolex通过在每个联邦迭代中滚动子模型来解决这个挑战,这样全局模型的参数就会在所有设备的全局数据分布上均匀地训练,使其更类似于模型同质化训练。
[^DReS-FL]: The data-owning clients may drop out of the training process arbitrarily. These characteristics will significantly degrade the training performance. This paper proposes a Dropout-Resilient Secure Federated Learning (DReS-FL) framework based on Lagrange coded computing (LCC) to tackle both the non-IID and dropout problems. The key idea is to utilize Lagrange coding to secretly share the private datasets among clients so that the effects of non-IID distribution and client dropouts can be compensated during local gradient computations. To provide a strict privacy guarantee for local datasets and correctly decode the gradient at the server, the gradient has to be a polynomial function in a finite field, and thus we construct polynomial integer neural networks (PINNs) to enable our framework. Theoretical analysis shows that DReS-FL is resilient to client dropouts and provides privacy protection for the local datasets. 拥有数据的客户可能会任意退出训练过程。这些特点将大大降低训练性能。本文提出了一个基于拉格朗日编码计算(LCC)的辍学弹性安全联邦学习(DReS-FL)框架来解决非IID和辍学问题。其关键思想是利用拉格朗日编码在客户之间秘密分享私人数据集,以便在本地梯度计算中补偿非IID分布和客户退出的影响。为了给本地数据集提供严格的隐私保证并在服务器上正确解码梯度,梯度必须是有限域中的多项式函数,因此我们构建了多项式整数神经网络(PINNs)来实现我们的框架。理论分析表明,DReS-FL对客户端辍学有弹性,并为本地数据集提供隐私保护。
[^FairVFL]: Since in real-world applications the data may contain bias on fairness-sensitive features (e.g., gender), VFL models may inherit bias from training data and become unfair for some user groups. However, existing fair machine learning methods usually rely on the centralized storage of fairness-sensitive features to achieve model fairness, which are usually inapplicable in federated scenarios. In this paper, we propose a fair vertical federated learning framework (FairVFL), which can improve the fairness of VFL models. The core idea of FairVFL is to learn unified and fair representations of samples based on the decentralized feature fields in a privacy-preserving way. Specifically, each platform with fairness-insensitive features first learns local data representations from local features. Then, these local representations are uploaded to a server and aggregated into a unified representation for the target task. In order to learn a fair unified representation, we send it to each platform storing fairness-sensitive features and apply adversarial learning to remove bias from the unified representation inherited from the biased data. Moreover, for protecting user privacy, we further propose a contrastive adversarial learning method to remove private information from the unified representation in server before sending it to the platforms keeping fairness-sensitive features. 由于在现实世界的应用中,数据可能包含对公平性敏感的特征(如性别)的偏见,VFL模型可能会从训练数据中继承偏见,并对一些用户群体变得不公平。然而,现有的公平机器学习方法通常依赖于公平性敏感特征的集中存储来实现模型的公平性,这在联盟场景中通常是不适用的。在本文中,我们提出了一个公平的垂直联邦学习框架(FairVFL),它可以提高VFL模型的公平性。FairVFL的核心思想是以保护隐私的方式,基于分散的特征场学习统一的、公平的样本表示。具体来说,每个具有公平性不敏感特征的平台首先从本地特征中学习本地数据表示。然后,这些本地表征被上传到服务器上,并聚合成目标任务的一个统一表征。为了学习一个公平的统一表征,我们将其发送到每个存储公平性敏感特征的平台,并应用对抗性学习来消除从有偏见的数据中继承的统一表征的偏见。此外,为了保护用户的隐私,我们进一步提出了一种对比性的对抗性学习方法,在将统一表示发送到保存公平性敏感特征的平台之前,从服务器中去除私人信息。
[^VR-ProxSkip]: We study distributed optimization methods based on the local training (LT) paradigm, i.e., methods which achieve communication efficiency by performing richer local gradient-based training on the clients before (expensive) parameter averaging is allowed to take place. While these methods were first proposed about a decade ago, and form the algorithmic backbone of federated learning, there is an enormous gap between their practical performance, and our theoretical understanding. Looking back at the progress of the field, we identify 5 generations of LT methods: 1) heuristic, 2) homogeneous, 3) sublinear, 4) linear, and 5) accelerated. The 5th generation was initiated by the ProxSkip method of Mishchenko et al. (2022), whose analysis provided the first theoretical confirmation that LT is a communication acceleration mechanism. Inspired by this recent progress, we contribute to the 5th generation of LT methods by showing that it is possible to enhance ProxSkip further using variance reduction. While all previous theoretical results for LT methods ignore the cost of local work altogether, and are framed purely in terms of the number of communication rounds, we construct a method that can be substantially faster in terms of the total training time than the state-of-the-art method ProxSkip in theory and practice in the regime when local computation is sufficiently expensive. We characterize this threshold theoretically, and confirm our theoretical predictions with empirical results. Our treatment of variance reduction is generic, and can work with a large number of variance reduction techniques, which may lead to future applications in the future. 我们研究了基于局部训练(LT)范式的分布式优化方法,即在允许进行(昂贵的)参数平均化之前,通过在客户端进行更丰富的基于局部梯度的训练来实现通信效率。虽然这些方法是在大约十年前首次提出的,并且形成了联邦学习的算法支柱,但是在它们的实际性能和我们的理论理解之间存在着巨大的差距。回顾该领域的进展,我们确定了5代LT方法:1)启发式,2)同质式,3)亚线性,4)线性,以及5)加速式。第5代是由Mishchenko等人(2022)的ProxSkip方法发起的,其分析首次从理论上证实了LT是一种通信加速机制。受这一最新进展的启发,我们为第5代LT方法做出了贡献,表明有可能利用方差减少来进一步增强ProxSkip。虽然之前所有关于LT方法的理论结果都完全忽略了局部工作的成本,而仅仅是以通信轮数为框架,但我们构建了一种方法,在理论和实践中,当局部计算足够昂贵时,其总训练时间可以比最先进的方法ProxSkip快很多。我们从理论上描述了这个阈值,并通过经验结果证实了我们的理论预测。我们对方差减少的处理是通用的,可以与大量的方差减少技术一起工作,这可能导致未来的应用。
[^VF-PS]: Vertical Federated Learning (VFL) methods are facing two challenges: (1) scalability when \# participants grows to even modest scale and (2) diminishing return w.r.t. \# participants: not all participants are equally important and many will not introduce quality improvement in a large consortium. Inspired by these two challenges, in this paper, we ask: How can we select l out of m participants, where l≪m , that are most important?We call this problem Vertically Federated Participant Selection, and model it with a principled mutual information-based view. Our first technical contribution is VF-MINE---a Vertically Federated Mutual INformation Estimator---that uses one of the most celebrated algorithms in database theory---Fagin's algorithm as a building block. Our second contribution is to further optimize VF-MINE to enable VF-PS, a group testing-based participant selection framework. 垂直联邦学习(VFL)方法面临着两个挑战:(1)当参与者数量增长到一定规模时的可扩展性;(2)对参与者的回报递减:不是所有的参与者都同样重要,许多参与者不会在一个大型联盟中引入质量改进。受这两个挑战的启发,在本文中,我们问:我们如何从m个参与者中选择l个,其中l≪m,是最重要的。我们称这个问题为垂直联邦参与者选择,并以基于相互信息的原则性观点为其建模。我们的第一个技术贡献是VF-MINE--一个垂直联邦的相互信息估计器--它使用数据库理论中最著名的算法之一--Fagin的算法作为构建模块。我们的第二个贡献是进一步优化VF-MINE,以实现VF-PS,一个基于小组测试的参与者选择框架。
[^DENSE]: A novel two-stage Data-free One-Shot Federated Learning(DENSE) framework, which trains the global model by a data generation stage and a model distillation stage. DENSE is a practical one-shot FL method that can be applied in reality due to the following advantages:(1) DENSE requires no additional information compared with other methods (except the model parameters) to be transferred between clients and the server;(2) DENSE does not require any auxiliary dataset for training;(3) DENSE considers model heterogeneity in FL, i.e. different clients can have different model architectures. 一种新颖的两阶段无数据单次联邦学习(DENSE)框架,它通过数据生成阶段和模型提炼阶段来训练全局模型。DENSE是一种实用的一次性FL方法,由于以下优点可以在现实中应用:(1)与其他方法相比,DENSE不需要在客户端和服务器之间传输额外的信息(除了模型参数);(2)DENSE不需要任何辅助数据集进行训练;(3)DENSE考虑了FL中的模型异质性,即不同客户端可以有不同的模型架构。
[^CalFAT]: We study the problem of FAT(federated adversarial training) under label skewness, and firstly reveal one root cause of the training instability and natural accuracy degradation issues: skewed labels lead to non-identical class probabilities and heterogeneous local models. We then propose a Calibrated FAT (CalFAT) approach to tackle the instability issue by calibrating the logits adaptively to balance the classes. 我们研究了标签偏斜下的FAT(联邦对抗训练)问题,首先揭示了训练不稳定和自然准确率下降问题的一个根本原因:偏斜的标签导致了非相同的类概率和异质的局部模型。然后,我们提出了一种校准的FAT(CalFAT)方法,通过自适应地校准对数来平衡类,来解决不稳定问题。
[^SAGDA]: Federated min-max learning has received increasing attention in recent years thanks to its wide range of applications in various learning paradigms. We propose a new algorithmic framework called stochastic sampling averaging gradient descent ascent (SAGDA), which i) assembles stochastic gradient estimators from randomly sampled clients as control variates and ii) leverages two learning rates on both server and client sides. We show that SAGDA achieves a linear speedup in terms of both the number of clients and local update steps, which yields an O(ϵ−2) communication complexity that is orders of magnitude lower than the state of the art. Interestingly, by noting that the standard federated stochastic gradient descent ascent (FSGDA) is in fact a control-variate-free special version of SAGDA, we immediately arrive at an O(ϵ−2) communication complexity result for FSGDA. Therefore, through the lens of SAGDA, we also advance the current understanding on communication complexity of the standard FSGDA method for federated min-max learning. 近年来,由于其在各种学习范式中的广泛应用,联邦最小-最大学习得到了越来越多的关注。我们提出了一个新的算法框架,称为随机抽样平均梯度下降上升法(SAGDA),它i)从随机抽样的客户端组装随机梯度估计器作为控制变量,ii)在服务器和客户端利用两个学习速率。我们表明,SAGDA在客户数量和局部更新步骤方面都实现了线性加速,这产生了O(ϵ-2)的通信复杂度,比目前的技术水平要低几个数量级。有趣的是,通过注意到标准联邦随机梯度下降法(FSGDA)实际上是SAGDA的无控制变量的特殊版本,我们立即得出了FSGDA的O(ϵ-2)通信复杂度结果。因此,通过SAGDA的视角,我们也推进了目前对标准FSGDA方法的通信复杂度的理解,以实现联邦的最小最大学习。
[^FAT-Clipping]: A key assumption in most existing works on FL algorithms' convergence analysis is that the noise in stochastic first-order information has a finite variance. Although this assumption covers all light-tailed (i.e., sub-exponential) and some heavy-tailed noise distributions (e.g., log-normal, Weibull, and some Pareto distributions), it fails for many fat-tailed noise distributions (i.e., heavier-tailed'' with potentially infinite variance) that have been empirically observed in the FL literature. To date, it remains unclear whether one can design convergent algorithms for FL systems that experience fat-tailed noise. This motivates us to fill this gap in this paper by proposing an algorithmic framework called FAT-Clipping (federated averaging with two-sided learning rates and clipping), which contains two variants: FAT-Clipping per-round (FAT-Clipping-PR) and FAT-Clipping per-iteration (FAT-Clipping-PI). 在大多数现有的关于FL算法收敛性分析的工作中,一个关键的假设是随机一阶信息中的噪声具有有限的方差。尽管这一假设涵盖了所有轻尾(即亚指数)和一些重尾噪声分布(如对数正态分布、Weibull分布和一些Pareto分布),但对于FL文献中实证观察到的许多肥尾噪声分布(即可能具有无限方差的重尾'')来说,它是失败的。到目前为止,我们还不清楚是否可以为经历肥尾噪声的FL系统设计收敛算法。这促使我们在本文中提出了一个名为FAT-Clipping(具有双面学习率和剪切的联邦平均法)的算法框架来填补这一空白,该框架包含两个变体。FAT-Clipping per-round(FAT-Clipping-PR)和FAT-Clipping per-iteration(FAT-Clipping-PI)。
[^FedSubAvg]: FedSubAvg, We study federated learning from the new perspective of feature heat, where distinct data features normally involve different numbers of clients, generating the differentiation of hot and cold features. Meanwhile, each client’s local data tend to interact with part of features, updating only the feature-related part of the full model, called a submodel. We further identify that the classical federated averaging algorithm (FedAvg) or its variants, which randomly selects clients to participate and uniformly averages their submodel updates, will be severely slowed down, because different parameters of the global model are optimized at different speeds. More specifically, the model parameters related to hot (resp., cold) features will be updated quickly (resp., slowly). We thus propose federated submodel averaging (FedSubAvg), which introduces the number of feature-related clients as the metric of feature heat to correct the aggregation of submodel updates. We prove that due to the dispersion of feature heat, the global objective is ill-conditioned, and FedSubAvg works as a suitable diagonal preconditioner. We also rigorously analyze FedSubAvg’s convergence rate to stationary points. 我们从特征热的新角度来研究联邦学习,不同的数据特征通常涉及不同数量的客户端,产生了冷热特征的区分。同时,每个客户的本地数据往往与部分特征交互,只更新完整模型中与特征相关的部分,称为子模型。我们进一步确定,经典的联邦平均算法(FedAvg)或其变体,即随机选择客户参与并统一平均他们的子模型更新,将被严重减慢,因为全局模型的不同参数是以不同的速度优化。更具体地说,与热(或冷)特征相关的模型参数将被快速(或缓慢)更新。因此,我们提出了联邦子模型平均法(FedSubAvg),它引入了与特征相关的客户数量作为特征热度的度量,以修正子模型更新的聚合。我们证明,由于特征热度的分散,全局目标是无条件的,而FedSubAvg作为一个合适的对角线先决条件发挥作用。我们还严格分析了FedSubAvg对静止点的收敛率。
[^BooNTK]: BooNTK, State-of-the-art federated learning methods can perform far worse than their centralized counterparts when clients have dissimilar data distributions. We show that this performance disparity can largely be attributed to optimization challenges presented by nonconvexity. Specifically, we find that the early layers of the network do learn useful features, but the final layers fail to make use of them. That is, federated optimization applied to this non-convex problem distorts the learning of the final layers. Leveraging this observation, we propose a Train-Convexify-Train (TCT) procedure to sidestep this issue: first, learn features using off-the-shelf methods (e.g., FedAvg); then, optimize a convexified problem obtained from the network's empirical neural tangent kernel approximation. 当客户具有不同的数据分布时,最先进的联邦学习方法的表现会比集中式的对应方法差很多。我们表明,这种性能差异主要归因于非凸性带来的优化挑战。具体来说,我们发现网络的早期层确实学到了有用的特征,但最后一层却无法利用它们。也就是说,应用于这个非凸问题的联邦优化扭曲了最终层的学习。利用这一观察,我们提出了一个Train-Convexify-Train(TCT)程序来回避这一问题:首先,使用现成的方法(如FedAvg)学习特征;然后,优化一个从网络的经验神经切线核近似中得到的凸化问题。
[^SoteriaFL]: SoteriaFL, A unified framework that enhances the communication efficiency of private federated learning with communication compression. Exploiting both general compression operators and local differential privacy, we first examine a simple algorithm that applies compression directly to differentially-private stochastic gradient descent, and identify its limitations. We then propose a unified framework SoteriaFL for private federated learning, which accommodates a general family of local gradient estimators including popular stochastic variance-reduced gradient methods and the state-of-the-art shifted compression scheme. 具有通信压缩的增强私有联邦学习通信效率的统一框架。利用一般的压缩算子和局部差分隐私,我们首先研究了一种简单的直接将压缩应用于差分隐私随机梯度下降的算法,并指出其局限性。然后,我们提出了一个用于私有联邦学习的统一框架SoteriaFL,它包含了一个通用的局部梯度估计器家族,包括流行的随机方差减少梯度方法和最先进的移位压缩方案。
[^FILM]: FILM, A novel attack method FILM (Federated Inversion attack for Language Models) for federated learning of language models---for the first time, we show the feasibility of recovering text from large batch sizes of up to 128 sentences. Different from image-recovery methods which are optimized to match gradients, we take a distinct approach that first identifies a set of words from gradients and then directly reconstructs sentences based on beam search and a prior-based reordering strategy. The key insight of our attack is to leverage either prior knowledge in pre-trained language models or memorization during training. Despite its simplicity, we demonstrate that FILM can work well with several large-scale datasets---it can extract single sentences with high fidelity even for large batch sizes and recover multiple sentences from the batch successfully if the attack is applied iteratively. 一种新颖的针对语言模型联邦学习的攻击方法FILM (针对语言模型的联邦反演攻击) - -首次展示了从多达128个句子的大批量文本中恢复文本的可行性。与为匹配梯度而优化的图像恢复方法不同,我们采取了一种独特的方法,首先从梯度中识别一组单词,然后根据光束搜索和基于先验的重新排序策略直接重建句子。我们攻击的关键见解是在预训练的语言模型中利用先验知识,或者在训练过程中进行记忆。尽管FILM简单,但我们证明了它可以在几个大规模数据集上很好地工作- -即使对于大批量的数据集,它也可以高保真地提取单个句子,如果迭代地应用攻击,它可以成功地从批处理中恢复多个句子。
[^FedPCL]: FedPCL, A lightweight framework where clients jointly learn to fuse the representations generated by multiple fixed pre-trained models rather than training a large-scale model from scratch. This leads us to a more practical FL problem by considering how to capture more client-specific and class-relevant information from the pre-trained models and jointly improve each client's ability to exploit those off-the-shelf models. Here, we design a Federated Prototype-wise Contrastive Learning (FedPCL) approach which shares knowledge across clients through their class prototypes and builds client-specific representations in a prototype-wise contrastive manner. Sharing prototypes rather than learnable model parameters allows each client to fuse the representations in a personalized way while keeping the shared knowledge in a compact form for efficient communication. 一个轻量级的框架,客户共同学习融合多个固定的预训练模型所产生的表征,而不是从头开始训练一个大规模的模型。这将我们引向一个更实际的FL问题,即考虑如何从预训练的模型中获取更多特定于客户和与类相关的信息,并共同提高每个客户利用这些现成的模型的能力。在这里,我们设计了一个联邦原型对比学习(FedPCL)的方法,通过客户的类别原型在客户之间分享知识,并以原型对比的方式建立客户的特定表征。分享原型而不是可学习的模型参数允许每个客户以个性化的方式融合表征,同时将共享的知识保持在一个紧凑的形式,以便有效沟通。
[^FLANC]: To achieve resource-adaptive federated learning, we introduce a simple yet effective mechanism, termed All-In-One Neural Composition, to systematically support training complexity-adjustable models with flexible resource adaption. It is able to efficiently construct models at various complexities using one unified neural basis shared among clients, instead of pruning the global model into local ones. The proposed mechanism endows the system with unhindered access to the full range of knowledge scattered across clients and generalizes existing pruning-based solutions by allowing soft and learnable extraction of low footprint models. 为了实现资源自适应的联邦学习,我们引入了一种简单而有效的机制,称为"一体式神经合成",以系统支持具有灵活资源自适应的训练复杂度可调模型。它能够使用客户机之间共享的一个统一神经基础在各种复杂情况下高效地构建模型,而不是将全局模型剪枝为局部模型。所提出的机制使系统能够不受阻碍地访问分散在客户端的所有知识,并通过允许对低足迹模型进行软和可学习的提取来推广现有的基于剪枝的解决方案。
[^Self-FL]: Inspired by Bayesian hierarchical models, we develop a self-aware personalized FL method where each client can automatically balance the training of its local personal model and the global model that implicitly contributes to other clients' training. Such a balance is derived from the inter-client and intra-client uncertainty quantification. A larger inter-client variation implies more personalization is needed. Correspondingly, our method uses uncertainty-driven local training steps an aggregation rule instead of conventional local fine-tuning and sample size-based aggregation. 受贝叶斯层次模型的启发,我们开发了一种自感知的个性化FL方法,每个客户端可以自动平衡其本地个人模型和隐式贡献于其他客户端训练的全局模型的训练。这种平衡来自于客户端间和客户端内的不确定性量化。更大的客户间差异意味着更多的个性化需求。相应地,我们的方法使用不确定性驱动的局部训练步骤作为聚合规则,而不是传统的局部微调和基于样本量的聚合。
[^FedGDA-GT]: In this paper, we study a large-scale multi-agent minimax optimization problem, which models many interesting applications in statistical learning and game theory, including Generative Adversarial Networks (GANs). The overall objective is a sum of agents' private local objective functions. We first analyze an important special case, empirical minimax problem, where the overall objective approximates a true population minimax risk by statistical samples. We provide generalization bounds for learning with this objective through Rademacher complexity analysis. Then, we focus on the federated setting, where agents can perform local computation and communicate with a central server. Most existing federated minimax algorithms either require communication per iteration or lack performance guarantees with the exception of Local Stochastic Gradient Descent Ascent (SGDA), a multiple-local-update descent ascent algorithm which guarantees convergence under a diminishing stepsize. By analyzing Local SGDA under the ideal condition of no gradient noise, we show that generally it cannot guarantee exact convergence with constant stepsizes and thus suffers from slow rates of convergence. To tackle this issue, we propose FedGDA-GT, an improved Federated (Fed) Gradient Descent Ascent (GDA) method based on Gradient Tracking (GT). When local objectives are Lipschitz smooth and strongly-convex-strongly-concave, we prove that FedGDA-GT converges linearly with a constant stepsize to global ϵ-approximation solution with O(log(1/ϵ)) rounds of communication, which matches the time complexity of centralized GDA method. Finally, we numerically show that FedGDA-GT outperforms Local SGDA. 在本文中,我们研究了一个大规模的多代理最小优化问题,它模拟了统计学习和博弈论中许多有趣的应用,包括生成对抗网络(GANs)。总体目标是代理人的私有局部目标函数的总和。我们首先分析了一个重要的特例,即经验最小值问题,其中总体目标是通过统计样本逼近真实的群体最小值风险。我们通过Rademacher复杂度分析,为这个目标的学习提供泛化界线。然后,我们专注于联盟环境,其中代理可以执行本地计算并与中央服务器通信。大多数现有的联邦最小化算法要么需要每次迭代都进行通信,要么缺乏性能保证,但本地随机梯度上升算法(SGDA)除外,它是一种多本地更新的下降上升算法,保证在步长减小的情况下收敛。通过在没有梯度噪声的理想条件下分析Local SGDA,我们发现一般来说它不能保证在恒定的步长下准确收敛,因此存在收敛速度慢的问题。为了解决这个问题,我们提出了FedGDA-GT,一种基于梯度跟踪(GT)的改进的联邦(Fed)梯度下降上升(GDA)方法。当局部目标是Lipschitz平滑和强凸-强凹时,我们证明FedGDA-GT以恒定的步长线性收敛到全局的ϵ近似解,只需O(log(1/ϵ)) 轮通信,这与集中式GDA方法的时间复杂度相符。最后,我们用数字表明,FedGDA-GT优于Local SGDA。
[^SemiFL]: SemiFL to address the problem of combining communication efficient FL like FedAvg with Semi-Supervised Learning (SSL). In SemiFL, clients have completely unlabeled data and can train multiple local epochs to reduce communication costs, while the server has a small amount of labeled data. We provide a theoretical understanding of the success of data augmentation-based SSL methods to illustrate the bottleneck of a vanilla combination of communication efficient FL with SSL. To address this issue, we propose alternate training to 'fine-tune global model with labeled data' and 'generate pseudo-labels with global model.' SemiFL是为了解决像FedAvg这样的通信效率高的FL与半监督学习(SSL)相结合的问题。在SemiFL中,客户拥有完全未标记的数据,并且可以训练多个本地历时以减少通信成本,而服务器拥有少量的标记数据。我们对基于数据增强的SSL方法的成功提供了一个理论上的理解,以说明通信效率高的FL与SSL的虚构组合的瓶颈。为了解决这个问题,我们提出了 "用标签数据微调全局模型 "和 "用全局模型生成伪标签 "的替代训练。
[^FedNTD]: This study starts from an analogy to continual learning and suggests that forgetting could be the bottleneck of federated learning. We observe that the global model forgets the knowledge from previous rounds, and the local training induces forgetting the knowledge outside of the local distribution. Based on our findings, we hypothesize that tackling down forgetting will relieve the data heterogeneity problem. To this end, we propose a novel and effective algorithm, Federated Not-True Distillation (FedNTD), which preserves the global perspective on locally available data only for the not-true classes. 这项研究从持续学习的类比开始,表明遗忘可能是联邦学习的瓶颈。我们观察到全局模型忘记了前几轮的知识,而本地训练会导致忘记本地分布之外的知识。基于我们的发现,我们假设处理遗忘会缓解数据异质性问题。为此,我们提出了一种新颖而有效的算法- -联邦非真实蒸馏( FedNTD ),它仅对非真实类保留本地可用数据的全局视角。
[^FedSR]: We propose a simple yet novel representation learning framework, namely FedSR, which enables domain generalization while still respecting the decentralized and privacy-preserving natures of this FL setting. Motivated by classical machine learning algorithms, we aim to learn a simple representation of the data for better generalization. In particular, we enforce an L2-norm regularizer on the representation and a conditional mutual information (between the representation and the data given the label) regularizer to encourage the model to only learn essential information (while ignoring spurious correlations such as the background). Furthermore, we provide theoretical connections between the above two objectives and representation alignment in domain generalization. 我们提出了一个简单但新颖的表示学习框架,即FedSR,它允许领域泛化,同时仍然尊重这种FL设置的去中心化和隐私保护性质。受经典机器学习算法的启发,我们旨在学习数据的简单表示以获得更好的泛化能力。特别地,我们在表示上强制一个L2范数正则化器和一个条件互信息(在给定标签的表示和数据之间)正则化器,以鼓励模型只学习基本信息(而忽略虚假的相关性,如背景)。此外,我们提供了上述两个目标与领域泛化中的表示对齐之间的理论联系。
[^Factorized-FL]: In real-world federated learning scenarios, participants could have their own personalized labels which are incompatible with those from other clients, due to using different label permutations or tackling completely different tasks or domains. However, most existing FL approaches cannot effectively tackle such extremely heterogeneous scenarios since they often assume that (1) all participants use a synchronized set of labels, and (2) they train on the same tasks from the same domain. In this work, to tackle these challenges, we introduce Factorized-FL, which allows to effectively tackle label- and task-heterogeneous federated learning settings by factorizing the model parameters into a pair of rank-1 vectors, where one captures the common knowledge across different labels and tasks and the other captures knowledge specific to the task for each local model. Moreover, based on the distance in the client-specific vector space, Factorized-FL performs selective aggregation scheme to utilize only the knowledge from the relevant participants for each client. 在现实世界的联邦学习场景中,由于使用不同的标签组合或处理完全不同的任务或领域,参与者可能有自己的个性化标签,而这些标签与其他客户的标签不兼容。然而,大多数现有的FL方法不能有效地处理这种极端异质的场景,因为它们通常假设(1)所有参与者使用同步的标签集,以及(2)他们在同一领域的相同任务上训练。在这项工作中,为了应对这些挑战,我们引入了Factorized-FL,它可以通过将模型参数分解为一对等级1的向量来有效地解决标签和任务异质的联邦学习环境,其中一个捕捉不同标签和任务的共同知识,另一个捕捉每个本地模型的特定任务知识。此外,根据客户特定向量空间中的距离,Factorized-FL执行选择性聚合方案,只利用每个客户的相关参与者的知识。
[^FedLinUCB]: We study federated contextual linear bandits, where M agents cooperate with each other to solve a global contextual linear bandit problem with the help of a central server. We consider the asynchronous setting, where all agents work independently and the communication between one agent and the server will not trigger other agents' communication. We propose a simple algorithm named FedLinUCB based on the principle of optimism. We prove that the regret of FedLinUCB is bounded by ˜O(d√∑Mm=1Tm) and the communication complexity is ˜O(dM2), where d is the dimension of the contextual vector and Tm is the total number of interactions with the environment by agent m. To the best of our knowledge, this is the first provably efficient algorithm that allows fully asynchronous communication for federated linear bandits, while achieving the same regret guarantee as in the single-agent setting.我们研究联邦式的上下文线性匪徒问题,其中M个代理相互协作,借助中心服务器解决一个全局的上下文线性匪徒问题。我们考虑异步设置,其中所有代理独立工作,并且一个代理与服务器之间的通信不会触发其他代理的通信。我们基于乐观原则提出了一个简单的算法FedLinUCB。我们证明了FedLinUCB的后悔度以˜O(d√∑Mm=1Tm)为界,通信复杂度为˜O(dM2),其中d是上下文向量的维数,Tm是代理m与环境交互的总数。据我们所知,这是第一个可证明有效的算法,允许联邦线性匪徒完全异步通信,同时实现与单代理设置中相同的遗憾保证。
[^FedSim]: Vertical federated learning (VFL), where parties share the same set of samples but only hold partial features, has a wide range of real-world applications. However, most existing studies in VFL disregard the record linkage” process. They design algorithms either assuming the data from different parties can be exactly linked or simply linking each record with its most similar neighboring record. These approaches may fail to capture the key features from other less similar records. Moreover, such improper linkage cannot be corrected by training since existing approaches provide no feedback on linkage during training. In this paper, we design a novel coupled training paradigm, FedSim, that integrates one-to-many linkage into the training process. Besides enabling VFL in many real-world applications with fuzzy identifiers, FedSim also achieves better performance in traditional VFL tasks. Moreover, we theoretically analyze the additional privacy risk incurred by sharing similarities. 纵向联邦学习(VFL),其中各方共享相同的样本集,但只保留部分特征,它有广泛的实际应用。然而,VFL中的大多数现有研究忽略了记录链接过程。他们设计算法,要么假设来自不同方的数据可以完全链接,要么简单地将每个记录与其最相似的相邻记录链接起来。这些方法可能无法从其他不太相似的记录中捕获关键特征。而且,这种不恰当的联结不能通过训练来纠正,因为现有方法在训练过程中没有提供关于联结的反馈。在本文中,我们设计了一种新的耦合训练范式FedSim,它将一对多连接集成到训练过程中。除了在许多具有模糊标识符的实际应用程序中启用VFL之外,FedSim还在传统的VFL任务中实现了更好的性能。此外,我们从理论上分析了共享相似性所带来的额外隐私风险。
[^PPSGD]: TBC
[^PBM]: TBC
[^DisPFL]: TBC
[^FedNew]: TBC
[^DAdaQuant]: TBC
[^FedMLB]: TBC
[^FedScale]: FedScale, a federated learning (FL) benchmarking suite with realistic datasets and a scalable runtime to enable reproducible FL research. FedScale是一个联邦学习(FL)基准测试套件,具有现实的数据集和可扩展的运行时间,以实现可重复的FL研究。
[^FedPU]: TBC
[^Orchestra]: TBC
[^DFL]: TBC
[^FedHeNN]: TBC
[^KNN-PER]: TBC
[^ProxRR]: TBC
[^FedNL]: TBC
[^VFL]: TBC
[^FedNest]: TBC
[^EDEN]: TBC
[^ProgFed]: TBC
[^breaching]: TBC
[^QSFL]: TBC
[^Neurotoxin]: TBC
[^FedUL]: TBC
[^FedChain]: TBC
[^FedReg]: TBC
[^Fed-RoD]: TBC
[^HeteroFL]: TBC
[^FedMix]: TBC
[^FedFomo]: TBC
[^FedBN]: TBC
[^FedBE]: TBC
[^FL-NTK]: TBC
[^Sageflow]: TBC
[^CAFE]: TBC
[^QuPeD]: TBC
[^FedSage]: In this work, towards the novel yet realistic setting of subgraph federated learning, we propose two major techniques: (1) FedSage, which trains a GraphSage model based on FedAvg to integrate node features, link structures, and task labels on multiple local subgraphs; (2) FedSage+, which trains a missing neighbor generator along FedSage to deal with missing links across local subgraphs. 在本工作中,针对子图联邦学习的新颖而现实的设置,我们提出了两个主要技术:(1) FedSage,它基于FedAvg训练一个GraphSage模型,以整合多个局部子图上的节点特征、链接结构和任务标签;(2) FedSage +,它沿着FedSage训练一个缺失的邻居生成器,以处理跨本地子图的缺失链接。
[^GradAttack]: TBC
[^KT-pFL]: We exploit the potentials of heterogeneous model settings and propose a novel training framework to employ personalized models for different clients. Specifically, we formulate the aggregation procedure in original pFL into a personalized group knowledge transfer training algorithm, namely, KT-pFL, which enables each client to maintain a personalized soft prediction at the server side to guide the others' local training. KT-pFL updates the personalized soft prediction of each client by a linear combination of all local soft predictions using a knowledge coefficient matrix, which can adaptively reinforce the collaboration among clients who own similar data distribution. Furthermore, to quantify the contributions of each client to others' personalized training, the knowledge coefficient matrix is parameterized so that it can be trained simultaneously with the models. The knowledge coefficient matrix and the model parameters are alternatively updated in each round following the gradient descent way. 我们利用异质模型设置的潜力,提出了一个新的训练框架,为不同的客户采用个性化的模型。具体来说,我们将原始pFL中的聚合程序制定为一种个性化的群体知识转移训练算法,即KT-pFL,它使每个客户在服务器端保持一个个性化的软预测,以指导其他人的本地训练。KT-pFL通过使用知识系数矩阵对所有本地软预测进行线性组合来更新每个客户端的个性化软预测,这可以自适应地加强拥有相似数据分布的客户端之间的协作。此外,为了量化每个客户对其他客户的个性化训练的贡献,知识系数矩阵被参数化,以便它可以与模型同时训练。知识系数矩阵和模型参数在每一轮中按照梯度下降的方式交替更新。
[^FL-WBC]: TBC
[^FjORD]: TBC
[^GCFL]: Graphs can also be regarded as a special type of data samples. We analyze real-world graphs from different domains to confirm that they indeed share certain graph properties that are statistically significant compared with random graphs. However, we also find that different sets of graphs, even from the same domain or same dataset, are non-IID regarding both graph structures and node features. A graph clustered federated learning (GCFL) framework that dynamically finds clusters of local systems based on the gradients of GNNs, and theoretically justify that such clusters can reduce the structure and feature heterogeneity among graphs owned by the local systems. Moreover, we observe the gradients of GNNs to be rather fluctuating in GCFL which impedes high-quality clustering, and design a gradient sequence-based clustering mechanism based on dynamic time warping (GCFL+). 图也可以看作是一种特殊类型的数据样本。我们分析来自不同领域的真实图,以确认它们确实共享某些与随机图形相比具有统计意义的图属性。然而,我们也发现不同的图集,即使来自相同的域或相同的数据集,在图结构和节点特性方面都是非IID的。图聚类联邦学习(GCFL)框架,基于GNNs的梯度动态地找到本地系统的集群,并从理论上证明这样的集群可以减少本地系统所拥有的图之间的结构和特征异构性。此外,我们观察到GNNs的梯度在GCFL中波动较大,阻碍了高质量的聚类,并设计了基于动态时间规整的梯度序列聚类机制(GCFL+)。
[^FedEx]: TBC
[^Large-Cohort]: TBC
[^DeepReduce]: TBC
[^PartialFed]: TBC
[^FCFL]: TBC
[^Federated-EM]: TBC
[^FedDR]: TBC
[^fair-flearn]: TBC
[^FedMA]: TBC
[^FedBoost]: TBC
[^FetchSGD]: TBC
[^SCAFFOLD]: TBC
[^FedSplit]: TBC
[^fbo]: TBC
[^RobustFL]: TBC
[^ifca]: TBC
[^DRFA]: TBC
[^Per-FedAvg]: TBC
[^FedGKT]: TBC
[^FedNova]: TBC
[^FedAc]: TBC
[^FedDF]: TBC
[^CE]: CE propose the concept of benefit graph which describes how each client can benefit from collaborating with other clients and advance a Pareto optimization approach to identify the optimal collaborators. CE提出了利益图的概念,描述了每个客户如何从与其他客户的合作中获益,并提出了帕累托优化方法来确定最佳合作者。
[^SuPerFed]: SuPerFed, a personalized federated learning method that induces an explicit connection between the optima of the local and the federated model in weight space for boosting each other. SuPerFed,一种个性化联邦学习方法,该方法在本地模型和联邦模型的权重空间中诱导出一个明确的连接,以促进彼此的发展。
[^FedMSplit]: FedMSplit framework, which allows federated training over multimodal distributed data without assuming similar active sensors in all clients. The key idea is to employ a dynamic and multi-view graph structure to adaptively capture the correlations amongst multimodal client models. FedMSplit框架,该框架允许在多模态分布式数据上进行联邦训练,而不需要假设所有客户端都有类似的主动传感器。其关键思想是采用动态和多视图图结构来适应性地捕捉多模态客户模型之间的相关性。
[^Comm-FedBiO]: Comm-FedBiO propose a learning-based reweighting approach to mitigate the effect of noisy labels in FL. Comm-FedBiO提出了一种基于学习的重加权方法,以减轻FL中噪声标签的影响。
[^FLDetector]: FLDetector detects malicious clients via checking their model-updates consistency to defend against model poisoning attacks with a large number of malicious clients. FLDetector 通过检查其模型更新的一致性来检测恶意客户,以防御大量恶意客户的模型中毒攻击。
[^FedSVD]: FedSVD, a practical lossless federated SVD method over billion-scale data, which can simultaneously achieve lossless accuracy and high efficiency. FedSVD,是一种实用的亿级数据上的无损联邦SVD方法,可以同时实现无损精度和高效率。
[^FedWalk]: FedWalk, a random-walk-based unsupervised node embedding algorithm that operates in such a node-level visibility graph with raw graph information remaining locally. FedWalk,一个基于随机行走的无监督节点嵌入算法,在这样一个节点级可见度图中操作,原始图信息保留在本地。
[^FederatedScope-GNN]: FederatedScope-GNN present an easy-to-use FGL (federated graph learning) package. FederatedScope-GNN提出了一个易于使用的FGL(联邦图学习)软件包。
[^Fed-LTD]: Federated Learning-to-Dispatch (Fed-LTD), a framework that allows effective order dispatching by sharing both dispatching models and decisions while providing privacy protection of raw data and high efficiency. 解决跨平台叫车问题,即多平台在不共享数据的情况下协同进行订单分配。
[^Felicitas]: Felicitas is a distributed cross-device Federated Learning (FL) framework to solve the industrial difficulties of FL in large-scale device deployment scenarios. Felicitas是一个分布式的跨设备联邦学习(FL)框架,以解决FL在大规模设备部署场景中的工业困难。
[^InclusiveFL]: InclusiveFL is to assign models of different sizes to clients with different computing capabilities, bigger models for powerful clients and smaller ones for weak clients. InclusiveFL 将不同大小的模型分配给具有不同计算能力的客户,较大的模型用于强大的客户,较小的用于弱小的客户。
[^FedAttack]: FedAttack a simple yet effective and covert poisoning attack method on federated recommendation, core idea is using globally hardest samples to subvert model training. FedAttack是一种对联邦推荐的简单而有效的隐蔽中毒攻击方法,核心思想是利用全局最难的样本来颠覆模型训练。
[^PipAttack]: PipAttack present a systematic approach to backdooring federated recommender systems for targeted item promotion. The core tactic is to take advantage of the inherent popularity bias that commonly exists in data-driven recommenders. PipAttack 提出了一种系统化的方法,为联邦推荐系统提供后门,以实现目标项目的推广。其核心策略是利用数据驱动的推荐器中普遍存在的固有的流行偏见。
[^Fed2]: Fed2, a feature-aligned federated learning framework to resolve this issue by establishing a firm structure-feature alignment across the collaborative models. Fed2是一个特征对齐的联邦学习框架,通过在协作模型之间建立牢固的结构-特征对齐来解决这个问题。
[^FedRS]: FedRS focus on a special kind of non-iid scene, i.e., label distribution skew, where each client can only access a partial set of the whole class set. Considering top layers of neural networks are more task-specific, we advocate that the last classification layer is more vulnerable to the shift of label distribution. Hence, we in-depth study the classifier layer and point out that the standard softmax will encounter several problems caused by missing classes. As an alternative, we propose “Restricted Softmax" to limit the update of missing classes’ weights during the local procedure. FedRS专注于一种特殊的非iid场景,即标签分布倾斜,每个客户端只能访问整个类集的部分集合。考虑到神经网络的顶层更具有任务针对性,我们主张最后一个分类层更容易受到标签分布偏移的影响。因此,我们深入研究了分类器层,并指出标准的softmax会遇到由缺失类引起的一些问题。作为一个替代方案,提出了 "限制性Softmax",以限制在本地程序中对缺失类的权重进行更新。
[^FADE]: While adversarial learning is commonly used in centralized learning for mitigating bias, there are significant barriers when extending it to the federated framework. In this work, we study these barriers and address them by proposing a novel approach Federated Adversarial DEbiasing (FADE). FADE does not require users' sensitive group information for debiasing and offers users the freedom to opt-out from the adversarial component when privacy or computational costs become a concern. 虽然对抗性学习通常用于集中式学习以减轻偏见,但当把它扩展到联邦式框架中时,会有很大的障碍。 在这项工作中,我们研究了这些障碍,并通过提出一种新的方法 Federated Adversarial DEbiasing(FADE)来解决它们。FADE不需要用户的敏感群体信息来进行去偏,并且当隐私或计算成本成为一个问题时,用户可以自由地选择退出对抗性部分。
[^CNFGNN]: Cross-Node Federated Graph Neural Network (CNFGNN) , a federated spatio-temporal model, which explicitly encodes the underlying graph structure using graph neural network (GNN)-based architecture under the constraint of cross-node federated learning, which requires that data in a network of nodes is generated locally on each node and remains decentralized. CNFGNN operates by disentangling the temporal dynamics modeling on devices and spatial dynamics on the server, utilizing alternating optimization to reduce the communication cost, facilitating computations on the edge devices. 跨节点联邦图神经网络(CNFGNN),是一个联邦时空模型,在跨节点联邦学习的约束下,使用基于图神经网络(GNN)的架构对底层图结构进行显式编码,这要求节点网络中的数据是在每个节点上本地生成的,并保持分散。CNFGNN通过分解设备上的时间动态建模和服务器上的空间动态来运作,利用交替优化来降低通信成本,促进边缘设备的计算。
[^AsySQN]: To address the challenges of communication and computation resource utilization, we propose an asynchronous stochastic quasi-Newton (AsySQN) framework for Vertical federated learning(VFL), under which three algorithms, i.e. AsySQN-SGD, -SVRG and -SAGA, are proposed. The proposed AsySQN-type algorithms making descent steps scaled by approximate (without calculating the inverse Hessian matrix explicitly) Hessian information convergence much faster than SGD-based methods in practice and thus can dramatically reduce the number of communication rounds. Moreover, the adopted asynchronous computation can make better use of the computation resource. We theoretically prove the convergence rates of our proposed algorithms for strongly convex problems. 为了解决通信和计算资源利用的挑战,我们提出了一个异步随机准牛顿(AsySQN)的纵和联邦学习VFL框架,在这个框架下,我们提出了三种算法,即AsySQN-SGD、-SVRG和-SAGA。所提出的AsySQN型算法使下降步骤按近似(不明确计算逆Hessian矩阵)Hessian信息收敛的速度比基于SGD的方法在实践中快得多,因此可以极大地减少通信轮数。此外,采用异步计算可以更好地利用计算资源。我们从理论上证明了我们提出的算法在强凸问题上的收敛率。
[^FLOP]: A simple yet effective algorithm, named Federated Learning on Medical Datasets using Partial Networks (FLOP), that shares only a partial model between the server and clients. 一种简单而有效的算法,被命名为使用部分网络的医学数据集的联邦学习(FLOP),该算法在服务器和客户之间只共享部分模型。
[^Federated-Learning-source]: This paper have built a framework that enables Federated Learning (FL) for a small number of stakeholders. and described the framework architecture, communication protocol, and algorithms. 本文建立了一个框架,为少数利益相关者实现联邦学习(FL),并描述了框架架构、通信协议和算法。
[^FDKT]: A novel Federated Deep Knowledge Tracing (FDKT) framework to collectively train high-quality Deep Knowledge Tracing (DKT) models for multiple silos. 一个新颖的联邦深度知识追踪(FDKT)框架,为多个筒仓集体训练高质量的深度知识追踪(DKT)模型。
[^FedFast]: FedFast accelerates distributed learning which achieves good accuracy for all users very early in the training process. We achieve this by sampling from a diverse set of participating clients in each training round and applying an active aggregation method that propagates the updated model to the other clients. Consequently, with FedFast the users benefit from far lower communication costs and more accurate models that can be consumed anytime during the training process even at the very early stages. FedFast加速了分布式学习,在训练过程的早期为所有用户实现了良好的准确性。我们通过在每轮训练中从不同的参与客户中取样,并应用主动聚合方法,将更新的模型传播给其他客户来实现这一目标。因此,有了FedFast,用户可以从更低的通信成本和更准确的模型中受益,这些模型可以在训练过程中随时使用,即使是在最早期阶段。
[^FDSKL]: FDSKL, a federated doubly stochastic kernel learning algorithm for vertically partitioned data. Specifically, we use random features to approximate the kernel mapping function and use doubly stochastic gradients to update the solutions, which are all computed federatedly without the disclosure of data. FDSKL,一个针对纵向分割数据的联邦双随机核学习算法。具体来说,我们使用随机特征来近似核映射函数,并使用双重随机梯度来更新解决方案,这些都是在不透露数据的情况下联邦计算的。
[^FOLtR-ES]: Federated Online Learning to Rank setup (FOLtR) where on-mobile ranking models are trained in a way that respects the users' privacy. FOLtR-ES that satisfies these requirement: (a) preserving the user privacy, (b) low communication and computation costs, (c) learning from noisy bandit feedback, and (d) learning with non-continuous ranking quality measures. A part of FOLtR-ES is a privatization procedure that allows it to provide ε-local differential privacy guarantees, i.e. protecting the clients from an adversary who has access to the communicated messages. This procedure can be applied to any absolute online metric that takes finitely many values or can be discretized to a finite domain. 联邦在线学习排名设置(FOLtR)中,移动端排名模型是以尊重用户隐私的方式来训练的。FOLtR-ES满足这些要求:(a)保护用户隐私,(b)低通信和计算成本,(c)从嘈杂的强盗反馈中学习,以及(d)用非连续的排名质量指标学习。FOLtR-ES的一部分是一个私有化程序,使其能够提供ε-local差异化的隐私保证,即保护客户不受能够接触到通信信息的对手的伤害。 这个程序可以应用于任何绝对在线度量,其取值有限,或者可以离散到一个有限域。
[^FedRecover]: Federated learning is vulnerable to poisoning attacks in which malicious clients poison the global model via sending malicious model updates to the server. Existing defenses focus on preventing a small number of malicious clients from poisoning the global model via robust federated learning methods and detecting malicious clients when there are a large number of them. However, it is still an open challenge how to recover the global model from poisoning attacks after the malicious clients are detected. A naive solution is to remove the detected malicious clients and train a new global model from scratch using the remaining clients. However, such train-from-scratch recovery method incurs a large computation and communication cost, which may be intolerable for resource-constrained clients such as smartphones and IoT devices. In this work, we propose FedRecover, a method that can recover an accurate global model from poisoning attacks with a small computation and communication cost for the clients. Our key idea is that the server estimates the clients’ model updates instead of asking the clients to compute and communicate them during the recovery process. In particular, the server stores the historical information, including the global models and clients’ model updates in each round, when training the poisoned global model before the malicious clients are detected. During the recovery process, the server estimates a client’s model update in each round using its stored historical information. Moreover, we further optimize FedRecover to recover a more accurate global model using warm-up, periodic correction, abnormality fixing, and final tuning strategies, in which the server asks the clients to compute and communicate their exact model updates. Theoretically, we show that the global model recovered by FedRecover is close to or the same as that recovered by train-from-scratch under some assumptions. 联合学习很容易受到中毒攻击,即恶意客户通过向服务器发送恶意的模型更新来毒害全局模型。现有的防御措施主要是通过强大的联合学习方法来防止少量的恶意客户毒害全局模型,并在有大量的恶意客户时检测他们。然而,在检测到恶意客户后,如何从中毒攻击中恢复全局模型仍然是一个公开的挑战。一个天真的解决方案是删除检测到的恶意客户,然后用剩下的客户从头开始训练一个新的全局模型。然而,这种从头开始训练的恢复方法会产生大量的计算和通信成本,这对于资源受限的客户(如智能手机和物联网设备)来说可能是不可容忍的。在这项工作中,我们提出了FedRecover,一种可以从中毒攻击中恢复准确的全局模型的方法,而客户的计算和通信成本却很小。我们的关键想法是,服务器估计客户的模型更新,而不是要求客户在恢复过程中进行计算和通信。特别是,在恶意客户被发现之前,服务器在训练中毒的全局模型时,储存了历史信息,包括全局模型和客户在每一轮的模型更新。在恢复过程中,服务器利用其存储的历史信息估计客户在每一轮的模型更新。此外,我们进一步优化FedRecover,使用预热、定期修正、异常修复和最终调整策略来恢复更准确的全局模型,其中服务器要求客户计算并传达他们的准确模型更新。理论上,我们表明FedRecover恢复的全局模型在某些假设条件下接近或与从头开始训练恢复的模型相同。
[^PEA]: We are motivated to resolve the above issue by proposing a solution, referred to as PEA (Private, Efficient, Accurate), which consists of a secure differentially private stochastic gradient descent (DPSGD for short) protocol and two optimization methods. First, we propose a secure DPSGD protocol to enforce DPSGD, which is a popular differentially private machine learning algorithm, in secret sharing-based MPL frameworks. Second, to reduce the accuracy loss led by differential privacy noise and the huge communication overhead of MPL, we propose two optimization methods for the training process of MPL. 提出一个安全差分隐私随机梯度下降协议以在基于秘密共享的安全多方学习框架中实现差分隐私随机梯度下降算法。为了降低差分隐私带来的精度损失并提升安全多方学习的效率,从安全多方学习训练过程的角度提出了两项优化方法,多方可以在MPL模型训练过程中平衡。做到隐私、效率和准确性三者之间的权衡。
[^SIMC]: TBC
[^FLAME]: TBC
[^FedCRI]: TBC
[^DeepSight]: TBC
[^FSMAFL]: This paper studies a new challenging problem, namely few-shot model agnostic federated learning, where the local participants design their independent models from their limited private datasets. Considering the scarcity of the private data, we propose to utilize the abundant public available datasets for bridging the gap between local private participants. However, its usage also brings in two problems: inconsistent labels and large domain gap between the public and private datasets. To address these issues, this paper presents a novel framework with two main parts: 1) model agnostic federated learning, it performs public-private communication by unifying the model prediction outputs on the shared public datasets; 2) latent embedding adaptation, it addresses the domain gap with an adversarial learning scheme to discriminate the public and private domains. 本文研究了一个新的具有挑战性的问题,即少量模型不可知的联合学习,其中本地参与者从他们有限的私人数据集中设计他们的独立模型。考虑到私有数据的稀缺性,我们建议利用丰富的公共数据集来弥合本地私有参与者之间的差距。然而,它的使用也带来了两个问题:不一致的标签和公共和私人数据集之间的巨大领域差距。为了解决这些问题,本文提出了一个新颖的框架,包括两个主要部分:1)模型不可知的联合学习,它通过统一共享的公共数据集上的模型预测输出来进行公私交流;2)潜在嵌入适应,它通过对抗性学习方案来解决领域差距问题,以区分公共和私人领域。
[^EmoFed]: TBC
[^FedSAM]: Models trained in federated settings often suffer from degraded performances and fail at generalizing, especially when facing heterogeneous scenarios. FedSAM investigate such behavior through the lens of geometry of the loss and Hessian eigenspectrum, linking the model's lack of generalization capacity to the sharpness of the solution. 联邦学习环境下训练的模型经常会出现性能下降和泛化失败的情况,特别是在面对异质场景时。FedSAM 通过损失和Hessian特征谱的几何角度来研究这种行为,将模型缺乏泛化能力与解决方案的锐度联系起来
[^FedX]: TBC
[^LC-Fed]: LC-Fed propose a personalized federated framework with Local Calibration, to leverage the inter-site in-consistencies in both feature- and prediction- levels to boost the segmentation. LC-Fed提出了一个带有本地校准的个性化联邦学习框架,以利用特征和预测层面的站点间不一致来提高分割效果。
[^ATPFL]: ATPFL helps users federate multi-source trajectory datasets to automatically design and train a powerful TP model. ATPFL帮助用户联邦多源轨迹数据集,自动设计和训练强大的TP轨迹预测模型。
[^ViT-FL]: ViT-FL demonstrate that self-attention-based architectures (e.g., Transformers) are more robust to distribution shifts and hence improve federated learning over heterogeneous data. ViT-FL证明了基于自注意力机制架构(如 Transformers)对分布的转变更加稳健,从而改善了异构数据的联邦学习。
[^FedCorr]: FedCorr, a general multi-stage framework to tackle heterogeneous label noise in FL, without making any assumptions on the noise models of local clients, while still maintaining client data privacy. FedCorr 一个通用的多阶段框架来处理FL中的异质标签噪声,不对本地客户的噪声模型做任何假设,同时仍然保持客户数据的隐私。
[^FedCor]: FedCor, an FL framework built on a correlation-based client selection strategy, to boost the convergence rate of FL. FedCor 一个建立在基于相关性的客户选择策略上的FL框架,以提高FL的收敛率。
[^pFedLA]: A novel pFL training framework dubbed Layer-wised Personalized Federated learning (pFedLA) that can discern the importance of each layer from different clients, and thus is able to optimize the personalized model aggregation for clients with heterogeneous data. "层级个性化联邦学习"(pFedLA),它可以从不同的客户那里分辨出每一层的重要性,从而能够为拥有异质数据的客户优化个性化的模型聚合。
[^FedAlign]: FedAlign rethinks solutions to data heterogeneity in FL with a focus on local learning generality rather than proximal restriction. 我们重新思考FL中数据异质性的解决方案,重点是本地学习的通用性(generality)而不是近似限制。
[^PANs]: Position-Aware Neurons (PANs) , fusing position-related values (i.e., position encodings) into neuron outputs, making parameters across clients pre-aligned and facilitating coordinate-based parameter averaging. 位置感知神经元(PANs)将位置相关的值(即位置编码)融合到神经元输出中,使各客户的参数预先对齐,并促进基于坐标的参数平均化。
[^RSCFed]: Federated semi-supervised learning (FSSL) aims to derive a global model by training fully-labeled and fully-unlabeled clients or training partially labeled clients. RSCFed presents a Random Sampling Consensus Federated learning, by considering the uneven reliability among models from fully-labeled clients, fully-unlabeled clients or partially labeled clients. 联邦半监督学习(FSSL)旨在通过训练有监督和无监督的客户或半监督的客户来得出一个全局模型。 随机抽样共识联邦学习,即RSCFed,考虑来自有监督的客户、无监督的客户或半监督的客户的模型之间不均匀的可靠性。
[^FCCL]: FCCL (Federated Cross-Correlation and Continual Learning) For heterogeneity problem, FCCL leverages unlabeled public data for communication and construct cross-correlation matrix to learn a generalizable representation under domain shift. Meanwhile, for catastrophic forgetting, FCCL utilizes knowledge distillation in local updating, providing inter and intra domain information without leaking privacy. FCCL(联邦交叉相关和持续学习)对于异质性问题,FCCL利用未标记的公共数据进行交流,并构建交叉相关矩阵来学习领域转移下的可泛化表示。同时,对于灾难性遗忘,FCCL利用局部更新中的知识提炼,在不泄露隐私的情况下提供域间和域内信息。
[^RHFL]: RHFL (Robust Heterogeneous Federated Learning) simultaneously handles the label noise and performs federated learning in a single framework. RHFL(稳健模型异构联邦学习),它同时处理标签噪声并在一个框架内执行联邦学习。
[^ResSFL]: ResSFL, a Split Federated Learning Framework that is designed to be MI-resistant during training. ResSFL一个分割学习的联邦学习框架,它被设计成在训练期间可以抵抗MI模型逆向攻击。 Model Inversion (MI) attack 模型逆向攻击 。
[^FedDC]: FedDC propose a novel federated learning algorithm with local drift decoupling and correction. FedDC 一种带有本地漂移解耦和校正的新型联邦学习算法。
[^GLFC]: Global-Local Forgetting Compensation (GLFC) model, to learn a global class incremental model for alleviating the catastrophic forgetting from both local and global perspectives. 全局-局部遗忘补偿(GLFC)模型,从局部和全局的角度学习一个全局类增量模型来缓解灾难性的遗忘问题。
[^FedFTG]: FedFTG, a data-free knowledge distillation method to fine-tune the global model in the server, which relieves the issue of direct model aggregation. FedFTG, 一种无数据的知识蒸馏方法来微调服务器中的全局模型,它缓解了直接模型聚合的问题。
[^DP-FedAvgplusBLURplusLUS]: DP-FedAvg+BLUR+LUS study the cause of model performance degradation in federated learning under user-level DP guarantee and propose two techniques, Bounded Local Update Regularization and Local Update Sparsification, to increase model quality without sacrificing privacy. DP-FedAvg+BLUR+LUS 研究了在用户级DP保证下联邦学习中模型性能下降的原因,提出了两种技术,即有界局部更新正则化和局部更新稀疏化,以提高模型质量而不牺牲隐私。
[^GGL]: Generative Gradient Leakage (GGL) validate that the private training data can still be leaked under certain defense settings with a new type of leakage. 生成梯度泄漏(GGL)验证了在某些防御设置下,私人训练数据仍可被泄漏。
[^CD2-pFed]: CD2-pFed, a novel Cyclic Distillation-guided Channel Decoupling framework, to personalize the global model in FL, under various settings of data heterogeneity. CD2-pFed,一个新的循环蒸馏引导的通道解耦框架,在各种数据异质性的设置下,在FL中实现全局模型的个性化。
[^FedSM]: FedSM propose a novel training framework to avoid the client drift issue and successfully close the generalization gap compared with the centralized training for medical image segmentation tasks for the first time. 新的训练框架FedSM,以避免客户端漂移问题,并首次成功地缩小了与集中式训练相比在医学图像分割任务中的泛化差距。
[^FL-MRCM]: FL-MRCM propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. FL-MRCM 一个基于联邦学习(FL)的解决方案,其中我们利用了不同机构的MR数据,同时保护了病人的隐私。
[^MOON]: MOON
[^FedDG-ELCFS]: FedDG-ELCFS A novel problem setting of federated domain generalization (FedDG), which aims to learn a federated model from multiple distributed source domains such that it can directly generalize to unseen target domains. Episodic Learning in Continuous Frequency Space (ELCFS), for this problem by enabling each client to exploit multi-source data distributions under the challenging constraint of data decentralization. FedDG-ELCFS 联邦域泛化(FedDG)旨在从多个分布式源域中学习一个联邦模型,使其能够直接泛化到未见过的目标域中。连续频率空间中的偶发学习(ELCFS),使每个客户能够在数据分散的挑战约束下利用多源数据分布。
[^Soteria]: Soteria propose a defense against model inversion attack in FL, learning to perturb data representation such that the quality of the reconstructed data is severely degraded, while FL performance is maintained. Soteria 一种防御FL中模型反转攻击的方法,关键思想是学习扰乱数据表示,使重建数据的质量严重下降,而FL性能保持不变。
[^FedUFO]: FedUFO a Unified Feature learning and Optimization objectives alignment method for non-IID FL. FedUFO 一种针对non IID FL的统一特征学习和优化目标对齐算法。
[^FedAD]: FedAD propose a new distillation-based FL frame-work that can preserve privacy by design, while also consuming substantially less network communication resources when compared to the current methods. FedAD 一个新的基于蒸馏的FL框架,它可以通过设计来保护隐私,同时与目前的方法相比,消耗的网络通信资源也大大减少
[^FedU]: FedU a novel federated unsupervised learning framework. FedU 一个新颖的无监督联邦学习框架.
[^FedUReID]: FedUReID, a federated unsupervised person ReID system to learn person ReID models without any labels while preserving privacy. FedUReID,一个联邦的无监督人物识别系统,在没有任何标签的情况下学习人物识别模型,同时保护隐私。
[^FedVCplusFedIR]: Introduce two new large-scale datasets for species and landmark classification, with realistic per-user data splits that simulate real-world edge learning scenarios. We also develop two new algorithms (FedVC, FedIR) that intelligently resample and reweight over the client pool, bringing large improvements in accuracy and stability in training. 为物种和地标分类引入了两个新的大规模数据集,每个用户的现实数据分割模拟了真实世界的边缘学习场景。我们还开发了两种新的算法(FedVC、FedIR),在客户池上智能地重新取样和重新加权,在训练中带来了准确性和稳定性的巨大改进
[^InvisibleFL]: InvisibleFL propose a privacy-preserving solution that avoids multimedia privacy leakages in federated learning. InvisibleFL 提出了一个保护隐私的解决方案,以避免联邦学习中的多媒体隐私泄漏。
[^FedReID]: FedReID implement federated learning to person re-identification and optimize its performance affected by statistical heterogeneity in the real-world scenario. FedReID 实现了对行人重识别任务的联邦学习,并优化了其在真实世界场景中受统计异质性影响的性能。
[^FedR]: In this paper, we first develop a novel attack that aims to recover the original data based on embedding information, which is further used to evaluate the vulnerabilities of FedE. Furthermore, we propose a Federated learning paradigm with privacy-preserving Relation embedding aggregation (FedR) to tackle the privacy issue in FedE. Compared to entity embedding sharing, relation embedding sharing policy can significantly reduce the communication cost due to its smaller size of queries. 在本文中,我们首先开发了一个新颖的攻击,旨在基于嵌入信息恢复原始数据,并进一步用于评估FedE的漏洞。此外,我们提出了一种带有隐私保护的关系嵌入聚合(FedR)的联邦学习范式,以解决FedE的隐私问题。与实体嵌入共享相比,关系嵌入共享策略由于其较小的查询规模,可以大大降低通信成本。
[^SLM-FL]: Due to the server-client communication and on-device computation bottlenecks, **this paper explores whether the big language model can be achieved using cross-device federated learning.** First, they investigate **quantization and partial model training** to address the per round communication and computation cost. Then, they study fast convergence techniques by reducing the number of communication rounds, using **transfer learning and centralized pretraining** methods. They demonstrated that these techniques, individually or in combination, can scale to larger models in cross-device federated learning. 由于通讯和计算资源受限,他们研究是否能在跨设备联邦学习中训练参数较多的模型,如21M的Transformer, 20.2M的Conformer。首先,他们调查了量化、部分训练技术来减少通讯和计算成本;其次,他们研究快速收敛技术通过减少通讯轮次,运用迁移学习和Centralized pretraining技术。他们的研究表明,运用上述技术,或这些技术的组合,可以在跨设备联邦学习中扩展到更大的模型。
[^IGC-FL]: **Communication cost** is the largest barrier to the wider adoption of federated learning. This paper addresses this issue by **investigating a family of new gradient compression strategies**, including static compression, time-varying compression and K-subspace compression. They call it intrinsic gradient compression algorithms. These three gradient compression algorithms can be applied to different levels of bandwidth scenarios and can be used in combination in special scenarios.Moreover, they provide **theoretical guarantees** on the performance. They train big models with 100M parameters compared to current state-of-the-art gradient compression methods (e.g. FetchSGD). 通讯成本是联邦学习大规模部署面临的最大阻碍。这篇文章研究一系列新的梯度压缩策略来减轻这一挑战,包括static compression, time-varying compression and K-subspace compression,他们称之为intrinstic gradient compression algorighms. 这三种梯度压缩算法可应用于不同级别带宽的场景,在特殊的场景也可以组合使用。而且,他们提供了理论分析保证。他们训练了100M参数的大模型,与其他梯度压缩方法(如FetchSGD)相比,达到SOTA.
[^ActPerFL]: Inspired by **Bayesian hierarchical models,** this paper investigates how to achieve better personalized federated learning by balancing local model improvement and global model tuning. They develop Act-PerFL, a self-aware personalized FL method where leveraging local training and global aggregation via inter- and intra-client uncertainty quantification. Specifically, ActPerFL **adaptively adjusts local training steps** with automated hyper-parameter selection and performs **uncertainty-weighted global aggregation** (Non-sample size based weighted average) . 受贝叶斯分层模型的启发,本文研究如何通过平衡本地模型和全局模型实现更好的个性化联邦学习。他们提出了ActPerFL,利用客户间和客户内部的不确定性量化来指导本地训练和全局聚合。具体来说,ActPerFL通过自动超参数选择自适应地调整本次训练次数,并执行不确定性加权全局聚合(非基于样本数量的带权平均)。
[^FedNLP]: This paper present **a benchmarking framework for evaluating federated learning methods on four common formulations** of NLP tasks: text classification, sequence tagging, question answering, and seq2seq generation. 联邦学习在NLP领域的一个基准框架,提供常见的联邦学习算法实现(FedAvg、FedProx、FedOPT),支持四种常见NLP任务(文本分类、序列标记、问答、seq2seq)的对比。
[^FedNoisy]: In realistic human-computer interaction, there are usually many noisy user feedback signals. This paper investigates whether federated learning can be trained directly based on positive and negative user feedback. They show that, under mild to moderate noise conditions, incorporating feedback improves model performance over self-supervised baselines.They also study different levels of noise hoping to **mitigate the impact of user feedback noise on model performance.** 在现实的人机交互中,通常有很多带噪声的用户反馈信号。本文研究是否能直接基于积极和消极的用户反馈来进行联邦学习训练。他们表明,在轻度至中度噪声条件下,与自监督基准相比,结合不同反馈可以提高模型性能。他们还对不同程度的噪声展开研究,希望能减轻用户反馈噪声对模型性能的影响。
[^FedMDT]: Due to the real-world limitations of centralized training, when training mixed-domain translation models with federated learning, this paper finds that the global aggregation strategy of federated learning can effectively aggregate information from different domains, so that NMT (neural machine translation) can benefit from federated learning. At the same time, they propose a novel and practical solution to reduce the **communication bandwidth**. Specifically, they design **Dynamic Pulling**, which pulls only one type of high volatility tensor in each round of communication. 由于中心式训练在现实世界存在诸多限制,在用联邦学习训练mixed-domain translation models时候,本文发现联邦学习的全局聚合策略可以有效融合来自不同领域的信息,使得NMT(neural machine translation)可以从联邦学习中受益。同时由于通信瓶颈,他们提出一种新颖且实用的方案来降低通信带宽。具体来说,他们设计了 Dynamic Pulling, 在每轮通信中只拉取一种类型的高波动张量。
[^Efficient-FedRec]: TBC
[^noniid-foltr]: In this perspective paper we study the effect of non independent and identically distributed (non-IID) data on federated online learning to rank (FOLTR) and chart directions for future work in this new and largely unexplored research area of Information Retrieval. 在这篇前瞻论文中,我们研究了非独立和相同分布(非IID)数据对联邦在线学习排名(FOLTR)的影响,并为这个新的、基本上未被开发的信息检索研究领域的未来工作指明了方向。
[^FedCT]: The cross-domain recommendation problem is formalized under a decentralized computing environment with multiple domain servers. And we identify two key challenges for this setting: the unavailability of direct transfer and the heterogeneity of the domain-specific user representations. We then propose to learn and maintain a decentralized user encoding on each user's personal space. The optimization follows a variational inference framework that maximizes the mutual information between the user's encoding and the domain-specific user information from all her interacted domains. 跨域推荐问题在具有多个域服务器的去中心化计算环境下被形式化。我们确定了这种情况下的两个关键挑战:直接传输的不可用性和特定领域用户表征的异质性。然后,我们建议在每个用户的个人空间上学习和维护一个分散的用户编码。优化遵循一个变分推理框架,使用户的编码和来自她所有互动领域的特定用户信息之间的互信息最大化。
[^FedGWAS]: Under some circumstances, the private data can be reconstructed from the model parameters, which implies that data leakage can occur in FL.In this paper, we draw attention to another risk associated with FL: Even if federated algorithms are individually privacy-preserving, combining them into pipelines is not necessarily privacy-preserving. We provide a concrete example from genome-wide association studies, where the combination of federated principal component analysis and federated linear regression allows the aggregator to retrieve sensitive patient data by solving an instance of the multidimensional subset sum problem. This supports the increasing awareness in the field that, for FL to be truly privacy-preserving, measures have to be undertaken to protect against data leakage at the aggregator. 在某些情况下,私人数据可以从模型参数中重建,这意味着在联邦学习中可能发生数据泄漏。 在本文中,我们提请注意与FL相关的另一个风险。即使联邦算法是单独保护隐私的,将它们组合成管道也不一定是保护隐私的。我们提供了一个来自全基因组关联研究的具体例子,其中联邦主成分分析和联邦线性回归的组合允许聚合器通过解决多维子集和问题的实例来检索敏感的病人数据。这支持了该领域日益增长的意识,即为了使FL真正保护隐私,必须采取措施防止聚合器的数据泄漏。
[^FedCMR]: The federated cross-modal retrieval (FedCMR), which learns the model with decentralized multi-modal data. 联邦跨模式检索(FedCMR),它用分散的多模式数据学习模型。
[^MetaMF]: A federated matrix factorization (MF) framework, named meta matrix factorization (MetaMF) for rating prediction (RP) for mobile environments. 一个联邦矩阵分解(MF)框架,命名为元矩阵分解(MetaMF),用于移动环境的评级预测(RP)。
[^SMM]: We design and develop distributed Skellam mechanism DSM, a novel solution for enforcing differential privacy on models built through an MPC-based federated learning process. Compared to existing approaches, DSM has the advantage that its privacy guarantee is independent of the dimensionality of the gradients; further, DSM allows tight privacy accounting due to the nice composition and sub-sampling properties of the Skellam distribution, which are key to enforce differential privacy on models built through an MPC-based federated learning process. 我们设计并开发了分布式Skellam机制DSM,这是一种新的解决方案,用于在基于MPC的联邦学习过程构建的模型上强制实现差分隐私。与现有方法相比,DSM的优势在于其隐私保护独立于梯度的维度;此外,由于Skellam分布的良好组成和子采样特性,DSM允许进行严格的隐私计算,这对于通过基于MPC的联邦学习过程建立的模型实施差分隐私是关键。
[^CELU-VFL]: CELU-VFL, a novel and efficient Vertical federated learning (VFL) training framework that exploits the local update technique to reduce the cross-party communication rounds. CELU-VFL caches the stale statistics and reuses them to estimate model gradients without exchanging the ad hoc statistics. Significant techniques are proposed to improve the convergence performance. First, to handle the stochastic variance problem, we propose a uniform sampling strategy to fairly choose the stale statistics for local updates. Second, to harness the errors brought by the staleness, we devise an instance weighting mechanism that measures the reliability of the estimated gradients. Theoretical analysis proves that CELU-VFL achieves a similar sub-linear convergence rate as vanilla VFL training but requires much fewer communication rounds. CELU-VFL,一种新颖高效的纵向联邦学习 (VFL) 训练框架,它利用本地更新技术来减少跨方通信轮次。 CELU-VFL 缓存过时的统计数据并重用它们来估计模型梯度,而无需交换临时统计数据。 提出了重要的技术来提高收敛性能。 首先,为了处理随机方差问题,我们提出了一种统一的抽样策略来公平地选择用于局部更新的陈旧统计数据。 其次,为了利用过时带来的误差,我们设计了一种实例加权机制来衡量估计梯度的可靠性。 理论分析证明,CELU-VFL 实现了与普通 VFL 训练相似的亚线性收敛速度,但需要的通信轮数要少得多。
[^FedTSC]: FedTSC, a novel federated learning (FL) system for interpretable time series classification (TSC). FedTSC is an FL-based TSC solution that makes a great balance among security, interpretability, accuracy, and efficiency. We achieve this by firstextending the concept of FL to consider both stronger security and model interpretability. Then, we propose three novel TSC methods based on explainable features to deal with the challengeable FL problem. To build the model in the FL setting, we propose several security protocols that are well optimized by maximally reducing the bottlenecked communication complexity. We build the FedTSC system based on such a solution, and provide the user Sklearn-like Python APIs for practical utility. FedTSC,一种用于可解释时间序列分类 (TSC) 的新型联邦学习 (FL) 系统。 FedTSC 是基于 FL 的 TSC 解决方案,在安全性、可解释性、准确性和效率之间取得了很好的平衡。 我们通过首先扩展 FL 的概念来考虑更强的安全性和模型可解释性来实现这一点。 然后,我们提出了三种基于可解释特征的新型 TSC 方法来处理具有挑战性的 FL 问题。 为了在 FL 设置中构建模型,我们提出了几种安全协议,这些协议通过最大限度地降低瓶颈通信复杂性而得到了很好的优化。 我们基于这样的解决方案构建了 FedTSC 系统,并为用户提供了类似于 Sklearn 的 Python API 以供实用。
[^CSFV]: TBC
[^FedADMM]: Federated Learning (FL) is an emerging framework for distributed processing of large data volumes by edge devices subject to limited communication bandwidths, heterogeneity in data distributions and computational resources, as well as privacy considerations. In this paper, we introduce a new FL protocol termed FedADMM based on primal-dual optimization. The proposed method leverages dual variables to tackle statistical heterogeneity, and accommodates system heterogeneity by tolerating variable amount of work performed by clients. FedADMM maintains identical communication costs per round as FedAvg/Prox, and generalizes them via the augmented Lagrangian. A convergence proof is established for nonconvex objectives, under no restrictions in terms of data dissimilarity or number of participants per round of the algorithm. We demonstrate the merits through extensive experiments on real datasets, under both IID and non-IID data distributions across clients. FedADMM consistently outperforms all baseline methods in terms of communication efficiency, with the number of rounds needed to reach a prescribed accuracy reduced by up to 87%. The algorithm effectively adapts to heterogeneous data distributions through the use of dual variables, without the need for hyperparameter tuning, and its advantages are more pronounced in large-scale systems. 联邦学习 (FL) 是一种新兴框架,用于边缘设备分布式处理大数据量,受限于有限的通信带宽、数据分布和计算资源的异构性以及隐私考虑。在本文中,我们介绍了一种基于原始对偶优化的称为 FedADMM 的新 FL 协议。所提出的方法利用双变量来解决统计异质性,并通过容忍客户执行的可变工作量来适应系统异质性。 FedADMM 保持与 FedAvg/Prox 相同的每轮通信成本,并通过增强的拉格朗日量对其进行推广。为非凸目标建立了收敛证明,不受数据差异或每轮算法参与者数量的限制。我们在跨客户端的 IID 和非 IID 数据分布下,通过对真实数据集的广泛实验证明了这些优点。 FedADMM 在通信效率方面始终优于所有基线方法,达到规定精度所需的轮数减少了高达 87%。该算法通过使用对偶变量有效适应异构数据分布,无需超参数调优,在大规模系统中优势更加明显。
[^FedMP]: The existing FL frameworks usually suffer from the difficulties of resource limitation and edge heterogeneity. Herein, we design and implement FedMP, an efficient FL framework through adaptive model pruning. We theoretically analyze the impact of pruning ratio on model training performance, and propose to employ a Multi-Armed Bandit based online learning algorithm to adaptively determine different pruning ratios for heterogeneous edge nodes, even without any prior knowledge of their computation and communication capabilities. With adaptive model pruning, FedMP can not only reduce resource consumption but also achieve promising accuracy. To prevent the diverse structures of pruned models from affecting the training convergence, we further present a new parameter synchronization scheme, called Residual Recovery Synchronous Parallel (R2SP), and provide a theoretical convergence guarantee. Extensive experiments on the classical models and datasets demonstrate that FedMP is effective for different heterogeneous scenarios and data distributions, and can provide up to 4.1× speedup compared to the existing FL methods.现有的 FL 框架通常存在资源限制和边缘异构的困难。在这里,我们通过自适应模型修剪设计并实现了一个高效的 FL 框架 FedMP。我们从理论上分析了剪枝率对模型训练性能的影响,并提出采用基于多臂老虎机的在线学习算法来自适应地确定异构边缘节点的不同剪枝率,即使对它们的计算和通信能力没有任何先验知识。通过自适应模型修剪,FedMP 不仅可以减少资源消耗,而且可以实现有希望的准确性。为了防止剪枝模型的多种结构影响训练收敛,我们进一步提出了一种新的参数同步方案,称为残差恢复同步并行(R2SP),并提供了理论上的收敛保证。对经典模型和数据集的大量实验表明,FedMP 对于不同的异构场景和数据分布是有效的,与现有的 FL 方法相比,可以提供高达 4.1 倍的加速。
[^ESND]: A key and common challenge on distributed databases is the heterogeneity of the data distribution among the parties. The data of different parties are usually non-independently and identically distributed (i.e., non-IID). There have been many FL algorithms to address the learning effectiveness under non-IID data settings. However, there lacks an experimental study on systematically understanding their advantages and disadvantages, as previous studies have very rigid data partitioning strategies among parties, which are hardly representative and thorough. In this paper, to help researchers better understand and study the non-IID data setting in federated learning, we propose comprehensive data partitioning strategies to cover the typical non-IID data cases. Moreover, we conduct extensive experiments to evaluate state-of-the-art FL algorithms. We find that non-IID does bring signifificant challenges in learning accuracy of FL algorithms, and none of the existing state-of-the-art FL algorithms outperforms others in all cases. Our experiments provide insights for future studies of addressing the challenges in “data silos”. 分布式数据库的一个关键和常见挑战是各方之间数据分布的异质性。不同各方的数据通常是非独立同分布的(即非IID)。已经有许多FL算法来解决在非IID数据设置下的学习有效性。然而,由于以往的研究具有非常僵硬单一的数据划分策略,难以具有代表性和彻底,因此缺乏系统理解其优缺点的实验研究。在本文中,为了帮助研究者更好地理解和研究联邦学习中的非IID数据设置,我们提出了综合的数据划分策略来覆盖典型的非IID数据案例。此外,我们还进行了广泛的实验来评估最先进的FL算法。我们发现,非IID确实在FL算法的学习准确性方面带来了重大挑战,而且现有的最先进的FL算法在所有情况下都没有一种优于其他算法。我们的实验为未来研究解决“数据竖井”中的挑战提供了见解。
[^FedMigr]: To approach the challenges of non-IID data and limited communication resource raised by the emerging federated learning (FL) in mobile edge computing (MEC), we propose an efficient framework, called FedMigr, which integrates a deep reinforcement learning (DRL) based model migration strategy into the pioneer FL algorithm FedAvg. According to the data distribution and resource constraints, our FedMigr will intelligently guide one client to forward its local model to another client after local updating, rather than directly sending the local models to the server for global aggregation as in FedAvg. Intuitively, migrating a local model from one client to another is equivalent to training it over more data from different clients, contributing to alleviating the influence of non-IID issue. We prove that FedMigr can help to reduce the parameter divergences between different local models and the global model from a theoretical perspective, even over local datasets with non-IID settings. Extensive experiments on three popular benchmark datasets demonstrate that FedMigr can achieve an average accuracy improvement of around 13%, and reduce bandwidth consumption for global communication by 42% on average, compared with the baselines. 为了应对移动边缘计算 (MEC) 中新兴的联邦学习 (FL) 带来的非 IID 数据和有限通信资源的挑战,我们提出了一个名为 FedMigr 的高效框架,该框架集成了基于深度强化学习 (DRL) 的模型迁移策略进入先驱 FL 算法 FedAvg。根据数据分布和资源限制,我们的 FedMigr 会智能地引导一个客户端在本地更新后将其本地模型转发给另一个客户端,而不是像 FedAvg 那样直接将本地模型发送到服务器进行全局聚合。直观地说,将本地模型从一个客户端迁移到另一个客户端相当于在来自不同客户端的更多数据上对其进行训练,有助于减轻非 IID 问题的影响。我们证明 FedMigr 从理论角度可以帮助减少不同局部模型和全局模型之间的参数差异,即使在具有非 IID 设置的局部数据集上也是如此。在三个流行的基准数据集上进行的大量实验表明,与基线相比,FedMigr 可以实现约 13% 的平均准确度提升,并将全局通信的带宽消耗平均减少 42%。
[^Samba]: The federated learning paradigm allows several data owners to contribute to a machine learning task without exposing their potentially sensitive data. We focus on cumulative reward maximization in Multi-Armed Bandits (MAB), a classical reinforcement learning model for decision making under uncertainty. We demonstrate Samba, a generic framework for Secure federAted Multi-armed BAndits. The demonstration platform is a Web interface that simulates the distributed components of Samba, and which helps the data scientist to configure the end-to-end workflow of deploying a federated MAB algorithm. The user-friendly interface of Samba, allows the users to examine the interaction between three key dimensions of federated MAB: cumulative reward, computation time, and security guarantees. We demonstrate Samba with two real-world datasets: Google Local Reviews and Steam Video Game. 联邦学习允许多个数据所有者为机器学习任务做出贡献,而不会暴露他们潜在的敏感数据。我们专注于多臂老虎机(MAB)中的累积奖励最大化,这是一种用于在不确定性下进行决策的经典强化学习模型。我们演示了 Samba,这是一个用于安全联邦多臂强盗的通用框架。该演示平台是一个模拟 Samba 分布式组件的 Web 界面,可帮助数据科学家配置部署联邦 MAB 算法的端到端工作流程。 Samba 的用户友好界面允许用户检查联邦 MAB 的三个关键维度之间的交互:累积奖励、计算时间和安全保证。我们使用两个真实数据集演示 Samba:Google 本地评论和 Steam 视频游戏。
[^FedRecAttack]: Federated Recommendation (FR) has received considerable popularity and attention in the past few years. In FR, for each user, its feature vector and interaction data are kept locally on its own client thus are private to others. Without the access to above information, most existing poisoning attacks against recommender systems or federated learning lose validity. Benifiting from this characteristic, FR is commonly considered fairly secured. However, we argue that there is still possible and necessary security improvement could be made in FR. To prove our opinion, in this paper we present FedRecAttack, a model poisoning attack to FR aiming to raise the exposure ratio of target items. In most recommendation scenarios, apart from private user-item interactions (e.g., clicks, watches and purchases), some interactions are public (e.g., likes, follows and comments). Motivated by this point, in FedRecAttack we make use of the public interactions to approximate users' feature vectors, thereby attacker can generate poisoned gradients accordingly and control malicious users to upload the poisoned gradients in a well-designed way. To evaluate the effectiveness and side effects of FedRecAttack, we conduct extensive experiments on three real-world datasets of different sizes from two completely different scenarios. Experimental results demonstrate that our proposed FedRecAttack achieves the state-of-the-art effectiveness while its side effects are negligible. Moreover, even with small proportion (3%) of malicious users and small proportion (1%) of public interactions, FedRecAttack remains highly effective, which reveals that FR is more vulnerable to attack than people commonly considered. 联邦推荐(FR)在过去几年中受到了相当大的欢迎和关注。在 FR 中,对于每个用户,其特征向量和交互数据都本地保存在自己的客户端上,因此对其他人来说是私有的。如果无法访问上述信息,大多数现有的针对推荐系统或联邦学习的中毒攻击都会失去有效性。得益于这一特性,FR 通常被认为是相当安全的。然而,我们认为在 FR 中仍有可能和必要的安全改进。为了证明我们的观点,在本文中,我们提出了 FedRecAttack,这是一种针对 FR 的模型中毒攻击,旨在提高目标项目的曝光率。在大多数推荐场景中,除了私人用户-项目交互(例如,点击、观看和购买)之外,一些交互是公开的(例如,喜欢、关注和评论)。受此启发,在 FedRecAttack 中,我们利用公共交互来近似用户的特征向量,从而攻击者可以相应地生成投毒梯度,并控制恶意用户以精心设计的方式上传投毒梯度。为了评估 FedRecAttack 的有效性和副作用,我们对来自两个完全不同场景的三个不同大小的真实数据集进行了广泛的实验。实验结果表明,我们提出的 FedRecAttack 实现了最先进的效果,而其副作用可以忽略不计。此外,即使恶意用户的比例很小(3%)和公共交互的比例很小(1%),FedRecAttack 仍然非常有效,这表明 FR 比人们通常认为的更容易受到攻击。
[^Ada-FedSemi]: This work focus on the scenario of federated semi-supervised learning where there are insufficient on-device labeled data and numerous in-cloud unlabeled data. Considering the number of participating clients and the pseudo labeling quality of in-cloud unlabeled data will have a significant impact on the performance, the authors introduce a multi-armed bandit (MAB) based online algorithm to adaptively determine the participating fraction in FL and the confidence threshold. The experimental results show 3%-14.8% higher test accuracy and saves up to 48% training cost compared with baselines. 这项工作聚焦联邦半监督学习的场景,即设备上的有标签数据不足,而云端中的无标签数据很多。考虑到参与客户的数量和云端无标签数据的伪标签质量将对性能产生重大影响,作者引入了一种基于多臂老虎机的在线算法,以适应性地确定联邦学习客户端参与比例和用于伪标签的阈值。实验结果显示,与基线相比,测试精度提高了3%-14.8%,并最高节省了48%的训练成本。
[^DIG-FL]: The performance of the FL model heavily depends on the quality of participants' local data, which makes measuring the contributions of participants an essential task for various purposes, e.g., participant selection and reward allocation. The Shapley value is widely adopted by previous work for contribution assessment, which, however, requires repeatedly leave-one-out retraining and thus incurs the prohibitive cost for FL. In this paper, we propose a highly efficient approach, named DIG-FL, to estimate the Shapley value of each participant without any model retraining. It's worth noting that our approach is applicable to both vertical federated learning (VFL) and horizontal federated learning (HFL), and we provide concrete design for VFL and HFL. In addition, we propose a DIG-FL based reweight mechanism to improve the model training in terms of accuracy and convergence speed by dynamically adjusting the weights of participants according to their per-epoch contributions, and theoretically analyze the convergence speed. Our extensive evaluations on 14 public datasets show that the estimated Shapley value is very close to the actual Shapley value with Pearson's correlation coefficient up to 0.987, while the cost is orders of magnitude smaller than state-of-the-art methods. When there are more than 80% participants holding low-quality data, by dynamically adjusting the weights, DIG-FL can effectively accelerate the convergence and improve the model accuracy. FL 模型的性能在很大程度上取决于参与者本地数据的质量,这使得衡量参与者的贡献成为各种目的的基本任务,例如参与者选择和奖励分配。 Shapley 值被以前的贡献评估工作广泛采用,然而,这需要反复留一再培训,因此导致 FL 的成本过高。在本文中,我们提出了一种名为 DIG-FL 的高效方法来估计每个参与者的 Shapley 值,而无需任何模型再训练。值得注意的是,我们的方法适用于垂直联邦学习 (VFL) 和水平联邦学习 (HFL),我们为 VFL 和 HFL 提供了具体设计。此外,我们提出了一种基于 DIG-FL 的重加权机制,通过根据参与者的每个时期的贡献动态调整参与者的权重来提高模型训练的准确性和收敛速度,并从理论上分析收敛速度。我们对 14 个公共数据集的广泛评估表明,估计的 Shapley 值非常接近实际的 Shapley 值,Pearson 相关系数高达 0.987,而成本比最先进的方法小几个数量级。当有 80% 以上的参与者持有低质量数据时,通过动态调整权重,DIG-FL 可以有效加速收敛,提高模型精度。
[^FCT]: Federated Computation is an emerging area that seeks to provide stronger privacy for user data, by performing large scale, distributed computations where the data remains in the hands of users. Only the necessary summary information is shared, and additional security and privacy tools can be employed to provide strong guarantees of secrecy. The most prominent application of federated computation is in training machine learning models (federated learning), but many additional applications are emerging, more broadly relevant to data management and querying data. This tutorial gives an overview of federated computation models and algorithms. It includes an introduction to security and privacy techniques and guarantees, and shows how they can be applied to solve a variety of distributed computations providing statistics and insights to distributed data. It also discusses the issues that arise when implementing systems to support federated computation, and open problems for future research. 联邦计算是一个新兴的领域,它试图为用户数据提供更强的隐私,通过执行大规模的分布式计算,数据仍然在用户手中。只有必要的摘要信息被共享,并且可以采用额外的安全和隐私工具来提供强大的保密保证。联邦计算最突出的应用是训练机器学习模型(联邦学习),但许多其他的应用正在出现,更广泛地与数据管理和数据查询有关。本教程概述了联邦计算的模型和算法。它包括对安全和隐私技术和保证的介绍,并展示了如何应用它们来解决各种分布式计算,为分布式数据提供统计和洞察力。它还讨论了在实现支持联邦计算的系统时出现的问题,以及未来研究的开放问题。
[^BlindFL]: Due to the rising concerns on privacy protection, how to build machine learning (ML) models over different data sources with security guarantees is gaining more popularity. Vertical federated learning (VFL) describes such a case where ML models are built upon the private data of different participated parties that own disjoint features for the same set of instances, which fits many real-world collaborative tasks. Nevertheless, we find that existing solutions for VFL either support limited kinds of input features or suffer from potential data leakage during the federated execution. To this end, this paper aims to investigate both the functionality and security of ML modes in the VFL scenario.To be specific, we introduce BlindFL, a novel framework for VFL training and inference. First, to address the functionality of VFL models, we propose the federated source layers to unite the data from different parties. Various kinds of features can be supported efficiently by the federated source layers, including dense, sparse, numerical, and categorical features. Second, we carefully analyze the security during the federated execution and formalize the privacy requirements. Based on the analysis, we devise secure and accurate algorithm protocols, and further prove the security guarantees under the ideal-real simulation paradigm. Extensive experiments show that BlindFL supports diverse datasets and models efficiently whilst achieves robust privacy guarantees. 垂直联邦学习 (VFL) 描述了这样一种情况,其中 ML 模型建立在不同参与方的私有数据之上,这些参与方对同一组实例拥有不相交的特征,这适合许多现实世界的协作任务。尽管如此,我们发现现有的 VFL 解决方案要么支持有限种类的输入特征,要么在联邦执行期间遭受潜在的数据泄漏。为此,本文旨在研究 VFL 场景中 ML 模式的功能和安全性。具体来说,我们介绍了 BlindFL,这是一种用于 VFL 训练和推理的新框架。首先,为了解决 VFL 模型的功能,我们提出了federated source layers来统一来自不同方的数据。federated source layers可以有效地支持各种特征,包括密集、稀疏、数值和分类特征。其次,我们仔细分析了联邦学习执行期间的安全性,并正式确定了隐私要求。在分析的基础上,我们设计了安全准确的算法协议,进一步证明了理想-现实仿真范式下的安全保证。大量实验表明,BlindFL 有效地支持各种数据集和模型,同时实现了强大的隐私保证。
[^CS-F-LTR]: Traditional learning-to-rank (LTR) models are usually trained in a centralized approach based upon a large amount of data. However, with the increasing awareness of data privacy, it is harder to collect data from multiple owners as before, and the resultant data isolation problem makes the performance of learned LTR models severely compromised. Inspired by the recent progress in federated learning, we propose a novel framework named Cross-Silo Federated Learning-to-Rank (CS-F-LTR), where the efficiency issue becomes the major bottleneck. To deal with the challenge, we first devise a privacy-preserving cross-party term frequency querying scheme based on sketching algorithms and differential privacy. To further improve the overall efficiency, we propose a new structure named reverse top-K sketch (RTK-Sketch) which significantly accelerates the feature generation process while holding theoretical guarantees on accuracy loss. Extensive experiments conducted on public datasets verify the effectiveness and efficiency of the proposed approach. 传统的排序学习 (LTR) 模型通常基于大量数据以集中方法进行训练。然而,随着数据隐私意识的增强,像以前一样从多个所有者那里收集数据变得更加困难,由此产生的数据隔离问题使得学习到的 LTR 模型的性能受到严重影响。受联邦学习最近进展的启发,我们提出了一个新的框架,称为Cross-silo联邦学习排序(CS-F-LTR),其中效率问题成为主要瓶颈。为了应对这一挑战,我们首先设计了一种基于草图算法和差分隐私的隐私保护跨方词频查询方案。为了进一步提高整体效率,我们提出了一种名为反向 top-K 草图(RTK-Sketch)的新结构,它显着加快了特征生成过程,同时保持了精度损失的理论保证。在公共数据集上进行的大量实验验证了所提出方法的有效性和效率。
[^FIA]: Recently, vertical FL, where the participating organizations hold the same set of samples but with disjoint features and only one organization owns the labels, has received increased attention. This paper presents several feature inference attack methods to investigate the potential privacy leakages in the model prediction stage of vertical FL. The attack methods consider the most stringent setting that the adversary controls only the trained vertical FL model and the model predictions, relying on no background information of the attack target's data distribution. We first propose two specific attacks on the logistic regression (LR) and decision tree (DT) models, according to individual prediction output. We further design a general attack method based on multiple prediction outputs accumulated by the adversary to handle complex models, such as neural networks (NN) and random forest (RF) models. Experimental evaluations demonstrate the effectiveness of the proposed attacks and highlight the need for designing private mechanisms to protect the prediction outputs in vertical FL. 最近,纵向 FL 受到越来越多的关注,其中参与组织持有相同的样本集但具有不相交的特征并且只有一个组织拥有标签。本文提出了几种特征推理攻击方法来研究纵向 FL 模型预测阶段潜在的隐私泄露。攻击方法考虑了最严格的设置,即对手仅控制训练好的纵向 FL 模型和模型预测,不依赖于攻击目标数据分布的背景信息。我们首先根据个体预测输出对逻辑回归 (LR) 和决策树 (DT) 模型提出两种特定攻击。我们进一步设计了一种基于对手累积的多个预测输出的通用攻击方法,以处理复杂的模型,例如神经网络(NN)和随机森林(RF)模型。实验评估证明了所提出的攻击的有效性,并强调需要设计私有机制来保护纵向 FL 中的预测输出。
[^FLDebugger]: A fundamental issue in FL is the susceptibility to the erroneous training data. This problem is especially challenging due to the invisibility of clients' local training data and training process, as well as the resource constraints of a large number of mobile and edge devices. In this paper, we try to tackle this challenging issue by introducing the first FL debugging framework, FLDebugger, for mitigating test error caused by erroneous training data. The pro-posed solution traces the global model's bugs (test errors), jointly through the training log and the underlying learning algorithm, back to first identify the clients and subsequently their training samples that are most responsible for the errors. In addition, we devise an influence-based participant selection strategy to fix bugs as well as to accelerate the convergence of model retraining. The performance of the identification algorithm is evaluated via extensive experiments on a real AIoT system (50 clients, including 20 edge computers, 20 laptops and 10 desktops) and in larger-scale simulated environments. The evaluation results attest to that our framework achieves accurate and efficient identification of negatively influential clients and samples, and significantly improves the model performance by fixing bugs. FL中的一个基本问题是对错误训练数据的敏感性。由于客户端本地训练数据和训练过程的不可见性,以及大量移动和边缘设备的资源限制,这个问题尤其具有挑战性。在本文中,我们尝试通过引入第一个 FL 调试框架 FLDebugger 来解决这个具有挑战性的问题,以减轻由错误训练数据引起的测试错误。所提出的解决方案通过训练日志和底层学习算法共同跟踪全局模型的错误(测试错误),以首先识别对错误负有最大责任的客户,然后是他们的训练样本。此外,我们设计了一种基于影响力的参与者选择策略来修复错误并加速模型再训练的收敛。识别算法的性能通过在真实 AIoT 系统(50 个客户端,包括 20 台边缘计算机、20 台笔记本电脑和 10 台台式机)和更大规模的模拟环境中的广泛实验来评估。评估结果证明,我们的框架实现了对负面影响的客户和样本的准确高效识别,并通过修复错误显着提高了模型性能。
[^FMFPG]: This paper comprehensively studies the problem of matrix factorization in different *federated learning* (FL) settings, where a set of parties want to cooperate in training but refuse to share data directly. We first propose a generic algorithmic framework for various settings of federated matrix factorization (FMF) and provide a theoretical convergence guarantee. We then systematically characterize privacy-leakage risks in data collection, training, and publishing stages for three different settings and introduce privacy notions to provide end-to-end privacy protections. The first one is *vertical federated learning* (VFL), where multiple parties have the ratings from the same set of users but on disjoint sets of items. The second one is *horizontal federated learning* (HFL), where parties have ratings from different sets of users but on the same set of items. The third setting is *local federated learning* (LFL), where the ratings of the users are only stored on their local devices. We introduce adapted versions of FMF with the privacy notions guaranteed in the three settings. In particular, a new private learning technique called *embedding clipping* is introduced and used in all the three settings to ensure differential privacy. For the LFL setting, we combine differential privacy with secure aggregation to protect the communication between user devices and the server with a strength similar to the local differential privacy model, but much better accuracy. We perform experiments to demonstrate the effectiveness of our approaches. 本文全面研究了不同联邦学习(FL)设置中的矩阵分解问题,其中一组方希望在训练中进行合作,但拒绝直接共享数据。我们首先为federated matrix factorization (FMF) 的各种设置提出了一个通用算法框架,并提供了理论上的收敛保证。然后,我们系统地描述了三种不同设置的数据收集、训练和发布阶段的隐私泄露风险,并引入了隐私概念以提供端到端的隐私保护。第一个是垂直联邦学习(VFL),其中多方具有来自同一组用户但不相交的项目集的评分。第二个是横向联邦学习(HFL),各方对同一组项目的不同用户集进行评分。第三个设置是本地联邦学习 (LFL),其中用户的评分仅存储在他们的本地设备上。我们引入了 FMF 的改编版本,并在三种设置中保证了隐私概念。特别是,在所有三种设置中引入并使用了一种称为嵌入裁剪的新私有学习技术,以确保差异隐私。对于 LFL 设置,我们将差分隐私与安全聚合相结合,以保护用户设备与服务器之间的通信,其强度类似于本地差分隐私模型,但精度要高得多。我们进行实验来证明我们的方法的有效性。
[^PFA-DB]: In practice, different clients may have different privacy requirements due to varying policies or preferences.In this paper, we focus on explicitly modeling and leveraging the heterogeneous privacy requirements of different clients and study how to optimize utility for the joint model while minimizing communication cost. As differentially private perturbations affect the model utility, a natural idea is to make better use of information submitted by the clients with higher privacy budgets (referred to as "public" clients, and the opposite as "private" clients). The challenge is how to use such information without biasing the joint model. We propose Projected Federated Averaging (PFA), which extracts the top singular subspace of the model updates submitted by "public" clients and utilizes them to project the model updates of "private" clients before aggregating them. We then propose communication-efficient PFA+, which allows "private" clients to upload projected model updates instead of original ones. Our experiments verify the utility boost of both algorithms compared to the baseline methods, whereby PFA+ achieves over 99% uplink communication reduction for "private" clients. 在实践中,由于不同的政策或偏好,不同的客户可能有不同的隐私要求。在本文中,我们专注于显式建模和利用不同客户端的异构隐私需求,并研究如何在最小化通信成本的同时优化联邦模型的效用。由于不同的私人扰动会影响模型效用,一个自然的想法是更好地利用具有较高隐私预算的客户(称为“公共”客户,反之称为“私人”客户)提交的信息。挑战在于如何在不影响联邦模型的情况下使用这些信息。我们提出Projected Federated Averaging (PFA),它提取“公共”客户端提交的模型更新的顶部奇异子空间,并在聚合它们之前,利用它们来预测“私人”客户端的模型更新。然后,我们提出了高效的通信 PFA+,它允许“私人”客户端上传预计的模型更新而不是原始模型更新。我们的实验验证了这两种算法与基线方法相比的效用提升,其中 PFA+ 为“私人”客户端实现了超过 99% 的上行链路通信减少。
[^FedRain-and-Frog]: How can we debug a logistical regression model in a federated learning setting when seeing the model behave unexpectedly (e.g., the model rejects all high-income customers' loan applications)? The SQL-based training data debugging framework has proved effective to fix this kind of issue in a non-federated learning setting. Given an unexpected query result over model predictions, this framework automatically removes the label errors from training data such that the unexpected behavior disappears in the retrained model. In this paper, we enable this powerful framework for federated learning. The key challenge is how to develop a security protocol for federated debugging which is proved to be secure, efficient, and accurate. Achieving this goal requires us to investigate how to seamlessly integrate the techniques from multiple fields (Databases, Machine Learning, and Cybersecurity). We first propose FedRain, which extends Rain, the state-of-the-art SQL-based training data debugging framework, to our federated learning setting. We address several technical challenges to make FedRain work and analyze its security guarantee and time complexity. The analysis results show that FedRain falls short in terms of both efficiency and security. To overcome these limitations, we redesign our security protocol and propose Frog, a novel SQL-based training data debugging framework tailored for federated learning. Our theoretical analysis shows that Frog is more secure, more accurate, and more efficient than FedRain. We conduct extensive experiments using several real-world datasets and a case study. The experimental results are consistent with our theoretical analysis and validate the effectiveness of Frog in practice. 当模型表现异常时(例如,模型拒绝所有高收入客户的贷款申请),我们如何在联邦学习环境中调试逻辑回归模型?事实证明,基于 SQL 的训练数据调试框架可以有效地解决非联邦学习环境中的此类问题。给定模型预测的意外查询结果,该框架会自动从训练数据中删除标签错误,从而使重新训练的模型中的意外行为消失。在本文中,我们为联邦学习启用了这个强大的框架。关键的挑战是如何为联邦调试开发一种被证明是安全、高效和准确的安全协议。实现这一目标需要我们研究如何无缝集成来自多个领域(数据库、机器学习和网络安全)的技术。我们首先提出 FedRain,它将最先进的基于 SQL 的训练数据调试框架 Rain 扩展到我们的联邦学习设置。我们解决了几个技术挑战以使 FedRain 工作并分析其安全保证和时间复杂度。分析结果表明,FedRain 在效率和安全性方面都存在不足。为了克服这些限制,我们重新设计了我们的安全协议并提出了 Frog,这是一种为联邦学习量身定制的基于 SQL 的新型训练数据调试框架。我们的理论分析表明,Frog 比 FedRain 更安全、更准确、更高效。我们使用几个真实世界的数据集和一个案例研究进行了广泛的实验。实验结果与我们的理论分析一致,在实践中验证了 Frog 的有效性。
[^Refiner]: Techniques for learning models from decentralized data must properly handle two natures of such data, namely privacy and massive engagement. Federated learning (FL) is a promising approach for such a learning task since the technique learns models from data without exposing privacy. However, traditional FL methods assume that the participating mobile devices are honest volunteers. This |
3,462 | A collection of corpora for named entity recognition (NER) and entity recognition tasks. These annotated datasets cover a variety of languages, domains and entity types. | null |
3,463 | A curated list of NLP resources focused on Transformer networks, attention mechanism, GPT, BERT, ChatGPT, LLMs, and transfer learning. | # Awesome Transformer & Transfer Learning in NLP [](https://awesome.re)
This repository contains a hand-curated of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, ChatGPT, and transfer learning in NLP.


Transformer (BERT) ([Source](https://web.archive.org/web/20201217063603/https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/bert-encoder))
<!-- <br />
<p align="center">
<img src="https://user-images.githubusercontent.com/145605/79639176-9ca33d80-81bc-11ea-8cde-f7ff68ee2042.png" width="600" />
<h4 align="center">Transformer (BERT) (<a href="https://web.archive.org/web/20201217063603/https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/bert-encoder">Source</a>)</h4>
</p>
<br /> -->
# Table of Contents
<details>
<summary><b>Expand Table of Contents</b></summary>
- [Papers](#papers)
- [Articles](#articles)
- [BERT and Transformer](#bert-and-transformer)
- [Attention Concept](#attention-concept)
- [Transformer Architecture](#transformer-architecture)
- [Generative Pre-Training Transformer (GPT)](#generative-pre-training-transformer-gpt)
- [ChatGPT](#chatgpt)
- [Large Language Model (LLM)](#large-language-model-llm)
- [Transformer Reinforcement Learning](#transformer-reinforcement-learning)
- [Additional Reading](#additional-reading)
- [Educational](#educational)
- [Tutorials](#tutorials)
- [AI Safety](#ai-safety)
- [Videos](#videos)
- [BERTology](#bertology)
- [Attention and Transformer Networks](#attention-and-transformer-networks)
- [Official BERT Implementations](#official-bert-implementations)
- [Transformer Implementations By Communities](#transformer-implementations-by-communities)
- [PyTorch and TensorFlow](#pytorch-and-tensorflow)
- [PyTorch](#pytorch)
- [Keras](#keras)
- [TensorFlow](#tensorflow)
- [Chainer](#chainer)
- [Transfer Learning in NLP](#transfer-learning-in-nlp)
- [Books](#books)
- [Other Resources](#other-resources)
- [Tools](#tools)
- [Tasks](#tasks)
- [Named-Entity Recognition (NER)](#named-entity-recognition-ner)
- [Classification](#classification)
- [Text Generation](#text-generation)
- [Question Answering (QA)](#question-answering-qa)
- [Knowledge Graph](#knowledge-graph)
</details>
---
## Papers
1. [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
2. [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, William W. Cohen, Jaime Carbonell, Quoc V. Le and Ruslan Salakhutdinov.
- Uses smart caching to improve the learning of long-term dependency in Transformer. Key results: state-of-art on 5 language modeling benchmarks, including ppl of 21.8 on One Billion Word (LM1B) and 0.99 on enwiki8. The authors claim that the method is more flexible, faster during evaluation (1874 times speedup), generalizes well on small datasets, and is effective at modeling short and long sequences.
2. [Conditional BERT Contextual Augmentation](https://arxiv.org/abs/1812.06705) by Xing Wu, Shangwen Lv, Liangjun Zang, Jizhong Han and Songlin Hu.
3. [SDNet: Contextualized Attention-based Deep Network for Conversational Question Answering](https://arxiv.org/pdf/1812.03593) by Chenguang Zhu, Michael Zeng and Xuedong Huang.
4. [Language Models are Unsupervised Multitask Learners](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
5. [The Evolved Transformer](https://arxiv.org/abs/1901.11117) by David R. So, Chen Liang and Quoc V. Le.
- They used architecture search to improve Transformer architecture. Key is to use evolution and seed initial population with Transformer itself. The architecture is better and more efficient, especially for small size models.
6. [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
- A new pretraining method for NLP that significantly improves upon BERT on 20 tasks (e.g., SQuAD, GLUE, RACE).
- "Transformer-XL is a shifted model (each hyper-column ends with next token) while XLNet is a direct model (each hyper-column ends with contextual representation of same token)." — [Thomas Wolf](https://twitter.com/Thom_Wolf/status/1141803437719506944?s=20).
- [Comments from HN](https://news.ycombinator.com/item?id=20229145):
<details>
<summary>A clever dual masking-and-caching algorithm.</summary>
- This is NOT "just throwing more compute" at the problem.
- The authors have devised a clever dual-masking-plus-caching mechanism to induce an attention-based model to learn to predict tokens from all possible permutations of the factorization order of all other tokens in the same input sequence.
- In expectation, the model learns to gather information from all positions on both sides of each token in order to predict the token.
- For example, if the input sequence has four tokens, ["The", "cat", "is", "furry"], in one training step the model will try to predict "is" after seeing "The", then "cat", then "furry".
- In another training step, the model might see "furry" first, then "The", then "cat".
- Note that the original sequence order is always retained, e.g., the model always knows that "furry" is the fourth token.
- The masking-and-caching algorithm that accomplishes this does not seem trivial to me.
- The improvements to SOTA performance in a range of tasks are significant -- see tables 2, 3, 4, 5, and 6 in the paper.
</details>
7. [CTRL: Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar, Richard Socher et al. [[Code](https://github.com/salesforce/ctrl)].
8. [PLMpapers](https://github.com/thunlp/PLMpapers) - BERT (Transformer, transfer learning) has catalyzed research in pretrained language models (PLMs) and has sparked many extensions. This repo contains a list of papers on PLMs.
9. [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Google Brain.
- The group perform a systematic study of transfer learning for NLP using a unified Text-to-Text Transfer Transformer (T5) model and push the limits to achieve SoTA on SuperGLUE (approaching human baseline), SQuAD, and CNN/DM benchmark. [[Code](https://git.io/Je0cZ)].
10. [Reformer: The Efficient Transformer](https://openreview.net/forum?id=rkgNKkHtvB) by Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya.
- "They present techniques to reduce the time and memory complexity of Transformer, allowing batches of very long sequences (64K) to fit on one GPU. Should pave way for Transformer to be really impactful beyond NLP domain." — @hardmaru
11. [Supervised Multimodal Bitransformers for Classifying Images and Text](https://arxiv.org/abs/1909.02950) (MMBT) by Facebook AI.
11. [A Primer in BERTology: What we know about how BERT works](https://arxiv.org/abs/2002.12327) by Anna Rogers et al.
- "Have you been drowning in BERT papers?". The group survey over 40 papers on BERT's linguistic knowledge, architecture tweaks, compression, multilinguality, and so on.
12. [tomohideshibata/BERT-related papers](https://github.com/tomohideshibata/BERT-related-papers)
13. [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by Google Brain. [[Code]](https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py) | [[Blog post (unofficial)]](https://syncedreview.com/2021/01/14/google-brains-switch-transformer-language-model-packs-1-6-trillion-parameters/)
- Key idea: the architecture use a subset of parameters on every training step and on each example. Upside: model train much faster. Downside: super large model that won't fit in a lot of environments.
14. [An Attention Free Transformer](https://arxiv.org/abs/2105.14103) by Apple.
15. [A Survey of Transformers](https://arxiv.org/abs/2106.04554) by Tianyang Lin et al.
16. [Evaluating Large Language Models Trained on Code](https://arxiv.org/abs/2107.03374) by OpenAI.
- Codex, a GPT language model that powers GitHub Copilot.
- They investigate their model limitations (and strengths).
- They discuss the potential broader impacts of deploying powerful code generation techs, covering safety, security, and economics.
17. [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) by OpenAI. They call the resulting models [InstructGPT](https://openai.com/blog/instruction-following/). [ChatGPT](https://openai.com/blog/chatgpt/) is a sibling model to InstructGPT.
18. [LaMDA: Language Models for Dialog Applications](https://arxiv.org/abs/2201.08239) by Google.
19. [Training Compute-Optimal Large Language Models](https://arxiv.org/abs/2203.15556) by Hoffmann et al. at DeepMind. TLDR: introduces a new 70B LM called "Chinchilla" that outperforms much bigger LMs (GPT-3, Gopher). DeepMind has found the secret to cheaply scale large language models — to be compute-optimal, model size and training data must be scaled equally. It shows that most LLMs are severely starved of data and under-trained. Given the [new scaling law](https://www.alignmentforum.org/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications), even if you pump a quadrillion parameters into a model (GPT-4 urban myth), the gains will not compensate for 4x more training tokens.
20. [Improving language models by retrieving from trillions of tokens](https://arxiv.org/abs/2112.04426) by Borgeaud et al. at DeepMind - The group explore an alternate path for efficient training with Internet-scale retrieval. The method is known as RETRO, for "Retrieval Enhanced TRansfOrmers". With RETRO **the model is not limited to the data seen during training – it has access to the entire training dataset through the retrieval mechanism. This results in significant performance gains compared to a standard Transformer with the same number of parameters**. RETRO obtains comparable performance to GPT-3 on the Pile dataset, despite using 25 times fewer parameters. They show that language modeling improves continuously as they increase the size of the retrieval database. [[blog post](https://www.deepmind.com/blog/improving-language-models-by-retrieving-from-trillions-of-tokens)]
21. [Scaling Instruction-Finetuned Language Models](https://arxiv.org/abs/2210.11416) by Google - They find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks. Flan-PaLM 540B achieves SoTA performance on several benchmarks. They also publicly release [Flan-T5 checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints), which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B.
22. [Emergent Abilities of Large Language Models](https://arxiv.org/abs/2206.07682) by Google Research, Stanford University, DeepMind, and UNC Chapel Hill.
23. [Nonparametric Masked (NPM) Language Modeling](https://arxiv.org/abs/2212.01349) by Meta AI et al. [[code](https://github.com/facebookresearch/NPM)] - Nonparametric models with **500x fewer parameters outperform GPT-3 on zero-shot tasks.**
> It, crucially, does not have a softmax over a fixed output vocabulary, but instead has a fully nonparametric distribution over phrases. This
is in contrast to a recent (2022) body of work that incorporates nonparametric components in a parametric model.
>
> Results show that NPM is significantly more parameter-efficient, outperforming up to 500x larger parametric models and up to 37x larger retrieve-and-generate models.
## Articles
### BERT and Transformer
1. [Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing](https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html) from Google AI.
2. [The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)](https://jalammar.github.io/illustrated-bert/).
3. [Dissecting BERT](https://medium.com/dissecting-bert) by Miguel Romero and Francisco Ingham - Understand BERT in depth with an intuitive, straightforward explanation of the relevant concepts.
3. [A Light Introduction to Transformer-XL](https://medium.com/dair-ai/a-light-introduction-to-transformer-xl-be5737feb13).
4. [Generalized Language Models](https://lilianweng.github.io/lil-log/2019/01/31/generalized-language-models.html) by Lilian Weng, Research Scientist at OpenAI.
5. [What is XLNet and why it outperforms BERT](https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335)
- Permutation Language Modeling objective is the core of XLNet.
6. [DistilBERT](https://github.com/huggingface/pytorch-transformers/tree/master/examples/distillation) (from HuggingFace), released together with the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5).
7. [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations paper](https://arxiv.org/abs/1909.11942v3) from Google Research and Toyota Technological Institute. — Improvements for more efficient parameter usage: factorized embedding parameterization, cross-layer parameter sharing, and Sentence Order Prediction (SOP) loss to model inter-sentence coherence. [[Blog post](https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html) | [Code](https://github.com/google-research/ALBERT)]
8. [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/forum?id=r1xMH1BtvB) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning - A BERT variant like ALBERT and cost less to train. They trained a model that outperforms GPT by using only one GPU; match the performance of RoBERTa by using 1/4 computation. It uses a new pre-training approach, called replaced token detection (RTD), that trains a bidirectional model while learning from all input positions. [[Blog post](https://ai.googleblog.com/2020/03/more-efficient-nlp-model-pre-training.html) | [Code](https://github.com/google-research/electra)]
9. [Visual Paper Summary: ALBERT (A Lite BERT)](https://amitness.com/2020/02/albert-visual-summary/)
10. [Cramming: Training a Language Model on a Single GPU in One Day (paper)](https://arxiv.org/abs/2212.14034) (2022) - While most in the community are asking how to push the limits of extreme computation, we ask the opposite question: How far can we get with a single GPU in just one day? ... Through the lens of scaling laws, we categorize a range of recent improvements to training and architecture and discuss their merit and practical applicability (or lack thereof) for the limited compute setting.
### Attention Concept
1. [The Annotated Transformer by Harvard NLP Group](http://nlp.seas.harvard.edu/2018/04/03/attention.html) - Further reading to understand the "Attention is all you need" paper.
2. [Attention? Attention!](https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html) - Attention guide by Lilian Weng from OpenAI.
3. [Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)](https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/) by Jay Alammar, an Instructor from Udacity ML Engineer Nanodegree.
4. [Making Transformer networks simpler and more efficient](https://ai.facebook.com/blog/making-transformer-networks-simpler-and-more-efficient/) - FAIR released an all-attention layer to simplify the Transformer model and an adaptive attention span method to make it more efficient (reduce computation time and memory footprint).
5. [What Does BERT Look At? An Analysis of BERT’s Attention paper](https://arxiv.org/abs/1906.04341) by Stanford NLP Group.
### Transformer Architecture
1. [The Transformer blog post](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html).
2. [The Illustrated Transformer](https://jalammar.github.io/illustrated-transformer/) by Jay Alammar, an Instructor from Udacity ML Engineer Nanodegree.
3. Watch [Łukasz Kaiser’s talk](https://www.youtube.com/watch?v=rBCqOTEfxvg) walking through the model and its details.
4. [Transformer-XL: Unleashing the Potential of Attention Models](https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html) by Google Brain.
5. [Generative Modeling with Sparse Transformers](https://openai.com/blog/sparse-transformer/) by OpenAI - an algorithmic improvement of the attention mechanism to extract patterns from sequences 30x longer than possible previously.
6. [Stabilizing Transformers for Reinforcement Learning](https://arxiv.org/abs/1910.06764) paper by DeepMind and CMU - they propose architectural modifications to the original Transformer and XL variant by moving layer-norm and adding gating creates Gated Transformer-XL (GTrXL). It substantially improve the stability and learning speed (integrating experience through time) in RL.
7. [The Transformer Family](https://lilianweng.github.io/lil-log/2020/04/07/the-transformer-family.html) by Lilian Weng - since the paper "Attention Is All You Need", many new things have happened to improve the Transformer model. This post is about that.
8. [DETR (**DE**tection **TR**ansformer): End-to-End Object Detection with Transformers](https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers/) by FAIR - :fire: Computer vision has not yet been swept up by the Transformer revolution. DETR completely changes the architecture compared with previous object detection systems. ([PyTorch Code and pretrained models](https://github.com/facebookresearch/detr)). "A solid swing at (non-autoregressive) end-to-end detection. Anchor boxes + Non-Max Suppression (NMS) is a mess. I was hoping detection would go end-to-end back in ~2013)" — Andrej Karpathy
9. [Transformers for software engineers](https://blog.nelhage.com/post/transformers-for-software-engineers/) - This post will be helpful to software engineers who are interested in learning ML models, especially anyone interested in Transformer interpretability. The post walk through a (mostly) complete implementation of a GPT-style Transformer, but the goal will not be running code; instead, they use the language of software engineering and programming to explain how these models work and articulate some of the perspectives they bring to them when doing interpretability work.
10. [Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html) - PaLM is a dense decoder-only Transformer model trained with the Pathways system, which enabled Google to efficiently train a single model across multiple TPU v4 Pods. The example explaining a joke is remarkable. This shows that it can generate explicit explanations for scenarios that require a complex combination of multi-step logical inference, world knowledge, and deep language understanding.
11. [Efficient Long Sequence Modeling via State Space Augmented Transformer (paper)](https://arxiv.org/abs/2212.08136) by Georgia Institute of Technology and Microsoft - The quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. They propose SPADE, short for State sPace AugmenteD TransformEr, which performs various baselines, including Mega, on the Long Range Arena benchmark and various LM tasks. This is an interesting direction. SSMs and Transformers were combined a while back.
12. [DeepNet: Scaling Transformers to 1,000 Layers (paper)](https://arxiv.org/abs/2203.00555) by Microsoft Research (2022) - The group introduced a **new normalization function (DEEPNORM)** to modify the residual connection in Transformer and showed that model updates can be bounded in a **stable way**. This improve the training stability of deep Transformers and scale the model depth by orders of magnitude (10x) compared to Gpipe (pipeline parallelism) by Google Brain (2019). (who remembers what ResNet (2015) did to ConvNet?)
13. [A Length-Extrapolatable Transformer (paper)](https://arxiv.org/abs/2212.10554) by Microsoft (2022) [[TorchScale code](https://github.com/microsoft/torchscale)] - This improves **modeling capability** of scaling Transformers.
14. [Hungry Hungry Hippos (H3): Towards Language Modeling with State Space Models (SSMs) (paper)](https://arxiv.org/abs/2212.14052) by Stanford AI Lab (2022) - A new language modeling architecture. It **scales nearly linearly with context size instead of quadratically**. No more fixed context windows, long context for everyone. Despite that, SSMs are still slower than Transformers due to poor hardware utilization. So, a Transformer successor? [[Tweet](https://twitter.com/realDanFu/status/1617605971395891201)]
15. [Accelerating Large Language Model Decoding with Speculative Sampling (paper)](https://arxiv.org/abs/2302.01318) by DeepMind (2023) - Speculative sampling algorithm enable the generation of multiple tokens from each transformer call. Achieves a 2–2.5x decoding speedup with Chinchilla in a distributed setup, without compromising the sample quality or making modifications to the model itself.
### Generative Pre-Training Transformer (GPT)
1. [Better Language Models and Their Implications](https://openai.com/blog/better-language-models/).
2. [Improving Language Understanding with Unsupervised Learning](https://blog.openai.com/language-unsupervised/) - this is an overview of the original OpenAI GPT model.
3. [🦄 How to build a State-of-the-Art Conversational AI with Transfer Learning](https://convai.huggingface.co/) by Hugging Face.
4. [The Illustrated GPT-2 (Visualizing Transformer Language Models)](https://jalammar.github.io/illustrated-gpt2/) by Jay Alammar.
5. [MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism](https://nv-adlr.github.io/MegatronLM) by NVIDIA ADLR.
6. [OpenGPT-2: We Replicated GPT-2 Because You Can Too](https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc) - the authors trained a 1.5 billion parameter GPT-2 model on a similar sized text dataset and they reported results that can be compared with the original model.
7. [MSBuild demo of an OpenAI generative text model generating Python code](https://www.youtube.com/watch?v=fZSFNUT6iY8) [video] - The model that was trained on GitHub OSS repos. The model uses English-language code comments or simply function signatures to generate entire Python functions. Cool!
8. [GPT-3: Language Models are Few-Shot Learners (paper)](https://arxiv.org/abs/2005.14165) by Tom B. Brown (OpenAI) et al. - "We train GPT-3, an autoregressive language model with 175 billion parameters :scream:, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting."
9. [elyase/awesome-gpt3](https://github.com/elyase/awesome-gpt3) - A collection of demos and articles about the OpenAI GPT-3 API.
10. [How GPT3 Works - Visualizations and Animations](https://jalammar.github.io/how-gpt3-works-visualizations-animations/) by Jay Alammar.
11. [GPT-Neo](https://www.eleuther.ai/projects/gpt-neo/) - Replicate a GPT-3 sized model and open source it for free. GPT-Neo is "an implementation of model parallel GPT2 & GPT3-like models, with the ability to scale up to full GPT3 sizes (and possibly more!), using the mesh-tensorflow library." [[Code](https://github.com/EleutherAI/gpt-neo)].
12. [GitHub Copilot](https://copilot.github.com/), powered by OpenAI Codex - Codex is a descendant of GPT-3. Codex translates natural language into code.
13. [GPT-4 Rumors From Silicon Valley](https://thealgorithmicbridge.substack.com/p/gpt-4-rumors-from-silicon-valley) - GPT-4 is almost ready. GPT-4 would be multimodal, accepting text, audio, image, and possibly video inputs. Release window: Dec - Feb. #hype
14. [New GPT-3 model: text-Davinci-003](https://beta.openai.com/docs/models/davinci) - Improvements:
- Handle more complex intents — you can get even more creative with how you make use of its capabilities now.
- Higher quality writing — clearer, more engaging, and more compelling content.
- Better at longer form content generation.
#### ChatGPT
[What is ChatGPT?](https://openai.com/blog/chatgpt/)
**TL;DR:** ChatGPT is a conversational web interface, backed by OpenAI's newest language model fine-tuned from a model in the [GPT-3.5 series](https://beta.openai.com/docs/model-index-for-researchers) (which finished training in early 2022), optimized for dialogue. It is trained using Reinforcement Learning from Human Feedback (RLHF); human AI trainers provide supervised fine-tuning by playing both sides of the conversation.
It's evidently better than GPT-3 at following user instructions and context. [People have noticed](https://archive.ph/m6AOQ) ChatGPT's output quality seems to represent a notable improvement over previous GPT-3 models.
For more, please take a look at [ChatGPT Universe](https://github.com/cedrickchee/chatgpt-universe). This is my fleeting notes on everything I understand about ChatGPT and stores a collection of interesting things about ChatGPT.
### Large Language Model (LLM)
1. [GPT-J-6B](https://towardsdatascience.com/cant-access-gpt-3-here-s-gpt-j-its-open-source-cousin-8af86a638b11) - Can't access GPT-3? Here's GPT-J — its open-source cousin.
2. [Fun and Dystopia With AI-Based Code Generation Using GPT-J-6B](https://minimaxir.com/2021/06/gpt-j-6b/) - Prior to GitHub Copilot tech preview launch, Max Woolf, a data scientist tested GPT-J-6B's code "writing" abilities.
3. [GPT-Code-Clippy (GPT-CC)](https://github.com/CodedotAl/gpt-code-clippy) - An open source version of GitHub Copilot. The GPT-CC models are fine-tuned versions of GPT-2 and GPT-Neo.
4. [GPT-NeoX-20B](https://blog.eleuther.ai/announcing-20b/) - A 20 billion parameter model trained using EleutherAI’s [GPT-NeoX](https://github.com/EleutherAI/gpt-neox) framework. They expect it to perform well on many tasks. You can try out the model on [GooseAI](https://goose.ai/) playground.
5. [Metaseq](https://github.com/facebookresearch/metaseq) - A codebase for working with [Open Pre-trained Transformers (OPT)](https://arxiv.org/abs/2205.01068).
6. [YaLM 100B](https://github.com/yandex/YaLM-100B) by Yandex is a GPT-like pretrained language model with 100B parameters for generating and processing text. It can be used **freely** by developers and researchers from all over the world.
7. [BigScience's BLOOM-176B](https://huggingface.co/bigscience/bloom) from the Hugging Face repository [[paper](https://arxiv.org/abs/2210.15424), [blog post](https://bigscience.huggingface.co/blog/bloom)] - BLOOM is a 175-billion parameter model for language processing, able to generate text much like GPT-3 and OPT-175B. It was developed to be multilingual, being deliberately trained on datasets containing 46 natural languages and 13 programming languages.
8. [bitsandbytes-Int8 inference for Hugging Face models](https://docs.google.com/document/d/1JxSo4lQgMDBdnd19VBEoaG-mMfQupQ3XvOrgmRAVtpU/edit) - You can run BLOOM-176B/OPT-175B easily on a single machine, without performance degradation. If true, this could be a game changer in enabling people outside of big tech companies being able to use these LLMs.
9. [WeLM: A Well-Read Pre-trained Language Model for Chinese (paper)](https://arxiv.org/abs/2209.10372) by WeChat. [[online demo](https://welm.weixin.qq.com/docs/playground/)]
10. [GLM-130B: An Open Bilingual (Chinese and English) Pre-Trained Model (code and paper)](https://github.com/THUDM/GLM-130B) by Tsinghua University, China [[article](https://keg.cs.tsinghua.edu.cn/glm-130b/posts/glm-130b/)] - One of the major contributions is making LLMs cost affordable using int4 quantization so it can run in limited compute environments.
> The resultant GLM-130B model offers **significant outperformance over GPT-3 175B** on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage **a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss**, making it the first among 100B-scale models. **More importantly, the property allows its effective inference on 4×RTX 3090 (24G) or 8×RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models**.
11. [Teaching Small Language Models to Reason (paper)](https://arxiv.org/abs/2212.08410) - They finetune a student model on the chain of thought (CoT) outputs generated by a larger teacher model. For example, the **accuracy of T5 XXL on GSM8K improves from 8.11% to 21.99%** when finetuned on PaLM-540B generated chains of thought.
12. [ALERT: Adapting Language Models to Reasoning Tasks (paper)](https://arxiv.org/abs/2212.08286) by Meta AI - They introduce ALERT, a benchmark and suite of analyses for assessing language models' reasoning ability comparing pre-trained and finetuned models on complex tasks that require reasoning skills to solve. It covers 10 different reasoning skills including logistic, causal, common-sense, abductive, spatial, analogical, argument and deductive reasoning as well as textual entailment, and mathematics.
13. [Evaluating Human-Language Model Interaction (paper)](https://arxiv.org/abs/2212.09746) by Stanford University and Imperial College London - They find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
14. [Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor (paper)](https://arxiv.org/abs/2212.09689) by Meta AI [[data](https://github.com/orhonovich/unnatural-instructions)] - Fine-tuning a T5 on a large dataset collected with virtually no human labor leads to a model that surpassing the performance of models such as T0++ and Tk-Instruct across various benchmarks. These results demonstrate the potential of model-generated data as a **cost-effective alternative to crowdsourcing for dataset expansion and diversification**.
15. [OPT-IML (OPT + Instruction Meta-Learning) (paper)](https://raw.githubusercontent.com/facebookresearch/metaseq/main/projects/OPT-IML/optimal_paper_v1.pdf) by Meta AI - OPT-IML is a set of instruction-tuned versions of OPT, on a collection of ~2000 NLP tasks — for research use cases. It boosts the performance of the original OPT-175B model using instruction tuning to improve zero-shot and few-shot generalization abilities — allowing it to adapt for more diverse language applications (i.e., answering Q’s, summarizing text). This improves the model's ability to better process natural instruction style prompts. Ultimately, humans should be able to "talk" to models as naturally and fluidly as possible. [[code (available soon), weights released](https://github.com/facebookresearch/metaseq/tree/main/projects/OPT-IML)]
16. [jeffhj/LM-reasoning](https://github.com/jeffhj/LM-reasoning) - This repository contains a collection of papers and resources on reasoning in Large Language Models.
17. [Rethinking with Retrieval: Faithful Large Language Model Inference (paper)](https://arxiv.org/abs/2301.00303) by University of Pennsylvania et al., 2022 - They shows the potential of enhancing LLMs by retrieving relevant external knowledge based on decomposed reasoning steps obtained through chain-of-thought (CoT) prompting. I predict we're going to see many of these types of retrieval-enhanced LLMs in 2023.
18. [REPLUG: Retrieval-Augmented Black-Box Language Models (paper)](https://arxiv.org/abs/2301.12652) by Meta AI et al., 2023 - TL;DR: Enhancing GPT-3 with world knowledge — a retrieval-augmented LM framework that combines a frozen LM with a frozen/tunable retriever. It improves GPT-3 in language modeling and downstream tasks by prepending retrieved documents to LM inputs. [[Tweet](https://twitter.com/WeijiaShi2/status/1620497381962977281)]
19. [Progressive Prompts: Continual Learning for Language Models (paper)](https://arxiv.org/abs/2301.12314) by Meta AI et al., 2023 - Current LLMs have hard time with catastrophic forgetting and leveraging past experiences. The approach learns a prompt for new task and concatenates with frozen previously learned prompts. This efficiently transfers knowledge to future tasks. [[code](https://github.com/arazd/ProgressivePrompts)]
20. [Large Language Models Can Be Easily Distracted by Irrelevant Context (paper)](https://arxiv.org/abs/2302.00093) by Google Research et al., 2023 - Adding the instruction "Feel free to ignore irrelevant information given in the questions." consistently improves robustness to irrelevant context.
### Transformer Reinforcement Learning
Transformer Reinforcement Learning from Human Feedback (RLHF).
- [Illustrating Reinforcement Learning from Human Feedback](https://huggingface.co/blog/rlhf) - Recent advances with language models (ChatGPT for example) have been powered by RLHF.
- [Training a Helpful and Harmless Assistant with RLHF (paper)](https://arxiv.org/abs/2204.05862) by Anthropic. [[code and red teaming data](https://huggingface.co/datasets/Anthropic/hh-rlhf), [tweet](https://twitter.com/anthropicai/status/1514277273070825476)]
#### Tools for RLHF
- [lvwerra/TRL](https://github.com/lvwerra/trl) - Train transformer language models with reinforcement learning.
Open source effort towards ChatGPT:
- [CarperAI/TRLX](https://github.com/CarperAI/trlx) - Originated as a fork of TRL. It allows you to fine-tune Hugging Face language models (GPT2, GPT-NeoX based) up to 20B parameters using Reinforcement Learning. Brought to you by CarperAI (born at EleutherAI, an org part of StabilityAI family). CarperAI is developing production ready open-source RLHF tools. They have [announced plans for the first open-source "instruction-tuned" LM](https://carper.ai/instruct-gpt-announcement/).
- [allenai/RL4LMs](https://github.com/allenai/RL4LMs) - RL for language models (RL4LMs) by Allen AI. It's a modular RL library to fine-tune language models to human preferences.
### Additional Reading
1. [How to Build OpenAI's GPT-2: "The AI That's Too Dangerous to Release"](https://www.reddit.com/r/MachineLearning/comments/bj0dsa/d_how_to_build_openais_gpt2_the_ai_thats_too/).
2. [OpenAI’s GPT2 - Food to Media hype or Wake Up Call?](https://www.skynettoday.com/briefs/gpt2)
3. [How the Transformers broke NLP leaderboards](https://hackingsemantics.xyz/2019/leaderboards/) by Anna Rogers. :fire::fire::fire:
- A well put summary post on problems with large models that dominate NLP these days.
- Larger models + more data = progress in Machine Learning research :question:
4. [Transformers From Scratch](http://www.peterbloem.nl/blog/transformers) tutorial by Peter Bloem.
5. [Real-time Natural Language Understanding with BERT using NVIDIA TensorRT](https://devblogs.nvidia.com/nlu-with-tensorrt-bert/) on Google Cloud T4 GPUs achieves 2.2 ms latency for inference. Optimizations are open source on GitHub.
6. [NLP's Clever Hans Moment has Arrived](https://thegradient.pub/nlps-clever-hans-moment-has-arrived/) by The Gradient.
7. [Language, trees, and geometry in neural networks](https://pair-code.github.io/interpretability/bert-tree/) - a series of expository notes accompanying the paper, "Visualizing and Measuring the Geometry of BERT" by Google's People + AI Research (PAIR) team.
8. [Benchmarking Transformers: PyTorch and TensorFlow](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) by Hugging Face - a comparison of inference time (on CPU and GPU) and memory usage for a wide range of transformer architectures.
9. [Evolution of representations in the Transformer](https://lena-voita.github.io/posts/emnlp19_evolution.html) - An accessible article that presents the insights of their EMNLP 2019 paper. They look at how the representations of individual tokens in Transformers trained with different objectives change.
10. [The dark secrets of BERT](https://text-machine-lab.github.io/blog/2020/bert-secrets/) - This post probes fine-tuned BERT models for linguistic knowledge. In particular, the authors analyse how many self-attention patterns with some linguistic interpretation are actually used to solve downstream tasks. TL;DR: They are unable to find evidence that linguistically interpretable self-attention maps are crucial for downstream performance.
11. [A Visual Guide to Using BERT for the First Time](https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/) - Tutorial on using BERT in practice, such as for sentiment analysis on movie reviews by Jay Alammar.
12. [Turing-NLG: A 17-billion-parameter language model](https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/) by Microsoft that outperforms the state of the art on many downstream NLP tasks. This work would not be possible without breakthroughs produced by the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) (compatible with PyTorch) and [ZeRO optimizer](https://arxiv.org/abs/1910.02054), which can be explored more in this accompanying [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters).
13. [MUM (Multitask Unified Model): A new AI milestone for understanding information](https://blog.google/products/search/introducing-mum/) by Google.
- Based on transformer architecture but more powerful.
- Multitask means: supports text and images, knowledge transfer between 75 languages, understand context and go deeper in a topic, and generate content.
14. [GPT-3 is No Longer the Only Game in Town](https://lastweekin.ai/p/gpt-3-is-no-longer-the-only-game) - GPT-3 was by far the largest AI model of its kind last year (2020). Now? Not so much.
15. [OpenAI's API Now Available with No Waitlist](https://openai.com/blog/api-no-waitlist/) - GPT-3 access without the wait. However, apps must be approved before [going live](https://beta.openai.com/docs/going-live). This release also allow them to review applications, monitor for misuse, and better understand the effects of this tech.
16. [The Inherent Limitations of GPT-3](https://lastweekin.ai/p/the-inherent-limitations-of-gpt-3) - One thing missing from the article if you've read [Gwern's GPT-3 Creative Fiction article](https://www.gwern.net/GPT-3#repetitiondivergence-sampling) before is the mystery known as "Repetition/Divergence Sampling":
> when you generate free-form completions, they have a tendency to eventually fall into repetitive loops of gibberish.
For those using Copilot, you should have experienced this wierdness where it generates the same line or block of code over and over again.
17. [Language Modelling at Scale: Gopher, Ethical considerations, and Retrieval](https://deepmind.com/blog/article/language-modelling-at-scale) by DeepMind - The paper present an analysis of Transformer-based language model performance across a wide range of model scales — from models with tens of millions of parameters up to a 280 billion parameter model called Gopher.
18. [Competitive programming with AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode) by DeepMind - AlphaCode uses transformer-based language models to generate code that can create novel solutions to programming problems which require an understanding of algorithms.
19. [Building games and apps entirely through natural language using OpenAI's code-davinci model](https://andrewmayneblog.wordpress.com/2022/03/17/building-games-and-apps-entirely-through-natural-language-using-openais-davinci-code-model/) - The author built several small games and apps without touching a single line of code, simply by telling the model what they want.
20. [Open AI gets GPT-3 to work by hiring an army of humans to fix GPT’s bad answers](https://statmodeling.stat.columbia.edu/2022/03/28/is-open-ai-cooking-the-books-on-gpt-3/)
21. [GPT-3 can run code](https://mayt.substack.com/p/gpt-3-can-run-code) - You provide an input text and a command and GPT-3 will transform them into an expected output. It works well for tasks like changing coding style, translating between programming languages, refactoring, and adding doc. For example, converts JSON into YAML, translates Python code to JavaScript, improve the runtime complexity of the function.
22. [Using GPT-3 to explain how code works](https://simonwillison.net/2022/Jul/9/gpt-3-explain-code/) by Simon Willison.
23. [Character AI announces they're building a full stack AGI company](https://blog.character.ai/introducing-character/) so you could create your own AI to help you with anything, using conversational AI research. The co-founders Noam Shazeer (co-invented Transformers, scaled them to supercomputers for the first time, and pioneered large-scale pretraining) and Daniel de Freitas (led the development of LaMDA), all of which are foundational to recent AI progress.
24. [How Much Better is OpenAI’s Newest GPT-3 Model?](https://scale.com/blog/gpt-3-davinci-003-comparison) - In addition to ChatGPT, OpenAI releases text-davinci-003, a Reinforcement Learning-tuned model that performs better long-form writing. Example, it can explain code in the style of Eminem. 😀
25. [OpenAI rival Cohere launches language model API](https://venturebeat.com/uncategorized/openai-rival-cohere-launches-language-model-api/) - Backed by AI experts, they aims to bring Google-quality predictive language to the masses. Aidan Gomez co-wrote a seminal 2017 paper at Google Brain that invented a concept known as "Transformers".
26. [Startups competing with OpenAI's GPT-3 all need to solve the same problems](https://www.theregister.com/2022/03/03/language_model_gpt3/) - Last year, two startups released their own proprietary text-generation APIs. AI21 Labs, launched its 178-billion-parameter Jurassic-1 in Aug 2021, and Cohere, released a range of models. Cohere hasn't disclosed how many parameters its models contain. ... There are other up-and-coming startups looking to solve the same issues. Anthropic, the AI safety and research company started by a group of ex-OpenAI employees. Several researchers have left Google Brain to join two new ventures started by their colleagues. One outfit is named Character.ai, and the other Persimmon Labs.
27. [Cohere Wants to Build the Definitive NLP Platform](https://albertoromgar.medium.com/cohere-wants-to-build-the-definitive-nlp-platform-7d090c0de9ca) - Beyond generative models like GPT-3.
28. [Transformer Inference Arithmetic](https://kipp.ly/blog/transformer-inference-arithmetic/) technical write-up from Carol Chen, ML Ops at Cohere. This article presents detailed few-principles reasoning about LLM inference performance, with no experiments or difficult math.
29. [State of AI Report 2022](https://www.stateof.ai/2022-report-launch.html) - Key takeaways:
- New independent research labs are rapidly open sourcing the closed source output of major labs.
- AI safety is attracting more talent... yet remains extremely neglected.
- OpenAI's Codex, which drives GitHub Copilot, has impressed the computer science community with its ability to complete code on multiple lines or directly from natural language instructions. This success spurred more research in this space.
- DeepMind revisited LM scaling laws and found that current LMs are significantly undertrained: they’re not trained on enough data given their large size. They train Chinchilla, a 4x smaller version of their Gopher, on 4.6x more data, and find that Chinchilla outperforms Gopher and other large models on BIG-bench.
- Reinforcement Learning from Human Feedback (RLHF) has emerged as a key method to finetune LLMs and align them with human values. This involves humans ranking language model outputs sampled for a given input, using these rankings to learn a reward model of human preferences, and then using this as a reward signal to finetune the language model with using RL.
30. [The Scaling Hypothesis](https://www.gwern.net/Scaling-hypothesis) by Gwern - On GPT-3: meta-learning, scaling, implications, and deep theory.
31. [AI And The Limits Of Language — An AI system trained on words and sentences alone will never approximate human understanding](https://www.noemamag.com/ai-and-the-limits-of-language/) by Jacob Browning and Yann LeCun - What LLMs like ChatGPT can and cannot do, and why AGI is not here yet.
## Educational
- [minGPT](https://github.com/karpathy/minGPT) by Andrej Karpathy - A PyTorch re-implementation of GPT, both training and inference. minGPT tries to be small, clean, interpretable and educational, as most of the currently available GPT model implementations can a bit sprawling. GPT is not a complicated model and this implementation is appropriately about 300 lines of code.
- [nanoGPT](https://github.com/karpathy/nanoGPT) - It's a re-write of minGPT. Still under active development. The associated and ongoing video lecture series _[Neural Networks: Zero to Hero](https://karpathy.ai/zero-to-hero.html)_, build GPT, from scratch, in code and aspire to spell everything out. Note that Karpathy's bottom up approach and fast.ai teaching style work well together. (FYI, fast.ai has both top-down ("part 1") and bottom-up ("part 2") approach.)
- [A visual intro to large language models (LLMs) by Jay Alammar/Cohere](https://jalammar.github.io/applying-large-language-models-cohere/) - A high-level look at LLMs and some of their applications for language processing. It covers text generation models (like GPT) and representation models (like BERT).
- [Interfaces for Explaining Transformer Language Models](https://jalammar.github.io/explaining-transformers/) by Jay Alammar - A gentle visual to Transformer models by looking at input saliency and neuron activation inside neural networks. **Our understanding of why these models work so well, however, still lags behind these developments**.
- [The GPT-3 Architecture, on a Napkin](https://dugas.ch/artificial_curiosity/GPT_architecture.html)
### Tutorials
1. [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train) tutorial by Hugging Face. :fire:
## AI Safety
Interpretability research and AI alignment research.
- [Transformer Circuits Thread](https://transformer-circuits.pub/) project by Anthropic - Can we reverse engineer transformer language models into human-understandable computer programs? Interpretability research benefits a lot from interactive articles. As part of their effort, they've created several other resources besides their paper like "A Mathematical Framework for Transformer Circuits" and ["toy models of superposition"](https://threadreaderapp.com/thread/1570087876053942272.html).
- [Discovering Language Model Behaviors with Model-Written Evaluations (paper)](https://arxiv.org/abs/2212.09251) by Anthropic et al. - They automatically generate evaluations with LMs. They discover new cases of inverse scaling where LMs get worse with size. They also find some of the first examples of inverse scaling in RLHF, where more RLHF makes LMs worse.
- [Transformers learn in-context by gradient descent (paper)](https://arxiv.org/abs/2212.07677) by J von Oswald et al. [[AI Alignment Forum](https://www.alignmentforum.org/posts/firtXAWGdvzXYAh9B/paper-transformers-learn-in-context-by-gradient-descent)]
- [Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers (paper)](https://arxiv.org/abs/2212.10559v2) by Microsoft Research.
- [Cognitive Biases in Large Language Models](https://universalprior.substack.com/p/cognitive-biases-in-large-language)
- [Tracr: Compiled Transformers as a Laboratory for Interpretability (paper)](https://arxiv.org/abs/2301.05062) (2023) by DeepMind - TRACR (TRAnsformer Compiler for RASP) is a compiler for converting RASP programs (DSL for Transformers) into weights of a GPT-like model. Usually, we train Transformers to encode algorithms in their weights. With TRACR, we go in the reverse direction; compile weights **directly** from explicit code. Why do this? Accelerate interpretability research. Think of it like formal methods (from software eng.) on Transformers. It can be difficult to check if the explanation an interpretability tool provides is correct. [[Tweet](https://twitter.com/davlindner/status/1613900577804525573), [code](https://github.com/deepmind/tracr)]
## Videos
### [BERTology](https://huggingface.co/transformers/bertology.html)
1. [XLNet Explained](https://www.youtube.com/watch?v=naOuE9gLbZo) by NLP Breakfasts.
- Clear explanation. Also covers the two-stream self-attention idea.
2. [The Future of NLP](https://youtu.be/G5lmya6eKtc) by 🤗
- Dense overview of what is going on in transfer learning in NLP currently, limits, and future directions.
3. [The Transformer neural network architecture explained](https://youtu.be/FWFA4DGuzSc) by AI Coffee Break with Letitia Parcalabescu.
- High-level explanation, best suited when unfamiliar with Transformers.
### Attention and Transformer Networks
1. [Sequence to Sequence Learning Animated (Inside Transformer Neural Networks and Attention Mechanisms)](https://youtu.be/GTVgJhSlHEk) by learningcurve.
## Official BERT Implementations
1. [google-research/bert](https://github.com/google-research/bert) - TensorFlow code and pre-trained models for BERT.
## Transformer Implementations By Communities
GPT and/or BERT implementations.
### PyTorch and TensorFlow
1. [🤗 Hugging Face Transformers](https://github.com/huggingface/transformers) (formerly known as [pytorch-transformers](https://github.com/huggingface/pytorch-transformers) and [pytorch-pretrained-bert](https://github.com/huggingface/pytorch-pretrained-BERT)) provides state-of-the-art general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, CTRL...) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch. [[Paper](https://arxiv.org/abs/1910.03771)]
2. [spacy-transformers](https://github.com/explosion/spacy-transformers) - a library that wrap Hugging Face's Transformers, in order to extract features to power NLP pipelines. It also calculates an alignment so the Transformer features can be related back to actual words instead of just wordpieces.
3. [FasterTransformer](https://github.com/NVIDIA/FasterTransformer) - Transformer related optimization, including BERT and GPT. This repo provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
### PyTorch
1. [codertimo/BERT-pytorch](https://github.com/codertimo/BERT-pytorch) - Google AI 2018 BERT pytorch implementation.
2. [innodatalabs/tbert](https://github.com/innodatalabs/tbert) - PyTorch port of BERT ML model.
3. [kimiyoung/transformer-xl](https://github.com/kimiyoung/transformer-xl) - Code repository associated with the Transformer-XL paper.
4. [dreamgonfly/BERT-pytorch](https://github.com/dreamgonfly/BERT-pytorch) - A PyTorch implementation of BERT in "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding".
5. [dhlee347/pytorchic-bert](https://github.com/dhlee347/pytorchic-bert) - A Pytorch implementation of Google BERT.
6. [pingpong-ai/xlnet-pytorch](https://github.com/pingpong-ai/xlnet-pytorch) - A Pytorch implementation of Google Brain XLNet.
7. [facebook/fairseq](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md) - RoBERTa: A Robustly Optimized BERT Pretraining Approach by Facebook AI Research. SoTA results on GLUE, SQuAD and RACE.
8. [NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM) - Ongoing research training transformer language models at scale, including: BERT.
9. [deepset-ai/FARM](https://github.com/deepset-ai/FARM) - Simple & flexible transfer learning for the industry.
10. [NervanaSystems/nlp-architect](https://www.intel.ai/nlp-transformer-models/) - NLP Architect by Intel AI. Among other libraries, it provides a quantized version of Transformer models and efficient training method.
11. [kaushaltrivedi/fast-bert](https://github.com/kaushaltrivedi/fast-bert) - Super easy library for BERT based NLP models. Built based on 🤗 Transformers and is inspired by fast.ai.
12. [NVIDIA/NeMo](https://github.com/NVIDIA/NeMo) - Neural Modules is a toolkit for conversational AI by NVIDIA. They are trying to [improve speech recognition with BERT post-processing](https://nvidia.github.io/NeMo/nlp/intro.html#improving-speech-recognition-with-bertx2-post-processing-model).
13. [facebook/MMBT](https://github.com/facebookresearch/mmbt/) from Facebook AI - Multimodal transformers model that can accept a transformer model and a computer vision model for classifying image and text.
14. [dbiir/UER-py](https://github.com/dbiir/UER-py) from Tencent and RUC - Open Source Pre-training Model Framework in PyTorch & Pre-trained Model Zoo (with more focus on Chinese).
### Keras
1. [Separius/BERT-keras](https://github.com/Separius/BERT-keras) - Keras implementation of BERT with pre-trained weights.
2. [CyberZHG/keras-bert](https://github.com/CyberZHG/keras-bert) - Implementation of BERT that could load official pre-trained models for feature extraction and prediction.
3. [bojone/bert4keras](https://github.com/bojone/bert4keras) - Light reimplement of BERT for Keras.
### TensorFlow
1. [guotong1988/BERT-tensorflow](https://github.com/guotong1988/BERT-tensorflow) - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
2. [kimiyoung/transformer-xl](https://github.com/kimiyoung/transformer-xl) - Code repository associated with the Transformer-XL paper.
3. [zihangdai/xlnet](https://github.com/zihangdai/xlnet) - Code repository associated with the XLNet paper.
### Chainer
1. [soskek/bert-chainer](https://github.com/soskek/bert-chainer) - Chainer implementation of "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding".
## Transfer Learning in NLP
<details>
<summary>NLP finally had a way to do transfer learning probably as well as Computer Vision could.</summary>
As Jay Alammar put it:
> The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short). Our conceptual understanding of how best to represent words and sentences in a way that best captures underlying meanings and relationships is rapidly evolving. Moreover, the NLP community has been putting forward incredibly powerful components that you can freely download and use in your own models and pipelines (It's been referred to as [NLP's ImageNet moment](http://ruder.io/nlp-imagenet/), referencing how years ago similar developments accelerated the development of machine learning in Computer Vision tasks).
>
> One of the latest milestones in this development is the [release](https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html) of [BERT](https://github.com/google-research/bert), an event [described](https://twitter.com/lmthang/status/1050543868041555969) as marking the beginning of a new era in NLP. BERT is a model that broke several records for how well models can handle language-based tasks. Soon after the release of the paper describing the model, the team also open-sourced the code of the model, and made available for download versions of the model that were already pre-trained on massive datasets. This is a momentous development since it enables anyone building a machine learning model involving language processing to use this powerhouse as a readily-available component – saving the time, energy, knowledge, and resources that would have gone to training a language-processing model from scratch.
>
> BERT builds on top of a number of clever ideas that have been bubbling up in the NLP community recently – including but not limited to [Semi-supervised Sequence Learning](https://arxiv.org/abs/1511.01432) (by [Andrew Dai](https://twitter.com/iamandrewdai) and [Quoc Le](https://twitter.com/quocleix)), [ELMo](https://arxiv.org/abs/1802.05365) (by Matthew Peters and researchers from [AI2](https://allenai.org/) and [UW CSE](https://www.engr.washington.edu/about/bldgs/cse)), [ULMFiT](https://arxiv.org/abs/1801.06146) (by [fast.ai](https://fast.ai) founder [Jeremy Howard](https://twitter.com/jeremyphoward) and [Sebastian Ruder](https://twitter.com/seb_ruder)), the [OpenAI transformer](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf) (by OpenAI researchers [Radford](https://twitter.com/alecrad), [Narasimhan](https://twitter.com/karthik_r_n), [Salimans](https://twitter.com/timsalimans), and [Sutskever](https://twitter.com/ilyasut)), and the Transformer ([Vaswani et al](https://arxiv.org/abs/1706.03762)).
>
> **ULMFiT: Nailing down Transfer Learning in NLP**
>
> [ULMFiT introduced methods to effectively utilize a lot of what the model learns during pre-training](http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html) – more than just embeddings, and more than contextualized embeddings. ULMFiT introduced a language model and a process to effectively fine-tune that language model for various tasks.
>
> NLP finally had a way to do transfer learning probably as well as Computer Vision could.
</details>
[MultiFiT: Efficient Multi-lingual Language Model Fine-tuning](http://nlp.fast.ai/classification/2019/09/10/multifit.html) by Sebastian Ruder et al. MultiFiT extends ULMFiT to make it more efficient and more suitable for language modelling beyond English. ([EMNLP 2019 paper](https://arxiv.org/abs/1909.04761))
## Books
1. [Transfer Learning for Natural Language Processing](https://www.manning.com/books/transfer-learning-for-natural-language-processing) - A book that is a practical primer to transfer learning techniques capable of delivering huge improvements to your NLP models.
2. [Natural Language Processing with Transformers](https://transformersbook.com/) by Lewis Tunstall, Leandro von Werra, and Thomas Wolf - This practical book shows you how to train and scale these large models using Hugging Face Transformers. The authors use a hands-on approach to teach you how transformers work and how to integrate them in your applications.
## Other Resources
<details>
<summary><b>Expand Other Resources</b></summary>
1. [hanxiao/bert-as-service](https://github.com/hanxiao/bert-as-service) - Mapping a variable-length sentence to a fixed-length vector using pretrained BERT model.
2. [brightmart/bert_language_understanding](https://github.com/brightmart/bert_language_understanding) - Pre-training of Deep Bidirectional Transformers for Language Understanding: pre-train TextCNN.
3. [algteam/bert-examples](https://github.com/algteam/bert-examples) - BERT examples.
4. [JayYip/bert-multiple-gpu](https://github.com/JayYip/bert-multiple-gpu) - A multiple GPU support version of BERT.
5. [HighCWu/keras-bert-tpu](https://github.com/HighCWu/keras-bert-tpu) - Implementation of BERT that could load official pre-trained models for feature extraction and prediction on TPU.
6. [whqwill/seq2seq-keyphrase-bert](https://github.com/whqwill/seq2seq-keyphrase-bert) - Add BERT to encoder part for https://github.com/memray/seq2seq-keyphrase-pytorch
7. [xu-song/bert_as_language_model](https://github.com/xu-song/bert_as_language_model) - BERT as language model, a fork from Google official BERT implementation.
8. [Y1ran/NLP-BERT--Chinese version](https://github.com/Y1ran/NLP-BERT--ChineseVersion)
9. [yuanxiaosc/Deep_dynamic_word_representation](https://github.com/yuanxiaosc/Deep_dynamic_word_representation) - TensorFlow code and pre-trained models for deep dynamic word representation (DDWR). It combines the BERT model and ELMo's deep context word representation.
10. [yangbisheng2009/cn-bert](https://github.com/yangbisheng2009/cn-bert)
11. [Willyoung2017/Bert_Attempt](https://github.com/Willyoung2017/Bert_Attempt)
12. [Pydataman/bert_examples](https://github.com/Pydataman/bert_examples) - Some examples of BERT. `run_classifier.py` based on Google BERT for Kaggle Quora Insincere Questions Classification challenge. `run_ner.py` is based on the first season of the Ruijin Hospital AI contest and a NER written by BERT.
13. [guotong1988/BERT-chinese](https://github.com/guotong1988/BERT-chinese) - Pre-training of deep bidirectional transformers for Chinese language understanding.
14. [zhongyunuestc/bert_multitask](https://github.com/zhongyunuestc/bert_multitask) - Multi-task.
15. [Microsoft/AzureML-BERT](https://github.com/Microsoft/AzureML-BERT) - End-to-end walk through for fine-tuning BERT using Azure Machine Learning.
16. [bigboNed3/bert_serving](https://github.com/bigboNed3/bert_serving) - Export BERT model for serving.
17. [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese) - BERT with SentencePiece for Japanese text.
18. [nickwalton/AIDungeon](https://github.com/nickwalton/AIDungeon) - AI Dungeon 2 is a completely AI generated text adventure built with OpenAI's largest 1.5B param GPT-2 model. It's a first of it's kind game that allows you to enter and will react to any action you can imagine.
19. [turtlesoupy/this-word-does-not-exist](https://github.com/turtlesoupy/this-word-does-not-exist) - "This Word Does Not Exist" is a project that allows people to train a variant of GPT-2 that makes up words, definitions and examples from scratch. We've never seen fake text so real.
</details>
## Tools
1. [jessevig/bertviz](https://github.com/jessevig/bertviz) - Tool for visualizing attention in the Transformer model.
2. [FastBert](https://github.com/kaushaltrivedi/fast-bert) - A simple deep learning library that allows developers and data scientists to train and deploy BERT based models for NLP tasks beginning with text classification. The work on FastBert is inspired by fast.ai.
3. [gpt2tc](https://bellard.org/libnc/gpt2tc.html) - A small program using the GPT-2 LM to complete and compress texts. It has no external dependency, requires no GPU and is quite fast. The smallest model (117M parameters) is provided. Larger models can be downloaded as well. (no waitlist, no sign up required).
## Tasks
### Named-Entity Recognition (NER)
<details>
<summary><b>Expand NER</b></summary>
1. [kyzhouhzau/BERT-NER](https://github.com/kyzhouhzau/BERT-NER) - Use google BERT to do CoNLL-2003 NER.
2. [zhpmatrix/bert-sequence-tagging](https://github.com/zhpmatrix/bert-sequence-tagging) - Chinese sequence labeling.
3. [JamesGu14/BERT-NER-CLI](https://github.com/JamesGu14/BERT-NER-CLI) - Bert NER command line tester with step by step setup guide.
4. [sberbank-ai/ner-bert](https://github.com/sberbank-ai/ner-bert)
5. [mhcao916/NER_Based_on_BERT](https://github.com/mhcao916/NER_Based_on_BERT) - This project is based on Google BERT model, which is a Chinese NER.
6. [macanv/BERT-BiLSMT-CRF-NER](https://github.com/macanv/BERT-BiLSMT-CRF-NER) - TensorFlow solution of NER task using Bi-LSTM-CRF model with Google BERT fine-tuning.
7. [ProHiryu/bert-chinese-ner](https://github.com/ProHiryu/bert-chinese-ner) - Use the pre-trained language model BERT to do Chinese NER.
8. [FuYanzhe2/Name-Entity-Recognition](https://github.com/FuYanzhe2/Name-Entity-Recognition) - Lstm-CRF, Lattice-CRF, recent NER related papers.
9. [king-menin/ner-bert](https://github.com/king-menin/ner-bert) - NER task solution (BERT-Bi-LSTM-CRF) with Google BERT https://github.com/google-research.
</details>
### Classification
<details>
<summary><b>Expand Classification</b></summary>
1. [brightmart/sentiment_analysis_fine_grain](https://github.com/brightmart/sentiment_analysis_fine_grain) - Multi-label classification with BERT; Fine Grained Sentiment Analysis from AI challenger.
2. [zhpmatrix/Kaggle-Quora-Insincere-Questions-Classification](https://github.com/zhpmatrix/Kaggle-Quora-Insincere-Questions-Classification) - Kaggle baseline—fine-tuning BERT and tensor2tensor based Transformer encoder solution.
3. [maksna/bert-fine-tuning-for-chinese-multiclass-classification](https://github.com/maksna/bert-fine-tuning-for-chinese-multiclass-classification) - Use Google pre-training model BERT to fine-tune for the Chinese multiclass classification.
4. [NLPScott/bert-Chinese-classification-task](https://github.com/NLPScott/bert-Chinese-classification-task) - BERT Chinese classification practice.
5. [fooSynaptic/BERT_classifer_trial](https://github.com/fooSynaptic/BERT_classifer_trial) - BERT trial for Chinese corpus classfication.
6. [xiaopingzhong/bert-finetune-for-classfier](https://github.com/xiaopingzhong/bert-finetune-for-classfier) - Fine-tuning the BERT model while building your own dataset for classification.
7. [Socialbird-AILab/BERT-Classification-Tutorial](https://github.com/Socialbird-AILab/BERT-Classification-Tutorial) - Tutorial.
8. [malteos/pytorch-bert-document-classification](https://github.com/malteos/pytorch-bert-document-classification/) - Enriching BERT with Knowledge Graph Embedding for Document Classification (PyTorch)
</details>
### Text Generation
<details>
<summary><b>Expand Text Generation</b></summary>
1. [asyml/texar](https://github.com/asyml/texar) - Toolkit for Text Generation and Beyond. [Texar](https://texar.io) is a general-purpose text generation toolkit, has also implemented BERT here for classification, and text generation applications by combining with Texar's other modules.
2. [Plug and Play Language Models: a Simple Approach to Controlled Text Generation](https://arxiv.org/abs/1912.02164) (PPLM) paper by Uber AI.
</details>
### Question Answering (QA)
<details>
<summary><b>Expand QA</b></summary>
1. [matthew-z/R-net](https://github.com/matthew-z/R-net) - R-net in PyTorch, with BERT and ELMo.
2. [vliu15/BERT](https://github.com/vliu15/BERT) - TensorFlow implementation of BERT for QA.
3. [benywon/ChineseBert](https://github.com/benywon/ChineseBert) - This is a Chinese BERT model specific for question answering.
4. [xzp27/BERT-for-Chinese-Question-Answering](https://github.com/xzp27/BERT-for-Chinese-Question-Answering)
5. [facebookresearch/SpanBERT](https://github.com/facebookresearch/SpanBERT) - Question Answering on SQuAD; improving pre-training by representing and predicting spans.
</details>
### Knowledge Graph
<details>
<summary><b>Expand Knowledge Graph</b></summary>
1. [sakuranew/BERT-AttributeExtraction](https://github.com/sakuranew/BERT-AttributeExtraction) - Using BERT for attribute extraction in knowledge graph. Fine-tuning and feature extraction. The BERT-based fine-tuning and feature extraction methods are used to extract knowledge attributes of Baidu Encyclopedia characters.
2. [lvjianxin/Knowledge-extraction](https://github.com/lvjianxin/Knowledge-extraction) - Chinese knowledge-based extraction. Baseline: bi-LSTM+CRF upgrade: BERT pre-training.
</details>
## License
<details>
<summary><b>Expand License</b></summary>
This repository contains a variety of content; some developed by Cedric Chee, and some from third-parties. The third-party content is distributed under the license provided by those parties.
*I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer.*
The content developed by Cedric Chee is distributed under the following license:
### Code
The code in this repository, including all code samples in the notebooks listed above, is released under the [MIT license](LICENSE). Read more at the [Open Source Initiative](https://opensource.org/licenses/MIT).
### Text
The text content is released under the CC-BY-SA 4.0 license. Read more at [Creative Commons](https://creativecommons.org/licenses/by-sa/4.0/).
</details>
|
3,464 | Summarization Papers | <p align="center">
<h1 align="center"> <img src="./pic/summary.png" width="30" />Summarization Papers</h1>
</p>
<p align="center">
<h3 align="center"> <img src="./pic/collect.png" width="30" />I am trying to collect 50 summarization papers before 2016.</h3>
</p>
Organized by [Xiachong Feng](http://xcfeng.net/).
## Contributor
[Yichong Huang](https://github.com/OrangeInSouth), [Haozheng Yang](https://github.com/hzyang95), [Jiaan Wang](https://github.com/krystalan)
## Summarization Learning Route
[Summarization Learning Route (with link)](http://xcfeng.net/res/summarization-route.pdf)

## Trending

## Presentations && Notes
* [Dialogue Summarization (2022.1)](slides/presentation/Dialogue_Summarization_DAMO.pdf) 
* [Cross-lingual Summarization](slides/presentation/Cross-lingual_Summarization.pdf) 
* [如何把DialoGPT用到对话摘要任务?@ ACL 2021](https://mp.weixin.qq.com/s/GQQRRS3F7p4Zv6wSuDh0ng) 
* [对话摘要最新进展简述](https://mp.weixin.qq.com/s/628OAOW1_-Yc_vQbeuY_uA) 
* [Dialogue Summarization (2021.5)](slides/presentation/Dialogue_Summarization.pdf) 
* [融入常识知识的生成式对话摘要](https://mp.weixin.qq.com/s/x3zqGc4pqh4x3q_uorNKcg) 
* [会议摘要有难度?快来引入对话篇章结构信息](https://mp.weixin.qq.com/s/Be7AYUPdux8NvAO4wo6_fg) 
* [文本摘要论文列表(Chinese)](https://mp.weixin.qq.com/s/tLdLGSFl229selxeogQk-w) 
* [事实感知的生成式文本摘要(Chinese)](https://mp.weixin.qq.com/s/Aye9FBwG-v2JO2MLoEjo0g) 
* [多模态摘要简述(Chinese)](https://mp.weixin.qq.com/s/Ce6jtp-gTtqeh9lgi-kHtQ) 
* [文本摘要简述](https://mp.weixin.qq.com/s/NGpDrYilAeuH6pQji0ujaA) 
* [Multi-modal Summarization](slides/presentation/Multi-modal-Summarization.pdf) 
* [ACL20 Summarization](slides/presentation/acl2020-summarization.pdf) 
* [文本摘要简述 (Chinese)](slides/presentation/文本摘要简述.pdf) 
* [ACL19 Summarization](slides/presentation/ACL19%20Summarization.pdf) 
* [Brief intro to summarization (Chinese)](slides/notes/Brief-intro-to-summarization.pdf) 
* [EMNLP19 Summarization (Chinese)](slides/notes/EMNLP19_Summarization.pdf) 
* [ACL19-A Simple Theoretical Model of Importance for Summarization](slides/paper-slides/A%20Simple%20Theoretical%20Model%20of%20Importance%20for%20Summarization.pdf) 
* [ACL19-Multimodal Abstractive Summarization for How2 Videos](slides/paper-slides/Multimodal%20Abstractive%20Summarization%20for%20How2%20Videos.pdf) 
## Benchmark
* **Benchmarking Large Language Models for News Summarizatio** *Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, Tatsunori B. Hashimoto* [[pdf]](https://arxiv.org/abs/2301.13848) <details> <summary>[Abs]</summary> Large language models (LLMs) have shown promise for automatic summarization but the reasons behind their successes are poorly understood. By conducting a human evaluation on ten LLMs across different pretraining methods, prompts, and model scales, we make two important observations. First, we find instruction tuning, and not model size, is the key to the LLM's zero-shot summarization capability. Second, existing studies have been limited by low-quality references, leading to underestimates of human performance and lower few-shot and finetuning performance. To better evaluate LLMs, we perform human evaluation over high-quality summaries we collect from freelance writers. Despite major stylistic differences such as the amount of paraphrasing, we find that LMM summaries are judged to be on par with human written summaries. </details>
* **MuLD: The Multitask Long Document Benchmark** *G Thomas Hudson, Noura Al Moubayed* [[pdf]](https://arxiv.org/abs/2202.07362) [[data]](https://github.com/ghomasHudson/muld)
* **EXPLAINABOARD: An Explainable Leaderboard for NLP** *Pengfei Liu, Jinlan Fu, Yang Xiao, Weizhe Yuan, Shuaichen Chang, Junqi Dai, Yixin Liu, Zihuiwen Ye, Graham Neubig* [[pdf]](http://explainaboard.nlpedia.ai/ExplainaBoard.pdf) [[ExplainaBoard]](http://explainaboard.nlpedia.ai/leaderboard/task-summ/index.php)
* **GLGE: A New General Language Generation Evaluation Benchmark** *Dayiheng Liu, Yu Yan, Yeyun Gong, Weizhen Qi, Hang Zhang, Jian Jiao, Weizhu Chen, Jie Fu, Linjun Shou, Ming Gong, Pengcheng Wang, Jiusheng Chen, Daxin Jiang, Jiancheng Lv, Ruofei Zhang, Winnie Wu, Ming Zhou, Nan Duan* [[pdf]](https://arxiv.org/abs/2011.11928) [[benchmark]](https://github.com/microsoft/glge)
## Survey
1. **A Survey on Medical Document Summarization** *Raghav Jain, Anubhav Jangra, Sriparna Saha, Adam Jatowt* [[pdf]](https://arxiv.org/abs/2212.01669) <details> <summary>[Abs]</summary> The internet has had a dramatic effect on the healthcare industry, allowing documents to be saved, shared, and managed digitally. This has made it easier to locate and share important data, improving patient care and providing more opportunities for medical studies. As there is so much data accessible to doctors and patients alike, summarizing it has become increasingly necessary - this has been supported through the introduction of deep learning and transformer-based networks, which have boosted the sector significantly in recent years. This paper gives a comprehensive survey of the current techniques and trends in medical summarization </details>
2. **Taxonomy of Abstractive Dialogue Summarization: Scenarios, Approaches and Future Directions** *Qi Jia, Siyu Ren, Yizhu Liu, Kenny Q. Zhu* [[pdf]](https://arxiv.org/abs/2210.09894) <details> <summary>[Abs]</summary> Abstractive dialogue summarization is to generate a concise and fluent summary covering the salient information in a dialogue among two or more interlocutors. It has attracted great attention in recent years based on the massive emergence of social communication platforms and an urgent requirement for efficient dialogue information understanding and digestion. Different from news or articles in traditional document summarization, dialogues bring unique characteristics and additional challenges, including different language styles and formats, scattered information, flexible discourse structures and unclear topic boundaries. This survey provides a comprehensive investigation on existing work for abstractive dialogue summarization from scenarios, approaches to evaluations. It categorizes the task into two broad categories according to the type of input dialogues, i.e., open-domain and task-oriented, and presents a taxonomy of existing techniques in three directions, namely, injecting dialogue features, designing auxiliary training tasks and using additional data.A list of datasets under different scenarios and widely-accepted evaluation metrics are summarized for completeness. After that, the trends of scenarios and techniques are summarized, together with deep insights on correlations between extensively exploited features and different scenarios. Based on these analyses, we recommend future directions including more controlled and complicated scenarios, technical innovations and comparisons, publicly available datasets in special domains, etc. </details>
3. **A Survey of Automatic Text Summarization Using Graph Neural Networks** *Marco Ferdinand Salchner, Adam Jatowt* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.536/) <details> <summary>[Abs]</summary> Although automatic text summarization (ATS) has been researched for several decades, the application of graph neural networks (GNNs) to this task started relatively recently. In this survey we provide an overview on the rapidly evolving approach of using GNNs for the task of automatic text summarization. In particular we provide detailed information on the functionality of GNNs in the context of ATS, and a comprehensive overview of models utilizing this approach. </details>
4. **A Survey on Cross-Lingual Summarization** *Jiaan Wang, Fandong Meng, Duo Zheng, Yunlong Liang, Zhixu Li, Jianfeng Qu, Jie Zhou* `TACL 2022` [[pdf]](https://arxiv.org/abs/2203.12515) <details> <summary>[Abs]</summary> Cross-lingual summarization is the task of generating a summary in one language (e.g., English) for the given document(s) in a different language (e.g., Chinese). Under the globalization background, this task has attracted increasing attention of the computational linguistics community. Nevertheless, there still remains a lack of comprehensive review for this task. Therefore, we present the first systematic critical review on the datasets, approaches, and challenges in this field. Specifically, we carefully organize existing datasets and approaches according to different construction methods and solution paradigms, respectively. For each type of datasets or approaches, we thoroughly introduce and summarize previous efforts and further compare them with each other to provide deeper analyses. In the end, we also discuss promising directions and offer our thoughts to facilitate future research. This survey is for both beginners and experts in cross-lingual summarization, and we hope it will serve as a starting point as well as a source of new ideas for researchers and engineers interested in this area. </details>
5. **An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics** *uan Yee Koh, Jiaxin Ju, Ming Liu, Shirui Pan* `ACM Computing Surveys` [[pdf]](https://arxiv.org/abs/2207.00939) <details> <summary>[Abs]</summary> Long documents such as academic articles and business reports have been the standard format to detail out important issues and complicated subjects that require extra attention. An automatic summarization system that can effectively condense long documents into short and concise texts to encapsulate the most important information would thus be significant in aiding the reader's comprehension. Recently, with the advent of neural architectures, significant research efforts have been made to advance automatic text summarization systems, and numerous studies on the challenges of extending these systems to the long document domain have emerged. In this survey, we provide a comprehensive overview of the research on long document summarization and a systematic evaluation across the three principal components of its research setting: benchmark datasets, summarization models, and evaluation metrics. For each component, we organize the literature within the context of long document summarization and conduct an empirical analysis to broaden the perspective on current research progress. The empirical analysis includes a study on the intrinsic characteristics of benchmark datasets, a multi-dimensional analysis of summarization models, and a review of the summarization evaluation metrics. Based on the overall findings, we conclude by proposing possible directions for future exploration in this rapidly growing field. </details>
6. **Multi-document Summarization via Deep Learning Techniques: A Survey** *Congbo Ma, Wei Emma Zhang, Mingyu Guo, Hu Wang, QUAN Z. Sheng* [[pdf]](https://dl.acm.org/doi/10.1145/3529754)
7. **Embedding Knowledge for Document Summarization: A Survey** *Yutong Qu, Wei Emma Zhang, Jian Yang, Lingfei Wu, Jia Wu, Xindong Wu* [[pdf]](https://arxiv.org/abs/2204.11190)
8. **A Survey on Dialogue Summarization: Recent Advances and New Frontiers** *Xiachong Feng, Xiaocheng Feng, Bing Qin* `IJCAI 2022, Survey Track` [[pdf]](https://arxiv.org/abs/2107.03175)
9. **Automatic Text Summarization Methods: A Comprehensive Review** *Divakar Yadav, Jalpa Desai, Arun Kumar Yadav* [[pdf]](https://arxiv.org/abs/2204.01849)
10. **Faithfulness in Natural Language Generation: A Systematic Survey of Analysis, Evaluation and Optimization Methods** *Wei Li, Wenhao Wu, Moye Chen, Jiachen Liu, Xinyan Xiao, Hua Wu* [[pdf]](https://arxiv.org/abs/2203.05227)
11. **Recent Advances in Neural Text Generation: A Task-Agnostic Survey** *Chen Tang, Frank Guerin, Yucheng Li, Chenghua Lin* [[pdf]](https://arxiv.org/abs/2203.03047)
12. **Survey of Hallucination in Natural Language Generation** *Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, Pascale Fung* [[pdf]](https://arxiv.org/abs/2202.03629)
13. **A Survey on Retrieval-Augmented Text Generation** *Huayang Li, Yixuan Su, Deng Cai, Yan Wang, Lemao Liu* [[pdf]](https://arxiv.org/abs/2202.01110)
14. **A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models** *Hanqing Zhang, Haolin Song, Shaoyu Li, Ming Zhou, Dawei Song* [[pdf]](https://arxiv.org/abs/2201.05337)
15. **A Survey of Pretrained Language Models Based Text Generation** *Junyi Li, Tianyi Tang, Wayne Xin Zhao, Jian-Yun Nie, Ji-Rong Wen* [[pdf]](https://arxiv.org/abs/2201.05273)
16. **A Comprehensive Review on Summarizing Financial News Using Deep Learning** *Saurabh Kamal, Sahil Sharma* [[pdf]](https://arxiv.org/abs/2109.10118)
17. **A Survey on Multi-modal Summarization** *Anubhav Jangra, Adam Jatowt, Sriparna Saha, Mohammad Hasanuzzaman* [[pdf]](https://arxiv.org/abs/2109.05199)
18. **Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing** *Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig* [[pdf]](https://arxiv.org/abs/2107.13586)
19. **Pretrained Language Models for Text Generation: A Survey** *Junyi Li, Tianyi Tang, Wayne Xin Zhao, Ji-Rong Wen* `IJCAI21` [[pdf]](https://arxiv.org/abs/2105.10311)
20. **A Survey of Recent Abstract Summarization Techniques** *Diyah Puspitaningrum* `ICICT21` [[pdf]](https://arxiv.org/abs/2105.00824)
21. **A Survey of the State-of-the-Art Models in Neural Abstractive Text Summarization** *AYESHA AYUB SYED, FORD LUMBAN GAOL, TOKURO MATSUO* [[pdf]](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9328413)
22. **Automatic summarization of scientific articles: A survey** *Nouf Ibrahim Altmami, Mohamed El Bachir Menai* `Journal of King Saud University - Computer and Information Sciences` [[pdf]](https://www.sciencedirect.com/science/article/pii/S1319157820303554)
23. **Multi-document Summarization via Deep Learning Techniques: A Survey** *Congbo Ma, Wei Emma Zhang, Mingyu Guo, Hu Wang, Quan Z. Sheng* [[pdf]](https://arxiv.org/abs/2011.04843)
24. **Deep Learning Based Abstractive Text Summarization: Approaches, Datasets, Evaluation Measures, and Challenges** *Dima Suleiman, Arafat A. Awajan* [[pdf]](https://www.semanticscholar.org/paper/Deep-Learning-Based-Abstractive-Text-Summarization%3A-Suleiman-Awajan/b7da726c244287748575ef404009609afde45bea)
25. **A Survey of Knowledge-Enhanced Text Generation** *Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang* [[pdf]](https://arxiv.org/abs/2010.04389)
26. **From Standard Summarization to New Tasks and Beyond: Summarization with Manifold Information** *Shen Gao, Xiuying Chen, Zhaochun Ren, Dongyan Zhao, Rui Yan* `IJCAI20` [[pdf]](https://arxiv.org/abs/2005.04684)
27. **Neural Abstractive Text Summarization with Sequence-to-Sequence Models** *Tian Shi, Yaser Keneshloo, Naren Ramakrishnan, Chandan K. Reddy* [[pdf]](https://arxiv.org/abs/1812.02303)
28. **A Survey on Neural Network-Based Summarization Methods** *Yue Dong* [[pdf]](https://arxiv.org/abs/1804.04589)
29. **Automated text summarisation and evidence-based medicine: A survey of two domains** *Abeed Sarker, Diego Molla, Cecile Paris* [[pdf]](https://arxiv.org/abs/1706.08162)
30. **Automatic Keyword Extraction for Text Summarization: A Survey** *Santosh Kumar Bharti, Korra Sathya Babu* [[pdf]](https://arxiv.org/abs/1704.03242)
31. **Text Summarization Techniques: A Brief Survey** *Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, Krys Kochut* [[pdf]](https://arxiv.org/abs/1707.02268)
32. **Recent automatic text summarization techniques: a survey** *Mahak Gambhir, Vishal Gupta* [[pdf]](https://link.springer.com/article/10.1007/s10462-016-9475-9)
## Toolkit
1. **Summary Workbench: Unifying Application and Evaluation of Text Summarization Models** *Shahbaz Syed, Dominik Schwabe, Martin Potthast* `EMNLP 2022 Demo` [[pdf]](https://arxiv.org/abs/2210.09587) [[demo]](https://tldr.demo.webis.de/summarize) <details> <summary>[Abs]</summary> This paper presents Summary Workbench, a new tool for developing and evaluating text summarization models. New models and evaluation measures can be easily integrated as Docker-based plugins, allowing to examine the quality of their summaries against any input and to evaluate them using various evaluation measures. Visual analyses combining multiple measures provide insights into the models' strengths and weaknesses. The tool is hosted at \url{this https URL} and also supports local deployment for private resources. </details>
1. **iFacetSum: Coreference-based Interactive Faceted Summarization for Multi-Document Exploration** *Eran Hirsch, Alon Eirew, Ori Shapira, Avi Caciularu, Arie Cattan, Ori Ernst, Ramakanth Pasunuru, Hadar Ronen, Mohit Bansal, Ido Dagan* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.11621) [[demo]](https://biu-nlp.github.io/iFACETSUM/WebApp/client/)
1. **SummerTime: Text Summarization Toolkit for Non-experts** *Ansong Ni, Zhangir Azerbayev, Mutethia Mutuma, Troy Feng, Yusen Zhang, Tao Yu, Ahmed Hassan Awadallah, Dragomir Radev* `EMNLP 2021 Demo Track` [[pdf]](https://arxiv.org/abs/2108.12738) [[Demo]](https://github.com/Yale-LILY/SummerTime)
1. **Summary Explorer: Visualizing the State of the Art in Text Summarization** *Shahbaz Syed, Tariq Yousef, Khalid Al-Khatib, Stefan Jänicke, Martin Potthast* [[pdf]](https://arxiv.org/abs/2108.01879) [[web]](https://tldr.webis.de/)
1. **fastnlp/fastSum** [[code]](https://github.com/fastnlp/fastSum)
1. **Graph4NLP** [[code]](https://github.com/graph4ai/graph4nlp) [[summarization]](https://github.com/graph4ai/graph4nlp/tree/master/examples/pytorch/summarization)
1. **CTRLsum: Towards Generic Controllable Text Summarization** [[pdf]](https://arxiv.org/abs/2012.04281) [[code]](https://github.com/hyunwoongko/summarizers) `EMNLP 2022` <details> <summary>[Abs]</summary> Current summarization systems yield generic summaries that are disconnected from users’ preferences and expectations. To address this limitation, we present CTRLsum, a generic framework to control generated summaries through a set of keywords. During training keywords are extracted automatically without requiring additional human annotations. At test time CTRLsum features a control function to map control signal to keywords; through engineering the control function, the same trained model is able to be applied to control summaries on various dimensions, while neither affecting the model training process nor the pretrained models. We additionally explore the combination of keywords and text prompts for more control tasks. Experiments demonstrate the effectiveness of CTRLsum on three domains of summarization datasets and five control tasks: (1) entity-centric and (2) length-controllable summarization, (3) contribution summarization on scientific papers, (4) invention purpose summarization on patent filings, and (5) question-guided summarization on news articles. Moreover, when used in a standard, unconstrained summarization setting, CTRLsum is comparable or better than strong pretrained systems. </details>
1. **OpenNMT-py: Open-Source Neural Machine Translation** [[pdf]](https://www.aclweb.org/anthology/W18-1817.pdf) [[code]](https://github.com/OpenNMT/OpenNMT-py)
2. **Fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python.** [[code]](https://github.com/pytorch/fairseq)
3. **LeafNATS: An Open-Source Toolkit and Live Demo System for Neural Abstractive Text Summarization** *Tian Shi, Ping Wang, Chandan K. Reddy* `NAACL19` [[pdf]](https://www.aclweb.org/anthology/N19-4012/) [[code]](https://github.com/tshi04/LeafNATS)
4. **TransformerSum** [[code]](https://github.com/HHousen/TransformerSum)
## Analysis
   
1. **Analyzing Multi-Task Learning for Abstractive Text Summarization** *Frederic Kirstein, Jan Philip Wahle, Terry Ruas, Bela Gipp* `` [[pdf]](https://arxiv.org/abs/2210.14606) <details> <summary>[Abs]</summary> Despite the recent success of multi-task learning and pre-finetuning for natural language understanding, few works have studied the effects of task families on abstractive text summarization. Task families are a form of task grouping during the pre-finetuning stage to learn common skills, such as reading comprehension. To close this gap, we analyze the influence of multi-task learning strategies using task families for the English abstractive text summarization task. We group tasks into one of three strategies, i.e., sequential, simultaneous, and continual multi-task learning, and evaluate trained models through two downstream tasks. We find that certain combinations of task families (e.g., advanced reading comprehension and natural language inference) positively impact downstream performance. Further, we find that choice and combinations of task families influence downstream performance more than the training scheme, supporting the use of task families for abstractive text summarization. </details>
1. **On Decoding Strategies for Neural Text Generators** *Gian Wiher, Clara Meister, Ryan Cotterell* [[pdf]](https://arxiv.org/abs/2203.15721)
1. **Training Dynamics for Text Summarization Models** *Tanya Goyal, Jiacheng Xu, Junyi Jessy Li, Greg Durrett* [https://arxiv.org/abs/2110.08370]
1. **Does Summary Evaluation Survive Translation to Other Languages?** *Neslihan Iskender, Oleg Vasilyev, Tim Polzehl, John Bohannon, Sebastian Möller* [[pdf]](https://arxiv.org/abs/2109.08129)
1. **How well do you know your summarization datasets?** *Priyam Tejaswin, Dhruv Naik, Pengfei Liu* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.11388) [[code]](https://github.com/priyamtejaswin/howwelldoyouknow)
1. **Dissecting Generation Modes for Abstractive Summarization Models via Ablation and Attribution** *Jiacheng Xu, Greg Durrett* `ACL2021` [[pdf]](https://aclanthology.org/2021.acl-long.539/) [[code]](https://github.com/jiacheng-xu/sum-interpret)
1. **To Point or Not to Point: Understanding How Abstractive Summarizers Paraphrase Text** *Matt Wilber, William Timkey, Marten Van Schijndel* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.01581) [[code]](https://github.com/mwilbz/pointer-generator-analysis)
1. **What Makes a Good Summary? Reconsidering the Focus of Automatic Summarization** *Maartje ter Hoeve, Julia Kiseleva, Maarten de Rijke* [[pdf]](https://arxiv.org/abs/2012.07619)
1. **Intrinsic Evaluation of Summarization Datasets** *Rishi Bommasani, Claire Cardie* `EMNLP20` [[pdf]](https://www.aclweb.org/anthology/2020.emnlp-main.649/) 
1. **Metrics also Disagree in the Low Scoring Range: Revisiting Summarization Evaluation Metrics** *Manik Bhandari, Pranav Gour, Atabak Ashfaq, Pengfei Liu* `COLING20 Short` [[pdf]](https://arxiv.org/abs/2011.04096) [[code]](https://github.com/manikbhandari/RevisitSummEvalMetrics) 
1. **At Which Level Should We Extract? An Empirical Analysis on Extractive Document Summarization** *Qingyu Zhou, Furu Wei, Ming Zhou* `COLING20` [[pdf]](https://arxiv.org/abs/2004.02664) 
1. **Corpora Evaluation and System Bias detection in Multi Document Summarization** *Alvin Dey, Tanya Chowdhury, Yash Kumar, Tanmoy Chakraborty* `Findings of EMNLP` [[pdf]](https://www.aclweb.org/anthology/2020.findings-emnlp.254/) 
1. **Understanding the Extent to which Summarization Evaluation Metrics Measure the Information Quality of Summaries** *Daniel Deutsch, Dan Roth* [[pdf]](https://arxiv.org/abs/2010.12495) [[code]](https://github.com/CogComp/content-analysis-experiments)
1. **Understanding Neural Abstractive Summarization Models via Uncertainty** *Jiacheng Xu, Shrey Desai, Greg Durrett* `EMNLP20 Short` [[pdf]](https://arxiv.org/abs/2010.07882) [[code]](https://github.com/jiacheng-xu/text-sum-uncertainty) 
2. **Re-evaluating Evaluation in Text Summarization** *Manik Bhandari, Pranav Gour, Atabak Ashfaq, Pengfei Liu, Graham Neubig* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.07100) [[code]](https://github.com/neulab/REALSumm) 
3. **CDEvalSumm: An Empirical Study of Cross-Dataset Evaluation for Neural Summarization Systems** *Yiran Chen, Pengfei Liu, Ming Zhong, Zi-Yi Dou, Danqing Wang, Xipeng Qiu, Xuanjing Huang* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.05139) [[code]](https://github.com/zide05/CDEvalSumm) 
4. **What Have We Achieved on Text Summarization?** *Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.04529) 
5. **Conditional Neural Generation using Sub-Aspect Functions for Extractive News Summarization** *Zhengyuan Liu, Ke Shi, Nancy F. Chen* `Findings of EMNLP20` [[pdf]](https://arxiv.org/abs/2004.13983) 
6. **Extractive Summarization as Text Matching** *Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang* `ACL20` [[pdf]](https://arxiv.org/abs/2004.08795) [[code]](https://github.com/maszhongming/MatchSum)  
7. **Neural Text Summarization: A Critical Evaluation** *Wojciech Kryściński, Nitish Shirish Keskar, Bryan McCann, Caiming Xiong, Richard Socher* `EMNLP19` [[pdf]](https://www.aclweb.org/anthology/D19-1051/) 
8. **Earlier Isn’t Always Better:Sub-aspect Analysis on Corpus and System Biases in Summarization** *Taehee Jung, Dongyeop Kang, Lucas Mentch, Eduard Hovy* `EMNLP19` [[pdf]](https://arxiv.org/abs/1908.11723) [[code]](https://github.com/dykang/biassum) 
9. **A Closer Look at Data Bias in Neural Extractive Summarization Models** *Ming Zhong, Danqing Wang, Pengfei Liu, Xipeng Qiu, Xuanjing Huang* `EMNLP19 Workshop` [[pdf]](https://arxiv.org/abs/1909.13705) 
10. **Countering the Effects of Lead Bias in News Summarization via Multi-Stage Training and Auxiliary Losses** *Matt Grenander, Yue Dong, Jackie Chi Kit Cheung, Annie Louis* `EMNLP19 Short` [[pdf]](https://arxiv.org/abs/1909.04028) 
11. **Searching for Effective Neural Extractive Summarization: What Works and What's Next** *Ming Zhong, Pengfei Liu, Danqing Wang, Xipeng Qiu, Xuanjing Huang* `ACL19` [[pdf]](https://arxiv.org/abs/1907.03491) [[code]](https://github.com/maszhongming/Effective_Extractive_Summarization) 
12. **Content Selection in Deep Learning Models of Summarization** *Chris Kedzie, Kathleen McKeown, Hal Daumé III* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1208/) [[code]](https://github.com/kedz/nnsum/tree/emnlp18-release) 
## Thesis
1. **Principled Approaches to Automatic Text Summarization** *Maxime Peyrard* [[pdf]](https://tuprints.ulb.tu-darmstadt.de/9012/)
2. **Neural Text Summarization and Generation** *Piji Li* [[pdf]](http://lipiji.com/docs/thesis.pdf)
## Theory
1. **Bayesian Active Summarization** *Alexios Gidiotis, Grigorios Tsoumakas* [[pdf]](https://arxiv.org/abs/2110.04480)
1. **RefSum: Refactoring Neural Summarization** *Yixin Liu, Zi-Yi Dou, Pengfei Liu* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.07210) [[code]](https://github.com/yixinL7/Refactoring-Summarization)
1. **Principled Approaches to Automatic Text Summarization** *Maxime Peyrard* [[pdf]](https://tuprints.ulb.tu-darmstadt.de/9012/) 
1. **KLearn: Background Knowledge Inference from Summarization Data** *Maxime Peyrard, Robert West* `Findings of EMNLP20` [[pdf]](https://arxiv.org/abs/2010.06213) [[code]](https://github.com/epfl-dlab/KLearn)
2. **A Simple Theoretical Model of Importance for Summarization** *Maxime Peyrard* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1101/)
3. **BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle** *Peter West, Ari Holtzman, Jan Buys, Yejin Choi* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.07405) [[code]](https://github.com/peterwestuw/BottleSum)
## Dataset
|ID|Name|Description|Paper|Conference|
|:---:|:---:|:---:|:---:|:---:|
| 1 | [CNN-DailyMail](https://github.com/harvardnlp/sent-summary) | News | [Abstractive Text Summarization using Sequence\-to\-sequence RNNs and Beyond ](https://www.aclweb.org/anthology/K16-1028/)|SIGNLL16|
| 2 | [New York Times](https://catalog.ldc.upenn.edu/LDC2008T19)| News | [The New York Times Annotated Corpus](https://catalog.ldc.upenn.edu/LDC2008T19) ||
| 3 | [DUC](https://duc.nist.gov/data.html)| News | [The Effects Of Human Variation In DUC Summarization Evaluation](https://www.aclweb.org/anthology/W04-1003/) ||
| 4 | [Gigaword](https://github.com/harvardnlp/sent-summary) | News | [A Neural Attention Model For Abstractive Sentence Summarization](https://arxiv.org/abs/1509.00685) |EMNLP15|
| 5 | [Newsroom](http://lil.nlp.cornell.edu/newsroom/) | News | [Newsroom: A Dataset of 1\.3 Million Summaries with Diverse Extractive Strategies](https://www.aclweb.org/anthology/N18-1065)|NAACL18|
| 6 | [Xsum](https://github.com/EdinburghNLP/XSum) | News | [Don’t Give Me the Details, Just the Summary\! Topic\-Aware Convolutional Neural Networks for Extreme Summarization](https://www.aclweb.org/anthology/D18-1206/)|EMNLP18|
| 7 | [Multi-News](https://github.com/Alex-Fabbri/Multi-News)| Multi-document News | [Multi\-News: a Large\-Scale Multi\-Document Summarization Dataset and Abstractive Hierarchical Model](https://arxiv.org/abs/1906.01749)|ACL19|
| 8 | [SAMSum](https://arxiv.org/abs/1911.12237)| Multi-party conversation | [SAMSum Corpus: A Human\-annotated Dialogue Dataset for Abstractive Summarization](https://arxiv.org/abs/1911.12237)|EMNLP19|
| 9 | [AMI](http://groups.inf.ed.ac.uk/ami/download/) | Meeting | [The AMI Meeting Corpus: A pre\-announcement\. ](http://groups.inf.ed.ac.uk/ami/download/)||
| 10 | [ICSI](http://groups.inf.ed.ac.uk/ami/icsi/download/)| Meeting | [The ICSI Meeting Corpus](http://groups.inf.ed.ac.uk/ami/icsi/) ||
| 11 | [MSMO](http://www.nlpr.ia.ac.cn/cip/jjzhang.htm)| Multi-modal | [MSMO: Multimodal Summarization with Multimodal Output](https://www.aclweb.org/anthology/D18-1448/) |EMNLP18|
| 12 | [How2](https://github.com/srvk/how2-dataset) | Multi-modal | [How2: A Large\-scale Dataset for Multimodal Language Understanding](https://arxiv.org/abs/1811.00347)| NIPS18|
| 13 | [ScisummNet](https://cs.stanford.edu/~myasu/projects/scisumm_net/) | Scientific paper | [ScisummNet: A Large Annotated Corpus and Content\-Impact Models for Scientific Paper Summarization with Citation Networks](https://arxiv.org/abs/1909.01716) |AAAI19|
| 14 | [PubMed, ArXiv](https://github.com/armancohan/long-summarization)| Scientific paper | [A Discourse\-Aware Attention Model for Abstractive Summarization of Long Documents](https://arxiv.org/abs/1804.05685)| NAACL18 |
| 15 | [TALKSUMM](https://github.com/levguy/talksumm) | Scientific paper | [TALKSUMM: A Dataset and Scalable Annotation Method for Scientific Paper Summarization Based on Conference Talks](https://www.aclweb.org/anthology/P19-1204/) | ACL19 |
| 16 | [BillSum](https://github.com/FiscalNote/BillSum) | Legal | [BillSum: A Corpus for Automatic Summarization of US Legislation](https://www.aclweb.org/anthology/D19-5406/) |EMNLP19|
| 17 | [LCSTS](http://icrc.hitsz.edu.cn/Article/show/139.html)| Chinese Weibo| [LCSTS: A Large Scale Chinese Short Text Summarization Dataset ](https://www.aclweb.org/anthology/D15-1229/)|EMNLP15|
| 18 | [WikiHow](https://github.com/mahnazkoupaee/WikiHow-Dataset)| Online Knowledge Base | [WikiHow: A Large Scale Text Summarization Dataset](https://arxiv.org/abs/1810.09305) ||
| 19 | [Concept-map-based MDS Corpus](https://github.com/UKPLab/emnlp2017-cmapsum-corpus/)| Educational Multi-document| [Bringing Structure into Summaries : Crowdsourcing a Benchmark Corpus of Concept Maps](https://www.aclweb.org/anthology/D17-1320/)|EMNLP17|
| 20 | [WikiSum](https://github.com/tensorflow/tensor2tensor/tree/master/tensor2tensor/data_generators/wikisum) | Wikipedia Multi-document | [Generating Wikipedia By Summarizing Long Sequence](https://arxiv.org/abs/1801.10198) |ICLR18|
| 21 | [GameWikiSum](https://github.com/Diego999/GameWikiSum) | Game Multi-document | [GameWikiSum : a Novel Large Multi\-Document Summarization Dataset](https://arxiv.org/abs/2002.06851) |LREC20|
| 22 | [En2Zh CLS, Zh2En CLS](http://www.nlpr.ia.ac.cn/cip/dataset.htm)| Cross-Lingual | [NCLS: Neural Cross\-Lingual Summarization](https://arxiv.org/abs/1909.00156) |EMNLP19|
| 23 | [Timeline Summarization Dataset](https://github.com/yingtaomj/Learning-towards-Abstractive-Timeline-Summarization)| Baidu timeline| [Learning towards Abstractive Timeline Summarization ](https://www.ijcai.org/Proceedings/2019/686)|IJCAI19|
| 24 | [Reddit TIFU](https://github.com/ctr4si/MMN) | online discussion | [Abstractive Summarization of Reddit Posts with Multi\-level Memory Networks](https://arxiv.org/abs/1811.00783)| NAACL19 |
| 25 | [TripAtt](https://github.com/Junjieli0704/ASN) | Review | [Attribute\-aware Sequence Network for Review Summarization](https://www.aclweb.org/anthology/D19-1297/)|EMNLP19|
| 26 | [Reader Comments Summarization Corpus](https://drive.google.com/file/d/1_YH5cBtvNnUNJjGj7kiTMjuHydBqWYQT/view?usp=drive_open) | Comments-based Weibo | [Abstractive Text Summarization by Incorporating Reader Comments ](https://arxiv.org/abs/1812.05407)|AAAI19|
| 27 | [BIGPATENT](https://evasharma.github.io/bigpatent/) | Patent| [BIGPATENT: A Large\-Scale Dataset for Abstractive and Coherent Summarization](https://arxiv.org/abs/1906.03741)|ACL19|
| 28 | [Curation Corpus](https://github.com/CurationCorp/curation-corpus) | News | [Curation Corpus for Abstractive Text Summarisation](https://github.com/CurationCorp/curation-corpus) ||
| 29 | [MATINF](https://github.com/WHUIR/MATINF)|Multi-task|[MATINF: A Jointly Labeled Large-Scale Dataset for Classification, Question Answering and Summarization](https://arxiv.org/abs/2004.12302)|ACL20|
| 30 | [MLSUM](https://github.com/recitalAI/MLSUM) |Multi-Lingual Summarization Dataset|[MLSUM: The Multilingual Summarization Corpus](https://arxiv.org/abs/2004.14900)|EMNLP20|
| 31 | Dialogue(Debate)|Argumentative Dialogue Summary Corpus |[Using Summarization to Discover Argument Facets in Online Idealogical Dialog](https://www.aclweb.org/anthology/N15-1046/)|NAACL15|
|32|[WCEP](https://github.com/complementizer/wcep-mds-dataset)|News Multi-document|[A Large-Scale Multi-Document Summarization Dataset from the Wikipedia Current Events Portal](https://arxiv.org/abs/2005.10070)|ACL20 Short|
|33|[ArgKP](https://www.research.ibm.com/haifa/dept/vst/debating_data.shtml)|Argument-to-key Point Mapping|[From Arguments to Key Points: Towards Automatic Argument Summarization](https://arxiv.org/abs/2005.01619)|ACL20|
|34|[CRD3](https://github.com/RevanthRameshkumar/CRD3)|Dialogue|[Storytelling with Dialogue: A Critical Role Dungeons and Dragons Dataset](https://www.aclweb.org/anthology/2020.acl-main.459/)|2020|
|35|[Gazeta](https://github.com/IlyaGusev/gazeta)|Russian news|[Dataset for Automatic Summarization of Russian News](https://arxiv.org/abs/2006.11063)||
|36|[MIND](https://msnews.github.io/)|English news recommendation, Summarization, Classification, Entity|[MIND: A Large-scale Dataset for News Recommendation](https://www.aclweb.org/anthology/2020.acl-main.331/)|ACL20|
|37|[public_meetings](https://github.com/pltrdy/autoalign)|french meeting(test set)|[Align then Summarize: Automatic Alignment Methods for Summarization Corpus Creation](https://www.aclweb.org/anthology/2020.lrec-1.829)|LREC|
|38|Enron|Email|[Building a Dataset for Summarization and Keyword Extraction from Emails](https://www.aclweb.org/anthology/L14-1028/)|2014|
|39|Columbia|Email|[Summarizing Email Threads]([https://www.aclweb.org/anthology/N04-4027.pdf](https://dl.acm.org/doi/10.5555/1613984.1614011))|2004|
|40|[BC3](https://www.cs.ubc.ca/cs-research/lci/research-groups/natural-language-processing/bc3.html)|Email|[A publicly available annotated corpus for supervised email summarization](https://www.ufv.ca/media/assets/computer-information-systems/gabriel-murray/publications/aaai08.pdf)||
|41|[WikiLingua](https://github.com/esdurmus/Wikilingua)|Cross-Lingual|[WikiLingua- A New Benchmark Dataset for Cross-Lingual Abstractive Summarization](https://arxiv.org/abs/2010.03093)|Findings of EMNLP20|
|42|[LcsPIRT](http://eie.usts.edu.cn/prj/NLPoSUST/LcsPIRT.htm)|Chinese Dialogue|[Global Encoding for Long Chinese Text Summarization](https://dl.acm.org/doi/10.1145/3407911)|TALLIP|
|43|[CLTS](https://github.com/lxj5957/CLTS-Dataset),[CLTS-plus](https://github.com/lxj5957/CLTS-plus-Dataset)|Chinese News|[CLTS: A New Chinese Long Text Summarization Dataset](https://link.springer.com/chapter/10.1007/978-3-030-60450-9_42) [CLTS+: A New Chinese Long Text Summarization Dataset with Abstractive Summaries](https://arxiv.org/abs/2206.04253)|NLPCC20|
|44|[VMSMO](https://github.com/yingtaomj/VMSMO)|Multi-modal|[VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles](https://arxiv.org/abs/2010.05406)|EMNLP20 |
|45|[Multi-XScience](https://github.com/yaolu/Multi-XScience)|Multi-document|[Multi-XScience: A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles](https://arxiv.org/abs/2010.14235)|EMNLP20 short|
|46|[SCITLDR](https://github.com/allenai/scitldr)|Scientific Document|[TLDR: Extreme Summarization of Scientific Documents](https://arxiv.org/abs/2004.15011)|Findings of EMNLP20|
|47|[scisumm-corpus](https://github.com/WING-NUS/scisumm-corpus)|Scientific Document|||
|48|[QBSUM](https://www.dropbox.com/sh/t2cp7ml1kb8ako0/AADmS2RMfJvLbukyQbb08CGGa?dl=0)|Query-Based Chinese|[QBSUM: a Large-Scale Query-Based Document Summarization Dataset from Real-world Applications](https://arxiv.org/abs/2010.14108)|Computer Speech & Language|
|49|[qMDS](https://github.com/google-research-datasets/aquamuse)|Query-Based Multi-Document|[AQuaMuSe: Automatically Generating Datasets for Query-Based Multi-Document Summarization](https://arxiv.org/abs/2010.12694)||
|50|[Liputan6](https://github.com/fajri91/sum_liputan6)|Indonesian|[Liputan6: A Large-scale Indonesian Dataset for Text Summarization](https://arxiv.org/pdf/2011.00679.pdf)|AACL20|
|51|[SportsSum](https://github.com/ej0cl6/SportsSum)|Sports Game|[Generating Sports News from Live Commentary: A Chinese Dataset for Sports Game Summarization](https://khhuang.me/docs/aacl2020sportssum.pdf)|AACL20|
|52|[WikiAsp](https://github.com/neulab/wikiasp)|Aspect-based|[WikiAsp: A Dataset for Multi-domain Aspect-based Summarization](https://arxiv.org/abs/2011.07832)|Transaction of the ACL|
|53|[DebateSum](https://github.com/Hellisotherpeople/DebateSum)|argument|[DebateSum:A large-scale argument mining and summarization dataset](https://arxiv.org/abs/2011.07251)|ARGMIN 2020|
|54|[Open4Business](https://github.com/amanpreet692/Open4Business)|Business|[Open4Business (O4B): An Open Access Dataset for Summarizing Business Documents](https://arxiv.org/abs/2011.07636)|Workshop on Dataset Curation and Security-NeurIPS 2020|
|55|[OrangeSum](https://github.com/moussaKam/OrangeSum)|French|[BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)||
|56|[Medical Conversation](https://github.com/cuhksz-nlp/HET-MC)|medical conversation|[Summarizing Medical Conversations via Identifying Important Utterances](https://www.aclweb.org/anthology/2020.coling-main.63/)|COLING20|
|57|[SumTitles](https://github.com/huawei-noah/sumtitles)|movie dialogue|[SumTitles: a Summarization Dataset with Low Extractiveness](https://www.aclweb.org/anthology/2020.coling-main.503/)|COLING20|
|58|[BANS](https://www.kaggle.com/datasets/prithwirajsust/bengali-news-summarization-dataset)|bengali news|[Bengali Abstractive News Summarization (BANS): A Neural Attention Approach]()|TCCE-2020|
|59|[e-commerce](https://github.com/ypnlp/coling)|E-commerce|[On the Faithfulness for E-commerce Product Summarization](https://www.aclweb.org/anthology/2020.coling-main.502/)|COLING20|
|60|[TWEETSUM]()|Twitter|[TWEETSUM: Event-oriented Social Summarization Dataset](https://www.aclweb.org/anthology/2020.coling-main.504/)|COLING20|
|61|[SPACE](https://github.com/stangelid/qt)|Opinion|[Extractive Opinion Summarization in Quantized Transformer Spaces](https://arxiv.org/abs/2012.04443)|TACL|
|62|[pn-summary](https://github.com/hooshvare/pn-summary)|Persian|[Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization](https://arxiv.org/abs/2012.11204)|csicc2021|
|63|[E-commerce1](https://github.com/RowitZou/topic-dialog-summ)*desensitized*|Dialogue|[Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling](https://arxiv.org/abs/2012.07311)|AAAI21|
|64|[E-commerce2](https://github.com/RowitZou/RankAE)*desensitized*|Dialogue|[Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders](https://arxiv.org/abs/2012.07300)|AAAI21|
|65|[BengaliSummarization](https://github.com/tafseer-nayeem/BengaliSummarization)|Bengali|[Unsupervised Abstractive Summarization of Bengali Text Documents](https://arxiv.org/abs/2102.04490)|EACL21|
|66|[MediaSum](https://github.com/zcgzcgzcg1/MediaSum)|Dialogue|[MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization](https://arxiv.org/abs/2103.06410)|NAACL21|
|67|[Healthline and BreastCancer](https://github.com/darsh10/Nutribullets)|multi-document|[Nutri-bullets: Summarizing Health Studies by Composing Segments](https://arxiv.org/abs/2103.11921)|AAAI21|
|68|[GOVREPORT](https://gov-report-data.github.io/)|Long Government reports|[Efficient Attentions for Long Document Summarization](https://arxiv.org/abs/2104.02112)|NAACL21|
|69|[SSN](https://github.com/ChenxinAn-fdu/CGSum)|Scientific Paper|[Enhancing Scientific Papers Summarization with Citation Graph](https://arxiv.org/abs/2104.03057)|AAAI21|
|70|[MTSamples](https://github.com/babylonhealth/medical-note-summarisation)|Medical|[Towards objectively evaluating the quality of generated medical summaries](https://arxiv.org/abs/2104.04412)||
|71|[QMSum](https://github.com/Yale-LILY/QMSum)|Meeting, Query|[QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization](https://arxiv.org/abs/2104.05938)|NAACL21|
|72|[MS2](https://github.com/allenai/ms2)|Medical, Multi-Document|[MS2: Multi-Document Summarization of Medical Studies](https://arxiv.org/abs/2104.06486)||
|73|[SummScreen](https://github.com/mingdachen/SummScreen)|Television Series|[SummScreen: A Dataset for Abstractive Screenplay Summarization](https://aclanthology.org/2022.acl-long.589/)|ACL 2022|
|74|[SciDuet](https://github.com/IBM/document2slides)|Scientific Papers and Slides|[D2S: Document-to-Slide Generation Via Query-Based Text Summarization](https://github.com/IBM/document2slides)|NAACL21|
|75|[MultiHumES](https://deephelp.zendesk.com/hc/en-us/sections/360011925552-MultiHumES)|Multilingual|[MultiHumES: Multilingual Humanitarian Dataset for Extractive Summarization](https://www.aclweb.org/anthology/2021.eacl-main.146/)|EACL21|
|76|[DialSumm](https://github.com/cylnlp/DialSumm)|Dialogue|[DialSumm: A Real-Life Scenario Dialogue Summarization Dataset](https://arxiv.org/abs/2105.06762)|Findings of ACL21|
|77|[BookSum](https://github.com/salesforce/booksum)|Book, Long-form|[BookSum: A Collection of Datasets for Long-form Narrative Summarization](https://arxiv.org/abs/2105.08209)||
|78|[CLES](http://icrc.hitsz.edu.cn/xszy/yjzy.htm)|Chinese Weibo |[A Large-Scale Chinese Long-Text Extractive Summarization Corpus](https://ieeexplore.ieee.org/abstract/document/9414946)|ICASSP|
|79|[FacetSum](https://github.com/hfthair/emerald_crawler)|Scientific Paper|[Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents](https://aclanthology.org/2021.acl-short.137/)|ACL2021 short|
|80|[ConvoSumm](https://github.com/Yale-LILY/ConvoSumm)|Dialogue|[ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining](https://aclanthology.org/2021.acl-long.535/)|ACL2021|
|81|[AgreeSum](https://github.com/google-research-datasets/AgreeSum)|Multi-document with entailment annotations|[AgreeSum: Agreement-Oriented Multi-Document Summarization](https://arxiv.org/abs/2106.02278)|Findings of ACL2021|
|82|[En2De](https://github.com/ybai-nlp/MCLAS)|Cross-Lingual En2De|[Cross-Lingual Abstractive Summarization with Limited Parallel Resources](https://arxiv.org/abs/2105.13648)|ACL 2021|
|83|[VT-SSum]()|Spoken|[VT-SSum: A Benchmark Dataset for Video Transcript Segmentation and Summarization](https://arxiv.org/abs/2106.05606)||
|84|[AESLC](https://github.com/ryanzhumich/AESLC)|Email|[This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation](https://www.aclweb.org/anthology/P19-1043/)|ACL 2019|
|85|[XL-Sum](https://github.com/csebuetnlp/xl-sum)|Cross-lingual|[XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages](http://rifatshahriyar.github.io/files/XL-Sum.pdf)|Findings of ACL2021|
|86|[TES 2012-2016](https://github.com/JoeBloggsIR/TSSuBERT)|Tweet|[TSSuBERT: Tweet Stream Summarization Using BERT](https://arxiv.org/abs/2106.08770)||
|87|[PENS](https://msnews.github.io/pens.html)|Personalized Headline|[PENS: A Dataset and Generic Framework for Personalized News Headline Generation](https://www.microsoft.com/en-us/research/uploads/prod/2021/06/ACL2021_PENS_Camera_Ready_1862_Paper.pdf)|ACL 2021|
|88|[XSum Hallucination Annotations](https://github.com/google-research-datasets/xsum_hallucination_annotations)|Factuality|[On Faithfulness and Factuality in Abstractive Summarization](https://arxiv.org/abs/2005.00661)|ACL 2020|
|89|[factuality-datasets](https://github.com/tagoyal/factuality-datasets#factuality-datasets)|Factuality|[Annotating and Modeling Fine-grained Factuality in Summarization](https://arxiv.org/abs/2104.04302)|NAACL 2021|
|90|[frank](https://github.com/artidoro/frank)|Factuality|[Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics](https://arxiv.org/abs/2104.13346)|NAACL 2021|
|91|[TRIPOD](https://github.com/ppapalampidi/GraphTP)|Movie|[Movie Summarization via Sparse Graph Construction](https://arxiv.org/abs/2012.07536)|AAAI 2021|
|92|[AdaptSum](https://github.com/TysonYu/AdaptSum)|Low-Resource|[AdaptSum: Towards Low-Resource Domain Adaptation for Abstractive Summarization](https://arxiv.org/abs/2103.11332)|NAACL 2021|
|93|[PTS](https://github.com/FeiSun/ProductTitleSummarizationCorpus)|Product|[Multi-Source Pointer Network for Product Title Summarization](https://arxiv.org/abs/1808.06885)|CIKM 2018|
|94|[RAMDS](https://github.com/lipiji/vae-salience-ramds)|Reader-Aware|[Reader-Aware Multi-Document Summarization: An Enhanced Model and The First Dataset](https://arxiv.org/abs/1708.01065)|EMNLP 2017 Workshop|
|95|[court judgment](https://github.com/gsh199449/proto-summ)|court judgment|[How to Write Summaries with Patterns? Learning towards Abstractive Summarization through Prototype Editing](https://arxiv.org/abs/1909.08837)|EMNLP 2019|
|96|[ADEGBTS](https://github.com/MMLabTHUSZ/ADEGBTS)|gaze behaviors|[A Dataset for Exploring Gaze Behaviors in Text Summarization](https://dl.acm.org/doi/abs/10.1145/3339825.3394928)|ACM MMSys'20|
|97|[MeQSum](https://github.com/abachaa/MeQSum)|Medical|[On the Summarization of Consumer Health Questions](https://www.aclweb.org/anthology/P19-1215/)|ACL 2019|
|98|[OpoSum](https://github.com/stangelid/oposum)|Opinion|[Summarizing Opinions: Aspect Extraction Meets Sentiment Prediction and They Are Both Weakly Supervised](https://www.aclweb.org/anthology/D18-1403/)|EMNLP 2018|
|99|[MM-AVS](https://github.com/xiyan524/MM-AVS)|Multi-modal|[Multi-modal Summarization for Video-containing Documents](https://arxiv.org/abs/2009.08018)|NAACL 2021|
|100|[WikiCatSum](https://github.com/lauhaide/WikiCatSum)|multi-doc|[Generating Summaries with Topic Templates and Structured Convolutional Decoders](https://arxiv.org/abs/1906.04687)|ACL 2019|
|101|[SDF-TLS](https://github.com/MorenoLaQuatra/SDF-TLS)|Timeline|[Summarize Dates First: A Paradigm Shift in Timeline Summarization](https://dl.acm.org/doi/10.1145/3404835.3462954)|SIGIR 2021|
|102|[RWS-Cit](https://github.com/jingqiangchen/RWS-Cit)||[*Automatic generation of related work through summarizing citations](https://onlinelibrary.wiley.com/doi/epdf/10.1002/cpe.4261)|2017|
|103|[MTLS](https://yiyualt.github.io/mtlsdata/)|Timeline|[Multi-TimeLine Summarization (MTLS): Improving Timeline Summarization by Generating Multiple Summaries](https://aclanthology.org/2021.acl-long.32/)|ACL 2021|
|104|[EMAILSUM](https://github.com/ZhangShiyue/EmailSum)|Email|[EmailSum: Abstractive Email Thread Summarization](https://aclanthology.org/2021.acl-long.537/)|ACL 2021|
|105|[WikiSum](https://registry.opendata.aws/wikisum/)|WikiHow|[WikiSum: Coherent Summarization Dataset for Efficient Human-Evaluation](https://aclanthology.org/2021.acl-short.28/)|ACL 2021 Short|
|106|[SumPubMed](https://github.com/vgupta123/sumpubmed)|PubMed Scientific Article|[SumPubMed: Summarization Dataset of PubMed Scientific Articles](https://aclanthology.org/2021.acl-srw.30/)|ACL 2021 Student Research Workshop|
|107|[MLGSum](https://github.com/brxx122/CALMS)|Multi-lingual|[Contrastive Aligned Joint Learning for Multilingual Summarization](https://aclanthology.org/2021.findings-acl.242/)|ACL 2021 Findings|
|108|[SMARTPHONE,COMPUTER](https://github.com/JD-AI-Research-NLP/CUSTOM)|Product|[CUSTOM: Aspect-Oriented Product Summarization for E-Commerce](https://arxiv.org/abs/2108.08010)||
|109|[CSDS](https://github.com/xiaolinAndy/CSDS)|Customer Service Dialogue|[CSDS: A Fine-grained Chinese Dataset for Customer Service Dialogue Summarization](https://arxiv.org/abs/2108.13139)|EMNLP 2021|
|110|[persian-dataset](https://github.com/mohammadiahmad/persian-dataset)|persian|[ARMAN: Pre-training with Semantically Selecting and Reordering of Sentences for Persian Abstractive Summarization](https://arxiv.org/abs/2109.04098)||
|111|[StreamHover](https://github.com/ucfnlp/streamhover)|spoken livestream|[StreamHover: Livestream Transcript Summarization and Annotation](https://arxiv.org/abs/2109.05160)|EMNLP 2021|
|112|[CNewSum](https://dqwang122.github.io/projects/CNewSum/)|News|[CNewSum: A Large-scale Chinese News Summarization Dataset with Human-annotated Adequacy and Deducibility Level](https://lileicc.github.io/pubs/wang2021cnewsum.pdf)|NLPCC 2021|
|113|[MiRANews](https://github.com/XinnuoXu/MiRANews)|news, factual|[MiRANews: Dataset and Benchmarks for Multi-Resource-Assisted News Summarization](https://arxiv.org/abs/2109.10650)|EMNLP 2021 Findings|
|114|[HowSumm](https://github.com/odelliab/HowSumm)|query multi-doc|[HowSumm: A Multi-Document Summarization Dataset Derived from WikiHow Articles](https://arxiv.org/abs/2110.03179)||
|115|[SportsSum2.0](https://github.com/krystalan/SportsSum2.0)|Sports|[SportsSum2.0: Generating High-Quality Sports News from Live Text Commentary](https://arxiv.org/abs/2110.05750)||
|116|[CoCoSum](https://github.com/megagonlabs/cocosum)|opinion multi-ref|[Comparative Opinion Summarization via Collaborative Decoding](https://arxiv.org/abs/2110.07520)||
|117|[MReD](https://github.com/Shen-Chenhui/MReD/)|Controllable|[MReD: A Meta-Review Dataset for Controllable Text Generation](https://arxiv.org/abs/2110.07474)||
|118|[MSˆ2](https://github.com/allenai/ms2)|Multi-Document, Medical|[MSˆ2: Multi-Document Summarization of Medical Studies](https://aclanthology.org/2021.emnlp-main.594/)|EMNLP 2021|
|119|[MassiveSumm](https://github.com/danielvarab/massive-summ)||[MassiveSumm: a very large-scale, very multilingual, news summarisation dataset](https://aclanthology.org/2021.emnlp-main.797/)|EMNLP 2021|
|120|[XWikis](https://github.com/lauhaide/clads)|multilingual|[Models and Datasets for Cross-Lingual Summarisation](https://aclanthology.org/2021.emnlp-main.742/)|EMNLP 2021|
|121|[SUBSUME](https://github.com/afariha/SubSumE)|Intent, subjective|[SUBSUME: A Dataset for Subjective Summary Extraction from Wikipedia Documents](https://aclanthology.org/2021.newsum-1.14/)|EMNLP 2021 newsum|
|122|[TLDR9+](https://github.com/sajastu/reddit_collector)||[TLDR9+: A Large Scale Resource for Extreme Summarization of Social Media Posts](https://aclanthology.org/2021.newsum-1.15/)|EMNLP 2021 newsum|
|123|[20 Minuten](https://github.com/ZurichNLP/20Minuten)|German|[A New Dataset and Efficient Baselines for Document-level Text Simplification in German](https://aclanthology.org/2021.newsum-1.16/)|EMNLP 2021 newsum|
|124|[WSD](https://github.com/MehwishFatimah/wsd)|multi-lingual|[A Novel Wikipedia based Dataset for Monolingual and Cross-Lingual Summarization](https://aclanthology.org/2021.newsum-1.5/)|EMNLP 2021 newsum|
|125|[TEDSummary](https://github.com/nttcslab-sp-admin/TEDSummary)|Speech|[Attention-based Multi-hypothesis Fusion for Speech Summarization](https://arxiv.org/abs/2111.08201)||
|126|[SummaC Benchmark](https://github.com/tingofurro/summac/)|Factual, NLI|[SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization](https://arxiv.org/abs/2111.09525)||
|127|[ForumSum](https://huggingface.co/datasets/forumsum)|Conversation|[ForumSum: A Multi-Speaker Conversation Summarization Dataset](ttps://aclanthology.org/2021.findings-emnlp.391/)|EMNLP 2021 Findings|
|128|[K-SportsSum](https://github.com/krystalan/K-SportsSum)|Sports|[Knowledge Enhanced Sports Game Summarization](https://arxiv.org/abs/2111.12535)|WSDM 2022|
|129|[Test-Amazon](https://github.com/abrazinskas/Copycat-abstractive-opinion-summarizer)|Opinion, New test for Amazon reviews|[Unsupervised Opinion Summarization as Copycat-Review Generation](https://aclanthology.org/2020.acl-main.461/)|ACL 2020|
|130|[Test-Amazon-Yelp](https://github.com/abrazinskas/FewSum)|Opinion, New test for Amazon(180) and Yelp(300)|[Few-Shot Learning for Opinion Summarization](https://aclanthology.org/2020.emnlp-main.337/)|EMNLP 2020|
|131|[AmaSum](https://github.com/abrazinskas/SelSum)|Opinion|[Learning Opinion Summarizers by Selecting Informative Reviews](https://aclanthology.org/2021.emnlp-main.743/)|EMNLP 2021|
|132|[CrossSum](https://github.com/csebuetnlp/CrossSum)|Cross lingual|[CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs](https://arxiv.org/abs/2112.08804)||
|133|[HCSCL-MSDataset](https://github.com/LitianD/HCSCL-MSDataset)|Multi-modal|[Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization](https://arxiv.org/abs/2112.12072)|AAAI 2022|
|134|[Klexikon](https://github.com/dennlinger/klexikon)|German|[Klexikon: A German Dataset for Joint Summarization and Simplification](https://arxiv.org/abs/2201.07198)||
|135|[TODSum]()|Customer Service|[TODSum: Task-Oriented Dialogue Summarization with State Tracking](https://arxiv.org/abs/2110.12680)||
|136|[TWEETSUMM](https://aclanthology.org/2021.findings-emnlp.24/)|Customer Service|[TWEETSUMM - A Dialog Summarization Dataset for Customer Service](https://aclanthology.org/2021.findings-emnlp.24/)|Findings of EMNLP 2021|
|137|[PeerSum](https://github.com/oaimli/PeerSum)|Multi-document, Scientific|[PeerSum: A Peer Review Dataset for Abstractive Multi-document Summarization](https://arxiv.org/abs/2203.01769)||
|138|[Celebrity TS, Event TS, Wiki TS](https://github.com/iriscxy/Unified-Timeline-Summarizer)|Timeline, person, event|[Follow the Timeline! Generating Abstractive and Extractive Timeline Summary in Chronological Order](https://dl.acm.org/doi/abs/10.1145/3517221)|TOSI 2022|
|139|[Chart-to-Text](https://github.com/vis-nlp/Chart-to-text)|chart|[Chart-to-Text: A Large-Scale Benchmark for Chart Summarization](https://arxiv.org/abs/2203.06486)||
|140|[GovReport-QS](https://gov-report-data.github.io/)|Long Document|[HIBRIDS: Attention with Hierarchical Biases for Structure-aware Long Document Summarization](https://arxiv.org/abs/2203.10741)|ACL 2022|
|141|[EntSUM](https://zenodo.org/record/6359875)|Entity|[EntSUM: A Data Set for Entity-Centric Summarization](https://github.com/bloomberg/entsum)|ACL 2022|
|142|[ALLSIDES](https://github.com/HLTCHKUST/framing-bias-metric)|Framing Bias|[NeuS: Neutral Multi-News Summarization for Mitigating Framing Bias](https://arxiv.org/abs/2204.04902)|ACL 2022|
|143|[GRAPHELSUMS](https://github.com/maartjeth/summarization_with_graphical_elements)|graph|[Summarization with Graphical Elements](https://arxiv.org/abs/2204.07551)||
|144|[Annotated-Wikilarge-Newsela](https://github.com/AshOlogn/Evaluating-Factuality-in-Text-Simplification)|Factuality|[Evaluating Factuality in Text Simplification](https://arxiv.org/abs/2204.07562)|ACL 2022|
|145|[WikiMulti](https://github.com/tikhonovpavel/wikimulti)|Cross-lingual|[WikiMulti: a Corpus for Cross-Lingual Summarization](https://arxiv.org/abs/2204.11104)||
|146|[Welsh](https://github.com/UCREL/welsh-summarization-dataset)||[Introducing the Welsh Text Summarisation Dataset and Baseline Systems](https://arxiv.org/abs/2205.02545)||
|147|[SuMe](https://stonybrooknlp.github.io/SuMe/)|Biomedical|[SuMe: A Dataset Towards Summarizing Biomedical Mechanisms](https://arxiv.org/abs/2205.04652)|LREC 2022|
|148|[CiteSum](https://github.com/morningmoni/CiteSum)||[CiteSum: Citation Text-guided Scientific Extreme Summarization and Low-resource Domain Adaptation](https://arxiv.org/abs/2205.06207)||
|148|[MSAMSum](https://github.com/xcfcode/MSAMSum)|Dialogue|[MSAMSum: Towards Benchmarking Multi-lingual Dialogue Summarization](https://aclanthology.org/2022.dialdoc-1.1/)|ACL 2022 DialDoc|
|149|[SQuALITY](https://github.com/nyu-mll/SQuALITY)| Long-Document|[SQuALITY: Building a Long-Document Summarization Dataset the Hard Way](https://aclanthology.org/2022.emnlp-main.75/)|EMNLP 2022|
|150|[X-SCITLDR](https://github.com/sobamchan/xscitldr)||[X-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents](https://arxiv.org/abs/2205.15051)|JCDL 2022|
|151|[NEWTS](https://github.com/ali-bahrainian/NEWTS)|News|[NEWTS: A Corpus for News Topic-Focused Summarization](https://arxiv.org/abs/2205.15661)||
|152|[EntSUM](https://github.com/bloomberg/entsum)|Entity|[EntSUM: A Data Set for Entity-Centric Extractive Summarization](https://aclanthology.org/2022.acl-long.237/)|ACL 2022|
|153|[ASPECTNEWS](https://github.com/oja/aosumm)||[ASPECTNEWS: Aspect-Oriented Summarization of News Documents](https://aclanthology.org/2022.acl-long.449/)|ACL 2022|
|154|[RNSum]()|Commit Logs|[RNSum: A Large-Scale Dataset for Automatic Release Note Generation via Commit Logs Summarization](https://aclanthology.org/2022.acl-long.597/)|ACL 2022|
|155|[AnswerSumm](https://github.com/Alex-Fabbri/AnswerSumm)|query multi-doc|[AnswerSumm: A Manually-Curated Dataset and Pipeline for Answer Summarization](https://arxiv.org/abs/2111.06474)|NAACL 2022|
|156|[CHQ-Summ](https://github.com/shwetanlp/Yahoo-CHQ-Summ)||[CHQ-Summ: A Dataset for Consumer Healthcare Question Summarization](https://arxiv.org/abs/2206.06581)||
|157|[Multi-LexSum](https://github.com/multilexsum/dataset)|multi-doc|[Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities](https://arxiv.org/abs/2206.10883)||
|158|[DACSA](https://xarrador.dsic.upv.es/resources/dacsa)|Catalan and Spanish|[DACSA: A large-scale Dataset for Automatic summarization of Catalan and Spanish newspaper Articles](https://aclanthology.org/2022.naacl-main.434/)|NAACL 2022|
|159|[BigSurvey](https://github.com/StevenLau6/BigSurvey)|Academic Multi-doc|[Generating a Structured Summary of Numerous Academic Papers: Dataset and Method](https://www.ijcai.org/proceedings/2022/0591.pdf)|IJCAI 2022|
|160|[CSL](https://github.com/ydli-ai/CSL)|Chinese, Academic|[CSL: A Large-scale Chinese Scientific Literature Dataset](https://arxiv.org/abs/2209.05034)|COLING 2022|
|161|[PCC Summaries](https://github.com/fhewett/pcc-summaries)|German|[Extractive Summarisation for German-language Data: A Text-level Approach with Discourse Features](https://aclanthology.org/2022.coling-1.63/)|COLING 2022|
|162|[LipKey](https://github.com/fajri91/LipKey)|abstractive summaries, absent keyphrases, and titles|[LipKey: A Large-Scale News Dataset for Absent Keyphrases Generation and Abstractive Summarization](https://aclanthology.org/2022.coling-1.303/)|COLING 2022|
|163|[PLOS](https://github.com/TGoldsack1/Corpora_for_Lay_Summarisation)|Lay summary of biomedical journal articles|[Making Science Simple: Corpora for the Lay Summarisation of Scientific Literature](https://arxiv.org/abs/2210.09932)|EMNLP 2022|
|164|[eLife](https://github.com/TGoldsack1/Corpora_for_Lay_Summarisation)|Lay summary of biomedical journal articles|[Making Science Simple: Corpora for the Lay Summarisation of Scientific Literature](https://arxiv.org/abs/2210.09932)|EMNLP 2022|
|165|[ECTSum](https://github.com/rajdeep345/ECTSum)|Long Earnings Call Transcripts|[ECTSum: A New Benchmark Dataset For Bullet Point Summarization of Long Earnings Call Transcripts](https://arxiv.org/abs/2210.12467)|EMNLP 2022|
|166|[EUR-Lex-Sum](https://github.com/achouhan93/eur-lex-sum)|Multi- and Cross-lingual Legal|[EUR-Lex-Sum: A Multi- and Cross-lingual Dataset for Long-form Summarization in the Legal Domain](https://arxiv.org/abs/2210.13448)|EMNLP2022|
|167|[CrisisLTLSum](https://github.com/CrisisLTLSum/CrisisTimelines)|Timeline|[CrisisLTLSum: A Benchmark for Local Crisis Event Timeline Extraction and Summarization](https://arxiv.org/abs/2210.14190)||
|168|LANS(`upon request`)|Arabic|[LANS: Large-scale Arabic News Summarization Corpus](https://arxiv.org/abs/2210.13600)||
|169|[MACSUM](https://github.com/psunlpgroup/MACSum)|Controllable News Dialogue|[MACSUM: Controllable Summarization with Mixed Attributes](https://arxiv.org/abs/2211.05041)||
|170|[NarraSum](https://github.com/zhaochaocs/narrasum)|Narrative|[NarraSum: A Large-Scale Dataset for Abstractive Narrative Summarization](https://arxiv.org/abs/2212.01476)|EMNLP Findings 2022|
|171|[LoRaLay](https://github.com/recitalAI/loralay-datasets)|Long Scientific Visual|[LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization](https://arxiv.org/abs/2301.11312)|EACL 2023|
|172|[HunSum-1](https://github.com/dorinapetra/summarization)|Hungarian|[HunSum-1: an Abstractive Summarization Dataset for Hungarian](https://arxiv.org/abs/2302.00455)||
|173|[MCLS](https://github.com/korokes/MCLS)|ultimodal Cross-Lingual|[Assist Non-native Viewers: Multimodal Cross-Lingual Summarization for How2 Videos](https://aclanthology.org/2022.emnlp-main.468/)|EMNLP 2022|
## Dialogue
### Dataset
1. **ECTSum: A New Benchmark Dataset For Bullet Point Summarization of Long Earnings Call Transcripts** *Rajdeep Mukherjee, Abhinav Bohra, Akash Banerjee, Soumya Sharma, Manjunath Hegde, Afreen Shaikh, Shivani Shrivastava, Koustuv Dasgupta, Niloy Ganguly, Saptarshi Ghosh, Pawan Goyal* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.12467) [[data]](https://github.com/rajdeep345/ECTSum) <details> <summary>[Abs]</summary> Despite tremendous progress in automatic summarization, state-of-the-art methods are predominantly trained to excel in summarizing short newswire articles, or documents with strong layout biases such as scientific articles or government reports. Efficient techniques to summarize financial documents, including facts and figures, have largely been unexplored, majorly due to the unavailability of suitable datasets. In this work, we present ECTSum, a new dataset with transcripts of earnings calls (ECTs), hosted by publicly traded companies, as documents, and short experts-written telegram-style bullet point summaries derived from corresponding Reuters articles. ECTs are long unstructured documents without any prescribed length limit or format. We benchmark our dataset with state-of-the-art summarizers across various metrics evaluating the content quality and factual consistency of the generated summaries. Finally, we present a simple-yet-effective approach, ECT-BPS, to generate a set of bullet points that precisely capture the important facts discussed in the calls.</details>
1. **TODSum: Task-Oriented Dialogue Summarization with State Tracking** *Lulu Zhao, Fujia Zheng, Keqing He, Weihao Zeng, Yuejie Lei, Huixing Jiang, Wei Wu, Weiran Xu, Jun Guo, Fanyu Meng* [[pdf]](https://arxiv.org/abs/2110.12680)
2. **TWEETSUMM - A Dialog Summarization Dataset for Customer Service** *Guy Feigenblat, Chulaka Gunasekara, Benjamin Sznajder, Sachindra Joshi, David Konopnicki, Ranit Aharonov* `Findings of EMNLP 2021` [[pdf]](https://aclanthology.org/2021.findings-emnlp.24/) [[data]](https://github.com/guyfe/Tweetsumm)
3. **ForumSum: A Multi-Speaker Conversation Summarization Dataset** *Misha Khalman, Yao Zhao, Mohammad Saleh* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.391/) [[data]](https://huggingface.co/datasets/forumsum)
4. **CSDS: A Fine-grained Chinese Dataset for Customer Service Dialogue Summarization** *Haitao Lin, Liqun Ma, Junnan Zhu, Lu Xiang, Yu Zhou, Jiajun Zhang, Chengqing Zong* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.365/) [[data]](https://github.com/xiaolinAndy/CSDS)
5. **EmailSum: Abstractive Email Thread Summarization** *Shiyue Zhang, Asli Celikyilmaz, Jianfeng Gao, Mohit Bansal* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.537/) [[data]](https://github.com/ZhangShiyue/EmailSum)
6. **DialSumm: A Real-Life Scenario Dialogue Summarization Dataset** *Yulong Chen, Yang Liu, Liang Chen, Yue Zhang* `Findings of ACL21` [[pdf]](https://arxiv.org/abs/2105.06762) [[data]](https://github.com/cylnlp/DialSumm)
7. **ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining** *Alexander R. Fabbri, Faiaz Rahman, Imad Rizvi, Borui Wang, Haoran Li, Yashar Mehdad, Dragomir Radev* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.535/) [[code]](https://github.com/Yale-LILY/ConvoSumm)
8. **MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization** *Chenguang Zhu, Yang Liu, Jie Mei, Michael Zeng* `NAACL21` [[pdf]](https://arxiv.org/abs/2103.06410) [[code]](https://github.com/zcgzcgzcg1/MediaSum)
9. **QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization** *Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, Dragomir Radev* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.05938) [[data]](https://github.com/Yale-LILY/QMSum)
10. **Storytelling with Dialogue: A Critical Role Dungeons and Dragons Dataset** *Revanth Rameshkumar, Peter Bailey* `ACL20` [[pdf]](https://www.aclweb.org/anthology/2020.acl-main.459/) [[data]](https://github.com/RevanthRameshkumar/CRD3)
11. **SumTitles: a Summarization Dataset with Low Extractiveness** *Valentin Malykh, Konstantin Chernis, Ekaterina Artemova, Irina Piontkovskaya* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.503/) [[code]](https://github.com/huawei-noah/sumtitles)
12. **Summarizing Medical Conversations via Identifying Important Utterances** *Yan Song, Yuanhe Tian, Nan Wang, Fei Xia* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.63/) [[code]](https://github.com/cuhksz-nlp/HET-MC)
13. **GupShup: Summarizing Open-Domain Code-Switched Conversations** *Laiba Mehnaz, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle G. Lee, Anish Acharya, Rajiv Ratn Shah* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.499/)[[code]](https://github.com/midas-research/gupshup)
14. **SummScreen: A Dataset for Abstractive Screenplay Summarization** *Mingda Chen, Zewei Chu, Sam Wiseman, Kevin Gimpel* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.589/) [[data]](https://github.com/mingdachen/SummScreen) <details> <summary>[Abs]</summary> We introduce SummScreen, a summarization dataset comprised of pairs of TV series transcripts and human written recaps. The dataset provides a challenging testbed for abstractive summarization for several reasons. Plot details are often expressed indirectly in character dialogues and may be scattered across the entirety of the transcript. These details must be found and integrated to form the succinct plot descriptions in the recaps. Also, TV scripts contain content that does not directly pertain to the central plot but rather serves to develop characters or provide comic relief. This information is rarely contained in recaps. Since characters are fundamental to TV series, we also propose two entity-centric evaluation metrics. Empirically, we characterize the dataset by evaluating several methods, including neural models and those based on nearest neighbors. An oracle extractive approach outperforms all benchmarked models according to automatic metrics, showing that the neural models are unable to fully exploit the input transcripts. Human evaluation and qualitative analysis reveal that our non-oracle models are competitive with their oracle counterparts in terms of generating faithful plot events and can benefit from better content selectors. Both oracle and non-oracle models generate unfaithful facts, suggesting future research directions. </details>
15. **SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization** *Bogdan Gliwa, Iwona Mochol, Maciej Biesek, Aleksander Wawer* `EMNLP19` [[pdf]](https://arxiv.org/abs/1911.12237) [[data]](https://arxiv.org/src/1911.12237v2/anc/corpus.7z)
16. **Dial2Desc: End-to-end Dialogue Description Generation** *Haojie Pan, Junpei Zhou, Zhou Zhao, Yan Liu, Deng Cai, Min Yang* [[pdf]](https://arxiv.org/abs/1811.00185)
17. **The AMI meeting corpus: A pre-announcement** *Carletta, Jean and Ashby, Simone and Bourban, Sebastien and Flynn, Mike and Guillemot, Mael and Hain, Thomas and Kadlec, Jaroslav and Karaiskos, Vasilis and Kraaij, Wessel and Kronenthal, Melissa and others* [[pdf]](https://link.springer.com/chapter/10.1007/11677482_3)
18. **The ICSI meeting corpus** *Janin, Adam and Baron, Don and Edwards, Jane and Ellis, Dan and Gelbart, David and Morgan, Nelson and Peskin, Barbara and Pfau, Thilo and Shriberg, Elizabeth and Stolcke, Andreas and others* [[pdf]](https://www.researchgate.net/publication/4015071_The_ICSI_meeting_corpus)
### Email Summarization
1. **Focus on the Action: Learning to Highlight and Summarize Jointly for Email To-Do Items Summarization** *Kexun Zhang, Jiaao Chen, Diyi Yang* `Findings of ACL 2022` [[pdf]](https://faculty.cc.gatech.edu/~dyang888/docs/acl22_summarization.pdf)
1. **EmailSum: Abstractive Email Thread Summarization** *Shiyue Zhang, Asli Celikyilmaz, Jianfeng Gao, Mohit Bansal* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.537/) [[data]](https://github.com/ZhangShiyue/EmailSum)
2. **Smart To-Do: Automatic Generation of To-Do Items from Emails** *Sudipto Mukherjee, Subhabrata Mukherjee, Marcello Hasegawa, Ahmed Hassan Awadallah, Ryen White* `ACL 2020` [[pdf]](https://www.aclweb.org/anthology/2020.acl-main.767/) [[code]](https://github.com/MSR-LIT/SmartToDo) [[bib]](https://www.aclweb.org/anthology/2020.acl-main.767.bib)
3. **Identifying Implicit Quotes for Unsupervised Extractive Summarization of Conversations** *Ryuji Kano, Yasuhide Miura, Tomoki Taniguchi, Tomoko Ohkuma* `AACL20` [[pdf]](https://www.aclweb.org/anthology/2020.aacl-main.32/)
4. **This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation** *Rui Zhang, Joel Tetreault* `ACL 2019` [[pdf]](https://www.aclweb.org/anthology/P19-1043/) [[data]](https://github.com/ryanzhumich/AESLC) [[bib]](https://www.aclweb.org/anthology/P19-1043.bib)
5. **Building a Dataset for Summarization and Keyword Extraction from Emails** *Vanessa Loza, Shibamouli Lahiri, Rada Mihalcea, Po-Hsiang Lai* `LREC 2014` [[pdf]](https://www.aclweb.org/anthology/L14-1028/)
6. **A Publicly Available Annotated Corpus for Supervised Email Summarization** *Jan Ulrich, Gabriel Murray, Giuseppe Carenini* `AAAI 2008` [[pdf]](https://www.aaai.org/Papers/Workshops/2008/WS-08-04/WS08-04-014.pdf)
7. **Summarizing Email Conversations with Clue Words** *Giuseppe Carenini, Raymond T. Ng, Xiaodong Zhou* `WWW 2007` [[pdf]](https://www2007.org/papers/paper631.pdf)
8. **Task-focused Summarization of Email** *Simon H. Corston-Oliver Eric Ringger Michael Gamon Richard Campbell* `ACL 2004` [[pdf]](https://www.aclweb.org/anthology/W04-1008.pdf)
9. **Summarizing email threads** *Owen Rambow, Lokesh Shrestha, John Chen, Chirsty Lauridsen* `NAACL 2004` [[pdf]](https://www.aclweb.org/anthology/N04-4027/) [[bib]](https://www.aclweb.org/anthology/N04-4027.bib)
10. **Facilitating email thread access by extractive summary generation** *Ani Nenkova* `Recent advances in natural language processing III: selected papers from RANLP` [[pdf]](https://www.academia.edu/21603342/Facilitating_email_thread_access_by_extractive_summary_generation)
11. **Summarizing Archived Discussions: A Beginning** *Paula S. Newman, John C. Blitzer* `Proceedings of the 8th international conference on Intelligent user interfaces` [[pdf]](http://john.blitzer.com/papers/iui.pdf)
12. **Combining linguistic and machine learning techniques for email summarization** *Smaranda Muresan, Evelyne Tzoukermann, Judith L. Klavans* `Proceedings of the ACL 2001 Workshop on Computational Natural Language Learning (ConLL) 2001` [[pdf]](https://www.aclweb.org/anthology/W01-0719/) [[bib]](https://www.aclweb.org/anthology/W01-0719.bib)
### Meeting Summarization
1. **Meeting Decision Tracker: Making Meeting Minutes with De-Contextualized Utterances** *Shumpei Inoue, Hy Nguyen, Pham Viet Hoang, Tsungwei Liu, Minh-Tien Nguyen* `AACL-IJCNLP 2022` [[pdf]](https://arxiv.org/abs/2210.11374) [[demo]](https://www.youtube.com/watch?v=TG1pJJo0Iqo&feature=youtu.be) <details> <summary>[Abs]</summary> Meetings are a universal process to make decisions in business and project collaboration. The capability to automatically itemize the decisions in daily meetings allows for extensive tracking of past discussions. To that end, we developed Meeting Decision Tracker, a prototype system to construct decision items comprising decision utterance detector (DUD) and decision utterance rewriter (DUR). We show that DUR makes a sizable contribution to improving the user experience by dealing with utterance collapse in natural conversation. An introduction video of our system is also available at this https URL. </details>
1. **ESSumm: Extractive Speech Summarization from Untranscribed Meeting** *Jun Wang* `Interspeech 2022` [[pdf]](https://arxiv.org/abs/2209.06913) <details> <summary>[Abs]</summary> In this paper, we propose a novel architecture for direct extractive speech-to-speech summarization, ESSumm, which is an unsupervised model without dependence on intermediate transcribed text. Different from previous methods with text presentation, we are aimed at generating a summary directly from speech without transcription. First, a set of smaller speech segments are extracted based on speech signal's acoustic features. For each candidate speech segment, a distance-based summarization confidence score is designed for latent speech representation measure. Specifically, we leverage the off-the-shelf self-supervised convolutional neural network to extract the deep speech features from raw audio. Our approach automatically predicts the optimal sequence of speech segments that capture the key information with a target summary length. Extensive results on two well-known meeting datasets (AMI and ICSI corpora) show the effectiveness of our direct speech-based method to improve the summarization quality with untranscribed data. We also observe that our unsupervised speech-based method even performs on par with recent transcript-based summarization approaches, where extra speech recognition is required. </details>
1. **Abstractive Meeting Summarization: A Survey** *Virgile Rennard, Guokan Shang, Julie Hunter, Michalis Vazirgiannis* [[pdf]](https://arxiv.org/abs/2208.04163) <details> <summary>[Abs]</summary> Recent advances in deep learning, and especially the invention of encoder-decoder architectures, has significantly improved the performance of abstractive summarization systems. While the majority of research has focused on written documents, we have observed an increasing interest in the summarization of dialogues and multi-party conversation over the past few years. A system that could reliably transform the audio or transcript of a human conversation into an abridged version that homes in on the most important points of the discussion would be valuable in a wide variety of real-world contexts, from business meetings to medical consultations to customer service calls. This paper focuses on abstractive summarization for multi-party meetings, providing a survey of the challenges, datasets and systems relevant to this task and a discussion of promising directions for future study. </details>
1. **ALIGNMEET: A Comprehensive Tool for Meeting Annotation, Alignment, and Evaluation** *Peter Polák, Muskaan Singh, Anna Nedoluzhko, Ondřej Bojar* `LREC 2022` [[pdf]](https://arxiv.org/abs/2205.05433) [[data]](https://github.com/ELITR/alignmeet)
1. **TANet: Thread-Aware Pretraining for Abstractive Conversational Summarization** *Ze Yang, Liran Wang, Zhoujin Tian, Wei Wu, Zhoujun Li* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.198/) <details> <summary>[Abs]</summary> Although pre-trained language models (PLMs) have achieved great success and become a milestone in NLP, abstractive conversational summarization remains a challenging but less studied task. The difficulty lies in two aspects. One is the lack of large-scale conversational summary data. Another is that applying the existing pre-trained models to this task is tricky because of the structural dependence within the conversation and its informal expression, etc. In this work, we first build a large-scale (11M) pretraining dataset called RCSum, based on the multi-person discussions in the Reddit community. We then present TANet, a thread-aware Transformer-based network. Unlike the existing pre-trained models that treat a conversation as a sequence of sentences, we argue that the inherent contextual dependency among the utterances plays an essential role in understanding the entire conversation and thus propose two new techniques to incorporate the structural information into our model. The first is thread-aware attention which is computed by taking into account the contextual dependency within utterances. Second, we apply thread prediction loss to predict the relations between utterances. We evaluate our model on four datasets of real conversations, covering types of meeting transcripts, customer-service records, and forum threads. Experimental results demonstrate that TANet achieves a new state-of-the-art in terms of both automatic evaluation and human judgment. </details>
3. **Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents** *Yusen Zhang, Ansong Ni, Ziming Mao, Chen Henry Wu, Chenguang Zhu, Budhaditya Deb, Ahmed H. Awadallah, Dragomir Radev, Rui Zhang* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.112/) [[code]](https://github.com/psunlpgroup/Summ-N) <details> <summary>[Abs]</summary> Text summarization helps readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models (LM) are unable to efficiently process long text for many summarization tasks. In this paper, we propose SummN, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context length of typical pretrained LMs. SummN first splits the data samples and generates a coarse summary in multiple stages and then produces the final fine-grained summary based on it. Our framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM input size fixed. Moreover, it can deal with both single-source documents and dialogues, and it can be used on top of different backbone abstractive summarization models. To the best of our knowledge, SummN is the first multi-stage split-then-summarize framework for long input summarization. Our experiments demonstrate that SummN outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a long document summarization dataset GovReport. Our data and code are available at https://github.com/psunlpgroup/Summ-N. </details>
4. **Exploring Neural Models for Query-Focused Summarization** *Jesse Vig, Alexander R. Fabbri, Wojciech Kryściński* [[pdf]](https://arxiv.org/abs/2112.07637) [[code]](https://github.com/salesforce/query-focused-sum)
5. **Improving Abstractive Dialogue Summarization with Hierarchical Pretraining and Topic Segment** *MengNan Qi, Hao Liu, YuZhuo Fu, Ting Liu* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.97/)
6. **Meeting Summarization with Pre-training and Clustering Methods** *Andras Huebner, Wei Ji, Xiang Xiao* [[pdf]](https://arxiv.org/abs/2111.08210) [[code]](https://github.com/wxj77/MeetingSummarization)
7. **Context or No Context? A preliminary exploration of human-in-the-loop approach for Incremental Temporal Summarization in meetings** *Nicole Beckage, Shachi H Kumar, Saurav Sahay, Ramesh Manuvinakurike* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.11/)
8. **RetrievalSum: A Retrieval Enhanced Framework for Abstractive Summarization** *Chenxin An, Ming Zhong, Zhichao Geng, Jianqiang Yang, Xipeng Qiu* [[pdf]](https://arxiv.org/abs/2109.07943)
9. **An Exploratory Study on Long Dialogue Summarization: What Works and What's Next** *Yusen Zhang, Ansong Ni, Tao Yu, Rui Zhang, Chenguang Zhu, Budhaditya Deb, Asli Celikyilmaz, Ahmed Hassan Awadallah, Dragomir Radev* `Findings of EMNLP 2021 Short` [[pdf]](https://arxiv.org/abs/2109.04609)
10. **DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization** *Ming Zhong, Yang Liu, Yichong Xu, Chenguang Zhu, Michael Zeng* `AAAI 2022` [[pdf]](https://arxiv.org/abs/2109.02492) [[code]](https://github.com/microsoft/DialogLM)
11. **Dynamic Sliding Window for Meeting Summarization** *Zhengyuan Liu, Nancy F. Chen* `SummDial@SIGDial 2021` [[pdf]](https://arxiv.org/abs/2108.13629)
12. **MeetSum: Transforming Meeting Transcript Summarization using Transformers!** *Nima Sadri, Bohan Zhang, Bihan Liu* [[pdf]](https://arxiv.org/abs/2108.06310)
13. **Incremental temporal summarization in multiparty meetings** *Ramesh Manuvinakurike, Saurav Sahay, Wenda Chen, Lama Nachman* `SIGIR 2021` [[pdf]](https://sigdial.org/sites/default/files/workshops/conference22/Proceedings/pdf/2021.sigdial-1.56.pdf)
14. **Abstractive Spoken Document Summarization using Hierarchical Model with Multi-stage Attention Diversity Optimization** *Potsawee Manakul, Mark J. F. Gales, Linlin Wang* `INTERSPEECH 2020` [[pdf]](http://www.interspeech2020.org/uploadfile/pdf/Thu-2-6-2.pdf) [[code]](https://github.com/potsawee/spoken_summ_div)
15. **What are meeting summaries? An analysis of human extractive summaries in meeting corpus** *Fei Liu, Yang Liu* `SIGDIAL 2008` [[pdf]](https://www.aclweb.org/anthology/W08-0112/)
16. **Exploring Speaker Characteristics for Meeting Summarization** *Fei Liu, Yang Liu* `INTERSPEECH 2010` [[pdf]](https://www.isca-speech.org/archive/archive_papers/interspeech_2010/i10_2518.pdf)
17. **Automatic meeting summarization and topic detection system** *Tai-Chia Huang, Chia-Hsuan Hsieh, Hei-Chia Wang* [[pdf]](https://www.emerald.com/insight/content/doi/10.1108/DTA-09-2017-0062/full/html)
18. **A keyphrase based approach to interactive meeting summarization** *Korbinian Riedhammer, Benoit Favre, Dilek Hakkani-T¨ur* `2008 IEEE Spoken Language Technology Workshop` [[pdf]](https://ieeexplore.ieee.org/document/4777863)
19. **A global optimization framework for meeting summarization** *Dan Gillick, Korbinian Riedhammerm, Benoit Favre, Dilek Hakkani-Tur* `2009 IEEE International Conference on Acoustics, Speech and Signal Processing` [[pdf]](https://ieeexplore.ieee.org/document/4960697)
20. **Evaluating the effectiveness of features and sampling in extractive meeting summarization** *Shasha Xie, Yang Liu, Hui Lin* `SLT 2008` [[pdf]](https://ieeexplore.ieee.org/document/4777864)
21. **Abstractive Meeting Summarization Using Dependency Graph Fusion** *Siddhartha Banerjee, Prasenjit Mitra, Kazunari Sugiyama* `WWW 2015` [[pdf]](https://arxiv.org/abs/1609.07035)
22. **Automatic Community Creation for Abstractive Spoken Conversation Summarization** *Karan Singla, Evgeny Stepanov, Ali Orkan Bayer, Giuseppe Carenini, Giuseppe Riccardi* `ACL 2017 workshop` [[pdf]](https://www.aclweb.org/anthology/W17-4506/) [[bib]](https://www.aclweb.org/anthology/W17-4506.bib)
23. **Unsupervised Abstractive Meeting Summarization with Multi-Sentence Compression and Budgeted Submodular Maximization** *Guokan Shang, Wensi Ding, Zekun Zhang, Antoine Jean-Pierre Tixier, Polykarpos Meladianos, Michalis Vazirgiannis, Jean-Pierre Lorré* `ACL18` [[pdf]](https://arxiv.org/abs/1805.05271) [[code]](https://bitbucket.org/dascim/acl2018_abssumm/src)
24. **Abstractive meeting summarization based on an attentional neural model** *Nouha Dammak, Yassine BenAyed* [[pdf]](https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11605/1160504/Abstractive-meeting-summarization-based-on-an-attentional-neural-model/10.1117/12.2587172.full)
25. **A Study of Text Summarization Techniques for Generating Meeting Minutes** *Tu My Doan, Francois Jacquenet, Christine Largeron, Marc Bernard* `RCIS 2020` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-030-50316-1_33)
26. **Meeting Summarization, A Challenge for Deep Learning** *Francois Jacquenet, Marc Bernard, Christine Largeron* `IWANN 2019` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-030-20521-8_53)
27. **Generating Abstractive Summaries from Meeting Transcripts** *Siddhartha Banerjee, Prasenjit Mitra, Kazunari Sugiyama* `Proceedings of the 2015 ACM Symposium on Document Engineering, DocEng' 2015` [[pdf]](https://arxiv.org/abs/1609.07033)
28. **Align then Summarize: Automatic Alignment Methods for Summarization Corpus Creation** *Paul Tardy, David Janiszek, Yannick Estève, Vincent Nguyen* `LREC 2020` [[pdf]](https://www.aclweb.org/anthology/2020.lrec-1.829) [[bib]](https://www.aclweb.org/anthology/2020.lrec-1.829.bib)
29. **Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization** *Xiachong Feng, Xiaocheng Feng, Bing Qin, Xinwei Geng* `IJCAI21` [[pdf]](https://arxiv.org/abs/2012.03502) [[code]](https://github.com/xcfcode/DDAMS)
30. **How Domain Terminology Affects Meeting Summarization Performance** *Jia Jin Koay, Alexander Roustai, Xiaojin Dai, Dillon Burns, Alec Kerrigan, Fei Liu* `COLING20 Short` [[pdf]](https://arxiv.org/abs/2011.00692) [[code]](https://github.com/ucfnlp/meeting-domain-terminology)
31. **How to Interact and Change? Abstractive Dialogue Summarization with Dialogue Act Weight and Topic Change Info** *Jiasheng Di, Xiao Wei, Zhenyu Zhang* `KSEM 2020` [[pdf]](https://link.springer.com/content/pdf/10.1007/978-3-030-55393-7_22.pdf) [[code]](https://github.com/d1jiasheng/DialogueSum)
32. **Abstractive Dialogue Summarization with Sentence-Gated Modeling Optimized by Dialogue Acts** *Chih-Wen Goo, Yun-Nung Chen* `SLT18` [[pdf]](https://arxiv.org/abs/1809.05715) [[code]](https://github.com/MiuLab/DialSum)
33. **A Sliding-Window Approach to Automatic Creation of Meeting Minutes** *Jia Jin Koay, Alexander Roustai, Xiaojin Dai, Fei Liu* [[pdf]](https://arxiv.org/abs/2104.12324)
34. **Hierarchical Learning for Generation with Long Source Sequences** *Tobias Rohde, Xiaoxia Wu, Yinhan Liu* [[pdf]](https://arxiv.org/abs/2104.07545) [[code]](https://github.com/birch-research/hierarchical-learning)
35. **A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining** *Chenguang Zhu, Ruochen Xu, Michael Zeng, Xuedong Huang* `Findings of EMNLP20` [[pdf]](https://arxiv.org/abs/2004.02016) [[code]](https://github.com/microsoft/HMNet) [[unofficial-code]](https://github.com/JudeLee19/HMNet-End-to-End-Abstractive-Summarization-for-Meetings)
36. **Abstractive Meeting Summarization via Hierarchical Adaptive Segmental Network Learning** *Zhou Zhao, Haojie Pan, Changjie Fan, Yan Liu, Linlin Li, Min Yang* `WWW19` [[pdf]](https://dl.acm.org/doi/10.1145/3308558.3313619)
37. **Restructuring Conversations using Discourse Relations for Zero-shot Abstractive Dialogue Summarization** *Prakhar Ganesh, Saket Dingliwal* [[pdf]](https://arxiv.org/abs/1902.01615)
38. **Keep Meeting Summaries on Topic: Abstractive Multi-Modal Meeting Summarization** *Manling Li, Lingyu Zhang, Heng Ji, Richard J. Radke* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1210/)
39. **Automatic analysis of multiparty meetings** *STEVE RENALS* [[pdf]](https://link.springer.com/article/10.1007/s12046-011-0051-3)
40. **A Multimodal Meeting Browser that Implements an Important Utterance Detection Model based on Multimodal Information** *Fumio Nihei, Yukiko I. Nakano* [[pdf]](https://dl.acm.org/doi/abs/10.1145/3379336.3381491)
41. **Exploring Methods for Predicting Important Utterances Contributing to Meeting Summarization** *Fumio Nihei, Yukiko I. Nakano* [[pdf]](https://www.mdpi.com/2414-4088/3/3/50)
42. **Fusing Verbal and Nonverbal Information for Extractive Meeting Summarization** *Fumio Nihei, Yukiko I. Nakano, Yutaka Takase* `GIFT18` [[pdf]](https://dl.acm.org/doi/10.1145/3279981.3279987)
43. **Meeting Extracts for Discussion Summarization Based on Multimodal Nonverbal Information** *Fumio Nihei, Yukiko I. Nakano, Yutaka Takase* `ICMI16` [[pdf]](https://dl.acm.org/doi/10.1145/2993148.2993160)
44. **Extractive Summarization of Meeting Recordings** *Gabriel Murray, Steve Renals, Jean Carletta* [[pdf]](https://www.cstr.ed.ac.uk/downloads/publications/2005/murray-eurospeech05.pdf)
45. **Multimodal Summarization of Meeting Recordings** *Bema Erol, Dar-Shyang Lee, Jonathan Hull* `ICME 2003` [[pdf]](https://ieeexplore.ieee.org/document/1221239)
46. **Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data** *Sanjeev Kumar Karn, Francine Chen, Yan-Ying Chen, Ulli Waltinger, Hinrich Schütze* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.adaptnlp-1.24/)
47. **Leverage Unlabeled Data for Abstractive Speech Summarization with Self-Supervised Learning and Back-Summarization** *SPECOM 2020* `SPECOM 2020` [[pdf]](https://arxiv.org/abs/2007.15296)
48. **Focused Meeting Summarization via Unsupervised Relation Extraction** *Lu Wang, Claire Cardie* `SIGDIAL 2012` [[pdf]](https://www.aclweb.org/anthology/W12-1642.pdf)
49. **QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization** *Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, Dragomir Radev* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.05938) [[data]](https://github.com/Yale-LILY/QMSum)
50. **Domain-Independent Abstract Generation for Focused Meeting Summarization** *Lu Wang, Claire Cardie* `ACL 2013` [[pdf]](https://www.aclweb.org/anthology/P13-1137.pdf)
51. **Summarizing Decisions in Spoken Meetings** *Lu Wang, Claire Cardie* `ACL 2011` [[pdf]](https://arxiv.org/abs/1606.07965)
52. **Extracting Decisions from Multi-Party Dialogue Using Directed Graphical Models and Semantic Similarity** *Trung Bui, Matthew Frampton, John Dowding, Stanley Peters* `SIGDIAL 2009` [[pdf]](https://www.aclweb.org/anthology/W09-3934/) [[bib]](https://www.aclweb.org/anthology/W09-3934.bib)
53. **ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining** *Alexander R. Fabbri, Faiaz Rahman, Imad Rizvi, Borui Wang, Haoran Li, Yashar Mehdad, Dragomir Radev* `ACL2021` [[pdf]](https://arxiv.org/abs/2106.00829) [[code]](https://github.com/Yale-LILY/ConvoSumm)
### Chat Summarization
1. **Mind the Gap! Injecting Commonsense Knowledge for Abstractive Dialogue Summarization** *Seungone Kim, Se June Joo, Hyungjoo Chae, Chaehyeong Kim, Seung-won Hwang, Jinyoung Yeo* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.548/) <details> <summary>[Abs]</summary> In this paper, we propose to leverage the unique characteristics of dialogues sharing commonsense knowledge across participants, to resolve the difficulties in summarizing them. We present SICK, a framework that uses commonsense inferences as additional context. Compared to previous work that solely relies on the input dialogue, SICK uses an external knowledge model to generate a rich set of commonsense inferences and selects the most probable one with a similarity-based selection method. Built upon SICK, SICK++ utilizes commonsense as supervision, where the task of generating commonsense inferences is added upon summarizing the dialogue in a multi-task learning setting. Experimental results show that with injected commonsense knowledge, our framework generates more informative and consistent summaries than existing methods. </details>
1. **A Finer-grain Universal Dialogue Semantic Structures based Model For Abstractive Dialogue Summarization** *Yuejie Lei, Fujia Zheng, Yuanmeng Yan, Keqing He, Weiran Xu* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.117/) [[code]](https://github.com/apexmeister/FINDS)
1. **Capturing Speaker Incorrectness: Speaker-Focused Post-Correction for Abstractive Dialogue Summarization** *Dongyub Lee, Jungwoo Lim, Taesun Whang, Chanhee Lee, Seungwoo Cho, Mingun Park, Heuiseok Lim* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.8/)
1. **Who says like a style of Vitamin: Towards Syntax-Aware DialogueSummarization using Multi-task Learning** *Seolhwa Lee, Kisu Yang, Chanjun Park, João Sedoc, Heuiseok Lim* [[pdf]](https://arxiv.org/abs/2109.14199)
1. **Controllable Neural Dialogue Summarization with Personal Named Entity Planning** *Zhengyuan Liu, Nancy F. Chen* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.13070)
8. **GupShup: Summarizing Open-Domain Code-Switched Conversations** *Laiba Mehnaz, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle G. Lee, Anish Acharya, Rajiv Ratn Shah* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.499/)[[code]](https://github.com/midas-research/gupshup)
1. **Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization** *Junpeng Liu, Yanyan Zou, Hainan Zhang, Hongshen Chen, Zhuoye Ding, Caixia Yuan, Xiaojie Wang* `EMNLP 2021 Findings` [[pdf]](https://arxiv.org/abs/2109.04994) [[code]](https://github.com/Junpliu/ConDigSum)
1. **Give the Truth: Incorporate Semantic Slot into Abstractive Dialogue Summarization** *Lulu Zhao, Weihao Zeng, Weiran Xu, Jun Guo* `EMNLP 2021 Findings` [[pdf]](https://www.researchgate.net/publication/354162497_Give_the_Truth_Incorporate_Semantic_Slot_into_Abstractive_Dialogue_Summarization)
1. **Low-Resource Dialogue Summarization with Domain-Agnostic Multi-Source Pretraining** *Yicheng Zou, Bolin Zhu, Xingwu Hu, Tao Gui, Qi Zhang* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.04080) [[code]](https://github.com/RowitZou/DAMS)
1. **Enhancing Semantic Understanding with Self-Supervised Methods for Abstractive Dialogue Summarization** *Hyunjae Lee, Jaewoong Yun, Hyunjin Choi, Seongho Joe, Youngjune L. Gwon* `Interspeech 2021` [[pdf]](https://www.isca-speech.org/archive/interspeech_2021/lee21_interspeech.html)
1. **Dialogue summarization with supporting utterance flow modeling and fact regularization** *Wang Chen, Piji Li, Hou PongChan, Irwin King* `Knowledge-Based Systems` [[pdf]](https://www.sciencedirect.com/science/article/pii/S0950705121005906)
1. **Situation-Based Multiparticipant Chat Summarization: a Concept, an Exploration-Annotation Tool and an Example Collection** *Anna Smirnova, Evgeniy Slobodkin, George Chernishev* `ACL 2021 Student Research Workshop` [[pdf]](https://aclanthology.org/2021.acl-srw.14/) [[tool]](https://github.com/mechanicpanic/Chat-Corpora-Annotator) [[data]](https://github.com/mechanicpanic/Situation_Dataset)
1. **Coreference-Aware Dialogue Summarization** *Zhengyuan Liu, Ke Shi, Nancy F. Chen* `SIGDIAL 2021` [[pdf]](https://arxiv.org/abs/2106.08556)
1. **Incorporating Commonsense Knowledge into Abstractive Dialogue Summarization via Heterogeneous Graph Networks** *Xiachong Feng, Xiaocheng Feng, Bing Qin* `CCL 2021` [[pdf]](https://arxiv.org/abs/2010.10044)
1. **Hierarchical Speaker-Aware Sequence-to-Sequence Model for Dialogue Summarization** *Yuejie Lei, Yuanmeng Yan, Zhiyuan Zeng, Keqing He, Ximing Zhang, Weiran Xu* `ICASSP21` [[pdf]](https://ieeexplore.ieee.org/document/9414547)
1. **Summary Grounded Conversation Generation** *Chulaka Gunasekara, Guy Feigenblat, Benjamin Sznajder, Sachindra Joshi, David Konopnicki* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.03337)
1. **Controllable Abstractive Dialogue Summarization with Sketch Supervision** *Chien-Sheng Wu, Linqing Liu, Wenhao Liu, Pontus Stenetorp, Caiming Xiong* `ACL-Findings 2021` [[pdf]](https://arxiv.org/abs/2105.14064) [[code]](https://github.com/salesforce/ConvSumm)
1. **Structure-Aware Abstractive Conversation Summarization via Discourse and Action Graphs** *Jiaao Chen, Diyi Yang* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.08400) [[code]](https://github.com/GT-SALT/Structure-Aware-BART)
2. **Planning with Learned Entity Prompts for Abstractive Summarization** *Shashi Narayan, Yao Zhao, Joshua Maynez, Gonçalo Simoes, Ryan McDonald* `TACL 2021` [[pdf]](https://aclanthology.org/2021.tacl-1.88/)
3. **Improving Abstractive Dialogue Summarization with Graph Structures and Topic Words** *Lulu Zhao, Weiran Xu, Jun Guo* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.39/)
3. **Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization** *Jiaao Chen, Diyi Yang* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.01672) [[code]](https://github.com/GT-SALT/Multi-View-Seq2Seq)
4. **SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization** *Bogdan Gliwa, Iwona Mochol, Maciej Biesek, Aleksander Wawer* `EMNLP19` [[pdf]](https://arxiv.org/abs/1911.12237) [[data]](https://arxiv.org/src/1911.12237v2/anc/corpus.7z)
### Medical Dialogue Summarization
1. **COSSUM: Towards Conversation-Oriented Structured Summarization for Automatic Medical Insurance Assessment** *Sheng Xu, Xiaojun Wan, Sen Hu, Mengdi Zhou, Teng Xu, Hongbin Wang, Haitao Mi* `KDD 2022` [[pdf]](https://dl.acm.org/doi/abs/10.1145/3534678.3539116) <details> <summary>[Abs]</summary> In medical insurance industry, a lot of human labor is required to collect information of claimants. Human assessors need to converse with claimants in order to record key information and organize it into a structured summary. With the purpose of helping save human labor, we propose the task of conversation-oriented structured summarization which aims to automatically produce the desired structured summary from a conversation automatically. One major challenge of the task is that the structured summary contains multiple fields of different types. To tackle this problem, we propose a unified approach COSSUM based on prompting to generate the values of all fields simultaneously. By learning all fields together, our approach can capture the inherent relationship between them. Moreover, we propose a specially designed curriculum learning strategy for model training. Both automatic and human evaluations are performed, and the results show the effectiveness of our proposed approach. </details>
1. **Counseling Summarization using Mental Health Knowledge Guided Utterance Filtering** *Aseem Srivastava, Tharun Suresh, Sarah Peregrine (Grin)Lord, Md. Shad Akhtar, Tanmoy Chakraborty* `KDD 2022 ADS Track` [[pdf]](https://arxiv.org/abs/2206.03886) <details> <summary>[Abs]</summary> The psychotherapy intervention technique is a multifaceted conversation between a therapist and a patient. Unlike general clinical discussions, psychotherapy's core components (viz. symptoms) are hard to distinguish, thus becoming a complex problem to summarize later. A structured counseling conversation may contain discussions about symptoms, history of mental health issues, or the discovery of the patient's behavior. It may also contain discussion filler words irrelevant to a clinical summary. We refer to these elements of structured psychotherapy as counseling components. In this paper, the aim is mental health counseling summarization to build upon domain knowledge and to help clinicians quickly glean meaning. We create a new dataset after annotating 12.9K utterances of counseling components and reference summaries for each dialogue. Further, we propose ConSum, a novel counseling-component guided summarization model. ConSum undergoes three independent modules. First, to assess the presence of depressive symptoms, it filters utterances utilizing the Patient Health Questionnaire (PHQ-9), while the second and third modules aim to classify counseling components. At last, we propose a problem-specific Mental Health Information Capture (MHIC) evaluation metric for counseling summaries. Our comparative study shows that we improve on performance and generate cohesive, semantic, and coherent summaries. We comprehensively analyze the generated summaries to investigate the capturing of psychotherapy elements. Human and clinical evaluations on the summary show that ConSum generates quality summary. Further, mental health experts validate the clinical acceptability of the ConSum. Lastly, we discuss the uniqueness in mental health counseling summarization in the real world and show evidences of its deployment on an online application with the support of http://mpathic.ai/ </details>
1. **Adding more data does not always help: A study in medical conversation summarization with PEGASUS** *Varun Nair, Namit Katariya, Xavier Amatriain, Ilya Valmianski, Anitha Kannan* [[pdf]](https://arxiv.org/abs/2111.07564)
1. **Leveraging Pretrained Models for Automatic Summarization of Doctor-Patient Conversations** *Longxiang Zhang, Renato Negrinho, Arindam Ghosh, Vasudevan Jagannathan, Hamid Reza Hassanzadeh, Thomas Schaaf, and Matthew R. Gormley* `Findings of EMNLP 2021` [[pdf]](https://www.cs.cmu.edu/~mgormley/papers/zhang+al.emnlp.2021.pdf)
1. **Medically Aware GPT-3 as a Data Generator for Medical Dialogue Summarization** *Bharath Chintagunta, Namit Katariya, Xavier Amatriain, Anitha Kannan* `NAACL | NLPMC 2021` [[pdf1]](https://aclanthology.org/2021.nlpmc-1.9/) [[pdf2]](https://arxiv.org/abs/2110.07356)
1. **Generating SOAP Notes from Doctor-Patient Conversations Using Modular Summarization Techniques** *Kundan Krishna, Sopan Khosla, Jeffrey P. Bigham, Zachary C. Lipton* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.384/) [[code]](https://github.com/acmi-lab/modular-summarization)
1. **Summarizing Medical Conversations via Identifying Important Utterances** *Yan Song, Yuanhe Tian, Nan Wang, Fei Xia* `COLING 2020` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.63/) [[code]](https://github.com/cuhksz-nlp/HET-MC) [[bib]](https://www.aclweb.org/anthology/2020.coling-main.63.bib)
2. **Dr.Summarize: Global Summarization of Medical Dialogue by Exploiting Local Structures** *Anirudh Joshi, Namit Katariya, Xavier Amatriain, Anitha Kannan* `Findings of EMNLP 2020` [[pdf]](https://arxiv.org/abs/2009.08666) [[bib]](https://www.aclweb.org/anthology/2020.findings-emnlp.335.bib)
3. **Medical Dialogue Summarization for Automated Reporting in Healthcare** *Sabine Molenaar, Lientje Maas, Verónica Burriel, Fabiano Dalpiaz,Sjaak Brinkkemper* `Advanced Information Systems Engineering Workshops 2020` [[pdf]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7225507/) [[bib]]()
4. **Generating Medical Reports from Patient-Doctor Conversations using Sequence-to-Sequence Models** *Seppo Enarvi, Marilisa Amoia, Miguel Del-Agua Teba, Brian Delaney, Frank Diehl, Stefan Hahn, Kristina Harris, Liam McGrath, Yue Pan, Joel Pinto, Luca Rubini, Miguel Ruiz, Gagandeep Singh, Fabian Stemmer, Weiyi Sun, Paul Vozila, Thomas Lin, Ranjani Ramamurthy* `ACL 2020 Short` [[pdf]](https://www.aclweb.org/anthology/2020.nlpmc-1.4/) [[bib]](https://www.aclweb.org/anthology/2020.nlpmc-1.4.bib)
5. **Automatically Generating Psychiatric Case Notes From Digital Transcripts of Doctor-Patient Conversations** *Nazmul Kazi, Indika Kahanda* `NAACL 2019` [[pdf]](https://www.aclweb.org/anthology/W19-1918/) [[bib]](https://www.aclweb.org/anthology/W19-1918.bib)
7. **Alignment Annotation for Clinic Visit Dialogue to Clinical Note Sentence Language Generation** *Wen-wai Yim, Meliha Yetisgen, Jenny Huang, Micah Grossman* `LREC 2020` [[pdf]](https://www.aclweb.org/anthology/2020.lrec-1.52/) [[bib]](https://www.aclweb.org/anthology/2020.lrec-1.52.bib)
8. **Topic-aware Pointer-Generator Networks for Summarizing Spoken Conversations** *Zhengyuan Liu, Angela Ng, Sheldon Lee, Ai Ti Aw, Nancy F. Chen* ` ASRU 2019` [[pdf]](https://arxiv.org/abs/1910.01335)
### Customer Service Summarization
1. **Other Roles Matter! Enhancing Role-Oriented Dialogue Summarization via Role Interactions** *Haitao Lin, Junnan Zhu, Lu Xiang, Yu Zhou, Jiajun Zhang, Chengqing Zong* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.182/) [[code]](https://github.com/xiaolinandy/rods) <details> <summary>[Abs]</summary> Role-oriented dialogue summarization is to generate summaries for different roles in the dialogue, e.g., merchants and consumers. Existing methods handle this task by summarizing each role’s content separately and thus are prone to ignore the information from other roles. However, we believe that other roles’ content could benefit the quality of summaries, such as the omitted information mentioned by other roles. Therefore, we propose a novel role interaction enhanced method for role-oriented dialogue summarization. It adopts cross attention and decoder self-attention interactions to interactively acquire other roles’ critical information. The cross attention interaction aims to select other roles’ critical dialogue utterances, while the decoder self-attention interaction aims to obtain key information from other roles’ summaries. Experimental results have shown that our proposed method significantly outperforms strong baselines on two public role-oriented dialogue summarization datasets. Extensive analyses have demonstrated that other roles’ content could help generate summaries with more complete semantics and correct topic structures. </details>
1. **An End-to-End Dialogue Summarization System for Sales Calls** *Abedelkadir Asi, Song Wang, Roy Eisenstadt, Dean Geckt, Yarin Kuper, Yi Mao, Royi Ronen* `NAACL 2022` [[pdf]](https://arxiv.org/abs/2204.12951)
1. **Heuristic-based Inter-training to Improve Few-shot Multi-perspective Dialog Summarization** *Benjamin Sznajder, Chulaka Gunasekara, Guy Lev, Sachin Joshi, Eyal Shnarch, Noam Slonim* [[pdf]](https://arxiv.org/abs/2203.15590)
1. **Dialogue Summaries as Dialogue States (DS2), Template-Guided Summarization for Few-shot Dialogue State Tracking** *Jamin Shin, Hangyeol Yu, Hyeongdon Moon, Andrea Madotto, Juneyoung Park* `Findings of ACL 2022` [[pdf]](https://arxiv.org/abs/2203.01552) [[code]](https://github.com/jshin49/ds2)
1. **TWEETSUMM - A Dialog Summarization Dataset for Customer Service** *Guy Feigenblat, Chulaka Gunasekara, Benjamin Sznajder, Sachindra Joshi, David Konopnicki, Ranit Aharonov* [[pdf]](https://aclanthology.org/2021.findings-emnlp.24/) [[data]](https://github.com/guyfe/Tweetsumm)
1. **Extractive Dialogue Summarization Without Annotation Based on Distantly Supervised Machine Reading Comprehension in Customer Service** *Bing Ma, Haifeng Sun , Jingyu Wang , Qi Qi, and Jianxin Liao* `TASLP` [[pdf]](https://ieeexplore.ieee.org/document/9645319/authors#authors)
1. **TODSum: Task-Oriented Dialogue Summarization with State Tracking** *Lulu Zhao, Fujia Zheng, Keqing He, Weihao Zeng, Yuejie Lei, Huixing Jiang, Wei Wu, Weiran Xu, Jun Guo, Fanyu Meng* [[pdf]](https://arxiv.org/abs/2110.12680)
1. **CSDS: A Fine-grained Chinese Dataset for Customer Service Dialogue Summarization** *Haitao Lin, Liqun Ma, Junnan Zhu, Lu Xiang, Yu Zhou, Jiajun Zhang, Chengqing Zong* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2108.13139) [[data]](https://github.com/xiaolinAndy/CSDS)
1. **Distant Supervision based Machine Reading Comprehension for Extractive Summarization in Customer Service** *Bing Ma, Cao Liu, Jingyu Wang, Shujie Hu, Fan Yang, Xunliang Cai, Guanglu Wan, Jiansong Chen, Jianxin Liao* `SIGIR 2021` [[pdf]](https://dl.acm.org/doi/10.1145/3404835.3463046)
1. **Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes** *Xinyuan Zhang, Ruiyi Zhang, Manzil Zaheer, Amr Ahmed* `AAAI21` [[pdf]](https://arxiv.org/abs/2009.06851)
1. **Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling** *Yicheng Zou, Lujun Zhao, Yangyang Kang, Jun Lin, Minlong Peng, Zhuoren Jiang, Changlong Sun, Qi Zhang, Xuanjing Huang, Xiaozhong Liu* `AAAI21` [[pdf]](https://arxiv.org/abs/2012.07311) [[code]](https://github.com/RowitZou/topic-dialog-summ)
1. **Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders** *Yicheng Zou, Jun Lin, Lujun Zhao, Yangyang Kang, Zhuoren Jiang, Changlong Sun, Qi Zhang, Xuanjing Huang, Xiaozhong Liu* `AAAI21` [[pdf]](https://arxiv.org/abs/2012.07300) [[code]](https://github.com/RowitZou/RankAE)
1. **Abstractive Dialog Summarization with Semantic Scaffolds** *Lin Yuan, Zhou Yu* [[pdf]](https://arxiv.org/abs/1910.00825)
1. **Automatic Dialogue Summary Generation for Customer Service** *Chunyi Liu, Peng Wang, Jiang Xu, Zang Li and Jieping Ye* `KDD19` [[pdf]](https://dl.acm.org/doi/10.1145/3292500.3330683)
### Domain Adaption
1. **DIONYSUS: A Pre-trained Model for Low-Resource Dialogue Summarization** *Yu Li, Baolin Peng, Pengcheng He, Michel Galley, Zhou Yu, Jianfeng Gao* [[pdf]](https://arxiv.org/abs/2212.10018) <details> <summary>[Abs]</summary> Dialogue summarization has recently garnered significant attention due to its wide range of applications. However, existing methods for summarizing dialogues are suboptimal because they do not take into account the inherent structure of dialogue and rely heavily on labeled data, which can lead to poor performance in new domains. In this work, we propose DIONYSUS (dynamic input optimization in pre-training for dialogue summarization), a pre-trained encoder-decoder model for summarizing dialogues in any new domain. To pre-train DIONYSUS, we create two pseudo summaries for each dialogue example: one is produced by a fine-tuned summarization model, and the other is a collection of dialogue turns that convey important information. We then choose one of these pseudo summaries based on the difference in information distribution across different types of dialogues. This selected pseudo summary serves as the objective for pre-training DIONYSUS using a self-supervised approach on a large dialogue corpus. Our experiments show that DIONYSUS outperforms existing methods on six datasets, as demonstrated by its ROUGE scores in zero-shot and few-shot settings. </details>
1. **Domain-Oriented Prefix-Tuning: Towards Efficient and Generalizable Fine-tuning for Zero-Shot Dialogue Summarization** *Lulu Zhao, Fujia Zheng, Weihao Zeng, Keqing He, Weiran Xu, Huixing Jiang, Wei Wu, Yanan Wu* `NAACL 2022` [[pdf]](https://arxiv.org/abs/2204.04362) [[code]](https://github.com/Zeng-WH/DOP-Tuning)
1. **AdaptSum: Towards Low-Resource Domain Adaptation for Abstractive Summarization** *Tiezheng Yu, Zihan Liu, Pascale Fung* `NAACL21` [[pdf]](https://arxiv.org/abs/2103.11332) [[code]](https://github.com/TysonYu/AdaptSum)
2. **Domain Adaptation to Summarize Human Conversations** *Oana Sandu, Giuseppe Carenini, Gabriel Murray, Raymond Ng* `ACL2010 Workshop` [[pdf]](https://www.aclweb.org/anthology/W10-2603/)
### Others
1. **Summarizing Community-based Question-Answer Pairs** *Ting-Yao Hsu, Yoshi Suhara, Xiaolan Wang* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.250/) [[code]](https://github.com/megagonlabs/qa-summarization) <details> <summary>[Abs]</summary> Community-based Question Answering (CQA), which allows users to acquire their desired information, has increasingly become an essential component of online services in various domains such as E-commerce, travel, and dining. However, an overwhelming number of CQA pairs makes it difficult for users without particular intent to find useful information spread over CQA pairs. To help users quickly digest the key information, we propose the novel CQA summarization task that aims to create a concise summary from CQA pairs. To this end, we first design a multi-stage data annotation process and create a benchmark dataset, COQASUM, based on the Amazon QA corpus. We then compare a collection of extractive and abstractive summarization methods and establish a strong baseline approach DedupLED for the CQA summarization task. Our experiment further confirms two key challenges, sentence-type transfer and deduplication removal, towards the CQA summarization task. Our data and code are publicly available. </details>
1. **Curriculum Prompt Learning with Self-Training for Abstractive Dialogue Summarization** *Changqun Li, Linlin Wang, Xin Lin, Gerard de Melo, Liang He* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.72/) <details> <summary>[Abs]</summary> Succinctly summarizing dialogue is a task of growing interest, but inherent challenges, such as insufficient training data and low information density impede our ability to train abstractive models. In this work, we propose a novel curriculum-based prompt learning method with self-training to address these problems. Specifically, prompts are learned using a curriculum learning strategy that gradually increases the degree of prompt perturbation, thereby improving the dialogue understanding and modeling capabilities of our model. Unlabeled dialogue is incorporated by means of self-training so as to reduce the dependency on labeled data. We further investigate topic-aware prompts to better plan for the generation of summaries. Experiments confirm that our model substantially outperforms strong baselines and achieves new state-of-the-art results on the AMI and ICSI datasets. Human evaluations also show the superiority of our model with regard to the summary generation quality. </details>
1. **STRUDEL: Structured Dialogue Summarization for Dialogue Comprehension** *Borui Wang, Chengcheng Feng, Arjun Nair, Madelyn Mao, Jai Desai, Asli Celikyilmaz, Haoran Li, Yashar Mehdad, Dragomir Radev* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2212.12652) <details> <summary>[Abs]</summary> Abstractive dialogue summarization has long been viewed as an important standalone task in natural language processing, but no previous work has explored the possibility of whether abstractive dialogue summarization can also be used as a means to boost an NLP system's performance on other important dialogue comprehension tasks. In this paper, we propose a novel type of dialogue summarization task - STRUctured DiaLoguE Summarization - that can help pre-trained language models to better understand dialogues and improve their performance on important dialogue comprehension tasks. We further collect human annotations of STRUDEL summaries over 400 dialogues and introduce a new STRUDEL dialogue comprehension modeling framework that integrates STRUDEL into a graph-neural-network-based dialogue reasoning module over transformer encoder language models to improve their dialogue comprehension abilities. In our empirical experiments on two important downstream dialogue comprehension tasks - dialogue question answering and dialogue response prediction - we show that our STRUDEL dialogue comprehension model can significantly improve the dialogue comprehension performance of transformer encoder language models. </details>
1. **Enhancing Dialogue Summarization with Topic-Aware Global- and Local- Level Centrality** *Xinnian Liang, Shuangzhi Wu, Chenhao Cui, Jiaqi Bai, Chao Bian, Zhoujun Li* `EACL 2023` [[pdf]](https://arxiv.org/abs/2301.12376) [[code]](https://github.com/xnliang98/bart-glc) <details> <summary>[Abs]</summary> Dialogue summarization aims to condense a given dialogue into a simple and focused summary text. Typically, both the roles' viewpoints and conversational topics change in the dialogue stream. Thus how to effectively handle the shifting topics and select the most salient utterance becomes one of the major challenges of this task. In this paper, we propose a novel topic-aware Global-Local Centrality (GLC) model to help select the salient context from all sub-topics. The centralities are constructed at both the global and local levels. The global one aims to identify vital sub-topics in the dialogue and the local one aims to select the most important context in each sub-topic. Specifically, the GLC collects sub-topic based on the utterance representations. And each utterance is aligned with one sub-topic. Based on the sub-topics, the GLC calculates global- and local-level centralities. Finally, we combine the two to guide the model to capture both salient context and sub-topics when generating summaries. Experimental results show that our model outperforms strong baselines on three public dialogue summarization datasets: CSDS, MC, and SAMSUM. Further analysis demonstrates that our GLC can exactly identify vital contents from sub-topics. </details>
1. **SWING: Balancing Coverage and Faithfulness for Dialogue Summarization** *Kung-Hsiang Huang, Siffi Singh, Xiaofei Ma, Wei Xiao, Feng Nan, Nicholas Dingwall, William Yang Wang, Kathleen McKeown* `Findings of EACL 2023` [[pdf]](https://arxiv.org/abs/2301.10483) [[code]](https://github.com/amazon-science/AWS-SWING) <details> <summary>[Abs]</summary> Missing information is a common issue of dialogue summarization where some information in the reference summaries is not covered in the generated summaries. To address this issue, we propose to utilize natural language inference (NLI) models to improve coverage while avoiding introducing factual inconsistencies. Specifically, we use NLI to compute fine-grained training signals to encourage the model to generate content in the reference summaries that have not been covered, as well as to distinguish between factually consistent and inconsistent generated sentences. Experiments on the DialogSum and SAMSum datasets confirm the effectiveness of the proposed approach in balancing coverage and faithfulness, validated with automatic metrics and human evaluations. Additionally, we compute the correlation between commonly used automatic metrics with human judgments in terms of three different dimensions regarding coverage and factual consistency to provide insight into the most suitable metric for evaluating dialogue summaries. </details>
1. **Human-in-the-loop Abstractive Dialogue Summarization** *Jiaao Chen, Mohan Dodda, Diyi Yang* [[pdf]](https://arxiv.org/abs/2212.09750) <details> <summary>[Abs]</summary> Abstractive dialogue summarization has received increasing attention recently. Despite the fact that most of the current dialogue summarization systems are trained to maximize the likelihood of human-written summaries and have achieved significant results, there is still a huge gap in generating high-quality summaries as determined by humans, such as coherence and faithfulness, partly due to the misalignment in maximizing a single human-written summary. To this end, we propose to incorporate different levels of human feedback into the training process. This will enable us to guide the models to capture the behaviors humans care about for summaries. Specifically, we ask humans to highlight the salient information to be included in summaries to provide the local feedback , and to make overall comparisons among summaries in terms of coherence, accuracy, coverage, concise and overall quality, as the global feedback. We then combine both local and global feedback to fine-tune the dialog summarization policy with Reinforcement Learning. Experiments conducted on multiple datasets demonstrate the effectiveness and generalization of our methods over the state-of-the-art supervised baselines, especially in terms of human judgments. </details>
2. **ED-FAITH: Evaluating Dialogue Summarization on Faithfulness** *Sicong Huang, Asli Celikyilmaz, Haoran Li* [[pdf]](https://arxiv.org/pdf/2211.08464.pdf) <details> <summary>[Abs]</summary> Abstractive summarization models typically generate content unfaithful to the input, thus highlighting the significance of evaluating the faithfulness of generated summaries. Most faithfulness metrics are only evaluated on news domain, can they be transferred to other summarization tasks? In this work, we first present a systematic study of faithfulness metrics for dialogue summarization. We evaluate common faithfulness metrics on dialogue datasets and observe that most metrics correlate poorly with human judgements despite performing well on news datasets. Given these findings, to improve existing metrics’ performance on dialogue summarization, we first finetune on in-domain dataset, then apply unlikelihood training on negative samples, and show that they can successfully improve metric performance on dialogue data. Inspired by the strong zero-shot performance of the T0 language model, we further propose T0-Score – a new metric for faithfulness evaluation, which shows consistent improvement against baseline metrics across multiple domains. </details>
3. **Towards Understanding Omission in Dialogue Summarization** *Yicheng Zou, Kaitao Song, Xu Tan, Zhongkai Fu, Tao Gui, Qi Zhang, Dongsheng Li* `` [[pdf]](https://arxiv.org/abs/2211.07145) <details> <summary>[Abs]</summary> Dialogue summarization aims to condense the lengthy dialogue into a concise summary, and has recently achieved significant progress. However, the result of existing methods is still far from satisfactory. Previous works indicated that omission is a major factor in affecting the quality of summarization, but few of them have further explored the omission problem, such as how omission affects summarization results and how to detect omission, which is critical for reducing omission and improving summarization quality. Moreover, analyzing and detecting omission relies on summarization datasets with omission labels (i.e., which dialogue utterances are omitted in the summarization), which are not available in the current literature. In this paper, we propose the OLDS dataset, which provides high-quality Omission Labels for Dialogue Summarization. By analyzing this dataset, we find that a large improvement in summarization quality can be achieved by providing ground-truth omission labels for the summarization model to recover omission information, which demonstrates the importance of omission detection for omission mitigation in dialogue summarization. Therefore, we formulate an omission detection task and demonstrate our proposed dataset can support the training and evaluation of this task well. We also call for research action on omission detection based on our proposed datasets. Our dataset and codes are publicly available. </details>
4. **Analyzing and Evaluating Faithfulness in Dialogue Summarization** *Bin Wang, Chen Zhang, Yan Zhang, Yiming Chen, Haizhou Li* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.325/) [[code]](https://github.com/BinWang28/FacEval) <details> <summary>[Abs]</summary> Dialogue summarization is abstractive in nature, making it suffer from factual errors. The factual correctness of summaries has the highest priority before practical applications. Many efforts have been made to improve faithfulness in text summarization. However, there is a lack of systematic study on dialogue summarization systems. In this work, we first perform the fine-grained human analysis on the faithfulness of dialogue summaries and observe that over 35% of generated summaries are faithfully inconsistent respective the source dialogues. Furthermore, we present a new model-level faithfulness evaluation method. It examines generation models with multi-choice questions created by rule-based transformations. Experimental results show that our evaluation schema is a strong proxy for the factual correctness of summarization models. The human-annotated faithfulness samples and the evaluation toolkit are released to facilitate future research toward faithful dialogue summarization. </details>
5. **Taxonomy of Abstractive Dialogue Summarization: Scenarios, Approaches and Future Directions** *Qi Jia, Siyu Ren, Yizhu Liu, Kenny Q. Zhu* [[pdf]](https://arxiv.org/abs/2210.09894) <details> <summary>[Abs]</summary> Abstractive dialogue summarization is to generate a concise and fluent summary covering the salient information in a dialogue among two or more interlocutors. It has attracted great attention in recent years based on the massive emergence of social communication platforms and an urgent requirement for efficient dialogue information understanding and digestion. Different from news or articles in traditional document summarization, dialogues bring unique characteristics and additional challenges, including different language styles and formats, scattered information, flexible discourse structures and unclear topic boundaries. This survey provides a comprehensive investigation on existing work for abstractive dialogue summarization from scenarios, approaches to evaluations. It categorizes the task into two broad categories according to the type of input dialogues, i.e., open-domain and task-oriented, and presents a taxonomy of existing techniques in three directions, namely, injecting dialogue features, designing auxiliary training tasks and using additional data.A list of datasets under different scenarios and widely-accepted evaluation metrics are summarized for completeness. After that, the trends of scenarios and techniques are summarized, together with deep insights on correlations between extensively exploited features and different scenarios. Based on these analyses, we recommend future directions including more controlled and complicated scenarios, technical innovations and comparisons, publicly available datasets in special domains, etc. </details>
6. **Leveraging Non-dialogue Summaries for Dialogue Summarization** *Seongmin Park, Dongchan Shin, Jihwa Lee* `Transcript Understanding Workshop at COLING 2022` [[pdf]](https://arxiv.org/abs/2210.09474) <details> <summary>[Abs]</summary> To mitigate the lack of diverse dialogue summarization datasets in academia, we present methods to utilize non-dialogue summarization data for enhancing dialogue summarization systems. We apply transformations to document summarization data pairs to create training data that better befit dialogue summarization. The suggested transformations also retain desirable properties of non-dialogue datasets, such as improved faithfulness to the source text. We conduct extensive experiments across both English and Korean to verify our approach. Although absolute gains in ROUGE naturally plateau as more dialogue summarization samples are introduced, utilizing non-dialogue data for training significantly improves summarization performance in zero- and few-shot settings and enhances faithfulness across all training regimes. </details>
7. **Improving Abstractive Dialogue Summarization with Speaker-Aware Supervised Contrastive Learning** *Zhichao Geng, Ming Zhong, Zhangyue Yin, Xipeng Qiu, Xuanjing Huang* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.569/) <details> <summary>[Abs]</summary> Pre-trained models have brought remarkable success on the text summarization task. For dialogue summarization, the subdomain of text summarization, utterances are concatenated to flat text before being processed. As a result, existing summarization systems based on pre-trained models are unable to recognize the unique format of the speaker-utterance pair well in the dialogue. To investigate this issue, we conduct probing tests and manual analysis, and find that the powerful pre-trained model can not identify different speakers well in the conversation, which leads to various factual errors. Moreover, we propose three speaker-aware supervised contrastive learning (SCL) tasks: Token-level SCL, Turn-level SCL, and Global-level SCL. Comprehensive experiments demonstrate that our methods achieve significant performance improvement on two mainstream dialogue summarization datasets. According to detailed human evaluations, pre-trained models equipped with SCL tasks effectively generate summaries with better factual consistency. </details>
8. **View Dialogue in 2D: A Two-stream Model in Time-speaker Perspective for Dialogue Summarization and beyond** *Keli Xie, Dongchen He, Jiaxin Zhuang, Siyuan Lu, Zhongfeng Wang* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.531/) [[code]](https://github.com/shakeley/View2dSum) <details> <summary>[Abs]</summary> Existing works on dialogue summarization often follow the common practice in document summarization and view the dialogue, which comprises utterances of different speakers, as a single utterance stream ordered by time. However, this single-stream approach without specific attention to the speaker-centered points has limitations in fully understanding the dialogue. To better capture the dialogue information, we propose a 2D view of dialogue based on a time-speaker perspective, where the time and speaker streams of dialogue can be obtained as strengthened input. Based on this 2D view, we present an effective two-stream model called ATM to combine the two streams. Extensive experiments on various summarization datasets demonstrate that ATM significantly surpasses other models regarding diverse metrics and beats the state-of-the-art models on the QMSum dataset in ROUGE scores. Besides, ATM achieves great improvements in summary faithfulness and human evaluation. Moreover, results on machine reading comprehension datasets show the generalization ability of the proposed methods and shed light on other dialogue-based tasks. Our code will be publicly available online. </details>
9. **Summarizing Dialogues with Negative Cues** *Junpeng Liu, Yanyan Zou, Yuxuan Xi, Shengjie Li, Mian Ma, Zhuoye Ding* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.528/) <details> <summary>[Abs]</summary> Abstractive dialogue summarization aims to convert a long dialogue content into its short form where the salient information is preserved while the redundant pieces are ignored. Different from the well-structured text, such as news and scientific articles, dialogues often consist of utterances coming from two or more interlocutors, where the conversations are often informal, verbose, and repetitive, sprinkled with false-starts, backchanneling, reconfirmations, hesitations, speaker interruptions and the salient information is often scattered across the whole chat. The above properties of conversations make it difficult to directly concentrate on scattered outstanding utterances and thus present new challenges of summarizing dialogues. In this work, rather than directly forcing a summarization system to merely pay more attention to the salient pieces, we propose to explicitly have the model perceive the redundant parts of an input dialogue history during the training phase. To be specific, we design two strategies to construct examples without salient pieces as negative cues. Then, the sequence-to-sequence likelihood loss is cooperated with the unlikelihood objective to drive the model to focus less on the unimportant information and also pay more attention to the salient pieces. Extensive experiments on the benchmark dataset demonstrate that our simple method significantly outperforms the baselines with regard to both semantic matching and factual consistent based metrics. The human evaluation also proves the performance gains. </details>
10. **ClidSum: A Benchmark Dataset for Cross-Lingual Dialogue Summarization** *Jiaan Wang, Fandong Meng, Ziyao Lu, Duo Zheng, Zhixu Li, Jianfeng Qu, Jie Zhou* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2202.05599) [[code]](https://github.com/krystalan/ClidSum) <details> <summary>[Abs]</summary> We present ClidSum, a benchmark dataset for building cross-lingual summarization systems on dialogue documents. It consists of 67k+ dialogue documents from two subsets (i.e., SAMSum and MediaSum) and 112k+ annotated summaries in different target languages. Based on the proposed ClidSum, we introduce two benchmark settings for supervised and semi-supervised scenarios, respectively. We then build various baseline systems in different paradigms (pipeline and end-to-end) and conduct extensive experiments on ClidSum to provide deeper analyses. Furthermore, we propose mDialBART which extends mBART-50 (a multi-lingual BART) via further pre-training. The multiple objectives used in the further pre-training stage help the pre-trained model capture the structural characteristics as well as important content in dialogues and the transformation from source to the target language. Experimental results show the superiority of mDialBART, as an end-to-end model, outperforms strong pipeline models on ClidSum. Finally, we discuss specific challenges that current approaches faced with this task and give multiple promising directions for future research. </details>
11. **A Focused Study on Sequence Length for Dialogue Summarization** *Bin Wang, Chen Zhang, Chengwei Wei, Haizhou Li* [[pdf]](https://arxiv.org/abs/2209.11910) <details> <summary>[Abs]</summary> Output length is critical to dialogue summarization systems. The dialogue summary length is determined by multiple factors, including dialogue complexity, summary objective, and personal preferences. In this work, we approach dialogue summary length from three perspectives. First, we analyze the length differences between existing models' outputs and the corresponding human references and find that summarization models tend to produce more verbose summaries due to their pretraining objectives. Second, we identify salient features for summary length prediction by comparing different model settings. Third, we experiment with a length-aware summarizer and show notable improvement on existing models if summary length can be well incorporated. Analysis and experiments are conducted on popular DialogSum and SAMSum datasets to validate our findings. </details>
12. **DialogSum Challenge: Results of the Dialogue Summarization Shared Task** *Yulong Chen, Naihao Deng, Yang Liu, Yue Zhang* [[pdf]](https://arxiv.org/abs/2208.03898) <details> <summary>[Abs]</summary> We report the results of DialogSum Challenge, the shared task on summarizing real-life scenario dialogues at INLG 2022. Four teams participate in this shared task and three submit their system reports, exploring different methods to improve the performance of dialogue summarization. Although there is a great improvement over the baseline models regarding automatic evaluation metrics, such as Rouge scores, we find that there is a salient gap between model generated outputs and human annotated summaries by human evaluation from multiple aspects. These findings demonstrate the difficulty of dialogue summarization and suggest that more fine-grained evaluatuion metrics are in need. </details>
13. **Effectiveness of French Language Models on Abstractive Dialogue Summarization Task** *Yongxin Zhou, François Portet, Fabien Ringeval* `LREC 2022` [[pdf]](https://arxiv.org/abs/2207.08305) <details> <summary>[Abs]</summary> Pre-trained language models have established the state-of-the-art on various natural language processing tasks, including dialogue summarization, which allows the reader to quickly access key information from long conversations in meetings, interviews or phone calls. However, such dialogues are still difficult to handle with current models because the spontaneity of the language involves expressions that are rarely present in the corpora used for pre-training the language models. Moreover, the vast majority of the work accomplished in this field has been focused on English. In this work, we present a study on the summarization of spontaneous oral dialogues in French using several language specific pre-trained models: BARThez, and BelGPT-2, as well as multilingual pre-trained models: mBART, mBARThez, and mT5. Experiments were performed on the DECODA (Call Center) dialogue corpus whose task is to generate abstractive synopses from call center conversations between a caller and one or several agents depending on the situation. Results show that the BARThez models offer the best performance far above the previous state-of-the-art on DECODA. We further discuss the limits of such pre-trained models and the challenges that must be addressed for summarizing spontaneous dialogues. </details>
14. **Data Augmentation for Low-Resource Dialogue Summarization** *Yongtai Liu, Joshua Maynez, Gonçalo Simões, Shashi Narayan* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.53/) <details> <summary>[Abs]</summary> We present DADS, a novel Data Augmentation technique for low-resource Dialogue Summarization. Our method generates synthetic examples by replacing sections of text from both the input dialogue and summary while preserving the augmented summary to correspond to a viable summary for the augmented dialogue. We utilize pretrained language models that produce highly likely dialogue alternatives while still being free to generate diverse alternatives. We applied our data augmentation method to the SAMSum dataset in low resource scenarios, mimicking real world problems such as chat, thread, and meeting summarization where large scale supervised datasets with human-written summaries are scarce. Through both automatic and human evaluations, we show that DADS shows strong improvements for low resource scenarios while generating topically diverse summaries without introducing additional hallucinations to the summaries. </details>
15. **An End-to-End Dialogue Summarization System for Sales Calls** *Abedelkadir Asi, Song Wang, Roy Eisenstadt, Dean Geckt, Yarin Kuper, Yi Mao, Royi Ronen* `NAACL 2022 Industry Track` [[pdf]](https://aclanthology.org/2022.naacl-industry.6/) <details> <summary>[Abs]</summary> Summarizing sales calls is a routine task performed manually by salespeople. We present a production system which combines generative models fine-tuned for customer-agent setting, with a human-in-the-loop user experience for an interactive summary curation process. We address challenging aspects of dialogue summarization task in a real-world setting including long input dialogues, content validation, lack of labeled data and quality evaluation. We show how GPT-3 can be leveraged as an offline data labeler to handle training data scarcity and accommodate privacy constraints in an industrial setting. Experiments show significant improvements by our models in tackling the summarization and content validation tasks on public datasets. </details>
16. **Few-shot fine-tuning SOTA summarization models for medical dialogues** *David Fraile Navarro, Mark Dras, Shlomo Berkovsky* `NAACL 2022 Student Research Workshop` [[pdf]](https://aclanthology.org/2022.naacl-srw.32/) [[code]](https://github.com/dafraile/Clinical-Dialogue-Summarization) <details> <summary>[Abs]</summary> Abstractive summarization of medical dialogues presents a challenge for standard training approaches, given the paucity of suitable datasets. We explore the performance of state-of-the-art models with zero-shot and few-shot learning strategies and measure the impact of pretraining with general domain and dialogue-specific text on the summarization performance. </details>
17. **DialSummEval: Revisiting Summarization Evaluation for Dialogues** *Mingqi Gao, Xiaojun Wan* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.418/) [[code]](https://github.com/kite99520/DialSummEval) <details> <summary>[Abs]</summary> Dialogue summarization is receiving increasing attention from researchers due to its extraordinary difficulty and unique application value. We observe that current dialogue summarization models have flaws that may not be well exposed by frequently used metrics such as ROUGE. In our paper, we re-evaluate 18 categories of metrics in terms of four dimensions: coherence, consistency, fluency and relevance, as well as a unified human evaluation of various models for the first time. Some noteworthy trends which are different from the conventional summarization tasks are identified. We will release DialSummEval, a multi-faceted dataset of human judgments containing the outputs of 14 models on SAMSum. </details>
18. **Domain-Oriented Prefix-Tuning: Towards Efficient and Generalizable Fine-tuning for Zero-Shot Dialogue Summarization** *Lulu Zhao, Fujia Zheng, Weihao Zeng, Keqing He, Weiran Xu, Huixing Jiang, Wei Wu, Yanan Wu* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.357/) [[code]](https://github.com/Zeng-WH/DOP-Tuning) <details> <summary>[Abs]</summary> The most advanced abstractive dialogue summarizers lack generalization ability on new domains and the existing researches for domain adaptation in summarization generally rely on large-scale pre-trainings. To explore the lightweight fine-tuning methods for domain adaptation of dialogue summarization, in this paper, we propose an efficient and generalizable Domain-Oriented Prefix-tuning model, which utilizes a domain word initialized prefix module to alleviate domain entanglement and adopts discrete prompts to guide the model to focus on key contents of dialogues and enhance model generalization. We conduct zero-shot experiments and build domain adaptation benchmarks on two multi-domain dialogue summarization datasets, TODSum and QMSum. Adequate experiments and qualitative analysis prove the effectiveness of our methods. </details>
19. **From spoken dialogue to formal summary: An utterance rewriting for dialogue summarization** *Yue Fang, Hainan Zhang, Hongshen Chen, Zhuoye Ding, Bo Long, Yanyan Lan, Yanquan Zhou* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.283/) <details> <summary>[Abs]</summary> Due to the dialogue characteristics of unstructured contexts and multi-parties with first-person perspective, many successful text summarization works have failed when dealing with dialogue summarization. In dialogue summarization task, the input dialogue is usually spoken style with ellipsis and co-references but the output summaries are more formal and complete. Therefore, the dialogue summarization model should be able to complete the ellipsis content and co-reference information and then produce a suitable summary accordingly. However, the current state-of-the-art models pay more attention on the topic or structure of summary, rather than the consistency of dialogue summary with its input dialogue context, which may suffer from the personal and logical inconsistency problem. In this paper, we propose a new model, named ReWriteSum, to tackle this problem. Firstly, an utterance rewriter is conducted to complete the ellipsis content of dialogue content and then obtain the rewriting utterances. Then, the co-reference data augmentation mechanism is utilized to replace the referential person name with its specific name to enhance the personal information. Finally, the rewriting utterances and the co-reference replacement data are used in the standard BART model. Experimental results on both SAMSum and DialSum datasets show that our ReWriteSum significantly outperforms baseline models, in terms of both metric-based and human evaluations. Further analysis on multi-speakers also shows that ReWriteSum can obtain relatively higher improvement with more speakers, validating the correctness and property of ReWriteSum. </details>
20. **Unsupervised Abstractive Dialogue Summarization with Word Graphs and POV Conversion** *Seongmin Park, Jihwa Lee* `WIT Workshop @ ACL2022` [[pdf]](https://arxiv.org/abs/2205.13108) [[code]](https://github.com/seongminp/graph-dialogue-summary)
21. **MSAMSum: Towards Benchmarking Multi-lingual Dialogue Summarization** *Xiachong Feng, Xiaocheng Feng, Bing Qin* `ACL 2022 DialDoc Workshop` [[pdf]](https://aclanthology.org/2022.dialdoc-1.1/) [[data]](https://github.com/xcfcode/MSAMSum)
22. **The Cross-lingual Conversation Summarization Challenge** *Yulong Chen, Ming Zhong, Xuefeng Bai, Naihao Deng, Jing Li, Xianchao Zhu, Yue Zhang* [[pdf]](https://arxiv.org/abs/2205.00379)
23. **Post-Training Dialogue Summarization using Pseudo-Paraphrasing** *Qi Jia, Yizhu Liu, Haifeng Tang, Kenny Q. Zhu* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.125/) [[code]](https://github.com/JiaQiSJTU/DialSent-PGG) <details> <summary>[Abs]</summary> Previous dialogue summarization techniques adapt large language models pretrained on the narrative text by injecting dialogue-specific features into the models. These features either require additional knowledge to recognize or make the resulting models harder to tune. To bridge the format gap between dialogues and narrative summaries in dialogue summarization tasks, we propose to post-train pretrained language models (PLMs) to rephrase from dialogue to narratives. After that, the model is fine-tuned for dialogue summarization as usual. Comprehensive experiments show that our approach significantly improves vanilla PLMs on dialogue summarization and outperforms other SOTA models by the summary quality and implementation costs. </details>
24. **CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning** *Xiangru Tang, Arjun Nair, Borui Wang, Bingyao Wang, Jai Desai, Aaron Wade, Haoran Li, Asli Celikyilmaz, Yashar Mehdad, Dragomir Radev* [[pdf]](https://arxiv.org/abs/2112.08713)
25. **Are We Summarizing the Right Way? A Survey of Dialogue Summarization Data Sets** *Don Tuggener, Margot Mieskes, Jan Deriu, Mark Cieliebak* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.12/)
26. **Dialogue Inspectional Summarization with Factual Inconsistency Awareness** *Leilei Gan, Yating Zhang, Kun Kuang, Lin Yuan, Shuo Li, Changlong Sun, Xiaozhong Liu, Fei Wu* [[pdf]](https://arxiv.org/abs/2111.03284)
27. **Do Boat and Ocean Suggest Beach? Dialogue Summarization with External Knowledge** *Tianqing Fang, Haojie Pan, Hongming Zhang, Yangqiu Song, Kun Xu, Dong Yu* `AKBC 2021` [[pdf]](https://www.akbc.ws/2021/papers/AJKd0iIFMDc) [[code]](https://github.com/HKUST-KnowComp/CODC-Dialogue-Summarization)
28. **Prompt scoring system for dialogue summarization using GPT3** *Prodan, George; Pelican, Elena* [[pdf]](https://www.techrxiv.org/articles/preprint/Prompt_scoring_system_for_dialogue_summarization_using_GPT-3/16652392)
29. **Simple Conversational Data Augmentation for Semi-supervised Abstractive Dialogue SummarizationJiaao** *Jiaao Chen, Diyi Yang* `EMNLP 2021` [[pdf]](https://www.cc.gatech.edu/~dyang888/docs/emnlp21_chen_coda.pdf) [[code]](https://github.com/GT-SALT/CODA)
30. **A Bag of Tricks for Dialogue Summarization** *Muhammad Khalifa, Miguel Ballesteros, Kathleen McKeown* `EMNLP 2021 Short` [[pdf]](https://arxiv.org/abs/2109.08232)
31. **Hierarchical Summarization for Longform Spoken Dialog** *Daniel Li, Thomas Chen, Albert Tung, Lydia Chilton* `UIST 2021` [[pdf]](https://arxiv.org/abs/2108.09597)
32. **RepSum: Unsupervised Dialogue Summarization based on Replacement Strategy** *Xiyan Fu, Yating Zhang, Tianyi Wang, Xiaozhong Liu, Changlong Sun, Zhenglu Yang* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.471/) [[code]](https://github.com/xiyan524/RepSum)
33. **Language Model as an Annotator: Exploring DialoGPT for Dialogue Summarization** *Xiachong Feng, Xiaocheng Feng, Libo Qin, Bing Qin, Ting Liu* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.117/) [[code]](https://github.com/xcfcode/PLM_annotator)
34. **A Two-Phase Approach for Abstractive Podcast Summarization** *Chujie Zheng, Kunpeng Zhang, Harry Jiannan Wang, Ling Fan* `TREC 2020 Podcasts Track` [[pdf]](https://arxiv.org/abs/2011.08291)
35. **Hierarchical Learning for Generation with Long Source Sequences** *Tobias Rohde, Xiaoxia Wu, Yinhan Liu* [[pdf]](https://arxiv.org/abs/2104.07545) [[code]](https://github.com/birch-research/hierarchical-learning)
36. **Improving Online Forums Summarization via Unifying Hierarchical Attention Networks with Convolutional Neural Networks** *Sansiri Tarnpradab, Fereshteh Jafariakinabad, Kien A. Hua* [[pdf]](https://arxiv.org/abs/2103.13587) [[code]](https://github.com/sansiri20/forums_summ)
37. **Extractive Summarization of Call Transcripts** *Pratik K. Biswas, Aleksandr Iakubovich* [[pdf]](https://arxiv.org/abs/2103.10599)
38. **Legal Summarization for Multi-role Debate Dialogue via Controversy Focus Mining and Multi-task Learning** *Xinyu Duan, Yating Zhang, Lin Yuan, Xin Zhou, Xiaozhong Liu, Tianyi Wang, Ruocheng Wang, Qiong Zhang, Changlong Sun, Fei Wu* `CIKM 2019` [[pdf]](https://dl.acm.org/doi/10.1145/3357384.3357940)
39. **Collabot: Personalized Group Chat Summarization** *Naama Tepper, Anat Hashavit, Maya Barnea, Inbal Ronen, Lior Leiba* `WSDM 2018` [[pdf]](https://dl.acm.org/doi/10.1145/3159652.3160588)
40. **Summarizing Dialogic Arguments from Social Media** *Amita Misra, Shereen Oraby, Shubhangi Tandon, Sharath TS, Pranav Anand, Marilyn Walker* `SemDial 2017` [[pdf]](https://arxiv.org/abs/1711.00092)
41. **The SENSEI Annotated Corpus: Human Summaries of Reader Comment Conversations in On-line News** *Emma Barker, Monica Lestari Paramita, Ahmet Aker, Emina Kurtic, Mark Hepple, Robert Gaizauskas* `SIGDIAL 2016` [[pdf]](https://www.aclweb.org/anthology/W16-3605/)
42. **Semantic Similarity Applied to Spoken Dialogue Summarization** *Iryna Gurevych, Michael Strube* `COLING 2004` [[pdf]](https://www.aclweb.org/anthology/C04-1110/) [[bib]](https://www.aclweb.org/anthology/C04-1110.bib) Switchboard dialogues
## Long Document
1. **LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization** *Kalpesh Krishna, Erin Bransom, Bailey Kuehl, Mohit Iyyer, Pradeep Dasigi, Arman Cohan, Kyle Lo* `EACL 2023` [[pdf]](https://arxiv.org/abs/2301.13298) [[code]](https://github.com/martiansideofthemoon/longeval-summarization) <details> <summary>[Abs]</summary> While human evaluation remains best practice for accurately judging the faithfulness of automatically-generated summaries, few solutions exist to address the increased difficulty and workload when evaluating long-form summaries. Through a survey of 162 papers on long-form summarization, we first shed light on current human evaluation practices surrounding long-form summaries. We find that 73% of these papers do not perform any human evaluation on model-generated summaries, while other works face new difficulties that manifest when dealing with long documents (e.g., low inter-annotator agreement). Motivated by our survey, we present LongEval, a set of guidelines for human evaluation of faithfulness in long-form summaries that addresses the following challenges: (1) How can we achieve high inter-annotator agreement on faithfulness scores? (2) How can we minimize annotator workload while maintaining accurate faithfulness scores? and (3) Do humans benefit from automated alignment between summary and source snippets? We deploy LongEval in annotation studies on two long-form summarization datasets in different domains (SQuALITY and PubMed), and we find that switching to a finer granularity of judgment (e.g., clause-level) reduces inter-annotator variance in faithfulness scores (e.g., std-dev from 18.5 to 6.8). We also show that scores from a partial annotation of fine-grained units highly correlates with scores from a full annotation workload (0.89 Kendall's tau using 50% judgments). We release our human judgments, annotation templates, and our software as a Python library for future research. </details>
1. **LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization** *Laura Nguyen, Thomas Scialom, Benjamin Piwowarski, Jacopo Staiano* `EACL 2023` [[pdf]](https://arxiv.org/abs/2301.11312) [[code]](https://github.com/recitalAI/loralay-datasets) <details> <summary>[Abs]</summary> Text Summarization is a popular task and an active area of research for the Natural Language Processing community. By definition, it requires to account for long input texts, a characteristic which poses computational challenges for neural models. Moreover, real-world documents come in a variety of complex, visually-rich, layouts. This information is of great relevance, whether to highlight salient content or to encode long-range interactions between textual passages. Yet, all publicly available summarization datasets only provide plain text content. To facilitate research on how to exploit visual/layout information to better capture long-range dependencies in summarization models, we present LoRaLay, a collection of datasets for long-range summarization with accompanying visual/layout information. We extend existing and popular English datasets (arXiv and PubMed) with layout information and propose four novel datasets -- consistently built from scholar resources -- covering French, Spanish, Portuguese, and Korean languages. Further, we propose new baselines merging layout-aware and long-range models -- two orthogonal approaches -- and obtain state-of-the-art results, showing the importance of combining both lines of research. </details>
1. **GoSum: Extractive Summarization of Long Documents by Reinforcement Learning and Graph Organized discourse state** *Junyi Bian, Xiaodi Huang, Hong Zhou, Shanfeng Zhu* [[pdf]](https://arxiv.org/abs/2211.10247) <details> <summary>[Abs]</summary> Handling long texts with structural information and excluding redundancy between summary sentences are essential in extractive document summarization. In this work, we propose GoSum, a novel reinforcement-learning-based extractive model for long-paper summarization. GoSum encodes states by building a heterogeneous graph from different discourse levels for each input document. We evaluate the model on two datasets of scientific articles summarization: PubMed and arXiv where it outperforms all extractive summarization models and most of the strong abstractive baselines. </details>
1. **Novel Chapter Abstractive Summarization using Spinal Tree Aware Sub-Sentential Content Selection** *Hardy Hardy, Miguel Ballesteros, Faisal Ladhak, Muhammad Khalifa, Vittorio Castelli, Kathleen McKeown* [[pdf]](https://arxiv.org/abs/2211.04903) <details> <summary>[Abs]</summary> Summarizing novel chapters is a difficult task due to the input length and the fact that sentences that appear in the desired summaries draw content from multiple places throughout the chapter. We present a pipelined extractive-abstractive approach where the extractive step filters the content that is passed to the abstractive component. Extremely lengthy input also results in a highly skewed dataset towards negative instances for extractive summarization; we thus adopt a margin ranking loss for extraction to encourage separation between positive and negative examples. Our extraction component operates at the constituent level; our approach to this problem enriches the text with spinal tree information which provides syntactic context (in the form of constituents) to the extraction model. We show an improvement of 3.71 Rouge-1 points over best results reported in prior work on an existing novel chapter dataset. </details>
1. **How Far are We from Robust Long Abstractive Summarization?** *Huan Yee Koh, Jiaxin Ju, He Zhang, Ming Liu, Shirui Pan* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.16732) [[code]](https://github.com/huankoh/How-Far-are-We-from-Robust-Long-Abstractive-Summarization) <details> <summary>[Abs]</summary> Abstractive summarization has made tremendous progress in recent years. In this work, we perform fine-grained human annotations to evaluate long document abstractive summarization systems (i.e., models and metrics) with the aim of implementing them to generate reliable summaries. For long document abstractive models, we show that the constant strive for state-of-the-art ROUGE results can lead us to generate more relevant summaries but not factual ones. For long document evaluation metrics, human evaluation results show that ROUGE remains the best at evaluating the relevancy of a summary. It also reveals important limitations of factuality metrics in detecting different types of factual errors and the reasons behind the effectiveness of BARTScore. We then suggest promising directions in the endeavor of developing factual consistency metrics. Finally, we release our annotated long document dataset with the hope that it can contribute to the development of metrics across a broader range of summarization settings. </details>
1. **Toward Unifying Text Segmentation and Long Document Summarization** *Sangwoo Cho, Kaiqiang Song, Xiaoyang Wang, Fei Liu, Dong Yu* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.8/) [[code]](https://github.com/tencent-ailab/Lodoss) <details> <summary>[Abs]</summary> Text segmentation is important for signaling a document's structure. Without segmenting a long document into topically coherent sections, it is difficult for readers to comprehend the text, let alone find important information. The problem is only exacerbated by a lack of segmentation in transcripts of audio/video recordings. In this paper, we explore the role that section segmentation plays in extractive summarization of written and spoken documents. Our approach learns robust sentence representations by performing summarization and segmentation simultaneously, which is further enhanced by an optimization-based regularizer to promote selection of diverse summary sentences. We conduct experiments on multiple datasets ranging from scientific articles to spoken transcripts to evaluate the model's performance. Our findings suggest that the model can not only achieve state-of-the-art performance on publicly available benchmarks, but demonstrate better cross-genre transferability when equipped with text segmentation. We perform a series of analyses to quantify the impact of section segmentation on summarizing written and spoken documents of substantial length and complexity. </details>
1. **HeterGraphLongSum: Heterogeneous Graph Neural Network with Passage Aggregation for Extractive Long Document Summarization** *Tuan-Anh Phan, Ngoc-Dung Ngoc Nguyen, Khac-Hoai Nam Bui* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.545/) [[code]](https://github.com/tuananhphan97vn/HeterGraphLongSum) <details> <summary>[Abs]</summary> Graph Neural Network (GNN)-based models have proven effective in various Natural Language Processing (NLP) tasks in recent years. Specifically, in the case of the Extractive Document Summarization (EDS) task, modeling documents under graph structure is able to analyze the complex relations between semantic units (e.g., word-to-word, word-to-sentence, sentence-to-sentence) and enrich sentence representations via valuable information from their neighbors. However, long-form document summarization using graph-based methods is still an open research issue. The main challenge is to represent long documents in a graph structure in an effective way. In this regard, this paper proposes a new heterogeneous graph neural network (HeterGNN) model to improve the performance of long document summarization (HeterGraphLongSum). Specifically, the main idea is to add the passage nodes into the heterogeneous graph structure of word and sentence nodes for enriching the final representation of sentences. In this regard, HeterGraphLongSum is designed with three types of semantic units such as word, sentence, and passage. Experiments on two benchmark datasets for long documents such as Pubmed and Arxiv indicate promising results of the proposed model for the extractive long document summarization problem. Especially, HeterGraphLongSum is able to achieve state-of-the-art performance without relying on any pre-trained language models (e.g., BERT). The source code is available for further exploitation on the Github. </details>
1. **Multi Graph Neural Network for Extractive Long Document Summarization** *Xuan-Dung Doan, Le-Minh Nguyen, Khac-Hoai Nam Bui* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.512/) [[code]](https://github.com/dungdx34/MTGNN-SUM) <details> <summary>[Abs]</summary> Heterogeneous Graph Neural Networks (HeterGNN) have been recently introduced as an emergent approach for extracting document summarization (EDS) by exploiting the cross-relations between words and sentences. However, applying HeterGNN for long documents is still an open research issue. One of the main majors is the lacking of inter-sentence connections. In this regard, this paper exploits how to apply HeterGNN for long documents by building a graph on sentence-level nodes (homogeneous graph) and combine with HeterGNN for capturing the semantic information in terms of both inter and intra-sentence connections. Experiments on two benchmark datasets of long documents such as PubMed and ArXiv show that our method is able to achieve state-of-the-art results in this research field. </details>
1. **HEGEL: Hypergraph Transformer for Long Document Summarization** *Haopeng Zhang, Xiao Liu, Jiawei Zhang* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.04126) <details> <summary>[Abs]</summary> Extractive summarization for long documents is challenging due to the extended structured input context. The long-distance sentence dependency hinders cross-sentence relations modeling, the critical step of extractive summarization. This paper proposes HEGEL, a hypergraph neural network for long document summarization by capturing high-order cross-sentence relations. HEGEL updates and learns effective sentence representations with hypergraph transformer layers and fuses different types of sentence dependencies, including latent topics, keywords coreference, and section structure. We validate HEGEL by conducting extensive experiments on two benchmark datasets, and experimental results demonstrate the effectiveness and efficiency of HEGEL. </details>
1. **GRETEL: Graph Contrastive Topic Enhanced Language Model for Long Document Extractive Summarization** *Qianqian Xie, Jimin Huang, Tulika Saha, Sophia Ananiadou* `COLING2022` [[pdf]](https://aclanthology.org/2022.coling-1.546/) [[code]](https://github.com/xashely/GRETEL_extractive) <details> <summary>[Abs]</summary> Recently, neural topic models (NTMs) have been incorporated into pre-trained language models (PLMs), to capture the global semantic information for text summarization. However, in these methods, there remain limitations in the way they capture and integrate the global semantic information. In this paper, we propose a novel model, the graph contrastive topic enhanced language model (GRETEL), that incorporates the graph contrastive topic model with the pre-trained language model, to fully leverage both the global and local contextual semantics for long document extractive summarization. To better capture and incorporate the global semantic information into PLMs, the graph contrastive topic model integrates the hierarchical transformer encoder and the graph contrastive learning to fuse the semantic information from the global document context and the gold summary. To this end, GRETEL encourages the model to efficiently extract salient sentences that are topically related to the gold summary, rather than redundant sentences that cover sub-optimal topics. Experimental results on both general domain and biomedical datasets demonstrate that our proposed method outperforms SOTA methods. </details>
1. **Sparse Optimization for Unsupervised Extractive Summarization of Long Documents with the Frank-Wolfe Algorithm** *Alicia Y. Tsai, Laurent El Ghaoui* `SustaiNLP at EMNLP 2020` [[pdf]](https://arxiv.org/abs/2208.09454) <details> <summary>[Abs]</summary> We address the problem of unsupervised extractive document summarization, especially for long documents. We model the unsupervised problem as a sparse auto-regression one and approximate the resulting combinatorial problem via a convex, norm-constrained problem. We solve it using a dedicated Frank-Wolfe algorithm. To generate a summary with k sentences, the algorithm only needs to execute ≈k iterations, making it very efficient. We explain how to avoid explicit calculation of the full gradient and how to include sentence embedding information. We evaluate our approach against two other unsupervised methods using both lexical (standard) ROUGE scores, as well as semantic (embedding-based) ones. Our method achieves better results with both datasets and works especially well when combined with embeddings for highly paraphrased summaries. </details>
1. **An Efficient Coarse-to-Fine Facet-Aware Unsupervised Summarization Framework based on Semantic Blocks** *Xinnian Liang, Jing Li, Shuangzhi Wu, Jiali Zeng, Yufan Jiang, Mu Li, Zhoujun Li* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.558/) [[code]](https://github.com/xnliang98/c2f-far) <details> <summary>[Abs]</summary> Unsupervised summarization methods have achieved remarkable results by incorporating representations from pre-trained language models. However, existing methods fail to consider efficiency and effectiveness at the same time when the input document is extremely long. To tackle this problem, in this paper, we proposed an efficient Coarse-to-Fine Facet-Aware Ranking (C2F-FAR) framework for unsupervised long document summarization, which is based on the semantic block. The semantic block refers to continuous sentences in the document that describe the same facet. Specifically, we address this problem by converting the one-step ranking method into the hierarchical multi-granularity two-stage ranking. In the coarse-level stage, we propose a new segment algorithm to split the document into facet-aware semantic blocks and then filter insignificant blocks. In the fine-level stage, we select salient sentences in each block and then extract the final summary from selected sentences. We evaluate our framework on four long document summarization datasets: Gov-Report, BillSum, arXiv, and PubMed. Our C2F-FAR can achieve new state-of-the-art unsupervised summarization results on Gov-Report and BillSum. In addition, our method speeds up 4-28 times more than previous methods.\footnote{\url{this https URL}} </details>
1. **Investigating Efficiently Extending Transformers for Long Input Summarization** *Jason Phang, Yao Zhao, Peter J. Liu* [[pdf]](https://arxiv.org/abs/2208.04347) [[code]](https://github.com/google-research/pegasus/tree/main/pegasus/flax) <details> <summary>[Abs]</summary> While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train. </details>
1. **An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics** *uan Yee Koh, Jiaxin Ju, Ming Liu, Shirui Pan* `ACM Computing Surveys` [[pdf]](https://arxiv.org/abs/2207.00939) <details> <summary>[Abs]</summary> Long documents such as academic articles and business reports have been the standard format to detail out important issues and complicated subjects that require extra attention. An automatic summarization system that can effectively condense long documents into short and concise texts to encapsulate the most important information would thus be significant in aiding the reader's comprehension. Recently, with the advent of neural architectures, significant research efforts have been made to advance automatic text summarization systems, and numerous studies on the challenges of extending these systems to the long document domain have emerged. In this survey, we provide a comprehensive overview of the research on long document summarization and a systematic evaluation across the three principal components of its research setting: benchmark datasets, summarization models, and evaluation metrics. For each component, we organize the literature within the context of long document summarization and conduct an empirical analysis to broaden the perspective on current research progress. The empirical analysis includes a study on the intrinsic characteristics of benchmark datasets, a multi-dimensional analysis of summarization models, and a review of the summarization evaluation metrics. Based on the overall findings, we conclude by proposing possible directions for future exploration in this rapidly growing field. </details>
1. **MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes** *Nianlong Gu, Elliott Ash, Richard Hahnloser* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.450/) [[code]](https://github.com/nianlonggu/memsum) <details> <summary>[Abs]</summary> We introduce MemSum (Multi-step Episodic Markov decision process extractive SUMmarizer), a reinforcement-learning-based extractive summarizer enriched at each step with information on the current extraction history. When MemSum iteratively selects sentences into the summary, it considers a broad information set that would intuitively also be used by humans in this task: 1) the text content of the sentence, 2) the global text context of the rest of the document, and 3) the extraction history consisting of the set of sentences that have already been extracted. With a lightweight architecture, MemSum obtains state-of-the-art test-set performance (ROUGE) in summarizing long documents taken from PubMed, arXiv, and GovReport. Ablation studies demonstrate the importance of local, global, and history information. A human evaluation confirms the high quality and low redundancy of the generated summaries, stemming from MemSum’s awareness of extraction history. </details>
1. **Semantic Self-Segmentation for Abstractive Summarization of Long Legal Documents in Low-Resource Regimes** *Gianluca Moro, Luca Ragazzi* `AAAI 2022` [[pdf]](https://www.aaai.org/AAAI22Papers/AAAI-3882.MoroG.pdf)
1. **Factorizing Content and Budget Decisions in Abstractive Summarization of Long Documents by Sampling Summary Views** *Marcio Fonseca, Yftah Ziser, Shay B. Cohen* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2205.12486) <details> <summary>[Abs]</summary> We argue that disentangling content selection from the budget used to cover salient content improves the performance and applicability of abstractive summarizers. Our method, FactorSum, does this disentanglement by factorizing summarization into two steps through an energy function: (1) generation of abstractive summary views covering salient information in subsets of the input document (document views); (2) combination of these views into a final summary, following a budget and content guidance. This guidance may come from different sources, including from an advisor model such as BART or BigBird, or in oracle mode – from the reference. This factorization achieves significantly higher ROUGE scores on multiple benchmarks for long document summarization, namely PubMed, arXiv, and GovReport. Most notably, our model is effective for domain adaptation. When trained only on PubMed samples, it achieves a 46.29 ROUGE-1 score on arXiv, outperforming PEGASUS trained in domain by a large margin. Our experimental results indicate that the performance gains are due to more flexible budget adaptation and processing of shorter contexts provided by partial document views. </details>
1. **Leveraging Locality in Abstractive Text Summarization** *Yixin Liu, Ansong Ni, Linyong Nan, Budhaditya Deb, Chenguang Zhu, Ahmed H. Awadallah, Dragomir Radev* [[pdf]](https://arxiv.org/abs/2205.12476) `EMNLP 2022` <details> <summary>[Abs]</summary> Neural attention models have achieved significant improvements on many natural language processing tasks. However, the quadratic memory complexity of the self-attention module with respect to the input length hinders their applications in long text summarization. Instead of designing more efficient attention modules, we approach this problem by investigating if models with a restricted context can have competitive performance compared with the memory-efficient attention models that maintain a global context by treating the input as a single sequence. Our model is applied to individual pages, which contain parts of inputs grouped by the principle of locality, during both the encoding and decoding stages. We empirically investigated three kinds of locality in text summarization at different levels of granularity, ranging from sentences to documents. Our experimental results show that our model has a better performance compared with strong baseline models with efficient attention modules, and our analysis provides further insights into our locality-aware modeling strategy. </details>
1. **SNaC: Coherence Error Detection for Narrative Summarization** *Tanya Goyal, Junyi Jessy Li, Greg Durrett* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.29/) [[data]](https://github.com/tagoyal/snac) <details> <summary>[Abs]</summary> Progress in summarizing long texts is inhibited by the lack of appropriate evaluation frameworks. A long summary that appropriately covers the facets of that text must also present a coherent narrative, but current automatic and human evaluation methods fail to identify gaps in coherence. In this work, we introduce SNaC, a narrative coherence evaluation framework for fine-grained annotations of long summaries. We develop a taxonomy of coherence errors in generated narrative summaries and collect span-level annotations for 6.6k sentences across 150 book and movie summaries. Our work provides the first characterization of coherence errors generated by state-of-the-art summarization models and a protocol for eliciting coherence judgments from crowdworkers. Furthermore, we show that the collected annotations allow us to benchmark past work in coherence modeling and train a strong classifier for automatically localizing coherence errors in generated summaries. Finally, our SNaC framework can support future work in long document summarization and coherence evaluation, including improved summarization modeling and post-hoc summary correction. </details>
1. **Sequence-Based Extractive Summarisation for Scientific Articles** *Daniel Kershaw, Rob Koeling* `` [[pdf]](https://arxiv.org/abs/2204.03301)
1. **LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents** *Debanjan Mahata, Naveen Agarwal, Dibya Gautam, Amardeep Kumar, Swapnil Parekh, Yaman Kumar Singla, Anish Acharya, Rajiv Ratn Shah* [[pdf]](https://arxiv.org/abs/2203.15349) [[data1]](https://huggingface.co/datasets/midas/ldkp3k) [[data2]](https://huggingface.co/datasets/midas/ldkp10k)
1. **HIBRIDS: Attention with Hierarchical Biases for Structure-aware Long Document Summarization** *Shuyang Cao, Lu Wang* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.58/) [[code]](https://github.com/ShuyangCao/hibrids_summ) [[data]](https://gov-report-data.github.io/) <details> <summary>[Abs]</summary> Document structure is critical for efficient information consumption. However, it is challenging to encode it efficiently into the modern Transformer architecture. In this work, we present HIBRIDS, which injects Hierarchical Biases foR Incorporating Document Structure into attention score calculation. We further present a new task, hierarchical question-summary generation, for summarizing salient content in the source document into a hierarchy of questions and summaries, where each follow-up question inquires about the content of its parent question-summary pair. We also annotate a new dataset with 6,153 question-summary hierarchies labeled on government reports. Experiment results show that our model produces better question-summary hierarchies than comparisons on both hierarchy quality and content coverage, a finding also echoed by human judges. Additionally, our model improves the generation of long-form summaries from long government reports and Wikipedia articles, as measured by ROUGE scores. </details>
1. **HiStruct+: Improving Extractive Text Summarization with Hierarchical Structure Information** *Qian Ruan, Malte Ostendorff, Georg Rehm* [[pdf]](https://arxiv.org/abs/2203.09629) [[code]](https://github.com/QianRuan/histruct)
1. **Long Document Summarization with Top-down and Bottom-up Inference** *Bo Pang, Erik Nijkamp, Wojciech Kryściński, Silvio Savarese, Yingbo Zhou, Caiming Xiong* [[pdf]](https://arxiv.org/abs/2203.07586)
1. **Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents** *Yusen Zhang, Ansong Ni, Ziming Mao, Chen Henry Wu, Chenguang Zhu, Budhaditya Deb, Ahmed H. Awadallah, Dragomir Radev, Rui Zhang* `ACL 2022` [[pdf]](https://arxiv.org/abs/2110.10150)
1. **DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization** *Ziming Mao, Chen Henry Wu, Ansong Ni, Yusen Zhang, Rui Zhang, Tao Yu, Budhaditya Deb, Chenguang Zhu, Ahmed H. Awadallah, Dragomir Radev* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.118/) [[code]](https://github.com/Yale-LILY/DYLE) <details> <summary>[Abs]</summary> Transformer-based models have achieved state-of-the-art performance on short-input summarization. However, they still struggle with summarizing longer text. In this paper, we present DYLE, a novel dynamic latent extraction approach for abstractive long-input summarization. DYLE jointly trains an extractor and a generator and treats the extracted text snippets as the latent variable, allowing dynamic snippet-level attention weights during decoding. To provide adequate supervision, we propose simple yet effective heuristics for oracle extraction as well as a consistency loss term, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We evaluate our method on different long-document and long-dialogue summarization tasks: GovReport, QMSum, and arXiv. Experiment results show that DYLE outperforms all existing methods on GovReport and QMSum, with gains up to 6.1 ROUGE, while yielding strong results on arXiv. Further analysis shows that the proposed dynamic weights provide interpretability of our generation process. </details>
1. **SciBERTSUM: Extractive Summarization for Scientific Documents** *Athar Sefid, C Lee Giles* [[pdf]](https://arxiv.org/abs/2201.08495) [[code]](https://github.com/atharsefid/SciBERTSUM)
1. **Neural Content Extraction for Poster Generation of Scientific Papers** *Sheng Xu, Xiaojun Wan* [[pdf]](https://arxiv.org/abs/2112.08550)
1. **LongT5: Efficient Text-To-Text Transformer for Long Sequences** *Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang* [[pdf]](https://arxiv.org/abs/2112.07916)
1. **The Influence of Data Pre-processing and Post-processing on Long Document Summarization** *Xinwei Du, Kailun Dong, Yuchen Zhang, Yongsheng Li, Ruei-Yu Tsay* [[pdf]](https://arxiv.org/abs/2112.01660)
1. **End-to-End Segmentation-based News Summarization** *Yang Liu, Chenguang Zhu, Michael Zeng* [[pdf]](https://arxiv.org/abs/2110.07850)
1. **Leveraging Information Bottleneck for Scientific Document Summarization** *Jiaxin Ju, Ming Liu, Huan Yee Koh, Yuan Jin, Lan Du, Shirui Pan* `EMNLP 2021 Findings` [[pdf]](https://arxiv.org/abs/2110.01280)
1. **Generating Summaries for Scientific Paper Review** *Ana Sabina Uban, Cornelia Caragea* [[pdf]](https://arxiv.org/abs/2109.14059)
1. **Sparsity and Sentence Structure in Encoder-Decoder Attention of Summarization Systems** *Potsawee Manakul, Mark J. F. Gales* `EMNLP 2021 short paper` [[pdf]](https://arxiv.org/abs/2109.03888) [[code]](https://github.com/potsawee/encdec_attn_sparse)
1. **Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents** *Rui Meng, Khushboo Thaker, Lei Zhang, Yue Dong, Xingdi Yuan, Tong Wang, Daqing He* `ACL 2021 short` [[pdf]](https://aclanthology.org/2021.acl-short.137/) [[data]](https://github.com/hfthair/emerald_crawler)
1. **Sliding Selector Network with Dynamic Memory for Extractive Summarization of Long Documents** *Peng Cui, Le Hu* `NAACL21` [[pdf]](https://www.aclweb.org/anthology/2021.naacl-main.470/) [[code]](https://github.com/pcui-nlp/SSN_DM)
1. **Long-Span Summarization via Local Attention and Content Selection** *Potsawee Manakul, Mark J. F. Gales* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.470/)
1. **Globalizing BERT-based Transformer Architectures for Long Document Summarization** *Quentin Grail, Julien Perez, Eric Gaussier* `EACL 2021` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.154/)
1. **Discourse-Aware Unsupervised Summarization for Long Scientific Documents** *Yue Dong, Andrei Mircea Romascanu, Jackie Chi Kit Cheung* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.93/) [[code]](https://github.com/mirandrom/HipoRank)
1. **Enhancing Scientific Papers Summarization with Citation Graph** *Chenxin An, Ming Zhong, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang* `AAAI 2021` [[pdf]](https://arxiv.org/abs/2104.03057) [[code]](https://github.com/ChenxinAn-fdu/CGSum)
1. **Efficient Attentions for Long Document Summarization** *Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, Lu Wang* `NAACL 2021` [[pdf]](https://arxiv.org/abs/2104.02112) [[code]](https://github.com/luyang-huang96/LongDocSum) [[data]](https://gov-report-data.github.io/)
1. **Can We Automate Scientific Reviewing?** *Weizhe Yuan, Pengfei Liu, and Graham Neubig* [[pdf]](https://arxiv.org/abs/2102.00176) [[code]](https://github.com/neulab/ReviewAdvisor)
1. **Long Document Summarization in a Low Resource Setting using Pretrained Language Models** *Ahsaas Bajaj, Pavitra Dangati, Kalpesh Krishna, Pradhiksha Ashok Kumar, Rheeya Uppaal, Bradford Windsor, Eliot Brenner, Dominic Dotterrer, Rajarshi Das, Andrew McCallum* `ACL 2021 Student Research Workshop` [[pdf]](https://aclanthology.org/2021.acl-srw.7/)
1. **Summaformers @ LaySumm 20, LongSumm 20** *Sayar Ghosh Roy, Nikhil Pinnaparaju, Risubh Jain, Manish Gupta, Vasudeva Varma* `SDP EMNLP 2020` [[pdf]](https://arxiv.org/abs/2101.03553)
1. **On Generating Extended Summaries of Long Documents** *Sajad Sotudeh, Arman Cohan, Nazli Goharian* `SDU21` [[pdf]](https://arxiv.org/abs/2012.14136) [[code]](https://github.com/Georgetown-IR-Lab/ExtendedSumm)
1. **Self-Supervised Learning for Visual Summary Identification in Scientific Publications** *Shintaro Yamamoto, Anne Lauscher, Simone Paolo Ponzetto, Goran Glavaš, Shigeo Morishima* [[pdf]](https://arxiv.org/abs/2012.11213)
1. **Systematically Exploring Redundancy Reduction in Summarizing Long Documents** *Wen Xiao, Giuseppe Carenini* `AACL20` [[pdf](https://www.aclweb.org/anthology/2020.aacl-main.51/) [[code]](http://www.cs.ubc.ca/cs-research/lci/research-groups/natural-language-processing/)
1. **On Extractive and Abstractive Neural Document Summarization with Transformer Language Models** *Sandeep Subramanian, Raymond Li, Jonathan Pilault, Christopher Pal* `EMNLP20` [[pdf]](https://arxiv.org/abs/1909.03186)
2. **Dimsum @LaySumm 20: BART-based Approach for Scientific Document Summarization** *Tiezheng Yu, Dan Su, Wenliang Dai, Pascale Fung* [[pdf]](https://arxiv.org/abs/2010.09252) [[code]](https://github.com/TysonYu/Laysumm)
2. **SciSummPip: An Unsupervised Scientific Paper Summarization Pipeline** *Jiaxin Ju, Ming Liu, Longxiang Gao, Shirui Pan* [[pdf]](https://arxiv.org/abs/2010.09190) [[code]](https://github.com/mingzi151/SummPip)
3. **Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks** *Peng Cui, Le Hu, Yuanchao Liu* `COLING20` [[pdf]](https://arxiv.org/abs/2010.06253)
4. **Multi-XScience: A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles** *Yao Lu, Yue Dong, Laurent Charlin* `EMNLP20 Short` [[pdf]](https://arxiv.org/abs/2010.14235) [[data]](https://github.com/yaolu/Multi-XScience)
5. **A Divide-and-Conquer Approach to the Summarization of Long Documents** *Alexios Gidiotis, Grigorios Tsoumakas* `IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING` [[pdf]](https://arxiv.org/abs/2004.06190)
5. **TLDR: Extreme Summarization of Scientific Documents** *Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld* `Findings of EMNLP20` [[pdf]](https://arxiv.org/abs/2004.15011) [[data]](https://github.com/allenai/scitldr)
6. **Extractive Summarization of Long Documents by Combining Global and Local Context** *Wen Xiao, Giuseppe Carenini* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.08089) [[code]](https://github.com/Wendy-Xiao/Extsumm_local_global_context)
7. **ScisummNet: A Large Annotated Corpus and Content\-Impact Models for Scientific Paper Summarization with Citation Networks** *Michihiro Yasunaga, Jungo Kasai, Rui Zhang, Alexander R. Fabbri, Irene Li, Dan Friedman, Dragomir R. Radev* `AAAI19` [[pdf]](https://arxiv.org/abs/1909.01716) [[data]](https://cs.stanford.edu/~myasu/projects/scisumm_net/)
8. **TalkSumm: A Dataset and Scalable Annotation Method for Scientific Paper Summarization Based on Conference Talks** *Guy Lev, Michal Shmueli-Scheuer, Jonathan Herzig, Achiya Jerbi, David Konopnicki* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1204/) [[data]](https://github.com/levguy/talksumm)
9. **A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents** *Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, Nazli Goharian* `NAACL18` [[pdf]](https://arxiv.org/abs/1804.05685) [[data]](https://github.com/armancohan/long-summarization)
## Factual Consistency
<br>
<br>
<br>
<br>
Toolkit: [factsumm](https://github.com/Huffon/factsumm)
1. **Learning with Rejection for Abstractive Text Summarization** *Meng Cao, Yue Dong, Jingyi He, Jackie Chi Kit Cheung* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.663/) [[code]](https://github.com/mcao516/rej-summ) <details> <summary>[Abs]</summary> State-of-the-art abstractive summarization systems frequently hallucinate content that is not supported by the source document, mainly due to noise in the training dataset.Existing methods opt to drop the noisy samples or tokens from the training set entirely, reducing the effective training set size and creating an artificial propensity to copy words from the source. In this work, we propose a training objective for abstractive summarization based on rejection learning, in which the model learns whether or not to reject potentially noisy tokens. We further propose a regularized decoding objective that penalizes non-factual candidate summaries during inference by using the rejection probability learned during training.We show that our method considerably improves the factuality of generated summaries in automatic and human evaluations when compared to five baseline models, and that it does so while increasing the abstractiveness of the generated summaries. </details>
1. **X-FACTOR: A Cross-metric Evaluation of Factual Correctness in Abstractive Summarization** ** `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.478/) <details> <summary>[Abs]</summary> Abstractive summarization models often produce factually inconsistent summaries that are not supported by the original article. Recently, a number of fact-consistent evaluation techniques have been proposed to address this issue; however, a detailed analysis of how these metrics agree with one another has yet to be conducted. In this paper, we present X-FACTOR, a cross-evaluation of three high-performing fact-aware abstractive summarization methods. First, we show that summarization models are often fine-tuned on datasets that contain factually inconsistent summaries and propose a fact-aware filtering mechanism that improves the quality of training data and, consequently, the factuality of these models. Second, we propose a corrector module that can be used to improve the factual consistency of generated summaries. Third, we present a re-ranking technique that samples summary instances from the output distribution of a summarization model and re-ranks the sampled instances based on their factuality. Finally, we provide a detailed cross-metric agreement analysis that shows how tuning a model to output summaries based on a particular factuality metric influences factuality as determined by the other metrics. Our goal in this work is to facilitate research that improves the factuality and faithfulness of abstractive summarization models. </details>
1. **LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization** *Kalpesh Krishna, Erin Bransom, Bailey Kuehl, Mohit Iyyer, Pradeep Dasigi, Arman Cohan, Kyle Lo* `EACL 2023` [[pdf]](https://arxiv.org/abs/2301.13298) [[code]](https://github.com/martiansideofthemoon/longeval-summarization) <details> <summary>[Abs]</summary> While human evaluation remains best practice for accurately judging the faithfulness of automatically-generated summaries, few solutions exist to address the increased difficulty and workload when evaluating long-form summaries. Through a survey of 162 papers on long-form summarization, we first shed light on current human evaluation practices surrounding long-form summaries. We find that 73% of these papers do not perform any human evaluation on model-generated summaries, while other works face new difficulties that manifest when dealing with long documents (e.g., low inter-annotator agreement). Motivated by our survey, we present LongEval, a set of guidelines for human evaluation of faithfulness in long-form summaries that addresses the following challenges: (1) How can we achieve high inter-annotator agreement on faithfulness scores? (2) How can we minimize annotator workload while maintaining accurate faithfulness scores? and (3) Do humans benefit from automated alignment between summary and source snippets? We deploy LongEval in annotation studies on two long-form summarization datasets in different domains (SQuALITY and PubMed), and we find that switching to a finer granularity of judgment (e.g., clause-level) reduces inter-annotator variance in faithfulness scores (e.g., std-dev from 18.5 to 6.8). We also show that scores from a partial annotation of fine-grained units highly correlates with scores from a full annotation workload (0.89 Kendall's tau using 50% judgments). We release our human judgments, annotation templates, and our software as a Python library for future research. </details>
1. **mFACE: Multilingual Summarization with Factual Consistency Evaluation** *Roee Aharoni, Shashi Narayan, Joshua Maynez, Jonathan Herzig, Elizabeth Clark, Mirella Lapata* [[pdf]](https://arxiv.org/abs/2212.10622) <details> <summary>[Abs]</summary> Abstractive summarization has enjoyed renewed interest in recent years, thanks to pre-trained language models and the availability of large-scale datasets. Despite promising results, current models still suffer from generating factually inconsistent summaries, reducing their utility for real-world application. Several recent efforts attempt to address this by devising models that automatically detect factual inconsistencies in machine generated summaries. However, they focus exclusively on English, a language with abundant resources. In this work, we leverage factual consistency evaluation models to improve multilingual summarization. We explore two intuitive approaches to mitigate hallucinations based on the signal provided by a multilingual NLI model, namely data filtering and controlled generation. Experimental results in the 45 languages from the XLSum dataset show gains over strong baselines in both automatic and human evaluation. </details>
1. **Improving Faithfulness of Abstractive Summarization by Controlling Confounding Effect of Irrelevant Sentences** *Asish Ghoshal, Arash Einolghozati, Ankit Arun, Haoran Li, Lili Yu, Yashar Mehdad, Scott Wen-tau Yih, Asli Celikyilmaz*[[pdf]](https://arxiv.org/abs/2212.09726) <details> <summary>[Abs]</summary> Lack of factual correctness is an issue that still plagues state-of-the-art summarization systems despite their impressive progress on generating seemingly fluent summaries. In this paper, we show that factual inconsistency can be caused by irrelevant parts of the input text, which act as confounders. To that end, we leverage information-theoretic measures of causal effects to quantify the amount of confounding and precisely quantify how they affect the summarization performance. Based on insights derived from our theoretical results, we design a simple multi-task model to control such confounding by leveraging human-annotated relevant sentences when available. Crucially, we give a principled characterization of data distributions where such confounding can be large thereby necessitating the use of human annotated relevant sentences to generate factual summaries. Our approach improves faithfulness scores by 20\% over strong baselines on AnswerSumm \citep{fabbri2021answersumm}, a conversation summarization dataset where lack of faithfulness is a significant issue due to the subjective nature of the task. Our best method achieves the highest faithfulness score while also achieving state-of-the-art results on standard metrics like ROUGE and METEOR. We corroborate these improvements through human evaluation.</details>
1. **Improved Beam Search for Hallucination Mitigation in Abstractive Summarization** *Arvind Krishna Sridhar, Erik Visser* [[pdf]](https://arxiv.org/abs/2212.02712) <details> <summary>[Abs]</summary> Advancement in large pretrained language models has significantly improved their performance for conditional language generation tasks including summarization albeit with hallucinations. To reduce hallucinations, conventional methods proposed improving beam search or using a fact checker as a postprocessing step. In this paper, we investigate the use of the Natural Language Inference (NLI) entailment metric to detect and prevent hallucinations in summary generation. We propose an NLI-assisted beam re-ranking mechanism by computing entailment probability scores between the input context and summarization model-generated beams during saliency-enhanced greedy decoding. Moreover, a diversity metric is introduced to compare its effectiveness against vanilla beam search. Our proposed algorithm significantly outperforms vanilla beam decoding on XSum and CNN/DM datasets. </details>
1. **Revisiting text decomposition methods for NLI-based factuality scoring of summaries** *John Glover, Federico Fancellu, Vasudevan Jagannathan, Matthew R. Gormley, Thomas Schaaf* [[pdf]](https://arxiv.org/abs/2211.16853) <details> <summary>[Abs]</summary> Scoring the factuality of a generated summary involves measuring the degree to which a target text contains factual information using the input document as support. Given the similarities in the problem formulation, previous work has shown that Natural Language Inference models can be effectively repurposed to perform this task. As these models are trained to score entailment at a sentence level, several recent studies have shown that decomposing either the input document or the summary into sentences helps with factuality scoring. But is fine-grained decomposition always a winning strategy? In this paper we systematically compare different granularities of decomposition -- from document to sub-sentence level, and we show that the answer is no. Our results show that incorporating additional context can yield improvement, but that this does not necessarily apply to all datasets. We also show that small changes to previously proposed entailment-based scoring methods can result in better performance, highlighting the need for caution in model and methodology selection for downstream tasks.</details>
1. **HaRiM+: Evaluating Summary Quality with Hallucination Risk** *Seonil Son, Junsoo Park, Jeong-in Hwang, Junghwa Lee, Hyungjong Noh, Yeonsoo Lee* `AACL 2022` [[pdf]](https://arxiv.org/abs/2211.12118) <details> <summary>[Abs]</summary> One of the challenges of developing a summarization model arises from the difficulty in measuring the factual inconsistency of the generated text. In this study, we reinterpret the decoder overconfidence-regularizing objective suggested in (Miao et al., 2021) as a hallucination risk measurement to better estimate the quality of generated summaries. We propose a reference-free metric, HaRiM+, which only requires an off-the-shelf summarization model to compute the hallucination risk based on token likelihoods. Deploying it requires no additional training of models or ad-hoc modules, which usually need alignment to human judgments. For summary-quality estimation, HaRiM+ records state-of-the-art correlation to human judgment on three summary-quality annotation sets: FRANK, QAGS, and SummEval. We hope that our work, which merits the use of summarization models, facilitates the progress of both automated evaluation and generation of summary. </details>
1. **ED-FAITH: Evaluating Dialogue Summarization on Faithfulness** *Sicong Huang, Asli Celikyilmaz, Haoran Li* [[pdf]](https://arxiv.org/pdf/2211.08464.pdf) <details> <summary>[Abs]</summary> Abstractive summarization models typically generate content unfaithful to the input, thus highlighting the significance of evaluating the faithfulness of generated summaries. Most faithfulness metrics are only evaluated on news domain, can they be transferred to other summarization tasks? In this work, we first present a systematic study of faithfulness metrics for dialogue summarization. We evaluate common faithfulness metrics on dialogue datasets and observe that most metrics correlate poorly with human judgements despite performing well on news datasets. Given these findings, to improve existing metrics’ performance on dialogue summarization, we first finetune on in-domain dataset, then apply unlikelihood training on negative samples, and show that they can successfully improve metric performance on dialogue data. Inspired by the strong zero-shot performance of the T0 language model, we further propose T0-Score – a new metric for faithfulness evaluation, which shows consistent improvement against baseline metrics across multiple domains. </details>
1. **Evaluating the Factual Consistency of Large Language Models Through Summarization** *Derek Tam, Anisha Mascarenhas, Shiyue Zhang, Sarah Kwan, Mohit Bansal, Colin Raffel* [[pdf]](https://arxiv.org/abs/2211.08412) <details> <summary>[Abs]</summary> While large language models (LLMs) have proven to be effective on a large variety of tasks, they are also known to hallucinate information. To measure whether an LLM prefers factually consistent continuations of its input, we propose a new benchmark called FIB(Factual Inconsistency Benchmark) that focuses on the task of summarization. Specifically, our benchmark involves comparing the scores an LLM assigns to a factually consistent versus a factually inconsistent summary for an input news article. For factually consistent summaries, we use human-written reference summaries that we manually verify as factually consistent. To generate summaries that are factually inconsistent, we generate summaries from a suite of summarization models that we have manually annotated as factually inconsistent. A model's factual consistency is then measured according to its accuracy, i.e.\ the proportion of documents where it assigns a higher score to the factually consistent summary. To validate the usefulness of FIB, we evaluate 23 large language models ranging from 1B to 176B parameters from six different model families including BLOOM and OPT. We find that existing LLMs generally assign a higher score to factually consistent summaries than to factually inconsistent summaries. However, if the factually inconsistent summaries occur verbatim in the document, then LLMs assign a higher score to these factually inconsistent summaries than factually consistent summaries. We validate design choices in our benchmark including the scoring method and source of distractor summaries. Our code and benchmark data can be found at this https URL. </details>
1. **Improving Factual Consistency in Summarization with Compression-Based Post-Editing** *Alexander R. Fabbri, Prafulla Kumar Choubey, Jesse Vig, Chien-Sheng Wu, Caiming Xiong* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2211.06196) [[code]](https://github.com/salesforce/CompEdit) <details> <summary>[Abs]</summary> State-of-the-art summarization models still struggle to be factually consistent with the input text. A model-agnostic way to address this problem is post-editing the generated summaries. However, existing approaches typically fail to remove entity errors if a suitable input entity replacement is not available or may insert erroneous content. In our work, we focus on removing extrinsic entity errors, or entities not in the source, to improve consistency while retaining the summary's essential information and form. We propose to use sentence-compression data to train the post-editing model to take a summary with extrinsic entity errors marked with special tokens and output a compressed, well-formed summary with those errors removed. We show that this model improves factual consistency while maintaining ROUGE, improving entity precision by up to 30% on XSum, and that this model can be applied on top of another post-editor, improving entity precision by up to a total of 38%. We perform an extensive comparison of post-editing approaches that demonstrate trade-offs between factual consistency, informativeness, and grammaticality, and we analyze settings where post-editors show the largest improvements. </details>
1. **Evaluating and Improving Factuality in Multimodal Abstractive Summarization** *David Wan, Mohit Bansal* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2211.02580) [[code]](https://github.com/meetdavidwan/faithful-multimodal-summ) <details> <summary>[Abs]</summary> Current metrics for evaluating factuality for abstractive document summarization have achieved high correlations with human judgment, but they do not account for the vision modality and thus are not adequate for vision-and-language summarization. We propose CLIPBERTScore, a simple weighted combination of CLIPScore and BERTScore to leverage the robustness and strong factuality detection performance between image-summary and document-summary, respectively. Next, due to the lack of meta-evaluation benchmarks to evaluate the quality of multimodal factuality metrics, we collect human judgments of factuality with respect to documents and images. We show that this simple combination of two metrics in the zero-shot setting achieves higher correlations than existing factuality metrics for document summarization, outperforms an existing multimodal summarization metric, and performs competitively with strong multimodal factuality metrics specifically fine-tuned for the task. Our thorough analysis demonstrates the robustness and high correlation of CLIPBERTScore and its components on four factuality metric-evaluation benchmarks. Finally, we demonstrate two practical downstream applications of our CLIPBERTScore metric: for selecting important images to focus on during training, and as a reward for reinforcement learning to improve factuality of multimodal summary generation w.r.t automatic and human evaluation. Our data and code are publicly available at this https URL </details>
1. **FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness** *Wenhao Wu, Wei Li, Jiachen Liu, Xinyan Xiao, Ziqiang Cao, Sujian Li, Hua Wu* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2211.00294) <details> <summary>[Abs]</summary> Despite being able to generate fluent and grammatical text, current Seq2Seq summarization models still suffering from the unfaithful generation problem. In this paper, we study the faithfulness of existing systems from a new perspective of factual robustness which is the ability to correctly generate factual information over adversarial unfaithful information. We first measure a model's factual robustness by its success rate to defend against adversarial attacks when generating factual information. The factual robustness analysis on a wide range of current systems shows its good consistency with human judgments on faithfulness. Inspired by these findings, we propose to improve the faithfulness of a model by enhancing its factual robustness. Specifically, we propose a novel training strategy, namely FRSUM, which teaches the model to defend against both explicit adversarial samples and implicit factual adversarial perturbations. Extensive automatic and human evaluation results show that FRSUM consistently improves the faithfulness of various Seq2Seq models, such as T5, BART. </details>
1. **Questioning the Validity of Summarization Datasets and Improving Their Factual Consistency** *Yanzhu Guo, Chloé Clavel, Moussa Kamal Eddine, Michalis Vazirgiannis* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.17378) [[data]](https://github.com/YanzhuGuo/SummFC) <details> <summary>[Abs]</summary> The topic of summarization evaluation has recently attracted a surge of attention due to the rapid development of abstractive summarization systems. However, the formulation of the task is rather ambiguous, neither the linguistic nor the natural language processing community has succeeded in giving a mutually agreed-upon definition. Due to this lack of well-defined formulation, a large number of popular abstractive summarization datasets are constructed in a manner that neither guarantees validity nor meets one of the most essential criteria of summarization: factual consistency. In this paper, we address this issue by combining state-of-the-art factual consistency models to identify the problematic instances present in popular summarization datasets. We release SummFC, a filtered summarization dataset with improved factual consistency, and demonstrate that models trained on this dataset achieve improved performance in nearly all quality aspects. We argue that our dataset should become a valid benchmark for developing and evaluating summarization systems. </details>
1. **Mutual Information Alleviates Hallucinations in Abstractive Summarization** *Liam van der Poel, Ryan Cotterell, Clara Meister* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.13210) [[code]](https://github.com/VanderpoelLiam/CPMI) <details> <summary>[Abs]</summary> Despite significant progress in the quality of language generated from abstractive summarization models, these models still exhibit the tendency to hallucinate, i.e., output content not supported by the source document. A number of works have tried to fix--or at least uncover the source of--the problem with limited success. In this paper, we identify a simple criterion under which models are significantly more likely to assign more probability to hallucinated content during generation: high model uncertainty. This finding offers a potential explanation for hallucinations: models default to favoring text with high marginal probability, i.e., high-frequency occurrences in the training set, when uncertain about a continuation. It also motivates possible routes for real-time intervention during decoding to prevent such hallucinations. We propose a decoding strategy that switches to optimizing for pointwise mutual information of the source and target token--rather than purely the probability of the target token--when the model exhibits uncertainty. Experiments on the XSum dataset show that our method decreases the probability of hallucinated tokens while maintaining the Rouge and BertS scores of top-performing decoding strategies. </details>
1. **Correcting Diverse Factual Errors in Abstractive Summarization via Post-Editing and Language Model Infilling** *Vidhisha Balachandran, Hannaneh Hajishirzi, William Cohen, Yulia Tsvetkov* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.12378) [[code]](https://github.com/vidhishanair/FactEdit) <details> <summary>[Abs]</summary> Abstractive summarization models often generate inconsistent summaries containing factual errors or hallucinated content. Recent works focus on correcting factual errors in generated summaries via post-editing. Such correction models are trained using adversarial non-factual summaries constructed using heuristic rules for injecting errors. However, generating non-factual summaries using heuristics often does not generalize well to actual model errors. In this work, we propose to generate hard, representative synthetic examples of non-factual summaries through infilling language models. With this data, we train a more robust fact-correction model to post-edit the summaries to improve factual consistency. Through quantitative and qualitative experiments on two popular summarization datasets -- CNN/DM and XSum -- we show that our approach vastly outperforms prior methods in correcting erroneous summaries. Our model -- FactEdit -- improves factuality scores by over ~11 points on CNN/DM and over ~31 points on XSum on average across multiple summarization models, producing more factual summaries while maintaining competitive summarization quality. </details>
1. **Phrase-Level Localization of Inconsistency Errors in Summarization by Weak Supervision** *Masato Takatsuka, Tetsunori Kobayashi, Yoshihiko Hayashi* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.537/) [[code]](https://github.com/taka2946/sumphrase) <details> <summary>[Abs]</summary> Although the fluency of automatically generated abstractive summaries has improved significantly with advanced methods, the inconsistency that remains in summarization is recognized as an issue to be addressed. In this study, we propose a methodology for localizing inconsistency errors in summarization. A synthetic dataset that contains a variety of factual errors likely to be produced by a common summarizer is created by applying sentence fusion, compression, and paraphrasing operations. In creating the dataset, we automatically label erroneous phrases and the dependency relations between them as “inconsistent,” which can contribute to detecting errors more adequately than existing models that rely only on dependency arc-level labels. Subsequently, this synthetic dataset is employed as weak supervision to train a model called SumPhrase, which jointly localizes errors in a summary and their corresponding sentences in the source document. The empirical results demonstrate that our SumPhrase model can detect factual errors in summarization more effectively than existing weakly supervised methods owing to the phrase-level labeling. Moreover, the joint identification of error-corresponding original sentences is proven to be effective in improving error detection accuracy. </details>
1. **Just ClozE! A Fast and Simple Method for Evaluating the Factual Consistency in Abstractive Summarization** *Yiyang Li, Lei Li, Qing Yang, Marina Litvak, Natalia Vanetik, Dingxin Hu, Yuze Li, Yanquan Zhou, Dongliang Xu, Xuanyu Zhang* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.02804) <details> <summary>[Abs]</summary> The issue of factual consistency in abstractive summarization has attracted much attention in recent years, and the evaluation of factual consistency between summary and document has become an important and urgent task. Most of the current evaluation metrics are adopted from the question answering (QA). However, the application of QA-based metrics is extremely time-consuming in practice, causing the iteration cycle of abstractive summarization research to be severely prolonged. In this paper, we propose a new method called ClozE to evaluate factual consistency by cloze model, instantiated based on masked language model(MLM), with strong interpretability and substantially higher speed. We demonstrate that ClozE can reduce the evaluation time by nearly 96% relative to QA-based metrics while retaining their interpretability and performance through experiments on six human-annotated datasets and a meta-evaluation benchmark GO FIGURE \citep{gabriel2020go}. We also implement experiments to further demonstrate more characteristics of ClozE in terms of performance and speed. In addition, we conduct an experimental analysis of the limitations of ClozE, which suggests future research directions. The code and models for ClozE will be released upon the paper acceptance. </details>
1. **Extractive is not Faithful: An Investigation of Broad Unfaithfulness Problems in Extractive Summarization** *Shiyue Zhang, David Wan, Mohit Bansal* [[pdf]](https://arxiv.org/abs/2209.03549) [[code]](https://github.com/ZhangShiyue/extractive_is_not_faithful) <details> <summary>[Abs]</summary> The problems of unfaithful summaries have been widely discussed under the context of abstractive summarization. Though extractive summarization is less prone to the common unfaithfulness issues of abstractive summaries, does that mean extractive is equal to faithful? Turns out that the answer is no. In this work, we define a typology with five types of broad unfaithfulness problems (including and beyond not-entailment) that can appear in extractive summaries, including incorrect coreference, incomplete coreference, incorrect discourse, incomplete discourse, as well as other misleading information. We ask humans to label these problems out of 1500 English summaries produced by 15 diverse extractive systems. We find that 33% of the summaries have at least one of the five issues. To automatically detect these problems, we find that 5 existing faithfulness evaluation metrics for summarization have poor correlations with human judgment. To remedy this, we propose a new metric, ExtEval, that is designed for detecting unfaithful extractive summaries and is shown to have the best performance. We hope our work can increase the awareness of unfaithfulness problems in extractive summarization and help future work to evaluate and resolve these issues. Our data and code are publicly available at this https URL </details>
1. **Entity-based SpanCopy for Abstractive Summarization to Improve the Factual Consistency** *Wen Xiao, Giuseppe Carenini* [[pdf]](https://arxiv.org/abs/2209.03479) [[code]](https://github.com/Wendy-Xiao/Entity-based-SpanCopy) <details> <summary>[Abs]</summary> Despite the success of recent abstractive summarizers on automatic evaluation metrics, the generated summaries still present factual inconsistencies with the source document. In this paper, we focus on entity-level factual inconsistency, i.e. reducing the mismatched entities between the generated summaries and the source documents. We therefore propose a novel entity-based SpanCopy mechanism, and explore its extension with a Global Relevance component. Experiment results on four summarization datasets show that SpanCopy can effectively improve the entity-level factual consistency with essentially no change in the word-level and entity-level saliency. The code is available at this https URL </details>
1. **Jointly Learning Guidance Induction and Faithful Summary Generation via Conditional Variational Autoencoders** *Wang Xu, Tiejun Zhao* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.180/) <details> <summary>[Abs]</summary> Abstractive summarization can generate high quality results with the development of the neural network. However, generating factual consistency summaries is a challenging task for abstractive summarization. Recent studies extract the additional information with off-the-shelf tools from the source document as a clue to guide the summary generation, which shows effectiveness to improve the faithfulness. Unlike these work, we present a novel framework based on conditional variational autoencoders, which induces the guidance information and generates the summary equipment with the guidance synchronously. Experiments on XSUM and CNNDM dataset show that our approach can generate relevant and fluent summaries which is more faithful than the existing state-of-the-art approaches, according to multiple factual consistency metrics. </details>
1. **Masked Summarization to Generate Factually Inconsistent Summaries for Improved Factual Consistency Checking** *Hwanhee Lee, Kang Min Yoo, Joonsuk Park, Hwaran Lee, Kyomin Jung* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.76/) [[code]](https://github.com/hwanheelee1993/MFMA) <details> <summary>[Abs]</summary> Despite the recent advances in abstractive summarization systems, it is still difficult to determine whether a generated summary is factual consistent with the source text. To this end, the latest approach is to train a factual consistency classifier on factually consistent and inconsistent summaries. Luckily, the former is readily available as reference summaries in existing summarization datasets. However, generating the latter remains a challenge, as they need to be factually inconsistent, yet closely relevant to the source text to be effective. In this paper, we propose to generate factually inconsistent summaries using source texts and reference summaries with key information masked. Experiments on seven benchmark datasets demonstrate that factual consistency classifiers trained on summaries generated using our method generally outperform existing models and show a competitive correlation with human judgments. We also analyze the characteristics of the summaries generated using our method. We will release the pre-trained model and the code at https://github.com/hwanheelee1993/MFMA. </details>
1. **Improving the Faithfulness of Abstractive Summarization via Entity Coverage Control** *Haopeng Zhang, Semih Yavuz, Wojciech Kryscinski, Kazuma Hashimoto, Yingbo Zhou* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.40/) [[code]]() <details> <summary>[Abs]</summary> Abstractive summarization systems leveraging pre-training language models have achieved superior results on benchmark datasets. However, such models have been shown to be more prone to hallucinate facts that are unfaithful to the input context. In this paper, we propose a method to remedy entity-level extrinsic hallucinations with Entity Coverage Control (ECC). We first compute entity coverage precision and prepend the corresponding control code for each training example, which implicitly guides the model to recognize faithfulness contents in the training phase. We further extend our method via intermediate fine-tuning on large but noisy data extracted from Wikipedia to unlock zero-shot summarization. We show that the proposed method leads to more faithful and salient abstractive summarization in supervised fine-tuning and zero-shot settings according to our experimental results on three benchmark datasets XSum, Pubmed, and SAMSum of very different domains and styles. </details>
1. **FactPEGASUS: Factuality-Aware Pre-training and Fine-tuning for Abstractive Summarization** *David Wan, Mohit Bansal* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.74/) [[code]](https://github.com/meetdavidwan/factpegasus) <details> <summary>[Abs]</summary> We present FactPEGASUS, an abstractive summarization model that addresses the problem of factuality during pre-training and fine-tuning: (1) We augment the sentence selection strategy of PEGASUS’s (Zhang et al., 2019) pre-training objective to create pseudo-summaries that are both important and factual; (2) We introduce three complementary components for fine-tuning. The corrector removes hallucinations present in the reference summary, the contrastor uses contrastive learning to better differentiate nonfactual summaries from factual ones, and the connector bridges the gap between the pre-training and fine-tuning for better transfer of knowledge. Experiments on three downstream tasks demonstrate that FactPEGASUS substantially improves factuality evaluated by multiple automatic metrics and humans. Our thorough analysis suggests that FactPEGASUS is more factual than using the original pre-training objective in zero-shot and few-shot settings, retains factual behavior more robustly than strong baselines, and does not rely entirely on becoming more extractive to improve factuality. </details>
1. **Improving the Faithfulness of Abstractive Summarization via Entity Coverage Control** *Haopeng Zhang, Semih Yavuz, Wojciech Kryscinski, Kazuma Hashimoto, Yingbo Zhou* `NAACL 2022 findings` [[pdf]](https://arxiv.org/abs/2207.02263) <details> <summary>[Abs]</summary> Abstractive summarization systems leveraging pre-training language models have achieved superior results on benchmark datasets. However, such models have been shown to be more prone to hallucinate facts that are unfaithful to the input context. In this paper, we propose a method to remedy entity-level extrinsic hallucinations with Entity Coverage Control (ECC). We first compute entity coverage precision and prepend the corresponding control code for each training example, which implicitly guides the model to recognize faithfulness contents in the training phase. We further extend our method via intermediate fine-tuning on large but noisy data extracted from Wikipedia to unlock zero-shot summarization. We show that the proposed method leads to more faithful and salient abstractive summarization in supervised fine-tuning and zero-shot settings according to our experimental results on three benchmark datasets XSum, Pubmed, and SAMSum of very different domains and styles. </details>
1. **SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization** *Philippe Laban, Tobias Schnabel, Paul N. Bennett, Marti A. Hearst* `TACL 2022 Volume 10` [[pdf]](https://aclanthology.org/2022.tacl-1.10/) [[code]](https://github.com/tingofurro/summac/) <details> <summary>[Abs]</summary> In the summarization domain, a key requirement for summaries is to be factually consistent with the input document. Previous work has found that natural language inference (NLI) models do not perform competitively when applied to inconsistency detection. In this work, we revisit the use of NLI for inconsistency detection, finding that past work suffered from a mismatch in input granularity between NLI datasets (sentence-level), and inconsistency detection (document level). We provide a highly effective and light-weight method called SummaCConv that enables NLI models to be successfully used for this task by segmenting documents into sentence units and aggregating scores between pairs of sentences. We furthermore introduce a new benchmark called SummaC (Summary Consistency) which consists of six large inconsistency detection datasets. On this dataset, SummaCConv obtains state-of-the-art results with a balanced accuracy of 74.4%, a 5% improvement compared with prior work. </details>
1. **Hallucinated but Factual! Inspecting the Factuality of Hallucinations in Abstractive Summarization** *Meng Cao, Yue Dong, Jackie Cheung* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.236/) [[code]](https://github.com/mcao516/entfa) <details> <summary>[Abs]</summary> State-of-the-art abstractive summarization systems often generate hallucinations; i.e., content that is not directly inferable from the source text. Despite being assumed to be incorrect, we find that much hallucinated content is actually consistent with world knowledge, which we call factual hallucinations. Including these factual hallucinations in a summary can be beneficial because they provide useful background information. In this work, we propose a novel detection approach that separates factual from non-factual hallucinations of entities. Our method is based on an entity’s prior and posterior probabilities according to pre-trained and finetuned masked language models, respectively. Empirical results suggest that our method vastly outperforms two baselines in both accuracy and F1 scores and has a strong correlation with human judgments on factuality classification tasks.Furthermore, we use our method as a reward signal to train a summarization system using an off-line reinforcement learning (RL) algorithm that can significantly improve the factuality of generated summaries while maintaining the level of abstractiveness. </details>
1. **Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors** *Liyan Tang, Tanya Goyal, Alexander R. Fabbri, Philippe Laban, Jiacheng Xu, Semih Yahvuz, Wojciech Kryściński, Justin F. Rousseau, Greg Durrett* [[pdf]](https://arxiv.org/abs/2205.12854) [[code]](https://github.com/Liyan06/AggreFact)
1. **Falsesum: Generating Document-level NLI Examples for Recognizing Factual Inconsistency in Summarization** *Prasetya Ajie Utama, Joshua Bambrick, Nafise Sadat Moosavi, Iryna Gurevych* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.199/) [[code]](https://github.com/joshbambrick/Falsesum) <details> <summary>[Abs]</summary> Neural abstractive summarization models are prone to generate summaries that are factually inconsistent with their source documents. Previous work has introduced the task of recognizing such factual inconsistency as a downstream application of natural language inference (NLI). However, state-of-the-art NLI models perform poorly in this context due to their inability to generalize to the target task. In this work, we show that NLI models can be effective for this task when the training data is augmented with high-quality task-oriented examples. We introduce Falsesum, a data generation pipeline leveraging a controllable text generation model to perturb human-annotated summaries, introducing varying types of factual inconsistencies. Unlike previously introduced document-level NLI datasets, our generated dataset contains examples that are diverse and inconsistent yet plausible. We show that models trained on a Falsesum-augmented NLI dataset improve the state-of-the-art performance across four benchmarks for detecting factual inconsistency in summarization. </details>
1. **Masked Summarization to Generate Factually Inconsistent Summaries for Improved Factual Consistency Checking** *Hwanhee Lee, Kang Min Yoo, Joonsuk Park, Hwaran Lee, Kyomin Jung* `NAACL 2022 Findings` [[pdf]](https://arxiv.org/abs/2205.02035) [[code]](https://github.com/hwanheelee1993/MFMA)
1. **Faithful to the Document or to the World? Mitigating Hallucinations via Entity-linked Knowledge in Abstractive Summarization** *Yue Dong, John Wieting, Pat Verga* [[pdf]](https://arxiv.org/abs/2204.13761)
1. **Learning to Revise References for Faithful Summarization** *Griffin Adams, Han-Chin Shing, Qing Sun, Christopher Winestock, Kathleen McKeown, Noémie Elhadad* [[pdf]](https://arxiv.org/abs/2204.10290) [[code]](https://github.com/amazon-research/summary-reference-revision)
1. **Factual Error Correction for Abstractive Summaries Using Entity Retrieval** *Hwanhee Lee, Cheoneum Park, Seunghyun Yoon, Trung Bui, Franck Dernoncourt, Juae Kim, Kyomin Jung* [[pdf]](https://arxiv.org/abs/2204.08263)
1. **Evaluating Factuality in Text Simplification** *Ashwin Devaraj, William Sheffield, Byron C. Wallace, Junyi Jessy Li* `ACL 2022` [[pdf]](https://arxiv.org/abs/2204.07562) [[code]](https://github.com/AshOlogn/Evaluating-Factuality-in-Text-Simplification)
1. **FactGraph: Evaluating Factuality in Summarization with Semantic Graph Representations** *Leonardo F. R. Ribeiro, Mengwen Liu, Iryna Gurevych, Markus Dreyer, Mohit Bansal* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.236/) [[code]](https://github.com/amazon-research/fact-graph)<details> <summary>[Abs]</summary> Despite recent improvements in abstractive summarization, most current approaches generate summaries that are not factually consistent with the source document, severely restricting their trust and usage in real-world applications. Recent works have shown promising improvements in factuality error identification using text or dependency arc entailments; however, they do not consider the entire semantic graph simultaneously. To this end, we propose FactGraph, a method that decomposes the document and the summary into structured meaning representations (MR), which are more suitable for factuality evaluation. MRs describe core semantic concepts and their relations, aggregating the main content in both document and summary in a canonical form, and reducing data sparsity. FactGraph encodes such graphs using a graph encoder augmented with structure-aware adapters to capture interactions among the concepts based on the graph connectivity, along with text representations using an adapter-based text encoder. Experiments on different benchmarks for evaluating factuality show that FactGraph outperforms previous approaches by up to 15%. Furthermore, FactGraph improves performance on identifying content verifiability errors and better captures subsentence-level factual inconsistencies. </details>
1. **Don't Say What You Don't Know: Improving the Consistency of Abstractive Summarization by Constraining Beam Search** *Daniel King, Zejiang Shen, Nishant Subramani, Daniel S. Weld, Iz Beltagy, Doug Downey* [[pdf]](https://arxiv.org/abs/2203.08436) [[code]](https://github.com/allenai/pinocchio)
1. **CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning** *Xiangru Tang, Arjun Nair, Borui Wang, Bingyao Wang, Jai Desai, Aaron Wade, Haoran Li, Asli Celikyilmaz, Yashar Mehdad, Dragomir Radev* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.415/) <details> <summary>[Abs]</summary> Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained neural language models, substantial amounts of hallucinated content are found during the human evaluation. In this work, we first devised a typology of factual errors to better understand the types of hallucinations generated by current models and conducted human evaluation on popular dialog summarization dataset. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called CONFIT. To tackle top factual errors from our annotation, we introduce additional contrastive loss with carefully designed hard negative samples and self-supervised dialogue-specific loss to capture the key information between speakers. We show that our model significantly reduces all kinds of factual errors on both SAMSum dialogue summarization and AMI meeting summarization. On both datasets, we achieve significant improvements over state-of-the-art baselines using both automatic metrics, ROUGE and BARTScore, and human evaluation. </details>
1. **QAFactEval: Improved QA-Based Factual Consistency Evaluation for Summarization** *Alexander R. Fabbri, Chien-Sheng Wu, Wenhao Liu, Caiming Xiong* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.187/) [[code]](https://github.com/salesforce/QAFactEval) <details> <summary>[Abs]</summary> Factual consistency is an essential quality of text summarization models in practical settings. Existing work in evaluating this dimension can be broadly categorized into two lines of research, entailment-based and question answering (QA)-based metrics, and different experimental setups often lead to contrasting conclusions as to which paradigm performs the best. In this work, we conduct an extensive comparison of entailment and QA-based metrics, demonstrating that carefully choosing the components of a QA-based metric, especially question generation and answerability classification, is critical to performance. Building on those insights, we propose an optimized metric, which we call QAFactEval, that leads to a 14% average improvement over previous QA-based metrics on the SummaC factual consistency benchmark, and also outperforms the best-performing entailment-based metric. Moreover, we find that QA-based and entailment-based metrics can offer complementary signals and be combined into a single metric for a further performance boost. </details>
1. **CO2Sum:Contrastive Learning for Factual-Consistent Abstractive Summarization** *Wei Liu, Huanqin Wu, Wenjing Mu, Zhen Li, Tao Chen, Dan Nie* [[pdf]](https://arxiv.org/abs/2112.01147)
1. **Are Factuality Checkers Reliable? Adversarial Meta-evaluation of Factuality in Summarization** *Yiran Chen, Pengfei Liu, Xipeng Qiu* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.179/) [[code]](https://github.com/zide05/AdvFact)
1. **SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization** *Philippe Laban, Tobias Schnabel, Paul N. Bennett, Marti A. Hearst* [[pdf]](https://arxiv.org/abs/2111.09525) [[code]](https://github.com/tingofurro/summac/)
2. **Dialogue Inspectional Summarization with Factual Inconsistency Awareness** *Leilei Gan, Yating Zhang, Kun Kuang, Lin Yuan, Shuo Li, Changlong Sun, Xiaozhong Liu, Fei Wu* [[pdf]](https://arxiv.org/abs/2111.03284)
1. **Fine-grained Factual Consistency Assessment for Abstractive Summarization Models** *Sen Zhang, Jianwei Niu, Chuyuan Wei* `` [[pdf]](https://aclanthology.org/2021.emnlp-main.9/)
1. **MoFE: Mixture of Factual Experts for Controlling Hallucinations in Abstractive Summarization** *Prafulla Kumar Choubey, Jesse Vig, Wenhao Liu, Nazneen Fatema Rajani* [[pdf]](https://arxiv.org/abs/2110.07166)
1. **Investigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries** *Xiangru Tang, Alexander R. Fabbri, Ziming Mao, Griffin Adams, Borui Wang, Haoran Li, Yashar Mehdad, Dragomir Radev* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.417/) <details> <summary>[Abs]</summary> Current pre-trained models applied for summarization are prone to factual inconsistencies that misrepresent the source text. Evaluating the factual consistency of summaries is thus necessary to develop better models. However, the human evaluation setup for evaluating factual consistency has not been standardized. To determine the factors that affect the reliability of the human evaluation, we crowdsource evaluations for factual consistency across state-of-the-art models on two news summarization datasets using the rating-based Likert Scale and ranking-based Best-Worst Scaling. Our analysis reveals that the ranking-based Best-Worst Scaling offers a more reliable measure of summary quality across datasets and that the reliability of Likert ratings highly depends on the target dataset and the evaluation design. To improve crowdsourcing reliability, we extend the scale of the Likert rating and present a scoring algorithm for Best-Worst Scaling that we call value learning. Our crowdsourcing guidelines will be publicly available to facilitate future work on factual consistency in summarization. </details>
1. **MiRANews: Dataset and Benchmarks for Multi-Resource-Assisted News Summarization** *Xinnuo Xu, Ondřej Dušek, Shashi Narayan, Verena Rieser, Ioannis Konstas* `EMNLP2021 Findings` [[pdf]](https://arxiv.org/abs/2109.10650) [[data]](https://github.com/XinnuoXu/MiRANews)
1. **Inspecting the Factuality of Hallucinated Entities in Abstractive Summarization** *Meng Cao, Yue Dong, Jackie Chi Kit Cheung* [[pdf]](https://arxiv.org/abs/2109.09784)
1. **CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization** *Shuyang Cao, Lu Wang* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.09209) [[code]](https://shuyangcao.github.io/projects/cliff_summ)
1. **Faithful or Extractive? On Mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization** *Faisal Ladhak, Esin Durmus, He He, Claire Cardie, Kathleen McKeown* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.100/) [[code]](https://github.com/fladhak/effective-faithfulness) <details> <summary>[Abs]</summary> Despite recent progress in abstractive summarization, systems still suffer from faithfulness errors. While prior work has proposed models that improve faithfulness, it is unclear whether the improvement comes from an increased level of extractiveness of the model outputs as one naive way to improve faithfulness is to make summarization models more extractive. In this work, we present a framework for evaluating the effective faithfulness of summarization systems, by generating a faithfulness-abstractiveness trade-off curve that serves as a control at different operating points on the abstractiveness spectrum. We then show that the Maximum Likelihood Estimation (MLE) baseline as well as recently proposed methods for improving faithfulness, fail to consistently improve over the control at the same level of abstractiveness. Finally, we learn a selector to identify the most faithful and abstractive summary for a given document, and show that this system can attain higher faithfulness scores in human evaluations while being more abstractive than the baseline system on two datasets. Moreover, we show that our system is able to achieve a better faithfulness-abstractiveness trade-off than the control at the same level of abstractiveness. </details>
1. **Factual Consistency Evaluation for Text Summarization via Counterfactual Estimation** *Yuexiang Xie, Fei Sun, Yang Deng, Yaliang Li, Bolin Ding* `EMNLP 2021 Findings` [[pdf]](https://arxiv.org/abs/2108.13134) [[code]](https://github.com/xieyxclack/factual_coco)
1. **Improving Factual Consistency of Abstractive Summarization on Customer Feedback** *Yang Liu, Yifei Sun, Vincent Gao* `ACL 2021 Proceedings of The 4th Workshop on e-Commerce and NLP` [[pdf]](https://aclanthology.org/2021.ecnlp-1.19/)
1. **AgreeSum: Agreement-Oriented Multi-Document Summarization** *Richard Yuanzhe Pang, Adam D. Lelkes, Vinh Q. Tran, Cong Yu* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.02278) [[data]](https://github.com/google-research-datasets/AgreeSum)
1. **Focus Attention: Promoting Faithfulness and Diversity in Summarization** *Rahul Aralikatte, Shashi Narayan, Joshua Maynez, Sascha Rothe, Ryan McDonald* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.474/)
1. **Improving Factual Consistency of Abstractive Summarization via Question Answering** *Feng Nan, Cicero Nogueira dos Santos, Henghui Zhu, Patrick Ng, Kathleen McKeown, Ramesh Nallapati, Dejiao Zhang, Zhiguo Wang, Andrew O. Arnold, Bing Xiang* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.536/) [[code]](https://github.com/amazon-research/fact-check-summarization)
1. **Discourse Understanding and Factual Consistency in Abstractive Summarization** *Saadia Gabriel, Antoine Bosselut, Jeff Da, Ari Holtzman, Jan Buys, Kyle Lo, Asli Celikyilmaz, Yejin Choi* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.34/) [[code]](https://github.com/skgabriel/coopnet)
1. **Improving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection** *Sihao Chen, Fan Zhang, Kazoo Sone and Dan Roth* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.09061) [[code]](https://github.com/CogComp/faithful_summarization) 
2. **Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics** *Artidoro Pagnoni, Vidhisha Balachandran and Yulia Tsvetkov* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.13346) [[code]](https://github.com/artidoro/frank) 
3. **Annotating and Modeling Fine-grained Factuality in Summarization** *Tanya Goyal, Greg Durrett* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.04302) [[code]](https://github.com/tagoyal/factuality-datasets)
4. **SAFEval: Summarization Asks for Fact-based Evaluation** *Thomas Scialom, Paul-Alexis Dray, Patrick Gallinari, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano, Alex Wang* [[pdf]](https://arxiv.org/abs/2103.12693) [[code]](https://github.com/recitalAI/QuestEval) 
5. **Enhancing Factual Consistency of Abstractive Summarization** *Chenguang Zhu, William Hinthorn, Ruochen Xu, Qingkai Zeng, Michael Zeng, Xuedong Huang, Meng Jiang* `NAACL21` [[pdf]](https://arxiv.org/abs/2003.08612) 
6. **Entity-level Factual Consistency of Abstractive Text Summarization** *Feng Nan, Ramesh Nallapati, Zhiguo Wang, Cicero Nogueira dos Santos, Henghui Zhu, Dejiao Zhang, Kathleen McKeown, Bing Xiang* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.235/) [[code]](https://github.com/amazon-research/fact-check-summarization) 
7. **On the Faithfulness for E-commerce Product Summarization** *Peng Yuan, Haoran Li, Song Xu, Youzheng Wu, Xiaodong He, Bowen Zhou* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.502/) [[code]](https://github.com/ypnlp/coling) 
8. **FFCI: A Framework for Interpretable Automatic Evaluation of Summarization** *Fajri Koto, Jey Han Lau, Timothy Baldwin* [[pdf]](https://arxiv.org/abs/2011.13662) [[code]](https://github.com/fajri91/ffci) 
9. **GSum: A General Framework for Guided Neural Abstractive Summarization** *Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi, Zhengbao Jiang, Graham Neubig* `NAACL21` [[pdf]](https://arxiv.org/abs/2010.08014) [[code]](https://github.com/neulab/guided_summarization) 
10. **Truth or Error? Towards systematic analysis of factual errors in abstractive summaries** *Klaus-Michael Lux, Maya Sappelli, Martha Larson* `EMNLP | Eval4NLP 20` [[pdf]](https://www.aclweb.org/anthology/2020.eval4nlp-1.1/)
11. **Detecting Hallucinated Content in Conditional Neural Sequence Generation** *Chunting Zhou, Jiatao Gu, Mona Diab, Paco Guzman, Luke Zettlemoyer, Marjan Ghazvininejad* [[pdf]](https://arxiv.org/abs/2011.02593) [[code]](https://github.com/violet-zct/fairseq-detect-hallucination)
12. **Go Figure! A Meta Evaluation of Factuality in Summarization** *Saadia Gabriel, Asli Celikyilmaz, Rahul Jha, Yejin Choi, Jianfeng Gao* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2010.12834) 
13. **Constrained Abstractive Summarization: Preserving Factual Consistency with Constrained Generation** *Yuning Mao, Xiang Ren, Heng Ji, Jiawei Han* [[pdf]](https://arxiv.org/abs/2010.12723) 
14. **Factual Error Correction for Abstractive Summarization Models** *Meng Cao, Yue Dong, Jiapeng Wu, Jackie Chi Kit Cheung* `EMNLP20 short` [[pdf]](https://arxiv.org/abs/2010.08712) [[code]](https://github.com/mcao610/Factual-Error-Correction) 
15. **Multi-Fact Correction in Abstractive Text Summarization.** *Yue Dong, Shuohang Wang, Zhe Gan, Yu Cheng, Jackie Chi Kit Cheung, Jingjing Liu* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.02443) 
16. **Factual Error Correction for Abstractive Summarization Models** *Cao Meng, Yue Cheung Dong, Jiapeng Wu, and Jackie Chi Kit* `EMNLP20` [[pdf]]() 
17. **Evaluating the Factual Consistency of Abstractive Text Summarization** *Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher* `EMNLP20` [[pdf]](https://arxiv.org/abs/1910.12840) [[code]](https://github.com/salesforce/factCC)
18. **Reducing Quantity Hallucinations in Abstractive Summarization** *Zheng Zhao, Shay B. Cohen, Bonnie Webber* `Findings of EMNLP` [[pdf]](https://arxiv.org/abs/2009.13312) 
19. **On Faithfulness and Factuality in Abstractive Summarization** *Joshua Maynez, Shashi Narayan, Bernd Bohnet, Ryan McDonald*`ACL20` [[pdf]](https://arxiv.org/abs/2005.00661) [[data]](https://github.com/google-research-datasets/xsum_hallucination_annotations) 
20. **Improving Truthfulness of Headline Generation** *Kazuki Matsumaru, Sho Takase, Naoaki Okazaki* `ACL20`[[pdf]](https://arxiv.org/abs/2005.00882) 
21. **Optimizing the Factual Correctness of a Summary: A Study of Summarizing Radiology Reports** *Yuhao Zhang, Derek Merck, Emily Bao Tsai, Christopher D. Manning, Curtis P. Langlotz* `ACL20`[[pdf]](https://arxiv.org/abs/1911.02541) 
22. **FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization** *Esin Durmus, He He, Mona Diab* `ACL20` [[pdf]](https://arxiv.org/abs/2005.03754) [[code]](https://github.com/esdurmus/feqa) 
23. **Asking and Answering Questions to Evaluate the Factual Consistency of Summaries** *Alex Wang, Kyunghyun Cho, Mike Lewis* `ACL20` [[pdf]](https://arxiv.org/abs/2004.04228) [[code]](https://github.com/W4ngatang/qags)
24. **Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward** *Luyang Huang, Lingfei Wu, Lu Wang* `ACL20` [[pdf]](https://arxiv.org/abs/2005.01159) 
25. **Mind The Facts: Knowledge-Boosted Coherent Abstractive Text Summarization** *Beliz Gunel, Chenguang Zhu, Michael Zeng, Xuedong Huang* `NIPS19` [[pdf]](https://arxiv.org/abs/2006.15435) 
26. **Assessing The Factual Accuracy of Generated Text** *Ben Goodrich, Vinay Rao, Mohammad Saleh, Peter J Liu* `KDD19` [[pdf]](https://arxiv.org/abs/1905.13322) 
27. **Ranking Generated Summaries by Correctness: An Interesting but Challenging Application for Natural Language Inference** *Tobias Falke, Leonardo F. R. Ribeiro, Prasetya Ajie Utama, Ido Dagan, Iryna Gurevych* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1213/) [[data]](https://tudatalib.ulb.tu-darmstadt.de/handle/tudatalib/2002) 
28. **Ensure the Correctness of the Summary: Incorporate Entailment Knowledge into Abstractive Sentence Summarization** *Haoran Li, Junnan Zhu, Jiajun Zhang, Chengqing Zong* `COLING18` [[pdf]](https://www.aclweb.org/anthology/C18-1121/) [[code]](https://github.com/hrlinlp/entail_sum) 
29. **Faithful to the Original: Fact-Aware Neural Abstractive Summarization** *Ziqiang Cao, Furu Wei, Wenjie Li, Sujian Li* `AAAI18` [[pdf]](https://arxiv.org/abs/1711.04434) 
30. **FAR-ASS:Fact-aware reinforced abstractive sentence summarization** *MengLi Zhanga, Gang Zhoua, Wanting Yua, Wenfen Liub* [[pdf]](https://www.sciencedirect.com/science/article/abs/pii/S0306457320309675) 
## Contrastive Learning
1. **COLO: A Contrastive Learning based Re-ranking Framework for One-Stage Summarization** *COLO: A Contrastive Learning based Re-ranking Framework for One-Stage Summarization* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.508/) [[code]](https://github.com/ChenxinAn-fdu/CoLo) <details> <summary>[Abs]</summary> Traditional training paradigms for extractive and abstractive summarization systems always only use token-level or sentence-level training objectives. However, the output summary is always evaluated from summary-level which leads to the inconsistency in training and evaluation. In this paper, we propose a Contrastive Learning based re-ranking framework for one-stage summarization called COLO. By modeling a contrastive objective, we show that the summarization model is able to directly generate summaries according to the summary-level score without additional modules and parameters. Extensive experiments demonstrate that COLO boosts the extractive and abstractive results of one-stage systems on CNN/DailyMail benchmark to 44.58 and 46.33 ROUGE-1 score while preserving the parameter efficiency and inference efficiency. Compared with state-of-the-art multi-stage systems, we save more than 100 GPU training hours and obtaining 3~8 speed-up ratio during inference while maintaining comparable results.</details>
1. **CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization** *Shuyang Cao, Lu Wang* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.09209) [[code]](https://shuyangcao.github.io/projects/cliff_summ)
1. **Sequence Level Contrastive Learning for Text Summarization** *Shusheng Xu, Xingxing Zhang, Yi Wu, Furu Wei* `AAAI 2022` [pdf]](https://arxiv.org/abs/2109.03481)
1. **Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization** *Chujie Zheng, Kunpeng Zhang, Harry Jiannan Wang, Ling Fan, Zhe Wang* [[pdf]](https://arxiv.org/abs/2108.11992) [[code]](https://github.com/chz816/esacl)
1. **Constructing Contrastive samples via Summarization for Text Classification with limited annotations** *Yangkai Du, Tengfei Ma, Lingfei Wu, Fangli Xu, Xuhong Zhang, Shouling Ji* `Findings of EMNLP 2021 Short` [[pdf]](https://arxiv.org/abs/2104.05094)
1. **Alleviating Exposure Bias via Contrastive Learning for Abstractive Text Summarization** *Shichao Sun, Wenjie Li* [[pdf]](https://arxiv.org/abs/2108.11846) [[code]](https://github.com/ShichaoSun/ConAbsSum)
1. **SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization** *Yixin Liu, Pengfei Liu* `ACL 2021 short` [[pdf]](https://aclanthology.org/2021.acl-short.135/) [[code]](https://github.com/yixinL7/SimCLS)
1. **Contrastive Learning with Adversarial Perturbations for Conditional Text Generation** *Seanie Lee, Dong Bok Lee, Sung Ju Hwang* `ICLR 2021` [[pdf]](https://arxiv.org/abs/2012.07280)
1. **DeepChannel: Salience Estimation by Contrastive Learning for Extractive Document Summarization** *Jiaxin Shi, Chen Liang, Lei Hou, Juanzi Li, Zhiyuan Liu, Hanwang Zhang* `AAAI 2019` [[pdf]](https://arxiv.org/abs/1811.02394) [[code]](https://github.com/lliangchenc/DeepChannel)
3. **Unsupervised Reference-Free Summary Quality Evaluation via Contrastive Learning** *Hanlu Wu, Tengfei Ma, Lingfei Wu, Tariro Manyumwa, Shouling Ji* `EMNLP 2020` [[pdf]](https://arxiv.org/abs/2010.01781) [[code]](https://github.com/whl97/LS-Score)
4. **Contrastive Attention Mechanism for Abstractive Sentence Summarization** *Xiangyu Duan, Hongfei Yu, Mingming Yin, Min Zhang, Weihua Luo, Yue Zhang* `EMNLP 2019` [[pdf]](https://www.aclweb.org/anthology/D19-1301/) [[code]](https://github.com/travel-go/Abstractive-Text-Summarization)
## Evaluation
1. **Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization** *Lining Zhang, João Sedoc, Simon Mille, Yufang Hou, Sebastian Gehrmann, Daniel Deutsch, Elizabeth Clark, Yixin Liu, Miruna Clinciu, Saad Mahamood, Khyathi Chandu* [[pdf]](https://arxiv.org/abs/2212.10397) <details> <summary>[Abs]</summary> The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks. </details>
1. **DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely** *Forrest Sheng Bao, Ruixuan Tu, Ge Luo* [[pdf]](https://arxiv.org/abs/2212.10013) <details> <summary>[Abs]</summary> Summary quality assessment metrics have two categories: reference-based and reference-free. Reference-based metrics are theoretically more accurate but are limited by the availability and quality of the human-written references, which are both difficulty to ensure. This inspires the development of reference-free metrics, which are independent from human-written references, in the past few years. However, existing reference-free metrics cannot be both zero-shot and accurate. In this paper, we propose a zero-shot but accurate reference-free approach in a sneaky way: feeding documents, based upon which summaries generated, as references into reference-based metrics. Experimental results show that this zero-shot approach can give us the best-performing reference-free metrics on nearly all aspects on several recently-released datasets, even beating reference-free metrics specifically trained for this task sometimes. We further investigate what reference-based metrics can benefit from such repurposing and whether our additional tweaks help. </details>
1. **RISE: Leveraging Retrieval Techniques for Summarization Evaluation** *David Uthus, Jianmo Ni* [[pdf]](https://arxiv.org/abs/2212.08775) [[code]](https://github.com/google-research/google-research/tree/master/rise) <details> <summary>[Abs]</summary> Evaluating automatically-generated text summaries is a challenging task. While there have been many interesting approaches, they still fall short of human evaluations. We present RISE, a new approach for evaluating summaries by leveraging techniques from information retrieval. RISE is first trained as a retrieval task using a dual-encoder retrieval setup, and can then be subsequently utilized for evaluating a generated summary given an input document, without gold reference summaries. RISE is especially well suited when working on new datasets where one may not have reference summaries available for evaluation. We conduct comprehensive experiments on the SummEval benchmark (Fabbri et al., 2021) and the results show that RISE has higher correlation with human evaluations compared to many past approaches to summarization evaluation. Furthermore, RISE also demonstrates data-efficiency and generalizability across languages. </details>
2. **Universal Evasion Attacks on Summarization Scoring** *Wenchuan Mu, Kwan Hui Lim* [[pdf]](https://arxiv.org/abs/2210.14260) <details> <summary>[Abs]</summary> The automatic scoring of summaries is important as it guides the development of summarizers. Scoring is also complex, as it involves multiple aspects such as fluency, grammar, and even textual entailment with the source text. However, summary scoring has not been considered a machine learning task to study its accuracy and robustness. In this study, we place automatic scoring in the context of regression machine learning tasks and perform evasion attacks to explore its robustness. Attack systems predict a non-summary string from each input, and these non-summary strings achieve competitive scores with good summarizers on the most popular metrics: ROUGE, METEOR, and BERTScore. Attack systems also "outperform" state-of-the-art summarization methods on ROUGE-1 and ROUGE-L, and score the second-highest on METEOR. Furthermore, a BERTScore backdoor is observed: a simple trigger can score higher than any automatic summarization method. The evasion attacks in this work indicate the low robustness of current scoring systems at the system level. We hope that our highlighting of these proposed attacks will facilitate the development of summary scores. </details>
3. **Self-Repetition in Abstractive Neural Summarizers** *Nikita Salkar, Thomas Trikalinos, Byron C. Wallace, Ani Nenkova* [[pdf]](https://arxiv.org/abs/2210.08145) <details> <summary>[Abs]</summary> We provide a quantitative and qualitative analysis of self-repetition in the output of neural summarizers. We measure self-repetition as the number of n-grams of length four or longer that appear in multiple outputs of the same system. We analyze the behavior of three popular architectures (BART, T5, and Pegasus), fine-tuned on five datasets. In a regression analysis, we find that the three architectures have different propensities for repeating content across output summaries for inputs, with BART being particularly prone to self-repetition. Fine-tuning on more abstractive data, and on data featuring formulaic language, is associated with a higher rate of self-repetition. In qualitative analysis we find systems produce artefacts such as ads and disclaimers unrelated to the content being summarized, as well as formulaic phrases common in the fine-tuning domain. Our approach to corpus-level analysis of self-repetition may help practitioners clean up training data for summarizers and ultimately support methods for minimizing the amount of self-repetition. </details>
4. **How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation** *Julius Steen, Katja Markert* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.527/) [[code]](https://github.com/julmaxi/summary_coherence_evaluation) <details> <summary>[Abs]</summary> Automatically evaluating the coherence of summaries is of great significance both to enable cost-efficient summarizer evaluation and as a tool for improving coherence by selecting high-scoring candidate summaries. While many different approaches have been suggested to model summary coherence, they are often evaluated using disparate datasets and metrics. This makes it difficult to understand their relative performance and identify ways forward towards better summary coherence modelling. In this work, we conduct a large-scale investigation of various methods for summary coherence modelling on an even playing field. Additionally, we introduce two novel analysis measures, _intra-system correlation_ and _bias matrices_, that help identify biases in coherence measures and provide robustness against system-level confounders. While none of the currently available automatic coherence measures are able to assign reliable coherence scores to system summaries across all evaluation metrics, large-scale language models fine-tuned on self-supervised tasks show promising results, as long as fine-tuning takes into account that they need to generalize across different summary lengths. </details>
5. **PrefScore: Pairwise Preference Learning for Reference-free Summarization Quality Assessment** *Ge Luo, Hebi Li, Youbiao He, Forrest Sheng Bao* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.515/) [[code]](https://github.com/NKWBTB/PrefScore) <details> <summary>[Abs]</summary> Evaluating machine-generated summaries without a human-written reference summary has been a need for a long time. Inspired by preference labeling in existing work of summarization evaluation, we propose to judge summary quality by learning the preference rank of summaries using the Bradley-Terry power ranking model from inferior summaries generated by corrupting base summaries. Extensive experiments on several datasets show that our weakly supervised scheme can produce scores highly correlated with human ratings. </details>
6. **How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation** *Julius Steen, Katja Markert* `COLING 2022` [[pdf]](https://arxiv.org/abs/2209.06517) [[code]](https://github.com/julmaxi/summary_coherence_evaluation) <details> <summary>[Abs]</summary> Automatically evaluating the coherence of summaries is of great significance both to enable cost-efficient summarizer evaluation and as a tool for improving coherence by selecting high-scoring candidate summaries. While many different approaches have been suggested to model summary coherence, they are often evaluated using disparate datasets and metrics. This makes it difficult to understand their relative performance and identify ways forward towards better summary coherence modelling. In this work, we conduct a large-scale investigation of various methods for summary coherence modelling on an even playing field. Additionally, we introduce two novel analysis measures, intra-system correlation and bias matrices, that help identify biases in coherence measures and provide robustness against system-level confounders. While none of the currently available automatic coherence measures are able to assign reliable coherence scores to system summaries across all evaluation metrics, large-scale language models fine-tuned on self-supervised tasks show promising results, as long as fine-tuning takes into account that they need to generalize across different summary lengths.</details>
7. **SummScore: A Comprehensive Evaluation Metric for Summary Quality Based on Cross-Encoder** *Wuhang Lin, Shasha Li, Chen Zhang, Bin Ji, Jie Yu, Jun Ma, Zibo Yi* `APWeb-WAIM2022` [[pdf]](https://arxiv.org/abs/2207.04660) <details> <summary>[Abs]</summary> Text summarization models are often trained to produce summaries that meet human quality requirements. However, the existing evaluation metrics for summary text are only rough proxies for summary quality, suffering from low correlation with human scoring and inhibition of summary diversity. To solve these problems, we propose SummScore, a comprehensive metric for summary quality evaluation based on CrossEncoder. Firstly, by adopting the original-summary measurement mode and comparing the semantics of the original text, SummScore gets rid of the inhibition of summary diversity. With the help of the text-matching pre-training Cross-Encoder, SummScore can effectively capture the subtle differences between the semantics of summaries. Secondly, to improve the comprehensiveness and interpretability, SummScore consists of four fine-grained submodels, which measure Coherence, Consistency, Fluency, and Relevance separately. We use semi-supervised multi-rounds of training to improve the performance of our model on extremely limited annotated data. Extensive experiments show that SummScore significantly outperforms existing evaluation metrics in the above four dimensions in correlation with human scoring. We also provide the quality evaluation results of SummScore on 16 mainstream summarization models for later research. </details>
8. **Does Summary Evaluation Survive Translation to Other Languages?** *Spencer Braun, Oleg Vasilyev, Neslihan Iskender, John Bohannon* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.173/) [[code]](https://github.com/PrimerAI/primer-research/) <details> <summary>[Abs]</summary> The creation of a quality summarization dataset is an expensive, time-consuming effort, requiring the production and evaluation of summaries by both trained humans and machines. The returns to such an effort would increase significantly if the dataset could be used in additional languages without repeating human annotations. To investigate how much we can trust machine translation of summarization datasets, we translate the English SummEval dataset to seven languages and compare performances across automatic evaluation measures. We explore equivalence testing as the appropriate statistical paradigm for evaluating correlations between human and automated scoring of summaries. We also consider the effect of translation on the relative performance between measures. We find some potential for dataset reuse in languages similar to the source and along particular dimensions of summary quality. Our code and data can be found at https://github.com/PrimerAI/primer-research/. </details>
9. **Re-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics** *Daniel Deutsch, Rotem Dror, Dan Roth* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.442/) [[code]](https://cogcomp.seas.upenn.edu/page/publication_view/973) <details> <summary>[Abs]</summary> How reliably an automatic summarization evaluation metric replicates human judgments of summary quality is quantified by system-level correlations. We identify two ways in which the definition of the system-level correlation is inconsistent with how metrics are used to evaluate systems in practice and propose changes to rectify this disconnect. First, we calculate the system score for an automatic metric using the full test set instead of the subset of summaries judged by humans, which is currently standard practice. We demonstrate how this small change leads to more precise estimates of system-level correlations. Second, we propose to calculate correlations only on pairs of systems that are separated by small differences in automatic scores which are commonly observed in practice. This allows us to demonstrate that our best estimate of the correlation of ROUGE to human judgments is near 0 in realistic scenarios. The results from the analyses point to the need to collect more high-quality human judgments and to improve automatic metrics when differences in system scores are small. </details>
10. **SueNes: A Weakly Supervised Approach to Evaluating Single-Document Summarization via Negative Sampling** *Forrest Bao, Ge Luo, Hebi Li, Minghui Qiu, Yinfei Yang, Youbiao He, Cen Chen* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.175/) [[code]](https://github.com/forrestbao/SueNes/) <details> <summary>[Abs]</summary> Canonical automatic summary evaluation metrics, such as ROUGE, focus on lexical similarity which cannot well capture semantics nor linguistic quality and require a reference summary which is costly to obtain. Recently, there have been a growing number of efforts to alleviate either or both of the two drawbacks. In this paper, we present a proof-of-concept study to a weakly supervised summary evaluation approach without the presence of reference summaries. Massive data in existing summarization datasets are transformed for training by pairing documents with corrupted reference summaries. In cross-domain tests, our strategy outperforms baselines with promising improvements, and show a great advantage in gauging linguistic qualities over all metrics. </details>
11. **Reference-free Summarization Evaluation via Semantic Correlation and Compression Ratio** *Yizhu Liu, Qi Jia, Kenny Zhu* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.153/) [[code]](https://github.com/YizhuLiu/summeval) <details> <summary>[Abs]</summary> A document can be summarized in a number of ways. Reference-based evaluation of summarization has been criticized for its inflexibility. The more sufficient the number of abstracts, the more accurate the evaluation results. However, it is difficult to collect sufficient reference summaries. In this paper, we propose a new automatic reference-free evaluation metric that compares semantic distribution between source document and summary by pretrained language models and considers summary compression ratio. The experiments show that this metric is more consistent with human evaluation in terms of coherence, consistency, relevance and fluency. </details>
12. **MaskEval: Weighted MLM-Based Evaluation for Text Summarization and Simplification** *Yu Lu Liu, Rachel Bawden, Thomas Scaliom, Benoît Sagot, Jackie Chi Kit Cheung* [[pdf]](https://arxiv.org/abs/2205.12394) [[code]](https://github.com/YuLuLiu/MaskEval)
13. **TRUE: Re-evaluating Factual Consistency Evaluation** `NAACL 2022` [[pdf]](https://arxiv.org/abs/2204.04991)
14. **Play the Shannon Game With Language Models: A Human-Free Approach to Summary Evaluation** *Nicholas Egan, Oleg Vasilyev, John Bohannon* `AAAI 2022` [[pdf]](https://arxiv.org/abs/2103.10918) [[code]](https://github.com/PrimerAI/blanc/tree/master/shannon)
15. **Differentiable N-gram Objective on Abstractive Summarization** *Yunqi Zhu, Wensheng Zhang, Mingjin Zhu* [[pdf]](https://arxiv.org/abs/2202.04003) [[code]](https://github.com/zhuyunqi96/ngramObj)
16. **DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence** *Wei Zhao, Michael Strube, Steffen Eger* [[pdf]](https://arxiv.org/abs/2201.11176) [[code]](https://github.com/AIPHES/DiscoScore)
17. **WIDAR -- Weighted Input Document Augmented ROUGE** *Raghav Jain, Vaibhav Mavi, Anubhav Jangra, Sriparna Saha* `ECIR 2022` [[pdf]](https://arxiv.org/abs/2201.09282) [[code]](https://github.com/Raghav10j/WIDAR)
18. **InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation** *Pierre Colombo, Chloe Clave, Pablo Piantanida* `AAAI 2022` [[pdf]](https://arxiv.org/abs/2112.01589)
19. **Evaluation of Summarization Systems across Gender, Age, and Race** *Anna Jørgensen, Anders Søgaard* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.6/)
20. **Evaluation of Abstractive Summarisation Models with Machine Translation in Deliberative Processes** *M. Arana-Catania, Rob Procter, Yulan He, Maria Liakata* `EMNLP 2021 New Frontiers in Summarization Workshop` [[pdf]](https://arxiv.org/abs/2110.05847)
21. **Evaluation of Summarization Systems across Gender, Age, and Race** *Anna Jørgensen, Anders Søgaard* [[pdf]](https://arxiv.org/abs/2110.04384)
22. **Finding a Balanced Degree of Automation for Summary Evaluation** *Shiyue Zhang, Mohit Bansal* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.11503) [[code]](https://github.com/ZhangShiyue/Lite2-3Pyramid)
23. **QuestEval: Summarization Asks for Fact-based Evaluation** *Thomas Scialom, Paul-Alexis Dray, Patrick Gallinari, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano, Alex Wang* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2103.12693) [[code]](https://github.com/recitalAI/QuestEval)
24. **BARTScore: Evaluating Generated Text as Text Generation** *Weizhe Yuan, Graham Neubig, Pengfei Liu* [[pdf]](https://arxiv.org/abs/2106.11520) [[code]](https://github.com/neulab/BARTScore)
25. **A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy** *Wang Chen, Piji Li, Irwin King* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.34/) [[code]](https://github.com/Chen-Wang-CUHK/Training-Free-and-Ref-Free-Summ-Evaluation)
26. **Evaluating the Efficacy of Summarization Evaluation across Languages** *Fajri Koto, Jey Han Lau, Timothy Baldwin* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.01478)
27. **Question-aware Transformer Models for Consumer Health Question Summarization** *Shweta Yadav, Deepak Gupta, Asma Ben Abacha, Dina Demner-Fushman* [[pdf]](https://arxiv.org/abs/2106.00219)
28. **Towards Human-Free Automatic Quality Evaluation of German Summarization** *Neslihan Iskender, Oleg Vasilyev, Tim Polzehl, John Bohannon, Sebastian Möller* [[pdf]](https://arxiv.org/abs/2105.06027)
29. **Reliability of Human Evaluation for Text Summarization: Lessons Learned and Challenges Ahead** *Neslihan Iskender, Tim Polzehl, Sebastian Möller* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.humeval-1.10/) [[code]](https://github.com/nesliskender/reliability_humeval_summarization)
30. **SummVis: Interactive Visual Analysis of Models, Data, and Evaluation for Text Summarization** *Jesse Vig, Wojciech Kryscinski, Karan Goel, Nazneen Fatema Rajani* `ACL 2021 demo` [[pdf]](https://aclanthology.org/2021.acl-demo.18/) [[data]](https://github.com/robustness-gym/summvis)
31. **Is human scoring the best criteria for summary evaluation?** `Findings of ACL 2021` *Oleg Vasilyev, John Bohannon* [[pdf]](https://arxiv.org/abs/2012.14602)
32. **How to Evaluate a Summarizer: Study Design and Statistical Analysis for Manual Linguistic Quality Evaluation** *Julius Steen, Katja Markert* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.160/) [[code]](https://github.com/julmaxi/summary_lq_analysis)
33. **HOLMS: Alternative Summary Evaluation with Large Language Models** *Yassine Mrabet, Dina Demner-Fushman* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.498/) [[bib]](https://www.aclweb.org/anthology/2020.coling-main.498.bib)
34. **FFCI: A Framework for Interpretable Automatic Evaluation of Summarization** *Fajri Koto, Jey Han Lau, Timothy Baldwin* [[pdf]](https://arxiv.org/abs/2011.13662) [[code]](https://github.com/fajri91/ffci) 
35. **Unsupervised Reference-Free Summary Quality Evaluation via Contrastive Learning** *Hanlu Wu, Tengfei Ma, Lingfei Wu, Tariro Manyumwa, Shouling Ji* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.01781) [[code]](https://github.com/whl97/LS-Score)
36. **SacreROUGE: An Open-Source Library for Using and Developing Summarization Evaluation Metrics** *Daniel Deutsch, Dan Roth* [[pdf]](https://arxiv.org/abs/2007.05374) [[code]](https://github.com/danieldeutsch/sacrerouge)
37. **SummEval: Re-evaluating Summarization Evaluation** *Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, Dragomir Radev* [[pdf]](https://arxiv.org/abs/2007.12626) [[code]](https://github.com/Yale-LILY/SummEval)
38. **HIGHRES: Highlight-based Reference-less Evaluation of Summarization** *Hardy, Shashi Narayan, Andreas Vlachos* `ACL19` [[pdf]](https://arxiv.org/abs/1906.01361) [[code]](https://github.com/sheffieldnlp/highres)
## Multi-Document
1. **Do Multi-Document Summarization Models Synthesize?** *Jay DeYoung, Stephanie C. Martinez, Iain J. Marshall, Byron C. Wallace* [[pdf]](https://arxiv.org/abs/2301.13844) <details> <summary>[Abs]</summary> Multi-document summarization entails producing concise synopses of collections of inputs. For some applications, the synopsis should accurately \emph{synthesize} inputs with respect to a key property or aspect. For example, a synopsis of film reviews all written about a particular movie should reflect the average critic consensus. As a more consequential example, consider narrative summaries that accompany biomedical \emph{systematic reviews} of clinical trial results. These narratives should fairly summarize the potentially conflicting results from individual trials. In this paper we ask: To what extent do modern multi-document summarization models implicitly perform this type of synthesis? To assess this we perform a suite of experiments that probe the degree to which conditional generation models trained for summarization using standard methods yield outputs that appropriately synthesize inputs. We find that existing models do partially perform synthesis, but do so imperfectly. In particular, they are over-sensitive to changes in input ordering and under-sensitive to changes in input compositions (e.g., the ratio of positive to negative movie reviews). We propose a simple, general method for improving model synthesis capabilities by generating an explicitly diverse set of candidate outputs, and then selecting from these the string best aligned with the expected aggregate measure for the inputs, or \emph{abstaining} when the model produces no good candidate. This approach improves model synthesis performance. We hope highlighting the need for synthesis (in some summarization settings), motivates further research into multi-document summarization methods and learning objectives that explicitly account for the need to synthesize. </details>
1. **Exploring the Challenges of Open Domain Multi-Document Summarization** *John Giorgi, Luca Soldaini, Bo Wang, Gary Bader, Kyle Lo, Lucy Lu Wang, Arman Cohan* [[pdf]](https://arxiv.org/abs/2212.10526) [[code]](https://github.com/allenai/open-mds) <details> <summary>[Abs]</summary> Multi-document summarization (MDS) has traditionally been studied assuming a set of ground-truth topic-related input documents is provided. In practice, the input document set is unlikely to be available a priori and would need to be retrieved based on an information need, a setting we call open-domain MDS. We experiment with current state-of-the-art retrieval and summarization models on several popular MDS datasets extended to the open-domain setting. We find that existing summarizers suffer large reductions in performance when applied as-is to this more realistic task, though training summarizers with retrieved inputs can reduce their sensitivity retrieval errors. To further probe these findings, we conduct perturbation experiments on summarizer inputs to study the impact of different types of document retrieval errors. Based on our results, we provide practical guidelines to help facilitate a shift to open-domain MDS. We release our code and experimental results alongside all data or model artifacts created during our investigation. </details>
1. **How "Multi" is Multi-Document Summarization?** *Ruben Wolhandler, Arie Cattan, Ori Ernst, Ido Dagan* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.12688) [[code]](https://github.com/ariecattan/multi_mds) <details> <summary>[Abs]</summary> The task of multi-document summarization (MDS) aims at models that, given multiple documents as input, are able to generate a summary that combines disperse information, originally spread across these documents. Accordingly, it is expected that both reference summaries in MDS datasets, as well as system summaries, would indeed be based on such dispersed information. In this paper, we argue for quantifying and assessing this expectation. To that end, we propose an automated measure for evaluating the degree to which a summary is ``disperse'', in the sense of the number of source documents needed to cover its content. We apply our measure to empirically analyze several popular MDS datasets, with respect to their reference summaries, as well as the output of state-of-the-art systems. Our results show that certain MDS datasets barely require combining information from multiple documents, where a single document often covers the full summary content. Overall, we advocate using our metric for assessing and improving the degree to which summarization datasets require combining multi-document information, and similarly how summarization models actually meet this challenge. Our code is available in this https URL. </details>
1. **Analyzing the Dialect Diversity in Multi-document Summaries** *Olubusayo Olabisi, Aaron Hudson, Antonie Jetter, Ameeta Agrawal* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.542/) [[code]](https://github.com/PortNLP/DivSumm) <details> <summary>[Abs]</summary> Social media posts provide a compelling, yet challenging source of data of diverse perspectives from many socially salient groups. Automatic text summarization algorithms make this data accessible at scale by compressing large collections of documents into short summaries that preserve salient information from the source text. In this work, we take a complementary approach to analyzing and improving the quality of summaries generated from social media data in terms of their ability to represent salient as well as diverse perspectives. We introduce a novel dataset, DivSumm, of dialect diverse tweets and human-written extractive and abstractive summaries. Then, we study the extent of dialect diversity reflected in human-written reference summaries as well as system-generated summaries. The results of our extensive experiments suggest that humans annotate fairly well-balanced dialect diverse summaries, and that cluster-based pre-processing approaches seem beneficial in improving the overall quality of the system-generated summaries without loss in diversity. </details>
1. **Document-aware Positional Encoding and Linguistic-guided Encoding for Abstractive Multi-document Summarization** *Congbo Ma, Wei Emma Zhang, Pitawelayalage Dasun Dileepa Pitawela, Yutong Qu, Haojie Zhuang, Hu Wang* [[pdf]](https://arxiv.org/abs/2209.05929) <details> <summary>[Abs]</summary> One key challenge in multi-document summarization is to capture the relations among input documents that distinguish between single document summarization (SDS) and multi-document summarization (MDS). Few existing MDS works address this issue. One effective way is to encode document positional information to assist models in capturing cross-document relations. However, existing MDS models, such as Transformer-based models, only consider token-level positional information. Moreover, these models fail to capture sentences' linguistic structure, which inevitably causes confusions in the generated summaries. Therefore, in this paper, we propose document-aware positional encoding and linguistic-guided encoding that can be fused with Transformer architecture for MDS. For document-aware positional encoding, we introduce a general protocol to guide the selection of document encoding functions. For linguistic-guided encoding, we propose to embed syntactic dependency relations into the dependency relation mask with a simple but effective non-linear encoding learner for feature learning. Extensive experiments show the proposed model can generate summaries with high quality. </details>
1. **Multi-Document Scientific Summarization from a Knowledge Graph-Centric View** *Pancheng Wang, Shasha Li, Kunyuan Pang, Liangliang He, Dong Li, Jintao Tang, Ting Wang* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.543/) [[code]](https://github.com/muguruzawang/KGSum) <details> <summary>[Abs]</summary> Multi-Document Scientific Summarization (MDSS) aims to produce coherent and concise summaries for clusters of topic-relevant scientific papers. This task requires precise understanding of paper content and accurate modeling of cross-paper relationships. Knowledge graphs convey compact and interpretable structured information for documents, which makes them ideal for content modeling and relationship modeling. In this paper, we present KGSum, an MDSS model centred on knowledge graphs during both the encoding and decoding process. Specifically, in the encoding process, two graph-based modules are proposed to incorporate knowledge graph information into paper encoding, while in the decoding process, we propose a two-stage decoder by first generating knowledge graph information of summary in the form of descriptive sentences, followed by generating the final summary. Empirical results show that the proposed architecture brings substantial improvements over baselines on the Multi-Xscience dataset. </details>
1. **Generating a Structured Summary of Numerous Academic Papers: Dataset and Method** *Shuaiqi LIU, Jiannong Cao, Ruosong Yang, Zhiyuan Wen* `IJCAI 2022` [[pdf]](https://www.ijcai.org/proceedings/2022/591) [[data]](https://github.com/StevenLau6/BigSurvey) <details> <summary>[Abs]</summary> Writing a survey paper on one research topic usually needs to cover the salient content from numerous related papers, which can be modeled as a multi-document summarization (MDS) task. Existing MDS datasets usually focus on producing the structureless summary covering a few input documents. Meanwhile, previous structured summary generation works focus on summarizing a single document into a multi-section summary. These existing datasets and methods cannot meet the requirements of summarizing numerous academic papers into a structured summary. To deal with the scarcity of available data, we propose BigSurvey, the first large-scale dataset for generating comprehensive summaries of numerous academic papers on each topic. We collect target summaries from more than seven thousand survey papers and utilize their 430 thousand reference papers’ abstracts as input documents. To organize the diverse content from dozens of input documents and ensure the efficiency of processing long text sequences, we propose a summarization method named category-based alignment and sparse transformer (CAST). The experimental results show that our CAST method outperforms various advanced summarization methods. </details>
1. **Proposition-Level Clustering for Multi-Document Summarization** *Ori Ernst, Avi Caciularu, Ori Shapira, Ramakanth Pasunuru, Mohit Bansal, Jacob Goldberger, Ido Dagan* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.128/) [[code]](https://github.com/oriern/ProCluster) <details> <summary>[Abs]</summary> Text clustering methods were traditionally incorporated into multi-document summarization (MDS) as a means for coping with considerable information repetition. Particularly, clusters were leveraged to indicate information saliency as well as to avoid redundancy. Such prior methods focused on clustering sentences, even though closely related sentences usually contain also non-aligned parts. In this work, we revisit the clustering approach, grouping together sub-sentential propositions, aiming at more precise information alignment. Specifically, our method detects salient propositions, clusters them into paraphrastic clusters, and generates a representative sentence for each cluster via text fusion.Our summarization method improves over the previous state-of-the-art MDS method in the DUC 2004 and TAC 2011 datasets, both in automatic ROUGE scores and human preference. </details>
1. **Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities** *Zejiang Shen, Kyle Lo, Lauren Yu, Nathan Dahlberg, Margo Schlanger, Doug Downey* [[pdf]](https://arxiv.org/abs/2206.10883) [[data]](https://github.com/multilexsum/dataset) <details> <summary>[Abs]</summary> With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC) (this https URL),which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further research in summarization methods as well as to facilitate development of applications to assist in the CRLC's mission at this https URL. </details>
1. **AnswerSumm: A Manually-Curated Dataset and Pipeline for Answer Summarization** *Alexander R. Fabbri, Xiaojian Wu, Srini Iyer, Haoran Li, Mona Diab* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.180/) [[code]](https://github.com/Alex-Fabbri/AnswerSumm) <details> <summary>[Abs]</summary> Community Question Answering (CQA) fora such as Stack Overflow and Yahoo! Answers contain a rich resource of answers to a wide range of community-based questions. Each question thread can receive a large number of answers with different perspectives. One goal of answer summarization is to produce a summary that reflects the range of answer perspectives. A major obstacle for this task is the absence of a dataset to provide supervision for producing such summaries. Recent works propose heuristics to create such data, but these are often noisy and do not cover all answer perspectives present. This work introduces a novel dataset of 4,631 CQA threads for answer summarization curated by professional linguists. Our pipeline gathers annotations for all subtasks of answer summarization, including relevant answer sentence selection, grouping these sentences based on perspectives, summarizing each perspective, and producing an overall summary. We analyze and benchmark state-of-the-art models on these subtasks and introduce a novel unsupervised approach for multi-perspective data augmentation that boosts summarization performance according to automatic evaluation. Finally, we propose reinforcement learning rewards to improve factual consistency and answer coverage and analyze areas for improvement. </details>
1. **The patient is more dead than alive: exploring the current state of the multi-document summarisation of the biomedical literature** *Yulia Otmakhova, Karin Verspoor, Timothy Baldwin, Jey Han Lau* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.350/) <details> <summary>[Abs]</summary> Although multi-document summarisation (MDS) of the biomedical literature is a highly valuable task that has recently attracted substantial interest, evaluation of the quality of biomedical summaries lacks consistency and transparency. In this paper, we examine the summaries generated by two current models in order to understand the deficiencies of existing evaluation approaches in the context of the challenges that arise in the MDS task. Based on this analysis, we propose a new approach to human evaluation and identify several challenges that must be overcome to develop effective biomedical MDS systems. </details>
1. **Predicting Intervention Approval in Clinical Trials through Multi-Document Summarization** *Georgios Katsimpras, Georgios Paliouras* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.137/) [[code]]() <details> <summary>[Abs]</summary> Clinical trials offer a fundamental opportunity to discover new treatments and advance the medical knowledge. However, the uncertainty of the outcome of a trial can lead to unforeseen costs and setbacks. In this study, we propose a new method to predict the effectiveness of an intervention in a clinical trial. Our method relies on generating an informative summary from multiple documents available in the literature about the intervention under study. Specifically, our method first gathers all the abstracts of PubMed articles related to the intervention. Then, an evidence sentence, which conveys information about the effectiveness of the intervention, is extracted automatically from each abstract. Based on the set of evidence sentences extracted from the abstracts, a short summary about the intervention is constructed. Finally, the produced summaries are used to train a BERT-based classifier, in order to infer the effectiveness of an intervention. To evaluate our proposed method, we introduce a new dataset which is a collection of clinical trials together with their associated PubMed articles. Our experiments, demonstrate the effectiveness of producing short informative summaries and using them to predict the effectiveness of an intervention. </details>
1. **Discriminative Marginalized Probabilistic Neural Method for Multi-Document Summarization of Medical Literature** *Gianluca Moro, Luca Ragazzi, Lorenzo Valgimigli, Davide Freddi* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.15/) [[code]](https://disi-unibo-nlp.github.io/projects/damen/) <details> <summary>[Abs]</summary> Although current state-of-the-art Transformer-based solutions succeeded in a wide range for single-document NLP tasks, they still struggle to address multi-input tasks such as multi-document summarization. Many solutions truncate the inputs, thus ignoring potential summary-relevant contents, which is unacceptable in the medical domain where each information can be vital. Others leverage linear model approximations to apply multi-input concatenation, worsening the results because all information is considered, even if it is conflicting or noisy with respect to a shared background. Despite the importance and social impact of medicine, there are no ad-hoc solutions for multi-document summarization. For this reason, we propose a novel discriminative marginalized probabilistic method (DAMEN) trained to discriminate critical information from a cluster of topic-related medical documents and generate a multi-document summary via token probability marginalization. Results prove we outperform the previous state-of-the-art on a biomedical dataset for multi-document summarization of systematic literature reviews. Moreover, we perform extensive ablation studies to motivate the design choices and prove the importance of each module of our method. </details>
1. **ACM -- Attribute Conditioning for Abstractive Multi Document Summarization** *Aiswarya Sankar, Ankit Chadha* [[pdf]](https://arxiv.org/abs/2205.03978)
1. **Improving Multi-Document Summarization through Referenced Flexible Extraction with Credit-Awareness** *Yun-Zhu Song, Yi-Syuan Chen, Hong-Han Shuai* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.120/) [[code]](https://github.com/yunzhusong/NAACL2022-REFLECT) <details> <summary>[Abs]</summary> A notable challenge in Multi-Document Summarization (MDS) is the extremely-long length of the input. In this paper, we present an extract-then-abstract Transformer framework to overcome the problem. Specifically, we leverage pre-trained language models to construct a hierarchical extractor for salient sentence selection across documents and an abstractor for rewriting the selected contents as summaries. However, learning such a framework is challenging since the optimal contents for the abstractor are generally unknown. Previous works typically create pseudo extraction oracle to enable the supervised learning for both the extractor and the abstractor. Nevertheless, we argue that the performance of such methods could be restricted due to the insufficient information for prediction and inconsistent objectives between training and testing. To this end, we propose a loss weighting mechanism that makes the model aware of the unequal importance for the sentences not in the pseudo extraction oracle, and leverage the fine-tuned abstractor to generate summary references as auxiliary signals for learning the extractor. Moreover, we propose a reinforcement learning method that can efficiently apply to the extractor for harmonizing the optimization between training and testing. Experiment results show that our framework substantially outperforms strong baselines with comparable model sizes and achieves the best results on the Multi-News, Multi-XScience, and WikiCatSum corpora. </details>
1. **NeuS: Neutral Multi-News Summarization for Mitigating Framing Bias** *Nayeon Lee, Yejin Bang, Tiezheng Yu, Andrea Madotto, Pascale Fung* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.228/) [[code]](https://github.com/HLTCHKUST/framing-bias-metric) <details> <summary>[Abs]</summary> Media news framing bias can increase political polarization and undermine civil society. The need for automatic mitigation methods is therefore growing. We propose a new task, a neutral summary generation from multiple news articles of the varying political leaningsto facilitate balanced and unbiased news reading.In this paper, we first collect a new dataset, illustrate insights about framing bias through a case study, and propose a new effective metric and model (NeuS-Title) for the task. Based on our discovery that title provides a good signal for framing bias, we present NeuS-Title that learns to neutralize news content in hierarchical order from title to article. Our hierarchical multi-task learning is achieved by formatting our hierarchical data pair (title, article) sequentially with identifier-tokens (“TITLE=>”, “ARTICLE=>”) and fine-tuning the auto-regressive decoder with the standard negative log-likelihood objective.We then analyze and point out the remaining challenges and future directions. One of the most interesting observations is that neural NLG models can hallucinate not only factually inaccurate or unverifiable content but also politically biased content. </details>
1. **Read Top News First: A Document Reordering Approach for Multi-Document News Summarization** *Chao Zhao, Tenghao Huang, Somnath Basu Roy Chowdhury, Muthu Kumar Chandrasekaran, Kathleen McKeown, Snigdha Chaturvedi* `Findings of ACL 2022` [[pdf]](https://arxiv.org/abs/2203.10254) [[code]](https://github.com/zhaochaocs/MDS-DR)
1. **A Multi-Document Coverage Reward for RELAXed Multi-Document Summarization** *Jacob Parnell, Inigo Jauregi Unanue, Massimo Piccardi* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.351/) [[code]](https://github.com/jacob-parnell-rozetta/longformer_coverage/) <details> <summary>[Abs]</summary> Multi-document summarization (MDS) has made significant progress in recent years, in part facilitated by the availability of new, dedicated datasets and capacious language models. However, a standing limitation of these models is that they are trained against limited references and with plain maximum-likelihood objectives. As for many other generative tasks, reinforcement learning (RL) offers the potential to improve the training of MDS models; yet, it requires a carefully-designed reward that can ensure appropriate leverage of both the reference summaries and the input documents. For this reason, in this paper we propose fine-tuning an MDS baseline with a reward that balances a reference-based metric such as ROUGE with coverage of the input documents. To implement the approach, we utilize RELAX (Grathwohl et al., 2018), a contemporary gradient estimator which is both low-variance and unbiased, and we fine-tune the baseline in a few-shot style for both stability and computational efficiency. Experimental results over the Multi-News and WCEP MDS datasets show significant improvements of up to +0.95 pp average ROUGE score and +3.17 pp METEOR score over the baseline, and competitive results with the literature. In addition, they show that the coverage of the input documents is increased, and evenly across all documents. </details>
1. **PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization** *Wen Xiao, Iz Beltagy, Giuseppe Carenini, Arman Cohan* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.360/) [[code]](https://github.com/allenai/PRIMER) <details> <summary>[Abs]</summary> We introduce PRIMERA, a pre-trained model for multi-document representation with a focus on summarization that reduces the need for dataset-specific architectures and large amounts of fine-tuning labeled data. PRIMERA uses our newly proposed pre-training objective designed to teach the model to connect and aggregate information across documents. It also uses efficient encoder-decoder transformers to simplify the processing of concatenated input documents. With extensive experiments on 6 multi-document summarization datasets from 3 different domains on zero-shot, few-shot and full-supervised settings, PRIMERA outperforms current state-of-the-art dataset-specific and pre-trained models on most of these settings with large margins. </details>
1. **PeerSum: A Peer Review Dataset for Abstractive Multi-document Summarization** *Miao Li, Jianzhong Qi, Jey Han Lau* [[pdf]](https://arxiv.org/abs/2203.01769) [[data]](https://github.com/oaimli/PeerSum)
1. **A Proposition-Level Clustering Approach for Multi-Document Summarization** *Ori Ernst, Avi Caciularu, Ori Shapira, Ramakanth Pasunuru, Mohit Bansal, Jacob Goldberger, Ido Dagan* [[pdf]](https://arxiv.org/abs/2112.08770) [[code]](https://github.com/oriern/ClusterProp)
1. **MSˆ2: Multi-Document Summarization of Medical Studies** *Jay DeYoung, Iz Beltagy, Madeleine van Zuylen, Bailey Kuehl, Lucy Wang* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.594/) [[data]](https://github.com/allenai/ms2)
1. **SgSum: Transforming Multi-document Summarization into Sub-graph Selection** *Moye Chen, Wei Li, Jiachen Liu, Xinyan Xiao, Hua Wu, Haifeng Wang* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2110.12645) [[code]](https://github.com/PaddlePaddle/Research/tree/master/NLP/EMNLP2021-SgSum)
1. **Topic-Guided Abstractive Multi-Document Summarization** *Peng Cui, Le Hu* `Findings of EMNLP 2021` [[pdf]](https://arxiv.org/abs/2110.11207)
1. **Modeling Endorsement for Multi-Document Abstractive Summarization** *Logan Lebanoff, Bingqing Wang, Zhe Feng, Fei Liu* `EMNLP 2021|newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.13/)
1. **Incorporating Linguistic Knowledge for Abstractive Multi-document Summarization** *Congbo Ma, Wei Emma Zhang, Hu Wang, Shubham Gupta, Mingyu Guo* [[pdf]](https://arxiv.org/abs/2109.11199)
1. **Capturing Relations between Scientific Papers: An Abstractive Model for Related Work Section Generation** *Xiuying Chen, Hind Alamro, Mingzhe Li, Shen Gao, Xiangliang Zhang, Dongyan Zhao, Rui Yan* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.473/) [[data]](https://github.com/iriscxy/relatedworkgeneration)
1. **Highlight-Transformer: Leveraging Key Phrase Aware Attention to Improve Abstractive Multi-Document Summarization** *Shuaiqi Liu, Jiannong Cao, Ruosong Yang, Zhiyuan Wen* `ACL 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-acl.445/)
1. **Entity-Aware Abstractive Multi-Document Summarization** *Hao Zhou, Weidong Ren, Gongshen Liu, Bo Su, Wei Lu* `ACL 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-acl.30/) [[code]](https://github.com/Oceandam/EMSum)
1. **TWAG: A Topic-Guided Wikipedia Abstract Generator** *Fangwei Zhu, Shangqing Tu, Jiaxin Shi, Juanzi Li, Lei Hou, Tong Cui* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.356/) [[code]](https://github.com/THU-KEG/TWAG)
1. **AgreeSum: Agreement-Oriented Multi-Document Summarization** *Richard Yuanzhe Pang, Adam D. Lelkes, Vinh Q. Tran, Cong Yu* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.02278) [[data]](https://github.com/google-research-datasets/AgreeSum)
1. **Analysis of GraphSum's Attention Weights to Improve the Explainability of Multi-Document Summarization** *M. Lautaro Hickmann, Fabian Wurzberger, Megi Hoxhalli, Arne Lochner, Jessica Töllich, Ansgar Scherp* [[pdf]](https://arxiv.org/abs/2105.11908)
1. **Extending Multi-Document Summarization Evaluation to the Interactive Setting** *Ori Shapira, Ramakanth Pasunuru, Hadar Ronen, Mohit Bansal, Yael Amsterdamer, Ido Dagan* `NAACL21` [[pdf]](https://www.aclweb.org/anthology/2021.naacl-main.54/) [[code]](https://github.com/OriShapira/InterExp)
1. **Efficiently Summarizing Text and Graph Encodings of Multi-Document Clusters** *Ramakanth Pasunuru, Mengwen Liu, Mohit Bansal, Sujith Ravi, Markus Dreyer* `NAACL21` [[pdf]](https://www.aclweb.org/anthology/2021.naacl-main.380/) [[code]](https://github.com/amazon-research/BartGraphSumm)
1. **Self-Supervised and Controlled Multi-Document Opinion Summarization** *Hady Elsahar, Maximin Coavoux, Jos Rozen, Matthias Gallé* `EACL 2021` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.141/)
1. **MS2: Multi-Document Summarization of Medical Studies** *Jay DeYoung, Iz Beltagy, Madeleine van Zuylen, Bailey Keuhl, Lucy Lu Wang* [[pdf]](https://arxiv.org/abs/2104.06486) [[data]](https://github.com/allenai/ms2)
1. **Nutri-bullets: Summarizing Health Studies by Composing Segments** *Darsh J Shah, Lili Yu, Tao Lei, Regina Barzilay* `AAAI21` [[pdf]](https://arxiv.org/abs/2103.11921) [[code]](https://github.com/darsh10/Nutribullets)
1. **Multi-document Summarization using Semantic Role Labeling and Semantic Graph for Indonesian News Article** *Yuly Haruka Berliana Gunawan, Masayu Leylia Khodra* [[pdf]](https://arxiv.org/abs/2103.03736)
1. **Flight of the PEGASUS? Comparing Transformers on Few-Shot and Zero-Shot Multi-document Abstractive Summarization** *Travis Goodwin, Max Savery, Dina Demner-Fushman* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.494/)
2. **Abstractive Multi-Document Summarization via Joint Learning with Single-Document Summarization** *Hanqi Jin, Xiaojun Wan* `Findings of EMNLP` [[pdf]](https://www.aclweb.org/anthology/2020.findings-emnlp.231/) [[code]](https://github.com/zhongxia96/MDS-and-SDS)
3. **Coarse-to-Fine Query Focused Multi-Document Summarization** *Yumo Xu, Mirella Lapata* `EMNLP20` [[pdf]](https://www.aclweb.org/anthology/2020.emnlp-main.296/) [[code]](https://github.com/yumoxu/querysum) [[code]](https://github.com/yumoxu/querysum)
4. **WSL-DS: Weakly Supervised Learning with Distant Supervision for Query Focused Multi-Document Abstractive Summarization** *Md Tahmid Rahman Laskar, Enamul Hoque, Jimmy Xiangji Huang* `COLING20 Short` [[pdf]](https://arxiv.org/abs/2011.01421) [[code]](https://github.com/tahmedge/WSL-DS-COLING-2020)
5. **AQuaMuSe: Automatically Generating Datasets for Query-Based Multi-Document Summarization** *Sayali Kulkarni, Sheide Chammas, Wan Zhu, Fei Sha, Eugene Ie* [[pdf]](https://arxiv.org/abs/2010.12694) [[data]](https://github.com/google-research-datasets/aquamuse)
6. **Multi-document Summarization with Maximal Marginal Relevance-guided Reinforcement Learning** *Yuning Mao, Yanru Qu, Yiqing Xie, Xiang Ren, Jiawei Han* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.00117) [[code]](https://github.com/morningmoni/RL-MMR.git)
7. **Heterogeneous Graph Neural Networks for Extractive Document Summarization** *Danqing Wang, Pengfei Liu, Yining Zheng, Xipeng Qiu, Xuanjing Huang* `ACL20` [[pdf]](https://arxiv.org/abs/2004.12393v1) [[code]](https://github.com/brxx122/HeterSUMGraph)
8. **Multi-Granularity Interaction Network for Extractive and Abstractive Multi-Document Summarization** *Hanqi Jin, Tianming Wang, Xiaojun Wan* `ACL20` [[pdf]](https://www.aclweb.org/anthology/2020.acl-main.556/)
9. **SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization** *Yang Gao, Wei Zhao, Steffen Eger* `ACL20` [[pdf]](https://arxiv.org/abs/2005.03724) [[code]](https://github.com/yg211/acl20-ref-free-eval.git)
10. **Leveraging Graph to Improve Abstractive Multi-Document Summarization** *Wei Li, Xinyan Xiao, Jiachen Liu, Hua Wu, Haifeng Wang, Junping Du* `ACL20` [[pdf]](https://arxiv.org/abs/2005.10043) [[code]](https://github.com/PaddlePaddle/Research/tree/master/NLP/ACL2020-GraphSum)
11. **Generating Representative Headlines for News Stories** *Xiaotao Gu, Yuning Mao, Jiawei Han, Jialu Liu, Hongkun Yu, You Wu, Cong Yu, Daniel Finnie, Jiaqi Zhai, Nicholas Zukoski* `WWW20` [[pdf]](https://arxiv.org/abs/2001.09386) [[code]](https://github.com/google-research-datasets/NewSHead.git)
12. **Learning to Create Sentence Semantic Relation Graphs for Multi-Document Summarization** *Diego Antognini, Boi Faltings* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.12231)
13. **Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization** *Sangwoo Cho, Logan Lebanoff, Hassan Foroosh, Fei Liu* `ACL19` [[pdf]](https://arxiv.org/abs/1906.00072) [[code]](https://github.com/ucfnlp/summarization-dpp-capsnet)
14. **Hierarchical Transformers for Multi-Document Summarization** *Yang Liu, Mirella Lapata* `ACL19` [[pdf]](https://arxiv.org/abs/1905.13164) [[code]](https://github.com/nlpyang/hiersumm)
15. **MeanSum: A Neural Model for Unsupervised Multi-Document Abstractive Summarization** *Eric Chu, Peter J. Liu* `ICML19` [[pdf]](https://arxiv.org/abs/1810.05739) [[code]](https://github.com/sosuperic/MeanSum)
16. **Generating Wikipedia By Summarizing Long Sequence** *Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, Noam Shazeer* `ICLR18` [[pdf]](https://arxiv.org/abs/1801.10198) [[code]](https://github.com/lucidrains/memory-compressed-attention.git)
17. **Adapting the Neural Encoder-Decoder Framework from Single to Multi-Document Summarization** *Logan Lebanoff, Kaiqiang Song, Fei Liu* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1446/) [[code]](https://github.com/ucfnlp/multidoc_summarization)
18. **Graph-based Neural Multi-Document Summarization** *Michihiro Yasunaga, Rui Zhang, Kshitijh Meelu, Ayush Pareek, Krishnan Srinivasan, Dragomir Radev* `CoNLL17` [[pdf]](https://www.aclweb.org/anthology/K17-1045/)
19. **Improving Multi-Document Summarization via Text Classification** *Ziqiang Cao, Wenjie Li, Sujian Li, Furu Wei* `AAAI17` [[pdf]](https://arxiv.org/abs/1611.09238)
20. **Automatic generation of related work through summarizing citations** *Jingqiang Chen, Hai Zhuge* [[pdf]](https://onlinelibrary.wiley.com/doi/epdf/10.1002/cpe.4261) [[data]](https://github.com/jingqiangchen/RWS-Cit)
20. **An Unsupervised Multi-Document Summarization Framework Based on Neural Document Model** *Shulei Ma, Zhi-Hong Deng, Yunlun Yang* `COLING16` [[pdf]](https://www.aclweb.org/anthology/C16-1143/)
21. **Event-Centric Summary Generation** *Lucy Vanderwende Michele Banko Arul Menezes* `ACL04` [[pdf]](https://www.microsoft.com/en-us/research/publication/event-centric-summary-generation/)
## Cross-Lingual
1. **Understanding Translationese in Cross-Lingual Summarization** *Jiaan Wang, Fandong Meng, Tingyi Zhang, Yunlong Liang, Jiarong Xu, Zhixu Li, Jie Zhou* [[pdf]](https://arxiv.org/abs/2212.07220) <details> <summary>[Abs]</summary> Given a document in a source language, cross-lingual summarization (CLS) aims at generating a concise summary in a different target language. Unlike monolingual summarization (MS), naturally occurring source-language documents paired with target-language summaries are rare. To collect large-scale CLS samples, existing datasets typically involve translation in their creation. However, the translated text is distinguished from the text originally written in that language, i.e., translationese. Though many efforts have been devoted to CLS, none of them notice the phenomenon of translationese. In this paper, we first confirm that the different approaches to constructing CLS datasets will lead to different degrees of translationese. Then we design systematic experiments to investigate how translationese affects CLS model evaluation and performance when it appears in source documents or target summaries. In detail, we find that (1) the translationese in documents or summaries of test sets might lead to the discrepancy between human judgment and automatic evaluation; (2) the translationese in training sets would harm model performance in the real scene; (3) though machine-translated documents involve translationese, they are very useful for building CLS systems on low-resource languages under specific training strategies. Furthermore, we give suggestions for future CLS research including dataset and model developments. We hope that our work could let researchers notice the phenomenon of translationese in CLS and take it into account in the future. </details>
1. **Searching for Effective Multilingual Fine-Tuning Methods: A Case Study in Summarization** *Yiwei Qin, Graham Neubig, Pengfei Liu* `` [[pdf]](https://arxiv.org/abs/2212.05740) [[code]](https://github.com/qinyiwei/Multi-Sum) <details> <summary>[Abs]</summary> Recently, a large number of tuning strategies have been proposed to adapt pre-trained language models to downstream tasks. In this paper, we perform an extensive empirical evaluation of various tuning strategies for multilingual learning, particularly in the context of text summarization. Specifically, we explore the relative advantages of three families of multilingual tuning strategies (a total of five models) and empirically evaluate them for summarization over 45 languages. Experimentally, we not only established a new state-of-the-art on the XL-Sum dataset but also derive a series of observations that hopefully can provide hints for future research on the design of multilingual tuning strategies. </details>
1. **ClidSum: A Benchmark Dataset for Cross-Lingual Dialogue Summarization** *Jiaan Wang, Fandong Meng, Ziyao Lu, Duo Zheng, Zhixu Li, Jianfeng Qu, Jie Zhou* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2202.05599) [[code]](https://github.com/krystalan/ClidSum)
1. **A Survey on Cross-Lingual Summarization** *Jiaan Wang, Fandong Meng, Duo Zheng, Yunlong Liang, Zhixu Li, Jianfeng Qu, Jie Zhou* `TACL 2022` [[pdf]](https://arxiv.org/abs/2203.12515)
1. **Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation** *Tu Vu, Aditya Barua, Brian Lester, Daniel Cer, Mohit Iyyer, Noah Constant* [[pdf]](https://arxiv.org/abs/2205.12647)
1. **MSAMSum: Towards Benchmarking Multi-lingual Dialogue Summarization** *Xiachong Feng, Xiaocheng Feng, Bing Qin* `ACL 2022 DialDoc Workshop` [[pdf]](https://aclanthology.org/2022.dialdoc-1.1/) [[data]](https://github.com/xcfcode/MSAMSum)
1. **The Cross-lingual Conversation Summarization Challenge** *Yulong Chen, Ming Zhong, Xuefeng Bai, Naihao Deng, Jing Li, Xianchao Zhu, Yue Zhang* [[pdf]](https://arxiv.org/abs/2205.00379)
1. **Neural Label Search for Zero-Shot Multi-Lingual Extractive Summarization** *Ruipeng Jia, Xingxing Zhang, Yanan Cao, Shi Wang, Zheng Lin, Furu Wei* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.42/) <details> <summary>[Abs]</summary> In zero-shot multilingual extractive text summarization, a model is typically trained on English summarization dataset and then applied on summarization datasets of other languages. Given English gold summaries and documents, sentence-level labels for extractive summarization are usually generated using heuristics. However, these monolingual labels created on English datasets may not be optimal on datasets of other languages, for that there is the syntactic or semantic discrepancy between different languages. In this way, it is possible to translate the English dataset to other languages and obtain different sets of labels again using heuristics. To fully leverage the information of these different sets of labels, we propose NLSSum (Neural Label Search for Summarization), which jointly learns hierarchical weights for these different sets of labels together with our summarization model. We conduct multilingual zero-shot summarization experiments on MLSUM and WikiLingua datasets, and we achieve state-of-the-art results using both human and automatic evaluations across these two datasets. </details>
1. **Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation** *Changtong Zan, Liang Ding, Li Shen, Yu Cao, Weifeng Liu, Dacheng Tao* [[pdf]](https://arxiv.org/abs/2204.07834)
1. **A Variational Hierarchical Model for Neural Cross-Lingual Summarization** *Yunlong Liang, Fandong Meng, Chulun Zhou, Jinan Xu, Yufeng Chen, Jinsong Su, Jie Zhou* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.148/) [[code]](https://github.com/XL2248/VHM) <details> <summary>[Abs]</summary> The goal of the cross-lingual summarization (CLS) is to convert a document in one language (e.g., English) to a summary in another one (e.g., Chinese). The CLS task is essentially the combination of machine translation (MT) and monolingual summarization (MS), and thus there exists the hierarchical relationship between MT&MS and CLS. Existing studies on CLS mainly focus on utilizing pipeline methods or jointly training an end-to-end model through an auxiliary MT or MS objective. However, it is very challenging for the model to directly conduct CLS as it requires both the abilities to translate and summarize. To address this issue, we propose a hierarchical model for the CLS task, based on the conditional variational auto-encoder. The hierarchical model contains two kinds of latent variables at the local and global levels, respectively. At the local level, there are two latent variables, one for translation and the other for summarization. As for the global level, there is another latent variable for cross-lingual summarization conditioned on the two local-level variables. Experiments on two language directions (English-Chinese) verify the effectiveness and superiority of the proposed approach. In addition, we show that our model is able to generate better cross-lingual summaries than comparison models in the few-shot setting. </details>
1. **CptGraphSum: Let key clues guide the cross-lingual abstractive summarization** *Shuyu Jiang, Dengbiao Tu, Xingshu Chen, Rui Tang, Wenxian Wang, Haizhou Wang* [[pdf]](https://arxiv.org/abs/2203.02797)
1. **CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs** *Tahmid Hasan, Abhik Bhattacharjee, Wasi Uddin Ahmad, Yuan-Fang Li, Yong-Bin Kang, Rifat Shahriyar* [[pdf]](https://arxiv.org/abs/2112.08804) [[code]](https://github.com/csebuetnlp/CrossSum)
1. **Improving Neural Cross-Lingual Summarization via Employing Optimal Transport Distance for Knowledge Distillation** *Thong Nguyen, Luu Anh Tuan* `AAAI 2022` [[pdf]](https://arxiv.org/abs/2112.03473) [[code]](https://github.com/nguyentthong/CrossSummOptimalTransport)
1. **Evaluation of Abstractive Summarisation Models with Machine Translation in Deliberative Processes** *Miguel Arana-Catania, Rob Procter, Yulan He, Maria Liakata* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.7/)
1. **Models and Datasets for Cross-Lingual Summarisation** *Laura Perez-Beltrachini, Mirella Lapata* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.742/) [[data]](https://github.com/lauhaide/clads)
1. **MassiveSumm: a very large-scale, very multilingual, news summarisation dataset** *Daniel Varab, Natalie Schluter* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.797/) [[code]](https://github.com/danielvarab/massive-summ)
1. **Bridging the Gap: Cross-Lingual Summarization with Compression Rate** *Yu Bai, Heyan Huang, Kai Fan, Yang Gao, Zewen Chi, Boxing Chen* [[pdf]](https://arxiv.org/abs/2110.07936)
1. **Contrastive Aligned Joint Learning for Multilingual Summarization** *Danqing Wang, Jiaze Chen, Hao Zhou, Xipeng Qiu, Lei Li* `ACL 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-acl.242/) [[data]](https://github.com/brxx122/CALMS)
1. **XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages** *T. Hasan, A. Bhattacharjee, M. S. Islam, K. Samin, Y. Li, Y. Kang, M. S. Rahman, R. Shahriyar* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.13822) [[data]](https://github.com/csebuetnlp/xl-sum)
1. **ZmBART: An Unsupervised Cross-lingual Transfer Framework for Language Generation** *Kaushal Kumar Maurya, Maunendra Sankar Desarkar, Yoshinobu Kano, Kumari Deepshikha* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.01597) [[code]](https://github.com/kaushal0494/ZmBART)
1. **mT6: Multilingual Pretrained Text-to-Text Transformer with Translation Pairs** *Zewen Chi, Li Dong, Shuming Ma, Shaohan Huang Xian-Ling Mao, Heyan Huang, Furu Wei* [[pdf]](https://arxiv.org/abs/2104.08692) [[code]](https://github.com/microsoft/unilm)
1. **Evaluating the Efficacy of Summarization Evaluation across Languages** *Fajri Koto, Jey Han Lau, Timothy Baldwin* `Findings of ACL 2021` [[pdf]](https://arxiv.org/abs/2106.01478)
1. **Cross-Lingual Abstractive Summarization with Limited Parallel Resources** *Yu Bai, Yang Gao, Heyan Huang* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.538/) [[code]](https://github.com/WoodenWhite/MCLAS)
1. **Unsupervised Approach to Multilingual User Comments Summarization** *Aleš Žagar, Marko Robnik-Šikonja* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.hackashop-1.13/) [[code]](https://colab.research.google.com/drive/12wUDg64k4oK24rNSd4DRZL9xywNMiPil?usp=sharing)
1. **MultiHumES: Multilingual Humanitarian Dataset for Extractive Summarization** *Jenny Paola Yela-Bello, Ewan Oglethorpe, Navid Rekabsaz* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.146/) [[data]](https://deephelp.zendesk.com/hc/en-us/sections/360011925552-MultiHumES)
1. **Cross-lingual Approach to Abstractive Summarization** *Aleš Žagar, Marko Robnik-Šikonja* [[pdf]](https://arxiv.org/abs/2012.04307)
1. **Mixed-Lingual Pre-training for Cross-lingual Summarization** *Ruochen Xu, Chenguang Zhu, Yu Shi, Michael Zeng, Xuedong Huang* `AACL20` [[pdf]](https://arxiv.org/abs/2010.08892)
2. **Multi-Task Learning for Cross-Lingual Abstractive Summarization** *Sho Takase, Naoaki Okazaki* [[pdf]](https://arxiv.org/abs/2010.07503)
3. **WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization** *Faisal Ladhak, Esin Durmus, Claire Cardie, Kathleen McKeown* `Findings of EMNLP20` [[pdf]](https://arxiv.org/abs/2010.03093) [[data]](https://github.com/esdurmus/Wikilingua)
4. **A Deep Reinforced Model for Zero-Shot Cross-Lingual Summarization with Bilingual Semantic Similarity Rewards** *Zi-Yi Dou, Sachin Kumar, Yulia Tsvetkov* `ACL20 workshop` [[pdf]](https://www.aclweb.org/anthology/2020.ngt-1.7/) [[code]](https://github.com/zdou0830/crosslingual_summarization_semantic)
5. **Jointly Learning to Align and Summarize for Neural Cross-Lingual Summarization** *Yue Cao, Hui Liu, Xiaojun Wan* `ACL20` [[pdf]](https://www.aclweb.org/anthology/2020.acl-main.554/)
6. **Attend, Translate and Summarize: An Efficient Method for Neural Cross-Lingual Summarization** *Junnan Zhu, Yu Zhou, Jiajun Zhang, Chengqing Zong* `ACL20` [[pdf]](https://www.aclweb.org/anthology/2020.acl-main.121/) [[code]](https://github.com/ZNLP/ATSum)
7. **MultiSumm: Towards a Unified Model for Multi-Lingual Abstractive Summarization** *Yue Cao, Xiaojun Wan, Jinge Yao, Dian Yu* `AAAI20` [[pdf]](https://aaai.org/ojs/index.php/AAAI/article/view/5328) [[code]](https://github.com/ycao1996/Multi-Lingual-Summarization)
8. **Cross-Lingual Natural Language Generation via Pre-Training** *Zewen Chi, Li Dong, Furu Wei, Wenhui Wang, Xian-Ling Mao, Heyan Huang* `AAAI 2020` [[pdf]](https://arxiv.org/abs/1909.10481) [[code]](https://github.com/CZWin32768/XNLG)
8. **Global Voices: Crossing Borders in Automatic News Summarization** *Khanh Nguyen, Hal Daumé III* `EMNLP19 workshop ` [[pdf]](https://arxiv.org/abs/1910.00421) [[data]](https://forms.gle/gpkJDT6RJWHM1Ztz9)
9. **NCLS: Neural Cross-Lingual Summarization** *Junnan Zhu, Qian Wang, Yining Wang, Yu Zhou, Jiajun Zhang, Shaonan Wang, Chengqing Zong* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.00156) [[code]](http://www.nlpr.ia.ac.cn/cip/dataset.htm)
10. **Zero-Shot Cross-Lingual Abstractive Sentence Summarization through Teaching Generation and Attention** *Xiangyu Duan, Mingming Yin, Min Zhang, Boxing Chen, Weihua Luo* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1305/) [[code]](https://github.com/KelleyYin/Cross-lingual-Summarization)
11. **A Robust Abstractive System for Cross-Lingual Summarization** *Jessica Ouyang, Boya Song, Kathy McKeown* `NAACL19` [[pdf]](https://www.aclweb.org/anthology/N19-1204/)
12. **Cross-Lingual Korean Speech-to-Text Summarization** *HyoJeon Yoon, Dinh Tuyen Hoang, Ngoc Thanh Nguyen, Dosam Hwang* `ACIIDS19` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-030-14799-0_17)
13. **Cross-language document summarization via extraction and ranking of multiple summaries** *Xiaojun Wan, Fuli Luo, Xue Sun, Songfang Huang & Jin-ge Yao* [[pdf]](https://link.springer.com/article/10.1007/s10115-018-1152-7)
14. **Zero-Shot Cross-Lingual Neural Headline Generation** *Shi-qi Shen, Yun Chen, Cheng Yang, Zhi-yuan Liu, Mao-song Sun* `TASLP18` [[pdf]](https://dl.acm.org/doi/10.1109/TASLP.2018.2842432)
15. **Cross-Language Text Summarization using Sentence and Multi-Sentence Compression** *Elvys Linhares Pontes, Stéphane Huet, Juan-Manuel Torres-Moreno, Andréa Carneiro Linhares* `NLDB18` [[pdf]](https://hal.archives-ouvertes.fr/hal-01779465/document)
16. **Abstractive Cross-Language Summarization via Translation Model Enhanced Predicate Argument Structure Fusing** *Jiajun Zhang, Yu Zhou, Chengqing Zong* `TASLP16` [[pdf]](http://www.nlpr.ia.ac.cn/cip/ZhangPublications/zhang-taslp-2016.pdf)
17. **Phrase-based Compressive Cross-Language Summarization** *Jin-ge Yao ,Xiaojun Wan ,Jianguo Xiao* `EMNLP15` [[pdf]](https://www.aclweb.org/anthology/D15-1012.pdf)
18. **Multilingual Single-Document Summarization with MUSE** *Marina Litvak, Mark Last* `MultiLing13` [[pdf]](https://www.aclweb.org/anthology/W13-3111/)
19. **Using bilingual information for cross-language document summarization** *Xiaojun Wan* `ACL11` [[pdf]](https://www.aclweb.org/anthology/P11-1155.pdf)
1. **A Graph-based Approach to Cross-language Multi-document Summarization** *Florian Boudin, Stéphane Huet, Juan-Manuel Torres-Moreno* [[pdf]](https://hal.archives-ouvertes.fr/hal-02021891/file/Polibits11.pdf)
1. **Cross-language document summarization based on machine translation quality prediction** *Xiaojun Wan, Huiying Li, Jianguo Xiao* `ACL10` [[pdf]](https://www.aclweb.org/anthology/P10-1094/)
1. **Evaluation of a Cross-lingual Romanian-English Multi-document Summariser** *Constantin Orasan, Oana Andreea Chiorean* `LREC08` [[pdf]](http://www.lrec-conf.org/proceedings/lrec2008/pdf/539_paper.pdf)
1. **Cross-lingual C\*ST\*RD: English access to Hindi information** *Anton Leuski, Chin-Yew Lin, Liang Zhou, Ulrich Germann, Franz Josef Och, Eduard Hovy* [[pdf]](https://dl.acm.org/doi/10.1145/979872.979877)
## Multi-modal
1. **Assist Non-native Viewers: Multimodal Cross-Lingual Summarization for How2 Videos** *Nayu Liu, Kaiwen Wei, Xian Sun, Hongfeng Yu, Fanglong Yao, Li Jin, Guo Zhi, Guangluan Xu* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.468/) [[data]](https://github.com/korokes/MCLS) <details> <summary>[Abs]</summary> Multimodal summarization for videos aims to generate summaries from multi-source information (videos, audio transcripts), which has achieved promising progress. However, existing works are restricted to monolingual video scenarios, ignoring the demands of non-native video viewers to understand the cross-language videos in practical applications. It stimulates us to propose a new task, named Multimodal Cross-Lingual Summarization for videos (MCLS), which aims to generate cross-lingual summaries from multimodal inputs of videos. First, to make it applicable to MCLS scenarios, we conduct a Video-guided Dual Fusion network (VDF) that integrates multimodal and cross-lingual information via diverse fusion strategies at both encoder and decoder. Moreover, to alleviate the problem of high annotation costs and limited resources in MCLS, we propose a triple-stage training framework to assist MCLS by transferring the knowledge from monolingual multimodal summarization data, which includes: 1) multimodal summarization on sufficient prevalent language videos with a VDF model; 2) knowledge distillation (KD) guided adjustment on bilingual transcripts; 3) multimodal summarization for cross-lingual videos with a KD induced VDF model. Experiment results on the reorganized How2 dataset show that the VDF model alone outperforms previous methods for multimodal summarization, and the performance further improves by a large margin via the proposed triple-stage training framework. </details>
1. **TLDW: Extreme Multimodal Summarisation of News Videos** *Peggy Tang, Kun Hu, Lei Zhang, Jiebo Luo, Zhiyong Wang* [[pdf]](https://arxiv.org/abs/2210.08481) <details> <summary>[Abs]</summary> Multimodal summarisation with multimodal output is drawing increasing attention due to the rapid growth of multimedia data. While several methods have been proposed to summarise visual-text contents, their multimodal outputs are not succinct enough at an extreme level to address the information overload issue. To the end of extreme multimodal summarisation, we introduce a new task, eXtreme Multimodal Summarisation with Multimodal Output (XMSMO) for the scenario of TL;DW - Too Long; Didn't Watch, akin to TL;DR. XMSMO aims to summarise a video-document pair into a summary with an extremely short length, which consists of one cover frame as the visual summary and one sentence as the textual summary. We propose a novel unsupervised Hierarchical Optimal Transport Network (HOT-Net) consisting of three components: hierarchical multimodal encoders, hierarchical multimodal fusion decoders, and optimal transport solvers. Our method is trained, without using reference summaries, by optimising the visual and textual coverage from the perspectives of the distance between the semantic distributions under optimal transport plans. To facilitate the study on this task, we collect a large-scale dataset XMSMO-News by harvesting 4,891 video-document pairs. The experimental results show that our method achieves promising performance in terms of ROUGE and IoU metrics. </details>
1. **Hierarchical3D Adapters for Long Video-to-text Summarization** *Pinelopi Papalampidi, Mirella Lapata* [[pdf]](https://arxiv.org/abs/2210.04829) <details> <summary>[Abs]</summary> In this paper, we focus on video-to-text summarization and investigate how to best utilize multimodal information for summarizing long inputs (e.g., an hour-long TV show) into long outputs (e.g., a multi-sentence summary). We extend SummScreen (Chen et al., 2021), a dialogue summarization dataset consisting of transcripts of TV episodes with reference summaries, and create a multimodal variant by collecting corresponding full-length videos. We incorporate multimodal information into a pre-trained textual summarizer efficiently using adapter modules augmented with a hierarchical structure while tuning only 3.8\% of model parameters. Our experiments demonstrate that multimodal information offers superior performance over more memory-heavy and fully fine-tuned textual summarization methods. </details>
1. **Modeling Paragraph-Level Vision-Language Semantic Alignment for Multi-Modal Summarization** *Xinnian Liang, Chenhao Cui, Shuangzhi Wu, Jiali Zeng, Yufan Jiang, Zhoujun Li* [[pdf]](https://arxiv.org/abs/2208.11303) <details> <summary>[Abs]</summary> Most current multi-modal summarization methods follow a cascaded manner, where an off-the-shelf object detector is first used to extract visual features, then these features are fused with language representations to generate the summary with an encoder-decoder model. The cascaded way cannot capture the semantic alignments between images and paragraphs, which are crucial to a precise summary. In this paper, we propose ViL-Sum to jointly model paragraph-level \textbf{Vi}sion-\textbf{L}anguage Semantic Alignment and Multi-Modal \textbf{Sum}marization. The core of ViL-Sum is a joint multi-modal encoder with two well-designed tasks, image reordering and image selection. The joint multi-modal encoder captures the interactions between modalities, where the reordering task guides the model to learn paragraph-level semantic alignment and the selection task guides the model to selected summary-related images in the final summary. Experimental results show that our proposed ViL-Sum significantly outperforms current state-of-the-art methods. In further analysis, we find that two well-designed tasks and joint multi-modal encoder can effectively guide the model to learn reasonable paragraphs-images and summary-images relations. </details>
1. **MHMS: Multimodal Hierarchical Multimedia Summarization** *Jielin Qiu, Jiacheng Zhu, Mengdi Xu, Franck Dernoncourt, Trung Bui, Zhaowen Wang, Bo Li, Ding Zhao, Hailin Jin* [[pdf]](https://arxiv.org/abs/2204.03734)
1. **Video Summarization Based on Video-text Representation** *Li Haopeng, Ke Qiuhong, Gong Mingming, Zhang Rui* [[pdf]](https://arxiv.org/abs/2201.02494)
1. **UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation** *Zhengkun Zhang, Xiaojun Meng, Yasheng Wang, Xin Jiang, Qun Liu, Zhenglu Yang* `AAAI 2022` [[pdf]](https://arxiv.org/abs/2109.05812)
1. **Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization** *Litian Zhang, Xiaoming Zhang, Junshu Pan, Feiran Huang* `AAAI 2022` [[pdf]](https://arxiv.org/abs/2112.12072) [[data]](https://github.com/LitianD/HCSCL-MSDataset)
1. **Attention-based Multi-hypothesis Fusion for Speech Summarization** *Takatomo Kano, Atsunori Ogawa, Marc Delcroix, Shinji Watanabe* [[pdf]](https://arxiv.org/abs/2111.08201)
1. **Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization** *Tiezheng Yu, Wenliang Dai, Zihan Liu, Pascale Fung* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.02401) [[code]](https://github.com/HLTCHKUST/VG-GPLMs)
1. **Multi-Modal Supplementary-Complementary Summarization using Multi-Objective Optimization** *Anubhav Jangra, Sriparna Saha, Adam Jatowt, Mohammad Hasanuzzaman* `SIGIR 2021` [[pdf]](https://dl.acm.org/doi/10.1145/3404835.3462877)
1. **Self-Supervised Multimodal Opinion Summarization** *Jinbae Im, Moonki Kim, Hoyeop Lee, Hyunsouk Cho, Sehee Chung* `ACL21` [[pdf]](https://aclanthology.org/2021.acl-long.33/) [[code]](https://github.com/nc-ai/knowledge/tree/master/publications/MultimodalSum)
1. **GPT2MVS: Generative Pre-trained Transformer-2 for Multi-modal Video Summarization** *Jia-Hong Huang, Luka Murn, Marta Mrak, Marcel Worring* `ICMR21` [[pdf]](https://arxiv.org/abs/2104.12465)
1. **Multimodal Sentence Summarization via Multimodal Selective Encoding** *Haoran Li, Junnan Zhu, Jiajun Zhang, Xiaodong He, Chengqing Zong* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.496/)
1. **Multistage Fusion with Forget Gate for Multimodal Summarization in Open-Domain Videos** *Nayu Liu, Xian Sun, Hongfeng Yu, Wenkai Zhang, Guangluan Xu* `EMNLP20` [[pdf]](https://www.aclweb.org/anthology/2020.emnlp-main.144/)
1. **MAST: Multimodal Abstractive Summarization with Trimodal Hierarchical Attention** *Aman Khullar, Udit Arora* `EMNLP20 Workshop` [[pdf]](https://arxiv.org/abs/2010.08021) [[code]](https://github.com/amankhullar/mast)
2. **VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles** *Mingzhe Li, Xiuying Chen, Shen Gao, Zhangming Chan, Dongyan Zhao, Rui Yan* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.05406) [[data]](https://github.com/yingtaomj/VMSMO)
3. **Multi-modal Summarization for Video-containing Documents** *Xiyan Fu, Jun Wang, Zhenglu Yang* [[pdf]](https://arxiv.org/abs/2009.08018) [[code]](https://github.com/xiyan524/MM-AVS)
4. **Text-Image-Video Summary Generation Using Joint Integer Linear Programming** *Anubhav Jangra, Adam Jatowt, Mohammad Hasanuzzaman, Sriparna Saha* `ECIR20` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-030-45442-5_24)
5. **Aspect-Aware Multimodal Summarization for Chinese E-Commerce Products** *Haoran Li, Peng Yuan, Song Xu, Youzheng Wu, Xiaodong He, Bowen Zhou* `AAAI20` [[pdf]](https://aaai.org/ojs/index.php/AAAI/article/view/6332/6188) [[code]](https://github.com/hrlinlp/cepsum)
6. **Convolutional Hierarchical Attention Network for Query-Focused Video Summarization** *Shuwen Xiao, Zhou Zhao, Zijian Zhang, Xiaohui Yan, Min Yang* `AAAI20` [[pdf]](https://arxiv.org/abs/2002.03740)
7. **Multimodal Summarization with Guidance of Multimodal Reference** *Junnan Zhu, Yu Zhou, Jiajun Zhang, Haoran Li, Chengqing Zong, Changliang Li* `AAAI20` [[pdf]](https://aaai.org/ojs/index.php/AAAI/article/view/6525/6381)
8. **EmotionCues: Emotion-Oriented Visual Summarization of Classroom Videos** *Haipeng Zeng, Xinhuan Shu, Yanbang Wang, Yong Wang, Liguo Zhang, Ting-Chuen Pong, Huamin Qu* [[pdf]](https://ieeexplore.ieee.org/document/8948010)
9. **A Survey on Automatic Summarization Using Multi-Modal Summarization System for Asynchronous Collections** *Shilpadevi Vasant Bhagwat, Sheetal .S. Thokal* [[pdf]](http://www.ijirset.com/upload/2019/february/4_shilpa_IEEE.pdf)
10. **Extractive summarization of documents with images based on multi-modal RNN** *Jingqiang Chen, Hai Zhuge* [[pdf]](https://research.aston.ac.uk/en/publications/extractive-summarization-of-documents-with-images-based-on-multi-)
11. **Keep Meeting Summaries on Topic: Abstractive Multi-Modal Meeting Summarization** *Manling Li, Lingyu Zhang, Heng Ji, Richard J. Radke* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1210/)
12. **Multimodal Abstractive Summarization for How2 Videos** *Shruti Palaskar, Jindřich Libovický, Spandana Gella, Florian Metze* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1659/)
13. **MSMO: Multimodal Summarization with Multimodal Output** *Junnan Zhu, Haoran Li, Tianshang Liu, Yu Zhou, Jiajun Zhang, Chengqing Zong* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1448/) [[data]](http://www.nlpr.ia.ac.cn/cip/jjzhang.htm)
14. **Abstractive Text-Image Summarization Using Multi-Modal Attentional Hierarchical RNN** *Jingqiang Chen, Hai Zhuge* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1438/)
15. **Multi-modal Sentence Summarization with Modality Attention and Image Filtering** *Haoran Li, Junnan Zhu, Tianshang Liu, Jiajun Zhang, Chengqing Zong* `IJCAI18` [[pdf]](https://www.ijcai.org/Proceedings/2018/0577.pdf)
16. **Multimodal Abstractive Summarization for Open-Domain Videos** *Jindrich Libovický, Shruti Palaskar, Spandana Gella, Florian Metze* `NIPS18` [[pdf]](https://nips2018vigil.github.io/static/papers/accepted/8.pdf) [[data]](https://github.com/srvk/how2-dataset)
17. **Read, Watch, Listen, and Summarize: Multi-Modal Summarization for Asynchronous Text, Image, Audio and Video** *Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, Chengqing Zong* [[pdf]](https://ieeexplore.ieee.org/document/8387512)
18. **Fusing Verbal and Nonverbal Information for Extractive Meeting Summarization** *Fumio Nihei, Yukiko Nakano, Yukiko I. Nakano, Yutaka Takase, Yutaka Takase* `GIFT18` [[pdf]](https://dl.acm.org/doi/10.1145/3279981.3279987)
19. **Multi-modal Summarization for Asynchronous Collection of Text, Image, Audio and Video** *Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, Chengqing Zong* `EMNLP17` [[pdf]](https://www.aclweb.org/anthology/D17-1114/)
20. **Meeting Extracts for Discussion Summarization Based on Multimodal Nonverbal Information** *Fumio Nihei, Yukiko Nakano, Yukiko I. Nakano, Yutaka Takase, Yutaka Takase* `ICMI16` [[pdf]](https://dl.acm.org/doi/10.1145/2993148.2993160)
21. **Summarizing a multimodal set of documents in a Smart Room** *Maria Fuentes, Horacio Rodríguez, Jordi Turmo* `LREC12` [[pdf]](https://www.aclweb.org/anthology/L12-1524/)
22. **Multi-modal summarization of key events and top players in sports tournament videos** *Dian Tjondronegoro, Xiaohui Tao, Johannes Sasongko and Cher Han Lau* [[pdf]](https://eprints.qut.edu.au/43479/1/WACV_266_%281%29.pdf)
23. **Multimodal Summarization of Complex Sentences** *Naushad UzZaman, Jeffrey P. Bigham, James F. Allen* [[pdf]](https://www.cs.cmu.edu/~jbigham/pubs/pdfs/2011/multimodal_summarization.pdf)
24. **Summarization of Multimodal Information** *Saif Ahmad, Paulo C F de Oliveira, Khurshid Ahmad* `LREC04` [[pdf]](http://www.lrec-conf.org/proceedings/lrec2004/pdf/502.pdf)
25. **Multimodal Summarization of Meeting Recordings** *Berna Erol, Dar-Shyang Lee, and Jonathan Hull* `ICME03` [[pdf]](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.862.6509&rep=rep1&type=pdf)
## Sentiment Related
1. **Why Do You Feel This Way? Summarizing Triggers of Emotions in Social Media Posts** *Hongli Zhan, Tiberiu Sosea, Cornelia Caragea, Junyi Jessy Li* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.642/) [[code]](https://github.com/honglizhan/CovidET) <details> <summary>[Abs]</summary> Crises such as the COVID-19 pandemic continuously threaten our world and emotionally affect billions of people worldwide in distinct ways. Understanding the triggers leading to people’s emotions is of crucial importance. Social media posts can be a good source of such analysis, yet these texts tend to be charged with multiple emotions, with triggers scattering across multiple sentences. This paper takes a novel angle, namely, emotion detection and trigger summarization, aiming to both detect perceived emotions in text, and summarize events and their appraisals that trigger each emotion. To support this goal, we introduce CovidET (Emotions and their Triggers during Covid-19), a dataset of ~1,900 English Reddit posts related to COVID-19, which contains manual annotations of perceived emotions and abstractive summaries of their triggers described in the post. We develop strong baselines to jointly detect emotions and summarize emotion triggers. Our analyses show that CovidET presents new challenges in emotion-specific summarization, as well as multi-emotion detection in long social media posts. </details>
1. **Making the Best Use of Review Summary for Sentiment Analysis** *Sen Yang, Leyang Cui, Jun Xie, Yue Zhang* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.15/) [[code]](https://github.com/RingoS/sentiment-review-summary) [[bib]](https://www.aclweb.org/anthology/2020.coling-main.15.bib)
1. **A Unified Dual-view Model for Review Summarization and Sentiment Classification with Inconsistency Loss** *Hou Pong Chan, Wang Chen, Irwin King* `SIGIR20` [[pdf]](https://arxiv.org/abs/2006.01592) [[code]](https://github.com/kenchan0226/dual_view_review_sum)
2. **A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classification** *Shuming Ma, Xu Sun, Junyang Lin, Xuancheng Ren* `IJCAI18` [[pdf]](https://arxiv.org/abs/1805.01089)
3. **Two-level Text Summarization from Online News Sources with Sentiment Analysis** *Tarun B. Mirani, Sreela Sasi* `IEEE17` [[pdf]](https://ieeexplore.ieee.org/document/8076735)
4. **Creating Video Summarization From Emotion Perspective** *Yijie Lan, Shikui Wei, Ruoyu Liu, Yao Zhao* `ICSP16` [[pdf]](https://ieeexplore.ieee.org/document/7878001/)
## Pre-trained Language Model Based
1. **Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization** *Pengcheng He, Baolin Peng, Liyang Lu, Song Wang, Jie Mei, Yang Liu, Ruochen Xu, Hany Hassan Awadalla, Yu Shi, Chenguang Zhu, Wayne Xiong, Michael Zeng, Jianfeng Gao, Xuedong Huang* [[pdf]](https://arxiv.org/abs/2208.09770) <details> <summary>[Abs]</summary> This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models. </details>
1. **MVP: Multi-task Supervised Pre-training for Natural Language Generation** *Tianyi Tang, Junyi Li, Wayne Xin Zhao, Ji-Rong Wen* [[pdf]](https://arxiv.org/abs/2206.12131) [[code]](https://github.com/RUCAIBox/MVP) <details> <summary>[Abs]</summary> Pre-trained language models (PLMs) have achieved notable success in natural language generation (NLG) tasks. Up to now, most of the PLMs are pre-trained in an unsupervised manner using large-scale general corpus. In the meanwhile, an increasing number of models pre-trained with less labeled data showcase superior performance compared to unsupervised models. Motivated by the success of supervised pre-training, we propose Multi-task superVised Pre-training (MVP) for natural language generation. For pre-training the text generation model MVP, we collect a labeled pre-training corpus from 45 datasets over seven generation tasks. For each task, we further pre-train specific soft prompts to stimulate the model capacity in performing a specific task. Extensive experiments have demonstrated the effectiveness of our supervised pre-training in a number of NLG tasks, and our general methods achieve state-of-the-art performance on 12 of 17 datasets. </details>
1. **E2S2: Encoding-Enhanced Sequence-to-Sequence Pretraining for Language Understanding and Generation** *Qihuang Zhong, Liang Ding, Juhua Liu, Bo Du, Dacheng Tao* [[pdf]](https://arxiv.org/abs/2205.14912)
2. **Does Pretraining for Summarization Require Knowledge Transfer?** *Kundan Krishna, Jeffrey Bigham, Zachary C. Lipton* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.273/) [[code]](https://github.com/acmi-lab/pretraining-with-nonsense)
3. **ARMAN: Pre-training with Semantically Selecting and Reordering of Sentences for Persian Abstractive Summarization** *Alireza Salemi, Emad Kebriaei, Ghazal Neisi Minaei, Azadeh Shakery* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.741/) [[code]](https://github.com/alirezasalemi7/ARMAN)
4. **Leveraging Lead Bias for Zero-shot Abstractive News Summarization** *Chenguang Zhu, Ziyi Yang, Robert Gmyr, Michael Zeng, Xuedong Huang* `SIGIR 2021` [[pdf]](https://dl.acm.org/doi/10.1145/3404835.3462846)
5. **ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation** *Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, Weixin Liu, Zhihua Wu, Weibao Gong, Jianzhong Liang, Zhizhou Shang, Peng Sun, Wei Liu, Xuan Ouyang, Dianhai Yu, Hao Tian, Hua Wu, Haifeng Wang* [[pdf]](https://arxiv.org/abs/2107.02137)
6. **BANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining** *Weizhen Qi, Yeyun Gong, Jian Jiao, Yu Yan, Weizhu Chen, Dayiheng Liu, Kewen Tang, Houqiang Li, Jiusheng Chen, Ruofei Zhang, Ming Zhou, Nan Duan* `ICML 2021` [[pdf]](https://arxiv.org/abs/2012.15525) [[code]](https://github.com/microsoft/BANG)
7. **Fact-level Extractive Summarization with Hierarchical Graph Mask on BERT** *Ruifeng Yuan, Zili Wang, Wenjie Li* `COLING20` [[pdf]](https://arxiv.org/abs/2011.09739) [[code]](https://github.com/Ruifeng-paper/FactExsum-coling2020)
8. **Towards Zero-Shot Conditional Summarization with Adaptive Multi-Task Fine-Tuning** *Travis Goodwin, Max Savery, Dina Demner-Fushman* `Findings of EMNLP` [[pdf]](https://www.aclweb.org/anthology/2020.findings-emnlp.289/) [[code]](https://github.com/h4ste/mtft_zsl)
9. **Improving Zero and Few-Shot Abstractive Summarization with Intermediate Fine-tuning and Data Augmentation** *Alexander R. Fabbri, Simeng Han, Haoyuan Li, Haoran Li, Marjan Ghazvininejad, Shafiq Joty, Dragomir Radev, Yashar Mehdad* [[pdf]](https://arxiv.org/abs/2010.12836)
10. **Pre-trained Summarization Distillation** *Sam Shleifer, Alexander M. Rush* [[pdf]](https://arxiv.org/abs/2010.13002) [[code]](https://github.com/huggingface/transformers)
11. **Pre-training for Abstractive Document Summarization by Reinstating Source Text** *Yanyan Zou, Xingxing Zhang, Wei Lu, Furu Wei, Ming Zhou* `EMNLP20` [[pdf]](https://arxiv.org/abs/2004.01853v3) [[code]](https://github.com/zoezou2015/abs_pretraining)
12. **PALM: Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation** *Bin Bi, Chenliang Li, Chen Wu, Ming Yan, Wei Wang, Songfang Huang, Fei Huang, Luo Si* `EMNLP20` [[pdf]](https://arxiv.org/abs/2004.07159)
13. **TED: A Pretrained Unsupervised Summarization Model with Theme Modeling and Denoising** *Ziyi Yang Chenguang Zhu Robert Gmyr Michael Zeng Xuedong Huang Eric Darve* `Findings of EMNLP20` [[pdf]](https://arxiv.org/abs/2001.00725)
14. **QURIOUS: Question Generation Pretraining for Text Generation** *Shashi Narayan, Gonçalo Simoes, Ji Ma, Hannah Craighead, Ryan Mcdonald* `ACL20 Short` [[pdf]](https://arxiv.org/abs/2004.11026)
15. **PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization** *Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu* `ICML20` [[pdf]](https://arxiv.org/abs/1912.08777) [[code]](https://github.com/google-research/pegasus)
16. **Abstractive Text Summarization based on Language Model Conditioning and Locality Modeling** *Dmitrii Aksenov, Julián Moreno-Schneider, Peter Bourgonje, Robert Schwarzenberg, Leonhard Hennig, Georg Rehm* `LREC20` [[pdf]](https://arxiv.org/abs/2003.13027)
17. **Abstractive Summarization with Combination of Pre-trained Sequence-to-Sequence and Saliency Models** *Dmitrii Aksenov, Julián Moreno-Schneider, Peter Bourgonje, Robert Schwarzenberg, Leonhard Hennig, Georg Rehm* [[pdf]](https://arxiv.org/abs/2003.13028)
18. **Learning by Semantic Similarity Makes Abstractive Summarization Better** *Wonjin Yoon, Yoon Sun Yeo, Minbyul Jeong, Bong-Jun Yi, Jaewoo Kang* `ICML20` [[pdf]](https://arxiv.org/abs/2002.07767) [[code]](https://github.com/icml-2020-nlp/semsim)
19. **Text Summarization with Pretrained Encoders** *Yang Liu, Mirella Lapata* `EMNLP19` [[pdf]](https://arxiv.org/abs/1908.08345) [[code]](https://github.com/nlpyang/PreSumm)
20. **HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization** *Xingxing Zhang, Furu Wei, Ming Zhou* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1499/)
21. **MASS: Masked Sequence to Sequence Pre-training for Language Generation** *Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu* `ICML19` [[pdf]](https://arxiv.org/abs/1905.02450) [[code]](https://github.com/microsoft/MASS)
22. **Pretraining-Based Natural Language Generation for Text Summarization** *Haoyu Zhang, Jianjun Xu, Ji Wang* [[pdf]](https://arxiv.org/abs/1902.09243)
23. **Fine-tune BERT for Extractive Summarization** *Yang Liu* [[pdf]](https://arxiv.org/abs/1903.10318) [[code]](https://github.com/nlpyang/BertSum)
24. **Unified Language Model Pre-training for Natural Language Understanding and Generation** *Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon* `NIPS19` [[pdf]](https://arxiv.org/abs/1905.03197) [[code]](https://github.com/microsoft/unilm)
25. **Self-Supervised Learning for Contextualized Extractive Summarization** *Hong Wang, Xin Wang, Wenhan Xiong, Mo Yu, Xiaoxiao Guo, Shiyu Chang, William Yang Wang* `ACL19` [[pdf]](https://arxiv.org/abs/1906.04466) [[code]](https://github.com/hongwang600/Summarization)
26. **Efficient Adaptation of Pretrained Transformers for Abstractive Summarization** *Andrew Hoang, Antoine Bosselut, Asli Celikyilmaz, Yejin Choi* [[pdf]](https://arxiv.org/abs/1906.00138) [[code]](https://github.com/Andrew03/transformer-abstractive-summarization)
## Controllable
1. **HydraSum: Disentangling Style Features in Text Summarization with Multi-Decoder Models** *Tanya Goyal, Nazneen Rajani, Wenhao Liu, Wojciech Kryscinski* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.30/) [[code]](https://github.com/salesforce/hydra-sum) <details> <summary>[Abs]</summary> Summarization systems make numerous “decisions” about summary properties during inference, e.g. degree of copying, specificity and length of outputs, etc. However, these are implicitly encoded within model parameters and specific styles cannot be enforced. To address this, we introduce HydraSum, a new summarization architecture that extends the single decoder framework of current models to a mixture-of-experts version with multiple decoders. We show that HydraSum’s multiple decoders automatically learn contrasting summary styles when trained under the standard training objective without any extra supervision. Through experiments on three summarization datasets (CNN, Newsroom and XSum), we show that HydraSum provides a simple mechanism to obtain stylistically-diverse summaries by sampling from either individual decoders or their mixtures, outperforming baseline models. Finally, we demonstrate that a small modification to the gating strategy during training can enforce an even stricter style partitioning, e.g. high- vs low-abstractiveness or high- vs low-specificity, allowing users to sample from a larger area in the generation space and vary summary styles along multiple dimensions. </details>
1. **Socratic Pretraining: Question-Driven Pretraining for Controllable Summarization** *Artidoro Pagnoni, Alexander R. Fabbri, Wojciech Kryściński, Chien-Sheng Wu* [[pdf]](https://arxiv.org/abs/2212.10449) [[code]](https://github.com/salesforce/socratic-pretraining) <details> <summary>[Abs]</summary> In long document controllable summarization, where labeled data is scarce, pretrained models struggle to adapt to the task and effectively respond to user queries. In this paper, we introduce Socratic pretraining, a question-driven, unsupervised pretraining objective specifically designed to improve controllability in summarization tasks. By training a model to generate and answer relevant questions in a given context, Socratic pretraining enables the model to more effectively adhere to user-provided queries and identify relevant content to be summarized. We demonstrate the effectiveness of this approach through extensive experimentation on two summarization domains, short stories and dialogue, and multiple control strategies: keywords, questions, and factoid QA pairs. Our pretraining method relies only on unlabeled documents and a question generation system and outperforms pre-finetuning approaches that use additional supervised data. Furthermore, our results show that Socratic pretraining cuts task-specific labeled data requirements in half, is more faithful to user-provided queries, and achieves state-of-the-art performance on QMSum and SQuALITY. </details>
1. **Attend to the Right Context: A Plug-and-Play Module for Content-Controllable Summarization** *Wen Xiao, Lesly Miculicich, Yang Liu, Pengcheng He, Giuseppe Carenini* [[pdf]](https://arxiv.org/abs/2212.10819) [[code]](https://github.com/Wendy-Xiao/relattn_controllable_summ) <details> <summary>[Abs]</summary> Content-Controllable Summarization generates summaries focused on the given controlling signals. Due to the lack of large-scale training corpora for the task, we propose a plug-and-play module RelAttn to adapt any general summarizers to the content-controllable summarization task. RelAttn first identifies the relevant content in the source documents, and then makes the model attend to the right context by directly steering the attention weight. We further apply an unsupervised online adaptive parameter searching algorithm to determine the degree of control in the zero-shot setting, while such parameters are learned in the few-shot setting. By applying the module to three backbone summarization models, experiments show that our method effectively improves all the summarizers, and outperforms the prefix-based method and a widely used plug-and-play model in both zero- and few-shot settings. Tellingly, more benefit is observed in the scenarios when more control is needed. </details>
1. **MACSUM: Controllable Summarization with Mixed Attributes** *Yusen Zhang, Yang Liu, Ziyi Yang, Yuwei Fang, Yulong Chen, Dragomir Radev, Chenguang Zhu, Michael Zeng, Rui Zhang* [[pdf]](https://arxiv.org/abs/2211.05041) [[code]](https://github.com/psunlpgroup/MACSum) <details> <summary>[Abs]</summary> Controllable summarization allows users to generate customized summaries with specified attributes. However, due to the lack of designated annotations of controlled summaries, existing works have to craft pseudo datasets by adapting generic summarization benchmarks. Furthermore, most research focuses on controlling single attributes individually (e.g., a short summary or a highly abstractive summary) rather than controlling a mix of attributes together (e.g., a short and highly abstractive summary). In this paper, we propose MACSum, the first human-annotated summarization dataset for controlling mixed attributes. It contains source texts from two domains, news articles and dialogues, with human-annotated summaries controlled by five designed attributes (Length, Extractiveness, Specificity, Topic, and Speaker). We propose two simple and effective parameter-efficient approaches for the new task of mixed controllable summarization based on hard prompt tuning and soft prefix tuning. Results and analysis demonstrate that hard prompt models yield the best performance on all metrics and human evaluations. However, mixed-attribute control is still challenging for summarization tasks. Our dataset and code are available at this https URL. </details>
1. **SentBS: Sentence-level Beam Search for Controllable Summarization** *Chenhui Shen, Liying Cheng, Lidong Bing, Yang You, Luo Si* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.14502) [[code]](https://github.com/Shen-Chenhui/SentBS) <details> <summary>[Abs]</summary> A wide range of control perspectives have been explored in controllable text generation. Structure-controlled summarization is recently proposed as a useful and interesting research direction. However, current structure-controlling methods have limited effectiveness in enforcing the desired structure. To address this limitation, we propose a sentence-level beam search generation method (SentBS), where evaluation is conducted throughout the generation process to select suitable sentences for subsequent generations. We experiment with different combinations of decoding methods to be used as subcomponents by SentBS and evaluate results on the structure-controlled dataset MReD. Experiments show that all explored combinations for SentBS can improve the agreement between the generated text and the desired structure, with the best method significantly reducing the structural discrepancies suffered by the existing model, by approximately 68%. </details>
1. **Readability Controllable Biomedical Document Summarization** *Readability Controllable Biomedical Document Summarization* `Findings of EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.04705) <details> <summary>[Abs]</summary> Different from general documents, it is recognised that the ease with which people can understand a biomedical text is eminently varied, owing to the highly technical nature of biomedical documents and the variance of readers' domain knowledge. However, existing biomedical document summarization systems have paid little attention to readability control, leaving users with summaries that are incompatible with their levels of expertise. In recognition of this urgent demand, we introduce a new task of readability controllable summarization for biomedical documents, which aims to recognise users' readability demands and generate summaries that better suit their needs: technical summaries for experts and plain language summaries (PLS) for laymen. To establish this task, we construct a corpus consisting of biomedical papers with technical summaries and PLSs written by the authors, and benchmark multiple advanced controllable abstractive and extractive summarization models based on pre-trained language models (PLMs) with prevalent controlling and generation techniques. Moreover, we propose a novel masked language model (MLM) based metric and its variant to effectively evaluate the readability discrepancy between lay and technical summaries. Experimental results from automated and human evaluations show that though current control techniques allow for a certain degree of readability adjustment during generation, the performance of existing controllable summarization methods is far from desirable in this task. </details>
1. **EDU-level Extractive Summarization with Varying Summary Lengths** *Yuping Wu, Ching-Hsun Tseng, Jiayu Shang, Shengzhong Mao, Goran Nenadic, Xiao-Jun Zeng* `` [[pdf]](https://arxiv.org/abs/2210.04029) <details> <summary>[Abs]</summary> Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various k values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models. </details>
1. **Topic-Aware Evaluation and Transformer Methods for Topic-Controllable Summarization** *Tatiana Passali, Grigorios Tsoumakas* `` [[pdf]](https://arxiv.org/abs/2206.04317) [[code]]() <details> <summary>[Abs]</summary> Topic-controllable summarization is an emerging research area with a wide range of potential applications. However, existing approaches suffer from significant limitations. First, there is currently no established evaluation metric for this task. Furthermore, existing methods built upon recurrent architectures, which can significantly limit their performance compared to more recent Transformer-based architectures, while they also require modifications to the model's architecture for controlling the topic. In this work, we propose a new topic-oriented evaluation measure to automatically evaluate the generated summaries based on the topic affinity between the generated summary and the desired topic. We also conducted a user study that validates the reliability of this measure. Finally, we propose simple, yet powerful methods for topic-controllable summarization either incorporating topic embeddings into the model's architecture or employing control tokens to guide the summary generation. Experimental results show that control tokens can achieve better performance compared to more complicated embedding-based approaches while being at the same time significantly faster. </details>
1. **Length Control in Abstractive Summarization by Pretraining Information Selection** *Yizhu Liu, Qi Jia, Kenny Zhu* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.474/) [[code]](https://github.com/yizhuliu/lengthcontrol) <details> <summary>[Abs]</summary> Previous length-controllable summarization models mostly control lengths at the decoding stage, whereas the encoding or the selection of information from the source document is not sensitive to the designed length. They also tend to generate summaries as long as those in the training data. In this paper, we propose a length-aware attention mechanism (LAAM) to adapt the encoding of the source based on the desired length. Our approach works by training LAAM on a summary length balanced dataset built from the original training data, and then fine-tuning as usual. Results show that this approach is effective in generating high-quality summaries with desired lengths and even those short lengths never seen in the original training set.</details>
3. **A Character-Level Length-Control Algorithm for Non-Autoregressive Sentence Summarization** *Puyuan Liu, Xiang Zhang, Lili Mou* [[pdf]](https://arxiv.org/abs/2205.14522) [[code]](https://github.com/MANGA-UOFA/NACC)
4. **EntSUM: A Data Set for Entity-Centric Summarization** *Mounica Maddela, Mayank Kulkarni, Daniel Preotiuc-Pietro* `ACL 2022` [[pdf]](https://arxiv.org/abs/2204.02213) [[code]](https://github.com/bloomberg/entsum) [[data]](https://zenodo.org/record/6359875)
5. **Reinforced Abstractive Summarization with Adaptive Length Controlling** *Mingyang Song, Yi Feng, Liping Jing* [[pdf]](https://arxiv.org/abs/2112.07534)
6. **HydraSum -- Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models** *Tanya Goyal, Nazneen Fatema Rajani, Wenhao Liu, Wojciech Kryściński* [[pdf]](https://arxiv.org/abs/2110.04400)
7. **RetrievalSum: A Retrieval Enhanced Framework for Abstractive Summarization** *Chenxin An, Ming Zhong, Zhichao Geng, Jianqiang Yang, Xipeng Qiu* [[pdf]](https://arxiv.org/abs/2109.07943)
8. **Aspect-Controllable Opinion Summarization** *Reinald Kim Amplayo, Stefanos Angelidis, Mirella Lapata* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.03171) [[code]](https://github.com/rktamplayo/AceSum)
9. **Extract, Denoise, and Enforce: Evaluating and Predicting Lexical Constraints for Conditional Text Generation** *Yuning Mao, Wenchang Ma, Deren Lei, Xiang Ren* [[pdf]](https://arxiv.org/abs/2104.08724) [[code]](https://github.com/morningmoni/LCGen-eval)
10. **Planning with Learned Entity Prompts for Abstractive Summarization** *Shashi Narayan, Yao Zhao, Joshua Maynez, Gonçalo Simoes, Ryan McDonald* `TACL` [[pdf]](https://arxiv.org/abs/2104.07606)
11. **GSum: A General Framework for Guided Neural Abstractive Summarization** *Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi, Zhengbao Jiang, Graham Neubig* `NAACL21` [[pdf]](https://arxiv.org/abs/2010.08014) [[code]](https://github.com/neulab/guided_summarization)    
12. **Abstractive summarization with combination of pre-trained sequence-to-sequence and saliency models** *Itsumi Saito, Kyosuke Nishida, Kosuke Nishida, Junji Tomita* [[pdf]](https://arxiv.org/abs/2003.13028)  
13. **Self-Supervised and Controlled Multi-Document Opinion Summarization** *Hady Elsahar, Maximin Coavoux, Jos Rozen, Matthias Gallé* `EACL 2021` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.141/)
14. **Controllable Summarization with Constrained Markov Decision Process** *Hou Pong Chan, Lu Wang, Irwin King* `TACL 2021` [[pdf]](https://arxiv.org/abs/2108.03405) [[code]](https://github.com/kenchan0226/control-sum-cmdp)
15. **LenAtten: An Effective Length Controlling Unit For Text Summarization** *Zhongyi Yu, Zhenghao Wu, Hao Zheng, Zhe XuanYuan, Jefferson Fong, Weifeng Su* ` Findings of ACL 2021 (short)` [[pdf]](https://arxiv.org/abs/2106.00316) [[code]](https://github.com/X-AISIG/LenAtten)
16. **Controllable Abstractive Dialogue Summarization with Sketch Supervision** *Chien-Sheng Wu, Linqing Liu, Wenhao Liu, Pontus Stenetorp, Caiming Xiong* `ACL-Findings 2021` [[pdf]](https://arxiv.org/abs/2105.14064) [[code]](https://github.com/salesforce/ConvSumm)
17. **Enhancing Factual Consistency of Abstractive Summarization** *Chenguang Zhu, William Hinthorn, Ruochen Xu, Qingkai Zeng, Michael Zeng, Xuedong Huang, Meng Jiang* `NAACL21` [[pdf]](https://arxiv.org/abs/2003.08612) 
18. **Inference Time Style Control for Summarization** *Shuyang Cao, Lu Wang* `NAACL21 short` [[pdf]](https://arxiv.org/abs/2104.01724) [[code]](https://shuyangcao.github.io/projects/inference_style_control/)
19. **CTRLsum: Towards Generic Controllable Text Summarization** *Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong* [[pdf]](https://arxiv.org/abs/2012.04281) [[code]](https://github.com/salesforce/ctrl-sum)
20. **Constrained Abstractive Summarization: Preserving Factual Consistency with Constrained Generation** *Yuning Mao, Xiang Ren, Heng Ji, Jiawei Han* [[pdf]](https://arxiv.org/abs/2010.12723) 
21. **Keywords-Guided Abstractive Sentence Summarization** *Haoran Li, Junnan Zhu, Jiajun Zhang, Chengqing Zong, Xiaodong He* `AAAI20` [[pdf]](https://ojs.aaai.org/index.php/AAAI/article/view/6333) 
22. **SemSUM: Semantic Dependency Guided Neural Abstractive Summarization** *Hanqi Jin, Tianming Wang, Xiaojun Wan* `AAAI2020` [[pdf]](https://ojs.aaai.org//index.php/AAAI/article/view/6312) [[code]](https://github.com/zhongxia96/SemSUM) 
23. **Interpretable Multi-Headed Attention for Abstractive Summarization at Controllable Lengths** *Ritesh Sarkhel, Moniba Keymanesh, Arnab Nandi, Srinivasan Parthasarathy* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.606/)
24. **Controllable Abstractive Sentence Summarization with Guiding Entities** *Changmeng Zheng, Yi Cai, Guanjie Zhang, Qing Li* `COLING20` [[pdf]](https://www.aclweb.org/anthology/2020.coling-main.497/) [[code]](https://github.com/thecharm/Abs-LRModel) 
25. **Summarizing Text on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach** *Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu* `EMNLP20 Short` [[pdf]](https://arxiv.org/abs/2010.06792) [[code]](https://github.com/tanyuqian/aspect-based-summarization)
26. **Length-controllable Abstractive Summarization by Guiding with Summary Prototype** *Itsumi Saito, Kyosuke Nishida, Kosuke Nishida, Atsushi Otsuka, Hisako Asano, Junji Tomita, Hiroyuki Shindo, Yuji Matsumoto* [[pdf]](https://arxiv.org/abs/2001.07331)
27. **The Summary Loop: Learning to Write Abstractive Summaries Without Examples** *Philippe Laban, Andrew Hsi, John Canny, Marti A. Hearst* `ACL20` [[pdf]](https://www.aclweb.org/anthology/2020.acl-main.460/)
28. **Hooks in the Headline: Learning to Generate Headlines with Controlled Styles** *Di Jin, Zhijing Jin, Joey Tianyi Zhou, Lisa Orii, Peter Szolovits* `ACL20` [[pdf]](https://arxiv.org/abs/2004.01980) [[code]](https://github.com/jind11/TitleStylist)
29. **BiSET: Bi-directional Selective Encoding with Template for Abstractive Summarization** *Kai Wang, Xiaojun Quan, Rui Wang* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1207/) [[code]](https://github.com/InitialBug/BiSET) 
30. **Improving Abstractive Document Summarization with Salient Information Modeling** *Yongjian You, Weijia Jia, Tianyi Liu, Wenmian Yang* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1205/) [[code]](https://github.com/StevenWD/ETADS)
31. **Positional Encoding to Control Output Sequence Length** *Sho Takase, Naoaki Okazaki* `NAACL19` [[pdf]](https://www.aclweb.org/anthology/N19-1401/) [[code]](https://github.com/takase/control-length)
32. **Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models** *Tal Baumel, Matan Eyal, Michael Elhadad* [[pdf]](https://arxiv.org/abs/1801.07704)
33. **Guiding Generation for Abstractive Text Summarization based on Key Information Guide Network** *Chenliang Li, Weiran Xu, Si Li, Sheng Gao* `NAACL18` [[pdf]](https://www.aclweb.org/anthology/N18-2009/) 
34. **Controllable Abstractive Summarization** *Angela Fan, David Grangier, Michael Auli* `ACL2018 Workshop` [[pdf]](https://arxiv.org/abs/1711.05217)
35. **Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization** *Ziqiang Cao, Wenjie Li, Sujian Li, Furu Wei* `ACL18` [[pdf]](https://www.aclweb.org/anthology/P18-1015/) 
36. **Controlling Length in Abstractive Summarization Using a Convolutional Neural Network** *Yizhu Liu, Zhiyi Luo, Kenny Zhu* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1444/) [[code]](http://202.120.38.146/sumlen)
37. **Generating Wikipedia By Summarizing Long Sequence** *Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, Noam Shazeer* `ICLR18` [[pdf]](https://arxiv.org/abs/1801.10198) [[code]](https://github.com/lucidrains/memory-compressed-attention.git) 
38. **Controlling Output Length in Neural Encoder-Decoders** *Yuta Kikuchi, Graham Neubig, Ryohei Sasano, Hiroya Takamura, Manabu Okumura* `EMNLP16` [[pdf]](https://www.aclweb.org/anthology/D16-1140/) [[code]](https://github.com/kiyukuta/lencon)
## Abstractive
1. **R-TeaFor: Regularized Teacher-Forcing for Abstractive Summarization** *Guan-Yu Lin, Pu-Jen Cheng* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.423/) <details> <summary>[Abs]</summary> Teacher-forcing is widely used in training sequence generation models to improve sampling efficiency and to stabilize training. However, teacher-forcing is vulnerable to the exposure bias problem. Previous works have attempted to address exposure bias by modifying the training data to simulate model-generated results. Nevertheless, they do not consider the pairwise relationship between the original training data and the modified ones, which provides more information during training. Hence, we propose Regularized Teacher-Forcing (R-TeaFor) to utilize this relationship for better regularization. Empirically, our experiments show that R-TeaFor outperforms previous summarization state-of-the-art models, and the results can be generalized to different pre-trained models. </details>
1. **Improving abstractive summarization with energy-based re-ranking** *Diogo Pernes, Afonso Mendes, André F.T. Martins* `GEM at EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.15553) [[code]](https://github.com/Priberam/SummEBR) <details> <summary>[Abs]</summary> Current abstractive summarization systems present important weaknesses which prevent their deployment in real-world applications, such as the omission of relevant information and the generation of factual inconsistencies (also known as hallucinations). At the same time, automatic evaluation metrics such as CTC scores have been recently proposed that exhibit a higher correlation with human judgments than traditional lexical-overlap metrics such as ROUGE. In this work, we intend to close the loop by leveraging the recent advances in summarization metrics to create quality-aware abstractive summarizers. Namely, we propose an energy-based model that learns to re-rank summaries according to one or a combination of these metrics. We experiment using several metrics to train our energy-based re-ranker and show that it consistently improves the scores achieved by the predicted summaries. Nonetheless, human evaluation results show that the re-ranking approach should be used with care for highly abstractive summaries, as the available metrics are not yet sufficiently reliable for this purpose. </details>
1. **Salience Allocation as Guidance for Abstractive Summarization** *Fei Wang, Kaiqiang Song, Hongming Zhang, Lifeng Jin, Sangwoo Cho, Wenlin Yao, Xiaoyang Wang, Muhao Chen, Dong Yu* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.12330) [[code]](https://github.com/tencent-ailab/season) <details> <summary>[Abs]</summary> Abstractive summarization models typically learn to capture the salient information from scratch implicitly. Recent literature adds extractive summaries as guidance for abstractive summarization models to provide hints of salient content and achieves better performance. However, extractive summaries as guidance could be over strict, leading to information loss or noisy signals. Furthermore, it cannot easily adapt to documents with various abstractiveness. As the number and allocation of salience content pieces vary, it is hard to find a fixed threshold deciding which content should be included in the guidance. In this paper, we propose a novel summarization approach with a flexible and reliable salience guidance, namely SEASON (SaliencE Allocation as Guidance for Abstractive SummarizatiON). SEASON utilizes the allocation of salience expectation to guide abstractive summarization and adapts well to articles in different abstractiveness. Automatic and human evaluations on two benchmark datasets show that the proposed method is effective and reliable. Empirical results on more than one million news articles demonstrate a natural fifteen-fifty salience split for news article sentences, providing a useful insight for composing news articles. </details>
1. **Towards Summary Candidates Fusion** *Mathieu Ravaut, Shafiq Joty, Nancy F. Chen* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.08779) [[code]](https://github.com/ntunlp/SummaFusion/) <details> <summary>[Abs]</summary> Sequence-to-sequence deep neural models fine-tuned for abstractive summarization can achieve great performance on datasets with enough human annotations. Yet, it has been shown that they have not reached their full potential, with a wide gap between the top beam search output and the oracle beam. Recently, re-ranking methods have been proposed, to learn to select a better summary candidate. However, such methods are limited by the summary quality aspects captured by the first-stage candidates. To bypass this limitation, we propose a new paradigm in second-stage abstractive summarization called SummaFusion that fuses several summary candidates to produce a novel abstractive second-stage summary. Our method works well on several summarization datasets, improving both the ROUGE scores and qualitative properties of fused summaries. It is especially good when the candidates to fuse are worse, such as in the few-shot setup where we set a new state-of-the-art. We will make our code and checkpoints available at this https URL. </details>
1. **Generation of Patient After-Visit Summaries to Support Physicians** *Pengshan Cai, Fei Liu, Adarsha Bajracharya, Joe Sills, Alok Kapoor, Weisong Liu, Dan Berlowitz, David Levy, Richeek Pradhan, Hong Yu* `` [[pdf]](https://aclanthology.org/2022.coling-1.544/) [[code]](https://github.com/pengshancai/AVS_gen) <details> <summary>[Abs]</summary> An after-visit summary (AVS) is a summary note given to patients after their clinical visit. It recaps what happened during their clinical visit and guides patients’ disease self-management. Studies have shown that a majority of patients found after-visit summaries useful. However, many physicians face excessive workloads and do not have time to write clear and informative summaries. In this paper, we study the problem of automatic generation of after-visit summaries and examine whether those summaries can convey the gist of clinical visits. We report our findings on a new clinical dataset that contains a large number of electronic health record (EHR) notes and their associated summaries. Our results suggest that generation of lay language after-visit summaries remains a challenging task. Crucially, we introduce a feedback mechanism that alerts physicians when an automatic summary fails to capture the important details of the clinical notes or when it contains hallucinated facts that are potentially detrimental to the summary quality. Automatic and human evaluation demonstrates the effectiveness of our approach in providing writing feedback and supporting physicians. </details>
1. **ArgLegalSumm: Improving Abstractive Summarization of Legal Documents with Argument Mining** *Mohamed Elaraby, Diane Litman* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.540/) [[code]](https://github.com/EngSalem/arglegalsumm) <details> <summary>[Abs]</summary> A challenging task when generating summaries of legal documents is the ability to address their argumentative nature. We introduce a simple technique to capture the argumentative structure of legal documents by integrating argument role labeling into the summarization process. Experiments with pretrained language models show that our proposed approach improves performance over strong baselines. </details>
1. **Source-summary Entity Aggregation in Abstractive Summarization** *José Ángel González, Annie Louis, Jackie Chi Kit Cheung* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.526/) [[code]]() <details> <summary>[Abs]</summary> In a text, entities mentioned earlier can be referred to in later discourse by a more general description. For example, Celine Dion and Justin Bieber can be referred to by Canadian singers or celebrities. In this work, we study this phenomenon in the context of summarization, where entities from a source text are generalized in the summary. We call such instances source-summary entity aggregations. We categorize these aggregations into two types and analyze them in the Cnn/Dailymail corpus, showing that they are reasonably frequent. We then examine how well three state-of-the-art summarization systems can generate such aggregations within summaries. We also develop techniques to encourage them to generate more aggregations. Our results show that there is significant room for improvement in producing semantically correct aggregations. </details>
1. **Summarizing Patients Problems from Hospital Progress Notes Using Pre-trained Sequence-to-Sequence Models** *Yanjun Gao, Dmitry Dligach, Timothy Miller, Dongfang Xu, Matthew M. Churpek, Majid Afshar* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.264/) <details> <summary>[Abs]</summary> Automatically summarizing patients' main problems from daily progress notes using natural language processing methods helps to battle against information and cognitive overload in hospital settings and potentially assists providers with computerized diagnostic decision support. Problem list summarization requires a model to understand, abstract, and generate clinical documentation. In this work, we propose a new NLP task that aims to generate a list of problems in a patient's daily care plan using input from the provider's progress notes during hospitalization. We investigate the performance of T5 and BART, two state-of-the-art seq2seq transformer architectures, in solving this problem. We provide a corpus built on top of progress notes from publicly available electronic health record progress notes in the Medical Information Mart for Intensive Care (MIMIC)-III. T5 and BART are trained on general domain text, and we experiment with a data augmentation method and a domain adaptation pre-training method to increase exposure to medical vocabulary and knowledge. Evaluation methods include ROUGE, BERTScore, cosine similarity on sentence embedding, and F-score on medical concepts. Results show that T5 with domain adaptive pre-training achieves significant performance gains compared to a rule-based system and general domain pre-trained language models, indicating a promising direction for tackling the problem summarization task. </details>
1. **Semantic-Preserving Abstractive Text Summarization with Siamese Generative Adversarial Net** *Xin Sheng, Linli Xu, Yinlong Xu, Deqiang Jiang, Bo Ren* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.163/) <details> <summary>[Abs]</summary> We propose a novel siamese generative adversarial net for abstractive text summarization (SSPGAN), which can preserve the main semantics of the source text. Different from previous generative adversarial net based methods, SSPGAN is equipped with a siamese semantic-preserving discriminator, which can not only be trained to discriminate the machine-generated summaries from the human-summarized ones, but also ensure the semantic consistency between the source text and target summary. As a consequence of the min-max game between the generator and the siamese semantic-preserving discriminator, the generator can generate a summary that conveys the key content of the source text more accurately. Extensive experiments on several text summarization benchmarks in different languages demonstrate that the proposed model can achieve significant improvements over the state-of-the-art methods. </details>
1. **ExtraPhrase: Efficient Data Augmentation for Abstractive Summarization** *Mengsay Loem, Sho Takase, Masahiro Kaneko, Naoaki Okazaki* `NAACL 2022 Student Research Workshop` [[pdf]](https://aclanthology.org/2022.naacl-srw.3/) [[code]](https://github.com/loem-ms/ExtraPhrase) <details> <summary>[Abs]</summary> TNeural models trained with large amount of parallel data have achieved impressive performance in abstractive summarization tasks. However, large-scale parallel corpora are expensive and challenging to construct. In this work, we introduce a low-cost and effective strategy, ExtraPhrase, to augment training data for abstractive summarization tasks. ExtraPhrase constructs pseudo training data in two steps: extractive summarization and paraphrasing. We extract major parts of an input text in the extractive summarization step and obtain its diverse expressions with the paraphrasing step. Through experiments, we show that ExtraPhrase improves the performance of abstractive summarization tasks by more than 0.50 points in ROUGE scores compared to the setting without data augmentation. ExtraPhrase also outperforms existing methods such as back-translation and self-training. We also show that ExtraPhrase is significantly effective when the amount of genuine training data is remarkably small, i.e., a low-resource setting. Moreover, ExtraPhrase is more cost-efficient than the existing approaches </details>
1. **BRIO: Bringing Order to Abstractive Summarization** *Yixin Liu, Pengfei Liu, Dragomir Radev, Graham Neubig* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.207/) [[code]](https://github.com/yixinL7/BRIO) <details> <summary>[Abs]</summary> Abstractive summarization models are commonly trained using maximum likelihood estimation, which assumes a deterministic (one-point) target distribution in which an ideal model will assign all the probability mass to the reference summary. This assumption may lead to performance degradation during inference, where the model needs to compare several system-generated (candidate) summaries that have deviated from the reference summary. To address this problem, we propose a novel training paradigm which assumes a non-deterministic distribution so that different candidate summaries are assigned probability mass according to their quality. Our method achieves a new state-of-the-art result on the CNN/DailyMail (47.78 ROUGE-1) and XSum (49.07 ROUGE-1) datasets. Further analysis also shows that our model can estimate probabilities of candidate summaries that are more correlated with their level of quality. </details>
1. **SummaReranker: A Multi-Task Mixture-of-Experts Re-ranking Framework for Abstractive Summarization** *Mathieu Ravaut, Shafiq Joty, Nancy F. Chen* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.309/) [[code]](https://github.com/ntunlp/SummaReranker) <details> <summary>[Abs]</summary> Sequence-to-sequence neural networks have recently achieved great success in abstractive summarization, especially through fine-tuning large pre-trained language models on the downstream dataset. These models are typically decoded with beam search to generate a unique summary. However, the search space is very large, and with the exposure bias, such decoding is not optimal. In this paper, we show that it is possible to directly train a second-stage model performing re-ranking on a set of summary candidates. Our mixture-of-experts SummaReranker learns to select a better candidate and consistently improves the performance of the base model. With a base PEGASUS, we push ROUGE scores by 5.44% on CNN- DailyMail (47.16 ROUGE-1), 1.31% on XSum (48.12 ROUGE-1) and 9.34% on Reddit TIFU (29.83 ROUGE-1), reaching a new state-of-the-art. Our code and checkpoints will be available at https://github.com/ntunlp/SummaReranker. </details>
1. **Adaptive Beam Search to Enhance On-device Abstractive Summarization** *Harichandana B S S, Sumit Kumar* `IEEE INDICON 2021` [[pdf]](https://arxiv.org/abs/2201.02739)
1. **PLSUM: Generating PT-BR Wikipedia by Summarizing Multiple Websites** *André Seidel Oliveira, Anna Helena Reali Costa* `ENIAC 2021` [[pdf]](https://arxiv.org/abs/2112.01591)
1. **Pointer over Attention: An Improved Bangla Text Summarization Approach Using Hybrid Pointer Generator Network** *Nobel Dhar, Gaurob Saha, Prithwiraj Bhattacharjee, Avi Mallick, Md Saiful Islam* [[pdf]](https://arxiv.org/abs/2111.10269)
1. **Template-aware Attention Model for Earnings Call Report Generation** *Yangchen Huang, Prashant K. Dhingra, Seyed Danial Mohseni Taheri* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.2/)
1. **Rewards with Negative Examples for Reinforced Topic-Focused Abstractive Summarization** *Khalil Mrini, Can Liu, Markus Dreyer* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.4/)
1. **Knowledge and Keywords Augmented Abstractive Sentence Summarization** *Shuo Guan, Ping Zhu, Zhihua Wei* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.3.pdf) [[code]](https://github.com/SeanG-325/KAS)
1. **Sentence-level Planning for Especially Abstractive Summarization** *Andreas Marfurt, James Henderson* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.1/) [[code]](https://github.com/idiap/sentence-planner)
1. **Learn to Copy from the Copying History: Correlational Copy Network for Abstractive Summarization** *Haoran Li, Song Xu, Peng Yuan, Yujia Wang, Youzheng Wu, Xiaodong He, Bowen Zhou* `EMNLP 2021` [[pdf]](https://aclanthology.org/2021.emnlp-main.336/) [[code]](https://github.com/hrlinlp/coconet)
1. **Enhance Long Text Understanding via Distilled Gist Detector from Abstractive Summarization** *Yan Liu, Yazheng Yang* [[pdf]](https://arxiv.org/abs/2110.04741)
1. **VieSum: How Robust Are Transformer-based Models on Vietnamese Summarization?** *Hieu Nguyen, Long Phan, James Anibal, Alec Peltekian, Hieu Tran* [[pdf]](https://arxiv.org/abs/2110.04257)
1. **Enriching and Controlling Global Semantics for Text Summarization** *Thong Nguyen, Anh Tuan Luu, Truc Lu, Tho Quan* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.10616)
1. **Augmented Abstractive Summarization With Document-LevelSemantic Graph** *Qiwei Bi, Haoyuan Li, Kun Lu, Hanfang Yang* `Journal of Data Science` [[pdf]](https://arxiv.org/abs/2109.06046)
1. **ARMAN: Pre-training with Semantically Selecting and Reordering of Sentences for Persian Abstractive Summarization** *Alireza Salemi, Emad Kebriaei, Ghazal Neisi Minaei, Azadeh Shakery* [[pdf]](https://arxiv.org/abs/2109.04098) [[data]](https://github.com/mohammadiahmad/persian-dataset)
1. **Subjective Bias in Abstractive Summarization** *Lei Li, Wei Liu, Marina Litvak, Natalia Vanetik, Jiacheng Pei, Yinan Liu, Siya Qi* [[pdf]](https://arxiv.org/abs/2106.10084) [[code]](https://github.com/thinkwee/SubjectiveBiasABS)
1. **Neural Abstractive Unsupervised Summarization of Online News Discussions** *Ignacio Tampe Palma, Marcelo Mendoza, Evangelos Milios* [[pdf]](https://arxiv.org/abs/2106.03953)
1. **Attention Temperature Matters in Abstractive Summarization Distillation** *Shengqiang Zhang, Xingxing Zhang, Hangbo Bao, Furu Wei* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.11/) [[code]](https://github.com/Shengqiang-Zhang/plate) <details> <summary>[Abs]</summary> Recent progress of abstractive text summarization largely relies on large pre-trained sequence-to-sequence Transformer models, which are computationally expensive. This paper aims to distill these large models into smaller ones for faster inference and with minimal performance loss. Pseudo-labeling based methods are popular in sequence-to-sequence model distillation. In this paper, we find simply manipulating attention temperatures in Transformers can make pseudo labels easier to learn for student models. Our experiments on three summarization datasets show our proposed method consistently improves vanilla pseudo-labeling based methods. Further empirical analysis shows that both pseudo labels and summaries produced by our students are shorter and more abstractive. </details>
1. **BASS: Boosting Abstractive Summarization with Unified Semantic Graph** *Wenhao Wu, Wei Li, Xinyan Xiao, Jiachen Liu, Ziqiang Cao, Sujian Li, Hua Wu, Haifeng Wang* `ACL21` [[pdf]](https://aclanthology.org/2021.acl-long.472/)
1. **Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization** *Yichen Jiang, Asli Celikyilmaz, Paul Smolensky, Paul Soulos, Sudha Rao, Hamid Palangi, Roland Fernandez, Caitlin Smith, Mohit Bansal, Jianfeng Gao* `NAACL21` [[pdf]](https://www.aclweb.org/anthology/2021.naacl-main.381/) [[code]](https://github.com/jiangycTarheel/TPT-Summ)
1. **Uncertainty-Aware Abstractive Summarization** *Alexios Gidiotis, Grigorios Tsoumakas* [[pdf]](https://arxiv.org/abs/2105.10155)
1. **What's in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization** *Griffin Adams, Emily Alsentzer, Mert Ketenci, Jason Zucker, Noémie Elhadad* `NAACL21` [[pdf]](https://arxiv.org/abs/2105.00816)
1. **Generating abstractive summaries of Lithuanian news articles using a transformer model** *Lukas Stankevičius, Mantas Lukoševičius* [[pdf]](https://arxiv.org/abs/2105.03279)
1. **Summarization, Simplification, and Generation: The Case of Patents** *Silvia Casola, Alberto Lavelli* [[pdf]](https://arxiv.org/abs/2104.14860)
1. **Quantifying Appropriateness of Summarization Data for Curriculum Learning** *Ryuji Kano, Takumi Takahashi, Toru Nishino, Motoki Taniguchi, Tomoki Taniguchi, Tomoko Ohkuma* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.119/)
1. **Text Summarization of Czech News Articles Using Named Entities** *Petr Marek, Štěpán Müller, Jakub Konrád, Petr Lorenc, Jan Pichl, Jan Šedivý* `Journal` [[pdf]](https://arxiv.org/abs/2104.10454)
1. **Planning with Entity Chains for Abstractive Summarization** *Shashi Narayan, Yao Zhao, Joshua Maynez, Gonçalo Simoes, Ryan McDonald* [[pdf]](https://arxiv.org/abs/2104.07606)
1. **Attention Head Masking for Inference Time Content Selection in Abstractive Summarization** *Shuyang Cao, Lu Wang* `NAACL21 short` [[pdf]](https://arxiv.org/abs/2104.02205) [[code]](https://shuyangcao.github.io/projects/inference_head_masking/)
1. **A New Approach to Overgenerating and Scoring Abstractive Summaries** *Kaiqiang Song, Bingqing Wang, Zhe Feng, Fei Liu* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.01726) [[code]](https://github.com/ucfnlp/varying-length-summ)
1. **Exploring Explainable Selection to Control Abstractive Summarization** *Wang Haonan, Gao Yang, Bai Yu, Mirella Lapata, Huang Heyan* `AAAI21` [[pdf]](https://arxiv.org/abs/2004.11779) [[code]](https://github.com/Wanghn95/Esca_Code)
1. **Friendly Topic Assistant for Transformer Based Abstractive Summarization** *Zhengjue Wang, Zhibin Duan, Hao Zhang, Chaojie Wang, Long Tian, Bo Chen, Mingyuan Zhou* `EMNLP20` [[pdf]](https://www.aclweb.org/anthology/2020.emnlp-main.35/) [[code]](https://github.com/BoChenGroup/TA)
1. **Neural Abstractive Text Summarizer for Telugu Language** *Mohan Bharath B, Aravindh Gowtham B, Akhil M* `ICSCSP20` [[pdf]](https://arxiv.org/abs/2101.07120)
1. **Topic-Aware Abstractive Text Summarization** *Chujie Zheng, Kunpeng Zhang, Harry Jiannan Wang, Ling Fan* [[pdf]](https://arxiv.org/abs/2010.10323) [[code]](https://github.com/taas-www21/taas)
2. **Multi-hop Inference for Question-driven Summarization** *Yang Deng, Wenxuan Zhang, Wai Lam* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.03738)
3. **Quantitative Argument Summarization and Beyond-Cross-Domain Key Point Analysis** *Roy Bar-Haim, Yoav Kantor, Lilach Eden, Roni Friedman, Dan Lahav, Noam Slonim* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.05369)
4. **Learning to Fuse Sentences with Transformers for Summarization** *Logan Lebanoff, Franck Dernoncourt, Doo Soon Kim, Lidan Wang, Walter Chang, Fei Liu* `EMNLP20 short` [[pdf]](https://arxiv.org/abs/2010.03726) [[code]](https://github.com/ucfnlp/sent-fusion-transformers)
5. **A Cascade Approach to Neural Abstractive Summarization with Content Selection and Fusion** *Logan Lebanoff, Franck Dernoncourt, Doo Soon Kim, Walter Chang, Fei Liu* `AACL20` [[pdf]](https://arxiv.org/abs/2010.03722) [[code]](https://github.com/ucfnlp/cascaded-summ)
5. **AutoSurvey: Automatic Survey Generation based on a Research Draft** *Hen-Hsen Huang* `IJCAI20` [[pdf]](https://www.ijcai.org/Proceedings/2020/0761.pdf) [[code]](http://www.cs.nccu.edu.tw/~hhhuang/auto_survey/)
6. **Neural Abstractive Summarization with Structural Attention** *Tanya Chowdhury, Sachin Kumar, Tanmoy Chakraborty* `IJCAI20` [[pdf]](https://arxiv.org/abs/2004.09739)
7. **A Unified Model for Financial Event Classification, Detection and Summarization** *Quanzhi Li, Qiong Zhang* `IJCAI20 Special Track on AI in FinTech` [[pdf]](https://www.ijcai.org/Proceedings/2020/644)
9. **Discriminative Adversarial Search for Abstractive Summarization** *Thomas Scialom, Paul-Alexis Dray, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano* `ICML20` [[pdf]](https://arxiv.org/abs/2002.10375)
10. **Controlling the Amount of Verbatim Copying in Abstractive Summarization** *Kaiqiang Song, Bingqing Wang, Zhe Feng, Liu Ren, Fei Liu* `AAAI20` [[pdf]](https://arxiv.org/abs/1911.10390) [[code]](https://github.com/ucfnlp/control-over-copying)
11. **GRET:Global Representation Enhanced Transformer** *Rongxiang Weng, Haoran Wei, Shujian Huang, Heng Yu, Lidong Bing, Weihua Luo, Jiajun Chen* `AAAI20` [[pdf]](https://arxiv.org/abs/2002.10101)
12. **Abstractive Summarization of Spoken and Written Instructions with BERT** *Alexandra Savelieva, Bryan Au-Yeung, Vasanth Ramani* `KDD Converse 2020` [[pdf]](https://arxiv.org/abs/2008.09676)
13. **Concept Pointer Network for Abstractive Summarization** *Wang Wenbo, Gao Yang, Huang Heyan, Zhou Yuxiang* `EMNLP19` [[pdf]](https://arxiv.org/abs/1910.08486) [[code]](https://github.com/wprojectsn/codes)
14. **Co-opNet: Cooperative Generator–Discriminator Networks for Abstractive Summarization with Narrative Flow** *Saadia Gabriel, Antoine Bosselut, Ari Holtzman, Kyle Lo, Asli Celikyilmaz, Yejin Choi* [[pdf]](https://arxiv.org/abs/1907.01272)
15. **Contrastive Attention Mechanism for Abstractive Sentence Summarization** *Xiangyu Duan, Hongfei Yu, Mingming Yin, Min Zhang, Weihua Luo, Yue Zhang* `EMNLP19` [[pdf]](https://www.aclweb.org/anthology/D19-1301/) [[code]](https://github.com/travel-go/Abstractive-Text-Summarization)
16. **An Entity-Driven Framework for Abstractive Summarization** *Eva Sharma, Luyang Huang, Zhe Hu, Lu Wang* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.02059) [[code]](https://evasharma.github.io/SENECA/)
17. **Abstract Text Summarization: A Low Resource Challenge** *Shantipriya Parida, Petr Motlicek* `EMNLP19` [[pdf]](https://www.aclweb.org/anthology/D19-1616/) [[code]]()
18. **Attention Optimization for Abstractive Document Summarization** *Min Gui, Junfeng Tian, Rui Wang, Zhenglu Yang* `EMNLP19` [[pdf]](https://arxiv.org/abs/1910.11491) [[code]]()
20. **Scoring Sentence Singletons and Pairs for Abstractive Summarization** *Logan Lebanoff, Kaiqiang Song, Franck Dernoncourt, Doo Soon Kim, Seokhwan Kim, Walter Chang, Fei Liu* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1209/) [[code]](https://github.com/ucfnlp/summarization-sing-pair-mix)
21. **Inducing Document Structure for Aspect-based Summarization** *Lea Frermann, Alexandre Klementiev* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1630/) [[code]](https://github.com/ColiLea/aspect_based_summarization)
22. **Generating Summaries with Topic Templates and Structured Convolutional Decoders** *Laura Perez-Beltrachini, Yang Liu, Mirella Lapata* `ACL19` [[pdf]](https://arxiv.org/abs/1906.04687) [[code]](https://github.com/lauhaide/WikiCatSum)
24. **Summary Refinement through Denoising** *Nikola I. Nikolov, Alessandro Calmanovici, Richard H.R. Hahnloser* `RANLP19` [[pdf]](https://arxiv.org/abs/1907.10873) [[code]](https://github.com/ninikolov/summary-denoising)
25. **Closed-Book Training to Improve Summarization Encoder Memory** *Yichen Jiang, Mohit Bansal* `EMNLP18` [[pdf]](https://arxiv.org/abs/1809.04585)
26. **Improving Neural Abstractive Document Summarization with Structural Regularization** *Wei Li, Xinyan Xiao, Yajuan Lyu, Yuanzhuo Wang* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1441/)
26. **Bottom-Up Abstractive Summarization** *Sebastian Gehrmann, Yuntian Deng, Alexander M. Rush* `EMNLP18` [[pdf]](https://arxiv.org/abs/1808.10792) [[code]](https://github.com/sebastianGehrmann/bottom-up-summary)
27. **A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss** *Wan-Ting Hsu, Chieh-Kai Lin, Ming-Ying Lee, Kerui Min, Jing Tang, Min Sun* `ACL18` [[pdf]](https://www.aclweb.org/anthology/P18-1013/)
28. **Soft Layer-Specific Multi-Task Summarization with Entailment and Question Generation** *Han Guo, Ramakanth Pasunuru, Mohit Bansal* `ACL18` [[pdf]](https://www.aclweb.org/anthology/P18-1064/)
30. **Abstractive Document Summarization via Bidirectional Decoder** *Xin WanChen LiRuijia WangDing XiaoChuan Shi* `ADMA18` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-030-05090-0_31)
32. **Entity Commonsense Representation for Neural Abstractive Summarization** *Reinald Kim Amplayo, Seonjae Lim, Seung-won Hwang* `NAACL18` [[pdf]](https://www.aclweb.org/anthology/N18-1064/)
33. **Get To The Point: Summarization with Pointer-Generator Networks** *Abigail See, Peter J. Liu, Christopher D. Manning* `ACL17` [[pdf]](https://arxiv.org/abs/1704.04368) [[code]](https://github.com/abisee/pointer-generator)
34. **Selective Encoding for Abstractive Sentence Summarization** *Qingyu Zhou, Nan Yang, Furu Wei, Ming Zhou* `ACL17` [[pdf]](https://arxiv.org/abs/1704.07073)
35. **Abstractive Document Summarization with a Graph-Based Attentional Neural Model** *Jiwei Tan, Xiaojun Wan, Jianguo Xiao* `ACL17` [[pdf]](https://www.aclweb.org/anthology/P17-1108/)
39. **Toward Abstractive Summarization Using Semantic Representations** *Fei Liu, Jeffrey Flanigan, Sam Thomson, Norman Sadeh, Noah A. Smith* `NAACL15` [[pdf]](https://www.aclweb.org/anthology/N15-1114/)
40. **Abstractive Meeting Summarization with Entailment and Fusion** *Yashar Mehdad, Giuseppe Carenini, Frank Tompa, Raymond T. Ng* `ENLG13` [[pdf]](https://www.aclweb.org/anthology/W13-2117/)
## Graph-Based
1. **Abstractive Summarization Guided by Latent Hierarchical Document Structure** *Yifu Qiu, Shay B. Cohen* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2211.09458) [[code]](https://github.com/yfqiu-nlp/hiergnn) <details> <summary>[Abs]</summary> Sequential abstractive neural summarizers often do not use the underlying structure in the input article or dependencies between the input sentences. This structure is essential to integrate and consolidate information from different parts of the text. To address this shortcoming, we propose a hierarchy-aware graph neural network (HierGNN) which captures such dependencies through three main steps: 1) learning a hierarchical document structure through a latent structure tree learned by a sparse matrix-tree computation; 2) propagating sentence information over this structure using a novel message-passing node propagation mechanism to identify salient information; 3) using graph-level attention to concentrate the decoder on salient information. Experiments confirm HierGNN improves strong sequence models such as BART, with a 0.55 and 0.75 margin in average ROUGE-1/2/L for CNN/DM and XSum. Further human evaluation demonstrates that summaries produced by our model are more relevant and less redundant than the baselines, into which HierGNN is incorporated. We also find HierGNN synthesizes summaries by fusing multiple source sentences more, rather than compressing a single source sentence, and that it processes long inputs more effectively. </details>
1. **Hierarchical Heterogeneous Graph Attention Network for Syntax-Aware Summarization** *Zixing Song, Irwin King* `AAAI 2022` [[pdf]](https://www.aaai.org/AAAI22Papers/AAAI-6812.SongZ.pdf)
1. **Summarization with Graphical Elements** *Maartje ter Hoeve, Julia Kiseleva, Maarten de Rijke* [[pdf]](https://arxiv.org/abs/2204.07551) [[code]](https://github.com/maartjeth/summarization_with_graphical_elements)
1. **HETFORMER: Heterogeneous Transformer with Sparse Attention for Long-Text Extractive Summarization** *Ye Liu, Jian-Guo Zhang, Yao Wan, Congying Xia, Lifang He, Philip S. Yu* `EMNLP 2021 short` [[pdf]](https://arxiv.org/abs/2110.06388)
1. **Centrality Meets Centroid: A Graph-based Approach for Unsupervised Document Summarization** *Haopeng Zhang, Jiawei Zhang* [[pdf]](https://arxiv.org/abs/2103.15327)
1. **Neural Extractive Summarization with Hierarchical Attentive Heterogeneous Graph Network** *Ruipeng Jia, Yanan Cao, Hengzhu Tang, Fang Fang, Cong Cao, Shi Wang* `EMNLP20` [[pdf]](https://www.aclweb.org/anthology/2020.emnlp-main.295/) [[code]](https://github.com/coder352/HAHSum)
1. **Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks** *Peng Cui, Le Hu, Yuanchao Liu* `COLING20` [[pdf]](https://arxiv.org/abs/2010.06253)
2. **Heterogeneous Graph Neural Networks for Extractive Document Summarization** *Danqing Wang, Pengfei Liu, Yining Zheng, Xipeng Qiu, Xuanjing Huang* `ACL20` [[pdf]](https://arxiv.org/abs/2004.12393) [[code]](https://github.com/brxx122/HeterSUMGraph)
3. **Structured Neural Summarization** *Patrick Fernandes, Miltiadis Allamanis, Marc Brockschmidt* `ICLR19` [[pdf]](https://arxiv.org/abs/1811.01824) [[code]](https://github.com/CoderPat/structured-neural-summarization)
4. **Hierarchical Transformers for Multi-Document Summarization** *Yang Liu, Mirella Lapata* `ACL19` [[pdf]](https://arxiv.org/abs/1905.13164) [[code]](https://github.com/nlpyang/hiersumm)
5. **Learning to Create Sentence Semantic Relation Graphs for Multi-Document Summarization** *Diego Antognini, Boi Faltings* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.12231)
6. **Graph-based Neural Multi-Document Summarization** *Michihiro Yasunaga, Rui Zhang, Kshitijh Meelu, Ayush Pareek, Krishnan Srinivasan, Dragomir Radev* `CoNLL17` [[pdf]](https://www.aclweb.org/anthology/K17-1045/)
7. **Abstractive Document Summarization with a Graph-Based Attentional Neural Model** *Jiwei Tan, Xiaojun Wan, Jianguo Xiao* `ACL17` [[pdf]](https://www.aclweb.org/anthology/P17-1108/)
## Unsupervised
1. **Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization** *Dongmin Hyun, Xiting Wang, Chanyoung Park, Xing Xie, Hwanjo Yu* [[pdf]](https://arxiv.org/abs/2212.10843) [[code]](https://github.com/dmhyun/MSRP) <details> <summary>[Abs]</summary> Sentence summarization shortens given texts while maintaining core contents of the texts. Unsupervised approaches have been studied to summarize texts without human-written summaries. However, recent unsupervised models are extractive, which remove words from texts and thus they are less flexible than abstractive summarization. In this work, we devise an abstractive model based on reinforcement learning without ground-truth summaries. We formulate the unsupervised summarization based on the Markov decision process with rewards representing the summary quality. To further enhance the summary quality, we develop a multi-summary learning mechanism that generates multiple summaries with varying lengths for a given text, while making the summaries mutually enhance each other. Experimental results show that the proposed model substantially outperforms both abstractive and extractive models, yet frequently generating new words not contained in input texts. </details>
1. **Referee: Reference-Free Sentence Summarization with Sharper Controllability through Symbolic Knowledge Distillation** *Melanie Sclar, Peter West, Sachin Kumar, Yulia Tsvetkov, Yejin Choi* `EMNLP 2022` [[pdf]](https://arxiv.org/abs/2210.13800) [[code]](https://github.com/msclar/referee) <details> <summary>[Abs]</summary> We present Referee, a novel framework for sentence summarization that can be trained reference-free (i.e., requiring no gold summaries for supervision), while allowing direct control for compression ratio. Our work is the first to demonstrate that reference-free, controlled sentence summarization is feasible via the conceptual framework of Symbolic Knowledge Distillation (West et al., 2022), where latent knowledge in pre-trained language models is distilled via explicit examples sampled from the teacher models, further purified with three types of filters: length, fidelity, and Information Bottleneck. Moreover, we uniquely propose iterative distillation of knowledge, where student models from the previous iteration of distillation serve as teacher models in the next iteration. Starting off from a relatively modest set of GPT3-generated summaries, we demonstrate how iterative knowledge distillation can lead to considerably smaller, but better summarizers with sharper controllability. A useful by-product of this iterative distillation process is a high-quality dataset of sentence-summary pairs with varying degrees of compression ratios. Empirical results demonstrate that the final student models vastly outperform the much larger GPT3-Instruct model in terms of the controllability of compression ratios, without compromising the quality of resulting summarization. </details>
1. **UPER: Boosting Multi-Document Summarization with an Unsupervised Prompt-based Extractor** *Shangqing Tu, Jifan Yu, Fangwei Zhu, Juanzi Li, Lei Hou, Jian-Yun Nie* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.550/) [[code]](https://github.com/THU-KEG/UPER) <details> <summary>[Abs]</summary> Multi-Document Summarization (MDS) commonly employs the 2-stage extract-then-abstract paradigm, which first extracts a relatively short meta-document, then feeds it into the deep neural networks to generate an abstract. Previous work usually takes the ROUGE score as the label for training a scoring model to evaluate source documents. However, the trained scoring model is prone to under-fitting for low-resource settings, as it relies on the training data. To extract documents effectively, we construct prompting templates that invoke the underlying knowledge in Pre-trained Language Model (PLM) to calculate the document and keyword’s perplexity, which can assess the document’s semantic salience. Our unsupervised approach can be applied as a plug-in to boost other metrics for evaluating a document’s salience, thus improving the subsequent abstract generation. We get positive results on 2 MDS datasets, 2 data settings, and 2 abstractive backbone models, showing our method’s effectiveness. Our code is available at https://github.com/THU-KEG/UPER </details>
1. **Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization** *Puyuan Liu, Chenyang Huang, Lili Mou* `ACL 2022` [[[pdf]](https://aclanthology.org/2022.acl-long.545/) [[code]](https://github.com/manga-uofa/naus) <details> <summary>[Abs]</summary> Text summarization aims to generate a short summary for an input text. In this work, we propose a Non-Autoregressive Unsupervised Summarization (NAUS) approach, which does not require parallel data for training. Our NAUS first performs edit-based search towards a heuristically defined score, and generates a summary as pseudo-groundtruth. Then, we train an encoder-only non-autoregressive Transformer based on the search result. We also propose a dynamic programming approach for length-control decoding, which is important for the summarization task. Experiments on two datasets show that NAUS achieves state-of-the-art performance for unsupervised summarization, yet largely improving inference efficiency. Further, our algorithm is able to perform explicit length-transfer summary generation. </details>
1. **Unsupervised Extractive Opinion Summarization Using Sparse Coding** *Somnath Basu Roy Chowdhury, Chao Zhao, Snigdha Chaturvedi* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.86/) [[code]](https://github.com/brcsomnath/SemAE) <details> <summary>[Abs]</summary> Opinion summarization is the task of automatically generating summaries that encapsulate information expressed in multiple user reviews. We present Semantic Autoencoder (SemAE) to perform extractive opinion summarization in an unsupervised manner. SemAE uses dictionary learning to implicitly capture semantic information from the review text and learns a latent representation of each sentence over semantic units. Our extractive summarization algorithm leverages the representations to identify representative opinions among hundreds of reviews. SemAE is also able to perform controllable summarization to generate aspect-specific summaries using only a few samples. We report strong performance on SPACE and AMAZON datasets and perform experiments to investigate the functioning of our model. </details>
1. **Want To Reduce Labeling Cost? GPT-3 Can Help** *Shuohang Wang, Yang Liu, Yichong Xu, Chenguang Zhu, Michael Zeng* `Findings of EMNLP 2021` [[pdf]](https://arxiv.org/abs/2108.13487)
1. **Improving Unsupervised Extractive Summarization with Facet-Aware Modeling** *Xinnian Liang, Shuangzhi Wu, Mu Li, Zhoujun Li* `ACL 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-acl.147/) [[code]]()
1. **MRCBert: A Machine Reading ComprehensionApproach for Unsupervised Summarization** *Saurabh Jain, Guokai Tang, Lim Sze Chi* [[pdf]](https://arxiv.org/abs/2105.00239) [[code]](https://github.com/saurabhhssaurabh/reviews_summarization)
1. **Centrality Meets Centroid: A Graph-based Approach for Unsupervised Document Summarization** *Haopeng Zhang, Jiawei Zhang* [[pdf]](https://arxiv.org/abs/2103.15327)
1. **Unsupervised Opinion Summarization with Content Planning** *Reinald Kim Amplayo, Stefanos Angelidis, Mirella Lapata* `AAAI21` [[pdf]](https://arxiv.org/abs/2012.07808) [[code]](https://github.com/rktamplayo/PlanSum)
1. **Biased TextRank: Unsupervised Graph-Based Content Extraction** *Ashkan Kazemi, Verónica Pérez-Rosas, Rada Mihalcea* `COLING20` [[pdf]](https://arxiv.org/abs/2011.01026) [[code]](https://lit.eecs.umich.edu/downloads.html)
1. **Unsupervised Extractive Summarization by Pre-training Hierarchical Transformers** *Shusheng Xu, Xingxing Zhang, Yi Wu, Furu Wei, Ming Zhou* [[pdf]](https://arxiv.org/abs/2010.08242) [[code]](https://github.com/xssstory/STAS)
2. **Q-learning with Language Model for Edit-based Unsupervised Summarization** *Ryosuke Kohita, Akifumi Wachi, Yang Zhao, Ryuki Tachibana* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.04379) [[code]](https://github.com/kohilin/ealm)
3. **Abstractive Document Summarization without Parallel Data** *Nikola I. Nikolov, Richard H.R. Hahnloser* `LREC20` [[pdf]](https://arxiv.org/abs/1907.12951) [[code]](https://github.com/ninikolov/low_resource_summarization)
4. **Unsupervised Neural Single-Document Summarization of Reviews via Learning Latent Discourse Structure and its Ranking** *Masaru Isonuma, Junichiro Mori, Ichiro Sakata* `ACL19` [[pdf]](https://arxiv.org/abs/1906.05691) [[code]](https://github.com/misonuma/strsum)
5. **Sentence Centrality Revisited for Unsupervised Summarization** *Hao Zheng, Mirella Lapata* `ACL19` [[pdf]](https://www.aclweb.org/anthology/P19-1628/) [[code]](https://github.com/mswellhao/PacSum)
6. **Discrete Optimization for Unsupervised Sentence Summarization with Word-Level Extraction** *Raphael Schumann, Lili Mou, Yao Lu, Olga Vechtomova, Katja Markert* `ACL20` [[pdf]](https://arxiv.org/abs/2005.01791) [[code]](https://github.com/raphael-sch/HC_Sentence_Summarization)
1. **SummAE: Zero-Shot Abstractive Text Summarization using Length-Agnostic Auto-Encoders** *Peter J. Liu, Yu-An Chung, Jie Ren* [[pdf]](https://arxiv.org/abs/1910.00998) [[code]](https://github.com/google-research/google-research/tree/master/summae)
7. **MeanSum : A Neural Model for Unsupervised Multi-Document Abstractive Summarization** *Eric Chu, Peter J. Liu* `ICML19` [[pdf]](https://arxiv.org/abs/1810.05739) [[code]](https://github.com/sosuperic/MeanSum)
8. **SEQ3: Differentiable Sequence-to-Sequence-to-Sequence Autoencoder for Unsupervised Abstractive Sentence Compression** *Christos Baziotis, Ion Androutsopoulos, Ioannis Konstas, Alexandros Potamianos* `NAACL19` [[pdf]](https://arxiv.org/abs/1904.03651) [[code]](https://github.com/cbaziotis/seq3)
9. **Learning to Encode Text as Human-Readable Summaries usingGenerative Adversarial Networks** *Yaushian Wang, Hung-Yi Lee* `EMNLP18` [[pdf]](https://www.aclweb.org/anthology/D18-1451/) [[code]](https://github.com/yaushian/Unparalleled-Text-Summarization-using-GAN)
10. **Unsupervised Abstractive Meeting Summarization with Multi-Sentence Compression and Budgeted Submodular Maximization** *Guokan Shang, Wensi Ding, Zekun Zhang, Antoine Tixier, Polykarpos Meladianos, Michalis Vazirgiannis, Jean-Pierre Lorré* `ACL18` [[pdf]](https://arxiv.org/abs/1805.05271) [[code]](https://bitbucket.org/dascim/acl2018_abssumm)
## Concept-map-based
1. **Fast Concept Mention Grouping for Concept Map–based Multi-Document Summarization** *Tobias Falke, Iryna Gurevych* `NAACL19` [[pdf]](https://www.aclweb.org/anthology/N19-1074/) [[code]](https://github.com/UKPLab/naacl2019-cmaps-lshcw)
2. **Bringing Structure into Summaries : Crowdsourcing a Benchmark Corpus of Concept Maps** *Tobias Falke, Iryna Gurevych* `EMNLP17` [[pdf]](https://www.aclweb.org/anthology/D17-1320/) [[code]](https://github.com/UKPLab/emnlp2017-cmapsum-corpus/)
## Timeline
1. **Follow the Timeline! Generating Abstractive and Extractive Timeline Summary in Chronological Order** *Xiuying Chen, Mingzhe Li, Shen Gao, Zhangming Chan, Dongyan Zhao, Xin Gao, Xiangliang Zhang, Rui Yan* `TOIS` [[pdf]](https://arxiv.org/abs/2301.00867) [[code]](https://github.com/iriscxy/Unified-Timeline-Summarizer) <details> <summary>[Abs]</summary> Nowadays, time-stamped web documents related to a general news query floods spread throughout the Internet, and timeline summarization targets concisely summarizing the evolution trajectory of events along the timeline. Unlike traditional document summarization, timeline summarization needs to model the time series information of the input events and summarize important events in chronological order. To tackle this challenge, in this paper, we propose a Unified Timeline Summarizer (UTS) that can generate abstractive and extractive timeline summaries in time order. Concretely, in the encoder part, we propose a graph-based event encoder that relates multiple events according to their content dependency and learns a global representation of each event. In the decoder part, to ensure the chronological order of the abstractive summary, we propose to extract the feature of event-level attention in its generation process with sequential information remained and use it to simulate the evolutionary attention of the ground truth summary. The event-level attention can also be used to assist in extracting summary, where the extracted summary also comes in time sequence. We augment the previous Chinese large-scale timeline summarization dataset and collect a new English timeline dataset. Extensive experiments conducted on these datasets and on the out-of-domain Timeline 17 dataset show that UTS achieves state-of-the-art performance in terms of both automatic and human evaluations. </details>
1. **CrisisLTLSum: A Benchmark for Local Crisis Event Timeline Extraction and Summarization** *Hossein Rajaby Faghihi, Bashar Alhafni, Ke Zhang, Shihao Ran, Joel Tetreault, Alejandro Jaimes* [[pdf]](https://arxiv.org/abs/2210.14190) [[data]](https://github.com/CrisisLTLSum/CrisisTimelines) <details> <summary>[Abs]</summary> Social media has increasingly played a key role in emergency response: first responders can use public posts to better react to ongoing crisis events and deploy the necessary resources where they are most needed. Timeline extraction and abstractive summarization are critical technical tasks to leverage large numbers of social media posts about events. Unfortunately, there are few datasets for benchmarking technical approaches for those tasks. This paper presents CrisisLTLSum, the largest dataset of local crisis event timelines available to date. CrisisLTLSum contains 1,000 crisis event timelines across four domains: wildfires, local fires, traffic, and storms. We built CrisisLTLSum using a semi-automated cluster-then-refine approach to collect data from the public Twitter stream. Our initial experiments indicate a significant gap between the performance of strong baselines compared to the human performance on both tasks. Our dataset, code, and models are publicly available. </details>
1. **Joint Learning-based Heterogeneous Graph Attention Network for Timeline Summarization** *Jingyi You, Dongyuan Li, Hidetaka Kamigaito, Kotaro Funakoshi, Manabu Okumura* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.301/) [[data]](https://github.com/MorenoLaQuatra/SDF-TLS) <details> <summary>[Abs]</summary> Previous studies on the timeline summarization (TLS) task ignored the information interaction between sentences and dates, and adopted pre-defined unlearnable representations for them. They also considered date selection and event detection as two independent tasks, which makes it impossible to integrate their advantages and obtain a globally optimal summary. In this paper, we present a joint learning-based heterogeneous graph attention network for TLS (HeterTls), in which date selection and event detection are combined into a unified framework to improve the extraction accuracy and remove redundant sentences simultaneously. Our heterogeneous graph involves multiple types of nodes, the representations of which are iteratively learned across the heterogeneous graph attention layer. We evaluated our model on four datasets, and found that it significantly outperformed the current state-of-the-art baselines with regard to ROUGE scores and date selection metrics. </details>
1. **Updated Headline Generation: Creating Updated Summaries for Evolving News Stories** *Sheena Panthaplackel, Adrian Benton, Mark Dredze* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.446/) [[code]](https://github.com/panthap2/updated-headline-generation) <details> <summary>[Abs]</summary> We propose the task of updated headline generation, in which a system generates a headline for an updated article, considering both the previous article and headline. The system must identify the novel information in the article update, and modify the existing headline accordingly. We create data for this task using the NewsEdits corpus by automatically identifying contiguous article versions that are likely to require a substantive headline update. We find that models conditioned on the prior headline and body revisions produce headlines judged by humans to be as factual as gold headlines while making fewer unnecessary edits compared to a standard headline generation model. Our experiments establish benchmarks for this new contextual summarization task. </details>
1. **Abstractive summarization of hospitalisation histories with transformer networks** *Alexander Yalunin, Dmitriy Umerenkov, Vladimir Kokh* [[pdf]](https://arxiv.org/abs/2204.02208)
1. **Follow the Timeline! Generating Abstractive and Extractive Timeline Summary in Chronological Order** *Xiuying Chen, Mingzhe Li, Shen Gao, Zhangming Chan, Dongyan Zhao, Xin Gao, Xiangliang Zhang, Rui Yan* `TOIS` [[pdf]](https://dl.acm.org/doi/abs/10.1145/3517221) [[data]](https://github.com/iriscxy/Unified-Timeline-Summarizer)
1. **Multi-TimeLine Summarization (MTLS): Improving Timeline Summarization by Generating Multiple Summaries** *Yi Yu, Adam Jatowt, Antoine Doucet, Kazunari Sugiyama, Masatoshi Yoshikawa* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.32/) [[data]](https://yiyualt.github.io/mtlsdata/)
1. **Summarize Dates First: A Paradigm Shift in Timeline Summarization** *Moreno La Quatra, Luca Cagliero, Elena Baralis, Alberto Messina, Maurizio Montagnuolo* `SIGIR 2021` [[pdf]](https://dl.acm.org/doi/10.1145/3404835.3462954) [[data]](https://github.com/MorenoLaQuatra/SDF-TLS)
1. **Examining the State-of-the-Art in News Timeline Summarization** *Demian Gholipour Ghalandari, Georgiana Ifrim* `ACL20` [[pdf]](https://arxiv.org/abs/2005.10107) [[code]](https://github.com/complementizer/news-tls)
2. **Learning towards Abstractive Timeline Summarization** *Xiuying Chen, Zhangming Chan, Shen Gao, Meng-Hsuan Yu, Dongyan Zhao, Rui Yan* `IJCAI19` [[pdf]](https://www.ijcai.org/Proceedings/2019/686) [[data]](https://github.com/yingtaomj/Learning-towards-Abstractive-Timeline-Summarization)
## Opinion
1. **Opinion Summarization by Weak-Supervision from Mix-structured Data** *Yizhu Liu, Qi Jia, Kenny Zhu* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.201/) [[code]](https://github.com/YizhuLiu/Opinion-Summarization) <details> <summary>[Abs]</summary> Opinion summarization of multiple reviews suffers from the lack of reference summaries for training.Most previous approaches construct multiple reviews and their summary based on textual similarities between reviews,resulting in information mismatch between the review input and the summary. In this paper, we convert each review into a mixof structured and unstructured data, which we call opinion-aspect pairs (OAs) and implicit sentences (ISs).We propose a new method to synthesize training pairs of such mix-structured data as input and the textual summary as output,and design a summarization model with OA encoder and IS encoder.Experiments show that our approach outperforms previous methods on Yelp, Amazon and RottenTomatos datasets. </details>
1. **OpineSum: Entailment-based self-training for abstractive opinion summarization** *Annie Louis, Joshua Maynez* [[pdf]](https://arxiv.org/abs/2212.10791) <details> <summary>[Abs]</summary> A typical product or place often has hundreds of reviews, and summarization of these texts is an important and challenging problem. Recent progress on abstractive summarization in domains such as news has been driven by supervised systems trained on hundreds of thousands of news articles paired with human-written summaries. However for opinion texts, such large scale datasets are rarely available. Unsupervised methods, self-training, and few-shot learning approaches bridge that gap. In this work, we present a novel self-training approach, OpineSum, for abstractive opinion summarization. The summaries in this approach are built using a novel application of textual entailment and capture the consensus of opinions across the various reviews for an item. This method can be used to obtain silver-standard summaries on a large scale and train both unsupervised and few-shot abstractive summarization systems. OpineSum achieves state-of-the-art performance in both settings. </details>
1. **Zero-Shot Opinion Summarization with GPT-3** *Adithya Bhaskar, Alexander R. Fabbri, Greg Durrett* [[pdf]](https://arxiv.org/abs/2211.15914) [[code]](https://github.com/testzer0/ZS-Summ-GPT3) <details> <summary>[Abs]</summary> Very large language models such as GPT-3 have shown impressive performance across a wide variety of tasks, including text summarization. In this paper, we show that this strong performance extends to opinion summarization. We explore several pipeline methods for applying GPT-3 to summarize a large collection of user reviews in a zero-shot fashion, notably approaches based on recursive summarization and selecting salient content to summarize through supervised clustering or extraction. On two datasets, an aspect-oriented summarization dataset of hotel reviews and a generic summarization dataset of Amazon and Yelp reviews, we show that the GPT-3 models achieve very strong performance in human evaluation. We argue that standard evaluation metrics do not reflect this, and evaluate against several new measures targeting faithfulness, factuality, and genericity to contrast these different methods. </details>
1. **Unsupervised Opinion Summarisation in the Wasserstein Space** *Jiayu Song, Iman Munire Bilal, Adam Tsakalidis, Rob Procter, Maria Liakata* [[pdf]](https://arxiv.org/abs/2211.14923) <details> <summary>[Abs]</summary> Opinion summarisation synthesises opinions expressed in a group of documents discussing the same topic to produce a single summary. Recent work has looked at opinion summarisation of clusters of social media posts. Such posts are noisy and have unpredictable structure, posing additional challenges for the construction of the summary distribution and the preservation of meaning compared to online reviews, which has been so far the focus of opinion summarisation. To address these challenges we present \textit{WassOS}, an unsupervised abstractive summarization model which makes use of the Wasserstein distance. A Variational Autoencoder is used to get the distribution of documents/posts, and the distributions are disentangled into separate semantic and syntactic spaces. The summary distribution is obtained using the Wasserstein barycenter of the semantic and syntactic distributions. A latent variable sampled from the summary distribution is fed into a GRU decoder with a transformer layer to produce the final summary. Our experiments on multiple datasets including Twitter clusters, Reddit threads, and reviews show that WassOS almost always outperforms the state-of-the-art on ROUGE metrics and consistently produces the best summaries with respect to meaning preservation according to human evaluations. </details>
1. **Noisy Pairing and Partial Supervision for Opinion Summarization** *Hayate Iso, Xiaolan Wang, Yoshi Suhara* [[pdf]](https://arxiv.org/abs/2211.08723) <details> <summary>[Abs]</summary> Current opinion summarization systems simply generate summaries reflecting important opinions from customer reviews, but the generated summaries may not attract the reader's attention. Although it is helpful to automatically generate professional reviewer-like summaries from customer reviews, collecting many training pairs of customer and professional reviews is generally tricky. We propose a weakly supervised opinion summarization framework, Noisy Pairing and Partial Supervision (NAPA) that can build a stylized opinion summarization system with no customer-professional review pairs. Experimental results show consistent improvements in automatic evaluation metrics, and qualitative analysis shows that our weakly supervised opinion summarization system can generate summaries that look more like those written by professional reviewers. </details>
1. **Unsupervised Opinion Summarization Using Approximate Geodesics** *Somnath Basu Roy Chowdhury, Nicholas Monath, Avinava Dubey, Amr Ahmed, Snigdha Chaturvedi* [[pdf]](https://arxiv.org/abs/2209.07496) <details> <summary>[Abs]</summary> Opinion summarization is the task of creating summaries capturing popular opinions from user reviews. In this paper, we introduce Geodesic Summarizer (GeoSumm), a novel system to perform unsupervised extractive opinion summarization. GeoSumm involves an encoder-decoder based representation learning model, that generates representations of text as a distribution over latent semantic units. GeoSumm generates these representations by performing dictionary learning over pre-trained text representations at multiple decoder layers. We then use these representations to quantify the relevance of review sentences using a novel approximate geodesic distance based scoring mechanism. We use the relevance scores to identify popular opinions in order to compose general and aspect-specific summaries. Our proposed model, GeoSumm, achieves state-of-the-art performance on three opinion summarization datasets. We perform additional experiments to analyze the functioning of our model and showcase the generalization ability of {\X} across different domains. </details>
1. **Template-based Abstractive Microblog Opinion Summarisation** *Iman Munire Bilal, Bo Wang, Adam Tsakalidis, Dong Nguyen, Rob Procter, Maria Liakata* `TACL 2022` [[pdf]](https://arxiv.org/abs/2208.04083) <details> <summary>[Abs]</summary> We introduce the task of microblog opinion summarisation (MOS) and share a dataset of 3100 gold-standard opinion summaries to facilitate research in this domain. The dataset contains summaries of tweets spanning a 2-year period and covers more topics than any other public Twitter summarisation dataset. Summaries are abstractive in nature and have been created by journalists skilled in summarising news articles following a template separating factual information (main story) from author opinions. Our method differs from previous work on generating gold-standard summaries from social media, which usually involves selecting representative posts and thus favours extractive summarisation models. To showcase the dataset's utility and challenges, we benchmark a range of abstractive and extractive state-of-the-art summarisation models and achieve good performance, with the former outperforming the latter. We also show that fine-tuning is necessary to improve performance and investigate the benefits of using different sample sizes. </details>
1. **Efficient Few-Shot Fine-Tuning for Opinion Summarization** *Arthur Bražinskas, Ramesh Nallapati, Mohit Bansal, Markus Dreyer* `Findings of NAACL 202` [[pdf]](https://aclanthology.org/2022.findings-naacl.113/) [[code]](https://github.com/amazon-research/adasum) <details> <summary>[Abs]</summary> Abstractive summarization models are typically pre-trained on large amounts of generic texts, then fine-tuned on tens or hundreds of thousands of annotated samples. However, in opinion summarization, large annotated datasets of reviews paired with reference summaries are not available and would be expensive to create. This calls for fine-tuning methods robust to overfitting on small datasets. In addition, generically pre-trained models are often not accustomed to the specifics of customer reviews and, after fine-tuning, yield summaries with disfluencies and semantic mistakes. To address these problems, we utilize an efficient few-shot method based on adapters which, as we show, can easily store in-domain knowledge. Instead of fine-tuning the entire model, we add adapters and pre-train them in a task-specific way on a large corpus of unannotated customer reviews, using held-out reviews as pseudo summaries. Then, fine-tune the adapters on the small available human-annotated dataset. We show that this self-supervised adapter pre-training improves summary quality over standard fine-tuning by 2.0 and 1.3 ROUGE-L points on the Amazon and Yelp datasets, respectively. Finally, for summary personalization, we condition on aspect keyword queries, automatically created from generic datasets. In the same vein, we pre-train the adapters in a query-based manner on customer reviews and then fine-tune them on annotated datasets. This results in better-organized summary content reflected in improved coherence and fewer redundancies. </details>
1. **DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization** *Xueying Zhang, Yunjiang Jiang, Yue Shang, Zhaomeng Cheng, Chi Zhang, Xiaochuan Fan, Yun Xiao, Bo Long* `SIGIR 2021` [[pdf]](https://arxiv.org/abs/2112.08414)
1. **Convex Aggregation for Opinion Summarization** *Hayate Iso, Xiaolan Wang, Yoshihiko Suhara, Stefanos Angelidis, Wang-Chiew Tan* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.328/) [[code]](https://github.com/megagonlabs/coop)
1. **Measuring Similarity of Opinion-bearing Sentences** *Wenyi Tay, Xiuzhen Zhang, Stephen Wan, Sarvnaz Karimi* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.9/) [[data]](https://github.com/wenyi-tay/sos)
1. **Comparative Opinion Summarization via Collaborative Decoding** *Hayate Iso, Xiaolan Wang, Yoshihiko Suhara* [[pdf]](https://arxiv.org/abs/2110.07520) [[data]](https://github.com/megagonlabs/cocosum)
1. **Learning Opinion Summarizers by Selecting Informative Reviews** *Arthur Bražinskas, Mirella Lapata, Ivan Titov* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.04325) [[code]](https://github.com/abrazinskas/SelSum)
1. **Aspect-Controllable Opinion Summarization** *Reinald Kim Amplayo, Stefanos Angelidis, Mirella Lapata* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.03171) [[code]](https://github.com/rktamplayo/AceSum)
1. **CUSTOM: Aspect-Oriented Product Summarization for E-Commerce** *Jiahui Liang, Junwei Bao, Yifan Wang, Youzheng Wu, Xiaodong He, Bowen Zhou* [[pdf]](https://arxiv.org/abs/2108.08010) [[code]](https://github.com/JD-AI-Research-NLP/CUSTOM)
1. **TransSum: Translating Aspect and Sentiment Embeddings for Self-Supervised Opinion Summarization** *Ke Wang, Xiaojun Wan* `ACL 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-acl.65/)
1. **Unsupervised Abstractive Opinion Summarization by Generating Sentences with Tree-Structured Topic Guidance** *Masaru Isonuma, Junichiro Mori, Danushka Bollegala, Ichiro Sakata* `TACL 2021` [[pdf]](https://arxiv.org/abs/2106.08007)
1. **PASS: Perturb-and-Select Summarizer for Product Reviews** *Nadav Oved, Ran Levy* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.30/)
1. **Self-Supervised Multimodal Opinion Summarization** *Jinbae Im, Moonki Kim, Hoyeop Lee, Hyunsouk Cho, Sehee Chung* `ACL21` [[pdf]](https://arxiv.org/abs/2105.13135) [[code]](https://github.com/nc-ai/knowledge/tree/master/publications/MultimodalSum)
1. **MRCBert: A Machine Reading Comprehension Approach for Unsupervised Summarization** *Saurabh Jain, Guokai Tang, Lim Sze Chi* [[pdf]](https://arxiv.org/abs/2105.00239) [[code]](https://github.com/saurabhhssaurabh/reviews_summarization)
1. **Informative and Controllable Opinion Summarization** *Reinald Kim Amplayo, Mirella Lapata* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.229/) [[code]](https://github.com/rktamplayo/CondaSum)
1. **Self-Supervised and Controlled Multi-Document Opinion Summarization** *Hady Elsahar, Maximin Coavoux, Jos Rozen, Matthias Gallé* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.141/)
1. **Unsupervised Opinion Summarization with Content Planning** *Reinald Kim Amplayo, Stefanos Angelidis, Mirella Lapata* `AAAI21` [[pdf]](https://arxiv.org/abs/2012.07808) [[code]](https://github.com/rktamplayo/PlanSum)
1. **Extractive Opinion Summarization in Quantized Transformer Spaces** *Stefanos Angelidis, Reinald Kim Amplayo, Yoshihiko Suhara, Xiaolan Wang, Mirella Lapata* `TACL` [[pdf]](https://arxiv.org/abs/2012.04443) [[code]](https://github.com/stangelid/qt)
1. **Few-Shot Learning for Opinion Summarization** *Arthur Bražinskas, Mirella Lapata, Ivan Titov* `EMNLP20` [[pdf]](https://arxiv.org/abs/2004.14884) [[code]](https://github.com/abrazinskas/FewSum)
2. **Unsupervised Opinion Summarization as Copycat-Review Generation** *Arthur Bražinskas, Mirella Lapata, Ivan Titov* `ACL20` [[pdf]](https://arxiv.org/abs/1911.02247) [[code]](https://github.com/abrazinskas/Copycat-abstractive-opinion-summarizer)
3. **Unsupervised Opinion Summarization with Noising and Denoising** *Reinald Kim Amplayo, Mirella Lapata* `ACL20` [[pdf]](https://arxiv.org/abs/2004.10150) [[code]](https://github.com/rktamplayo/DenoiseSum)
4. **OPINIONDIGEST: A Simple Framework for Opinion Summarization** *Yoshihiko Suhara, Xiaolan Wang, Stefanos Angelidis, Wang-Chiew Tan* `ACL20 Short` [[pdf]](https://arxiv.org/abs/2005.01901) [[code]](https://github.com/megagonlabs/opiniondigest)
5. **Weakly-Supervised Opinion Summarization by Leveraging External Information** *Chao Zhao, Snigdha Chaturvedi* `AAAI20` [[pdf]](https://arxiv.org/abs/1911.09844) [[code]](https://github.com/zhaochaocs/AspMem)
6. **MeanSum: A Neural Model for Unsupervised Multi-Document Abstractive Summarization** *Eric Chu, Peter J. Liu* `ICML19` [[pdf]](https://arxiv.org/abs/1810.05739) [[code]](https://github.com/sosuperic/MeanSum)
## Reinforcement Learning
1. **Reinforcement Learning for Abstractive Question Summarization with Question-aware Semantic Rewards** *Shweta Yadav, Deepak Gupta, Asma Ben Abacha, Dina Demner-Fushman* `ACL 2021 short` [[pdf]](https://aclanthology.org/2021.acl-short.33/) [[code]](https://github.com/shwetanlp/CHQ-Summ)
1. **RewardsOfSum: Exploring Reinforcement Learning Rewards for Summarisation** *Jacob Parnell, Inigo Jauregi Unanue, Massimo Piccardi* `5th Workshop on Structured Prediction for NLP ACL-IJCNLP 2021` [[pdf]](https://arxiv.org/abs/2106.04080)
1. **Reinforced Generative Adversarial Network for Abstractive Text Summarization** *Tianyang Xu, Chunyun Zhang* [[pdf]](https://arxiv.org/abs/2105.15176)
1. **Answers Unite! Unsupervised Metrics for Reinforced Summarization Models** *Thomas Scialom, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.01610)
2. **Deep Reinforcement Learning with Distributional Semantic Rewards for Abstractive Summarization** *Siyao Li, Deren Lei, Pengda Qin, William Yang Wang* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.00141)
3. **Reinforced Extractive Summarization with Question-Focused Rewards** *Kristjan Arumae, Fei Liu* `ACL18` [[pdf]](https://www.aclweb.org/anthology/P18-3015/)
4. **Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting** *Yen-Chun Chen, Mohit Bansal* `ACL18` [[pdf]](https://arxiv.org/abs/1805.11080) [[code]](https://github.com/ChenRocks/fast_abs_rl)
5. **Multi-Reward Reinforced Summarization with Saliency and Entailmen** *Ramakanth Pasunuru, Mohit Bansal* `NAACL18` [[pdf]](https://www.aclweb.org/anthology/N18-2102/)
6. **Deep Communicating Agents for Abstractive Summarization** *Asli Celikyilmaz, Antoine Bosselut, Xiaodong He, Yejin Choi* `NAACL18` [[pdf]](https://arxiv.org/abs/1803.10357)
7. **Ranking Sentences for Extractive Summarization with Reinforcement Learning** *Shashi Narayan, Shay B. Cohen, Mirella Lapata* `NAACL18` [[pdf]](https://www.aclweb.org/anthology/N18-1158/) [[code]](https://github.com/EdinburghNLP/Refresh)
8. **A Deep Reinforced Model For Abstractive Summarization** *Romain Paulus, Caiming Xiong, Richard Socher* `ICLR18` [[pdf]](https://arxiv.org/abs/1705.04304)
## Reward Learning
1. **Recursively Summarizing Books with Human Feedback** *Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nissan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano* [[pdf]](https://arxiv.org/abs/2109.10862) [[code]](https://openaipublic.blob.core.windows.net/recursive-book-summ/website/index.html#/)
1. **Learning to summarize from human feedback** *Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano* [[pdf]](https://arxiv.org/abs/2009.01325) [[code]](https://github.com/openai/summarize-from-feedback)
2. **Better Rewards Yield Better Summaries: Learning to Summarise Without References** *Florian Böhm, Yang Gao, Christian M. Meyer, Ori Shapira, Ido Dagan, Iryna Gurevych* `EMNLP19` [[pdf]](https://arxiv.org/abs/1909.01214) [[code]](https://github.com/yg211/summary-reward-no-reference)
## Extractive
1. **Extractive Text Summarization Using Generalized Additive Models with Interactions for Sentence Selection** *Vinícius Camargo da Silva, João Paulo Papa, Kelton Augusto Pontara da Costa* [[pdf]](https://arxiv.org/abs/2212.10707) <details> <summary>[Abs]</summary> Automatic Text Summarization (ATS) is becoming relevant with the growth of textual data; however, with the popularization of public large-scale datasets, some recent machine learning approaches have focused on dense models and architectures that, despite producing notable results, usually turn out in models difficult to interpret. Given the challenge behind interpretable learning-based text summarization and the importance it may have for evolving the current state of the ATS field, this work studies the application of two modern Generalized Additive Models with interactions, namely Explainable Boosting Machine and GAMI-Net, to the extractive summarization problem based on linguistic features and binary classification. </details>
1. **Noise-injected Consistency Training and Entropy-constrained Pseudo Labeling for Semi-supervised Extractive Summarization** *Yiming Wang, Qianren Mao, Junnan Liu, Weifeng Jiang, Hongdong Zhu, Jianxin Li* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.561/) [[code]](https://github.com/OpenSUM/CPSUM) <details> <summary>[Abs]</summary> Labeling large amounts of extractive summarization data is often prohibitive expensive due to time, financial, and expertise constraints, which poses great challenges to incorporating summarization system in practical applications. This limitation can be overcome by semi-supervised approaches: consistency-training and pseudo-labeling to make full use of unlabeled data. Researches on the two, however, are conducted independently, and very few works try to connect them. In this paper, we first use the noise-injected consistency training paradigm to regularize model predictions. Subsequently, we propose a novel entropy-constrained pseudo labeling strategy to obtain high-confidence labels from unlabeled predictions, which can obtain high-confidence labels from unlabeled predictions by comparing the entropy of supervised and unsupervised predictions. By combining consistency training and pseudo-labeling, this framework enforce a low-density separation between classes, which decently improves the performance of supervised learning over an insufficient labeled extractive summarization dataset. </details>
1. **Summarize, Outline, and Elaborate: Long-Text Generation via Hierarchical Supervision from Extractive Summaries** *Xiaofei Sun, Chun Fan, Zijun Sun, Yuxian Meng, Fei Wu, Jiwei Li* [[pdf]](https://aclanthology.org/2022.coling-1.556/) <details> <summary>[Abs]</summary> The difficulty of generating coherent long texts lies in the fact that existing models overwhelmingly focus on the tasks of local word prediction, and cannot make high level plans on what to generate or capture the high-level discourse dependencies between chunks of texts. Inspired by how humans write, where a list of bullet points or a catalog is first outlined, and then each bullet point is expanded to form the whole article, we propose SOE, a pipelined system that involves of summarizing, outlining and elaborating for long text generation: the model first outlines the summaries for different segments of long texts, and then elaborates on each bullet point to generate the corresponding segment. To avoid the labor-intensive process of summary soliciting, we propose the reconstruction strategy, which extracts segment summaries in an unsupervised manner by selecting its most informative part to reconstruct the segment. The proposed generation system comes with the following merits: (1) the summary provides high-level guidance for text generation and avoids the local minimum of individual word predictions; (2) the high-level discourse dependencies are captured in the conditional dependencies between summaries and are preserved during the summary expansion process and (3) additionally, we are able to consider significantly more contexts by representing contexts as concise summaries. Extensive experiments demonstrate that SOE produces long texts with significantly better quality, along with faster convergence speed. </details>
2. **Extractive Summarisation for German-language Data: A Text-level Approach with Discourse Features** *Freya Hewett, Manfred Stede* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.63/) [[data]](https://github.com/fhewett/pcc-summaries) <details> <summary>[Abs]</summary> We examine the link between facets of Rhetorical Structure Theory (RST) and the selection of content for extractive summarisation, for German-language texts. For this purpose, we produce a set of extractive summaries for a dataset of German-language newspaper commentaries, a corpus which already has several layers of annotation. We provide an in-depth analysis of the connection between summary sentences and several RST-based features and transfer these insights to various automated summarisation models. Our results show that RST features are informative for the task of extractive summarisation, particularly nuclearity and relations at sentence-level. </details>
3. **Text Summarization with Oracle Expectation** *Yumo Xu, Mirella Lapata* [[pdf]](https://arxiv.org/abs/2209.12714) [[code]](https://github.com/yumoxu/oreo) <details> <summary>[Abs]</summary> Extractive summarization produces summaries by identifying and concatenating the most important sentences in a document. Since most summarization datasets do not come with gold labels indicating whether document sentences are summary-worthy, different labeling algorithms have been proposed to extrapolate oracle extracts for model training. In this work, we identify two flaws with the widely used greedy labeling approach: it delivers suboptimal and deterministic oracles. To alleviate both issues, we propose a simple yet effective labeling algorithm that creates soft, expectation-based sentence labels. We define a new learning objective for extractive summarization which incorporates learning signals from multiple oracle summaries and prove it is equivalent to estimating the oracle expectation for each document sentence. Without any architectural modifications, the proposed labeling scheme achieves superior performance on a variety of summarization benchmarks across domains and languages, in both supervised and zero-shot settings. </details>
4. **OTExtSum: Extractive Text Summarisation with Optimal Transport** *Peggy Tang, Kun Hu, Rui Yan, Lei Zhang, Junbin Gao, Zhiyong Wang* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.85/) [[code]](https://github.com/peggypytang/OTExtSum/) <details> <summary>[Abs]</summary> Extractive text summarisation aims to select salient sentences from a document to form a short yet informative summary. While learning-based methods have achieved promising results, they have several limitations, such as dependence on expensive training and lack of interpretability. Therefore, in this paper, we propose a novel non-learning-based method by for the first time formulating text summarisation as an Optimal Transport (OT) problem, namely Optimal Transport Extractive Summariser (OTExtSum). Optimal sentence extraction is conceptualised as obtaining an optimal summary that minimises the transportation cost to a given document regarding their semantic distributions. Such a cost is defined by the Wasserstein distance and used to measure the summary’s semantic coverage of the original document. Comprehensive experiments on four challenging and widely used datasets - MultiNews, PubMed, BillSum, and CNN/DM demonstrate that our proposed method outperforms the state-of-the-art non-learning-based methods and several recent learning-based methods in terms of the ROUGE metric. </details>
5. **Post-Editing Extractive Summaries by Definiteness Prediction** *Jad Kabbara, Jackie Chi Kit Cheung* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.312/)
6. **Decision-Focused Summarization** *Chao-Chun Hsu, Chenhao Tan* `EMNLP 2021` [[pdf]](https://arxiv.org/abs/2109.06896) [[code]](https://github.com/ChicagoHAI/decsum)
7. **Monolingual versus Multilingual BERTology for Vietnamese Extractive Multi-Document Summarization** *Huy To Quoc, Kiet Van Nguyen, Ngan Luu-Thuy Nguyen, Anh Gia-Tuan Nguyen* [[pdf]](https://arxiv.org/abs/2108.13741)
8. **Multiplex Graph Neural Network for Extractive Text Summarization** *Baoyu Jing, Zeyu You, Tao Yang, Wei Fan, Hanghang Tong* `EMNLP 2021 Short` [[pdf]](https://arxiv.org/abs/2108.12870)
9. **Unsupervised Extractive Summarization-Based Representations for Accurate and Explainable Collaborative Filtering** *Reinald Adrian Pugoy, Hung-Yu Kao* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.232/)
10. **Deep Differential Amplifier for Extractive Summarization** *Ruipeng Jia, Yanan Cao, Fang Fang, Yuchen Zhou, Zheng Fang, Yanbing Liu, Shi Wang* `ACL 2021` [[pdf]](https://aclanthology.org/2021.acl-long.31/)
11. **Incorporating Domain Knowledge for Extractive Summarization of Legal Case Documents** *Paheli Bhattacharya, Soham Poddar, Koustav Rudra, Kripabandhu Ghosh, Saptarshi Ghosh* `ICAIL 2021` [[pdf]](https://arxiv.org/abs/2106.15876)
12. **Topic Modeling Based Extractive Text Summarization** *Kalliath Abdul Rasheed Issam, Shivam Patel, Subalalitha C. N* `Journal` [[pdf]](https://arxiv.org/abs/2106.15313)
13. **Demoting the Lead Bias in News Summarization via Alternating Adversarial Learning** *Linzi Xing, Wen Xiao, Giuseppe Carenini* `ACL2021-short` [[pdf]](https://aclanthology.org/2021.acl-short.119/) [[code]](https://github.com/lxing532/Debiasing)
14. **Genetic Algorithms For Extractive Summarization** *William Chen, Kensal Ramos, Kalyan Naidu Mullaguri* [[pdf]](https://arxiv.org/abs/2105.02365)
15. **Extractive Summarization Considering Discourse and Coreference Relations based on Heterogeneous Graph** *Yin Jou Huang, Sadao Kurohashi* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.265/)
16. **AREDSUM: Adaptive Redundancy-Aware Iterative Sentence Ranking for Extractive Document Summarization** *Keping Bi, Rahul Jha, Bruce Croft, Asli Celikyilmaz* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.22/)
17. **Unsupervised Extractive Summarization using Pointwise Mutual Information** *Vishakh Padmakumar, He He* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.213/) [[code]](https://github.com/vishakhpk/mi-unsup-summ)
18. **Better Highlighting: Creating Sub-Sentence Summary Highlights** *Sangwoo Cho, Kaiqiang Song, Chen Li, Dong Yu, Hassan Foroosh, Fei Liu* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.10566) [[code]](https://github.com/ucfnlp/better-highlighting)
19. **SupMMD: A Sentence Importance Model for Extractive Summarization using Maximum Mean Discrepancy** *Umanga Bista, Alexander Patrick Mathews, Aditya Krishna Menon, Lexing Xie* [[pdf]](https://arxiv.org/abs/2010.02568) [[code]](https://github.com/computationalmedia/supmmd)
20. **Stepwise Extractive Summarization and Planning with Structured Transformers** *Shashi Narayan, Joshua Maynez, Jakub Adamek, Daniele Pighin, Blaž Bratanič, Ryan McDonald* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.02744) [[code]](https://github.com/google-research/google-research/tree/master/etcsum)
21. **A Discourse-Aware Neural Extractive Model for Text Summarization** *Jiacheng Xu, Zhe Gan, Yu Cheng, Jingjing Liu* `ACL20` [[pdf]](https://arxiv.org/abs/1910.14142) [[code]](https://github.com/jiacheng-xu/DiscoBERT)
22. **Reading Like HER: Human Reading Inspired Extractive Summarization** *Ling Luo, Xiang Ao, Yan Song, Feiyang Pan, Min Yang, Qing He* `EMNLP19` [[pdf]](https://www.aclweb.org/anthology/D19-1300/)
23. **Exploiting Discourse-Level Segmentation for Extractive Summarization** *Zhengyuan Liu, Nancy Chen* `EMNLP19` [[pdf]](https://www.aclweb.org/anthology/D19-5415/)
24. **DeepChannel: Salience Estimation by Contrastive Learning for Extractive Document Summarization** *Jiaxin Shi, Chen Liang, Lei Hou, Juanzi Li, Zhiyuan Liu, Hanwang Zhang* `AAAI19` [[pdf]](https://arxiv.org/abs/1811.02394) [[code]](https://github.com/lliangchenc/DeepChannel)
25. **Extractive Summarization with SWAP-NET: Sentences and Words from Alternating Pointer Networks** *Aishwarya Jadhav, Vaibhav Rajan* `ACL18` [[pdf]](https://www.aclweb.org/anthology/P18-1014/)
26. **Neural Document Summarization by Jointly Learning to Score and Select Sentences** *Qingyu Zhou, Nan Yang, Furu Wei, Shaohan Huang, Ming Zhou, Tiejun Zhao* `ACL18` [[pdf]](https://www.aclweb.org/anthology/P18-1061/)
27. **Neural Latent Extractive Document Summarization** *Xingxing Zhang, Mirella Lapata, Furu Wei, Ming Zhou* `ACL18` [[pdf]](https://www.aclweb.org/anthology/D18-1088/)
28. **Generative Adversarial Network for Abstractive Text Summarization** *Linqing Liu, Yao Lu, Min Yang, Qiang Qu, Jia Zhu, Hongyan Li* `AAAI18` [[pdf]](https://arxiv.org/abs/1711.09357) [[code]](https://github.com/iwangjian/textsum-gan)
29. **Improving Neural Abstractive Document Summarization with Explicit Information Selection Modeling** *Wei Li, Xinyan Xiao, Yajuan Lyu, Yuanzhuo Wang* `EMNLP18`[[pdf]](https://www.aclweb.org/anthology/D18-1205/)
30. **Extractive Summarization Using Multi-Task Learning with Document Classification** *Masaru Isonuma, Toru Fujino, Junichiro Mori, Yutaka Matsuo, Ichiro Sakata* `EMNLP17` [[pdf]](https://www.aclweb.org/anthology/D17-1223/)
31. **SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents** *Ramesh Nallapati, Feifei Zhai, Bowen Zhou* `AAAI17` [[pdf]](https://arxiv.org/abs/1611.04230) [[code]](https://github.com/hpzhao/SummaRuNNer)
32. **Text Summarization through Entailment-based Minimum Vertex Cover** *Anand Gupta, Manpreet Kaur, Shachar Mirkin, Adarsh Singh, Aseem Goyal* `ENLG13` [[pdf]](https://www.aclweb.org/anthology/S14-1010/)
## Extractive-Abstractive
1. **EASE: Extractive-Abstractive Summarization with Explanations** *Haoran Li, Arash Einolghozati, Srinivasan Iyer, Bhargavi Paranjape, Yashar Mehdad, Sonal Gupta, Marjan Ghazvininejad* `EMNLP 2021| newsum` [[pdf]](https://aclanthology.org/2021.newsum-1.10/)
1. **Semantic Extractor-Paraphraser based Abstractive Summarization** *Anubhav Jangra, Raghav Jain, Vaibhav Mavi, Sriparna Saha, Pushpak Bhattacharyya* [[pdf]](https://arxiv.org/abs/2105.01296)
1. **Contextualized Rewriting for Text Summarization** *Guangsheng Bao, Yue Zhang* `AAAI21` [[pdf]](https://arxiv.org/abs/2102.00385)
1. **Jointly Extracting and Compressing Documents with Summary State Representations** *Afonso Mendes, Shashi Narayan, Sebastião Miranda, Zita Marinho, André F. T. Martins, Shay B. Cohen* `NAACL19` [[pdf]](https://arxiv.org/abs/1904.02020) [[code]](https://github.com/Priberam/exconsumm)
## VAE
1. **Deep Recurrent Generative Decoder for Abstractive Text Summarization** *Piji Li, Wai Lam, Lidong Bing, Zihao Wang* `EMNLP17` [[pdf]](https://www.aclweb.org/anthology/D17-1222/)
2. **Document Summarization with VHTM: Variational Hierarchical Topic-Aware Mechanism** *Xiyan Fu, Jun Wang, Jinghan Zhang, Jinmao Wei, Zhenglu Yang* `AAAI20` [[pdf]](https://ojs.aaai.org//index.php/AAAI/article/view/6277)
## Syntactic
1. **Compressive Summarization with Plausibility and Salience Modeling** *Shrey Desai, Jiacheng Xu, Greg Durrett* `EMNLP20` [[pdf]](https://arxiv.org/abs/2010.07886) [[code]](https://github.com/shreydesai/cups)
2. **StructSum: Incorporating Latent and Explicit Sentence Dependencies for Single Document Summarization** *Vidhisha Balachandran, Artidoro Pagnoni, Jay Yoon Lee, Dheeraj Rajagopal, Jaime Carbonell, Yulia Tsvetkov* `EACL21` [[pdf]](https://www.aclweb.org/anthology/events/eacl-2021/) [[code]](https://github.com/vidhishanair/structured_summarizer)
3. **Joint Parsing and Generation for Abstractive Summarization** *Kaiqiang Song, Logan Lebanoff, Qipeng Guo, Xipeng Qiu, Xiangyang Xue, Chen Li, Dong Yu, Fei Liu* `AAAI20` [[pdf]](https://arxiv.org/abs/1911.10389) [[code]](https://github.com/KaiQiangSong/joint_parse_summ)
4. **Neural Extractive Text Summarization with Syntactic Compression** *Jiacheng Xu, Greg Durrett* `EMNLP19` [[pdf]](https://arxiv.org/abs/1902.00863) [[code]](https://github.com/jiacheng-xu/neu-compression-sum)
5. **Single Document Summarization as Tree Induction** *Yang Liu, Ivan Titov, Mirella Lapata* `NAACL19` [[pdf]](https://www.aclweb.org/anthology/N19-1173/) [[code]](https://github.com/nlpyang/SUMO)
## QA Related
1. **Less is More: Summary of Long Instructions is Better for Program Synthesis** *Kirby Kuznia, Swaroop Mishra, Mihir Parmar, Chitta Baral* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.301/) [[code]](https://github.com/kurbster/Prompt-Summarization) <details> <summary>[Abs]</summary> Despite the success of large pre-trained language models (LMs) such as Codex, they show below-par performance on the larger and more complicated programming related questions. We show that LMs benefit from the summarized version of complicated questions. Our findings show that superfluous information often present in problem description such as human characters, background stories, and names (which are included to help humans in understanding a task) does not help models in understanding a task. To this extent, we create a meta-dataset from the frequently used APPS dataset and the newly created CodeContests dataset for the program synthesis task. Our meta-dataset consists of human and synthesized summaries of the long and complicated programming questions. Experimental results on Codex show that our proposed approach outperforms baseline by 8.13% on the APPS dataset and 11.88% on the CodeContests dataset on an average in terms of strict accuracy. Our analysis shows that summaries significantly improve performance for introductory (9.86%) and interview (11.48%) related programming questions. However, it shows improvement by a small margin (2%) for competitive programming questions, implying the scope for future research direction. </details>
1. **Focus-Driven Contrastive Learning for Medical Question Summarization** *Ming Zhang, Shuai Dou, Ziyang Wang, Yunfang Wu* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.539/) <details> <summary>[Abs]</summary> Automatic medical question summarization can significantly help the system to understand consumer health questions and retrieve correct answers. The Seq2Seq model based on maximum likelihood estimation (MLE) has been applied in this task, which faces two general problems: the model can not capture well question focus and the traditional MLE strategy lacks the ability to understand sentence-level semantics. To alleviate these problems, we propose a novel question focus-driven contrastive learning framework (QFCL). Specially, we propose an easy and effective approach to generate hard negative samples based on the question focus, and exploit contrastive learning at both encoder and decoder to obtain better sentence level representations. On three medical benchmark datasets, our proposed model achieves new state-of-the-art results, and obtains a performance gain of 5.33, 12.85 and 3.81 points over the baseline BART model on three datasets respectively. Further human judgement and detailed analysis prove that our QFCL model learns better sentence representations with the ability to distinguish different sentence meanings, and generates high-quality summaries by capturing question focus. </details>
1. **Educational Question Generation of Children Storybooks via Question Type Distribution Learning and Event-centric Summarization** *Zhenjie Zhao, Yufang Hou, Dakuo Wang, Mo Yu, Chengzhong Liu, Xiaojuan Ma* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.348/) [[code]](https://github.com/zhaozj89/Educational-Question-Generation) <details> <summary>[Abs]</summary> Generating educational questions of fairytales or storybooks is vital for improving children’s literacy ability. However, it is challenging to generate questions that capture the interesting aspects of a fairytale story with educational meaningfulness. In this paper, we propose a novel question generation method that first learns the question type distribution of an input story paragraph, and then summarizes salient events which can be used to generate high-cognitive-demand questions. To train the event-centric summarizer, we finetune a pre-trained transformer-based sequence-to-sequence model using silver samples composed by educational question-answer pairs. On a newly proposed educational question-answering dataset FairytaleQA, we show good performance of our method on both automatic and human evaluation metrics. Our work indicates the necessity of decomposing question type distribution learning and event-centric summary generation for educational question generation. </details>
1. **Benchmarking Answer Verification Methods for Question Answering-Based Summarization Evaluation Metrics** *Daniel Deutsch, Dan Roth* [[pdf]](https://arxiv.org/abs/2204.10206)
1. **Using Question Answering Rewards to Improve Abstractive Summarization** *Chulaka Gunasekara, Guy Feigenblat, Benjamin Sznajder, Ranit Aharonov, Sachindra Joshi* `EMNLP 2021 Findings` [[pdf]](https://aclanthology.org/2021.findings-emnlp.47/)
1. **Question-Based Salient Span Selection for More Controllable Text Summarization** *Daniel Deutsch, Dan Roth* [[pdf]](https://arxiv.org/abs/2111.07935)
1. **Text Summarization with Latent Queries** *Yumo Xu, Mirella Lapata* [[pdf]](https://arxiv.org/abs/2106.00104)
1. **Summarizing Chinese Medical Answer with Graph Convolution Networks and Question-focused Dual Attention** *Ningyu Zhang, Shumin Deng, Juan Li, Xi Chen, Wei Zhang, Huajun Chen* `Findings of EMNLP` [[pdf]](https://www.aclweb.org/anthology/2020.findings-emnlp.2/)
1. **Towards Question-Answering as an Automatic Metric for Evaluating the Content Quality of a Summary** *Daniel Deutsch, Tania Bedrax-Weiss, Dan Roth* [[pdf]](https://arxiv.org/abs/2010.00490) [[code]](https://github.com/CogComp/qaeval-experiments)
2. **Guiding Extractive Summarization with Question-Answering Rewards** *Kristjan Arumae, Fei Liu* `NAACL19` [[pdf]](https://arxiv.org/abs/1904.02321) [[code]](https://github.com/ucfnlp/summ_qa_rewards)
3. **A Semantic QA-Based Approach for Text Summarization Evaluation** *Ping Chen, Fei Wu, Tong Wang, Wei Ding* `AAAI18` [[pdf]](https://arxiv.org/abs/1704.06259)
## Query
1. **OASum: Large-Scale Open Domain Aspect-based Summarization** *Xianjun Yang, Kaiqiang Song, Sangwoo Cho, Xiaoyang Wang, Xiaoman Pan, Linda Petzold, Dong Yu* [[pdf]](https://arxiv.org/abs/2212.09233) [[code]](https://github.com/tencent-ailab/OASum) <details> <summary>[Abs]</summary> Aspect or query-based summarization has recently caught more attention, as it can generate differentiated summaries based on users' interests. However, the current dataset for aspect or query-based summarization either focuses on specific domains, contains relatively small-scale instances, or includes only a few aspect types. Such limitations hinder further explorations in this direction. In this work, we take advantage of crowd-sourcing knowledge on [this http URL](http://wikipedia.org/) and automatically create a high-quality, large-scale open-domain aspect-based summarization dataset named OASum, which contains more than 3.7 million instances with around 1 million different aspects on 2 million Wikipedia pages. We provide benchmark results on OAsum and demonstrate its ability for diverse aspect-based summarization generation. To overcome the data scarcity problem on specific domains, we also perform zero-shot, few-shot, and fine-tuning on seven downstream datasets. Specifically, zero/few-shot and fine-tuning results show that the model pre-trained on our corpus demonstrates a strong aspect or query-focused generation ability compared with the backbone model. Our dataset and pre-trained checkpoints are publicly available </details>
2. **Constrained Regeneration for Cross-Lingual Query-Focused Extractive Summarization** *Elsbeth Turcan, David Wan, Faisal Ladhak, Petra Galuscakova, Sukanta Sen, Svetlana Tchistiakova, Weijia Xu, Marine Carpuat, Kenneth Heafield, Douglas Oard, Kathleen McKeown* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.236/) <details> <summary>[Abs]</summary> Query-focused summaries of foreign-language, retrieved documents can help a user understand whether a document is actually relevant to the query term. A standard approach to this problem is to first translate the source documents and then perform extractive summarization to find relevant snippets. However, in a cross-lingual setting, the query term does not necessarily appear in the translations of relevant documents. In this work, we show that constrained machine translation and constrained post-editing can improve human relevance judgments by including a query term in a summary when its translation appears in the source document. We also present several strategies for selecting only certain documents for regeneration which yield further improvements </details>
3. **Focus-Driven Contrastive Learning for Medical Question Summarization** *Ming Zhang, Shuai Dou, Ziyang Wang, Yunfang Wu* `COLING 2022` [[pdf]](https://arxiv.org/abs/2209.00484) <details> <summary>[Abs]</summary> Automatic medical question summarization can significantly help the system to understand consumer health questions and retrieve correct answers. The Seq2Seq model based on maximum likelihood estimation (MLE) has been applied in this task, which faces two general problems: the model can not capture well question focus and and the traditional MLE strategy lacks the ability to understand sentence-level semantics. To alleviate these problems, we propose a novel question focus-driven contrastive learning framework (QFCL). Specially, we propose an easy and effective approach to generate hard negative samples based on the question focus, and exploit contrastive learning at both encoder and decoder to obtain better sentence level representations. On three medical benchmark datasets, our proposed model achieves new state-of-the-art results, and obtains a performance gain of 5.33, 12.85 and 3.81 points over the baseline BART model on three datasets respectively. Further human judgement and detailed analysis prove that our QFCL model learns better sentence representations with the ability to distinguish different sentence meanings, and generates high-quality summaries by capturing question focus. </details>
4. **Domain Adaptation with Pre-trained Transformers for Query Focused Abstractive Text Summarization** *Md Tahmid Rahman Laskar, Enamul Hoque, Jimmy Xiangji Huang* [[pdf]](https://arxiv.org/abs/2112.11670) [[code]](https://github.com/tahmedge/PreQFAS)
5. **Exploring Neural Models for Query-Focused Summarization** *Jesse Vig, Alexander R. Fabbri, Wojciech Kryściński* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.109/) [[code]](https://github.com/salesforce/query-focused-sum) <details> <summary>[Abs]</summary> Query-focused summarization (QFS) aims to produce summaries that answer particular questions of interest, enabling greater user control and personalization. While recently released datasets, such as QMSum or AQuaMuSe, facilitate research efforts in QFS, the field lacks a comprehensive study of the broad space of applicable modeling methods. In this paper we conduct a systematic exploration of neural approaches to QFS, considering two general classes of methods: two-stage extractive-abstractive solutions and end-to-end models. Within those categories, we investigate existing models and explore strategies for transfer learning. We also present two modeling extensions that achieve state-of-the-art performance on the QMSum dataset, up to a margin of 3.38 ROUGE-1, 3.72 ROUGE2, and 3.28 ROUGE-L when combined with transfer learning strategies. Results from human evaluation suggest that the best models produce more comprehensive and factually consistent summaries compared to a baseline model. Code and checkpoints are made publicly available: https://github.com/salesforce/query-focused-sum. </details>
6. **Aspect-Oriented Summarization through Query-Focused Extraction** *Ojas Ahuja, Jiacheng Xu, Akshay Gupta, Kevin Horecka, Greg Durrett* [[pdf]](https://arxiv.org/abs/2110.08296)
7. **Query-Focused Extractive Summarisation for Finding Ideal Answers to Biomedical and COVID-19 Questions** *Diego Mollá (1 and 2), Urvashi Khanna (1), Dima Galat (1), Vincent Nguyen (2 and 3)Maciej Rybinski (3) ( (1) Macquarie University, (2) CSIRO Data61, (3) Australian National University)* [[pdf]](https://arxiv.org/abs/2108.12189)
8. **Summary-Oriented Question Generation for Informational Queries** *Xusen Yin, Li Zhou, Kevin Small, Jonathan May* `Proceedings of the 1st Workshop on Document-grounded Dialogue and Conversational Question Answering (DialDoc 2021)` [[pdf]](https://aclanthology.org/2021.dialdoc-1.11/)
9. **Reinforcement Learning for Abstractive Question Summarization with Question-aware Semantic Rewards** *Shweta Yadav, Deepak Gupta, Asma Ben Abacha, Dina Demner-Fushman* `ACL 2021 short` [[pdf]](https://arxiv.org/abs/2107.00176) [[code]](https://github.com/shwetanlp/CHQ-Summ)
10. **Generating Query Focused Summaries from Query-Free Resources** `ACL 2021` *Yumo Xu, Mirella Lapata* [[pdf]](https://aclanthology.org/2021.acl-long.475/) [[code]](https://github.com/yumoxu/margesum)
11. **Improve Query Focused Abstractive Summarization by Incorporating Answer Relevance** *Dan Su, Tiezheng Yu, Pascale Fung* `ACL21` [[pdf]](https://arxiv.org/abs/2105.12969) [[code]](https://github.com/HLTCHKUST/QFS)
12. **D2S: Document-to-Slide Generation Via Query-Based Text Summarization** *Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, Nancy X.R. Wang* `NAACL21` [[pdf]](https://arxiv.org/abs/2105.03664) [[code]](https://github.com/IBM/document2slides)
## EncoderFusion
1. **Understanding and Improving Encoder Layer Fusion in Sequence-to-Sequence Learning** *Xuebo Liu, Longyue Wang, Derek F. Wong, Liang Ding, Lidia S. Chao, Zhaopeng Tu* `ICLR21` [[pdf]](https://openreview.net/pdf?id=n1HD8M6WGn)
2. **Improving Abstractive Text Summarization with History Aggregation** *Pengcheng Liao, Chuang Zhang, Xiaojun Chen, Xiaofei Zhou* [[pdf]](https://arxiv.org/abs/1912.11046) [[code]](https://github.com/Pc-liao/Transformer_agg)
## Discourse
1. **Discourse-Aware Unsupervised Summarization for Long Scientific Documents** *Yue Dong, Andrei Mircea Romascanu, Jackie Chi Kit Cheung* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.93/) [[code]](https://github.com/mirandrom/HipoRank)
1. **Discourse Understanding and Factual Consistency in Abstractive Summarization** *Saadia Gabriel, Antoine Bosselut, Jeff Da, Ari Holtzman, Jan Buys, Kyle Lo, Asli Celikyilmaz, Yejin Choi* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.eacl-main.34/) [[code]](https://github.com/skgabriel/coopnet)
1. **Predicting Discourse Trees from Transformer-based Neural Summarizers** *Wen Xiao, Patrick Huber, Giuseppe Carenini* `NAACL21` [[pdf]](https://arxiv.org/abs/2104.07058) [[code]](https://github.com/Wendy-Xiao/summ_guided_disco_parser)
1. **Do We Really Need That Many Parameters In Transformer For Extractive Summarization? Discourse Can Help !** *Wen Xiao, Patrick Huber, Giuseppe Carenini* `EMNLP20 Workshop` [[pdf]](https://arxiv.org/abs/2012.02144)
2. **Dialogue Discourse-Aware Graph Convolutional Networks for Abstractive Meeting Summarization** *Xiachong Feng, Xiaocheng Feng, Bing Qin, Xinwei Geng, Ting Liu* [[pdf]](https://arxiv.org/abs/2012.03502) 
3. **Restructuring Conversations using Discourse Relations for Zero-shot Abstractive Dialogue Summarization** *Prakhar Ganesh, Saket Dingliwal* [[pdf]](https://arxiv.org/abs/1902.01615) 
4. **Unsupervised Neural Single-Document Summarization of Reviews via Learning Latent Discourse Structure and its Ranking** *Masaru Isonuma, Junichiro Mori, Ichiro Sakata* `ACL19` [[pdf]](https://arxiv.org/abs/1906.05691) [[code]](https://github.com/misonuma/strsum)
5. **Exploiting Discourse-Level Segmentation for Extractive Summarization** *Zhengyuan Liu, Nancy Chen* `EMNLP19` [[pdf]](https://www.aclweb.org/anthology/D19-5415/)
6. **A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents** *Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, Nazli Goharian* `NAACL18` [[pdf]](https://arxiv.org/abs/1804.05685) [[data]](https://github.com/armancohan/long-summarization)
## Movie
1. **Movie Summarization via Sparse Graph Construction** *Pinelopi Papalampidi, Frank Keller, Mirella Lapata* `AAAI21` [[pdf]](https://arxiv.org/abs/2012.07536) [[code]](https://github.com/ppapalampidi/GraphTP)
## Low Resource
1. **LR-Sum: Summarization for Less-Resourced Languages** *Chester Palen-Michel, Constantine Lignos* [[pdf]](https://arxiv.org/abs/2212.09674) [[code]](https://github.com/bltlab/lr-sum) <details> <summary>[Abs]</summary> This preprint describes work in progress on LR-Sum, a new permissively-licensed dataset created with the goal of enabling further research in automatic summarization for less-resourced languages. LR-Sum contains human-written summaries for 40 languages, many of which are less-resourced. We describe our process for extracting and filtering the dataset from the Multilingual Open Text corpus (Palen-Michel et al., 2022). The source data is public domain newswire collected from from Voice of America websites, and LR-Sum is released under a Creative Commons license (CC BY 4.0), making it one of the most openly-licensed multilingual summarization datasets. We describe how we plan to use the data for modeling experiments and discuss limitations of the dataset. </details>
1. **Implementing Deep Learning-Based Approaches for Article Summarization in Indian Languages** *Rahul Tangsali, Aabha Pingle, Aditya Vyawahare, Isha Joshi, Raviraj Joshi* `ILSUM at FIRE 2022` [[pdf]](https://arxiv.org/abs/2212.05702) <details> <summary>[Abs]</summary> The research on text summarization for low-resource Indian languages has been limited due to the availability of relevant datasets. This paper presents a summary of various deep-learning approaches used for the ILSUM 2022 Indic language summarization datasets. The ISUM 2022 dataset consists of news articles written in Indian English, Hindi, and Gujarati respectively, and their ground-truth summarizations. In our work, we explore different pre-trained seq2seq models and fine-tune those with the ILSUM 2022 datasets. In our case, the fine-tuned SoTA PEGASUS model worked the best for English, the fine-tuned IndicBART model with augmented data for Hindi, and again fine-tuned PEGASUS model along with a translation mapping-based approach for Gujarati. Our scores on the obtained inferences were evaluated using ROUGE-1, ROUGE-2, and ROUGE-4 as the evaluation metrics. </details>
2. **PSP: Pre-trained Soft Prompts for Few-Shot Abstractive Summarization** *Xiaochen Liu, Yu Bai, Jiawei Li, Yinan Hu, Yang Gao* [[pdf]](https://aclanthology.org/2022.coling-1.553/) <details> <summary>[Abs]</summary> Few-shot abstractive summarization has become a challenging task in natural language generation. To support it, we developed a novel soft prompts architecture coupled with a prompt pre-training plus prompt fine-tuning paradigm, which is effective and tunes only extremely light parameters. To meet the structure of the generation models, the soft prompts comprise continuous input embeddings across an encoder and a decoder. Importantly, a new inner-prompt placed in the text is introduced to capture document-level information. The aim is to devote attention to understanding the document that better prompts the model to generate document-related content. In the training process, the prompt pre-training with self-supervised pseudo-data firstly teaches the model basic summarizing capability. Then, with few-shot examples, only the designed lightweight soft prompts are fine-tuned. Experimental results on the CNN/DailyMail and XSum datasets show that our method, with only 0.1% of the parameters, outperforms full-model tuning where all model parameters are tuned. It also surpasses Prompt Tuning by a large margin and delivers competitive results against Prefix-Tuning with 3% of the parameters. </details>
3. **Towards Summarizing Healthcare Questions in Low-Resource Setting** *Shweta Yadav, Cornelia Caragea* `COLING 2022` [[pdf]](https://aclanthology.org/2022.coling-1.255/) <details> <summary>[Abs]</summary> The current advancement in abstractive document summarization depends to a large extent on a considerable amount of human-annotated datasets. However, the creation of large-scale datasets is often not feasible in closed domains, such as medical and healthcare domains, where human annotation requires domain expertise. This paper presents a novel data selection strategy to generate diverse and semantic questions in a low-resource setting with the aim to summarize healthcare questions. Our method exploits the concept of guided semantic-overlap and diversity-based objective functions to optimally select the informative and diverse set of synthetic samples for data augmentation. Our extensive experiments on benchmark healthcare question summarization datasets demonstrate the effectiveness of our proposed data selection strategy by achieving new state-of-the-art results. Our human evaluation shows that our method generates diverse, fluent, and informative summarized questions. </details>
4. **Automatic Summarization of Russian Texts: Comparison of Extractive and Abstractive Methods** *Valeriya Goloviznina, Evgeny Kotelnikov* `Dialogue-2022` [[pdf]](https://arxiv.org/abs/2206.09253) <details> <summary>[Abs]</summary> The development of large and super-large language models, such as GPT-3, T5, Switch Transformer, ERNIE, etc., has significantly improved the performance of text generation. One of the important research directions in this area is the generation of texts with arguments. The solution of this problem can be used in business meetings, political debates, dialogue systems, for preparation of student essays. One of the main domains for these applications is the economic sphere. The key problem of the argument text generation for the Russian language is the lack of annotated argumentation corpora. In this paper, we use translated versions of the Argumentative Microtext, Persuasive Essays and UKP Sentential corpora to fine-tune RuBERT model. Further, this model is used to annotate the corpus of economic news by argumentation. Then the annotated corpus is employed to fine-tune the ruGPT-3 model, which generates argument texts. The results show that this approach improves the accuracy of the argument generation by more than 20 percentage points (63.2% vs. 42.5%) compared to the original ruGPT-3 model. </details>
5. **Indian Legal Text Summarization: A Text Normalisation-based Approach** *Satyajit Ghosh, Mousumi Dutta, Tanaya Das* [[pdf]](https://arxiv.org/abs/2206.06238) <details> <summary>[Abs]</summary> In the Indian court system, pending cases have long been a problem. There are more than 4 crore cases outstanding. Manually summarising hundreds of documents is a time-consuming and tedious task for legal stakeholders. Many state-of-the-art models for text summarization have emerged as machine learning has progressed. Domain-independent models don't do well with legal texts, and fine-tuning those models for the Indian Legal System is problematic due to a lack of publicly available datasets. To improve the performance of domain-independent models, the authors have proposed a methodology for normalising legal texts in the Indian context. The authors experimented with two state-of-the-art domain-independent models for legal text summarization, namely BART and PEGASUS. BART and PEGASUS are put through their paces in terms of extractive and abstractive summarization to understand the effectiveness of the text normalisation approach. Summarised texts are evaluated by domain experts on multiple parameters and using ROUGE metrics. It shows the proposed text normalisation approach is effective in legal texts with domain-independent models. </details>
6. **Domain Specific Fine-tuning of Denoising Sequence-to-Sequence Models for Natural Language Summarization** *Brydon Parker, Alik Sokolov, Mahtab Ahmed, Matt Kalebic, Sedef Akinli Kocak, Ofer Shai* `` [[pdf]](https://arxiv.org/abs/2204.09716) [[code]](https://github.com/VectorInstitute/Vector_NLP_Domain-Summ) [[data]](https://www.kaggle.com/datasets/vectorinstitute/domainspecific-reddit-data-medical-and-financial)
7. **An Overview of Indian Language Datasets used for Text Summarization** *Shagun Sinha, Girish Nath Jha* [[pdf]](https://arxiv.org/abs/2203.16127)
8. **AraBART: a Pretrained Arabic Sequence-to-Sequence Model for Abstractive Summarization** *Moussa Kamal Eddine, Nadi Tomeh, Nizar Habash, Joseph Le Roux, Michalis Vazirgiannis* [[pdf]](https://arxiv.org/abs/2203.10945) [[code]](https://huggingface.co/moussaKam/AraBART)
9. **ExtraPhrase: Efficient Data Augmentation for Abstractive Summarization** *Mengsay Loem, Sho Takase, Masahiro Kaneko, Naoaki Okazaki* [[pdf]](https://arxiv.org/abs/2201.05313)
10. **Mitigating Data Scarceness through Data Synthesis, Augmentation and Curriculum for Abstractive Summarization** *Ahmed Magooda, Diane Litman* `Findings of EMNLP 2021 Short` [[pdf]](https://arxiv.org/abs/2109.08569)
11. **Exploring Multitask Learning for Low-Resource Abstractive Summarization** *Ahmed Magooda, Mohamed Elaraby, Diane Litman* `EMNLP 2021 short` [[pdf]](https://arxiv.org/abs/2109.08565)
12. **Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data** *Sanjeev Kumar Karn, Francine Chen, Yan-Ying Chen, Ulli Waltinger, Hinrich Schütze* `EACL21` [[pdf]](https://www.aclweb.org/anthology/2021.adaptnlp-1.24/)
13. **AdaptSum: Towards Low-Resource Domain Adaptation for Abstractive Summarization** *Tiezheng Yu, Zihan Liu, Pascale Fung* `NAACL21` [[pdf]](https://arxiv.org/abs/2103.11332) [[code]](https://github.com/TysonYu/AdaptSum)
14. **Meta-Transfer Learning for Low-Resource Abstractive Summarization** *Yi-Syuan Chen, Hong-Han Shuai* `AAAI21` [[pdf]](https://basiclab.nctu.edu.tw/assets/LowResourceSummarization.pdf) [[code]](https://github.com/YiSyuanChen/MTL-ABS)
## Personalized
1. **Unsupervised Summarization with Customized Granularities** *Ming Zhong, Yang Liu, Suyu Ge, Yuning Mao, Yizhu Jiao, Xingxing Zhang, Yichong Xu, Chenguang Zhu, Michael Zeng, Jiawei Han* [[pdf]](https://arxiv.org/abs/2201.12502)
1. **Transformer Reasoning Network for Personalized Review Summarization** *Hongyan Xu, Hongtao Liu, Pengfei Jiao, Wenjun Wang* `SIGIR 2021` [[pdf]](https://dl.acm.org/doi/10.1145/3404835.3462854)
1. **PENS: A Dataset and Generic Framework for Personalized News Headline Generation** *Xiang Ao Xiting Wang Ling Luo Ying Qiao Qing He Xing Xie* `ACL 2021` [[pdf]](https://www.microsoft.com/en-us/research/uploads/prod/2021/06/ACL2021_PENS_Camera_Ready_1862_Paper.pdf) [[data]](https://msnews.github.io/pens.html)
1. **Collabot: Personalized Group Chat Summarization** *Naama Tepper, Anat Hashavit, Maya Barnea, Inbal Ronen, Lior Leiba* `WSDM 2018` [[pdf]](https://dl.acm.org/doi/abs/10.1145/3159652.3160588)
1. **Joint Optimization of User-desired Content in Multi-document Summaries by Learning from User Feedback** *Avinesh P.V.S, Christian M. Meyer* `ACL 2017` [[pdf]](https://aclanthology.org/P17-1124/) [[code]](https://github.com/UKPLab/acl2017-interactive_summarizer)
1. **Context Enhanced Personalized Social Summarization** *Po Hu, Donghong Ji, Chong Teng, Yujing Guo* `COLING12` [[pdf]](https://www.aclweb.org/anthology/C12-1075.pdf)
1. **Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization** *Rui Yan, Jian-Yun Nie, Xiaoming Li* `EMNLP 2011` [[pdf]](https://aclanthology.org/D11-1124/)
1. **In-Browser Summarisation: Generating Elaborative Summaries Biased Towards the Reading Context** *Stephen Wan, Cécile Paris* `ACL 2008` [[pdf]](https://aclanthology.org/P08-2033/)
1. **Personalized Summarization Agent Using Non-negative Matrix Factorization** *Sun Park* `PRICAI 2008` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-540-89197-0_103)
1. **Aspect-Based Personalized Text Summarization** *Shlomo Berkovsky, Timothy Baldwin, Ingrid Zukerman* `AH 2008` [[pdf]](https://link.springer.com/chapter/10.1007/978-3-540-70987-9_31)
1. **User-model based personalized summarization** *Alberto Díaz, Pablo Gervás* [[pdf]](https://doi.org/10.1016/j.ipm.2007.01.009)
1. **Machine Learning of Generic and User-Focused Summarization** *Inderjeet Mani, Eric Bloedorn* `AAAI 1998` [[pdf]](https://arxiv.org/abs/cs/9811006)
## Interactive
1. **Make The Most of Prior Data: A Solution for Interactive Text Summarization with Preference Feedback** *Duy-Hung Nguyen, Nguyen Viet Dung Nghiem, Bao-Sinh Nguyen, Dung Tien Tien Le, Shahab Sabahi, Minh-Tien Nguyen, Hung Le* `Findings of NAACL 2022` [[pdf]](https://aclanthology.org/2022.findings-naacl.147/) <details> <summary>[Abs]</summary> For summarization, human preferences is critical to tame outputs of the summarizer in favor of human interests, as ground-truth summaries are scarce and ambiguous. Practical settings require dynamic exchanges between humans and AI agents wherein feedback is provided in an online manner, a few at a time. In this paper, we introduce a new framework to train summarization models with preference feedback interactively. By properly leveraging offline data and a novel reward model, we improve the performance regarding ROUGE scores and sample-efficiency. Our experiments on three various datasets confirm the benefit of the proposed framework in active, few-shot and online settings of preference learning. </details>
2. **Interactive Query-Assisted Summarization via Deep Reinforcement Learning** *Ori Shapira, Ramakanth Pasunuru, Mohit Bansal, Ido Dagan, Yael Amsterdamer* `NAACL 2022` [[pdf]](https://aclanthology.org/2022.naacl-main.184/) [[code]](https://github.com/OriShapira/InterExp_DeepRL) <details> <summary>[Abs]</summary> Interactive summarization is a task that facilitates user-guided exploration of information within a document set. While one would like to employ state of the art neural models to improve the quality of interactive summarization, many such technologies cannot ingest the full document set or cannot operate at sufficient speed for interactivity. To that end, we propose two novel deep reinforcement learning models for the task that address, respectively, the subtask of summarizing salient information that adheres to user queries, and the subtask of listing suggested queries to assist users throughout their exploration. In particular, our models allow encoding the interactive session state and history to refrain from redundancy. Together, these models compose a state of the art solution that addresses all of the task requirements. We compare our solution to a recent interactive summarization system, and show through an experimental study involving real users that our models are able to improve informativeness while preserving positive user experience. </details>
3. **Hone as You Read: A Practical Type of Interactive Summarization** *Tanner Bohn, Charles X. Ling* [[pdf]](https://arxiv.org/abs/2105.02923)
## Speech
1. **Speech Summarization using Restricted Self-Attention** *Roshan Sharma, Shruti Palaskar, Alan W Black, Florian Metze* `ICASSP 2022` [[pdf]](https://arxiv.org/abs/2110.06263)
## Prompt
1. **Few-shot Query-Focused Summarization with Prefix-Merging** *Ruifeng Yuan, Zili Wang, Ziqiang Cao, Wenjie Li* `EMNLP 2022` [[pdf]](https://aclanthology.org/2022.emnlp-main.243/) <details> <summary>[Abs]</summary> Query-focused summarization has been considered as an important extension for text summarization. It aims to generate a concise highlight for a given query. Different from text summarization, query-focused summarization has long been plagued by the problem of lacking high-quality large-scale datasets. In this paper, we investigate the idea that whether we can integrate and transfer the knowledge of text summarization and question answering to assist the few-shot learning in query-focused summarization. Here, we propose prefix-merging, a prefix-based pretraining strategy for few-shot learning in query-focused summarization. Drawn inspiration from prefix-tuning, we are allowed to integrate the task knowledge from text summarization and question answering into a properly designed prefix and apply the merged prefix to query-focused summarization. With only a small amount of trainable parameters, prefix-merging outperforms fine-tuning on query-focused summarization. We further discuss the influence of different prefix designs and propose a visualized explanation for how prefix-merging works. </details>
1. **UniSumm: Unified Few-shot Summarization with Multi-Task Pre-Training and Prefix-Tuning** *Yulong Chen, Yang Liu, Ruochen Xu, Ziyi Yang, Chenguang Zhu, Michael Zeng, Yue Zhang* [[pdf]](https://arxiv.org/abs/2211.09783) [[code]](https://github.com/microsoft/UniSumm) <details> <summary>[Abs]</summary> The diverse demands of different summarization tasks and their high annotation costs are driving a need for few-shot summarization. However, despite the emergence of many summarization tasks and datasets, the current training paradigm for few-shot summarization systems ignores potentially shareable knowledge in heterogeneous datasets. To this end, we propose \textsc{UniSumm}, a unified few-shot summarization model pre-trained with multiple summarization tasks and can be prefix-tuned to excel at any few-shot summarization datasets. Meanwhile, to better evaluate few-shot summarization systems, under the principles of diversity and robustness, we assemble and publicize a new benchmark \textsc{SummZoo}. It consists of 8 diverse summarization tasks with multiple sets of few-shot samples for each task, covering both monologue and dialogue domains. Experimental results and ablation studies show that \textsc{UniSumm} outperforms strong baseline systems by a large margin across all tasks in \textsc{SummZoo} under both automatic and human evaluations. We release our code and benchmark at \url{this https URL}. </details>
1. **News Summarization and Evaluation in the Era of GPT-3** *Tanya Goyal, Junyi Jessy Li, Greg Durrett* [[pdf]](https://arxiv.org/abs/2209.12356) [[code]](https://tagoyal.github.io/zeroshot-news-annotations.html) <details> <summary>[Abs]</summary> The recent success of zero- and few-shot prompting with models like GPT-3 has led to a paradigm shift in NLP research. In this paper, we study its impact on text summarization, focusing on the classic benchmark domain of news summarization. First, we investigate how zero-shot GPT-3 compares against fine-tuned models trained on large summarization datasets. We show that not only do humans overwhelmingly prefer GPT-3 summaries, but these also do not suffer from common dataset-specific issues such as poor factuality. Next, we study what this means for evaluation, particularly the role of gold standard test sets. Our experiments show that both reference-based and reference-free automatic metrics, e.g. recently proposed QA- or entailment-based factuality approaches, cannot reliably evaluate zero-shot summaries. Finally, we discuss future research challenges beyond generic summarization, specifically, keyword- and aspect-based summarization, showing how dominant fine-tuning approaches compare to zero-shot prompting. To support further research, we release: (a) a corpus of 10K generated summaries from fine-tuned and zero-shot models across 4 standard summarization benchmarks, (b) 1K human preference judgments and rationales comparing different systems for generic- and keyword-based summarization. </details>
1. **To Adapt or to Fine-tune: A Case Study on Abstractive Summarization** *Zheng Zhao, Pinzhen Chen* [[pdf]](https://arxiv.org/abs/2208.14559) <details> <summary>[Abs]</summary> Recent advances in the field of abstractive summarization leverage pre-trained language models rather than train a model from scratch. However, such models are sluggish to train and accompanied by a massive overhead. Researchers have proposed a few lightweight alternatives such as smaller adapters to mitigate the drawbacks. Nonetheless, it remains uncertain whether using adapters benefits the task of summarization, in terms of improved efficiency without an unpleasant sacrifice in performance. In this work, we carry out multifaceted investigations on fine-tuning and adapters for summarization tasks with varying complexity: language, domain, and task transfer. In our experiments, fine-tuning a pre-trained language model generally attains a better performance than using adapters; the performance gap positively correlates with the amount of training data used. Notably, adapters exceed fine-tuning under extremely low-resource conditions. We further provide insights on multilinguality, model convergence, and robustness, hoping to shed light on the pragmatic choice of fine-tuning or adapters in abstractive summarization. </details>
1. **Discourse-Aware Prompt Design for Text Generation** *Marjan Ghazvininejad, Vladimir Karpukhin, Asli Celikyilmaz* [[pdf]](https://arxiv.org/abs/2112.05717)
## Temp
1. **What to Read in a Contract? Party-Specific Summarization of Important Obligations, Entitlements, and Prohibitions in Legal Documents** *Abhilasha Sancheti, Aparna Garimella, Balaji Vasan Srinivasan, Rachel Rudinger* [[pdf]](https://arxiv.org/abs/2212.09825) <details> <summary>[Abs]</summary> Legal contracts, such as employment or lease agreements, are important documents as they govern the obligations and entitlements of the various contracting parties. However, these documents are typically long and written in legalese resulting in lots of manual hours spent in understanding them. In this paper, we address the task of summarizing legal contracts for each of the contracting parties, to enable faster reviewing and improved understanding of them. Specifically, we collect a dataset consisting of pairwise importance comparison annotations by legal experts for ~293K sentence pairs from lease agreements. We propose a novel extractive summarization system to automatically produce a summary consisting of the most important obligations, entitlements, and prohibitions in a contract. It consists of two modules: (1) a content categorize to identify sentences containing each of the categories (i.e., obligation, entitlement, and prohibition) for a party, and (2) an importance ranker to compare the importance among sentences of each category for a party to obtain a ranked list. The final summary is produced by selecting the most important sentences of a category for each of the parties. We demonstrate the effectiveness of our proposed system by comparing it against several text ranking baselines via automatic and human evaluation. </details>
1. **SumREN: Summarizing Reported Speech about Events in News** *Revanth Gangi Reddy, Heba Elfardy, Hou Pong Chan, Kevin Small, Heng Ji* `AAAI 2023` [[pdf]](https://arxiv.org/abs/2212.01146) [[code]](https://github.com/amazon-science/) <details> <summary>[Abs]</summary> A primary objective of news articles is to establish the factual record for an event, frequently achieved by conveying both the details of the specified event (i.e., the 5 Ws; Who, What, Where, When and Why regarding the event) and how people reacted to it (i.e., reported statements). However, existing work on news summarization almost exclusively focuses on the event details. In this work, we propose the novel task of summarizing the reactions of different speakers, as expressed by their reported statements, to a given event. To this end, we create a new multi-document summarization benchmark, SUMREN, comprising 745 summaries of reported statements from various public figures obtained from 633 news articles discussing 132 events. We propose an automatic silver training data generation approach for our task, which helps smaller models like BART achieve GPT-3 level performance on this task. Finally, we introduce a pipeline-based framework for summarizing reported speech, which we empirically show to generate summaries that are more abstractive and factual than baseline query-focused summarization approaches. </details>
2. **Harnessing Abstractive Summarization for Fact-Checked Claim Detection** *Harnessing Abstractive Summarization for Fact-Checked Claim Detection* `COLING 2022` [[pdf]](https://arxiv.org/abs/2209.04612) [[code]](https://github.com/varadhbhatnagar/FC-Claim-Det/) <details> <summary>[Abs]</summary> Social media platforms have become new battlegrounds for anti-social elements, with misinformation being the weapon of choice. Fact-checking organizations try to debunk as many claims as possible while staying true to their journalistic processes but cannot cope with its rapid dissemination. We believe that the solution lies in partial automation of the fact-checking life cycle, saving human time for tasks which require high cognition. We propose a new workflow for efficiently detecting previously fact-checked claims that uses abstractive summarization to generate crisp queries. These queries can then be executed on a general-purpose retrieval system associated with a collection of previously fact-checked claims. We curate an abstractive text summarization dataset comprising noisy claims from Twitter and their gold summaries. It is shown that retrieval performance improves 2x by using popular out-of-the-box summarization models and 3x by fine-tuning them on the accompanying dataset compared to verbatim querying. Our approach achieves Recall@5 and MRR of 35% and 0.3, compared to baseline values of 10% and 0.1, respectively. Our dataset, code, and models are available publicly: this https URL </details>
3. **Stage-wise Stylistic Headline Generation: Style Generation and Summarized Content Insertion** *Jiaao Zhan, Yang Gao∗, Yu Bai, Qianhui Liu* `IJCAI 2022` [[pdf]](https://www.ijcai.org/proceedings/2022/0623.pdf) <details> <summary>[Abs]</summary> A quality headline with a high click-rate should notonly summarize the content of an article, but alsorefect a style that attracts users. Such demand hasdrawn rising attention to the task of stylistic headline generation (SHG). An intuitive method is to frstgenerate plain headlines leveraged by documentheadline parallel data then transfer them to a targetstyle. However, this inevitably suffers from errorpropagation. Therefore, to unify the two sub-tasksand explicitly decompose style-relevant attributesand summarize content, we propose an end-to-endstage-wise SHG model containing the style generation component and the content insertion component, where the former generates stylistic-relevantintermediate outputs and the latter receives theseoutputs then inserts the summarized content. The intermediate outputs are observable, making the stylegeneration easy to control. Our system is comprehensively evaluated by both quantitative and qualitative metrics, and it achieves state-of-the-art resultsin SHG over three different stylistic datasets. </details>
4. **Beyond Text Generation: Supporting Writers with Continuous Automatic Text Summaries** *Hai Dang, Karim Benharrak, Florian Lehmann, Daniel Buschek* `ACM UIST 2022` [[pdf]](https://arxiv.org/abs/2208.09323) <details> <summary>[Abs]</summary> We propose a text editor to help users plan, structure and reflect on their writing process. It provides continuously updated paragraph-wise summaries as margin annotations, using automatic text summarization. Summary levels range from full text, to selected (central) sentences, down to a collection of keywords. To understand how users interact with this system during writing, we conducted two user studies (N=4 and N=8) in which people wrote analytic essays about a given topic and article. As a key finding, the summaries gave users an external perspective on their writing and helped them to revise the content and scope of their drafted paragraphs. People further used the tool to quickly gain an overview of the text and developed strategies to integrate insights from the automated summaries. More broadly, this work explores and highlights the value of designing AI tools for writers, with Natural Language Processing (NLP) capabilities that go beyond direct text generation and correction. </details>
5. **SETSum: Summarization and Visualization of Student Evaluations of Teaching** *Yinuo Hu, Shiyue Zhang, Viji Sathy, Abigail Panter, Mohit Bansal* `NAACL 2022 Demo` [[pdf]](https://aclanthology.org/2022.naacl-demo.9/) [[code]](https://github.com/evahuyn/SETSum) <details> <summary>[Abs]</summary> Student Evaluations of Teaching (SETs) are widely used in colleges and universities. Typically SET results are summarized for instructors in a static PDF report. The report often includes summary statistics for quantitative ratings and an unsorted list of open-ended student comments. The lack of organization and summarization of the raw comments hinders those interpreting the reports from fully utilizing informative feedback, making accurate inferences, and designing appropriate instructional improvements. In this work, we introduce a novel system, SETSUM, that leverages sentiment analysis, aspect extraction, summarization, and visualization techniques to provide organized illustrations of SET findings to instructors and other reviewers. Ten university professors from diverse departments serve as evaluators of the system and all agree that SETSUM help them interpret SET results more efficiently; and 6 out of 10 instructors prefer our system over the standard static PDF report (while the remaining 4 would like to have both). This demonstrates that our work holds the potential of reforming the SET reporting conventions in the future. </details>
6. **ASPECTNEWS: Aspect-Oriented Summarization of News Documents** *Ojas Ahuja, Jiacheng Xu, Akshay Gupta, Kevin Horecka, Greg Durrett* `ACL 2022` [[pdf]](https://aclanthology.org/2022.acl-long.449/) [[code]](https://github.com/oja/aosumm) <details> <summary>[Abs]</summary> Generic summaries try to cover an entire document and query-based summaries try to answer document-specific questions. But real users’ needs often fall in between these extremes and correspond to aspects, high-level topics discussed among similar types of documents. In this paper, we collect a dataset of realistic aspect-oriented summaries, AspectNews, which covers different subtopics about articles in news sub-domains. We annotate data across two domains of articles, earthquakes and fraud investigations, where each |