TVLT
This model is in maintenance mode only, we don’t accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
You can do so by running the following command: pip install -U transformers==4.40.2.
Overview
The TVLT model was proposed in TVLT: Textless Vision-Language Transformer by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text.
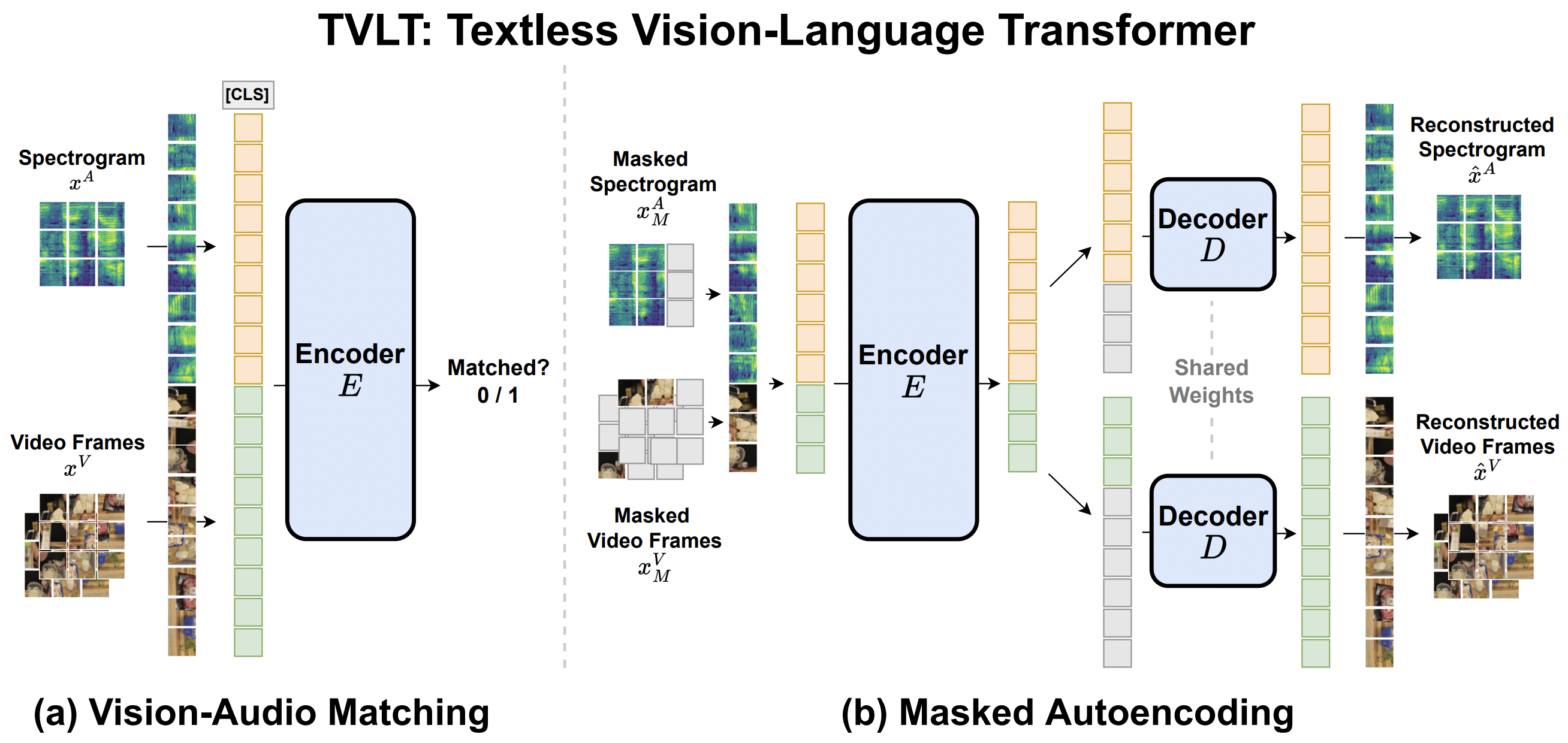
The original code can be found here. This model was contributed by Zineng Tang.
Usage tips
- TVLT is a model that takes both
pixel_valuesandaudio_valuesas input. One can use TvltProcessor to prepare data for the model. This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one. - TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a
pixel_maskthat indicates which pixels are real/padding andaudio_maskthat indicates which audio values are real/padding. - The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in ViTMAE. The difference is that the model includes embedding layers for the audio modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
TvltConfig
class transformers.TvltConfig
< source >( image_size = 224 spectrogram_length = 2048 frequency_length = 128 image_patch_size = [16, 16] audio_patch_size = [16, 16] num_image_channels = 3 num_audio_channels = 1 num_frames = 8 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-06 qkv_bias = True use_mean_pooling = False decoder_num_attention_heads = 16 decoder_hidden_size = 512 decoder_num_hidden_layers = 8 decoder_intermediate_size = 2048 pixel_mask_ratio = 0.75 audio_mask_ratio = 0.15 audio_mask_type = 'frame-level' task_matching = True task_mae = True loss_type = 'classification' **kwargs )
Parameters
- image_size (
int, optional, defaults to 224) — The size (resolution) of each image. - spectrogram_length (
int, optional, defaults to 2048) — The time length of each audio spectrogram. - frequency_length (
int, optional, defaults to 128) — The frequency length of audio spectrogram. - image_patch_size (
List[int], optional, defaults to[16, 16]) — The size (resolution) of each image patch. - audio_patch_size (
List[int], optional, defaults to[16, 16]) — The size (resolution) of each audio patch. - num_image_channels (
int, optional, defaults to 3) — The number of input image channels. - num_audio_channels (
int, optional, defaults to 1) — The number of input audio channels. - num_frames (
int, optional, defaults to 8) — The maximum number of frames for an input video. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - hidden_dropout_prob (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_probs_dropout_prob (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the layer normalization layers. - qkv_bias (
bool, optional, defaults toTrue) — Whether to add a bias to the queries, keys and values. - use_mean_pooling (
bool, optional, defaults toFalse) — Whether to mean pool the final hidden states instead of using the final hidden state of the [CLS] token. - decoder_num_attention_heads (
int, optional, defaults to 16) — Number of attention heads for each attention layer in the decoder. - decoder_hidden_size (
int, optional, defaults to 512) — Dimensionality of the decoder. - decoder_num_hidden_layers (
int, optional, defaults to 8) — Number of hidden layers in the decoder. - decoder_intermediate_size (
int, optional, defaults to 2048) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the decoder. - pixel_mask_ratio (
float, optional, defaults to 0.75) — Image patch masking ratio. - audio_mask_ratio (
float, optional, defaults to 0.15) — Audio patch masking ratio. - audio_mask_type (
str, optional, defaults to"frame-level") — Audio patch masking type, choose between “frame-level” and “patch-level”. - task_matching (
bool, optional, defaults toTrue) — Whether to use vision audio matching task in pretraining. - task_mae (
bool, optional, defaults toTrue) — Whether to use the masked auto-encoder (MAE) in pretraining. - loss_type (
str, optional, defaults to"classification") — Loss types including regression and classification.
This is the configuration class to store the configuration of a TvltModel. It is used to instantiate a TVLT model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the TVLT ZinengTang/tvlt-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import TvltConfig, TvltModel
>>> # # Initializing a TVLT ZinengTang/tvlt-base style configuration
>>> configuration = TvltConfig()
>>> # # Initializing a model (with random weights) from the ZinengTang/tvlt-base style configuration
>>> model = TvltModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTvltProcessor
class transformers.TvltProcessor
< source >( image_processor feature_extractor )
Parameters
- image_processor (
TvltImageProcessor) — An instance of TvltImageProcessor. The image processor is a required input. - feature_extractor (
TvltFeatureExtractor) — An instance of TvltFeatureExtractor. The feature extractor is a required input.
Constructs a TVLT processor which wraps a TVLT image processor and TVLT feature extractor into a single processor.
TvltProcessor offers all the functionalities of TvltImageProcessor and TvltFeatureExtractor. See the docstring of call() for more information.
__call__
< source >( images = None audio = None images_mixed = None sampling_rate = None mask_audio = False mask_pixel = False *args **kwargs )
Forwards the images argument to TvltImageProcessor’s preprocess() and the audio
argument to TvltFeatureExtractor’s call(). Please refer to the docstring of the
above two methods for more information.
TvltImageProcessor
class transformers.TvltImageProcessor
< source >( do_resize: bool = True size: Dict = None patch_size: List = [16, 16] num_frames: int = 8 resample: Resampling = <Resampling.BILINEAR: 2> do_center_crop: bool = True crop_size: Dict = None do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = [0.5, 0.5, 0.5] image_std: Union = [0.5, 0.5, 0.5] init_mask_generator = False **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"shortest_edge" -- 224}): Size of the output image after resizing. The shortest edge of the image will be resized tosize["shortest_edge"]while maintaining the aspect ratio of the original image. Can be overriden bysizein thepreprocessmethod. - patch_size (
List[int]optional, defaults to [16,16]) — The patch size of image patch embedding. - num_frames (
intoptional, defaults to 8) — The maximum number of video frames. - resample (
PILImageResampling, optional, defaults toPILImageResampling.BILINEAR) — Resampling filter to use if resizing the image. Can be overridden by theresampleparameter in thepreprocessmethod. - do_center_crop (
bool, optional, defaults toTrue) — Whether to center crop the image to the specifiedcrop_size. Can be overridden by thedo_center_cropparameter in thepreprocessmethod. - crop_size (
Dict[str, int], optional, defaults to{"height" -- 224, "width": 224}): Size of the image after applying the center crop. Can be overridden by thecrop_sizeparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to 1/255) — Defines the scale factor to use if rescaling the image. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod.
Constructs a TVLT image processor.
This processor can be used to prepare either videos or images for the model by converting images to 1-frame videos.
preprocess
< source >( videos: Union do_resize: bool = None size: Dict = None patch_size: List = None num_frames: int = None resample: Resampling = None do_center_crop: bool = None crop_size: Dict = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None is_mixed: bool = False return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs ) → BatchFeature
Parameters
- videos (
ImageInput) — Images or videos to preprocess. Expects a single or batch of frames with pixel values ranging from 0 to 255. If passing in frames with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size of the image after applying resize. - patch_size (
List[int]optional, defaults to self.patch_size) — The patch size of image patch embedding. - num_frames (
intoptional, defaults to self.num_frames) — The maximum number of video frames. - resample (
PILImageResampling, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling, Only has an effect ifdo_resizeis set toTrue. - do_center_crop (
bool, optional, defaults toself.do_centre_crop) — Whether to centre crop the image. - crop_size (
Dict[str, int], optional, defaults toself.crop_size) — Size of the image after applying the centre crop. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation. - is_mixed (
bool, optional) — If the input video has negative samples. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the inferred channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Returns
A BatchFeature with the following fields:
-
pixel_values — Pixel values to be fed to a model, of shape (batch_size, num_channels, height, width).
-
pixel_mask — Pixel masks to be fed to a model, of shape (batch_size, num_pixel_patches).
-
pixel_values_mixed — Pixel values with both postive or negative to be fed to a model, of shape (batch_size, num_channels, height, width).
-
pixel_mask_mixed — Pixel masks with both postive or negative to be fed to a model, of shape (batch_size, num_pixel_patches).
Preprocess an videos or image or batch of videos or images.
TvltFeatureExtractor
class transformers.TvltFeatureExtractor
< source >( spectrogram_length = 2048 num_channels = 1 patch_size = [16, 16] feature_size = 128 sampling_rate = 44100 hop_length_to_sampling_rate = 86 n_fft = 2048 padding_value = 0.0 **kwargs )
Parameters
- spectrogram_length (
Dict[str, int]optional, defaults to 2048) — The time length of each audio spectrogram. - num_channels (
intoptional, defaults to 1) — Number of audio channels. - patch_size (
List[int]optional, defaults to[16, 16]) — The patch size of audio patch embedding. - feature_size (
int, optional, defaults to 128) — The frequency length of audio spectrogram. - sampling_rate (
int, optional, defaults to 44100) — The sampling rate at which the audio files should be digitalized expressed in Hertz (Hz). - hop_length_to_sampling_rate (
int, optional, defaults to 86) — Hop length is length of the overlaping windows for the STFT used to obtain the Mel Frequency coefficients. For example, with sampling rate 44100, the hop length is 512, with 44100 / 512 = 86 - n_fft (
int, optional, defaults to 2048) — Size of the Fourier transform. - padding_value (
float, optional, defaults to 0.0) — Padding value used to pad the audio. Should correspond to silences.
Constructs a TVLT audio feature extractor. This feature extractor can be used to prepare audios for the model.
This feature extractor inherits from FeatureExtractionMixin which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( raw_speech: Union return_tensors: Union = None return_attention_mask: Optional = True sampling_rate: Optional = None resample: bool = False mask_audio: bool = False **kwargs ) → BatchFeature
Parameters
- raw_speech (
np.ndarray,List[float],List[np.ndarray],List[List[float]]) — The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float values, a list of numpy arrays or a list of list of float values. Must be mono channel audio, not stereo, i.e. single float per timestep. - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
- return_attention_mask (
bool, optional, default toTrue) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific feature_extractor’s default. What are attention masks?For TvltTransformer models,
attention_maskshould alwys be passed for batched inference, to avoid subtle bugs. - sampling_rate (
int, optional) — The sampling rate at which theraw_speechinput was sampled. It is strongly recommended to passsampling_rateat the forward call to prevent silent errors and allow automatic speech recognition pipeline. Current model supports sampling rate 16000 and 44100. - resample (
bool, optional, defaults toFalse) — If the sampling rate is not matched, resample the input audio to match. - mask_audio (
bool, optional, defaults toFalse) — Whether or not to mask input audio for MAE task.
Returns
A BatchFeature with the following fields:
-
audio_values — Audio values to be fed to a model, of shape (batch_size, num_channels, height, width).
-
audio_mask — Audio masks to be fed to a model, of shape (batch_size, num_audio_patches).
Main method to prepare one or several audio(s) for the model.
TvltModel
class transformers.TvltModel
< source >( config )
Parameters
- config (TvltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare TVLT Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor audio_values: FloatTensor pixel_mask: Optional = None audio_mask: Optional = None mask_pixel: bool = False mask_audio: bool = False output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.deprecated.tvlt.modeling_tvlt.TvltModelOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values. Pixel values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - audio_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Audio values. Audio values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask (
torch.FloatTensorof shape(batch_size, num_pixel_patches)) — Pixel masks. Pixel masks can be obtained using TvltProcessor. See TvltProcessor.call() for details. - audio_mask (
torch.FloatTensorof shape(batch_size, num_audio_patches)) — Audio masks. Audio masks can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values that mix positive and negative samples in Tvlt vision-audio matching. Pixel values mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel masks of pixel_values_mixed. Pixel masks mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - mask_pixel (
bool, optional) — Whether to mask pixel for MAE tasks. Only set to True in TvltForPreTraining. - mask_audio (
bool, optional) — Whether to mask audio for MAE tasks. Only set to True in TvltForPreTraining. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.deprecated.tvlt.modeling_tvlt.TvltModelOutput or tuple(torch.FloatTensor)
A transformers.models.deprecated.tvlt.modeling_tvlt.TvltModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TvltConfig) and inputs.
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - last_pixel_hidden_state (
torch.FloatTensorof shape(batch_size, pixel_sequence_length, hidden_size)) — Pixel sequence of hidden-states at the output of the last layer of the model. - last_audio_hidden_state (
torch.FloatTensorof shape(batch_size, audio_sequence_length, hidden_size)) — Audio sequence of hidden-states at the output of the last layer of the model. - pixel_label_masks (
torch.FloatTensorof shape(batch_size, pixel_patch_length)) — Tensor indicating which pixel patches are masked (1) and which are not (0). - audio_label_masks (
torch.FloatTensorof shape(batch_size, audio_patch_length)) — Tensor indicating which audio patches are masked (1) and which are not (0). - pixel_ids_restore (
torch.LongTensorof shape(batch_size, pixel_patch_length)) — Tensor containing the ids permutation of pixel masking. - audio_ids_restore (
torch.LongTensorof shape(batch_size, audio_patch_length)) — Tensor containing the ids permutation of audio masking. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings and one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TvltModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import TvltProcessor, TvltModel
>>> import numpy as np
>>> import torch
>>> num_frames = 8
>>> images = list(np.random.randn(num_frames, 3, 224, 224))
>>> audio = list(np.random.randn(10000))
>>> processor = TvltProcessor.from_pretrained("ZinengTang/tvlt-base")
>>> model = TvltModel.from_pretrained("ZinengTang/tvlt-base")
>>> input_dict = processor(images, audio, sampling_rate=44100, return_tensors="pt")
>>> outputs = model(**input_dict)
>>> loss = outputs.lossTvltForPreTraining
class transformers.TvltForPreTraining
< source >( config )
Parameters
- config (TvltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The TVLT Model transformer with the decoder on top for self-supervised pre-training. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor audio_values: FloatTensor pixel_mask: Optional = None audio_mask: Optional = None labels: Optional = None pixel_values_mixed: Optional = None pixel_mask_mixed: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.deprecated.tvlt.modeling_tvlt.TvltForPreTrainingOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values. Pixel values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - audio_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Audio values. Audio values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask (
torch.FloatTensorof shape(batch_size, num_pixel_patches)) — Pixel masks. Pixel masks can be obtained using TvltProcessor. See TvltProcessor.call() for details. - audio_mask (
torch.FloatTensorof shape(batch_size, num_audio_patches)) — Audio masks. Audio masks can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values that mix positive and negative samples in Tvlt vision-audio matching. Pixel values mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel masks of pixel_values_mixed. Pixel masks mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - mask_pixel (
bool, optional) — Whether to mask pixel for MAE tasks. Only set to True in TvltForPreTraining. - mask_audio (
bool, optional) — Whether to mask audio for MAE tasks. Only set to True in TvltForPreTraining. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values that mix positive and negative samples in Tvlt vision-audio matching. Audio values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel masks of pixel_values_mixed. Pixel values mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - labels (
torch.LongTensorof shape(batch_size, num_labels), optional) — Labels for computing the vision audio matching loss. Indices should be in[0, 1]. num_labels has to be 1.
Returns
transformers.models.deprecated.tvlt.modeling_tvlt.TvltForPreTrainingOutput or tuple(torch.FloatTensor)
A transformers.models.deprecated.tvlt.modeling_tvlt.TvltForPreTrainingOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TvltConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,)) — Pixel reconstruction loss. - matching_logits (
torch.FloatTensorof shape(batch_size, 1)) — Matching objective logits. - pixel_logits (
torch.FloatTensorof shape(batch_size, pixel_patch_length, image_patch_size ** 3 * pixel_num_channels)): Pixel reconstruction logits. - audio_logits (
torch.FloatTensorof shape(batch_size, audio_patch_length, image_patch_size[0] * image_patch_size[1])): Audio reconstruction logits. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings and one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TvltForPreTraining forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import TvltProcessor, TvltForPreTraining
>>> import numpy as np
>>> import torch
>>> num_frames = 8
>>> images = list(np.random.randn(num_frames, 3, 224, 224))
>>> images_mixed = list(np.random.randn(num_frames, 3, 224, 224))
>>> audio = list(np.random.randn(10000))
>>> processor = TvltProcessor.from_pretrained("ZinengTang/tvlt-base")
>>> model = TvltForPreTraining.from_pretrained("ZinengTang/tvlt-base")
>>> input_dict = processor(
... images, audio, images_mixed, sampling_rate=44100, mask_pixel=True, mask_audio=True, return_tensors="pt"
... )
>>> outputs = model(**input_dict)
>>> loss = outputs.lossTvltForAudioVisualClassification
class transformers.TvltForAudioVisualClassification
< source >( config )
Parameters
- config (TvltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tvlt Model transformer with a classifier head on top (an MLP on top of the final hidden state of the [CLS] token) for audiovisual classification tasks, e.g. CMU-MOSEI Sentiment Analysis and Audio to Video Retrieval.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor audio_values: FloatTensor pixel_mask: Optional = None audio_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values. Pixel values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - audio_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Audio values. Audio values can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask (
torch.FloatTensorof shape(batch_size, num_pixel_patches)) — Pixel masks. Pixel masks can be obtained using TvltProcessor. See TvltProcessor.call() for details. - audio_mask (
torch.FloatTensorof shape(batch_size, num_audio_patches)) — Audio masks. Audio masks can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — Pixel values that mix positive and negative samples in Tvlt vision-audio matching. Pixel values mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel masks of pixel_values_mixed. Pixel masks mixed can be obtained using TvltProcessor. See TvltProcessor.call() for details. - mask_pixel (
bool, optional) — Whether to mask pixel for MAE tasks. Only set to True in TvltForPreTraining. - mask_audio (
bool, optional) — Whether to mask audio for MAE tasks. Only set to True in TvltForPreTraining. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, num_labels), optional) — Labels for computing the audiovisual loss. Indices should be in[0, ..., num_classes-1]where num_classes refers to the number of classes in audiovisual tasks.
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TvltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TvltForAudioVisualClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import TvltProcessor, TvltForAudioVisualClassification
>>> import numpy as np
>>> import torch
>>> num_frames = 8
>>> images = list(np.random.randn(num_frames, 3, 224, 224))
>>> audio = list(np.random.randn(10000))
>>> processor = TvltProcessor.from_pretrained("ZinengTang/tvlt-base")
>>> model = TvltForAudioVisualClassification.from_pretrained("ZinengTang/tvlt-base")
>>> input_dict = processor(images, audio, sampling_rate=44100, return_tensors="pt")
>>> outputs = model(**input_dict)
>>> loss = outputs.loss