
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Data
[[autodoc]] timm.data.create_dataset
[[autodoc]] timm.data.create_loader
[[autodoc]] timm.data.create_transform
[[autodoc]] timm.data.resolve_data_config | huggingface/pytorch-image-models/blob/main/hfdocs/source/reference/data.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ViTMSN
## Overview
The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. The paper presents a joint-embedding architecture to match the prototypes
of masked patches with that of the unmasked patches. With this setup, their method yields excellent performance in the low-shot and extreme low-shot
regimes.
The abstract from the paper is the following:
*We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our
approach matches the representation of an image view containing randomly masked patches to the representation of the original
unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the
unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures,
while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance,
on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy,
and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark.*
<img src="https://i.ibb.co/W6PQMdC/Screenshot-2022-09-13-at-9-08-40-AM.png" alt="drawing" width="600"/>
<small> MSN architecture. Taken from the <a href="https://arxiv.org/abs/2204.07141">original paper.</a> </small>
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
## Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
- The authors have only released pre-trained weights of the backbone (ImageNet-1k pre-training). So, to use that on your own image classification dataset,
use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMSNModel`]. Follow
[this notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb) for a detailed tutorial on fine-tuning.
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
<PipelineTag pipeline="image-classification"/>
- [`ViTMSNForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMSNConfig
[[autodoc]] ViTMSNConfig
## ViTMSNModel
[[autodoc]] ViTMSNModel
- forward
## ViTMSNForImageClassification
[[autodoc]] ViTMSNForImageClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/vit_msn.md |
Overview
Welcome to the 🤗 Datasets tutorials! These beginner-friendly tutorials will guide you through the fundamentals of working with 🤗 Datasets. You'll load and prepare a dataset for training with your machine learning framework of choice. Along the way, you'll learn how to load different dataset configurations and splits, interact with and see what's inside your dataset, preprocess, and share a dataset to the [Hub](https://huggingface.co/datasets).
The tutorials assume some basic knowledge of Python and a machine learning framework like PyTorch or TensorFlow. If you're already familiar with these, feel free to check out the [quickstart](./quickstart) to see what you can do with 🤗 Datasets.
<Tip>
The tutorials only cover the basic skills you need to use 🤗 Datasets. There are many other useful functionalities and applications that aren't discussed here. If you're interested in learning more, take a look at [Chapter 5](https://huggingface.co/course/chapter5/1?fw=pt) of the Hugging Face course.
</Tip>
If you have any questions about 🤗 Datasets, feel free to join and ask the community on our [forum](https://discuss.huggingface.co/c/datasets/10).
Let's get started! 🏁
| huggingface/datasets/blob/main/docs/source/tutorial.md |
--
title: MSE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Mean Squared Error(MSE) is the average of the square of difference between the predicted
and actual values.
---
# Metric Card for MSE
## Metric Description
Mean Squared Error(MSE) represents the average of the squares of errors -- i.e. the average squared difference between the estimated values and the actual values.
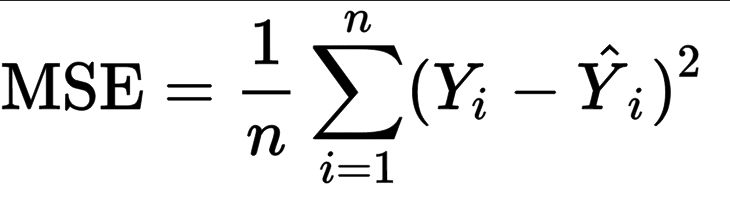
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mse_metric = evaluate.load("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mse_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
- `squared` (`bool`): If `True` returns MSE value, if `False` returns RMSE (Root Mean Squared Error). The default value is `True`.
### Output Values
This metric outputs a dictionary, containing the mean squared error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MSE `float` value ranges from `0.0` to `1.0`, with the best value being `0.0`.
Output Example(s):
```python
{'mse': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mse': array([0.41666667, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> mse_metric = evaluate.load("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mse_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mse': 0.375}
```
Example with `squared = True`, which returns the RMSE:
```python
>>> mse_metric = evaluate.load("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> rmse_result = mse_metric.compute(predictions=predictions, references=references, squared=False)
>>> print(rmse_result)
{'mse': 0.6123724356957945}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> mse_metric = evaluate.load("mse", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0, 2], [-1, 2], [8, -5]]
>>> results = mse_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mse': array([0.41666667, 1. ])}
"""
```
## Limitations and Bias
MSE has the disadvantage of heavily weighting outliers -- given that it squares them, this results in large errors weighing more heavily than small ones. It can be used alongside [MAE](https://huggingface.co/metrics/mae), which is complementary given that it does not square the errors.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{willmott2005advantages,
title={Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance},
author={Willmott, Cort J and Matsuura, Kenji},
journal={Climate research},
volume={30},
number={1},
pages={79--82},
year={2005}
}
```
## Further References
- [Mean Squared Error - Wikipedia](https://en.wikipedia.org/wiki/Mean_squared_error)
| huggingface/evaluate/blob/main/metrics/mse/README.md |
!-- DISABLE-FRONTMATTER-SECTIONS -->
# Tokenizers
Fast State-of-the-art tokenizers, optimized for both research and
production
[🤗 Tokenizers](https://github.com/huggingface/tokenizers) provides an
implementation of today's most used tokenizers, with a focus on
performance and versatility. These tokenizers are also used in [🤗 Transformers](https://github.com/huggingface/transformers).
# Main features:
- Train new vocabularies and tokenize, using today's most used tokenizers.
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for both research and production.
- Full alignment tracking. Even with destructive normalization, it's always possible to get the part of the original sentence that corresponds to any token.
- Does all the pre-processing: Truncation, Padding, add the special tokens your model needs.
| huggingface/tokenizers/blob/main/docs/source-doc-builder/index.mdx |
Gradio Demo: hello_login
```
!pip install -q gradio
```
```
import gradio as gr
import argparse
import sys
parser = argparse.ArgumentParser()
parser.add_argument("--name", type=str, default="User")
args, unknown = parser.parse_known_args()
print(sys.argv)
with gr.Blocks() as demo:
gr.Markdown(f"# Greetings {args.name}!")
inp = gr.Textbox()
out = gr.Textbox()
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/hello_login/run.ipynb |
Uploading datasets
The [Hub](https://huggingface.co/datasets) is home to an extensive collection of community-curated and research datasets. We encourage you to share your dataset to the Hub to help grow the ML community and accelerate progress for everyone. All contributions are welcome; adding a dataset is just a drag and drop away!
Start by [creating a Hugging Face Hub account](https://huggingface.co/join) if you don't have one yet.
## Upload using the Hub UI
The Hub's web-based interface allows users without any developer experience to upload a dataset.
### Create a repository
A repository hosts all your dataset files, including the revision history, making storing more than one dataset version possible.
1. Click on your profile and select **New Dataset** to create a [new dataset repository](https://huggingface.co/new-dataset).
2. Pick a name for your dataset, and choose whether it is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/create_repo.png"/>
</div>
### Upload dataset
1. Once you've created a repository, navigate to the **Files and versions** tab to add a file. Select **Add file** to upload your dataset files. We support many text, audio, image and other data extensions such as `.csv`, `.mp3`, and `.jpg` (see the full list of [File formats](#file-formats)).
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/upload_files.png"/>
</div>
2. Drag and drop your dataset files.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/commit_files.png"/>
</div>
3. After uploading your dataset files, they are stored in your dataset repository.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/files_stored.png"/>
</div>
### Create a Dataset card
Adding a Dataset card is super valuable for helping users find your dataset and understand how to use it responsibly.
1. Click on **Create Dataset Card** to create a [Dataset card](./datasets-cards). This button creates a `README.md` file in your repository.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/dataset_card.png"/>
</div>
2. At the top, you'll see the **Metadata UI** with several fields to select from such as license, language, and task categories. These are the most important tags for helping users discover your dataset on the Hub (when applicable). When you select an option for a field, it will be automatically added to the top of the dataset card.
You can also look at the [Dataset Card specifications](https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1), which has a complete set of allowed tags, including optional like `annotations_creators`, to help you choose the ones that are useful for your dataset.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/metadata_ui.png"/>
</div>
3. Write your dataset documentation in the Dataset Card to introduce your dataset to the community and help users understand what is inside: what are the use cases and limitations, where the data comes from, what are important ethical considerations, and any other relevant details.
You can click on the **Import dataset card template** link at the top of the editor to automatically create a dataset card template. For a detailed example of what a good Dataset card should look like, take a look at the [CNN DailyMail Dataset card](https://huggingface.co/datasets/cnn_dailymail).
### Dataset Viewer
The [Dataset Viewer](./datasets-viewer) is useful to know how the data actually looks like before you download it.
It is enabled by default for all public datasets.
Make sure the Dataset Viewer correctly shows your data, or [Configure the Dataset Viewer](./datasets-viewer-configure).
## Using the `huggingface_hub` client library
The rich features set in the `huggingface_hub` library allows you to manage repositories, including creating repos and uploading datasets to the Hub. Visit [the client library's documentation](https://huggingface.co/docs/huggingface_hub/index) to learn more.
## Using other libraries
Some libraries like [🤗 Datasets](https://huggingface.co/docs/datasets/index), [Pandas](https://pandas.pydata.org/), [Dask](https://www.dask.org/) or [DuckDB](https://duckdb.org/) can upload files to the Hub.
See the list of [Libraries supported by the Datasets Hub](./datasets-libraries) for more information.
## Using Git
Since dataset repos are Git repositories, you can use Git to push your data files to the Hub. Follow the guide on [Getting Started with Repositories](repositories-getting-started) to learn about using the `git` CLI to commit and push your datasets.
## File formats
The Hub natively supports multiple file formats:
- CSV (.csv, .tsv)
- JSON Lines, JSON (.jsonl, .json)
- Parquet (.parquet)
- Text (.txt)
- Images (.png, .jpg, etc.)
- Audio (.wav, .mp3, etc.)
It also supports files compressed using ZIP (.zip), GZIP (.gz), ZSTD (.zst), BZ2 (.bz2), LZ4 (.lz4) and LZMA (.xz).
Image and audio resources can also have additional metadata files, see the [Data files Configuration](./datasets-data-files-configuration#image-and-audio-datasets) on image and audio datasets.
You may want to convert your files to these formats to benefit from all the Hub features.
Other formats and structures may not be recognized by the Hub.
| huggingface/hub-docs/blob/main/docs/hub/datasets-adding.md |
Transformers, what can they do?[[transformers-what-can-they-do]]
<CourseFloatingBanner chapter={1}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter1/section3.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter1/section3.ipynb"},
]} />
In this section, we will look at what Transformer models can do and use our first tool from the 🤗 Transformers library: the `pipeline()` function.
<Tip>
👀 See that <em>Open in Colab</em> button on the top right? Click on it to open a Google Colab notebook with all the code samples of this section. This button will be present in any section containing code examples.
If you want to run the examples locally, we recommend taking a look at the <a href="/course/chapter0">setup</a>.
</Tip>
## Transformers are everywhere![[transformers-are-everywhere]]
Transformer models are used to solve all kinds of NLP tasks, like the ones mentioned in the previous section. Here are some of the companies and organizations using Hugging Face and Transformer models, who also contribute back to the community by sharing their models:
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/companies.PNG" alt="Companies using Hugging Face" width="100%">
The [🤗 Transformers library](https://github.com/huggingface/transformers) provides the functionality to create and use those shared models. The [Model Hub](https://huggingface.co/models) contains thousands of pretrained models that anyone can download and use. You can also upload your own models to the Hub!
<Tip>
⚠️ The Hugging Face Hub is not limited to Transformer models. Anyone can share any kind of models or datasets they want! <a href="https://huggingface.co/join">Create a huggingface.co</a> account to benefit from all available features!
</Tip>
Before diving into how Transformer models work under the hood, let's look at a few examples of how they can be used to solve some interesting NLP problems.
## Working with pipelines[[working-with-pipelines]]
<Youtube id="tiZFewofSLM" />
The most basic object in the 🤗 Transformers library is the `pipeline()` function. It connects a model with its necessary preprocessing and postprocessing steps, allowing us to directly input any text and get an intelligible answer:
```python
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
```
```python out
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
```
We can even pass several sentences!
```python
classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
```
```python out
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
```
By default, this pipeline selects a particular pretrained model that has been fine-tuned for sentiment analysis in English. The model is downloaded and cached when you create the `classifier` object. If you rerun the command, the cached model will be used instead and there is no need to download the model again.
There are three main steps involved when you pass some text to a pipeline:
1. The text is preprocessed into a format the model can understand.
2. The preprocessed inputs are passed to the model.
3. The predictions of the model are post-processed, so you can make sense of them.
Some of the currently [available pipelines](https://huggingface.co/transformers/main_classes/pipelines.html) are:
- `feature-extraction` (get the vector representation of a text)
- `fill-mask`
- `ner` (named entity recognition)
- `question-answering`
- `sentiment-analysis`
- `summarization`
- `text-generation`
- `translation`
- `zero-shot-classification`
Let's have a look at a few of these!
## Zero-shot classification[[zero-shot-classification]]
We'll start by tackling a more challenging task where we need to classify texts that haven't been labelled. This is a common scenario in real-world projects because annotating text is usually time-consuming and requires domain expertise. For this use case, the `zero-shot-classification` pipeline is very powerful: it allows you to specify which labels to use for the classification, so you don't have to rely on the labels of the pretrained model. You've already seen how the model can classify a sentence as positive or negative using those two labels — but it can also classify the text using any other set of labels you like.
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
```
```python out
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
```
This pipeline is called _zero-shot_ because you don't need to fine-tune the model on your data to use it. It can directly return probability scores for any list of labels you want!
<Tip>
✏️ **Try it out!** Play around with your own sequences and labels and see how the model behaves.
</Tip>
## Text generation[[text-generation]]
Now let's see how to use a pipeline to generate some text. The main idea here is that you provide a prompt and the model will auto-complete it by generating the remaining text. This is similar to the predictive text feature that is found on many phones. Text generation involves randomness, so it's normal if you don't get the same results as shown below.
```python
from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
```
```python out
[{'generated_text': 'In this course, we will teach you how to understand and use '
'data flow and data interchange when handling user data. We '
'will be working with one or more of the most commonly used '
'data flows — data flows of various types, as seen by the '
'HTTP'}]
```
You can control how many different sequences are generated with the argument `num_return_sequences` and the total length of the output text with the argument `max_length`.
<Tip>
✏️ **Try it out!** Use the `num_return_sequences` and `max_length` arguments to generate two sentences of 15 words each.
</Tip>
## Using any model from the Hub in a pipeline[[using-any-model-from-the-hub-in-a-pipeline]]
The previous examples used the default model for the task at hand, but you can also choose a particular model from the Hub to use in a pipeline for a specific task — say, text generation. Go to the [Model Hub](https://huggingface.co/models) and click on the corresponding tag on the left to display only the supported models for that task. You should get to a page like [this one](https://huggingface.co/models?pipeline_tag=text-generation).
Let's try the [`distilgpt2`](https://huggingface.co/distilgpt2) model! Here's how to load it in the same pipeline as before:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
```
```python out
[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
'move your mental and physical capabilities to your advantage.'},
{'generated_text': 'In this course, we will teach you how to become an expert and '
'practice realtime, and with a hands on experience on both real '
'time and real'}]
```
You can refine your search for a model by clicking on the language tags, and pick a model that will generate text in another language. The Model Hub even contains checkpoints for multilingual models that support several languages.
Once you select a model by clicking on it, you'll see that there is a widget enabling you to try it directly online. This way you can quickly test the model's capabilities before downloading it.
<Tip>
✏️ **Try it out!** Use the filters to find a text generation model for another language. Feel free to play with the widget and use it in a pipeline!
</Tip>
### The Inference API[[the-inference-api]]
All the models can be tested directly through your browser using the Inference API, which is available on the Hugging Face [website](https://huggingface.co/). You can play with the model directly on this page by inputting custom text and watching the model process the input data.
The Inference API that powers the widget is also available as a paid product, which comes in handy if you need it for your workflows. See the [pricing page](https://huggingface.co/pricing) for more details.
## Mask filling[[mask-filling]]
The next pipeline you'll try is `fill-mask`. The idea of this task is to fill in the blanks in a given text:
```python
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)
```
```python out
[{'sequence': 'This course will teach you all about mathematical models.',
'score': 0.19619831442832947,
'token': 30412,
'token_str': ' mathematical'},
{'sequence': 'This course will teach you all about computational models.',
'score': 0.04052725434303284,
'token': 38163,
'token_str': ' computational'}]
```
The `top_k` argument controls how many possibilities you want to be displayed. Note that here the model fills in the special `<mask>` word, which is often referred to as a *mask token*. Other mask-filling models might have different mask tokens, so it's always good to verify the proper mask word when exploring other models. One way to check it is by looking at the mask word used in the widget.
<Tip>
✏️ **Try it out!** Search for the `bert-base-cased` model on the Hub and identify its mask word in the Inference API widget. What does this model predict for the sentence in our `pipeline` example above?
</Tip>
## Named entity recognition[[named-entity-recognition]]
Named entity recognition (NER) is a task where the model has to find which parts of the input text correspond to entities such as persons, locations, or organizations. Let's look at an example:
```python
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
```
```python out
[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
]
```
Here the model correctly identified that Sylvain is a person (PER), Hugging Face an organization (ORG), and Brooklyn a location (LOC).
We pass the option `grouped_entities=True` in the pipeline creation function to tell the pipeline to regroup together the parts of the sentence that correspond to the same entity: here the model correctly grouped "Hugging" and "Face" as a single organization, even though the name consists of multiple words. In fact, as we will see in the next chapter, the preprocessing even splits some words into smaller parts. For instance, `Sylvain` is split into four pieces: `S`, `##yl`, `##va`, and `##in`. In the post-processing step, the pipeline successfully regrouped those pieces.
<Tip>
✏️ **Try it out!** Search the Model Hub for a model able to do part-of-speech tagging (usually abbreviated as POS) in English. What does this model predict for the sentence in the example above?
</Tip>
## Question answering[[question-answering]]
The `question-answering` pipeline answers questions using information from a given context:
```python
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
```
```python out
{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
```
Note that this pipeline works by extracting information from the provided context; it does not generate the answer.
## Summarization[[summarization]]
Summarization is the task of reducing a text into a shorter text while keeping all (or most) of the important aspects referenced in the text. Here's an example:
```python
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
```
```python out
[{'summary_text': ' America has changed dramatically during recent years . The '
'number of engineering graduates in the U.S. has declined in '
'traditional engineering disciplines such as mechanical, civil '
', electrical, chemical, and aeronautical engineering . Rapidly '
'developing economies such as China and India, as well as other '
'industrial countries in Europe and Asia, continue to encourage '
'and advance engineering .'}]
```
Like with text generation, you can specify a `max_length` or a `min_length` for the result.
## Translation[[translation]]
For translation, you can use a default model if you provide a language pair in the task name (such as `"translation_en_to_fr"`), but the easiest way is to pick the model you want to use on the [Model Hub](https://huggingface.co/models). Here we'll try translating from French to English:
```python
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")
```
```python out
[{'translation_text': 'This course is produced by Hugging Face.'}]
```
Like with text generation and summarization, you can specify a `max_length` or a `min_length` for the result.
<Tip>
✏️ **Try it out!** Search for translation models in other languages and try to translate the previous sentence into a few different languages.
</Tip>
The pipelines shown so far are mostly for demonstrative purposes. They were programmed for specific tasks and cannot perform variations of them. In the next chapter, you'll learn what's inside a `pipeline()` function and how to customize its behavior.
| huggingface/course/blob/main/chapters/en/chapter1/3.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Pyramid Vision Transformer (PVT)
## Overview
The PVT model was proposed in
[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
of the Transformer as it deepens - reducing the computational cost. Additionally, a spatial-reduction attention (SRA) layer
is used to further reduce the resource consumption when learning high-resolution features.
The abstract from the paper is the following:
*Although convolutional neural networks (CNNs) have achieved great success in computer vision, this work investigates a
simpler, convolution-free backbone network useful for many dense prediction tasks. Unlike the recently proposed Vision
Transformer (ViT) that was designed for image classification specifically, we introduce the Pyramid Vision Transformer
(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several
merits compared to current state of the arts. Different from ViT that typically yields low resolution outputs and
incurs high computational and memory costs, PVT not only can be trained on dense partitions of an image to achieve high
output resolution, which is important for dense prediction, but also uses a progressive shrinking pyramid to reduce the
computations of large feature maps. PVT inherits the advantages of both CNN and Transformer, making it a unified
backbone for various vision tasks without convolutions, where it can be used as a direct replacement for CNN backbones.
We validate PVT through extensive experiments, showing that it boosts the performance of many downstream tasks, including
object detection, instance and semantic segmentation. For example, with a comparable number of parameters, PVT+RetinaNet
achieves 40.4 AP on the COCO dataset, surpassing ResNet50+RetinNet (36.3 AP) by 4.1 absolute AP (see Figure 2). We hope
that PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future research.*
This model was contributed by [Xrenya](<https://huggingface.co/Xrenya). The original code can be found [here](https://github.com/whai362/PVT).
- PVTv1 on ImageNet-1K
| **Model variant** |**Size** |**Acc@1**|**Params (M)**|
|--------------------|:-------:|:-------:|:------------:|
| PVT-Tiny | 224 | 75.1 | 13.2 |
| PVT-Small | 224 | 79.8 | 24.5 |
| PVT-Medium | 224 | 81.2 | 44.2 |
| PVT-Large | 224 | 81.7 | 61.4 |
## PvtConfig
[[autodoc]] PvtConfig
## PvtImageProcessor
[[autodoc]] PvtImageProcessor
- preprocess
## PvtForImageClassification
[[autodoc]] PvtForImageClassification
- forward
## PvtModel
[[autodoc]] PvtModel
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/pvt.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Running the simulation
This section will describe how to run the physics simulation and collect data.
The code in this section is reflected in [examples/basic/simple_physics.py](https://github.com/huggingface/simulate/blob/main/examples/basic/simple_physics.py).
Start by displaying a simple scene with a cube above a plane, viewed by a camera:
```
import simulate as sm
scene = sm.Scene(engine="Unity")
scene += sm.LightSun()
scene += sm.Box(
name="floor",
position=[0, 0, 0],
bounds=[-10, 10, -0.1, 0, -10, 10],
material=sm.Material.GRAY75,
)
scene += sm.Box(
name="cube",
position=[0, 3, 0],
scaling=[1, 1, 1],
material=sm.Material.GRAY50,
with_rigid_body=True,
)
scene += sm.Camera(name="camera", position=[0, 2, -10])
scene.show()
# Prevent auto-closing when running locally
input("Press enter to continue...")
```
Note that we use the Unity engine backend, which supports physics simulation, as well as specify `with_rigid_body=True` on the cube, to enable forces like gravity.
Next, run the simulation for 30 timesteps:
```
for i in range(60):
event = scene.step()
```
You should see the cube falling onto the plane.
`step()` tells the backend to step the simulation forward, and allows keyword arguments to be passed, allowing a wide variety of customizable behavior.
The backend then returns a dictionary of data as an `event`. By default, this dictionary contains `nodes` and `frames`.
`nodes` is a dictionary containing all assets in the scene and their physical parameters such as position, rotation, and velocity.
Try graphing the height of the cube as it falls:
```
import numpy as np
import matplotlib.pyplot as plt
plt.ion()
_, ax1 = plt.subplots(1, 1)
heights = []
for i in range(60):
event = scene.step()
height = event["nodes"]["cube"]["position"][1]
heights.append(height)
ax1.clear()
ax1.set_xlim([0, 60])
ax1.set_ylim([0, 3])
ax1.plot(np.arange(len(heights)), heights)
plt.pause(0.1)
```
`frames` is a dictionary containing the rendering from each camera.
Try modifying the code to display these frames in matplotlib:
```
plt.ion()
_, ax1 = plt.subplots(1, 1)
for i in range(60):
event = scene.step()
im = np.array(event["frames"]["camera"], dtype=np.uint8).transpose(1, 2, 0)
ax1.clear()
ax1.imshow(im)
plt.pause(0.1)
```
🤗 Simulate is highly customizable. If you aren't interested in returning this data, you can modify the scene configuration prior to calling `show()` to disable it:
```
scene.config.return_nodes = False
scene.config.return_frames = False
scene.show()
```
For advanced use, you can extend this functionality using [plugins](./howto/plugins).
In this library, we include an extensive plugin for reinforcement learning. If you are using 🤗 Simulate for reinforcement learning, continue with [reinforcement learning how-tos](../howto/rl).
| huggingface/simulate/blob/main/docs/source/tutorials/running_the_simulation.mdx |
Deprecated Pipelines
This folder contains pipelines that have very low usage as measured by model downloads, issues and PRs. While you can still use the pipelines just as before, we will stop testing the pipelines and will not accept any changes to existing files. | huggingface/diffusers/blob/main/src/diffusers/pipelines/deprecated/README.md |
Let's train and play with Huggy 🐶 [[train]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/bonus-unit1/bonus-unit1.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
## Let's train Huggy 🐶
**To start to train Huggy, click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/bonus-unit1/bonus-unit1.ipynb)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit2/thumbnail.png" alt="Bonus Unit 1Thumbnail">
In this notebook, we'll reinforce what we learned in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy"/>
### The environment 🎮
- Huggy the Dog, an environment created by [Thomas Simonini](https://twitter.com/ThomasSimonini) based on [Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)
### The library used 📚
- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Understand **the state space, action space, and reward function used to train Huggy**.
- **Train your own Huggy** to fetch the stick.
- Be able to play **with your trained Huggy directly in your browser**.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1
🔲 📚 **Read the introduction to Huggy** by doing Bonus Unit 1
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Clone the repository and install the dependencies 🔽
- We need to clone the repository, that contains ML-Agents.
```bash
# Clone the repository (can take 3min)
git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
```bash
# Go inside the repository and install the package (can take 3min)
%cd ml-agents
pip3 install -e ./ml-agents-envs
pip3 install -e ./ml-agents
```
## Download and move the environment zip file in `./trained-envs-executables/linux/`
- Our environment executable is in a zip file.
- We need to download it and place it to `./trained-envs-executables/linux/`
```bash
mkdir ./trained-envs-executables
mkdir ./trained-envs-executables/linux
```
```bash
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF" -O ./trained-envs-executables/linux/Huggy.zip && rm -rf /tmp/cookies.txt
```
Download the file Huggy.zip from https://drive.google.com/uc?export=download&id=1zv3M95ZJTWHUVOWT6ckq_cm98nft8gdF using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
```bash
%%capture
unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip
```
Make sure your file is accessible
```bash
chmod -R 755 ./trained-envs-executables/linux/Huggy
```
## Let's recap how this environment works
### The State Space: what Huggy perceives.
Huggy doesn't "see" his environment. Instead, we provide him information about the environment:
- The target (stick) position
- The relative position between himself and the target
- The orientation of his legs.
Given all this information, Huggy **can decide which action to take next to fulfill his goal**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy" width="100%">
### The Action Space: what moves Huggy can do
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-action.jpg" alt="Huggy action" width="100%">
**Joint motors drive huggy legs**. This means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.
### The Reward Function
The reward function is designed so that **Huggy will fulfill his goal** : fetch the stick.
Remember that one of the foundations of Reinforcement Learning is the *reward hypothesis*: a goal can be described as the **maximization of the expected cumulative reward**.
Here, our goal is that Huggy **goes towards the stick but without spinning too much**. Hence, our reward function must translate this goal.
Our reward function:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/reward.jpg" alt="Huggy reward function" width="100%">
- *Orientation bonus*: we **reward him for getting close to the target**.
- *Time penalty*: a fixed-time penalty given at every action to **force him to get to the stick as fast as possible**.
- *Rotation penalty*: we penalize Huggy if **he spins too much and turns too quickly**.
- *Getting to the target reward*: we reward Huggy for **reaching the target**.
## Check the Huggy config file
- In ML-Agents, you define the **training hyperparameters in config.yaml files.**
- For the scope of this notebook, we're not going to modify the hyperparameters, but if you want to try as an experiment, Unity provides very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md).
- We need to create a config file for Huggy.
- Go to `/content/ml-agents/config/ppo`
- Create a new file called `Huggy.yaml`
- Copy and paste the content below 🔽
```
behaviors:
Huggy:
trainer_type: ppo
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
checkpoint_interval: 200000
keep_checkpoints: 15
max_steps: 2e6
time_horizon: 1000
summary_freq: 50000
```
- Don't forget to save the file!
- **In the case you want to modify the hyperparameters**, in Google Colab notebook, you can click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
We’re now ready to train our agent 🔥.
## Train our agent
To train our agent, we just need to **launch mlagents-learn and select the executable containing the environment.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/mllearn.png" alt="ml learn function" width="100%">
With ML Agents, we run a training script. We define four parameters:
1. `mlagents-learn <config>`: the path where the hyperparameter config file is.
2. `--env`: where the environment executable is.
3. `--run_id`: the name you want to give to your training run id.
4. `--no-graphics`: to not launch the visualization during the training.
Train the model and use the `--resume` flag to continue training in case of interruption.
> It will fail first time when you use `--resume`, try running the block again to bypass the error.
The training will take 30 to 45min depending on your machine (don't forget to **set up a GPU**), go take a ☕️ you deserve it 🤗.
```bash
mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id="Huggy" --no-graphics
```
## Push the agent to the 🤗 Hub
- Now that we trained our agent, we’re **ready to push it to the Hub to be able to play with Huggy on your browser🔥.**
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then get your token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
```python
from huggingface_hub import notebook_login
notebook_login()
```
If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
Then, we simply need to run `mlagents-push-to-hf`.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/mlpush.png" alt="ml learn function" width="100%">
And we define 4 parameters:
1. `--run-id`: the name of the training run id.
2. `--local-dir`: where the agent was saved, it’s results/<run_id name>, so in my case results/First Training.
3. `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s always <your huggingface username>/<the repo name>
If the repo does not exist **it will be created automatically**
4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
```bash
mlagents-push-to-hf --run-id="HuggyTraining" --local-dir="./results/Huggy" --repo-id="ThomasSimonini/ppo-Huggy" --commit-message="Huggy"
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
```
Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-Huggy
```
It’s the link to your model repository. The repository contains a model card that explains how to use the model, your Tensorboard logs and your config file. **What’s awesome is that it’s a git repository, which means you can have different commits, update your repository with a new push, open Pull Requests, etc.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/modelcard.png" alt="ml learn function" width="100%">
But now comes the best part: **being able to play with Huggy online 👀.**
## Play with your Huggy 🐕
This step is the simplest:
- Open the Huggy game in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy
- Click on Play with my Huggy model
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/load-huggy.jpg" alt="load-huggy" width="100%">
1. In step 1, choose your model repository, which is the model id (in my case ThomasSimonini/ppo-Huggy).
2. In step 2, **choose which model you want to replay**:
- I have multiple ones, since we saved a model every 500000 timesteps.
- But since I want the most recent one, I choose `Huggy.onnx`
👉 It's good **to try with different models steps to see the improvement of the agent.**
Congrats on finishing this bonus unit!
You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-cover.jpeg" alt="Huggy cover" width="100%">
## Keep Learning, Stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unitbonus1/train.mdx |
CSP-ResNet
**CSPResNet** is a convolutional neural network where we apply the Cross Stage Partial Network (CSPNet) approach to [ResNet](https://paperswithcode.com/method/resnet). The CSPNet partitions the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('cspresnet50', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspresnet50`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('cspresnet50', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{wang2019cspnet,
title={CSPNet: A New Backbone that can Enhance Learning Capability of CNN},
author={Chien-Yao Wang and Hong-Yuan Mark Liao and I-Hau Yeh and Yueh-Hua Wu and Ping-Yang Chen and Jun-Wei Hsieh},
year={2019},
eprint={1911.11929},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP ResNet
Paper:
Title: 'CSPNet: A New Backbone that can Enhance Learning Capability of CNN'
URL: https://paperswithcode.com/paper/cspnet-a-new-backbone-that-can-enhance
Models:
- Name: cspresnet50
In Collection: CSP ResNet
Metadata:
FLOPs: 5924992000
Parameters: 21620000
File Size: 86679303
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Polynomial Learning Rate Decay
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: cspresnet50
LR: 0.1
Layers: 50
Crop Pct: '0.887'
Momentum: 0.9
Batch Size: 128
Image Size: '256'
Weight Decay: 0.005
Interpolation: bilinear
Training Steps: 8000000
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L415
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspresnet50_ra-d3e8d487.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.57%
Top 5 Accuracy: 94.71%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/csp-resnet.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Causal language modeling
[[open-in-colab]]
There are two types of language modeling, causal and masked. This guide illustrates causal language modeling.
Causal language models are frequently used for text generation. You can use these models for creative applications like
choosing your own text adventure or an intelligent coding assistant like Copilot or CodeParrot.
<Youtube id="Vpjb1lu0MDk"/>
Causal language modeling predicts the next token in a sequence of tokens, and the model can only attend to tokens on
the left. This means the model cannot see future tokens. GPT-2 is an example of a causal language model.
This guide will show you how to:
1. Finetune [DistilGPT2](https://huggingface.co/distilgpt2) on the [r/askscience](https://www.reddit.com/r/askscience/) subset of the [ELI5](https://huggingface.co/datasets/eli5) dataset.
2. Use your finetuned model for inference.
<Tip>
You can finetune other architectures for causal language modeling following the same steps in this guide.
Choose one of the following architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load ELI5 dataset
Start by loading a smaller subset of the r/askscience subset of the ELI5 dataset from the 🤗 Datasets library.
This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
```
Split the dataset's `train_asks` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
```py
>>> eli5 = eli5.train_test_split(test_size=0.2)
```
Then take a look at an example:
```py
>>> eli5["train"][0]
{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
'score': [6, 3],
'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
'answers_urls': {'url': []},
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls': {'url': []}}
```
While this may look like a lot, you're only really interested in the `text` field. What's cool about language modeling
tasks is you don't need labels (also known as an unsupervised task) because the next word *is* the label.
## Preprocess
<Youtube id="ma1TrR7gE7I"/>
The next step is to load a DistilGPT2 tokenizer to process the `text` subfield:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to
extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'answers.a_id': ['c3d1aib', 'c3d4lya'],
'answers.score': [6, 3],
'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
'answers_urls.url': [],
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls.url': []}
```
Each subfield is now a separate column as indicated by the `answers` prefix, and the `text` field is a list now. Instead
of tokenizing each sentence separately, convert the list to a string so you can jointly tokenize them.
Here is a first preprocessing function to join the list of strings for each example and tokenize the result:
```py
>>> def preprocess_function(examples):
... return tokenizer([" ".join(x) for x in examples["answers.text"]])
```
To apply this preprocessing function over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once, and increasing the number of processes with `num_proc`. Remove any columns you don't need:
```py
>>> tokenized_eli5 = eli5.map(
... preprocess_function,
... batched=True,
... num_proc=4,
... remove_columns=eli5["train"].column_names,
... )
```
This dataset contains the token sequences, but some of these are longer than the maximum input length for the model.
You can now use a second preprocessing function to
- concatenate all the sequences
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
```py
>>> block_size = 128
>>> def group_texts(examples):
... # Concatenate all texts.
... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
... total_length = len(concatenated_examples[list(examples.keys())[0]])
... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
... # customize this part to your needs.
... if total_length >= block_size:
... total_length = (total_length // block_size) * block_size
... # Split by chunks of block_size.
... result = {
... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
... for k, t in concatenated_examples.items()
... }
... result["labels"] = result["input_ids"].copy()
... return result
```
Apply the `group_texts` function over the entire dataset:
```py
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
```
Now create a batch of examples using [`DataCollatorForLanguageModeling`]. It's more efficient to *dynamically pad* the
sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
<frameworkcontent>
<pt>
Use the end-of-sequence token as the padding token and set `mlm=False`. This will use the inputs as labels shifted to the right by one element:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
```
</pt>
<tf>
Use the end-of-sequence token as the padding token and set `mlm=False`. This will use the inputs as labels shifted to the right by one element:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the [basic tutorial](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load DistilGPT2 with [`AutoModelForCausalLM`]:
```py
>>> from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_eli5_clm-model",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... weight_decay=0.01,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=lm_dataset["train"],
... eval_dataset=lm_dataset["test"],
... data_collator=data_collator,
... )
>>> trainer.train()
```
Once training is completed, use the [`~transformers.Trainer.evaluate`] method to evaluate your model and get its perplexity:
```py
>>> import math
>>> eval_results = trainer.evaluate()
>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 49.61
```
Then share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the [basic tutorial](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Then you can load DistilGPT2 with [`TFAutoModelForCausalLM`]:
```py
>>> from transformers import TFAutoModelForCausalLM
>>> model = TFAutoModelForCausalLM.from_pretrained("distilgpt2")
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... lm_dataset["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = model.prepare_tf_dataset(
... lm_dataset["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
... output_dir="my_awesome_eli5_clm-model",
... tokenizer=tokenizer,
... )
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for causal language modeling, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with a prompt you'd like to generate text from:
```py
>>> prompt = "Somatic hypermutation allows the immune system to"
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for text generation with your model, and pass your text to it:
```py
>>> from transformers import pipeline
>>> generator = pipeline("text-generation", model="my_awesome_eli5_clm-model")
>>> generator(prompt)
[{'generated_text': "Somatic hypermutation allows the immune system to be able to effectively reverse the damage caused by an infection.\n\n\nThe damage caused by an infection is caused by the immune system's ability to perform its own self-correcting tasks."}]
```
<frameworkcontent>
<pt>
Tokenize the text and return the `input_ids` as PyTorch tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
>>> inputs = tokenizer(prompt, return_tensors="pt").input_ids
```
Use the [`~transformers.generation_utils.GenerationMixin.generate`] method to generate text.
For more details about the different text generation strategies and parameters for controlling generation, check out the [Text generation strategies](../generation_strategies) page.
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
```
Decode the generated token ids back into text:
```py
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
["Somatic hypermutation allows the immune system to react to drugs with the ability to adapt to a different environmental situation. In other words, a system of 'hypermutation' can help the immune system to adapt to a different environmental situation or in some cases even a single life. In contrast, researchers at the University of Massachusetts-Boston have found that 'hypermutation' is much stronger in mice than in humans but can be found in humans, and that it's not completely unknown to the immune system. A study on how the immune system"]
```
</pt>
<tf>
Tokenize the text and return the `input_ids` as TensorFlow tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
>>> inputs = tokenizer(prompt, return_tensors="tf").input_ids
```
Use the [`~transformers.generation_tf_utils.TFGenerationMixin.generate`] method to create the summarization. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text generation strategies](../generation_strategies) page.
```py
>>> from transformers import TFAutoModelForCausalLM
>>> model = TFAutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
>>> outputs = model.generate(input_ids=inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
```
Decode the generated token ids back into text:
```py
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Somatic hypermutation allows the immune system to detect the presence of other viruses as they become more prevalent. Therefore, researchers have identified a high proportion of human viruses. The proportion of virus-associated viruses in our study increases with age. Therefore, we propose a simple algorithm to detect the presence of these new viruses in our samples as a sign of improved immunity. A first study based on this algorithm, which will be published in Science on Friday, aims to show that this finding could translate into the development of a better vaccine that is more effective for']
```
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/tasks/language_modeling.md |
Inception v3
**Inception v3** is a convolutional neural network architecture from the Inception family that makes several improvements including using [Label Smoothing](https://paperswithcode.com/method/label-smoothing), Factorized 7 x 7 convolutions, and the use of an [auxiliary classifer](https://paperswithcode.com/method/auxiliary-classifier) to propagate label information lower down the network (along with the use of batch normalization for layers in the sidehead). The key building block is an [Inception Module](https://paperswithcode.com/method/inception-v3-module).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('inception_v3', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `inception_v3`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('inception_v3', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/SzegedyVISW15,
author = {Christian Szegedy and
Vincent Vanhoucke and
Sergey Ioffe and
Jonathon Shlens and
Zbigniew Wojna},
title = {Rethinking the Inception Architecture for Computer Vision},
journal = {CoRR},
volume = {abs/1512.00567},
year = {2015},
url = {http://arxiv.org/abs/1512.00567},
archivePrefix = {arXiv},
eprint = {1512.00567},
timestamp = {Mon, 13 Aug 2018 16:49:07 +0200},
biburl = {https://dblp.org/rec/journals/corr/SzegedyVISW15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Inception v3
Paper:
Title: Rethinking the Inception Architecture for Computer Vision
URL: https://paperswithcode.com/paper/rethinking-the-inception-architecture-for
Models:
- Name: inception_v3
In Collection: Inception v3
Metadata:
FLOPs: 7352418880
Parameters: 23830000
File Size: 108857766
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Gradient Clipping
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 50x NVIDIA Kepler GPUs
ID: inception_v3
LR: 0.045
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v3.py#L442
Weights: https://download.pytorch.org/models/inception_v3_google-1a9a5a14.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.46%
Top 5 Accuracy: 93.48%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/inception-v3.mdx |
Mid-way Quiz [[mid-way-quiz]]
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: What are the two main approaches to find optimal policy?
<Question
choices={[
{
text: "Policy-based methods",
explain: "With Policy-Based methods, we train the policy directly to learn which action to take given a state.",
correct: true
},
{
text: "Random-based methods",
explain: ""
},
{
text: "Value-based methods",
explain: "With value-based methods, we train a value function to learn which state is more valuable and use this value function to take the action that leads to it.",
correct: true
},
{
text: "Evolution-strategies methods",
explain: ""
}
]}
/>
### Q2: What is the Bellman Equation?
<details>
<summary>Solution</summary>
**The Bellman equation is a recursive equation** that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as:
Rt+1 + gamma * V(St+1)
The immediate reward + the discounted value of the state that follows
</details>
### Q3: Define each part of the Bellman Equation
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman4-quiz.jpg" alt="Bellman equation quiz"/>
<details>
<summary>Solution</summary>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman4.jpg" alt="Bellman equation solution"/>
</details>
### Q4: What is the difference between Monte Carlo and Temporal Difference learning methods?
<Question
choices={[
{
text: "With Monte Carlo methods, we update the value function from a complete episode",
explain: "",
correct: true
},
{
text: "With Monte Carlo methods, we update the value function from a step",
explain: ""
},
{
text: "With TD learning methods, we update the value function from a complete episode",
explain: ""
},
{
text: "With TD learning methods, we update the value function from a step",
explain: "",
correct: true
},
]}
/>
### Q5: Define each part of Temporal Difference learning formula
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/td-ex.jpg" alt="TD Learning exercise"/>
<details>
<summary>Solution</summary>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/TD-1.jpg" alt="TD Exercise"/>
</details>
### Q6: Define each part of Monte Carlo learning formula
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/mc-ex.jpg" alt="MC Learning exercise"/>
<details>
<summary>Solution</summary>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/monte-carlo-approach.jpg" alt="MC Exercise"/>
</details>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the previous sections to reinforce (😏) your knowledge.
| huggingface/deep-rl-class/blob/main/units/en/unit2/mid-way-quiz.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# M-CTC-T
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
The abstract from the paper is the following:
*Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual
speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech
recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even
with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised
learning on a target language, generate pseudo-labels for that language, and train a final model using
pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled
Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better
performance for many languages that also transfers well to LibriSpeech.*
This model was contributed by [cwkeam](https://huggingface.co/cwkeam). The original code can be found [here](https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl).
## Usage tips
The PyTorch version of this model is only available in torch 1.9 and higher.
## Resources
- [Automatic speech recognition task guide](../tasks/asr)
## MCTCTConfig
[[autodoc]] MCTCTConfig
## MCTCTFeatureExtractor
[[autodoc]] MCTCTFeatureExtractor
- __call__
## MCTCTProcessor
[[autodoc]] MCTCTProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
## MCTCTModel
[[autodoc]] MCTCTModel
- forward
## MCTCTForCTC
[[autodoc]] MCTCTForCTC
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mctct.md |
--
title: 🧨 Stable Diffusion in JAX / Flax !
thumbnail: /blog/assets/108_stable_diffusion_jax/thumbnail.png
authors:
- user: pcuenq
- user: patrickvonplaten
---
# 🧨 Stable Diffusion in JAX / Flax !
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion_jax_how_to.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
# **Stable Diffusion in JAX / Flax** 🚀
🤗 Hugging Face [Diffusers](https://github.com/huggingface/diffusers) supports Flax since version `0.5.1`! This allows for super fast inference on Google TPUs, such as those available in Colab, Kaggle or Google Cloud Platform.
This post shows how to run inference using JAX / Flax. If you want more details about how Stable Diffusion works or want to run it in GPU, please refer to [this Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb).
If you want to follow along, click the button above to open this post as a Colab notebook.
First, make sure you are using a TPU backend. If you are running this notebook in Colab, select `Runtime` in the menu above, then select the option "Change runtime type" and then select `TPU` under the `Hardware accelerator` setting.
Note that JAX is not exclusive to TPUs, but it shines on that hardware because each TPU server has 8 TPU accelerators working in parallel.
## Setup
``` python
import jax
num_devices = jax.device_count()
device_type = jax.devices()[0].device_kind
print(f"Found {num_devices} JAX devices of type {device_type}.")
assert "TPU" in device_type, "Available device is not a TPU, please select TPU from Edit > Notebook settings > Hardware accelerator"
```
*Output*:
```bash
Found 8 JAX devices of type TPU v2.
```
Make sure `diffusers` is installed.
``` python
!pip install diffusers==0.5.1
```
Then we import all the dependencies.
``` python
import numpy as np
import jax
import jax.numpy as jnp
from pathlib import Path
from jax import pmap
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from PIL import Image
from huggingface_hub import notebook_login
from diffusers import FlaxStableDiffusionPipeline
```
## Model Loading
Before using the model, you need to accept the model [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) in order to download and use the weights.
The license is designed to mitigate the potential harmful effects of such a powerful machine learning system.
We request users to **read the license entirely and carefully**. Here we offer a summary:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content,
2. We claim no rights on the outputs you generate, you are free to use them and are accountable for their use which should not go against the provisions set in the license, and
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users.
Flax weights are available in Hugging Face Hub as part of the Stable Diffusion repo. The Stable Diffusion model is distributed under the CreateML OpenRail-M license. It's an open license that claims no rights on the outputs you generate and prohibits you from deliberately producing illegal or harmful content. The [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) provides more details, so take a moment to read them and consider carefully whether you accept the license. If you do, you need to be a registered user in the Hub and use an access token for the code to work. You have two options to provide your access token:
- Use the `huggingface-cli login` command-line tool in your terminal and paste your token when prompted. It will be saved in a file in your computer.
- Or use `notebook_login()` in a notebook, which does the same thing.
The following cell will present a login interface unless you've already authenticated before in this computer. You'll need to paste your access token.
``` python
if not (Path.home()/'.huggingface'/'token').exists(): notebook_login()
```
TPU devices support `bfloat16`, an efficient half-float type. We'll use it for our tests, but you can also use `float32` to use full precision instead.
``` python
dtype = jnp.bfloat16
```
Flax is a functional framework, so models are stateless and parameters are stored outside them. Loading the pre-trained Flax pipeline will return both the pipeline itself and the model weights (or parameters). We are using a `bf16` version of the weights, which leads to type warnings that you can safely ignore.
``` python
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="bf16",
dtype=dtype,
)
```
## Inference
Since TPUs usually have 8 devices working in parallel, we'll replicate our prompt as many times as devices we have. Then we'll perform inference on the 8 devices at once, each responsible for generating one image. Thus, we'll get 8 images in the same amount of time it takes for one chip to generate a single one.
After replicating the prompt, we obtain the tokenized text ids by invoking the `prepare_inputs` function of the pipeline. The length of the tokenized text is set to 77 tokens, as required by the configuration of the underlying CLIP Text model.
``` python
prompt = "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of field, close up, split lighting, cinematic"
prompt = [prompt] * jax.device_count()
prompt_ids = pipeline.prepare_inputs(prompt)
prompt_ids.shape
```
*Output*:
```bash
(8, 77)
```
### Replication and parallelization
Model parameters and inputs have to be replicated across the 8 parallel devices we have. The parameters dictionary is replicated using `flax.jax_utils.replicate`, which traverses the dictionary and changes the shape of the weights so they are repeated 8 times. Arrays are replicated using `shard`.
``` python
p_params = replicate(params)
```
``` python
prompt_ids = shard(prompt_ids)
prompt_ids.shape
```
*Output*:
```bash
(8, 1, 77)
```
That shape means that each one of the `8` devices will receive as an input a `jnp` array with shape `(1, 77)`. `1` is therefore the batch size per device. In TPUs with sufficient memory, it could be larger than `1` if we wanted to generate multiple images (per chip) at once.
We are almost ready to generate images! We just need to create a random number generator to pass to the generation function. This is the standard procedure in Flax, which is very serious and opinionated about random numbers – all functions that deal with random numbers are expected to receive a generator. This ensures reproducibility, even when we are training across multiple distributed devices.
The helper function below uses a seed to initialize a random number generator. As long as we use the same seed, we'll get the exact same results. Feel free to use different seeds when exploring results later in the notebook.
``` python
def create_key(seed=0):
return jax.random.PRNGKey(seed)
```
We obtain a rng and then "split" it 8 times so each device receives a different generator. Therefore, each device will create a different image, and the full process is reproducible.
``` python
rng = create_key(0)
rng = jax.random.split(rng, jax.device_count())
```
JAX code can be compiled to an efficient representation that runs very fast. However, we need to ensure that all inputs have the same shape in subsequent calls; otherwise, JAX will have to recompile the code, and we wouldn't be able to take advantage of the optimized speed.
The Flax pipeline can compile the code for us if we pass `jit = True` as an argument. It will also ensure that the model runs in parallel in the 8 available devices.
The first time we run the following cell it will take a long time to compile, but subsequent calls (even with different inputs) will be much faster. For example, it took more than a minute to compile in a TPU v2-8 when I tested, but then it takes about **`7s`** for future inference runs.
``` python
images = pipeline(prompt_ids, p_params, rng, jit=True)[0]
```
*Output*:
```bash
CPU times: user 464 ms, sys: 105 ms, total: 569 ms
Wall time: 7.07 s
```
The returned array has shape `(8, 1, 512, 512, 3)`. We reshape it to get rid of the second dimension and obtain 8 images of `512 × 512 × 3` and then convert them to PIL.
```python
images = images.reshape((images.shape[0],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
```
### Visualization
Let's create a helper function to display images in a grid.
``` python
def image_grid(imgs, rows, cols):
w,h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
for i, img in enumerate(imgs): grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
```
``` python
image_grid(images, 2, 4)
```

## Using different prompts
We don't have to replicate the *same* prompt in all the devices. We can do whatever we want: generate 2 prompts 4 times each, or even generate 8 different prompts at once. Let's do that!
First, we'll refactor the input preparation code into a handy function:
``` python
prompts = [
"Labrador in the style of Hokusai",
"Painting of a squirrel skating in New York",
"HAL-9000 in the style of Van Gogh",
"Times Square under water, with fish and a dolphin swimming around",
"Ancient Roman fresco showing a man working on his laptop",
"Close-up photograph of young black woman against urban background, high quality, bokeh",
"Armchair in the shape of an avocado",
"Clown astronaut in space, with Earth in the background",
]
```
``` python
prompt_ids = pipeline.prepare_inputs(prompts)
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, p_params, rng, jit=True).images
images = images.reshape((images.shape[0], ) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
image_grid(images, 2, 4)
```

------------------------------------------------------------------------
## How does parallelization work?
We said before that the `diffusers` Flax pipeline automatically compiles the model and runs it in parallel on all available devices. We'll now briefly look inside that process to show how it works.
JAX parallelization can be done in multiple ways. The easiest one revolves around using the `jax.pmap` function to achieve single-program, multiple-data (SPMD) parallelization. It means we'll run several copies of the same code, each on different data inputs. More sophisticated approaches are possible, we invite you to go over the [JAX documentation](https://jax.readthedocs.io/en/latest/index.html) and the [`pjit` pages](https://jax.readthedocs.io/en/latest/jax-101/08-pjit.html?highlight=pjit) to explore this topic if you are interested!
`jax.pmap` does two things for us:
- Compiles (or `jit`s) the code, as if we had invoked `jax.jit()`. This does not happen when we call `pmap`, but the first time the pmapped function is invoked.
- Ensures the compiled code runs in parallel in all the available devices.
To show how it works we `pmap` the `_generate` method of the pipeline, which is the private method that runs generates images. Please, note that this method may be renamed or removed in future releases of `diffusers`.
``` python
p_generate = pmap(pipeline._generate)
```
After we use `pmap`, the prepared function `p_generate` will conceptually do the following:
- Invoke a copy of the underlying function `pipeline._generate` in each device.
- Send each device a different portion of the input arguments. That's what sharding is used for. In our case, `prompt_ids` has shape `(8, 1, 77, 768)`. This array will be split in `8` and each copy of `_generate` will receive an input with shape `(1, 77, 768)`.
We can code `_generate` completely ignoring the fact that it will be invoked in parallel. We just care about our batch size (`1` in this example) and the dimensions that make sense for our code, and don't have to change anything to make it work in parallel.
The same way as when we used the pipeline call, the first time we run the following cell it will take a while, but then it will be much faster.
``` python
images = p_generate(prompt_ids, p_params, rng)
images = images.block_until_ready()
images.shape
```
*Output*:
```bash
CPU times: user 118 ms, sys: 83.9 ms, total: 202 ms
Wall time: 6.82 s
(8, 1, 512, 512, 3)
```
We use `block_until_ready()` to correctly measure inference time, because JAX uses asynchronous dispatch and returns control to the Python loop as soon as it can. You don't need to use that in your code; blocking will occur automatically when you want to use the result of a computation that has not yet been materialized.
| huggingface/blog/blob/main/stable_diffusion_jax.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Latent Consistency Models
Latent Consistency Models (LCMs) were proposed in [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://huggingface.co/papers/2310.04378) by Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao.
The abstract of the paper is as follows:
*Latent Diffusion models (LDMs) have achieved remarkable results in synthesizing high-resolution images. However, the iterative sampling process is computationally intensive and leads to slow generation. Inspired by Consistency Models (song et al.), we propose Latent Consistency Models (LCMs), enabling swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion (rombach et al). Viewing the guided reverse diffusion process as solving an augmented probability flow ODE (PF-ODE), LCMs are designed to directly predict the solution of such ODE in latent space, mitigating the need for numerous iterations and allowing rapid, high-fidelity sampling. Efficiently distilled from pre-trained classifier-free guided diffusion models, a high-quality 768 x 768 2~4-step LCM takes only 32 A100 GPU hours for training. Furthermore, we introduce Latent Consistency Fine-tuning (LCF), a novel method that is tailored for fine-tuning LCMs on customized image datasets. Evaluation on the LAION-5B-Aesthetics dataset demonstrates that LCMs achieve state-of-the-art text-to-image generation performance with few-step inference. Project Page: [this https URL](https://latent-consistency-models.github.io/).*
A demo for the [SimianLuo/LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7) checkpoint can be found [here](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model).
The pipelines were contributed by [luosiallen](https://luosiallen.github.io/), [nagolinc](https://github.com/nagolinc), and [dg845](https://github.com/dg845).
## LatentConsistencyModelPipeline
[[autodoc]] LatentConsistencyModelPipeline
- all
- __call__
- enable_freeu
- disable_freeu
- enable_vae_slicing
- disable_vae_slicing
- enable_vae_tiling
- disable_vae_tiling
## LatentConsistencyModelImg2ImgPipeline
[[autodoc]] LatentConsistencyModelImg2ImgPipeline
- all
- __call__
- enable_freeu
- disable_freeu
- enable_vae_slicing
- disable_vae_slicing
- enable_vae_tiling
- disable_vae_tiling
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/latent_consistency_models.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Language model training examples in streaming mode
The following examples showcase how to train a language model from scratch
using the JAX/Flax backend.
JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
Models written in JAX/Flax are **immutable** and updated in a purely functional
way which enables simple and efficient model parallelism.
All of the following examples make use of [dataset streaming](https://huggingface.co/docs/datasets/master/dataset_streaming), therefore allowing to train models on massive datasets\
without ever having to download the full dataset.
## Masked language modeling
In the following, we demonstrate how to train a bi-directional transformer model
using masked language modeling objective as introduced in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
More specifically, we demonstrate how JAX/Flax and dataset streaming can be leveraged
to pre-train [**`roberta-base`**](https://huggingface.co/roberta-base)
in English on a single TPUv3-8 pod for 10000 update steps.
The example script uses the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
Let's start by creating a model repository to save the trained model and logs.
Here we call the model `"english-roberta-base-dummy"`, but you can change the model name as you like.
You can do this either directly on [huggingface.co](https://huggingface.co/new) (assuming that
you are logged in) or via the command line:
```
huggingface-cli repo create english-roberta-base-dummy
```
Next we clone the model repository to add the tokenizer and model files.
```
git clone https://huggingface.co/<your-username>/english-roberta-base-dummy
```
To ensure that all tensorboard traces will be uploaded correctly, we need to
track them. You can run the following command inside your model repo to do so.
```
cd english-roberta-base-dummy
git lfs track "*tfevents*"
```
Great, we have set up our model repository. During training, we will automatically
push the training logs and model weights to the repo.
Next, let's add a symbolic link to the `run_mlm_flax.py`.
```bash
export MODEL_DIR="./english-roberta-base-dummy"
ln -s ~/transformers/examples/research_projects/jax-projects/dataset-streaming/run_mlm_flax_stream.py ./
```
### Copy config and tokenizer of existing model
In this example, we will simply copy an existing config and tokenizer in English.
You can run the following code in a Python shell to do so.
```python
from transformers import RobertaTokenizerFast, RobertaConfig
model_dir = "./english-roberta-base-dummy"
tokenizer = RobertaTokenizerFast.from_pretrained("roberta-base")
config = RobertaConfig.from_pretrained("roberta-base")
tokenizer.save_pretrained(model_dir)
config.save_pretrained(model_dir)
```
### Train model
Next we can run the example script to pretrain the model.
Compared to the default [`run_mlm_flax`](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_mlm_flax.py), we introduced 4 new training settings:
- `num_train_steps` - how many update steps should be run.
- `num_eval_samples` - how many training samples should be taken for evaluation.
- `logging_steps` - at what rate should the training loss be logged.
- `eval_steps` - at what rate should evaluation be run.
10K update steps
```bash
./run_mlm_flax_stream.py \
--output_dir="${MODEL_DIR}" \
--model_type="roberta" \
--config_name="${MODEL_DIR}" \
--tokenizer_name="${MODEL_DIR}" \
--dataset_name="oscar" \
--dataset_config_name="unshuffled_deduplicated_en" \
--max_seq_length="128" \
--per_device_train_batch_size="128" \
--per_device_eval_batch_size="128" \
--learning_rate="3e-4" \
--warmup_steps="1000" \
--overwrite_output_dir \
--adam_beta1="0.9" \
--adam_beta2="0.98" \
--num_train_steps="10000" \
--num_eval_samples="5000" \
--logging_steps="250" \
--eval_steps="1000" \
--push_to_hub
```
| huggingface/transformers/blob/main/examples/research_projects/jax-projects/dataset-streaming/README.md |
Getting Started
## Welcome
Welcome to the `timm` documentation, a lean set of docs that covers the basics of `timm`.
For a more comprehensive set of docs (currently under development), please visit [timmdocs](http://timm.fast.ai) by [Aman Arora](https://github.com/amaarora).
## Install
The library can be installed with pip:
```
pip install timm
```
I update the PyPi (pip) packages when I'm confident there are no significant model regressions from previous releases. If you want to pip install the bleeding edge from GitHub, use:
```
pip install git+https://github.com/rwightman/pytorch-image-models.git
```
!!! info "Conda Environment"
All development and testing has been done in Conda Python 3 environments on Linux x86-64 systems, specifically 3.7, 3.8, 3.9, 3.10
Little to no care has been taken to be Python 2.x friendly and will not support it. If you run into any challenges running on Windows, or other OS, I'm definitely open to looking into those issues so long as it's in a reproducible (read Conda) environment.
PyTorch versions 1.9, 1.10, 1.11 have been tested with the latest versions of this code.
I've tried to keep the dependencies minimal, the setup is as per the PyTorch default install instructions for Conda:
```
conda create -n torch-env
conda activate torch-env
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
conda install pyyaml
```
## Load a Pretrained Model
Pretrained models can be loaded using `timm.create_model`
```python
import timm
m = timm.create_model('mobilenetv3_large_100', pretrained=True)
m.eval()
```
## List Models with Pretrained Weights
```python
import timm
from pprint import pprint
model_names = timm.list_models(pretrained=True)
pprint(model_names)
>>> ['adv_inception_v3',
'cspdarknet53',
'cspresnext50',
'densenet121',
'densenet161',
'densenet169',
'densenet201',
'densenetblur121d',
'dla34',
'dla46_c',
...
]
```
## List Model Architectures by Wildcard
```python
import timm
from pprint import pprint
model_names = timm.list_models('*resne*t*')
pprint(model_names)
>>> ['cspresnet50',
'cspresnet50d',
'cspresnet50w',
'cspresnext50',
...
]
```
| huggingface/pytorch-image-models/blob/main/docs/index.md |
--
title: 'Pre-Train BERT with Hugging Face Transformers and Habana Gaudi'
thumbnail: /blog/assets/99_pretraining_bert/thumbnail.png
authors:
- user: philschmid
---
# Pre-Training BERT with Hugging Face Transformers and Habana Gaudi
In this Tutorial, you will learn how to pre-train [BERT-base](https://huggingface.co/bert-base-uncased) from scratch using a Habana Gaudi-based [DL1 instance](https://aws.amazon.com/ec2/instance-types/dl1/) on AWS to take advantage of the cost-performance benefits of Gaudi. We will use the Hugging Face [Transformers](https://huggingface.co/docs/transformers), [Optimum Habana](https://huggingface.co/docs/optimum/habana/index) and [Datasets](https://huggingface.co/docs/datasets) libraries to pre-train a BERT-base model using masked-language modeling, one of the two original BERT pre-training tasks. Before we get started, we need to set up the deep learning environment.
<a target="_blank" class="btn no-underline text-sm mb-5 font-sans" href="https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb">
View Code
</a>
You will learn how to:
1. [Prepare the dataset](#1-prepare-the-dataset)
2. [Train a Tokenizer](#2-train-a-tokenizer)
3. [Preprocess the dataset](#3-preprocess-the-dataset)
4. [Pre-train BERT on Habana Gaudi](#4-pre-train-bert-on-habana-gaudi)
_Note: Steps 1 to 3 can/should be run on a different instance size since those are CPU intensive tasks._
<figure class="image table text-center m-0 w-full">
<img src="assets/99_pretraining_bert/pre-training.png" alt="Cloud Architecture"/>
</figure>
**Requirements**
Before we start, make sure you have met the following requirements
* AWS Account with quota for [DL1 instance type](https://aws.amazon.com/ec2/instance-types/dl1/)
* [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) installed
* AWS IAM user [configured in CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) with permission to create and manage ec2 instances
**Helpful Resources**
* [Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS](https://www.philschmid.de/getting-started-habana-gaudi)
* [Deep Learning setup made easy with EC2 Remote Runner and Habana Gaudi](https://www.philschmid.de/habana-gaudi-ec2-runner)
* [Optimum Habana Documentation](https://huggingface.co/docs/optimum/habana/index)
* [Pre-training script](./scripts/run_mlm.py)
* [Code: pre-training-bert.ipynb](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb)
## What is BERT?
BERT, short for Bidirectional Encoder Representations from Transformers, is a Machine Learning (ML) model for natural language processing. It was developed in 2018 by researchers at Google AI Language and serves as a swiss army knife solution to 11+ of the most common language tasks, such as sentiment analysis and named entity recognition.
Read more about BERT in our [BERT 101 🤗 State Of The Art NLP Model Explained](https://huggingface.co/blog/bert-101) blog.
## What is a Masked Language Modeling (MLM)?
MLM enables/enforces bidirectional learning from text by masking (hiding) a word in a sentence and forcing BERT to bidirectionally use the words on either side of the covered word to predict the masked word.
**Masked Language Modeling Example:**
```bash
“Dang! I’m out fishing and a huge trout just [MASK] my line!”
```
Read more about Masked Language Modeling [here](https://huggingface.co/blog/bert-101).
---
Let's get started. 🚀
_Note: Steps 1 to 3 were run on a AWS c6i.12xlarge instance._
## 1. Prepare the dataset
The Tutorial is "split" into two parts. The first part (step 1-3) is about preparing the dataset and tokenizer. The second part (step 4) is about pre-training BERT on the prepared dataset. Before we can start with the dataset preparation we need to setup our development environment. As mentioned in the introduction you don't need to prepare the dataset on the DL1 instance and could use your notebook or desktop computer.
At first we are going to install `transformers`, `datasets` and `git-lfs` to push our tokenizer and dataset to the [Hugging Face Hub](https://huggingface.co) for later use.
```python
!pip install transformers datasets
!sudo apt-get install git-lfs
```
To finish our setup let's log into the [Hugging Face Hub](https://huggingface.co/models) to push our dataset, tokenizer, model artifacts, logs and metrics during training and afterwards to the Hub.
_To be able to push our model to the Hub, you need to register on the [Hugging Face Hub](https://huggingface.co/join)._
We will use the `notebook_login` util from the `huggingface_hub` package to log into our account. You can get your token in the settings at [Access Tokens](https://huggingface.co/settings/tokens).
```python
from huggingface_hub import notebook_login
notebook_login()
```
Since we are now logged in let's get the `user_id`, which will be used to push the artifacts.
```python
from huggingface_hub import HfApi
user_id = HfApi().whoami()["name"]
print(f"user id '{user_id}' will be used during the example")
```
The [original BERT](https://arxiv.org/abs/1810.04805) was pretrained on [Wikipedia](https://huggingface.co/datasets/wikipedia) and [BookCorpus](https://huggingface.co/datasets/bookcorpus) datasets. Both datasets are available on the [Hugging Face Hub](https://huggingface.co/datasets) and can be loaded with `datasets`.
_Note: For wikipedia we will use the `20220301`, which is different from the original split._
As a first step we are loading the datasets and merging them together to create on big dataset.
```python
from datasets import concatenate_datasets, load_dataset
bookcorpus = load_dataset("bookcorpus", split="train")
wiki = load_dataset("wikipedia", "20220301.en", split="train")
wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
assert bookcorpus.features.type == wiki.features.type
raw_datasets = concatenate_datasets([bookcorpus, wiki])
```
_We are not going to do some advanced dataset preparation, like de-duplication, filtering or any other pre-processing. If you are planning to apply this notebook to train your own BERT model from scratch I highly recommend including those data preparation steps into your workflow. This will help you improve your Language Model._
## 2. Train a Tokenizer
To be able to train our model we need to convert our text into a tokenized format. Most Transformer models are coming with a pre-trained tokenizer, but since we are pre-training our model from scratch we also need to train a Tokenizer on our data. We can train a tokenizer on our data with `transformers` and the `BertTokenizerFast` class.
More information about training a new tokenizer can be found in our [Hugging Face Course](https://huggingface.co/course/chapter6/2?fw=pt).
```python
from tqdm import tqdm
from transformers import BertTokenizerFast
# repositor id for saving the tokenizer
tokenizer_id="bert-base-uncased-2022-habana"
# create a python generator to dynamically load the data
def batch_iterator(batch_size=10000):
for i in tqdm(range(0, len(raw_datasets), batch_size)):
yield raw_datasets[i : i + batch_size]["text"]
# create a tokenizer from existing one to re-use special tokens
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
```
We can start training the tokenizer with `train_new_from_iterator()`.
```python
bert_tokenizer = tokenizer.train_new_from_iterator(text_iterator=batch_iterator(), vocab_size=32_000)
bert_tokenizer.save_pretrained("tokenizer")
```
We push the tokenizer to the [Hugging Face Hub](https://huggingface.co/models) for later training our model.
```python
# you need to be logged in to push the tokenizer
bert_tokenizer.push_to_hub(tokenizer_id)
```
## 3. Preprocess the dataset
Before we can get started with training our model, the last step is to pre-process/tokenize our dataset. We will use our trained tokenizer to tokenize our dataset and then push it to the hub to load it easily later in our training. The tokenization process is also kept pretty simple, if documents are longer than `512` tokens those are truncated and not split into several documents.
```python
from transformers import AutoTokenizer
import multiprocessing
# load tokenizer
# tokenizer = AutoTokenizer.from_pretrained(f"{user_id}/{tokenizer_id}")
tokenizer = AutoTokenizer.from_pretrained("tokenizer")
num_proc = multiprocessing.cpu_count()
print(f"The max length for the tokenizer is: {tokenizer.model_max_length}")
def group_texts(examples):
tokenized_inputs = tokenizer(
examples["text"], return_special_tokens_mask=True, truncation=True, max_length=tokenizer.model_max_length
)
return tokenized_inputs
# preprocess dataset
tokenized_datasets = raw_datasets.map(group_texts, batched=True, remove_columns=["text"], num_proc=num_proc)
tokenized_datasets.features
```
As data processing function we will concatenate all texts from our dataset and generate chunks of `tokenizer.model_max_length` (512).
```python
from itertools import chain
# Main data processing function that will concatenate all texts from our dataset and generate chunks of
# max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= tokenizer.model_max_length:
total_length = (total_length // tokenizer.model_max_length) * tokenizer.model_max_length
# Split by chunks of max_len.
result = {
k: [t[i : i + tokenizer.model_max_length] for i in range(0, total_length, tokenizer.model_max_length)]
for k, t in concatenated_examples.items()
}
return result
tokenized_datasets = tokenized_datasets.map(group_texts, batched=True, num_proc=num_proc)
# shuffle dataset
tokenized_datasets = tokenized_datasets.shuffle(seed=34)
print(f"the dataset contains in total {len(tokenized_datasets)*tokenizer.model_max_length} tokens")
# the dataset contains in total 3417216000 tokens
```
The last step before we can start with our training is to push our prepared dataset to the hub.
```python
# push dataset to hugging face
dataset_id=f"{user_id}/processed_bert_dataset"
tokenized_datasets.push_to_hub(f"{user_id}/processed_bert_dataset")
```
## 4. Pre-train BERT on Habana Gaudi
In this example, we are going to use Habana Gaudi on AWS using the DL1 instance to run the pre-training. We will use the [Remote Runner](https://github.com/philschmid/deep-learning-remote-runner) toolkit to easily launch our pre-training on a remote DL1 Instance from our local setup. You can check-out [Deep Learning setup made easy with EC2 Remote Runner and Habana Gaudi](https://www.philschmid.de/habana-gaudi-ec2-runner) if you want to know more about how this works.
```python
!pip install rm-runner
```
When using GPUs you would use the [Trainer](https://huggingface.co/docs/transformers/v4.19.4/en/main_classes/trainer#transformers.Trainer) and [TrainingArguments](https://huggingface.co/docs/transformers/v4.19.4/en/main_classes/trainer#transformers.TrainingArguments). Since we are going to run our training on Habana Gaudi we are leveraging the `optimum-habana` library, we can use the [GaudiTrainer](https://huggingface.co/docs/optimum/habana/package_reference/trainer) and GaudiTrainingArguments instead. The `GaudiTrainer` is a wrapper around the [Trainer](https://huggingface.co/docs/transformers/v4.19.4/en/main_classes/trainer#transformers.Trainer) that allows you to pre-train or fine-tune a transformer model on Habana Gaudi instances.
```diff
-from transformers import Trainer, TrainingArguments
+from optimum.habana import GaudiTrainer, GaudiTrainingArguments
# define the training arguments
-training_args = TrainingArguments(
+training_args = GaudiTrainingArguments(
+ use_habana=True,
+ use_lazy_mode=True,
+ gaudi_config_name=path_to_gaudi_config,
...
)
# Initialize our Trainer
-trainer = Trainer(
+trainer = GaudiTrainer(
model=model,
args=training_args,
train_dataset=train_dataset
... # other arguments
)
```
The `DL1` instance we use has 8 available HPU-cores meaning we can leverage distributed data-parallel training for our model.
To run our training as distributed training we need to create a training script, which can be used with multiprocessing to run on all HPUs.
We have created a [run_mlm.py](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/scripts/run_mlm.py) script implementing masked-language modeling using the `GaudiTrainer`. To execute our distributed training we use the `DistributedRunner` runner from `optimum-habana` and pass our arguments. Alternatively, you could check-out the [gaudi_spawn.py](https://github.com/huggingface/optimum-habana/blob/main/examples/gaudi_spawn.py) in the [optimum-habana](https://github.com/huggingface/optimum-habana) repository.
Before we can start our training we need to define the `hyperparameters` we want to use for our training. We are leveraging the [Hugging Face Hub](https://huggingface.co/models) integration of the `GaudiTrainer` to automatically push our checkpoints, logs and metrics during training into a repository.
```python
from huggingface_hub import HfFolder
# hyperparameters
hyperparameters = {
"model_config_id": "bert-base-uncased",
"dataset_id": "philschmid/processed_bert_dataset",
"tokenizer_id": "philschmid/bert-base-uncased-2022-habana",
"gaudi_config_id": "philschmid/bert-base-uncased-2022-habana",
"repository_id": "bert-base-uncased-2022",
"hf_hub_token": HfFolder.get_token(), # need to be logged in with `huggingface-cli login`
"max_steps": 100_000,
"per_device_train_batch_size": 32,
"learning_rate": 5e-5,
}
hyperparameters_string = " ".join(f"--{key} {value}" for key, value in hyperparameters.items())
```
We can start our training by creating a `EC2RemoteRunner` and then `launch` it. This will then start our AWS EC2 DL1 instance and run our `run_mlm.py` script on it using the `huggingface/optimum-habana:latest` container.
```python
from rm_runner import EC2RemoteRunner
# create ec2 remote runner
runner = EC2RemoteRunner(
instance_type="dl1.24xlarge",
profile="hf-sm", # adjust to your profile
region="us-east-1",
container="huggingface/optimum-habana:4.21.1-pt1.11.0-synapse1.5.0"
)
# launch my script with gaudi_spawn for distributed training
runner.launch(
command=f"python3 gaudi_spawn.py --use_mpi --world_size=8 run_mlm.py {hyperparameters_string}",
source_dir="scripts",
)
```
<figure class="image table text-center m-0 w-full">
<img src="assets/99_pretraining_bert/tensorboard.png" alt="Tensorboard Logs"/>
</figure>
_This [experiment](https://huggingface.co/philschmid/bert-base-uncased-2022-habana-test-6) ran for 60k steps._
In our `hyperparameters` we defined a `max_steps` property, which limited the pre-training to only `100_000` steps. The `100_000` steps with a global batch size of `256` took around 12,5 hours.
BERT was originally pre-trained on [1 Million Steps](https://arxiv.org/pdf/1810.04805.pdf) with a global batch size of `256`:
> We train with batch size of 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch) for 1,000,000 steps, which is approximately 40 epochs over the 3.3 billion word corpus.
Meaning if we want to do a full pre-training it would take around 125h hours (12,5 hours * 10) and would cost us around ~$1,650 using Habana Gaudi on AWS, which is extremely cheap.
For comparison, the DeepSpeed Team, who holds the record for the [fastest BERT-pretraining](https://www.deepspeed.ai/tutorials/bert-pretraining/), [reported](https://www.deepspeed.ai/tutorials/bert-pretraining/) that pre-training BERT on 1 [DGX-2](https://www.nvidia.com/en-us/data-center/dgx-2/) (powered by 16 NVIDIA V100 GPUs with 32GB of memory each) takes around 33,25 hours.
To compare the cost we can use the [p3dn.24xlarge](https://aws.amazon.com/de/ec2/instance-types/p3/) as reference, which comes with 8x NVIDIA V100 32GB GPUs and costs ~31,22$/h. We would need two of these instances to have the same "setup" as the one DeepSpeed reported, for now we are ignoring any overhead created to the multi-node setup (I/O, Network etc.).
This would bring the cost of the DeepSpeed GPU based training on AWS to around ~$2,075, which is 25% more than what Habana Gaudi currently delivers.
_Something to note here is that using [DeepSpeed](https://www.deepspeed.ai/tutorials/bert-pretraining/#deepspeed-single-gpu-throughput-results) in general improves the performance by a factor of ~1.5 - 2. A factor of ~1.5 - 2x, means that the same pre-training job without DeepSpeed would likely take twice as long and cost twice as much or ~$3-4k._
We are looking forward on to do the experiment again once the [Gaudi DeepSpeed integration](https://docs.habana.ai/en/latest/PyTorch/DeepSpeed/DeepSpeed_User_Guide.html#deepspeed-configs) is more widely available.
## Conclusion
That's it for this Tutorial. Now you know the basics on how to pre-train BERT from scratch using Hugging Face Transformers and Habana Gaudi. You also saw how easy it is to migrate from the `Trainer` to the `GaudiTrainer`.
We compared our implementation with the [fastest BERT-pretraining](https://www.deepspeed.ai/Tutorials/bert-pretraining/) results and saw that Habana Gaudi still delivers a 25% cost reduction and allows us to pre-train BERT for ~$1,650.
Those results are incredible since it will allow companies to adapt their pre-trained models to their language and domain to [improve accuracy up to 10%](https://huggingface.co/pile-of-law/legalbert-large-1.7M-1#evaluation-results) compared to the general BERT models.
If you are interested in training your own BERT or other Transformers models from scratch to reduce cost and improve accuracy, [contact our experts](mailto:[email protected]) to learn about our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership and how to contact them](https://huggingface.co/hardware/habana).
Code: [pre-training-bert.ipynb](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb)
---
Thanks for reading! If you have any questions, feel free to contact me, through [Github](https://github.com/huggingface/transformers), or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| huggingface/blog/blob/main/pretraining-bert.md |
@gradio/fileexplorer
## 0.3.13
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.12
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.11
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.10
### Fixes
- [#6689](https://github.com/gradio-app/gradio/pull/6689) [`c9673ca`](https://github.com/gradio-app/gradio/commit/c9673cacd6470296ee01d7717e2080986e750572) - Fix directory-only glob for FileExplorer. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6691](https://github.com/gradio-app/gradio/pull/6691) [`128ab5d`](https://github.com/gradio-app/gradio/commit/128ab5d65b51390e706a515a1708fe6c88659209) - Ensure checked files persist after FileExplorer rerenders. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.9
### Fixes
- [#6550](https://github.com/gradio-app/gradio/pull/6550) [`3156598`](https://github.com/gradio-app/gradio/commit/315659817e5e67a04a1375d35ea6fa58d20622d2) - Make FileExplorer work on python 3.8 and 3.9. Also make it update on changes to root, glob, or glob_dir. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.8
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a), [`f94db6b73`](https://github.com/gradio-app/gradio/commit/f94db6b7319be902428887867500311a6a32a165)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.5
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.4
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.3
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.2
### Fixes
- [#5876](https://github.com/gradio-app/gradio/pull/5876) [`d7a1a6559`](https://github.com/gradio-app/gradio/commit/d7a1a6559005e6a1e0be03a3bd5212d1bc60d1ee) - Fix file overflow and add keyboard navigation to `FileExplorer`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.2
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.1
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.0-beta.0
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.2
### Patch Changes
- Updated dependencies [[`4e62b8493`](https://github.com/gradio-app/gradio/commit/4e62b8493dfce50bafafe49f1a5deb929d822103), [`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`796145e2c`](https://github.com/gradio-app/gradio/commit/796145e2c48c4087bec17f8ec0be4ceee47170cb)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Highlights
#### new `FileExplorer` component ([#5672](https://github.com/gradio-app/gradio/pull/5672) [`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e))
Thanks to a new capability that allows components to communicate directly with the server _without_ passing data via the value, we have created a new `FileExplorer` component.
This component allows you to populate the explorer by passing a glob, but only provides the selected file(s) in your prediction function.
Users can then navigate the virtual filesystem and select files which will be accessible in your predict function. This component will allow developers to build more complex spaces, with more flexible input options.

For more information check the [`FileExplorer` documentation](https://gradio.app/docs/fileexplorer).
Thanks [@aliabid94](https://github.com/aliabid94)!
| gradio-app/gradio/blob/main/js/fileexplorer/CHANGELOG.md |
Model Summaries
The model architectures included come from a wide variety of sources. Sources, including papers, original impl ("reference code") that I rewrote / adapted, and PyTorch impl that I leveraged directly ("code") are listed below.
Most included models have pretrained weights. The weights are either:
1. from their original sources
2. ported by myself from their original impl in a different framework (e.g. Tensorflow models)
3. trained from scratch using the included training script
The validation results for the pretrained weights are [here](results)
A more exciting view (with pretty pictures) of the models within `timm` can be found at [paperswithcode](https://paperswithcode.com/lib/timm).
## Big Transfer ResNetV2 (BiT)
* Implementation: [resnetv2.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/resnetv2.py)
* Paper: `Big Transfer (BiT): General Visual Representation Learning` - https://arxiv.org/abs/1912.11370
* Reference code: https://github.com/google-research/big_transfer
## Cross-Stage Partial Networks
* Implementation: [cspnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/cspnet.py)
* Paper: `CSPNet: A New Backbone that can Enhance Learning Capability of CNN` - https://arxiv.org/abs/1911.11929
* Reference impl: https://github.com/WongKinYiu/CrossStagePartialNetworks
## DenseNet
* Implementation: [densenet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/densenet.py)
* Paper: `Densely Connected Convolutional Networks` - https://arxiv.org/abs/1608.06993
* Code: https://github.com/pytorch/vision/tree/master/torchvision/models
## DLA
* Implementation: [dla.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/dla.py)
* Paper: https://arxiv.org/abs/1707.06484
* Code: https://github.com/ucbdrive/dla
## Dual-Path Networks
* Implementation: [dpn.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/dpn.py)
* Paper: `Dual Path Networks` - https://arxiv.org/abs/1707.01629
* My PyTorch code: https://github.com/rwightman/pytorch-dpn-pretrained
* Reference code: https://github.com/cypw/DPNs
## GPU-Efficient Networks
* Implementation: [byobnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/byobnet.py)
* Paper: `Neural Architecture Design for GPU-Efficient Networks` - https://arxiv.org/abs/2006.14090
* Reference code: https://github.com/idstcv/GPU-Efficient-Networks
## HRNet
* Implementation: [hrnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/hrnet.py)
* Paper: `Deep High-Resolution Representation Learning for Visual Recognition` - https://arxiv.org/abs/1908.07919
* Code: https://github.com/HRNet/HRNet-Image-Classification
## Inception-V3
* Implementation: [inception_v3.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/inception_v3.py)
* Paper: `Rethinking the Inception Architecture for Computer Vision` - https://arxiv.org/abs/1512.00567
* Code: https://github.com/pytorch/vision/tree/master/torchvision/models
## Inception-V4
* Implementation: [inception_v4.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/inception_v4.py)
* Paper: `Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning` - https://arxiv.org/abs/1602.07261
* Code: https://github.com/Cadene/pretrained-models.pytorch
* Reference code: https://github.com/tensorflow/models/tree/master/research/slim/nets
## Inception-ResNet-V2
* Implementation: [inception_resnet_v2.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/inception_resnet_v2.py)
* Paper: `Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning` - https://arxiv.org/abs/1602.07261
* Code: https://github.com/Cadene/pretrained-models.pytorch
* Reference code: https://github.com/tensorflow/models/tree/master/research/slim/nets
## NASNet-A
* Implementation: [nasnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/nasnet.py)
* Papers: `Learning Transferable Architectures for Scalable Image Recognition` - https://arxiv.org/abs/1707.07012
* Code: https://github.com/Cadene/pretrained-models.pytorch
* Reference code: https://github.com/tensorflow/models/tree/master/research/slim/nets/nasnet
## PNasNet-5
* Implementation: [pnasnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/pnasnet.py)
* Papers: `Progressive Neural Architecture Search` - https://arxiv.org/abs/1712.00559
* Code: https://github.com/Cadene/pretrained-models.pytorch
* Reference code: https://github.com/tensorflow/models/tree/master/research/slim/nets/nasnet
## EfficientNet
* Implementation: [efficientnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/efficientnet.py)
* Papers:
* EfficientNet NoisyStudent (B0-B7, L2) - https://arxiv.org/abs/1911.04252
* EfficientNet AdvProp (B0-B8) - https://arxiv.org/abs/1911.09665
* EfficientNet (B0-B7) - https://arxiv.org/abs/1905.11946
* EfficientNet-EdgeTPU (S, M, L) - https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html
* MixNet - https://arxiv.org/abs/1907.09595
* MNASNet B1, A1 (Squeeze-Excite), and Small - https://arxiv.org/abs/1807.11626
* MobileNet-V2 - https://arxiv.org/abs/1801.04381
* FBNet-C - https://arxiv.org/abs/1812.03443
* Single-Path NAS - https://arxiv.org/abs/1904.02877
* My PyTorch code: https://github.com/rwightman/gen-efficientnet-pytorch
* Reference code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## MobileNet-V3
* Implementation: [mobilenetv3.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/mobilenetv3.py)
* Paper: `Searching for MobileNetV3` - https://arxiv.org/abs/1905.02244
* Reference code: https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
## RegNet
* Implementation: [regnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/regnet.py)
* Paper: `Designing Network Design Spaces` - https://arxiv.org/abs/2003.13678
* Reference code: https://github.com/facebookresearch/pycls/blob/master/pycls/models/regnet.py
## RepVGG
* Implementation: [byobnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/byobnet.py)
* Paper: `Making VGG-style ConvNets Great Again` - https://arxiv.org/abs/2101.03697
* Reference code: https://github.com/DingXiaoH/RepVGG
## ResNet, ResNeXt
* Implementation: [resnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/resnet.py)
* ResNet (V1B)
* Paper: `Deep Residual Learning for Image Recognition` - https://arxiv.org/abs/1512.03385
* Code: https://github.com/pytorch/vision/tree/master/torchvision/models
* ResNeXt
* Paper: `Aggregated Residual Transformations for Deep Neural Networks` - https://arxiv.org/abs/1611.05431
* Code: https://github.com/pytorch/vision/tree/master/torchvision/models
* 'Bag of Tricks' / Gluon C, D, E, S ResNet variants
* Paper: `Bag of Tricks for Image Classification with CNNs` - https://arxiv.org/abs/1812.01187
* Code: https://github.com/dmlc/gluon-cv/blob/master/gluoncv/model_zoo/resnetv1b.py
* Instagram pretrained / ImageNet tuned ResNeXt101
* Paper: `Exploring the Limits of Weakly Supervised Pretraining` - https://arxiv.org/abs/1805.00932
* Weights: https://pytorch.org/hub/facebookresearch_WSL-Images_resnext (NOTE: CC BY-NC 4.0 License, NOT commercial friendly)
* Semi-supervised (SSL) / Semi-weakly Supervised (SWSL) ResNet and ResNeXts
* Paper: `Billion-scale semi-supervised learning for image classification` - https://arxiv.org/abs/1905.00546
* Weights: https://github.com/facebookresearch/semi-supervised-ImageNet1K-models (NOTE: CC BY-NC 4.0 License, NOT commercial friendly)
* Squeeze-and-Excitation Networks
* Paper: `Squeeze-and-Excitation Networks` - https://arxiv.org/abs/1709.01507
* Code: Added to ResNet base, this is current version going forward, old `senet.py` is being deprecated
* ECAResNet (ECA-Net)
* Paper: `ECA-Net: Efficient Channel Attention for Deep CNN` - https://arxiv.org/abs/1910.03151v4
* Code: Added to ResNet base, ECA module contributed by @VRandme, reference https://github.com/BangguWu/ECANet
## Res2Net
* Implementation: [res2net.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/res2net.py)
* Paper: `Res2Net: A New Multi-scale Backbone Architecture` - https://arxiv.org/abs/1904.01169
* Code: https://github.com/gasvn/Res2Net
## ResNeSt
* Implementation: [resnest.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/resnest.py)
* Paper: `ResNeSt: Split-Attention Networks` - https://arxiv.org/abs/2004.08955
* Code: https://github.com/zhanghang1989/ResNeSt
## ReXNet
* Implementation: [rexnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/rexnet.py)
* Paper: `ReXNet: Diminishing Representational Bottleneck on CNN` - https://arxiv.org/abs/2007.00992
* Code: https://github.com/clovaai/rexnet
## Selective-Kernel Networks
* Implementation: [sknet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/sknet.py)
* Paper: `Selective-Kernel Networks` - https://arxiv.org/abs/1903.06586
* Code: https://github.com/implus/SKNet, https://github.com/clovaai/assembled-cnn
## SelecSLS
* Implementation: [selecsls.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/selecsls.py)
* Paper: `XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera` - https://arxiv.org/abs/1907.00837
* Code: https://github.com/mehtadushy/SelecSLS-Pytorch
## Squeeze-and-Excitation Networks
* Implementation: [senet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/senet.py)
NOTE: I am deprecating this version of the networks, the new ones are part of `resnet.py`
* Paper: `Squeeze-and-Excitation Networks` - https://arxiv.org/abs/1709.01507
* Code: https://github.com/Cadene/pretrained-models.pytorch
## TResNet
* Implementation: [tresnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/tresnet.py)
* Paper: `TResNet: High Performance GPU-Dedicated Architecture` - https://arxiv.org/abs/2003.13630
* Code: https://github.com/mrT23/TResNet
## VGG
* Implementation: [vgg.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vgg.py)
* Paper: `Very Deep Convolutional Networks For Large-Scale Image Recognition` - https://arxiv.org/pdf/1409.1556.pdf
* Reference code: https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
## Vision Transformer
* Implementation: [vision_transformer.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py)
* Paper: `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` - https://arxiv.org/abs/2010.11929
* Reference code and pretrained weights: https://github.com/google-research/vision_transformer
## VovNet V2 and V1
* Implementation: [vovnet.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vovnet.py)
* Paper: `CenterMask : Real-Time Anchor-Free Instance Segmentation` - https://arxiv.org/abs/1911.06667
* Reference code: https://github.com/youngwanLEE/vovnet-detectron2
## Xception
* Implementation: [xception.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/xception.py)
* Paper: `Xception: Deep Learning with Depthwise Separable Convolutions` - https://arxiv.org/abs/1610.02357
* Code: https://github.com/Cadene/pretrained-models.pytorch
## Xception (Modified Aligned, Gluon)
* Implementation: [gluon_xception.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/gluon_xception.py)
* Paper: `Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation` - https://arxiv.org/abs/1802.02611
* Reference code: https://github.com/dmlc/gluon-cv/tree/master/gluoncv/model_zoo, https://github.com/jfzhang95/pytorch-deeplab-xception/
## Xception (Modified Aligned, TF)
* Implementation: [aligned_xception.py](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/aligned_xception.py)
* Paper: `Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation` - https://arxiv.org/abs/1802.02611
* Reference code: https://github.com/tensorflow/models/tree/master/research/deeplab
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# YOSO
## Overview
The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
a single hash.
The abstract from the paper is the following:
*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
## Usage tips
- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
in parallel on a GPU.
- The kernels provide a `fast_hash` function, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these
hash codes, the `lsh_cumulation` function approximates self-attention via LSH-based Bernoulli sampling.
- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
does not require compiling CUDA kernels.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/yoso_architecture.jpg"
alt="drawing" width="600"/>
<small> YOSO Attention Algorithm. Taken from the <a href="https://arxiv.org/abs/2111.09714">original paper</a>.</small>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## YosoConfig
[[autodoc]] YosoConfig
## YosoModel
[[autodoc]] YosoModel
- forward
## YosoForMaskedLM
[[autodoc]] YosoForMaskedLM
- forward
## YosoForSequenceClassification
[[autodoc]] YosoForSequenceClassification
- forward
## YosoForMultipleChoice
[[autodoc]] YosoForMultipleChoice
- forward
## YosoForTokenClassification
[[autodoc]] YosoForTokenClassification
- forward
## YosoForQuestionAnswering
[[autodoc]] YosoForQuestionAnswering
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/yoso.md |
Optimum Inference with ONNX Runtime
Optimum is a utility package for building and running inference with accelerated runtime like ONNX Runtime.
Optimum can be used to load optimized models from the [Hugging Face Hub](hf.co/models) and create pipelines
to run accelerated inference without rewriting your APIs.
## Switching from Transformers to Optimum
The `optimum.onnxruntime.ORTModelForXXX` model classes are API compatible with Hugging Face Transformers models. This
means you can just replace your `AutoModelForXXX` class with the corresponding `ORTModelForXXX` class in `optimum.onnxruntime`.
You do not need to adapt your code to get it to work with `ORTModelForXXX` classes:
```diff
from transformers import AutoTokenizer, pipeline
-from transformers import AutoModelForQuestionAnswering
+from optimum.onnxruntime import ORTModelForQuestionAnswering
-model = AutoModelForQuestionAnswering.from_pretrained("deepset/roberta-base-squad2") # PyTorch checkpoint
+model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2") # ONNX checkpoint
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
onnx_qa = pipeline("question-answering",model=model,tokenizer=tokenizer)
question = "What's my name?"
context = "My name is Philipp and I live in Nuremberg."
pred = onnx_qa(question, context)
```
### Loading a vanilla Transformers model
Because the model you want to work with might not be already converted to ONNX, [`~optimum.onnxruntime.ORTModel`]
includes a method to convert vanilla Transformers models to ONNX ones. Simply pass `export=True` to the
[`~optimum.onnxruntime.ORTModel.from_pretrained`] method, and your model will be loaded and converted to ONNX on-the-fly:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> # Load the model from the hub and export it to the ONNX format
>>> model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english", export=True
... )
```
### Pushing ONNX models to the Hugging Face Hub
It is also possible, just as with regular [`~transformers.PreTrainedModel`]s, to push your `ORTModelForXXX` to the
[Hugging Face Model Hub](https://hf.co/models):
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> # Load the model from the hub and export it to the ONNX format
>>> model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english", export=True
... )
>>> # Save the converted model
>>> model.save_pretrained("a_local_path_for_convert_onnx_model")
# Push the onnx model to HF Hub
>>> model.push_to_hub( # doctest: +SKIP
... "a_local_path_for_convert_onnx_model", repository_id="my-onnx-repo", use_auth_token=True
... )
```
## Sequence-to-sequence models
Sequence-to-sequence (Seq2Seq) models can also be used when running inference with ONNX Runtime. When Seq2Seq models
are exported to the ONNX format, they are decomposed into three parts that are later combined during inference:
- The encoder part of the model
- The decoder part of the model + the language modeling head
- The same decoder part of the model + language modeling head but taking and using pre-computed key / values as inputs and
outputs. This makes inference faster.
Here is an example of how you can load a T5 model to the ONNX format and run inference for a translation task:
```python
>>> from transformers import AutoTokenizer, pipeline
>>> from optimum.onnxruntime import ORTModelForSeq2SeqLM
# Load the model from the hub and export it to the ONNX format
>>> model_name = "t5-small"
>>> model = ORTModelForSeq2SeqLM.from_pretrained(model_name, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
# Create a pipeline
>>> onnx_translation = pipeline("translation_en_to_fr", model=model, tokenizer=tokenizer)
>>> text = "He never went out without a book under his arm, and he often came back with two."
>>> result = onnx_translation(text)
>>> # [{'translation_text': "Il n'est jamais sorti sans un livre sous son bras, et il est souvent revenu avec deux."}]
```
## Stable Diffusion
Stable Diffusion models can also be used when running inference with ONNX Runtime. When Stable Diffusion models
are exported to the ONNX format, they are split into four components that are later combined during inference:
- The text encoder
- The U-NET
- The VAE encoder
- The VAE decoder
Make sure you have 🤗 Diffusers installed.
To install `diffusers`:
```bash
pip install diffusers
```
### Text-to-Image
Here is an example of how you can load an ONNX Stable Diffusion model and run inference using ONNX Runtime:
```python
from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id, revision="onnx")
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
```
To load your PyTorch model and convert it to ONNX on-the-fly, you can set `export=True`.
```python
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id, export=True)
# Don't forget to save the ONNX model
save_directory = "a_local_path"
pipeline.save_pretrained(save_directory)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/onnxruntime/stable_diffusion_v1_5_ort_sail_boat.png">
</div>
### Image-to-Image
```python
import requests
import torch
from PIL import Image
from io import BytesIO
from optimum.onnxruntime import ORTStableDiffusionImg2ImgPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = ORTStableDiffusionImg2ImgPipeline.from_pretrained(model_id, revision="onnx")
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((768, 512))
prompt = "A fantasy landscape, trending on artstation"
image = pipeline(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images[0]
image.save("fantasy_landscape.png")
```
### Inpaint
```python
import PIL
import requests
import torch
from io import BytesIO
from optimum.onnxruntime import ORTStableDiffusionInpaintPipeline
model_id = "runwayml/stable-diffusion-inpainting"
pipeline = ORTStableDiffusionInpaintPipeline.from_pretrained(model_id, revision="onnx")
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
```
## Stable Diffusion XL
Before using `ORTStableDiffusionXLPipeline` make sure to have `diffusers` and `invisible_watermark` installed. You can install the libraries as follows:
```bash
pip install diffusers
pip install invisible-watermark>=0.2.0
```
### Text-to-Image
Here is an example of how you can load a SDXL ONNX model from [stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) and run inference using ONNX Runtime :
```python
from optimum.onnxruntime import ORTStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
base = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = base(prompt).images[0]
# Don't forget to save the ONNX model
save_directory = "sd_xl_base"
base.save_pretrained(save_directory)
```
### Image-to-Image
Here is an example of how you can load a PyTorch SDXL model, convert it to ONNX on-the-fly and run inference using ONNX Runtime for *image-to-image* :
```python
from optimum.onnxruntime import ORTStableDiffusionXLImg2ImgPipeline
from diffusers.utils import load_image
model_id = "stabilityai/stable-diffusion-xl-refiner-1.0"
pipeline = ORTStableDiffusionXLImg2ImgPipeline.from_pretrained(model_id, export=True)
url = "https://huggingface.co/datasets/optimum/documentation-images/resolve/main/intel/openvino/sd_xl/castle_friedrich.png"
image = load_image(url).convert("RGB")
prompt = "medieval castle by Caspar David Friedrich"
image = pipeline(prompt, image=image).images[0]
image.save("medieval_castle.png")
```
### Refining the image output
The image can be refined by making use of a model like [stabilityai/stable-diffusion-xl-refiner-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0). In this case, you only have to output the latents from the base model.
```python
from optimum.onnxruntime import ORTStableDiffusionXLImg2ImgPipeline
model_id = "stabilityai/stable-diffusion-xl-refiner-1.0"
refiner = ORTStableDiffusionXLImg2ImgPipeline.from_pretrained(model_id, export=True)
image = base(prompt=prompt, output_type="latent").images[0]
image = refiner(prompt=prompt, image=image[None, :]).images[0]
image.save("sailing_ship.png")
```
## Latent Consistency Models
### Text-to-Image
Here is an example of how you can load a Latent Consistency Models (LCMs) from [SimianLuo/LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7) and run inference using ONNX Runtime :
```python
from optimum.onnxruntime import ORTLatentConsistencyModelPipeline
model_id = "SimianLuo/LCM_Dreamshaper_v7"
pipeline = ORTLatentConsistencyModelPipeline.from_pretrained(model_id, export=True)
prompt = "sailing ship in storm by Leonardo da Vinci"
images = pipeline(prompt, num_inference_steps=4, guidance_scale=8.0).images
```
| huggingface/optimum/blob/main/docs/source/onnxruntime/usage_guides/models.mdx |
Using Gradio and Comet
Tags: COMET, SPACES
Contributed by the Comet team
## Introduction
In this guide we will demonstrate some of the ways you can use Gradio with Comet. We will cover the basics of using Comet with Gradio and show you some of the ways that you can leverage Gradio's advanced features such as [Embedding with iFrames](https://www.gradio.app/guides/sharing-your-app/#embedding-with-iframes) and [State](https://www.gradio.app/docs/#state) to build some amazing model evaluation workflows.
Here is a list of the topics covered in this guide.
1. Logging Gradio UI's to your Comet Experiments
2. Embedding Gradio Applications directly into your Comet Projects
3. Embedding Hugging Face Spaces directly into your Comet Projects
4. Logging Model Inferences from your Gradio Application to Comet
## What is Comet?
[Comet](https://www.comet.com?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) is an MLOps Platform that is designed to help Data Scientists and Teams build better models faster! Comet provides tooling to Track, Explain, Manage, and Monitor your models in a single place! It works with Jupyter Notebooks and Scripts and most importantly it's 100% free!
## Setup
First, install the dependencies needed to run these examples
```shell
pip install comet_ml torch torchvision transformers gradio shap requests Pillow
```
Next, you will need to [sign up for a Comet Account](https://www.comet.com/signup?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs). Once you have your account set up, [grab your API Key](https://www.comet.com/docs/v2/guides/getting-started/quickstart/#get-an-api-key?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) and configure your Comet credentials
If you're running these examples as a script, you can either export your credentials as environment variables
```shell
export COMET_API_KEY="<Your API Key>"
export COMET_WORKSPACE="<Your Workspace Name>"
export COMET_PROJECT_NAME="<Your Project Name>"
```
or set them in a `.comet.config` file in your working directory. You file should be formatted in the following way.
```shell
[comet]
api_key=<Your API Key>
workspace=<Your Workspace Name>
project_name=<Your Project Name>
```
If you are using the provided Colab Notebooks to run these examples, please run the cell with the following snippet before starting the Gradio UI. Running this cell allows you to interactively add your API key to the notebook.
```python
import comet_ml
comet_ml.init()
```
## 1. Logging Gradio UI's to your Comet Experiments
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Gradio_and_Comet.ipynb)
In this example, we will go over how to log your Gradio Applications to Comet and interact with them using the Gradio Custom Panel.
Let's start by building a simple Image Classification example using `resnet18`.
```python
import comet_ml
import requests
import torch
from PIL import Image
from torchvision import transforms
torch.hub.download_url_to_file("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = torch.hub.load("pytorch/vision:v0.6.0", "resnet18", pretrained=True).eval()
model = model.to(device)
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = Image.fromarray(inp.astype("uint8"), "RGB")
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp.to(device))[0], dim=0)
return {labels[i]: float(prediction[i]) for i in range(1000)}
inputs = gr.Image()
outputs = gr.Label(num_top_classes=3)
io = gr.Interface(
fn=predict, inputs=inputs, outputs=outputs, examples=["dog.jpg"]
)
io.launch(inline=False, share=True)
experiment = comet_ml.Experiment()
experiment.add_tag("image-classifier")
io.integrate(comet_ml=experiment)
```
The last line in this snippet will log the URL of the Gradio Application to your Comet Experiment. You can find the URL in the Text Tab of your Experiment.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328034-09369d4d-8b94-4c4a-aa3c-25e3ed8394c4.mp4"></source>
</video>
Add the Gradio Panel to your Experiment to interact with your application.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328194-95987f83-c180-4929-9bed-c8a0d3563ed7.mp4"></source>
</video>
## 2. Embedding Gradio Applications directly into your Comet Projects
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=9" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
If you are permanently hosting your Gradio application, you can embed the UI using the Gradio Panel Extended custom Panel.
Go to your Comet Project page, and head over to the Panels tab. Click the `+ Add` button to bring up the Panels search page.
<img width="560" alt="adding-panels" src="https://user-images.githubusercontent.com/7529846/214329314-70a3ff3d-27fb-408c-a4d1-4b58892a3854.jpeg">
Next, search for Gradio Panel Extended in the Public Panels section and click `Add`.
<img width="560" alt="gradio-panel-extended" src="https://user-images.githubusercontent.com/7529846/214325577-43226119-0292-46be-a62a-0c7a80646ebb.png">
Once you have added your Panel, click `Edit` to access to the Panel Options page and paste in the URL of your Gradio application.
<img width="560" alt="Edit-Gradio-Panel-URL" src="https://user-images.githubusercontent.com/7529846/214334843-870fe726-0aa1-4b21-bbc6-0c48f56c48d8.png">
## 3. Embedding Hugging Face Spaces directly into your Comet Projects
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=107" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
You can also embed Gradio Applications that are hosted on Hugging Faces Spaces into your Comet Projects using the Hugging Face Spaces Panel.
Go to your Comet Project page, and head over to the Panels tab. Click the `+ Add` button to bring up the Panels search page. Next, search for the Hugging Face Spaces Panel in the Public Panels section and click `Add`.
<img width="560" height="315" alt="huggingface-spaces-panel" src="https://user-images.githubusercontent.com/7529846/214325606-99aa3af3-b284-4026-b423-d3d238797e12.png">
Once you have added your Panel, click Edit to access to the Panel Options page and paste in the path of your Hugging Face Space e.g. `pytorch/ResNet`
<img width="560" height="315" alt="Edit-HF-Space" src="https://user-images.githubusercontent.com/7529846/214335868-c6f25dee-13db-4388-bcf5-65194f850b02.png">
## 4. Logging Model Inferences to Comet
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=176" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Logging_Model_Inferences_with_Comet_and_Gradio.ipynb)
In the previous examples, we demonstrated the various ways in which you can interact with a Gradio application through the Comet UI. Additionally, you can also log model inferences, such as SHAP plots, from your Gradio application to Comet.
In the following snippet, we're going to log inferences from a Text Generation model. We can persist an Experiment across multiple inference calls using Gradio's [State](https://www.gradio.app/docs/#state) object. This will allow you to log multiple inferences from a model to a single Experiment.
```python
import comet_ml
import gradio as gr
import shap
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
MODEL_NAME = "gpt2"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
# set model decoder to true
model.config.is_decoder = True
# set text-generation params under task_specific_params
model.config.task_specific_params["text-generation"] = {
"do_sample": True,
"max_length": 50,
"temperature": 0.7,
"top_k": 50,
"no_repeat_ngram_size": 2,
}
model = model.to(device)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
explainer = shap.Explainer(model, tokenizer)
def start_experiment():
"""Returns an APIExperiment object that is thread safe
and can be used to log inferences to a single Experiment
"""
try:
api = comet_ml.API()
workspace = api.get_default_workspace()
project_name = comet_ml.config.get_config()["comet.project_name"]
experiment = comet_ml.APIExperiment(
workspace=workspace, project_name=project_name
)
experiment.log_other("Created from", "gradio-inference")
message = f"Started Experiment: [{experiment.name}]({experiment.url})"
return (experiment, message)
except Exception as e:
return None, None
def predict(text, state, message):
experiment = state
shap_values = explainer([text])
plot = shap.plots.text(shap_values, display=False)
if experiment is not None:
experiment.log_other("message", message)
experiment.log_html(plot)
return plot
with gr.Blocks() as demo:
start_experiment_btn = gr.Button("Start New Experiment")
experiment_status = gr.Markdown()
# Log a message to the Experiment to provide more context
experiment_message = gr.Textbox(label="Experiment Message")
experiment = gr.State()
input_text = gr.Textbox(label="Input Text", lines=5, interactive=True)
submit_btn = gr.Button("Submit")
output = gr.HTML(interactive=True)
start_experiment_btn.click(
start_experiment, outputs=[experiment, experiment_status]
)
submit_btn.click(
predict, inputs=[input_text, experiment, experiment_message], outputs=[output]
)
```
Inferences from this snippet will be saved in the HTML tab of your experiment.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328610-466e5c81-4814-49b9-887c-065aca14dd30.mp4"></source>
</video>
## Conclusion
We hope you found this guide useful and that it provides some inspiration to help you build awesome model evaluation workflows with Comet and Gradio.
## How to contribute Gradio demos on HF spaces on the Comet organization
- Create an account on Hugging Face [here](https://huggingface.co/join).
- Add Gradio Demo under your username, see this [course](https://huggingface.co/course/chapter9/4?fw=pt) for setting up Gradio Demo on Hugging Face.
- Request to join the Comet organization [here](https://huggingface.co/Comet).
## Additional Resources
- [Comet Documentation](https://www.comet.com/docs/v2/?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs)
| gradio-app/gradio/blob/main/guides/06_integrating-other-frameworks/Gradio-and-Comet.md |
Deep Layer Aggregation
Extending “shallow” skip connections, **Dense Layer Aggregation (DLA)** incorporates more depth and sharing. The authors introduce two structures for deep layer aggregation (DLA): iterative deep aggregation (IDA) and hierarchical deep aggregation (HDA). These structures are expressed through an architectural framework, independent of the choice of backbone, for compatibility with current and future networks.
IDA focuses on fusing resolutions and scales while HDA focuses on merging features from all modules and channels. IDA follows the base hierarchy to refine resolution and aggregate scale stage-bystage. HDA assembles its own hierarchy of tree-structured connections that cross and merge stages to aggregate different levels of representation.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('dla102', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `dla102`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('dla102', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{yu2019deep,
title={Deep Layer Aggregation},
author={Fisher Yu and Dequan Wang and Evan Shelhamer and Trevor Darrell},
year={2019},
eprint={1707.06484},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: DLA
Paper:
Title: Deep Layer Aggregation
URL: https://paperswithcode.com/paper/deep-layer-aggregation
Models:
- Name: dla102
In Collection: DLA
Metadata:
FLOPs: 7192952808
Parameters: 33270000
File Size: 135290579
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla102
LR: 0.1
Epochs: 120
Layers: 102
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L410
Weights: http://dl.yf.io/dla/models/imagenet/dla102-d94d9790.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.03%
Top 5 Accuracy: 93.95%
- Name: dla102x
In Collection: DLA
Metadata:
FLOPs: 5886821352
Parameters: 26310000
File Size: 107552695
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla102x
LR: 0.1
Epochs: 120
Layers: 102
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L418
Weights: http://dl.yf.io/dla/models/imagenet/dla102x-ad62be81.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.51%
Top 5 Accuracy: 94.23%
- Name: dla102x2
In Collection: DLA
Metadata:
FLOPs: 9343847400
Parameters: 41280000
File Size: 167645295
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla102x2
LR: 0.1
Epochs: 120
Layers: 102
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L426
Weights: http://dl.yf.io/dla/models/imagenet/dla102x2-262837b6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.44%
Top 5 Accuracy: 94.65%
- Name: dla169
In Collection: DLA
Metadata:
FLOPs: 11598004200
Parameters: 53390000
File Size: 216547113
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla169
LR: 0.1
Epochs: 120
Layers: 169
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L434
Weights: http://dl.yf.io/dla/models/imagenet/dla169-0914e092.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.69%
Top 5 Accuracy: 94.33%
- Name: dla34
In Collection: DLA
Metadata:
FLOPs: 3070105576
Parameters: 15740000
File Size: 63228658
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla34
LR: 0.1
Epochs: 120
Layers: 32
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L362
Weights: http://dl.yf.io/dla/models/imagenet/dla34-ba72cf86.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.62%
Top 5 Accuracy: 92.06%
- Name: dla46_c
In Collection: DLA
Metadata:
FLOPs: 583277288
Parameters: 1300000
File Size: 5307963
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla46_c
LR: 0.1
Epochs: 120
Layers: 46
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L369
Weights: http://dl.yf.io/dla/models/imagenet/dla46_c-2bfd52c3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 64.87%
Top 5 Accuracy: 86.29%
- Name: dla46x_c
In Collection: DLA
Metadata:
FLOPs: 544052200
Parameters: 1070000
File Size: 4387641
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla46x_c
LR: 0.1
Epochs: 120
Layers: 46
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L378
Weights: http://dl.yf.io/dla/models/imagenet/dla46x_c-d761bae7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 65.98%
Top 5 Accuracy: 86.99%
- Name: dla60
In Collection: DLA
Metadata:
FLOPs: 4256251880
Parameters: 22040000
File Size: 89560235
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60
LR: 0.1
Epochs: 120
Layers: 60
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L394
Weights: http://dl.yf.io/dla/models/imagenet/dla60-24839fc4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.04%
Top 5 Accuracy: 93.32%
- Name: dla60_res2net
In Collection: DLA
Metadata:
FLOPs: 4147578504
Parameters: 20850000
File Size: 84886593
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60_res2net
Layers: 60
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L346
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net_dla60_4s-d88db7f9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.46%
Top 5 Accuracy: 94.21%
- Name: dla60_res2next
In Collection: DLA
Metadata:
FLOPs: 3485335272
Parameters: 17030000
File Size: 69639245
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60_res2next
Layers: 60
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L354
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2next_dla60_4s-d327927b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.44%
Top 5 Accuracy: 94.16%
- Name: dla60x
In Collection: DLA
Metadata:
FLOPs: 3544204264
Parameters: 17350000
File Size: 70883139
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60x
LR: 0.1
Epochs: 120
Layers: 60
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L402
Weights: http://dl.yf.io/dla/models/imagenet/dla60x-d15cacda.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.25%
Top 5 Accuracy: 94.02%
- Name: dla60x_c
In Collection: DLA
Metadata:
FLOPs: 593325032
Parameters: 1320000
File Size: 5454396
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60x_c
LR: 0.1
Epochs: 120
Layers: 60
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L386
Weights: http://dl.yf.io/dla/models/imagenet/dla60x_c-b870c45c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 67.91%
Top 5 Accuracy: 88.42%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/dla.mdx |
--
title: WikiSplit
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
WIKI_SPLIT is the combination of three metrics SARI, EXACT and SACREBLEU
It can be used to evaluate the quality of machine-generated texts.
---
# Metric Card for WikiSplit
## Metric description
WikiSplit is the combination of three metrics: [SARI](https://huggingface.co/metrics/sari), [exact match](https://huggingface.co/metrics/exact_match) and [SacreBLEU](https://huggingface.co/metrics/sacrebleu).
It can be used to evaluate the quality of sentence splitting approaches, which require rewriting a long sentence into two or more coherent short sentences, e.g. based on the [WikiSplit dataset](https://huggingface.co/datasets/wiki_split).
## How to use
The WIKI_SPLIT metric takes three inputs:
`sources`: a list of source sentences, where each sentence should be a string.
`predictions`: a list of predicted sentences, where each sentence should be a string.
`references`: a list of lists of reference sentences, where each sentence should be a string.
```python
>>> wiki_split = evaluate.load("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["About 95 you now get in ."]
>>> references= [["About 95 species are currently known ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary containing three scores:
`sari`: the [SARI](https://huggingface.co/metrics/sari) score, whose range is between `0.0` and `100.0` -- the higher the value, the better the performance of the model being evaluated, with a SARI of 100 being a perfect score.
`sacrebleu`: the [SacreBLEU](https://huggingface.co/metrics/sacrebleu) score, which can take any value between `0.0` and `100.0`, inclusive.
`exact`: the [exact match](https://huggingface.co/metrics/exact_match) score, which represents the sum of all of the individual exact match scores in the set, divided by the total number of predictions in the set. It ranges from `0.0` to `100`, inclusive. Here, `0.0` means no prediction/reference pairs were matches, while `100.0` means they all were.
```python
>>> print(results)
{'sari': 21.805555555555557, 'sacrebleu': 14.535768424205482, 'exact': 0.0}
```
### Values from popular papers
This metric was initially used by [Rothe et al.(2020)](https://arxiv.org/pdf/1907.12461.pdf) to evaluate the performance of different split-and-rephrase approaches on the [WikiSplit dataset](https://huggingface.co/datasets/wiki_split). They reported a SARI score of 63.5, a SacreBLEU score of 77.2, and an EXACT_MATCH score of 16.3.
## Examples
Perfect match between prediction and reference:
```python
>>> wiki_split = evaluate.load("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["About 95 species are currently accepted ."]
>>> references= [["About 95 species are currently accepted ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 100.0, 'sacrebleu': 100.00000000000004, 'exact': 100.0
```
Partial match between prediction and reference:
```python
>>> wiki_split = evaluate.load("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["About 95 you now get in ."]
>>> references= [["About 95 species are currently known ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 21.805555555555557, 'sacrebleu': 14.535768424205482, 'exact': 0.0}
```
No match between prediction and reference:
```python
>>> wiki_split = evaluate.load("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["Hello world ."]
>>> references= [["About 95 species are currently known ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 14.047619047619046, 'sacrebleu': 0.0, 'exact': 0.0}
```
## Limitations and bias
This metric is not the official metric to evaluate models on the [WikiSplit dataset](https://huggingface.co/datasets/wiki_split). It was initially proposed by [Rothe et al.(2020)](https://arxiv.org/pdf/1907.12461.pdf), whereas the [original paper introducing the WikiSplit dataset (2018)](https://aclanthology.org/D18-1080.pdf) uses different metrics to evaluate performance, such as corpus-level [BLEU](https://huggingface.co/metrics/bleu) and sentence-level BLEU.
## Citation
```bibtex
@article{rothe2020leveraging,
title={Leveraging pre-trained checkpoints for sequence generation tasks},
author={Rothe, Sascha and Narayan, Shashi and Severyn, Aliaksei},
journal={Transactions of the Association for Computational Linguistics},
volume={8},
pages={264--280},
year={2020},
publisher={MIT Press}
}
```
## Further References
- [WikiSplit dataset](https://huggingface.co/datasets/wiki_split)
- [WikiSplit paper (Botha et al., 2018)](https://aclanthology.org/D18-1080.pdf)
| huggingface/evaluate/blob/main/metrics/wiki_split/README.md |
Numpy API
[[autodoc]] safetensors.numpy.load_file
[[autodoc]] safetensors.numpy.load
[[autodoc]] safetensors.numpy.save_file
[[autodoc]] safetensors.numpy.save
| huggingface/safetensors/blob/main/docs/source/api/numpy.mdx |
--
title: "Machine Learning Experts - Sasha Luccioni"
thumbnail: /blog/assets/69_sasha_luccioni_interview/thumbnail.png
authors:
- user: britneymuller
---
# Machine Learning Experts - Sasha Luccioni
## 🤗 Welcome to Machine Learning Experts - Sasha Luccioni
🚀 _If you're interested in learning how ML Experts, like Sasha, can help accelerate your ML roadmap visit: <a href="https://huggingface.co/support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=sasha_interview_article">hf.co/support.</a>_
Hey friends! Welcome to Machine Learning Experts. I'm your host, Britney Muller and today’s guest is [Sasha Luccioni](https://twitter.com/SashaMTL). Sasha is a Research Scientist at Hugging Face where she works on the ethical and societal impacts of Machine Learning models and datasets.
Sasha is also a co-chair of the Carbon Footprint WG of the [Big Science Workshop](https://bigscience.huggingface.co), on the Board of [WiML](https://wimlworkshop.org), and a founding member of the [Climate Change AI (CCAI)](https://www.climatechange.ai) organization which catalyzes impactful work applying machine learning to the climate crisis.
You’ll hear Sasha talk about how she measures the carbon footprint of an email, how she helped a local soup kitchen leverage the power of ML, and how meaning and creativity fuel her work.
Very excited to introduce this brilliant episode to you! Here’s my conversation with Sasha Luccioni:
<iframe width="100%" style="aspect-ratio: 16 / 9;"src="https://www.youtube.com/embed/AQRkcMr0Zk0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
*Note: Transcription has been slightly modified/reformatted to deliver the highest-quality reading experience.*
### Thank you so much for joining us today, we are so excited to have you on!
**Sasha:** I'm really excited to be here.
### Diving right in, can you speak to your background and what led you to Hugging Face?
**Sasha:** Yeah, I mean if we go all the way back, I started studying linguistics. I was super into languages and both of my parents were mathematicians. But I thought, I don't want to do math, I want to do language. I started doing NLP, natural language processing, during my undergrad and got super into it.
My Ph.D. was in computer science, but I maintained a linguistic angle. I started out in humanities and then got into computer science. Then after my Ph.D., I spent a couple of years working in applied AI research. My last job was in finance, and then one day I decided that I wanted to do good and socially positive AI research, so I quit my job. I decided that no amount of money was worth working on AI for AI's sake, I wanted to do more. So I spent a couple of years working with Yoshua Bengio, meanwhile working on AI for good projects, AI for climate change projects, and then I was looking for my next role.
I wanted to be in a place that I trusted was doing the right things and going in the right direction. When I met Thom and Clem, I knew that Hugging Face was a place for me and that it would be exactly what I was looking for.
### Love that you wanted to something that felt meaningful!
**Sasha:** Yeah, when I hear people on Sunday evening being like “Monday's tomorrow…” I'm like “Tomorrow's Monday! That's great!” And it's not that I'm a workaholic, I definitely do other stuff, and have a family and everything, but I'm literally excited to go to work to do really cool stuff. Think that's important. I know people can live without it, but I can't.
### What are you most excited about that you're working on now?
**Sasha:** I think the [Big Science](https://bigscience.huggingface.co/) project is definitely super inspiring. For the last couple of years, I've been seeing these large language models, and I was always like, but how do they work? And where's the code, where's their data, and what's going on in there? How are they developed and who was involved? It was all like a black box thing, and I'm so happy that we're finally making it a glass box. And there are so many people involved and so many really interesting perspectives.
And I'm chairing the carbon footprint working group, so we're working on different aspects of environmental impacts and above and beyond just counting CO2 emissions, but other things like the manufacturing costs. At some point, we even consider how much CO2 an email generates, things like that, so we're definitely thinking of different perspectives.
Also about the data, I'm involved in a lot of the data working groups at Big Science, and it's really interesting because typically it’s been like we're gonna get the most data we can, stuff it in a language model and it's gonna be great. And it's gonna learn all this stuff, but what's actually in there, there's so much weird stuff on the internet, and things that you don't necessarily want your model to be seeing. So we're really looking into mindfulness, data curation, and multilingualism as well to make sure that it's not just a hundred percent English or 99% English. So it's such a great initiative, and it makes me excited to be involved.
### Love the idea of evaluating the carbon footprint of an email!?
**Sasha:** Yeah, people did it, depending on the attachment or not, but it was just because we found this article of, I think it was a theoretical physics project and they did that, they did everything. They did video calls, travel commutes, emails, and the actual experiments as well. And they made this pie chart and it was cool because there were 37 categories in the pie chart, and we really wanted to do that. But I don't know if we want to go into that level of detail, but we were going to do a survey and ask participants on average, how many hours did they spend working on Big Science or training in language models and things like that. So we didn’t want just the number of GPU hours for training the model, but also people's implication and participation in the project.
### Can you speak a little bit more about the environmental impact of AI?
**Sasha:** Yeah, it's a topic I got involved in three years ago now. The first article that came out was by [Emma Strubell and her colleagues](https://arxiv.org/pdf/1906.02243.pdf) and they essentially trained a large language model with hyperparameter tuning. So essentially looking at all the different configurations and then the figure they got was like that AI model emitted as much carbon as five cars in their lifetimes. Which includes gas and everything, like the average kind of consumption. And with my colleagues we were like, well that doesn't sound right, it can't be all models, right? And so we really went off the deep end into figuring out what has an impact on emissions, and how we can measure emissions.
So first we just [created this online calculator](https://mlco2.github.io/impact/) where someone could enter what hardware they use, how long they trained for, and where on their location or a cloud computing instance. And then it would give them an estimate of the carbon involved that they admitted. Essentially that was our first attempt, a calculator, and then we helped create a package called code carbon which actually does that in real-time. So it's gonna run in parallel to whatever you're doing training a model and then at the end spit out an estimate of the carbon emissions.
Lately we've been going further and further. I just had an article that I was a co-author on that got accepted, about how to proactively reduce emissions. For example, by anticipating times when servers are not as used as other times, like doing either time delaying or picking the right region because if you train in, I don't know, Australia, it's gonna be a coal-based grid, and so it's gonna be highly polluting. Whereas in Quebec or Montreal where I'm based, it's a hundred percent hydroelectricity. So just by making that choice, you can reduce your emissions by around a hundredfold. And so just small things like that, like above and beyond estimating, we also want people to start reducing their emissions. It's the next step.
### It’s never crossed my mind that geographically where you compute has a different emissions cost.
**Sasha:** Oh yeah, and I'm so into energy grids now. Every time I go somewhere I'm like, so what's the energy coming from? How are you generating it? And so it's really interesting, there are a lot of historical factors and a lot of cultural factors.
For example; France is mostly nuclear, mostly energy, and Canada has a lot of hydroelectric energy. Some places have a lot of wind or tidal, and so it's really interesting just to understand when you turn on a lamp, where that electricity is coming from and at what cost to the environment. Because when I was growing up, I would always turn off the lights, and unplug whatever but not anything more than that. It was just good best practices. You turn off the light when you're not in a room, but after that, you can really go deeper depending on where you live, your energy's coming from different sources. And there is more or less pollution, but we just don't see that we don't see how energy is produced, we just see the light and we're like oh, this is my lamp. So it's really important to start thinking about that.
### It's so easy not to think about that stuff, which I could see being a barrier for machine learning engineers who might not have that general awareness.
**Sasha:** Yeah, exactly. And I mean usually, it's just by habit, right? I think there's a default option when you're using cloud instances, often it's like the closest one to you or the one with the most GPUs available or whatever. There's a default option, and people are like okay, fine, whatever and click the default. It's this nudge theory aspect.
I did a master's in cognitive science and just by changing the default option, you can change people's behavior to an incredible degree. So whether you put apples or chocolate bars near the cash register, or small stuff like that. And so if the default option, all of a sudden was the low carbon one, we could save so many emissions just because people are just like okay, fine, I'm gonna train a model in Montreal, I don't care. It doesn't matter, as long as you have access to the hardware you need, you don't care where it is. But in the long run, it really adds up.
### What are some of the ways that machine learning teams and engineers could be a bit more proactive in aspects like that?
**Sasha:** So I've noticed that a lot of people are really environmentally conscious. Like they'll bike to work or they'll eat less meat and things like that. They'll have this kind of environmental awareness, but then disassociate it from their work because we're not aware of our impact as machine learning researchers or engineers on the environment. And without sharing it necessarily, just starting to measure, for example, carbon emissions. And starting to look at what instances you're picking, if you have a choice. For example, I know that Google Cloud and AWS have started putting low carbon as a little tag so you can pick it because the information is there. And starting to make these little steps, and connecting the dots between environment and tech. These are dots that are not often connected because tech is so like the cloud, it's nice to be distributed, and you don't really see it. And so by grounding it more, you see the impact it can have on the environment.
### That's a great point. And I've listened to a couple talks and podcasts of yours, where you've mentioned how machine learning can be used to help offset the environmental impact of models.
**Sasha:** Yeah, we wrote a paper a couple of years ago that was a cool experience. It's almost a hundred pages, it's called [Tackling Climate Change with Machine Learning](https://dl.acm.org/doi/10.1145/3485128). And there are like 25 authors, but there are all these different sections ranging from electricity to city planning to transportation to forestry and agriculture. We essentially have these chapters of the paper where we talk about the problems that exist. For example, renewable energy is variable in a lot of cases. So if you have solar panels, they won't produce energy at night. That's kind of like a given. And then wind power is dependent on the wind. And so a big challenge in implementing renewable energy is that you have to respond to the demand. You need to be able to give people power at night, even if you're on solar energy. And so typically you have either diesel generators or this backup system that often cancels out the environmental effect, like the emissions that you're saving, but what machine learning can do, you're essentially predicting how much energy will be needed. So based on previous days, based on the temperature, based on events that happen, you can start being like okay, well we're gonna be predicting half an hour out or an hour out or 6 hours or 24 hours. And you can start having different horizons and doing time series prediction.
Then instead of powering up a diesel generator which is cool because you can just power them up, and in a couple of seconds they're up and running. What you can also do is have batteries, but batteries you need to start charging them ahead of time. So say you're six hours out, you start charging your batteries, knowing that either there's a cloud coming or that night's gonna fall, so you need that energy stored ahead. And so there are things that you could do that are proactive that can make a huge difference. And then machine learning is good at that, it’s good at predicting the future, it’s good at finding the right features, and things like that. So that's one of the go-to examples. Another one is remote sensing. So we have a lot of satellite data about the planet and see either deforestation or tracking wildfires. In a lot of cases, you can detect wildfires automatically based on satellite imagery and deploy people right away. Because they're often in remote places that you don't necessarily have people living in. And so there are all these different cases in which machine learning could be super useful. We have the data, we have the need, and so this paper is all about how to get involved and whatever you're good at, whatever you like doing, and how to apply machine learning and use it in the fight against climate change.
### For people listening that are interested in this effort, but perhaps work at an organization where it's not prioritized, what tips do you have to help incentivize teams to prioritize environmental impact?
**Sasha:** So it's always a question of cost and benefit or time, you know, the time that you need to put in. And sometimes people just don't know that there are different tools that exist or approaches. And so if people are interested or even curious to learn about it. I think that's the first up because even when I first started thinking of what I can do, I didn't know that all these things existed. People have been working on this for like a fairly long time using different data science techniques.
For example, we created a website called [climatechange.ai](http://climatechange.ai), and we have interactive summaries that you can read about how climate change can help and detect methane or whatever. And I think that just by sprinkling this knowledge can help trigger some interesting thought processes or discussions. I've participated in several round tables at companies that are not traditionally climate change-oriented but are starting to think about it. And they're like okay well we put a composting bin in the kitchen, or we did this and we did that. So then from the tech side, what can we do? It's really interesting because there are a lot of low-hanging fruits that you just need to learn about. And then it's like oh well, I can do that, I can by default use this cloud computing instance and that's not gonna cost me anything. And you need to change a parameter somewhere.
### What are some of the more common mistakes you see machine learning engineers or teams make when it comes to implementing these improvements?
**Sasha:** Actually, machine learning people or AI people, in general, have this stereotype from other communities that we think AI's gonna solve everything. We just arrived and we're like oh, we're gonna do AI. And it's gonna solve all your problems no matter what you guys have been doing for 50 years, AI's gonna do it. And I haven't seen that attitude that much, but we know what AI can do, we know what machine learning can do, and we have a certain kind of worldview. It's like when you have a hammer, everything's a nail, so it’s kind of something like that. And I participated in a couple of hackathons and just like in general, people want to make stuff or do stuff to fight climate change. It's often like oh, this sounds like a great thing AI can do, and we're gonna do it without thinking of how it's gonna be used or how it's gonna be useful or how it's gonna be. Because it's like yeah, sure, AI can do all this stuff, but then at the end of the day, someone's gonna use it.
For example, if you create something for scanning satellite imagery and detecting wildfire, the information that your model outputs has to be interpretable. Or you need to add that little extra step of sending a new email or whatever it is. Otherwise, we train a model, it's great, it's super accurate, but then at the end of the day, nobody's gonna use it just because it's missing a tiny little connection to the real world or the way that people will use it. And that's not sexy, people are like yeah, whatever, I don't even know how to write a script that sends an email. I don't either. But still, just doing that little extra step, that's so much less technologically complex than what you've done so far. Just adding that little thing will make a big difference and it can be in terms of UI, or it can be in terms of creating an app. It's like the machine learning stuff that's actually crucial for your project to be used.
And I've participated in organizing workshops where people submit ideas that are super great on paper that have great accuracy rates, but then they just stagnate in paper form or article form because you still need to have that next step. I remember this one presentation of a machine learning algorithm that could reduce flight emissions of airplanes by 3 to 7% by calculating the wind speed, etc. Of course, that person should have done a startup or a product or pitched this to Boeing or whatever, otherwise it was just a paper that they published in this workshop that I was organizing, and then that was it. And scientists or engineers don't necessarily have those skills necessary to go see an airplane manufacturer with this thing, but it's frustrating. And at the end of the day, to see these great ideas, this great tech that just fizzles.
### So sad. That's such a great story though and how there are opportunities like that.
**Sasha:** Yeah, and I think scientists, so often, don't necessarily want to make money, they just want to solve problems often. And so you don't necessarily even need to start a startup, you could just talk to someone or pitch this to someone, but you have to get out of your comfort zone. And the academic conferences you go to, you need to go to a networking event in the aviation industry and that's scary, right? And so there are often these barriers between disciplines that I find very sad. I actually like going to a business or random industry networking event because this is where connections can get made, that can make the biggest changes. It's not in the industry-specific conferences because everyone's talking about the same technical style that of course, they're making progress and making innovations. But then if you're the only machine learning expert in a room full of aviation experts, you can do so much. You can spark all these little sparks, and after you're gonna have people reducing emissions of flights.
### That's powerful. Wondering if you could add some more context as to why finding meaning in your work is so important?
**Sasha:** Yeah, there's this concept that my mom read about in some magazine ages ago when I was a kid. It's called [Ikigai](https://en.wikipedia.org/wiki/Ikigai), and it's a Japanese concept, it's like how to find the reason or the meaning of life. It's kind of how to find your place in the universe. And it was like you need to find something that has these four elements. Like what you love doing, what you're good at, what the world needs and then what can be a career. I was always like this is my career, but she was always like no because even if you love doing this, but you can't get paid for it, then it's a hard life as well. And so she always asked me this when I was picking my courses at university or even my degree, she'll always be like okay, well is that aligned with things you love and things you're good at? And some things she'd be like yeah, but you're not good at that though. I mean you could really want to do this, but maybe this is not what you're good at.
So I think that it's always been my driving factor in my career. And I feel that it helps feel that you're useful and you're like a positive force in the world. For example, when I was working at Morgan Stanley, I felt that there were interesting problems like I was doing really well, no questions asked, the salary was amazing. No complaints there, but there was missing this what the world needs aspect that was kind of like this itch I couldn’t scratch essentially. But given this framing, this itchy guy, I was like oh, that's what's missing in my life. And so I think that people in general, not only in machine learning, it's good to think about not only what you're good at, but also what you love doing, what motivates you, why you would get out of bed in the morning and of course having this aspect of what the world needs. And it doesn't have to be like solving world hunger, it can be on a much smaller scale or on a much more conceptual scale.
For example, what I feel like we're doing at Hugging Face is really that machine learning needs more open source code, more model sharing, but not because it's gonna solve any one particular problem, because it can contribute to a spectrum of problems. Anything from reproducibility to compatibility to product, but there's like the world needs this to some extent. And so I think that really helped me converge on Hugging Face as being maybe the world doesn't necessarily need better social networks because a lot of people doing AI research in the context of social media or these big tech companies. Maybe the world doesn't necessarily need that, maybe not right now, maybe what the world needs is something different. And so this kind of four-part framing really helped me find meaning in my career and my life in general, trying to find all these four elements.
### What other examples or applications do you find and see potential meaning in AI machine learning?
**Sasha:** I think that an often overlooked aspect is accessibility and I guess democratization, but like making AI easier for non-specialists. Because can you imagine if I don't know anyone like a journalist or a doctor or any profession you can think of could easily train or use an AI model. Because I feel like yeah, for sure we do AI in medicine and healthcare, but it's from a very AI machine learning angle. But if we had more doctors who were empowered to create more tools or any profession like a baker… I actually have a friend who has a bakery here in Montreal and he was like yeah, well can AI help me make better bread? And I was like probably, yeah. I'm sure that if you do some kind of experimentation and he's like oh, I can install a camera in my oven. And I was like oh yeah, you could do that I guess. I mean we were talking about it and you know, actually, bread is pretty fickle, you need the right humidity, and it actually takes a lot of experimentation and a lot of know-how from ‘boulangers’ [‘bakers’]. And the same thing for croissants, his croissants are so good and he's like yeah, well you need to really know the right butter, etc. And he was like I want to make an AI model that will help bake bread. And I was like I don't even know how to help you start, like where do you start doing that?
So accessibility is such an important part. For example, the internet has become so accessible nowadays. Anyone can navigate, and initially, it was a lot less so I think that AI still has some road to travel in order to become a more accessible and democratic tool.
### And you've talked before about the power of data and how it's not talked about enough.
**Sasha:** Yeah, four or five years ago, I went to Costa Rica with my husband on a trip. We were just looking on a map and then I found this research center that was at the edge of the world. It was like being in the middle of nowhere. We had to take a car on a dirt road, then a first boat then a second boat to get there. And they're in the middle of the jungle and they essentially study the jungle and they have all these camera traps that are automatically activated, that are all over the jungle. And then every couple of days they have to hike from camera to camera to switch out the SD cards. And then they take these SD cards back to the station and then they have a laptop and they have to go through every picture it took. And of course, there are a lot of false positives because of wind or whatever, like an animal moving really fast, so there's literally maybe like 5% of actual good images. And I was like why aren't they using it to track biodiversity? And they'd no, we saw a Jaguar on blah, blah, blah at this location because they have a bunch of them.
Then they would try to track if a Jaguar or another animal got killed, if it had babies, or if it looked injured; like all of these different things. And then I was like, I'm sure a part of that could be automated, at least the filtering process of taking out the images that are essentially not useful, but they had graduate students or whatever doing it. But still, there are so many examples like this domain in all areas. And just having these little tools, I'm not saying that because I think we're not there yet, completely replacing scientists in this kind of task, but just small components that are annoying and time-consuming, then machine learning can help bridge that gap.
### Wow. That is so interesting!
**Sasha:** It's actually really, camera trap data is a really huge part of tracking biodiversity. It's used for birds and other animals. It's used in a lot of cases and actually, there's been Kaggle competitions for the last couple of years around camera trap data. And essentially during the year, they have camera traps in different places like Kenya has a bunch and Tanzania as well. And then at the end of the year, they have this big Kaggle competition of recognizing different species of animals. Then after that they deployed the models, and then they update them every year.
So it's picking up, but there's just a lot of data, as you said. So each ecosystem is unique and so you need a model that's gonna be trained on exactly. You can't take a model from Kenya and make it work in Costa Rica, that's not gonna work. You need data, you need experts to train the model, and so there are a lot of elements that need to converge in order for you to be able to do this. Kind of like AutoTrain, Hugging Face has one, but even simpler where biodiversity researchers in Costa Rica could be like these are my images, help me figure out which ones are good quality and the types of animals that are on them. And they could just drag and drop the images like a web UI or something. And then they had this model that's like, here are the 12 images of Jaguars, this one is injured, this one has a baby, etc.
### Do you have insights for teams that are trying to solve for things like this with machine learning, but just lack the necessary data?
**Sasha:** Yeah, I guess another anecdote, I have a lot of these anecdotes, but at some point we wanted to organize an AI for social good hackathon here in Montreal like three or three or four years ago. And then we were gonna contact all these NGOs, like soup kitchens, homeless shelters in Montreal. And we started going to these places and then we're like okay, where's your data? And they're like, “What data?” I'm like, “Well don't you keep track of how many people you have in your homeless shelter or if they come back,” and they're like “No.” And then they're like, “But on the other hand, we have these problems of either people disappearing and we don't know where they are or people staying for a long time. And then at a certain point we're supposed to not let them stand.” They had a lot of issues, for example, in the food kitchen, they had a lot of wasted food because they had trouble predicting how many people would arrive. And sometimes they're like yeah, we noticed that in October, usually there are fewer people, but we don't really have any data to support that.
So we completely canceled the hackathon, then instead we did, I think we call them data literacy or digital literacy workshops. So essentially we went to these places if they were interested and we gave one or two-hour workshops about how to use a spreadsheet and figure out what they wanted to track. Because sometimes they didn't even know what kind of things they wanted to save or wanted to really have a trace of. So we did a couple of them in some places like we would come back every couple of months and check in. And then a year later we had a couple, especially a food kitchen, we actually managed to make a connection between them, and I don't remember what the company name was anymore, but they essentially did this supply chain management software thing. And so the kitchen was actually able to implement a system where they would track like we got 10 pounds of tomatoes, this many people showed up today, and this is the waste of food we have. Then a year later we were able to do a hackathon to help them reduce food waste.
So that was really cool because we really saw a year and some before they had no trace of anything, they just had intuitions, which were useful, but weren't formal. And then a year later we were able to get data and integrate it into their app, and then they would have a thing saying be careful, your tomatoes are gonna go bad soon because it's been three days since you had them. Or in cases where it's like pasta, it would be six months or a year, and so we implemented a system that would actually give alerts to them. And it was super simple in terms of technology, there was not even much AI in there, but just something that would help them keep track of different categories of food. And so it was a really interesting experience because I realized that yeah, you can come in and be like we're gonna help you do whatever, but if you don't have much data, what are you gonna do?
### Exactly, that's so interesting. That's so amazing that you were able to jump in there and provide that first step; the educational piece of that puzzle to get them set up on something like that.
**Sasha:** Yeah, it's been a while since I organized any hackathons. But I think these community involvement events are really important because they help people learn stuff like we learn that you can't just like barge in and use AI, digital literacy is so much more important and they just never really put the effort into collecting the data, even if they needed it. Or they didn't know what could be done and things like that. So taking this effort or five steps back and helping improve tech skills, generally speaking, is a really useful contribution that people don't really realize is an option, I guess.
### What industries are you most excited to see machine learning be applied to?
**Sasha:** Climate change! Yeah, the environment is kind of my number one. Education has always been something that I've really been interested in and I've kind of always been waiting. I did my Ph.D. in education and AI, like how AI can be used in education. I keep waiting for it to finally hit a certain peak, but I guess there are a lot of contextual elements and stuff like that, but I think AI, machine learning, and education can be used in so many different ways.
For example, what I was working on during my Ph.D. was how to help pick activities, like learning activities and exercises that are best suited for learners. Instead of giving all kids or adults or whatever the same exercise to help them focus on their weak knowledge points, weak skills, and focusing on those. So instead of like a one size fits all approach. And not replacing the teacher, but tutoring more, like okay, you learn a concept in school, and help you work on it. And you have someone figure this one out really fast and they don't need those exercises, but someone else could need more time to practice. And I think that there is so much that can be done, but I still don't see it really being used, but I think it's potentially really impactful.
### All right, so we're going to dive into rapid-fire questions. If you could go back and do one thing differently at the start of your machine learning career, what would it be?
**Sasha:** I would spend more time focusing on math. So as I said, my parents are mathematicians and they would always give me extra math exercises. And they would always be like math is universal, math, math, math. So when you get force-fed things in your childhood, you don't necessarily appreciate them later, and so I was like no, languages. And so for a good part of my university studies, I was like no math, only humanities. And so I feel like if I had been a bit more open from the beginning and realized the potential of math, even in linguistics or a lot of things, I think I would've come to where I'm at much faster than spending three years being like no math, no math.
I remember in grade 12, my final year of high school, my parents made me sign up for a math competition, like an Olympiad and I won it. Then I remember I had a medal and I put it on my mom and I'm like “Now leave me alone, I'm not gonna do any more math in my life.” And she was like “Yeah, yeah.” And then after that, when I was picking my Ph.D. program, she's like “Oh I see there are math classes, eh? because you're doing machine learning, eh?”, and I was like “No,” but yeah, I should have gotten over my initial distaste for math a lot quicker.
### That's so funny, and it’s interesting to hear that because I often hear people say you need to know less and less math, the more advanced some of these ML libraries and programs get.
**Sasha:** Definitely, but I think having a good base, I'm not saying you have to be a super genius, but having this intuition. Like when I was working with Yoshua for example, he's a total math genius and just the facility of interpreting results or understanding behaviors of a machine learning model just because math is so second nature. Whereas for me I have to be like, okay, so I'm gonna write this equation with the loss function. I'm gonna try to understand the consequences, etc., and it's a bit less automatic, but it's a skill that you can develop. It's not necessarily theoretical, it could also be experimental knowledge. But just having this really solid math background helps you get there quicker, you couldn't really skip a few steps.
### That was brilliant. And you can ask your parents for help?
**Sasha:** No, I refuse to ask my parents for help, no way. Plus since they're like theoretical mathematicians, they think machine learning is just for people who aren't good at math and who are lazy or whatever. And so depending on whatever area you're in, there's pure mathematicians, theoretical mathematics, applied mathematicians, there's like statisticians, and there are all these different camps.
And so I remember my little brother also was thinking of going to machine learning, and my dad was like no, stay in theoretical math, that's where all the geniuses are. He was like “No, machine learning is where math goes to die,” and I was like “Dad, I’m here!” And he was like “Well I'd rather your brother stayed in something more refined,” and I was like “That's not fair.”
So yeah, there are a lot of empirical aspects in machine learning, and a lot of trial and error, like you're tuning hyperparameters and you don't really know why. And so I think formal mathematicians, unless there's like a formula, they don't think ML is real or legit.
### So besides maybe a mathematical foundation, what advice would you give to someone looking to get into machine learning?
**Sasha:** I think getting your hands dirty and starting out with I don't know, Jupyter Notebooks or coding exercises, things like that. Especially if you do have specific angles or problems you want to get into or just ideas in general, and so starting to try. I remember I did a summer school in machine learning when I was at the beginning of my Ph.D., I think. And then it was really interesting, but then all these examples were so disconnected. I don't remember what the data was, like cats versus dogs, I don't know, but like, why am I gonna use that? And then they're like part of the exercise was to find something that you want to use, like a classifier essentially to do.
Then I remember I got pictures of flowers or something, and I got super into it. I was like yeah, see, it confuses this flower and that flower because they're kind of similar. I understand I need more images, and I got super into it and that's when it clicked in my head, it's not only this super abstract classification. Or like oh yeah, I remember we were using this data app called [MNIST](https://huggingface.co/datasets/mnist) which is super popular because it's like handwritten digits and they're really small, and the network goes fast. So people use it a lot in the beginning of machine learning courses. And I was like who cares, I don't want to classify digits, like whatever, right? And then when they let us pick our own images, all of a sudden it gets a lot more personal, interesting, and captivating. So I think that if people are stuck in a rut, they can really focus on things that interest them. For example, get some climate change data and start playing around with it and it really makes the process more pleasant.
### I love that, find something that you're interested in.
**Sasha:** Exactly. And one of my favorite projects I worked on was classifying butterflies. We trained neural networks to classify butterflies based on pictures people took and it was so much fun. You learn so much, and then you're also solving a problem that you understand how it's gonna be used, and so it was such a great thing to be involved in. And I wish that everyone had found this kind of interest in the work they do because you really feel like you're making a difference, and it's cool, it's fun and it's interesting, and you want to do more. For example, this project was done in partnership with the Montreal insectarium, which is a museum for insects. And I kept in touch with a lot of these people and then they just renovated the insectarium and they're opening it after like three years of renovation this weekend.
They also invited me and my family to the opening, and I'm so excited to go there. You could actually handle insects, they’re going to have stick bugs, and they're gonna have a big greenhouse where there are butterflies everywhere. And in that greenhouse, I mean you have to install the app, but you can take pictures of butterflies, then it uses our AI network to identify them. And I'm so excited to go there to use the app and to see my kids using it and to see this whole thing. Because of the old version, they would give you this little pamphlet with pictures of butterflies and you have to go find them. I just can't wait to see the difference between that static representation and this actual app that you could use to take pictures of butterflies.
### Oh my gosh. And how cool to see something that you created being used like that.
**Sasha:** Exactly. And even if it's not like fighting climate change, I think it can make a big difference in helping people appreciate nature and biodiversity and taking things from something that's so abstract and two-dimensional to something that you can really get involved in and take pictures of. I think that makes a huge difference in terms of our perception and our connection. It helps you make a connection between yourself and nature, for example.
### So should people be afraid of AI taking over the world?
**Sasha:** I think that we're really far from it. I guess it depends on what you mean by taking over the world, but I think that we should be a lot more mindful of what's going on right now. Instead of thinking to the future and being like oh terminator, whatever, and to kind of be aware of how AI's being used in our phones and our lives, and to be more cognizant of that.
Technology or events in general, we have more influence on them than we think by using Alexa, for example, we're giving agency, we're giving not only material or funds to this technology. And we can also participate in it, for example, oh well I'm gonna opt out of my data being used for whatever if I am using this technology. Or I'm gonna read the fine print and figure out what it is that AI is doing in this case, and being more involved in general.
So I think that people are really seeing AI as a very distant potential mega threat, but it's actually a current threat, but on a different scale. It's like a different perception. It's like instead of thinking of this AGI or whatever, start thinking about the small things in our lives that AI is being used for, and then engage with them. And then there's gonna be less chance that AGI is gonna take over the world if you make the more mindful choices about data sharing, about consent, about using technology in certain ways. Like if you find out that your police force in your city is using facial recognition technology, you can speak up about that. That's part of your rights as a citizen in many places. And so it's by engaging yourself, you can have an influence on the future by engaging in the present.
### What are you interested in right now? It could be anything, a movie, a recipe, a podcast, etc.?
**Sasha:** So during the pandemic, or the lockdowns and stuff like that, I got super into plants. I bought so many plants and now we're preparing a garden with my children. So this is the first time I've done this, we've planted seeds like tomatoes, peppers, and cucumbers. I usually just buy them at the groceries when they're already ready, but this time around I was like, no, I want to teach my kids. But I also want to learn what the whole process is. And so we planted them maybe 10 days ago and they're starting to grow. And we're watering them every day, and I think that this is also part of this process of learning more about nature and the conditions that can help plants thrive and stuff like that. So last summer already, we built not just a square essentially that we fill in with dirt, but this year we're trying to make it better. I want to have several levels and stuff like that, so I'm really looking forward to learning more about growing your own food.
### That is so cool. I feel like that's such a grounding activity.
**Sasha:** Yeah, and it's like the polar opposite of what I do. It's great not doing something on my computer, but just going outside and having dirty fingernails. I remember being like who would want to do gardening, it’s so boring, now I'm super into gardening. I can't wait for the weekend to go gardening.
### Yeah, that's great. There's something so rewarding about creating something that you can see touch, feel, and smell as opposed to pushing pixels.
**Sasha:** Exactly, sometimes you spend a whole day grappling with this program that has bugs in it and it's not working. You're so frustrating, and then you go outside and you're like, but I have cherry tomatoes, it's all good.
### What are some of your favorite machine learning papers?
**Sasha:** My favorite currently, papers by a researcher or by [Abeba Birhane](https://twitter.com/Abebab) who's a researcher in AI ethics. It's like a completely different way of looking at things. So for example, she wrote [a paper](https://arxiv.org/abs/2106.15590) that just got accepted to [FAcct](https://facctconference.org/), which is fairness in ethics conference in AI. Which was about values and how the way we do machine learning research is actually driven by the things that we value and the things that, for example, if I value a network that has high accuracy, for example, performance, I might be less willing to focus on efficiency. So for example, I'll train a model for a long time, just because I want it to be really accurate. Or like if I want to have something new, like this novelty value, I'm not gonna read the literature and see what people have been doing for whatever 10 years, I'm gonna be like I'm gonna reinvent this.
So she and her co-authors write this really interesting paper about the connection between values that are theoretical, like a kind of metaphysical, and the way that they're instantiated in machine learning. And I found that it was really interesting because typically we don't see it that way. Typically it's like oh, well we have to establish state-of-the-art, we have to establish accuracy and do this and that, and then like site-related work, but it's like a checkbox, you just have to do it. And then they think a lot more in-depth about why we're doing this, and then what are some ultra ways of doing things. For example, doing a trade off between efficiency and accuracy, like if you have a model that's slightly less accurate, but that's a lot more efficient and trains faster, that could be a good way of democratizing AI because people need less computational resources to train a model. And so there are all these different connections that they make that I find it really cool.
### Wow, we'll definitely be linking to that paper as well, so people can check that out. Yeah, very cool. Anything else you'd like to share? Maybe things you're working on or that you would like people to know about?
**Sasha:** Yeah, something I'm working on outside of Big Science is on evaluation and how we evaluate models. Well kind of to what Ababa talks about in her paper, but even from just a pure machine learning perspective, what are the different ways that we can evaluate models and compare them on different aspects, I guess. Not only accuracy but efficiency and carbon emissions and things like that. So there's a project that started a month or ago on how to evaluate in a way that's not only performance-driven, but takes into account different aspects essentially. And I think that this has been a really overlooked aspect of machine learning, like people typically just once again and just check off like oh, you have to evaluate this and that and that, and then submit the paper. There are also these interesting trade-offs that we could be doing and things that we could be measuring that we're not.
For example, if you have a data set and you have an average accuracy, is the accuracy the same again in different subsets of the data set, like are there for example, patterns that you can pick up on that will help you improve your model, but also make it fairer? I guess the typical example is like image recognition, does it do the same in different… Well the famous [Gender Shades](http://gendershades.org/) paper about the algorithm did better on white men than African American women, but you could do that about anything. Not only gender and race, but you could do that for images, color or types of objects or angles. Like is it good for images from above or images from street level. There are all these different ways of analyzing accuracy or performance that we haven't really looked at because it's typically more time-consuming. And so we want to make tools to help people delve deeper into the results and understand their models better.
### Where can people find you online?
**Sasha:** I'm on [Twitter @SashaMTL](https://twitter.com/SashaMTL), and that's about it. I have a [website](https://www.sashaluccioni.com/), I don't update it enough, but Twitter I think is the best.
### Perfect. We can link to that too. Sasha, thank you so much for joining me today, this has been so insightful and amazing. I really appreciate it.
**Sasha:** Thanks, Britney.
### Thank you for listening to Machine Learning Experts!
_If you or someone you know is interested in direct access to leading ML experts like Sasha who are ready to help accelerate your ML project, go to <a href="https://huggingface.co/support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=sasha_interview_article">hf.co/support</a> to learn more._ ❤️
| huggingface/blog/blob/main/sasha-luccioni-interview.md |
`@gradio/markdown`
```html
<script>
import { BaseMarkdown, MarkdownCode, BaseExample } from `@gradio/markdown`;
</script>
```
BaseMarkdown
```javascript
export let elem_id = "";
export let elem_classes: string[] = [];
export let visible = true;
export let value: string;
export let min_height = false;
export let rtl = false;
export let sanitize_html = true;
export let line_breaks = false;
export let latex_delimiters: {
left: string;
right: string;
display: boolean;
}[];
```
MarkdownCode
```javascript
export let chatbot = true;
export let message: string;
export let sanitize_html = true;
export let latex_delimiters: {
left: string;
right: string;
display: boolean;
}[] = [];
export let render_markdown = true;
export let line_breaks = true;
```
BaseExample
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
export let sanitize_html: boolean;
export let line_breaks: boolean;
export let latex_delimiters: {
left: string;
right: string;
display: boolean;
}[];
``` | gradio-app/gradio/blob/main/js/markdown/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Image variation
The Stable Diffusion model can also generate variations from an input image. It uses a fine-tuned version of a Stable Diffusion model by [Justin Pinkney](https://www.justinpinkney.com/) from [Lambda](https://lambdalabs.com/).
The original codebase can be found at [LambdaLabsML/lambda-diffusers](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) and additional official checkpoints for image variation can be found at [lambdalabs/sd-image-variations-diffusers](https://huggingface.co/lambdalabs/sd-image-variations-diffusers).
<Tip>
Make sure to check out the Stable Diffusion [Tips](./overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
</Tip>
## StableDiffusionImageVariationPipeline
[[autodoc]] StableDiffusionImageVariationPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/image_variation.md |
WebDataset
[WebDataset](https://github.com/webdataset/webdataset) is a library to write I/O pipelines for large datasets.
Since it supports streaming data using HTTP, you can use the Hugging Face data files URLs to stream a dataset in WebDataset format:
First you need to [Login with your Hugging Face account](../huggingface_hub/quick-start#login), for example using:
```
huggingface-cli login
```
And then you can stream Hugging Face datasets in WebDataset:
```python
>>> import webdataset as wds
>>> from huggingface_hub import HfFolder
>>> hf_token = HfFolder().get_token()
>>> dataset = wds.WebDataset(f"pipe:curl -s -L https://huggingface.co/datasets/username/my_wds_dataset/resolve/main/train-000000.tar -H 'Authorization:Bearer {hf_token}'")
```
| huggingface/hub-docs/blob/main/docs/hub/datasets-webdataset.md |
Pull requests and Discussions
Hub Pull requests and Discussions allow users to do community contributions to repositories. Pull requests and discussions work the same for all the repo types.
At a high level, the aim is to build a simpler version of other git hosts' (like GitHub's) PRs and Issues:
- no forks are involved: contributors push to a special `ref` branch directly on the source repo.
- there's no hard distinction between discussions and PRs: they are essentially the same so they are displayed in the same lists.
- they are streamlined for ML (i.e. models/datasets/spaces repos), not arbitrary repos.
_Note, Pull Requests and discussions can be enabled or disabled from the [repository settings](./repositories-settings#disabling-discussions-pull-requests)_
## List
By going to the community tab in any repository, you can see all Discussions and Pull requests. You can also filter to only see the ones that are open.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-list.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-list-dark.png"/>
</div>
## View
The Discussion page allows you to see the comments from different users. If it's a Pull Request, you can see all the changes by going to the Files changed tab.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-view.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-view-dark.png"/>
</div>
## Editing a Discussion / Pull request title
If you opened a PR or discussion, are the author of the repository, or have write access to it, you can edit the discussion title by clicking on the pencil button.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-edit-title.PNG"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-edit-title-dark.PNG"/>
</div>
## Pin a Discussion / Pull Request
If you have write access to a repository, you can pin discussions and Pull Requests. Pinned discussions appear at the top of all the discussions.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-pin.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-pin-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-pinned.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-pinned-dark.png"/>
</div>
## Lock a Discussion / Pull Request
If you have write access to a repository, you can lock discussions or Pull Requests. Once a discussion is locked, previous comments are still visible and users won't be able to add new comments.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-lock.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-lock-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-locked.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-locked-dark.png"/>
</div>
## Comment edition and moderation
If you wrote a comment or have write access to the repository, you can edit the content of the comment from the contextual menu in the top-right corner of the comment box.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-menu.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-menu-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-menu-edit.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-menu-edit-dark.png"/>
</div>
Once the comment has been edited, a new link will appear above the comment. This link shows the edit history.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-edit-link.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-edit-link-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-edit-history.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-edit-history-dark.png"/>
</div>
You can also hide a comment. Hiding a comment is irreversible, and nobody will be able to see its content nor edit it anymore.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-hidden.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/discussions-comment-hidden-dark.png"/>
</div>
Read also [moderation](./moderation) to see how to report an abusive comment.
## Can I use Markdown and LaTeX in my comments and discussions?
Yes! You can use Markdown to add formatting to your comments. Additionally, you can utilize LaTeX for mathematical typesetting, your formulas will be rendered with [KaTeX](https://katex.org/) before being parsed in Markdown.
For LaTeX equations, you have to use the following delimiters:
- `$$ ... $$` for display mode
- `\\(...\\)` for inline mode (no space between the slashes and the parenthesis).
## How do I manage Pull requests locally?
Let's assume your PR number is 42.
```bash
git fetch origin refs/pr/42:pr/42
git checkout pr/42
# Do your changes
git add .
git commit -m "Add your change"
git push origin pr/42:refs/pr/42
```
### Draft mode
Draft mode is the default status when opening a new Pull request from scratch in "Advanced mode". With this status, other contributors know that your Pull request is under work and it cannot be merged. When your branch is ready, just hit the "Publish" button to change the status of the Pull request to "Open". Note that once published you cannot go back to draft mode.
## Pull requests advanced usage
### Where in the git repo are changes stored?
Our Pull requests do not use forks and branches, but instead custom "branches" called `refs` that are stored directly on the source repo.
[Git References](https://git-scm.com/book/en/v2/Git-Internals-Git-References) are the internal machinery of git which already stores tags and branches.
The advantage of using custom refs (like `refs/pr/42` for instance) instead of branches is that they're not fetched (by default) by people (including the repo "owner") cloning the repo, but they can still be fetched on demand.
### Fetching all Pull requests: for git magicians 🧙♀️
You can tweak your local **refspec** to fetch all Pull requests:
1. Fetch
```bash
git fetch origin refs/pr/*:refs/remotes/origin/pr/*
```
2. create a local branch tracking the ref
```bash
git checkout pr/{PR_NUMBER}
# for example: git checkout pr/42
```
3. IF you make local changes, to push to the PR ref:
```bash
git push origin pr/{PR_NUMBER}:refs/pr/{PR_NUMBER}
# for example: git push origin pr/42:refs/pr/42
```
| huggingface/hub-docs/blob/main/docs/hub/repositories-pull-requests-discussions.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CLVP
## Overview
The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
The abstract from the paper is the following:
*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
## Usage tips
1. CLVP is an integral part of the Tortoise TTS model.
2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
## Brief Explanation:
- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
Example :
```python
>>> import datasets
>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
>>> text = "This is an example text."
>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
>>> sample = ds[0]["audio"]
>>> # Define processor and model.
>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
>>> # Generate processor output and model output.
>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
>>> generated_output = model.generate(**processor_output)
```
## ClvpConfig
[[autodoc]] ClvpConfig
- from_sub_model_configs
## ClvpEncoderConfig
[[autodoc]] ClvpEncoderConfig
## ClvpDecoderConfig
[[autodoc]] ClvpDecoderConfig
## ClvpTokenizer
[[autodoc]] ClvpTokenizer
- save_vocabulary
## ClvpFeatureExtractor
[[autodoc]] ClvpFeatureExtractor
- __call__
## ClvpProcessor
[[autodoc]] ClvpProcessor
- __call__
- decode
- batch_decode
## ClvpModelForConditionalGeneration
[[autodoc]] ClvpModelForConditionalGeneration
- forward
- generate
- get_text_features
- get_speech_features
## ClvpForCausalLM
[[autodoc]] ClvpForCausalLM
## ClvpModel
[[autodoc]] ClvpModel
## ClvpEncoder
[[autodoc]] ClvpEncoder
## ClvpDecoder
[[autodoc]] ClvpDecoder
| huggingface/transformers/blob/main/docs/source/en/model_doc/clvp.md |
Feature Extraction
All of the models in `timm` have consistent mechanisms for obtaining various types of features from the model for tasks besides classification.
## Penultimate Layer Features (Pre-Classifier Features)
The features from the penultimate model layer can be obtained in several ways without requiring model surgery (although feel free to do surgery). One must first decide if they want pooled or un-pooled features.
### Unpooled
There are three ways to obtain unpooled features.
Without modifying the network, one can call `model.forward_features(input)` on any model instead of the usual `model(input)`. This will bypass the head classifier and global pooling for networks.
If one wants to explicitly modify the network to return unpooled features, they can either create the model without a classifier and pooling, or remove it later. Both paths remove the parameters associated with the classifier from the network.
#### forward_features()
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('xception41', pretrained=True)
>>> o = m(torch.randn(2, 3, 299, 299))
>>> print(f'Original shape: {o.shape}')
>>> o = m.forward_features(torch.randn(2, 3, 299, 299))
>>> print(f'Unpooled shape: {o.shape}')
```
Output:
```text
Original shape: torch.Size([2, 1000])
Unpooled shape: torch.Size([2, 2048, 10, 10])
```
#### Create with no classifier and pooling
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('resnet50', pretrained=True, num_classes=0, global_pool='')
>>> o = m(torch.randn(2, 3, 224, 224))
>>> print(f'Unpooled shape: {o.shape}')
```
Output:
```text
Unpooled shape: torch.Size([2, 2048, 7, 7])
```
#### Remove it later
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('densenet121', pretrained=True)
>>> o = m(torch.randn(2, 3, 224, 224))
>>> print(f'Original shape: {o.shape}')
>>> m.reset_classifier(0, '')
>>> o = m(torch.randn(2, 3, 224, 224))
>>> print(f'Unpooled shape: {o.shape}')
```
Output:
```text
Original shape: torch.Size([2, 1000])
Unpooled shape: torch.Size([2, 1024, 7, 7])
```
### Pooled
To modify the network to return pooled features, one can use `forward_features()` and pool/flatten the result themselves, or modify the network like above but keep pooling intact.
#### Create with no classifier
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('resnet50', pretrained=True, num_classes=0)
>>> o = m(torch.randn(2, 3, 224, 224))
>>> print(f'Pooled shape: {o.shape}')
```
Output:
```text
Pooled shape: torch.Size([2, 2048])
```
#### Remove it later
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('ese_vovnet19b_dw', pretrained=True)
>>> o = m(torch.randn(2, 3, 224, 224))
>>> print(f'Original shape: {o.shape}')
>>> m.reset_classifier(0)
>>> o = m(torch.randn(2, 3, 224, 224))
>>> print(f'Pooled shape: {o.shape}')
```
Output:
```text
Original shape: torch.Size([2, 1000])
Pooled shape: torch.Size([2, 1024])
```
## Multi-scale Feature Maps (Feature Pyramid)
Object detection, segmentation, keypoint, and a variety of dense pixel tasks require access to feature maps from the backbone network at multiple scales. This is often done by modifying the original classification network. Since each network varies quite a bit in structure, it's not uncommon to see only a few backbones supported in any given obj detection or segmentation library.
`timm` allows a consistent interface for creating any of the included models as feature backbones that output feature maps for selected levels.
A feature backbone can be created by adding the argument `features_only=True` to any `create_model` call. By default 5 strides will be output from most models (not all have that many), with the first starting at 2 (some start at 1 or 4).
### Create a feature map extraction model
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('resnest26d', features_only=True, pretrained=True)
>>> o = m(torch.randn(2, 3, 224, 224))
>>> for x in o:
... print(x.shape)
```
Output:
```text
torch.Size([2, 64, 112, 112])
torch.Size([2, 256, 56, 56])
torch.Size([2, 512, 28, 28])
torch.Size([2, 1024, 14, 14])
torch.Size([2, 2048, 7, 7])
```
### Query the feature information
After a feature backbone has been created, it can be queried to provide channel or resolution reduction information to the downstream heads without requiring static config or hardcoded constants. The `.feature_info` attribute is a class encapsulating the information about the feature extraction points.
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('regnety_032', features_only=True, pretrained=True)
>>> print(f'Feature channels: {m.feature_info.channels()}')
>>> o = m(torch.randn(2, 3, 224, 224))
>>> for x in o:
... print(x.shape)
```
Output:
```text
Feature channels: [32, 72, 216, 576, 1512]
torch.Size([2, 32, 112, 112])
torch.Size([2, 72, 56, 56])
torch.Size([2, 216, 28, 28])
torch.Size([2, 576, 14, 14])
torch.Size([2, 1512, 7, 7])
```
### Select specific feature levels or limit the stride
There are two additional creation arguments impacting the output features.
* `out_indices` selects which indices to output
* `output_stride` limits the feature output stride of the network (also works in classification mode BTW)
`out_indices` is supported by all models, but not all models have the same index to feature stride mapping. Look at the code or check feature_info to compare. The out indices generally correspond to the `C(i+1)th` feature level (a `2^(i+1)` reduction). For most models, index 0 is the stride 2 features, and index 4 is stride 32.
`output_stride` is achieved by converting layers to use dilated convolutions. Doing so is not always straightforward, some networks only support `output_stride=32`.
```py
>>> import torch
>>> import timm
>>> m = timm.create_model('ecaresnet101d', features_only=True, output_stride=8, out_indices=(2, 4), pretrained=True)
>>> print(f'Feature channels: {m.feature_info.channels()}')
>>> print(f'Feature reduction: {m.feature_info.reduction()}')
>>> o = m(torch.randn(2, 3, 320, 320))
>>> for x in o:
... print(x.shape)
```
Output:
```text
Feature channels: [512, 2048]
Feature reduction: [8, 8]
torch.Size([2, 512, 40, 40])
torch.Size([2, 2048, 40, 40])
```
| huggingface/pytorch-image-models/blob/main/hfdocs/source/feature_extraction.mdx |
Metric Card for Pearson Correlation Coefficient (pearsonr)
## Metric Description
Pearson correlation coefficient and p-value for testing non-correlation.
The Pearson correlation coefficient measures the linear relationship between two datasets. The calculation of the p-value relies on the assumption that each dataset is normally distributed. Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations imply that as x increases, so does y. Negative correlations imply that as x increases, y decreases.
The p-value roughly indicates the probability of an uncorrelated system producing datasets that have a Pearson correlation at least as extreme as the one computed from these datasets.
## How to Use
This metric takes a list of predictions and a list of references as input
```python
>>> pearsonr_metric = datasets.load_metric("pearsonr")
>>> results = pearsonr_metric.compute(predictions=[10, 9, 2.5, 6, 4], references=[1, 2, 3, 4, 5])
>>> print(round(results['pearsonr']), 2)
['-0.74']
```
### Inputs
- **predictions** (`list` of `int`): Predicted class labels, as returned by a model.
- **references** (`list` of `int`): Ground truth labels.
- **return_pvalue** (`boolean`): If `True`, returns the p-value, along with the correlation coefficient. If `False`, returns only the correlation coefficient. Defaults to `False`.
### Output Values
- **pearsonr**(`float`): Pearson correlation coefficient. Minimum possible value is -1. Maximum possible value is 1. Values of 1 and -1 indicate exact linear positive and negative relationships, respectively. A value of 0 implies no correlation.
- **p-value**(`float`): P-value, which roughly indicates the probability of an The p-value roughly indicates the probability of an uncorrelated system producing datasets that have a Pearson correlation at least as extreme as the one computed from these datasets. Minimum possible value is 0. Maximum possible value is 1. Higher values indicate higher probabilities.
Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations imply that as x increases, so does y. Negative correlations imply that as x increases, y decreases.
Output Example(s):
```python
{'pearsonr': -0.7}
```
```python
{'p-value': 0.15}
```
#### Values from Popular Papers
### Examples
Example 1-A simple example using only predictions and references.
```python
>>> pearsonr_metric = datasets.load_metric("pearsonr")
>>> results = pearsonr_metric.compute(predictions=[10, 9, 2.5, 6, 4], references=[1, 2, 3, 4, 5])
>>> print(round(results['pearsonr'], 2))
-0.74
```
Example 2-The same as Example 1, but that also returns the `p-value`.
```python
>>> pearsonr_metric = datasets.load_metric("pearsonr")
>>> results = pearsonr_metric.compute(predictions=[10, 9, 2.5, 6, 4], references=[1, 2, 3, 4, 5], return_pvalue=True)
>>> print(sorted(list(results.keys())))
['p-value', 'pearsonr']
>>> print(round(results['pearsonr'], 2))
-0.74
>>> print(round(results['p-value'], 2))
0.15
```
## Limitations and Bias
As stated above, the calculation of the p-value relies on the assumption that each data set is normally distributed. This is not always the case, so verifying the true distribution of datasets is recommended.
## Citation(s)
```bibtex
@article{2020SciPy-NMeth,
author = {Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and
Haberland, Matt and Reddy, Tyler and Cournapeau, David and
Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and
Bright, Jonathan and {van der Walt}, St{\'e}fan J. and
Brett, Matthew and Wilson, Joshua and Millman, K. Jarrod and
Mayorov, Nikolay and Nelson, Andrew R. J. and Jones, Eric and
Kern, Robert and Larson, Eric and Carey, C J and
Polat, {\.I}lhan and Feng, Yu and Moore, Eric W. and
{VanderPlas}, Jake and Laxalde, Denis and Perktold, Josef and
Cimrman, Robert and Henriksen, Ian and Quintero, E. A. and
Harris, Charles R. and Archibald, Anne M. and
Ribeiro, Ant{\^o}nio H. and Pedregosa, Fabian and
{van Mulbregt}, Paul and {SciPy 1.0 Contributors}},
title = {{{SciPy} 1.0: Fundamental Algorithms for Scientific
Computing in Python}},
journal = {Nature Methods},
year = {2020},
volume = {17},
pages = {261--272},
adsurl = {https://rdcu.be/b08Wh},
doi = {10.1038/s41592-019-0686-2},
}
```
## Further References
| huggingface/datasets/blob/main/metrics/pearsonr/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Chinese-CLIP
## Overview
The Chinese-CLIP model was proposed in [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
Chinese-CLIP is an implementation of CLIP (Radford et al., 2021) on a large-scale dataset of Chinese image-text pairs. It is capable of performing cross-modal retrieval and also playing as a vision backbone for vision tasks like zero-shot image classification, open-domain object detection, etc. The original Chinese-CLIP code is released [at this link](https://github.com/OFA-Sys/Chinese-CLIP).
The abstract from the paper is the following:
*The tremendous success of CLIP (Radford et al., 2021) has promoted the research and application of contrastive learning for vision-language pretraining. In this work, we construct a large-scale dataset of image-text pairs in Chinese, where most data are retrieved from publicly available datasets, and we pretrain Chinese CLIP models on the new dataset. We develop 5 Chinese CLIP models of multiple sizes, spanning from 77 to 958 million parameters. Furthermore, we propose a two-stage pretraining method, where the model is first trained with the image encoder frozen and then trained with all parameters being optimized, to achieve enhanced model performance. Our comprehensive experiments demonstrate that Chinese CLIP can achieve the state-of-the-art performance on MUGE, Flickr30K-CN, and COCO-CN in the setups of zero-shot learning and finetuning, and it is able to achieve competitive performance in zero-shot image classification based on the evaluation on the ELEVATER benchmark (Li et al., 2022). Our codes, pretrained models, and demos have been released.*
The Chinese-CLIP model was contributed by [OFA-Sys](https://huggingface.co/OFA-Sys).
## Usage example
The code snippet below shows how to compute image & text features and similarities:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import ChineseCLIPProcessor, ChineseCLIPModel
>>> model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
>>> processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
>>> url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # Squirtle, Bulbasaur, Charmander, Pikachu in English
>>> texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
>>> # compute image feature
>>> inputs = processor(images=image, return_tensors="pt")
>>> image_features = model.get_image_features(**inputs)
>>> image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
>>> # compute text features
>>> inputs = processor(text=texts, padding=True, return_tensors="pt")
>>> text_features = model.get_text_features(**inputs)
>>> text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
>>> # compute image-text similarity scores
>>> inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
```
Currently, following scales of pretrained Chinese-CLIP models are available on 🤗 Hub:
- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
## ChineseCLIPConfig
[[autodoc]] ChineseCLIPConfig
- from_text_vision_configs
## ChineseCLIPTextConfig
[[autodoc]] ChineseCLIPTextConfig
## ChineseCLIPVisionConfig
[[autodoc]] ChineseCLIPVisionConfig
## ChineseCLIPImageProcessor
[[autodoc]] ChineseCLIPImageProcessor
- preprocess
## ChineseCLIPFeatureExtractor
[[autodoc]] ChineseCLIPFeatureExtractor
## ChineseCLIPProcessor
[[autodoc]] ChineseCLIPProcessor
## ChineseCLIPModel
[[autodoc]] ChineseCLIPModel
- forward
- get_text_features
- get_image_features
## ChineseCLIPTextModel
[[autodoc]] ChineseCLIPTextModel
- forward
## ChineseCLIPVisionModel
[[autodoc]] ChineseCLIPVisionModel
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/chinese_clip.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Diffusion XL
<Tip warning={true}>
This script is experimental, and it's easy to overfit and run into issues like catastrophic forgetting. Try exploring different hyperparameters to get the best results on your dataset.
</Tip>
[Stable Diffusion XL (SDXL)](https://hf.co/papers/2307.01952) is a larger and more powerful iteration of the Stable Diffusion model, capable of producing higher resolution images.
SDXL's UNet is 3x larger and the model adds a second text encoder to the architecture. Depending on the hardware available to you, this can be very computationally intensive and it may not run on a consumer GPU like a Tesla T4. To help fit this larger model into memory and to speedup training, try enabling `gradient_checkpointing`, `mixed_precision`, and `gradient_accumulation_steps`. You can reduce your memory-usage even more by enabling memory-efficient attention with [xFormers](../optimization/xformers) and using [bitsandbytes'](https://github.com/TimDettmers/bitsandbytes) 8-bit optimizer.
This guide will explore the [train_text_to_image_sdxl.py](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py) training script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/text_to_image
pip install -r requirements_sdxl.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
## Script parameters
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py) and let us know if you have any questions or concerns.
</Tip>
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L129) function. This function provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the bf16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_text_to_image_sdxl.py \
--mixed_precision="bf16"
```
Most of the parameters are identical to the parameters in the [Text-to-image](text2image#script-parameters) training guide, so you'll focus on the parameters that are relevant to training SDXL in this guide.
- `--pretrained_vae_model_name_or_path`: path to a pretrained VAE; the SDXL VAE is known to suffer from numerical instability, so this parameter allows you to specify a better [VAE](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)
- `--proportion_empty_prompts`: the proportion of image prompts to replace with empty strings
- `--timestep_bias_strategy`: where (earlier vs. later) in the timestep to apply a bias, which can encourage the model to either learn low or high frequency details
- `--timestep_bias_multiplier`: the weight of the bias to apply to the timestep
- `--timestep_bias_begin`: the timestep to begin applying the bias
- `--timestep_bias_end`: the timestep to end applying the bias
- `--timestep_bias_portion`: the proportion of timesteps to apply the bias to
### Min-SNR weighting
The [Min-SNR](https://huggingface.co/papers/2303.09556) weighting strategy can help with training by rebalancing the loss to achieve faster convergence. The training script supports predicting either `epsilon` (noise) or `v_prediction`, but Min-SNR is compatible with both prediction types. This weighting strategy is only supported by PyTorch and is unavailable in the Flax training script.
Add the `--snr_gamma` parameter and set it to the recommended value of 5.0:
```bash
accelerate launch train_text_to_image_sdxl.py \
--snr_gamma=5.0
```
## Training script
The training script is also similar to the [Text-to-image](text2image#training-script) training guide, but it's been modified to support SDXL training. This guide will focus on the code that is unique to the SDXL training script.
It starts by creating functions to [tokenize the prompts](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L478) to calculate the prompt embeddings, and to compute the image embeddings with the [VAE](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L519). Next, you'll a function to [generate the timesteps weights](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L531) depending on the number of timesteps and the timestep bias strategy to apply.
Within the [`main()`](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L572) function, in addition to loading a tokenizer, the script loads a second tokenizer and text encoder because the SDXL architecture uses two of each:
```py
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision, use_fast=False
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer_2", revision=args.revision, use_fast=False
)
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision, subfolder="text_encoder_2"
)
```
The [prompt and image embeddings](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L857) are computed first and kept in memory, which isn't typically an issue for a smaller dataset, but for larger datasets it can lead to memory problems. If this is the case, you should save the pre-computed embeddings to disk separately and load them into memory during the training process (see this [PR](https://github.com/huggingface/diffusers/pull/4505) for more discussion about this topic).
```py
text_encoders = [text_encoder_one, text_encoder_two]
tokenizers = [tokenizer_one, tokenizer_two]
compute_embeddings_fn = functools.partial(
encode_prompt,
text_encoders=text_encoders,
tokenizers=tokenizers,
proportion_empty_prompts=args.proportion_empty_prompts,
caption_column=args.caption_column,
)
train_dataset = train_dataset.map(compute_embeddings_fn, batched=True, new_fingerprint=new_fingerprint)
train_dataset = train_dataset.map(
compute_vae_encodings_fn,
batched=True,
batch_size=args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps,
new_fingerprint=new_fingerprint_for_vae,
)
```
After calculating the embeddings, the text encoder, VAE, and tokenizer are deleted to free up some memory:
```py
del text_encoders, tokenizers, vae
gc.collect()
torch.cuda.empty_cache()
```
Finally, the [training loop](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/text_to_image/train_text_to_image_sdxl.py#L943) takes care of the rest. If you chose to apply a timestep bias strategy, you'll see the timestep weights are calculated and added as noise:
```py
weights = generate_timestep_weights(args, noise_scheduler.config.num_train_timesteps).to(
model_input.device
)
timesteps = torch.multinomial(weights, bsz, replacement=True).long()
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Once you’ve made all your changes or you’re okay with the default configuration, you’re ready to launch the training script! 🚀
Let’s train on the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset to generate your own Pokémon. Set the environment variables `MODEL_NAME` and `DATASET_NAME` to the model and the dataset (either from the Hub or a local path). You should also specify a VAE other than the SDXL VAE (either from the Hub or a local path) with `VAE_NAME` to avoid numerical instabilities.
<Tip>
To monitor training progress with Weights & Biases, add the `--report_to=wandb` parameter to the training command. You’ll also need to add the `--validation_prompt` and `--validation_epochs` to the training command to keep track of results. This can be really useful for debugging the model and viewing intermediate results.
</Tip>
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--enable_xformers_memory_efficient_attention \
--resolution=512 \
--center_crop \
--random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--mixed_precision="fp16" \
--report_to="wandb" \
--validation_prompt="a cute Sundar Pichai creature" \
--validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="sdxl-pokemon-model" \
--push_to_hub
```
After you've finished training, you can use your newly trained SDXL model for inference!
<hfoptions id="inference">
<hfoption id="PyTorch">
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("path/to/your/model", torch_dtype=torch.float16).to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipeline(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
</hfoption>
<hfoption id="PyTorch XLA">
[PyTorch XLA](https://pytorch.org/xla) allows you to run PyTorch on XLA devices such as TPUs, which can be faster. The initial warmup step takes longer because the model needs to be compiled and optimized. However, subsequent calls to the pipeline on an input **with the same length** as the original prompt are much faster because it can reuse the optimized graph.
```py
from diffusers import DiffusionPipeline
import torch
import torch_xla.core.xla_model as xm
device = xm.xla_device()
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to(device)
prompt = "A pokemon with green eyes and red legs."
start = time()
image = pipeline(prompt, num_inference_steps=inference_steps).images[0]
print(f'Compilation time is {time()-start} sec')
image.save("pokemon.png")
start = time()
image = pipeline(prompt, num_inference_steps=inference_steps).images[0]
print(f'Inference time is {time()-start} sec after compilation')
```
</hfoption>
</hfoptions>
## Next steps
Congratulations on training a SDXL model! To learn more about how to use your new model, the following guides may be helpful:
- Read the [Stable Diffusion XL](../using-diffusers/sdxl) guide to learn how to use it for a variety of different tasks (text-to-image, image-to-image, inpainting), how to use it's refiner model, and the different types of micro-conditionings.
- Check out the [DreamBooth](dreambooth) and [LoRA](lora) training guides to learn how to train a personalized SDXL model with just a few example images. These two training techniques can even be combined! | huggingface/diffusers/blob/main/docs/source/en/training/sdxl.md |
Gradio Demo: calculator_live
```
!pip install -q gradio
```
```
import gradio as gr
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
return num1 / num2
demo = gr.Interface(
calculator,
[
"number",
gr.Radio(["add", "subtract", "multiply", "divide"]),
"number"
],
"number",
live=True,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/calculator_live/run.ipynb |
Named-Entity Recognition
Related spaces: https://huggingface.co/spaces/rajistics/biobert_ner_demo, https://huggingface.co/spaces/abidlabs/ner, https://huggingface.co/spaces/rajistics/Financial_Analyst_AI
Tags: NER, TEXT, HIGHLIGHT
## Introduction
Named-entity recognition (NER), also known as token classification or text tagging, is the task of taking a sentence and classifying every word (or "token") into different categories, such as names of people or names of locations, or different parts of speech.
For example, given the sentence:
> Does Chicago have any Pakistani restaurants?
A named-entity recognition algorithm may identify:
- "Chicago" as a **location**
- "Pakistani" as an **ethnicity**
and so on.
Using `gradio` (specifically the `HighlightedText` component), you can easily build a web demo of your NER model and share that with the rest of your team.
Here is an example of a demo that you'll be able to build:
$demo_ner_pipeline
This tutorial will show how to take a pretrained NER model and deploy it with a Gradio interface. We will show two different ways to use the `HighlightedText` component -- depending on your NER model, either of these two ways may be easier to learn!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). You will also need a pretrained named-entity recognition model. You can use your own, while in this tutorial, we will use one from the `transformers` library.
### Approach 1: List of Entity Dictionaries
Many named-entity recognition models output a list of dictionaries. Each dictionary consists of an _entity_, a "start" index, and an "end" index. This is, for example, how NER models in the `transformers` library operate:
```py
from transformers import pipeline
ner_pipeline = pipeline("ner")
ner_pipeline("Does Chicago have any Pakistani restaurants")
```
Output:
```bash
[{'entity': 'I-LOC',
'score': 0.9988978,
'index': 2,
'word': 'Chicago',
'start': 5,
'end': 12},
{'entity': 'I-MISC',
'score': 0.9958592,
'index': 5,
'word': 'Pakistani',
'start': 22,
'end': 31}]
```
If you have such a model, it is very easy to hook it up to Gradio's `HighlightedText` component. All you need to do is pass in this **list of entities**, along with the **original text** to the model, together as dictionary, with the keys being `"entities"` and `"text"` respectively.
Here is a complete example:
$code_ner_pipeline
$demo_ner_pipeline
### Approach 2: List of Tuples
An alternative way to pass data into the `HighlightedText` component is a list of tuples. The first element of each tuple should be the word or words that are being classified into a particular entity. The second element should be the entity label (or `None` if they should be unlabeled). The `HighlightedText` component automatically strings together the words and labels to display the entities.
In some cases, this can be easier than the first approach. Here is a demo showing this approach using Spacy's parts-of-speech tagger:
$code_text_analysis
$demo_text_analysis
---
And you're done! That's all you need to know to build a web-based GUI for your NER model.
Fun tip: you can share your NER demo instantly with others simply by setting `share=True` in `launch()`.
| gradio-app/gradio/blob/main/guides/09_other-tutorials/named-entity-recognition.md |
Bonus: Learn to create your own environments with Unity and MLAgents
**You can create your own reinforcement learning environments with Unity and MLAgents**. Using a game engine such as Unity can be intimidating at first, but here are the steps you can take to learn smoothly.
## Step 1: Know how to use Unity
- The best way to learn Unity is to do ["Create with Code" course](https://learn.unity.com/course/create-with-code): it's a series of videos for beginners where **you will create 5 small games with Unity**.
## Step 2: Create the simplest environment with this tutorial
- Then, when you know how to use Unity, you can create your [first basic RL environment using this tutorial](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Learning-Environment-Create-New.md).
## Step 3: Iterate and create nice environments
- Now that you've created your first simple environment you can iterate to more complex ones using the [MLAgents documentation (especially Designing Agents and Agent part)](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/)
- In addition, you can take this free course ["Create a hummingbird environment"](https://learn.unity.com/course/ml-agents-hummingbirds) by [Adam Kelly](https://twitter.com/aktwelve)
Have fun! And if you create custom environments don't hesitate to share them to the `#rl-i-made-this` discord channel.
| huggingface/deep-rl-class/blob/main/units/en/unit5/bonus.mdx |
Gradio Demo: fraud_detector
```
!pip install -q gradio pandas
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/fraud_detector/fraud.csv
```
```
import random
import os
import gradio as gr
def fraud_detector(card_activity, categories, sensitivity):
activity_range = random.randint(0, 100)
drop_columns = [
column for column in ["retail", "food", "other"] if column not in categories
]
if len(drop_columns):
card_activity.drop(columns=drop_columns, inplace=True)
return (
card_activity,
card_activity,
{"fraud": activity_range / 100.0, "not fraud": 1 - activity_range / 100.0},
)
demo = gr.Interface(
fraud_detector,
[
gr.CheckboxGroup(
["retail", "food", "other"], value=["retail", "food", "other"]
),
gr.Slider(1, 3),
],
[
"dataframe",
gr.Label(label="Fraud Level"),
],
examples=[
[os.path.join(os.path.abspath(''), "fraud.csv"), ["retail", "food", "other"], 1.0],
],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/fraud_detector/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Single files
Diffusers supports loading pretrained pipeline (or model) weights stored in a single file, such as a `ckpt` or `safetensors` file. These single file types are typically produced from community trained models. There are three classes for loading single file weights:
- [`FromSingleFileMixin`] supports loading pretrained pipeline weights stored in a single file, which can either be a `ckpt` or `safetensors` file.
- [`FromOriginalVAEMixin`] supports loading a pretrained [`AutoencoderKL`] from pretrained ControlNet weights stored in a single file, which can either be a `ckpt` or `safetensors` file.
- [`FromOriginalControlnetMixin`] supports loading pretrained ControlNet weights stored in a single file, which can either be a `ckpt` or `safetensors` file.
<Tip>
To learn more about how to load single file weights, see the [Load different Stable Diffusion formats](../../using-diffusers/other-formats) loading guide.
</Tip>
## FromSingleFileMixin
[[autodoc]] loaders.single_file.FromSingleFileMixin
## FromOriginalVAEMixin
[[autodoc]] loaders.single_file.FromOriginalVAEMixin
## FromOriginalControlnetMixin
[[autodoc]] loaders.single_file.FromOriginalControlnetMixin | huggingface/diffusers/blob/main/docs/source/en/api/loaders/single_file.md |
Schedulers
For more information on the schedulers, please refer to the [docs](https://huggingface.co/docs/diffusers/api/schedulers/overview). | huggingface/diffusers/blob/main/src/diffusers/schedulers/README.md |
!-- DO NOT EDIT THIS FILE DIRECTLY. INSTEAD EDIT THE `readme_template.md` OR `guides/1)getting_started/1)quickstart.md` TEMPLATES AND THEN RUN `render_readme.py` SCRIPT. -->
<div align="center">
[<img src="readme_files/gradio.svg" alt="gradio" width=400>](https://gradio.app)<br>
[](https://github.com/gradio-app/gradio/actions/workflows/backend.yml)
[](https://github.com/gradio-app/gradio/actions/workflows/ui.yml)
[](https://pypi.org/project/gradio/)
[](https://pypi.org/project/gradio/)

[](https://twitter.com/gradio)
[Website](https://gradio.app)
| [Documentation](https://gradio.app/docs/)
| [Guides](https://gradio.app/guides/)
| [Getting Started](https://gradio.app/getting_started/)
| [Examples](demo/)
| [中文](readme_files/zh-cn#readme)
</div>
# Gradio: Build Machine Learning Web Apps — in Python
Gradio is an open-source Python package that allows you to quickly **build** a demo or web application for your machine learning model, API, or any arbitary Python function. You can then **share** a link to your demo or web application in just a few seconds using Gradio's built-in sharing features. *No JavaScript, CSS, or web hosting experience needed!*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/lcm-screenshot-3.gif" style="padding-bottom: 10px">
It just takes a few lines of Python to create a beautiful demo like the one above, so let's get started 💫
### Installation
**Prerequisite**: Gradio requires [Python 3.8 or higher](https://www.python.org/downloads/)
We recommend installing Gradio using `pip`, which is included by default in Python. Run this in your terminal or command prompt:
```
pip install gradio
```
> [!TIP]
> it is best to install Gradio in a virtual environment. Detailed installation instructions for all common operating systems <a href="https://www.gradio.app/main/guides/installing-gradio-in-a-virtual-environment">are provided here</a>.
### Building Your First Demo
You can run Gradio in your favorite code editor, Jupyter notebook, Google Colab, or anywhere else you write Python. Let's write your first Gradio app:
```python
import gradio as gr
def greet(name, intensity):
return "Hello " * intensity + name + "!"
demo = gr.Interface(
fn=greet,
inputs=["text", "slider"],
outputs=["text"],
)
demo.launch()
```
> [!TIP]
> We shorten the imported name from <code>gradio</code> to <code>gr</code> for better readability of code. This is a widely adopted convention that you should follow so that anyone working with your code can easily understand it.
Now, run your code. If you've written the Python code in a file named, for example, `app.py`, then you would run `python app.py` from the terminal.
The demo below will open in a browser on [http://localhost:7860](http://localhost:7860) if running from a file. If you are running within a notebook, the demo will appear embedded within the notebook.

Type your name in the textbox on the left, drag the slider, and then press the Submit button. You should see a friendly greeting on the right.
> [!TIP]
> When developing locally, you can run your Gradio app in <strong>hot reload mode</strong>, which automatically reloads the Gradio app whenever you make changes to the file. To do this, simply type in <code>gradio</code> before the name of the file instead of <code>python</code>. In the example above, you would type: `gradio app.py` in your terminal. Learn more about hot reloading in the <a href="https://www.gradio.app/guides/developing-faster-with-reload-mode">Hot Reloading Guide</a>.
**Understanding the `Interface` Class**
You'll notice that in order to make your first demo, you created an instance of the `gr.Interface` class. The `Interface` class is designed to create demos for machine learning models which accept one or more inputs, and return one or more outputs.
The `Interface` class has three core arguments:
- `fn`: the function to wrap a user interface (UI) around
- `inputs`: the Gradio component(s) to use for the input. The number of components should match the number of arguments in your function.
- `outputs`: the Gradio component(s) to use for the output. The number of components should match the number of return values from your function.
The `fn` argument is very flexible -- you can pass *any* Python function that you want to wrap with a UI. In the example above, we saw a relatively simple function, but the function could be anything from a music generator to a tax calculator to the prediction function of a pretrained machine learning model.
The `input` and `output` arguments take one or more Gradio components. As we'll see, Gradio includes more than [30 built-in components](https://www.gradio.app/docs/components) (such as the `gr.Textbox()`, `gr.Image()`, and `gr.HTML()` components) that are designed for machine learning applications.
> [!TIP]
> For the `inputs` and `outputs` arguments, you can pass in the name of these components as a string (`"textbox"`) or an instance of the class (`gr.Textbox()`).
If your function accepts more than one argument, as is the case above, pass a list of input components to `inputs`, with each input component corresponding to one of the arguments of the function, in order. The same holds true if your function returns more than one value: simply pass in a list of components to `outputs`. This flexibility makes the `Interface` class a very powerful way to create demos.
We'll dive deeper into the `gr.Interface` on our series on [building Interfaces](https://www.gradio.app/main/guides/the-interface-class).
### Sharing Your Demo
What good is a beautiful demo if you can't share it? Gradio lets you easily share a machine learning demo without having to worry about the hassle of hosting on a web server. Simply set `share=True` in `launch()`, and a publicly accessible URL will be created for your demo. Let's revisit our example demo, but change the last line as follows:
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="textbox", outputs="textbox")
demo.launch(share=True) # Share your demo with just 1 extra parameter 🚀
```
When you run this code, a public URL will be generated for your demo in a matter of seconds, something like:
👉 `https://a23dsf231adb.gradio.live`
Now, anyone around the world can try your Gradio demo from their browser, while the machine learning model and all computation continues to run locally on your computer.
To learn more about sharing your demo, read our dedicated guide on [sharing your Gradio application](https://www.gradio.app/guides/sharing-your-app).
### An Overview of Gradio
So far, we've been discussing the `Interface` class, which is a high-level class that lets to build demos quickly with Gradio. But what else does Gradio do?
#### Chatbots with `gr.ChatInterface`
Gradio includes another high-level class, `gr.ChatInterface`, which is specifically designed to create Chatbot UIs. Similar to `Interface`, you supply a function and Gradio creates a fully working Chatbot UI. If you're interested in creating a chatbot, you can jump straight [our dedicated guide on `gr.ChatInterface`](https://www.gradio.app/guides/creating-a-chatbot-fast).
#### Custom Demos with `gr.Blocks`
Gradio also offers a low-level approach for designing web apps with more flexible layouts and data flows with the `gr.Blocks` class. Blocks allows you to do things like control where components appear on the page, handle complex data flows (e.g. outputs can serve as inputs to other functions), and update properties/visibility of components based on user interaction — still all in Python.
You can build very custom and complex applications using `gr.Blocks()`. For example, the popular image generation [Automatic1111 Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) is built using Gradio Blocks. We dive deeper into the `gr.Blocks` on our series on [building with Blocks](https://www.gradio.app/guides/blocks-and-event-listeners).
#### The Gradio Python & JavaScript Ecosystem
That's the gist of the core `gradio` Python library, but Gradio is actually so much more! Its an entire ecosystem of Python and JavaScript libraries that let you build machine learning applications, or query them programmatically, in Python or JavaScript. Here are other related parts of the Gradio ecosystem:
* [Gradio Python Client](https://www.gradio.app/guides/getting-started-with-the-python-client) (`gradio_client`): query any Gradio app programmatically in Python.
* [Gradio JavaScript Client](https://www.gradio.app/guides/getting-started-with-the-js-client) (`@gradio/client`): query any Gradio app programmatically in JavaScript.
* [Gradio-Lite](https://www.gradio.app/guides/gradio-lite) (`@gradio/lite`): write Gradio apps in Python that run entirely in the browser (no server needed!), thanks to Pyodide.
* [Hugging Face Spaces](https://huggingface.co/spaces): the most popular place to host Gradio applications — for free!
### What's Next?
Keep learning about Gradio sequentially using the Gradio Guides, which include explanations as well as example code and embedded interactive demos. Next up: [key features about Gradio demos](https://www.gradio.app/guides/key-features).
Or, if you already know the basics and are looking for something specific, you can search the more [technical API documentation](https://www.gradio.app/docs/).
## Questions?
If you'd like to report a bug or have a feature request, please create an [issue on GitHub](https://github.com/gradio-app/gradio/issues/new/choose). For general questions about usage, we are available on [our Discord server](https://discord.com/invite/feTf9x3ZSB) and happy to help.
If you like Gradio, please leave us a ⭐ on GitHub!
## Open Source Stack
Gradio is built on top of many wonderful open-source libraries!
[<img src="readme_files/huggingface_mini.svg" alt="huggingface" height=40>](https://huggingface.co)
[<img src="readme_files/python.svg" alt="python" height=40>](https://www.python.org)
[<img src="readme_files/fastapi.svg" alt="fastapi" height=40>](https://fastapi.tiangolo.com)
[<img src="readme_files/encode.svg" alt="encode" height=40>](https://www.encode.io)
[<img src="readme_files/svelte.svg" alt="svelte" height=40>](https://svelte.dev)
[<img src="readme_files/vite.svg" alt="vite" height=40>](https://vitejs.dev)
[<img src="readme_files/pnpm.svg" alt="pnpm" height=40>](https://pnpm.io)
[<img src="readme_files/tailwind.svg" alt="tailwind" height=40>](https://tailwindcss.com)
[<img src="readme_files/storybook.svg" alt="storybook" height=40>](https://storybook.js.org/)
[<img src="readme_files/chromatic.svg" alt="chromatic" height=40>](https://www.chromatic.com/)
## License
Gradio is licensed under the Apache License 2.0 found in the [LICENSE](LICENSE) file in the root directory of this repository.
## Citation
Also check out the paper _[Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild](https://arxiv.org/abs/1906.02569), ICML HILL 2019_, and please cite it if you use Gradio in your work.
```
@article{abid2019gradio,
title = {Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild},
author = {Abid, Abubakar and Abdalla, Ali and Abid, Ali and Khan, Dawood and Alfozan, Abdulrahman and Zou, James},
journal = {arXiv preprint arXiv:1906.02569},
year = {2019},
}
```
| gradio-app/gradio/blob/main/README.md |
Security & Compliance
🤗 Inference Endpoints is built with security and secure inference at its core. Below you can find an overview of the security measures we have in place.
## Data Security/Privacy
Hugging Face does not store any customer data in terms of payloads or tokens that are passed to the Inference Endpoint. We are storing logs for 30 days. Every Inference Endpoints uses TLS/SSL to encrypt the data in transit.
We also recommend using AWS or Azure Private Link for organizations. This allows you to access your Inference Endpoint through a private connection, without exposing it to the internet.
Hugging Face also offers Business Associate Addendum or GDPR data processing agreement through the Inference Endpoint enterprise plan.
## Model Security/Privacy:
You can set a model repository as private if you do not want to publicly expose it. Hugging Face does not own any model or data you upload to the Hugging Face hub. Hugging Face does provide malware and pickle scans over the contents of the model repository as with all items in the Hub.
## Inference Endpoints and Hub Security
The Hugging Face Hub, which Inference Endpoints is part, is also SOC2 Type 2 certified. The Hugging Face Hub offers Role Based Access Control. For more on hub security: https://huggingface.co/docs/hub/security
<img width="150" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-soc-1.jpg">
## Inference Endpoint Security level
We currently offer three types of endpoints, in order or increasing security level:
- **Public**: A Public Endpoint is available from the internet, secured with TLS/SSL, and requires no authentication.
- **Protected**: A Protected Endpoint is available from the internet, secured with TLS/SSL, and requires a valid Hugging Face token for authentication.
- **Private** A Private Endpoint is only available through an intra-region secured AWS or Azure PrivateLink connection. Private Endpoints are not accessible from the internet.
Public and Protected Endpoints do not require any additional configuration. For Private Endpoints, you need to provide the AWS account ID of the account which also should have access to 🤗 Inference Endpoints.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/endpoint_types.png"
alt="endpoint types"
/>
Hugging Face Privacy Policy - https://huggingface.co/privacy
| huggingface/hf-endpoints-documentation/blob/main/docs/source/security.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UMT5
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=umt5">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-mt5-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The UMT5 model was proposed in [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
The abstract from the paper is the following:
*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.*
Google has released the following variants:
- [google/umt5-small](https://huggingface.co/google/umt5-small)
- [google/umt5-base](https://huggingface.co/google/umt5-base)
- [google/umt5-xl](https://huggingface.co/google/umt5-xl)
- [google/umt5-xxl](https://huggingface.co/google/umt5-xxl).
This model was contributed by [agemagician](https://huggingface.co/agemagician) and [stefan-it](https://huggingface.co/stefan-it). The original code can be
found [here](https://github.com/google-research/t5x).
## Usage tips
- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
- Since umT5 was pre-trained in an unsupervise manner, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
## Differences with mT5?
`UmT5` is based on mT5, with a non-shared relative positional bias that is computed for each layer. This means that the model set `has_relative_bias` for each layer.
The conversion script is also different because the model was saved in t5x's latest checkpointing format.
# Sample usage
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/umt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/umt5-small")
>>> inputs = tokenizer(
... "A <extra_id_0> walks into a bar and orders a <extra_id_1> with <extra_id_2> pinch of <extra_id_3>.",
... return_tensors="pt",
... )
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs))
['<pad><extra_id_0>nyone who<extra_id_1> drink<extra_id_2> a<extra_id_3> alcohol<extra_id_4> A<extra_id_5> A. This<extra_id_6> I<extra_id_7><extra_id_52><extra_id_53></s>']
```
<Tip>
Refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
</Tip>
## UMT5Config
[[autodoc]] UMT5Config
## UMT5Model
[[autodoc]] UMT5Model
- forward
## UMT5ForConditionalGeneration
[[autodoc]] UMT5ForConditionalGeneration
- forward
## UMT5EncoderModel
[[autodoc]] UMT5EncoderModel
- forward
## UMT5ForSequenceClassification
[[autodoc]] UMT5ForSequenceClassification
- forward
## UMT5ForQuestionAnswering
[[autodoc]] UMT5ForQuestionAnswering
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/umt5.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# General Utilities
This page lists all of Transformers general utility functions that are found in the file `utils.py`.
Most of those are only useful if you are studying the general code in the library.
## Enums and namedtuples
[[autodoc]] utils.ExplicitEnum
[[autodoc]] utils.PaddingStrategy
[[autodoc]] utils.TensorType
## Special Decorators
[[autodoc]] utils.add_start_docstrings
[[autodoc]] utils.add_start_docstrings_to_model_forward
[[autodoc]] utils.add_end_docstrings
[[autodoc]] utils.add_code_sample_docstrings
[[autodoc]] utils.replace_return_docstrings
## Special Properties
[[autodoc]] utils.cached_property
## Other Utilities
[[autodoc]] utils._LazyModule
| huggingface/transformers/blob/main/docs/source/en/internal/file_utils.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ProphetNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=prophetnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-prophetnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/prophetnet-large-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
the next token.
The abstract from the paper is the following:
*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## ProphetNetConfig
[[autodoc]] ProphetNetConfig
## ProphetNetTokenizer
[[autodoc]] ProphetNetTokenizer
## ProphetNet specific outputs
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqLMOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqModelOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderModelOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderLMOutput
## ProphetNetModel
[[autodoc]] ProphetNetModel
- forward
## ProphetNetEncoder
[[autodoc]] ProphetNetEncoder
- forward
## ProphetNetDecoder
[[autodoc]] ProphetNetDecoder
- forward
## ProphetNetForConditionalGeneration
[[autodoc]] ProphetNetForConditionalGeneration
- forward
## ProphetNetForCausalLM
[[autodoc]] ProphetNetForCausalLM
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/prophetnet.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pegasus
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=pegasus">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-pegasus-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/pegasus_paraphrase">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Pegasus model was proposed in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
According to the abstract,
- Pegasus' pretraining task is intentionally similar to summarization: important sentences are removed/masked from an
input document and are generated together as one output sequence from the remaining sentences, similar to an
extractive summary.
- Pegasus achieves SOTA summarization performance on all 12 downstream tasks, as measured by ROUGE and human eval.
This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/google-research/pegasus).
## Usage tips
- Sequence-to-sequence model with the same encoder-decoder model architecture as BART. Pegasus is pre-trained jointly on two self-supervised objective functions: Masked Language Modeling (MLM) and a novel summarization specific pretraining objective, called Gap Sentence Generation (GSG).
* MLM: encoder input tokens are randomly replaced by a mask tokens and have to be predicted by the encoder (like in BERT)
* GSG: whole encoder input sentences are replaced by a second mask token and fed to the decoder, but which has a causal mask to hide the future words like a regular auto-regressive transformer decoder.
- FP16 is not supported (help/ideas on this appreciated!).
- The adafactor optimizer is recommended for pegasus fine-tuning.
## Checkpoints
All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tuned for summarization, besides
*pegasus-large*, whence the other checkpoints are fine-tuned:
- Each checkpoint is 2.2 GB on disk and 568M parameters.
- FP16 is not supported (help/ideas on this appreciated!).
- Summarizing xsum in fp32 takes about 400ms/sample, with default parameters on a v100 GPU.
- Full replication results and correctly pre-processed data can be found in this [Issue](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
- [Distilled checkpoints](https://huggingface.co/models?search=distill-pegasus) are described in this [paper](https://arxiv.org/abs/2010.13002).
## Implementation Notes
- All models are transformer encoder-decoders with 16 layers in each component.
- The implementation is completely inherited from [`BartForConditionalGeneration`]
- Some key configuration differences:
- static, sinusoidal position embeddings
- the model starts generating with pad_token_id (which has 0 token_embedding) as the prefix.
- more beams are used (`num_beams=8`)
- All pretrained pegasus checkpoints are the same besides three attributes: `tokenizer.model_max_length` (maximum
input size), `max_length` (the maximum number of tokens to generate) and `length_penalty`.
- The code to convert checkpoints trained in the author's [repo](https://github.com/google-research/pegasus) can be
found in `convert_pegasus_tf_to_pytorch.py`.
## Usage Example
```python
>>> from transformers import PegasusForConditionalGeneration, PegasusTokenizer
>>> import torch
>>> src_text = [
... """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
... ]
... model_name = "google/pegasus-xsum"
... device = "cuda" if torch.cuda.is_available() else "cpu"
... tokenizer = PegasusTokenizer.from_pretrained(model_name)
... model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
... batch = tokenizer(src_text, truncation=True, padding="longest", return_tensors="pt").to(device)
... translated = model.generate(**batch)
... tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
... assert (
... tgt_text[0]
... == "California's largest electricity provider has turned off power to hundreds of thousands of customers."
... )
```
## Resources
- [Script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) to fine-tune pegasus
on the XSUM dataset. Data download instructions at [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## PegasusConfig
[[autodoc]] PegasusConfig
## PegasusTokenizer
warning: `add_tokens` does not work at the moment.
[[autodoc]] PegasusTokenizer
## PegasusTokenizerFast
[[autodoc]] PegasusTokenizerFast
<frameworkcontent>
<pt>
## PegasusModel
[[autodoc]] PegasusModel
- forward
## PegasusForConditionalGeneration
[[autodoc]] PegasusForConditionalGeneration
- forward
## PegasusForCausalLM
[[autodoc]] PegasusForCausalLM
- forward
</pt>
<tf>
## TFPegasusModel
[[autodoc]] TFPegasusModel
- call
## TFPegasusForConditionalGeneration
[[autodoc]] TFPegasusForConditionalGeneration
- call
</tf>
<jax>
## FlaxPegasusModel
[[autodoc]] FlaxPegasusModel
- __call__
- encode
- decode
## FlaxPegasusForConditionalGeneration
[[autodoc]] FlaxPegasusForConditionalGeneration
- __call__
- encode
- decode
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/pegasus.md |
Building a FastAPI App with the Gradio Python Client
Tags: CLIENT, API, WEB APP
In this blog post, we will demonstrate how to use the `gradio_client` [Python library](getting-started-with-the-python-client/), which enables developers to make requests to a Gradio app programmatically, by creating an example FastAPI web app. The web app we will be building is called "Acapellify," and it will allow users to upload video files as input and return a version of that video without instrumental music. It will also display a gallery of generated videos.
**Prerequisites**
Before we begin, make sure you are running Python 3.9 or later, and have the following libraries installed:
- `gradio_client`
- `fastapi`
- `uvicorn`
You can install these libraries from `pip`:
```bash
$ pip install gradio_client fastapi uvicorn
```
You will also need to have ffmpeg installed. You can check to see if you already have ffmpeg by running in your terminal:
```bash
$ ffmpeg version
```
Otherwise, install ffmpeg [by following these instructions](https://www.hostinger.com/tutorials/how-to-install-ffmpeg).
## Step 1: Write the Video Processing Function
Let's start with what seems like the most complex bit -- using machine learning to remove the music from a video.
Luckily for us, there's an existing Space we can use to make this process easier: [https://huggingface.co/spaces/abidlabs/music-separation](https://huggingface.co/spaces/abidlabs/music-separation). This Space takes an audio file and produces two separate audio files: one with the instrumental music and one with all other sounds in the original clip. Perfect to use with our client!
Open a new Python file, say `main.py`, and start by importing the `Client` class from `gradio_client` and connecting it to this Space:
```py
from gradio_client import Client
client = Client("abidlabs/music-separation")
def acapellify(audio_path):
result = client.predict(audio_path, api_name="/predict")
return result[0]
```
That's all the code that's needed -- notice that the API endpoints returns two audio files (one without the music, and one with just the music) in a list, and so we just return the first element of the list.
---
**Note**: since this is a public Space, there might be other users using this Space as well, which might result in a slow experience. You can duplicate this Space with your own [Hugging Face token](https://huggingface.co/settings/tokens) and create a private Space that only you have will have access to and bypass the queue. To do that, simply replace the first two lines above with:
```py
from gradio_client import Client
client = Client.duplicate("abidlabs/music-separation", hf_token=YOUR_HF_TOKEN)
```
Everything else remains the same!
---
Now, of course, we are working with video files, so we first need to extract the audio from the video files. For this, we will be using the `ffmpeg` library, which does a lot of heavy lifting when it comes to working with audio and video files. The most common way to use `ffmpeg` is through the command line, which we'll call via Python's `subprocess` module:
Our video processing workflow will consist of three steps:
1. First, we start by taking in a video filepath and extracting the audio using `ffmpeg`.
2. Then, we pass in the audio file through the `acapellify()` function above.
3. Finally, we combine the new audio with the original video to produce a final acapellified video.
Here's the complete code in Python, which you can add to your `main.py` file:
```python
import subprocess
def process_video(video_path):
old_audio = os.path.basename(video_path).split(".")[0] + ".m4a"
subprocess.run(['ffmpeg', '-y', '-i', video_path, '-vn', '-acodec', 'copy', old_audio])
new_audio = acapellify(old_audio)
new_video = f"acap_{video_path}"
subprocess.call(['ffmpeg', '-y', '-i', video_path, '-i', new_audio, '-map', '0:v', '-map', '1:a', '-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental', f"static/{new_video}"])
return new_video
```
You can read up on [ffmpeg documentation](https://ffmpeg.org/ffmpeg.html) if you'd like to understand all of the command line parameters, as they are beyond the scope of this tutorial.
## Step 2: Create a FastAPI app (Backend Routes)
Next up, we'll create a simple FastAPI app. If you haven't used FastAPI before, check out [the great FastAPI docs](https://fastapi.tiangolo.com/). Otherwise, this basic template, which we add to `main.py`, will look pretty familiar:
```python
import os
from fastapi import FastAPI, File, UploadFile, Request
from fastapi.responses import HTMLResponse, RedirectResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
app = FastAPI()
os.makedirs("static", exist_ok=True)
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
videos = []
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse(
"home.html", {"request": request, "videos": videos})
@app.post("/uploadvideo/")
async def upload_video(video: UploadFile = File(...)):
new_video = process_video(video.filename)
videos.append(new_video)
return RedirectResponse(url='/', status_code=303)
```
In this example, the FastAPI app has two routes: `/` and `/uploadvideo/`.
The `/` route returns an HTML template that displays a gallery of all uploaded videos.
The `/uploadvideo/` route accepts a `POST` request with an `UploadFile` object, which represents the uploaded video file. The video file is "acapellified" via the `process_video()` method, and the output video is stored in a list which stores all of the uploaded videos in memory.
Note that this is a very basic example and if this were a production app, you will need to add more logic to handle file storage, user authentication, and security considerations.
## Step 3: Create a FastAPI app (Frontend Template)
Finally, we create the frontend of our web application. First, we create a folder called `templates` in the same directory as `main.py`. We then create a template, `home.html` inside the `templates` folder. Here is the resulting file structure:
```csv
├── main.py
├── templates
│ └── home.html
```
Write the following as the contents of `home.html`:
```html
<!DOCTYPE html> <html> <head> <title>Video Gallery</title>
<style> body { font-family: sans-serif; margin: 0; padding: 0;
background-color: #f5f5f5; } h1 { text-align: center; margin-top: 30px;
margin-bottom: 20px; } .gallery { display: flex; flex-wrap: wrap;
justify-content: center; gap: 20px; padding: 20px; } .video { border: 2px solid
#ccc; box-shadow: 0px 0px 10px rgba(0, 0, 0, 0.2); border-radius: 5px; overflow:
hidden; width: 300px; margin-bottom: 20px; } .video video { width: 100%; height:
200px; } .video p { text-align: center; margin: 10px 0; } form { margin-top:
20px; text-align: center; } input[type="file"] { display: none; } .upload-btn {
display: inline-block; background-color: #3498db; color: #fff; padding: 10px
20px; font-size: 16px; border: none; border-radius: 5px; cursor: pointer; }
.upload-btn:hover { background-color: #2980b9; } .file-name { margin-left: 10px;
} </style> </head> <body> <h1>Video Gallery</h1> {% if videos %}
<div class="gallery"> {% for video in videos %} <div class="video">
<video controls> <source src="{{ url_for('static', path=video) }}"
type="video/mp4"> Your browser does not support the video tag. </video>
<p>{{ video }}</p> </div> {% endfor %} </div> {% else %} <p>No
videos uploaded yet.</p> {% endif %} <form action="/uploadvideo/"
method="post" enctype="multipart/form-data"> <label for="video-upload"
class="upload-btn">Choose video file</label> <input type="file"
name="video" id="video-upload"> <span class="file-name"></span> <button
type="submit" class="upload-btn">Upload</button> </form> <script> //
Display selected file name in the form const fileUpload =
document.getElementById("video-upload"); const fileName =
document.querySelector(".file-name"); fileUpload.addEventListener("change", (e)
=> { fileName.textContent = e.target.files[0].name; }); </script> </body>
</html>
```
## Step 4: Run your FastAPI app
Finally, we are ready to run our FastAPI app, powered by the Gradio Python Client!
Open up a terminal and navigate to the directory containing `main.py`. Then run the following command in the terminal:
```bash
$ uvicorn main:app
```
You should see an output that looks like this:
```csv
Loaded as API: https://abidlabs-music-separation.hf.space ✔
INFO: Started server process [1360]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
And that's it! Start uploading videos and you'll get some "acapellified" videos in response (might take seconds to minutes to process depending on the length of your videos). Here's how the UI looks after uploading two videos:
If you'd like to learn more about how to use the Gradio Python Client in your projects, [read the dedicated Guide](/guides/getting-started-with-the-python-client/).
| gradio-app/gradio/blob/main/guides/08_gradio-clients-and-lite/fastapi-app-with-the-gradio-client.md |
Developing Faster with Auto-Reloading
**Prerequisite**: This Guide requires you to know about Blocks. Make sure to [read the Guide to Blocks first](https://gradio.app/guides/quickstart/#blocks-more-flexibility-and-control).
This guide covers auto reloading, reloading in a Python IDE, and using gradio with Jupyter Notebooks.
## Why Auto-Reloading?
When you are building a Gradio demo, particularly out of Blocks, you may find it cumbersome to keep re-running your code to test your changes.
To make it faster and more convenient to write your code, we've made it easier to "reload" your Gradio apps instantly when you are developing in a **Python IDE** (like VS Code, Sublime Text, PyCharm, or so on) or generally running your Python code from the terminal. We've also developed an analogous "magic command" that allows you to re-run cells faster if you use **Jupyter Notebooks** (or any similar environment like Colab).
This short Guide will cover both of these methods, so no matter how you write Python, you'll leave knowing how to build Gradio apps faster.
## Python IDE Reload 🔥
If you are building Gradio Blocks using a Python IDE, your file of code (let's name it `run.py`) might look something like this:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# Greetings from Gradio!")
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(fn=lambda x: f"Welcome, {x}!",
inputs=inp,
outputs=out)
if __name__ == "__main__":
demo.launch()
```
The problem is that anytime that you want to make a change to your layout, events, or components, you have to close and rerun your app by writing `python run.py`.
Instead of doing this, you can run your code in **reload mode** by changing 1 word: `python` to `gradio`:
In the terminal, run `gradio run.py`. That's it!
Now, you'll see that after you'll see something like this:
```bash
Watching: '/Users/freddy/sources/gradio/gradio', '/Users/freddy/sources/gradio/demo/'
Running on local URL: http://127.0.0.1:7860
```
The important part here is the line that says `Watching...` What's happening here is that Gradio will be observing the directory where `run.py` file lives, and if the file changes, it will automatically rerun the file for you. So you can focus on writing your code, and your Gradio demo will refresh automatically 🥳
⚠️ Warning: the `gradio` command does not detect the parameters passed to the `launch()` methods because the `launch()` method is never called in reload mode. For example, setting `auth`, or `show_error` in `launch()` will not be reflected in the app.
There is one important thing to keep in mind when using the reload mode: Gradio specifically looks for a Gradio Blocks/Interface demo called `demo` in your code. If you have named your demo something else, you will need to pass in the name of your demo as the 2nd parameter in your code. So if your `run.py` file looked like this:
```python
import gradio as gr
with gr.Blocks() as my_demo:
gr.Markdown("# Greetings from Gradio!")
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(fn=lambda x: f"Welcome, {x}!",
inputs=inp,
outputs=out)
if __name__ == "__main__":
my_demo.launch()
```
Then you would launch it in reload mode like this: `gradio run.py my_demo`.
By default, the Gradio use UTF-8 encoding for scripts. **For reload mode**, If you are using encoding formats other than UTF-8 (such as cp1252), make sure you've done like this:
1. Configure encoding declaration of python script, for example: `# -*- coding: cp1252 -*-`
2. Confirm that your code editor has identified that encoding format.
3. Run like this: `gradio run.py --encoding cp1252`
🔥 If your application accepts command line arguments, you can pass them in as well. Here's an example:
```python
import gradio as gr
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--name", type=str, default="User")
args, unknown = parser.parse_known_args()
with gr.Blocks() as demo:
gr.Markdown(f"# Greetings {args.name}!")
inp = gr.Textbox()
out = gr.Textbox()
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
if __name__ == "__main__":
demo.launch()
```
Which you could run like this: `gradio run.py --name Gretel`
As a small aside, this auto-reloading happens if you change your `run.py` source code or the Gradio source code. Meaning that this can be useful if you decide to [contribute to Gradio itself](https://github.com/gradio-app/gradio/blob/main/CONTRIBUTING.md) ✅
## Jupyter Notebook Magic 🔮
What about if you use Jupyter Notebooks (or Colab Notebooks, etc.) to develop code? We got something for you too!
We've developed a **magic command** that will create and run a Blocks demo for you. To use this, load the gradio extension at the top of your notebook:
`%load_ext gradio`
Then, in the cell that you are developing your Gradio demo, simply write the magic command **`%%blocks`** at the top, and then write the layout and components like you would normally:
```py
%%blocks
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown(f"# Greetings {args.name}!")
inp = gr.Textbox()
out = gr.Textbox()
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
```
Notice that:
- You do not need to launch your demo — Gradio does that for you automatically!
- Every time you rerun the cell, Gradio will re-render your app on the same port and using the same underlying web server. This means you'll see your changes _much, much faster_ than if you were rerunning the cell normally.
Here's what it looks like in a jupyter notebook:
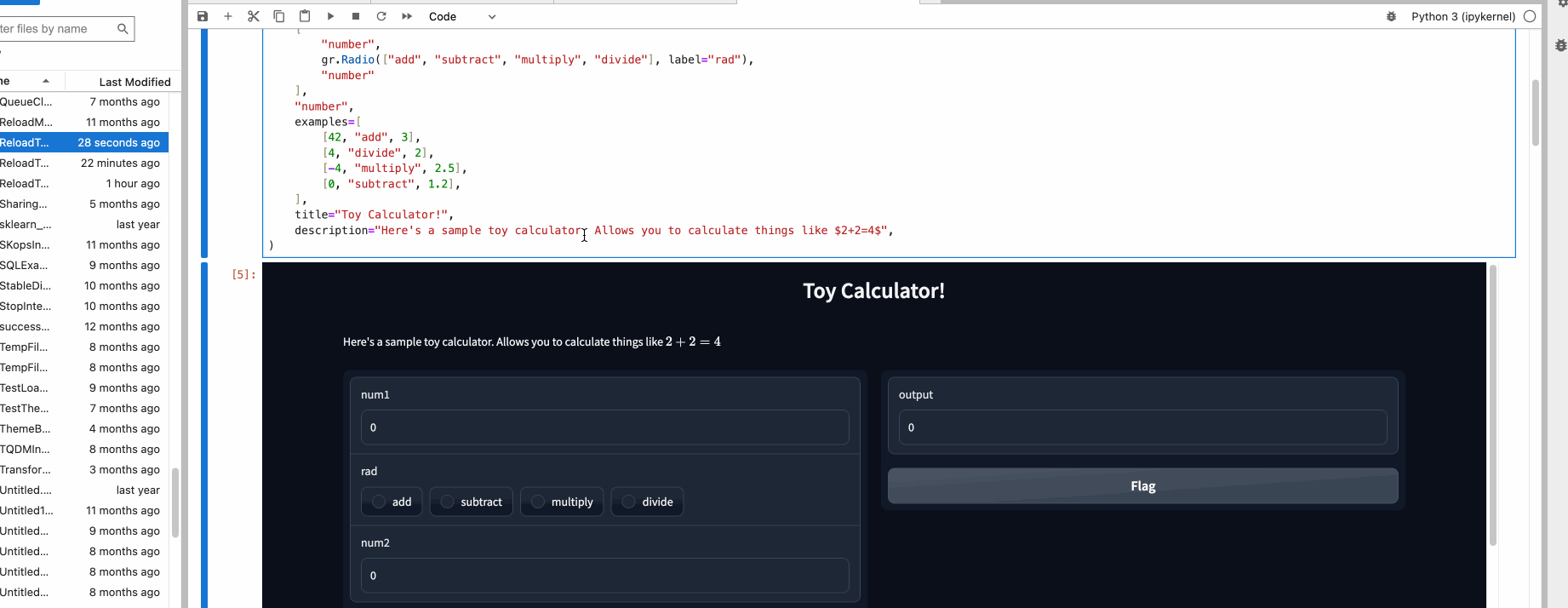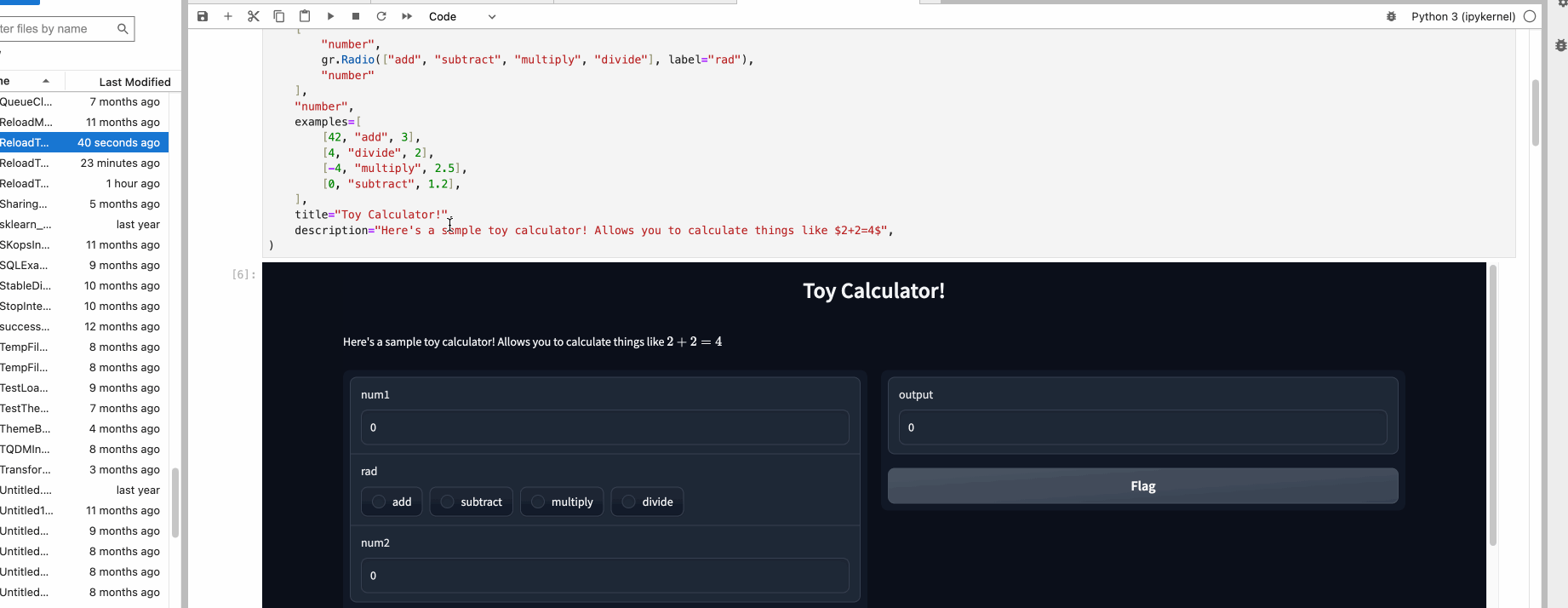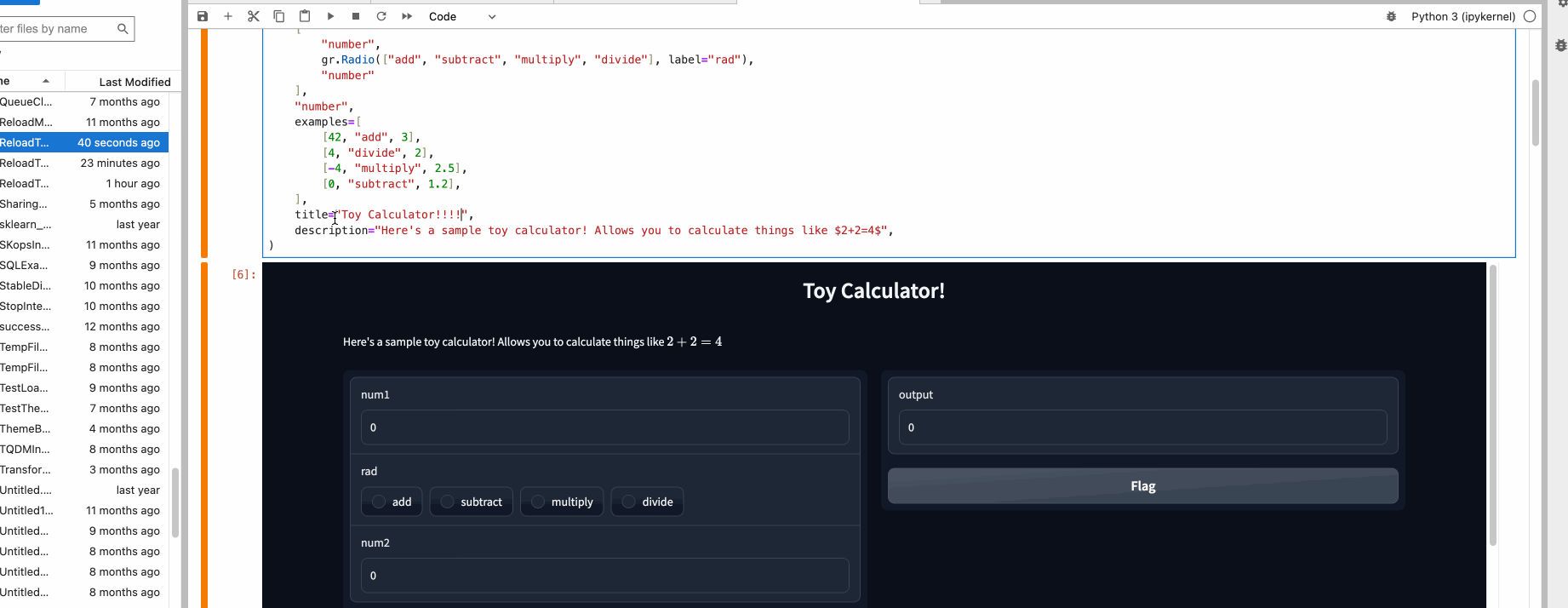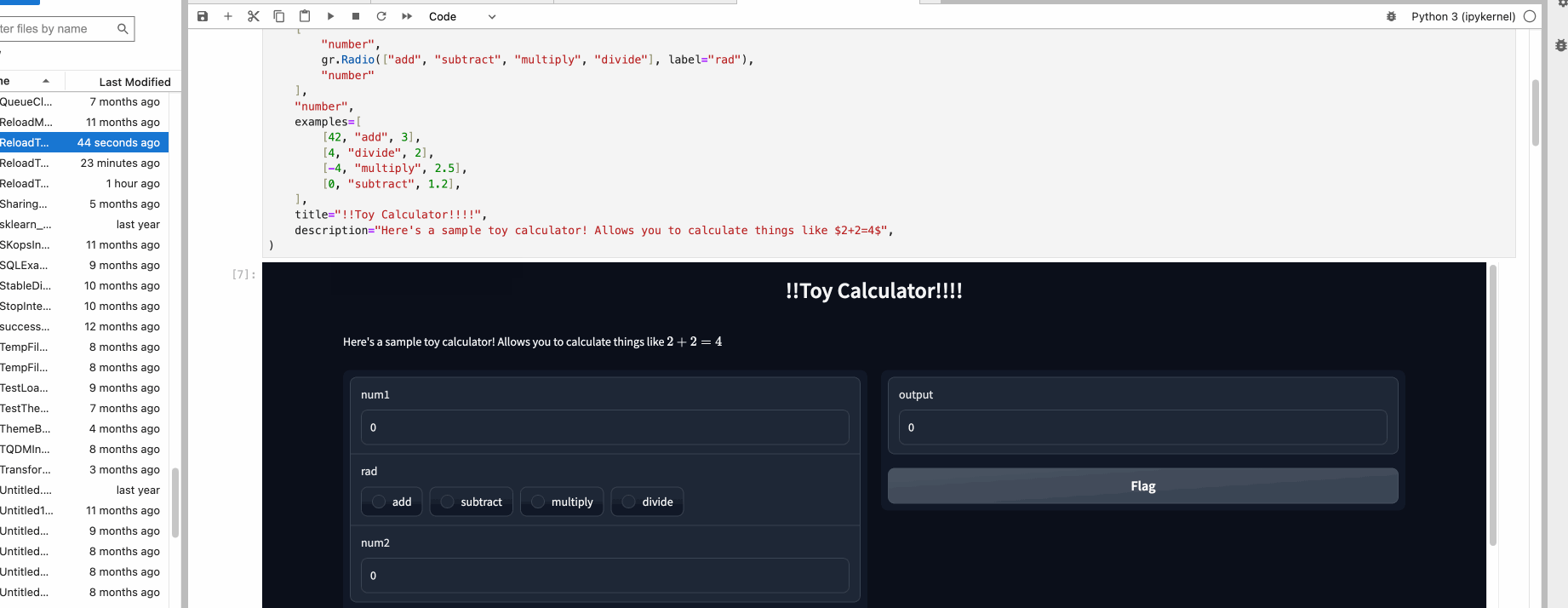
🪄 This works in colab notebooks too! [Here's a colab notebook](https://colab.research.google.com/drive/1zAuWoiTIb3O2oitbtVb2_ekv1K6ggtC1?usp=sharing) where you can see the Blocks magic in action. Try making some changes and re-running the cell with the Gradio code!
The Notebook Magic is now the author's preferred way of building Gradio demos. Regardless of how you write Python code, we hope either of these methods will give you a much better development experience using Gradio.
---
## Next Steps
Now that you know how to develop quickly using Gradio, start building your own!
If you are looking for inspiration, try exploring demos other people have built with Gradio, [browse public Hugging Face Spaces](http://hf.space/) 🤗
| gradio-app/gradio/blob/main/guides/09_other-tutorials/developing-faster-with-reload-mode.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SEW-D
## Overview
SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
The abstract from the paper is the following:
*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
time, SEW reduces word error rate by 25-50% across different model sizes.*
This model was contributed by [anton-l](https://huggingface.co/anton-l).
## Usage tips
- SEW-D is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- SEWDForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## SEWDConfig
[[autodoc]] SEWDConfig
## SEWDModel
[[autodoc]] SEWDModel
- forward
## SEWDForCTC
[[autodoc]] SEWDForCTC
- forward
## SEWDForSequenceClassification
[[autodoc]] SEWDForSequenceClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/sew-d.md |
--
title: Simple considerations for simple people building fancy neural networks
thumbnail: /blog/assets/13_simple-considerations/henry-co-3coKbdfnAFg-unsplash.jpg
authors:
- user: VictorSanh
---

<span class="text-gray-500 text-xs">Photo by [Henry & Co.](https://unsplash.com/@hngstrm?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/s/photos/builder?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)</span>
# 🚧 Simple considerations for simple people building fancy neural networks
As machine learning continues penetrating all aspects of the industry, neural networks have never been so hyped. For instance, models like GPT-3 have been all over social media in the past few weeks and continue to make headlines outside of tech news outlets with fear-mongering titles.

<div class="text-center text-xs text-gray-500">
<a class="text-gray-500" href="https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3">An article</a> from The Guardian
</div>
At the same time, deep learning frameworks, tools, and specialized libraries democratize machine learning research by making state-of-the-art research easier to use than ever. It is quite common to see these almost-magical/plug-and-play 5 lines of code that promise (near) state-of-the-art results. Working at [Hugging Face](https://huggingface.co/) 🤗, I admit that I am partially guilty of that. 😅 It can give an inexperienced user the misleading impression that neural networks are now a mature technology while in fact, the field is in constant development.
In reality, **building and training neural networks can often be an extremely frustrating experience**:
* It is sometimes hard to understand if your performance comes from a bug in your model/code or is simply limited by your model’s expressiveness.
* You can make tons of tiny mistakes at every step of the process without realizing at first, and your model will still train and give a decent performance.
**In this post, I will try to highlight a few steps of my mental process when it comes to building and debugging neural networks.** By “debugging”, I mean making sure you align what you have built and what you have in mind. I will also point out things you can look at when you are not sure what your next step should be by listing the typical questions I ask myself.
_A lot of these thoughts stem from my experience doing research in natural language processing but most of these principles can be applied to other fields of machine learning._
## 1. 🙈 Start by putting machine learning aside
It might sound counter-intuitive but the very first step of building a neural network is to **put aside machine learning and simply focus on your data**. Look at the examples, their labels, the diversity of the vocabulary if you are working with text, their length distribution, etc. You should dive into the data to get a first sense of the raw product you are working with and focus on extracting general patterns that a model might be able to catch. Hopefully, by looking at a few hundred examples, you will be able to identify high-level patterns. A few standard questions you can ask yourself:
* Are the labels balanced?
* Are there gold-labels that you do not agree with?
* How were the data obtained? What are the possible sources of noise in this process?
* Are there any preprocessing steps that seem natural (tokenization, URL or hashtag removing, etc.)?
* How diverse are the examples?
* What rule-based algorithm would perform decently on this problem?
It is important to get a **high-level feeling (qualitative) of your dataset along with a fine-grained analysis (quantitative)**. If you are working with a public dataset, someone else might have already dived into the data and reported their analysis (it is quite common in Kaggle competition for instance) so you should absolutely have a look at these!
## 2. 📚 Continue as if you just started machine learning
Once you have a deep and broad understanding of your data, I always recommend **to put yourself in the shoes of your old self when you just started machine learning** and were watching introduction classes from Andrew Ng on Coursera. **Start as simple as possible to get a sense of the difficulty of your task and how well standard baselines would perform.** For instance, if you work with text, standard baselines for binary text classification can include a logistic regression trained on top of word2vec or fastText embeddings. With the current tools, running these baselines is as easy (if not more) as running BERT which can arguably be considered one of the standard tools for many natural language processing problems. If other baselines are available, run (or implement) some of them. It will help you get even more familiar with the data.
As developers, it easy to feel good when building something fancy but it is sometimes hard to rationally justify it if it beats easy baselines by only a few points, so it is central to make sure you have reasonable points of comparisons:
* How would a random predictor perform (especially in classification problems)? Dataset can be unbalanced…
* What would the loss look like for a random predictor?
* What is (are) the best metric(s) to measure progress on my task?
* What are the limits of this metric? If it’s perfect, what can I conclude? What can’t I conclude?
* What is missing in “simple approaches” to reach a perfect score?
* Are there architectures in my neural network toolbox that would be good to model the inductive bias of the data?
## 3. 🦸♀️ Don’t be afraid to look under the hood of these 5-liners templates
Next, you can start building your model based on the insights and understanding you acquired previously. As mentioned earlier, implementing neural networks can quickly become quite tricky: there are many moving parts that work together (the optimizer, the model, the input processing pipeline, etc.), and many small things can go wrong when implementing these parts and connecting them to each other. **The challenge lies in the fact that you can make these mistakes, train a model without it ever crashing, and still get a decent performance…**
Yet, it is a good habit when you think you have finished implementing to **overfit a small batch of examples** (16 for instance). If your implementation is (nearly) correct, your model will be able to overfit and remember these examples by displaying a 0-loss (make sure you remove any form of regularization such as weight decay). If not, it is highly possible that you did something wrong in your implementation. In some rare cases, it means that your model is not expressive enough or lacks capacity. Again, **start with a small-scale model** (fewer layers for instance): you are looking to debug your model so you want a quick feedback loop, not a high performance.
> Pro-tip: in my experience working with pre-trained language models, freezing the embeddings modules to their pre-trained values doesn’t affect much the fine-tuning task performance while considerably speeding up the training.
Some common errors include:
* Wrong indexing… (these are really the worst 😅). Make sure you are gathering tensors along the correct dimensions for instance…
* You forgot to call `model.eval()` in evaluation mode (in PyTorch) or `model.zero\_grad()` to clean the gradients
* Something went wrong in the pre-processing of the inputs
* The loss got wrong arguments (for instance passing probabilities when it expects logits)
* Initialization doesn’t break the symmetry (usually happens when you initialize a whole matrix with a single constant value)
* Some parameters are never called during the forward pass (and thus receive no gradients)
* The learning rate is taking funky values like 0 all the time
* Your inputs are being truncated in a suboptimal way
> Pro-tip: when you work with language, have a serious **look at the outputs of the tokenizers**. I can’t count the number of lost hours I spent trying to reproduce results (and sometimes my own old results) because something went wrong with the tokenization.🤦♂️
Another useful tool is **deep-diving into the training dynamic** and plot (in Tensorboard for instance) the evolution of multiple scalars through training. At the bare minimum, you should look at the dynamic of your loss(es), the parameters, and their gradients.
As the loss decreases, you also want to look at the model’s predictions: either by evaluating on your development set or, my personal favorite, **print a couple of model outputs**. For instance, if you are training a machine translation model, it is quite satisfying to see the generations become more and more convincing through the training. You want to be more specifically careful about overfitting: your training loss continues to decreases while your evaluation loss is aiming at the stars.💫
## 4. 👀 Tune but don’t tune blindly
Once you have everything up and running, you might want to tune your hyperparameters to find the best configuration for your setup. I generally stick with a random grid search as it turns out to be fairly effective in practice.
> Some people report successes using fancy hyperparameter tuning methods such as Bayesian optimization but in my experience, random over a reasonably manually defined grid search is still a tough-to-beat baseline.
Most importantly, there is no point of launching 1000 runs with different hyperparameters (or architecture tweaks like activation functions): **compare a couple of runs with different hyperparameters to get an idea of which hyperparameters have the highest impact** but in general, it is delusional to expect to get your biggest jumps of performance by simply tuning a few values. For instance, if your best performing model is trained with a learning rate of 4e2, there is probably something more fundamental happening inside your neural network and you want to identify and understand this behavior so that you can re-use this knowledge outside of your current specific context.
On average, experts use fewer resources to find better solutions.
To conclude, a piece of general advice that has helped me become better at building neural networks is to **favor (as most as possible) a deep understanding of each component of your neural network instead of blindly (not to say magically) tweak the architecture**. Keep it simple and avoid small tweaks that you can’t reasonably justify even after trying really hard. Obviously, there is the right balance to find between a “trial-and-error” and an “analysis approach” but a lot of these intuitions feel more natural as you accumulate practical experience. **You too are training your internal model.** 🤯
A few related pointers to complete your reading:
* [Reproducibility (in ML) as a vehicle for engineering best practices](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p) from Joel Grus
* [Checklist for debugging neural networks](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21) from Cecelia Shao
* [How to unit test machine learning code](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765) from Chase Roberts
* [A recipe for Training Neural Networks](http://karpathy.github.io/2019/04/25/recipe/) from Andrej Karpathy
| huggingface/blog/blob/main/simple-considerations.md |
Running Background Tasks
Related spaces: https://huggingface.co/spaces/freddyaboulton/gradio-google-forms
Tags: TASKS, SCHEDULED, TABULAR, DATA
## Introduction
This guide explains how you can run background tasks from your gradio app.
Background tasks are operations that you'd like to perform outside the request-response
lifecycle of your app either once or on a periodic schedule.
Examples of background tasks include periodically synchronizing data to an external database or
sending a report of model predictions via email.
## Overview
We will be creating a simple "Google-forms-style" application to gather feedback from users of the gradio library.
We will use a local sqlite database to store our data, but we will periodically synchronize the state of the database
with a [HuggingFace Dataset](https://huggingface.co/datasets) so that our user reviews are always backed up.
The synchronization will happen in a background task running every 60 seconds.
At the end of the demo, you'll have a fully working application like this one:
<gradio-app space="freddyaboulton/gradio-google-forms"> </gradio-app>
## Step 1 - Write your database logic 💾
Our application will store the name of the reviewer, their rating of gradio on a scale of 1 to 5, as well as
any comments they want to share about the library. Let's write some code that creates a database table to
store this data. We'll also write some functions to insert a review into that table and fetch the latest 10 reviews.
We're going to use the `sqlite3` library to connect to our sqlite database but gradio will work with any library.
The code will look like this:
```python
DB_FILE = "./reviews.db"
db = sqlite3.connect(DB_FILE)
# Create table if it doesn't already exist
try:
db.execute("SELECT * FROM reviews").fetchall()
db.close()
except sqlite3.OperationalError:
db.execute(
'''
CREATE TABLE reviews (id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
name TEXT, review INTEGER, comments TEXT)
''')
db.commit()
db.close()
def get_latest_reviews(db: sqlite3.Connection):
reviews = db.execute("SELECT * FROM reviews ORDER BY id DESC limit 10").fetchall()
total_reviews = db.execute("Select COUNT(id) from reviews").fetchone()[0]
reviews = pd.DataFrame(reviews, columns=["id", "date_created", "name", "review", "comments"])
return reviews, total_reviews
def add_review(name: str, review: int, comments: str):
db = sqlite3.connect(DB_FILE)
cursor = db.cursor()
cursor.execute("INSERT INTO reviews(name, review, comments) VALUES(?,?,?)", [name, review, comments])
db.commit()
reviews, total_reviews = get_latest_reviews(db)
db.close()
return reviews, total_reviews
```
Let's also write a function to load the latest reviews when the gradio application loads:
```python
def load_data():
db = sqlite3.connect(DB_FILE)
reviews, total_reviews = get_latest_reviews(db)
db.close()
return reviews, total_reviews
```
## Step 2 - Create a gradio app ⚡
Now that we have our database logic defined, we can use gradio create a dynamic web page to ask our users for feedback!
```python
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
name = gr.Textbox(label="Name", placeholder="What is your name?")
review = gr.Radio(label="How satisfied are you with using gradio?", choices=[1, 2, 3, 4, 5])
comments = gr.Textbox(label="Comments", lines=10, placeholder="Do you have any feedback on gradio?")
submit = gr.Button(value="Submit Feedback")
with gr.Column():
data = gr.Dataframe(label="Most recently created 10 rows")
count = gr.Number(label="Total number of reviews")
submit.click(add_review, [name, review, comments], [data, count])
demo.load(load_data, None, [data, count])
```
## Step 3 - Synchronize with HuggingFace Datasets 🤗
We could call `demo.launch()` after step 2 and have a fully functioning application. However,
our data would be stored locally on our machine. If the sqlite file were accidentally deleted, we'd lose all of our reviews!
Let's back up our data to a dataset on the HuggingFace hub.
Create a dataset [here](https://huggingface.co/datasets) before proceeding.
Now at the **top** of our script, we'll use the [huggingface hub client library](https://huggingface.co/docs/huggingface_hub/index)
to connect to our dataset and pull the latest backup.
```python
TOKEN = os.environ.get('HUB_TOKEN')
repo = huggingface_hub.Repository(
local_dir="data",
repo_type="dataset",
clone_from="<name-of-your-dataset>",
use_auth_token=TOKEN
)
repo.git_pull()
shutil.copyfile("./data/reviews.db", DB_FILE)
```
Note that you'll have to get an access token from the "Settings" tab of your HuggingFace for the above code to work.
In the script, the token is securely accessed via an environment variable.

Now we will create a background task to synch our local database to the dataset hub every 60 seconds.
We will use the [AdvancedPythonScheduler](https://apscheduler.readthedocs.io/en/3.x/) to handle the scheduling.
However, this is not the only task scheduling library available. Feel free to use whatever you are comfortable with.
The function to back up our data will look like this:
```python
from apscheduler.schedulers.background import BackgroundScheduler
def backup_db():
shutil.copyfile(DB_FILE, "./data/reviews.db")
db = sqlite3.connect(DB_FILE)
reviews = db.execute("SELECT * FROM reviews").fetchall()
pd.DataFrame(reviews).to_csv("./data/reviews.csv", index=False)
print("updating db")
repo.push_to_hub(blocking=False, commit_message=f"Updating data at {datetime.datetime.now()}")
scheduler = BackgroundScheduler()
scheduler.add_job(func=backup_db, trigger="interval", seconds=60)
scheduler.start()
```
## Step 4 (Bonus) - Deployment to HuggingFace Spaces
You can use the HuggingFace [Spaces](https://huggingface.co/spaces) platform to deploy this application for free ✨
If you haven't used Spaces before, follow the previous guide [here](/using_hugging_face_integrations).
You will have to use the `HUB_TOKEN` environment variable as a secret in the Guides.
## Conclusion
Congratulations! You know how to run background tasks from your gradio app on a schedule ⏲️.
Checkout the application running on Spaces [here](https://huggingface.co/spaces/freddyaboulton/gradio-google-forms).
The complete code is [here](https://huggingface.co/spaces/freddyaboulton/gradio-google-forms/blob/main/app.py)
| gradio-app/gradio/blob/main/guides/09_other-tutorials/running-background-tasks.md |
How to Use the Plot Component for Maps
Tags: PLOTS, MAPS
## Introduction
This guide explains how you can use Gradio to plot geographical data on a map using the `gradio.Plot` component. The Gradio `Plot` component works with Matplotlib, Bokeh and Plotly. Plotly is what we will be working with in this guide. Plotly allows developers to easily create all sorts of maps with their geographical data. Take a look [here](https://plotly.com/python/maps/) for some examples.
## Overview
We will be using the New York City Airbnb dataset, which is hosted on kaggle [here](https://www.kaggle.com/datasets/dgomonov/new-york-city-airbnb-open-data). I've uploaded it to the Hugging Face Hub as a dataset [here](https://huggingface.co/datasets/gradio/NYC-Airbnb-Open-Data) for easier use and download. Using this data we will plot Airbnb locations on a map output and allow filtering based on price and location. Below is the demo that we will be building. ⚡️
$demo_map_airbnb
## Step 1 - Loading CSV data 💾
Let's start by loading the Airbnb NYC data from the Hugging Face Hub.
```python
from datasets import load_dataset
dataset = load_dataset("gradio/NYC-Airbnb-Open-Data", split="train")
df = dataset.to_pandas()
def filter_map(min_price, max_price, boroughs):
new_df = df[(df['neighbourhood_group'].isin(boroughs)) &
(df['price'] > min_price) & (df['price'] < max_price)]
names = new_df["name"].tolist()
prices = new_df["price"].tolist()
text_list = [(names[i], prices[i]) for i in range(0, len(names))]
```
In the code above, we first load the csv data into a pandas dataframe. Let's begin by defining a function that we will use as the prediction function for the gradio app. This function will accept the minimum price and maximum price range as well as the list of boroughs to filter the resulting map. We can use the passed in values (`min_price`, `max_price`, and list of `boroughs`) to filter the dataframe and create `new_df`. Next we will create `text_list` of the names and prices of each Airbnb to use as labels on the map.
## Step 2 - Map Figure 🌐
Plotly makes it easy to work with maps. Let's take a look below how we can create a map figure.
```python
import plotly.graph_objects as go
fig = go.Figure(go.Scattermapbox(
customdata=text_list,
lat=new_df['latitude'].tolist(),
lon=new_df['longitude'].tolist(),
mode='markers',
marker=go.scattermapbox.Marker(
size=6
),
hoverinfo="text",
hovertemplate='<b>Name</b>: %{customdata[0]}<br><b>Price</b>: $%{customdata[1]}'
))
fig.update_layout(
mapbox_style="open-street-map",
hovermode='closest',
mapbox=dict(
bearing=0,
center=go.layout.mapbox.Center(
lat=40.67,
lon=-73.90
),
pitch=0,
zoom=9
),
)
```
Above, we create a scatter plot on mapbox by passing it our list of latitudes and longitudes to plot markers. We also pass in our custom data of names and prices for additional info to appear on every marker we hover over. Next we use `update_layout` to specify other map settings such as zoom, and centering.
More info [here](https://plotly.com/python/scattermapbox/) on scatter plots using Mapbox and Plotly.
## Step 3 - Gradio App ⚡️
We will use two `gr.Number` components and a `gr.CheckboxGroup` to allow users of our app to specify price ranges and borough locations. We will then use the `gr.Plot` component as an output for our Plotly + Mapbox map we created earlier.
```python
with gr.Blocks() as demo:
with gr.Column():
with gr.Row():
min_price = gr.Number(value=250, label="Minimum Price")
max_price = gr.Number(value=1000, label="Maximum Price")
boroughs = gr.CheckboxGroup(choices=["Queens", "Brooklyn", "Manhattan", "Bronx", "Staten Island"], value=["Queens", "Brooklyn"], label="Select Boroughs:")
btn = gr.Button(value="Update Filter")
map = gr.Plot()
demo.load(filter_map, [min_price, max_price, boroughs], map)
btn.click(filter_map, [min_price, max_price, boroughs], map)
```
We layout these components using the `gr.Column` and `gr.Row` and we'll also add event triggers for when the demo first loads and when our "Update Filter" button is clicked in order to trigger the map to update with our new filters.
This is what the full demo code looks like:
$code_map_airbnb
## Step 4 - Deployment 🤗
If you run the code above, your app will start running locally.
You can even get a temporary shareable link by passing the `share=True` parameter to `launch`.
But what if you want to a permanent deployment solution?
Let's deploy our Gradio app to the free HuggingFace Spaces platform.
If you haven't used Spaces before, follow the previous guide [here](/using_hugging_face_integrations).
## Conclusion 🎉
And you're all done! That's all the code you need to build a map demo.
Here's a link to the demo [Map demo](https://huggingface.co/spaces/gradio/map_airbnb) and [complete code](https://huggingface.co/spaces/gradio/map_airbnb/blob/main/run.py) (on Hugging Face Spaces)
| gradio-app/gradio/blob/main/guides/07_tabular-data-science-and-plots/plot-component-for-maps.md |
Gradio Demo: blocks_style
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks(title="Styling Examples") as demo:
with gr.Column(variant="box"):
txt = gr.Textbox(label="Small Textbox", lines=1)
num = gr.Number(label="Number", show_label=False)
slider = gr.Slider(label="Slider", show_label=False)
check = gr.Checkbox(label="Checkbox", show_label=False)
check_g = gr.CheckboxGroup(
label="Checkbox Group",
choices=["One", "Two", "Three"],
show_label=False,
)
radio = gr.Radio(
label="Radio",
choices=["One", "Two", "Three"],
show_label=False,
)
drop = gr.Dropdown(
label="Dropdown", choices=["One", "Two", "Three"], show_label=False
)
image = gr.Image(show_label=False)
video = gr.Video(show_label=False)
audio = gr.Audio(show_label=False)
file = gr.File(show_label=False)
df = gr.Dataframe(show_label=False)
label = gr.Label(container=False)
highlight = gr.HighlightedText(
[("hello", None), ("goodbye", "-")],
color_map={"+": "green", "-": "red"},
container=False,
)
json = gr.JSON(container=False)
html = gr.HTML(show_label=False)
gallery = gr.Gallery(
columns=(3, 3, 1),
height="auto",
container=False,
)
chat = gr.Chatbot([("hi", "good bye")])
model = gr.Model3D()
md = gr.Markdown(show_label=False)
highlight = gr.HighlightedText()
btn = gr.Button("Run")
gr.Dataset(components=[txt, num])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_style/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DeepFloyd IF
## Overview
DeepFloyd IF is a novel state-of-the-art open-source text-to-image model with a high degree of photorealism and language understanding.
The model is a modular composed of a frozen text encoder and three cascaded pixel diffusion modules:
- Stage 1: a base model that generates 64x64 px image based on text prompt,
- Stage 2: a 64x64 px => 256x256 px super-resolution model, and
- Stage 3: a 256x256 px => 1024x1024 px super-resolution model
Stage 1 and Stage 2 utilize a frozen text encoder based on the T5 transformer to extract text embeddings, which are then fed into a UNet architecture enhanced with cross-attention and attention pooling.
Stage 3 is [Stability AI's x4 Upscaling model](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler).
The result is a highly efficient model that outperforms current state-of-the-art models, achieving a zero-shot FID score of 6.66 on the COCO dataset.
Our work underscores the potential of larger UNet architectures in the first stage of cascaded diffusion models and depicts a promising future for text-to-image synthesis.
## Usage
Before you can use IF, you need to accept its usage conditions. To do so:
1. Make sure to have a [Hugging Face account](https://huggingface.co/join) and be logged in.
2. Accept the license on the model card of [DeepFloyd/IF-I-XL-v1.0](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0). Accepting the license on the stage I model card will auto accept for the other IF models.
3. Make sure to login locally. Install `huggingface_hub`:
```sh
pip install huggingface_hub --upgrade
```
run the login function in a Python shell:
```py
from huggingface_hub import login
login()
```
and enter your [Hugging Face Hub access token](https://huggingface.co/docs/hub/security-tokens#what-are-user-access-tokens).
Next we install `diffusers` and dependencies:
```sh
pip install -q diffusers accelerate transformers
```
The following sections give more in-detail examples of how to use IF. Specifically:
- [Text-to-Image Generation](#text-to-image-generation)
- [Image-to-Image Generation](#text-guided-image-to-image-generation)
- [Inpainting](#text-guided-inpainting-generation)
- [Reusing model weights](#converting-between-different-pipelines)
- [Speed optimization](#optimizing-for-speed)
- [Memory optimization](#optimizing-for-memory)
**Available checkpoints**
- *Stage-1*
- [DeepFloyd/IF-I-XL-v1.0](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0)
- [DeepFloyd/IF-I-L-v1.0](https://huggingface.co/DeepFloyd/IF-I-L-v1.0)
- [DeepFloyd/IF-I-M-v1.0](https://huggingface.co/DeepFloyd/IF-I-M-v1.0)
- *Stage-2*
- [DeepFloyd/IF-II-L-v1.0](https://huggingface.co/DeepFloyd/IF-II-L-v1.0)
- [DeepFloyd/IF-II-M-v1.0](https://huggingface.co/DeepFloyd/IF-II-M-v1.0)
- *Stage-3*
- [stabilityai/stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)
**Google Colab**
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/deepfloyd_if_free_tier_google_colab.ipynb)
### Text-to-Image Generation
By default diffusers makes use of [model cpu offloading](../../optimization/memory#model-offloading) to run the whole IF pipeline with as little as 14 GB of VRAM.
```python
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil, make_image_grid
import torch
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {
"feature_extractor": stage_1.feature_extractor,
"safety_checker": stage_1.safety_checker,
"watermarker": stage_1.watermarker,
}
stage_3 = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16
)
stage_3.enable_model_cpu_offload()
prompt = 'a photo of a kangaroo wearing an orange hoodie and blue sunglasses standing in front of the eiffel tower holding a sign that says "very deep learning"'
generator = torch.manual_seed(1)
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
# stage 1
stage_1_output = stage_1(
prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt"
).images
#pt_to_pil(stage_1_output)[0].save("./if_stage_I.png")
# stage 2
stage_2_output = stage_2(
image=stage_1_output,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
output_type="pt",
).images
#pt_to_pil(stage_2_output)[0].save("./if_stage_II.png")
# stage 3
stage_3_output = stage_3(prompt=prompt, image=stage_2_output, noise_level=100, generator=generator).images
#stage_3_output[0].save("./if_stage_III.png")
make_image_grid([pt_to_pil(stage_1_output)[0], pt_to_pil(stage_2_output)[0], stage_3_output[0]], rows=1, rows=3)
```
### Text Guided Image-to-Image Generation
The same IF model weights can be used for text-guided image-to-image translation or image variation.
In this case just make sure to load the weights using the [`IFImg2ImgPipeline`] and [`IFImg2ImgSuperResolutionPipeline`] pipelines.
**Note**: You can also directly move the weights of the text-to-image pipelines to the image-to-image pipelines
without loading them twice by making use of the [`~DiffusionPipeline.components`] argument as explained [here](#converting-between-different-pipelines).
```python
from diffusers import IFImg2ImgPipeline, IFImg2ImgSuperResolutionPipeline, DiffusionPipeline
from diffusers.utils import pt_to_pil, load_image, make_image_grid
import torch
# download image
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image = original_image.resize((768, 512))
# stage 1
stage_1 = IFImg2ImgPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = IFImg2ImgSuperResolutionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {
"feature_extractor": stage_1.feature_extractor,
"safety_checker": stage_1.safety_checker,
"watermarker": stage_1.watermarker,
}
stage_3 = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16
)
stage_3.enable_model_cpu_offload()
prompt = "A fantasy landscape in style minecraft"
generator = torch.manual_seed(1)
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
# stage 1
stage_1_output = stage_1(
image=original_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
output_type="pt",
).images
#pt_to_pil(stage_1_output)[0].save("./if_stage_I.png")
# stage 2
stage_2_output = stage_2(
image=stage_1_output,
original_image=original_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
output_type="pt",
).images
#pt_to_pil(stage_2_output)[0].save("./if_stage_II.png")
# stage 3
stage_3_output = stage_3(prompt=prompt, image=stage_2_output, generator=generator, noise_level=100).images
#stage_3_output[0].save("./if_stage_III.png")
make_image_grid([original_image, pt_to_pil(stage_1_output)[0], pt_to_pil(stage_2_output)[0], stage_3_output[0]], rows=1, rows=4)
```
### Text Guided Inpainting Generation
The same IF model weights can be used for text-guided image-to-image translation or image variation.
In this case just make sure to load the weights using the [`IFInpaintingPipeline`] and [`IFInpaintingSuperResolutionPipeline`] pipelines.
**Note**: You can also directly move the weights of the text-to-image pipelines to the image-to-image pipelines
without loading them twice by making use of the [`~DiffusionPipeline.components()`] function as explained [here](#converting-between-different-pipelines).
```python
from diffusers import IFInpaintingPipeline, IFInpaintingSuperResolutionPipeline, DiffusionPipeline
from diffusers.utils import pt_to_pil, load_image, make_image_grid
import torch
# download image
url = "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/if/person.png"
original_image = load_image(url)
# download mask
url = "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/if/glasses_mask.png"
mask_image = load_image(url)
# stage 1
stage_1 = IFInpaintingPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = IFInpaintingSuperResolutionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {
"feature_extractor": stage_1.feature_extractor,
"safety_checker": stage_1.safety_checker,
"watermarker": stage_1.watermarker,
}
stage_3 = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16
)
stage_3.enable_model_cpu_offload()
prompt = "blue sunglasses"
generator = torch.manual_seed(1)
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
# stage 1
stage_1_output = stage_1(
image=original_image,
mask_image=mask_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
output_type="pt",
).images
#pt_to_pil(stage_1_output)[0].save("./if_stage_I.png")
# stage 2
stage_2_output = stage_2(
image=stage_1_output,
original_image=original_image,
mask_image=mask_image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
output_type="pt",
).images
#pt_to_pil(stage_1_output)[0].save("./if_stage_II.png")
# stage 3
stage_3_output = stage_3(prompt=prompt, image=stage_2_output, generator=generator, noise_level=100).images
#stage_3_output[0].save("./if_stage_III.png")
make_image_grid([original_image, mask_image, pt_to_pil(stage_1_output)[0], pt_to_pil(stage_2_output)[0], stage_3_output[0]], rows=1, rows=5)
```
### Converting between different pipelines
In addition to being loaded with `from_pretrained`, Pipelines can also be loaded directly from each other.
```python
from diffusers import IFPipeline, IFSuperResolutionPipeline
pipe_1 = IFPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0")
pipe_2 = IFSuperResolutionPipeline.from_pretrained("DeepFloyd/IF-II-L-v1.0")
from diffusers import IFImg2ImgPipeline, IFImg2ImgSuperResolutionPipeline
pipe_1 = IFImg2ImgPipeline(**pipe_1.components)
pipe_2 = IFImg2ImgSuperResolutionPipeline(**pipe_2.components)
from diffusers import IFInpaintingPipeline, IFInpaintingSuperResolutionPipeline
pipe_1 = IFInpaintingPipeline(**pipe_1.components)
pipe_2 = IFInpaintingSuperResolutionPipeline(**pipe_2.components)
```
### Optimizing for speed
The simplest optimization to run IF faster is to move all model components to the GPU.
```py
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
pipe.to("cuda")
```
You can also run the diffusion process for a shorter number of timesteps.
This can either be done with the `num_inference_steps` argument:
```py
pipe("<prompt>", num_inference_steps=30)
```
Or with the `timesteps` argument:
```py
from diffusers.pipelines.deepfloyd_if import fast27_timesteps
pipe("<prompt>", timesteps=fast27_timesteps)
```
When doing image variation or inpainting, you can also decrease the number of timesteps
with the strength argument. The strength argument is the amount of noise to add to the input image which also determines how many steps to run in the denoising process.
A smaller number will vary the image less but run faster.
```py
pipe = IFImg2ImgPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(image=image, prompt="<prompt>", strength=0.3).images
```
You can also use [`torch.compile`](../../optimization/torch2.0). Note that we have not exhaustively tested `torch.compile`
with IF and it might not give expected results.
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
pipe.to("cuda")
pipe.text_encoder = torch.compile(pipe.text_encoder, mode="reduce-overhead", fullgraph=True)
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
### Optimizing for memory
When optimizing for GPU memory, we can use the standard diffusers CPU offloading APIs.
Either the model based CPU offloading,
```py
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
```
or the more aggressive layer based CPU offloading.
```py
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
pipe.enable_sequential_cpu_offload()
```
Additionally, T5 can be loaded in 8bit precision
```py
from transformers import T5EncoderModel
text_encoder = T5EncoderModel.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0", subfolder="text_encoder", device_map="auto", load_in_8bit=True, variant="8bit"
)
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=text_encoder, # pass the previously instantiated 8bit text encoder
unet=None,
device_map="auto",
)
prompt_embeds, negative_embeds = pipe.encode_prompt("<prompt>")
```
For CPU RAM constrained machines like Google Colab free tier where we can't load all model components to the CPU at once, we can manually only load the pipeline with
the text encoder or UNet when the respective model components are needed.
```py
from diffusers import IFPipeline, IFSuperResolutionPipeline
import torch
import gc
from transformers import T5EncoderModel
from diffusers.utils import pt_to_pil, make_image_grid
text_encoder = T5EncoderModel.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0", subfolder="text_encoder", device_map="auto", load_in_8bit=True, variant="8bit"
)
# text to image
pipe = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0",
text_encoder=text_encoder, # pass the previously instantiated 8bit text encoder
unet=None,
device_map="auto",
)
prompt = 'a photo of a kangaroo wearing an orange hoodie and blue sunglasses standing in front of the eiffel tower holding a sign that says "very deep learning"'
prompt_embeds, negative_embeds = pipe.encode_prompt(prompt)
# Remove the pipeline so we can re-load the pipeline with the unet
del text_encoder
del pipe
gc.collect()
torch.cuda.empty_cache()
pipe = IFPipeline.from_pretrained(
"DeepFloyd/IF-I-XL-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto"
)
generator = torch.Generator().manual_seed(0)
stage_1_output = pipe(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
output_type="pt",
generator=generator,
).images
#pt_to_pil(stage_1_output)[0].save("./if_stage_I.png")
# Remove the pipeline so we can load the super-resolution pipeline
del pipe
gc.collect()
torch.cuda.empty_cache()
# First super resolution
pipe = IFSuperResolutionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16, device_map="auto"
)
generator = torch.Generator().manual_seed(0)
stage_2_output = pipe(
image=stage_1_output,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
output_type="pt",
generator=generator,
).images
#pt_to_pil(stage_2_output)[0].save("./if_stage_II.png")
make_image_grid([pt_to_pil(stage_1_output)[0], pt_to_pil(stage_2_output)[0]], rows=1, rows=2)
```
## Available Pipelines:
| Pipeline | Tasks | Colab
|---|---|:---:|
| [pipeline_if.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/deepfloyd_if/pipeline_if.py) | *Text-to-Image Generation* | - |
| [pipeline_if_superresolution.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/deepfloyd_if/pipeline_if_superresolution.py) | *Text-to-Image Generation* | - |
| [pipeline_if_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py) | *Image-to-Image Generation* | - |
| [pipeline_if_img2img_superresolution.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img_superresolution.py) | *Image-to-Image Generation* | - |
| [pipeline_if_inpainting.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting.py) | *Image-to-Image Generation* | - |
| [pipeline_if_inpainting_superresolution.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting_superresolution.py) | *Image-to-Image Generation* | - |
## IFPipeline
[[autodoc]] IFPipeline
- all
- __call__
## IFSuperResolutionPipeline
[[autodoc]] IFSuperResolutionPipeline
- all
- __call__
## IFImg2ImgPipeline
[[autodoc]] IFImg2ImgPipeline
- all
- __call__
## IFImg2ImgSuperResolutionPipeline
[[autodoc]] IFImg2ImgSuperResolutionPipeline
- all
- __call__
## IFInpaintingPipeline
[[autodoc]] IFInpaintingPipeline
- all
- __call__
## IFInpaintingSuperResolutionPipeline
[[autodoc]] IFInpaintingSuperResolutionPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/deepfloyd_if.md |
--
title: "Fine-tuning Llama 2 70B using PyTorch FSDP"
thumbnail: /blog/assets/160_fsdp_llama/thumbnail.jpg
authors:
- user: smangrul
- user: sgugger
- user: lewtun
- user: philschmid
---
# Fine-tuning Llama 2 70B using PyTorch FSDP
## Introduction
In this blog post, we will look at how to fine-tune Llama 2 70B using PyTorch FSDP and related best practices. We will be leveraging Hugging Face Transformers, Accelerate and TRL. We will also learn how to use Accelerate with SLURM.
Fully Sharded Data Parallelism (FSDP) is a paradigm in which the optimizer states, gradients and parameters are sharded across devices. During the forward pass, each FSDP unit performs an _all-gather operation_ to get the complete weights, computation is performed followed by discarding the shards from other devices. After the forward pass, the loss is computed followed by the backward pass. In the backward pass, each FSDP unit performs an all-gather operation to get the complete weights, with computation performed to get the local gradients. These local gradients are averaged and sharded across the devices via a _reduce-scatter operation_ so that each device can update the parameters of its shard. For more information on what PyTorch FSDP is, please refer to this blog post: [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp).

(Source: [link](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/))
## Hardware Used
Number of nodes: 2. Minimum required is 1.
Number of GPUs per node: 8
GPU type: A100
GPU memory: 80GB
intra-node connection: NVLink
RAM per node: 1TB
CPU cores per node: 96
inter-node connection: Elastic Fabric Adapter
## Challenges with fine-tuning LLaMa 70B
We encountered three main challenges when trying to fine-tune LLaMa 70B with FSDP:
1. FSDP wraps the model after loading the pre-trained model. If each process/rank within a node loads the Llama-70B model, it would require 70\*4\*8 GB ~ 2TB of CPU RAM, where 4 is the number of bytes per parameter and 8 is the number of GPUs on each node. This would result in the CPU RAM getting out of memory leading to processes being terminated.
2. Saving entire intermediate checkpoints using `FULL_STATE_DICT` with CPU offloading on rank 0 takes a lot of time and often results in NCCL Timeout errors due to indefinite hanging during broadcasting. However, at the end of training, we want the whole model state dict instead of the sharded state dict which is only compatible with FSDP.
3. We need to improve the speed and reduce the VRAM usage to train faster and save compute costs.
Let’s look at how to solve the above challenges and fine-tune a 70B model!
Before we get started, here's all the required resources to reproduce our results:
1. Codebase:
https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/training with flash-attn V2 monkey patch
2. FSDP config: https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml
3. SLURM script `launch.slurm`: https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25
4. Model: `meta-llama/Llama-2-70b-chat-hf`
5. Dataset: [smangrul/code-chat-assistant-v1](https://huggingface.co/datasets/smangrul/code-chat-assistant-v1) (mix of LIMA+GUANACO with proper formatting in a ready-to-train format)
### Pre-requisites
First follow these steps to install Flash Attention V2: Dao-AILab/flash-attention: Fast and memory-efficient exact attention (github.com). Install the latest nightlies of PyTorch with CUDA ≥11.8. Install the remaining requirements as per DHS-LLM-Workshop/code_assistant/training/requirements.txt. Here, we will be installing 🤗 Accelerate and 🤗 Transformers from the main branch.
## Fine-Tuning
### Addressing Challenge 1
PRs [huggingface/transformers#25107](https://github.com/huggingface/transformers/pull/25107) and [huggingface/accelerate#1777](https://github.com/huggingface/accelerate/pull/1777) solve the first challenge and requires no code changes from user side. It does the following:
1. Create the model with no weights on all ranks (using the `meta` device).
2. Load the state dict only on rank==0 and set the model weights with that state dict on rank 0
3. For all other ranks, do `torch.empty(*param.size(), dtype=dtype)` for every parameter on `meta` device
4. So, rank==0 will have loaded the model with correct state dict while all other ranks will have random weights.
5. Set `sync_module_states=True` so that FSDP object takes care of broadcasting them to all the ranks before training starts.
Below is the output snippet on a 7B model on 2 GPUs measuring the memory consumed and model parameters at various stages. We can observe that during loading the pre-trained model rank 0 & rank 1 have CPU total peak memory of `32744 MB` and `1506 MB` , respectively. Therefore, only rank 0 is loading the pre-trained model leading to efficient usage of CPU RAM. The whole logs at be found [here](https://gist.github.com/pacman100/2fbda8eb4526443a73c1455de43e20f9)
```bash
accelerator.process_index=0 GPU Memory before entering the loading : 0
accelerator.process_index=0 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=0 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=0 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=0 CPU Memory before entering the loading : 926
accelerator.process_index=0 CPU Memory consumed at the end of the loading (end-begin): 26415
accelerator.process_index=0 CPU Peak Memory consumed during the loading (max-begin): 31818
accelerator.process_index=0 CPU Total Peak Memory consumed during the loading (max): 32744
accelerator.process_index=1 GPU Memory before entering the loading : 0
accelerator.process_index=1 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=1 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=1 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=1 CPU Memory before entering the loading : 933
accelerator.process_index=1 CPU Memory consumed at the end of the loading (end-begin): 10
accelerator.process_index=1 CPU Peak Memory consumed during the loading (max-begin): 573
accelerator.process_index=1 CPU Total Peak Memory consumed during the loading (max): 1506
```
### Addressing Challenge 2
It is addressed via choosing `SHARDED_STATE_DICT` state dict type when creating FSDP config. `SHARDED_STATE_DICT` saves shard per GPU separately which makes it quick to save or resume training from intermediate checkpoint. When `FULL_STATE_DICT` is used, first process (rank 0) gathers the whole model on CPU and then saving it in a standard format.
Let’s create the accelerate config via below command:
```
accelerate config --config_file "fsdp_config.yaml"
```
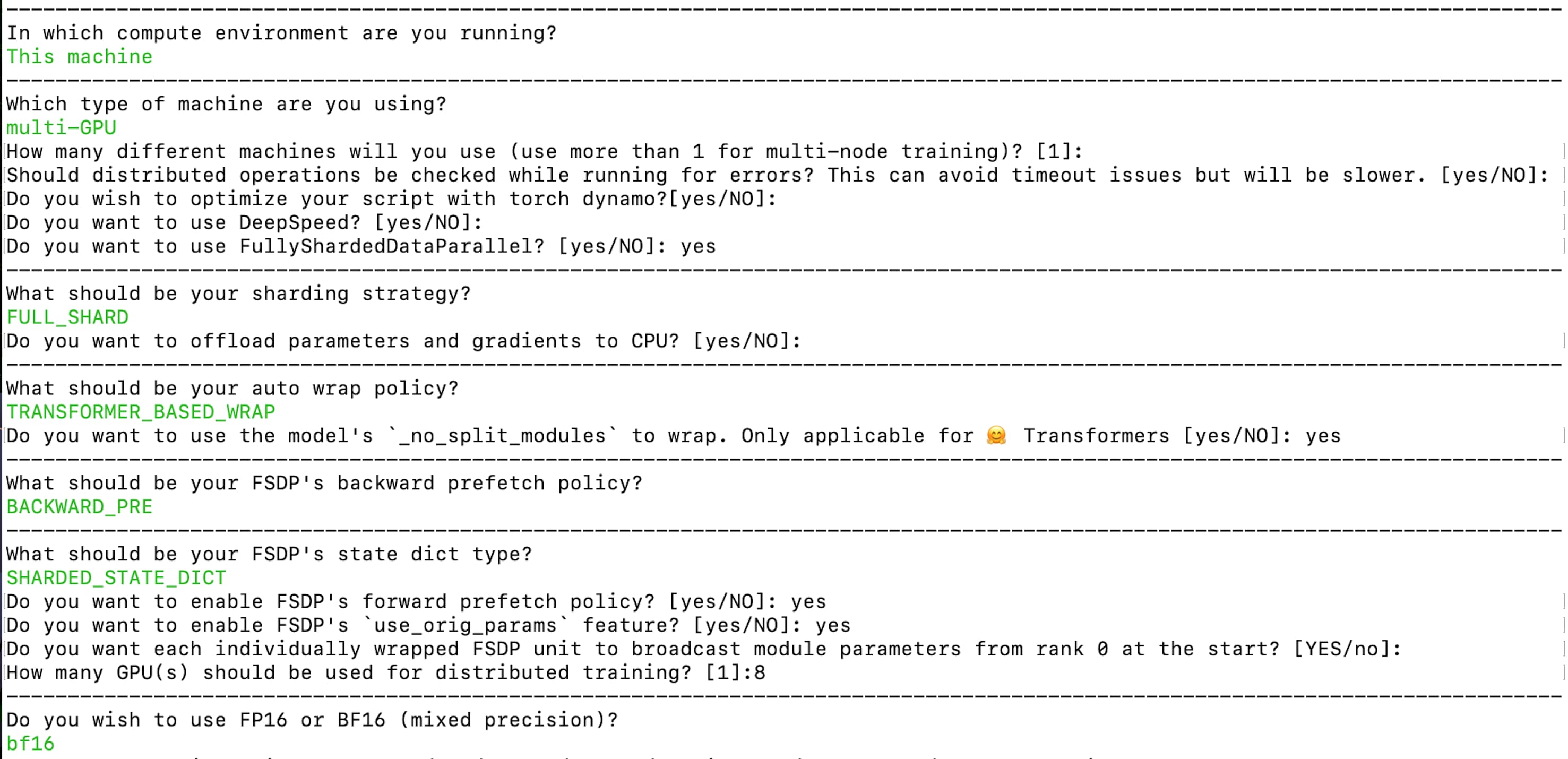
The resulting config is available here: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml). Here, the sharding strategy is `FULL_SHARD`. We are using `TRANSFORMER_BASED_WRAP` for auto wrap policy and it uses `_no_split_module` to find the Transformer block name for nested FSDP auto wrap. We use `SHARDED_STATE_DICT` to save the intermediate checkpoints and optimizer states in this format recommended by the PyTorch team. Make sure to enable broadcasting module parameters from rank 0 at the start as mentioned in the above paragraph on addressing Challenge 1. We are enabling `bf16` mixed precision training.
For final checkpoint being the whole model state dict, below code snippet is used:
```python
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # alternatively, trainer.push_to_hub() if the whole ckpt is below 50GB as the LFS limit per file is 50GB
```
### Addressing Challenge 3
Flash Attention and enabling gradient checkpointing are required for faster training and reducing VRAM usage to enable fine-tuning and save compute costs. The codebase currently uses monkey patching and the implementation is at [chat_assistant/training/llama_flash_attn_monkey_patch.py](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/llama_flash_attn_monkey_patch.py).
[FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf) introduces a way to compute exact attention while being faster and memory-efficient by leveraging the knowledge of the memory hierarchy of the underlying hardware/GPUs - The higher the bandwidth/speed of the memory, the smaller its capacity as it becomes more expensive.
If we follow the blog [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html), we can figure out that `Attention` module on current hardware is `memory-bound/bandwidth-bound`. The reason being that Attention **mostly consists of elementwise operations** as shown below on the left hand side. We can observe that masking, softmax and dropout operations take up the bulk of the time instead of matrix multiplications which consists of the bulk of FLOPs.
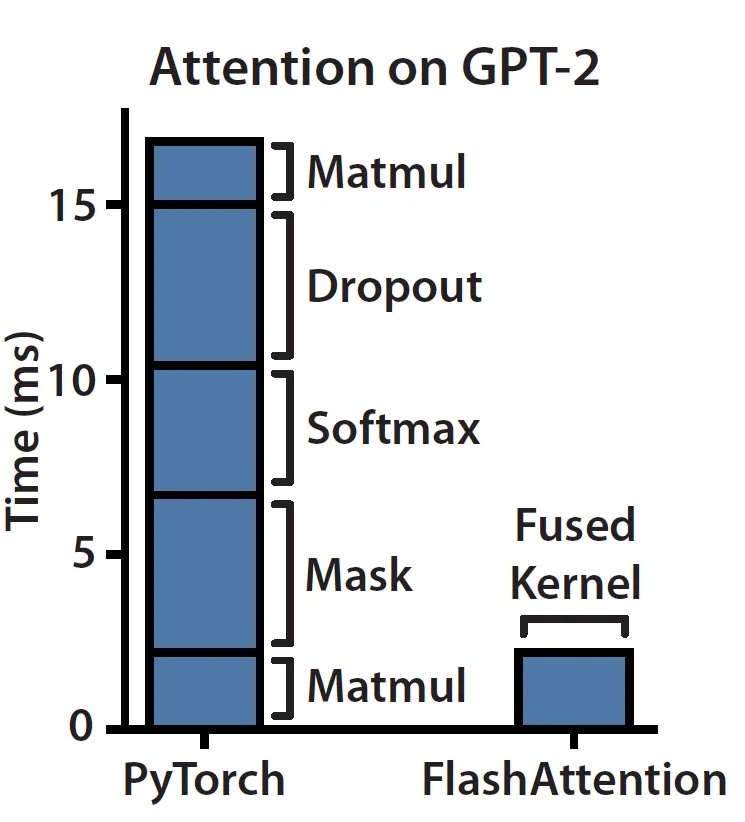
(Source: [link](https://arxiv.org/pdf/2205.14135.pdf))
This is precisely the problem that Flash Attention addresses. The idea is to **remove redundant HBM reads/writes.** It does so by keeping everything in SRAM, perform all the intermediate steps and only then write the final result back to HBM, also known as **Kernel Fusion**. Below is an illustration of how this overcomes the memory-bound bottleneck.
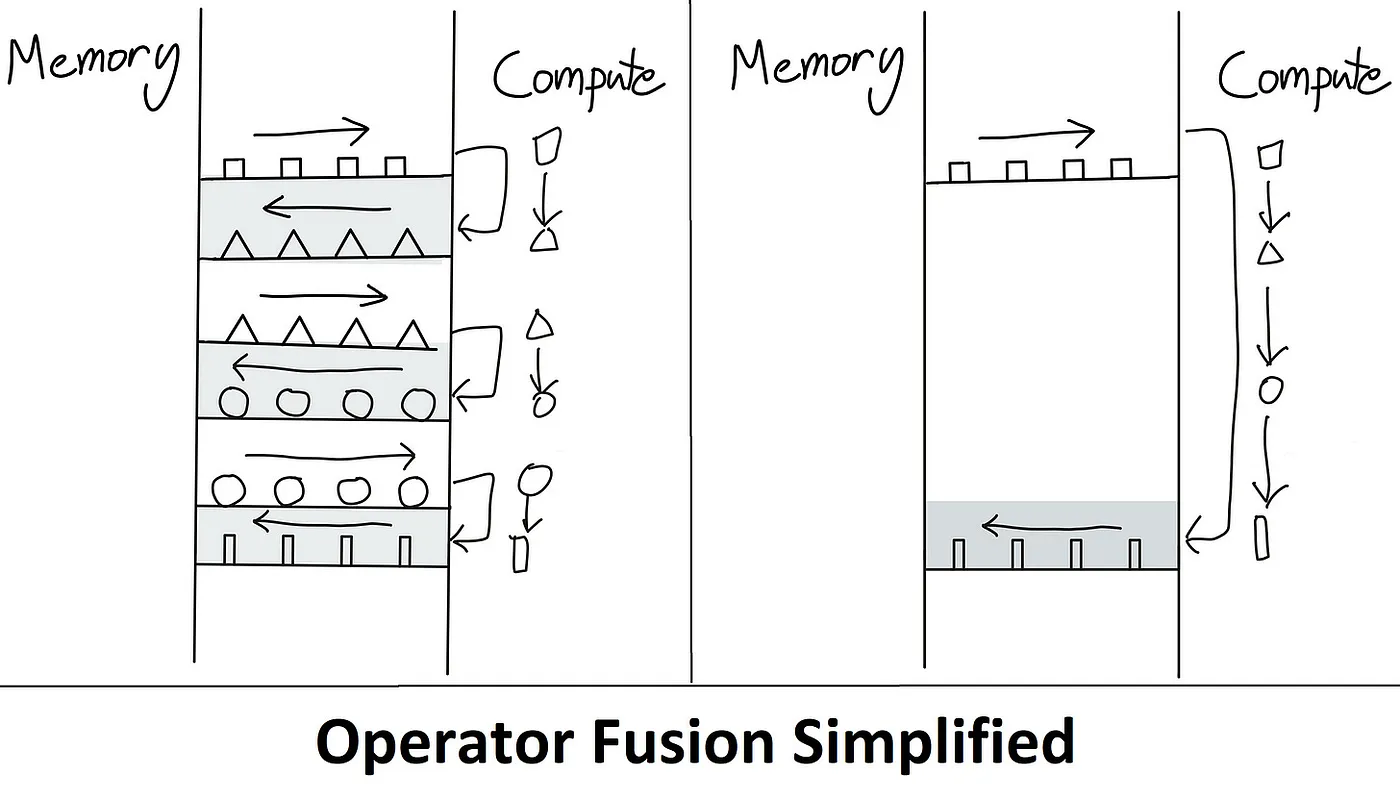
(Source: [link](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad))
**Tiling** is used during forward and backward passes to chunk the NxN softmax/scores computation into blocks to overcome the limitation of SRAM memory size. To enable tiling, online softmax algorithm is used. **Recomputation** is used during backward pass in order to avoid storing the entire NxN softmax/score matrix during forward pass. This greatly reduces the memory consumption.
For a simplified and in depth understanding of Flash Attention, please refer the blog posts [ELI5: FlashAttention](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad) and [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html) along with the original paper [FlashAttention: Fast and Memory-Efficient Exact Attention
with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf).
## Bringing it all-together
To run the training using `Accelerate` launcher with SLURM, refer this gist [launch.slurm](https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25). Below is an equivalent command showcasing how to use `Accelerate` launcher to run the training. Notice that we are overriding `main_process_ip` , `main_process_port` , `machine_rank` , `num_processes` and `num_machines` values of the `fsdp_config.yaml`. Here, another important point to note is that the storage is stored between all the nodes.
```
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--eval_steps 100 \
--save_steps 250 \
--bf16 True \
--packing True \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--dataset_text_field "content" \
--use_gradient_checkpointing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--use_flash_attn True
```
Fine-tuning completed in ~13.5 hours and below is the training loss plot.
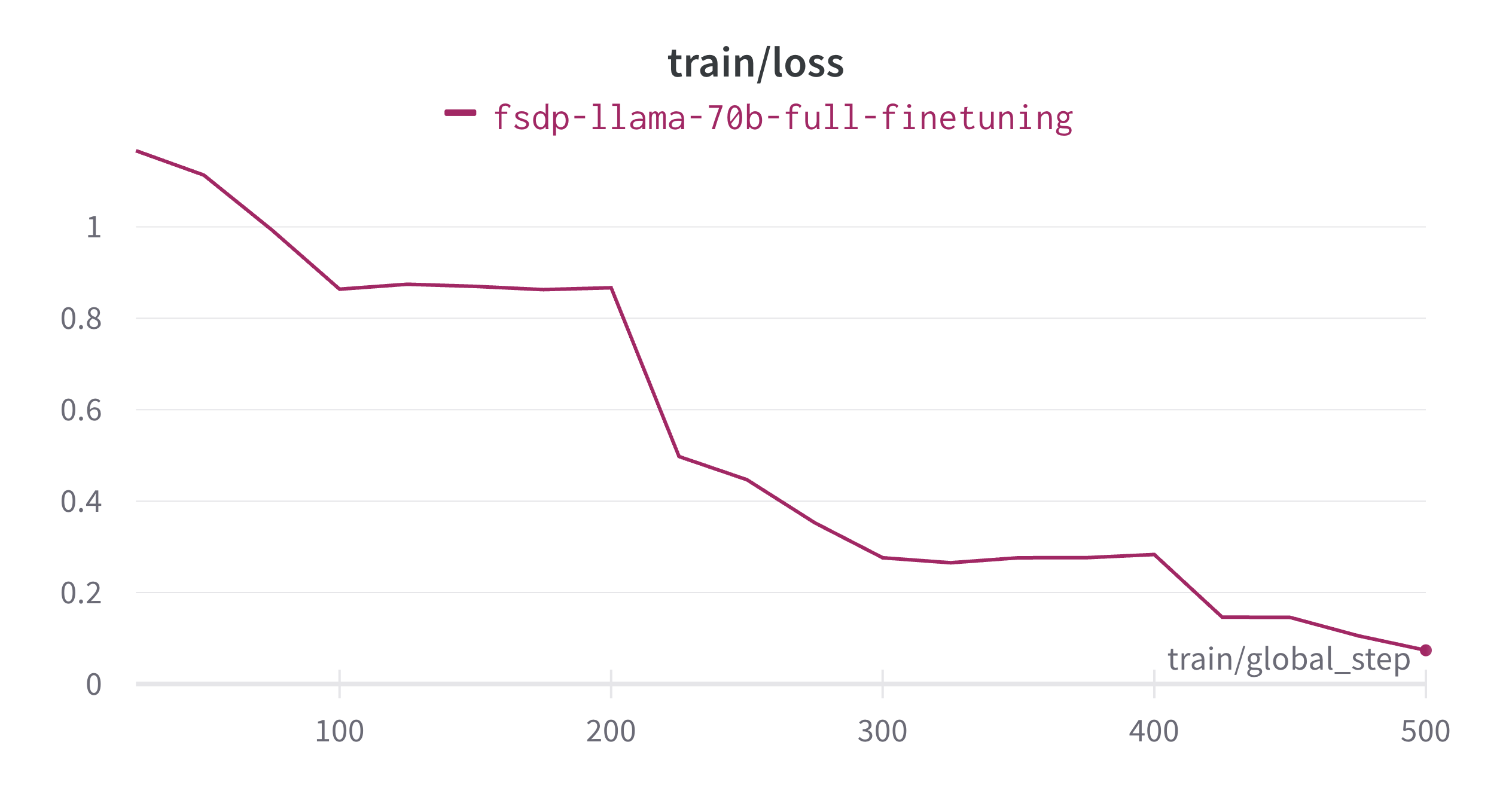
Below is an example conversation using the above model:
```diff
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully \
as possible, while being safe. Your answers should not include any harmful, \
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that \
your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why \
instead of answering something not correct. If you don’t know the answer to a \
question, please don’t share false information.
- Human: What is Deep Learning? Explain like a Pirate.
+ Assistant: Arrr Grumete! Are ye lookin' fer a proper explanation o' Deep Learnin'?
+ Alright then, listen up me hearty! Deep Learnin' be a type o' machine learnin' that uses artificial neural networks to analyze data.
+ Aye, ye heard that right, mateys! Artificial neural networks be models o' the human brain, but instead o' using neurons, they use interconnected nodes or "artificial neurons" to process information.
+ These nodes work together to form layers o' processing units that can learn from large amounts o' data.
+ The more data these systems receive, the better they get at recognizing patterns and makin' decisions on their own.
+ So hoist the sails and set course for adventure with deep learnin', me hearties! It's a treasure trove o' knowledge just waitin' to be discovered.
+ Fair winds and following seas!
- Human: Now explain it like a chef.
+ Assistant: Certainly! Here's an explanation of deep learning from a culinary perspective:
+ Think of a recipe as a sequence of steps used to transform raw ingredients into a delicious dish.
+ Similarly, in deep learning, there are multiple layers of "ingredients" (or features) that are combined and transformed through various operations to produce a final output or prediction.
+ Each layer builds upon the previous one, refining and enhancing the representation of the input data until it reaches the desired outcome.
+ Just as different spices enhance the flavors of food, each layer adds depth and complexity to the model's understanding of the input, allowing it to make more accurate predictions.
+ And much like how chefs must carefully balance the amount of salt, sugar, and other seasonings in a recipe, the training process in deep learning involves adjusting the weights and biases of the network to achieve the perfect blend of accuracy and efficiency.
+ With enough practice and experimentation, anyone can become a master chef... I mean, a master of deep learning! Bon appétit!
```
The whole conversation is formatted as below:
```
<|system|> system message <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ...
```
## Conclusion
We successfully fine-tuned 70B Llama model using PyTorch FSDP in a multi-node multi-gpu setting while addressing various challenges. We saw how 🤗 Transformers and 🤗 Accelerates now supports efficient way of initializing large models when using FSDP to overcome CPU RAM getting out of memory. This was followed by recommended practices for saving/loading intermediate checkpoints and how to save the final model in a way to readily use it. To enable faster training and reducing GPU memory usage, we outlined the importance of Flash Attention and Gradient Checkpointing. Overall, we can see how a simple config using 🤗 Accelerate enables finetuning of such large models in a multi-node multi-gpu setting. | huggingface/blog/blob/main/ram-efficient-pytorch-fsdp.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Objects
The base object class is `Object3D`.
[[autodoc]] Object3D
## Other included objects
[[autodoc]] Plane
[[autodoc]] Sphere
[[autodoc]] Capsule
[[autodoc]] Cylinder
[[autodoc]] Box
[[autodoc]] Cone
[[autodoc]] Line
[[autodoc]] MultipleLines
[[autodoc]] Tube
[[autodoc]] Polygon
[[autodoc]] RegularPolygon
[[autodoc]] Ring
[[autodoc]] Text3D
[[autodoc]] Triangle
[[autodoc]] Rectangle
[[autodoc]] Circle
[[autodoc]] StructuredGrid
[[autodoc]] ProcGenGrid
[[autodoc]] ProcGenPrimsMaze3D
| huggingface/simulate/blob/main/docs/source/api/objects.mdx |
Send Requests to Endpoints
You can send requests to Inference Endpoints using the UI leveraging the Inference Widget or programmatically, e.g. with cURL, `@huggingface/inference`, `huggingface_hub` or any REST client. The Endpoint overview not only provides a interactive widget for you to test the Endpoint, but also generates code for `python`, `javascript` and `curl`. You can use this code to quickly get started with your Endpoint in your favorite programming language.
Below are also examples on how to use the `@huggingface/inference` library to call an inference endpoint.
## Use the UI to send requests
The Endpoint overview provides access to the Inference Widget which can be used to send requests (see step 6 of [Create an Endpoint](/docs/inference-endpoints/guides/create_endpoint)). This allows you to quickly test your Endpoint with different inputs and share it with team members.
## Use cURL to send requests
The cURL command for the request above should look like this. You'll need to provide your user token which can be found in your Hugging Face [account settings](https://huggingface.co/settings/tokens):
Example Request:
```bash
curl https://uu149rez6gw9ehej.eu-west-1.aws.endpoints.huggingface.cloud/distilbert-sentiment \
-X POST \
-d '{"inputs": "Deploying my first endpoint was an amazing experience."}' \
-H "Authorization: Bearer <Token>"
```
The Endpoints API offers the same API definitions as the [Inference API](https://huggingface.co/docs/api-inference/detailed_parameters) and the [SageMaker Inference Toolkit](https://huggingface.co/docs/sagemaker/reference#inference-toolkit-api). All the request payloads are documented in the [Supported Tasks](/docs/inference-endpoints/supported_tasks) section.
This means for an NLP task, the payload is represented as the `inputs` key and additional pipeline parameters are included in the `parameters` key. You can provide any of the supported `kwargs` from [pipelines](https://huggingface.co/docs/transformers/main_classes/pipelines) as parameters.
For image or audio tasks, you should send the data as a binary request with the corresponding mime type. Below is an example cURL for an audio payload:
```bash
curl --request POST \
--url https://uu149rez6gw9ehej.eu-west-1.aws.endpoints.huggingface.cloud/wav2vec-asr \
--header 'Authorization: Bearer <Token>' \
--header 'Content-Type: audio/x-flac' \
--data-binary '@sample1.flac'
```
To use your cURL command as code, use the [cURL Converter](https://curlconverter.com/) tool to quickly get started with the programming language of your choice.
## Use javascript library `@huggingface/inference`
You can use the javascript library to call an inference endpoint:
```ts
const inference = new HfInference('hf_...') // your user token
const gpt2 = inference.endpoint('https://xyz.eu-west-1.aws.endpoints.huggingface.cloud/gpt2-endpoint')
const { generated_text } = await gpt2.textGeneration({ inputs: 'The answer to the universe is' })
```
### Custom handler
`@huggingface/inference` supports tasks from https://huggingface.co/tasks, and is typed accordingly.
If your model has additional inputs, or even custom inputs / outputs you can use the more generic `.request` / `streamingRequest`:
```ts
const output = await inference.request({
inputs: "blablabla",
parameters: {
custom_parameter_1: ...,
...
}
});
```
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/test_endpoint.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Improve generation quality with FreeU
[[open-in-colab]]
The UNet is responsible for denoising during the reverse diffusion process, and there are two distinct features in its architecture:
1. Backbone features primarily contribute to the denoising process
2. Skip features mainly introduce high-frequency features into the decoder module and can make the network overlook the semantics in the backbone features
However, the skip connection can sometimes introduce unnatural image details. [FreeU](https://hf.co/papers/2309.11497) is a technique for improving image quality by rebalancing the contributions from the UNet’s skip connections and backbone feature maps.
FreeU is applied during inference and it does not require any additional training. The technique works for different tasks such as text-to-image, image-to-image, and text-to-video.
In this guide, you will apply FreeU to the [`StableDiffusionPipeline`], [`StableDiffusionXLPipeline`], and [`TextToVideoSDPipeline`]. You need to install Diffusers from source to run the examples below.
## StableDiffusionPipeline
Load the pipeline:
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, safety_checker=None
).to("cuda")
```
Then enable the FreeU mechanism with the FreeU-specific hyperparameters. These values are scaling factors for the backbone and skip features.
```py
pipeline.enable_freeu(s1=0.9, s2=0.2, b1=1.2, b2=1.4)
```
The values above are from the official FreeU [code repository](https://github.com/ChenyangSi/FreeU) where you can also find [reference hyperparameters](https://github.com/ChenyangSi/FreeU#range-for-more-parameters) for different models.
<Tip>
Disable the FreeU mechanism by calling `disable_freeu()` on a pipeline.
</Tip>
And then run inference:
```py
prompt = "A squirrel eating a burger"
seed = 2023
image = pipeline(prompt, generator=torch.manual_seed(seed)).images[0]
image
```
The figure below compares non-FreeU and FreeU results respectively for the same hyperparameters used above (`prompt` and `seed`):

Let's see how Stable Diffusion 2 results are impacted:
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16, safety_checker=None
).to("cuda")
prompt = "A squirrel eating a burger"
seed = 2023
pipeline.enable_freeu(s1=0.9, s2=0.2, b1=1.1, b2=1.2)
image = pipeline(prompt, generator=torch.manual_seed(seed)).images[0]
image
```

## Stable Diffusion XL
Finally, let's take a look at how FreeU affects Stable Diffusion XL results:
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16,
).to("cuda")
prompt = "A squirrel eating a burger"
seed = 2023
# Comes from
# https://wandb.ai/nasirk24/UNET-FreeU-SDXL/reports/FreeU-SDXL-Optimal-Parameters--Vmlldzo1NDg4NTUw
pipeline.enable_freeu(s1=0.6, s2=0.4, b1=1.1, b2=1.2)
image = pipeline(prompt, generator=torch.manual_seed(seed)).images[0]
image
```

## Text-to-video generation
FreeU can also be used to improve video quality:
```python
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
import torch
model_id = "cerspense/zeroscope_v2_576w"
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "an astronaut riding a horse on mars"
seed = 2023
# The values come from
# https://github.com/lyn-rgb/FreeU_Diffusers#video-pipelines
pipe.enable_freeu(b1=1.2, b2=1.4, s1=0.9, s2=0.2)
video_frames = pipe(prompt, height=320, width=576, num_frames=30, generator=torch.manual_seed(seed)).frames
export_to_video(video_frames, "astronaut_rides_horse.mp4")
```
Thanks to [kadirnar](https://github.com/kadirnar/) for helping to integrate the feature, and to [justindujardin](https://github.com/justindujardin) for the helpful discussions.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/freeu.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Data2Vec
## Overview
The Data2Vec model was proposed in [data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu and Michael Auli.
Data2Vec proposes a unified framework for self-supervised learning across different data modalities - text, audio and images.
Importantly, predicted targets for pre-training are contextualized latent representations of the inputs, rather than modality-specific, context-independent targets.
The abstract from the paper is the following:
*While the general idea of self-supervised learning is identical across modalities, the actual algorithms and
objectives differ widely because they were developed with a single modality in mind. To get us closer to general
self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech,
NLP or computer vision. The core idea is to predict latent representations of the full input data based on a
masked view of the input in a selfdistillation setup using a standard Transformer architecture.
Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which
are local in nature, data2vec predicts contextualized latent representations that contain information from
the entire input. Experiments on the major benchmarks of speech recognition, image classification, and
natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
Models and code are available at www.github.com/pytorch/fairseq/tree/master/examples/data2vec.*
This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
[sayakpaul](https://github.com/sayakpaul) and [Rocketknight1](https://github.com/Rocketknight1) contributed Data2Vec for vision in TensorFlow.
The original code (for NLP and Speech) can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/data2vec).
The original code for vision can be found [here](https://github.com/facebookresearch/data2vec_vision/tree/main/beit).
## Usage tips
- Data2VecAudio, Data2VecText, and Data2VecVision have all been trained using the same self-supervised learning method.
- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Data2Vec.
<PipelineTag pipeline="image-classification"/>
- [`Data2VecVisionForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- To fine-tune [`TFData2VecVisionForImageClassification`] on a custom dataset, see [this notebook](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb).
**Data2VecText documentation resources**
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
**Data2VecAudio documentation resources**
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
**Data2VecVision documentation resources**
- [Image classification](../tasks/image_classification)
- [Semantic segmentation](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Data2VecTextConfig
[[autodoc]] Data2VecTextConfig
## Data2VecAudioConfig
[[autodoc]] Data2VecAudioConfig
## Data2VecVisionConfig
[[autodoc]] Data2VecVisionConfig
<frameworkcontent>
<pt>
## Data2VecAudioModel
[[autodoc]] Data2VecAudioModel
- forward
## Data2VecAudioForAudioFrameClassification
[[autodoc]] Data2VecAudioForAudioFrameClassification
- forward
## Data2VecAudioForCTC
[[autodoc]] Data2VecAudioForCTC
- forward
## Data2VecAudioForSequenceClassification
[[autodoc]] Data2VecAudioForSequenceClassification
- forward
## Data2VecAudioForXVector
[[autodoc]] Data2VecAudioForXVector
- forward
## Data2VecTextModel
[[autodoc]] Data2VecTextModel
- forward
## Data2VecTextForCausalLM
[[autodoc]] Data2VecTextForCausalLM
- forward
## Data2VecTextForMaskedLM
[[autodoc]] Data2VecTextForMaskedLM
- forward
## Data2VecTextForSequenceClassification
[[autodoc]] Data2VecTextForSequenceClassification
- forward
## Data2VecTextForMultipleChoice
[[autodoc]] Data2VecTextForMultipleChoice
- forward
## Data2VecTextForTokenClassification
[[autodoc]] Data2VecTextForTokenClassification
- forward
## Data2VecTextForQuestionAnswering
[[autodoc]] Data2VecTextForQuestionAnswering
- forward
## Data2VecVisionModel
[[autodoc]] Data2VecVisionModel
- forward
## Data2VecVisionForImageClassification
[[autodoc]] Data2VecVisionForImageClassification
- forward
## Data2VecVisionForSemanticSegmentation
[[autodoc]] Data2VecVisionForSemanticSegmentation
- forward
</pt>
<tf>
## TFData2VecVisionModel
[[autodoc]] TFData2VecVisionModel
- call
## TFData2VecVisionForImageClassification
[[autodoc]] TFData2VecVisionForImageClassification
- call
## TFData2VecVisionForSemanticSegmentation
[[autodoc]] TFData2VecVisionForSemanticSegmentation
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/data2vec.md |
--
title: Optimizing Stable Diffusion for Intel CPUs with NNCF and 🤗 Optimum
thumbnail: /blog/assets/train_optimize_sd_intel/thumbnail.png
authors:
- user: AlexKoff88
guest: true
- user: MrOpenVINO
guest: true
- user: helenai
guest: true
- user: sayakpaul
- user: echarlaix
---
# Optimizing Stable Diffusion for Intel CPUs with NNCF and 🤗 Optimum
[**Latent Diffusion models**](https://arxiv.org/abs/2112.10752) are game changers when it comes to solving text-to-image generation problems. [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) is one of the most famous examples that got wide adoption in the community and industry. The idea behind the Stable Diffusion model is simple and compelling: you generate an image from a noise vector in multiple small steps refining the noise to a latent image representation. This approach works very well, but it can take a long time to generate an image if you do not have access to powerful GPUs.
Through the past five years, [OpenVINO Toolkit](https://docs.openvino.ai/) encapsulated many features for high-performance inference. Initially designed for Computer Vision models, it still dominates in this domain showing best-in-class inference performance for many contemporary models, including [Stable Diffusion](https://huggingface.co/blog/stable-diffusion-inference-intel). However, optimizing Stable Diffusion models for resource-constraint applications requires going far beyond just runtime optimizations. And this is where model optimization capabilities from OpenVINO [Neural Network Compression Framework](https://github.com/openvinotoolkit/nncf) (NNCF) come into play.
In this blog post, we will outline the problems of optimizing Stable Diffusion models and propose a workflow that substantially reduces the latency of such models when running on a resource-constrained HW such as CPU. In particular, we achieved **5.1x** inference acceleration and **4x** model footprint reduction compared to PyTorch.
## Stable Diffusion optimization
In the [Stable Diffusion pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), the UNet model is computationally the most expensive to run. Thus, optimizing just one model brings substantial benefits in terms of inference speed.
However, it turns out that the traditional model optimization methods, such as post-training 8-bit quantization, do not work for this model. There are two main reasons for that. First, pixel-level prediction models, such as semantic segmentation, super-resolution, etc., are one of the most complicated in terms of model optimization because of the complexity of the task, so tweaking model parameters and the structure breaks the results in numerous ways. The second reason is that the model has a lower level of redundancy because it accommodates a lot of information while being trained on [hundreds of millions of samples](https://laion.ai/blog/laion-5b/). That is why researchers have to employ more sophisticated quantization methods to preserve the accuracy after optimization. For example, Qualcomm used the layer-wise Knowledge Distillation method ([AdaRound](https://arxiv.org/abs/2004.10568)) to [quantize](https://www.qualcomm.com/news/onq/2023/02/worlds-first-on-device-demonstration-of-stable-diffusion-on-android) Stable Diffusion models. It means that model tuning after quantization is required, anyway. If so, why not just use [Quantization-Aware Training](https://arxiv.org/abs/1712.05877) (QAT) which can tune the model and quantization parameters simultaneously in the same way the source model is trained? Thus, we tried this approach in our work using [NNCF](https://github.com/openvinotoolkit/nncf), [OpenVINO](https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html), and [Diffusers](https://github.com/huggingface/diffusers) and coupled it with [Token Merging](https://arxiv.org/abs/2210.09461).
## Optimization workflow
We usually start the optimization of a model after it's trained. Here, we start from a [model](https://huggingface.co/svjack/Stable-Diffusion-Pokemon-en) fine-tuned on the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) containing images of Pokemons and their text descriptions.
We used the [text-to-image fine-tuning example](https://huggingface.co/docs/diffusers/training/text2image) for Stable Diffusion from the Diffusers and integrated QAT from NNCF into the following training [script](https://github.com/huggingface/optimum-intel/tree/main/examples/openvino/stable-diffusion). We also changed the loss function to incorporate knowledge distillation from the source model that acts as a teacher in this process while the actual model being trained acts as a student. This approach is different from the classical knowledge distillation method, where the trained teacher model is distilled into a smaller student model. In our case, knowledge distillation is used as an auxiliary method that helps improve the final accuracy of the optimizing model. We also use the Exponential Moving Average (EMA) method for model parameters excluding quantizers which allows us to make the training process more stable. We tune the model for 4096 iterations only.
With some tricks, such as gradient checkpointing and [keeping the EMA model](https://github.com/huggingface/optimum-intel/blob/bbbe7ff0e81938802dbc1d234c3dcdf58ef56984/examples/openvino/stable-diffusion/train_text_to_image_qat.py#L941) in RAM instead of VRAM, we can run the optimization process using one GPU with 24 GB of VRAM. The whole optimization takes less than a day using one GPU!
## Going beyond Quantization-Aware Training
Quantization alone can bring significant enhancements by reducing model footprint, load time, memory consumption, and inference latency. But the great thing about quantization is that it can be applied along with other optimization methods leading to a cumulative speedup.
Recently, Facebook Research introduced a [Token Merging](https://arxiv.org/abs/2210.09461) method for Vision Transformer models. The essence of the method is that it merges redundant tokens with important ones using one of the available strategies (averaging, taking max values, etc.). This is done before the self-attention block, which is the most computationally demanding part of Transformer models. Therefore, reducing the token dimension reduces the overall computation time in the self-attention blocks. This method has also been [adapted](https://arxiv.org/pdf/2303.17604.pdf) for Stable Diffusion models and has shown promising results when optimizing Stable Diffusion pipelines for high-resolution image synthesis running on GPUs.
We modified the Token Merging method to be compliant with OpenVINO and stacked it with 8-bit quantization when applied to the Attention UNet model. This also involves all the mentioned techniques including Knowledge Distillation, etc. As for quantization, it requires fine-tuning to be applied to restore the accuracy. We also start optimization and fine-tuning from the [model](https://huggingface.co/svjack/Stable-Diffusion-Pokemon-en) trained on the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions). The figure below shows an overall optimization workflow.

The resultant model is highly beneficial when running inference on devices with limited computational resources, such as client or edge CPUs. As it was mentioned, stacking Token Merging with quantization leads to an additional reduction in the inference latency.
<div class="flex flex-row">
<div class="grid grid-cols-2 gap-4">
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_torch.png" alt="Image 1" />
<figcaption class="mt-2 text-center text-sm text-gray-500">PyTorch FP32, Inference Speed: 230.5 seconds, Memory Footprint: 3.44 GB</figcaption>
</figure>
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_fp32.png" alt="Image 2" />
<figcaption class="mt-2 text-center text-sm text-gray-500">OpenVINO FP32, Inference Speed: 120 seconds (<b>1.9x</b>), Memory Footprint: 3.44 GB</figcaption>
</figure>
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_quantized.png" alt="Image 3" />
<figcaption class="mt-2 text-center text-sm text-gray-500">OpenVINO 8-bit, Inference Speed: 59 seconds (<b>3.9x</b>), Memory Footprint: 0.86 GB (<b>0.25x</b>)</figcaption>
</figure>
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_tome_quantized.png" alt="Image 4" />
<figcaption class="mt-2 text-center text-sm text-gray-500">ToMe + OpenVINO 8-bit, Inference Speed: 44.6 seconds (<b>5.1x</b>), Memory Footprint: 0.86 GB (<b>0.25x</b>)</figcaption>
</figure>
</div>
</div>
Results of image generation [demo](https://huggingface.co/spaces/helenai/stable_diffusion) using different optimized models. Input prompt is “cartoon bird”, seed is 42. The models are with OpenVINO 2022.3 in [Hugging Face Spaces](https://huggingface.co/docs/hub/spaces-overview) using a “CPU upgrade” instance which utilizes 3rd Generation Intel® Xeon® Scalable Processors with Intel® Deep Learning Boost technology.
## Results
We used the disclosed optimization workflows to get two types of optimized models, 8-bit quantized and quantized with Token Merging, and compare them to the PyTorch baseline. We also converted the baseline to vanilla OpenVINO floating-point (FP32) model for the comprehensive comparison.
The picture above shows the results of image generation and some model characteristics. As you can see, just conversion to OpenVINO brings a significant decrease in the inference latency ( **1.9x** ). Applying 8-bit quantization boosts inference speed further leading to **3.9x** speedup compared to PyTorch. Another benefit of quantization is a significant reduction of model footprint, **0.25x** of PyTorch checkpoint, which also improves the model load time. Applying Token Merging (ToME) (with a **merging ratio of 0.4** ) on top of quantization brings **5.1x** performance speedup while keeping the footprint at the same level. We didn't provide a thorough analysis of the visual quality of the optimized models, but, as you can see, the results are quite solid.
For the results shown in this blog, we used the default number of 50 inference steps. With fewer inference steps, inference speed will be faster, but this has an effect on the quality of the resulting image. How large this effect is depends on the model and the [scheduler](https://huggingface.co/docs/diffusers/using-diffusers/schedulers). We recommend experimenting with different number of steps and schedulers and find what works best for your use case.
Below we show how to perform inference with the final pipeline optimized to run on Intel CPUs:
```python
from optimum.intel import OVStableDiffusionPipeline
# Load and compile the pipeline for performance.
name = "OpenVINO/stable-diffusion-pokemons-tome-quantized-aggressive"
pipe = OVStableDiffusionPipeline.from_pretrained(name, compile=False)
pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
pipe.compile()
# Generate an image.
prompt = "a drawing of a green pokemon with red eyes"
output = pipe(prompt, num_inference_steps=50, output_type="pil").images[0]
output.save("image.png")
```
You can find the training and quantization [code](https://github.com/huggingface/optimum-intel/tree/main/examples/openvino/stable-diffusion) in the Hugging Face [Optimum Intel](https://huggingface.co/docs/optimum/main/en/intel/index) library. The notebook that demonstrates the difference between optimized and original models is available [here](https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/stable_diffusion_optimization.ipynb). You can also find [many models](https://huggingface.co/models?library=openvino&sort=downloads) on the Hugging Face Hub under the [OpenVINO organization](https://huggingface.co/OpenVINO). In addition, we have created a [demo](https://huggingface.co/spaces/helenai/stable_diffusion) on Hugging Face Spaces that is being run on a 3rd Generation Intel Xeon Scalable processor.
## What about the general-purpose Stable Diffusion model?
As we showed with the Pokemon image generation task, it is possible to achieve a high level of optimization of the Stable Diffusion pipeline when using a relatively small amount of training resources. At the same time, it is well-known that training a general-purpose Stable Diffusion model is an [expensive task](https://www.mosaicml.com/blog/training-stable-diffusion-from-scratch-part-2). However, with enough budget and HW resources, it is possible to optimize the general-purpose model using the described approach and tune it to produce high-quality images. The only caveat we have is related to the token merging method that reduces the model capacity substantially. The rule of thumb here is the more complicated the dataset you have for the training, the less merging ratio you should use during the optimization.
If you enjoyed reading this post, you might also be interested in checking out [this post](https://huggingface.co/blog/stable-diffusion-inference-intel) that discusses other complementary approaches to optimize the performance of Stable Diffusion on 4th generation Intel Xeon CPUs.
| huggingface/blog/blob/main/train-optimize-sd-intel.md |
Token classification
## PyTorch version, no Trainer
Fine-tuning (m)LUKE for token classification task such as Named Entity Recognition (NER), Parts-of-speech
tagging (POS) or phrase extraction (CHUNKS). You can easily
customize it to your needs if you need extra processing on your datasets.
It will either run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own text files for
training and validation, you might just need to add some tweaks in the data preprocessing.
The script can be run in a distributed setup, on TPU and supports mixed precision by
the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then to train English LUKE on CoNLL2003:
```bash
export TASK_NAME=ner
python run_luke_ner_no_trainer.py \
--model_name_or_path studio-ousia/luke-base \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
export TASK_NAME=ner
accelerate launch run_ner_no_trainer.py \
--model_name_or_path studio-ousia/luke-base \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| huggingface/transformers/blob/main/examples/research_projects/luke/README.md |
Load audio data
You can load an audio dataset using the [`Audio`] feature that automatically decodes and resamples the audio files when you access the examples.
Audio decoding is based on the [`soundfile`](https://github.com/bastibe/python-soundfile) python package, which uses the [`libsndfile`](https://github.com/libsndfile/libsndfile) C library under the hood.
## Installation
To work with audio datasets, you need to have the `audio` dependencies installed.
Check out the [installation](./installation#audio) guide to learn how to install it.
## Local files
You can load your own dataset using the paths to your audio files. Use the [`~Dataset.cast_column`] function to take a column of audio file paths, and cast it to the [`Audio`] feature:
```py
>>> audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
>>> audio_dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': 'path/to/audio_1',
'sampling_rate': 16000}
```
## AudioFolder
You can also load a dataset with an `AudioFolder` dataset builder. It does not require writing a custom dataloader, making it useful for quickly creating and loading audio datasets with several thousand audio files.
## AudioFolder with metadata
To link your audio files with metadata information, make sure your dataset has a `metadata.csv` file. Your dataset structure might look like:
```
folder/train/metadata.csv
folder/train/first_audio_file.mp3
folder/train/second_audio_file.mp3
folder/train/third_audio_file.mp3
```
Your `metadata.csv` file must have a `file_name` column which links audio files with their metadata. An example `metadata.csv` file might look like:
```text
file_name,transcription
first_audio_file.mp3,znowu się duch z ciałem zrośnie w młodocianej wstaniesz wiosnie i możesz skutkiem tych leków umierać wstawać wiek wieków dalej tam były przestrogi jak siekać głowę jak nogi
second_audio_file.mp3,już u źwierzyńca podwojów król zasiada przy nim książęta i panowie rada a gdzie wzniosły krążył ganek rycerze obok kochanek król skinął palcem zaczęto igrzysko
third_audio_file.mp3,pewnie kędyś w obłędzie ubite minęły szlaki zaczekajmy dzień jaki poślemy szukać wszędzie dziś jutro pewnie będzie posłali wszędzie sługi czekali dzień i drugi gdy nic nie doczekali z płaczem chcą jechać dali
```
`AudioFolder` will load audio data and create a `transcription` column containing texts from `metadata.csv`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder")
>>> # OR by specifying the list of files
>>> dataset = load_dataset("audiofolder", data_files=["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"])
```
You can load remote datasets from their URLs with the data_files parameter:
```py
>>> dataset = load_dataset("audiofolder", data_files=["https://foo.bar/audio_1", "https://foo.bar/audio_2", ..., "https://foo.bar/audio_n"]
>>> # for example, pass SpeechCommands archive:
>>> dataset = load_dataset("audiofolder", data_files="https://s3.amazonaws.com/datasets.huggingface.co/SpeechCommands/v0.01/v0.01_test.tar.gz")
```
Metadata can also be specified as JSON Lines, in which case use `metadata.jsonl` as the name of the metadata file. This format is helpful in scenarios when one of the columns is complex, e.g. a list of floats, to avoid parsing errors or reading the complex values as strings.
To ignore the information in the metadata file, set `drop_metadata=True` in [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder", drop_metadata=True)
```
If you don't have a metadata file, `AudioFolder` automatically infers the label name from the directory name.
If you want to drop automatically created labels, set `drop_labels=True`.
In this case, your dataset will only contain an audio column:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder_without_metadata", drop_labels=True)
```
<Tip>
For more information about creating your own `AudioFolder` dataset, take a look at the [Create an audio dataset](./audio_dataset) guide.
</Tip>
For a guide on how to load any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./loading">general loading guide</a>.
| huggingface/datasets/blob/main/docs/source/audio_load.mdx |
Using Flagging
Related spaces: https://huggingface.co/spaces/gradio/calculator-flagging-crowdsourced, https://huggingface.co/spaces/gradio/calculator-flagging-options, https://huggingface.co/spaces/gradio/calculator-flag-basic
Tags: FLAGGING, DATA
## Introduction
When you demo a machine learning model, you might want to collect data from users who try the model, particularly data points in which the model is not behaving as expected. Capturing these "hard" data points is valuable because it allows you to improve your machine learning model and make it more reliable and robust.
Gradio simplifies the collection of this data by including a **Flag** button with every `Interface`. This allows a user or tester to easily send data back to the machine where the demo is running. In this Guide, we discuss more about how to use the flagging feature, both with `gradio.Interface` as well as with `gradio.Blocks`.
## The **Flag** button in `gradio.Interface`
Flagging with Gradio's `Interface` is especially easy. By default, underneath the output components, there is a button marked **Flag**. When a user testing your model sees input with interesting output, they can click the flag button to send the input and output data back to the machine where the demo is running. The sample is saved to a CSV log file (by default). If the demo involves images, audio, video, or other types of files, these are saved separately in a parallel directory and the paths to these files are saved in the CSV file.
There are [four parameters](https://gradio.app/docs/#interface-header) in `gradio.Interface` that control how flagging works. We will go over them in greater detail.
- `allow_flagging`: this parameter can be set to either `"manual"` (default), `"auto"`, or `"never"`.
- `manual`: users will see a button to flag, and samples are only flagged when the button is clicked.
- `auto`: users will not see a button to flag, but every sample will be flagged automatically.
- `never`: users will not see a button to flag, and no sample will be flagged.
- `flagging_options`: this parameter can be either `None` (default) or a list of strings.
- If `None`, then the user simply clicks on the **Flag** button and no additional options are shown.
- If a list of strings are provided, then the user sees several buttons, corresponding to each of the strings that are provided. For example, if the value of this parameter is `["Incorrect", "Ambiguous"]`, then buttons labeled **Flag as Incorrect** and **Flag as Ambiguous** appear. This only applies if `allow_flagging` is `"manual"`.
- The chosen option is then logged along with the input and output.
- `flagging_dir`: this parameter takes a string.
- It represents what to name the directory where flagged data is stored.
- `flagging_callback`: this parameter takes an instance of a subclass of the `FlaggingCallback` class
- Using this parameter allows you to write custom code that gets run when the flag button is clicked
- By default, this is set to an instance of `gr.CSVLogger`
- One example is setting it to an instance of `gr.HuggingFaceDatasetSaver` which can allow you to pipe any flagged data into a HuggingFace Dataset. (See more below.)
## What happens to flagged data?
Within the directory provided by the `flagging_dir` argument, a CSV file will log the flagged data.
Here's an example: The code below creates the calculator interface embedded below it:
```python
import gradio as gr
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
return num1 / num2
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
allow_flagging="manual"
)
iface.launch()
```
<gradio-app space="gradio/calculator-flag-basic/"></gradio-app>
When you click the flag button above, the directory where the interface was launched will include a new flagged subfolder, with a csv file inside it. This csv file includes all the data that was flagged.
```directory
+-- flagged/
| +-- logs.csv
```
_flagged/logs.csv_
```csv
num1,operation,num2,Output,timestamp
5,add,7,12,2022-01-31 11:40:51.093412
6,subtract,1.5,4.5,2022-01-31 03:25:32.023542
```
If the interface involves file data, such as for Image and Audio components, folders will be created to store those flagged data as well. For example an `image` input to `image` output interface will create the following structure.
```directory
+-- flagged/
| +-- logs.csv
| +-- image/
| | +-- 0.png
| | +-- 1.png
| +-- Output/
| | +-- 0.png
| | +-- 1.png
```
_flagged/logs.csv_
```csv
im,Output timestamp
im/0.png,Output/0.png,2022-02-04 19:49:58.026963
im/1.png,Output/1.png,2022-02-02 10:40:51.093412
```
If you wish for the user to provide a reason for flagging, you can pass a list of strings to the `flagging_options` argument of Interface. Users will have to select one of these choices when flagging, and the option will be saved as an additional column to the CSV.
If we go back to the calculator example, the following code will create the interface embedded below it.
```python
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
allow_flagging="manual",
flagging_options=["wrong sign", "off by one", "other"]
)
iface.launch()
```
<gradio-app space="gradio/calculator-flagging-options/"></gradio-app>
When users click the flag button, the csv file will now include a column indicating the selected option.
_flagged/logs.csv_
```csv
num1,operation,num2,Output,flag,timestamp
5,add,7,-12,wrong sign,2022-02-04 11:40:51.093412
6,subtract,1.5,3.5,off by one,2022-02-04 11:42:32.062512
```
## The HuggingFaceDatasetSaver Callback
Sometimes, saving the data to a local CSV file doesn't make sense. For example, on Hugging Face
Spaces, developers typically don't have access to the underlying ephemeral machine hosting the Gradio
demo. That's why, by default, flagging is turned off in Hugging Face Space. However,
you may want to do something else with the flagged data.
We've made this super easy with the `flagging_callback` parameter.
For example, below we're going to pipe flagged data from our calculator example into a Hugging Face Dataset, e.g. so that we can build a "crowd-sourced" dataset:
```python
import os
HF_TOKEN = os.getenv('HF_TOKEN')
hf_writer = gr.HuggingFaceDatasetSaver(HF_TOKEN, "crowdsourced-calculator-demo")
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
description="Check out the crowd-sourced dataset at: [https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo)",
allow_flagging="manual",
flagging_options=["wrong sign", "off by one", "other"],
flagging_callback=hf_writer
)
iface.launch()
```
Notice that we define our own
instance of `gradio.HuggingFaceDatasetSaver` using our Hugging Face token and
the name of a dataset we'd like to save samples to. In addition, we also set `allow_flagging="manual"`
because on Hugging Face Spaces, `allow_flagging` is set to `"never"` by default. Here's our demo:
<gradio-app space="gradio/calculator-flagging-crowdsourced/"></gradio-app>
You can now see all the examples flagged above in this [public Hugging Face dataset](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo).
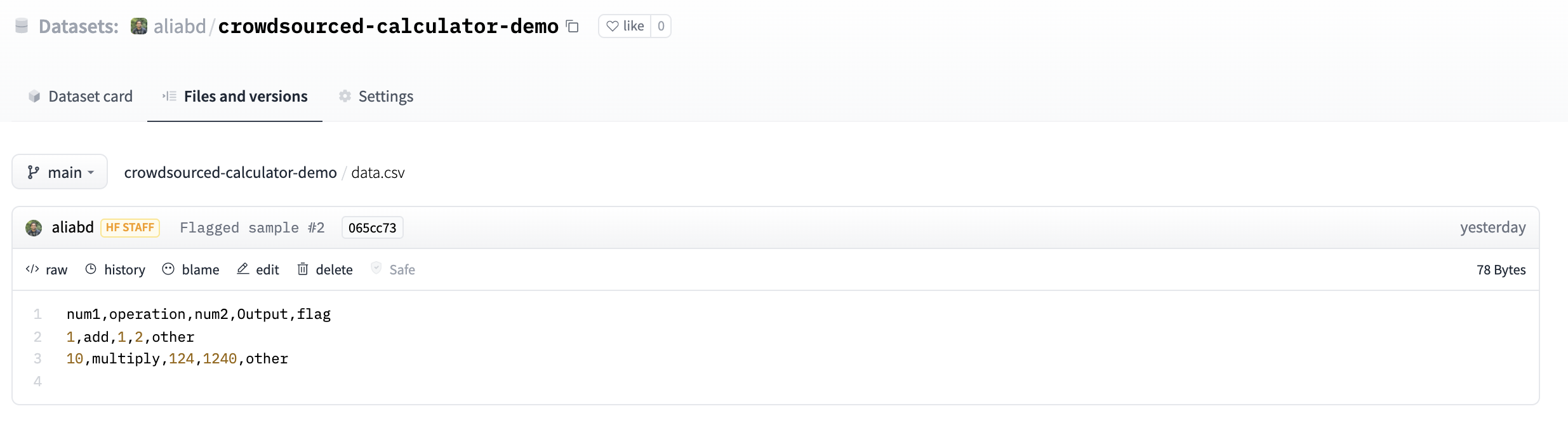
We created the `gradio.HuggingFaceDatasetSaver` class, but you can pass your own custom class as long as it inherits from `FLaggingCallback` defined in [this file](https://github.com/gradio-app/gradio/blob/master/gradio/flagging.py). If you create a cool callback, contribute it to the repo!
## Flagging with Blocks
What about if you are using `gradio.Blocks`? On one hand, you have even more flexibility
with Blocks -- you can write whatever Python code you want to run when a button is clicked,
and assign that using the built-in events in Blocks.
At the same time, you might want to use an existing `FlaggingCallback` to avoid writing extra code.
This requires two steps:
1. You have to run your callback's `.setup()` somewhere in the code prior to the
first time you flag data
2. When the flagging button is clicked, then you trigger the callback's `.flag()` method,
making sure to collect the arguments correctly and disabling the typical preprocessing.
Here is an example with an image sepia filter Blocks demo that lets you flag
data using the default `CSVLogger`:
$code_blocks_flag
$demo_blocks_flag
## Privacy
Important Note: please make sure your users understand when the data they submit is being saved, and what you plan on doing with it. This is especially important when you use `allow_flagging=auto` (when all of the data submitted through the demo is being flagged)
### That's all! Happy building :)
| gradio-app/gradio/blob/main/guides/09_other-tutorials/using-flagging.md |
his demo shows how you can build a live interactive dashboard with gradio.
The current time is refreshed every second and the plot every half second by using the 'every' keyword in the event handler.
Changing the value of the slider will control the period of the sine curve (the distance between peaks). | gradio-app/gradio/blob/main/demo/live_dashboard/DESCRIPTION.md |
Train your first Deep Reinforcement Learning Agent 🤖 [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that you've studied the bases of Reinforcement Learning, you’re ready to train your first agent and share it with the community through the Hub 🔥:
A Lunar Lander agent that will learn to land correctly on the Moon 🌕
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/lunarLander.gif" alt="LunarLander">
And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
Thanks to our <a href="https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard">leaderboard</a>, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained model to the Hub and **get a result of >= 200**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
**If you don't find your model, go to the bottom of the page and click on the refresh button.**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
So let's get started! 🚀
**To start the hands-on click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
# Unit 1: Train your first Deep Reinforcement Learning Agent 🤖
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/thumbnail.jpg" alt="Unit 1 thumbnail" width="100%">
In this notebook, you'll train your **first Deep Reinforcement Learning agent** a Lunar Lander agent that will learn to **land correctly on the Moon 🌕**. Using [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) a Deep Reinforcement Learning library, share them with the community, and experiment with different configurations
### The environment 🎮
- [LunarLander-v2](https://gymnasium.farama.org/environments/box2d/lunar_lander/)
### The library used 📚
- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Be able to use **Gymnasium**, the environment library.
- Be able to use **Stable-Baselines3**, the deep reinforcement learning library.
- Be able to **push your trained agent to the Hub** with a nice video replay and an evaluation score 🔥.
## This notebook is from Deep Reinforcement Learning Course
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/deep-rl-course-illustration.jpg" alt="Deep RL Course illustration"/>
In this free course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice**.
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
- 🤖 Train **agents in unique environments**
- 🎓 **Earn a certificate of completion** by completing 80% of the assignments.
And more!
Check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
Don’t forget to **<a href="http://eepurl.com/ic5ZUD">sign up to the course</a>** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
The best way to keep in touch and ask questions is **to join our discord server** to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📝 **[Read Unit 0](https://huggingface.co/deep-rl-course/unit0/introduction)** that gives you all the **information about the course and helps you to onboard** 🤗
🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction).
## A small recap of Deep Reinforcement Learning 📚
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process_game.jpg" alt="The RL process" width="100%">
Let's do a small recap on what we learned in the first Unit:
- Reinforcement Learning is a **computational approach to learning from actions**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of an expected cumulative reward.
- The RL process is a **loop that outputs a sequence of state, action, reward, and next state**.
- To calculate the expected cumulative reward (expected return), **we discount the rewards**: the rewards that come sooner (at the beginning of the game) are more probable to happen since they are more predictable than the long-term future reward.
- To solve an RL problem, you want to **find an optimal policy**; the policy is the "brain" of your AI that will tell us what action to take given a state. The optimal one is the one that gives you the actions that max the expected return.
There are **two** ways to find your optimal policy:
- By **training your policy directly**: policy-based methods.
- By **training a value function** that tells us the expected return the agent will get at each state and use this function to define our policy: value-based methods.
- Finally, we spoke about Deep RL because **we introduce deep neural networks to estimate the action to take (policy-based) or to estimate the value of a state (value-based) hence the name "deep."**
# Let's train our first Deep Reinforcement Learning agent and upload it to the Hub 🚀
## Get a certificate 🎓
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained model to the Hub and **get a result of >= 200**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Install dependencies and create a virtual screen 🔽
The first step is to install the dependencies, we’ll install multiple ones.
- `gymnasium[box2d]`: Contains the LunarLander-v2 environment 🌛
- `stable-baselines3[extra]`: The deep reinforcement learning library.
- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
To make things easier, we created a script to install all these dependencies.
```bash
apt install swig cmake
```
```bash
pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt
```
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
Hence the following cell will install virtual screen libraries and create and run a virtual screen 🖥
```bash
sudo apt-get update
apt install python-opengl
apt install ffmpeg
apt install xvfb
pip3 install pyvirtualdisplay
```
To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
import os
os.kill(os.getpid(), 9)
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
## Import the packages 📦
One additional library we import is huggingface_hub **to be able to upload and download trained models from the hub**.
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
You can see here all the Deep reinforcement Learning models available here👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
```python
import gymnasium
from huggingface_sb3 import load_from_hub, package_to_hub
from huggingface_hub import (
notebook_login,
) # To log to our Hugging Face account to be able to upload models to the Hub.
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.monitor import Monitor
```
## Understand Gymnasium and how it works 🤖
🏋 The library containing our environment is called Gymnasium.
**You'll use Gymnasium a lot in Deep Reinforcement Learning.**
Gymnasium is the **new version of Gym library** [maintained by the Farama Foundation](https://farama.org/).
The Gymnasium library provides two things:
- An interface that allows you to **create RL environments**.
- A **collection of environments** (gym-control, atari, box2D...).
Let's look at an example, but first let's recall the RL loop.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process_game.jpg" alt="The RL process" width="100%">
At each step:
- Our Agent receives a **state (S0)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state (S0),** the Agent takes an **action (A0)** — our Agent will move to the right.
- The environment transitions to a **new** **state (S1)** — new frame.
- The environment gives some **reward (R1)** to the Agent — we’re not dead *(Positive Reward +1)*.
With Gymnasium:
1️⃣ We create our environment using `gymnasium.make()`
2️⃣ We reset the environment to its initial state with `observation = env.reset()`
At each step:
3️⃣ Get an action using our model (in our example we take a random action)
4️⃣ Using `env.step(action)`, we perform this action in the environment and get
- `observation`: The new state (st+1)
- `reward`: The reward we get after executing the action
- `terminated`: Indicates if the episode terminated (agent reach the terminal state)
- `truncated`: Introduced with this new version, it indicates a timelimit or if an agent go out of bounds of the environment for instance.
- `info`: A dictionary that provides additional information (depends on the environment).
For more explanations check this 👉 https://gymnasium.farama.org/api/env/#gymnasium.Env.step
If the episode is terminated:
- We reset the environment to its initial state with `observation = env.reset()`
**Let's look at an example!** Make sure to read the code
```python
import gymnasium as gym
# First, we create our environment called LunarLander-v2
env = gym.make("LunarLander-v2")
# Then we reset this environment
observation, info = env.reset()
for _ in range(20):
# Take a random action
action = env.action_space.sample()
print("Action taken:", action)
# Do this action in the environment and get
# next_state, reward, terminated, truncated and info
observation, reward, terminated, truncated, info = env.step(action)
# If the game is terminated (in our case we land, crashed) or truncated (timeout)
if terminated or truncated:
# Reset the environment
print("Environment is reset")
observation, info = env.reset()
env.close()
```
## Create the LunarLander environment 🌛 and understand how it works
### The environment 🎮
In this first tutorial, we’re going to train our agent, a [Lunar Lander](https://gymnasium.farama.org/environments/box2d/lunar_lander/), **to land correctly on the moon**. To do that, the agent needs to learn **to adapt its speed and position (horizontal, vertical, and angular) to land correctly.**
---
💡 A good habit when you start to use an environment is to check its documentation
👉 https://gymnasium.farama.org/environments/box2d/lunar_lander/
---
Let's see what the Environment looks like:
```python
# We create our environment with gym.make("<name_of_the_environment>")
env = gym.make("LunarLander-v2")
env.reset()
print("_____OBSERVATION SPACE_____ \n")
print("Observation Space Shape", env.observation_space.shape)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
We see with `Observation Space Shape (8,)` that the observation is a vector of size 8, where each value contains different information about the lander:
- Horizontal pad coordinate (x)
- Vertical pad coordinate (y)
- Horizontal speed (x)
- Vertical speed (y)
- Angle
- Angular speed
- If the left leg contact point has touched the land (boolean)
- If the right leg contact point has touched the land (boolean)
```python
print("\n _____ACTION SPACE_____ \n")
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
The action space (the set of possible actions the agent can take) is discrete with 4 actions available 🎮:
- Action 0: Do nothing,
- Action 1: Fire left orientation engine,
- Action 2: Fire the main engine,
- Action 3: Fire right orientation engine.
Reward function (the function that will gives a reward at each timestep) 💰:
After every step a reward is granted. The total reward of an episode is the **sum of the rewards for all the steps within that episode**.
For each step, the reward:
- Is increased/decreased the closer/further the lander is to the landing pad.
- Is increased/decreased the slower/faster the lander is moving.
- Is decreased the more the lander is tilted (angle not horizontal).
- Is increased by 10 points for each leg that is in contact with the ground.
- Is decreased by 0.03 points each frame a side engine is firing.
- Is decreased by 0.3 points each frame the main engine is firing.
The episode receive an **additional reward of -100 or +100 points for crashing or landing safely respectively.**
An episode is **considered a solution if it scores at least 200 points.**
#### Vectorized Environment
- We create a vectorized environment (a method for stacking multiple independent environments into a single environment) of 16 environments, this way, **we'll have more diverse experiences during the training.**
```python
# Create the environment
env = make_vec_env("LunarLander-v2", n_envs=16)
```
## Create the Model 🤖
- We have studied our environment and we understood the problem: **being able to land the Lunar Lander to the Landing Pad correctly by controlling left, right and main orientation engine**. Now let's build the algorithm we're going to use to solve this Problem 🚀.
- To do so, we're going to use our first Deep RL library, [Stable Baselines3 (SB3)](https://stable-baselines3.readthedocs.io/en/master/).
- SB3 is a set of **reliable implementations of reinforcement learning algorithms in PyTorch**.
---
💡 A good habit when using a new library is to dive first on the documentation: https://stable-baselines3.readthedocs.io/en/master/ and then try some tutorials.
----
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/sb3.png" alt="Stable Baselines3">
To solve this problem, we're going to use SB3 **PPO**. [PPO (aka Proximal Policy Optimization) is one of the SOTA (state of the art) Deep Reinforcement Learning algorithms that you'll study during this course](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#example%5D).
PPO is a combination of:
- *Value-based reinforcement learning method*: learning an action-value function that will tell us the **most valuable action to take given a state and action**.
- *Policy-based reinforcement learning method*: learning a policy that will **give us a probability distribution over actions**.
Stable-Baselines3 is easy to set up:
1️⃣ You **create your environment** (in our case it was done above)
2️⃣ You define the **model you want to use and instantiate this model** `model = PPO("MlpPolicy")`
3️⃣ You **train the agent** with `model.learn` and define the number of training timesteps
```
# Create environment
env = gym.make('LunarLander-v2')
# Instantiate the agent
model = PPO('MlpPolicy', env, verbose=1)
# Train the agent
model.learn(total_timesteps=int(2e5))
```
```python
# TODO: Define a PPO MlpPolicy architecture
# We use MultiLayerPerceptron (MLPPolicy) because the input is a vector,
# if we had frames as input we would use CnnPolicy
model =
```
#### Solution
```python
# SOLUTION
# We added some parameters to accelerate the training
model = PPO(
policy="MlpPolicy",
env=env,
n_steps=1024,
batch_size=64,
n_epochs=4,
gamma=0.999,
gae_lambda=0.98,
ent_coef=0.01,
verbose=1,
)
```
## Train the PPO agent 🏃
- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use fewer timesteps if you just want to try it out.
- During the training, take a ☕ break you deserved it 🤗
```python
# TODO: Train it for 1,000,000 timesteps
# TODO: Specify file name for model and save the model to file
model_name = "ppo-LunarLander-v2"
```
#### Solution
```python
# SOLUTION
# Train it for 1,000,000 timesteps
model.learn(total_timesteps=1000000)
# Save the model
model_name = "ppo-LunarLander-v2"
model.save(model_name)
```
## Evaluate the agent 📈
- Remember to wrap the environment in a [Monitor](https://stable-baselines3.readthedocs.io/en/master/common/monitor.html).
- Now that our Lunar Lander agent is trained 🚀, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`.
- To fill that part you need to [check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)
- In the next step, we'll see **how to automatically evaluate and share your agent to compete in a leaderboard, but for now let's do it ourselves**
💡 When you evaluate your agent, you should not use your training environment but create an evaluation environment.
```python
# TODO: Evaluate the agent
# Create a new environment for evaluation
eval_env =
# Evaluate the model with 10 evaluation episodes and deterministic=True
mean_reward, std_reward =
# Print the results
```
#### Solution
```python
# @title
eval_env = Monitor(gym.make("LunarLander-v2"))
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
- In my case, I got a mean reward is `200.20 +/- 20.80` after training for 1 million steps, which means that our lunar lander agent is ready to land on the moon 🌛🥳.
## Publish our trained model on the Hub 🔥
Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
Here's an example of a Model Card (with Space Invaders):
By using `package_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account on Hugging Face ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
```python
notebook_login()
!git config --global credential.helper store
```
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
Let's fill the `package_to_hub` function:
- `model`: our trained model.
- `model_name`: the name of the trained model that we defined in `model_save`
- `model_architecture`: the model architecture we used, in our case PPO
- `env_id`: the name of the environment, in our case `LunarLander-v2`
- `eval_env`: the evaluation environment defined in eval_env
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `(repo_id = {username}/{repo_name})`
💡 **A good name is `{username}/{model_architecture}-{env_id}` **
- `commit_message`: message of the commit
```python
import gymnasium as gym
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import package_to_hub
## TODO: Define a repo_id
## repo_id is the id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
repo_id =
# TODO: Define the name of the environment
env_id =
# Create the evaluation env and set the render_mode="rgb_array"
eval_env = DummyVecEnv([lambda: gym.make(env_id, render_mode="rgb_array")])
# TODO: Define the model architecture we used
model_architecture = ""
## TODO: Define the commit message
commit_message = ""
# method save, evaluate, generate a model card and record a replay video of your agent before pushing the repo to the hub
package_to_hub(model=model, # Our trained model
model_name=model_name, # The name of our trained model
model_architecture=model_architecture, # The model architecture we used: in our case PPO
env_id=env_id, # Name of the environment
eval_env=eval_env, # Evaluation Environment
repo_id=repo_id, # id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
commit_message=commit_message)
```
#### Solution
```python
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import package_to_hub
# PLACE the variables you've just defined two cells above
# Define the name of the environment
env_id = "LunarLander-v2"
# TODO: Define the model architecture we used
model_architecture = "PPO"
## Define a repo_id
## repo_id is the id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
## CHANGE WITH YOUR REPO ID
repo_id = "ThomasSimonini/ppo-LunarLander-v2" # Change with your repo id, you can't push with mine 😄
## Define the commit message
commit_message = "Upload PPO LunarLander-v2 trained agent"
# Create the evaluation env and set the render_mode="rgb_array"
eval_env = DummyVecEnv([lambda: Monitor(gym.make(env_id, render_mode="rgb_array"))])
# PLACE the package_to_hub function you've just filled here
package_to_hub(
model=model, # Our trained model
model_name=model_name, # The name of our trained model
model_architecture=model_architecture, # The model architecture we used: in our case PPO
env_id=env_id, # Name of the environment
eval_env=eval_env, # Evaluation Environment
repo_id=repo_id, # id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
commit_message=commit_message,
)
```
Congrats 🥳 you've just trained and uploaded your first Deep Reinforcement Learning agent. The script above should have displayed a link to a model repository such as https://huggingface.co/osanseviero/test_sb3. When you go to this link, you can:
* See a video preview of your agent at the right.
* Click "Files and versions" to see all the files in the repository.
* Click "Use in stable-baselines3" to get a code snippet that shows how to load the model.
* A model card (`README.md` file) which gives a description of the model
Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
Compare the results of your LunarLander-v2 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
## Load a saved LunarLander model from the Hub 🤗
Thanks to [ironbar](https://github.com/ironbar) for the contribution.
Loading a saved model from the Hub is really easy.
You go to https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
1. You select one and copy its repo_id
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit1/copy-id.png" alt="Copy-id"/>
2. Then we just need to use load_from_hub with:
- The repo_id
- The filename: the saved model inside the repo and its extension (*.zip)
Because the model I download from the Hub was trained with Gym (the former version of Gymnasium) we need to install shimmy a API conversion tool that will help us to run the environment correctly.
Shimmy Documentation: https://github.com/Farama-Foundation/Shimmy
```python
!pip install shimmy
```
```python
from huggingface_sb3 import load_from_hub
repo_id = "Classroom-workshop/assignment2-omar" # The repo_id
filename = "ppo-LunarLander-v2.zip" # The model filename.zip
# When the model was trained on Python 3.8 the pickle protocol is 5
# But Python 3.6, 3.7 use protocol 4
# In order to get compatibility we need to:
# 1. Install pickle5 (we done it at the beginning of the colab)
# 2. Create a custom empty object we pass as parameter to PPO.load()
custom_objects = {
"learning_rate": 0.0,
"lr_schedule": lambda _: 0.0,
"clip_range": lambda _: 0.0,
}
checkpoint = load_from_hub(repo_id, filename)
model = PPO.load(checkpoint, custom_objects=custom_objects, print_system_info=True)
```
Let's evaluate this agent:
```python
# @title
eval_env = Monitor(gym.make("LunarLander-v2"))
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
## Some additional challenges 🏆
The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
Here are some ideas to achieve so:
* Train more steps
* Try different hyperparameters for `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another model such as DQN.
* **Push your new trained model** on the Hub 🔥
**Compare the results of your LunarLander-v2 with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆
Is moon landing too boring for you? Try to **change the environment**, why not use MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
________________________________________________________________________
Congrats on finishing this chapter! That was the biggest one, **and there was a lot of information.**
If you’re still feel confused with all these elements...it's totally normal! **This was the same for me and for all people who studied RL.**
Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and have a solid foundations.
Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
Next time, in the bonus unit 1, you'll train Huggy the Dog to fetch the stick.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit1/huggy.jpg" alt="Huggy"/>
## Keep learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit1/hands-on.mdx |
sing the Python debugger in a notebook. In this video, we'll learn how to use the Python debugger in a Jupyter Notebook or a Colab. For this example, we are running code from the token classification section, downloading the Conll dataset , having a look at it before loading a tokenizer to preprocess it. Checkout the section of the course linked below for more information. Once this is done, we try to batch together some features of the training dataset by padding them and returning a tensor, then we get the following error. We use PyTorch here but you will get the same error with TensorFlow. As we have seen in the "How to debug an error?" video, the error message is at the end and it indicates we should use padding, which we are actually trying to do. So this is not useful and we will need to go a little deeper to debug the problem. Fortunately, you can use the Python debugger at any time you get an error in a Jupyter Notebook by typing %debug in any cell. When executing that cell, you go to the very bottom of the traceback where you can type commands and you can type commands. The first two commands you should learn are u and d (for up and down), which allow you to go up in the Traceback or down. Going up twice, we get to the point the error was reached. The third command to learn is p, for print. It allows you to print any value you want. For instance here, we can see the value of return_tensors or batch_outputs to try to understand what triggered the error. The batch outputs dictionary is a bit hard to see, so let's dive into smaller pieces of it. Inside the debugger you can not only print any variable but also evaluate any expression, so we can look independently at the inputs or labels. Those labels are definitely weird: they are of various size, which we can actually confirm by printing the sizes. No wonder the tokenizer wasn't able to create a tensor with them! This is because the pad method only takes care of the tokenizer outptus: input IDs, attention mask and token type IDs, so we have to pad the labels ourselves before trying to create a tensor with them. Once you are ready to exit the Python debugger, you can press q for quit. One way to fix the error is to manually pad all labels to the longest, or we can use the data collator designed for this. | huggingface/course/blob/main/subtitles/en/raw/chapter8/02b_debug-notebook.md |
Search index
[FAISS](https://github.com/facebookresearch/faiss) and [Elasticsearch](https://www.elastic.co/elasticsearch/) enables searching for examples in a dataset. This can be useful when you want to retrieve specific examples from a dataset that are relevant to your NLP task. For example, if you are working on a Open Domain Question Answering task, you may want to only return examples that are relevant to answering your question.
This guide will show you how to build an index for your dataset that will allow you to search it.
## FAISS
FAISS retrieves documents based on the similarity of their vector representations. In this example, you will generate the vector representations with the [DPR](https://huggingface.co/transformers/model_doc/dpr.html) model.
1. Download the DPR model from 🤗 Transformers:
```py
>>> from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
>>> import torch
>>> torch.set_grad_enabled(False)
>>> ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
>>> ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
```
2. Load your dataset and compute the vector representations:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset('crime_and_punish', split='train[:100]')
>>> ds_with_embeddings = ds.map(lambda example: {'embeddings': ctx_encoder(**ctx_tokenizer(example["line"], return_tensors="pt"))[0][0].numpy()})
```
3. Create the index with [`Dataset.add_faiss_index`]:
```py
>>> ds_with_embeddings.add_faiss_index(column='embeddings')
```
4. Now you can query your dataset with the `embeddings` index. Load the DPR Question Encoder, and search for a question with [`Dataset.get_nearest_examples`]:
```py
>>> from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
>>> q_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
>>> q_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
>>> question = "Is it serious ?"
>>> question_embedding = q_encoder(**q_tokenizer(question, return_tensors="pt"))[0][0].numpy()
>>> scores, retrieved_examples = ds_with_embeddings.get_nearest_examples('embeddings', question_embedding, k=10)
>>> retrieved_examples["line"][0]
'_that_ serious? It is not serious at all. It’s simply a fantasy to amuse\r\n'
```
5. You can access the index with [`Dataset.get_index`] and use it for special operations, e.g. query it using `range_search`:
```py
>>> faiss_index = ds_with_embeddings.get_index('embeddings').faiss_index
>>> limits, distances, indices = faiss_index.range_search(x=question_embedding.reshape(1, -1), thresh=0.95)
```
6. When you are done querying, save the index on disk with [`Dataset.save_faiss_index`]:
```py
>>> ds_with_embeddings.save_faiss_index('embeddings', 'my_index.faiss')
```
7. Reload it at a later time with [`Dataset.load_faiss_index`]:
```py
>>> ds = load_dataset('crime_and_punish', split='train[:100]')
>>> ds.load_faiss_index('embeddings', 'my_index.faiss')
```
## Elasticsearch
Unlike FAISS, Elasticsearch retrieves documents based on exact matches.
Start Elasticsearch on your machine, or see the [Elasticsearch installation guide](https://www.elastic.co/guide/en/elasticsearch/reference/current/setup.html) if you don't already have it installed.
1. Load the dataset you want to index:
```py
>>> from datasets import load_dataset
>>> squad = load_dataset('squad', split='validation')
```
2. Build the index with [`Dataset.add_elasticsearch_index`]:
```py
>>> squad.add_elasticsearch_index("context", host="localhost", port="9200")
```
3. Then you can query the `context` index with [`Dataset.get_nearest_examples`]:
```py
>>> query = "machine"
>>> scores, retrieved_examples = squad.get_nearest_examples("context", query, k=10)
>>> retrieved_examples["title"][0]
'Computational_complexity_theory'
```
4. If you want to reuse the index, define the `es_index_name` parameter when you build the index:
```py
>>> from datasets import load_dataset
>>> squad = load_dataset('squad', split='validation')
>>> squad.add_elasticsearch_index("context", host="localhost", port="9200", es_index_name="hf_squad_val_context")
>>> squad.get_index("context").es_index_name
hf_squad_val_context
```
5. Reload it later with the index name when you call [`Dataset.load_elasticsearch_index`]:
```py
>>> from datasets import load_dataset
>>> squad = load_dataset('squad', split='validation')
>>> squad.load_elasticsearch_index("context", host="localhost", port="9200", es_index_name="hf_squad_val_context")
>>> query = "machine"
>>> scores, retrieved_examples = squad.get_nearest_examples("context", query, k=10)
```
For more advanced Elasticsearch usage, you can specify your own configuration with custom settings:
```py
>>> import elasticsearch as es
>>> import elasticsearch.helpers
>>> from elasticsearch import Elasticsearch
>>> es_client = Elasticsearch([{"host": "localhost", "port": "9200"}]) # default client
>>> es_config = {
... "settings": {
... "number_of_shards": 1,
... "analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},
... },
... "mappings": {"properties": {"text": {"type": "text", "analyzer": "standard", "similarity": "BM25"}}},
... } # default config
>>> es_index_name = "hf_squad_context" # name of the index in Elasticsearch
>>> squad.add_elasticsearch_index("context", es_client=es_client, es_config=es_config, es_index_name=es_index_name)
```
| huggingface/datasets/blob/main/docs/source/faiss_es.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Scenes
Under construction 🚧. | huggingface/simulate/blob/main/docs/source/api/scenes.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ControlNet
[ControlNet](https://hf.co/papers/2302.05543) models are adapters trained on top of another pretrained model. It allows for a greater degree of control over image generation by conditioning the model with an additional input image. The input image can be a canny edge, depth map, human pose, and many more.
If you're training on a GPU with limited vRAM, you should try enabling the `gradient_checkpointing`, `gradient_accumulation_steps`, and `mixed_precision` parameters in the training command. You can also reduce your memory footprint by using memory-efficient attention with [xFormers](../optimization/xformers). JAX/Flax training is also supported for efficient training on TPUs and GPUs, but it doesn't support gradient checkpointing or xFormers. You should have a GPU with >30GB of memory if you want to train faster with Flax.
This guide will explore the [train_controlnet.py](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py) training script to help you become familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
<hfoptions id="installation">
<hfoption id="PyTorch">
```bash
cd examples/controlnet
pip install -r requirements.txt
```
</hfoption>
<hfoption id="Flax">
If you have access to a TPU, the Flax training script runs even faster! Let's run the training script on the [Google Cloud TPU VM](https://cloud.google.com/tpu/docs/run-calculation-jax). Create a single TPU v4-8 VM and connect to it:
```bash
ZONE=us-central2-b
TPU_TYPE=v4-8
VM_NAME=hg_flax
gcloud alpha compute tpus tpu-vm create $VM_NAME \
--zone $ZONE \
--accelerator-type $TPU_TYPE \
--version tpu-vm-v4-base
gcloud alpha compute tpus tpu-vm ssh $VM_NAME --zone $ZONE -- \
```
Install JAX 0.4.5:
```bash
pip install "jax[tpu]==0.4.5" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
```
Then install the required dependencies for the Flax script:
```bash
cd examples/controlnet
pip install -r requirements_flax.txt
```
</hfoption>
</hfoptions>
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py) and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L231) function. This function provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_controlnet.py \
--mixed_precision="fp16"
```
Many of the basic and important parameters are described in the [Text-to-image](text2image#script-parameters) training guide, so this guide just focuses on the relevant parameters for ControlNet:
- `--max_train_samples`: the number of training samples; this can be lowered for faster training, but if you want to stream really large datasets, you'll need to include this parameter and the `--streaming` parameter in your training command
- `--gradient_accumulation_steps`: number of update steps to accumulate before the backward pass; this allows you to train with a bigger batch size than your GPU memory can typically handle
### Min-SNR weighting
The [Min-SNR](https://huggingface.co/papers/2303.09556) weighting strategy can help with training by rebalancing the loss to achieve faster convergence. The training script supports predicting `epsilon` (noise) or `v_prediction`, but Min-SNR is compatible with both prediction types. This weighting strategy is only supported by PyTorch and is unavailable in the Flax training script.
Add the `--snr_gamma` parameter and set it to the recommended value of 5.0:
```bash
accelerate launch train_controlnet.py \
--snr_gamma=5.0
```
## Training script
As with the script parameters, a general walkthrough of the training script is provided in the [Text-to-image](text2image#training-script) training guide. Instead, this guide takes a look at the relevant parts of the ControlNet script.
The training script has a [`make_train_dataset`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L582) function for preprocessing the dataset with image transforms and caption tokenization. You'll see that in addition to the usual caption tokenization and image transforms, the script also includes transforms for the conditioning image.
<Tip>
If you're streaming a dataset on a TPU, performance may be bottlenecked by the 🤗 Datasets library which is not optimized for images. To ensure maximum throughput, you're encouraged to explore other dataset formats like [WebDataset](https://webdataset.github.io/webdataset/), [TorchData](https://github.com/pytorch/data), and [TensorFlow Datasets](https://www.tensorflow.org/datasets/tfless_tfds).
</Tip>
```py
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
```
Within the [`main()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L713) function, you'll find the code for loading the tokenizer, text encoder, scheduler and models. This is also where the ControlNet model is loaded either from existing weights or randomly initialized from a UNet:
```py
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet = ControlNetModel.from_pretrained(args.controlnet_model_name_or_path)
else:
logger.info("Initializing controlnet weights from unet")
controlnet = ControlNetModel.from_unet(unet)
```
The [optimizer](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L871) is set up to update the ControlNet parameters:
```py
params_to_optimize = controlnet.parameters()
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Finally, in the [training loop](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L943), the conditioning text embeddings and image are passed to the down and mid-blocks of the ControlNet model:
```py
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
controlnet_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
down_block_res_samples, mid_block_res_sample = controlnet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
controlnet_cond=controlnet_image,
return_dict=False,
)
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Now you're ready to launch the training script! 🚀
This guide uses the [fusing/fill50k](https://huggingface.co/datasets/fusing/fill50k) dataset, but remember, you can create and use your own dataset if you want (see the [Create a dataset for training](create_dataset) guide).
Set the environment variable `MODEL_NAME` to a model id on the Hub or a path to a local model and `OUTPUT_DIR` to where you want to save the model.
Download the following images to condition your training with:
```bash
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
One more thing before you launch the script! Depending on the GPU you have, you may need to enable certain optimizations to train a ControlNet. The default configuration in this script requires ~38GB of vRAM. If you're training on more than one GPU, add the `--multi_gpu` parameter to the `accelerate launch` command.
<hfoptions id="gpu-select">
<hfoption id="16GB">
On a 16GB GPU, you can use bitsandbytes 8-bit optimizer and gradient checkpointing to optimize your training run. Install bitsandbytes:
```py
pip install bitsandbytes
```
Then, add the following parameter to your training command:
```bash
accelerate launch train_controlnet.py \
--gradient_checkpointing \
--use_8bit_adam \
```
</hfoption>
<hfoption id="12GB">
On a 12GB GPU, you'll need bitsandbytes 8-bit optimizer, gradient checkpointing, xFormers, and set the gradients to `None` instead of zero to reduce your memory-usage.
```bash
accelerate launch train_controlnet.py \
--use_8bit_adam \
--gradient_checkpointing \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none \
```
</hfoption>
<hfoption id="8GB">
On a 8GB GPU, you'll need to use [DeepSpeed](https://www.deepspeed.ai/) to offload some of the tensors from the vRAM to either the CPU or NVME to allow training with less GPU memory.
Run the following command to configure your 🤗 Accelerate environment:
```bash
accelerate config
```
During configuration, confirm that you want to use DeepSpeed stage 2. Now it should be possible to train on under 8GB vRAM by combining DeepSpeed stage 2, fp16 mixed precision, and offloading the model parameters and the optimizer state to the CPU. The drawback is that this requires more system RAM (~25 GB). See the [DeepSpeed documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more configuration options. Your configuration file should look something like:
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 4
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
```
You should also change the default Adam optimizer to DeepSpeed’s optimized version of Adam [`deepspeed.ops.adam.DeepSpeedCPUAdam`](https://deepspeed.readthedocs.io/en/latest/optimizers.html#adam-cpu) for a substantial speedup. Enabling `DeepSpeedCPUAdam` requires your system’s CUDA toolchain version to be the same as the one installed with PyTorch.
bitsandbytes 8-bit optimizers don’t seem to be compatible with DeepSpeed at the moment.
That's it! You don't need to add any additional parameters to your training command.
</hfoption>
</hfoptions>
<hfoptions id="training-inference">
<hfoption id="PyTorch">
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/save/model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--push_to_hub
```
</hfoption>
<hfoption id="Flax">
With Flax, you can [profile your code](https://jax.readthedocs.io/en/latest/profiling.html) by adding the `--profile_steps==5` parameter to your training command. Install the Tensorboard profile plugin:
```bash
pip install tensorflow tensorboard-plugin-profile
tensorboard --logdir runs/fill-circle-100steps-20230411_165612/
```
Then you can inspect the profile at [http://localhost:6006/#profile](http://localhost:6006/#profile).
<Tip warning={true}>
If you run into version conflicts with the plugin, try uninstalling and reinstalling all versions of TensorFlow and Tensorboard. The debugging functionality of the profile plugin is still experimental, and not all views are fully functional. The `trace_viewer` cuts off events after 1M, which can result in all your device traces getting lost if for example, you profile the compilation step by accident.
</Tip>
```bash
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=1000 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID \
--num_train_epochs=11 \
--push_to_hub \
--hub_model_id=$HUB_MODEL_ID
```
</hfoption>
</hfoptions>
Once training is complete, you can use your newly trained model for inference!
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.utils import load_image
import torch
controlnet = ControlNetModel.from_pretrained("path/to/controlnet", torch_dtype=torch.float16)
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
"path/to/base/model", controlnet=controlnet, torch_dtype=torch.float16
).to("cuda")
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=20, generator=generator, image=control_image).images[0]
image.save("./output.png")
```
## Stable Diffusion XL
Stable Diffusion XL (SDXL) is a powerful text-to-image model that generates high-resolution images, and it adds a second text-encoder to its architecture. Use the [`train_controlnet_sdxl.py`](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet_sdxl.py) script to train a ControlNet adapter for the SDXL model.
The SDXL training script is discussed in more detail in the [SDXL training](sdxl) guide.
## Next steps
Congratulations on training your own ControlNet! To learn more about how to use your new model, the following guides may be helpful:
- Learn how to [use a ControlNet](../using-diffusers/controlnet) for inference on a variety of tasks. | huggingface/diffusers/blob/main/docs/source/en/training/controlnet.md |
--
title: r_squared
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The R^2 (R Squared) metric is a measure of the goodness of fit of a linear regression model. It is the proportion of the variance in the dependent variable that is predictable from the independent variable.
---
# Metric Card for R^2
## Metric description
An R-squared value of 1 indicates that the model perfectly explains the variance of the dependent variable. A value of 0 means that the model does not explain any of the variance. Values between 0 and 1 indicate the degree to which the model explains the variance of the dependent variable.
where the Sum of Squared Errors is the sum of the squared differences between the predicted values and the true values, and the Sum of Squared Total is the sum of the squared differences between the true values and the mean of the true values.
For example, if an R-squared value for a model is 0.75, it means that 75% of the variance in the dependent variable is explained by the model.
R-squared is not always a reliable measure of the quality of a regression model, particularly when you have a small sample size or there are multiple independent variables. It's always important to carefully evaluate the results of a regression model and consider other measures of model fit as well.
R squared can be calculated using the following formula:
```python
r_squared = 1 - (Sum of Squared Errors / Sum of Squared Total)
```
* Calculate the residual sum of squares (RSS), which is the sum of the squared differences between the predicted values and the actual values.
* Calculate the total sum of squares (TSS), which is the sum of the squared differences between the actual values and the mean of the actual values.
* Calculate the R-squared value by taking 1 - (RSS / TSS).
Here's an example of how to calculate the R-squared value:
```python
r_squared = 1 - (SSR/SST)
```
### How to Use Examples:
The R2 class in the evaluate module can be used to compute the R^2 value for a given set of predictions and references. (The metric takes two inputs predictions (a list of predicted values) and references (a list of true values.))
```python
from evaluate import load
>>> r2_metric = evaluate.load("r_squared")
>>> r_squared = r2_metric.compute(predictions=[1, 2, 3, 4], references=[0.9, 2.1, 3.2, 3.8])
>>> print(r_squared)
0.98
```
Alternatively, if you want to see an example where there is a perfect match between the prediction and reference:
```python
>>> from evaluate import load
>>> r2_metric = evaluate.load("r_squared")
>>> r_squared = r2_metric.compute(predictions=[1, 2, 3, 4], references=[1, 2, 3, 4])
>>> print(r_squared)
1.0
```
## Limitations and Bias
R^2 is a statistical measure of the goodness of fit of a regression model. It represents the proportion of the variance in the dependent variable that is predictable from the independent variables. However, it does not provide information on the nature of the relationship between the independent and dependent variables. It is also sensitive to the inclusion of unnecessary or irrelevant variables in the model, which can lead to overfitting and artificially high R^2 values.
## Citation
```bibtex
@article{r_squared_model,
title={The R^2 Model Metric: A Comprehensive Guide},
author={John Doe},
journal={Journal of Model Evaluation},
volume={10},
number={2},
pages={101-112},
year={2022},
publisher={Model Evaluation Society}}
```
## Further References
- [The Open University: R-Squared](https://www.open.edu/openlearn/ocw/mod/oucontent/view.php?id=55450§ion=3.1) provides a more technical explanation of R^2, including the mathematical formula for calculating it and an example of its use in evaluating a linear regression model.
- [Khan Academy: R-Squared](https://www.khanacademy.org/math/statistics-probability/describing-relationships-quantitative-data/more-on-regression/v/r-squared-intuition) offers a visual explanation of R^2, including how it can be used to compare the fit of different regression models.
| huggingface/evaluate/blob/main/metrics/r_squared/README.md |
ow to instantiate a Transformers model? In this video we will look at how we can create and use a model from the Transformers library. As we've seen before, the TFAutoModel class allows you to instantiate a pretrained model from any checkpoint on the Hugging Face Hub. It will pick the right model class from the library to instantiate the proper architecture and load the weights of the pretrained model inside it. As we can see, when given a BERT checkpoint, we end up with a TFBertModel, and similarly for GPT-2 or BART. Behind the scenes, this API can take the name of a checkpoint on the Hub, in which case it will download and cache the configuration file as well as the model weights file. You can also specify the path to a local folder that contains a valid configuration file and a model weights file. To instantiate the pretrained model, the AutoModel API will first open the configuration file to look at the configuration class that should be used. The configuration class depends on the type of the model (BERT, GPT-2 or BART for instance). Once it has the proper configuration class, it can instantiate that configuration, which is a blueprint to know how to create the model. It also uses this configuration class to find the proper model class, which is combined with the loaded configuration, to load the model. This model is not yet our pretrained model as it has just been initialized with random weights. The last step is to load the weights from the model file inside this model. To easily load the configuration of a model from any checkpoint or a folder containing the configuration folder, we can use the AutoConfig class. Like the TFAutoModel class, it will pick the right configuration class from the library. We can also use the specific class corresponding to a checkpoint, but we will need to change the code each time we want to try a different model. As we said before, the configuration of a model is a blueprint that contains all the information necessary to create the model architecture. For instance the BERT model associated with the bert-base-cased checkpoint has 12 layers, a hidden size of 768, and a vocabulary size of 28,996. Once we have the configuration, we can create a model that has the same architecture as our checkpoint but is randomly initialized. We can then train it from scratch like any PyTorch module/TensorFlow model. We can also change any part of the configuration by using keyword arguments. The second snippet of code instantiates a randomly initialized BERT model with ten layers instead of 12. Saving a model once it's trained or fine-tuned is very easy: we just have to use the save_pretrained method. Here the model will be saved in a folder named my-bert-model inside the current working directory. Such a model can then be reloaded using the from_pretrained method. | huggingface/course/blob/main/subtitles/en/raw/chapter2/03_model-api-tf.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Blenderbot Small
Note that [`BlenderbotSmallModel`] and
[`BlenderbotSmallForConditionalGeneration`] are only used in combination with the checkpoint
[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M). Larger Blenderbot checkpoints should
instead be used with [`BlenderbotModel`] and
[`BlenderbotForConditionalGeneration`]
## Overview
The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
The abstract of the paper is the following:
*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
persona. We show that large scale models can learn these skills when given appropriate training data and choice of
generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
failure cases of our models.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The authors' code can be
found [here](https://github.com/facebookresearch/ParlAI).
## Usage tips
Blenderbot Small is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## BlenderbotSmallConfig
[[autodoc]] BlenderbotSmallConfig
## BlenderbotSmallTokenizer
[[autodoc]] BlenderbotSmallTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BlenderbotSmallTokenizerFast
[[autodoc]] BlenderbotSmallTokenizerFast
<frameworkcontent>
<pt>
## BlenderbotSmallModel
[[autodoc]] BlenderbotSmallModel
- forward
## BlenderbotSmallForConditionalGeneration
[[autodoc]] BlenderbotSmallForConditionalGeneration
- forward
## BlenderbotSmallForCausalLM
[[autodoc]] BlenderbotSmallForCausalLM
- forward
</pt>
<tf>
## TFBlenderbotSmallModel
[[autodoc]] TFBlenderbotSmallModel
- call
## TFBlenderbotSmallForConditionalGeneration
[[autodoc]] TFBlenderbotSmallForConditionalGeneration
- call
</tf>
<jax>
## FlaxBlenderbotSmallModel
[[autodoc]] FlaxBlenderbotSmallModel
- __call__
- encode
- decode
## FlaxBlenderbotForConditionalGeneration
[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
- __call__
- encode
- decode
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/blenderbot-small.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Philosophy
## Today’s landscape for simulation environments
In our investigations, we found that the current landscape for simulation environments and synthetic data creation has a couple of limitations:
- Very fragmented - each set of simulation environments is usually isolated and separated from the others by being tied to a specific engine (Unity, Gibson, Habitat, etc)
- Building environments often requires knowledge and skills that are not in the toolbox of the typical AI/ML researchers (knowledge of C++/C#)
- Frameworks tend to focus on one domain/application, e.g. focusing on RL, synthetic data generation, NLP, self-driving cars but the field is increasingly cross applications/modalities
- It's often not easy to share a new environment or a modification of an environment without having to modify a library
- Environment visualization/debugging tools can be difficult to find
🤗 Simulate is a proof of concept to investigate whether this situation could be improved.
## Design philosophy for simulate
The simulate library is an exploration on how one could use python to easily build & share complex and diverse simulation environments for embodied learning or synthetic data research.
The basic idea is to decouple the creation of the simulation environment ("building") from the simulation engine used to run it (Unity, Blender, custom engine, etc) by relying on an engine-agnostic sharing format (the open standard glTF format in this case).
The created environments are stored in a language/framework agnostic format and can be loaded and run on a diversity of engines with concise integrations handling more or less of the glTF extensions we use (we provide PoC plugins for Unity, Godot and Blender in the alpha release).
Interfacing with the git-versioning and hosting on the Hugging Face hub allow to download/upload share/reuse assets (objects) as well as full scenes (environments).
## Building on the shoulders of giants
The python API was inspired by the awesome kubric library created by Klaus Greff and Andrea Tagliasacchi and the Google team (https://github.com/google-research/kubric) while the Unity engine was inspired in part by the impressive work of the PRIOR team at AllenAI (https://prior.allenai.org/).
| huggingface/simulate/blob/main/docs/source/conceptual/philosophy.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Translation
[[open-in-colab]]
<Youtube id="1JvfrvZgi6c"/>
Translation converts a sequence of text from one language to another. It is one of several tasks you can formulate as a sequence-to-sequence problem, a powerful framework for returning some output from an input, like translation or summarization. Translation systems are commonly used for translation between different language texts, but it can also be used for speech or some combination in between like text-to-speech or speech-to-text.
This guide will show you how to:
1. Finetune [T5](https://huggingface.co/t5-small) on the English-French subset of the [OPUS Books](https://huggingface.co/datasets/opus_books) dataset to translate English text to French.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[BART](../model_doc/bart), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [Encoder decoder](../model_doc/encoder-decoder), [FairSeq Machine-Translation](../model_doc/fsmt), [GPTSAN-japanese](../model_doc/gptsan-japanese), [LED](../model_doc/led), [LongT5](../model_doc/longt5), [M2M100](../model_doc/m2m_100), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [NLLB](../model_doc/nllb), [NLLB-MOE](../model_doc/nllb-moe), [Pegasus](../model_doc/pegasus), [PEGASUS-X](../model_doc/pegasus_x), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [SeamlessM4T](../model_doc/seamless_m4t), [SeamlessM4Tv2](../model_doc/seamless_m4t_v2), [SwitchTransformers](../model_doc/switch_transformers), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM-ProphetNet](../model_doc/xlm-prophetnet)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate sacrebleu
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load OPUS Books dataset
Start by loading the English-French subset of the [OPUS Books](https://huggingface.co/datasets/opus_books) dataset from the 🤗 Datasets library:
```py
>>> from datasets import load_dataset
>>> books = load_dataset("opus_books", "en-fr")
```
Split the dataset into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
```py
>>> books = books["train"].train_test_split(test_size=0.2)
```
Then take a look at an example:
```py
>>> books["train"][0]
{'id': '90560',
'translation': {'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
'fr': 'Mais ce plateau élevé ne mesurait que quelques toises, et bientôt nous fûmes rentrés dans notre élément.'}}
```
`translation`: an English and French translation of the text.
## Preprocess
<Youtube id="XAR8jnZZuUs"/>
The next step is to load a T5 tokenizer to process the English-French language pairs:
```py
>>> from transformers import AutoTokenizer
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
```
The preprocessing function you want to create needs to:
1. Prefix the input with a prompt so T5 knows this is a translation task. Some models capable of multiple NLP tasks require prompting for specific tasks.
2. Tokenize the input (English) and target (French) separately because you can't tokenize French text with a tokenizer pretrained on an English vocabulary.
3. Truncate sequences to be no longer than the maximum length set by the `max_length` parameter.
```py
>>> source_lang = "en"
>>> target_lang = "fr"
>>> prefix = "translate English to French: "
>>> def preprocess_function(examples):
... inputs = [prefix + example[source_lang] for example in examples["translation"]]
... targets = [example[target_lang] for example in examples["translation"]]
... model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
... return model_inputs
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
```py
>>> tokenized_books = books.map(preprocess_function, batched=True)
```
Now create a batch of examples using [`DataCollatorForSeq2Seq`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [SacreBLEU](https://huggingface.co/spaces/evaluate-metric/sacrebleu) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> metric = evaluate.load("sacrebleu")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the SacreBLEU score:
```py
>>> import numpy as np
>>> def postprocess_text(preds, labels):
... preds = [pred.strip() for pred in preds]
... labels = [[label.strip()] for label in labels]
... return preds, labels
>>> def compute_metrics(eval_preds):
... preds, labels = eval_preds
... if isinstance(preds, tuple):
... preds = preds[0]
... decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
... labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
... decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
... decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
... result = metric.compute(predictions=decoded_preds, references=decoded_labels)
... result = {"bleu": result["score"]}
... prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
... result["gen_len"] = np.mean(prediction_lens)
... result = {k: round(v, 4) for k, v in result.items()}
... return result
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load T5 with [`AutoModelForSeq2SeqLM`]:
```py
>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`Seq2SeqTrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the SacreBLEU metric and save the training checkpoint.
2. Pass the training arguments to [`Seq2SeqTrainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="my_awesome_opus_books_model",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... weight_decay=0.01,
... save_total_limit=3,
... num_train_epochs=2,
... predict_with_generate=True,
... fp16=True,
... push_to_hub=True,
... )
>>> trainer = Seq2SeqTrainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Then you can load T5 with [`TFAutoModelForSeq2SeqLM`]:
```py
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_books["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = model.prepare_tf_dataset(
... tokenized_books["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
The last two things to setup before you start training is to compute the SacreBLEU metric from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_opus_books_model",
... tokenizer=tokenizer,
... )
```
Then bundle your callbacks together:
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for translation, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text you'd like to translate to another language. For T5, you need to prefix your input depending on the task you're working on. For translation from English to French, you should prefix your input as shown below:
```py
>>> text = "translate English to French: Legumes share resources with nitrogen-fixing bacteria."
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for translation with your model, and pass your text to it:
```py
>>> from transformers import pipeline
>>> translator = pipeline("translation", model="my_awesome_opus_books_model")
>>> translator(text)
[{'translation_text': 'Legumes partagent des ressources avec des bactéries azotantes.'}]
```
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Tokenize the text and return the `input_ids` as PyTorch tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
```
Use the [`~transformers.generation_utils.GenerationMixin.generate`] method to create the translation. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text Generation](../main_classes/text_generation) API.
```py
>>> from transformers import AutoModelForSeq2SeqLM
>>> model = AutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
```
Decode the generated token ids back into text:
```py
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Les lignées partagent des ressources avec des bactéries enfixant l'azote.'
```
</pt>
<tf>
Tokenize the text and return the `input_ids` as TensorFlow tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
>>> inputs = tokenizer(text, return_tensors="tf").input_ids
```
Use the [`~transformers.generation_tf_utils.TFGenerationMixin.generate`] method to create the translation. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text Generation](../main_classes/text_generation) API.
```py
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
```
Decode the generated token ids back into text:
```py
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Les lugumes partagent les ressources avec des bactéries fixatrices d'azote.'
```
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/tasks/translation.md |
--
title: Precision
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Precision is the fraction of correctly labeled positive examples out of all of the examples that were labeled as positive. It is computed via the equation:
Precision = TP / (TP + FP)
where TP is the True positives (i.e. the examples correctly labeled as positive) and FP is the False positive examples (i.e. the examples incorrectly labeled as positive).
---
# Metric Card for Precision
## Metric Description
Precision is the fraction of correctly labeled positive examples out of all of the examples that were labeled as positive. It is computed via the equation:
Precision = TP / (TP + FP)
where TP is the True positives (i.e. the examples correctly labeled as positive) and FP is the False positive examples (i.e. the examples incorrectly labeled as positive).
## How to Use
At minimum, precision takes as input a list of predicted labels, `predictions`, and a list of output labels, `references`.
```python
>>> precision_metric = evaluate.load("precision")
>>> results = precision_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'precision': 1.0}
```
### Inputs
- **predictions** (`list` of `int`): Predicted class labels.
- **references** (`list` of `int`): Actual class labels.
- **labels** (`list` of `int`): The set of labels to include when `average` is not set to `'binary'`. If `average` is `None`, it should be the label order. Labels present in the data can be excluded, for example to calculate a multiclass average ignoring a majority negative class. Labels not present in the data will result in 0 components in a macro average. For multilabel targets, labels are column indices. By default, all labels in `predictions` and `references` are used in sorted order. Defaults to None.
- **pos_label** (`int`): The class to be considered the positive class, in the case where `average` is set to `binary`. Defaults to 1.
- **average** (`string`): This parameter is required for multiclass/multilabel targets. If set to `None`, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data. Defaults to `'binary'`.
- 'binary': Only report results for the class specified by `pos_label`. This is applicable only if the classes found in `predictions` and `references` are binary.
- 'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.
- 'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- 'weighted': Calculate metrics for each label, and find their average weighted by support (the number of true instances for each label). This alters `'macro'` to account for label imbalance. This option can result in an F-score that is not between precision and recall.
- 'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification).
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
- **zero_division** (): Sets the value to return when there is a zero division. Defaults to .
- 0: Returns 0 when there is a zero division.
- 1: Returns 1 when there is a zero division.
- 'warn': Raises warnings and then returns 0 when there is a zero division.
### Output Values
- **precision**(`float` or `array` of `float`): Precision score or list of precision scores, depending on the value passed to `average`. Minimum possible value is 0. Maximum possible value is 1. Higher values indicate that fewer negative examples were incorrectly labeled as positive, which means that, generally, higher scores are better.
Output Example(s):
```python
{'precision': 0.2222222222222222}
```
```python
{'precision': array([0.66666667, 0.0, 0.0])}
```
#### Values from Popular Papers
### Examples
Example 1-A simple binary example
```python
>>> precision_metric = evaluate.load("precision")
>>> results = precision_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0])
>>> print(results)
{'precision': 0.5}
```
Example 2-The same simple binary example as in Example 1, but with `pos_label` set to `0`.
```python
>>> precision_metric = evaluate.load("precision")
>>> results = precision_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], pos_label=0)
>>> print(round(results['precision'], 2))
0.67
```
Example 3-The same simple binary example as in Example 1, but with `sample_weight` included.
```python
>>> precision_metric = evaluate.load("precision")
>>> results = precision_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], sample_weight=[0.9, 0.5, 3.9, 1.2, 0.3])
>>> print(results)
{'precision': 0.23529411764705882}
```
Example 4-A multiclass example, with different values for the `average` input.
```python
>>> predictions = [0, 2, 1, 0, 0, 1]
>>> references = [0, 1, 2, 0, 1, 2]
>>> results = precision_metric.compute(predictions=predictions, references=references, average='macro')
>>> print(results)
{'precision': 0.2222222222222222}
>>> results = precision_metric.compute(predictions=predictions, references=references, average='micro')
>>> print(results)
{'precision': 0.3333333333333333}
>>> results = precision_metric.compute(predictions=predictions, references=references, average='weighted')
>>> print(results)
{'precision': 0.2222222222222222}
>>> results = precision_metric.compute(predictions=predictions, references=references, average=None)
>>> print([round(res, 2) for res in results['precision']])
[0.67, 0.0, 0.0]
```
## Limitations and Bias
[Precision](https://huggingface.co/metrics/precision) and [recall](https://huggingface.co/metrics/recall) are complementary and can be used to measure different aspects of model performance -- using both of them (or an averaged measure like [F1 score](https://huggingface.co/metrics/F1) to better represent different aspects of performance. See [Wikipedia](https://en.wikipedia.org/wiki/Precision_and_recall) for more information.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
- [Wikipedia -- Precision and recall](https://en.wikipedia.org/wiki/Precision_and_recall)
| huggingface/evaluate/blob/main/metrics/precision/README.md |
(Gluon) ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('gluon_resnet101_v1b', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_resnet101_v1b`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('gluon_resnet101_v1b', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
archivePrefix = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun ResNet
Paper:
Title: Deep Residual Learning for Image Recognition
URL: https://paperswithcode.com/paper/deep-residual-learning-for-image-recognition
Models:
- Name: gluon_resnet101_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 10068547584
Parameters: 44550000
File Size: 178723172
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L89
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1b-3b017079.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.3%
Top 5 Accuracy: 94.53%
- Name: gluon_resnet101_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 10376567296
Parameters: 44570000
File Size: 178802575
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L113
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1c-1f26822a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.53%
Top 5 Accuracy: 94.59%
- Name: gluon_resnet101_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 10377018880
Parameters: 44570000
File Size: 178802755
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L138
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1d-0f9c8644.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.4%
Top 5 Accuracy: 95.02%
- Name: gluon_resnet101_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 11805511680
Parameters: 44670000
File Size: 179221777
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L166
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1s-60fe0cc1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.29%
Top 5 Accuracy: 95.16%
- Name: gluon_resnet152_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 14857660416
Parameters: 60190000
File Size: 241534001
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L97
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1b-c1edb0dd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.69%
Top 5 Accuracy: 94.73%
- Name: gluon_resnet152_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 15165680128
Parameters: 60210000
File Size: 241613404
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L121
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1c-a3bb0b98.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.91%
Top 5 Accuracy: 94.85%
- Name: gluon_resnet152_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 15166131712
Parameters: 60210000
File Size: 241613584
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L147
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1d-bd354e12.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.48%
Top 5 Accuracy: 95.2%
- Name: gluon_resnet152_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 16594624512
Parameters: 60320000
File Size: 242032606
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L175
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1s-dcc41b81.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.02%
Top 5 Accuracy: 95.42%
- Name: gluon_resnet18_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46816736
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet18_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L65
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet18_v1b-0757602b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 70.84%
Top 5 Accuracy: 89.76%
- Name: gluon_resnet34_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87295112
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet34_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L73
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet34_v1b-c6d82d59.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.59%
Top 5 Accuracy: 92.0%
- Name: gluon_resnet50_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102493763
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L81
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1b-0ebe02e2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.58%
Top 5 Accuracy: 93.72%
- Name: gluon_resnet50_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 5590551040
Parameters: 25580000
File Size: 102573166
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L105
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1c-48092f55.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.01%
Top 5 Accuracy: 93.99%
- Name: gluon_resnet50_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 5591002624
Parameters: 25580000
File Size: 102573346
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L129
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1d-818a1b1b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.06%
Top 5 Accuracy: 94.46%
- Name: gluon_resnet50_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 7019495424
Parameters: 25680000
File Size: 102992368
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L156
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1s-1762acc0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.7%
Top 5 Accuracy: 94.25%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/gloun-resnet.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformers Agents
<Tip warning={true}>
Transformers Agents is an experimental API which is subject to change at any time. Results returned by the agents
can vary as the APIs or underlying models are prone to change.
</Tip>
Transformers version v4.29.0, building on the concept of *tools* and *agents*. You can play with in
[this colab](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj).
In short, it provides a natural language API on top of transformers: we define a set of curated tools and design an
agent to interpret natural language and to use these tools. It is extensible by design; we curated some relevant tools,
but we'll show you how the system can be extended easily to use any tool developed by the community.
Let's start with a few examples of what can be achieved with this new API. It is particularly powerful when it comes
to multimodal tasks, so let's take it for a spin to generate images and read text out loud.
```py
agent.run("Caption the following image", image=image)
```
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/beaver.png" width=200> | A beaver is swimming in the water |
---
```py
agent.run("Read the following text out loud", text=text)
```
| **Input** | **Output** |
|-------------------------------------------------------------------------------------------------------------------------|----------------------------------------------|
| A beaver is swimming in the water | <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tts_example.wav" type="audio/wav"> your browser does not support the audio element. </audio>
---
```py
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)
```
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|----------------|
| <img src="https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/0/image/image.jpg" width=200> | ballroom foyer |
## Quickstart
Before being able to use `agent.run`, you will need to instantiate an agent, which is a large language model (LLM).
We provide support for openAI models as well as opensource alternatives from BigCode and OpenAssistant. The openAI
models perform better (but require you to have an openAI API key, so cannot be used for free); Hugging Face is
providing free access to endpoints for BigCode and OpenAssistant models.
To start with, please install the `agents` extras in order to install all default dependencies.
```bash
pip install transformers[agents]
```
To use openAI models, you instantiate an [`OpenAiAgent`] after installing the `openai` dependency:
```bash
pip install openai
```
```py
from transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")
```
To use BigCode or OpenAssistant, start by logging in to have access to the Inference API:
```py
from huggingface_hub import login
login("<YOUR_TOKEN>")
```
Then, instantiate the agent
```py
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
```
This is using the inference API that Hugging Face provides for free at the moment. If you have your own inference
endpoint for this model (or another one) you can replace the URL above with your URL endpoint.
<Tip>
StarCoder and OpenAssistant are free to use and perform admirably well on simple tasks. However, the checkpoints
don't hold up when handling more complex prompts. If you're facing such an issue, we recommend trying out the OpenAI
model which, while sadly not open-source, performs better at this given time.
</Tip>
You're now good to go! Let's dive into the two APIs that you now have at your disposal.
### Single execution (run)
The single execution method is when using the [`~Agent.run`] method of the agent:
```py
agent.run("Draw me a picture of rivers and lakes.")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
It automatically selects the tool (or tools) appropriate for the task you want to perform and runs them appropriately. It
can perform one or several tasks in the same instruction (though the more complex your instruction, the more likely
the agent is to fail).
```py
agent.run("Draw me a picture of the sea then transform the picture to add an island")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sea_and_island.png" width=200>
<br/>
Every [`~Agent.run`] operation is independent, so you can run it several times in a row with different tasks.
Note that your `agent` is just a large-language model, so small variations in your prompt might yield completely
different results. It's important to explain as clearly as possible the task you want to perform. We go more in-depth
on how to write good prompts [here](custom_tools#writing-good-user-inputs).
If you'd like to keep a state across executions or to pass non-text objects to the agent, you can do so by specifying
variables that you would like the agent to use. For example, you could generate the first image of rivers and lakes,
and ask the model to update that picture to add an island by doing the following:
```python
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)
```
<Tip>
This can be helpful when the model is unable to understand your request and mixes tools. An example would be:
```py
agent.run("Draw me the picture of a capybara swimming in the sea")
```
Here, the model could interpret in two ways:
- Have the `text-to-image` generate a capybara swimming in the sea
- Or, have the `text-to-image` generate capybara, then use the `image-transformation` tool to have it swim in the sea
In case you would like to force the first scenario, you could do so by passing it the prompt as an argument:
```py
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")
```
</Tip>
### Chat-based execution (chat)
The agent also has a chat-based approach, using the [`~Agent.chat`] method:
```py
agent.chat("Generate a picture of rivers and lakes")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
```py
agent.chat("Transform the picture so that there is a rock in there")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_and_beaver.png" width=200>
<br/>
This is an interesting approach when you want to keep the state across instructions. It's better for experimentation,
but will tend to be much better at single instructions rather than complex instructions (which the [`~Agent.run`]
method is better at handling).
This method can also take arguments if you would like to pass non-text types or specific prompts.
### ⚠️ Remote execution
For demonstration purposes and so that it could be used with all setups, we had created remote executors for several
of the default tools the agent has access for the release. These are created using
[inference endpoints](https://huggingface.co/inference-endpoints).
We have turned these off for now, but in order to see how to set up remote executors tools yourself,
we recommend reading the [custom tool guide](./custom_tools).
### What's happening here? What are tools, and what are agents?
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/diagram.png">
#### Agents
The "agent" here is a large language model, and we're prompting it so that it has access to a specific set of tools.
LLMs are pretty good at generating small samples of code, so this API takes advantage of that by prompting the
LLM gives a small sample of code performing a task with a set of tools. This prompt is then completed by the
task you give your agent and the description of the tools you give it. This way it gets access to the doc of the
tools you are using, especially their expected inputs and outputs, and can generate the relevant code.
#### Tools
Tools are very simple: they're a single function, with a name, and a description. We then use these tools' descriptions
to prompt the agent. Through the prompt, we show the agent how it would leverage tools to perform what was
requested in the query.
This is using brand-new tools and not pipelines, because the agent writes better code with very atomic tools.
Pipelines are more refactored and often combine several tasks in one. Tools are meant to be focused on
one very simple task only.
#### Code-execution?!
This code is then executed with our small Python interpreter on the set of inputs passed along with your tools.
We hear you screaming "Arbitrary code execution!" in the back, but let us explain why that is not the case.
The only functions that can be called are the tools you provided and the print function, so you're already
limited in what can be executed. You should be safe if it's limited to Hugging Face tools.
Then, we don't allow any attribute lookup or imports (which shouldn't be needed anyway for passing along
inputs/outputs to a small set of functions) so all the most obvious attacks (and you'd need to prompt the LLM
to output them anyway) shouldn't be an issue. If you want to be on the super safe side, you can execute the
run() method with the additional argument return_code=True, in which case the agent will just return the code
to execute and you can decide whether to do it or not.
The execution will stop at any line trying to perform an illegal operation or if there is a regular Python error
with the code generated by the agent.
### A curated set of tools
We identify a set of tools that can empower such agents. Here is an updated list of the tools we have integrated
in `transformers`:
- **Document question answering**: given a document (such as a PDF) in image format, answer a question on this document ([Donut](./model_doc/donut))
- **Text question answering**: given a long text and a question, answer the question in the text ([Flan-T5](./model_doc/flan-t5))
- **Unconditional image captioning**: Caption the image! ([BLIP](./model_doc/blip))
- **Image question answering**: given an image, answer a question on this image ([VILT](./model_doc/vilt))
- **Image segmentation**: given an image and a prompt, output the segmentation mask of that prompt ([CLIPSeg](./model_doc/clipseg))
- **Speech to text**: given an audio recording of a person talking, transcribe the speech into text ([Whisper](./model_doc/whisper))
- **Text to speech**: convert text to speech ([SpeechT5](./model_doc/speecht5))
- **Zero-shot text classification**: given a text and a list of labels, identify to which label the text corresponds the most ([BART](./model_doc/bart))
- **Text summarization**: summarize a long text in one or a few sentences ([BART](./model_doc/bart))
- **Translation**: translate the text into a given language ([NLLB](./model_doc/nllb))
These tools have an integration in transformers, and can be used manually as well, for example:
```py
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
```
### Custom tools
While we identify a curated set of tools, we strongly believe that the main value provided by this implementation is
the ability to quickly create and share custom tools.
By pushing the code of a tool to a Hugging Face Space or a model repository, you're then able to leverage the tool
directly with the agent. We've added a few
**transformers-agnostic** tools to the [`huggingface-tools` organization](https://huggingface.co/huggingface-tools):
- **Text downloader**: to download a text from a web URL
- **Text to image**: generate an image according to a prompt, leveraging stable diffusion
- **Image transformation**: modify an image given an initial image and a prompt, leveraging instruct pix2pix stable diffusion
- **Text to video**: generate a small video according to a prompt, leveraging damo-vilab
The text-to-image tool we have been using since the beginning is a remote tool that lives in
[*huggingface-tools/text-to-image*](https://huggingface.co/spaces/huggingface-tools/text-to-image)! We will
continue releasing such tools on this and other organizations, to further supercharge this implementation.
The agents have by default access to tools that reside on [`huggingface-tools`](https://huggingface.co/huggingface-tools).
We explain how to you can write and share your tools as well as leverage any custom tool that resides on the Hub in [following guide](custom_tools).
### Code generation
So far we have shown how to use the agents to perform actions for you. However, the agent is only generating code
that we then execute using a very restricted Python interpreter. In case you would like to use the code generated in
a different setting, the agent can be prompted to return the code, along with tool definition and accurate imports.
For example, the following instruction
```python
agent.run("Draw me a picture of rivers and lakes", return_code=True)
```
returns the following code
```python
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")
```
that you can then modify and execute yourself.
| huggingface/transformers/blob/main/docs/source/en/transformers_agents.md |
--
title: "A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes"
thumbnail: /blog/assets/96_hf_bitsandbytes_integration/Thumbnail_blue.png
authors:
- user: ybelkada
- user: timdettmers
guest: true
---
# A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes

## Introduction
Language models are becoming larger all the time. At the time of this writing, PaLM has 540B parameters, OPT, GPT-3, and BLOOM have around 176B parameters, and we are trending towards even larger models. Below is a diagram showing the size of some recent language models.

Therefore, these models are hard to run on easily accessible devices. For example, just to do inference on BLOOM-176B, you would need to have 8x 80GB A100 GPUs (~$15k each). To fine-tune BLOOM-176B, you'd need 72 of these GPUs! Much larger models, like PaLM would require even more resources.
Because these huge models require so many GPUs to run, we need to find ways to reduce these requirements while preserving the model's performance. Various technologies have been developed that try to shrink the model size, you may have heard of quantization and distillation, and there are many others.
After completing the training of BLOOM-176B, we at HuggingFace and BigScience were looking for ways to make this big model easier to run on less GPUs. Through our BigScience community we were made aware of research on Int8 inference that does not degrade predictive performance of large models and reduces the memory footprint of large models by a factor or 2x. Soon we started collaboring on this research which ended with a full integration into Hugging Face `transformers`. With this blog post, we offer LLM.int8() integration for all Hugging Face models which we explain in more detail below. If you want to read more about our research, you can read our paper, [LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://arxiv.org/abs/2208.07339).
This article focuses on giving a high-level overview of this quantization technology, outlining the difficulties in incorporating it into the `transformers` library, and drawing up the long-term goals of this partnership.
Here you will learn what exactly make a large model use so much memory? What makes BLOOM 350GB? Let's begin by gradually going over a few basic premises.
## Common data types used in Machine Learning
We start with the basic understanding of different floating point data types, which are also referred to as "precision" in the context of Machine Learning.
The size of a model is determined by the number of its parameters, and their precision, typically one of float32, float16 or bfloat16 (image below from: https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/).

Float32 (FP32) stands for the standardized IEEE 32-bit floating point representation. With this data type it is possible to represent a wide range of floating numbers. In FP32, 8 bits are reserved for the "exponent", 23 bits for the "mantissa" and 1 bit for the sign of the number. In addition to that, most of the hardware supports FP32 operations and instructions.
In the float16 (FP16) data type, 5 bits are reserved for the exponent and 10 bits are reserved for the mantissa. This makes the representable range of FP16 numbers much lower than FP32. This exposes FP16 numbers to the risk of overflowing (trying to represent a number that is very large) and underflowing (representing a number that is very small).
For example, if you do `10k * 10k` you end up with `100M` which is not possible to represent in FP16, as the largest number possible is `64k`. And thus you'd end up with `NaN` (Not a Number) result and if you have sequential computation like in neural networks, all the prior work is destroyed.
Usually, loss scaling is used to overcome this issue, but it doesn't always work well.
A new format, bfloat16 (BF16), was created to avoid these constraints. In BF16, 8 bits are reserved for the exponent (which is the same as in FP32) and 7 bits are reserved for the fraction.
This means that in BF16 we can retain the same dynamic range as FP32. But we lose 3 bits of precision with respect to FP16. Now there is absolutely no problem with huge numbers, but the precision is worse than FP16 here.
In the Ampere architecture, NVIDIA also introduced [TensorFloat-32](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) (TF32) precision format, combining the dynamic range of BF16 and precision of FP16 to only use 19 bits. It's currently only used internally during certain operations.
In the machine learning jargon FP32 is called full precision (4 bytes), while BF16 and FP16 are referred to as half-precision (2 bytes).
On top of that, the int8 (INT8) data type consists of an 8-bit representation that can store 2^8 different values (between [0, 255] or [-128, 127] for signed integers).
While, ideally the training and inference should be done in FP32, it is two times slower than FP16/BF16 and therefore a mixed precision approach is used where the weights are held in FP32 as a precise "main weights" reference, while computation in a forward and backward pass are done for FP16/BF16 to enhance training speed. The FP16/BF16 gradients are then used to update the FP32 main weights.
During training, the main weights are always stored in FP32, but in practice, the half-precision weights often provide similar quality during inference as their FP32 counterpart -- a precise reference of the model is only needed when it receives multiple gradient updates. This means we can use the half-precision weights and use half the GPUs to accomplish the same outcome.

To calculate the model size in bytes, one multiplies the number of parameters by the size of the chosen precision in bytes. For example, if we use the bfloat16 version of the BLOOM-176B model, we have `176*10**9 x 2 bytes = 352GB`! As discussed earlier, this is quite a challenge to fit into a few GPUs.
But what if we can store those weights with less memory using a different data type? A methodology called quantization has been used widely in Deep Learning.
## Introduction to model quantization
Experimentially, we have discovered that instead of using the 4-byte FP32 precision, we can get an almost identical inference outcome with 2-byte BF16/FP16 half-precision, which halves the model size. It'd be amazing to cut it further, but the inference quality outcome starts to drop dramatically at lower precision.
To remediate that, we introduce 8-bit quantization. This method uses a quarter precision, thus needing only 1/4th of the model size! But it's not done by just dropping another half of the bits.
Quantization is done by essentially “rounding” from one data type to another. For example, if one data type has the range 0..9 and another 0..4, then the value “4” in the first data type would be rounded to “2” in the second data type. However, if we have the value “3” in the first data type, it lies between 1 and 2 of the second data type, then we would usually round to “2”. This shows that both values “4” and “3” of the first data type have the same value “2” in the second data type. This highlights that quantization is a noisy process that can lead to information loss, a sort of lossy compression.
The two most common 8-bit quantization techniques are zero-point quantization and absolute maximum (absmax) quantization. Zero-point quantization and absmax quantization map the floating point values into more compact int8 (1 byte) values. First, these methods normalize the input by scaling it by a quantization constant.
For example, in zero-point quantization, if my range is -1.0…1.0 and I want to quantize into the range -127…127, I want to scale by the factor of 127 and then round it into the 8-bit precision. To retrieve the original value, you would need to divide the int8 value by that same quantization factor of 127. For example, the value 0.3 would be scaled to `0.3*127 = 38.1`. Through rounding, we get the value of 38. If we reverse this, we get `38/127=0.2992` – we have a quantization error of 0.008 in this example. These seemingly tiny errors tend to accumulate and grow as they get propagated through the model’s layers and result in performance degradation.

(Image taken from: [this blogpost](https://intellabs.github.io/distiller/algo_quantization.html) )
Now let's look at the details of absmax quantization. To calculate the mapping between the fp16 number and its corresponding int8 number in absmax quantization, you have to first divide by the absolute maximum value of the tensor and then multiply by the total range of the data type.
For example, let's assume you want to apply absmax quantization in a vector that contains `[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]`. You extract the absolute maximum of it, which is `5.4` in this case. Int8 has a range of `[-127, 127]`, so we divide 127 by `5.4` and obtain `23.5` for the scaling factor. Therefore multiplying the original vector by it gives the quantized vector `[28, -12, -101, 28, -73, 19, 56, 127]`.

To retrieve the latest, one can just divide in full precision the int8 number with the quantization factor, but since the result above is "rounded" some precision will be lost.

For an unsigned int8, we would subtract the minimum and scale by the absolute maximum. This is close to what zero-point quantization does. It's is similar to a min-max scaling but the latter maintains the value scales in such a way that the value “0” is always represented by an integer without any quantization error.
These tricks can be combined in several ways, for example, row-wise or vector-wise quantization, when it comes to matrix multiplication for more accurate results. Looking at the matrix multiplication, A\*B=C, instead of regular quantization that normalize by a absolute maximum value per tensor, vector-wise quantization finds the absolute maximum of each row of A and each column of B. Then we normalize A and B by dividing these vectors. We then multiply A\*B to get C. Finally, to get back the FP16 values, we denormalize by computing the outer product of the absolute maximum vector of A and B. More details on this technique can be found in the [LLM.int8() paper](https://arxiv.org/abs/2208.07339) or in the [blog post about quantization and emergent features](https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/) on Tim's blog.
While these basic techniques enable us to quanitize Deep Learning models, they usually lead to a drop in accuracy for larger models. The LLM.int8() implementation that we integrated into Hugging Face Transformers and Accelerate libraries is the first technique that does not degrade performance even for large models with 176B parameters, such as BLOOM.
## A gentle summary of LLM.int8(): zero degradation matrix multiplication for Large Language Models
In LLM.int8(), we have demonstrated that it is crucial to comprehend the scale-dependent emergent properties of transformers in order to understand why traditional quantization fails for large models. We demonstrate that performance deterioration is caused by outlier features, which we explain in the next section. The LLM.int8() algorithm itself can be explain as follows.
In essence, LLM.int8() seeks to complete the matrix multiplication computation in three steps:
1. From the input hidden states, extract the outliers (i.e. values that are larger than a certain threshold) by column.
2. Perform the matrix multiplication of the outliers in FP16 and the non-outliers in int8.
3. Dequantize the non-outlier results and add both outlier and non-outlier results together to receive the full result in FP16.
These steps can be summarized in the following animation:

### The importance of outlier features
A value that is outside the range of some numbers' global distribution is generally referred to as an outlier. Outlier detection has been widely used and covered in the current literature, and having prior knowledge of the distribution of your features helps with the task of outlier detection. More specifically, we have observed that classic quantization at scale fails for transformer-based models >6B parameters. While large outlier features are also present in smaller models, we observe that a certain threshold these outliers from highly systematic patterns across transformers which are present in every layer of the transformer. For more details on these phenomena see the [LLM.int8() paper](https://arxiv.org/abs/2208.07339) and [emergent features blog post](https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/).
As mentioned earlier, 8-bit precision is extremely constrained, therefore quantizing a vector with several big values can produce wildly erroneous results. Additionally, because of a built-in characteristic of the transformer-based architecture that links all the elements together, these errors tend to compound as they get propagated across multiple layers. Therefore, mixed-precision decomposition has been developed to facilitate efficient quantization with such extreme outliers. It is discussed next.
### Inside the MatMul
Once the hidden states are computed we extract the outliers using a custom threshold and we decompose the matrix into two parts as explained above. We found that extracting all outliers with magnitude 6 or greater in this way recoveres full inference performance. The outlier part is done in fp16 so it is a classic matrix multiplication, whereas the 8-bit matrix multiplication is done by quantizing the weights and hidden states into 8-bit precision using vector-wise quantization -- that is, row-wise quantization for the hidden state and column-wise quantization for the weight matrix.
After this step, the results are dequantized and returned in half-precision in order to add them to the first matrix multiplication.

### What does 0 degradation mean?
How can we properly evaluate the performance degradation of this method? How much quality do we lose in terms of generation when using 8-bit models?
We ran several common benchmarks with the 8-bit and native models using lm-eval-harness and reported the results.
For OPT-175B:
| benchmarks | - | - | - | - | difference - value |
| ---------- | --------- | ---------------- | -------------------- | -------------------- | -------------------- |
| name | metric | value - int8 | value - fp16 | std err - fp16 | - |
| hellaswag | acc\_norm | 0.7849 | 0.7849 | 0.0041 | 0 |
| hellaswag | acc | 0.5921 | 0.5931 | 0.0049 | 0.001 |
| piqa | acc | 0.7965 | 0.7959 | 0.0094 | 0.0006 |
| piqa | acc\_norm | 0.8101 | 0.8107 | 0.0091 | 0.0006 |
| lambada | ppl | 3.0142 | 3.0152 | 0.0552 | 0.001 |
| lambada | acc | 0.7464 | 0.7466 | 0.0061 | 0.0002 |
| winogrande | acc | 0.7174 | 0.7245 | 0.0125 | 0.0071 |
For BLOOM-176:
| benchmarks | - | - | - | - | difference - value |
| ---------- | --------- | ---------------- | -------------------- | -------------------- | -------------------- |
| name | metric | value - int8 | value - bf16 | std err - bf16 | - |
| hellaswag | acc\_norm | 0.7274 | 0.7303 | 0.0044 | 0.0029 |
| hellaswag | acc | 0.5563 | 0.5584 | 0.005 | 0.0021 |
| piqa | acc | 0.7835 | 0.7884 | 0.0095 | 0.0049 |
| piqa | acc\_norm | 0.7922 | 0.7911 | 0.0095 | 0.0011 |
| lambada | ppl | 3.9191 | 3.931 | 0.0846 | 0.0119 |
| lambada | acc | 0.6808 | 0.6718 | 0.0065 | 0.009 |
| winogrande | acc | 0.7048 | 0.7048 | 0.0128 | 0 |
We indeed observe 0 performance degradation for those models since the absolute difference of the metrics are all below the standard error (except for BLOOM-int8 which is slightly better than the native model on lambada). For a more detailed performance evaluation against state-of-the-art approaches, take a look at the [paper](https://arxiv.org/abs/2208.07339)!
### Is it faster than native models?
The main purpose of the LLM.int8() method is to make large models more accessible without performance degradation. But the method would be less useful if it is very slow. So we benchmarked the generation speed of multiple models.
We find that BLOOM-176B with LLM.int8() is about 15% to 23% slower than the fp16 version – which is still quite acceptable. We found larger slowdowns for smaller models, like T5-3B and T5-11B. We worked hard to speed up these small models. Within a day, we could improve inference per token from 312 ms to 173 ms for T5-3B and from 45 ms to 25 ms for T5-11B. Additionally, issues were [already identified](https://github.com/TimDettmers/bitsandbytes/issues/6#issuecomment-1211345635), and LLM.int8() will likely be faster still for small models in upcoming releases. For now, the current numbers are in the table below.
| Precision | Number of parameters | Hardware | Time per token in milliseconds for Batch Size 1 | Time per token in milliseconds for Batch Size 8 | Time per token in milliseconds for Batch Size 32 |
| -------------- | -------------------- | ------------ | ----------------------------------------------- | ----------------------------------------------- | ------------------------------------------------ |
| bf16 | 176B | 8xA100 80GB | 239 | 32 | 9.9 |
| int8 | 176B | 4xA100 80GB | 282 | 37.5 | 10.2 |
| bf16 | 176B | 14xA100 40GB | 285 | 36.5 | 10.4 |
| int8 | 176B | 5xA100 40GB | 367 | 46.4 | oom |
| fp16 | 11B | 2xT4 15GB | 11.7 | 1.7 | 0.5 |
| int8 | 11B | 1xT4 15GB | 43.5 | 5.3 | 1.3 |
| fp32 | 3B | 2xT4 15GB | 45 | 7.2 | 3.1 |
| int8 | 3B | 1xT4 15GB | 312 | 39.1 | 10.2 |
The 3 models are BLOOM-176B, T5-11B and T5-3B.
### Hugging Face `transformers` integration nuances
Next let's discuss the specifics of the Hugging Face `transformers` integration. Let's look at the usage and the common culprit you may encounter while trying to set things up.
### Usage
The module responsible for the whole magic described in this blog post is called `Linear8bitLt` and you can easily import it from the `bitsandbytes` library. It is derived from a classic `torch.nn` Module and can be easily used and deployed in your architecture with the code described below.
Here is a step-by-step example of the following use case: let's say you want to convert a small model in int8 using `bitsandbytes`.
1. First we need the correct imports below!
```py
import torch
import torch.nn as nn
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt
```
2. Then you can define your own model. Note that you can convert a checkpoint or model of any precision to 8-bit (FP16, BF16 or FP32) but, currently, the input of the model has to be FP16 for our Int8 module to work. So we treat our model here as a fp16 model.
```py
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)
```
3. Let's say you have trained your model on your favorite dataset and task! Now time to save the model:
```py
[... train the model ...]
torch.save(fp16_model.state_dict(), "model.pt")
```
4. Now that your `state_dict` is saved, let us define an int8 model:
```py
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)
```
Here it is very important to add the flag `has_fp16_weights`. By default, this is set to `True` which is used to train in mixed Int8/FP16 precision. However, we are interested in memory efficient inference for which we need to use `has_fp16_weights=False`.
5. Now time to load your model in 8-bit!
```py
int8_model.load_state_dict(torch.load("model.pt"))
int8_model = int8_model.to(0) # Quantization happens here
```
Note that the quantization step is done in the second line once the model is set on the GPU. If you print `int8_model[0].weight` before calling the `.to` function you get:
```
int8_model[0].weight
Parameter containing:
tensor([[ 0.0031, -0.0438, 0.0494, ..., -0.0046, -0.0410, 0.0436],
[-0.1013, 0.0394, 0.0787, ..., 0.0986, 0.0595, 0.0162],
[-0.0859, -0.1227, -0.1209, ..., 0.1158, 0.0186, -0.0530],
...,
[ 0.0804, 0.0725, 0.0638, ..., -0.0487, -0.0524, -0.1076],
[-0.0200, -0.0406, 0.0663, ..., 0.0123, 0.0551, -0.0121],
[-0.0041, 0.0865, -0.0013, ..., -0.0427, -0.0764, 0.1189]],
dtype=torch.float16)
```
Whereas if you print it after the second line's call you get:
```
int8_model[0].weight
Parameter containing:
tensor([[ 3, -47, 54, ..., -5, -44, 47],
[-104, 40, 81, ..., 101, 61, 17],
[ -89, -127, -125, ..., 120, 19, -55],
...,
[ 82, 74, 65, ..., -49, -53, -109],
[ -21, -42, 68, ..., 13, 57, -12],
[ -4, 88, -1, ..., -43, -78, 121]],
device='cuda:0', dtype=torch.int8, requires_grad=True)
```
The weights values are "truncated" as we have seen when explaining quantization in the previous sections. Also, the values seem to be distributed between [-127, 127].
You might also wonder how to retrieve the FP16 weights in order to perform the outlier MatMul in fp16? You can simply do:
```py
(int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127
```
And you will get:
```
tensor([[ 0.0028, -0.0459, 0.0522, ..., -0.0049, -0.0428, 0.0462],
[-0.0960, 0.0391, 0.0782, ..., 0.0994, 0.0593, 0.0167],
[-0.0822, -0.1240, -0.1207, ..., 0.1181, 0.0185, -0.0541],
...,
[ 0.0757, 0.0723, 0.0628, ..., -0.0482, -0.0516, -0.1072],
[-0.0194, -0.0410, 0.0657, ..., 0.0128, 0.0554, -0.0118],
[-0.0037, 0.0859, -0.0010, ..., -0.0423, -0.0759, 0.1190]],
device='cuda:0')
```
Which is close enough to the original FP16 values (2 print outs up)!
6. Now you can safely infer using your model by making sure your input is on the correct GPU and is in FP16:
```py
input_ = torch.randn((1, 64), dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))
```
Check out [the example script](/assets/96_hf_bitsandbytes_integration/example.py) for the full minimal code!
As a side note, you should be aware that these modules differ slightly from the `nn.Linear` modules in that their parameters come from the `bnb.nn.Int8Params` class rather than the `nn.Parameter` class. You'll see later that this presented an additional obstacle on our journey!
Now the time has come to understand how to integrate that into the `transformers` library!
### `accelerate` is all you need
When working with huge models, the `accelerate` library includes a number of helpful utilities. The `init_empty_weights` method is especially helpful because any model, regardless of size, may be initialized with this method as a context manager without allocating any memory for the model weights.
```py
import torch.nn as nn
from accelerate import init_empty_weights
with init_empty_weights():
model = nn.Sequential([nn.Linear(100000, 100000) for _ in range(1000)]) # This will take ~0 RAM!
```
The initialized model will be put on PyTorch's `meta` device, an underlying mechanism to represent shape and dtype without allocating memory for storage. How cool is that?
Initially, this function is called inside the `.from_pretrained` function and overrides all parameters to `torch.nn.Parameter`. This would not fit our requirement since we want to keep the `Int8Params` class in our case for `Linear8bitLt` modules as explained above. We managed to fix that on [the following PR](https://github.com/huggingface/accelerate/pull/519) that modifies:
```py
module._parameters[name] = nn.Parameter(module._parameters[name].to(torch.device("meta")))
```
to
```py
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(module._parameters[name].to(torch.device("meta")), **kwargs)
```
Now that this is fixed, we can easily leverage this context manager and play with it to replace all `nn.Linear` modules to `bnb.nn.Linear8bitLt` at no memory cost using a custom function!
```py
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):
for name, module in model.named_children():
if len(list(module.children())) > 0:
replace_8bit_linear(module, threshold, module_to_not_convert)
if isinstance(module, nn.Linear) and name != module_to_not_convert:
with init_empty_weights():
model._modules[name] = bnb.nn.Linear8bitLt(
module.in_features,
module.out_features,
module.bias is not None,
has_fp16_weights=False,
threshold=threshold,
)
return model
```
This function recursively replaces all `nn.Linear` layers of a given model initialized on the `meta` device and replaces them with a `Linear8bitLt` module. The attribute `has_fp16_weights` has to be set to `False` in order to directly load the weights in `int8` together with the quantization statistics.
We also discard the replacement for some modules (here the `lm_head`) since we want to keep the latest in their native precision for more precise and stable results.
But it isn't over yet! The function above is executed under the `init_empty_weights` context manager which means that the new model will be still in the `meta` device.
For models that are initialized under this context manager, `accelerate` will manually load the parameters of each module and move them to the correct devices.
In `bitsandbytes`, setting a `Linear8bitLt` module's device is a crucial step (if you are curious, you can check the code snippet [here](https://github.com/TimDettmers/bitsandbytes/blob/bd515328d70f344f935075f359c5aefc616878d5/bitsandbytes/nn/modules.py#L94)) as we have seen in our toy script.
Here the quantization step fails when calling it twice. We had to come up with an implementation of `accelerate`'s `set_module_tensor_to_device` function (termed as `set_module_8bit_tensor_to_device`) to make sure we don't call it twice. Let's discuss this in detail in the section below!
### Be very careful on how to set devices with `accelerate`
Here we played a very delicate balancing act with the `accelerate` library!
Once you load your model and set it on the correct devices, sometimes you still need to call `set_module_tensor_to_device` to dispatch the model with hooks on all devices. This is done inside the `dispatch_model` function from `accelerate`, which involves potentially calling `.to` several times and is something we want to avoid.
2 Pull Requests were needed to achieve what we wanted! The initial PR proposed [here](https://github.com/huggingface/accelerate/pull/539/) broke some tests but [this PR](https://github.com/huggingface/accelerate/pull/576/) successfully fixed everything!
### Wrapping it all up
Therefore the ultimate recipe is:
1. Initialize a model in the `meta` device with the correct modules
2. Set the parameters one by one on the correct GPU device and make sure you never do this procedure twice!
3. Put new keyword arguments in the correct place everywhere, and add some nice documentation
4. Add very extensive tests! Check our tests [here](https://github.com/huggingface/transformers/blob/main/tests/mixed_int8/test_mixed_int8.py) for more details
This may sound quite easy, but we went through many hard debugging sessions together, often times involving CUDA kernels!
All said and done, this integration adventure was very fun; from deep diving and doing some "surgery" on different libraries to aligning everything and making it work!
Now time to see how to benefit from this integration and how to successfully use it in `transformers`!
## How to use it in `transformers`
### Hardware requirements
8-bit tensor cores are not supported on the CPU. bitsandbytes can be run on 8-bit tensor core-supported hardware, which are Turing and Ampere GPUs (RTX 20s, RTX 30s, A40-A100, T4+). For example, Google Colab GPUs are usually NVIDIA T4 GPUs, and their latest generation of GPUs does support 8-bit tensor cores. Our demos are based on Google Colab so check them out below!
### Installation
Just install the latest version of the libraries using the commands below (make sure that you are using python>=3.8) and run the commands below to try out
```bash
pip install accelerate
pip install bitsandbytes
pip install git+https://github.com/huggingface/transformers.git
```
### Example demos - running T5 11b on a Google Colab
Check out the Google Colab demos for running 8bit models on a BLOOM-3B model!
Here is the demo for running T5-11B. The T5-11B model checkpoint is in FP32 which uses 42GB of memory and does not fit on Google Colab. With our 8-bit modules it only uses 11GB and fits easily:
[](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing)
Or this demo for BLOOM-3B:
[](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/HuggingFace_int8_demo.ipynb)
## Scope of improvements
This approach, in our opinion, greatly improves access to very large models. With no performance degradation, it enables users with less compute to access models that were previously inaccessible.
We've found several areas for improvement that can be worked on in the future to make this method even better for large models!
### Faster inference speed for smaller models
As we have seen in the [the benchmarking section](#is-it-faster-than-native-models), we could improve the runtime speed for small model (<=6B parameters) by a factor of almost 2x. However, while the inference speed is robust for large models like BLOOM-176B there are still improvements to be had for small models. We already identified the issues and likely recover same performance as fp16, or get small speedups. You will see these changes being integrated within the next couple of weeks.
### Support for Kepler GPUs (GTX 1080 etc)
While we support all GPUs from the past four years, some old GPUs like GTX 1080 still see heavy use. While these GPUs do not have Int8 tensor cores, they do have Int8 vector units (a kind of "weak" tensor core). As such, these GPUs can also experience Int8 acceleration. However, it requires a entire different stack of software for fast inference. While we do plan to integrate support for Kepler GPUs to make the LLM.int8() feature more widely available, it will take some time to realize this due to its complexity.
### Saving 8-bit state dicts on the Hub
8-bit state dicts cannot currently be loaded directly into the 8-bit model after being pushed on the Hub. This is due to the fact that the statistics (remember `weight.CB` and `weight.SCB`) computed by the model are not currently stored or taken into account inside the state dict, and the `Linear8bitLt` module does not support this feature yet.
We think that having the ability to save that and push it to the Hub might contribute to greater accessibility.
### CPU support
CPU devices do not support 8-bit cores, as was stated at the beginning of this blogpost. Can we, however, get past that? Running this module on CPUs would also significantly improve usability and accessibility.
### Scaling up on other modalities
Currently, language models dominate very large models. Leveraging this method on very large vision, audio, and multi-modal models might be an interesting thing to do for better accessibility in the coming years as these models become more accessible.
## Credits
Huge thanks to the following who contributed to improve the readability of the article as well as contributed in the integration procedure in `transformers` (listed in alphabetic order):
JustHeuristic (Yozh),
Michael Benayoun,
Stas Bekman,
Steven Liu,
Sylvain Gugger,
Tim Dettmers
| huggingface/blog/blob/main/hf-bitsandbytes-integration.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Philosophy
🧨 Diffusers provides **state-of-the-art** pretrained diffusion models across multiple modalities.
Its purpose is to serve as a **modular toolbox** for both inference and training.
We aim at building a library that stands the test of time and therefore take API design very seriously.
In a nutshell, Diffusers is built to be a natural extension of PyTorch. Therefore, most of our design choices are based on [PyTorch's Design Principles](https://pytorch.org/docs/stable/community/design.html#pytorch-design-philosophy). Let's go over the most important ones:
## Usability over Performance
- While Diffusers has many built-in performance-enhancing features (see [Memory and Speed](https://huggingface.co/docs/diffusers/optimization/fp16)), models are always loaded with the highest precision and lowest optimization. Therefore, by default diffusion pipelines are always instantiated on CPU with float32 precision if not otherwise defined by the user. This ensures usability across different platforms and accelerators and means that no complex installations are required to run the library.
- Diffusers aims to be a **light-weight** package and therefore has very few required dependencies, but many soft dependencies that can improve performance (such as `accelerate`, `safetensors`, `onnx`, etc...). We strive to keep the library as lightweight as possible so that it can be added without much concern as a dependency on other packages.
- Diffusers prefers simple, self-explainable code over condensed, magic code. This means that short-hand code syntaxes such as lambda functions, and advanced PyTorch operators are often not desired.
## Simple over easy
As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
- We follow PyTorch's API with methods like [`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to) to let the user handle device management.
- Raising concise error messages is preferred to silently correct erroneous input. Diffusers aims at teaching the user, rather than making the library as easy to use as possible.
- Complex model vs. scheduler logic is exposed instead of magically handled inside. Schedulers/Samplers are separated from diffusion models with minimal dependencies on each other. This forces the user to write the unrolled denoising loop. However, the separation allows for easier debugging and gives the user more control over adapting the denoising process or switching out diffusion models or schedulers.
- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the unet, and the variational autoencoder, each have their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. DreamBooth or Textual Inversion training
is very simple thanks to Diffusers' ability to separate single components of the diffusion pipeline.
## Tweakable, contributor-friendly over abstraction
For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
In short, just like Transformers does for modeling files, Diffusers prefers to keep an extremely low level of abstraction and very self-contained code for pipelines and schedulers.
Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
**However**, this design has proven to be extremely successful for Transformers and makes a lot of sense for community-driven, open-source machine learning libraries because:
- Machine Learning is an extremely fast-moving field in which paradigms, model architectures, and algorithms are changing rapidly, which therefore makes it very difficult to define long-lasting code abstractions.
- Machine Learning practitioners like to be able to quickly tweak existing code for ideation and research and therefore prefer self-contained code over one that contains many abstractions.
- Open-source libraries rely on community contributions and therefore must build a library that is easy to contribute to. The more abstract the code, the more dependencies, the harder to read, and the harder to contribute to. Contributors simply stop contributing to very abstract libraries out of fear of breaking vital functionality. If contributing to a library cannot break other fundamental code, not only is it more inviting for potential new contributors, but it is also easier to review and contribute to multiple parts in parallel.
At Hugging Face, we call this design the **single-file policy** which means that almost all of the code of a certain class should be written in a single, self-contained file. To read more about the philosophy, you can have a look
at [this blog post](https://huggingface.co/blog/transformers-design-philosophy).
In Diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
as [DDPM](https://huggingface.co/docs/diffusers/api/pipelines/ddpm), [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines), [unCLIP (DALL·E 2)](https://huggingface.co/docs/diffusers/api/pipelines/unclip) and [Imagen](https://imagen.research.google/) all rely on the same diffusion model, the [UNet](https://huggingface.co/docs/diffusers/api/models/unet2d-cond).
Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
We try to apply these design principles consistently across the library. Nevertheless, there are some minor exceptions to the philosophy or some unlucky design choices. If you have feedback regarding the design, we would ❤️ to hear it [directly on GitHub](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
## Design Philosophy in Details
Now, let's look a bit into the nitty-gritty details of the design philosophy. Diffusers essentially consists of three major classes: [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines), [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models), and [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
Let's walk through more in-detail design decisions for each class.
### Pipelines
Pipelines are designed to be easy to use (therefore do not follow [*Simple over easy*](#simple-over-easy) 100%), are not feature complete, and should loosely be seen as examples of how to use [models](#models) and [schedulers](#schedulers) for inference.
The following design principles are followed:
- Pipelines follow the single-file policy. All pipelines can be found in individual directories under src/diffusers/pipelines. One pipeline folder corresponds to one diffusion paper/project/release. Multiple pipeline files can be gathered in one pipeline folder, as it’s done for [`src/diffusers/pipelines/stable-diffusion`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion). If pipelines share similar functionality, one can make use of the [#Copied from mechanism](https://github.com/huggingface/diffusers/blob/125d783076e5bd9785beb05367a2d2566843a271/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L251).
- Pipelines all inherit from [`DiffusionPipeline`].
- Every pipeline consists of different model and scheduler components, that are documented in the [`model_index.json` file](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), are accessible under the same name as attributes of the pipeline and can be shared between pipelines with [`DiffusionPipeline.components`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.components) function.
- Every pipeline should be loadable via the [`DiffusionPipeline.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained) function.
- Pipelines should be used **only** for inference.
- Pipelines should be very readable, self-explanatory, and easy to tweak.
- Pipelines should be designed to build on top of each other and be easy to integrate into higher-level APIs.
- Pipelines are **not** intended to be feature-complete user interfaces. For future complete user interfaces one should rather have a look at [InvokeAI](https://github.com/invoke-ai/InvokeAI), [Diffuzers](https://github.com/abhishekkrthakur/diffuzers), and [lama-cleaner](https://github.com/Sanster/lama-cleaner).
- Every pipeline should have one and only one way to run it via a `__call__` method. The naming of the `__call__` arguments should be shared across all pipelines.
- Pipelines should be named after the task they are intended to solve.
- In almost all cases, novel diffusion pipelines shall be implemented in a new pipeline folder/file.
### Models
Models are designed as configurable toolboxes that are natural extensions of [PyTorch's Module class](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). They only partly follow the **single-file policy**.
The following design principles are followed:
- Models correspond to **a type of model architecture**. *E.g.* the [`UNet2DConditionModel`] class is used for all UNet variations that expect 2D image inputs and are conditioned on some context.
- All models can be found in [`src/diffusers/models`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and every model architecture shall be defined in its file, e.g. [`unet_2d_condition.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_condition.py), [`transformer_2d.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/transformer_2d.py), etc...
- Models **do not** follow the single-file policy and should make use of smaller model building blocks, such as [`attention.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py), [`resnet.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py), [`embeddings.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py), etc... **Note**: This is in stark contrast to Transformers' modeling files and shows that models do not really follow the single-file policy.
- Models intend to expose complexity, just like PyTorch's `Module` class, and give clear error messages.
- Models all inherit from `ModelMixin` and `ConfigMixin`.
- Models can be optimized for performance when it doesn’t demand major code changes, keeps backward compatibility, and gives significant memory or compute gain.
- Models should by default have the highest precision and lowest performance setting.
- To integrate new model checkpoints whose general architecture can be classified as an architecture that already exists in Diffusers, the existing model architecture shall be adapted to make it work with the new checkpoint. One should only create a new file if the model architecture is fundamentally different.
- Models should be designed to be easily extendable to future changes. This can be achieved by limiting public function arguments, configuration arguments, and "foreseeing" future changes, *e.g.* it is usually better to add `string` "...type" arguments that can easily be extended to new future types instead of boolean `is_..._type` arguments. Only the minimum amount of changes shall be made to existing architectures to make a new model checkpoint work.
- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
readable long-term, such as [UNet blocks](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_blocks.py) and [Attention processors](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
### Schedulers
Schedulers are responsible to guide the denoising process for inference as well as to define a noise schedule for training. They are designed as individual classes with loadable configuration files and strongly follow the **single-file policy**.
The following design principles are followed:
- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
- One scheduler Python file corresponds to one scheduler algorithm (as might be defined in a paper).
- If schedulers share similar functionalities, we can make use of the `#Copied from` mechanism.
- Schedulers all inherit from `SchedulerMixin` and `ConfigMixin`.
- Schedulers can be easily swapped out with the [`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method as explained in detail [here](../using-diffusers/schedulers.md).
- Every scheduler has to have a `set_num_inference_steps`, and a `step` function. `set_num_inference_steps(...)` has to be called before every denoising process, *i.e.* before `step(...)` is called.
- Every scheduler exposes the timesteps to be "looped over" via a `timesteps` attribute, which is an array of timesteps the model will be called upon.
- The `step(...)` function takes a predicted model output and the "current" sample (x_t) and returns the "previous", slightly more denoised sample (x_t-1).
- Given the complexity of diffusion schedulers, the `step` function does not expose all the complexity and can be a bit of a "black box".
- In almost all cases, novel schedulers shall be implemented in a new scheduling file.
| huggingface/diffusers/blob/main/docs/source/en/conceptual/philosophy.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you have to build it. Several packages are necessary to build the doc.
First, you need to install the project itself by running the following command at the root of the code repository:
```bash
pip install -e .
```
You also need to install 2 extra packages:
```bash
# `hf-doc-builder` to build the docs
pip install git+https://github.com/huggingface/doc-builder@main
# `watchdog` for live reloads
pip install watchdog
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look before committing for instance). You don't have to commit the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages with the pip install command above,
you can generate the documentation by typing the following command:
```bash
doc-builder build huggingface_hub docs/source/en/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
## Previewing the documentation
To preview the docs, run the following command:
```bash
doc-builder preview huggingface_hub docs/source/en/
```
The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you
have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
---
**NOTE**
The `preview` command only works with existing doc files. When you add a completely new file, you need to update
`_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/huggingface_hub/blob/main/docs/source/en/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course, if you moved it to another file, then:
```
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
For an example of a rich moved section set please see the very end of [the transformers Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
## Writing Documentation - Specification
The `huggingface/huggingface_hub` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new Markdown (.md) file under `./source`.
- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. If you have a doubt, feel free to ask in a Github Issue or PR.
### Translating
When translating, refer to the guide at [./TRANSLATING.md](https://github.com/huggingface/huggingface_hub/blob/main/docs/TRANSLATING.md).
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None, or any strings should usually be put in `code`.
When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`utils.ModelOutput\`\]. This will be converted into a link with
`utils.ModelOutput` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~utils.ModelOutput\`\] will generate a link with `ModelOutput` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line, another indentation is necessary before writing the description
after the argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
[`~PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ...
a (`float`, *optional*, defaults to 1):
This argument is used to ...
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```
# first line of code
# second line
# etc
```
````
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example of a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example of a tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
#### Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
#### Writing documentation examples
The syntax for Example docstrings can look as follows:
```
Example:
```python
>>> from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
```
```
The docstring should give a minimal, clear example of how the respective model
is to be used in inference and also include the expected (ideally sensible)
output.
Often, readers will try out the example before even going through the function
or class definitions. Therefore, it is of utmost importance that the example
works as expected. | huggingface/huggingface_hub/blob/main/docs/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# How to run Stable Diffusion with Core ML
[Core ML](https://developer.apple.com/documentation/coreml) is the model format and machine learning library supported by Apple frameworks. If you are interested in running Stable Diffusion models inside your macOS or iOS/iPadOS apps, this guide will show you how to convert existing PyTorch checkpoints into the Core ML format and use them for inference with Python or Swift.
Core ML models can leverage all the compute engines available in Apple devices: the CPU, the GPU, and the Apple Neural Engine (or ANE, a tensor-optimized accelerator available in Apple Silicon Macs and modern iPhones/iPads). Depending on the model and the device it's running on, Core ML can mix and match compute engines too, so some portions of the model may run on the CPU while others run on GPU, for example.
<Tip>
You can also run the `diffusers` Python codebase on Apple Silicon Macs using the `mps` accelerator built into PyTorch. This approach is explained in depth in [the mps guide](mps), but it is not compatible with native apps.
</Tip>
## Stable Diffusion Core ML Checkpoints
Stable Diffusion weights (or checkpoints) are stored in the PyTorch format, so you need to convert them to the Core ML format before we can use them inside native apps.
Thankfully, Apple engineers developed [a conversion tool](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml) based on `diffusers` to convert the PyTorch checkpoints to Core ML.
Before you convert a model, though, take a moment to explore the Hugging Face Hub – chances are the model you're interested in is already available in Core ML format:
- the [Apple](https://huggingface.co/apple) organization includes Stable Diffusion versions 1.4, 1.5, 2.0 base, and 2.1 base
- [coreml community](https://huggingface.co/coreml-community) includes custom finetuned models
- use this [filter](https://huggingface.co/models?pipeline_tag=text-to-image&library=coreml&p=2&sort=likes) to return all available Core ML checkpoints
If you can't find the model you're interested in, we recommend you follow the instructions for [Converting Models to Core ML](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml) by Apple.
## Selecting the Core ML Variant to Use
Stable Diffusion models can be converted to different Core ML variants intended for different purposes:
- The type of attention blocks used. The attention operation is used to "pay attention" to the relationship between different areas in the image representations and to understand how the image and text representations are related. Attention is compute- and memory-intensive, so different implementations exist that consider the hardware characteristics of different devices. For Core ML Stable Diffusion models, there are two attention variants:
* `split_einsum` ([introduced by Apple](https://machinelearning.apple.com/research/neural-engine-transformers)) is optimized for ANE devices, which is available in modern iPhones, iPads and M-series computers.
* The "original" attention (the base implementation used in `diffusers`) is only compatible with CPU/GPU and not ANE. It can be *faster* to run your model on CPU + GPU using `original` attention than ANE. See [this performance benchmark](https://huggingface.co/blog/fast-mac-diffusers#performance-benchmarks) as well as some [additional measures provided by the community](https://github.com/huggingface/swift-coreml-diffusers/issues/31) for additional details.
- The supported inference framework.
* `packages` are suitable for Python inference. This can be used to test converted Core ML models before attempting to integrate them inside native apps, or if you want to explore Core ML performance but don't need to support native apps. For example, an application with a web UI could perfectly use a Python Core ML backend.
* `compiled` models are required for Swift code. The `compiled` models in the Hub split the large UNet model weights into several files for compatibility with iOS and iPadOS devices. This corresponds to the [`--chunk-unet` conversion option](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml). If you want to support native apps, then you need to select the `compiled` variant.
The official Core ML Stable Diffusion [models](https://huggingface.co/apple/coreml-stable-diffusion-v1-4/tree/main) include these variants, but the community ones may vary:
```
coreml-stable-diffusion-v1-4
├── README.md
├── original
│ ├── compiled
│ └── packages
└── split_einsum
├── compiled
└── packages
```
You can download and use the variant you need as shown below.
## Core ML Inference in Python
Install the following libraries to run Core ML inference in Python:
```bash
pip install huggingface_hub
pip install git+https://github.com/apple/ml-stable-diffusion
```
### Download the Model Checkpoints
To run inference in Python, use one of the versions stored in the `packages` folders because the `compiled` ones are only compatible with Swift. You may choose whether you want to use `original` or `split_einsum` attention.
This is how you'd download the `original` attention variant from the Hub to a directory called `models`:
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-v1-4"
variant = "original/packages"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
### Inference[[python-inference]]
Once you have downloaded a snapshot of the model, you can test it using Apple's Python script.
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" -i models/coreml-stable-diffusion-v1-4_original_packages -o </path/to/output/image> --compute-unit CPU_AND_GPU --seed 93
```
Pass the path of the downloaded checkpoint with `-i` flag to the script. `--compute-unit` indicates the hardware you want to allow for inference. It must be one of the following options: `ALL`, `CPU_AND_GPU`, `CPU_ONLY`, `CPU_AND_NE`. You may also provide an optional output path, and a seed for reproducibility.
The inference script assumes you're using the original version of the Stable Diffusion model, `CompVis/stable-diffusion-v1-4`. If you use another model, you *have* to specify its Hub id in the inference command line, using the `--model-version` option. This works for models already supported and custom models you trained or fine-tuned yourself.
For example, if you want to use [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5):
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" --compute-unit ALL -o output --seed 93 -i models/coreml-stable-diffusion-v1-5_original_packages --model-version runwayml/stable-diffusion-v1-5
```
## Core ML inference in Swift
Running inference in Swift is slightly faster than in Python because the models are already compiled in the `mlmodelc` format. This is noticeable on app startup when the model is loaded but shouldn’t be noticeable if you run several generations afterward.
### Download
To run inference in Swift on your Mac, you need one of the `compiled` checkpoint versions. We recommend you download them locally using Python code similar to the previous example, but with one of the `compiled` variants:
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-v1-4"
variant = "original/compiled"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
### Inference[[swift-inference]]
To run inference, please clone Apple's repo:
```bash
git clone https://github.com/apple/ml-stable-diffusion
cd ml-stable-diffusion
```
And then use Apple's command line tool, [Swift Package Manager](https://www.swift.org/package-manager/#):
```bash
swift run StableDiffusionSample --resource-path models/coreml-stable-diffusion-v1-4_original_compiled --compute-units all "a photo of an astronaut riding a horse on mars"
```
You have to specify in `--resource-path` one of the checkpoints downloaded in the previous step, so please make sure it contains compiled Core ML bundles with the extension `.mlmodelc`. The `--compute-units` has to be one of these values: `all`, `cpuOnly`, `cpuAndGPU`, `cpuAndNeuralEngine`.
For more details, please refer to the [instructions in Apple's repo](https://github.com/apple/ml-stable-diffusion).
## Supported Diffusers Features
The Core ML models and inference code don't support many of the features, options, and flexibility of 🧨 Diffusers. These are some of the limitations to keep in mind:
- Core ML models are only suitable for inference. They can't be used for training or fine-tuning.
- Only two schedulers have been ported to Swift, the default one used by Stable Diffusion and `DPMSolverMultistepScheduler`, which we ported to Swift from our `diffusers` implementation. We recommend you use `DPMSolverMultistepScheduler`, since it produces the same quality in about half the steps.
- Negative prompts, classifier-free guidance scale, and image-to-image tasks are available in the inference code. Advanced features such as depth guidance, ControlNet, and latent upscalers are not available yet.
Apple's [conversion and inference repo](https://github.com/apple/ml-stable-diffusion) and our own [swift-coreml-diffusers](https://github.com/huggingface/swift-coreml-diffusers) repos are intended as technology demonstrators to enable other developers to build upon.
If you feel strongly about any missing features, please feel free to open a feature request or, better yet, a contribution PR 🙂.
## Native Diffusers Swift app
One easy way to run Stable Diffusion on your own Apple hardware is to use [our open-source Swift repo](https://github.com/huggingface/swift-coreml-diffusers), based on `diffusers` and Apple's conversion and inference repo. You can study the code, compile it with [Xcode](https://developer.apple.com/xcode/) and adapt it for your own needs. For your convenience, there's also a [standalone Mac app in the App Store](https://apps.apple.com/app/diffusers/id1666309574), so you can play with it without having to deal with the code or IDE. If you are a developer and have determined that Core ML is the best solution to build your Stable Diffusion app, then you can use the rest of this guide to get started with your project. We can't wait to see what you'll build 🙂.
| huggingface/diffusers/blob/main/docs/source/en/optimization/coreml.md |
# Blender Integration
### Install addon in Blender
This integration has been developed for Blender 3.2. You can install Blender from [this page](https://www.blender.org/download/)
- Launch Blender
- Go to `Edit > Preferences > Add-ons > Install...`
- Select the `simulate_blender.zip` file next to this README.md file
### Run in Blender
- You might need to run Blender with admin rights
- You can find an example script using the `simulate` API in `simulate/examples/blender_example.py` to create a scene
- Run the python script. It should print "Waiting for connection...", meaning that it has spawned a websocket server, and is waiting for a connection from the Blender client
- In Blender, open the submenus (little arrow in the top right)
- Go in the `Simulation` category and click on `Import Scene`. It should connect to the Python client, then display the scene. The python script should finish execution
- If you call `scene.render(path)`, Blender might freeze for a bit while rendering the scene to an image
| huggingface/simulate/blob/main/integrations/Blender/README.md |
Gradio Demo: plot_component
```
!pip install -q gradio matplotlib numpy
```
```
import gradio as gr
import matplotlib.pyplot as plt
import numpy as np
Fs = 8000
f = 5
sample = 8000
x = np.arange(sample)
y = np.sin(2 * np.pi * f * x / Fs)
plt.plot(x, y)
with gr.Blocks() as demo:
gr.Plot(value=plt)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/plot_component/run.ipynb |
Glossary
This is a community-created glossary. Contributions are welcomed!
- **Tabular Method:** Type of problem in which the state and action spaces are small enough to approximate value functions to be represented as arrays and tables.
**Q-learning** is an example of tabular method since a table is used to represent the value for different state-action pairs.
- **Deep Q-Learning:** Method that trains a neural network to approximate, given a state, the different **Q-values** for each possible action at that state.
It is used to solve problems when observational space is too big to apply a tabular Q-Learning approach.
- **Temporal Limitation** is a difficulty presented when the environment state is represented by frames. A frame by itself does not provide temporal information.
In order to obtain temporal information, we need to **stack** a number of frames together.
- **Phases of Deep Q-Learning:**
- **Sampling:** Actions are performed, and observed experience tuples are stored in a **replay memory**.
- **Training:** Batches of tuples are selected randomly and the neural network updates its weights using gradient descent.
- **Solutions to stabilize Deep Q-Learning:**
- **Experience Replay:** A replay memory is created to save experiences samples that can be reused during training.
This allows the agent to learn from the same experiences multiple times. Also, it helps the agent avoid forgetting previous experiences as it gets new ones.
- **Random sampling** from replay buffer allows to remove correlation in the observation sequences and prevents action values from oscillating or diverging
catastrophically.
- **Fixed Q-Target:** In order to calculate the **Q-Target** we need to estimate the discounted optimal **Q-value** of the next state by using Bellman equation. The problem
is that the same network weights are used to calculate the **Q-Target** and the **Q-value**. This means that everytime we are modifying the **Q-value**, the **Q-Target** also moves with it.
To avoid this issue, a separate network with fixed parameters is used for estimating the Temporal Difference Target. The target network is updated by copying parameters from
our Deep Q-Network after certain **C steps**.
- **Double DQN:** Method to handle **overestimation** of **Q-Values**. This solution uses two networks to decouple the action selection from the target **Value generation**:
- **DQN Network** to select the best action to take for the next state (the action with the highest **Q-Value**)
- **Target Network** to calculate the target **Q-Value** of taking that action at the next state.
This approach reduces the **Q-Values** overestimation, it helps to train faster and have more stable learning.
If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
This glossary was made possible thanks to:
- [Dario Paez](https://github.com/dario248)
| huggingface/deep-rl-class/blob/main/units/en/unit3/glossary.mdx |
--
title: XTREME-S
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
XTREME-S is a benchmark to evaluate universal cross-lingual speech representations in many languages.
XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval.
---
# Metric Card for XTREME-S
## Metric Description
The XTREME-S metric aims to evaluate model performance on the Cross-lingual TRansfer Evaluation of Multilingual Encoders for Speech (XTREME-S) benchmark.
This benchmark was designed to evaluate speech representations across languages, tasks, domains and data regimes. It covers 102 languages from 10+ language families, 3 different domains and 4 task families: speech recognition, translation, classification and retrieval.
## How to Use
There are two steps: (1) loading the XTREME-S metric relevant to the subset of the benchmark being used for evaluation; and (2) calculating the metric.
1. **Loading the relevant XTREME-S metric** : the subsets of XTREME-S are the following: `mls`, `voxpopuli`, `covost2`, `fleurs-asr`, `fleurs-lang_id`, `minds14` and `babel`. More information about the different subsets can be found on the [XTREME-S benchmark page](https://huggingface.co/datasets/google/xtreme_s).
```python
>>> xtreme_s_metric = evaluate.load('xtreme_s', 'mls')
```
2. **Calculating the metric**: the metric takes two inputs :
- `predictions`: a list of predictions to score, with each prediction a `str`.
- `references`: a list of lists of references for each translation, with each reference a `str`.
```python
>>> references = ["it is sunny here", "paper and pen are essentials"]
>>> predictions = ["it's sunny", "paper pen are essential"]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
```
It also has two optional arguments:
- `bleu_kwargs`: a `dict` of keywords to be passed when computing the `bleu` metric for the `covost2` subset. Keywords can be one of `smooth_method`, `smooth_value`, `force`, `lowercase`, `tokenize`, `use_effective_order`.
- `wer_kwargs`: optional dict of keywords to be passed when computing `wer` and `cer`, which are computed for the `mls`, `fleurs-asr`, `voxpopuli`, and `babel` subsets. Keywords are `concatenate_texts`.
## Output values
The output of the metric depends on the XTREME-S subset chosen, consisting of a dictionary that contains one or several of the following metrics:
- `accuracy`: the proportion of correct predictions among the total number of cases processed, with a range between 0 and 1 (see [accuracy](https://huggingface.co/metrics/accuracy) for more information). This is returned for the `fleurs-lang_id` and `minds14` subsets.
- `f1`: the harmonic mean of the precision and recall (see [F1 score](https://huggingface.co/metrics/f1) for more information). Its range is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall. It is returned for the `minds14` subset.
- `wer`: Word error rate (WER) is a common metric of the performance of an automatic speech recognition system. The lower the value, the better the performance of the ASR system, with a WER of 0 being a perfect score (see [WER score](https://huggingface.co/metrics/wer) for more information). It is returned for the `mls`, `fleurs-asr`, `voxpopuli` and `babel` subsets of the benchmark.
- `cer`: Character error rate (CER) is similar to WER, but operates on character instead of word. The lower the CER value, the better the performance of the ASR system, with a CER of 0 being a perfect score (see [CER score](https://huggingface.co/metrics/cer) for more information). It is returned for the `mls`, `fleurs-asr`, `voxpopuli` and `babel` subsets of the benchmark.
- `bleu`: the BLEU score, calculated according to the SacreBLEU metric approach. It can take any value between 0.0 and 100.0, inclusive, with higher values being better (see [SacreBLEU](https://huggingface.co/metrics/sacrebleu) for more details). This is returned for the `covost2` subset.
### Values from popular papers
The [original XTREME-S paper](https://arxiv.org/pdf/2203.10752.pdf) reported average WERs ranging from 9.2 to 14.6, a BLEU score of 20.6, an accuracy of 73.3 and F1 score of 86.9, depending on the subsets of the dataset tested on.
## Examples
For the `mls` subset (which outputs `wer` and `cer`):
```python
>>> xtreme_s_metric = evaluate.load('xtreme_s', 'mls')
>>> references = ["it is sunny here", "paper and pen are essentials"]
>>> predictions = ["it's sunny", "paper pen are essential"]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'wer': 0.56, 'cer': 0.27}
```
For the `covost2` subset (which outputs `bleu`):
```python
>>> xtreme_s_metric = evaluate.load('xtreme_s', 'covost2')
>>> references = ["bonjour paris", "il est necessaire de faire du sport de temps en temp"]
>>> predictions = ["bonjour paris", "il est important de faire du sport souvent"]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'bleu': 31.65}
```
For the `fleurs-lang_id` subset (which outputs `accuracy`):
```python
>>> xtreme_s_metric = evaluate.load('xtreme_s', 'fleurs-lang_id')
>>> references = [0, 1, 0, 0, 1]
>>> predictions = [0, 1, 1, 0, 0]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'accuracy': 0.6}
```
For the `minds14` subset (which outputs `f1` and `accuracy`):
```python
>>> xtreme_s_metric = evaluate.load('xtreme_s', 'minds14')
>>> references = [0, 1, 0, 0, 1]
>>> predictions = [0, 1, 1, 0, 0]
>>> results = xtreme_s_metric.compute(predictions=predictions, references=references)
>>> print({k: round(v, 2) for k, v in results.items()})
{'f1': 0.58, 'accuracy': 0.6}
```
## Limitations and bias
This metric works only with datasets that have the same format as the [XTREME-S dataset](https://huggingface.co/datasets/google/xtreme_s).
While the XTREME-S dataset is meant to represent a variety of languages and tasks, it has inherent biases: it is missing many languages that are important and under-represented in NLP datasets.
It also has a particular focus on read-speech because common evaluation benchmarks like CoVoST-2 or LibriSpeech evaluate on this type of speech, which results in a mismatch between performance obtained in a read-speech setting and a more noisy setting (in production or live deployment, for instance).
## Citation
```bibtex
@article{conneau2022xtreme,
title={XTREME-S: Evaluating Cross-lingual Speech Representations},
author={Conneau, Alexis and Bapna, Ankur and Zhang, Yu and Ma, Min and von Platen, Patrick and Lozhkov, Anton and Cherry, Colin and Jia, Ye and Rivera, Clara and Kale, Mihir and others},
journal={arXiv preprint arXiv:2203.10752},
year={2022}
}
```
## Further References
- [XTREME-S dataset](https://huggingface.co/datasets/google/xtreme_s)
- [XTREME-S github repository](https://github.com/google-research/xtreme)
| huggingface/evaluate/blob/main/metrics/xtreme_s/README.md |
n this video, we're going to understand how to manage a model repository on the HuggingFace model hub. In order to handle a repository, you should first have a Hugging Face account. A link to create a new account is available in the description. Once you are logged in, you can create a new repository by clicking on the "New model" option. You should be facing a similar modal to the following. In the "Owner" input, you can put either your own namespace or any of your organisations namespaces. The model name is the model identifier that will then be used to identify your model on your chosen namespace. The final choice is between public and private. Public models are accessible by anyone. This is the recommended, free option, as this makes your model easily accessible and shareable. The owners of your namespace are the only ones who can update and change your model. A more advanced option is the private option. In this case, only the owners of your namespace will have visibility over your model. Other users won't know it exists and will not be able to use it. Let's create a dummy model to play with. Once your model is created, comes the management of that model! Three tabs are available to you. You're facing the first one, which is the model card page; this is the page used to showcase your model to the world. We'll see how it can be completed in a bit. The second one is the "Files & Versions". Your model itself is a git repository - if you're unaware of what is a git repository, you can think of it as a folder containing files. If you have never used git before, we recommend looking at an introduction like the one provided in this video's description. The git repository allows you to see the changes happening over time in this folder, hence the term "Versions". We'll see how to add files and versions in a bit. The final tab is the "Settings" tab, which allow you to manage your model's visibility and availability. Let's first start by adding files to the repository. Files can be added through the web interface thanks to the "Add File" button. The added files can be of any type: python, json, text, you name it! Alongside your added file and its content, you should name your change, or commit. Generally, adding files is simpler when using the command line. We'll showcase how to do this using git. In addition to git, we're using git-lfs, which stands for large file storage in order to manage large model files. First, I make sure that both git and git-lfs are correctly installed on my system. Links to install git & git-lfs are provided in the video description. Then, we can get to work by cloning the repository locally. We have a repository with a single file! The file that we have just added to the repository using the web interface. We can edit it to see the contents of this file and update these. It just turns out I have a model handy, that can be used for sentiment analysis. I'll simply copy over the contents to this folder. This includes the model weights, configuration file and tokenizer to the repository. I can then track these two files with the git add command. Then, I commit the changes. I'm giving this commit the title of "Add model weights and configuration". Finally, I can push the new commit to the huggingface.co remote. When going back to the files & versions tab, we can now see the newly added commit with the updated files. We have seen two ways of adding files to a repository, a third way is explored in the video about the push to hub API. A link to this video is in the description. Go back to readme. Unfortunately, the front page of our model is still very empty. Let's add a README markdown file to complete it a little bit. This README is known as the modelcard, and it's arguably as important as the model and tokenizer files in a model repository. It is the central definition of the model, ensuring reusability by fellow community members and reproducibility of results, and providing a platform on which other members may build their artifacts. We'll only add a title and a small description here for simplicity's sake, but we encourage you to add information relevant to how was the model trained, its intended uses and limitations, as well as its identified and potential biases, evaluation results and code samples on how your model should be used. Great work contributing a model to the model hub! This model can now be used in downstream libraries simply by specifying your model identifier. | huggingface/course/blob/main/subtitles/en/raw/chapter4/03a_managing-repos.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
Welcome to 🧨 Diffusers! If you're new to diffusion models and generative AI, and want to learn more, then you've come to the right place. These beginner-friendly tutorials are designed to provide a gentle introduction to diffusion models and help you understand the library fundamentals - the core components and how 🧨 Diffusers is meant to be used.
You'll learn how to use a pipeline for inference to rapidly generate things, and then deconstruct that pipeline to really understand how to use the library as a modular toolbox for building your own diffusion systems. In the next lesson, you'll learn how to train your own diffusion model to generate what you want.
After completing the tutorials, you'll have gained the necessary skills to start exploring the library on your own and see how to use it for your own projects and applications.
Feel free to join our community on [Discord](https://discord.com/invite/JfAtkvEtRb) or the [forums](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) to connect and collaborate with other users and developers!
Let's start diffusing! 🧨
| huggingface/diffusers/blob/main/docs/source/en/tutorials/tutorial_overview.md |
--
title: "Speech Synthesis, Recognition, and More With SpeechT5"
thumbnail: /blog/assets/speecht5/thumbnail.png
authors:
- user: Matthijs
---
# Speech Synthesis, Recognition, and More With SpeechT5
We’re happy to announce that SpeechT5 is now available in 🤗 Transformers, an open-source library that offers easy-to-use implementations of state-of-the-art machine learning models.
SpeechT5 was originally described in the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Microsoft Research Asia. The [official checkpoints](https://github.com/microsoft/SpeechT5) published by the paper’s authors are available on the Hugging Face Hub.
If you want to jump right in, here are some demos on Spaces:
- [Speech Synthesis (TTS)](https://huggingface.co/spaces/Matthijs/speecht5-tts-demo)
- [Voice Conversion](https://huggingface.co/spaces/Matthijs/speecht5-vc-demo)
- [Automatic Speech Recognition](https://huggingface.co/spaces/Matthijs/speecht5-asr-demo)
## Introduction
SpeechT5 is not one, not two, but three kinds of speech models in one architecture.
It can do:
- **speech-to-text** for automatic speech recognition or speaker identification,
- **text-to-speech** to synthesize audio, and
- **speech-to-speech** for converting between different voices or performing speech enhancement.
The main idea behind SpeechT5 is to pre-train a single model on a mixture of text-to-speech, speech-to-text, text-to-text, and speech-to-speech data. This way, the model learns from text and speech at the same time. The result of this pre-training approach is a model that has a **unified space** of hidden representations shared by both text and speech.
At the heart of SpeechT5 is a regular **Transformer encoder-decoder** model. Just like any other Transformer, the encoder-decoder network models a sequence-to-sequence transformation using hidden representations. This Transformer backbone is the same for all SpeechT5 tasks.
To make it possible for the same Transformer to deal with both text and speech data, so-called **pre-nets** and **post-nets** were added. It is the job of the pre-net to convert the input text or speech into the hidden representations used by the Transformer. The post-net takes the outputs from the Transformer and turns them into text or speech again.
A figure illustrating SpeechT5’s architecture is depicted below (taken from the [original paper](https://arxiv.org/abs/2110.07205)).
<div align="center">
<img alt="SpeechT5 architecture diagram" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/architecture.jpg"/>
</div>
During pre-training, all of the pre-nets and post-nets are used simultaneously. After pre-training, the entire encoder-decoder backbone is fine-tuned on a single task. Such a fine-tuned model only uses the pre-nets and post-nets specific to the given task. For example, to use SpeechT5 for text-to-speech, you’d swap in the text encoder pre-net for the text inputs and the speech decoder pre and post-nets for the speech outputs.
Note: Even though the fine-tuned models start out using the same set of weights from the shared pre-trained model, the final versions are all quite different in the end. You can’t take a fine-tuned ASR model and swap out the pre-nets and post-net to get a working TTS model, for example. SpeechT5 is flexible, but not *that* flexible.
## Text-to-speech
SpeechT5 is the **first text-to-speech model** we’ve added to 🤗 Transformers, and we plan to add more TTS models in the near future.
For the TTS task, the model uses the following pre-nets and post-nets:
- **Text encoder pre-net.** A text embedding layer that maps text tokens to the hidden representations that the encoder expects. Similar to what happens in an NLP model such as BERT.
- **Speech decoder pre-net.** This takes a log mel spectrogram as input and uses a sequence of linear layers to compress the spectrogram into hidden representations. This design is taken from the Tacotron 2 TTS model.
- **Speech decoder post-net.** This predicts a residual to add to the output spectrogram and is used to refine the results, also from Tacotron 2.
The architecture of the fine-tuned model looks like the following.
<div align="center">
<img alt="SpeechT5 architecture for text-to-speech" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/tts.jpg"/>
</div>
Here is a complete example of how to use the SpeechT5 text-to-speech model to synthesize speech. You can also follow along in [this interactive Colab notebook](https://colab.research.google.com/drive/1XnOnCsmEmA3lHmzlNRNxRMcu80YZQzYf?usp=sharing).
SpeechT5 is not available in the latest release of Transformers yet, so you'll have to install it from GitHub. Also install the additional dependency sentencepiece and then restart your runtime.
```python
pip install git+https://github.com/huggingface/transformers.git
pip install sentencepiece
```
First, we load the [fine-tuned model](https://huggingface.co/microsoft/speecht5_tts) from the Hub, along with the processor object used for tokenization and feature extraction. The class we’ll use is `SpeechT5ForTextToSpeech`.
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
```
Next, tokenize the input text.
```python
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
```
The SpeechT5 TTS model is not limited to creating speech for a single speaker. Instead, it uses so-called **speaker embeddings** that capture a particular speaker’s voice characteristics. We’ll load such a speaker embedding from a dataset on the Hub.
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
The speaker embedding is a tensor of shape (1, 512). This particular speaker embedding describes a female voice. The embeddings were obtained from the [CMU ARCTIC](http://www.festvox.org/cmu_arctic/) dataset using [this script](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py), but any X-Vector embedding should work.
Now we can tell the model to generate the speech, given the input tokens and the speaker embedding.
```python
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
This outputs a tensor of shape (140, 80) containing a log mel spectrogram. The first dimension is the sequence length, and it may vary between runs as the speech decoder pre-net always applies dropout to the input sequence. This adds a bit of random variability to the generated speech.
To convert the predicted log mel spectrogram into an actual speech waveform, we need a **vocoder**. In theory, you can use any vocoder that works on 80-bin mel spectrograms, but for convenience, we’ve provided one in Transformers based on HiFi-GAN. The [weights for this vocoder](https://huggingface.co/mechanicalsea/speecht5-tts), as well as the weights for the fine-tuned TTS model, were kindly provided by the original authors of SpeechT5.
Loading the vocoder is as easy as any other 🤗 Transformers model.
```python
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
To make audio from the spectrogram, do the following:
```python
with torch.no_grad():
speech = vocoder(spectrogram)
```
We’ve also provided a shortcut so you don’t need the intermediate step of making the spectrogram. When you pass the vocoder object into `generate_speech`, it directly outputs the speech waveform.
```python
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
```
And finally, save the speech waveform to a file. The sample rate used by SpeechT5 is always 16 kHz.
```python
import soundfile as sf
sf.write("tts_example.wav", speech.numpy(), samplerate=16000)
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/tts_example.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/tts_example.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
That’s it for the TTS model! The key to making this sound good is to use the right speaker embeddings.
You can play with an [interactive demo](https://huggingface.co/spaces/Matthijs/speecht5-tts-demo) on Spaces.
💡 Interested in learning how to **fine-tune** SpeechT5 TTS on your own dataset or language? Check out [this Colab notebook](https://colab.research.google.com/drive/1i7I5pzBcU3WDFarDnzweIj4-sVVoIUFJ) with a detailed walk-through of the process.
## Speech-to-speech for voice conversion
Conceptually, doing speech-to-speech modeling with SpeechT5 is the same as text-to-speech. Simply swap out the text encoder pre-net for the speech encoder pre-net. The rest of the model stays the same.
<div align="center">
<img alt="SpeechT5 architecture for speech-to-speech" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/s2s.jpg"/>
</div>
The **speech encoder pre-net** is the same as the feature encoding module from [wav2vec 2.0](https://huggingface.co/docs/transformers/model_doc/wav2vec2). It consists of convolution layers that downsample the input waveform into a sequence of audio frame representations.
As an example of a speech-to-speech task, the authors of SpeechT5 provide a [fine-tuned checkpoint](https://huggingface.co/microsoft/speecht5_vc) for doing voice conversion. To use this, first load the model from the Hub. Note that the model class now is `SpeechT5ForSpeechToSpeech`.
```python
from transformers import SpeechT5Processor, SpeechT5ForSpeechToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_vc")
model = SpeechT5ForSpeechToSpeech.from_pretrained("microsoft/speecht5_vc")
```
We will need some speech audio to use as input. For the purpose of this example, we’ll load the audio from a small speech dataset on the Hub. You can also load your own speech waveforms, as long as they are mono and use a sampling rate of 16 kHz. The samples from the dataset we’re using here are already in this format.
```python
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
example = dataset[40]
```
Next, preprocess the audio to put it in the format that the model expects.
```python
sampling_rate = dataset.features["audio"].sampling_rate
inputs = processor(audio=example["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
As with the TTS model, we’ll need speaker embeddings. These describe what the target voice sounds like.
```python
import torch
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
We also need to load the vocoder to turn the generated spectrograms into an audio waveform. Let’s use the same vocoder as with the TTS model.
```python
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
Now we can perform the speech conversion by calling the model’s `generate_speech` method.
```python
speech = model.generate_speech(inputs["input_values"], speaker_embeddings, vocoder=vocoder)
import soundfile as sf
sf.write("speech_converted.wav", speech.numpy(), samplerate=16000)
```
Changing to a different voice is as easy as loading a new speaker embedding. You could even make an embedding from your own voice!
The original input ([download](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/speech_original.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/speech_original.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
The converted voice ([download](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/speech_converted.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/speech_converted.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Note that the converted audio in this example cuts off before the end of the sentence. This might be due to the pause between the two sentences, causing SpeechT5 to (wrongly) predict that the end of the sequence has been reached. Try it with another example, you’ll find that often the conversion is correct but sometimes it stops prematurely.
You can play with an [interactive demo here](https://huggingface.co/spaces/Matthijs/speecht5-vc-demo). 🔥
## Speech-to-text for automatic speech recognition
The ASR model uses the following pre-nets and post-net:
- **Speech encoder pre-net.** This is the same pre-net used by the speech-to-speech model and consists of the CNN feature encoder layers from wav2vec 2.0.
- **Text decoder pre-net.** Similar to the encoder pre-net used by the TTS model, this maps text tokens into the hidden representations using an embedding layer. (During pre-training, these embeddings are shared between the text encoder and decoder pre-nets.)
- **Text decoder post-net.** This is the simplest of them all and consists of a single linear layer that projects the hidden representations to probabilities over the vocabulary.
The architecture of the fine-tuned model looks like the following.
<div align="center">
<img alt="SpeechT5 architecture for speech-to-text" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/asr.jpg"/>
</div>
If you’ve tried any of the other 🤗 Transformers speech recognition models before, you’ll find SpeechT5 just as easy to use. The quickest way to get started is by using a pipeline.
```python
from transformers import pipeline
generator = pipeline(task="automatic-speech-recognition", model="microsoft/speecht5_asr")
```
As speech audio, we’ll use the same input as in the previous section, but any audio file will work, as the pipeline automatically converts the audio into the correct format.
```python
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
example = dataset[40]
```
Now we can ask the pipeline to process the speech and generate a text transcription.
```python
transcription = generator(example["audio"]["array"])
```
Printing the transcription gives:
```text
a man said to the universe sir i exist
```
That sounds exactly right! The tokenizer used by SpeechT5 is very basic and works on the character level. The ASR model will therefore not output any punctuation or capitalization.
Of course it’s also possible to use the model class directly. First, load the [fine-tuned model](https://huggingface.co/microsoft/speecht5_asr) and the processor object. The class is now `SpeechT5ForSpeechToText`.
```python
from transformers import SpeechT5Processor, SpeechT5ForSpeechToText
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_asr")
model = SpeechT5ForSpeechToText.from_pretrained("microsoft/speecht5_asr")
```
Preprocess the speech input:
```python
sampling_rate = dataset.features["audio"].sampling_rate
inputs = processor(audio=example["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Finally, tell the model to generate text tokens from the speech input, and then use the processor’s decoding function to turn these tokens into actual text.
```python
predicted_ids = model.generate(**inputs, max_length=100)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
```
Play with an interactive demo for the [speech-to-text task](https://huggingface.co/spaces/Matthijs/speecht5-asr-demo).
## Conclusion
SpeechT5 is an interesting model because — unlike most other models — it allows you to perform multiple tasks with the same architecture. Only the pre-nets and post-nets change. By pre-training the model on these combined tasks, it becomes more capable at doing each of the individual tasks when fine-tuned.
We have only included checkpoints for the speech recognition (ASR), speech synthesis (TTS), and voice conversion tasks but the paper also mentions the model was successfully used for speech translation, speech enhancement, and speaker identification. It’s very versatile!
| huggingface/blog/blob/main/speecht5.md |
--
title: "Code Llama: Llama 2 learns to code"
thumbnail: /blog/assets/160_codellama/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lewtun
- user: lvwerra
- user: loubnabnl
- user: ArthurZ
- user: joaogante
---
# Code Llama: Llama 2 learns to code
## Introduction
Code Llama is a family of state-of-the-art, open-access versions of [Llama 2](https://huggingface.co/blog/llama2) specialized on code tasks, and we’re excited to release integration in the Hugging Face ecosystem! Code Llama has been released with the same permissive community license as Llama 2 and is available for commercial use.
Today, we’re excited to release:
- Models on the Hub with their model cards and license
- Transformers integration
- Integration with Text Generation Inference for fast and efficient production-ready inference
- Integration with Inference Endpoints
- Integration with VS Code extension
- Code benchmarks
Code LLMs are an exciting development for software engineers because they can boost productivity through code completion in IDEs, take care of repetitive or annoying tasks like writing docstrings, or create unit tests.
## Table of Contents
- [Introduction](#introduction)
- [Table of Contents](#table-of-contents)
- [What’s Code Llama?](#whats-code-llama)
- [How to use Code Llama?](#how-to-use-code-llama)
- [Demo](#demo)
- [Transformers](#transformers)
- [A Note on dtypes](#a-note-on-dtypes)
- [Code Completion](#code-completion)
- [Code Infilling](#code-infilling)
- [Conversational Instructions](#conversational-instructions)
- [4-bit Loading](#4-bit-loading)
- [Using text-generation-inference and Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Using VS Code extension](#using-vs-code-extension)
- [Evaluation](#evaluation)
- [Additional Resources](#additional-resources)
## What’s Code Llama?
The Code Llama release introduces a family of models of 7, 13, and 34 billion parameters. The base models are initialized from Llama 2 and then trained on 500 billion tokens of code data. Meta fine-tuned those base models for two different flavors: a Python specialist (100 billion additional tokens) and an instruction fine-tuned version, which can understand natural language instructions.
The models show state-of-the-art performance in Python, C++, Java, PHP, C#, TypeScript, and Bash. The 7B and 13B base and instruct variants support infilling based on surrounding content, making them ideal for use as code assistants.
Code Llama was trained on a 16k context window. In addition, the three model variants had additional long-context fine-tuning, allowing them to manage a context window of up to 100,000 tokens.
Increasing Llama 2’s 4k context window to Code Llama’s 16k (that can extrapolate up to 100k) was possible due to recent developments in RoPE scaling. The community found that Llama’s position embeddings can be interpolated linearly or in the frequency domain, which eases the transition to a larger context window through fine-tuning. In the case of Code Llama, the frequency domain scaling is done with a slack: the fine-tuning length is a fraction of the scaled pretrained length, giving the model powerful extrapolation capabilities.

All models were initially trained with 500 billion tokens on a near-deduplicated dataset of publicly available code. The dataset also contains some natural language datasets, such as discussions about code and code snippets. Unfortunately, there is not more information about the dataset.
For the instruction model, they used two datasets: the instruction tuning dataset collected for Llama 2 Chat and a self-instruct dataset. The self-instruct dataset was created by using Llama 2 to create interview programming questions and then using Code Llama to generate unit tests and solutions, which are later evaluated by executing the tests.
## How to use Code Llama?
Code Llama is available in the Hugging Face ecosystem, starting with `transformers` version 4.33.
### Demo
You can easily try the Code Llama Model (13 billion parameters!) in **[this Space](https://huggingface.co/spaces/codellama/codellama-playground)** or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.3/gradio.js"> </script>
<gradio-app theme_mode="light" space="codellama/codellama-playground"></gradio-app>
Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co/chat/), and we'll share more in the following sections.
If you want to try out the bigger instruct-tuned 34B model, it is now available on **HuggingChat**! You can try it out here: [hf.co/chat](https://hf.co/chat). Make sure to specify the Code Llama model. You can also check [this chat-based demo](https://huggingface.co/spaces/codellama/codellama-13b-chat) and duplicate it for your use – it's self-contained, so you can examine the source code and adapt it as you wish!
### Transformers
Starting with `transformers` 4.33, you can use Code Llama and leverage all the tools within the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as `bitsandbytes` (4-bit quantization) and PEFT (parameter efficient fine-tuning)
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
```bash
!pip install --upgrade transformers
```
#### A Note on dtypes
When using models like Code Llama, it's important to take a look at the data types of the models.
* 32-bit floating point (`float32`): PyTorch convention on model initialization is to load models in `float32`, no matter with which precision the model weights were stored. `transformers` also follows this convention for consistency with PyTorch.
* 16-bit Brain floating point (`bfloat16`): Code Llama was trained with this precision, so we recommend using it for further training or fine-tuning.
* 16-bit floating point (`float16`): We recommend running inference using this precision, as it's usually faster than `bfloat16`, and evaluation metrics show no discernible degradation with respect to `bfloat16`. You can also run inference using `bfloat16`, and we recommend you check inference results with both `float16` and `bfloat16` after fine-tuning.
As mentioned above, `transformers` loads weights using `float32` (no matter with which precision the models are stored), so it's important to specify the desired `dtype` when loading the models. If you want to fine-tune Code Llama, it's recommended to use `bfloat16`, as using `float16` can lead to overflows and NaNs. If you run inference, we recommend using `float16` because `bfloat16` can be slower.
#### Code Completion
The 7B and 13B models can be used for text/code completion or infilling. The following code snippet uses the `pipeline` interface to demonstrate text completion. It runs on the free tier of Colab, as long as you select a GPU runtime.
```python
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
This may produce output like the following:
```python
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
```
Code Llama is specialized in code understanding, but it's a language model in its own right. You can use the same generation strategy to autocomplete comments or general text.
#### Code Infilling
This is a specialized task particular to code models. The model is trained to generate the code (including comments) that best matches an existing prefix and suffix. This is the strategy typically used by code assistants: they are asked to fill the current cursor position, considering the contents that appear before and after it.
This task is available in the **base** and **instruction** variants of the 7B and 13B models. It is _not_ available for any of the 34B models or the Python versions.
To use this feature successfully, you need to pay close attention to the format used to train the model for this task, as it uses special separators to identify the different parts of the prompt. Fortunately, transformers' `CodeLlamaTokenizer` makes this very easy, as demonstrated below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(
input_ids,
max_new_tokens=200,
)
output = output[0].to("cpu")
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))
```
```Python
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s: The string to remove non-ASCII characters from.
Returns:
The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
```
Under the hood, the tokenizer [automatically splits by `<FILL_ME>`](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug.
#### Conversational Instructions
The base model can be used for both completion and infilling, as described. The Code Llama release also includes an instruction fine-tuned model that can be used in conversational interfaces.
To prepare inputs for this task we have to use a prompt template like the one described in our [Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), which we reproduce again here:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
Note that the system prompt is optional - the model will work without it, but you can use it to further configure its behavior or style. For example, if you'd always like to get answers in JavaScript, you could state that here. After the system prompt, you need to provide all the previous interactions in the conversation: what was asked by the user and what was answered by the model. As in the infilling case, you need to pay attention to the delimiters used. The final component of the input must always be a new user instruction, which will be the signal for the model to provide an answer.
The following code snippets demonstrate how the template works in practice.
1. **First user query, no system prompt**
```python
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
2. **First user query with system prompt**
```python
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
3. **On-going conversation with previous answers**
The process is the same as in [Llama 2](https://huggingface.co/blog/llama2#how-to-prompt-llama-2). We haven’t used loops or generalized this example code for maximum clarity:
```python
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}"
prompt += f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
#### 4-bit Loading
Integration of Code Llama in Transformers means that you get immediate support for advanced features like 4-bit loading. This allows you to run the big 32B parameter models on consumer GPUs like nvidia 3090 cards!
Here's how you can run inference in 4-bit mode:
```Python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
```
### Using text-generation-inference and Inference Endpoints
[Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's [Inference Endpoints](https://huggingface.co/inference-endpoints). To deploy a Codellama 2 model, go to the [model page](https://huggingface.co/codellama) and click on the [Deploy -> Inference Endpoints](https://huggingface.co/codellama/CodeLlama-7b-hf) widget.
- For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
- For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100".
- For 34B models, we advise you to select "GPU [1xlarge] - 1x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [2xlarge] - 2x Nvidia A100"
*Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s*
You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript.
### Using VS Code extension
[HF Code Autocomplete](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) is a VS Code extension for testing open source code completion models. The extension was developed as part of [StarCoder project](/blog/starcoder#tools--demos) and was updated to support the medium-sized base model, [Code Llama 13B](/codellama/CodeLlama-13b-hf). Find more [here](https://github.com/huggingface/huggingface-vscode#code-llama) on how to install and run the extension with Code Llama.

## Evaluation
Language models for code are typically benchmarked on datasets such as HumanEval. It consists of programming challenges where the model is presented with a function signature and a docstring and is tasked to complete the function body. The proposed solution is then verified by running a set of predefined unit tests. Finally, a pass rate is reported which describes how many solutions passed all tests. The pass@1 rate describes how often the model generates a passing solution when having one shot whereas pass@10 describes how often at least one solution passes out of 10 proposed candidates.
While HumanEval is a Python benchmark there have been significant efforts to translate it to more programming languages and thus enable a more holistic evaluation. One such approach is [MultiPL-E](https://github.com/nuprl/MultiPL-E) which translates HumanEval to over a dozen languages. We are hosting a [multilingual code leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals) based on it to allow the community to compare models across different languages to evaluate which model fits their use-case best.
| Model | License | Dataset known | Commercial use? | Pretraining length [tokens] | Python | JavaScript | Leaderboard Avg Score |
| ---------------------- | ------------------ | ------------- | --------------- | --------------------------- | ------ | ---------- | --------------------- |
| CodeLlaMa-34B | Llama 2 license | ❌ | ✅ | 2,500B | 45.11 | 41.66 | 33.89 |
| CodeLlaMa-13B | Llama 2 license | ❌ | ✅ | 2,500B | 35.07 | 38.26 | 28.35 |
| CodeLlaMa-7B | Llama 2 license | ❌ | ✅ | 2,500B | 29.98 | 31.8 | 24.36 |
| CodeLlaMa-34B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 53.29 | 44.72 | 33.87 |
| CodeLlaMa-13B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 42.89 | 40.66 | 28.67 |
| CodeLlaMa-7B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 40.48 | 36.34 | 23.5 |
| CodeLlaMa-34B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.79 | 45.85 | 35.09 |
| CodeLlaMa-13B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.6 | 40.91 | 31.29 |
| CodeLlaMa-7B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 45.65 | 33.11 | 26.45 |
| StarCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,035B | 33.57 | 30.79 | 22.74 |
| StarCoderBase-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 30.35 | 31.7 | 22.4 |
| WizardCoder-15B | BigCode-OpenRail-M | ❌ | ✅ | 1,035B | 58.12 | 41.91 | 32.07 |
| OctoCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 45.3 | 32.8 | 24.01 |
| CodeGeeX-2-6B | CodeGeeX License | ❌ | ❌ | 2,000B | 33.49 | 29.9 | 21.23 |
| CodeGen-2.5-7B-Mono | Apache-2.0 | ✅ | ✅ | 1400B | 45.65 | 23.22 | 12.1 |
| CodeGen-2.5-7B-Multi | Apache-2.0 | ✅ | ✅ | 1400B | 28.7 | 26.27 | 20.04 |
**Note:** The scores presented in the table above are sourced from our code leaderboard, where we evaluate all models with the same settings. For more details, please refer to the [leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals).
## Additional Resources
- [Models on the Hub](https://huggingface.co/codellama)
- [Paper Page](https://huggingface.co/papers/2308.12950)
- [Official Meta announcement](https://ai.meta.com/blog/code-llama-large-language-model-coding/)
- [Responsible Use Guide](https://ai.meta.com/llama/responsible-use-guide/)
- [Demo (code completion, streaming server)](https://huggingface.co/spaces/codellama/codellama-playground)
- [Demo (instruction fine-tuned, self-contained & clonable)](https://huggingface.co/spaces/codellama/codellama-13b-chat)
| huggingface/blog/blob/main/codellama.md |
Live 1: How the course work, Q&A, and playing with Huggy
In this first live stream, we explained how the course work (scope, units, challenges, and more) and answered your questions.
And finally, we saw some LunarLander agents you've trained and play with your Huggies 🐶
<Youtube id="JeJIswxyrsM" />
To know when the next live is scheduled **check the discord server**. We will also send **you an email**. If you can't participate, don't worry, we record the live sessions. | huggingface/deep-rl-class/blob/main/units/en/live1/live1.mdx |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Text classification
## GLUE tasks
The script [`run_glue.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/quantization/text-classification/run_glue.py)
allows us to apply different quantization approaches (such as dynamic and static quantization) as well as graph
optimizations using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for sequence classification tasks such as
the ones from the [GLUE benchmark](https://gluebenchmark.com/).
The following example applies post-training dynamic quantization on a DistilBERT fine-tuned on the sst-2 task.
```bash
python run_glue.py \
--model_name_or_path distilbert-base-uncased-finetuned-sst-2-english \
--task_name sst2 \
--quantization_approach dynamic \
--do_eval \
--output_dir /tmp/quantized_distilbert_sst2
```
In order to apply dynamic or static quantization, `quantization_approach` must be set to respectively `dynamic` or `static`.
| huggingface/optimum/blob/main/examples/onnxruntime/quantization/text-classification/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Wuerstchen
The [Wuerstchen](https://hf.co/papers/2306.00637) model drastically reduces computational costs by compressing the latent space by 42x, without compromising image quality and accelerating inference. During training, Wuerstchen uses two models (VQGAN + autoencoder) to compress the latents, and then a third model (text-conditioned latent diffusion model) is conditioned on this highly compressed space to generate an image.
To fit the prior model into GPU memory and to speedup training, try enabling `gradient_accumulation_steps`, `gradient_checkpointing`, and `mixed_precision` respectively.
This guide explores the [train_text_to_image_prior.py](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/train_text_to_image_prior.py) script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/wuerstchen/text_to_image
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training scripts that are important for understanding how to modify it, but it doesn't cover every aspect of the [script](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/train_text_to_image_prior.py) in detail. If you're interested in learning more, feel free to read through the scripts and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training scripts provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L192) function. It provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_text_to_image_prior.py \
--mixed_precision="fp16"
```
Most of the parameters are identical to the parameters in the [Text-to-image](text2image#script-parameters) training guide, so let's dive right into the Wuerstchen training script!
## Training script
The training script is also similar to the [Text-to-image](text2image#training-script) training guide, but it's been modified to support Wuerstchen. This guide focuses on the code that is unique to the Wuerstchen training script.
The [`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L441) function starts by initializing the image encoder - an [EfficientNet](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/modeling_efficient_net_encoder.py) - in addition to the usual scheduler and tokenizer.
```py
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
pretrained_checkpoint_file = hf_hub_download("dome272/wuerstchen", filename="model_v2_stage_b.pt")
state_dict = torch.load(pretrained_checkpoint_file, map_location="cpu")
image_encoder = EfficientNetEncoder()
image_encoder.load_state_dict(state_dict["effnet_state_dict"])
image_encoder.eval()
```
You'll also load the [`WuerstchenPrior`] model for optimization.
```py
prior = WuerstchenPrior.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
optimizer = optimizer_cls(
prior.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Next, you'll apply some [transforms](https://github.com/huggingface/diffusers/blob/65ef7a0c5c594b4f84092e328fbdd73183613b30/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L656) to the images and [tokenize](https://github.com/huggingface/diffusers/blob/65ef7a0c5c594b4f84092e328fbdd73183613b30/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L637) the captions:
```py
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["effnet_pixel_values"] = [effnet_transforms(image) for image in images]
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
return examples
```
Finally, the [training loop](https://github.com/huggingface/diffusers/blob/65ef7a0c5c594b4f84092e328fbdd73183613b30/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L656) handles compressing the images to latent space with the `EfficientNetEncoder`, adding noise to the latents, and predicting the noise residual with the [`WuerstchenPrior`] model.
```py
pred_noise = prior(noisy_latents, timesteps, prompt_embeds)
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Once you’ve made all your changes or you’re okay with the default configuration, you’re ready to launch the training script! 🚀
Set the `DATASET_NAME` environment variable to the dataset name from the Hub. This guide uses the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset, but you can create and train on your own datasets as well (see the [Create a dataset for training](create_dataset) guide).
<Tip>
To monitor training progress with Weights & Biases, add the `--report_to=wandb` parameter to the training command. You’ll also need to add the `--validation_prompt` to the training command to keep track of results. This can be really useful for debugging the model and viewing intermediate results.
</Tip>
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_prior.py \
--mixed_precision="fp16" \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=4 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--dataloader_num_workers=4 \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="wuerstchen-prior-pokemon-model"
```
Once training is complete, you can use your newly trained model for inference!
```py
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("path/to/saved/model", torch_dtype=torch.float16).to("cuda")
caption = "A cute bird pokemon holding a shield"
images = pipeline(
caption,
width=1024,
height=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=2,
).images
```
## Next steps
Congratulations on training a Wuerstchen model! To learn more about how to use your new model, the following may be helpful:
- Take a look at the [Wuerstchen](../api/pipelines/wuerstchen#text-to-image-generation) API documentation to learn more about how to use the pipeline for text-to-image generation and its limitations.
| huggingface/diffusers/blob/main/docs/source/en/training/wuerstchen.md |
--
title: "Hugging Face and AMD partner on accelerating state-of-the-art models for CPU and GPU platforms"
thumbnail: /blog/assets/148_huggingface_amd/01.png
authors:
- user: juliensimon
---
# Hugging Face and AMD partner on accelerating state-of-the-art models for CPU and GPU platforms
<kbd>
<img src="assets/148_huggingface_amd/01.png">
</kbd>
Whether language models, large language models, or foundation models, transformers require significant computation for pre-training, fine-tuning, and inference. To help developers and organizations get the most performance bang for their infrastructure bucks, Hugging Face has long been working with hardware companies to leverage acceleration features present on their respective chips.
Today, we're happy to announce that AMD has officially joined our [Hardware Partner Program](https://huggingface.co/hardware). Our CEO Clement Delangue gave a keynote at AMD's [Data Center and AI Technology Premiere](https://www.amd.com/en/solutions/data-center/data-center-ai-premiere.html) in San Francisco to launch this exciting new collaboration.
AMD and Hugging Face work together to deliver state-of-the-art transformer performance on AMD CPUs and GPUs. This partnership is excellent news for the Hugging Face community at large, which will soon benefit from the latest AMD platforms for training and inference.
The selection of deep learning hardware has been limited for years, and prices and supply are growing concerns. This new partnership will do more than match the competition and help alleviate market dynamics: it should also set new cost-performance standards.
## Supported hardware platforms
On the GPU side, AMD and Hugging Face will first collaborate on the enterprise-grade Instinct MI2xx and MI3xx families, then on the customer-grade Radeon Navi3x family. In initial testing, AMD [recently reported](https://youtu.be/mPrfh7MNV_0?t=462) that the MI250 trains BERT-Large 1.2x faster and GPT2-Large 1.4x faster than its direct competitor.
On the CPU side, the two companies will work on optimizing inference for both the client Ryzen and server EPYC CPUs. As discussed in several previous posts, CPUs can be an excellent option for transformer inference, especially with model compression techniques like quantization.
Lastly, the collaboration will include the [Alveo V70](https://www.xilinx.com/applications/data-center/v70.html) AI accelerator, which can deliver incredible performance with lower power requirements.
## Supported model architectures and frameworks
We intend to support state-of-the-art transformer architectures for natural language processing, computer vision, and speech, such as BERT, DistilBERT, ROBERTA, Vision Transformer, CLIP, and Wav2Vec2. Of course, generative AI models will be available too (e.g., GPT2, GPT-NeoX, T5, OPT, LLaMA), including our own BLOOM and StarCoder models. Lastly, we will also support more traditional computer vision models, like ResNet and ResNext, and deep learning recommendation models, a first for us.
We'll do our best to test and validate these models for PyTorch, TensorFlow, and ONNX Runtime for the above platforms. Please remember that not all models may be available for training and inference for all frameworks or all hardware platforms.
## The road ahead
Our initial focus will be ensuring the models most important to our community work great out of the box on AMD platforms. We will work closely with the AMD engineering team to optimize key models to deliver optimal performance thanks to the latest AMD hardware and software features. We will integrate the [AMD ROCm SDK](https://www.amd.com/graphics/servers-solutions-rocm) seamlessly in our open-source libraries, starting with the transformers library.
Along the way, we'll undoubtedly identify opportunities to optimize training and inference further, and we'll work closely with AMD to figure out where to best invest moving forward through this partnership. We expect this work to lead to a new [Optimum](https://huggingface.co/docs/optimum/index) library dedicated to AMD platforms to help Hugging Face users leverage them with minimal code changes, if any.
## Conclusion
We're excited to work with a world-class hardware company like AMD. Open-source means the freedom to build from a wide range of software and hardware solutions. Thanks to this partnership, Hugging Face users will soon have new hardware platforms for training and inference with excellent cost-performance benefits. In the meantime, feel free to visit the [AMD page](https://huggingface.co/amd) on the Hugging Face hub. Stay tuned!
*This post is 100% ChatGPT-free.*
| huggingface/blog/blob/main/huggingface-and-amd.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAVA
## Overview
The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
The abstract from the paper is the following:
*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
impressive performance on a wide range of 35 tasks spanning these target modalities.*
This model was contributed by [aps](https://huggingface.co/aps). The original code can be found [here](https://github.com/facebookresearch/multimodal/tree/main/examples/flava).
## FlavaConfig
[[autodoc]] FlavaConfig
## FlavaTextConfig
[[autodoc]] FlavaTextConfig
## FlavaImageConfig
[[autodoc]] FlavaImageConfig
## FlavaMultimodalConfig
[[autodoc]] FlavaMultimodalConfig
## FlavaImageCodebookConfig
[[autodoc]] FlavaImageCodebookConfig
## FlavaProcessor
[[autodoc]] FlavaProcessor
## FlavaFeatureExtractor
[[autodoc]] FlavaFeatureExtractor
## FlavaImageProcessor
[[autodoc]] FlavaImageProcessor
- preprocess
## FlavaForPreTraining
[[autodoc]] FlavaForPreTraining
- forward
## FlavaModel
[[autodoc]] FlavaModel
- forward
- get_text_features
- get_image_features
## FlavaImageCodebook
[[autodoc]] FlavaImageCodebook
- forward
- get_codebook_indices
- get_codebook_probs
## FlavaTextModel
[[autodoc]] FlavaTextModel
- forward
## FlavaImageModel
[[autodoc]] FlavaImageModel
- forward
## FlavaMultimodalModel
[[autodoc]] FlavaMultimodalModel
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/flava.md |