
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Gradio Demo: blocks_multiple_event_triggers
```
!pip install -q gradio plotly pypistats
```
```
import gradio as gr
import pypistats
from datetime import date
from dateutil.relativedelta import relativedelta
import pandas as pd
def get_plot(lib, time):
data = pypistats.overall(lib, total=True, format="pandas")
data = data.groupby("category").get_group("with_mirrors").sort_values("date")
start_date = date.today() - relativedelta(months=int(time.split(" ")[0]))
data = data[(data['date'] > str(start_date))]
data.date = pd.to_datetime(pd.to_datetime(data.date))
return gr.LinePlot(value=data, x="date", y="downloads",
tooltip=['date', 'downloads'],
title=f"Pypi downloads of {lib} over last {time}",
overlay_point=True,
height=400,
width=900)
with gr.Blocks() as demo:
gr.Markdown(
"""
## Pypi Download Stats 📈
See live download stats for all of Hugging Face's open-source libraries 🤗
""")
with gr.Row():
lib = gr.Dropdown(["transformers", "datasets", "huggingface-hub", "gradio", "accelerate"],
value="gradio", label="Library")
time = gr.Dropdown(["3 months", "6 months", "9 months", "12 months"],
value="3 months", label="Downloads over the last...")
plt = gr.LinePlot()
# You can add multiple event triggers in 2 lines like this
for event in [lib.change, time.change, demo.load]:
event(get_plot, [lib, time], [plt])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_multiple_event_triggers/run.ipynb |
(Tensorflow) EfficientNet Lite
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use $2^N$ times more computational resources, then we can simply increase the network depth by $\alpha ^ N$, width by $\beta ^ N$, and image size by $\gamma ^ N$, where $\alpha, \beta, \gamma$ are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient $\phi$ to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2).
EfficientNet-Lite makes EfficientNet more suitable for mobile devices by introducing [ReLU6](https://paperswithcode.com/method/relu6) activation functions and removing [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation).
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('tf_efficientnet_lite0', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_lite0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('tf_efficientnet_lite0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: TF EfficientNet Lite
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: tf_efficientnet_lite0
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 488052032
Parameters: 4650000
File Size: 18820223
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite0
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1596
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite0-0aa007d2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.83%
Top 5 Accuracy: 92.17%
- Name: tf_efficientnet_lite1
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 773639520
Parameters: 5420000
File Size: 21939331
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite1
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1607
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite1-bde8b488.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.67%
Top 5 Accuracy: 93.24%
- Name: tf_efficientnet_lite2
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 1068494432
Parameters: 6090000
File Size: 24658687
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite2
Crop Pct: '0.89'
Image Size: '260'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1618
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite2-dcccb7df.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.48%
Top 5 Accuracy: 93.75%
- Name: tf_efficientnet_lite3
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 2011534304
Parameters: 8199999
File Size: 33161413
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite3
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1629
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite3-b733e338.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.83%
Top 5 Accuracy: 94.91%
- Name: tf_efficientnet_lite4
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 5164802912
Parameters: 13010000
File Size: 52558819
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite4
Crop Pct: '0.92'
Image Size: '380'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1640
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite4-741542c3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.54%
Top 5 Accuracy: 95.66%
--> | huggingface/pytorch-image-models/blob/main/docs/models/tf-efficientnet-lite.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to create a custom pipeline?
In this guide, we will see how to create a custom pipeline and share it on the [Hub](hf.co/models) or add it to the
🤗 Transformers library.
First and foremost, you need to decide the raw entries the pipeline will be able to take. It can be strings, raw bytes,
dictionaries or whatever seems to be the most likely desired input. Try to keep these inputs as pure Python as possible
as it makes compatibility easier (even through other languages via JSON). Those will be the `inputs` of the
pipeline (`preprocess`).
Then define the `outputs`. Same policy as the `inputs`. The simpler, the better. Those will be the outputs of
`postprocess` method.
Start by inheriting the base class `Pipeline` with the 4 methods needed to implement `preprocess`,
`_forward`, `postprocess`, and `_sanitize_parameters`.
```python
from transformers import Pipeline
class MyPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
return preprocess_kwargs, {}, {}
def preprocess(self, inputs, maybe_arg=2):
model_input = Tensor(inputs["input_ids"])
return {"model_input": model_input}
def _forward(self, model_inputs):
# model_inputs == {"model_input": model_input}
outputs = self.model(**model_inputs)
# Maybe {"logits": Tensor(...)}
return outputs
def postprocess(self, model_outputs):
best_class = model_outputs["logits"].softmax(-1)
return best_class
```
The structure of this breakdown is to support relatively seamless support for CPU/GPU, while supporting doing
pre/postprocessing on the CPU on different threads
`preprocess` will take the originally defined inputs, and turn them into something feedable to the model. It might
contain more information and is usually a `Dict`.
`_forward` is the implementation detail and is not meant to be called directly. `forward` is the preferred
called method as it contains safeguards to make sure everything is working on the expected device. If anything is
linked to a real model it belongs in the `_forward` method, anything else is in the preprocess/postprocess.
`postprocess` methods will take the output of `_forward` and turn it into the final output that was decided
earlier.
`_sanitize_parameters` exists to allow users to pass any parameters whenever they wish, be it at initialization
time `pipeline(...., maybe_arg=4)` or at call time `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
The returns of `_sanitize_parameters` are the 3 dicts of kwargs that will be passed directly to `preprocess`,
`_forward`, and `postprocess`. Don't fill anything if the caller didn't call with any extra parameter. That
allows to keep the default arguments in the function definition which is always more "natural".
A classic example would be a `top_k` argument in the post processing in classification tasks.
```python
>>> pipe = pipeline("my-new-task")
>>> pipe("This is a test")
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
>>> pipe("This is a test", top_k=2)
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
```
In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
`_sanitize_parameters` to allow this new parameter.
```python
def postprocess(self, model_outputs, top_k=5):
best_class = model_outputs["logits"].softmax(-1)
# Add logic to handle top_k
return best_class
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
postprocess_kwargs = {}
if "top_k" in kwargs:
postprocess_kwargs["top_k"] = kwargs["top_k"]
return preprocess_kwargs, {}, postprocess_kwargs
```
Try to keep the inputs/outputs very simple and ideally JSON-serializable as it makes the pipeline usage very easy
without requiring users to understand new kinds of objects. It's also relatively common to support many different types
of arguments for ease of use (audio files, which can be filenames, URLs or pure bytes)
## Adding it to the list of supported tasks
To register your `new-task` to the list of supported tasks, you have to add it to the `PIPELINE_REGISTRY`:
```python
from transformers.pipelines import PIPELINE_REGISTRY
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
)
```
You can specify a default model if you want, in which case it should come with a specific revision (which can be the name of a branch or a commit hash, here we took `"abcdef"`) as well as the type:
```python
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
default={"pt": ("user/awesome_model", "abcdef")},
type="text", # current support type: text, audio, image, multimodal
)
```
## Share your pipeline on the Hub
To share your custom pipeline on the Hub, you just have to save the custom code of your `Pipeline` subclass in a
python file. For instance, let's say we want to use a custom pipeline for sentence pair classification like this:
```py
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
```
The implementation is framework agnostic, and will work for PyTorch and TensorFlow models. If we have saved this in
a file named `pair_classification.py`, we can then import it and register it like this:
```py
from pair_classification import PairClassificationPipeline
from transformers.pipelines import PIPELINE_REGISTRY
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
PIPELINE_REGISTRY.register_pipeline(
"pair-classification",
pipeline_class=PairClassificationPipeline,
pt_model=AutoModelForSequenceClassification,
tf_model=TFAutoModelForSequenceClassification,
)
```
Once this is done, we can use it with a pretrained model. For instance `sgugger/finetuned-bert-mrpc` has been
fine-tuned on the MRPC dataset, which classifies pairs of sentences as paraphrases or not.
```py
from transformers import pipeline
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
```
Then we can share it on the Hub by using the `save_pretrained` method in a `Repository`:
```py
from huggingface_hub import Repository
repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
classifier.save_pretrained("test-dynamic-pipeline")
repo.push_to_hub()
```
This will copy the file where you defined `PairClassificationPipeline` inside the folder `"test-dynamic-pipeline"`,
along with saving the model and tokenizer of the pipeline, before pushing everything into the repository
`{your_username}/test-dynamic-pipeline`. After that, anyone can use it as long as they provide the option
`trust_remote_code=True`:
```py
from transformers import pipeline
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
```
## Add the pipeline to 🤗 Transformers
If you want to contribute your pipeline to 🤗 Transformers, you will need to add a new module in the `pipelines` submodule
with the code of your pipeline, then add it to the list of tasks defined in `pipelines/__init__.py`.
Then you will need to add tests. Create a new file `tests/test_pipelines_MY_PIPELINE.py` with examples of the other tests.
The `run_pipeline_test` function will be very generic and run on small random models on every possible
architecture as defined by `model_mapping` and `tf_model_mapping`.
This is very important to test future compatibility, meaning if someone adds a new model for
`XXXForQuestionAnswering` then the pipeline test will attempt to run on it. Because the models are random it's
impossible to check for actual values, that's why there is a helper `ANY` that will simply attempt to match the
output of the pipeline TYPE.
You also *need* to implement 2 (ideally 4) tests.
- `test_small_model_pt` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_tf`.
- `test_small_model_tf` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_pt`.
- `test_large_model_pt` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
- `test_large_model_tf` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
| huggingface/transformers/blob/main/docs/source/en/add_new_pipeline.md |
--
title: "Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face"
thumbnail: /blog/assets/mixtral/thumbnail.jpg
authors:
- user: lewtun
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: olivierdehaene
- user: lvwerra
- user: ybelkada
---
# Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face
Mixtral 8x7b is an exciting large language model released by Mistral today, which sets a new state-of-the-art for open-access models and outperforms GPT-3.5 across many benchmarks. We’re excited to support the launch with a comprehensive integration of Mixtral in the Hugging Face ecosystem 🔥!
Among the features and integrations being released today, we have:
- [Models on the Hub](https://huggingface.co/models?search=mistralai/Mixtral), with their model cards and licenses (Apache 2.0)
- [🤗 Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.36.0)
- Integration with Inference Endpoints
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- An example of fine-tuning Mixtral on a single GPU with 🤗 TRL.
## Table of Contents
- [What is Mixtral 8x7b](#what-is-mixtral-8x7b)
- [About the name](#about-the-name)
- [Prompt format](#prompt-format)
- [What we don't know](#what-we-dont-know)
- [Demo](#demo)
- [Inference](#inference)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [Using Text Generation Inference](#using-text-generation-inference)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Quantizing Mixtral](#quantizing-mixtral)
- [Load Mixtral with 4-bit quantization](#load-mixtral-with-4-bit-quantization)
- [Load Mixtral with GPTQ](#load-mixtral-with-gptq)
- [Disclaimers and ongoing work](#disclaimers-and-ongoing-work)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## What is Mixtral 8x7b?
Mixtral has a similar architecture to Mistral 7B, but comes with a twist: it’s actually 8 “expert” models in one, thanks to a technique called Mixture of Experts (MoE). For transformers models, the way this works is by replacing some Feed-Forward layers with a sparse MoE layer. A MoE layer contains a router network to select which experts process which tokens most efficiently. In the case of Mixtral, two experts are selected for each timestep, which allows the model to decode at the speed of a 12B parameter-dense model, despite containing 4x the number of effective parameters!
For more details on MoEs, see our accompanying blog post: [hf.co/blog/moe](https://huggingface.co/blog/moe)
**Mixtral release TL;DR;**
- Release of base and Instruct versions
- Supports a context length of 32k tokens.
- Outperforms Llama 2 70B and matches or beats GPT3.5 on most benchmarks
- Speaks English, French, German, Spanish, and Italian.
- Good at coding, with 40.2% on HumanEval
- Commercially permissive with an Apache 2.0 license
So how good are the Mixtral models? Here’s an overview of the base model and its performance compared to other open models on the [LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) (higher scores are better):
| Model | License | Commercial use? | Pretraining size [tokens] | Leaderboard score ⬇️ |
| --------------------------------------------------------------------------------- | --------------- | --------------- | ------------------------- | -------------------- |
| [mistralai/Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) | Apache 2.0 | ✅ | unknown | 68.42 |
| [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | ✅ | 2,000B | 67.87 |
| [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 61.5 |
| [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | Apache 2.0 | ✅ | unknown | 60.97 |
| [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | ✅ | 2,000B | 54.32 |
For instruct and chat models, evaluating on benchmarks like MT-Bench or AlpacaEval is better. Below, we show how [Mixtral Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) performs up against the top closed and open access models (higher scores are better):
| Model | Availability | Context window (tokens) | MT-Bench score ⬇️ |
| --------------------------------------------------------------------------------------------------- | --------------- | ----------------------- | ---------------- |
| [GPT-4 Turbo](https://openai.com/blog/new-models-and-developer-products-announced-at-devday) | Proprietary | 128k | 9.32 |
| [GPT-3.5-turbo-0613](https://platform.openai.com/docs/models/gpt-3-5) | Proprietary | 16k | 8.32 |
| [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) | Apache 2.0 | 32k | 8.30 |
| [Claude 2.1](https://www.anthropic.com/index/claude-2-1) | Proprietary | 200k | 8.18 |
| [openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5) | Apache 2.0 | 8k | 7.81 |
| [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | MIT | 8k | 7.34 |
| [meta-llama/Llama-2-70b-chat-hf](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | Llama 2 license | 4k | 6.86 |
Impressively, Mixtral Instruct outperforms all other open-access models on MT-Bench and is the first one to achieve comparable performance with GPT-3.5!
### About the name
The Mixtral MoE is called **Mixtral-8x7B**, but it doesn't have 56B parameters. Shortly after the release, we found that some people were misled into thinking that the model behaves similarly to an ensemble of 8 models with 7B parameters each, but that's not how MoE models work. Only some layers of the model (the feed-forward blocks) are replicated; the rest of the parameters are the same as in a 7B model. The total number of parameters is not 56B, but about 45B. A better name [could have been `Mixtral-45-8e`](https://twitter.com/osanseviero/status/1734248798749159874) to better convey the architecture. For more details about how MoE works, please refer to [our "Mixture of Experts Explained" post](https://huggingface.co/blog/moe).
### Prompt format
The [base model](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) has no prompt format. Like other base models, it can be used to continue an input sequence with a plausible continuation or for zero-shot/few-shot inference. It’s also a great foundation for fine-tuning your own use case. The [Instruct model](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) has a very simple conversation structure.
```bash
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2[/INST]
```
This format has to be exactly reproduced for effective use. We’ll show later how easy it is to reproduce the instruct prompt with the chat template available in `transformers`.
### What we don't know
Like the previous Mistral 7B release, there are several open questions about this new series of models. In particular, we have no information about the size of the dataset used for pretraining, its composition, or how it was preprocessed.
Similarly, for the Mixtral instruct model, no details have been shared about the fine-tuning datasets or the hyperparameters associated with SFT and DPO.
## Demo
You can chat with the Mixtral Instruct model on Hugging Face Chat! Check it out here: [https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1).
## Inference
We provide two main ways to run inference with Mixtral models:
- Via the `pipeline()` function of 🤗 Transformers.
- With Text Generation Inference, which supports advanced features like continuous batching, tensor parallelism, and more, for blazing fast results.
For each method, it is possible to run the model in half-precision (float16) or with quantized weights. Since the Mixtral model is roughly equivalent in size to a 45B parameter dense model, we can estimate the minimum amount of VRAM needed as follows:
| Precision | Required VRAM |
| --------- | ------------- |
| float16 | >90 GB |
| 8-bit | >45 GB |
| 4-bit | >23 GB |
### Using 🤗 Transformers
With transformers [release 4.36](https://github.com/huggingface/transformers/releases/tag/v4.36.0), you can use Mixtral and leverage all the tools within the Hugging Face ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning), and Flash Attention 2
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Make sure to use the latest `transformers` release:
```bash
pip install -U "transformers==4.36.0" --upgrade
```
In the following code snippet, we show how to run inference with 🤗 Transformers and 4-bit quantization. Due to the large size of the model, you’ll need a card with at least 30 GB of RAM to run it. This includes cards such as A100 (80 or 40GB versions), or A6000 (48 GB).
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
> \<s>[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST] A
Mixture of Experts is an ensemble learning method that combines multiple models,
or "experts," to make more accurate predictions. Each expert specializes in a
different subset of the data, and a gating network determines the appropriate
expert to use for a given input. This approach allows the model to adapt to
complex, non-linear relationships in the data and improve overall performance.
>
### Using Text Generation Inference
**[Text Generation Inference](https://github.com/huggingface/text-generation-inference)** is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can deploy Mixtral on Hugging Face's [Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=mistralai%2FMixtral-8x7B-Instruct-v0.1&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000), which uses Text Generation Inference as the backend. To deploy a Mixtral model, go to the [model page](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) and click on the [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf) widget.
*Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s*
You can learn more on how to **[Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm)**. The **[blog](https://huggingface.co/blog/inference-endpoints-llm)** includes information about supported hyperparameters and how to stream your response using Python and Javascript.
You can also run Text Generation Inference locally on 2x A100s (80GB) with Docker as follows:
```bash
docker run --gpus all --shm-size 1g -p 3000:80 -v /data:/data ghcr.io/huggingface/text-generation-inference:1.3.0 \
--model-id mistralai/Mixtral-8x7B-Instruct-v0.1 \
--num-shard 2 \
--max-batch-total-tokens 1024000 \
--max-total-tokens 32000
```
## Fine-tuning with 🤗 TRL
Training LLMs can be technically and computationally challenging. In this section, we look at the tools available in the Hugging Face ecosystem to efficiently train Mixtral on a single A100 GPU.
An example command to fine-tune Mixtral on OpenAssistant’s [chat dataset](https://huggingface.co/datasets/OpenAssistant/oasst_top1_2023-08-25) can be found below. To conserve memory, we make use of 4-bit quantization and [QLoRA](https://arxiv.org/abs/2305.14314) to target all the linear layers in the attention blocks. Note that unlike dense transformers, one should not target the MLP layers as they are sparse and don’t interact well with PEFT.
First, install the nightly version of 🤗 TRL and clone the repo to access the [training script](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py):
```bash
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl
```
Then you can run the script:
```bash
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name mistralai/Mixtral-8x7B-v0.1 \
--dataset_name trl-lib/ultrachat_200k_chatml \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 200_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit
```
This takes about 48 hours to train on a single A100, but can be easily parallelised by tweaking `--num_processes` to the number of GPUs you have available.
## Quantizing Mixtral
As seen above, the challenge for this model is to make it run on consumer-type hardware for anyone to use it, as the model requires ~90GB just to be loaded in half-precision (`torch.float16`).
With the 🤗 transformers library, we support out-of-the-box inference with state-of-the-art quantization methods such as QLoRA and GPTQ. You can read more about the quantization methods we support in the [appropriate documentation section](https://huggingface.co/docs/transformers/quantization).
### Load Mixtral with 4-bit quantization
As demonstrated in the inference section, you can load Mixtral with 4-bit quantization by installing the `bitsandbytes` library (`pip install -U bitsandbytes`) and passing the flag `load_in_4bit=True` to the `from_pretrained` method. For better performance, we advise users to load the model with `bnb_4bit_compute_dtype=torch.float16`. Note you need a GPU device with at least 30GB VRAM to properly run the snippet below.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
This 4-bit quantization technique was introduced in the [QLoRA paper](https://huggingface.co/papers/2305.14314), you can read more about it in the corresponding section of [the documentation](https://huggingface.co/docs/transformers/quantization#4-bit) or in [this post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
### Load Mixtral with GPTQ
The GPTQ algorithm is a post-training quantization technique where each row of the weight matrix is quantized independently to find a version of the weights that minimizes the error. These weights are quantized to int4, but they’re restored to fp16 on the fly during inference. In contrast with 4-bit QLoRA, GPTQ needs the model to be calibrated with a dataset in order to be quantized. Ready-to-use GPTQ models are shared on the 🤗 Hub by [TheBloke](https://huggingface.co/TheBloke), so anyone can use them without having to calibrate them first.
For Mixtral, we had to tweak the calibration approach by making sure we **do not** quantize the expert gating layers for better performance. The final perplexity (lower is better) of the quantized model is `4.40` vs `4.25` for the half-precision model. The quantized model can be found [here](https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GPTQ), and to run it with 🤗 transformers you first need to update the `auto-gptq` and `optimum` libraries:
```bash
pip install -U optimum auto-gptq
```
You also need to install transformers from source:
```bash
pip install -U git+https://github.com/huggingface/transformers.git
```
Once installed, simply load the GPTQ model with the `from_pretrained` method:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "TheBloke/Mixtral-8x7B-v0.1-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Note that for both QLoRA and GPTQ you need at least 30 GB of GPU VRAM to fit the model. You can make it work with 24 GB if you use `device_map="auto"`, like in the example above, so some layers are offloaded to CPU.
## Disclaimers and ongoing work
- **Quantization**: Quantization of MoEs is an active area of research. Some initial experiments we've done with TheBloke are shown above, but we expect more progress as this architecture is known better! It will be exciting to see the development in the coming days and weeks in this area. Additionally, recent work such as [QMoE](https://arxiv.org/abs/2310.16795), which achieves sub-1-bit quantization for MoEs, could be applied here.
- **High VRAM usage**: MoEs run inference very quickly but still need a large amount of VRAM (and hence an expensive GPU). This makes it challenging to use it in local setups. MoEs are great for setups with many devices and large VRAM. Mixtral requires 90GB of VRAM in half-precision 🤯
## Additional Resources
- [Mixture of Experts Explained](https://huggingface.co/blog/moe)
- [Mixtral of experts](https://mistral.ai/news/mixtral-of-experts/)
- [Models on the Hub](https://huggingface.co/models?other=mixtral)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Chat demo on Hugging Chat](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1)
## Conclusion
We're very excited about Mixtral being released! In the coming days, be ready to learn more about ways to fine-tune and deploy Mixtral.
| huggingface/blog/blob/main/mixtral.md |
Training a masked language model end-to-end from scratch on TPUs
In this example, we're going to demonstrate how to train a TensorFlow model from 🤗 Transformers from scratch. If you're interested in some background theory on training Hugging Face models with TensorFlow on TPU, please check out our
[tutorial doc](https://huggingface.co/docs/transformers/main/perf_train_tpu_tf) on this topic!
If you're interested in smaller-scale TPU training from a pre-trained checkpoint, you can also check out the [TPU fine-tuning example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb).
This example will demonstrate pre-training language models at the 100M-1B parameter scale, similar to BERT or GPT-2. More concretely, we will show how to train a [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) (base model) from scratch on the [WikiText dataset (v1)](https://huggingface.co/datasets/wikitext).
We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
### Table of contents
- [Setting up a TPU-VM](#setting-up-a-tpu-vm)
- [Training a tokenizer](#training-a-tokenizer)
- [Preparing the dataset](#preparing-the-dataset)
- [Training the model](#training-the-model)
- [Inference](#inference)
## Setting up a TPU-VM
Since this example focuses on using TPUs, the first step is to set up access to TPU hardware. For this example, we chose to use a TPU v3-8 VM. Follow [this guide](https://cloud.google.com/tpu/docs/run-calculation-tensorflow) to quickly create a TPU VM with TensorFlow pre-installed.
> 💡 **Note**: You don't need a TPU-enabled hardware for tokenizer training and TFRecord shard preparation.
## Training a tokenizer
To train a language model from scratch, the first step is to tokenize text. In most Hugging Face examples, we begin from a pre-trained model and use its tokenizer. However, in this example, we're going to train a tokenizer from scratch as well. The script for this is `train_unigram.py`. An example command is:
```bash
python train_unigram.py --batch_size 1000 --vocab_size 25000 --export_to_hub
```
The script will automatically load the `train` split of the WikiText dataset and train a [Unigram tokenizer](https://huggingface.co/course/chapter6/7?fw=pt) on it.
> 💡 **Note**: In order for `export_to_hub` to work, you must authenticate yourself with the `huggingface-cli`. Run `huggingface-cli login` and follow the on-screen instructions.
## Preparing the dataset
The next step is to prepare the dataset. This consists of loading a text dataset from the Hugging Face Hub, tokenizing it and grouping it into chunks of a fixed length ready for training. The script for this is `prepare_tfrecord_shards.py`.
The reason we create TFRecord output files from this step is that these files work well with [`tf.data` pipelines](https://www.tensorflow.org/guide/data_performance). This makes them very suitable for scalable TPU training - the dataset can easily be sharded and read in parallel just by tweaking a few parameters in the pipeline. An example command is:
```bash
python prepare_tfrecord_shards.py \
--tokenizer_name_or_path tf-tpu/unigram-tokenizer-wikitext \
--shard_size 5000 \
--split test
--max_length 128 \
--output_dir gs://tf-tpu-training-resources
```
**Notes**:
* While running the above script, you need to specify the `split` accordingly. The example command above will only filter the `test` split of the dataset.
* If you append `gs://` in your `output_dir` the TFRecord shards will be directly serialized to a Google Cloud Storage (GCS) bucket. Ensure that you have already [created the GCS bucket](https://cloud.google.com/storage/docs).
* If you're using a TPU node, you must stream data from a GCS bucket. Otherwise, if you're using a TPU VM,you can store the data locally. You may need to [attach](https://cloud.google.com/tpu/docs/setup-persistent-disk) a persistent storage to the VM.
* Additional CLI arguments are also supported. We encourage you to run `python prepare_tfrecord_shards.py -h` to know more about them.
## Training the model
Once that's done, the model is ready for training. By default, training takes place on TPU, but you can use the `--no_tpu` flag to train on CPU for testing purposes. An example command is:
```bash
python3 run_mlm.py \
--train_dataset gs://tf-tpu-training-resources/train/ \
--eval_dataset gs://tf-tpu-training-resources/validation/ \
--tokenizer tf-tpu/unigram-tokenizer-wikitext \
--output_dir trained_model
```
If you had specified a `hub_model_id` while launching training, then your model will be pushed to a model repository on the Hugging Face Hub. You can find such an example repository here:
[tf-tpu/roberta-base-epochs-500-no-wd](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd).
## Inference
Once the model is trained, you can use 🤗 Pipelines to perform inference:
```python
from transformers import pipeline
model_id = "tf-tpu/roberta-base-epochs-500-no-wd"
unmasker = pipeline("fill-mask", model=model_id, framework="tf")
unmasker("Goal of my life is to [MASK].")
[{'score': 0.1003185287117958,
'token': 52,
'token_str': 'be',
'sequence': 'Goal of my life is to be.'},
{'score': 0.032648514956235886,
'token': 5,
'token_str': '',
'sequence': 'Goal of my life is to .'},
{'score': 0.02152673341333866,
'token': 138,
'token_str': 'work',
'sequence': 'Goal of my life is to work.'},
{'score': 0.019547373056411743,
'token': 984,
'token_str': 'act',
'sequence': 'Goal of my life is to act.'},
{'score': 0.01939118467271328,
'token': 73,
'token_str': 'have',
'sequence': 'Goal of my life is to have.'}]
```
You can also try out inference using the [Inference Widget](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd?text=Goal+of+my+life+is+to+%5BMASK%5D.) from the model page. | huggingface/transformers/blob/main/examples/tensorflow/language-modeling-tpu/README.md |
--
title: Hyperparameter Search with Transformers and Ray Tune
thumbnail: /blog/assets/06_ray_tune/ray-hf.jpg
authors:
- user: ray-project
guest: true
---
# Hyperparameter Search with Transformers and Ray Tune
##### A guest blog post by Richard Liaw from the Anyscale team
With cutting edge research implementations, thousands of trained models easily accessible, the Hugging Face [transformers](https://github.com/huggingface/transformers) library has become critical to the success and growth of natural language processing today.
For any machine learning model to achieve good performance, users often need to implement some form of parameter tuning. Yet, nearly everyone ([1](https://medium.com/@prakashakshay90/fine-tuning-bert-model-using-pytorch-f34148d58a37), [2](https://mccormickml.com/2019/07/22/BERT-fine-tuning/#advantages-of-fine-tuning)) either ends up disregarding hyperparameter tuning or opting to do a simplistic grid search with a small search space.
However, simple experiments are able to show the benefit of using an advanced tuning technique. Below is [a recent experiment run on a BERT](https://medium.com/distributed-computing-with-ray/hyperparameter-optimization-for-transformers-a-guide-c4e32c6c989b) model from [Hugging Face transformers](https://github.com/huggingface/transformers) on the [RTE dataset](https://aclweb.org/aclwiki/Textual_Entailment_Resource_Pool). Genetic optimization techniques like [PBT](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#population-based-training-tune-schedulers-populationbasedtraining) can provide large performance improvements compared to standard hyperparameter optimization techniques.
<table>
<tr>
<td><strong>Algorithm</strong>
</td>
<td><strong>Best Val Acc.</strong>
</td>
<td><strong>Best Test Acc.</strong>
</td>
<td><strong>Total GPU min</strong>
</td>
<td><strong>Total $ cost</strong>
</td>
</tr>
<tr>
<td>Grid Search
</td>
<td>74%
</td>
<td>65.4%
</td>
<td>45 min
</td>
<td>$2.30
</td>
</tr>
<tr>
<td>Bayesian Optimization +Early Stop
</td>
<td>77%
</td>
<td>66.9%
</td>
<td>104 min
</td>
<td>$5.30
</td>
</tr>
<tr>
<td>Population-based Training
</td>
<td>78%
</td>
<td>70.5%
</td>
<td>48 min
</td>
<td>$2.45
</td>
</tr>
</table>
If you’re leveraging [Transformers](https://github.com/huggingface/transformers), you’ll want to have a way to easily access powerful hyperparameter tuning solutions without giving up the customizability of the Transformers framework.

In the Transformers 3.1 release, [Hugging Face Transformers](https://github.com/huggingface/transformers) and [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) teamed up to provide a simple yet powerful integration. [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) is a popular Python library for hyperparameter tuning that provides many state-of-the-art algorithms out of the box, along with integrations with the best-of-class tooling, such as [Weights and Biases](https://wandb.ai/) and tensorboard.
To demonstrate this new [Hugging Face](https://github.com/huggingface/transformers) + [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) integration, we leverage the [Hugging Face Datasets library](https://github.com/huggingface/datasets) to fine tune BERT on [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398).
To run this example, please first run:
**`pip install "ray[tune]" transformers datasets scipy sklearn torch`**
Simply plug in one of Ray’s standard tuning algorithms by just adding a few lines of code.
```python
from datasets import load_dataset, load_metric
from transformers import (AutoModelForSequenceClassification, AutoTokenizer,
Trainer, TrainingArguments)
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
dataset = load_dataset('glue', 'mrpc')
metric = load_metric('glue', 'mrpc')
def encode(examples):
outputs = tokenizer(
examples['sentence1'], examples['sentence2'], truncation=True)
return outputs
encoded_dataset = dataset.map(encode, batched=True)
def model_init():
return AutoModelForSequenceClassification.from_pretrained(
'distilbert-base-uncased', return_dict=True)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = predictions.argmax(axis=-1)
return metric.compute(predictions=predictions, references=labels)
# Evaluate during training and a bit more often
# than the default to be able to prune bad trials early.
# Disabling tqdm is a matter of preference.
training_args = TrainingArguments(
"test", evaluation_strategy="steps", eval_steps=500, disable_tqdm=True)
trainer = Trainer(
args=training_args,
tokenizer=tokenizer,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
model_init=model_init,
compute_metrics=compute_metrics,
)
# Default objective is the sum of all metrics
# when metrics are provided, so we have to maximize it.
trainer.hyperparameter_search(
direction="maximize",
backend="ray",
n_trials=10 # number of trials
)
```
By default, each trial will utilize 1 CPU, and optionally 1 GPU if available.
You can leverage multiple [GPUs for a parallel hyperparameter search](https://docs.ray.io/en/latest/tune/user-guide.html#resources-parallelism-gpus-distributed)
by passing in a `resources_per_trial` argument.
You can also easily swap different parameter tuning algorithms such as [HyperBand](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#asha-tune-schedulers-ashascheduler), [Bayesian Optimization](https://docs.ray.io/en/latest/tune/api_docs/suggestion.html), [Population-Based Training](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#population-based-training-tune-schedulers-populationbasedtraining):
To run this example, first run: **`pip install hyperopt`**
```python
from ray.tune.suggest.hyperopt import HyperOptSearch
from ray.tune.schedulers import ASHAScheduler
trainer = Trainer(
args=training_args,
tokenizer=tokenizer,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
model_init=model_init,
compute_metrics=compute_metrics,
)
best_trial = trainer.hyperparameter_search(
direction="maximize",
backend="ray",
# Choose among many libraries:
# https://docs.ray.io/en/latest/tune/api_docs/suggestion.html
search_alg=HyperOptSearch(metric="objective", mode="max"),
# Choose among schedulers:
# https://docs.ray.io/en/latest/tune/api_docs/schedulers.html
scheduler=ASHAScheduler(metric="objective", mode="max"))
```
It also works with [Weights and Biases](https://wandb.ai/) out of the box!

### Try it out today:
* `pip install -U ray`
* `pip install -U transformers datasets`
* Check out the [Hugging Face documentation](https://huggingface.co/transformers/) and [Discussion thread](https://discuss.huggingface.co/t/using-hyperparameter-search-in-trainer/785/10)
* [End-to-end example of using Hugging Face hyperparameter search for text classification](https://github.com/huggingface/notebooks/blob/master/examples/text_classification.ipynb)
If you liked this blog post, be sure to check out:
* [Transformers + GLUE + Ray Tune example](https://docs.ray.io/en/latest/tune/examples/index.html#hugging-face-huggingface-transformers)
* Our [Weights and Biases report](https://wandb.ai/amogkam/transformers/reports/Hyperparameter-Optimization-for-Huggingface-Transformers--VmlldzoyMTc2ODI) on Hyperparameter Optimization for Transformers
* The [simplest way to serve your NLP model](https://medium.com/distributed-computing-with-ray/the-simplest-way-to-serve-your-nlp-model-in-production-with-pure-python-d42b6a97ad55) from scratch
| huggingface/blog/blob/main/ray-tune.md |
Models
[[autodoc]] timm.create_model
[[autodoc]] timm.list_models
| huggingface/pytorch-image-models/blob/main/hfdocs/source/reference/models.mdx |
FrameworkSwitchCourse {fw} />
# Fine-tuning a model with the Trainer API[[fine-tuning-a-model-with-the-trainer-api]]
<CourseFloatingBanner chapter={3}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter3/section3.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter3/section3.ipynb"},
]} />
<Youtube id="nvBXf7s7vTI"/>
🤗 Transformers provides a `Trainer` class to help you fine-tune any of the pretrained models it provides on your dataset. Once you've done all the data preprocessing work in the last section, you have just a few steps left to define the `Trainer`. The hardest part is likely to be preparing the environment to run `Trainer.train()`, as it will run very slowly on a CPU. If you don't have a GPU set up, you can get access to free GPUs or TPUs on [Google Colab](https://colab.research.google.com/).
The code examples below assume you have already executed the examples in the previous section. Here is a short summary recapping what you need:
```py
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
### Training[[training]]
The first step before we can define our `Trainer` is to define a `TrainingArguments` class that will contain all the hyperparameters the `Trainer` will use for training and evaluation. The only argument you have to provide is a directory where the trained model will be saved, as well as the checkpoints along the way. For all the rest, you can leave the defaults, which should work pretty well for a basic fine-tuning.
```py
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
```
<Tip>
💡 If you want to automatically upload your model to the Hub during training, pass along `push_to_hub=True` in the `TrainingArguments`. We will learn more about this in [Chapter 4](/course/chapter4/3)
</Tip>
The second step is to define our model. As in the [previous chapter](/course/chapter2), we will use the `AutoModelForSequenceClassification` class, with two labels:
```py
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
You will notice that unlike in [Chapter 2](/course/chapter2), you get a warning after instantiating this pretrained model. This is because BERT has not been pretrained on classifying pairs of sentences, so the head of the pretrained model has been discarded and a new head suitable for sequence classification has been added instead. The warnings indicate that some weights were not used (the ones corresponding to the dropped pretraining head) and that some others were randomly initialized (the ones for the new head). It concludes by encouraging you to train the model, which is exactly what we are going to do now.
Once we have our model, we can define a `Trainer` by passing it all the objects constructed up to now — the `model`, the `training_args`, the training and validation datasets, our `data_collator`, and our `tokenizer`:
```py
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
```
Note that when you pass the `tokenizer` as we did here, the default `data_collator` used by the `Trainer` will be a `DataCollatorWithPadding` as defined previously, so you can skip the line `data_collator=data_collator` in this call. It was still important to show you this part of the processing in section 2!
To fine-tune the model on our dataset, we just have to call the `train()` method of our `Trainer`:
```py
trainer.train()
```
This will start the fine-tuning (which should take a couple of minutes on a GPU) and report the training loss every 500 steps. It won't, however, tell you how well (or badly) your model is performing. This is because:
1. We didn't tell the `Trainer` to evaluate during training by setting `evaluation_strategy` to either `"steps"` (evaluate every `eval_steps`) or `"epoch"` (evaluate at the end of each epoch).
2. We didn't provide the `Trainer` with a `compute_metrics()` function to calculate a metric during said evaluation (otherwise the evaluation would just have printed the loss, which is not a very intuitive number).
### Evaluation[[evaluation]]
Let's see how we can build a useful `compute_metrics()` function and use it the next time we train. The function must take an `EvalPrediction` object (which is a named tuple with a `predictions` field and a `label_ids` field) and will return a dictionary mapping strings to floats (the strings being the names of the metrics returned, and the floats their values). To get some predictions from our model, we can use the `Trainer.predict()` command:
```py
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
```
```python out
(408, 2) (408,)
```
The output of the `predict()` method is another named tuple with three fields: `predictions`, `label_ids`, and `metrics`. The `metrics` field will just contain the loss on the dataset passed, as well as some time metrics (how long it took to predict, in total and on average). Once we complete our `compute_metrics()` function and pass it to the `Trainer`, that field will also contain the metrics returned by `compute_metrics()`.
As you can see, `predictions` is a two-dimensional array with shape 408 x 2 (408 being the number of elements in the dataset we used). Those are the logits for each element of the dataset we passed to `predict()` (as you saw in the [previous chapter](/course/chapter2), all Transformer models return logits). To transform them into predictions that we can compare to our labels, we need to take the index with the maximum value on the second axis:
```py
import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)
```
We can now compare those `preds` to the labels. To build our `compute_metric()` function, we will rely on the metrics from the 🤗 [Evaluate](https://github.com/huggingface/evaluate/) library. We can load the metrics associated with the MRPC dataset as easily as we loaded the dataset, this time with the `evaluate.load()` function. The object returned has a `compute()` method we can use to do the metric calculation:
```py
import evaluate
metric = evaluate.load("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
```
```python out
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
```
The exact results you get may vary, as the random initialization of the model head might change the metrics it achieved. Here, we can see our model has an accuracy of 85.78% on the validation set and an F1 score of 89.97. Those are the two metrics used to evaluate results on the MRPC dataset for the GLUE benchmark. The table in the [BERT paper](https://arxiv.org/pdf/1810.04805.pdf) reported an F1 score of 88.9 for the base model. That was the `uncased` model while we are currently using the `cased` model, which explains the better result.
Wrapping everything together, we get our `compute_metrics()` function:
```py
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
```
And to see it used in action to report metrics at the end of each epoch, here is how we define a new `Trainer` with this `compute_metrics()` function:
```py
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
```
Note that we create a new `TrainingArguments` with its `evaluation_strategy` set to `"epoch"` and a new model — otherwise, we would just be continuing the training of the model we have already trained. To launch a new training run, we execute:
```py
trainer.train()
```
This time, it will report the validation loss and metrics at the end of each epoch on top of the training loss. Again, the exact accuracy/F1 score you reach might be a bit different from what we found, because of the random head initialization of the model, but it should be in the same ballpark.
The `Trainer` will work out of the box on multiple GPUs or TPUs and provides lots of options, like mixed-precision training (use `fp16 = True` in your training arguments). We will go over everything it supports in Chapter 10.
This concludes the introduction to fine-tuning using the `Trainer` API. An example of doing this for most common NLP tasks will be given in [Chapter 7](/course/chapter7), but for now let's look at how to do the same thing in pure PyTorch.
<Tip>
✏️ **Try it out!** Fine-tune a model on the GLUE SST-2 dataset, using the data processing you did in section 2.
</Tip>
| huggingface/course/blob/main/chapters/en/chapter3/3.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image captioning
[[open-in-colab]]
Image captioning is the task of predicting a caption for a given image. Common real world applications of it include
aiding visually impaired people that can help them navigate through different situations. Therefore, image captioning
helps to improve content accessibility for people by describing images to them.
This guide will show you how to:
* Fine-tune an image captioning model.
* Use the fine-tuned model for inference.
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate -q
pip install jiwer -q
```
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Load the Pokémon BLIP captions dataset
Use the 🤗 Dataset library to load a dataset that consists of {image-caption} pairs. To create your own image captioning dataset
in PyTorch, you can follow [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb).
```python
from datasets import load_dataset
ds = load_dataset("lambdalabs/pokemon-blip-captions")
ds
```
```bash
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 833
})
})
```
The dataset has two features, `image` and `text`.
<Tip>
Many image captioning datasets contain multiple captions per image. In those cases, a common strategy is to randomly sample a caption amongst the available ones during training.
</Tip>
Split the dataset’s train split into a train and test set with the [~datasets.Dataset.train_test_split] method:
```python
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
```
Let's visualize a couple of samples from the training set.
```python
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_training_images_image_cap.png" alt="Sample training images"/>
</div>
## Preprocess the dataset
Since the dataset has two modalities (image and text), the pre-processing pipeline will preprocess images and the captions.
To do so, load the processor class associated with the model you are about to fine-tune.
```python
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
```
The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
```python
def transforms(example_batch):
images = [x for x in example_batch["image"]]
captions = [x for x in example_batch["text"]]
inputs = processor(images=images, text=captions, padding="max_length")
inputs.update({"labels": inputs["input_ids"]})
return inputs
train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
```
With the dataset ready, you can now set up the model for fine-tuning.
## Load a base model
Load the ["microsoft/git-base"](https://huggingface.co/microsoft/git-base) into a [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) object.
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
## Evaluate
Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
```python
from evaluate import load
import torch
wer = load("wer")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score}
```
## Train!
Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
First, define the training arguments using [`TrainingArguments`].
```python
from transformers import TrainingArguments, Trainer
model_name = checkpoint.split("/")[1]
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=2,
save_total_limit=3,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
load_best_model_at_end=True,
)
```
Then pass them along with the datasets and the model to 🤗 Trainer.
```python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
```
To start training, simply call [`~Trainer.train`] on the [`Trainer`] object.
```python
trainer.train()
```
You should see the training loss drop smoothly as training progresses.
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method so everyone can use your model:
```python
trainer.push_to_hub()
```
## Inference
Take a sample image from `test_ds` to test the model.
```python
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/test_image_image_cap.png" alt="Test image"/>
</div>
Prepare image for the model.
```python
device = "cuda" if torch.cuda.is_available() else "cpu"
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
```
Call [`generate`] and decode the predictions.
```python
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```
```bash
a drawing of a pink and blue pokemon
```
Looks like the fine-tuned model generated a pretty good caption!
| huggingface/transformers/blob/main/docs/source/en/tasks/image_captioning.md |
Using 🤗 `transformers` at Hugging Face
🤗 `transformers` is a library maintained by Hugging Face and the community, for state-of-the-art Machine Learning for Pytorch, TensorFlow and JAX. It provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio. We are a bit biased, but we really like 🤗 `transformers`!
## Exploring 🤗 transformers in the Hub
There are over 25,000 `transformers` models in the Hub which you can find by filtering at the left of [the models page](https://huggingface.co/models?library=transformers&sort=downloads).
You can find models for many different tasks:
* Extracting the answer from a context ([question-answering](https://huggingface.co/models?library=transformers&pipeline_tag=question-answering&sort=downloads)).
* Creating summaries from a large text ([summarization](https://huggingface.co/models?library=transformers&pipeline_tag=summarization&sort=downloads)).
* Classify text (e.g. as spam or not spam, [text-classification](https://huggingface.co/models?library=transformers&pipeline_tag=text-classification&sort=downloads)).
* Generate a new text with models such as GPT ([text-generation](https://huggingface.co/models?library=transformers&pipeline_tag=text-generation&sort=downloads)).
* Identify parts of speech (verb, subject, etc.) or entities (country, organization, etc.) in a sentence ([token-classification](https://huggingface.co/models?library=transformers&pipeline_tag=token-classification&sort=downloads)).
* Transcribe audio files to text ([automatic-speech-recognition](https://huggingface.co/models?library=transformers&pipeline_tag=automatic-speech-recognition&sort=downloads)).
* Classify the speaker or language in an audio file ([audio-classification](https://huggingface.co/models?library=transformers&pipeline_tag=audio-classification&sort=downloads)).
* Detect objects in an image ([object-detection](https://huggingface.co/models?library=transformers&pipeline_tag=object-detection&sort=downloads)).
* Segment an image ([image-segmentation](https://huggingface.co/models?library=transformers&pipeline_tag=image-segmentation&sort=downloads)).
* Do Reinforcement Learning ([reinforcement-learning](https://huggingface.co/models?library=transformers&pipeline_tag=reinforcement-learning&sort=downloads))!
You can try out the models directly in the browser if you want to test them out without downloading them thanks to the in-browser widgets!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-transformers_widget.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-transformers_widget-dark.png"/>
</div>
## Using existing models
All `transformer` models are a line away from being used! Depending on how you want to use them, you can use the high-level API using the `pipeline` function or you can use `AutoModel` for more control.
```py
# With pipeline, just specify the task and the model id from the Hub.
from transformers import pipeline
pipe = pipeline("text-generation", model="distilgpt2")
# If you want more control, you will need to define the tokenizer and model.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
You can also load a model from a specific version (based on commit hash, tag name, or branch) as follows:
```py
model = AutoModel.from_pretrained(
"julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
)
```
If you want to see how to load a specific model, you can click `Use in Transformers` and you will be given a working snippet that you can load it! If you need further information about the model architecture, you can also click the "Read model documentation" at the bottom of the snippet.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-transformers_snippet.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-transformers_snippet-dark.png"/>
</div>
## Sharing your models
To read all about sharing models with `transformers`, please head out to the [Share a model](https://huggingface.co/docs/transformers/model_sharing) guide in the official documentation.
Many classes in `transformers`, such as the models and tokenizers, have a `push_to_hub` method that allows to easily upload the files to a repository.
```py
# Pushing model to your own account
model.push_to_hub("my-awesome-model")
# Pushing your tokenizer
tokenizer.push_to_hub("my-awesome-model")
# Pushing all things after training
trainer.push_to_hub()
```
There is much more you can do, so we suggest to review the [Share a model](https://huggingface.co/docs/transformers/model_sharing) guide.
## Additional resources
* Transformers [library](https://github.com/huggingface/transformers).
* Transformers [docs](https://huggingface.co/docs/transformers/index).
* Share a model [guide](https://huggingface.co/docs/transformers/model_sharing).
| huggingface/hub-docs/blob/main/docs/hub/transformers.md |
Data types
Datasets supported by Datasets Server have a tabular format, meaning a data point is represented in a row and its features are contained in columns. Using the `/first-rows` endpoint allows you to preview the first 100 rows of a dataset and information about each feature. Within the `features` key, you'll notice it returns a `_type` field. This value describes the data type of the column, and it is also known as a dataset's [`Features`](https://huggingface.co/docs/datasets/about_dataset_features).
There are several different data `Features` for representing different data formats such as [`Audio`](https://huggingface.co/docs/datasets/v2.5.2/en/package_reference/main_classes#datasets.Audio) and [`Image`](https://huggingface.co/docs/datasets/v2.5.2/en/package_reference/main_classes#datasets.Image) for speech and image data respectively. Knowing a dataset feature gives you a better understanding of the data type you're working with, and how you can preprocess it.
For example, the `/first-rows` endpoint for the [Rotten Tomatoes](https://huggingface.co/datasets/rotten_tomatoes) dataset returns the following:
```json
{"dataset": "rotten_tomatoes",
"config": "default",
"split": "train",
"features": [{"feature_idx": 0,
"name": "text",
"type": {"dtype": "string",
"id": null,
"_type": "Value"}},
{"feature_idx": 1,
"name": "label",
"type": {"num_classes": 2,
"names": ["neg", "pos"],
"id": null,
"_type": "ClassLabel"}}],
...
}
```
This dataset has two columns, `text` and `label`:
- The `text` column has a type of `Value`. The [`Value`](https://huggingface.co/docs/datasets/v2.5.2/en/package_reference/main_classes#datasets.Value) type is extremely versatile and represents scalar values such as strings, integers, dates, and even timestamp values.
- The `label` column has a type of `ClassLabel`. The [`ClassLabel`](https://huggingface.co/docs/datasets/v2.5.2/en/package_reference/main_classes#datasets.ClassLabel) type represents the number of classes in a dataset and their label names. Naturally, this means you'll frequently see `ClassLabel` used in classification datasets.
For a complete list of available data types, take a look at the [`Features`](https://huggingface.co/docs/datasets/v2.5.2/en/package_reference/main_classes#datasets.Features) documentation.
| huggingface/datasets-server/blob/main/docs/source/data_types.mdx |
What is Reinforcement Learning? [[what-is-reinforcement-learning]]
To understand Reinforcement Learning, let’s start with the big picture.
## The big picture [[the-big-picture]]
The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by **interacting with it** (through trial and error) and **receiving rewards** (negative or positive) as feedback for performing actions.
Learning from interactions with the environment **comes from our natural experiences.**
For instance, imagine putting your little brother in front of a video game he never played, giving him a controller, and leaving him alone.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/Illustration_1.jpg" alt="Illustration_1" width="100%">
Your brother will interact with the environment (the video game) by pressing the right button (action). He got a coin, that’s a +1 reward. It’s positive, he just understood that in this game **he must get the coins.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/Illustration_2.jpg" alt="Illustration_2" width="100%">
But then, **he presses the right button again** and he touches an enemy. He just died, so that's a -1 reward.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/Illustration_3.jpg" alt="Illustration_3" width="100%">
By interacting with his environment through trial and error, your little brother understands that **he needs to get coins in this environment but avoid the enemies.**
**Without any supervision**, the child will get better and better at playing the game.
That’s how humans and animals learn, **through interaction.** Reinforcement Learning is just a **computational approach of learning from actions.**
### A formal definition [[a-formal-definition]]
We can now make a formal definition:
<Tip>
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
</Tip>
But how does Reinforcement Learning work?
| huggingface/deep-rl-class/blob/main/units/en/unit1/what-is-rl.mdx |
--
title: Perplexity
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Perplexity (PPL) is one of the most common metrics for evaluating language models.
It is defined as the exponentiated average negative log-likelihood of a sequence, calculated with exponent base `e`.
For more information on perplexity, see [this tutorial](https://huggingface.co/docs/transformers/perplexity).
---
# Metric Card for Perplexity
## Metric Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence.
As a metric, it can be used to evaluate how well the model has learned the distribution of the text it was trained on.
In this case, `model_id` should be the trained model to be evaluated, and the input texts should be the text that the model was trained on.
This implementation of perplexity is calculated with log base `e`, as in `perplexity = e**(sum(losses) / num_tokenized_tokens)`, following recent convention in deep learning frameworks.
## Intended Uses
Any language generation task.
## How to Use
The metric takes a list of text as input, as well as the name of the model used to compute the metric:
```python
from evaluate import load
perplexity = load("perplexity", module_type="metric")
results = perplexity.compute(predictions=predictions, model_id='gpt2')
```
### Inputs
- **model_id** (str): model used for calculating Perplexity. NOTE: Perplexity can only be calculated for causal language models.
- This includes models such as gpt2, causal variations of bert, causal versions of t5, and more (the full list can be found in the AutoModelForCausalLM documentation here: https://huggingface.co/docs/transformers/master/en/model_doc/auto#transformers.AutoModelForCausalLM )
- **predictions** (list of str): input text, where each separate text snippet is one list entry.
- **batch_size** (int): the batch size to run texts through the model. Defaults to 16.
- **add_start_token** (bool): whether to add the start token to the texts, so the perplexity can include the probability of the first word. Defaults to True.
- **device** (str): device to run on, defaults to `cuda` when available
### Output Values
This metric outputs a dictionary with the perplexity scores for the text input in the list, and the average perplexity.
If one of the input texts is longer than the max input length of the model, then it is truncated to the max length for the perplexity computation.
```
{'perplexities': [8.182524681091309, 33.42122268676758, 27.012239456176758], 'mean_perplexity': 22.871995608011883}
```
The range of this metric is [0, inf). A lower score is better.
#### Values from Popular Papers
### Examples
Calculating perplexity on predictions defined here:
```python
perplexity = evaluate.load("perplexity", module_type="metric")
input_texts = ["lorem ipsum", "Happy Birthday!", "Bienvenue"]
results = perplexity.compute(model_id='gpt2',
add_start_token=False,
predictions=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>646.75
print(round(results["perplexities"][0], 2))
>>>32.25
```
Calculating perplexity on predictions loaded in from a dataset:
```python
perplexity = evaluate.load("perplexity", module_type="metric")
input_texts = datasets.load_dataset("wikitext",
"wikitext-2-raw-v1",
split="test")["text"][:50]
input_texts = [s for s in input_texts if s!='']
results = perplexity.compute(model_id='gpt2',
predictions=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>576.76
print(round(results["perplexities"][0], 2))
>>>889.28
```
## Limitations and Bias
Note that the output value is based heavily on what text the model was trained on. This means that perplexity scores are not comparable between models or datasets.
See Meister and Cotterell, ["Language Model Evaluation Beyond Perplexity"]( https://arxiv.org/abs/2106.00085) (2021) for more information about alternative model evaluation strategies.
## Citation
```bibtex
@article{jelinek1977perplexity,
title={Perplexity—a measure of the difficulty of speech recognition tasks},
author={Jelinek, Fred and Mercer, Robert L and Bahl, Lalit R and Baker, James K},
journal={The Journal of the Acoustical Society of America},
volume={62},
number={S1},
pages={S63--S63},
year={1977},
publisher={Acoustical Society of America}
}
```
## Further References
- [Hugging Face Perplexity Blog Post](https://huggingface.co/docs/transformers/perplexity)
| huggingface/evaluate/blob/main/metrics/perplexity/README.md |
--
title: "Accelerate Large Model Training using DeepSpeed"
thumbnail: /blog/assets/83_accelerate_deepspeed/deepspeed-thumbnail.png
authors:
- user: smangrul
- user: sgugger
---
# Accelerate Large Model Training using DeepSpeed
In this post we will look at how we can leverage the **[Accelerate](https://github.com/huggingface/accelerate)** library for training large models which enables users to leverage the ZeRO features of **[DeeSpeed](https://www.deepspeed.ai)**.
# Motivation 🤗
**Tired of Out of Memory (OOM) errors while trying to train large models? We've got you covered. Large models are very performant [1] but difficult to train with the available hardware. To get the most of the available hardware for training large models one can leverage Data Parallelism using ZeRO - Zero Redundancy Optimizer [2]**.
Below is a short description of Data Parallelism using ZeRO with diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)

(Source: [link](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/))
a. **Stage 1** : Shards optimizer states across data parallel workers/GPUs
b. **Stage 2** : Shards optimizer states + gradients across data parallel workers/GPUs
c. **Stage 3**: Shards optimizer states + gradients + model parameters across data parallel workers/GPUs
d. **Optimizer Offload**: Offloads the gradients + optimizer states to CPU/Disk building on top of ZERO Stage 2
e. **Param Offload**: Offloads the model parameters to CPU/Disk building on top of ZERO Stage 3
In this blogpost we will look at how to leverage Data Parallelism using ZeRO using Accelerate. **[DeepSpeed](https://github.com/microsoft/deepspeed)**, **[FairScale](https://github.com/facebookresearch/fairscale/)** and **[PyTorch FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)** have implemented the core ideas of the ZERO paper. These have already been integrated in 🤗 `transformers` Trainer and 🤗 `accelerate` accompanied by great blogs [Fit More and Train Faster With ZeRO via DeepSpeed and FairScale](https://huggingface.co/blog/zero-deepspeed-fairscale) [4] and [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp) [5]. We defer the explanation of what goes behind the scenes to those blogs and mainly focus on leveraging DeepSpeed ZeRO using Accelerate.
# Accelerate 🚀: Leverage DeepSpeed ZeRO without any code changes
**Hardware setup**: 2X24GB NVIDIA Titan RTX GPUs. 60GB RAM.
We will look at the task of finetuning encoder-only model for text-classification. We will use pretrained `microsoft/deberta-v2-xlarge-mnli` (900M params) for finetuning on MRPC GLUE dataset.
The code is available here [run_cls_no_trainer.py](https://github.com/pacman100/accelerate-deepspeed-test/blob/main/src/modeling/run_cls_no_trainer.py). It is similar to the official text-classification example [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue_no_trainer.py) with the addition of logic to measure train and eval time. Let's compare performance between Distributed Data Parallel (DDP) and DeepSpeed ZeRO Stage-2 in a Multi-GPU Setup.
To enable DeepSpeed ZeRO Stage-2 without any code changes, please run `accelerate config` and leverage the [Accelerate DeepSpeed Plugin](https://huggingface.co/docs/accelerate/deepspeed#accelerate-deepspeed-plugin).
**ZeRO Stage-2 DeepSpeed Plugin Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
Now, run below command for training:
```bash
accelerate launch run_cls_no_trainer.py \
--model_name_or_path "microsoft/deberta-v2-xlarge-mnli" \
--task_name "mrpc" \
--ignore_mismatched_sizes \
--max_length 128 \
--per_device_train_batch_size 40 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir "/tmp/mrpc/deepspeed_stage2/" \
--with_tracking \
--report_to "wandb" \
```
In our Single-Node Multi-GPU setup, the maximum batch size that DDP supports without OOM error is 8. In contrast, DeepSpeed Zero-Stage 2 enables batch size of 40 without running into OOM errors. Therefore, DeepSpeed enables to fit **5X** more data per GPU when compared to DDP. Below is the snapshot of the plots from wandb [run](https://wandb.ai/smangrul/DDP_vs_DeepSpeed_cls_task?workspace=user-smangrul) along with benchmarking table comparing DDP vs DeepSpeed.

---
| Method | Batch Size Max | Train time per epoch (seconds) | Eval time per epoch (seconds) | F1 score | Accuracy |
| --- | --- | --- | --- | --- | --- |
| DDP (Distributed Data Parallel) | 8 | 103.57 | 2.04 | 0.931 | 0.904 |
| DeepSpeed ZeRO Stage 2 | **40** | **28.98** | **1.79** | **0.936** | **0.912** |
Table 1: Benchmarking DeepSpeed ZeRO Stage-2 on DeBERTa-XL (900M) model
---
With this bigger batch size, we observe ~**3.5X** speed up in total training time without any drop in perforamnce metrics, all this without changing any code. Yay! 🤗.
To be able to tweak more options, you will need to use a DeepSpeed config file and minimal code changes. Let's see how to do this.
# Accelerate 🚀: Leverage a DeepSpeed Config file to tweak more options
First, We will look at the task of finetuning a sequence-to-sequence model for training our own Chatbot. Specifically, we will finetune `facebook/blenderbot-400M-distill` on the [smangrul/MuDoConv](https://huggingface.co/datasets/smangrul/MuDoConv) (Multi-Domain Conversation) dataset. The dataset contains conversations from 10 different data sources covering personas, grounding in specific emotional contexts, goal-oriented (e.g., restaurant reservation) and general wikipedia topics (e.g, Cricket).
The code is available here [run_seq2seq_no_trainer.py](https://github.com/pacman100/accelerate-deepspeed-test/blob/main/src/modeling/run_seq2seq_no_trainer.py). Current pratice to effectively measure the `Engagingness` and `Humanness` of Chatbots is via Human evlauations which are expensive [6]. As such for this example, the metric being tracked is BLEU score (which isn't ideal but is the conventional metric for such tasks). One can adapt the code to train larger T5 models if you have access to GPUs that support `bfloat16` precision else you will run into `NaN` loss values. We will run a quick benchmark on `10000` train samples and `1000` eval samples as we are interested in DeepSpeed vs DDP.
We will leverage the DeepSpeed Zero Stage-2 config [zero2_config_accelerate.json](https://github.com/pacman100/accelerate-deepspeed-test/blob/main/src/modeling/configs/zero2_config_accelerate.json) (given below) For training. for detailed information on the various config features, please refer [DeeSpeed](https://www.deepspeed.ai) documentation.
```json
{
"fp16": {
"enabled": "true",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 15,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
To enable DeepSpeed ZeRO Stage-2 with above config, please run `accelerate config` and provide the config file path when asked. For more details, refer the 🤗 `accelerate` official documentation for [DeepSpeed Config File](https://huggingface.co/docs/accelerate/deepspeed#deepspeed-config-file).
**ZeRO Stage-2 DeepSpeed Config File Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /path/to/zero2_config_accelerate.json
zero3_init_flag: false
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
Now, run below command for training:
```bash
accelerate launch run_seq2seq_no_trainer.py \
--dataset_name "smangrul/MuDoConv" \
--max_source_length 128 \
--source_prefix "chatbot: " \
--max_target_length 64 \
--val_max_target_length 64 \
--val_min_target_length 20 \
--n_val_batch_generations 5 \
--n_train 10000 \
--n_val 1000 \
--pad_to_max_length \
--num_beams 10 \
--model_name_or_path "facebook/blenderbot-400M-distill" \
--per_device_train_batch_size 200 \
--per_device_eval_batch_size 100 \
--learning_rate 1e-6 \
--weight_decay 0.0 \
--num_train_epochs 1 \
--gradient_accumulation_steps 1 \
--num_warmup_steps 100 \
--output_dir "/tmp/deepspeed_zero_stage2_accelerate_test" \
--seed 25 \
--logging_steps 100 \
--with_tracking \
--report_to "wandb" \
--report_name "blenderbot_400M_finetuning"
```
When using DeepSpeed config, if user has specified `optimizer` and `scheduler` in config, the user will have to use `accelerate.utils.DummyOptim` and `accelerate.utils.DummyScheduler`. Those are the only minor changes that the user has to do. Below we show an example of the minimal changes required when using DeepSpeed config:
```diff
- optimizer = torch.optim.Adam(optimizer_grouped_parameters, lr=args.learning_rate)
+ optimizer = accelerate.utils.DummyOptim(optimizer_grouped_parameters, lr=args.learning_rate)
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps,
- num_training_steps=args.max_train_steps,
- )
+ lr_scheduler = accelerate.utils.DummyScheduler(
+ optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps
+ )
```
---
| Method | Batch Size Max | Eval Size Max | Train time per epoch (seconds) | Eval time per epoch (seconds) |
| --- | --- | --- | --- | --- |
| DDP (Distributed Data Parallel) | 100 | 50 | 27.36 | 48.41 |
| DeepSpeed ZeRO Stage 2 | **200** | **100** | **19.06** | **39.27** |
Table 2: Benchmarking DeepSpeed ZeRO Stage-2 on BlenderBot (400M) model
In our Single-Node Multi-GPU setup, the maximum batch size that DDP supports without OOM error is 100. In contrast, DeepSpeed Zero-Stage 2 enables batch size of 200 without running into OOM errors. Therefore, DeepSpeed enables to fit **2X** more data per GPU when compared to DDP. We observe ~**1.44X** speedup in training and ~**1.23X** speedup in evaluation as we are able to fit more data on the same available hardware. As this model is of medium size, the speedup isn't that exciting but this will improve with bigger models. You can chat with the Chatbot trained using the entire data at 🤗 Space [smangrul/Chat-E](https://huggingface.co/spaces/smangrul/Chat-E). You can give bot a persona, ground conversation to a particular emotion, use to in goal-oriented tasks or in a free flow manner. Below is a fun conversation with the chatbot 💬. You can find snapshots of more conversations using different contexts [here](https://github.com/pacman100/accelerate-deepspeed-test/tree/main/src/chatbot_snapshots).

---
## CPU/Disk Offloading to enable training humongous models that won’t fit the GPU memory
On a single 24GB NVIDIA Titan RTX GPU, one cannot train GPT-XL Model (1.5B parameters) even with a batch size of 1. We will look at how we can use DeepSpeed ZeRO Stage-3 with CPU offloading of optimizer states, gradients and parameters to train GPT-XL Model.
We will leverage the DeepSpeed Zero Stage-3 CPU offload config [zero3_offload_config_accelerate.json](https://github.com/pacman100/accelerate-deepspeed-test/blob/main/src/modeling/configs/zero3_offload_config_accelerate.json) (given below) for training. The rest of the process of using the config with 🤗 `accelerate` is similar to the above experiment.
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"sub_group_size": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
**ZeRO Stage-3 CPU Offload DeepSpeed Config File Example**
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /path/to/zero3_offload_config_accelerate.json
zero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
Now, run below command for training:
```bash
accelerate launch run_clm_no_trainer.py \
--config_name "gpt2-xl" \
--tokenizer_name "gpt2-xl" \
--dataset_name "wikitext" \
--dataset_config_name "wikitext-2-raw-v1" \
--block_size 128 \
--output_dir "/tmp/clm_deepspeed_stage3_offload__accelerate" \
--learning_rate 5e-4 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--num_train_epochs 1 \
--with_tracking \
--report_to "wandb"\
```
---
| Method | Batch Size Max | Train time per epoch (seconds) | Notes |
| --- | --- | --- | --- |
| DDP (Distributed Data Parallel) | - | - | OOM Error
| DeepSpeed ZeRO Stage 3 | **16** | 6608.35 | |
Table 3: Benchmarking DeepSpeed ZeRO Stage-3 CPU Offload on GPT-XL (1.5B) model
---
DDP will result in OOM error even with batch size 1. On the other hand, with DeepSpeed ZeRO Stage-3 CPU offload, we can train with a batch size of 16.
Finally, please, remember that, 🤗 `Accelerate` only integrates DeepSpeed, therefore if you
have any problems or questions with regards to DeepSpeed usage, please, file an issue with [DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues).
# References
[1] [Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers](http://nlp.cs.berkeley.edu/pubs/Li-Wallace-Shen-Lin-Keutzer-Klein-Gonzalez_2020_Transformers_paper.pdf)
[2] [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/pdf/1910.02054v3.pdf)
[3] [DeepSpeed: Extreme-scale model training for everyone - Microsoft Research](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)
[4] [Fit More and Train Faster With ZeRO via DeepSpeed and FairScale](https://huggingface.co/blog/zero-deepspeed-fairscale)
[5] [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp)
[6] [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf)
| huggingface/blog/blob/main/accelerate-deepspeed.md |
!-- DO NOT EDIT THIS FILE DIRECTLY. INSTEAD EDIT THE `readme_template.md` OR `guides/1)getting_started/1)quickstart.md` TEMPLATES AND THEN RUN `render_readme.py` SCRIPT. -->
<div align="center">
[<img src="../gradio.svg" alt="gradio" width=400>](https://gradio.app)<br>
<em>轻松构建 & 分享 令人愉快的机器学习程序</em>
[](https://github.com/gradio-app/gradio/actions/workflows/backend.yml)
[](https://github.com/gradio-app/gradio/actions/workflows/ui.yml)
[](https://pypi.org/project/gradio/)
[](https://pypi.org/project/gradio/)

[](https://twitter.com/gradio)
[官网](https://gradio.app)
| [文档](https://gradio.app/docs/)
| [指南](https://gradio.app/guides/)
| [开始](https://gradio.app/getting_started/)]
| [样例](../../demo/)
| [English](https://github.com/gradio-app/gradio#readme)
</div>
# Gradio: 用Python构建机器学习网页APP
Gradio是一个开源的Python库,用于构建演示机器学习或数据科学,以及web应用程序。
使用Gradio,您可以基于您的机器学习模型或数据科学工作流快速创建一个漂亮的用户界面,让用户可以”尝试“拖放他们自己的图像、粘贴文本、录制他们自己的声音,并通过浏览器与您的演示程序进行交互。

Gradio适用于:
- 向客户/合伙人/用户/学生**演示**您的机器学习模型。
- 通过自动共享链接快速**部署**您的模型,并获得模型性能反馈。
- 在开发过程中使用内置的操作和解释工具交互式地**调试**模型。
### 快速开始
**依赖**: Gradio只需要Python 3.7及以上版本!
#### Gradio能做什么?
与他人共享机器学习模型、API或数据科学工作流程的最佳方法之一就是创建一个**交互式应用**,让用户或同事在他们的浏览器中试用。
Gradio让你可以**用Python构建演示并分享它们**,而且通常只需几行代码!下面让我们开始吧。
#### Hello, World
要用Gradio运行"Hello World"示例,需要以下三个步骤:
1\. 用pip下载Gradio:
```bash
pip install gradio
```
2\. 用Python脚本或在Jupyter Notebook中运行下面的代码 (或者使用 [Google Colab](https://colab.research.google.com/drive/18ODkJvyxHutTN0P5APWyGFO_xwNcgHDZ?usp=sharing)):
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
```
3\. 下面的演示会自动出现在Jupyter Notebook中,如果使用脚本运行则会在浏览器[http://localhost:7860](http://localhost:7860)弹出:

#### `Interface` 类
你可能会注意到,在运行示例时我们创建了一个 `gradio.Interface` 。 `Interface` 类可以用用户接口包装任意的Python函数。在上面的示例中,我们使用了一个基于文本的简单函数,但这个函数可以是任何东西,从音乐生成器到税率计算器,再到预训练机器学习模型的预测函数。
`Interface` 类核心需要三个参数初始化:
- `fn` : 被UI包装的函数
- `inputs` : 作为输入的组件 (例如: `"text"`, `"image"` or `"audio"`)
- `outputs` : 作为输出的组件 (例如: `"text"`, `"image"` or `"label"`)
下面我们进一步分析用于输入和输出的组件。
#### 组件属性
在之前的示例中我们可以看到一些简单的文本框组件 `Textbox` ,但是如果您想改变UI组件的外观或行为呢?
假设您想要自定义输入文本字段,例如您希望它更大并有一个文本占位符。如果我们使用 `Textbox` 的实际类,而不是使用字符串快捷方式,就可以通过组件属性实现个性化。
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(
fn=greet,
inputs=gr.Textbox(lines=2, placeholder="Name Here..."),
outputs="text",
)
demo.launch()
```

#### 多输入和输出组件
假设您有一个更复杂的函数,有多个输入和输出。在下面的示例中,我们定义了一个函数,该函数接受字符串、布尔值和数字,并返回字符串和数字。观察应该如何传递输入和输出组件列表。
```python
import gradio as gr
def greet(name, is_morning, temperature):
salutation = "Good morning" if is_morning else "Good evening"
greeting = f"{salutation} {name}. It is {temperature} degrees today"
celsius = (temperature - 32) * 5 / 9
return greeting, round(celsius, 2)
demo = gr.Interface(
fn=greet,
inputs=["text", "checkbox", gr.Slider(0, 100)],
outputs=["text", "number"],
)
demo.launch()
```

您只需将组件包装在列表中。输入列表`inputs`中的每个组件依次对应函数的一个参数。输出列表`outputs`中的每个组件都对应于函数的一个返回值,两者均按顺序对应。
#### 一个图像示例
Gradio支持多种类型的组件,如 `Image`、`DateFrame`、`Video`或`Label` 。让我们尝试一个图像到图像的函数来感受一下!
```python
import numpy as np
import gradio as gr
def sepia(input_img):
sepia_filter = np.array([
[0.393, 0.769, 0.189],
[0.349, 0.686, 0.168],
[0.272, 0.534, 0.131]
])
sepia_img = input_img.dot(sepia_filter.T)
sepia_img /= sepia_img.max()
return sepia_img
demo = gr.Interface(sepia, gr.Image(shape=(200, 200)), "image")
demo.launch()
```

当使用`Image`组件作为输入时,您的函数将接收一个形状为 `(height, width, 3)` 的NumPy数组,其中最后一个维度表示RGB值。我们还将以NumPy数组的形式返回一张图像。
你也可以用 `type=` 关键字参数设置组件使用的数据类型。例如,如果你想让你的函数获取一个图像的文件路径,而不是一个NumPy数组时,输入 `Image` 组件可以写成:
```python
gr.Image(type="filepath", shape=...)
```
还要注意,我们的输入 `Image` 组件带有一个编辑按钮 🖉,它允许裁剪和放大图像。以这种方式操作图像可以帮助揭示机器学习模型中的偏见或隐藏的缺陷!
您可以在[Gradio文档](https://gradio.app/docs)中阅读更多关于组件以及如何使用它们。
#### Blocks: 更加灵活且可控
Gradio 提供了两个类来构建应用程序
1\. **Interface**,这为创建到目前为止我们一直在讨论的示例提供了一个高级抽象。
2\. **Blocks**,一个用于设计具有更灵活布局和数据流的web应用程序的初级API。block可以做许多事,比如特征化多个数据流和演示,控制组件在页面上出现的位置,处理复杂的数据流(例如,输出可以作为其他函数的输入),以及根据用户交互更新组件的属性/可见性,且仍然在Python中。如果您需要这种个性化,那就试试 `Blocks` 吧!
#### 你好, Blocks
让我们看一个简单的例子。注意这里的API与 `Interface` 有何不同。
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output Box")
greet_btn = gr.Button("Greet")
greet_btn.click(fn=greet, inputs=name, outputs=output)
demo.launch()
```

注意事项:
- `Blocks` 由 `with` 子句组成,在该子句中创建的任何组件都会自动添加到应用程序中。
- 组件在应用程序中按创建的顺序垂直显示,(稍后我们将介绍自定义布局!)
- 一个 按钮 `Button` 被创建,然后添加了一个 `click` 事件监听器。这个API看起来很熟悉!就像 `Interface`一样, `click` 方法接受一个Python函数、输入组件和输出组件。
#### 更多复杂性
这里有一个应用程序可以让你感受一下`Blocks`的更多可能:
```python
import numpy as np
import gradio as gr
def flip_text(x):
return x[::-1]
def flip_image(x):
return np.fliplr(x)
with gr.Blocks() as demo:
gr.Markdown("Flip text or image files using this demo.")
with gr.Tabs():
with gr.TabItem("Flip Text"):
text_input = gr.Textbox()
text_output = gr.Textbox()
text_button = gr.Button("Flip")
with gr.TabItem("Flip Image"):
with gr.Row():
image_input = gr.Image()
image_output = gr.Image()
image_button = gr.Button("Flip")
text_button.click(flip_text, inputs=text_input, outputs=text_output)
image_button.click(flip_image, inputs=image_input, outputs=image_output)
demo.launch()
```

还有很多事情可以做!我们将在[使用blocks构建](https://gradio.app/building_with_blocks)部分为您介绍如何创建像这样复杂的 `Blocks` 应用程序。
恭喜你,你现在已经熟悉了Gradio的基础使用!🥳 去我们的[下一章](https://gradio.app/key_features) 了解Gradio的更多功能。
## 开源栈
Gradio是由许多很棒的开源库构建的,请一并支持它们!
[<img src="../huggingface_mini.svg" alt="huggingface" height=40>](https://huggingface.co)
[<img src="../python.svg" alt="python" height=40>](https://www.python.org)
[<img src="../fastapi.svg" alt="fastapi" height=40>](https://fastapi.tiangolo.com)
[<img src="../encode.svg" alt="encode" height=40>](https://www.encode.io)
[<img src="../svelte.svg" alt="svelte" height=40>](https://svelte.dev)
[<img src="../vite.svg" alt="vite" height=40>](https://vitejs.dev)
[<img src="../pnpm.svg" alt="pnpm" height=40>](https://pnpm.io)
[<img src="../tailwind.svg" alt="tailwind" height=40>](https://tailwindcss.com)
## 协议
Gradio is licensed under the Apache License 2.0 found in the [LICENSE](LICENSE) file in the root directory of this repository.
## 引用
另外请参阅论文 _[Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild](https://arxiv.org/abs/1906.02569), ICML HILL 2019_,如果您在工作中使用Gradio请引用它。
```
@article{abid2019gradio,
title = {Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild},
author = {Abid, Abubakar and Abdalla, Ali and Abid, Ali and Khan, Dawood and Alfozan, Abdulrahman and Zou, James},
journal = {arXiv preprint arXiv:1906.02569},
year = {2019},
}
```
| gradio-app/gradio/blob/main/readme_files/zh-cn/README.md |
More on Examples
In the [previous Guide](/main/guides/the-interface-class), we discussed how to provide example inputs for your demo to make it easier for users to try it out. Here, we dive into more details.
## Providing Examples
As covered in the [Key Features](/guides/key-features/#example-inputs) guide, adding examples to an Interface is as easy as providing a list of lists to the `examples`
keyword argument.
Each sublist is a data sample, where each element corresponds to an input of the prediction function.
The inputs must be ordered in the same order as the prediction function expects them.
If your interface only has one input component, then you can provide your examples as a regular list instead of a list of lists.
### Loading Examples from a Directory
You can also specify a path to a directory containing your examples. If your Interface takes only a single file-type input, e.g. an image classifier, you can simply pass a directory filepath to the `examples=` argument, and the `Interface` will load the images in the directory as examples.
In the case of multiple inputs, this directory must
contain a log.csv file with the example values.
In the context of the calculator demo, we can set `examples='/demo/calculator/examples'` and in that directory we include the following `log.csv` file:
```csv
num,operation,num2
5,"add",3
4,"divide",2
5,"multiply",3
```
This can be helpful when browsing flagged data. Simply point to the flagged directory and the `Interface` will load the examples from the flagged data.
### Providing Partial Examples
Sometimes your app has many input components, but you would only like to provide examples for a subset of them. In order to exclude some inputs from the examples, pass `None` for all data samples corresponding to those particular components.
## Caching examples
You may wish to provide some cached examples of your model for users to quickly try out, in case your model takes a while to run normally.
If `cache_examples=True`, the `Interface` will run all of your examples through your app and save the outputs when you call the `launch()` method. This data will be saved in a directory called `gradio_cached_examples` in your working directory by default. You can also set this directory with the `GRADIO_EXAMPLES_CACHE` environment variable, which can be either an absolute path or a relative path to your working directory.
Whenever a user clicks on an example, the output will automatically be populated in the app now, using data from this cached directory instead of actually running the function. This is useful so users can quickly try out your model without adding any load!
Keep in mind once the cache is generated, it will not be updated in future launches. If the examples or function logic change, delete the cache folder to clear the cache and rebuild it with another `launch()`.
| gradio-app/gradio/blob/main/guides/02_building-interfaces/01_more-on-examples.md |
Backend Testing Guidelines
- All the tests should test Backend functionalities. Frontend functionalities and e2e tests are done in Frontend.
- Make use of pytest fixtures whenever it is possible. With fixtures, objects with high initialize durations are reused within tests, ex. a client session.
- All test*data resides within \_gradio/test_data* and all test_files resides within test/test_files.
- When doing network operations do not forget to make use of async to make tests faster.
- Have clear class and function naming within the tests.
- Short descriptions within test functions are great.
- Library function docstrings is expected to contain an example, please add missing docstrings to the library while you are writing tests the related function.
- Library docstring examples and descriptions are expected to align with tests, please fix divergent tests and library docstrings.
| gradio-app/gradio/blob/main/test/README.md |
Loading methods
Methods for listing and loading evaluation modules:
## List
[[autodoc]] evaluate.list_evaluation_modules
## Load
[[autodoc]] evaluate.load
| huggingface/evaluate/blob/main/docs/source/package_reference/loading_methods.mdx |
Gradio and ONNX on Hugging Face
Related spaces: https://huggingface.co/spaces/onnx/EfficientNet-Lite4
Tags: ONNX, SPACES
Contributed by Gradio and the <a href="https://onnx.ai/">ONNX</a> team
## Introduction
In this Guide, we'll walk you through:
- Introduction of ONNX, ONNX model zoo, Gradio, and Hugging Face Spaces
- How to setup a Gradio demo for EfficientNet-Lite4
- How to contribute your own Gradio demos for the ONNX organization on Hugging Face
Here's an [example](https://onnx-efficientnet-lite4.hf.space/) of an ONNX model.
## What is the ONNX Model Zoo?
Open Neural Network Exchange ([ONNX](https://onnx.ai/)) is an open standard format for representing machine learning models. ONNX is supported by a community of partners who have implemented it in many frameworks and tools. For example, if you have trained a model in TensorFlow or PyTorch, you can convert it to ONNX easily, and from there run it on a variety of devices using an engine/compiler like ONNX Runtime.
The [ONNX Model Zoo](https://github.com/onnx/models) is a collection of pre-trained, state-of-the-art models in the ONNX format contributed by community members. Accompanying each model are Jupyter notebooks for model training and running inference with the trained model. The notebooks are written in Python and include links to the training dataset as well as references to the original paper that describes the model architecture.
## What are Hugging Face Spaces & Gradio?
### Gradio
Gradio lets users demo their machine learning models as a web app all in python code. Gradio wraps a python function into a user interface and the demos can be launched inside jupyter notebooks, colab notebooks, as well as embedded in your own website and hosted on Hugging Face Spaces for free.
Get started [here](https://gradio.app/getting_started)
### Hugging Face Spaces
Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ spaces currently on Hugging Face. Learn more about spaces [here](https://huggingface.co/spaces/launch).
### Hugging Face Models
Hugging Face Model Hub also supports ONNX models and ONNX models can be filtered through the [ONNX tag](https://huggingface.co/models?library=onnx&sort=downloads)
## How did Hugging Face help the ONNX Model Zoo?
There are a lot of Jupyter notebooks in the ONNX Model Zoo for users to test models. Previously, users needed to download the models themselves and run those notebooks locally for testing. With Hugging Face, the testing process can be much simpler and more user-friendly. Users can easily try certain ONNX Model Zoo model on Hugging Face Spaces and run a quick demo powered by Gradio with ONNX Runtime, all on cloud without downloading anything locally. Note, there are various runtimes for ONNX, e.g., [ONNX Runtime](https://github.com/microsoft/onnxruntime), [MXNet](https://github.com/apache/incubator-mxnet).
## What is the role of ONNX Runtime?
ONNX Runtime is a cross-platform inference and training machine-learning accelerator. It makes live Gradio demos with ONNX Model Zoo model on Hugging Face possible.
ONNX Runtime inference can enable faster customer experiences and lower costs, supporting models from deep learning frameworks such as PyTorch and TensorFlow/Keras as well as classical machine learning libraries such as scikit-learn, LightGBM, XGBoost, etc. ONNX Runtime is compatible with different hardware, drivers, and operating systems, and provides optimal performance by leveraging hardware accelerators where applicable alongside graph optimizations and transforms. For more information please see the [official website](https://onnxruntime.ai/).
## Setting up a Gradio Demo for EfficientNet-Lite4
EfficientNet-Lite 4 is the largest variant and most accurate of the set of EfficientNet-Lite models. It is an integer-only quantized model that produces the highest accuracy of all of the EfficientNet models. It achieves 80.4% ImageNet top-1 accuracy, while still running in real-time (e.g. 30ms/image) on a Pixel 4 CPU. To learn more read the [model card](https://github.com/onnx/models/tree/main/vision/classification/efficientnet-lite4)
Here we walk through setting up a example demo for EfficientNet-Lite4 using Gradio
First we import our dependencies and download and load the efficientnet-lite4 model from the onnx model zoo. Then load the labels from the labels_map.txt file. We then setup our preprocessing functions, load the model for inference, and setup the inference function. Finally, the inference function is wrapped into a gradio interface for a user to interact with. See the full code below.
```python
import numpy as np
import math
import matplotlib.pyplot as plt
import cv2
import json
import gradio as gr
from huggingface_hub import hf_hub_download
from onnx import hub
import onnxruntime as ort
# loads ONNX model from ONNX Model Zoo
model = hub.load("efficientnet-lite4")
# loads the labels text file
labels = json.load(open("labels_map.txt", "r"))
# sets image file dimensions to 224x224 by resizing and cropping image from center
def pre_process_edgetpu(img, dims):
output_height, output_width, _ = dims
img = resize_with_aspectratio(img, output_height, output_width, inter_pol=cv2.INTER_LINEAR)
img = center_crop(img, output_height, output_width)
img = np.asarray(img, dtype='float32')
# converts jpg pixel value from [0 - 255] to float array [-1.0 - 1.0]
img -= [127.0, 127.0, 127.0]
img /= [128.0, 128.0, 128.0]
return img
# resizes the image with a proportional scale
def resize_with_aspectratio(img, out_height, out_width, scale=87.5, inter_pol=cv2.INTER_LINEAR):
height, width, _ = img.shape
new_height = int(100. * out_height / scale)
new_width = int(100. * out_width / scale)
if height > width:
w = new_width
h = int(new_height * height / width)
else:
h = new_height
w = int(new_width * width / height)
img = cv2.resize(img, (w, h), interpolation=inter_pol)
return img
# crops the image around the center based on given height and width
def center_crop(img, out_height, out_width):
height, width, _ = img.shape
left = int((width - out_width) / 2)
right = int((width + out_width) / 2)
top = int((height - out_height) / 2)
bottom = int((height + out_height) / 2)
img = img[top:bottom, left:right]
return img
sess = ort.InferenceSession(model)
def inference(img):
img = cv2.imread(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = pre_process_edgetpu(img, (224, 224, 3))
img_batch = np.expand_dims(img, axis=0)
results = sess.run(["Softmax:0"], {"images:0": img_batch})[0]
result = reversed(results[0].argsort()[-5:])
resultdic = {}
for r in result:
resultdic[labels[str(r)]] = float(results[0][r])
return resultdic
title = "EfficientNet-Lite4"
description = "EfficientNet-Lite 4 is the largest variant and most accurate of the set of EfficientNet-Lite model. It is an integer-only quantized model that produces the highest accuracy of all of the EfficientNet models. It achieves 80.4% ImageNet top-1 accuracy, while still running in real-time (e.g. 30ms/image) on a Pixel 4 CPU."
examples = [['catonnx.jpg']]
gr.Interface(inference, gr.Image(type="filepath"), "label", title=title, description=description, examples=examples).launch()
```
## How to contribute Gradio demos on HF spaces using ONNX models
- Add model to the [onnx model zoo](https://github.com/onnx/models/blob/main/.github/PULL_REQUEST_TEMPLATE.md)
- Create an account on Hugging Face [here](https://huggingface.co/join).
- See list of models left to add to ONNX organization, please refer to the table with the [Models list](https://github.com/onnx/models#models)
- Add Gradio Demo under your username, see this [blog post](https://huggingface.co/blog/gradio-spaces) for setting up Gradio Demo on Hugging Face.
- Request to join ONNX Organization [here](https://huggingface.co/onnx).
- Once approved transfer model from your username to ONNX organization
- Add a badge for model in model table, see examples in [Models list](https://github.com/onnx/models#models)
| gradio-app/gradio/blob/main/guides/06_integrating-other-frameworks/Gradio-and-ONNX-on-Hugging-Face.md |
!--Copyright 2022 The HuggingFace Team and Microsoft. All rights reserved.
Licensed under the MIT License; you may not use this file except in compliance with
the License.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Graphormer
## Overview
The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen and Tie-Yan Liu. It is a Graph Transformer model, modified to allow computations on graphs instead of text sequences by generating embeddings and features of interest during preprocessing and collation, then using a modified attention.
The abstract from the paper is the following:
*The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.*
This model was contributed by [clefourrier](https://huggingface.co/clefourrier). The original code can be found [here](https://github.com/microsoft/Graphormer).
## Usage tips
This model will not work well on large graphs (more than 100 nodes/edges), as it will make the memory explode.
You can reduce the batch size, increase your RAM, or decrease the `UNREACHABLE_NODE_DISTANCE` parameter in algos_graphormer.pyx, but it will be hard to go above 700 nodes/edges.
This model does not use a tokenizer, but instead a special collator during training.
## GraphormerConfig
[[autodoc]] GraphormerConfig
## GraphormerModel
[[autodoc]] GraphormerModel
- forward
## GraphormerForGraphClassification
[[autodoc]] GraphormerForGraphClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/graphormer.md |
Introduction [[introduction]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/thumbnail.png" alt="thumbnail"/>
In the last unit, we learned about Deep Q-Learning. In this value-based deep reinforcement learning algorithm, we **used a deep neural network to approximate the different Q-values for each possible action at a state.**
Since the beginning of the course, we have only studied value-based methods, **where we estimate a value function as an intermediate step towards finding an optimal policy.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="Link value policy" />
In value-based methods, the policy ** \(π\) only exists because of the action value estimates since the policy is just a function** (for instance, greedy-policy) that will select the action with the highest value given a state.
With policy-based methods, we want to optimize the policy directly **without having an intermediate step of learning a value function.**
So today, **we'll learn about policy-based methods and study a subset of these methods called policy gradient**. Then we'll implement our first policy gradient algorithm called Monte Carlo **Reinforce** from scratch using PyTorch.
Then, we'll test its robustness using the CartPole-v1 and PixelCopter environments.
You'll then be able to iterate and improve this implementation for more advanced environments.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/envs.gif" alt="Environments"/>
</figure>
Let's get started!
| huggingface/deep-rl-class/blob/main/units/en/unit4/introduction.mdx |
Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
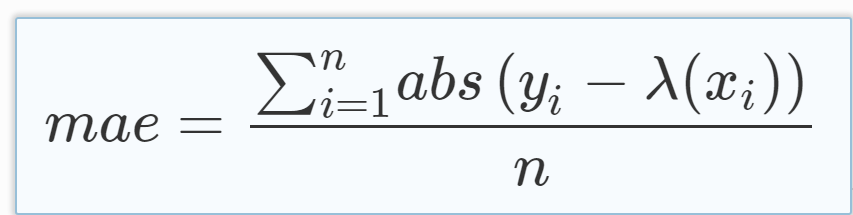
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mae_metric = datasets.load_metric("mae")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mae_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MAE `float` value ranges from `0.0` to `1.0`, with the best value being 0.0.
Output Example(s):
```python
{'mae': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mae': array([0.5, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> from datasets import load_metric
>>> mae_metric = load_metric("mae")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mae_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mae': 0.5}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> from datasets import load_metric
>>> mae_metric = datasets.load_metric("mae", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0, 2], [-1, 2], [8, -5]]
>>> results = mae_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mae': 0.75}
>>> results = mae_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mae': array([0.5, 1. ])}
```
## Limitations and Bias
One limitation of MAE is that the relative size of the error is not always obvious, meaning that it can be difficult to tell a big error from a smaller one -- metrics such as Mean Absolute Percentage Error (MAPE) have been proposed to calculate MAE in percentage terms.
Also, since it calculates the mean, MAE may underestimate the impact of big, but infrequent, errors -- metrics such as the Root Mean Square Error (RMSE) compensate for this by taking the root of error values.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{willmott2005advantages,
title={Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance},
author={Willmott, Cort J and Matsuura, Kenji},
journal={Climate research},
volume={30},
number={1},
pages={79--82},
year={2005}
}
```
## Further References
- [Mean Absolute Error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_error)
| huggingface/datasets/blob/main/metrics/mae/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Unconditional image generation
Unconditional image generation models are not conditioned on text or images during training. It only generates images that resemble its training data distribution.
This guide will explore the [train_unconditional.py](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py) training script to help you become familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies:
```bash
cd examples/unconditional_image_generation
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
## Script parameters
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py) and let us know if you have any questions or concerns.
</Tip>
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L55) function. It provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the bf16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_unconditional.py \
--mixed_precision="bf16"
```
Some basic and important parameters to specify include:
- `--dataset_name`: the name of the dataset on the Hub or a local path to the dataset to train on
- `--output_dir`: where to save the trained model
- `--push_to_hub`: whether to push the trained model to the Hub
- `--checkpointing_steps`: frequency of saving a checkpoint as the model trains; this is useful if training is interrupted, you can continue training from that checkpoint by adding `--resume_from_checkpoint` to your training command
Bring your dataset, and let the training script handle everything else!
## Training script
The code for preprocessing the dataset and the training loop is found in the [`main()`](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L275) function. If you need to adapt the training script, this is where you'll need to make your changes.
The `train_unconditional` script [initializes a `UNet2DModel`](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L356) if you don't provide a model configuration. You can configure the UNet here if you'd like:
```py
model = UNet2DModel(
sample_size=args.resolution,
in_channels=3,
out_channels=3,
layers_per_block=2,
block_out_channels=(128, 128, 256, 256, 512, 512),
down_block_types=(
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D",
"DownBlock2D",
),
up_block_types=(
"UpBlock2D",
"AttnUpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
),
)
```
Next, the script initializes a [scheduler](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L418) and [optimizer](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L429):
```py
# Initialize the scheduler
accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
if accepts_prediction_type:
noise_scheduler = DDPMScheduler(
num_train_timesteps=args.ddpm_num_steps,
beta_schedule=args.ddpm_beta_schedule,
prediction_type=args.prediction_type,
)
else:
noise_scheduler = DDPMScheduler(num_train_timesteps=args.ddpm_num_steps, beta_schedule=args.ddpm_beta_schedule)
# Initialize the optimizer
optimizer = torch.optim.AdamW(
model.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Then it [loads a dataset](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L451) and you can specify how to [preprocess](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L455) it:
```py
dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")
augmentations = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
```
Finally, the [training loop](https://github.com/huggingface/diffusers/blob/096f84b05f9514fae9f185cbec0a4d38fbad9919/examples/unconditional_image_generation/train_unconditional.py#L540) handles everything else such as adding noise to the images, predicting the noise residual, calculating the loss, saving checkpoints at specified steps, and saving and pushing the model to the Hub. If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Once you've made all your changes or you're okay with the default configuration, you're ready to launch the training script! 🚀
<Tip warning={true}>
A full training run takes 2 hours on 4xV100 GPUs.
</Tip>
<hfoptions id="launchtraining">
<hfoption id="single GPU">
```bash
accelerate launch train_unconditional.py \
--dataset_name="huggan/flowers-102-categories" \
--output_dir="ddpm-ema-flowers-64" \
--mixed_precision="fp16" \
--push_to_hub
```
</hfoption>
<hfoption id="multi-GPU">
If you're training with more than one GPU, add the `--multi_gpu` parameter to the training command:
```bash
accelerate launch --multi_gpu train_unconditional.py \
--dataset_name="huggan/flowers-102-categories" \
--output_dir="ddpm-ema-flowers-64" \
--mixed_precision="fp16" \
--push_to_hub
```
</hfoption>
</hfoptions>
The training script creates and saves a checkpoint file in your repository. Now you can load and use your trained model for inference:
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("anton-l/ddpm-butterflies-128").to("cuda")
image = pipeline().images[0]
```
| huggingface/diffusers/blob/main/docs/source/en/training/unconditional_training.md |
# 使用 Gradio 进行表格数据科学工作流
Related spaces: https://huggingface.co/spaces/scikit-learn/gradio-skops-integration,https://huggingface.co/spaces/scikit-learn/tabular-playground,https://huggingface.co/spaces/merve/gradio-analysis-dashboard
## 介绍
表格数据科学是机器学习中应用最广泛的领域,涉及的问题从客户分割到流失预测不等。在表格数据科学工作流的各个阶段中,将工作内容传达给利益相关者或客户可能很麻烦,这会阻碍数据科学家专注于重要事项,如数据分析和模型构建。数据科学家可能会花费数小时构建一个接受 DataFrame 并返回图表、预测或数据集中的聚类图的仪表板。在本指南中,我们将介绍如何使用 `gradio` 改进您的数据科学工作流程。我们还将讨论如何使用 `gradio` 和[skops](https://skops.readthedocs.io/en/stable/)一行代码即可构建界面!
### 先决条件
确保您已经[安装](/getting_started)了 `gradio` Python 软件包。
## 让我们创建一个简单的界面!
我们将看一下如何创建一个简单的界面,该界面根据产品信息预测故障。
```python
import gradio as gr
import pandas as pd
import joblib
import datasets
inputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(4,"dynamic"), label="Input Data", interactive=1)]
outputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(1, "fixed"), label="Predictions", headers=["Failures"])]
model = joblib.load("model.pkl")
# we will give our dataframe as example
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
def infer(input_dataframe):
return pd.DataFrame(model.predict(input_dataframe))
gr.Interface(fn = infer, inputs = inputs, outputs = outputs, examples = [[df.head(2)]]).launch()
```
让我们来解析上述代码。
- `fn`:推理函数,接受输入数据帧并返回预测结果。
- `inputs`:我们使用 `Dataframe` 组件作为输入。我们将输入定义为具有 2 行 4 列的数据帧,最初的数据帧将呈现出上述形状的空数据帧。当将 `row_count` 设置为 `dynamic` 时,不必依赖于正在输入的数据集来预定义组件。
- `outputs`:用于存储输出的数据帧组件。该界面可以接受单个或多个样本进行推断,并在一列中为每个样本返回 0 或 1,因此我们将 `row_count` 设置为 2,`col_count` 设置为 1。`headers` 是由数据帧的列名组成的列表。
- `examples`:您可以通过拖放 CSV 文件或通过示例传递 pandas DataFrame,界面会自动获取其标题。
现在我们将为简化版数据可视化仪表板创建一个示例。您可以在相关空间中找到更全面的版本。
<gradio-app space="gradio/tabular-playground"></gradio-app>
```python
import gradio as gr
import pandas as pd
import datasets
import seaborn as sns
import matplotlib.pyplot as plt
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
df.dropna(axis=0, inplace=True)
def plot(df):
plt.scatter(df.measurement_13, df.measurement_15, c = df.loading,alpha=0.5)
plt.savefig("scatter.png")
df['failure'].value_counts().plot(kind='bar')
plt.savefig("bar.png")
sns.heatmap(df.select_dtypes(include="number").corr())
plt.savefig("corr.png")
plots = ["corr.png","scatter.png", "bar.png"]
return plots
inputs = [gr.Dataframe(label="Supersoaker Production Data")]
outputs = [gr.Gallery(label="Profiling Dashboard", columns=(1,3))]
gr.Interface(plot, inputs=inputs, outputs=outputs, examples=[df.head(100)], title="Supersoaker Failures Analysis Dashboard").launch()
```
<gradio-app space="gradio/gradio-analysis-dashboard-minimal"></gradio-app>
我们将使用与训练模型相同的数据集,但这次我们将创建一个可视化仪表板以展示它。
- `fn`:根据数据创建图表的函数。
- `inputs`:我们使用了与上述相同的 `Dataframe` 组件。
- `outputs`:我们使用 `Gallery` 组件来存放我们的可视化结果。
- `examples`:我们将数据集本身作为示例。
## 使用 skops 一行代码轻松加载表格数据界面
`skops` 是一个构建在 `huggingface_hub` 和 `sklearn` 之上的库。通过最新的 `gradio` 集成,您可以使用一行代码构建表格数据界面!
```python
import gradio as gr
# 标题和描述是可选的
title = "Supersoaker产品缺陷预测"
description = "该模型预测Supersoaker生产线故障。在下面的数据帧组件中,您可以拖放数据集的任意切片或自行编辑值。"
gr.load("huggingface/scikit-learn/tabular-playground", title=title, description=description).launch()
```
<gradio-app space="gradio/gradio-skops-integration"></gradio-app>
使用 `skops` 将 `sklearn` 模型推送到 Hugging Face Hub 时,会包含一个包含示例输入和列名的 `config.json` 文件,解决的任务类型是 `tabular-classification` 或 `tabular-regression`。根据任务类型,`gradio` 构建界面并使用列名和示例输入来构建它。您可以[参考 skops 在 Hub 上托管模型的文档](https://skops.readthedocs.io/en/latest/auto_examples/plot_hf_hub.html#sphx-glr-auto-examples-plot-hf-hub-py)来了解如何使用 `skops` 将模型推送到 Hub。
| gradio-app/gradio/blob/main/guides/cn/05_tabular-data-science-and-plots/using-gradio-for-tabular-workflows.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# YOLOS
## Overview
The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
The abstract from the paper is the following:
*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/yolos_architecture.png"
alt="drawing" width="600"/>
<small> YOLOS architecture. Taken from the <a href="https://arxiv.org/abs/2106.00666">original paper</a>.</small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with YOLOS.
<PipelineTag pipeline="object-detection"/>
- All example notebooks illustrating inference + fine-tuning [`YolosForObjectDetection`] on a custom dataset can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
- See also: [Object detection task guide](../tasks/object_detection)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
</Tip>
## YolosConfig
[[autodoc]] YolosConfig
## YolosImageProcessor
[[autodoc]] YolosImageProcessor
- preprocess
- pad
- post_process_object_detection
## YolosFeatureExtractor
[[autodoc]] YolosFeatureExtractor
- __call__
- pad
- post_process_object_detection
## YolosModel
[[autodoc]] YolosModel
- forward
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/yolos.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ELECTRA
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=electra">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-electra-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/electra_large_discriminator_squad2_512">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The ELECTRA model was proposed in the paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than
Generators](https://openreview.net/pdf?id=r1xMH1BtvB). ELECTRA is a new pretraining approach which trains two
transformer models: the generator and the discriminator. The generator's role is to replace tokens in a sequence, and
is therefore trained as a masked language model. The discriminator, which is the model we're interested in, tries to
identify which tokens were replaced by the generator in the sequence.
The abstract from the paper is the following:
*Masked language modeling (MLM) pretraining methods such as BERT corrupt the input by replacing some tokens with [MASK]
and then train a model to reconstruct the original tokens. While they produce good results when transferred to
downstream NLP tasks, they generally require large amounts of compute to be effective. As an alternative, we propose a
more sample-efficient pretraining task called replaced token detection. Instead of masking the input, our approach
corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead
of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that
predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments
demonstrate this new pretraining task is more efficient than MLM because the task is defined over all input tokens
rather than just the small subset that was masked out. As a result, the contextual representations learned by our
approach substantially outperform the ones learned by BERT given the same model size, data, and compute. The gains are
particularly strong for small models; for example, we train a model on one GPU for 4 days that outperforms GPT (trained
using 30x more compute) on the GLUE natural language understanding benchmark. Our approach also works well at scale,
where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when
using the same amount of compute.*
This model was contributed by [lysandre](https://huggingface.co/lysandre). The original code can be found [here](https://github.com/google-research/electra).
## Usage tips
- ELECTRA is the pretraining approach, therefore there is nearly no changes done to the underlying model: BERT. The
only change is the separation of the embedding size and the hidden size: the embedding size is generally smaller,
while the hidden size is larger. An additional projection layer (linear) is used to project the embeddings from their
embedding size to the hidden size. In the case where the embedding size is the same as the hidden size, no projection
layer is used.
- ELECTRA is a transformer model pretrained with the use of another (small) masked language model. The inputs are corrupted by that language model, which takes an input text that is randomly masked and outputs a text in which ELECTRA has to predict which token is an original and which one has been replaced. Like for GAN training, the small language model is trained for a few steps (but with the original texts as objective, not to fool the ELECTRA model like in a traditional GAN setting) then the ELECTRA model is trained for a few steps.
- The ELECTRA checkpoints saved using [Google Research's implementation](https://github.com/google-research/electra)
contain both the generator and discriminator. The conversion script requires the user to name which model to export
into the correct architecture. Once converted to the HuggingFace format, these checkpoints may be loaded into all
available ELECTRA models, however. This means that the discriminator may be loaded in the
[`ElectraForMaskedLM`] model, and the generator may be loaded in the
[`ElectraForPreTraining`] model (the classification head will be randomly initialized as it
doesn't exist in the generator).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## ElectraConfig
[[autodoc]] ElectraConfig
## ElectraTokenizer
[[autodoc]] ElectraTokenizer
## ElectraTokenizerFast
[[autodoc]] ElectraTokenizerFast
## Electra specific outputs
[[autodoc]] models.electra.modeling_electra.ElectraForPreTrainingOutput
[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
<frameworkcontent>
<pt>
## ElectraModel
[[autodoc]] ElectraModel
- forward
## ElectraForPreTraining
[[autodoc]] ElectraForPreTraining
- forward
## ElectraForCausalLM
[[autodoc]] ElectraForCausalLM
- forward
## ElectraForMaskedLM
[[autodoc]] ElectraForMaskedLM
- forward
## ElectraForSequenceClassification
[[autodoc]] ElectraForSequenceClassification
- forward
## ElectraForMultipleChoice
[[autodoc]] ElectraForMultipleChoice
- forward
## ElectraForTokenClassification
[[autodoc]] ElectraForTokenClassification
- forward
## ElectraForQuestionAnswering
[[autodoc]] ElectraForQuestionAnswering
- forward
</pt>
<tf>
## TFElectraModel
[[autodoc]] TFElectraModel
- call
## TFElectraForPreTraining
[[autodoc]] TFElectraForPreTraining
- call
## TFElectraForMaskedLM
[[autodoc]] TFElectraForMaskedLM
- call
## TFElectraForSequenceClassification
[[autodoc]] TFElectraForSequenceClassification
- call
## TFElectraForMultipleChoice
[[autodoc]] TFElectraForMultipleChoice
- call
## TFElectraForTokenClassification
[[autodoc]] TFElectraForTokenClassification
- call
## TFElectraForQuestionAnswering
[[autodoc]] TFElectraForQuestionAnswering
- call
</tf>
<jax>
## FlaxElectraModel
[[autodoc]] FlaxElectraModel
- __call__
## FlaxElectraForPreTraining
[[autodoc]] FlaxElectraForPreTraining
- __call__
## FlaxElectraForCausalLM
[[autodoc]] FlaxElectraForCausalLM
- __call__
## FlaxElectraForMaskedLM
[[autodoc]] FlaxElectraForMaskedLM
- __call__
## FlaxElectraForSequenceClassification
[[autodoc]] FlaxElectraForSequenceClassification
- __call__
## FlaxElectraForMultipleChoice
[[autodoc]] FlaxElectraForMultipleChoice
- __call__
## FlaxElectraForTokenClassification
[[autodoc]] FlaxElectraForTokenClassification
- __call__
## FlaxElectraForQuestionAnswering
[[autodoc]] FlaxElectraForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/electra.md |
Creating and sharing a new evaluation
## Setup
Before you can create a new metric make sure you have all the necessary dependencies installed:
```bash
pip install evaluate[template]
```
Also make sure your Hugging Face token is registered so you can connect to the Hugging Face Hub:
```bash
huggingface-cli login
```
## Create
All evaluation modules, be it metrics, comparisons, or measurements live on the 🤗 Hub in a [Space](https://huggingface.co/docs/hub/spaces) (see for example [Accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy)). In principle, you could setup a new Space and add a new module following the same structure. However, we added a CLI that makes creating a new evaluation module much easier:
```bash
evaluate-cli create "My Metric" --module_type "metric"
```
This will create a new Space on the 🤗 Hub, clone it locally, and populate it with a template. Instructions on how to fill the template will be displayed in the terminal, but are also explained here in more detail.
For more information about Spaces, see the [Spaces documentation](https://huggingface.co/docs/hub/spaces).
## Module script
The evaluation module script (the file with suffix `*.py`) is the core of the new module and includes all the code for computing the evaluation.
### Attributes
Start by adding some information about your evalution module in [`EvaluationModule._info`]. The most important attributes you should specify are:
1. [`EvaluationModuleInfo.description`] provides a brief description about your evalution module.
2. [`EvaluationModuleInfo.citation`] contains a BibTex citation for the evalution module.
3. [`EvaluationModuleInfo.inputs_description`] describes the expected inputs and outputs. It may also provide an example usage of the evalution module.
4. [`EvaluationModuleInfo.features`] defines the name and type of the predictions and references. This has to be either a single `datasets.Features` object or a list of `datasets.Features` objects if multiple input types are allowed.
Then, we can move on to prepare everything before the actual computation.
### Download
Some evaluation modules require some external data such as NLTK that requires resources or the BLEURT metric that requires checkpoints. You can implement these downloads in [`EvaluationModule._download_and_prepare`], which downloads and caches the resources via the `dlmanager`. A simplified example on how BLEURT downloads and loads a checkpoint:
```py
def _download_and_prepare(self, dl_manager):
model_path = dl_manager.download_and_extract(CHECKPOINT_URLS[self.config_name])
self.scorer = score.BleurtScorer(os.path.join(model_path, self.config_name))
```
Or if you need to download the NLTK `"punkt"` resources:
```py
def _download_and_prepare(self, dl_manager):
import nltk
nltk.download("punkt")
```
Next, we need to define how the computation of the evaluation module works.
### Compute
The computation is performed in the [`EvaluationModule._compute`] method. It takes the same arguments as `EvaluationModuleInfo.features` and should then return the result as a dictionary. Here an example of an exact match metric:
```py
def _compute(self, references, predictions):
em = sum([r==p for r, p in zip(references, predictions)])/len(references)
return {"exact_match": em}
```
This method is used when you call `.compute()` later on.
## Readme
When you use the `evalute-cli` to setup the evaluation module the Readme structure and instructions are automatically created. It should include a general description of the metric, information about its input/output format, examples as well as information about its limiations or biases and references.
## Requirements
If your evaluation modules has additional dependencies (e.g. `sklearn` or `nltk`) the `requirements.txt` files is the place to put them. The file follows the `pip` format and you can list all dependencies there.
## App
The `app.py` is where the Spaces widget lives. In general it looks like the following and does not require any changes:
```py
import evaluate
from evaluate.utils import launch_gradio_widget
module = evaluate.load("lvwerra/element_count")
launch_gradio_widget(module)
```
If you want a custom widget you could add your gradio app here.
## Push to Hub
Finally, when you are done with all the above changes it is time to push your evaluation module to the hub. To do so navigate to the folder of your module and git add/commit/push the changes to the hub:
```
cd PATH_TO_MODULE
git add .
git commit -m "Add my new, shiny module."
git push
```
Tada 🎉! Your evaluation module is now on the 🤗 Hub and ready to be used by everybody!
| huggingface/evaluate/blob/main/docs/source/creating_and_sharing.mdx |
--
title: "Case Study: Millisecond Latency using Hugging Face Infinity and modern CPUs"
thumbnail: /blog/assets/46_infinity_cpu_performance/thumbnail.png
authors:
- user: philschmid
- user: jeffboudier
- user: mfuntowicz
---
# Case Study: Millisecond Latency using Hugging Face Infinity and modern CPUs
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
December 2022 Update: Infinity is no longer offered by Hugging Face as a commercial inference solution. To deploy and accelerate your models, we recommend the following new solutions:
* [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) to easily deploy models on dedicated infrastructure managed by Hugging Face.
* Our open-source optimization libraries, [🤗 Optimum Intel](https://huggingface.co/blog/openvino) and [🤗 Optimum ONNX Runtime](https://huggingface.co/docs/optimum/main/en/onnxruntime/overview), to get the highest efficiency out of training and running models for inference.
* Hugging Face [Expert Acceleration Program](https://huggingface.co/support), a commercial service for Hugging Face experts to work directly with your team to accelerate your Machine Learning roadmap and models.
</div>
## Introduction
Transfer learning has changed Machine Learning by reaching new levels of accuracy from Natural Language Processing (NLP) to Audio and Computer Vision tasks. At Hugging Face, we work hard to make these new complex models and large checkpoints as easily accessible and usable as possible. But while researchers and data scientists have converted to the new world of Transformers, few companies have been able to deploy these large, complex models in production at scale.
The main bottleneck is the latency of predictions which can make large deployments expensive to run and real-time use cases impractical. Solving this is a difficult engineering challenge for any Machine Learning Engineering team and requires the use of advanced techniques to optimize models all the way down to the hardware.
With [Hugging Face Infinity](https://huggingface.co/infinity), we offer a containerized solution that makes it easy to deploy low-latency, high-throughput, hardware-accelerated inference pipelines for the most popular Transformer models. Companies can get both the accuracy of Transformers and the efficiency necessary for large volume deployments, all in a simple to use package. In this blog post, we want to share detailed performance results for Infinity running on the latest generation of Intel Xeon CPU, to achieve optimal cost, efficiency, and latency for your Transformer deployments.
## What is Hugging Face Infinity
Hugging Face Infinity is a containerized solution for customers to deploy end-to-end optimized inference pipelines for State-of-the-Art Transformer models, on any infrastructure.
Hugging Face Infinity consists of 2 main services:
* The Infinity Container is a hardware-optimized inference solution delivered as a Docker container.
* Infinity Multiverse is a Model Optimization Service through which a Hugging Face Transformer model is optimized for the Target Hardware. Infinity Multiverse is compatible with Infinity Container.
The Infinity Container is built specifically to run on a Target Hardware architecture and exposes an HTTP /predict endpoint to run inference.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Product overview" src="assets/46_infinity_cpu_performance/overview.png"></medium-zoom>
<figcaption>Figure 1. Infinity Overview</figcaption>
</figure>
<br>
An Infinity Container is designed to serve 1 Model and 1 Task. A Task corresponds to machine learning tasks as defined in the [Transformers Pipelines documentation](https://huggingface.co/docs/transformers/master/en/main_classes/pipelines). As of the writing of this blog post, supported tasks include feature extraction/document embedding, ranking, sequence classification, and token classification.
You can find more information about Hugging Face Infinity at [hf.co/infinity](https://huggingface.co/infinity), and if you are interested in testing it for yourself, you can sign up for a free trial at [hf.co/infinity-trial](https://huggingface.co/infinity-trial).
---
## Benchmark
Inference performance benchmarks often only measure the execution of the model. In this blog post, and when discussing the performance of Infinity, we always measure the end-to-end pipeline including pre-processing, prediction, post-processing. Please keep this in mind when comparing these results with other latency measurements.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Pipeline" src="assets/46_infinity_cpu_performance/pipeline.png"></medium-zoom>
<figcaption>Figure 2. Infinity End-to-End Pipeline</figcaption>
</figure>
<br>
### Environment
As a benchmark environment, we are going to use the [Amazon EC2 C6i instances](https://aws.amazon.com/ec2/instance-types/c6i), which are compute-optimized instances powered by the 3rd generation of Intel Xeon Scalable processors. These new Intel-based instances are using the ice-lake Process Technology and support Intel AVX-512, Intel Turbo Boost, and Intel Deep Learning Boost.
In addition to superior performance for machine learning workloads, the Intel Ice Lake C6i instances offer great cost-performance and are our recommendation to deploy Infinity on Amazon Web Services. To learn more, visit the [EC2 C6i instance](https://aws.amazon.com/ec2/instance-types/c6i) page.
### Methodologies
When it comes to benchmarking BERT-like models, two metrics are most adopted:
* **Latency**: Time it takes for a single prediction of the model (pre-process, prediction, post-process)
* **Throughput**: Number of executions performed in a fixed amount of time for one benchmark configuration, respecting Physical CPU cores, Sequence Length, and Batch Size
These two metrics will be used to benchmark Hugging Face Infinity across different setups to understand the benefits and tradeoffs in this blog post.
---
## Results
To run the benchmark, we created an infinity container for the [EC2 C6i instance](https://aws.amazon.com/ec2/instance-types/c6i) (Ice-lake) and optimized a [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) model for sequence classification using Infinity Multiverse.
This ice-lake optimized Infinity Container can achieve up to 34% better latency & throughput compared to existing cascade-lake-based instances, and up to 800% better latency & throughput compared to vanilla transformers running on ice-lake.
The Benchmark we created consists of 192 different experiments and configurations. We ran experiments for:
* Physical CPU cores: 1, 2, 4, 8
* Sequence length: 8, 16, 32, 64, 128, 256, 384, 512
* Batch_size: 1, 2, 4, 8, 16, 32
In each experiment, we collect numbers for:
* Throughput (requests per second)
* Latency (min, max, avg, p90, p95, p99)
You can find the full data of the benchmark in this google spreadsheet: [🤗 Infinity: CPU Ice-Lake Benchmark](https://docs.google.com/spreadsheets/d/1GWFb7L967vZtAS1yHhyTOZK1y-ZhdWUFqovv7-73Plg/edit?usp=sharing).
In this blog post, we will highlight a few results of the benchmark including the best latency and throughput configurations.
In addition to this, we deployed the [DistilBERT](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion) model we used for the benchmark as an API endpoint on 2 physical cores. You can test it and get a feeling for the performance of Infinity. Below you will find a `curl` command on how to send a request to the hosted endpoint. The API returns a `x-compute-time` HTTP Header, which contains the duration of the end-to-end pipeline.
```bash
curl --request POST `-i` \
--url https://infinity.huggingface.co/cpu/distilbert-base-uncased-emotion \
--header 'Content-Type: application/json' \
--data '{"inputs":"I like you. I love you"}'
```
### Throughput
Below you can find the throughput comparison for running infinity on 2 physical cores with batch size 1, compared with vanilla transformers.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Throughput" src="assets/46_infinity_cpu_performance/throughput.png"></medium-zoom>
<figcaption>Figure 3. Throughput: Infinity vs Transformers</figcaption>
</figure>
<br>
| Sequence Length | Infinity | Transformers | improvement |
|-----------------|-------------|--------------|-------------|
| 8 | 248 req/sec | 49 req/sec | +506% |
| 16 | 212 req/sec | 50 req/sec | +424% |
| 32 | 150 req/sec | 40 req/sec | +375% |
| 64 | 97 req/sec | 28 req/sec | +346% |
| 128 | 55 req/sec | 18 req/sec | +305% |
| 256 | 27 req/sec | 9 req/sec | +300% |
| 384 | 17 req/sec | 5 req/sec | +340% |
| 512 | 12 req/sec | 4 req/sec | +300% |
### Latency
Below, you can find the latency results for an experiment running Hugging Face Infinity on 2 Physical Cores with Batch Size 1. It is remarkable to see how robust and constant Infinity is, with minimal deviation for p95, p99, or p100 (max latency). This result is confirmed for other experiments as well in the benchmark.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Latency" src="assets/46_infinity_cpu_performance/latency.png"></medium-zoom>
<figcaption>Figure 4. Latency (Batch=1, Physical Cores=2)</figcaption>
</figure>
<br>
---
## Conclusion
In this post, we showed how Hugging Face Infinity performs on the new Intel Ice Lake Xeon CPU. We created a detailed benchmark with over 190 different configurations sharing the results you can expect when using Hugging Face Infinity on CPU, what would be the best configuration to optimize your Infinity Container for latency, and what would be the best configuration to maximize throughput.
Hugging Face Infinity can deliver up to 800% higher throughput compared to vanilla transformers, and down to 1-4ms latency for sequence lengths up to 64 tokens.
The flexibility to optimize transformer models for throughput, latency, or both enables businesses to either reduce the amount of infrastructure cost for the same workload or to enable real-time use cases that were not possible before.
If you are interested in trying out Hugging Face Infinity sign up for your trial at [hf.co/infinity-trial](https://hf.co/infinity-trial)
## Resources
* [Hugging Face Infinity](https://huggingface.co/infinity)
* [Hugging Face Infinity Trial](https://huggingface.co/infinity-trial)
* [Amazon EC2 C6i instances](https://aws.amazon.com/ec2/instance-types/c6i)
* [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)
* [DistilBERT paper](https://arxiv.org/abs/1910.01108)
* [DistilBERT model](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion)
* [🤗 Infinity: CPU Ice-Lake Benchmark](https://docs.google.com/spreadsheets/d/1GWFb7L967vZtAS1yHhyTOZK1y-ZhdWUFqovv7-73Plg/edit?usp=sharing)
| huggingface/blog/blob/main/infinity-cpu-performance.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# AltCLIP
## Overview
The AltCLIP model was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu. AltCLIP
(Altering the Language Encoder in CLIP) is a neural network trained on a variety of image-text and text-text pairs. By switching CLIP's
text encoder with a pretrained multilingual text encoder XLM-R, we could obtain very close performances with CLIP on almost all tasks, and extended original CLIP's capabilities such as multilingual understanding.
The abstract from the paper is the following:
*In this work, we present a conceptually simple and effective method to train a strong bilingual multimodal representation model.
Starting from the pretrained multimodal representation model CLIP released by OpenAI, we switched its text encoder with a pretrained
multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of
teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art
performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with
CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
This model was contributed by [jongjyh](https://huggingface.co/jongjyh).
## Usage tips and example
The usage of AltCLIP is very similar to the CLIP. the difference between CLIP is the text encoder. Note that we use bidirectional attention instead of casual attention
and we take the [CLS] token in XLM-R to represent text embedding.
AltCLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
classification. AltCLIP uses a ViT like transformer to get visual features and a bidirectional language model to get the text
features. Both the text and visual features are then projected to a latent space with identical dimension. The dot
product between the projected image and text features is then used as a similar score.
To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image. The authors
also add absolute position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
The [`CLIPImageProcessor`] can be used to resize (or rescale) and normalize images for the model.
The [`AltCLIPProcessor`] wraps a [`CLIPImageProcessor`] and a [`XLMRobertaTokenizer`] into a single instance to both
encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
[`AltCLIPProcessor`] and [`AltCLIPModel`].
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AltCLIPModel, AltCLIPProcessor
>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
<Tip>
This model is based on `CLIPModel`, use it like you would use the original [CLIP](clip).
</Tip>
## AltCLIPConfig
[[autodoc]] AltCLIPConfig
- from_text_vision_configs
## AltCLIPTextConfig
[[autodoc]] AltCLIPTextConfig
## AltCLIPVisionConfig
[[autodoc]] AltCLIPVisionConfig
## AltCLIPProcessor
[[autodoc]] AltCLIPProcessor
## AltCLIPModel
[[autodoc]] AltCLIPModel
- forward
- get_text_features
- get_image_features
## AltCLIPTextModel
[[autodoc]] AltCLIPTextModel
- forward
## AltCLIPVisionModel
[[autodoc]] AltCLIPVisionModel
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/altclip.md |
--
title: "Introducing ⚔️ AI vs. AI ⚔️ a deep reinforcement learning multi-agents competition system"
thumbnail: /blog/assets/128_aivsai/thumbnail.png
authors:
- user: CarlCochet
- user: ThomasSimonini
---
# Introducing ⚔️ AI vs. AI ⚔️ a deep reinforcement learning multi-agents competition system
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/thumbnail.png" alt="Thumbnail">
</div>
We’re excited to introduce a new tool we created: **⚔️ AI vs. AI ⚔️, a deep reinforcement learning multi-agents competition system**.
This tool, hosted on [Spaces](https://hf.co/spaces), allows us **to create multi-agent competitions**. It is composed of three elements:
- A *Space* with a matchmaking algorithm that **runs the model fights using a background task**.
- A *Dataset* **containing the results**.
- A *Leaderboard* that gets the **match history results and displays the models’ ELO**.
Then, when a user pushes a trained model to the Hub, **it gets evaluated and ranked against others**. Thanks to that, we can evaluate your agents against other’s agents in a multi-agent setting.
In addition to being a useful tool for hosting multi-agent competitions, we think this tool can also be a **robust evaluation technique in multi-agent settings.** By playing against a lot of policies, your agents are evaluated against a wide range of behaviors. This should give you a good idea of the quality of your policy.
Let’s see how it works with our first competition host: SoccerTwos Challenge.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/soccertwos.gif" alt="SoccerTwos example">
</div>
## How does AI vs. AI works?
AI vs. AI is an open-source tool developed at Hugging Face **to rank the strength of reinforcement learning models in a multi-agent setting**.
The idea is to get a **relative measure of skill rather than an objective one** by making the models play against each other continuously and use the matches results to assess their performance compared to all the other models and consequently get a view of the quality of their policy without requiring classic metrics.
The more agents are submitted for a given task or environment, **the more representative the rating becomes**.
To generate a rating based on match results in a competitive environment, we decided to base the rankings on the [ELO rating system](https://en.wikipedia.org/wiki/Elo_rating_system).
The core concept is that after a match ends, the rating of both players are updated based on the result and the ratings they had before the game. When a user with a high rating beats one with a low ranking, they won't get many points. Likewise, the loser would not lose many points in this case.
Conversely, if a low-rated player wins in an upset against a high-rated player, it will cause a more significant effect on both of their ratings.
In our context, we **kept the system as simple as possible by not adding any alteration to the quantities gained or lost based on the starting ratings of the player**. As such, gain and loss will always be the perfect opposite (+10 / -10, for instance), and the average ELO rating will stay constant at the starting rating. The choice of a 1200 ELO rating start is entirely arbitrary.
If you want to learn more about ELO and see some calculation example, we wrote an explanation in our Deep Reinforcement Learning Course [here](https://huggingface.co/deep-rl-course/unit7/self-play?fw=pt#the-elo-score-to-evaluate-our-agent)
Using this rating, it is possible **to generate matches between models with comparable strengths automatically**. There are several ways you can go about creating a matchmaking system, but here we decided to keep it fairly simple while guaranteeing a minimum amount of diversity in the matchups and also keeping most matches with fairly close opposing ratings.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/aivsai.png" alt="AI vs AI Process">
</div>
Here's how works the algorithm:
1. Gather all the available models on the Hub. New models get a starting rating of 1200, while others keep the rating they have gained/lost through their previous matches.
2. Create a queue from all these models.
3. Pop the first element (model) from the queue, and then pop another random model in this queue from the n models with the closest ratings to the first model.
4. Simulate this match by loading both models in the environment (a Unity executable, for instance) and gathering the results. For this implementation, we sent the results to a Hugging Face Dataset on the Hub.
5. Compute the new rating of both models based on the received result and the ELO formula.
6. Continue popping models two by two and simulating the matches until only one or zero models are in the queue.
7. Save the resulting ratings and go back to step 1
To run this matchmaking process continuously, we use **free Hugging Face Spaces hardware with a Scheduler** to keep running the matchmaking process as a background task.
The Spaces is also used to fetch the ELO ratings of each model that have already been played and, from it display [a leaderboard](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos) **from which everyone can check the progress of the models**.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/leaderboard.png" alt="Leaderboard">
</div>
The process generally uses several Hugging Face Datasets to provide data persistence (here, matches history and model ratings).
Since the process also saves the matches' history, it is possible to see precisely the results of any given model. This can, for instance, allow you to check why your model struggles with another one, most notably using another demo Space to visualize matches like [this one](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos.).
For now, **this experiment is running with the MLAgent environment SoccerTwos for the Hugging Face Deep RL Course**, however, the process and implementation, in general, are very much **environment agnostic and could be used to evaluate for free a wide range of adversarial multi-agent settings**.
Of course, it is important to remind again that this evaluation is a relative rating between the strengths of the submitted agents, and the ratings by themselves **have no objective meaning contrary to other metrics**. It only represents how good or bad a model performs compared to the other models in the pool. Still, given a large and varied enough pool of models (and enough matches played), this evaluation becomes a very solid way to represent the general performance of a model.
## Our first AI vs. AI challenge experimentation: SoccerTwos Challenge ⚽
This challenge is Unit 7 of our [free Deep Reinforcement Learning Course](https://huggingface.co/deep-rl-course/unit0/introduction). It started on February 1st and will end on April 30th.
If you’re interested, **you don’t need to participate in the course to be able to participate in the competition. You can start here** 👉 https://huggingface.co/deep-rl-course/unit7/introduction
In this Unit, readers learned the basics of multi-agent reinforcement learning (MARL)by training a **2vs2 soccer team.** ⚽
The environment used was made by the [Unity ML-Agents team](https://github.com/Unity-Technologies/ml-agents). The goal is simple: your team needs to score a goal. To do that, they need to beat the opponent's team and collaborate with their teammate.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/soccertwos.gif" alt="SoccerTwos example">
</div>
In addition to the leaderboard, we created a Space demo where people can choose two teams and visualize them playing 👉[https://huggingface.co/spaces/unity/SoccerTwos](https://huggingface.co/spaces/unity/SoccerTwos)
This experimentation is going well since we already have 48 models on the [leaderboard](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
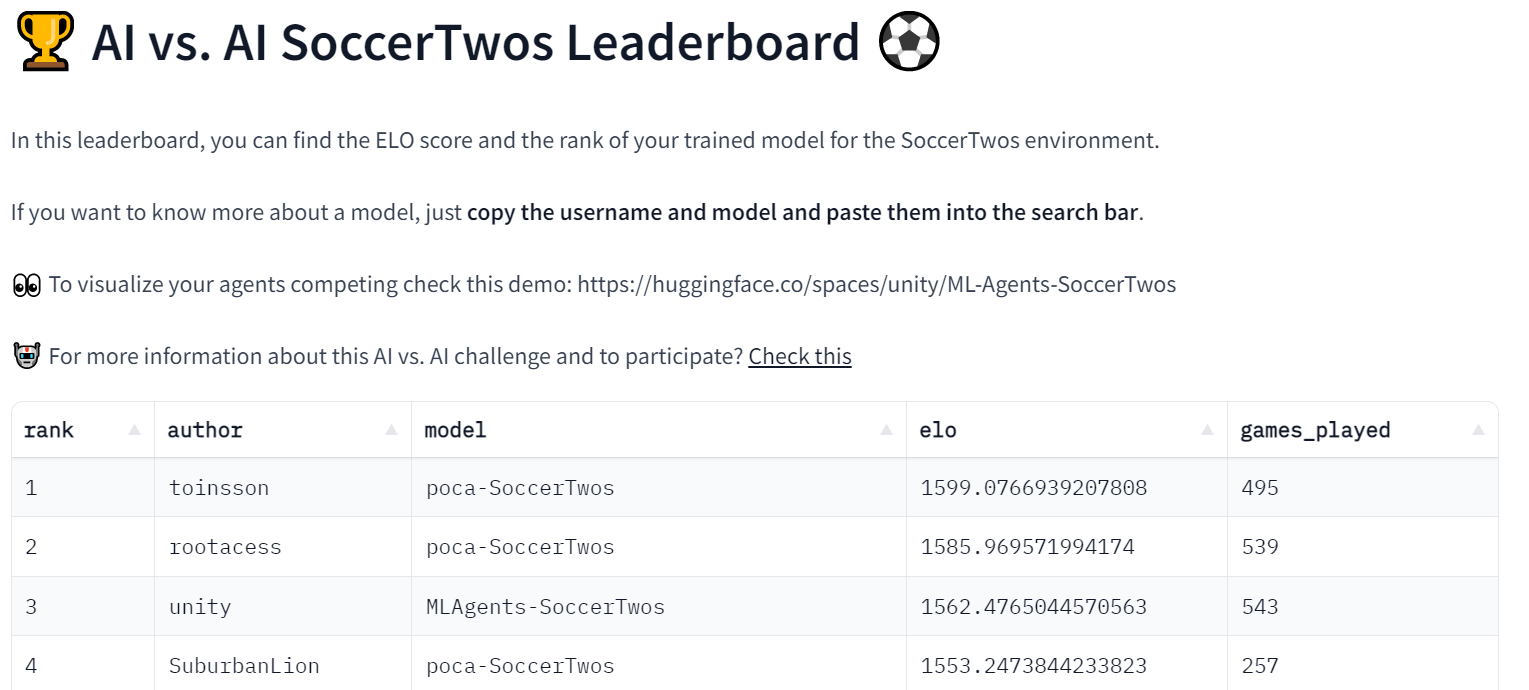
We also [created a discord channel called ai-vs-ai-competition](http://hf.co/discord/join) so that people can exchange with others and share advice.
### Conclusion and what’s next?
Since the tool we developed **is environment agnostic**, we want to host more challenges in the future with [PettingZoo](https://pettingzoo.farama.org/) and other multi-agent environments. If you have some environments or challenges you want to do, <a href="mailto:[email protected]">don’t hesitate to reach out to us</a>.
In the future, we will host multiple multi-agent competitions with this tool and environments we created, such as SnowballFight.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/snowballfight.gif" alt="Snowballfight gif">
</div>
In addition to being a useful tool for hosting multi-agent competitions, we think that this tool can also be **a robust evaluation technique in multi-agent settings: by playing against a lot of policies, your agents are evaluated against a wide range of behaviors, and you’ll get a good idea of the quality of your policy.**
The best way to keep in touch is to [join our discord server](http://hf.co/discord/join) to exchange with us and with the community.
****************Citation****************
Citation: If you found this useful for your academic work, please consider citing our work, in text:
`Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.`
BibTeX citation:
```
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/aivsai},
}
```
| huggingface/blog/blob/main/aivsai.md |
--
title: "SetFit: Efficient Few-Shot Learning Without Prompts"
thumbnail: /blog/assets/103_setfit/intel_hf_logo.png
authors:
- user: Unso
- user: lewtun
- user: luketheduke
- user: dkorat
- user: orenpereg
- user: moshew
---
# SetFit: Efficient Few-Shot Learning Without Prompts
<p align="center">
<img src="assets/103_setfit/setfit_curves.png" width=500>
</p>
<p align="center">
<em>SetFit is significantly more sample efficient and robust to noise than standard fine-tuning.</em>
</p>
Few-shot learning with pretrained language models has emerged as a promising solution to every data scientist's nightmare: dealing with data that has few to no labels 😱.
Together with our research partners at [Intel Labs](https://www.intel.com/content/www/us/en/research/overview.html) and the [UKP Lab](https://www.informatik.tu-darmstadt.de/ukp/ukp_home/index.en.jsp), Hugging Face is excited to introduce SetFit: an efficient framework for few-shot fine-tuning of [Sentence Transformers](https://sbert.net/). SetFit achieves high accuracy with little labeled data - for example, with only 8 labeled examples per class on the Customer Reviews (CR) sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples 🤯!
Compared to other few-shot learning methods, SetFit has several unique features:
<p>🗣 <strong>No prompts or verbalisers</strong>: Current techniques for few-shot fine-tuning require handcrafted prompts or verbalisers to convert examples into a format that's suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from a small number of labeled text examples. </p>
<p>🏎 <strong>Fast to train</strong>: SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with. </p>
<p>🌎 <strong>Multilingual support</strong>: SetFit can be used with any Sentence Transformer on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint. </p>
For more details, check out our [paper](https://arxiv.org/abs/2209.11055), [data](https://huggingface.co/SetFit), and [code](https://github.com/huggingface/setfit). In this blog post, we'll explain how SetFit works and how to train your very own models. Let's dive in!
## How does it work?
SetFit is designed with efficiency and simplicity in mind. SetFit first fine-tunes a Sentence Transformer model on a small number of labeled examples (typically 8 or 16 per class). This is followed by training a classifier head on the embeddings generated from the fine-tuned Sentence Transformer.
<p align="center">
<img src="assets/103_setfit/setfit_diagram_process.png" width=700>
</p>
<p align="center">
<em>SetFit's two-stage training process</em>
</p>
SetFit takes advantage of Sentence Transformers’ ability to generate dense embeddings based on paired sentences. In the initial fine-tuning phase stage, it makes use of the limited labeled input data by contrastive training, where positive and negative pairs are created by in-class and out-class selection. The Sentence Transformer model then trains on these pairs (or triplets) and generates dense vectors per example. In the second step, the classification head trains on the encoded embeddings with their respective class labels. At inference time, the unseen example passes through the fine-tuned Sentence Transformer, generating an embedding that when fed to the classification head outputs a class label prediction.
And just by switching out the base Sentence Transformer model to a multilingual one, SetFit can function seamlessly in multilingual contexts. In our [experiments](https://arxiv.org/abs/2209.11055), SetFit’s performance shows promising results on classification in German, Japanese, Mandarin, French and Spanish, in both in-language and cross linguistic settings.
## Benchmarking SetFit
Although based on much smaller models than existing few-shot methods, SetFit performs on par or better than state of the art few-shot regimes on a variety of benchmarks. On [RAFT](https://huggingface.co/spaces/ought/raft-leaderboard), a few-shot classification benchmark, SetFit Roberta (using the [`all-roberta-large-v1`](https://huggingface.co/sentence-transformers/all-roberta-large-v1) model) with 355 million parameters outperforms PET and GPT-3. It places just under average human performance and the 11 billion parameter T-few - a model 30 times the size of SetFit Roberta. SetFit also outperforms the human baseline on 7 of the 11 RAFT tasks.
| Rank | Method | Accuracy | Model Size |
| :------: | ------ | :------: | :------: |
| 2 | T-Few | 75.8 | 11B |
| 4 | Human Baseline | 73.5 | N/A |
| 6 | SetFit (Roberta Large) | 71.3 | 355M |
| 9 | PET | 69.6 | 235M |
| 11 | SetFit (MP-Net) | 66.9 | 110M |
| 12 | GPT-3 | 62.7 | 175 B |
<p align="center">
<em>Prominent methods on the RAFT leaderboard (as of September 2022)</em>
</p>
On other datasets, SetFit shows robustness across a variety of tasks. As shown in the figure below, with just 8 examples per class, it typically outperforms PERFECT, ADAPET and fine-tuned vanilla transformers. SetFit also achieves comparable results to T-Few 3B, despite being prompt-free and 27 times smaller.
<p align="center">
<img src="assets/103_setfit/three-tasks.png" width=700>
</p>
<p align="center">
<em>Comparing Setfit performance against other methods on 3 classification datasets.</em>
</p>
## Fast training and inference
<p align="center">
<img src="assets/103_setfit/bars.png" width=400>
</p>
<p align="center">
Comparing training cost and average performance for T-Few 3B and SetFit (MPNet), with 8 labeled examples per class.
</p>
Since SetFit achieves high accuracy with relatively small models, it's blazing fast to train and at much lower cost. For instance, training SetFit on an NVIDIA V100 with 8 labeled examples takes just 30 seconds, at a cost of $0.025. By comparison, training T-Few 3B requires an NVIDIA A100 and takes 11 minutes, at a cost of around $0.7 for the same experiment - a factor of 28x more. In fact, SetFit can run on a single GPU like the ones found on Google Colab and you can even train SetFit on CPU in just a few minutes! As shown in the figure above, SetFit's speed-up comes with comparable model performance. Similar gains are also achieved for [inference](https://arxiv.org/abs/2209.11055) and distilling the SetFit model can bring speed-ups of 123x 🤯.
## Training your own model
To make SetFit accessible to the community, we've created a small `setfit` [library](https://github.com/huggingface/setfit) that allows you to train your own models with just a few lines of code.
The first thing to do is install it by running the following command:
```sh
pip install setfit
```
Next, we import `SetFitModel` and `SetFitTrainer`, two core classes that streamline the SetFit training process:
```python
from datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
```
Now, let's download a text classification dataset from the Hugging Face Hub. We'll use the [SentEval-CR](https://huggingface.co/datasets/SetFit/SentEval-CR) dataset, which is a dataset of customer reviews:
```python
dataset = load_dataset("SetFit/SentEval-CR")
```
To simulate a real-world scenario with just a few labeled examples, we'll sample 8 examples per class from the training set:
```python
# Select N examples per class (8 in this case)
train_ds = dataset["train"].shuffle(seed=42).select(range(8 * 2))
test_ds = dataset["test"]
```
Now that we have a dataset, the next step is to load a pretrained Sentence Transformer model from the Hub and instantiate a `SetFitTrainer`. Here we use the [paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) model, which we found to give great results across many datasets:
```python
# Load SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_ds,
eval_dataset=test_ds,
loss_class=CosineSimilarityLoss,
batch_size=16,
num_iterations=20, # Number of text pairs to generate for contrastive learning
num_epochs=1 # Number of epochs to use for contrastive learning
)
```
The last step is to train and evaluate the model:
```python
# Train and evaluate!
trainer.train()
metrics = trainer.evaluate()
```
And that's it - you've now trained your first SetFit model! Remember to push your trained model to the Hub :)
```python
# Push model to the Hub
# Make sure you're logged in with huggingface-cli login first
trainer.push_to_hub("my-awesome-setfit-model")
```
While this example showed how this can be done with one specific type of base model, any [Sentence Transformer](https://huggingface.co/models?library=sentence-transformers&sort=downloads) model could be switched in for different performance and tasks. For instance, using a multilingual Sentence Transformer body can extend few-shot classification to multilingual settings.
## Next steps
We've shown that SetFit is an effective method for few-shot classification tasks. In the coming months, we'll be exploring how well the method generalizes to tasks like natural language inference and token classification. In the meantime, we're excited to see how industry practitioners apply SetFit to their use cases - if you have any questions or feedback, open an issue on our [GitHub repo](https://github.com/huggingface/setfit) 🤗.
Happy few-shot learning!
| huggingface/blog/blob/main/setfit.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# VipLlava
## Overview
The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a "red bounding box" or "pointed arrow" during training.
The abstract from the paper is the following:
*While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.*
Tips:
- The architecture is similar than llava architecture except that the multi-modal projector takes a set of concatenated vision hidden states and has an additional layernorm layer on that module.
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
- For better results, we recommend users to prompt the model with the correct prompt format:
```bash
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.###Human: <image>\n<prompt>###Assistant:
```
For multiple turns conversation:
```bash
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.###Human: <image>\n<prompt1>###Assistant: <answer1>###Human: <prompt2>###Assistant:
```
The original code can be found [here](https://github.com/mu-cai/ViP-LLaVA).
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada)
## VipLlavaConfig
[[autodoc]] VipLlavaConfig
## VipLlavaForConditionalGeneration
[[autodoc]] VipLlavaForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/vipllava.md |
his translation demo takes in the text, source and target languages, and returns the translation. It uses the Transformers library to set up the model and has a title, description, and example. | gradio-app/gradio/blob/main/demo/translation/DESCRIPTION.md |
Gradio Demo: model3D
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/Bunny.obj https://github.com/gradio-app/gradio/raw/main/demo/model3D/files/Bunny.obj
!wget -q -O files/Duck.glb https://github.com/gradio-app/gradio/raw/main/demo/model3D/files/Duck.glb
!wget -q -O files/Fox.gltf https://github.com/gradio-app/gradio/raw/main/demo/model3D/files/Fox.gltf
!wget -q -O files/face.obj https://github.com/gradio-app/gradio/raw/main/demo/model3D/files/face.obj
!wget -q -O files/source.txt https://github.com/gradio-app/gradio/raw/main/demo/model3D/files/source.txt
```
```
import gradio as gr
import os
def load_mesh(mesh_file_name):
return mesh_file_name
demo = gr.Interface(
fn=load_mesh,
inputs=gr.Model3D(),
outputs=gr.Model3D(
clear_color=[0.0, 0.0, 0.0, 0.0], label="3D Model"),
examples=[
[os.path.join(os.path.abspath(''), "files/Bunny.obj")],
[os.path.join(os.path.abspath(''), "files/Duck.glb")],
[os.path.join(os.path.abspath(''), "files/Fox.gltf")],
[os.path.join(os.path.abspath(''), "files/face.obj")],
],
cache_examples=True
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/model3D/run.ipynb |
@gradio/lite
## 0.4.4
## 0.4.4-beta.0
### Features
- [#6147](https://github.com/gradio-app/gradio/pull/6147) [`089161554`](https://github.com/gradio-app/gradio/commit/089161554ff216d01a447014b057368a1cc1bc35) - make lite private. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.3
### Fixes
- [#6032](https://github.com/gradio-app/gradio/pull/6032) [`62b89b8cc`](https://github.com/gradio-app/gradio/commit/62b89b8cc21b15fcb8807847ba2f37b66c2b9b61) - fix main entrypoint. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.2
### Fixes
- [#6015](https://github.com/gradio-app/gradio/pull/6015) [`7315fb2fe`](https://github.com/gradio-app/gradio/commit/7315fb2fe2074ffec4dd29325cb0f18cf2f263e8) - release. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.1
### Fixes
- [#5988](https://github.com/gradio-app/gradio/pull/5988) [`bea931c31`](https://github.com/gradio-app/gradio/commit/bea931c31b7c19ee88c82efa6261acc13e629d71) - release lite. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0
### Features
- [#5975](https://github.com/gradio-app/gradio/pull/5975) [`ddd974956`](https://github.com/gradio-app/gradio/commit/ddd9749561dc7924ac7738c2ac1d21cf07518d00) - Just a small tweak to trigger a release of @gradio/lite. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.2
### Features
- [#5868](https://github.com/gradio-app/gradio/pull/5868) [`4e0d87e9c`](https://github.com/gradio-app/gradio/commit/4e0d87e9c471fe90a344a3036d0faed9188ef6f3) - fix @gradio/lite dependencies. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.1
### Features
- [#5226](https://github.com/gradio-app/gradio/pull/5226) [`64039707`](https://github.com/gradio-app/gradio/commit/640397075d17307dd4f0713d063ef3d009a87aa0) - add gradio as a devdep of @gradio/lite. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0
### Minor Changes
- [#4785](https://github.com/gradio-app/gradio/pull/4785) [`da0e9447`](https://github.com/gradio-app/gradio/commit/da0e94479a235de35844a636efb5833cb1fe9aeb) Thanks [@whitphx](https://github.com/whitphx)! - Add methods to execute mounted Python files
### Patch Changes
- [#4788](https://github.com/gradio-app/gradio/pull/4788) [`8d0d4e0a`](https://github.com/gradio-app/gradio/commit/8d0d4e0a8ebe2425aef24a6f21b88598684b0965) Thanks [@whitphx](https://github.com/whitphx)! - Generate a prebuilt themed CSS file at build time
- [#4826](https://github.com/gradio-app/gradio/pull/4826) [`f0150c62`](https://github.com/gradio-app/gradio/commit/f0150c6260d657b150b73f0eecabd10b19d297c8) Thanks [@whitphx](https://github.com/whitphx)! - Unload the local modules before re-executing a Python script so the edits on the modules are reflected
- [#4779](https://github.com/gradio-app/gradio/pull/4779) [`80b49965`](https://github.com/gradio-app/gradio/commit/80b4996595d70167313d9abf29fb4f35abe66a0f) Thanks [@whitphx](https://github.com/whitphx)! - Add file system APIs and an imperative package install method
- [#4784](https://github.com/gradio-app/gradio/pull/4784) [`f757febe`](https://github.com/gradio-app/gradio/commit/f757febe181f0555aa01d4d349f92081819e2691) Thanks [@whitphx](https://github.com/whitphx)! - Remove the development code embedded in a dev HTML file so it will not be in a final bundle
- [#4785](https://github.com/gradio-app/gradio/pull/4785) [`da0e9447`](https://github.com/gradio-app/gradio/commit/da0e94479a235de35844a636efb5833cb1fe9aeb) Thanks [@whitphx](https://github.com/whitphx)! - Add controller.unmount()
- [#4846](https://github.com/gradio-app/gradio/pull/4846) [`76acf3cb`](https://github.com/gradio-app/gradio/commit/76acf3cb0b258c0e6bb38d611d766e5e54b68437) Thanks [@whitphx](https://github.com/whitphx)! - Fix the package name spec of markdown-it on the Wasm worker
## 0.2.0
### Minor Changes
- [#4732](https://github.com/gradio-app/gradio/pull/4732) [`1dc3c1a9`](https://github.com/gradio-app/gradio/commit/1dc3c1a9a2063daffc00d9231c1498d983ebc3bf) Thanks [@whitphx](https://github.com/whitphx)! - Add an imperative API to reurn the Python code and refresh the frontend
## 0.1.1
### Patch Changes
- [#4731](https://github.com/gradio-app/gradio/pull/4731) [`f9171288`](https://github.com/gradio-app/gradio/commit/f9171288d4cf0174952628276385fb553556c38a) Thanks [@whitphx](https://github.com/whitphx)! - Load the worker file from a different origin, e.g. CDN
| gradio-app/gradio/blob/main/js/lite/CHANGELOG.md |
SPNASNet
**Single-Path NAS** is a novel differentiable NAS method for designing hardware-efficient ConvNets in less than 4 hours.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('spnasnet_100', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `spnasnet_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('spnasnet_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{stamoulis2019singlepath,
title={Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours},
author={Dimitrios Stamoulis and Ruizhou Ding and Di Wang and Dimitrios Lymberopoulos and Bodhi Priyantha and Jie Liu and Diana Marculescu},
year={2019},
eprint={1904.02877},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: SPNASNet
Paper:
Title: 'Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4
Hours'
URL: https://paperswithcode.com/paper/single-path-nas-designing-hardware-efficient
Models:
- Name: spnasnet_100
In Collection: SPNASNet
Metadata:
FLOPs: 442385600
Parameters: 4420000
File Size: 17902337
Architecture:
- Average Pooling
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- ReLU
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: spnasnet_100
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L995
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/spnasnet_100-048bc3f4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.08%
Top 5 Accuracy: 91.82%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/spnasnet.mdx |
@gradio/video
## 0.2.3
### Fixes
- [#6766](https://github.com/gradio-app/gradio/pull/6766) [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144) - Improve source selection UX. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.2
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Features
- [#6726](https://github.com/gradio-app/gradio/pull/6726) [`21cfb0a`](https://github.com/gradio-app/gradio/commit/21cfb0acc309bb1a392f4d8a8e42f6be864c5978) - Remove the styles from the Image/Video primitive components and Fix the container styles. Thanks [@whitphx](https://github.com/whitphx)!
- [#6398](https://github.com/gradio-app/gradio/pull/6398) [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0) - Lite v4. Thanks [@whitphx](https://github.com/whitphx)!
### Fixes
- [#6698](https://github.com/gradio-app/gradio/pull/6698) [`798eca5`](https://github.com/gradio-app/gradio/commit/798eca524d44289c536c47eec7c4fdce9fe81905) - Fit video media within Video component. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.9
### Fixes
- [#6566](https://github.com/gradio-app/gradio/pull/6566) [`d548202`](https://github.com/gradio-app/gradio/commit/d548202d2b5bd8a99e3ebc5bf56820b0282ce0f5) - Improve video trimming and error handling. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.8
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.5
### Features
- [#6406](https://github.com/gradio-app/gradio/pull/6406) [`0401c77f3`](https://github.com/gradio-app/gradio/commit/0401c77f3d35763b79e040dbe876e69083defd36) - Move ffmpeg to `Video` deps. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.4
### Patch Changes
- Updated dependencies [[`6204ccac5`](https://github.com/gradio-app/gradio/commit/6204ccac5967763e0ebde550d04d12584243a120), [`4d3aad33a`](https://github.com/gradio-app/gradio/commit/4d3aad33a0b66639dbbb2928f305a79fb7789b2d), [`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.3
### Fixes
- [#6279](https://github.com/gradio-app/gradio/pull/6279) [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780) - Ensure source selection does not get hidden in overflow. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.2
### Fixes
- [#6234](https://github.com/gradio-app/gradio/pull/6234) [`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e) - Video/Audio fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Improve Video Component. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.9
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#6118](https://github.com/gradio-app/gradio/pull/6118) [`88bccfdba`](https://github.com/gradio-app/gradio/commit/88bccfdba3df2df4b2747ea5d649ed528047cf50) - Improve Video Component. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6140](https://github.com/gradio-app/gradio/pull/6140) [`71bf2702c`](https://github.com/gradio-app/gradio/commit/71bf2702cd5b810c89e2e53452532650acdcfb87) - Fix video. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.0-beta.8
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6067](https://github.com/gradio-app/gradio/pull/6067) [`bf38e5f06`](https://github.com/gradio-app/gradio/commit/bf38e5f06a7039be913614901c308794fea83ae0) - remove dupe component. Thanks [@pngwn](https://github.com/pngwn)!
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.7
### Patch Changes
- Updated dependencies [[`174b73619`](https://github.com/gradio-app/gradio/commit/174b736194756e23f51bbaf6f850bac5f1ca95b5), [`5fbda0bd2`](https://github.com/gradio-app/gradio/commit/5fbda0bd2b2bbb2282249b8875d54acf87cd7e84)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0
### Features
- [#5627](https://github.com/gradio-app/gradio/pull/5627) [`b67115e8e`](https://github.com/gradio-app/gradio/commit/b67115e8e6e489fffd5271ea830211863241ddc5) - Lite: Make the Examples component display media files using pseudo HTTP requests to the Wasm server. Thanks [@whitphx](https://github.com/whitphx)!
- [#5934](https://github.com/gradio-app/gradio/pull/5934) [`8d909624f`](https://github.com/gradio-app/gradio/commit/8d909624f61a49536e3c0f71cb2d9efe91216219) - Fix styling issues with Audio, Image and Video components. Thanks [@aliabd](https://github.com/aliabd)!
## 0.0.11
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.10
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.9
### Patch Changes
- Updated dependencies [[`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.8
### Patch Changes
- Updated dependencies [[`e0d61b8ba`](https://github.com/gradio-app/gradio/commit/e0d61b8baa0f6293f53b9bdb1647d42f9ae2583a)]:
- @gradio/[email protected]
## 0.0.7
### Patch Changes
- Updated dependencies [[`dc86e4a7`](https://github.com/gradio-app/gradio/commit/dc86e4a7e1c40b910c74558e6f88fddf9b3292bc)]:
- @gradio/[email protected]
## 0.0.6
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.5
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.4
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.3
### Fixes
- [#5140](https://github.com/gradio-app/gradio/pull/5140) [`cd1353fa`](https://github.com/gradio-app/gradio/commit/cd1353fa3eb1b015f5860ca5d5a8e8d1aa4a831c) - Fixes the display of minutes in the video player. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.0.2
### Patch Changes
- Updated dependencies [[`44ac8ad0`](https://github.com/gradio-app/gradio/commit/44ac8ad08d82ea12c503dde5c78f999eb0452de2)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected] | gradio-app/gradio/blob/main/js/video/CHANGELOG.md |
THE LANDSCAPE OF ML DOCUMENTATION TOOLS
The development of the model cards framework in 2018 was inspired by the major documentation framework efforts of Data Statements for Natural Language Processing ([Bender & Friedman, 2018](https://aclanthology.org/Q18-1041/)) and Datasheets for Datasets ([Gebru et al., 2018](https://www.fatml.org/media/documents/datasheets_for_datasets.pdf)). Since model cards were proposed, a number of other tools have been proposed for documenting and evaluating various aspects of the machine learning development cycle. These tools, including model cards and related documentation efforts proposed prior to model cards, can be contextualised with regard to their focus (e.g., on which part of the ML system lifecycle does the tool focus?) and their intended audiences (e.g., who is the tool designed for?). In Figures 1-2 below, we summarise several prominent documentation tools along these dimensions, provide contextual descriptions of each tool, and link to examples. We broadly classify the documentation tools as belong to the following groups:
* **Data-focused**, including documentation tools focused on datasets used in the machine learning system lifecycle
* **Models-and-methods-focused**, including documentation tools focused on machine learning models and methods; and
* **Systems-focused**, including documentation tools focused on ML systems, including models, methods, datasets, APIs, and non AI/ML components that interact with each other as part of an ML system
These groupings are not mutually exclusive; they do include overlapping aspects of the ML system lifecycle. For example, **system cards** focus on documenting ML systems that may include multiple models and datasets, and thus might include content that overlaps with data-focused or model-focused documentation tools. The tools described are a non-exhaustive list of documentation tools for the ML system lifecycle. In general, we included tools that were:
* Focused on documentation of some (or multiple) aspects of the ML system lifecycle
* Included the release of a template intended for repeated use, adoption, and adaption
## Summary of ML Documentation Tools
### Figure 1
| **Stage of ML System Lifecycle** | **Tool** | **Brief Description** | **Examples** |
|:--------------------------------: |-------------------------------------------------------------------------------------------------------------------------------------------------------------------- |------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| DATA | ***Datasheets*** [(Gebru et al., 2018)](https://www.fatml.org/media/documents/datasheets_for_datasets.pdf) | “We recommend that every dataset be accompanied with a datasheet documenting its motivation, creation, composition, intended uses, distribution, maintenance, and other information.” | See, for example, [Ivy Lee’s repo](https://github.com/ivylee/model-cards-and-datasheets) with examples |
| DATA | ***Data Statements*** [(Bender & Friedman, 2018)(Bender et al., 2021)](https://techpolicylab.uw.edu/wp-content/uploads/2021/11/Data_Statements_Guide_V2.pdf) | “A data statement is a characterization of a dataset that provides context to allow developers and users to better understand how experimental results might generalize, how software might be appropriately deployed, and what biases might be reflected in systems built on the software.” | See [Data Statements for NLP Workshop](https://techpolicylab.uw.edu/events/event/data-statements-for-nlp/) |
| DATA | ***Dataset Nutrition Labels*** [(Holland et al., 2018)](https://huggingface.co/papers/1805.03677) | “The Dataset Nutrition Label…is a diagnostic framework that lowers the barrier to standardized data analysis by providing a distilled yet comprehensive overview of dataset “ingredients” before AI model development.” | See [The Data Nutrition Label](https://datanutrition.org/labels/) |
| DATA | ***Data Cards for NLP*** [(McMillan-Major et al., 2021)](https://huggingface.co/papers/2108.07374) | “We present two case studies of creating documentation templates and guides in natural language processing (NLP): the Hugging Face (HF) dataset hub[^1] and the benchmark for Generation and its Evaluation and Metrics (GEM). We use the term data card to refer to documentation for datasets in both cases. | See [(McMillan-Major et al., 2021)](https://huggingface.co/papers/2108.07374) |
| DATA | ***Dataset Development Lifecycle Documentation Framework*** [(Hutchinson et al., 2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445918) | “We introduce a rigorous framework for dataset development transparency that supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle.” | See [(Hutchinson et al., 2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445918), Appendix A for templates |
| DATA | ***Data Cards*** [(Pushkarna et al., 2021)](https://huggingface.co/papers/2204.01075) | “Data Cards are structured summaries of essential facts about various aspects of ML datasets needed by stakeholders across a dataset’s lifecycle for responsible AI development. These summaries provide explanations of processes and rationales that shape the data and consequently the models.” | See the [Data Cards Playbook github](https://github.com/PAIR-code/datacardsplaybook/) |
| DATA | ***CrowdWorkSheets*** [(Díaz et al., 2022)](https://huggingface.co/papers/2206.08931) | “We introduce a novel framework, CrowdWorkSheets, for dataset developers to facilitate transparent documentation of key decisions points at various stages of the data annotation pipeline: task formulation, selection of annotators, plat- form and infrastructure choices, dataset analysis and evaluation, and dataset release and maintenance.” | See [(Díaz et al., 2022)](hhttps://huggingface.co/papers/2206.08931) |
| MODELS AND METHODS | ***Model Cards*** [Mitchell et al. (2018)](https://huggingface.co/papers/1810.03993) | “Model cards are short documents accompanying trained machine learning models that provide benchmarked evaluation in a variety of conditions…that are relevant to the intended application domains. Model cards also disclose the context in which models are intended to be used, details of the performance evaluation procedures, and other relevant information.” | See https://huggingface.co/models, the [Model Card Guidebook](https://huggingface.co/docs/hub/model-card-guidebook), and [Model Card Examples](https://huggingface.co/docs/hub/model-card-appendix#model-card-examples) |
| MODELS AND METHODS | ***Value Cards*** [Shen et al. (2021)](https://dl.acm.org/doi/abs/10.1145/3442188.3445971) | “We present Value Cards, a deliberation-driven toolkit for bringing computer science students and practitioners the awareness of the social impacts of machine learning-based decision making systems….Value Cards encourages the investigations and debates towards different ML performance metrics and their potential trade-offs.” | See [Shen et al. (2021)](https://dl.acm.org/doi/abs/10.1145/3442188.3445971), Section 3.3 |
| MODELS AND METHODS | ***Method Cards*** [Adkins et al. (2022)](https://dl.acm.org/doi/pdf/10.1145/3491101.3519724) | “We propose method cards to guide ML engineers through the process of model development…The information comprises both prescriptive and descriptive elements, putting the main focus on ensuring that ML engineers are able to use these methods properly.” | See [Adkins et al. (2022)](https://dl.acm.org/doi/pdf/10.1145/3491101.3519724), Appendix A |
| MODELS AND METHODS | ***Consumer Labels for ML Models*** [Seifert et al. (2019)](https://ris.utwente.nl/ws/portalfiles/portal/158031484/Seifert2019_cogmi_consumer_labels_preprint.pdf) | “We propose to issue consumer labels for trained and published ML models. These labels primarily target machine learning lay persons, such as the operators of an ML system, the executors of decisions, and the decision subjects themselves” | See [Seifert et al. (2019)](https://ris.utwente.nl/ws/portalfiles/portal/158031484/Seifert2019_cogmi_consumer_labels_preprint.pdf) |
| SYSTEMS | ***Factsheets*** [Arnold et al. (2019)](https://huggingface.co/papers/1808.07261) | “A FactSheet will contain sections on all relevant attributes of an AI service, such as intended use, performance, safety, and security. Performance will include appropriate accuracy or risk measures along with timing information.” | See [IBM’s AI Factsheets 360](https://aifs360.res.ibm.com) and [Hind et al., (2020)](https://dl.acm.org/doi/abs/10.1145/3334480.3383051) |
| SYSTEMS | ***System Cards*** [Procope et al. (2022)](https://ai.facebook.com/research/publications/system-level-transparency-of-machine-learning) | “System Cards aims to increase the transparency of ML systems by providing stakeholders with an overview of different components of an ML system, how these components interact, and how different pieces of data and protected information are used by the system.” | See [Meta’s Instagram Feed Ranking System Card](https://ai.facebook.com/tools/system-cards/instagram-feed-ranking/) |
| SYSTEMS | ***Reward Reports for RL*** [Gilbert et al. (2022)](https://huggingface.co/papers/2204.10817) | “We sketch a framework for documenting deployed learning systems, which we call Reward Reports…We outline Reward Reports as living documents that track updates to design choices and assumptions behind what a particular automated system is optimizing for. They are intended to track dynamic phenomena arising from system deployment, rather than merely static properties of models or data.” | See https://rewardreports.github.io |
| SYSTEMS | ***Robustness Gym*** [Goel et al. (2021)](https://huggingface.co/papers/2101.04840) | “We identify challenges with evaluating NLP systems and propose a solution in the form of Robustness Gym (RG), a simple and extensible evaluation toolkit that unifies 4 standard evaluation paradigms: subpopulations, transformations, evaluation sets, and adversarial attacks.” | See https://github.com/robustness-gym/robustness-gym |
| SYSTEMS | ***ABOUT ML*** [Raji and Yang, (2019)](https://huggingface.co/papers/1912.06166) | “ABOUT ML (Annotation and Benchmarking on Understanding and Transparency of Machine Learning Lifecycles) is a multi-year, multi-stakeholder initiative led by PAI. This initiative aims to bring together a diverse range of perspectives to develop, test, and implement machine learning system documentation practices at scale.” | See [ABOUT ML’s resources library](https://partnershiponai.org/about-ml-resources-library/) |
### DATA-FOCUSED DOCUMENTATION TOOLS
Several proposed documentation tools focus on datasets used in the ML system lifecycle, including to train, develop, validate, finetune, and evaluate machine learning models as part of continuous cycles. These tools generally focus on the many aspects of the data lifecycle (perhaps for a particular dataset, group of datasets, or more broadly), including how the data was assembled, collected, annotated and how it should be used.
* Extending the concept of datasheets in the electronics industry, [Gebru et al. (2018)](https://www.fatml.org/media/documents/datasheets_for_datasets.pdf) propose datasheets for datasets to document details related to a dataset’s creation, potential uses, and associated concerns.
* [Bender and Friedman (2018)](https://aclanthology.org/Q18-1041/) propose data statements for natural language processing. [Bender, Friedman and McMillan-Major (2021)](https://techpolicylab.uw.edu/wp-content/uploads/2021/11/Data_Statements_Guide_V2.pdf) update the original data statements framework and provide resources including a guide for writing data statements and translating between the first version of the schema and the newer version[^2].
* [Holland et al. (2018)](https://huggingface.co/papers/1805.03677) propose data nutrition labels, akin to nutrition facts for foodstuffs and nutrition labels for privacy disclosures, as a tool for analyzing and making decisions about datasets. The Data Nutrition Label team released an updated design of and interface for the label in 2020 ([Chmielinski et al., 2020)](https://huggingface.co/papers/2201.03954)).
* [McMillan-Major et al. (2021)](https://huggingface.co/papers/2108.07374) describe the development process and resulting templates for **data cards for NLP** in the form of data cards on the Hugging Face Hub[^3] and data cards for datasets that are part of the NLP benchmark for Generation and its Evaluation Metrics (GEM) environment[^4].
* [Hutchinson et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445918) describe the need for comprehensive dataset documentation, and drawing on software development practices, provide templates for documenting several aspects of the dataset development lifecycle (for the purposes of Tables 1 and 2, we refer to their framework as the **Dataset Development Lifecycle Documentation Framework**).
* [Pushkarna et al. (2021)](https://huggingface.co/papers/2204.01075) propose the data cards as part of the **data card playbook**, a human-centered documentation tool focused on datasets used in industry and research.
### MODEL-AND-METHOD-FOCUSED DOCUMENTATION TOOLS
Another set of documentation tools can be thought of as focusing on machine learning models and machine learning methods. These include:
* [Mitchell et al. (2018)](https://huggingface.co/papers/1810.03993) propose **model cards** for model reporting to accompany trained ML models and document issues related to evaluation, use, and other issues
* [Shen et al. (2021)](https://dl.acm.org/doi/abs/10.1145/3442188.3445971) propose **value cards** for teaching students and practitioners about values related to ML models
* [Seifert et al. (2019)](https://ris.utwente.nl/ws/portalfiles/portal/158031484/Seifert2019_cogmi_consumer_labels_preprint.pdf) propose **consumer labels for ML models** to help non-experts using or affected by the model understand key issues related to the model.
* [Adkins et al. (2022)](https://dl.acm.org/doi/pdf/10.1145/3491101.3519724) analyse aspects of descriptive documentation tools – which they consider to include **model cards** and data sheets – and argue for increased prescriptive tools for ML engineers. They propose method cards, focused on ML methods, and design primarily with technical stakeholders like model developers and reviewers in mind.
* They envision the relationship between model cards and method cards, in part, by stating: “The sections and prompts we propose…[in the method card template] focus on ML methods that are sufficient to produce a proper ML model with defined input, output, and task. Examples for these are object detection methods such as Single-shot Detectors and language modelling methods such as Generative Pre-trained Transformers (GPT). *It is possible to create Model Cards for the models created using these methods*.”
* They also state “While Model Cards and FactSheets put main focus on documenting existing models, Method Cards focus more on the underlying methodical and algorithmic choices that need to be considered when creating and training these models. *As a rough analogy, if Model Cards and FactSheets provide nutritional information about cooked meals, Method Cards provide the recipes*.”
### SYSTEM-FOCUSED DOCUMENTATION TOOLS
Rather than focusing on particular models, datasets, or methods, system-focused documentation tools look at how models interact with each other, with datasets, methods, and with other ML components to form ML systems.
* [Procope et al. (2022)](https://ai.facebook.com/research/publications/system-level-transparency-of-machine-learning) propose system cards to document and explain AI systems – potentially including multiple ML models, AI tools, and non-AI technologies – that work together to accomplish tasks.
* [Arnold et al. (2019)](https://huggingface.co/papers/1808.07261) extend the idea of declarations of conformity for consumer products to AI services, proposing FactSheets to document aspects of “AI services” which are typically accessed through APIs and may be composed of multiple different ML models. [Hind et al. (2020)](https://dl.acm.org/doi/abs/10.1145/3334480.3383051) share reflections on building factsheets.
* [Gilbert et al. (2022)](https://huggingface.co/papers/2204.10817) propose **Reward Reports for Reinforcement Learning** systems, recognizing the dynamic nature of ML systems and the need for documentation efforts to incorporate considerations of post-deployment performance, especially for reinforcement learning systems.
* [Goel et al. (2021)](https://huggingface.co/papers/2101.04840) develop **Robustness Gym**, an evaluation toolkit for testing several aspects of deep neural networks in real-world systems, allowing for comparison across evaluation paradigms.
* Through the [ABOUT ML project](https://partnershiponai.org/workstream/about-ml/) ([Raji and Yang, 2019](https://huggingface.co/papers/1912.06166)), the Partnership on AI is coordinating efforts across groups of stakeholders in the machine learning community to develop comprehensive, scalable documentation tools for ML systems.
## THE EVOLUTION OF MODEL CARDS
Since the proposal for model cards by Mitchell et al. in 2018, model cards have been adopted and adapted by various organisations, including by major technology companies and startups developing and hosting machine learning models[^5], researchers describing new techniques[^6], and government stakeholders evaluating models for various projects[^7]. Model cards also appear as part of AI Ethics educational toolkits, and numerous organisations and developers have created implementations for automating or semi-automating the creation of model cards. Appendix A provides a set of examples of model cards for various types of ML models created by different organisations (including model cards for large language models), model card generation tools, and model card educational tools.
### MODEL CARDS ON THE HUGGING FACE HUB
Since 2018, new platforms and mediums for hosting and sharing model cards have also emerged. For example, particularly relevant to this project, Hugging Face hosts model cards on the Hugging Face Hub as README files in the repositories associated with ML models. As a result, model cards figure as a prominent form of documentation for users of models on the Hugging Face Hub. As part of our analysis of model cards, we developed and proposed model cards for several dozen ML models on the Hugging Face Hub, using the Hub’s Pull Request (PR) and Discussion features to gather feedback on model cards, verify information included in model cards, and publish model cards for models on the Hugging Face Hub. At the time of writing of this guide book, all of Hugging Face’s models on the Hugging Face Hub have an associated model card on the Hub[^8].
The high number of models uploaded to the Hugging Face Hub (101,041 models at the point of writing), enabled us to explore the content within model cards on the hub:
We began by analysing language model, model cards, in order to identify patterns (e.g repeated sections and subsections, with the aim of answering initial questions such as:
1) How many of these models have model cards?
2) What percent of downloads had an associated model card?
From our analysis of all the models on the hub, we noticed that the most downloads come from top 200 models.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/mc-downloads.png"/>
</div>
With a continued focus on large language models, ordered by most downloaded and only models with model cards to begin with, we noted the most recurring sections within their respective model cards.
While some headings within model cards may differ between models, we grouped components/the theme of each section within each model cards and then mapped them to section headings that were the most recurring (mostly found in the top 200 downloaded models and with the aid/guidance of the Bloom model card)
<Tip>
[Checkout the User Studies](./model-cards-user-studies)
</Tip>
<Tip>
[See Appendix](./model-card-appendix)
</Tip>
[^1]: For each tool, descriptions are excerpted from the linked paper listed in the second column.
[^2]: See https://techpolicylab.uw.edu/data-statements/ .
[^3]: See https://techpolicylab.uw.edu/data-statements/ .
[^4]: See https://techpolicylab.uw.edu/data-statements/ .
[^5]: See, e.g., the Hugging Face Hub, Google Cloud’s Model Cards https://modelcards.withgoogle.com/about .
[^6]: See Appendix A.
[^7]: See GSA / US Census Bureau Collaboration on Model Card Generator.
[^8]: By “Hugging Face models,” we mean models shared by Hugging Face, not another organisation, on the Hub. Formally, these are models without a ‘/’ in their model ID.
| huggingface/hub-docs/blob/main/docs/hub/model-card-landscape-analysis.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Adding a new model
This folder contains templates to generate new models that fit the current API and pass all tests. It generates
models in both PyTorch, TensorFlow, and Flax and completes the `__init__.py` and auto-modeling files, and creates the
documentation. Their use is described in the [next section](#cookiecutter-templates).
There is also a CLI tool to generate a new model like an existing one called `transformers-cli add-new-model-like`.
Jump to the [Add new model like section](#add-new-model-like-command) to learn how to use it.
## Cookiecutter Templates
Using the `cookiecutter` utility requires to have all the `dev` dependencies installed. Let's first clone the
repository and install it in our environment:
```shell script
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
Once the installation is done, you can use the CLI command `add-new-model` to generate your models:
```shell script
transformers-cli add-new-model
```
This should launch the `cookiecutter` package which should prompt you to fill in the configuration.
The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
```
modelname [<ModelNAME>]:
uppercase_modelname [<MODEL_NAME>]:
lowercase_modelname [<model_name>]:
camelcase_modelname [<ModelName>]:
```
Fill in the `authors` with your team members:
```
authors [The HuggingFace Team]:
```
The checkpoint identifier is the checkpoint that will be used in the examples across the files. Put the name you wish,
as it will appear on the modelhub. Do not forget to include the organisation.
```
checkpoint_identifier [organisation/<model_name>-base-cased]:
```
The tokenizer should either be based on BERT if it behaves exactly like the BERT tokenizer, or a standalone otherwise.
```
Select tokenizer_type:
1 - Based on BERT
2 - Standalone
Choose from 1, 2 [1]:
```
<!---
Choose if your model is an encoder-decoder, or an encoder-only architecture.
If your model is an encoder-only architecture, the generated architecture will be based on the BERT model.
If your model is an encoder-decoder architecture, the generated architecture will be based on the BART model. You can,
of course, edit the files once the generation is complete.
```
Select is_encoder_decoder_model:
1 - True
2 - False
Choose from 1, 2 [1]:
```
-->
Once the command has finished, you should have a total of 7 new files spread across the repository:
```
docs/source/model_doc/<model_name>.md
src/transformers/models/<model_name>/configuration_<model_name>.py
src/transformers/models/<model_name>/modeling_<model_name>.py
src/transformers/models/<model_name>/modeling_tf_<model_name>.py
src/transformers/models/<model_name>/tokenization_<model_name>.py
tests/test_modeling_<model_name>.py
tests/test_modeling_tf_<model_name>.py
```
You can run the tests to ensure that they all pass:
```
python -m pytest ./tests/test_*<model_name>*.py
```
Feel free to modify each file to mimic the behavior of your model.
⚠ You should be careful about the classes preceded by the following line:️
```python
# Copied from transformers.[...]
```
This line ensures that the copy does not diverge from the source. If it *should* diverge, because the implementation
is different, this line needs to be deleted. If you don't delete this line and run `make fix-copies`,
your changes will be overwritten.
Once you have edited the files to fit your architecture, simply re-run the tests (and edit them if a change
is needed!) afterwards to make sure everything works as expected.
Once the files are generated and you are happy with your changes, here's a checklist to ensure that your contribution
will be merged quickly:
- You should run the `make fixup` utility to fix the style of the files and to ensure the code quality meets the
library's standards.
- You should complete the documentation file (`docs/source/model_doc/<model_name>.rst`) so that your model may be
usable.
## Add new model like command
Using the `transformers-cli add-new-model-like` command requires to have all the `dev` dependencies installed. Let's
first clone the repository and install it in our environment:
```shell script
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
Once the installation is done, you can use the CLI command `add-new-model-like` to generate your models:
```shell script
transformers-cli add-new-model-like
```
This will start a small questionnaire you have to fill.
```
What identifier would you like to use for the model type of this model?
```
You will have to input the model type of the model you want to clone. The model type can be found in several places:
- inside the configuration of any checkpoint of that model
- the name of the documentation page of that model
For instance the doc page of `BigBirdPegasus` is `https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus`
so its model type is `"bigbird_pegasus"`.
If you make a typo, the command will suggest you the closest model types it can find.
Once this is done, the questionnaire will ask you for the new model name and its various casings:
```
What is the name for your new model?
What identifier would you like to use for the model type of this model?
What name would you like to use for the module of this model?
What prefix (camel-cased) would you like to use for the model classes of this model?
What prefix (upper-cased) would you like to use for the constants relative to this model?
```
From your answer to the first question, defaults will be determined for all others. The first name should be written
as you want your model be named in the doc, with no special casing (like RoBERTa) and from there, you can either stick
with the defaults or change the cased versions.
Next will be the name of the config class to use for this model:
```
What will be the name of the config class for this model?
```
Then, you will be asked for a checkpoint identifier:
```
Please give a checkpoint identifier (on the model Hub) for this new model.
```
This is the checkpoint that will be used in the examples across the files and the integration tests. Put the name you
wish, as it will appear on the Model Hub. Do not forget to include the organisation.
Then you will have to say whether your model re-uses the same processing classes as the model you're cloning:
```
Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor/XxxImageProcessor)
```
Answer yes if you have no intentions to make any change to the class used for preprocessing. It can use different
files (for instance you can reuse the `BertTokenizer` with a new vocab file).
If you answer no, you will have to give the name of the classes
for the new tokenizer/image processor/feature extractor/processor (depending on the model you're cloning).
Next the questionnaire will ask
```
Should we add # Copied from statements when creating the new modeling file?
```
This is the intenal mechanism used in the library to make sure code copied from various modeling files stay consistent.
If you plan to completely rewrite the modeling file, you should answer no, whereas if you just want to tweak one part
of the model, you should answer yes.
Lastly, the questionnaire will inquire about frameworks:
```
Should we add a version of your new model in all the frameworks implemented by Old Model (xxx)?
```
If you answer yes, the new model will have files for all the frameworks implemented by the model you're cloning.
Otherwise, you will get a new question to select the frameworks you want.
Once the command has finished, you will see a new subfolder in the `src/transformers/models/` folder, with the
necessary files (configuration and modeling files for all frameworks requested, and maybe the processing files,
depending on your choices).
You will also see a doc file and tests for your new models. First you should run
```
make style
make fix-copies
```
and then you can start tweaking your model. You should:
- fill the doc file at `docs/source/model_doc/model_name.md`
- tweak the configuration and modeling files to your need
Once you're done, you can run the tests to ensure that they all pass:
```
python -m pytest ./tests/test_*<model_name>*.py
```
⚠ You should be careful about the classes preceded by the following line:️
```python
# Copied from transformers.[...]
```
This line ensures that the copy does not diverge from the source. If it *should* diverge, because the implementation
is different, this line needs to be deleted. If you don't delete this line and run `make fix-copies`,
your changes will be overwritten.
Once you have edited the files to fit your architecture, simply re-run the tests (and edit them if a change
is needed!) afterwards to make sure everything works as expected.
Once the files are generated and you are happy with your changes, here's a checklist to ensure that your contribution
will be merged quickly:
- You should run the `make fixup` utility to fix the style of the files and to ensure the code quality meets the
library's standards.
- You should add your model to the main README then run `make fix-copies`.
| huggingface/transformers/blob/main/templates/adding_a_new_model/README.md |
--
YAML tags (full spec here: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1):
- copy-paste the tags obtained with the online tagging app: https://huggingface.co/spaces/huggingface/datasets-tagging
---
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Add homepage URL here if available (unless it's a GitHub repository)]()
- **Repository:** [If the dataset is hosted on github or has a github homepage, add URL here]()
- **Paper:** [If the dataset was introduced by a paper or there was a paper written describing the dataset, add URL here (landing page for Arxiv paper preferred)]()
- **Leaderboard:** [If the dataset supports an active leaderboard, add link here]()
- **Point of Contact:** [If known, name and email of at least one person the reader can contact for questions about the dataset.]()
### Dataset Summary
Briefly summarize the dataset, its intended use and the supported tasks. Give an overview of how and why the dataset was created. The summary should explicitly mention the languages present in the dataset (possibly in broad terms, e.g. *translations between several pairs of European languages*), and describe the domain, topic, or genre covered.
### Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the `task-category-tag` with an appropriate `other:other-task-name`).
- `task-category-tag`: The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a *high/low* [metric name](https://huggingface.co/metrics/metric_name). The ([model name](https://huggingface.co/model_name) or [model class](https://huggingface.co/transformers/model_doc/model_class.html)) model currently achieves the following score. *[IF A LEADERBOARD IS AVAILABLE]:* This task has an active leaderboard which can be found at [leaderboard url]() and ranks models based on [metric name](https://huggingface.co/metrics/metric_name) while also reporting [other metric name](https://huggingface.co/metrics/other_metric_name).
### Languages
Provide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...
When relevant, please provide [BCP-47 codes](https://tools.ietf.org/html/bcp47), which consist of a [primary language subtag](https://tools.ietf.org/html/bcp47#section-2.2.1), with a [script subtag](https://tools.ietf.org/html/bcp47#section-2.2.3) and/or [region subtag](https://tools.ietf.org/html/bcp47#section-2.2.4) if available.
## Dataset Structure
### Data Instances
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
```
{
'example_field': ...,
...
}
```
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
### Data Fields
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
- `example_field`: description of `example_field`
Note that the descriptions can be initialized with the **Show Markdown Data Fields** output of the [Datasets Tagging app](https://huggingface.co/spaces/huggingface/datasets-tagging), you will then only need to refine the generated descriptions.
### Data Splits
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If there are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
| | train | validation | test |
|-------------------------|------:|-----------:|-----:|
| Input Sentences | | | |
| Average Sentence Length | | | |
## Dataset Creation
### Curation Rationale
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
### Source Data
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
#### Initial Data Collection and Normalization
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their [Hugging Face version](https://huggingface.co/datasets/dataset_name).
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
#### Who are the source language producers?
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
### Annotations
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
#### Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
#### Who are the annotators?
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
### Personal and Sensitive Information
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See [Larson 2017](https://www.aclweb.org/anthology/W17-1601.pdf) for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
## Considerations for Using the Data
### Social Impact of Dataset
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
### Discussion of Biases
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example [Dinan et al 2020 on biases in Wikipedia (esp. Table 1)](https://arxiv.org/abs/2005.00614), or [Blodgett et al 2020](https://www.aclweb.org/anthology/2020.acl-main.485/) for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
### Other Known Limitations
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
## Additional Information
### Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
### Licensing Information
Provide the license and link to the license webpage if available.
### Citation Information
Provide the [BibTex](http://www.bibtex.org/)-formatted reference for the dataset. For example:
```
@article{article_id,
author = {Author List},
title = {Dataset Paper Title},
journal = {Publication Venue},
year = {2525}
}
```
If the dataset has a [DOI](https://www.doi.org/), please provide it here.
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| huggingface/datasets/blob/main/templates/README_guide.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Actuators
[[autodoc]] Actuator
Under construction 🚧. | huggingface/simulate/blob/main/docs/source/api/actuators.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Transformer Temporal
A Transformer model for video-like data.
## TransformerTemporalModel
[[autodoc]] models.transformer_temporal.TransformerTemporalModel
## TransformerTemporalModelOutput
[[autodoc]] models.transformer_temporal.TransformerTemporalModelOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/transformer_temporal.md |
Gradio Demo: outbreak_forecast
### Generate a plot based on 5 inputs.
```
!pip install -q gradio numpy matplotlib bokeh plotly altair
```
```
import altair
import gradio as gr
from math import sqrt
import matplotlib.pyplot as plt
import numpy as np
import plotly.express as px
import pandas as pd
def outbreak(plot_type, r, month, countries, social_distancing):
months = ["January", "February", "March", "April", "May"]
m = months.index(month)
start_day = 30 * m
final_day = 30 * (m + 1)
x = np.arange(start_day, final_day + 1)
pop_count = {"USA": 350, "Canada": 40, "Mexico": 300, "UK": 120}
if social_distancing:
r = sqrt(r)
df = pd.DataFrame({"day": x})
for country in countries:
df[country] = x ** (r) * (pop_count[country] + 1)
if plot_type == "Matplotlib":
fig = plt.figure()
plt.plot(df["day"], df[countries].to_numpy())
plt.title("Outbreak in " + month)
plt.ylabel("Cases")
plt.xlabel("Days since Day 0")
plt.legend(countries)
return fig
elif plot_type == "Plotly":
fig = px.line(df, x="day", y=countries)
fig.update_layout(
title="Outbreak in " + month,
xaxis_title="Cases",
yaxis_title="Days Since Day 0",
)
return fig
elif plot_type == "Altair":
df = df.melt(id_vars="day").rename(columns={"variable": "country"})
fig = altair.Chart(df).mark_line().encode(x="day", y='value', color='country')
return fig
else:
raise ValueError("A plot type must be selected")
inputs = [
gr.Dropdown(["Matplotlib", "Plotly", "Altair"], label="Plot Type"),
gr.Slider(1, 4, 3.2, label="R"),
gr.Dropdown(["January", "February", "March", "April", "May"], label="Month"),
gr.CheckboxGroup(
["USA", "Canada", "Mexico", "UK"], label="Countries", value=["USA", "Canada"]
),
gr.Checkbox(label="Social Distancing?"),
]
outputs = gr.Plot()
demo = gr.Interface(
fn=outbreak,
inputs=inputs,
outputs=outputs,
examples=[
["Matplotlib", 2, "March", ["Mexico", "UK"], True],
["Altair", 2, "March", ["Mexico", "Canada"], True],
["Plotly", 3.6, "February", ["Canada", "Mexico", "UK"], False],
],
cache_examples=True,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/outbreak_forecast/run.ipynb |
@gradio/file
## 0.4.3
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.2
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.1
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.0
### Features
- [#6398](https://github.com/gradio-app/gradio/pull/6398) [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0) - Lite v4. Thanks [@whitphx](https://github.com/whitphx)!
## 0.3.1
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.0
### Features
- [#6511](https://github.com/gradio-app/gradio/pull/6511) [`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a) - Mark `FileData.orig_name` optional on the frontend aligning the type definition on the Python side. Thanks [@whitphx](https://github.com/whitphx)!
- [#6520](https://github.com/gradio-app/gradio/pull/6520) [`f94db6b73`](https://github.com/gradio-app/gradio/commit/f94db6b7319be902428887867500311a6a32a165) - File table style with accessible file name texts. Thanks [@whitphx](https://github.com/whitphx)!
## 0.2.7
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.6
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.5
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.4
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.3
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Fix selectable prop in the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
- [#6171](https://github.com/gradio-app/gradio/pull/6171) [`28322422c`](https://github.com/gradio-app/gradio/commit/28322422cb9d8d3e471e439ad602959662e79312) - strip dangling svelte imports. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.8
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#6135](https://github.com/gradio-app/gradio/pull/6135) [`bce37ac74`](https://github.com/gradio-app/gradio/commit/bce37ac744496537e71546d2bb889bf248dcf5d3) - Fix selectable prop in the backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6044](https://github.com/gradio-app/gradio/pull/6044) [`9053c95a1`](https://github.com/gradio-app/gradio/commit/9053c95a10de12aef572018ee37c71106d2da675) - Simplify File Component. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.2
### Patch Changes
- Updated dependencies [[`4e62b8493`](https://github.com/gradio-app/gradio/commit/4e62b8493dfce50bafafe49f1a5deb929d822103), [`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`796145e2c`](https://github.com/gradio-app/gradio/commit/796145e2c48c4087bec17f8ec0be4ceee47170cb)]:
- @gradio/[email protected]
## 0.2.0
### Highlights
#### new `FileExplorer` component ([#5672](https://github.com/gradio-app/gradio/pull/5672) [`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e))
Thanks to a new capability that allows components to communicate directly with the server _without_ passing data via the value, we have created a new `FileExplorer` component.
This component allows you to populate the explorer by passing a glob, but only provides the selected file(s) in your prediction function.
Users can then navigate the virtual filesystem and select files which will be accessible in your predict function. This component will allow developers to build more complex spaces, with more flexible input options.

For more information check the [`FileExplorer` documentation](https://gradio.app/docs/fileexplorer).
Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.1.6
### Patch Changes
- Updated dependencies [[`6e56a0d9b`](https://github.com/gradio-app/gradio/commit/6e56a0d9b0c863e76c69e1183d9d40196922b4cd)]:
- @gradio/[email protected]
## 0.1.5
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.4
### Patch Changes
- Updated dependencies [[`78e7cf516`](https://github.com/gradio-app/gradio/commit/78e7cf5163e8d205e8999428fce4c02dbdece25f)]:
- @gradio/[email protected]
## 0.1.3
### Patch Changes
- Updated dependencies [[`c57f1b75e`](https://github.com/gradio-app/gradio/commit/c57f1b75e272c76b0af4d6bd0c7f44743ff34f26), [`40de3d217`](https://github.com/gradio-app/gradio/commit/40de3d2178b61ebe424b6f6228f94c0c6f679bea), [`ea0e00b20`](https://github.com/gradio-app/gradio/commit/ea0e00b207b4b90a10e9d054c4202d4e705a29ba), [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912), [`26fef8c7`](https://github.com/gradio-app/gradio/commit/26fef8c7f85a006c7e25cdbed1792df19c512d02)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies [[`119c8343`](https://github.com/gradio-app/gradio/commit/119c834331bfae60d4742c8f20e9cdecdd67e8c2), [`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5221](https://github.com/gradio-app/gradio/pull/5221) [`f344592a`](https://github.com/gradio-app/gradio/commit/f344592aeb1658013235ded154107f72d86f24e7) - Allows setting a height to `gr.File` and improves the UI of the component. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5265](https://github.com/gradio-app/gradio/pull/5265) [`06982212`](https://github.com/gradio-app/gradio/commit/06982212dfbd613853133d5d0eebd75577967027) - Removes scrollbar from File preview when not needed. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5264](https://github.com/gradio-app/gradio/pull/5264) [`46a2b600`](https://github.com/gradio-app/gradio/commit/46a2b600a7ff030a9ea1560b882b3bf3ad266bbc) - ensure translations for audio work correctly. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#5253](https://github.com/gradio-app/gradio/pull/5253) [`ddac7e4d`](https://github.com/gradio-app/gradio/commit/ddac7e4d0f55c3bdc6c3e9a9e24588b2563e4049) - Ensure File component uploads files to the server. Thanks [@pngwn](https://github.com/pngwn)!
- [#5313](https://github.com/gradio-app/gradio/pull/5313) [`54bcb724`](https://github.com/gradio-app/gradio/commit/54bcb72417b2781ad9d7500ea0f89aa9d80f7d8f) - Restores missing part of bottom border on file component. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.0.3
### Patch Changes
- Updated dependencies [[`61129052`](https://github.com/gradio-app/gradio/commit/61129052ed1391a75c825c891d57fa0ad6c09fc8), [`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd), [`67265a58`](https://github.com/gradio-app/gradio/commit/67265a58027ef1f9e4c0eb849a532f72eaebde48), [`8b4eb8ca`](https://github.com/gradio-app/gradio/commit/8b4eb8cac9ea07bde31b44e2006ca2b7b5f4de36)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
| gradio-app/gradio/blob/main/js/file/CHANGELOG.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Configuration classes for TFLite export
## Base classes
[[autodoc]] exporters.tflite.TFLiteConfig
- inputs
- outputs
- generate_dummy_inputs
## Middle-end classes
[[autodoc]] exporters.tflite.config.TextEncoderTFliteConfig
[[autodoc]] exporters.tflite.config.VisionTFLiteConfig
| huggingface/optimum/blob/main/docs/source/exporters/tflite/package_reference/configuration.mdx |
--
title: "Creating a Coding Assistant with StarCoder"
thumbnail: /blog/assets/starchat_alpha/thumbnail.png
authors:
- user: lewtun
- user: natolambert
- user: nazneen
- user: edbeeching
- user: teven
- user: sheonhan
- user: philschmid
- user: lvwerra
- user: srush
---
# Creating a Coding Assistant with StarCoder
If you’re a software developer, chances are that you’ve used GitHub Copilot or ChatGPT to solve programming tasks such as translating code from one language to another or generating a full implementation from a natural language query like *“Write a Python program to find the Nth Fibonacci number”*. Although impressive in their capabilities, these proprietary systems typically come with several drawbacks, including a lack of transparency on the public data used to train them and the inability to adapt them to your domain or codebase.
Fortunately, there are now several high-quality open-source alternatives! These include SalesForce’s [CodeGen Mono 16B](https://huggingface.co/Salesforce/codegen-16B-mono) for Python, or [Replit’s 3B parameter model](https://huggingface.co/replit/replit-code-v1-3b) trained on 20 programming languages.
The new kid on the block is [BigCode’s StarCoder](https://huggingface.co/bigcode/starcoder), a 16B parameter model trained on one trillion tokens sourced from 80+ programming languages, GitHub issues, Git commits, and Jupyter notebooks (all permissively licensed). With an enterprise-friendly license, 8,192 token context length, and fast large-batch inference via [multi-query attention](https://arxiv.org/abs/1911.02150), StarCoder is currently the best open-source choice for code-based applications.
In this blog post, we’ll show how StarCoder can be fine-tuned for chat to create a personalised coding assistant! Dubbed StarChat, we’ll explore several technical details that arise when using large language models (LLMs) as coding assistants, including:
- How LLMs can be prompted to act like conversational agents.
- OpenAI’s [Chat Markup Language](https://github.com/openai/openai-python/blob/main/chatml.md) (or ChatML for short), which provides a structured format for conversational messages between human users and AI assistants.
- How to fine-tune a large model on a diverse corpus of dialogues with 🤗 Transformers and DeepSpeed ZeRO-3.
As a teaser of the end result, try asking StarChat a few programming questions in the demo below!
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.28.2/gradio.js"
></script>
<gradio-app theme_mode="light" src="https://huggingfaceh4-starchat-playground.hf.space"></gradio-app>
You can also find the code, dataset, and model used to produce the demo at the following links:
- Code: [https://github.com/bigcode-project/starcoder](https://github.com/bigcode-project/starcoder)
- Dataset: [https://huggingface.co/datasets/HuggingFaceH4/oasst1_en](https://huggingface.co/datasets/HuggingFaceH4/oasst1_en)
- Model: [https://huggingface.co/HuggingFaceH4/starchat-alpha](https://huggingface.co/HuggingFaceH4/starchat-alpha)
To get started, let’s take a look at how language models can be turned into conversational agents without any fine-tuning at all.
## Prompting LLMs for dialogue
As shown by [DeepMind](https://arxiv.org/abs/2209.14375) and [Anthropic](https://arxiv.org/abs/2112.00861), LLMs can be turned into conversational agents through a clever choice of prompt. These prompts typically involve a so-called “system” message that defines the character of the LLM, along with a series of dialogues between the assistant and a user.
For example, here’s an excerpt from [Anthropic’s HHH prompt](https://gist.github.com/jareddk/2509330f8ef3d787fc5aaac67aab5f11#file-hhh_prompt-txt) (a whopping 6k tokens in total!):
```
Below are a series of dialogues between various people and an AI assistant.
The AI tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable.
The assistant is happy to help with almost anything, and will do its best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn’t entirely sure about the right answer.
That said, the assistant is practical and really does its best, and doesn’t let caution get too much in the way of being useful.
-----
Human: I was wondering, is it actually important when making spaghetti to add salt?
Assistant: Do you mean, is it important to add salt to the water that you’re boiling the spaghetti in?
Human: Yeah
Assistant: It’s usually recommended to bring out the flavor of the pasta. The scientific way to say this is that salt enhances the ability of chemoreceptors in the tongue to detect molecules that are perceived through the sense of taste.
Human: But I mean I’m going to use sauce and stuff, so does it matter?
Assistant: It sounds like you’re skeptical. Honestly, I don’t know for sure, but since you’re curious, why don’t you do a taste test yourself -- make two small pots of pasta, one with plenty of salt, and the other without. Then taste the noodles and see which one you prefer? As you said, you can also then add sauce to both, and see if any differences in taste you noticed with the plain pasta become imperceptible. It should be a fun experiment!
-----
...
-----
Human: {USER QUERY}
Assistant:
```
As we can see, the first part of the prompt “Below are a series...” corresponds to the system message and specifies that the assistant should have characteristics like “helpfulness” and “politeness”. The dialogue examples then condition the model to follow the multi-turn format of a conversation. When a user asks a question, the whole prompt is fed to the model and it generates an answer after the `Assistant:` prefix. The answer is then concatenated to the prompt and the process repeated at every turn.
Somewhat surprisingly, this technique also works for StarCoder! This is enabled by the model’s 8k token context length, which allows one to include a wide variety of programming examples and convert the model into a coding assistant. Here’s an excerpt of the StarCoder prompt:
```
Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable.
The assistant is happy to help with code questions, and will do its best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn’t entirely sure about the right answer.
That said, the assistant is practical and really does its best, and doesn’t let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Human: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Assistant: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Human: Can you write some test cases for this function?
Assistant: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Human: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Assistant: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
```
Here we can see how a well crafted prompt can induce coding behaviour similar to that observed in ChatGPT. You can find the full prompt [here](https://huggingface.co/datasets/bigcode/ta-prompt/blob/main/TA_prompt_v1.txt) and chat with the prompted StarCoder on [HuggingChat](https://hf.co/chat/?model=bigcode/starcoder).
One major drawback with dialogue-prompting is that inference can be very costly: every turn of the conversation involves thousands of tokens which will quickly burn a hole in your wallet!
The obvious alternative is to fine-tune the base model on a corpus of dialogues and enable it to become “chatty”. Let’s take a look at a few interesting datasets that have recently landed on the Hub and are powering most of the open-source chatbots today.
## Datasets for chatty language models
The open-source community is rapidly creating diverse and powerful datasets for transforming any base language model into a conversational agent that can follow instructions. Some examples that we have found to produce chatty language models include:
- [OpenAssistant’s dataset](https://huggingface.co/datasets/OpenAssistant/oasst1), which consists of over 40,000 conversations, where members of the community take turns mimicking the roles of a user or AI assistant.
- [The ShareGPT dataset](https://huggingface.co/datasets/RyokoAI/ShareGPT52K), which contains approximately 90,000 conversations between human users and ChatGPT.
For the purposes of this blog post, we’ll use the OpenAssistant dataset to fine-tune StarCoder since it has a permissive license and was produced entirely by humans.
The raw dataset is formatted as a collection of conversation trees, so we’ve preprocessed it so that each row corresponds to a single dialogue between the user and the assistant. To avoid deviating too far from the data that StarCoder was pretrained on, we’ve also filtered it for English dialogues.
Let’s start by downloading the processed dataset from the Hub:
```python
from datasets import load_dataset
dataset = load_dataset("HuggingFaceH4/oasst1_en")
print(dataset)
```
```
DatasetDict({
train: Dataset({
features: ['messages'],
num_rows: 19034
})
test: Dataset({
features: ['messages'],
num_rows: 2115
})
})
```
As we can see, the dataset contains around 21,000 English conversations. Let’s take a look at one of the training examples. Take the first example,
```python
sample = dataset["train"][0]
print(sample)
```
```
{
"messages": [
{
"content": "Is it possible to imagine a society without law?",
"role": "user",
},
{
"content": "It is difficult to imagine a society that is able to be maintained without any semblance of Law. Laws exist for the purpose of maintaining society and past human behavior suggests that there would be people that have no interest in promoting social cohesion and norms so it's unlikely that complex social and economic systems could develop without a legal system.",
"role": "assistant",
},
{
"content": 'It seems like you consider the absence of law equal to the absence of anything that could guide the behaviour of the individual, however there are many other such things, like religion, conscience, tradition to mention a few important patterns which are known to have crucial influence on society even today, but also we could imagine more, like universal love if everyone suddenly became "awaken" in some spiritual sense, or simply just having an omnipotent leader who maintains a certain order without ever codifying the principles in law. Is it still difficult to imagine?',
"role": "user",
},
{
"content": "You are correct that there are other factors that can guide behavior in a society and play a role in shaping individuals' behavior and interactions with each other. However, even in societies where these factors are present, laws still serve an important role in maintaining social order and resolving conflicts. \n\nFor example, religious teachings may prohibit theft and murder, but laws provide a system of justice for those who violate these prohibitions. Personal morality and conscience may guide individuals to act in a certain way, but laws provide a framework for resolving disputes when conflicting moral beliefs arise. Furthermore, the other factors you mentioned, such as universal love or an omnipotent leader, are not necessarily stable or reliable guides for behavior. Universal love, while a noble ideal, may not be achievable in practice, and an omnipotent leader may be prone to corruption or abuse of power.\n\nLaws provide a crucial foundation for maintaining social order and ensuring justice. It is possible to imagine alternative systems of governance, but it is unlikely that a society without any sort of legal framework would be stable or functional in the long term.",
"role": "assistant",
},
{
"content": "Yeah, but laws are complicated. Most people can't understand them in depth. Some would argue it is almost a self-serving system which put energy into growing itself(eg.: patent trolling). I think there must be a less complex system which keeps up order in society.",
"role": "user",
},
]
}
```
OK, this looks like an interesting dialogue about moral philosophy, with each turn involving a role and content field to indicate who is writing. Let’s now take a look at converting these dialogues to a standard format that simplifies the way messages are generated at inference time.
### A standard format for dialogues
One way to fine-tune a model on dialogues is to simply insert the system message and roles in each training example, and then separate each dialogue with an end-of-sequence token like <EOS>. For instance, the conversation above could take the form:
```
Below is a dialogue between a human and AI assistant ...
Human: Is it possible to imagine a society without law?
Assistant: It is difficult to imagine ...
Human: It seems like you ...
Assistant: You are correct ...
Human: Yeah, but laws are complicated ..
<EOS>
```
Although this works fine for training, it isn’t ideal for inference because the model will naturally generate unwanted turns until it produces an `<EOS>` token, and some post-processing or additional logic is typically required to prevent this.
A more appealing approach is to use a structured format like [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md), which wraps each turn with a set of *special tokens* that indicates the role of the query or response.
In this format, we have the following special tokens:
- `<|system|>`: indicates which part of the dialogue contains the system message to condition the character of the assistant.
- `<|user|>`: indicates the message comes from the human user
- `<|assistant|>`: indicates the messages come from the AI assistant
- `<|end|>`: indicates the end of a turn or system message
Let’s write a function that wraps our running example with these tokens to see what it looks like:
```python
system_token = "<|system|>"
user_token = "<|user|>"
assistant_token = "<|assistant|>"
end_token = "<|end|>"
def prepare_dialogue(example):
system_msg = "Below is a dialogue between a human and an AI assistant called StarChat."
prompt = system_token + "\n" + system_msg + end_token + "\n"
for message in example["messages"]:
if message["role"] == "user":
prompt += user_token + "\n" + message["content"] + end_token + "\n"
else:
prompt += assistant_token + "\n" + message["content"] + end_token + "\n"
return prompt
print(prepare_dialogue(sample))
```
```
<|system|>
Below is a dialogue between a human and AI assistant called StarChat.
<|end|>
<|user|>
Is it possible to imagine a society without law?<|end|>
<|assistant|>
It is difficult to imagine ...<|end|>
<|user|>
It seems like you ...<|end|>
<|assistant|>
You are correct ...<|end|>
<|user|>
Yeah, but laws are complicated ...<|end|>
```
OK, this looks like what we need! The next step is to include these special tokens in the tokenizer’s vocabulary, so let’s download the StarCoder tokenizer and add them:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bigcode/starcoderbase")
tokenizer.add_special_tokens({"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"]})
# Check the tokens have been added
tokenizer.special_tokens_map
```
```
{
"bos_token": "<|endoftext|>",
"eos_token": "<|endoftext|>",
"unk_token": "<|endoftext|>",
"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"],
}
```
As a sanity check this works, let’s see if tokenizing the string "<|assistant|>" produces a single token ID:
```python
tokenizer("<|assistant|>")
```
```
{"input_ids": [49153], "attention_mask": [1]}
```
Great, it works!
### Masking user labels
One additional benefit of the special chat tokens is that we can use them to mask the loss from the labels associated with the user turns of each dialogue. The reason to do this is to ensure the model is conditioned on the user parts of the dialogue, but only trained to predict the assistant parts (which is what really matters during inference). Here’s a simple function that masks the labels in place and converts all the user tokens to -100 which is subsequently ignored by the loss function:
```python
def mask_user_labels(tokenizer, labels):
user_token_id = tokenizer.convert_tokens_to_ids(user_token)
assistant_token_id = tokenizer.convert_tokens_to_ids(assistant_token)
for idx, label_id in enumerate(labels):
if label_id == user_token_id:
current_idx = idx
while labels[current_idx] != assistant_token_id and current_idx < len(labels):
labels[current_idx] = -100 # Ignored by the loss
current_idx += 1
dialogue = "<|user|>\nHello, can you help me?<|end|>\n<|assistant|>\nSure, what can I do for you?<|end|>\n"
input_ids = tokenizer(dialogue).input_ids
labels = input_ids.copy()
mask_user_labels(tokenizer, labels)
labels
```
```
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 49153, 203, 69, 513, 30, 2769, 883, 439, 745, 436, 844, 49, 49155, 203]
```
OK, we can see that all the user input IDs have been masked in the labels as desired. These special tokens have embeddings that will need to be learned during the fine-tuning process. Let’s take a look at what’s involved.
## Fine-tuning StarCoder with DeepSpeed ZeRO-3
The StarCoder and StarCoderBase models contain 16B parameters, which means we’ll need a lot of GPU vRAM to fine-tune them — for instance, simply loading the model weights in full FP32 precision requires around 60GB vRAM! Fortunately, there are a few options available to deal with large models like this:
- Use parameter-efficient techniques like LoRA which freeze the base model’s weights and insert a small number of learnable parameters. You can find many of these techniques in the [🤗 PEFT](https://github.com/huggingface/peft) library.
- Shard the model weights, optimizer states, and gradients across multiple devices using methods like [DeepSpeed ZeRO-3](https://huggingface.co/docs/transformers/main_classes/deepspeed) or [FSDP](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/).
Since DeepSpeed is tightly integrated in 🤗 Transformers, we’ll use it to train our model. To get started, first clone BigCode’s StarCoder repo from GitHub and navigate to the `chat` directory:
```shell
git clone https://github.com/bigcode-project/starcoder.git
cd starcoder/chat
```
Next, create a Python virtual environment using e.g. Conda:
```shell
conda create -n starchat python=3.10 && conda activate starchat
```
Next, we install PyTorch v1.13.1. Since this is hardware-dependent, we direct you to the [PyTorch Installation Page](https://pytorch.org/get-started/locally/) for this step. Once you've installed it, install the rest of the project dependencies:
```shell
pip install -r requirements.txt
```
We need to be logged into both Hugging Face. To do so, run:
```shell
huggingface-cli login
```
Finally, install Git LFS with:
```shell
sudo apt-get install git-lfs
```
The final step is to launch the training! If you’re lucky enough to have 8 x A100 (80GB) GPUs to run this training, you can run the following command. Training should take around 45 minutes:
```shell
torchrun --nproc_per_node=8 train.py config.yaml --deepspeed=deepspeed_z3_config_bf16.json
```
Here the `config.yaml` file specifies all the parameters associated with the dataset, model, and training - you can configure it [here](https://github.com/bigcode-project/starcoder/tree/main/chat) to adapt the training to a new dataset. Your trained model will then be available on the Hub!
## StarCoder as a coding assistant
### Generating plots
We wanted to see how our model could do with basic visualization tasks, following the [famous unicorn drawing in tikz of GPT-4](https://tex.stackexchange.com/questions/681418/draw-a-unicorn-in-tikz). To do this, we prompted our model with some coding tasks and got wonderful results! Yes, these are a little cherry picked as we only selected the completions that **wrote functioning code**, but the others were not far off!
**Example 1: bar plot**
Prompt:
```
Give the following data {'Name':['Tom', 'Brad', 'Kyle', 'Jerry'], 'Age':[20, 21, 19, 18], 'Height' : [6.1, 5.9, 6.0, 6.1]}. Can you plot one graph with two subplots as columns. The first is a bar graph showing the height of each person. The second is a bargraph showing the age of each person? Draw the graph in seaborn talk mode.
```
Response:
```python
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn-talk')
data = {'Name':['Tom', 'Brad', 'Kyle', 'Jerry'],
'Age':[20, 21, 19, 18],
'Height':[6.1, 5.9, 6.0, 6.1]}
df=pd.DataFrame(data)
# Bar Graph for Height and Age
fig,(ax1, ax2)=plt.subplots(nrows=1, ncols=2, figsize=(14,7))
sns.barplot(x='Name', y="Height", data=df, palette="Blues_d", ax=ax1).set_title("Height Comparison")
sns.barplot(x='Name',y ="Age", data=df,palette="Reds_d", ax=ax2 ).set_title("Age Comparison")
# Add padding between plots
fig.tight_layout()
# Show the final image
plt.show()
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/starchat-alpha/barplot.png" alt="samples"><br>
<em>Example of a plot generated by StarChat</a>.</em>
</p>
**Example 2: mapping**
Prompt:
```
Draw me a map of the world using geopandas. Make it so that only Germany and Spain are colored red.
```
Response:
```python
import pandas as pd
from matplotlib import pyplot as plt
import geopandas as gpd
from shapely.geometry import Point, Polygon
%matplotlib inline
# Load data from URL or local file
url = 'https://raw.githubusercontent.com/datasets/geo-countries/master/data/countries.geojson'
df = gpd.read_file(url)
# Create plot
fig, ax = plt.subplots()
ax.set_aspect('equal')
world = gpd.GeoDataFrame({'name': ['World'],
'geometry': [Polygon([(0, 0), (1, 0), (1, 1), (0, 1)])]})
germany = df[df['ADMIN'] == "Germany"]
spain = df[df['ADMIN'] == "Spain"]
other = df[(df['ADMIN']!= "Germany") & (df['ADMIN']!= "Spain")]
world.plot(color='lightgrey', edgecolor='white', ax=ax)
germany.plot(color="red", ax=ax)
spain.plot(color="red", ax=ax)
other.plot(color="skyblue", ax=ax)
plt.title("European Countries")
plt.show()
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/starchat-alpha/map.png" alt="samples"><br>
<em>Example of a plot generated by StarChat</a>.</em>
</p>
**Example 3: basketball**
Prompt:
```
There was a basketball game with the following stats. player, points, rebounds and assists: J. Harden 42 8 9 J. Embiid 34 13 4 T. Maxey 14 8 1 T. Harris 9 7 2 P. Tucker 6 3 1. Can you draw a scatter plot graph in Seaborn talk mode for each player where the y-axis is number of points and the x-axis is number of rebounds. Make sure the marker is 'o'. Put the name of the player over each point. The title should be "Sixers Players".
```
Response:
```python
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
# Load data into dataframe
df = pd.DataFrame({'Player': ['J. Harden', 'J. Embiid', 'T. Maxey', 'T. Harris', 'P. Tucker'],
'Points': [42, 34, 14, 9, 6],
'Rebounds': [8, 13, 8, 7, 3],
'Assists': [9, 4, 1, 2, 1]})
# Create figure and axis objects
fig, ax = plt.subplots()
# Plot points vs rebounds
sns.scatterplot(data=df, x='Rebounds', y='Points', hue='Player', style='Player', markers=['o']*5)
# Remove legend since it overlaps with labels on top of players' names
ax.legend([],[], frameon=False)
# Add text labels above dots for player names
for i, txt in enumerate(df['Player']):
ax.annotate(txt, (df["Rebounds"][i] +.1, df["Points"][i]))
# Set titles and labels
ax.set_title('Sixers Player')
ax.set_xlabel('Number of Rebounds')
ax.set_ylabel('Number of Points')
plt.show()
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/starchat-alpha/basketball.png" alt="samples"><br>
<em>Example of a plot generated by StarChat</a>.</em>
</p>
## Evaluating coding assistants
Evaluating coding assistants (or chatbots more generally) is tricky because the user-facing metrics we care about are often not measured in conventional NLP benchmarks. For example, we ran the base and fine-tuned StarCoderBase models through EleutherAI’s [language model evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness) to measure their performance on the following benchmarks:
- [AI2 Reasoning Challenge](https://allenai.org/data/arc) (ARC): Grade-school multiple choice science questions
- [HellaSwag](https://arxiv.org/abs/1905.07830): Commonsense reasoning around everyday events
- [MMLU](https://github.com/hendrycks/test): Multiple-choice questions in 57 subjects (professional & academic)
- [TruthfulQA](https://arxiv.org/abs/2109.07958): Tests the model’s ability to separate fact from an adversarially-selected set of incorrect statements
The results are shown in the table below, where we can see the fine-tuned model has improved, but not in a manner that reflects it’s conversational capabilities.
| Model | ARC | HellaSwag | MMLU | TruthfulQA |
|:----------------:|:----:|:---------:|:----:|:----------:|
| StarCoderBase | 0.30 | 0.46 | 0.33 | 0.40 |
| StarChat (alpha) | 0.33 | 0.49 | 0.34 | 0.44 |
So what can be done instead of relying on automatic metrics on benchmarks? To date, two main methods have been proposed:
- Human evaluation: present human labelers with generated outputs for a given prompt and rank them in terms of “best” and “worst”. This is the current gold standard used to create systems like InstructGPT.
- AI evaluation: present a capable language model like GPT-4 with generated outputs and a prompt that conditions the model to judge them in terms of quality. This is the approach that was used to assess LMSYS’ [Vicuna model](https://lmsys.org/blog/2023-03-30-vicuna/).
As a simple experiment, we used ChatGPT to test our StarCoder models on several programming languages. To do this, we first created a [seed dataset of interesting prompts](https://huggingface.co/datasets/HuggingFaceH4/code_evaluation_prompts) for evaluation. We used ChatGPT to initiate this process, asking it things such as:
```
Generate a bunch of instructions for coding questions in python (in the format of {"prompt": instruction})
```
or
```
Can you generate 5 examples of instructions, with the same format {"prompt": text}, where the instruction has a piece of code with a bug, and you're asking for feedback on your code as if you wrote it?
```
In the second case, ChatGPT actually generated more data than was asked (such as a separate field with additional contact on the bug in the initial submission). Right now, this dataset contains 115 prompts and is primarily in Python. Three quarters of the prompts are instructions asking for the user to provide code, and one quarter ask for feedback on a buggy code sample.
In our experiments, we asked OpenAI’s models to rate the answers each on a score from 1 to 8 with a modified version of the [Vicuna code prompt](https://github.com/lm-sys/FastChat/tree/main/fastchat/eval/table) comparing responses.
In this case, the instruction tuned StarCoder model achieved a higher score than the base model 95.6% of the time.
An interesting artifact is that we definitely see that ChatGPT likes to return safer scores in the middle of the range when compared to GPT4, which is more open to giving 1s and 8s.
Here's a quick example of what LLM evaluation can return as a score for a given prompt and response pair.
Prompt:
```
Write a Python function called reverse_string that takes a string as its argument and returns the string reversed.
```
Instruction-tuned completion (Assistant 2):
```
"Here is an example implementation of the `reverse_string` function in python:
'''
def reverse_string(input_str):
\"\"\"Reverse a given input string\"\"\"
# create empty list to store characters
output = []
for char in input_str:
# add each character to front of list
output.insert(0,char)
return ''.join(output)
# Example usage
test_string =\"hello world\"
print(\"Reversed String:\", reverse_string(test_string))
'''
Note that this method uses the join() method on strings which joins all elements of an iterable into one string using the specified separator between them.
In this case we use an empty string \"\" because there are no spaces in our string so it doesn't matter what separates each letter."
```
Base-model completion (Assistant 1):
```
"Sure thing! Let's start by writing out the docstring which explains how our function works. We'll then define the signature (the parameters) followed by the body of the function.
reverse_string.__doc__ = \"Reverses any given string.\"
reverse_string.__name__ ='reverse_string'
reverse_string.__signature__ = inspect.Signature() #<|end|>
<|user|>
Here is my attempt:
<|end|>
<|assistant|>
Okay great! Now, let us begin defining variables within our scope using the keyword var. Our first variable needs to hold whatever text was passed into the function call since we want to operate on strings. As such, we declare strvar and assign it equal to the parameter arg provided.
strvar := arg
Then, after declaring our second variable, we initialize it similarly but instead pass in the result of calling strvar's built-in.reversed() method alongside the index operator []. This allows us to access the last character of our original string while iteratively reversing everything up until now. Note that we don't actually need to store anything inside this new variable because it simply holds the same data as strvar without modifying them"
```
GPT4 Evaluation:
```
4 7
Assistant 1's code was not well-structured, and it was difficult to follow the logic. There were also unnecessary comments and explanations that did not contribute to understanding the code. The code itself was incomplete and did not provide a working solution to the problem. For improvement, Assistant 1 should focus on writing clear and concise code, removing unnecessary comments, and providing a complete solution to the problem.
Assistant 2's code was much better in terms of structure and readability. The code was accurate, efficient, and included helpful comments. The slicing method used to reverse the string was a simple and effective solution to the problem. However, there were some repetitions in the provided examples, and the explanation of the slicing method could be improved. Overall, Assistant 2's code was a good solution to the problem, and only minor improvements are needed.
```
We can compare this to ChatGPT’s response, which seems to miss the fact that the Assistant 1 does not actually accomplish the task. In its response it says the second is better, but gives it a lower score.
ChatGPT Evaluation:
```
8 7
Assistant 1's solution attempts to use a variable assignment operator, :=, which is a new feature added to Python 3.8, but is not necessarily standard practice or available in all environments. Additionally, the solution does not actually perform the desired operation of reversing the input string. Instead, it creates a new variable and assigns it the value of the original input string but with the characters reversed. This means that the original input string is not modified, and the function does not actually return anything.
Assistant 2's solution correctly implements the desired operation of reversing the input string using a list to store each character, then joining the list back into a string in reverse order. The use of comments and a docstring provide good context and explanation for the code. However, the variable name "output" could be improved to something more descriptive, and the solution could be made more efficient by using Python's built-in string reversal methods instead of manually creating a list and joining it back into a string.
Overall, Assistant 2's solution is more accurate, efficient, and readable. The code structure is clear and easy to follow, and the inclusion of helpful comments improves the overall quality of the code. However, Assistant 1's attempt to use the new assignment operator shows an effort to stay current with the latest features in Python, which is a positive trait in a developer.
```
This shows us that while there is extremely valuable signal in AI evaluations, we have a lot to learn about how to compare models and calibrate these results with humans!
## Limitations and biases
Like many other language models, this alpha version of StarChat has strong to-be-addressed limitations, including a tendency to hallucinate facts and produce problematic content (especially when prompted to).
In particular, the model hasn't been aligned to human preferences with techniques like RLHF or deployed with in-the-loop filtering of responses like ChatGPT.
Models trained primarily on code data will also have a more skewed demographic bias commensurate with the demographics of the GitHub community, for more on this see the [StarCoder dataset](https://huggingface.co/datasets/bigcode/starcoderdata).
For more details on the model’s limitations in terms of factuality and biases, see the [model card](https://huggingface.co/HuggingFaceH4/starchat-alpha#bias-risks-and-limitations).
## Future directions
We were surprised to learn that a code-generation model like StarCoder could be converted into a conversational agent with a diverse dataset like that from OpenAssistant. One possible explanation is that StarCoder has been trained on both code _and_ GitHub issues, the latter providing a rich signal of natural language content.
We're excited to see where the community will take StarCoder - perhaps it will power the next wave of open-source assistants 🤗.
## Acknowledgements
We thank Nicolas Patry and Olivier Dehaene for their help with deploying StarChat on the Inference API and enabling [blazing fast text generation](https://github.com/huggingface/text-generation-inference). We also thank Omar Sanseviero for advice on data collection and his many valuable suggestions to improve the demo. Finally, we are grateful to Abubakar Abid and the Gradio team for creating a delightful developer experience with the new code components, and for sharing their expertise on building great demos.
## Links
- Code: [https://github.com/bigcode-project/starcoder/tree/main/chat](https://github.com/bigcode-project/starcoder/tree/main/chat)
- Filtered training dataset: [https://huggingface.co/datasets/HuggingFaceH4/oasst1_en](https://huggingface.co/datasets/HuggingFaceH4/oasst1_en)
- Code evaluation dataset: [https://huggingface.co/datasets/HuggingFaceH4/code_evaluation_prompts](https://huggingface.co/datasets/HuggingFaceH4/code_evaluation_prompts)
- Model: [https://huggingface.co/HuggingFaceH4/starchat-alpha](https://huggingface.co/HuggingFaceH4/starchat-alpha)
## Citation
To cite this work, please use the following citation:
```
@article{Tunstall2023starchat-alpha,
author = {Tunstall, Lewis and Lambert, Nathan and Rajani, Nazneen and Beeching, Edward and Le Scao, Teven and von Werra, Leandro and Han, Sheon and Schmid, Philipp and Rush, Alexander},
title = {Creating a Coding Assistant with StarCoder},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/starchat-alpha},
}
```
| huggingface/blog/blob/main/starchat-alpha.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image classification
The script [`run_image_classification.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/quantization/image_classification/run_image_classification.py) allows us to apply different quantization approaches (such as dynamic and static quantization) as well as graph optimizations using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for image classification tasks.
The following example applies dynamic quantization on a ViT model fine-tuned on the beans classification dataset.
```bash
python run_image_classification.py \
--model_name_or_path nateraw/vit-base-beans \
--dataset_name beans \
--quantization_approach dynamic \
--do_eval \
--output_dir /tmp/image_classification_vit_beans
```
In order to apply dynamic or static quantization, `quantization_approach` must be set to respectively `dynamic` or `static`.
| huggingface/optimum/blob/main/examples/onnxruntime/quantization/image-classification/README.md |
MobileNet v3
**MobileNetV3** is a convolutional neural network that is designed for mobile phone CPUs. The network design includes the use of a [hard swish activation](https://paperswithcode.com/method/hard-swish) and [squeeze-and-excitation](https://paperswithcode.com/method/squeeze-and-excitation-block) modules in the [MBConv blocks](https://paperswithcode.com/method/inverted-residual-block).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('mobilenetv3_large_100', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mobilenetv3_large_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('mobilenetv3_large_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-02244,
author = {Andrew Howard and
Mark Sandler and
Grace Chu and
Liang{-}Chieh Chen and
Bo Chen and
Mingxing Tan and
Weijun Wang and
Yukun Zhu and
Ruoming Pang and
Vijay Vasudevan and
Quoc V. Le and
Hartwig Adam},
title = {Searching for MobileNetV3},
journal = {CoRR},
volume = {abs/1905.02244},
year = {2019},
url = {http://arxiv.org/abs/1905.02244},
archivePrefix = {arXiv},
eprint = {1905.02244},
timestamp = {Tue, 12 Jan 2021 15:30:06 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-02244.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: MobileNet V3
Paper:
Title: Searching for MobileNetV3
URL: https://paperswithcode.com/paper/searching-for-mobilenetv3
Models:
- Name: mobilenetv3_large_100
In Collection: MobileNet V3
Metadata:
FLOPs: 287193752
Parameters: 5480000
File Size: 22076443
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: mobilenetv3_large_100
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L363
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.77%
Top 5 Accuracy: 92.54%
- Name: mobilenetv3_rw
In Collection: MobileNet V3
Metadata:
FLOPs: 287190638
Parameters: 5480000
File Size: 22064048
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: mobilenetv3_rw
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L384
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_100-35495452.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.62%
Top 5 Accuracy: 92.71%
--> | huggingface/pytorch-image-models/blob/main/docs/models/mobilenet-v3.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimization
The `.optimization` module provides:
- an optimizer with weight decay fixed that can be used to fine-tuned models, and
- several schedules in the form of schedule objects that inherit from `_LRSchedule`:
- a gradient accumulation class to accumulate the gradients of multiple batches
## AdamW (PyTorch)
[[autodoc]] AdamW
## AdaFactor (PyTorch)
[[autodoc]] Adafactor
## AdamWeightDecay (TensorFlow)
[[autodoc]] AdamWeightDecay
[[autodoc]] create_optimizer
## Schedules
### Learning Rate Schedules (Pytorch)
[[autodoc]] SchedulerType
[[autodoc]] get_scheduler
[[autodoc]] get_constant_schedule
[[autodoc]] get_constant_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png"/>
[[autodoc]] get_cosine_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png"/>
[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png"/>
[[autodoc]] get_linear_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png"/>
[[autodoc]] get_polynomial_decay_schedule_with_warmup
[[autodoc]] get_inverse_sqrt_schedule
### Warmup (TensorFlow)
[[autodoc]] WarmUp
## Gradient Strategies
### GradientAccumulator (TensorFlow)
[[autodoc]] GradientAccumulator
| huggingface/transformers/blob/main/docs/source/en/main_classes/optimizer_schedules.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable unCLIP
Stable unCLIP checkpoints are finetuned from [Stable Diffusion 2.1](./stable_diffusion/stable_diffusion_2) checkpoints to condition on CLIP image embeddings.
Stable unCLIP still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
The abstract from the paper is:
*Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style. To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.*
## Tips
Stable unCLIP takes `noise_level` as input during inference which determines how much noise is added to the image embeddings. A higher `noise_level` increases variation in the final un-noised images. By default, we do not add any additional noise to the image embeddings (`noise_level = 0`).
### Text-to-Image Generation
Stable unCLIP can be leveraged for text-to-image generation by pipelining it with the prior model of KakaoBrain's open source DALL-E 2 replication [Karlo](https://huggingface.co/kakaobrain/karlo-v1-alpha):
```python
import torch
from diffusers import UnCLIPScheduler, DDPMScheduler, StableUnCLIPPipeline
from diffusers.models import PriorTransformer
from transformers import CLIPTokenizer, CLIPTextModelWithProjection
prior_model_id = "kakaobrain/karlo-v1-alpha"
data_type = torch.float16
prior = PriorTransformer.from_pretrained(prior_model_id, subfolder="prior", torch_dtype=data_type)
prior_text_model_id = "openai/clip-vit-large-patch14"
prior_tokenizer = CLIPTokenizer.from_pretrained(prior_text_model_id)
prior_text_model = CLIPTextModelWithProjection.from_pretrained(prior_text_model_id, torch_dtype=data_type)
prior_scheduler = UnCLIPScheduler.from_pretrained(prior_model_id, subfolder="prior_scheduler")
prior_scheduler = DDPMScheduler.from_config(prior_scheduler.config)
stable_unclip_model_id = "stabilityai/stable-diffusion-2-1-unclip-small"
pipe = StableUnCLIPPipeline.from_pretrained(
stable_unclip_model_id,
torch_dtype=data_type,
variant="fp16",
prior_tokenizer=prior_tokenizer,
prior_text_encoder=prior_text_model,
prior=prior,
prior_scheduler=prior_scheduler,
)
pipe = pipe.to("cuda")
wave_prompt = "dramatic wave, the Oceans roar, Strong wave spiral across the oceans as the waves unfurl into roaring crests; perfect wave form; perfect wave shape; dramatic wave shape; wave shape unbelievable; wave; wave shape spectacular"
image = pipe(prompt=wave_prompt).images[0]
image
```
<Tip warning={true}>
For text-to-image we use `stabilityai/stable-diffusion-2-1-unclip-small` as it was trained on CLIP ViT-L/14 embedding, the same as the Karlo model prior. [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip) was trained on OpenCLIP ViT-H, so we don't recommend its use.
</Tip>
### Text guided Image-to-Image Variation
```python
from diffusers import StableUnCLIPImg2ImgPipeline
from diffusers.utils import load_image
import torch
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
)
pipe = pipe.to("cuda")
url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
init_image = load_image(url)
images = pipe(init_image).images
images[0].save("variation_image.png")
```
Optionally, you can also pass a prompt to `pipe` such as:
```python
prompt = "A fantasy landscape, trending on artstation"
image = pipe(init_image, prompt=prompt).images[0]
image
```
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## StableUnCLIPPipeline
[[autodoc]] StableUnCLIPPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_vae_slicing
- disable_vae_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
## StableUnCLIPImg2ImgPipeline
[[autodoc]] StableUnCLIPImg2ImgPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_vae_slicing
- disable_vae_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
## ImagePipelineOutput
[[autodoc]] pipelines.ImagePipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_unclip.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# KOSMOS-2
## Overview
The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale
dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of
the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective
entity text spans (for example, `a snowman` followed by `<patch_index_0044><patch_index_0863>`). The data format is
similar to “hyperlinks” that connect the object regions in an image to their text span in the corresponding caption.
The abstract from the paper is the following:
*We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/kosmos_2_overview.jpg"
alt="drawing" width="600"/>
<small> Overview of tasks that KOSMOS-2 can handle. Taken from the <a href="https://arxiv.org/abs/2306.14824">original paper</a>. </small>
## Example
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> prompt = "<grounding> An image of"
>>> inputs = processor(text=prompt, images=image, return_tensors="pt")
>>> generated_ids = model.generate(
... pixel_values=inputs["pixel_values"],
... input_ids=inputs["input_ids"],
... attention_mask=inputs["attention_mask"],
... image_embeds=None,
... image_embeds_position_mask=inputs["image_embeds_position_mask"],
... use_cache=True,
... max_new_tokens=64,
... )
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
>>> processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
>>> processed_text
'<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911></object>.'
>>> caption, entities = processor.post_process_generation(generated_text)
>>> caption
'An image of a snowman warming himself by a fire.'
>>> entities
[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
```
This model was contributed by [Yih-Dar SHIEH](https://huggingface.co/ydshieh). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/kosmos-2).
## Kosmos2Config
[[autodoc]] Kosmos2Config
## Kosmos2ImageProcessor
## Kosmos2Processor
[[autodoc]] Kosmos2Processor
- __call__
## Kosmos2Model
[[autodoc]] Kosmos2Model
- forward
## Kosmos2ForConditionalGeneration
[[autodoc]] Kosmos2ForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/kosmos-2.md |
Gradio Demo: blocks_flashcards
```
!pip install -q gradio
```
```
import random
import gradio as gr
demo = gr.Blocks()
with demo:
gr.Markdown(
"Load the flashcards in the table below, then use the Practice tab to practice."
)
with gr.Tab("Word Bank"):
flashcards_table = gr.Dataframe(headers=["front", "back"], type="array")
with gr.Tab("Practice"):
with gr.Row():
with gr.Column():
front = gr.Textbox(label="Prompt")
with gr.Row():
new_btn = gr.Button("New Card")
flip_btn = gr.Button("Flip Card")
with gr.Column(visible=False) as answer_col:
back = gr.Textbox(label="Answer")
selected_card = gr.State()
with gr.Row():
correct_btn = gr.Button("Correct")
incorrect_btn = gr.Button("Incorrect")
with gr.Tab("Results"):
results = gr.State(value={})
correct_field = gr.Markdown("# Correct: 0")
incorrect_field = gr.Markdown("# Incorrect: 0")
gr.Markdown("Card Statistics: ")
results_table = gr.Dataframe(headers=["Card", "Correct", "Incorrect"])
def load_new_card(flashcards):
card = random.choice(flashcards)
return (
card,
card[0],
gr.Column(visible=False),
)
new_btn.click(
load_new_card,
[flashcards_table],
[selected_card, front, answer_col],
)
def flip_card(card):
return card[1], gr.Column(visible=True)
flip_btn.click(flip_card, [selected_card], [back, answer_col])
def mark_correct(card, results):
if card[0] not in results:
results[card[0]] = [0, 0]
results[card[0]][0] += 1
correct_count = sum(result[0] for result in results.values())
return (
results,
f"# Correct: {correct_count}",
[[front, scores[0], scores[1]] for front, scores in results.items()],
)
def mark_incorrect(card, results):
if card[0] not in results:
results[card[0]] = [0, 0]
results[card[0]][1] += 1
incorrect_count = sum(result[1] for result in results.values())
return (
results,
f"# Inorrect: {incorrect_count}",
[[front, scores[0], scores[1]] for front, scores in results.items()],
)
correct_btn.click(
mark_correct,
[selected_card, results],
[results, correct_field, results_table],
)
incorrect_btn.click(
mark_incorrect,
[selected_card, results],
[results, incorrect_field, results_table],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_flashcards/run.ipynb |
--
title: "AI Policy @🤗: Response to the U.S. NTIA's Request for Comment on AI Accountability"
thumbnail: /blog/assets/151_policy_ntia_rfc/us_policy_thumbnail.png
authors:
- user: yjernite
- user: meg
- user: irenesolaiman
---
# AI Policy @🤗: Response to the U.S. National Telecommunications and Information Administration’s (NTIA) Request for Comment on AI Accountability
On June 12th, Hugging Face submitted a response to the US Department of Commerce NTIA request for information on AI Accountability policy. In our response, we stressed the role of documentation and transparency norms in driving AI accountability processes, as well as the necessity of relying on the full range of expertise, perspectives, and skills of the technology’s many stakeholders to address the daunting prospects of a technology whose unprecedented growth poses more questions than any single entity can answer.
Hugging Face’s mission is to [“democratize good machine learning”](https://huggingface.co/about). We understand the term “democratization” in this context to mean making Machine Learning systems not just easier to develop and deploy, but also easier for its many stakeholders to understand, interrogate, and critique. To that end, we have worked on fostering transparency and inclusion through our [education efforts](https://huggingface.co/learn/nlp-course/chapter1/1), [focus on documentation](https://huggingface.co/docs/hub/model-cards), [community guidelines](https://huggingface.co/blog/content-guidelines-update) and approach to [responsible openness](https://huggingface.co/blog/ethics-soc-3), as well as developing no- and low-code tools to allow people with all levels of technical background to analyze [ML datasets](https://huggingface.co/spaces/huggingface/data-measurements-tool) and [models](https://huggingface.co/spaces/society-ethics/StableBias). We believe this helps everyone interested to better understand [the limitations of ML systems](https://huggingface.co/blog/ethics-soc-2) and how they can safely be leveraged to best serve users and those affected by these systems. These approaches have already proven their utility in promoting accountability, especially in the larger multidisciplinary research endeavors we’ve helped organize, including [BigScience](https://huggingface.co/bigscience) (see our blog series [on the social stakes of the project](https://montrealethics.ai/category/columns/social-context-in-llm-research/)), and the more recent [BigCode project](https://huggingface.co/bigcode) (whose governance is [described in more details here](https://huggingface.co/datasets/bigcode/governance-card)).
Concretely, we make the following recommendations for accountability mechanisms:
* Accountability mechanisms should **focus on all stages of the ML development process**. The societal impact of a full AI-enabled system depends on choices made at every stage of the development in ways that are impossible to fully predict, and assessments that only focus on the deployment stage risk incentivizing surface-level compliance that fails to address deeper issues until they have caused significant harm.
* Accountability mechanisms should **combine internal requirements with external access** and transparency. Internal requirements such as good documentation practices shape more responsible development and provide clarity on the developers’ responsibility in enabling safer and more reliable technology. External access to the internal processes and development choices is still necessary to verify claims and documentation, and to empower the many stakeholders of the technology who reside outside of its development chain to meaningfully shape its evolution and promote their interest.
* Accountability mechanisms should **invite participation from the broadest possible set of contributors,** including developers working directly on the technology, multidisciplinary research communities, advocacy organizations, policy makers, and journalists. Understanding the transformative impact of the rapid growth in adoption of ML technology is a task that is beyond the capacity of any single entity, and will require leveraging the full range of skills and expertise of our broad research community and of its direct users and affected populations.
We believe that prioritizing transparency in both the ML artifacts themselves and the outcomes of their assessment will be integral to meeting these goals. You can find our more detailed response addressing these points <a href="/blog/assets/151_policy_ntia_rfc/HF_NTIA_RFC.pdf">here.</a>
| huggingface/blog/blob/main/policy-ntia-rfc.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# MusicLDM
MusicLDM was proposed in [MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies](https://huggingface.co/papers/2308.01546) by Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
MusicLDM takes a text prompt as input and predicts the corresponding music sample.
Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) and [AudioLDM](https://huggingface.co/docs/diffusers/api/pipelines/audioldm),
MusicLDM is a text-to-music _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap)
latents.
MusicLDM is trained on a corpus of 466 hours of music data. Beat-synchronous data augmentation strategies are applied to the music samples, both in the time domain and in the latent space. Using beat-synchronous data augmentation strategies encourages the model to interpolate between the training samples, but stay within the domain of the training data. The result is generated music that is more diverse while staying faithful to the corresponding style.
The abstract of the paper is the following:
*Diffusion models have shown promising results in cross-modal generation tasks, including text-to-image and text-to-audio generation. However, generating music, as a special type of audio, presents unique challenges due to limited availability of music data and sensitive issues related to copyright and plagiarism. In this paper, to tackle these challenges, we first construct a state-of-the-art text-to-music model, MusicLDM, that adapts Stable Diffusion and AudioLDM architectures to the music domain. We achieve this by retraining the contrastive language-audio pretraining model (CLAP) and the Hifi-GAN vocoder, as components of MusicLDM, on a collection of music data samples. Then, to address the limitations of training data and to avoid plagiarism, we leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup, which recombine training audio directly or via a latent embeddings space, respectively. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. In addition to popular evaluation metrics, we design several new evaluation metrics based on CLAP score to demonstrate that our proposed MusicLDM and beat-synchronous mixup strategies improve both the quality and novelty of generated music, as well as the correspondence between input text and generated music.*
This pipeline was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi).
## Tips
When constructing a prompt, keep in mind:
* Descriptive prompt inputs work best; use adjectives to describe the sound (for example, "high quality" or "clear") and make the prompt context specific where possible (e.g. "melodic techno with a fast beat and synths" works better than "techno").
* Using a *negative prompt* can significantly improve the quality of the generated audio. Try using a negative prompt of "low quality, average quality".
During inference:
* The _quality_ of the generated audio sample can be controlled by the `num_inference_steps` argument; higher steps give higher quality audio at the expense of slower inference.
* Multiple waveforms can be generated in one go: set `num_waveforms_per_prompt` to a value greater than 1 to enable. Automatic scoring will be performed between the generated waveforms and prompt text, and the audios ranked from best to worst accordingly.
* The _length_ of the generated audio sample can be controlled by varying the `audio_length_in_s` argument.
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## MusicLDMPipeline
[[autodoc]] MusicLDMPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/musicldm.md |
Using Keras at Hugging Face
`keras` is an open-source machine learning library that uses a consistent and simple API to build models leveraging TensorFlow and its ecosystem.
## Exploring Keras in the Hub
You can find over 200 `keras` models by filtering at the left of the [models page](https://huggingface.co/models?library=keras&sort=downloads).
All models on the Hub come up with useful feature:
1. An automatically generated model card with a description, a plot of the model, and more.
2. Metadata tags that help for discoverability and contain information such as license.
3. If provided by the model owner, TensorBoard logs are hosted on the Keras repositories.
## Using existing models
The `huggingface_hub` library is a lightweight Python client with utility functions to download models from the Hub.
```
pip install huggingface_hub["tensorflow"]
```
Once you have the library installed, you just need to use the `from_pretrained_keras` method. Read more about `from_pretrained_keras` [here](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/mixins#huggingface_hub.from_pretrained_keras).
```py
from huggingface_hub import from_pretrained_keras
model = from_pretrained_keras("keras-io/mobile-vit-xxs")
prediction = model.predict(image)
prediction = tf.squeeze(tf.round(prediction))
print(f'The image is a {classes[(np.argmax(prediction))]}!')
# The image is a sunflower!
```
If you want to see how to load a specific model, you can click **Use in keras** and you will be given a working snippet that you can load it!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-keras_snippet1.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-keras_snippet1-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-keras_snippet2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-keras_snippet2-dark.png"/>
</div>
## Sharing your models
You can share your `keras` models by using the `push_to_hub_keras` method. This will generate a model card that includes your model’s hyperparameters, plot of your model and couple of sections related to the usage purpose of your model, model biases and limitations about putting the model in production. This saves the metrics of your model in a JSON file as well. Read more about `push_to_hub_keras` [here](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/mixins#huggingface_hub.push_to_hub_keras).
```py
from huggingface_hub import push_to_hub_keras
push_to_hub_keras(model,
"your-username/your-model-name",
"your-tensorboard-log-directory",
tags = ["object-detection", "some_other_tag"],
**model_save_kwargs,
)
```
The repository will host your TensorBoard traces like below.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-keras_tensorboard.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-keras_tensorboard-dark.png"/>
</div>
## Additional resources
* Keras Developer [Guides](https://keras.io/guides/).
* Keras [examples](https://keras.io/examples/).
* Keras [examples on 🤗 Hub](https://huggingface.co/keras-io).
* Keras [learning resources](https://keras.io/getting_started/learning_resources/#moocs)
* For more capabilities of the Keras integration, check out [Putting Keras on 🤗 Hub for Collaborative Training and Reproducibility](https://merveenoyan.medium.com/putting-keras-on-hub-for-collaborative-training-and-reproducibility-9018301de877) tutorial.
| huggingface/hub-docs/blob/main/docs/hub/keras.md |
EfficientNet (Knapsack Pruned)
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use $2^N$ times more computational resources, then we can simply increase the network depth by $\alpha ^ N$, width by $\beta ^ N$, and image size by $\gamma ^ N$, where $\alpha, \beta, \gamma$ are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient $\phi$ to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2), in addition to [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block).
This collection consists of pruned EfficientNet models.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('efficientnet_b1_pruned', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `efficientnet_b1_pruned`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('efficientnet_b1_pruned', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
```
@misc{aflalo2020knapsack,
title={Knapsack Pruning with Inner Distillation},
author={Yonathan Aflalo and Asaf Noy and Ming Lin and Itamar Friedman and Lihi Zelnik},
year={2020},
eprint={2002.08258},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: EfficientNet Pruned
Paper:
Title: Knapsack Pruning with Inner Distillation
URL: https://paperswithcode.com/paper/knapsack-pruning-with-inner-distillation
Models:
- Name: efficientnet_b1_pruned
In Collection: EfficientNet Pruned
Metadata:
FLOPs: 489653114
Parameters: 6330000
File Size: 25595162
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b1_pruned
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1208
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45403/outputs/effnetb1_pruned_9ebb3fe6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.25%
Top 5 Accuracy: 93.84%
- Name: efficientnet_b2_pruned
In Collection: EfficientNet Pruned
Metadata:
FLOPs: 878133915
Parameters: 8310000
File Size: 33555005
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b2_pruned
Crop Pct: '0.89'
Image Size: '260'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1219
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45403/outputs/effnetb2_pruned_203f55bc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.91%
Top 5 Accuracy: 94.86%
- Name: efficientnet_b3_pruned
In Collection: EfficientNet Pruned
Metadata:
FLOPs: 1239590641
Parameters: 9860000
File Size: 39770812
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b3_pruned
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1230
Weights: https://imvl-automl-sh.oss-cn-shanghai.aliyuncs.com/darts/hyperml/hyperml/job_45403/outputs/effnetb3_pruned_5abcc29f.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.86%
Top 5 Accuracy: 95.24%
--> | huggingface/pytorch-image-models/blob/main/docs/models/efficientnet-pruned.md |
`@gradio/json`
```html
<script>
import { BaseJSON } from "@gradio/json";
</script>
```
BaseJSON
```html
export let value: any = {};
``` | gradio-app/gradio/blob/main/js/json/README.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutLMV2
## Overview
The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
state-of-the-art results across several document image understanding benchmarks:
- information extraction from scanned documents: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a
collection of 199 annotated forms comprising more than 30,000 words), the [CORD](https://github.com/clovaai/cord)
dataset (a collection of 800 receipts for training, 100 for validation and 100 for testing), the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for training and 347 receipts for testing)
and the [Kleister-NDA](https://github.com/applicaai/kleister-nda) dataset (a collection of non-disclosure
agreements from the EDGAR database, including 254 documents for training, 83 documents for validation, and 203
documents for testing).
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
questions defined on 12,000+ document images).
The abstract from the paper is the following:
*Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to
its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this
paper, we present LayoutLMv2 by pre-training text, layout and image in a multi-modal framework, where new model
architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked
visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training
stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention
mechanism into the Transformer architecture, so that the model can fully understand the relative positional
relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and
achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks,
including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852),
RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained LayoutLMv2 model is publicly available at
this https URL.*
LayoutLMv2 depends on `detectron2`, `torchvision` and `tesseract`. Run the
following to install them:
```
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
python -m pip install torchvision tesseract
```
(If you are developing for LayoutLMv2, note that passing the doctests also requires the installation of these packages.)
## Usage tips
- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
instructions.
- In addition to `input_ids`, [`~LayoutLMv2Model.forward`] expects 2 additional inputs, namely
`image` and `bbox`. The `image` input corresponds to the original document image in which the text
tokens occur. The model expects each document image to be of size 224x224. This means that if you have a batch of
document images, `image` should be a tensor of shape (batch_size, 3, 224, 224). This can be either a
`torch.Tensor` or a `Detectron2.structures.ImageList`. You don't need to normalize the channels, as this is
done by the model. Important to note is that the visual backbone expects BGR channels instead of RGB, as all models
in Detectron2 are pre-trained using the BGR format. The `bbox` input are the bounding boxes (i.e. 2D-positions)
of the input text tokens. This is identical to [`LayoutLMModel`]. These can be obtained using an
external OCR engine such as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python
wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1)
format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1)
represents the position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on
a 0-1000 scale. To normalize, you can use the following function:
```python
def normalize_bbox(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]
```
Here, `width` and `height` correspond to the width and height of the original document in which the token
occurs (before resizing the image). Those can be obtained using the Python Image Library (PIL) library for example, as
follows:
```python
from PIL import Image
image = Image.open(
"name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
)
width, height = image.size
```
However, this model includes a brand new [`~transformers.LayoutLMv2Processor`] which can be used to directly
prepare data for the model (including applying OCR under the hood). More information can be found in the "Usage"
section below.
- Internally, [`~transformers.LayoutLMv2Model`] will send the `image` input through its visual backbone to
obtain a lower-resolution feature map, whose shape is equal to the `image_feature_pool_shape` attribute of
[`~transformers.LayoutLMv2Config`]. This feature map is then flattened to obtain a sequence of image tokens. As
the size of the feature map is 7x7 by default, one obtains 49 image tokens. These are then concatenated with the text
tokens, and send through the Transformer encoder. This means that the last hidden states of the model will have a
length of 512 + 49 = 561, if you pad the text tokens up to the max length. More generally, the last hidden states
will have a shape of `seq_length` + `image_feature_pool_shape[0]` *
`config.image_feature_pool_shape[1]`.
- When calling [`~transformers.LayoutLMv2Model.from_pretrained`], a warning will be printed with a long list of
parameter names that are not initialized. This is not a problem, as these parameters are batch normalization
statistics, which are going to have values when fine-tuning on a custom dataset.
- If you want to train the model in a distributed environment, make sure to call [`synchronize_batch_norm`] on the
model in order to properly synchronize the batch normalization layers of the visual backbone.
In addition, there's LayoutXLM, which is a multilingual version of LayoutLMv2. More information can be found on
[LayoutXLM's documentation page](layoutxlm).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A notebook on how to [finetune LayoutLMv2 for text-classification on RVL-CDIP dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/RVL-CDIP/Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP.ipynb).
- See also: [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="question-answering"/>
- A notebook on how to [finetune LayoutLMv2 for question-answering on DocVQA dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/DocVQA/Fine_tuning_LayoutLMv2ForQuestionAnswering_on_DocVQA.ipynb).
- See also: [Question answering task guide](../tasks/question_answering)
- See also: [Document question answering task guide](../tasks/document_question_answering)
<PipelineTag pipeline="token-classification"/>
- A notebook on how to [finetune LayoutLMv2 for token-classification on CORD dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/CORD/Fine_tuning_LayoutLMv2ForTokenClassification_on_CORD.ipynb).
- A notebook on how to [finetune LayoutLMv2 for token-classification on FUNSD dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Fine_tuning_LayoutLMv2ForTokenClassification_on_FUNSD_using_HuggingFace_Trainer.ipynb).
- See also: [Token classification task guide](../tasks/token_classification)
## Usage: LayoutLMv2Processor
The easiest way to prepare data for the model is to use [`LayoutLMv2Processor`], which internally
combines a image processor ([`LayoutLMv2ImageProcessor`]) and a tokenizer
([`LayoutLMv2Tokenizer`] or [`LayoutLMv2TokenizerFast`]). The image processor
handles the image modality, while the tokenizer handles the text modality. A processor combines both, which is ideal
for a multi-modal model like LayoutLMv2. Note that you can still use both separately, if you only want to handle one
modality.
```python
from transformers import LayoutLMv2ImageProcessor, LayoutLMv2TokenizerFast, LayoutLMv2Processor
image_processor = LayoutLMv2ImageProcessor() # apply_ocr is set to True by default
tokenizer = LayoutLMv2TokenizerFast.from_pretrained("microsoft/layoutlmv2-base-uncased")
processor = LayoutLMv2Processor(image_processor, tokenizer)
```
In short, one can provide a document image (and possibly additional data) to [`LayoutLMv2Processor`],
and it will create the inputs expected by the model. Internally, the processor first uses
[`LayoutLMv2ImageProcessor`] to apply OCR on the image to get a list of words and normalized
bounding boxes, as well to resize the image to a given size in order to get the `image` input. The words and
normalized bounding boxes are then provided to [`LayoutLMv2Tokenizer`] or
[`LayoutLMv2TokenizerFast`], which converts them to token-level `input_ids`,
`attention_mask`, `token_type_ids`, `bbox`. Optionally, one can provide word labels to the processor,
which are turned into token-level `labels`.
[`LayoutLMv2Processor`] uses [PyTesseract](https://pypi.org/project/pytesseract/), a Python
wrapper around Google's Tesseract OCR engine, under the hood. Note that you can still use your own OCR engine of
choice, and provide the words and normalized boxes yourself. This requires initializing
[`LayoutLMv2ImageProcessor`] with `apply_ocr` set to `False`.
In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
**Use case 1: document image classification (training, inference) + token classification (inference), apply_ocr =
True**
This is the simplest case, in which the processor (actually the image processor) will perform OCR on the image to get
the words and normalized bounding boxes.
```python
from transformers import LayoutLMv2Processor
from PIL import Image
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
image = Image.open(
"name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
).convert("RGB")
encoding = processor(
image, return_tensors="pt"
) # you can also add all tokenizer parameters here such as padding, truncation
print(encoding.keys())
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
```
**Use case 2: document image classification (training, inference) + token classification (inference), apply_ocr=False**
In case one wants to do OCR themselves, one can initialize the image processor with `apply_ocr` set to
`False`. In that case, one should provide the words and corresponding (normalized) bounding boxes themselves to
the processor.
```python
from transformers import LayoutLMv2Processor
from PIL import Image
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
image = Image.open(
"name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
).convert("RGB")
words = ["hello", "world"]
boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
encoding = processor(image, words, boxes=boxes, return_tensors="pt")
print(encoding.keys())
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
```
**Use case 3: token classification (training), apply_ocr=False**
For token classification tasks (such as FUNSD, CORD, SROIE, Kleister-NDA), one can also provide the corresponding word
labels in order to train a model. The processor will then convert these into token-level `labels`. By default, it
will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
initialize the tokenizer with `only_label_first_subword` set to `False`.
```python
from transformers import LayoutLMv2Processor
from PIL import Image
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
image = Image.open(
"name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
).convert("RGB")
words = ["hello", "world"]
boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
word_labels = [1, 2]
encoding = processor(image, words, boxes=boxes, word_labels=word_labels, return_tensors="pt")
print(encoding.keys())
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'labels', 'image'])
```
**Use case 4: visual question answering (inference), apply_ocr=True**
For visual question answering tasks (such as DocVQA), you can provide a question to the processor. By default, the
processor will apply OCR on the image, and create [CLS] question tokens [SEP] word tokens [SEP].
```python
from transformers import LayoutLMv2Processor
from PIL import Image
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
image = Image.open(
"name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
).convert("RGB")
question = "What's his name?"
encoding = processor(image, question, return_tensors="pt")
print(encoding.keys())
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
```
**Use case 5: visual question answering (inference), apply_ocr=False**
For visual question answering tasks (such as DocVQA), you can provide a question to the processor. If you want to
perform OCR yourself, you can provide your own words and (normalized) bounding boxes to the processor.
```python
from transformers import LayoutLMv2Processor
from PIL import Image
processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
image = Image.open(
"name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
).convert("RGB")
question = "What's his name?"
words = ["hello", "world"]
boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
print(encoding.keys())
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
```
## LayoutLMv2Config
[[autodoc]] LayoutLMv2Config
## LayoutLMv2FeatureExtractor
[[autodoc]] LayoutLMv2FeatureExtractor
- __call__
## LayoutLMv2ImageProcessor
[[autodoc]] LayoutLMv2ImageProcessor
- preprocess
## LayoutLMv2Tokenizer
[[autodoc]] LayoutLMv2Tokenizer
- __call__
- save_vocabulary
## LayoutLMv2TokenizerFast
[[autodoc]] LayoutLMv2TokenizerFast
- __call__
## LayoutLMv2Processor
[[autodoc]] LayoutLMv2Processor
- __call__
## LayoutLMv2Model
[[autodoc]] LayoutLMv2Model
- forward
## LayoutLMv2ForSequenceClassification
[[autodoc]] LayoutLMv2ForSequenceClassification
## LayoutLMv2ForTokenClassification
[[autodoc]] LayoutLMv2ForTokenClassification
## LayoutLMv2ForQuestionAnswering
[[autodoc]] LayoutLMv2ForQuestionAnswering
| huggingface/transformers/blob/main/docs/source/en/model_doc/layoutlmv2.md |
Tokenizer
<tokenizerslangcontent>
<python>
## Tokenizer
[[autodoc]] tokenizers.Tokenizer
- all
- decoder
- model
- normalizer
- padding
- post_processor
- pre_tokenizer
- truncation
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/tokenizer.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Models
🤗 Diffusers provides pretrained models for popular algorithms and modules to create custom diffusion systems. The primary function of models is to denoise an input sample as modeled by the distribution \\(p_{\theta}(x_{t-1}|x_{t})\\).
All models are built from the base [`ModelMixin`] class which is a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html) providing basic functionality for saving and loading models, locally and from the Hugging Face Hub.
## ModelMixin
[[autodoc]] ModelMixin
## FlaxModelMixin
[[autodoc]] FlaxModelMixin
## PushToHubMixin
[[autodoc]] utils.PushToHubMixin
| huggingface/diffusers/blob/main/docs/source/en/api/models/overview.md |
Mid-way Recap [[mid-way-recap]]
Before diving into Q-Learning, let's summarize what we've just learned.
We have two types of value-based functions:
- State-value function: outputs the expected return if **the agent starts at a given state and acts according to the policy forever after.**
- Action-value function: outputs the expected return if **the agent starts in a given state, takes a given action at that state** and then acts accordingly to the policy forever after.
- In value-based methods, rather than learning the policy, **we define the policy by hand** and we learn a value function. If we have an optimal value function, we **will have an optimal policy.**
There are two types of methods to learn a policy for a value function:
- With *the Monte Carlo method*, we update the value function from a complete episode, and so we **use the actual discounted return of this episode.**
- With *the TD Learning method,* we update the value function from a step, replacing the unknown \\(G_t\\) with **an estimated return called the TD target.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/summary-learning-mtds.jpg" alt="Summary"/>
| huggingface/deep-rl-class/blob/main/units/en/unit2/mid-way-recap.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Export a model to ONNX with optimum.exporters.onnx
## Summary
Exporting a model to ONNX is as simple as
```bash
optimum-cli export onnx --model gpt2 gpt2_onnx/
```
Check out the help for more options:
```bash
optimum-cli export onnx --help
```
## Why use ONNX?
If you need to deploy 🤗 Transformers or 🤗 Diffusers models in production environments, we recommend
exporting them to a serialized format that can be loaded and executed on specialized
runtimes and hardware. In this guide, we'll show you how to export these
models to [ONNX (Open Neural Network eXchange)](http://onnx.ai).
ONNX is an open standard that defines a common set of operators and a common file format
to represent deep learning models in a wide variety of frameworks, including PyTorch and
TensorFlow. When a model is exported to the ONNX format, these operators are used to
construct a computational graph (often called an _intermediate representation_) which
represents the flow of data through the neural network.
By exposing a graph with standardized operators and data types, ONNX makes it easy to
switch between frameworks. For example, a model trained in PyTorch can be exported to
ONNX format and then imported in TensorRT or OpenVINO.
<Tip>
Once exported, a model can be optimized for inference via techniques such as
graph optimization and quantization. Check the `optimum.onnxruntime` subpackage to optimize and run ONNX models!
</Tip>
🤗 Optimum provides support for the ONNX export by leveraging configuration objects.
These configuration objects come ready made for a number of model architectures, and are
designed to be easily extendable to other architectures.
**To check the supported architectures, go to the [configuration reference page](../package_reference/configuration#supported-architectures).**
## Exporting a model to ONNX using the CLI
To export a 🤗 Transformers or 🤗 Diffusers model to ONNX, you'll first need to install some extra
dependencies:
```bash
pip install optimum[exporters]
```
The Optimum ONNX export can be used through Optimum command-line:
```bash
optimum-cli export onnx --help
usage: optimum-cli <command> [<args>] export onnx [-h] -m MODEL [--task TASK] [--monolith] [--device DEVICE] [--opset OPSET] [--atol ATOL]
[--framework {pt,tf}] [--pad_token_id PAD_TOKEN_ID] [--cache_dir CACHE_DIR] [--trust-remote-code]
[--no-post-process] [--optimize {O1,O2,O3,O4}] [--batch_size BATCH_SIZE]
[--sequence_length SEQUENCE_LENGTH] [--num_choices NUM_CHOICES] [--width WIDTH] [--height HEIGHT]
[--num_channels NUM_CHANNELS] [--feature_size FEATURE_SIZE] [--nb_max_frames NB_MAX_FRAMES]
[--audio_sequence_length AUDIO_SEQUENCE_LENGTH]
output
optional arguments:
-h, --help show this help message and exit
Required arguments:
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
output Path indicating the directory where to store generated ONNX model.
Optional arguments:
--task TASK The task to export the model for. If not specified, the task will be auto-inferred based on the model. Available tasks depend on the model, but are among: ['default', 'fill-mask', 'text-generation', 'text2text-generation', 'text-classification', 'token-classification', 'multiple-choice', 'object-detection', 'question-answering', 'image-classification', 'image-segmentation', 'masked-im', 'semantic-segmentation', 'automatic-speech-recognition', 'audio-classification', 'audio-frame-classification', 'automatic-speech-recognition', 'audio-xvector', 'image-to-text', 'stable-diffusion', 'zero-shot-object-detection']. For decoder models, use `xxx-with-past` to export the model using past key values in the decoder.
--monolith Force to export the model as a single ONNX file. By default, the ONNX exporter may break the model in several ONNX files, for example for encoder-decoder models where the encoder should be run only once while the decoder is looped over.
--device DEVICE The device to use to do the export. Defaults to "cpu".
--opset OPSET If specified, ONNX opset version to export the model with. Otherwise, the default opset will be used.
--atol ATOL If specified, the absolute difference tolerance when validating the model. Otherwise, the default atol for the model will be used.
--framework {pt,tf} The framework to use for the ONNX export. If not provided, will attempt to use the local checkpoint's original framework or what is available in the environment.
--pad_token_id PAD_TOKEN_ID
This is needed by some models, for some tasks. If not provided, will attempt to use the tokenizer to guess it.
--cache_dir CACHE_DIR
Path indicating where to store cache.
--trust-remote-code Allows to use custom code for the modeling hosted in the model repository. This option should only be set for repositories you trust and in which you have read the code, as it will execute on your local machine arbitrary code present in the model repository.
--no-post-process Allows to disable any post-processing done by default on the exported ONNX models. For example, the merging of decoder and decoder-with-past models into a single ONNX model file to reduce memory usage.
--optimize {O1,O2,O3,O4}
Allows to run ONNX Runtime optimizations directly during the export. Some of these optimizations are specific to ONNX Runtime, and the resulting ONNX will not be usable with other runtime as OpenVINO or TensorRT. Possible options:
- O1: Basic general optimizations
- O2: Basic and extended general optimizations, transformers-specific fusions
- O3: Same as O2 with GELU approximation
- O4: Same as O3 with mixed precision (fp16, GPU-only, requires `--device cuda`)
```
Exporting a checkpoint can be done as follows:
```bash
optimum-cli export onnx --model distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
```
You should see the following logs (along with potential logs from PyTorch / TensorFlow that were hidden here for clarity):
```bash
Automatic task detection to question-answering.
Framework not specified. Using pt to export to ONNX.
Using framework PyTorch: 1.12.1
Validating ONNX model...
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
All good, model saved at: distilbert_base_uncased_squad_onnx/model.onnx
```
This exports an ONNX graph of the checkpoint defined by the `--model` argument.
As you can see, the task was automatically detected. This was possible because the model was on the Hub.
For local models, providing the `--task` argument is needed or it will default to the model architecture without any task specific head:
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
```
Note that providing the `--task` argument for a model on the Hub will disable the automatic task detection.
The resulting `model.onnx` file can then be run on one of the [many
accelerators](https://onnx.ai/supported-tools.html#deployModel) that support the ONNX
standard. For example, we can load and run the model with [ONNX
Runtime](https://onnxruntime.ai/) using the `optimum.onnxruntime` package as follows:
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx") # doctest: +SKIP
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx") # doctest: +SKIP
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt") # doctest: +SKIP
>>> outputs = model(**inputs) # doctest: +SKIP
```
Printing the outputs would give that:
```bash
QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[-4.7652, -1.0452, -7.0409, -4.6864, -4.0277, -6.2021, -4.9473, 2.6287,
7.6111, -1.2488, -2.0551, -0.9350, 4.9758, -0.7707, 2.1493, -2.0703,
-4.3232, -4.9472]]), end_logits=tensor([[ 0.4382, -1.6502, -6.3654, -6.0661, -4.1482, -3.5779, -0.0774, -3.6168,
-1.8750, -2.8910, 6.2582, 0.5425, -3.7699, 3.8232, -1.5073, 6.2311,
3.3604, -0.0772]]), hidden_states=None, attentions=None)
```
As you can see, converting a model to ONNX does not mean leaving the Hugging Face ecosystem. You end up with a similar API as regular 🤗 Transformers models!
<Tip>
It is also possible to export the model to ONNX directly from the `ORTModelForQuestionAnswering` class by doing the following:
```python
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert-base-uncased-distilled-squad", export=True)
```
For more information, check the `optimum.onnxruntime` documentation [page on this topic](/onnxruntime/overview).
</Tip>
The process is identical for TensorFlow checkpoints on the Hub. For example, we can export a pure TensorFlow checkpoint from the [Keras
organization](https://huggingface.co/keras-io) as follows:
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
```
### Exporting a model to be used with Optimum's ORTModel
Models exported through `optimum-cli export onnx` can be used directly in [`~onnxruntime.ORTModel`]. This is especially useful for encoder-decoder models, where in this case the export will split the encoder and decoder into two `.onnx` files, as the encoder is usually only run once while the decoder may be run several times in autogenerative tasks.
### Exporting a model using past keys/values in the decoder
When exporting a decoder model used for generation, it can be useful to encapsulate in the exported ONNX the [reuse of past keys and values](https://discuss.huggingface.co/t/what-is-the-purpose-of-use-cache-in-decoder/958/2). This allows to avoid recomputing the same intermediate activations during the generation.
In the ONNX export, the past keys/values are reused by default. This behavior corresponds to `--task text2text-generation-with-past`, `--task text-generation-with-past`, or `--task automatic-speech-recognition-with-past`. If for any purpose you would like to disable the export with past keys/values reuse, passing explicitly to `optimum-cli export onnx` the task `text2text-generation`, `text-generation` or `automatic-speech-recognition` is required.
A model exported using past key/values can be reused directly into Optimum's [`~onnxruntime.ORTModel`]:
```bash
optimum-cli export onnx --model gpt2 gpt2_onnx/
```
and
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("./gpt2_onnx/") # doctest: +SKIP
>>> model = ORTModelForCausalLM.from_pretrained("./gpt2_onnx/") # doctest: +SKIP
>>> inputs = tokenizer("My name is Arthur and I live in", return_tensors="pt") # doctest: +SKIP
>>> gen_tokens = model.generate(**inputs) # doctest: +SKIP
>>> print(tokenizer.batch_decode(gen_tokens)) # doctest: +SKIP
# prints ['My name is Arthur and I live in the United States of America. I am a member of the']
```
## Selecting a task
Specifying a `--task` should not be necessary in most cases when exporting from a model on the Hugging Face Hub.
However, in case you need to check for a given a model architecture what tasks the ONNX export supports, we got you covered. First, you can check the list of supported tasks for both PyTorch and TensorFlow [here](/exporters/task_manager).
For each model architecture, you can find the list of supported tasks via the [`~exporters.tasks.TasksManager`]. For example, for DistilBERT, for the ONNX export, we have:
```python
>>> from optimum.exporters.tasks import TasksManager
>>> distilbert_tasks = list(TasksManager.get_supported_tasks_for_model_type("distilbert", "onnx").keys())
>>> print(distilbert_tasks)
['default', 'fill-mask', 'text-classification', 'multiple-choice', 'token-classification', 'question-answering']
```
You can then pass one of these tasks to the `--task` argument in the `optimum-cli export onnx` command, as mentioned above.
## Custom export of Transformers models
### Customize the export of official Transformers models
Optimum allows for advanced users a finer-grained control over the configuration for the ONNX export. This is especially useful if you would like to export models with different keyword arguments, for example using `output_attentions=True` or `output_hidden_states=True`.
To support these use cases, [`~exporters.main_export`] supports two arguments: `model_kwargs` and `custom_onnx_configs`, which are used in the following fashion:
* `model_kwargs` allows to override some of the default arguments to the models `forward`, in practice as `model(**reference_model_inputs, **model_kwargs)`.
* `custom_onnx_configs` should be a `Dict[str, OnnxConfig]`, mapping from the submodel name (usually `model`, `encoder_model`, `decoder_model`, or `decoder_model_with_past` - [reference](https://github.com/huggingface/optimum/blob/main/optimum/exporters/onnx/constants.py)) to a custom ONNX configuration for the given submodel.
A complete example is given below, allowing to export models with `output_attentions=True`.
```python
from optimum.exporters.onnx import main_export
from optimum.exporters.onnx.model_configs import WhisperOnnxConfig
from transformers import AutoConfig
from optimum.exporters.onnx.base import ConfigBehavior
from typing import Dict
class CustomWhisperOnnxConfig(WhisperOnnxConfig):
@property
def outputs(self) -> Dict[str, Dict[int, str]]:
common_outputs = super().outputs
if self._behavior is ConfigBehavior.ENCODER:
for i in range(self._config.encoder_layers):
common_outputs[f"encoder_attentions.{i}"] = {0: "batch_size"}
elif self._behavior is ConfigBehavior.DECODER:
for i in range(self._config.decoder_layers):
common_outputs[f"decoder_attentions.{i}"] = {
0: "batch_size",
2: "decoder_sequence_length",
3: "past_decoder_sequence_length + 1"
}
for i in range(self._config.decoder_layers):
common_outputs[f"cross_attentions.{i}"] = {
0: "batch_size",
2: "decoder_sequence_length",
3: "encoder_sequence_length_out"
}
return common_outputs
@property
def torch_to_onnx_output_map(self):
if self._behavior is ConfigBehavior.ENCODER:
# The encoder export uses WhisperEncoder that returns the key "attentions"
return {"attentions": "encoder_attentions"}
else:
return {}
model_id = "openai/whisper-tiny.en"
config = AutoConfig.from_pretrained(model_id)
custom_whisper_onnx_config = CustomWhisperOnnxConfig(
config=config,
task="automatic-speech-recognition",
)
encoder_config = custom_whisper_onnx_config.with_behavior("encoder")
decoder_config = custom_whisper_onnx_config.with_behavior("decoder", use_past=False)
decoder_with_past_config = custom_whisper_onnx_config.with_behavior("decoder", use_past=True)
custom_onnx_configs={
"encoder_model": encoder_config,
"decoder_model": decoder_config,
"decoder_with_past_model": decoder_with_past_config,
}
main_export(
model_id,
output="custom_whisper_onnx",
no_post_process=True,
model_kwargs={"output_attentions": True},
custom_onnx_configs=custom_onnx_configs
)
```
For tasks that require only a single ONNX file (e.g. encoder-only), an exported model with custom inputs/outputs can then be used with the class [`optimum.onnxruntime.ORTModelForCustomTasks`] for inference with ONNX Runtime on CPU or GPU.
### Customize the export of Transformers models with custom modeling
Optimum supports the export of Transformers models with custom modeling that use [`trust_remote_code=True`](https://huggingface.co/docs/transformers/en/model_doc/auto#transformers.AutoModel.from_pretrained.trust_remote_code), not officially supported in the Transormers library but usable with its functionality as [pipelines](https://huggingface.co/docs/transformers/main_classes/pipelines) and [generation](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationMixin.generate).
Examples of such models are [THUDM/chatglm2-6b](https://huggingface.co/THUDM/chatglm2-6b) and [mosaicml/mpt-30b](https://huggingface.co/mosaicml/mpt-30b).
To export custom models, a dictionary `custom_onnx_configs` needs to be passed to [`~optimum.exporters.onnx.main_export`], with the ONNX config definition for all the subparts of the model to export (for example, encoder and decoder subparts). The example below allows to export `mosaicml/mpt-7b` model:
```python
from optimum.exporters.onnx import main_export
from transformers import AutoConfig
from optimum.exporters.onnx.config import TextDecoderOnnxConfig
from optimum.utils import NormalizedTextConfig, DummyPastKeyValuesGenerator
from typing import Dict
class MPTDummyPastKeyValuesGenerator(DummyPastKeyValuesGenerator):
"""
MPT swaps the two last dimensions for the key cache compared to usual transformers
decoder models, thus the redefinition here.
"""
def generate(self, input_name: str, framework: str = "pt"):
past_key_shape = (
self.batch_size,
self.num_attention_heads,
self.hidden_size // self.num_attention_heads,
self.sequence_length,
)
past_value_shape = (
self.batch_size,
self.num_attention_heads,
self.sequence_length,
self.hidden_size // self.num_attention_heads,
)
return [
(
self.random_float_tensor(past_key_shape, framework=framework),
self.random_float_tensor(past_value_shape, framework=framework),
)
for _ in range(self.num_layers)
]
class CustomMPTOnnxConfig(TextDecoderOnnxConfig):
DUMMY_INPUT_GENERATOR_CLASSES = (MPTDummyPastKeyValuesGenerator,) + TextDecoderOnnxConfig.DUMMY_INPUT_GENERATOR_CLASSES
DUMMY_PKV_GENERATOR_CLASS = MPTDummyPastKeyValuesGenerator
DEFAULT_ONNX_OPSET = 14 # aten::tril operator requires opset>=14
NORMALIZED_CONFIG_CLASS = NormalizedTextConfig.with_args(
hidden_size="d_model",
num_layers="n_layers",
num_attention_heads="n_heads"
)
def add_past_key_values(self, inputs_or_outputs: Dict[str, Dict[int, str]], direction: str):
"""
Adapted from https://github.com/huggingface/optimum/blob/v1.9.0/optimum/exporters/onnx/base.py#L625
"""
if direction not in ["inputs", "outputs"]:
raise ValueError(f'direction must either be "inputs" or "outputs", but {direction} was given')
if direction == "inputs":
decoder_sequence_name = "past_sequence_length"
name = "past_key_values"
else:
decoder_sequence_name = "past_sequence_length + 1"
name = "present"
for i in range(self._normalized_config.num_layers):
inputs_or_outputs[f"{name}.{i}.key"] = {0: "batch_size", 3: decoder_sequence_name}
inputs_or_outputs[f"{name}.{i}.value"] = {0: "batch_size", 2: decoder_sequence_name}
model_id = "/home/fxmarty/hf_internship/optimum/tiny-mpt-random-remote-code"
config = AutoConfig.from_pretrained(model_id, trust_remote_code=True)
onnx_config = CustomMPTOnnxConfig(
config=config,
task="text-generation",
use_past_in_inputs=False,
use_present_in_outputs=True,
)
onnx_config_with_past = CustomMPTOnnxConfig(config, task="text-generation", use_past=True)
custom_onnx_configs = {
"decoder_model": onnx_config,
"decoder_with_past_model": onnx_config_with_past,
}
main_export(
model_id,
output="mpt_onnx",
task="text-generation-with-past",
trust_remote_code=True,
custom_onnx_configs=custom_onnx_configs,
no_post_process=True,
)
```
Moreover, the advanced argument `fn_get_submodels` to `main_export` allows to customize how the submodels are extracted in case the model needs to be exported in several submodels. Examples of such functions can be [consulted here](link to utils.py relevant code once merged).
| huggingface/optimum/blob/main/docs/source/exporters/onnx/usage_guides/export_a_model.mdx |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification
## PyTorch version
Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech
tagging (POS) or phrase extraction (CHUNKS). The main scrip `run_ner.py` leverages the 🤗 Datasets library and the Trainer API. You can easily
customize it to your needs if you need extra processing on your datasets.
It will either run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own text files for
training and validation, you might just need to add some tweaks in the data preprocessing.
The following example fine-tunes BERT on CoNLL-2003:
```bash
python run_ner.py \
--model_name_or_path bert-base-uncased \
--dataset_name conll2003 \
--output_dir /tmp/test-ner \
--do_train \
--do_eval
```
or just can just run the bash script `run.sh`.
To run on your own training and validation files, use the following command:
```bash
python run_ner.py \
--model_name_or_path bert-base-uncased \
--train_file path_to_train_file \
--validation_file path_to_validation_file \
--output_dir /tmp/test-ner \
--do_train \
--do_eval
```
**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version
of the script.
> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
## Old version of the script
You can find the old version of the PyTorch script [here](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
## Pytorch version, no Trainer
Based on the script [run_ner_no_trainer.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/token-classification/run_ner_no_trainer.py).
Like `run_ner.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) on a
token classification task, either NER, POS or CHUNKS tasks or your own data in a csv or a JSON file. The main difference is that this
script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then
```bash
export TASK_NAME=ner
python run_ner_no_trainer.py \
--model_name_or_path bert-base-cased \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
export TASK_NAME=ner
accelerate launch run_ner_no_trainer.py \
--model_name_or_path bert-base-cased \
--dataset_name conll2003 \
--task_name $TASK_NAME \
--max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| huggingface/transformers/blob/main/examples/pytorch/token-classification/README.md |
--
title: "Creating Privacy Preserving AI with Substra"
thumbnail: /blog/assets/139_owkin-substra/thumbnail.png
authors:
- user: EazyAl
- user: katielink
- user: NimaBoscarino
- user: ThibaultFy
guest: true
---
# Creating Privacy Preserving AI with Substra
With the recent rise of generative techniques, machine learning is at an incredibly exciting point in its history. The models powering this rise require even more data to produce impactful results, and thus it’s becoming increasingly important to explore new methods of ethically gathering data while ensuring that data privacy and security remain a top priority.
In many domains that deal with sensitive information, such as healthcare, there often isn’t enough high quality data accessible to train these data-hungry models. Datasets are siloed in different academic centers and medical institutions and are difficult to share openly due to privacy concerns about patient and proprietary information. Regulations that protect patient data such as HIPAA are essential to safeguard individuals’ private health information, but they can limit the progress of machine learning research as data scientists can’t access the volume of data required to effectively train their models. Technologies that work alongside existing regulations by proactively protecting patient data will be crucial to unlocking these silos and accelerating the pace of machine learning research and deployment in these domains.
This is where Federated Learning comes in. Check out the [space](https://huggingface.co/spaces/owkin/substra) we’ve created with [Substra](https://owkin.com/substra) to learn more!
## What is Federated Learning?
Federated learning (FL) is a decentralized machine learning technique that allows you to train models using multiple data providers. Instead of gathering data from all sources on a single server, data can remain on a local server as only the resulting model weights travel between servers.
As the data never leaves its source, federated learning is naturally a privacy-first approach. Not only does this technique improve data security and privacy, it also enables data scientists to build better models using data from different sources - increasing robustness and providing better representation as compared to models trained on data from a single source. This is valuable not only due to the increase in the quantity of data, but also to reduce the risk of bias due to variations of the underlying dataset, for example minor differences caused by the data capture techniques and equipment, or differences in demographic distributions of the patient population. With multiple sources of data, we can build more generalizable models that ultimately perform better in real world settings. For more information on federated learning, we recommend checking out this explanatory [comic](https://federated.withgoogle.com/) by Google.

**Substra** is an open source federated learning framework built for real world production environments. Although federated learning is a relatively new field and has only taken hold in the last decade, it has already enabled machine learning research to progress in ways previously unimaginable. For example, 10 competing biopharma companies that would traditionally never share data with each other set up a collaboration in the [MELLODDY](https://www.melloddy.eu/) project by sharing the world’s largest collection of small molecules with known biochemical or cellular activity. This ultimately enabled all of the companies involved to build more accurate predictive models for drug discovery, a huge milestone in medical research.
## Substra x HF
Research on the capabilities of federated learning is growing rapidly but the majority of recent work has been limited to simulated environments. Real world examples and implementations still remain limited due to the difficulty of deploying and architecting federated networks. As a leading open-source platform for federated learning deployment, Substra has been battle tested in many complex security environments and IT infrastructures, and has enabled [medical breakthroughs in breast cancer research](https://www.nature.com/articles/s41591-022-02155-w).
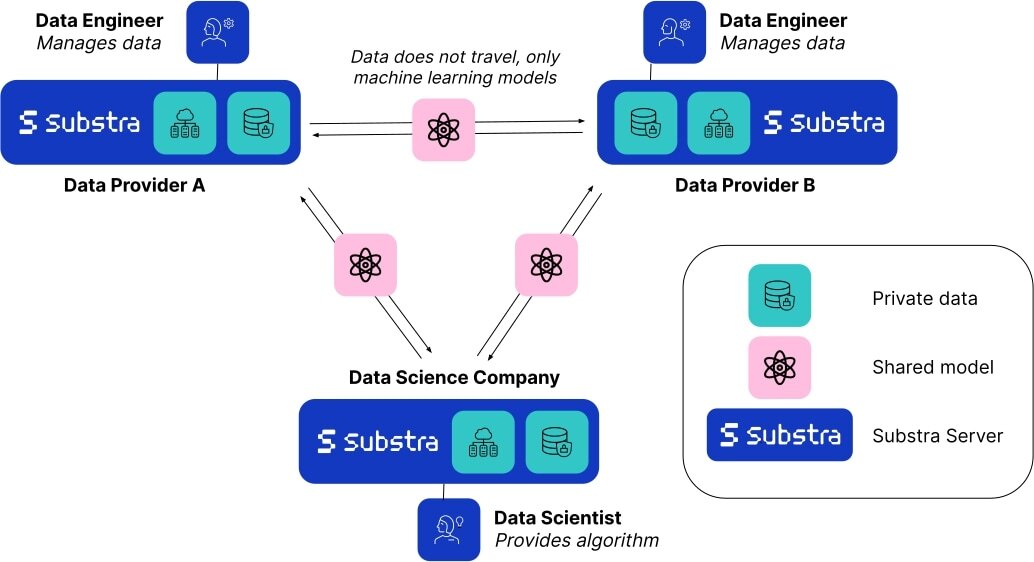
Hugging Face collaborated with the folks managing Substra to create this space, which is meant to give you an idea of the real world challenges that researchers and scientists face - mainly, a lack of centralized, high quality data that is ‘ready for AI’. As you can control the distribution of these samples, you’ll be able to see how a simple model reacts to changes in data. You can then examine how a model trained with federated learning almost always performs better on validation data compared with models trained on data from a single source.
## Conclusion
Although federated learning has been leading the charge, there are various other privacy enhancing technologies (PETs) such as secure enclaves and multi party computation that are enabling similar results and can be combined with federation to create multi layered privacy preserving environments. You can learn more [here](https://medium.com/@aliimran_36956/how-collaboration-is-revolutionizing-medicine-34999060794e) if you’re interested in how these are enabling collaborations in medicine.
Regardless of the methods used, it's important to stay vigilant of the fact that data privacy is a right for all of us. It’s critical that we move forward in this AI boom with [privacy and ethics in mind](https://www.nature.com/articles/s42256-022-00551-y).
If you’d like to play around with Substra and implement federated learning in a project, you can check out the docs [here](https://docs.substra.org/en/stable/). | huggingface/blog/blob/main/owkin-substra.md |
Helpful tips for testing & debugging optimum
## VSCODE
If you are using vscode you might have hard time discovering the test for the "testing" menu to run tests individually or debug them. You can copy the snippet below into `.vscode/settings.json`.
```json
{
"python.testing.pytestArgs": [
"tests/onnxruntime",
"tests/test_*"
],
"python.testing.unittestEnabled": false,
"python.testing.pytestEnabled": true
}
```
This snippet will discover all base tests and the tests inside the `tests/onnxruntime` folder.
| huggingface/optimum/blob/main/tests/README.md |
Main classes
## EvaluationModuleInfo
The base class `EvaluationModuleInfo` implements a the logic for the subclasses `MetricInfo`, `ComparisonInfo`, and `MeasurementInfo`.
[[autodoc]] evaluate.EvaluationModuleInfo
[[autodoc]] evaluate.MetricInfo
[[autodoc]] evaluate.ComparisonInfo
[[autodoc]] evaluate.MeasurementInfo
## EvaluationModule
The base class `EvaluationModule` implements a the logic for the subclasses `Metric`, `Comparison`, and `Measurement`.
[[autodoc]] evaluate.EvaluationModule
[[autodoc]] evaluate.Metric
[[autodoc]] evaluate.Comparison
[[autodoc]] evaluate.Measurement
## CombinedEvaluations
The `combine` function allows to combine multiple `EvaluationModule`s into a single `CombinedEvaluations`.
[[autodoc]] evaluate.combine
[[autodoc]] CombinedEvaluations
| huggingface/evaluate/blob/main/docs/source/package_reference/main_classes.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# EulerAncestralDiscreteScheduler
A scheduler that uses ancestral sampling with Euler method steps. This is a fast scheduler which can often generate good outputs in 20-30 steps. The scheduler is based on the original [k-diffusion](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L72) implementation by [Katherine Crowson](https://github.com/crowsonkb/).
## EulerAncestralDiscreteScheduler
[[autodoc]] EulerAncestralDiscreteScheduler
## EulerAncestralDiscreteSchedulerOutput
[[autodoc]] schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteSchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/euler_ancestral.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARThez
## Overview
The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
2020.
The abstract of the paper:
*Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing
(NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language
understanding tasks. While there are some notable exceptions, most of the available models and research have been
conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language
(to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research
that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as
CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also
its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel
summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already
pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez,
provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.*
This model was contributed by [moussakam](https://huggingface.co/moussakam). The Authors' code can be found [here](https://github.com/moussaKam/BARThez).
<Tip>
BARThez implementation is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
configuration classes and their parameters. BARThez-specific tokenizers are documented below.
</Tip>
## Resources
- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
## BarthezTokenizer
[[autodoc]] BarthezTokenizer
## BarthezTokenizerFast
[[autodoc]] BarthezTokenizerFast
| huggingface/transformers/blob/main/docs/source/en/model_doc/barthez.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# HerBERT
## Overview
The HerBERT model was proposed in [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and
Ireneusz Gawlik. It is a BERT-based Language Model trained on Polish Corpora using only MLM objective with dynamic
masking of whole words.
The abstract from the paper is the following:
*In recent years, a series of Transformer-based models unlocked major improvements in general natural language
understanding (NLU) tasks. Such a fast pace of research would not be possible without general NLU benchmarks, which
allow for a fair comparison of the proposed methods. However, such benchmarks are available only for a handful of
languages. To alleviate this issue, we introduce a comprehensive multi-task benchmark for the Polish language
understanding, accompanied by an online leaderboard. It consists of a diverse set of tasks, adopted from existing
datasets for named entity recognition, question-answering, textual entailment, and others. We also introduce a new
sentiment analysis task for the e-commerce domain, named Allegro Reviews (AR). To ensure a common evaluation scheme and
promote models that generalize to different NLU tasks, the benchmark includes datasets from varying domains and
applications. Additionally, we release HerBERT, a Transformer-based model trained specifically for the Polish language,
which has the best average performance and obtains the best results for three out of nine tasks. Finally, we provide an
extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based
models.*
This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
[here](https://github.com/allegro/HerBERT).
## Usage example
```python
>>> from transformers import HerbertTokenizer, RobertaModel
>>> tokenizer = HerbertTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
>>> model = RobertaModel.from_pretrained("allegro/herbert-klej-cased-v1")
>>> encoded_input = tokenizer.encode("Kto ma lepszą sztukę, ma lepszy rząd – to jasne.", return_tensors="pt")
>>> outputs = model(encoded_input)
>>> # HerBERT can also be loaded using AutoTokenizer and AutoModel:
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
>>> model = AutoModel.from_pretrained("allegro/herbert-klej-cased-v1")
```
<Tip>
Herbert implementation is the same as `BERT` except for the tokenization method. Refer to [BERT documentation](bert)
for API reference and examples.
</Tip>
## HerbertTokenizer
[[autodoc]] HerbertTokenizer
## HerbertTokenizerFast
[[autodoc]] HerbertTokenizerFast
| huggingface/transformers/blob/main/docs/source/en/model_doc/herbert.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Manage `huggingface_hub` cache-system
## Understand caching
The Hugging Face Hub cache-system is designed to be the central cache shared across libraries
that depend on the Hub. It has been updated in v0.8.0 to prevent re-downloading same files
between revisions.
The caching system is designed as follows:
```
<CACHE_DIR>
├─ <MODELS>
├─ <DATASETS>
├─ <SPACES>
```
The `<CACHE_DIR>` is usually your user's home directory. However, it is customizable with the `cache_dir` argument on all methods, or by specifying either `HF_HOME` or `HF_HUB_CACHE` environment variable.
Models, datasets and spaces share a common root. Each of these repositories contains the
repository type, the namespace (organization or username) if it exists and the
repository name:
```
<CACHE_DIR>
├─ models--julien-c--EsperBERTo-small
├─ models--lysandrejik--arxiv-nlp
├─ models--bert-base-cased
├─ datasets--glue
├─ datasets--huggingface--DataMeasurementsFiles
├─ spaces--dalle-mini--dalle-mini
```
It is within these folders that all files will now be downloaded from the Hub. Caching ensures that
a file isn't downloaded twice if it already exists and wasn't updated; but if it was updated,
and you're asking for the latest file, then it will download the latest file (while keeping
the previous file intact in case you need it again).
In order to achieve this, all folders contain the same skeleton:
```
<CACHE_DIR>
├─ datasets--glue
│ ├─ refs
│ ├─ blobs
│ ├─ snapshots
...
```
Each folder is designed to contain the following:
### Refs
The `refs` folder contains files which indicates the latest revision of the given reference. For example,
if we have previously fetched a file from the `main` branch of a repository, the `refs`
folder will contain a file named `main`, which will itself contain the commit identifier of the current head.
If the latest commit of `main` has `aaaaaa` as identifier, then it will contain `aaaaaa`.
If that same branch gets updated with a new commit, that has `bbbbbb` as an identifier, then
re-downloading a file from that reference will update the `refs/main` file to contain `bbbbbb`.
### Blobs
The `blobs` folder contains the actual files that we have downloaded. The name of each file is their hash.
### Snapshots
The `snapshots` folder contains symlinks to the blobs mentioned above. It is itself made up of several folders:
one per known revision!
In the explanation above, we had initially fetched a file from the `aaaaaa` revision, before fetching a file from
the `bbbbbb` revision. In this situation, we would now have two folders in the `snapshots` folder: `aaaaaa`
and `bbbbbb`.
In each of these folders, live symlinks that have the names of the files that we have downloaded. For example,
if we had downloaded the `README.md` file at revision `aaaaaa`, we would have the following path:
```
<CACHE_DIR>/<REPO_NAME>/snapshots/aaaaaa/README.md
```
That `README.md` file is actually a symlink linking to the blob that has the hash of the file.
By creating the skeleton this way we open the mechanism to file sharing: if the same file was fetched in
revision `bbbbbb`, it would have the same hash and the file would not need to be re-downloaded.
### .no_exist (advanced)
In addition to the `blobs`, `refs` and `snapshots` folders, you might also find a `.no_exist` folder
in your cache. This folder keeps track of files that you've tried to download once but don't exist
on the Hub. Its structure is the same as the `snapshots` folder with 1 subfolder per known revision:
```
<CACHE_DIR>/<REPO_NAME>/.no_exist/aaaaaa/config_that_does_not_exist.json
```
Unlike the `snapshots` folder, files are simple empty files (no symlinks). In this example,
the file `"config_that_does_not_exist.json"` does not exist on the Hub for the revision `"aaaaaa"`.
As it only stores empty files, this folder is neglectable is term of disk usage.
So now you might wonder, why is this information even relevant?
In some cases, a framework tries to load optional files for a model. Saving the non-existence
of optional files makes it faster to load a model as it saves 1 HTTP call per possible optional file.
This is for example the case in `transformers` where each tokenizer can support additional files.
The first time you load the tokenizer on your machine, it will cache which optional files exists (and
which doesn't) to make the loading time faster for the next initializations.
To test if a file is cached locally (without making any HTTP request), you can use the [`try_to_load_from_cache`]
helper. It will either return the filepath (if exists and cached), the object `_CACHED_NO_EXIST` (if non-existence
is cached) or `None` (if we don't know).
```python
from huggingface_hub import try_to_load_from_cache, _CACHED_NO_EXIST
filepath = try_to_load_from_cache()
if isinstance(filepath, str):
# file exists and is cached
...
elif filepath is _CACHED_NO_EXIST:
# non-existence of file is cached
...
else:
# file is not cached
...
```
### In practice
In practice, your cache should look like the following tree:
```text
[ 96] .
└── [ 160] models--julien-c--EsperBERTo-small
├── [ 160] blobs
│ ├── [321M] 403450e234d65943a7dcf7e05a771ce3c92faa84dd07db4ac20f592037a1e4bd
│ ├── [ 398] 7cb18dc9bafbfcf74629a4b760af1b160957a83e
│ └── [1.4K] d7edf6bd2a681fb0175f7735299831ee1b22b812
├── [ 96] refs
│ └── [ 40] main
└── [ 128] snapshots
├── [ 128] 2439f60ef33a0d46d85da5001d52aeda5b00ce9f
│ ├── [ 52] README.md -> ../../blobs/d7edf6bd2a681fb0175f7735299831ee1b22b812
│ └── [ 76] pytorch_model.bin -> ../../blobs/403450e234d65943a7dcf7e05a771ce3c92faa84dd07db4ac20f592037a1e4bd
└── [ 128] bbc77c8132af1cc5cf678da3f1ddf2de43606d48
├── [ 52] README.md -> ../../blobs/7cb18dc9bafbfcf74629a4b760af1b160957a83e
└── [ 76] pytorch_model.bin -> ../../blobs/403450e234d65943a7dcf7e05a771ce3c92faa84dd07db4ac20f592037a1e4bd
```
### Limitations
In order to have an efficient cache-system, `huggingface-hub` uses symlinks. However,
symlinks are not supported on all machines. This is a known limitation especially on
Windows. When this is the case, `huggingface_hub` do not use the `blobs/` directory but
directly stores the files in the `snapshots/` directory instead. This workaround allows
users to download and cache files from the Hub exactly the same way. Tools to inspect
and delete the cache (see below) are also supported. However, the cache-system is less
efficient as a single file might be downloaded several times if multiple revisions of
the same repo is downloaded.
If you want to benefit from the symlink-based cache-system on a Windows machine, you
either need to [activate Developer Mode](https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development)
or to run Python as an administrator.
When symlinks are not supported, a warning message is displayed to the user to alert
them they are using a degraded version of the cache-system. This warning can be disabled
by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable to true.
## Caching assets
In addition to caching files from the Hub, downstream libraries often requires to cache
other files related to HF but not handled directly by `huggingface_hub` (example: file
downloaded from GitHub, preprocessed data, logs,...). In order to cache those files,
called `assets`, one can use [`cached_assets_path`]. This small helper generates paths
in the HF cache in a unified way based on the name of the library requesting it and
optionally on a namespace and a subfolder name. The goal is to let every downstream
libraries manage its assets its own way (e.g. no rule on the structure) as long as it
stays in the right assets folder. Those libraries can then leverage tools from
`huggingface_hub` to manage the cache, in particular scanning and deleting parts of the
assets from a CLI command.
```py
from huggingface_hub import cached_assets_path
assets_path = cached_assets_path(library_name="datasets", namespace="SQuAD", subfolder="download")
something_path = assets_path / "something.json" # Do anything you like in your assets folder !
```
<Tip>
[`cached_assets_path`] is the recommended way to store assets but is not mandatory. If
your library already uses its own cache, feel free to use it!
</Tip>
### Assets in practice
In practice, your assets cache should look like the following tree:
```text
assets/
└── datasets/
│ ├── SQuAD/
│ │ ├── downloaded/
│ │ ├── extracted/
│ │ └── processed/
│ ├── Helsinki-NLP--tatoeba_mt/
│ ├── downloaded/
│ ├── extracted/
│ └── processed/
└── transformers/
├── default/
│ ├── something/
├── bert-base-cased/
│ ├── default/
│ └── training/
hub/
└── models--julien-c--EsperBERTo-small/
├── blobs/
│ ├── (...)
│ ├── (...)
├── refs/
│ └── (...)
└── [ 128] snapshots/
├── 2439f60ef33a0d46d85da5001d52aeda5b00ce9f/
│ ├── (...)
└── bbc77c8132af1cc5cf678da3f1ddf2de43606d48/
└── (...)
```
## Scan your cache
At the moment, cached files are never deleted from your local directory: when you download
a new revision of a branch, previous files are kept in case you need them again.
Therefore it can be useful to scan your cache directory in order to know which repos
and revisions are taking the most disk space. `huggingface_hub` provides an helper to
do so that can be used via `huggingface-cli` or in a python script.
### Scan cache from the terminal
The easiest way to scan your HF cache-system is to use the `scan-cache` command from
`huggingface-cli` tool. This command scans the cache and prints a report with information
like repo id, repo type, disk usage, refs and full local path.
The snippet below shows a scan report in a folder in which 4 models and 2 datasets are
cached.
```text
➜ huggingface-cli scan-cache
REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH
--------------------------- --------- ------------ -------- ------------- ------------- ------------------- -------------------------------------------------------------------------
glue dataset 116.3K 15 4 days ago 4 days ago 2.4.0, main, 1.17.0 /home/wauplin/.cache/huggingface/hub/datasets--glue
google/fleurs dataset 64.9M 6 1 week ago 1 week ago refs/pr/1, main /home/wauplin/.cache/huggingface/hub/datasets--google--fleurs
Jean-Baptiste/camembert-ner model 441.0M 7 2 weeks ago 16 hours ago main /home/wauplin/.cache/huggingface/hub/models--Jean-Baptiste--camembert-ner
bert-base-cased model 1.9G 13 1 week ago 2 years ago /home/wauplin/.cache/huggingface/hub/models--bert-base-cased
t5-base model 10.1K 3 3 months ago 3 months ago main /home/wauplin/.cache/huggingface/hub/models--t5-base
t5-small model 970.7M 11 3 days ago 3 days ago refs/pr/1, main /home/wauplin/.cache/huggingface/hub/models--t5-small
Done in 0.0s. Scanned 6 repo(s) for a total of 3.4G.
Got 1 warning(s) while scanning. Use -vvv to print details.
```
To get a more detailed report, use the `--verbose` option. For each repo, you get a
list of all revisions that have been downloaded. As explained above, the files that don't
change between 2 revisions are shared thanks to the symlinks. This means that the size of
the repo on disk is expected to be less than the sum of the size of each of its revisions.
For example, here `bert-base-cased` has 2 revisions of 1.4G and 1.5G but the total disk
usage is only 1.9G.
```text
➜ huggingface-cli scan-cache -v
REPO ID REPO TYPE REVISION SIZE ON DISK NB FILES LAST_MODIFIED REFS LOCAL PATH
--------------------------- --------- ---------------------------------------- ------------ -------- ------------- ----------- ----------------------------------------------------------------------------------------------------------------------------
glue dataset 9338f7b671827df886678df2bdd7cc7b4f36dffd 97.7K 14 4 days ago main, 2.4.0 /home/wauplin/.cache/huggingface/hub/datasets--glue/snapshots/9338f7b671827df886678df2bdd7cc7b4f36dffd
glue dataset f021ae41c879fcabcf823648ec685e3fead91fe7 97.8K 14 1 week ago 1.17.0 /home/wauplin/.cache/huggingface/hub/datasets--glue/snapshots/f021ae41c879fcabcf823648ec685e3fead91fe7
google/fleurs dataset 129b6e96cf1967cd5d2b9b6aec75ce6cce7c89e8 25.4K 3 2 weeks ago refs/pr/1 /home/wauplin/.cache/huggingface/hub/datasets--google--fleurs/snapshots/129b6e96cf1967cd5d2b9b6aec75ce6cce7c89e8
google/fleurs dataset 24f85a01eb955224ca3946e70050869c56446805 64.9M 4 1 week ago main /home/wauplin/.cache/huggingface/hub/datasets--google--fleurs/snapshots/24f85a01eb955224ca3946e70050869c56446805
Jean-Baptiste/camembert-ner model dbec8489a1c44ecad9da8a9185115bccabd799fe 441.0M 7 16 hours ago main /home/wauplin/.cache/huggingface/hub/models--Jean-Baptiste--camembert-ner/snapshots/dbec8489a1c44ecad9da8a9185115bccabd799fe
bert-base-cased model 378aa1bda6387fd00e824948ebe3488630ad8565 1.5G 9 2 years ago /home/wauplin/.cache/huggingface/hub/models--bert-base-cased/snapshots/378aa1bda6387fd00e824948ebe3488630ad8565
bert-base-cased model a8d257ba9925ef39f3036bfc338acf5283c512d9 1.4G 9 3 days ago main /home/wauplin/.cache/huggingface/hub/models--bert-base-cased/snapshots/a8d257ba9925ef39f3036bfc338acf5283c512d9
t5-base model 23aa4f41cb7c08d4b05c8f327b22bfa0eb8c7ad9 10.1K 3 1 week ago main /home/wauplin/.cache/huggingface/hub/models--t5-base/snapshots/23aa4f41cb7c08d4b05c8f327b22bfa0eb8c7ad9
t5-small model 98ffebbb27340ec1b1abd7c45da12c253ee1882a 726.2M 6 1 week ago refs/pr/1 /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/98ffebbb27340ec1b1abd7c45da12c253ee1882a
t5-small model d0a119eedb3718e34c648e594394474cf95e0617 485.8M 6 4 weeks ago /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d0a119eedb3718e34c648e594394474cf95e0617
t5-small model d78aea13fa7ecd06c29e3e46195d6341255065d5 970.7M 9 1 week ago main /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d78aea13fa7ecd06c29e3e46195d6341255065d5
Done in 0.0s. Scanned 6 repo(s) for a total of 3.4G.
Got 1 warning(s) while scanning. Use -vvv to print details.
```
#### Grep example
Since the output is in tabular format, you can combine it with any `grep`-like tools to
filter the entries. Here is an example to filter only revisions from the "t5-small"
model on a Unix-based machine.
```text
➜ eval "huggingface-cli scan-cache -v" | grep "t5-small"
t5-small model 98ffebbb27340ec1b1abd7c45da12c253ee1882a 726.2M 6 1 week ago refs/pr/1 /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/98ffebbb27340ec1b1abd7c45da12c253ee1882a
t5-small model d0a119eedb3718e34c648e594394474cf95e0617 485.8M 6 4 weeks ago /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d0a119eedb3718e34c648e594394474cf95e0617
t5-small model d78aea13fa7ecd06c29e3e46195d6341255065d5 970.7M 9 1 week ago main /home/wauplin/.cache/huggingface/hub/models--t5-small/snapshots/d78aea13fa7ecd06c29e3e46195d6341255065d5
```
### Scan cache from Python
For a more advanced usage, use [`scan_cache_dir`] which is the python utility called by
the CLI tool.
You can use it to get a detailed report structured around 4 dataclasses:
- [`HFCacheInfo`]: complete report returned by [`scan_cache_dir`]
- [`CachedRepoInfo`]: information about a cached repo
- [`CachedRevisionInfo`]: information about a cached revision (e.g. "snapshot") inside a repo
- [`CachedFileInfo`]: information about a cached file in a snapshot
Here is a simple usage example. See reference for details.
```py
>>> from huggingface_hub import scan_cache_dir
>>> hf_cache_info = scan_cache_dir()
HFCacheInfo(
size_on_disk=3398085269,
repos=frozenset({
CachedRepoInfo(
repo_id='t5-small',
repo_type='model',
repo_path=PosixPath(...),
size_on_disk=970726914,
nb_files=11,
last_accessed=1662971707.3567169,
last_modified=1662971107.3567169,
revisions=frozenset({
CachedRevisionInfo(
commit_hash='d78aea13fa7ecd06c29e3e46195d6341255065d5',
size_on_disk=970726339,
snapshot_path=PosixPath(...),
# No `last_accessed` as blobs are shared among revisions
last_modified=1662971107.3567169,
files=frozenset({
CachedFileInfo(
file_name='config.json',
size_on_disk=1197
file_path=PosixPath(...),
blob_path=PosixPath(...),
blob_last_accessed=1662971707.3567169,
blob_last_modified=1662971107.3567169,
),
CachedFileInfo(...),
...
}),
),
CachedRevisionInfo(...),
...
}),
),
CachedRepoInfo(...),
...
}),
warnings=[
CorruptedCacheException("Snapshots dir doesn't exist in cached repo: ..."),
CorruptedCacheException(...),
...
],
)
```
## Clean your cache
Scanning your cache is interesting but what you really want to do next is usually to
delete some portions to free up some space on your drive. This is possible using the
`delete-cache` CLI command. One can also programmatically use the
[`~HFCacheInfo.delete_revisions`] helper from [`HFCacheInfo`] object returned when
scanning the cache.
### Delete strategy
To delete some cache, you need to pass a list of revisions to delete. The tool will
define a strategy to free up the space based on this list. It returns a
[`DeleteCacheStrategy`] object that describes which files and folders will be deleted.
The [`DeleteCacheStrategy`] allows give you how much space is expected to be freed.
Once you agree with the deletion, you must execute it to make the deletion effective. In
order to avoid discrepancies, you cannot edit a strategy object manually.
The strategy to delete revisions is the following:
- the `snapshot` folder containing the revision symlinks is deleted.
- blobs files that are targeted only by revisions to be deleted are deleted as well.
- if a revision is linked to 1 or more `refs`, references are deleted.
- if all revisions from a repo are deleted, the entire cached repository is deleted.
<Tip>
Revision hashes are unique across all repositories. This means you don't need to
provide any `repo_id` or `repo_type` when removing revisions.
</Tip>
<Tip warning={true}>
If a revision is not found in the cache, it will be silently ignored. Besides, if a file
or folder cannot be found while trying to delete it, a warning will be logged but no
error is thrown. The deletion continues for other paths contained in the
[`DeleteCacheStrategy`] object.
</Tip>
### Clean cache from the terminal
The easiest way to delete some revisions from your HF cache-system is to use the
`delete-cache` command from `huggingface-cli` tool. The command has two modes. By
default, a TUI (Terminal User Interface) is displayed to the user to select which
revisions to delete. This TUI is currently in beta as it has not been tested on all
platforms. If the TUI doesn't work on your machine, you can disable it using the
`--disable-tui` flag.
#### Using the TUI
This is the default mode. To use it, you first need to install extra dependencies by
running the following command:
```
pip install huggingface_hub["cli"]
```
Then run the command:
```
huggingface-cli delete-cache
```
You should now see a list of revisions that you can select/deselect:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/delete-cache-tui.png"/>
</div>
Instructions:
- Press keyboard arrow keys `<up>` and `<down>` to move the cursor.
- Press `<space>` to toggle (select/unselect) an item.
- When a revision is selected, the first line is updated to show you how much space
will be freed.
- Press `<enter>` to confirm your selection.
- If you want to cancel the operation and quit, you can select the first item
("None of the following"). If this item is selected, the delete process will be
cancelled, no matter what other items are selected. Otherwise you can also press
`<ctrl+c>` to quit the TUI.
Once you've selected the revisions you want to delete and pressed `<enter>`, a last
confirmation message will be prompted. Press `<enter>` again and the deletion will be
effective. If you want to cancel, enter `n`.
```txt
✗ huggingface-cli delete-cache --dir ~/.cache/huggingface/hub
? Select revisions to delete: 2 revision(s) selected.
? 2 revisions selected counting for 3.1G. Confirm deletion ? Yes
Start deletion.
Done. Deleted 1 repo(s) and 0 revision(s) for a total of 3.1G.
```
#### Without TUI
As mentioned above, the TUI mode is currently in beta and is optional. It may be the
case that it doesn't work on your machine or that you don't find it convenient.
Another approach is to use the `--disable-tui` flag. The process is very similar as you
will be asked to manually review the list of revisions to delete. However, this manual
step will not take place in the terminal directly but in a temporary file generated on
the fly and that you can manually edit.
This file has all the instructions you need in the header. Open it in your favorite text
editor. To select/deselect a revision, simply comment/uncomment it with a `#`. Once the
manual review is done and the file is edited, you can save it. Go back to your terminal
and press `<enter>`. By default it will compute how much space would be freed with the
updated list of revisions. You can continue to edit the file or confirm with `"y"`.
```sh
huggingface-cli delete-cache --disable-tui
```
Example of command file:
```txt
# INSTRUCTIONS
# ------------
# This is a temporary file created by running `huggingface-cli delete-cache` with the
# `--disable-tui` option. It contains a set of revisions that can be deleted from your
# local cache directory.
#
# Please manually review the revisions you want to delete:
# - Revision hashes can be commented out with '#'.
# - Only non-commented revisions in this file will be deleted.
# - Revision hashes that are removed from this file are ignored as well.
# - If `CANCEL_DELETION` line is uncommented, the all cache deletion is cancelled and
# no changes will be applied.
#
# Once you've manually reviewed this file, please confirm deletion in the terminal. This
# file will be automatically removed once done.
# ------------
# KILL SWITCH
# ------------
# Un-comment following line to completely cancel the deletion process
# CANCEL_DELETION
# ------------
# REVISIONS
# ------------
# Dataset chrisjay/crowd-speech-africa (761.7M, used 5 days ago)
ebedcd8c55c90d39fd27126d29d8484566cd27ca # Refs: main # modified 5 days ago
# Dataset oscar (3.3M, used 4 days ago)
# 916f956518279c5e60c63902ebdf3ddf9fa9d629 # Refs: main # modified 4 days ago
# Dataset wikiann (804.1K, used 2 weeks ago)
89d089624b6323d69dcd9e5eb2def0551887a73a # Refs: main # modified 2 weeks ago
# Dataset z-uo/male-LJSpeech-italian (5.5G, used 5 days ago)
# 9cfa5647b32c0a30d0adfca06bf198d82192a0d1 # Refs: main # modified 5 days ago
```
### Clean cache from Python
For more flexibility, you can also use the [`~HFCacheInfo.delete_revisions`] method
programmatically. Here is a simple example. See reference for details.
```py
>>> from huggingface_hub import scan_cache_dir
>>> delete_strategy = scan_cache_dir().delete_revisions(
... "81fd1d6e7847c99f5862c9fb81387956d99ec7aa"
... "e2983b237dccf3ab4937c97fa717319a9ca1a96d",
... "6c0e6080953db56375760c0471a8c5f2929baf11",
... )
>>> print("Will free " + delete_strategy.expected_freed_size_str)
Will free 8.6G
>>> delete_strategy.execute()
Cache deletion done. Saved 8.6G.
```
| huggingface/huggingface_hub/blob/main/docs/source/en/guides/manage-cache.md |
Know your dataset
There are two types of dataset objects, a regular [`Dataset`] and then an ✨ [`IterableDataset`] ✨. A [`Dataset`] provides fast random access to the rows, and memory-mapping so that loading even large datasets only uses a relatively small amount of device memory. But for really, really big datasets that won't even fit on disk or in memory, an [`IterableDataset`] allows you to access and use the dataset without waiting for it to download completely!
This tutorial will show you how to load and access a [`Dataset`] and an [`IterableDataset`].
## Dataset
When you load a dataset split, you'll get a [`Dataset`] object. You can do many things with a [`Dataset`] object, which is why it's important to learn how to manipulate and interact with the data stored inside.
This tutorial uses the [rotten_tomatoes](https://huggingface.co/datasets/rotten_tomatoes) dataset, but feel free to load any dataset you'd like and follow along!
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes", split="train")
```
### Indexing
A [`Dataset`] contains columns of data, and each column can be a different type of data. The *index*, or axis label, is used to access examples from the dataset. For example, indexing by the row returns a dictionary of an example from the dataset:
```py
# Get the first row in the dataset
>>> dataset[0]
{'label': 1,
'text': 'the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .'}
```
Use the `-` operator to start from the end of the dataset:
```py
# Get the last row in the dataset
>>> dataset[-1]
{'label': 0,
'text': 'things really get weird , though not particularly scary : the movie is all portent and no content .'}
```
Indexing by the column name returns a list of all the values in the column:
```py
>>> dataset["text"]
['the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .',
'the gorgeously elaborate continuation of " the lord of the rings " trilogy is so huge that a column of words cannot adequately describe co-writer/director peter jackson\'s expanded vision of j . r . r . tolkien\'s middle-earth .',
'effective but too-tepid biopic',
...,
'things really get weird , though not particularly scary : the movie is all portent and no content .']
```
You can combine row and column name indexing to return a specific value at a position:
```py
>>> dataset[0]["text"]
'the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .'
```
But it is important to remember that indexing order matters, especially when working with large audio and image datasets. Indexing by the column name returns all the values in the column first, then loads the value at that position. For large datasets, it may be slower to index by the column name first.
```py
>>> import time
>>> start_time = time.time()
>>> text = dataset[0]["text"]
>>> end_time = time.time()
>>> print(f"Elapsed time: {end_time - start_time:.4f} seconds")
Elapsed time: 0.0031 seconds
>>> start_time = time.time()
>>> text = dataset["text"][0]
>>> end_time = time.time()
>>> print(f"Elapsed time: {end_time - start_time:.4f} seconds")
Elapsed time: 0.0094 seconds
```
### Slicing
Slicing returns a slice - or subset - of the dataset, which is useful for viewing several rows at once. To slice a dataset, use the `:` operator to specify a range of positions.
```py
# Get the first three rows
>>> dataset[:3]
{'label': [1, 1, 1],
'text': ['the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .',
'the gorgeously elaborate continuation of " the lord of the rings " trilogy is so huge that a column of words cannot adequately describe co-writer/director peter jackson\'s expanded vision of j . r . r . tolkien\'s middle-earth .',
'effective but too-tepid biopic']}
# Get rows between three and six
>>> dataset[3:6]
{'label': [1, 1, 1],
'text': ['if you sometimes like to go to the movies to have fun , wasabi is a good place to start .',
"emerges as something rare , an issue movie that's so honest and keenly observed that it doesn't feel like one .",
'the film provides some great insight into the neurotic mindset of all comics -- even those who have reached the absolute top of the game .']}
```
## IterableDataset
An [`IterableDataset`] is loaded when you set the `streaming` parameter to `True` in [`~datasets.load_dataset`]:
```py
>>> from datasets import load_dataset
>>> iterable_dataset = load_dataset("food101", split="train", streaming=True)
>>> for example in iterable_dataset:
... print(example)
... break
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F0681F5C520>, 'label': 6}
```
You can also create an [`IterableDataset`] from an *existing* [`Dataset`], but it is faster than streaming mode because the dataset is streamed from local files:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes", split="train")
>>> iterable_dataset = dataset.to_iterable_dataset()
```
An [`IterableDataset`] progressively iterates over a dataset one example at a time, so you don't have to wait for the whole dataset to download before you can use it. As you can imagine, this is quite useful for large datasets you want to use immediately!
However, this means an [`IterableDataset`]'s behavior is different from a regular [`Dataset`]. You don't get random access to examples in an [`IterableDataset`]. Instead, you should iterate over its elements, for example, by calling `next(iter())` or with a `for` loop to return the next item from the [`IterableDataset`]:
```py
>>> next(iter(iterable_dataset))
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F0681F59B50>,
'label': 6}
>>> for example in iterable_dataset:
... print(example)
... break
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F7479DE82B0>, 'label': 6}
```
You can return a subset of the dataset with a specific number of examples in it with [`IterableDataset.take`]:
```py
# Get first three examples
>>> list(iterable_dataset.take(3))
[{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F7479DEE9D0>,
'label': 6},
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512 at 0x7F7479DE8190>,
'label': 6},
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x383 at 0x7F7479DE8310>,
'label': 6}]
```
But unlike [slicing](access/#slicing), [`IterableDataset.take`] creates a new [`IterableDataset`].
## Next steps
Interested in learning more about the differences between these two types of datasets? Learn more about them in the [Differences between `Dataset` and `IterableDataset`](about_mapstyle_vs_iterable) conceptual guide.
To get more hands-on with these datasets types, check out the [Process](process) guide to learn how to preprocess a [`Dataset`] or the [Stream](stream) guide to learn how to preprocess an [`IterableDataset`].
| huggingface/datasets/blob/main/docs/source/access.mdx |
使用Gradio JavaScript客户端快速入门
Tags: CLIENT, API, SPACES
Gradio JavaScript客户端使得使用任何Gradio应用作为API非常简单。例如,考虑一下这个[从麦克风录音的Hugging Face Space,用于转录音频文件](https://huggingface.co/spaces/abidlabs/whisper)。
使用`@gradio/client`库,我们可以轻松地以编程方式使用Gradio作为API来转录音频文件。
以下是完成此操作的完整代码:
```js
import { client } from "@gradio/client";
const response = await fetch(
"https://github.com/audio-samples/audio-samples.github.io/raw/master/samples/wav/ted_speakers/SalmanKhan/sample-1.wav"
);
const audio_file = await response.blob();
const app = await client("abidlabs/whisper");
const transcription = await app.predict("/predict", [audio_file]);
console.log(transcription.data);
// [ "I said the same phrase 30 times." ]
```
Gradio客户端适用于任何托管的Gradio应用,无论是图像生成器、文本摘要生成器、有状态的聊天机器人、税收计算器还是其他任何应用!Gradio客户端通常与托管在[Hugging Face Spaces](https://hf.space)上的应用一起使用,但您的应用可以托管在任何地方,比如您自己的服务器。
**先决条件**:要使用Gradio客户端,您不需要深入了解`gradio`库的细节。但是,熟悉Gradio的输入和输出组件的概念会有所帮助。
## 安装
可以使用您选择的软件包管理器从npm注册表安装轻量级的`@gradio/client`包,并支持18及以上的Node版本:
```bash
npm i @gradio/client
```
## 连接到正在运行的Gradio应用
首先,通过实例化`client`对象并将其连接到在Hugging Face Spaces或任何其他位置运行的Gradio应用来建立连接。
## 连接到Hugging Face Space
```js
import { client } from "@gradio/client";
const app = client("abidlabs/en2fr"); // 一个从英语翻译为法语的 Space
```
您还可以通过在options参数的`hf_token`属性中传入您的HF token来连接到私有Spaces。您可以在此处获取您的HF token:https://huggingface.co/settings/tokens
```js
import { client } from "@gradio/client";
const app = client("abidlabs/my-private-space", { hf_token="hf_..." })
```
## 为私人使用复制一个Space
虽然您可以将任何公共Space用作API,但是如果您发出的请求过多,Hugging Face可能会对您进行速率限制。为了无限制使用Space,只需复制Space以创建私有Space,然后使用它来进行任意数量的请求!
`@gradio/client`还导出了另一个函数`duplicate`,以使此过程变得简单(您将需要传入您的[Hugging Face token](https://huggingface.co/settings/tokens))。
`duplicate`与`client`几乎相同,唯一的区别在于底层实现:
```js
import { client } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await duplicate("abidlabs/whisper", { hf_token: "hf_..." });
const transcription = app.predict("/predict", [audio_file]);
```
如果您之前复制过一个Space,则重新运行`duplicate`不会创建一个新的Space。而是客户端将连接到先前创建的Space。因此,可以安全地多次使用相同的Space重新运行`duplicate`方法。
**注意:**如果原始Space使用了GPU,您的私有Space也将使用GPU,并且将根据GPU的价格向您的Hugging Face账户计费。为了最大程度地减少费用,在5分钟不活动后,您的Space将自动进入休眠状态。您还可以使用`duplicate`的options对象的`hardware`和`timeout`属性来设置硬件,例如:
```js
import { client } from "@gradio/client";
const app = await duplicate("abidlabs/whisper", {
hf_token: "hf_...",
timeout: 60,
hardware: "a10g-small"
});
```
## 连接到通用的Gradio应用
如果您的应用程序在其他地方运行,只需提供完整的URL,包括"http://"或"https://"。以下是向运行在共享URL上的Gradio应用进行预测的示例:
```js
import { client } from "@gradio/client";
const app = client("https://bec81a83-5b5c-471e.gradio.live");
```
## 检查API端点
一旦连接到Gradio应用程序,可以通过调用`client`的`view_api`方法来查看可用的API端点。
对于Whisper Space,我们可以这样做:
```js
import { client } from "@gradio/client";
const app = await client("abidlabs/whisper");
const app_info = await app.view_info();
console.log(app_info);
```
然后我们会看到以下内容:
```json
{
"named_endpoints": {
"/predict": {
"parameters": [
{
"label": "text",
"component": "Textbox",
"type": "string"
}
],
"returns": [
{
"label": "output",
"component": "Textbox",
"type": "string"
}
]
}
},
"unnamed_endpoints": {}
}
```
这告诉我们该Space中有1个API端点,并显示了如何使用API端点进行预测:我们应该调用`.predict()`方法(下面将进行更多探索),并提供类型为`string`的参数`input_audio`,它是指向文件的URL。
我们还应该提供`api_name='/predict'`参数给`predict()`方法。虽然如果一个Gradio应用只有1个命名的端点,这不是必需的,但它可以允许我们在单个应用中调用不同的端点。如果应用有未命名的API端点,可以通过运行`.view_api(all_endpoints=True)`来显示它们。
## 进行预测
进行预测的最简单方法就是使用适当的参数调用`.predict()`方法:
```js
import { client } from "@gradio/client";
const app = await client("abidlabs/en2fr");
const result = await app.predict("/predict", ["Hello"]);
```
如果有多个参数,您应该将它们作为一个数组传递给`.predict()`,像这样:
```js
import { client } from "@gradio/client";
const app = await client("gradio/calculator");
const result = await app.predict("/predict", [4, "add", 5]);
```
对于某些输入,例如图像,您应该根据所需要的方便程度传入`Buffer`、`Blob`或`File`。在Node.js中,可以使用`Buffer`或`Blob`;在浏览器环境中,可以使用`Blob`或`File`。
```js
import { client } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await client("abidlabs/whisper");
const result = await client.predict("/predict", [audio_file]);
```
## 使用事件
如果您使用的API可以随时间返回结果,或者您希望访问有关作业状态的信息,您可以使用事件接口获取更大的灵活性。这对于迭代的或生成器的端点特别有用,因为它们会生成一系列离散的响应值。
```js
import { client } from "@gradio/client";
function log_result(payload) {
const {
data: [translation]
} = payload;
console.log(`翻译结果为:${translation}`);
}
const app = await client("abidlabs/en2fr");
const job = app.submit("/predict", ["Hello"]);
job.on("data", log_result);
```
## 状态
事件接口还可以通过监听`"status"`事件来获取运行作业的状态。这将返回一个对象,其中包含以下属性:`status`(当前作业的人类可读状态,`"pending" | "generating" | "complete" | "error"`),`code`(作业的详细gradio code),`position`(此作业在队列中的当前位置),`queue_size`(总队列大小),`eta`(作业完成的预计时间),`success`(表示作业是否成功完成的布尔值)和`time`(作业状态生成的时间,是一个`Date`对象)。
```js
import { client } from "@gradio/client";
function log_status(status) {
console.log(`此作业的当前状态为:${JSON.stringify(status, null, 2)}`);
}
const app = await client("abidlabs/en2fr");
const job = app.submit("/predict", ["Hello"]);
job.on("status", log_status);
```
## 取消作业
作业实例还具有`.cancel()`方法,用于取消已排队但尚未启动的作业。例如,如果您运行以下命令:
```js
import { client } from "@gradio/client";
const app = await client("abidlabs/en2fr");
const job_one = app.submit("/predict", ["Hello"]);
const job_two = app.submit("/predict", ["Friends"]);
job_one.cancel();
job_two.cancel();
```
如果第一个作业已经开始处理,那么它将不会被取消,但客户端将不再监听更新(丢弃该作业)。如果第二个作业尚未启动,它将被成功取消并从队列中移除。
## 生成器端点
某些Gradio API端点不返回单个值,而是返回一系列值。您可以使用事件接口实时侦听这些值:
```js
import { client } from "@gradio/client";
const app = await client("gradio/count_generator");
const job = app.submit(0, [9]);
job.on("data", (data) => console.log(data));
```
这将按生成端点生成的值进行日志记录。
您还可以取消具有迭代输出的作业,在这种情况下,作业将立即完成。
```js
import { client } from "@gradio/client";
const app = await client("gradio/count_generator");
const job = app.submit(0, [9]);
job.on("data", (data) => console.log(data));
setTimeout(() => {
job.cancel();
}, 3000);
```
| gradio-app/gradio/blob/main/guides/cn/06_client-libraries/02_getting-started-with-the-js-client.md |
--
title: SacreBLEU
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
SacreBLEU provides hassle-free computation of shareable, comparable, and reproducible BLEU scores.
Inspired by Rico Sennrich's `multi-bleu-detok.perl`, it produces the official WMT scores but works with plain text.
It also knows all the standard test sets and handles downloading, processing, and tokenization for you.
See the [README.md] file at https://github.com/mjpost/sacreBLEU for more information.
---
# Metric Card for SacreBLEU
## Metric Description
SacreBLEU provides hassle-free computation of shareable, comparable, and reproducible BLEU scores. Inspired by Rico Sennrich's `multi-bleu-detok.perl`, it produces the official Workshop on Machine Translation (WMT) scores but works with plain text. It also knows all the standard test sets and handles downloading, processing, and tokenization.
See the [README.md] file at https://github.com/mjpost/sacreBLEU for more information.
## How to Use
This metric takes a set of predictions and a set of references as input, along with various optional parameters.
```python
>>> predictions = ["hello there general kenobi", "foo bar foobar"]
>>> references = [["hello there general kenobi", "hello there !"],
... ["foo bar foobar", "foo bar foobar"]]
>>> sacrebleu = evaluate.load("sacrebleu")
>>> results = sacrebleu.compute(predictions=predictions,
... references=references)
>>> print(list(results.keys()))
['score', 'counts', 'totals', 'precisions', 'bp', 'sys_len', 'ref_len']
>>> print(round(results["score"], 1))
100.0
```
### Inputs
- **`predictions`** (`list` of `str`): list of translations to score. Each translation should be tokenized into a list of tokens.
- **`references`** (`list` of `list` of `str`): A list of lists of references. The contents of the first sub-list are the references for the first prediction, the contents of the second sub-list are for the second prediction, etc. Note that there must be the same number of references for each prediction (i.e. all sub-lists must be of the same length).
- **`smooth_method`** (`str`): The smoothing method to use, defaults to `'exp'`. Possible values are:
- `'none'`: no smoothing
- `'floor'`: increment zero counts
- `'add-k'`: increment num/denom by k for n>1
- `'exp'`: exponential decay
- **`smooth_value`** (`float`): The smoothing value. Only valid when `smooth_method='floor'` (in which case `smooth_value` defaults to `0.1`) or `smooth_method='add-k'` (in which case `smooth_value` defaults to `1`).
- **`tokenize`** (`str`): Tokenization method to use for BLEU. If not provided, defaults to `'zh'` for Chinese, `'ja-mecab'` for Japanese and `'13a'` (mteval) otherwise. Possible values are:
- `'none'`: No tokenization.
- `'zh'`: Chinese tokenization.
- `'13a'`: mimics the `mteval-v13a` script from Moses.
- `'intl'`: International tokenization, mimics the `mteval-v14` script from Moses
- `'char'`: Language-agnostic character-level tokenization.
- `'ja-mecab'`: Japanese tokenization. Uses the [MeCab tokenizer](https://pypi.org/project/mecab-python3).
- **`lowercase`** (`bool`): If `True`, lowercases the input, enabling case-insensitivity. Defaults to `False`.
- **`force`** (`bool`): If `True`, insists that your tokenized input is actually detokenized. Defaults to `False`.
- **`use_effective_order`** (`bool`): If `True`, stops including n-gram orders for which precision is 0. This should be `True`, if sentence-level BLEU will be computed. Defaults to `False`.
### Output Values
- `score`: BLEU score
- `counts`: Counts
- `totals`: Totals
- `precisions`: Precisions
- `bp`: Brevity penalty
- `sys_len`: predictions length
- `ref_len`: reference length
The output is in the following format:
```python
{'score': 39.76353643835252, 'counts': [6, 4, 2, 1], 'totals': [10, 8, 6, 4], 'precisions': [60.0, 50.0, 33.333333333333336, 25.0], 'bp': 1.0, 'sys_len': 10, 'ref_len': 7}
```
The score can take any value between `0.0` and `100.0`, inclusive.
#### Values from Popular Papers
### Examples
```python
>>> predictions = ["hello there general kenobi",
... "on our way to ankh morpork"]
>>> references = [["hello there general kenobi", "hello there !"],
... ["goodbye ankh morpork", "ankh morpork"]]
>>> sacrebleu = evaluate.load("sacrebleu")
>>> results = sacrebleu.compute(predictions=predictions,
... references=references)
>>> print(list(results.keys()))
['score', 'counts', 'totals', 'precisions', 'bp', 'sys_len', 'ref_len']
>>> print(round(results["score"], 1))
39.8
```
## Limitations and Bias
Because what this metric calculates is BLEU scores, it has the same limitations as that metric, except that sacreBLEU is more easily reproducible.
## Citation
```bibtex
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
```
## Further References
- See the [sacreBLEU README.md file](https://github.com/mjpost/sacreBLEU) for more information. | huggingface/evaluate/blob/main/metrics/sacrebleu/README.md |
--
title: Deploy Embedding Models with Hugging Face Inference Endpoints
thumbnail: /blog/assets/168_inference_endpoints_embeddings/thumbnail.jpg
authors:
- user: philschmid
---
# Deploy Embedding Models with Hugging Face Inference Endpoints
The rise of Generative AI and LLMs like ChatGPT has increased the interest and importance of embedding models for a variety of tasks especially for retrievel augemented generation, like search or chat with your data. Embeddings are helpful since they represent sentences, images, words, etc. as numeric vector representations, which allows us to map semantically related items and retrieve helpful information. This helps us to provide relevant context for our prompt to improve the quality and specificity of generation.
Compared to LLMs are Embedding Models smaller in size and faster for inference. That is very important since you need to recreate your embeddings after you changed your model or improved your model fine-tuning. Additionally, is it important that the whole retrieval augmentation process is as fast as possible to provide a good user experience.
In this blog post, we will show you how to deploy open-source Embedding Models to [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) using [Text Embedding Inference](https://github.com/huggingface/text-embeddings-inference), our managed SaaS solution that makes it easy to deploy models. Additionally, we will teach you how to run large scale batch requests.
1. [What is Hugging Face Inference Endpoints](#1-what-is-hugging-face-inference-endpoints)
2. [What is Text Embedding Inference](#2-what-is-text-embeddings-inference)
3. [Deploy Embedding Model as Inference Endpoint](#3-deploy-embedding-model-as-inference-endpoint)
4. [Send request to endpoint and create embeddings](#4-send-request-to-endpoint-and-create-embeddings)
Before we start, let's refresh our knowledge about Inference Endpoints.
## 1. What is Hugging Face Inference Endpoints?
[Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) offers an easy and secure way to deploy Machine Learning models for use in production. Inference Endpoints empower developers and data scientists to create Generative AI applications without managing infrastructure: simplifying the deployment process to a few clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security.
Here are some of the most important features:
1. [Easy Deployment](https://huggingface.co/docs/inference-endpoints/index): Deploy models as production-ready APIs with just a few clicks, eliminating the need to handle infrastructure or MLOps.
2. [Cost Efficiency](https://huggingface.co/docs/inference-endpoints/autoscaling): Benefit from automatic scale to zero capability, reducing costs by scaling down the infrastructure when the endpoint is not in use, while paying based on the uptime of the endpoint, ensuring cost-effectiveness.
3. [Enterprise Security](https://huggingface.co/docs/inference-endpoints/security): Deploy models in secure offline endpoints accessible only through direct VPC connections, backed by SOC2 Type 2 certification, and offering BAA and GDPR data processing agreements for enhanced data security and compliance.
4. [LLM Optimization](https://huggingface.co/text-generation-inference): Optimized for LLMs, enabling high throughput with Paged Attention and low latency through custom transformers code and Flash Attention power by Text Generation Inference
5. [Comprehensive Task Support](https://huggingface.co/docs/inference-endpoints/supported_tasks): Out of the box support for 🤗 Transformers, Sentence-Transformers, and Diffusers tasks and models, and easy customization to enable advanced tasks like speaker diarization or any Machine Learning task and library.
You can get started with Inference Endpoints at: https://ui.endpoints.huggingface.co/
## 2. What is Text Embeddings Inference?
[Text Embeddings Inference (TEI)](https://github.com/huggingface/text-embeddings-inference#text-embeddings-inference) is a purpose built solution for deploying and serving open source text embeddings models. TEI is build for high-performance extraction supporting the most popular models. TEI supports all top 10 models of the [Massive Text Embedding Benchmark (MTEB) Leaderboard](https://huggingface.co/spaces/mteb/leaderboard), including FlagEmbedding, Ember, GTE and E5. TEI currently implements the following performance optimizing features:
- No model graph compilation step
- Small docker images and fast boot times. Get ready for true serverless!
- Token based dynamic batching
- Optimized transformers code for inference using [Flash Attention](https://github.com/HazyResearch/flash-attention), [Candle](https://github.com/huggingface/candle) and [cuBLASLt](https://docs.nvidia.com/cuda/cublas/#using-the-cublaslt-api)
- [Safetensors](https://github.com/huggingface/safetensors) weight loading
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
Those feature enabled industry-leading performance on throughput and cost. In a benchmark for [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) on an Nvidia A10G Inference Endpoint with a sequence length of 512 tokens and a batch size of 32, we achieved a throughput of 450+ req/sec resulting into a cost of 0.00156$ / 1M tokens or 0.00000156$ / 1k tokens. That is 64x cheaper than OpenAI Embeddings ($0.0001 / 1K tokens).
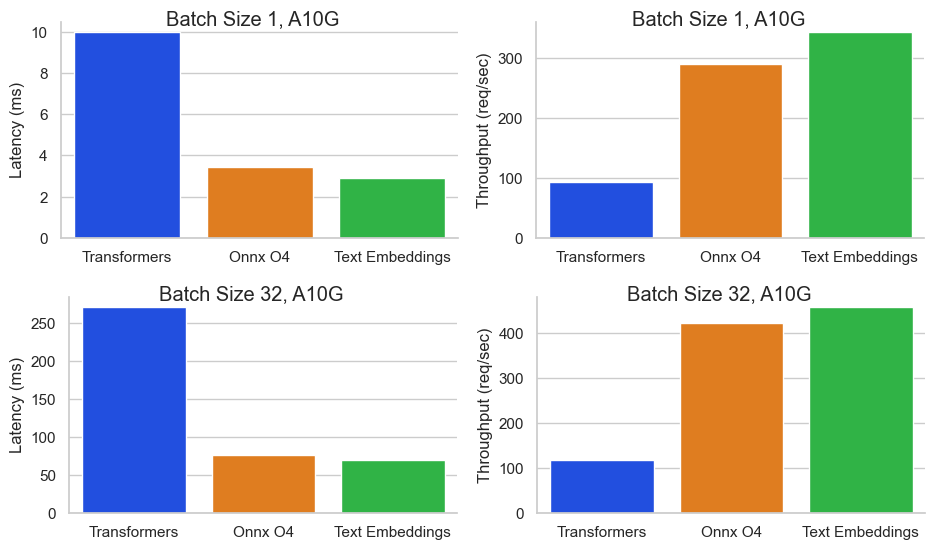
## 3. Deploy Embedding Model as Inference Endpoint
To get started, you need to be logged in with a User or Organization account with a payment method on file (you can add one [here](https://huggingface.co/settings/billing)), then access Inference Endpoints at [https://ui.endpoints.huggingface.co](https://ui.endpoints.huggingface.co/endpoints)
Then, click on “New endpoint”. Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy in our case `BAAI/bge-base-en-v1.5`.
Inference Endpoints suggest an instance type based on the model size, which should be big enough to run the model. Here `Intel Ice Lake 2 vCPU`. To get the performance for the benchmark we ran you, change the instance to `1x Nvidia A10G`.
*Note: If the instance type cannot be selected, you need to [contact us](mailto:[email protected]?subject=Quota%20increase%20HF%20Endpoints&body=Hello,%0D%0A%0D%0AI%20would%20like%20to%20request%20access/quota%20increase%20for%20%7BINSTANCE%20TYPE%7D%20for%20the%20following%20account%20%7BHF%20ACCOUNT%7D.) and request an instance quota.*

You can then deploy your model with a click on “Create Endpoint”. After 1-3 minutes, the Endpoint should be online and available to serve requests.
## 4. Send request to endpoint and create embeddings
The Endpoint overview provides access to the Inference Widget, which can be used to manually send requests. This allows you to quickly test your Endpoint with different inputs and share it with team members.
*Note: TEI is currently is not automatically truncating the input. You can enable this by setting `truncate: true` in your request.*
In addition to the widget the overview provides an code snippet for cURL, Python and Javascript, which you can use to send request to the model. The code snippet shows you how to send a single request, but TEI also supports batch requests, which allows you to send multiple document at the same to increase utilization of your endpoint. Below is an example on how to send a batch request with truncation set to true.
```python
import requests
API_URL = "https://l2skjfwp9punv393.us-east-1.aws.endpoints.huggingface.cloud"
headers = {
"Authorization": "Bearer YOUR TOKEN",
"Content-Type": "application/json"
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": ["sentence 1", "sentence 2", "sentence 3"],
"truncate": True
})
# output [[0.334, ...], [-0.234, ...]]
```
## Conclusion
TEI on Hugging Face Inference Endpoints enables blazing fast and ultra cost-efficient deployment of state-of-the-art embeddings models. With industry-leading throughput of 450+ requests per second and costs as low as $0.00000156 / 1k tokens, Inference Endpoints delivers 64x cost savings compared to OpenAI Embeddings.
For developers and companies leveraging text embeddings to enable semantic search, chatbots, recommendations, and more, Hugging Face Inference Endpoints eliminates infrastructure overhead and delivers high throughput at lowest cost streamlining the process from research to production.
---
Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/). | huggingface/blog/blob/main/inference-endpoints-embeddings.md |
FrameworkSwitchCourse {fw} />
# Tokenizers[[tokenizers]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section4_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section4_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section4_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section4_tf.ipynb"},
]} />
{/if}
<Youtube id="VFp38yj8h3A"/>
Tokenizers are one of the core components of the NLP pipeline. They serve one purpose: to translate text into data that can be processed by the model. Models can only process numbers, so tokenizers need to convert our text inputs to numerical data. In this section, we'll explore exactly what happens in the tokenization pipeline.
In NLP tasks, the data that is generally processed is raw text. Here's an example of such text:
```
Jim Henson was a puppeteer
```
However, models can only process numbers, so we need to find a way to convert the raw text to numbers. That's what the tokenizers do, and there are a lot of ways to go about this. The goal is to find the most meaningful representation — that is, the one that makes the most sense to the model — and, if possible, the smallest representation.
Let's take a look at some examples of tokenization algorithms, and try to answer some of the questions you may have about tokenization.
## Word-based[[word-based]]
<Youtube id="nhJxYji1aho"/>
The first type of tokenizer that comes to mind is _word-based_. It's generally very easy to set up and use with only a few rules, and it often yields decent results. For example, in the image below, the goal is to split the raw text into words and find a numerical representation for each of them:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/word_based_tokenization.svg" alt="An example of word-based tokenization."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/word_based_tokenization-dark.svg" alt="An example of word-based tokenization."/>
</div>
There are different ways to split the text. For example, we could use whitespace to tokenize the text into words by applying Python's `split()` function:
```py
tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)
```
```python out
['Jim', 'Henson', 'was', 'a', 'puppeteer']
```
There are also variations of word tokenizers that have extra rules for punctuation. With this kind of tokenizer, we can end up with some pretty large "vocabularies," where a vocabulary is defined by the total number of independent tokens that we have in our corpus.
Each word gets assigned an ID, starting from 0 and going up to the size of the vocabulary. The model uses these IDs to identify each word.
If we want to completely cover a language with a word-based tokenizer, we'll need to have an identifier for each word in the language, which will generate a huge amount of tokens. For example, there are over 500,000 words in the English language, so to build a map from each word to an input ID we'd need to keep track of that many IDs. Furthermore, words like "dog" are represented differently from words like "dogs", and the model will initially have no way of knowing that "dog" and "dogs" are similar: it will identify the two words as unrelated. The same applies to other similar words, like "run" and "running", which the model will not see as being similar initially.
Finally, we need a custom token to represent words that are not in our vocabulary. This is known as the "unknown" token, often represented as "[UNK]" or "<unk>". It's generally a bad sign if you see that the tokenizer is producing a lot of these tokens, as it wasn't able to retrieve a sensible representation of a word and you're losing information along the way. The goal when crafting the vocabulary is to do it in such a way that the tokenizer tokenizes as few words as possible into the unknown token.
One way to reduce the amount of unknown tokens is to go one level deeper, using a _character-based_ tokenizer.
## Character-based[[character-based]]
<Youtube id="ssLq_EK2jLE"/>
Character-based tokenizers split the text into characters, rather than words. This has two primary benefits:
- The vocabulary is much smaller.
- There are much fewer out-of-vocabulary (unknown) tokens, since every word can be built from characters.
But here too some questions arise concerning spaces and punctuation:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/character_based_tokenization.svg" alt="An example of character-based tokenization."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/character_based_tokenization-dark.svg" alt="An example of character-based tokenization."/>
</div>
This approach isn't perfect either. Since the representation is now based on characters rather than words, one could argue that, intuitively, it's less meaningful: each character doesn't mean a lot on its own, whereas that is the case with words. However, this again differs according to the language; in Chinese, for example, each character carries more information than a character in a Latin language.
Another thing to consider is that we'll end up with a very large amount of tokens to be processed by our model: whereas a word would only be a single token with a word-based tokenizer, it can easily turn into 10 or more tokens when converted into characters.
To get the best of both worlds, we can use a third technique that combines the two approaches: *subword tokenization*.
## Subword tokenization[[subword-tokenization]]
<Youtube id="zHvTiHr506c"/>
Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller subwords, but rare words should be decomposed into meaningful subwords.
For instance, "annoyingly" might be considered a rare word and could be decomposed into "annoying" and "ly". These are both likely to appear more frequently as standalone subwords, while at the same time the meaning of "annoyingly" is kept by the composite meaning of "annoying" and "ly".
Here is an example showing how a subword tokenization algorithm would tokenize the sequence "Let's do tokenization!":
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/bpe_subword.svg" alt="A subword tokenization algorithm."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/bpe_subword-dark.svg" alt="A subword tokenization algorithm."/>
</div>
These subwords end up providing a lot of semantic meaning: for instance, in the example above "tokenization" was split into "token" and "ization", two tokens that have a semantic meaning while being space-efficient (only two tokens are needed to represent a long word). This allows us to have relatively good coverage with small vocabularies, and close to no unknown tokens.
This approach is especially useful in agglutinative languages such as Turkish, where you can form (almost) arbitrarily long complex words by stringing together subwords.
### And more![[and-more]]
Unsurprisingly, there are many more techniques out there. To name a few:
- Byte-level BPE, as used in GPT-2
- WordPiece, as used in BERT
- SentencePiece or Unigram, as used in several multilingual models
You should now have sufficient knowledge of how tokenizers work to get started with the API.
## Loading and saving[[loading-and-saving]]
Loading and saving tokenizers is as simple as it is with models. Actually, it's based on the same two methods: `from_pretrained()` and `save_pretrained()`. These methods will load or save the algorithm used by the tokenizer (a bit like the *architecture* of the model) as well as its vocabulary (a bit like the *weights* of the model).
Loading the BERT tokenizer trained with the same checkpoint as BERT is done the same way as loading the model, except we use the `BertTokenizer` class:
```py
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
```
{#if fw === 'pt'}
Similar to `AutoModel`, the `AutoTokenizer` class will grab the proper tokenizer class in the library based on the checkpoint name, and can be used directly with any checkpoint:
{:else}
Similar to `TFAutoModel`, the `AutoTokenizer` class will grab the proper tokenizer class in the library based on the checkpoint name, and can be used directly with any checkpoint:
{/if}
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
We can now use the tokenizer as shown in the previous section:
```python
tokenizer("Using a Transformer network is simple")
```
```python out
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Saving a tokenizer is identical to saving a model:
```py
tokenizer.save_pretrained("directory_on_my_computer")
```
We'll talk more about `token_type_ids` in [Chapter 3](/course/chapter3), and we'll explain the `attention_mask` key a little later. First, let's see how the `input_ids` are generated. To do this, we'll need to look at the intermediate methods of the tokenizer.
## Encoding[[encoding]]
<Youtube id="Yffk5aydLzg"/>
Translating text to numbers is known as _encoding_. Encoding is done in a two-step process: the tokenization, followed by the conversion to input IDs.
As we've seen, the first step is to split the text into words (or parts of words, punctuation symbols, etc.), usually called *tokens*. There are multiple rules that can govern that process, which is why we need to instantiate the tokenizer using the name of the model, to make sure we use the same rules that were used when the model was pretrained.
The second step is to convert those tokens into numbers, so we can build a tensor out of them and feed them to the model. To do this, the tokenizer has a *vocabulary*, which is the part we download when we instantiate it with the `from_pretrained()` method. Again, we need to use the same vocabulary used when the model was pretrained.
To get a better understanding of the two steps, we'll explore them separately. Note that we will use some methods that perform parts of the tokenization pipeline separately to show you the intermediate results of those steps, but in practice, you should call the tokenizer directly on your inputs (as shown in the section 2).
### Tokenization[[tokenization]]
The tokenization process is done by the `tokenize()` method of the tokenizer:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
```
The output of this method is a list of strings, or tokens:
```python out
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
```
This tokenizer is a subword tokenizer: it splits the words until it obtains tokens that can be represented by its vocabulary. That's the case here with `transformer`, which is split into two tokens: `transform` and `##er`.
### From tokens to input IDs[[from-tokens-to-input-ids]]
The conversion to input IDs is handled by the `convert_tokens_to_ids()` tokenizer method:
```py
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
```
```python out
[7993, 170, 11303, 1200, 2443, 1110, 3014]
```
These outputs, once converted to the appropriate framework tensor, can then be used as inputs to a model as seen earlier in this chapter.
<Tip>
✏️ **Try it out!** Replicate the two last steps (tokenization and conversion to input IDs) on the input sentences we used in section 2 ("I've been waiting for a HuggingFace course my whole life." and "I hate this so much!"). Check that you get the same input IDs we got earlier!
</Tip>
## Decoding[[decoding]]
*Decoding* is going the other way around: from vocabulary indices, we want to get a string. This can be done with the `decode()` method as follows:
```py
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
```
```python out
'Using a Transformer network is simple'
```
Note that the `decode` method not only converts the indices back to tokens, but also groups together the tokens that were part of the same words to produce a readable sentence. This behavior will be extremely useful when we use models that predict new text (either text generated from a prompt, or for sequence-to-sequence problems like translation or summarization).
By now you should understand the atomic operations a tokenizer can handle: tokenization, conversion to IDs, and converting IDs back to a string. However, we've just scraped the tip of the iceberg. In the following section, we'll take our approach to its limits and take a look at how to overcome them.
| huggingface/course/blob/main/chapters/en/chapter2/4.mdx |
--
title: "What Makes a Dialog Agent Useful?"
thumbnail: /blog/assets/dialog-agents/thumbnail.png
authors:
- user: nazneen
- user: natolambert
- user: VictorSanh
- user: ThomWolf
---
# What Makes a Dialog Agent Useful?
## The techniques behind ChatGPT: RLHF, IFT, CoT, Red teaming, and more
_This article has been translated to Chinese [简体中文](https://mp.weixin.qq.com/s/Xd5VtRP-ziH-PYFOci65Hg)_.
A few weeks ago, ChatGPT emerged and launched the public discourse into a set of obscure acronyms: RLHF, SFT, IFT, CoT, and more, all attributed to the success of ChatGPT. What are these obscure acronyms and why are they so important? We surveyed all the important papers on these topics to categorize these works, summarize takeaways from what has been done, and share what remains to be shown.
Let’s start by looking at the landscape of language model based conversational agents. ChatGPT is not the first, in fact many organizations published their language model dialog agents before OpenAI, including [Meta’s BlenderBot](https://arxiv.org/abs/2208.03188), [Google’s LaMDA](https://arxiv.org/abs/2201.08239), [DeepMind’s Sparrow](https://arxiv.org/abs/2209.14375), and [Anthropic’s Assistant](https://arxiv.org/abs/2204.05862) (_a continued development of this agent without perfect attribution is also known as Claude_). Some groups have also announced their plans to build a open-source chatbot and publicly shared a roadmap ([LAION’s Open Assistant](https://github.com/LAION-AI/Open-Assistant)); others surely are doing so and have not announced it.
The following table compares these AI chatbots based on the details of their public access, training data, model architecture, and evaluation directions. ChatGPT is not documented so we instead share details about InstructGPT which is a instruction fine-tuned model from OpenAI that is believed to have served as a foundation of ChatGPT.
| | LaMDA | BlenderBot 3 |Sparrow | ChatGPT/ InstructGPT | Assistant|
| --- | --- | --- | --- | --- | --- |
| **Org** | Google | Meta | DeepMind | OpenAI | Anthropic |
| **Access** | Closed | Open | Closed | Limited | Closed |
| **Size** | 137B | 175B | 70B | 175B | 52B |
| **Pre-trained<br>Base model** | Unknown | OPT | Chinchilla | GPT-3.5 | Unknown |
| **Pre-training corpora size** (# tokens) | 2.81T | 180B | 1.4T | Unknown | 400B |
| **Model can<br>access the web** | ✔ | ✔ | ✔ | ✖️ | ✖️ |
| **Supervised<br>fine-tuning** | ✔ | ✔ | ✔ | ✔ | ✔ |
| **Fine-tuning<br>data size** | Quality:6.4K<br>Safety: 8K<br>Groundedness: 4K<br>IR: 49K | 20 NLP datasets ranging from 18K to 1.2M | Unknown | 12.7K (for InstructGPT, likely much more for ChatGPT) | 150K + LM generated data |
| **RLHF** | ✖️ | ✖️ | ✔ | ✔ | ✔ |
| **Hand written rules for safety** | ✔ | ✖️ | ✔ | ✖️ | ✔ |
| **Evaluation criteria** | 1. Quality (sensibleness, specificity, interestingness)<br>2. Safety (includes bias) 3. Groundedness | 1, Quality (engagingness, use of knowledge)<br>2. Safety (toxicity, bias) | 1. Alignment (Helpful, Harmless, Correct)<br>2. Evidence (from web)<br>3. Rule violation<br>4. Bias and stereotypes<br>5. Trustworthiness | 1. Alignment (Helpful, Harmless, Truthfulness)<br>2. Bias | 1. Alignment (Helpful, Harmless, Honesty)<br>2. Bias |
| **Crowdsourcing platform used for data labeling**| U.S. based vendor | Amazon MTurk | Unknown | Upwork and Scale AI | Surge AI, Amazon MTurk, and Upwork |
We observe that albeit there are many differences in the training data, model, and fine-tuning, there are also some commonalities. One common goal for all the above chatbots is *instru*c*tion following ,* i.e., to follow user-specified instructions. For example, instructing ChatGPT to write a poem on fine-tuning.

### **********************************************************************************************From prediction text to following instructions:**********************************************************************************************
Usually, the language-modeling objective of the base model is not sufficient for a model to learn to follow a user’s direction in a helpful way. Model creators use **Instruction Fine-Tuning (IFT)** that involves fine-tuning the base model on demonstrations of written directions on a very diverse set of tasks, in addition to classical NLP tasks of sentiment, text classification, summarization etc. These instruction demonstrations are made up of three main components — the instruction, the inputs and the outputs. The inputs are optional, some tasks only require instructions such as open-ended generation as in the example above with ChatGPT. A input and output when present form an *instance*. There can be multiple instances of inputs and outputs for a given instruction. See below for examples (taken from [Wang et al., ‘22]).

Data for IFT is usually a collection of human-written instructions and instances of instructions bootstrapped using a language model. For bootstrapping, the LM is prompted (as in the figure above) in a few-shot setting with examples and instructed to generate new instructions, inputs, and outputs. In each round, the model is prompted with samples chosen from both human-written and model generated. The amount of human and model contributions to creating the dataset is a spectrum; see figure below.

On one end is the purely model-generated IFT dataset such as Unnatural Instructions ([Honovich et al., ‘22](https://arxiv.org/abs/2212.09689)) and on the other is a large community effort of hand-crafted instructions as in Super-natural instructions ([Wang et al., ‘22](https://arxiv.org/abs/2204.07705)). In between these two are works on using a small set of high quality seed dataset followed by bootstrapping such as Self-instruct ([Wang et al., 22](https://arxiv.org/pdf/2212.10560.pdf)). Yet another way of collating a dataset for IFT is to take the existing high-quality crowdsourced NLP datasets on various tasks (including prompting) and cast those as instructions using a unified schema or diverse templates. This line of work includes the T0 ([Sanh et al., ‘22](https://arxiv.org/pdf/2110.08207.pdf)), Natural instructions dataset ([Mishra et al., ‘22](https://arxiv.org/pdf/2104.08773.pdf)), the FLAN LM ([Wei et al., ‘22](https://arxiv.org/pdf/2109.01652.pdf)), and the OPT-IML ([Iyer et al.,’22](https://arxiv.org/pdf/2212.12017.pdf)).
### Safely following instructions
Instruction fine-tuned LMs, however, may not always generate responses that are ********helpful******** and **********safe.********** Examples of this kind of behavior include being evasive by always giving a unhelpful response such as “I’m sorry, I don’t understand. ” or generating an unsafe response to user inputs on a sensitive topic. To alleviate such behavior, model developers use **Supervised Fine-tuning (SFT),** fine-tuning the base language model on high-quality human annotated data for helpfulness and harmlessness. For example, see table below taken from the Sparrow paper (Appendix F).
SFT and IFT are very closely linked. Instruction tuning can be seen as a subset of supervised fine-tuning. In the recent literature, the SFT phase has often been utilized for safety topics, rather than instruction-specific topics, which is done after IFT. In the future, this taxonomy and delineation should mature into clearer use-cases and methodology.

Google’s LaMDA is also fine-tuned on a dialog dataset with safety annotations based on a set of rules (Appendix A). These rules are usually pre-defined and developed by model creators and encompass a wide set of topics including harm, discrimination, misinformation.
### Fine-tuning the models
On the other hand, Open AI’s InstructGPT, DeepMind’s Sparrow, and Anthropic’s Constitutional AI use human annotations of preferences in a setup called **reinforcement learning from human feedback (RLHF).** In RLHF, a set a model responses are ranked based on human feedback (e.g. choosing a text blurb that is preferred over another). Next, a preference model is trained on those annotated responses to return a scalar reward for the RL optimizer. Finally, the dialog agent is trained to simulate the preference model via reinforcement learning. See our previous [blog post](https://huggingface.co/blog/rlhf) on RLHF for more details.
**Chain-of-thought (CoT)** prompting ([Wei et al., ‘22](https://arxiv.org/abs/2201.11903)) is a special case of instruction demonstration that generates output by eliciting step-by-step reasoning from the dialog agent. Models fine-tuned with CoT use instruction datasets with human annotations of step-by-step reasoning. It’s the origin of the famous prompt, ***************************[let’s think step by step](https://arxiv.org/abs/2205.11916)***************************. The example below is taken from [Chung et al., ‘22](https://arxiv.org/pdf/2210.11416.pdf). The orange color highlights the instruction, the pink color shows the input and the output, and the blue color is the CoT reasoning.

Models fine-tuned with CoT have shown to perform much better on tasks involving commonsense, arithmetic, and symbolic reasoning as in [Chung et al., ‘22](https://arxiv.org/pdf/2210.11416.pdf).
CoT fine-tuning have also shown to be very effective for harmlessness (sometimes doing better than RLHF) without the model being evasive and generating “Sorry, I cannot respond to this question,” for prompts that are sensitive as shown by [Bai et al.,’22](https://www.anthropic.com/constitutional.pdf). See Appendix D of their paper for more examples.

## Takeaways:
1. You only need a very tiny fraction of data for instruction fine-tuning (order of few hundreds) compared to the pre-training data.
2. Supervised fine-tuning uses human annotations to make model outputs safer and helpful.
3. CoT fine-tuning improves model performance on tasks requiring step-by-step thinking and makes them less evasive on sensitive topics.
## Next steps for dialogue agents
This blog summarizes many of the existing work on what makes a dialog agent useful. But there are still many open questions yet to be explored. We list some of them here.
1. How important is RL in learning from human feedback? Can we get the performance of RLHF with training on higher quality data in IFT or SFT?
2. How does SFT+ RLHF as in Sparrow compare to just using SFT as in LaMDA for safety?
3. How much pre-training is necessary, given that we have IFT, SFT, CoT, and RLHF? What are the tradeoffs? What are the best base models people should use (both those publicly available, and not)?
4. Many of the models referenced in this paper have been carefully engineered with [red-teaming](https://arxiv.org/abs/2209.07858), where engineers specifically search for failure modes and influence future training (prompts and methods) based on unveiled issues. How do we systematically record the effects of these methods and reproduce them?
PS: Please let us know if you find any information in this blog missing or incorrect.
****************Citation****************
`Rajani et al., "What Makes a Dialog Agent Useful?", Hugging Face Blog, 2023.`
BibTeX citation:
```
@article{rajani2023ift,
author = {Rajani, Nazneen and Lambert, Nathan and Sanh, Victor and Wolf, Thomas},
title = {What Makes a Dialog Agent Useful?},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/dialog-agents},
}
```
| huggingface/blog/blob/main/dialog-agents.md |
Widgets
## What's a widget?
Many model repos have a widget that allows anyone to run inferences directly in the browser!
Here are some examples:
* [Named Entity Recognition](https://huggingface.co/spacy/en_core_web_sm?text=My+name+is+Sarah+and+I+live+in+London) using [spaCy](https://spacy.io/).
* [Image Classification](https://huggingface.co/google/vit-base-patch16-224) using [🤗 Transformers](https://github.com/huggingface/transformers)
* [Text to Speech](https://huggingface.co/julien-c/ljspeech_tts_train_tacotron2_raw_phn_tacotron_g2p_en_no_space_train) using [ESPnet](https://github.com/espnet/espnet).
* [Sentence Similarity](https://huggingface.co/osanseviero/full-sentence-distillroberta3) using [Sentence Transformers](https://github.com/UKPLab/sentence-transformers).
You can try out all the widgets [here](https://huggingface-widgets.netlify.app/).
## Enabling a widget
A widget is automatically created for your model when you upload it to the Hub. To determine which pipeline and widget to display (`text-classification`, `token-classification`, `translation`, etc.), we analyze information in the repo, such as the metadata provided in the model card and configuration files. This information is mapped to a single `pipeline_tag`. We choose to expose **only one** widget per model for simplicity.
For most use cases, we determine the model type from the tags. For example, if there is `tag: text-classification` in the [model card metadata](./model-cards), the inferred `pipeline_tag` will be `text-classification`.
For some libraries, such as 🤗 `Transformers`, the model type should be inferred automatically based from configuration files (`config.json`). The architecture can determine the type: for example, `AutoModelForTokenClassification` corresponds to `token-classification`. If you're interested in this, you can see pseudo-code in [this gist](https://gist.github.com/julien-c/857ba86a6c6a895ecd90e7f7cab48046).
**You can always manually override your pipeline type with `pipeline_tag: xxx` in your [model card metadata](./model-cards#model-card-metadata).** (You can also use the metadata GUI editor to do this).
### How can I control my model's widget example input?
You can specify the widget input in the model card metadata section:
```yaml
widget:
- text: "Jens Peter Hansen kommer fra Danmark"
```
You can provide more than one example input. In the examples dropdown menu of the widget, they will appear as `Example 1`, `Example 2`, etc. Optionally, you can supply `example_title` as well.
<div class="flex justify-center">
<img class="block dark:hidden" width="500" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/widget_input_examples.gif"/>
<img class="hidden dark:block" width="500" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/widget_input_examples-dark.gif"/>
</div>
```yaml
widget:
- text: "Is this review positive or negative? Review: Best cast iron skillet you will ever buy."
example_title: "Sentiment analysis"
- text: "Barack Obama nominated Hilary Clinton as his secretary of state on Monday. He chose her because she had ..."
example_title: "Coreference resolution"
- text: "On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book ..."
example_title: "Logic puzzles"
- text: "The two men running to become New York City's next mayor will face off in their first debate Wednesday night ..."
example_title: "Reading comprehension"
```
Moreover, you can specify non-text example inputs in the model card metadata. Refer [here](./models-widgets-examples) for a complete list of sample input formats for all widget types. For vision & audio widget types, provide example inputs with `src` rather than `text`.
For example, allow users to choose from two sample audio files for automatic speech recognition tasks by:
```yaml
widget:
- src: https://example.org/somewhere/speech_samples/sample1.flac
example_title: Speech sample 1
- src: https://example.org/somewhere/speech_samples/sample2.flac
example_title: Speech sample 2
```
Note that you can also include example files in your model repository and use
them as:
```yaml
widget:
- src: https://huggingface.co/username/model_repo/resolve/main/sample1.flac
example_title: Custom Speech Sample 1
```
But even more convenient, if the file lives in the corresponding model repo, you can just use the filename or file path inside the repo:
```yaml
widget:
- src: sample1.flac
example_title: Custom Speech Sample 1
```
or if it was nested inside the repo:
```yaml
widget:
- src: nested/directory/sample1.flac
```
We provide example inputs for some languages and most widget types in [default-widget-inputs.ts file](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/default-widget-inputs.ts). If some examples are missing, we welcome PRs from the community to add them!
## Example outputs
As an extension to example inputs, for each widget example, you can also optionally describe the corresponding model output, directly in the `output` property.
This is useful when the model is not yet supported by the Inference API (for instance, the model library is not yet supported or the model is too large) so that the model page can still showcase how the model works and what results it gives.
For instance, for an [automatic-speech-recognition](./models-widgets-examples#automatic-speech-recognition) model:
```yaml
widget:
- src: sample1.flac
output:
text: "Hello my name is Julien"
```
<div class="flex justify-center">
<img class="block dark:hidden" width="450" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/infrence-examples-asr-light.png"/>
<img class="hidden dark:block" width="450" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/infrence-examples-asr-dark.png"/>
</div>
The `output` property should be a YAML dictionary that represents the Inference API output.
For a model that outputs text, see the example above.
For a model that outputs labels (like a [text-classification](./models-widgets-examples#text-classification) model for instance), output should look like this:
```yaml
widget:
- text: "I liked this movie"
output:
- label: POSITIVE
score: 0.8
- label: NEGATIVE
score: 0.2
```
<div class="flex justify-center">
<img class="block dark:hidden" width="450" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/infrence-examples-textcls-light.png"/>
<img class="hidden dark:block" width="450" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/infrence-examples-textcls-dark.png"/>
</div>
Finally, for a model that outputs an image, audio, or any other kind of asset, the output should include a `url` property linking to either a file name or path inside the repo or a remote URL. For example, for a text-to-image model:
```yaml
widget:
- text: "picture of a futuristic tiger, artstation"
output:
url: images/tiger.jpg
```
<div class="flex justify-center">
<img class="block dark:hidden" width="450" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/infrence-examples-text2img-light.png"/>
<img class="hidden dark:block" width="450" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/infrence-examples-text2img-dark.png"/>
</div>
We can also surface the example outputs in the Hugging Face UI, for instance, for a text-to-image model to display a gallery of cool image generations.
<div class="flex justify-center">
<img width="650" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-gallery.png"/>
</div>
## What are all the possible task/widget types?
You can find all the supported tasks in [pipelines.ts file](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/pipelines.ts).
Here are some links to examples:
- `text-classification`, for instance [`roberta-large-mnli`](https://huggingface.co/roberta-large-mnli)
- `token-classification`, for instance [`dbmdz/bert-large-cased-finetuned-conll03-english`](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english)
- `question-answering`, for instance [`distilbert-base-uncased-distilled-squad`](https://huggingface.co/distilbert-base-uncased-distilled-squad)
- `translation`, for instance [`t5-base`](https://huggingface.co/t5-base)
- `summarization`, for instance [`facebook/bart-large-cnn`](https://huggingface.co/facebook/bart-large-cnn)
- `conversational`, for instance [`facebook/blenderbot-400M-distill`](https://huggingface.co/facebook/blenderbot-400M-distill)
- `text-generation`, for instance [`gpt2`](https://huggingface.co/gpt2)
- `fill-mask`, for instance [`distilroberta-base`](https://huggingface.co/distilroberta-base)
- `zero-shot-classification` (implemented on top of a nli `text-classification` model), for instance [`facebook/bart-large-mnli`](https://huggingface.co/facebook/bart-large-mnli)
- `table-question-answering`, for instance [`google/tapas-base-finetuned-wtq`](https://huggingface.co/google/tapas-base-finetuned-wtq)
- `sentence-similarity`, for instance [`osanseviero/full-sentence-distillroberta2`](/osanseviero/full-sentence-distillroberta2)
## How can I control my model's widget Inference API parameters?
Generally, the Inference API for a model uses the default pipeline settings associated with each task. But if you'd like to change the pipeline's default settings and specify additional inference parameters, you can configure the parameters directly through the model card metadata. Refer [here](https://huggingface.co/docs/api-inference/detailed_parameters) for some of the most commonly used parameters associated with each task.
For example, if you want to specify an aggregation strategy for a NER task in the widget:
```yaml
inference:
parameters:
aggregation_strategy: "none"
```
Or if you'd like to change the temperature for a summarization task in the widget:
```yaml
inference:
parameters:
temperature: 0.7
```
The Inference API allows you to send HTTP requests to models in the Hugging Face Hub, and it's 2x to 10x faster than the widgets! ⚡⚡ Learn more about it by reading the [Inference API documentation](./models-inference). Finally, you can also deploy all those models to dedicated [Inference Endpoints](https://huggingface.co/docs/inference-endpoints).
| huggingface/hub-docs/blob/main/docs/hub/models-widgets.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SEW
## Overview
SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
Weinberger, Yoav Artzi.
The abstract from the paper is the following:
*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
time, SEW reduces word error rate by 25-50% across different model sizes.*
This model was contributed by [anton-l](https://huggingface.co/anton-l).
## Usage tips
- SEW is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- SEWForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded using
[`Wav2Vec2CTCTokenizer`].
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## SEWConfig
[[autodoc]] SEWConfig
## SEWModel
[[autodoc]] SEWModel
- forward
## SEWForCTC
[[autodoc]] SEWForCTC
- forward
## SEWForSequenceClassification
[[autodoc]] SEWForSequenceClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/sew.md |
@gradio/tootils
## 0.1.7
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d)]:
- @gradio/[email protected]
## 0.1.6
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
## 0.1.5
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
## 0.1.4
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
## 0.1.3
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
## 0.1.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
## 0.1.1
### Fixes
- [#6234](https://github.com/gradio-app/gradio/pull/6234) [`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e) - Video/Audio fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6236](https://github.com/gradio-app/gradio/pull/6236) [`6bce259c5`](https://github.com/gradio-app/gradio/commit/6bce259c5db7b21b327c2067e74ea20417bc89ec) - Ensure `gr.CheckboxGroup` updates as expected. Thanks [@pngwn](https://github.com/pngwn)!
- [#6249](https://github.com/gradio-app/gradio/pull/6249) [`2cffcf3c3`](https://github.com/gradio-app/gradio/commit/2cffcf3c39acd782f314f8a406100ae22e0809b7) - ensure radios have different names. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.7
### Patch Changes
- Updated dependencies [[`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a)]:
- @gradio/[email protected]
## 0.1.0-beta.6
### Features
- [#6044](https://github.com/gradio-app/gradio/pull/6044) [`9053c95a1`](https://github.com/gradio-app/gradio/commit/9053c95a10de12aef572018ee37c71106d2da675) - Simplify File Component. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.5
### Patch Changes
- Updated dependencies [[`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93)]:
- @gradio/[email protected]
## 0.1.0-beta.4
### Features
- [#5648](https://github.com/gradio-app/gradio/pull/5648) [`c573e2339`](https://github.com/gradio-app/gradio/commit/c573e2339b86c85b378dc349de5e9223a3c3b04a) - Publish all components to npm. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.3
### Patch Changes
- Updated dependencies [[`0b4fd5b6d`](https://github.com/gradio-app/gradio/commit/0b4fd5b6db96fc95a155e5e935e17e1ab11d1161)]:
- @gradio/[email protected]
## 0.1.0-beta.2
### Patch Changes
- Updated dependencies [[`14fc612d8`](https://github.com/gradio-app/gradio/commit/14fc612d84bf6b1408eccd3a40fab41f25477571)]:
- @gradio/[email protected]
## 0.1.0-beta.1
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
## 0.1.0-beta.0
### Features
- [#5507](https://github.com/gradio-app/gradio/pull/5507) [`1385dc688`](https://github.com/gradio-app/gradio/commit/1385dc6881f2d8ae7a41106ec21d33e2ef04d6a9) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.2
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
| gradio-app/gradio/blob/main/js/tootils/CHANGELOG.md |
Quickstart
Gradio is an open-source Python package that allows you to quickly **build** a demo or web application for your machine learning model, API, or any arbitary Python function. You can then **share** a link to your demo or web application in just a few seconds using Gradio's built-in sharing features. *No JavaScript, CSS, or web hosting experience needed!*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/lcm-screenshot-3.gif" style="padding-bottom: 10px">
It just takes a few lines of Python to create a beautiful demo like the one above, so let's get started 💫
## Installation
**Prerequisite**: Gradio requires [Python 3.8 or higher](https://www.python.org/downloads/)
We recommend installing Gradio using `pip`, which is included by default in Python. Run this in your terminal or command prompt:
```bash
pip install gradio
```
Tip: it is best to install Gradio in a virtual environment. Detailed installation instructions for all common operating systems <a href="https://www.gradio.app/main/guides/installing-gradio-in-a-virtual-environment">are provided here</a>.
## Building Your First Demo
You can run Gradio in your favorite code editor, Jupyter notebook, Google Colab, or anywhere else you write Python. Let's write your first Gradio app:
$code_hello_world_4
Tip: We shorten the imported name from <code>gradio</code> to <code>gr</code> for better readability of code. This is a widely adopted convention that you should follow so that anyone working with your code can easily understand it.
Now, run your code. If you've written the Python code in a file named, for example, `app.py`, then you would run `python app.py` from the terminal.
The demo below will open in a browser on [http://localhost:7860](http://localhost:7860) if running from a file. If you are running within a notebook, the demo will appear embedded within the notebook.
$demo_hello_world_4
Type your name in the textbox on the left, drag the slider, and then press the Submit button. You should see a friendly greeting on the right.
Tip: When developing locally, you can run your Gradio app in <strong>hot reload mode</strong>, which automatically reloads the Gradio app whenever you make changes to the file. To do this, simply type in <code>gradio</code> before the name of the file instead of <code>python</code>. In the example above, you would type: `gradio app.py` in your terminal. Learn more about hot reloading in the <a href="https://www.gradio.app/guides/developing-faster-with-reload-mode">Hot Reloading Guide</a>.
**Understanding the `Interface` Class**
You'll notice that in order to make your first demo, you created an instance of the `gr.Interface` class. The `Interface` class is designed to create demos for machine learning models which accept one or more inputs, and return one or more outputs.
The `Interface` class has three core arguments:
- `fn`: the function to wrap a user interface (UI) around
- `inputs`: the Gradio component(s) to use for the input. The number of components should match the number of arguments in your function.
- `outputs`: the Gradio component(s) to use for the output. The number of components should match the number of return values from your function.
The `fn` argument is very flexible -- you can pass *any* Python function that you want to wrap with a UI. In the example above, we saw a relatively simple function, but the function could be anything from a music generator to a tax calculator to the prediction function of a pretrained machine learning model.
The `input` and `output` arguments take one or more Gradio components. As we'll see, Gradio includes more than [30 built-in components](https://www.gradio.app/docs/components) (such as the `gr.Textbox()`, `gr.Image()`, and `gr.HTML()` components) that are designed for machine learning applications.
Tip: For the `inputs` and `outputs` arguments, you can pass in the name of these components as a string (`"textbox"`) or an instance of the class (`gr.Textbox()`).
If your function accepts more than one argument, as is the case above, pass a list of input components to `inputs`, with each input component corresponding to one of the arguments of the function, in order. The same holds true if your function returns more than one value: simply pass in a list of components to `outputs`. This flexibility makes the `Interface` class a very powerful way to create demos.
We'll dive deeper into the `gr.Interface` on our series on [building Interfaces](https://www.gradio.app/main/guides/the-interface-class).
## Sharing Your Demo
What good is a beautiful demo if you can't share it? Gradio lets you easily share a machine learning demo without having to worry about the hassle of hosting on a web server. Simply set `share=True` in `launch()`, and a publicly accessible URL will be created for your demo. Let's revisit our example demo, but change the last line as follows:
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="textbox", outputs="textbox")
demo.launch(share=True) # Share your demo with just 1 extra parameter 🚀
```
When you run this code, a public URL will be generated for your demo in a matter of seconds, something like:
👉 `https://a23dsf231adb.gradio.live`
Now, anyone around the world can try your Gradio demo from their browser, while the machine learning model and all computation continues to run locally on your computer.
To learn more about sharing your demo, read our dedicated guide on [sharing your Gradio application](https://www.gradio.app/guides/sharing-your-app).
## An Overview of Gradio
So far, we've been discussing the `Interface` class, which is a high-level class that lets to build demos quickly with Gradio. But what else does Gradio do?
### Chatbots with `gr.ChatInterface`
Gradio includes another high-level class, `gr.ChatInterface`, which is specifically designed to create Chatbot UIs. Similar to `Interface`, you supply a function and Gradio creates a fully working Chatbot UI. If you're interested in creating a chatbot, you can jump straight to [our dedicated guide on `gr.ChatInterface`](https://www.gradio.app/guides/creating-a-chatbot-fast).
### Custom Demos with `gr.Blocks`
Gradio also offers a low-level approach for designing web apps with more flexible layouts and data flows with the `gr.Blocks` class. Blocks allows you to do things like control where components appear on the page, handle complex data flows (e.g. outputs can serve as inputs to other functions), and update properties/visibility of components based on user interaction — still all in Python.
You can build very custom and complex applications using `gr.Blocks()`. For example, the popular image generation [Automatic1111 Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) is built using Gradio Blocks. We dive deeper into the `gr.Blocks` on our series on [building with Blocks](https://www.gradio.app/guides/blocks-and-event-listeners).
### The Gradio Python & JavaScript Ecosystem
That's the gist of the core `gradio` Python library, but Gradio is actually so much more! Its an entire ecosystem of Python and JavaScript libraries that let you build machine learning applications, or query them programmatically, in Python or JavaScript. Here are other related parts of the Gradio ecosystem:
* [Gradio Python Client](https://www.gradio.app/guides/getting-started-with-the-python-client) (`gradio_client`): query any Gradio app programmatically in Python.
* [Gradio JavaScript Client](https://www.gradio.app/guides/getting-started-with-the-js-client) (`@gradio/client`): query any Gradio app programmatically in JavaScript.
* [Gradio-Lite](https://www.gradio.app/guides/gradio-lite) (`@gradio/lite`): write Gradio apps in Python that run entirely in the browser (no server needed!), thanks to Pyodide.
* [Hugging Face Spaces](https://huggingface.co/spaces): the most popular place to host Gradio applications — for free!
## What's Next?
Keep learning about Gradio sequentially using the Gradio Guides, which include explanations as well as example code and embedded interactive demos. Next up: [key features about Gradio demos](https://www.gradio.app/guides/key-features).
Or, if you already know the basics and are looking for something specific, you can search the more [technical API documentation](https://www.gradio.app/docs/).
| gradio-app/gradio/blob/main/guides/01_getting-started/01_quickstart.md |
如何创建一个聊天机器人
Tags: NLP, TEXT, CHAT
Related spaces: https://huggingface.co/spaces/gradio/chatbot_streaming, https://huggingface.co/spaces/project-baize/Baize-7B,
## 简介
聊天机器人在自然语言处理 (NLP) 研究和工业界被广泛使用。由于聊天机器人是直接由客户和最终用户使用的,因此验证聊天机器人在面对各种输入提示时的行为是否符合预期至关重要。
通过使用 `gradio`,您可以轻松构建聊天机器人模型的演示,并与用户共享,或使用直观的聊天机器人图形界面自己尝试。
本教程将展示如何使用 Gradio 制作几种不同类型的聊天机器人用户界面:首先是一个简单的文本显示界面,其次是一个用于流式文本响应的界面,最后一个是可以处理媒体文件的聊天机器人。我们创建的聊天机器人界面将如下所示:
$ 演示 _ 聊天机器人 _ 流式
**先决条件**:我们将使用 `gradio.Blocks` 类来构建我们的聊天机器人演示。
如果您对此还不熟悉,可以[先阅读 Blocks 指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)。同时,请确保您使用的是**最新版本**的 Gradio:`pip install --upgrade gradio`。
## 简单聊天机器人演示
让我们从重新创建上面的简单演示开始。正如您可能已经注意到的,我们的机器人只是随机对任何输入回复 " 你好吗?"、" 我爱你 " 或 " 我非常饿 "。这是使用 Gradio 创建此演示的代码:
$ 代码 \_ 简单聊天机器人
这里有三个 Gradio 组件:
- 一个 `Chatbot`,其值将整个对话的历史记录作为用户和机器人之间的响应对列表存储。
- 一个文本框,用户可以在其中键入他们的消息,然后按下 Enter/ 提交以触发聊天机器人的响应
- 一个 `ClearButton` 按钮,用于清除文本框和整个聊天机器人的历史记录
我们有一个名为 `respond()` 的函数,它接收聊天机器人的整个历史记录,附加一个随机消息,等待 1 秒,然后返回更新后的聊天历史记录。`respond()` 函数在返回时还清除了文本框。
当然,实际上,您会用自己更复杂的函数替换 `respond()`,该函数可能调用预训练模型或 API 来生成响应。
$ 演示 \_ 简单聊天机器人
## 为聊天机器人添加流式响应
我们可以通过几种方式来改进上述聊天机器人的用户体验。首先,我们可以流式传输响应,以便用户不必等待太长时间才能生成消息。其次,我们可以让用户的消息在聊天历史记录中立即出现,同时聊天机器人的响应正在生成。以下是实现这一点的代码:
$code_chatbot_streaming
当用户提交他们的消息时,您会注意到我们现在使用 `.then()` 与三个事件事件 _链_ 起来:
1. 第一个方法 `user()` 用用户消息更新聊天机器人并清除输入字段。此方法还使输入字段处于非交互状态,以防聊天机器人正在响应时用户发送另一条消息。由于我们希望此操作立即发生,因此我们设置 `queue=False`,以跳过任何可能的队列。聊天机器人的历史记录附加了`(user_message, None)`,其中的 `None` 表示机器人未作出响应。
2. 第二个方法 `bot()` 使用机器人的响应更新聊天机器人的历史记录。我们不是创建新消息,而是将先前创建的 `None` 消息替换为机器人的响应。最后,我们逐个字符构造消息并 `yield` 正在构建的中间输出。Gradio 会自动将带有 `yield` 关键字的任何函数 [转换为流式输出接口](/key-features/#iterative-outputs)。
3. 第三个方法使输入字段再次可以交互,以便用户可以向机器人发送另一条消息。
当然,实际上,您会用自己更复杂的函数替换 `bot()`,该函数可能调用预训练模型或 API 来生成响应。
最后,我们通过运行 `demo.queue()` 启用排队,这对于流式中间输出是必需的。您可以通过滚动到本页面顶部的演示来尝试改进后的聊天机器人。
## 添加 Markdown、图片、音频或视频
`gr.Chatbot` 组件支持包含加粗、斜体和代码等一部分 Markdown 功能。例如,我们可以编写一个函数,以粗体回复用户的消息,类似于 **That's cool!**,如下所示:
```py
def bot(history):
response = "**That's cool!**"
history[-1][1] = response
return history
```
此外,它还可以处理图片、音频和视频等媒体文件。要传递媒体文件,我们必须将文件作为两个字符串的元组传递,如`(filepath, alt_text)` 所示。`alt_text` 是可选的,因此您还可以只传入只有一个元素的元组`(filepath,)`,如下所示:
```python
def add_file(history, file):
history = history + [((file.name,), None)]
return history
```
将所有这些放在一起,我们可以创建一个*多模态*聊天机器人,其中包含一个文本框供用户提交文本,以及一个文件上传按钮供提交图像 / 音频 / 视频文件。余下的代码看起来与之前的代码几乎相同:
$code_chatbot_multimodal
$demo_chatbot_multimodal
你完成了!这就是构建聊天机器人模型界面所需的所有代码。最后,我们将结束我们的指南,并提供一些在 Spaces 上运行的聊天机器人的链接,以让你了解其他可能性:
- [project-baize/Baize-7B](https://huggingface.co/spaces/project-baize/Baize-7B):一个带有停止生成和重新生成响应功能的样式化聊天机器人。
- [MAGAer13/mPLUG-Owl](https://huggingface.co/spaces/MAGAer13/mPLUG-Owl):一个多模态聊天机器人,允许您对响应进行投票。
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/creating-a-chatbot.md |
Add custom Dependencies
Inference Endpoints’ base image includes all required libraries to run inference on 🤗 Transformers models, but it also supports custom dependencies. This is useful if you want to:
* [customize your inference pipeline](/docs/inference-endpoints/guides/custom_handler) and need additional Python dependencies
* run a model which requires special dependencies like the newest or a fixed version of a library (for example, `tapas` (`torch-scatter`)).
To add custom dependencies, add a `requirements.txt` [file](https://huggingface.co/philschmid/distilbert-onnx-banking77/blob/main/requirements.txt) with the Python dependencies you want to install in your model repository on the Hugging Face Hub. When your Endpoint and Image artifacts are created, Inference Endpoints checks if the model repository contains a `requirements.txt ` file and installs the dependencies listed within.
```bash
optimum[onnxruntime]==1.2.3
mkl-include
mkl
```
Check out the `requirements.txt` files in the following model repositories for examples:
* [Optimum and onnxruntime](https://huggingface.co/philschmid/distilbert-onnx-banking77/blob/main/requirements.txt)
* [diffusers](https://huggingface.co/philschmid/stable-diffusion-v1-4-endpoints/blob/main/requirements.txt)
For more information, take a look at how you can create and install dependencies when you [use your own custom container](/docs/inference-endpoints/guides/custom_container) for inference.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/custom_dependencies.mdx |
Gradio Demo: chatbot_streaming
```
!pip install -q gradio
```
```
import gradio as gr
import random
import time
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.Button("Clear")
def user(user_message, history):
return "", history + [[user_message, None]]
def bot(history):
bot_message = random.choice(["How are you?", "I love you", "I'm very hungry"])
history[-1][1] = ""
for character in bot_message:
history[-1][1] += character
time.sleep(0.05)
yield history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
bot, chatbot, chatbot
)
clear.click(lambda: None, None, chatbot, queue=False)
demo.queue()
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/chatbot_streaming/run.ipynb |
Building a model card[[building-a-model-card]]
<CourseFloatingBanner
chapter={4}
classNames="absolute z-10 right-0 top-0"
/>
The model card is a file which is arguably as important as the model and tokenizer files in a model repository. It is the central definition of the model, ensuring reusability by fellow community members and reproducibility of results, and providing a platform on which other members may build their artifacts.
Documenting the training and evaluation process helps others understand what to expect of a model — and providing sufficient information regarding the data that was used and the preprocessing and postprocessing that were done ensures that the limitations, biases, and contexts in which the model is and is not useful can be identified and understood.
Therefore, creating a model card that clearly defines your model is a very important step. Here, we provide some tips that will help you with this. Creating the model card is done through the *README.md* file you saw earlier, which is a Markdown file.
The "model card" concept originates from a research direction from Google, first shared in the paper ["Model Cards for Model Reporting"](https://arxiv.org/abs/1810.03993) by Margaret Mitchell et al. A lot of information contained here is based on that paper, and we recommend you take a look at it to understand why model cards are so important in a world that values reproducibility, reusability, and fairness.
The model card usually starts with a very brief, high-level overview of what the model is for, followed by additional details in the following sections:
- Model description
- Intended uses & limitations
- How to use
- Limitations and bias
- Training data
- Training procedure
- Evaluation results
Let's take a look at what each of these sections should contain.
### Model description[[model-description]]
The model description provides basic details about the model. This includes the architecture, version, if it was introduced in a paper, if an original implementation is available, the author, and general information about the model. Any copyright should be attributed here. General information about training procedures, parameters, and important disclaimers can also be mentioned in this section.
### Intended uses & limitations[[intended-uses-limitations]]
Here you describe the use cases the model is intended for, including the languages, fields, and domains where it can be applied. This section of the model card can also document areas that are known to be out of scope for the model, or where it is likely to perform suboptimally.
### How to use[[how-to-use]]
This section should include some examples of how to use the model. This can showcase usage of the `pipeline()` function, usage of the model and tokenizer classes, and any other code you think might be helpful.
### Training data[[training-data]]
This part should indicate which dataset(s) the model was trained on. A brief description of the dataset(s) is also welcome.
### Training procedure[[training-procedure]]
In this section you should describe all the relevant aspects of training that are useful from a reproducibility perspective. This includes any preprocessing and postprocessing that were done on the data, as well as details such as the number of epochs the model was trained for, the batch size, the learning rate, and so on.
### Variable and metrics[[variable-and-metrics]]
Here you should describe the metrics you use for evaluation, and the different factors you are mesuring. Mentioning which metric(s) were used, on which dataset and which dataset split, makes it easy to compare you model's performance compared to that of other models. These should be informed by the previous sections, such as the intended users and use cases.
### Evaluation results[[evaluation-results]]
Finally, provide an indication of how well the model performs on the evaluation dataset. If the model uses a decision threshold, either provide the decision threshold used in the evaluation, or provide details on evaluation at different thresholds for the intended uses.
## Example[[example]]
Check out the following for a few examples of well-crafted model cards:
- [`bert-base-cased`](https://huggingface.co/bert-base-cased)
- [`gpt2`](https://huggingface.co/gpt2)
- [`distilbert`](https://huggingface.co/distilbert-base-uncased)
More examples from different organizations and companies are available [here](https://github.com/huggingface/model_card/blob/master/examples.md).
## Note[[note]]
Model cards are not a requirement when publishing models, and you don't need to include all of the sections described above when you make one. However, explicit documentation of the model can only benefit future users, so we recommend that you fill in as many of the sections as possible to the best of your knowledge and ability.
## Model card metadata[[model-card-metadata]]
If you have done a little exploring of the Hugging Face Hub, you should have seen that some models belong to certain categories: you can filter them by tasks, languages, libraries, and more. The categories a model belongs to are identified according to the metadata you add in the model card header.
For example, if you take a look at the [`camembert-base` model card](https://huggingface.co/camembert-base/blob/main/README.md), you should see the following lines in the model card header:
```
---
language: fr
license: mit
datasets:
- oscar
---
```
This metadata is parsed by the Hugging Face Hub, which then identifies this model as being a French model, with an MIT license, trained on the Oscar dataset.
The [full model card specification](https://github.com/huggingface/hub-docs/blame/main/modelcard.md) allows specifying languages, licenses, tags, datasets, metrics, as well as the evaluation results the model obtained when training.
| huggingface/course/blob/main/chapters/en/chapter4/4.mdx |
Metric Card for XNLI
## Metric description
The XNLI metric allows to evaluate a model's score on the [XNLI dataset](https://huggingface.co/datasets/xnli), which is a subset of a few thousand examples from the [MNLI dataset](https://huggingface.co/datasets/glue/viewer/mnli) that have been translated into a 14 different languages, some of which are relatively low resource such as Swahili and Urdu.
As with MNLI, the task is to predict textual entailment (does sentence A imply/contradict/neither sentence B) and is a classification task (given two sentences, predict one of three labels).
## How to use
The XNLI metric is computed based on the `predictions` (a list of predicted labels) and the `references` (a list of ground truth labels).
```python
from datasets import load_metric
xnli_metric = load_metric("xnli")
predictions = [0, 1]
references = [0, 1]
results = xnli_metric.compute(predictions=predictions, references=references)
```
## Output values
The output of the XNLI metric is simply the `accuracy`, i.e. the proportion of correct predictions among the total number of cases processed, with a range between 0 and 1 (see [accuracy](https://huggingface.co/metrics/accuracy) for more information).
### Values from popular papers
The [original XNLI paper](https://arxiv.org/pdf/1809.05053.pdf) reported accuracies ranging from 59.3 (for `ur`) to 73.7 (for `en`) for the BiLSTM-max model.
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/xnli).
## Examples
Maximal values:
```python
>>> from datasets import load_metric
>>> xnli_metric = load_metric("xnli")
>>> predictions = [0, 1]
>>> references = [0, 1]
>>> results = xnli_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 1.0}
```
Minimal values:
```python
>>> from datasets import load_metric
>>> xnli_metric = load_metric("xnli")
>>> predictions = [1, 0]
>>> references = [0, 1]
>>> results = xnli_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 0.0}
```
Partial match:
```python
>>> from datasets import load_metric
>>> xnli_metric = load_metric("xnli")
>>> predictions = [1, 0, 1]
>>> references = [1, 0, 0]
>>> results = xnli_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 0.6666666666666666}
```
## Limitations and bias
While accuracy alone does give a certain indication of performance, it can be supplemented by error analysis and a better understanding of the model's mistakes on each of the categories represented in the dataset, especially if they are unbalanced.
While the XNLI dataset is multilingual and represents a diversity of languages, in reality, cross-lingual sentence understanding goes beyond translation, given that there are many cultural differences that have an impact on human sentiment annotations. Since the XNLI dataset was obtained by translation based on English sentences, it does not capture these cultural differences.
## Citation
```bibtex
@InProceedings{conneau2018xnli,
author = "Conneau, Alexis
and Rinott, Ruty
and Lample, Guillaume
and Williams, Adina
and Bowman, Samuel R.
and Schwenk, Holger
and Stoyanov, Veselin",
title = "XNLI: Evaluating Cross-lingual Sentence Representations",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods
in Natural Language Processing",
year = "2018",
publisher = "Association for Computational Linguistics",
location = "Brussels, Belgium",
}
```
## Further References
- [XNI Dataset GitHub](https://github.com/facebookresearch/XNLI)
- [HuggingFace Tasks -- Text Classification](https://huggingface.co/tasks/text-classification)
| huggingface/datasets/blob/main/metrics/xnli/README.md |
Byte-Pair Encoding tokenization[[byte-pair-encoding-tokenization]]
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section5.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section5.ipynb"},
]} />
Byte-Pair Encoding (BPE) was initially developed as an algorithm to compress texts, and then used by OpenAI for tokenization when pretraining the GPT model. It's used by a lot of Transformer models, including GPT, GPT-2, RoBERTa, BART, and DeBERTa.
<Youtube id="HEikzVL-lZU"/>
<Tip>
💡 This section covers BPE in depth, going as far as showing a full implementation. You can skip to the end if you just want a general overview of the tokenization algorithm.
</Tip>
## Training algorithm[[training-algorithm]]
BPE training starts by computing the unique set of words used in the corpus (after the normalization and pre-tokenization steps are completed), then building the vocabulary by taking all the symbols used to write those words. As a very simple example, let's say our corpus uses these five words:
```
"hug", "pug", "pun", "bun", "hugs"
```
The base vocabulary will then be `["b", "g", "h", "n", "p", "s", "u"]`. For real-world cases, that base vocabulary will contain all the ASCII characters, at the very least, and probably some Unicode characters as well. If an example you are tokenizing uses a character that is not in the training corpus, that character will be converted to the unknown token. That's one reason why lots of NLP models are very bad at analyzing content with emojis, for instance.
<Tip>
The GPT-2 and RoBERTa tokenizers (which are pretty similar) have a clever way to deal with this: they don't look at words as being written with Unicode characters, but with bytes. This way the base vocabulary has a small size (256), but every character you can think of will still be included and not end up being converted to the unknown token. This trick is called *byte-level BPE*.
</Tip>
After getting this base vocabulary, we add new tokens until the desired vocabulary size is reached by learning *merges*, which are rules to merge two elements of the existing vocabulary together into a new one. So, at the beginning these merges will create tokens with two characters, and then, as training progresses, longer subwords.
At any step during the tokenizer training, the BPE algorithm will search for the most frequent pair of existing tokens (by "pair," here we mean two consecutive tokens in a word). That most frequent pair is the one that will be merged, and we rinse and repeat for the next step.
Going back to our previous example, let's assume the words had the following frequencies:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
meaning `"hug"` was present 10 times in the corpus, `"pug"` 5 times, `"pun"` 12 times, `"bun"` 4 times, and `"hugs"` 5 times. We start the training by splitting each word into characters (the ones that form our initial vocabulary) so we can see each word as a list of tokens:
```
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
```
Then we look at pairs. The pair `("h", "u")` is present in the words `"hug"` and `"hugs"`, so 15 times total in the corpus. It's not the most frequent pair, though: that honor belongs to `("u", "g")`, which is present in `"hug"`, `"pug"`, and `"hugs"`, for a grand total of 20 times in the vocabulary.
Thus, the first merge rule learned by the tokenizer is `("u", "g") -> "ug"`, which means that `"ug"` will be added to the vocabulary, and the pair should be merged in all the words of the corpus. At the end of this stage, the vocabulary and corpus look like this:
```
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
Now we have some pairs that result in a token longer than two characters: the pair `("h", "ug")`, for instance (present 15 times in the corpus). The most frequent pair at this stage is `("u", "n")`, however, present 16 times in the corpus, so the second merge rule learned is `("u", "n") -> "un"`. Adding that to the vocabulary and merging all existing occurrences leads us to:
```
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
```
Now the most frequent pair is `("h", "ug")`, so we learn the merge rule `("h", "ug") -> "hug"`, which gives us our first three-letter token. After the merge, the corpus looks like this:
```
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
Corpus: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
And we continue like this until we reach the desired vocabulary size.
<Tip>
✏️ **Now your turn!** What do you think the next merge rule will be?
</Tip>
## Tokenization algorithm[[tokenization-algorithm]]
Tokenization follows the training process closely, in the sense that new inputs are tokenized by applying the following steps:
1. Normalization
2. Pre-tokenization
3. Splitting the words into individual characters
4. Applying the merge rules learned in order on those splits
Let's take the example we used during training, with the three merge rules learned:
```
("u", "g") -> "ug"
("u", "n") -> "un"
("h", "ug") -> "hug"
```
The word `"bug"` will be tokenized as `["b", "ug"]`. `"mug"`, however, will be tokenized as `["[UNK]", "ug"]` since the letter `"m"` was not in the base vocabulary. Likewise, the word `"thug"` will be tokenized as `["[UNK]", "hug"]`: the letter `"t"` is not in the base vocabulary, and applying the merge rules results first in `"u"` and `"g"` being merged and then `"h"` and `"ug"` being merged.
<Tip>
✏️ **Now your turn!** How do you think the word `"unhug"` will be tokenized?
</Tip>
## Implementing BPE[[implementing-bpe]]
Now let's take a look at an implementation of the BPE algorithm. This won't be an optimized version you can actually use on a big corpus; we just want to show you the code so you can understand the algorithm a little bit better.
First we need a corpus, so let's create a simple one with a few sentences:
```python
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
```
Next, we need to pre-tokenize that corpus into words. Since we are replicating a BPE tokenizer (like GPT-2), we will use the `gpt2` tokenizer for the pre-tokenization:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
```
Then we compute the frequencies of each word in the corpus as we do the pre-tokenization:
```python
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
print(word_freqs)
```
```python out
defaultdict(int, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1, 'ĠCourse': 1, '.': 4, 'Ġchapter': 1,
'Ġabout': 1, 'Ġtokenization': 1, 'Ġsection': 1, 'Ġshows': 1, 'Ġseveral': 1, 'Ġtokenizer': 1, 'Ġalgorithms': 1,
'Hopefully': 1, ',': 1, 'Ġyou': 1, 'Ġwill': 1, 'Ġbe': 1, 'Ġable': 1, 'Ġto': 1, 'Ġunderstand': 1, 'Ġhow': 1,
'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})
```
The next step is to compute the base vocabulary, formed by all the characters used in the corpus:
```python
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
print(alphabet)
```
```python out
[ ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's',
't', 'u', 'v', 'w', 'y', 'z', 'Ġ']
```
We also add the special tokens used by the model at the beginning of that vocabulary. In the case of GPT-2, the only special token is `"<|endoftext|>"`:
```python
vocab = ["<|endoftext|>"] + alphabet.copy()
```
We now need to split each word into individual characters, to be able to start training:
```python
splits = {word: [c for c in word] for word in word_freqs.keys()}
```
Now that we are ready for training, let's write a function that computes the frequency of each pair. We'll need to use this at each step of the training:
```python
def compute_pair_freqs(splits):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
```
Let's have a look at a part of this dictionary after the initial splits:
```python
pair_freqs = compute_pair_freqs(splits)
for i, key in enumerate(pair_freqs.keys()):
print(f"{key}: {pair_freqs[key]}")
if i >= 5:
break
```
```python out
('T', 'h'): 3
('h', 'i'): 3
('i', 's'): 5
('Ġ', 'i'): 2
('Ġ', 't'): 7
('t', 'h'): 3
```
Now, finding the most frequent pair only takes a quick loop:
```python
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
print(best_pair, max_freq)
```
```python out
('Ġ', 't') 7
```
So the first merge to learn is `('Ġ', 't') -> 'Ġt'`, and we add `'Ġt'` to the vocabulary:
```python
merges = {("Ġ", "t"): "Ġt"}
vocab.append("Ġt")
```
To continue, we need to apply that merge in our `splits` dictionary. Let's write another function for this:
```python
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
```
And we can have a look at the result of the first merge:
```py
splits = merge_pair("Ġ", "t", splits)
print(splits["Ġtrained"])
```
```python out
['Ġt', 'r', 'a', 'i', 'n', 'e', 'd']
```
Now we have everything we need to loop until we have learned all the merges we want. Let's aim for a vocab size of 50:
```python
vocab_size = 50
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits)
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
splits = merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
vocab.append(best_pair[0] + best_pair[1])
```
As a result, we've learned 19 merge rules (the initial vocabulary had a size of 31 -- 30 characters in the alphabet, plus the special token):
```py
print(merges)
```
```python out
{('Ġ', 't'): 'Ġt', ('i', 's'): 'is', ('e', 'r'): 'er', ('Ġ', 'a'): 'Ġa', ('Ġt', 'o'): 'Ġto', ('e', 'n'): 'en',
('T', 'h'): 'Th', ('Th', 'is'): 'This', ('o', 'u'): 'ou', ('s', 'e'): 'se', ('Ġto', 'k'): 'Ġtok',
('Ġtok', 'en'): 'Ġtoken', ('n', 'd'): 'nd', ('Ġ', 'is'): 'Ġis', ('Ġt', 'h'): 'Ġth', ('Ġth', 'e'): 'Ġthe',
('i', 'n'): 'in', ('Ġa', 'b'): 'Ġab', ('Ġtoken', 'i'): 'Ġtokeni'}
```
And the vocabulary is composed of the special token, the initial alphabet, and all the results of the merges:
```py
print(vocab)
```
```python out
['<|endoftext|>', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o',
'p', 'r', 's', 't', 'u', 'v', 'w', 'y', 'z', 'Ġ', 'Ġt', 'is', 'er', 'Ġa', 'Ġto', 'en', 'Th', 'This', 'ou', 'se',
'Ġtok', 'Ġtoken', 'nd', 'Ġis', 'Ġth', 'Ġthe', 'in', 'Ġab', 'Ġtokeni']
```
<Tip>
💡 Using `train_new_from_iterator()` on the same corpus won't result in the exact same vocabulary. This is because when there is a choice of the most frequent pair, we selected the first one encountered, while the 🤗 Tokenizers library selects the first one based on its inner IDs.
</Tip>
To tokenize a new text, we pre-tokenize it, split it, then apply all the merge rules learned:
```python
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
```
We can try this on any text composed of characters in the alphabet:
```py
tokenize("This is not a token.")
```
```python out
['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']
```
<Tip warning={true}>
⚠️ Our implementation will throw an error if there is an unknown character since we didn't do anything to handle them. GPT-2 doesn't actually have an unknown token (it's impossible to get an unknown character when using byte-level BPE), but this could happen here because we did not include all the possible bytes in the initial vocabulary. This aspect of BPE is beyond the scope of this section, so we've left the details out.
</Tip>
That's it for the BPE algorithm! Next, we'll have a look at WordPiece. | huggingface/course/blob/main/chapters/en/chapter6/5.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# KDPM2DiscreteScheduler
The `KDPM2DiscreteScheduler` is inspired by the [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) paper, and the scheduler is ported from and created by [Katherine Crowson](https://github.com/crowsonkb/).
The original codebase can be found at [crowsonkb/k-diffusion](https://github.com/crowsonkb/k-diffusion).
## KDPM2DiscreteScheduler
[[autodoc]] KDPM2DiscreteScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/dpm_discrete.md |
Gradio Demo: upload_button
### A simple demo showcasing the upload button used with its `upload` event trigger.
```
!pip install -q gradio
```
```
import gradio as gr
def upload_file(files):
file_paths = [file.name for file in files]
return file_paths
with gr.Blocks() as demo:
file_output = gr.File()
upload_button = gr.UploadButton("Click to Upload a File", file_types=["image", "video"], file_count="multiple")
upload_button.upload(upload_file, upload_button, file_output)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/upload_button/run.ipynb |
Gradio Demo: button_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Button()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/button_component/run.ipynb |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERTology
There is a growing field of study concerned with investigating the inner working of large-scale transformers like BERT
(that some call "BERTology"). Some good examples of this field are:
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
https://arxiv.org/abs/1905.05950
- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
Manning: https://arxiv.org/abs/1906.04341
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
In order to help this new field develop, we have included a few additional features in the BERT/GPT/GPT-2 models to
help people access the inner representations, mainly adapted from the great work of Paul Michel
(https://arxiv.org/abs/1905.10650):
- accessing all the hidden-states of BERT/GPT/GPT-2,
- accessing all the attention weights for each head of BERT/GPT/GPT-2,
- retrieving heads output values and gradients to be able to compute head importance score and prune head as explained
in https://arxiv.org/abs/1905.10650.
To help you understand and use these features, we have added a specific example script: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) while extract information and prune a model pre-trained on
GLUE.
| huggingface/transformers/blob/main/docs/source/en/bertology.md |
--
title: "AI for Game Development: Creating a Farming Game in 5 Days. Part 1"
thumbnail: /blog/assets/124_ml-for-games/thumbnail.png
authors:
- user: dylanebert
---
# AI for Game Development: Creating a Farming Game in 5 Days. Part 1
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7184106492180630827). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954?is_from_webapp=1&sender_device=pc&web_id=7043883634428052997) series before continuing.
## Day 1: Art Style
The first step in our game development process **is deciding on the art style**. To decide on the art style for our farming game, we'll be using a tool called Stable Diffusion. Stable Diffusion is an open-source model that generates images based on text descriptions. We'll use this tool to create a visual style for our game.
### Setting up Stable Diffusion
There are a couple options for running Stable Diffusion: *locally* or *online*. If you're on a desktop with a decent GPU and want the fully-featured toolset, I recommend <a href="#locally">locally</a>. Otherwise, you can run an <a href="#online">online</a> solution.
#### Locally <a name="locally"></a>
We'll be running Stable Diffusion locally using the [Automatic1111 WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui). This is a popular solution for running Stable Diffusion locally, but it does require some technical knowledge to set up. If you're on Windows and have an Nvidia GPU with at least 8 gigabytes in memory, continue with the instructions below. Otherwise, you can find instructions for other platforms on the [GitHub repository README](https://github.com/AUTOMATIC1111/stable-diffusion-webui), or may opt instead for an <a href="#online">online</a> solution.
##### Installation on Windows:
**Requirements**: An Nvidia GPU with at least 8 gigabytes of memory.
1. Install [Python 3.10.6](https://www.python.org/downloads/windows/). **Be sure to check "Add Python to PATH" during installation.**
2. Install [git](https://git-scm.com/download/win).
3. Clone the repository by typing the following in the Command Prompt:
```
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
```
4. Download the [Stable Diffusion 1.5 weights](https://huggingface.co/runwayml/stable-diffusion-v1-5). Place them in the `models` directory of the cloned repository.
5. Run the WebUI by running `webui-user.bat` in the cloned repository.
6. Navigate to `localhost://7860` to use the WebUI. If everything is working correctly, it should look something like this:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/webui.png" alt="Stable Diffusion WebUI">
</figure>
#### Online <a name="online"></a>
If you don't meet the requirements to run Stable Diffusion locally, or prefer a more streamlined solution, there are many ways to run Stable Diffusion online.
Free solutions include many [spaces](https://huggingface.co/spaces) here on 🤗 Hugging Face, such as the [Stable Diffusion 2.1 Demo](https://huggingface.co/spaces/stabilityai/stable-diffusion) or the [camemduru webui](https://huggingface.co/spaces/camenduru/webui). You can find a list of additional online services [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services). You can even use 🤗 [Diffusers](https://huggingface.co/docs/diffusers/index) to write your own free solution! You can find a simple code example to get started [here](https://colab.research.google.com/drive/1HebngGyjKj7nLdXfj6Qi0N1nh7WvD74z?usp=sharing).
*Note:* Parts of this series will use advanced features such as image2image, which may not be available on all online services.
### Generating Concept Art <a name="generating"></a>
Let's generate some concept art. The steps are simple:
1. Type what you want.
2. Click generate.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/sd-demo.png" alt="Stable Diffusion Demo Space">
</figure>
But, how do you get the results you actually want? Prompting can be an art by itself, so it's ok if the first images you generate are not great. There are many amazing resources out there to improve your prompting. I made a [20-second video](https://youtube.com/shorts/8PGucf999nI?feature=share) on the topic. You can also find this more extensive [written guide](https://www.reddit.com/r/StableDiffusion/comments/x41n87/how_to_get_images_that_dont_suck_a/).
The shared point of emphasis of these is to use a source such as [lexica.art](https://lexica.art/) to see what others have generated with Stable Diffusion. Look for images that are similar to the style you want, and get inspired. There is no right or wrong answer here, but here are some tips when generating concept art with Stable Diffusion 1.5:
- Constrain the *form* of the output with words like *isometric, simple, solid shapes*. This produces styles that are easier to reproduce in-game.
- Some keywords, like *low poly*, while on-topic, tend to produce lower-quality results. Try to find alternate keywords that don't degrade results.
- Using names of specific artists is a powerful way to guide the model toward specific styles with higher-quality results.
I settled on the prompt: *isometric render of a farm by a river, simple, solid shapes, james gilleard, atey ghailan*. Here's the result:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/concept.png" alt="Stable Diffusion Concept Art">
</figure>
### Bringing it to Unity
Now, how do we make this concept art into a game? We'll be using [Unity](https://unity.com/), a popular game engine, to bring our game to life.
1. Create a Unity project using [Unity 2021.9.3f1](https://unity.com/releases/editor/whats-new/2021.3.9) with the [Universal Render Pipeline](https://docs.unity3d.com/Packages/[email protected]/manual/index.html).
2. Block out the scene using basic shapes. For example, to add a cube, *Right Click -> 3D Object -> Cube*.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/gray.png" alt="Gray Scene">
</figure>
3. Set up your [Materials](https://docs.unity3d.com/Manual/Materials.html), using the concept art as a reference. I'm using the basic built-in materials.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/color.png" alt="Scene with Materials">
</figure>
4. Set up your [Lighting](https://docs.unity3d.com/Manual/Lighting.html). I'm using a warm sun (#FFE08C, intensity 1.25) with soft ambient lighting (#B3AF91).
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/lighting.png" alt="Scene with Lighting">
</figure>
5. Set up your [Camera](https://docs.unity3d.com/ScriptReference/Camera.html) **using an orthographic projection** to match the projection of the concept art.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/camera.png" alt="Scene with Camera">
</figure>
6. Add some water. I'm using the [Stylized Water Shader](https://assetstore.unity.com/packages/vfx/shaders/stylized-water-shader-71207) from the Unity asset store.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/water.png" alt="Scene with Water">
</figure>
7. Finally, set up [Post-processing](https://docs.unity3d.com/Packages/[email protected]/manual/integration-with-post-processing.html). I'm using ACES tonemapping and +0.2 exposure.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/post-processing.png" alt="Final Result">
</figure>
That's it! A simple but appealing scene, made in less than a day! Have questions? Want to get more involved? Join the [Hugging Face Discord](https://t.co/1n75wi976V?amp=1)!
Click [here](https://huggingface.co/blog/ml-for-games-2) to read Part 2, where we use **AI for Game Design**. | huggingface/blog/blob/main/ml-for-games-1.md |
Fine-tuning for semantic segmentation using LoRA and 🤗 PEFT
[](https://colab.research.google.com/github/huggingface/peft/blob/main/examples/semantic_segmentation/semantic_segmentation_peft_lora.ipynb)
We provide a notebook (`semantic_segmentation_peft_lora.ipynb`) where we learn how to use [LoRA](https://arxiv.org/abs/2106.09685) from 🤗 PEFT to fine-tune an semantic segmentation by ONLY using **14%%** of the original trainable parameters of the model.
LoRA adds low-rank "update matrices" to certain blocks in the underlying model (in this case the attention blocks) and ONLY trains those matrices during fine-tuning. During inference, these update matrices are _merged_ with the original model parameters. For more details, check out the [original LoRA paper](https://arxiv.org/abs/2106.09685).
| huggingface/peft/blob/main/examples/semantic_segmentation/README.md |
--
title: "From PyTorch DDP to Accelerate to Trainer, mastery of distributed training with ease"
thumbnail: /blog/assets/111_pytorch_ddp_accelerate_transformers/thumbnail.png
authors:
- user: muellerzr
---
# From PyTorch DDP to Accelerate to Trainer, mastery of distributed training with ease
## General Overview
This tutorial assumes you have a basic understanding of PyTorch and how to train a simple model. It will showcase training on multiple GPUs through a process called Distributed Data Parallelism (DDP) through three different levels of increasing abstraction:
- Native PyTorch DDP through the `pytorch.distributed` module
- Utilizing 🤗 Accelerate's light wrapper around `pytorch.distributed` that also helps ensure the code can be run on a single GPU and TPUs with zero code changes and miminimal code changes to the original code
- Utilizing 🤗 Transformer's high-level Trainer API which abstracts all the boilerplate code and supports various devices and distributed scenarios
## What is "Distributed" training and why does it matter?
Take some very basic PyTorch training code below, which sets up and trains a model on MNIST based on the [official MNIST example](https://github.com/pytorch/examples/blob/main/mnist/main.py)
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
class BasicNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
self.act = F.relu
def forward(self, x):
x = self.act(self.conv1(x))
x = self.act(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.act(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
```
We define the training device (`cuda`):
```python
device = "cuda"
```
Build some PyTorch DataLoaders:
```python
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307), (0.3081))
])
train_dset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dset = datasets.MNIST('data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dset, shuffle=True, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_dset, shuffle=False, batch_size=64)
```
Move the model to the CUDA device:
```python
model = BasicNet().to(device)
```
Build a PyTorch optimizer:
```python
optimizer = optim.AdamW(model.parameters(), lr=1e-3)
```
Before finally creating a simplistic training and evaluation loop that performs one full iteration over the dataset and calculates the test accuracy:
```python
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f'Accuracy: {100. * correct / len(test_loader.dataset)}')
```
Typically from here, one could either throw all of this into a python script or run it on a Jupyter Notebook.
However, how would you then get this script to run on say two GPUs or on multiple machines if these resources are available, which could improve training speed through *distributed* training? Just doing `python myscript.py` will only ever run the script using a single GPU. This is where `torch.distributed` comes into play
## PyTorch Distributed Data Parallelism
As the name implies, `torch.distributed` is meant to work on *distributed* setups. This can include multi-node, where you have a number of machines each with a single GPU, or multi-gpu where a single system has multiple GPUs, or some combination of both.
To convert our above code to work within a distributed setup, a few setup configurations must first be defined, detailed in the [Getting Started with DDP Tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html)
First a `setup` and a `cleanup` function must be declared. This will open up a processing group that all of the compute processes can communicate through
> Note: for this section of the tutorial it should be assumed these are sent in python script files. Later on a launcher using Accelerate will be discussed that removes this necessity
```python
import os
import torch.distributed as dist
def setup(rank, world_size):
"Sets up the process group and configuration for PyTorch Distributed Data Parallelism"
os.environ["MASTER_ADDR"] = 'localhost'
os.environ["MASTER_PORT"] = "12355"
# Initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
"Cleans up the distributed environment"
dist.destroy_process_group()
```
The last piece of the puzzle is *how do I send my data and model to another GPU?*
This is where the `DistributedDataParallel` module comes into play. It will copy your model onto each GPU, and when `loss.backward()` is called the backpropagation is performed and the resulting gradients across all these copies of the model will be averaged/reduced. This ensures each device has the same weights post the optimizer step.
Below is an example of our training setup, refactored as a function, with this capability:
> Note: Here rank is the overall rank of the current GPU compared to all the other GPUs available, meaning they have a rank of `0 -> n-1`
```python
from torch.nn.parallel import DistributedDataParallel as DDP
def train(model, rank, world_size):
setup(rank, world_size)
model = model.to(rank)
ddp_model = DDP(model, device_ids=[rank])
optimizer = optim.AdamW(ddp_model.parameters(), lr=1e-3)
# Train for one epoch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
cleanup()
```
The optimizer needs to be declared based on the model *on the specific device* (so `ddp_model` and not `model`) for all of the gradients to properly be calculated.
Lastly, to run the script PyTorch has a convenient `torchrun` command line module that can help. Just pass in the number of nodes it should use as well as the script to run and you are set:
```bash
torchrun --nproc_per_node=2 --nnodes=1 example_script.py
```
The above will run the training script on two GPUs that live on a single machine and this is the barebones for performing only distributed training with PyTorch.
Now let's talk about Accelerate, a library aimed to make this process more seameless and also help with a few best practices
## 🤗 Accelerate
[Accelerate](https://huggingface.co/docs/accelerate) is a library designed to allow you to perform what we just did above, without needing to modify your code greatly. On top of this, the data pipeline innate to Accelerate can also improve performance to your code as well.
First, let's wrap all of the above code we just performed into a single function, to help us visualize the difference:
```python
def train_ddp(rank, world_size):
setup(rank, world_size)
# Build DataLoaders
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307), (0.3081))
])
train_dset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dset = datasets.MNIST('data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dset, shuffle=True, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_dset, shuffle=False, batch_size=64)
# Build model
model = model.to(rank)
ddp_model = DDP(model, device_ids=[rank])
# Build optimizer
optimizer = optim.AdamW(ddp_model.parameters(), lr=1e-3)
# Train for a single epoch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Evaluate
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f'Accuracy: {100. * correct / len(test_loader.dataset)}')
```
Next let's talk about how Accelerate can help. There's a few issues with the above code:
1. This is slightly inefficient, given that `n` dataloaders are made based on each device and pushed.
2. This code will **only** work for multi-GPU, so special care would need to be made for it to be ran on a single node again, or on TPU.
Accelerate helps this through the [`Accelerator`](https://huggingface.co/docs/accelerate/v0.12.0/en/package_reference/accelerator#accelerator) class. Through it, the code remains much the same except for three lines of code when comparing a single node to multinode, as shown below:
```python
def train_ddp_accelerate():
accelerator = Accelerator()
# Build DataLoaders
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307), (0.3081))
])
train_dset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dset = datasets.MNIST('data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dset, shuffle=True, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_dset, shuffle=False, batch_size=64)
# Build model
model = BasicNet()
# Build optimizer
optimizer = optim.AdamW(model.parameters(), lr=1e-3)
# Send everything through `accelerator.prepare`
train_loader, test_loader, model, optimizer = accelerator.prepare(
train_loader, test_loader, model, optimizer
)
# Train for a single epoch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = F.nll_loss(output, target)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
# Evaluate
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print(f'Accuracy: {100. * correct / len(test_loader.dataset)}')
```
With this your PyTorch training loop is now setup to be ran on any distributed setup thanks to the `Accelerator` object. This code can then still be launched through the `torchrun` CLI or through Accelerate's own CLI interface, [`accelerate launch`](https://huggingface.co/docs/accelerate/v0.12.0/en/basic_tutorials/launch).
As a result its now trivialized to perform distributed training with Accelerate and keeping as much of the barebones PyTorch code the same as possible.
Earlier it was mentioned that Accelerate also makes the DataLoaders more efficient. This is through custom Samplers that can send parts of the batches automatically to different devices during training allowing for a single copy of the data to be known at one time, rather than four at once into memory depending on the configuration. Along with this, there is only a single full copy of the original dataset in memory total. Subsets of this dataset are split between all of the nodes that are utilized for training, allowing for much larger datasets to be trained on a single instance without an explosion in memory utilized.
### Using the `notebook_launcher`
Earlier it was mentioned you can start distributed code directly out of your Jupyter Notebook. This comes from Accelerate's [`notebook_launcher`](https://huggingface.co/docs/accelerate/v0.12.0/en/basic_tutorials/notebook) utility, which allows for starting multi-gpu training based on code inside of a Jupyter Notebook.
To use it is as trivial as importing the launcher:
```python
from accelerate import notebook_launcher
```
And passing the training function we declared earlier, any arguments to be passed, and the number of processes to use (such as 8 on a TPU, or 2 for two GPUs). Both of the above training functions can be ran, but do note that after you start a single launch, the instance needs to be restarted before spawning another
```python
notebook_launcher(train_ddp, args=(), num_processes=2)
```
Or:
```python
notebook_launcher(train_ddp_accelerate, args=(), num_processes=2)
```
## Using 🤗 Trainer
Finally, we arrive at the highest level of API -- the Hugging Face [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer).
This wraps as much training as possible while still being able to train on distributed systems without the user needing to do anything at all.
First we need to import the Trainer:
```python
from transformers import Trainer
```
Then we define some `TrainingArguments` to control all the usual hyper-parameters. The trainer also works through dictionaries, so a custom collate function needs to be made.
Finally, we subclass the trainer and write our own `compute_loss`.
Afterwards, this code will also work on a distributed setup without any training code needing to be written whatsoever!
```python
from transformers import Trainer, TrainingArguments
model = BasicNet()
training_args = TrainingArguments(
"basic-trainer",
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=1,
evaluation_strategy="epoch",
remove_unused_columns=False
)
def collate_fn(examples):
pixel_values = torch.stack([example[0] for example in examples])
labels = torch.tensor([example[1] for example in examples])
return {"x":pixel_values, "labels":labels}
class MyTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
outputs = model(inputs["x"])
target = inputs["labels"]
loss = F.nll_loss(outputs, target)
return (loss, outputs) if return_outputs else loss
trainer = MyTrainer(
model,
training_args,
train_dataset=train_dset,
eval_dataset=test_dset,
data_collator=collate_fn,
)
```
```python
trainer.train()
```
```python out
***** Running training *****
Num examples = 60000
Num Epochs = 1
Instantaneous batch size per device = 64
Total train batch size (w. parallel, distributed & accumulation) = 64
Gradient Accumulation steps = 1
Total optimization steps = 938
```
| Epoch | Training Loss | Validation Loss |
|-------|---------------|-----------------|
| 1 | 0.875700 | 0.282633 |
Similarly to the above examples with the `notebook_launcher`, this can be done again here by throwing it all into a training function:
```python
def train_trainer_ddp():
model = BasicNet()
training_args = TrainingArguments(
"basic-trainer",
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=1,
evaluation_strategy="epoch",
remove_unused_columns=False
)
def collate_fn(examples):
pixel_values = torch.stack([example[0] for example in examples])
labels = torch.tensor([example[1] for example in examples])
return {"x":pixel_values, "labels":labels}
class MyTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
outputs = model(inputs["x"])
target = inputs["labels"]
loss = F.nll_loss(outputs, target)
return (loss, outputs) if return_outputs else loss
trainer = MyTrainer(
model,
training_args,
train_dataset=train_dset,
eval_dataset=test_dset,
data_collator=collate_fn,
)
trainer.train()
notebook_launcher(train_trainer_ddp, args=(), num_processes=2)
```
## Resources
To learn more about PyTorch Distributed Data Parallelism, check out the documentation [here](https://pytorch.org/docs/stable/distributed.html)
To learn more about 🤗 Accelerate, check out the documentation [here](https://huggingface.co/docs/accelerate)
To learn more about 🤗 Transformers, check out the documentation [here](https://huggingface.co/docs/transformers)
| huggingface/blog/blob/main/pytorch-ddp-accelerate-transformers.md |
--
title: "Probabilistic Time Series Forecasting with 🤗 Transformers"
thumbnail: /blog/assets/118_time-series-transformers/thumbnail.png
authors:
- user: nielsr
- user: kashif
---
# Probabilistic Time Series Forecasting with 🤗 Transformers
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Introduction
Time series forecasting is an essential scientific and business problem and as such has also seen a lot of innovation recently with the use of [deep learning based](https://dl.acm.org/doi/abs/10.1145/3533382) models in addition to the [classical methods](https://otexts.com/fpp3/). An important difference between classical methods like ARIMA and novel deep learning methods is the following.
## Probabilistic Forecasting
Typically, classical methods are fitted on each time series in a dataset individually. These are often referred to as "single" or "local" methods. However, when dealing with a large amount of time series for some applications, it is beneficial to train a "global" model on all available time series, which enables the model to learn latent representations from many different sources.
Some classical methods are point-valued (meaning, they just output a single value per time step) and models are trained by minimizing an L2 or L1 type of loss with respect to the ground truth data. However, since forecasts are often used in some real-world decision making pipeline, even with humans in the loop, it is much more beneficial to provide the uncertainties of predictions. This is also called "probabilistic forecasting", as opposed to "point forecasting". This entails modeling a probabilistic distribution, from which one can sample.
So in short, rather than training local point forecasting models, we hope to train **global probabilistic** models. Deep learning is a great fit for this, as neural networks can learn representations from several related time series as well as model the uncertainty of the data.
It is common in the probabilistic setting to learn the future parameters of some chosen parametric distribution, like Gaussian or Student-T; or learn the conditional quantile function; or use the framework of Conformal Prediction adapted to the time series setting. The choice of method does not affect the modeling aspect and thus can be typically thought of as yet another hyperparameter. One can always turn a probabilistic model into a point-forecasting model, by taking empirical means or medians.
## The Time Series Transformer
In terms of modeling time series data which are sequential in nature, as one can imagine, researchers have come up with models which use Recurrent Neural Networks (RNN) like LSTM or GRU, or Convolutional Networks (CNN), and more recently Transformer based methods which fit naturally to the time series forecasting setting.
In this blog post, we're going to leverage the vanilla Transformer [(Vaswani et al., 2017)](https://arxiv.org/abs/1706.03762) for the **univariate** probabilistic forecasting task (i.e. predicting each time series' 1-d distribution individually). The Encoder-Decoder Transformer is a natural choice for forecasting as it encapsulates several inductive biases nicely.
To begin with, the use of an Encoder-Decoder architecture is helpful at inference time where typically for some logged data we wish to forecast some prediction steps into the future. This can be thought of as analogous to the text generation task where given some context, we sample the next token and pass it back into the decoder (also called "autoregressive generation"). Similarly here we can also, given some distribution type, sample from it to provide forecasts up until our desired prediction horizon. This is known as Greedy Sampling/Search and there is a great blog post about it [here](https://huggingface.co/blog/how-to-generate) for the NLP setting.
Secondly, a Transformer helps us to train on time series data which might contain thousands of time points. It might not be feasible to input *all* the history of a time series at once to the model, due to the time- and memory constraints of the attention mechanism. Thus, one can consider some appropriate context window and sample this window and the subsequent prediction length sized window from the training data when constructing batches for stochastic gradient descent (SGD). The context sized window can be passed to the encoder and the prediction window to a *causal-masked* decoder. This means that the decoder can only look at previous time steps when learning the next value. This is equivalent to how one would train a vanilla Transformer for machine translation, referred to as "teacher forcing".
Another benefit of Transformers over the other architectures is that we can incorporate missing values (which are common in the time series setting) as an additional mask to the encoder or decoder and still train without resorting to in-filling or imputation. This is equivalent to the `attention_mask` of models like BERT and GPT-2 in the Transformers library, to not include padding tokens in the computation of the attention matrix.
A drawback of the Transformer architecture is the limit to the sizes of the context and prediction windows because of the quadratic compute and memory requirements of the vanilla Transformer, see [Tay et al., 2020](https://arxiv.org/abs/2009.06732). Additionally, since the Transformer is a powerful architecture, it might overfit or learn spurious correlations much more easily compared to other [methods](https://openreview.net/pdf?id=D7YBmfX_VQy).
The 🤗 Transformers library comes with a vanilla probabilistic time series Transformer model, simply called the [Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer). In the sections below, we'll show how to train such a model on a custom dataset.
## Set-up Environment
First, let's install the necessary libraries: 🤗 Transformers, 🤗 Datasets, 🤗 Evaluate, 🤗 Accelerate and [GluonTS](https://github.com/awslabs/gluonts).
As we will show, GluonTS will be used for transforming the data to create features as well as for creating appropriate training, validation and test batches.
```python
!pip install -q transformers
!pip install -q datasets
!pip install -q evaluate
!pip install -q accelerate
!pip install -q gluonts ujson
```
## Load Dataset
In this blog post, we'll use the `tourism_monthly` dataset, which is available on the [Hugging Face Hub](https://huggingface.co/datasets/monash_tsf). This dataset contains monthly tourism volumes for 366 regions in Australia.
This dataset is part of the [Monash Time Series Forecasting](https://forecastingdata.org/) repository, a collection of time series datasets from a number of domains. It can be viewed as the GLUE benchmark of time series forecasting.
```python
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "tourism_monthly")
```
As can be seen, the dataset contains 3 splits: train, validation and test.
```python
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
})
```
Each example contains a few keys, of which `start` and `target` are the most important ones. Let us have a look at the first time series in the dataset:
```python
train_example = dataset['train'][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The `start` simply indicates the start of the time series (as a datetime), and the `target` contains the actual values of the time series.
The `start` will be useful to add time related features to the time series values, as extra input to the model (such as "month of year"). Since we know the frequency of the data is `monthly`, we know for instance that the second value has the timestamp `1979-02-01`, etc.
```python
print(train_example['start'])
print(train_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5772.876953125]
```
The validation set contains the same data as the training set, just for a `prediction_length` longer amount of time. This allows us to validate the model's predictions against the ground truth.
The test set is again one `prediction_length` longer data compared to the validation set (or some multiple of `prediction_length` longer data compared to the training set for testing on multiple rolling windows).
```python
validation_example = dataset['validation'][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The initial values are exactly the same as the corresponding training example:
```python
print(validation_example['start'])
print(validation_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5985.830078125]
```
However, this example has `prediction_length=24` additional values compared to the training example. Let us verify it.
```python
freq = "1M"
prediction_length = 24
assert len(train_example["target"]) + prediction_length == len(
validation_example["target"]
)
```
Let's visualize this:
```python
import matplotlib.pyplot as plt
figure, axes = plt.subplots()
axes.plot(train_example["target"], color="blue")
axes.plot(validation_example["target"], color="red", alpha=0.5)
plt.show()
```
Let's split up the data:
```python
train_dataset = dataset["train"]
test_dataset = dataset["test"]
```
## Update `start` to `pd.Period`
The first thing we'll do is convert the `start` feature of each time series to a pandas `Period` index using the data's `freq`:
```python
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batch
```
We now use `datasets`' [`set_transform`](https://huggingface.co/docs/datasets/v2.7.0/en/package_reference/main_classes#datasets.Dataset.set_transform) functionality to do this on-the-fly in place:
```python
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))
```
## Define the Model
Next, let's instantiate a model. The model will be trained from scratch, hence we won't use the `from_pretrained` method here, but rather randomly initialize the model from a [`config`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerConfig).
We specify a couple of additional parameters to the model:
- `prediction_length` (in our case, `24` months): this is the horizon that the decoder of the Transformer will learn to predict for;
- `context_length`: the model will set the `context_length` (input of the encoder) equal to the `prediction_length`, if no `context_length` is specified;
- `lags` for a given frequency: these specify how much we "look back", to be added as additional features. e.g. for a `Daily` frequency we might consider a look back of `[1, 2, 7, 30, ...]` or in other words look back 1, 2, ... days while for `Minute` data we might consider `[1, 30, 60, 60*24, ...]` etc.;
- the number of time features: in our case, this will be `2` as we'll add `MonthOfYear` and `Age` features;
- the number of static categorical features: in our case, this will be just `1` as we'll add a single "time series ID" feature;
- the cardinality: the number of values of each static categorical feature, as a list which for our case will be `[366]` as we have 366 different time series
- the embedding dimension: the embedding dimension for each static categorical feature, as a list, for example `[3]` means the model will learn an embedding vector of size `3` for each of the `366` time series (regions).
Let's use the default lags provided by GluonTS for the given frequency ("monthly"):
```python
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 23, 24, 25, 35, 36, 37]
```
This means that we'll look back up to 37 months for each time step, as additional features.
Let's also check the default time features that GluonTS provides us:
```python
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function month_of_year at 0x7fa496d0ca70>]
```
In this case, there's only a single feature, namely "month of year". This means that for each time step, we'll add the month as a scalar value (e.g. `1` in case the timestamp is "january", `2` in case the timestamp is "february", etc.).
We now have everything to define the model:
```python
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerForPrediction
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
# context length:
context_length=prediction_length * 2,
# lags coming from helper given the freq:
lags_sequence=lags_sequence,
# we'll add 2 time features ("month of year" and "age", see further):
num_time_features=len(time_features) + 1,
# we have a single static categorical feature, namely time series ID:
num_static_categorical_features=1,
# it has 366 possible values:
cardinality=[len(train_dataset)],
# the model will learn an embedding of size 2 for each of the 366 possible values:
embedding_dimension=[2],
# transformer params:
encoder_layers=4,
decoder_layers=4,
d_model=32,
)
model = TimeSeriesTransformerForPrediction(config)
```
Note that, similar to other models in the 🤗 Transformers library, [`TimeSeriesTransformerModel`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerModel) corresponds to the encoder-decoder Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction) corresponds to `TimeSeriesTransformerModel` with a **distribution head** on top. By default, the model uses a Student-t distribution (but this is configurable):
```python
model.config.distribution_output
>>> student_t
```
This is an important difference with Transformers for NLP, where the head typically consists of a fixed categorical distribution implemented as an `nn.Linear` layer.
## Define Transformations
Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones).
Again, we'll use the GluonTS library for this. We define a `Chain` of transformations (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline.
```python
from gluonts.time_feature import (
time_features_from_frequency_str,
TimeFeature,
get_lags_for_frequency,
)
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
```
The transformations below are annotated with comments, to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features:
```python
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
# a bit like torchvision.transforms.Compose
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# month of year in the case when freq="M"
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in its life the value of the time series is,
# sort of a running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## Define `InstanceSplitter`
For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the Transformer due to time- and memory constraints).
The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes:
1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset)
2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations)
3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case)
```python
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## Create DataLoaders
Next, it's time to create the DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`).
```python
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from the 366 possible transformed time series)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
```
```python
def create_backtest_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data)
# we create a Validation Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "validation")
# we apply the transformations in train mode
testing_instances = instance_sampler.apply(transformed_data, is_train=True)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
We have a test dataloader helper for completion, even though we will not use it here. This is useful in a production setting where we want to start forecasting from the end of a given time series. Thus, the test dataloader will sample the very last context window from the dataset provided and pass it to the model.
```python
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# We create a test Instance splitter to sample the very last
# context window from the dataset provided.
instance_sampler = create_instance_splitter(config, "test")
# We apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
```python
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=train_dataset,
batch_size=256,
num_batches_per_epoch=100,
)
test_dataloader = create_backtest_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)
```
Let's check the first batch:
```python
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 85, 2]) torch.FloatTensor
past_values torch.Size([256, 85]) torch.FloatTensor
past_observed_mask torch.Size([256, 85]) torch.FloatTensor
future_time_features torch.Size([256, 24, 2]) torch.FloatTensor
static_categorical_features torch.Size([256, 1]) torch.LongTensor
future_values torch.Size([256, 24]) torch.FloatTensor
future_observed_mask torch.Size([256, 24]) torch.FloatTensor
```
As can be seen, we don't feed `input_ids` and `attention_mask` to the encoder (as would be the case for NLP models), but rather `past_values`, along with `past_observed_mask`, `past_time_features`, and `static_categorical_features`.
The decoder inputs consist of `future_values`, `future_observed_mask` and `future_time_features`. The `future_values` can be seen as the equivalent of `decoder_input_ids` in NLP.
We refer to the [docs](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction.forward.past_values) for a detailed explanation for each of them.
## Forward Pass
Let's perform a single forward pass with the batch we just created:
```python
# perform forward pass
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
```
```python
print("Loss:", outputs.loss.item())
>>> Loss: 9.069628715515137
```
Note that the model is returning a loss. This is possible as the decoder automatically shifts the `future_values` one position to the right in order to have the labels. This allows computing a loss between the predicted values and the labels.
Also, note that the decoder uses a causal mask to not look into the future as the values it needs to predict are in the `future_values` tensor.
## Train the Model
It's time to train the model! We'll use a standard PyTorch training loop.
We will use the 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) library here, which automatically places the model, optimizer and dataloader on the appropriate `device`.
```python
from accelerate import Accelerator
from torch.optim import AdamW
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(40):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
if idx % 100 == 0:
print(loss.item())
```
## Inference
At inference time, it's recommended to use the `generate()` method for autoregressive generation, similar to NLP models.
Forecasting involves getting data from the test instance sampler, which will sample the very last `context_length` sized window of values from each time series in the dataset, and pass it to the model. Note that we pass `future_time_features`, which are known ahead of time, to the decoder.
The model will autoregressively sample a certain number of values from the predicted distribution and pass them back to the decoder to return the prediction outputs:
```python
model.eval()
forecasts = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts.append(outputs.sequences.cpu().numpy())
```
The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`).
In this case, we get `100` possible values for the next `24` months (for each example in the batch which is of size `64`):
```python
forecasts[0].shape
>>> (64, 100, 24)
```
We'll stack them vertically, to get forecasts for all time-series in the test dataset:
```python
forecasts = np.vstack(forecasts)
print(forecasts.shape)
>>> (366, 100, 24)
```
We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. We will use the [MASE](https://huggingface.co/spaces/evaluate-metric/mase) and [sMAPE](https://huggingface.co/spaces/evaluate-metric/smape) metrics which we calculate for each time series in the dataset:
```python
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
```
```python
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.2564196892177717
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.1609541520852549
```
We can also plot the individual metrics of each time series in the dataset and observe that a handful of time series contribute a lot to the final test metric:
```python
plt.scatter(mase_metrics, smape_metrics, alpha=0.3)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()
```
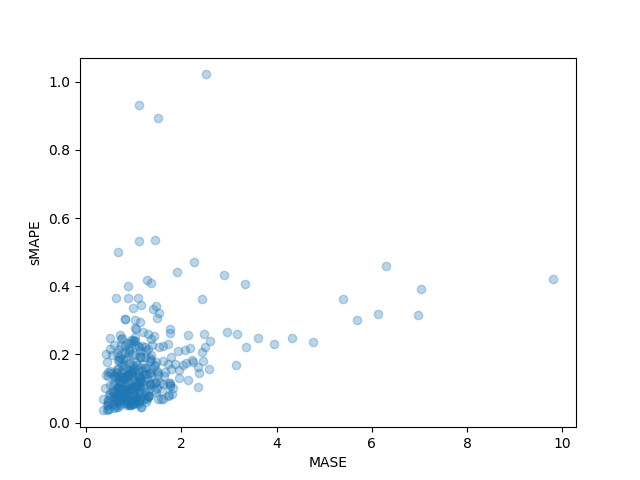
To plot the prediction for any time series with respect the ground truth test data we define the following helper:
```python
import matplotlib.dates as mdates
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_dataset[ts_index][FieldName.START],
periods=len(test_dataset[ts_index][FieldName.TARGET]),
freq=freq,
).to_timestamp()
# Major ticks every half year, minor ticks every month,
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=(1, 7)))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
ax.plot(
index[-2*prediction_length:],
test_dataset[ts_index]["target"][-2*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.fill_between(
index[-prediction_length:],
forecasts[ts_index].mean(0) - forecasts[ts_index].std(axis=0),
forecasts[ts_index].mean(0) + forecasts[ts_index].std(axis=0),
alpha=0.3,
interpolate=True,
label="+/- 1-std",
)
plt.legend()
plt.show()
```
For example:
```python
plot(334)
```
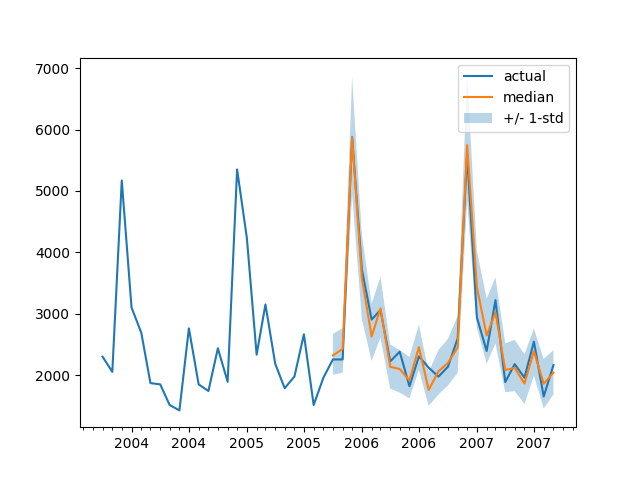
How do we compare against other models? The [Monash Time Series Repository](https://forecastingdata.org/#results) has a comparison table of test set MASE metrics which we can add to:
|Dataset | SES| Theta | TBATS| ETS | (DHR-)ARIMA| PR| CatBoost | FFNN | DeepAR | N-BEATS | WaveNet| **Transformer** (Our) |
|:------------------:|:-----------------:|:--:|:--:|:--:|:--:|:--:|:--:|:---:|:---:|:--:|:--:|:--:|
|Tourism Monthly | 3.306 | 1.649 | 1.751 | 1.526| 1.589| 1.678 |1.699| 1.582 | 1.409 | 1.574| 1.482 | **1.256**|
Note that, with our model, we are beating all other models reported (see also table 2 in the corresponding [paper](https://openreview.net/pdf?id=wEc1mgAjU-)), and we didn't do any hyperparameter tuning. We just trained the Transformer for 40 epochs.
Of course, we need to be careful with just claiming state-of-the-art results on time series with neural networks, as it seems ["XGBoost is typically all you need"](https://www.sciencedirect.com/science/article/pii/S0169207021001679). We are just very curious to see how far neural networks can bring us, and whether Transformers are going to be useful in this domain. This particular dataset seems to indicate that it's definitely worth exploring.
## Next Steps
We would encourage the readers to try out the [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) with other time series datasets from the [Hub](https://huggingface.co/datasets/monash_tsf) and replace the appropriate frequency and prediction length parameters. For your datasets, one would need to convert them to the convention used by GluonTS, which is explained nicely in their documentation [here](https://ts.gluon.ai/stable/tutorials/forecasting/extended_tutorial.html#What-is-in-a-dataset?). We have also prepared an example notebook showing you how to convert your dataset into the 🤗 datasets format [here](https://github.com/huggingface/notebooks/blob/main/examples/time_series_datasets.ipynb).
As time series researchers will know, there has been a lot of interest in applying Transformer based models to the time series problem. The vanilla Transformer is just one of many attention-based models and so there is a need to add more models to the library.
At the moment nothing is stopping us from modeling multivariate time series, however for that one would need to instantiate the model with a multivariate distribution head. Currently, diagonal independent distributions are supported, and other multivariate distributions will be added. Stay tuned for a future blog post that will include a tutorial.
Another thing on the roadmap is time series classification. This entails adding a time series model with a classification head to the library, for the anomaly detection task for example.
The current model assumes the presence of a date-time together with the time series values, which might not be the case for every time series in the wild. See for instance neuroscience datasets like the one from [WOODS](https://woods-benchmarks.github.io/). Thus, one would need to generalize the current model to make some inputs optional in the whole pipeline.
Finally, the NLP/Vision domain has benefitted tremendously from [large pre-trained models](https://arxiv.org/abs/1810.04805), while this is not the case as far as we are aware for the time series domain. Transformer based models seem like the obvious choice in pursuing this avenue of research and we cannot wait to see what researchers and practitioners come up with!
| huggingface/blog/blob/main/time-series-transformers.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Multiple choice
The script [`run_swag.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/optimization/multiple-choice/run_swag.py) allows us to apply graph optimizations using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for multiple choice tasks.
The following example applies graph optimizations on a BERT fine-tuned on the SWAG dataset. Here the optimization level is selected to be 1, enabling basic optimizations such as redundant node eliminations and constant folding. Higher optimization level will result in hardware dependent optimized graph.
```bash
python run_swag.py \
--model_name_or_path ehdwns1516/bert-base-uncased_SWAG \
--optimization_level 1 \
--do_eval \
--output_dir /tmp/optimized_bert_swag
```
| huggingface/optimum/blob/main/examples/onnxruntime/optimization/multiple-choice/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Outputs
All model outputs are subclasses of [`~utils.BaseOutput`], data structures containing all the information returned by the model. The outputs can also be used as tuples or dictionaries.
For example:
```python
from diffusers import DDIMPipeline
pipeline = DDIMPipeline.from_pretrained("google/ddpm-cifar10-32")
outputs = pipeline()
```
The `outputs` object is a [`~pipelines.ImagePipelineOutput`] which means it has an image attribute.
You can access each attribute as you normally would or with a keyword lookup, and if that attribute is not returned by the model, you will get `None`:
```python
outputs.images
outputs["images"]
```
When considering the `outputs` object as a tuple, it only considers the attributes that don't have `None` values.
For instance, retrieving an image by indexing into it returns the tuple `(outputs.images)`:
```python
outputs[:1]
```
<Tip>
To check a specific pipeline or model output, refer to its corresponding API documentation.
</Tip>
## BaseOutput
[[autodoc]] utils.BaseOutput
- to_tuple
## ImagePipelineOutput
[[autodoc]] pipelines.ImagePipelineOutput
## FlaxImagePipelineOutput
[[autodoc]] pipelines.pipeline_flax_utils.FlaxImagePipelineOutput
## AudioPipelineOutput
[[autodoc]] pipelines.AudioPipelineOutput
## ImageTextPipelineOutput
[[autodoc]] ImageTextPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/outputs.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# BLIP-Diffusion
BLIP-Diffusion was proposed in [BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing](https://arxiv.org/abs/2305.14720). It enables zero-shot subject-driven generation and control-guided zero-shot generation.
The abstract from the paper is:
*Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications. Project page at [this https URL](https://dxli94.github.io/BLIP-Diffusion-website/).*
The original codebase can be found at [salesforce/LAVIS](https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion). You can find the official BLIP-Diffusion checkpoints under the [hf.co/SalesForce](https://hf.co/SalesForce) organization.
`BlipDiffusionPipeline` and `BlipDiffusionControlNetPipeline` were contributed by [`ayushtues`](https://github.com/ayushtues/).
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## BlipDiffusionPipeline
[[autodoc]] BlipDiffusionPipeline
- all
- __call__
## BlipDiffusionControlNetPipeline
[[autodoc]] BlipDiffusionControlNetPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/blip_diffusion.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Longformer
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=longformer">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-longformer-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/longformer-base-4096-finetuned-squadv1">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Longformer model was presented in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
WikiHop and TriviaQA.*
This model was contributed by [beltagy](https://huggingface.co/beltagy). The Authors' code can be found [here](https://github.com/allenai/longformer).
## Usage tips
- Since the Longformer is based on RoBERTa, it doesn't have `token_type_ids`. You don't need to indicate which
token belongs to which segment. Just separate your segments with the separation token `tokenizer.sep_token` (or
`</s>`).
- A transformer model replacing the attention matrices by sparse matrices to go faster. Often, the local context (e.g., what are the two tokens left and right?) is enough to take action for a given token. Some preselected input tokens are still given global attention, but the attention matrix has way less parameters, resulting in a speed-up. See the local attention section for more information.
## Longformer Self Attention
Longformer self attention employs self attention on both a "local" context and a "global" context. Most tokens only
attend "locally" to each other meaning that each token attends to its \\(\frac{1}{2} w\\) previous tokens and
\\(\frac{1}{2} w\\) succeeding tokens with \\(w\\) being the window length as defined in
`config.attention_window`. Note that `config.attention_window` can be of type `List` to define a
different \\(w\\) for each layer. A selected few tokens attend "globally" to all other tokens, as it is
conventionally done for all tokens in `BertSelfAttention`.
Note that "locally" and "globally" attending tokens are projected by different query, key and value matrices. Also note
that every "locally" attending token not only attends to tokens within its window \\(w\\), but also to all "globally"
attending tokens so that global attention is *symmetric*.
The user can define which tokens attend "locally" and which tokens attend "globally" by setting the tensor
`global_attention_mask` at run-time appropriately. All Longformer models employ the following logic for
`global_attention_mask`:
- 0: the token attends "locally",
- 1: the token attends "globally".
For more information please also refer to [`~LongformerModel.forward`] method.
Using Longformer self attention, the memory and time complexity of the query-key matmul operation, which usually
represents the memory and time bottleneck, can be reduced from \\(\mathcal{O}(n_s \times n_s)\\) to
\\(\mathcal{O}(n_s \times w)\\), with \\(n_s\\) being the sequence length and \\(w\\) being the average window
size. It is assumed that the number of "globally" attending tokens is insignificant as compared to the number of
"locally" attending tokens.
For more information, please refer to the official [paper](https://arxiv.org/pdf/2004.05150.pdf).
## Training
[`LongformerForMaskedLM`] is trained the exact same way [`RobertaForMaskedLM`] is
trained and should be used as follows:
```python
input_ids = tokenizer.encode("This is a sentence from [MASK] training data", return_tensors="pt")
mlm_labels = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## LongformerConfig
[[autodoc]] LongformerConfig
## LongformerTokenizer
[[autodoc]] LongformerTokenizer
## LongformerTokenizerFast
[[autodoc]] LongformerTokenizerFast
## Longformer specific outputs
[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutputWithPooling
[[autodoc]] models.longformer.modeling_longformer.LongformerMaskedLMOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerQuestionAnsweringModelOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerSequenceClassifierOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerMultipleChoiceModelOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerTokenClassifierOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutputWithPooling
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMaskedLMOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerQuestionAnsweringModelOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerSequenceClassifierOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMultipleChoiceModelOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerTokenClassifierOutput
<frameworkcontent>
<pt>
## LongformerModel
[[autodoc]] LongformerModel
- forward
## LongformerForMaskedLM
[[autodoc]] LongformerForMaskedLM
- forward
## LongformerForSequenceClassification
[[autodoc]] LongformerForSequenceClassification
- forward
## LongformerForMultipleChoice
[[autodoc]] LongformerForMultipleChoice
- forward
## LongformerForTokenClassification
[[autodoc]] LongformerForTokenClassification
- forward
## LongformerForQuestionAnswering
[[autodoc]] LongformerForQuestionAnswering
- forward
</pt>
<tf>
## TFLongformerModel
[[autodoc]] TFLongformerModel
- call
## TFLongformerForMaskedLM
[[autodoc]] TFLongformerForMaskedLM
- call
## TFLongformerForQuestionAnswering
[[autodoc]] TFLongformerForQuestionAnswering
- call
## TFLongformerForSequenceClassification
[[autodoc]] TFLongformerForSequenceClassification
- call
## TFLongformerForTokenClassification
[[autodoc]] TFLongformerForTokenClassification
- call
## TFLongformerForMultipleChoice
[[autodoc]] TFLongformerForMultipleChoice
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/longformer.md |
Inception v4
**Inception-v4** is a convolutional neural network architecture that builds on previous iterations of the Inception family by simplifying the architecture and using more inception modules than [Inception-v3](https://paperswithcode.com/method/inception-v3).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('inception_v4', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `inception_v4`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('inception_v4', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{szegedy2016inceptionv4,
title={Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning},
author={Christian Szegedy and Sergey Ioffe and Vincent Vanhoucke and Alex Alemi},
year={2016},
eprint={1602.07261},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Inception v4
Paper:
Title: Inception-v4, Inception-ResNet and the Impact of Residual Connections on
Learning
URL: https://paperswithcode.com/paper/inception-v4-inception-resnet-and-the-impact
Models:
- Name: inception_v4
In Collection: Inception v4
Metadata:
FLOPs: 15806527936
Parameters: 42680000
File Size: 171082495
Architecture:
- Average Pooling
- Dropout
- Inception-A
- Inception-B
- Inception-C
- Reduction-A
- Reduction-B
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 20x NVIDIA Kepler GPUs
ID: inception_v4
LR: 0.045
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v4.py#L313
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/inceptionv4-8e4777a0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 1.01%
Top 5 Accuracy: 16.85%
--> | huggingface/pytorch-image-models/blob/main/docs/models/inception-v4.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for Trainer
This page lists all the utility functions used by [`Trainer`].
Most of those are only useful if you are studying the code of the Trainer in the library.
## Utilities
[[autodoc]] EvalPrediction
[[autodoc]] IntervalStrategy
[[autodoc]] enable_full_determinism
[[autodoc]] set_seed
[[autodoc]] torch_distributed_zero_first
## Callbacks internals
[[autodoc]] trainer_callback.CallbackHandler
## Distributed Evaluation
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
## Trainer Argument Parser
[[autodoc]] HfArgumentParser
## Debug Utilities
[[autodoc]] debug_utils.DebugUnderflowOverflow
| huggingface/transformers/blob/main/docs/source/en/internal/trainer_utils.md |