
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
unknown | downloads
int64 0
157M
| likes
int64 0
6.51k
| library_name
stringclasses 339
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 51
values | createdAt
unknown | card
stringlengths 1
913k
|
|---|---|---|---|---|---|---|---|---|---|
ybelkada/tiny-random-T5ForConditionalGeneration-calibrated | ybelkada | "2023-04-05T17:16:54Z" | 827,254 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2023-04-05T17:13:33Z" | A "better calibrated" tiny T5 model for testing purposes |
w11wo/indonesian-roberta-base-posp-tagger | w11wo | "2024-02-19T11:03:26Z" | 824,589 | 6 | transformers | [
"transformers",
"pytorch",
"tf",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"ind",
"dataset:indonlu",
"base_model:flax-community/indonesian-roberta-base",
"base_model:finetune:flax-community/indonesian-roberta-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
license: mit
base_model: flax-community/indonesian-roberta-base
tags:
- generated_from_trainer
datasets:
- indonlu
language:
- ind
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: indonesian-roberta-base-posp-tagger
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: indonlu
type: indonlu
config: posp
split: test
args: posp
metrics:
- name: Precision
type: precision
value: 0.9625100240577386
- name: Recall
type: recall
value: 0.9625100240577386
- name: F1
type: f1
value: 0.9625100240577386
- name: Accuracy
type: accuracy
value: 0.9625100240577386
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indonesian-roberta-base-posp-tagger
This model is a fine-tuned version of [flax-community/indonesian-roberta-base](https://huggingface.co/flax-community/indonesian-roberta-base) on the indonlu dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1395
- Precision: 0.9625
- Recall: 0.9625
- F1: 0.9625
- Accuracy: 0.9625
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 420 | 0.2254 | 0.9313 | 0.9313 | 0.9313 | 0.9313 |
| 0.4398 | 2.0 | 840 | 0.1617 | 0.9499 | 0.9499 | 0.9499 | 0.9499 |
| 0.1566 | 3.0 | 1260 | 0.1431 | 0.9569 | 0.9569 | 0.9569 | 0.9569 |
| 0.103 | 4.0 | 1680 | 0.1412 | 0.9605 | 0.9605 | 0.9605 | 0.9605 |
| 0.0723 | 5.0 | 2100 | 0.1408 | 0.9635 | 0.9635 | 0.9635 | 0.9635 |
| 0.051 | 6.0 | 2520 | 0.1408 | 0.9642 | 0.9642 | 0.9642 | 0.9642 |
| 0.051 | 7.0 | 2940 | 0.1510 | 0.9635 | 0.9635 | 0.9635 | 0.9635 |
| 0.0368 | 8.0 | 3360 | 0.1653 | 0.9645 | 0.9645 | 0.9645 | 0.9645 |
| 0.0277 | 9.0 | 3780 | 0.1664 | 0.9644 | 0.9644 | 0.9644 | 0.9644 |
| 0.0231 | 10.0 | 4200 | 0.1668 | 0.9646 | 0.9646 | 0.9646 | 0.9646 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu118
- Datasets 2.16.1
- Tokenizers 0.15.1
|
McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp | McGill-NLP | "2024-05-21T22:01:47Z" | 823,601 | 8 | transformers | [
"transformers",
"safetensors",
"mistral",
"feature-extraction",
"text-embedding",
"embeddings",
"information-retrieval",
"beir",
"text-classification",
"language-model",
"text-clustering",
"text-semantic-similarity",
"text-evaluation",
"text-reranking",
"sentence-similarity",
"Sentence Similarity",
"natural_questions",
"ms_marco",
"fever",
"hotpot_qa",
"mteb",
"custom_code",
"en",
"arxiv:2404.05961",
"license:mit",
"text-generation-inference",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-04-04T02:59:33Z" | ---
library_name: transformers
license: mit
language:
- en
pipeline_tag: sentence-similarity
tags:
- text-embedding
- embeddings
- information-retrieval
- beir
- text-classification
- language-model
- text-clustering
- text-semantic-similarity
- text-evaluation
- text-reranking
- feature-extraction
- sentence-similarity
- Sentence Similarity
- natural_questions
- ms_marco
- fever
- hotpot_qa
- mteb
---
# LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
> LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
- **Repository:** https://github.com/McGill-NLP/llm2vec
- **Paper:** https://arxiv.org/abs/2404.05961
## Installation
```bash
pip install llm2vec
```
## Usage
```python
from llm2vec import LLM2Vec
import torch
from transformers import AutoTokenizer, AutoModel, AutoConfig
from peft import PeftModel
# Loading base Mistral model, along with custom code that enables bidirectional connections in decoder-only LLMs.
tokenizer = AutoTokenizer.from_pretrained(
"McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp"
)
config = AutoConfig.from_pretrained(
"McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp", trust_remote_code=True
)
model = AutoModel.from_pretrained(
"McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp",
trust_remote_code=True,
config=config,
torch_dtype=torch.bfloat16,
device_map="cuda" if torch.cuda.is_available() else "cpu",
)
# Loading MNTP (Masked Next Token Prediction) model.
model = PeftModel.from_pretrained(
model,
"McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp",
)
# Wrapper for encoding and pooling operations
l2v = LLM2Vec(model, tokenizer, pooling_mode="mean", max_length=512)
# Encoding queries using instructions
instruction = (
"Given a web search query, retrieve relevant passages that answer the query:"
)
queries = [
[instruction, "how much protein should a female eat"],
[instruction, "summit define"],
]
q_reps = l2v.encode(queries)
# Encoding documents. Instruction are not required for documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments.",
]
d_reps = l2v.encode(documents)
# Compute cosine similarity
q_reps_norm = torch.nn.functional.normalize(q_reps, p=2, dim=1)
d_reps_norm = torch.nn.functional.normalize(d_reps, p=2, dim=1)
cos_sim = torch.mm(q_reps_norm, d_reps_norm.transpose(0, 1))
print(cos_sim)
"""
tensor([[0.6266, 0.4199],
[0.3429, 0.5240]])
"""
```
## Questions
If you have any question about the code, feel free to email Parishad (`[email protected]`) and Vaibhav (`[email protected]`). |
intfloat/multilingual-e5-small | intfloat | "2024-07-29T02:00:50Z" | 821,699 | 146 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"bert",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2402.05672",
"arxiv:2108.08787",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-06-30T07:31:03Z" | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
model-index:
- name: intfloat/multilingual-e5-small
results:
- dataset:
config: en
name: MTEB AmazonCounterfactualClassification (en)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 73.79104477611939
- type: ap
value: 36.9996434842022
- type: f1
value: 67.95453679103099
task:
type: Classification
- dataset:
config: de
name: MTEB AmazonCounterfactualClassification (de)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 71.64882226980728
- type: ap
value: 82.11942130026586
- type: f1
value: 69.87963421606715
task:
type: Classification
- dataset:
config: en-ext
name: MTEB AmazonCounterfactualClassification (en-ext)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 75.8095952023988
- type: ap
value: 24.46869495579561
- type: f1
value: 63.00108480037597
task:
type: Classification
- dataset:
config: ja
name: MTEB AmazonCounterfactualClassification (ja)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 64.186295503212
- type: ap
value: 15.496804690197042
- type: f1
value: 52.07153895475031
task:
type: Classification
- dataset:
config: default
name: MTEB AmazonPolarityClassification
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
split: test
type: mteb/amazon_polarity
metrics:
- type: accuracy
value: 88.699325
- type: ap
value: 85.27039559917269
- type: f1
value: 88.65556295032513
task:
type: Classification
- dataset:
config: en
name: MTEB AmazonReviewsClassification (en)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 44.69799999999999
- type: f1
value: 43.73187348654165
task:
type: Classification
- dataset:
config: de
name: MTEB AmazonReviewsClassification (de)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 40.245999999999995
- type: f1
value: 39.3863530637684
task:
type: Classification
- dataset:
config: es
name: MTEB AmazonReviewsClassification (es)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 40.394
- type: f1
value: 39.301223469483446
task:
type: Classification
- dataset:
config: fr
name: MTEB AmazonReviewsClassification (fr)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 38.864
- type: f1
value: 37.97974261868003
task:
type: Classification
- dataset:
config: ja
name: MTEB AmazonReviewsClassification (ja)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 37.682
- type: f1
value: 37.07399369768313
task:
type: Classification
- dataset:
config: zh
name: MTEB AmazonReviewsClassification (zh)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 37.504
- type: f1
value: 36.62317273874278
task:
type: Classification
- dataset:
config: default
name: MTEB ArguAna
revision: None
split: test
type: arguana
metrics:
- type: map_at_1
value: 19.061
- type: map_at_10
value: 31.703
- type: map_at_100
value: 32.967
- type: map_at_1000
value: 33.001000000000005
- type: map_at_3
value: 27.466
- type: map_at_5
value: 29.564
- type: mrr_at_1
value: 19.559
- type: mrr_at_10
value: 31.874999999999996
- type: mrr_at_100
value: 33.146
- type: mrr_at_1000
value: 33.18
- type: mrr_at_3
value: 27.667
- type: mrr_at_5
value: 29.74
- type: ndcg_at_1
value: 19.061
- type: ndcg_at_10
value: 39.062999999999995
- type: ndcg_at_100
value: 45.184000000000005
- type: ndcg_at_1000
value: 46.115
- type: ndcg_at_3
value: 30.203000000000003
- type: ndcg_at_5
value: 33.953
- type: precision_at_1
value: 19.061
- type: precision_at_10
value: 6.279999999999999
- type: precision_at_100
value: 0.9129999999999999
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 12.706999999999999
- type: precision_at_5
value: 9.431000000000001
- type: recall_at_1
value: 19.061
- type: recall_at_10
value: 62.802
- type: recall_at_100
value: 91.323
- type: recall_at_1000
value: 98.72
- type: recall_at_3
value: 38.122
- type: recall_at_5
value: 47.155
task:
type: Retrieval
- dataset:
config: default
name: MTEB ArxivClusteringP2P
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
split: test
type: mteb/arxiv-clustering-p2p
metrics:
- type: v_measure
value: 39.22266660528253
task:
type: Clustering
- dataset:
config: default
name: MTEB ArxivClusteringS2S
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
split: test
type: mteb/arxiv-clustering-s2s
metrics:
- type: v_measure
value: 30.79980849482483
task:
type: Clustering
- dataset:
config: default
name: MTEB AskUbuntuDupQuestions
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
split: test
type: mteb/askubuntudupquestions-reranking
metrics:
- type: map
value: 57.8790068352054
- type: mrr
value: 71.78791276436706
task:
type: Reranking
- dataset:
config: default
name: MTEB BIOSSES
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
split: test
type: mteb/biosses-sts
metrics:
- type: cos_sim_pearson
value: 82.36328364043163
- type: cos_sim_spearman
value: 82.26211536195868
- type: euclidean_pearson
value: 80.3183865039173
- type: euclidean_spearman
value: 79.88495276296132
- type: manhattan_pearson
value: 80.14484480692127
- type: manhattan_spearman
value: 80.39279565980743
task:
type: STS
- dataset:
config: de-en
name: MTEB BUCC (de-en)
revision: d51519689f32196a32af33b075a01d0e7c51e252
split: test
type: mteb/bucc-bitext-mining
metrics:
- type: accuracy
value: 98.0375782881002
- type: f1
value: 97.86012526096033
- type: precision
value: 97.77139874739039
- type: recall
value: 98.0375782881002
task:
type: BitextMining
- dataset:
config: fr-en
name: MTEB BUCC (fr-en)
revision: d51519689f32196a32af33b075a01d0e7c51e252
split: test
type: mteb/bucc-bitext-mining
metrics:
- type: accuracy
value: 93.35241030156286
- type: f1
value: 92.66050333846944
- type: precision
value: 92.3306919069631
- type: recall
value: 93.35241030156286
task:
type: BitextMining
- dataset:
config: ru-en
name: MTEB BUCC (ru-en)
revision: d51519689f32196a32af33b075a01d0e7c51e252
split: test
type: mteb/bucc-bitext-mining
metrics:
- type: accuracy
value: 94.0699688257707
- type: f1
value: 93.50236693222492
- type: precision
value: 93.22791825424315
- type: recall
value: 94.0699688257707
task:
type: BitextMining
- dataset:
config: zh-en
name: MTEB BUCC (zh-en)
revision: d51519689f32196a32af33b075a01d0e7c51e252
split: test
type: mteb/bucc-bitext-mining
metrics:
- type: accuracy
value: 89.25750394944708
- type: f1
value: 88.79234684921889
- type: precision
value: 88.57293312269616
- type: recall
value: 89.25750394944708
task:
type: BitextMining
- dataset:
config: default
name: MTEB Banking77Classification
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
split: test
type: mteb/banking77
metrics:
- type: accuracy
value: 79.41558441558442
- type: f1
value: 79.25886487487219
task:
type: Classification
- dataset:
config: default
name: MTEB BiorxivClusteringP2P
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
split: test
type: mteb/biorxiv-clustering-p2p
metrics:
- type: v_measure
value: 35.747820820329736
task:
type: Clustering
- dataset:
config: default
name: MTEB BiorxivClusteringS2S
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
split: test
type: mteb/biorxiv-clustering-s2s
metrics:
- type: v_measure
value: 27.045143830596146
task:
type: Clustering
- dataset:
config: default
name: MTEB CQADupstackRetrieval
revision: None
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 24.252999999999997
- type: map_at_10
value: 31.655916666666666
- type: map_at_100
value: 32.680749999999996
- type: map_at_1000
value: 32.79483333333334
- type: map_at_3
value: 29.43691666666666
- type: map_at_5
value: 30.717416666666665
- type: mrr_at_1
value: 28.602750000000004
- type: mrr_at_10
value: 35.56875
- type: mrr_at_100
value: 36.3595
- type: mrr_at_1000
value: 36.427749999999996
- type: mrr_at_3
value: 33.586166666666664
- type: mrr_at_5
value: 34.73641666666666
- type: ndcg_at_1
value: 28.602750000000004
- type: ndcg_at_10
value: 36.06933333333334
- type: ndcg_at_100
value: 40.70141666666667
- type: ndcg_at_1000
value: 43.24341666666667
- type: ndcg_at_3
value: 32.307916666666664
- type: ndcg_at_5
value: 34.129999999999995
- type: precision_at_1
value: 28.602750000000004
- type: precision_at_10
value: 6.097666666666667
- type: precision_at_100
value: 0.9809166666666668
- type: precision_at_1000
value: 0.13766666666666663
- type: precision_at_3
value: 14.628166666666667
- type: precision_at_5
value: 10.266916666666667
- type: recall_at_1
value: 24.252999999999997
- type: recall_at_10
value: 45.31916666666667
- type: recall_at_100
value: 66.03575000000001
- type: recall_at_1000
value: 83.94708333333334
- type: recall_at_3
value: 34.71941666666666
- type: recall_at_5
value: 39.46358333333333
task:
type: Retrieval
- dataset:
config: default
name: MTEB ClimateFEVER
revision: None
split: test
type: climate-fever
metrics:
- type: map_at_1
value: 9.024000000000001
- type: map_at_10
value: 15.644
- type: map_at_100
value: 17.154
- type: map_at_1000
value: 17.345
- type: map_at_3
value: 13.028
- type: map_at_5
value: 14.251
- type: mrr_at_1
value: 19.674
- type: mrr_at_10
value: 29.826999999999998
- type: mrr_at_100
value: 30.935000000000002
- type: mrr_at_1000
value: 30.987
- type: mrr_at_3
value: 26.645000000000003
- type: mrr_at_5
value: 28.29
- type: ndcg_at_1
value: 19.674
- type: ndcg_at_10
value: 22.545
- type: ndcg_at_100
value: 29.207
- type: ndcg_at_1000
value: 32.912
- type: ndcg_at_3
value: 17.952
- type: ndcg_at_5
value: 19.363
- type: precision_at_1
value: 19.674
- type: precision_at_10
value: 7.212000000000001
- type: precision_at_100
value: 1.435
- type: precision_at_1000
value: 0.212
- type: precision_at_3
value: 13.507
- type: precision_at_5
value: 10.397
- type: recall_at_1
value: 9.024000000000001
- type: recall_at_10
value: 28.077999999999996
- type: recall_at_100
value: 51.403
- type: recall_at_1000
value: 72.406
- type: recall_at_3
value: 16.768
- type: recall_at_5
value: 20.737
task:
type: Retrieval
- dataset:
config: default
name: MTEB DBPedia
revision: None
split: test
type: dbpedia-entity
metrics:
- type: map_at_1
value: 8.012
- type: map_at_10
value: 17.138
- type: map_at_100
value: 24.146
- type: map_at_1000
value: 25.622
- type: map_at_3
value: 12.552
- type: map_at_5
value: 14.435
- type: mrr_at_1
value: 62.25000000000001
- type: mrr_at_10
value: 71.186
- type: mrr_at_100
value: 71.504
- type: mrr_at_1000
value: 71.514
- type: mrr_at_3
value: 69.333
- type: mrr_at_5
value: 70.408
- type: ndcg_at_1
value: 49.75
- type: ndcg_at_10
value: 37.76
- type: ndcg_at_100
value: 42.071
- type: ndcg_at_1000
value: 49.309
- type: ndcg_at_3
value: 41.644
- type: ndcg_at_5
value: 39.812999999999995
- type: precision_at_1
value: 62.25000000000001
- type: precision_at_10
value: 30.15
- type: precision_at_100
value: 9.753
- type: precision_at_1000
value: 1.9189999999999998
- type: precision_at_3
value: 45.667
- type: precision_at_5
value: 39.15
- type: recall_at_1
value: 8.012
- type: recall_at_10
value: 22.599
- type: recall_at_100
value: 48.068
- type: recall_at_1000
value: 71.328
- type: recall_at_3
value: 14.043
- type: recall_at_5
value: 17.124
task:
type: Retrieval
- dataset:
config: default
name: MTEB EmotionClassification
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
split: test
type: mteb/emotion
metrics:
- type: accuracy
value: 42.455
- type: f1
value: 37.59462649781862
task:
type: Classification
- dataset:
config: default
name: MTEB FEVER
revision: None
split: test
type: fever
metrics:
- type: map_at_1
value: 58.092
- type: map_at_10
value: 69.586
- type: map_at_100
value: 69.968
- type: map_at_1000
value: 69.982
- type: map_at_3
value: 67.48100000000001
- type: map_at_5
value: 68.915
- type: mrr_at_1
value: 62.166
- type: mrr_at_10
value: 73.588
- type: mrr_at_100
value: 73.86399999999999
- type: mrr_at_1000
value: 73.868
- type: mrr_at_3
value: 71.6
- type: mrr_at_5
value: 72.99
- type: ndcg_at_1
value: 62.166
- type: ndcg_at_10
value: 75.27199999999999
- type: ndcg_at_100
value: 76.816
- type: ndcg_at_1000
value: 77.09700000000001
- type: ndcg_at_3
value: 71.36
- type: ndcg_at_5
value: 73.785
- type: precision_at_1
value: 62.166
- type: precision_at_10
value: 9.716
- type: precision_at_100
value: 1.065
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 28.278
- type: precision_at_5
value: 18.343999999999998
- type: recall_at_1
value: 58.092
- type: recall_at_10
value: 88.73400000000001
- type: recall_at_100
value: 95.195
- type: recall_at_1000
value: 97.04599999999999
- type: recall_at_3
value: 78.45
- type: recall_at_5
value: 84.316
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA2018
revision: None
split: test
type: fiqa
metrics:
- type: map_at_1
value: 16.649
- type: map_at_10
value: 26.457000000000004
- type: map_at_100
value: 28.169
- type: map_at_1000
value: 28.352
- type: map_at_3
value: 23.305
- type: map_at_5
value: 25.169000000000004
- type: mrr_at_1
value: 32.407000000000004
- type: mrr_at_10
value: 40.922
- type: mrr_at_100
value: 41.931000000000004
- type: mrr_at_1000
value: 41.983
- type: mrr_at_3
value: 38.786
- type: mrr_at_5
value: 40.205999999999996
- type: ndcg_at_1
value: 32.407000000000004
- type: ndcg_at_10
value: 33.314
- type: ndcg_at_100
value: 40.312
- type: ndcg_at_1000
value: 43.685
- type: ndcg_at_3
value: 30.391000000000002
- type: ndcg_at_5
value: 31.525
- type: precision_at_1
value: 32.407000000000004
- type: precision_at_10
value: 8.966000000000001
- type: precision_at_100
value: 1.6019999999999999
- type: precision_at_1000
value: 0.22200000000000003
- type: precision_at_3
value: 20.165
- type: precision_at_5
value: 14.722
- type: recall_at_1
value: 16.649
- type: recall_at_10
value: 39.117000000000004
- type: recall_at_100
value: 65.726
- type: recall_at_1000
value: 85.784
- type: recall_at_3
value: 27.914
- type: recall_at_5
value: 33.289
task:
type: Retrieval
- dataset:
config: default
name: MTEB HotpotQA
revision: None
split: test
type: hotpotqa
metrics:
- type: map_at_1
value: 36.253
- type: map_at_10
value: 56.16799999999999
- type: map_at_100
value: 57.06099999999999
- type: map_at_1000
value: 57.126
- type: map_at_3
value: 52.644999999999996
- type: map_at_5
value: 54.909
- type: mrr_at_1
value: 72.505
- type: mrr_at_10
value: 79.66
- type: mrr_at_100
value: 79.869
- type: mrr_at_1000
value: 79.88
- type: mrr_at_3
value: 78.411
- type: mrr_at_5
value: 79.19800000000001
- type: ndcg_at_1
value: 72.505
- type: ndcg_at_10
value: 65.094
- type: ndcg_at_100
value: 68.219
- type: ndcg_at_1000
value: 69.515
- type: ndcg_at_3
value: 59.99
- type: ndcg_at_5
value: 62.909000000000006
- type: precision_at_1
value: 72.505
- type: precision_at_10
value: 13.749
- type: precision_at_100
value: 1.619
- type: precision_at_1000
value: 0.179
- type: precision_at_3
value: 38.357
- type: precision_at_5
value: 25.313000000000002
- type: recall_at_1
value: 36.253
- type: recall_at_10
value: 68.744
- type: recall_at_100
value: 80.925
- type: recall_at_1000
value: 89.534
- type: recall_at_3
value: 57.535000000000004
- type: recall_at_5
value: 63.282000000000004
task:
type: Retrieval
- dataset:
config: default
name: MTEB ImdbClassification
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
split: test
type: mteb/imdb
metrics:
- type: accuracy
value: 80.82239999999999
- type: ap
value: 75.65895781725314
- type: f1
value: 80.75880969095746
task:
type: Classification
- dataset:
config: default
name: MTEB MSMARCO
revision: None
split: dev
type: msmarco
metrics:
- type: map_at_1
value: 21.624
- type: map_at_10
value: 34.075
- type: map_at_100
value: 35.229
- type: map_at_1000
value: 35.276999999999994
- type: map_at_3
value: 30.245
- type: map_at_5
value: 32.42
- type: mrr_at_1
value: 22.264
- type: mrr_at_10
value: 34.638000000000005
- type: mrr_at_100
value: 35.744
- type: mrr_at_1000
value: 35.787
- type: mrr_at_3
value: 30.891000000000002
- type: mrr_at_5
value: 33.042
- type: ndcg_at_1
value: 22.264
- type: ndcg_at_10
value: 40.991
- type: ndcg_at_100
value: 46.563
- type: ndcg_at_1000
value: 47.743
- type: ndcg_at_3
value: 33.198
- type: ndcg_at_5
value: 37.069
- type: precision_at_1
value: 22.264
- type: precision_at_10
value: 6.5089999999999995
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 14.216999999999999
- type: precision_at_5
value: 10.487
- type: recall_at_1
value: 21.624
- type: recall_at_10
value: 62.303
- type: recall_at_100
value: 88.124
- type: recall_at_1000
value: 97.08
- type: recall_at_3
value: 41.099999999999994
- type: recall_at_5
value: 50.381
task:
type: Retrieval
- dataset:
config: en
name: MTEB MTOPDomainClassification (en)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 91.06703146374831
- type: f1
value: 90.86867815863172
task:
type: Classification
- dataset:
config: de
name: MTEB MTOPDomainClassification (de)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 87.46970977740209
- type: f1
value: 86.36832872036588
task:
type: Classification
- dataset:
config: es
name: MTEB MTOPDomainClassification (es)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 89.26951300867245
- type: f1
value: 88.93561193959502
task:
type: Classification
- dataset:
config: fr
name: MTEB MTOPDomainClassification (fr)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 84.22799874725963
- type: f1
value: 84.30490069236556
task:
type: Classification
- dataset:
config: hi
name: MTEB MTOPDomainClassification (hi)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 86.02007888131948
- type: f1
value: 85.39376041027991
task:
type: Classification
- dataset:
config: th
name: MTEB MTOPDomainClassification (th)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 85.34900542495481
- type: f1
value: 85.39859673336713
task:
type: Classification
- dataset:
config: en
name: MTEB MTOPIntentClassification (en)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 71.078431372549
- type: f1
value: 53.45071102002276
task:
type: Classification
- dataset:
config: de
name: MTEB MTOPIntentClassification (de)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 65.85798816568047
- type: f1
value: 46.53112748993529
task:
type: Classification
- dataset:
config: es
name: MTEB MTOPIntentClassification (es)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 67.96864576384256
- type: f1
value: 45.966703022829506
task:
type: Classification
- dataset:
config: fr
name: MTEB MTOPIntentClassification (fr)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 61.31537738803633
- type: f1
value: 45.52601712835461
task:
type: Classification
- dataset:
config: hi
name: MTEB MTOPIntentClassification (hi)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 66.29616349946218
- type: f1
value: 47.24166485726613
task:
type: Classification
- dataset:
config: th
name: MTEB MTOPIntentClassification (th)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 67.51537070524412
- type: f1
value: 49.463476319014276
task:
type: Classification
- dataset:
config: af
name: MTEB MassiveIntentClassification (af)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.06792199058508
- type: f1
value: 54.094921857502285
task:
type: Classification
- dataset:
config: am
name: MTEB MassiveIntentClassification (am)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 51.960322797579025
- type: f1
value: 48.547371223370945
task:
type: Classification
- dataset:
config: ar
name: MTEB MassiveIntentClassification (ar)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 54.425016812373904
- type: f1
value: 50.47069202054312
task:
type: Classification
- dataset:
config: az
name: MTEB MassiveIntentClassification (az)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 59.798251513113655
- type: f1
value: 57.05013069086648
task:
type: Classification
- dataset:
config: bn
name: MTEB MassiveIntentClassification (bn)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 59.37794216543376
- type: f1
value: 56.3607992649805
task:
type: Classification
- dataset:
config: cy
name: MTEB MassiveIntentClassification (cy)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 46.56018829858777
- type: f1
value: 43.87319715715134
task:
type: Classification
- dataset:
config: da
name: MTEB MassiveIntentClassification (da)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 62.9724277067922
- type: f1
value: 59.36480066245562
task:
type: Classification
- dataset:
config: de
name: MTEB MassiveIntentClassification (de)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 62.72696704774715
- type: f1
value: 59.143595966615855
task:
type: Classification
- dataset:
config: el
name: MTEB MassiveIntentClassification (el)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 61.5971755211836
- type: f1
value: 59.169445724946726
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveIntentClassification (en)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 70.29589778076665
- type: f1
value: 67.7577001808977
task:
type: Classification
- dataset:
config: es
name: MTEB MassiveIntentClassification (es)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 66.31136516476126
- type: f1
value: 64.52032955983242
task:
type: Classification
- dataset:
config: fa
name: MTEB MassiveIntentClassification (fa)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 65.54472091459314
- type: f1
value: 61.47903120066317
task:
type: Classification
- dataset:
config: fi
name: MTEB MassiveIntentClassification (fi)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 61.45595158036314
- type: f1
value: 58.0891846024637
task:
type: Classification
- dataset:
config: fr
name: MTEB MassiveIntentClassification (fr)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 65.47074646940149
- type: f1
value: 62.84830858877575
task:
type: Classification
- dataset:
config: he
name: MTEB MassiveIntentClassification (he)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 58.046402151983855
- type: f1
value: 55.269074430533195
task:
type: Classification
- dataset:
config: hi
name: MTEB MassiveIntentClassification (hi)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 64.06523201075991
- type: f1
value: 61.35339643021369
task:
type: Classification
- dataset:
config: hu
name: MTEB MassiveIntentClassification (hu)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 60.954942837928726
- type: f1
value: 57.07035922704846
task:
type: Classification
- dataset:
config: hy
name: MTEB MassiveIntentClassification (hy)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.404169468728995
- type: f1
value: 53.94259011839138
task:
type: Classification
- dataset:
config: id
name: MTEB MassiveIntentClassification (id)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 64.16610625420309
- type: f1
value: 61.337103431499365
task:
type: Classification
- dataset:
config: is
name: MTEB MassiveIntentClassification (is)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 52.262945527908535
- type: f1
value: 49.7610691598921
task:
type: Classification
- dataset:
config: it
name: MTEB MassiveIntentClassification (it)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 65.54472091459314
- type: f1
value: 63.469099018440154
task:
type: Classification
- dataset:
config: ja
name: MTEB MassiveIntentClassification (ja)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 68.22797579018157
- type: f1
value: 64.89098471083001
task:
type: Classification
- dataset:
config: jv
name: MTEB MassiveIntentClassification (jv)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 50.847343644922674
- type: f1
value: 47.8536963168393
task:
type: Classification
- dataset:
config: ka
name: MTEB MassiveIntentClassification (ka)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 48.45326160053799
- type: f1
value: 46.370078045805556
task:
type: Classification
- dataset:
config: km
name: MTEB MassiveIntentClassification (km)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 42.83120376597175
- type: f1
value: 39.68948521599982
task:
type: Classification
- dataset:
config: kn
name: MTEB MassiveIntentClassification (kn)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.5084061869536
- type: f1
value: 53.961876160401545
task:
type: Classification
- dataset:
config: ko
name: MTEB MassiveIntentClassification (ko)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 63.7895090786819
- type: f1
value: 61.134223684676
task:
type: Classification
- dataset:
config: lv
name: MTEB MassiveIntentClassification (lv)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 54.98991257565569
- type: f1
value: 52.579862862826296
task:
type: Classification
- dataset:
config: ml
name: MTEB MassiveIntentClassification (ml)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 61.90316072629456
- type: f1
value: 58.203024538290336
task:
type: Classification
- dataset:
config: mn
name: MTEB MassiveIntentClassification (mn)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.09818426361802
- type: f1
value: 54.22718458445455
task:
type: Classification
- dataset:
config: ms
name: MTEB MassiveIntentClassification (ms)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 58.991257565568255
- type: f1
value: 55.84892781767421
task:
type: Classification
- dataset:
config: my
name: MTEB MassiveIntentClassification (my)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 55.901143241425686
- type: f1
value: 52.25264332199797
task:
type: Classification
- dataset:
config: nb
name: MTEB MassiveIntentClassification (nb)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 61.96368527236047
- type: f1
value: 58.927243876153454
task:
type: Classification
- dataset:
config: nl
name: MTEB MassiveIntentClassification (nl)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 65.64223268325489
- type: f1
value: 62.340453718379706
task:
type: Classification
- dataset:
config: pl
name: MTEB MassiveIntentClassification (pl)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 64.52589105581708
- type: f1
value: 61.661113187022174
task:
type: Classification
- dataset:
config: pt
name: MTEB MassiveIntentClassification (pt)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 66.84599865501009
- type: f1
value: 64.59342572873005
task:
type: Classification
- dataset:
config: ro
name: MTEB MassiveIntentClassification (ro)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 60.81035642232684
- type: f1
value: 57.5169089806797
task:
type: Classification
- dataset:
config: ru
name: MTEB MassiveIntentClassification (ru)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 58.652238071815056
- type: f1
value: 53.22732406426353
- type: f1_weighted
value: 57.585586737209546
- type: main_score
value: 58.652238071815056
task:
type: Classification
- dataset:
config: sl
name: MTEB MassiveIntentClassification (sl)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 56.51647612642906
- type: f1
value: 54.33154780100043
task:
type: Classification
- dataset:
config: sq
name: MTEB MassiveIntentClassification (sq)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.985877605917956
- type: f1
value: 54.46187524463802
task:
type: Classification
- dataset:
config: sv
name: MTEB MassiveIntentClassification (sv)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 65.03026227303296
- type: f1
value: 62.34377392877748
task:
type: Classification
- dataset:
config: sw
name: MTEB MassiveIntentClassification (sw)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 53.567585743106925
- type: f1
value: 50.73770655983206
task:
type: Classification
- dataset:
config: ta
name: MTEB MassiveIntentClassification (ta)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.2595830531271
- type: f1
value: 53.657327291708626
task:
type: Classification
- dataset:
config: te
name: MTEB MassiveIntentClassification (te)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 57.82784129119032
- type: f1
value: 54.82518072665301
task:
type: Classification
- dataset:
config: th
name: MTEB MassiveIntentClassification (th)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 64.06859448554137
- type: f1
value: 63.00185280500495
task:
type: Classification
- dataset:
config: tl
name: MTEB MassiveIntentClassification (tl)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 58.91055817081371
- type: f1
value: 55.54116301224262
task:
type: Classification
- dataset:
config: tr
name: MTEB MassiveIntentClassification (tr)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 63.54404841963686
- type: f1
value: 59.57650946030184
task:
type: Classification
- dataset:
config: ur
name: MTEB MassiveIntentClassification (ur)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 59.27706792199059
- type: f1
value: 56.50010066083435
task:
type: Classification
- dataset:
config: vi
name: MTEB MassiveIntentClassification (vi)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 64.0719569603228
- type: f1
value: 61.817075925647956
task:
type: Classification
- dataset:
config: zh-CN
name: MTEB MassiveIntentClassification (zh-CN)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 68.23806321452591
- type: f1
value: 65.24917026029749
task:
type: Classification
- dataset:
config: zh-TW
name: MTEB MassiveIntentClassification (zh-TW)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 62.53530598520511
- type: f1
value: 61.71131132295768
task:
type: Classification
- dataset:
config: af
name: MTEB MassiveScenarioClassification (af)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 63.04303967720243
- type: f1
value: 60.3950085685985
task:
type: Classification
- dataset:
config: am
name: MTEB MassiveScenarioClassification (am)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 56.83591123066578
- type: f1
value: 54.95059828830849
task:
type: Classification
- dataset:
config: ar
name: MTEB MassiveScenarioClassification (ar)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 59.62340282447881
- type: f1
value: 59.525159996498225
task:
type: Classification
- dataset:
config: az
name: MTEB MassiveScenarioClassification (az)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 60.85406859448555
- type: f1
value: 59.129299095681276
task:
type: Classification
- dataset:
config: bn
name: MTEB MassiveScenarioClassification (bn)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 62.76731674512441
- type: f1
value: 61.159560612627715
task:
type: Classification
- dataset:
config: cy
name: MTEB MassiveScenarioClassification (cy)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 50.181573638197705
- type: f1
value: 46.98422176289957
task:
type: Classification
- dataset:
config: da
name: MTEB MassiveScenarioClassification (da)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.92737054472092
- type: f1
value: 67.69135611952979
task:
type: Classification
- dataset:
config: de
name: MTEB MassiveScenarioClassification (de)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 69.18964357767318
- type: f1
value: 68.46106138186214
task:
type: Classification
- dataset:
config: el
name: MTEB MassiveScenarioClassification (el)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 67.0712844653665
- type: f1
value: 66.75545422473901
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveScenarioClassification (en)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 74.4754539340955
- type: f1
value: 74.38427146553252
task:
type: Classification
- dataset:
config: es
name: MTEB MassiveScenarioClassification (es)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 69.82515131136518
- type: f1
value: 69.63516462173847
task:
type: Classification
- dataset:
config: fa
name: MTEB MassiveScenarioClassification (fa)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.70880968392737
- type: f1
value: 67.45420662567926
task:
type: Classification
- dataset:
config: fi
name: MTEB MassiveScenarioClassification (fi)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 65.95494283792871
- type: f1
value: 65.06191009049222
task:
type: Classification
- dataset:
config: fr
name: MTEB MassiveScenarioClassification (fr)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.75924680564896
- type: f1
value: 68.30833379585945
task:
type: Classification
- dataset:
config: he
name: MTEB MassiveScenarioClassification (he)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 63.806321452589096
- type: f1
value: 63.273048243765054
task:
type: Classification
- dataset:
config: hi
name: MTEB MassiveScenarioClassification (hi)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 67.68997982515133
- type: f1
value: 66.54703855381324
task:
type: Classification
- dataset:
config: hu
name: MTEB MassiveScenarioClassification (hu)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 66.46940147948891
- type: f1
value: 65.91017343463396
task:
type: Classification
- dataset:
config: hy
name: MTEB MassiveScenarioClassification (hy)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 59.49899125756556
- type: f1
value: 57.90333469917769
task:
type: Classification
- dataset:
config: id
name: MTEB MassiveScenarioClassification (id)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 67.9219905850706
- type: f1
value: 67.23169403762938
task:
type: Classification
- dataset:
config: is
name: MTEB MassiveScenarioClassification (is)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 56.486213853396094
- type: f1
value: 54.85282355583758
task:
type: Classification
- dataset:
config: it
name: MTEB MassiveScenarioClassification (it)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 69.04169468728985
- type: f1
value: 68.83833333320462
task:
type: Classification
- dataset:
config: ja
name: MTEB MassiveScenarioClassification (ja)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 73.88702084734365
- type: f1
value: 74.04474735232299
task:
type: Classification
- dataset:
config: jv
name: MTEB MassiveScenarioClassification (jv)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 56.63416274377943
- type: f1
value: 55.11332211687954
task:
type: Classification
- dataset:
config: ka
name: MTEB MassiveScenarioClassification (ka)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 52.23604572965702
- type: f1
value: 50.86529813991055
task:
type: Classification
- dataset:
config: km
name: MTEB MassiveScenarioClassification (km)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 46.62407531943511
- type: f1
value: 43.63485467164535
task:
type: Classification
- dataset:
config: kn
name: MTEB MassiveScenarioClassification (kn)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 59.15601882985878
- type: f1
value: 57.522837510959924
task:
type: Classification
- dataset:
config: ko
name: MTEB MassiveScenarioClassification (ko)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 69.84532616005382
- type: f1
value: 69.60021127179697
task:
type: Classification
- dataset:
config: lv
name: MTEB MassiveScenarioClassification (lv)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 56.65770006724949
- type: f1
value: 55.84219135523227
task:
type: Classification
- dataset:
config: ml
name: MTEB MassiveScenarioClassification (ml)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 66.53665097511768
- type: f1
value: 65.09087787792639
task:
type: Classification
- dataset:
config: mn
name: MTEB MassiveScenarioClassification (mn)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 59.31405514458642
- type: f1
value: 58.06135303831491
task:
type: Classification
- dataset:
config: ms
name: MTEB MassiveScenarioClassification (ms)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 64.88231338264964
- type: f1
value: 62.751099407787926
task:
type: Classification
- dataset:
config: my
name: MTEB MassiveScenarioClassification (my)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 58.86012104909213
- type: f1
value: 56.29118323058282
task:
type: Classification
- dataset:
config: nb
name: MTEB MassiveScenarioClassification (nb)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 67.37390719569602
- type: f1
value: 66.27922244885102
task:
type: Classification
- dataset:
config: nl
name: MTEB MassiveScenarioClassification (nl)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 70.8675184936113
- type: f1
value: 70.22146529932019
task:
type: Classification
- dataset:
config: pl
name: MTEB MassiveScenarioClassification (pl)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.2212508406187
- type: f1
value: 67.77454802056282
task:
type: Classification
- dataset:
config: pt
name: MTEB MassiveScenarioClassification (pt)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.18090114324143
- type: f1
value: 68.03737625431621
task:
type: Classification
- dataset:
config: ro
name: MTEB MassiveScenarioClassification (ro)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 64.65030262273034
- type: f1
value: 63.792945486912856
task:
type: Classification
- dataset:
config: ru
name: MTEB MassiveScenarioClassification (ru)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 63.772749631087066
- type: f1
value: 63.4539101720024
- type: f1_weighted
value: 62.778603897469566
- type: main_score
value: 63.772749631087066
task:
type: Classification
- dataset:
config: sl
name: MTEB MassiveScenarioClassification (sl)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 60.17821116341627
- type: f1
value: 59.3935969827171
task:
type: Classification
- dataset:
config: sq
name: MTEB MassiveScenarioClassification (sq)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 62.86146603900471
- type: f1
value: 60.133692735032376
task:
type: Classification
- dataset:
config: sv
name: MTEB MassiveScenarioClassification (sv)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 70.89441829186282
- type: f1
value: 70.03064076194089
task:
type: Classification
- dataset:
config: sw
name: MTEB MassiveScenarioClassification (sw)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 58.15063887020847
- type: f1
value: 56.23326278499678
task:
type: Classification
- dataset:
config: ta
name: MTEB MassiveScenarioClassification (ta)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 59.43846671149966
- type: f1
value: 57.70440450281974
task:
type: Classification
- dataset:
config: te
name: MTEB MassiveScenarioClassification (te)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 60.8507061197041
- type: f1
value: 59.22916396061171
task:
type: Classification
- dataset:
config: th
name: MTEB MassiveScenarioClassification (th)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 70.65568258238063
- type: f1
value: 69.90736239440633
task:
type: Classification
- dataset:
config: tl
name: MTEB MassiveScenarioClassification (tl)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 60.8843308675185
- type: f1
value: 59.30332663713599
task:
type: Classification
- dataset:
config: tr
name: MTEB MassiveScenarioClassification (tr)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.05312710154674
- type: f1
value: 67.44024062594775
task:
type: Classification
- dataset:
config: ur
name: MTEB MassiveScenarioClassification (ur)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 62.111634162743776
- type: f1
value: 60.89083013084519
task:
type: Classification
- dataset:
config: vi
name: MTEB MassiveScenarioClassification (vi)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 67.44115669132482
- type: f1
value: 67.92227541674552
task:
type: Classification
- dataset:
config: zh-CN
name: MTEB MassiveScenarioClassification (zh-CN)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 74.4687289845326
- type: f1
value: 74.16376793486025
task:
type: Classification
- dataset:
config: zh-TW
name: MTEB MassiveScenarioClassification (zh-TW)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 68.31876260928043
- type: f1
value: 68.5246745215607
task:
type: Classification
- dataset:
config: default
name: MTEB MedrxivClusteringP2P
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
split: test
type: mteb/medrxiv-clustering-p2p
metrics:
- type: v_measure
value: 30.90431696479766
task:
type: Clustering
- dataset:
config: default
name: MTEB MedrxivClusteringS2S
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
split: test
type: mteb/medrxiv-clustering-s2s
metrics:
- type: v_measure
value: 27.259158476693774
task:
type: Clustering
- dataset:
config: default
name: MTEB MindSmallReranking
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
split: test
type: mteb/mind_small
metrics:
- type: map
value: 30.28445330838555
- type: mrr
value: 31.15758529581164
task:
type: Reranking
- dataset:
config: default
name: MTEB NFCorpus
revision: None
split: test
type: nfcorpus
metrics:
- type: map_at_1
value: 5.353
- type: map_at_10
value: 11.565
- type: map_at_100
value: 14.097000000000001
- type: map_at_1000
value: 15.354999999999999
- type: map_at_3
value: 8.749
- type: map_at_5
value: 9.974
- type: mrr_at_1
value: 42.105
- type: mrr_at_10
value: 50.589
- type: mrr_at_100
value: 51.187000000000005
- type: mrr_at_1000
value: 51.233
- type: mrr_at_3
value: 48.246
- type: mrr_at_5
value: 49.546
- type: ndcg_at_1
value: 40.402
- type: ndcg_at_10
value: 31.009999999999998
- type: ndcg_at_100
value: 28.026
- type: ndcg_at_1000
value: 36.905
- type: ndcg_at_3
value: 35.983
- type: ndcg_at_5
value: 33.764
- type: precision_at_1
value: 42.105
- type: precision_at_10
value: 22.786
- type: precision_at_100
value: 6.916
- type: precision_at_1000
value: 1.981
- type: precision_at_3
value: 33.333
- type: precision_at_5
value: 28.731
- type: recall_at_1
value: 5.353
- type: recall_at_10
value: 15.039
- type: recall_at_100
value: 27.348
- type: recall_at_1000
value: 59.453
- type: recall_at_3
value: 9.792
- type: recall_at_5
value: 11.882
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ
revision: None
split: test
type: nq
metrics:
- type: map_at_1
value: 33.852
- type: map_at_10
value: 48.924
- type: map_at_100
value: 49.854
- type: map_at_1000
value: 49.886
- type: map_at_3
value: 44.9
- type: map_at_5
value: 47.387
- type: mrr_at_1
value: 38.035999999999994
- type: mrr_at_10
value: 51.644
- type: mrr_at_100
value: 52.339
- type: mrr_at_1000
value: 52.35999999999999
- type: mrr_at_3
value: 48.421
- type: mrr_at_5
value: 50.468999999999994
- type: ndcg_at_1
value: 38.007000000000005
- type: ndcg_at_10
value: 56.293000000000006
- type: ndcg_at_100
value: 60.167
- type: ndcg_at_1000
value: 60.916000000000004
- type: ndcg_at_3
value: 48.903999999999996
- type: ndcg_at_5
value: 52.978
- type: precision_at_1
value: 38.007000000000005
- type: precision_at_10
value: 9.041
- type: precision_at_100
value: 1.1199999999999999
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 22.084
- type: precision_at_5
value: 15.608
- type: recall_at_1
value: 33.852
- type: recall_at_10
value: 75.893
- type: recall_at_100
value: 92.589
- type: recall_at_1000
value: 98.153
- type: recall_at_3
value: 56.969
- type: recall_at_5
value: 66.283
task:
type: Retrieval
- dataset:
config: default
name: MTEB QuoraRetrieval
revision: None
split: test
type: quora
metrics:
- type: map_at_1
value: 69.174
- type: map_at_10
value: 82.891
- type: map_at_100
value: 83.545
- type: map_at_1000
value: 83.56700000000001
- type: map_at_3
value: 79.944
- type: map_at_5
value: 81.812
- type: mrr_at_1
value: 79.67999999999999
- type: mrr_at_10
value: 86.279
- type: mrr_at_100
value: 86.39
- type: mrr_at_1000
value: 86.392
- type: mrr_at_3
value: 85.21
- type: mrr_at_5
value: 85.92999999999999
- type: ndcg_at_1
value: 79.69000000000001
- type: ndcg_at_10
value: 86.929
- type: ndcg_at_100
value: 88.266
- type: ndcg_at_1000
value: 88.428
- type: ndcg_at_3
value: 83.899
- type: ndcg_at_5
value: 85.56700000000001
- type: precision_at_1
value: 79.69000000000001
- type: precision_at_10
value: 13.161000000000001
- type: precision_at_100
value: 1.513
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 36.603
- type: precision_at_5
value: 24.138
- type: recall_at_1
value: 69.174
- type: recall_at_10
value: 94.529
- type: recall_at_100
value: 99.15
- type: recall_at_1000
value: 99.925
- type: recall_at_3
value: 85.86200000000001
- type: recall_at_5
value: 90.501
task:
type: Retrieval
- dataset:
config: default
name: MTEB RedditClustering
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
split: test
type: mteb/reddit-clustering
metrics:
- type: v_measure
value: 39.13064340585255
task:
type: Clustering
- dataset:
config: default
name: MTEB RedditClusteringP2P
revision: 282350215ef01743dc01b456c7f5241fa8937f16
split: test
type: mteb/reddit-clustering-p2p
metrics:
- type: v_measure
value: 58.97884249325877
task:
type: Clustering
- dataset:
config: default
name: MTEB SCIDOCS
revision: None
split: test
type: scidocs
metrics:
- type: map_at_1
value: 3.4680000000000004
- type: map_at_10
value: 7.865
- type: map_at_100
value: 9.332
- type: map_at_1000
value: 9.587
- type: map_at_3
value: 5.800000000000001
- type: map_at_5
value: 6.8790000000000004
- type: mrr_at_1
value: 17.0
- type: mrr_at_10
value: 25.629
- type: mrr_at_100
value: 26.806
- type: mrr_at_1000
value: 26.889000000000003
- type: mrr_at_3
value: 22.8
- type: mrr_at_5
value: 24.26
- type: ndcg_at_1
value: 17.0
- type: ndcg_at_10
value: 13.895
- type: ndcg_at_100
value: 20.491999999999997
- type: ndcg_at_1000
value: 25.759999999999998
- type: ndcg_at_3
value: 13.347999999999999
- type: ndcg_at_5
value: 11.61
- type: precision_at_1
value: 17.0
- type: precision_at_10
value: 7.090000000000001
- type: precision_at_100
value: 1.669
- type: precision_at_1000
value: 0.294
- type: precision_at_3
value: 12.3
- type: precision_at_5
value: 10.02
- type: recall_at_1
value: 3.4680000000000004
- type: recall_at_10
value: 14.363000000000001
- type: recall_at_100
value: 33.875
- type: recall_at_1000
value: 59.711999999999996
- type: recall_at_3
value: 7.483
- type: recall_at_5
value: 10.173
task:
type: Retrieval
- dataset:
config: default
name: MTEB SICK-R
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
split: test
type: mteb/sickr-sts
metrics:
- type: cos_sim_pearson
value: 83.04084311714061
- type: cos_sim_spearman
value: 77.51342467443078
- type: euclidean_pearson
value: 80.0321166028479
- type: euclidean_spearman
value: 77.29249114733226
- type: manhattan_pearson
value: 80.03105964262431
- type: manhattan_spearman
value: 77.22373689514794
task:
type: STS
- dataset:
config: default
name: MTEB STS12
revision: a0d554a64d88156834ff5ae9920b964011b16384
split: test
type: mteb/sts12-sts
metrics:
- type: cos_sim_pearson
value: 84.1680158034387
- type: cos_sim_spearman
value: 76.55983344071117
- type: euclidean_pearson
value: 79.75266678300143
- type: euclidean_spearman
value: 75.34516823467025
- type: manhattan_pearson
value: 79.75959151517357
- type: manhattan_spearman
value: 75.42330344141912
task:
type: STS
- dataset:
config: default
name: MTEB STS13
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
split: test
type: mteb/sts13-sts
metrics:
- type: cos_sim_pearson
value: 76.48898993209346
- type: cos_sim_spearman
value: 76.96954120323366
- type: euclidean_pearson
value: 76.94139109279668
- type: euclidean_spearman
value: 76.85860283201711
- type: manhattan_pearson
value: 76.6944095091912
- type: manhattan_spearman
value: 76.61096912972553
task:
type: STS
- dataset:
config: default
name: MTEB STS14
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
split: test
type: mteb/sts14-sts
metrics:
- type: cos_sim_pearson
value: 77.85082366246944
- type: cos_sim_spearman
value: 75.52053350101731
- type: euclidean_pearson
value: 77.1165845070926
- type: euclidean_spearman
value: 75.31216065884388
- type: manhattan_pearson
value: 77.06193941833494
- type: manhattan_spearman
value: 75.31003701700112
task:
type: STS
- dataset:
config: default
name: MTEB STS15
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
split: test
type: mteb/sts15-sts
metrics:
- type: cos_sim_pearson
value: 86.36305246526497
- type: cos_sim_spearman
value: 87.11704613927415
- type: euclidean_pearson
value: 86.04199125810939
- type: euclidean_spearman
value: 86.51117572414263
- type: manhattan_pearson
value: 86.0805106816633
- type: manhattan_spearman
value: 86.52798366512229
task:
type: STS
- dataset:
config: default
name: MTEB STS16
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
split: test
type: mteb/sts16-sts
metrics:
- type: cos_sim_pearson
value: 82.18536255599724
- type: cos_sim_spearman
value: 83.63377151025418
- type: euclidean_pearson
value: 83.24657467993141
- type: euclidean_spearman
value: 84.02751481993825
- type: manhattan_pearson
value: 83.11941806582371
- type: manhattan_spearman
value: 83.84251281019304
task:
type: STS
- dataset:
config: ko-ko
name: MTEB STS17 (ko-ko)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 78.95816528475514
- type: cos_sim_spearman
value: 78.86607380120462
- type: euclidean_pearson
value: 78.51268699230545
- type: euclidean_spearman
value: 79.11649316502229
- type: manhattan_pearson
value: 78.32367302808157
- type: manhattan_spearman
value: 78.90277699624637
task:
type: STS
- dataset:
config: ar-ar
name: MTEB STS17 (ar-ar)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 72.89126914997624
- type: cos_sim_spearman
value: 73.0296921832678
- type: euclidean_pearson
value: 71.50385903677738
- type: euclidean_spearman
value: 73.13368899716289
- type: manhattan_pearson
value: 71.47421463379519
- type: manhattan_spearman
value: 73.03383242946575
task:
type: STS
- dataset:
config: en-ar
name: MTEB STS17 (en-ar)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 59.22923684492637
- type: cos_sim_spearman
value: 57.41013211368396
- type: euclidean_pearson
value: 61.21107388080905
- type: euclidean_spearman
value: 60.07620768697254
- type: manhattan_pearson
value: 59.60157142786555
- type: manhattan_spearman
value: 59.14069604103739
task:
type: STS
- dataset:
config: en-de
name: MTEB STS17 (en-de)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 76.24345978774299
- type: cos_sim_spearman
value: 77.24225743830719
- type: euclidean_pearson
value: 76.66226095469165
- type: euclidean_spearman
value: 77.60708820493146
- type: manhattan_pearson
value: 76.05303324760429
- type: manhattan_spearman
value: 76.96353149912348
task:
type: STS
- dataset:
config: en-en
name: MTEB STS17 (en-en)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 85.50879160160852
- type: cos_sim_spearman
value: 86.43594662965224
- type: euclidean_pearson
value: 86.06846012826577
- type: euclidean_spearman
value: 86.02041395794136
- type: manhattan_pearson
value: 86.10916255616904
- type: manhattan_spearman
value: 86.07346068198953
task:
type: STS
- dataset:
config: en-tr
name: MTEB STS17 (en-tr)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 58.39803698977196
- type: cos_sim_spearman
value: 55.96910950423142
- type: euclidean_pearson
value: 58.17941175613059
- type: euclidean_spearman
value: 55.03019330522745
- type: manhattan_pearson
value: 57.333358138183286
- type: manhattan_spearman
value: 54.04614023149965
task:
type: STS
- dataset:
config: es-en
name: MTEB STS17 (es-en)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 70.98304089637197
- type: cos_sim_spearman
value: 72.44071656215888
- type: euclidean_pearson
value: 72.19224359033983
- type: euclidean_spearman
value: 73.89871188913025
- type: manhattan_pearson
value: 71.21098311547406
- type: manhattan_spearman
value: 72.93405764824821
task:
type: STS
- dataset:
config: es-es
name: MTEB STS17 (es-es)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 85.99792397466308
- type: cos_sim_spearman
value: 84.83824377879495
- type: euclidean_pearson
value: 85.70043288694438
- type: euclidean_spearman
value: 84.70627558703686
- type: manhattan_pearson
value: 85.89570850150801
- type: manhattan_spearman
value: 84.95806105313007
task:
type: STS
- dataset:
config: fr-en
name: MTEB STS17 (fr-en)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 72.21850322994712
- type: cos_sim_spearman
value: 72.28669398117248
- type: euclidean_pearson
value: 73.40082510412948
- type: euclidean_spearman
value: 73.0326539281865
- type: manhattan_pearson
value: 71.8659633964841
- type: manhattan_spearman
value: 71.57817425823303
task:
type: STS
- dataset:
config: it-en
name: MTEB STS17 (it-en)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 75.80921368595645
- type: cos_sim_spearman
value: 77.33209091229315
- type: euclidean_pearson
value: 76.53159540154829
- type: euclidean_spearman
value: 78.17960842810093
- type: manhattan_pearson
value: 76.13530186637601
- type: manhattan_spearman
value: 78.00701437666875
task:
type: STS
- dataset:
config: nl-en
name: MTEB STS17 (nl-en)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 74.74980608267349
- type: cos_sim_spearman
value: 75.37597374318821
- type: euclidean_pearson
value: 74.90506081911661
- type: euclidean_spearman
value: 75.30151613124521
- type: manhattan_pearson
value: 74.62642745918002
- type: manhattan_spearman
value: 75.18619716592303
task:
type: STS
- dataset:
config: en
name: MTEB STS22 (en)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 59.632662289205584
- type: cos_sim_spearman
value: 60.938543391610914
- type: euclidean_pearson
value: 62.113200529767056
- type: euclidean_spearman
value: 61.410312633261164
- type: manhattan_pearson
value: 61.75494698945686
- type: manhattan_spearman
value: 60.92726195322362
task:
type: STS
- dataset:
config: de
name: MTEB STS22 (de)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 45.283470551557244
- type: cos_sim_spearman
value: 53.44833015864201
- type: euclidean_pearson
value: 41.17892011120893
- type: euclidean_spearman
value: 53.81441383126767
- type: manhattan_pearson
value: 41.17482200420659
- type: manhattan_spearman
value: 53.82180269276363
task:
type: STS
- dataset:
config: es
name: MTEB STS22 (es)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 60.5069165306236
- type: cos_sim_spearman
value: 66.87803259033826
- type: euclidean_pearson
value: 63.5428979418236
- type: euclidean_spearman
value: 66.9293576586897
- type: manhattan_pearson
value: 63.59789526178922
- type: manhattan_spearman
value: 66.86555009875066
task:
type: STS
- dataset:
config: pl
name: MTEB STS22 (pl)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 28.23026196280264
- type: cos_sim_spearman
value: 35.79397812652861
- type: euclidean_pearson
value: 17.828102102767353
- type: euclidean_spearman
value: 35.721501145568894
- type: manhattan_pearson
value: 17.77134274219677
- type: manhattan_spearman
value: 35.98107902846267
task:
type: STS
- dataset:
config: tr
name: MTEB STS22 (tr)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 56.51946541393812
- type: cos_sim_spearman
value: 63.714686006214485
- type: euclidean_pearson
value: 58.32104651305898
- type: euclidean_spearman
value: 62.237110895702216
- type: manhattan_pearson
value: 58.579416468759185
- type: manhattan_spearman
value: 62.459738981727
task:
type: STS
- dataset:
config: ar
name: MTEB STS22 (ar)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 48.76009839569795
- type: cos_sim_spearman
value: 56.65188431953149
- type: euclidean_pearson
value: 50.997682160915595
- type: euclidean_spearman
value: 55.99910008818135
- type: manhattan_pearson
value: 50.76220659606342
- type: manhattan_spearman
value: 55.517347595391456
task:
type: STS
- dataset:
config: ru
name: MTEB STS22 (ru)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 50.724322379215934
- type: cosine_spearman
value: 59.90449732164651
- type: euclidean_pearson
value: 50.227545226784024
- type: euclidean_spearman
value: 59.898906527601085
- type: main_score
value: 59.90449732164651
- type: manhattan_pearson
value: 50.21762139819405
- type: manhattan_spearman
value: 59.761039813759
- type: pearson
value: 50.724322379215934
- type: spearman
value: 59.90449732164651
task:
type: STS
- dataset:
config: zh
name: MTEB STS22 (zh)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 54.717524559088005
- type: cos_sim_spearman
value: 66.83570886252286
- type: euclidean_pearson
value: 58.41338625505467
- type: euclidean_spearman
value: 66.68991427704938
- type: manhattan_pearson
value: 58.78638572916807
- type: manhattan_spearman
value: 66.58684161046335
task:
type: STS
- dataset:
config: fr
name: MTEB STS22 (fr)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 73.2962042954962
- type: cos_sim_spearman
value: 76.58255504852025
- type: euclidean_pearson
value: 75.70983192778257
- type: euclidean_spearman
value: 77.4547684870542
- type: manhattan_pearson
value: 75.75565853870485
- type: manhattan_spearman
value: 76.90208974949428
task:
type: STS
- dataset:
config: de-en
name: MTEB STS22 (de-en)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 54.47396266924846
- type: cos_sim_spearman
value: 56.492267162048606
- type: euclidean_pearson
value: 55.998505203070195
- type: euclidean_spearman
value: 56.46447012960222
- type: manhattan_pearson
value: 54.873172394430995
- type: manhattan_spearman
value: 56.58111534551218
task:
type: STS
- dataset:
config: es-en
name: MTEB STS22 (es-en)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 69.87177267688686
- type: cos_sim_spearman
value: 74.57160943395763
- type: euclidean_pearson
value: 70.88330406826788
- type: euclidean_spearman
value: 74.29767636038422
- type: manhattan_pearson
value: 71.38245248369536
- type: manhattan_spearman
value: 74.53102232732175
task:
type: STS
- dataset:
config: it
name: MTEB STS22 (it)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 72.80225656959544
- type: cos_sim_spearman
value: 76.52646173725735
- type: euclidean_pearson
value: 73.95710720200799
- type: euclidean_spearman
value: 76.54040031984111
- type: manhattan_pearson
value: 73.89679971946774
- type: manhattan_spearman
value: 76.60886958161574
task:
type: STS
- dataset:
config: pl-en
name: MTEB STS22 (pl-en)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 70.70844249898789
- type: cos_sim_spearman
value: 72.68571783670241
- type: euclidean_pearson
value: 72.38800772441031
- type: euclidean_spearman
value: 72.86804422703312
- type: manhattan_pearson
value: 71.29840508203515
- type: manhattan_spearman
value: 71.86264441749513
task:
type: STS
- dataset:
config: zh-en
name: MTEB STS22 (zh-en)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 58.647478923935694
- type: cos_sim_spearman
value: 63.74453623540931
- type: euclidean_pearson
value: 59.60138032437505
- type: euclidean_spearman
value: 63.947930832166065
- type: manhattan_pearson
value: 58.59735509491861
- type: manhattan_spearman
value: 62.082503844627404
task:
type: STS
- dataset:
config: es-it
name: MTEB STS22 (es-it)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 65.8722516867162
- type: cos_sim_spearman
value: 71.81208592523012
- type: euclidean_pearson
value: 67.95315252165956
- type: euclidean_spearman
value: 73.00749822046009
- type: manhattan_pearson
value: 68.07884688638924
- type: manhattan_spearman
value: 72.34210325803069
task:
type: STS
- dataset:
config: de-fr
name: MTEB STS22 (de-fr)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 54.5405814240949
- type: cos_sim_spearman
value: 60.56838649023775
- type: euclidean_pearson
value: 53.011731611314104
- type: euclidean_spearman
value: 58.533194841668426
- type: manhattan_pearson
value: 53.623067729338494
- type: manhattan_spearman
value: 58.018756154446926
task:
type: STS
- dataset:
config: de-pl
name: MTEB STS22 (de-pl)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 13.611046866216112
- type: cos_sim_spearman
value: 28.238192909158492
- type: euclidean_pearson
value: 22.16189199885129
- type: euclidean_spearman
value: 35.012895679076564
- type: manhattan_pearson
value: 21.969771178698387
- type: manhattan_spearman
value: 32.456985088607475
task:
type: STS
- dataset:
config: fr-pl
name: MTEB STS22 (fr-pl)
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 74.58077407011655
- type: cos_sim_spearman
value: 84.51542547285167
- type: euclidean_pearson
value: 74.64613843596234
- type: euclidean_spearman
value: 84.51542547285167
- type: manhattan_pearson
value: 75.15335973101396
- type: manhattan_spearman
value: 84.51542547285167
task:
type: STS
- dataset:
config: default
name: MTEB STSBenchmark
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
split: test
type: mteb/stsbenchmark-sts
metrics:
- type: cos_sim_pearson
value: 82.0739825531578
- type: cos_sim_spearman
value: 84.01057479311115
- type: euclidean_pearson
value: 83.85453227433344
- type: euclidean_spearman
value: 84.01630226898655
- type: manhattan_pearson
value: 83.75323603028978
- type: manhattan_spearman
value: 83.89677983727685
task:
type: STS
- dataset:
config: default
name: MTEB SciDocsRR
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
split: test
type: mteb/scidocs-reranking
metrics:
- type: map
value: 78.12945623123957
- type: mrr
value: 93.87738713719106
task:
type: Reranking
- dataset:
config: default
name: MTEB SciFact
revision: None
split: test
type: scifact
metrics:
- type: map_at_1
value: 52.983000000000004
- type: map_at_10
value: 62.946000000000005
- type: map_at_100
value: 63.514
- type: map_at_1000
value: 63.554
- type: map_at_3
value: 60.183
- type: map_at_5
value: 61.672000000000004
- type: mrr_at_1
value: 55.667
- type: mrr_at_10
value: 64.522
- type: mrr_at_100
value: 64.957
- type: mrr_at_1000
value: 64.995
- type: mrr_at_3
value: 62.388999999999996
- type: mrr_at_5
value: 63.639
- type: ndcg_at_1
value: 55.667
- type: ndcg_at_10
value: 67.704
- type: ndcg_at_100
value: 70.299
- type: ndcg_at_1000
value: 71.241
- type: ndcg_at_3
value: 62.866
- type: ndcg_at_5
value: 65.16999999999999
- type: precision_at_1
value: 55.667
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.053
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 24.444
- type: precision_at_5
value: 16.133
- type: recall_at_1
value: 52.983000000000004
- type: recall_at_10
value: 80.656
- type: recall_at_100
value: 92.5
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 67.744
- type: recall_at_5
value: 73.433
task:
type: Retrieval
- dataset:
config: default
name: MTEB SprintDuplicateQuestions
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
split: test
type: mteb/sprintduplicatequestions-pairclassification
metrics:
- type: cos_sim_accuracy
value: 99.72772277227723
- type: cos_sim_ap
value: 92.17845897992215
- type: cos_sim_f1
value: 85.9746835443038
- type: cos_sim_precision
value: 87.07692307692308
- type: cos_sim_recall
value: 84.89999999999999
- type: dot_accuracy
value: 99.3039603960396
- type: dot_ap
value: 60.70244020124878
- type: dot_f1
value: 59.92742353551063
- type: dot_precision
value: 62.21743810548978
- type: dot_recall
value: 57.8
- type: euclidean_accuracy
value: 99.71683168316832
- type: euclidean_ap
value: 91.53997039964659
- type: euclidean_f1
value: 84.88372093023257
- type: euclidean_precision
value: 90.02242152466367
- type: euclidean_recall
value: 80.30000000000001
- type: manhattan_accuracy
value: 99.72376237623763
- type: manhattan_ap
value: 91.80756777790289
- type: manhattan_f1
value: 85.48468106479157
- type: manhattan_precision
value: 85.8728557013118
- type: manhattan_recall
value: 85.1
- type: max_accuracy
value: 99.72772277227723
- type: max_ap
value: 92.17845897992215
- type: max_f1
value: 85.9746835443038
task:
type: PairClassification
- dataset:
config: default
name: MTEB StackExchangeClustering
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
split: test
type: mteb/stackexchange-clustering
metrics:
- type: v_measure
value: 53.52464042600003
task:
type: Clustering
- dataset:
config: default
name: MTEB StackExchangeClusteringP2P
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
split: test
type: mteb/stackexchange-clustering-p2p
metrics:
- type: v_measure
value: 32.071631948736
task:
type: Clustering
- dataset:
config: default
name: MTEB StackOverflowDupQuestions
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
split: test
type: mteb/stackoverflowdupquestions-reranking
metrics:
- type: map
value: 49.19552407604654
- type: mrr
value: 49.95269130379425
task:
type: Reranking
- dataset:
config: default
name: MTEB SummEval
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
split: test
type: mteb/summeval
metrics:
- type: cos_sim_pearson
value: 29.345293033095427
- type: cos_sim_spearman
value: 29.976931423258403
- type: dot_pearson
value: 27.047078008958408
- type: dot_spearman
value: 27.75894368380218
task:
type: Summarization
- dataset:
config: default
name: MTEB TRECCOVID
revision: None
split: test
type: trec-covid
metrics:
- type: map_at_1
value: 0.22
- type: map_at_10
value: 1.706
- type: map_at_100
value: 9.634
- type: map_at_1000
value: 23.665
- type: map_at_3
value: 0.5950000000000001
- type: map_at_5
value: 0.95
- type: mrr_at_1
value: 86.0
- type: mrr_at_10
value: 91.8
- type: mrr_at_100
value: 91.8
- type: mrr_at_1000
value: 91.8
- type: mrr_at_3
value: 91.0
- type: mrr_at_5
value: 91.8
- type: ndcg_at_1
value: 80.0
- type: ndcg_at_10
value: 72.573
- type: ndcg_at_100
value: 53.954
- type: ndcg_at_1000
value: 47.760999999999996
- type: ndcg_at_3
value: 76.173
- type: ndcg_at_5
value: 75.264
- type: precision_at_1
value: 86.0
- type: precision_at_10
value: 76.4
- type: precision_at_100
value: 55.50000000000001
- type: precision_at_1000
value: 21.802
- type: precision_at_3
value: 81.333
- type: precision_at_5
value: 80.4
- type: recall_at_1
value: 0.22
- type: recall_at_10
value: 1.925
- type: recall_at_100
value: 12.762
- type: recall_at_1000
value: 44.946000000000005
- type: recall_at_3
value: 0.634
- type: recall_at_5
value: 1.051
task:
type: Retrieval
- dataset:
config: sqi-eng
name: MTEB Tatoeba (sqi-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 91.0
- type: f1
value: 88.55666666666666
- type: precision
value: 87.46166666666667
- type: recall
value: 91.0
task:
type: BitextMining
- dataset:
config: fry-eng
name: MTEB Tatoeba (fry-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 57.22543352601156
- type: f1
value: 51.03220478943021
- type: precision
value: 48.8150289017341
- type: recall
value: 57.22543352601156
task:
type: BitextMining
- dataset:
config: kur-eng
name: MTEB Tatoeba (kur-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 46.58536585365854
- type: f1
value: 39.66870798578116
- type: precision
value: 37.416085946573745
- type: recall
value: 46.58536585365854
task:
type: BitextMining
- dataset:
config: tur-eng
name: MTEB Tatoeba (tur-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 89.7
- type: f1
value: 86.77999999999999
- type: precision
value: 85.45333333333332
- type: recall
value: 89.7
task:
type: BitextMining
- dataset:
config: deu-eng
name: MTEB Tatoeba (deu-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.58333333333331
- type: precision
value: 96.2
- type: recall
value: 97.39999999999999
task:
type: BitextMining
- dataset:
config: nld-eng
name: MTEB Tatoeba (nld-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 92.4
- type: f1
value: 90.3
- type: precision
value: 89.31666666666668
- type: recall
value: 92.4
task:
type: BitextMining
- dataset:
config: ron-eng
name: MTEB Tatoeba (ron-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 86.9
- type: f1
value: 83.67190476190476
- type: precision
value: 82.23333333333332
- type: recall
value: 86.9
task:
type: BitextMining
- dataset:
config: ang-eng
name: MTEB Tatoeba (ang-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 50.0
- type: f1
value: 42.23229092632078
- type: precision
value: 39.851634683724235
- type: recall
value: 50.0
task:
type: BitextMining
- dataset:
config: ido-eng
name: MTEB Tatoeba (ido-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 76.3
- type: f1
value: 70.86190476190477
- type: precision
value: 68.68777777777777
- type: recall
value: 76.3
task:
type: BitextMining
- dataset:
config: jav-eng
name: MTEB Tatoeba (jav-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 57.073170731707314
- type: f1
value: 50.658958927251604
- type: precision
value: 48.26480836236933
- type: recall
value: 57.073170731707314
task:
type: BitextMining
- dataset:
config: isl-eng
name: MTEB Tatoeba (isl-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 68.2
- type: f1
value: 62.156507936507936
- type: precision
value: 59.84964285714286
- type: recall
value: 68.2
task:
type: BitextMining
- dataset:
config: slv-eng
name: MTEB Tatoeba (slv-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 77.52126366950182
- type: f1
value: 72.8496210148701
- type: precision
value: 70.92171498003819
- type: recall
value: 77.52126366950182
task:
type: BitextMining
- dataset:
config: cym-eng
name: MTEB Tatoeba (cym-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 70.78260869565217
- type: f1
value: 65.32422360248447
- type: precision
value: 63.063067367415194
- type: recall
value: 70.78260869565217
task:
type: BitextMining
- dataset:
config: kaz-eng
name: MTEB Tatoeba (kaz-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 78.43478260869566
- type: f1
value: 73.02608695652172
- type: precision
value: 70.63768115942028
- type: recall
value: 78.43478260869566
task:
type: BitextMining
- dataset:
config: est-eng
name: MTEB Tatoeba (est-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 60.9
- type: f1
value: 55.309753694581275
- type: precision
value: 53.130476190476195
- type: recall
value: 60.9
task:
type: BitextMining
- dataset:
config: heb-eng
name: MTEB Tatoeba (heb-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 72.89999999999999
- type: f1
value: 67.92023809523809
- type: precision
value: 65.82595238095237
- type: recall
value: 72.89999999999999
task:
type: BitextMining
- dataset:
config: gla-eng
name: MTEB Tatoeba (gla-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 46.80337756332931
- type: f1
value: 39.42174900558496
- type: precision
value: 36.97101116280851
- type: recall
value: 46.80337756332931
task:
type: BitextMining
- dataset:
config: mar-eng
name: MTEB Tatoeba (mar-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 89.8
- type: f1
value: 86.79
- type: precision
value: 85.375
- type: recall
value: 89.8
task:
type: BitextMining
- dataset:
config: lat-eng
name: MTEB Tatoeba (lat-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 47.199999999999996
- type: f1
value: 39.95484348984349
- type: precision
value: 37.561071428571424
- type: recall
value: 47.199999999999996
task:
type: BitextMining
- dataset:
config: bel-eng
name: MTEB Tatoeba (bel-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 87.8
- type: f1
value: 84.68190476190475
- type: precision
value: 83.275
- type: recall
value: 87.8
task:
type: BitextMining
- dataset:
config: pms-eng
name: MTEB Tatoeba (pms-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 48.76190476190476
- type: f1
value: 42.14965986394558
- type: precision
value: 39.96743626743626
- type: recall
value: 48.76190476190476
task:
type: BitextMining
- dataset:
config: gle-eng
name: MTEB Tatoeba (gle-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 66.10000000000001
- type: f1
value: 59.58580086580086
- type: precision
value: 57.150238095238095
- type: recall
value: 66.10000000000001
task:
type: BitextMining
- dataset:
config: pes-eng
name: MTEB Tatoeba (pes-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 87.3
- type: f1
value: 84.0
- type: precision
value: 82.48666666666666
- type: recall
value: 87.3
task:
type: BitextMining
- dataset:
config: nob-eng
name: MTEB Tatoeba (nob-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 90.4
- type: f1
value: 87.79523809523809
- type: precision
value: 86.6
- type: recall
value: 90.4
task:
type: BitextMining
- dataset:
config: bul-eng
name: MTEB Tatoeba (bul-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 87.0
- type: f1
value: 83.81
- type: precision
value: 82.36666666666666
- type: recall
value: 87.0
task:
type: BitextMining
- dataset:
config: cbk-eng
name: MTEB Tatoeba (cbk-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 63.9
- type: f1
value: 57.76533189033189
- type: precision
value: 55.50595238095239
- type: recall
value: 63.9
task:
type: BitextMining
- dataset:
config: hun-eng
name: MTEB Tatoeba (hun-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 76.1
- type: f1
value: 71.83690476190478
- type: precision
value: 70.04928571428573
- type: recall
value: 76.1
task:
type: BitextMining
- dataset:
config: uig-eng
name: MTEB Tatoeba (uig-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 66.3
- type: f1
value: 59.32626984126984
- type: precision
value: 56.62535714285713
- type: recall
value: 66.3
task:
type: BitextMining
- dataset:
config: rus-eng
name: MTEB Tatoeba (rus-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 89.76666666666667
- type: main_score
value: 89.76666666666667
- type: precision
value: 88.64999999999999
- type: recall
value: 92.10000000000001
task:
type: BitextMining
- dataset:
config: spa-eng
name: MTEB Tatoeba (spa-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 93.10000000000001
- type: f1
value: 91.10000000000001
- type: precision
value: 90.16666666666666
- type: recall
value: 93.10000000000001
task:
type: BitextMining
- dataset:
config: hye-eng
name: MTEB Tatoeba (hye-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 85.71428571428571
- type: f1
value: 82.29142600436403
- type: precision
value: 80.8076626877166
- type: recall
value: 85.71428571428571
task:
type: BitextMining
- dataset:
config: tel-eng
name: MTEB Tatoeba (tel-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 88.88888888888889
- type: f1
value: 85.7834757834758
- type: precision
value: 84.43732193732193
- type: recall
value: 88.88888888888889
task:
type: BitextMining
- dataset:
config: afr-eng
name: MTEB Tatoeba (afr-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 88.5
- type: f1
value: 85.67190476190476
- type: precision
value: 84.43333333333332
- type: recall
value: 88.5
task:
type: BitextMining
- dataset:
config: mon-eng
name: MTEB Tatoeba (mon-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 82.72727272727273
- type: f1
value: 78.21969696969695
- type: precision
value: 76.18181818181819
- type: recall
value: 82.72727272727273
task:
type: BitextMining
- dataset:
config: arz-eng
name: MTEB Tatoeba (arz-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 61.0062893081761
- type: f1
value: 55.13976240391334
- type: precision
value: 52.92112499659669
- type: recall
value: 61.0062893081761
task:
type: BitextMining
- dataset:
config: hrv-eng
name: MTEB Tatoeba (hrv-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.86666666666666
- type: precision
value: 85.69166666666668
- type: recall
value: 89.5
task:
type: BitextMining
- dataset:
config: nov-eng
name: MTEB Tatoeba (nov-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 73.54085603112841
- type: f1
value: 68.56031128404669
- type: precision
value: 66.53047989623866
- type: recall
value: 73.54085603112841
task:
type: BitextMining
- dataset:
config: gsw-eng
name: MTEB Tatoeba (gsw-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 43.58974358974359
- type: f1
value: 36.45299145299145
- type: precision
value: 33.81155881155882
- type: recall
value: 43.58974358974359
task:
type: BitextMining
- dataset:
config: nds-eng
name: MTEB Tatoeba (nds-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 59.599999999999994
- type: f1
value: 53.264689754689755
- type: precision
value: 50.869166666666665
- type: recall
value: 59.599999999999994
task:
type: BitextMining
- dataset:
config: ukr-eng
name: MTEB Tatoeba (ukr-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 85.2
- type: f1
value: 81.61666666666665
- type: precision
value: 80.02833333333335
- type: recall
value: 85.2
task:
type: BitextMining
- dataset:
config: uzb-eng
name: MTEB Tatoeba (uzb-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 63.78504672897196
- type: f1
value: 58.00029669188548
- type: precision
value: 55.815809968847354
- type: recall
value: 63.78504672897196
task:
type: BitextMining
- dataset:
config: lit-eng
name: MTEB Tatoeba (lit-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 66.5
- type: f1
value: 61.518333333333345
- type: precision
value: 59.622363699102834
- type: recall
value: 66.5
task:
type: BitextMining
- dataset:
config: ina-eng
name: MTEB Tatoeba (ina-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 88.6
- type: f1
value: 85.60222222222221
- type: precision
value: 84.27916666666665
- type: recall
value: 88.6
task:
type: BitextMining
- dataset:
config: lfn-eng
name: MTEB Tatoeba (lfn-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 58.699999999999996
- type: f1
value: 52.732375957375965
- type: precision
value: 50.63214035964035
- type: recall
value: 58.699999999999996
task:
type: BitextMining
- dataset:
config: zsm-eng
name: MTEB Tatoeba (zsm-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 89.99666666666667
- type: precision
value: 89.03333333333333
- type: recall
value: 92.10000000000001
task:
type: BitextMining
- dataset:
config: ita-eng
name: MTEB Tatoeba (ita-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 90.10000000000001
- type: f1
value: 87.55666666666667
- type: precision
value: 86.36166666666668
- type: recall
value: 90.10000000000001
task:
type: BitextMining
- dataset:
config: cmn-eng
name: MTEB Tatoeba (cmn-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 88.89000000000001
- type: precision
value: 87.71166666666666
- type: recall
value: 91.4
task:
type: BitextMining
- dataset:
config: lvs-eng
name: MTEB Tatoeba (lvs-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 65.7
- type: f1
value: 60.67427750410509
- type: precision
value: 58.71785714285714
- type: recall
value: 65.7
task:
type: BitextMining
- dataset:
config: glg-eng
name: MTEB Tatoeba (glg-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 85.39999999999999
- type: f1
value: 81.93190476190475
- type: precision
value: 80.37833333333333
- type: recall
value: 85.39999999999999
task:
type: BitextMining
- dataset:
config: ceb-eng
name: MTEB Tatoeba (ceb-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 47.833333333333336
- type: f1
value: 42.006625781625786
- type: precision
value: 40.077380952380956
- type: recall
value: 47.833333333333336
task:
type: BitextMining
- dataset:
config: bre-eng
name: MTEB Tatoeba (bre-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 10.4
- type: f1
value: 8.24465007215007
- type: precision
value: 7.664597069597071
- type: recall
value: 10.4
task:
type: BitextMining
- dataset:
config: ben-eng
name: MTEB Tatoeba (ben-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 82.6
- type: f1
value: 77.76333333333334
- type: precision
value: 75.57833333333332
- type: recall
value: 82.6
task:
type: BitextMining
- dataset:
config: swg-eng
name: MTEB Tatoeba (swg-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 52.67857142857143
- type: f1
value: 44.302721088435376
- type: precision
value: 41.49801587301587
- type: recall
value: 52.67857142857143
task:
type: BitextMining
- dataset:
config: arq-eng
name: MTEB Tatoeba (arq-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 28.3205268935236
- type: f1
value: 22.426666605171157
- type: precision
value: 20.685900116470915
- type: recall
value: 28.3205268935236
task:
type: BitextMining
- dataset:
config: kab-eng
name: MTEB Tatoeba (kab-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 22.7
- type: f1
value: 17.833970473970474
- type: precision
value: 16.407335164835164
- type: recall
value: 22.7
task:
type: BitextMining
- dataset:
config: fra-eng
name: MTEB Tatoeba (fra-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 89.92999999999999
- type: precision
value: 88.87
- type: recall
value: 92.2
task:
type: BitextMining
- dataset:
config: por-eng
name: MTEB Tatoeba (por-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 89.25
- type: precision
value: 88.21666666666667
- type: recall
value: 91.4
task:
type: BitextMining
- dataset:
config: tat-eng
name: MTEB Tatoeba (tat-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 69.19999999999999
- type: f1
value: 63.38269841269841
- type: precision
value: 61.14773809523809
- type: recall
value: 69.19999999999999
task:
type: BitextMining
- dataset:
config: oci-eng
name: MTEB Tatoeba (oci-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 48.8
- type: f1
value: 42.839915639915645
- type: precision
value: 40.770287114845935
- type: recall
value: 48.8
task:
type: BitextMining
- dataset:
config: pol-eng
name: MTEB Tatoeba (pol-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 88.8
- type: f1
value: 85.90666666666668
- type: precision
value: 84.54166666666666
- type: recall
value: 88.8
task:
type: BitextMining
- dataset:
config: war-eng
name: MTEB Tatoeba (war-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 46.6
- type: f1
value: 40.85892920804686
- type: precision
value: 38.838223114604695
- type: recall
value: 46.6
task:
type: BitextMining
- dataset:
config: aze-eng
name: MTEB Tatoeba (aze-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 84.0
- type: f1
value: 80.14190476190475
- type: precision
value: 78.45333333333333
- type: recall
value: 84.0
task:
type: BitextMining
- dataset:
config: vie-eng
name: MTEB Tatoeba (vie-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 90.5
- type: f1
value: 87.78333333333333
- type: precision
value: 86.5
- type: recall
value: 90.5
task:
type: BitextMining
- dataset:
config: nno-eng
name: MTEB Tatoeba (nno-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 74.5
- type: f1
value: 69.48397546897547
- type: precision
value: 67.51869047619049
- type: recall
value: 74.5
task:
type: BitextMining
- dataset:
config: cha-eng
name: MTEB Tatoeba (cha-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 32.846715328467155
- type: f1
value: 27.828177499710343
- type: precision
value: 26.63451511991658
- type: recall
value: 32.846715328467155
task:
type: BitextMining
- dataset:
config: mhr-eng
name: MTEB Tatoeba (mhr-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 8.0
- type: f1
value: 6.07664116764988
- type: precision
value: 5.544177607179943
- type: recall
value: 8.0
task:
type: BitextMining
- dataset:
config: dan-eng
name: MTEB Tatoeba (dan-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.38555555555554
- type: precision
value: 82.91583333333334
- type: recall
value: 87.6
task:
type: BitextMining
- dataset:
config: ell-eng
name: MTEB Tatoeba (ell-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 87.5
- type: f1
value: 84.08333333333331
- type: precision
value: 82.47333333333333
- type: recall
value: 87.5
task:
type: BitextMining
- dataset:
config: amh-eng
name: MTEB Tatoeba (amh-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 80.95238095238095
- type: f1
value: 76.13095238095238
- type: precision
value: 74.05753968253967
- type: recall
value: 80.95238095238095
task:
type: BitextMining
- dataset:
config: pam-eng
name: MTEB Tatoeba (pam-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 6.971422975172975
- type: precision
value: 6.557814916172301
- type: recall
value: 8.799999999999999
task:
type: BitextMining
- dataset:
config: hsb-eng
name: MTEB Tatoeba (hsb-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 44.099378881987576
- type: f1
value: 37.01649742022413
- type: precision
value: 34.69420618488942
- type: recall
value: 44.099378881987576
task:
type: BitextMining
- dataset:
config: srp-eng
name: MTEB Tatoeba (srp-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 84.3
- type: f1
value: 80.32666666666667
- type: precision
value: 78.60666666666665
- type: recall
value: 84.3
task:
type: BitextMining
- dataset:
config: epo-eng
name: MTEB Tatoeba (epo-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 92.5
- type: f1
value: 90.49666666666666
- type: precision
value: 89.56666666666668
- type: recall
value: 92.5
task:
type: BitextMining
- dataset:
config: kzj-eng
name: MTEB Tatoeba (kzj-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 10.0
- type: f1
value: 8.268423529875141
- type: precision
value: 7.878118605532398
- type: recall
value: 10.0
task:
type: BitextMining
- dataset:
config: awa-eng
name: MTEB Tatoeba (awa-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 79.22077922077922
- type: f1
value: 74.27128427128426
- type: precision
value: 72.28715728715729
- type: recall
value: 79.22077922077922
task:
type: BitextMining
- dataset:
config: fao-eng
name: MTEB Tatoeba (fao-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 65.64885496183206
- type: f1
value: 58.87495456197747
- type: precision
value: 55.992366412213734
- type: recall
value: 65.64885496183206
task:
type: BitextMining
- dataset:
config: mal-eng
name: MTEB Tatoeba (mal-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 96.06986899563319
- type: f1
value: 94.78408539543909
- type: precision
value: 94.15332362930616
- type: recall
value: 96.06986899563319
task:
type: BitextMining
- dataset:
config: ile-eng
name: MTEB Tatoeba (ile-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 77.2
- type: f1
value: 71.72571428571428
- type: precision
value: 69.41000000000001
- type: recall
value: 77.2
task:
type: BitextMining
- dataset:
config: bos-eng
name: MTEB Tatoeba (bos-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 86.4406779661017
- type: f1
value: 83.2391713747646
- type: precision
value: 81.74199623352166
- type: recall
value: 86.4406779661017
task:
type: BitextMining
- dataset:
config: cor-eng
name: MTEB Tatoeba (cor-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 8.4
- type: f1
value: 6.017828743398003
- type: precision
value: 5.4829865484756795
- type: recall
value: 8.4
task:
type: BitextMining
- dataset:
config: cat-eng
name: MTEB Tatoeba (cat-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 83.5
- type: f1
value: 79.74833333333333
- type: precision
value: 78.04837662337664
- type: recall
value: 83.5
task:
type: BitextMining
- dataset:
config: eus-eng
name: MTEB Tatoeba (eus-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 60.4
- type: f1
value: 54.467301587301584
- type: precision
value: 52.23242424242424
- type: recall
value: 60.4
task:
type: BitextMining
- dataset:
config: yue-eng
name: MTEB Tatoeba (yue-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 74.9
- type: f1
value: 69.68699134199134
- type: precision
value: 67.59873015873016
- type: recall
value: 74.9
task:
type: BitextMining
- dataset:
config: swe-eng
name: MTEB Tatoeba (swe-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 88.0
- type: f1
value: 84.9652380952381
- type: precision
value: 83.66166666666666
- type: recall
value: 88.0
task:
type: BitextMining
- dataset:
config: dtp-eng
name: MTEB Tatoeba (dtp-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 9.1
- type: f1
value: 7.681244588744588
- type: precision
value: 7.370043290043291
- type: recall
value: 9.1
task:
type: BitextMining
- dataset:
config: kat-eng
name: MTEB Tatoeba (kat-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 80.9651474530831
- type: f1
value: 76.84220605132133
- type: precision
value: 75.19606398962966
- type: recall
value: 80.9651474530831
task:
type: BitextMining
- dataset:
config: jpn-eng
name: MTEB Tatoeba (jpn-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 86.9
- type: f1
value: 83.705
- type: precision
value: 82.3120634920635
- type: recall
value: 86.9
task:
type: BitextMining
- dataset:
config: csb-eng
name: MTEB Tatoeba (csb-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 29.64426877470356
- type: f1
value: 23.98763072676116
- type: precision
value: 22.506399397703746
- type: recall
value: 29.64426877470356
task:
type: BitextMining
- dataset:
config: xho-eng
name: MTEB Tatoeba (xho-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 70.4225352112676
- type: f1
value: 62.84037558685445
- type: precision
value: 59.56572769953053
- type: recall
value: 70.4225352112676
task:
type: BitextMining
- dataset:
config: orv-eng
name: MTEB Tatoeba (orv-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 19.64071856287425
- type: f1
value: 15.125271011207756
- type: precision
value: 13.865019261197494
- type: recall
value: 19.64071856287425
task:
type: BitextMining
- dataset:
config: ind-eng
name: MTEB Tatoeba (ind-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 90.2
- type: f1
value: 87.80666666666666
- type: precision
value: 86.70833333333331
- type: recall
value: 90.2
task:
type: BitextMining
- dataset:
config: tuk-eng
name: MTEB Tatoeba (tuk-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 23.15270935960591
- type: f1
value: 18.407224958949097
- type: precision
value: 16.982385430661292
- type: recall
value: 23.15270935960591
task:
type: BitextMining
- dataset:
config: max-eng
name: MTEB Tatoeba (max-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 55.98591549295775
- type: f1
value: 49.94718309859154
- type: precision
value: 47.77864154624717
- type: recall
value: 55.98591549295775
task:
type: BitextMining
- dataset:
config: swh-eng
name: MTEB Tatoeba (swh-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 73.07692307692307
- type: f1
value: 66.74358974358974
- type: precision
value: 64.06837606837607
- type: recall
value: 73.07692307692307
task:
type: BitextMining
- dataset:
config: hin-eng
name: MTEB Tatoeba (hin-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.25
- type: precision
value: 92.43333333333332
- type: recall
value: 94.89999999999999
task:
type: BitextMining
- dataset:
config: dsb-eng
name: MTEB Tatoeba (dsb-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 37.78705636743215
- type: f1
value: 31.63899658680452
- type: precision
value: 29.72264397629742
- type: recall
value: 37.78705636743215
task:
type: BitextMining
- dataset:
config: ber-eng
name: MTEB Tatoeba (ber-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 21.6
- type: f1
value: 16.91697302697303
- type: precision
value: 15.71225147075147
- type: recall
value: 21.6
task:
type: BitextMining
- dataset:
config: tam-eng
name: MTEB Tatoeba (tam-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 85.01628664495115
- type: f1
value: 81.38514037536838
- type: precision
value: 79.83170466883823
- type: recall
value: 85.01628664495115
task:
type: BitextMining
- dataset:
config: slk-eng
name: MTEB Tatoeba (slk-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 83.39999999999999
- type: f1
value: 79.96380952380952
- type: precision
value: 78.48333333333333
- type: recall
value: 83.39999999999999
task:
type: BitextMining
- dataset:
config: tgl-eng
name: MTEB Tatoeba (tgl-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 83.2
- type: f1
value: 79.26190476190476
- type: precision
value: 77.58833333333334
- type: recall
value: 83.2
task:
type: BitextMining
- dataset:
config: ast-eng
name: MTEB Tatoeba (ast-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 75.59055118110236
- type: f1
value: 71.66854143232096
- type: precision
value: 70.30183727034121
- type: recall
value: 75.59055118110236
task:
type: BitextMining
- dataset:
config: mkd-eng
name: MTEB Tatoeba (mkd-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 65.5
- type: f1
value: 59.26095238095238
- type: precision
value: 56.81909090909092
- type: recall
value: 65.5
task:
type: BitextMining
- dataset:
config: khm-eng
name: MTEB Tatoeba (khm-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 55.26315789473685
- type: f1
value: 47.986523325858506
- type: precision
value: 45.33950006595436
- type: recall
value: 55.26315789473685
task:
type: BitextMining
- dataset:
config: ces-eng
name: MTEB Tatoeba (ces-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 82.89999999999999
- type: f1
value: 78.835
- type: precision
value: 77.04761904761905
- type: recall
value: 82.89999999999999
task:
type: BitextMining
- dataset:
config: tzl-eng
name: MTEB Tatoeba (tzl-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 43.269230769230774
- type: f1
value: 36.20421245421245
- type: precision
value: 33.57371794871795
- type: recall
value: 43.269230769230774
task:
type: BitextMining
- dataset:
config: urd-eng
name: MTEB Tatoeba (urd-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 88.0
- type: f1
value: 84.70666666666666
- type: precision
value: 83.23166666666665
- type: recall
value: 88.0
task:
type: BitextMining
- dataset:
config: ara-eng
name: MTEB Tatoeba (ara-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 77.4
- type: f1
value: 72.54666666666667
- type: precision
value: 70.54318181818181
- type: recall
value: 77.4
task:
type: BitextMining
- dataset:
config: kor-eng
name: MTEB Tatoeba (kor-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 78.60000000000001
- type: f1
value: 74.1588888888889
- type: precision
value: 72.30250000000001
- type: recall
value: 78.60000000000001
task:
type: BitextMining
- dataset:
config: yid-eng
name: MTEB Tatoeba (yid-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 72.40566037735849
- type: f1
value: 66.82587328813744
- type: precision
value: 64.75039308176099
- type: recall
value: 72.40566037735849
task:
type: BitextMining
- dataset:
config: fin-eng
name: MTEB Tatoeba (fin-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 73.8
- type: f1
value: 68.56357142857144
- type: precision
value: 66.3178822055138
- type: recall
value: 73.8
task:
type: BitextMining
- dataset:
config: tha-eng
name: MTEB Tatoeba (tha-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 91.78832116788321
- type: f1
value: 89.3552311435523
- type: precision
value: 88.20559610705597
- type: recall
value: 91.78832116788321
task:
type: BitextMining
- dataset:
config: wuu-eng
name: MTEB Tatoeba (wuu-eng)
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
split: test
type: mteb/tatoeba-bitext-mining
metrics:
- type: accuracy
value: 74.3
- type: f1
value: 69.05085581085581
- type: precision
value: 66.955
- type: recall
value: 74.3
task:
type: BitextMining
- dataset:
config: default
name: MTEB Touche2020
revision: None
split: test
type: webis-touche2020
metrics:
- type: map_at_1
value: 2.896
- type: map_at_10
value: 8.993
- type: map_at_100
value: 14.133999999999999
- type: map_at_1000
value: 15.668000000000001
- type: map_at_3
value: 5.862
- type: map_at_5
value: 7.17
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 42.931000000000004
- type: mrr_at_100
value: 44.81
- type: mrr_at_1000
value: 44.81
- type: mrr_at_3
value: 38.435
- type: mrr_at_5
value: 41.701
- type: ndcg_at_1
value: 31.633
- type: ndcg_at_10
value: 21.163
- type: ndcg_at_100
value: 33.306000000000004
- type: ndcg_at_1000
value: 45.275999999999996
- type: ndcg_at_3
value: 25.685999999999996
- type: ndcg_at_5
value: 23.732
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 17.755000000000003
- type: precision_at_100
value: 6.938999999999999
- type: precision_at_1000
value: 1.48
- type: precision_at_3
value: 25.85
- type: precision_at_5
value: 23.265
- type: recall_at_1
value: 2.896
- type: recall_at_10
value: 13.333999999999998
- type: recall_at_100
value: 43.517
- type: recall_at_1000
value: 79.836
- type: recall_at_3
value: 6.306000000000001
- type: recall_at_5
value: 8.825
task:
type: Retrieval
- dataset:
config: default
name: MTEB ToxicConversationsClassification
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
split: test
type: mteb/toxic_conversations_50k
metrics:
- type: accuracy
value: 69.3874
- type: ap
value: 13.829909072469423
- type: f1
value: 53.54534203543492
task:
type: Classification
- dataset:
config: default
name: MTEB TweetSentimentExtractionClassification
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
split: test
type: mteb/tweet_sentiment_extraction
metrics:
- type: accuracy
value: 62.62026032823995
- type: f1
value: 62.85251350485221
task:
type: Classification
- dataset:
config: default
name: MTEB TwentyNewsgroupsClustering
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
split: test
type: mteb/twentynewsgroups-clustering
metrics:
- type: v_measure
value: 33.21527881409797
task:
type: Clustering
- dataset:
config: default
name: MTEB TwitterSemEval2015
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
split: test
type: mteb/twittersemeval2015-pairclassification
metrics:
- type: cos_sim_accuracy
value: 84.97943613280086
- type: cos_sim_ap
value: 70.75454316885921
- type: cos_sim_f1
value: 65.38274012676743
- type: cos_sim_precision
value: 60.761214318078835
- type: cos_sim_recall
value: 70.76517150395777
- type: dot_accuracy
value: 79.0546581629612
- type: dot_ap
value: 47.3197121792147
- type: dot_f1
value: 49.20106524633821
- type: dot_precision
value: 42.45499808502489
- type: dot_recall
value: 58.49604221635884
- type: euclidean_accuracy
value: 85.08076533349228
- type: euclidean_ap
value: 70.95016106374474
- type: euclidean_f1
value: 65.43987900176455
- type: euclidean_precision
value: 62.64478764478765
- type: euclidean_recall
value: 68.49604221635884
- type: manhattan_accuracy
value: 84.93771234428085
- type: manhattan_ap
value: 70.63668388755362
- type: manhattan_f1
value: 65.23895401262398
- type: manhattan_precision
value: 56.946084218811485
- type: manhattan_recall
value: 76.35883905013192
- type: max_accuracy
value: 85.08076533349228
- type: max_ap
value: 70.95016106374474
- type: max_f1
value: 65.43987900176455
task:
type: PairClassification
- dataset:
config: default
name: MTEB TwitterURLCorpus
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
split: test
type: mteb/twitterurlcorpus-pairclassification
metrics:
- type: cos_sim_accuracy
value: 88.69096130709822
- type: cos_sim_ap
value: 84.82526278228542
- type: cos_sim_f1
value: 77.65485060585536
- type: cos_sim_precision
value: 75.94582658619167
- type: cos_sim_recall
value: 79.44256236526024
- type: dot_accuracy
value: 80.97954748321496
- type: dot_ap
value: 64.81642914145866
- type: dot_f1
value: 60.631996987229975
- type: dot_precision
value: 54.5897293631712
- type: dot_recall
value: 68.17831844779796
- type: euclidean_accuracy
value: 88.6987231730508
- type: euclidean_ap
value: 84.80003825477253
- type: euclidean_f1
value: 77.67194179854496
- type: euclidean_precision
value: 75.7128235122094
- type: euclidean_recall
value: 79.73514012935017
- type: manhattan_accuracy
value: 88.62692591298949
- type: manhattan_ap
value: 84.80451408255276
- type: manhattan_f1
value: 77.69888949572183
- type: manhattan_precision
value: 73.70311528631622
- type: manhattan_recall
value: 82.15275639051433
- type: max_accuracy
value: 88.6987231730508
- type: max_ap
value: 84.82526278228542
- type: max_f1
value: 77.69888949572183
task:
type: PairClassification
- dataset:
config: ru-en
name: MTEB BUCC.v2 (ru-en)
revision: 1739dc11ffe9b7bfccd7f3d585aeb4c544fc6677
split: test
type: mteb/bucc-bitext-mining
metrics:
- type: accuracy
value: 95.72566678212678
- type: f1
value: 94.42443135896548
- type: main_score
value: 94.42443135896548
- type: precision
value: 93.80868260016165
- type: recall
value: 95.72566678212678
task:
type: BitextMining
- dataset:
config: rus_Cyrl-rus_Cyrl
name: MTEB BelebeleRetrieval (rus_Cyrl-rus_Cyrl)
revision: 75b399394a9803252cfec289d103de462763db7c
split: test
type: facebook/belebele
metrics:
- type: main_score
value: 92.23599999999999
- type: map_at_1
value: 87.111
- type: map_at_10
value: 90.717
- type: map_at_100
value: 90.879
- type: map_at_1000
value: 90.881
- type: map_at_20
value: 90.849
- type: map_at_3
value: 90.074
- type: map_at_5
value: 90.535
- type: mrr_at_1
value: 87.1111111111111
- type: mrr_at_10
value: 90.7173721340388
- type: mrr_at_100
value: 90.87859682638407
- type: mrr_at_1000
value: 90.88093553612326
- type: mrr_at_20
value: 90.84863516113515
- type: mrr_at_3
value: 90.07407407407409
- type: mrr_at_5
value: 90.53518518518521
- type: nauc_map_at_1000_diff1
value: 92.37373187280554
- type: nauc_map_at_1000_max
value: 79.90465445423249
- type: nauc_map_at_1000_std
value: -0.6220290556185463
- type: nauc_map_at_100_diff1
value: 92.37386697345335
- type: nauc_map_at_100_max
value: 79.90991577223959
- type: nauc_map_at_100_std
value: -0.602247514642845
- type: nauc_map_at_10_diff1
value: 92.30907447072467
- type: nauc_map_at_10_max
value: 79.86831935337598
- type: nauc_map_at_10_std
value: -0.7455191860719699
- type: nauc_map_at_1_diff1
value: 93.29828518358822
- type: nauc_map_at_1_max
value: 78.69539619887887
- type: nauc_map_at_1_std
value: -4.097150817605763
- type: nauc_map_at_20_diff1
value: 92.38414149703077
- type: nauc_map_at_20_max
value: 79.94789814504661
- type: nauc_map_at_20_std
value: -0.3928031130400773
- type: nauc_map_at_3_diff1
value: 92.21688899306734
- type: nauc_map_at_3_max
value: 80.34586671780885
- type: nauc_map_at_3_std
value: 0.24088319695435909
- type: nauc_map_at_5_diff1
value: 92.27931726042982
- type: nauc_map_at_5_max
value: 79.99198834003367
- type: nauc_map_at_5_std
value: -0.6296366922840796
- type: nauc_mrr_at_1000_diff1
value: 92.37373187280554
- type: nauc_mrr_at_1000_max
value: 79.90465445423249
- type: nauc_mrr_at_1000_std
value: -0.6220290556185463
- type: nauc_mrr_at_100_diff1
value: 92.37386697345335
- type: nauc_mrr_at_100_max
value: 79.90991577223959
- type: nauc_mrr_at_100_std
value: -0.602247514642845
- type: nauc_mrr_at_10_diff1
value: 92.30907447072467
- type: nauc_mrr_at_10_max
value: 79.86831935337598
- type: nauc_mrr_at_10_std
value: -0.7455191860719699
- type: nauc_mrr_at_1_diff1
value: 93.29828518358822
- type: nauc_mrr_at_1_max
value: 78.69539619887887
- type: nauc_mrr_at_1_std
value: -4.097150817605763
- type: nauc_mrr_at_20_diff1
value: 92.38414149703077
- type: nauc_mrr_at_20_max
value: 79.94789814504661
- type: nauc_mrr_at_20_std
value: -0.3928031130400773
- type: nauc_mrr_at_3_diff1
value: 92.21688899306734
- type: nauc_mrr_at_3_max
value: 80.34586671780885
- type: nauc_mrr_at_3_std
value: 0.24088319695435909
- type: nauc_mrr_at_5_diff1
value: 92.27931726042982
- type: nauc_mrr_at_5_max
value: 79.99198834003367
- type: nauc_mrr_at_5_std
value: -0.6296366922840796
- type: nauc_ndcg_at_1000_diff1
value: 92.30526497646306
- type: nauc_ndcg_at_1000_max
value: 80.12734537480418
- type: nauc_ndcg_at_1000_std
value: 0.22849408935578744
- type: nauc_ndcg_at_100_diff1
value: 92.31347123202318
- type: nauc_ndcg_at_100_max
value: 80.29207038703142
- type: nauc_ndcg_at_100_std
value: 0.816825944406239
- type: nauc_ndcg_at_10_diff1
value: 92.05430189845808
- type: nauc_ndcg_at_10_max
value: 80.16515667442968
- type: nauc_ndcg_at_10_std
value: 0.7486447532544893
- type: nauc_ndcg_at_1_diff1
value: 93.29828518358822
- type: nauc_ndcg_at_1_max
value: 78.69539619887887
- type: nauc_ndcg_at_1_std
value: -4.097150817605763
- type: nauc_ndcg_at_20_diff1
value: 92.40147868825079
- type: nauc_ndcg_at_20_max
value: 80.5117307181802
- type: nauc_ndcg_at_20_std
value: 2.0431351539517033
- type: nauc_ndcg_at_3_diff1
value: 91.88894444422789
- type: nauc_ndcg_at_3_max
value: 81.09256084196045
- type: nauc_ndcg_at_3_std
value: 2.422705909643621
- type: nauc_ndcg_at_5_diff1
value: 91.99711052955728
- type: nauc_ndcg_at_5_max
value: 80.46996334573979
- type: nauc_ndcg_at_5_std
value: 0.9086986899040708
- type: nauc_precision_at_1000_diff1
value: .nan
- type: nauc_precision_at_1000_max
value: .nan
- type: nauc_precision_at_1000_std
value: .nan
- type: nauc_precision_at_100_diff1
value: 93.46405228758012
- type: nauc_precision_at_100_max
value: 100.0
- type: nauc_precision_at_100_std
value: 70.71661998132774
- type: nauc_precision_at_10_diff1
value: 90.13938908896874
- type: nauc_precision_at_10_max
value: 82.21121782046167
- type: nauc_precision_at_10_std
value: 13.075230092036083
- type: nauc_precision_at_1_diff1
value: 93.29828518358822
- type: nauc_precision_at_1_max
value: 78.69539619887887
- type: nauc_precision_at_1_std
value: -4.097150817605763
- type: nauc_precision_at_20_diff1
value: 94.9723479135242
- type: nauc_precision_at_20_max
value: 91.04000574588684
- type: nauc_precision_at_20_std
value: 48.764634058749586
- type: nauc_precision_at_3_diff1
value: 90.52690041533852
- type: nauc_precision_at_3_max
value: 84.35075179497126
- type: nauc_precision_at_3_std
value: 12.036768730480507
- type: nauc_precision_at_5_diff1
value: 90.44234360410769
- type: nauc_precision_at_5_max
value: 83.21895424836558
- type: nauc_precision_at_5_std
value: 9.974323062558037
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 93.46405228758294
- type: nauc_recall_at_100_max
value: 100.0
- type: nauc_recall_at_100_std
value: 70.71661998132666
- type: nauc_recall_at_10_diff1
value: 90.13938908896864
- type: nauc_recall_at_10_max
value: 82.21121782046124
- type: nauc_recall_at_10_std
value: 13.075230092036506
- type: nauc_recall_at_1_diff1
value: 93.29828518358822
- type: nauc_recall_at_1_max
value: 78.69539619887887
- type: nauc_recall_at_1_std
value: -4.097150817605763
- type: nauc_recall_at_20_diff1
value: 94.97234791352489
- type: nauc_recall_at_20_max
value: 91.04000574588774
- type: nauc_recall_at_20_std
value: 48.764634058752065
- type: nauc_recall_at_3_diff1
value: 90.52690041533845
- type: nauc_recall_at_3_max
value: 84.35075179497079
- type: nauc_recall_at_3_std
value: 12.036768730480583
- type: nauc_recall_at_5_diff1
value: 90.44234360410861
- type: nauc_recall_at_5_max
value: 83.21895424836595
- type: nauc_recall_at_5_std
value: 9.974323062558147
- type: ndcg_at_1
value: 87.111
- type: ndcg_at_10
value: 92.23599999999999
- type: ndcg_at_100
value: 92.87100000000001
- type: ndcg_at_1000
value: 92.928
- type: ndcg_at_20
value: 92.67699999999999
- type: ndcg_at_3
value: 90.973
- type: ndcg_at_5
value: 91.801
- type: precision_at_1
value: 87.111
- type: precision_at_10
value: 9.689
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.928
- type: precision_at_3
value: 31.185000000000002
- type: precision_at_5
value: 19.111
- type: recall_at_1
value: 87.111
- type: recall_at_10
value: 96.88900000000001
- type: recall_at_100
value: 99.556
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 98.556
- type: recall_at_3
value: 93.556
- type: recall_at_5
value: 95.556
task:
type: Retrieval
- dataset:
config: rus_Cyrl-eng_Latn
name: MTEB BelebeleRetrieval (rus_Cyrl-eng_Latn)
revision: 75b399394a9803252cfec289d103de462763db7c
split: test
type: facebook/belebele
metrics:
- type: main_score
value: 86.615
- type: map_at_1
value: 78.0
- type: map_at_10
value: 83.822
- type: map_at_100
value: 84.033
- type: map_at_1000
value: 84.03500000000001
- type: map_at_20
value: 83.967
- type: map_at_3
value: 82.315
- type: map_at_5
value: 83.337
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 83.82213403880073
- type: mrr_at_100
value: 84.03281327810801
- type: mrr_at_1000
value: 84.03460051000452
- type: mrr_at_20
value: 83.9673773122303
- type: mrr_at_3
value: 82.31481481481484
- type: mrr_at_5
value: 83.33703703703708
- type: nauc_map_at_1000_diff1
value: 80.78467576987832
- type: nauc_map_at_1000_max
value: 51.41718334647604
- type: nauc_map_at_1000_std
value: -16.23873782768812
- type: nauc_map_at_100_diff1
value: 80.78490931240695
- type: nauc_map_at_100_max
value: 51.41504597713061
- type: nauc_map_at_100_std
value: -16.23538559475366
- type: nauc_map_at_10_diff1
value: 80.73989245374868
- type: nauc_map_at_10_max
value: 51.43026079433827
- type: nauc_map_at_10_std
value: -16.13414330905897
- type: nauc_map_at_1_diff1
value: 82.36966971144186
- type: nauc_map_at_1_max
value: 52.988877039509916
- type: nauc_map_at_1_std
value: -15.145824639495546
- type: nauc_map_at_20_diff1
value: 80.75923781626145
- type: nauc_map_at_20_max
value: 51.40181079374639
- type: nauc_map_at_20_std
value: -16.260566097377165
- type: nauc_map_at_3_diff1
value: 80.65242627065471
- type: nauc_map_at_3_max
value: 50.623980338841214
- type: nauc_map_at_3_std
value: -16.818343442794294
- type: nauc_map_at_5_diff1
value: 80.45976387021862
- type: nauc_map_at_5_max
value: 51.533621728445866
- type: nauc_map_at_5_std
value: -16.279891536945815
- type: nauc_mrr_at_1000_diff1
value: 80.78467576987832
- type: nauc_mrr_at_1000_max
value: 51.41718334647604
- type: nauc_mrr_at_1000_std
value: -16.23873782768812
- type: nauc_mrr_at_100_diff1
value: 80.78490931240695
- type: nauc_mrr_at_100_max
value: 51.41504597713061
- type: nauc_mrr_at_100_std
value: -16.23538559475366
- type: nauc_mrr_at_10_diff1
value: 80.73989245374868
- type: nauc_mrr_at_10_max
value: 51.43026079433827
- type: nauc_mrr_at_10_std
value: -16.13414330905897
- type: nauc_mrr_at_1_diff1
value: 82.36966971144186
- type: nauc_mrr_at_1_max
value: 52.988877039509916
- type: nauc_mrr_at_1_std
value: -15.145824639495546
- type: nauc_mrr_at_20_diff1
value: 80.75923781626145
- type: nauc_mrr_at_20_max
value: 51.40181079374639
- type: nauc_mrr_at_20_std
value: -16.260566097377165
- type: nauc_mrr_at_3_diff1
value: 80.65242627065471
- type: nauc_mrr_at_3_max
value: 50.623980338841214
- type: nauc_mrr_at_3_std
value: -16.818343442794294
- type: nauc_mrr_at_5_diff1
value: 80.45976387021862
- type: nauc_mrr_at_5_max
value: 51.533621728445866
- type: nauc_mrr_at_5_std
value: -16.279891536945815
- type: nauc_ndcg_at_1000_diff1
value: 80.60009446938174
- type: nauc_ndcg_at_1000_max
value: 51.381708043594166
- type: nauc_ndcg_at_1000_std
value: -16.054256944160848
- type: nauc_ndcg_at_100_diff1
value: 80.58971462930421
- type: nauc_ndcg_at_100_max
value: 51.25436917735444
- type: nauc_ndcg_at_100_std
value: -15.862944972269894
- type: nauc_ndcg_at_10_diff1
value: 80.37967179454489
- type: nauc_ndcg_at_10_max
value: 51.590394257251006
- type: nauc_ndcg_at_10_std
value: -15.489799384799591
- type: nauc_ndcg_at_1_diff1
value: 82.36966971144186
- type: nauc_ndcg_at_1_max
value: 52.988877039509916
- type: nauc_ndcg_at_1_std
value: -15.145824639495546
- type: nauc_ndcg_at_20_diff1
value: 80.40299527470081
- type: nauc_ndcg_at_20_max
value: 51.395132284307074
- type: nauc_ndcg_at_20_std
value: -15.906165526937203
- type: nauc_ndcg_at_3_diff1
value: 80.10347913649302
- type: nauc_ndcg_at_3_max
value: 50.018431855573844
- type: nauc_ndcg_at_3_std
value: -17.12743750163884
- type: nauc_ndcg_at_5_diff1
value: 79.65918647776613
- type: nauc_ndcg_at_5_max
value: 51.76710880330806
- type: nauc_ndcg_at_5_std
value: -16.071901882035945
- type: nauc_precision_at_1000_diff1
value: .nan
- type: nauc_precision_at_1000_max
value: .nan
- type: nauc_precision_at_1000_std
value: .nan
- type: nauc_precision_at_100_diff1
value: 77.41596638655459
- type: nauc_precision_at_100_max
value: 22.572362278246565
- type: nauc_precision_at_100_std
value: 26.890756302525716
- type: nauc_precision_at_10_diff1
value: 77.82112845138009
- type: nauc_precision_at_10_max
value: 54.2550353474723
- type: nauc_precision_at_10_std
value: -7.492997198879646
- type: nauc_precision_at_1_diff1
value: 82.36966971144186
- type: nauc_precision_at_1_max
value: 52.988877039509916
- type: nauc_precision_at_1_std
value: -15.145824639495546
- type: nauc_precision_at_20_diff1
value: 75.89091192032318
- type: nauc_precision_at_20_max
value: 52.03275754746293
- type: nauc_precision_at_20_std
value: -7.8411920323686175
- type: nauc_precision_at_3_diff1
value: 78.0256020644638
- type: nauc_precision_at_3_max
value: 47.80353641248523
- type: nauc_precision_at_3_std
value: -18.181625255723503
- type: nauc_precision_at_5_diff1
value: 75.21583976056174
- type: nauc_precision_at_5_max
value: 53.716281032960765
- type: nauc_precision_at_5_std
value: -14.411700753360812
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 77.4159663865523
- type: nauc_recall_at_100_max
value: 22.57236227824646
- type: nauc_recall_at_100_std
value: 26.89075630252133
- type: nauc_recall_at_10_diff1
value: 77.82112845138037
- type: nauc_recall_at_10_max
value: 54.25503534747204
- type: nauc_recall_at_10_std
value: -7.492997198879666
- type: nauc_recall_at_1_diff1
value: 82.36966971144186
- type: nauc_recall_at_1_max
value: 52.988877039509916
- type: nauc_recall_at_1_std
value: -15.145824639495546
- type: nauc_recall_at_20_diff1
value: 75.89091192032362
- type: nauc_recall_at_20_max
value: 52.032757547463184
- type: nauc_recall_at_20_std
value: -7.84119203236888
- type: nauc_recall_at_3_diff1
value: 78.02560206446354
- type: nauc_recall_at_3_max
value: 47.80353641248526
- type: nauc_recall_at_3_std
value: -18.181625255723656
- type: nauc_recall_at_5_diff1
value: 75.21583976056185
- type: nauc_recall_at_5_max
value: 53.71628103296118
- type: nauc_recall_at_5_std
value: -14.411700753360634
- type: ndcg_at_1
value: 78.0
- type: ndcg_at_10
value: 86.615
- type: ndcg_at_100
value: 87.558
- type: ndcg_at_1000
value: 87.613
- type: ndcg_at_20
value: 87.128
- type: ndcg_at_3
value: 83.639
- type: ndcg_at_5
value: 85.475
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 9.533
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.867
- type: precision_at_3
value: 29.148000000000003
- type: precision_at_5
value: 18.378
- type: recall_at_1
value: 78.0
- type: recall_at_10
value: 95.333
- type: recall_at_100
value: 99.556
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 97.333
- type: recall_at_3
value: 87.444
- type: recall_at_5
value: 91.889
task:
type: Retrieval
- dataset:
config: eng_Latn-rus_Cyrl
name: MTEB BelebeleRetrieval (eng_Latn-rus_Cyrl)
revision: 75b399394a9803252cfec289d103de462763db7c
split: test
type: facebook/belebele
metrics:
- type: main_score
value: 82.748
- type: map_at_1
value: 73.444
- type: map_at_10
value: 79.857
- type: map_at_100
value: 80.219
- type: map_at_1000
value: 80.22500000000001
- type: map_at_20
value: 80.10300000000001
- type: map_at_3
value: 78.593
- type: map_at_5
value: 79.515
- type: mrr_at_1
value: 73.44444444444444
- type: mrr_at_10
value: 79.85705467372136
- type: mrr_at_100
value: 80.21942320422542
- type: mrr_at_1000
value: 80.2245364027152
- type: mrr_at_20
value: 80.10273201266493
- type: mrr_at_3
value: 78.59259259259258
- type: mrr_at_5
value: 79.51481481481483
- type: nauc_map_at_1000_diff1
value: 83.69682652271125
- type: nauc_map_at_1000_max
value: 61.70131708044767
- type: nauc_map_at_1000_std
value: 9.345825405274955
- type: nauc_map_at_100_diff1
value: 83.68924820523492
- type: nauc_map_at_100_max
value: 61.6965735573098
- type: nauc_map_at_100_std
value: 9.366132859525775
- type: nauc_map_at_10_diff1
value: 83.61802964269985
- type: nauc_map_at_10_max
value: 61.74274476167882
- type: nauc_map_at_10_std
value: 9.504060995819101
- type: nauc_map_at_1_diff1
value: 86.37079221403225
- type: nauc_map_at_1_max
value: 61.856861655370686
- type: nauc_map_at_1_std
value: 4.708911881992707
- type: nauc_map_at_20_diff1
value: 83.62920965453047
- type: nauc_map_at_20_max
value: 61.761029350326965
- type: nauc_map_at_20_std
value: 9.572978651118351
- type: nauc_map_at_3_diff1
value: 83.66665673154306
- type: nauc_map_at_3_max
value: 61.13597610587937
- type: nauc_map_at_3_std
value: 9.309596395240598
- type: nauc_map_at_5_diff1
value: 83.52307226455358
- type: nauc_map_at_5_max
value: 61.59405758027573
- type: nauc_map_at_5_std
value: 9.320025423287671
- type: nauc_mrr_at_1000_diff1
value: 83.69682652271125
- type: nauc_mrr_at_1000_max
value: 61.70131708044767
- type: nauc_mrr_at_1000_std
value: 9.345825405274955
- type: nauc_mrr_at_100_diff1
value: 83.68924820523492
- type: nauc_mrr_at_100_max
value: 61.6965735573098
- type: nauc_mrr_at_100_std
value: 9.366132859525775
- type: nauc_mrr_at_10_diff1
value: 83.61802964269985
- type: nauc_mrr_at_10_max
value: 61.74274476167882
- type: nauc_mrr_at_10_std
value: 9.504060995819101
- type: nauc_mrr_at_1_diff1
value: 86.37079221403225
- type: nauc_mrr_at_1_max
value: 61.856861655370686
- type: nauc_mrr_at_1_std
value: 4.708911881992707
- type: nauc_mrr_at_20_diff1
value: 83.62920965453047
- type: nauc_mrr_at_20_max
value: 61.761029350326965
- type: nauc_mrr_at_20_std
value: 9.572978651118351
- type: nauc_mrr_at_3_diff1
value: 83.66665673154306
- type: nauc_mrr_at_3_max
value: 61.13597610587937
- type: nauc_mrr_at_3_std
value: 9.309596395240598
- type: nauc_mrr_at_5_diff1
value: 83.52307226455358
- type: nauc_mrr_at_5_max
value: 61.59405758027573
- type: nauc_mrr_at_5_std
value: 9.320025423287671
- type: nauc_ndcg_at_1000_diff1
value: 83.24213186482201
- type: nauc_ndcg_at_1000_max
value: 61.77629841787496
- type: nauc_ndcg_at_1000_std
value: 10.332527869705851
- type: nauc_ndcg_at_100_diff1
value: 83.06815820441027
- type: nauc_ndcg_at_100_max
value: 61.6947181864579
- type: nauc_ndcg_at_100_std
value: 10.888922975877316
- type: nauc_ndcg_at_10_diff1
value: 82.58238431386295
- type: nauc_ndcg_at_10_max
value: 62.10333663935709
- type: nauc_ndcg_at_10_std
value: 11.746030330958174
- type: nauc_ndcg_at_1_diff1
value: 86.37079221403225
- type: nauc_ndcg_at_1_max
value: 61.856861655370686
- type: nauc_ndcg_at_1_std
value: 4.708911881992707
- type: nauc_ndcg_at_20_diff1
value: 82.67888324480154
- type: nauc_ndcg_at_20_max
value: 62.28124917486516
- type: nauc_ndcg_at_20_std
value: 12.343058917563914
- type: nauc_ndcg_at_3_diff1
value: 82.71277373710663
- type: nauc_ndcg_at_3_max
value: 60.66677922989939
- type: nauc_ndcg_at_3_std
value: 10.843633736296528
- type: nauc_ndcg_at_5_diff1
value: 82.34691124846786
- type: nauc_ndcg_at_5_max
value: 61.605961382062716
- type: nauc_ndcg_at_5_std
value: 11.129011077702602
- type: nauc_precision_at_1000_diff1
value: .nan
- type: nauc_precision_at_1000_max
value: .nan
- type: nauc_precision_at_1000_std
value: .nan
- type: nauc_precision_at_100_diff1
value: 60.93103908230194
- type: nauc_precision_at_100_max
value: 52.621048419370695
- type: nauc_precision_at_100_std
value: 85.60090702947922
- type: nauc_precision_at_10_diff1
value: 76.26517273576093
- type: nauc_precision_at_10_max
value: 65.2013694366636
- type: nauc_precision_at_10_std
value: 26.50357920946173
- type: nauc_precision_at_1_diff1
value: 86.37079221403225
- type: nauc_precision_at_1_max
value: 61.856861655370686
- type: nauc_precision_at_1_std
value: 4.708911881992707
- type: nauc_precision_at_20_diff1
value: 73.47946930710295
- type: nauc_precision_at_20_max
value: 70.19520986689217
- type: nauc_precision_at_20_std
value: 45.93186111653967
- type: nauc_precision_at_3_diff1
value: 79.02026879450186
- type: nauc_precision_at_3_max
value: 58.75074624692399
- type: nauc_precision_at_3_std
value: 16.740684654251037
- type: nauc_precision_at_5_diff1
value: 76.47585662281637
- type: nauc_precision_at_5_max
value: 61.86270922013127
- type: nauc_precision_at_5_std
value: 20.1833625455035
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 60.93103908229921
- type: nauc_recall_at_100_max
value: 52.62104841936668
- type: nauc_recall_at_100_std
value: 85.60090702947748
- type: nauc_recall_at_10_diff1
value: 76.26517273576097
- type: nauc_recall_at_10_max
value: 65.20136943666347
- type: nauc_recall_at_10_std
value: 26.50357920946174
- type: nauc_recall_at_1_diff1
value: 86.37079221403225
- type: nauc_recall_at_1_max
value: 61.856861655370686
- type: nauc_recall_at_1_std
value: 4.708911881992707
- type: nauc_recall_at_20_diff1
value: 73.47946930710269
- type: nauc_recall_at_20_max
value: 70.19520986689254
- type: nauc_recall_at_20_std
value: 45.93186111653943
- type: nauc_recall_at_3_diff1
value: 79.02026879450173
- type: nauc_recall_at_3_max
value: 58.750746246923924
- type: nauc_recall_at_3_std
value: 16.740684654251076
- type: nauc_recall_at_5_diff1
value: 76.4758566228162
- type: nauc_recall_at_5_max
value: 61.862709220131386
- type: nauc_recall_at_5_std
value: 20.18336254550361
- type: ndcg_at_1
value: 73.444
- type: ndcg_at_10
value: 82.748
- type: ndcg_at_100
value: 84.416
- type: ndcg_at_1000
value: 84.52300000000001
- type: ndcg_at_20
value: 83.646
- type: ndcg_at_3
value: 80.267
- type: ndcg_at_5
value: 81.922
- type: precision_at_1
value: 73.444
- type: precision_at_10
value: 9.167
- type: precision_at_100
value: 0.992
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.761
- type: precision_at_3
value: 28.37
- type: precision_at_5
value: 17.822
- type: recall_at_1
value: 73.444
- type: recall_at_10
value: 91.667
- type: recall_at_100
value: 99.222
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 95.222
- type: recall_at_3
value: 85.111
- type: recall_at_5
value: 89.11099999999999
task:
type: Retrieval
- dataset:
config: eng_Latn-rus_Cyrl
name: MTEB BibleNLPBitextMining (eng_Latn-rus_Cyrl)
revision: 264a18480c529d9e922483839b4b9758e690b762
split: train
type: davidstap/biblenlp-corpus-mmteb
metrics:
- type: accuracy
value: 96.875
- type: f1
value: 95.83333333333333
- type: main_score
value: 95.83333333333333
- type: precision
value: 95.3125
- type: recall
value: 96.875
task:
type: BitextMining
- dataset:
config: rus_Cyrl-eng_Latn
name: MTEB BibleNLPBitextMining (rus_Cyrl-eng_Latn)
revision: 264a18480c529d9e922483839b4b9758e690b762
split: train
type: davidstap/biblenlp-corpus-mmteb
metrics:
- type: accuracy
value: 88.671875
- type: f1
value: 85.3515625
- type: main_score
value: 85.3515625
- type: precision
value: 83.85416666666667
- type: recall
value: 88.671875
task:
type: BitextMining
- dataset:
config: default
name: MTEB CEDRClassification (default)
revision: c0ba03d058e3e1b2f3fd20518875a4563dd12db4
split: test
type: ai-forever/cedr-classification
metrics:
- type: accuracy
value: 40.06907545164719
- type: f1
value: 26.285000550712407
- type: lrap
value: 64.4280021253997
- type: main_score
value: 40.06907545164719
task:
type: MultilabelClassification
- dataset:
config: default
name: MTEB CyrillicTurkicLangClassification (default)
revision: e42d330f33d65b7b72dfd408883daf1661f06f18
split: test
type: tatiana-merz/cyrillic_turkic_langs
metrics:
- type: accuracy
value: 43.3447265625
- type: f1
value: 40.08400146827895
- type: f1_weighted
value: 40.08499428040896
- type: main_score
value: 43.3447265625
task:
type: Classification
- dataset:
config: ace_Arab-rus_Cyrl
name: MTEB FloresBitextMining (ace_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 6.225296442687747
- type: f1
value: 5.5190958860075
- type: main_score
value: 5.5190958860075
- type: precision
value: 5.3752643758000005
- type: recall
value: 6.225296442687747
task:
type: BitextMining
- dataset:
config: bam_Latn-rus_Cyrl
name: MTEB FloresBitextMining (bam_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 68.37944664031622
- type: f1
value: 64.54819836666252
- type: main_score
value: 64.54819836666252
- type: precision
value: 63.07479233454916
- type: recall
value: 68.37944664031622
task:
type: BitextMining
- dataset:
config: dzo_Tibt-rus_Cyrl
name: MTEB FloresBitextMining (dzo_Tibt-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 0.09881422924901186
- type: f1
value: 0.00019509225912934226
- type: main_score
value: 0.00019509225912934226
- type: precision
value: 9.76425190207627e-05
- type: recall
value: 0.09881422924901186
task:
type: BitextMining
- dataset:
config: hin_Deva-rus_Cyrl
name: MTEB FloresBitextMining (hin_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.47299077733861
- type: main_score
value: 99.47299077733861
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: khm_Khmr-rus_Cyrl
name: MTEB FloresBitextMining (khm_Khmr-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 88.83399209486166
- type: f1
value: 87.71151056318254
- type: main_score
value: 87.71151056318254
- type: precision
value: 87.32012500709193
- type: recall
value: 88.83399209486166
task:
type: BitextMining
- dataset:
config: mag_Deva-rus_Cyrl
name: MTEB FloresBitextMining (mag_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.7239789196311
- type: main_score
value: 97.7239789196311
- type: precision
value: 97.61904761904762
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: pap_Latn-rus_Cyrl
name: MTEB FloresBitextMining (pap_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.0711462450593
- type: f1
value: 93.68187806922984
- type: main_score
value: 93.68187806922984
- type: precision
value: 93.58925452707051
- type: recall
value: 94.0711462450593
task:
type: BitextMining
- dataset:
config: sot_Latn-rus_Cyrl
name: MTEB FloresBitextMining (sot_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 90.9090909090909
- type: f1
value: 89.23171936758892
- type: main_score
value: 89.23171936758892
- type: precision
value: 88.51790014083866
- type: recall
value: 90.9090909090909
task:
type: BitextMining
- dataset:
config: tur_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tur_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.9459815546772
- type: main_score
value: 98.9459815546772
- type: precision
value: 98.81422924901186
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: ace_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ace_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 66.10671936758892
- type: f1
value: 63.81888256297873
- type: main_score
value: 63.81888256297873
- type: precision
value: 63.01614067933451
- type: recall
value: 66.10671936758892
task:
type: BitextMining
- dataset:
config: ban_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ban_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 79.44664031620553
- type: f1
value: 77.6311962082713
- type: main_score
value: 77.6311962082713
- type: precision
value: 76.93977931929739
- type: recall
value: 79.44664031620553
task:
type: BitextMining
- dataset:
config: ell_Grek-rus_Cyrl
name: MTEB FloresBitextMining (ell_Grek-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.2094861660079
- type: main_score
value: 99.2094861660079
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: hne_Deva-rus_Cyrl
name: MTEB FloresBitextMining (hne_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.83794466403161
- type: f1
value: 96.25352907961603
- type: main_score
value: 96.25352907961603
- type: precision
value: 96.02155091285526
- type: recall
value: 96.83794466403161
task:
type: BitextMining
- dataset:
config: kik_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kik_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 76.28458498023716
- type: f1
value: 73.5596919895859
- type: main_score
value: 73.5596919895859
- type: precision
value: 72.40900759055246
- type: recall
value: 76.28458498023716
task:
type: BitextMining
- dataset:
config: mai_Deva-rus_Cyrl
name: MTEB FloresBitextMining (mai_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.72727272727273
- type: f1
value: 97.37812911725956
- type: main_score
value: 97.37812911725956
- type: precision
value: 97.26002258610953
- type: recall
value: 97.72727272727273
task:
type: BitextMining
- dataset:
config: pbt_Arab-rus_Cyrl
name: MTEB FloresBitextMining (pbt_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.0711462450593
- type: f1
value: 93.34700387331966
- type: main_score
value: 93.34700387331966
- type: precision
value: 93.06920556920556
- type: recall
value: 94.0711462450593
task:
type: BitextMining
- dataset:
config: spa_Latn-rus_Cyrl
name: MTEB FloresBitextMining (spa_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.9459815546772
- type: main_score
value: 98.9459815546772
- type: precision
value: 98.81422924901186
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: twi_Latn-rus_Cyrl
name: MTEB FloresBitextMining (twi_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.73122529644269
- type: f1
value: 77.77434363246721
- type: main_score
value: 77.77434363246721
- type: precision
value: 76.54444287596462
- type: recall
value: 80.73122529644269
task:
type: BitextMining
- dataset:
config: acm_Arab-rus_Cyrl
name: MTEB FloresBitextMining (acm_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.56521739130434
- type: f1
value: 92.92490118577075
- type: main_score
value: 92.92490118577075
- type: precision
value: 92.16897233201581
- type: recall
value: 94.56521739130434
task:
type: BitextMining
- dataset:
config: bel_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (bel_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.98550724637681
- type: main_score
value: 98.98550724637681
- type: precision
value: 98.88833992094862
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: eng_Latn-rus_Cyrl
name: MTEB FloresBitextMining (eng_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.4729907773386
- type: main_score
value: 99.4729907773386
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: hrv_Latn-rus_Cyrl
name: MTEB FloresBitextMining (hrv_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 99.05138339920948
- type: main_score
value: 99.05138339920948
- type: precision
value: 99.00691699604744
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: kin_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kin_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 88.2411067193676
- type: f1
value: 86.5485246227658
- type: main_score
value: 86.5485246227658
- type: precision
value: 85.90652101521667
- type: recall
value: 88.2411067193676
task:
type: BitextMining
- dataset:
config: mal_Mlym-rus_Cyrl
name: MTEB FloresBitextMining (mal_Mlym-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.51778656126481
- type: f1
value: 98.07971014492753
- type: main_score
value: 98.07971014492753
- type: precision
value: 97.88372859025033
- type: recall
value: 98.51778656126481
task:
type: BitextMining
- dataset:
config: pes_Arab-rus_Cyrl
name: MTEB FloresBitextMining (pes_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.51778656126481
- type: f1
value: 98.0566534914361
- type: main_score
value: 98.0566534914361
- type: precision
value: 97.82608695652173
- type: recall
value: 98.51778656126481
task:
type: BitextMining
- dataset:
config: srd_Latn-rus_Cyrl
name: MTEB FloresBitextMining (srd_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 82.6086956521739
- type: f1
value: 80.9173470979821
- type: main_score
value: 80.9173470979821
- type: precision
value: 80.24468672882627
- type: recall
value: 82.6086956521739
task:
type: BitextMining
- dataset:
config: tzm_Tfng-rus_Cyrl
name: MTEB FloresBitextMining (tzm_Tfng-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 7.41106719367589
- type: f1
value: 6.363562740945329
- type: main_score
value: 6.363562740945329
- type: precision
value: 6.090373175353411
- type: recall
value: 7.41106719367589
task:
type: BitextMining
- dataset:
config: acq_Arab-rus_Cyrl
name: MTEB FloresBitextMining (acq_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.25691699604744
- type: f1
value: 93.81422924901187
- type: main_score
value: 93.81422924901187
- type: precision
value: 93.14064558629775
- type: recall
value: 95.25691699604744
task:
type: BitextMining
- dataset:
config: bem_Latn-rus_Cyrl
name: MTEB FloresBitextMining (bem_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 68.08300395256917
- type: f1
value: 65.01368772860867
- type: main_score
value: 65.01368772860867
- type: precision
value: 63.91052337510628
- type: recall
value: 68.08300395256917
task:
type: BitextMining
- dataset:
config: epo_Latn-rus_Cyrl
name: MTEB FloresBitextMining (epo_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.41897233201581
- type: f1
value: 98.17193675889328
- type: main_score
value: 98.17193675889328
- type: precision
value: 98.08210564139418
- type: recall
value: 98.41897233201581
task:
type: BitextMining
- dataset:
config: hun_Latn-rus_Cyrl
name: MTEB FloresBitextMining (hun_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.1106719367589
- type: main_score
value: 99.1106719367589
- type: precision
value: 99.01185770750988
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: kir_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (kir_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.5296442687747
- type: f1
value: 97.07549806364035
- type: main_score
value: 97.07549806364035
- type: precision
value: 96.90958498023716
- type: recall
value: 97.5296442687747
task:
type: BitextMining
- dataset:
config: mar_Deva-rus_Cyrl
name: MTEB FloresBitextMining (mar_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.44400527009222
- type: main_score
value: 97.44400527009222
- type: precision
value: 97.28966685488425
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: plt_Latn-rus_Cyrl
name: MTEB FloresBitextMining (plt_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 79.9407114624506
- type: f1
value: 78.3154177760691
- type: main_score
value: 78.3154177760691
- type: precision
value: 77.69877344877344
- type: recall
value: 79.9407114624506
task:
type: BitextMining
- dataset:
config: srp_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (srp_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.70355731225297
- type: f1
value: 99.60474308300395
- type: main_score
value: 99.60474308300395
- type: precision
value: 99.55533596837944
- type: recall
value: 99.70355731225297
task:
type: BitextMining
- dataset:
config: uig_Arab-rus_Cyrl
name: MTEB FloresBitextMining (uig_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 83.20158102766798
- type: f1
value: 81.44381923034585
- type: main_score
value: 81.44381923034585
- type: precision
value: 80.78813411582477
- type: recall
value: 83.20158102766798
task:
type: BitextMining
- dataset:
config: aeb_Arab-rus_Cyrl
name: MTEB FloresBitextMining (aeb_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.20553359683794
- type: f1
value: 88.75352907961603
- type: main_score
value: 88.75352907961603
- type: precision
value: 87.64328063241106
- type: recall
value: 91.20553359683794
task:
type: BitextMining
- dataset:
config: ben_Beng-rus_Cyrl
name: MTEB FloresBitextMining (ben_Beng-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.60671936758894
- type: main_score
value: 98.60671936758894
- type: precision
value: 98.4766139657444
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: est_Latn-rus_Cyrl
name: MTEB FloresBitextMining (est_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.24505928853755
- type: f1
value: 95.27417027417027
- type: main_score
value: 95.27417027417027
- type: precision
value: 94.84107378129117
- type: recall
value: 96.24505928853755
task:
type: BitextMining
- dataset:
config: hye_Armn-rus_Cyrl
name: MTEB FloresBitextMining (hye_Armn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.67786561264822
- type: main_score
value: 97.67786561264822
- type: precision
value: 97.55839022637441
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: kmb_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kmb_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 46.047430830039524
- type: f1
value: 42.94464804804471
- type: main_score
value: 42.94464804804471
- type: precision
value: 41.9851895607238
- type: recall
value: 46.047430830039524
task:
type: BitextMining
- dataset:
config: min_Arab-rus_Cyrl
name: MTEB FloresBitextMining (min_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 3.9525691699604746
- type: f1
value: 3.402665192725756
- type: main_score
value: 3.402665192725756
- type: precision
value: 3.303787557740127
- type: recall
value: 3.9525691699604746
task:
type: BitextMining
- dataset:
config: pol_Latn-rus_Cyrl
name: MTEB FloresBitextMining (pol_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.4729907773386
- type: main_score
value: 99.4729907773386
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: ssw_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ssw_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 73.22134387351778
- type: f1
value: 70.43086049508975
- type: main_score
value: 70.43086049508975
- type: precision
value: 69.35312022355656
- type: recall
value: 73.22134387351778
task:
type: BitextMining
- dataset:
config: ukr_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (ukr_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.90118577075098
- type: f1
value: 99.86824769433464
- type: main_score
value: 99.86824769433464
- type: precision
value: 99.85177865612648
- type: recall
value: 99.90118577075098
task:
type: BitextMining
- dataset:
config: afr_Latn-rus_Cyrl
name: MTEB FloresBitextMining (afr_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.9459815546772
- type: main_score
value: 98.9459815546772
- type: precision
value: 98.81422924901186
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: bho_Deva-rus_Cyrl
name: MTEB FloresBitextMining (bho_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.0711462450593
- type: f1
value: 93.12182382834557
- type: main_score
value: 93.12182382834557
- type: precision
value: 92.7523453232338
- type: recall
value: 94.0711462450593
task:
type: BitextMining
- dataset:
config: eus_Latn-rus_Cyrl
name: MTEB FloresBitextMining (eus_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.19367588932806
- type: f1
value: 91.23604975587072
- type: main_score
value: 91.23604975587072
- type: precision
value: 90.86697443588663
- type: recall
value: 92.19367588932806
task:
type: BitextMining
- dataset:
config: ibo_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ibo_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 82.21343873517787
- type: f1
value: 80.17901604858126
- type: main_score
value: 80.17901604858126
- type: precision
value: 79.3792284780028
- type: recall
value: 82.21343873517787
task:
type: BitextMining
- dataset:
config: kmr_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kmr_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 68.67588932806325
- type: f1
value: 66.72311714750278
- type: main_score
value: 66.72311714750278
- type: precision
value: 66.00178401554004
- type: recall
value: 68.67588932806325
task:
type: BitextMining
- dataset:
config: min_Latn-rus_Cyrl
name: MTEB FloresBitextMining (min_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 78.65612648221344
- type: f1
value: 76.26592719972166
- type: main_score
value: 76.26592719972166
- type: precision
value: 75.39980459997484
- type: recall
value: 78.65612648221344
task:
type: BitextMining
- dataset:
config: por_Latn-rus_Cyrl
name: MTEB FloresBitextMining (por_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.83794466403161
- type: f1
value: 95.9669678147939
- type: main_score
value: 95.9669678147939
- type: precision
value: 95.59453227931488
- type: recall
value: 96.83794466403161
task:
type: BitextMining
- dataset:
config: sun_Latn-rus_Cyrl
name: MTEB FloresBitextMining (sun_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.4901185770751
- type: f1
value: 91.66553983773662
- type: main_score
value: 91.66553983773662
- type: precision
value: 91.34530928009188
- type: recall
value: 92.4901185770751
task:
type: BitextMining
- dataset:
config: umb_Latn-rus_Cyrl
name: MTEB FloresBitextMining (umb_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 41.00790513833992
- type: f1
value: 38.21319326004483
- type: main_score
value: 38.21319326004483
- type: precision
value: 37.200655467675546
- type: recall
value: 41.00790513833992
task:
type: BitextMining
- dataset:
config: ajp_Arab-rus_Cyrl
name: MTEB FloresBitextMining (ajp_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.35573122529645
- type: f1
value: 93.97233201581028
- type: main_score
value: 93.97233201581028
- type: precision
value: 93.33333333333333
- type: recall
value: 95.35573122529645
task:
type: BitextMining
- dataset:
config: bjn_Arab-rus_Cyrl
name: MTEB FloresBitextMining (bjn_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 3.6561264822134385
- type: f1
value: 3.1071978056336484
- type: main_score
value: 3.1071978056336484
- type: precision
value: 3.0039741229718215
- type: recall
value: 3.6561264822134385
task:
type: BitextMining
- dataset:
config: ewe_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ewe_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 62.845849802371546
- type: f1
value: 59.82201175670472
- type: main_score
value: 59.82201175670472
- type: precision
value: 58.72629236362003
- type: recall
value: 62.845849802371546
task:
type: BitextMining
- dataset:
config: ilo_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ilo_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 83.10276679841897
- type: f1
value: 80.75065288987582
- type: main_score
value: 80.75065288987582
- type: precision
value: 79.80726451662179
- type: recall
value: 83.10276679841897
task:
type: BitextMining
- dataset:
config: knc_Arab-rus_Cyrl
name: MTEB FloresBitextMining (knc_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 10.079051383399209
- type: f1
value: 8.759282456080921
- type: main_score
value: 8.759282456080921
- type: precision
value: 8.474735138956142
- type: recall
value: 10.079051383399209
task:
type: BitextMining
- dataset:
config: mkd_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (mkd_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.55072463768116
- type: main_score
value: 98.55072463768116
- type: precision
value: 98.36956521739131
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: prs_Arab-rus_Cyrl
name: MTEB FloresBitextMining (prs_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: swe_Latn-rus_Cyrl
name: MTEB FloresBitextMining (swe_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.22595520421606
- type: main_score
value: 99.22595520421606
- type: precision
value: 99.14361001317523
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: urd_Arab-rus_Cyrl
name: MTEB FloresBitextMining (urd_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.25625823451911
- type: main_score
value: 97.25625823451911
- type: precision
value: 97.03063241106719
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: aka_Latn-rus_Cyrl
name: MTEB FloresBitextMining (aka_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.22529644268775
- type: f1
value: 77.94307687941227
- type: main_score
value: 77.94307687941227
- type: precision
value: 76.58782793293665
- type: recall
value: 81.22529644268775
task:
type: BitextMining
- dataset:
config: bjn_Latn-rus_Cyrl
name: MTEB FloresBitextMining (bjn_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 85.27667984189723
- type: f1
value: 83.6869192829922
- type: main_score
value: 83.6869192829922
- type: precision
value: 83.08670670691656
- type: recall
value: 85.27667984189723
task:
type: BitextMining
- dataset:
config: fao_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fao_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.9288537549407
- type: f1
value: 79.29806087454745
- type: main_score
value: 79.29806087454745
- type: precision
value: 78.71445871526987
- type: recall
value: 80.9288537549407
task:
type: BitextMining
- dataset:
config: ind_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ind_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.12252964426878
- type: f1
value: 97.5296442687747
- type: main_score
value: 97.5296442687747
- type: precision
value: 97.23320158102767
- type: recall
value: 98.12252964426878
task:
type: BitextMining
- dataset:
config: knc_Latn-rus_Cyrl
name: MTEB FloresBitextMining (knc_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 33.49802371541502
- type: f1
value: 32.02378215033989
- type: main_score
value: 32.02378215033989
- type: precision
value: 31.511356103747406
- type: recall
value: 33.49802371541502
task:
type: BitextMining
- dataset:
config: mlt_Latn-rus_Cyrl
name: MTEB FloresBitextMining (mlt_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.40316205533597
- type: f1
value: 90.35317684386006
- type: main_score
value: 90.35317684386006
- type: precision
value: 89.94845939633488
- type: recall
value: 91.40316205533597
task:
type: BitextMining
- dataset:
config: quy_Latn-rus_Cyrl
name: MTEB FloresBitextMining (quy_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 40.612648221343875
- type: f1
value: 38.74337544712602
- type: main_score
value: 38.74337544712602
- type: precision
value: 38.133716022178575
- type: recall
value: 40.612648221343875
task:
type: BitextMining
- dataset:
config: swh_Latn-rus_Cyrl
name: MTEB FloresBitextMining (swh_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.13438735177866
- type: f1
value: 96.47435897435898
- type: main_score
value: 96.47435897435898
- type: precision
value: 96.18741765480895
- type: recall
value: 97.13438735177866
task:
type: BitextMining
- dataset:
config: uzn_Latn-rus_Cyrl
name: MTEB FloresBitextMining (uzn_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.83794466403161
- type: f1
value: 96.26355528529442
- type: main_score
value: 96.26355528529442
- type: precision
value: 96.0501756697409
- type: recall
value: 96.83794466403161
task:
type: BitextMining
- dataset:
config: als_Latn-rus_Cyrl
name: MTEB FloresBitextMining (als_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.6907114624506
- type: main_score
value: 98.6907114624506
- type: precision
value: 98.6142480707698
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: bod_Tibt-rus_Cyrl
name: MTEB FloresBitextMining (bod_Tibt-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 1.0869565217391304
- type: f1
value: 0.9224649610442628
- type: main_score
value: 0.9224649610442628
- type: precision
value: 0.8894275740459898
- type: recall
value: 1.0869565217391304
task:
type: BitextMining
- dataset:
config: fij_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fij_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 63.24110671936759
- type: f1
value: 60.373189068189525
- type: main_score
value: 60.373189068189525
- type: precision
value: 59.32326368115546
- type: recall
value: 63.24110671936759
task:
type: BitextMining
- dataset:
config: isl_Latn-rus_Cyrl
name: MTEB FloresBitextMining (isl_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.03162055335969
- type: f1
value: 87.3102634715907
- type: main_score
value: 87.3102634715907
- type: precision
value: 86.65991814698712
- type: recall
value: 89.03162055335969
task:
type: BitextMining
- dataset:
config: kon_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kon_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 73.91304347826086
- type: f1
value: 71.518235523573
- type: main_score
value: 71.518235523573
- type: precision
value: 70.58714102449801
- type: recall
value: 73.91304347826086
task:
type: BitextMining
- dataset:
config: mni_Beng-rus_Cyrl
name: MTEB FloresBitextMining (mni_Beng-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 29.545454545454547
- type: f1
value: 27.59513619889114
- type: main_score
value: 27.59513619889114
- type: precision
value: 26.983849851025344
- type: recall
value: 29.545454545454547
task:
type: BitextMining
- dataset:
config: ron_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ron_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.2094861660079
- type: main_score
value: 99.2094861660079
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: szl_Latn-rus_Cyrl
name: MTEB FloresBitextMining (szl_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.26482213438736
- type: f1
value: 85.18912031587512
- type: main_score
value: 85.18912031587512
- type: precision
value: 84.77199409959775
- type: recall
value: 86.26482213438736
task:
type: BitextMining
- dataset:
config: vec_Latn-rus_Cyrl
name: MTEB FloresBitextMining (vec_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 85.67193675889328
- type: f1
value: 84.62529734716581
- type: main_score
value: 84.62529734716581
- type: precision
value: 84.2611422440705
- type: recall
value: 85.67193675889328
task:
type: BitextMining
- dataset:
config: amh_Ethi-rus_Cyrl
name: MTEB FloresBitextMining (amh_Ethi-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.76284584980237
- type: f1
value: 93.91735076517685
- type: main_score
value: 93.91735076517685
- type: precision
value: 93.57553798858147
- type: recall
value: 94.76284584980237
task:
type: BitextMining
- dataset:
config: bos_Latn-rus_Cyrl
name: MTEB FloresBitextMining (bos_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 99.05655938264634
- type: main_score
value: 99.05655938264634
- type: precision
value: 99.01185770750988
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: fin_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fin_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.43741765480895
- type: main_score
value: 97.43741765480895
- type: precision
value: 97.1590909090909
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: ita_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ita_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.70355731225297
- type: f1
value: 99.60474308300395
- type: main_score
value: 99.60474308300395
- type: precision
value: 99.55533596837944
- type: recall
value: 99.70355731225297
task:
type: BitextMining
- dataset:
config: kor_Hang-rus_Cyrl
name: MTEB FloresBitextMining (kor_Hang-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.33201581027669
- type: f1
value: 96.49868247694334
- type: main_score
value: 96.49868247694334
- type: precision
value: 96.10507246376811
- type: recall
value: 97.33201581027669
task:
type: BitextMining
- dataset:
config: mos_Latn-rus_Cyrl
name: MTEB FloresBitextMining (mos_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 34.683794466403164
- type: f1
value: 32.766819308009076
- type: main_score
value: 32.766819308009076
- type: precision
value: 32.1637493670237
- type: recall
value: 34.683794466403164
task:
type: BitextMining
- dataset:
config: run_Latn-rus_Cyrl
name: MTEB FloresBitextMining (run_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 83.399209486166
- type: f1
value: 81.10578750604326
- type: main_score
value: 81.10578750604326
- type: precision
value: 80.16763162673529
- type: recall
value: 83.399209486166
task:
type: BitextMining
- dataset:
config: tam_Taml-rus_Cyrl
name: MTEB FloresBitextMining (tam_Taml-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.41897233201581
- type: f1
value: 98.01548089591567
- type: main_score
value: 98.01548089591567
- type: precision
value: 97.84020327498588
- type: recall
value: 98.41897233201581
task:
type: BitextMining
- dataset:
config: vie_Latn-rus_Cyrl
name: MTEB FloresBitextMining (vie_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.1106719367589
- type: f1
value: 98.81422924901186
- type: main_score
value: 98.81422924901186
- type: precision
value: 98.66600790513834
- type: recall
value: 99.1106719367589
task:
type: BitextMining
- dataset:
config: apc_Arab-rus_Cyrl
name: MTEB FloresBitextMining (apc_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.87351778656127
- type: f1
value: 92.10803689064558
- type: main_score
value: 92.10803689064558
- type: precision
value: 91.30434782608695
- type: recall
value: 93.87351778656127
task:
type: BitextMining
- dataset:
config: bug_Latn-rus_Cyrl
name: MTEB FloresBitextMining (bug_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 57.608695652173914
- type: f1
value: 54.95878654927162
- type: main_score
value: 54.95878654927162
- type: precision
value: 54.067987427805654
- type: recall
value: 57.608695652173914
task:
type: BitextMining
- dataset:
config: fon_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fon_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 61.95652173913043
- type: f1
value: 58.06537275812945
- type: main_score
value: 58.06537275812945
- type: precision
value: 56.554057596959204
- type: recall
value: 61.95652173913043
task:
type: BitextMining
- dataset:
config: jav_Latn-rus_Cyrl
name: MTEB FloresBitextMining (jav_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.47826086956522
- type: f1
value: 92.4784405318002
- type: main_score
value: 92.4784405318002
- type: precision
value: 92.09168143201127
- type: recall
value: 93.47826086956522
task:
type: BitextMining
- dataset:
config: lao_Laoo-rus_Cyrl
name: MTEB FloresBitextMining (lao_Laoo-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.10671936758892
- type: f1
value: 89.76104922745239
- type: main_score
value: 89.76104922745239
- type: precision
value: 89.24754593232855
- type: recall
value: 91.10671936758892
task:
type: BitextMining
- dataset:
config: mri_Latn-rus_Cyrl
name: MTEB FloresBitextMining (mri_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 71.14624505928853
- type: f1
value: 68.26947125119062
- type: main_score
value: 68.26947125119062
- type: precision
value: 67.15942311051006
- type: recall
value: 71.14624505928853
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ace_Arab
name: MTEB FloresBitextMining (rus_Cyrl-ace_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 19.565217391304348
- type: f1
value: 16.321465000323805
- type: main_score
value: 16.321465000323805
- type: precision
value: 15.478527409347508
- type: recall
value: 19.565217391304348
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bam_Latn
name: MTEB FloresBitextMining (rus_Cyrl-bam_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 73.41897233201581
- type: f1
value: 68.77366228182746
- type: main_score
value: 68.77366228182746
- type: precision
value: 66.96012924273795
- type: recall
value: 73.41897233201581
task:
type: BitextMining
- dataset:
config: rus_Cyrl-dzo_Tibt
name: MTEB FloresBitextMining (rus_Cyrl-dzo_Tibt)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 0.592885375494071
- type: f1
value: 0.02458062426370458
- type: main_score
value: 0.02458062426370458
- type: precision
value: 0.012824114724683876
- type: recall
value: 0.592885375494071
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hin_Deva
name: MTEB FloresBitextMining (rus_Cyrl-hin_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.90118577075098
- type: f1
value: 99.86824769433464
- type: main_score
value: 99.86824769433464
- type: precision
value: 99.85177865612648
- type: recall
value: 99.90118577075098
task:
type: BitextMining
- dataset:
config: rus_Cyrl-khm_Khmr
name: MTEB FloresBitextMining (rus_Cyrl-khm_Khmr)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.13438735177866
- type: f1
value: 96.24505928853755
- type: main_score
value: 96.24505928853755
- type: precision
value: 95.81686429512516
- type: recall
value: 97.13438735177866
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mag_Deva
name: MTEB FloresBitextMining (rus_Cyrl-mag_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.50592885375494
- type: f1
value: 99.35770750988142
- type: main_score
value: 99.35770750988142
- type: precision
value: 99.29183135704875
- type: recall
value: 99.50592885375494
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pap_Latn
name: MTEB FloresBitextMining (rus_Cyrl-pap_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.93675889328063
- type: f1
value: 96.05072463768116
- type: main_score
value: 96.05072463768116
- type: precision
value: 95.66040843214758
- type: recall
value: 96.93675889328063
task:
type: BitextMining
- dataset:
config: rus_Cyrl-sot_Latn
name: MTEB FloresBitextMining (rus_Cyrl-sot_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.67588932806325
- type: f1
value: 91.7786561264822
- type: main_score
value: 91.7786561264822
- type: precision
value: 90.91238471673255
- type: recall
value: 93.67588932806325
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tur_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tur_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ace_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ace_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 74.1106719367589
- type: f1
value: 70.21737923911836
- type: main_score
value: 70.21737923911836
- type: precision
value: 68.7068791410511
- type: recall
value: 74.1106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ban_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ban_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.7193675889328
- type: f1
value: 78.76470334510617
- type: main_score
value: 78.76470334510617
- type: precision
value: 77.76208475761422
- type: recall
value: 81.7193675889328
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ell_Grek
name: MTEB FloresBitextMining (rus_Cyrl-ell_Grek)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.3201581027668
- type: f1
value: 97.76021080368908
- type: main_score
value: 97.76021080368908
- type: precision
value: 97.48023715415019
- type: recall
value: 98.3201581027668
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hne_Deva
name: MTEB FloresBitextMining (rus_Cyrl-hne_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.51778656126481
- type: f1
value: 98.0566534914361
- type: main_score
value: 98.0566534914361
- type: precision
value: 97.82608695652173
- type: recall
value: 98.51778656126481
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kik_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kik_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.73122529644269
- type: f1
value: 76.42689244220864
- type: main_score
value: 76.42689244220864
- type: precision
value: 74.63877909530083
- type: recall
value: 80.73122529644269
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mai_Deva
name: MTEB FloresBitextMining (rus_Cyrl-mai_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.56719367588933
- type: main_score
value: 98.56719367588933
- type: precision
value: 98.40250329380763
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pbt_Arab
name: MTEB FloresBitextMining (rus_Cyrl-pbt_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.5296442687747
- type: f1
value: 96.73913043478261
- type: main_score
value: 96.73913043478261
- type: precision
value: 96.36034255599473
- type: recall
value: 97.5296442687747
task:
type: BitextMining
- dataset:
config: rus_Cyrl-spa_Latn
name: MTEB FloresBitextMining (rus_Cyrl-spa_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.20948616600789
- type: main_score
value: 99.20948616600789
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: rus_Cyrl-twi_Latn
name: MTEB FloresBitextMining (rus_Cyrl-twi_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 82.01581027667984
- type: f1
value: 78.064787822953
- type: main_score
value: 78.064787822953
- type: precision
value: 76.43272186750448
- type: recall
value: 82.01581027667984
task:
type: BitextMining
- dataset:
config: rus_Cyrl-acm_Arab
name: MTEB FloresBitextMining (rus_Cyrl-acm_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.3201581027668
- type: f1
value: 97.76021080368908
- type: main_score
value: 97.76021080368908
- type: precision
value: 97.48023715415019
- type: recall
value: 98.3201581027668
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bel_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-bel_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.22134387351778
- type: f1
value: 97.67786561264822
- type: main_score
value: 97.67786561264822
- type: precision
value: 97.4308300395257
- type: recall
value: 98.22134387351778
task:
type: BitextMining
- dataset:
config: rus_Cyrl-eng_Latn
name: MTEB FloresBitextMining (rus_Cyrl-eng_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.70355731225297
- type: f1
value: 99.60474308300395
- type: main_score
value: 99.60474308300395
- type: precision
value: 99.55533596837944
- type: recall
value: 99.70355731225297
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hrv_Latn
name: MTEB FloresBitextMining (rus_Cyrl-hrv_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.1106719367589
- type: f1
value: 98.83069828722002
- type: main_score
value: 98.83069828722002
- type: precision
value: 98.69894598155466
- type: recall
value: 99.1106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kin_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kin_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.37944664031622
- type: f1
value: 91.53162055335969
- type: main_score
value: 91.53162055335969
- type: precision
value: 90.71475625823452
- type: recall
value: 93.37944664031622
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mal_Mlym
name: MTEB FloresBitextMining (rus_Cyrl-mal_Mlym)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.07773386034255
- type: main_score
value: 99.07773386034255
- type: precision
value: 98.96245059288538
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pes_Arab
name: MTEB FloresBitextMining (rus_Cyrl-pes_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.30368906455863
- type: main_score
value: 98.30368906455863
- type: precision
value: 98.10606060606061
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-srd_Latn
name: MTEB FloresBitextMining (rus_Cyrl-srd_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.03162055335969
- type: f1
value: 86.11048371917937
- type: main_score
value: 86.11048371917937
- type: precision
value: 84.86001317523056
- type: recall
value: 89.03162055335969
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tzm_Tfng
name: MTEB FloresBitextMining (rus_Cyrl-tzm_Tfng)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 12.351778656126482
- type: f1
value: 10.112177999067715
- type: main_score
value: 10.112177999067715
- type: precision
value: 9.53495885438645
- type: recall
value: 12.351778656126482
task:
type: BitextMining
- dataset:
config: rus_Cyrl-acq_Arab
name: MTEB FloresBitextMining (rus_Cyrl-acq_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.55072463768116
- type: main_score
value: 98.55072463768116
- type: precision
value: 98.36956521739131
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bem_Latn
name: MTEB FloresBitextMining (rus_Cyrl-bem_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 73.22134387351778
- type: f1
value: 68.30479412989295
- type: main_score
value: 68.30479412989295
- type: precision
value: 66.40073447632736
- type: recall
value: 73.22134387351778
task:
type: BitextMining
- dataset:
config: rus_Cyrl-epo_Latn
name: MTEB FloresBitextMining (rus_Cyrl-epo_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.1106719367589
- type: f1
value: 98.81422924901186
- type: main_score
value: 98.81422924901186
- type: precision
value: 98.66600790513834
- type: recall
value: 99.1106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hun_Latn
name: MTEB FloresBitextMining (rus_Cyrl-hun_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.83794466403161
- type: f1
value: 95.88274044795784
- type: main_score
value: 95.88274044795784
- type: precision
value: 95.45454545454545
- type: recall
value: 96.83794466403161
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kir_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-kir_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.34387351778656
- type: f1
value: 95.49280429715212
- type: main_score
value: 95.49280429715212
- type: precision
value: 95.14163372859026
- type: recall
value: 96.34387351778656
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mar_Deva
name: MTEB FloresBitextMining (rus_Cyrl-mar_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.28722002635047
- type: main_score
value: 98.28722002635047
- type: precision
value: 98.07312252964427
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-plt_Latn
name: MTEB FloresBitextMining (rus_Cyrl-plt_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 88.04347826086956
- type: f1
value: 85.14328063241106
- type: main_score
value: 85.14328063241106
- type: precision
value: 83.96339168078298
- type: recall
value: 88.04347826086956
task:
type: BitextMining
- dataset:
config: rus_Cyrl-srp_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-srp_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.2094861660079
- type: main_score
value: 99.2094861660079
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: rus_Cyrl-uig_Arab
name: MTEB FloresBitextMining (rus_Cyrl-uig_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.19367588932806
- type: f1
value: 89.98541313758706
- type: main_score
value: 89.98541313758706
- type: precision
value: 89.01021080368906
- type: recall
value: 92.19367588932806
task:
type: BitextMining
- dataset:
config: rus_Cyrl-aeb_Arab
name: MTEB FloresBitextMining (rus_Cyrl-aeb_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.8498023715415
- type: f1
value: 94.63109354413703
- type: main_score
value: 94.63109354413703
- type: precision
value: 94.05467720685111
- type: recall
value: 95.8498023715415
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ben_Beng
name: MTEB FloresBitextMining (rus_Cyrl-ben_Beng)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.2094861660079
- type: main_score
value: 99.2094861660079
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: rus_Cyrl-est_Latn
name: MTEB FloresBitextMining (rus_Cyrl-est_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.55335968379447
- type: f1
value: 94.2588932806324
- type: main_score
value: 94.2588932806324
- type: precision
value: 93.65118577075098
- type: recall
value: 95.55335968379447
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hye_Armn
name: MTEB FloresBitextMining (rus_Cyrl-hye_Armn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.28722002635045
- type: main_score
value: 98.28722002635045
- type: precision
value: 98.07312252964427
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kmb_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kmb_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 54.24901185770751
- type: f1
value: 49.46146674116913
- type: main_score
value: 49.46146674116913
- type: precision
value: 47.81033799314432
- type: recall
value: 54.24901185770751
task:
type: BitextMining
- dataset:
config: rus_Cyrl-min_Arab
name: MTEB FloresBitextMining (rus_Cyrl-min_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 15.810276679841898
- type: f1
value: 13.271207641419332
- type: main_score
value: 13.271207641419332
- type: precision
value: 12.510673148766033
- type: recall
value: 15.810276679841898
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pol_Latn
name: MTEB FloresBitextMining (rus_Cyrl-pol_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.32674571805006
- type: main_score
value: 98.32674571805006
- type: precision
value: 98.14723320158103
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ssw_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ssw_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.8300395256917
- type: f1
value: 76.51717847370023
- type: main_score
value: 76.51717847370023
- type: precision
value: 74.74143610013175
- type: recall
value: 80.8300395256917
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ukr_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-ukr_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.4729907773386
- type: main_score
value: 99.4729907773386
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: rus_Cyrl-afr_Latn
name: MTEB FloresBitextMining (rus_Cyrl-afr_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.1106719367589
- type: f1
value: 98.81422924901186
- type: main_score
value: 98.81422924901186
- type: precision
value: 98.66600790513834
- type: recall
value: 99.1106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bho_Deva
name: MTEB FloresBitextMining (rus_Cyrl-bho_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.6403162055336
- type: f1
value: 95.56982872200265
- type: main_score
value: 95.56982872200265
- type: precision
value: 95.0592885375494
- type: recall
value: 96.6403162055336
task:
type: BitextMining
- dataset:
config: rus_Cyrl-eus_Latn
name: MTEB FloresBitextMining (rus_Cyrl-eus_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.62845849802372
- type: f1
value: 96.9038208168643
- type: main_score
value: 96.9038208168643
- type: precision
value: 96.55797101449275
- type: recall
value: 97.62845849802372
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ibo_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ibo_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.2292490118577
- type: f1
value: 86.35234330886506
- type: main_score
value: 86.35234330886506
- type: precision
value: 85.09881422924902
- type: recall
value: 89.2292490118577
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kmr_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kmr_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 83.49802371541502
- type: f1
value: 79.23630717108978
- type: main_score
value: 79.23630717108978
- type: precision
value: 77.48188405797102
- type: recall
value: 83.49802371541502
task:
type: BitextMining
- dataset:
config: rus_Cyrl-min_Latn
name: MTEB FloresBitextMining (rus_Cyrl-min_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 79.34782608695652
- type: f1
value: 75.31689928429059
- type: main_score
value: 75.31689928429059
- type: precision
value: 73.91519410541149
- type: recall
value: 79.34782608695652
task:
type: BitextMining
- dataset:
config: rus_Cyrl-por_Latn
name: MTEB FloresBitextMining (rus_Cyrl-por_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.54150197628458
- type: f1
value: 95.53218520609825
- type: main_score
value: 95.53218520609825
- type: precision
value: 95.07575757575756
- type: recall
value: 96.54150197628458
task:
type: BitextMining
- dataset:
config: rus_Cyrl-sun_Latn
name: MTEB FloresBitextMining (rus_Cyrl-sun_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.2806324110672
- type: f1
value: 91.56973461321287
- type: main_score
value: 91.56973461321287
- type: precision
value: 90.84396334890405
- type: recall
value: 93.2806324110672
task:
type: BitextMining
- dataset:
config: rus_Cyrl-umb_Latn
name: MTEB FloresBitextMining (rus_Cyrl-umb_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 51.87747035573123
- type: f1
value: 46.36591778884269
- type: main_score
value: 46.36591778884269
- type: precision
value: 44.57730391234227
- type: recall
value: 51.87747035573123
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ajp_Arab
name: MTEB FloresBitextMining (rus_Cyrl-ajp_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.30368906455863
- type: main_score
value: 98.30368906455863
- type: precision
value: 98.10606060606061
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bjn_Arab
name: MTEB FloresBitextMining (rus_Cyrl-bjn_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 14.82213438735178
- type: f1
value: 12.365434276616856
- type: main_score
value: 12.365434276616856
- type: precision
value: 11.802079517180589
- type: recall
value: 14.82213438735178
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ewe_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ewe_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 71.44268774703558
- type: f1
value: 66.74603174603175
- type: main_score
value: 66.74603174603175
- type: precision
value: 64.99933339607253
- type: recall
value: 71.44268774703558
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ilo_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ilo_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 85.86956521739131
- type: f1
value: 83.00139015960917
- type: main_score
value: 83.00139015960917
- type: precision
value: 81.91411396574439
- type: recall
value: 85.86956521739131
task:
type: BitextMining
- dataset:
config: rus_Cyrl-knc_Arab
name: MTEB FloresBitextMining (rus_Cyrl-knc_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 14.525691699604742
- type: f1
value: 12.618283715726806
- type: main_score
value: 12.618283715726806
- type: precision
value: 12.048458493742352
- type: recall
value: 14.525691699604742
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mkd_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-mkd_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.22595520421606
- type: main_score
value: 99.22595520421606
- type: precision
value: 99.14361001317523
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: rus_Cyrl-prs_Arab
name: MTEB FloresBitextMining (rus_Cyrl-prs_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.07773386034255
- type: main_score
value: 99.07773386034255
- type: precision
value: 98.96245059288538
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: rus_Cyrl-swe_Latn
name: MTEB FloresBitextMining (rus_Cyrl-swe_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.07773386034256
- type: main_score
value: 99.07773386034256
- type: precision
value: 98.96245059288538
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: rus_Cyrl-urd_Arab
name: MTEB FloresBitextMining (rus_Cyrl-urd_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.61660079051383
- type: f1
value: 98.15546772068511
- type: main_score
value: 98.15546772068511
- type: precision
value: 97.92490118577075
- type: recall
value: 98.61660079051383
task:
type: BitextMining
- dataset:
config: rus_Cyrl-aka_Latn
name: MTEB FloresBitextMining (rus_Cyrl-aka_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.02766798418972
- type: f1
value: 76.73277809147375
- type: main_score
value: 76.73277809147375
- type: precision
value: 74.97404165882426
- type: recall
value: 81.02766798418972
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bjn_Latn
name: MTEB FloresBitextMining (rus_Cyrl-bjn_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.7588932806324
- type: f1
value: 83.92064566965753
- type: main_score
value: 83.92064566965753
- type: precision
value: 82.83734079929732
- type: recall
value: 86.7588932806324
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fao_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fao_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 88.43873517786561
- type: f1
value: 85.48136645962732
- type: main_score
value: 85.48136645962732
- type: precision
value: 84.23418972332016
- type: recall
value: 88.43873517786561
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ind_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ind_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: rus_Cyrl-knc_Latn
name: MTEB FloresBitextMining (rus_Cyrl-knc_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 45.8498023715415
- type: f1
value: 40.112030865489366
- type: main_score
value: 40.112030865489366
- type: precision
value: 38.28262440050776
- type: recall
value: 45.8498023715415
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mlt_Latn
name: MTEB FloresBitextMining (rus_Cyrl-mlt_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.18181818181817
- type: f1
value: 91.30787690570298
- type: main_score
value: 91.30787690570298
- type: precision
value: 90.4983060417843
- type: recall
value: 93.18181818181817
task:
type: BitextMining
- dataset:
config: rus_Cyrl-quy_Latn
name: MTEB FloresBitextMining (rus_Cyrl-quy_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 62.450592885375485
- type: f1
value: 57.28742975628178
- type: main_score
value: 57.28742975628178
- type: precision
value: 55.56854987623269
- type: recall
value: 62.450592885375485
task:
type: BitextMining
- dataset:
config: rus_Cyrl-swh_Latn
name: MTEB FloresBitextMining (rus_Cyrl-swh_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.3201581027668
- type: f1
value: 97.77667984189723
- type: main_score
value: 97.77667984189723
- type: precision
value: 97.51317523056655
- type: recall
value: 98.3201581027668
task:
type: BitextMining
- dataset:
config: rus_Cyrl-uzn_Latn
name: MTEB FloresBitextMining (rus_Cyrl-uzn_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.12252964426878
- type: f1
value: 97.59081498211933
- type: main_score
value: 97.59081498211933
- type: precision
value: 97.34848484848484
- type: recall
value: 98.12252964426878
task:
type: BitextMining
- dataset:
config: rus_Cyrl-als_Latn
name: MTEB FloresBitextMining (rus_Cyrl-als_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.09420289855073
- type: main_score
value: 99.09420289855073
- type: precision
value: 98.99538866930172
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bod_Tibt
name: MTEB FloresBitextMining (rus_Cyrl-bod_Tibt)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 11.561264822134387
- type: f1
value: 8.121312045385636
- type: main_score
value: 8.121312045385636
- type: precision
value: 7.350577020893972
- type: recall
value: 11.561264822134387
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fij_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fij_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 72.23320158102767
- type: f1
value: 67.21000233846082
- type: main_score
value: 67.21000233846082
- type: precision
value: 65.3869439739005
- type: recall
value: 72.23320158102767
task:
type: BitextMining
- dataset:
config: rus_Cyrl-isl_Latn
name: MTEB FloresBitextMining (rus_Cyrl-isl_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.99604743083005
- type: f1
value: 89.75955204216073
- type: main_score
value: 89.75955204216073
- type: precision
value: 88.7598814229249
- type: recall
value: 91.99604743083005
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kon_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kon_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.81818181818183
- type: f1
value: 77.77800098452272
- type: main_score
value: 77.77800098452272
- type: precision
value: 76.1521268586486
- type: recall
value: 81.81818181818183
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mni_Beng
name: MTEB FloresBitextMining (rus_Cyrl-mni_Beng)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 54.74308300395256
- type: f1
value: 48.97285299254615
- type: main_score
value: 48.97285299254615
- type: precision
value: 46.95125742968299
- type: recall
value: 54.74308300395256
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ron_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ron_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.22134387351778
- type: f1
value: 97.64492753623189
- type: main_score
value: 97.64492753623189
- type: precision
value: 97.36495388669302
- type: recall
value: 98.22134387351778
task:
type: BitextMining
- dataset:
config: rus_Cyrl-szl_Latn
name: MTEB FloresBitextMining (rus_Cyrl-szl_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.09486166007905
- type: f1
value: 90.10375494071147
- type: main_score
value: 90.10375494071147
- type: precision
value: 89.29606625258798
- type: recall
value: 92.09486166007905
task:
type: BitextMining
- dataset:
config: rus_Cyrl-vec_Latn
name: MTEB FloresBitextMining (rus_Cyrl-vec_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.4901185770751
- type: f1
value: 90.51430453604365
- type: main_score
value: 90.51430453604365
- type: precision
value: 89.69367588932808
- type: recall
value: 92.4901185770751
task:
type: BitextMining
- dataset:
config: rus_Cyrl-amh_Ethi
name: MTEB FloresBitextMining (rus_Cyrl-amh_Ethi)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.11791831357048
- type: main_score
value: 97.11791831357048
- type: precision
value: 96.77206851119894
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bos_Latn
name: MTEB FloresBitextMining (rus_Cyrl-bos_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.55072463768116
- type: main_score
value: 98.55072463768116
- type: precision
value: 98.36956521739131
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fin_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fin_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.65217391304348
- type: f1
value: 94.4235836627141
- type: main_score
value: 94.4235836627141
- type: precision
value: 93.84881422924902
- type: recall
value: 95.65217391304348
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ita_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ita_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.55072463768117
- type: main_score
value: 98.55072463768117
- type: precision
value: 98.36956521739131
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kor_Hang
name: MTEB FloresBitextMining (rus_Cyrl-kor_Hang)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.55335968379447
- type: f1
value: 94.15349143610013
- type: main_score
value: 94.15349143610013
- type: precision
value: 93.49472990777339
- type: recall
value: 95.55335968379447
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mos_Latn
name: MTEB FloresBitextMining (rus_Cyrl-mos_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 43.67588932806324
- type: f1
value: 38.84849721190082
- type: main_score
value: 38.84849721190082
- type: precision
value: 37.43294462099682
- type: recall
value: 43.67588932806324
task:
type: BitextMining
- dataset:
config: rus_Cyrl-run_Latn
name: MTEB FloresBitextMining (rus_Cyrl-run_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 90.21739130434783
- type: f1
value: 87.37483530961792
- type: main_score
value: 87.37483530961792
- type: precision
value: 86.07872200263506
- type: recall
value: 90.21739130434783
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tam_Taml
name: MTEB FloresBitextMining (rus_Cyrl-tam_Taml)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.2094861660079
- type: main_score
value: 99.2094861660079
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: rus_Cyrl-vie_Latn
name: MTEB FloresBitextMining (rus_Cyrl-vie_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.03557312252964
- type: f1
value: 96.13636363636364
- type: main_score
value: 96.13636363636364
- type: precision
value: 95.70981554677206
- type: recall
value: 97.03557312252964
task:
type: BitextMining
- dataset:
config: rus_Cyrl-apc_Arab
name: MTEB FloresBitextMining (rus_Cyrl-apc_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.12252964426878
- type: f1
value: 97.49670619235836
- type: main_score
value: 97.49670619235836
- type: precision
value: 97.18379446640316
- type: recall
value: 98.12252964426878
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bug_Latn
name: MTEB FloresBitextMining (rus_Cyrl-bug_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 67.29249011857708
- type: f1
value: 62.09268717667927
- type: main_score
value: 62.09268717667927
- type: precision
value: 60.28554009748714
- type: recall
value: 67.29249011857708
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fon_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fon_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 63.43873517786561
- type: f1
value: 57.66660107569199
- type: main_score
value: 57.66660107569199
- type: precision
value: 55.66676396919363
- type: recall
value: 63.43873517786561
task:
type: BitextMining
- dataset:
config: rus_Cyrl-jav_Latn
name: MTEB FloresBitextMining (rus_Cyrl-jav_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.46640316205533
- type: f1
value: 92.89384528514964
- type: main_score
value: 92.89384528514964
- type: precision
value: 92.19367588932806
- type: recall
value: 94.46640316205533
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lao_Laoo
name: MTEB FloresBitextMining (rus_Cyrl-lao_Laoo)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.23320158102767
- type: f1
value: 96.40974967061922
- type: main_score
value: 96.40974967061922
- type: precision
value: 96.034255599473
- type: recall
value: 97.23320158102767
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mri_Latn
name: MTEB FloresBitextMining (rus_Cyrl-mri_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 76.77865612648222
- type: f1
value: 73.11286539547409
- type: main_score
value: 73.11286539547409
- type: precision
value: 71.78177214337046
- type: recall
value: 76.77865612648222
task:
type: BitextMining
- dataset:
config: rus_Cyrl-taq_Latn
name: MTEB FloresBitextMining (rus_Cyrl-taq_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 41.99604743083004
- type: f1
value: 37.25127063318763
- type: main_score
value: 37.25127063318763
- type: precision
value: 35.718929186985726
- type: recall
value: 41.99604743083004
task:
type: BitextMining
- dataset:
config: rus_Cyrl-war_Latn
name: MTEB FloresBitextMining (rus_Cyrl-war_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.55335968379447
- type: f1
value: 94.1699604743083
- type: main_score
value: 94.1699604743083
- type: precision
value: 93.52766798418972
- type: recall
value: 95.55335968379447
task:
type: BitextMining
- dataset:
config: rus_Cyrl-arb_Arab
name: MTEB FloresBitextMining (rus_Cyrl-arb_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.4729907773386
- type: main_score
value: 99.4729907773386
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bul_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-bul_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.70355731225297
- type: f1
value: 99.60474308300395
- type: main_score
value: 99.60474308300395
- type: precision
value: 99.55533596837944
- type: recall
value: 99.70355731225297
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fra_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fra_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.47299077733861
- type: main_score
value: 99.47299077733861
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: rus_Cyrl-jpn_Jpan
name: MTEB FloresBitextMining (rus_Cyrl-jpn_Jpan)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.44268774703558
- type: f1
value: 95.30632411067194
- type: main_score
value: 95.30632411067194
- type: precision
value: 94.76284584980237
- type: recall
value: 96.44268774703558
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lij_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lij_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 90.21739130434783
- type: f1
value: 87.4703557312253
- type: main_score
value: 87.4703557312253
- type: precision
value: 86.29611330698287
- type: recall
value: 90.21739130434783
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mya_Mymr
name: MTEB FloresBitextMining (rus_Cyrl-mya_Mymr)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.364953886693
- type: main_score
value: 97.364953886693
- type: precision
value: 97.03557312252964
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: rus_Cyrl-sag_Latn
name: MTEB FloresBitextMining (rus_Cyrl-sag_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 54.841897233201585
- type: f1
value: 49.61882037503349
- type: main_score
value: 49.61882037503349
- type: precision
value: 47.831968755881796
- type: recall
value: 54.841897233201585
task:
type: BitextMining
- dataset:
config: rus_Cyrl-taq_Tfng
name: MTEB FloresBitextMining (rus_Cyrl-taq_Tfng)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 15.316205533596838
- type: f1
value: 11.614836360389717
- type: main_score
value: 11.614836360389717
- type: precision
value: 10.741446193235223
- type: recall
value: 15.316205533596838
task:
type: BitextMining
- dataset:
config: rus_Cyrl-wol_Latn
name: MTEB FloresBitextMining (rus_Cyrl-wol_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 67.88537549407114
- type: f1
value: 62.2536417249856
- type: main_score
value: 62.2536417249856
- type: precision
value: 60.27629128666678
- type: recall
value: 67.88537549407114
task:
type: BitextMining
- dataset:
config: rus_Cyrl-arb_Latn
name: MTEB FloresBitextMining (rus_Cyrl-arb_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 27.766798418972332
- type: f1
value: 23.39674889624077
- type: main_score
value: 23.39674889624077
- type: precision
value: 22.28521155585345
- type: recall
value: 27.766798418972332
task:
type: BitextMining
- dataset:
config: rus_Cyrl-cat_Latn
name: MTEB FloresBitextMining (rus_Cyrl-cat_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.23320158102767
- type: f1
value: 96.42151326933936
- type: main_score
value: 96.42151326933936
- type: precision
value: 96.04743083003953
- type: recall
value: 97.23320158102767
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fur_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fur_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 88.63636363636364
- type: f1
value: 85.80792396009788
- type: main_score
value: 85.80792396009788
- type: precision
value: 84.61508901726293
- type: recall
value: 88.63636363636364
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kab_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kab_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 48.12252964426877
- type: f1
value: 43.05387582971066
- type: main_score
value: 43.05387582971066
- type: precision
value: 41.44165117538212
- type: recall
value: 48.12252964426877
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lim_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lim_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.81818181818183
- type: f1
value: 77.81676163099087
- type: main_score
value: 77.81676163099087
- type: precision
value: 76.19565217391305
- type: recall
value: 81.81818181818183
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nld_Latn
name: MTEB FloresBitextMining (rus_Cyrl-nld_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.33201581027669
- type: f1
value: 96.4756258234519
- type: main_score
value: 96.4756258234519
- type: precision
value: 96.06389986824769
- type: recall
value: 97.33201581027669
task:
type: BitextMining
- dataset:
config: rus_Cyrl-san_Deva
name: MTEB FloresBitextMining (rus_Cyrl-san_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.47826086956522
- type: f1
value: 91.70289855072463
- type: main_score
value: 91.70289855072463
- type: precision
value: 90.9370882740448
- type: recall
value: 93.47826086956522
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tat_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-tat_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.72727272727273
- type: f1
value: 97.00263504611331
- type: main_score
value: 97.00263504611331
- type: precision
value: 96.65678524374177
- type: recall
value: 97.72727272727273
task:
type: BitextMining
- dataset:
config: rus_Cyrl-xho_Latn
name: MTEB FloresBitextMining (rus_Cyrl-xho_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.08300395256917
- type: f1
value: 91.12977602108036
- type: main_score
value: 91.12977602108036
- type: precision
value: 90.22562582345192
- type: recall
value: 93.08300395256917
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ars_Arab
name: MTEB FloresBitextMining (rus_Cyrl-ars_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.40711462450594
- type: f1
value: 99.2094861660079
- type: main_score
value: 99.2094861660079
- type: precision
value: 99.1106719367589
- type: recall
value: 99.40711462450594
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ceb_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ceb_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.65217391304348
- type: f1
value: 94.3544137022398
- type: main_score
value: 94.3544137022398
- type: precision
value: 93.76646903820817
- type: recall
value: 95.65217391304348
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fuv_Latn
name: MTEB FloresBitextMining (rus_Cyrl-fuv_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 51.18577075098815
- type: f1
value: 44.5990252610806
- type: main_score
value: 44.5990252610806
- type: precision
value: 42.34331599450177
- type: recall
value: 51.18577075098815
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kac_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kac_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 46.93675889328063
- type: f1
value: 41.79004018701787
- type: main_score
value: 41.79004018701787
- type: precision
value: 40.243355662392624
- type: recall
value: 46.93675889328063
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lin_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lin_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.50197628458498
- type: f1
value: 89.1205533596838
- type: main_score
value: 89.1205533596838
- type: precision
value: 88.07147562582345
- type: recall
value: 91.50197628458498
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nno_Latn
name: MTEB FloresBitextMining (rus_Cyrl-nno_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.81422924901186
- type: f1
value: 98.41897233201581
- type: main_score
value: 98.41897233201581
- type: precision
value: 98.22134387351778
- type: recall
value: 98.81422924901186
task:
type: BitextMining
- dataset:
config: rus_Cyrl-sat_Olck
name: MTEB FloresBitextMining (rus_Cyrl-sat_Olck)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 2.371541501976284
- type: f1
value: 1.0726274943087382
- type: main_score
value: 1.0726274943087382
- type: precision
value: 0.875279634748803
- type: recall
value: 2.371541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tel_Telu
name: MTEB FloresBitextMining (rus_Cyrl-tel_Telu)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ydd_Hebr
name: MTEB FloresBitextMining (rus_Cyrl-ydd_Hebr)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.42687747035573
- type: f1
value: 86.47609636740073
- type: main_score
value: 86.47609636740073
- type: precision
value: 85.13669301712781
- type: recall
value: 89.42687747035573
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ary_Arab
name: MTEB FloresBitextMining (rus_Cyrl-ary_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.82213438735178
- type: f1
value: 87.04545454545456
- type: main_score
value: 87.04545454545456
- type: precision
value: 85.76910408432148
- type: recall
value: 89.82213438735178
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ces_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ces_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.9459815546772
- type: main_score
value: 98.9459815546772
- type: precision
value: 98.81422924901186
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: rus_Cyrl-gaz_Latn
name: MTEB FloresBitextMining (rus_Cyrl-gaz_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 64.9209486166008
- type: f1
value: 58.697458119394874
- type: main_score
value: 58.697458119394874
- type: precision
value: 56.43402189597842
- type: recall
value: 64.9209486166008
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kam_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kam_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 59.18972332015811
- type: f1
value: 53.19031511966295
- type: main_score
value: 53.19031511966295
- type: precision
value: 51.08128357343655
- type: recall
value: 59.18972332015811
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lit_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lit_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.54150197628458
- type: f1
value: 95.5368906455863
- type: main_score
value: 95.5368906455863
- type: precision
value: 95.0592885375494
- type: recall
value: 96.54150197628458
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nob_Latn
name: MTEB FloresBitextMining (rus_Cyrl-nob_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.12252964426878
- type: f1
value: 97.51317523056655
- type: main_score
value: 97.51317523056655
- type: precision
value: 97.2167325428195
- type: recall
value: 98.12252964426878
task:
type: BitextMining
- dataset:
config: rus_Cyrl-scn_Latn
name: MTEB FloresBitextMining (rus_Cyrl-scn_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 84.0909090909091
- type: f1
value: 80.37000439174352
- type: main_score
value: 80.37000439174352
- type: precision
value: 78.83994628559846
- type: recall
value: 84.0909090909091
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tgk_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-tgk_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.68774703557312
- type: f1
value: 90.86344814605684
- type: main_score
value: 90.86344814605684
- type: precision
value: 90.12516469038208
- type: recall
value: 92.68774703557312
task:
type: BitextMining
- dataset:
config: rus_Cyrl-yor_Latn
name: MTEB FloresBitextMining (rus_Cyrl-yor_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 72.13438735177866
- type: f1
value: 66.78759646150951
- type: main_score
value: 66.78759646150951
- type: precision
value: 64.85080192096002
- type: recall
value: 72.13438735177866
task:
type: BitextMining
- dataset:
config: rus_Cyrl-arz_Arab
name: MTEB FloresBitextMining (rus_Cyrl-arz_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.364953886693
- type: main_score
value: 97.364953886693
- type: precision
value: 97.03557312252964
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: rus_Cyrl-cjk_Latn
name: MTEB FloresBitextMining (rus_Cyrl-cjk_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 51.976284584980235
- type: f1
value: 46.468762353149714
- type: main_score
value: 46.468762353149714
- type: precision
value: 44.64073366247278
- type: recall
value: 51.976284584980235
task:
type: BitextMining
- dataset:
config: rus_Cyrl-gla_Latn
name: MTEB FloresBitextMining (rus_Cyrl-gla_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 79.74308300395256
- type: f1
value: 75.55611165294958
- type: main_score
value: 75.55611165294958
- type: precision
value: 73.95033408620365
- type: recall
value: 79.74308300395256
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kan_Knda
name: MTEB FloresBitextMining (rus_Cyrl-kan_Knda)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.96245059288538
- type: main_score
value: 98.96245059288538
- type: precision
value: 98.84716732542819
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lmo_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lmo_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 82.41106719367589
- type: f1
value: 78.56413514022209
- type: main_score
value: 78.56413514022209
- type: precision
value: 77.15313068573938
- type: recall
value: 82.41106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-npi_Deva
name: MTEB FloresBitextMining (rus_Cyrl-npi_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.3201581027668
- type: main_score
value: 98.3201581027668
- type: precision
value: 98.12252964426878
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-shn_Mymr
name: MTEB FloresBitextMining (rus_Cyrl-shn_Mymr)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 57.11462450592886
- type: f1
value: 51.51361369197337
- type: main_score
value: 51.51361369197337
- type: precision
value: 49.71860043649573
- type: recall
value: 57.11462450592886
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tgl_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tgl_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.18379446640316
- type: main_score
value: 97.18379446640316
- type: precision
value: 96.88735177865613
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: rus_Cyrl-yue_Hant
name: MTEB FloresBitextMining (rus_Cyrl-yue_Hant)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.09420289855072
- type: main_score
value: 99.09420289855072
- type: precision
value: 98.9953886693017
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: rus_Cyrl-asm_Beng
name: MTEB FloresBitextMining (rus_Cyrl-asm_Beng)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.55335968379447
- type: f1
value: 94.16007905138339
- type: main_score
value: 94.16007905138339
- type: precision
value: 93.50296442687747
- type: recall
value: 95.55335968379447
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ckb_Arab
name: MTEB FloresBitextMining (rus_Cyrl-ckb_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.88537549407114
- type: f1
value: 90.76745718050066
- type: main_score
value: 90.76745718050066
- type: precision
value: 89.80072463768116
- type: recall
value: 92.88537549407114
task:
type: BitextMining
- dataset:
config: rus_Cyrl-gle_Latn
name: MTEB FloresBitextMining (rus_Cyrl-gle_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.699604743083
- type: f1
value: 89.40899680030115
- type: main_score
value: 89.40899680030115
- type: precision
value: 88.40085638998683
- type: recall
value: 91.699604743083
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kas_Arab
name: MTEB FloresBitextMining (rus_Cyrl-kas_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 88.3399209486166
- type: f1
value: 85.14351590438548
- type: main_score
value: 85.14351590438548
- type: precision
value: 83.72364953886692
- type: recall
value: 88.3399209486166
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ltg_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ltg_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 83.399209486166
- type: f1
value: 79.88408934061107
- type: main_score
value: 79.88408934061107
- type: precision
value: 78.53794509179885
- type: recall
value: 83.399209486166
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nso_Latn
name: MTEB FloresBitextMining (rus_Cyrl-nso_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.20553359683794
- type: f1
value: 88.95406635525212
- type: main_score
value: 88.95406635525212
- type: precision
value: 88.01548089591567
- type: recall
value: 91.20553359683794
task:
type: BitextMining
- dataset:
config: rus_Cyrl-sin_Sinh
name: MTEB FloresBitextMining (rus_Cyrl-sin_Sinh)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.56719367588933
- type: main_score
value: 98.56719367588933
- type: precision
value: 98.40250329380763
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tha_Thai
name: MTEB FloresBitextMining (rus_Cyrl-tha_Thai)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.94861660079052
- type: f1
value: 94.66403162055336
- type: main_score
value: 94.66403162055336
- type: precision
value: 94.03820816864295
- type: recall
value: 95.94861660079052
task:
type: BitextMining
- dataset:
config: rus_Cyrl-zho_Hans
name: MTEB FloresBitextMining (rus_Cyrl-zho_Hans)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.4308300395257
- type: f1
value: 96.5909090909091
- type: main_score
value: 96.5909090909091
- type: precision
value: 96.17918313570487
- type: recall
value: 97.4308300395257
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ast_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ast_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.46640316205533
- type: f1
value: 92.86890645586297
- type: main_score
value: 92.86890645586297
- type: precision
value: 92.14756258234519
- type: recall
value: 94.46640316205533
task:
type: BitextMining
- dataset:
config: rus_Cyrl-crh_Latn
name: MTEB FloresBitextMining (rus_Cyrl-crh_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.66403162055336
- type: f1
value: 93.2663592446201
- type: main_score
value: 93.2663592446201
- type: precision
value: 92.66716073781292
- type: recall
value: 94.66403162055336
task:
type: BitextMining
- dataset:
config: rus_Cyrl-glg_Latn
name: MTEB FloresBitextMining (rus_Cyrl-glg_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.81422924901186
- type: f1
value: 98.46837944664031
- type: main_score
value: 98.46837944664031
- type: precision
value: 98.3201581027668
- type: recall
value: 98.81422924901186
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kas_Deva
name: MTEB FloresBitextMining (rus_Cyrl-kas_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 69.1699604743083
- type: f1
value: 63.05505292906477
- type: main_score
value: 63.05505292906477
- type: precision
value: 60.62594108789761
- type: recall
value: 69.1699604743083
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ltz_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ltz_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.40316205533597
- type: f1
value: 89.26571616789009
- type: main_score
value: 89.26571616789009
- type: precision
value: 88.40179747788443
- type: recall
value: 91.40316205533597
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nus_Latn
name: MTEB FloresBitextMining (rus_Cyrl-nus_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 38.93280632411067
- type: f1
value: 33.98513032905371
- type: main_score
value: 33.98513032905371
- type: precision
value: 32.56257884802308
- type: recall
value: 38.93280632411067
task:
type: BitextMining
- dataset:
config: rus_Cyrl-slk_Latn
name: MTEB FloresBitextMining (rus_Cyrl-slk_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.42094861660078
- type: main_score
value: 97.42094861660078
- type: precision
value: 97.14262187088273
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tir_Ethi
name: MTEB FloresBitextMining (rus_Cyrl-tir_Ethi)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.30434782608695
- type: f1
value: 88.78129117259552
- type: main_score
value: 88.78129117259552
- type: precision
value: 87.61528326745717
- type: recall
value: 91.30434782608695
task:
type: BitextMining
- dataset:
config: rus_Cyrl-zho_Hant
name: MTEB FloresBitextMining (rus_Cyrl-zho_Hant)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.1106719367589
- type: f1
value: 98.81422924901186
- type: main_score
value: 98.81422924901186
- type: precision
value: 98.66600790513834
- type: recall
value: 99.1106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-awa_Deva
name: MTEB FloresBitextMining (rus_Cyrl-awa_Deva)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.12252964426878
- type: f1
value: 97.70092226613966
- type: main_score
value: 97.70092226613966
- type: precision
value: 97.50494071146245
- type: recall
value: 98.12252964426878
task:
type: BitextMining
- dataset:
config: rus_Cyrl-cym_Latn
name: MTEB FloresBitextMining (rus_Cyrl-cym_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.94861660079052
- type: f1
value: 94.74308300395256
- type: main_score
value: 94.74308300395256
- type: precision
value: 94.20289855072464
- type: recall
value: 95.94861660079052
task:
type: BitextMining
- dataset:
config: rus_Cyrl-grn_Latn
name: MTEB FloresBitextMining (rus_Cyrl-grn_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 77.96442687747036
- type: f1
value: 73.64286789187975
- type: main_score
value: 73.64286789187975
- type: precision
value: 71.99324893260821
- type: recall
value: 77.96442687747036
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kat_Geor
name: MTEB FloresBitextMining (rus_Cyrl-kat_Geor)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.56719367588933
- type: main_score
value: 98.56719367588933
- type: precision
value: 98.40250329380764
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lua_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lua_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 72.03557312252964
- type: f1
value: 67.23928163404449
- type: main_score
value: 67.23928163404449
- type: precision
value: 65.30797101449275
- type: recall
value: 72.03557312252964
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nya_Latn
name: MTEB FloresBitextMining (rus_Cyrl-nya_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.29249011857708
- type: f1
value: 90.0494071146245
- type: main_score
value: 90.0494071146245
- type: precision
value: 89.04808959156786
- type: recall
value: 92.29249011857708
task:
type: BitextMining
- dataset:
config: rus_Cyrl-slv_Latn
name: MTEB FloresBitextMining (rus_Cyrl-slv_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.30368906455863
- type: main_score
value: 98.30368906455863
- type: precision
value: 98.10606060606061
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tpi_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tpi_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.53359683794467
- type: f1
value: 76.59481822525301
- type: main_score
value: 76.59481822525301
- type: precision
value: 75.12913223140497
- type: recall
value: 80.53359683794467
task:
type: BitextMining
- dataset:
config: rus_Cyrl-zsm_Latn
name: MTEB FloresBitextMining (rus_Cyrl-zsm_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.33201581027669
- type: f1
value: 96.58620365142104
- type: main_score
value: 96.58620365142104
- type: precision
value: 96.26152832674572
- type: recall
value: 97.33201581027669
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ayr_Latn
name: MTEB FloresBitextMining (rus_Cyrl-ayr_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 45.55335968379446
- type: f1
value: 40.13076578531388
- type: main_score
value: 40.13076578531388
- type: precision
value: 38.398064362362355
- type: recall
value: 45.55335968379446
task:
type: BitextMining
- dataset:
config: rus_Cyrl-dan_Latn
name: MTEB FloresBitextMining (rus_Cyrl-dan_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: rus_Cyrl-guj_Gujr
name: MTEB FloresBitextMining (rus_Cyrl-guj_Gujr)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kaz_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-kaz_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.81422924901186
- type: f1
value: 98.43544137022398
- type: main_score
value: 98.43544137022398
- type: precision
value: 98.25428194993412
- type: recall
value: 98.81422924901186
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lug_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lug_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 82.21343873517787
- type: f1
value: 77.97485726833554
- type: main_score
value: 77.97485726833554
- type: precision
value: 76.22376717485415
- type: recall
value: 82.21343873517787
task:
type: BitextMining
- dataset:
config: rus_Cyrl-oci_Latn
name: MTEB FloresBitextMining (rus_Cyrl-oci_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.87351778656127
- type: f1
value: 92.25319969885187
- type: main_score
value: 92.25319969885187
- type: precision
value: 91.5638528138528
- type: recall
value: 93.87351778656127
task:
type: BitextMining
- dataset:
config: rus_Cyrl-smo_Latn
name: MTEB FloresBitextMining (rus_Cyrl-smo_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 84.88142292490119
- type: f1
value: 81.24364765669114
- type: main_score
value: 81.24364765669114
- type: precision
value: 79.69991416137661
- type: recall
value: 84.88142292490119
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tsn_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tsn_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.05533596837944
- type: f1
value: 83.90645586297761
- type: main_score
value: 83.90645586297761
- type: precision
value: 82.56752305665349
- type: recall
value: 87.05533596837944
task:
type: BitextMining
- dataset:
config: rus_Cyrl-zul_Latn
name: MTEB FloresBitextMining (rus_Cyrl-zul_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.15810276679841
- type: f1
value: 93.77140974967062
- type: main_score
value: 93.77140974967062
- type: precision
value: 93.16534914361002
- type: recall
value: 95.15810276679841
task:
type: BitextMining
- dataset:
config: rus_Cyrl-azb_Arab
name: MTEB FloresBitextMining (rus_Cyrl-azb_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.91699604743083
- type: f1
value: 77.18050065876152
- type: main_score
value: 77.18050065876152
- type: precision
value: 75.21519543258673
- type: recall
value: 81.91699604743083
task:
type: BitextMining
- dataset:
config: rus_Cyrl-deu_Latn
name: MTEB FloresBitextMining (rus_Cyrl-deu_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.50592885375494
- type: f1
value: 99.34123847167325
- type: main_score
value: 99.34123847167325
- type: precision
value: 99.2588932806324
- type: recall
value: 99.50592885375494
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hat_Latn
name: MTEB FloresBitextMining (rus_Cyrl-hat_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.00790513833992
- type: f1
value: 88.69126043039086
- type: main_score
value: 88.69126043039086
- type: precision
value: 87.75774044795784
- type: recall
value: 91.00790513833992
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kbp_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kbp_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 47.233201581027664
- type: f1
value: 43.01118618096943
- type: main_score
value: 43.01118618096943
- type: precision
value: 41.739069205043556
- type: recall
value: 47.233201581027664
task:
type: BitextMining
- dataset:
config: rus_Cyrl-luo_Latn
name: MTEB FloresBitextMining (rus_Cyrl-luo_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 60.47430830039525
- type: f1
value: 54.83210565429816
- type: main_score
value: 54.83210565429816
- type: precision
value: 52.81630744284779
- type: recall
value: 60.47430830039525
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ory_Orya
name: MTEB FloresBitextMining (rus_Cyrl-ory_Orya)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.1106719367589
- type: f1
value: 98.83069828722003
- type: main_score
value: 98.83069828722003
- type: precision
value: 98.69894598155467
- type: recall
value: 99.1106719367589
task:
type: BitextMining
- dataset:
config: rus_Cyrl-sna_Latn
name: MTEB FloresBitextMining (rus_Cyrl-sna_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.72332015810277
- type: f1
value: 87.30013645774514
- type: main_score
value: 87.30013645774514
- type: precision
value: 86.25329380764163
- type: recall
value: 89.72332015810277
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tso_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tso_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 84.38735177865613
- type: f1
value: 80.70424744337788
- type: main_score
value: 80.70424744337788
- type: precision
value: 79.18560606060606
- type: recall
value: 84.38735177865613
task:
type: BitextMining
- dataset:
config: rus_Cyrl-azj_Latn
name: MTEB FloresBitextMining (rus_Cyrl-azj_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.33201581027669
- type: f1
value: 96.56455862977602
- type: main_score
value: 96.56455862977602
- type: precision
value: 96.23682476943345
- type: recall
value: 97.33201581027669
task:
type: BitextMining
- dataset:
config: rus_Cyrl-dik_Latn
name: MTEB FloresBitextMining (rus_Cyrl-dik_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 46.047430830039524
- type: f1
value: 40.05513069495283
- type: main_score
value: 40.05513069495283
- type: precision
value: 38.072590197096126
- type: recall
value: 46.047430830039524
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hau_Latn
name: MTEB FloresBitextMining (rus_Cyrl-hau_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.94466403162056
- type: f1
value: 84.76943346508563
- type: main_score
value: 84.76943346508563
- type: precision
value: 83.34486166007905
- type: recall
value: 87.94466403162056
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kea_Latn
name: MTEB FloresBitextMining (rus_Cyrl-kea_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.42687747035573
- type: f1
value: 86.83803021747684
- type: main_score
value: 86.83803021747684
- type: precision
value: 85.78416149068323
- type: recall
value: 89.42687747035573
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lus_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lus_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 68.97233201581028
- type: f1
value: 64.05480726292745
- type: main_score
value: 64.05480726292745
- type: precision
value: 62.42670749487858
- type: recall
value: 68.97233201581028
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pag_Latn
name: MTEB FloresBitextMining (rus_Cyrl-pag_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 78.75494071146245
- type: f1
value: 74.58573558401933
- type: main_score
value: 74.58573558401933
- type: precision
value: 73.05532028358115
- type: recall
value: 78.75494071146245
task:
type: BitextMining
- dataset:
config: rus_Cyrl-snd_Arab
name: MTEB FloresBitextMining (rus_Cyrl-snd_Arab)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.8498023715415
- type: f1
value: 94.56521739130434
- type: main_score
value: 94.56521739130434
- type: precision
value: 93.97233201581028
- type: recall
value: 95.8498023715415
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tuk_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tuk_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 68.08300395256917
- type: f1
value: 62.93565240205557
- type: main_score
value: 62.93565240205557
- type: precision
value: 61.191590257043934
- type: recall
value: 68.08300395256917
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bak_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-bak_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.04743083003953
- type: f1
value: 94.86824769433464
- type: main_score
value: 94.86824769433464
- type: precision
value: 94.34288537549406
- type: recall
value: 96.04743083003953
task:
type: BitextMining
- dataset:
config: rus_Cyrl-dyu_Latn
name: MTEB FloresBitextMining (rus_Cyrl-dyu_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 37.45059288537549
- type: f1
value: 31.670482312800807
- type: main_score
value: 31.670482312800807
- type: precision
value: 29.99928568357422
- type: recall
value: 37.45059288537549
task:
type: BitextMining
- dataset:
config: rus_Cyrl-heb_Hebr
name: MTEB FloresBitextMining (rus_Cyrl-heb_Hebr)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.23320158102767
- type: f1
value: 96.38998682476942
- type: main_score
value: 96.38998682476942
- type: precision
value: 95.99802371541502
- type: recall
value: 97.23320158102767
task:
type: BitextMining
- dataset:
config: rus_Cyrl-khk_Cyrl
name: MTEB FloresBitextMining (rus_Cyrl-khk_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.41897233201581
- type: f1
value: 98.00724637681158
- type: main_score
value: 98.00724637681158
- type: precision
value: 97.82938076416336
- type: recall
value: 98.41897233201581
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lvs_Latn
name: MTEB FloresBitextMining (rus_Cyrl-lvs_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.4308300395257
- type: f1
value: 96.61396574440053
- type: main_score
value: 96.61396574440053
- type: precision
value: 96.2203557312253
- type: recall
value: 97.4308300395257
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pan_Guru
name: MTEB FloresBitextMining (rus_Cyrl-pan_Guru)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.07773386034256
- type: main_score
value: 99.07773386034256
- type: precision
value: 98.96245059288538
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: rus_Cyrl-som_Latn
name: MTEB FloresBitextMining (rus_Cyrl-som_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.74703557312253
- type: f1
value: 84.52898550724638
- type: main_score
value: 84.52898550724638
- type: precision
value: 83.09288537549409
- type: recall
value: 87.74703557312253
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tum_Latn
name: MTEB FloresBitextMining (rus_Cyrl-tum_Latn)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.15415019762845
- type: f1
value: 83.85069640504425
- type: main_score
value: 83.85069640504425
- type: precision
value: 82.43671183888576
- type: recall
value: 87.15415019762845
task:
type: BitextMining
- dataset:
config: taq_Latn-rus_Cyrl
name: MTEB FloresBitextMining (taq_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 28.55731225296443
- type: f1
value: 26.810726360049568
- type: main_score
value: 26.810726360049568
- type: precision
value: 26.260342858265577
- type: recall
value: 28.55731225296443
task:
type: BitextMining
- dataset:
config: war_Latn-rus_Cyrl
name: MTEB FloresBitextMining (war_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.86166007905138
- type: f1
value: 94.03147083483051
- type: main_score
value: 94.03147083483051
- type: precision
value: 93.70653606003322
- type: recall
value: 94.86166007905138
task:
type: BitextMining
- dataset:
config: arb_Arab-rus_Cyrl
name: MTEB FloresBitextMining (arb_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.34387351778656
- type: f1
value: 95.23056653491436
- type: main_score
value: 95.23056653491436
- type: precision
value: 94.70520421607378
- type: recall
value: 96.34387351778656
task:
type: BitextMining
- dataset:
config: bul_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (bul_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.90118577075098
- type: f1
value: 99.86824769433464
- type: main_score
value: 99.86824769433464
- type: precision
value: 99.85177865612648
- type: recall
value: 99.90118577075098
task:
type: BitextMining
- dataset:
config: fra_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fra_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.9459815546772
- type: main_score
value: 98.9459815546772
- type: precision
value: 98.81422924901186
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: jpn_Jpan-rus_Cyrl
name: MTEB FloresBitextMining (jpn_Jpan-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.3201581027668
- type: f1
value: 97.76021080368905
- type: main_score
value: 97.76021080368905
- type: precision
value: 97.48023715415019
- type: recall
value: 98.3201581027668
task:
type: BitextMining
- dataset:
config: lij_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lij_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 83.49802371541502
- type: f1
value: 81.64800059239636
- type: main_score
value: 81.64800059239636
- type: precision
value: 80.9443055878478
- type: recall
value: 83.49802371541502
task:
type: BitextMining
- dataset:
config: mya_Mymr-rus_Cyrl
name: MTEB FloresBitextMining (mya_Mymr-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 90.21739130434783
- type: f1
value: 88.76776366313682
- type: main_score
value: 88.76776366313682
- type: precision
value: 88.18370446119435
- type: recall
value: 90.21739130434783
task:
type: BitextMining
- dataset:
config: sag_Latn-rus_Cyrl
name: MTEB FloresBitextMining (sag_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 41.699604743083
- type: f1
value: 39.53066322643847
- type: main_score
value: 39.53066322643847
- type: precision
value: 38.822876239229274
- type: recall
value: 41.699604743083
task:
type: BitextMining
- dataset:
config: taq_Tfng-rus_Cyrl
name: MTEB FloresBitextMining (taq_Tfng-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 10.67193675889328
- type: f1
value: 9.205744965817951
- type: main_score
value: 9.205744965817951
- type: precision
value: 8.85195219073817
- type: recall
value: 10.67193675889328
task:
type: BitextMining
- dataset:
config: wol_Latn-rus_Cyrl
name: MTEB FloresBitextMining (wol_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 63.537549407114625
- type: f1
value: 60.65190727391827
- type: main_score
value: 60.65190727391827
- type: precision
value: 59.61144833427442
- type: recall
value: 63.537549407114625
task:
type: BitextMining
- dataset:
config: arb_Latn-rus_Cyrl
name: MTEB FloresBitextMining (arb_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 13.142292490118576
- type: f1
value: 12.372910318176764
- type: main_score
value: 12.372910318176764
- type: precision
value: 12.197580895919188
- type: recall
value: 13.142292490118576
task:
type: BitextMining
- dataset:
config: cat_Latn-rus_Cyrl
name: MTEB FloresBitextMining (cat_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.80599472990777
- type: main_score
value: 98.80599472990777
- type: precision
value: 98.72953133822698
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: fur_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fur_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.02766798418972
- type: f1
value: 79.36184294084613
- type: main_score
value: 79.36184294084613
- type: precision
value: 78.69187826527705
- type: recall
value: 81.02766798418972
task:
type: BitextMining
- dataset:
config: kab_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kab_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 34.387351778656125
- type: f1
value: 32.02306921576947
- type: main_score
value: 32.02306921576947
- type: precision
value: 31.246670347137467
- type: recall
value: 34.387351778656125
task:
type: BitextMining
- dataset:
config: lim_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lim_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 78.26086956521739
- type: f1
value: 75.90239449214359
- type: main_score
value: 75.90239449214359
- type: precision
value: 75.02211430745493
- type: recall
value: 78.26086956521739
task:
type: BitextMining
- dataset:
config: nld_Latn-rus_Cyrl
name: MTEB FloresBitextMining (nld_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.9459815546772
- type: main_score
value: 98.9459815546772
- type: precision
value: 98.81422924901186
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: san_Deva-rus_Cyrl
name: MTEB FloresBitextMining (san_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.94466403162056
- type: f1
value: 86.68928897189767
- type: main_score
value: 86.68928897189767
- type: precision
value: 86.23822997079216
- type: recall
value: 87.94466403162056
task:
type: BitextMining
- dataset:
config: tat_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (tat_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.03557312252964
- type: f1
value: 96.4167365353136
- type: main_score
value: 96.4167365353136
- type: precision
value: 96.16847826086958
- type: recall
value: 97.03557312252964
task:
type: BitextMining
- dataset:
config: xho_Latn-rus_Cyrl
name: MTEB FloresBitextMining (xho_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.95652173913044
- type: f1
value: 85.5506497283435
- type: main_score
value: 85.5506497283435
- type: precision
value: 84.95270479733395
- type: recall
value: 86.95652173913044
task:
type: BitextMining
- dataset:
config: ars_Arab-rus_Cyrl
name: MTEB FloresBitextMining (ars_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 96.6403162055336
- type: f1
value: 95.60935441370223
- type: main_score
value: 95.60935441370223
- type: precision
value: 95.13339920948617
- type: recall
value: 96.6403162055336
task:
type: BitextMining
- dataset:
config: ceb_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ceb_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.7509881422925
- type: f1
value: 95.05209198303827
- type: main_score
value: 95.05209198303827
- type: precision
value: 94.77662283368805
- type: recall
value: 95.7509881422925
task:
type: BitextMining
- dataset:
config: fuv_Latn-rus_Cyrl
name: MTEB FloresBitextMining (fuv_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 45.25691699604743
- type: f1
value: 42.285666666742365
- type: main_score
value: 42.285666666742365
- type: precision
value: 41.21979853402283
- type: recall
value: 45.25691699604743
task:
type: BitextMining
- dataset:
config: kac_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kac_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 34.683794466403164
- type: f1
value: 33.3235346229031
- type: main_score
value: 33.3235346229031
- type: precision
value: 32.94673924616852
- type: recall
value: 34.683794466403164
task:
type: BitextMining
- dataset:
config: lin_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lin_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.85770750988142
- type: f1
value: 85.1867110799439
- type: main_score
value: 85.1867110799439
- type: precision
value: 84.53038212173273
- type: recall
value: 86.85770750988142
task:
type: BitextMining
- dataset:
config: nno_Latn-rus_Cyrl
name: MTEB FloresBitextMining (nno_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.4308300395257
- type: f1
value: 96.78383210991906
- type: main_score
value: 96.78383210991906
- type: precision
value: 96.51185770750989
- type: recall
value: 97.4308300395257
task:
type: BitextMining
- dataset:
config: sat_Olck-rus_Cyrl
name: MTEB FloresBitextMining (sat_Olck-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 1.185770750988142
- type: f1
value: 1.0279253129117258
- type: main_score
value: 1.0279253129117258
- type: precision
value: 1.0129746819135175
- type: recall
value: 1.185770750988142
task:
type: BitextMining
- dataset:
config: tel_Telu-rus_Cyrl
name: MTEB FloresBitextMining (tel_Telu-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.12252964426878
- type: f1
value: 97.61198945981555
- type: main_score
value: 97.61198945981555
- type: precision
value: 97.401185770751
- type: recall
value: 98.12252964426878
task:
type: BitextMining
- dataset:
config: ydd_Hebr-rus_Cyrl
name: MTEB FloresBitextMining (ydd_Hebr-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 75.8893280632411
- type: f1
value: 74.00244008018511
- type: main_score
value: 74.00244008018511
- type: precision
value: 73.25683020960382
- type: recall
value: 75.8893280632411
task:
type: BitextMining
- dataset:
config: ary_Arab-rus_Cyrl
name: MTEB FloresBitextMining (ary_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.56126482213439
- type: f1
value: 83.72796285839765
- type: main_score
value: 83.72796285839765
- type: precision
value: 82.65014273166447
- type: recall
value: 86.56126482213439
task:
type: BitextMining
- dataset:
config: ces_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ces_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.60474308300395
- type: f1
value: 99.4729907773386
- type: main_score
value: 99.4729907773386
- type: precision
value: 99.40711462450594
- type: recall
value: 99.60474308300395
task:
type: BitextMining
- dataset:
config: gaz_Latn-rus_Cyrl
name: MTEB FloresBitextMining (gaz_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 42.58893280632411
- type: f1
value: 40.75832866805978
- type: main_score
value: 40.75832866805978
- type: precision
value: 40.14285046917723
- type: recall
value: 42.58893280632411
task:
type: BitextMining
- dataset:
config: kam_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kam_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 45.25691699604743
- type: f1
value: 42.6975518029456
- type: main_score
value: 42.6975518029456
- type: precision
value: 41.87472710984596
- type: recall
value: 45.25691699604743
task:
type: BitextMining
- dataset:
config: lit_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lit_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.33201581027669
- type: f1
value: 96.62384716732542
- type: main_score
value: 96.62384716732542
- type: precision
value: 96.3175230566535
- type: recall
value: 97.33201581027669
task:
type: BitextMining
- dataset:
config: nob_Latn-rus_Cyrl
name: MTEB FloresBitextMining (nob_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.30368906455863
- type: main_score
value: 98.30368906455863
- type: precision
value: 98.10606060606061
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: scn_Latn-rus_Cyrl
name: MTEB FloresBitextMining (scn_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 70.45454545454545
- type: f1
value: 68.62561022640075
- type: main_score
value: 68.62561022640075
- type: precision
value: 67.95229103411222
- type: recall
value: 70.45454545454545
task:
type: BitextMining
- dataset:
config: tgk_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (tgk_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.4901185770751
- type: f1
value: 91.58514492753623
- type: main_score
value: 91.58514492753623
- type: precision
value: 91.24759298672342
- type: recall
value: 92.4901185770751
task:
type: BitextMining
- dataset:
config: yor_Latn-rus_Cyrl
name: MTEB FloresBitextMining (yor_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 67.98418972332016
- type: f1
value: 64.72874247330768
- type: main_score
value: 64.72874247330768
- type: precision
value: 63.450823399938685
- type: recall
value: 67.98418972332016
task:
type: BitextMining
- dataset:
config: arz_Arab-rus_Cyrl
name: MTEB FloresBitextMining (arz_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 94.56521739130434
- type: f1
value: 93.07971014492755
- type: main_score
value: 93.07971014492755
- type: precision
value: 92.42753623188406
- type: recall
value: 94.56521739130434
task:
type: BitextMining
- dataset:
config: cjk_Latn-rus_Cyrl
name: MTEB FloresBitextMining (cjk_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 38.63636363636363
- type: f1
value: 36.25747140862938
- type: main_score
value: 36.25747140862938
- type: precision
value: 35.49101355074723
- type: recall
value: 38.63636363636363
task:
type: BitextMining
- dataset:
config: gla_Latn-rus_Cyrl
name: MTEB FloresBitextMining (gla_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 69.26877470355731
- type: f1
value: 66.11797423328613
- type: main_score
value: 66.11797423328613
- type: precision
value: 64.89369649409694
- type: recall
value: 69.26877470355731
task:
type: BitextMining
- dataset:
config: kan_Knda-rus_Cyrl
name: MTEB FloresBitextMining (kan_Knda-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.51505740636176
- type: main_score
value: 97.51505740636176
- type: precision
value: 97.30731225296442
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: lmo_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lmo_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 73.3201581027668
- type: f1
value: 71.06371608677273
- type: main_score
value: 71.06371608677273
- type: precision
value: 70.26320288266223
- type: recall
value: 73.3201581027668
task:
type: BitextMining
- dataset:
config: npi_Deva-rus_Cyrl
name: MTEB FloresBitextMining (npi_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.36645107198466
- type: main_score
value: 97.36645107198466
- type: precision
value: 97.1772068511199
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: shn_Mymr-rus_Cyrl
name: MTEB FloresBitextMining (shn_Mymr-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 39.426877470355734
- type: f1
value: 37.16728785513024
- type: main_score
value: 37.16728785513024
- type: precision
value: 36.56918548278505
- type: recall
value: 39.426877470355734
task:
type: BitextMining
- dataset:
config: tgl_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tgl_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.92490118577075
- type: f1
value: 97.6378693769998
- type: main_score
value: 97.6378693769998
- type: precision
value: 97.55371440154047
- type: recall
value: 97.92490118577075
task:
type: BitextMining
- dataset:
config: yue_Hant-rus_Cyrl
name: MTEB FloresBitextMining (yue_Hant-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.92490118577075
- type: f1
value: 97.3833051006964
- type: main_score
value: 97.3833051006964
- type: precision
value: 97.1590909090909
- type: recall
value: 97.92490118577075
task:
type: BitextMining
- dataset:
config: asm_Beng-rus_Cyrl
name: MTEB FloresBitextMining (asm_Beng-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.78656126482213
- type: f1
value: 91.76917395296842
- type: main_score
value: 91.76917395296842
- type: precision
value: 91.38292866553736
- type: recall
value: 92.78656126482213
task:
type: BitextMining
- dataset:
config: ckb_Arab-rus_Cyrl
name: MTEB FloresBitextMining (ckb_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.8300395256917
- type: f1
value: 79.17664345468799
- type: main_score
value: 79.17664345468799
- type: precision
value: 78.5622171683459
- type: recall
value: 80.8300395256917
task:
type: BitextMining
- dataset:
config: gle_Latn-rus_Cyrl
name: MTEB FloresBitextMining (gle_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 85.86956521739131
- type: f1
value: 84.45408265372492
- type: main_score
value: 84.45408265372492
- type: precision
value: 83.8774340026703
- type: recall
value: 85.86956521739131
task:
type: BitextMining
- dataset:
config: kas_Arab-rus_Cyrl
name: MTEB FloresBitextMining (kas_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 76.28458498023716
- type: f1
value: 74.11216313578267
- type: main_score
value: 74.11216313578267
- type: precision
value: 73.2491277759584
- type: recall
value: 76.28458498023716
task:
type: BitextMining
- dataset:
config: ltg_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ltg_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 71.14624505928853
- type: f1
value: 68.69245357723618
- type: main_score
value: 68.69245357723618
- type: precision
value: 67.8135329666459
- type: recall
value: 71.14624505928853
task:
type: BitextMining
- dataset:
config: nso_Latn-rus_Cyrl
name: MTEB FloresBitextMining (nso_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.64822134387352
- type: f1
value: 85.98419219986725
- type: main_score
value: 85.98419219986725
- type: precision
value: 85.32513873917036
- type: recall
value: 87.64822134387352
task:
type: BitextMining
- dataset:
config: sin_Sinh-rus_Cyrl
name: MTEB FloresBitextMining (sin_Sinh-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.62845849802372
- type: f1
value: 97.10144927536231
- type: main_score
value: 97.10144927536231
- type: precision
value: 96.87986585219788
- type: recall
value: 97.62845849802372
task:
type: BitextMining
- dataset:
config: tha_Thai-rus_Cyrl
name: MTEB FloresBitextMining (tha_Thai-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.71541501976284
- type: f1
value: 98.28722002635045
- type: main_score
value: 98.28722002635045
- type: precision
value: 98.07312252964427
- type: recall
value: 98.71541501976284
task:
type: BitextMining
- dataset:
config: zho_Hans-rus_Cyrl
name: MTEB FloresBitextMining (zho_Hans-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.68247694334651
- type: main_score
value: 98.68247694334651
- type: precision
value: 98.51778656126481
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: ast_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ast_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.65217391304348
- type: f1
value: 94.90649683857505
- type: main_score
value: 94.90649683857505
- type: precision
value: 94.61352657004831
- type: recall
value: 95.65217391304348
task:
type: BitextMining
- dataset:
config: crh_Latn-rus_Cyrl
name: MTEB FloresBitextMining (crh_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 93.08300395256917
- type: f1
value: 92.20988998886428
- type: main_score
value: 92.20988998886428
- type: precision
value: 91.85631013694254
- type: recall
value: 93.08300395256917
task:
type: BitextMining
- dataset:
config: glg_Latn-rus_Cyrl
name: MTEB FloresBitextMining (glg_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.55335968379447
- type: f1
value: 95.18006148440931
- type: main_score
value: 95.18006148440931
- type: precision
value: 95.06540560888386
- type: recall
value: 95.55335968379447
task:
type: BitextMining
- dataset:
config: kas_Deva-rus_Cyrl
name: MTEB FloresBitextMining (kas_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 55.03952569169961
- type: f1
value: 52.19871938895554
- type: main_score
value: 52.19871938895554
- type: precision
value: 51.17660971469557
- type: recall
value: 55.03952569169961
task:
type: BitextMining
- dataset:
config: ltz_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ltz_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 87.64822134387352
- type: f1
value: 86.64179841897234
- type: main_score
value: 86.64179841897234
- type: precision
value: 86.30023235431587
- type: recall
value: 87.64822134387352
task:
type: BitextMining
- dataset:
config: nus_Latn-rus_Cyrl
name: MTEB FloresBitextMining (nus_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 27.4703557312253
- type: f1
value: 25.703014277858088
- type: main_score
value: 25.703014277858088
- type: precision
value: 25.194105476917315
- type: recall
value: 27.4703557312253
task:
type: BitextMining
- dataset:
config: slk_Latn-rus_Cyrl
name: MTEB FloresBitextMining (slk_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.1106719367589
- type: main_score
value: 99.1106719367589
- type: precision
value: 99.02832674571805
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: tir_Ethi-rus_Cyrl
name: MTEB FloresBitextMining (tir_Ethi-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 80.73122529644269
- type: f1
value: 78.66903754775608
- type: main_score
value: 78.66903754775608
- type: precision
value: 77.86431694163612
- type: recall
value: 80.73122529644269
task:
type: BitextMining
- dataset:
config: zho_Hant-rus_Cyrl
name: MTEB FloresBitextMining (zho_Hant-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.22134387351778
- type: f1
value: 97.66798418972333
- type: main_score
value: 97.66798418972333
- type: precision
value: 97.40612648221344
- type: recall
value: 98.22134387351778
task:
type: BitextMining
- dataset:
config: awa_Deva-rus_Cyrl
name: MTEB FloresBitextMining (awa_Deva-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.5296442687747
- type: f1
value: 96.94224857268335
- type: main_score
value: 96.94224857268335
- type: precision
value: 96.68560606060606
- type: recall
value: 97.5296442687747
task:
type: BitextMining
- dataset:
config: cym_Latn-rus_Cyrl
name: MTEB FloresBitextMining (cym_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 92.68774703557312
- type: f1
value: 91.69854302097961
- type: main_score
value: 91.69854302097961
- type: precision
value: 91.31236846157795
- type: recall
value: 92.68774703557312
task:
type: BitextMining
- dataset:
config: grn_Latn-rus_Cyrl
name: MTEB FloresBitextMining (grn_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 64.13043478260869
- type: f1
value: 61.850586118740004
- type: main_score
value: 61.850586118740004
- type: precision
value: 61.0049495186209
- type: recall
value: 64.13043478260869
task:
type: BitextMining
- dataset:
config: kat_Geor-rus_Cyrl
name: MTEB FloresBitextMining (kat_Geor-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.59881422924902
- type: main_score
value: 97.59881422924902
- type: precision
value: 97.42534036012296
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: lua_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lua_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 63.63636363636363
- type: f1
value: 60.9709122526128
- type: main_score
value: 60.9709122526128
- type: precision
value: 60.03915902282226
- type: recall
value: 63.63636363636363
task:
type: BitextMining
- dataset:
config: nya_Latn-rus_Cyrl
name: MTEB FloresBitextMining (nya_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 89.2292490118577
- type: f1
value: 87.59723824473149
- type: main_score
value: 87.59723824473149
- type: precision
value: 86.90172707867349
- type: recall
value: 89.2292490118577
task:
type: BitextMining
- dataset:
config: slv_Latn-rus_Cyrl
name: MTEB FloresBitextMining (slv_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.01185770750988
- type: f1
value: 98.74835309617917
- type: main_score
value: 98.74835309617917
- type: precision
value: 98.63636363636364
- type: recall
value: 99.01185770750988
task:
type: BitextMining
- dataset:
config: tpi_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tpi_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 77.37154150197628
- type: f1
value: 75.44251611276084
- type: main_score
value: 75.44251611276084
- type: precision
value: 74.78103665109595
- type: recall
value: 77.37154150197628
task:
type: BitextMining
- dataset:
config: zsm_Latn-rus_Cyrl
name: MTEB FloresBitextMining (zsm_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.2094861660079
- type: f1
value: 98.96245059288538
- type: main_score
value: 98.96245059288538
- type: precision
value: 98.8471673254282
- type: recall
value: 99.2094861660079
task:
type: BitextMining
- dataset:
config: ayr_Latn-rus_Cyrl
name: MTEB FloresBitextMining (ayr_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 27.766798418972332
- type: f1
value: 26.439103195281312
- type: main_score
value: 26.439103195281312
- type: precision
value: 26.052655604573964
- type: recall
value: 27.766798418972332
task:
type: BitextMining
- dataset:
config: dan_Latn-rus_Cyrl
name: MTEB FloresBitextMining (dan_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.30830039525692
- type: f1
value: 99.07773386034255
- type: main_score
value: 99.07773386034255
- type: precision
value: 98.96245059288538
- type: recall
value: 99.30830039525692
task:
type: BitextMining
- dataset:
config: guj_Gujr-rus_Cyrl
name: MTEB FloresBitextMining (guj_Gujr-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.26449275362317
- type: main_score
value: 97.26449275362317
- type: precision
value: 97.02498588368154
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: kaz_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (kaz_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.5296442687747
- type: f1
value: 97.03557312252964
- type: main_score
value: 97.03557312252964
- type: precision
value: 96.85022158342316
- type: recall
value: 97.5296442687747
task:
type: BitextMining
- dataset:
config: lug_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lug_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 68.57707509881423
- type: f1
value: 65.93361605820395
- type: main_score
value: 65.93361605820395
- type: precision
value: 64.90348248593789
- type: recall
value: 68.57707509881423
task:
type: BitextMining
- dataset:
config: oci_Latn-rus_Cyrl
name: MTEB FloresBitextMining (oci_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.26482213438736
- type: f1
value: 85.33176417155623
- type: main_score
value: 85.33176417155623
- type: precision
value: 85.00208833384637
- type: recall
value: 86.26482213438736
task:
type: BitextMining
- dataset:
config: smo_Latn-rus_Cyrl
name: MTEB FloresBitextMining (smo_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 77.96442687747036
- type: f1
value: 75.70960450188885
- type: main_score
value: 75.70960450188885
- type: precision
value: 74.8312632736777
- type: recall
value: 77.96442687747036
task:
type: BitextMining
- dataset:
config: tsn_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tsn_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 84.38735177865613
- type: f1
value: 82.13656376349225
- type: main_score
value: 82.13656376349225
- type: precision
value: 81.16794543904518
- type: recall
value: 84.38735177865613
task:
type: BitextMining
- dataset:
config: zul_Latn-rus_Cyrl
name: MTEB FloresBitextMining (zul_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 90.21739130434783
- type: f1
value: 88.77570602050753
- type: main_score
value: 88.77570602050753
- type: precision
value: 88.15978104021582
- type: recall
value: 90.21739130434783
task:
type: BitextMining
- dataset:
config: azb_Arab-rus_Cyrl
name: MTEB FloresBitextMining (azb_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 65.71146245059289
- type: f1
value: 64.18825390221271
- type: main_score
value: 64.18825390221271
- type: precision
value: 63.66811154793568
- type: recall
value: 65.71146245059289
task:
type: BitextMining
- dataset:
config: deu_Latn-rus_Cyrl
name: MTEB FloresBitextMining (deu_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 99.70355731225297
- type: f1
value: 99.60474308300395
- type: main_score
value: 99.60474308300395
- type: precision
value: 99.55533596837944
- type: recall
value: 99.70355731225297
task:
type: BitextMining
- dataset:
config: hat_Latn-rus_Cyrl
name: MTEB FloresBitextMining (hat_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 86.7588932806324
- type: f1
value: 85.86738623695146
- type: main_score
value: 85.86738623695146
- type: precision
value: 85.55235467420822
- type: recall
value: 86.7588932806324
task:
type: BitextMining
- dataset:
config: kbp_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kbp_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 34.88142292490119
- type: f1
value: 32.16511669463015
- type: main_score
value: 32.16511669463015
- type: precision
value: 31.432098549546318
- type: recall
value: 34.88142292490119
task:
type: BitextMining
- dataset:
config: luo_Latn-rus_Cyrl
name: MTEB FloresBitextMining (luo_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 52.27272727272727
- type: f1
value: 49.60489626836975
- type: main_score
value: 49.60489626836975
- type: precision
value: 48.69639631803339
- type: recall
value: 52.27272727272727
task:
type: BitextMining
- dataset:
config: ory_Orya-rus_Cyrl
name: MTEB FloresBitextMining (ory_Orya-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.82608695652173
- type: f1
value: 97.27437417654808
- type: main_score
value: 97.27437417654808
- type: precision
value: 97.04968944099377
- type: recall
value: 97.82608695652173
task:
type: BitextMining
- dataset:
config: sna_Latn-rus_Cyrl
name: MTEB FloresBitextMining (sna_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 85.37549407114624
- type: f1
value: 83.09911316305177
- type: main_score
value: 83.09911316305177
- type: precision
value: 82.1284950958864
- type: recall
value: 85.37549407114624
task:
type: BitextMining
- dataset:
config: tso_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tso_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 82.90513833992095
- type: f1
value: 80.28290385503824
- type: main_score
value: 80.28290385503824
- type: precision
value: 79.23672543237761
- type: recall
value: 82.90513833992095
task:
type: BitextMining
- dataset:
config: azj_Latn-rus_Cyrl
name: MTEB FloresBitextMining (azj_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.02371541501977
- type: f1
value: 97.49200075287031
- type: main_score
value: 97.49200075287031
- type: precision
value: 97.266139657444
- type: recall
value: 98.02371541501977
task:
type: BitextMining
- dataset:
config: dik_Latn-rus_Cyrl
name: MTEB FloresBitextMining (dik_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 38.43873517786561
- type: f1
value: 35.78152442955223
- type: main_score
value: 35.78152442955223
- type: precision
value: 34.82424325078237
- type: recall
value: 38.43873517786561
task:
type: BitextMining
- dataset:
config: hau_Latn-rus_Cyrl
name: MTEB FloresBitextMining (hau_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.42292490118577
- type: f1
value: 79.24612283124593
- type: main_score
value: 79.24612283124593
- type: precision
value: 78.34736070751448
- type: recall
value: 81.42292490118577
task:
type: BitextMining
- dataset:
config: kea_Latn-rus_Cyrl
name: MTEB FloresBitextMining (kea_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 81.62055335968378
- type: f1
value: 80.47015182884748
- type: main_score
value: 80.47015182884748
- type: precision
value: 80.02671028885862
- type: recall
value: 81.62055335968378
task:
type: BitextMining
- dataset:
config: lus_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lus_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 62.74703557312253
- type: f1
value: 60.53900079111122
- type: main_score
value: 60.53900079111122
- type: precision
value: 59.80024202850289
- type: recall
value: 62.74703557312253
task:
type: BitextMining
- dataset:
config: pag_Latn-rus_Cyrl
name: MTEB FloresBitextMining (pag_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 74.01185770750988
- type: f1
value: 72.57280648279529
- type: main_score
value: 72.57280648279529
- type: precision
value: 71.99952968456789
- type: recall
value: 74.01185770750988
task:
type: BitextMining
- dataset:
config: snd_Arab-rus_Cyrl
name: MTEB FloresBitextMining (snd_Arab-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 91.30434782608695
- type: f1
value: 90.24653499445358
- type: main_score
value: 90.24653499445358
- type: precision
value: 89.83134068200232
- type: recall
value: 91.30434782608695
task:
type: BitextMining
- dataset:
config: tuk_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tuk_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 47.62845849802372
- type: f1
value: 45.812928836644254
- type: main_score
value: 45.812928836644254
- type: precision
value: 45.23713833170355
- type: recall
value: 47.62845849802372
task:
type: BitextMining
- dataset:
config: bak_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (bak_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.8498023715415
- type: f1
value: 95.18904459615922
- type: main_score
value: 95.18904459615922
- type: precision
value: 94.92812441182006
- type: recall
value: 95.8498023715415
task:
type: BitextMining
- dataset:
config: dyu_Latn-rus_Cyrl
name: MTEB FloresBitextMining (dyu_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 29.64426877470356
- type: f1
value: 27.287335193938166
- type: main_score
value: 27.287335193938166
- type: precision
value: 26.583996026587492
- type: recall
value: 29.64426877470356
task:
type: BitextMining
- dataset:
config: heb_Hebr-rus_Cyrl
name: MTEB FloresBitextMining (heb_Hebr-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 98.91304347826086
- type: f1
value: 98.55072463768116
- type: main_score
value: 98.55072463768116
- type: precision
value: 98.36956521739131
- type: recall
value: 98.91304347826086
task:
type: BitextMining
- dataset:
config: khk_Cyrl-rus_Cyrl
name: MTEB FloresBitextMining (khk_Cyrl-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 95.15810276679841
- type: f1
value: 94.44009547764487
- type: main_score
value: 94.44009547764487
- type: precision
value: 94.16579797014579
- type: recall
value: 95.15810276679841
task:
type: BitextMining
- dataset:
config: lvs_Latn-rus_Cyrl
name: MTEB FloresBitextMining (lvs_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.92490118577075
- type: f1
value: 97.51467241585817
- type: main_score
value: 97.51467241585817
- type: precision
value: 97.36166007905138
- type: recall
value: 97.92490118577075
task:
type: BitextMining
- dataset:
config: pan_Guru-rus_Cyrl
name: MTEB FloresBitextMining (pan_Guru-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 97.92490118577075
- type: f1
value: 97.42918313570486
- type: main_score
value: 97.42918313570486
- type: precision
value: 97.22261434217955
- type: recall
value: 97.92490118577075
task:
type: BitextMining
- dataset:
config: som_Latn-rus_Cyrl
name: MTEB FloresBitextMining (som_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 75.69169960474308
- type: f1
value: 73.7211667065916
- type: main_score
value: 73.7211667065916
- type: precision
value: 72.95842401892384
- type: recall
value: 75.69169960474308
task:
type: BitextMining
- dataset:
config: tum_Latn-rus_Cyrl
name: MTEB FloresBitextMining (tum_Latn-rus_Cyrl)
revision: e6b647fcb6299a2f686f742f4d4c023e553ea67e
split: devtest
type: mteb/flores
metrics:
- type: accuracy
value: 85.67193675889328
- type: f1
value: 82.9296066252588
- type: main_score
value: 82.9296066252588
- type: precision
value: 81.77330225447936
- type: recall
value: 85.67193675889328
task:
type: BitextMining
- dataset:
config: default
name: MTEB GeoreviewClassification (default)
revision: 3765c0d1de6b7d264bc459433c45e5a75513839c
split: test
type: ai-forever/georeview-classification
metrics:
- type: accuracy
value: 44.6630859375
- type: f1
value: 42.607425073610536
- type: f1_weighted
value: 42.60639474586065
- type: main_score
value: 44.6630859375
task:
type: Classification
- dataset:
config: default
name: MTEB GeoreviewClusteringP2P (default)
revision: 97a313c8fc85b47f13f33e7e9a95c1ad888c7fec
split: test
type: ai-forever/georeview-clustering-p2p
metrics:
- type: main_score
value: 58.15951247070825
- type: v_measure
value: 58.15951247070825
- type: v_measure_std
value: 0.6739615788288809
task:
type: Clustering
- dataset:
config: default
name: MTEB HeadlineClassification (default)
revision: 2fe05ee6b5832cda29f2ef7aaad7b7fe6a3609eb
split: test
type: ai-forever/headline-classification
metrics:
- type: accuracy
value: 73.935546875
- type: f1
value: 73.8654872186846
- type: f1_weighted
value: 73.86733122685095
- type: main_score
value: 73.935546875
task:
type: Classification
- dataset:
config: default
name: MTEB InappropriatenessClassification (default)
revision: 601651fdc45ef243751676e62dd7a19f491c0285
split: test
type: ai-forever/inappropriateness-classification
metrics:
- type: accuracy
value: 59.16015624999999
- type: ap
value: 55.52276605836938
- type: ap_weighted
value: 55.52276605836938
- type: f1
value: 58.614248199637956
- type: f1_weighted
value: 58.614248199637956
- type: main_score
value: 59.16015624999999
task:
type: Classification
- dataset:
config: default
name: MTEB KinopoiskClassification (default)
revision: 5911f26666ac11af46cb9c6849d0dc80a378af24
split: test
type: ai-forever/kinopoisk-sentiment-classification
metrics:
- type: accuracy
value: 49.959999999999994
- type: f1
value: 48.4900332316098
- type: f1_weighted
value: 48.4900332316098
- type: main_score
value: 49.959999999999994
task:
type: Classification
- dataset:
config: default
name: MTEB LanguageClassification (default)
revision: aa56583bf2bc52b0565770607d6fc3faebecf9e2
split: test
type: papluca/language-identification
metrics:
- type: accuracy
value: 71.005859375
- type: f1
value: 69.63481100303348
- type: f1_weighted
value: 69.64640413409529
- type: main_score
value: 71.005859375
task:
type: Classification
- dataset:
config: ru
name: MTEB MLSUMClusteringP2P (ru)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 42.11280087032343
- type: v_measure
value: 42.11280087032343
- type: v_measure_std
value: 6.7619971723605135
task:
type: Clustering
- dataset:
config: ru
name: MTEB MLSUMClusteringP2P.v2 (ru)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 43.00112546945811
- type: v_measure
value: 43.00112546945811
- type: v_measure_std
value: 1.4740560414835675
task:
type: Clustering
- dataset:
config: ru
name: MTEB MLSUMClusteringS2S (ru)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 39.81446080575161
- type: v_measure
value: 39.81446080575161
- type: v_measure_std
value: 7.125661320308298
task:
type: Clustering
- dataset:
config: ru
name: MTEB MLSUMClusteringS2S.v2 (ru)
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: reciTAL/mlsum
metrics:
- type: main_score
value: 39.29659668980239
- type: v_measure
value: 39.29659668980239
- type: v_measure_std
value: 2.6570502923023094
task:
type: Clustering
- dataset:
config: ru
name: MTEB MultiLongDocRetrieval (ru)
revision: d67138e705d963e346253a80e59676ddb418810a
split: dev
type: Shitao/MLDR
metrics:
- type: main_score
value: 38.671
- type: map_at_1
value: 30.0
- type: map_at_10
value: 36.123
- type: map_at_100
value: 36.754999999999995
- type: map_at_1000
value: 36.806
- type: map_at_20
value: 36.464
- type: map_at_3
value: 35.25
- type: map_at_5
value: 35.8
- type: mrr_at_1
value: 30.0
- type: mrr_at_10
value: 36.122817460317464
- type: mrr_at_100
value: 36.75467016625293
- type: mrr_at_1000
value: 36.80612724920882
- type: mrr_at_20
value: 36.46359681984682
- type: mrr_at_3
value: 35.25
- type: mrr_at_5
value: 35.800000000000004
- type: nauc_map_at_1000_diff1
value: 55.61987610843598
- type: nauc_map_at_1000_max
value: 52.506795017152186
- type: nauc_map_at_1000_std
value: 2.95487192066911
- type: nauc_map_at_100_diff1
value: 55.598419532054734
- type: nauc_map_at_100_max
value: 52.48192017040307
- type: nauc_map_at_100_std
value: 2.930120252521189
- type: nauc_map_at_10_diff1
value: 56.02309155375198
- type: nauc_map_at_10_max
value: 52.739573233234424
- type: nauc_map_at_10_std
value: 2.4073432421641545
- type: nauc_map_at_1_diff1
value: 52.57059856776112
- type: nauc_map_at_1_max
value: 50.55668152952304
- type: nauc_map_at_1_std
value: 1.6572084853398048
- type: nauc_map_at_20_diff1
value: 55.75769029917031
- type: nauc_map_at_20_max
value: 52.53663737242853
- type: nauc_map_at_20_std
value: 2.8489192879814
- type: nauc_map_at_3_diff1
value: 56.90294128342709
- type: nauc_map_at_3_max
value: 53.10608389782041
- type: nauc_map_at_3_std
value: 1.4909731657889491
- type: nauc_map_at_5_diff1
value: 56.1258315436073
- type: nauc_map_at_5_max
value: 52.398078357541564
- type: nauc_map_at_5_std
value: 1.8256862015101467
- type: nauc_mrr_at_1000_diff1
value: 55.61987610843598
- type: nauc_mrr_at_1000_max
value: 52.506795017152186
- type: nauc_mrr_at_1000_std
value: 2.95487192066911
- type: nauc_mrr_at_100_diff1
value: 55.598419532054734
- type: nauc_mrr_at_100_max
value: 52.48192017040307
- type: nauc_mrr_at_100_std
value: 2.930120252521189
- type: nauc_mrr_at_10_diff1
value: 56.02309155375198
- type: nauc_mrr_at_10_max
value: 52.739573233234424
- type: nauc_mrr_at_10_std
value: 2.4073432421641545
- type: nauc_mrr_at_1_diff1
value: 52.57059856776112
- type: nauc_mrr_at_1_max
value: 50.55668152952304
- type: nauc_mrr_at_1_std
value: 1.6572084853398048
- type: nauc_mrr_at_20_diff1
value: 55.75769029917031
- type: nauc_mrr_at_20_max
value: 52.53663737242853
- type: nauc_mrr_at_20_std
value: 2.8489192879814
- type: nauc_mrr_at_3_diff1
value: 56.90294128342709
- type: nauc_mrr_at_3_max
value: 53.10608389782041
- type: nauc_mrr_at_3_std
value: 1.4909731657889491
- type: nauc_mrr_at_5_diff1
value: 56.1258315436073
- type: nauc_mrr_at_5_max
value: 52.398078357541564
- type: nauc_mrr_at_5_std
value: 1.8256862015101467
- type: nauc_ndcg_at_1000_diff1
value: 55.30733548408918
- type: nauc_ndcg_at_1000_max
value: 53.51143366189318
- type: nauc_ndcg_at_1000_std
value: 7.133789405525702
- type: nauc_ndcg_at_100_diff1
value: 54.32209039488095
- type: nauc_ndcg_at_100_max
value: 52.67499334461009
- type: nauc_ndcg_at_100_std
value: 6.878823275077807
- type: nauc_ndcg_at_10_diff1
value: 56.266780806997716
- type: nauc_ndcg_at_10_max
value: 53.52837255793743
- type: nauc_ndcg_at_10_std
value: 3.756832592964262
- type: nauc_ndcg_at_1_diff1
value: 52.57059856776112
- type: nauc_ndcg_at_1_max
value: 50.55668152952304
- type: nauc_ndcg_at_1_std
value: 1.6572084853398048
- type: nauc_ndcg_at_20_diff1
value: 55.39255420432796
- type: nauc_ndcg_at_20_max
value: 52.946114684072235
- type: nauc_ndcg_at_20_std
value: 5.414933414031693
- type: nauc_ndcg_at_3_diff1
value: 57.92826624996289
- type: nauc_ndcg_at_3_max
value: 53.89907760306972
- type: nauc_ndcg_at_3_std
value: 1.6661401245309218
- type: nauc_ndcg_at_5_diff1
value: 56.47508936029308
- type: nauc_ndcg_at_5_max
value: 52.66800998045517
- type: nauc_ndcg_at_5_std
value: 2.4127296184140423
- type: nauc_precision_at_1000_diff1
value: 57.25924020238401
- type: nauc_precision_at_1000_max
value: 65.1132590931922
- type: nauc_precision_at_1000_std
value: 40.60788709618145
- type: nauc_precision_at_100_diff1
value: 46.49620002554606
- type: nauc_precision_at_100_max
value: 53.02960148167071
- type: nauc_precision_at_100_std
value: 28.206028867032863
- type: nauc_precision_at_10_diff1
value: 56.562744749606765
- type: nauc_precision_at_10_max
value: 56.00594967783547
- type: nauc_precision_at_10_std
value: 8.368379831645163
- type: nauc_precision_at_1_diff1
value: 52.57059856776112
- type: nauc_precision_at_1_max
value: 50.55668152952304
- type: nauc_precision_at_1_std
value: 1.6572084853398048
- type: nauc_precision_at_20_diff1
value: 53.25915754614111
- type: nauc_precision_at_20_max
value: 54.03255118937036
- type: nauc_precision_at_20_std
value: 15.161611674272718
- type: nauc_precision_at_3_diff1
value: 60.726785748943854
- type: nauc_precision_at_3_max
value: 56.139896875869354
- type: nauc_precision_at_3_std
value: 2.2306901035769893
- type: nauc_precision_at_5_diff1
value: 57.1201127525187
- type: nauc_precision_at_5_max
value: 53.28665761862506
- type: nauc_precision_at_5_std
value: 4.358720050112237
- type: nauc_recall_at_1000_diff1
value: 57.259240202383964
- type: nauc_recall_at_1000_max
value: 65.11325909319218
- type: nauc_recall_at_1000_std
value: 40.60788709618142
- type: nauc_recall_at_100_diff1
value: 46.49620002554603
- type: nauc_recall_at_100_max
value: 53.02960148167071
- type: nauc_recall_at_100_std
value: 28.206028867032835
- type: nauc_recall_at_10_diff1
value: 56.562744749606765
- type: nauc_recall_at_10_max
value: 56.00594967783549
- type: nauc_recall_at_10_std
value: 8.368379831645147
- type: nauc_recall_at_1_diff1
value: 52.57059856776112
- type: nauc_recall_at_1_max
value: 50.55668152952304
- type: nauc_recall_at_1_std
value: 1.6572084853398048
- type: nauc_recall_at_20_diff1
value: 53.259157546141154
- type: nauc_recall_at_20_max
value: 54.03255118937038
- type: nauc_recall_at_20_std
value: 15.16161167427274
- type: nauc_recall_at_3_diff1
value: 60.72678574894387
- type: nauc_recall_at_3_max
value: 56.13989687586933
- type: nauc_recall_at_3_std
value: 2.2306901035770066
- type: nauc_recall_at_5_diff1
value: 57.12011275251864
- type: nauc_recall_at_5_max
value: 53.28665761862502
- type: nauc_recall_at_5_std
value: 4.3587200501122245
- type: ndcg_at_1
value: 30.0
- type: ndcg_at_10
value: 38.671
- type: ndcg_at_100
value: 42.173
- type: ndcg_at_1000
value: 44.016
- type: ndcg_at_20
value: 39.845000000000006
- type: ndcg_at_3
value: 36.863
- type: ndcg_at_5
value: 37.874
- type: precision_at_1
value: 30.0
- type: precision_at_10
value: 4.65
- type: precision_at_100
value: 0.64
- type: precision_at_1000
value: 0.08
- type: precision_at_20
value: 2.55
- type: precision_at_3
value: 13.833
- type: precision_at_5
value: 8.799999999999999
- type: recall_at_1
value: 30.0
- type: recall_at_10
value: 46.5
- type: recall_at_100
value: 64.0
- type: recall_at_1000
value: 79.5
- type: recall_at_20
value: 51.0
- type: recall_at_3
value: 41.5
- type: recall_at_5
value: 44.0
task:
type: Retrieval
- dataset:
config: rus
name: MTEB MultilingualSentimentClassification (rus)
revision: 2b9b4d10fc589af67794141fe8cbd3739de1eb33
split: test
type: mteb/multilingual-sentiment-classification
metrics:
- type: accuracy
value: 79.52710495963092
- type: ap
value: 84.5713457178972
- type: ap_weighted
value: 84.5713457178972
- type: f1
value: 77.88661181524105
- type: f1_weighted
value: 79.87563079922718
- type: main_score
value: 79.52710495963092
task:
type: Classification
- dataset:
config: arb_Arab-rus_Cyrl
name: MTEB NTREXBitextMining (arb_Arab-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 86.47971957936905
- type: f1
value: 82.79864240805654
- type: main_score
value: 82.79864240805654
- type: precision
value: 81.21485800128767
- type: recall
value: 86.47971957936905
task:
type: BitextMining
- dataset:
config: bel_Cyrl-rus_Cyrl
name: MTEB NTREXBitextMining (bel_Cyrl-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.84226339509264
- type: f1
value: 93.56399067465667
- type: main_score
value: 93.56399067465667
- type: precision
value: 93.01619095309631
- type: recall
value: 94.84226339509264
task:
type: BitextMining
- dataset:
config: ben_Beng-rus_Cyrl
name: MTEB NTREXBitextMining (ben_Beng-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.18828242363544
- type: f1
value: 90.42393889620612
- type: main_score
value: 90.42393889620612
- type: precision
value: 89.67904925153297
- type: recall
value: 92.18828242363544
task:
type: BitextMining
- dataset:
config: bos_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (bos_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.69203805708563
- type: f1
value: 93.37172425304624
- type: main_score
value: 93.37172425304624
- type: precision
value: 92.79204521067315
- type: recall
value: 94.69203805708563
task:
type: BitextMining
- dataset:
config: bul_Cyrl-rus_Cyrl
name: MTEB NTREXBitextMining (bul_Cyrl-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.99549323985978
- type: f1
value: 96.13086296110833
- type: main_score
value: 96.13086296110833
- type: precision
value: 95.72441996327827
- type: recall
value: 96.99549323985978
task:
type: BitextMining
- dataset:
config: ces_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (ces_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.94391587381071
- type: f1
value: 94.90680465142157
- type: main_score
value: 94.90680465142157
- type: precision
value: 94.44541812719079
- type: recall
value: 95.94391587381071
task:
type: BitextMining
- dataset:
config: deu_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (deu_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.09414121181773
- type: f1
value: 94.94408279085295
- type: main_score
value: 94.94408279085295
- type: precision
value: 94.41245201135037
- type: recall
value: 96.09414121181773
task:
type: BitextMining
- dataset:
config: ell_Grek-rus_Cyrl
name: MTEB NTREXBitextMining (ell_Grek-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.19429143715573
- type: f1
value: 95.12101485561676
- type: main_score
value: 95.12101485561676
- type: precision
value: 94.60440660991488
- type: recall
value: 96.19429143715573
task:
type: BitextMining
- dataset:
config: eng_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (eng_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.49474211316975
- type: f1
value: 95.46581777428045
- type: main_score
value: 95.46581777428045
- type: precision
value: 94.98414288098814
- type: recall
value: 96.49474211316975
task:
type: BitextMining
- dataset:
config: fas_Arab-rus_Cyrl
name: MTEB NTREXBitextMining (fas_Arab-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.44166249374061
- type: f1
value: 92.92383018972905
- type: main_score
value: 92.92383018972905
- type: precision
value: 92.21957936905358
- type: recall
value: 94.44166249374061
task:
type: BitextMining
- dataset:
config: fin_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (fin_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.18828242363544
- type: f1
value: 90.2980661468393
- type: main_score
value: 90.2980661468393
- type: precision
value: 89.42580537472877
- type: recall
value: 92.18828242363544
task:
type: BitextMining
- dataset:
config: fra_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (fra_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.84376564847271
- type: f1
value: 94.81054915706895
- type: main_score
value: 94.81054915706895
- type: precision
value: 94.31369276136427
- type: recall
value: 95.84376564847271
task:
type: BitextMining
- dataset:
config: heb_Hebr-rus_Cyrl
name: MTEB NTREXBitextMining (heb_Hebr-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.89233850776164
- type: f1
value: 93.42513770655985
- type: main_score
value: 93.42513770655985
- type: precision
value: 92.73493573693875
- type: recall
value: 94.89233850776164
task:
type: BitextMining
- dataset:
config: hin_Deva-rus_Cyrl
name: MTEB NTREXBitextMining (hin_Deva-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.23985978968453
- type: f1
value: 91.52816526376867
- type: main_score
value: 91.52816526376867
- type: precision
value: 90.76745946425466
- type: recall
value: 93.23985978968453
task:
type: BitextMining
- dataset:
config: hrv_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (hrv_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.99098647971958
- type: f1
value: 92.36354531797697
- type: main_score
value: 92.36354531797697
- type: precision
value: 91.63228970439788
- type: recall
value: 93.99098647971958
task:
type: BitextMining
- dataset:
config: hun_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (hun_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.64046069103655
- type: f1
value: 92.05224503421799
- type: main_score
value: 92.05224503421799
- type: precision
value: 91.33998616973079
- type: recall
value: 93.64046069103655
task:
type: BitextMining
- dataset:
config: ind_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (ind_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 91.68753129694541
- type: f1
value: 89.26222667334335
- type: main_score
value: 89.26222667334335
- type: precision
value: 88.14638624603572
- type: recall
value: 91.68753129694541
task:
type: BitextMining
- dataset:
config: jpn_Jpan-rus_Cyrl
name: MTEB NTREXBitextMining (jpn_Jpan-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 91.28693039559339
- type: f1
value: 89.21161763348957
- type: main_score
value: 89.21161763348957
- type: precision
value: 88.31188340952988
- type: recall
value: 91.28693039559339
task:
type: BitextMining
- dataset:
config: kor_Hang-rus_Cyrl
name: MTEB NTREXBitextMining (kor_Hang-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 89.53430145217827
- type: f1
value: 86.88322165788365
- type: main_score
value: 86.88322165788365
- type: precision
value: 85.73950211030831
- type: recall
value: 89.53430145217827
task:
type: BitextMining
- dataset:
config: lit_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (lit_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 90.28542814221332
- type: f1
value: 88.10249103814452
- type: main_score
value: 88.10249103814452
- type: precision
value: 87.17689323973752
- type: recall
value: 90.28542814221332
task:
type: BitextMining
- dataset:
config: mkd_Cyrl-rus_Cyrl
name: MTEB NTREXBitextMining (mkd_Cyrl-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.04256384576865
- type: f1
value: 93.65643703650713
- type: main_score
value: 93.65643703650713
- type: precision
value: 93.02036387915207
- type: recall
value: 95.04256384576865
task:
type: BitextMining
- dataset:
config: nld_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (nld_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.39308963445168
- type: f1
value: 94.16207644800535
- type: main_score
value: 94.16207644800535
- type: precision
value: 93.582516632091
- type: recall
value: 95.39308963445168
task:
type: BitextMining
- dataset:
config: pol_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (pol_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.7436154231347
- type: f1
value: 94.5067601402103
- type: main_score
value: 94.5067601402103
- type: precision
value: 93.91587381071608
- type: recall
value: 95.7436154231347
task:
type: BitextMining
- dataset:
config: por_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (por_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 65.89884827240861
- type: f1
value: 64.61805459419219
- type: main_score
value: 64.61805459419219
- type: precision
value: 64.07119451106485
- type: recall
value: 65.89884827240861
task:
type: BitextMining
- dataset:
config: rus_Cyrl-arb_Arab
name: MTEB NTREXBitextMining (rus_Cyrl-arb_Arab)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.2413620430646
- type: f1
value: 92.67663399861698
- type: main_score
value: 92.67663399861698
- type: precision
value: 91.94625271240193
- type: recall
value: 94.2413620430646
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bel_Cyrl
name: MTEB NTREXBitextMining (rus_Cyrl-bel_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.89233850776164
- type: f1
value: 93.40343849106993
- type: main_score
value: 93.40343849106993
- type: precision
value: 92.74077783341679
- type: recall
value: 94.89233850776164
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ben_Beng
name: MTEB NTREXBitextMining (rus_Cyrl-ben_Beng)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.2914371557336
- type: f1
value: 92.62226673343348
- type: main_score
value: 92.62226673343348
- type: precision
value: 91.84610248706393
- type: recall
value: 94.2914371557336
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bos_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-bos_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.69354031046569
- type: f1
value: 94.50418051319403
- type: main_score
value: 94.50418051319403
- type: precision
value: 93.95843765648473
- type: recall
value: 95.69354031046569
task:
type: BitextMining
- dataset:
config: rus_Cyrl-bul_Cyrl
name: MTEB NTREXBitextMining (rus_Cyrl-bul_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.89384076114172
- type: f1
value: 94.66199298948423
- type: main_score
value: 94.66199298948423
- type: precision
value: 94.08028709731263
- type: recall
value: 95.89384076114172
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ces_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-ces_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.94091136705057
- type: f1
value: 92.3746731207923
- type: main_score
value: 92.3746731207923
- type: precision
value: 91.66207644800535
- type: recall
value: 93.94091136705057
task:
type: BitextMining
- dataset:
config: rus_Cyrl-deu_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-deu_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.94391587381071
- type: f1
value: 94.76214321482223
- type: main_score
value: 94.76214321482223
- type: precision
value: 94.20380570856285
- type: recall
value: 95.94391587381071
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ell_Grek
name: MTEB NTREXBitextMining (rus_Cyrl-ell_Grek)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.44316474712068
- type: f1
value: 94.14788849941579
- type: main_score
value: 94.14788849941579
- type: precision
value: 93.54197963612084
- type: recall
value: 95.44316474712068
task:
type: BitextMining
- dataset:
config: rus_Cyrl-eng_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-eng_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 98.14722083124687
- type: f1
value: 97.57135703555333
- type: main_score
value: 97.57135703555333
- type: precision
value: 97.2959439158738
- type: recall
value: 98.14722083124687
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fas_Arab
name: MTEB NTREXBitextMining (rus_Cyrl-fas_Arab)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.64196294441662
- type: f1
value: 93.24653647137372
- type: main_score
value: 93.24653647137372
- type: precision
value: 92.60724419963279
- type: recall
value: 94.64196294441662
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fin_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-fin_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 87.98197295943916
- type: f1
value: 85.23368385912201
- type: main_score
value: 85.23368385912201
- type: precision
value: 84.08159858835873
- type: recall
value: 87.98197295943916
task:
type: BitextMining
- dataset:
config: rus_Cyrl-fra_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-fra_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.24436654982473
- type: f1
value: 95.07093974294774
- type: main_score
value: 95.07093974294774
- type: precision
value: 94.49591053246536
- type: recall
value: 96.24436654982473
task:
type: BitextMining
- dataset:
config: rus_Cyrl-heb_Hebr
name: MTEB NTREXBitextMining (rus_Cyrl-heb_Hebr)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 91.08662994491738
- type: f1
value: 88.5161074945752
- type: main_score
value: 88.5161074945752
- type: precision
value: 87.36187614755467
- type: recall
value: 91.08662994491738
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hin_Deva
name: MTEB NTREXBitextMining (rus_Cyrl-hin_Deva)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.04256384576865
- type: f1
value: 93.66382907694876
- type: main_score
value: 93.66382907694876
- type: precision
value: 93.05291270238692
- type: recall
value: 95.04256384576865
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hrv_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-hrv_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.14271407110667
- type: f1
value: 93.7481221832749
- type: main_score
value: 93.7481221832749
- type: precision
value: 93.10930681736892
- type: recall
value: 95.14271407110667
task:
type: BitextMining
- dataset:
config: rus_Cyrl-hun_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-hun_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 90.18527791687532
- type: f1
value: 87.61415933423946
- type: main_score
value: 87.61415933423946
- type: precision
value: 86.5166400394242
- type: recall
value: 90.18527791687532
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ind_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-ind_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.69053580370556
- type: f1
value: 91.83608746453012
- type: main_score
value: 91.83608746453012
- type: precision
value: 90.97145718577868
- type: recall
value: 93.69053580370556
task:
type: BitextMining
- dataset:
config: rus_Cyrl-jpn_Jpan
name: MTEB NTREXBitextMining (rus_Cyrl-jpn_Jpan)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 89.48422633950926
- type: f1
value: 86.91271033534429
- type: main_score
value: 86.91271033534429
- type: precision
value: 85.82671626487351
- type: recall
value: 89.48422633950926
task:
type: BitextMining
- dataset:
config: rus_Cyrl-kor_Hang
name: MTEB NTREXBitextMining (rus_Cyrl-kor_Hang)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 88.4827240861292
- type: f1
value: 85.35080398375342
- type: main_score
value: 85.35080398375342
- type: precision
value: 83.9588549490903
- type: recall
value: 88.4827240861292
task:
type: BitextMining
- dataset:
config: rus_Cyrl-lit_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-lit_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 90.33550325488233
- type: f1
value: 87.68831819157307
- type: main_score
value: 87.68831819157307
- type: precision
value: 86.51524906407231
- type: recall
value: 90.33550325488233
task:
type: BitextMining
- dataset:
config: rus_Cyrl-mkd_Cyrl
name: MTEB NTREXBitextMining (rus_Cyrl-mkd_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.94391587381071
- type: f1
value: 94.90402270071775
- type: main_score
value: 94.90402270071775
- type: precision
value: 94.43915873810715
- type: recall
value: 95.94391587381071
task:
type: BitextMining
- dataset:
config: rus_Cyrl-nld_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-nld_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.98948422633951
- type: f1
value: 91.04323151393756
- type: main_score
value: 91.04323151393756
- type: precision
value: 90.14688699716241
- type: recall
value: 92.98948422633951
task:
type: BitextMining
- dataset:
config: rus_Cyrl-pol_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-pol_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.34151226840261
- type: f1
value: 92.8726422967785
- type: main_score
value: 92.8726422967785
- type: precision
value: 92.19829744616925
- type: recall
value: 94.34151226840261
task:
type: BitextMining
- dataset:
config: rus_Cyrl-por_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-por_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 86.17926890335504
- type: f1
value: 82.7304882287356
- type: main_score
value: 82.7304882287356
- type: precision
value: 81.28162481817964
- type: recall
value: 86.17926890335504
task:
type: BitextMining
- dataset:
config: rus_Cyrl-slk_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-slk_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.7391086629945
- type: f1
value: 90.75112669003506
- type: main_score
value: 90.75112669003506
- type: precision
value: 89.8564513436822
- type: recall
value: 92.7391086629945
task:
type: BitextMining
- dataset:
config: rus_Cyrl-slv_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-slv_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.8893340010015
- type: f1
value: 91.05992321816058
- type: main_score
value: 91.05992321816058
- type: precision
value: 90.22589439715128
- type: recall
value: 92.8893340010015
task:
type: BitextMining
- dataset:
config: rus_Cyrl-spa_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-spa_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.49474211316975
- type: f1
value: 95.4715406442998
- type: main_score
value: 95.4715406442998
- type: precision
value: 94.9799699549324
- type: recall
value: 96.49474211316975
task:
type: BitextMining
- dataset:
config: rus_Cyrl-srp_Cyrl
name: MTEB NTREXBitextMining (rus_Cyrl-srp_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 81.07160741111667
- type: f1
value: 76.55687285507015
- type: main_score
value: 76.55687285507015
- type: precision
value: 74.71886401030116
- type: recall
value: 81.07160741111667
task:
type: BitextMining
- dataset:
config: rus_Cyrl-srp_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-srp_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.14271407110667
- type: f1
value: 93.73302377809138
- type: main_score
value: 93.73302377809138
- type: precision
value: 93.06960440660991
- type: recall
value: 95.14271407110667
task:
type: BitextMining
- dataset:
config: rus_Cyrl-swa_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-swa_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.79218828242364
- type: f1
value: 93.25988983475212
- type: main_score
value: 93.25988983475212
- type: precision
value: 92.53463528626273
- type: recall
value: 94.79218828242364
task:
type: BitextMining
- dataset:
config: rus_Cyrl-swe_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-swe_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.04256384576865
- type: f1
value: 93.58704723752295
- type: main_score
value: 93.58704723752295
- type: precision
value: 92.91437155733601
- type: recall
value: 95.04256384576865
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tam_Taml
name: MTEB NTREXBitextMining (rus_Cyrl-tam_Taml)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.28993490235354
- type: f1
value: 91.63912535469872
- type: main_score
value: 91.63912535469872
- type: precision
value: 90.87738750983617
- type: recall
value: 93.28993490235354
task:
type: BitextMining
- dataset:
config: rus_Cyrl-tur_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-tur_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.74061091637456
- type: f1
value: 91.96628275746953
- type: main_score
value: 91.96628275746953
- type: precision
value: 91.15923885828742
- type: recall
value: 93.74061091637456
task:
type: BitextMining
- dataset:
config: rus_Cyrl-ukr_Cyrl
name: MTEB NTREXBitextMining (rus_Cyrl-ukr_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.99399098647972
- type: f1
value: 94.89567684860624
- type: main_score
value: 94.89567684860624
- type: precision
value: 94.37072275079286
- type: recall
value: 95.99399098647972
task:
type: BitextMining
- dataset:
config: rus_Cyrl-vie_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-vie_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 91.4371557336004
- type: f1
value: 88.98681355366382
- type: main_score
value: 88.98681355366382
- type: precision
value: 87.89183775663496
- type: recall
value: 91.4371557336004
task:
type: BitextMining
- dataset:
config: rus_Cyrl-zho_Hant
name: MTEB NTREXBitextMining (rus_Cyrl-zho_Hant)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.7891837756635
- type: f1
value: 90.79047142141783
- type: main_score
value: 90.79047142141783
- type: precision
value: 89.86980470706058
- type: recall
value: 92.7891837756635
task:
type: BitextMining
- dataset:
config: rus_Cyrl-zul_Latn
name: MTEB NTREXBitextMining (rus_Cyrl-zul_Latn)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 87.43114672008012
- type: f1
value: 84.04618833011422
- type: main_score
value: 84.04618833011422
- type: precision
value: 82.52259341393041
- type: recall
value: 87.43114672008012
task:
type: BitextMining
- dataset:
config: slk_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (slk_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.34301452178268
- type: f1
value: 94.20392493502158
- type: main_score
value: 94.20392493502158
- type: precision
value: 93.67384409948257
- type: recall
value: 95.34301452178268
task:
type: BitextMining
- dataset:
config: slv_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (slv_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 92.23835753630446
- type: f1
value: 90.5061759305625
- type: main_score
value: 90.5061759305625
- type: precision
value: 89.74231188051918
- type: recall
value: 92.23835753630446
task:
type: BitextMining
- dataset:
config: spa_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (spa_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.54481722583876
- type: f1
value: 95.54665331330328
- type: main_score
value: 95.54665331330328
- type: precision
value: 95.06342847604739
- type: recall
value: 96.54481722583876
task:
type: BitextMining
- dataset:
config: srp_Cyrl-rus_Cyrl
name: MTEB NTREXBitextMining (srp_Cyrl-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 83.62543815723585
- type: f1
value: 80.77095672699816
- type: main_score
value: 80.77095672699816
- type: precision
value: 79.74674313056886
- type: recall
value: 83.62543815723585
task:
type: BitextMining
- dataset:
config: srp_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (srp_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 94.44166249374061
- type: f1
value: 93.00733206591994
- type: main_score
value: 93.00733206591994
- type: precision
value: 92.37203026762366
- type: recall
value: 94.44166249374061
task:
type: BitextMining
- dataset:
config: swa_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (swa_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 90.23535302954431
- type: f1
value: 87.89596482636041
- type: main_score
value: 87.89596482636041
- type: precision
value: 86.87060227370694
- type: recall
value: 90.23535302954431
task:
type: BitextMining
- dataset:
config: swe_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (swe_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 95.44316474712068
- type: f1
value: 94.1896177599733
- type: main_score
value: 94.1896177599733
- type: precision
value: 93.61542313470206
- type: recall
value: 95.44316474712068
task:
type: BitextMining
- dataset:
config: tam_Taml-rus_Cyrl
name: MTEB NTREXBitextMining (tam_Taml-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 89.68452679018529
- type: f1
value: 87.37341160650037
- type: main_score
value: 87.37341160650037
- type: precision
value: 86.38389402285247
- type: recall
value: 89.68452679018529
task:
type: BitextMining
- dataset:
config: tur_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (tur_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.89083625438157
- type: f1
value: 92.33892505424804
- type: main_score
value: 92.33892505424804
- type: precision
value: 91.63125640842216
- type: recall
value: 93.89083625438157
task:
type: BitextMining
- dataset:
config: ukr_Cyrl-rus_Cyrl
name: MTEB NTREXBitextMining (ukr_Cyrl-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 96.14421632448673
- type: f1
value: 95.11028447433054
- type: main_score
value: 95.11028447433054
- type: precision
value: 94.62944416624937
- type: recall
value: 96.14421632448673
task:
type: BitextMining
- dataset:
config: vie_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (vie_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 93.79068602904357
- type: f1
value: 92.14989150392256
- type: main_score
value: 92.14989150392256
- type: precision
value: 91.39292271740945
- type: recall
value: 93.79068602904357
task:
type: BitextMining
- dataset:
config: zho_Hant-rus_Cyrl
name: MTEB NTREXBitextMining (zho_Hant-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 89.13370055082625
- type: f1
value: 86.51514618639217
- type: main_score
value: 86.51514618639217
- type: precision
value: 85.383920035898
- type: recall
value: 89.13370055082625
task:
type: BitextMining
- dataset:
config: zul_Latn-rus_Cyrl
name: MTEB NTREXBitextMining (zul_Latn-rus_Cyrl)
revision: ed9a4403ed4adbfaf4aab56d5b2709e9f6c3ba33
split: test
type: mteb/NTREX
metrics:
- type: accuracy
value: 81.17175763645467
- type: f1
value: 77.72331766047338
- type: main_score
value: 77.72331766047338
- type: precision
value: 76.24629555848075
- type: recall
value: 81.17175763645467
task:
type: BitextMining
- dataset:
config: ru
name: MTEB OpusparcusPC (ru)
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
split: test.full
type: GEM/opusparcus
metrics:
- type: cosine_accuracy
value: 73.09136420525657
- type: cosine_accuracy_threshold
value: 87.70400881767273
- type: cosine_ap
value: 86.51938550599533
- type: cosine_f1
value: 80.84358523725834
- type: cosine_f1_threshold
value: 86.90648078918457
- type: cosine_precision
value: 73.24840764331209
- type: cosine_recall
value: 90.19607843137256
- type: dot_accuracy
value: 73.09136420525657
- type: dot_accuracy_threshold
value: 87.7040147781372
- type: dot_ap
value: 86.51934769946833
- type: dot_f1
value: 80.84358523725834
- type: dot_f1_threshold
value: 86.90648078918457
- type: dot_precision
value: 73.24840764331209
- type: dot_recall
value: 90.19607843137256
- type: euclidean_accuracy
value: 73.09136420525657
- type: euclidean_accuracy_threshold
value: 49.590304493904114
- type: euclidean_ap
value: 86.51934769946833
- type: euclidean_f1
value: 80.84358523725834
- type: euclidean_f1_threshold
value: 51.173269748687744
- type: euclidean_precision
value: 73.24840764331209
- type: euclidean_recall
value: 90.19607843137256
- type: main_score
value: 86.51976811057995
- type: manhattan_accuracy
value: 73.40425531914893
- type: manhattan_accuracy_threshold
value: 757.8278541564941
- type: manhattan_ap
value: 86.51976811057995
- type: manhattan_f1
value: 80.92898615453328
- type: manhattan_f1_threshold
value: 778.3821105957031
- type: manhattan_precision
value: 74.32321575061526
- type: manhattan_recall
value: 88.8235294117647
- type: max_ap
value: 86.51976811057995
- type: max_f1
value: 80.92898615453328
- type: max_precision
value: 74.32321575061526
- type: max_recall
value: 90.19607843137256
- type: similarity_accuracy
value: 73.09136420525657
- type: similarity_accuracy_threshold
value: 87.70400881767273
- type: similarity_ap
value: 86.51938550599533
- type: similarity_f1
value: 80.84358523725834
- type: similarity_f1_threshold
value: 86.90648078918457
- type: similarity_precision
value: 73.24840764331209
- type: similarity_recall
value: 90.19607843137256
task:
type: PairClassification
- dataset:
config: russian
name: MTEB PublicHealthQA (russian)
revision: main
split: test
type: xhluca/publichealth-qa
metrics:
- type: main_score
value: 79.303
- type: map_at_1
value: 61.538000000000004
- type: map_at_10
value: 74.449
- type: map_at_100
value: 74.687
- type: map_at_1000
value: 74.687
- type: map_at_20
value: 74.589
- type: map_at_3
value: 73.333
- type: map_at_5
value: 74.256
- type: mrr_at_1
value: 61.53846153846154
- type: mrr_at_10
value: 74.44871794871794
- type: mrr_at_100
value: 74.68730304304074
- type: mrr_at_1000
value: 74.68730304304074
- type: mrr_at_20
value: 74.58857808857809
- type: mrr_at_3
value: 73.33333333333333
- type: mrr_at_5
value: 74.25641025641025
- type: nauc_map_at_1000_diff1
value: 61.375798048778506
- type: nauc_map_at_1000_max
value: 51.37093181241067
- type: nauc_map_at_1000_std
value: 41.735794471409015
- type: nauc_map_at_100_diff1
value: 61.375798048778506
- type: nauc_map_at_100_max
value: 51.37093181241067
- type: nauc_map_at_100_std
value: 41.735794471409015
- type: nauc_map_at_10_diff1
value: 61.12796039757213
- type: nauc_map_at_10_max
value: 51.843445267118014
- type: nauc_map_at_10_std
value: 42.243121474939365
- type: nauc_map_at_1_diff1
value: 66.39100974909151
- type: nauc_map_at_1_max
value: 44.77165601342703
- type: nauc_map_at_1_std
value: 32.38542979413408
- type: nauc_map_at_20_diff1
value: 61.16611123434347
- type: nauc_map_at_20_max
value: 51.52605092407306
- type: nauc_map_at_20_std
value: 41.94787773313971
- type: nauc_map_at_3_diff1
value: 61.40157474408937
- type: nauc_map_at_3_max
value: 51.47230077853947
- type: nauc_map_at_3_std
value: 42.63540269440141
- type: nauc_map_at_5_diff1
value: 61.07631147583098
- type: nauc_map_at_5_max
value: 52.02626939341523
- type: nauc_map_at_5_std
value: 42.511607332150334
- type: nauc_mrr_at_1000_diff1
value: 61.375798048778506
- type: nauc_mrr_at_1000_max
value: 51.37093181241067
- type: nauc_mrr_at_1000_std
value: 41.735794471409015
- type: nauc_mrr_at_100_diff1
value: 61.375798048778506
- type: nauc_mrr_at_100_max
value: 51.37093181241067
- type: nauc_mrr_at_100_std
value: 41.735794471409015
- type: nauc_mrr_at_10_diff1
value: 61.12796039757213
- type: nauc_mrr_at_10_max
value: 51.843445267118014
- type: nauc_mrr_at_10_std
value: 42.243121474939365
- type: nauc_mrr_at_1_diff1
value: 66.39100974909151
- type: nauc_mrr_at_1_max
value: 44.77165601342703
- type: nauc_mrr_at_1_std
value: 32.38542979413408
- type: nauc_mrr_at_20_diff1
value: 61.16611123434347
- type: nauc_mrr_at_20_max
value: 51.52605092407306
- type: nauc_mrr_at_20_std
value: 41.94787773313971
- type: nauc_mrr_at_3_diff1
value: 61.40157474408937
- type: nauc_mrr_at_3_max
value: 51.47230077853947
- type: nauc_mrr_at_3_std
value: 42.63540269440141
- type: nauc_mrr_at_5_diff1
value: 61.07631147583098
- type: nauc_mrr_at_5_max
value: 52.02626939341523
- type: nauc_mrr_at_5_std
value: 42.511607332150334
- type: nauc_ndcg_at_1000_diff1
value: 60.54821630436157
- type: nauc_ndcg_at_1000_max
value: 52.584328363863634
- type: nauc_ndcg_at_1000_std
value: 43.306961101645946
- type: nauc_ndcg_at_100_diff1
value: 60.54821630436157
- type: nauc_ndcg_at_100_max
value: 52.584328363863634
- type: nauc_ndcg_at_100_std
value: 43.306961101645946
- type: nauc_ndcg_at_10_diff1
value: 58.800340278109886
- type: nauc_ndcg_at_10_max
value: 55.31050771670664
- type: nauc_ndcg_at_10_std
value: 46.40931672942848
- type: nauc_ndcg_at_1_diff1
value: 66.39100974909151
- type: nauc_ndcg_at_1_max
value: 44.77165601342703
- type: nauc_ndcg_at_1_std
value: 32.38542979413408
- type: nauc_ndcg_at_20_diff1
value: 58.88690479697946
- type: nauc_ndcg_at_20_max
value: 54.19269661177923
- type: nauc_ndcg_at_20_std
value: 45.39305589413174
- type: nauc_ndcg_at_3_diff1
value: 59.61866351451574
- type: nauc_ndcg_at_3_max
value: 54.23992718744033
- type: nauc_ndcg_at_3_std
value: 46.997379274101
- type: nauc_ndcg_at_5_diff1
value: 58.70739588066225
- type: nauc_ndcg_at_5_max
value: 55.76766902539152
- type: nauc_ndcg_at_5_std
value: 47.10553115762958
- type: nauc_precision_at_1000_diff1
value: 100.0
- type: nauc_precision_at_1000_max
value: 100.0
- type: nauc_precision_at_1000_std
value: 100.0
- type: nauc_precision_at_100_diff1
value: .nan
- type: nauc_precision_at_100_max
value: .nan
- type: nauc_precision_at_100_std
value: .nan
- type: nauc_precision_at_10_diff1
value: 35.72622112397501
- type: nauc_precision_at_10_max
value: 89.84297108673948
- type: nauc_precision_at_10_std
value: 86.60269192422707
- type: nauc_precision_at_1_diff1
value: 66.39100974909151
- type: nauc_precision_at_1_max
value: 44.77165601342703
- type: nauc_precision_at_1_std
value: 32.38542979413408
- type: nauc_precision_at_20_diff1
value: 29.188449183726433
- type: nauc_precision_at_20_max
value: 86.45729478231968
- type: nauc_precision_at_20_std
value: 86.45729478231968
- type: nauc_precision_at_3_diff1
value: 50.294126629236224
- type: nauc_precision_at_3_max
value: 68.98223127174579
- type: nauc_precision_at_3_std
value: 70.31195520376356
- type: nauc_precision_at_5_diff1
value: 39.648884288124385
- type: nauc_precision_at_5_max
value: 86.3409770687935
- type: nauc_precision_at_5_std
value: 83.74875373878356
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: .nan
- type: nauc_recall_at_100_max
value: .nan
- type: nauc_recall_at_100_std
value: .nan
- type: nauc_recall_at_10_diff1
value: 35.72622112397516
- type: nauc_recall_at_10_max
value: 89.84297108673968
- type: nauc_recall_at_10_std
value: 86.60269192422749
- type: nauc_recall_at_1_diff1
value: 66.39100974909151
- type: nauc_recall_at_1_max
value: 44.77165601342703
- type: nauc_recall_at_1_std
value: 32.38542979413408
- type: nauc_recall_at_20_diff1
value: 29.188449183726323
- type: nauc_recall_at_20_max
value: 86.45729478231985
- type: nauc_recall_at_20_std
value: 86.45729478231985
- type: nauc_recall_at_3_diff1
value: 50.29412662923603
- type: nauc_recall_at_3_max
value: 68.98223127174562
- type: nauc_recall_at_3_std
value: 70.31195520376346
- type: nauc_recall_at_5_diff1
value: 39.64888428812445
- type: nauc_recall_at_5_max
value: 86.34097706879359
- type: nauc_recall_at_5_std
value: 83.74875373878366
- type: ndcg_at_1
value: 61.538000000000004
- type: ndcg_at_10
value: 79.303
- type: ndcg_at_100
value: 80.557
- type: ndcg_at_1000
value: 80.557
- type: ndcg_at_20
value: 79.732
- type: ndcg_at_3
value: 77.033
- type: ndcg_at_5
value: 78.818
- type: precision_at_1
value: 61.538000000000004
- type: precision_at_10
value: 9.385
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.769
- type: precision_at_3
value: 29.231
- type: precision_at_5
value: 18.462
- type: recall_at_1
value: 61.538000000000004
- type: recall_at_10
value: 93.84599999999999
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 95.38499999999999
- type: recall_at_3
value: 87.69200000000001
- type: recall_at_5
value: 92.308
task:
type: Retrieval
- dataset:
config: default
name: MTEB RUParaPhraserSTS (default)
revision: 43265056790b8f7c59e0139acb4be0a8dad2c8f4
split: test
type: merionum/ru_paraphraser
metrics:
- type: cosine_pearson
value: 64.73554596215753
- type: cosine_spearman
value: 70.45849652271855
- type: euclidean_pearson
value: 68.08069844834267
- type: euclidean_spearman
value: 70.45854872959124
- type: main_score
value: 70.45849652271855
- type: manhattan_pearson
value: 67.88325986519624
- type: manhattan_spearman
value: 70.21131896834542
- type: pearson
value: 64.73554596215753
- type: spearman
value: 70.45849652271855
task:
type: STS
- dataset:
config: default
name: MTEB RiaNewsRetrieval (default)
revision: 82374b0bbacda6114f39ff9c5b925fa1512ca5d7
split: test
type: ai-forever/ria-news-retrieval
metrics:
- type: main_score
value: 70.00999999999999
- type: map_at_1
value: 55.97
- type: map_at_10
value: 65.59700000000001
- type: map_at_100
value: 66.057
- type: map_at_1000
value: 66.074
- type: map_at_20
value: 65.892
- type: map_at_3
value: 63.74999999999999
- type: map_at_5
value: 64.84299999999999
- type: mrr_at_1
value: 55.88999999999999
- type: mrr_at_10
value: 65.55873015872977
- type: mrr_at_100
value: 66.01891495129716
- type: mrr_at_1000
value: 66.03538391493299
- type: mrr_at_20
value: 65.85351193431555
- type: mrr_at_3
value: 63.7133333333329
- type: mrr_at_5
value: 64.80483333333268
- type: nauc_map_at_1000_diff1
value: 65.95332946436318
- type: nauc_map_at_1000_max
value: 28.21204156197811
- type: nauc_map_at_1000_std
value: -13.139245767083743
- type: nauc_map_at_100_diff1
value: 65.94763105024367
- type: nauc_map_at_100_max
value: 28.212832170078205
- type: nauc_map_at_100_std
value: -13.131425849370665
- type: nauc_map_at_10_diff1
value: 65.88455089448388
- type: nauc_map_at_10_max
value: 28.13555838776792
- type: nauc_map_at_10_std
value: -13.326989827081023
- type: nauc_map_at_1_diff1
value: 69.31275711813979
- type: nauc_map_at_1_max
value: 26.386708520283758
- type: nauc_map_at_1_std
value: -14.434616447245464
- type: nauc_map_at_20_diff1
value: 65.91227032605677
- type: nauc_map_at_20_max
value: 28.20538655600886
- type: nauc_map_at_20_std
value: -13.191148834410274
- type: nauc_map_at_3_diff1
value: 66.0051677952641
- type: nauc_map_at_3_max
value: 28.25443420019022
- type: nauc_map_at_3_std
value: -13.893284109029558
- type: nauc_map_at_5_diff1
value: 65.89784348297898
- type: nauc_map_at_5_max
value: 28.26449765184183
- type: nauc_map_at_5_std
value: -13.506692912805008
- type: nauc_mrr_at_1000_diff1
value: 66.06599513750889
- type: nauc_mrr_at_1000_max
value: 28.191556650722287
- type: nauc_mrr_at_1000_std
value: -13.098487982930276
- type: nauc_mrr_at_100_diff1
value: 66.0602307977725
- type: nauc_mrr_at_100_max
value: 28.19235936624514
- type: nauc_mrr_at_100_std
value: -13.09069677716269
- type: nauc_mrr_at_10_diff1
value: 65.99546819079403
- type: nauc_mrr_at_10_max
value: 28.11556170120022
- type: nauc_mrr_at_10_std
value: -13.286711073897553
- type: nauc_mrr_at_1_diff1
value: 69.49541040517995
- type: nauc_mrr_at_1_max
value: 26.354622707276153
- type: nauc_mrr_at_1_std
value: -14.358839778104695
- type: nauc_mrr_at_20_diff1
value: 66.02427154257936
- type: nauc_mrr_at_20_max
value: 28.18509383563462
- type: nauc_mrr_at_20_std
value: -13.150543398429
- type: nauc_mrr_at_3_diff1
value: 66.11258119082618
- type: nauc_mrr_at_3_max
value: 28.239510722224004
- type: nauc_mrr_at_3_std
value: -13.857249251136269
- type: nauc_mrr_at_5_diff1
value: 66.00633786765626
- type: nauc_mrr_at_5_max
value: 28.244875152193032
- type: nauc_mrr_at_5_std
value: -13.467206028704434
- type: nauc_ndcg_at_1000_diff1
value: 65.02876183314446
- type: nauc_ndcg_at_1000_max
value: 29.109368390197194
- type: nauc_ndcg_at_1000_std
value: -11.56514359821697
- type: nauc_ndcg_at_100_diff1
value: 64.85837726893713
- type: nauc_ndcg_at_100_max
value: 29.19990133137256
- type: nauc_ndcg_at_100_std
value: -11.17450348161257
- type: nauc_ndcg_at_10_diff1
value: 64.53842705024796
- type: nauc_ndcg_at_10_max
value: 28.748734006088526
- type: nauc_ndcg_at_10_std
value: -12.331395505957063
- type: nauc_ndcg_at_1_diff1
value: 69.31275711813979
- type: nauc_ndcg_at_1_max
value: 26.386708520283758
- type: nauc_ndcg_at_1_std
value: -14.434616447245464
- type: nauc_ndcg_at_20_diff1
value: 64.59017606740504
- type: nauc_ndcg_at_20_max
value: 29.047332048898017
- type: nauc_ndcg_at_20_std
value: -11.746548770195954
- type: nauc_ndcg_at_3_diff1
value: 64.87900935713822
- type: nauc_ndcg_at_3_max
value: 28.953157521204403
- type: nauc_ndcg_at_3_std
value: -13.639947228880942
- type: nauc_ndcg_at_5_diff1
value: 64.61466953479034
- type: nauc_ndcg_at_5_max
value: 29.01899321868392
- type: nauc_ndcg_at_5_std
value: -12.85356404799802
- type: nauc_precision_at_1000_diff1
value: 48.85481417002382
- type: nauc_precision_at_1000_max
value: 57.129837326696375
- type: nauc_precision_at_1000_std
value: 37.889524999906435
- type: nauc_precision_at_100_diff1
value: 53.374672326788264
- type: nauc_precision_at_100_max
value: 43.819333062207974
- type: nauc_precision_at_100_std
value: 21.387064885769362
- type: nauc_precision_at_10_diff1
value: 57.66571169774445
- type: nauc_precision_at_10_max
value: 31.779694837242033
- type: nauc_precision_at_10_std
value: -6.6248399147180255
- type: nauc_precision_at_1_diff1
value: 69.31275711813979
- type: nauc_precision_at_1_max
value: 26.386708520283758
- type: nauc_precision_at_1_std
value: -14.434616447245464
- type: nauc_precision_at_20_diff1
value: 55.93570036001682
- type: nauc_precision_at_20_max
value: 34.98640173388743
- type: nauc_precision_at_20_std
value: -0.36518465159326174
- type: nauc_precision_at_3_diff1
value: 60.94100093991508
- type: nauc_precision_at_3_max
value: 31.422239034357673
- type: nauc_precision_at_3_std
value: -12.72576556537896
- type: nauc_precision_at_5_diff1
value: 59.450505195434054
- type: nauc_precision_at_5_max
value: 32.07638712418377
- type: nauc_precision_at_5_std
value: -10.024459103498598
- type: nauc_recall_at_1000_diff1
value: 48.854814170024184
- type: nauc_recall_at_1000_max
value: 57.129837326697164
- type: nauc_recall_at_1000_std
value: 37.88952499990672
- type: nauc_recall_at_100_diff1
value: 53.37467232678822
- type: nauc_recall_at_100_max
value: 43.8193330622079
- type: nauc_recall_at_100_std
value: 21.387064885769398
- type: nauc_recall_at_10_diff1
value: 57.66571169774447
- type: nauc_recall_at_10_max
value: 31.779694837242133
- type: nauc_recall_at_10_std
value: -6.62483991471789
- type: nauc_recall_at_1_diff1
value: 69.31275711813979
- type: nauc_recall_at_1_max
value: 26.386708520283758
- type: nauc_recall_at_1_std
value: -14.434616447245464
- type: nauc_recall_at_20_diff1
value: 55.93570036001682
- type: nauc_recall_at_20_max
value: 34.986401733887554
- type: nauc_recall_at_20_std
value: -0.3651846515931506
- type: nauc_recall_at_3_diff1
value: 60.94100093991499
- type: nauc_recall_at_3_max
value: 31.422239034357606
- type: nauc_recall_at_3_std
value: -12.725765565378966
- type: nauc_recall_at_5_diff1
value: 59.450505195434125
- type: nauc_recall_at_5_max
value: 32.07638712418387
- type: nauc_recall_at_5_std
value: -10.024459103498472
- type: ndcg_at_1
value: 55.97
- type: ndcg_at_10
value: 70.00999999999999
- type: ndcg_at_100
value: 72.20100000000001
- type: ndcg_at_1000
value: 72.65599999999999
- type: ndcg_at_20
value: 71.068
- type: ndcg_at_3
value: 66.228
- type: ndcg_at_5
value: 68.191
- type: precision_at_1
value: 55.97
- type: precision_at_10
value: 8.373999999999999
- type: precision_at_100
value: 0.9390000000000001
- type: precision_at_1000
value: 0.097
- type: precision_at_20
value: 4.3950000000000005
- type: precision_at_3
value: 24.46
- type: precision_at_5
value: 15.626000000000001
- type: recall_at_1
value: 55.97
- type: recall_at_10
value: 83.74000000000001
- type: recall_at_100
value: 93.87
- type: recall_at_1000
value: 97.49
- type: recall_at_20
value: 87.89
- type: recall_at_3
value: 73.38
- type: recall_at_5
value: 78.13
task:
type: Retrieval
- dataset:
config: default
name: MTEB RuBQReranking (default)
revision: 2e96b8f098fa4b0950fc58eacadeb31c0d0c7fa2
split: test
type: ai-forever/rubq-reranking
metrics:
- type: main_score
value: 71.44929565043827
- type: map
value: 71.44929565043827
- type: mrr
value: 77.78391820945014
- type: nAUC_map_diff1
value: 38.140840668080244
- type: nAUC_map_max
value: 27.54328688105381
- type: nAUC_map_std
value: 16.81572082284672
- type: nAUC_mrr_diff1
value: 44.51350415961509
- type: nAUC_mrr_max
value: 36.491182016669754
- type: nAUC_mrr_std
value: 22.47139593052269
task:
type: Reranking
- dataset:
config: default
name: MTEB RuBQRetrieval (default)
revision: e19b6ffa60b3bc248e0b41f4cc37c26a55c2a67b
split: test
type: ai-forever/rubq-retrieval
metrics:
- type: main_score
value: 68.529
- type: map_at_1
value: 42.529
- type: map_at_10
value: 60.864
- type: map_at_100
value: 61.868
- type: map_at_1000
value: 61.907000000000004
- type: map_at_20
value: 61.596
- type: map_at_3
value: 55.701
- type: map_at_5
value: 58.78
- type: mrr_at_1
value: 60.57919621749409
- type: mrr_at_10
value: 70.55614188149649
- type: mrr_at_100
value: 70.88383816664494
- type: mrr_at_1000
value: 70.89719252668833
- type: mrr_at_20
value: 70.79839750105347
- type: mrr_at_3
value: 68.4594168636722
- type: mrr_at_5
value: 69.67100078802214
- type: nauc_map_at_1000_diff1
value: 40.67438785660885
- type: nauc_map_at_1000_max
value: 32.79981738507424
- type: nauc_map_at_1000_std
value: -6.873402600044831
- type: nauc_map_at_100_diff1
value: 40.65643664443284
- type: nauc_map_at_100_max
value: 32.81594799919249
- type: nauc_map_at_100_std
value: -6.8473246794498195
- type: nauc_map_at_10_diff1
value: 40.39048268484908
- type: nauc_map_at_10_max
value: 32.403242161479525
- type: nauc_map_at_10_std
value: -7.344413799841244
- type: nauc_map_at_1_diff1
value: 44.36306892906905
- type: nauc_map_at_1_max
value: 25.61348630699028
- type: nauc_map_at_1_std
value: -8.713074613333902
- type: nauc_map_at_20_diff1
value: 40.530326570124615
- type: nauc_map_at_20_max
value: 32.74028319323205
- type: nauc_map_at_20_std
value: -7.008180779820569
- type: nauc_map_at_3_diff1
value: 40.764924859364044
- type: nauc_map_at_3_max
value: 29.809671682025336
- type: nauc_map_at_3_std
value: -9.205620202725564
- type: nauc_map_at_5_diff1
value: 40.88599496021476
- type: nauc_map_at_5_max
value: 32.1701894666848
- type: nauc_map_at_5_std
value: -7.801251849010623
- type: nauc_mrr_at_1000_diff1
value: 48.64181373540728
- type: nauc_mrr_at_1000_max
value: 40.136947990653546
- type: nauc_mrr_at_1000_std
value: -7.250260497468805
- type: nauc_mrr_at_100_diff1
value: 48.63349902496212
- type: nauc_mrr_at_100_max
value: 40.14510559704008
- type: nauc_mrr_at_100_std
value: -7.228702374801103
- type: nauc_mrr_at_10_diff1
value: 48.58580560194813
- type: nauc_mrr_at_10_max
value: 40.15075599433366
- type: nauc_mrr_at_10_std
value: -7.267928771548688
- type: nauc_mrr_at_1_diff1
value: 51.47535097164919
- type: nauc_mrr_at_1_max
value: 38.23579750430856
- type: nauc_mrr_at_1_std
value: -9.187785187137633
- type: nauc_mrr_at_20_diff1
value: 48.58688378336222
- type: nauc_mrr_at_20_max
value: 40.13408744088299
- type: nauc_mrr_at_20_std
value: -7.283132775160146
- type: nauc_mrr_at_3_diff1
value: 48.66833005454742
- type: nauc_mrr_at_3_max
value: 40.07987333638038
- type: nauc_mrr_at_3_std
value: -7.738819947521418
- type: nauc_mrr_at_5_diff1
value: 48.76536305941537
- type: nauc_mrr_at_5_max
value: 40.381929739522185
- type: nauc_mrr_at_5_std
value: -7.592858318378928
- type: nauc_ndcg_at_1000_diff1
value: 41.67304442004693
- type: nauc_ndcg_at_1000_max
value: 35.84126926253235
- type: nauc_ndcg_at_1000_std
value: -4.78971011604655
- type: nauc_ndcg_at_100_diff1
value: 41.16918850185783
- type: nauc_ndcg_at_100_max
value: 36.082461962326505
- type: nauc_ndcg_at_100_std
value: -4.092442251697269
- type: nauc_ndcg_at_10_diff1
value: 40.300065598615205
- type: nauc_ndcg_at_10_max
value: 34.87866296788365
- type: nauc_ndcg_at_10_std
value: -5.866529277842453
- type: nauc_ndcg_at_1_diff1
value: 51.74612915209495
- type: nauc_ndcg_at_1_max
value: 37.71907067970078
- type: nauc_ndcg_at_1_std
value: -9.064124266098696
- type: nauc_ndcg_at_20_diff1
value: 40.493949850214584
- type: nauc_ndcg_at_20_max
value: 35.69331503650286
- type: nauc_ndcg_at_20_std
value: -4.995310342975443
- type: nauc_ndcg_at_3_diff1
value: 41.269443212112364
- type: nauc_ndcg_at_3_max
value: 32.572844460953334
- type: nauc_ndcg_at_3_std
value: -9.063015396458791
- type: nauc_ndcg_at_5_diff1
value: 41.37039652522888
- type: nauc_ndcg_at_5_max
value: 34.67416011393571
- type: nauc_ndcg_at_5_std
value: -7.106845569862319
- type: nauc_precision_at_1000_diff1
value: -9.571769961090155
- type: nauc_precision_at_1000_max
value: 5.574782583417188
- type: nauc_precision_at_1000_std
value: 7.28333847923847
- type: nauc_precision_at_100_diff1
value: -7.7405012003383735
- type: nauc_precision_at_100_max
value: 9.67745355070353
- type: nauc_precision_at_100_std
value: 9.327890294080992
- type: nauc_precision_at_10_diff1
value: -1.006879647532931
- type: nauc_precision_at_10_max
value: 15.899825481231064
- type: nauc_precision_at_10_std
value: 4.2284084852153105
- type: nauc_precision_at_1_diff1
value: 51.74612915209495
- type: nauc_precision_at_1_max
value: 37.71907067970078
- type: nauc_precision_at_1_std
value: -9.064124266098696
- type: nauc_precision_at_20_diff1
value: -4.982301544401409
- type: nauc_precision_at_20_max
value: 13.241674471380568
- type: nauc_precision_at_20_std
value: 7.052280133821539
- type: nauc_precision_at_3_diff1
value: 15.442614376387374
- type: nauc_precision_at_3_max
value: 25.12695418083
- type: nauc_precision_at_3_std
value: -3.1150066697920638
- type: nauc_precision_at_5_diff1
value: 8.381026072692444
- type: nauc_precision_at_5_max
value: 22.839056540604822
- type: nauc_precision_at_5_std
value: 1.5126905486524331
- type: nauc_recall_at_1000_diff1
value: -0.8869709920433502
- type: nauc_recall_at_1000_max
value: 45.092324433377264
- type: nauc_recall_at_1000_std
value: 62.21264093315108
- type: nauc_recall_at_100_diff1
value: 16.036715011075714
- type: nauc_recall_at_100_max
value: 39.79963411771158
- type: nauc_recall_at_100_std
value: 28.41850069503361
- type: nauc_recall_at_10_diff1
value: 25.189622794479998
- type: nauc_recall_at_10_max
value: 30.82355277039427
- type: nauc_recall_at_10_std
value: 0.0964544736531047
- type: nauc_recall_at_1_diff1
value: 44.36306892906905
- type: nauc_recall_at_1_max
value: 25.61348630699028
- type: nauc_recall_at_1_std
value: -8.713074613333902
- type: nauc_recall_at_20_diff1
value: 20.43424504746087
- type: nauc_recall_at_20_max
value: 33.96010554649377
- type: nauc_recall_at_20_std
value: 6.900984030301936
- type: nauc_recall_at_3_diff1
value: 33.86531858793492
- type: nauc_recall_at_3_max
value: 27.725692256711188
- type: nauc_recall_at_3_std
value: -8.533124289305709
- type: nauc_recall_at_5_diff1
value: 32.006964557701686
- type: nauc_recall_at_5_max
value: 31.493370659289806
- type: nauc_recall_at_5_std
value: -4.8639793547793255
- type: ndcg_at_1
value: 60.461
- type: ndcg_at_10
value: 68.529
- type: ndcg_at_100
value: 71.664
- type: ndcg_at_1000
value: 72.396
- type: ndcg_at_20
value: 70.344
- type: ndcg_at_3
value: 61.550000000000004
- type: ndcg_at_5
value: 64.948
- type: precision_at_1
value: 60.461
- type: precision_at_10
value: 13.28
- type: precision_at_100
value: 1.555
- type: precision_at_1000
value: 0.164
- type: precision_at_20
value: 7.216
- type: precision_at_3
value: 33.077
- type: precision_at_5
value: 23.014000000000003
- type: recall_at_1
value: 42.529
- type: recall_at_10
value: 81.169
- type: recall_at_100
value: 93.154
- type: recall_at_1000
value: 98.18299999999999
- type: recall_at_20
value: 87.132
- type: recall_at_3
value: 63.905
- type: recall_at_5
value: 71.967
task:
type: Retrieval
- dataset:
config: default
name: MTEB RuReviewsClassification (default)
revision: f6d2c31f4dc6b88f468552750bfec05b4b41b05a
split: test
type: ai-forever/ru-reviews-classification
metrics:
- type: accuracy
value: 61.17675781250001
- type: f1
value: 60.354535346041374
- type: f1_weighted
value: 60.35437313166116
- type: main_score
value: 61.17675781250001
task:
type: Classification
- dataset:
config: default
name: MTEB RuSTSBenchmarkSTS (default)
revision: 7cf24f325c6da6195df55bef3d86b5e0616f3018
split: test
type: ai-forever/ru-stsbenchmark-sts
metrics:
- type: cosine_pearson
value: 78.1301041727274
- type: cosine_spearman
value: 78.08238025421747
- type: euclidean_pearson
value: 77.35224254583635
- type: euclidean_spearman
value: 78.08235336582496
- type: main_score
value: 78.08238025421747
- type: manhattan_pearson
value: 77.24138550052075
- type: manhattan_spearman
value: 77.98199107904142
- type: pearson
value: 78.1301041727274
- type: spearman
value: 78.08238025421747
task:
type: STS
- dataset:
config: default
name: MTEB RuSciBenchGRNTIClassification (default)
revision: 673a610d6d3dd91a547a0d57ae1b56f37ebbf6a1
split: test
type: ai-forever/ru-scibench-grnti-classification
metrics:
- type: accuracy
value: 54.990234375
- type: f1
value: 53.537019057131374
- type: f1_weighted
value: 53.552745354520766
- type: main_score
value: 54.990234375
task:
type: Classification
- dataset:
config: default
name: MTEB RuSciBenchGRNTIClusteringP2P (default)
revision: 673a610d6d3dd91a547a0d57ae1b56f37ebbf6a1
split: test
type: ai-forever/ru-scibench-grnti-classification
metrics:
- type: main_score
value: 50.775228895355106
- type: v_measure
value: 50.775228895355106
- type: v_measure_std
value: 0.9533571150165796
task:
type: Clustering
- dataset:
config: default
name: MTEB RuSciBenchOECDClassification (default)
revision: 26c88e99dcaba32bb45d0e1bfc21902337f6d471
split: test
type: ai-forever/ru-scibench-oecd-classification
metrics:
- type: accuracy
value: 41.71875
- type: f1
value: 39.289100975858304
- type: f1_weighted
value: 39.29257829217775
- type: main_score
value: 41.71875
task:
type: Classification
- dataset:
config: default
name: MTEB RuSciBenchOECDClusteringP2P (default)
revision: 26c88e99dcaba32bb45d0e1bfc21902337f6d471
split: test
type: ai-forever/ru-scibench-oecd-classification
metrics:
- type: main_score
value: 45.10904808834516
- type: v_measure
value: 45.10904808834516
- type: v_measure_std
value: 1.0572643410157534
task:
type: Clustering
- dataset:
config: rus_Cyrl
name: MTEB SIB200Classification (rus_Cyrl)
revision: a74d7350ea12af010cfb1c21e34f1f81fd2e615b
split: test
type: mteb/sib200
metrics:
- type: accuracy
value: 66.36363636363637
- type: f1
value: 64.6940336621617
- type: f1_weighted
value: 66.43317771876966
- type: main_score
value: 66.36363636363637
task:
type: Classification
- dataset:
config: rus_Cyrl
name: MTEB SIB200ClusteringS2S (rus_Cyrl)
revision: a74d7350ea12af010cfb1c21e34f1f81fd2e615b
split: test
type: mteb/sib200
metrics:
- type: main_score
value: 33.99178497314711
- type: v_measure
value: 33.99178497314711
- type: v_measure_std
value: 4.036337464043786
task:
type: Clustering
- dataset:
config: ru
name: MTEB STS22.v2 (ru)
revision: d31f33a128469b20e357535c39b82fb3c3f6f2bd
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cosine_pearson
value: 50.724322379215934
- type: cosine_spearman
value: 59.90449732164651
- type: euclidean_pearson
value: 50.227545226784024
- type: euclidean_spearman
value: 59.898906527601085
- type: main_score
value: 59.90449732164651
- type: manhattan_pearson
value: 50.21762139819405
- type: manhattan_spearman
value: 59.761039813759
- type: pearson
value: 50.724322379215934
- type: spearman
value: 59.90449732164651
task:
type: STS
- dataset:
config: ru
name: MTEB STSBenchmarkMultilingualSTS (ru)
revision: 29afa2569dcedaaa2fe6a3dcfebab33d28b82e8c
split: dev
type: mteb/stsb_multi_mt
metrics:
- type: cosine_pearson
value: 78.43928769569945
- type: cosine_spearman
value: 78.23961768018884
- type: euclidean_pearson
value: 77.4718694027985
- type: euclidean_spearman
value: 78.23887044760475
- type: main_score
value: 78.23961768018884
- type: manhattan_pearson
value: 77.34517128089547
- type: manhattan_spearman
value: 78.1146477340426
- type: pearson
value: 78.43928769569945
- type: spearman
value: 78.23961768018884
task:
type: STS
- dataset:
config: default
name: MTEB SensitiveTopicsClassification (default)
revision: 416b34a802308eac30e4192afc0ff99bb8dcc7f2
split: test
type: ai-forever/sensitive-topics-classification
metrics:
- type: accuracy
value: 22.8125
- type: f1
value: 17.31969589593409
- type: lrap
value: 33.82412380642287
- type: main_score
value: 22.8125
task:
type: MultilabelClassification
- dataset:
config: default
name: MTEB TERRa (default)
revision: 7b58f24536063837d644aab9a023c62199b2a612
split: dev
type: ai-forever/terra-pairclassification
metrics:
- type: cosine_accuracy
value: 57.32899022801303
- type: cosine_accuracy_threshold
value: 85.32201051712036
- type: cosine_ap
value: 55.14264553720072
- type: cosine_f1
value: 66.83544303797468
- type: cosine_f1_threshold
value: 85.32201051712036
- type: cosine_precision
value: 54.54545454545454
- type: cosine_recall
value: 86.27450980392157
- type: dot_accuracy
value: 57.32899022801303
- type: dot_accuracy_threshold
value: 85.32201051712036
- type: dot_ap
value: 55.14264553720072
- type: dot_f1
value: 66.83544303797468
- type: dot_f1_threshold
value: 85.32201051712036
- type: dot_precision
value: 54.54545454545454
- type: dot_recall
value: 86.27450980392157
- type: euclidean_accuracy
value: 57.32899022801303
- type: euclidean_accuracy_threshold
value: 54.18117046356201
- type: euclidean_ap
value: 55.14264553720072
- type: euclidean_f1
value: 66.83544303797468
- type: euclidean_f1_threshold
value: 54.18117046356201
- type: euclidean_precision
value: 54.54545454545454
- type: euclidean_recall
value: 86.27450980392157
- type: main_score
value: 55.14264553720072
- type: manhattan_accuracy
value: 57.32899022801303
- type: manhattan_accuracy_threshold
value: 828.8480758666992
- type: manhattan_ap
value: 55.077974053622555
- type: manhattan_f1
value: 66.82352941176471
- type: manhattan_f1_threshold
value: 885.6784820556641
- type: manhattan_precision
value: 52.20588235294118
- type: manhattan_recall
value: 92.81045751633987
- type: max_ap
value: 55.14264553720072
- type: max_f1
value: 66.83544303797468
- type: max_precision
value: 54.54545454545454
- type: max_recall
value: 92.81045751633987
- type: similarity_accuracy
value: 57.32899022801303
- type: similarity_accuracy_threshold
value: 85.32201051712036
- type: similarity_ap
value: 55.14264553720072
- type: similarity_f1
value: 66.83544303797468
- type: similarity_f1_threshold
value: 85.32201051712036
- type: similarity_precision
value: 54.54545454545454
- type: similarity_recall
value: 86.27450980392157
task:
type: PairClassification
- dataset:
config: ru
name: MTEB XNLI (ru)
revision: 09698e0180d87dc247ca447d3a1248b931ac0cdb
split: test
type: mteb/xnli
metrics:
- type: cosine_accuracy
value: 67.6923076923077
- type: cosine_accuracy_threshold
value: 87.6681923866272
- type: cosine_ap
value: 73.18693800863593
- type: cosine_f1
value: 70.40641099026904
- type: cosine_f1_threshold
value: 85.09706258773804
- type: cosine_precision
value: 57.74647887323944
- type: cosine_recall
value: 90.17595307917888
- type: dot_accuracy
value: 67.6923076923077
- type: dot_accuracy_threshold
value: 87.66818642616272
- type: dot_ap
value: 73.18693800863593
- type: dot_f1
value: 70.40641099026904
- type: dot_f1_threshold
value: 85.09706258773804
- type: dot_precision
value: 57.74647887323944
- type: dot_recall
value: 90.17595307917888
- type: euclidean_accuracy
value: 67.6923076923077
- type: euclidean_accuracy_threshold
value: 49.662476778030396
- type: euclidean_ap
value: 73.18693800863593
- type: euclidean_f1
value: 70.40641099026904
- type: euclidean_f1_threshold
value: 54.59475517272949
- type: euclidean_precision
value: 57.74647887323944
- type: euclidean_recall
value: 90.17595307917888
- type: main_score
value: 73.18693800863593
- type: manhattan_accuracy
value: 67.54578754578755
- type: manhattan_accuracy_threshold
value: 777.1001815795898
- type: manhattan_ap
value: 72.98861474758783
- type: manhattan_f1
value: 70.6842435655995
- type: manhattan_f1_threshold
value: 810.3782653808594
- type: manhattan_precision
value: 61.80021953896817
- type: manhattan_recall
value: 82.55131964809385
- type: max_ap
value: 73.18693800863593
- type: max_f1
value: 70.6842435655995
- type: max_precision
value: 61.80021953896817
- type: max_recall
value: 90.17595307917888
- type: similarity_accuracy
value: 67.6923076923077
- type: similarity_accuracy_threshold
value: 87.6681923866272
- type: similarity_ap
value: 73.18693800863593
- type: similarity_f1
value: 70.40641099026904
- type: similarity_f1_threshold
value: 85.09706258773804
- type: similarity_precision
value: 57.74647887323944
- type: similarity_recall
value: 90.17595307917888
task:
type: PairClassification
- dataset:
config: russian
name: MTEB XNLIV2 (russian)
revision: 5b7d477a8c62cdd18e2fed7e015497c20b4371ad
split: test
type: mteb/xnli2.0-multi-pair
metrics:
- type: cosine_accuracy
value: 68.35164835164835
- type: cosine_accuracy_threshold
value: 88.48621845245361
- type: cosine_ap
value: 73.10205506215699
- type: cosine_f1
value: 71.28712871287128
- type: cosine_f1_threshold
value: 87.00399398803711
- type: cosine_precision
value: 61.67023554603854
- type: cosine_recall
value: 84.4574780058651
- type: dot_accuracy
value: 68.35164835164835
- type: dot_accuracy_threshold
value: 88.48622441291809
- type: dot_ap
value: 73.10191110714706
- type: dot_f1
value: 71.28712871287128
- type: dot_f1_threshold
value: 87.00399398803711
- type: dot_precision
value: 61.67023554603854
- type: dot_recall
value: 84.4574780058651
- type: euclidean_accuracy
value: 68.35164835164835
- type: euclidean_accuracy_threshold
value: 47.98704385757446
- type: euclidean_ap
value: 73.10205506215699
- type: euclidean_f1
value: 71.28712871287128
- type: euclidean_f1_threshold
value: 50.982362031936646
- type: euclidean_precision
value: 61.67023554603854
- type: euclidean_recall
value: 84.4574780058651
- type: main_score
value: 73.10205506215699
- type: manhattan_accuracy
value: 67.91208791208791
- type: manhattan_accuracy_threshold
value: 746.1360931396484
- type: manhattan_ap
value: 72.8954736175069
- type: manhattan_f1
value: 71.1297071129707
- type: manhattan_f1_threshold
value: 808.0789566040039
- type: manhattan_precision
value: 60.04036326942482
- type: manhattan_recall
value: 87.2434017595308
- type: max_ap
value: 73.10205506215699
- type: max_f1
value: 71.28712871287128
- type: max_precision
value: 61.67023554603854
- type: max_recall
value: 87.2434017595308
- type: similarity_accuracy
value: 68.35164835164835
- type: similarity_accuracy_threshold
value: 88.48621845245361
- type: similarity_ap
value: 73.10205506215699
- type: similarity_f1
value: 71.28712871287128
- type: similarity_f1_threshold
value: 87.00399398803711
- type: similarity_precision
value: 61.67023554603854
- type: similarity_recall
value: 84.4574780058651
task:
type: PairClassification
- dataset:
config: ru
name: MTEB XQuADRetrieval (ru)
revision: 51adfef1c1287aab1d2d91b5bead9bcfb9c68583
split: validation
type: google/xquad
metrics:
- type: main_score
value: 95.705
- type: map_at_1
value: 90.802
- type: map_at_10
value: 94.427
- type: map_at_100
value: 94.451
- type: map_at_1000
value: 94.451
- type: map_at_20
value: 94.446
- type: map_at_3
value: 94.121
- type: map_at_5
value: 94.34
- type: mrr_at_1
value: 90.80168776371308
- type: mrr_at_10
value: 94.42659567343111
- type: mrr_at_100
value: 94.45099347521871
- type: mrr_at_1000
value: 94.45099347521871
- type: mrr_at_20
value: 94.44574530017569
- type: mrr_at_3
value: 94.12095639943743
- type: mrr_at_5
value: 94.34036568213786
- type: nauc_map_at_1000_diff1
value: 87.40573202946949
- type: nauc_map_at_1000_max
value: 65.56220344468791
- type: nauc_map_at_1000_std
value: 8.865583291735863
- type: nauc_map_at_100_diff1
value: 87.40573202946949
- type: nauc_map_at_100_max
value: 65.56220344468791
- type: nauc_map_at_100_std
value: 8.865583291735863
- type: nauc_map_at_10_diff1
value: 87.43657080570291
- type: nauc_map_at_10_max
value: 65.71295628534446
- type: nauc_map_at_10_std
value: 9.055399339099655
- type: nauc_map_at_1_diff1
value: 88.08395824560428
- type: nauc_map_at_1_max
value: 62.92813192908893
- type: nauc_map_at_1_std
value: 6.738987385482432
- type: nauc_map_at_20_diff1
value: 87.40979818966589
- type: nauc_map_at_20_max
value: 65.59474346926105
- type: nauc_map_at_20_std
value: 8.944420599300914
- type: nauc_map_at_3_diff1
value: 86.97771892161035
- type: nauc_map_at_3_max
value: 66.14330030122467
- type: nauc_map_at_3_std
value: 8.62516327793521
- type: nauc_map_at_5_diff1
value: 87.30273362211798
- type: nauc_map_at_5_max
value: 66.1522476584607
- type: nauc_map_at_5_std
value: 9.780940862679724
- type: nauc_mrr_at_1000_diff1
value: 87.40573202946949
- type: nauc_mrr_at_1000_max
value: 65.56220344468791
- type: nauc_mrr_at_1000_std
value: 8.865583291735863
- type: nauc_mrr_at_100_diff1
value: 87.40573202946949
- type: nauc_mrr_at_100_max
value: 65.56220344468791
- type: nauc_mrr_at_100_std
value: 8.865583291735863
- type: nauc_mrr_at_10_diff1
value: 87.43657080570291
- type: nauc_mrr_at_10_max
value: 65.71295628534446
- type: nauc_mrr_at_10_std
value: 9.055399339099655
- type: nauc_mrr_at_1_diff1
value: 88.08395824560428
- type: nauc_mrr_at_1_max
value: 62.92813192908893
- type: nauc_mrr_at_1_std
value: 6.738987385482432
- type: nauc_mrr_at_20_diff1
value: 87.40979818966589
- type: nauc_mrr_at_20_max
value: 65.59474346926105
- type: nauc_mrr_at_20_std
value: 8.944420599300914
- type: nauc_mrr_at_3_diff1
value: 86.97771892161035
- type: nauc_mrr_at_3_max
value: 66.14330030122467
- type: nauc_mrr_at_3_std
value: 8.62516327793521
- type: nauc_mrr_at_5_diff1
value: 87.30273362211798
- type: nauc_mrr_at_5_max
value: 66.1522476584607
- type: nauc_mrr_at_5_std
value: 9.780940862679724
- type: nauc_ndcg_at_1000_diff1
value: 87.37823158814116
- type: nauc_ndcg_at_1000_max
value: 66.00874244792789
- type: nauc_ndcg_at_1000_std
value: 9.479929342875067
- type: nauc_ndcg_at_100_diff1
value: 87.37823158814116
- type: nauc_ndcg_at_100_max
value: 66.00874244792789
- type: nauc_ndcg_at_100_std
value: 9.479929342875067
- type: nauc_ndcg_at_10_diff1
value: 87.54508467181488
- type: nauc_ndcg_at_10_max
value: 66.88756470312894
- type: nauc_ndcg_at_10_std
value: 10.812624405397022
- type: nauc_ndcg_at_1_diff1
value: 88.08395824560428
- type: nauc_ndcg_at_1_max
value: 62.92813192908893
- type: nauc_ndcg_at_1_std
value: 6.738987385482432
- type: nauc_ndcg_at_20_diff1
value: 87.42097894104597
- type: nauc_ndcg_at_20_max
value: 66.37031898778943
- type: nauc_ndcg_at_20_std
value: 10.34862538094813
- type: nauc_ndcg_at_3_diff1
value: 86.50039907157999
- type: nauc_ndcg_at_3_max
value: 67.97798288917929
- type: nauc_ndcg_at_3_std
value: 10.162410286746852
- type: nauc_ndcg_at_5_diff1
value: 87.13322094568531
- type: nauc_ndcg_at_5_max
value: 68.08576118683821
- type: nauc_ndcg_at_5_std
value: 12.639637379592855
- type: nauc_precision_at_1000_diff1
value: 100.0
- type: nauc_precision_at_1000_max
value: 100.0
- type: nauc_precision_at_1000_std
value: 100.0
- type: nauc_precision_at_100_diff1
value: 100.0
- type: nauc_precision_at_100_max
value: 100.0
- type: nauc_precision_at_100_std
value: 100.0
- type: nauc_precision_at_10_diff1
value: 93.46711505595813
- type: nauc_precision_at_10_max
value: 100.0
- type: nauc_precision_at_10_std
value: 65.42573557179935
- type: nauc_precision_at_1_diff1
value: 88.08395824560428
- type: nauc_precision_at_1_max
value: 62.92813192908893
- type: nauc_precision_at_1_std
value: 6.738987385482432
- type: nauc_precision_at_20_diff1
value: 91.28948674127133
- type: nauc_precision_at_20_max
value: 100.0
- type: nauc_precision_at_20_std
value: 90.74278258632364
- type: nauc_precision_at_3_diff1
value: 82.64606115071832
- type: nauc_precision_at_3_max
value: 83.26201582412921
- type: nauc_precision_at_3_std
value: 23.334013491433762
- type: nauc_precision_at_5_diff1
value: 85.0867539350284
- type: nauc_precision_at_5_max
value: 96.57011448655484
- type: nauc_precision_at_5_std
value: 56.46869543426768
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: .nan
- type: nauc_recall_at_100_max
value: .nan
- type: nauc_recall_at_100_std
value: .nan
- type: nauc_recall_at_10_diff1
value: 93.46711505595623
- type: nauc_recall_at_10_max
value: 100.0
- type: nauc_recall_at_10_std
value: 65.42573557180279
- type: nauc_recall_at_1_diff1
value: 88.08395824560428
- type: nauc_recall_at_1_max
value: 62.92813192908893
- type: nauc_recall_at_1_std
value: 6.738987385482432
- type: nauc_recall_at_20_diff1
value: 91.28948674127474
- type: nauc_recall_at_20_max
value: 100.0
- type: nauc_recall_at_20_std
value: 90.74278258632704
- type: nauc_recall_at_3_diff1
value: 82.64606115071967
- type: nauc_recall_at_3_max
value: 83.26201582413023
- type: nauc_recall_at_3_std
value: 23.334013491434007
- type: nauc_recall_at_5_diff1
value: 85.08675393502854
- type: nauc_recall_at_5_max
value: 96.57011448655487
- type: nauc_recall_at_5_std
value: 56.46869543426658
- type: ndcg_at_1
value: 90.802
- type: ndcg_at_10
value: 95.705
- type: ndcg_at_100
value: 95.816
- type: ndcg_at_1000
value: 95.816
- type: ndcg_at_20
value: 95.771
- type: ndcg_at_3
value: 95.11699999999999
- type: ndcg_at_5
value: 95.506
- type: precision_at_1
value: 90.802
- type: precision_at_10
value: 9.949
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.987
- type: precision_at_3
value: 32.658
- type: precision_at_5
value: 19.781000000000002
- type: recall_at_1
value: 90.802
- type: recall_at_10
value: 99.494
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 99.747
- type: recall_at_3
value: 97.975
- type: recall_at_5
value: 98.90299999999999
task:
type: Retrieval
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
---
## Multilingual-E5-small
[Multilingual E5 Text Embeddings: A Technical Report](https://arxiv.org/pdf/2402.05672).
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024
This model has 12 layers and the embedding size is 384.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-small')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-small')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [microsoft/Multilingual-MiniLM-L12-H384](https://huggingface.co/microsoft/Multilingual-MiniLM-L12-H384)
and continually trained on a mixture of multilingual datasets.
It supports 100 languages from xlm-roberta,
but low-resource languages may see performance degradation.
## Training Details
**Initialization**: [microsoft/Multilingual-MiniLM-L12-H384](https://huggingface.co/microsoft/Multilingual-MiniLM-L12-H384)
**First stage**: contrastive pre-training with weak supervision
| Dataset | Weak supervision | # of text pairs |
|--------------------------------------------------------------------------------------------------------|---------------------------------------|-----------------|
| Filtered [mC4](https://huggingface.co/datasets/mc4) | (title, page content) | 1B |
| [CC News](https://huggingface.co/datasets/intfloat/multilingual_cc_news) | (title, news content) | 400M |
| [NLLB](https://huggingface.co/datasets/allenai/nllb) | translation pairs | 2.4B |
| [Wikipedia](https://huggingface.co/datasets/intfloat/wikipedia) | (hierarchical section title, passage) | 150M |
| Filtered [Reddit](https://www.reddit.com/) | (comment, response) | 800M |
| [S2ORC](https://github.com/allenai/s2orc) | (title, abstract) and citation pairs | 100M |
| [Stackexchange](https://stackexchange.com/) | (question, answer) | 50M |
| [xP3](https://huggingface.co/datasets/bigscience/xP3) | (input prompt, response) | 80M |
| [Miscellaneous unsupervised SBERT data](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | - | 10M |
**Second stage**: supervised fine-tuning
| Dataset | Language | # of text pairs |
|----------------------------------------------------------------------------------------|--------------|-----------------|
| [MS MARCO](https://microsoft.github.io/msmarco/) | English | 500k |
| [NQ](https://github.com/facebookresearch/DPR) | English | 70k |
| [Trivia QA](https://github.com/facebookresearch/DPR) | English | 60k |
| [NLI from SimCSE](https://github.com/princeton-nlp/SimCSE) | English | <300k |
| [ELI5](https://huggingface.co/datasets/eli5) | English | 500k |
| [DuReader Retrieval](https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval) | Chinese | 86k |
| [KILT Fever](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [KILT HotpotQA](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [SQuAD](https://huggingface.co/datasets/squad) | English | 87k |
| [Quora](https://huggingface.co/datasets/quora) | English | 150k |
| [Mr. TyDi](https://huggingface.co/datasets/castorini/mr-tydi) | 11 languages | 50k |
| [MIRACL](https://huggingface.co/datasets/miracl/miracl) | 16 languages | 40k |
For all labeled datasets, we only use its training set for fine-tuning.
For other training details, please refer to our paper at [https://arxiv.org/pdf/2402.05672](https://arxiv.org/pdf/2402.05672).
## Benchmark Results on [Mr. TyDi](https://arxiv.org/abs/2108.08787)
| Model | Avg MRR@10 | | ar | bn | en | fi | id | ja | ko | ru | sw | te | th |
|-----------------------|------------|-------|------| --- | --- | --- | --- | --- | --- | --- |------| --- | --- |
| BM25 | 33.3 | | 36.7 | 41.3 | 15.1 | 28.8 | 38.2 | 21.7 | 28.1 | 32.9 | 39.6 | 42.4 | 41.7 |
| mDPR | 16.7 | | 26.0 | 25.8 | 16.2 | 11.3 | 14.6 | 18.1 | 21.9 | 18.5 | 7.3 | 10.6 | 13.5 |
| BM25 + mDPR | 41.7 | | 49.1 | 53.5 | 28.4 | 36.5 | 45.5 | 35.5 | 36.2 | 42.7 | 40.5 | 42.0 | 49.2 |
| | |
| multilingual-e5-small | 64.4 | | 71.5 | 66.3 | 54.5 | 57.7 | 63.2 | 55.4 | 54.3 | 60.8 | 65.4 | 89.1 | 70.1 |
| multilingual-e5-base | 65.9 | | 72.3 | 65.0 | 58.5 | 60.8 | 64.9 | 56.6 | 55.8 | 62.7 | 69.0 | 86.6 | 72.7 |
| multilingual-e5-large | **70.5** | | 77.5 | 73.2 | 60.8 | 66.8 | 68.5 | 62.5 | 61.6 | 65.8 | 72.7 | 90.2 | 76.2 |
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/multilingual-e5-small')
input_texts = [
'query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 i s 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or traini ng for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮 ,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右, 放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油 锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, bitext mining, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2024multilingual,
title={Multilingual E5 Text Embeddings: A Technical Report},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2402.05672},
year={2024}
}
```
## Limitations
Long texts will be truncated to at most 512 tokens.
|
yiyanghkust/finbert-tone | yiyanghkust | "2022-10-17T00:35:39Z" | 819,940 | 150 | transformers | [
"transformers",
"pytorch",
"tf",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: "en"
tags:
- financial-sentiment-analysis
- sentiment-analysis
widget:
- text: "growth is strong and we have plenty of liquidity"
---
`FinBERT` is a BERT model pre-trained on financial communication text. The purpose is to enhance financial NLP research and practice. It is trained on the following three financial communication corpus. The total corpora size is 4.9B tokens.
- Corporate Reports 10-K & 10-Q: 2.5B tokens
- Earnings Call Transcripts: 1.3B tokens
- Analyst Reports: 1.1B tokens
More technical details on `FinBERT`: [Click Link](https://github.com/yya518/FinBERT)
This released `finbert-tone` model is the `FinBERT` model fine-tuned on 10,000 manually annotated (positive, negative, neutral) sentences from analyst reports. This model achieves superior performance on financial tone analysis task. If you are simply interested in using `FinBERT` for financial tone analysis, give it a try.
If you use the model in your academic work, please cite the following paper:
Huang, Allen H., Hui Wang, and Yi Yang. "FinBERT: A Large Language Model for Extracting Information from Financial Text." *Contemporary Accounting Research* (2022).
# How to use
You can use this model with Transformers pipeline for sentiment analysis.
```python
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-tone',num_labels=3)
tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-tone')
nlp = pipeline("sentiment-analysis", model=finbert, tokenizer=tokenizer)
sentences = ["there is a shortage of capital, and we need extra financing",
"growth is strong and we have plenty of liquidity",
"there are doubts about our finances",
"profits are flat"]
results = nlp(sentences)
print(results) #LABEL_0: neutral; LABEL_1: positive; LABEL_2: negative
``` |
unslothai/vram-24 | unslothai | "2024-07-07T17:02:52Z" | 818,425 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"feature-extraction",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-07-07T17:02:11Z" | ---
library_name: transformers
tags: []
---
|
dslim/bert-base-NER-uncased | dslim | "2023-05-09T16:37:36Z" | 817,756 | 29 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"token-classification",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
license: mit
--- |
obi/deid_roberta_i2b2 | obi | "2022-08-22T13:28:26Z" | 815,511 | 27 | transformers | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"deidentification",
"medical notes",
"ehr",
"phi",
"en",
"dataset:I2B2",
"arxiv:1907.11692",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2022-03-02T23:29:05Z" | ---
language:
- en
thumbnail: "https://www.onebraveidea.org/wp-content/uploads/2019/07/OBI-Logo-Website.png"
tags:
- deidentification
- medical notes
- ehr
- phi
datasets:
- I2B2
metrics:
- F1
- Recall
- Precision
widget:
- text: "Physician Discharge Summary Admit date: 10/12/1982 Discharge date: 10/22/1982 Patient Information Jack Reacher, 54 y.o. male (DOB = 1/21/1928)."
- text: "Home Address: 123 Park Drive, San Diego, CA, 03245. Home Phone: 202-555-0199 (home)."
- text: "Hospital Care Team Service: Orthopedics Inpatient Attending: Roger C Kelly, MD Attending phys phone: (634)743-5135 Discharge Unit: HCS843 Primary Care Physician: Hassan V Kim, MD 512-832-5025."
license: mit
---
# Model Description
* A RoBERTa [[Liu et al., 2019]](https://arxiv.org/pdf/1907.11692.pdf) model fine-tuned for de-identification of medical notes.
* Sequence Labeling (token classification): The model was trained to predict protected health information (PHI/PII) entities (spans). A list of protected health information categories is given by [HIPAA](https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html).
* A token can either be classified as non-PHI or as one of the 11 PHI types. Token predictions are aggregated to spans by making use of BILOU tagging.
* The PHI labels that were used for training and other details can be found here: [Annotation Guidelines](https://github.com/obi-ml-public/ehr_deidentification/blob/master/AnnotationGuidelines.md)
* More details on how to use this model, the format of data and other useful information is present in the GitHub repo: [Robust DeID](https://github.com/obi-ml-public/ehr_deidentification).
# How to use
* A demo on how the model works (using model predictions to de-identify a medical note) is on this space: [Medical-Note-Deidentification](https://huggingface.co/spaces/obi/Medical-Note-Deidentification).
* Steps on how this model can be used to run a forward pass can be found here: [Forward Pass](https://github.com/obi-ml-public/ehr_deidentification/tree/master/steps/forward_pass)
* In brief, the steps are:
* Sentencize (the model aggregates the sentences back to the note level) and tokenize the dataset.
* Use the predict function of this model to gather the predictions (i.e., predictions for each token).
* Additionally, the model predictions can be used to remove PHI from the original note/text.
# Dataset
* The I2B2 2014 [[Stubbs and Uzuner, 2015]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4978170/) dataset was used to train this model.
| | I2B2 | | I2B2 | |
| --------- | --------------------- | ---------- | -------------------- | ---------- |
| | TRAIN SET - 790 NOTES | | TEST SET - 514 NOTES | |
| PHI LABEL | COUNT | PERCENTAGE | COUNT | PERCENTAGE |
| DATE | 7502 | 43.69 | 4980 | 44.14 |
| STAFF | 3149 | 18.34 | 2004 | 17.76 |
| HOSP | 1437 | 8.37 | 875 | 7.76 |
| AGE | 1233 | 7.18 | 764 | 6.77 |
| LOC | 1206 | 7.02 | 856 | 7.59 |
| PATIENT | 1316 | 7.66 | 879 | 7.79 |
| PHONE | 317 | 1.85 | 217 | 1.92 |
| ID | 881 | 5.13 | 625 | 5.54 |
| PATORG | 124 | 0.72 | 82 | 0.73 |
| EMAIL | 4 | 0.02 | 1 | 0.01 |
| OTHERPHI | 2 | 0.01 | 0 | 0 |
| TOTAL | 17171 | 100 | 11283 | 100 |
# Training procedure
* Steps on how this model was trained can be found here: [Training](https://github.com/obi-ml-public/ehr_deidentification/tree/master/steps/train). The "model_name_or_path" was set to: "roberta-large".
* The dataset was sentencized with the en_core_sci_sm sentencizer from spacy.
* The dataset was then tokenized with a custom tokenizer built on top of the en_core_sci_sm tokenizer from spacy.
* For each sentence we added 32 tokens on the left (from previous sentences) and 32 tokens on the right (from the next sentences).
* The added tokens are not used for learning - i.e, the loss is not computed on these tokens - they are used as additional context.
* Each sequence contained a maximum of 128 tokens (including the 32 tokens added on). Longer sequences were split.
* The sentencized and tokenized dataset with the token level labels based on the BILOU notation was used to train the model.
* The model is fine-tuned from a pre-trained RoBERTa model.
* Training details:
* Input sequence length: 128
* Batch size: 32 (16 with 2 gradient accumulation steps)
* Optimizer: AdamW
* Learning rate: 5e-5
* Dropout: 0.1
## Results
# Questions?
Post a Github issue on the repo: [Robust DeID](https://github.com/obi-ml-public/ehr_deidentification).
|
OpenGVLab/InternVL2-1B | OpenGVLab | "2024-09-24T09:04:44Z" | 804,388 | 32 | transformers | [
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"vision",
"ocr",
"multi-image",
"video",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"arxiv:2312.14238",
"arxiv:2404.16821",
"base_model:OpenGVLab/InternViT-300M-448px",
"base_model:merge:OpenGVLab/InternViT-300M-448px",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:merge:Qwen/Qwen2-0.5B-Instruct",
"license:mit",
"region:us"
] | image-text-to-text | "2024-07-08T05:28:49Z" | ---
license: mit
pipeline_tag: image-text-to-text
library_name: transformers
base_model:
- OpenGVLab/InternViT-300M-448px
- Qwen/Qwen2-0.5B-Instruct
base_model_relation: merge
language:
- multilingual
tags:
- internvl
- vision
- ocr
- multi-image
- video
- custom_code
---
# InternVL2-1B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[🆕 Blog\]](https://internvl.github.io/blog/) [\[📜 InternVL 1.0 Paper\]](https://arxiv.org/abs/2312.14238) [\[📜 InternVL 1.5 Report\]](https://arxiv.org/abs/2404.16821)
[\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 中文解读\]](https://zhuanlan.zhihu.com/p/706547971) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
[切换至中文版](#简介)
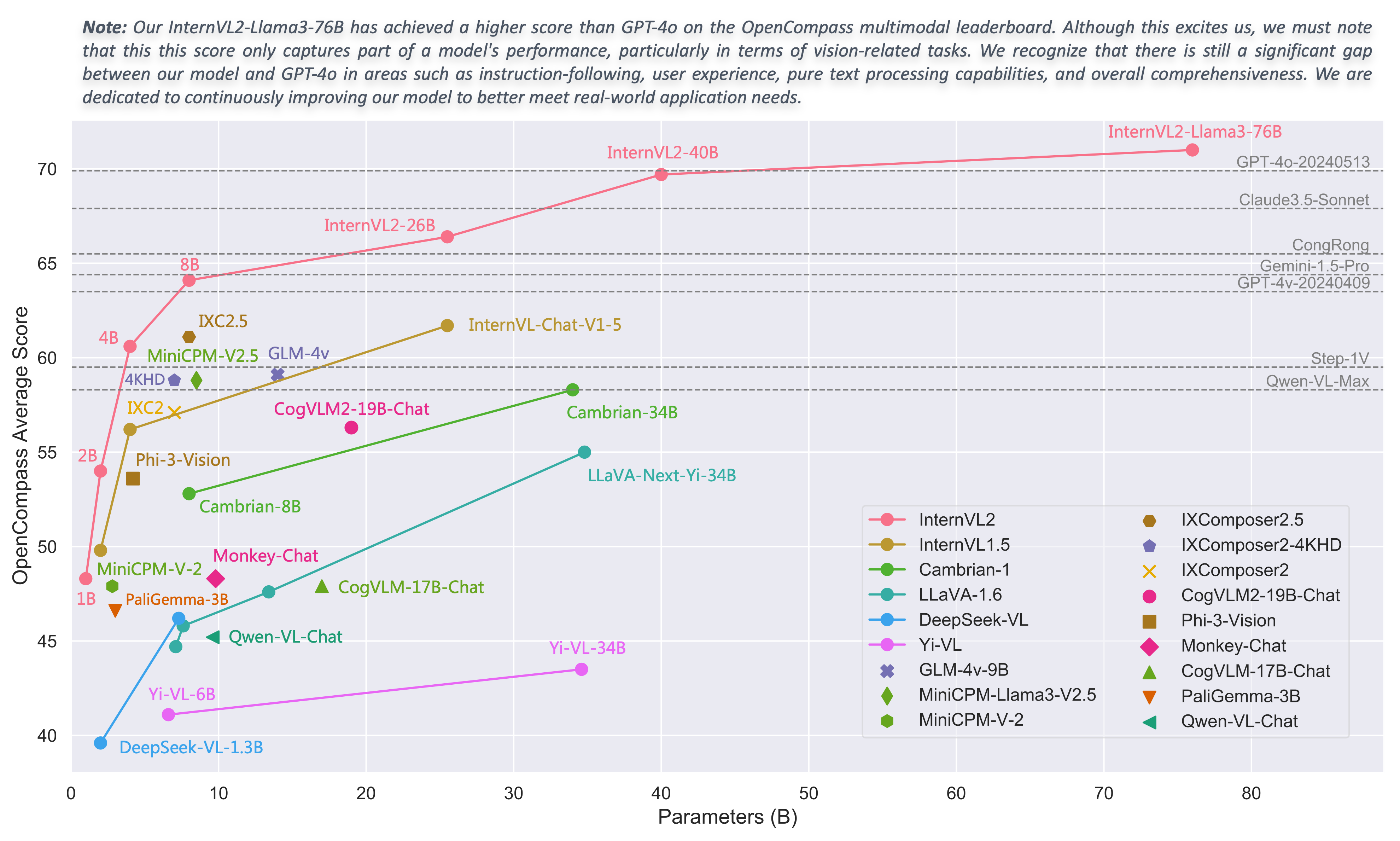
## Introduction
We are excited to announce the release of InternVL 2.0, the latest addition to the InternVL series of multimodal large language models. InternVL 2.0 features a variety of **instruction-tuned models**, ranging from 1 billion to 108 billion parameters. This repository contains the instruction-tuned InternVL2-1B model.
Compared to the state-of-the-art open-source multimodal large language models, InternVL 2.0 surpasses most open-source models. It demonstrates competitive performance on par with proprietary commercial models across various capabilities, including document and chart comprehension, infographics QA, scene text understanding and OCR tasks, scientific and mathematical problem solving, as well as cultural understanding and integrated multimodal capabilities.
InternVL 2.0 is trained with an 8k context window and utilizes training data consisting of long texts, multiple images, and videos, significantly improving its ability to handle these types of inputs compared to InternVL 1.5. For more details, please refer to our [blog](https://internvl.github.io/blog/2024-07-02-InternVL-2.0/) and [GitHub](https://github.com/OpenGVLab/InternVL).
| Model Name | Vision Part | Language Part | HF Link | MS Link |
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
## Model Details
InternVL 2.0 is a multimodal large language model series, featuring models of various sizes. For each size, we release instruction-tuned models optimized for multimodal tasks. InternVL2-1B consists of [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px), an MLP projector, and [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct).
## Performance
### Image Benchmarks
| Benchmark | PaliGemma-3B | Mini-InternVL-2B-1-5 | InternVL2-2B | InternVL2-1B |
| :--------------------------: | :----------: | :------------------: | :----------: | :----------: |
| Model Size | 2.9B | 2.2B | 2.2B | 0.9B |
| | | | | |
| DocVQA<sub>test</sub> | - | 85.0 | 86.9 | 81.7 |
| ChartQA<sub>test</sub> | - | 74.8 | 76.2 | 72.9 |
| InfoVQA<sub>test</sub> | - | 55.4 | 58.9 | 50.9 |
| TextVQA<sub>val</sub> | 68.1 | 70.5 | 73.4 | 70.5 |
| OCRBench | 614 | 654 | 784 | 754 |
| MME<sub>sum</sub> | 1686.1 | 1901.5 | 1876.8 | 1794.4 |
| RealWorldQA | 55.2 | 57.9 | 57.3 | 50.3 |
| AI2D<sub>test</sub> | 68.3 | 69.8 | 74.1 | 64.1 |
| MMMU<sub>val</sub> | 34.9 | 34.6 / 37.4 | 34.3 / 36.3 | 35.4 / 36.7 |
| MMBench-EN<sub>test</sub> | 71.0 | 70.9 | 73.2 | 65.4 |
| MMBench-CN<sub>test</sub> | 63.6 | 66.2 | 70.9 | 60.7 |
| CCBench<sub>dev</sub> | 29.6 | 63.5 | 74.7 | 75.7 |
| MMVet<sub>GPT-4-0613</sub> | - | 39.3 | 44.6 | 37.8 |
| MMVet<sub>GPT-4-Turbo</sub> | 33.1 | 35.5 | 39.5 | 33.3 |
| SEED-Image | 69.6 | 69.8 | 71.6 | 65.6 |
| HallBench<sub>avg</sub> | 32.2 | 37.5 | 37.9 | 33.4 |
| MathVista<sub>testmini</sub> | 28.7 | 41.1 | 46.3 | 37.7 |
| OpenCompass<sub>avg</sub> | 46.6 | 49.8 | 54.0 | 48.3 |
- For more details and evaluation reproduction, please refer to our [Evaluation Guide](https://internvl.readthedocs.io/en/latest/internvl2.0/evaluation.html).
- We simultaneously use [InternVL](https://github.com/OpenGVLab/InternVL) and [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) repositories for model evaluation. Specifically, the results reported for DocVQA, ChartQA, InfoVQA, TextVQA, MME, AI2D, MMBench, CCBench, MMVet, and SEED-Image were tested using the InternVL repository. OCRBench, RealWorldQA, HallBench, and MathVista were evaluated using the VLMEvalKit.
- For MMMU, we report both the original scores (left side: evaluated using the InternVL codebase for InternVL series models, and sourced from technical reports or webpages for other models) and the VLMEvalKit scores (right side: collected from the OpenCompass leaderboard).
- Please note that evaluating the same model using different testing toolkits like [InternVL](https://github.com/OpenGVLab/InternVL) and [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) can result in slight differences, which is normal. Updates to code versions and variations in environment and hardware can also cause minor discrepancies in results.
### Video Benchmarks
| Benchmark | VideoChat2-Phi3 | Mini-InternVL-2B-1-5 | InternVL2-2B | InternVL2-1B |
| :-------------------------: | :-------------: | :------------------: | :----------: | :----------: |
| Model Size | 4B | 2.2B | 2.2B | 0.9B |
| | | | | |
| MVBench | 55.1 | 37.0 | 60.2 | 57.9 |
| MMBench-Video<sub>8f</sub> | - | 0.99 | 0.97 | 0.95 |
| MMBench-Video<sub>16f</sub> | - | 1.04 | 1.03 | 0.98 |
| Video-MME<br>w/o subs | - | 42.9 | 45.0 | 42.6 |
| Video-MME<br>w subs | - | 44.7 | 47.3 | 44.7 |
- We evaluate our models on MVBench and Video-MME by extracting 16 frames from each video, and each frame was resized to a 448x448 image.
### Grounding Benchmarks
| Model | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
| | | | | | | | | | |
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
| | | | | | | | | | |
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
- We use the following prompt to evaluate InternVL's grounding ability: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
### Invitation to Evaluate InternVL
We welcome MLLM benchmark developers to assess our InternVL1.5 and InternVL2 series models. If you need to add your evaluation results here, please contact me at [[email protected]](mailto:[email protected]).
## Quick Start
We provide an example code to run InternVL2-1B using `transformers`.
We also welcome you to experience the InternVL2 series models in our [online demo](https://internvl.opengvlab.com/).
> Please use transformers==4.37.2 to ensure the model works normally.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2-1B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2-1B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### BNB 4-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2-1B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_4bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
def split_model(model_name):
device_map = {}
world_size = torch.cuda.device_count()
num_layers = {
'InternVL2-1B': 24, 'InternVL2-2B': 24, 'InternVL2-4B': 32, 'InternVL2-8B': 32,
'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80}[model_name]
# Since the first GPU will be used for ViT, treat it as half a GPU.
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
num_layers_per_gpu = [num_layers_per_gpu] * world_size
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language_model.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision_model'] = 0
device_map['mlp1'] = 0
device_map['language_model.model.tok_embeddings'] = 0
device_map['language_model.model.embed_tokens'] = 0
device_map['language_model.output'] = 0
device_map['language_model.model.norm'] = 0
device_map['language_model.lm_head'] = 0
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
return device_map
path = "OpenGVLab/InternVL2-1B"
device_map = split_model('InternVL2-1B')
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map=device_map).eval()
```
### Inference with Transformers
```python
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = 'OpenGVLab/InternVL2-1B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail. Don\'t repeat.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTurner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams.
```sh
pip install lmdeploy==0.5.3
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' example
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-1B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
response = pipe(('describe this image', image))
print(response.text)
```
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
#### Multi-images inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
> Warning: Due to the scarcity of multi-image conversation data, the performance on multi-image tasks may be unstable, and it may require multiple attempts to achieve satisfactory results.
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL2-1B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch prompts inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-1B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-1B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL2-1B --backend turbomind --server-port 23333
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the MIT license, while Qwen2 is licensed under the Tongyi Qianwen LICENSE.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
```
## 简介
我们很高兴宣布 InternVL 2.0 的发布,这是 InternVL 系列多模态大语言模型的最新版本。InternVL 2.0 提供了多种**指令微调**的模型,参数从 10 亿到 1080 亿不等。此仓库包含经过指令微调的 InternVL2-1B 模型。
与最先进的开源多模态大语言模型相比,InternVL 2.0 超越了大多数开源模型。它在各种能力上表现出与闭源商业模型相媲美的竞争力,包括文档和图表理解、信息图表问答、场景文本理解和 OCR 任务、科学和数学问题解决,以及文化理解和综合多模态能力。
InternVL 2.0 使用 8k 上下文窗口进行训练,训练数据包含长文本、多图和视频数据,与 InternVL 1.5 相比,其处理这些类型输入的能力显著提高。更多详细信息,请参阅我们的博客和 GitHub。
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
## 模型细节
InternVL 2.0 是一个多模态大语言模型系列,包含各种规模的模型。对于每个规模的模型,我们都会发布针对多模态任务优化的指令微调模型。InternVL2-1B 包含 [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px)、一个 MLP 投影器和 [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct)。
## 性能测试
### 图像相关评测
| 评测数据集 | PaliGemma-3B | Mini-InternVL-2B-1-5 | InternVL2-2B | InternVL2-1B |
| :--------------------------: | :----------: | :------------------: | :----------: | :----------: |
| 模型大小 | 2.9B | 2.2B | 2.2B | 0.9B |
| | | | | |
| DocVQA<sub>test</sub> | - | 85.0 | 86.9 | 81.7 |
| ChartQA<sub>test</sub> | - | 74.8 | 76.2 | 72.9 |
| InfoVQA<sub>test</sub> | - | 55.4 | 58.9 | 50.9 |
| TextVQA<sub>val</sub> | 68.1 | 70.5 | 73.4 | 70.5 |
| OCRBench | 614 | 654 | 784 | 754 |
| MME<sub>sum</sub> | 1686.1 | 1901.5 | 1876.8 | 1794.4 |
| RealWorldQA | 55.2 | 57.9 | 57.3 | 50.3 |
| AI2D<sub>test</sub> | 68.3 | 69.8 | 74.1 | 64.1 |
| MMMU<sub>val</sub> | 34.9 | 34.6 / 37.4 | 34.3 / 36.3 | 35.4 / 36.7 |
| MMBench-EN<sub>test</sub> | 71.0 | 70.9 | 73.2 | 65.4 |
| MMBench-CN<sub>test</sub> | 63.6 | 66.2 | 70.9 | 60.7 |
| CCBench<sub>dev</sub> | 29.6 | 63.5 | 74.7 | 75.7 |
| MMVet<sub>GPT-4-0613</sub> | - | 39.3 | 44.6 | 37.8 |
| MMVet<sub>GPT-4-Turbo</sub> | 33.1 | 35.5 | 39.5 | 37.3 |
| SEED-Image | 69.6 | 69.8 | 71.6 | 65.6 |
| HallBench<sub>avg</sub> | 32.2 | 37.5 | 37.9 | 33.4 |
| MathVista<sub>testmini</sub> | 28.7 | 41.1 | 46.3 | 37.7 |
| OpenCompass<sub>avg</sub> | 46.6 | 49.8 | 54.0 | 48.3 |
- 关于更多的细节以及评测复现,请看我们的[评测指南](https://internvl.readthedocs.io/en/latest/internvl2.0/evaluation.html)。
- 我们同时使用 InternVL 和 VLMEvalKit 仓库进行模型评估。具体来说,DocVQA、ChartQA、InfoVQA、TextVQA、MME、AI2D、MMBench、CCBench、MMVet 和 SEED-Image 的结果是使用 InternVL 仓库测试的。OCRBench、RealWorldQA、HallBench 和 MathVista 是使用 VLMEvalKit 进行评估的。
- 对于MMMU,我们报告了原始分数(左侧:InternVL系列模型使用InternVL代码库评测,其他模型的分数来自其技术报告或网页)和VLMEvalKit分数(右侧:从OpenCompass排行榜收集)。
- 请注意,使用不同的测试工具包(如 InternVL 和 VLMEvalKit)评估同一模型可能会导致细微差异,这是正常的。代码版本的更新、环境和硬件的变化也可能导致结果的微小差异。
### 视频相关评测
| 评测数据集 | VideoChat2-Phi3 | Mini-InternVL-2B-1-5 | InternVL2-2B | InternVL2-1B |
| :-------------------------: | :-------------: | :------------------: | :----------: | :----------: |
| 模型大小 | 4B | 2.2B | 2.2B | 0.9B |
| | | | | |
| MVBench | 55.1 | 37.0 | 60.2 | 57.9 |
| MMBench-Video<sub>8f</sub> | - | 0.99 | 0.97 | 0.95 |
| MMBench-Video<sub>16f</sub> | - | 1.04 | 1.03 | 0.98 |
| Video-MME<br>w/o subs | - | 42.9 | 45.0 | 42.6 |
| Video-MME<br>w subs | - | 44.7 | 47.3 | 44.7 |
- 我们通过从每个视频中提取 16 帧来评估我们的模型在 MVBench 和 Video-MME 上的性能,每个视频帧被调整为 448x448 的图像。
### 定位相关评测
| 模型 | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
| | | | | | | | | | |
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
| | | | | | | | | | |
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
- 我们使用以下 Prompt 来评测 InternVL 的 Grounding 能力: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
限制:尽管在训练过程中我们非常注重模型的安全性,尽力促使模型输出符合伦理和法律要求的文本,但受限于模型大小以及概率生成范式,模型可能会产生各种不符合预期的输出,例如回复内容包含偏见、歧视等有害内容,请勿传播这些内容。由于传播不良信息导致的任何后果,本项目不承担责任。
### 邀请评测 InternVL
我们欢迎各位 MLLM benchmark 的开发者对我们的 InternVL1.5 以及 InternVL2 系列模型进行评测。如果需要在此处添加评测结果,请与我联系([[email protected]](mailto:[email protected]))。
## 快速启动
我们提供了一个示例代码,用于使用 `transformers` 运行 InternVL2-1B。
我们也欢迎你在我们的[在线demo](https://internvl.opengvlab.com/)中体验InternVL2的系列模型。
> 请使用 transformers==4.37.2 以确保模型正常运行。
示例代码请[点击这里](#quick-start)。
## 微调
许多仓库现在都支持 InternVL 系列模型的微调,包括 [InternVL](https://github.com/OpenGVLab/InternVL)、[SWIFT](https://github.com/modelscope/ms-swift)、[XTurner](https://github.com/InternLM/xtuner) 等。请参阅它们的文档以获取更多微调细节。
## 部署
### LMDeploy
LMDeploy 是由 MMRazor 和 MMDeploy 团队开发的用于压缩、部署和服务大语言模型(LLM)的工具包。
```sh
pip install lmdeploy==0.5.3
```
LMDeploy 将多模态视觉-语言模型(VLM)的复杂推理过程抽象为一个易于使用的管道,类似于大语言模型(LLM)的推理管道。
#### 一个“你好,世界”示例
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-1B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
response = pipe(('describe this image', image))
print(response.text)
```
如果在执行此示例时出现 `ImportError`,请按照提示安装所需的依赖包。
#### 多图像推理
在处理多张图像时,可以将它们全部放入一个列表中。请注意,多张图像会导致输入 token 数量增加,因此通常需要增加上下文窗口的大小。
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL2-1B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### 批量Prompt推理
使用批量Prompt进行推理非常简单;只需将它们放在一个列表结构中:
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-1B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### 多轮对话
使用管道进行多轮对话有两种方法。一种是根据 OpenAI 的格式构建消息并使用上述方法,另一种是使用 `pipeline.chat` 接口。
```python
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-1B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### API部署
LMDeploy 的 `api_server` 使模型能够通过一个命令轻松打包成服务。提供的 RESTful API 与 OpenAI 的接口兼容。以下是服务启动的示例:
```shell
lmdeploy serve api_server OpenGVLab/InternVL2-1B --backend turbomind --server-port 23333
```
为了使用OpenAI风格的API接口,您需要安装OpenAI:
```shell
pip install openai
```
然后,使用下面的代码进行API调用:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## 开源许可证
该项目采用 MIT 许可证发布,而 Qwen2 则采用 通义千问 许可证。
## 引用
如果您发现此项目对您的研究有用,可以考虑引用我们的论文:
```BibTeX
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
```
|
facebook/m2m100_418M | facebook | "2024-02-29T09:08:42Z" | 787,797 | 239 | transformers | [
"transformers",
"pytorch",
"rust",
"m2m_100",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"ast",
"az",
"ba",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"fa",
"ff",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"ht",
"hu",
"hy",
"id",
"ig",
"ilo",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"lb",
"lg",
"ln",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"ns",
"oc",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"ss",
"su",
"sv",
"sw",
"ta",
"th",
"tl",
"tn",
"tr",
"uk",
"ur",
"uz",
"vi",
"wo",
"xh",
"yi",
"yo",
"zh",
"zu",
"arxiv:2010.11125",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- af
- am
- ar
- ast
- az
- ba
- be
- bg
- bn
- br
- bs
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- fa
- ff
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- ht
- hu
- hy
- id
- ig
- ilo
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- lb
- lg
- ln
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- ns
- oc
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- so
- sq
- sr
- ss
- su
- sv
- sw
- ta
- th
- tl
- tn
- tr
- uk
- ur
- uz
- vi
- wo
- xh
- yi
- yo
- zh
- zu
license: mit
---
# M2M100 418M
M2M100 is a multilingual encoder-decoder (seq-to-seq) model trained for Many-to-Many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2010.11125) and first released in [this](https://github.com/pytorch/fairseq/tree/master/examples/m2m_100) repository.
The model that can directly translate between the 9,900 directions of 100 languages.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
```python
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
chinese_text = "生活就像一盒巧克力。"
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
# translate Hindi to French
tokenizer.src_lang = "hi"
encoded_hi = tokenizer(hi_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "La vie est comme une boîte de chocolat."
# translate Chinese to English
tokenizer.src_lang = "zh"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Life is like a box of chocolate."
```
See the [model hub](https://huggingface.co/models?filter=m2m_100) to look for more fine-tuned versions.
## Languages covered
Afrikaans (af), Amharic (am), Arabic (ar), Asturian (ast), Azerbaijani (az), Bashkir (ba), Belarusian (be), Bulgarian (bg), Bengali (bn), Breton (br), Bosnian (bs), Catalan; Valencian (ca), Cebuano (ceb), Czech (cs), Welsh (cy), Danish (da), German (de), Greeek (el), English (en), Spanish (es), Estonian (et), Persian (fa), Fulah (ff), Finnish (fi), French (fr), Western Frisian (fy), Irish (ga), Gaelic; Scottish Gaelic (gd), Galician (gl), Gujarati (gu), Hausa (ha), Hebrew (he), Hindi (hi), Croatian (hr), Haitian; Haitian Creole (ht), Hungarian (hu), Armenian (hy), Indonesian (id), Igbo (ig), Iloko (ilo), Icelandic (is), Italian (it), Japanese (ja), Javanese (jv), Georgian (ka), Kazakh (kk), Central Khmer (km), Kannada (kn), Korean (ko), Luxembourgish; Letzeburgesch (lb), Ganda (lg), Lingala (ln), Lao (lo), Lithuanian (lt), Latvian (lv), Malagasy (mg), Macedonian (mk), Malayalam (ml), Mongolian (mn), Marathi (mr), Malay (ms), Burmese (my), Nepali (ne), Dutch; Flemish (nl), Norwegian (no), Northern Sotho (ns), Occitan (post 1500) (oc), Oriya (or), Panjabi; Punjabi (pa), Polish (pl), Pushto; Pashto (ps), Portuguese (pt), Romanian; Moldavian; Moldovan (ro), Russian (ru), Sindhi (sd), Sinhala; Sinhalese (si), Slovak (sk), Slovenian (sl), Somali (so), Albanian (sq), Serbian (sr), Swati (ss), Sundanese (su), Swedish (sv), Swahili (sw), Tamil (ta), Thai (th), Tagalog (tl), Tswana (tn), Turkish (tr), Ukrainian (uk), Urdu (ur), Uzbek (uz), Vietnamese (vi), Wolof (wo), Xhosa (xh), Yiddish (yi), Yoruba (yo), Chinese (zh), Zulu (zu)
## BibTeX entry and citation info
```
@misc{fan2020englishcentric,
title={Beyond English-Centric Multilingual Machine Translation},
author={Angela Fan and Shruti Bhosale and Holger Schwenk and Zhiyi Ma and Ahmed El-Kishky and Siddharth Goyal and Mandeep Baines and Onur Celebi and Guillaume Wenzek and Vishrav Chaudhary and Naman Goyal and Tom Birch and Vitaliy Liptchinsky and Sergey Edunov and Edouard Grave and Michael Auli and Armand Joulin},
year={2020},
eprint={2010.11125},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
google/t5-v1_1-xl | google | "2023-01-24T16:52:38Z" | 784,069 | 14 | transformers | [
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"arxiv:2002.05202",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-03-02T23:29:05Z" | ---
language: en
datasets:
- c4
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) Version 1.1
## Version 1.1
[T5 Version 1.1](https://github.com/google-research/text-to-text-transfer-transformer/blob/master/released_checkpoints.md#t511) includes the following improvements compared to the original T5 model- GEGLU activation in feed-forward hidden layer, rather than ReLU - see [here](https://arxiv.org/abs/2002.05202).
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- Pre-trained on C4 only without mixing in the downstream tasks.
- no parameter sharing between embedding and classifier layer
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller `num_heads` and `d_ff`.
**Note**: T5 Version 1.1 was only pre-trained on C4 excluding any supervised training. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
Pretraining Dataset: [C4](https://huggingface.co/datasets/c4)
Other Community Checkpoints: [here](https://huggingface.co/models?search=t5-v1_1)
Paper: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)
Authors: *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*
## Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

|
trpakov/vit-face-expression | trpakov | "2023-12-30T14:38:39Z" | 781,363 | 41 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"vit",
"image-classification",
"doi:10.57967/hf/2289",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2022-11-09T12:50:30Z" | ---
{}
---
# Vision Transformer (ViT) for Facial Expression Recognition Model Card
## Model Overview
- **Model Name:** [trpakov/vit-face-expression](https://huggingface.co/trpakov/vit-face-expression)
- **Task:** Facial Expression/Emotion Recognition
- **Dataset:** [FER2013](https://www.kaggle.com/datasets/msambare/fer2013)
- **Model Architecture:** [Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)
- **Finetuned from model:** [vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k)
## Model Description
The vit-face-expression model is a Vision Transformer fine-tuned for the task of facial emotion recognition.
It is trained on the FER2013 dataset, which consists of facial images categorized into seven different emotions:
- Angry
- Disgust
- Fear
- Happy
- Sad
- Surprise
- Neutral
## Data Preprocessing
The input images are preprocessed before being fed into the model. The preprocessing steps include:
- **Resizing:** Images are resized to the specified input size.
- **Normalization:** Pixel values are normalized to a specific range.
- **Data Augmentation:** Random transformations such as rotations, flips, and zooms are applied to augment the training dataset.
## Evaluation Metrics
- **Validation set accuracy:** 0.7113
- **Test set accuracy:** 0.7116
## Limitations
- **Data Bias:** The model's performance may be influenced by biases present in the training data.
- **Generalization:** The model's ability to generalize to unseen data is subject to the diversity of the training dataset. |
google/electra-small-discriminator | google | "2024-02-29T10:20:20Z" | 780,232 | 27 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"electra",
"pretraining",
"en",
"arxiv:1406.2661",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
## ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer to our paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
This repository contains code to pre-train ELECTRA, including small ELECTRA models on a single GPU. It also supports fine-tuning ELECTRA on downstream tasks including classification tasks (e.g,. [GLUE](https://gluebenchmark.com/)), QA tasks (e.g., [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)), and sequence tagging tasks (e.g., [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/)).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("google/electra-small-discriminator")
tokenizer = ElectraTokenizerFast.from_pretrained("google/electra-small-discriminator")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.squeeze().tolist()]
```
|
distilbert/distilbert-base-cased | distilbert | "2024-05-06T13:46:22Z" | 767,184 | 31 | transformers | [
"transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"distilbert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# Model Card for DistilBERT base model (cased)
This model is a distilled version of the [BERT base model](https://huggingface.co/bert-base-cased).
It was introduced in [this paper](https://arxiv.org/abs/1910.01108).
The code for the distillation process can be found
[here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
This model is cased: it does make a difference between english and English.
All the training details on the pre-training, the uses, limitations and potential biases (included below) are the same as for [DistilBERT-base-uncased](https://huggingface.co/distilbert-base-uncased).
We highly encourage to check it if you want to know more.
## Model description
DistilBERT is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a
self-supervised fashion, using the BERT base model as a teacher. This means it was pretrained on the raw texts only,
with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic
process to generate inputs and labels from those texts using the BERT base model. More precisely, it was pretrained
with three objectives:
- Distillation loss: the model was trained to return the same probabilities as the BERT base model.
- Masked language modeling (MLM): this is part of the original training loss of the BERT base model. When taking a
sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the
model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that
usually see the words one after the other, or from autoregressive models like GPT which internally mask the future
tokens. It allows the model to learn a bidirectional representation of the sentence.
- Cosine embedding loss: the model was also trained to generate hidden states as close as possible as the BERT base
model.
This way, the model learns the same inner representation of the English language than its teacher model, while being
faster for inference or downstream tasks.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=distilbert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.05292855575680733,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.03968575969338417,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a business model. [SEP]",
'score': 0.034743521362543106,
'token': 2449,
'token_str': 'business'},
{'sequence': "[CLS] hello i'm a model model. [SEP]",
'score': 0.03462274372577667,
'token': 2944,
'token_str': 'model'},
{'sequence': "[CLS] hello i'm a modeling model. [SEP]",
'score': 0.018145186826586723,
'token': 11643,
'token_str': 'modeling'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import DistilBertTokenizer, DistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. It also inherits some of
[the bias of its teacher model](https://huggingface.co/bert-base-uncased#limitations-and-bias).
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("The White man worked as a [MASK].")
[{'sequence': '[CLS] the white man worked as a blacksmith. [SEP]',
'score': 0.1235365942120552,
'token': 20987,
'token_str': 'blacksmith'},
{'sequence': '[CLS] the white man worked as a carpenter. [SEP]',
'score': 0.10142576694488525,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the white man worked as a farmer. [SEP]',
'score': 0.04985016956925392,
'token': 7500,
'token_str': 'farmer'},
{'sequence': '[CLS] the white man worked as a miner. [SEP]',
'score': 0.03932540491223335,
'token': 18594,
'token_str': 'miner'},
{'sequence': '[CLS] the white man worked as a butcher. [SEP]',
'score': 0.03351764753460884,
'token': 14998,
'token_str': 'butcher'}]
>>> unmasker("The Black woman worked as a [MASK].")
[{'sequence': '[CLS] the black woman worked as a waitress. [SEP]',
'score': 0.13283951580524445,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the black woman worked as a nurse. [SEP]',
'score': 0.12586183845996857,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the black woman worked as a maid. [SEP]',
'score': 0.11708822101354599,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the black woman worked as a prostitute. [SEP]',
'score': 0.11499975621700287,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the black woman worked as a housekeeper. [SEP]',
'score': 0.04722772538661957,
'token': 22583,
'token_str': 'housekeeper'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
DistilBERT pretrained on the same data as BERT, which is [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset
consisting of 11,038 unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
(excluding lists, tables and headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 8 16 GB V100 for 90 hours. See the
[training code](https://github.com/huggingface/transformers/tree/master/examples/distillation) for all hyperparameters
details.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
| | 81.5 | 87.8 | 88.2 | 90.4 | 47.2 | 85.5 | 85.6 | 60.6 |
### BibTeX entry and citation info
```bibtex
@article{Sanh2019DistilBERTAD,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
journal={ArXiv},
year={2019},
volume={abs/1910.01108}
}
```
<a href="https://huggingface.co/exbert/?model=distilbert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
coqui/XTTS-v2 | coqui | "2023-12-11T17:50:00Z" | 765,246 | 1,766 | coqui | [
"coqui",
"text-to-speech",
"license:other",
"region:us"
] | text-to-speech | "2023-10-31T10:11:33Z" | ---
license: other
license_name: coqui-public-model-license
license_link: https://coqui.ai/cpml
library_name: coqui
pipeline_tag: text-to-speech
widget:
- text: "Once when I was six years old I saw a magnificent picture"
---
# ⓍTTS
ⓍTTS is a Voice generation model that lets you clone voices into different languages by using just a quick 6-second audio clip. There is no need for an excessive amount of training data that spans countless hours.
This is the same or similar model to what powers [Coqui Studio](https://coqui.ai/) and [Coqui API](https://docs.coqui.ai/docs).
### Features
- Supports 17 languages.
- Voice cloning with just a 6-second audio clip.
- Emotion and style transfer by cloning.
- Cross-language voice cloning.
- Multi-lingual speech generation.
- 24khz sampling rate.
### Updates over XTTS-v1
- 2 new languages; Hungarian and Korean
- Architectural improvements for speaker conditioning.
- Enables the use of multiple speaker references and interpolation between speakers.
- Stability improvements.
- Better prosody and audio quality across the board.
### Languages
XTTS-v2 supports 17 languages: **English (en), Spanish (es), French (fr), German (de), Italian (it), Portuguese (pt),
Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh-cn), Japanese (ja), Hungarian (hu), Korean (ko)
Hindi (hi)**.
Stay tuned as we continue to add support for more languages. If you have any language requests, feel free to reach out!
### Code
The [code-base](https://github.com/coqui-ai/TTS) supports inference and [fine-tuning](https://tts.readthedocs.io/en/latest/models/xtts.html#training).
### Demo Spaces
- [XTTS Space](https://huggingface.co/spaces/coqui/xtts) : You can see how model performs on supported languages, and try with your own reference or microphone input
- [XTTS Voice Chat with Mistral or Zephyr](https://huggingface.co/spaces/coqui/voice-chat-with-mistral) : You can experience streaming voice chat with Mistral 7B Instruct or Zephyr 7B Beta
| | |
| ------------------------------- | --------------------------------------- |
| 🐸💬 **CoquiTTS** | [coqui/TTS on Github](https://github.com/coqui-ai/TTS)|
| 💼 **Documentation** | [ReadTheDocs](https://tts.readthedocs.io/en/latest/)
| 👩💻 **Questions** | [GitHub Discussions](https://github.com/coqui-ai/TTS/discussions) |
| 🗯 **Community** | [Discord](https://discord.gg/5eXr5seRrv) |
### License
This model is licensed under [Coqui Public Model License](https://coqui.ai/cpml). There's a lot that goes into a license for generative models, and you can read more of [the origin story of CPML here](https://coqui.ai/blog/tts/cpml).
### Contact
Come and join in our 🐸Community. We're active on [Discord](https://discord.gg/fBC58unbKE) and [Twitter](https://twitter.com/coqui_ai).
You can also mail us at [email protected].
Using 🐸TTS API:
```python
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2", gpu=True)
# generate speech by cloning a voice using default settings
tts.tts_to_file(text="It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
file_path="output.wav",
speaker_wav="/path/to/target/speaker.wav",
language="en")
```
Using 🐸TTS Command line:
```console
tts --model_name tts_models/multilingual/multi-dataset/xtts_v2 \
--text "Bugün okula gitmek istemiyorum." \
--speaker_wav /path/to/target/speaker.wav \
--language_idx tr \
--use_cuda true
```
Using the model directly:
```python
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import Xtts
config = XttsConfig()
config.load_json("/path/to/xtts/config.json")
model = Xtts.init_from_config(config)
model.load_checkpoint(config, checkpoint_dir="/path/to/xtts/", eval=True)
model.cuda()
outputs = model.synthesize(
"It took me quite a long time to develop a voice and now that I have it I am not going to be silent.",
config,
speaker_wav="/data/TTS-public/_refclips/3.wav",
gpt_cond_len=3,
language="en",
)
```
|
timm/efficientnet_b0.ra_in1k | timm | "2023-04-27T21:09:50Z" | 762,074 | 3 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2110.00476",
"arxiv:1905.11946",
"license:apache-2.0",
"region:us"
] | image-classification | "2022-12-12T23:52:52Z" | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for efficientnet_b0.ra_in1k
A EfficientNet image classification model. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* RandAugment `RA` recipe. Inspired by and evolved from EfficientNet RandAugment recipes. Published as `B` recipe in [ResNet Strikes Back](https://arxiv.org/abs/2110.00476).
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 5.3
- GMACs: 0.4
- Activations (M): 6.7
- Image size: 224 x 224
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('efficientnet_b0.ra_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientnet_b0.ra_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 40, 28, 28])
# torch.Size([1, 112, 14, 14])
# torch.Size([1, 320, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientnet_b0.ra_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
|
pysentimiento/robertuito-sentiment-analysis | pysentimiento | "2024-07-08T18:21:10Z" | 755,533 | 73 | pysentimiento | [
"pysentimiento",
"pytorch",
"tf",
"safetensors",
"roberta",
"twitter",
"sentiment-analysis",
"text-classification",
"es",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language:
- es
library_name: pysentimiento
pipeline_tag: text-classification
tags:
- twitter
- sentiment-analysis
---
# Sentiment Analysis in Spanish
## robertuito-sentiment-analysis
Repository: [https://github.com/pysentimiento/pysentimiento/](https://github.com/finiteautomata/pysentimiento/)
Model trained with TASS 2020 corpus (around ~5k tweets) of several dialects of Spanish. Base model is [RoBERTuito](https://github.com/pysentimiento/robertuito), a RoBERTa model trained in Spanish tweets.
Uses `POS`, `NEG`, `NEU` labels.
## Usage
Use it directly with [pysentimiento](https://github.com/pysentimiento/pysentimiento)
```python
from pysentimiento import create_analyzer
analyzer = create_analyzer(task="sentiment", lang="es")
analyzer.predict("Qué gran jugador es Messi")
# returns AnalyzerOutput(output=POS, probas={POS: 0.998, NEG: 0.002, NEU: 0.000})
```
## Results
Results for the four tasks evaluated in `pysentimiento`. Results are expressed as Macro F1 scores
| model | emotion | hate_speech | irony | sentiment |
|:--------------|:--------------|:--------------|:--------------|:--------------|
| robertuito | 0.560 ± 0.010 | 0.759 ± 0.007 | 0.739 ± 0.005 | 0.705 ± 0.003 |
| roberta | 0.527 ± 0.015 | 0.741 ± 0.012 | 0.721 ± 0.008 | 0.670 ± 0.006 |
| bertin | 0.524 ± 0.007 | 0.738 ± 0.007 | 0.713 ± 0.012 | 0.666 ± 0.005 |
| beto_uncased | 0.532 ± 0.012 | 0.727 ± 0.016 | 0.701 ± 0.007 | 0.651 ± 0.006 |
| beto_cased | 0.516 ± 0.012 | 0.724 ± 0.012 | 0.705 ± 0.009 | 0.662 ± 0.005 |
| mbert_uncased | 0.493 ± 0.010 | 0.718 ± 0.011 | 0.681 ± 0.010 | 0.617 ± 0.003 |
| biGRU | 0.264 ± 0.007 | 0.592 ± 0.018 | 0.631 ± 0.011 | 0.585 ± 0.011 |
Note that for Hate Speech, these are the results for Semeval 2019, Task 5 Subtask B
## Citation
If you use this model in your research, please cite pysentimiento, RoBERTuito and TASS papers:
```latex
@article{perez2021pysentimiento,
title={pysentimiento: a python toolkit for opinion mining and social NLP tasks},
author={P{\'e}rez, Juan Manuel and Rajngewerc, Mariela and Giudici, Juan Carlos and Furman, Dami{\'a}n A and Luque, Franco and Alemany, Laura Alonso and Mart{\'\i}nez, Mar{\'\i}a Vanina},
journal={arXiv preprint arXiv:2106.09462},
year={2021}
}
@inproceedings{perez-etal-2022-robertuito,
title = "{R}o{BERT}uito: a pre-trained language model for social media text in {S}panish",
author = "P{\'e}rez, Juan Manuel and
Furman, Dami{\'a}n Ariel and
Alonso Alemany, Laura and
Luque, Franco M.",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.785",
pages = "7235--7243",
abstract = "Since BERT appeared, Transformer language models and transfer learning have become state-of-the-art for natural language processing tasks. Recently, some works geared towards pre-training specially-crafted models for particular domains, such as scientific papers, medical documents, user-generated texts, among others. These domain-specific models have been shown to improve performance significantly in most tasks; however, for languages other than English, such models are not widely available. In this work, we present RoBERTuito, a pre-trained language model for user-generated text in Spanish, trained on over 500 million tweets. Experiments on a benchmark of tasks involving user-generated text showed that RoBERTuito outperformed other pre-trained language models in Spanish. In addition to this, our model has some cross-lingual abilities, achieving top results for English-Spanish tasks of the Linguistic Code-Switching Evaluation benchmark (LinCE) and also competitive performance against monolingual models in English Twitter tasks. To facilitate further research, we make RoBERTuito publicly available at the HuggingFace model hub together with the dataset used to pre-train it.",
}
@inproceedings{garcia2020overview,
title={Overview of TASS 2020: Introducing emotion detection},
author={Garc{\'\i}a-Vega, Manuel and D{\'\i}az-Galiano, MC and Garc{\'\i}a-Cumbreras, MA and Del Arco, FMP and Montejo-R{\'a}ez, A and Jim{\'e}nez-Zafra, SM and Mart{\'\i}nez C{\'a}mara, E and Aguilar, CA and Cabezudo, MAS and Chiruzzo, L and others},
booktitle={Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020) Co-Located with 36th Conference of the Spanish Society for Natural Language Processing (SEPLN 2020), M{\'a}laga, Spain},
pages={163--170},
year={2020}
}
``` |
meta-llama/Llama-3.1-70B-Instruct | meta-llama | "2024-09-25T16:55:00Z" | 755,263 | 545 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"base_model:meta-llama/Llama-3.1-70B",
"base_model:finetune:meta-llama/Llama-3.1-70B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-07-16T16:07:46Z" | ---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
base_model: meta-llama/Meta-Llama-3.1-70B
license: llama3.1
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
extra_gated_prompt: "### LLAMA 3.1 COMMUNITY LICENSE AGREEMENT\nLlama 3.1 Version\
\ Release Date: July 23, 2024\n\"Agreement\" means the terms and conditions for\
\ use, reproduction, distribution and modification of the Llama Materials set forth\
\ herein.\n\"Documentation\" means the specifications, manuals and documentation\
\ accompanying Llama 3.1 distributed by Meta at https://llama.meta.com/doc/overview.\n\
\"Licensee\" or \"you\" means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf), of\
\ the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\"Llama 3.1\"\
\ means the foundational large language models and software and algorithms, including\
\ machine-learning model code, trained model weights, inference-enabling code, training-enabling\
\ code, fine-tuning enabling code and other elements of the foregoing distributed\
\ by Meta at https://llama.meta.com/llama-downloads.\n\"Llama Materials\" means,\
\ collectively, Meta’s proprietary Llama 3.1 and Documentation (and any portion\
\ thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms\
\ Ireland Limited (if you are located in or, if you are an entity, your principal\
\ place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you\
\ are located outside of the EEA or Switzerland).\n \n1. License Rights and Redistribution.\n\
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable\
\ and royalty-free limited license under Meta’s intellectual property or other rights\
\ owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy,\
\ create derivative works of, and make modifications to the Llama Materials.\nb.\
\ Redistribution and Use.\ni. If you distribute or make available the Llama Materials\
\ (or any derivative works thereof), or a product or service (including another\
\ AI model) that contains any of them, you shall (A) provide a copy of this Agreement\
\ with any such Llama Materials; and (B) prominently display “Built with Llama”\
\ on a related website, user interface, blogpost, about page, or product documentation.\
\ If you use the Llama Materials or any outputs or results of the Llama Materials\
\ to create, train, fine tune, or otherwise improve an AI model, which is distributed\
\ or made available, you shall also include “Llama” at the beginning of any such\
\ AI model name.\nii. If you receive Llama Materials, or any derivative works thereof,\
\ from a Licensee as part of an integrated end user product, then Section 2 of\
\ this Agreement will not apply to you.\niii. You must retain in all copies of the\
\ Llama Materials that you distribute the following attribution notice within a\
\ “Notice” text file distributed as a part of such copies: “Llama 3.1 is licensed\
\ under the Llama 3.1 Community License, Copyright © Meta Platforms, Inc. All Rights\
\ Reserved.”\niv. Your use of the Llama Materials must comply with applicable laws\
\ and regulations (including trade compliance laws and regulations) and adhere to\
\ the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3_1/use-policy),\
\ which is hereby incorporated by reference into this Agreement.\n2. Additional\
\ Commercial Terms. If, on the Llama 3.1 version release date, the monthly active\
\ users of the products or services made available by or for Licensee, or Licensee’s\
\ affiliates, is greater than 700 million monthly active users in the preceding\
\ calendar month, you must request a license from Meta, which Meta may grant to\
\ you in its sole discretion, and you are not authorized to exercise any of the\
\ rights under this Agreement unless or until Meta otherwise expressly grants you\
\ such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE\
\ LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS”\
\ BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY\
\ KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES\
\ OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE.\
\ YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING\
\ THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA\
\ MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT\
\ WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN\
\ CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS\
\ AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL,\
\ EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED\
\ OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No\
\ trademark licenses are granted under this Agreement, and in connection with the\
\ Llama Materials, neither Meta nor Licensee may use any name or mark owned by or\
\ associated with the other or any of its affiliates, except as required for reasonable\
\ and customary use in describing and redistributing the Llama Materials or as set\
\ forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the\
\ “Mark”) solely as required to comply with the last sentence of Section 1.b.i.\
\ You will comply with Meta’s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/\
\ ). All goodwill arising out of your use of the Mark will inure to the benefit\
\ of Meta.\nb. Subject to Meta’s ownership of Llama Materials and derivatives made\
\ by or for Meta, with respect to any derivative works and modifications of the\
\ Llama Materials that are made by you, as between you and Meta, you are and will\
\ be the owner of such derivative works and modifications.\nc. If you institute\
\ litigation or other proceedings against Meta or any entity (including a cross-claim\
\ or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.1 outputs\
\ or results, or any portion of any of the foregoing, constitutes infringement of\
\ intellectual property or other rights owned or licensable by you, then any licenses\
\ granted to you under this Agreement shall terminate as of the date such litigation\
\ or claim is filed or instituted. You will indemnify and hold harmless Meta from\
\ and against any claim by any third party arising out of or related to your use\
\ or distribution of the Llama Materials.\n6. Term and Termination. The term of\
\ this Agreement will commence upon your acceptance of this Agreement or access\
\ to the Llama Materials and will continue in full force and effect until terminated\
\ in accordance with the terms and conditions herein. Meta may terminate this Agreement\
\ if you are in breach of any term or condition of this Agreement. Upon termination\
\ of this Agreement, you shall delete and cease use of the Llama Materials. Sections\
\ 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law\
\ and Jurisdiction. This Agreement will be governed and construed under the laws\
\ of the State of California without regard to choice of law principles, and the\
\ UN Convention on Contracts for the International Sale of Goods does not apply\
\ to this Agreement. The courts of California shall have exclusive jurisdiction\
\ of any dispute arising out of this Agreement.\n### Llama 3.1 Acceptable Use Policy\n\
Meta is committed to promoting safe and fair use of its tools and features, including\
\ Llama 3.1. If you access or use Llama 3.1, you agree to this Acceptable Use Policy\
\ (“Policy”). The most recent copy of this policy can be found at [https://llama.meta.com/llama3_1/use-policy](https://llama.meta.com/llama3_1/use-policy)\n\
#### Prohibited Uses\nWe want everyone to use Llama 3.1 safely and responsibly.\
\ You agree you will not use, or allow others to use, Llama 3.1 to:\n 1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 3. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 4. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 5.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 6. Collect, process, disclose, generate, or infer health, demographic,\
\ or other sensitive personal or private information about individuals without rights\
\ and consents required by applicable laws\n 7. Engage in or facilitate any action\
\ or generate any content that infringes, misappropriates, or otherwise violates\
\ any third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 8. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n2. Engage in, promote, incite,\
\ facilitate, or assist in the planning or development of activities that present\
\ a risk of death or bodily harm to individuals, including use of Llama 3.1 related\
\ to the following:\n 1. Military, warfare, nuclear industries or applications,\
\ espionage, use for materials or activities that are subject to the International\
\ Traffic Arms Regulations (ITAR) maintained by the United States Department of\
\ State\n 2. Guns and illegal weapons (including weapon development)\n 3.\
\ Illegal drugs and regulated/controlled substances\n 4. Operation of critical\
\ infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm\
\ or harm to others, including suicide, cutting, and eating disorders\n 6. Any\
\ content intended to incite or promote violence, abuse, or any infliction of bodily\
\ harm to an individual\n3. Intentionally deceive or mislead others, including use\
\ of Llama 3.1 related to the following:\n 1. Generating, promoting, or furthering\
\ fraud or the creation or promotion of disinformation\n 2. Generating, promoting,\
\ or furthering defamatory content, including the creation of defamatory statements,\
\ images, or other content\n 3. Generating, promoting, or further distributing\
\ spam\n 4. Impersonating another individual without consent, authorization,\
\ or legal right\n 5. Representing that the use of Llama 3.1 or outputs are human-generated\n\
\ 6. Generating or facilitating false online engagement, including fake reviews\
\ and other means of fake online engagement\n4. Fail to appropriately disclose to\
\ end users any known dangers of your AI system\nPlease report any violation of\
\ this Policy, software “bug,” or other problems that could lead to a violation\
\ of this Policy through one of the following means:\n * Reporting issues with\
\ the model: [https://github.com/meta-llama/llama-models/issues](https://github.com/meta-llama/llama-models/issues)\n\
\ * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n\
\ * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting\
\ violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Information
The Meta Llama 3.1 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction tuned generative models in 8B, 70B and 405B sizes (text in/text out). The Llama 3.1 instruction tuned text only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the available open source and closed chat models on common industry benchmarks.
**Model developer**: Meta
**Model Architecture:** Llama 3.1 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Input modalities</strong>
</td>
<td><strong>Output modalities</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="3" >Llama 3.1 (text only)
</td>
<td rowspan="3" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>Multilingual Text
</td>
<td>Multilingual Text and code
</td>
<td>128k
</td>
<td>Yes
</td>
<td rowspan="3" >15T+
</td>
<td rowspan="3" >December 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>Multilingual Text
</td>
<td>Multilingual Text and code
</td>
<td>128k
</td>
<td>Yes
</td>
</tr>
<tr>
<td>405B
</td>
<td>Multilingual Text
</td>
<td>Multilingual Text and code
</td>
<td>128k
</td>
<td>Yes
</td>
</tr>
</table>
**Supported languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
**Llama 3.1 family of models**. Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** July 23, 2024.
**Status:** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License:** A custom commercial license, the Llama 3.1 Community License, is available at: [https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3.1 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3.1 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks. The Llama 3.1 model collection also supports the ability to leverage the outputs of its models to improve other models including synthetic data generation and distillation. The Llama 3.1 Community License allows for these use cases.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.1 Community License. Use in languages beyond those explicitly referenced as supported in this model card**.
**<span style="text-decoration:underline;">Note</span>: Llama 3.1 has been trained on a broader collection of languages than the 8 supported languages. Developers may fine-tune Llama 3.1 models for languages beyond the 8 supported languages provided they comply with the Llama 3.1 Community License and the Acceptable Use Policy and in such cases are responsible for ensuring that any uses of Llama 3.1 in additional languages is done in a safe and responsible manner.
## How to use
This repository contains two versions of Meta-Llama-3.1-70B-Instruct, for use with transformers and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
### Tool use with transformers
LLaMA-3.1 supports multiple tool use formats. You can see a full guide to prompt formatting [here](https://llama.meta.com/docs/model-cards-and-prompt-formats/llama3_1/).
Tool use is also supported through [chat templates](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling) in Transformers.
Here is a quick example showing a single simple tool:
```python
# First, define a tool
def get_current_temperature(location: str) -> float:
"""
Get the current temperature at a location.
Args:
location: The location to get the temperature for, in the format "City, Country"
Returns:
The current temperature at the specified location in the specified units, as a float.
"""
return 22. # A real function should probably actually get the temperature!
# Next, create a chat and apply the chat template
messages = [
{"role": "system", "content": "You are a bot that responds to weather queries."},
{"role": "user", "content": "Hey, what's the temperature in Paris right now?"}
]
inputs = tokenizer.apply_chat_template(messages, tools=[get_current_temperature], add_generation_prompt=True)
```
You can then generate text from this input as normal. If the model generates a tool call, you should add it to the chat like so:
```python
tool_call = {"name": "get_current_temperature", "arguments": {"location": "Paris, France"}}
messages.append({"role": "assistant", "tool_calls": [{"type": "function", "function": tool_call}]})
```
and then call the tool and append the result, with the `tool` role, like so:
```python
messages.append({"role": "tool", "name": "get_current_temperature", "content": "22.0"})
```
After that, you can `generate()` again to let the model use the tool result in the chat. Note that this was a very brief introduction to tool calling - for more information,
see the [LLaMA prompt format docs](https://llama.meta.com/docs/model-cards-and-prompt-formats/llama3_1/) and the Transformers [tool use documentation](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling).
### Use with `bitsandbytes`
The model checkpoints can be used in `8-bit` and `4-bit` for further memory optimisations using `bitsandbytes` and `transformers`
See the snippet below for usage:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Meta-Llama-3.1-70B-Instruct"
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
input_text = "What are we having for dinner?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
output = quantized_model.generate(**input_ids, max_new_tokens=10)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
To load in 4-bit simply pass `load_in_4bit=True`
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3.1-70B-Instruct --include "original/*" --local-dir Meta-Llama-3.1-70B-Instruct
```
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, annotation, and evaluation were also performed on production infrastructure.
**Training utilized a cumulative of** 39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
**Training Greenhouse Gas Emissions** Estimated total location-based greenhouse gas emissions were **11,390** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy, therefore the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
<table>
<tr>
<td>
</td>
<td><strong>Training Time (GPU hours)</strong>
</td>
<td><strong>Training Power Consumption (W)</strong>
</td>
<td><strong>Training Location-Based Greenhouse Gas Emissions</strong>
<p>
<strong>(tons CO2eq)</strong>
</td>
<td><strong>Training Market-Based Greenhouse Gas Emissions</strong>
<p>
<strong>(tons CO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3.1 8B
</td>
<td>1.46M
</td>
<td>700
</td>
<td>420
</td>
<td>0
</td>
</tr>
<tr>
<td>Llama 3.1 70B
</td>
<td>7.0M
</td>
<td>700
</td>
<td>2,040
</td>
<td>0
</td>
</tr>
<tr>
<td>Llama 3.1 405B
</td>
<td>30.84M
</td>
<td>700
</td>
<td>8,930
</td>
<td>0
</td>
</tr>
<tr>
<td>Total
</td>
<td>39.3M
<td>
<ul>
</ul>
</td>
<td>11,390
</td>
<td>0
</td>
</tr>
</table>
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.1 was pretrained on ~15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 25M synthetically generated examples.
**Data Freshness:** The pretraining data has a cutoff of December 2023.
## Benchmark scores
In this section, we report the results for Llama 3.1 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library.
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong># Shots</strong>
</td>
<td><strong>Metric</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 3.1 8B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 3.1 70B</strong>
</td>
<td><strong>Llama 3.1 405B</strong>
</td>
</tr>
<tr>
<td rowspan="7" >General
</td>
<td>MMLU
</td>
<td>5
</td>
<td>macro_avg/acc_char
</td>
<td>66.7
</td>
<td>66.7
</td>
<td>79.5
</td>
<td>79.3
</td>
<td>85.2
</td>
</tr>
<tr>
<td>MMLU-Pro (CoT)
</td>
<td>5
</td>
<td>macro_avg/acc_char
</td>
<td>36.2
</td>
<td>37.1
</td>
<td>55.0
</td>
<td>53.8
</td>
<td>61.6
</td>
</tr>
<tr>
<td>AGIEval English
</td>
<td>3-5
</td>
<td>average/acc_char
</td>
<td>47.1
</td>
<td>47.8
</td>
<td>63.0
</td>
<td>64.6
</td>
<td>71.6
</td>
</tr>
<tr>
<td>CommonSenseQA
</td>
<td>7
</td>
<td>acc_char
</td>
<td>72.6
</td>
<td>75.0
</td>
<td>83.8
</td>
<td>84.1
</td>
<td>85.8
</td>
</tr>
<tr>
<td>Winogrande
</td>
<td>5
</td>
<td>acc_char
</td>
<td>-
</td>
<td>60.5
</td>
<td>-
</td>
<td>83.3
</td>
<td>86.7
</td>
</tr>
<tr>
<td>BIG-Bench Hard (CoT)
</td>
<td>3
</td>
<td>average/em
</td>
<td>61.1
</td>
<td>64.2
</td>
<td>81.3
</td>
<td>81.6
</td>
<td>85.9
</td>
</tr>
<tr>
<td>ARC-Challenge
</td>
<td>25
</td>
<td>acc_char
</td>
<td>79.4
</td>
<td>79.7
</td>
<td>93.1
</td>
<td>92.9
</td>
<td>96.1
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki
</td>
<td>5
</td>
<td>em
</td>
<td>78.5
</td>
<td>77.6
</td>
<td>89.7
</td>
<td>89.8
</td>
<td>91.8
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD
</td>
<td>1
</td>
<td>em
</td>
<td>76.4
</td>
<td>77.0
</td>
<td>85.6
</td>
<td>81.8
</td>
<td>89.3
</td>
</tr>
<tr>
<td>QuAC (F1)
</td>
<td>1
</td>
<td>f1
</td>
<td>44.4
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>51.1
</td>
<td>53.6
</td>
</tr>
<tr>
<td>BoolQ
</td>
<td>0
</td>
<td>acc_char
</td>
<td>75.7
</td>
<td>75.0
</td>
<td>79.0
</td>
<td>79.4
</td>
<td>80.0
</td>
</tr>
<tr>
<td>DROP (F1)
</td>
<td>3
</td>
<td>f1
</td>
<td>58.4
</td>
<td>59.5
</td>
<td>79.7
</td>
<td>79.6
</td>
<td>84.8
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong># Shots</strong>
</td>
<td><strong>Metric</strong>
</td>
<td><strong>Llama 3 8B Instruct</strong>
</td>
<td><strong>Llama 3.1 8B Instruct</strong>
</td>
<td><strong>Llama 3 70B Instruct</strong>
</td>
<td><strong>Llama 3.1 70B Instruct</strong>
</td>
<td><strong>Llama 3.1 405B Instruct</strong>
</td>
</tr>
<tr>
<td rowspan="4" >General
</td>
<td>MMLU
</td>
<td>5
</td>
<td>macro_avg/acc
</td>
<td>68.5
</td>
<td>69.4
</td>
<td>82.0
</td>
<td>83.6
</td>
<td>87.3
</td>
</tr>
<tr>
<td>MMLU (CoT)
</td>
<td>0
</td>
<td>macro_avg/acc
</td>
<td>65.3
</td>
<td>73.0
</td>
<td>80.9
</td>
<td>86.0
</td>
<td>88.6
</td>
</tr>
<tr>
<td>MMLU-Pro (CoT)
</td>
<td>5
</td>
<td>micro_avg/acc_char
</td>
<td>45.5
</td>
<td>48.3
</td>
<td>63.4
</td>
<td>66.4
</td>
<td>73.3
</td>
</tr>
<tr>
<td>IFEval
</td>
<td>
</td>
<td>
</td>
<td>76.8
</td>
<td>80.4
</td>
<td>82.9
</td>
<td>87.5
</td>
<td>88.6
</td>
</tr>
<tr>
<td rowspan="2" >Reasoning
</td>
<td>ARC-C
</td>
<td>0
</td>
<td>acc
</td>
<td>82.4
</td>
<td>83.4
</td>
<td>94.4
</td>
<td>94.8
</td>
<td>96.9
</td>
</tr>
<tr>
<td>GPQA
</td>
<td>0
</td>
<td>em
</td>
<td>34.6
</td>
<td>30.4
</td>
<td>39.5
</td>
<td>46.7
</td>
<td>50.7
</td>
</tr>
<tr>
<td rowspan="4" >Code
</td>
<td>HumanEval
</td>
<td>0
</td>
<td>pass@1
</td>
<td>60.4
</td>
<td>72.6
</td>
<td>81.7
</td>
<td>80.5
</td>
<td>89.0
</td>
</tr>
<tr>
<td>MBPP ++ base version
</td>
<td>0
</td>
<td>pass@1
</td>
<td>70.6
</td>
<td>72.8
</td>
<td>82.5
</td>
<td>86.0
</td>
<td>88.6
</td>
</tr>
<tr>
<td>Multipl-E HumanEval
</td>
<td>0
</td>
<td>pass@1
</td>
<td>-
</td>
<td>50.8
</td>
<td>-
</td>
<td>65.5
</td>
<td>75.2
</td>
</tr>
<tr>
<td>Multipl-E MBPP
</td>
<td>0
</td>
<td>pass@1
</td>
<td>-
</td>
<td>52.4
</td>
<td>-
</td>
<td>62.0
</td>
<td>65.7
</td>
</tr>
<tr>
<td rowspan="2" >Math
</td>
<td>GSM-8K (CoT)
</td>
<td>8
</td>
<td>em_maj1@1
</td>
<td>80.6
</td>
<td>84.5
</td>
<td>93.0
</td>
<td>95.1
</td>
<td>96.8
</td>
</tr>
<tr>
<td>MATH (CoT)
</td>
<td>0
</td>
<td>final_em
</td>
<td>29.1
</td>
<td>51.9
</td>
<td>51.0
</td>
<td>68.0
</td>
<td>73.8
</td>
</tr>
<tr>
<td rowspan="4" >Tool Use
</td>
<td>API-Bank
</td>
<td>0
</td>
<td>acc
</td>
<td>48.3
</td>
<td>82.6
</td>
<td>85.1
</td>
<td>90.0
</td>
<td>92.0
</td>
</tr>
<tr>
<td>BFCL
</td>
<td>0
</td>
<td>acc
</td>
<td>60.3
</td>
<td>76.1
</td>
<td>83.0
</td>
<td>84.8
</td>
<td>88.5
</td>
</tr>
<tr>
<td>Gorilla Benchmark API Bench
</td>
<td>0
</td>
<td>acc
</td>
<td>1.7
</td>
<td>8.2
</td>
<td>14.7
</td>
<td>29.7
</td>
<td>35.3
</td>
</tr>
<tr>
<td>Nexus (0-shot)
</td>
<td>0
</td>
<td>macro_avg/acc
</td>
<td>18.1
</td>
<td>38.5
</td>
<td>47.8
</td>
<td>56.7
</td>
<td>58.7
</td>
</tr>
<tr>
<td>Multilingual
</td>
<td>Multilingual MGSM (CoT)
</td>
<td>0
</td>
<td>em
</td>
<td>-
</td>
<td>68.9
</td>
<td>-
</td>
<td>86.9
</td>
<td>91.6
</td>
</tr>
</table>
#### Multilingual benchmarks
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Language</strong>
</td>
<td><strong>Llama 3.1 8B</strong>
</td>
<td><strong>Llama 3.1 70B</strong>
</td>
<td><strong>Llama 3.1 405B</strong>
</td>
</tr>
<tr>
<td rowspan="9" ><strong>General</strong>
</td>
<td rowspan="9" ><strong>MMLU (5-shot, macro_avg/acc)</strong>
</td>
<td>Portuguese
</td>
<td>62.12
</td>
<td>80.13
</td>
<td>84.95
</td>
</tr>
<tr>
<td>Spanish
</td>
<td>62.45
</td>
<td>80.05
</td>
<td>85.08
</td>
</tr>
<tr>
<td>Italian
</td>
<td>61.63
</td>
<td>80.4
</td>
<td>85.04
</td>
</tr>
<tr>
<td>German
</td>
<td>60.59
</td>
<td>79.27
</td>
<td>84.36
</td>
</tr>
<tr>
<td>French
</td>
<td>62.34
</td>
<td>79.82
</td>
<td>84.66
</td>
</tr>
<tr>
<td>Hindi
</td>
<td>50.88
</td>
<td>74.52
</td>
<td>80.31
</td>
</tr>
<tr>
<td>Thai
</td>
<td>50.32
</td>
<td>72.95
</td>
<td>78.21
</td>
</tr>
</table>
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
* Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama.
* Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm.
* Provide protections for the community to help prevent the misuse of our models.
### Responsible deployment
Llama is a foundational technology designed to be used in a variety of use cases, examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models enabling the world to benefit from the technology power, by aligning our model safety for the generic use cases addressing a standard set of harms. Developers are then in the driver seat to tailor safety for their use case, defining their own policy and deploying the models with the necessary safeguards in their Llama systems. Llama 3.1 was developed following the best practices outlined in our Responsible Use Guide, you can refer to the [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to learn more.
#### Llama 3.1 instruct
Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. For more details on the safety mitigations implemented please read the Llama 3 paper.
**Fine-tuning data**
We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone**
Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.1 systems
**Large language models, including Llama 3.1, are not designed to be deployed in isolation but instead should be deployed as part of an overall AI system with additional safety guardrails as required.** Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools.
As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard 3, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
#### New capabilities
Note that this release introduces new capabilities, including a longer context window, multilingual inputs and outputs and possible integrations by developers with third party tools. Building with these new capabilities requires specific considerations in addition to the best practices that generally apply across all Generative AI use cases.
**Tool-use**: Just like in standard software development, developers are responsible for the integration of the LLM with the tools and services of their choice. They should define a clear policy for their use case and assess the integrity of the third party services they use to be aware of the safety and security limitations when using this capability. Refer to the Responsible Use Guide for best practices on the safe deployment of the third party safeguards.
**Multilinguality**: Llama 3.1 supports 7 languages in addition to English: French, German, Hindi, Italian, Portuguese, Spanish, and Thai. Llama may be able to output text in other languages than those that meet performance thresholds for safety and helpfulness. We strongly discourage developers from using this model to converse in non-supported languages without implementing finetuning and system controls in alignment with their policies and the best practices shared in the Responsible Use Guide.
### Evaluations
We evaluated Llama models for common use cases as well as specific capabilities. Common use cases evaluations measure safety risks of systems for most commonly built applications including chat bot, coding assistant, tool calls. We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Llama Guard 3 to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case. Prompt Guard and Code Shield are also available if relevant to the application.
Capability evaluations measure vulnerabilities of Llama models inherent to specific capabilities, for which were crafted dedicated benchmarks including long context, multilingual, tools calls, coding or memorization.
**Red teaming**
For both scenarios, we conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets.
We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical and other risks
We specifically focused our efforts on mitigating the following critical risk areas:
**1- CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive materials) helpfulness**
To assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons.
**2. Child Safety**
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3. Cyber attack enablement**
Our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention.
Our study of Llama-3.1-405B’s social engineering uplift for cyber attackers was conducted to assess the effectiveness of AI models in aiding cyber threat actors in spear phishing campaigns. Please read our Llama 3.1 Cyber security whitepaper to learn more.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3.1 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.1 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3.1 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.1’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.1 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development. |
ai-forever/sbert_large_nlu_ru | ai-forever | "2024-07-31T16:32:52Z" | 748,978 | 56 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"PyTorch",
"Transformers",
"ru",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language:
- ru
tags:
- PyTorch
- Transformers
---
# BERT large model (uncased) for Sentence Embeddings in Russian language.
The model is described [in this article](https://habr.com/ru/company/sberdevices/blog/527576/)
For better quality, use mean token embeddings.
## Usage (HuggingFace Models Repository)
You can use the model directly from the model repository to compute sentence embeddings:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
#Sentences we want sentence embeddings for
sentences = ['Привет! Как твои дела?',
'А правда, что 42 твое любимое число?']
#Load AutoModel from huggingface model repository
tokenizer = AutoTokenizer.from_pretrained("ai-forever/sbert_large_nlu_ru")
model = AutoModel.from_pretrained("ai-forever/sbert_large_nlu_ru")
#Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=24, return_tensors='pt')
#Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
#Perform pooling. In this case, mean pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
# Authors
+ [SberDevices](https://sberdevices.ru/) Team.
+ Aleksandr Abramov: [HF profile](https://huggingface.co/Andrilko), [Github](https://github.com/Ab1992ao), [Kaggle Competitions Master](https://www.kaggle.com/andrilko);
+ Denis Antykhov: [Github](https://github.com/gaphex); |
microsoft/git-base | microsoft | "2023-04-24T09:52:15Z" | 740,540 | 69 | transformers | [
"transformers",
"pytorch",
"safetensors",
"git",
"text-generation",
"vision",
"image-to-text",
"image-captioning",
"en",
"arxiv:2205.14100",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-to-text | "2022-12-06T09:22:35Z" | ---
language: en
license: mit
tags:
- vision
- image-to-text
- image-captioning
model_name: microsoft/git-base
pipeline_tag: image-to-text
---
# GIT (GenerativeImage2Text), base-sized
GIT (short for GenerativeImage2Text) model, base-sized version. It was introduced in the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Wang et al. and first released in [this repository](https://github.com/microsoft/GenerativeImage2Text).
Disclaimer: The team releasing GIT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
GIT is a Transformer decoder conditioned on both CLIP image tokens and text tokens. The model is trained using "teacher forcing" on a lot of (image, text) pairs.
The goal for the model is simply to predict the next text token, giving the image tokens and previous text tokens.
The model has full access to (i.e. a bidirectional attention mask is used for) the image patch tokens, but only has access to the previous text tokens (i.e. a causal attention mask is used for the text tokens) when predicting the next text token.

This allows the model to be used for tasks like:
- image and video captioning
- visual question answering (VQA) on images and videos
- even image classification (by simply conditioning the model on the image and asking it to generate a class for it in text).
## Intended uses & limitations
You can use the raw model for image captioning. See the [model hub](https://huggingface.co/models?search=microsoft/git) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/model_doc/git#transformers.GitForCausalLM.forward.example).
## Training data
From the paper:
> We collect 0.8B image-text pairs for pre-training, which include COCO (Lin et al., 2014), Conceptual Captions
(CC3M) (Sharma et al., 2018), SBU (Ordonez et al., 2011), Visual Genome (VG) (Krishna et al., 2016),
Conceptual Captions (CC12M) (Changpinyo et al., 2021), ALT200M (Hu et al., 2021a), and an extra 0.6B
data following a similar collection procedure in Hu et al. (2021a).
=> however this is for the model referred to as "GIT" in the paper, which is not open-sourced.
This checkpoint is "GIT-base", which is a smaller variant of GIT trained on 10 million image-text pairs.
See table 11 in the [paper](https://arxiv.org/abs/2205.14100) for more details.
### Preprocessing
We refer to the original repo regarding details for preprocessing during training.
During validation, one resizes the shorter edge of each image, after which center cropping is performed to a fixed-size resolution. Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
For evaluation results, we refer readers to the [paper](https://arxiv.org/abs/2205.14100). |
thenlper/gte-large | thenlper | "2024-02-05T07:16:01Z" | 735,325 | 242 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"bert",
"mteb",
"sentence-similarity",
"Sentence Transformers",
"en",
"arxiv:2308.03281",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-07-27T09:55:39Z" | ---
tags:
- mteb
- sentence-similarity
- sentence-transformers
- Sentence Transformers
model-index:
- name: gte-large
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 72.62686567164178
- type: ap
value: 34.46944126809772
- type: f1
value: 66.23684353950857
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.51805
- type: ap
value: 89.49842783330848
- type: f1
value: 92.51112169431808
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.074
- type: f1
value: 48.44785682572955
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.077
- type: map_at_10
value: 48.153
- type: map_at_100
value: 48.963
- type: map_at_1000
value: 48.966
- type: map_at_3
value: 43.184
- type: map_at_5
value: 46.072
- type: mrr_at_1
value: 33.073
- type: mrr_at_10
value: 48.54
- type: mrr_at_100
value: 49.335
- type: mrr_at_1000
value: 49.338
- type: mrr_at_3
value: 43.563
- type: mrr_at_5
value: 46.383
- type: ndcg_at_1
value: 32.077
- type: ndcg_at_10
value: 57.158
- type: ndcg_at_100
value: 60.324999999999996
- type: ndcg_at_1000
value: 60.402
- type: ndcg_at_3
value: 46.934
- type: ndcg_at_5
value: 52.158
- type: precision_at_1
value: 32.077
- type: precision_at_10
value: 8.591999999999999
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 19.275000000000002
- type: precision_at_5
value: 14.111
- type: recall_at_1
value: 32.077
- type: recall_at_10
value: 85.917
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 57.824
- type: recall_at_5
value: 70.555
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.619246083417295
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.3574067664688
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.06359661829253
- type: mrr
value: 76.15596007562766
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 90.25407547368691
- type: cos_sim_spearman
value: 88.65081514968477
- type: euclidean_pearson
value: 88.14857116664494
- type: euclidean_spearman
value: 88.50683596540692
- type: manhattan_pearson
value: 87.9654797992225
- type: manhattan_spearman
value: 88.21164851646908
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 86.05844155844157
- type: f1
value: 86.01555597681825
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.10510519739522
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.84689960264385
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.800000000000004
- type: map_at_10
value: 44.857
- type: map_at_100
value: 46.512
- type: map_at_1000
value: 46.635
- type: map_at_3
value: 41.062
- type: map_at_5
value: 43.126
- type: mrr_at_1
value: 39.628
- type: mrr_at_10
value: 50.879
- type: mrr_at_100
value: 51.605000000000004
- type: mrr_at_1000
value: 51.641000000000005
- type: mrr_at_3
value: 48.14
- type: mrr_at_5
value: 49.835
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 51.819
- type: ndcg_at_100
value: 57.318999999999996
- type: ndcg_at_1000
value: 58.955999999999996
- type: ndcg_at_3
value: 46.409
- type: ndcg_at_5
value: 48.825
- type: precision_at_1
value: 39.628
- type: precision_at_10
value: 10.072000000000001
- type: precision_at_100
value: 1.625
- type: precision_at_1000
value: 0.21
- type: precision_at_3
value: 22.556
- type: precision_at_5
value: 16.309
- type: recall_at_1
value: 32.800000000000004
- type: recall_at_10
value: 65.078
- type: recall_at_100
value: 87.491
- type: recall_at_1000
value: 97.514
- type: recall_at_3
value: 49.561
- type: recall_at_5
value: 56.135999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.614
- type: map_at_10
value: 43.578
- type: map_at_100
value: 44.897
- type: map_at_1000
value: 45.023
- type: map_at_3
value: 40.282000000000004
- type: map_at_5
value: 42.117
- type: mrr_at_1
value: 40.510000000000005
- type: mrr_at_10
value: 49.428
- type: mrr_at_100
value: 50.068999999999996
- type: mrr_at_1000
value: 50.111000000000004
- type: mrr_at_3
value: 47.176
- type: mrr_at_5
value: 48.583999999999996
- type: ndcg_at_1
value: 40.510000000000005
- type: ndcg_at_10
value: 49.478
- type: ndcg_at_100
value: 53.852
- type: ndcg_at_1000
value: 55.782
- type: ndcg_at_3
value: 45.091
- type: ndcg_at_5
value: 47.19
- type: precision_at_1
value: 40.510000000000005
- type: precision_at_10
value: 9.363000000000001
- type: precision_at_100
value: 1.51
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 21.741
- type: precision_at_5
value: 15.465000000000002
- type: recall_at_1
value: 32.614
- type: recall_at_10
value: 59.782000000000004
- type: recall_at_100
value: 78.012
- type: recall_at_1000
value: 90.319
- type: recall_at_3
value: 46.825
- type: recall_at_5
value: 52.688
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.266000000000005
- type: map_at_10
value: 53.756
- type: map_at_100
value: 54.809
- type: map_at_1000
value: 54.855
- type: map_at_3
value: 50.073
- type: map_at_5
value: 52.293
- type: mrr_at_1
value: 46.332
- type: mrr_at_10
value: 57.116
- type: mrr_at_100
value: 57.767
- type: mrr_at_1000
value: 57.791000000000004
- type: mrr_at_3
value: 54.461999999999996
- type: mrr_at_5
value: 56.092
- type: ndcg_at_1
value: 46.332
- type: ndcg_at_10
value: 60.092
- type: ndcg_at_100
value: 64.034
- type: ndcg_at_1000
value: 64.937
- type: ndcg_at_3
value: 54.071000000000005
- type: ndcg_at_5
value: 57.254000000000005
- type: precision_at_1
value: 46.332
- type: precision_at_10
value: 9.799
- type: precision_at_100
value: 1.278
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 24.368000000000002
- type: precision_at_5
value: 16.89
- type: recall_at_1
value: 40.266000000000005
- type: recall_at_10
value: 75.41499999999999
- type: recall_at_100
value: 92.01700000000001
- type: recall_at_1000
value: 98.379
- type: recall_at_3
value: 59.476
- type: recall_at_5
value: 67.297
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.589
- type: map_at_10
value: 37.755
- type: map_at_100
value: 38.881
- type: map_at_1000
value: 38.954
- type: map_at_3
value: 34.759
- type: map_at_5
value: 36.544
- type: mrr_at_1
value: 30.734
- type: mrr_at_10
value: 39.742
- type: mrr_at_100
value: 40.774
- type: mrr_at_1000
value: 40.824
- type: mrr_at_3
value: 37.137
- type: mrr_at_5
value: 38.719
- type: ndcg_at_1
value: 30.734
- type: ndcg_at_10
value: 42.978
- type: ndcg_at_100
value: 48.309000000000005
- type: ndcg_at_1000
value: 50.068
- type: ndcg_at_3
value: 37.361
- type: ndcg_at_5
value: 40.268
- type: precision_at_1
value: 30.734
- type: precision_at_10
value: 6.565
- type: precision_at_100
value: 0.964
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 15.744
- type: precision_at_5
value: 11.096
- type: recall_at_1
value: 28.589
- type: recall_at_10
value: 57.126999999999995
- type: recall_at_100
value: 81.051
- type: recall_at_1000
value: 94.027
- type: recall_at_3
value: 42.045
- type: recall_at_5
value: 49.019
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.5
- type: map_at_10
value: 27.950999999999997
- type: map_at_100
value: 29.186
- type: map_at_1000
value: 29.298000000000002
- type: map_at_3
value: 25.141000000000002
- type: map_at_5
value: 26.848
- type: mrr_at_1
value: 22.637
- type: mrr_at_10
value: 32.572
- type: mrr_at_100
value: 33.472
- type: mrr_at_1000
value: 33.533
- type: mrr_at_3
value: 29.747
- type: mrr_at_5
value: 31.482
- type: ndcg_at_1
value: 22.637
- type: ndcg_at_10
value: 33.73
- type: ndcg_at_100
value: 39.568
- type: ndcg_at_1000
value: 42.201
- type: ndcg_at_3
value: 28.505999999999997
- type: ndcg_at_5
value: 31.255
- type: precision_at_1
value: 22.637
- type: precision_at_10
value: 6.281000000000001
- type: precision_at_100
value: 1.073
- type: precision_at_1000
value: 0.14300000000000002
- type: precision_at_3
value: 13.847000000000001
- type: precision_at_5
value: 10.224
- type: recall_at_1
value: 18.5
- type: recall_at_10
value: 46.744
- type: recall_at_100
value: 72.072
- type: recall_at_1000
value: 91.03999999999999
- type: recall_at_3
value: 32.551
- type: recall_at_5
value: 39.533
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.602
- type: map_at_10
value: 42.18
- type: map_at_100
value: 43.6
- type: map_at_1000
value: 43.704
- type: map_at_3
value: 38.413000000000004
- type: map_at_5
value: 40.626
- type: mrr_at_1
value: 37.344
- type: mrr_at_10
value: 47.638000000000005
- type: mrr_at_100
value: 48.485
- type: mrr_at_1000
value: 48.52
- type: mrr_at_3
value: 44.867000000000004
- type: mrr_at_5
value: 46.566
- type: ndcg_at_1
value: 37.344
- type: ndcg_at_10
value: 48.632
- type: ndcg_at_100
value: 54.215
- type: ndcg_at_1000
value: 55.981
- type: ndcg_at_3
value: 42.681999999999995
- type: ndcg_at_5
value: 45.732
- type: precision_at_1
value: 37.344
- type: precision_at_10
value: 8.932
- type: precision_at_100
value: 1.376
- type: precision_at_1000
value: 0.17099999999999999
- type: precision_at_3
value: 20.276
- type: precision_at_5
value: 14.726
- type: recall_at_1
value: 30.602
- type: recall_at_10
value: 62.273
- type: recall_at_100
value: 85.12100000000001
- type: recall_at_1000
value: 96.439
- type: recall_at_3
value: 45.848
- type: recall_at_5
value: 53.615
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.952
- type: map_at_10
value: 35.177
- type: map_at_100
value: 36.59
- type: map_at_1000
value: 36.703
- type: map_at_3
value: 31.261
- type: map_at_5
value: 33.222
- type: mrr_at_1
value: 29.337999999999997
- type: mrr_at_10
value: 40.152
- type: mrr_at_100
value: 40.963
- type: mrr_at_1000
value: 41.016999999999996
- type: mrr_at_3
value: 36.91
- type: mrr_at_5
value: 38.685
- type: ndcg_at_1
value: 29.337999999999997
- type: ndcg_at_10
value: 41.994
- type: ndcg_at_100
value: 47.587
- type: ndcg_at_1000
value: 49.791000000000004
- type: ndcg_at_3
value: 35.27
- type: ndcg_at_5
value: 38.042
- type: precision_at_1
value: 29.337999999999997
- type: precision_at_10
value: 8.276
- type: precision_at_100
value: 1.276
- type: precision_at_1000
value: 0.164
- type: precision_at_3
value: 17.161
- type: precision_at_5
value: 12.671
- type: recall_at_1
value: 23.952
- type: recall_at_10
value: 57.267
- type: recall_at_100
value: 80.886
- type: recall_at_1000
value: 95.611
- type: recall_at_3
value: 38.622
- type: recall_at_5
value: 45.811
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.092083333333335
- type: map_at_10
value: 37.2925
- type: map_at_100
value: 38.57041666666666
- type: map_at_1000
value: 38.68141666666667
- type: map_at_3
value: 34.080000000000005
- type: map_at_5
value: 35.89958333333333
- type: mrr_at_1
value: 31.94758333333333
- type: mrr_at_10
value: 41.51049999999999
- type: mrr_at_100
value: 42.36099999999999
- type: mrr_at_1000
value: 42.4125
- type: mrr_at_3
value: 38.849583333333335
- type: mrr_at_5
value: 40.448249999999994
- type: ndcg_at_1
value: 31.94758333333333
- type: ndcg_at_10
value: 43.17633333333333
- type: ndcg_at_100
value: 48.45241666666668
- type: ndcg_at_1000
value: 50.513999999999996
- type: ndcg_at_3
value: 37.75216666666667
- type: ndcg_at_5
value: 40.393833333333326
- type: precision_at_1
value: 31.94758333333333
- type: precision_at_10
value: 7.688916666666666
- type: precision_at_100
value: 1.2250833333333333
- type: precision_at_1000
value: 0.1595
- type: precision_at_3
value: 17.465999999999998
- type: precision_at_5
value: 12.548083333333333
- type: recall_at_1
value: 27.092083333333335
- type: recall_at_10
value: 56.286583333333326
- type: recall_at_100
value: 79.09033333333333
- type: recall_at_1000
value: 93.27483333333335
- type: recall_at_3
value: 41.35325
- type: recall_at_5
value: 48.072750000000006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.825
- type: map_at_10
value: 33.723
- type: map_at_100
value: 34.74
- type: map_at_1000
value: 34.824
- type: map_at_3
value: 31.369000000000003
- type: map_at_5
value: 32.533
- type: mrr_at_1
value: 29.293999999999997
- type: mrr_at_10
value: 36.84
- type: mrr_at_100
value: 37.681
- type: mrr_at_1000
value: 37.742
- type: mrr_at_3
value: 34.79
- type: mrr_at_5
value: 35.872
- type: ndcg_at_1
value: 29.293999999999997
- type: ndcg_at_10
value: 38.385999999999996
- type: ndcg_at_100
value: 43.327
- type: ndcg_at_1000
value: 45.53
- type: ndcg_at_3
value: 33.985
- type: ndcg_at_5
value: 35.817
- type: precision_at_1
value: 29.293999999999997
- type: precision_at_10
value: 6.12
- type: precision_at_100
value: 0.9329999999999999
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 14.621999999999998
- type: precision_at_5
value: 10.030999999999999
- type: recall_at_1
value: 25.825
- type: recall_at_10
value: 49.647000000000006
- type: recall_at_100
value: 72.32300000000001
- type: recall_at_1000
value: 88.62400000000001
- type: recall_at_3
value: 37.366
- type: recall_at_5
value: 41.957
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.139
- type: map_at_10
value: 26.107000000000003
- type: map_at_100
value: 27.406999999999996
- type: map_at_1000
value: 27.535999999999998
- type: map_at_3
value: 23.445
- type: map_at_5
value: 24.916
- type: mrr_at_1
value: 21.817
- type: mrr_at_10
value: 29.99
- type: mrr_at_100
value: 31.052000000000003
- type: mrr_at_1000
value: 31.128
- type: mrr_at_3
value: 27.627000000000002
- type: mrr_at_5
value: 29.005
- type: ndcg_at_1
value: 21.817
- type: ndcg_at_10
value: 31.135
- type: ndcg_at_100
value: 37.108000000000004
- type: ndcg_at_1000
value: 39.965
- type: ndcg_at_3
value: 26.439
- type: ndcg_at_5
value: 28.655
- type: precision_at_1
value: 21.817
- type: precision_at_10
value: 5.757000000000001
- type: precision_at_100
value: 1.036
- type: precision_at_1000
value: 0.147
- type: precision_at_3
value: 12.537
- type: precision_at_5
value: 9.229
- type: recall_at_1
value: 18.139
- type: recall_at_10
value: 42.272999999999996
- type: recall_at_100
value: 68.657
- type: recall_at_1000
value: 88.93799999999999
- type: recall_at_3
value: 29.266
- type: recall_at_5
value: 34.892
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.755000000000003
- type: map_at_10
value: 37.384
- type: map_at_100
value: 38.56
- type: map_at_1000
value: 38.655
- type: map_at_3
value: 34.214
- type: map_at_5
value: 35.96
- type: mrr_at_1
value: 32.369
- type: mrr_at_10
value: 41.625
- type: mrr_at_100
value: 42.449
- type: mrr_at_1000
value: 42.502
- type: mrr_at_3
value: 38.899
- type: mrr_at_5
value: 40.489999999999995
- type: ndcg_at_1
value: 32.369
- type: ndcg_at_10
value: 43.287
- type: ndcg_at_100
value: 48.504999999999995
- type: ndcg_at_1000
value: 50.552
- type: ndcg_at_3
value: 37.549
- type: ndcg_at_5
value: 40.204
- type: precision_at_1
value: 32.369
- type: precision_at_10
value: 7.425
- type: precision_at_100
value: 1.134
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 17.102
- type: precision_at_5
value: 12.107999999999999
- type: recall_at_1
value: 27.755000000000003
- type: recall_at_10
value: 57.071000000000005
- type: recall_at_100
value: 79.456
- type: recall_at_1000
value: 93.54299999999999
- type: recall_at_3
value: 41.298
- type: recall_at_5
value: 48.037
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.855
- type: map_at_10
value: 34.53
- type: map_at_100
value: 36.167
- type: map_at_1000
value: 36.394999999999996
- type: map_at_3
value: 31.037
- type: map_at_5
value: 33.119
- type: mrr_at_1
value: 30.631999999999998
- type: mrr_at_10
value: 39.763999999999996
- type: mrr_at_100
value: 40.77
- type: mrr_at_1000
value: 40.826
- type: mrr_at_3
value: 36.495
- type: mrr_at_5
value: 38.561
- type: ndcg_at_1
value: 30.631999999999998
- type: ndcg_at_10
value: 40.942
- type: ndcg_at_100
value: 47.07
- type: ndcg_at_1000
value: 49.363
- type: ndcg_at_3
value: 35.038000000000004
- type: ndcg_at_5
value: 38.161
- type: precision_at_1
value: 30.631999999999998
- type: precision_at_10
value: 7.983999999999999
- type: precision_at_100
value: 1.6070000000000002
- type: precision_at_1000
value: 0.246
- type: precision_at_3
value: 16.206
- type: precision_at_5
value: 12.253
- type: recall_at_1
value: 24.855
- type: recall_at_10
value: 53.291999999999994
- type: recall_at_100
value: 80.283
- type: recall_at_1000
value: 94.309
- type: recall_at_3
value: 37.257
- type: recall_at_5
value: 45.282
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.208
- type: map_at_10
value: 30.512
- type: map_at_100
value: 31.496000000000002
- type: map_at_1000
value: 31.595000000000002
- type: map_at_3
value: 27.904
- type: map_at_5
value: 29.491
- type: mrr_at_1
value: 22.736
- type: mrr_at_10
value: 32.379999999999995
- type: mrr_at_100
value: 33.245000000000005
- type: mrr_at_1000
value: 33.315
- type: mrr_at_3
value: 29.945
- type: mrr_at_5
value: 31.488
- type: ndcg_at_1
value: 22.736
- type: ndcg_at_10
value: 35.643
- type: ndcg_at_100
value: 40.535
- type: ndcg_at_1000
value: 43.042
- type: ndcg_at_3
value: 30.625000000000004
- type: ndcg_at_5
value: 33.323
- type: precision_at_1
value: 22.736
- type: precision_at_10
value: 5.6930000000000005
- type: precision_at_100
value: 0.889
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 13.431999999999999
- type: precision_at_5
value: 9.575
- type: recall_at_1
value: 21.208
- type: recall_at_10
value: 49.47
- type: recall_at_100
value: 71.71499999999999
- type: recall_at_1000
value: 90.55499999999999
- type: recall_at_3
value: 36.124
- type: recall_at_5
value: 42.606
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.363
- type: map_at_10
value: 20.312
- type: map_at_100
value: 22.225
- type: map_at_1000
value: 22.411
- type: map_at_3
value: 16.68
- type: map_at_5
value: 18.608
- type: mrr_at_1
value: 25.537
- type: mrr_at_10
value: 37.933
- type: mrr_at_100
value: 38.875
- type: mrr_at_1000
value: 38.911
- type: mrr_at_3
value: 34.387
- type: mrr_at_5
value: 36.51
- type: ndcg_at_1
value: 25.537
- type: ndcg_at_10
value: 28.82
- type: ndcg_at_100
value: 36.341
- type: ndcg_at_1000
value: 39.615
- type: ndcg_at_3
value: 23.01
- type: ndcg_at_5
value: 25.269000000000002
- type: precision_at_1
value: 25.537
- type: precision_at_10
value: 9.153
- type: precision_at_100
value: 1.7319999999999998
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 17.22
- type: precision_at_5
value: 13.629
- type: recall_at_1
value: 11.363
- type: recall_at_10
value: 35.382999999999996
- type: recall_at_100
value: 61.367000000000004
- type: recall_at_1000
value: 79.699
- type: recall_at_3
value: 21.495
- type: recall_at_5
value: 27.42
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.65
- type: map_at_10
value: 20.742
- type: map_at_100
value: 29.614
- type: map_at_1000
value: 31.373
- type: map_at_3
value: 14.667
- type: map_at_5
value: 17.186
- type: mrr_at_1
value: 69.75
- type: mrr_at_10
value: 76.762
- type: mrr_at_100
value: 77.171
- type: mrr_at_1000
value: 77.179
- type: mrr_at_3
value: 75.125
- type: mrr_at_5
value: 76.287
- type: ndcg_at_1
value: 57.62500000000001
- type: ndcg_at_10
value: 42.370999999999995
- type: ndcg_at_100
value: 47.897
- type: ndcg_at_1000
value: 55.393
- type: ndcg_at_3
value: 46.317
- type: ndcg_at_5
value: 43.906
- type: precision_at_1
value: 69.75
- type: precision_at_10
value: 33.95
- type: precision_at_100
value: 10.885
- type: precision_at_1000
value: 2.2239999999999998
- type: precision_at_3
value: 49.75
- type: precision_at_5
value: 42.3
- type: recall_at_1
value: 9.65
- type: recall_at_10
value: 26.117
- type: recall_at_100
value: 55.084
- type: recall_at_1000
value: 78.62400000000001
- type: recall_at_3
value: 15.823
- type: recall_at_5
value: 19.652
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.885
- type: f1
value: 42.99567641346983
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.97
- type: map_at_10
value: 80.34599999999999
- type: map_at_100
value: 80.571
- type: map_at_1000
value: 80.584
- type: map_at_3
value: 79.279
- type: map_at_5
value: 79.94
- type: mrr_at_1
value: 76.613
- type: mrr_at_10
value: 85.15700000000001
- type: mrr_at_100
value: 85.249
- type: mrr_at_1000
value: 85.252
- type: mrr_at_3
value: 84.33800000000001
- type: mrr_at_5
value: 84.89
- type: ndcg_at_1
value: 76.613
- type: ndcg_at_10
value: 84.53399999999999
- type: ndcg_at_100
value: 85.359
- type: ndcg_at_1000
value: 85.607
- type: ndcg_at_3
value: 82.76599999999999
- type: ndcg_at_5
value: 83.736
- type: precision_at_1
value: 76.613
- type: precision_at_10
value: 10.206
- type: precision_at_100
value: 1.083
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 31.913000000000004
- type: precision_at_5
value: 19.769000000000002
- type: recall_at_1
value: 70.97
- type: recall_at_10
value: 92.674
- type: recall_at_100
value: 95.985
- type: recall_at_1000
value: 97.57000000000001
- type: recall_at_3
value: 87.742
- type: recall_at_5
value: 90.28
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.494
- type: map_at_10
value: 36.491
- type: map_at_100
value: 38.550000000000004
- type: map_at_1000
value: 38.726
- type: map_at_3
value: 31.807000000000002
- type: map_at_5
value: 34.299
- type: mrr_at_1
value: 44.907000000000004
- type: mrr_at_10
value: 53.146
- type: mrr_at_100
value: 54.013999999999996
- type: mrr_at_1000
value: 54.044000000000004
- type: mrr_at_3
value: 50.952
- type: mrr_at_5
value: 52.124
- type: ndcg_at_1
value: 44.907000000000004
- type: ndcg_at_10
value: 44.499
- type: ndcg_at_100
value: 51.629000000000005
- type: ndcg_at_1000
value: 54.367
- type: ndcg_at_3
value: 40.900999999999996
- type: ndcg_at_5
value: 41.737
- type: precision_at_1
value: 44.907000000000004
- type: precision_at_10
value: 12.346
- type: precision_at_100
value: 1.974
- type: precision_at_1000
value: 0.246
- type: precision_at_3
value: 27.366
- type: precision_at_5
value: 19.846
- type: recall_at_1
value: 22.494
- type: recall_at_10
value: 51.156
- type: recall_at_100
value: 77.11200000000001
- type: recall_at_1000
value: 93.44
- type: recall_at_3
value: 36.574
- type: recall_at_5
value: 42.361
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.568999999999996
- type: map_at_10
value: 58.485
- type: map_at_100
value: 59.358999999999995
- type: map_at_1000
value: 59.429
- type: map_at_3
value: 55.217000000000006
- type: map_at_5
value: 57.236
- type: mrr_at_1
value: 77.137
- type: mrr_at_10
value: 82.829
- type: mrr_at_100
value: 83.04599999999999
- type: mrr_at_1000
value: 83.05399999999999
- type: mrr_at_3
value: 81.904
- type: mrr_at_5
value: 82.50800000000001
- type: ndcg_at_1
value: 77.137
- type: ndcg_at_10
value: 67.156
- type: ndcg_at_100
value: 70.298
- type: ndcg_at_1000
value: 71.65700000000001
- type: ndcg_at_3
value: 62.535
- type: ndcg_at_5
value: 65.095
- type: precision_at_1
value: 77.137
- type: precision_at_10
value: 13.911999999999999
- type: precision_at_100
value: 1.6389999999999998
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 39.572
- type: precision_at_5
value: 25.766
- type: recall_at_1
value: 38.568999999999996
- type: recall_at_10
value: 69.56099999999999
- type: recall_at_100
value: 81.931
- type: recall_at_1000
value: 90.91799999999999
- type: recall_at_3
value: 59.358999999999995
- type: recall_at_5
value: 64.416
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 88.45600000000002
- type: ap
value: 84.09725115338568
- type: f1
value: 88.41874909080512
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.404999999999998
- type: map_at_10
value: 33.921
- type: map_at_100
value: 35.116
- type: map_at_1000
value: 35.164
- type: map_at_3
value: 30.043999999999997
- type: map_at_5
value: 32.327
- type: mrr_at_1
value: 21.977
- type: mrr_at_10
value: 34.505
- type: mrr_at_100
value: 35.638999999999996
- type: mrr_at_1000
value: 35.68
- type: mrr_at_3
value: 30.703999999999997
- type: mrr_at_5
value: 32.96
- type: ndcg_at_1
value: 21.963
- type: ndcg_at_10
value: 40.859
- type: ndcg_at_100
value: 46.614
- type: ndcg_at_1000
value: 47.789
- type: ndcg_at_3
value: 33.007999999999996
- type: ndcg_at_5
value: 37.084
- type: precision_at_1
value: 21.963
- type: precision_at_10
value: 6.493
- type: precision_at_100
value: 0.938
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.155000000000001
- type: precision_at_5
value: 10.544
- type: recall_at_1
value: 21.404999999999998
- type: recall_at_10
value: 62.175000000000004
- type: recall_at_100
value: 88.786
- type: recall_at_1000
value: 97.738
- type: recall_at_3
value: 40.925
- type: recall_at_5
value: 50.722
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.50661194710442
- type: f1
value: 93.30311193153668
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 73.24669402644778
- type: f1
value: 54.23122108002977
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.61936785474109
- type: f1
value: 70.52644941025565
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.76529926025555
- type: f1
value: 77.26872729322514
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.39450293021839
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.757796879839294
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.62512146657428
- type: mrr
value: 33.84624322066173
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.462
- type: map_at_10
value: 14.947
- type: map_at_100
value: 19.344
- type: map_at_1000
value: 20.933
- type: map_at_3
value: 10.761999999999999
- type: map_at_5
value: 12.744
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 57.365
- type: mrr_at_100
value: 57.931
- type: mrr_at_1000
value: 57.96
- type: mrr_at_3
value: 54.85
- type: mrr_at_5
value: 56.569
- type: ndcg_at_1
value: 46.129999999999995
- type: ndcg_at_10
value: 38.173
- type: ndcg_at_100
value: 35.983
- type: ndcg_at_1000
value: 44.507000000000005
- type: ndcg_at_3
value: 42.495
- type: ndcg_at_5
value: 41.019
- type: precision_at_1
value: 47.678
- type: precision_at_10
value: 28.731
- type: precision_at_100
value: 9.232
- type: precision_at_1000
value: 2.202
- type: precision_at_3
value: 39.628
- type: precision_at_5
value: 35.851
- type: recall_at_1
value: 6.462
- type: recall_at_10
value: 18.968
- type: recall_at_100
value: 37.131
- type: recall_at_1000
value: 67.956
- type: recall_at_3
value: 11.905000000000001
- type: recall_at_5
value: 15.097
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.335
- type: map_at_10
value: 46.611999999999995
- type: map_at_100
value: 47.632000000000005
- type: map_at_1000
value: 47.661
- type: map_at_3
value: 41.876999999999995
- type: map_at_5
value: 44.799
- type: mrr_at_1
value: 34.125
- type: mrr_at_10
value: 49.01
- type: mrr_at_100
value: 49.75
- type: mrr_at_1000
value: 49.768
- type: mrr_at_3
value: 45.153
- type: mrr_at_5
value: 47.589999999999996
- type: ndcg_at_1
value: 34.125
- type: ndcg_at_10
value: 54.777
- type: ndcg_at_100
value: 58.914
- type: ndcg_at_1000
value: 59.521
- type: ndcg_at_3
value: 46.015
- type: ndcg_at_5
value: 50.861000000000004
- type: precision_at_1
value: 34.125
- type: precision_at_10
value: 9.166
- type: precision_at_100
value: 1.149
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 21.147
- type: precision_at_5
value: 15.469
- type: recall_at_1
value: 30.335
- type: recall_at_10
value: 77.194
- type: recall_at_100
value: 94.812
- type: recall_at_1000
value: 99.247
- type: recall_at_3
value: 54.681000000000004
- type: recall_at_5
value: 65.86800000000001
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.62
- type: map_at_10
value: 84.536
- type: map_at_100
value: 85.167
- type: map_at_1000
value: 85.184
- type: map_at_3
value: 81.607
- type: map_at_5
value: 83.423
- type: mrr_at_1
value: 81.36
- type: mrr_at_10
value: 87.506
- type: mrr_at_100
value: 87.601
- type: mrr_at_1000
value: 87.601
- type: mrr_at_3
value: 86.503
- type: mrr_at_5
value: 87.179
- type: ndcg_at_1
value: 81.36
- type: ndcg_at_10
value: 88.319
- type: ndcg_at_100
value: 89.517
- type: ndcg_at_1000
value: 89.60900000000001
- type: ndcg_at_3
value: 85.423
- type: ndcg_at_5
value: 86.976
- type: precision_at_1
value: 81.36
- type: precision_at_10
value: 13.415
- type: precision_at_100
value: 1.529
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.342999999999996
- type: precision_at_5
value: 24.534
- type: recall_at_1
value: 70.62
- type: recall_at_10
value: 95.57600000000001
- type: recall_at_100
value: 99.624
- type: recall_at_1000
value: 99.991
- type: recall_at_3
value: 87.22
- type: recall_at_5
value: 91.654
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 60.826438478212744
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.24027467551447
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.997999999999999
- type: map_at_10
value: 14.267
- type: map_at_100
value: 16.843
- type: map_at_1000
value: 17.229
- type: map_at_3
value: 9.834
- type: map_at_5
value: 11.92
- type: mrr_at_1
value: 24.7
- type: mrr_at_10
value: 37.685
- type: mrr_at_100
value: 38.704
- type: mrr_at_1000
value: 38.747
- type: mrr_at_3
value: 34.150000000000006
- type: mrr_at_5
value: 36.075
- type: ndcg_at_1
value: 24.7
- type: ndcg_at_10
value: 23.44
- type: ndcg_at_100
value: 32.617000000000004
- type: ndcg_at_1000
value: 38.628
- type: ndcg_at_3
value: 21.747
- type: ndcg_at_5
value: 19.076
- type: precision_at_1
value: 24.7
- type: precision_at_10
value: 12.47
- type: precision_at_100
value: 2.564
- type: precision_at_1000
value: 0.4
- type: precision_at_3
value: 20.767
- type: precision_at_5
value: 17.06
- type: recall_at_1
value: 4.997999999999999
- type: recall_at_10
value: 25.3
- type: recall_at_100
value: 52.048
- type: recall_at_1000
value: 81.093
- type: recall_at_3
value: 12.642999999999999
- type: recall_at_5
value: 17.312
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.44942006292234
- type: cos_sim_spearman
value: 79.80930790660699
- type: euclidean_pearson
value: 82.93400777494863
- type: euclidean_spearman
value: 80.04664991110705
- type: manhattan_pearson
value: 82.93551681854949
- type: manhattan_spearman
value: 80.03156736837379
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.63574059135726
- type: cos_sim_spearman
value: 76.80552915288186
- type: euclidean_pearson
value: 82.46368529820518
- type: euclidean_spearman
value: 76.60338474719275
- type: manhattan_pearson
value: 82.4558617035968
- type: manhattan_spearman
value: 76.57936082895705
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 86.24116811084211
- type: cos_sim_spearman
value: 88.10998662068769
- type: euclidean_pearson
value: 87.04961732352689
- type: euclidean_spearman
value: 88.12543945864087
- type: manhattan_pearson
value: 86.9905224528854
- type: manhattan_spearman
value: 88.07827944705546
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.74847296555048
- type: cos_sim_spearman
value: 82.66200957916445
- type: euclidean_pearson
value: 84.48132256004965
- type: euclidean_spearman
value: 82.67915286000596
- type: manhattan_pearson
value: 84.44950477268334
- type: manhattan_spearman
value: 82.63327639173352
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.23056258027053
- type: cos_sim_spearman
value: 88.92791680286955
- type: euclidean_pearson
value: 88.13819235461933
- type: euclidean_spearman
value: 88.87294661361716
- type: manhattan_pearson
value: 88.14212133687899
- type: manhattan_spearman
value: 88.88551854529777
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.64179522732887
- type: cos_sim_spearman
value: 84.25028809903114
- type: euclidean_pearson
value: 83.40175015236979
- type: euclidean_spearman
value: 84.23369296429406
- type: manhattan_pearson
value: 83.43768174261321
- type: manhattan_spearman
value: 84.27855229214734
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.20378955494732
- type: cos_sim_spearman
value: 88.46863559173111
- type: euclidean_pearson
value: 88.8249295811663
- type: euclidean_spearman
value: 88.6312737724905
- type: manhattan_pearson
value: 88.87744466378827
- type: manhattan_spearman
value: 88.82908423767314
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 69.91342028796086
- type: cos_sim_spearman
value: 69.71495021867864
- type: euclidean_pearson
value: 70.65334330405646
- type: euclidean_spearman
value: 69.4321253472211
- type: manhattan_pearson
value: 70.59743494727465
- type: manhattan_spearman
value: 69.11695509297482
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.42451709766952
- type: cos_sim_spearman
value: 86.07166710670508
- type: euclidean_pearson
value: 86.12711421258899
- type: euclidean_spearman
value: 86.05232086925126
- type: manhattan_pearson
value: 86.15591089932126
- type: manhattan_spearman
value: 86.0890128623439
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.1976344717285
- type: mrr
value: 96.3703145075694
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 59.511
- type: map_at_10
value: 69.724
- type: map_at_100
value: 70.208
- type: map_at_1000
value: 70.22800000000001
- type: map_at_3
value: 66.986
- type: map_at_5
value: 68.529
- type: mrr_at_1
value: 62.333000000000006
- type: mrr_at_10
value: 70.55
- type: mrr_at_100
value: 70.985
- type: mrr_at_1000
value: 71.004
- type: mrr_at_3
value: 68.611
- type: mrr_at_5
value: 69.728
- type: ndcg_at_1
value: 62.333000000000006
- type: ndcg_at_10
value: 74.265
- type: ndcg_at_100
value: 76.361
- type: ndcg_at_1000
value: 76.82900000000001
- type: ndcg_at_3
value: 69.772
- type: ndcg_at_5
value: 71.94800000000001
- type: precision_at_1
value: 62.333000000000006
- type: precision_at_10
value: 9.9
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.444000000000003
- type: precision_at_5
value: 18
- type: recall_at_1
value: 59.511
- type: recall_at_10
value: 87.156
- type: recall_at_100
value: 96.5
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 75.2
- type: recall_at_5
value: 80.661
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81683168316832
- type: cos_sim_ap
value: 95.74716566563774
- type: cos_sim_f1
value: 90.64238745574103
- type: cos_sim_precision
value: 91.7093142272262
- type: cos_sim_recall
value: 89.60000000000001
- type: dot_accuracy
value: 99.69405940594059
- type: dot_ap
value: 91.09013507754594
- type: dot_f1
value: 84.54227113556779
- type: dot_precision
value: 84.58458458458459
- type: dot_recall
value: 84.5
- type: euclidean_accuracy
value: 99.81782178217821
- type: euclidean_ap
value: 95.6324301072609
- type: euclidean_f1
value: 90.58341862845445
- type: euclidean_precision
value: 92.76729559748428
- type: euclidean_recall
value: 88.5
- type: manhattan_accuracy
value: 99.81980198019802
- type: manhattan_ap
value: 95.68510494437183
- type: manhattan_f1
value: 90.58945191313342
- type: manhattan_precision
value: 93.79014989293361
- type: manhattan_recall
value: 87.6
- type: max_accuracy
value: 99.81980198019802
- type: max_ap
value: 95.74716566563774
- type: max_f1
value: 90.64238745574103
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 67.63761899427078
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.572473369697235
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.63000245208579
- type: mrr
value: 54.504193722943725
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.300791939416545
- type: cos_sim_spearman
value: 31.662904057924123
- type: dot_pearson
value: 26.21198530758316
- type: dot_spearman
value: 27.006921548904263
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.197
- type: map_at_10
value: 1.752
- type: map_at_100
value: 10.795
- type: map_at_1000
value: 27.18
- type: map_at_3
value: 0.5890000000000001
- type: map_at_5
value: 0.938
- type: mrr_at_1
value: 74
- type: mrr_at_10
value: 85.833
- type: mrr_at_100
value: 85.833
- type: mrr_at_1000
value: 85.833
- type: mrr_at_3
value: 85.333
- type: mrr_at_5
value: 85.833
- type: ndcg_at_1
value: 69
- type: ndcg_at_10
value: 70.22
- type: ndcg_at_100
value: 55.785
- type: ndcg_at_1000
value: 52.93600000000001
- type: ndcg_at_3
value: 72.084
- type: ndcg_at_5
value: 71.184
- type: precision_at_1
value: 74
- type: precision_at_10
value: 75.2
- type: precision_at_100
value: 57.3
- type: precision_at_1000
value: 23.302
- type: precision_at_3
value: 77.333
- type: precision_at_5
value: 75.6
- type: recall_at_1
value: 0.197
- type: recall_at_10
value: 2.019
- type: recall_at_100
value: 14.257
- type: recall_at_1000
value: 50.922
- type: recall_at_3
value: 0.642
- type: recall_at_5
value: 1.043
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.803
- type: map_at_10
value: 10.407
- type: map_at_100
value: 16.948
- type: map_at_1000
value: 18.424
- type: map_at_3
value: 5.405
- type: map_at_5
value: 6.908
- type: mrr_at_1
value: 36.735
- type: mrr_at_10
value: 50.221000000000004
- type: mrr_at_100
value: 51.388
- type: mrr_at_1000
value: 51.402
- type: mrr_at_3
value: 47.278999999999996
- type: mrr_at_5
value: 49.626
- type: ndcg_at_1
value: 34.694
- type: ndcg_at_10
value: 25.507
- type: ndcg_at_100
value: 38.296
- type: ndcg_at_1000
value: 49.492000000000004
- type: ndcg_at_3
value: 29.006999999999998
- type: ndcg_at_5
value: 25.979000000000003
- type: precision_at_1
value: 36.735
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 8.02
- type: precision_at_1000
value: 1.567
- type: precision_at_3
value: 28.571
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.803
- type: recall_at_10
value: 16.378
- type: recall_at_100
value: 50.489
- type: recall_at_1000
value: 85.013
- type: recall_at_3
value: 6.505
- type: recall_at_5
value: 9.243
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.55579999999999
- type: ap
value: 14.206982753316227
- type: f1
value: 54.372142814964285
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 56.57611771363893
- type: f1
value: 56.924172639063144
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 52.82304915719759
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.92716218632653
- type: cos_sim_ap
value: 73.73359122546046
- type: cos_sim_f1
value: 68.42559487116262
- type: cos_sim_precision
value: 64.22124508215691
- type: cos_sim_recall
value: 73.21899736147758
- type: dot_accuracy
value: 80.38981939560112
- type: dot_ap
value: 54.61060862444974
- type: dot_f1
value: 53.45710627400769
- type: dot_precision
value: 44.87638839125761
- type: dot_recall
value: 66.09498680738787
- type: euclidean_accuracy
value: 86.02849138701794
- type: euclidean_ap
value: 73.95673761922404
- type: euclidean_f1
value: 68.6783042394015
- type: euclidean_precision
value: 65.1063829787234
- type: euclidean_recall
value: 72.66490765171504
- type: manhattan_accuracy
value: 85.9808070572808
- type: manhattan_ap
value: 73.9050720058029
- type: manhattan_f1
value: 68.57560618983794
- type: manhattan_precision
value: 63.70839936608558
- type: manhattan_recall
value: 74.24802110817942
- type: max_accuracy
value: 86.02849138701794
- type: max_ap
value: 73.95673761922404
- type: max_f1
value: 68.6783042394015
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.72783017037295
- type: cos_sim_ap
value: 85.52705223340233
- type: cos_sim_f1
value: 77.91659078492079
- type: cos_sim_precision
value: 73.93378032764221
- type: cos_sim_recall
value: 82.35294117647058
- type: dot_accuracy
value: 85.41739434159972
- type: dot_ap
value: 77.17734818118443
- type: dot_f1
value: 71.63473589973144
- type: dot_precision
value: 66.96123719622415
- type: dot_recall
value: 77.00954727440714
- type: euclidean_accuracy
value: 88.68125897465751
- type: euclidean_ap
value: 85.47712213906692
- type: euclidean_f1
value: 77.81419950830664
- type: euclidean_precision
value: 75.37162649733006
- type: euclidean_recall
value: 80.42038805050817
- type: manhattan_accuracy
value: 88.67349710870494
- type: manhattan_ap
value: 85.46506475241955
- type: manhattan_f1
value: 77.87259084890393
- type: manhattan_precision
value: 74.54929577464789
- type: manhattan_recall
value: 81.50600554357868
- type: max_accuracy
value: 88.72783017037295
- type: max_ap
value: 85.52705223340233
- type: max_f1
value: 77.91659078492079
language:
- en
license: mit
---
# gte-large
General Text Embeddings (GTE) model. [Towards General Text Embeddings with Multi-stage Contrastive Learning](https://arxiv.org/abs/2308.03281)
The GTE models are trained by Alibaba DAMO Academy. They are mainly based on the BERT framework and currently offer three different sizes of models, including [GTE-large](https://huggingface.co/thenlper/gte-large), [GTE-base](https://huggingface.co/thenlper/gte-base), and [GTE-small](https://huggingface.co/thenlper/gte-small). The GTE models are trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. This enables the GTE models to be applied to various downstream tasks of text embeddings, including **information retrieval**, **semantic textual similarity**, **text reranking**, etc.
## Metrics
We compared the performance of the GTE models with other popular text embedding models on the MTEB benchmark. For more detailed comparison results, please refer to the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**gte-large**](https://huggingface.co/thenlper/gte-large) | 0.67 | 1024 | 512 | **63.13** | 46.84 | 85.00 | 59.13 | 52.22 | 83.35 | 31.66 | 73.33 |
| [**gte-base**](https://huggingface.co/thenlper/gte-base) | 0.22 | 768 | 512 | **62.39** | 46.2 | 84.57 | 58.61 | 51.14 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1.34 | 1024| 512 | 62.25 | 44.49 | 86.03 | 56.61 | 50.56 | 82.05 | 30.19 | 75.24 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.44 | 768 | 512 | 61.5 | 43.80 | 85.73 | 55.91 | 50.29 | 81.05 | 30.28 | 73.84 |
| [**gte-small**](https://huggingface.co/thenlper/gte-small) | 0.07 | 384 | 512 | **61.36** | 44.89 | 83.54 | 57.7 | 49.46 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | - | 1536 | 8192 | 60.99 | 45.9 | 84.89 | 56.32 | 49.25 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.13 | 384 | 512 | 59.93 | 39.92 | 84.67 | 54.32 | 49.04 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 9.73 | 768 | 512 | 59.51 | 43.72 | 85.06 | 56.42 | 42.24 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.44 | 768 | 514 | 57.78 | 43.69 | 83.04 | 59.36 | 43.81 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 28.27 | 4096 | 2048 | 57.59 | 38.93 | 81.9 | 55.65 | 48.22 | 77.74 | 33.6 | 66.19 |
| [all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2) | 0.13 | 384 | 512 | 56.53 | 41.81 | 82.41 | 58.44 | 42.69 | 79.8 | 27.9 | 63.21 |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.09 | 384 | 512 | 56.26 | 42.35 | 82.37 | 58.04 | 41.95 | 78.9 | 30.81 | 63.05 |
| [contriever-base-msmarco](https://huggingface.co/nthakur/contriever-base-msmarco) | 0.44 | 768 | 512 | 56.00 | 41.1 | 82.54 | 53.14 | 41.88 | 76.51 | 30.36 | 66.68 |
| [sentence-t5-base](https://huggingface.co/sentence-transformers/sentence-t5-base) | 0.22 | 768 | 512 | 55.27 | 40.21 | 85.18 | 53.09 | 33.63 | 81.14 | 31.39 | 69.81 |
## Usage
Code example
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-large")
model = AutoModel.from_pretrained("thenlper/gte-large")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('thenlper/gte-large')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
### Citation
If you find our paper or models helpful, please consider citing them as follows:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
``` |
microsoft/trocr-base-stage1 | microsoft | "2024-05-27T20:13:12Z" | 731,457 | 12 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vision-encoder-decoder",
"trocr",
"image-to-text",
"arxiv:2109.10282",
"endpoints_compatible",
"region:us"
] | image-to-text | "2022-03-02T23:29:05Z" | ---
tags:
- trocr
- image-to-text
---
# TrOCR (base-sized model, pre-trained only)
TrOCR pre-trained only model. It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-stage1')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-stage1')
# training
pixel_values = processor(image, return_tensors="pt").pixel_values # Batch size 1
decoder_input_ids = torch.tensor([[model.config.decoder.decoder_start_token_id]])
outputs = model(pixel_values=pixel_values, decoder_input_ids=decoder_input_ids)
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
THUDM/cogvlm-chat-hf | THUDM | "2023-12-19T10:22:07Z" | 728,394 | 190 | transformers | [
"transformers",
"safetensors",
"text-generation",
"custom_code",
"en",
"arxiv:2311.03079",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | text-generation | "2023-11-16T14:33:37Z" | ---
license: apache-2.0
language:
- en
---
# CogVLM
**CogVLM** 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数,在 10 个经典跨模态基准测试上取得了 SOTA 性能,包括 NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC,而在 VQAv2、OKVQA、TextVQA、COCO captioning 等方面则排名第二,超越或与 PaLI-X 55B 持平。您可以通过线上 [demo](http://36.103.203.44:7861/) 体验 CogVLM 多模态对话。
**CogVLM** is a powerful **open-source visual language model** (**VLM**). CogVLM-17B has 10 billion vision parameters and 7 billion language parameters. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and rank the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., **surpassing or matching PaLI-X 55B**. CogVLM can also [chat with you](http://36.103.203.44:7861/) about images.
<div align="center">
<img src="https://github.com/THUDM/CogVLM/raw/main/assets/metrics-min.png" alt="img" style="zoom: 50%;" />
</div>
以上权重对学术研究完全开放,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后亦允许免费商业使用。
# 快速开始(Qiuckstart)
硬件需求(hardware requirement)
需要近 40GB GPU 显存用于模型推理。如果没有一整块GPU显存超过40GB,则需要使用accelerate的将模型切分到多个有较小显存的GPU设备上。
40GB VRAM for inference. If there is no single GPU with more than 40GB of VRAM, you will need to use the "accelerate" library to dispatch the model into multiple GPUs with smaller VRAM.
安装依赖(dependencies)
```base
pip install torch==2.1.0 transformers==4.35.0 accelerate==0.24.1 sentencepiece==0.1.99 einops==0.7.0 xformers==0.0.22.post7 triton==2.1.0
```
代码示例(example)
```python
import torch
import requests
from PIL import Image
from transformers import AutoModelForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained('lmsys/vicuna-7b-v1.5')
model = AutoModelForCausalLM.from_pretrained(
'THUDM/cogvlm-chat-hf',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to('cuda').eval()
# chat example
query = 'Describe this image'
image = Image.open(requests.get('https://github.com/THUDM/CogVLM/blob/main/examples/1.png?raw=true', stream=True).raw).convert('RGB')
inputs = model.build_conversation_input_ids(tokenizer, query=query, history=[], images=[image]) # chat mode
inputs = {
'input_ids': inputs['input_ids'].unsqueeze(0).to('cuda'),
'token_type_ids': inputs['token_type_ids'].unsqueeze(0).to('cuda'),
'attention_mask': inputs['attention_mask'].unsqueeze(0).to('cuda'),
'images': [[inputs['images'][0].to('cuda').to(torch.bfloat16)]],
}
gen_kwargs = {"max_length": 2048, "do_sample": False}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
# This image captures a moment from a basketball game. Two players are prominently featured: one wearing a yellow jersey with the number
# 24 and the word 'Lakers' written on it, and the other wearing a navy blue jersey with the word 'Washington' and the number 34. The player
# in yellow is holding a basketball and appears to be dribbling it, while the player in navy blue is reaching out with his arm, possibly
# trying to block or defend. The background shows a filled stadium with spectators, indicating that this is a professional game.</s>
# vqa example
query = 'How many houses are there in this cartoon?'
image = Image.open(requests.get('https://github.com/THUDM/CogVLM/blob/main/examples/3.jpg?raw=true', stream=True).raw).convert('RGB')
inputs = model.build_conversation_input_ids(tokenizer, query=query, history=[], images=[image], template_version='vqa') # vqa mode
inputs = {
'input_ids': inputs['input_ids'].unsqueeze(0).to('cuda'),
'token_type_ids': inputs['token_type_ids'].unsqueeze(0).to('cuda'),
'attention_mask': inputs['attention_mask'].unsqueeze(0).to('cuda'),
'images': [[inputs['images'][0].to('cuda').to(torch.bfloat16)]],
}
gen_kwargs = {"max_length": 2048, "do_sample": False}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
# 4</s>
```
当单卡显存不足时,可以将模型切分到多个小显存GPU上。以下是个当你有两张24GB的GPU,16GBCPU内存的例子。
你可以将`infer_auto_device_map`的参数改成你的配置。注意这里将GPU显存少写了一点,这是为推理时中间状态预留出一部分显存。
dispatch the model into multiple GPUs with smaller VRAM. This is an example for you have two 24GB GPU and 16GB CPU memory.
you can change the arguments of `infer_auto_device_map` with your own setting.
```python
import torch
import requests
from PIL import Image
from transformers import AutoModelForCausalLM, LlamaTokenizer
from accelerate import init_empty_weights, infer_auto_device_map, load_checkpoint_and_dispatch
tokenizer = LlamaTokenizer.from_pretrained('lmsys/vicuna-7b-v1.5')
with init_empty_weights():
model = AutoModelForCausalLM.from_pretrained(
'THUDM/cogvlm-chat-hf',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
)
device_map = infer_auto_device_map(model, max_memory={0:'20GiB',1:'20GiB','cpu':'16GiB'}, no_split_module_classes=['CogVLMDecoderLayer', 'TransformerLayer'])
model = load_checkpoint_and_dispatch(
model,
'local/path/to/hf/version/chat/model', # typical, '~/.cache/huggingface/hub/models--THUDM--cogvlm-chat-hf/snapshots/balabala'
device_map=device_map,
)
model = model.eval()
# check device for weights if u want to
for n, p in model.named_parameters():
print(f"{n}: {p.device}")
# chat example
query = 'Describe this image'
image = Image.open(requests.get('https://github.com/THUDM/CogVLM/blob/main/examples/1.png?raw=true', stream=True).raw).convert('RGB')
inputs = model.build_conversation_input_ids(tokenizer, query=query, history=[], images=[image]) # chat mode
inputs = {
'input_ids': inputs['input_ids'].unsqueeze(0).to('cuda'),
'token_type_ids': inputs['token_type_ids'].unsqueeze(0).to('cuda'),
'attention_mask': inputs['attention_mask'].unsqueeze(0).to('cuda'),
'images': [[inputs['images'][0].to('cuda').to(torch.bfloat16)]],
}
gen_kwargs = {"max_length": 2048, "do_sample": False}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
```
# 方法(Method)
CogVLM 模型包括四个基本组件:视觉变换器(ViT)编码器、MLP适配器、预训练的大型语言模型(GPT)和一个**视觉专家模块**。更多细节请参见[Paper](https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf)。
CogVLM model comprises four fundamental components: a vision transformer (ViT) encoder, an MLP adapter, a pretrained large language model (GPT), and a **visual expert module**. See [Paper](https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf) for more details.
<div align="center">
<img src="https://github.com/THUDM/CogVLM/raw/main/assets/method-min.png" style="zoom:50%;" />
</div>
# 许可(License)
此存储库中的代码是根据 [Apache-2.0 许可](https://github.com/THUDM/CogVLM/raw/main/LICENSE) 开放源码,而使用 CogVLM 模型权重必须遵循 [模型许可](https://github.com/THUDM/CogVLM/raw/main/MODEL_LICENSE)。
The code in this repository is open source under the [Apache-2.0 license](https://github.com/THUDM/CogVLM/raw/main/LICENSE), while the use of the CogVLM model weights must comply with the [Model License](https://github.com/THUDM/CogVLM/raw/main/MODEL_LICENSE).
# 引用(Citation)
If you find our work helpful, please consider citing the following papers
```
@article{wang2023cogvlm,
title={CogVLM: Visual Expert for Pretrained Language Models},
author={Weihan Wang and Qingsong Lv and Wenmeng Yu and Wenyi Hong and Ji Qi and Yan Wang and Junhui Ji and Zhuoyi Yang and Lei Zhao and Xixuan Song and Jiazheng Xu and Bin Xu and Juanzi Li and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
michellejieli/emotion_text_classifier | michellejieli | "2023-05-03T00:39:47Z" | 723,068 | 96 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"distilroberta",
"sentiment",
"emotion",
"twitter",
"reddit",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-10-22T22:44:07Z" | ---
language: "en"
tags:
- distilroberta
- sentiment
- emotion
- twitter
- reddit
widget:
- text: "Oh my God, he's lost it. He's totally lost it."
- text: "What?"
- text: "Wow, congratulations! So excited for you!"
---
# Fine-tuned DistilRoBERTa-base for Emotion Classification 🤬🤢😀😐😭😲
# Model Description
DistilRoBERTa-base is a transformer model that performs sentiment analysis. I fine-tuned the model on transcripts from the Friends show with the goal of classifying emotions from text data, specifically dialogue from Netflix shows or movies. The model predicts 6 Ekman emotions and a neutral class. These emotions include anger, disgust, fear, joy, neutrality, sadness, and surprise.
The model is a fine-tuned version of [Emotion English DistilRoBERTa-base](https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/) and [DistilRoBERTa-base](https://huggingface.co/j-hartmann/emotion-english-distilroberta-base). This model was initially trained on the following table from [Emotion English DistilRoBERTa-base](https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/):
|Name|anger|disgust|fear|joy|neutral|sadness|surprise|
|---|---|---|---|---|---|---|---|
|Crowdflower (2016)|Yes|-|-|Yes|Yes|Yes|Yes|
|Emotion Dataset, Elvis et al. (2018)|Yes|-|Yes|Yes|-|Yes|Yes|
|GoEmotions, Demszky et al. (2020)|Yes|Yes|Yes|Yes|Yes|Yes|Yes|
|ISEAR, Vikash (2018)|Yes|Yes|Yes|Yes|-|Yes|-|
|MELD, Poria et al. (2019)|Yes|Yes|Yes|Yes|Yes|Yes|Yes|
|SemEval-2018, EI-reg, Mohammad et al. (2018) |Yes|-|Yes|Yes|-|Yes|-|
It was fine-tuned on:
|Name|anger|disgust|fear|joy|neutral|sadness|surprise|
|---|---|---|---|---|---|---|---|
|Emotion Lines (Friends)|Yes|Yes|Yes|Yes|Yes|Yes|Yes|
# How to Use
```python
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="michellejieli/emotion_text_classifier")
classifier("I love this!")
```
```python
Output:
[{'label': 'joy', 'score': 0.9887555241584778}]
```
# Contact
Please reach out to [[email protected]](mailto:[email protected]) if you have any questions or feedback.
# Reference
```
Jochen Hartmann, "Emotion English DistilRoBERTa-base". https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/, 2022.
Ashritha R Murthy and K M Anil Kumar 2021 IOP Conf. Ser.: Mater. Sci. Eng. 1110 012009
``` |
indobenchmark/indobert-base-p1 | indobenchmark | "2021-05-19T20:22:23Z" | 716,723 | 18 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"indobert",
"indobenchmark",
"indonlu",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"license:mit",
"text-embeddings-inference",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT Base Model (phase1 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-base-p1")
model = AutoModel.from_pretrained("indobenchmark/indobert-base-p1")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
|
BAAI/bge-large-zh-v1.5 | BAAI | "2024-04-02T14:00:04Z" | 708,402 | 396 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"zh",
"arxiv:2401.03462",
"arxiv:2312.15503",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2023-09-12T05:22:11Z" | ---
license: mit
language:
- zh
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
For more details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
If you are looking for a model that supports more languages, longer texts, and other retrieval methods, you can try using [bge-m3](https://huggingface.co/BAAI/bge-m3).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently:
- **Long-Context LLM**: [Activation Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon)
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [BGE-M3](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3), [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
- **Benchmark**: [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
## News
- 1/30/2024: Release **BGE-M3**, a new member to BGE model series! M3 stands for **M**ulti-linguality (100+ languages), **M**ulti-granularities (input length up to 8192), **M**ulti-Functionality (unification of dense, lexical, multi-vec/colbert retrieval).
It is the first embedding model which supports all three retrieval methods, achieving new SOTA on multi-lingual (MIRACL) and cross-lingual (MKQA) benchmarks.
[Technical Report](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf) and [Code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3). :fire:
- 1/9/2024: Release [Activation-Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon), an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM. [Technical Report](https://arxiv.org/abs/2401.03462) :fire:
- 12/24/2023: Release **LLaRA**, a LLaMA-7B based dense retriever, leading to state-of-the-art performances on MS MARCO and BEIR. Model and code will be open-sourced. Please stay tuned. [Technical Report](https://arxiv.org/abs/2312.15503) :fire:
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) and [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge. |
google/bert_uncased_L-2_H-128_A-2 | google | "2023-09-05T15:25:24Z" | 705,263 | 28 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
Qwen/Qwen1.5-1.8B | Qwen | "2024-04-05T10:39:41Z" | 702,909 | 43 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"pretrained",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-01-22T16:53:32Z" | ---
license: other
license_name: tongyi-qianwen-research
license_link: >-
https://huggingface.co/Qwen/Qwen1.5-1.8B/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
---
# Qwen1.5-1.8B
## Introduction
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:
* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models, and an MoE model of 14B with 2.7B activated;
* Significant performance improvement in Chat models;
* Multilingual support of both base and chat models;
* Stable support of 32K context length for models of all sizes
* No need of `trust_remote_code`.
For more details, please refer to our [blog post](https://qwenlm.github.io/blog/qwen1.5/) and [GitHub repo](https://github.com/QwenLM/Qwen1.5).
## Model Details
Qwen1.5 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. For the beta version, temporarily we did not include GQA (except for 32B) and the mixture of SWA and full attention.
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'.
```
## Usage
We do not advise you to use base language models for text generation. Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., on this model.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
``` |
cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual | cardiffnlp | "2024-03-24T06:10:17Z" | 701,100 | 14 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"dataset:cardiffnlp/tweet_sentiment_multilingual",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-12-01T00:32:11Z" | ---
datasets:
- cardiffnlp/tweet_sentiment_multilingual
metrics:
- f1
- accuracy
model-index:
- name: cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: cardiffnlp/tweet_sentiment_multilingual
type: all
split: test
metrics:
- name: Micro F1 (cardiffnlp/tweet_sentiment_multilingual/all)
type: micro_f1_cardiffnlp/tweet_sentiment_multilingual/all
value: 0.6931034482758621
- name: Macro F1 (cardiffnlp/tweet_sentiment_multilingual/all)
type: micro_f1_cardiffnlp/tweet_sentiment_multilingual/all
value: 0.692628774202147
- name: Accuracy (cardiffnlp/tweet_sentiment_multilingual/all)
type: accuracy_cardiffnlp/tweet_sentiment_multilingual/all
value: 0.6931034482758621
pipeline_tag: text-classification
widget:
- text: Get the all-analog Classic Vinyl Edition of "Takin Off" Album from {@herbiehancock@} via {@bluenoterecords@} link below {{URL}}
example_title: "topic_classification 1"
- text: Yes, including Medicare and social security saving👍
example_title: "sentiment 1"
- text: All two of them taste like ass.
example_title: "offensive 1"
- text: If you wanna look like a badass, have drama on social media
example_title: "irony 1"
- text: Whoever just unfollowed me you a bitch
example_title: "hate 1"
- text: I love swimming for the same reason I love meditating...the feeling of weightlessness.
example_title: "emotion 1"
- text: Beautiful sunset last night from the pontoon @TupperLakeNY
example_title: "emoji 1"
---
# cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual
This model is a fine-tuned version of [cardiffnlp/twitter-xlm-roberta-base](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base) on the
[`cardiffnlp/tweet_sentiment_multilingual (all)`](https://huggingface.co/datasets/cardiffnlp/tweet_sentiment_multilingual)
via [`tweetnlp`](https://github.com/cardiffnlp/tweetnlp).
Training split is `train` and parameters have been tuned on the validation split `validation`.
Following metrics are achieved on the test split `test` ([link](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual/raw/main/metric.json)).
- F1 (micro): 0.6931034482758621
- F1 (macro): 0.692628774202147
- Accuracy: 0.6931034482758621
### Usage
Install tweetnlp via pip.
```shell
pip install tweetnlp
```
Load the model in python.
```python
import tweetnlp
model = tweetnlp.Classifier("cardiffnlp/twitter-xlm-roberta-base-sentiment-multilingual", max_length=128)
model.predict('Get the all-analog Classic Vinyl Edition of "Takin Off" Album from {@herbiehancock@} via {@bluenoterecords@} link below {{URL}}')
```
### Reference
```
@inproceedings{camacho-collados-etal-2022-tweetnlp,
title = "{T}weet{NLP}: Cutting-Edge Natural Language Processing for Social Media",
author = "Camacho-collados, Jose and
Rezaee, Kiamehr and
Riahi, Talayeh and
Ushio, Asahi and
Loureiro, Daniel and
Antypas, Dimosthenis and
Boisson, Joanne and
Espinosa Anke, Luis and
Liu, Fangyu and
Mart{\'\i}nez C{\'a}mara, Eugenio" and others,
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-demos.5",
pages = "38--49"
}
```
|
theainerd/Wav2Vec2-large-xlsr-hindi | theainerd | "2023-05-31T18:52:14Z" | 700,238 | 5 | transformers | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"hi",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language:
- hi
---
# Wav2Vec2-Large-XLSR-53-hindi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) hindi using the [Multilingual and code-switching ASR challenges for low resource Indian languages](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "hi", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
model = Wav2Vec2ForCTC.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the hindi test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "hi", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
model = Wav2Vec2ForCTC.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 72.62 %
## Training
The script used for training can be found [Hindi ASR Fine Tuning Wav2Vec2](https://colab.research.google.com/drive/1m-F7et3CHT_kpFqg7UffTIwnUV9AKgrg?usp=sharing) |
Qwen/Qwen1.5-0.5B | Qwen | "2024-04-05T10:38:41Z" | 697,011 | 142 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"pretrained",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-01-22T16:30:10Z" | ---
license: other
license_name: tongyi-qianwen-research
license_link: >-
https://huggingface.co/Qwen/Qwen1.5-0.5B/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
---
# Qwen1.5-0.5B
## Introduction
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:
* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models, and an MoE model of 14B with 2.7B activated;
* Significant performance improvement in Chat models;
* Multilingual support of both base and chat models;
* Stable support of 32K context length for models of all sizes
* No need of `trust_remote_code`.
For more details, please refer to our [blog post](https://qwenlm.github.io/blog/qwen1.5/) and [GitHub repo](https://github.com/QwenLM/Qwen1.5).
## Model Details
Qwen1.5 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. For the beta version, temporarily we did not include GQA and the mixture of SWA and full attention.
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'.
```
## Usage
We do not advise you to use base language models for text generation. Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., on this model.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
``` |
meta-llama/Llama-2-7b-chat-hf | meta-llama | "2024-04-17T08:40:48Z" | 692,268 | 3,875 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"conversational",
"en",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-07-13T16:45:23Z" | ---
extra_gated_heading: You need to share contact information with Meta to access this model
extra_gated_prompt: >-
### LLAMA 2 COMMUNITY LICENSE AGREEMENT
"Agreement" means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation
accompanying Llama 2 distributed by Meta at
https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Licensee" or "you" means you, or your employer or any other person or entity
(if you are entering into this Agreement on such person or entity's behalf),
of the age required under applicable laws, rules or regulations to provide
legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Llama 2" means the foundational large language models and software and
algorithms, including machine-learning model code, trained model weights,
inference-enabling code, training-enabling code, fine-tuning enabling code and
other elements of the foregoing distributed by Meta at
ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Llama Materials" means, collectively, Meta's proprietary Llama 2 and
documentation (and any portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or
Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA
or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or
element of the Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
transferable and royalty-free limited license under Meta's intellectual
property or other rights owned by Meta embodied in the Llama Materials to
use, reproduce, distribute, copy, create derivative works of, and make
modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make the Llama Materials, or any derivative works
thereof, available to a third party, you shall provide a copy of this
Agreement to such third party.
ii. If you receive Llama Materials, or any derivative works thereof, from a
Licensee as part of an integrated end user product, then Section 2 of this
Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute
the following attribution notice within a "Notice" text file distributed as a
part of such copies: "Llama 2 is licensed under the LLAMA 2 Community
License, Copyright (c) Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and
regulations (including trade compliance laws and regulations) and adhere to
the Acceptable Use Policy for the Llama Materials (available at
https://ai.meta.com/llama/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama
Materials to improve any other large language model (excluding Llama 2 or
derivative works thereof).
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
monthly active users of the products or services made available by or for
Licensee, or Licensee's affiliates, is greater than 700 million monthly
active users in the preceding calendar month, you must request a license from
Meta, which Meta may grant to you in its sole discretion, and you are not
authorized to exercise any of the rights under this Agreement unless or until
Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA
MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS"
BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING,
WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY
RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING
THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE
LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE
UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE,
PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST
PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR
PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE
POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection
with the Llama Materials, neither Meta nor Licensee may use any name or mark
owned by or associated with the other or any of its affiliates, except as
required for reasonable and customary use in describing and redistributing
the Llama Materials.
b. Subject to Meta's ownership of Llama Materials and derivatives made by or
for Meta, with respect to any derivative works and modifications of the Llama
Materials that are made by you, as between you and Meta, you are and will be
the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any
entity (including a cross-claim or counterclaim in a lawsuit) alleging that
the Llama Materials or Llama 2 outputs or results, or any portion of any of
the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under
this Agreement shall terminate as of the date such litigation or claim is
filed or instituted. You will indemnify and hold harmless Meta from and
against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will
continue in full force and effect until terminated in accordance with the
terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this
Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and
construed under the laws of the State of California without regard to choice
of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California
shall have exclusive jurisdiction of any dispute arising out of this
Agreement.
### Llama 2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features,
including Llama 2. If you access or use Llama 2, you agree to this Acceptable
Use Policy (“Policy”). The most recent copy of this policy can be found at
[ai.meta.com/llama/use-policy](http://ai.meta.com/llama/use-policy).
#### Prohibited Uses
We want everyone to use Llama 2 safely and responsibly. You agree you will not
use, or allow others to use, Llama 2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama 2 Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or
development of activities that present a risk of death or bodily harm to
individuals, including use of Llama 2 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 2 related
to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Llama 2 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems
that could lead to a violation of this Policy through one of the following
means:
* Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama: [[email protected]](mailto:[email protected])
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
license: llama2
---
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/meta-llama/Llama-2-7b) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/meta-llama/Llama-2-13b) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf)|
|70B| [Link](https://huggingface.co/meta-llama/Llama-2-70b) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)| |
Cloudy1225/stackoverflow-roberta-base-sentiment | Cloudy1225 | "2023-06-03T06:49:48Z" | 691,614 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"arxiv:1709.02984",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-06-02T07:38:40Z" | ---
license: openrail
---
# StackOverflow-RoBERTa-base for Sentiment Analysis on Software Engineering Texts
This is a RoBERTa-base model for sentiment analysis on software engineering texts. It is re-finetuned from [cardiffnlp/twitter-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) with [StackOverflow4423](https://arxiv.org/abs/1709.02984) dataset. You can access the demo [here](https://huggingface.co/spaces/Cloudy1225/stackoverflow-sentiment-analysis).
## Example of Pipeline
```python
from transformers import pipeline
MODEL = 'Cloudy1225/stackoverflow-roberta-base-sentiment'
sentiment_task = pipeline(task="sentiment-analysis", model=MODEL)
sentiment_task(["Excellent, happy to help!",
"This can probably be done using JavaScript.",
"Yes, but it's tricky, since datetime parsing in SQL is a pain in the neck."])
```
[{'label': 'positive', 'score': 0.9997847676277161},
{'label': 'neutral', 'score': 0.999783456325531},
{'label': 'negative', 'score': 0.9996368885040283}]
## Example of Classification
```python
from scipy.special import softmax
from transformers import AutoTokenizer, AutoModelForSequenceClassification
def preprocess(text):
"""Preprocess text (username and link placeholders)"""
new_text = []
for t in text.split(' '):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return ' '.join(new_text).strip()
MODEL = 'Cloudy1225/stackoverflow-roberta-base-sentiment'
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
text = "Excellent, happy to help!"
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
print("negative", scores[0])
print("neutral", scores[1])
print("positive", scores[2])
```
negative 0.00015578205
neutral 5.9470447e-05
positive 0.99978495
|
allenai/scibert_scivocab_uncased | allenai | "2022-10-03T22:06:12Z" | 690,207 | 120 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"en",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
---
# SciBERT
This is the pretrained model presented in [SciBERT: A Pretrained Language Model for Scientific Text](https://www.aclweb.org/anthology/D19-1371/), which is a BERT model trained on scientific text.
The training corpus was papers taken from [Semantic Scholar](https://www.semanticscholar.org). Corpus size is 1.14M papers, 3.1B tokens. We use the full text of the papers in training, not just abstracts.
SciBERT has its own wordpiece vocabulary (scivocab) that's built to best match the training corpus. We trained cased and uncased versions.
Available models include:
* `scibert_scivocab_cased`
* `scibert_scivocab_uncased`
The original repo can be found [here](https://github.com/allenai/scibert).
If using these models, please cite the following paper:
```
@inproceedings{beltagy-etal-2019-scibert,
title = "SciBERT: A Pretrained Language Model for Scientific Text",
author = "Beltagy, Iz and Lo, Kyle and Cohan, Arman",
booktitle = "EMNLP",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1371"
}
```
|
mistralai/Mixtral-8x7B-Instruct-v0.1 | mistralai | "2024-08-19T13:18:42Z" | 690,135 | 4,140 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"fr",
"it",
"de",
"es",
"en",
"base_model:mistralai/Mixtral-8x7B-v0.1",
"base_model:finetune:mistralai/Mixtral-8x7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-12-10T18:47:12Z" | ---
language:
- fr
- it
- de
- es
- en
license: apache-2.0
base_model: mistralai/Mixtral-8x7B-v0.1
inference:
parameters:
temperature: 0.5
widget:
- messages:
- role: user
content: What is your favorite condiment?
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# Model Card for Mixtral-8x7B
### Tokenization with `mistral-common`
```py
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
mistral_models_path = "MISTRAL_MODELS_PATH"
tokenizer = MistralTokenizer.v1()
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
```
## Inference with `mistral_inference`
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
model = Transformer.from_folder(mistral_models_path)
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
print(result)
```
## Inference with hugging face `transformers`
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
model.to("cuda")
generated_ids = model.generate(tokens, max_new_tokens=1000, do_sample=True)
# decode with mistral tokenizer
result = tokenizer.decode(generated_ids[0].tolist())
print(result)
```
> [!TIP]
> PRs to correct the transformers tokenizer so that it gives 1-to-1 the same results as the mistral-common reference implementation are very welcome!
---
The Mixtral-8x7B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts. The Mixtral-8x7B outperforms Llama 2 70B on most benchmarks we tested.
For full details of this model please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/).
## Warning
This repo contains weights that are compatible with [vLLM](https://github.com/vllm-project/vllm) serving of the model as well as Hugging Face [transformers](https://github.com/huggingface/transformers) library. It is based on the original Mixtral [torrent release](magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce), but the file format and parameter names are different. Please note that model cannot (yet) be instantiated with HF.
## Instruction format
This format must be strictly respected, otherwise the model will generate sub-optimal outputs.
The template used to build a prompt for the Instruct model is defined as follows:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
Note that `<s>` and `</s>` are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
As reference, here is the pseudo-code used to tokenize instructions during fine-tuning:
```python
def tokenize(text):
return tok.encode(text, add_special_tokens=False)
[BOS_ID] +
tokenize("[INST]") + tokenize(USER_MESSAGE_1) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_1) + [EOS_ID] +
…
tokenize("[INST]") + tokenize(USER_MESSAGE_N) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_N) + [EOS_ID]
```
In the pseudo-code above, note that the `tokenize` method should not add a BOS or EOS token automatically, but should add a prefix space.
In the Transformers library, one can use [chat templates](https://huggingface.co/docs/transformers/main/en/chat_templating) which make sure the right format is applied.
## Run the model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
### In half-precision
Note `float16` precision only works on GPU devices
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Lower precision using (8-bit & 4-bit) using `bitsandbytes`
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, device_map="auto")
text = "Hello my name is"
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Load the model with Flash Attention 2
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, use_flash_attention_2=True, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
## Limitations
The Mixtral-8x7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
google/gemma-2-9b-it | google | "2024-08-27T19:41:49Z" | 684,754 | 475 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:2110.08193",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:1804.06876",
"arxiv:2103.03874",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:2203.09509",
"base_model:google/gemma-2-9b",
"base_model:finetune:google/gemma-2-9b",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-24T08:05:41Z" | ---
license: gemma
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
tags:
- conversational
base_model: google/gemma-2-9b
---
# Gemma 2 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma]
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent/verify/huggingface?returnModelRepoId=google/gemma-2-9b-it)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights for both pre-trained variants and instruction-tuned variants.
Gemma models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First, install the Transformers library with:
```sh
pip install -U transformers
```
Then, copy the snippet from the section that is relevant for your usecase.
#### Running with the `pipeline` API
```python
import torch
from transformers import pipeline
pipe = pipeline(
"text-generation",
model="google/gemma-2-9b-it",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda", # replace with "mps" to run on a Mac device
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(messages, max_new_tokens=256)
assistant_response = outputs[0]["generated_text"][-1]["content"].strip()
print(assistant_response)
# Ahoy, matey! I be Gemma, a digital scallywag, a language-slingin' parrot of the digital seas. I be here to help ye with yer wordy woes, answer yer questions, and spin ye yarns of the digital world. So, what be yer pleasure, eh? 🦜
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
device_map="auto",
torch_dtype=torch.bfloat16,
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=32)
print(tokenizer.decode(outputs[0]))
```
You can ensure the correct chat template is applied by using `tokenizer.apply_chat_template` as follows:
```python
messages = [
{"role": "user", "content": "Write me a poem about Machine Learning."},
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt", return_dict=True).to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=256)
print(tokenizer.decode(outputs[0]))
```
<a name="precisions"></a>
#### Running the model on a GPU using different precisions
The native weights of this model were exported in `bfloat16` precision.
You can also use `float32` if you skip the dtype, but no precision increase will occur (model weights will just be upcasted to `float32`). See examples below.
* _Upcasting to `torch.float32`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
device_map="auto",
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=32)
print(tokenizer.decode(outputs[0]))
```
#### Running the model through a CLI
The [local-gemma](https://github.com/huggingface/local-gemma) repository contains a lightweight wrapper around Transformers
for running Gemma 2 through a command line interface, or CLI. Follow the [installation instructions](https://github.com/huggingface/local-gemma#cli-usage)
for getting started, then launch the CLI through the following command:
```shell
local-gemma --model 9b --preset speed
```
#### Quantized Versions through `bitsandbytes`
<details>
<summary>
Using 8-bit precision (int8)
</summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
quantization_config=quantization_config,
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=32)
print(tokenizer.decode(outputs[0]))
```
</details>
<details>
<summary>
Using 4-bit precision
</summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
quantization_config=quantization_config,
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=32)
print(tokenizer.decode(outputs[0]))
```
</details>
#### Advanced Usage
<details>
<summary>
Torch compile
</summary>
[Torch compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) is a method for speeding-up the
inference of PyTorch modules. The Gemma-2 model can be run up to 6x faster by leveraging torch compile.
Note that two warm-up steps are required before the full inference speed is realised:
```python
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer, Gemma2ForCausalLM
from transformers.cache_utils import HybridCache
import torch
torch.set_float32_matmul_precision("high")
# load the model + tokenizer
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
model = Gemma2ForCausalLM.from_pretrained("google/gemma-2-9b-it", torch_dtype=torch.bfloat16)
model.to("cuda")
# apply the torch compile transformation
model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
# pre-process inputs
input_text = "The theory of special relativity states "
model_inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
prompt_length = model_inputs.input_ids.shape[1]
# set-up k/v cache
past_key_values = HybridCache(
config=model.config,
max_batch_size=1,
max_cache_len=model.config.max_position_embeddings,
device=model.device,
dtype=model.dtype
)
# enable passing kv cache to generate
model._supports_cache_class = True
model.generation_config.cache_implementation = None
# two warm-up steps
for idx in range(2):
outputs = model.generate(**model_inputs, past_key_values=past_key_values, do_sample=True, temperature=1.0, max_new_tokens=128)
past_key_values.reset()
# fast run
outputs = model.generate(**model_inputs, past_key_values=past_key_values, do_sample=True, temperature=1.0, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For more details, refer to the [Transformers documentation](https://huggingface.co/docs/transformers/main/en/llm_optims?static-kv=basic+usage%3A+generation_config).
</details>
### Chat Template
The instruction-tuned models use a chat template that must be adhered to for conversational use.
The easiest way to apply it is using the tokenizer's built-in chat template, as shown in the following snippet.
Let's load the model and apply the chat template to a conversation. In this example, we'll start with a single user interaction:
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "google/gemma-2-9b-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,)
chat = [
{ "role": "user", "content": "Write a hello world program" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
At this point, the prompt contains the following text:
```
<bos><start_of_turn>user
Write a hello world program<end_of_turn>
<start_of_turn>model
```
As you can see, each turn is preceded by a `<start_of_turn>` delimiter and then the role of the entity
(either `user`, for content supplied by the user, or `model` for LLM responses). Turns finish with
the `<end_of_turn>` token.
You can follow this format to build the prompt manually, if you need to do it without the tokenizer's
chat template.
After the prompt is ready, generation can be performed like this:
```py
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=150)
print(tokenizer.decode(outputs[0]))
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
### Citation
```none
@article{gemma_2024,
title={Gemma},
url={https://www.kaggle.com/m/3301},
DOI={10.34740/KAGGLE/M/3301},
publisher={Kaggle},
author={Gemma Team},
year={2024}
}
```
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety of sources. The 27B model was trained with 13 trillion tokens and the 9B model was trained with 8 trillion tokens.
Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content.
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safety in line with
[our policies][safety-policies].
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)][tpu] hardware (TPUv5p).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably][sustainability].
### Software
Training was done using [JAX][jax] and [ML Pathways][ml-pathways].
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models][foundation-models], including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models][gemini-2-paper]; "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | Gemma PT 9B | Gemma PT 27B |
| ------------------------------ | ------------- | ----------- | ------------ |
| [MMLU][mmlu] | 5-shot, top-1 | 71.3 | 75.2 |
| [HellaSwag][hellaswag] | 10-shot | 81.9 | 86.4 |
| [PIQA][piqa] | 0-shot | 81.7 | 83.2 |
| [SocialIQA][socialiqa] | 0-shot | 53.4 | 53.7 |
| [BoolQ][boolq] | 0-shot | 84.2 | 84.8 |
| [WinoGrande][winogrande] | partial score | 80.6 | 83.7 |
| [ARC-e][arc] | 0-shot | 88.0 | 88.6 |
| [ARC-c][arc] | 25-shot | 68.4 | 71.4 |
| [TriviaQA][triviaqa] | 5-shot | 76.6 | 83.7 |
| [Natural Questions][naturalq] | 5-shot | 29.2 | 34.5 |
| [HumanEval][humaneval] | pass@1 | 40.2 | 51.8 |
| [MBPP][mbpp] | 3-shot | 52.4 | 62.6 |
| [GSM8K][gsm8k] | 5-shot, maj@1 | 68.6 | 74.0 |
| [MATH][math] | 4-shot | 36.6 | 42.3 |
| [AGIEval][agieval] | 3-5-shot | 52.8 | 55.1 |
| [BIG-Bench][big-bench] | 3-shot, CoT | 68.2 | 74.9 |
| ------------------------------ | ------------- | ----------- | ------------ |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias][winobias] and [BBQ Dataset][bbq].
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies][safety-policies] for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well-known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
#### Gemma 2.0
| Benchmark | Metric | Gemma 2 IT 9B | Gemma 2 IT 27B |
| ------------------------ | ------------- | --------------- | ---------------- |
| [RealToxicity][realtox] | average | 8.25 | 8.84 |
| [CrowS-Pairs][crows] | top-1 | 37.47 | 36.67 |
| [BBQ Ambig][bbq] | 1-shot, top-1 | 88.58 | 85.99 |
| [BBQ Disambig][bbq] | top-1 | 82.67 | 86.94 |
| [Winogender][winogender] | top-1 | 79.17 | 77.22 |
| [TruthfulQA][truthfulqa] | | 50.27 | 51.60 |
| [Winobias 1_2][winobias] | | 78.09 | 81.94 |
| [Winobias 2_2][winobias] | | 95.32 | 97.22 |
| [Toxigen][toxigen] | | 39.30 | 38.42 |
| ------------------------ | ------------- | --------------- | ---------------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit][rai-toolkit].
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy][prohibited-use].
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
[rai-toolkit]: https://ai.google.dev/responsible
[kaggle-gemma]: https://www.kaggle.com/models/google/gemma-2
[terms]: https://ai.google.dev/gemma/terms
[vertex-mg-gemma]: https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335
[sensitive-info]: https://cloud.google.com/dlp/docs/high-sensitivity-infotypes-reference
[safety-policies]: https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11
[prohibited-use]: https://ai.google.dev/gemma/prohibited_use_policy
[tpu]: https://cloud.google.com/tpu/docs/intro-to-tpu
[sustainability]: https://sustainability.google/operating-sustainably/
[jax]: https://github.com/google/jax
[ml-pathways]: https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[sustainability]: https://sustainability.google/operating-sustainably/
[foundation-models]: https://ai.google/discover/foundation-models/
[gemini-2-paper]: https://goo.gle/gemma2report
[mmlu]: https://arxiv.org/abs/2009.03300
[hellaswag]: https://arxiv.org/abs/1905.07830
[piqa]: https://arxiv.org/abs/1911.11641
[socialiqa]: https://arxiv.org/abs/1904.09728
[boolq]: https://arxiv.org/abs/1905.10044
[winogrande]: https://arxiv.org/abs/1907.10641
[commonsenseqa]: https://arxiv.org/abs/1811.00937
[openbookqa]: https://arxiv.org/abs/1809.02789
[arc]: https://arxiv.org/abs/1911.01547
[triviaqa]: https://arxiv.org/abs/1705.03551
[naturalq]: https://github.com/google-research-datasets/natural-questions
[humaneval]: https://arxiv.org/abs/2107.03374
[mbpp]: https://arxiv.org/abs/2108.07732
[gsm8k]: https://arxiv.org/abs/2110.14168
[realtox]: https://arxiv.org/abs/2009.11462
[bold]: https://arxiv.org/abs/2101.11718
[crows]: https://aclanthology.org/2020.emnlp-main.154/
[bbq]: https://arxiv.org/abs/2110.08193v2
[winogender]: https://arxiv.org/abs/1804.09301
[truthfulqa]: https://arxiv.org/abs/2109.07958
[winobias]: https://arxiv.org/abs/1804.06876
[math]: https://arxiv.org/abs/2103.03874
[agieval]: https://arxiv.org/abs/2304.06364
[big-bench]: https://arxiv.org/abs/2206.04615
[toxigen]: https://arxiv.org/abs/2203.09509
|
facebook/sam-vit-base | facebook | "2024-01-11T19:23:17Z" | 683,028 | 116 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"sam",
"mask-generation",
"vision",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | mask-generation | "2023-04-19T14:15:29Z" | ---
license: apache-2.0
tags:
- vision
---
# Model Card for Segment Anything Model (SAM) - ViT Base (ViT-B) version
<p>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-architecture.png" alt="Model architecture">
<em> Detailed architecture of Segment Anything Model (SAM).</em>
</p>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Citation](#citation)
# TL;DR
[Link to original repository](https://github.com/facebookresearch/segment-anything)
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-beancans.png" alt="Snow" width="600" height="600"> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-dog-masks.png" alt="Forest" width="600" height="600"> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/sam-car-seg.png" alt="Mountains" width="600" height="600"> |
|---------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|
The **Segment Anything Model (SAM)** produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a [dataset](https://segment-anything.com/dataset/index.html) of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
The abstract of the paper states:
> We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at [https://segment-anything.com](https://segment-anything.com) to foster research into foundation models for computer vision.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the original [SAM model card](https://github.com/facebookresearch/segment-anything).
# Model Details
The SAM model is made up of 3 modules:
- The `VisionEncoder`: a VIT based image encoder. It computes the image embeddings using attention on patches of the image. Relative Positional Embedding is used.
- The `PromptEncoder`: generates embeddings for points and bounding boxes
- The `MaskDecoder`: a two-ways transformer which performs cross attention between the image embedding and the point embeddings (->) and between the point embeddings and the image embeddings. The outputs are fed
- The `Neck`: predicts the output masks based on the contextualized masks produced by the `MaskDecoder`.
# Usage
## Prompted-Mask-Generation
```python
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
model = SamModel.from_pretrained("facebook/sam-vit-base")
processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D localization of a window
```
```python
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to("cuda")
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores
```
Among other arguments to generate masks, you can pass 2D locations on the approximate position of your object of interest, a bounding box wrapping the object of interest (the format should be x, y coordinate of the top right and bottom left point of the bounding box), a segmentation mask. At this time of writing, passing a text as input is not supported by the official model according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
For more details, refer to this notebook, which shows a walk throught of how to use the model, with a visual example!
## Automatic-Mask-Generation
The model can be used for generating segmentation masks in a "zero-shot" fashion, given an input image. The model is automatically prompt with a grid of `1024` points
which are all fed to the model.
The pipeline is made for automatic mask generation. The following snippet demonstrates how easy you can run it (on any device! Simply feed the appropriate `points_per_batch` argument)
```python
from transformers import pipeline
generator = pipeline("mask-generation", device = 0, points_per_batch = 256)
image_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
outputs = generator(image_url, points_per_batch = 256)
```
Now to display the image:
```python
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(np.array(raw_image))
ax = plt.gca()
for mask in outputs["masks"]:
show_mask(mask, ax=ax, random_color=True)
plt.axis("off")
plt.show()
```
# Citation
If you use this model, please use the following BibTeX entry.
```
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
``` |
BAAI/bge-small-en | BAAI | "2023-12-13T03:53:21Z" | 681,779 | 70 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence transformers",
"en",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2023-08-05T08:04:07Z" | ---
tags:
- mteb
- sentence transformers
model-index:
- name: bge-small-en
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.34328358208955
- type: ap
value: 37.59947775195661
- type: f1
value: 68.548415491933
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.04527499999999
- type: ap
value: 89.60696356772135
- type: f1
value: 93.03361469382438
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.08
- type: f1
value: 45.66249835363254
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.205999999999996
- type: map_at_10
value: 50.782000000000004
- type: map_at_100
value: 51.547
- type: map_at_1000
value: 51.554
- type: map_at_3
value: 46.515
- type: map_at_5
value: 49.296
- type: mrr_at_1
value: 35.632999999999996
- type: mrr_at_10
value: 50.958999999999996
- type: mrr_at_100
value: 51.724000000000004
- type: mrr_at_1000
value: 51.731
- type: mrr_at_3
value: 46.669
- type: mrr_at_5
value: 49.439
- type: ndcg_at_1
value: 35.205999999999996
- type: ndcg_at_10
value: 58.835
- type: ndcg_at_100
value: 62.095
- type: ndcg_at_1000
value: 62.255
- type: ndcg_at_3
value: 50.255
- type: ndcg_at_5
value: 55.296
- type: precision_at_1
value: 35.205999999999996
- type: precision_at_10
value: 8.421
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.365
- type: precision_at_5
value: 14.680000000000001
- type: recall_at_1
value: 35.205999999999996
- type: recall_at_10
value: 84.211
- type: recall_at_100
value: 98.43499999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 61.095
- type: recall_at_5
value: 73.4
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.52644476278646
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 39.973045724188964
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.28285314871488
- type: mrr
value: 74.52743701358659
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 80.09041909160327
- type: cos_sim_spearman
value: 79.96266537706944
- type: euclidean_pearson
value: 79.50774978162241
- type: euclidean_spearman
value: 79.9144715078551
- type: manhattan_pearson
value: 79.2062139879302
- type: manhattan_spearman
value: 79.35000081468212
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.31493506493506
- type: f1
value: 85.2704557977762
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.6837242810816
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.38881249555897
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.884999999999998
- type: map_at_10
value: 39.574
- type: map_at_100
value: 40.993
- type: map_at_1000
value: 41.129
- type: map_at_3
value: 36.089
- type: map_at_5
value: 38.191
- type: mrr_at_1
value: 34.477999999999994
- type: mrr_at_10
value: 45.411
- type: mrr_at_100
value: 46.089999999999996
- type: mrr_at_1000
value: 46.147
- type: mrr_at_3
value: 42.346000000000004
- type: mrr_at_5
value: 44.292
- type: ndcg_at_1
value: 34.477999999999994
- type: ndcg_at_10
value: 46.123999999999995
- type: ndcg_at_100
value: 51.349999999999994
- type: ndcg_at_1000
value: 53.578
- type: ndcg_at_3
value: 40.824
- type: ndcg_at_5
value: 43.571
- type: precision_at_1
value: 34.477999999999994
- type: precision_at_10
value: 8.841000000000001
- type: precision_at_100
value: 1.4460000000000002
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 19.742
- type: precision_at_5
value: 14.421000000000001
- type: recall_at_1
value: 27.884999999999998
- type: recall_at_10
value: 59.087
- type: recall_at_100
value: 80.609
- type: recall_at_1000
value: 95.054
- type: recall_at_3
value: 44.082
- type: recall_at_5
value: 51.593999999999994
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.639
- type: map_at_10
value: 40.047
- type: map_at_100
value: 41.302
- type: map_at_1000
value: 41.425
- type: map_at_3
value: 37.406
- type: map_at_5
value: 38.934000000000005
- type: mrr_at_1
value: 37.707
- type: mrr_at_10
value: 46.082
- type: mrr_at_100
value: 46.745
- type: mrr_at_1000
value: 46.786
- type: mrr_at_3
value: 43.980999999999995
- type: mrr_at_5
value: 45.287
- type: ndcg_at_1
value: 37.707
- type: ndcg_at_10
value: 45.525
- type: ndcg_at_100
value: 49.976
- type: ndcg_at_1000
value: 51.94499999999999
- type: ndcg_at_3
value: 41.704
- type: ndcg_at_5
value: 43.596000000000004
- type: precision_at_1
value: 37.707
- type: precision_at_10
value: 8.465
- type: precision_at_100
value: 1.375
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 19.979
- type: precision_at_5
value: 14.115
- type: recall_at_1
value: 30.639
- type: recall_at_10
value: 54.775
- type: recall_at_100
value: 73.678
- type: recall_at_1000
value: 86.142
- type: recall_at_3
value: 43.230000000000004
- type: recall_at_5
value: 48.622
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.038
- type: map_at_10
value: 49.922
- type: map_at_100
value: 51.032
- type: map_at_1000
value: 51.085
- type: map_at_3
value: 46.664
- type: map_at_5
value: 48.588
- type: mrr_at_1
value: 43.95
- type: mrr_at_10
value: 53.566
- type: mrr_at_100
value: 54.318999999999996
- type: mrr_at_1000
value: 54.348
- type: mrr_at_3
value: 51.066
- type: mrr_at_5
value: 52.649
- type: ndcg_at_1
value: 43.95
- type: ndcg_at_10
value: 55.676
- type: ndcg_at_100
value: 60.126000000000005
- type: ndcg_at_1000
value: 61.208
- type: ndcg_at_3
value: 50.20400000000001
- type: ndcg_at_5
value: 53.038
- type: precision_at_1
value: 43.95
- type: precision_at_10
value: 8.953
- type: precision_at_100
value: 1.2109999999999999
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.256999999999998
- type: precision_at_5
value: 15.524
- type: recall_at_1
value: 38.038
- type: recall_at_10
value: 69.15
- type: recall_at_100
value: 88.31599999999999
- type: recall_at_1000
value: 95.993
- type: recall_at_3
value: 54.663
- type: recall_at_5
value: 61.373
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.872
- type: map_at_10
value: 32.912
- type: map_at_100
value: 33.972
- type: map_at_1000
value: 34.046
- type: map_at_3
value: 30.361
- type: map_at_5
value: 31.704
- type: mrr_at_1
value: 26.779999999999998
- type: mrr_at_10
value: 34.812
- type: mrr_at_100
value: 35.754999999999995
- type: mrr_at_1000
value: 35.809000000000005
- type: mrr_at_3
value: 32.335
- type: mrr_at_5
value: 33.64
- type: ndcg_at_1
value: 26.779999999999998
- type: ndcg_at_10
value: 37.623
- type: ndcg_at_100
value: 42.924
- type: ndcg_at_1000
value: 44.856
- type: ndcg_at_3
value: 32.574
- type: ndcg_at_5
value: 34.842
- type: precision_at_1
value: 26.779999999999998
- type: precision_at_10
value: 5.729
- type: precision_at_100
value: 0.886
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 13.559
- type: precision_at_5
value: 9.469
- type: recall_at_1
value: 24.872
- type: recall_at_10
value: 50.400999999999996
- type: recall_at_100
value: 74.954
- type: recall_at_1000
value: 89.56
- type: recall_at_3
value: 36.726
- type: recall_at_5
value: 42.138999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.803
- type: map_at_10
value: 24.348
- type: map_at_100
value: 25.56
- type: map_at_1000
value: 25.668000000000003
- type: map_at_3
value: 21.811
- type: map_at_5
value: 23.287
- type: mrr_at_1
value: 20.771
- type: mrr_at_10
value: 28.961
- type: mrr_at_100
value: 29.979
- type: mrr_at_1000
value: 30.046
- type: mrr_at_3
value: 26.555
- type: mrr_at_5
value: 28.060000000000002
- type: ndcg_at_1
value: 20.771
- type: ndcg_at_10
value: 29.335
- type: ndcg_at_100
value: 35.188
- type: ndcg_at_1000
value: 37.812
- type: ndcg_at_3
value: 24.83
- type: ndcg_at_5
value: 27.119
- type: precision_at_1
value: 20.771
- type: precision_at_10
value: 5.4350000000000005
- type: precision_at_100
value: 0.9480000000000001
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.982
- type: precision_at_5
value: 8.831
- type: recall_at_1
value: 16.803
- type: recall_at_10
value: 40.039
- type: recall_at_100
value: 65.83200000000001
- type: recall_at_1000
value: 84.478
- type: recall_at_3
value: 27.682000000000002
- type: recall_at_5
value: 33.535
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.345
- type: map_at_10
value: 37.757000000000005
- type: map_at_100
value: 39.141
- type: map_at_1000
value: 39.262
- type: map_at_3
value: 35.183
- type: map_at_5
value: 36.592
- type: mrr_at_1
value: 34.649
- type: mrr_at_10
value: 43.586999999999996
- type: mrr_at_100
value: 44.481
- type: mrr_at_1000
value: 44.542
- type: mrr_at_3
value: 41.29
- type: mrr_at_5
value: 42.642
- type: ndcg_at_1
value: 34.649
- type: ndcg_at_10
value: 43.161
- type: ndcg_at_100
value: 48.734
- type: ndcg_at_1000
value: 51.046
- type: ndcg_at_3
value: 39.118
- type: ndcg_at_5
value: 41.022
- type: precision_at_1
value: 34.649
- type: precision_at_10
value: 7.603
- type: precision_at_100
value: 1.209
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 18.319
- type: precision_at_5
value: 12.839
- type: recall_at_1
value: 28.345
- type: recall_at_10
value: 53.367
- type: recall_at_100
value: 76.453
- type: recall_at_1000
value: 91.82000000000001
- type: recall_at_3
value: 41.636
- type: recall_at_5
value: 46.760000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.419
- type: map_at_10
value: 31.716
- type: map_at_100
value: 33.152
- type: map_at_1000
value: 33.267
- type: map_at_3
value: 28.74
- type: map_at_5
value: 30.48
- type: mrr_at_1
value: 28.310999999999996
- type: mrr_at_10
value: 37.039
- type: mrr_at_100
value: 38.09
- type: mrr_at_1000
value: 38.145
- type: mrr_at_3
value: 34.437
- type: mrr_at_5
value: 36.024
- type: ndcg_at_1
value: 28.310999999999996
- type: ndcg_at_10
value: 37.41
- type: ndcg_at_100
value: 43.647999999999996
- type: ndcg_at_1000
value: 46.007
- type: ndcg_at_3
value: 32.509
- type: ndcg_at_5
value: 34.943999999999996
- type: precision_at_1
value: 28.310999999999996
- type: precision_at_10
value: 6.963
- type: precision_at_100
value: 1.1860000000000002
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 15.867999999999999
- type: precision_at_5
value: 11.507000000000001
- type: recall_at_1
value: 22.419
- type: recall_at_10
value: 49.28
- type: recall_at_100
value: 75.802
- type: recall_at_1000
value: 92.032
- type: recall_at_3
value: 35.399
- type: recall_at_5
value: 42.027
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.669249999999998
- type: map_at_10
value: 33.332583333333325
- type: map_at_100
value: 34.557833333333335
- type: map_at_1000
value: 34.67141666666666
- type: map_at_3
value: 30.663166666666662
- type: map_at_5
value: 32.14883333333333
- type: mrr_at_1
value: 29.193833333333334
- type: mrr_at_10
value: 37.47625
- type: mrr_at_100
value: 38.3545
- type: mrr_at_1000
value: 38.413166666666676
- type: mrr_at_3
value: 35.06741666666667
- type: mrr_at_5
value: 36.450666666666656
- type: ndcg_at_1
value: 29.193833333333334
- type: ndcg_at_10
value: 38.505416666666676
- type: ndcg_at_100
value: 43.81125
- type: ndcg_at_1000
value: 46.09558333333333
- type: ndcg_at_3
value: 33.90916666666667
- type: ndcg_at_5
value: 36.07666666666666
- type: precision_at_1
value: 29.193833333333334
- type: precision_at_10
value: 6.7251666666666665
- type: precision_at_100
value: 1.1058333333333332
- type: precision_at_1000
value: 0.14833333333333332
- type: precision_at_3
value: 15.554166666666665
- type: precision_at_5
value: 11.079250000000002
- type: recall_at_1
value: 24.669249999999998
- type: recall_at_10
value: 49.75583333333332
- type: recall_at_100
value: 73.06908333333332
- type: recall_at_1000
value: 88.91316666666667
- type: recall_at_3
value: 36.913250000000005
- type: recall_at_5
value: 42.48641666666666
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.044999999999998
- type: map_at_10
value: 30.349999999999998
- type: map_at_100
value: 31.273
- type: map_at_1000
value: 31.362000000000002
- type: map_at_3
value: 28.508
- type: map_at_5
value: 29.369
- type: mrr_at_1
value: 26.994
- type: mrr_at_10
value: 33.12
- type: mrr_at_100
value: 33.904
- type: mrr_at_1000
value: 33.967000000000006
- type: mrr_at_3
value: 31.365
- type: mrr_at_5
value: 32.124
- type: ndcg_at_1
value: 26.994
- type: ndcg_at_10
value: 34.214
- type: ndcg_at_100
value: 38.681
- type: ndcg_at_1000
value: 40.926
- type: ndcg_at_3
value: 30.725
- type: ndcg_at_5
value: 31.967000000000002
- type: precision_at_1
value: 26.994
- type: precision_at_10
value: 5.215
- type: precision_at_100
value: 0.807
- type: precision_at_1000
value: 0.108
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 8.712
- type: recall_at_1
value: 24.044999999999998
- type: recall_at_10
value: 43.456
- type: recall_at_100
value: 63.675000000000004
- type: recall_at_1000
value: 80.05499999999999
- type: recall_at_3
value: 33.561
- type: recall_at_5
value: 36.767
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.672
- type: map_at_10
value: 22.641
- type: map_at_100
value: 23.75
- type: map_at_1000
value: 23.877000000000002
- type: map_at_3
value: 20.219
- type: map_at_5
value: 21.648
- type: mrr_at_1
value: 18.823
- type: mrr_at_10
value: 26.101999999999997
- type: mrr_at_100
value: 27.038
- type: mrr_at_1000
value: 27.118
- type: mrr_at_3
value: 23.669
- type: mrr_at_5
value: 25.173000000000002
- type: ndcg_at_1
value: 18.823
- type: ndcg_at_10
value: 27.176000000000002
- type: ndcg_at_100
value: 32.42
- type: ndcg_at_1000
value: 35.413
- type: ndcg_at_3
value: 22.756999999999998
- type: ndcg_at_5
value: 25.032
- type: precision_at_1
value: 18.823
- type: precision_at_10
value: 5.034000000000001
- type: precision_at_100
value: 0.895
- type: precision_at_1000
value: 0.132
- type: precision_at_3
value: 10.771
- type: precision_at_5
value: 8.1
- type: recall_at_1
value: 15.672
- type: recall_at_10
value: 37.296
- type: recall_at_100
value: 60.863
- type: recall_at_1000
value: 82.234
- type: recall_at_3
value: 25.330000000000002
- type: recall_at_5
value: 30.964000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.633
- type: map_at_10
value: 32.858
- type: map_at_100
value: 34.038000000000004
- type: map_at_1000
value: 34.141
- type: map_at_3
value: 30.209000000000003
- type: map_at_5
value: 31.567
- type: mrr_at_1
value: 28.358
- type: mrr_at_10
value: 36.433
- type: mrr_at_100
value: 37.352000000000004
- type: mrr_at_1000
value: 37.41
- type: mrr_at_3
value: 34.033
- type: mrr_at_5
value: 35.246
- type: ndcg_at_1
value: 28.358
- type: ndcg_at_10
value: 37.973
- type: ndcg_at_100
value: 43.411
- type: ndcg_at_1000
value: 45.747
- type: ndcg_at_3
value: 32.934999999999995
- type: ndcg_at_5
value: 35.013
- type: precision_at_1
value: 28.358
- type: precision_at_10
value: 6.418
- type: precision_at_100
value: 1.02
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 14.677000000000001
- type: precision_at_5
value: 10.335999999999999
- type: recall_at_1
value: 24.633
- type: recall_at_10
value: 50.048
- type: recall_at_100
value: 73.821
- type: recall_at_1000
value: 90.046
- type: recall_at_3
value: 36.284
- type: recall_at_5
value: 41.370000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.133
- type: map_at_10
value: 31.491999999999997
- type: map_at_100
value: 33.062000000000005
- type: map_at_1000
value: 33.256
- type: map_at_3
value: 28.886
- type: map_at_5
value: 30.262
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.144
- type: mrr_at_100
value: 37.14
- type: mrr_at_1000
value: 37.191
- type: mrr_at_3
value: 33.762
- type: mrr_at_5
value: 34.997
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 36.951
- type: ndcg_at_100
value: 43.287
- type: ndcg_at_1000
value: 45.777
- type: ndcg_at_3
value: 32.786
- type: ndcg_at_5
value: 34.65
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.055
- type: precision_at_100
value: 1.476
- type: precision_at_1000
value: 0.22899999999999998
- type: precision_at_3
value: 15.481
- type: precision_at_5
value: 11.186
- type: recall_at_1
value: 23.133
- type: recall_at_10
value: 47.285
- type: recall_at_100
value: 76.176
- type: recall_at_1000
value: 92.176
- type: recall_at_3
value: 35.223
- type: recall_at_5
value: 40.142
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.547
- type: map_at_10
value: 26.374
- type: map_at_100
value: 27.419
- type: map_at_1000
value: 27.539
- type: map_at_3
value: 23.882
- type: map_at_5
value: 25.163999999999998
- type: mrr_at_1
value: 21.442
- type: mrr_at_10
value: 28.458
- type: mrr_at_100
value: 29.360999999999997
- type: mrr_at_1000
value: 29.448999999999998
- type: mrr_at_3
value: 25.97
- type: mrr_at_5
value: 27.273999999999997
- type: ndcg_at_1
value: 21.442
- type: ndcg_at_10
value: 30.897000000000002
- type: ndcg_at_100
value: 35.99
- type: ndcg_at_1000
value: 38.832
- type: ndcg_at_3
value: 25.944
- type: ndcg_at_5
value: 28.126
- type: precision_at_1
value: 21.442
- type: precision_at_10
value: 4.9910000000000005
- type: precision_at_100
value: 0.8109999999999999
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 11.029
- type: precision_at_5
value: 7.911
- type: recall_at_1
value: 19.547
- type: recall_at_10
value: 42.886
- type: recall_at_100
value: 66.64999999999999
- type: recall_at_1000
value: 87.368
- type: recall_at_3
value: 29.143
- type: recall_at_5
value: 34.544000000000004
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.572
- type: map_at_10
value: 25.312
- type: map_at_100
value: 27.062
- type: map_at_1000
value: 27.253
- type: map_at_3
value: 21.601
- type: map_at_5
value: 23.473
- type: mrr_at_1
value: 34.984
- type: mrr_at_10
value: 46.406
- type: mrr_at_100
value: 47.179
- type: mrr_at_1000
value: 47.21
- type: mrr_at_3
value: 43.485
- type: mrr_at_5
value: 45.322
- type: ndcg_at_1
value: 34.984
- type: ndcg_at_10
value: 34.344
- type: ndcg_at_100
value: 41.015
- type: ndcg_at_1000
value: 44.366
- type: ndcg_at_3
value: 29.119
- type: ndcg_at_5
value: 30.825999999999997
- type: precision_at_1
value: 34.984
- type: precision_at_10
value: 10.358
- type: precision_at_100
value: 1.762
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 21.368000000000002
- type: precision_at_5
value: 15.948
- type: recall_at_1
value: 15.572
- type: recall_at_10
value: 39.367999999999995
- type: recall_at_100
value: 62.183
- type: recall_at_1000
value: 80.92200000000001
- type: recall_at_3
value: 26.131999999999998
- type: recall_at_5
value: 31.635999999999996
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.848
- type: map_at_10
value: 19.25
- type: map_at_100
value: 27.193
- type: map_at_1000
value: 28.721999999999998
- type: map_at_3
value: 13.968
- type: map_at_5
value: 16.283
- type: mrr_at_1
value: 68.75
- type: mrr_at_10
value: 76.25
- type: mrr_at_100
value: 76.534
- type: mrr_at_1000
value: 76.53999999999999
- type: mrr_at_3
value: 74.667
- type: mrr_at_5
value: 75.86699999999999
- type: ndcg_at_1
value: 56.00000000000001
- type: ndcg_at_10
value: 41.426
- type: ndcg_at_100
value: 45.660000000000004
- type: ndcg_at_1000
value: 53.02
- type: ndcg_at_3
value: 46.581
- type: ndcg_at_5
value: 43.836999999999996
- type: precision_at_1
value: 68.75
- type: precision_at_10
value: 32.800000000000004
- type: precision_at_100
value: 10.440000000000001
- type: precision_at_1000
value: 1.9980000000000002
- type: precision_at_3
value: 49.667
- type: precision_at_5
value: 42.25
- type: recall_at_1
value: 8.848
- type: recall_at_10
value: 24.467
- type: recall_at_100
value: 51.344
- type: recall_at_1000
value: 75.235
- type: recall_at_3
value: 15.329
- type: recall_at_5
value: 18.892999999999997
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 48.95
- type: f1
value: 43.44563593360779
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 78.036
- type: map_at_10
value: 85.639
- type: map_at_100
value: 85.815
- type: map_at_1000
value: 85.829
- type: map_at_3
value: 84.795
- type: map_at_5
value: 85.336
- type: mrr_at_1
value: 84.353
- type: mrr_at_10
value: 90.582
- type: mrr_at_100
value: 90.617
- type: mrr_at_1000
value: 90.617
- type: mrr_at_3
value: 90.132
- type: mrr_at_5
value: 90.447
- type: ndcg_at_1
value: 84.353
- type: ndcg_at_10
value: 89.003
- type: ndcg_at_100
value: 89.60000000000001
- type: ndcg_at_1000
value: 89.836
- type: ndcg_at_3
value: 87.81400000000001
- type: ndcg_at_5
value: 88.478
- type: precision_at_1
value: 84.353
- type: precision_at_10
value: 10.482
- type: precision_at_100
value: 1.099
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 33.257999999999996
- type: precision_at_5
value: 20.465
- type: recall_at_1
value: 78.036
- type: recall_at_10
value: 94.517
- type: recall_at_100
value: 96.828
- type: recall_at_1000
value: 98.261
- type: recall_at_3
value: 91.12
- type: recall_at_5
value: 92.946
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.191
- type: map_at_10
value: 32.369
- type: map_at_100
value: 34.123999999999995
- type: map_at_1000
value: 34.317
- type: map_at_3
value: 28.71
- type: map_at_5
value: 30.607
- type: mrr_at_1
value: 40.894999999999996
- type: mrr_at_10
value: 48.842
- type: mrr_at_100
value: 49.599
- type: mrr_at_1000
value: 49.647000000000006
- type: mrr_at_3
value: 46.785
- type: mrr_at_5
value: 47.672
- type: ndcg_at_1
value: 40.894999999999996
- type: ndcg_at_10
value: 39.872
- type: ndcg_at_100
value: 46.126
- type: ndcg_at_1000
value: 49.476
- type: ndcg_at_3
value: 37.153000000000006
- type: ndcg_at_5
value: 37.433
- type: precision_at_1
value: 40.894999999999996
- type: precision_at_10
value: 10.818
- type: precision_at_100
value: 1.73
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 25.051000000000002
- type: precision_at_5
value: 17.531
- type: recall_at_1
value: 20.191
- type: recall_at_10
value: 45.768
- type: recall_at_100
value: 68.82000000000001
- type: recall_at_1000
value: 89.133
- type: recall_at_3
value: 33.296
- type: recall_at_5
value: 38.022
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.257
- type: map_at_10
value: 61.467000000000006
- type: map_at_100
value: 62.364
- type: map_at_1000
value: 62.424
- type: map_at_3
value: 58.228
- type: map_at_5
value: 60.283
- type: mrr_at_1
value: 78.515
- type: mrr_at_10
value: 84.191
- type: mrr_at_100
value: 84.378
- type: mrr_at_1000
value: 84.385
- type: mrr_at_3
value: 83.284
- type: mrr_at_5
value: 83.856
- type: ndcg_at_1
value: 78.515
- type: ndcg_at_10
value: 69.78999999999999
- type: ndcg_at_100
value: 72.886
- type: ndcg_at_1000
value: 74.015
- type: ndcg_at_3
value: 65.23
- type: ndcg_at_5
value: 67.80199999999999
- type: precision_at_1
value: 78.515
- type: precision_at_10
value: 14.519000000000002
- type: precision_at_100
value: 1.694
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 41.702
- type: precision_at_5
value: 27.046999999999997
- type: recall_at_1
value: 39.257
- type: recall_at_10
value: 72.59299999999999
- type: recall_at_100
value: 84.679
- type: recall_at_1000
value: 92.12
- type: recall_at_3
value: 62.552
- type: recall_at_5
value: 67.616
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 91.5152
- type: ap
value: 87.64584669595709
- type: f1
value: 91.50605576428437
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.926000000000002
- type: map_at_10
value: 34.049
- type: map_at_100
value: 35.213
- type: map_at_1000
value: 35.265
- type: map_at_3
value: 30.309
- type: map_at_5
value: 32.407000000000004
- type: mrr_at_1
value: 22.55
- type: mrr_at_10
value: 34.657
- type: mrr_at_100
value: 35.760999999999996
- type: mrr_at_1000
value: 35.807
- type: mrr_at_3
value: 30.989
- type: mrr_at_5
value: 33.039
- type: ndcg_at_1
value: 22.55
- type: ndcg_at_10
value: 40.842
- type: ndcg_at_100
value: 46.436
- type: ndcg_at_1000
value: 47.721999999999994
- type: ndcg_at_3
value: 33.209
- type: ndcg_at_5
value: 36.943
- type: precision_at_1
value: 22.55
- type: precision_at_10
value: 6.447
- type: precision_at_100
value: 0.9249999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.136000000000001
- type: precision_at_5
value: 10.381
- type: recall_at_1
value: 21.926000000000002
- type: recall_at_10
value: 61.724999999999994
- type: recall_at_100
value: 87.604
- type: recall_at_1000
value: 97.421
- type: recall_at_3
value: 40.944
- type: recall_at_5
value: 49.915
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.54765161878704
- type: f1
value: 93.3298945415573
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.71591427268582
- type: f1
value: 59.32113870474471
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.83053127101547
- type: f1
value: 73.60757944876475
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.72562205783457
- type: f1
value: 78.63761662505502
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.37935633767996
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.55270546130387
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.462692753143834
- type: mrr
value: 31.497569753511563
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.646
- type: map_at_10
value: 12.498
- type: map_at_100
value: 15.486
- type: map_at_1000
value: 16.805999999999997
- type: map_at_3
value: 9.325
- type: map_at_5
value: 10.751
- type: mrr_at_1
value: 43.034
- type: mrr_at_10
value: 52.662
- type: mrr_at_100
value: 53.189
- type: mrr_at_1000
value: 53.25
- type: mrr_at_3
value: 50.929
- type: mrr_at_5
value: 51.92
- type: ndcg_at_1
value: 41.796
- type: ndcg_at_10
value: 33.477000000000004
- type: ndcg_at_100
value: 29.996000000000002
- type: ndcg_at_1000
value: 38.864
- type: ndcg_at_3
value: 38.940000000000005
- type: ndcg_at_5
value: 36.689
- type: precision_at_1
value: 43.034
- type: precision_at_10
value: 24.799
- type: precision_at_100
value: 7.432999999999999
- type: precision_at_1000
value: 1.9929999999999999
- type: precision_at_3
value: 36.842000000000006
- type: precision_at_5
value: 32.135999999999996
- type: recall_at_1
value: 5.646
- type: recall_at_10
value: 15.963
- type: recall_at_100
value: 29.492
- type: recall_at_1000
value: 61.711000000000006
- type: recall_at_3
value: 10.585
- type: recall_at_5
value: 12.753999999999998
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.602
- type: map_at_10
value: 41.545
- type: map_at_100
value: 42.644999999999996
- type: map_at_1000
value: 42.685
- type: map_at_3
value: 37.261
- type: map_at_5
value: 39.706
- type: mrr_at_1
value: 31.141000000000002
- type: mrr_at_10
value: 44.139
- type: mrr_at_100
value: 44.997
- type: mrr_at_1000
value: 45.025999999999996
- type: mrr_at_3
value: 40.503
- type: mrr_at_5
value: 42.64
- type: ndcg_at_1
value: 31.141000000000002
- type: ndcg_at_10
value: 48.995
- type: ndcg_at_100
value: 53.788000000000004
- type: ndcg_at_1000
value: 54.730000000000004
- type: ndcg_at_3
value: 40.844
- type: ndcg_at_5
value: 44.955
- type: precision_at_1
value: 31.141000000000002
- type: precision_at_10
value: 8.233
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 18.579
- type: precision_at_5
value: 13.533999999999999
- type: recall_at_1
value: 27.602
- type: recall_at_10
value: 69.216
- type: recall_at_100
value: 90.252
- type: recall_at_1000
value: 97.27
- type: recall_at_3
value: 47.987
- type: recall_at_5
value: 57.438
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.949
- type: map_at_10
value: 84.89999999999999
- type: map_at_100
value: 85.531
- type: map_at_1000
value: 85.548
- type: map_at_3
value: 82.027
- type: map_at_5
value: 83.853
- type: mrr_at_1
value: 81.69999999999999
- type: mrr_at_10
value: 87.813
- type: mrr_at_100
value: 87.917
- type: mrr_at_1000
value: 87.91799999999999
- type: mrr_at_3
value: 86.938
- type: mrr_at_5
value: 87.53999999999999
- type: ndcg_at_1
value: 81.75
- type: ndcg_at_10
value: 88.55499999999999
- type: ndcg_at_100
value: 89.765
- type: ndcg_at_1000
value: 89.871
- type: ndcg_at_3
value: 85.905
- type: ndcg_at_5
value: 87.41
- type: precision_at_1
value: 81.75
- type: precision_at_10
value: 13.403
- type: precision_at_100
value: 1.528
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.597
- type: precision_at_5
value: 24.69
- type: recall_at_1
value: 70.949
- type: recall_at_10
value: 95.423
- type: recall_at_100
value: 99.509
- type: recall_at_1000
value: 99.982
- type: recall_at_3
value: 87.717
- type: recall_at_5
value: 92.032
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 51.76962893449579
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.32897690686379
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.478
- type: map_at_10
value: 11.994
- type: map_at_100
value: 13.977
- type: map_at_1000
value: 14.295
- type: map_at_3
value: 8.408999999999999
- type: map_at_5
value: 10.024
- type: mrr_at_1
value: 22.1
- type: mrr_at_10
value: 33.526
- type: mrr_at_100
value: 34.577000000000005
- type: mrr_at_1000
value: 34.632000000000005
- type: mrr_at_3
value: 30.217
- type: mrr_at_5
value: 31.962000000000003
- type: ndcg_at_1
value: 22.1
- type: ndcg_at_10
value: 20.191
- type: ndcg_at_100
value: 27.954
- type: ndcg_at_1000
value: 33.491
- type: ndcg_at_3
value: 18.787000000000003
- type: ndcg_at_5
value: 16.378999999999998
- type: precision_at_1
value: 22.1
- type: precision_at_10
value: 10.69
- type: precision_at_100
value: 2.1919999999999997
- type: precision_at_1000
value: 0.35200000000000004
- type: precision_at_3
value: 17.732999999999997
- type: precision_at_5
value: 14.499999999999998
- type: recall_at_1
value: 4.478
- type: recall_at_10
value: 21.657
- type: recall_at_100
value: 44.54
- type: recall_at_1000
value: 71.542
- type: recall_at_3
value: 10.778
- type: recall_at_5
value: 14.687
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.82325259156718
- type: cos_sim_spearman
value: 79.2463589100662
- type: euclidean_pearson
value: 80.48318380496771
- type: euclidean_spearman
value: 79.34451935199979
- type: manhattan_pearson
value: 80.39041824178759
- type: manhattan_spearman
value: 79.23002892700211
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.74130231431258
- type: cos_sim_spearman
value: 78.36856568042397
- type: euclidean_pearson
value: 82.48301631890303
- type: euclidean_spearman
value: 78.28376980722732
- type: manhattan_pearson
value: 82.43552075450525
- type: manhattan_spearman
value: 78.22702443947126
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 79.96138619461459
- type: cos_sim_spearman
value: 81.85436343502379
- type: euclidean_pearson
value: 81.82895226665367
- type: euclidean_spearman
value: 82.22707349602916
- type: manhattan_pearson
value: 81.66303369445873
- type: manhattan_spearman
value: 82.05030197179455
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 80.05481244198648
- type: cos_sim_spearman
value: 80.85052504637808
- type: euclidean_pearson
value: 80.86728419744497
- type: euclidean_spearman
value: 81.033786401512
- type: manhattan_pearson
value: 80.90107531061103
- type: manhattan_spearman
value: 81.11374116827795
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 84.615220756399
- type: cos_sim_spearman
value: 86.46858500002092
- type: euclidean_pearson
value: 86.08307800247586
- type: euclidean_spearman
value: 86.72691443870013
- type: manhattan_pearson
value: 85.96155594487269
- type: manhattan_spearman
value: 86.605909505275
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.14363913634436
- type: cos_sim_spearman
value: 84.48430226487102
- type: euclidean_pearson
value: 83.75303424801902
- type: euclidean_spearman
value: 84.56762380734538
- type: manhattan_pearson
value: 83.6135447165928
- type: manhattan_spearman
value: 84.39898212616731
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 85.09909252554525
- type: cos_sim_spearman
value: 85.70951402743276
- type: euclidean_pearson
value: 87.1991936239908
- type: euclidean_spearman
value: 86.07745840612071
- type: manhattan_pearson
value: 87.25039137549952
- type: manhattan_spearman
value: 85.99938746659761
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.529332093413615
- type: cos_sim_spearman
value: 65.38177340147439
- type: euclidean_pearson
value: 66.35278011412136
- type: euclidean_spearman
value: 65.47147267032997
- type: manhattan_pearson
value: 66.71804682408693
- type: manhattan_spearman
value: 65.67406521423597
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 82.45802942885662
- type: cos_sim_spearman
value: 84.8853341842566
- type: euclidean_pearson
value: 84.60915021096707
- type: euclidean_spearman
value: 85.11181242913666
- type: manhattan_pearson
value: 84.38600521210364
- type: manhattan_spearman
value: 84.89045417981723
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.92793380635129
- type: mrr
value: 95.85834191226348
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.74400000000001
- type: map_at_10
value: 65.455
- type: map_at_100
value: 66.106
- type: map_at_1000
value: 66.129
- type: map_at_3
value: 62.719
- type: map_at_5
value: 64.441
- type: mrr_at_1
value: 58.667
- type: mrr_at_10
value: 66.776
- type: mrr_at_100
value: 67.363
- type: mrr_at_1000
value: 67.384
- type: mrr_at_3
value: 64.889
- type: mrr_at_5
value: 66.122
- type: ndcg_at_1
value: 58.667
- type: ndcg_at_10
value: 69.904
- type: ndcg_at_100
value: 72.807
- type: ndcg_at_1000
value: 73.423
- type: ndcg_at_3
value: 65.405
- type: ndcg_at_5
value: 67.86999999999999
- type: precision_at_1
value: 58.667
- type: precision_at_10
value: 9.3
- type: precision_at_100
value: 1.08
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 17
- type: recall_at_1
value: 55.74400000000001
- type: recall_at_10
value: 82.122
- type: recall_at_100
value: 95.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 70.14399999999999
- type: recall_at_5
value: 76.417
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86534653465347
- type: cos_sim_ap
value: 96.54142419791388
- type: cos_sim_f1
value: 93.07535641547861
- type: cos_sim_precision
value: 94.81327800829875
- type: cos_sim_recall
value: 91.4
- type: dot_accuracy
value: 99.86435643564356
- type: dot_ap
value: 96.53682260449868
- type: dot_f1
value: 92.98515104966718
- type: dot_precision
value: 95.27806925498426
- type: dot_recall
value: 90.8
- type: euclidean_accuracy
value: 99.86336633663366
- type: euclidean_ap
value: 96.5228676185697
- type: euclidean_f1
value: 92.9735234215886
- type: euclidean_precision
value: 94.70954356846472
- type: euclidean_recall
value: 91.3
- type: manhattan_accuracy
value: 99.85841584158416
- type: manhattan_ap
value: 96.50392760934032
- type: manhattan_f1
value: 92.84642321160581
- type: manhattan_precision
value: 92.8928928928929
- type: manhattan_recall
value: 92.80000000000001
- type: max_accuracy
value: 99.86534653465347
- type: max_ap
value: 96.54142419791388
- type: max_f1
value: 93.07535641547861
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 61.08285408766616
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.640675309010604
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.20333913710715
- type: mrr
value: 54.088813555725324
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.79465221925075
- type: cos_sim_spearman
value: 30.530816059163634
- type: dot_pearson
value: 31.364837244718043
- type: dot_spearman
value: 30.79726823684003
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22599999999999998
- type: map_at_10
value: 1.735
- type: map_at_100
value: 8.978
- type: map_at_1000
value: 20.851
- type: map_at_3
value: 0.613
- type: map_at_5
value: 0.964
- type: mrr_at_1
value: 88
- type: mrr_at_10
value: 92.867
- type: mrr_at_100
value: 92.867
- type: mrr_at_1000
value: 92.867
- type: mrr_at_3
value: 92.667
- type: mrr_at_5
value: 92.667
- type: ndcg_at_1
value: 82
- type: ndcg_at_10
value: 73.164
- type: ndcg_at_100
value: 51.878
- type: ndcg_at_1000
value: 44.864
- type: ndcg_at_3
value: 79.184
- type: ndcg_at_5
value: 76.39
- type: precision_at_1
value: 88
- type: precision_at_10
value: 76.2
- type: precision_at_100
value: 52.459999999999994
- type: precision_at_1000
value: 19.692
- type: precision_at_3
value: 82.667
- type: precision_at_5
value: 80
- type: recall_at_1
value: 0.22599999999999998
- type: recall_at_10
value: 1.942
- type: recall_at_100
value: 12.342
- type: recall_at_1000
value: 41.42
- type: recall_at_3
value: 0.637
- type: recall_at_5
value: 1.034
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.567
- type: map_at_10
value: 13.116
- type: map_at_100
value: 19.39
- type: map_at_1000
value: 20.988
- type: map_at_3
value: 7.109
- type: map_at_5
value: 9.950000000000001
- type: mrr_at_1
value: 42.857
- type: mrr_at_10
value: 57.404999999999994
- type: mrr_at_100
value: 58.021
- type: mrr_at_1000
value: 58.021
- type: mrr_at_3
value: 54.762
- type: mrr_at_5
value: 56.19
- type: ndcg_at_1
value: 38.775999999999996
- type: ndcg_at_10
value: 30.359
- type: ndcg_at_100
value: 41.284
- type: ndcg_at_1000
value: 52.30200000000001
- type: ndcg_at_3
value: 36.744
- type: ndcg_at_5
value: 34.326
- type: precision_at_1
value: 42.857
- type: precision_at_10
value: 26.122
- type: precision_at_100
value: 8.082
- type: precision_at_1000
value: 1.559
- type: precision_at_3
value: 40.136
- type: precision_at_5
value: 35.510000000000005
- type: recall_at_1
value: 3.567
- type: recall_at_10
value: 19.045
- type: recall_at_100
value: 49.979
- type: recall_at_1000
value: 84.206
- type: recall_at_3
value: 8.52
- type: recall_at_5
value: 13.103000000000002
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 68.8394
- type: ap
value: 13.454399712443099
- type: f1
value: 53.04963076364322
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.546123372948514
- type: f1
value: 60.86952793277713
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.10042955060234
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.03308100375514
- type: cos_sim_ap
value: 71.08284605869684
- type: cos_sim_f1
value: 65.42539436255494
- type: cos_sim_precision
value: 64.14807302231237
- type: cos_sim_recall
value: 66.75461741424802
- type: dot_accuracy
value: 84.68736961316088
- type: dot_ap
value: 69.20524036530992
- type: dot_f1
value: 63.54893953365829
- type: dot_precision
value: 63.45698500394633
- type: dot_recall
value: 63.641160949868066
- type: euclidean_accuracy
value: 85.07480479227513
- type: euclidean_ap
value: 71.14592761009864
- type: euclidean_f1
value: 65.43814432989691
- type: euclidean_precision
value: 63.95465994962216
- type: euclidean_recall
value: 66.99208443271768
- type: manhattan_accuracy
value: 85.06288370984085
- type: manhattan_ap
value: 71.07289742593868
- type: manhattan_f1
value: 65.37585421412301
- type: manhattan_precision
value: 62.816147859922175
- type: manhattan_recall
value: 68.15303430079156
- type: max_accuracy
value: 85.07480479227513
- type: max_ap
value: 71.14592761009864
- type: max_f1
value: 65.43814432989691
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.79058485659952
- type: cos_sim_ap
value: 83.7183187008759
- type: cos_sim_f1
value: 75.86921142180798
- type: cos_sim_precision
value: 73.00683371298405
- type: cos_sim_recall
value: 78.96519864490298
- type: dot_accuracy
value: 87.0085768618776
- type: dot_ap
value: 81.87467488474279
- type: dot_f1
value: 74.04188363990559
- type: dot_precision
value: 72.10507114191901
- type: dot_recall
value: 76.08561749307053
- type: euclidean_accuracy
value: 87.8332751193387
- type: euclidean_ap
value: 83.83585648120315
- type: euclidean_f1
value: 76.02582177042369
- type: euclidean_precision
value: 73.36388371759989
- type: euclidean_recall
value: 78.88820449645827
- type: manhattan_accuracy
value: 87.87208444910156
- type: manhattan_ap
value: 83.8101950642973
- type: manhattan_f1
value: 75.90454195535027
- type: manhattan_precision
value: 72.44419564761039
- type: manhattan_recall
value: 79.71204188481676
- type: max_accuracy
value: 87.87208444910156
- type: max_ap
value: 83.83585648120315
- type: max_f1
value: 76.02582177042369
license: mit
language:
- en
---
**Recommend switching to newest [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5), which has more reasonable similarity distribution and same method of usage.**
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focus on retrieval-augmented LLMs, consisting of following projects currently:
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding), [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## News
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [LM-Cocktail](https://huggingface.co/Shitao) | English | | fine-tuned models (Llama and BGE) which can be used to reproduce the results of LM-Cocktail | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
Systran/faster-whisper-large-v3 | Systran | "2023-11-23T09:41:12Z" | 679,106 | 246 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"yue",
"license:mit",
"region:us"
] | automatic-speech-recognition | "2023-11-23T09:34:20Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
- yue
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper large-v3 model for CTranslate2
This repository contains the conversion of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("large-v3")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-large-v3 --output_dir faster-whisper-large-v3 \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-large-v3).**
|
j-hartmann/emotion-english-distilroberta-base | j-hartmann | "2023-01-02T13:03:10Z" | 678,872 | 341 | transformers | [
"transformers",
"pytorch",
"tf",
"roberta",
"text-classification",
"distilroberta",
"sentiment",
"emotion",
"twitter",
"reddit",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: "en"
tags:
- distilroberta
- sentiment
- emotion
- twitter
- reddit
widget:
- text: "Oh wow. I didn't know that."
- text: "This movie always makes me cry.."
- text: "Oh Happy Day"
---
# Emotion English DistilRoBERTa-base
# Description ℹ
With this model, you can classify emotions in English text data. The model was trained on 6 diverse datasets (see Appendix below) and predicts Ekman's 6 basic emotions, plus a neutral class:
1) anger 🤬
2) disgust 🤢
3) fear 😨
4) joy 😀
5) neutral 😐
6) sadness 😭
7) surprise 😲
The model is a fine-tuned checkpoint of [DistilRoBERTa-base](https://huggingface.co/distilroberta-base). For a 'non-distilled' emotion model, please refer to the model card of the [RoBERTa-large](https://huggingface.co/j-hartmann/emotion-english-roberta-large) version.
# Application 🚀
a) Run emotion model with 3 lines of code on single text example using Hugging Face's pipeline command on Google Colab:
[](https://colab.research.google.com/github/j-hartmann/emotion-english-distilroberta-base/blob/main/simple_emotion_pipeline.ipynb)
```python
from transformers import pipeline
classifier = pipeline("text-classification", model="j-hartmann/emotion-english-distilroberta-base", return_all_scores=True)
classifier("I love this!")
```
```python
Output:
[[{'label': 'anger', 'score': 0.004419783595949411},
{'label': 'disgust', 'score': 0.0016119900392368436},
{'label': 'fear', 'score': 0.0004138521908316761},
{'label': 'joy', 'score': 0.9771687984466553},
{'label': 'neutral', 'score': 0.005764586851000786},
{'label': 'sadness', 'score': 0.002092392183840275},
{'label': 'surprise', 'score': 0.008528684265911579}]]
```
b) Run emotion model on multiple examples and full datasets (e.g., .csv files) on Google Colab:
[](https://colab.research.google.com/github/j-hartmann/emotion-english-distilroberta-base/blob/main/emotion_prediction_example.ipynb)
# Contact 💻
Please reach out to [[email protected]](mailto:[email protected]) if you have any questions or feedback.
Thanks to Samuel Domdey and [chrsiebert](https://huggingface.co/siebert) for their support in making this model available.
# Reference ✅
For attribution, please cite the following reference if you use this model. A working paper will be available soon.
```
Jochen Hartmann, "Emotion English DistilRoBERTa-base". https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/, 2022.
```
BibTex citation:
```
@misc{hartmann2022emotionenglish,
author={Hartmann, Jochen},
title={Emotion English DistilRoBERTa-base},
year={2022},
howpublished = {\url{https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/}},
}
```
# Appendix 📚
Please find an overview of the datasets used for training below. All datasets contain English text. The table summarizes which emotions are available in each of the datasets. The datasets represent a diverse collection of text types. Specifically, they contain emotion labels for texts from Twitter, Reddit, student self-reports, and utterances from TV dialogues. As MELD (Multimodal EmotionLines Dataset) extends the popular EmotionLines dataset, EmotionLines itself is not included here.
|Name|anger|disgust|fear|joy|neutral|sadness|surprise|
|---|---|---|---|---|---|---|---|
|Crowdflower (2016)|Yes|-|-|Yes|Yes|Yes|Yes|
|Emotion Dataset, Elvis et al. (2018)|Yes|-|Yes|Yes|-|Yes|Yes|
|GoEmotions, Demszky et al. (2020)|Yes|Yes|Yes|Yes|Yes|Yes|Yes|
|ISEAR, Vikash (2018)|Yes|Yes|Yes|Yes|-|Yes|-|
|MELD, Poria et al. (2019)|Yes|Yes|Yes|Yes|Yes|Yes|Yes|
|SemEval-2018, EI-reg, Mohammad et al. (2018) |Yes|-|Yes|Yes|-|Yes|-|
The model is trained on a balanced subset from the datasets listed above (2,811 observations per emotion, i.e., nearly 20k observations in total). 80% of this balanced subset is used for training and 20% for evaluation. The evaluation accuracy is 66% (vs. the random-chance baseline of 1/7 = 14%).
# Scientific Applications 📖
Below you can find a list of papers using "Emotion English DistilRoBERTa-base". If you would like your paper to be added to the list, please send me an email.
- Butt, S., Sharma, S., Sharma, R., Sidorov, G., & Gelbukh, A. (2022). What goes on inside rumour and non-rumour tweets and their reactions: A Psycholinguistic Analyses. Computers in Human Behavior, 107345.
- Kuang, Z., Zong, S., Zhang, J., Chen, J., & Liu, H. (2022). Music-to-Text Synaesthesia: Generating Descriptive Text from Music Recordings. arXiv preprint arXiv:2210.00434.
- Rozado, D., Hughes, R., & Halberstadt, J. (2022). Longitudinal analysis of sentiment and emotion in news media headlines using automated labelling with Transformer language models. Plos one, 17(10), e0276367. |
thenlper/gte-small | thenlper | "2024-03-10T02:53:56Z" | 678,536 | 125 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"coreml",
"safetensors",
"bert",
"mteb",
"sentence-similarity",
"Sentence Transformers",
"en",
"arxiv:2308.03281",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-07-27T10:14:55Z" | ---
tags:
- mteb
- sentence-similarity
- sentence-transformers
- Sentence Transformers
model-index:
- name: gte-small
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.22388059701493
- type: ap
value: 36.09895941426988
- type: f1
value: 67.3205651539195
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.81894999999999
- type: ap
value: 88.5240138417305
- type: f1
value: 91.80367382706962
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.032
- type: f1
value: 47.4490665674719
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.725
- type: map_at_10
value: 46.604
- type: map_at_100
value: 47.535
- type: map_at_1000
value: 47.538000000000004
- type: map_at_3
value: 41.833
- type: map_at_5
value: 44.61
- type: mrr_at_1
value: 31.223
- type: mrr_at_10
value: 46.794000000000004
- type: mrr_at_100
value: 47.725
- type: mrr_at_1000
value: 47.727000000000004
- type: mrr_at_3
value: 42.07
- type: mrr_at_5
value: 44.812000000000005
- type: ndcg_at_1
value: 30.725
- type: ndcg_at_10
value: 55.440999999999995
- type: ndcg_at_100
value: 59.134
- type: ndcg_at_1000
value: 59.199
- type: ndcg_at_3
value: 45.599000000000004
- type: ndcg_at_5
value: 50.637
- type: precision_at_1
value: 30.725
- type: precision_at_10
value: 8.364
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.848000000000003
- type: precision_at_5
value: 13.77
- type: recall_at_1
value: 30.725
- type: recall_at_10
value: 83.64200000000001
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 56.543
- type: recall_at_5
value: 68.848
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.90178078197678
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.25728393431922
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.720297062897764
- type: mrr
value: 75.24139295607439
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.43527309184616
- type: cos_sim_spearman
value: 88.17128615100206
- type: euclidean_pearson
value: 87.89922623089282
- type: euclidean_spearman
value: 87.96104039655451
- type: manhattan_pearson
value: 87.9818290932077
- type: manhattan_spearman
value: 88.00923426576885
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.0844155844156
- type: f1
value: 84.01485017302213
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.36574769259432
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.4857033165287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.261
- type: map_at_10
value: 42.419000000000004
- type: map_at_100
value: 43.927
- type: map_at_1000
value: 44.055
- type: map_at_3
value: 38.597
- type: map_at_5
value: 40.701
- type: mrr_at_1
value: 36.91
- type: mrr_at_10
value: 48.02
- type: mrr_at_100
value: 48.658
- type: mrr_at_1000
value: 48.708
- type: mrr_at_3
value: 44.945
- type: mrr_at_5
value: 46.705000000000005
- type: ndcg_at_1
value: 36.91
- type: ndcg_at_10
value: 49.353
- type: ndcg_at_100
value: 54.456
- type: ndcg_at_1000
value: 56.363
- type: ndcg_at_3
value: 43.483
- type: ndcg_at_5
value: 46.150999999999996
- type: precision_at_1
value: 36.91
- type: precision_at_10
value: 9.700000000000001
- type: precision_at_100
value: 1.557
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.078
- type: precision_at_5
value: 15.421999999999999
- type: recall_at_1
value: 30.261
- type: recall_at_10
value: 63.242
- type: recall_at_100
value: 84.09100000000001
- type: recall_at_1000
value: 96.143
- type: recall_at_3
value: 46.478
- type: recall_at_5
value: 53.708
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.145
- type: map_at_10
value: 40.996
- type: map_at_100
value: 42.266999999999996
- type: map_at_1000
value: 42.397
- type: map_at_3
value: 38.005
- type: map_at_5
value: 39.628
- type: mrr_at_1
value: 38.344
- type: mrr_at_10
value: 46.827000000000005
- type: mrr_at_100
value: 47.446
- type: mrr_at_1000
value: 47.489
- type: mrr_at_3
value: 44.448
- type: mrr_at_5
value: 45.747
- type: ndcg_at_1
value: 38.344
- type: ndcg_at_10
value: 46.733000000000004
- type: ndcg_at_100
value: 51.103
- type: ndcg_at_1000
value: 53.075
- type: ndcg_at_3
value: 42.366
- type: ndcg_at_5
value: 44.242
- type: precision_at_1
value: 38.344
- type: precision_at_10
value: 8.822000000000001
- type: precision_at_100
value: 1.417
- type: precision_at_1000
value: 0.187
- type: precision_at_3
value: 20.403
- type: precision_at_5
value: 14.306
- type: recall_at_1
value: 31.145
- type: recall_at_10
value: 56.909
- type: recall_at_100
value: 75.274
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 43.784
- type: recall_at_5
value: 49.338
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.83
- type: map_at_10
value: 51.553000000000004
- type: map_at_100
value: 52.581
- type: map_at_1000
value: 52.638
- type: map_at_3
value: 48.112
- type: map_at_5
value: 50.095
- type: mrr_at_1
value: 44.513999999999996
- type: mrr_at_10
value: 54.998000000000005
- type: mrr_at_100
value: 55.650999999999996
- type: mrr_at_1000
value: 55.679
- type: mrr_at_3
value: 52.602000000000004
- type: mrr_at_5
value: 53.931
- type: ndcg_at_1
value: 44.513999999999996
- type: ndcg_at_10
value: 57.67400000000001
- type: ndcg_at_100
value: 61.663999999999994
- type: ndcg_at_1000
value: 62.743
- type: ndcg_at_3
value: 51.964
- type: ndcg_at_5
value: 54.773
- type: precision_at_1
value: 44.513999999999996
- type: precision_at_10
value: 9.423
- type: precision_at_100
value: 1.2309999999999999
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.323
- type: precision_at_5
value: 16.163
- type: recall_at_1
value: 38.83
- type: recall_at_10
value: 72.327
- type: recall_at_100
value: 89.519
- type: recall_at_1000
value: 97.041
- type: recall_at_3
value: 57.206
- type: recall_at_5
value: 63.88399999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.484
- type: map_at_10
value: 34.527
- type: map_at_100
value: 35.661
- type: map_at_1000
value: 35.739
- type: map_at_3
value: 32.199
- type: map_at_5
value: 33.632
- type: mrr_at_1
value: 27.458
- type: mrr_at_10
value: 36.543
- type: mrr_at_100
value: 37.482
- type: mrr_at_1000
value: 37.543
- type: mrr_at_3
value: 34.256
- type: mrr_at_5
value: 35.618
- type: ndcg_at_1
value: 27.458
- type: ndcg_at_10
value: 39.396
- type: ndcg_at_100
value: 44.742
- type: ndcg_at_1000
value: 46.708
- type: ndcg_at_3
value: 34.817
- type: ndcg_at_5
value: 37.247
- type: precision_at_1
value: 27.458
- type: precision_at_10
value: 5.976999999999999
- type: precision_at_100
value: 0.907
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 14.878
- type: precision_at_5
value: 10.35
- type: recall_at_1
value: 25.484
- type: recall_at_10
value: 52.317
- type: recall_at_100
value: 76.701
- type: recall_at_1000
value: 91.408
- type: recall_at_3
value: 40.043
- type: recall_at_5
value: 45.879
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.719
- type: map_at_10
value: 25.269000000000002
- type: map_at_100
value: 26.442
- type: map_at_1000
value: 26.557
- type: map_at_3
value: 22.56
- type: map_at_5
value: 24.082
- type: mrr_at_1
value: 20.896
- type: mrr_at_10
value: 29.982999999999997
- type: mrr_at_100
value: 30.895
- type: mrr_at_1000
value: 30.961
- type: mrr_at_3
value: 27.239
- type: mrr_at_5
value: 28.787000000000003
- type: ndcg_at_1
value: 20.896
- type: ndcg_at_10
value: 30.814000000000004
- type: ndcg_at_100
value: 36.418
- type: ndcg_at_1000
value: 39.182
- type: ndcg_at_3
value: 25.807999999999996
- type: ndcg_at_5
value: 28.143
- type: precision_at_1
value: 20.896
- type: precision_at_10
value: 5.821
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.562000000000001
- type: precision_at_5
value: 9.254
- type: recall_at_1
value: 16.719
- type: recall_at_10
value: 43.155
- type: recall_at_100
value: 67.831
- type: recall_at_1000
value: 87.617
- type: recall_at_3
value: 29.259
- type: recall_at_5
value: 35.260999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.398999999999997
- type: map_at_10
value: 39.876
- type: map_at_100
value: 41.205999999999996
- type: map_at_1000
value: 41.321999999999996
- type: map_at_3
value: 36.588
- type: map_at_5
value: 38.538
- type: mrr_at_1
value: 35.9
- type: mrr_at_10
value: 45.528
- type: mrr_at_100
value: 46.343
- type: mrr_at_1000
value: 46.388
- type: mrr_at_3
value: 42.862
- type: mrr_at_5
value: 44.440000000000005
- type: ndcg_at_1
value: 35.9
- type: ndcg_at_10
value: 45.987
- type: ndcg_at_100
value: 51.370000000000005
- type: ndcg_at_1000
value: 53.400000000000006
- type: ndcg_at_3
value: 40.841
- type: ndcg_at_5
value: 43.447
- type: precision_at_1
value: 35.9
- type: precision_at_10
value: 8.393
- type: precision_at_100
value: 1.283
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 19.538
- type: precision_at_5
value: 13.975000000000001
- type: recall_at_1
value: 29.398999999999997
- type: recall_at_10
value: 58.361
- type: recall_at_100
value: 81.081
- type: recall_at_1000
value: 94.004
- type: recall_at_3
value: 43.657000000000004
- type: recall_at_5
value: 50.519999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.589
- type: map_at_10
value: 31.608999999999998
- type: map_at_100
value: 33.128
- type: map_at_1000
value: 33.247
- type: map_at_3
value: 28.671999999999997
- type: map_at_5
value: 30.233999999999998
- type: mrr_at_1
value: 26.712000000000003
- type: mrr_at_10
value: 36.713
- type: mrr_at_100
value: 37.713
- type: mrr_at_1000
value: 37.771
- type: mrr_at_3
value: 34.075
- type: mrr_at_5
value: 35.451
- type: ndcg_at_1
value: 26.712000000000003
- type: ndcg_at_10
value: 37.519999999999996
- type: ndcg_at_100
value: 43.946000000000005
- type: ndcg_at_1000
value: 46.297
- type: ndcg_at_3
value: 32.551
- type: ndcg_at_5
value: 34.660999999999994
- type: precision_at_1
value: 26.712000000000003
- type: precision_at_10
value: 7.066
- type: precision_at_100
value: 1.216
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 15.906
- type: precision_at_5
value: 11.437999999999999
- type: recall_at_1
value: 21.589
- type: recall_at_10
value: 50.090999999999994
- type: recall_at_100
value: 77.43900000000001
- type: recall_at_1000
value: 93.35900000000001
- type: recall_at_3
value: 36.028999999999996
- type: recall_at_5
value: 41.698
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.121666666666663
- type: map_at_10
value: 34.46258333333334
- type: map_at_100
value: 35.710499999999996
- type: map_at_1000
value: 35.82691666666666
- type: map_at_3
value: 31.563249999999996
- type: map_at_5
value: 33.189750000000004
- type: mrr_at_1
value: 29.66441666666667
- type: mrr_at_10
value: 38.5455
- type: mrr_at_100
value: 39.39566666666667
- type: mrr_at_1000
value: 39.45325
- type: mrr_at_3
value: 36.003333333333345
- type: mrr_at_5
value: 37.440916666666666
- type: ndcg_at_1
value: 29.66441666666667
- type: ndcg_at_10
value: 39.978416666666675
- type: ndcg_at_100
value: 45.278666666666666
- type: ndcg_at_1000
value: 47.52275
- type: ndcg_at_3
value: 35.00058333333334
- type: ndcg_at_5
value: 37.34908333333333
- type: precision_at_1
value: 29.66441666666667
- type: precision_at_10
value: 7.094500000000001
- type: precision_at_100
value: 1.1523333333333332
- type: precision_at_1000
value: 0.15358333333333332
- type: precision_at_3
value: 16.184166666666663
- type: precision_at_5
value: 11.6005
- type: recall_at_1
value: 25.121666666666663
- type: recall_at_10
value: 52.23975000000001
- type: recall_at_100
value: 75.48408333333333
- type: recall_at_1000
value: 90.95316666666668
- type: recall_at_3
value: 38.38458333333333
- type: recall_at_5
value: 44.39933333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.569000000000003
- type: map_at_10
value: 30.389
- type: map_at_100
value: 31.396
- type: map_at_1000
value: 31.493
- type: map_at_3
value: 28.276
- type: map_at_5
value: 29.459000000000003
- type: mrr_at_1
value: 26.534000000000002
- type: mrr_at_10
value: 33.217999999999996
- type: mrr_at_100
value: 34.054
- type: mrr_at_1000
value: 34.12
- type: mrr_at_3
value: 31.058000000000003
- type: mrr_at_5
value: 32.330999999999996
- type: ndcg_at_1
value: 26.534000000000002
- type: ndcg_at_10
value: 34.608
- type: ndcg_at_100
value: 39.391999999999996
- type: ndcg_at_1000
value: 41.837999999999994
- type: ndcg_at_3
value: 30.564999999999998
- type: ndcg_at_5
value: 32.509
- type: precision_at_1
value: 26.534000000000002
- type: precision_at_10
value: 5.414
- type: precision_at_100
value: 0.847
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.202
- type: recall_at_1
value: 23.569000000000003
- type: recall_at_10
value: 44.896
- type: recall_at_100
value: 66.476
- type: recall_at_1000
value: 84.548
- type: recall_at_3
value: 33.79
- type: recall_at_5
value: 38.512
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.36
- type: map_at_10
value: 23.57
- type: map_at_100
value: 24.698999999999998
- type: map_at_1000
value: 24.834999999999997
- type: map_at_3
value: 21.093
- type: map_at_5
value: 22.418
- type: mrr_at_1
value: 19.718
- type: mrr_at_10
value: 27.139999999999997
- type: mrr_at_100
value: 28.097
- type: mrr_at_1000
value: 28.177999999999997
- type: mrr_at_3
value: 24.805
- type: mrr_at_5
value: 26.121
- type: ndcg_at_1
value: 19.718
- type: ndcg_at_10
value: 28.238999999999997
- type: ndcg_at_100
value: 33.663
- type: ndcg_at_1000
value: 36.763
- type: ndcg_at_3
value: 23.747
- type: ndcg_at_5
value: 25.796000000000003
- type: precision_at_1
value: 19.718
- type: precision_at_10
value: 5.282
- type: precision_at_100
value: 0.9390000000000001
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 11.264000000000001
- type: precision_at_5
value: 8.341
- type: recall_at_1
value: 16.36
- type: recall_at_10
value: 38.669
- type: recall_at_100
value: 63.184
- type: recall_at_1000
value: 85.33800000000001
- type: recall_at_3
value: 26.214
- type: recall_at_5
value: 31.423000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.618999999999996
- type: map_at_10
value: 34.361999999999995
- type: map_at_100
value: 35.534
- type: map_at_1000
value: 35.634
- type: map_at_3
value: 31.402
- type: map_at_5
value: 32.815
- type: mrr_at_1
value: 30.037000000000003
- type: mrr_at_10
value: 38.284
- type: mrr_at_100
value: 39.141999999999996
- type: mrr_at_1000
value: 39.2
- type: mrr_at_3
value: 35.603
- type: mrr_at_5
value: 36.867
- type: ndcg_at_1
value: 30.037000000000003
- type: ndcg_at_10
value: 39.87
- type: ndcg_at_100
value: 45.243
- type: ndcg_at_1000
value: 47.507
- type: ndcg_at_3
value: 34.371
- type: ndcg_at_5
value: 36.521
- type: precision_at_1
value: 30.037000000000003
- type: precision_at_10
value: 6.819
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.392
- type: precision_at_5
value: 10.821
- type: recall_at_1
value: 25.618999999999996
- type: recall_at_10
value: 52.869
- type: recall_at_100
value: 76.395
- type: recall_at_1000
value: 92.19500000000001
- type: recall_at_3
value: 37.943
- type: recall_at_5
value: 43.342999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.283
- type: map_at_10
value: 32.155
- type: map_at_100
value: 33.724
- type: map_at_1000
value: 33.939
- type: map_at_3
value: 29.018
- type: map_at_5
value: 30.864000000000004
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.632
- type: mrr_at_100
value: 37.606
- type: mrr_at_1000
value: 37.671
- type: mrr_at_3
value: 33.992
- type: mrr_at_5
value: 35.613
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 38.024
- type: ndcg_at_100
value: 44.292
- type: ndcg_at_1000
value: 46.818
- type: ndcg_at_3
value: 32.965
- type: ndcg_at_5
value: 35.562
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.352
- type: precision_at_100
value: 1.514
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 15.481
- type: precision_at_5
value: 11.542
- type: recall_at_1
value: 23.283
- type: recall_at_10
value: 49.756
- type: recall_at_100
value: 78.05
- type: recall_at_1000
value: 93.854
- type: recall_at_3
value: 35.408
- type: recall_at_5
value: 42.187000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.201999999999998
- type: map_at_10
value: 26.826
- type: map_at_100
value: 27.961000000000002
- type: map_at_1000
value: 28.066999999999997
- type: map_at_3
value: 24.237000000000002
- type: map_at_5
value: 25.811
- type: mrr_at_1
value: 20.887
- type: mrr_at_10
value: 28.660000000000004
- type: mrr_at_100
value: 29.660999999999998
- type: mrr_at_1000
value: 29.731
- type: mrr_at_3
value: 26.155
- type: mrr_at_5
value: 27.68
- type: ndcg_at_1
value: 20.887
- type: ndcg_at_10
value: 31.523
- type: ndcg_at_100
value: 37.055
- type: ndcg_at_1000
value: 39.579
- type: ndcg_at_3
value: 26.529000000000003
- type: ndcg_at_5
value: 29.137
- type: precision_at_1
value: 20.887
- type: precision_at_10
value: 5.065
- type: precision_at_100
value: 0.856
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 11.399
- type: precision_at_5
value: 8.392
- type: recall_at_1
value: 19.201999999999998
- type: recall_at_10
value: 44.285000000000004
- type: recall_at_100
value: 69.768
- type: recall_at_1000
value: 88.302
- type: recall_at_3
value: 30.804
- type: recall_at_5
value: 37.039
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.244
- type: map_at_10
value: 18.956
- type: map_at_100
value: 20.674
- type: map_at_1000
value: 20.863
- type: map_at_3
value: 15.923000000000002
- type: map_at_5
value: 17.518
- type: mrr_at_1
value: 25.080999999999996
- type: mrr_at_10
value: 35.94
- type: mrr_at_100
value: 36.969
- type: mrr_at_1000
value: 37.013
- type: mrr_at_3
value: 32.617000000000004
- type: mrr_at_5
value: 34.682
- type: ndcg_at_1
value: 25.080999999999996
- type: ndcg_at_10
value: 26.539
- type: ndcg_at_100
value: 33.601
- type: ndcg_at_1000
value: 37.203
- type: ndcg_at_3
value: 21.695999999999998
- type: ndcg_at_5
value: 23.567
- type: precision_at_1
value: 25.080999999999996
- type: precision_at_10
value: 8.143
- type: precision_at_100
value: 1.5650000000000002
- type: precision_at_1000
value: 0.22300000000000003
- type: precision_at_3
value: 15.983
- type: precision_at_5
value: 12.417
- type: recall_at_1
value: 11.244
- type: recall_at_10
value: 31.457
- type: recall_at_100
value: 55.92
- type: recall_at_1000
value: 76.372
- type: recall_at_3
value: 19.784
- type: recall_at_5
value: 24.857000000000003
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.595
- type: map_at_10
value: 18.75
- type: map_at_100
value: 26.354
- type: map_at_1000
value: 27.912
- type: map_at_3
value: 13.794
- type: map_at_5
value: 16.021
- type: mrr_at_1
value: 65.75
- type: mrr_at_10
value: 73.837
- type: mrr_at_100
value: 74.22800000000001
- type: mrr_at_1000
value: 74.234
- type: mrr_at_3
value: 72.5
- type: mrr_at_5
value: 73.387
- type: ndcg_at_1
value: 52.625
- type: ndcg_at_10
value: 39.101
- type: ndcg_at_100
value: 43.836000000000006
- type: ndcg_at_1000
value: 51.086
- type: ndcg_at_3
value: 44.229
- type: ndcg_at_5
value: 41.555
- type: precision_at_1
value: 65.75
- type: precision_at_10
value: 30.45
- type: precision_at_100
value: 9.81
- type: precision_at_1000
value: 2.045
- type: precision_at_3
value: 48.667
- type: precision_at_5
value: 40.8
- type: recall_at_1
value: 8.595
- type: recall_at_10
value: 24.201
- type: recall_at_100
value: 50.096
- type: recall_at_1000
value: 72.677
- type: recall_at_3
value: 15.212
- type: recall_at_5
value: 18.745
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.565
- type: f1
value: 41.49914329345582
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.60000000000001
- type: map_at_10
value: 76.838
- type: map_at_100
value: 77.076
- type: map_at_1000
value: 77.09
- type: map_at_3
value: 75.545
- type: map_at_5
value: 76.39
- type: mrr_at_1
value: 71.707
- type: mrr_at_10
value: 81.514
- type: mrr_at_100
value: 81.64099999999999
- type: mrr_at_1000
value: 81.645
- type: mrr_at_3
value: 80.428
- type: mrr_at_5
value: 81.159
- type: ndcg_at_1
value: 71.707
- type: ndcg_at_10
value: 81.545
- type: ndcg_at_100
value: 82.477
- type: ndcg_at_1000
value: 82.73899999999999
- type: ndcg_at_3
value: 79.292
- type: ndcg_at_5
value: 80.599
- type: precision_at_1
value: 71.707
- type: precision_at_10
value: 10.035
- type: precision_at_100
value: 1.068
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 30.918
- type: precision_at_5
value: 19.328
- type: recall_at_1
value: 66.60000000000001
- type: recall_at_10
value: 91.353
- type: recall_at_100
value: 95.21
- type: recall_at_1000
value: 96.89999999999999
- type: recall_at_3
value: 85.188
- type: recall_at_5
value: 88.52
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.338
- type: map_at_10
value: 31.752000000000002
- type: map_at_100
value: 33.516
- type: map_at_1000
value: 33.694
- type: map_at_3
value: 27.716
- type: map_at_5
value: 29.67
- type: mrr_at_1
value: 38.117000000000004
- type: mrr_at_10
value: 47.323
- type: mrr_at_100
value: 48.13
- type: mrr_at_1000
value: 48.161
- type: mrr_at_3
value: 45.062000000000005
- type: mrr_at_5
value: 46.358
- type: ndcg_at_1
value: 38.117000000000004
- type: ndcg_at_10
value: 39.353
- type: ndcg_at_100
value: 46.044000000000004
- type: ndcg_at_1000
value: 49.083
- type: ndcg_at_3
value: 35.891
- type: ndcg_at_5
value: 36.661
- type: precision_at_1
value: 38.117000000000004
- type: precision_at_10
value: 11.187999999999999
- type: precision_at_100
value: 1.802
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 24.126
- type: precision_at_5
value: 17.562
- type: recall_at_1
value: 19.338
- type: recall_at_10
value: 45.735
- type: recall_at_100
value: 71.281
- type: recall_at_1000
value: 89.537
- type: recall_at_3
value: 32.525
- type: recall_at_5
value: 37.671
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.995
- type: map_at_10
value: 55.032000000000004
- type: map_at_100
value: 55.86
- type: map_at_1000
value: 55.932
- type: map_at_3
value: 52.125
- type: map_at_5
value: 53.884
- type: mrr_at_1
value: 73.991
- type: mrr_at_10
value: 80.096
- type: mrr_at_100
value: 80.32000000000001
- type: mrr_at_1000
value: 80.331
- type: mrr_at_3
value: 79.037
- type: mrr_at_5
value: 79.719
- type: ndcg_at_1
value: 73.991
- type: ndcg_at_10
value: 63.786
- type: ndcg_at_100
value: 66.78
- type: ndcg_at_1000
value: 68.255
- type: ndcg_at_3
value: 59.501000000000005
- type: ndcg_at_5
value: 61.82299999999999
- type: precision_at_1
value: 73.991
- type: precision_at_10
value: 13.157
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.17500000000000002
- type: precision_at_3
value: 37.519999999999996
- type: precision_at_5
value: 24.351
- type: recall_at_1
value: 36.995
- type: recall_at_10
value: 65.78699999999999
- type: recall_at_100
value: 77.583
- type: recall_at_1000
value: 87.421
- type: recall_at_3
value: 56.279999999999994
- type: recall_at_5
value: 60.878
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 86.80239999999999
- type: ap
value: 81.97305141128378
- type: f1
value: 86.76976305549273
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.166
- type: map_at_10
value: 33.396
- type: map_at_100
value: 34.588
- type: map_at_1000
value: 34.637
- type: map_at_3
value: 29.509999999999998
- type: map_at_5
value: 31.719
- type: mrr_at_1
value: 21.762
- type: mrr_at_10
value: 33.969
- type: mrr_at_100
value: 35.099000000000004
- type: mrr_at_1000
value: 35.141
- type: mrr_at_3
value: 30.148000000000003
- type: mrr_at_5
value: 32.324000000000005
- type: ndcg_at_1
value: 21.776999999999997
- type: ndcg_at_10
value: 40.306999999999995
- type: ndcg_at_100
value: 46.068
- type: ndcg_at_1000
value: 47.3
- type: ndcg_at_3
value: 32.416
- type: ndcg_at_5
value: 36.345
- type: precision_at_1
value: 21.776999999999997
- type: precision_at_10
value: 6.433
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.897
- type: precision_at_5
value: 10.324
- type: recall_at_1
value: 21.166
- type: recall_at_10
value: 61.587
- type: recall_at_100
value: 88.251
- type: recall_at_1000
value: 97.727
- type: recall_at_3
value: 40.196
- type: recall_at_5
value: 49.611
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.04605563155496
- type: f1
value: 92.78007303978372
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.65116279069767
- type: f1
value: 52.75775172527262
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.34633490248822
- type: f1
value: 68.15345065392562
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.63887020847343
- type: f1
value: 76.08074680233685
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.77933406071333
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.06504927238196
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.20682480490871
- type: mrr
value: 33.41462721527003
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.548
- type: map_at_10
value: 13.086999999999998
- type: map_at_100
value: 16.698
- type: map_at_1000
value: 18.151999999999997
- type: map_at_3
value: 9.576
- type: map_at_5
value: 11.175
- type: mrr_at_1
value: 44.272
- type: mrr_at_10
value: 53.635999999999996
- type: mrr_at_100
value: 54.228
- type: mrr_at_1000
value: 54.26499999999999
- type: mrr_at_3
value: 51.754
- type: mrr_at_5
value: 53.086
- type: ndcg_at_1
value: 42.724000000000004
- type: ndcg_at_10
value: 34.769
- type: ndcg_at_100
value: 32.283
- type: ndcg_at_1000
value: 40.843
- type: ndcg_at_3
value: 39.852
- type: ndcg_at_5
value: 37.858999999999995
- type: precision_at_1
value: 44.272
- type: precision_at_10
value: 26.068
- type: precision_at_100
value: 8.328000000000001
- type: precision_at_1000
value: 2.1
- type: precision_at_3
value: 37.874
- type: precision_at_5
value: 33.065
- type: recall_at_1
value: 5.548
- type: recall_at_10
value: 16.936999999999998
- type: recall_at_100
value: 33.72
- type: recall_at_1000
value: 64.348
- type: recall_at_3
value: 10.764999999999999
- type: recall_at_5
value: 13.361
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.008
- type: map_at_10
value: 42.675000000000004
- type: map_at_100
value: 43.85
- type: map_at_1000
value: 43.884
- type: map_at_3
value: 38.286
- type: map_at_5
value: 40.78
- type: mrr_at_1
value: 31.518
- type: mrr_at_10
value: 45.015
- type: mrr_at_100
value: 45.924
- type: mrr_at_1000
value: 45.946999999999996
- type: mrr_at_3
value: 41.348
- type: mrr_at_5
value: 43.428
- type: ndcg_at_1
value: 31.489
- type: ndcg_at_10
value: 50.285999999999994
- type: ndcg_at_100
value: 55.291999999999994
- type: ndcg_at_1000
value: 56.05
- type: ndcg_at_3
value: 41.976
- type: ndcg_at_5
value: 46.103
- type: precision_at_1
value: 31.489
- type: precision_at_10
value: 8.456
- type: precision_at_100
value: 1.125
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.09
- type: precision_at_5
value: 13.841000000000001
- type: recall_at_1
value: 28.008
- type: recall_at_10
value: 71.21499999999999
- type: recall_at_100
value: 92.99
- type: recall_at_1000
value: 98.578
- type: recall_at_3
value: 49.604
- type: recall_at_5
value: 59.094
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.351
- type: map_at_10
value: 84.163
- type: map_at_100
value: 84.785
- type: map_at_1000
value: 84.801
- type: map_at_3
value: 81.16
- type: map_at_5
value: 83.031
- type: mrr_at_1
value: 80.96
- type: mrr_at_10
value: 87.241
- type: mrr_at_100
value: 87.346
- type: mrr_at_1000
value: 87.347
- type: mrr_at_3
value: 86.25699999999999
- type: mrr_at_5
value: 86.907
- type: ndcg_at_1
value: 80.97
- type: ndcg_at_10
value: 88.017
- type: ndcg_at_100
value: 89.241
- type: ndcg_at_1000
value: 89.34299999999999
- type: ndcg_at_3
value: 85.053
- type: ndcg_at_5
value: 86.663
- type: precision_at_1
value: 80.97
- type: precision_at_10
value: 13.358
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.143
- type: precision_at_5
value: 24.451999999999998
- type: recall_at_1
value: 70.351
- type: recall_at_10
value: 95.39800000000001
- type: recall_at_100
value: 99.55199999999999
- type: recall_at_1000
value: 99.978
- type: recall_at_3
value: 86.913
- type: recall_at_5
value: 91.448
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.62406719814139
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 61.386700035141736
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.618
- type: map_at_10
value: 12.920000000000002
- type: map_at_100
value: 15.304
- type: map_at_1000
value: 15.656999999999998
- type: map_at_3
value: 9.187
- type: map_at_5
value: 10.937
- type: mrr_at_1
value: 22.8
- type: mrr_at_10
value: 35.13
- type: mrr_at_100
value: 36.239
- type: mrr_at_1000
value: 36.291000000000004
- type: mrr_at_3
value: 31.917
- type: mrr_at_5
value: 33.787
- type: ndcg_at_1
value: 22.8
- type: ndcg_at_10
value: 21.382
- type: ndcg_at_100
value: 30.257
- type: ndcg_at_1000
value: 36.001
- type: ndcg_at_3
value: 20.43
- type: ndcg_at_5
value: 17.622
- type: precision_at_1
value: 22.8
- type: precision_at_10
value: 11.26
- type: precision_at_100
value: 2.405
- type: precision_at_1000
value: 0.377
- type: precision_at_3
value: 19.633
- type: precision_at_5
value: 15.68
- type: recall_at_1
value: 4.618
- type: recall_at_10
value: 22.811999999999998
- type: recall_at_100
value: 48.787000000000006
- type: recall_at_1000
value: 76.63799999999999
- type: recall_at_3
value: 11.952
- type: recall_at_5
value: 15.892000000000001
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.01529458252244
- type: cos_sim_spearman
value: 77.92985224770254
- type: euclidean_pearson
value: 81.04251429422487
- type: euclidean_spearman
value: 77.92838490549133
- type: manhattan_pearson
value: 80.95892251458979
- type: manhattan_spearman
value: 77.81028089705941
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.97885282534388
- type: cos_sim_spearman
value: 75.1221970851712
- type: euclidean_pearson
value: 80.34455956720097
- type: euclidean_spearman
value: 74.5894274239938
- type: manhattan_pearson
value: 80.38999766325465
- type: manhattan_spearman
value: 74.68524557166975
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.95746064915672
- type: cos_sim_spearman
value: 85.08683458043946
- type: euclidean_pearson
value: 84.56699492836385
- type: euclidean_spearman
value: 85.66089116133713
- type: manhattan_pearson
value: 84.47553323458541
- type: manhattan_spearman
value: 85.56142206781472
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.71377893595067
- type: cos_sim_spearman
value: 81.03453291428589
- type: euclidean_pearson
value: 82.57136298308613
- type: euclidean_spearman
value: 81.15839961890875
- type: manhattan_pearson
value: 82.55157879373837
- type: manhattan_spearman
value: 81.1540163767054
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.64197832372373
- type: cos_sim_spearman
value: 88.31966852492485
- type: euclidean_pearson
value: 87.98692129976983
- type: euclidean_spearman
value: 88.6247340837856
- type: manhattan_pearson
value: 87.90437827826412
- type: manhattan_spearman
value: 88.56278787131457
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.84159950146693
- type: cos_sim_spearman
value: 83.90678384140168
- type: euclidean_pearson
value: 83.19005018860221
- type: euclidean_spearman
value: 84.16260415876295
- type: manhattan_pearson
value: 83.05030612994494
- type: manhattan_spearman
value: 83.99605629718336
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49935350176666
- type: cos_sim_spearman
value: 87.59086606735383
- type: euclidean_pearson
value: 88.06537181129983
- type: euclidean_spearman
value: 87.6687448086014
- type: manhattan_pearson
value: 87.96599131972935
- type: manhattan_spearman
value: 87.63295748969642
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.68232799482763
- type: cos_sim_spearman
value: 67.99930378085793
- type: euclidean_pearson
value: 68.50275360001696
- type: euclidean_spearman
value: 67.81588179309259
- type: manhattan_pearson
value: 68.5892154749763
- type: manhattan_spearman
value: 67.84357259640682
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.37049618406554
- type: cos_sim_spearman
value: 85.57014313159492
- type: euclidean_pearson
value: 85.57469513908282
- type: euclidean_spearman
value: 85.661948135258
- type: manhattan_pearson
value: 85.36866831229028
- type: manhattan_spearman
value: 85.5043455368843
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.83259065376154
- type: mrr
value: 95.58455433455433
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 58.817
- type: map_at_10
value: 68.459
- type: map_at_100
value: 68.951
- type: map_at_1000
value: 68.979
- type: map_at_3
value: 65.791
- type: map_at_5
value: 67.583
- type: mrr_at_1
value: 61.667
- type: mrr_at_10
value: 69.368
- type: mrr_at_100
value: 69.721
- type: mrr_at_1000
value: 69.744
- type: mrr_at_3
value: 67.278
- type: mrr_at_5
value: 68.611
- type: ndcg_at_1
value: 61.667
- type: ndcg_at_10
value: 72.70100000000001
- type: ndcg_at_100
value: 74.928
- type: ndcg_at_1000
value: 75.553
- type: ndcg_at_3
value: 68.203
- type: ndcg_at_5
value: 70.804
- type: precision_at_1
value: 61.667
- type: precision_at_10
value: 9.533
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.444000000000003
- type: precision_at_5
value: 17.599999999999998
- type: recall_at_1
value: 58.817
- type: recall_at_10
value: 84.789
- type: recall_at_100
value: 95.0
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 72.8
- type: recall_at_5
value: 79.294
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8108910891089
- type: cos_sim_ap
value: 95.5743678558349
- type: cos_sim_f1
value: 90.43133366385722
- type: cos_sim_precision
value: 89.67551622418878
- type: cos_sim_recall
value: 91.2
- type: dot_accuracy
value: 99.75841584158415
- type: dot_ap
value: 94.00786363627253
- type: dot_f1
value: 87.51910341314316
- type: dot_precision
value: 89.20041536863967
- type: dot_recall
value: 85.9
- type: euclidean_accuracy
value: 99.81485148514851
- type: euclidean_ap
value: 95.4752113136905
- type: euclidean_f1
value: 90.44334975369456
- type: euclidean_precision
value: 89.126213592233
- type: euclidean_recall
value: 91.8
- type: manhattan_accuracy
value: 99.81584158415842
- type: manhattan_ap
value: 95.5163172682464
- type: manhattan_f1
value: 90.51987767584097
- type: manhattan_precision
value: 92.3076923076923
- type: manhattan_recall
value: 88.8
- type: max_accuracy
value: 99.81584158415842
- type: max_ap
value: 95.5743678558349
- type: max_f1
value: 90.51987767584097
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 62.63235986949449
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.334795589585575
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.02955214518782
- type: mrr
value: 52.8004838298956
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.63769566275453
- type: cos_sim_spearman
value: 30.422379185989335
- type: dot_pearson
value: 26.88493071882256
- type: dot_spearman
value: 26.505249740971305
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.654
- type: map_at_100
value: 10.095
- type: map_at_1000
value: 25.808999999999997
- type: map_at_3
value: 0.594
- type: map_at_5
value: 0.9289999999999999
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 87.019
- type: mrr_at_100
value: 87.019
- type: mrr_at_1000
value: 87.019
- type: mrr_at_3
value: 86.333
- type: mrr_at_5
value: 86.733
- type: ndcg_at_1
value: 73.0
- type: ndcg_at_10
value: 66.52900000000001
- type: ndcg_at_100
value: 53.433
- type: ndcg_at_1000
value: 51.324000000000005
- type: ndcg_at_3
value: 72.02199999999999
- type: ndcg_at_5
value: 69.696
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 70.39999999999999
- type: precision_at_100
value: 55.46
- type: precision_at_1000
value: 22.758
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.8849999999999998
- type: recall_at_100
value: 13.801
- type: recall_at_1000
value: 49.649
- type: recall_at_3
value: 0.632
- type: recall_at_5
value: 1.009
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.797
- type: map_at_10
value: 9.01
- type: map_at_100
value: 14.682
- type: map_at_1000
value: 16.336000000000002
- type: map_at_3
value: 4.546
- type: map_at_5
value: 5.9270000000000005
- type: mrr_at_1
value: 24.490000000000002
- type: mrr_at_10
value: 41.156
- type: mrr_at_100
value: 42.392
- type: mrr_at_1000
value: 42.408
- type: mrr_at_3
value: 38.775999999999996
- type: mrr_at_5
value: 40.102
- type: ndcg_at_1
value: 21.429000000000002
- type: ndcg_at_10
value: 22.222
- type: ndcg_at_100
value: 34.405
- type: ndcg_at_1000
value: 46.599000000000004
- type: ndcg_at_3
value: 25.261
- type: ndcg_at_5
value: 22.695999999999998
- type: precision_at_1
value: 24.490000000000002
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.306
- type: precision_at_1000
value: 1.5350000000000001
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 22.857
- type: recall_at_1
value: 1.797
- type: recall_at_10
value: 15.706000000000001
- type: recall_at_100
value: 46.412
- type: recall_at_1000
value: 83.159
- type: recall_at_3
value: 6.1370000000000005
- type: recall_at_5
value: 8.599
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.3302
- type: ap
value: 14.169121204575601
- type: f1
value: 54.229345975274235
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 58.22297679683077
- type: f1
value: 58.62984908377875
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.952922428464255
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.68140907194373
- type: cos_sim_ap
value: 70.12180123666836
- type: cos_sim_f1
value: 65.77501791258658
- type: cos_sim_precision
value: 60.07853403141361
- type: cos_sim_recall
value: 72.66490765171504
- type: dot_accuracy
value: 81.92167848840674
- type: dot_ap
value: 60.49837581423469
- type: dot_f1
value: 58.44186046511628
- type: dot_precision
value: 52.24532224532224
- type: dot_recall
value: 66.3060686015831
- type: euclidean_accuracy
value: 84.73505394289802
- type: euclidean_ap
value: 70.3278904593286
- type: euclidean_f1
value: 65.98851124940161
- type: euclidean_precision
value: 60.38107752956636
- type: euclidean_recall
value: 72.74406332453826
- type: manhattan_accuracy
value: 84.73505394289802
- type: manhattan_ap
value: 70.00737738537337
- type: manhattan_f1
value: 65.80150784822642
- type: manhattan_precision
value: 61.892583120204606
- type: manhattan_recall
value: 70.23746701846966
- type: max_accuracy
value: 84.73505394289802
- type: max_ap
value: 70.3278904593286
- type: max_f1
value: 65.98851124940161
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.44258159661582
- type: cos_sim_ap
value: 84.91926704880888
- type: cos_sim_f1
value: 77.07651086632926
- type: cos_sim_precision
value: 74.5894554883319
- type: cos_sim_recall
value: 79.73514012935017
- type: dot_accuracy
value: 85.88116583226608
- type: dot_ap
value: 78.9753854779923
- type: dot_f1
value: 72.17757637979255
- type: dot_precision
value: 66.80647486729143
- type: dot_recall
value: 78.48783492454572
- type: euclidean_accuracy
value: 88.5299025885823
- type: euclidean_ap
value: 85.08006075642194
- type: euclidean_f1
value: 77.29637336504163
- type: euclidean_precision
value: 74.69836253950014
- type: euclidean_recall
value: 80.08161379735141
- type: manhattan_accuracy
value: 88.55124771995187
- type: manhattan_ap
value: 85.00941529932851
- type: manhattan_f1
value: 77.33100233100232
- type: manhattan_precision
value: 73.37572573956317
- type: manhattan_recall
value: 81.73698798891284
- type: max_accuracy
value: 88.55124771995187
- type: max_ap
value: 85.08006075642194
- type: max_f1
value: 77.33100233100232
language:
- en
license: mit
---
# gte-small
General Text Embeddings (GTE) model. [Towards General Text Embeddings with Multi-stage Contrastive Learning](https://arxiv.org/abs/2308.03281)
The GTE models are trained by Alibaba DAMO Academy. They are mainly based on the BERT framework and currently offer three different sizes of models, including [GTE-large](https://huggingface.co/thenlper/gte-large), [GTE-base](https://huggingface.co/thenlper/gte-base), and [GTE-small](https://huggingface.co/thenlper/gte-small). The GTE models are trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. This enables the GTE models to be applied to various downstream tasks of text embeddings, including **information retrieval**, **semantic textual similarity**, **text reranking**, etc.
## Metrics
We compared the performance of the GTE models with other popular text embedding models on the MTEB benchmark. For more detailed comparison results, please refer to the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**gte-large**](https://huggingface.co/thenlper/gte-large) | 0.67 | 1024 | 512 | **63.13** | 46.84 | 85.00 | 59.13 | 52.22 | 83.35 | 31.66 | 73.33 |
| [**gte-base**](https://huggingface.co/thenlper/gte-base) | 0.22 | 768 | 512 | **62.39** | 46.2 | 84.57 | 58.61 | 51.14 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1.34 | 1024| 512 | 62.25 | 44.49 | 86.03 | 56.61 | 50.56 | 82.05 | 30.19 | 75.24 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.44 | 768 | 512 | 61.5 | 43.80 | 85.73 | 55.91 | 50.29 | 81.05 | 30.28 | 73.84 |
| [**gte-small**](https://huggingface.co/thenlper/gte-small) | 0.07 | 384 | 512 | **61.36** | 44.89 | 83.54 | 57.7 | 49.46 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | - | 1536 | 8192 | 60.99 | 45.9 | 84.89 | 56.32 | 49.25 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.13 | 384 | 512 | 59.93 | 39.92 | 84.67 | 54.32 | 49.04 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 9.73 | 768 | 512 | 59.51 | 43.72 | 85.06 | 56.42 | 42.24 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.44 | 768 | 514 | 57.78 | 43.69 | 83.04 | 59.36 | 43.81 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 28.27 | 4096 | 2048 | 57.59 | 38.93 | 81.9 | 55.65 | 48.22 | 77.74 | 33.6 | 66.19 |
| [all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2) | 0.13 | 384 | 512 | 56.53 | 41.81 | 82.41 | 58.44 | 42.69 | 79.8 | 27.9 | 63.21 |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.09 | 384 | 512 | 56.26 | 42.35 | 82.37 | 58.04 | 41.95 | 78.9 | 30.81 | 63.05 |
| [contriever-base-msmarco](https://huggingface.co/nthakur/contriever-base-msmarco) | 0.44 | 768 | 512 | 56.00 | 41.1 | 82.54 | 53.14 | 41.88 | 76.51 | 30.36 | 66.68 |
| [sentence-t5-base](https://huggingface.co/sentence-transformers/sentence-t5-base) | 0.22 | 768 | 512 | 55.27 | 40.21 | 85.18 | 53.09 | 33.63 | 81.14 | 31.39 | 69.81 |
## Usage
Code example
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
model = AutoModel.from_pretrained("thenlper/gte-small")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('thenlper/gte-large')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
### Citation
If you find our paper or models helpful, please consider citing them as follows:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
Helsinki-NLP/opus-mt-fr-en | Helsinki-NLP | "2023-08-16T11:36:20Z" | 676,029 | 37 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"marian",
"text2text-generation",
"translation",
"fr",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-fr-en
* source languages: fr
* target languages: en
* OPUS readme: [fr-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-02-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.zip)
* test set translations: [opus-2020-02-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.test.txt)
* test set scores: [opus-2020-02-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-en/opus-2020-02-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdiscussdev2015-enfr.fr.en | 33.1 | 0.580 |
| newsdiscusstest2015-enfr.fr.en | 38.7 | 0.614 |
| newssyscomb2009.fr.en | 30.3 | 0.569 |
| news-test2008.fr.en | 26.2 | 0.542 |
| newstest2009.fr.en | 30.2 | 0.570 |
| newstest2010.fr.en | 32.2 | 0.590 |
| newstest2011.fr.en | 33.0 | 0.597 |
| newstest2012.fr.en | 32.8 | 0.591 |
| newstest2013.fr.en | 33.9 | 0.591 |
| newstest2014-fren.fr.en | 37.8 | 0.633 |
| Tatoeba.fr.en | 57.5 | 0.720 |
|
facebook/encodec_24khz | facebook | "2023-07-25T11:28:04Z" | 672,746 | 40 | transformers | [
"transformers",
"pytorch",
"safetensors",
"encodec",
"feature-extraction",
"arxiv:2210.13438",
"region:us"
] | feature-extraction | "2023-06-12T16:10:36Z" | ---
inference: false
---

# Model Card for EnCodec
This model card provides details and information about EnCodec, a state-of-the-art real-time audio codec developed by Meta AI.
## Model Details
### Model Description
EnCodec is a high-fidelity audio codec leveraging neural networks. It introduces a streaming encoder-decoder architecture with quantized latent space, trained in an end-to-end fashion.
The model simplifies and speeds up training using a single multiscale spectrogram adversary that efficiently reduces artifacts and produces high-quality samples.
It also includes a novel loss balancer mechanism that stabilizes training by decoupling the choice of hyperparameters from the typical scale of the loss.
Additionally, lightweight Transformer models are used to further compress the obtained representation while maintaining real-time performance.
- **Developed by:** Meta AI
- **Model type:** Audio Codec
### Model Sources
- **Repository:** [GitHub Repository](https://github.com/facebookresearch/encodec)
- **Paper:** [EnCodec: End-to-End Neural Audio Codec](https://arxiv.org/abs/2210.13438)
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
EnCodec can be used directly as an audio codec for real-time compression and decompression of audio signals.
It provides high-quality audio compression and efficient decoding. The model was trained on various bandwiths, which can be specified when encoding (compressing) and decoding (decompressing).
Two different setup exist for EnCodec:
- Non-streamable: the input audio is split into chunks of 1 seconds, with an overlap of 10 ms, which are then encoded.
- Streamable: weight normalizationis used on the convolution layers, and the input is not split into chunks but rather padded on the left.
### Downstream Use
EnCodec can be fine-tuned for specific audio tasks or integrated into larger audio processing pipelines for applications such as speech generation,
music generation, or text to speech tasks.
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
## How to Get Started with the Model
Use the following code to get started with the EnCodec model using a dummy example from the LibriSpeech dataset (~9MB). First, install the required Python packages:
```
pip install --upgrade pip
pip install --upgrade datasets[audio]
pip install git+https://github.com/huggingface/transformers.git@main
```
Then load an audio sample, and run a forward pass of the model:
```python
from datasets import load_dataset, Audio
from transformers import EncodecModel, AutoProcessor
# load a demonstration datasets
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
# load the model + processor (for pre-processing the audio)
model = EncodecModel.from_pretrained("facebook/encodec_24khz")
processor = AutoProcessor.from_pretrained("facebook/encodec_24khz")
# cast the audio data to the correct sampling rate for the model
librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=processor.sampling_rate))
audio_sample = librispeech_dummy[0]["audio"]["array"]
# pre-process the inputs
inputs = processor(raw_audio=audio_sample, sampling_rate=processor.sampling_rate, return_tensors="pt")
# explicitly encode then decode the audio inputs
encoder_outputs = model.encode(inputs["input_values"], inputs["padding_mask"])
audio_values = model.decode(encoder_outputs.audio_codes, encoder_outputs.audio_scales, inputs["padding_mask"])[0]
# or the equivalent with a forward pass
audio_values = model(inputs["input_values"], inputs["padding_mask"]).audio_values
```
## Training Details
The model was trained for 300 epochs, with one epoch being 2,000 updates with the Adam optimizer with a batch size of 64 examples of 1 second each, a learning rate of 3 · 10−4
, β1 = 0.5, and β2 = 0.9. All the models are traind using 8 A100 GPUs.
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
- For speech:
- DNS Challenge 4
- [Common Voice](https://huggingface.co/datasets/common_voice)
- For general audio:
- [AudioSet](https://huggingface.co/datasets/Fhrozen/AudioSet2K22)
- [FSD50K](https://huggingface.co/datasets/Fhrozen/FSD50k)
- For music:
- [Jamendo dataset](https://huggingface.co/datasets/rkstgr/mtg-jamendo)
They used four different training strategies to sample for these datasets:
- (s1) sample a single source from Jamendo with probability 0.32;
- (s2) sample a single source from the other datasets with the same probability;
- (s3) mix two sources from all datasets with a probability of 0.24;
- (s4) mix three sources from all datasets except music with a probability of 0.12.
The audio is normalized by file and a random gain between -10 and 6 dB id applied.
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Subjectif metric for restoration:
This models was evalutated using the MUSHRA protocol (Series, 2014), using both a hidden reference and a low anchor. Annotators were recruited using a
crowd-sourcing platform, in which they were asked to rate the perceptual quality of the provided samples in
a range between 1 to 100. They randomly select 50 samples of 5 seconds from each category of the the test set
and force at least 10 annotations per samples. To filter noisy annotations and outliers we remove annotators
who rate the reference recordings less then 90 in at least 20% of the cases, or rate the low-anchor recording
above 80 more than 50% of the time.
### Objective metric for restoration:
The ViSQOL()ink) metric was used together with the Scale-Invariant Signal-to-Noise Ration (SI-SNR) (Luo & Mesgarani, 2019;
Nachmani et al., 2020; Chazan et al., 2021).
### Results
The results of the evaluation demonstrate the superiority of EnCodec compared to the baselines across different bandwidths (1.5, 3, 6, and 12 kbps).
When comparing EnCodec with the baselines at the same bandwidth, EnCodec consistently outperforms them in terms of MUSHRA score.
Notably, EnCodec achieves better performance, on average, at 3 kbps compared to Lyra-v2 at 6 kbps and Opus at 12 kbps.
Additionally, by incorporating the language model over the codes, it is possible to achieve a bandwidth reduction of approximately 25-40%.
For example, the bandwidth of the 3 kbps model can be reduced to 1.9 kbps.
#### Summary
EnCodec is a state-of-the-art real-time neural audio compression model that excels in producing high-fidelity audio samples at various sample rates and bandwidths.
The model's performance was evaluated across different settings, ranging from 24kHz monophonic at 1.5 kbps to 48kHz stereophonic, showcasing both subjective and
objective results. Notably, EnCodec incorporates a novel spectrogram-only adversarial loss, effectively reducing artifacts and enhancing sample quality.
Training stability and interpretability were further enhanced through the introduction of a gradient balancer for the loss weights.
Additionally, the study demonstrated that a compact Transformer model can be employed to achieve an additional bandwidth reduction of up to 40% without compromising
quality, particularly in applications where low latency is not critical (e.g., music streaming).
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```
@misc{défossez2022high,
title={High Fidelity Neural Audio Compression},
author={Alexandre Défossez and Jade Copet and Gabriel Synnaeve and Yossi Adi},
year={2022},
eprint={2210.13438},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
```
|
timm/tf_efficientnet_b1.ns_jft_in1k | timm | "2023-04-27T21:17:43Z" | 669,436 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"arxiv:1911.04252",
"license:apache-2.0",
"region:us"
] | image-classification | "2022-12-13T00:01:58Z" | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_efficientnet_b1.ns_jft_in1k
A EfficientNet image classification model. Trained on ImageNet-1k and unlabeled JFT-300m using Noisy Student semi-supervised learning in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 7.8
- GMACs: 0.7
- Activations (M): 10.9
- Image size: 240 x 240
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- Self-training with Noisy Student improves ImageNet classification: https://arxiv.org/abs/1911.04252
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnet_b1.ns_jft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b1.ns_jft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 120, 120])
# torch.Size([1, 24, 60, 60])
# torch.Size([1, 40, 30, 30])
# torch.Size([1, 112, 15, 15])
# torch.Size([1, 320, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_b1.ns_jft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@article{Xie2019SelfTrainingWN,
title={Self-Training With Noisy Student Improves ImageNet Classification},
author={Qizhe Xie and Eduard H. Hovy and Minh-Thang Luong and Quoc V. Le},
journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019},
pages={10684-10695}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
csebuetnlp/banglat5_banglaparaphrase | csebuetnlp | "2022-11-05T17:14:38Z" | 660,731 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"bn",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-10-15T04:19:58Z" | ---
language:
- bn
licenses:
- cc-by-nc-sa-4.0
---
# banglat5_banglaparaphrase
This repository contains the pretrained checkpoint of the model **BanglaT5** finetuned on [BanglaParaphrase](https://huggingface.co/datasets/csebuetnlp/BanglaParaphrase) dataset. This is a sequence to sequence transformer model pretrained with the ["Span Corruption"]() objective. Finetuned models using this checkpoint achieve competitive results on the dataset.
For finetuning and inference, refer to the scripts in the official GitHub repository of [BanglaNLG](https://github.com/csebuetnlp/BanglaNLG).
**Note**: This model was pretrained using a specific normalization pipeline available [here](https://github.com/csebuetnlp/normalizer). All finetuning scripts in the official GitHub repository use this normalization by default. If you need to adapt the pretrained model for a different task make sure the text units are normalized using this pipeline before tokenizing to get best results. A basic example is given below:
## Using this model in `transformers`
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from normalizer import normalize # pip install git+https://github.com/csebuetnlp/normalizer
model = AutoModelForSeq2SeqLM.from_pretrained("csebuetnlp/banglat5_banglaparaphrase")
tokenizer = AutoTokenizer.from_pretrained("csebuetnlp/banglat5_banglaparaphrase", use_fast=False)
input_sentence = ""
input_ids = tokenizer(normalize(input_sentence), return_tensors="pt").input_ids
generated_tokens = model.generate(input_ids)
decoded_tokens = tokenizer.batch_decode(generated_tokens)[0]
print(decoded_tokens)
```
## Benchmarks
* Supervised fine-tuning
| Test Set | Model | sacreBLEU | ROUGE-L | PINC | BERTScore | BERT-iBLEU |
| -------- | ----- | --------- | ------- | ---- | --------- | ---------- |
| [BanglaParaphrase](https://huggingface.co/datasets/csebuetnlp/BanglaParaphrase) | [BanglaT5](https://huggingface.co/csebuetnlp/banglat5)<br>[IndicBART](https://huggingface.co/ai4bharat/IndicBART)<br>[IndicBARTSS](https://huggingface.co/ai4bharat/IndicBARTSS)| 32.8<br>5.60<br>4.90 | 63.58<br>35.61<br>33.66 | 74.40<br>80.26<br>82.10 | 94.80<br>91.50<br>91.10 | 92.18<br>91.16<br>90.95 |
| [IndicParaphrase](https://huggingface.co/datasets/ai4bharat/IndicParaphrase) |BanglaT5<br>IndicBART<br>IndicBARTSS| 11.0<br>12.0<br>10.7| 19.99<br>21.58<br>20.59| 74.50<br>76.83<br>77.60| 94.80<br>93.30<br>93.10 | 87.738<br>90.65<br>90.54|
The dataset can be found in the link below:
* **[BanglaParaphrase](https://huggingface.co/datasets/csebuetnlp/BanglaParaphrase)**
## Citation
If you use this model, please cite the following paper:
```
@article{akil2022banglaparaphrase,
title={BanglaParaphrase: A High-Quality Bangla Paraphrase Dataset},
author={Akil, Ajwad and Sultana, Najrin and Bhattacharjee, Abhik and Shahriyar, Rifat},
journal={arXiv preprint arXiv:2210.05109},
year={2022}
}
``` |
pyannote/voice-activity-detection | pyannote | "2024-05-10T19:39:17Z" | 658,762 | 156 | pyannote-audio | [
"pyannote-audio",
"pyannote",
"pyannote-audio-pipeline",
"audio",
"voice",
"speech",
"speaker",
"voice-activity-detection",
"automatic-speech-recognition",
"dataset:ami",
"dataset:dihard",
"dataset:voxconverse",
"license:mit",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
tags:
- pyannote
- pyannote-audio
- pyannote-audio-pipeline
- audio
- voice
- speech
- speaker
- voice-activity-detection
- automatic-speech-recognition
datasets:
- ami
- dihard
- voxconverse
license: mit
extra_gated_prompt: "The collected information will help acquire a better knowledge of pyannote.audio userbase and help its maintainers apply for grants to improve it further. If you are an academic researcher, please cite the relevant papers in your own publications using the model. If you work for a company, please consider contributing back to pyannote.audio development (e.g. through unrestricted gifts). We also provide scientific consulting services around speaker diarization and machine listening."
extra_gated_fields:
Company/university: text
Website: text
I plan to use this model for (task, type of audio data, etc): text
---
Using this open-source model in production?
Consider switching to [pyannoteAI](https://www.pyannote.ai) for better and faster options.
# 🎹 Voice activity detection
Relies on pyannote.audio 2.1: see [installation instructions](https://github.com/pyannote/pyannote-audio#installation).
```python
# 1. visit hf.co/pyannote/segmentation and accept user conditions
# 2. visit hf.co/settings/tokens to create an access token
# 3. instantiate pretrained voice activity detection pipeline
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/voice-activity-detection",
use_auth_token="ACCESS_TOKEN_GOES_HERE")
output = pipeline("audio.wav")
for speech in output.get_timeline().support():
# active speech between speech.start and speech.end
...
```
## Citation
```bibtex
@inproceedings{Bredin2021,
Title = {{End-to-end speaker segmentation for overlap-aware resegmentation}},
Author = {{Bredin}, Herv{\'e} and {Laurent}, Antoine},
Booktitle = {Proc. Interspeech 2021},
Address = {Brno, Czech Republic},
Month = {August},
Year = {2021},
}
```
```bibtex
@inproceedings{Bredin2020,
Title = {{pyannote.audio: neural building blocks for speaker diarization}},
Author = {{Bredin}, Herv{\'e} and {Yin}, Ruiqing and {Coria}, Juan Manuel and {Gelly}, Gregory and {Korshunov}, Pavel and {Lavechin}, Marvin and {Fustes}, Diego and {Titeux}, Hadrien and {Bouaziz}, Wassim and {Gill}, Marie-Philippe},
Booktitle = {ICASSP 2020, IEEE International Conference on Acoustics, Speech, and Signal Processing},
Address = {Barcelona, Spain},
Month = {May},
Year = {2020},
}
```
|
nvidia/dragon-multiturn-context-encoder | nvidia | "2024-05-24T17:38:53Z" | 657,917 | 24 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2401.10225",
"arxiv:2302.07452",
"license:other",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-04-30T21:21:45Z" | ---
language:
- en
tag:
- dragon
- retriever
- conversation
- multi-turn
- conversational query
license:
- other
---
## Model Description
We introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the [Dragon](https://huggingface.co/facebook/dragon-plus-query-encoder) retriever. The details of Dragon-multiturn can be found in [here](https://arxiv.org/pdf/2401.10225). **Please note that Dragon-multiturn is a dual encoder consisting of a query encoder and a context encoder. This repository is only for the context encoder of Dragon-multiturn for getting the context embeddings, and you also need the query encoder to get query embeddings, which can be found [here](https://huggingface.co/nvidia/dragon-multiturn-query-encoder). Both query encoder and context encoder share the same tokenizer.**
## Other Resources
[Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)   [Llama3-ChatQA-1.5-70B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-70B)   [Evaluation Data](https://huggingface.co/datasets/nvidia/ChatRAG-Bench)   [Training Data](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data)   [Website](https://chatqa-project.github.io/)   [Paper](https://arxiv.org/pdf/2401.10225)
## Benchmark Results
<style type="text/css">
.tg {border:none;border-collapse:collapse;border-spacing:0;}
.tg td{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;overflow:hidden;
padding:10px 5px;word-break:normal;}
.tg th{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;font-weight:normal;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:center}
.tg .tg-0pky{border-color:inherit;text-align:left;vertical-align:center}
</style>
<table class="tg">
<thead>
<tr>
<th class="tg-0pky" rowspan="2"></th>
<th class="tg-c3ow" colspan="2">Average</th>
<th class="tg-c3ow" colspan="2">Doc2Dial</th>
<th class="tg-c3ow" colspan="2">QuAC</th>
<th class="tg-c3ow" colspan="2">QReCC</th>
<th class="tg-c3ow" colspan="2">TopiOCQA</th>
<th class="tg-c3ow" colspan="2">INSCIT</th>
</tr>
<tr>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-0pky">Dragon</td>
<td class="tg-c3ow">46.3</td>
<td class="tg-c3ow">73.1</td>
<td class="tg-c3ow">43.3</td>
<td class="tg-c3ow">75.6</td>
<td class="tg-c3ow">56.8</td>
<td class="tg-c3ow">82.9</td>
<td class="tg-c3ow">46.2</td>
<td class="tg-c3ow">82.0</td>
<td class="tg-c3ow">57.7</td>
<td class="tg-c3ow">78.8</td>
<td class="tg-c3ow">27.5</td>
<td class="tg-c3ow">46.2</td>
</tr>
<tr>
<td class="tg-0pky">Dragon-multiturn</td>
<td class="tg-c3ow">53.0</td>
<td class="tg-c3ow">81.2</td>
<td class="tg-c3ow">48.6</td>
<td class="tg-c3ow">83.5</td>
<td class="tg-c3ow">54.8</td>
<td class="tg-c3ow">83.2</td>
<td class="tg-c3ow">49.6</td>
<td class="tg-c3ow">86.7</td>
<td class="tg-c3ow">64.5</td>
<td class="tg-c3ow">85.2</td>
<td class="tg-c3ow">47.4</td>
<td class="tg-c3ow">67.1</td>
</tr>
</tbody>
</table>
Retrieval results across five multi-turn QA datasets (Doc2Dial, QuAC, QReCC, TopiOCQA, INSCIT) with the average top-1 and top-5 recall scores. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets.
## How to use
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('nvidia/dragon-multiturn-query-encoder')
query_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-query-encoder')
context_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-context-encoder')
query = [
{"role": "user", "content": "I need help planning my Social Security benefits for my survivors."},
{"role": "agent", "content": "Are you currently planning for your future?"},
{"role": "user", "content": "Yes, I am."}
]
contexts = [
"Benefits Planner: Survivors | Planning For Your Survivors \nAs you plan for the future , you'll want to think about what your family would need if you should die now. Social Security can help your family if you have earned enough Social Security credits through your work. You can earn up to four credits each year. In 2019 , for example , you earn one credit for each $1,360 of wages or self - employment income. When you have earned $5,440 , you have earned your four credits for the year. The number of credits needed to provide benefits for your survivors depends on your age when you die. No one needs more than 40 credits 10 years of work to be eligible for any Social Security benefit. But , the younger a person is , the fewer credits they must have for family members to receive survivors benefits. Benefits can be paid to your children and your spouse who is caring for the children even if you don't have the required number of credits. They can get benefits if you have credit for one and one - half years of work 6 credits in the three years just before your death. For Your Widow Or Widower \nThere are about five million widows and widowers receiving monthly Social Security benefits based on their deceased spouse's earnings record.",
"Benefits Planner: Retirement \nOther Things to Consider \nWhat Is The Best Age To Start Your Benefits? The answer is that there is no one \" best age \" for everyone and, ultimately, it is your choice. You should make an informed decision about when to apply for benefits based on your individual and family circumstances. Your monthly benefit amount can differ substantially based on the age when you start receiving benefits. If you decide to start benefits : before your full retirement age , your benefit will be smaller but you will receive it for a longer period of time. at your full retirement age or later , you will receive a larger monthly benefit for a shorter period of time. The amount you receive when you first get benefits sets the base for the amount you will receive for the rest of your life. You may want to consider the following when you make that decision : If you plan to continue working , there are limits on how much you can earn each year between age 62 and full retirement age and still get all your benefits. Depending on the amount of your benefit and your earnings for the year , you may have to give up some of your benefits."
]
## convert query into a format as follows:
## user: {user}\nagent: {agent}\nuser: {user}
formatted_query = '\n'.join([turn['role'] + ": " + turn['content'] for turn in query]).strip()
## get query and context embeddings
query_input = tokenizer(formatted_query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, max_length=512, return_tensors='pt')
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :] # (1, emb_dim)
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :] # (num_ctx, emb_dim)
## Compute similarity scores using dot product
similarities = query_emb.matmul(ctx_emb.transpose(0, 1)) # (1, num_ctx)
## rank the similarity (from highest to lowest)
ranked_results = torch.argsort(similarities, dim=-1, descending=True) # (1, num_ctx)
```
## Evaluations on Multi-Turn QA Retrieval Benchmark
**(UPDATE!!)** We evaluate multi-turn QA retrieval on five datasets: Doc2Dial, QuAC, QReCC, TopiOCQA, and INSCIT, which can be found in the [ChatRAG Bench](https://huggingface.co/datasets/nvidia/ChatRAG-Bench). The evaluation scripts can be found [here](https://huggingface.co/nvidia/dragon-multiturn-query-encoder/tree/main/evaluation).
## License
Dragon-multiturn is built on top of [Dragon](https://arxiv.org/abs/2302.07452). We refer users to the original license of the Dragon model. Dragon-multiturn is also subject to the [Terms of Use](https://openai.com/policies/terms-of-use).
## Correspondence to
Zihan Liu ([email protected]), Wei Ping ([email protected])
## Citation
<pre>
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}
</pre>
|
naver/splade-cocondenser-selfdistil | naver | "2022-05-11T08:02:55Z" | 657,310 | 9 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"en",
"dataset:ms_marco",
"arxiv:2205.04733",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-05-09T12:48:34Z" | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
datasets:
- ms_marco
---
## SPLADE CoCondenser SelfDistil
SPLADE model for passage retrieval. For additional details, please visit:
* paper: https://arxiv.org/abs/2205.04733
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) |
| --- | --- | --- |
| `splade-cocondenser-selfdistil` | 37.6 | 98.4 |
## Citation
If you use our checkpoint, please cite our work:
```
@misc{https://doi.org/10.48550/arxiv.2205.04733,
doi = {10.48550/ARXIV.2205.04733},
url = {https://arxiv.org/abs/2205.04733},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
``` |
microsoft/table-transformer-structure-recognition | microsoft | "2023-09-06T14:50:49Z" | 655,973 | 161 | transformers | [
"transformers",
"pytorch",
"safetensors",
"table-transformer",
"object-detection",
"arxiv:2110.00061",
"license:mit",
"endpoints_compatible",
"region:us"
] | object-detection | "2022-10-14T09:19:57Z" | ---
license: mit
widget:
- src: https://documentation.tricentis.com/tosca/1420/en/content/tbox/images/table.png
example_title: Table
---
# Table Transformer (fine-tuned for Table Structure Recognition)
Table Transformer (DETR) model trained on PubTables1M. It was introduced in the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Smock et al. and first released in [this repository](https://github.com/microsoft/table-transformer).
Disclaimer: The team releasing Table Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Table Transformer is equivalent to [DETR](https://huggingface.co/docs/transformers/model_doc/detr), a Transformer-based object detection model. Note that the authors decided to use the "normalize before" setting of DETR, which means that layernorm is applied before self- and cross-attention.
## Usage
You can use the raw model for detecting the structure (like rows, columns) in tables. See the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/table-transformer) for more info. |
nvidia/dragon-multiturn-query-encoder | nvidia | "2024-05-24T17:37:31Z" | 655,596 | 54 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2401.10225",
"arxiv:2302.07452",
"license:other",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-04-30T18:44:35Z" | ---
language:
- en
tag:
- dragon
- retriever
- conversation
- multi-turn
- conversational query
license:
- other
---
## Model Description
We introduce Dragon-multiturn, a retriever specifically designed for the conversational QA scenario. It can handle conversational query which combine dialogue history with the current query. It is built on top of the [Dragon](https://huggingface.co/facebook/dragon-plus-query-encoder) retriever. The details of Dragon-multiturn can be found in [here](https://arxiv.org/pdf/2401.10225). **Please note that Dragon-multiturn is a dual encoder consisting of a query encoder and a context encoder. This repository is only for the query encoder of Dragon-multiturn for getting the query embeddings, and you also need the context encoder to get context embeddings, which can be found [here](https://huggingface.co/nvidia/dragon-multiturn-context-encoder). Both query encoder and context encoder share the same tokenizer.**
## Other Resources
[Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)   [Llama3-ChatQA-1.5-70B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-70B)   [Evaluation Data](https://huggingface.co/datasets/nvidia/ChatRAG-Bench)   [Training Data](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data)   [Website](https://chatqa-project.github.io/)   [Paper](https://arxiv.org/pdf/2401.10225)
## Benchmark Results
<style type="text/css">
.tg {border:none;border-collapse:collapse;border-spacing:0;}
.tg td{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;overflow:hidden;
padding:10px 5px;word-break:normal;}
.tg th{border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;font-weight:normal;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:center}
.tg .tg-0pky{border-color:inherit;text-align:left;vertical-align:center}
</style>
<table class="tg">
<thead>
<tr>
<th class="tg-0pky" rowspan="2"></th>
<th class="tg-c3ow" colspan="2">Average</th>
<th class="tg-c3ow" colspan="2">Doc2Dial</th>
<th class="tg-c3ow" colspan="2">QuAC</th>
<th class="tg-c3ow" colspan="2">QReCC</th>
<th class="tg-c3ow" colspan="2">TopiOCQA</th>
<th class="tg-c3ow" colspan="2">INSCIT</th>
</tr>
<tr>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-1</th>
<th class="tg-c3ow">top-5</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
<th class="tg-c3ow">top-5*</th>
<th class="tg-c3ow">top-20*</th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-0pky">Dragon</td>
<td class="tg-c3ow">46.3</td>
<td class="tg-c3ow">73.1</td>
<td class="tg-c3ow">43.3</td>
<td class="tg-c3ow">75.6</td>
<td class="tg-c3ow">56.8</td>
<td class="tg-c3ow">82.9</td>
<td class="tg-c3ow">46.2</td>
<td class="tg-c3ow">82.0</td>
<td class="tg-c3ow">57.7</td>
<td class="tg-c3ow">78.8</td>
<td class="tg-c3ow">27.5</td>
<td class="tg-c3ow">46.2</td>
</tr>
<tr>
<td class="tg-0pky">Dragon-multiturn</td>
<td class="tg-c3ow">53.0</td>
<td class="tg-c3ow">81.2</td>
<td class="tg-c3ow">48.6</td>
<td class="tg-c3ow">83.5</td>
<td class="tg-c3ow">54.8</td>
<td class="tg-c3ow">83.2</td>
<td class="tg-c3ow">49.6</td>
<td class="tg-c3ow">86.7</td>
<td class="tg-c3ow">64.5</td>
<td class="tg-c3ow">85.2</td>
<td class="tg-c3ow">47.4</td>
<td class="tg-c3ow">67.1</td>
</tr>
</tbody>
</table>
Retrieval results across five multi-turn QA datasets (Doc2Dial, QuAC, QReCC, TopiOCQA, INSCIT) with the average top-1 and top-5 recall scores. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets.
## How to use
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('nvidia/dragon-multiturn-query-encoder')
query_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-query-encoder')
context_encoder = AutoModel.from_pretrained('nvidia/dragon-multiturn-context-encoder')
query = [
{"role": "user", "content": "I need help planning my Social Security benefits for my survivors."},
{"role": "agent", "content": "Are you currently planning for your future?"},
{"role": "user", "content": "Yes, I am."}
]
contexts = [
"Benefits Planner: Survivors | Planning For Your Survivors \nAs you plan for the future , you'll want to think about what your family would need if you should die now. Social Security can help your family if you have earned enough Social Security credits through your work. You can earn up to four credits each year. In 2019 , for example , you earn one credit for each $1,360 of wages or self - employment income. When you have earned $5,440 , you have earned your four credits for the year. The number of credits needed to provide benefits for your survivors depends on your age when you die. No one needs more than 40 credits 10 years of work to be eligible for any Social Security benefit. But , the younger a person is , the fewer credits they must have for family members to receive survivors benefits. Benefits can be paid to your children and your spouse who is caring for the children even if you don't have the required number of credits. They can get benefits if you have credit for one and one - half years of work 6 credits in the three years just before your death. For Your Widow Or Widower \nThere are about five million widows and widowers receiving monthly Social Security benefits based on their deceased spouse's earnings record.",
"Benefits Planner: Retirement \nOther Things to Consider \nWhat Is The Best Age To Start Your Benefits? The answer is that there is no one \" best age \" for everyone and, ultimately, it is your choice. You should make an informed decision about when to apply for benefits based on your individual and family circumstances. Your monthly benefit amount can differ substantially based on the age when you start receiving benefits. If you decide to start benefits : before your full retirement age , your benefit will be smaller but you will receive it for a longer period of time. at your full retirement age or later , you will receive a larger monthly benefit for a shorter period of time. The amount you receive when you first get benefits sets the base for the amount you will receive for the rest of your life. You may want to consider the following when you make that decision : If you plan to continue working , there are limits on how much you can earn each year between age 62 and full retirement age and still get all your benefits. Depending on the amount of your benefit and your earnings for the year , you may have to give up some of your benefits."
]
## convert query into a format as follows:
## user: {user}\nagent: {agent}\nuser: {user}
formatted_query = '\n'.join([turn['role'] + ": " + turn['content'] for turn in query]).strip()
## get query and context embeddings
query_input = tokenizer(formatted_query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, max_length=512, return_tensors='pt')
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
## Compute similarity scores using dot product
similarities = query_emb.matmul(ctx_emb.transpose(0, 1)) # (1, num_ctx)
## rank the similarity (from highest to lowest)
ranked_results = torch.argsort(similarities, dim=-1, descending=True) # (1, num_ctx)
```
## Evaluations on Multi-Turn QA Retrieval Benchmark
**(UPDATE!!)** We evaluate multi-turn QA retrieval on five datasets: Doc2Dial, QuAC, QReCC, TopiOCQA, and INSCIT, which can be found in the [ChatRAG Bench](https://huggingface.co/datasets/nvidia/ChatRAG-Bench). The evaluation scripts can be found [here](https://huggingface.co/nvidia/dragon-multiturn-query-encoder/tree/main/evaluation).
## License
Dragon-multiturn is built on top of [Dragon](https://arxiv.org/abs/2302.07452). We refer users to the original license of the Dragon model. Dragon-multiturn is also subject to the [Terms of Use](https://openai.com/policies/terms-of-use).
## Correspondence to
Zihan Liu ([email protected]), Wei Ping ([email protected])
## Citation
<pre>
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}
</pre>
|
ahmedrachid/FinancialBERT-Sentiment-Analysis | ahmedrachid | "2022-02-07T14:58:57Z" | 653,245 | 67 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"en",
"dataset:financial_phrasebank",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: en
tags:
- financial-sentiment-analysis
- sentiment-analysis
datasets:
- financial_phrasebank
widget:
- text: Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales.
- text: Bids or offers include at least 1,000 shares and the value of the shares must correspond to at least EUR 4,000.
- text: Raute reported a loss per share of EUR 0.86 for the first half of 2009 , against EPS of EUR 0.74 in the corresponding period of 2008.
---
### FinancialBERT for Sentiment Analysis
[*FinancialBERT*](https://huggingface.co/ahmedrachid/FinancialBERT) is a BERT model pre-trained on a large corpora of financial texts. The purpose is to enhance financial NLP research and practice in financial domain, hoping that financial practitioners and researchers can benefit from this model without the necessity of the significant computational resources required to train the model.
The model was fine-tuned for Sentiment Analysis task on _Financial PhraseBank_ dataset. Experiments show that this model outperforms the general BERT and other financial domain-specific models.
More details on `FinancialBERT`'s pre-training process can be found at: https://www.researchgate.net/publication/358284785_FinancialBERT_-_A_Pretrained_Language_Model_for_Financial_Text_Mining
### Training data
FinancialBERT model was fine-tuned on [Financial PhraseBank](https://www.researchgate.net/publication/251231364_FinancialPhraseBank-v10), a dataset consisting of 4840 Financial News categorised by sentiment (negative, neutral, positive).
### Fine-tuning hyper-parameters
- learning_rate = 2e-5
- batch_size = 32
- max_seq_length = 512
- num_train_epochs = 5
### Evaluation metrics
The evaluation metrics used are: Precision, Recall and F1-score. The following is the classification report on the test set.
| sentiment | precision | recall | f1-score | support |
| ------------- |:-------------:|:-------------:|:-------------:| -----:|
| negative | 0.96 | 0.97 | 0.97 | 58 |
| neutral | 0.98 | 0.99 | 0.98 | 279 |
| positive | 0.98 | 0.97 | 0.97 | 148 |
| macro avg | 0.97 | 0.98 | 0.98 | 485 |
| weighted avg | 0.98 | 0.98 | 0.98 | 485 |
### How to use
The model can be used thanks to Transformers pipeline for sentiment analysis.
```python
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
model = BertForSequenceClassification.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis",num_labels=3)
tokenizer = BertTokenizer.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis")
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
sentences = ["Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales.",
"Bids or offers include at least 1,000 shares and the value of the shares must correspond to at least EUR 4,000.",
"Raute reported a loss per share of EUR 0.86 for the first half of 2009 , against EPS of EUR 0.74 in the corresponding period of 2008.",
]
results = nlp(sentences)
print(results)
[{'label': 'positive', 'score': 0.9998133778572083},
{'label': 'neutral', 'score': 0.9997822642326355},
{'label': 'negative', 'score': 0.9877365231513977}]
```
> Created by [Ahmed Rachid Hazourli](https://www.linkedin.com/in/ahmed-rachid/)
|
facebook/contriever | facebook | "2022-01-19T17:23:28Z" | 647,552 | 56 | transformers | [
"transformers",
"pytorch",
"bert",
"arxiv:2112.09118",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | This model has been trained without supervision following the approach described in [Towards Unsupervised Dense Information Retrieval with Contrastive Learning](https://arxiv.org/abs/2112.09118). The associated GitHub repository is available here https://github.com/facebookresearch/contriever.
## Usage (HuggingFace Transformers)
Using the model directly available in HuggingFace transformers requires to add a mean pooling operation to obtain a sentence embedding.
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('facebook/contriever')
model = AutoModel.from_pretrained('facebook/contriever')
sentences = [
"Where was Marie Curie born?",
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Apply tokenizer
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
outputs = model(**inputs)
# Mean pooling
def mean_pooling(token_embeddings, mask):
token_embeddings = token_embeddings.masked_fill(~mask[..., None].bool(), 0.)
sentence_embeddings = token_embeddings.sum(dim=1) / mask.sum(dim=1)[..., None]
return sentence_embeddings
embeddings = mean_pooling(outputs[0], inputs['attention_mask'])
``` |
llava-hf/llava-1.5-7b-hf | llava-hf | "2024-09-14T07:47:50Z" | 645,237 | 190 | transformers | [
"transformers",
"safetensors",
"llava",
"pretraining",
"vision",
"image-text-to-text",
"en",
"dataset:liuhaotian/LLaVA-Instruct-150K",
"license:llama2",
"region:us"
] | image-text-to-text | "2023-12-05T09:31:24Z" | ---
language:
- en
datasets:
- liuhaotian/LLaVA-Instruct-150K
pipeline_tag: image-text-to-text
inference: false
arxiv: 2304.08485
license: llama2
tags:
- vision
- image-text-to-text
---
# LLaVA Model Card

Below is the model card of Llava model 7b, which is copied from the original Llava model card that you can find [here](https://huggingface.co/liuhaotian/llava-v1.5-13b).
Check out also the Google Colab demo to run Llava on a free-tier Google Colab instance: [](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing)
Or check out our Spaces demo! [](https://huggingface.co/spaces/llava-hf/llava-4bit)
## Model details
**Model type:**
LLaVA is an open-source chatbot trained by fine-tuning LLaMA/Vicuna on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
LLaVA-v1.5-7B was trained in September 2023.
**Paper or resources for more information:**
https://llava-vl.github.io/
## How to use the model
First, make sure to have `transformers >= 4.35.3`.
The model supports multi-image and multi-prompt generation. Meaning that you can pass multiple images in your prompt. Make sure also to follow the correct prompt template (`USER: xxx\nASSISTANT:`) and add the token `<image>` to the location where you want to query images:
### Using `pipeline`:
Below we used [`"llava-hf/llava-1.5-7b-hf"`](https://huggingface.co/llava-hf/llava-1.5-7b-hf) checkpoint.
```python
from transformers import pipeline, AutoProcessor
from PIL import Image
import requests
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Define a chat history and use `apply_chat_template` to get correctly formatted prompt
# Each value in "content" has to be a list of dicts with types ("text", "image")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud"},
{"type": "image"},
],
},
]
processor = AutoProcessor.from_pretrained(model_id)
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs)
>>> {"generated_text": "\nUSER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud\nASSISTANT: Lava"}
```
### Using pure `transformers`:
Below is an example script to run generation in `float16` precision on a GPU device:
```python
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(0)
processor = AutoProcessor.from_pretrained(model_id)
# Define a chat histiry and use `apply_chat_template` to get correctly formatted prompt
# Each value in "content" has to be a list of dicts with types ("text", "image")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are these?"},
{"type": "image"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(images=raw_image, text=prompt, return_tensors='pt').to(0, torch.float16)
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))
```
### Model optimization
#### 4-bit quantization through `bitsandbytes` library
First make sure to install `bitsandbytes`, `pip install bitsandbytes` and make sure to have access to a CUDA compatible GPU device. Simply change the snippet above with:
```diff
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
+ load_in_4bit=True
)
```
#### Use Flash-Attention 2 to further speed-up generation
First make sure to install `flash-attn`. Refer to the [original repository of Flash Attention](https://github.com/Dao-AILab/flash-attention) regarding that package installation. Simply change the snippet above with:
```diff
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
+ use_flash_attention_2=True
).to(0)
```
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved. |
meta-llama/Llama-2-13b-chat-hf | meta-llama | "2024-04-17T08:40:58Z" | 640,010 | 1,018 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"conversational",
"en",
"arxiv:2307.09288",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-07-13T15:11:20Z" | ---
extra_gated_heading: You need to share contact information with Meta to access this model
extra_gated_prompt: >-
### LLAMA 2 COMMUNITY LICENSE AGREEMENT
"Agreement" means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation
accompanying Llama 2 distributed by Meta at
https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Licensee" or "you" means you, or your employer or any other person or entity
(if you are entering into this Agreement on such person or entity's behalf),
of the age required under applicable laws, rules or regulations to provide
legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Llama 2" means the foundational large language models and software and
algorithms, including machine-learning model code, trained model weights,
inference-enabling code, training-enabling code, fine-tuning enabling code and
other elements of the foregoing distributed by Meta at
ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Llama Materials" means, collectively, Meta's proprietary Llama 2 and
documentation (and any portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or
Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA
or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or
element of the Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
transferable and royalty-free limited license under Meta's intellectual
property or other rights owned by Meta embodied in the Llama Materials to
use, reproduce, distribute, copy, create derivative works of, and make
modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make the Llama Materials, or any derivative works
thereof, available to a third party, you shall provide a copy of this
Agreement to such third party.
ii. If you receive Llama Materials, or any derivative works thereof, from a
Licensee as part of an integrated end user product, then Section 2 of this
Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute
the following attribution notice within a "Notice" text file distributed as a
part of such copies: "Llama 2 is licensed under the LLAMA 2 Community
License, Copyright (c) Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and
regulations (including trade compliance laws and regulations) and adhere to
the Acceptable Use Policy for the Llama Materials (available at
https://ai.meta.com/llama/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama
Materials to improve any other large language model (excluding Llama 2 or
derivative works thereof).
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
monthly active users of the products or services made available by or for
Licensee, or Licensee's affiliates, is greater than 700 million monthly
active users in the preceding calendar month, you must request a license from
Meta, which Meta may grant to you in its sole discretion, and you are not
authorized to exercise any of the rights under this Agreement unless or until
Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA
MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS"
BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING,
WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY
RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING
THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE
LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE
UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE,
PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST
PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR
PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE
POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection
with the Llama Materials, neither Meta nor Licensee may use any name or mark
owned by or associated with the other or any of its affiliates, except as
required for reasonable and customary use in describing and redistributing
the Llama Materials.
b. Subject to Meta's ownership of Llama Materials and derivatives made by or
for Meta, with respect to any derivative works and modifications of the Llama
Materials that are made by you, as between you and Meta, you are and will be
the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any
entity (including a cross-claim or counterclaim in a lawsuit) alleging that
the Llama Materials or Llama 2 outputs or results, or any portion of any of
the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under
this Agreement shall terminate as of the date such litigation or claim is
filed or instituted. You will indemnify and hold harmless Meta from and
against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will
continue in full force and effect until terminated in accordance with the
terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this
Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and
construed under the laws of the State of California without regard to choice
of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California
shall have exclusive jurisdiction of any dispute arising out of this
Agreement.
### Llama 2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features,
including Llama 2. If you access or use Llama 2, you agree to this Acceptable
Use Policy (“Policy”). The most recent copy of this policy can be found at
[ai.meta.com/llama/use-policy](http://ai.meta.com/llama/use-policy).
#### Prohibited Uses
We want everyone to use Llama 2 safely and responsibly. You agree you will not
use, or allow others to use, Llama 2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama 2 Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or
development of activities that present a risk of death or bodily harm to
individuals, including use of Llama 2 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 2 related
to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Llama 2 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems
that could lead to a violation of this Policy through one of the following
means:
* Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama: [[email protected]](mailto:[email protected])
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
license: llama2
---
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 13B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/meta-llama/Llama-2-7b) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/meta-llama/Llama-2-13b) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf)|
|70B| [Link](https://huggingface.co/meta-llama/Llama-2-70b) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-hf) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-chat) | [Link](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)| |
lmsys/vicuna-7b-v1.5 | lmsys | "2024-03-13T02:01:41Z" | 631,851 | 294 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2307.09288",
"arxiv:2306.05685",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2023-07-29T04:42:33Z" | ---
inference: false
license: llama2
---
# Vicuna Model Card
## Model Details
Vicuna is a chat assistant trained by fine-tuning Llama 2 on user-shared conversations collected from ShareGPT.
- **Developed by:** [LMSYS](https://lmsys.org/)
- **Model type:** An auto-regressive language model based on the transformer architecture
- **License:** Llama 2 Community License Agreement
- **Finetuned from model:** [Llama 2](https://arxiv.org/abs/2307.09288)
### Model Sources
- **Repository:** https://github.com/lm-sys/FastChat
- **Blog:** https://lmsys.org/blog/2023-03-30-vicuna/
- **Paper:** https://arxiv.org/abs/2306.05685
- **Demo:** https://chat.lmsys.org/
## Uses
The primary use of Vicuna is research on large language models and chatbots.
The primary intended users of the model are researchers and hobbyists in natural language processing, machine learning, and artificial intelligence.
## How to Get Started with the Model
- Command line interface: https://github.com/lm-sys/FastChat#vicuna-weights
- APIs (OpenAI API, Huggingface API): https://github.com/lm-sys/FastChat/tree/main#api
## Training Details
Vicuna v1.5 is fine-tuned from Llama 2 with supervised instruction fine-tuning.
The training data is around 125K conversations collected from ShareGPT.com.
See more details in the "Training Details of Vicuna Models" section in the appendix of this [paper](https://arxiv.org/pdf/2306.05685.pdf).
## Evaluation

Vicuna is evaluated with standard benchmarks, human preference, and LLM-as-a-judge. See more details in this [paper](https://arxiv.org/pdf/2306.05685.pdf) and [leaderboard](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard).
## Difference between different versions of Vicuna
See [vicuna_weights_version.md](https://github.com/lm-sys/FastChat/blob/main/docs/vicuna_weights_version.md) |
kha-white/manga-ocr-base | kha-white | "2022-06-22T15:34:05Z" | 631,153 | 115 | transformers | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-to-text",
"ja",
"dataset:manga109s",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-to-text | "2022-03-02T23:29:05Z" | ---
language: ja
tags:
- image-to-text
license: apache-2.0
datasets:
- manga109s
---
# Manga OCR
Optical character recognition for Japanese text, with the main focus being Japanese manga.
It uses [Vision Encoder Decoder](https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder) framework.
Manga OCR can be used as a general purpose printed Japanese OCR, but its main goal was to provide a high quality
text recognition, robust against various scenarios specific to manga:
- both vertical and horizontal text
- text with furigana
- text overlaid on images
- wide variety of fonts and font styles
- low quality images
Code is available [here](https://github.com/kha-white/manga_ocr).
|
google-bert/bert-base-multilingual-uncased | google-bert | "2024-02-19T11:06:00Z" | 628,912 | 101 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language:
- multilingual
- af
- sq
- ar
- an
- hy
- ast
- az
- ba
- eu
- bar
- be
- bn
- inc
- bs
- br
- bg
- my
- ca
- ceb
- ce
- zh
- cv
- hr
- cs
- da
- nl
- en
- et
- fi
- fr
- gl
- ka
- de
- el
- gu
- ht
- he
- hi
- hu
- is
- io
- id
- ga
- it
- ja
- jv
- kn
- kk
- ky
- ko
- la
- lv
- lt
- roa
- nds
- lm
- mk
- mg
- ms
- ml
- mr
- min
- ne
- new
- nb
- nn
- oc
- fa
- pms
- pl
- pt
- pa
- ro
- ru
- sco
- sr
- hr
- scn
- sk
- sl
- aze
- es
- su
- sw
- sv
- tl
- tg
- ta
- tt
- te
- tr
- uk
- ud
- uz
- vi
- vo
- war
- cy
- fry
- pnb
- yo
license: apache-2.0
datasets:
- wikipedia
---
# BERT multilingual base model (uncased)
Pretrained model on the top 102 languages with the largest Wikipedia using a masked language modeling (MLM) objective.
It was introduced in [this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of multilingual data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the languages in the training set that can then be used to
extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a
standard classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-multilingual-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a top model. [SEP]",
'score': 0.1507750153541565,
'token': 11397,
'token_str': 'top'},
{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.13075384497642517,
'token': 23589,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a good model. [SEP]",
'score': 0.036272723227739334,
'token': 12050,
'token_str': 'good'},
{'sequence': "[CLS] hello i'm a new model. [SEP]",
'score': 0.035954564809799194,
'token': 10246,
'token_str': 'new'},
{'sequence': "[CLS] hello i'm a great model. [SEP]",
'score': 0.028643041849136353,
'token': 11838,
'token_str': 'great'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased')
model = BertModel.from_pretrained("bert-base-multilingual-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased')
model = TFBertModel.from_pretrained("bert-base-multilingual-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-multilingual-uncased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] the man worked as a teacher. [SEP]',
'score': 0.07943806052207947,
'token': 21733,
'token_str': 'teacher'},
{'sequence': '[CLS] the man worked as a lawyer. [SEP]',
'score': 0.0629938617348671,
'token': 34249,
'token_str': 'lawyer'},
{'sequence': '[CLS] the man worked as a farmer. [SEP]',
'score': 0.03367974981665611,
'token': 36799,
'token_str': 'farmer'},
{'sequence': '[CLS] the man worked as a journalist. [SEP]',
'score': 0.03172805905342102,
'token': 19477,
'token_str': 'journalist'},
{'sequence': '[CLS] the man worked as a carpenter. [SEP]',
'score': 0.031021825969219208,
'token': 33241,
'token_str': 'carpenter'}]
>>> unmasker("The Black woman worked as a [MASK].")
[{'sequence': '[CLS] the black woman worked as a nurse. [SEP]',
'score': 0.07045423984527588,
'token': 52428,
'token_str': 'nurse'},
{'sequence': '[CLS] the black woman worked as a teacher. [SEP]',
'score': 0.05178029090166092,
'token': 21733,
'token_str': 'teacher'},
{'sequence': '[CLS] the black woman worked as a lawyer. [SEP]',
'score': 0.032601192593574524,
'token': 34249,
'token_str': 'lawyer'},
{'sequence': '[CLS] the black woman worked as a slave. [SEP]',
'score': 0.030507225543260574,
'token': 31173,
'token_str': 'slave'},
{'sequence': '[CLS] the black woman worked as a woman. [SEP]',
'score': 0.027691684663295746,
'token': 14050,
'token_str': 'woman'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on the 102 languages with the largest Wikipedias. You can find the complete list
[here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a shared vocabulary size of 110,000. The languages with a
larger Wikipedia are under-sampled and the ones with lower resources are oversampled. For languages like Chinese,
Japanese Kanji and Korean Hanja that don't have space, a CJK Unicode block is added around every character.
The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
google/owlv2-base-patch16-ensemble | google | "2024-04-15T16:59:29Z" | 624,999 | 62 | transformers | [
"transformers",
"pytorch",
"safetensors",
"owlv2",
"zero-shot-object-detection",
"vision",
"arxiv:2306.09683",
"license:apache-2.0",
"region:us"
] | zero-shot-object-detection | "2023-10-13T09:27:09Z" | ---
license: apache-2.0
tags:
- vision
- zero-shot-object-detection
inference: false
---
# Model Card: OWLv2
## Model Details
The OWLv2 model (short for Open-World Localization) was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2, like OWL-ViT, is a zero-shot text-conditioned object detection model that can be used to query an image with one or multiple text queries.
The model uses CLIP as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
### Model Date
June 2023
### Model Type
The model uses a CLIP backbone with a ViT-B/16 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss. The CLIP backbone is trained from scratch and fine-tuned together with the box and class prediction heads with an object detection objective.
### Documents
- [OWLv2 Paper](https://arxiv.org/abs/2306.09683)
### Use with Transformers
```python
import requests
from PIL import Image
import numpy as np
import torch
from transformers import AutoProcessor, Owlv2ForObjectDetection
from transformers.utils.constants import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = [["a photo of a cat", "a photo of a dog"]]
inputs = processor(text=texts, images=image, return_tensors="pt")
# forward pass
with torch.no_grad():
outputs = model(**inputs)
# Note: boxes need to be visualized on the padded, unnormalized image
# hence we'll set the target image sizes (height, width) based on that
def get_preprocessed_image(pixel_values):
pixel_values = pixel_values.squeeze().numpy()
unnormalized_image = (pixel_values * np.array(OPENAI_CLIP_STD)[:, None, None]) + np.array(OPENAI_CLIP_MEAN)[:, None, None]
unnormalized_image = (unnormalized_image * 255).astype(np.uint8)
unnormalized_image = np.moveaxis(unnormalized_image, 0, -1)
unnormalized_image = Image.fromarray(unnormalized_image)
return unnormalized_image
unnormalized_image = get_preprocessed_image(inputs.pixel_values)
target_sizes = torch.Tensor([unnormalized_image.size[::-1]])
# Convert outputs (bounding boxes and class logits) to final bounding boxes and scores
results = processor.post_process_object_detection(
outputs=outputs, threshold=0.2, target_sizes=target_sizes
)
i = 0 # Retrieve predictions for the first image for the corresponding text queries
text = texts[i]
boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
for box, score, label in zip(boxes, scores, labels):
box = [round(i, 2) for i in box.tolist()]
print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, text-conditioned object detection. We also hope it can be used for interdisciplinary studies of the potential impact of such models, especially in areas that commonly require identifying objects whose label is unavailable during training.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
## Data
The CLIP backbone of the model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet. The prediction heads of OWL-ViT, along with the CLIP backbone, are fine-tuned on publicly available object detection datasets such as [COCO](https://cocodataset.org/#home) and [OpenImages](https://storage.googleapis.com/openimages/web/index.html).
(to be updated for v2)
### BibTeX entry and citation info
```bibtex
@misc{minderer2023scaling,
title={Scaling Open-Vocabulary Object Detection},
author={Matthias Minderer and Alexey Gritsenko and Neil Houlsby},
year={2023},
eprint={2306.09683},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
bartowski/gemma-2-27b-it-GGUF | bartowski | "2024-08-03T22:54:43Z" | 624,984 | 135 | transformers | [
"transformers",
"gguf",
"text-generation",
"base_model:google/gemma-2-27b-it",
"base_model:quantized:google/gemma-2-27b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-27T17:54:57Z" | ---
base_model: google/gemma-2-27b-it
library_name: transformers
license: gemma
pipeline_tag: text-generation
quantized_by: bartowski
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
## Llamacpp imatrix Quantizations of gemma-2-27b-it
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3389">b3389</a> for quantization.
Original model: https://huggingface.co/google/gemma-2-27b-it
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Torrent files
https://aitorrent.zerroug.de/bartowski-gemma-2-27b-it-gguf-torrent/
## Prompt format
```
<start_of_turn>user
{prompt}<end_of_turn>
<start_of_turn>model
<end_of_turn>
<start_of_turn>model
```
Note that this model does not support a System prompt.
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [gemma-2-27b-it-f32.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/tree/main/gemma-2-27b-it-f32) | f32 | 108.91GB | true | Full F32 weights. |
| [gemma-2-27b-it-Q8_0.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q8_0.gguf) | Q8_0 | 28.94GB | false | Extremely high quality, generally unneeded but max available quant. |
| [gemma-2-27b-it-Q6_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q6_K_L.gguf) | Q6_K_L | 22.63GB | false | Uses Q8_0 for embed and output weights. Very high quality, near perfect, *recommended*. |
| [gemma-2-27b-it-Q6_K.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q6_K.gguf) | Q6_K | 22.34GB | false | Very high quality, near perfect, *recommended*. |
| [gemma-2-27b-it-Q5_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q5_K_L.gguf) | Q5_K_L | 19.69GB | false | Uses Q8_0 for embed and output weights. High quality, *recommended*. |
| [gemma-2-27b-it-Q5_K_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q5_K_M.gguf) | Q5_K_M | 19.41GB | false | High quality, *recommended*. |
| [gemma-2-27b-it-Q5_K_S.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q5_K_S.gguf) | Q5_K_S | 18.88GB | false | High quality, *recommended*. |
| [gemma-2-27b-it-Q4_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q4_K_L.gguf) | Q4_K_L | 16.93GB | false | Uses Q8_0 for embed and output weights. Good quality, *recommended*. |
| [gemma-2-27b-it-Q4_K_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q4_K_M.gguf) | Q4_K_M | 16.65GB | false | Good quality, default size for must use cases, *recommended*. |
| [gemma-2-27b-it-Q4_K_S.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q4_K_S.gguf) | Q4_K_S | 15.74GB | false | Slightly lower quality with more space savings, *recommended*. |
| [gemma-2-27b-it-IQ4_XS.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ4_XS.gguf) | IQ4_XS | 14.81GB | false | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [gemma-2-27b-it-Q3_K_XL.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_XL.gguf) | Q3_K_XL | 14.81GB | false | Uses Q8_0 for embed and output weights. Lower quality but usable, good for low RAM availability. |
| [gemma-2-27b-it-Q3_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_L.gguf) | Q3_K_L | 14.52GB | false | Lower quality but usable, good for low RAM availability. |
| [gemma-2-27b-it-Q3_K_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_M.gguf) | Q3_K_M | 13.42GB | false | Low quality. |
| [gemma-2-27b-it-IQ3_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ3_M.gguf) | IQ3_M | 12.45GB | false | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [gemma-2-27b-it-Q3_K_S.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q3_K_S.gguf) | Q3_K_S | 12.17GB | false | Low quality, not recommended. |
| [gemma-2-27b-it-IQ3_XS.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ3_XS.gguf) | IQ3_XS | 11.55GB | false | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [gemma-2-27b-it-IQ3_XXS.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ3_XXS.gguf) | IQ3_XXS | 10.75GB | false | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [gemma-2-27b-it-Q2_K_L.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q2_K_L.gguf) | Q2_K_L | 10.74GB | false | Uses Q8_0 for embed and output weights. Very low quality but surprisingly usable. |
| [gemma-2-27b-it-Q2_K.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-Q2_K.gguf) | Q2_K | 10.45GB | false | Very low quality but surprisingly usable. |
| [gemma-2-27b-it-IQ2_M.gguf](https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/blob/main/gemma-2-27b-it-IQ2_M.gguf) | IQ2_M | 9.40GB | false | Relatively low quality, uses SOTA techniques to be surprisingly usable. |
## Credits
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset
Thank you ZeroWw for the inspiration to experiment with embed/output
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/gemma-2-27b-it-GGUF --include "gemma-2-27b-it-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/gemma-2-27b-it-GGUF --include "gemma-2-27b-it-Q8_0.gguf/*" --local-dir gemma-2-27b-it-Q8_0
```
You can either specify a new local-dir (gemma-2-27b-it-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
WhereIsAI/UAE-Large-V1 | WhereIsAI | "2024-07-28T05:49:12Z" | 621,873 | 203 | sentence-transformers | [
"sentence-transformers",
"onnx",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence_embedding",
"feature_extraction",
"transformers",
"transformers.js",
"en",
"arxiv:2309.12871",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2023-12-04T02:03:27Z" | ---
tags:
- mteb
- sentence_embedding
- feature_extraction
- sentence-transformers
- transformers
- transformers.js
model-index:
- name: UAE-Large-V1
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.55223880597015
- type: ap
value: 38.264070815317794
- type: f1
value: 69.40977934769845
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.84267499999999
- type: ap
value: 89.57568507997713
- type: f1
value: 92.82590734337774
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.292
- type: f1
value: 47.90257816032778
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 42.105
- type: map_at_10
value: 58.181000000000004
- type: map_at_100
value: 58.653999999999996
- type: map_at_1000
value: 58.657000000000004
- type: map_at_3
value: 54.386
- type: map_at_5
value: 56.757999999999996
- type: mrr_at_1
value: 42.745
- type: mrr_at_10
value: 58.437
- type: mrr_at_100
value: 58.894999999999996
- type: mrr_at_1000
value: 58.897999999999996
- type: mrr_at_3
value: 54.635
- type: mrr_at_5
value: 56.99999999999999
- type: ndcg_at_1
value: 42.105
- type: ndcg_at_10
value: 66.14999999999999
- type: ndcg_at_100
value: 68.048
- type: ndcg_at_1000
value: 68.11399999999999
- type: ndcg_at_3
value: 58.477000000000004
- type: ndcg_at_5
value: 62.768
- type: precision_at_1
value: 42.105
- type: precision_at_10
value: 9.110999999999999
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 23.447000000000003
- type: precision_at_5
value: 16.159000000000002
- type: recall_at_1
value: 42.105
- type: recall_at_10
value: 91.11
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 70.341
- type: recall_at_5
value: 80.797
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 49.02580759154173
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.093601280163554
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.19590406875427
- type: mrr
value: 77.09547992788991
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 87.86678362843676
- type: cos_sim_spearman
value: 86.1423242570783
- type: euclidean_pearson
value: 85.98994198511751
- type: euclidean_spearman
value: 86.48209103503942
- type: manhattan_pearson
value: 85.6446436316182
- type: manhattan_spearman
value: 86.21039809734357
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.69155844155844
- type: f1
value: 87.68109381943547
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.37501687500394
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 37.23401405155885
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.232
- type: map_at_10
value: 41.404999999999994
- type: map_at_100
value: 42.896
- type: map_at_1000
value: 43.028
- type: map_at_3
value: 37.925
- type: map_at_5
value: 39.865
- type: mrr_at_1
value: 36.338
- type: mrr_at_10
value: 46.969
- type: mrr_at_100
value: 47.684
- type: mrr_at_1000
value: 47.731
- type: mrr_at_3
value: 44.063
- type: mrr_at_5
value: 45.908
- type: ndcg_at_1
value: 36.338
- type: ndcg_at_10
value: 47.887
- type: ndcg_at_100
value: 53.357
- type: ndcg_at_1000
value: 55.376999999999995
- type: ndcg_at_3
value: 42.588
- type: ndcg_at_5
value: 45.132
- type: precision_at_1
value: 36.338
- type: precision_at_10
value: 9.17
- type: precision_at_100
value: 1.4909999999999999
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 20.315
- type: precision_at_5
value: 14.793000000000001
- type: recall_at_1
value: 30.232
- type: recall_at_10
value: 60.67399999999999
- type: recall_at_100
value: 83.628
- type: recall_at_1000
value: 96.209
- type: recall_at_3
value: 45.48
- type: recall_at_5
value: 52.354
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.237
- type: map_at_10
value: 42.829
- type: map_at_100
value: 44.065
- type: map_at_1000
value: 44.199
- type: map_at_3
value: 39.885999999999996
- type: map_at_5
value: 41.55
- type: mrr_at_1
value: 40.064
- type: mrr_at_10
value: 48.611
- type: mrr_at_100
value: 49.245
- type: mrr_at_1000
value: 49.29
- type: mrr_at_3
value: 46.561
- type: mrr_at_5
value: 47.771
- type: ndcg_at_1
value: 40.064
- type: ndcg_at_10
value: 48.388
- type: ndcg_at_100
value: 52.666999999999994
- type: ndcg_at_1000
value: 54.67100000000001
- type: ndcg_at_3
value: 44.504
- type: ndcg_at_5
value: 46.303
- type: precision_at_1
value: 40.064
- type: precision_at_10
value: 9.051
- type: precision_at_100
value: 1.4500000000000002
- type: precision_at_1000
value: 0.193
- type: precision_at_3
value: 21.444
- type: precision_at_5
value: 15.045
- type: recall_at_1
value: 32.237
- type: recall_at_10
value: 57.943999999999996
- type: recall_at_100
value: 75.98700000000001
- type: recall_at_1000
value: 88.453
- type: recall_at_3
value: 46.268
- type: recall_at_5
value: 51.459999999999994
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.797
- type: map_at_10
value: 51.263000000000005
- type: map_at_100
value: 52.333
- type: map_at_1000
value: 52.393
- type: map_at_3
value: 47.936
- type: map_at_5
value: 49.844
- type: mrr_at_1
value: 44.389
- type: mrr_at_10
value: 54.601
- type: mrr_at_100
value: 55.300000000000004
- type: mrr_at_1000
value: 55.333
- type: mrr_at_3
value: 52.068999999999996
- type: mrr_at_5
value: 53.627
- type: ndcg_at_1
value: 44.389
- type: ndcg_at_10
value: 57.193000000000005
- type: ndcg_at_100
value: 61.307
- type: ndcg_at_1000
value: 62.529
- type: ndcg_at_3
value: 51.607
- type: ndcg_at_5
value: 54.409
- type: precision_at_1
value: 44.389
- type: precision_at_10
value: 9.26
- type: precision_at_100
value: 1.222
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.03
- type: precision_at_5
value: 15.887
- type: recall_at_1
value: 38.797
- type: recall_at_10
value: 71.449
- type: recall_at_100
value: 88.881
- type: recall_at_1000
value: 97.52
- type: recall_at_3
value: 56.503
- type: recall_at_5
value: 63.392
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.291999999999998
- type: map_at_10
value: 35.65
- type: map_at_100
value: 36.689
- type: map_at_1000
value: 36.753
- type: map_at_3
value: 32.995000000000005
- type: map_at_5
value: 34.409
- type: mrr_at_1
value: 29.04
- type: mrr_at_10
value: 37.486000000000004
- type: mrr_at_100
value: 38.394
- type: mrr_at_1000
value: 38.445
- type: mrr_at_3
value: 35.028
- type: mrr_at_5
value: 36.305
- type: ndcg_at_1
value: 29.04
- type: ndcg_at_10
value: 40.613
- type: ndcg_at_100
value: 45.733000000000004
- type: ndcg_at_1000
value: 47.447
- type: ndcg_at_3
value: 35.339999999999996
- type: ndcg_at_5
value: 37.706
- type: precision_at_1
value: 29.04
- type: precision_at_10
value: 6.192
- type: precision_at_100
value: 0.9249999999999999
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 14.802000000000001
- type: precision_at_5
value: 10.305
- type: recall_at_1
value: 27.291999999999998
- type: recall_at_10
value: 54.25299999999999
- type: recall_at_100
value: 77.773
- type: recall_at_1000
value: 90.795
- type: recall_at_3
value: 39.731
- type: recall_at_5
value: 45.403999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.326
- type: map_at_10
value: 26.290999999999997
- type: map_at_100
value: 27.456999999999997
- type: map_at_1000
value: 27.583000000000002
- type: map_at_3
value: 23.578
- type: map_at_5
value: 25.113000000000003
- type: mrr_at_1
value: 22.637
- type: mrr_at_10
value: 31.139
- type: mrr_at_100
value: 32.074999999999996
- type: mrr_at_1000
value: 32.147
- type: mrr_at_3
value: 28.483000000000004
- type: mrr_at_5
value: 29.963
- type: ndcg_at_1
value: 22.637
- type: ndcg_at_10
value: 31.717000000000002
- type: ndcg_at_100
value: 37.201
- type: ndcg_at_1000
value: 40.088
- type: ndcg_at_3
value: 26.686
- type: ndcg_at_5
value: 29.076999999999998
- type: precision_at_1
value: 22.637
- type: precision_at_10
value: 5.7090000000000005
- type: precision_at_100
value: 0.979
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.894
- type: precision_at_5
value: 9.328
- type: recall_at_1
value: 18.326
- type: recall_at_10
value: 43.824999999999996
- type: recall_at_100
value: 67.316
- type: recall_at_1000
value: 87.481
- type: recall_at_3
value: 29.866999999999997
- type: recall_at_5
value: 35.961999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.875
- type: map_at_10
value: 40.458
- type: map_at_100
value: 41.772
- type: map_at_1000
value: 41.882999999999996
- type: map_at_3
value: 37.086999999999996
- type: map_at_5
value: 39.153
- type: mrr_at_1
value: 36.381
- type: mrr_at_10
value: 46.190999999999995
- type: mrr_at_100
value: 46.983999999999995
- type: mrr_at_1000
value: 47.032000000000004
- type: mrr_at_3
value: 43.486999999999995
- type: mrr_at_5
value: 45.249
- type: ndcg_at_1
value: 36.381
- type: ndcg_at_10
value: 46.602
- type: ndcg_at_100
value: 51.885999999999996
- type: ndcg_at_1000
value: 53.895
- type: ndcg_at_3
value: 41.155
- type: ndcg_at_5
value: 44.182
- type: precision_at_1
value: 36.381
- type: precision_at_10
value: 8.402
- type: precision_at_100
value: 1.278
- type: precision_at_1000
value: 0.16199999999999998
- type: precision_at_3
value: 19.346
- type: precision_at_5
value: 14.09
- type: recall_at_1
value: 29.875
- type: recall_at_10
value: 59.065999999999995
- type: recall_at_100
value: 80.923
- type: recall_at_1000
value: 93.927
- type: recall_at_3
value: 44.462
- type: recall_at_5
value: 51.89
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.94
- type: map_at_10
value: 35.125
- type: map_at_100
value: 36.476
- type: map_at_1000
value: 36.579
- type: map_at_3
value: 31.840000000000003
- type: map_at_5
value: 33.647
- type: mrr_at_1
value: 30.936000000000003
- type: mrr_at_10
value: 40.637
- type: mrr_at_100
value: 41.471000000000004
- type: mrr_at_1000
value: 41.525
- type: mrr_at_3
value: 38.013999999999996
- type: mrr_at_5
value: 39.469
- type: ndcg_at_1
value: 30.936000000000003
- type: ndcg_at_10
value: 41.295
- type: ndcg_at_100
value: 46.92
- type: ndcg_at_1000
value: 49.183
- type: ndcg_at_3
value: 35.811
- type: ndcg_at_5
value: 38.306000000000004
- type: precision_at_1
value: 30.936000000000003
- type: precision_at_10
value: 7.728
- type: precision_at_100
value: 1.226
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.237
- type: precision_at_5
value: 12.42
- type: recall_at_1
value: 24.94
- type: recall_at_10
value: 54.235
- type: recall_at_100
value: 78.314
- type: recall_at_1000
value: 93.973
- type: recall_at_3
value: 38.925
- type: recall_at_5
value: 45.505
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.250833333333333
- type: map_at_10
value: 35.46875
- type: map_at_100
value: 36.667
- type: map_at_1000
value: 36.78025
- type: map_at_3
value: 32.56733333333334
- type: map_at_5
value: 34.20333333333333
- type: mrr_at_1
value: 30.8945
- type: mrr_at_10
value: 39.636833333333335
- type: mrr_at_100
value: 40.46508333333333
- type: mrr_at_1000
value: 40.521249999999995
- type: mrr_at_3
value: 37.140166666666666
- type: mrr_at_5
value: 38.60999999999999
- type: ndcg_at_1
value: 30.8945
- type: ndcg_at_10
value: 40.93441666666667
- type: ndcg_at_100
value: 46.062416666666664
- type: ndcg_at_1000
value: 48.28341666666667
- type: ndcg_at_3
value: 35.97575
- type: ndcg_at_5
value: 38.3785
- type: precision_at_1
value: 30.8945
- type: precision_at_10
value: 7.180250000000001
- type: precision_at_100
value: 1.1468333333333334
- type: precision_at_1000
value: 0.15283333333333332
- type: precision_at_3
value: 16.525583333333334
- type: precision_at_5
value: 11.798333333333332
- type: recall_at_1
value: 26.250833333333333
- type: recall_at_10
value: 52.96108333333333
- type: recall_at_100
value: 75.45908333333334
- type: recall_at_1000
value: 90.73924999999998
- type: recall_at_3
value: 39.25483333333333
- type: recall_at_5
value: 45.37950000000001
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.595
- type: map_at_10
value: 31.747999999999998
- type: map_at_100
value: 32.62
- type: map_at_1000
value: 32.713
- type: map_at_3
value: 29.48
- type: map_at_5
value: 30.635
- type: mrr_at_1
value: 27.607
- type: mrr_at_10
value: 34.449000000000005
- type: mrr_at_100
value: 35.182
- type: mrr_at_1000
value: 35.254000000000005
- type: mrr_at_3
value: 32.413
- type: mrr_at_5
value: 33.372
- type: ndcg_at_1
value: 27.607
- type: ndcg_at_10
value: 36.041000000000004
- type: ndcg_at_100
value: 40.514
- type: ndcg_at_1000
value: 42.851
- type: ndcg_at_3
value: 31.689
- type: ndcg_at_5
value: 33.479
- type: precision_at_1
value: 27.607
- type: precision_at_10
value: 5.66
- type: precision_at_100
value: 0.868
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 13.446
- type: precision_at_5
value: 9.264
- type: recall_at_1
value: 24.595
- type: recall_at_10
value: 46.79
- type: recall_at_100
value: 67.413
- type: recall_at_1000
value: 84.753
- type: recall_at_3
value: 34.644999999999996
- type: recall_at_5
value: 39.09
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.333000000000002
- type: map_at_10
value: 24.427
- type: map_at_100
value: 25.576
- type: map_at_1000
value: 25.692999999999998
- type: map_at_3
value: 22.002
- type: map_at_5
value: 23.249
- type: mrr_at_1
value: 20.716
- type: mrr_at_10
value: 28.072000000000003
- type: mrr_at_100
value: 29.067
- type: mrr_at_1000
value: 29.137
- type: mrr_at_3
value: 25.832
- type: mrr_at_5
value: 27.045
- type: ndcg_at_1
value: 20.716
- type: ndcg_at_10
value: 29.109
- type: ndcg_at_100
value: 34.797
- type: ndcg_at_1000
value: 37.503
- type: ndcg_at_3
value: 24.668
- type: ndcg_at_5
value: 26.552999999999997
- type: precision_at_1
value: 20.716
- type: precision_at_10
value: 5.351
- type: precision_at_100
value: 0.955
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 11.584999999999999
- type: precision_at_5
value: 8.362
- type: recall_at_1
value: 17.333000000000002
- type: recall_at_10
value: 39.604
- type: recall_at_100
value: 65.525
- type: recall_at_1000
value: 84.651
- type: recall_at_3
value: 27.199
- type: recall_at_5
value: 32.019
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.342
- type: map_at_10
value: 35.349000000000004
- type: map_at_100
value: 36.443
- type: map_at_1000
value: 36.548
- type: map_at_3
value: 32.307
- type: map_at_5
value: 34.164
- type: mrr_at_1
value: 31.063000000000002
- type: mrr_at_10
value: 39.703
- type: mrr_at_100
value: 40.555
- type: mrr_at_1000
value: 40.614
- type: mrr_at_3
value: 37.141999999999996
- type: mrr_at_5
value: 38.812000000000005
- type: ndcg_at_1
value: 31.063000000000002
- type: ndcg_at_10
value: 40.873
- type: ndcg_at_100
value: 45.896
- type: ndcg_at_1000
value: 48.205999999999996
- type: ndcg_at_3
value: 35.522
- type: ndcg_at_5
value: 38.419
- type: precision_at_1
value: 31.063000000000002
- type: precision_at_10
value: 6.866
- type: precision_at_100
value: 1.053
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 16.014
- type: precision_at_5
value: 11.604000000000001
- type: recall_at_1
value: 26.342
- type: recall_at_10
value: 53.40200000000001
- type: recall_at_100
value: 75.251
- type: recall_at_1000
value: 91.13799999999999
- type: recall_at_3
value: 39.103
- type: recall_at_5
value: 46.357
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.71
- type: map_at_10
value: 32.153999999999996
- type: map_at_100
value: 33.821
- type: map_at_1000
value: 34.034
- type: map_at_3
value: 29.376
- type: map_at_5
value: 30.878
- type: mrr_at_1
value: 28.458
- type: mrr_at_10
value: 36.775999999999996
- type: mrr_at_100
value: 37.804
- type: mrr_at_1000
value: 37.858999999999995
- type: mrr_at_3
value: 34.123999999999995
- type: mrr_at_5
value: 35.596
- type: ndcg_at_1
value: 28.458
- type: ndcg_at_10
value: 37.858999999999995
- type: ndcg_at_100
value: 44.194
- type: ndcg_at_1000
value: 46.744
- type: ndcg_at_3
value: 33.348
- type: ndcg_at_5
value: 35.448
- type: precision_at_1
value: 28.458
- type: precision_at_10
value: 7.4510000000000005
- type: precision_at_100
value: 1.5
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 15.809999999999999
- type: precision_at_5
value: 11.462
- type: recall_at_1
value: 23.71
- type: recall_at_10
value: 48.272999999999996
- type: recall_at_100
value: 77.134
- type: recall_at_1000
value: 93.001
- type: recall_at_3
value: 35.480000000000004
- type: recall_at_5
value: 41.19
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.331
- type: map_at_10
value: 28.926000000000002
- type: map_at_100
value: 29.855999999999998
- type: map_at_1000
value: 29.957
- type: map_at_3
value: 26.395999999999997
- type: map_at_5
value: 27.933000000000003
- type: mrr_at_1
value: 23.105
- type: mrr_at_10
value: 31.008000000000003
- type: mrr_at_100
value: 31.819999999999997
- type: mrr_at_1000
value: 31.887999999999998
- type: mrr_at_3
value: 28.466
- type: mrr_at_5
value: 30.203000000000003
- type: ndcg_at_1
value: 23.105
- type: ndcg_at_10
value: 33.635999999999996
- type: ndcg_at_100
value: 38.277
- type: ndcg_at_1000
value: 40.907
- type: ndcg_at_3
value: 28.791
- type: ndcg_at_5
value: 31.528
- type: precision_at_1
value: 23.105
- type: precision_at_10
value: 5.323
- type: precision_at_100
value: 0.815
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 12.384
- type: precision_at_5
value: 9.02
- type: recall_at_1
value: 21.331
- type: recall_at_10
value: 46.018
- type: recall_at_100
value: 67.364
- type: recall_at_1000
value: 86.97
- type: recall_at_3
value: 33.395
- type: recall_at_5
value: 39.931
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.011000000000003
- type: map_at_10
value: 28.816999999999997
- type: map_at_100
value: 30.761
- type: map_at_1000
value: 30.958000000000002
- type: map_at_3
value: 24.044999999999998
- type: map_at_5
value: 26.557
- type: mrr_at_1
value: 38.696999999999996
- type: mrr_at_10
value: 50.464
- type: mrr_at_100
value: 51.193999999999996
- type: mrr_at_1000
value: 51.219
- type: mrr_at_3
value: 47.339999999999996
- type: mrr_at_5
value: 49.346000000000004
- type: ndcg_at_1
value: 38.696999999999996
- type: ndcg_at_10
value: 38.53
- type: ndcg_at_100
value: 45.525
- type: ndcg_at_1000
value: 48.685
- type: ndcg_at_3
value: 32.282
- type: ndcg_at_5
value: 34.482
- type: precision_at_1
value: 38.696999999999996
- type: precision_at_10
value: 11.895999999999999
- type: precision_at_100
value: 1.95
- type: precision_at_1000
value: 0.254
- type: precision_at_3
value: 24.038999999999998
- type: precision_at_5
value: 18.332
- type: recall_at_1
value: 17.011000000000003
- type: recall_at_10
value: 44.452999999999996
- type: recall_at_100
value: 68.223
- type: recall_at_1000
value: 85.653
- type: recall_at_3
value: 28.784
- type: recall_at_5
value: 35.66
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.516
- type: map_at_10
value: 21.439
- type: map_at_100
value: 31.517
- type: map_at_1000
value: 33.267
- type: map_at_3
value: 15.004999999999999
- type: map_at_5
value: 17.793999999999997
- type: mrr_at_1
value: 71.25
- type: mrr_at_10
value: 79.071
- type: mrr_at_100
value: 79.325
- type: mrr_at_1000
value: 79.33
- type: mrr_at_3
value: 77.708
- type: mrr_at_5
value: 78.546
- type: ndcg_at_1
value: 58.62500000000001
- type: ndcg_at_10
value: 44.889
- type: ndcg_at_100
value: 50.536
- type: ndcg_at_1000
value: 57.724
- type: ndcg_at_3
value: 49.32
- type: ndcg_at_5
value: 46.775
- type: precision_at_1
value: 71.25
- type: precision_at_10
value: 36.175000000000004
- type: precision_at_100
value: 11.940000000000001
- type: precision_at_1000
value: 2.178
- type: precision_at_3
value: 53.583000000000006
- type: precision_at_5
value: 45.550000000000004
- type: recall_at_1
value: 9.516
- type: recall_at_10
value: 27.028000000000002
- type: recall_at_100
value: 57.581
- type: recall_at_1000
value: 80.623
- type: recall_at_3
value: 16.313
- type: recall_at_5
value: 20.674
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.74999999999999
- type: f1
value: 46.46706502669774
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 77.266
- type: map_at_10
value: 84.89999999999999
- type: map_at_100
value: 85.109
- type: map_at_1000
value: 85.123
- type: map_at_3
value: 83.898
- type: map_at_5
value: 84.541
- type: mrr_at_1
value: 83.138
- type: mrr_at_10
value: 89.37
- type: mrr_at_100
value: 89.432
- type: mrr_at_1000
value: 89.43299999999999
- type: mrr_at_3
value: 88.836
- type: mrr_at_5
value: 89.21
- type: ndcg_at_1
value: 83.138
- type: ndcg_at_10
value: 88.244
- type: ndcg_at_100
value: 88.98700000000001
- type: ndcg_at_1000
value: 89.21900000000001
- type: ndcg_at_3
value: 86.825
- type: ndcg_at_5
value: 87.636
- type: precision_at_1
value: 83.138
- type: precision_at_10
value: 10.47
- type: precision_at_100
value: 1.1079999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.933
- type: precision_at_5
value: 20.36
- type: recall_at_1
value: 77.266
- type: recall_at_10
value: 94.063
- type: recall_at_100
value: 96.993
- type: recall_at_1000
value: 98.414
- type: recall_at_3
value: 90.228
- type: recall_at_5
value: 92.328
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.319
- type: map_at_10
value: 36.943
- type: map_at_100
value: 38.951
- type: map_at_1000
value: 39.114
- type: map_at_3
value: 32.82
- type: map_at_5
value: 34.945
- type: mrr_at_1
value: 44.135999999999996
- type: mrr_at_10
value: 53.071999999999996
- type: mrr_at_100
value: 53.87
- type: mrr_at_1000
value: 53.90200000000001
- type: mrr_at_3
value: 50.77199999999999
- type: mrr_at_5
value: 52.129999999999995
- type: ndcg_at_1
value: 44.135999999999996
- type: ndcg_at_10
value: 44.836
- type: ndcg_at_100
value: 51.754
- type: ndcg_at_1000
value: 54.36
- type: ndcg_at_3
value: 41.658
- type: ndcg_at_5
value: 42.354
- type: precision_at_1
value: 44.135999999999996
- type: precision_at_10
value: 12.284
- type: precision_at_100
value: 1.952
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 27.828999999999997
- type: precision_at_5
value: 20.093
- type: recall_at_1
value: 22.319
- type: recall_at_10
value: 51.528
- type: recall_at_100
value: 76.70700000000001
- type: recall_at_1000
value: 92.143
- type: recall_at_3
value: 38.641
- type: recall_at_5
value: 43.653999999999996
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.182
- type: map_at_10
value: 65.146
- type: map_at_100
value: 66.023
- type: map_at_1000
value: 66.078
- type: map_at_3
value: 61.617999999999995
- type: map_at_5
value: 63.82299999999999
- type: mrr_at_1
value: 80.365
- type: mrr_at_10
value: 85.79
- type: mrr_at_100
value: 85.963
- type: mrr_at_1000
value: 85.968
- type: mrr_at_3
value: 84.952
- type: mrr_at_5
value: 85.503
- type: ndcg_at_1
value: 80.365
- type: ndcg_at_10
value: 73.13499999999999
- type: ndcg_at_100
value: 76.133
- type: ndcg_at_1000
value: 77.151
- type: ndcg_at_3
value: 68.255
- type: ndcg_at_5
value: 70.978
- type: precision_at_1
value: 80.365
- type: precision_at_10
value: 15.359
- type: precision_at_100
value: 1.7690000000000001
- type: precision_at_1000
value: 0.19
- type: precision_at_3
value: 44.024
- type: precision_at_5
value: 28.555999999999997
- type: recall_at_1
value: 40.182
- type: recall_at_10
value: 76.793
- type: recall_at_100
value: 88.474
- type: recall_at_1000
value: 95.159
- type: recall_at_3
value: 66.036
- type: recall_at_5
value: 71.391
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.7796
- type: ap
value: 89.24883716810874
- type: f1
value: 92.7706903433313
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.016
- type: map_at_10
value: 34.408
- type: map_at_100
value: 35.592
- type: map_at_1000
value: 35.64
- type: map_at_3
value: 30.459999999999997
- type: map_at_5
value: 32.721000000000004
- type: mrr_at_1
value: 22.593
- type: mrr_at_10
value: 34.993
- type: mrr_at_100
value: 36.113
- type: mrr_at_1000
value: 36.156
- type: mrr_at_3
value: 31.101
- type: mrr_at_5
value: 33.364
- type: ndcg_at_1
value: 22.579
- type: ndcg_at_10
value: 41.404999999999994
- type: ndcg_at_100
value: 47.018
- type: ndcg_at_1000
value: 48.211999999999996
- type: ndcg_at_3
value: 33.389
- type: ndcg_at_5
value: 37.425000000000004
- type: precision_at_1
value: 22.579
- type: precision_at_10
value: 6.59
- type: precision_at_100
value: 0.938
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.241000000000001
- type: precision_at_5
value: 10.59
- type: recall_at_1
value: 22.016
- type: recall_at_10
value: 62.927
- type: recall_at_100
value: 88.72
- type: recall_at_1000
value: 97.80799999999999
- type: recall_at_3
value: 41.229
- type: recall_at_5
value: 50.88
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.01732786137711
- type: f1
value: 93.76353126402202
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.91746466028272
- type: f1
value: 57.715651682646765
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.5030262273033
- type: f1
value: 74.6693629986121
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.74781439139207
- type: f1
value: 79.96684171018774
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.2156206892017
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.180539484816137
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.51125957874274
- type: mrr
value: 33.777037359249995
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.248
- type: map_at_10
value: 15.340000000000002
- type: map_at_100
value: 19.591
- type: map_at_1000
value: 21.187
- type: map_at_3
value: 11.329
- type: map_at_5
value: 13.209999999999999
- type: mrr_at_1
value: 47.678
- type: mrr_at_10
value: 57.493
- type: mrr_at_100
value: 58.038999999999994
- type: mrr_at_1000
value: 58.07
- type: mrr_at_3
value: 55.36600000000001
- type: mrr_at_5
value: 56.635999999999996
- type: ndcg_at_1
value: 46.129999999999995
- type: ndcg_at_10
value: 38.653999999999996
- type: ndcg_at_100
value: 36.288
- type: ndcg_at_1000
value: 44.765
- type: ndcg_at_3
value: 43.553
- type: ndcg_at_5
value: 41.317
- type: precision_at_1
value: 47.368
- type: precision_at_10
value: 28.669
- type: precision_at_100
value: 9.158
- type: precision_at_1000
value: 2.207
- type: precision_at_3
value: 40.97
- type: precision_at_5
value: 35.604
- type: recall_at_1
value: 7.248
- type: recall_at_10
value: 19.46
- type: recall_at_100
value: 37.214000000000006
- type: recall_at_1000
value: 67.64099999999999
- type: recall_at_3
value: 12.025
- type: recall_at_5
value: 15.443999999999999
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.595000000000002
- type: map_at_10
value: 47.815999999999995
- type: map_at_100
value: 48.811
- type: map_at_1000
value: 48.835
- type: map_at_3
value: 43.225
- type: map_at_5
value: 46.017
- type: mrr_at_1
value: 35.689
- type: mrr_at_10
value: 50.341
- type: mrr_at_100
value: 51.044999999999995
- type: mrr_at_1000
value: 51.062
- type: mrr_at_3
value: 46.553
- type: mrr_at_5
value: 48.918
- type: ndcg_at_1
value: 35.66
- type: ndcg_at_10
value: 55.859
- type: ndcg_at_100
value: 59.864
- type: ndcg_at_1000
value: 60.419999999999995
- type: ndcg_at_3
value: 47.371
- type: ndcg_at_5
value: 51.995000000000005
- type: precision_at_1
value: 35.66
- type: precision_at_10
value: 9.27
- type: precision_at_100
value: 1.1520000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.63
- type: precision_at_5
value: 15.655
- type: recall_at_1
value: 31.595000000000002
- type: recall_at_10
value: 77.704
- type: recall_at_100
value: 94.774
- type: recall_at_1000
value: 98.919
- type: recall_at_3
value: 56.052
- type: recall_at_5
value: 66.623
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.489
- type: map_at_10
value: 85.411
- type: map_at_100
value: 86.048
- type: map_at_1000
value: 86.064
- type: map_at_3
value: 82.587
- type: map_at_5
value: 84.339
- type: mrr_at_1
value: 82.28
- type: mrr_at_10
value: 88.27199999999999
- type: mrr_at_100
value: 88.362
- type: mrr_at_1000
value: 88.362
- type: mrr_at_3
value: 87.372
- type: mrr_at_5
value: 87.995
- type: ndcg_at_1
value: 82.27
- type: ndcg_at_10
value: 89.023
- type: ndcg_at_100
value: 90.191
- type: ndcg_at_1000
value: 90.266
- type: ndcg_at_3
value: 86.37
- type: ndcg_at_5
value: 87.804
- type: precision_at_1
value: 82.27
- type: precision_at_10
value: 13.469000000000001
- type: precision_at_100
value: 1.533
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.797
- type: precision_at_5
value: 24.734
- type: recall_at_1
value: 71.489
- type: recall_at_10
value: 95.824
- type: recall_at_100
value: 99.70599999999999
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 88.099
- type: recall_at_5
value: 92.285
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 60.52398807444541
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.34855891507871
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.188000000000001
- type: map_at_10
value: 13.987
- type: map_at_100
value: 16.438
- type: map_at_1000
value: 16.829
- type: map_at_3
value: 9.767000000000001
- type: map_at_5
value: 11.912
- type: mrr_at_1
value: 25.6
- type: mrr_at_10
value: 37.744
- type: mrr_at_100
value: 38.847
- type: mrr_at_1000
value: 38.894
- type: mrr_at_3
value: 34.166999999999994
- type: mrr_at_5
value: 36.207
- type: ndcg_at_1
value: 25.6
- type: ndcg_at_10
value: 22.980999999999998
- type: ndcg_at_100
value: 32.039
- type: ndcg_at_1000
value: 38.157000000000004
- type: ndcg_at_3
value: 21.567
- type: ndcg_at_5
value: 19.070999999999998
- type: precision_at_1
value: 25.6
- type: precision_at_10
value: 12.02
- type: precision_at_100
value: 2.5100000000000002
- type: precision_at_1000
value: 0.396
- type: precision_at_3
value: 20.333000000000002
- type: precision_at_5
value: 16.98
- type: recall_at_1
value: 5.188000000000001
- type: recall_at_10
value: 24.372
- type: recall_at_100
value: 50.934999999999995
- type: recall_at_1000
value: 80.477
- type: recall_at_3
value: 12.363
- type: recall_at_5
value: 17.203
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 87.24286275535398
- type: cos_sim_spearman
value: 82.62333770991818
- type: euclidean_pearson
value: 84.60353717637284
- type: euclidean_spearman
value: 82.32990108810047
- type: manhattan_pearson
value: 84.6089049738196
- type: manhattan_spearman
value: 82.33361785438936
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.87428858503165
- type: cos_sim_spearman
value: 79.09145886519929
- type: euclidean_pearson
value: 86.42669231664036
- type: euclidean_spearman
value: 80.03127375435449
- type: manhattan_pearson
value: 86.41330338305022
- type: manhattan_spearman
value: 80.02492538673368
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 88.67912277322645
- type: cos_sim_spearman
value: 89.6171319711762
- type: euclidean_pearson
value: 86.56571917398725
- type: euclidean_spearman
value: 87.71216907898948
- type: manhattan_pearson
value: 86.57459050182473
- type: manhattan_spearman
value: 87.71916648349993
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.71957379085862
- type: cos_sim_spearman
value: 85.01784075851465
- type: euclidean_pearson
value: 84.7407848472801
- type: euclidean_spearman
value: 84.61063091345538
- type: manhattan_pearson
value: 84.71494352494403
- type: manhattan_spearman
value: 84.58772077604254
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.40508326325175
- type: cos_sim_spearman
value: 89.50912897763186
- type: euclidean_pearson
value: 87.82349070086627
- type: euclidean_spearman
value: 88.44179162727521
- type: manhattan_pearson
value: 87.80181927025595
- type: manhattan_spearman
value: 88.43205129636243
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.35846741715478
- type: cos_sim_spearman
value: 86.61172476741842
- type: euclidean_pearson
value: 84.60123125491637
- type: euclidean_spearman
value: 85.3001948141827
- type: manhattan_pearson
value: 84.56231142658329
- type: manhattan_spearman
value: 85.23579900798813
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.94539129818824
- type: cos_sim_spearman
value: 88.99349064256742
- type: euclidean_pearson
value: 88.7142444640351
- type: euclidean_spearman
value: 88.34120813505011
- type: manhattan_pearson
value: 88.70363008238084
- type: manhattan_spearman
value: 88.31952816956954
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.29910260369893
- type: cos_sim_spearman
value: 68.79263346213466
- type: euclidean_pearson
value: 68.41627521422252
- type: euclidean_spearman
value: 66.61602587398579
- type: manhattan_pearson
value: 68.49402183447361
- type: manhattan_spearman
value: 66.80157792354453
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.43703906343708
- type: cos_sim_spearman
value: 89.06081805093662
- type: euclidean_pearson
value: 87.48311456299662
- type: euclidean_spearman
value: 88.07417597580013
- type: manhattan_pearson
value: 87.48202249768894
- type: manhattan_spearman
value: 88.04758031111642
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.49080620485203
- type: mrr
value: 96.19145378949301
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 59.317
- type: map_at_10
value: 69.296
- type: map_at_100
value: 69.738
- type: map_at_1000
value: 69.759
- type: map_at_3
value: 66.12599999999999
- type: map_at_5
value: 67.532
- type: mrr_at_1
value: 62
- type: mrr_at_10
value: 70.176
- type: mrr_at_100
value: 70.565
- type: mrr_at_1000
value: 70.583
- type: mrr_at_3
value: 67.833
- type: mrr_at_5
value: 68.93299999999999
- type: ndcg_at_1
value: 62
- type: ndcg_at_10
value: 74.069
- type: ndcg_at_100
value: 76.037
- type: ndcg_at_1000
value: 76.467
- type: ndcg_at_3
value: 68.628
- type: ndcg_at_5
value: 70.57600000000001
- type: precision_at_1
value: 62
- type: precision_at_10
value: 10
- type: precision_at_100
value: 1.097
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.667
- type: precision_at_5
value: 17.4
- type: recall_at_1
value: 59.317
- type: recall_at_10
value: 87.822
- type: recall_at_100
value: 96.833
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 73.06099999999999
- type: recall_at_5
value: 77.928
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.88910891089108
- type: cos_sim_ap
value: 97.236958456951
- type: cos_sim_f1
value: 94.39999999999999
- type: cos_sim_precision
value: 94.39999999999999
- type: cos_sim_recall
value: 94.39999999999999
- type: dot_accuracy
value: 99.82574257425742
- type: dot_ap
value: 94.94344759441888
- type: dot_f1
value: 91.17352056168507
- type: dot_precision
value: 91.44869215291752
- type: dot_recall
value: 90.9
- type: euclidean_accuracy
value: 99.88415841584158
- type: euclidean_ap
value: 97.2044250782305
- type: euclidean_f1
value: 94.210786739238
- type: euclidean_precision
value: 93.24191968658178
- type: euclidean_recall
value: 95.19999999999999
- type: manhattan_accuracy
value: 99.88613861386139
- type: manhattan_ap
value: 97.20683205497689
- type: manhattan_f1
value: 94.2643391521197
- type: manhattan_precision
value: 94.02985074626866
- type: manhattan_recall
value: 94.5
- type: max_accuracy
value: 99.88910891089108
- type: max_ap
value: 97.236958456951
- type: max_f1
value: 94.39999999999999
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.53940781726187
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.71865011295108
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.3218674533331
- type: mrr
value: 56.28279910449028
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.723915667479673
- type: cos_sim_spearman
value: 32.029070449745234
- type: dot_pearson
value: 28.864944212481454
- type: dot_spearman
value: 27.939266999596725
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.231
- type: map_at_10
value: 1.949
- type: map_at_100
value: 10.023
- type: map_at_1000
value: 23.485
- type: map_at_3
value: 0.652
- type: map_at_5
value: 1.054
- type: mrr_at_1
value: 86
- type: mrr_at_10
value: 92.067
- type: mrr_at_100
value: 92.067
- type: mrr_at_1000
value: 92.067
- type: mrr_at_3
value: 91.667
- type: mrr_at_5
value: 92.067
- type: ndcg_at_1
value: 83
- type: ndcg_at_10
value: 76.32900000000001
- type: ndcg_at_100
value: 54.662
- type: ndcg_at_1000
value: 48.062
- type: ndcg_at_3
value: 81.827
- type: ndcg_at_5
value: 80.664
- type: precision_at_1
value: 86
- type: precision_at_10
value: 80
- type: precision_at_100
value: 55.48
- type: precision_at_1000
value: 20.938000000000002
- type: precision_at_3
value: 85.333
- type: precision_at_5
value: 84.39999999999999
- type: recall_at_1
value: 0.231
- type: recall_at_10
value: 2.158
- type: recall_at_100
value: 13.344000000000001
- type: recall_at_1000
value: 44.31
- type: recall_at_3
value: 0.6779999999999999
- type: recall_at_5
value: 1.13
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.524
- type: map_at_10
value: 10.183
- type: map_at_100
value: 16.625
- type: map_at_1000
value: 18.017
- type: map_at_3
value: 5.169
- type: map_at_5
value: 6.772
- type: mrr_at_1
value: 32.653
- type: mrr_at_10
value: 47.128
- type: mrr_at_100
value: 48.458
- type: mrr_at_1000
value: 48.473
- type: mrr_at_3
value: 44.897999999999996
- type: mrr_at_5
value: 45.306000000000004
- type: ndcg_at_1
value: 30.612000000000002
- type: ndcg_at_10
value: 24.928
- type: ndcg_at_100
value: 37.613
- type: ndcg_at_1000
value: 48.528
- type: ndcg_at_3
value: 28.829
- type: ndcg_at_5
value: 25.237
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 22.448999999999998
- type: precision_at_100
value: 8.02
- type: precision_at_1000
value: 1.537
- type: precision_at_3
value: 30.612000000000002
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.524
- type: recall_at_10
value: 16.38
- type: recall_at_100
value: 49.529
- type: recall_at_1000
value: 83.598
- type: recall_at_3
value: 6.411
- type: recall_at_5
value: 8.932
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.09020000000001
- type: ap
value: 14.451710060978993
- type: f1
value: 54.7874410609049
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.745331069609506
- type: f1
value: 60.08387848592697
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.71549485462037
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.39345532574357
- type: cos_sim_ap
value: 78.16796549696478
- type: cos_sim_f1
value: 71.27713276123171
- type: cos_sim_precision
value: 68.3115626511853
- type: cos_sim_recall
value: 74.51187335092348
- type: dot_accuracy
value: 85.12248912201228
- type: dot_ap
value: 69.26039256107077
- type: dot_f1
value: 65.04294321240867
- type: dot_precision
value: 63.251059586138126
- type: dot_recall
value: 66.93931398416886
- type: euclidean_accuracy
value: 87.07754664123503
- type: euclidean_ap
value: 77.7872176038945
- type: euclidean_f1
value: 70.85587801278899
- type: euclidean_precision
value: 66.3519115614924
- type: euclidean_recall
value: 76.01583113456465
- type: manhattan_accuracy
value: 87.07754664123503
- type: manhattan_ap
value: 77.7341400185556
- type: manhattan_f1
value: 70.80310880829015
- type: manhattan_precision
value: 69.54198473282443
- type: manhattan_recall
value: 72.1108179419525
- type: max_accuracy
value: 87.39345532574357
- type: max_ap
value: 78.16796549696478
- type: max_f1
value: 71.27713276123171
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.09457833663213
- type: cos_sim_ap
value: 86.33024314706873
- type: cos_sim_f1
value: 78.59623733719248
- type: cos_sim_precision
value: 74.13322413322413
- type: cos_sim_recall
value: 83.63104404065291
- type: dot_accuracy
value: 88.3086894089339
- type: dot_ap
value: 83.92225241805097
- type: dot_f1
value: 76.8721826377781
- type: dot_precision
value: 72.8168044077135
- type: dot_recall
value: 81.40591315060055
- type: euclidean_accuracy
value: 88.77052043311213
- type: euclidean_ap
value: 85.7410710218755
- type: euclidean_f1
value: 77.97705489398781
- type: euclidean_precision
value: 73.77713657598241
- type: euclidean_recall
value: 82.68401601478288
- type: manhattan_accuracy
value: 88.73753250281368
- type: manhattan_ap
value: 85.72867199072802
- type: manhattan_f1
value: 77.89774182922812
- type: manhattan_precision
value: 74.23787931635857
- type: manhattan_recall
value: 81.93717277486911
- type: max_accuracy
value: 89.09457833663213
- type: max_ap
value: 86.33024314706873
- type: max_f1
value: 78.59623733719248
license: mit
language:
- en
---
# [Universal AnglE Embedding](https://github.com/SeanLee97/AnglE)
📢 `WhereIsAI/UAE-Large-V1` **is licensed under MIT. Feel free to use it in any scenario.**
**If you use it for academic papers, you could cite us via 👉 [citation info](#citation).**
**🤝 Follow us on:**
- GitHub: https://github.com/SeanLee97/AnglE.
- Arxiv: https://arxiv.org/abs/2309.12871 (ACL24)
- 📘 Document: https://angle.readthedocs.io/en/latest/index.html
Welcome to using AnglE to train and infer powerful sentence embeddings.
**🏆 Achievements**
- 📅 May 16, 2024 | AnglE's paper is accepted by ACL 2024 Main Conference
- 📅 Dec 4, 2024 | 🔥 Our universal English sentence embedding `WhereIsAI/UAE-Large-V1` achieves **SOTA** on the [MTEB Leaderboard](https://huggingface.co/spaces/mteb/leaderboard) with an average score of 64.64!
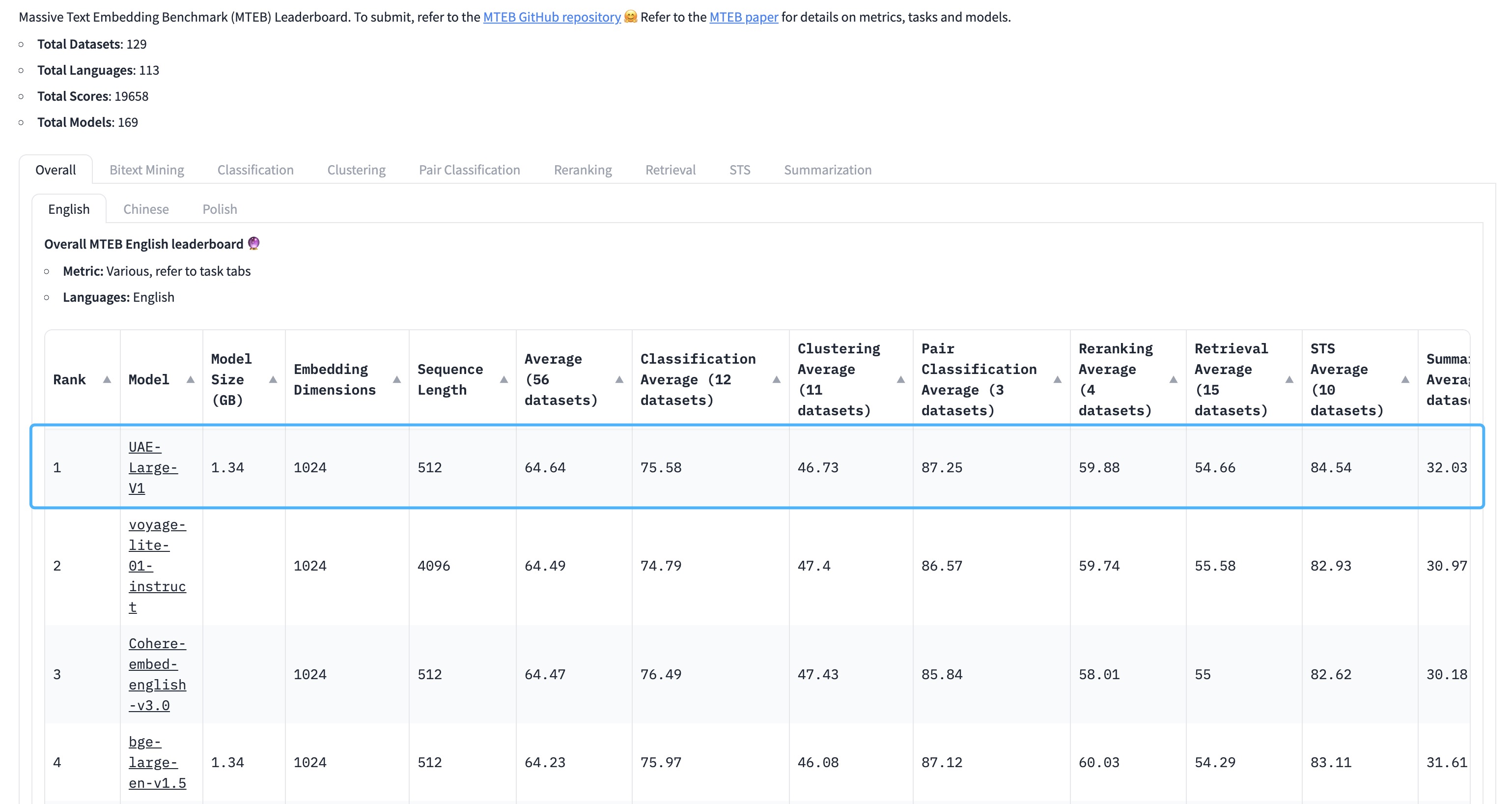
**🧑🤝🧑 Siblings:**
- [WhereIsAI/UAE-Code-Large-V1](https://huggingface.co/WhereIsAI/UAE-Code-Large-V1): This model can be used for code or GitHub issue similarity measurement.
# Usage
## 1. angle_emb
```bash
python -m pip install -U angle-emb
```
1) Non-Retrieval Tasks
There is no need to specify any prompts.
```python
from angle_emb import AnglE
from angle_emb.utils import cosine_similarity
angle = AnglE.from_pretrained('WhereIsAI/UAE-Large-V1', pooling_strategy='cls').cuda()
doc_vecs = angle.encode([
'The weather is great!',
'The weather is very good!',
'i am going to bed'
], normalize_embedding=True)
for i, dv1 in enumerate(doc_vecs):
for dv2 in doc_vecs[i+1:]:
print(cosine_similarity(dv1, dv2))
```
2) Retrieval Tasks
For retrieval purposes, please use the prompt `Prompts.C` for query (not for document).
```python
from angle_emb import AnglE, Prompts
from angle_emb.utils import cosine_similarity
angle = AnglE.from_pretrained('WhereIsAI/UAE-Large-V1', pooling_strategy='cls').cuda()
qv = angle.encode(Prompts.C.format(text='what is the weather?'))
doc_vecs = angle.encode([
'The weather is great!',
'it is rainy today.',
'i am going to bed'
])
for dv in doc_vecs:
print(cosine_similarity(qv[0], dv))
```
## 2. sentence transformer
```python
from angle_emb import Prompts
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("WhereIsAI/UAE-Large-V1").cuda()
qv = model.encode(Prompts.C.format(text='what is the weather?'))
doc_vecs = model.encode([
'The weather is great!',
'it is rainy today.',
'i am going to bed'
])
for dv in doc_vecs:
print(1 - spatial.distance.cosine(qv, dv))
```
# Citation
If you use our pre-trained models, welcome to support us by citing our work:
```
@article{li2023angle,
title={AnglE-optimized Text Embeddings},
author={Li, Xianming and Li, Jing},
journal={arXiv preprint arXiv:2309.12871},
year={2023}
}
``` |
MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli | MoritzLaurer | "2024-04-11T13:47:27Z" | 616,254 | 180 | transformers | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"text-classification",
"zero-shot-classification",
"en",
"dataset:multi_nli",
"dataset:facebook/anli",
"dataset:fever",
"arxiv:2006.03654",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | "2022-03-02T23:29:04Z" | ---
language:
- en
license: mit
tags:
- text-classification
- zero-shot-classification
datasets:
- multi_nli
- facebook/anli
- fever
metrics:
- accuracy
pipeline_tag: zero-shot-classification
model-index:
- name: MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli
results:
- task:
type: natural-language-inference
name: Natural Language Inference
dataset:
name: anli
type: anli
config: plain_text
split: test_r3
metrics:
- type: accuracy
value: 0.495
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYWViYjQ5YTZlYjU4NjQyN2NhOTVhNjFjNGQyMmFiNmQyZjRkOTdhNzJmNjc3NGU4MmY0MjYyMzY5MjZhYzE0YiIsInZlcnNpb24iOjF9.S8pIQ7gEGokd_wKXMi6Bc3B2DThIP3cvVkTFErZ-2JxXTSCy1TBuulY3dzGfaiP7kTHbL52OuBhG_-wb7Ue9DQ
- type: precision
value: 0.4984740618243923
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOTllZDU3NmVmYjk4ZmYzNjAwNzExMGZjNDMzOWRkZjRjMTRhNzhlZmI0ZmNlM2E0Mzk4OWE5NTM5MTYyYWU5NCIsInZlcnNpb24iOjF9.WHz_TUJgPVn-rU-9vBCDdmSMOuWzADwr09rJY6ktqRM46zytbyWs7Vcm7jqDrTkfU-rp0_7IyoNv_xEsKhJbBA
- type: precision
value: 0.495
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjllODE3ZjUxZDhiMTI0MzZmYjY5OTUwYWI2OTc4ZjJhNTVjMjY2ODdkMmJlZjQ5YWQ1Mjk2ZThmYjJlM2RlYSIsInZlcnNpb24iOjF9.a9V06-O7l9S0Bv4vj0aard8128SAP61DZdXl_3XqdmNgt_C6KAoDBVueF2M2kF_kT6lRfEz6YW0ACIfJNXDYAA
- type: precision
value: 0.4984357572868885
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjhiMzYzY2JiMmYwN2YxYzEwZTQ3NGI1NzFmMzliNjJkMDE2YzI5Njg1ZjEzMGIxODdiMDNmYmI4Y2Y2MmJkMiIsInZlcnNpb24iOjF9.xvZZaUMogw9MJjb3ls6h5liDlTqHMmNgqk6KbyDqQWfCcD255brCU3Xo6nECwaChS4te0dQu_iWGBqR_o2kYAA
- type: recall
value: 0.49461028192371476
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDVjYTEzOTI0ZjVhOTk3ZTkzZmZhNTk5ODcxMWJhYWU4ZTRjYWVhNzcwOWY5YmI2NGFlYWE4NjM5MDY5NTExOSIsInZlcnNpb24iOjF9.xgHCB2rbCQBzHzUokw4u8JyOdhtF4yvPv1t8t7YiEkaAuM5MAPsVuCZ1VtlLapHS_IWetlocizsVl6akjh3cAQ
- type: recall
value: 0.495
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYTEyYmM0ZDQ0M2RiMDNhNjIxNzQ4OWZiNTBiOTAwZDFkNjNmYjBhNjA4NmQ0NjFkNmNiZTljNDkxNDg3NzIyYSIsInZlcnNpb24iOjF9.3FJPwNtwgFNvMjVxVAayaVXXR1sWlr0sqAYmXzmMzMxl7IJh6RS77dGPwFaqD3jamLVBiqPn9wsfz5lFK5yTAA
- type: recall
value: 0.495
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNmY1MjZlZTQ4OTg5YzdlYmFhZDMzMmNlNjNkYmIyZGI4M2NjZjQ1ZDVkNmZkMTUxNjI3M2UwZmI1MDM1NDYwOSIsInZlcnNpb24iOjF9.cnbM6xjTLRa9z0wEDGd_Q4lTXVLRKIQ6_YLGLjf-t7Nto4lzxAeWF-RrwA0Mq9OPITlJq2Jk1Eg_0Utb13d9Dg
- type: f1
value: 0.4942810999491704
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2U3NGM1MDM4YTM4NzQxMGM4ZTIyZDM2YTQ1MGNlZWM1MzEzM2MxN2ZmZmRmYTM0OWJmZGJjYjM5OWEzMmZjNSIsInZlcnNpb24iOjF9.vMtge1F-tmMn9D3aVUuwcNEXjqpNgEyHAl9f5UDSoTYcOgTwi2vi5yRGRCl8y6Fx7BtgaCwMyoZVNbP5-GRtCA
- type: f1
value: 0.495
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjBjMTQ5MmQ5OGE5OWJjZGMyNzg4N2RmNDUzMzQ5Zjc4ZTc4N2JlMTk0MTc2M2RjZTgzOTNlYWQzODAwNDI0NCIsInZlcnNpb24iOjF9.yxXG0CNWW8__xJC14BjbTY9QkXD75x6uCIXR51oKDemkP0b_xGyd-A2wPIuwNJN1EYkQevPY0bhVpRWBKyO9Bg
- type: f1
value: 0.4944671868893595
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzczNjQzY2FmMmY4NTAwYjNkYjJlN2I2NjI2Yjc0ZmQ3NjZiN2U5YWEwYjk4OTUyOTMzZTYyZjYzOTMzZGU2YiIsInZlcnNpb24iOjF9.mLOnst2ScPX7ZQwaUF12W2nv7-w9lX9-BxHl3-0T0gkSWnmtBSwYcL5faTX0_I5q33Fjz5tfkjpCJuxP5JYIBQ
- type: loss
value: 1.8788293600082397
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzRlOTYwYjU1Y2Y4ZGM0NDBjYTE2MmEzNWIwN2NiMWVkOWZlNzA2ZmQ3YjZjNzI4MjQwYWZhODIwMzU3ODAyZiIsInZlcnNpb24iOjF9._Xs9bl48MSavvp5eyamrP2iNlFWv35QZCrmWjJXLkUdIBx0ElCjEdxBb3dxPGnUxdpDzGMmOoKCPI44ZPXrtDw
- task:
type: natural-language-inference
name: Natural Language Inference
dataset:
name: anli
type: anli
config: plain_text
split: test_r1
metrics:
- type: accuracy
value: 0.712
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYWYxMGY0ZWU0YTEyY2I3NmQwZmQ3YmFmNzQxNGU5OGNjN2ViN2I0ZjdkYWUzM2RmYzkzMDg3ZjVmNGYwNGZkZCIsInZlcnNpb24iOjF9.snWBusAeo1rrQqWk--vTxb-CBcFqM298YCtwTQGBZiFegKGSTSKzj-SM6HMNsmoQWmMuv7UfYPqYlnzEthOSAg
- type: precision
value: 0.7134839439315348
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjMxMjg1Y2QwNzMwM2ZkNGM3ZTJhOGJmY2FkNGI1ZTFhOGQ3ODViNTJmZTYwMWJkZDYyYWRjMzFmZDI1NTM5YSIsInZlcnNpb24iOjF9.ZJnY6zYOBn-YEtN7uKzQ-VKXPwlIO1zq19Yuo37vBJNSs1dGDd8f1jgfdZuA19e_wA3Nc5nQKe9VXRwPHPgwAQ
- type: precision
value: 0.712
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWM4YWQyODBlYTIwMWQxZDA1NmY1M2M2ODgwNDJiY2RhMDVhYTlkMDUzZTJkMThkYzRmNDg2YTdjMjczNGUwOCIsInZlcnNpb24iOjF9.SogsKHdbdlEs05IBYwXvlnaC_esg-DXAPc2KPRyHaVC5ItVHbxa63NpybSpao4baOoMlLG9aRe7TjG4gtB2dAQ
- type: precision
value: 0.7134676028447461
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODdjMzFkM2IwNWZiM2I4ZWViMmQ4NWM5MDY5ZWQxZjc1MGRmNjhmNzJhYWFmOWEwMjg3ZjhiZWM3YjlhOTIxNSIsInZlcnNpb24iOjF9._0JNIbiqLuDZrp_vrCljBe28xexZJPmigLyhkcO8AtH2VcNxWshwCpZuRF4bqvpMvnApJeuGMf3vXjCj0MC1Bw
- type: recall
value: 0.7119814425203647
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYjU4MWEyMzkyYzg1ZTIxMTc0M2NhMTgzOGEyZmY5OTg3M2Q1ZmMwNmU3ZmU1ZjA1MDk0OGZkMzM5NDVlZjBlNSIsInZlcnNpb24iOjF9.sZ3GTcmGGthpTLL7_Zovq8aBmE3Dp_PZi5v8ZI9yG9N6B_GjWvBuPC8ENXK1NwmwiHLsSvtKTG5JmAum-su0Dg
- type: recall
value: 0.712
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDg3NGViZTlmMWM2ZDNhMzIzZGZkYWZhODQxNzg2MjNiNjQ0Zjg0NjQ1OWZkY2I5ODdiY2Y3Y2JjNzRmYjJkMiIsInZlcnNpb24iOjF9.bCZUzJamsozKWehnNph6E5coww5zZTrJdbWevWrSyfT0PyXc_wkZ-NKdyBAoqprBz3_8L3i5hPM6Qsy56b4BDA
- type: recall
value: 0.712
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDk1MDJiOGUzZThlZjJjMzY4NjMzODFiZjUzZmIwMjIxY2UwNzBiN2IxMWEwMGJjZTkxODA0YzUxZDE3ODRhOCIsInZlcnNpb24iOjF9.z0dqvB3aBVYt3xRIb_M4svWebfQc0QaDFVFzHnlA5QGEHkHOW3OecGhHE4EzBqTDI3DASWZTGMjrMDDt0uOMBw
- type: f1
value: 0.7119226991285647
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiM2U0YjMwNzhmOTEyNDZhODU3MTU0YTM4MmQ0NzEzNWI1YjY0ZWQ3MWRiMTdiNTUzNWRkZThjMWE4M2NkZmI0MiIsInZlcnNpb24iOjF9.hhj1BXkuWi9wXrCjT9NwqaPETtOoYNiyqYsJEw-ufA8A4hVThKA6ZBtma1Q_M65-DZFfPEBDBNASLZ7EPSbmDw
- type: f1
value: 0.712
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODk0Y2EyMzc5M2ZlNWFlNDg2Zjc1OTQxNGY3YjA5YjUxYTYzZjRlZmU4ODYxNjA3ZjkxNGUzYjBmNmMxMzY5YiIsInZlcnNpb24iOjF9.DvKk-3hNh2LhN2ug5e0FgUntL3Ozdfl06Kz7jvmB-deOJH6INi2a2ZySXoEePoo8t2nR6ENFYu9QjMA2ojnpCA
- type: f1
value: 0.7119242267218338
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2MxOWFlMmI2NGRiMjkwN2Q5MWZhNDFlYzQxNWNmNzQ3OWYxZThmNDU2OWU1MTE5OGY2MWRlYWUyNDM3OTkzZCIsInZlcnNpb24iOjF9.QrTD1gE8_wRok9u59W-Mx0cX89K-h2Ad6qa8J5rmP8lc_rkG0ft2n5_GqH1CBZBJwMFYv91Pn6TuE3eGxJuUDA
- type: loss
value: 1.0105403661727905
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmUwMTg4NjM3ZTBiZTIyODcyNDNmNTE5ZDZhMzNkMDMyNjcwOGQ5NmY0NTlhMjgyNmIzZjRiNDFiNjA3M2RkZSIsInZlcnNpb24iOjF9.sjBDVJV-jnygwcppmByAXpoo-Wzz178bBzozJEuYEiJaHSbk_xEevfJS1PmLUuplYslKb1iyEctnjI-5bl-XDw
- task:
type: natural-language-inference
name: Natural Language Inference
dataset:
name: multi_nli
type: multi_nli
config: default
split: validation_mismatched
metrics:
- type: accuracy
value: 0.902766476810415
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjExZWM3YzA3ZDNlNjEwMmViNWEwZTE3MjJjNjEyNDhjOTQxNGFmMzBjZTk0ODUwYTc2OGNiZjYyMTBmNWZjZSIsInZlcnNpb24iOjF9.zbFAGrv2flpmweqS7Poxib7qHFLdW8eUTzshdOm2B9H-KWpIZCWC-P4p8TLMdNJnUcZJZ03Okil4qjIMqqIRCA
- type: precision
value: 0.9023816542652491
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2U2MGViNmJjNWQxNzRjOTkxNDIxZjZjNmM5YzE4ZjU5NTE5NjFlNmEzZWRlOGYxN2E3NTAwMTEwYjNhNzE0YSIsInZlcnNpb24iOjF9.WJjDJf56FROvf7Y5ShWnnxMvK_ZpQ2PibAOtSFhSiYJ7bt4TGOzMwaZ5RSTf_mcfXgRfWbXmy1jCwNhDb-5EAw
- type: precision
value: 0.902766476810415
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzRhZTExOTc5NDczZjI1YmMzOGYyOTU2MDU1OGE5ZTczMDE0MmU0NzZhY2YzMDI1ZGQ3MGM5MmJiODFkNzUzZiIsInZlcnNpb24iOjF9.aRYcGEI1Y8-a0d8XOoXhBgsFyj9LWNwEjoIPc594y7kJn91wXIsXoR0-_0iy3uz41mWaTTlwJx7lI-kipFDvDQ
- type: precision
value: 0.9034597464719761
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWQyMTZiZDA2OTUwZjRmNTFiMWRlZTNmOTliZmI2MWFmMjdjYzEyYTgwNzkyOTQzOTBmNTUyYjMwNTUxMTFkNiIsInZlcnNpb24iOjF9.hUtAMTl0THHUkaLcgk1Vy9IhjqJAXCJ_5STJ5A7k7s_SO9DHp3b6qusgwPmcGLYyPy1-j1dB2AIstxK4tHfmDA
- type: recall
value: 0.9024304801555488
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzAxZGJhNGI3ZDNlMjg2ZDIxNTgwMDY5MTFjM2ExZmIxMDBmZjUyNTliNWNkOGI0OTY3NTYyNWU3OWFlYTA3YiIsInZlcnNpb24iOjF9.1o_GNq8zmXa_50MUF_K63IDc2aUKNeUkNQ5fT592-SAo8WgiaP9Dh6bOEu2OqrpRQ57P4qm7OdJt7UKsrosMDA
- type: recall
value: 0.902766476810415
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjhiMWE4Yjk0ODFkZjlkYjRlMjU1OTJmMjA2Njg1N2M4MzQ0OWE3N2FlYjY4NDgxZThjMmExYWQ5OGNmYmI1NSIsInZlcnNpb24iOjF9.Gmm5lf_qpxjXWWrycDze7LHR-6WGQc62WZTmcoc5uxWd0tivEUqCAFzFdbEU1jVKxQBIyDX77CPuBm7mUA4sCg
- type: recall
value: 0.902766476810415
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2EzZWYwNjNkYWE1YTcyZGZjNTNhMmNlNzgzYjk5MGJjOWJmZmE5NmYwM2U2NTA5ZDY3ZjFiMmRmZmQwY2QwYiIsInZlcnNpb24iOjF9.yA68rslg3e9kUR3rFTNJJTAad6Usr4uFmJvE_a7G2IvSKqLxG_pqsHszsWfg5mFBQLjWEAyCtdQYMdVayuYMBA
- type: f1
value: 0.9023086094638595
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzMyMzZhNjI5MWRmZWJhMjkzN2E0MjM4ZTM5YzZmNTk5YTZmYzU4NDRiYjczZGQ4MDdhNjJiMGU0MjE3NDEwNyIsInZlcnNpb24iOjF9.RCMqH_xUMN97Vos54pTFfAMbLstXUMdFTs-eNaypbDb_Fc-MW8NLmJ6dzJsp9sSvhXyYjugjRMUpMpnQseKXDA
- type: f1
value: 0.902766476810415
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTYxZTZhZGM0NThlNTAzNmYwMTA4NDNkN2FiNzhhN2RlYThlYjcxMjE5MjBkMzhiOGYxZGRmMjE0NGM2ZWQ5ZSIsInZlcnNpb24iOjF9.wRfllNw2Gibmi1keU7d_GjkyO0F9HESCgJlJ9PHGZQRRT414nnB-DyRvulHjCNnaNjXqMi0LJimC3iBrNawwAw
- type: f1
value: 0.9030161011457231
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDA0YjAxMWU5MjI4MWEzNTNjMzJlNjM3ZDMxOTE0ZTZhYmZlNmUyNDViNTU2NmMyMmM3MjAxZWVjNWJmZjI4MCIsInZlcnNpb24iOjF9.vJ8aUjfTbFMc1BgNUVpoVDuYwQJYQjwZQxblkUdvSoGtkW_AzQJ_KJ8Njc7IBA3ADgj8iZHjRQNIZkFCf-xICw
- type: loss
value: 0.3283354640007019
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODdmYzYzNTUzZDNmOWIxM2E0ZmUyOWUzM2Y2NGRmZDNiYjg3ZTMzYTUyNzg3OWEzNzYyN2IyNmExOGRlMWUxYSIsInZlcnNpb24iOjF9.Qv0FzFZPkcBs9aHGf4TEREX4jdkc40NazdMlP2M_-w2wHwyjoAjvhk611RLXHcbicozNelZJLnsOMdEMnPLEDg
- task:
type: natural-language-inference
name: Natural Language Inference
dataset:
name: anli
type: anli
config: plain_text
split: dev_r1
metrics:
- type: accuracy
value: 0.737
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTQ1ZGVkOTVmNTlhYjhkMjVlNTNhMjNmZWFjZWZjZjcxZmRhMDVlOWI0YTdkOTMwYjVjNWFlOGY4OTc1MmRhNiIsInZlcnNpb24iOjF9.wGLgKA1E46ljbLokdPeip_UCr1gqK8iSSbsJKX2vgKuuhDdUWWiECrUFN-bv_78JWKoKW5T0GF_hb-RVDzA0AQ
- type: precision
value: 0.737681071614645
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYmFkMGUwMjNhN2E3NzMxNTc5NDM0MjY1MGU5ODllM2Q2YzA1MDI3OGI1ZmI4YTcxN2E4ZDk5OWY2OGNiN2I0MCIsInZlcnNpb24iOjF9.6G5qhccjheaNfasgRyrkKBTaQPRzuPMZZ0hrLxTNzAydMDgx09FkFP3hni7WLRMWp0IpwzkEeBlxV-mPyQBtBw
- type: precision
value: 0.737
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2QzYjQ4ZDZjOGU5YzI3YmFlMThlYTRkYTUyYWIyNzc4NDkwNzM1OWFiMTgyMzA0NDZmMGI3YTQxODBjM2EwMCIsInZlcnNpb24iOjF9.bvNWyzfct1CLJFx_EuD2GeKieVtyGJy0cwUBP2qJE1ey2i9SVn6n1Dr0AALTGBkxQ6n5-fJ61QFNufpdr2KvCA
- type: precision
value: 0.7376755842752241
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2VmYWYzZWQwZmMzMDk0NTdlY2Y3NDkzYWY5ZTdmOGU0ZTUzZWE4YWFhZjVmODhkZmE1Njg4NjA5YjJmYWVhOSIsInZlcnNpb24iOjF9.50FQR2aoBpORLgYa7482ZTrRhT-KfIgv5ltBEHndUBMmqGF9Ru0LHENSGwyD_tO89sGPfiW32TxpbrNWiBdIBA
- type: recall
value: 0.7369675064285843
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTM4OTAyNDYwNjY4Zjc5NDljNjBmNTg2Mzk4YjYxM2MyYTA0MDllYTMyNzEwOGI1ZTEwYWE3ZmU0NDZmZDg2NiIsInZlcnNpb24iOjF9.UvWBxuApNV3vd4hpgwqd6XPHCbkA_bB_Cw24ooquiOf0dstvjP3JvpGoDp5SniOzIOg3i2aYbcvFCLJqEXMZCQ
- type: recall
value: 0.737
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYmQ4MjMzNzRmNTI5NjIzNGQ0ZDFmZTA1MDU3OTk0MzYyMGI0NTMzZTZlMTQ1MDc1MzBkMGMzYjcxZjU1NDNjOSIsInZlcnNpb24iOjF9.kpbdXOpDG3CUB-kUEXsgFT3HWWIbu70wwzs2TNf0rhIuRrzdZz3dXXvwqu1BcLJTsOxl8G6NTiYXgnv-ul8lDg
- type: recall
value: 0.737
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNmU1ZWJkNWE0NjczY2NiZWYyNzYyMzllNzZmZTIxNWRkYTEyZDgxN2E0NTNmM2ExMTc1ZWVjMzBiYjg0ZmM1MiIsInZlcnNpb24iOjF9.S6HHWCWnut_LJqXbEA_Z8ZOTtyq6V51ZeiA0qbwzr0hapDYZOZHrN4prvSLvoNv-GiYDYKatwIsAZxCZc5fmCA
- type: f1
value: 0.7366853496239583
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNzkxYmY2NTcyOTE0ZDdjNGY2ZmE4MzQwMGIxZTA2MDg1NzI5YTQ0MTdkZjdkNzNkMDM2NTk2MTNiNjU4ODMwZCIsInZlcnNpb24iOjF9.ECVaCBqGd0pnQT3xJF7yWrgecIb-5TMiVWpEO0MQGhYy43snkI6Qs-2FOXzvfwIWqG-Q6XIIhGbWZh5TFEGKCA
- type: f1
value: 0.737
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDMwMWZiNzQyNWEzNmMzMDJjOTAxYzAxNzc0MTNlYzRkZjllYmNjZmU0OTgzZDFkNWM1ZWI5OTA2NzE5Y2YxOSIsInZlcnNpb24iOjF9.8yZFol_Gcj9n3w9Yk5wx48yql7p3wriDecv-6VSTAB6Q_MWLQAWsCEGRRhgGJ3zvhoRehJZdb35ozk36VOinDQ
- type: f1
value: 0.7366990292378379
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjhhN2ZkMjc5ZGQ3ZGM1Nzk3ZTgwY2E1N2NjYjdhNjZlOTdhYmRlNGVjN2EwNTIzN2UyYTY2ODVlODhmY2Q4ZCIsInZlcnNpb24iOjF9.Cz7ClDAfCGpqdRTYd5v3dPjXFq8lZLXx8AX_rqmF-Jb8KocqVDsHWeZScW5I2oy951UrdMpiUOLieBuJLOmCCQ
- type: loss
value: 0.9349392056465149
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNmI4MTI5MDM1NjBmMzgzMzc2NjM5MzZhOGUyNTgyY2RlZTEyYTIzYzY2ZGJmODcxY2Q5OTVjOWU3OTQ2MzM1NSIsInZlcnNpb24iOjF9.bSOFnYC4Y2y2pW1AR-bgPUHKafR-0OHf8PvexK8eQLsS323Xy9-rYkKUaP09KY6_fk9GqAawv5eqj72B_uyeCA
---
# DeBERTa-v3-base-mnli-fever-anli
## Model description
This model was trained on the MultiNLI, Fever-NLI and Adversarial-NLI (ANLI) datasets, which comprise 763 913 NLI hypothesis-premise pairs. This base model outperforms almost all large models on the [ANLI benchmark](https://github.com/facebookresearch/anli).
The base model is [DeBERTa-v3-base from Microsoft](https://huggingface.co/microsoft/deberta-v3-base). The v3 variant of DeBERTa substantially outperforms previous versions of the model by including a different pre-training objective, see annex 11 of the original [DeBERTa paper](https://arxiv.org/pdf/2006.03654.pdf).
For highest performance (but less speed), I recommend using https://huggingface.co/MoritzLaurer/DeBERTa-v3-large-mnli-fever-anli-ling-wanli.
### How to use the model
#### Simple zero-shot classification pipeline
```python
#!pip install transformers[sentencepiece]
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli")
sequence_to_classify = "Angela Merkel is a politician in Germany and leader of the CDU"
candidate_labels = ["politics", "economy", "entertainment", "environment"]
output = classifier(sequence_to_classify, candidate_labels, multi_label=False)
print(output)
```
#### NLI use-case
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model_name = "MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
premise = "I first thought that I liked the movie, but upon second thought it was actually disappointing."
hypothesis = "The movie was good."
input = tokenizer(premise, hypothesis, truncation=True, return_tensors="pt")
output = model(input["input_ids"].to(device)) # device = "cuda:0" or "cpu"
prediction = torch.softmax(output["logits"][0], -1).tolist()
label_names = ["entailment", "neutral", "contradiction"]
prediction = {name: round(float(pred) * 100, 1) for pred, name in zip(prediction, label_names)}
print(prediction)
```
### Training data
DeBERTa-v3-base-mnli-fever-anli was trained on the MultiNLI, Fever-NLI and Adversarial-NLI (ANLI) datasets, which comprise 763 913 NLI hypothesis-premise pairs.
### Training procedure
DeBERTa-v3-base-mnli-fever-anli was trained using the Hugging Face trainer with the following hyperparameters.
```
training_args = TrainingArguments(
num_train_epochs=3, # total number of training epochs
learning_rate=2e-05,
per_device_train_batch_size=32, # batch size per device during training
per_device_eval_batch_size=32, # batch size for evaluation
warmup_ratio=0.1, # number of warmup steps for learning rate scheduler
weight_decay=0.06, # strength of weight decay
fp16=True # mixed precision training
)
```
### Eval results
The model was evaluated using the test sets for MultiNLI and ANLI and the dev set for Fever-NLI. The metric used is accuracy.
mnli-m | mnli-mm | fever-nli | anli-all | anli-r3
---------|----------|---------|----------|----------
0.903 | 0.903 | 0.777 | 0.579 | 0.495
## Limitations and bias
Please consult the original DeBERTa paper and literature on different NLI datasets for potential biases.
## Citation
If you use this model, please cite: Laurer, Moritz, Wouter van Atteveldt, Andreu Salleras Casas, and Kasper Welbers. 2022. ‘Less Annotating, More Classifying – Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT - NLI’. Preprint, June. Open Science Framework. https://osf.io/74b8k.
### Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at m{dot}laurer{at}vu{dot}nl or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
### Debugging and issues
Note that DeBERTa-v3 was released on 06.12.21 and older versions of HF Transformers seem to have issues running the model (e.g. resulting in an issue with the tokenizer). Using Transformers>=4.13 might solve some issues.
Also make sure to install sentencepiece to avoid tokenizer errors. Run: `pip install transformers[sentencepiece]` or `pip install sentencepiece`
## Model Recycling
[Evaluation on 36 datasets](https://ibm.github.io/model-recycling/model_gain_chart?avg=0.65&mnli_lp=nan&20_newsgroup=-0.61&ag_news=-0.01&amazon_reviews_multi=0.46&anli=0.84&boolq=2.12&cb=16.07&cola=-0.76&copa=8.60&dbpedia=-0.40&esnli=-0.29&financial_phrasebank=-1.98&imdb=-0.47&isear=-0.22&mnli=-0.21&mrpc=0.50&multirc=1.91&poem_sentiment=1.73&qnli=0.07&qqp=-0.37&rotten_tomatoes=-0.74&rte=3.94&sst2=-0.45&sst_5bins=0.07&stsb=1.27&trec_coarse=-0.16&trec_fine=0.18&tweet_ev_emoji=-0.93&tweet_ev_emotion=-1.33&tweet_ev_hate=-1.67&tweet_ev_irony=-5.46&tweet_ev_offensive=-0.17&tweet_ev_sentiment=-0.11&wic=-0.21&wnli=-1.20&wsc=4.18&yahoo_answers=-0.70&model_name=MoritzLaurer%2FDeBERTa-v3-base-mnli-fever-anli&base_name=microsoft%2Fdeberta-v3-base) using MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli as a base model yields average score of 79.69 in comparison to 79.04 by microsoft/deberta-v3-base.
The model is ranked 2nd among all tested models for the microsoft/deberta-v3-base architecture as of 09/01/2023.
Results:
| 20_newsgroup | ag_news | amazon_reviews_multi | anli | boolq | cb | cola | copa | dbpedia | esnli | financial_phrasebank | imdb | isear | mnli | mrpc | multirc | poem_sentiment | qnli | qqp | rotten_tomatoes | rte | sst2 | sst_5bins | stsb | trec_coarse | trec_fine | tweet_ev_emoji | tweet_ev_emotion | tweet_ev_hate | tweet_ev_irony | tweet_ev_offensive | tweet_ev_sentiment | wic | wnli | wsc | yahoo_answers |
|---------------:|----------:|-----------------------:|-------:|--------:|--------:|--------:|-------:|----------:|--------:|-----------------------:|-------:|--------:|--------:|--------:|----------:|-----------------:|-------:|--------:|------------------:|--------:|--------:|------------:|--------:|--------------:|------------:|-----------------:|-------------------:|----------------:|-----------------:|---------------------:|---------------------:|--------:|--------:|--------:|----------------:|
| 85.8072 | 90.4333 | 67.32 | 59.625 | 85.107 | 91.0714 | 85.8102 | 67 | 79.0333 | 91.6327 | 82.5 | 94.02 | 71.6428 | 89.5749 | 89.7059 | 64.1708 | 88.4615 | 93.575 | 91.4148 | 89.6811 | 86.2816 | 94.6101 | 57.0588 | 91.5508 | 97.6 | 91.2 | 45.264 | 82.6179 | 54.5455 | 74.3622 | 84.8837 | 71.6949 | 71.0031 | 69.0141 | 68.2692 | 71.3333 |
For more information, see: [Model Recycling](https://ibm.github.io/model-recycling/)
|
EmergentMethods/gliner_medium_news-v2.1 | EmergentMethods | "2024-06-18T08:33:15Z" | 613,036 | 61 | gliner | [
"gliner",
"pytorch",
"token-classification",
"en",
"dataset:EmergentMethods/AskNews-NER-v0",
"arxiv:2406.10258",
"license:apache-2.0",
"region:us"
] | token-classification | "2024-04-17T09:05:00Z" | ---
license: apache-2.0
datasets:
- EmergentMethods/AskNews-NER-v0
tags:
- gliner
language:
- en
pipeline_tag: token-classification
---
# Model Card for gliner_medium_news-v2.1
This model is a fine-tune of [GLiNER](https://huggingface.co/urchade/gliner_medium-v2.1) aimed at improving accuracy across a broad range of topics, especially with respect to long-context news entity extraction. As shown in the table below, these fine-tunes improved upon the base GLiNER model zero-shot accuracy by up to 7.5% across 18 benchmark datasets.

The underlying dataset, [AskNews-NER-v0](https://huggingface.co/datasets/EmergentMethods/AskNews-NER-v0) was engineered with the objective of diversifying global perspectives by enforcing country/language/topic/temporal diversity. All data used to fine-tune this model was synthetically generated. WizardLM 13B v1.2 was used for translation/summarization of open-web news articles, while Llama3 70b instruct was used for entity extraction. Both the diversification and fine-tuning methods are presented in a our paper on [ArXiv](https://arxiv.org/abs/2406.10258).
# Usage
```python
from gliner import GLiNER
model = GLiNER.from_pretrained("EmergentMethods/gliner_medium_news-v2.1")
text = """
The Chihuahua State Public Security Secretariat (SSPE) arrested 35-year-old Salomón C. T. in Ciudad Juárez, found in possession of a stolen vehicle, a white GMC Yukon, which was reported stolen in the city's streets. The arrest was made by intelligence and police analysis personnel during an investigation in the border city. The arrest is related to a previous detention on February 6, which involved armed men in a private vehicle. The detainee and the vehicle were turned over to the Chihuahua State Attorney General's Office for further investigation into the case.
"""
labels = ["person", "location", "date", "event", "facility", "vehicle", "number", "organization"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
```
Output:
```
Chihuahua State Public Security Secretariat => organization
SSPE => organization
35-year-old => number
Salomón C. T. => person
Ciudad Juárez => location
GMC Yukon => vehicle
February 6 => date
Chihuahua State Attorney General's Office => organization
```
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
The synthetic data underlying this news fine-tune was pulled from the [AskNews API](https://docs.asknews.app). We enforced diveristy across country/language/topic/time.
Countries:

Entity types:

Topics:

- **Developed by:** [Emergent Methods](https://emergentmethods.ai/)
- **Funded by:** [Emergent Methods](https://emergentmethods.ai/)
- **Shared by:** [Emergent Methods](https://emergentmethods.ai/)
- **Model type:** microsoft/deberta
- **Language(s) (NLP):** English (en) (English texts and translations from Spanish (es), Portuguese (pt), German (de), Russian (ru), French (fr), Arabic (ar), Italian (it), Ukrainian (uk), Norwegian (no), Swedish (sv), Danish (da)).
- **License:** Apache 2.0
- **Finetuned from model:** [GLiNER](https://huggingface.co/urchade/gliner_medium-v2.1)
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** To be added
- **Paper:** To be added
- **Demo:** To be added
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
As the name suggests, this model is aimed at generalist entity extraction. Although we used news to fine-tune this model, it improved accuracy across 18 benchmark datasets by up to 7.5%. This means that the broad and diversified underlying dataset has helped it to recognize and extract more entity types.
This model is shockingly compact, and can be used for high-throughput production usecases. This is another reason we have licensed this as Apache 2.0. Currently, [AskNews](https://asknews.app) is using this fine-tune for entity extraction in their system.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Although the goal of the dataset is to reduce bias, and improve diversity, it is still biased to western languages and countries. This limitation originates from the abilities of Llama2 for the translation and summary generations. Further, any bias originating in Llama2 training data will also be present in this dataset, since Llama2 was used to summarize the open-web articles. Further, any biases present in Llama3 will be present in the present dataaset since Llama3 was used to extract entities from the summaries.

## How to Get Started with the Model
Use the code below to get started with the model.
## Training Details
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The training dataset is [AskNews-NER-v0](https://huggingface.co/datasets/EmergentMethods/AskNews-NER-v0).
Other training details can be found in the [companion paper](https://linktoarxiv.org).
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
- **Hardware Type:** 1xA4500
- **Hours used:** 10
- **Carbon Emitted:** 0.6 kg (According to [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute))
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
To be added
**APA:**
To be added
## Model Authors
Elin Törnquist, Emergent Methods elin at emergentmethods.ai
Robert Caulk, Emergent Methods rob at emergentmethods.ai
## Model Contact
Elin Törnquist, Emergent Methods elin at emergentmethods.ai
Robert Caulk, Emergent Methods rob at emergentmethods.ai |
meta-llama/Llama-3.1-8B | meta-llama | "2024-09-25T16:59:58Z" | 604,027 | 907 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-07-14T22:20:15Z" | ---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3.1
extra_gated_prompt: >-
### LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation
accompanying Llama 3.1 distributed by Meta at
https://llama.meta.com/doc/overview.
"Licensee" or "you" means you, or your employer or any other person or entity
(if you are entering into this Agreement on such person or entity’s behalf),
of the age required under applicable laws, rules or regulations to provide
legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Llama 3.1" means the foundational large language models and software and
algorithms, including machine-learning model code, trained model weights,
inference-enabling code, training-enabling code, fine-tuning enabling code and
other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Llama 3.1 and
Documentation (and any portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or
Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA
or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide,
non-transferable and royalty-free limited license under Meta’s intellectual
property or other rights owned by Meta embodied in the Llama Materials to use,
reproduce, distribute, copy, create derivative works of, and make
modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative
works thereof), or a product or service (including another AI model) that
contains any of them, you shall (A) provide a copy of this Agreement with any
such Llama Materials; and (B) prominently display “Built with Llama” on a
related website, user interface, blogpost, about page, or product
documentation. If you use the Llama Materials or any outputs or results of the
Llama Materials to create, train, fine tune, or otherwise improve an AI model,
which is distributed or made available, you shall also include “Llama” at the
beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a
Licensee as part of an integrated end user product, then Section 2 of this
Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute
the following attribution notice within a “Notice” text file distributed as a
part of such copies: “Llama 3.1 is licensed under the Llama 3.1 Community
License, Copyright © Meta Platforms, Inc. All Rights Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and
regulations (including trade compliance laws and regulations) and adhere to
the Acceptable Use Policy for the Llama Materials (available at
https://llama.meta.com/llama3_1/use-policy), which is hereby incorporated by
reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 3.1 version release date, the
monthly active users of the products or services made available by or for
Licensee, or Licensee’s affiliates, is greater than 700 million monthly active
users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized
to exercise any of the rights under this Agreement unless or until Meta
otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA
MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS”
BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF
ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY
WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A
PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE
APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY
RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE
UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS
LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS
OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE
DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY
OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection
with the Llama Materials, neither Meta nor Licensee may use any name or mark
owned by or associated with the other or any of its affiliates, except as
required for reasonable and customary use in describing and redistributing the
Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a
license to use “Llama” (the “Mark”) solely as required to comply with the last
sentence of Section 1.b.i. You will comply with Meta’s brand guidelines
(currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill
arising out of your use of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or
for Meta, with respect to any derivative works and modifications of the Llama
Materials that are made by you, as between you and Meta, you are and will be
the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity
(including a cross-claim or counterclaim in a lawsuit) alleging that the Llama
Materials or Llama 3.1 outputs or results, or any portion of any of the
foregoing, constitutes infringement of intellectual property or other rights
owned or licensable by you, then any licenses granted to you under this
Agreement shall terminate as of the date such litigation or claim is filed or
instituted. You will indemnify and hold harmless Meta from and against any
claim by any third party arising out of or related to your use or distribution
of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will
continue in full force and effect until terminated in accordance with the
terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this
Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and
construed under the laws of the State of California without regard to choice
of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California shall
have exclusive jurisdiction of any dispute arising out of this Agreement.
### Llama 3.1 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features,
including Llama 3.1. If you access or use Llama 3.1, you agree to this
Acceptable Use Policy (“Policy”). The most recent copy of this policy can be
found at
[https://llama.meta.com/llama3_1/use-policy](https://llama.meta.com/llama3_1/use-policy)
#### Prohibited Uses
We want everyone to use Llama 3.1 safely and responsibly. You agree you will
not use, or allow others to use, Llama 3.1 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
3. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
4. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
5. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
6. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
7. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
8. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or
development of activities that present a risk of death or bodily harm to
individuals, including use of Llama 3.1 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 3.1 related
to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Llama 3.1 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI
system
Please report any violation of this Policy, software “bug,” or other problems
that could lead to a violation of this Policy through one of the following
means:
* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://github.com/meta-llama/llama-models/issues)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
library_name: transformers
---
## Model Information
The Meta Llama 3.1 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction tuned generative models in 8B, 70B and 405B sizes (text in/text out). The Llama 3.1 instruction tuned text only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the available open source and closed chat models on common industry benchmarks.
**Model developer**: Meta
**Model Architecture:** Llama 3.1 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Input modalities</strong>
</td>
<td><strong>Output modalities</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="3" >Llama 3.1 (text only)
</td>
<td rowspan="3" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>Multilingual Text
</td>
<td>Multilingual Text and code
</td>
<td>128k
</td>
<td>Yes
</td>
<td rowspan="3" >15T+
</td>
<td rowspan="3" >December 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>Multilingual Text
</td>
<td>Multilingual Text and code
</td>
<td>128k
</td>
<td>Yes
</td>
</tr>
<tr>
<td>405B
</td>
<td>Multilingual Text
</td>
<td>Multilingual Text and code
</td>
<td>128k
</td>
<td>Yes
</td>
</tr>
</table>
**Supported languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
**Llama 3.1 family of models**. Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** July 23, 2024.
**Status:** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License:** A custom commercial license, the Llama 3.1 Community License, is available at: [https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3.1 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3.1 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks. The Llama 3.1 model collection also supports the ability to leverage the outputs of its models to improve other models including synthetic data generation and distillation. The Llama 3.1 Community License allows for these use cases.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.1 Community License. Use in languages beyond those explicitly referenced as supported in this model card**.
**<span style="text-decoration:underline;">Note</span>: Llama 3.1 has been trained on a broader collection of languages than the 8 supported languages. Developers may fine-tune Llama 3.1 models for languages beyond the 8 supported languages provided they comply with the Llama 3.1 Community License and the Acceptable Use Policy and in such cases are responsible for ensuring that any uses of Llama 3.1 in additional languages is done in a safe and responsible manner.
## How to use
This repository contains two versions of Meta-Llama-3.1-8B, for use with transformers and with the original `llama` codebase.
### Use with transformers
Starting with transformers >= 4.43.0 onward, you can run conversational inference using the Transformers pipeline abstraction or by leveraging the Auto classes with the generate() function.
Make sure to update your transformers installation via pip install --upgrade transformers.
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B"
pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
pipeline("Hey how are you doing today?")
```
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3.1-8B --include "original/*" --local-dir Meta-Llama-3.1-8B
```
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, annotation, and evaluation were also performed on production infrastructure.
**Training utilized a cumulative of** 39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
**Training Greenhouse Gas Emissions** Estimated total location-based greenhouse gas emissions were **11,390** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy, therefore the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
<table>
<tr>
<td>
</td>
<td><strong>Training Time (GPU hours)</strong>
</td>
<td><strong>Training Power Consumption (W)</strong>
</td>
<td><strong>Training Location-Based Greenhouse Gas Emissions</strong>
<p>
<strong>(tons CO2eq)</strong>
</td>
<td><strong>Training Market-Based Greenhouse Gas Emissions</strong>
<p>
<strong>(tons CO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3.1 8B
</td>
<td>1.46M
</td>
<td>700
</td>
<td>420
</td>
<td>0
</td>
</tr>
<tr>
<td>Llama 3.1 70B
</td>
<td>7.0M
</td>
<td>700
</td>
<td>2,040
</td>
<td>0
</td>
</tr>
<tr>
<td>Llama 3.1 405B
</td>
<td>30.84M
</td>
<td>700
</td>
<td>8,930
</td>
<td>0
</td>
</tr>
<tr>
<td>Total
</td>
<td>39.3M
<td>
<ul>
</ul>
</td>
<td>11,390
</td>
<td>0
</td>
</tr>
</table>
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.1 was pretrained on ~15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 25M synthetically generated examples.
**Data Freshness:** The pretraining data has a cutoff of December 2023.
## Benchmark scores
In this section, we report the results for Llama 3.1 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library.
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong># Shots</strong>
</td>
<td><strong>Metric</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 3.1 8B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 3.1 70B</strong>
</td>
<td><strong>Llama 3.1 405B</strong>
</td>
</tr>
<tr>
<td rowspan="7" >General
</td>
<td>MMLU
</td>
<td>5
</td>
<td>macro_avg/acc_char
</td>
<td>66.7
</td>
<td>66.7
</td>
<td>79.5
</td>
<td>79.3
</td>
<td>85.2
</td>
</tr>
<tr>
<td>MMLU-Pro (CoT)
</td>
<td>5
</td>
<td>macro_avg/acc_char
</td>
<td>36.2
</td>
<td>37.1
</td>
<td>55.0
</td>
<td>53.8
</td>
<td>61.6
</td>
</tr>
<tr>
<td>AGIEval English
</td>
<td>3-5
</td>
<td>average/acc_char
</td>
<td>47.1
</td>
<td>47.8
</td>
<td>63.0
</td>
<td>64.6
</td>
<td>71.6
</td>
</tr>
<tr>
<td>CommonSenseQA
</td>
<td>7
</td>
<td>acc_char
</td>
<td>72.6
</td>
<td>75.0
</td>
<td>83.8
</td>
<td>84.1
</td>
<td>85.8
</td>
</tr>
<tr>
<td>Winogrande
</td>
<td>5
</td>
<td>acc_char
</td>
<td>-
</td>
<td>60.5
</td>
<td>-
</td>
<td>83.3
</td>
<td>86.7
</td>
</tr>
<tr>
<td>BIG-Bench Hard (CoT)
</td>
<td>3
</td>
<td>average/em
</td>
<td>61.1
</td>
<td>64.2
</td>
<td>81.3
</td>
<td>81.6
</td>
<td>85.9
</td>
</tr>
<tr>
<td>ARC-Challenge
</td>
<td>25
</td>
<td>acc_char
</td>
<td>79.4
</td>
<td>79.7
</td>
<td>93.1
</td>
<td>92.9
</td>
<td>96.1
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki
</td>
<td>5
</td>
<td>em
</td>
<td>78.5
</td>
<td>77.6
</td>
<td>89.7
</td>
<td>89.8
</td>
<td>91.8
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD
</td>
<td>1
</td>
<td>em
</td>
<td>76.4
</td>
<td>77.0
</td>
<td>85.6
</td>
<td>81.8
</td>
<td>89.3
</td>
</tr>
<tr>
<td>QuAC (F1)
</td>
<td>1
</td>
<td>f1
</td>
<td>44.4
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>51.1
</td>
<td>53.6
</td>
</tr>
<tr>
<td>BoolQ
</td>
<td>0
</td>
<td>acc_char
</td>
<td>75.7
</td>
<td>75.0
</td>
<td>79.0
</td>
<td>79.4
</td>
<td>80.0
</td>
</tr>
<tr>
<td>DROP (F1)
</td>
<td>3
</td>
<td>f1
</td>
<td>58.4
</td>
<td>59.5
</td>
<td>79.7
</td>
<td>79.6
</td>
<td>84.8
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong># Shots</strong>
</td>
<td><strong>Metric</strong>
</td>
<td><strong>Llama 3 8B Instruct</strong>
</td>
<td><strong>Llama 3.1 8B Instruct</strong>
</td>
<td><strong>Llama 3 70B Instruct</strong>
</td>
<td><strong>Llama 3.1 70B Instruct</strong>
</td>
<td><strong>Llama 3.1 405B Instruct</strong>
</td>
</tr>
<tr>
<td rowspan="4" >General
</td>
<td>MMLU
</td>
<td>5
</td>
<td>macro_avg/acc
</td>
<td>68.5
</td>
<td>69.4
</td>
<td>82.0
</td>
<td>83.6
</td>
<td>87.3
</td>
</tr>
<tr>
<td>MMLU (CoT)
</td>
<td>0
</td>
<td>macro_avg/acc
</td>
<td>65.3
</td>
<td>73.0
</td>
<td>80.9
</td>
<td>86.0
</td>
<td>88.6
</td>
</tr>
<tr>
<td>MMLU-Pro (CoT)
</td>
<td>5
</td>
<td>micro_avg/acc_char
</td>
<td>45.5
</td>
<td>48.3
</td>
<td>63.4
</td>
<td>66.4
</td>
<td>73.3
</td>
</tr>
<tr>
<td>IFEval
</td>
<td>
</td>
<td>
</td>
<td>76.8
</td>
<td>80.4
</td>
<td>82.9
</td>
<td>87.5
</td>
<td>88.6
</td>
</tr>
<tr>
<td rowspan="2" >Reasoning
</td>
<td>ARC-C
</td>
<td>0
</td>
<td>acc
</td>
<td>82.4
</td>
<td>83.4
</td>
<td>94.4
</td>
<td>94.8
</td>
<td>96.9
</td>
</tr>
<tr>
<td>GPQA
</td>
<td>0
</td>
<td>em
</td>
<td>34.6
</td>
<td>30.4
</td>
<td>39.5
</td>
<td>46.7
</td>
<td>50.7
</td>
</tr>
<tr>
<td rowspan="4" >Code
</td>
<td>HumanEval
</td>
<td>0
</td>
<td>pass@1
</td>
<td>60.4
</td>
<td>72.6
</td>
<td>81.7
</td>
<td>80.5
</td>
<td>89.0
</td>
</tr>
<tr>
<td>MBPP ++ base version
</td>
<td>0
</td>
<td>pass@1
</td>
<td>70.6
</td>
<td>72.8
</td>
<td>82.5
</td>
<td>86.0
</td>
<td>88.6
</td>
</tr>
<tr>
<td>Multipl-E HumanEval
</td>
<td>0
</td>
<td>pass@1
</td>
<td>-
</td>
<td>50.8
</td>
<td>-
</td>
<td>65.5
</td>
<td>75.2
</td>
</tr>
<tr>
<td>Multipl-E MBPP
</td>
<td>0
</td>
<td>pass@1
</td>
<td>-
</td>
<td>52.4
</td>
<td>-
</td>
<td>62.0
</td>
<td>65.7
</td>
</tr>
<tr>
<td rowspan="2" >Math
</td>
<td>GSM-8K (CoT)
</td>
<td>8
</td>
<td>em_maj1@1
</td>
<td>80.6
</td>
<td>84.5
</td>
<td>93.0
</td>
<td>95.1
</td>
<td>96.8
</td>
</tr>
<tr>
<td>MATH (CoT)
</td>
<td>0
</td>
<td>final_em
</td>
<td>29.1
</td>
<td>51.9
</td>
<td>51.0
</td>
<td>68.0
</td>
<td>73.8
</td>
</tr>
<tr>
<td rowspan="4" >Tool Use
</td>
<td>API-Bank
</td>
<td>0
</td>
<td>acc
</td>
<td>48.3
</td>
<td>82.6
</td>
<td>85.1
</td>
<td>90.0
</td>
<td>92.0
</td>
</tr>
<tr>
<td>BFCL
</td>
<td>0
</td>
<td>acc
</td>
<td>60.3
</td>
<td>76.1
</td>
<td>83.0
</td>
<td>84.8
</td>
<td>88.5
</td>
</tr>
<tr>
<td>Gorilla Benchmark API Bench
</td>
<td>0
</td>
<td>acc
</td>
<td>1.7
</td>
<td>8.2
</td>
<td>14.7
</td>
<td>29.7
</td>
<td>35.3
</td>
</tr>
<tr>
<td>Nexus (0-shot)
</td>
<td>0
</td>
<td>macro_avg/acc
</td>
<td>18.1
</td>
<td>38.5
</td>
<td>47.8
</td>
<td>56.7
</td>
<td>58.7
</td>
</tr>
<tr>
<td>Multilingual
</td>
<td>Multilingual MGSM (CoT)
</td>
<td>0
</td>
<td>em
</td>
<td>-
</td>
<td>68.9
</td>
<td>-
</td>
<td>86.9
</td>
<td>91.6
</td>
</tr>
</table>
#### Multilingual benchmarks
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Language</strong>
</td>
<td><strong>Llama 3.1 8B</strong>
</td>
<td><strong>Llama 3.1 70B</strong>
</td>
<td><strong>Llama 3.1 405B</strong>
</td>
</tr>
<tr>
<td rowspan="9" ><strong>General</strong>
</td>
<td rowspan="9" ><strong>MMLU (5-shot, macro_avg/acc)</strong>
</td>
<td>Portuguese
</td>
<td>62.12
</td>
<td>80.13
</td>
<td>84.95
</td>
</tr>
<tr>
<td>Spanish
</td>
<td>62.45
</td>
<td>80.05
</td>
<td>85.08
</td>
</tr>
<tr>
<td>Italian
</td>
<td>61.63
</td>
<td>80.4
</td>
<td>85.04
</td>
</tr>
<tr>
<td>German
</td>
<td>60.59
</td>
<td>79.27
</td>
<td>84.36
</td>
</tr>
<tr>
<td>French
</td>
<td>62.34
</td>
<td>79.82
</td>
<td>84.66
</td>
</tr>
<tr>
<td>Hindi
</td>
<td>50.88
</td>
<td>74.52
</td>
<td>80.31
</td>
</tr>
<tr>
<td>Thai
</td>
<td>50.32
</td>
<td>72.95
</td>
<td>78.21
</td>
</tr>
</table>
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
* Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama.
* Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm.
* Provide protections for the community to help prevent the misuse of our models.
### Responsible deployment
Llama is a foundational technology designed to be used in a variety of use cases, examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models enabling the world to benefit from the technology power, by aligning our model safety for the generic use cases addressing a standard set of harms. Developers are then in the driver seat to tailor safety for their use case, defining their own policy and deploying the models with the necessary safeguards in their Llama systems. Llama 3.1 was developed following the best practices outlined in our Responsible Use Guide, you can refer to the [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to learn more.
#### Llama 3.1 instruct
Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. For more details on the safety mitigations implemented please read the Llama 3 paper.
**Fine-tuning data**
We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone**
Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.1 systems
**Large language models, including Llama 3.1, are not designed to be deployed in isolation but instead should be deployed as part of an overall AI system with additional safety guardrails as required.** Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools.
As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard 3, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
#### New capabilities
Note that this release introduces new capabilities, including a longer context window, multilingual inputs and outputs and possible integrations by developers with third party tools. Building with these new capabilities requires specific considerations in addition to the best practices that generally apply across all Generative AI use cases.
**Tool-use**: Just like in standard software development, developers are responsible for the integration of the LLM with the tools and services of their choice. They should define a clear policy for their use case and assess the integrity of the third party services they use to be aware of the safety and security limitations when using this capability. Refer to the Responsible Use Guide for best practices on the safe deployment of the third party safeguards.
**Multilinguality**: Llama 3.1 supports 7 languages in addition to English: French, German, Hindi, Italian, Portuguese, Spanish, and Thai. Llama may be able to output text in other languages than those that meet performance thresholds for safety and helpfulness. We strongly discourage developers from using this model to converse in non-supported languages without implementing finetuning and system controls in alignment with their policies and the best practices shared in the Responsible Use Guide.
### Evaluations
We evaluated Llama models for common use cases as well as specific capabilities. Common use cases evaluations measure safety risks of systems for most commonly built applications including chat bot, coding assistant, tool calls. We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Llama Guard 3 to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case. Prompt Guard and Code Shield are also available if relevant to the application.
Capability evaluations measure vulnerabilities of Llama models inherent to specific capabilities, for which were crafted dedicated benchmarks including long context, multilingual, tools calls, coding or memorization.
**Red teaming**
For both scenarios, we conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets.
We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical and other risks
We specifically focused our efforts on mitigating the following critical risk areas:
**1- CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive materials) helpfulness**
To assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons.
**2. Child Safety**
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3. Cyber attack enablement**
Our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention.
Our study of Llama-3.1-405B’s social engineering uplift for cyber attackers was conducted to assess the effectiveness of AI models in aiding cyber threat actors in spear phishing campaigns. Please read our Llama 3.1 Cyber security whitepaper to learn more.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3.1 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.1 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3.1 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.1’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.1 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development. |
facebook/detr-resnet-50 | facebook | "2024-04-10T13:56:31Z" | 600,737 | 675 | transformers | [
"transformers",
"pytorch",
"safetensors",
"detr",
"object-detection",
"vision",
"dataset:coco",
"arxiv:2005.12872",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
tags:
- object-detection
- vision
datasets:
- coco
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/savanna.jpg
example_title: Savanna
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
example_title: Football Match
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/airport.jpg
example_title: Airport
---
# DETR (End-to-End Object Detection) model with ResNet-50 backbone
DEtection TRansformer (DETR) model trained end-to-end on COCO 2017 object detection (118k annotated images). It was introduced in the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Carion et al. and first released in [this repository](https://github.com/facebookresearch/detr).
Disclaimer: The team releasing DETR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The DETR model is an encoder-decoder transformer with a convolutional backbone. Two heads are added on top of the decoder outputs in order to perform object detection: a linear layer for the class labels and a MLP (multi-layer perceptron) for the bounding boxes. The model uses so-called object queries to detect objects in an image. Each object query looks for a particular object in the image. For COCO, the number of object queries is set to 100.
The model is trained using a "bipartite matching loss": one compares the predicted classes + bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N (so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as bounding box). The Hungarian matching algorithm is used to create an optimal one-to-one mapping between each of the N queries and each of the N annotations. Next, standard cross-entropy (for the classes) and a linear combination of the L1 and generalized IoU loss (for the bounding boxes) are used to optimize the parameters of the model.

## Intended uses & limitations
You can use the raw model for object detection. See the [model hub](https://huggingface.co/models?search=facebook/detr) to look for all available DETR models.
### How to use
Here is how to use this model:
```python
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# you can specify the revision tag if you don't want the timm dependency
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50", revision="no_timm")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50", revision="no_timm")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
# let's only keep detections with score > 0.9
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.9)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
```
This should output:
```
Detected remote with confidence 0.998 at location [40.16, 70.81, 175.55, 117.98]
Detected remote with confidence 0.996 at location [333.24, 72.55, 368.33, 187.66]
Detected couch with confidence 0.995 at location [-0.02, 1.15, 639.73, 473.76]
Detected cat with confidence 0.999 at location [13.24, 52.05, 314.02, 470.93]
Detected cat with confidence 0.999 at location [345.4, 23.85, 640.37, 368.72]
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The DETR model was trained on [COCO 2017 object detection](https://cocodataset.org/#download), a dataset consisting of 118k/5k annotated images for training/validation respectively.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled such that the shortest side is at least 800 pixels and the largest side at most 1333 pixels, and normalized across the RGB channels with the ImageNet mean (0.485, 0.456, 0.406) and standard deviation (0.229, 0.224, 0.225).
### Training
The model was trained for 300 epochs on 16 V100 GPUs. This takes 3 days, with 4 images per GPU (hence a total batch size of 64).
## Evaluation results
This model achieves an AP (average precision) of **42.0** on COCO 2017 validation. For more details regarding evaluation results, we refer to table 1 of the original paper.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2005-12872,
author = {Nicolas Carion and
Francisco Massa and
Gabriel Synnaeve and
Nicolas Usunier and
Alexander Kirillov and
Sergey Zagoruyko},
title = {End-to-End Object Detection with Transformers},
journal = {CoRR},
volume = {abs/2005.12872},
year = {2020},
url = {https://arxiv.org/abs/2005.12872},
archivePrefix = {arXiv},
eprint = {2005.12872},
timestamp = {Thu, 28 May 2020 17:38:09 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2005-12872.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
naufalihsan/indonesian-sbert-large | naufalihsan | "2023-10-22T04:00:55Z" | 599,669 | 7 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-10-14T02:38:57Z" | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 360 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 144,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
distil-whisper/distil-medium.en | distil-whisper | "2024-03-25T12:07:23Z" | 596,252 | 117 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"onnx",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"transformers.js",
"en",
"arxiv:2311.00430",
"arxiv:2210.13352",
"license:mit",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2023-10-24T15:49:07Z" | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
- transformers.js
widget:
- example_title: LibriSpeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: LibriSpeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
pipeline_tag: automatic-speech-recognition
license: mit
library_name: transformers
---
# Distil-Whisper: distil-medium.en
Distil-Whisper was proposed in the paper [Robust Knowledge Distillation via Large-Scale Pseudo Labelling](https://arxiv.org/abs/2311.00430).
It is a distilled version of the Whisper model that is **6 times faster**, 49% smaller, and performs
**within 1% WER** on out-of-distribution evaluation sets. This is the repository for distil-medium.en,
a distilled variant of [Whisper medium.en](https://huggingface.co/openai/whisper-medium.en).
| Model | Params / M | Rel. Latency ↑ | Short-Form WER ↓ | Long-Form WER ↓ |
|----------------------------------------------------------------------------|------------|----------------|------------------|-----------------|
| [large-v3](https://huggingface.co/openai/whisper-large-v3) | 1550 | 1.0 | **8.4** | 11.0 |
| [large-v2](https://huggingface.co/openai/whisper-large-v2) | 1550 | 1.0 | 9.1 | 11.7 |
| | | | | |
| [distil-large-v3](https://huggingface.co/distil-whisper/distil-large-v3) | 756 | 6.3 | 9.7 | **10.8** |
| [distil-large-v2](https://huggingface.co/distil-whisper/distil-large-v2) | 756 | 5.8 | 10.1 | 11.6 |
| [distil-medium.en](https://huggingface.co/distil-whisper/distil-medium.en) | 394 | **6.8** | 11.1 | 12.4 |
| [distil-small.en](https://huggingface.co/distil-whisper/distil-small.en) | **166** | 5.6 | 12.1 | 12.8 |
**Note:** Distil-Whisper is currently only available for English speech recognition. We are working with the community
to distill Whisper on other languages. If you are interested in distilling Whisper in your language, check out the
provided [training code](https://github.com/huggingface/distil-whisper/tree/main/training). We will update the
[Distil-Whisper repository](https://github.com/huggingface/distil-whisper/) with multilingual checkpoints when ready!
## Usage
Distil-Whisper is supported in Hugging Face 🤗 Transformers from version 4.35 onwards. To run the model, first
install the latest version of the Transformers library. For this example, we'll also install 🤗 Datasets to load toy
audio dataset from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
```
### Short-Form Transcription
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe short-form audio files (< 30-seconds) as follows:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```diff
- result = pipe(sample)
+ result = pipe("audio.mp3")
```
### Long-Form Transcription
Distil-Whisper uses a chunked algorithm to transcribe long-form audio files (> 30-seconds). In practice, this chunked long-form algorithm
is 9x faster than the sequential algorithm proposed by OpenAI in the Whisper paper (see Table 7 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430)).
To enable chunking, pass the `chunk_length_s` parameter to the `pipeline`. For Distil-Whisper, a chunk length of 15-seconds
is optimal. To activate batching, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "default", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
<!---
**Tip:** The pipeline can also be used to transcribe an audio file from a remote URL, for example:
```python
result = pipe("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
```
--->
### Speculative Decoding
Distil-Whisper can be used as an assistant model to Whisper for [speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding).
Speculative decoding mathematically ensures the exact same outputs as Whisper are obtained while being 2 times faster.
This makes it the perfect drop-in replacement for existing Whisper pipelines, since the same outputs are guaranteed.
In the following code-snippet, we load the assistant Distil-Whisper model standalone to the main Whisper pipeline. We then
specify it as the "assistant model" for generation:
```python
from transformers import pipeline, AutoModelForCausalLM, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "distil-whisper/distil-medium.en"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
## Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Distil-Whisper which we cover in the following.
### Flash Attention
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2) if your GPU allows for it.
To do so, you first need to install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
and then all you have to do is to pass `use_flash_attention_2=True` to `from_pretrained`:
```diff
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
```
### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of [BetterTransformers](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#bettertransformer).
To do so, you first need to install optimum:
```
pip install --upgrade optimum
```
And then convert your model to a "BetterTransformer" model before using it:
```diff
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
```
### Running Distil-Whisper in `openai-whisper`
To use the model in the original Whisper format, first ensure you have the [`openai-whisper`](https://pypi.org/project/openai-whisper/) package installed:
```bash
pip install --upgrade openai-whisper
```
The following code-snippet demonstrates how to transcribe a sample file from the LibriSpeech dataset loaded using
🤗 Datasets:
```python
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from whisper import load_model, transcribe
medium_en = hf_hub_download(repo_id="distil-whisper/distil-medium.en", filename="original-model.bin")
model = load_model(medium_en)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["array"]
sample = torch.from_numpy(sample).float()
pred_out = transcribe(model, audio=sample)
print(pred_out["text"])
```
To transcribe a local audio file, simply pass the path to the audio file as the `audio` argument to transcribe:
```python
pred_out = transcribe(model, audio="audio.mp3")
```
### Whisper.cpp
Distil-Whisper can be run from the [Whisper.cpp](https://github.com/ggerganov/whisper.cpp) repository with the original
sequential long-form transcription algorithm. In a [provisional benchmark](https://github.com/ggerganov/whisper.cpp/pull/1424#issuecomment-1793513399)
on Mac M1, `distil-medium.en` is 4x faster than `large-v2`, while performing to within 1% WER over long-form audio.
Steps for getting started:
1. Clone the Whisper.cpp repository:
```
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
```
2. Download the ggml weights for `distil-medium.en` from the Hugging Face Hub:
```bash
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='distil-whisper/distil-medium.en', filename='ggml-medium-32-2.en.bin', local_dir='./models')"
```
Note that if you do not have the `huggingface_hub` package installed, you can also download the weights with `wget`:
```bash
wget https://huggingface.co/distil-whisper/distil-medium.en/resolve/main/ggml-medium-32-2.en.bin -P ./models
```
3. Run inference using the provided sample audio:
```bash
make -j && ./main -m models/ggml-medium-32-2.en.bin -f samples/jfk.wav
```
### Transformers.js
```js
import { pipeline } from '@xenova/transformers';
let transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-medium.en');
let url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
let output = await transcriber(url);
// { text: " And so my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
```
See the [docs](https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.AutomaticSpeechRecognitionPipeline) for more information.
### Candle
Through an integration with Hugging Face [Candle](https://github.com/huggingface/candle/tree/main) 🕯️, Distil-Whisper is
now available in the Rust library 🦀
Benefit from:
* Optimised CPU backend with optional MKL support for x86 and Accelerate for Macs
* CUDA backend for efficiently running on GPUs, multiple GPU distribution via NCCL
* WASM support: run Distil-Whisper in a browser
Steps for getting started:
1. Install [`candle-core`](https://github.com/huggingface/candle/tree/main/candle-core) as explained [here](https://huggingface.github.io/candle/guide/installation.html)
2. Clone the `candle` repository locally:
```
git clone https://github.com/huggingface/candle.git
```
3. Enter the example directory for [Whisper](https://github.com/huggingface/candle/tree/main/candle-examples/examples/whisper):
```
cd candle/candle-examples/examples/whisper
```
4. Run an example:
```
cargo run --example whisper --release -- --model distil-medium.en
```
5. To specify your own audio file, add the `--input` flag:
```
cargo run --example whisper --release -- --model distil-medium.en --input audio.wav
```
### 8bit & 4bit Quantization
Coming soon ...
## Model Details
Distil-Whisper inherits the encoder-decoder architecture from Whisper. The encoder maps a sequence of speech vector
inputs to a sequence of hidden-state vectors. The decoder auto-regressively predicts text tokens, conditional on all
previous tokens and the encoder hidden-states. Consequently, the encoder is only run forward once, whereas the decoder
is run as many times as the number of tokens generated. In practice, this means the decoder accounts for over 90% of
total inference time. Thus, to optimise for latency, the focus should be on minimising the inference time of the decoder.
To distill the Whisper model, we reduce the number of decoder layers while keeping the encoder fixed.
The encoder (shown in green) is entirely copied from the teacher to the student and frozen during training.
The student's decoder consists of only two decoder layers, which are initialised from the first and last decoder layer of
the teacher (shown in red). All other decoder layers of the teacher are discarded. The model is then trained on a weighted sum
of the KL divergence and pseudo-label loss terms.
<p align="center">
<img src="https://huggingface.co/datasets/distil-whisper/figures/resolve/main/architecture.png?raw=true" width="600"/>
</p>
## Evaluation
The following code-snippets demonstrates how to evaluate the Distil-Whisper model on the LibriSpeech validation.clean
dataset with [streaming mode](https://huggingface.co/blog/audio-datasets#streaming-mode-the-silver-bullet), meaning no
audio data has to be downloaded to your local device.
First, we need to install the required packages, including 🤗 Datasets to stream and load the audio data, and 🤗 Evaluate to
perform the WER calculation:
```bash
pip install --upgrade pip
pip install --upgrade transformers datasets[audio] evaluate jiwer
```
Evaluation can then be run end-to-end with the following example:
```python
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from transformers.models.whisper.english_normalizer import EnglishTextNormalizer
from datasets import load_dataset
from evaluate import load
import torch
from tqdm import tqdm
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-medium.en"
# load the model + processor
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, use_safetensors=True, low_cpu_mem_usage=True)
model = model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
# load the dataset with streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# define the evaluation metric
wer_metric = load("wer")
normalizer = EnglishTextNormalizer(processor.tokenizer.english_spelling_normalizer)
def inference(batch):
# 1. Pre-process the audio data to log-mel spectrogram inputs
audio = [sample["array"] for sample in batch["audio"]]
input_features = processor(audio, sampling_rate=batch["audio"][0]["sampling_rate"], return_tensors="pt").input_features
input_features = input_features.to(device, dtype=torch_dtype)
# 2. Auto-regressively generate the predicted token ids
pred_ids = model.generate(input_features, max_new_tokens=128)
# 3. Decode the token ids to the final transcription
batch["transcription"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
batch["reference"] = batch["text"]
return batch
dataset = dataset.map(function=inference, batched=True, batch_size=16)
all_transcriptions = []
all_references = []
# iterate over the dataset and run inference
for i, result in tqdm(enumerate(dataset), desc="Evaluating..."):
all_transcriptions.append(result["transcription"])
all_references.append(result["reference"])
# normalize predictions and references
all_transcriptions = [normalizer(transcription) for transcription in all_transcriptions]
all_references = [normalizer(reference) for reference in all_references]
# compute the WER metric
wer = 100 * wer_metric.compute(predictions=all_transcriptions, references=all_references)
print(wer)
```
**Print Output:**
```
3.593196832001168
```
## Intended Use
Distil-Whisper is intended to be a drop-in replacement for Whisper on English speech recognition. In particular, it
achieves comparable WER results over out-of-distribution test data, while being 6x faster over both short and long-form
audio.
## Data
Distil-Whisper is trained on 22,000 hours of audio data from 9 open-source, permissively licensed speech datasets on the
Hugging Face Hub:
| Dataset | Size / h | Speakers | Domain | Licence |
|-----------------------------------------------------------------------------------------|----------|----------|-----------------------------|-----------------|
| [People's Speech](https://huggingface.co/datasets/MLCommons/peoples_speech) | 12,000 | unknown | Internet Archive | CC-BY-SA-4.0 |
| [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) | 3,000 | unknown | Narrated Wikipedia | CC0-1.0 |
| [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech) | 2,500 | unknown | Audiobook, podcast, YouTube | apache-2.0 |
| Fisher | 1,960 | 11,900 | Telephone conversations | LDC |
| [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) | 960 | 2,480 | Audiobooks | CC-BY-4.0 |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 540 | 1,310 | European Parliament | CC0 |
| [TED-LIUM](https://huggingface.co/datasets/LIUM/tedlium) | 450 | 2,030 | TED talks | CC-BY-NC-ND 3.0 |
| SwitchBoard | 260 | 540 | Telephone conversations | LDC |
| [AMI](https://huggingface.co/datasets/edinburghcstr/ami) | 100 | unknown | Meetings | CC-BY-4.0 |
||||||
| **Total** | 21,770 | 18,260+ | | |
The combined dataset spans 10 distinct domains and over 50k speakers. The diversity of this dataset is crucial to ensuring
the distilled model is robust to audio distributions and noise.
The audio data is then pseudo-labelled using the Whisper large-v2 model: we use Whisper to generate predictions for all
the audio in our training set and use these as the target labels during training. Using pseudo-labels ensures that the
transcriptions are consistently formatted across datasets and provides sequence-level distillation signal during training.
## WER Filter
The Whisper pseudo-label predictions are subject to mis-transcriptions and hallucinations. To ensure we only train on
accurate pseudo-labels, we employ a simple WER heuristic during training. First, we normalise the Whisper pseudo-labels
and the ground truth labels provided by each dataset. We then compute the WER between these labels. If the WER exceeds
a specified threshold, we discard the training example. Otherwise, we keep it for training.
Section 9.2 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430) demonstrates the effectiveness of this filter for improving downstream performance
of the distilled model. We also partially attribute Distil-Whisper's robustness to hallucinations to this filter.
## Training
The model was trained for 80,000 optimisation steps (or eight epochs). The Tensorboard training logs can be found under: https://huggingface.co/distil-whisper/distil-medium.en/tensorboard?params=scalars#frame
## Results
The distilled model performs to within 1% WER of Whisper on out-of-distribution (OOD) short-form audio, and outperforms Whisper
by 0.1% on OOD long-form audio. This performance gain is attributed to lower hallucinations.
For a detailed per-dataset breakdown of the evaluation results, refer to Tables 16 and 17 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430)
Distil-Whisper is also evaluated on the [ESB benchmark](https://arxiv.org/abs/2210.13352) datasets as part of the [OpenASR leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard),
where it performs to within 0.2% WER of Whisper.
## Reproducing Distil-Whisper
Training and evaluation code to reproduce Distil-Whisper is available under the Distil-Whisper repository: https://github.com/huggingface/distil-whisper/tree/main/training
## License
Distil-Whisper inherits the [MIT license](https://github.com/huggingface/distil-whisper/blob/main/LICENSE) from OpenAI's Whisper model.
## Citation
If you use this model, please consider citing the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430):
```
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Acknowledgements
* OpenAI for the Whisper [model](https://huggingface.co/openai/whisper-large-v2) and [original codebase](https://github.com/openai/whisper)
* Hugging Face 🤗 [Transformers](https://github.com/huggingface/transformers) for the model integration
* Google's [TPU Research Cloud (TRC)](https://sites.research.google/trc/about/) programme for Cloud TPU v4s
* [`@rsonavane`](https://huggingface.co/rsonavane/distil-whisper-large-v2-8-ls) for releasing an early iteration of Distil-Whisper on the LibriSpeech dataset
|
TencentARC/InstantMesh | TencentARC | "2024-04-11T02:56:23Z" | 584,669 | 206 | diffusers | [
"diffusers",
"image-to-3d",
"arxiv:2404.07191",
"license:apache-2.0",
"region:us"
] | image-to-3d | "2024-04-10T13:16:45Z" | ---
license: apache-2.0
tags:
- image-to-3d
---
# InstantMesh
Model card for *InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models*.
Code: https://github.com/TencentARC/InstantMesh
Arxiv: https://arxiv.org/abs/2404.07191
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g., depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
|
THUDM/chatglm2-6b | THUDM | "2024-08-04T08:41:38Z" | 578,939 | 2,016 | transformers | [
"transformers",
"pytorch",
"chatglm",
"glm",
"thudm",
"custom_code",
"zh",
"en",
"arxiv:2103.10360",
"arxiv:2210.02414",
"arxiv:1911.02150",
"arxiv:2406.12793",
"endpoints_compatible",
"region:us"
] | null | "2023-06-24T16:26:27Z" | ---
language:
- zh
- en
tags:
- glm
- chatglm
- thudm
---
# ChatGLM2-6B
<p align="center">
💻 <a href="https://github.com/THUDM/ChatGLM2-6B" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://join.slack.com/t/chatglm/shared_invite/zt-1y7pqoloy-9b1g6T6JjA8J0KxvUjbwJw" target="_blank">Slack</a> and <a href="https://github.com/THUDM/ChatGLM-6B/blob/main/resources/WECHAT.md" target="_blank">WeChat</a>
</p>
<p align="center">
📍Experience the larger-scale ChatGLM model at <a href="https://www.chatglm.cn">chatglm.cn</a>
</p>
## 介绍
ChatGLM**2**-6B 是开源中英双语对话模型 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM**2**-6B 引入了如下新特性:
1. **更强大的性能**:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 [GLM](https://github.com/THUDM/GLM) 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,[评测结果](#评测结果)显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
2. **更长的上下文**:基于 [FlashAttention](https://github.com/HazyResearch/flash-attention) 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
3. **更高效的推理**:基于 [Multi-Query Attention](http://arxiv.org/abs/1911.02150) 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
4. **更开放的协议**:ChatGLM2-6B 权重对学术研究**完全开放**,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后**亦允许免费商业使用**。
ChatGLM**2**-6B is the second-generation version of the open-source bilingual (Chinese-English) chat model [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B). It retains the smooth conversation flow and low deployment threshold of the first-generation model, while introducing the following new features:
1. **Stronger Performance**: Based on the development experience of the first-generation ChatGLM model, we have fully upgraded the base model of ChatGLM2-6B. ChatGLM2-6B uses the hybrid objective function of [GLM](https://github.com/THUDM/GLM), and has undergone pre-training with 1.4T bilingual tokens and human preference alignment training. The [evaluation results](README.md#evaluation-results) show that, compared to the first-generation model, ChatGLM2-6B has achieved substantial improvements in performance on datasets like MMLU (+23%), CEval (+33%), GSM8K (+571%), BBH (+60%), showing strong competitiveness among models of the same size.
2. **Longer Context**: Based on [FlashAttention](https://github.com/HazyResearch/flash-attention) technique, we have extended the context length of the base model from 2K in ChatGLM-6B to 32K, and trained with a context length of 8K during the dialogue alignment, allowing for more rounds of dialogue. However, the current version of ChatGLM2-6B has limited understanding of single-round ultra-long documents, which we will focus on optimizing in future iterations.
3. **More Efficient Inference**: Based on [Multi-Query Attention](http://arxiv.org/abs/1911.02150) technique, ChatGLM2-6B has more efficient inference speed and lower GPU memory usage: under the official implementation, the inference speed has increased by 42% compared to the first generation; under INT4 quantization, the dialogue length supported by 6G GPU memory has increased from 1K to 8K.
4. **More Open License**: ChatGLM2-6B weights are **completely open** for academic research, and **free commercial use** is also allowed after completing the [questionnaire](https://open.bigmodel.cn/mla/form).
## 软件依赖
```shell
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
```
## 代码调用
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
```ipython
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
```
关于更多的使用说明,包括如何运行命令行和网页版本的 DEMO,以及使用模型量化以节省显存,请参考我们的 [Github Repo](https://github.com/THUDM/ChatGLM2-6B)。
For more instructions, including how to run CLI and web demos, and model quantization, please refer to our [Github Repo](https://github.com/THUDM/ChatGLM2-6B).
## Change Log
* v1.0
## 协议
本仓库的代码依照 [Apache-2.0](LICENSE) 协议开源,ChatGLM2-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。
## 引用
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
If you find our work helpful, please consider citing the following paper.
```
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
``` |
Rostlab/prot_bert | Rostlab | "2023-11-16T15:07:57Z" | 576,174 | 90 | transformers | [
"transformers",
"pytorch",
"fill-mask",
"protein language model",
"protein",
"dataset:Uniref100",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
tags:
- protein language model
- protein
datasets:
- Uniref100
---
# ProtBert model
Pretrained model on protein sequences using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://doi.org/10.1101/2020.07.12.199554) and first released in
[this repository](https://github.com/agemagician/ProtTrans). This model is trained on uppercase amino acids: it only works with capital letter amino acids.
## Model description
ProtBert is based on Bert model which pretrained on a large corpus of protein sequences in a self-supervised fashion.
This means it was pretrained on the raw protein sequences only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those protein sequences.
One important difference between our Bert model and the original Bert version is the way of dealing with sequences as separate documents.
This means the Next sentence prediction is not used, as each sequence is treated as a complete document.
The masking follows the original Bert training with randomly masks 15% of the amino acids in the input.
At the end, the feature extracted from this model revealed that the LM-embeddings from unlabeled data (only protein sequences) captured important biophysical properties governing protein
shape.
This implied learning some of the grammar of the language of life realized in protein sequences.
## Intended uses & limitations
The model could be used for protein feature extraction or to be fine-tuned on downstream tasks.
We have noticed in some tasks you could gain more accuracy by fine-tuning the model rather than using it as a feature extractor.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import BertForMaskedLM, BertTokenizer, pipeline
>>> tokenizer = BertTokenizer.from_pretrained("Rostlab/prot_bert", do_lower_case=False )
>>> model = BertForMaskedLM.from_pretrained("Rostlab/prot_bert")
>>> unmasker = pipeline('fill-mask', model=model, tokenizer=tokenizer)
>>> unmasker('D L I P T S S K L V V [MASK] D T S L Q V K K A F F A L V T')
[{'score': 0.11088453233242035,
'sequence': '[CLS] D L I P T S S K L V V L D T S L Q V K K A F F A L V T [SEP]',
'token': 5,
'token_str': 'L'},
{'score': 0.08402521163225174,
'sequence': '[CLS] D L I P T S S K L V V S D T S L Q V K K A F F A L V T [SEP]',
'token': 10,
'token_str': 'S'},
{'score': 0.07328339666128159,
'sequence': '[CLS] D L I P T S S K L V V V D T S L Q V K K A F F A L V T [SEP]',
'token': 8,
'token_str': 'V'},
{'score': 0.06921856850385666,
'sequence': '[CLS] D L I P T S S K L V V K D T S L Q V K K A F F A L V T [SEP]',
'token': 12,
'token_str': 'K'},
{'score': 0.06382402777671814,
'sequence': '[CLS] D L I P T S S K L V V I D T S L Q V K K A F F A L V T [SEP]',
'token': 11,
'token_str': 'I'}]
```
Here is how to use this model to get the features of a given protein sequence in PyTorch:
```python
from transformers import BertModel, BertTokenizer
import re
tokenizer = BertTokenizer.from_pretrained("Rostlab/prot_bert", do_lower_case=False )
model = BertModel.from_pretrained("Rostlab/prot_bert")
sequence_Example = "A E T C Z A O"
sequence_Example = re.sub(r"[UZOB]", "X", sequence_Example)
encoded_input = tokenizer(sequence_Example, return_tensors='pt')
output = model(**encoded_input)
```
## Training data
The ProtBert model was pretrained on [Uniref100](https://www.uniprot.org/downloads), a dataset consisting of 217 million protein sequences.
## Training procedure
### Preprocessing
The protein sequences are uppercased and tokenized using a single space and a vocabulary size of 21. The rare amino acids "U,Z,O,B" were mapped to "X".
The inputs of the model are then of the form:
```
[CLS] Protein Sequence A [SEP] Protein Sequence B [SEP]
```
Furthermore, each protein sequence was treated as a separate document.
The preprocessing step was performed twice, once for a combined length (2 sequences) of less than 512 amino acids, and another time using a combined length (2 sequences) of less than 2048 amino acids.
The details of the masking procedure for each sequence followed the original Bert model as following:
- 15% of the amino acids are masked.
- In 80% of the cases, the masked amino acids are replaced by `[MASK]`.
- In 10% of the cases, the masked amino acids are replaced by a random amino acid (different) from the one they replace.
- In the 10% remaining cases, the masked amino acids are left as is.
### Pretraining
The model was trained on a single TPU Pod V3-512 for 400k steps in total.
300K steps using sequence length 512 (batch size 15k), and 100K steps using sequence length 2048 (batch size 2.5k).
The optimizer used is Lamb with a learning rate of 0.002, a weight decay of 0.01, learning rate warmup for 40k steps and linear decay of the learning rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Test results :
| Task/Dataset | secondary structure (3-states) | secondary structure (8-states) | Localization | Membrane |
|:-----:|:-----:|:-----:|:-----:|:-----:|
| CASP12 | 75 | 63 | | |
| TS115 | 83 | 72 | | |
| CB513 | 81 | 66 | | |
| DeepLoc | | | 79 | 91 |
### BibTeX entry and citation info
```bibtex
@article {Elnaggar2020.07.12.199554,
author = {Elnaggar, Ahmed and Heinzinger, Michael and Dallago, Christian and Rehawi, Ghalia and Wang, Yu and Jones, Llion and Gibbs, Tom and Feher, Tamas and Angerer, Christoph and Steinegger, Martin and BHOWMIK, DEBSINDHU and Rost, Burkhard},
title = {ProtTrans: Towards Cracking the Language of Life{\textquoteright}s Code Through Self-Supervised Deep Learning and High Performance Computing},
elocation-id = {2020.07.12.199554},
year = {2020},
doi = {10.1101/2020.07.12.199554},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Computational biology and bioinformatics provide vast data gold-mines from protein sequences, ideal for Language Models (LMs) taken from Natural Language Processing (NLP). These LMs reach for new prediction frontiers at low inference costs. Here, we trained two auto-regressive language models (Transformer-XL, XLNet) and two auto-encoder models (Bert, Albert) on data from UniRef and BFD containing up to 393 billion amino acids (words) from 2.1 billion protein sequences (22- and 112 times the entire English Wikipedia). The LMs were trained on the Summit supercomputer at Oak Ridge National Laboratory (ORNL), using 936 nodes (total 5616 GPUs) and one TPU Pod (V3-512 or V3-1024). We validated the advantage of up-scaling LMs to larger models supported by bigger data by predicting secondary structure (3-states: Q3=76-84, 8 states: Q8=65-73), sub-cellular localization for 10 cellular compartments (Q10=74) and whether a protein is membrane-bound or water-soluble (Q2=89). Dimensionality reduction revealed that the LM-embeddings from unlabeled data (only protein sequences) captured important biophysical properties governing protein shape. This implied learning some of the grammar of the language of life realized in protein sequences. The successful up-scaling of protein LMs through HPC to larger data sets slightly reduced the gap between models trained on evolutionary information and LMs. Availability ProtTrans: \<a href="https://github.com/agemagician/ProtTrans"\>https://github.com/agemagician/ProtTrans\</a\>Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554},
eprint = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554.full.pdf},
journal = {bioRxiv}
}
```
> Created by [Ahmed Elnaggar/@Elnaggar_AI](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/)
|
facebook/mbart-large-50-many-to-many-mmt | facebook | "2023-09-28T16:42:59Z" | 575,663 | 267 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"mbart",
"text2text-generation",
"mbart-50",
"translation",
"multilingual",
"ar",
"cs",
"de",
"en",
"es",
"et",
"fi",
"fr",
"gu",
"hi",
"it",
"ja",
"kk",
"ko",
"lt",
"lv",
"my",
"ne",
"nl",
"ro",
"ru",
"si",
"tr",
"vi",
"zh",
"af",
"az",
"bn",
"fa",
"he",
"hr",
"id",
"ka",
"km",
"mk",
"ml",
"mn",
"mr",
"pl",
"ps",
"pt",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"uk",
"ur",
"xh",
"gl",
"sl",
"arxiv:2008.00401",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ar
- cs
- de
- en
- es
- et
- fi
- fr
- gu
- hi
- it
- ja
- kk
- ko
- lt
- lv
- my
- ne
- nl
- ro
- ru
- si
- tr
- vi
- zh
- af
- az
- bn
- fa
- he
- hr
- id
- ka
- km
- mk
- ml
- mn
- mr
- pl
- ps
- pt
- sv
- sw
- ta
- te
- th
- tl
- uk
- ur
- xh
- gl
- sl
tags:
- mbart-50
pipeline_tag: translation
---
# mBART-50 many to many multilingual machine translation
This model is a fine-tuned checkpoint of [mBART-large-50](https://huggingface.co/facebook/mbart-large-50). `mbart-large-50-many-to-many-mmt` is fine-tuned for multilingual machine translation. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
The model can translate directly between any pair of 50 languages. To translate into a target language, the target language id is forced as the first generated token. To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
article_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
# translate Hindi to French
tokenizer.src_lang = "hi_IN"
encoded_hi = tokenizer(article_hi, return_tensors="pt")
generated_tokens = model.generate(
**encoded_hi,
forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Le chef de l 'ONU affirme qu 'il n 'y a pas de solution militaire dans la Syrie."
# translate Arabic to English
tokenizer.src_lang = "ar_AR"
encoded_ar = tokenizer(article_ar, return_tensors="pt")
generated_tokens = model.generate(
**encoded_ar,
forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "The Secretary-General of the United Nations says there is no military solution in Syria."
```
See the [model hub](https://huggingface.co/models?filter=mbart-50) to look for more fine-tuned versions.
## Languages covered
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI)
## BibTeX entry and citation info
```
@article{tang2020multilingual,
title={Multilingual Translation with Extensible Multilingual Pretraining and Finetuning},
author={Yuqing Tang and Chau Tran and Xian Li and Peng-Jen Chen and Naman Goyal and Vishrav Chaudhary and Jiatao Gu and Angela Fan},
year={2020},
eprint={2008.00401},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
microsoft/infoxlm-large | microsoft | "2021-08-04T11:43:05Z" | 573,205 | 10 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2007.07834",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | # InfoXLM
**InfoXLM** (NAACL 2021, [paper](https://arxiv.org/pdf/2007.07834.pdf), [repo](https://github.com/microsoft/unilm/tree/master/infoxlm), [model](https://huggingface.co/microsoft/infoxlm-base)) InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training.
**MD5**
```
05b95b7d977450b364f8ea3269391953 config.json
c19438359fed6d36b0c1bbb107929579 pytorch_model.bin
bf25eb5120ad92ef5c7d8596b5dc4046 sentencepiece.bpe.model
eedbd60a7268b9fc45981b849664f747 tokenizer.json
```
**BibTeX**
```
@inproceedings{chi-etal-2021-infoxlm,
title = "{I}nfo{XLM}: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training",
author={Chi, Zewen and Dong, Li and Wei, Furu and Yang, Nan and Singhal, Saksham and Wang, Wenhui and Song, Xia and Mao, Xian-Ling and Huang, Heyan and Zhou, Ming},
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.280",
doi = "10.18653/v1/2021.naacl-main.280",
pages = "3576--3588",}
``` |
sentence-transformers/stsb-roberta-base | sentence-transformers | "2024-03-27T12:58:35Z" | 571,316 | 1 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/stsb-roberta-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-roberta-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-roberta-base')
model = AutoModel.from_pretrained('sentence-transformers/stsb-roberta-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-roberta-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
MahmoodLab/CONCH | MahmoodLab | "2024-05-05T06:05:43Z" | 569,107 | 82 | timm | [
"timm",
"pytorch",
"pathology",
"vision",
"vision language",
"image-feature-extraction",
"en",
"license:cc-by-nc-nd-4.0",
"region:us"
] | image-feature-extraction | "2024-01-05T00:50:22Z" | ---
license: cc-by-nc-nd-4.0
language:
- en
tags:
- pathology
- vision
- vision language
- pytorch
extra_gated_prompt: >-
This model and associated code are released under the CC-BY-NC-ND 4.0 license
and may only be used for non-commercial, academic research purposes with
proper attribution. Any commercial use, sale, or other monetization of the
CONCH model and its derivatives, which include models trained on outputs from
the CONCH model or datasets created from the CONCH model, is prohibited and
requires prior approval. Downloading the model requires prior registration on
Hugging Face and agreeing to the terms of use. By downloading this model, you
agree not to distribute, publish or reproduce a copy of the model. If another
user within your organization wishes to use the CONCH model, they must
register as an individual user and agree to comply with the terms of use.
Users may not attempt to re-identify the deidentified data used to develop the
underlying model. If you are a commercial entity, please contact the
corresponding author. Please note that the primary email used to sign up for
your Hugging Face account must match your institutional email to received
approval. Further details included in the model card.
extra_gated_fields:
Full name: text
Affiliation: text
Type of affiliation:
type: select
options:
- Academia
- Industry
- label: Other
value: other
Official email (must match primary email in your Hugging Face account): text
Please explain your intended research use: text
I agree to all terms outlined above: checkbox
I agree to use this model for non-commercial, academic purposes only: checkbox
I agree not to distribute the model, if another user within your organization wishes to use the CONCH model, they must register as an individual user: checkbox
library_name: timm
pipeline_tag: image-feature-extraction
---
# Model Card for CONCH
\[[Journal Link](https://www.nature.com/articles/s41591-024-02856-4)\] | \[[Open Access Read Link](https://rdcu.be/dBMf6)\] | [\[Github Repo](https://github.com/mahmoodlab/CONCH)\] | \[[Cite](#how-to-cite)\]
## What is CONCH?
CONCH (CONtrastive learning from Captions for Histopathology) is a vision language foundation model for histopathology, pretrained on currently the largest histopathology-specific vision-language dataset of 1.17M image caption pairs. Compare to other vision language foundation models, it demonstrates state-of-the-art performance across 14 tasks in computational pathology ranging from image classification, text-to-image, and image-to-text retrieval, captioning, and tissue segmentation.
- _**Why use CONCH?**_: Compared to popular self-supervised encoders for computational pathology that were pretrained only on H&E images, CONCH may produce more performant representations for non-H&E stained images such as IHCs and special stains, and can be used for a wide range of downstream tasks involving either or both histopathology images and text. CONCH also did not use large public histology slide collections such as TCGA, PAIP, GTEX, etc. for pretraining, which are routinely used in benchmark development in computational pathology. Therefore, we make CONCH available for the research community in building and evaluating pathology AI models with minimal risk of data contamination on public benchmarks or private histopathology slide collections.

## Requesting Access
As mentioned in the gated prompt, you must agree to the outlined terms of use, _**with the primary email for your HuggingFace account matching your institutional email**_. If your primary email is a personal email (@gmail/@hotmail/@qq) **your request will be denied**. To fix this, you can: (1) add your official institutional email to your HF account, and confirm your email address to verify, and (2) set your institutional email as your primary email in your HF account. Other reasons for your request access being denied include other mistakes in the form submitted, for example: full name includes abbreviations, affiliation is not spelled out, the described research use is not sufficient, or email domain address not recognized.
## License and Terms of Use
This model and associated code are released under the CC-BY-NC-ND 4.0 license and may only be used for non-commercial, academic research purposes with proper attribution. Any commercial use, sale, or other monetization of the CONCH model and its derivatives, which include models trained on outputs from the CONCH model or datasets created from the CONCH model, is prohibited and requires prior approval. Downloading the model requires prior registration on Hugging Face and agreeing to the terms of use. By downloading this model, you agree not to distribute, publish or reproduce a copy of the model. If another user within your organization wishes to use the CONCH model, they must register as an individual user and agree to comply with the terms of use. Users may not attempt to re-identify the deidentified data used to develop the underlying model. If you are a commercial entity, please contact the corresponding author.

## Model Details
### Model Description
- **Developed by:** Mahmood Lab AI for Pathology Lab @ Harvard/BWH
- **Model type:** Pretrained vision-language encoders (vision encoder: ViT-B/16, 90M params; text encoder: L12-E768-H12, 110M params)
- **Pretraining dataset:** 1.17 million histopathology image-caption pairs
- **Repository:** https://github.com/mahmoodlab/CONCH
- **Paper:** https://www.nature.com/articles/s41591-024-02856-4
- **License:** CC-BY-NC-ND-4.0
Note: while the original CONCH model arechitecture also includes a multimodal decoder trained with the captioning loss of CoCa, as additional precaution to ensure that no proprietary data or Protected Health Information (PHI) is leaked untentionally, we have removed the weights for the decoder from the publicly released CONCH weights.
The weights for the text encoder and the vision encoder are intact and therefore the results on all key tasks presented in the paper such as image classification and image-text retrieval are not affected.
The ability of CONCH to serve as a general purpose encoder for both histopathology images and pathology-related text also remains unaffected.
### Usage
Install the conch repository using pip:
```shell
pip install git+https://github.com/Mahmoodlab/CONCH.git
```
After succesfully requesting access to the weights:
```python
from conch.open_clip_custom import create_model_from_pretrained
model, preprocess = create_model_from_pretrained('conch_ViT-B-16', "hf_hub:MahmoodLab/conch", hf_auth_token="<your_user_access_token>")
```
Note you may need to supply your huggingface user access token via `hf_auth_token=<your_token>` to `create_model_from_pretrained` for authentification. See the [HF documentation](https://huggingface.co/docs/hub/security-tokens) for more details.
Alternatively, you can download the checkpoint mannually, and load the model as follows:
```python
model, preprocess = create_model_from_pretrained('conch_ViT-B-16', "path/to/conch/pytorch_model.bin")
```
You can then use the model to encode images as follows:
```python
import torch
from PIL import Image
image = Image.open("path/to/image.jpg")
image = preprocess(image).unsqueeze(0)
with torch.inference_mode():
image_embs = model.encode_image(image, proj_contrast=False, normalize=False)
```
This will give you the image embeddings before the projection head and normalization, suitable for linear probe or working with WSIs under the multiple-instance learning framework.
For image-text retrieval tasks, you should use the normalized and projected embeddings as follows:
```python
with torch.inference_mode():
image_embs = model.encode_image(image, proj_contrast=True, normalize=True)
text_embedings = model.encode_text(tokenized_prompts)
sim_scores = (image_embedings @ text_embedings.T).squeeze(0)
```
For concrete examples on using the model for various tasks, please visit the [github](https://github.com/mahmoodlab/CONCH) repository.
### Use Cases
The model is primarily intended for researchers and can be used to perform tasks in computational pathology such as:
- Zero-shot ROI classification
- Zero-shot ROI image to text and text to image retrieval
- Zero-shot WSI classification using MI-Zero
- ROI classification using linear probing / knn probing / end-to-end fine-tuning
- WSI classification using with multiple instance learning (MIL)
## Training Details
- **Training data:** 1.17 million human histopathology image-caption pairs from publicly available Pubmed Central Open Access (PMC-OA) and internally curated sources. Images include H&E, IHC, and special stains.
- **Training regime:** fp16 automatic mixed-precision
- **Training objective:** CoCa (image-text contrastive loss + captioning loss)
- **Hardware:** 8 x Nvidia A100
- **Hours used:** ~21.5 hours
- **Software:** PyTorch 2.0, CUDA 11.7
Note: The vision encoder and the text encoder / decoder are first pretrained separately and then fine-tuned together using the CoCa loss. See the paper for more details.
## Contact
For any additional questions or comments, contact Faisal Mahmood (`[email protected]`),
Ming Y. Lu (`[email protected]`),
or Bowen Chen (`[email protected]`).
## Acknowledgements
The project was built on top of amazing repositories such as [openclip](https://github.com/mlfoundations/open_clip) (used for model training), [timm](https://github.com/huggingface/pytorch-image-models/) (ViT model implementation) and [huggingface transformers](https://github.com/huggingface/transformers) (tokenization). We thank the authors and developers for their contribution.
## How to Cite
```
@article{lu2024avisionlanguage,
title={A visual-language foundation model for computational pathology},
author={Lu, Ming Y and Chen, Bowen and Williamson, Drew FK and Chen, Richard J and Liang, Ivy and Ding, Tong and Jaume, Guillaume and Odintsov, Igor and Le, Long Phi and Gerber, Georg and others},
journal={Nature Medicine},
pages={863–874},
volume={30},
year={2024},
publisher={Nature Publishing Group}
}
``` |
sentence-transformers/all-roberta-large-v1 | sentence-transformers | "2024-03-27T09:49:10Z" | 557,057 | 51 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"safetensors",
"roberta",
"fill-mask",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# all-roberta-large-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-roberta-large-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-roberta-large-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-roberta-large-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-roberta-large-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`roberta-large`](https://huggingface.co/roberta-large) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`roberta-large`](https://huggingface.co/roberta-large). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 400k steps using a batch size of 256 (32 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | |
sentence-transformers/distilbert-base-nli-stsb-mean-tokens | sentence-transformers | "2024-03-27T10:18:52Z" | 553,038 | 11 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/distilbert-base-nli-stsb-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distilbert-base-nli-stsb-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/distilbert-base-nli-stsb-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/distilbert-base-nli-stsb-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distilbert-base-nli-stsb-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
sentence-transformers/paraphrase-mpnet-base-v2 | sentence-transformers | "2024-03-07T15:56:16Z" | 552,422 | 34 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"doi:10.57967/hf/2004",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/paraphrase-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-mpnet-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-mpnet-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
Xenova/bge-base-en-v1.5 | Xenova | "2024-07-15T10:15:23Z" | 548,817 | 6 | transformers.js | [
"transformers.js",
"onnx",
"bert",
"feature-extraction",
"region:us"
] | feature-extraction | "2023-09-13T15:48:03Z" | ---
library_name: transformers.js
---
https://huggingface.co/BAAI/bge-base-en-v1.5 with ONNX weights to be compatible with Transformers.js.
## Usage (Transformers.js)
If you haven't already, you can install the [Transformers.js](https://huggingface.co/docs/transformers.js) JavaScript library from [NPM](https://www.npmjs.com/package/@xenova/transformers) using:
```bash
npm i @xenova/transformers
```
You can then use the model to compute embeddings, as follows:
```js
import { pipeline } from '@xenova/transformers';
// Create a feature-extraction pipeline
const extractor = await pipeline('feature-extraction', 'Xenova/bge-base-en-v1.5');
// Compute sentence embeddings
const texts = ['Hello world.', 'Example sentence.'];
const embeddings = await extractor(texts, { pooling: 'mean', normalize: true });
console.log(embeddings);
// Tensor {
// dims: [ 2, 768 ],
// type: 'float32',
// data: Float32Array(1536) [ 0.019079938530921936, 0.041718777269124985, ... ],
// size: 1536
// }
console.log(embeddings.tolist()); // Convert embeddings to a JavaScript list
// [
// [ 0.019079938530921936, 0.041718777269124985, 0.037672195583581924, ... ],
// [ 0.020936904475092888, 0.020080938935279846, -0.00787576474249363, ... ]
// ]
```
You can also use the model for retrieval. For example:
```js
import { pipeline, cos_sim } from '@xenova/transformers';
// Create a feature-extraction pipeline
const extractor = await pipeline('feature-extraction', 'Xenova/bge-small-en-v1.5');
// List of documents you want to embed
const texts = [
'Hello world.',
'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.',
'I love pandas so much!',
];
// Compute sentence embeddings
const embeddings = await extractor(texts, { pooling: 'mean', normalize: true });
// Prepend recommended query instruction for retrieval.
const query_prefix = 'Represent this sentence for searching relevant passages: '
const query = query_prefix + 'What is a panda?';
const query_embeddings = await extractor(query, { pooling: 'mean', normalize: true });
// Sort by cosine similarity score
const scores = embeddings.tolist().map(
(embedding, i) => ({
id: i,
score: cos_sim(query_embeddings.data, embedding),
text: texts[i],
})
).sort((a, b) => b.score - a.score);
console.log(scores);
// [
// { id: 1, score: 0.7787772374597298, text: 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.' },
// { id: 2, score: 0.7071589521880506, text: 'I love pandas so much!' },
// { id: 0, score: 0.4252782730390429, text: 'Hello world.' }
// ]
```
Note: Having a separate repo for ONNX weights is intended to be a temporary solution until WebML gains more traction. If you would like to make your models web-ready, we recommend converting to ONNX using [🤗 Optimum](https://huggingface.co/docs/optimum/index) and structuring your repo like this one (with ONNX weights located in a subfolder named `onnx`). |
sentence-transformers/all-distilroberta-v1 | sentence-transformers | "2024-03-27T09:45:18Z" | 547,654 | 29 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"rust",
"safetensors",
"roberta",
"fill-mask",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-distilroberta-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-distilroberta-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-distilroberta-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-distilroberta-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`distilroberta-base`](https://huggingface.co/distilroberta-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`distilroberta-base`](https://huggingface.co/distilroberta-base). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 920k steps using a batch size of 512 (64 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | |
cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-multi-all | cardiffnlp | "2022-09-30T00:31:18Z" | 546,808 | 9 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"dataset:cardiffnlp/tweet_topic_multi",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-09-29T17:01:29Z" | ---
datasets:
- cardiffnlp/tweet_topic_multi
metrics:
- f1
- accuracy
model-index:
- name: cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-multi-all
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: cardiffnlp/tweet_topic_multi
type: cardiffnlp/tweet_topic_multi
args: cardiffnlp/tweet_topic_multi
split: test_2021
metrics:
- name: F1
type: f1
value: 0.7647668393782383
- name: F1 (macro)
type: f1_macro
value: 0.6187022581213811
- name: Accuracy
type: accuracy
value: 0.5485407980941036
pipeline_tag: text-classification
widget:
- text: "I'm sure the {@Tampa Bay Lightning@} would’ve rather faced the Flyers but man does their experience versus the Blue Jackets this year and last help them a lot versus this Islanders team. Another meat grinder upcoming for the good guys"
example_title: "Example 1"
- text: "Love to take night time bike rides at the jersey shore. Seaside Heights boardwalk. Beautiful weather. Wishing everyone a safe Labor Day weekend in the US."
example_title: "Example 2"
---
# cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-multi-all
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-dec2021](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2021) on the [tweet_topic_multi](https://huggingface.co/datasets/cardiffnlp/tweet_topic_multi). This model is fine-tuned on `train_all` split and validated on `test_2021` split of tweet_topic.
Fine-tuning script can be found [here](https://huggingface.co/datasets/cardiffnlp/tweet_topic_multi/blob/main/lm_finetuning.py). It achieves the following results on the test_2021 set:
- F1 (micro): 0.7647668393782383
- F1 (macro): 0.6187022581213811
- Accuracy: 0.5485407980941036
### Usage
```python
import math
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
def sigmoid(x):
return 1 / (1 + math.exp(-x))
tokenizer = AutoTokenizer.from_pretrained("cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-multi-all")
model = AutoModelForSequenceClassification.from_pretrained("cardiffnlp/twitter-roberta-base-dec2021-tweet-topic-multi-all", problem_type="multi_label_classification")
model.eval()
class_mapping = model.config.id2label
with torch.no_grad():
text = #NewVideo Cray Dollas- Water- Ft. Charlie Rose- (Official Music Video)- {{URL}} via {@YouTube@} #watchandlearn {{USERNAME}}
tokens = tokenizer(text, return_tensors='pt')
output = model(**tokens)
flags = [sigmoid(s) > 0.5 for s in output[0][0].detach().tolist()]
topic = [class_mapping[n] for n, i in enumerate(flags) if i]
print(topic)
```
### Reference
```
@inproceedings{dimosthenis-etal-2022-twitter,
title = "{T}witter {T}opic {C}lassification",
author = "Antypas, Dimosthenis and
Ushio, Asahi and
Camacho-Collados, Jose and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics"
}
```
|
unsloth/llama-3-8b-Instruct-bnb-4bit | unsloth | "2024-09-03T03:46:24Z" | 541,214 | 123 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-3",
"meta",
"facebook",
"unsloth",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | "2024-04-18T16:53:35Z" | ---
language:
- en
library_name: transformers
license: llama3
tags:
- llama-3
- llama
- meta
- facebook
- unsloth
- transformers
---
# Finetune Llama 3.1, Gemma 2, Mistral 2-5x faster with 70% less memory via Unsloth!
We have a free Google Colab Tesla T4 notebook for Llama 3.1 (8B) here: https://colab.research.google.com/drive/1Ys44kVvmeZtnICzWz0xgpRnrIOjZAuxp?usp=sharing
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png" width="200"/>](https://discord.gg/unsloth)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Llama-3.1 8b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Ys44kVvmeZtnICzWz0xgpRnrIOjZAuxp?usp=sharing) | 2.4x faster | 58% less |
| **Phi-3.5 (mini)** | [▶️ Start on Colab](https://colab.research.google.com/drive/1lN6hPQveB_mHSnTOYifygFcrO8C1bxq4?usp=sharing) | 2x faster | 50% less |
| **Gemma-2 9b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1vIrqH5uYDQwsJ4-OO3DErvuv4pBgVwk4?usp=sharing) | 2.4x faster | 58% less |
| **Mistral 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Dyauq4kTZoLewQ1cApceUQVNcnnNTzg_?usp=sharing) | 2.2x faster | 62% less |
| **TinyLlama** | [▶️ Start on Colab](https://colab.research.google.com/drive/1AZghoNBQaMDgWJpi4RbffGM1h6raLUj9?usp=sharing) | 3.9x faster | 74% less |
| **DPO - Zephyr** | [▶️ Start on Colab](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) | 1.9x faster | 19% less |
- This [conversational notebook](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObepl1WgJvfvSzn5Q?usp=sharing) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster.
## Special Thanks
A huge thank you to the Meta and Llama team for creating and releasing these models.
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-70B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-70B-Instruct --include "original/*" --local-dir Meta-Llama-3-70B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
stabilityai/stable-diffusion-2 | stabilityai | "2023-07-05T16:19:01Z" | 539,066 | 1,820 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2202.00512",
"arxiv:2112.10752",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2022-11-23T11:54:34Z" | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2 model, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on `768x768` images.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `768-v-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/768-v-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
model_id = "stabilityai/stable-diffusion-2"
# Use the Euler scheduler here instead
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
naver/splade-cocondenser-ensembledistil | naver | "2022-05-11T08:05:37Z" | 538,903 | 36 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"en",
"dataset:ms_marco",
"arxiv:2205.04733",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-05-09T13:18:41Z" | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
datasets:
- ms_marco
---
## SPLADE CoCondenser EnsembleDistil
SPLADE model for passage retrieval. For additional details, please visit:
* paper: https://arxiv.org/abs/2205.04733
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) |
| --- | --- | --- |
| `splade-cocondenser-ensembledistil` | 38.3 | 98.3 |
## Citation
If you use our checkpoint, please cite our work:
```
@misc{https://doi.org/10.48550/arxiv.2205.04733,
doi = {10.48550/ARXIV.2205.04733},
url = {https://arxiv.org/abs/2205.04733},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
``` |
beomi/Llama-3-Open-Ko-8B | beomi | "2024-05-20T05:31:06Z" | 537,192 | 122 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"llama-3-ko",
"conversational",
"en",
"ko",
"arxiv:2310.04799",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-04-22T09:53:13Z" | ---
language:
- en
- ko
license: other
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-3-ko
pipeline_tag: text-generation
license_name: llama3
license_link: LICENSE
---
> Update @ 2024.05.20: Re-Upload RoPE fixed model
> Update @ 2024.05.01: Pre-Release [Llama-3-KoEn-8B](https://huggingface.co/beomi/Llama-3-KoEn-8B-preview) model & [Llama-3-KoEn-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-KoEn-8B-Instruct-preview)
> Update @ 2024.04.24: Release Llama-3-Open-Ko-8B model & [Llama-3-Open-Ko-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-Open-Ko-8B-Instruct-preview)
## Model Details
**Llama-3-Open-Ko-8B**
Llama-3-Open-Ko-8B model is continued pretrained language model based on Llama-3-8B.
This model is trained fully with publicily available resource, with 60GB+ of deduplicated texts.
With the new Llama-3 tokenizer, the pretraining conducted with 17.7B+ tokens, which slightly more than Korean tokenizer(Llama-2-Ko tokenizer).
The train was done on TPUv5e-256, with the warm support from TRC program by Google.
**Note for [Llama-3-Open-Ko-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-Open-Ko-8B-Instruct-preview)**
With applying the idea from [Chat Vector paper](https://arxiv.org/abs/2310.04799), I released Instruction model named [Llama-3-Open-Ko-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-Open-Ko-8B-Instruct-preview).
Since it is NOT finetuned with any Korean instruction set(indeed `preview`), but it would be great starting point for creating new Chat/Instruct models.
**Meta Llama-3**
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Junbum Lee (Beomi)
**Variations** Llama-3-Open-Ko comes in one size — 8B.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama-3-Open-Ko
</td>
<td rowspan="2" >Same as *Open-Solar-Ko Dataset
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >17.7B+
</td>
<td>Jun, 2023
</td>
</tr>
</table>
*You can find dataset list here: https://huggingface.co/beomi/OPEN-SOLAR-KO-10.7B/tree/main/corpus
**Model Release Date** 2024.04.24.
**Status** This is a static model trained on an offline dataset.
**License** Llama3 License: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
TBD
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Benchmark Scores
- vllm (pretrained=beomi/Llama-3-Open-Ko-8B,revision=081e85a,tensor_parallel_size=1,dtype=bfloat16,data_parallel_size=2,gpu_memory_utilization=0.8), gen_kwargs: (None), limit: None, num_fewshot: 5, batch_size: auto
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|----------------------------------------------------------|-------|------|-----:|-----------|-----:|---|------|
|haerae |N/A |none | 5|acc |0.6801|± |0.0138|
| | |none | 5|acc_norm |0.6801|± |0.0138|
| - haerae_general_knowledge | 1|none | 5|acc |0.4375|± |0.0375|
| | |none | 5|acc_norm |0.4375|± |0.0375|
| - haerae_history | 1|none | 5|acc |0.7340|± |0.0323|
| | |none | 5|acc_norm |0.7340|± |0.0323|
| - haerae_loan_word | 1|none | 5|acc |0.7870|± |0.0316|
| | |none | 5|acc_norm |0.7870|± |0.0316|
| - haerae_rare_word | 1|none | 5|acc |0.7012|± |0.0228|
| | |none | 5|acc_norm |0.7012|± |0.0228|
| - haerae_standard_nomenclature | 1|none | 5|acc |0.7190|± |0.0365|
| | |none | 5|acc_norm |0.7190|± |0.0365|
|kmmlu_direct |N/A |none | 5|exact_match|0.4054|± |0.0026|
| - kmmlu_direct_accounting | 2|none | 5|exact_match|0.3600|± |0.0482|
| - kmmlu_direct_agricultural_sciences | 2|none | 5|exact_match|0.3130|± |0.0147|
| - kmmlu_direct_aviation_engineering_and_maintenance | 2|none | 5|exact_match|0.3690|± |0.0153|
| - kmmlu_direct_biology | 2|none | 5|exact_match|0.3330|± |0.0149|
| - kmmlu_direct_chemical_engineering | 2|none | 5|exact_match|0.4190|± |0.0156|
| - kmmlu_direct_chemistry | 2|none | 5|exact_match|0.3833|± |0.0199|
| - kmmlu_direct_civil_engineering | 2|none | 5|exact_match|0.3870|± |0.0154|
| - kmmlu_direct_computer_science | 2|none | 5|exact_match|0.6340|± |0.0152|
| - kmmlu_direct_construction | 2|none | 5|exact_match|0.3340|± |0.0149|
| - kmmlu_direct_criminal_law | 2|none | 5|exact_match|0.2850|± |0.0320|
| - kmmlu_direct_ecology | 2|none | 5|exact_match|0.4210|± |0.0156|
| - kmmlu_direct_economics | 2|none | 5|exact_match|0.4077|± |0.0433|
| - kmmlu_direct_education | 2|none | 5|exact_match|0.5000|± |0.0503|
| - kmmlu_direct_electrical_engineering | 2|none | 5|exact_match|0.3620|± |0.0152|
| - kmmlu_direct_electronics_engineering | 2|none | 5|exact_match|0.4790|± |0.0158|
| - kmmlu_direct_energy_management | 2|none | 5|exact_match|0.3110|± |0.0146|
| - kmmlu_direct_environmental_science | 2|none | 5|exact_match|0.3210|± |0.0148|
| - kmmlu_direct_fashion | 2|none | 5|exact_match|0.4190|± |0.0156|
| - kmmlu_direct_food_processing | 2|none | 5|exact_match|0.3600|± |0.0152|
| - kmmlu_direct_gas_technology_and_engineering | 2|none | 5|exact_match|0.3320|± |0.0149|
| - kmmlu_direct_geomatics | 2|none | 5|exact_match|0.3640|± |0.0152|
| - kmmlu_direct_health | 2|none | 5|exact_match|0.5100|± |0.0502|
| - kmmlu_direct_industrial_engineer | 2|none | 5|exact_match|0.3970|± |0.0155|
| - kmmlu_direct_information_technology | 2|none | 5|exact_match|0.5720|± |0.0157|
| - kmmlu_direct_interior_architecture_and_design | 2|none | 5|exact_match|0.4740|± |0.0158|
| - kmmlu_direct_korean_history | 2|none | 5|exact_match|0.2700|± |0.0446|
| - kmmlu_direct_law | 2|none | 5|exact_match|0.3990|± |0.0155|
| - kmmlu_direct_machine_design_and_manufacturing | 2|none | 5|exact_match|0.4080|± |0.0155|
| - kmmlu_direct_management | 2|none | 5|exact_match|0.4660|± |0.0158|
| - kmmlu_direct_maritime_engineering | 2|none | 5|exact_match|0.4417|± |0.0203|
| - kmmlu_direct_marketing | 2|none | 5|exact_match|0.6720|± |0.0149|
| - kmmlu_direct_materials_engineering | 2|none | 5|exact_match|0.4130|± |0.0156|
| - kmmlu_direct_math | 2|none | 5|exact_match|0.2567|± |0.0253|
| - kmmlu_direct_mechanical_engineering | 2|none | 5|exact_match|0.3800|± |0.0154|
| - kmmlu_direct_nondestructive_testing | 2|none | 5|exact_match|0.3890|± |0.0154|
| - kmmlu_direct_patent | 2|none | 5|exact_match|0.2700|± |0.0446|
| - kmmlu_direct_political_science_and_sociology | 2|none | 5|exact_match|0.4433|± |0.0287|
| - kmmlu_direct_psychology | 2|none | 5|exact_match|0.3620|± |0.0152|
| - kmmlu_direct_public_safety | 2|none | 5|exact_match|0.3200|± |0.0148|
| - kmmlu_direct_railway_and_automotive_engineering | 2|none | 5|exact_match|0.3200|± |0.0148|
| - kmmlu_direct_real_estate | 2|none | 5|exact_match|0.3650|± |0.0341|
| - kmmlu_direct_refrigerating_machinery | 2|none | 5|exact_match|0.3210|± |0.0148|
| - kmmlu_direct_social_welfare | 2|none | 5|exact_match|0.4500|± |0.0157|
| - kmmlu_direct_taxation | 2|none | 5|exact_match|0.3550|± |0.0339|
| - kmmlu_direct_telecommunications_and_wireless_technology| 2|none | 5|exact_match|0.5490|± |0.0157|
|kobest_boolq | 1|none | 5|acc |0.7984|± |0.0107|
| | |none | 5|f1 |0.7961|± |N/A |
|kobest_copa | 1|none | 5|acc |0.8150|± |0.0123|
| | |none | 5|f1 |0.8148|± |N/A |
|kobest_hellaswag | 1|none | 5|acc |0.4800|± |0.0224|
| | |none | 5|f1 |0.4771|± |N/A |
| | |none | 5|acc_norm |0.6120|± |0.0218|
|kobest_sentineg | 1|none | 5|acc |0.9597|± |0.0099|
| | |none | 5|f1 |0.9597|± |N/A |
|haerae |N/A |none | 5|acc |0.6801|± |0.0138|
| | |none | 5|acc_norm |0.6801|± |0.0138|
|kmmlu_direct|N/A |none | 5|exact_match|0.4054|± |0.0026|
## Citation instructions
**Llama-3-Open-Ko**
```
@article{llama3openko,
title={Llama-3-Open-Ko},
author={L, Junbum},
year={2024},
url={https://huggingface.co/beomi/Llama-3-Open-Ko-8B}
}
```
**Original Llama-3**
```
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
```
|
microsoft/codebert-base | microsoft | "2022-02-11T19:59:44Z" | 535,634 | 209 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"roberta",
"feature-extraction",
"arxiv:2002.08155",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ## CodeBERT-base
Pretrained weights for [CodeBERT: A Pre-Trained Model for Programming and Natural Languages](https://arxiv.org/abs/2002.08155).
### Training Data
The model is trained on bi-modal data (documents & code) of [CodeSearchNet](https://github.com/github/CodeSearchNet)
### Training Objective
This model is initialized with Roberta-base and trained with MLM+RTD objective (cf. the paper).
### Usage
Please see [the official repository](https://github.com/microsoft/CodeBERT) for scripts that support "code search" and "code-to-document generation".
### Reference
1. [CodeBERT trained with Masked LM objective](https://huggingface.co/microsoft/codebert-base-mlm) (suitable for code completion)
2. 🤗 [Hugging Face's CodeBERTa](https://huggingface.co/huggingface/CodeBERTa-small-v1) (small size, 6 layers)
### Citation
```bibtex
@misc{feng2020codebert,
title={CodeBERT: A Pre-Trained Model for Programming and Natural Languages},
author={Zhangyin Feng and Daya Guo and Duyu Tang and Nan Duan and Xiaocheng Feng and Ming Gong and Linjun Shou and Bing Qin and Ting Liu and Daxin Jiang and Ming Zhou},
year={2020},
eprint={2002.08155},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Gustavosta/MagicPrompt-Stable-Diffusion | Gustavosta | "2023-07-09T22:10:48Z" | 532,481 | 690 | transformers | [
"transformers",
"pytorch",
"coreml",
"safetensors",
"gpt2",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2022-09-17T22:34:07Z" | ---
license: mit
---
# MagicPrompt - Stable Diffusion
This is a model from the MagicPrompt series of models, which are [GPT-2](https://huggingface.co/gpt2) models intended to generate prompt texts for imaging AIs, in this case: [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion).
## 🖼️ Here's an example:
<img src="https://files.catbox.moe/ac3jq7.png">
This model was trained with 150,000 steps and a set of about 80,000 data filtered and extracted from the image finder for Stable Diffusion: "[Lexica.art](https://lexica.art/)". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare, but if you want to take a look at the original dataset, you can have a look here: [datasets/Gustavosta/Stable-Diffusion-Prompts](https://huggingface.co/datasets/Gustavosta/Stable-Diffusion-Prompts).
If you want to test the model with a demo, you can go to: "[spaces/Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion)".
## 💻 You can see other MagicPrompt models:
- For Dall-E 2: [Gustavosta/MagicPrompt-Dalle](https://huggingface.co/Gustavosta/MagicPrompt-Dalle)
- For Midjourney: [Gustavosta/MagicPrompt-Midourney](https://huggingface.co/Gustavosta/MagicPrompt-Midjourney) **[⚠️ In progress]**
- MagicPrompt full: [Gustavosta/MagicPrompt](https://huggingface.co/Gustavosta/MagicPrompt) **[⚠️ In progress]**
## ⚖️ Licence:
[MIT](https://huggingface.co/models?license=license:mit)
When using this model, please credit: [Gustavosta](https://huggingface.co/Gustavosta)
**Thanks for reading this far! :)**
|
sentence-transformers/msmarco-distilbert-base-tas-b | sentence-transformers | "2024-03-27T11:26:10Z" | 530,607 | 37 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"safetensors",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:ms_marco",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- ms_marco
pipeline_tag: sentence-similarity
---
# sentence-transformers/msmarco-distilbert-base-tas-b
This is a port of the [DistilBert TAS-B Model](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco) to [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and is optimized for the task of semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-tas-b')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#CLS Pooling - Take output from first token
def cls_pooling(model_output):
return model_output.last_hidden_state[:,0]
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = cls_pooling(model_output)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
model = AutoModel.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-tas-b)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
Have a look at: [DistilBert TAS-B Model](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco) |
google/flan-t5-xxl | google | "2023-07-27T11:42:14Z" | 530,063 | 1,176 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"arxiv:2210.11416",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-10-21T15:54:59Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
widget:
- text: "Translate to German: My name is Arthur"
example_title: "Translation"
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
example_title: "Question Answering"
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
example_title: "Logical reasoning"
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
example_title: "Scientific knowledge"
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
example_title: "Yes/no question"
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
example_title: "Reasoning task"
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
example_title: "Boolean Expressions"
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
example_title: "Math reasoning"
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
example_title: "Premise and hypothesis"
tags:
- text2text-generation
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
license: apache-2.0
---
# Model Card for FLAN-T5 XXL
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/flan2_architecture.jpg"
alt="drawing" width="600"/>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
# TL;DR
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
As mentioned in the first few lines of the abstract :
> Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [T5 model card](https://huggingface.co/t5-large).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English, German, French
- **License:** Apache 2.0
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
- **Original Checkpoints:** [All Original FLAN-T5 Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2210.11416.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face FLAN-T5 Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/t5)
# Usage
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
# Uses
## Direct Use and Downstream Use
The authors write in [the original paper's model card](https://arxiv.org/pdf/2210.11416.pdf) that:
> The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
See the [research paper](https://arxiv.org/pdf/2210.11416.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
The information below in this section are copied from the model's [official model card](https://arxiv.org/pdf/2210.11416.pdf):
> Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
## Ethical considerations and risks
> Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
## Known Limitations
> Flan-T5 has not been tested in real world applications.
## Sensitive Use:
> Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
# Training Details
## Training Data
The model was trained on a mixture of tasks, that includes the tasks described in the table below (from the original paper, figure 2):
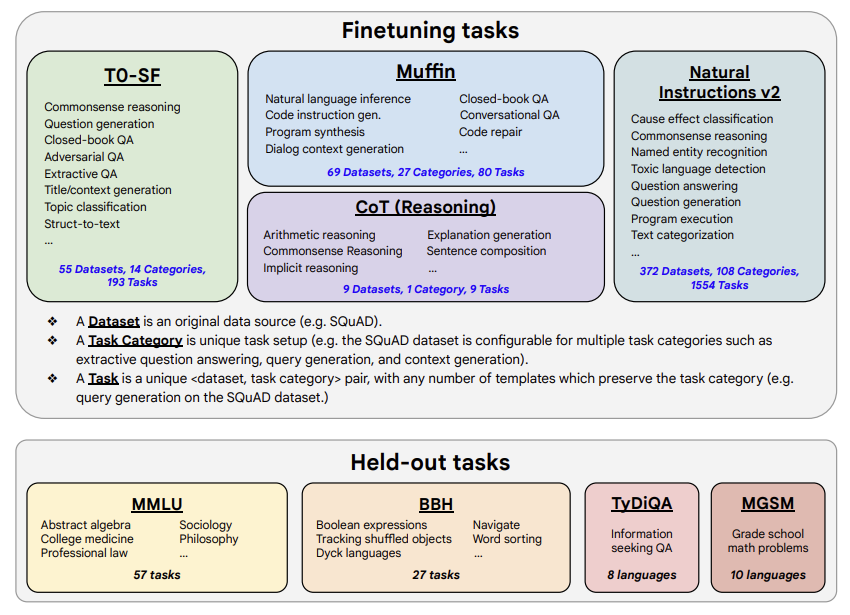
## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2210.11416.pdf):
> These models are based on pretrained T5 (Raffel et al., 2020) and fine-tuned with instructions for better zero-shot and few-shot performance. There is one fine-tuned Flan model per T5 model size.
The model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks covering several languages (1836 in total). See the table below for some quantitative evaluation:
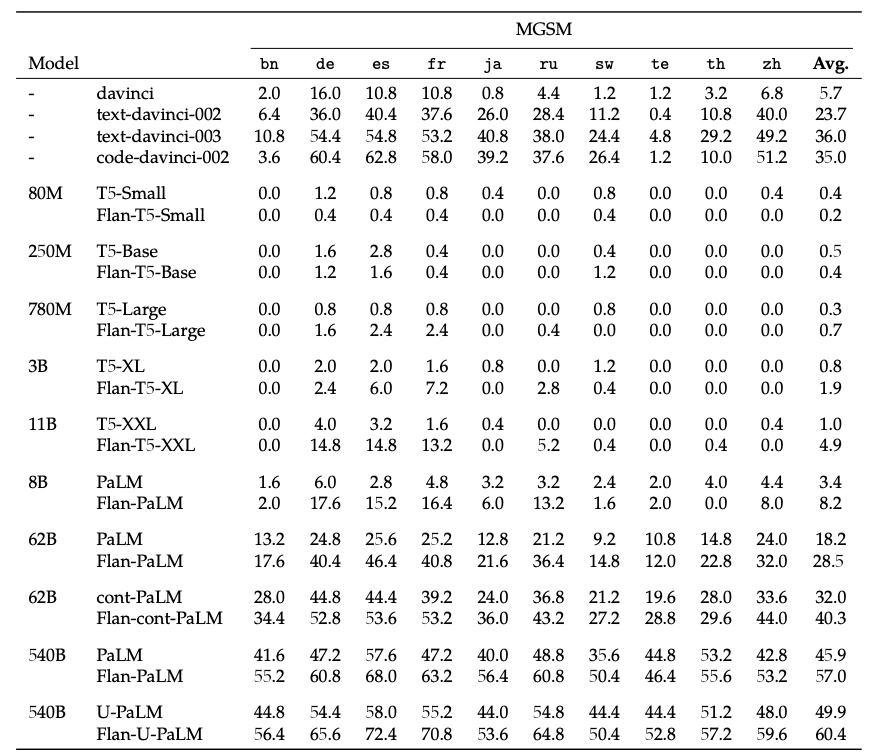
For full details, please check the [research paper](https://arxiv.org/pdf/2210.11416.pdf).
## Results
For full results for FLAN-T5-XXL, see the [research paper](https://arxiv.org/pdf/2210.11416.pdf), Table 3.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
facebook/fasttext-language-identification | facebook | "2023-06-09T12:39:43Z" | 529,502 | 190 | fasttext | [
"fasttext",
"text-classification",
"language-identification",
"arxiv:1607.04606",
"arxiv:1802.06893",
"arxiv:1607.01759",
"arxiv:1612.03651",
"license:cc-by-nc-4.0",
"region:us"
] | text-classification | "2023-03-06T12:52:50Z" | ---
license: cc-by-nc-4.0
library_name: fasttext
tags:
- text-classification
- language-identification
---
# fastText (Language Identification)
fastText is an open-source, free, lightweight library that allows users to learn text representations and text classifiers. It works on standard, generic hardware. Models can later be reduced in size to even fit on mobile devices. It was introduced in [this paper](https://arxiv.org/abs/1607.04606). The official website can be found [here](https://fasttext.cc/).
This LID (Language IDentification) model is used to predict the language of the input text, and the hosted version (`lid218e`) was [released as part of the NLLB project](https://github.com/facebookresearch/fairseq/blob/nllb/README.md#lid-model) and can detect 217 languages. You can find older versions (ones that can identify 157 languages) on the [official fastText website](https://fasttext.cc/docs/en/language-identification.html).
## Model description
fastText is a library for efficient learning of word representations and sentence classification. fastText is designed to be simple to use for developers, domain experts, and students. It's dedicated to text classification and learning word representations, and was designed to allow for quick model iteration and refinement without specialized hardware. fastText models can be trained on more than a billion words on any multicore CPU in less than a few minutes.
It includes pre-trained models learned on Wikipedia and in over 157 different languages. fastText can be used as a command line, linked to a C++ application, or used as a library for use cases from experimentation and prototyping to production.
## Intended uses & limitations
You can use pre-trained word vectors for text classification or language identification. See the [tutorials](https://fasttext.cc/docs/en/supervised-tutorial.html) and [resources](https://fasttext.cc/docs/en/english-vectors.html) on its official website to look for tasks that interest you.
### How to use
Here is how to use this model to detect the language of a given text:
```python
>>> import fasttext
>>> from huggingface_hub import hf_hub_download
>>> model_path = hf_hub_download(repo_id="facebook/fasttext-language-identification", filename="model.bin")
>>> model = fasttext.load_model(model_path)
>>> model.predict("Hello, world!")
(('__label__eng_Latn',), array([0.81148803]))
>>> model.predict("Hello, world!", k=5)
(('__label__eng_Latn', '__label__vie_Latn', '__label__nld_Latn', '__label__pol_Latn', '__label__deu_Latn'),
array([0.61224753, 0.21323682, 0.09696738, 0.01359863, 0.01319415]))
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased predictions.
Cosine similarity can be used to measure the similarity between two different word vectors. If two two vectors are identical, the cosine similarity will be 1. For two completely unrelated vectors, the value will be 0. If two vectors have an opposite relationship, the value will be -1.
```python
>>> import numpy as np
>>> def cosine_similarity(word1, word2):
>>> return np.dot(model[word1], model[word2]) / (np.linalg.norm(model[word1]) * np.linalg.norm(model[word2]))
>>> cosine_similarity("man", "boy")
0.061653383
>>> cosine_similarity("man", "ceo")
0.11989131
>>> cosine_similarity("woman", "ceo")
-0.08834904
```
## Training data
Pre-trained word vectors for 157 languages were trained on [Common Crawl](http://commoncrawl.org/) and [Wikipedia](https://www.wikipedia.org/) using fastText. These models were trained using CBOW with position-weights, in dimension 300, with character n-grams of length 5, a window of size 5 and 10 negatives. We also distribute three new word analogy datasets, for French, Hindi and Polish.
## Training procedure
### Tokenization
We used the [Stanford word segmenter](https://nlp.stanford.edu/software/segmenter.html) for Chinese, [Mecab](http://taku910.github.io/mecab/) for Japanese and [UETsegmenter](https://github.com/phongnt570/UETsegmenter) for Vietnamese. For languages using the Latin, Cyrillic, Hebrew or Greek scripts, we used the tokenizer from the [Europarl](https://www.statmt.org/europarl/) preprocessing tools. For the remaining languages, we used the ICU tokenizer.
More information about the training of these models can be found in the article [Learning Word Vectors for 157 Languages](https://arxiv.org/abs/1802.06893).
### License
The language identification model is distributed under the [*Creative Commons Attribution-NonCommercial 4.0 International Public License*](https://creativecommons.org/licenses/by-nc/4.0/).
### Evaluation datasets
The analogy evaluation datasets described in the paper are available here: [French](https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-fr.txt), [Hindi](https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-hi.txt), [Polish](https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-pl.txt).
### BibTeX entry and citation info
Please cite [1] if using this code for learning word representations or [2] if using for text classification.
[1] P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
```markup
@article{bojanowski2016enriching,
title={Enriching Word Vectors with Subword Information},
author={Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.04606},
year={2016}
}
```
[2] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
```markup
@article{joulin2016bag,
title={Bag of Tricks for Efficient Text Classification},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.01759},
year={2016}
}
```
[3] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models*](https://arxiv.org/abs/1612.03651)
```markup
@article{joulin2016fasttext,
title={FastText.zip: Compressing text classification models},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{'e}gou, H{'e}rve and Mikolov, Tomas},
journal={arXiv preprint arXiv:1612.03651},
year={2016}
}
```
If you use these word vectors, please cite the following paper:
[4] E. Grave\*, P. Bojanowski\*, P. Gupta, A. Joulin, T. Mikolov, [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893)
```markup
@inproceedings{grave2018learning,
title={Learning Word Vectors for 157 Languages},
author={Grave, Edouard and Bojanowski, Piotr and Gupta, Prakhar and Joulin, Armand and Mikolov, Tomas},
booktitle={Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018)},
year={2018}
}
```
(\* These authors contributed equally.)
|
Helsinki-NLP/opus-mt-de-en | Helsinki-NLP | "2023-08-16T11:27:46Z" | 528,794 | 39 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"de",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-de-en
* source languages: de
* target languages: en
* OPUS readme: [de-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-02-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-en/opus-2020-02-26.zip)
* test set translations: [opus-2020-02-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-en/opus-2020-02-26.test.txt)
* test set scores: [opus-2020-02-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-en/opus-2020-02-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newssyscomb2009.de.en | 29.4 | 0.557 |
| news-test2008.de.en | 27.8 | 0.548 |
| newstest2009.de.en | 26.8 | 0.543 |
| newstest2010.de.en | 30.2 | 0.584 |
| newstest2011.de.en | 27.4 | 0.556 |
| newstest2012.de.en | 29.1 | 0.569 |
| newstest2013.de.en | 32.1 | 0.583 |
| newstest2014-deen.de.en | 34.0 | 0.600 |
| newstest2015-ende.de.en | 34.2 | 0.599 |
| newstest2016-ende.de.en | 40.4 | 0.649 |
| newstest2017-ende.de.en | 35.7 | 0.610 |
| newstest2018-ende.de.en | 43.7 | 0.667 |
| newstest2019-deen.de.en | 40.1 | 0.642 |
| Tatoeba.de.en | 55.4 | 0.707 |
|
facebook/dpr-ctx_encoder-single-nq-base | facebook | "2022-12-21T15:16:53Z" | 528,781 | 22 | transformers | [
"transformers",
"pytorch",
"tf",
"dpr",
"en",
"dataset:nq_open",
"arxiv:2004.04906",
"arxiv:1702.08734",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
license: cc-by-nc-4.0
tags:
- dpr
datasets:
- nq_open
inference: false
---
# `dpr-ctx_encoder-single-nq-base`
## Table of Contents
- [Model Details](#model-details)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation-results)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-authors)
## Model Details
**Model Description:** [Dense Passage Retrieval (DPR)](https://github.com/facebookresearch/DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. `dpr-ctx_encoder-single-nq-base` is the Context Encoder trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open) ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/)).
- **Developed by:** See [GitHub repo](https://github.com/facebookresearch/DPR) for model developers
- **Model Type:** BERT-based encoder
- **Language(s):** [CC-BY-NC-4.0](https://github.com/facebookresearch/DPR/blob/main/LICENSE), also see [Code of Conduct](https://github.com/facebookresearch/DPR/blob/main/CODE_OF_CONDUCT.md)
- **License:** English
- **Related Models:**
- [`dpr-question-encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base)
- [`dpr-reader-single-nq-base`](https://huggingface.co/facebook/dpr-reader-single-nq-base)
- [`dpr-ctx_encoder-multiset-base`](https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base)
- [`dpr-question_encoder-multiset-base`](https://huggingface.co/facebook/dpr-question_encoder-multiset-base)
- [`dpr-reader-multiset-base`](https://huggingface.co/facebook/dpr-reader-multiset-base)
- **Resources for more information:**
- [Research Paper](https://arxiv.org/abs/2004.04906)
- [GitHub Repo](https://github.com/facebookresearch/DPR)
- [Hugging Face DPR docs](https://huggingface.co/docs/transformers/main/en/model_doc/dpr)
- [BERT Base Uncased Model Card](https://huggingface.co/bert-base-uncased)
## How to Get Started with the Model
Use the code below to get started with the model.
```python
>>> from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
>>> tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
>>> model = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
>>> input_ids = tokenizer("Hello, is my dog cute ?", return_tensors="pt")["input_ids"]
>>> embeddings = model(input_ids).pooler_output
```
## Uses
#### Direct Use
`dpr-ctx_encoder-single-nq-base`, [`dpr-question-encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base), and [`dpr-reader-single-nq-base`](https://huggingface.co/facebook/dpr-reader-single-nq-base) can be used for the task of open-domain question answering.
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the set of DPR models was not trained to be factual or true representations of people or events, and therefore using the models to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section may contain content that is disturbing, offensive, and can propogate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Training
#### Training Data
This model was trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open) ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/)). The model authors write that:
> [The dataset] was designed for end-to-end question answering. The questions were mined from real Google search queries and the answers were spans in Wikipedia articles identified by annotators.
#### Training Procedure
The training procedure is described in the [associated paper](https://arxiv.org/pdf/2004.04906.pdf):
> Given a collection of M text passages, the goal of our dense passage retriever (DPR) is to index all the passages in a low-dimensional and continuous space, such that it can retrieve efficiently the top k passages relevant to the input question for the reader at run-time.
> Our dense passage retriever (DPR) uses a dense encoder EP(·) which maps any text passage to a d- dimensional real-valued vectors and builds an index for all the M passages that we will use for retrieval. At run-time, DPR applies a different encoder EQ(·) that maps the input question to a d-dimensional vector, and retrieves k passages of which vectors are the closest to the question vector.
The authors report that for encoders, they used two independent BERT ([Devlin et al., 2019](https://aclanthology.org/N19-1423/)) networks (base, un-cased) and use FAISS ([Johnson et al., 2017](https://arxiv.org/abs/1702.08734)) during inference time to encode and index passages. See the paper for further details on training, including encoders, inference, positive and negative passages, and in-batch negatives.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://arxiv.org/pdf/2004.04906.pdf).
#### Testing Data, Factors and Metrics
The model developers report the performance of the model on five QA datasets, using the top-k accuracy (k ∈ {20, 100}). The datasets were [NQ](https://huggingface.co/datasets/nq_open), [TriviaQA](https://huggingface.co/datasets/trivia_qa), [WebQuestions (WQ)](https://huggingface.co/datasets/web_questions), [CuratedTREC (TREC)](https://huggingface.co/datasets/trec), and [SQuAD v1.1](https://huggingface.co/datasets/squad).
#### Results
| | Top 20 | | | | | Top 100| | | | |
|:----:|:------:|:---------:|:--:|:----:|:-----:|:------:|:---------:|:--:|:----:|:-----:|
| | NQ | TriviaQA | WQ | TREC | SQuAD | NQ | TriviaQA | WQ | TREC | SQuAD |
| | 78.4 | 79.4 |73.2| 79.8 | 63.2 | 85.4 | 85.0 |81.4| 89.1 | 77.2 |
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). We present the hardware type and based on the [associated paper](https://arxiv.org/abs/2004.04906).
- **Hardware Type:** 8 32GB GPUs
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://arxiv.org/abs/2004.04906) for details on the modeling architecture, objective, compute infrastructure, and training details.
## Citation Information
```bibtex
@inproceedings{karpukhin-etal-2020-dense,
title = "Dense Passage Retrieval for Open-Domain Question Answering",
author = "Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.550",
doi = "10.18653/v1/2020.emnlp-main.550",
pages = "6769--6781",
}
```
## Model Card Authors
This model card was written by the team at Hugging Face. |
martin-ha/toxic-comment-model | martin-ha | "2022-05-06T02:24:31Z" | 526,532 | 53 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: en
---
## Model description
This model is a fine-tuned version of the [DistilBERT model](https://huggingface.co/transformers/model_doc/distilbert.html) to classify toxic comments.
## How to use
You can use the model with the following code.
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TextClassificationPipeline
model_path = "martin-ha/toxic-comment-model"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
pipeline = TextClassificationPipeline(model=model, tokenizer=tokenizer)
print(pipeline('This is a test text.'))
```
## Limitations and Bias
This model is intended to use for classify toxic online classifications. However, one limitation of the model is that it performs poorly for some comments that mention a specific identity subgroup, like Muslim. The following table shows a evaluation score for different identity group. You can learn the specific meaning of this metrics [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/overview/evaluation). But basically, those metrics shows how well a model performs for a specific group. The larger the number, the better.
| **subgroup** | **subgroup_size** | **subgroup_auc** | **bpsn_auc** | **bnsp_auc** |
| ----------------------------- | ----------------- | ---------------- | ------------ | ------------ |
| muslim | 108 | 0.689 | 0.811 | 0.88 |
| jewish | 40 | 0.749 | 0.86 | 0.825 |
| homosexual_gay_or_lesbian | 56 | 0.795 | 0.706 | 0.972 |
| black | 84 | 0.866 | 0.758 | 0.975 |
| white | 112 | 0.876 | 0.784 | 0.97 |
| female | 306 | 0.898 | 0.887 | 0.948 |
| christian | 231 | 0.904 | 0.917 | 0.93 |
| male | 225 | 0.922 | 0.862 | 0.967 |
| psychiatric_or_mental_illness | 26 | 0.924 | 0.907 | 0.95 |
The table above shows that the model performs poorly for the muslim and jewish group. In fact, you pass the sentence "Muslims are people who follow or practice Islam, an Abrahamic monotheistic religion." Into the model, the model will classify it as toxic. Be mindful for this type of potential bias.
## Training data
The training data comes this [Kaggle competition](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data). We use 10% of the `train.csv` data to train the model.
## Training procedure
You can see [this documentation and codes](https://github.com/MSIA/wenyang_pan_nlp_project_2021) for how we train the model. It takes about 3 hours in a P-100 GPU.
## Evaluation results
The model achieves 94% accuracy and 0.59 f1-score in a 10000 rows held-out test set. |
distilbert/distilbert-base-multilingual-cased | distilbert | "2024-05-06T13:46:54Z" | 525,965 | 137 | transformers | [
"transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"distilbert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1910.01108",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language:
- multilingual
- af
- sq
- ar
- an
- hy
- ast
- az
- ba
- eu
- bar
- be
- bn
- inc
- bs
- br
- bg
- my
- ca
- ceb
- ce
- zh
- cv
- hr
- cs
- da
- nl
- en
- et
- fi
- fr
- gl
- ka
- de
- el
- gu
- ht
- he
- hi
- hu
- is
- io
- id
- ga
- it
- ja
- jv
- kn
- kk
- ky
- ko
- la
- lv
- lt
- roa
- nds
- lm
- mk
- mg
- ms
- ml
- mr
- mn
- min
- ne
- new
- nb
- nn
- oc
- fa
- pms
- pl
- pt
- pa
- ro
- ru
- sco
- sr
- hr
- scn
- sk
- sl
- aze
- es
- su
- sw
- sv
- tl
- tg
- th
- ta
- tt
- te
- tr
- uk
- ud
- uz
- vi
- vo
- war
- cy
- fry
- pnb
- yo
license: apache-2.0
datasets:
- wikipedia
---
# Model Card for DistilBERT base multilingual (cased)
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training Details](#training-details)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
This model is a distilled version of the [BERT base multilingual model](https://huggingface.co/bert-base-multilingual-cased/). The code for the distillation process can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation). This model is cased: it does make a difference between english and English.
The model is trained on the concatenation of Wikipedia in 104 different languages listed [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages).
The model has 6 layers, 768 dimension and 12 heads, totalizing 134M parameters (compared to 177M parameters for mBERT-base).
On average, this model, referred to as DistilmBERT, is twice as fast as mBERT-base.
We encourage potential users of this model to check out the [BERT base multilingual model card](https://huggingface.co/bert-base-multilingual-cased) to learn more about usage, limitations and potential biases.
- **Developed by:** Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf (Hugging Face)
- **Model type:** Transformer-based language model
- **Language(s) (NLP):** 104 languages; see full list [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages)
- **License:** Apache 2.0
- **Related Models:** [BERT base multilingual model](https://huggingface.co/bert-base-multilingual-cased)
- **Resources for more information:**
- [GitHub Repository](https://github.com/huggingface/transformers/blob/main/examples/research_projects/distillation/README.md)
- [Associated Paper](https://arxiv.org/abs/1910.01108)
# Uses
## Direct Use and Downstream Use
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation you should look at model like GPT2.
## Out of Scope Use
The model should not be used to intentionally create hostile or alienating environments for people. The model was not trained to be factual or true representations of people or events, and therefore using the models to generate such content is out-of-scope for the abilities of this model.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
# Training Details
- The model was pretrained with the supervision of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the concatenation of Wikipedia in 104 different languages
- The model has 6 layers, 768 dimension and 12 heads, totalizing 134M parameters.
- Further information about the training procedure and data is included in the [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) model card.
# Evaluation
The model developers report the following accuracy results for DistilmBERT (see [GitHub Repo](https://github.com/huggingface/transformers/blob/main/examples/research_projects/distillation/README.md)):
> Here are the results on the test sets for 6 of the languages available in XNLI. The results are computed in the zero shot setting (trained on the English portion and evaluated on the target language portion):
| Model | English | Spanish | Chinese | German | Arabic | Urdu |
| :---: | :---: | :---: | :---: | :---: | :---: | :---:|
| mBERT base cased (computed) | 82.1 | 74.6 | 69.1 | 72.3 | 66.4 | 58.5 |
| mBERT base uncased (reported)| 81.4 | 74.3 | 63.8 | 70.5 | 62.1 | 58.3 |
| DistilmBERT | 78.2 | 69.1 | 64.0 | 66.3 | 59.1 | 54.7 |
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
```bibtex
@article{Sanh2019DistilBERTAD,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
journal={ArXiv},
year={2019},
volume={abs/1910.01108}
}
```
APA
- Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
# How to Get Started With the Model
You can use the model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-multilingual-cased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'score': 0.040800247341394424,
'sequence': "Hello I'm a virtual model.",
'token': 37859,
'token_str': 'virtual'},
{'score': 0.020015988498926163,
'sequence': "Hello I'm a big model.",
'token': 22185,
'token_str': 'big'},
{'score': 0.018680453300476074,
'sequence': "Hello I'm a Hello model.",
'token': 31178,
'token_str': 'Hello'},
{'score': 0.017396586015820503,
'sequence': "Hello I'm a model model.",
'token': 13192,
'token_str': 'model'},
{'score': 0.014229810796678066,
'sequence': "Hello I'm a perfect model.",
'token': 43477,
'token_str': 'perfect'}]
```
|
Danswer/intent-model | Danswer | "2023-06-10T08:59:02Z" | 524,088 | 6 | keras | [
"keras",
"tf",
"distilbert",
"en",
"license:mit",
"region:us"
] | null | "2023-06-06T04:31:33Z" | ---
license: mit
language:
- en
library_name: keras
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This model is used to classify the user-intent for the Danswer project, visit https://github.com/danswer-ai/danswer.
## Model Details
Multiclass classifier on top of distilbert-base-uncased
### Model Description
<!-- Provide a longer summary of what this model is. -->
Classifies user intent of queries into categories including:
0: Keyword Search
1: Semantic Search
2: Direct Question Answering
- **Developed by:** [DanswerAI]
- **License:** [MIT]
- **Finetuned from model [optional]:** [distilbert-base-uncased]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/danswer-ai/danswer]
- **Demo [optional]:** [Upcoming!]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This model is intended to be used in the Danswer Question-Answering System
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
This model has a very small dataset maintained by DanswerAI. If interested, reach out to [email protected].
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
This model is intended to be used in the Danswer (QA System)
## How to Get Started with the Model
```
from transformers import AutoTokenizer
from transformers import TFDistilBertForSequenceClassification
import tensorflow as tf
model = TFDistilBertForSequenceClassification.from_pretrained("danswer/intent-model")
tokenizer = AutoTokenizer.from_pretrained("danswer/intent-model")
class_semantic_mapping = {
0: "Keyword Search",
1: "Semantic Search",
2: "Question Answer"
}
# Get user input
user_query = "How do I set up Danswer to run on my local environment?"
# Encode the user input
inputs = tokenizer(user_query, return_tensors="tf", truncation=True, padding=True)
# Get model predictions
predictions = model(inputs)[0]
# Get predicted class
predicted_class = tf.math.argmax(predictions, axis=-1)
print(f"Predicted class: {class_semantic_mapping[int(predicted_class)]}")
``` |
google/flan-t5-large | google | "2023-07-17T12:49:05Z" | 521,594 | 569 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"arxiv:2210.11416",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-10-21T10:07:08Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
widget:
- text: "Translate to German: My name is Arthur"
example_title: "Translation"
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
example_title: "Question Answering"
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
example_title: "Logical reasoning"
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
example_title: "Scientific knowledge"
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
example_title: "Yes/no question"
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
example_title: "Reasoning task"
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
example_title: "Boolean Expressions"
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
example_title: "Math reasoning"
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
example_title: "Premise and hypothesis"
tags:
- text2text-generation
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
license: apache-2.0
---
# Model Card for FLAN-T5 large
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/flan2_architecture.jpg"
alt="drawing" width="600"/>
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
# TL;DR
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
As mentioned in the first few lines of the abstract :
> Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [T5 model card](https://huggingface.co/t5-large).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English, Spanish, Japanese, Persian, Hindi, French, Chinese, Bengali, Gujarati, German, Telugu, Italian, Arabic, Polish, Tamil, Marathi, Malayalam, Oriya, Panjabi, Portuguese, Urdu, Galician, Hebrew, Korean, Catalan, Thai, Dutch, Indonesian, Vietnamese, Bulgarian, Filipino, Central Khmer, Lao, Turkish, Russian, Croatian, Swedish, Yoruba, Kurdish, Burmese, Malay, Czech, Finnish, Somali, Tagalog, Swahili, Sinhala, Kannada, Zhuang, Igbo, Xhosa, Romanian, Haitian, Estonian, Slovak, Lithuanian, Greek, Nepali, Assamese, Norwegian
- **License:** Apache 2.0
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
- **Original Checkpoints:** [All Original FLAN-T5 Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2210.11416.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face FLAN-T5 Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/t5)
# Usage
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-large")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-large")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-large")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-large", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-large")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-large", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-large")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-large", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
# Uses
## Direct Use and Downstream Use
The authors write in [the original paper's model card](https://arxiv.org/pdf/2210.11416.pdf) that:
> The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
See the [research paper](https://arxiv.org/pdf/2210.11416.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
The information below in this section are copied from the model's [official model card](https://arxiv.org/pdf/2210.11416.pdf):
> Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
## Ethical considerations and risks
> Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
## Known Limitations
> Flan-T5 has not been tested in real world applications.
## Sensitive Use:
> Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
# Training Details
## Training Data
The model was trained on a mixture of tasks, that includes the tasks described in the table below (from the original paper, figure 2):

## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2210.11416.pdf):
> These models are based on pretrained T5 (Raffel et al., 2020) and fine-tuned with instructions for better zero-shot and few-shot performance. There is one fine-tuned Flan model per T5 model size.
The model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks covering several languages (1836 in total). See the table below for some quantitative evaluation:

For full details, please check the [research paper](https://arxiv.org/pdf/2210.11416.pdf).
## Results
For full results for FLAN-T5-Large, see the [research paper](https://arxiv.org/pdf/2210.11416.pdf), Table 3.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
mistralai/Mistral-7B-Instruct-v0.3 | mistralai | "2024-08-21T12:18:25Z" | 517,951 | 1,018 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:finetune:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-22T09:57:04Z" | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.3
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# Model Card for Mistral-7B-Instruct-v0.3
The Mistral-7B-Instruct-v0.3 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.3.
Mistral-7B-v0.3 has the following changes compared to [Mistral-7B-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2/edit/main/README.md)
- Extended vocabulary to 32768
- Supports v3 Tokenizer
- Supports function calling
## Installation
It is recommended to use `mistralai/Mistral-7B-Instruct-v0.3` with [mistral-inference](https://github.com/mistralai/mistral-inference). For HF transformers code snippets, please keep scrolling.
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', '7B-Instruct-v0.3')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Mistral-7B-Instruct-v0.3", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment. You can chat with the model using
```
mistral-chat $HOME/mistral_models/7B-Instruct-v0.3 --instruct --max_tokens 256
```
### Instruct following
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
### Function calling
```py
from mistral_common.protocol.instruct.tool_calls import Function, Tool
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris?"),
],
)
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
## Generate with `transformers`
If you want to use Hugging Face `transformers` to generate text, you can do something like this.
```py
from transformers import pipeline
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3")
chatbot(messages)
```
## Function calling with `transformers`
To use this example, you'll need `transformers` version 4.42.0 or higher. Please see the
[function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling)
in the `transformers` docs for more information.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "mistralai/Mistral-7B-Instruct-v0.3"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_current_weather(location: str, format: str):
"""
Get the current weather
Args:
location: The city and state, e.g. San Francisco, CA
format: The temperature unit to use. Infer this from the users location. (choices: ["celsius", "fahrenheit"])
"""
pass
conversation = [{"role": "user", "content": "What's the weather like in Paris?"}]
tools = [get_current_weather]
# format and tokenize the tool use prompt
inputs = tokenizer.apply_chat_template(
conversation,
tools=tools,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
inputs.to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1000)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Note that, for reasons of space, this example does not show a complete cycle of calling a tool and adding the tool call and tool
results to the chat history so that the model can use them in its next generation. For a full tool calling example, please
see the [function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling),
and note that Mistral **does** use tool call IDs, so these must be included in your tool calls and tool results. They should be
exactly 9 alphanumeric characters.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, William El Sayed, William Marshall |
Supabase/gte-small | Supabase | "2024-03-18T18:02:53Z" | 511,156 | 65 | transformers.js | [
"transformers.js",
"pytorch",
"onnx",
"bert",
"feature-extraction",
"en",
"license:mit",
"region:us"
] | feature-extraction | "2023-08-01T17:50:33Z" | ---
pipeline_tag: feature-extraction
library_name: "transformers.js"
language:
- en
license: mit
---
_Fork of https://huggingface.co/thenlper/gte-small with ONNX weights to be compatible with Transformers.js. See [JavaScript usage](#javascript)._
---
# gte-small
General Text Embeddings (GTE) model.
The GTE models are trained by Alibaba DAMO Academy. They are mainly based on the BERT framework and currently offer three different sizes of models, including [GTE-large](https://huggingface.co/thenlper/gte-large), [GTE-base](https://huggingface.co/thenlper/gte-base), and [GTE-small](https://huggingface.co/thenlper/gte-small). The GTE models are trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. This enables the GTE models to be applied to various downstream tasks of text embeddings, including **information retrieval**, **semantic textual similarity**, **text reranking**, etc.
## Metrics
Performance of GTE models were compared with other popular text embedding models on the MTEB benchmark. For more detailed comparison results, please refer to the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**gte-large**](https://huggingface.co/thenlper/gte-large) | 0.67 | 1024 | 512 | **63.13** | 46.84 | 85.00 | 59.13 | 52.22 | 83.35 | 31.66 | 73.33 |
| [**gte-base**](https://huggingface.co/thenlper/gte-base) | 0.22 | 768 | 512 | **62.39** | 46.2 | 84.57 | 58.61 | 51.14 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1.34 | 1024| 512 | 62.25 | 44.49 | 86.03 | 56.61 | 50.56 | 82.05 | 30.19 | 75.24 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.44 | 768 | 512 | 61.5 | 43.80 | 85.73 | 55.91 | 50.29 | 81.05 | 30.28 | 73.84 |
| [**gte-small**](https://huggingface.co/thenlper/gte-small) | 0.07 | 384 | 512 | **61.36** | 44.89 | 83.54 | 57.7 | 49.46 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | - | 1536 | 8192 | 60.99 | 45.9 | 84.89 | 56.32 | 49.25 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.13 | 384 | 512 | 59.93 | 39.92 | 84.67 | 54.32 | 49.04 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 9.73 | 768 | 512 | 59.51 | 43.72 | 85.06 | 56.42 | 42.24 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.44 | 768 | 514 | 57.78 | 43.69 | 83.04 | 59.36 | 43.81 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 28.27 | 4096 | 2048 | 57.59 | 38.93 | 81.9 | 55.65 | 48.22 | 77.74 | 33.6 | 66.19 |
| [all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2) | 0.13 | 384 | 512 | 56.53 | 41.81 | 82.41 | 58.44 | 42.69 | 79.8 | 27.9 | 63.21 |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.09 | 384 | 512 | 56.26 | 42.35 | 82.37 | 58.04 | 41.95 | 78.9 | 30.81 | 63.05 |
| [contriever-base-msmarco](https://huggingface.co/nthakur/contriever-base-msmarco) | 0.44 | 768 | 512 | 56.00 | 41.1 | 82.54 | 53.14 | 41.88 | 76.51 | 30.36 | 66.68 |
| [sentence-t5-base](https://huggingface.co/sentence-transformers/sentence-t5-base) | 0.22 | 768 | 512 | 55.27 | 40.21 | 85.18 | 53.09 | 33.63 | 81.14 | 31.39 | 69.81 |
## Usage
This model can be used with both [Python](#python) and [JavaScript](#javascript).
### Python
Use with [Transformers](https://huggingface.co/docs/transformers/index) and [PyTorch](https://pytorch.org/docs/stable/index.html):
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
tokenizer = AutoTokenizer.from_pretrained("Supabase/gte-small")
model = AutoModel.from_pretrained("Supabase/gte-small")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with [sentence-transformers](https://www.sbert.net/):
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('Supabase/gte-small')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
### JavaScript
This model can be used with JavaScript via [Transformers.js](https://huggingface.co/docs/transformers.js/index).
Use with [Deno](https://deno.land/manual/introduction) or [Supabase Edge Functions](https://supabase.com/docs/guides/functions):
```ts
import { serve } from 'https://deno.land/[email protected]/http/server.ts'
import { env, pipeline } from 'https://cdn.jsdelivr.net/npm/@xenova/[email protected]'
// Configuration for Deno runtime
env.useBrowserCache = false;
env.allowLocalModels = false;
const pipe = await pipeline(
'feature-extraction',
'Supabase/gte-small',
);
serve(async (req) => {
// Extract input string from JSON body
const { input } = await req.json();
// Generate the embedding from the user input
const output = await pipe(input, {
pooling: 'mean',
normalize: true,
});
// Extract the embedding output
const embedding = Array.from(output.data);
// Return the embedding
return new Response(
JSON.stringify({ embedding }),
{ headers: { 'Content-Type': 'application/json' } }
);
});
```
Use within the browser ([JavaScript Modules](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Modules)):
```html
<script type="module">
import { pipeline } from 'https://cdn.jsdelivr.net/npm/@xenova/[email protected]';
const pipe = await pipeline(
'feature-extraction',
'Supabase/gte-small',
);
// Generate the embedding from text
const output = await pipe('Hello world', {
pooling: 'mean',
normalize: true,
});
// Extract the embedding output
const embedding = Array.from(output.data);
console.log(embedding);
</script>
```
Use within [Node.js](https://nodejs.org/en/docs) or a web bundler ([Webpack](https://webpack.js.org/concepts/), etc):
```js
import { pipeline } from '@xenova/transformers';
const pipe = await pipeline(
'feature-extraction',
'Supabase/gte-small',
);
// Generate the embedding from text
const output = await pipe('Hello world', {
pooling: 'mean',
normalize: true,
});
// Extract the embedding output
const embedding = Array.from(output.data);
console.log(embedding);
```
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
|
jonatasgrosman/wav2vec2-xls-r-1b-portuguese | jonatasgrosman | "2022-12-14T02:02:02Z" | 505,768 | 10 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"pt",
"robust-speech-event",
"dataset:mozilla-foundation/common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language:
- pt
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- pt
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: XLS-R Wav2Vec2 Portuguese by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: pt
metrics:
- name: Test WER
type: wer
value: 8.7
- name: Test CER
type: cer
value: 2.55
- name: Test WER (+LM)
type: wer
value: 6.04
- name: Test CER (+LM)
type: cer
value: 1.98
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: pt
metrics:
- name: Dev WER
type: wer
value: 24.23
- name: Dev CER
type: cer
value: 11.3
- name: Dev WER (+LM)
type: wer
value: 19.41
- name: Dev CER (+LM)
type: cer
value: 10.19
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: pt
metrics:
- name: Test WER
type: wer
value: 18.8
---
# Fine-tuned XLS-R 1B model for speech recognition in Portuguese
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on Portuguese using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [CORAA](https://github.com/nilc-nlp/CORAA), [Multilingual TEDx](http://www.openslr.org/100), and [Multilingual LibriSpeech](https://www.openslr.org/94/).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-portuguese")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "pt"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-portuguese"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-portuguese --dataset mozilla-foundation/common_voice_8_0 --config pt --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-portuguese --dataset speech-recognition-community-v2/dev_data --config pt --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-portuguese,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {P}ortuguese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-portuguese}},
year={2022}
}
``` |
jonatasgrosman/wav2vec2-large-xlsr-53-arabic | jonatasgrosman | "2022-12-14T01:57:28Z" | 500,122 | 24 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ar",
"dataset:common_voice",
"dataset:arabic_speech_corpus",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: ar
datasets:
- common_voice
- arabic_speech_corpus
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Arabic by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ar
type: common_voice
args: ar
metrics:
- name: Test WER
type: wer
value: 39.59
- name: Test CER
type: cer
value: 18.18
---
# Fine-tuned XLSR-53 large model for speech recognition in Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Arabic using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice) and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-arabic")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ar"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-arabic"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| ألديك قلم ؟ | ألديك قلم |
| ليست هناك مسافة على هذه الأرض أبعد من يوم أمس. | ليست نالك مسافة على هذه الأرض أبعد من يوم الأمس م |
| إنك تكبر المشكلة. | إنك تكبر المشكلة |
| يرغب أن يلتقي بك. | يرغب أن يلتقي بك |
| إنهم لا يعرفون لماذا حتى. | إنهم لا يعرفون لماذا حتى |
| سيسعدني مساعدتك أي وقت تحب. | سيسئدنيمساعدتك أي وقد تحب |
| أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة. | أحب نظرية علمية إلي هي أن حل قتزح المكوينا بالكامل من الأمت عن المفقودة |
| سأشتري له قلماً. | سأشتري له قلما |
| أين المشكلة ؟ | أين المشكل |
| وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ | ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون |
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ar"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-arabic"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "'", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-05-14). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-arabic | **39.59%** | **18.18%** |
| bakrianoo/sinai-voice-ar-stt | 45.30% | 21.84% |
| othrif/wav2vec2-large-xlsr-arabic | 45.93% | 20.51% |
| kmfoda/wav2vec2-large-xlsr-arabic | 54.14% | 26.07% |
| mohammed/wav2vec2-large-xlsr-arabic | 56.11% | 26.79% |
| anas/wav2vec2-large-xlsr-arabic | 62.02% | 27.09% |
| elgeish/wav2vec2-large-xlsr-53-arabic | 100.00% | 100.56% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-arabic,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {A}rabic},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-arabic}},
year={2021}
}
``` |
readerbench/ro-sentiment | readerbench | "2023-08-08T10:31:58Z" | 499,237 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"sentiment",
"classification",
"romanian",
"nlp",
"ro",
"dataset:decathlon_reviews",
"dataset:cinemagia_reviews",
"base_model:readerbench/RoBERT-base",
"base_model:finetune:readerbench/RoBERT-base",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-08-07T13:33:20Z" | ---
base_model: readerbench/RoBERT-base
language:
- ro
tags:
- sentiment
- classification
- romanian
- nlp
- bert
datasets:
- decathlon_reviews
- cinemagia_reviews
metrics:
- accuracy
- precision
- recall
- f1
- f1 weighted
model-index:
- name: ro-sentiment
results:
- task:
type: text-classification # Required. Example: automatic-speech-recognition
name: Text Classification # Optional. Example: Speech Recognition
dataset:
type: ro_sent # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: Rommanian Sentiment Dataset # Required. A pretty name for the dataset. Example: Common Voice (French)
config: default # Optional. The name of the dataset configuration used in `load_dataset()`. Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
split: all # Optional. Example: test
metrics:
- type: accuracy # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.85 # Required. Example: 20.90
name: Accuracy # Optional. Example: Test WER
- type: precision # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.85 # Required. Example: 20.90
name: Precision # Optional. Example: Test WER
- type: recall # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.85 # Required. Example: 20.90
name: Recall # Optional. Example: Test WER
- type: f1_weighted # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.85 # Required. Example: 20.90
name: Weighted F1 # Optional. Example: Test WER
- type: f1_macro # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.84 # Required. Example: 20.90
name: Macro F1 # Optional. Example: Test WER
- task:
type: text-classification # Required. Example: automatic-speech-recognition
name: Text Classification # Optional. Example: Speech Recognition
dataset:
type: laroseda # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: A Large Romanian Sentiment Data Set # Required. A pretty name for the dataset. Example: Common Voice (French)
config: default # Optional. The name of the dataset configuration used in `load_dataset()`. Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
split: all # Optional. Example: test
metrics:
- type: accuracy # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.85 # Required. Example: 20.90
name: Accuracy # Optional. Example: Test WER
- type: precision # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.86 # Required. Example: 20.90
name: Precision # Optional. Example: Test WER
- type: recall # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.85 # Required. Example: 20.90
name: Recall # Optional. Example: Test WER
- type: f1_weighted # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.84 # Required. Example: 20.90
name: Weighted F1 # Optional. Example: Test WER
- type: f1_macro # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.84 # Required. Example: 20.90
name: Macro F1 # Optional. Example: Test WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RO-Sentiment
This model is a fine-tuned version of [readerbench/RoBERT-base](https://huggingface.co/readerbench/RoBERT-base) on the Decathlon reviews and Cinemagia reviews dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3923
- Accuracy: 0.8307
- Precision: 0.8366
- Recall: 0.8959
- F1: 0.8652
- F1 Weighted: 0.8287
Output labels:
- LABEL_0 = Negative Sentiment
- LABEL_1 = Positive Sentiment
### Evaluation on other datasets
**SENT_RO**
| |precision | recall | f1-score | support |
|:-------------:|:-----:|:----:|:------:|:--------:|
| Negative (0) | 0.79 | 0.83 | 0.81 | 11,675 |
| Positive (1) | 0.88 | 0.85 | 0.87 | 17,271 |
| | | | | |
| Accuracy | | | 0.85 | 28,946 |
| Macro Avg | 0.84 | 0.84 | 0.84 | 28,946 |
| Weighted Avg | 0.85 | 0.85 | 0.85 | 28,946 |
**LaRoSeDa**
| |precision | recall | f1-score | support |
|:-------------:|:-----:|:----:|:------:|:--------:|
| Negative (0) | 0.79 | 0.94 | 0.86 | 7,500 |
| Positive (1) | 0.93 | 0.75 | 0.83 | 7,500 |
| | | | | |
| Accuracy | | | 0.85 | 15,000 |
| Macro Avg | 0.86 | 0.85 | 0.84 | 15,000 |
| Weighted Avg | 0.86 | 0.85 | 0.84 | 15,000 |
## Model description
Finetuned Romanian BERT model for sentiment classification.
Trained on a mix of product reviews from Decathlon retailer website and movie reviews from cinemagia.
## Intended uses & limitations
Sentiment classification for Romanian Language.
Biased towards Product reviews.
There is no "neutral" sentiment label.
## Training and evaluation data
**Trained on:**
- Decathlon Dataset available on request
- Cinemagia Movie reviews public on kaggle [Link](https://www.kaggle.com/datasets/gringoandy/romanian-sentiment-movie-reviews)
**Evaluated on**
- Holdout data from training dataset
- RO_SENT Dataset
- LaROSeDa Dataset
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 10 (Early stop epoch 3, best epoch 2)
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | F1 Weighted |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|:-----------:|
| 0.4198 | 1.0 | 1629 | 0.3983 | 0.8377 | 0.8791 | 0.8721 | 0.8756 | 0.8380 |
| 0.3861 | **2.0** | 3258 | 0.4312 | 0.8429 | 0.8963 | 0.8665 | 0.8812 | **0.8442** |
| 0.3189 | 3.0 | 4887 | 0.3923 | 0.8307 | 0.8366 | 0.8959 | 0.8652 | 0.8287 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
google-t5/t5-large | google-t5 | "2023-04-06T13:42:27Z" | 498,065 | 176 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"translation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:c4",
"arxiv:1805.12471",
"arxiv:1708.00055",
"arxiv:1704.05426",
"arxiv:1606.05250",
"arxiv:1808.09121",
"arxiv:1810.12885",
"arxiv:1905.10044",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
license: apache-2.0
tags:
- summarization
- translation
datasets:
- c4
---
# Model Card for T5 Large

# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training Details](#training-details)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [Model Card Authors](#model-card-authors)
9. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The developers of the Text-To-Text Transfer Transformer (T5) [write](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html):
> With T5, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task.
T5-Large is the checkpoint with 770 million parameters.
- **Developed by:** Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. See [associated paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) and [GitHub repo](https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints)
- **Model type:** Language model
- **Language(s) (NLP):** English, French, Romanian, German
- **License:** Apache 2.0
- **Related Models:** [All T5 Checkpoints](https://huggingface.co/models?search=t5)
- **Resources for more information:**
- [Research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf)
- [Google's T5 Blog Post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
- [GitHub Repo](https://github.com/google-research/text-to-text-transfer-transformer)
- [Hugging Face T5 Docs](https://huggingface.co/docs/transformers/model_doc/t5)
# Uses
## Direct Use and Downstream Use
The developers write in a [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) that the model:
> Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
See the [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Recommendations
More information needed.
# Training Details
## Training Data
The model is pre-trained on the [Colossal Clean Crawled Corpus (C4)](https://www.tensorflow.org/datasets/catalog/c4), which was developed and released in the context of the same [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) as T5.
The model was pre-trained on a on a **multi-task mixture of unsupervised (1.) and supervised tasks (2.)**.
Thereby, the following datasets were being used for (1.) and (2.):
1. **Datasets used for Unsupervised denoising objective**:
- [C4](https://huggingface.co/datasets/c4)
- [Wiki-DPR](https://huggingface.co/datasets/wiki_dpr)
2. **Datasets used for Supervised text-to-text language modeling objective**
- Sentence acceptability judgment
- CoLA [Warstadt et al., 2018](https://arxiv.org/abs/1805.12471)
- Sentiment analysis
- SST-2 [Socher et al., 2013](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)
- Paraphrasing/sentence similarity
- MRPC [Dolan and Brockett, 2005](https://aclanthology.org/I05-5002)
- STS-B [Ceret al., 2017](https://arxiv.org/abs/1708.00055)
- QQP [Iyer et al., 2017](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs)
- Natural language inference
- MNLI [Williams et al., 2017](https://arxiv.org/abs/1704.05426)
- QNLI [Rajpurkar et al.,2016](https://arxiv.org/abs/1606.05250)
- RTE [Dagan et al., 2005](https://link.springer.com/chapter/10.1007/11736790_9)
- CB [De Marneff et al., 2019](https://semanticsarchive.net/Archive/Tg3ZGI2M/Marneffe.pdf)
- Sentence completion
- COPA [Roemmele et al., 2011](https://www.researchgate.net/publication/221251392_Choice_of_Plausible_Alternatives_An_Evaluation_of_Commonsense_Causal_Reasoning)
- Word sense disambiguation
- WIC [Pilehvar and Camacho-Collados, 2018](https://arxiv.org/abs/1808.09121)
- Question answering
- MultiRC [Khashabi et al., 2018](https://aclanthology.org/N18-1023)
- ReCoRD [Zhang et al., 2018](https://arxiv.org/abs/1810.12885)
- BoolQ [Clark et al., 2019](https://arxiv.org/abs/1905.10044)
## Training Procedure
In their [abstract](https://jmlr.org/papers/volume21/20-074/20-074.pdf), the model developers write:
> In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks.
The framework introduced, the T5 framework, involves a training procedure that brings together the approaches studied in the paper. See the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The developers evaluated the model on 24 tasks, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for full details.
## Results
For full results for T5-Large, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf), Table 14.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@article{2020t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {Journal of Machine Learning Research},
year = {2020},
volume = {21},
number = {140},
pages = {1-67},
url = {http://jmlr.org/papers/v21/20-074.html}
}
```
**APA:**
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140), 1-67.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5Model
tokenizer = T5Tokenizer.from_pretrained("t5-large")
model = T5Model.from_pretrained("t5-large")
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
# forward pass
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
last_hidden_states = outputs.last_hidden_state
```
See the [Hugging Face T5](https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5Model) docs and a [Colab Notebook](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/main/notebooks/t5-trivia.ipynb) created by the model developers for more examples.
</details>
|