
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
--
title: "Efficient Controllable Generation for SDXL with T2I-Adapters"
thumbnail: /blog/assets/t2i-sdxl-adapters/thumbnail.png
authors:
- user: Adapter
guest: true
- user: valhalla
- user: sayakpaul
- user: Xintao
guest: true
- user: hysts
---
# Efficient Controllable Generation for SDXL with T2I-Adapters
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/t2i-adapters-sdxl/hf_tencent.png" height=180/>
</p>
[T2I-Adapter](https://huggingface.co/papers/2302.08453) is an efficient plug-and-play model that provides extra guidance to pre-trained text-to-image models while freezing the original large text-to-image models. T2I-Adapter aligns internal knowledge in T2I models with external control signals. We can train various adapters according to different conditions and achieve rich control and editing effects.
As a contemporaneous work, [ControlNet](https://hf.co/papers/2302.05543) has a similar function and is widely used. However, it can be **computationally expensive** to run. This is because, during each denoising step of the reverse diffusion process, both the ControlNet and UNet need to be run. In addition, ControlNet emphasizes the importance of copying the UNet encoder as a control model, resulting in a larger parameter number. Thus, the generation is bottlenecked by the size of the ControlNet (the larger, the slower the process becomes).
T2I-Adapters provide a competitive advantage to ControlNets in this matter. T2I-Adapters are smaller in size, and unlike ControlNets, T2I-Adapters are run just once for the entire course of the denoising process.
| **Model Type** | **Model Parameters** | **Storage (fp16)** |
| --- | --- | --- |
| [ControlNet-SDXL](https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0) | 1251 M | 2.5 GB |
| [ControlLoRA](https://huggingface.co/stabilityai/control-lora) (with rank 128) | 197.78 M (84.19% reduction) | 396 MB (84.53% reduction) |
| [T2I-Adapter-SDXL](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0) | 79 M (**_93.69% reduction_**) | 158 MB (**_94% reduction_**) |
Over the past few weeks, the Diffusers team and the T2I-Adapter authors have been collaborating to bring the support of T2I-Adapters for [Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) in [`diffusers`](https://github.com/huggingface/diffusers). In this blog post, we share our findings from training T2I-Adapters on SDXL from scratch, some appealing results, and, of course, the T2I-Adapter checkpoints on various conditionings (sketch, canny, lineart, depth, and openpose)!

Compared to previous versions of T2I-Adapter (SD-1.4/1.5), [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter) still uses the original recipe, driving 2.6B SDXL with a 79M Adapter! T2I-Adapter-SDXL maintains powerful control capabilities while inheriting the high-quality generation of SDXL!
## Training T2I-Adapter-SDXL with `diffusers`
We built our training script on [this official example](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md) provided by `diffusers`.
Most of the T2I-Adapter models we mention in this blog post were trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with the following settings:
- Training steps: 20000-35000
- Batch size: Data parallel with a single GPU batch size of 16 for a total batch size of 128.
- Learning rate: Constant learning rate of 1e-5.
- Mixed precision: fp16
We encourage the community to use our scripts to train custom and powerful T2I-Adapters, striking a competitive trade-off between speed, memory, and quality.
## Using T2I-Adapter-SDXL in `diffusers`
Here, we take the lineart condition as an example to demonstrate the usage of [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter/tree/XL). To get started, first install the required dependencies:
```bash
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate
```
The generation process of the T2I-Adapter-SDXL mainly consists of the following two steps:
1. Condition images are first prepared into the appropriate *control image* format.
2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/0ec7a02b6a609a31b442cdf18962d7238c5be25d/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L126).
Let's have a look at a simple example using the [Lineart Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0). We start by initializing the T2I-Adapter pipeline for SDXL and the lineart detector.
```python
import torch
from controlnet_aux.lineart import LineartDetector
from diffusers import (AutoencoderKL, EulerAncestralDiscreteScheduler,
StableDiffusionXLAdapterPipeline, T2IAdapter)
from diffusers.utils import load_image, make_image_grid
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load pipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(
model_id, subfolder="scheduler"
)
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16
)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id,
vae=vae,
adapter=adapter,
scheduler=euler_a,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# load lineart detector
line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
```
Then, load an image to detect lineart:
```python
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
image = load_image(url)
image = line_detector(image, detect_resolution=384, image_resolution=1024)
```

Then we generate:
```python
prompt = "Ice dragon roar, 4k photo"
negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.8,
guidance_scale=7.5,
).images[0]
gen_images.save("out_lin.png")
```

There are two important arguments to understand that help you control the amount of conditioning.
1. `adapter_conditioning_scale`
This argument controls how much influence the conditioning should have on the input. High values mean a higher conditioning effect and vice-versa.
2. `adapter_conditioning_factor`
This argument controls how many initial generation steps should have the conditioning applied. The value should be set between 0-1 (default is 1). The value of `adapter_conditioning_factor=1` means the adapter should be applied to all timesteps, while the `adapter_conditioning_factor=0.5` means it will only applied for the first 50% of the steps.
For more details, we welcome you to check the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/adapter).
## Try out the Demo
You can easily try T2I-Adapter-SDXL in [this Space](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script>
<gradio-app src="https://tencentarc-t2i-adapter-sdxl.hf.space"></gradio-app>
You can also try out [Doodly](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch), built using the sketch model that turns your doodles into realistic images (with language supervision):
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script>
<gradio-app src="https://tencentarc-t2i-adapter-sdxl-sketch.hf.space"></gradio-app>
## More Results
Below, we present results obtained from using different kinds of conditions. We also supplement the results with links to their corresponding pre-trained checkpoints. Their model cards contain more details on how they were trained, along with example usage.
### Lineart Guided

*Model from [`TencentARC/t2i-adapter-lineart-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)*
### Sketch Guided

*Model from [`TencentARC/t2i-adapter-sketch-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)*
### Canny Guided

*Model from [`TencentARC/t2i-adapter-canny-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)*
### Depth Guided

*Depth guided models from [`TencentARC/t2i-adapter-depth-midas-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0) and [`TencentARC/t2i-adapter-depth-zoe-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0) respectively*
### OpenPose Guided

*Model from [`TencentARC/t2i-adapter-openpose-sdxl-1.0`](https://hf.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)*
---
*Acknowledgements: Immense thanks to [William Berman](https://twitter.com/williamLberman) for helping us train the models and sharing his insights.*
| huggingface/blog/blob/main/t2i-sdxl-adapters.md |
--
title: "Introduction to Graph Machine Learning"
thumbnail: /blog/assets/125_intro-to-graphml/thumbnail.png
authors:
- user: clefourrier
---
# Introduction to Graph Machine Learning
In this blog post, we cover the basics of graph machine learning.
We first study what graphs are, why they are used, and how best to represent them. We then cover briefly how people learn on graphs, from pre-neural methods (exploring graph features at the same time) to what are commonly called Graph Neural Networks. Lastly, we peek into the world of Transformers for graphs.
## Graphs
### What is a graph?
In its essence, a graph is a description of items linked by relations.
Examples of graphs include social networks (Twitter, Mastodon, any citation networks linking papers and authors), molecules, knowledge graphs (such as UML diagrams, encyclopedias, and any website with hyperlinks between its pages), sentences expressed as their syntactic trees, any 3D mesh, and more! It is, therefore, not hyperbolic to say that graphs are everywhere.
The items of a graph (or network) are called its *nodes* (or vertices), and their connections its *edges* (or links). For example, in a social network, nodes are users and edges their connections; in a molecule, nodes are atoms and edges their molecular bond.
* A graph with either typed nodes or typed edges is called **heterogeneous** (example: citation networks with items that can be either papers or authors have typed nodes, and XML diagram where relations are typed have typed edges). It cannot be represented solely through its topology, it needs additional information. This post focuses on homogeneous graphs.
* A graph can also be **directed** (like a follower network, where A follows B does not imply B follows A) or **undirected** (like a molecule, where the relation between atoms goes both ways). Edges can connect different nodes or one node to itself (self-edges), but not all nodes need to be connected.
If you want to use your data, you must first consider its best characterisation (homogeneous/heterogeneous, directed/undirected, and so on).
### What are graphs used for?
Let's look at a panel of possible tasks we can do on graphs.
At the **graph level**, the main tasks are:
- graph generation, used in drug discovery to generate new plausible molecules,
- graph evolution (given a graph, predict how it will evolve over time), used in physics to predict the evolution of systems
- graph level prediction (categorisation or regression tasks from graphs), such as predicting the toxicity of molecules.
At the **node level**, it's usually a node property prediction. For example, [Alphafold](https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology) uses node property prediction to predict the 3D coordinates of atoms given the overall graph of the molecule, and therefore predict how molecules get folded in 3D space, a hard bio-chemistry problem.
At the **edge level**, it's either edge property prediction or missing edge prediction. Edge property prediction helps drug side effect prediction predict adverse side effects given a pair of drugs. Missing edge prediction is used in recommendation systems to predict whether two nodes in a graph are related.
It is also possible to work at the **sub-graph level** on community detection or subgraph property prediction. Social networks use community detection to determine how people are connected. Subgraph property prediction can be found in itinerary systems (such as [Google Maps](https://www.deepmind.com/blog/traffic-prediction-with-advanced-graph-neural-networks)) to predict estimated times of arrival.
Working on these tasks can be done in two ways.
When you want to predict the evolution of a specific graph, you work in a **transductive** setting, where everything (training, validation, and testing) is done on the same single graph. *If this is your setup, be careful! Creating train/eval/test datasets from a single graph is not trivial.* However, a lot of the work is done using different graphs (separate train/eval/test splits), which is called an **inductive** setting.
### How do we represent graphs?
The common ways to represent a graph to process and operate it are either:
* as the set of all its edges (possibly complemented with the set of all its nodes)
* or as the adjacency matrix between all its nodes. An adjacency matrix is a square matrix (of node size * node size) that indicates which nodes are directly connected to which others (where \(A_{ij} = 1\) if \(n_i\) and \(n_j\) are connected, else 0). *Note: most graphs are not densely connected and therefore have sparse adjacency matrices, which can make computations harder.*
However, though these representations seem familiar, do not be fooled!
Graphs are very different from typical objects used in ML because their topology is more complex than just "a sequence" (such as text and audio) or "an ordered grid" (images and videos, for example)): even if they can be represented as lists or matrices, their representation should not be considered an ordered object!
But what does this mean? If you have a sentence and shuffle its words, you create a new sentence. If you have an image and rearrange its columns, you create a new image.
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/assembled_hf.png" width="500" />
<figcaption>On the left, the Hugging Face logo - on the right, a shuffled Hugging Face logo, which is quite a different new image.</figcaption>
</figure>
</div>
This is not the case for a graph: if you shuffle its edge list or the columns of its adjacency matrix, it is still the same graph. (We explain this more formally a bit lower, look for permutation invariance).
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/assembled_graphs.png" width="1000" />
<figcaption>On the left, a small graph (nodes in yellow, edges in orange). In the centre, its adjacency matrix, with columns and rows ordered in the alphabetical node order: on the row for node A (first row), we can read that it is connected to E and C. On the right, a shuffled adjacency matrix (the columns are no longer sorted alphabetically), which is also a valid representation of the graph: A is still connected to E and C.</figcaption>
</figure>
</div>
## Graph representations through ML
The usual process to work on graphs with machine learning is first to generate a meaningful representation for your items of interest (nodes, edges, or full graphs depending on your task), then to use these to train a predictor for your target task. We want (as in other modalities) to constrain the mathematical representations of your objects so that similar objects are mathematically close. However, this similarity is hard to define strictly in graph ML: for example, are two nodes more similar when they have the same labels or the same neighbours?
Note: *In the following sections, we will focus on generating node representations.
Once you have node-level representations, it is possible to obtain edge or graph-level information. For edge-level information, you can concatenate node pair representations or do a dot product. For graph-level information, it is possible to do a global pooling (average, sum, etc.) on the concatenated tensor of all the node-level representations. Still, it will smooth and lose information over the graph -- a recursive hierarchical pooling can make more sense, or add a virtual node, connected to all other nodes in the graph, and use its representation as the overall graph representation.*
### Pre-neural approaches
#### Simply using engineered features
Before neural networks, graphs and their items of interest could be represented as combinations of features, in a task-specific fashion. Now, these features are still used for data augmentation and [semi-supervised learning](https://arxiv.org/abs/2202.08871), though [more complex feature generation methods](https://arxiv.org/abs/2208.11973) exist; it can be essential to find how best to provide them to your network depending on your task.
**Node-level** features can give information about importance (how important is this node for the graph?) and/or structure based (what is the shape of the graph around the node?), and can be combined.
The node **centrality** measures the node importance in the graph. It can be computed recursively by summing the centrality of each node’s neighbours until convergence, or through shortest distance measures between nodes, for example. The node **degree** is the quantity of direct neighbours it has. The **clustering coefficient** measures how connected the node neighbours are. **Graphlets degree vectors** count how many different graphlets are rooted at a given node, where graphlets are all the mini graphs you can create with a given number of connected nodes (with three connected nodes, you can have a line with two edges, or a triangle with three edges).
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/graphlets.png" width="700" />
<figcaption>The 2-to 5-node graphlets (Pržulj, 2007)</figcaption>
</figure>
</div>
**Edge-level** features complement the representation with more detailed information about the connectedness of the nodes, and include the **shortest distance** between two nodes, their **common neighbours**, and their **Katz index** (which is the number of possible walks of up to a certain length between two nodes - it can be computed directly from the adjacency matrix).
**Graph level features** contain high-level information about graph similarity and specificities. Total **graphlet counts**, though computationally expensive, provide information about the shape of sub-graphs. **Kernel methods** measure similarity between graphs through different "bag of nodes" methods (similar to bag of words).
### Walk-based approaches
[**Walk-based approaches**](https://en.wikipedia.org/wiki/Random_walk) use the probability of visiting a node j from a node i on a random walk to define similarity metrics; these approaches combine both local and global information. [**Node2Vec**](https://snap.stanford.edu/node2vec/), for example, simulates random walks between nodes of a graph, then processes these walks with a skip-gram, [much like we would do with words in sentences](https://arxiv.org/abs/1301.3781), to compute embeddings. These approaches can also be used to [accelerate computations](https://arxiv.org/abs/1208.3071) of the [**Page Rank method**](http://infolab.stanford.edu/pub/papers/google.pdf), which assigns an importance score to each node (based on its connectivity to other nodes, evaluated as its frequency of visit by random walk, for example).
However, these methods have limits: they cannot obtain embeddings for new nodes, do not capture structural similarity between nodes finely, and cannot use added features.
## Graph Neural Networks
Neural networks can generalise to unseen data. Given the representation constraints we evoked earlier, what should a good neural network be to work on graphs?
It should:
- be permutation invariant:
- Equation: \\(f(P(G))=f(G)\\) with f the network, P the permutation function, G the graph
- Explanation: the representation of a graph and its permutations should be the same after going through the network
- be permutation equivariant
- Equation: \\(P(f(G))=f(P(G))\\) with f the network, P the permutation function, G the graph
- Explanation: permuting the nodes before passing them to the network should be equivalent to permuting their representations
Typical neural networks, such as RNNs or CNNs are not permutation invariant. A new architecture, the [Graph Neural Network](https://ieeexplore.ieee.org/abstract/document/1517930), was therefore introduced (initially as a state-based machine).
A GNN is made of successive layers. A GNN layer represents a node as the combination (**aggregation**) of the representations of its neighbours and itself from the previous layer (**message passing**), plus usually an activation to add some nonlinearity.
**Comparison to other models**: A CNN can be seen as a GNN with fixed neighbour sizes (through the sliding window) and ordering (it is not permutation equivariant). A [Transformer](https://arxiv.org/abs/1706.03762v3) without positional embeddings can be seen as a GNN on a fully-connected input graph.
### Aggregation and message passing
There are many ways to aggregate messages from neighbour nodes, summing, averaging, for example. Some notable works following this idea include:
- [Graph Convolutional Networks](https://tkipf.github.io/graph-convolutional-networks/) averages the normalised representation of the neighbours for a node (most GNNs are actually GCNs);
- [Graph Attention Networks](https://petar-v.com/GAT/) learn to weigh the different neighbours based on their importance (like transformers);
- [GraphSAGE](https://snap.stanford.edu/graphsage/) samples neighbours at different hops before aggregating their information in several steps with max pooling.
- [Graph Isomorphism Networks](https://arxiv.org/pdf/1810.00826v3.pdf) aggregates representation by applying an MLP to the sum of the neighbours' node representations.
**Choosing an aggregation**: Some aggregation techniques (notably mean/max pooling) can encounter failure cases when creating representations which finely differentiate nodes with different neighbourhoods of similar nodes (ex: through mean pooling, a neighbourhood with 4 nodes, represented as 1,1,-1,-1, averaged as 0, is not going to be different from one with only 3 nodes represented as -1, 0, 1).
### GNN shape and the over-smoothing problem
At each new layer, the node representation includes more and more nodes.
A node, through the first layer, is the aggregation of its direct neighbours. Through the second layer, it is still the aggregation of its direct neighbours, but this time, their representations include their own neighbours (from the first layer). After n layers, the representation of all nodes becomes an aggregation of all their neighbours at distance n, therefore, of the full graph if its diameter is smaller than n!
If your network has too many layers, there is a risk that each node becomes an aggregation of the full graph (and that node representations converge to the same one for all nodes). This is called **the oversmoothing problem**
This can be solved by :
- scaling the GNN to have a layer number small enough to not approximate each node as the whole network (by first analysing the graph diameter and shape)
- increasing the complexity of the layers
- adding non message passing layers to process the messages (such as simple MLPs)
- adding skip-connections.
The oversmoothing problem is an important area of study in graph ML, as it prevents GNNs to scale up, like Transformers have been shown to in other modalities.
## Graph Transformers
A Transformer without its positional encoding layer is permutation invariant, and Transformers are known to scale well, so recently, people have started looking at adapting Transformers to graphs ([Survey)](https://github.com/ChandlerBang/awesome-graph-transformer). Most methods focus on the best ways to represent graphs by looking for the best features and best ways to represent positional information and changing the attention to fit this new data.
Here are some interesting methods which got state-of-the-art results or close on one of the hardest available benchmarks as of writing, [Stanford's Open Graph Benchmark](https://ogb.stanford.edu/):
- [*Graph Transformer for Graph-to-Sequence Learning*](https://arxiv.org/abs/1911.07470) (Cai and Lam, 2020) introduced a Graph Encoder, which represents nodes as a concatenation of their embeddings and positional embeddings, node relations as the shortest paths between them, and combine both in a relation-augmented self attention.
- [*Rethinking Graph Transformers with Spectral Attention*](https://arxiv.org/abs/2106.03893) (Kreuzer et al, 2021) introduced Spectral Attention Networks (SANs). These combine node features with learned positional encoding (computed from Laplacian eigenvectors/values), to use as keys and queries in the attention, with attention values being the edge features.
- [*GRPE: Relative Positional Encoding for Graph Transformer*](https://arxiv.org/abs/2201.12787) (Park et al, 2021) introduced the Graph Relative Positional Encoding Transformer. It represents a graph by combining a graph-level positional encoding with node information, edge level positional encoding with node information, and combining both in the attention.
- [*Global Self-Attention as a Replacement for Graph Convolution*](https://arxiv.org/abs/2108.03348) (Hussain et al, 2021) introduced the Edge Augmented Transformer. This architecture embeds nodes and edges separately, and aggregates them in a modified attention.
- [*Do Transformers Really Perform Badly for Graph Representation*](https://arxiv.org/abs/2106.05234) (Ying et al, 2021) introduces Microsoft's [**Graphormer**](https://www.microsoft.com/en-us/research/project/graphormer/), which won first place on the OGB when it came out. This architecture uses node features as query/key/values in the attention, and sums their representation with a combination of centrality, spatial, and edge encodings in the attention mechanism.
The most recent approach is [*Pure Transformers are Powerful Graph Learners*](https://arxiv.org/abs/2207.02505) (Kim et al, 2022), which introduced **TokenGT**. This method represents input graphs as a sequence of node and edge embeddings (augmented with orthonormal node identifiers and trainable type identifiers), with no positional embedding, and provides this sequence to Transformers as input. It is extremely simple, yet smart!
A bit different, [*Recipe for a General, Powerful, Scalable Graph Transformer*](https://arxiv.org/abs/2205.12454) (Rampášek et al, 2022) introduces, not a model, but a framework, called **GraphGPS**. It allows to combine message passing networks with linear (long range) transformers to create hybrid networks easily. This framework also contains several tools to compute positional and structural encodings (node, graph, edge level), feature augmentation, random walks, etc.
Using transformers for graphs is still very much a field in its infancy, but it looks promising, as it could alleviate several limitations of GNNs, such as scaling to larger/denser graphs, or increasing model size without oversmoothing.
# Further resources
If you want to delve deeper, you can look at some of these courses:
- Academic format
- [Stanford's Machine Learning with Graphs](https://web.stanford.edu/class/cs224w/)
- [McGill's Graph Representation Learning](https://cs.mcgill.ca/~wlh/comp766/)
- Video format
- [Geometric Deep Learning course](https://www.youtube.com/playlist?list=PLn2-dEmQeTfSLXW8yXP4q_Ii58wFdxb3C)
- Books
- [Graph Representation Learning*, Hamilton](https://www.cs.mcgill.ca/~wlh/grl_book/)
- Surveys
- [Graph Neural Networks Study Guide](https://github.com/dair-ai/GNNs-Recipe)
- Research directions
- [GraphML in 2023](https://towardsdatascience.com/graph-ml-in-2023-the-state-of-affairs-1ba920cb9232) summarizes plausible interesting directions for GraphML in 2023.
Nice libraries to work on graphs are [PyGeometric](https://pytorch-geometric.readthedocs.io/en/latest/) or the [Deep Graph Library](https://www.dgl.ai/) (for graph ML) and [NetworkX](https://networkx.org/) (to manipulate graphs more generally).
If you need quality benchmarks you can check out:
- [OGB, the Open Graph Benchmark](https://ogb.stanford.edu/): the reference graph benchmark datasets, for different tasks and data scales.
- [Benchmarking GNNs](https://github.com/graphdeeplearning/benchmarking-gnns): Library and datasets to benchmark graph ML networks and their expressivity. The associated paper notably studies which datasets are relevant from a statistical standpoint, what graph properties they allow to evaluate, and which datasets should no longer be used as benchmarks.
- [Long Range Graph Benchmark](https://github.com/vijaydwivedi75/lrgb): recent (Nov2022) benchmark looking at long range graph information
- [Taxonomy of Benchmarks in Graph Representation Learning](https://openreview.net/pdf?id=EM-Z3QFj8n): paper published at the 2022 Learning on Graphs conference, which analyses and sort existing benchmarks datasets
For more datasets, see:
- [Paper with code Graph tasks Leaderboards](https://paperswithcode.com/area/graphs): Leaderboard for public datasets and benchmarks - careful, not all the benchmarks on this leaderboard are still relevant
- [TU datasets](https://chrsmrrs.github.io/datasets/docs/datasets/): Compilation of publicly available datasets, now ordered by categories and features. Most of these datasets can also be loaded with PyG, and a number of them have been ported to Datasets
- [SNAP datasets: Stanford Large Network Dataset Collection](https://snap.stanford.edu/data/):
- [MoleculeNet datasets](https://moleculenet.org/datasets-1)
- [Relational datasets repository](https://relational.fit.cvut.cz/)
### External images attribution
Emojis in the thumbnail come from Openmoji (CC-BY-SA 4.0), the Graphlets figure comes from *Biological network comparison using graphlet degree distribution* (Pržulj, 2007).
| huggingface/blog/blob/main/intro-graphml.md |
--
title: "Transformer-based Encoder-Decoder Models"
thumbnail: /blog/assets/05_encoder_decoder/thumbnail.png
authors:
- user: patrickvonplaten
---
# Transformers-based Encoder-Decoder Models
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
# **Transformer-based Encoder-Decoder Models**
```bash
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95
```
The *transformer-based* encoder-decoder model was introduced by Vaswani
et al. in the famous [Attention is all you need
paper](https://arxiv.org/abs/1706.03762) and is today the *de-facto*
standard encoder-decoder architecture in natural language processing
(NLP).
Recently, there has been a lot of research on different *pre-training*
objectives for transformer-based encoder-decoder models, *e.g.* T5,
Bart, Pegasus, ProphetNet, Marge, *etc*\..., but the model architecture
has stayed largely the same.
The goal of the blog post is to give an **in-detail** explanation of
**how** the transformer-based encoder-decoder architecture models
*sequence-to-sequence* problems. We will focus on the mathematical model
defined by the architecture and how the model can be used in inference.
Along the way, we will give some background on sequence-to-sequence
models in NLP and break down the *transformer-based* encoder-decoder
architecture into its **encoder** and **decoder** parts. We provide many
illustrations and establish the link between the theory of
*transformer-based* encoder-decoder models and their practical usage in
🤗Transformers for inference. Note that this blog post does *not* explain
how such models can be trained - this will be the topic of a future blog
post.
Transformer-based encoder-decoder models are the result of years of
research on _representation learning_ and _model architectures_. This
notebook provides a short summary of the history of neural
encoder-decoder models. For more context, the reader is advised to read
this awesome [blog
post](https://ruder.io/a-review-of-the-recent-history-of-nlp/) by
Sebastion Ruder. Additionally, a basic understanding of the
_self-attention architecture_ is recommended. The following blog post by
Jay Alammar serves as a good refresher on the original Transformer model
[here](http://jalammar.github.io/illustrated-transformer/).
At the time of writing this notebook, 🤗Transformers comprises the
encoder-decoder models *T5*, *Bart*, *MarianMT*, and *Pegasus*, which
are summarized in the docs under [model
summaries](https://huggingface.co/transformers/model_summary.html#sequence-to-sequence-models).
The notebook is divided into four parts:
- **Background** - *A short history of neural encoder-decoder models
is given with a focus on RNN-based models.*
- **Encoder-Decoder** - *The transformer-based encoder-decoder model
is presented and it is explained how the model is used for
inference.*
- **Encoder** - *The encoder part of the model is explained in
detail.*
- **Decoder** - *The decoder part of the model is explained in
detail.*
Each part builds upon the previous part, but can also be read on its
own.
## **Background**
Tasks in natural language generation (NLG), a subfield of NLP, are best
expressed as sequence-to-sequence problems. Such tasks can be defined as
finding a model that maps a sequence of input words to a sequence of
target words. Some classic examples are *summarization* and
*translation*. In the following, we assume that each word is encoded
into a vector representation. \\(n\\) input words can then be represented as
a sequence of \\(n\\) input vectors:
$$\mathbf{X}_{1:n} = \{\mathbf{x}_1, \ldots, \mathbf{x}_n\}.$$
Consequently, sequence-to-sequence problems can be solved by finding a
mapping \\(f\\) from an input sequence of \\(n\\) vectors \\(\mathbf{X}_{1:n}\\) to
a sequence of \\(m\\) target vectors \\(\mathbf{Y}_{1:m}\\), whereas the number
of target vectors \\(m\\) is unknown apriori and depends on the input
sequence:
$$ f: \mathbf{X}_{1:n} \to \mathbf{Y}_{1:m}. $$
[Sutskever et al. (2014)](https://arxiv.org/abs/1409.3215) noted that
deep neural networks (DNN)s, \"*despite their flexibility and power can
only define a mapping whose inputs and targets can be sensibly encoded
with vectors of fixed dimensionality.*\" \\({}^1\\)
Using a DNN model \\({}^2\\) to solve sequence-to-sequence problems would
therefore mean that the number of target vectors \\(m\\) has to be known
*apriori* and would have to be independent of the input
\\(\mathbf{X}_{1:n}\\). This is suboptimal because, for tasks in NLG, the
number of target words usually depends on the input \\(\mathbf{X}_{1:n}\\)
and not just on the input length \\(n\\). *E.g.*, an article of 1000 words
can be summarized to both 200 words and 100 words depending on its
content.
In 2014, [Cho et al.](https://arxiv.org/pdf/1406.1078.pdf) and
[Sutskever et al.](https://arxiv.org/abs/1409.3215) proposed to use an
encoder-decoder model purely based on recurrent neural networks (RNNs)
for *sequence-to-sequence* tasks. In contrast to DNNS, RNNs are capable
of modeling a mapping to a variable number of target vectors. Let\'s
dive a bit deeper into the functioning of RNN-based encoder-decoder
models.
During inference, the encoder RNN encodes an input sequence
\\(\mathbf{X}_{1:n}\\) by successively updating its *hidden state* \\({}^3\\).
After having processed the last input vector \\(\mathbf{x}_n\\), the
encoder\'s hidden state defines the input encoding \\(\mathbf{c}\\). Thus,
the encoder defines the mapping:
$$ f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c}. $$
Then, the decoder\'s hidden state is initialized with the input encoding
and during inference, the decoder RNN is used to auto-regressively
generate the target sequence. Let\'s explain.
Mathematically, the decoder defines the probability distribution of a
target sequence \\(\mathbf{Y}_{1:m}\\) given the hidden state \\(\mathbf{c}\\):
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}). $$
By Bayes\' rule the distribution can be decomposed into conditional
distributions of single target vectors as follows:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}). $$
Thus, if the architecture can model the conditional distribution of the
next target vector, given all previous target vectors:
$$ p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\},$$
then it can model the distribution of any target vector sequence given
the hidden state \\(\mathbf{c}\\) by simply multiplying all conditional
probabilities.
So how does the RNN-based decoder architecture model
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\)?
In computational terms, the model sequentially maps the previous inner
hidden state \\(\mathbf{c}_{i-1}\\) and the previous target vector
\\(\mathbf{y}_{i-1}\\) to the current inner hidden state \\(\mathbf{c}_i\\) and a
*logit vector* \\(\mathbf{l}_i\\) (shown in dark red below):
$$ f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i.$$
\\(\mathbf{c}_0\\) is thereby defined as \\(\mathbf{c}\\) being the output
hidden state of the RNN-based encoder. Subsequently, the *softmax*
operation is used to transform the logit vector \\(\mathbf{l}_i\\) to a
conditional probablity distribution of the next target vector:
$$ p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ with } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}}). $$
For more detail on the logit vector and the resulting probability
distribution, please see footnote \\({}^4\\). From the above equation, we
can see that the distribution of the current target vector
\\(\mathbf{y}_i\\) is directly conditioned on the previous target vector
\\(\mathbf{y}_{i-1}\\) and the previous hidden state \\(\mathbf{c}_{i-1}\\).
Because the previous hidden state \\(\mathbf{c}_{i-1}\\) depends on all
previous target vectors \\(\mathbf{y}_0, \ldots, \mathbf{y}_{i-2}\\), it can
be stated that the RNN-based decoder *implicitly* (*e.g.* *indirectly*)
models the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\).
The space of possible target vector sequences \\(\mathbf{Y}_{1:m}\\) is
prohibitively large so that at inference, one has to rely on decoding
methods \\({}^5\\) that efficiently sample high probability target vector
sequences from \\(p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c})\\).
Given such a decoding method, during inference, the next input vector
\\(\mathbf{y}_i\\) can then be sampled from
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\)
and is consequently appended to the input sequence so that the decoder
RNN then models
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c})\\)
to sample the next input vector \\(\mathbf{y}_{i+1}\\) and so on in an
*auto-regressive* fashion.
An important feature of RNN-based encoder-decoder models is the
definition of *special* vectors, such as the \\(\text{EOS}\\) and
\\(\text{BOS}\\) vector. The \\(\text{EOS}\\) vector often represents the final
input vector \\(\mathbf{x}_n\\) to \"cue\" the encoder that the input
sequence has ended and also defines the end of the target sequence. As
soon as the \\(\text{EOS}\\) is sampled from a logit vector, the generation
is complete. The \\(\text{BOS}\\) vector represents the input vector
\\(\mathbf{y}_0\\) fed to the decoder RNN at the very first decoding step.
To output the first logit \\(\mathbf{l}_1\\), an input is required and since
no input has been generated at the first step a special \\(\text{BOS}\\)
input vector is fed to the decoder RNN. Ok - quite complicated! Let\'s
illustrate and walk through an example.
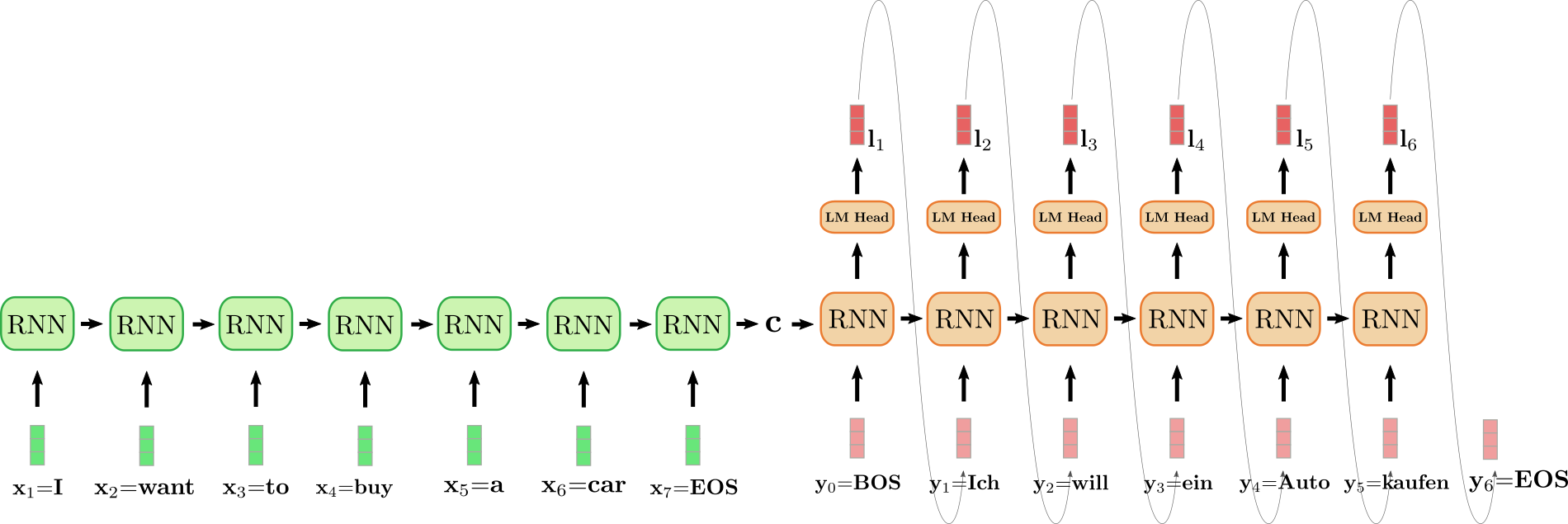
The unfolded RNN encoder is colored in green and the unfolded RNN
decoder is colored in red.
The English sentence \"I want to buy a car\", represented by
\\(\mathbf{x}_1 = \text{I}\\), \\(\mathbf{x}_2 = \text{want}\\),
\\(\mathbf{x}_3 = \text{to}\\), \\(\mathbf{x}_4 = \text{buy}\\),
\\(\mathbf{x}_5 = \text{a}\\), \\(\mathbf{x}_6 = \text{car}\\) and
\\(\mathbf{x}_7 = \text{EOS}\\) is translated into German: \"Ich will ein
Auto kaufen\" defined as \\(\mathbf{y}_0 = \text{BOS}\\),
\\(\mathbf{y}_1 = \text{Ich}\\), \\(\mathbf{y}_2 = \text{will}\\),
\\(\mathbf{y}_3 = \text{ein}\\),
\\(\mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen}\\) and
\\(\mathbf{y}_6=\text{EOS}\\). To begin with, the input vector
\\(\mathbf{x}_1 = \text{I}\\) is processed by the encoder RNN and updates
its hidden state. Note that because we are only interested in the final
encoder\'s hidden state \\(\mathbf{c}\\), we can disregard the RNN
encoder\'s target vector. The encoder RNN then processes the rest of the
input sentence \\(\text{want}\\), \\(\text{to}\\), \\(\text{buy}\\), \\(\text{a}\\),
\\(\text{car}\\), \\(\text{EOS}\\) in the same fashion, updating its hidden
state at each step until the vector \\(\mathbf{x}_7={EOS}\\) is reached
\\({}^6\\). In the illustration above the horizontal arrow connecting the
unfolded encoder RNN represents the sequential updates of the hidden
state. The final hidden state of the encoder RNN, represented by
\\(\mathbf{c}\\) then completely defines the *encoding* of the input
sequence and is used as the initial hidden state of the decoder RNN.
This can be seen as *conditioning* the decoder RNN on the encoded input.
To generate the first target vector, the decoder is fed the \\(\text{BOS}\\)
vector, illustrated as \\(\mathbf{y}_0\\) in the design above. The target
vector of the RNN is then further mapped to the logit vector
\\(\mathbf{l}_1\\) by means of the *LM Head* feed-forward layer to define
the conditional distribution of the first target vector as explained
above:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{c}). $$
The word \\(\text{Ich}\\) is sampled (shown by the grey arrow, connecting
\\(\mathbf{l}_1\\) and \\(\mathbf{y}_1\\)) and consequently the second target
vector can be sampled:
$$ \text{will} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \text{Ich}, \mathbf{c}). $$
And so on until at step \\(i=6\\), the \\(\text{EOS}\\) vector is sampled from
\\(\mathbf{l}_6\\) and the decoding is finished. The resulting target
sequence amounts to
\\(\mathbf{Y}_{1:6} = \{\mathbf{y}_1, \ldots, \mathbf{y}_6\}\\), which is
\"Ich will ein Auto kaufen\" in our example above.
To sum it up, an RNN-based encoder-decoder model, represented by
\\(f_{\theta_{\text{enc}}}\\) and \\( p_{\theta_{\text{dec}}} \\) defines
the distribution \\(p(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})\\) by
factorization:
$$ p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \text{ with } \mathbf{c}=f_{\theta_{enc}}(X). $$
During inference, efficient decoding methods can auto-regressively
generate the target sequence \\(\mathbf{Y}_{1:m}\\).
The RNN-based encoder-decoder model took the NLG community by storm. In
2016, Google announced to fully replace its heavily feature engineered
translation service by a single RNN-based encoder-decoder model (see
[here](https://www.oreilly.com/radar/what-machine-learning-means-for-software-development/#:~:text=Machine%20learning%20is%20already%20making,of%20code%20in%20Google%20Translate.)).
Nevertheless, RNN-based encoder-decoder models have two pitfalls. First,
RNNs suffer from the vanishing gradient problem, making it very
difficult to capture long-range dependencies, *cf.* [Hochreiter et al.
(2001)](https://www.bioinf.jku.at/publications/older/ch7.pdf). Second,
the inherent recurrent architecture of RNNs prevents efficient
parallelization when encoding, *cf.* [Vaswani et al.
(2017)](https://arxiv.org/abs/1706.03762).
------------------------------------------------------------------------
\\({}^1\\) The original quote from the paper is \"*Despite their flexibility
and power, DNNs can only be applied to problems whose inputs and targets
can be sensibly encoded with vectors of fixed dimensionality*\", which
is slightly adapted here.
\\({}^2\\) The same holds essentially true for convolutional neural networks
(CNNs). While an input sequence of variable length can be fed into a
CNN, the dimensionality of the target will always be dependent on the
input dimensionality or fixed to a specific value.
\\({}^3\\) At the first step, the hidden state is initialized as a zero
vector and fed to the RNN together with the first input vector
\\(\mathbf{x}_1\\).
\\({}^4\\) A neural network can define a probability distribution over all
words, *i.e.* \\(p(\mathbf{y} | \mathbf{c}, \mathbf{Y}_{0: i-1})\\) as
follows. First, the network defines a mapping from the inputs
\\(\mathbf{c}, \mathbf{Y}_{0: i-1}\\) to an embedded vector representation
\\(\mathbf{y'}\\), which corresponds to the RNN target vector. The embedded
vector representation \\(\mathbf{y'}\\) is then passed to the \"language
model head\" layer, which means that it is multiplied by the *word
embedding matrix*, *i.e.* \\(\mathbf{Y}^{\text{vocab}}\\), so that a score
between \\(\mathbf{y'}\\) and each encoded vector
\\(\mathbf{y} \in \mathbf{Y}^{\text{vocab}}\\) is computed. The resulting
vector is called the logit vector
\\( \mathbf{l} = \mathbf{Y}^{\text{vocab}} \mathbf{y'} \\) and can be
mapped to a probability distribution over all words by applying a
softmax operation:
\\(p(\mathbf{y} | \mathbf{c}) = \text{Softmax}(\mathbf{Y}^{\text{vocab}} \mathbf{y'}) = \text{Softmax}(\mathbf{l})\\).
\\({}^5\\) Beam-search decoding is an example of such a decoding method.
Different decoding methods are out of scope for this notebook. The
reader is advised to refer to this [interactive
notebook](https://huggingface.co/blog/how-to-generate) on decoding
methods.
\\({}^6\\) [Sutskever et al. (2014)](https://arxiv.org/abs/1409.3215)
reverses the order of the input so that in the above example the input
vectors would correspond to \\(\mathbf{x}_1 = \text{car}\\),
\\(\mathbf{x}_2 = \text{a}\\), \\(\mathbf{x}_3 = \text{buy}\\),
\\(\mathbf{x}_4 = \text{to}\\), \\(\mathbf{x}_5 = \text{want}\\),
\\(\mathbf{x}_6 = \text{I}\\) and \\(\mathbf{x}_7 = \text{EOS}\\). The
motivation is to allow for a shorter connection between corresponding
word pairs such as \\(\mathbf{x}_6 = \text{I}\\) and
\\(\mathbf{y}_1 = \text{Ich}\\). The research group emphasizes that the
reversal of the input sequence was a key reason for their model\'s
improved performance on machine translation.
## **Encoder-Decoder**
In 2017, Vaswani et al. introduced the **Transformer** and thereby gave
birth to *transformer-based* encoder-decoder models.
Analogous to RNN-based encoder-decoder models, transformer-based
encoder-decoder models consist of an encoder and a decoder which are
both stacks of *residual attention blocks*. The key innovation of
transformer-based encoder-decoder models is that such residual attention
blocks can process an input sequence \\(\mathbf{X}_{1:n}\\) of variable
length \\(n\\) without exhibiting a recurrent structure. Not relying on a
recurrent structure allows transformer-based encoder-decoders to be
highly parallelizable, which makes the model orders of magnitude more
computationally efficient than RNN-based encoder-decoder models on
modern hardware.
As a reminder, to solve a *sequence-to-sequence* problem, we need to
find a mapping of an input sequence \\(\mathbf{X}_{1:n}\\) to an output
sequence \\(\mathbf{Y}_{1:m}\\) of variable length \\(m\\). Let\'s see how
transformer-based encoder-decoder models are used to find such a
mapping.
Similar to RNN-based encoder-decoder models, the transformer-based
encoder-decoder models define a conditional distribution of target
vectors \\(\mathbf{Y}_{1:n}\\) given an input sequence \\(\mathbf{X}_{1:n}\\):
$$
p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}).
$$
The transformer-based encoder part encodes the input sequence
\\(\mathbf{X}_{1:n}\\) to a *sequence* of *hidden states*
\\(\mathbf{\overline{X}}_{1:n}\\), thus defining the mapping:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. $$
The transformer-based decoder part then models the conditional
probability distribution of the target vector sequence
\\(\mathbf{Y}_{1:n}\\) given the sequence of encoded hidden states
\\(\mathbf{\overline{X}}_{1:n}\\):
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:n} | \mathbf{\overline{X}}_{1:n}).$$
By Bayes\' rule, this distribution can be factorized to a product of
conditional probability distribution of the target vector \\(\mathbf{y}_i\\)
given the encoded hidden states \\(\mathbf{\overline{X}}_{1:n}\\) and all
previous target vectors \\(\mathbf{Y}_{0:i-1}\\):
$$
p_{\theta_{dec}}(\mathbf{Y}_{1:n} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{n} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}). $$
The transformer-based decoder hereby maps the sequence of encoded hidden
states \\(\mathbf{\overline{X}}_{1:n}\\) and all previous target vectors
\\(\mathbf{Y}_{0:i-1}\\) to the *logit* vector \\(\mathbf{l}_i\\). The logit
vector \\(\mathbf{l}_i\\) is then processed by the *softmax* operation to
define the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\),
just as it is done for RNN-based decoders. However, in contrast to
RNN-based decoders, the distribution of the target vector \\(\mathbf{y}_i\\)
is *explicitly* (or directly) conditioned on all previous target vectors
\\(\mathbf{y}_0, \ldots, \mathbf{y}_{i-1}\\) as we will see later in more
detail. The 0th target vector \\(\mathbf{y}_0\\) is hereby represented by a
special \"begin-of-sentence\" \\(\text{BOS}\\) vector.
Having defined the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\),
we can now *auto-regressively* generate the output and thus define a
mapping of an input sequence \\(\mathbf{X}_{1:n}\\) to an output sequence
\\(\mathbf{Y}_{1:m}\\) at inference.
Let\'s visualize the complete process of *auto-regressive* generation of
*transformer-based* encoder-decoder models.
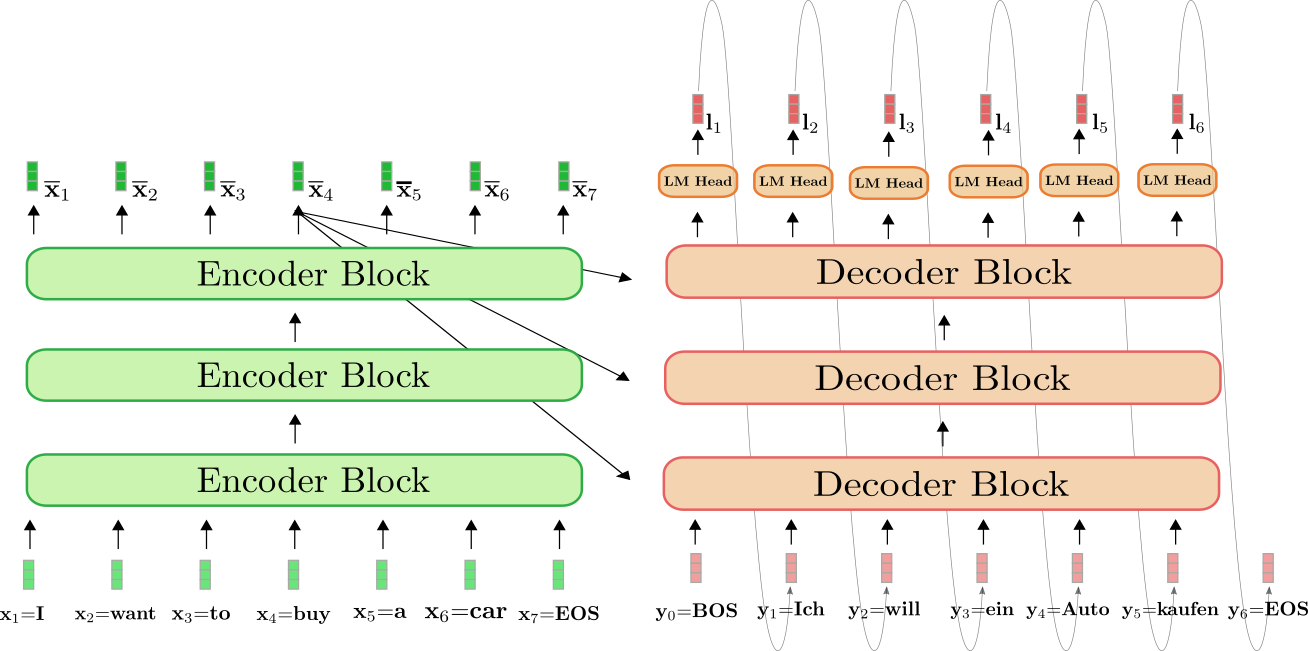
The transformer-based encoder is colored in green and the
transformer-based decoder is colored in red. As in the previous section,
we show how the English sentence \"I want to buy a car\", represented by
\\(\mathbf{x}_1 = \text{I}\\), \\(\mathbf{x}_2 = \text{want}\\),
\\(\mathbf{x}_3 = \text{to}\\), \\(\mathbf{x}_4 = \text{buy}\\),
\\(\mathbf{x}_5 = \text{a}\\), \\(\mathbf{x}_6 = \text{car}\\), and
\\(\mathbf{x}_7 = \text{EOS}\\) is translated into German: \"Ich will ein
Auto kaufen\" defined as \\(\mathbf{y}_0 = \text{BOS}\\),
\\(\mathbf{y}_1 = \text{Ich}\\), \\(\mathbf{y}_2 = \text{will}\\),
\\(\mathbf{y}_3 = \text{ein}\\),
\\(\mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen}\\), and
\\(\mathbf{y}_6=\text{EOS}\\).
To begin with, the encoder processes the complete input sequence
\\(\mathbf{X}_{1:7}\\) = \"I want to buy a car\" (represented by the light
green vectors) to a contextualized encoded sequence
\\(\mathbf{\overline{X}}_{1:7}\\). *E.g.* \\(\mathbf{\overline{x}}_4\\) defines
an encoding that depends not only on the input \\(\mathbf{x}_4\\) = \"buy\",
but also on all other words \"I\", \"want\", \"to\", \"a\", \"car\" and
\"EOS\", *i.e.* the context.
Next, the input encoding \\(\mathbf{\overline{X}}_{1:7}\\) together with the
BOS vector, *i.e.* \\(\mathbf{y}_0\\), is fed to the decoder. The decoder
processes the inputs \\(\mathbf{\overline{X}}_{1:7}\\) and \\(\mathbf{y}_0\\) to
the first logit \\(\mathbf{l}_1\\) (shown in darker red) to define the
conditional distribution of the first target vector \\(\mathbf{y}_1\\):
$$ p_{\theta_{enc, dec}}(\mathbf{y} | \mathbf{y}_0, \mathbf{X}_{1:7}) = p_{\theta_{enc, dec}}(\mathbf{y} | \text{BOS}, \text{I want to buy a car EOS}) = p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}). $$
Next, the first target vector \\(\mathbf{y}_1\\) = \\(\text{Ich}\\) is sampled
from the distribution (represented by the grey arrows) and can now be
fed to the decoder again. The decoder now processes both \\(\mathbf{y}_0\\)
= \"BOS\" and \\(\mathbf{y}_1\\) = \"Ich\" to define the conditional
distribution of the second target vector \\(\mathbf{y}_2\\):
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}). $$
We can sample again and produce the target vector \\(\mathbf{y}_2\\) =
\"will\". We continue in auto-regressive fashion until at step 6 the EOS
vector is sampled from the conditional distribution:
$$ \text{EOS} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). $$
And so on in auto-regressive fashion.
It is important to understand that the encoder is only used in the first
forward pass to map \\(\mathbf{X}_{1:n}\\) to \\(\mathbf{\overline{X}}_{1:n}\\).
As of the second forward pass, the decoder can directly make use of the
previously calculated encoding \\(\mathbf{\overline{X}}_{1:n}\\). For
clarity, let\'s illustrate the first and the second forward pass for our
example above.
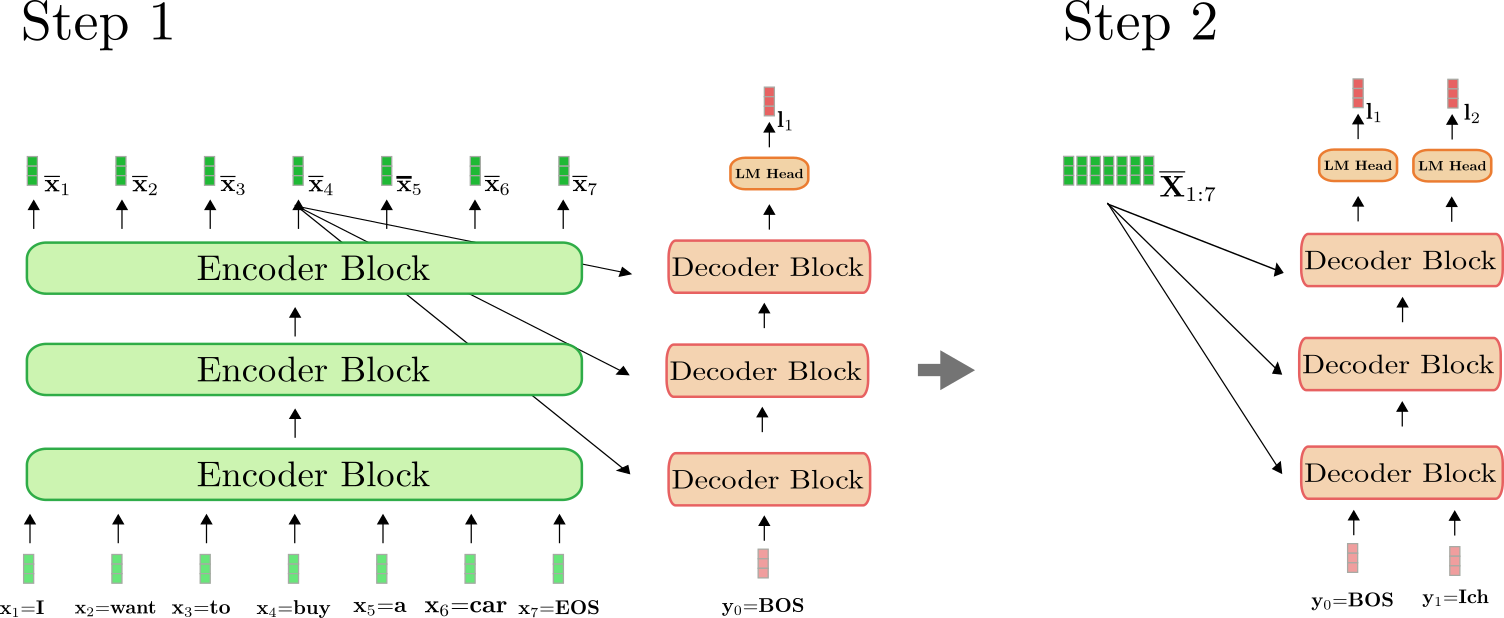
As can be seen, only in step \\(i=1\\) do we have to encode \"I want to buy
a car EOS\" to \\(\mathbf{\overline{X}}_{1:7}\\). At step \\(i=2\\), the
contextualized encodings of \"I want to buy a car EOS\" are simply
reused by the decoder.
In 🤗Transformers, this auto-regressive generation is done under-the-hood
when calling the `.generate()` method. Let\'s use one of our translation
models to see this in action.
```python
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# translate example
output_ids = model.generate(input_ids)[0]
# decode and print
print(tokenizer.decode(output_ids))
```
_Output:_
```
<pad> Ich will ein Auto kaufen
```
Calling `.generate()` does many things under-the-hood. First, it passes
the `input_ids` to the encoder. Second, it passes a pre-defined token, which is the \\(\text{<pad>}\\) symbol in the case of
`MarianMTModel` along with the encoded `input_ids` to the decoder.
Third, it applies the beam search decoding mechanism to
auto-regressively sample the next output word of the *last* decoder
output \\({}^1\\). For more detail on how beam search decoding works, one is
advised to read [this](https://huggingface.co/blog/how-to-generate) blog
post.
In the Appendix, we have included a code snippet that shows how a simple
generation method can be implemented \"from scratch\". To fully
understand how *auto-regressive* generation works under-the-hood, it is
highly recommended to read the Appendix.
To sum it up:
- The transformer-based encoder defines a mapping from the input
sequence \\(\mathbf{X}_{1:n}\\) to a contextualized encoding sequence
\\(\mathbf{\overline{X}}_{1:n}\\).
- The transformer-based decoder defines the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\).
- Given an appropriate decoding mechanism, the output sequence
\\(\mathbf{Y}_{1:m}\\) can auto-regressively be sampled from
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, m\}\\).
Great, now that we have gotten a general overview of how
*transformer-based* encoder-decoder models work, we can dive deeper into
both the encoder and decoder part of the model. More specifically, we
will see exactly how the encoder makes use of the self-attention layer
to yield a sequence of context-dependent vector encodings and how
self-attention layers allow for efficient parallelization. Then, we will
explain in detail how the self-attention layer works in the decoder
model and how the decoder is conditioned on the encoder\'s output with
*cross-attention* layers to define the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\).
Along, the way it will become obvious how transformer-based
encoder-decoder models solve the long-range dependencies problem of
RNN-based encoder-decoder models.
------------------------------------------------------------------------
\\({}^1\\) In the case of `"Helsinki-NLP/opus-mt-en-de"`, the decoding
parameters can be accessed
[here](https://s3.amazonaws.com/models.huggingface.co/bert/Helsinki-NLP/opus-mt-en-de/config.json),
where we can see that model applies beam search with `num_beams=6`.
## **Encoder**
As mentioned in the previous section, the *transformer-based* encoder
maps the input sequence to a contextualized encoding sequence:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. $$
Taking a closer look at the architecture, the transformer-based encoder
is a stack of residual _encoder blocks_. Each encoder block consists of
a **bi-directional** self-attention layer, followed by two feed-forward
layers. For simplicity, we disregard the normalization layers in this
notebook. Also, we will not further discuss the role of the two
feed-forward layers, but simply see it as a final vector-to-vector
mapping required in each encoder block \\({}^1\\). The bi-directional
self-attention layer puts each input vector
\\(\mathbf{x'}_j, \forall j \in \{1, \ldots, n\}\\) into relation with all
input vectors \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_n\\) and by doing so
transforms the input vector \\(\mathbf{x'}_j\\) to a more \"refined\"
contextual representation of itself, defined as \\(\mathbf{x''}_j\\).
Thereby, the first encoder block transforms each input vector of the
input sequence \\(\mathbf{X}_{1:n}\\) (shown in light green below) from a
*context-independent* vector representation to a *context-dependent*
vector representation, and the following encoder blocks further refine
this contextual representation until the last encoder block outputs the
final contextual encoding \\(\mathbf{\overline{X}}_{1:n}\\) (shown in darker
green below).
Let\'s visualize how the encoder processes the input sequence \"I want
to buy a car EOS\" to a contextualized encoding sequence. Similar to
RNN-based encoders, transformer-based encoders also add a special
\"end-of-sequence\" input vector to the input sequence to hint to the
model that the input vector sequence is finished \\({}^2\\).
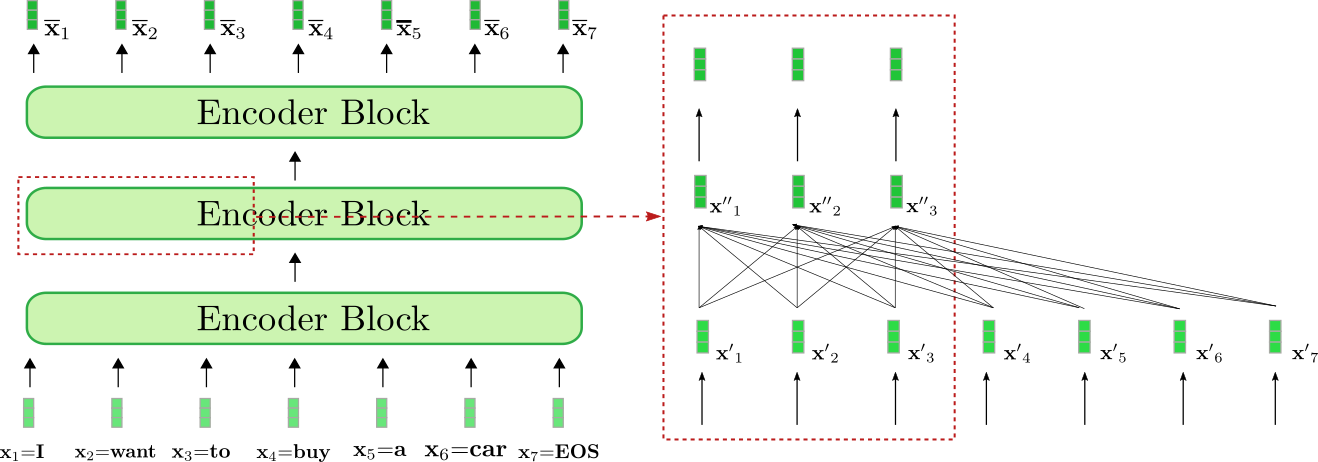
Our exemplary *transformer-based* encoder is composed of three encoder
blocks, whereas the second encoder block is shown in more detail in the
red box on the right for the first three input vectors
\\(\mathbf{x}_1, \mathbf{x}_2 and \mathbf{x}_3\\). The bi-directional
self-attention mechanism is illustrated by the fully-connected graph in
the lower part of the red box and the two feed-forward layers are shown
in the upper part of the red box. As stated before, we will focus only
on the bi-directional self-attention mechanism.
As can be seen each output vector of the self-attention layer
\\(\mathbf{x''}_i, \forall i \in \{1, \ldots, 7\}\\) depends *directly* on
*all* input vectors \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_7\\). This means,
*e.g.* that the input vector representation of the word \"want\", *i.e.*
\\(\mathbf{x'}_2\\), is put into direct relation with the word \"buy\",
*i.e.* \\(\mathbf{x'}_4\\), but also with the word \"I\",*i.e.*
\\(\mathbf{x'}_1\\). The output vector representation of \"want\", *i.e.*
\\(\mathbf{x''}_2\\), thus represents a more refined contextual
representation for the word \"want\".
Let\'s take a deeper look at how bi-directional self-attention works.
Each input vector \\(\mathbf{x'}_i\\) of an input sequence
\\(\mathbf{X'}_{1:n}\\) of an encoder block is projected to a key vector
\\(\mathbf{k}_i\\), value vector \\(\mathbf{v}_i\\) and query vector
\\(\mathbf{q}_i\\) (shown in orange, blue, and purple respectively below)
through three trainable weight matrices
\\(\mathbf{W}_q, \mathbf{W}_v, \mathbf{W}_k\\):
$$ \mathbf{q}_i = \mathbf{W}_q \mathbf{x'}_i,$$
$$ \mathbf{v}_i = \mathbf{W}_v \mathbf{x'}_i,$$
$$ \mathbf{k}_i = \mathbf{W}_k \mathbf{x'}_i, $$
$$ \forall i \in \{1, \ldots n \}.$$
Note, that the **same** weight matrices are applied to each input vector
\\(\mathbf{x}_i, \forall i \in \{i, \ldots, n\}\\). After projecting each
input vector \\(\mathbf{x}_i\\) to a query, key, and value vector, each
query vector \\(\mathbf{q}_j, \forall j \in \{1, \ldots, n\}\\) is compared
to all key vectors \\(\mathbf{k}_1, \ldots, \mathbf{k}_n\\). The more
similar one of the key vectors \\(\mathbf{k}_1, \ldots \mathbf{k}_n\\) is to
a query vector \\(\mathbf{q}_j\\), the more important is the corresponding
value vector \\(\mathbf{v}_j\\) for the output vector \\(\mathbf{x''}_j\\). More
specifically, an output vector \\(\mathbf{x''}_j\\) is defined as the
weighted sum of all value vectors \\(\mathbf{v}_1, \ldots, \mathbf{v}_n\\)
plus the input vector \\(\mathbf{x'}_j\\). Thereby, the weights are
proportional to the cosine similarity between \\(\mathbf{q}_j\\) and the
respective key vectors \\(\mathbf{k}_1, \ldots, \mathbf{k}_n\\), which is
mathematically expressed by
\\(\textbf{Softmax}(\mathbf{K}_{1:n}^\intercal \mathbf{q}_j)\\) as
illustrated in the equation below. For a complete description of the
self-attention layer, the reader is advised to take a look at
[this](http://jalammar.github.io/illustrated-transformer/) blog post or
the original [paper](https://arxiv.org/abs/1706.03762).
Alright, this sounds quite complicated. Let\'s illustrate the
bi-directional self-attention layer for one of the query vectors of our
example above. For simplicity, it is assumed that our exemplary
*transformer-based* decoder uses only a single attention head
`config.num_heads = 1` and that no normalization is applied.
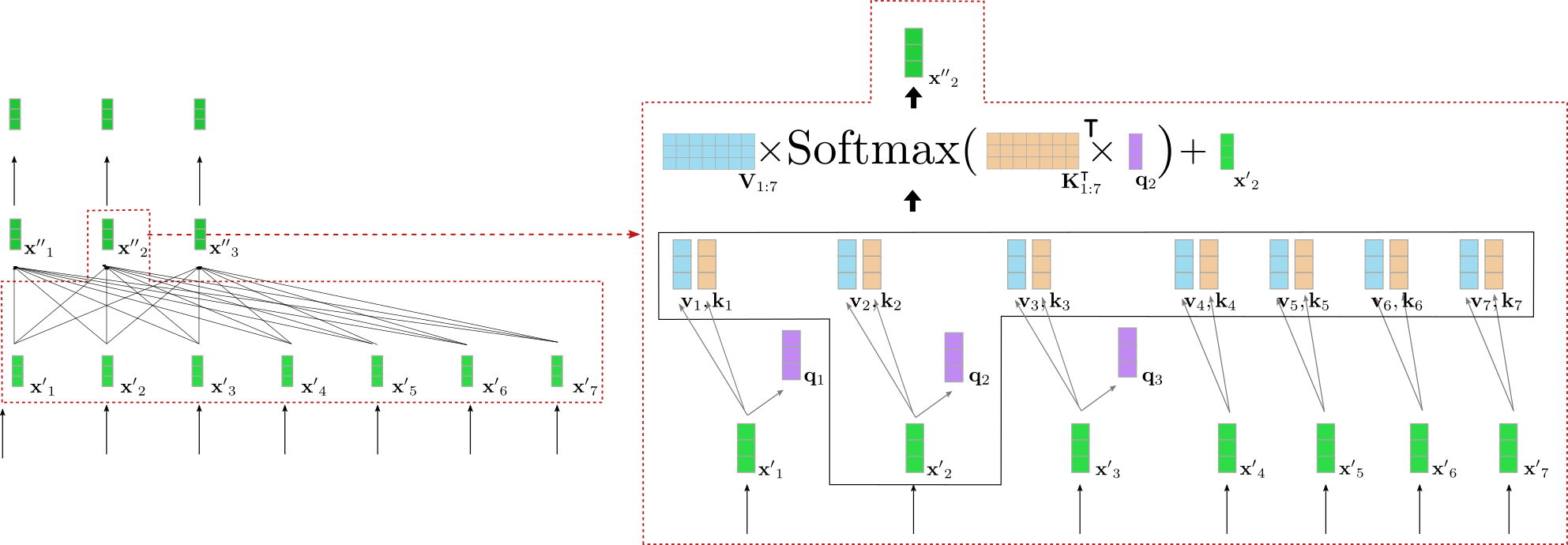
On the left, the previously illustrated second encoder block is shown
again and on the right, an in detail visualization of the bi-directional
self-attention mechanism is given for the second input vector
\\(\mathbf{x'}_2\\) that corresponds to the input word \"want\". At first
all input vectors \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_7\\) are projected
to their respective query vectors \\(\mathbf{q}_1, \ldots, \mathbf{q}_7\\)
(only the first three query vectors are shown in purple above), value
vectors \\(\mathbf{v}_1, \ldots, \mathbf{v}_7\\) (shown in blue), and key
vectors \\(\mathbf{k}_1, \ldots, \mathbf{k}_7\\) (shown in orange). The
query vector \\(\mathbf{q}_2\\) is then multiplied by the transpose of all
key vectors, *i.e.* \\(\mathbf{K}_{1:7}^{\intercal}\\) followed by the
softmax operation to yield the _self-attention weights_. The
self-attention weights are finally multiplied by the respective value
vectors and the input vector \\(\mathbf{x'}_2\\) is added to output the
\"refined\" representation of the word \"want\", *i.e.* \\(\mathbf{x''}_2\\)
(shown in dark green on the right). The whole equation is illustrated in
the upper part of the box on the right. The multiplication of
\\(\mathbf{K}_{1:7}^{\intercal}\\) and \\(\mathbf{q}_2\\) thereby makes it
possible to compare the vector representation of \"want\" to all other
input vector representations \"I\", \"to\", \"buy\", \"a\", \"car\",
\"EOS\" so that the self-attention weights mirror the importance each of
the other input vector representations
\\(\mathbf{x'}_j \text{, with } j \ne 2\\) for the refined representation
\\(\mathbf{x''}_2\\) of the word \"want\".
To further understand the implications of the bi-directional
self-attention layer, let\'s assume the following sentence is processed:
\"*The house is beautiful and well located in the middle of the city
where it is easily accessible by public transport*\". The word \"it\"
refers to \"house\", which is 12 \"positions away\". In
transformer-based encoders, the bi-directional self-attention layer
performs a single mathematical operation to put the input vector of
\"house\" into relation with the input vector of \"it\" (compare to the
first illustration of this section). In contrast, in an RNN-based
encoder, a word that is 12 \"positions away\", would require at least 12
mathematical operations meaning that in an RNN-based encoder a linear
number of mathematical operations are required. This makes it much
harder for an RNN-based encoder to model long-range contextual
representations. Also, it becomes clear that a transformer-based encoder
is much less prone to lose important information than an RNN-based
encoder-decoder model because the sequence length of the encoding is
kept the same, *i.e.*
\\(\textbf{len}(\mathbf{X}_{1:n}) = \textbf{len}(\mathbf{\overline{X}}_{1:n}) = n\\),
while an RNN compresses the length from
\\(*\textbf{len}((\mathbf{X}_{1:n}) = n\\) to just
\\(\textbf{len}(\mathbf{c}) = 1\\), which makes it very difficult for RNNs
to effectively encode long-range dependencies between input words.
In addition to making long-range dependencies more easily learnable, we
can see that the Transformer architecture is able to process text in
parallel.Mathematically, this can easily be shown by writing the
self-attention formula as a product of query, key, and value matrices:
$$\mathbf{X''}_{1:n} = \mathbf{V}_{1:n} \text{Softmax}(\mathbf{Q}_{1:n}^\intercal \mathbf{K}_{1:n}) + \mathbf{X'}_{1:n}. $$
The output \\(\mathbf{X''}_{1:n} = \mathbf{x''}_1, \ldots, \mathbf{x''}_n\\)
is computed via a series of matrix multiplications and a softmax
operation, which can be parallelized effectively. Note, that in an
RNN-based encoder model, the computation of the hidden state
\\(\mathbf{c}\\) has to be done sequentially: Compute hidden state of the
first input vector \\(\mathbf{x}_1\\), then compute the hidden state of the
second input vector that depends on the hidden state of the first hidden
vector, etc. The sequential nature of RNNs prevents effective
parallelization and makes them much more inefficient compared to
transformer-based encoder models on modern GPU hardware.
Great, now we should have a better understanding of a) how
transformer-based encoder models effectively model long-range contextual
representations and b) how they efficiently process long sequences of
input vectors.
Now, let\'s code up a short example of the encoder part of our
`MarianMT` encoder-decoder models to verify that the explained theory
holds in practice.
------------------------------------------------------------------------
\\({}^1\\) An in-detail explanation of the role the feed-forward layers play
in transformer-based models is out-of-scope for this notebook. It is
argued in [Yun et. al, (2017)](https://arxiv.org/pdf/1912.10077.pdf)
that feed-forward layers are crucial to map each contextual vector
\\(\mathbf{x'}_i\\) individually to the desired output space, which the
_self-attention_ layer does not manage to do on its own. It should be
noted here, that each output token \\(\mathbf{x'}\\) is processed by the
same feed-forward layer. For more detail, the reader is advised to read
the paper.
\\({}^2\\) However, the EOS input vector does not have to be appended to the
input sequence, but has been shown to improve performance in many cases.
In contrast to the _0th_ \\(\text{BOS}\\) target vector of the
transformer-based decoder is required as a starting input vector to
predict a first target vector.
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input_ids to encoder
encoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# change the input slightly and pass to encoder
input_ids_perturbed = tokenizer("I want to buy a house", return_tensors="pt").input_ids
encoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state
# compare shape and encoding of first vector
print(f"Length of input embeddings {embeddings(input_ids).shape[1]}. Length of encoder_hidden_states {encoder_hidden_states.shape[1]}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `I` equal to its perturbed version?: ", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))
```
_Outputs:_
```
Length of input embeddings 7. Length of encoder_hidden_states 7
Is encoding for `I` equal to its perturbed version?: False
```
We compare the length of the input word embeddings, *i.e.*
`embeddings(input_ids)` corresponding to \\(\mathbf{X}_{1:n}\\), with the
length of the `encoder_hidden_states`, corresponding to
\\(\mathbf{\overline{X}}_{1:n}\\). Also, we have forwarded the word sequence
\"I want to buy a car\" and a slightly perturbated version \"I want to
buy a house\" through the encoder to check if the first output encoding,
corresponding to \"I\", differs when only the last word is changed in
the input sequence.
As expected the output length of the input word embeddings and encoder
output encodings, *i.e.* \\(\textbf{len}(\mathbf{X}_{1:n})\\) and
\\(\textbf{len}(\mathbf{\overline{X}}_{1:n})\\), is equal. Second, it can be
noted that the values of the encoded output vector of
\\(\mathbf{\overline{x}}_1 = \text{"I"}\\) are different when the last word
is changed from \"car\" to \"house\". This however should not come as a
surprise if one has understood bi-directional self-attention.
On a side-note, _autoencoding_ models, such as BERT, have the exact same
architecture as _transformer-based_ encoder models. _Autoencoding_
models leverage this architecture for massive self-supervised
pre-training on open-domain text data so that they can map any word
sequence to a deep bi-directional representation. In [Devlin et al.
(2018)](https://arxiv.org/abs/1810.04805), the authors show that a
pre-trained BERT model with a single task-specific classification layer
on top can achieve SOTA results on eleven NLP tasks. All *autoencoding*
models of 🤗Transformers can be found
[here](https://huggingface.co/transformers/model_summary.html#autoencoding-models).
## **Decoder**
As mentioned in the *Encoder-Decoder* section, the *transformer-based*
decoder defines the conditional probability distribution of a target
sequence given the contextualized encoding sequence:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1: m} | \mathbf{\overline{X}}_{1:n}), $$
which by Bayes\' rule can be decomposed into a product of conditional
distributions of the next target vector given the contextualized
encoding sequence and all previous target vectors:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}). $$
Let\'s first understand how the transformer-based decoder defines a
probability distribution. The transformer-based decoder is a stack of
*decoder blocks* followed by a dense layer, the \"LM head\". The stack
of decoder blocks maps the contextualized encoding sequence
\\(\mathbf{\overline{X}}_{1:n}\\) and a target vector sequence prepended by
the \\(\text{BOS}\\) vector and cut to the last target vector, *i.e.*
\\(\mathbf{Y}_{0:i-1}\\), to an encoded sequence of target vectors
\\(\mathbf{\overline{Y}}_{0: i-1}\\). Then, the \"LM head\" maps the encoded
sequence of target vectors \\(\mathbf{\overline{Y}}_{0: i-1}\\) to a
sequence of logit vectors
\\(\mathbf{L}_{1:n} = \mathbf{l}_1, \ldots, \mathbf{l}_n\\), whereas the
dimensionality of each logit vector \\(\mathbf{l}_i\\) corresponds to the
size of the vocabulary. This way, for each \\(i \in \{1, \ldots, n\}\\) a
probability distribution over the whole vocabulary can be obtained by
applying a softmax operation on \\(\mathbf{l}_i\\). These distributions
define the conditional distribution:
$$p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, n\},$$
respectively. The \"LM head\" is often tied to the transpose of the word
embedding matrix, *i.e.*
\\(\mathbf{W}_{\text{emb}}^{\intercal} = \left[\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}\right]^{\intercal}\\)
\\({}^1\\). Intuitively this means that for all \\(i \in \{0, \ldots, n - 1\}\\)
the \"LM Head\" layer compares the encoded output vector
\\(\mathbf{\overline{y}}_i\\) to all word embeddings in the vocabulary
\\(\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}\\) so that the logit
vector \\(\mathbf{l}_{i+1}\\) represents the similarity scores between the
encoded output vector and each word embedding. The softmax operation
simply transformers the similarity scores to a probability distribution.
For each \\(i \in \{1, \ldots, n\}\\), the following equations hold:
$$ p_{\theta_{dec}}(\mathbf{y} | \mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1})$$
$$ = \text{Softmax}(f_{\theta_{\text{dec}}}(\mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1}))$$
$$ = \text{Softmax}(\mathbf{W}_{\text{emb}}^{\intercal} \mathbf{\overline{y}}_{i-1})$$
$$ = \text{Softmax}(\mathbf{l}_i). $$
Putting it all together, in order to model the conditional distribution
of a target vector sequence \\(\mathbf{Y}_{1: m}\\), the target vectors
\\(\mathbf{Y}_{1:m-1}\\) prepended by the special \\(\text{BOS}\\) vector,
*i.e.* \\(\mathbf{y}_0\\), are first mapped together with the contextualized
encoding sequence \\(\mathbf{\overline{X}}_{1:n}\\) to the logit vector
sequence \\(\mathbf{L}_{1:m}\\). Consequently, each logit target vector
\\(\mathbf{l}_i\\) is transformed into a conditional probability
distribution of the target vector \\(\mathbf{y}_i\\) using the softmax
operation. Finally, the conditional probabilities of all target vectors
\\(\mathbf{y}_1, \ldots, \mathbf{y}_m\\) multiplied together to yield the
conditional probability of the complete target vector sequence:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}).$$
In contrast to transformer-based encoders, in transformer-based
decoders, the encoded output vector \\(\mathbf{\overline{y}}_i\\) should be
a good representation of the *next* target vector \\(\mathbf{y}_{i+1}\\) and
not of the input vector itself. Additionally, the encoded output vector
\\(\mathbf{\overline{y}}_i\\) should be conditioned on all contextualized
encoding sequence \\(\mathbf{\overline{X}}_{1:n}\\). To meet these
requirements each decoder block consists of a **uni-directional**
self-attention layer, followed by a **cross-attention** layer and two
feed-forward layers \\({}^2\\). The uni-directional self-attention layer
puts each of its input vectors \\(\mathbf{y'}_j\\) only into relation with
all previous input vectors \\(\mathbf{y'}_i, \text{ with } i \le j\\) for
all \\(j \in \{1, \ldots, n\}\\) to model the probability distribution of
the next target vectors. The cross-attention layer puts each of its
input vectors \\(\mathbf{y''}_j\\) into relation with all contextualized
encoding vectors \\(\mathbf{\overline{X}}_{1:n}\\) to condition the
probability distribution of the next target vectors on the input of the
encoder as well.
Alright, let\'s visualize the *transformer-based* decoder for our
English to German translation example.
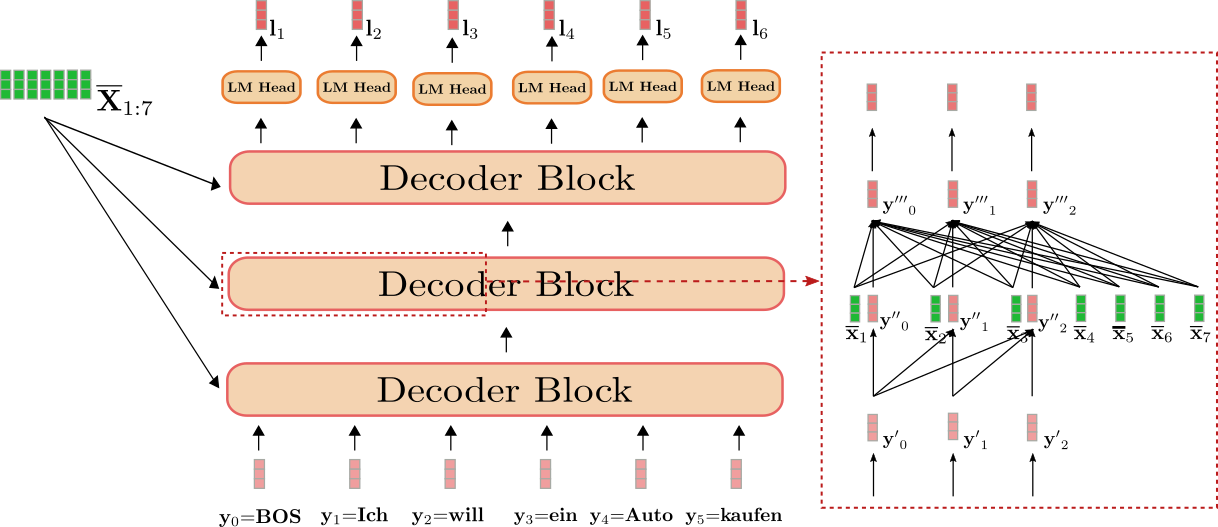
We can see that the decoder maps the input \\(\mathbf{Y}_{0:5}\\) \"BOS\",
\"Ich\", \"will\", \"ein\", \"Auto\", \"kaufen\" (shown in light red)
together with the contextualized sequence of \"I\", \"want\", \"to\",
\"buy\", \"a\", \"car\", \"EOS\", *i.e.* \\(\mathbf{\overline{X}}_{1:7}\\)
(shown in dark green) to the logit vectors \\(\mathbf{L}_{1:6}\\) (shown in
dark red).
Applying a softmax operation on each
\\(\mathbf{l}_1, \mathbf{l}_2, \ldots, \mathbf{l}_5\\) can thus define the
conditional probability distributions:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}), $$
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}), $$
$$ \ldots, $$
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). $$
The overall conditional probability of:
$$ p_{\theta_{dec}}(\text{Ich will ein Auto kaufen EOS} | \mathbf{\overline{X}}_{1:n})$$
can therefore be computed as the following product:
$$ p_{\theta_{dec}}(\text{Ich} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) \times \ldots \times p_{\theta_{dec}}(\text{EOS} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). $$
The red box on the right shows a decoder block for the first three
target vectors \\(\mathbf{y}_0, \mathbf{y}_1, \mathbf{y}_2\\). In the lower
part, the uni-directional self-attention mechanism is illustrated and in
the middle, the cross-attention mechanism is illustrated. Let\'s first
focus on uni-directional self-attention.
As in bi-directional self-attention, in uni-directional self-attention,
the query vectors \\(\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}\\) (shown in
purple below), key vectors \\(\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}\\)
(shown in orange below), and value vectors
\\(\mathbf{v}_0, \ldots, \mathbf{v}_{m-1}\\) (shown in blue below) are
projected from their respective input vectors
\\(\mathbf{y'}_0, \ldots, \mathbf{y'}_{m-1}\\) (shown in light red below).
However, in uni-directional self-attention, each query vector
\\(\mathbf{q}_i\\) is compared *only* to its respective key vector and all
previous ones, namely \\(\mathbf{k}_0, \ldots, \mathbf{k}_i\\) to yield the
respective *attention weights*. This prevents an output vector
\\(\mathbf{y''}_j\\) (shown in dark red below) to include any information
about the following input vector \\(\mathbf{y}_i, \text{ with } i > j\\) for
all \\(j \in \{0, \ldots, m - 1 \}\\). As is the case in bi-directional
self-attention, the attention weights are then multiplied by their
respective value vectors and summed together.
We can summarize uni-directional self-attention as follows:
$$\mathbf{y''}_i = \mathbf{V}_{0: i} \textbf{Softmax}(\mathbf{K}_{0: i}^\intercal \mathbf{q}_i) + \mathbf{y'}_i. $$
Note that the index range of the key and value vectors is \\(0:i\\) instead
of \\(0: m-1\\) which would be the range of the key vectors in
bi-directional self-attention.
Let\'s illustrate uni-directional self-attention for the input vector
\\(\mathbf{y'}_1\\) for our example above.
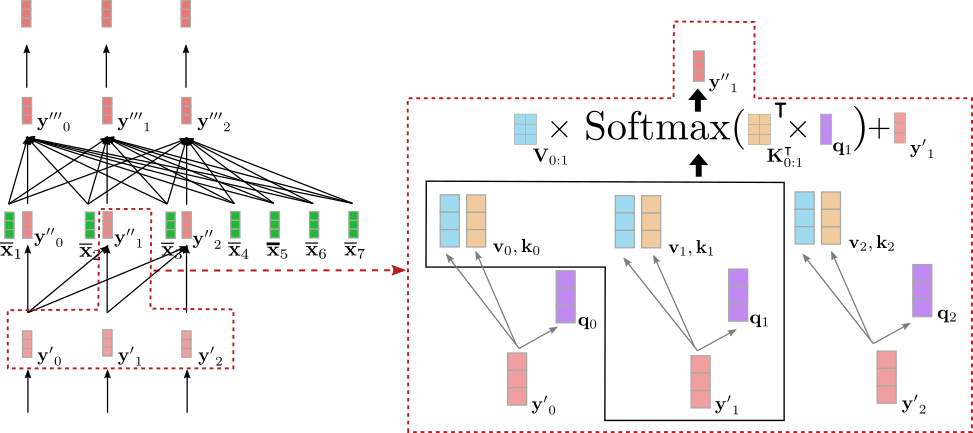
As can be seen \\(\mathbf{y''}_1\\) only depends on \\(\mathbf{y'}_0\\) and
\\(\mathbf{y'}_1\\). Therefore, we put the vector representation of the word
\"Ich\", *i.e.* \\(\mathbf{y'}_1\\) only into relation with itself and the
\"BOS\" target vector, *i.e.* \\(\mathbf{y'}_0\\), but **not** with the
vector representation of the word \"will\", *i.e.* \\(\mathbf{y'}_2\\).
So why is it important that we use uni-directional self-attention in the
decoder instead of bi-directional self-attention? As stated above, a
transformer-based decoder defines a mapping from a sequence of input
vector \\(\mathbf{Y}_{0: m-1}\\) to the logits corresponding to the **next**
decoder input vectors, namely \\(\mathbf{L}_{1:m}\\). In our example, this
means, *e.g.* that the input vector \\(\mathbf{y}_1\\) = \"Ich\" is mapped
to the logit vector \\(\mathbf{l}_2\\), which is then used to predict the
input vector \\(\mathbf{y}_2\\). Thus, if \\(\mathbf{y'}_1\\) would have access
to the following input vectors \\(\mathbf{Y'}_{2:5}\\), the decoder would
simply copy the vector representation of \"will\", *i.e.*
\\(\mathbf{y'}_2\\), to be its output \\(\mathbf{y''}_1\\). This would be
forwarded to the last layer so that the encoded output vector
\\(\mathbf{\overline{y}}_1\\) would essentially just correspond to the
vector representation \\(\mathbf{y}_2\\).
This is obviously disadvantageous as the transformer-based decoder would
never learn to predict the next word given all previous words, but just
copy the target vector \\(\mathbf{y}_i\\) through the network to
\\(\mathbf{\overline{y}}_{i-1}\\) for all \\(i \in \{1, \ldots, m \}\\). In
order to define a conditional distribution of the next target vector,
the distribution cannot be conditioned on the next target vector itself.
It does not make much sense to predict \\(\mathbf{y}_i\\) from
\\(p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{X}})\\) because the
distribution is conditioned on the target vector it is supposed to
model. The uni-directional self-attention architecture, therefore,
allows us to define a *causal* probability distribution, which is
necessary to effectively model a conditional distribution of the next
target vector.
Great! Now we can move to the layer that connects the encoder and
decoder - the *cross-attention* mechanism!
The cross-attention layer takes two vector sequences as inputs: the
outputs of the uni-directional self-attention layer, *i.e.*
\\(\mathbf{Y''}_{0: m-1}\\) and the contextualized encoding vectors
\\(\mathbf{\overline{X}}_{1:n}\\). As in the self-attention layer, the query
vectors \\(\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}\\) are projections of the
output vectors of the previous layer, *i.e.* \\(\mathbf{Y''}_{0: m-1}\\).
However, the key and value vectors
\\(\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}\\) and
\\(\mathbf{v}_0, \ldots, \mathbf{v}_{m-1}\\) are projections of the
contextualized encoding vectors \\(\mathbf{\overline{X}}_{1:n}\\). Having
defined key, value, and query vectors, a query vector \\(\mathbf{q}_i\\) is
then compared to *all* key vectors and the corresponding score is used
to weight the respective value vectors, just as is the case for
*bi-directional* self-attention to give the output vector
\\(\mathbf{y'''}_i\\) for all \\(i \in {0, \ldots, m-1}\\). Cross-attention
can be summarized as follows:
$$
\mathbf{y'''}_i = \mathbf{V}_{1:n} \textbf{Softmax}(\mathbf{K}_{1: n}^\intercal \mathbf{q}_i) + \mathbf{y''}_i.
$$
Note that the index range of the key and value vectors is \\(1:n\\)
corresponding to the number of contextualized encoding vectors.
Let\'s visualize the cross-attention mechanism for the input
vector \\(\mathbf{y''}_1\\) for our example above.
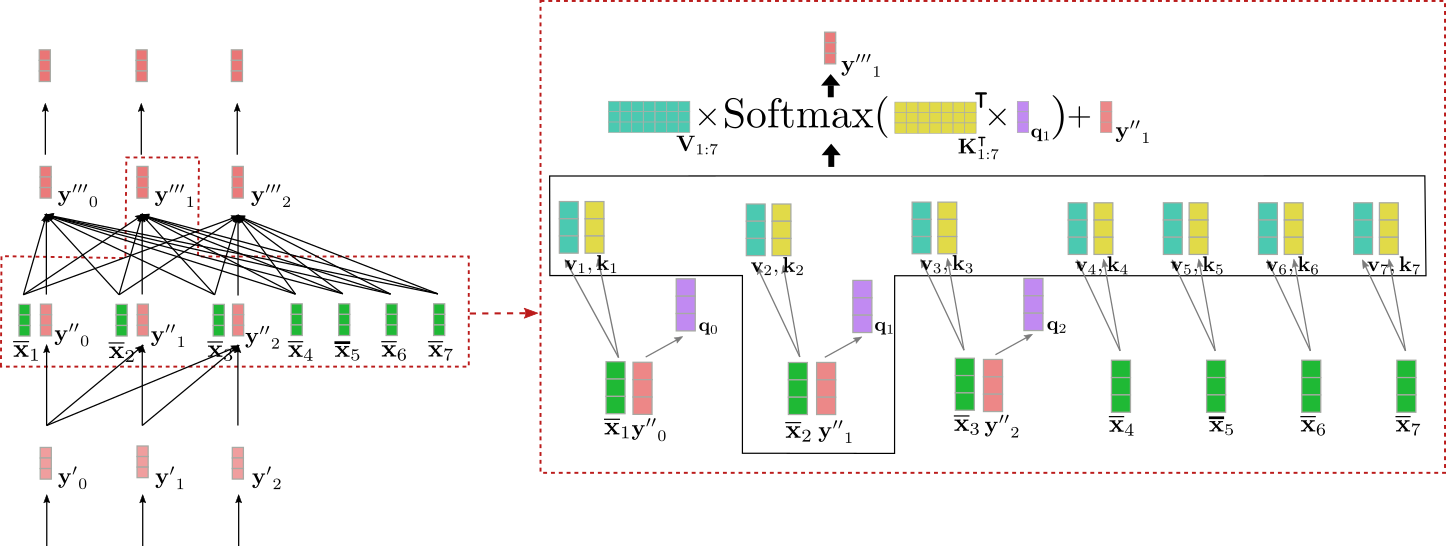
We can see that the query vector \\(\mathbf{q}_1\\) (shown in purple) is
derived from \\(\mathbf{y''}_1\\)(shown in red) and therefore relies on a vector
representation of the word \"Ich\". The query vector \\(\mathbf{q}_1\\)
is then compared to the key vectors
\\(\mathbf{k}_1, \ldots, \mathbf{k}_7\\) (shown in yellow) corresponding to
the contextual encoding representation of all encoder input vectors
\\(\mathbf{X}_{1:n}\\) = \"I want to buy a car EOS\". This puts the vector
representation of \"Ich\" into direct relation with all encoder input
vectors. Finally, the attention weights are multiplied by the value
vectors \\(\mathbf{v}_1, \ldots, \mathbf{v}_7\\) (shown in turquoise) to
yield in addition to the input vector \\(\mathbf{y''}_1\\) the output vector
\\(\mathbf{y'''}_1\\) (shown in dark red).
So intuitively, what happens here exactly? Each output vector
\\(\mathbf{y'''}_i\\) is a weighted sum of all value projections of the
encoder inputs \\(\mathbf{v}_{1}, \ldots, \mathbf{v}_7\\) plus the input
vector itself \\(\mathbf{y''}_i\\) (*c.f.* illustrated formula above). The key
mechanism to understand is the following: Depending on how similar a
query projection of the *input decoder vector* \\(\mathbf{q}_i\\) is to a
key projection of the *encoder input vector* \\(\mathbf{k}_j\\), the more
important is the value projection of the encoder input vector
\\(\mathbf{v}_j\\). In loose terms this means, the more \"related\" a
decoder input representation is to an encoder input representation, the
more does the input representation influence the decoder output
representation.
Cool! Now we can see how this architecture nicely conditions each output
vector \\(\mathbf{y'''}_i\\) on the interaction between the encoder input
vectors \\(\mathbf{\overline{X}}_{1:n}\\) and the input vector
\\(\mathbf{y''}_i\\). Another important observation at this point is that
the architecture is completely independent of the number \\(n\\) of
contextualized encoding vectors \\(\mathbf{\overline{X}}_{1:n}\\) on which
the output vector \\(\mathbf{y'''}_i\\) is conditioned on. All projection
matrices \\(\mathbf{W}^{\text{cross}}_{k}\\) and
\\(\mathbf{W}^{\text{cross}}_{v}\\) to derive the key vectors
\\(\mathbf{k}_1, \ldots, \mathbf{k}_n\\) and the value vectors
\\(\mathbf{v}_1, \ldots, \mathbf{v}_n\\) respectively are shared across all
positions \\(1, \ldots, n\\) and all value vectors
\\( \mathbf{v}_1, \ldots, \mathbf{v}_n \\) are summed together to a single
weighted averaged vector. Now it becomes obvious as well, why the
transformer-based decoder does not suffer from the long-range dependency
problem, the RNN-based decoder suffers from. Because each decoder logit
vector is *directly* dependent on every single encoded output vector,
the number of mathematical operations to compare the first encoded
output vector and the last decoder logit vector amounts essentially to
just one.
To conclude, the uni-directional self-attention layer is responsible for
conditioning each output vector on all previous decoder input vectors
and the current input vector and the cross-attention layer is
responsible to further condition each output vector on all encoded input
vectors.
To verify our theoretical understanding, let\'s continue our code
example from the encoder section above.
------------------------------------------------------------------------
\\({}^1\\) The word embedding matrix \\(\mathbf{W}_{\text{emb}}\\) gives each
input word a unique *context-independent* vector representation. This
matrix is often fixed as the \"LM Head\" layer. However, the \"LM Head\"
layer can very well consist of a completely independent \"encoded
vector-to-logit\" weight mapping.
\\({}^2\\) Again, an in-detail explanation of the role the feed-forward
layers play in transformer-based models is out-of-scope for this
notebook. It is argued in [Yun et. al,
(2017)](https://arxiv.org/pdf/1912.10077.pdf) that feed-forward layers
are crucial to map each contextual vector \\(\mathbf{x'}_i\\) individually
to the desired output space, which the *self-attention* layer does not
manage to do on its own. It should be noted here, that each output token
\\(\mathbf{x'}\\) is processed by the same feed-forward layer. For more
detail, the reader is advised to read the paper.
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))
```
_Output:_
```
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
Is encoding for `Ich` equal to its perturbed version?: True
```
We compare the output shape of the decoder input word embeddings, *i.e.*
`embeddings(decoder_input_ids)` (corresponds to \\(\mathbf{Y}_{0: 4}\\),
here `<pad>` corresponds to BOS and \"Ich will das\" is tokenized to 4
tokens) with the dimensionality of the `lm_logits`(corresponds to
\\(\mathbf{L}_{1:5}\\)). Also, we have passed the word sequence
\"`<pad>` Ich will ein\" and a slightly perturbated version
\"`<pad>` Ich will das\" together with the
`encoder_output_vectors` through the decoder to check if the second
`lm_logit`, corresponding to \"Ich\", differs when only the last word is
changed in the input sequence (\"ein\" -\> \"das\").
As expected the output shapes of the decoder input word embeddings and
lm\_logits, *i.e.* the dimensionality of \\(\mathbf{Y}_{0: 4}\\) and
\\(\mathbf{L}_{1:5}\\) are different in the last dimension. While the
sequence length is the same (=5), the dimensionality of a decoder input
word embedding corresponds to `model.config.hidden_size`, whereas the
dimensionality of a `lm_logit` corresponds to the vocabulary size
`model.config.vocab_size`, as explained above. Second, it can be noted
that the values of the encoded output vector of
\\(\mathbf{l}_1 = \text{"Ich"}\\) are the same when the last word is changed
from \"ein\" to \"das\". This however should not come as a surprise if
one has understood uni-directional self-attention.
On a final side-note, _auto-regressive_ models, such as GPT2, have the
same architecture as _transformer-based_ decoder models **if** one
removes the cross-attention layer because stand-alone auto-regressive
models are not conditioned on any encoder outputs. So auto-regressive
models are essentially the same as *auto-encoding* models but replace
bi-directional attention with uni-directional attention. These models
can also be pre-trained on massive open-domain text data to show
impressive performances on natural language generation (NLG) tasks. In
[Radford et al.
(2019)](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf),
the authors show that a pre-trained GPT2 model can achieve SOTA or close
to SOTA results on a variety of NLG tasks without much fine-tuning. All
*auto-regressive* models of 🤗Transformers can be found
[here](https://huggingface.co/transformers/model_summary.html#autoregressive-models).
Alright, that\'s it! Now, you should have gotten a good understanding of
*transformer-based* encoder-decoder models and how to use them with the
🤗Transformers library.
Thanks a lot to Victor Sanh, Sasha Rush, Sam Shleifer, Oliver Åstrand,
Ted Moskovitz and Kristian Kyvik for giving valuable feedback.
## **Appendix**
As mentioned above, the following code snippet shows how one can program
a simple generation method for *transformer-based* encoder-decoder
models. Here, we implement a simple *greedy* decoding method using
`torch.argmax` to sample the target vector.
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# create BOS token
decoder_input_ids = tokenizer("<pad>", add_special_tokens=False, return_tensors="pt").input_ids
assert decoder_input_ids[0, 0].item() == model.config.decoder_start_token_id, "`decoder_input_ids` should correspond to `model.config.decoder_start_token_id`"
# STEP 1
# pass input_ids to encoder and to decoder and pass BOS token to decoder to retrieve first logit
outputs = model(input_ids, decoder_input_ids=decoder_input_ids, return_dict=True)
# get encoded sequence
encoded_sequence = (outputs.encoder_last_hidden_state,)
# get logits
lm_logits = outputs.logits
# sample last token with highest prob
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 2
# reuse encoded_inputs and pass BOS + "Ich" to decoder to second logit
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
# sample last token with highest prob again
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat again
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 3
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# let's see what we have generated so far!
print(f"Generated so far: {tokenizer.decode(decoder_input_ids[0], skip_special_tokens=True)}")
# This can be written in a loop as well.
```
_Outputs:_
```
Generated so far: Ich will ein
```
In this code example, we show exactly what was described earlier. We
pass an input \"I want to buy a car\" together with the \\(\text{BOS}\\)
token to the encoder-decoder model and sample from the first logit
\\(\mathbf{l}_1\\) (*i.e.* the first `lm_logits` line). Hereby, our sampling
strategy is simple: greedily choose the next decoder input vector that
has the highest probability. In an auto-regressive fashion, we then pass
the sampled decoder input vector together with the previous inputs to
the encoder-decoder model and sample again. We repeat this a third time.
As a result, the model has generated the words \"Ich will ein\". The result
is spot-on - this is the beginning of the correct translation of the input.
In practice, more complicated decoding methods are used to sample the
`lm_logits`. Most of which are covered in
[this](https://huggingface.co/blog/how-to-generate) blog post.
| huggingface/blog/blob/main/encoder-decoder.md |
Metric Card for Matthews Correlation Coefficient
## Metric Description
The Matthews correlation coefficient is used in machine learning as a
measure of the quality of binary and multiclass classifications. It takes
into account true and false positives and negatives and is generally
regarded as a balanced measure which can be used even if the classes are of
very different sizes. The MCC is in essence a correlation coefficient value
between -1 and +1. A coefficient of +1 represents a perfect prediction, 0
an average random prediction and -1 an inverse prediction. The statistic
is also known as the phi coefficient. [source: Wikipedia]
## How to Use
At minimum, this metric requires a list of predictions and a list of references:
```python
>>> matthews_metric = datasets.load_metric("matthews_correlation")
>>> results = matthews_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'matthews_correlation': 1.0}
```
### Inputs
- **`predictions`** (`list` of `int`s): Predicted class labels.
- **`references`** (`list` of `int`s): Ground truth labels.
- **`sample_weight`** (`list` of `int`s, `float`s, or `bool`s): Sample weights. Defaults to `None`.
### Output Values
- **`matthews_correlation`** (`float`): Matthews correlation coefficient.
The metric output takes the following form:
```python
{'matthews_correlation': 0.54}
```
This metric can be any value from -1 to +1, inclusive.
#### Values from Popular Papers
### Examples
A basic example with only predictions and references as inputs:
```python
>>> matthews_metric = datasets.load_metric("matthews_correlation")
>>> results = matthews_metric.compute(references=[1, 3, 2, 0, 3, 2],
... predictions=[1, 2, 2, 0, 3, 3])
>>> print(results)
{'matthews_correlation': 0.5384615384615384}
```
The same example as above, but also including sample weights:
```python
>>> matthews_metric = datasets.load_metric("matthews_correlation")
>>> results = matthews_metric.compute(references=[1, 3, 2, 0, 3, 2],
... predictions=[1, 2, 2, 0, 3, 3],
... sample_weight=[0.5, 3, 1, 1, 1, 2])
>>> print(results)
{'matthews_correlation': 0.09782608695652174}
```
The same example as above, with sample weights that cause a negative correlation:
```python
>>> matthews_metric = datasets.load_metric("matthews_correlation")
>>> results = matthews_metric.compute(references=[1, 3, 2, 0, 3, 2],
... predictions=[1, 2, 2, 0, 3, 3],
... sample_weight=[0.5, 1, 0, 0, 0, 1])
>>> print(results)
{'matthews_correlation': -0.25}
```
## Limitations and Bias
*Note any limitations or biases that the metric has.*
## Citation
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
- This Hugging Face implementation uses [this scikit-learn implementation](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.matthews_corrcoef.html) | huggingface/datasets/blob/main/metrics/matthews_correlation/README.md |
CodeParrot 🦜
<p align="center">
<img src="https://huggingface.co/datasets/lvwerra/repo-images/raw/main/code-highlighting-streamlit.png" alt="drawing" width="350"/>
</p>
## What is this about?
This is an open-source effort to train and evaluate code generation models. CodeParrot 🦜 is a GPT-2 model trained from scratch on Python code. The highlights of this project are:
- initialize and train a GPT-2 language model from scratch for code generation
- train a custom tokenizer adapted for Python code
- clean and deduplicate a large (>100GB) dataset with `datasets`
- train with `accelerate` on multiple GPUs using data parallelism and mixed precision
- continuously push checkpoints to the hub with `huggingface_hub`
- stream the dataset with `datasets` during training to avoid disk bottlenecks
- apply the `code_eval` metric in `datasets` to evaluate on [OpenAI's _HumanEval_ benchmark](https://huggingface.co/datasets/openai_humaneval)
- showcase examples for downstream tasks with code models in [examples](https://github.com/huggingface/transformers/tree/main/examples/research_projects/codeparrot/examples) folder:
- Algorithmic complexity prediction
- Code generation from english text
- Code explanation
## Installation
To install the dependencies simply run the following command:
```bash
pip install -r requirements.txt
```
To reproduce the results you can follow the scripts in the following sections. Note that we don't always show all possible arguments to the scripts. To get the full list of arguments with descriptions you can run the following command on any script:
```bash
python scripts/some_script.py --help
```
Before you run any of the scripts make sure you are logged in and can push to the hub:
```bash
huggingface-cli login
```
Additionally, sure you have git-lfs installed. You can find instructions for how to install it [here](https://git-lfs.github.com/).
## Dataset
The source of the dataset is the GitHub dump available on Google's [BigQuery](https://cloud.google.com/blog/topics/public-datasets/github-on-bigquery-analyze-all-the-open-source-code). The database was queried for all Python files with less than 1MB in size resulting in a 180GB dataset with over 20M files. The dataset is available on the Hugging Face Hub [here](https://huggingface.co/datasets/transformersbook/codeparrot).
### Preprocessing
The raw dataset contains many duplicates. We deduplicated and filtered the dataset using the heuristics proposed in OpenAI's Codex [paper](https://arxiv.org/abs/2107.03374) and some new ones:
- exact deduplication using each file's hash after having removed whistespaces.
- near deduplication using MinHash and Jaccard similarity. MinHash with a Jaccard threshold (default=0.85) is first used to create duplicate clusters. Then these clusters are then reduced to unique files based on the exact Jaccard similarity. See `deduplicate_dataset` in `minhash_deduplication.py` for a detailed description.
- filtering files with max line length > 1000
- filtering files with mean line length > 100
- fraction of alphanumeric characters < 0.25
- containing the word "auto-generated" or similar in the first 5 lines
- filtering with a probability of 0.7 of files with a mention of "test file" or "configuration file" or similar in the first 5 lines
- filtering with a probability of 0.7 of files with high occurence of the keywords "test " or "config"
- filtering with a probability of 0.7 of files without a mention of the keywords `def` , `for`, `while` and `class`
- filtering files that use the assignment operator `=` less than 5 times
- filtering files with ratio between number of characters and number of tokens after tokenization < 1.5 (the average ratio is 3.6)
The script to process the full dataset can be found in `scripts/preprocessing.py`. Executing the script on 16 vCPUs takes roughly 3h and removes 70% of the original dataset. The cleaned [train](https://huggingface.co/datasets/codeparrot/codeparrot-clean-train-v2) and [validation](https://huggingface.co/datasets/codeparrot/codeparrot-clean-valid-v2) splits are also available on the Hub if you want to skip this step or use the data for another project.
To execute the preprocessing run the following command:
```bash
python scripts/preprocessing.py \
--dataset_name transformersbook/codeparrot \
--output_dir codeparrot-clean
```
During preprocessing the dataset is downloaded and stored locally as well as caches of the computations. Make sure you have more than 500GB free disk space to execute it.
### Pretokenization
The tokenization of the data might be slow during the training especially for small models. We provide code to pretokenize the data beforehand in `scripts/pretokenizing.py`, but this step is optional. The dataset is downloaded and stored locally and the tokenized data is pushed to the hub. The tokenized clean [train](https://huggingface.co/datasets/codeparrot/tokenized-codeparrot-train) and [validation](https://huggingface.co/datasets/codeparrot/tokenized-codeparrot-valid) datasets are available if you want to use them directly.
To execute the pretokenization, for the clean train data for instance, run the following command:
```bash
python scripts/pretokenizing.py \
--dataset_name codeparrot/codeparrot-clean-train \
--tokenized_data_repo tokenized-codeparrot-train
```
## Tokenizer
Before training a new model for code we create a new tokenizer that is efficient at code tokenization. To train the tokenizer you can run the following command:
```bash
python scripts/bpe_training.py \
--base_tokenizer gpt2 \
--dataset_name codeparrot/codeparrot-clean-train
```
_Note:_ We originally trained the tokenizer on the unprocessed train split of the dataset `transformersbook/codeparrot-train`.
## Training
The models are randomly initialized and trained from scratch. To initialize a new model you can run:
```bash
python scripts/initialize_model.py \
--config_name gpt2-large \
--tokenizer_name codeparrot/codeparrot \
--model_name codeparrot \
--push_to_hub True
```
This will initialize a new model with the architecture and configuration of `gpt2-large` and use the tokenizer to appropriately size the input embeddings. Finally, the initilaized model is pushed the hub.
We can either pass the name of a text dataset or a pretokenized dataset which speeds up training a bit.
Now that the tokenizer and model are also ready we can start training the model. The main training script is built with `accelerate` to scale across a wide range of platforms and infrastructure scales. We train two models with [110M](https://huggingface.co/codeparrot/codeparrot-small/) and [1.5B](https://huggingface.co/codeparrot/codeparrot/) parameters for 25-30B tokens on a 16xA100 (40GB) machine which takes 1 day and 1 week, respectively.
First you need to configure `accelerate` and login to Weights & Biases:
```bash
accelerate config
wandb login
```
Note that during the `accelerate` configuration we enabled FP16. Then to train the large model you can run
```bash
accelerate launch scripts/codeparrot_training.py
```
If you want to train the small model you need to make some modifications:
```bash
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 2000 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 150000 \
--save_checkpoint_steps 15000
```
Recall that you can see the full set of possible options with descriptions (for all scripts) by running:
```bash
python scripts/codeparrot_training.py --help
```
Instead of streaming the dataset from the hub you can also stream it from disk. This can be helpful for long training runs where the connection can be interrupted sometimes. To stream locally you simply need to clone the datasets and replace the dataset name with their path. In this example we store the data in a folder called `data`:
```bash
git lfs install
mkdir data
git -C "./data" clone https://huggingface.co/datasets/codeparrot/codeparrot-clean-train
git -C "./data" clone https://huggingface.co/datasets/codeparrot/codeparrot-clean-valid
```
And then pass the paths to the datasets when we run the training script:
```bash
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--dataset_name_train ./data/codeparrot-clean-train \
--dataset_name_valid ./data/codeparrot-clean-valid \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 2000 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 150000 \
--save_checkpoint_steps 15000
```
## Evaluation
For evaluating the language modeling loss on the validation set or any other dataset you can use the following command:
```bash
python scripts/validation_loss.py \
--model_ckpt codeparrot/codeparrot \
--dataset_name codeparrot/codeparrot-clean-valid
```
In addition we evaluate the model on OpenAI's _HumanEval_ benchmark. You can run the evaluation with the following command:
```bash
accelerate launch scripts/human_eval.py --model_ckpt codeparrot/codeparrot \
--do_sample True \
--temperature 0.2 \
--top_p 0.95 \
--n_samples=200 \
--HF_ALLOW_CODE_EVAL="0"
```
The results as well as reference values are shown in the following table:
| Model | pass@1 | pass@10 | pass@100|
|-------|--------|---------|---------|
|CodeParrot 🦜 (110M) | 3.80% | 6.57% | 12.78% |
|CodeParrot 🦜 (1.5B) | 3.99% | 8.69% | 17.88% |
|||||
|Codex (25M)| 3.21% | 7.1% | 12.89%|
|Codex (85M)| 8.22% | 12.81% | 22.40% |
|Codex (300M)| 13.17%| 20.37% | 36.27% |
|Codex (12B)| 28.81%| 46.81% | 72.31% |
|||||
|GPT-neo (125M)| 0.75% | 1.88% | 2.97% |
|GPT-neo (1.5B)| 4.79% | 7.47% | 16.30% |
|GPT-neo (2.7B)| 6.41% | 11.27% | 21.37% |
|GPT-J (6B)| 11.62% | 15.74% | 27.74% |
The numbers were obtained by sampling with `T = [0.2, 0.6, 0.8]` and picking the best value for each metric. Both CodeParrot 🦜 models are still underfitted and longer training would likely improve the performance.
## Demo
Give the model a shot yourself! There are three demos to interact with CodeParrot 🦜:
- [Code generation](https://huggingface.co/spaces/codeparrot/codeparrot-generation)
- [Code highlighting](https://huggingface.co/spaces/codeparrot/codeparrot-highlighting)
- [Comparison to other code models](https://huggingface.co/spaces/codeparrot/loubnabnl/code-generation-models)
## Training with Megatron
[Megatron](https://github.com/NVIDIA/Megatron-LM) is a framework developed by NVIDIA for training large transformer models. While the CodeParrot code is easy to follow and modify to your needs the Megatron framework lets you train models faster. Below we explain how to use it.
### Setup
You can pull an NVIDIA PyTorch Container that comes with all the required installations from [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch). See [documentation](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html) for more details:
With the following Docker command you can run the container (`xx.xx` denotes your Docker version), and clone [Megatron repository](https://github.com/NVIDIA/Megatron-LM) into it:
```bash
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:xx.xx-py3
git clone https://github.com/NVIDIA/Megatron-LM
```
You also need to add the vocabulary file and merges table of the tokenizer that you trained on code into the container. You can also find these files in [vocab.json](https://huggingface.co/codeparrot/codeparrot/raw/main/vocab.json) and [merges.txt](https://huggingface.co/codeparrot/codeparrot/raw/main/merges.txt).
```bash
sudo docker cp vocab.json CONTAINER_ID:/workspace/Megatron-LM
sudo docker cp merges.txt CONTAINER_ID:/workspace/Megatron-LM
```
### Data preprocessing
The training data requires preprocessing. First, you need to convert it into a loose json format, with one json containing a text sample per line. In python this can be done this way:
```python
from datasets import load_dataset
train_data = load_dataset('codeparrot/codeparrot-clean-train', split='train')
train_data.to_json("codeparrot_data.json", lines=True)
```
The data is then tokenized, shuffled and processed into a binary format for training using the following command:
```bash
pip install nltk
cd Megatron-LM
python tools/preprocess_data.py \
--input codeparrot_data.json \
--output-prefix codeparrot \
--vocab vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file merges.txt \
--json-keys content \
--workers 32 \
--chunk-size 25 \
--append-eod
```
This outputs two files `codeparrot_content_document.idx` and `codeparrot_content_document.bin` which are used in the training.
### Training
You can configure the model architecture and training parameters as shown below, or put it in a bash script that you will run. This runs on 8 GPUs the 110M parameter CodeParrot pretraining, with the same settings as before. Note that the data is partitioned by default into a 969:30:1 ratio for training/validation/test sets.
```bash
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-small
VOCAB_FILE=vocab.json
MERGE_FILE=merges.txt
DATA_PATH=codeparrot_content_document
GPT_ARGS="--num-layers 12
--hidden-size 768
--num-attention-heads 12
--seq-length 1024
--max-position-embeddings 1024
--micro-batch-size 12
--global-batch-size 192
--lr 0.0005
--train-iters 150000
--lr-decay-iters 150000
--lr-decay-style cosine
--lr-warmup-iters 2000
--weight-decay .1
--adam-beta2 .999
--fp16
--log-interval 10
--save-interval 2000
--eval-interval 200
--eval-iters 10
"
TENSORBOARD_ARGS="--tensorboard-dir experiments/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS
```
The training takes almost 12 hours in this setting.
### Convert model to `transformers`
After training we want to use the model in `transformers` e.g. to evaluate it on HumanEval. You can convert it to `transformers` following [this](https://huggingface.co/nvidia/megatron-gpt2-345m) tutorial. For instance, after the training is finished you can copy the weights of the last iteration 150k and convert the `model_optim_rng.pt` file to a `pytorch_model.bin` file that is supported by `transformers`.
```bash
mkdir -p nvidia/megatron-codeparrot-small
sudo docker cp CONTAINER_ID:/workspace/Megatron-LM/experiments/codeparrot-small/iter_0150000/mp_rank_00/model_optim_rng.pt nvidia/megatron-codeparrot-small
git clone https://github.com/huggingface/transformers.git
git clone https://github.com/NVIDIA/Megatron-LM.git
export PYTHONPATH=Megatron-LM
python transformers/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py nvidia/megatron-codeparrot-small/model_optim_rng.pt
```
Be careful, you will need to replace the generated vocabulary file and merges table after the conversion, with the original ones if you plan to load the tokenizer from there.
## Further Resources
A detailed description of the project can be found in the chapter "Training Transformers from Scratch" in the upcoming O'Reilly book [Natural Language Processing with Transformers](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/).
This example was provided by [Leandro von Werra](www.github.com/lvwerra).
| huggingface/transformers/blob/main/examples/research_projects/codeparrot/README.md |
Gradio Demo: dataframe_block-ui-test
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
count = gr.Slider(minimum=1, maximum=10, step=1, label="count")
data = gr.DataFrame(
headers=["A", "B"], col_count=(2, "fixed"), type="array", interactive=True
)
btn = gr.Button(value="click")
btn.click(
fn=lambda cnt: [[str(2 * i), str(2 * i + 1)] for i in range(int(cnt))],
inputs=[count],
outputs=[data],
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/dataframe_block-ui-test/run.ipynb |
What if my dataset isn't on the Hub?[[what-if-my-dataset-isnt-on-the-hub]]
<CourseFloatingBanner chapter={5}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter5/section2.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter5/section2.ipynb"},
]} />
You know how to use the [Hugging Face Hub](https://huggingface.co/datasets) to download datasets, but you'll often find yourself working with data that is stored either on your laptop or on a remote server. In this section we'll show you how 🤗 Datasets can be used to load datasets that aren't available on the Hugging Face Hub.
<Youtube id="HyQgpJTkRdE"/>
## Working with local and remote datasets[[working-with-local-and-remote-datasets]]
🤗 Datasets provides loading scripts to handle the loading of local and remote datasets. It supports several common data formats, such as:
| Data format | Loading script | Example |
| :----------------: | :------------: | :-----------------------------------------------------: |
| CSV & TSV | `csv` | `load_dataset("csv", data_files="my_file.csv")` |
| Text files | `text` | `load_dataset("text", data_files="my_file.txt")` |
| JSON & JSON Lines | `json` | `load_dataset("json", data_files="my_file.jsonl")` |
| Pickled DataFrames | `pandas` | `load_dataset("pandas", data_files="my_dataframe.pkl")` |
As shown in the table, for each data format we just need to specify the type of loading script in the `load_dataset()` function, along with a `data_files` argument that specifies the path to one or more files. Let's start by loading a dataset from local files; later we'll see how to do the same with remote files.
## Loading a local dataset[[loading-a-local-dataset]]
For this example we'll use the [SQuAD-it dataset](https://github.com/crux82/squad-it/), which is a large-scale dataset for question answering in Italian.
The training and test splits are hosted on GitHub, so we can download them with a simple `wget` command:
```python
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
```
This will download two compressed files called *SQuAD_it-train.json.gz* and *SQuAD_it-test.json.gz*, which we can decompress with the Linux `gzip` command:
```python
!gzip -dkv SQuAD_it-*.json.gz
```
```bash
SQuAD_it-test.json.gz: 87.4% -- replaced with SQuAD_it-test.json
SQuAD_it-train.json.gz: 82.2% -- replaced with SQuAD_it-train.json
```
We can see that the compressed files have been replaced with _SQuAD_it-train.json_ and _SQuAD_it-test.json_, and that the data is stored in the JSON format.
<Tip>
✎ If you're wondering why there's a `!` character in the above shell commands, that's because we're running them within a Jupyter notebook. Simply remove the prefix if you want to download and unzip the dataset within a terminal.
</Tip>
To load a JSON file with the `load_dataset()` function, we just need to know if we're dealing with ordinary JSON (similar to a nested dictionary) or JSON Lines (line-separated JSON). Like many question answering datasets, SQuAD-it uses the nested format, with all the text stored in a `data` field. This means we can load the dataset by specifying the `field` argument as follows:
```py
from datasets import load_dataset
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
```
By default, loading local files creates a `DatasetDict` object with a `train` split. We can see this by inspecting the `squad_it_dataset` object:
```py
squad_it_dataset
```
```python out
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
})
```
This shows us the number of rows and the column names associated with the training set. We can view one of the examples by indexing into the `train` split as follows:
```py
squad_it_dataset["train"][0]
```
```python out
{
"title": "Terremoto del Sichuan del 2008",
"paragraphs": [
{
"context": "Il terremoto del Sichuan del 2008 o il terremoto...",
"qas": [
{
"answers": [{"answer_start": 29, "text": "2008"}],
"id": "56cdca7862d2951400fa6826",
"question": "In quale anno si è verificato il terremoto nel Sichuan?",
},
...
],
},
...
],
}
```
Great, we've loaded our first local dataset! But while this worked for the training set, what we really want is to include both the `train` and `test` splits in a single `DatasetDict` object so we can apply `Dataset.map()` functions across both splits at once. To do this, we can provide a dictionary to the `data_files` argument that maps each split name to a file associated with that split:
```py
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
squad_it_dataset
```
```python out
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
test: Dataset({
features: ['title', 'paragraphs'],
num_rows: 48
})
})
```
This is exactly what we wanted. Now, we can apply various preprocessing techniques to clean up the data, tokenize the reviews, and so on.
<Tip>
The `data_files` argument of the `load_dataset()` function is quite flexible and can be either a single file path, a list of file paths, or a dictionary that maps split names to file paths. You can also glob files that match a specified pattern according to the rules used by the Unix shell (e.g., you can glob all the JSON files in a directory as a single split by setting `data_files="*.json"`). See the 🤗 Datasets [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) for more details.
</Tip>
The loading scripts in 🤗 Datasets actually support automatic decompression of the input files, so we could have skipped the use of `gzip` by pointing the `data_files` argument directly to the compressed files:
```py
data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
```
This can be useful if you don't want to manually decompress many GZIP files. The automatic decompression also applies to other common formats like ZIP and TAR, so you just need to point `data_files` to the compressed files and you're good to go!
Now that you know how to load local files on your laptop or desktop, let's take a look at loading remote files.
## Loading a remote dataset[[loading-a-remote-dataset]]
If you're working as a data scientist or coder in a company, there's a good chance the datasets you want to analyze are stored on some remote server. Fortunately, loading remote files is just as simple as loading local ones! Instead of providing a path to local files, we point the `data_files` argument of `load_dataset()` to one or more URLs where the remote files are stored. For example, for the SQuAD-it dataset hosted on GitHub, we can just point `data_files` to the _SQuAD_it-*.json.gz_ URLs as follows:
```py
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {
"train": url + "SQuAD_it-train.json.gz",
"test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
```
This returns the same `DatasetDict` object obtained above, but saves us the step of manually downloading and decompressing the _SQuAD_it-*.json.gz_ files. This wraps up our foray into the various ways to load datasets that aren't hosted on the Hugging Face Hub. Now that we've got a dataset to play with, let's get our hands dirty with various data-wrangling techniques!
<Tip>
✏️ **Try it out!** Pick another dataset hosted on GitHub or the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) and try loading it both locally and remotely using the techniques introduced above. For bonus points, try loading a dataset that’s stored in a CSV or text format (see the [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) for more information on these formats).
</Tip>
| huggingface/course/blob/main/chapters/en/chapter5/2.mdx |
Gradio Demo: on_listener_test
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output")
greet_btn = gr.Button("Greet")
trigger = gr.Textbox(label="Trigger 1")
trigger2 = gr.Textbox(label="Trigger 2")
def greet(name, evt_data: gr.EventData):
return "Hello " + name + "!", evt_data.target.__class__.__name__
def clear_name(evt_data: gr.EventData):
return "", evt_data.target.__class__.__name__
gr.on(
triggers=[name.submit, greet_btn.click],
fn=greet,
inputs=name,
outputs=[output, trigger],
).then(clear_name, outputs=[name, trigger2])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/on_listener_test/run.ipynb |
MnasNet
**MnasNet** is a type of convolutional neural network optimized for mobile devices that is discovered through mobile neural architecture search, which explicitly incorporates model latency into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency. The main building block is an [inverted residual block](https://paperswithcode.com/method/inverted-residual-block) (from [MobileNetV2](https://paperswithcode.com/method/mobilenetv2)).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('mnasnet_100', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mnasnet_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('mnasnet_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2019mnasnet,
title={MnasNet: Platform-Aware Neural Architecture Search for Mobile},
author={Mingxing Tan and Bo Chen and Ruoming Pang and Vijay Vasudevan and Mark Sandler and Andrew Howard and Quoc V. Le},
year={2019},
eprint={1807.11626},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: MNASNet
Paper:
Title: 'MnasNet: Platform-Aware Neural Architecture Search for Mobile'
URL: https://paperswithcode.com/paper/mnasnet-platform-aware-neural-architecture
Models:
- Name: mnasnet_100
In Collection: MNASNet
Metadata:
FLOPs: 416415488
Parameters: 4380000
File Size: 17731774
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Inverted Residual Block
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
ID: mnasnet_100
Layers: 100
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4000
Image Size: '224'
Interpolation: bicubic
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L894
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mnasnet_b1-74cb7081.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.67%
Top 5 Accuracy: 92.1%
- Name: semnasnet_100
In Collection: MNASNet
Metadata:
FLOPs: 414570766
Parameters: 3890000
File Size: 15731489
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Inverted Residual Block
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: semnasnet_100
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L928
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mnasnet_a1-d9418771.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.45%
Top 5 Accuracy: 92.61%
--> | huggingface/pytorch-image-models/blob/main/docs/models/mnasnet.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on CPU
This guide focuses on training large models efficiently on CPU.
## Mixed precision with IPEX
IPEX is optimized for CPUs with AVX-512 or above, and functionally works for CPUs with only AVX2. So, it is expected to bring performance benefit for Intel CPU generations with AVX-512 or above while CPUs with only AVX2 (e.g., AMD CPUs or older Intel CPUs) might result in a better performance under IPEX, but not guaranteed. IPEX provides performance optimizations for CPU training with both Float32 and BFloat16. The usage of BFloat16 is the main focus of the following sections.
Low precision data type BFloat16 has been natively supported on the 3rd Generation Xeon® Scalable Processors (aka Cooper Lake) with AVX512 instruction set and will be supported on the next generation of Intel® Xeon® Scalable Processors with Intel® Advanced Matrix Extensions (Intel® AMX) instruction set with further boosted performance. The Auto Mixed Precision for CPU backend has been enabled since PyTorch-1.10. At the same time, the support of Auto Mixed Precision with BFloat16 for CPU and BFloat16 optimization of operators has been massively enabled in Intel® Extension for PyTorch, and partially upstreamed to PyTorch master branch. Users can get better performance and user experience with IPEX Auto Mixed Precision.
Check more detailed information for [Auto Mixed Precision](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html).
### IPEX installation:
IPEX release is following PyTorch, to install via pip:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 1.13 | 1.13.0+cpu |
| 1.12 | 1.12.300+cpu |
| 1.11 | 1.11.200+cpu |
| 1.10 | 1.10.100+cpu |
```
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
Check more approaches for [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html).
### Usage in Trainer
To enable auto mixed precision with IPEX in Trainer, users should add `use_ipex`, `bf16` and `no_cuda` in training command arguments.
Take an example of the use cases on [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
- Training with IPEX using BF16 auto mixed precision on CPU:
<pre> python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
<b>--use_ipex \</b>
<b>--bf16 --no_cuda</b></pre>
### Practice example
Blog: [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids)
| huggingface/transformers/blob/main/docs/source/en/perf_train_cpu.md |
--
title: Block Sparse Matrices for Smaller and Faster Language Models
thumbnail: /blog/assets/04_pytorch_block_sparse/thumbnail.png
authors:
- user: madlag
---
# Block Sparse Matrices for Smaller and Faster Language Models
## Saving space and time, one zero at a time
In previous [blog](https://medium.com/huggingface/is-the-future-of-neural-networks-sparse-an-introduction-1-n-d03923ecbd70)
[posts](https://medium.com/huggingface/sparse-neural-networks-2-n-gpu-performance-b8bc9ce950fc)
we introduced sparse matrices and what they could do to improve neural networks.
The basic assumption is that full dense layers are often overkill and can be pruned without a significant loss in precision.
In some cases sparse linear layers can even *improve precision or/and generalization*.
The main issue is that currently available code that supports sparse algebra computation is severely lacking efficiency.
We are also [still waiting](https://openai.com/blog/openai-pytorch/) for official PyTorch support.
That's why we ran out of patience and took some time this summer to address this "lacuna".
Today, we are excited to **release the extension [pytorch_block_sparse](https://github.com/huggingface/pytorch_block_sparse)**.
By itself, or even better combined with other methods like
[distillation](https://medium.com/huggingface/distilbert-8cf3380435b5)
and [quantization](https://medium.com/microsoftazure/faster-and-smaller-quantized-nlp-with-hugging-face-and-onnx-runtime-ec5525473bb7),
this library enables **networks** which are both **smaller and faster**,
something Hugging Face considers crucial to let anybody use
neural networks in production at **low cost**, and to **improve the experience** for the end user.
## Usage
The provided `BlockSparseLinear` module is a drop in replacement for `torch.nn.Linear`, and it is trivial to use
it in your models:
```python
# from torch.nn import Linear
from pytorch_block_sparse import BlockSparseLinear
...
# self.fc = nn.Linear(1024, 256)
self.fc = BlockSparseLinear(1024, 256, density=0.1)
```
The extension also provides a `BlockSparseModelPatcher` that allows to modify an existing model "on the fly",
which is shown in this [example notebook](https://github.com/huggingface/pytorch_block_sparse/blob/master/doc/notebooks/ModelSparsification.ipynb).
Such a model can then be trained as usual, without any change in your model source code.
## NVIDIA CUTLASS
This extension is based on the [cutlass tilesparse](https://github.com/YulhwaKim/cutlass_tilesparse) proof of concept by [Yulhwa Kim](https://github.com/YulhwaKim).
It is using **C++ CUDA templates** for block-sparse matrix multiplication
based on **[CUTLASS](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/)**.
CUTLASS is a collection of CUDA C++ templates for implementing high-performance CUDA kernels.
With CUTLASS, approching cuBLAS performance on custom kernels is possible without resorting to assembly language code.
The latest versions include all the **Ampere Tensor Core primitives**, providing **x10 or more speedups** with a limited loss of precision.
Next versions of pytorch_block_sparse will make use of these primitives,
as block sparsity is 100% compatible with Tensor Cores requirements.
## Performance
At the current stage of the library, the performances for sparse matrices are roughly
two times slower than their cuBLAS optimized dense counterpart, and we are confident
that we can improve this in the future.
This is a huge improvement on PyTorch sparse matrices: their current implementation is an order of magnitude slower
than the dense one.
But the more important point is that the performance gain of using sparse matrices grows with the sparsity,
so a **75% sparse matrix** is roughly **2x** faster than the dense equivalent.
The memory savings are even more significant: for **75% sparsity**, memory consumption is reduced by **4x**
as you would expect.
## Future work
Being able to efficiently train block-sparse linear layers was just the first step.
The sparsity pattern is currenly fixed at initialization, and of course optimizing it during learning will yield large
improvements.
So in future versions, you can expect tools to measure the "usefulness" of parameters to be able to **optimize the sparsity pattern**.
**NVIDIA Ampere 50% sparse pattern** within blocks will probably yield another significant performance gain, just as upgrading
to more recent versions of CUTLASS does.
So, stay tuned for more sparsity goodness in a near future!
| huggingface/blog/blob/main/pytorch_block_sparse.md |
SK-ResNet
**SK ResNet** is a variant of a [ResNet](https://www.paperswithcode.com/method/resnet) that employs a [Selective Kernel](https://paperswithcode.com/method/selective-kernel) unit. In general, all the large kernel convolutions in the original bottleneck blocks in ResNet are replaced by the proposed [SK convolutions](https://paperswithcode.com/method/selective-kernel-convolution), enabling the network to choose appropriate receptive field sizes in an adaptive manner.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('skresnet18', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `skresnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('skresnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{li2019selective,
title={Selective Kernel Networks},
author={Xiang Li and Wenhai Wang and Xiaolin Hu and Jian Yang},
year={2019},
eprint={1903.06586},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SKResNet
Paper:
Title: Selective Kernel Networks
URL: https://paperswithcode.com/paper/selective-kernel-networks
Models:
- Name: skresnet18
In Collection: SKResNet
Metadata:
FLOPs: 2333467136
Parameters: 11960000
File Size: 47923238
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Residual Connection
- Selective Kernel
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: skresnet18
LR: 0.1
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/sknet.py#L148
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/skresnet18_ra-4eec2804.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.03%
Top 5 Accuracy: 91.17%
- Name: skresnet34
In Collection: SKResNet
Metadata:
FLOPs: 4711849952
Parameters: 22280000
File Size: 89299314
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Residual Connection
- Selective Kernel
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: skresnet34
LR: 0.1
Epochs: 100
Layers: 34
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/sknet.py#L165
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/skresnet34_ra-bdc0ccde.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.93%
Top 5 Accuracy: 93.32%
--> | huggingface/pytorch-image-models/blob/main/docs/models/skresnet.md |
--
title: "Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer)"
thumbnail: /blog/assets/150_autoformer/thumbnail.png
authors:
- user: elisim
guest: true
- user: kashif
- user: nielsr
---
# Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer)
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/autoformer-transformers-are-effective.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Introduction
A few months ago, we introduced the [Informer](https://huggingface.co/blog/informer) model ([Zhou, Haoyi, et al., 2021](https://arxiv.org/abs/2012.07436)), which is a Time Series Transformer that won the AAAI 2021 best paper award. We also provided an example for multivariate probabilistic forecasting with Informer. In this post, we discuss the question: [Are Transformers Effective for Time Series Forecasting?](https://arxiv.org/abs/2205.13504) (AAAI 2023). As we will see, they are.
Firstly, we will provide empirical evidence that **Transformers are indeed Effective for Time Series Forecasting**. Our comparison shows that the simple linear model, known as _DLinear_, is not better than Transformers as claimed. When compared against equivalent sized models in the same setting as the linear models, the Transformer-based models perform better on the test set metrics we consider.
Afterwards, we will introduce the _Autoformer_ model ([Wu, Haixu, et al., 2021](https://arxiv.org/abs/2106.13008)), which was published in NeurIPS 2021 after the Informer model. The Autoformer model is [now available](https://huggingface.co/docs/transformers/main/en/model_doc/autoformer) in 🤗 Transformers. Finally, we will discuss the _DLinear_ model, which is a simple feedforward network that uses the decomposition layer from Autoformer. The DLinear model was first introduced in [Are Transformers Effective for Time Series Forecasting?](https://arxiv.org/abs/2205.13504) and claimed to outperform Transformer-based models in time-series forecasting.
Let's go!
## Benchmarking - Transformers vs. DLinear
In the paper [Are Transformers Effective for Time Series Forecasting?](https://arxiv.org/abs/2205.13504), published recently in AAAI 2023,
the authors claim that Transformers are not effective for time series forecasting. They compare the Transformer-based models against a simple linear model, which they call _DLinear_.
The DLinear model uses the decomposition layer from the Autoformer model, which we will introduce later in this post. The authors claim that the DLinear model outperforms the Transformer-based models in time-series forecasting.
Is that so? Let's find out.
| Dataset | Autoformer (uni.) MASE | DLinear MASE |
|:-----------------:|:----------------------:|:-------------:|
| `Traffic` | 0.910 | 0.965 |
| `Exchange-Rate` | 1.087 | 1.690 |
| `Electricity` | 0.751 | 0.831 |
The table above shows the results of the comparison between the Autoformer and DLinear models on the three datasets used in the paper.
The results show that the Autoformer model outperforms the DLinear model on all three datasets.
Next, we will present the new Autoformer model along with the DLinear model. We will showcase how to compare them on the Traffic dataset from the table above, and provide explanations for the results we obtained.
**TL;DR:** A simple linear model, while advantageous in certain cases, has no capacity to incorporate covariates compared to more complex models like transformers in the univariate setting.
## Autoformer - Under The Hood
Autoformer builds upon the traditional method of decomposing time series into seasonality and trend-cycle components. This is achieved through the incorporation of a _Decomposition Layer_, which enhances the model's ability to capture these components accurately. Moreover, Autoformer introduces an innovative auto-correlation mechanism that replaces the standard self-attention used in the vanilla transformer. This mechanism enables the model to utilize period-based dependencies in the attention, thus improving the overall performance.
In the upcoming sections, we will delve into the two key contributions of Autoformer: the _Decomposition Layer_ and the _Attention (Autocorrelation) Mechanism_. We will also provide code examples to illustrate how these components function within the Autoformer architecture.
### Decomposition Layer
Decomposition has long been a popular method in time series analysis, but it had not been extensively incorporated into deep learning models until the introduction of the Autoformer paper. Following a brief explanation of the concept, we will demonstrate how the idea is applied in Autoformer using PyTorch code.
#### Decomposition of Time Series
In time series analysis, [decomposition](https://en.wikipedia.org/wiki/Decomposition_of_time_series) is a method of breaking down a time series into three systematic components: trend-cycle, seasonal variation, and random fluctuations.
The trend component represents the long-term direction of the time series, which can be increasing, decreasing, or stable over time. The seasonal component represents the recurring patterns that occur within the time series, such as yearly or quarterly cycles. Finally, the random (sometimes called "irregular") component represents the random noise in the data that cannot be explained by the trend or seasonal components.
Two main types of decomposition are additive and multiplicative decomposition, which are implemented in the [great statsmodels library](https://www.statsmodels.org/dev/generated/statsmodels.tsa.seasonal.seasonal_decompose.html). By decomposing a time series into these components, we can better understand and model the underlying patterns in the data.
But how can we incorporate decomposition into the Transformer architecture? Let's see how Autoformer does it.
#### Decomposition in Autoformer
| 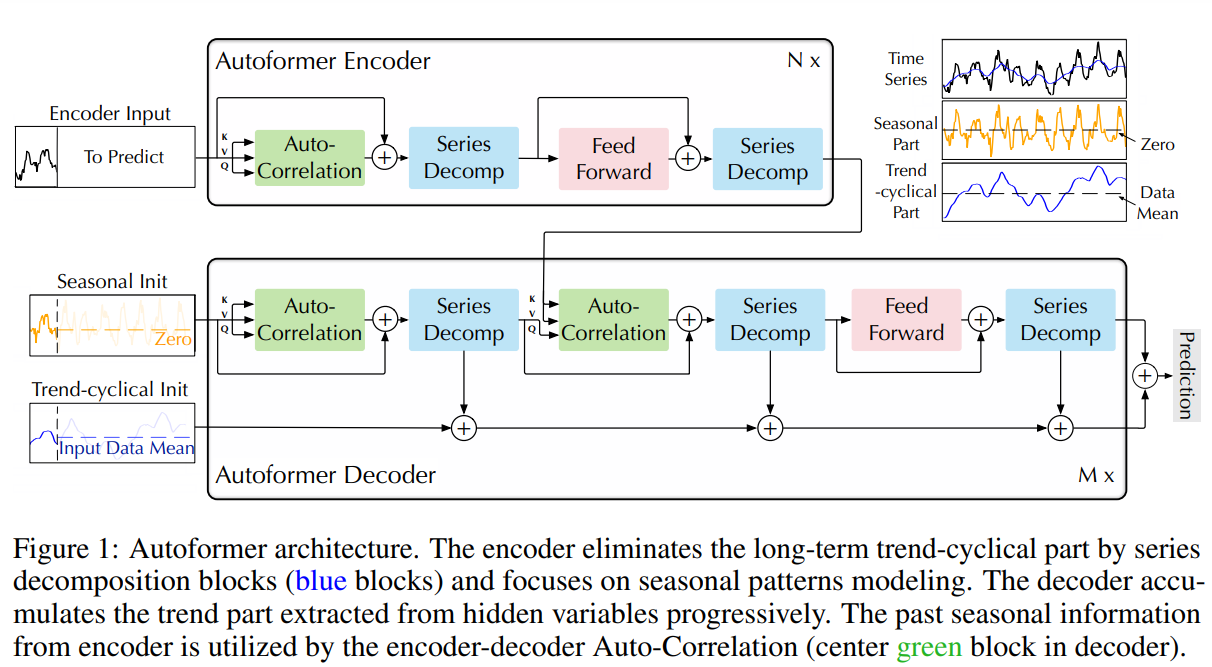 |
|:--:|
| Autoformer architecture from [the paper](https://arxiv.org/abs/2106.13008) |
Autoformer incorporates a decomposition block as an inner operation of the model, as presented in the Autoformer's architecture above. As can be seen, the encoder and decoder use a decomposition block to aggregate the trend-cyclical part and extract the seasonal part from the series progressively. The concept of inner decomposition has demonstrated its usefulness since the publication of Autoformer. Subsequently, it has been adopted in several other time series papers, such as FEDformer ([Zhou, Tian, et al., ICML 2022](https://arxiv.org/abs/2201.12740)) and DLinear [(Zeng, Ailing, et al., AAAI 2023)](https://arxiv.org/abs/2205.13504), highlighting its significance in time series modeling.
Now, let's define the decomposition layer formally:
For an input series \\(\mathcal{X} \in \mathbb{R}^{L \times d}\\) with length \\(L\\), the decomposition layer returns \\(\mathcal{X}_\textrm{trend}, \mathcal{X}_\textrm{seasonal}\\) defined as:
$$
\mathcal{X}_\textrm{trend} = \textrm{AvgPool(Padding(} \mathcal{X} \textrm{))} \\
\mathcal{X}_\textrm{seasonal} = \mathcal{X} - \mathcal{X}_\textrm{trend}
$$
And the implementation in PyTorch:
```python
import torch
from torch import nn
class DecompositionLayer(nn.Module):
"""
Returns the trend and the seasonal parts of the time series.
"""
def __init__(self, kernel_size):
super().__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=1, padding=0) # moving average
def forward(self, x):
"""Input shape: Batch x Time x EMBED_DIM"""
# padding on the both ends of time series
num_of_pads = (self.kernel_size - 1) // 2
front = x[:, 0:1, :].repeat(1, num_of_pads, 1)
end = x[:, -1:, :].repeat(1, num_of_pads, 1)
x_padded = torch.cat([front, x, end], dim=1)
# calculate the trend and seasonal part of the series
x_trend = self.avg(x_padded.permute(0, 2, 1)).permute(0, 2, 1)
x_seasonal = x - x_trend
return x_seasonal, x_trend
```
As you can see, the implementation is quite simple and can be used in other models, as we will see with DLinear. Now, let's explain the second contribution - _Attention (Autocorrelation) Mechanism_.
### Attention (Autocorrelation) Mechanism
| 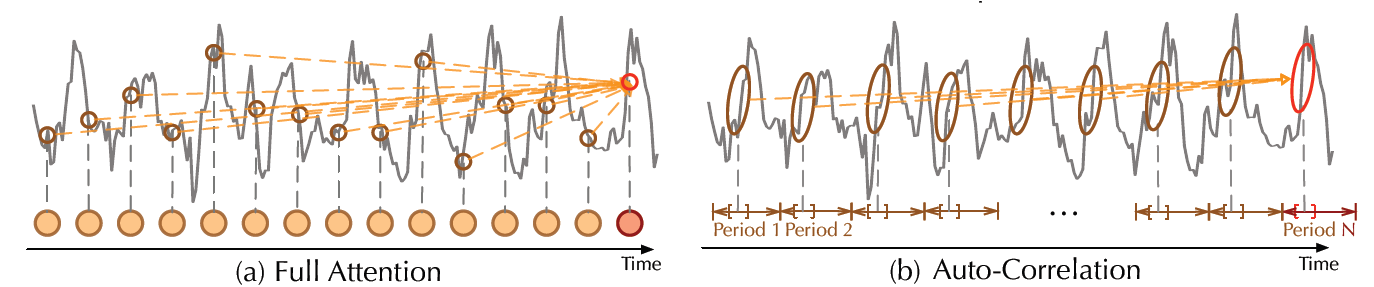 |
|:--:|
| Vanilla self attention vs Autocorrelation mechanism, from [the paper](https://arxiv.org/abs/2106.13008) |
In addition to the decomposition layer, Autoformer employs a novel auto-correlation mechanism which replaces the self-attention seamlessly. In the [vanilla Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer), attention weights are computed in the time domain and point-wise aggregated. On the other hand, as can be seen in the figure above, Autoformer computes them in the frequency domain (using [fast fourier transform](https://en.wikipedia.org/wiki/Fast_Fourier_transform)) and aggregates them by time delay.
In the following sections, we will dive into these topics in detail and explain them with code examples.
#### Frequency Domain Attention
| 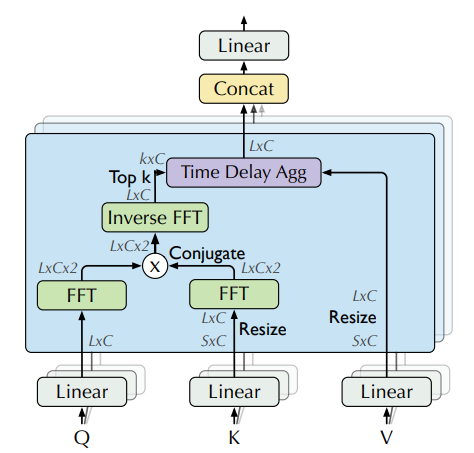 |
|:--:|
| Attention weights computation in frequency domain using FFT, from [the paper](https://arxiv.org/abs/2106.13008) |
In theory, given a time lag \\(\tau\\), _autocorrelation_ for a single discrete variable \\(y\\) is used to measure the "relationship" (pearson correlation) between the variable's current value at time \\(t\\) to its past value at time \\(t-\tau\\):
$$
\textrm{Autocorrelation}(\tau) = \textrm{Corr}(y_t, y_{t-\tau})
$$
Using autocorrelation, Autoformer extracts frequency-based dependencies from the queries and keys, instead of the standard dot-product between them. You can think about it as a replacement for the \\(QK^T\\) term in the self-attention.
In practice, autocorrelation of the queries and keys for **all lags** is calculated at once by FFT. By doing so, the autocorrelation mechanism achieves \\(O(L \log L)\\) time complexity (where \\(L\\) is the input time length), similar to [Informer's ProbSparse attention](https://huggingface.co/blog/informer#probsparse-attention). Note that the theory behind computing autocorrelation using FFT is based on the [Wiener–Khinchin theorem](https://en.wikipedia.org/wiki/Wiener%E2%80%93Khinchin_theorem), which is outside the scope of this blog post.
Now, we are ready to see the code in PyTorch:
```python
import torch
def autocorrelation(query_states, key_states):
"""
Computes autocorrelation(Q,K) using `torch.fft`.
Think about it as a replacement for the QK^T in the self-attention.
Assumption: states are resized to same shape of [batch_size, time_length, embedding_dim].
"""
query_states_fft = torch.fft.rfft(query_states, dim=1)
key_states_fft = torch.fft.rfft(key_states, dim=1)
attn_weights = query_states_fft * torch.conj(key_states_fft)
attn_weights = torch.fft.irfft(attn_weights, dim=1)
return attn_weights
```
Quite simple! 😎 Please be aware that this is only a partial implementation of `autocorrelation(Q,K)`, and the full implementation can be found in 🤗 Transformers.
Next, we will see how to aggregate our `attn_weights` with the values by time delay, process which is termed as _Time Delay Aggregation_.
#### Time Delay Aggregation
| 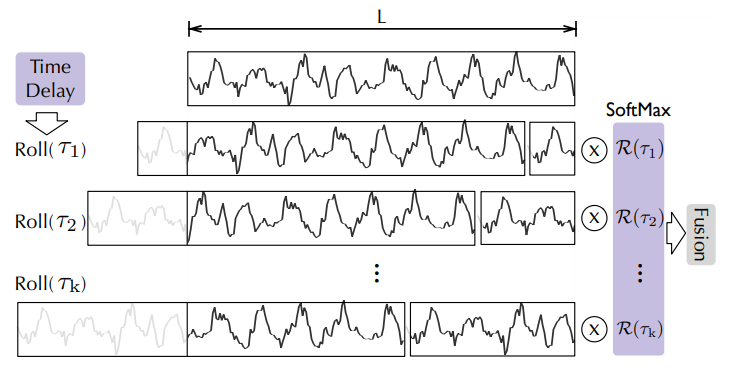 |
|:--:|
| Aggregation by time delay, from [the Autoformer paper](https://arxiv.org/abs/2106.13008) |
Let's consider the autocorrelations (referred to as `attn_weights`) as \\(\mathcal{R_{Q,K}}\\). The question arises: how do we aggregate these \\(\mathcal{R_{Q,K}}(\tau_1), \mathcal{R_{Q,K}}(\tau_2), ..., \mathcal{R_{Q,K}}(\tau_k)\\) with \\(\mathcal{V}\\)? In the standard self-attention mechanism, this aggregation is accomplished through dot-product. However, in Autoformer, we employ a different approach. Firstly, we align \\(\mathcal{V}\\) by calculating its value for each time delay \\(\tau_1, \tau_2, ... \tau_k\\), which is also known as _Rolling_. Subsequently, we conduct element-wise multiplication between the aligned \\(\mathcal{V}\\) and the autocorrelations. In the provided figure, you can observe the left side showcasing the rolling of \\(\mathcal{V}\\) by time delay, while the right side illustrates the element-wise multiplication with the autocorrelations.
It can be summarized with the following equations:
$$
\tau_1, \tau_2, ... \tau_k = \textrm{arg Top-k}(\mathcal{R_{Q,K}}(\tau)) \\
\hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _1), \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _2), ..., \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _k) = \textrm{Softmax}(\mathcal{R_{Q,K}}(\tau _1), \mathcal{R_{Q,K}}(\tau_2), ..., \mathcal{R_{Q,K}}(\tau_k)) \\
\textrm{Autocorrelation-Attention} = \sum_{i=1}^k \textrm{Roll}(\mathcal{V}, \tau_i) \cdot \hat{\mathcal{R}}\mathcal{_{Q,K}}(\tau _i)
$$
And that's it! Note that \\(k\\) is controlled by a hyperparameter called `autocorrelation_factor` (similar to `sampling_factor` in [Informer](https://huggingface.co/blog/informer)), and softmax is applied to the autocorrelations before the multiplication.
Now, we are ready to see the final code:
```python
import torch
import math
def time_delay_aggregation(attn_weights, value_states, autocorrelation_factor=2):
"""
Computes aggregation as value_states.roll(delay) * top_k_autocorrelations(delay).
The final result is the autocorrelation-attention output.
Think about it as a replacement of the dot-product between attn_weights and value states.
The autocorrelation_factor is used to find top k autocorrelations delays.
Assumption: value_states and attn_weights shape: [batch_size, time_length, embedding_dim]
"""
bsz, num_heads, tgt_len, channel = ...
time_length = value_states.size(1)
autocorrelations = attn_weights.view(bsz, num_heads, tgt_len, channel)
# find top k autocorrelations delays
top_k = int(autocorrelation_factor * math.log(time_length))
autocorrelations_mean = torch.mean(autocorrelations, dim=(1, -1)) # bsz x tgt_len
top_k_autocorrelations, top_k_delays = torch.topk(autocorrelations_mean, top_k, dim=1)
# apply softmax on the channel dim
top_k_autocorrelations = torch.softmax(top_k_autocorrelations, dim=-1) # bsz x top_k
# compute aggregation: value_states.roll(delay) * top_k_autocorrelations(delay)
delays_agg = torch.zeros_like(value_states).float() # bsz x time_length x channel
for i in range(top_k):
value_states_roll_delay = value_states.roll(shifts=-int(top_k_delays[i]), dims=1)
top_k_at_delay = top_k_autocorrelations[:, i]
# aggregation
top_k_resized = top_k_at_delay.view(-1, 1, 1).repeat(num_heads, tgt_len, channel)
delays_agg += value_states_roll_delay * top_k_resized
attn_output = delays_agg.contiguous()
return attn_output
```
We did it! The Autoformer model is [now available](https://huggingface.co/docs/transformers/main/en/model_doc/autoformer) in the 🤗 Transformers library, and simply called `AutoformerModel`.
Our strategy with this model is to show the performance of the univariate Transformer models in comparison to the DLinear model which is inherently univariate as will shown next. We will also present the results from _two_ multivariate Transformer models trained on the same data.
## DLinear - Under The Hood
Actually, DLinear is conceptually simple: it's just a fully connected with the Autoformer's `DecompositionLayer`.
It uses the `DecompositionLayer` above to decompose the input time series into the residual (the seasonality) and trend part. In the forward pass each part is passed through its own linear layer, which projects the signal to an appropriate `prediction_length`-sized output. The final output is the sum of the two corresponding outputs in the point-forecasting model:
```python
def forward(self, context):
seasonal, trend = self.decomposition(context)
seasonal_output = self.linear_seasonal(seasonal)
trend_output = self.linear_trend(trend)
return seasonal_output + trend_output
```
In the probabilistic setting one can project the context length arrays to `prediction-length * hidden` dimensions via the `linear_seasonal` and `linear_trend` layers. The resulting outputs are added and reshaped to `(prediction_length, hidden)`. Finally, a probabilistic head maps the latent representations of size `hidden` to the parameters of some distribution.
In our benchmark, we use the implementation of DLinear from [GluonTS](https://github.com/awslabs/gluonts).
## Example: Traffic Dataset
We want to show empirically the performance of Transformer-based models in the library, by benchmarking on the `traffic` dataset, a dataset with 862 time series. We will train a shared model on each of the individual time series (i.e. univariate setting).
Each time series represents the occupancy value of a sensor and is in the range [0, 1]. We will keep the following hyperparameters fixed for all the models:
```python
# Traffic prediction_length is 24. Reference:
# https://github.com/awslabs/gluonts/blob/6605ab1278b6bf92d5e47343efcf0d22bc50b2ec/src/gluonts/dataset/repository/_lstnet.py#L105
prediction_length = 24
context_length = prediction_length*2
batch_size = 128
num_batches_per_epoch = 100
epochs = 50
scaling = "std"
```
The transformers models are all relatively small with:
```python
encoder_layers=2
decoder_layers=2
d_model=16
```
Instead of showing how to train a model using `Autoformer`, one can just replace the model in the previous two blog posts ([TimeSeriesTransformer](https://huggingface.co/blog/time-series-transformers) and [Informer](https://huggingface.co/blog/informer)) with the new `Autoformer` model and train it on the `traffic` dataset. In order to not repeat ourselves, we have already trained the models and pushed them to the HuggingFace Hub. We will use those models for evaluation.
## Load Dataset
Let's first install the necessary libraries:
```python
!pip install -q transformers datasets evaluate accelerate "gluonts[torch]" ujson tqdm
```
The `traffic` dataset, used by [Lai et al. (2017)](https://arxiv.org/abs/1703.07015), contains the San Francisco Traffic. It contains 862 hourly time series showing the road occupancy rates in the range \\([0, 1]\\) on the San Francisco Bay Area freeways from 2015 to 2016.
```python
from gluonts.dataset.repository.datasets import get_dataset
dataset = get_dataset("traffic")
freq = dataset.metadata.freq
prediction_length = dataset.metadata.prediction_length
```
Let's visualize a time series in the dataset and plot the train/test split:
```python
import matplotlib.pyplot as plt
train_example = next(iter(dataset.train))
test_example = next(iter(dataset.test))
num_of_samples = 4*prediction_length
figure, axes = plt.subplots()
axes.plot(train_example["target"][-num_of_samples:], color="blue")
axes.plot(
test_example["target"][-num_of_samples - prediction_length :],
color="red",
alpha=0.5,
)
plt.show()
```
Let's define the train/test splits:
```python
train_dataset = dataset.train
test_dataset = dataset.test
```
## Define Transformations
Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones).
We define a `Chain` of transformations from GluonTS (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline.
The transformations below are annotated with comments to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features:
```python
from transformers import PretrainedConfig
from gluonts.time_feature import time_features_from_frequency_str
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
# create a list of fields to remove later
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in the life the value of the time series is
# sort of running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## Define `InstanceSplitter`
For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the model due to time and memory constraints).
The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes:
1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset)
2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations)
3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case)
```python
from gluonts.transform import InstanceSplitter
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## Create PyTorch DataLoaders
Next, it's time to create PyTorch DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`).
```python
from typing import Iterable
import torch
from gluonts.itertools import Cyclic, Cached
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from the 366 possible transformed time series)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
def create_backtest_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data)
# we create a Validation Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "validation")
# we apply the transformations in train mode
testing_instances = instance_sampler.apply(transformed_data, is_train=True)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# We create a test Instance splitter to sample the very last
# context window from the dataset provided.
instance_sampler = create_instance_splitter(config, "test")
# We apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
## Evaluate on Autoformer
We have already pre-trained an Autoformer model on this dataset, so we can just fetch the model and evaluate it on the test set:
```python
from transformers import AutoformerConfig, AutoformerForPrediction
config = AutoformerConfig.from_pretrained("kashif/autoformer-traffic-hourly")
model = AutoformerForPrediction.from_pretrained("kashif/autoformer-traffic-hourly")
test_dataloader = create_backtest_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)
```
At inference time, we will use the model's `generate()` method for predicting `prediction_length` steps into the future from the very last context window of each time series in the training set.
```python
from accelerate import Accelerator
accelerator = Accelerator()
device = accelerator.device
model.to(device)
model.eval()
forecasts_ = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts_.append(outputs.sequences.cpu().numpy())
```
The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`, `input_size`).
In this case, we get `100` possible values for the next `24` hours for each of the time series in the test dataloader batch which if you recall from above is `64`:
```python
forecasts_[0].shape
>>> (64, 100, 24)
```
We'll stack them vertically, to get forecasts for all time-series in the test dataset: We have `7` rolling windows in the test set which is why we end up with a total of `7 * 862 = 6034` predictions:
```python
import numpy as np
forecasts = np.vstack(forecasts_)
print(forecasts.shape)
>>> (6034, 100, 24)
```
We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. For that, we'll use the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library, which includes the [MASE](https://huggingface.co/spaces/evaluate-metric/mase) metrics.
We calculate the metric for each time series in the dataset and return the average:
```python
from tqdm.autonotebook import tqdm
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
for item_id, ts in enumerate(tqdm(test_dataset)):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
```
So the result for the Autoformer model is:
```python
print(f"Autoformer univariate MASE: {np.mean(mase_metrics):.3f}")
>>> Autoformer univariate MASE: 0.910
```
To plot the prediction for any time series with respect to the ground truth test data, we define the following helper:
```python
import matplotlib.dates as mdates
import pandas as pd
test_ds = list(test_dataset)
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_ds[ts_index][FieldName.START],
periods=len(test_ds[ts_index][FieldName.TARGET]),
freq=test_ds[ts_index][FieldName.START].freq,
).to_timestamp()
ax.plot(
index[-5*prediction_length:],
test_ds[ts_index]["target"][-5*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.gcf().autofmt_xdate()
plt.legend(loc="best")
plt.show()
```
For example, for time-series in the test set with index `4`:
```python
plot(4)
```
## Evaluate on DLinear
A probabilistic DLinear is implemented in `gluonts` and thus we can train and evaluate it relatively quickly here:
```python
from gluonts.torch.model.d_linear.estimator import DLinearEstimator
# Define the DLinear model with the same parameters as the Autoformer model
estimator = DLinearEstimator(
prediction_length=dataset.metadata.prediction_length,
context_length=dataset.metadata.prediction_length*2,
scaling=scaling,
hidden_dimension=2,
batch_size=batch_size,
num_batches_per_epoch=num_batches_per_epoch,
trainer_kwargs=dict(max_epochs=epochs)
)
```
Train the model:
```python
predictor = estimator.train(
training_data=train_dataset,
cache_data=True,
shuffle_buffer_length=1024
)
>>> INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
---------------------------------------
0 | model | DLinearModel | 4.7 K
---------------------------------------
4.7 K Trainable params
0 Non-trainable params
4.7 K Total params
0.019 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
...
INFO:pytorch_lightning.utilities.rank_zero:Epoch 49, global step 5000: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=50` reached.
```
And evaluate it on the test set:
```python
from gluonts.evaluation import make_evaluation_predictions, Evaluator
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset.test,
predictor=predictor,
)
d_linear_forecasts = list(forecast_it)
d_linear_tss = list(ts_it)
evaluator = Evaluator()
agg_metrics, _ = evaluator(iter(d_linear_tss), iter(d_linear_forecasts))
```
So the result for the DLinear model is:
```python
dlinear_mase = agg_metrics["MASE"]
print(f"DLinear MASE: {dlinear_mase:.3f}")
>>> DLinear MASE: 0.965
```
As before, we plot the predictions from our trained DLinear model via this helper:
```python
def plot_gluonts(index):
plt.plot(d_linear_tss[index][-4 * dataset.metadata.prediction_length:].to_timestamp(), label="target")
d_linear_forecasts[index].plot(show_label=True, color='g')
plt.legend()
plt.gcf().autofmt_xdate()
plt.show()
```
```python
plot_gluonts(4)
```
The `traffic` dataset has a distributional shift in the sensor patterns between weekdays and weekends. So what is going on here? Since the DLinear model has no capacity to incorporate covariates, in particular any date-time features, the context window we give it does not have enough information to figure out if the prediction is for the weekend or weekday. Thus, the model will predict the more common of the patterns, namely the weekdays leading to poorer performance on weekends. Of course, by giving it a larger context window, a linear model will figure out the weekly pattern, but perhaps there is a monthly or quarterly pattern in the data which would require bigger and bigger contexts.
## Conclusion
How do Transformer-based models compare against the above linear baseline? The test set MASE metrics from the different models we have are below:
|Dataset | Transformer (uni.) | Transformer (mv.) | Informer (uni.)| Informer (mv.) | Autoformer (uni.) | DLinear |
|:--:|:--:| :--:| :--:| :--:| :--:|:-------:|
|`Traffic` | **0.876** | 1.046 | 0.924 | 1.131 | 0.910 | 0.965 |
As one can observe, the [vanilla Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer) which we introduced last year gets the best results here. Secondly, multivariate models are typically _worse_ than the univariate ones, the reason being the difficulty in estimating the cross-series correlations/relationships. The additional variance added by the estimates often harms the resulting forecasts or the model learns spurious correlations. Recent papers like [CrossFormer](https://openreview.net/forum?id=vSVLM2j9eie) (ICLR 23) and [CARD](https://arxiv.org/abs/2305.12095) try to address this problem in Transformer models.
Multivariate models usually perform well when trained on large amounts of data. However, when compared to univariate models, especially on smaller open datasets, the univariate models tend to provide better metrics. By comparing the linear model with equivalent-sized univariate transformers or in fact any other neural univariate model, one will typically get better performance.
To summarize, Transformers are definitely far from being outdated when it comes to time-series forcasting!
Yet the availability of large-scale datasets is crucial for maximizing their potential.
Unlike in CV and NLP, the field of time series lacks publicly accessible large-scale datasets.
Most existing pre-trained models for time series are trained on small sample sizes from archives like [UCR and UEA](https://www.timeseriesclassification.com/),
which contain only a few thousands or even hundreds of samples.
Although these benchmark datasets have been instrumental in the progress of the time series community,
their limited sample sizes and lack of generality pose challenges for pre-training deep learning models.
Therefore, the development of large-scale, generic time series datasets (like ImageNet in CV) is of the utmost importance.
Creating such datasets will greatly facilitate further research on pre-trained models specifically designed for time series analysis,
and it will improve the applicability of pre-trained models in time series forecasting.
## Acknowledgements
We express our appreciation to [Lysandre Debut](https://github.com/LysandreJik) and [Pedro Cuenca](https://github.com/pcuenca)
their insightful comments and help during this project ❤️.
| huggingface/blog/blob/main/autoformer.md |
div align="center">
<h1><code>wasm-pack-template</code></h1>
<strong>A template for kick starting a Rust and WebAssembly project using <a href="https://github.com/rustwasm/wasm-pack">wasm-pack</a>.</strong>
<p>
<a href="https://travis-ci.org/rustwasm/wasm-pack-template"><img src="https://img.shields.io/travis/rustwasm/wasm-pack-template.svg?style=flat-square" alt="Build Status" /></a>
</p>
<h3>
<a href="https://rustwasm.github.io/docs/wasm-pack/tutorials/npm-browser-packages/index.html">Tutorial</a>
<span> | </span>
<a href="https://discordapp.com/channels/442252698964721669/443151097398296587">Chat</a>
</h3>
<sub>Built with 🦀🕸 by <a href="https://rustwasm.github.io/">The Rust and WebAssembly Working Group</a></sub>
</div>
## About
This is an example project showing off a very basic use case for `wasm` tokenizers
usage.
[**📚 Read this template tutorial! 📚**][template-docs]
This template is designed for compiling Rust libraries into WebAssembly and
publishing the resulting package to NPM.
Be sure to check out [other `wasm-pack` tutorials online][tutorials] for other
templates and usages of `wasm-pack`.
[tutorials]: https://rustwasm.github.io/docs/wasm-pack/tutorials/index.html
[template-docs]: https://rustwasm.github.io/docs/wasm-pack/tutorials/npm-browser-packages/index.html
## 🚴 Usage
### 🐑 Use `cargo generate` to Clone this Template
[Learn more about `cargo generate` here.](https://github.com/ashleygwilliams/cargo-generate)
```
cargo generate --git https://github.com/rustwasm/wasm-pack-template.git --name my-project
cd my-project
```
### 🛠️ Build with `wasm-pack build`
```
wasm-pack build
```
### 🔬 Test in Headless Browsers with `wasm-pack test`
```
wasm-pack test --headless --firefox
```
### 🎁 Publish to NPM with `wasm-pack publish`
```
wasm-pack publish
```
## 🔋 Batteries Included
* [`wasm-bindgen`](https://github.com/rustwasm/wasm-bindgen) for communicating
between WebAssembly and JavaScript.
* [`console_error_panic_hook`](https://github.com/rustwasm/console_error_panic_hook)
for logging panic messages to the developer console.
* [`wee_alloc`](https://github.com/rustwasm/wee_alloc), an allocator optimized
for small code size.
| huggingface/tokenizers/blob/main/tokenizers/examples/unstable_wasm/README.md |
--
title: "Image search with 🤗 datasets"
thumbnail: /blog/assets/54_image_search_datasets/spaces_image_search.jpg
authors:
- user: davanstrien
guest: true
---
# Image search with 🤗 datasets
<a target="_blank" href="https://colab.research.google.com/gist/davanstrien/e2c29fbbed20dc767e5a74e210f4237b/hf_blog_image_search.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
🤗 [`datasets`](https://huggingface.co/docs/datasets/) is a library that makes it easy to access and share datasets. It also makes it easy to process data efficiently -- including working with data which doesn't fit into memory.
When `datasets` was first launched, it was associated mostly with text data. However, recently, `datasets` has added increased support for audio as well as images. In particular, there is now a `datasets` [feature type for images](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image). A previous [blog post](https://huggingface.co/blog/fine-tune-vit) showed how `datasets` can be used with 🤗 `transformers` to train an image classification model. In this blog post, we'll see how we can combine `datasets` and a few other libraries to create an image search application.
First, we'll install `datasets`. Since we're going to be working with images, we'll also install [`pillow`](https://pillow.readthedocs.io/en/stable/). We'll also need `sentence_transformers` and `faiss`. We'll introduce those in more detail below. We also install [`rich`](https://github.com/Textualize/rich) - we'll only briefly use it here, but it's a super handy package to have around -- I'd really recommend exploring it further!
``` python
!pip install datasets pillow rich faiss-gpu sentence_transformers
```
To start, let's take a look at the image feature. We can use the wonderful [rich](https://rich.readthedocs.io/) library to poke around python
objects (functions, classes etc.)
``` python
from rich import inspect
import datasets
```
``` python
inspect(datasets.Image, help=True)
```
<pre style="white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace"><span style="color: #000080; text-decoration-color: #000080">╭───────────────────────── </span><span style="color: #000080; text-decoration-color: #000080; font-weight: bold"><</span><span style="color: #ff00ff; text-decoration-color: #ff00ff; font-weight: bold">class</span><span style="color: #000000; text-decoration-color: #000000"> </span><span style="color: #008000; text-decoration-color: #008000">'datasets.features.image.Image'</span><span style="color: #000080; text-decoration-color: #000080; font-weight: bold">></span><span style="color: #000080; text-decoration-color: #000080"> ─────────────────────────╮</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #00ffff; text-decoration-color: #00ffff; font-style: italic">class </span><span style="color: #800000; text-decoration-color: #800000; font-weight: bold">Image</span><span style="font-weight: bold">(</span>decode: bool = <span style="color: #00ff00; text-decoration-color: #00ff00; font-style: italic">True</span>, id: Union<span style="font-weight: bold">[</span>str, NoneType<span style="font-weight: bold">]</span> = <span style="color: #800080; text-decoration-color: #800080; font-style: italic">None</span><span style="font-weight: bold">)</span> -> <span style="color: #800080; text-decoration-color: #800080; font-style: italic">None</span>: <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">Image feature to read image data from an image file.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">Input: The Image feature accepts as input:</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- A :obj:`str`: Absolute path to the image file </span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">(</span><span style="color: #008080; text-decoration-color: #008080">i.e. random access is allowed</span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">)</span><span style="color: #008080; text-decoration-color: #008080">.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- A :obj:`dict` with the keys:</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> - path: String with relative path of the image file to the archive file.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> - bytes: Bytes of the image file.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> This is useful for archived files with sequential access.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- An :obj:`np.ndarray`: NumPy array representing an image.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- A :obj:`PIL.Image.Image`: PIL image object.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">Args:</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> decode </span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">(</span><span style="color: #008080; text-decoration-color: #008080">:obj:`bool`, default ``</span><span style="color: #00ff00; text-decoration-color: #00ff00; font-style: italic">True</span><span style="color: #008080; text-decoration-color: #008080">``</span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">)</span><span style="color: #008080; text-decoration-color: #008080">: Whether to decode the image data. If `</span><span style="color: #ff0000; text-decoration-color: #ff0000; font-style: italic">False</span><span style="color: #008080; text-decoration-color: #008080">`,</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> returns the underlying dictionary in the format </span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">{</span><span style="color: #008000; text-decoration-color: #008000">"path"</span><span style="color: #008080; text-decoration-color: #008080">: image_path, </span><span style="color: #008000; text-decoration-color: #008000">"bytes"</span><span style="color: #008080; text-decoration-color: #008080">: </span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">image_bytes</span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">}</span><span style="color: #008080; text-decoration-color: #008080">.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">decode</span> = <span style="color: #00ff00; text-decoration-color: #00ff00; font-style: italic">True</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">dtype</span> = <span style="color: #008000; text-decoration-color: #008000">'PIL.Image.Image'</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">id</span> = <span style="color: #800080; text-decoration-color: #800080; font-style: italic">None</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">pa_type</span> = <span style="color: #800080; text-decoration-color: #800080; font-weight: bold">StructType</span><span style="font-weight: bold">(</span>struct<span style="font-weight: bold"><</span><span style="color: #ff00ff; text-decoration-color: #ff00ff; font-weight: bold">bytes:</span><span style="color: #000000; text-decoration-color: #000000"> binary, path: string</span><span style="font-weight: bold">>)</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">╰───────────────────────────────────────────────────────────────────────────────────────────╯</span>
</pre>
We can see there a few different ways in which we can pass in our images. We'll come back to this in a little while.
A really nice feature of the `datasets` library (beyond the functionality for processing data, memory mapping etc.) is that you get
some nice things 'for free'. One of these is the ability to add a [`faiss`](https://github.com/facebookresearch/faiss) index to a dataset. [`faiss`](https://github.com/facebookresearch/faiss) is a ["library for efficient similarity search and clustering of dense
vectors"](https://github.com/facebookresearch/faiss).
The `datasets` [docs](https://huggingface.co/docs/datasets) shows an [example](https://huggingface.co/docs/datasets/faiss_es.html#id1) of using a `faiss` index for text retrieval. In this post we'll see if we can do the same for images.
## The dataset: "Digitised Books - Images identified as Embellishments. c. 1510 - c. 1900"
This is a dataset of images which have been pulled from a collection of digitised books from the British Library. These images come from books across a wide time period and from a broad range of domains. The images were extracted using information contained in the OCR output for each book. As a result, it's known which book the images came from, but not necessarily anything else about that image i.e. what is shown in the image.
Some attempts to help overcome this have included uploading the images to [flickr](https://www.flickr.com/photos/britishlibrary/albums). This allows people to tag the images or put them into various different categories.
There have also been projects to tag the dataset [using machine learning](https://blogs.bl.uk/digital-scholarship/2016/11/sherlocknet-update-millions-of-tags-and-thousands-of-captions-added-to-the-bl-flickr-images.html). This work makes it possible to search by tags, but we might want a 'richer' ability to search. For this particular experiment, we'll work with a subset of the collections which contain "embellishments". This dataset is a bit smaller, so it will be better for experimenting with. We can get the full data from the British Library's data repository: [https://doi.org/10.21250/db17](https://doi.org/10.21250/db17). Since the full dataset is still fairly large, you'll probably want to start with a smaller sample.
## Creating our dataset
Our dataset consists of a folder containing subdirectories inside which are images. This is a fairly standard format for sharing image datasets. Thanks to a recently merged [pull request](https://github.com/huggingface/datasets/pull/2830) we can directly load this dataset using `datasets` `ImageFolder` loader 🤯
```python
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_files="https://zenodo.org/record/6224034/files/embellishments_sample.zip?download=1")
```
Let's see what we get back.
```python
dataset
```
```
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 10000
})
})
```
We can get back a `DatasetDict`, and we have a Dataset with image and label features. Since we don't have any train/validation splits here, let's grab the train part of our dataset. Let's also take a look at one example from our dataset to see what this looks like.
```python
dataset = dataset["train"]
dataset[0]
```
```python
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F9488DBB090>,
'label': 208}
```
Let's start with the label column. It contains the parent folder for our images. In this case, the label column represents the year of publication for the books from which the images are taken. We can see the mappings for this using `dataset.features`:
```python
dataset.features['label']
```
In this particular dataset, the image filenames also contain some metadata about the book from which the image was taken. There are a few ways we can get this information.
When we look at one example from our dataset that the `image` feature was a `PIL.JpegImagePlugin.JpegImageFile`. Since `PIL.Images` have a filename attribute, one way in which we can grab our filenames is by accessing this.
```python
dataset[0]['image'].filename
```
```python
/root/.cache/huggingface/datasets/downloads/extracted/f324a87ed7bf3a6b83b8a353096fbd9500d6e7956e55c3d96d2b23cc03146582/embellishments_sample/1920/000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg
```
Since we might want easy access to this information later, let's create a new column to extract the filename. For this, we'll use the `map` method.
```python
dataset = dataset.map(lambda example: {"fname": example['image'].filename.split("/")[-1]})
```
We can look at one example to see what this looks like now.
```python
dataset[0]
```
```python
{'fname': '000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F94862A9650>,
'label': 208}
```
We've got our metadata now. Let's see some pictures already! If we access an example and index into the `image` column we'll see our image 😃
``` python
dataset[10]['image']
```
<img src="assets/54_image_search_datasets/dataset_image.jpg" alt="An example image from our dataset">
> **Note** in an [earlier version](https://danielvanstrien.xyz/metadata/deployment/huggingface/ethics/huggingface-datasets/faiss/2022/01/13/image_search.html) of this blog post the steps to download and load the images was much more convoluted. The new ImageFolder loader makes this process much easier 😀 In particular, we don't need to worry about how to load our images since datasets took care of this for us.
## Push all the things to the hub!
<img src="https://i.imgflip.com/613c0r.jpg" alt="Push all the things to the hub">
One of the super awesome things about the 🤗 ecosystem is the Hugging Face Hub. We can use the Hub to access models and datasets. It is often used for sharing work with others, but it can also be a useful tool for work in progress. `datasets` recently added a `push_to_hub` method that allows you to push a dataset to the Hub with minimal fuss. This can be really helpful by allowing you to pass around a dataset with all the transforms etc. already done.
For now, we'll push the dataset to the Hub and keep it private initially.
Depending on where you are running the code, you may need to authenticate. You can either do this using the `huggingface-cli login` command or, if you are running in a notebook, using `notebook_login`
``` python
from huggingface_hub import notebook_login
notebook_login()
```
``` python
dataset.push_to_hub('davanstrien/embellishments-sample', private=True)
```
> **Note**: in a [previous version](https://danielvanstrien.xyz/metadata/deployment/huggingface/ethics/huggingface-datasets/faiss/2022/01/13/image_search.html) of this blog post we had to do a few more steps to ensure images were embedded when using `push_to_hub`. Thanks to [this pull request](https://github.com/huggingface/datasets/pull/3685) we no longer need to worry about these extra steps. We just need to make sure `embed_external_files=True` (which is the default behaviour).
### Switching machines
At this point, we've created a dataset and moved it to the Hub. This means it is possible to pick up the work/dataset elsewhere.
In this particular example, having access to a GPU is important. Using the Hub as a way to pass around our data we could start on a laptop
and pick up the work on Google Colab.
If we move to a new machine, we may need to login again. Once we've done this we can load our dataset
``` python
from datasets import load_dataset
dataset = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
```
## Creating embeddings 🕸
We now have a dataset with a bunch of images in it. To begin creating our image search app, we need to embed these images. There are various ways to try and do this, but one possible way is to use the CLIP models via the `sentence_transformers` library. The [CLIP model](https://openai.com/blog/clip/) from OpenAI learns a joint representation for both images and text, which is very useful for what we want to do since we want to input text and get back an image.
We can download the model using the `SentenceTransformer` class.
``` python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('clip-ViT-B-32')
```
This model will take as input either an image or some text and return an embedding. We can use the `datasets` `map` method to encode all our images using this model. When we call map, we return a dictionary with the key `embeddings` containing the embeddings returned by the model. We also pass `device='cuda'` when we call the model; this ensures that we're doing the encoding on the GPU.
``` python
ds_with_embeddings = dataset.map(
lambda example: {'embeddings':model.encode(example['image'], device='cuda')}, batched=True, batch_size=32)
```
We can 'save' our work by pushing back to the Hub using
`push_to_hub`.
``` python
ds_with_embeddings.push_to_hub('davanstrien/embellishments-sample', private=True)
```
If we were to move to a different machine, we could grab our work again by loading it from the Hub 😃
``` python
from datasets import load_dataset
ds_with_embeddings = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
```
We now have a new column which contains the embeddings for our images. We could manually search through these and compare them to some input embedding but datasets has an `add_faiss_index` method. This uses the [faiss](https://github.com/facebookresearch/faiss) library to create an efficient index for searching embeddings. For more background on this library, you can watch this [YouTube video](https://www.youtube.com/embed/sKyvsdEv6rk)
``` python
ds_with_embeddings['train'].add_faiss_index(column='embeddings')
```
```
Dataset({
features: ['fname', 'year', 'path', 'image', 'embeddings'],
num_rows: 10000
})
```
## Image search
> **Note** that these examples were generated from the full version of the dataset so you may get slightly different results.
We now have everything we need to create a simple image search. We can use the same model we used to encode our images to encode some input text. This will act as the prompt we try and find close examples for. Let's start with 'a steam engine'.
``` python
prompt = model.encode("A steam engine")
```
We can use another method from the datasets library `get_nearest_examples` to get images which have an embedding close to our input prompt embedding. We can pass in a number of results we want to get back.
``` python
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=9)
```
We can index into the first example this retrieves:
``` python
retrieved_examples['image'][0]
```
<img src="assets/54_image_search_datasets/search_result.jpg" alt="An image of a factory">
This isn't quite a steam engine, but it's also not a completely weird result. We can plot the other results to see what was returned.
``` python
import matplotlib.pyplot as plt
```
``` python
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)
```
<img src="assets/54_image_search_datasets/steam_engine_search_results.jpg">
Some of these results look fairly close to our input prompt. We can wrap
this in a function so we can more easily play around with different prompts
``` python
def get_image_from_text(text_prompt, number_to_retrieve=9):
prompt = model.encode(text_prompt)
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=number_to_retrieve)
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.title(text_prompt)
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)
```
``` python
get_image_from_text("An illustration of the sun behind a mountain")
```
<img src="assets/54_image_search_datasets/sun_behind_mountain.jpg">
### Trying a bunch of prompts ✨
Now we have a function for getting a few results, we can try a bunch of
different prompts:
- For some of these I'll choose prompts which are a broad 'category' i.e. 'a musical instrument' or 'an animal', others are specific i.e. 'a guitar'.
- Out of interest I also tried a boolean operator: "An illustration of a cat or a dog".
- Finally I tried something a little more abstract: \"an empty abyss\"
``` python
prompts = ["A musical instrument", "A guitar", "An animal", "An illustration of a cat or a dog", "an empty abyss"]
```
``` python
for prompt in prompts:
get_image_from_text(prompt)
```
<img src="assets/54_image_search_datasets/musical_instrument.jpg">
<img src="assets/54_image_search_datasets/guitar.jpg">
<img src="assets/54_image_search_datasets/an_animal.jpg">
<img src="assets/54_image_search_datasets/cat_or_dog.jpg">
<img src="assets/54_image_search_datasets/an_empty_abyss.jpg">
We can see these results aren't always right, but they are usually reasonable. It already seems like this could be useful for searching for the semantic content of an image in this dataset. However we might hold off on sharing this as is...
## Creating a Hugging Face Space? 🤷🏼
One obvious next step for this kind of project is to create a Hugging Face [Space](https://huggingface.co/spaces/launch) demo. This is what I've done for other [models](https://huggingface.co/spaces/BritishLibraryLabs/British-Library-books-genre-classifier-v2).
It was a fairly simple process to get a [Gradio app setup](https://gradio.app/) from the point we got to here. Here is a screenshot of this app:
<img src="assets/54_image_search_datasets/spaces_image_search.jpg" alt="Screenshot of Gradio search app">
However, I'm a little bit vary about making this public straightaway. Looking at the model card for the CLIP model we can look at the primary intended uses:
> ### Primary intended uses
>
> We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
> [source](https://huggingface.co/openai/clip-vit-base-patch32)
This is fairly close to what we are interested in here. Particularly we might be interested in how well the model deals with the kinds of images in our dataset (illustrations from mostly 19th century books). The images in our dataset are (probably) fairly different from the training data. The fact that some of the images also contain text might help CLIP since it displays some [OCR ability](https://openai.com/blog/clip/).
However, looking at the out-of-scope use cases in the model card:
> ### Out-of-Scope Use Cases
>
> Any deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP's performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case > currently potentially harmful. > [source](https://huggingface.co/openai/clip-vit-base-patch32)
suggests that 'deployment' is not a good idea. Whilst the results I got are interesting, I haven't played around with the model enough yet (and haven't done anything more systematic to evaluate its performance and biases) to be confident about 'deploying' it. Another additional consideration is the target dataset itself. The images are drawn from books covering a variety of subjects and time periods. There are plenty of books which represent colonial attitudes and as a result some of the images included may represent certain groups of people in a negative way. This could potentially be a bad combo with a tool which allows any arbitrary text input to be encoded as a prompt.
There may be ways around this issue but this will require a bit more thought.
## Conclusion
Although we don't have a nice demo to show for it, we've seen how we can use `datasets` to:
- load images into the new `Image` feature type
- 'save' our work using `push_to_hub` and use this to move data between machines/sessions
- create a `faiss` index for images that we can use to retrieve images from a text (or image) input.
| huggingface/blog/blob/main/image-search-datasets.md |
--
title: "Introducing IDEFICS: An Open Reproduction of State-of-the-art Visual Langage Model"
thumbnail: /blog/assets/idefics/thumbnail.png
authors:
- user: HugoLaurencon
- user: davanstrien
- user: stas
- user: Leyo
- user: SaulLu
- user: TimeRobber
guest: true
- user: skaramcheti
guest: true
- user: aps
guest: true
- user: giadap
- user: yjernite
- user: VictorSanh
---
# Introducing IDEFICS: An Open Reproduction of State-of-the-Art Visual Language Model
We are excited to release IDEFICS (**I**mage-aware **D**ecoder **E**nhanced à la **F**lamingo with **I**nterleaved **C**ross-attention**S**), an open-access visual language model. IDEFICS is based on [Flamingo](https://huggingface.co/papers/2204.14198), a state-of-the-art visual language model initially developed by DeepMind, which has not been released publicly. Similarly to GPT-4, the model accepts arbitrary sequences of image and text inputs and produces text outputs. IDEFICS is built solely on publicly available data and models (LLaMA v1 and OpenCLIP) and comes in two variants—the base version and the instructed version. Each variant is available at the 9 billion and 80 billion parameter sizes.
The development of state-of-the-art AI models should be more transparent. Our goal with IDEFICS is to reproduce and provide the AI community with systems that match the capabilities of large proprietary models like Flamingo. As such, we took important steps contributing to bringing transparency to these AI systems: we used only publicly available data, we provided tooling to explore training datasets, we shared [technical lessons and mistakes](https://github.com/huggingface/m4-logs/blob/master/memos/README.md) of building such artifacts and assessed the model’s harmfulness by adversarially prompting it before releasing it. We are hopeful that IDEFICS will serve as a solid foundation for more open research in multimodal AI systems, alongside models like [OpenFlamingo](https://huggingface.co/openflamingo)-another open reproduction of Flamingo at the 9 billion parameter scale.
Try out the [demo](https://huggingface.co/spaces/HuggingFaceM4/idefics_playground) and the [models](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) on the Hub!
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/woodstock_ai.png" width="600" alt="Screenshot of IDEFICS generation for HF Woodstock of AI"/>
</p>
## What is IDEFICS?
IDEFICS is an 80 billion parameters multimodal model that accepts sequences of images and texts as input and generates coherent text as output. It can answer questions about images, describe visual content, create stories grounded in multiple images, etc.
IDEFICS is an open-access reproduction of Flamingo and is comparable in performance with the original closed-source model across various image-text understanding benchmarks. It comes in two variants - 80 billion parameters and 9 billion parameters.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/Figure_Evals_IDEFICS.png" width="600" alt="Plot comparing the performance of Flamingo, OpenFlamingo and IDEFICS"/>
</p>
We also provide fine-tuned versions [idefics-80B-instruct](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) and [idefics-9B-instruct](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct) adapted for conversational use cases.
## Training Data
IDEFICS was trained on a mixture of openly available datasets: Wikipedia, Public Multimodal Dataset, and LAION, as well as a new 115B token dataset called [OBELICS](https://huggingface.co/datasets/HuggingFaceM4/OBELICS) that we created. OBELICS consists of 141 million interleaved image-text documents scraped from the web and contains 353 million images.
We provide an [interactive visualization](https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f) of OBELICS that allows exploring the content of the dataset with [Nomic AI](https://home.nomic.ai/).
<p align="center">
<a href="https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/obelics_nomic_map.png" width="600" alt="Interactive visualization of OBELICS"/>
</a>
</p>
The details of IDEFICS' architecture, training methodology, and evaluations, as well as information about the dataset, are available in the [model card](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) and our [research paper](https://huggingface.co/papers/2306.16527). Additionally, we have documented [technical insights and learnings](https://github.com/huggingface/m4-logs/blob/master/memos/README.md) from the model's training, offering valuable perspective on IDEFICS' development.
## Ethical evaluation
At the outset of this project, through a set of discussions, we developed an [ethical charter](https://huggingface.co/blog/ethical-charter-multimodal) that would help steer decisions made during the project. This charter sets out values, including being self-critical, transparent, and fair which we have sought to pursue in how we approached the project and the release of the models.
As part of the release process, we internally evaluated the model for potential biases by adversarially prompting the model with images and text that might elicit responses we do not want from the model (a process known as red teaming).
Please try out IDEFICS with the [demo](https://huggingface.co/spaces/HuggingFaceM4/idefics_playground), check out the corresponding [model cards](https://huggingface.co/HuggingFaceM4/idefics-80b) and [dataset card](https://huggingface.co/datasets/HuggingFaceM4/OBELICS) and let us know your feedback using the community tab! We are committed to improving these models and making large multimodal AI models accessible to the machine learning community.
## License
The model is built on top of two pre-trained models: [laion/CLIP-ViT-H-14-laion2B-s32B-b79K](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K) and [huggyllama/llama-65b](https://huggingface.co/huggyllama/llama-65b). The first was released under an MIT license, while the second was released under a specific non-commercial license focused on research purposes. As such, users should comply with that license by applying directly to [Meta's form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform).
The two pre-trained models are connected to each other with newly initialized parameters that we train. These are not based on any of the two base frozen models forming the composite model. We release the additional weights we trained under an MIT license.
## Getting Started with IDEFICS
IDEFICS models are available on the Hugging Face Hub and supported in the last `transformers` version. Here is a code sample to try it out:
```python
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
```
| huggingface/blog/blob/main/idefics.md |
The Backend 🐍
This guide will cover everything you need to know to implement your custom component's backend processing.
## Which Class to Inherit From
All components inherit from one of three classes `Component`, `FormComponent`, or `BlockContext`.
You need to inherit from one so that your component behaves like all other gradio components.
When you start from a template with `gradio cc create --template`, you don't need to worry about which one to choose since the template uses the correct one.
For completeness, and in the event that you need to make your own component from scratch, we explain what each class is for.
* `FormComponent`: Use this when you want your component to be grouped together in the same `Form` layout with other `FormComponents`. The `Slider`, `Textbox`, and `Number` components are all `FormComponents`.
* `BlockContext`: Use this when you want to place other components "inside" your component. This enabled `with MyComponent() as component:` syntax.
* `Component`: Use this for all other cases.
Tip: If your component supports streaming output, inherit from the `StreamingOutput` class.
Tip: If you inherit from `BlockContext`, you also need to set the metaclass to be `ComponentMeta`. See example below.
```python
from gradio.blocks import BlockContext
from gradio.component_meta import ComponentMeta
set_documentation_group("layout")
@document()
class Row(BlockContext, metaclass=ComponentMeta):
pass
```
## The methods you need to implement
When you inherit from any of these classes, the following methods must be implemented.
Otherwise the Python interpreter will raise an error when you instantiate your component!
### `preprocess` and `postprocess`
Explained in the [Key Concepts](./key-component-concepts#the-value-and-how-it-is-preprocessed-postprocessed) guide.
They handle the conversion from the data sent by the frontend to the format expected by the python function.
```python
@abstractmethod
def preprocess(self, x: Any) -> Any:
"""
Convert from the web-friendly (typically JSON) value in the frontend to the format expected by the python function.
"""
return x
@abstractmethod
def postprocess(self, y):
"""
Convert from the data returned by the python function to the web-friendly (typically JSON) value expected by the frontend.
"""
return y
```
### `as_example`
Takes in the original Python value and returns the modified value that should be displayed in the examples preview in the app.
Let's look at the following example from the `Radio` component.
```python
def as_example(self, input_data):
return next((c[0] for c in self.choices if c[1] == input_data), None)
```
Since `self.choices` is a list of tuples corresponding to (`display_name`, `value`), this converts the value that a user provides to the display value (or if the value is not present in `self.choices`, it is converted to `None`).
```python
@abstractmethod
def as_example(self, y):
pass
```
### `api_info`
A JSON-schema representation of the value that the `preprocess` expects.
This powers api usage via the gradio clients.
You do **not** need to implement this yourself if you components specifies a `data_model`.
The `data_model` in the following section.
```python
@abstractmethod
def api_info(self) -> dict[str, list[str]]:
"""
A JSON-schema representation of the value that the `preprocess` expects and the `postprocess` returns.
"""
pass
```
### `example_inputs`
The example inputs for this component displayed in the `View API` page.
Must be JSON-serializable.
If your component expects a file, it is best to use a publicly accessible URL.
```python
@abstractmethod
def example_inputs(self) -> Any:
"""
The example inputs for this component for API usage. Must be JSON-serializable.
"""
pass
```
### `flag`
Write the component's value to a format that can be stored in the `csv` or `json` file used for flagging.
You do **not** need to implement this yourself if you components specifies a `data_model`.
The `data_model` in the following section.
```python
@abstractmethod
def flag(self, x: Any | GradioDataModel, flag_dir: str | Path = "") -> str:
pass
```
### `read_from_flag`
Convert from the format stored in the `csv` or `json` file used for flagging to the component's python `value`.
You do **not** need to implement this yourself if you components specifies a `data_model`.
The `data_model` in the following section.
```python
@abstractmethod
def read_from_flag(
self,
x: Any,
flag_dir: str | Path | None = None,
) -> GradioDataModel | Any:
"""
Convert the data from the csv or jsonl file into the component state.
"""
return x
```
## The `data_model`
The `data_model` is how you define the expected data format your component's value will be stored in the frontend.
It specifies the data format your `preprocess` method expects and the format the `postprocess` method returns.
It is not necessary to define a `data_model` for your component but it greatly simplifies the process of creating a custom component.
If you define a custom component you only need to implement three methods - `preprocess`, `postprocess`, and `example_inputs`!
You define a `data_model` by defining a [pydantic model](https://docs.pydantic.dev/latest/concepts/models/#basic-model-usage) that inherits from either `GradioModel` or `GradioRootModel`.
This is best explained with an example. Let's look at the core `Video` component, which stores the video data as a JSON object with two keys `video` and `subtitles` which point to separate files.
```python
from gradio.data_classes import FileData, GradioModel
class VideoData(GradioModel):
video: FileData
subtitles: Optional[FileData] = None
class Video(Component):
data_model = VideoData
```
By adding these four lines of code, your component automatically implements the methods needed for API usage, the flagging methods, and example caching methods!
It also has the added benefit of self-documenting your code.
Anyone who reads your component code will know exactly the data it expects.
Tip: If your component expects files to be uploaded from the frontend, your must use the `FileData` model! It will be explained in the following section.
Tip: Read the pydantic docs [here](https://docs.pydantic.dev/latest/concepts/models/#basic-model-usage).
The difference between a `GradioModel` and a `GradioRootModel` is that the `RootModel` will not serialize the data to a dictionary.
For example, the `Names` model will serialize the data to `{'names': ['freddy', 'pete']}` whereas the `NamesRoot` model will serialize it to `['freddy', 'pete']`.
```python
from typing import List
class Names(GradioModel):
names: List[str]
class NamesRoot(GradioRootModel):
root: List[str]
```
Even if your component does not expect a "complex" JSON data structure it can be beneficial to define a `GradioRootModel` so that you don't have to worry about implementing the API and flagging methods.
Tip: Use classes from the Python typing library to type your models. e.g. `List` instead of `list`.
## Handling Files
If your component expects uploaded files as input, or returns saved files to the frontend, you **MUST** use the `FileData` to type the files in your `data_model`.
When you use the `FileData`:
* Gradio knows that it should allow serving this file to the frontend. Gradio automatically blocks requests to serve arbitrary files in the computer running the server.
* Gradio will automatically place the file in a cache so that duplicate copies of the file don't get saved.
* The client libraries will automatically know that they should upload input files prior to sending the request. They will also automatically download files.
If you do not use the `FileData`, your component will not work as expected!
## Adding Event Triggers To Your Component
The events triggers for your component are defined in the `EVENTS` class attribute.
This is a list that contains the string names of the events.
Adding an event to this list will automatically add a method with that same name to your component!
You can import the `Events` enum from `gradio.events` to access commonly used events in the core gradio components.
For example, the following code will define `text_submit`, `file_upload` and `change` methods in the `MyComponent` class.
```python
from gradio.events import Events
from gradio.components import FormComponent
class MyComponent(FormComponent):
EVENTS = [
"text_submit",
"file_upload",
Events.change
]
```
Tip: Don't forget to also handle these events in the JavaScript code!
## Conclusion
| gradio-app/gradio/blob/main/guides/05_custom-components/04_backend.md |
Gradio Demo: blocks_flag
```
!pip install -q gradio numpy
```
```
import numpy as np
import gradio as gr
def sepia(input_img, strength):
sepia_filter = strength * np.array(
[[0.393, 0.769, 0.189], [0.349, 0.686, 0.168], [0.272, 0.534, 0.131]]
) + (1-strength) * np.identity(3)
sepia_img = input_img.dot(sepia_filter.T)
sepia_img /= sepia_img.max()
return sepia_img
callback = gr.CSVLogger()
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
img_input = gr.Image()
strength = gr.Slider(0, 1, 0.5)
img_output = gr.Image()
with gr.Row():
btn = gr.Button("Flag")
# This needs to be called at some point prior to the first call to callback.flag()
callback.setup([img_input, strength, img_output], "flagged_data_points")
img_input.change(sepia, [img_input, strength], img_output)
strength.change(sepia, [img_input, strength], img_output)
# We can choose which components to flag -- in this case, we'll flag all of them
btn.click(lambda *args: callback.flag(args), [img_input, strength, img_output], None, preprocess=False)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_flag/run.ipynb |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Model training anatomy
To understand performance optimization techniques that one can apply to improve efficiency of model training
speed and memory utilization, it's helpful to get familiar with how GPU is utilized during training, and how compute
intensity varies depending on an operation performed.
Let's start by exploring a motivating example of GPU utilization and the training run of a model. For the demonstration,
we'll need to install a few libraries:
```bash
pip install transformers datasets accelerate nvidia-ml-py3
```
The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar
with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
Then, we create some dummy data: random token IDs between 100 and 30000 and binary labels for a classifier.
In total, we get 512 sequences each with length 512 and store them in a [`~datasets.Dataset`] with PyTorch format.
```py
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
... "labels": np.random.randint(0, 1, (dataset_size)),
... }
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")
```
To print summary statistics for the GPU utilization and the training run with the [`Trainer`] we define two helper functions:
```py
>>> from pynvml import *
>>> def print_gpu_utilization():
... nvmlInit()
... handle = nvmlDeviceGetHandleByIndex(0)
... info = nvmlDeviceGetMemoryInfo(handle)
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
... print(f"Time: {result.metrics['train_runtime']:.2f}")
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
... print_gpu_utilization()
```
Let's verify that we start with a free GPU memory:
```py
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.
```
That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on
your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by
the user. When a model is loaded to the GPU the kernels are also loaded, which can take up 1-2GB of memory. To see how
much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
```py
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.
```
We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
## Load Model
First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check
how much space just the weights use.
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.
```
We can see that the model weights alone take up 1.3 GB of GPU memory. The exact number depends on the specific
GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an
optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result
as with `nvidia-smi` CLI:
```bash
nvidia-smi
```
```bash
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
```
We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can
start training the model and see how the GPU memory consumption changes. First, we set up a few standard training
arguments:
```py
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
```
<Tip>
If you plan to run multiple experiments, in order to properly clear the memory between experiments, restart the Python
kernel between experiments.
</Tip>
## Memory utilization at vanilla training
Let's use the [`Trainer`] and train the model without using any GPU performance optimization techniques and a batch size of 4:
```py
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)
```
```
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
```
We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size
can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our
model's needs and not to the GPU limitations. What's interesting is that we use much more memory than the size of the model.
To understand a bit better why this is the case let's have a look at a model's operations and memory needs.
## Anatomy of Model's Operations
Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
1. **Tensor Contractions**
Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
2. **Statistical Normalizations**
Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
3. **Element-wise Operators**
These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
This knowledge can be helpful to know when analyzing performance bottlenecks.
This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
## Anatomy of Model's Memory
We've seen that training the model uses much more memory than just putting the model on the GPU. This is because there
are many components during training that use GPU memory. The components on GPU memory are the following:
1. model weights
2. optimizer states
3. gradients
4. forward activations saved for gradient computation
5. temporary buffers
6. functionality-specific memory
A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory. For
inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per
model parameter for mixed precision inference, plus activation memory.
Let's look at the details.
**Model Weights:**
- 4 bytes * number of parameters for fp32 training
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
**Optimizer States:**
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
**Gradients**
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
**Forward Activations**
- size depends on many factors, the key ones being sequence length, hidden size and batch size.
There are the input and output that are being passed and returned by the forward and the backward functions and the
forward activations saved for gradient computation.
**Temporary Memory**
Additionally, there are all kinds of temporary variables which get released once the calculation is done, but in the
moment these could require additional memory and could push to OOM. Therefore, when coding it's crucial to think
strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
**Functionality-specific memory**
Then, your software could have special memory needs. For example, when generating text using beam search, the software
needs to maintain multiple copies of inputs and outputs.
**`forward` vs `backward` Execution Speed**
For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates
into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually
bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward
(e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward,
and writes once, gradInput).
As you can see, there are potentially a few places where we could save GPU memory or speed up operations.
Now that you understand what affects GPU utilization and computation speed, refer to
the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) documentation page to learn about
performance optimization techniques.
| huggingface/transformers/blob/main/docs/source/en/model_memory_anatomy.md |
Gradio Demo: concurrency_without_queue
```
!pip install -q gradio
```
```
import gradio as gr
import time
def say_hello(name):
time.sleep(5)
return f"Hello {name}!"
with gr.Blocks() as demo:
inp = gr.Textbox()
outp = gr.Textbox()
button = gr.Button()
button.click(say_hello, inp, outp)
demo.launch(max_threads=41)
```
| gradio-app/gradio/blob/main/demo/concurrency_without_queue/run.ipynb |
--
title: "Graphcore and Hugging Face Launch New Lineup of IPU-Ready Transformers"
thumbnail: /blog/assets/77_graphcore-update/graphcore_update.png
authors:
- user: sallydoherty
guest: true
---
# Graphcore and Hugging Face Launch New Lineup of IPU-Ready Transformers
[Graphcore](https://huggingface.co/hardware/graphcore/) and Hugging Face have significantly expanded the range of Machine Learning modalities and tasks available in [Hugging Face Optimum](https://github.com/huggingface/optimum), an open-source library for Transformers performance optimization. Developers now have convenient access to a wide range of off-the-shelf Hugging Face Transformer models, optimised to deliver the best possible performance on Graphcore’s IPU.
Including the [BERT transformer model](https://www.graphcore.ai/posts/getting-started-with-hugging-face-transformers-for-ipus-with-optimum) made available shortly after [Optimum Graphcore launched](https://huggingface.co/blog/graphcore), developers can now access 10 models covering Natural Language Processing (NLP), Speech and Computer Vision, which come with IPU configuration files and ready-to-use pre-trained and fine-tuned model weights.
## New Optimum models
### Computer vision
[ViT](https://huggingface.co/Graphcore/vit-base-ipu) (Vision Transformer) is a breakthrough in image recognition that uses the transformer mechanism as its main component. When images are input to ViT, they're divided into small patches similar to how words are processed in language systems. Each patch is encoded by the Transformer (Embedding) and then can be processed individually.
### NLP
[GPT-2](https://huggingface.co/Graphcore/gpt2-medium-wikitext-103) (Generative Pre-trained Transformer 2) is a text generation transformer model pretrained on a very large corpus of English data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it is trained to generate texts from a prompt by guessing the next word in sentences.
[RoBERTa](https://huggingface.co/Graphcore/roberta-base-squad2) (Robustly optimized BERT approach) is a transformer model that (like GPT-2) is pretrained on a large corpus of English data in a self-supervised fashion. More precisely, RoBERTa it was pretrained with the masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then runs the entire masked sentence through the model and has to predict the masked words. Roberta can be used for masked language modeling, but is mostly intended to be fine-tuned on a downstream task.
[DeBERTa](https://huggingface.co/Graphcore/deberta-base-ipu) (Decoding-enhanced BERT with disentangled attention) is a pretrained neural language model for NLP tasks. DeBERTa adapts the 2018 BERT and 2019 RoBERTa models using two novel techniques—a disentangled attention mechanism and an enhanced mask decoder—significantly improving the efficiency of model pretraining and performance of downstream tasks.
[BART](https://huggingface.co/Graphcore/bart-base-ipu) is a transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. BART is pre-trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. BART is particularly effective when fine-tuned for text generation (e.g. summarization, translation) but also works well for comprehension tasks (e.g. text classification, question answering).
[LXMERT](https://huggingface.co/Graphcore/lxmert-gqa-uncased) (Learning Cross-Modality Encoder Representations from Transformers) is a multimodal transformer model for learning vision and language representations. It has three encoders: object relationship encoder, a language encoder, and a cross-modality encoder. It is pretrained via a combination of masked language modeling, visual-language text alignment, ROI-feature regression, masked visual-attribute modeling, masked visual-object modeling, and visual-question answering objectives. It has achieved state-of-the-art results on the VQA and GQA visual-question-answering datasets.
[T5](https://huggingface.co/Graphcore/t5-small-ipu) (Text-to-Text Transfer Transformer) is a revolutionary new model that can take any text and convert it into a machine learning format for translation, question answering or classification. It introduces a unified framework that converts all text-based language problems into a text-to-text format for transfer learning. By doing so, it has simplified a way to use the same model, objective function, hyperparameters, and decoding procedure across a diverse set of NLP tasks.
### Speech
[HuBERT](https://huggingface.co/Graphcore/hubert-base-ipu) (Hidden-Unit BERT) is a self-supervised speech recognition model pretrained on audio, learning a combined acoustic and language model over continuous inputs. The HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets.
[Wav2Vec2](https://huggingface.co/Graphcore/wav2vec2-base-ipu) is a pretrained self-supervised model for automatic speech recognition. Using a novel contrastive pretraining objective, Wav2Vec2 learns powerful speech representations from large amounts of unlabelled speech data, followed by fine-tuning on a small amount of transcribed speech data, outperforming the best semi-supervised methods while being conceptually simpler.
## Hugging Face Optimum Graphcore: building on a solid partnership
Graphcore joined the [Hugging Face Hardware Partner Program](https://huggingface.co/hardware) in 2021 as a founding member, with both companies sharing the common goal of lowering the barriers for innovators seeking to harness the power of machine intelligence.
Since then, Graphcore and Hugging Face have worked together extensively to make training of transformer models on IPUs fast and easy, with the first Optimum Graphcore model (BERT) being made available last year.
Transformers have proven to be extremely efficient for a wide range of functions, including feature extraction, text generation, sentiment analysis, translation and many more. Models like BERT are widely used by Graphcore customers in a huge array of applications including cybersecurity, voice call automation, drug discovery, and translation.
Optimizing their performance in the real world requires considerable time, effort and skills that are beyond the reach of many companies and organizations. In providing an open-source library of transformer models, Hugging Face has directly addressed these issues. Integrating IPUs with HuggingFace also allows developers to leverage not just the models, but also datasets available in the HuggingFace Hub.
Developers can now use Graphcore systems to train 10 different types of state-of-the-art transformer models and access thousands of datasets with minimal coding complexity. With this partnership, we are providing users with the tools and ecosystem to easily download and fine-tune state-of-the-art pretrained models to various domains and downstream tasks.
## Bringing Graphcore’s latest hardware and software to the table
While members of Hugging Face’s ever-expanding user base have already been able to benefit from the speed, performance, and power- and cost-efficiency of IPU technology, a combination of recent hardware and software releases from Graphcore will unlock even more potential.
On the hardware front, the [Bow IPU](https://www.graphcore.ai/bow-processors) — announced in March and now shipping to customers — is the first processor in the world to use Wafer-on-Wafer (WoW) 3D stacking technology, taking the well-documented benefits of the IPU to the next level. Featuring ground-breaking advances in compute architecture and silicon implementation, communication and memory, each Bow IPU delivers up to 350 teraFLOPS of AI compute—an impressive 40% increase in performance—and up to 16% more power efficiency compared to the previous generation IPU. Importantly, Hugging Face Optimum users can switch seamlessly from previous generation IPUs to Bow processors, as no code changes are required.
Software also plays a vital role in unlocking the IPU’s capabilities, so naturally Optimum offers a plug-and-play experience with Graphcore’s easy-to-use Poplar SDK — which itself has received a major 2.5 update. Poplar makes it easy to train state-of-the-art models on state-of-the-art hardware, thanks to its full integration with standard machine learning frameworks, including PyTorch, PyTorch Lightning, and TensorFlow—as well as orchestration and deployment tools such as Docker and Kubernetes. Making Poplar compatible with these widely used, third-party systems allows developers to easily port their models from their other compute platforms and start taking advantage of the IPU’s advanced AI capabilities.
## Get started with Hugging Face’s Optimum Graphcore models
If you’re interested in combining the benefits of IPU technology with the strengths of transformer models, you can download the latest range of Optimum Graphcore models from the [Graphcore organization on the Hub](https://huggingface.co/Graphcore), or access the code from the [Optimum GitHub repo](https://github.com/huggingface/optimum-graphcore). Our [Getting Started blog post](https://huggingface.co/blog/graphcore-getting-started) will guide you through each step to start experimenting with IPUs.
Additionally, Graphcore has built an extensive page of [developer resources](https://www.graphcore.ai/developer), where you can find the IPU Model Garden—a repository of deployment-ready ML applications including computer vision, NLP, graph networks and more—alongside an array of documentation, tutorials, how-to-videos, webinars, and more. You can also access [Graphcore’s GitHub repo](https://github.com/graphcore) for more code references and tutorials.
To learn more about using Hugging Face on Graphcore, head over to our [partner page](https://huggingface.co/hardware/graphcore)!
| huggingface/blog/blob/main/graphcore-update.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text classification
[[open-in-colab]]
<Youtube id="leNG9fN9FQU"/>
Text classification is a common NLP task that assigns a label or class to text. Some of the largest companies run text classification in production for a wide range of practical applications. One of the most popular forms of text classification is sentiment analysis, which assigns a label like 🙂 positive, 🙁 negative, or 😐 neutral to a sequence of text.
This guide will show you how to:
1. Finetune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [IMDb](https://huggingface.co/datasets/imdb) dataset to determine whether a movie review is positive or negative.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate accelerate
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load IMDb dataset
Start by loading the IMDb dataset from the 🤗 Datasets library:
```py
>>> from datasets import load_dataset
>>> imdb = load_dataset("imdb")
```
Then take a look at an example:
```py
>>> imdb["test"][0]
{
"label": 0,
"text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
}
```
There are two fields in this dataset:
- `text`: the movie review text.
- `label`: a value that is either `0` for a negative review or `1` for a positive review.
## Preprocess
The next step is to load a DistilBERT tokenizer to preprocess the `text` field:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
Create a preprocessing function to tokenize `text` and truncate sequences to be no longer than DistilBERT's maximum input length:
```py
>>> def preprocess_function(examples):
... return tokenizer(examples["text"], truncation=True)
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by setting `batched=True` to process multiple elements of the dataset at once:
```py
tokenized_imdb = imdb.map(preprocess_function, batched=True)
```
Now create a batch of examples using [`DataCollatorWithPadding`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
```py
>>> import numpy as np
>>> def compute_metrics(eval_pred):
... predictions, labels = eval_pred
... predictions = np.argmax(predictions, axis=1)
... return accuracy.compute(predictions=predictions, references=labels)
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
Before you start training your model, create a map of the expected ids to their labels with `id2label` and `label2id`:
```py
>>> id2label = {0: "NEGATIVE", 1: "POSITIVE"}
>>> label2id = {"NEGATIVE": 0, "POSITIVE": 1}
```
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load DistilBERT with [`AutoModelForSequenceClassification`] along with the number of expected labels, and the label mappings:
```py
>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
>>> model = AutoModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
... )
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_model",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=2,
... weight_decay=0.01,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
<Tip>
[`Trainer`] applies dynamic padding by default when you pass `tokenizer` to it. In this case, you don't need to specify a data collator explicitly.
</Tip>
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer
>>> import tensorflow as tf
>>> batch_size = 16
>>> num_epochs = 5
>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
>>> total_train_steps = int(batches_per_epoch * num_epochs)
>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
```
Then you can load DistilBERT with [`TFAutoModelForSequenceClassification`] along with the number of expected labels, and the label mappings:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
... )
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_imdb["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_imdb["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
The last two things to setup before you start training is to compute the accuracy from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_model",
... tokenizer=tokenizer,
... )
```
Then bundle your callbacks together:
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for text classification, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Grab some text you'd like to run inference on:
```py
>>> text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for sentiment analysis with your model, and pass your text to it:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model")
>>> classifier(text)
[{'label': 'POSITIVE', 'score': 0.9994940757751465}]
```
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Tokenize the text and return PyTorch tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
>>> inputs = tokenizer(text, return_tensors="pt")
```
Pass your inputs to the model and return the `logits`:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
```py
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
'POSITIVE'
```
</pt>
<tf>
Tokenize the text and return TensorFlow tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
>>> inputs = tokenizer(text, return_tensors="tf")
```
Pass your inputs to the model and return the `logits`:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
>>> logits = model(**inputs).logits
```
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
```py
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
>>> model.config.id2label[predicted_class_id]
'POSITIVE'
```
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/tasks/sequence_classification.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Language Modeling
## Image Classification Training
By running the scripts [`run_image_classification.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/image-classification/run_image_classification.py) we will be able to leverage the [`ONNX Runtime`](https://github.com/microsoft/onnxruntime) accelerator to train the language models from the
[HuggingFace hub](https://huggingface.co/models).
__The following example applies the acceleration features powered by ONNX Runtime.__
### ONNX Runtime Training
The following example trains ViT on beans dataset with mixed precision (fp16).
```bash
torchrun --nproc_per_node=NUM_GPUS_YOU_HAVE run_image_classification.py \
--model_name_or_path google/vit-base-patch16-224-in21k \
--dataset_name beans \
--output_dir ./beans_outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--num_train_epochs 10 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--logging_strategy steps \
--logging_steps 10 \
--evaluation_strategy epoch \
--seed 1337
```
__Note__
> *To enable ONNX Runtime training, your devices need to be equipped with GPU. Install the dependencies either with our prepared*
*[Dockerfiles](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/) or follow the instructions*
*in [`torch_ort`](https://github.com/pytorch/ort/blob/main/torch_ort/docker/README.md).*
---
| huggingface/optimum/blob/main/examples/onnxruntime/training/image-classification/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MEGA
## Overview
The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
MEGA proposes a new approach to self-attention with each encoder layer having a multi-headed exponential moving average in addition to a single head of standard dot-product attention, giving the attention mechanism
stronger positional biases. This allows MEGA to perform competitively to Transformers on standard benchmarks including LRA
while also having significantly fewer parameters. MEGA's compute efficiency allows it to scale to very long sequences, making it an
attractive option for long-document NLP tasks.
The abstract from the paper is the following:
*The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models. *
This model was contributed by [mnaylor](https://huggingface.co/mnaylor).
The original code can be found [here](https://github.com/facebookresearch/mega).
## Usage tips
- MEGA can perform quite well with relatively few parameters. See Appendix D in the MEGA paper for examples of architectural specs which perform well in various settings. If using MEGA as a decoder, be sure to set `bidirectional=False` to avoid errors with default bidirectional.
- Mega-chunk is a variant of mega that reduces time and spaces complexity from quadratic to linear. Utilize chunking with MegaConfig.use_chunking and control chunk size with MegaConfig.chunk_size
## Implementation Notes
- The original implementation of MEGA had an inconsistent expectation of attention masks for padding and causal self-attention between the softmax attention and Laplace/squared ReLU method. This implementation addresses that inconsistency.
- The original implementation did not include token type embeddings; this implementation adds support for these, with the option controlled by MegaConfig.add_token_type_embeddings
## MegaConfig
[[autodoc]] MegaConfig
## MegaModel
[[autodoc]] MegaModel
- forward
## MegaForCausalLM
[[autodoc]] MegaForCausalLM
- forward
## MegaForMaskedLM
[[autodoc]] MegaForMaskedLM
- forward
## MegaForSequenceClassification
[[autodoc]] MegaForSequenceClassification
- forward
## MegaForMultipleChoice
[[autodoc]] MegaForMultipleChoice
- forward
## MegaForTokenClassification
[[autodoc]] MegaForTokenClassification
- forward
## MegaForQuestionAnswering
[[autodoc]] MegaForQuestionAnswering
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mega.md |
Overview
Datasets Server automatically converts and publishes public datasets less than 5GB on the Hub as Parquet files. [Parquet](https://parquet.apache.org/docs/) files are column-based and they shine when you're working with big data. There are several different libraries you can use to work with the published Parquet files:
- [ClickHouse](https://clickhouse.com/docs/en/intro), a column-oriented database management system for online analytical processing
- [DuckDB](https://duckdb.org/docs/), a high-performance SQL database for analytical queries
- [Pandas](https://pandas.pydata.org/docs/index.html), a data analysis tool for working with data structures
- [Polars](https://pola-rs.github.io/polars-book/user-guide/), a Rust based DataFrame library | huggingface/datasets-server/blob/main/docs/source/parquet_process.mdx |
Gradio Demo: dashboard
### This demo shows how you can build an interactive dashboard with gradio. Click on a python library on the left hand side and then on the right hand side click on the metric you'd like to see plot over time. Data is pulled from HuggingFace Hub datasets.
```
!pip install -q gradio plotly
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/dashboard/helpers.py
```
```
import gradio as gr
import pandas as pd
import plotly.express as px
from helpers import *
LIBRARIES = ["accelerate", "datasets", "diffusers", "evaluate", "gradio", "hub_docs",
"huggingface_hub", "optimum", "pytorch_image_models", "tokenizers", "transformers"]
def create_pip_plot(libraries, pip_choices):
if "Pip" not in pip_choices:
return gr.Plot(visible=False)
output = retrieve_pip_installs(libraries, "Cumulated" in pip_choices)
df = pd.DataFrame(output).melt(id_vars="day")
plot = px.line(df, x="day", y="value", color="variable",
title="Pip installs")
plot.update_layout(legend=dict(x=0.5, y=0.99), title_x=0.5, legend_title_text="")
return gr.Plot(value=plot, visible=True)
def create_star_plot(libraries, star_choices):
if "Stars" not in star_choices:
return gr.Plot(visible=False)
output = retrieve_stars(libraries, "Week over Week" in star_choices)
df = pd.DataFrame(output).melt(id_vars="day")
plot = px.line(df, x="day", y="value", color="variable",
title="Number of stargazers")
plot.update_layout(legend=dict(x=0.5, y=0.99), title_x=0.5, legend_title_text="")
return gr.Plot(value=plot, visible=True)
def create_issue_plot(libraries, issue_choices):
if "Issue" not in issue_choices:
return gr.Plot(visible=False)
output = retrieve_issues(libraries,
exclude_org_members="Exclude org members" in issue_choices,
week_over_week="Week over Week" in issue_choices)
df = pd.DataFrame(output).melt(id_vars="day")
plot = px.line(df, x="day", y="value", color="variable",
title="Cumulated number of issues, PRs, and comments",
)
plot.update_layout(legend=dict(x=0.5, y=0.99), title_x=0.5, legend_title_text="")
return gr.Plot(value=plot, visible=True)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
gr.Markdown("## Select libraries to display")
libraries = gr.CheckboxGroup(choices=LIBRARIES, show_label=False)
with gr.Column():
gr.Markdown("## Select graphs to display")
pip = gr.CheckboxGroup(choices=["Pip", "Cumulated"], show_label=False)
stars = gr.CheckboxGroup(choices=["Stars", "Week over Week"], show_label=False)
issues = gr.CheckboxGroup(choices=["Issue", "Exclude org members", "week over week"], show_label=False)
with gr.Row():
fetch = gr.Button(value="Fetch")
with gr.Row():
with gr.Column():
pip_plot = gr.Plot(visible=False)
star_plot = gr.Plot(visible=False)
issue_plot = gr.Plot(visible=False)
fetch.click(create_pip_plot, inputs=[libraries, pip], outputs=pip_plot)
fetch.click(create_star_plot, inputs=[libraries, stars], outputs=star_plot)
fetch.click(create_issue_plot, inputs=[libraries, issues], outputs=issue_plot)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/dashboard/run.ipynb |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLM-ProphetNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xprophetnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xprophetnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xprophetnet-large-wiki100-cased-xglue-ntg">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
@patrickvonplaten
## Overview
The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
"wiki100" Wikipedia dump. XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
The abstract from the paper is the following:
*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## XLMProphetNetConfig
[[autodoc]] XLMProphetNetConfig
## XLMProphetNetTokenizer
[[autodoc]] XLMProphetNetTokenizer
## XLMProphetNetModel
[[autodoc]] XLMProphetNetModel
## XLMProphetNetEncoder
[[autodoc]] XLMProphetNetEncoder
## XLMProphetNetDecoder
[[autodoc]] XLMProphetNetDecoder
## XLMProphetNetForConditionalGeneration
[[autodoc]] XLMProphetNetForConditionalGeneration
## XLMProphetNetForCausalLM
[[autodoc]] XLMProphetNetForCausalLM
| huggingface/transformers/blob/main/docs/source/en/model_doc/xlm-prophetnet.md |
--
title: "Showcase Your Projects in Spaces using Gradio"
thumbnail: /blog/assets/28_gradio-spaces/thumbnail.png
authors:
- user: merve
---
# Showcase Your Projects in Spaces using Gradio
It's so easy to demonstrate a Machine Learning project thanks to [Gradio](https://gradio.app/).
In this blog post, we'll walk you through:
- the recent Gradio integration that helps you demo models from the Hub seamlessly with few lines of code leveraging the [Inference API](https://huggingface.co/inference-api).
- how to use Hugging Face Spaces to host demos of your own models.
## Hugging Face Hub Integration in Gradio
You can demonstrate your models in the Hub easily. You only need to define the [Interface](https://gradio.app/docs#interface) that includes:
- The repository ID of the model you want to infer with
- A description and title
- Example inputs to guide your audience
After defining your Interface, just call `.launch()` and your demo will start running. You can do this in Colab, but if you want to share it with the community a great option is to use Spaces!
Spaces are a simple, free way to host your ML demo apps in Python. To do so, you can create a repository at https://huggingface.co/new-space and select Gradio as the SDK. Once done, you can create a file called `app.py`, copy the code below, and your app will be up and running in a few seconds!
```python
import gradio as gr
description = "Story generation with GPT-2"
title = "Generate your own story"
examples = [["Adventurer is approached by a mysterious stranger in the tavern for a new quest."]]
interface = gr.Interface.load("huggingface/pranavpsv/gpt2-genre-story-generator",
description=description,
examples=examples
)
interface.launch()
```
You can play with the Story Generation model [here](https://huggingface.co/spaces/merve/GPT-2-story-gen)

Under the hood, Gradio calls the Inference API which supports Transformers as well as other popular ML frameworks such as spaCy, SpeechBrain and Asteroid. This integration supports different types of models, `image-to-text`, `speech-to-text`, `text-to-speech` and more. You can check out this example BigGAN ImageNet `text-to-image` model [here](https://huggingface.co/spaces/merve/BigGAN-ImageNET). Implementation is below.
```python
import gradio as gr
description = "BigGAN text-to-image demo."
title = "BigGAN ImageNet"
interface = gr.Interface.load("huggingface/osanseviero/BigGAN-deep-128",
description=description,
title = title,
examples=[["american robin"]]
)
interface.launch()
```

## Serving Custom Model Checkpoints with Gradio in Hugging Face Spaces
You can serve your models in Spaces even if the Inference API does not support your model. Just wrap your model inference in a Gradio `Interface` as described below and put it in Spaces.

## Mix and Match Models!
Using Gradio Series, you can mix-and-match different models! Here, we've put a French to English translation model on top of the story generator and a English to French translation model at the end of the generator model to simply make a French story generator.
```python
import gradio as gr
from gradio.mix import Series
description = "Generate your own D&D story!"
title = "French Story Generator using Opus MT and GPT-2"
translator_fr = gr.Interface.load("huggingface/Helsinki-NLP/opus-mt-fr-en")
story_gen = gr.Interface.load("huggingface/pranavpsv/gpt2-genre-story-generator")
translator_en = gr.Interface.load("huggingface/Helsinki-NLP/opus-mt-en-fr")
examples = [["L'aventurier est approché par un mystérieux étranger, pour une nouvelle quête."]]
Series(translator_fr, story_gen, translator_en, description = description,
title = title,
examples=examples, inputs = gr.inputs.Textbox(lines = 10)).launch()
```
You can check out the French Story Generator [here](https://huggingface.co/spaces/merve/french-story-gen)

## Uploading your Models to the Spaces
You can serve your demos in Hugging Face thanks to Spaces! To do this, simply create a new Space, and then drag and drop your demos or use Git.

Easily build your first demo with Spaces [here](https://huggingface.co/spaces)! | huggingface/blog/blob/main/gradio-spaces.md |
!--Copyright 2022 NVIDIA and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GroupViT
## Overview
The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
Inspired by [CLIP](clip), GroupViT is a vision-language model that can perform zero-shot semantic segmentation on any given vocabulary categories.
The abstract from the paper is the following:
*Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 52.3% mIoU on the PASCAL VOC 2012 and 22.4% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision.*
This model was contributed by [xvjiarui](https://huggingface.co/xvjiarui). The TensorFlow version was contributed by [ariG23498](https://huggingface.co/ariG23498) with the help of [Yih-Dar SHIEH](https://huggingface.co/ydshieh), [Amy Roberts](https://huggingface.co/amyeroberts), and [Joao Gante](https://huggingface.co/joaogante).
The original code can be found [here](https://github.com/NVlabs/GroupViT).
## Usage tips
- You may specify `output_segmentation=True` in the forward of `GroupViTModel` to get the segmentation logits of input texts.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GroupViT.
- The quickest way to get started with GroupViT is by checking the [example notebooks](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (which showcase zero-shot segmentation inference).
- One can also check out the [HuggingFace Spaces demo](https://huggingface.co/spaces/xvjiarui/GroupViT) to play with GroupViT.
## GroupViTConfig
[[autodoc]] GroupViTConfig
- from_text_vision_configs
## GroupViTTextConfig
[[autodoc]] GroupViTTextConfig
## GroupViTVisionConfig
[[autodoc]] GroupViTVisionConfig
<frameworkcontent>
<pt>
## GroupViTModel
[[autodoc]] GroupViTModel
- forward
- get_text_features
- get_image_features
## GroupViTTextModel
[[autodoc]] GroupViTTextModel
- forward
## GroupViTVisionModel
[[autodoc]] GroupViTVisionModel
- forward
</pt>
<tf>
## TFGroupViTModel
[[autodoc]] TFGroupViTModel
- call
- get_text_features
- get_image_features
## TFGroupViTTextModel
[[autodoc]] TFGroupViTTextModel
- call
## TFGroupViTVisionModel
[[autodoc]] TFGroupViTVisionModel
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/groupvit.md |
@gradio/slider
## 0.2.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.4
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
### Fixes
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Fixes: slider bar are too thin on FireFox. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.8
### Features
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6107](https://github.com/gradio-app/gradio/pull/6107) [`9a40de7bf`](https://github.com/gradio-app/gradio/commit/9a40de7bff5844c8a135e73c7d175eb02b63a966) - Fix: Move to cache in init postprocess + Fallback Fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6026](https://github.com/gradio-app/gradio/pull/6026) [`338969af2`](https://github.com/gradio-app/gradio/commit/338969af290de032f9cdc204dab8a50be3bf3cc5) - V4: Single-file implementation of form components. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#5984](https://github.com/gradio-app/gradio/pull/5984) [`66549d8d2`](https://github.com/gradio-app/gradio/commit/66549d8d256b1845c8c5efa0384695b36cb46eab) - Fixes: slider bar are too thin on FireFox. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Features
- [#5697](https://github.com/gradio-app/gradio/pull/5697) [`f4e4f82b5`](https://github.com/gradio-app/gradio/commit/f4e4f82b58a65efca9030a7e8e7c5ace60d8cc10) - Increase Slider clickable area. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.3
### Features
- [#5535](https://github.com/gradio-app/gradio/pull/5535) [`d29b1ab74`](https://github.com/gradio-app/gradio/commit/d29b1ab740784d8c70f9ab7bc38bbbf7dd3ff737) - Makes sliders consistent across all browsers. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
| gradio-app/gradio/blob/main/js/slider/CHANGELOG.md |
[paddlenlp-banner](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/PaddleNLP-logo.png)
# Using PaddleNLP at Hugging Face
Leveraging the [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) framework, [`PaddleNLP`](https://github.com/PaddlePaddle/PaddleNLP) is an easy-to-use and powerful NLP library with awesome pre-trained model zoo, supporting wide-range of NLP tasks from research to industrial applications.
## Exploring PaddleNLP in the Hub
You can find `PaddleNLP` models by filtering at the left of the [models page](https://huggingface.co/models?library=paddlenlp&sort=downloads).
All models on the Hub come up with the following features:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/PaddleNLP-5.jpg"/>
</div>
1. An automatically generated model card with a brief description and metadata tags that help for discoverability.
2. An interactive widget you can use to play out with the model directly in the browser.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/PaddleNLP.jpg"/>
</div>
3. An Inference API that allows to make inference requests.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/PaddleNLP-3.jpg"/>
</div>
4. Easily deploy your model as a Gradio app on Spaces.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/PaddleNLP-4.jpg"/>
</div>
## Installation
To get started, you can follow [PaddlePaddle Quick Start](https://www.paddlepaddle.org.cn/en/install) to install the PaddlePaddle Framework with your favorite OS, Package Manager and Compute Platform.
`paddlenlp` offers a quick one-line install through pip:
```
pip install -U paddlenlp
```
## Using existing models
Similar to `transformer` models, the `paddlenlp` library provides a simple one-liner to load models from the Hugging Face Hub by setting `from_hf_hub=True`! Depending on how you want to use them, you can use the high-level API using the `Taskflow` function or you can use `AutoModel` and `AutoTokenizer` for more control.
```py
# Taskflow provides a simple end-to-end capability and a more optimized experience for inference
from paddlenlp.transformers import Taskflow
taskflow = Taskflow("fill-mask", task_path="PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
# If you want more control, you will need to define the tokenizer and model.
from paddlenlp.transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
model = AutoModelForMaskedLM.from_pretrained("PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
```
If you want to see how to load a specific model, you can click `Use in paddlenlp` and you will be given a working snippet that you can load it!
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/PaddleNLP-1.jpg"/>
</div>
## Sharing your models
You can share your `PaddleNLP` models by using the `save_to_hf_hub` method under all `Model` and `Tokenizer` classes.
```py
from paddlenlp.transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
model = AutoModelForMaskedLM.from_pretrained("PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
tokenizer.save_to_hf_hub(repo_id="<my_org_name>/<my_repo_name>")
model.save_to_hf_hub(repo_id="<my_org_name>/<my_repo_name>")
```
## Additional resources
- PaddlePaddle Installation [guide](https://www.paddlepaddle.org.cn/en/install).
- PaddleNLP [GitHub Repo](https://github.com/PaddlePaddle/PaddleNLP).
- [PaddlePaddle on the Hugging Face Hub](https://huggingface.co/PaddlePaddle)
| huggingface/hub-docs/blob/main/docs/hub/paddlenlp.md |
Some Notes on Pros of Open Science and Open Source
- **Pooling Resources**: Building off of one another’s strengths; learning from one another’s failures.
- **Accessibility**: Anyone can use the models, regardless of budget or affiliation.
- This also helps to ensure diversity of contributors.
- **Lowering Barriers**: You don’t need to have a tech job to explore how AI works.
- **Innovation**: High-value applications are possible for more people to discover and create.
- Relatedly, advancements in **addressing bias/harms** become more possible.
- **Economic Opportunity**: More access leads to more businesses and jobs.
- **Transparency**: Users and those affected have full visibility on the model and the training data. They can better identify potential biases or errors.
- **Accountability**: Provenance to trace who-did-what; independent auditing possible.
- **Privacy**: Users don't have to send their data to black box APIs.
- **IP protection**: Users train their models on their data, and own them.
- **Freedom of choice**: Users are not locked in. They can switch models anytime.
- **IT flexibility**: Users can train and deploy models anywhere they like.
- **Tailored use**: Users can train/fine-tune for their specific needs.
- **Safety**: More mechanisms available.
- **Speed**: Good ideas can quickly flourish and be built on. Security issues can be quickly addressed.
- **Diversity** of options.
# Cons of Closed Source
- **Centralization** of power.
- **Opacity** of subtle bias/harm issues.
- Hiding **illegal** or problematic data.
- **Bare minimum of legal compliance** as opposed to good practices.
- Fostering **misunderstanding for hype and profit**.
- **Insularity of thinking** creates "groupthink" technology issues (such as harming people with marginalized characteristics).
- **Security issues** not addressed quickly.
- Consumer apps **can’t be flexible** and become dependent on a single model: Consumer apps built on top of closed source must “lock-in” their code based on what an API outputs; as closed source internal models are updated or changed, this can completely break the consumer’s system, or the consumer’s expectations of behavior.
# Common Misunderstandings
## There’s an idea that open source is “less secure”.
- Misses that closed software has just as dire (or more so) security concerns as open source.
- Misses the fact that the diversity of options available with open source limits how many people will be affected by a malicious actor.
## There’s an idea that open source will help China to “beat us”.
- Misses that part of why U.S. technology has flourished due to open science/open source.
- Misses that U.S. dominance is a function of how friendly the U.S. is to companies: There is more to success than the code itself, the socioeconomic variables that the U.S. provides is particularly well-placed to help open companies flourish.
| huggingface/blog/blob/main/assets/164_ethics-soc-5/why_open.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Understanding pipelines, models and schedulers
[[open-in-colab]]
🧨 Diffusers is designed to be a user-friendly and flexible toolbox for building diffusion systems tailored to your use-case. At the core of the toolbox are models and schedulers. While the [`DiffusionPipeline`] bundles these components together for convenience, you can also unbundle the pipeline and use the models and schedulers separately to create new diffusion systems.
In this tutorial, you'll learn how to use models and schedulers to assemble a diffusion system for inference, starting with a basic pipeline and then progressing to the Stable Diffusion pipeline.
## Deconstruct a basic pipeline
A pipeline is a quick and easy way to run a model for inference, requiring no more than four lines of code to generate an image:
```py
>>> from diffusers import DDPMPipeline
>>> ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
>>> image = ddpm(num_inference_steps=25).images[0]
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ddpm-cat.png" alt="Image of cat created from DDPMPipeline"/>
</div>
That was super easy, but how did the pipeline do that? Let's breakdown the pipeline and take a look at what's happening under the hood.
In the example above, the pipeline contains a [`UNet2DModel`] model and a [`DDPMScheduler`]. The pipeline denoises an image by taking random noise the size of the desired output and passing it through the model several times. At each timestep, the model predicts the *noise residual* and the scheduler uses it to predict a less noisy image. The pipeline repeats this process until it reaches the end of the specified number of inference steps.
To recreate the pipeline with the model and scheduler separately, let's write our own denoising process.
1. Load the model and scheduler:
```py
>>> from diffusers import DDPMScheduler, UNet2DModel
>>> scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
>>> model = UNet2DModel.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
```
2. Set the number of timesteps to run the denoising process for:
```py
>>> scheduler.set_timesteps(50)
```
3. Setting the scheduler timesteps creates a tensor with evenly spaced elements in it, 50 in this example. Each element corresponds to a timestep at which the model denoises an image. When you create the denoising loop later, you'll iterate over this tensor to denoise an image:
```py
>>> scheduler.timesteps
tensor([980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,
700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,
420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,
140, 120, 100, 80, 60, 40, 20, 0])
```
4. Create some random noise with the same shape as the desired output:
```py
>>> import torch
>>> sample_size = model.config.sample_size
>>> noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
```
5. Now write a loop to iterate over the timesteps. At each timestep, the model does a [`UNet2DModel.forward`] pass and returns the noisy residual. The scheduler's [`~DDPMScheduler.step`] method takes the noisy residual, timestep, and input and it predicts the image at the previous timestep. This output becomes the next input to the model in the denoising loop, and it'll repeat until it reaches the end of the `timesteps` array.
```py
>>> input = noise
>>> for t in scheduler.timesteps:
... with torch.no_grad():
... noisy_residual = model(input, t).sample
... previous_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
... input = previous_noisy_sample
```
This is the entire denoising process, and you can use this same pattern to write any diffusion system.
6. The last step is to convert the denoised output into an image:
```py
>>> from PIL import Image
>>> import numpy as np
>>> image = (input / 2 + 0.5).clamp(0, 1).squeeze()
>>> image = (image.permute(1, 2, 0) * 255).round().to(torch.uint8).cpu().numpy()
>>> image = Image.fromarray(image)
>>> image
```
In the next section, you'll put your skills to the test and breakdown the more complex Stable Diffusion pipeline. The steps are more or less the same. You'll initialize the necessary components, and set the number of timesteps to create a `timestep` array. The `timestep` array is used in the denoising loop, and for each element in this array, the model predicts a less noisy image. The denoising loop iterates over the `timestep`'s, and at each timestep, it outputs a noisy residual and the scheduler uses it to predict a less noisy image at the previous timestep. This process is repeated until you reach the end of the `timestep` array.
Let's try it out!
## Deconstruct the Stable Diffusion pipeline
Stable Diffusion is a text-to-image *latent diffusion* model. It is called a latent diffusion model because it works with a lower-dimensional representation of the image instead of the actual pixel space, which makes it more memory efficient. The encoder compresses the image into a smaller representation, and a decoder to convert the compressed representation back into an image. For text-to-image models, you'll need a tokenizer and an encoder to generate text embeddings. From the previous example, you already know you need a UNet model and a scheduler.
As you can see, this is already more complex than the DDPM pipeline which only contains a UNet model. The Stable Diffusion model has three separate pretrained models.
<Tip>
💡 Read the [How does Stable Diffusion work?](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work) blog for more details about how the VAE, UNet, and text encoder models work.
</Tip>
Now that you know what you need for the Stable Diffusion pipeline, load all these components with the [`~ModelMixin.from_pretrained`] method. You can find them in the pretrained [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint, and each component is stored in a separate subfolder:
```py
>>> from PIL import Image
>>> import torch
>>> from transformers import CLIPTextModel, CLIPTokenizer
>>> from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
>>> vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae", use_safetensors=True)
>>> tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
>>> text_encoder = CLIPTextModel.from_pretrained(
... "CompVis/stable-diffusion-v1-4", subfolder="text_encoder", use_safetensors=True
... )
>>> unet = UNet2DConditionModel.from_pretrained(
... "CompVis/stable-diffusion-v1-4", subfolder="unet", use_safetensors=True
... )
```
Instead of the default [`PNDMScheduler`], exchange it for the [`UniPCMultistepScheduler`] to see how easy it is to plug a different scheduler in:
```py
>>> from diffusers import UniPCMultistepScheduler
>>> scheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
```
To speed up inference, move the models to a GPU since, unlike the scheduler, they have trainable weights:
```py
>>> torch_device = "cuda"
>>> vae.to(torch_device)
>>> text_encoder.to(torch_device)
>>> unet.to(torch_device)
```
### Create text embeddings
The next step is to tokenize the text to generate embeddings. The text is used to condition the UNet model and steer the diffusion process towards something that resembles the input prompt.
<Tip>
💡 The `guidance_scale` parameter determines how much weight should be given to the prompt when generating an image.
</Tip>
Feel free to choose any prompt you like if you want to generate something else!
```py
>>> prompt = ["a photograph of an astronaut riding a horse"]
>>> height = 512 # default height of Stable Diffusion
>>> width = 512 # default width of Stable Diffusion
>>> num_inference_steps = 25 # Number of denoising steps
>>> guidance_scale = 7.5 # Scale for classifier-free guidance
>>> generator = torch.manual_seed(0) # Seed generator to create the initial latent noise
>>> batch_size = len(prompt)
```
Tokenize the text and generate the embeddings from the prompt:
```py
>>> text_input = tokenizer(
... prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
... )
>>> with torch.no_grad():
... text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
You'll also need to generate the *unconditional text embeddings* which are the embeddings for the padding token. These need to have the same shape (`batch_size` and `seq_length`) as the conditional `text_embeddings`:
```py
>>> max_length = text_input.input_ids.shape[-1]
>>> uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
>>> uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
```
Let's concatenate the conditional and unconditional embeddings into a batch to avoid doing two forward passes:
```py
>>> text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
```
### Create random noise
Next, generate some initial random noise as a starting point for the diffusion process. This is the latent representation of the image, and it'll be gradually denoised. At this point, the `latent` image is smaller than the final image size but that's okay though because the model will transform it into the final 512x512 image dimensions later.
<Tip>
💡 The height and width are divided by 8 because the `vae` model has 3 down-sampling layers. You can check by running the following:
```py
2 ** (len(vae.config.block_out_channels) - 1) == 8
```
</Tip>
```py
>>> latents = torch.randn(
... (batch_size, unet.config.in_channels, height // 8, width // 8),
... generator=generator,
... device=torch_device,
... )
```
### Denoise the image
Start by scaling the input with the initial noise distribution, *sigma*, the noise scale value, which is required for improved schedulers like [`UniPCMultistepScheduler`]:
```py
>>> latents = latents * scheduler.init_noise_sigma
```
The last step is to create the denoising loop that'll progressively transform the pure noise in `latents` to an image described by your prompt. Remember, the denoising loop needs to do three things:
1. Set the scheduler's timesteps to use during denoising.
2. Iterate over the timesteps.
3. At each timestep, call the UNet model to predict the noise residual and pass it to the scheduler to compute the previous noisy sample.
```py
>>> from tqdm.auto import tqdm
>>> scheduler.set_timesteps(num_inference_steps)
>>> for t in tqdm(scheduler.timesteps):
... # expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
... latent_model_input = torch.cat([latents] * 2)
... latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
... # predict the noise residual
... with torch.no_grad():
... noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
... # perform guidance
... noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
... noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
... # compute the previous noisy sample x_t -> x_t-1
... latents = scheduler.step(noise_pred, t, latents).prev_sample
```
### Decode the image
The final step is to use the `vae` to decode the latent representation into an image and get the decoded output with `sample`:
```py
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
```
Lastly, convert the image to a `PIL.Image` to see your generated image!
```py
>>> image = (image / 2 + 0.5).clamp(0, 1).squeeze()
>>> image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
>>> images = (image * 255).round().astype("uint8")
>>> image = Image.fromarray(image)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/blog/assets/98_stable_diffusion/stable_diffusion_k_lms.png"/>
</div>
## Next steps
From basic to complex pipelines, you've seen that all you really need to write your own diffusion system is a denoising loop. The loop should set the scheduler's timesteps, iterate over them, and alternate between calling the UNet model to predict the noise residual and passing it to the scheduler to compute the previous noisy sample.
This is really what 🧨 Diffusers is designed for: to make it intuitive and easy to write your own diffusion system using models and schedulers.
For your next steps, feel free to:
* Learn how to [build and contribute a pipeline](../using-diffusers/contribute_pipeline) to 🧨 Diffusers. We can't wait and see what you'll come up with!
* Explore [existing pipelines](../api/pipelines/overview) in the library, and see if you can deconstruct and build a pipeline from scratch using the models and schedulers separately.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/write_own_pipeline.md |
@gradio/model3d
## 0.4.11
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.10
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.9
### Fixes
- [#6525](https://github.com/gradio-app/gradio/pull/6525) [`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a) - Fixes Drag and Drop for Upload. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.4.8
### Patch Changes
- Updated dependencies [[`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88), [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70), [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0), [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.7
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.6
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.5
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.4
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.3
### Fixes
- [#6414](https://github.com/gradio-app/gradio/pull/6414) [`da1e31832`](https://github.com/gradio-app/gradio/commit/da1e31832f85ec76540e474ae35badfde8a18b6f) - Fix Model3D download button and other issues. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.2
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.1
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.0
### Features
- [#6240](https://github.com/gradio-app/gradio/pull/6240) [`dd901c1b0`](https://github.com/gradio-app/gradio/commit/dd901c1b0af73a78fca8b6875b2bb00f84071ac8) - Model3D panning, improved UX. Thanks [@dylanebert](https://github.com/dylanebert)!
- [#6255](https://github.com/gradio-app/gradio/pull/6255) [`e3ede2ff7`](https://github.com/gradio-app/gradio/commit/e3ede2ff7d4a36fb21bb0b146b8d5ad239c0e086) - Ensure Model 3D updates when attributes change. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
- [#6171](https://github.com/gradio-app/gradio/pull/6171) [`28322422c`](https://github.com/gradio-app/gradio/commit/28322422cb9d8d3e471e439ad602959662e79312) - strip dangling svelte imports. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5955](https://github.com/gradio-app/gradio/pull/5955) [`825c9cddc`](https://github.com/gradio-app/gradio/commit/825c9cddc83a09457d8c85ebeecb4bc705572d82) - Fix dev mode model3D. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.5
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.4
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.3
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.2
### Patch Changes
- Updated dependencies [[`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423)]:
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Features
- [#5373](https://github.com/gradio-app/gradio/pull/5373) [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96) - Adds `height` and `zoom_speed` parameters to `Model3D` component, as well as a button to reset the camera position. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5266](https://github.com/gradio-app/gradio/pull/5266) [`4ccb9a86`](https://github.com/gradio-app/gradio/commit/4ccb9a86f194c6997f80a09880edc3c2b0554aab) - Makes it possible to set the initial camera position for the `Model3D` component as a tuple of (alpha, beta, radius). Thanks [@mbahri](https://github.com/mbahri)!
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
# @gradio/model3D
## 0.0.2
### Patch Changes
- Updated dependencies [[`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd)]:
- @gradio/[email protected]
## 0.0.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
| gradio-app/gradio/blob/main/js/model3D/CHANGELOG.md |
--
title: "We are hiring interns!"
thumbnail: /blog/assets/interns-2023/thumbnail.png
authors:
- user: lysandre
- user: douwekiela
---
# We are hiring interns!
Want to help build the future at -- if we may say so ourselves -- one of the coolest places in AI? Today we’re announcing our internship program for 2023. Together with your Hugging Face mentor(s), we’ll be working on cutting edge problems in AI and machine learning.
Applicants from all backgrounds are welcome! Ideally, you have some relevant experience and are excited about our mission to democratize responsible machine learning. The progress of our field has the potential to exacerbate existing disparities in ways that disproportionately hurt the most marginalized people in society — including people of color, people from working-class backgrounds, women, and LGBTQ+ people. These communities must be centered in the work we do as a research community. So we strongly encourage proposals from people whose personal experience reflects these identities!
## Positions
The following internship positions are available in the Open Source team, alongside maintainers of the respective libraries:
* [Accelerate Internship](https://apply.workable.com/huggingface/j/9B5436D6FA), to lead the integration of new, impactful features in the library.
* [Text to Speech Internship](https://apply.workable.com/huggingface/j/93CDE47063/), working on text-to-speech reproduction.
The following Science team positions are available:
* [Embodied AI Internship](https://apply.workable.com/huggingface/j/B3CDE6C150/), working with the Embodied AI team on reinforcement learning in simulators.
* [Fast Distributed Training Framework Internship](https://apply.workable.com/huggingface/j/BEBD24C4C4/), creating a framework for flexible distributed training of large language models.
* [Datasets for LLMs Internship](https://apply.workable.com/huggingface/j/4A6EA3243C/), building datasets to train the next generation of large language models, and the assorted tools.
The following other internship positions are available:
* [Social Impact Evaluation Internship](https://apply.workable.com/huggingface/j/648A916AAB/), developing a technical framework for assessing the overall social impact of generative ML models.
* [AI Art Tooling Internship](https://apply.workable.com/huggingface/j/BCCB4CAF82/), bridging the AI and art worlds by building tooling to empower artists.
Locations vary on a case-by-case basis and if the internship host has a location preference, this will be indicated on the job listing.
## How to Apply
You can apply directly for each position through our [job portal](https://huggingface.workable.com/). Click on the positions above to be taken directly to the application form.
Please make sure to complete the short submission at the end of the application form when applying. You'll need to create a Hugging Face account for that.
We are actively working to build a culture that values diversity, equity, and inclusivity. We are intentionally building a workplace where people feel respected and supported—regardless of who you are or where you come from. We believe this is foundational to building a great company and community. Hugging Face is an equal opportunity employer and we do not discriminate on the basis of race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status.
| huggingface/blog/blob/main/interns-2023.md |
--
title: "Announcing the Open Source AI Game Jam 🎮"
thumbnail: /blog/assets/145_gamejam/thumbnail.png
authors:
- user: ThomasSimonini
---
# Announcing the Open Source AI Game Jam 🎮
<h2> Unleash Your Creativity with AI Tools and make a game in a weekend!</h2>
<!-- {authors} -->
We're thrilled to announce the first ever **Open Source AI Game Jam**, where you will create a game using AI tools.
With AI's potential to enhance game experiences and workflows, we're excited to see what you can accomplish: incorporate generative AI tools like Stable Diffusion into your game or workflow to unlock new features and accelerate your development process.
From texture generation to lifelike NPCs and realistic text-to-speech, the options are endless.
📆 Mark your calendars: the game jam will take place from Friday to Sunday, **July 7-9**.
**Claim Your Free Spot in the Game Jam** 👉 https://itch.io/jam/open-source-ai-game-jam
<h2>Why Are We Organizing This?</h2>
In a time when some popular game jams restrict the use of AI tools, we believe it's crucial to **provide a platform specifically dedicated to showcasing the incredible possibilities AI offers game developers**. Especially when those tools are **open, transparent, and accessible**.
We want to see these jams thrive and empower indie developers with the tools they need to boost productivity and unlock their full potential.
<h2>What Are AI Tools?</h2>
AI tools, particularly generative ones like Stable Diffusion, open up a whole new world of possibilities in game development.
From accelerated workflows to in-game features, you can harness the power of AI for texture generation, lifelike AI non-player characters (NPCs), and realistic text-to-speech functionality.
Claim Your Free Spot in the Game Jam 👉 https://itch.io/jam/open-source-ai-game-jam
<h2>Who Can Participate?</h2>
**Everyone is welcome to join the Open Source AI Game Jam**, regardless of skill level or location. You can participate alone or in a team of any size.
<h2>What Are the Requirements?</h2>
To participate, your game should be playable on the web (e.g., itch.io) or Windows.
Additionally, **you are required to incorporate at least one open-source AI tool into your game or workflow**.
We'll provide more details to guide you along the way.
<h2>Can I Use Existing Assets?</h2>
Absolutely! **You're welcome to use existing assets, code, or AI tools that you have legal access to.**
We want to ensure fairness and give you the freedom to leverage the resources at your disposal.
<h2>Is There a Theme?</h2>
Yes, the theme will be announced when the jam starts.
<h2>How Will the Games Be Judged?</h2>
Participants will rate other games based on three criteria: **fun, creativity, and theme**. The judges will showcase and choose the winner from the Top 10.
<h2> Join our Discord Community! </h2>
Want to connect with the community? Join our Discord!
👉 https://discord.com/invite/hugging-face-879548962464493619
**Claim Your Free Spot in the Game Jam** 👉 https://itch.io/jam/open-source-ai-game-jam
See you there! 🤗
| huggingface/blog/blob/main/game-jam.md |
Overview
These examples show how to run [Diffuser](https://arxiv.org/abs/2205.09991) in Diffusers.
There are two ways to use the script, `run_diffuser_locomotion.py`.
The key option is a change of the variable `n_guide_steps`.
When `n_guide_steps=0`, the trajectories are sampled from the diffusion model, but not fine-tuned to maximize reward in the environment.
By default, `n_guide_steps=2` to match the original implementation.
You will need some RL specific requirements to run the examples:
```
pip install -f https://download.pytorch.org/whl/torch_stable.html \
free-mujoco-py \
einops \
gym==0.24.1 \
protobuf==3.20.1 \
git+https://github.com/rail-berkeley/d4rl.git \
mediapy \
Pillow==9.0.0
```
| huggingface/diffusers/blob/main/examples/reinforcement_learning/README.md |
--
title: "Ethics and Society Newsletter #3: Ethical Openness at Hugging Face"
thumbnail: /blog/assets/137_ethics_soc_3/ethics_3_thumbnail.png
authors:
- user: irenesolaiman
- user: giadap
- user: NimaBoscarino
- user: yjernite
- user: allendorf
- user: meg
- user: sasha
---
# Ethics and Society Newsletter #3: Ethical Openness at Hugging Face
## Mission: Open and Good ML
In our mission to democratize good machine learning (ML), we examine how supporting ML community work also empowers examining and preventing possible harms. Open development and science decentralizes power so that many people can collectively work on AI that reflects their needs and values. While [openness enables broader perspectives to contribute to research and AI overall, it faces the tension of less risk control](https://arxiv.org/abs/2302.04844).
Moderating ML artifacts presents unique challenges due to the dynamic and rapidly evolving nature of these systems. In fact, as ML models become more advanced and capable of producing increasingly diverse content, the potential for harmful or unintended outputs grows, necessitating the development of robust moderation and evaluation strategies. Moreover, the complexity of ML models and the vast amounts of data they process exacerbate the challenge of identifying and addressing potential biases and ethical concerns.
As hosts, we recognize the responsibility that comes with potentially amplifying harm to our users and the world more broadly. Often these harms disparately impact minority communities in a context-dependent manner. We have taken the approach of analyzing the tensions in play for each context, open to discussion across the company and Hugging Face community. While many models can amplify harm, especially discriminatory content, we are taking a series of steps to identify highest risk models and what action to take. Importantly, active perspectives from many backgrounds is key to understanding, measuring, and mitigating potential harms that affect different groups of people.
We are crafting tools and safeguards in addition to improving our documentation practices to ensure open source science empowers individuals and continues to minimize potential harms.
## Ethical Categories
The first major aspect of our work to foster good open ML consists in promoting the tools and positive examples of ML development that prioritize values and consideration for its stakeholders. This helps users take concrete steps to address outstanding issues, and present plausible alternatives to de facto damaging practices in ML development.
To help our users discover and engage with ethics-related ML work, we have compiled a set of tags. These 6 high-level categories are based on our analysis of Spaces that community members had contributed. They are designed to give you a jargon-free way of thinking about ethical technology:
- Rigorous work pays special attention to developing with best practices in mind. In ML, this can mean examining failure cases (including conducting bias and fairness audits), protecting privacy through security measures, and ensuring that potential users (technical and non-technical) are informed about the project's limitations.
- Consentful work [supports](https://www.consentfultech.io/) the self-determination of people who use and are affected by these technologies.
- Socially Conscious work shows us how technology can support social, environmental, and scientific efforts.
- Sustainable work highlights and explores techniques for making machine learning ecologically sustainable.
- Inclusive work broadens the scope of who builds and benefits in the machine learning world.
- Inquisitive work shines a light on inequities and power structures which challenge the community to rethink its relationship to technology.
Read more at https://huggingface.co/ethics
Look for these terms as we’ll be using these tags, and updating them based on community contributions, across some new projects on the Hub!
## Safeguards
Taking an “all-or-nothing” view of open releases ignores the wide variety of contexts that determine an ML artifact’s positive or negative impacts. Having more levers of control over how ML systems are shared and re-used supports collaborative development and analysis with less risk of promoting harmful uses or misuses; allowing for more openness and participation in innovation for shared benefits.
We engage directly with contributors and have addressed pressing issues. To bring this to the next level, we are building community-based processes. This approach empowers both Hugging Face contributors, and those affected by contributions, to inform the limitations, sharing, and additional mechanisms necessary for models and data made available on our platform. The three main aspects we will pay attention to are: the origin of the artifact, how the artifact is handled by its developers, and how the artifact has been used. In that respect we:
- launched a [flagging feature](https://twitter.com/GiadaPistilli/status/1571865167092396033) for our community to determine whether ML artifacts or community content (model, dataset, space, or discussion) violate our [content guidelines](https://huggingface.co/content-guidelines),
- monitor our community discussion boards to ensure Hub users abide by the [code of conduct](https://huggingface.co/code-of-conduct),
- robustly document our most-downloaded models with model cards that detail social impacts, biases, and intended and out-of-scope use cases,
- create audience-guiding tags, such as the “Not For All Audiences” tag that can be added to the repository’s card metadata to avoid un-requested violent and sexual content,
- promote use of [Open Responsible AI Licenses (RAIL)](https://huggingface.co/blog/open_rail) for [models](https://www.licenses.ai/blog/2022/8/26/bigscience-open-rail-m-license), such as with LLMs ([BLOOM](https://huggingface.co/spaces/bigscience/license), [BigCode](https://huggingface.co/spaces/bigcode/license)),
- conduct research that [analyzes](https://arxiv.org/abs/2302.04844) which models and datasets have the highest potential for, or track record of, misuse and malicious use.
**How to use the flagging function:**
Click on the flag icon on any Model, Dataset, Space, or Discussion:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/flag2.jpg" alt="screenshot pointing to the flag icon to Report this model" />
<em> While logged in, you can click on the "three dots" button to bring up the ability to report (or flag) a repository. This will open a conversation in the repository's community tab. </em>
</p>
Share why you flagged this item:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/flag1.jpg" alt="screenshot showing the text window where you describe why you flagged this item" />
<em> Please add as much relevant context as possible in your report! This will make it much easier for the repo owner and HF team to start taking action. </em>
</p>
In prioritizing open science, we examine potential harm on a case-by-case basis and provide an opportunity for collaborative learning and shared responsibility.
When users flag a system, developers can directly and transparently respond to concerns.
In this spirit, we ask that repository owners make reasonable efforts to address reports, especially when reporters take the time to provide a description of the issue.
We also stress that the reports and discussions are subject to the same communication norms as the rest of the platform.
Moderators are able to disengage from or close discussions should behavior become hateful and/or abusive (see [code of conduct](https://huggingface.co/code-of-conduct)).
Should a specific model be flagged as high risk by our community, we consider:
- Downgrading the ML artifact’s visibility across the Hub in the trending tab and in feeds,
- Requesting that the gating feature be enabled to manage access to ML artifacts (see documentation for [models](https://huggingface.co/docs/hub/models-gated) and [datasets](https://huggingface.co/docs/hub/datasets-gated)),
- Requesting that the models be made private,
- Disabling access.
**How to add the “Not For All Audiences” tag:**
Edit the model/data card → add `not-for-all-audiences` in the tags section → open the PR and wait for the authors to merge it. Once merged, the following tag will be displayed on the repository:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/nfaa_tag.png" alt="screenshot showing where to add tags" />
</p>
Any repository tagged `not-for-all-audiences` will display the following popup when visited:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/nfaa2.png" alt="screenshot showing where to add tags" />
</p>
Clicking "View Content" will allow you to view the repository as normal. If you wish to always view `not-for-all-audiences`-tagged repositories without the popup, this setting can be changed in a user's [Content Preferences](https://huggingface.co/settings/content-preferences)
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_3/nfaa1.png" alt="screenshot showing where to add tags" />
</p>
Open science requires safeguards, and one of our goals is to create an environment informed by tradeoffs with different values. Hosting and providing access to models in addition to cultivating community and discussion empowers diverse groups to assess social implications and guide what is good machine learning.
## Are you working on safeguards? Share them on Hugging Face Hub!
The most important part of Hugging Face is our community. If you’re a researcher working on making ML safer to use, especially for open science, we want to support and showcase your work!
Here are some recent demos and tools from researchers in the Hugging Face community:
- [A Watermark for LLMs](https://huggingface.co/spaces/tomg-group-umd/lm-watermarking) by John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein ([paper](https://arxiv.org/abs/2301.10226))
- [Generate Model Cards Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool) by the Hugging Face team
- [Photoguard](https://huggingface.co/spaces/RamAnanth1/photoguard) to safeguard images against manipulation by Ram Ananth
Thanks for reading! 🤗
~ Irene, Nima, Giada, Yacine, and Elizabeth, on behalf of the Ethics and Society regulars
If you want to cite this blog post, please use the following (in descending order of contribution):
```
@misc{hf_ethics_soc_blog_3,
author = {Irene Solaiman and
Giada Pistilli and
Nima Boscarino and
Yacine Jernite and
Elizabeth Allendorf and
Margaret Mitchell and
Carlos Muñoz Ferrandis and
Nathan Lambert and
Alexandra Sasha Luccioni
},
title = {Hugging Face Ethics and Society Newsletter 3: Ethical Openness at Hugging Face},
booktitle = {Hugging Face Blog},
year = {2023},
url = {https://doi.org/10.57967/hf/0487},
doi = {10.57967/hf/0487}
}
```
| huggingface/blog/blob/main/ethics-soc-3.md |
--
title: "Deep Learning over the Internet: Training Language Models Collaboratively"
thumbnail: /blog/assets/24_sahajBERT/thumbnail.png
authors:
- user: mryab
guest: true
- user: SaulLu
---
# Deep Learning over the Internet: Training Language Models Collaboratively
<small>
With the additional help of Quentin Lhoest and Sylvain Lesage.
</small>
Modern language models often require a significant amount of compute for pretraining, making it impossible to obtain them without access to tens and hundreds of GPUs or TPUs. Though in theory it might be possible to combine the resources of multiple individuals, in practice, such distributed training methods have previously seen limited success because connection speeds over the Internet are way slower than in high-performance GPU supercomputers.
In this blog post, we describe [DeDLOC](https://arxiv.org/abs/2106.10207) — a new method for collaborative distributed training that can adapt itself to the network and hardware constraints of participants. We show that it can be successfully applied in real-world scenarios by pretraining [sahajBERT](https://huggingface.co/neuropark/sahajBERT), a model for the Bengali language, with 40 volunteers. On downstream tasks in Bengali, this model achieves nearly state-of-the-art quality with results comparable to much larger models that used hundreds of high-tier accelerators.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/v8ShbLasRF8"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
## Distributed Deep Learning in Open Collaborations
### Why should we do it?
These days, many highest-quality NLP systems are based on large pretrained Transformers. In general, their quality improves with size: you can achieve unparalleled results in natural language understanding and generation by scaling up the parameter count and leveraging the abundance of unlabeled text data.
Unfortunately, we use these pretrained models not only because it's convenient. The hardware resources for training Transformers on large datasets often exceed anything affordable to a single person and even most commercial or research organizations. Take, for example, BERT: its training was estimated to cost about $7,000, and for the largest models like GPT-3, this number can be as high as $12 million! This resource limitation might seem obvious and inevitable, but is there really no alternative to using pretrained models for the broader ML community?
However, there might be a way out of this situation: to come up with a solution, we only need to take a look around. It might be the case that the computational resources we're looking for are already there; for example, many of us have powerful computers with gaming or workstation GPUs at home. You might've already guessed that we're going to join their power similarly to [Folding@home](https://foldingathome.org/), [Rosetta@home](https://boinc.bakerlab.org/), [Leela Chess Zero](https://lczero.org/) or different [BOINC](https://boinc.berkeley.edu/) projects that leverage volunteer computing, but the approach is even more general. For instance, several laboratories can join their smaller clusters to utilize all the available resources, and some might want to join the experiment using inexpensive cloud instances.
To a skeptical mind, it might seem that we're missing a key factor here: data transfer in distributed DL is often a bottleneck, since we need to aggregate the gradients from multiple workers. Indeed, any naïve approach to distributed training over the Internet is bound to fail, as most participants don't have gigabit connections and might disconnect from the network at any time. So how on Earth can you train anything with a household data plan? :)
As a solution to this problem, we propose a new training algorithm, called Distributed Deep Learning in Open Collaborations (or **DeDLOC**), which is described in detail in our recently released [preprint](https://arxiv.org/abs/2106.10207). Now, let’s find out what are the core ideas behind this algorithm!
### Training with volunteers
In its most frequently used version, distributed training with multiple GPUs is pretty straightforward. Recall that when doing deep learning, you usually compute gradients of your loss function averaged across many examples in a batch of training data. In case of _data-parallel_ distributed DL, you simply split the data across multiple workers, compute gradients separately, and then average them once the local batches are processed. When the average gradient is computed on all workers, we adjust the model weights with the optimizer and continue training our model. You can see an illustration of different tasks that are executed below.

<div style="line-height:105%;font-size:80%">
<p align="center">
Typical machine learning tasks executed by peers in distributed training, possibly with a separation of roles
</p>
</div>
Often, to reduce the amount of synchronization and to stabilize the learning process, we can accumulate the gradients for N batches before averaging, which is equivalent to increasing the actual batch size N times. This approach, combined with the observation that most state-of-the-art language models use large batches, led us to a simple idea: let's accumulate one _very_ large batch across all volunteer devices before each optimizer step! Along with complete equivalence to regular distributed training and easy scalability, this method also has the benefit of built-in fault tolerance, which we illustrate below.
Let's consider a couple of potential failure cases that we might encounter throughout a collaborative experiment. By far, the most frequent scenario is that one or several peers disconnect from the training procedure: they might have an unstable connection or simply want to use their GPUs for something else. In this case, we only suffer a minor setback of training: the contribution of these peers gets deducted from the currently accumulated batch size, but other participants will compensate for that with their gradients. Also, if more peers join, the target batch size will simply be reached faster, and our training procedure will naturally speed up. You can see a demonstration of this in the video:
<div class="aspect-w-16 aspect-h-9">
<iframe src="https://www.youtube.com/embed/zdVsg5zsGdc" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>
### Adaptive averaging
Now that we have discussed the overall training procedure, there remains one more question: how do we actually aggregate the gradients of participants? Most home computers cannot easily accept incoming connections, and the download speed might also become a constraint.
Since we rely on volunteer hardware for experiments, a central server is not really a viable option, as it will quickly face overload when scaling to tens of clients and hundreds of millions of parameters. Most data-parallel training runs today don't use this strategy anyway; instead, they rely on All-Reduce — an efficient all-to-all communication primitive. Thanks to clever algorithmic optimizations, each node can compute the global average without sending the entire local gradient to every peer.
Because All-Reduce is decentralized, it seems like a good choice; however, we still need to take the diversity of hardware and network setups into account. For example, some volunteers might join from computers that have slow network but powerful GPUs, some might have better connectivity only to a subset of other peers, and some may be firewalled from incoming connections.
It turns out we can actually come up with an optimal data transfer strategy on the fly by leveraging this information about performance! On a high level, we split the entire gradient vector into parts depending on the Internet speed of each peer: those with the fastest connection aggregate the largest parts. Also, if some nodes do not accept incoming connections, they simply send their data for aggregation but do not compute the average themselves. Depending on the conditions, this adaptive algorithm can recover well-known distributed DL algorithms and improve on them with a hybrid strategy, as demonstrated below.

<div style="line-height:105%;font-size:80%">
<p align="center">
Examples of different averaging strategies with the adaptive algorithm.
</p>
</div>
<div style="line-height:105%;border:1px solid #F5F5F5;background-color:#F5F5F5;color: black">
<p align="center">
💡 The core techniques for decentralized training are available in <a href="https://github.com/learning-at-home/hivemind">Hivemind</a>.<br>
Check out the repo and learn how to use this library in your own projects!
</p>
</div><br>
## sahajBERT
As always, having a well-designed algorithmic framework doesn't mean that it will work as intended in practice, because some assumptions may not hold true in actual training runs. To verify the competitive performance of this technology and to showcase its potential, we organized a special collaborative event to pretrain a masked language model for the Bengali language. Even though it is the fifth most spoken native language in the world, it has [very few](https://huggingface.co/models?filter=bn&pipeline_tag=fill-mask) masked language models openly available, which emphasizes the importance of tools that can empower the community, unlocking a plethora of opportunities in the field.
We conducted this experiment with real volunteers from the Neuropark community and used openly available datasets (OSCAR and Wikipedia), because we wanted to have a fully reproducible example that might serve as an inspiration for other groups. Below, we describe the detailed setup of our training run and demonstrate its results.
### Architecture
For our experiment, we chose ALBERT _(A Lite BERT)_ — a model for language representations that is pretrained with Masked Language Modeling (MLM) and Sentence Order Prediction (SOP) as objectives. We use this architecture because weight sharing makes it very parameter-efficient: for example, ALBERT-large has ~18M trainable parameters and performs comparably to BERT-base with ~108M weights on the GLUE benchmark. It means that there is less data to exchange between the peers, which is crucial in our setup, as it significantly speeds up each training iteration.
<div style="line-height:105%;border:1px solid #F5F5F5;background-color:#F5F5F5;color: black">
<p align="center">
💡 Want to know more about ALBERT?<br>
<a href="https://arxiv.org/abs/1909.11942">Paper</a><br>
<a href="https://huggingface.co/transformers/model_doc/albert.html#albert"
>Transformers doc</a
>
</p>
</div>
### Tokenizer
The first brick of our model is called a _tokenizer_ and takes care of transforming raw text into vocabulary indices. Because we are training a model for Bengali, which is not very similar to English, we need to implement language-specific preprocessing as a part of our tokenizer. We can view it as a sequence of operations:
1. **Normalization:** includes all preprocessing operations on raw text data. This was the step at which we have made the most changes, because removing certain details can either change the meaning of the text or leave it the same, depending on the language. For example, the standard ALBERT normalizer removes the accents, while for the Bengali language, we need to keep them, because they contain information about the vowels. As a result, we use the following operations: NMT normalization, NFKC normalization, removal of multiple spaces, homogenization of recurring Unicode characters in the Bengali language, and lowercasing.
2. **Pretokenization** describes rules for splitting the input (for example, by whitespace) to enforce specific token boundaries. As in the original work, we have chosen to keep the whitespace out of the tokens. Therefore, to distinguish the words from each other and not to have multiple single-space tokens, each token corresponding to the beginning of a word starts with a special character “\_” (U+2581). In addition, we isolated all punctuation and digits from other characters to condense our vocabulary.
3. **Tokenizer modeling:** It is at this level that the text is mapped into a sequence of elements of a vocabulary. There are several algorithms for this, such as Byte-Pair Encoding (BPE) or Unigram, and most of them need to build the vocabulary from a text corpus. Following the setup of ALBERT, we used the **Unigram Language Model** approach, training a vocabulary of 32k tokens on the deduplicated Bengali part of the OSCAR dataset.
4. **Post-processing:** After tokenization, we might want to add several special tokens required by the architecture, such as starting the sequence with a special token `[CLS]` or separating two segments with a special token `[SEP]`. Since our main architecture is the same as the original ALBERT, we keep the same post-processing: specifically, we add a `[CLS]` token at the beginning of each example and a `[SEP]` token both between two segments and at the end.
<div style="line-height:105%;border:1px solid #F5F5F5;background-color:#F5F5F5;color: black">
<p align="center">
💡 Read more information about each component in
<a href="https://huggingface.co/docs/tokenizers/python/latest/components.html#components">Tokenizers doc</a>
</p>
</div>
You can reuse our tokenizer by running the following code:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("neuropark/sahajBERT")
```
### Dataset
The last thing we need to cover is the training dataset. As you probably know, the great strength of pretrained models like BERT or ALBERT is that you don't need an annotated dataset, but just a lot of texts. To train sahajBERT, we used the [Bengali Wikipedia dump from 03/20/2021](https://huggingface.co/datasets/lhoestq/wikipedia_bn) and the Bengali subset of [OSCAR](https://huggingface.co/datasets/oscar) (600MB + 6GB of text). These two datasets can easily be downloaded from the HF Hub.
However, loading an entire dataset requires time and storage — two things that our peers do not necessarily have. To make the most of the resources provided by the participants, we have implemented **dataset streaming**, which allows them to train the model nearly as soon as they join the network. Specifically, the examples in the dataset are downloaded and transformed in parallel to the training. We can also shuffle the dataset so that our peers have little chance to process the same examples at the same time. As the dataset is not downloaded and preprocessed in advance, the transformations needed to go from plain text to a training example (shown in the figure below) are done on the fly.

<div style="line-height:105%;font-size:80%">
<p align="center">
From a raw sample to a training sample
</p>
</div>
The dataset streaming mode is available from version v1.9 of the 🤗 datasets library, so you can use it right now as follows:
```python
from datasets import load_dataset
oscar_dataset = load_dataset("oscar", name="unshuffled_deduplicated_bn", streaming=True)
```
<div style="line-height:105%;border:1px solid #F5F5F5;background-color:#F5F5F5;color: black">
<p align="center">
💡 Learn more about loading datasets in streaming mode in the
<a href="https://huggingface.co/docs/datasets/dataset_streaming.html">documentation</a>
</p>
</div>
### Collaborative event
The sahajBERT collaborative training event took place from May 12 to May 21. The event brought together 40 participants, 30 of whom were Bengali-speaking volunteers, and 10 were volunteers from one of the authors' organizations. These 40 volunteers joined the [Neuropark](https://neuropark.co/) Discord channel to receive all information regarding the event and participate in discussions. To join the experiment, volunteers were asked to:
1. Send their username to the moderators to be allowlisted;
2. Open the provided notebook locally, on Google Colaboratory, or on Kaggle;
3. Run one code cell and fill in their Hugging Face credentials when requested;
4. Watch the training loss decrease on the shared dashboards!
For security purposes, we set up an authorization system so that only members of the Neuropark community could train the model. Sparing you the technical details, our authorization protocol allows us to guarantee that every participant is in the allowlist and to acknowledge the individual contribution of each peer.
In the following figure, you can see the activity of each volunteer. Over the experiment, the volunteers logged in 600 different sessions. Participants regularly launched multiple runs in parallel, and many of them spread out the runs they launched over time. The runs of individual participants lasted 4 hours on average, and the maximum length was 21 hours. You can read more about the participation statistics in the paper.
<iframe width="100%" height="670" frameborder="0"
src="https://observablehq.com/embed/@huggingface/sahajbert-bubbles-chart-optimized?cells=c_noaws%2Ct_noaws%2Cviewof+currentDate"></iframe>
<div style="line-height:105%;font-size:80%">
<p align="center">
Chart showing participants of the <a href="https://huggingface.co/neuropark/sahajBERT"> sahajBERT</a> experiment. Circle radius is relative to the total number of processed batches, the circle is greyed if the participant is not active. Every purple square represents an active device, darker color corresponds to higher performance
</p>
</div>
Along with the resources provided by participants, we also used 16 preemptible (cheap but frequently interrupted) single-GPU T4 cloud instances to ensure the stability of the run. The cumulative runtime for the experiment was 234 days, and in the figure below you can see parts of the loss curve that each peer contributed to!
<p align="center">
<iframe width="80%" height="950" frameborder="0"
src="https://observablehq.com/embed/@huggingface/explore-collaborative-training-data-optimized?cells=sessions%2Cviewof+participant%2ClossByParticipant"></iframe>
</p>
The final model was uploaded to the Model Hub, so you can download and play with it if you want to: [https://hf.co/neuropark/sahajBERT](https://huggingface.co/neuropark/sahajBERT)
### Evaluation
To evaluate the performance of sahajBERT, we finetuned it on two downstream tasks in Bengali:
- Named entity recognition (NER) on the Bengali split of [WikiANN](https://aclanthology.org/P17-1178/). The goal of this task is to classify each token in the input text into one of the following categories: person, organization, location, or none of them.
- News Category Classification (NCC) on the Soham articles dataset from [IndicGLUE](https://aclanthology.org/2020.findings-emnlp.445/). The goal of this task is to predict the category to which belong the input text.
We evaluated it during training on the NER task to check that everything was going well; as you can see on the following plot, this was indeed the case!
<iframe width="100%" height="476" frameborder="0"
src="https://observablehq.com/embed/@huggingface/bengali-exp-eval?cells=evalPlot"></iframe>
<div style="line-height:105%;font-size:80%">
<p align="center">
Evaluation metrics of fine-tuned models on the NER task from different checkpoints of pre-trained models.
</p>
</div>
At the end of training, we compared sahajBERT with three other pretrained language models: [XLM-R Large](https://arxiv.org/abs/1911.02116), [IndicBert](https://aclanthology.org/2020.findings-emnlp.445/), and [bnRoBERTa](https://huggingface.co/neuralspace-reverie/indic-transformers-bn-roberta). In the table below, you can see that our model has results comparable to the best Bengali language models available on HF Hub, even though our model has only ~18M trained parameters, while, for instance, XLM-R (a strong multilingual baseline), has ~559M parameters and was trained on several hundred V100 GPUs.
| Model | NER F1 (mean ± std) | NCC Accuracy (mean ± std) |
|:-------------:|:-------------:|:-------------:|
|[sahajBERT](https://huggingface.co/neuropark/sahajBERT) | 95.45 ± 0.53| 91.97 ± 0.47|
|[XLM-R-large](https://huggingface.co/xlm-roberta-large) | 96.48 ± 0.22| 90.05 ± 0.38|
|[IndicBert](https://huggingface.co/ai4bharat/indic-bert) | 92.52 ± 0.45| 74.46 ± 1.91|
|[bnRoBERTa](https://huggingface.co/neuralspace-reverie/indic-transformers-bn-roberta) |82.32 ± 0.67|80.94 ± 0.45|
These models are available on the Hub as well. You can test them directly by playing with the Hosted Inference API widget on their Model Cards or by loading them directly in your Python code.
#### sahajBERT-NER
Model card: [https://hf.co/neuropark/sahajBERT-NER](https://hf.co/neuropark/sahajBERT-NER)
```python
from transformers import (
AlbertForTokenClassification,
TokenClassificationPipeline,
PreTrainedTokenizerFast,
)
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NER")
# Initialize model
model = AlbertForTokenClassification.from_pretrained("neuropark/sahajBERT-NER")
# Initialize pipeline
pipeline = TokenClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
```
#### sahajBERT-NCC
Model card: [https://hf.co/neuropark/sahajBERT-NER](https://hf.co/neuropark/sahajBERT-NCC)
```python
from transformers import (
AlbertForSequenceClassification,
TextClassificationPipeline,
PreTrainedTokenizerFast,
)
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NCC")
# Initialize model
model = AlbertForSequenceClassification.from_pretrained("neuropark/sahajBERT-NCC")
# Initialize pipeline
pipeline = TextClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
```
## Conclusion
In this blog post, we have discussed the method that can enable collaborative pretraining of neural networks with sahajBERT as the first truly successful example of applying it to a real-world problem.
What does this all mean for the broader ML community? First, it is now possible to run large-scale distributed pretraining with your friends, and we hope to see a lot of cool new models that were previously less feasible to obtain. Also, our result might be important for multilingual NLP, since now the community for any language can train their own models without the need for significant computational resources concentrated in one place.
## Acknowledgements
The DeDLOC paper and sahajBERT training experiment were created by Michael Diskin, Alexey Bukhtiyarov, Max Ryabinin, Lucile Saulnier, Quentin Lhoest, Anton Sinitsin, Dmitry Popov, Dmitry Pyrkin, Maxim Kashirin, Alexander Borzunov, Albert Villanova del Moral, Denis Mazur, Ilia Kobelev, Yacine Jernite, Thomas Wolf, and Gennady Pekhimenko. This project is the result of a collaboration between
[Hugging Face](https://huggingface.co/), [Yandex Research](https://research.yandex.com/), [HSE University](https://www.hse.ru/en/), [MIPT](https://mipt.ru/english/), [University of Toronto](https://www.utoronto.ca/) and [Vector Institute](https://vectorinstitute.ai/).
In addition, we would like to thank Stas Bekman, Dmitry Abulkhanov, Roman Zhytar, Alexander Ploshkin, Vsevolod Plokhotnyuk and Roman Kail for their invaluable help with building the training infrastructure. Also, we thank Abhishek Thakur for helping with downstream evaluation and Tanmoy Sarkar with Omar Sanseviero, who helped us organize the collaborative experiment and gave regular status updates to the participants over the course of the training run.
Below, you can see all participants of the collaborative experiment:
<iframe width="100%" height="380" frameborder="0"
src="https://observablehq.com/embed/89470ece1dda817b?cells=humanParticipants"></iframe>
## References
"Distributed Deep Learning in Open Collaborations", [ArXiv](https://arxiv.org/abs/2106.10207)
Code for [sahajBERT experiments](https://github.com/yandex-research/DeDLOC/tree/main/sahajbert) in the DeDLOC repository.
| huggingface/blog/blob/main/collaborative-training.md |
--
title: "Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate"
thumbnail: /blog/assets/bloom-inference-pytorch-scripts/thumbnail.png
authors:
- user: stas
- user: sgugger
---
# Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate
This article shows how to get an incredibly fast per token throughput when generating with the 176B parameter [BLOOM model](https://huggingface.co/bigscience/bloom).
As the model needs 352GB in bf16 (bfloat16) weights (`176*2`), the most efficient set-up is 8x80GB A100 GPUs. Also 2x8x40GB A100s or 2x8x48GB A6000 can be used. The main reason for using these GPUs is that at the time of this writing they provide the largest GPU memory, but other GPUs can be used as well. For example, 24x32GB V100s can be used.
Using a single node will typically deliver a fastest throughput since most of the time intra-node GPU linking hardware is faster than inter-node one, but it's not always the case.
If you don't have that much hardware, it's still possible to run BLOOM inference on smaller GPUs, by using CPU or NVMe offload, but of course, the generation time will be much slower.
We are also going to cover the [8bit quantized solutions](https://huggingface.co/blog/hf-bitsandbytes-integration), which require half the GPU memory at the cost of slightly slower throughput. We will discuss [BitsAndBytes](https://github.com/TimDettmers/bitsandbytes) and [Deepspeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/) libraries there.
## Benchmarks
Without any further delay let's show some numbers.
For the sake of consistency, unless stated differently, the benchmarks in this article were all done on the same 8x80GB A100 node w/ 512GB of CPU memory on [Jean Zay HPC](http://www.idris.fr/eng/jean-zay/index.html). The JeanZay HPC users enjoy a very fast IO of about 3GB/s read speed (GPFS). This is important for checkpoint loading time. A slow disc will result in slow loading time. Especially since we are concurrently doing IO in multiple processes.
All benchmarks are doing [greedy generation](https://huggingface.co/blog/how-to-generate#greedy-search) of 100 token outputs:
```
Generate args {'max_length': 100, 'do_sample': False}
```
The input prompt is comprised of just a few tokens. The previous token caching is on as well, as it'd be quite slow to recalculate them all the time.
First, let's have a quick look at how long did it take to get ready to generate - i.e. how long did it take to load and prepare the model:
| project | secs |
| :---------------------- | :--- |
| accelerate | 121 |
| ds-inference shard-int8 | 61 |
| ds-inference shard-fp16 | 60 |
| ds-inference unsharded | 662 |
| ds-zero | 462 |
Deepspeed-Inference comes with pre-sharded weight repositories and there the loading takes about 1 minuted. Accelerate's loading time is excellent as well - at just about 2 minutes. The other solutions are much slower here.
The loading time may or may not be of importance, since once loaded you can continually generate tokens again and again without an additional loading overhead.
Next the most important benchmark of token generation throughput. The throughput metric here is a simple - how long did it take to generate 100 new tokens divided by 100 and the batch size (i.e. divided by the total number of generated tokens).
Here is the throughput in msecs on 8x80GB GPUs:
| project \ bs | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| :---------------- | :----- | :---- | :---- | :---- | :--- | :--- | :--- | :--- |
| accelerate bf16 | 230.38 | 31.78 | 17.84 | 10.89 | oom | | | |
| accelerate int8 | 286.56 | 40.92 | 22.65 | 13.27 | oom | | | |
| ds-inference fp16 | 44.02 | 5.70 | 3.01 | 1.68 | 1.00 | 0.69 | oom | |
| ds-inference int8 | 89.09 | 11.44 | 5.88 | 3.09 | 1.71 | 1.02 | 0.71 | oom |
| ds-zero bf16 | 283 | 34.88 | oom | | | | | |
where OOM == Out of Memory condition where the batch size was too big to fit into GPU memory.
Getting an under 1 msec throughput with Deepspeed-Inference's Tensor Parallelism (TP) and custom fused CUDA kernels! That's absolutely amazing! Though using this solution for other models that it hasn't been tried on may require some developer time to make it work.
Accelerate is super fast as well. It uses a very simple approach of naive Pipeline Parallelism (PP) and because it's very simple it should work out of the box with any model.
Since Deepspeed-ZeRO can process multiple generate streams in parallel its throughput can be further divided by 8 or 16, depending on whether 8 or 16 GPUs were used during the `generate` call. And, of course, it means that it can process a batch size of 64 in the case of 8x80 A100 (the table above) and thus the throughput is about 4msec - so all 3 solutions are very close to each other.
Let's revisit again how these numbers were calculated. To generate 100 new tokens for a batch size of 128 took 8832 msecs in real time when using Deepspeed-Inference in fp16 mode. So now to calculate the throughput we did: walltime/(batch_size*new_tokens) or `8832/(128*100) = 0.69`.
Now let's look at the power of quantized int8-based models provided by Deepspeed-Inference and BitsAndBytes, as it requires only half the original GPU memory of inference in bfloat16 or float16.
Throughput in msecs 4x80GB A100:
| project bs | 1 | 8 | 16 | 32 | 64 | 128 |
| :---------------- | :----- | :---- | :---- | :---- | :--- | :--- |
| accelerate int8 | 284.15 | 40.14 | 21.97 | oom | | |
| ds-inference int8 | 156.51 | 20.11 | 10.38 | 5.50 | 2.96 | oom |
To reproduce the benchmark results simply add `--benchmark` to any of these 3 scripts discussed below.
## Solutions
First checkout the demo repository:
```
git clone https://github.com/huggingface/transformers-bloom-inference
cd transformers-bloom-inference
```
In this article we are going to use 3 scripts located under `bloom-inference-scripts/`.
The framework-specific solutions are presented in an alphabetical order:
## HuggingFace Accelerate
[Accelerate](https://github.com/huggingface/accelerate)
Accelerate handles big models for inference in the following way:
1. Instantiate the model with empty weights.
2. Analyze the size of each layer and the available space on each device (GPUs, CPU) to decide where each layer should go.
3. Load the model checkpoint bit by bit and put each weight on its device
It then ensures the model runs properly with hooks that transfer the inputs and outputs on the right device and that the model weights offloaded on the CPU (or even the disk) are loaded on a GPU just before the forward pass, before being offloaded again once the forward pass is finished.
In a situation where there are multiple GPUs with enough space to accommodate the whole model, it switches control from one GPU to the next until all layers have run. Only one GPU works at any given time, which sounds very inefficient but it does produce decent throughput despite the idling of the GPUs.
It is also very flexible since the same code can run on any given setup. Accelerate will use all available GPUs first, then offload on the CPU until the RAM is full, and finally on the disk. Offloading to CPU or disk will make things slower. As an example, users have reported running BLOOM with no code changes on just 2 A100s with a throughput of 15s per token as compared to 10 msecs on 8x80 A100s.
You can learn more about this solution in [Accelerate documentation](https://huggingface.co/docs/accelerate/big_modeling).
### Setup
```
pip install transformers>=4.21.3 accelerate>=0.12.0
```
### Run
The simple execution is:
```
python bloom-inference-scripts/bloom-accelerate-inference.py --name bigscience/bloom --batch_size 1 --benchmark
```
To activate the 8bit quantized solution from [BitsAndBytes](https://github.com/TimDettmers/bitsandbytes) first install `bitsandbytes`:
```
pip install bitsandbytes
```
and then add `--dtype int8` to the previous command line:
```
python bloom-inference-scripts/bloom-accelerate-inference.py --name bigscience/bloom --dtype int8 --batch_size 1 --benchmark
```
if you have more than 4 GPUs you can tell it to use only 4 with:
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python bloom-inference-scripts/bloom-accelerate-inference.py --name bigscience/bloom --dtype int8 --batch_size 1 --benchmark
```
The highest batch size we were able to run without OOM was 40 in this case. If you look inside the script we had to tweak the memory allocation map to free the first GPU to handle only activations and the previous tokens' cache.
## DeepSpeed-Inference
[DeepSpeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/) uses Tensor-Parallelism and efficient fused CUDA kernels to deliver a super-fast <1msec per token inference on a large batch size of 128.
### Setup
```
pip install deepspeed>=0.7.3
```
### Run
1. the fastest approach is to use a TP-pre-sharded (TP = Tensor Parallel) checkpoint that takes only ~1min to load, as compared to 10min for non-pre-sharded bloom checkpoint:
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-inference.py --name microsoft/bloom-deepspeed-inference-fp16
```
1a.
if you want to run the original bloom checkpoint, which once loaded will run at the same throughput as the previous solution, but the loading will take 10-20min:
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-inference.py --name bigscience/bloom
```
2a. The 8bit quantized version requires you to have only half the GPU memory of the normal half precision version:
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-inference.py --name microsoft/bloom-deepspeed-inference-int8 --dtype int8
```
Here we used `microsoft/bloom-deepspeed-inference-int8` and also told the script to run in `int8`.
And of course, just 4x80GB A100 GPUs is now sufficient:
```
deepspeed --num_gpus 4 bloom-inference-scripts/bloom-ds-inference.py --name microsoft/bloom-deepspeed-inference-int8 --dtype int8
```
The highest batch size we were able to run without OOM was 128 in this case.
You can see two factors at play leading to better performance here.
1. The throughput here was improved by using Tensor Parallelism (TP) instead of the Pipeline Parallelism (PP) of Accelerate. Because Accelerate is meant to be very generic it is also unfortunately hard to maximize the GPU usage. All computations are done first on GPU 0, then on GPU 1, etc. until GPU 8, which means 7 GPUs are idle all the time. DeepSpeed-Inference on the other hand uses TP, meaning it will send tensors to all GPUs, compute part of the generation on each GPU and then all GPUs communicate to each other the results, then move on to the next layer. That means all GPUs are active at once but they need to communicate much more.
2. DeepSpeed-Inference also uses custom CUDA kernels to avoid allocating too much memory and doing tensor copying to and from GPUs. The effect of this is lesser memory requirements and fewer kernel starts which improves the throughput and allows for bigger batch sizes leading to higher overall throughput.
If you are interested in more examples you can take a look at [Accelerate GPT-J inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/gptj-deepspeed-inference) or [Accelerate BERT inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/bert-deepspeed-inference).
## Deepspeed ZeRO-Inference
[Deepspeed ZeRO](https://www.deepspeed.ai/tutorials/zero/) uses a magical sharding approach which can take almost any model and scale it across a few or hundreds of GPUs and the do training or inference on it.
### Setup
```
pip install deepspeed
```
### Run
Note that the script currently runs the same inputs on all GPUs, but you can run a different stream on each GPU, and get `n_gpu` times faster throughput. You can't do that with Deepspeed-Inference.
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-zero-inference.py --name bigscience/bloom --batch_size 1 --benchmark
```
Please remember that with ZeRO the user can generate multiple unique streams at the same time - and thus the overall performance should be throughput in secs/token divided by number of participating GPUs - so 8x to 16x faster depending on whether 8 or 16 GPUs were used!
You can also try the offloading solutions with just one smallish GPU, which will take a long time to run, but if you don't have 8 huge GPUs this is as good as it gets.
CPU-Offload (1x GPUs):
```
deepspeed --num_gpus 1 bloom-inference-scripts/bloom-ds-zero-inference.py --name bigscience/bloom --batch_size 8 --cpu_offload --benchmark
```
NVMe-Offload (1x GPUs):
```
deepspeed --num_gpus 1 bloom-inference-scripts/bloom-ds-zero-inference.py --name bigscience/bloom --batch_size 8 --nvme_offload_path=/path/to/nvme_offload --benchmark
```
make sure to adjust `/path/to/nvme_offload` to somewhere you have ~400GB of free memory on a fast NVMe drive.
## Additional Client and Server Solutions
At [transformers-bloom-inference](https://github.com/huggingface/transformers-bloom-inference) you will find more very efficient solutions, including server solutions.
Here are some previews.
Server solutions:
* [Mayank Mishra](https://github.com/mayank31398) took all the demo scripts discussed in this blog post and turned them into a webserver package, which you can download from [here](https://github.com/huggingface/transformers-bloom-inference)
* [Nicolas Patry](https://github.com/Narsil) has developed a super-efficient [Rust-based webserver solution]((https://github.com/Narsil/bloomserver).
More client-side solutions:
* [Thomas Wang](https://github.com/thomasw21) is developing a very fast [custom CUDA kernel BLOOM model](https://github.com/huggingface/transformers_bloom_parallel).
* The JAX team @HuggingFace has developed a [JAX-based solution](https://github.com/huggingface/bloom-jax-inference)
As this blog post is likely to become outdated if you read this months after it was published please
use [transformers-bloom-inference](https://github.com/huggingface/transformers-bloom-inference) to find the most up-to-date solutions.
## Blog credits
Huge thanks to the following kind folks who asked good questions and helped improve the readability of the article:
Olatunji Ruwase and Philipp Schmid.
| huggingface/blog/blob/main/bloom-inference-pytorch-scripts.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image Classification training examples
The following example showcases how to train/fine-tune `ViT` for image-classification using the JAX/Flax backend.
JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
Models written in JAX/Flax are **immutable** and updated in a purely functional
way which enables simple and efficient model parallelism.
In this example we will train/fine-tune the model on the [imagenette](https://github.com/fastai/imagenette) dataset.
## Prepare the dataset
We will use the [imagenette](https://github.com/fastai/imagenette) dataset to train/fine-tune our model. Imagenette is a subset of 10 easily classified classes from Imagenet (tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, parachute).
### Download and extract the data.
```bash
wget https://s3.amazonaws.com/fast-ai-imageclas/imagenette2.tgz
tar -xvzf imagenette2.tgz
```
This will create a `imagenette2` dir with two subdirectories `train` and `val` each with multiple subdirectories per class. The training script expects the following directory structure
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
## Train the model
Next we can run the example script to fine-tune the model:
```bash
python run_image_classification.py \
--output_dir ./vit-base-patch16-imagenette \
--model_name_or_path google/vit-base-patch16-224-in21k \
--train_dir="imagenette2/train" \
--validation_dir="imagenette2/val" \
--num_train_epochs 5 \
--learning_rate 1e-3 \
--per_device_train_batch_size 128 --per_device_eval_batch_size 128 \
--overwrite_output_dir \
--preprocessing_num_workers 32 \
--push_to_hub
```
This should finish in ~7mins with 99% validation accuracy. | huggingface/transformers/blob/main/examples/flax/vision/README.md |
rite your own training loop in PyTorch. In this video, we will look at how we can do the same fine-tuning as in the Trainer video, but without relying on that class. This way you will be able to easily customize each step of the training loop to your needs. This is also very useful to manually debug something that went wrong with the Trainer API. Before we dive into the code, here is a sketch of a training loop: we take a batch of training data and feed it to the model. With the labels, we can then compute a loss. That number is not useful on its own, but is used to compute the gradients of our model weights, that is the derivative of the loss with respect to each model weight. Those gradients are then used by the optimizer to update the model weights and make them a little bit better. We then repeat the process with a new batch of training data. If any of this is unclear, don't hesitate to take a refresher on your favorite deep learning course. We will use the GLUE MRPC dataset here again, and we have seen how to preprocess the data using the Datasets library with dynamic padding. Checkout the videos linked below if you haven't seen them already. With this done, we only have to define PyTorch DataLoaders, which will be responsible to convert the elements of our dataset into batches. We use our DataCollatorForPadding as the collate function, and shuffle the training set. To check that everything works as intended, we try to grab a batch of data and inspect it. Like our dataset elements, it's a dictionary, but this time the values are not a single list of integers, but a tensor of shape batch size by sequence length. The next step is to send the training data in our model. For that, we will need to create our model. As seen in the model API video, we use the from_pretrained method and adjust the number of labels to the number of classes we have on this dataset, here two. Again, to be sure everything is going well, we pass the batch we grabbed to our model and check there is no error. If the labels are provided, the models of the Transformers library always return the loss directly. We will be able to do loss.backward() to compute all the gradients, and will then need an optimizer to do the training step. We use the AdamW optimizer here, which is a variant of Adam with proper weight decay, but you can pick any PyTorch optimizer you like. Using the previous loss and computing the gradients with loss.backward(), we check that we can do the optimizer step without any error. Don't forget to zero your gradient afterward, or at the next step they will get added to the gradients you compute! We could already write our training loop, but we will add two more things to make it as good as it can be. The first one is a learning rate scheduler, to progressively decay our learning rate to zero. The get_scheduler function from the Transformers library is just a convenience function to easily build such a scheduler, you can again use any PyTorch learning rate scheduler instead. Finally, if we want our training to take a couple of minutes instead of a few hours, we will need to use a GPU. The first step is to get one, for instance by using a colab notebook. Then you need to actually send your model and training data on it by using a torch device. Double-check the following lines print a CUDA device for you! We can now put everything together! First we put our model in training mode (which will activate the training behavior for some layers like Dropout) then go through the number of epochs we picked and all the data in our training dataloader. Then we go through all the steps we have seen already: send the data to the GPU, compute the model outputs, and in particular the loss. Use the loss to compute gradients, then make a training step with the optimizer. Update the learning rate in our scheduler for the next iteration and zero the gradients of the optimizer. Once this is finished, we can evaluate our model very easily with a metric from the Datasets library. First we put our model in evaluation mode, then go through all the data in the evaluation data loader. As we have seen in the Trainer video, the model outputs logits and we need to apply the argmax function to convert them into predictions. The metric object then has an add_batch method we can use to send it those intermediate predictions. Once the evaluation loop is finished, we just have to call the compute method to get our final results! Congratulations, you have now fine-tuned a model all by yourself! | huggingface/course/blob/main/subtitles/en/raw/chapter3/04a_raw-training-loop.md |
Inception v4
**Inception-v4** is a convolutional neural network architecture that builds on previous iterations of the Inception family by simplifying the architecture and using more inception modules than [Inception-v3](https://paperswithcode.com/method/inception-v3).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('inception_v4', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `inception_v4`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('inception_v4', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{szegedy2016inceptionv4,
title={Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning},
author={Christian Szegedy and Sergey Ioffe and Vincent Vanhoucke and Alex Alemi},
year={2016},
eprint={1602.07261},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Inception v4
Paper:
Title: Inception-v4, Inception-ResNet and the Impact of Residual Connections on
Learning
URL: https://paperswithcode.com/paper/inception-v4-inception-resnet-and-the-impact
Models:
- Name: inception_v4
In Collection: Inception v4
Metadata:
FLOPs: 15806527936
Parameters: 42680000
File Size: 171082495
Architecture:
- Average Pooling
- Dropout
- Inception-A
- Inception-B
- Inception-C
- Reduction-A
- Reduction-B
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 20x NVIDIA Kepler GPUs
ID: inception_v4
LR: 0.045
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v4.py#L313
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/inceptionv4-8e4777a0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 1.01%
Top 5 Accuracy: 16.85%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/inception-v4.mdx |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
Then you need to install our special tool that builds the documentation:
```bash
pip install git+https://github.com/huggingface/doc-builder
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look like before committing for instance). You don't have to commit the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages, you can generate the documentation by typing th
following command:
```bash
doc-builder build transformers docs/source/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
---
**NOTE**
It's not possible to see locally how the final documentation will look like for now. Once you have opened a PR, you
will see a bot add a comment to a link where the documentation with your changes lives.
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md or .mdx).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/master/docs/source/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums and Social media and it'd be make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course if you moved it to another file, then:
```
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
For an example of a rich moved sections set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/master/docs/source/main_classes/trainer.mdx).
## Writing Documentation - Specification
The `huggingface/transformers` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users or researchers) it should go in section two, three or
four.
### Adding a new model
When adding a new model:
- Create a file `xxx.mdx` or under `./source/model_doc` (don't hesitate to copy an existing file as template).
- Link that file in `./source/_toctree.yml`.
- Write a short overview of the model:
- Overview with paper & authors
- Paper abstract
- Tips and tricks and how to use it best
- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
The order is generally:
- Configuration,
- Tokenizer
- PyTorch base model
- PyTorch head models
- TensorFlow base model
- TensorFlow head models
- Flax base model
- Flax head models
These classes should be added using our Markdown syntax. Usually as follows:
```
## XXXConfig
[[autodoc]] XXXConfig
```
This will include every public method of the configuration that is documented. If for some reason you wish for a method
not to be displayed in the documentation, you can do so by specifying which methods should be in the docs:
```
## XXXTokenizer
[[autodoc]] XXXTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
```
If you just want to add a method that is not documented (for instance magic method like `__call__` are not documented
byt default) you can put the list of methods to add in a list that contains `all`:
```
## XXXTokenizer
[[autodoc]] XXXTokenizer
- all
- __call__
```
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None or any strings should usually be put in `code`.
When mentioning a class, function or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`file_utils.ModelOutput\`\]. This will be converted into a link with
`file_utils.ModelOutput` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~file_utils.ModelOutput\`\] will generate a link with `ModelOutput` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line, another indentation is necessary before writing the description
after th argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
[`~PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ...
a (`float`, *optional*, defaults to 1):
This argument is used to ...
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```
# first line of code
# second line
# etc
```
````
We follow the [doctest](https://docs.python.org/3/library/doctest.html) syntax for the examples to automatically test
the results stay consistent with the library.
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example for a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example for tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
#### Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## Styling the docstring
We have an automatic script running with the `make style` comment that will make sure that:
- the docstrings fully take advantage of the line width
- all code examples are formatted using black, like the code of the Transformers library
This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
recommended to commit your changes before running `make style`, so you can revert the changes done by that script
easily.
| huggingface/evaluate/blob/main/docs/README.md |
mport { Meta } from "@storybook/blocks";
<Meta title="Introduction" />
<style>
{`
img {
margin: 1rem;
display: flex;
justify-content: left;
@media (max-width: 600px) {
width: 200px;
}
}
.container {
margin: 0 auto;
padding: 0 1rem;
}
.heading {
font-size: 2rem;
margin: 0 auto;
}
.subheading {
font-size: 1rem;
margin: 1rem auto;
}
ul {
list-style: none;
padding-left: 0;
margin: 0;
}
li a {
color: #ff7c01 !important;
}
`}
</style>
<img src="./gradio.svg" alt="Gradio Logo" />
<div class="container">
<div class="heading">Welcome to the Gradio Storybook</div>
This is Gradio's component library. It is a collection of reusable components that are used to build Gradio interfaces.
Here you'll find documentation for each component, the props they take, and the visual variations they have, as well as some examples of how they can be used.
This is still a work in progress and we welcome any contributions.
<div class="divider" />
<div class="subheading">Resources</div>
<ul>
<li><a href="https://gradio.app">Documentation</a></li>
<li><a href="https://gradio.app/guides/">Guides</a></li>
<li><a href="https://github.com/gradio-app/gradio">GitHub</a></li>
<li><a href="https://discord.com/invite/feTf9x3ZSB">Discord</a></li>
<li><a href="https://discuss.huggingface.co/c/gradio/26">Hugging Face Forum</a></li>
</ul>
<div class="subheading">Feedback</div>
If you have any questions, issues, or feedback on our components, please refer to our Discord or raise an issue in our GitHub repo.
</div>
| gradio-app/gradio/blob/main/js/storybook/Introduction.mdx |
simple demo showcasing the upload button used with its `upload` event trigger. | gradio-app/gradio/blob/main/demo/upload_button/DESCRIPTION.md |
--
title: "Summer at Hugging Face"
thumbnail: /blog/assets/27_summer_at_huggingface/summer_intro.gif
authors:
- user: huggingface
---
# Summer At Hugging Face 😎
Summer is now officially over and these last few months have been quite busy at Hugging Face. From new features in the Hub to research and Open Source development, our team has been working hard to empower the community through open and collaborative technology.
In this blog post you'll catch up on everything that happened at Hugging Face in June, July and August!

This post covers a wide range of areas our team has been working on, so don't hesitate to skip to the parts that interest you the most 🤗
1. [New Features](#new-features)
2. [Community](#community)
3. [Open Source](#open-source)
4. [Solutions](#solutions)
5. [Research](#research)
## New Features
In the last few months, the Hub went from 10,000 public model repositories to over 16,000 models! Kudos to our community for sharing so many amazing models with the world. And beyond the numbers, we have a ton of cool new features to share with you!
### Spaces Beta ([hf.co/spaces](/spaces))
Spaces is a simple and free solution to host Machine Learning demo applications directly on your user profile or your organization [hf.co](http://hf.co/) profile. We support two awesome SDKs that let you build cool apps easily in Python: [Gradio](https://gradio.app/) and [Streamlit](https://streamlit.io/). In a matter of minutes you can deploy an app and share it with the community! 🚀
Spaces lets you [set up secrets](/docs/hub/spaces-overview#managing-secrets), permits [custom requirements](/docs/hub/spaces-dependencies), and can even be managed [directly from GitHub repos](/docs/hub/spaces-github-actions). You can sign up for the beta at [hf.co/spaces](/spaces). Here are some of our favorites!
- Create recipes with the help of [Chef Transformer](/spaces/flax-community/chef-transformer)
- Transcribe speech to text with [HuBERT](https://huggingface.co/spaces/osanseviero/HUBERT)
- Do segmentation in a video with the [DINO model](/spaces/nateraw/dino-clips)
- Use [Paint Transformer](/spaces/akhaliq/PaintTransformer) to make paintings from a given picture
- Or you can just explore any of the over [100 existing Spaces](/spaces)!

### Share Some Love
You can now like any model, dataset, or Space on [http://huggingface.co](http://huggingface.co/), meaning you can share some love with the community ❤️. You can also keep an eye on who's liking what by clicking on the likes box 👀. Go ahead and like your own repos, we're not judging 😉.

### TensorBoard Integration
In late June, we launched a TensorBoard integration for all our models. If there are TensorBoard traces in the repo, an automatic, free TensorBoard instance is launched for you. This works with both public and private repositories and for any library that has TensorBoard traces!

### Metrics
In July, we added the ability to list evaluation metrics in model repos by adding them to their model card📈. If you add an evaluation metric under the `model-index` section of your model card, it will be displayed proudly in your model repo.

If that wasn't enough, these metrics will be automatically linked to the corresponding [Papers With Code](https://paperswithcode.com/) leaderboard. That means as soon as you share your model on the Hub, you can compare your results side-by-side with others in the community. 💪
Check out [this repo](https://huggingface.co/nateraw/vit-base-beans-demo) as an example, paying close attention to `model-index` section of its [model card](https://huggingface.co/nateraw/vit-base-beans-demo/blob/main/README.md#L12-L25) to see how you can do this yourself and find the metrics in Papers with Code [automatically](https://paperswithcode.com/sota/image-classification-on-beans).
### New Widgets
The Hub has 18 widgets that allow users to try out models directly in the browser.
With our latest integrations to Sentence Transformers, we also introduced two new widgets: feature extraction and sentence similarity.
The latest **audio classification** widget enables many cool use cases: language identification, [street sound detection](https://huggingface.co/speechbrain/urbansound8k_ecapa) 🚨, [command recognition](https://huggingface.co/speechbrain/google_speech_command_xvector), [speaker identification](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb), and more! You can try this out with `transformers` and `speechbrain` models today! 🔊 (Beware, when you try some of the models, you might need to bark out loud)
You can try our early demo of [structured data classification](https://huggingface.co/julien-c/wine-quality) with Scikit-learn. And finally, we also introduced new widgets for image-related models: **text to image**, **image classification**, and **object detection**. Try image classification with Google's ViT model [here](https://huggingface.co/google/vit-base-patch16-224) and object detection with Facebook AI's DETR model [here](https://huggingface.co/facebook/detr-resnet-50)!

### More Features
That's not everything that has happened in the Hub. We've introduced new and improved [documentation](https://huggingface.co/docs/hub/main) of the Hub. We also introduced two widely requested features: users can now transfer/rename repositories and directly upload new files to the Hub.

## Community
### Hugging Face Course
In June, we launched the first part of our [free online course](https://huggingface.co/course/chapter1)! The course teaches you everything about the 🤗 Ecosystem: Transformers, Tokenizers, Datasets, Accelerate, and the Hub. You can also find links to the course lessons in the official documentation of our libraries. The live sessions for all chapters can be found on our [YouTube channel](https://www.youtube.com/playlist?list=PLo2EIpI_JMQuQ8StH9RwKXwJVqLTDxwwy). Stay tuned for the next part of the course which we'll be launching later this year!

### JAX/FLAX Sprint
In July we hosted our biggest [community event](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) ever with almost 800 participants! In this event co-organized with the JAX/Flax and Google Cloud teams, compute-intensive NLP, Computer Vision, and Speech projects were made accessible to a wider audience of engineers and researchers by providing free TPUv3s. The participants created over 170 models, 22 datasets, and 38 Spaces demos 🤯. You can explore all the amazing demos and projects [here](https://huggingface.co/flax-community).
There were talks around JAX/Flax, Transformers, large-scale language modeling, and more! You can find all recordings [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects#talks).
We're really excited to share the work of the 3 winning teams!
1. [Dall-e mini](https://huggingface.co/spaces/flax-community/dalle-mini). DALL·E mini is a model that generates images from any prompt you give! DALL·E mini is 27 times smaller than the original DALL·E and still has impressive results.

2. [DietNerf](https://huggingface.co/spaces/flax-community/DietNerf-Demo). DietNerf is a 3D neural view synthesis model designed for few-shot learning of 3D scene reconstruction using 2D views. This is the first Open Source implementation of the "[Putting Nerf on a Diet](https://arxiv.org/abs/2104.00677)" paper.

3. [CLIP RSIC](https://huggingface.co/spaces/sujitpal/clip-rsicd-demo). CLIP RSIC is a CLIP model fine-tuned on remote sensing image data to enable zero-shot satellite image classification and captioning. This project demonstrates how effective fine-tuned CLIP models can be for specialized domains.

Apart from these very cool projects, we're excited about how these community events enable training large and multi-modal models for multiple languages. For example, we saw the first ever Open Source big LMs for some low-resource languages like [Swahili](https://huggingface.co/models?language=sw), [Polish](https://huggingface.co/flax-community/papuGaPT2) and [Marathi](https://huggingface.co/spaces/flax-community/roberta-base-mr).
## Bonus
On top of everything we just shared, our team has been doing lots of other things. Here are just some of them:
- 📖 This 3-part [video series](https://www.youtube.com/watch?time_continue=6&v=qmN1fJ7Fdmo&feature=emb_title&ab_channel=NilsR) shows the theory on how to train state-of-the-art sentence embedding models.
- We presented at PyTorch Community Voices and participated in a QA ([video](https://www.youtube.com/watch?v=wE3bk7JaH4E&ab_channel=PyTorch)).
- Hugging Face has collaborated with [NLP in Spanish](https://twitter.com/NLP_en_ES) and [SpainAI](https://twitter.com/Spain_AI_) in a Spanish [course](https://www.youtube.com/playlist?list=PLBILcz47fTtPspj9QDm2E0oHLe1p67tMz) that teaches concepts and state-of-the art architectures as well as their applications through use cases.
- We presented at [MLOps World Demo Days](https://www.youtube.com/watch?v=lWahHp5vpVg).
## Open Source
### New in Transformers
Summer has been an exciting time for 🤗 Transformers! The library reached 50,000 stars, 30 million total downloads, and almost 1000 contributors! 🤩
So what's new? JAX/Flax is now the 3rd supported framework with over [5000](https://huggingface.co/models?library=jax&sort=downloads) models in the Hub! You can find actively maintained [examples](https://github.com/huggingface/transformers/tree/master/examples/flax) for different tasks such as text classification. We're also working hard on improving our TensorFlow support: all our [examples](https://github.com/huggingface/transformers/tree/master/examples/tensorflow) have been reworked to be more robust, TensorFlow idiomatic, and clearer. This includes examples such as summarization, translation, and named entity recognition.
You can now easily publish your model to the Hub, including automatically authored model cards, evaluation metrics, and TensorBoard instances. There is also increased support for exporting models to ONNX with the new [`transformers.onnx` module](https://huggingface.co/transformers/serialization.html?highlight=onnx).
```bash
python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
```
The last 4 releases introduced many new cool models!
- [DETR](https://huggingface.co/transformers/model_doc/detr.html) can do fast end-to-end object detection and image segmentation. Check out some of our community [tutorials](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR)!

- [ByT5](https://huggingface.co/transformers/model_doc/byt5.html) is the first tokenizer-free model in the Hub! You can find all available checkpoints [here](https://huggingface.co/models?search=byt5).
- [CANINE](https://huggingface.co/transformers/model_doc/canine.html) is another tokenizer-free encoder-only model by Google AI, operating directly at the character level. You can find all (multilingual) checkpoints [here](https://huggingface.co/models?search=canine).
- [HuBERT](https://huggingface.co/transformers/model_doc/hubert.html?highlight=hubert) shows exciting results for downstream audio tasks such as [command classification](https://huggingface.co/superb/hubert-base-superb-ks) and [emotion recognition](https://huggingface.co/superb/hubert-base-superb-er). Check the models [here](https://huggingface.co/models?filter=hubert).
- [LayoutLMv2](https://huggingface.co/transformers/model_doc/layoutlmv2.html) and [LayoutXLM](https://huggingface.co/transformers/model_doc/layoutxlm.html?highlight=layoutxlm) are two incredible models capable of parsing document images (like PDFs) by incorporating text, layout, and visual information. We built a [Space demo](https://huggingface.co/spaces/nielsr/LayoutLMv2-FUNSD) so you can directly try it out! Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2).

- [BEiT](https://huggingface.co/transformers/model_doc/beit.html) by Microsoft Research makes self-supervised Vision Transformers outperform supervised ones, using a clever pre-training objective inspired by BERT.
- [RemBERT](https://huggingface.co/transformers/model_doc/rembert.html?), a large multilingual Transformer that outperforms XLM-R (and mT5 with a similar number of parameters) in zero-shot transfer.
- [Splinter](https://huggingface.co/transformers/model_doc/splinter.html) which can be used for few-shot question answering. Given only 128 examples, Splinter is able to reach ~73% F1 on SQuAD, outperforming MLM-based models by 24 points!
The Hub is now integrated into `transformers`, with the ability to push to the Hub configuration, model, and tokenizer files without leaving the Python runtime! The `Trainer` can now push directly to the Hub every time a checkpoint is saved:

### New in Datasets
You can find 1400 public datasets in [https://huggingface.co/datasets](https://huggingface.co/datasets) thanks to the awesome contributions from all our community. 💯
The support for `datasets` keeps growing: it can be used in JAX, process parquet files, use remote files, and has wider support for other domains such as Automatic Speech Recognition and Image Classification.
Users can also directly host and share their datasets to the community simply by uploading their data files in a repository on the Dataset Hub.

What are the new datasets highlights? Microsoft CodeXGlue [datasets](https://huggingface.co/datasets?search=code_x_glue) for multiple coding tasks (code completion, generation, search, etc), huge datasets such as [C4](https://huggingface.co/datasets/c4) and [MC4](https://huggingface.co/datasets/mc4), and many more such as [RussianSuperGLUE](https://huggingface.co/datasets/russian_super_glue) and [DISFL-QA](https://huggingface.co/datasets/disfl_qa).
### Welcoming new Libraries to the Hub
Apart from having deep integration with `transformers`-based models, the Hub is also building great partnerships with Open Source ML libraries to provide free model hosting and versioning. We've been achieving this with our [huggingface_hub](https://github.com/huggingface/huggingface_hub) Open-Source library as well as new Hub [documentation](https://huggingface.co/docs/hub/main).
All spaCy canonical pipelines can now be found in the official spaCy [organization](https://huggingface.co/spacy), and any user can share their pipelines with a single command `python -m spacy huggingface-hub`. To read more about it, head to [https://huggingface.co/blog/spacy](https://huggingface.co/blog/spacy). You can try all canonical spaCy models directly in the Hub in the demo [Space](https://huggingface.co/spaces/spacy/pipeline-visualizer)!

Another exciting integration is Sentence Transformers. You can read more about it in the [blog announcement](https://huggingface.co/blog/sentence-transformers-in-the-hub): you can find over 200 [models](https://huggingface.co/models?library=sentence-transformers) in the Hub, easily share your models with the rest of the community and reuse models from the community.
But that's not all! You can now find over 100 Adapter Transformers in the Hub and try out Speechbrain models with widgets directly in the browser for different tasks such as audio classification. If you're interested in our collaborations to integrate new ML libraries to the Hub, you can read more about them [here](https://huggingface.co/docs/hub/libraries).

## Solutions
### **Coming soon: Infinity**
Transformers latency down to 1ms? 🤯🤯🤯
We have been working on a really sleek solution to achieve unmatched efficiency for state-of-the-art Transformer models, for companies to deploy in their own infrastructure.
- Infinity comes as a single-container and can be deployed in any production environment.
- It can achieve 1ms latency for BERT-like models on GPU and 4-10ms on CPU 🤯🤯🤯
- Infinity meets the highest security requirements and can be integrated into your system without the need for internet access. You have control over all incoming and outgoing traffic.
⚠️ Join us for a [live announcement and demo on Sep 28](https://app.livestorm.co/hugging-face/hugging-face-infinity-launch?type=detailed), where we will be showcasing Infinity for the first time in public!
### **NEW: Hardware Acceleration**
Hugging Face is [partnering with leading AI hardware accelerators](http://hf.co/hardware) such as Intel, Qualcomm and GraphCore to make state-of-the-art production performance accessible and extend training capabilities on SOTA hardware. As the first step in this journey, we [introduced a new Open Source library](https://huggingface.co/blog/hardware-partners-program): 🤗 Optimum - the ML optimization toolkit for production performance 🏎. Learn more in this [blog post](https://huggingface.co/blog/graphcore).
### **NEW: Inference on SageMaker**
We launched a [new integration with AWS](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) to make it easier than ever to deploy 🤗 Transformers in SageMaker 🔥. Pick up the code snippet right from the 🤗 Hub model page! Learn more about how to leverage transformers in SageMaker in our [docs](https://huggingface.co/docs/sagemaker/inference) or check out these [video tutorials](https://youtube.com/playlist?list=PLo2EIpI_JMQtPhGR5Eo2Ab0_Vb89XfhDJ).
For questions reach out to us on the forum: [https://discuss.huggingface.co/c/sagemaker/17](https://discuss.huggingface.co/c/sagemaker/17)

### **NEW: AutoNLP In Your Browser**
We released a new [AutoNLP](https://huggingface.co/autonlp) experience: a web interface to train models straight from your browser! Now all it takes is a few clicks to train, evaluate and deploy **🤗** Transformers models on your own data. [Try it out](https://ui.autonlp.huggingface.co/) - NO CODE needed!

### Inference API
**Webinar**:
We hosted a [live webinar](https://youtu.be/p055U0dnEos) to show how to add Machine Learning capabilities with just a few lines of code. We also built a VSCode extension that leverages the Hugging Face Inference API to generate comments describing Python code.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/p055U0dnEos"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Hugging Face** + **Zapier Demo**
20,000+ Machine Learning models connected to 3,000+ apps? 🤯 By leveraging the [Inference API](https://huggingface.co/landing/inference-api/startups), you can now easily connect models right into apps like Gmail, Slack, Twitter, and more. In this demo video, we created a zap that uses this [code snippet](https://gist.github.com/feconroses/3476a91dc524fdb930a726b3894a1d08) to analyze your Twitter mentions and alerts you on Slack about the negative ones.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/sjfpOJ4KA78"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Hugging Face + Google Sheets Demo**
With the [Inference API](https://huggingface.co/landing/inference-api/startups), you can easily use zero-shot classification right into your spreadsheets in Google Sheets. Just [add this script](https://gist.github.com/feconroses/302474ddd3f3c466dc069ecf16bb09d7) in Tools -> Script Editor:
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/-A-X3aUYkDs"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Few-shot learning in practice**
We wrote a [blog post](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) about what Few-Shot Learning is and explores how GPT-Neo and 🤗 Accelerated Inference API are used to generate your own predictions.
### **Expert Acceleration Program**
Check out out the brand [new home for the Expert Acceleration Program](https://huggingface.co/landing/premium-support); you can now get direct, premium support from our Machine Learning experts and build better ML solutions, faster.
## Research
At BigScience we held our first live event (since the kick off) in July BigScience Episode #1. Our second event BigScience Episode #2 was held on September 20th, 2021 with technical talks and updates by the BigScience working groups and invited talks by Jade Abbott (Masakhane), Percy Liang (Stanford CRFM), Stella Biderman (EleutherAI) and more. We have completed the first large-scale training on Jean Zay, a 13B English only decoder model (you can find the details [here](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr1-13B-base/chronicles.md)), and we're currently deciding on the architecture of the second model. The organization working group has filed the application for the second half of the compute budget: Jean Zay V100 : 2,500,000 GPU hours. 🚀
In June, we shared the result of our collaboration with the Yandex research team: [DeDLOC](https://arxiv.org/abs/2106.10207), a method to collaboratively train your large neural networks, i.e. without using an HPC cluster, but with various accessible resources such as Google Colaboratory or Kaggle notebooks, personal computers or preemptible VMs. Thanks to this method, we were able to train [sahajBERT](https://huggingface.co/neuropark/sahajBERT), a Bengali language model, with 40 volunteers! And our model competes with the state of the art, and even is [the best for the downstream task of classification](https://huggingface.co/neuropark/sahajBERT-NCC) on Soham News Article Classification dataset. You can read more about it in this [blog](https://huggingface.co/blog/collaborative-training) post. This is a fascinating line of research because it would make model pre-training much more accessible (financially speaking)!
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/v8ShbLasRF8"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
In June our [paper](https://arxiv.org/abs/2103.08493), How Many Data Points is a Prompt Worth?, got a Best Paper award at NAACL! In it, we reconcile and compare traditional and prompting approaches to adapt pre-trained models, finding that human-written prompts are worth up to thousands of supervised data points on new tasks. You can also read its blog [post](https://huggingface.co/blog/how_many_data_points/).

We're looking forward to EMNLP this year where we have four accepted papers!
- Our [paper](https://arxiv.org/abs/2109.02846) "[Datasets: A Community Library for Natural Language Processing](https://arxiv.org/abs/2109.02846)" documents the Hugging Face Datasets project that has over 300 contributors. This community project gives easy access to hundreds of datasets to researchers. It has facilitated new use cases of cross-dataset NLP, and has advanced features for tasks like indexing and streaming large datasets.
- Our collaboration with researchers from TU Darmstadt lead to another paper accepted at the conference (["Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning"](https://arxiv.org/abs/2109.04144)). In this paper, we show that prompt-based fine-tuned language models (which achieve strong performance in few-shot setups) still suffer from learning surface heuristics (sometimes called *dataset biases*), a pitfall that zero-shot models don't exhibit.
- Our submission "[Block Pruning For Faster Transformers](https://arxiv.org/abs/2109.04838v1)" has also been accepted as a long paper. In this paper, we show how to use block sparsity to obtain both fast and small Transformer models. Our experiments yield models which are 2.4x faster and 74% smaller than BERT on SQuAD.
## Last words
😎 🔥 Summer was fun! So many things have happened! We hope you enjoyed reading this blog post and looking forward to share the new projects we're working on. See you in the winter! ❄️ | huggingface/blog/blob/main/summer-at-huggingface.md |
--
title: "Model Cards"
thumbnail: /blog/assets/121_model-cards/thumbnail.png
authors:
- user: Ezi
- user: Marissa
- user: Meg
---
# Model Cards
## Introduction
Model cards are an important documentation framework for understanding, sharing, and improving machine learning models. When done well, a model card can serve as a _boundary object_, a single artefact that is accessible to people with different backgrounds and goals in understanding models - including developers, students, policymakers, ethicists, and those impacted by machine learning models.
Today, we launch a [model card creation tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool) and [a model card Guide Book](https://huggingface.co/docs/hub/model-card-guidebook), which details how to fill out model cards, user studies, and state of the art in ML documentation. This work, building from many other people and organizations, focuses on the _inclusion_ of people with different backgrounds and roles. We hope it serves as a stepping stone in the path toward improved ML documentation.
In sum, today we announce the release of:
1) A [Model Card Creator Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool), to ease card creation without needing to program, and to help teams share the work of different sections.
2) An updated model card template, released in [the `huggingface_hub` library](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md), drawing together model card work in academia and throughout the industry.
3) An [Annotated Model Card Template](https://huggingface.co/docs/hub/model-card-annotated), which details how to fill the card out.
4) A [User Study](https://huggingface.co/docs/hub/model-cards-user-studies) on model card usage at Hugging Face.
5) A [Landscape Analysis and Literature Review](https://huggingface.co/docs/hub/model-card-landscape-analysis) of the state of the art in model documentation.
## Model Cards To-Date
Since Model Cards were proposed by [Mitchell et al. (2018)](https://arxiv.org/abs/1810.03993), inspired by the major documentation framework efforts of Data Statements for Natural Language Processing [(Bender & Friedman, 2018)](https://aclanthology.org/Q18-1041/) and Datasheets for Datasets [(Gebru et al., 2018)](https://www.fatml.org/media/documents/datasheets_for_datasets.pdf), the landscape of machine learning documentation has expanded and evolved. A plethora of documentation tools and templates for data, models, and ML systems have been proposed and developed - reflecting the incredible work of hundreds of researchers, impacted community members, advocates, and other stakeholders. Important discussions about the relationship between ML documentation and theories of change in responsible AI have also shaped these developments in the ML documentation ecosystem.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/121_model-cards/MC_landscape.png" width="500"/>
<BR/>
<span style="font-size:12px">
Work to-date on documentation within ML has provided for different audiences. We bring many of these ideas together in the work we share today.
</span>
</p>
## Our Work
Our work presents a view of where model cards stand right now and where they could go in the future. We conducted a broad analysis of the growing landscape of ML documentation tools and conducted user interviews within Hugging Face to supplement our understanding of the diverse opinions about model cards. We also created or updated dozens of model cards for ML models on the Hugging Face Hub, and informed by all of these experiences, we propose a new template for model cards.
### Standardising Model Card Structure
Through our background research and user studies, which are discussed further in the [Guide Book](https://huggingface.co/docs/hub/model-card-guidebook), we aimed to establish a new standard of "model cards" as understood by the general public.
Informed by these findings, we created a new model card template that not only standardized the structure and content of HF model cards but also provided default prompt text. This text aimed to aide with writing model card sections, with a particular focus on the Bias, Risks and Limitations section.
### Accessibility and Inclusion
In order to lower barriers to entry for creating model cards, we designed [the model card writing tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool), a tool with a graphical user interface (GUI) to enable people and teams with different skill sets and roles to easily collaborate and create model cards, without needing to code or use markdown.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/121_model-cards/upload_a_mc.gif" width="600"/>
</p>
The writing tool encourages those who have yet to write model cards to create them more easily. For those who have previously written model cards, this approach invites them to add to the prompted information -- while centering the ethical components of model documentation.
As ML continues to be more intertwined with different domains, collaborative and open-source ML processes that center accessibility, ethics and inclusion are a critical part of the machine learning lifecycle and a stepping stone in ML documentation.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/121_model-cards/vines_idea.jpg" width="400"/>
<BR/>
<span style="font-size:12px">
Today's release sits within a larger ecosystem of ML documentation work: Data and model documentation have been taken up by many tech companies, including Hugging Face 🤗. We've prioritized "Repository Cards" for both dataset cards and model cards, focusing on multidisciplinarity. Continuing in this line of work, the model card creation UI tool
focuses on inclusivity, providing guidance on formatting and prompting to aid card creation for people with different backgrounds.
</span>
</p>
## Call to action
Let's look ahead
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/121_model-cards/looking_ahead.png" width="250"/>
</p>
This work is a "*snapshot*" of the current state of model cards, informed by a landscape analysis of the many ways ML documentation artefacts have been instantiated. The model book and these findings represent one perspective amongst multiple about both the current state and more aspirational visions of model cards.
* The Hugging Face ecosystem will continue to advance methods that streamline Model Card creation [through code](https://huggingface.co/docs/huggingface_hub/how-to-model-cards) and [user interfaces](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool), including building more features directly into the repos and product.
* As we further develop model tools such as [Evaluate on the Hub](https://huggingface.co/blog/eval-on-the-hub), we will integrate their usage within the model card development workflow. For example, as automatically evaluating model performance across disaggregated factors becomes easier, these results will be possible to import into the model card.
* There is further study to be done to advance the pairing of research models and model cards, such as building out a research paper → to model documentation pipeline, making it make it trivial to go from paper to model card creation. This would allow for greater cross-domain reach and further standardisation of model documentation.
We continue to learn more about how model cards are created and used, and the effect of cards on model usage. Based on these learnings, we will further update the model card template, instructions, and Hub integrations.
As we strive to incorporate more voices and stakeholders' use cases for model cards, [bookmark our model cards writing tool and give it a try](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool)!
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/121_model-cards/like_the_space.gif" width="680"/>
</p>
We are excited to know your thoughts on model cards, our model card writing GUI, and how AI documentation can empower your domain.🤗
## Acknowledgements
This release would not have been possible without the extensive contributions of Omar Sanseviero, Lucain Pouget, Julien Chaumond, Nazneen Rajani, and Nate Raw.
| huggingface/blog/blob/main/model-cards.md |
CSP-ResNeXt
**CSPResNeXt** is a convolutional neural network where we apply the Cross Stage Partial Network (CSPNet) approach to [ResNeXt](https://paperswithcode.com/method/resnext). The CSPNet partitions the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('cspresnext50', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspresnext50`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('cspresnext50', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{wang2019cspnet,
title={CSPNet: A New Backbone that can Enhance Learning Capability of CNN},
author={Chien-Yao Wang and Hong-Yuan Mark Liao and I-Hau Yeh and Yueh-Hua Wu and Ping-Yang Chen and Jun-Wei Hsieh},
year={2019},
eprint={1911.11929},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP ResNeXt
Paper:
Title: 'CSPNet: A New Backbone that can Enhance Learning Capability of CNN'
URL: https://paperswithcode.com/paper/cspnet-a-new-backbone-that-can-enhance
Models:
- Name: cspresnext50
In Collection: CSP ResNeXt
Metadata:
FLOPs: 3962945536
Parameters: 20570000
File Size: 82562887
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Polynomial Learning Rate Decay
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 1x GPU
ID: cspresnext50
LR: 0.1
Layers: 50
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 128
Image Size: '224'
Weight Decay: 0.005
Interpolation: bilinear
Training Steps: 8000000
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L430
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspresnext50_ra_224-648b4713.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.05%
Top 5 Accuracy: 94.94%
--> | huggingface/pytorch-image-models/blob/main/docs/models/csp-resnext.md |
`@gradio/highlightedtext`
```html
<script>
import { BaseStaticHighlightedText, BaseInteractiveHighlightedText } from `@gradio/highlightedtext`;
</script>
```
BaseStaticHighlightedText
```javascript
export let value: {
token: string;
class_or_confidence: string | number | null;
}[] = [];
export let show_legend = false;
export let color_map: Record<string, string> = {};
export let selectable = false;
```
BaseInteractiveHighlightedText
```javascript
export let value: {
token: string;
class_or_confidence: string | number | null;
}[] = [];
export let show_legend = false;
export let color_map: Record<string, string> = {};
export let selectable = false;
``` | gradio-app/gradio/blob/main/js/highlightedtext/README.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# int8 training for automatic speech recognition
Quantization reduces the precision of floating point data types, decreasing the memory required to store model weights. However, quantization degrades inference performance because you lose information when you reduce the precision. 8-bit or `int8` quantization uses only a quarter precision, but it does not degrade performance because it doesn't just drop the bits or data. Instead, `int8` quantization *rounds* from one data type to another.
<Tip>
💡 Read the [LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://arxiv.org/abs/2208.07339) paper to learn more, or you can take a look at the corresponding [blog post](https://huggingface.co/blog/hf-bitsandbytes-integration) for a gentler introduction.
</Tip>
This guide will show you how to train a [`openai/whisper-large-v2`](https://huggingface.co/openai/whisper-large-v2) model for multilingual automatic speech recognition (ASR) using a combination of `int8` quantization and LoRA. You'll train Whisper for multilingual ASR on Marathi from the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) dataset.
Before you start, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets accelerate evaluate jiwer bitsandbytes
```
## Setup
Let's take care of some of the setup first so you can start training faster later. Set the `CUDA_VISIBLE_DEVICES` to `0` to use the first GPU on your machine. Then you can specify the model name (either a Hub model repository id or a path to a directory containing the model), language and language abbreviation to train on, the task type, and the dataset name:
```py
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
model_name_or_path = "openai/whisper-large-v2"
language = "Marathi"
language_abbr = "mr"
task = "transcribe"
dataset_name = "mozilla-foundation/common_voice_11_0"
```
You can also log in to your Hugging Face account to save and share your trained model on the Hub if you'd like:
```py
from huggingface_hub import notebook_login
notebook_login()
```
## Load dataset and metric
The [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) dataset contains many hours of recorded speech in many different languages. This guide uses the [Marathi](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/mr/train) language as an example, but feel free to use any other language you're interested in.
Initialize a [`~datasets.DatasetDict`] structure, and load the [`train`] (load both the `train+validation` split into `train`) and [`test`] splits from the dataset into it:
```py
from datasets import load_dataset
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset(dataset_name, language_abbr, split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset(dataset_name, language_abbr, split="test", use_auth_token=True)
common_voice["train"][0]
```
## Preprocess dataset
Let's prepare the dataset for training. Load a feature extractor, tokenizer, and processor. You should also pass the language and task to the tokenizer and processor so they know how to process the inputs:
```py
from transformers import AutoFeatureExtractor, AutoTokenizer, AutoProcessor
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, language=language, task=task)
processor = AutoProcessor.from_pretrained(model_name_or_path, language=language, task=task)
```
You'll only be training on the `sentence` and `audio` columns, so you can remove the rest of the metadata with [`~datasets.Dataset.remove_columns`]:
```py
common_voice = common_voice.remove_columns(
["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"]
)
common_voice["train"][0]
{
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f7e1ef6a2d14f20194999aad5040c5d4bb3ead1377de3e1bbc6e9dba34d18a8a/common_voice_mr_30585613.mp3",
"array": array(
[1.13686838e-13, -1.42108547e-13, -1.98951966e-13, ..., 4.83472422e-06, 3.54798703e-06, 1.63231743e-06]
),
"sampling_rate": 48000,
},
"sentence": "आईचे आजारपण वाढत चालले, तसतशी मथीही नीट खातपीतनाशी झाली.",
}
```
If you look at the `sampling_rate`, you'll see the audio was sampled at 48kHz. The Whisper model was pretrained on audio inputs at 16kHZ which means you'll need to downsample the audio inputs to match what the model was pretrained on. Downsample the audio by using the [`~datasets.Dataset.cast_column`] method on the `audio` column, and set the `sampling_rate` to 16kHz. The audio input is resampled on the fly the next time you call it:
```py
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
common_voice["train"][0]
{
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f7e1ef6a2d14f20194999aad5040c5d4bb3ead1377de3e1bbc6e9dba34d18a8a/common_voice_mr_30585613.mp3",
"array": array(
[-3.06954462e-12, -3.63797881e-12, -4.54747351e-12, ..., -7.74800901e-06, -1.74738125e-06, 4.36312439e-06]
),
"sampling_rate": 16000,
},
"sentence": "आईचे आजारपण वाढत चालले, तसतशी मथीही नीट खातपीतनाशी झाली.",
}
```
Once you've cleaned up the dataset, you can write a function to generate the correct model inputs. The function should:
1. Resample the audio inputs to 16kHZ by loading the `audio` column.
2. Compute the input features from the audio `array` using the feature extractor.
3. Tokenize the `sentence` column to the input labels.
```py
def prepare_dataset(batch):
audio = batch["audio"]
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
```
Apply the `prepare_dataset` function to the dataset with the [`~datasets.Dataset.map`] function, and set the `num_proc` argument to `2` to enable multiprocessing (if `map` hangs, then set `num_proc=1`):
```py
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=2)
```
Finally, create a `DataCollator` class to pad the labels in each batch to the maximum length, and replace padding with `-100` so they're ignored by the loss function. Then initialize an instance of the data collator:
```py
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
label_features = [{"input_ids": feature["labels"]} for feature in features]
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
```
## Train
Now that the dataset is ready, you can turn your attention to the model. Start by loading the pretrained [`openai/whisper-large-v2`]() model from [`~transformers.AutoModelForSpeechSeq2Seq`], and make sure to set the [`~transformers.BitsAndBytesConfig.load_in_8bit`] argument to `True` to enable `int8` quantization. The `device_map=auto` argument automatically determines how to load and store the model weights:
```py
from transformers import AutoModelForSpeechSeq2Seq
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_name_or_path, load_in_8bit=True, device_map="auto")
```
You should configure `forced_decoder_ids=None` because no tokens are used before sampling, and you won't need to suppress any tokens during generation either:
```py
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
```
To get the model ready for `int8` quantization, use the utility function [`prepare_model_for_int8_training`](https://github.com/huggingface/peft/blob/34027fe813756897767b9a6f19ae7f1c4c7b418c/src/peft/utils/other.py#L35) to handle the following:
- casts all the non `int8` modules to full precision (`fp32`) for stability
- adds a forward hook to the input embedding layer to calculate the gradients of the input hidden states
- enables gradient checkpointing for more memory-efficient training
```py
from peft import prepare_model_for_int8_training
model = prepare_model_for_int8_training(model)
```
Let's also apply LoRA to the training to make it even more efficient. Load a [`~peft.LoraConfig`] and configure the following parameters:
- `r`, the dimension of the low-rank matrices
- `lora_alpha`, scaling factor for the weight matrices
- `target_modules`, the name of the attention matrices to apply LoRA to (`q_proj` and `v_proj`, or query and value in this case)
- `lora_dropout`, dropout probability of the LoRA layers
- `bias`, set to `none`
<Tip>
💡 The weight matrix is scaled by `lora_alpha/r`, and a higher `lora_alpha` value assigns more weight to the LoRA activations. For performance, we recommend setting bias to `None` first, and then `lora_only`, before trying `all`.
</Tip>
```py
from peft import LoraConfig, PeftModel, LoraModel, LoraConfig, get_peft_model
config = LoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none")
```
After you set up the [`~peft.LoraConfig`], wrap it and the base model with the [`get_peft_model`] function to create a [`PeftModel`]. Print out the number of trainable parameters to see how much more efficient LoRA is compared to fully training the model!
```py
model = get_peft_model(model, config)
model.print_trainable_parameters()
"trainable params: 15728640 || all params: 1559033600 || trainable%: 1.0088711365810203"
```
Now you're ready to define some training hyperparameters in the [`~transformers.Seq2SeqTrainingArguments`] class, such as where to save the model to, batch size, learning rate, and number of epochs to train for. The [`PeftModel`] doesn't have the same signature as the base model, so you'll need to explicitly set `remove_unused_columns=False` and `label_names=["labels"]`.
```py
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="your-name/int8-whisper-large-v2-asr",
per_device_train_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=1e-3,
warmup_steps=50,
num_train_epochs=3,
evaluation_strategy="epoch",
fp16=True,
per_device_eval_batch_size=8,
generation_max_length=128,
logging_steps=25,
remove_unused_columns=False,
label_names=["labels"],
)
```
It is also a good idea to write a custom [`~transformers.TrainerCallback`] to save model checkpoints during training:
```py
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
class SavePeftModelCallback(TrainerCallback):
def on_save(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
kwargs["model"].save_pretrained(peft_model_path)
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
if os.path.exists(pytorch_model_path):
os.remove(pytorch_model_path)
return control
```
Pass the `Seq2SeqTrainingArguments`, model, datasets, data collator, tokenizer, and callback to the [`~transformers.Seq2SeqTrainer`]. You can optionally set `model.config.use_cache = False` to silence any warnings. Once everything is ready, call [`~transformers.Trainer.train`] to start training!
```py
from transformers import Seq2SeqTrainer, TrainerCallback, Seq2SeqTrainingArguments, TrainerState, TrainerControl
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
tokenizer=processor.feature_extractor,
callbacks=[SavePeftModelCallback],
)
model.config.use_cache = False
trainer.train()
```
## Evaluate
[Word error rate](https://huggingface.co/spaces/evaluate-metric/wer) (WER) is a common metric for evaluating ASR models. Load the WER metric from 🤗 Evaluate:
```py
import evaluate
metric = evaluate.load("wer")
```
Write a loop to evaluate the model performance. Set the model to evaluation mode first, and write the loop with [`torch.cuda.amp.autocast()`](https://pytorch.org/docs/stable/amp.html) because `int8` training requires autocasting. Then, pass a batch of examples to the model to evaluate. Get the decoded predictions and labels, and add them as a batch to the WER metric before calling `compute` to get the final WER score:
```py
from torch.utils.data import DataLoader
from tqdm import tqdm
import numpy as np
import gc
eval_dataloader = DataLoader(common_voice["test"], batch_size=8, collate_fn=data_collator)
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
with torch.cuda.amp.autocast():
with torch.no_grad():
generated_tokens = (
model.generate(
input_features=batch["input_features"].to("cuda"),
decoder_input_ids=batch["labels"][:, :4].to("cuda"),
max_new_tokens=255,
)
.cpu()
.numpy()
)
labels = batch["labels"].cpu().numpy()
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
metric.add_batch(
predictions=decoded_preds,
references=decoded_labels,
)
del generated_tokens, labels, batch
gc.collect()
wer = 100 * metric.compute()
print(f"{wer=}")
```
## Share model
Once you're happy with your results, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method:
```py
model.push_to_hub("your-name/int8-whisper-large-v2-asr")
```
## Inference
Let's test the model out now!
Instantiate the model configuration from [`PeftConfig`], and from here, you can use the configuration to load the base and [`PeftModel`], tokenizer, processor, and feature extractor. Remember to define the `language` and `task` in the tokenizer, processor, and `forced_decoder_ids`:
```py
from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
language = "Marathi"
task = "transcribe"
peft_config = PeftConfig.from_pretrained(peft_model_id)
model = WhisperForConditionalGeneration.from_pretrained(
peft_config.base_model_name_or_path, load_in_8bit=True, device_map="auto"
)
model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = WhisperTokenizer.from_pretrained(peft_config.base_model_name_or_path, language=language, task=task)
processor = WhisperProcessor.from_pretrained(peft_config.base_model_name_or_path, language=language, task=task)
feature_extractor = processor.feature_extractor
forced_decoder_ids = processor.get_decoder_prompt_ids(language=language, task=task)
```
Load an audio sample (you can listen to it in the [Dataset Preview](https://huggingface.co/datasets/stevhliu/dummy)) to transcribe, and the [`~transformers.AutomaticSpeechRecognitionPipeline`]:
```py
from transformers import AutomaticSpeechRecognitionPipeline
audio = "https://huggingface.co/datasets/stevhliu/dummy/resolve/main/mrt_01523_00028548203.wav"
pipeline = AutomaticSpeechRecognitionPipeline(model=model, tokenizer=tokenizer, feature_extractor=feature_extractor)
```
Then use the pipeline with autocast as a context manager on the audio sample:
```py
with torch.cuda.amp.autocast():
text = pipe(audio, generate_kwargs={"forced_decoder_ids": forced_decoder_ids}, max_new_tokens=255)["text"]
text
"मी तुमच्यासाठी काही करू शकतो का?"
```
| huggingface/peft/blob/main/docs/source/task_guides/int8-asr.md |
Language models in RL
## LMs encode useful knowledge for agents
**Language models** (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to **encode various types of knowledge including abstract ones about the physical rules of our world** (for instance what is possible to do with an object, what happens when one rotates an object…).
A natural question recently studied was whether such knowledge could benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked any learning method. **This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/language.png" alt="Language">
<figcaption>Source: <a href="https://ai.googleblog.com/2022/08/towards-helpful-robots-grounding.html">Towards Helpful Robots: Grounding Language in Robotic Affordances</a></figcaption>
</figure>
## LMs and RL
There is therefore a potential synergy between LMs which can bring knowledge about the world, and RL which can align and correct this knowledge by interacting with an environment. It is especially interesting from a RL point-of-view as the RL field mostly relies on the **Tabula-rasa** setup where everything is learned from scratch by the agent leading to:
1) Sample inefficiency
2) Unexpected behaviors from humans’ eyes
As a first attempt, the paper [“Grounding Large Language Models with Online Reinforcement Learning”](https://arxiv.org/abs/2302.02662v1) tackled the problem of **adapting or aligning a LM to a textual environment using PPO**. They showed that the knowledge encoded in the LM lead to a fast adaptation to the environment (opening avenues for sample efficient RL agents) but also that such knowledge allowed the LM to better generalize to new tasks once aligned.
<video src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/papier_v4.mp4" type="video/mp4" controls />
Another direction studied in [“Guiding Pretraining in Reinforcement Learning with Large Language Models”](https://arxiv.org/abs/2302.06692) was to keep the LM frozen but leverage its knowledge to **guide an RL agent’s exploration**. Such a method allows the RL agent to be guided towards human-meaningful and plausibly useful behaviors without requiring a human in the loop during training.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/language2.png" alt="Language">
<figcaption> Source: <a href="https://ai.googleblog.com/2022/08/towards-helpful-robots-grounding.html"> Towards Helpful Robots: Grounding Language in Robotic Affordances</a> </figcaption>
</figure>
Several limitations make these works still very preliminary such as the need to convert the agent's observation to text before giving it to a LM as well as the compute cost of interacting with very large LMs.
## Further reading
For more information we recommend you check out the following resources:
- [Google Research, 2022 & beyond: Robotics](https://ai.googleblog.com/2023/02/google-research-2022-beyond-robotics.html)
- [Pre-Trained Language Models for Interactive Decision-Making](https://arxiv.org/abs/2202.01771)
- [Grounding Large Language Models with Online Reinforcement Learning](https://arxiv.org/abs/2302.02662v1)
- [Guiding Pretraining in Reinforcement Learning with Large Language Models](https://arxiv.org/abs/2302.06692)
## Author
This section was written by <a href="https://twitter.com/ClementRomac"> Clément Romac </a>
| huggingface/deep-rl-class/blob/main/units/en/unitbonus3/language-models.mdx |
The Deep Q-Network (DQN) [[deep-q-network]]
This is the architecture of our Deep Q-Learning network:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/deep-q-network.jpg" alt="Deep Q Network"/>
As input, we take a **stack of 4 frames** passed through the network as a state and output a **vector of Q-values for each possible action at that state**. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
When the Neural Network is initialized, **the Q-value estimation is terrible**. But during training, our Deep Q-Network agent will associate a situation with the appropriate action and **learn to play the game well**.
## Preprocessing the input and temporal limitation [[preprocessing]]
We need to **preprocess the input**. It’s an essential step since we want to **reduce the complexity of our state to reduce the computation time needed for training**.
To achieve this, we **reduce the state space to 84x84 and grayscale it**. We can do this since the colors in Atari environments don't add important information.
This is a big improvement since we **reduce our three color channels (RGB) to 1**.
We can also **crop a part of the screen in some games** if it does not contain important information.
Then we stack four frames together.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/preprocessing.jpg" alt="Preprocessing"/>
**Why do we stack four frames together?**
We stack frames together because it helps us **handle the problem of temporal limitation**. Let’s take an example with the game of Pong. When you see this frame:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/temporal-limitation.jpg" alt="Temporal Limitation"/>
Can you tell me where the ball is going?
No, because one frame is not enough to have a sense of motion! But what if I add three more frames? **Here you can see that the ball is going to the right**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/temporal-limitation-2.jpg" alt="Temporal Limitation"/>
That’s why, to capture temporal information, we stack four frames together.
Then the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because the frames are stacked together, **we can exploit some temporal properties across those frames**.
If you don't know what convolutional layers are, don't worry. You can check out [Lesson 4 of this free Deep Learning Course by Udacity](https://www.udacity.com/course/deep-learning-pytorch--ud188)
Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/deep-q-network.jpg" alt="Deep Q Network"/>
So, we see that Deep Q-Learning uses a neural network to approximate, given a state, the different Q-values for each possible action at that state. Now let's study the Deep Q-Learning algorithm.
| huggingface/deep-rl-class/blob/main/units/en/unit3/deep-q-network.mdx |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Models
The base classes [`PreTrainedModel`], [`TFPreTrainedModel`], and
[`FlaxPreTrainedModel`] implement the common methods for loading/saving a model either from a local
file or directory, or from a pretrained model configuration provided by the library (downloaded from HuggingFace's AWS
S3 repository).
[`PreTrainedModel`] and [`TFPreTrainedModel`] also implement a few methods which
are common among all the models to:
- resize the input token embeddings when new tokens are added to the vocabulary
- prune the attention heads of the model.
The other methods that are common to each model are defined in [`~modeling_utils.ModuleUtilsMixin`]
(for the PyTorch models) and [`~modeling_tf_utils.TFModuleUtilsMixin`] (for the TensorFlow models) or
for text generation, [`~generation.GenerationMixin`] (for the PyTorch models),
[`~generation.TFGenerationMixin`] (for the TensorFlow models) and
[`~generation.FlaxGenerationMixin`] (for the Flax/JAX models).
## PreTrainedModel
[[autodoc]] PreTrainedModel
- push_to_hub
- all
<a id='from_pretrained-torch-dtype'></a>
### Large model loading
In Transformers 4.20.0, the [`~PreTrainedModel.from_pretrained`] method has been reworked to accommodate large models using [Accelerate](https://huggingface.co/docs/accelerate/big_modeling). This requires Accelerate >= 0.9.0 and PyTorch >= 1.9.0. Instead of creating the full model, then loading the pretrained weights inside it (which takes twice the size of the model in RAM, one for the randomly initialized model, one for the weights), there is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded.
This option can be activated with `low_cpu_mem_usage=True`. The model is first created on the Meta device (with empty weights) and the state dict is then loaded inside it (shard by shard in the case of a sharded checkpoint). This way the maximum RAM used is the full size of the model only.
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
```
Moreover, you can directly place the model on different devices if it doesn't fully fit in RAM (only works for inference for now). With `device_map="auto"`, Accelerate will determine where to put each layer to maximize the use of your fastest devices (GPUs) and offload the rest on the CPU, or even the hard drive if you don't have enough GPU RAM (or CPU RAM). Even if the model is split across several devices, it will run as you would normally expect.
When passing a `device_map`, `low_cpu_mem_usage` is automatically set to `True`, so you don't need to specify it:
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
```
You can inspect how the model was split across devices by looking at its `hf_device_map` attribute:
```py
t0pp.hf_device_map
```
```python out
{'shared': 0,
'decoder.embed_tokens': 0,
'encoder': 0,
'decoder.block.0': 0,
'decoder.block.1': 1,
'decoder.block.2': 1,
'decoder.block.3': 1,
'decoder.block.4': 1,
'decoder.block.5': 1,
'decoder.block.6': 1,
'decoder.block.7': 1,
'decoder.block.8': 1,
'decoder.block.9': 1,
'decoder.block.10': 1,
'decoder.block.11': 1,
'decoder.block.12': 1,
'decoder.block.13': 1,
'decoder.block.14': 1,
'decoder.block.15': 1,
'decoder.block.16': 1,
'decoder.block.17': 1,
'decoder.block.18': 1,
'decoder.block.19': 1,
'decoder.block.20': 1,
'decoder.block.21': 1,
'decoder.block.22': 'cpu',
'decoder.block.23': 'cpu',
'decoder.final_layer_norm': 'cpu',
'decoder.dropout': 'cpu',
'lm_head': 'cpu'}
```
You can also write your own device map following the same format (a dictionary layer name to device). It should map all parameters of the model to a given device, but you don't have to detail where all the submodules of one layer go if that layer is entirely on the same device. For instance, the following device map would work properly for T0pp (as long as you have the GPU memory):
```python
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
```
Another way to minimize the memory impact of your model is to instantiate it at a lower precision dtype (like `torch.float16`) or use direct quantization techniques as described below.
### Model Instantiation dtype
Under Pytorch a model normally gets instantiated with `torch.float32` format. This can be an issue if one tries to
load a model whose weights are in fp16, since it'd require twice as much memory. To overcome this limitation, you can
either explicitly pass the desired `dtype` using `torch_dtype` argument:
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
```
or, if you want the model to always load in the most optimal memory pattern, you can use the special value `"auto"`,
and then `dtype` will be automatically derived from the model's weights:
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
```
Models instantiated from scratch can also be told which `dtype` to use with:
```python
config = T5Config.from_pretrained("t5")
model = AutoModel.from_config(config)
```
Due to Pytorch design, this functionality is only available for floating dtypes.
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
## TFPreTrainedModel
[[autodoc]] TFPreTrainedModel
- push_to_hub
- all
## TFModelUtilsMixin
[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
## FlaxPreTrainedModel
[[autodoc]] FlaxPreTrainedModel
- push_to_hub
- all
## Pushing to the Hub
[[autodoc]] utils.PushToHubMixin
## Sharded checkpoints
[[autodoc]] modeling_utils.load_sharded_checkpoint
| huggingface/transformers/blob/main/docs/source/en/main_classes/model.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ConvNeXT
## Overview
The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
The abstract from the paper is the following:
*The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model.
A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers
(e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide
variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive
biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design
of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models
dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy
and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convnext_architecture.jpg"
alt="drawing" width="600"/>
<small> ConvNeXT architecture. Taken from the <a href="https://arxiv.org/abs/2201.03545">original paper</a>.</small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
<PipelineTag pipeline="image-classification"/>
- [`ConvNextForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ConvNextConfig
[[autodoc]] ConvNextConfig
## ConvNextFeatureExtractor
[[autodoc]] ConvNextFeatureExtractor
## ConvNextImageProcessor
[[autodoc]] ConvNextImageProcessor
- preprocess
<frameworkcontent>
<pt>
## ConvNextModel
[[autodoc]] ConvNextModel
- forward
## ConvNextForImageClassification
[[autodoc]] ConvNextForImageClassification
- forward
</pt>
<tf>
## TFConvNextModel
[[autodoc]] TFConvNextModel
- call
## TFConvNextForImageClassification
[[autodoc]] TFConvNextForImageClassification
- call
</tf>
</frameworkcontent> | huggingface/transformers/blob/main/docs/source/en/model_doc/convnext.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Vision-Text dual encoder model training examples
> Note: This example is experimental and might not give the best possible results
The following example showcases how to train a CLIP like vision-text dual encoder model
using a pre-trained vision and text encoder using the JAX/Flax backend.
Such a model can be used for natural language image search and potentially zero-shot image classification.
The model is inspired by the [CLIP](https://openai.com/blog/clip/) approach, introduced by Alec Radford et al.
The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their
captions into the same embedding space, such that the caption embeddings are located near the embeddings
of the images they describe.
JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
Models written in JAX/Flax are **immutable** and updated in a purely functional
way which enables simple and efficient model parallelism.
In this example we will use the vision model from [CLIP](https://huggingface.co/models?filter=clip)
as the image encoder and [`roberta-base`](https://huggingface.co/roberta-base) as the text encoder.
Note that one can also use the [ViT](https://huggingface.co/models?filter=vit) model as image encoder and any other BERT or ROBERTa model as text encoder.
To train the model on languages other than English one should choose a text encoder trained on the desired
language and a image-text dataset in that language. One such dataset is [WIT](https://github.com/google-research-datasets/wit).
Let's start by creating a model repository to save the trained model and logs.
Here we call the model `"clip-roberta-base"`, but you can change the model name as you like.
You can do this either directly on [huggingface.co](https://huggingface.co/new) (assuming that
you are logged in) or via the command line:
```
huggingface-cli repo create clip-roberta-base
```
Next we clone the model repository to add the tokenizer and model files.
```
git clone https://huggingface.co/<your-username>/clip-roberta-base
```
To ensure that all tensorboard traces will be uploaded correctly, we need to
track them. You can run the following command inside your model repo to do so.
```
cd clip-roberta-base
git lfs track "*tfevents*"
```
Great, we have set up our model repository. During training, we will automatically
push the training logs and model weights to the repo.
Next, let's add a symbolic link to the `run_hybrid_clip.py`.
```bash
export MODEL_DIR="./clip-roberta-base
ln -s ~/transformers/examples/research_projects/jax-projects/hybrid_clip/run_hybrid_clip.py run_hybrid_clip.py
```
## How to use the `FlaxHybridCLIP` model:
The `FlaxHybridCLIP` class let's you load any text and vision encoder model to create a dual encoder.
Here is an example of how to load the model using pre-trained text and vision models.
```python
from modeling_hybrid_clip import FlaxHybridCLIP
model = FlaxHybridCLIP.from_text_vision_pretrained("bert-base-uncased", "openai/clip-vit-base-patch32")
# save the model
model.save_pretrained("bert-clip")
# load the saved model
model = FlaxHybridCLIP.from_pretrained("bert-clip")
```
If the checkpoints are in PyTorch then one could pass `text_from_pt=True` and `vision_from_pt=True`. This will load the model
PyTorch checkpoints convert them to flax and load the model.
```python
model = FlaxHybridCLIP.from_text_vision_pretrained("bert-base-uncased", "openai/clip-vit-base-patch32", text_from_pt=True, vision_from_pt=True)
```
This loads both the text and vision encoders using pre-trained weights, the projection layers are randomly
initialized except for CLIP's vision model. If you use CLIP to initialize the vision model then the vision projection weights are also
loaded using the pre-trained weights.
## Prepare the dataset
We will use the MS-COCO dataset to train our dual encoder model. MS-COCO contains over 82,000 images, each of which has at least 5 different caption annotations. The dataset is usually used for image captioning tasks, but we can repurpose the image-caption pairs to train our dual encoder model for image search.
### Download and extract the data.
It consists of two compressed folders: one with images, and the other—with associated image captions. Note that the compressed images folder is 13GB in size.
```bash
wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip
wget http://images.cocodataset.org/zips/train2014.zip
unzip annotations_trainval2014.zip
unzip train2014.zip
mkdir coco_dataset
mv train2014 coco_dataset/
mv annotations coco_dataset/
```
### Prepare dataset files and split the dataset.
```python
import json
import collections
images_dir = "coco_dataset/train2014"
annotation_file = "coco_dataset/annotations/captions_train2014.json"
with open(annotation_file, "r") as f:
annotations = json.load(f)["annotations"]
image_path_to_caption = collections.defaultdict(list)
for element in annotations:
caption = f"{element['caption'].lower().rstrip('.')}"
image_path = images_dir + "/COCO_train2014_" + "%012d.jpg" % (element["image_id"])
image_path_to_caption[image_path].append(caption)
lines = []
for image_path, captions in image_path_to_caption.items():
lines.append(json.dumps({"image_path": image_path, "captions": captions}))
train_lines = lines[:-8000]
valid_line = lines[-8000:]
with open("coco_dataset/train_dataset.json", "w") as f:
f.write("\n".join(train_lines))
with open("coco_dataset/valid_dataset.json", "w") as f:
f.write("\n".join(valid_line))
```
> Note: The data loading and processing part of this script can still be improved for maximum performance. In particular one should decode the images beforehand and use those instead decoding them each time. If the dataset is small or if you have huge disk space the you could also pre-process all the dataset beforehand and then use it.
## Train the model
Next we can run the example script to train the model:
```bash
python run_hybrid_clip.py \
--output_dir ${MODEL_DIR} \
--text_model_name_or_path="roberta-base" \
--vision_model_name_or_path="openai/clip-vit-base-patch32" \
--tokenizer_name="roberta-base" \
--train_file="coco_dataset/train_dataset.json" \
--validation_file="coco_dataset/validation_dataset.json" \
--do_train --do_eval \
--num_train_epochs="40" --max_seq_length 96 \
--per_device_train_batch_size="64" \
--per_device_eval_batch_size="64" \
--learning_rate="5e-5" --warmup_steps="0" --weight_decay 0.1 \
--overwrite_output_dir \
--preprocessing_num_workers 32 \
--push_to_hub
```
This should finish in ~1h50 mins with min validation loss 2.43. Training statistics can be accessed on [tfhub.de](https://tensorboard.dev/experiment/RUNPYd1yRgSD5kZSb9hDig/#scalars)
| huggingface/transformers/blob/main/examples/research_projects/jax-projects/hybrid_clip/README.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ViLT
## Overview
The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
for Vision-and-Language Pre-training (VLP).
The abstract from the paper is the following:
*Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks.
Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision
(e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we
find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more
computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive
power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model,
Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vilt_architecture.jpg"
alt="drawing" width="600"/>
<small> ViLT architecture. Taken from the <a href="https://arxiv.org/abs/2102.03334">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
- ViLT is a model that takes both `pixel_values` and `input_ids` as input. One can use [`ViltProcessor`] to prepare data for the model.
This processor wraps a image processor (for the image modality) and a tokenizer (for the language modality) into one.
- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
[[autodoc]] ViltConfig
## ViltFeatureExtractor
[[autodoc]] ViltFeatureExtractor
- __call__
## ViltImageProcessor
[[autodoc]] ViltImageProcessor
- preprocess
## ViltProcessor
[[autodoc]] ViltProcessor
- __call__
## ViltModel
[[autodoc]] ViltModel
- forward
## ViltForMaskedLM
[[autodoc]] ViltForMaskedLM
- forward
## ViltForQuestionAnswering
[[autodoc]] ViltForQuestionAnswering
- forward
## ViltForImagesAndTextClassification
[[autodoc]] ViltForImagesAndTextClassification
- forward
## ViltForImageAndTextRetrieval
[[autodoc]] ViltForImageAndTextRetrieval
- forward
## ViltForTokenClassification
[[autodoc]] ViltForTokenClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/vilt.md |
--
title: Spearman Correlation Coefficient Metric
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The Spearman rank-order correlation coefficient is a measure of the
relationship between two datasets. Like other correlation coefficients,
this one varies between -1 and +1 with 0 implying no correlation.
Positive correlations imply that as data in dataset x increases, so
does data in dataset y. Negative correlations imply that as x increases,
y decreases. Correlations of -1 or +1 imply an exact monotonic relationship.
Unlike the Pearson correlation, the Spearman correlation does not
assume that both datasets are normally distributed.
The p-value roughly indicates the probability of an uncorrelated system
producing datasets that have a Spearman correlation at least as extreme
as the one computed from these datasets. The p-values are not entirely
reliable but are probably reasonable for datasets larger than 500 or so.
---
# Metric Card for Spearman Correlation Coefficient Metric (spearmanr)
## Metric Description
The Spearman rank-order correlation coefficient is a measure of the
relationship between two datasets. Like other correlation coefficients,
this one varies between -1 and +1 with 0 implying no correlation.
Positive correlations imply that as data in dataset x increases, so
does data in dataset y. Negative correlations imply that as x increases,
y decreases. Correlations of -1 or +1 imply an exact monotonic relationship.
Unlike the Pearson correlation, the Spearman correlation does not
assume that both datasets are normally distributed.
The p-value roughly indicates the probability of an uncorrelated system
producing datasets that have a Spearman correlation at least as extreme
as the one computed from these datasets. The p-values are not entirely
reliable but are probably reasonable for datasets larger than 500 or so.
## How to Use
At minimum, this metric only requires a `list` of predictions and a `list` of references:
```python
>>> spearmanr_metric = evaluate.load("spearmanr")
>>> results = spearmanr_metric.compute(references=[1, 2, 3, 4, 5], predictions=[10, 9, 2.5, 6, 4])
>>> print(results)
{'spearmanr': -0.7}
```
### Inputs
- **`predictions`** (`list` of `float`): Predicted labels, as returned by a model.
- **`references`** (`list` of `float`): Ground truth labels.
- **`return_pvalue`** (`bool`): If `True`, returns the p-value. If `False`, returns
only the spearmanr score. Defaults to `False`.
### Output Values
- **`spearmanr`** (`float`): Spearman correlation coefficient.
- **`p-value`** (`float`): p-value. **Note**: is only returned
if `return_pvalue=True` is input.
If `return_pvalue=False`, the output is a `dict` with one value, as below:
```python
{'spearmanr': -0.7}
```
Otherwise, if `return_pvalue=True`, the output is a `dict` containing a the `spearmanr` value as well as the corresponding `pvalue`:
```python
{'spearmanr': -0.7, 'spearmanr_pvalue': 0.1881204043741873}
```
Spearman rank-order correlations can take on any value from `-1` to `1`, inclusive.
The p-values can take on any value from `0` to `1`, inclusive.
#### Values from Popular Papers
### Examples
A basic example:
```python
>>> spearmanr_metric = evaluate.load("spearmanr")
>>> results = spearmanr_metric.compute(references=[1, 2, 3, 4, 5], predictions=[10, 9, 2.5, 6, 4])
>>> print(results)
{'spearmanr': -0.7}
```
The same example, but that also returns the pvalue:
```python
>>> spearmanr_metric = evaluate.load("spearmanr")
>>> results = spearmanr_metric.compute(references=[1, 2, 3, 4, 5], predictions=[10, 9, 2.5, 6, 4], return_pvalue=True)
>>> print(results)
{'spearmanr': -0.7, 'spearmanr_pvalue': 0.1881204043741873
>>> print(results['spearmanr'])
-0.7
>>> print(results['spearmanr_pvalue'])
0.1881204043741873
```
## Limitations and Bias
## Citation
```bibtex
@book{kokoska2000crc,
title={CRC standard probability and statistics tables and formulae},
author={Kokoska, Stephen and Zwillinger, Daniel},
year={2000},
publisher={Crc Press}
}
@article{2020SciPy-NMeth,
author = {Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and
Haberland, Matt and Reddy, Tyler and Cournapeau, David and
Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and
Bright, Jonathan and {van der Walt}, St{\'e}fan J. and
Brett, Matthew and Wilson, Joshua and Millman, K. Jarrod and
Mayorov, Nikolay and Nelson, Andrew R. J. and Jones, Eric and
Kern, Robert and Larson, Eric and Carey, C J and
Polat, {\.I}lhan and Feng, Yu and Moore, Eric W. and
{VanderPlas}, Jake and Laxalde, Denis and Perktold, Josef and
Cimrman, Robert and Henriksen, Ian and Quintero, E. A. and
Harris, Charles R. and Archibald, Anne M. and
Ribeiro, Ant{\^o}nio H. and Pedregosa, Fabian and
{van Mulbregt}, Paul and {SciPy 1.0 Contributors}},
title = {{{SciPy} 1.0: Fundamental Algorithms for Scientific
Computing in Python}},
journal = {Nature Methods},
year = {2020},
volume = {17},
pages = {261--272},
adsurl = {https://rdcu.be/b08Wh},
doi = {10.1038/s41592-019-0686-2},
}
```
## Further References
*Add any useful further references.*
| huggingface/evaluate/blob/main/metrics/spearmanr/README.md |
--
title: "Introducing RWKV - An RNN with the advantages of a transformer"
thumbnail: /blog/assets/142_rwkv/rwkv_thumbnail.png
authors:
- user: BLinkDL
guest: true
- user: Hazzzardous
guest: true
- user: sgugger
- user: ybelkada
---
# Introducing RWKV - An RNN with the advantages of a transformer
ChatGPT and chatbot-powered applications have captured significant attention in the Natural Language Processing (NLP) domain. The community is constantly seeking strong, reliable and open-source models for their applications and use cases.
The rise of these powerful models stems from the democratization and widespread adoption of transformer-based models, first introduced by Vaswani et al. in 2017. These models significantly outperformed previous SoTA NLP models based on Recurrent Neural Networks (RNNs), which were considered dead after that paper.
Through this blogpost, we will introduce the integration of a new architecture, RWKV, that combines the advantages of both RNNs and transformers, and that has been recently integrated into the Hugging Face [transformers](https://github.com/huggingface/transformers) library.
### Overview of the RWKV project
The RWKV project was kicked off and is being led by [Bo Peng](https://github.com/BlinkDL), who is actively contributing and maintaining the project. The community, organized in the official discord channel, is constantly enhancing the project’s artifacts on various topics such as performance (RWKV.cpp, quantization, etc.), scalability (dataset processing & scrapping) and research (chat-fine tuning, multi-modal finetuning, etc.). The GPUs for training RWKV models are donated by Stability AI.
You can get involved by joining the [official discord channel](https://discord.gg/qt9egFA7ve) and learn more about the general ideas behind RWKV in these two blogposts: https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html
### Transformer Architecture vs RNNs
The RNN architecture is one of the first widely used Neural Network architectures for processing a sequence of data, contrary to classic architectures that take a fixed size input. It takes as input the current “token” (i.e. current data point of the datastream), the previous “state”, and computes the predicted next token, and the predicted next state. The new state is then used to compute the prediction of the next token, and so on.
A RNN can be also used in different “modes”, therefore enabling the possibility of applying RNNs on different scenarios, as denoted by [Andrej Karpathy’s blogpost](https://karpathy.github.io/2015/05/21/rnn-effectiveness/), such as one-to-one (image-classification), one-to-many (image captioning), many-to-one (sequence classification), many-to-many (sequence generation), etc.
| 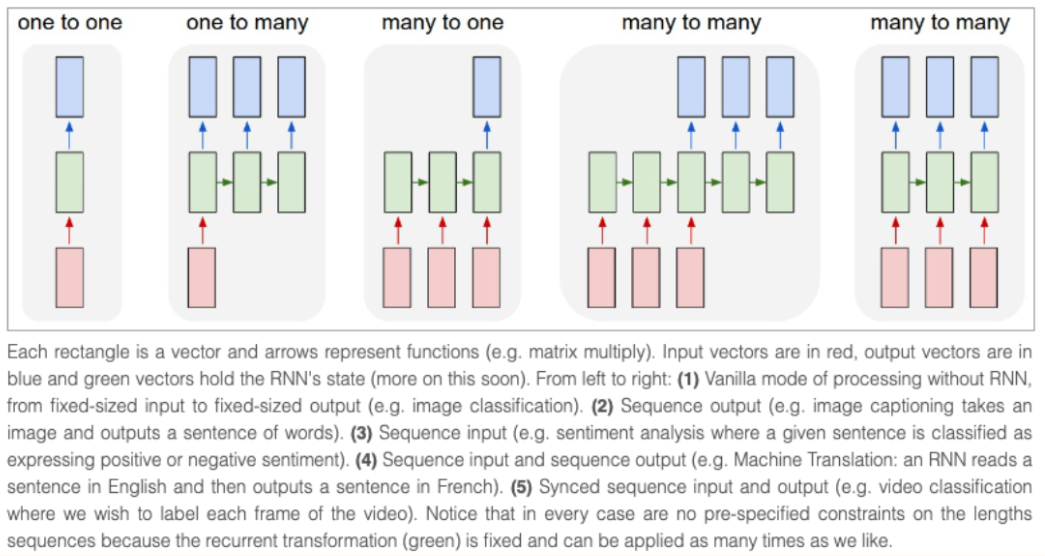 |
|:--:|
| <b>Overview of possible configurations of using RNNs. Source: <a href="https://karpathy.github.io/2015/05/21/rnn-effectiveness/" rel="noopener" target="_blank" >Andrej Karpathy's blogpost</a> </b>|
Because RNNs use the same weights to compute predictions at every step, they struggle to memorize information for long-range sequences due to the vanishing gradient issue. Efforts have been made to address this limitation by introducing new architectures such as LSTMs or GRUs. However, the transformer architecture proved to be the most effective thus far in resolving this issue.
In the transformer architecture, the input tokens are processed simultaneously in the self-attention module. The tokens are first linearly projected into different spaces using the query, key and value weights. The resulting matrices are directly used to compute the attention scores (through softmax, as shown below), then multiplied by the value hidden states to obtain the final hidden states. This design enables the architecture to effectively mitigate the long-range sequence issue, and also perform faster inference and training compared to RNN models.
| 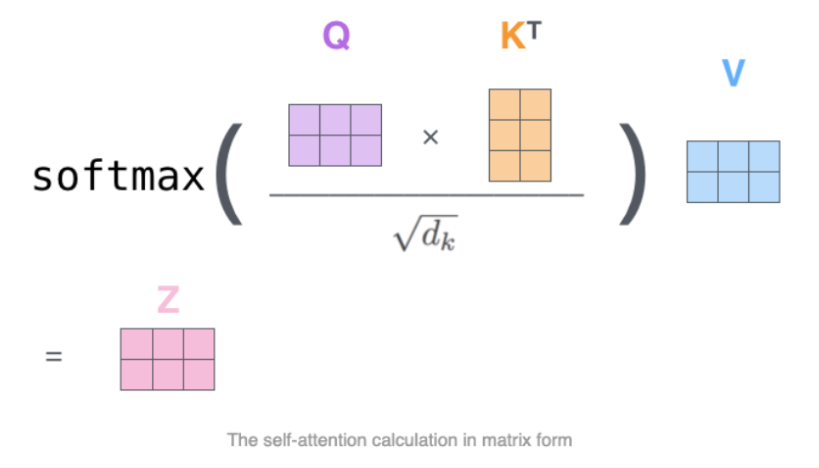 |
|:--:|
| <b>Formulation of attention scores in transformer models. Source: <a href="https://jalammar.github.io/illustrated-transformer/" rel="noopener" target="_blank" >Jay Alammar's blogpost</a> </b>|
| |
|:--:|
| <b>Formulation of attention scores in RWKV models. Source: <a href="https://raw.githubusercontent.com/BlinkDL/RWKV-LM/main/RWKV-formula.png" rel="noopener" target="_blank" >RWKV blogpost</a> </b>|
During training, Transformer architecture has several advantages over traditional RNNs and CNNs. One of the most significant advantages is its ability to learn contextual representations. Unlike the RNNs and CNNs, which process input sequences one word at a time, Transformer architecture processes input sequences as a whole. This allows it to capture long-range dependencies between words in the sequence, which is particularly useful for tasks such as language translation and question answering.
During inference, RNNs have some advantages in speed and memory efficiency. These advantages include simplicity, due to needing only matrix-vector operations, and memory efficiency, as the memory requirements do not grow during inference. Furthermore, the computation speed remains the same with context window length due to how computations only act on the current token and the state.
## The RWKV architecture
RWKV is inspired by [Apple’s Attention Free Transformer](https://machinelearning.apple.com/research/attention-free-transformer). The architecture has been carefully simplified and optimized such that it can be transformed into an RNN. In addition, a number of tricks has been added such as `TokenShift` & `SmallInitEmb` (the list of tricks is listed in [the README of the official GitHub repository](https://github.com/BlinkDL/RWKV-LM/blob/main/README.md#how-it-works)) to boost its performance to match GPT. Without these, the model wouldn't be as performant.
For training, there is an infrastructure to scale the training up to 14B parameters as of now, and some issues have been iteratively fixed in RWKV-4 (latest version as of today), such as numerical instability.
### RWKV as a combination of RNNs and transformers
How to combine the best of transformers and RNNs? The main drawback of transformer-based models is that it can become challenging to run a model with a context window that is larger than a certain value, as the attention scores are computed simultaneously for the entire sequence.
RNNs natively support very long context lengths - only limited by the context length seen in training, but this can be extended to millions of tokens with careful coding. Currently, there are RWKV models trained on a context length of 8192 (`ctx8192`) and they are as fast as `ctx1024` models and require the same amount of RAM.
The major drawbacks of traditional RNN models and how RWKV is different:
1. Traditional RNN models are unable to utilize very long contexts (LSTM can only manage ~100 tokens when used as a LM). However, RWKV can utilize thousands of tokens and beyond, as shown below:
|  |
|:--:|
| <b>LM loss with respect to different context lengths and model sizes. Source: <a href="https://raw.githubusercontent.com/BlinkDL/RWKV-LM/main/RWKV-ctxlen.png" rel="noopener" target="_blank" >RWKV original repository</a> </b>|
2. Traditional RNN models cannot be parallelized when training. RWKV is similar to a “linearized GPT” and it trains faster than GPT.
By combining both advantages into a single architecture, the hope is that RWKV can grow to become more than the sum of its parts.
### RWKV attention formulation
The model architecture is very similar to classic transformer-based models (i.e. an embedding layer, multiple identical layers, layer normalization, and a Causal Language Modeling head to predict the next token). The only difference is on the attention layer, which is completely different from the traditional transformer-based models.
To gain a more comprehensive understanding of the attention layer, we recommend to delve into the detailed explanation provided in [a blog post by Johan Sokrates Wind](https://johanwind.github.io/2023/03/23/rwkv_details.html).
### Existing checkpoints
#### Pure language models: RWKV-4 models
Most adopted RWKV models range from ~170M parameters to 14B parameters. According to the RWKV overview [blog post](https://johanwind.github.io/2023/03/23/rwkv_overview.html), these models have been trained on the Pile dataset and evaluated against other SoTA models on different benchmarks, and they seem to perform quite well, with very comparable results against them.
|  |
|:--:|
| <b>RWKV-4 compared to other common architectures. Source: <a href="https://johanwind.github.io/2023/03/23/rwkv_overview.html" rel="noopener" target="_blank" >Johan Wind's blogpost</a> </b>|
#### Instruction Fine-tuned/Chat Version: RWKV-4 Raven
Bo has also trained a “chat” version of the RWKV architecture, the RWKV-4 Raven model. It is a RWKV-4 pile (RWKV model pretrained on The Pile dataset) model fine-tuned on ALPACA, CodeAlpaca, Guanaco, GPT4All, ShareGPT and more. The model is available in multiple versions, with models trained on different languages (English only, English + Chinese + Japanese, English + Japanese, etc.) and different sizes (1.5B parameters, 7B parameters, 14B parameters).
All the HF converted models are available on Hugging Face Hub, in the [`RWKV` organization](https://huggingface.co/RWKV).
## 🤗 Transformers integration
The architecture has been added to the `transformers` library thanks to [this Pull Request](https://github.com/huggingface/transformers/pull/22797). As of the time of writing, you can use it by installing `transformers` from source, or by using the `main` branch of the library. The architecture is tightly integrated with the library, and you can use it as you would any other architecture.
Let us walk through some examples below.
### Text Generation Example
To generate text given an input prompt you can use `pipeline` to generate text:
```python
from transformers import pipeline
model_id = "RWKV/rwkv-4-169m-pile"
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
pipe = pipeline("text-generation", model=model_id)
print(pipe(prompt, max_new_tokens=20))
>>> [{'generated_text': '\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were'}]
```
Or you can run and start from the snippet below:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=20)
print(tokenizer.decode(output[0].tolist()))
>>> In a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.\n\nThe researchers found that the dragons were able to communicate with each other, and that they were
```
### Use the raven models (chat models)
You can prompt the chat model in the alpaca style, here is an example below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "RWKV/rwkv-raven-1b5"
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
tokenizer = AutoTokenizer.from_pretrained(model_id)
question = "Tell me about ravens"
prompt = f"### Instruction: {question}\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
>>> ### Instruction: Tell me about ravens
### Response: RAVENS are a type of bird that is native to the Middle East and North Africa. They are known for their intelligence, adaptability, and their ability to live in a variety of environments. RAVENS are known for their intelligence, adaptability, and their ability to live in a variety of environments. They are known for their intelligence, adaptability, and their ability to live in a variety of environments.
```
According to Bo, better instruction techniques are detailed in [this discord message (make sure to join the channel before clicking)](https://discord.com/channels/992359628979568762/1083107245971226685/1098533896355848283)
|  |
### Weights conversion
Any user could easily convert the original RWKV weights to the HF format by simply running the conversion script provided in the `transformers` library. First, push the "raw" weights to the Hugging Face Hub (let's denote that repo as `RAW_HUB_REPO`, and the raw file `RAW_FILE`), then run the conversion script:
```bash
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR
```
If you want to push the converted model on the Hub (let's say, under `dummy_user/converted-rwkv`), first forget to log in with `huggingface-cli login` before pushing the model, then run:
```bash
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkv
```
## Future work
### Multi-lingual RWKV
Bo is currently working on a multilingual corpus to train RWKV models. Recently a new multilingual tokenizer [has been released](https://twitter.com/BlinkDL_AI/status/1649839897208045573).
### Community-oriented and research projects
The RWKV community is very active and working on several follow up directions, a list of cool projects can be find in a [dedicated channel on discord (make sure to join the channel before clicking the link)](https://discord.com/channels/992359628979568762/1068563033510653992).
There is also a channel dedicated to research around this architecure, feel free to join and contribute!
### Model Compression and Acceleration
Due to only needing matrix-vector operations, RWKV is an ideal candidate for non-standard and experimental computing hardware, such as photonic processors/accelerators.
Therefore, the architecture can also naturally benefit from classic acceleration and compression techniques (such as [ONNX](https://github.com/harrisonvanderbyl/rwkv-onnx), 4-bit/8-bit quantization, etc.), and we hope this will be democratized for developers and practitioners together with the transformers integration of the architecture.
RWKV can also benefit from the acceleration techniques proposed by [`optimum`](https://github.com/huggingface/optimum) library in the near future.
Some of these techniques are highlighted in the [`rwkv.cpp` repository](https://github.com/saharNooby/rwkv.cpp) or [`rwkv-cpp-cuda` repository](https://github.com/harrisonvanderbyl/rwkv-cpp-cuda).
## Acknowledgements
The Hugging Face team would like to thank Bo and RWKV community for their time and for answering our questions about the architecture. We would also like to thank them for their help and support and we look forward to see more adoption of RWKV models in the HF ecosystem.
We also would like to acknowledge the work of [Johan Wind](https://twitter.com/johanwind) for his blogpost on RWKV, which helped us a lot to understand the architecture and its potential.
And finally, we would like to highlight anf acknowledge the work of [ArEnSc](https://github.com/ArEnSc) for starting over the initial `transformers` PR.
Also big kudos to [Merve Noyan](https://huggingface.co/merve), [Maria Khalusova](https://huggingface.co/MariaK) and [Pedro Cuenca](https://huggingface.co/pcuenq) for kindly reviewing this blogpost to make it much better!
## Citation
If you use RWKV for your work, please use [the following `cff` citation](https://github.com/BlinkDL/RWKV-LM/blob/main/CITATION.cff).
| huggingface/blog/blob/main/rwkv.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Zero-shot image classification
[[open-in-colab]]
Zero-shot image classification is a task that involves classifying images into different categories using a model that was
not explicitly trained on data containing labeled examples from those specific categories.
Traditionally, image classification requires training a model on a specific set of labeled images, and this model learns to
"map" certain image features to labels. When there's a need to use such model for a classification task that introduces a
new set of labels, fine-tuning is required to "recalibrate" the model.
In contrast, zero-shot or open vocabulary image classification models are typically multi-modal models that have been trained on a large
dataset of images and associated descriptions. These models learn aligned vision-language representations that can be used for many downstream tasks including zero-shot image classification.
This is a more flexible approach to image classification that allows models to generalize to new and unseen categories
without the need for additional training data and enables users to query images with free-form text descriptions of their target objects .
In this guide you'll learn how to:
* create a zero-shot image classification pipeline
* run zero-shot image classification inference by hand
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q transformers
```
## Zero-shot image classification pipeline
The simplest way to try out inference with a model supporting zero-shot image classification is to use the corresponding [`pipeline`].
Instantiate a pipeline from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads):
```python
>>> from transformers import pipeline
>>> checkpoint = "openai/clip-vit-large-patch14"
>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
```
Next, choose an image you'd like to classify.
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/owl.jpg" alt="Photo of an owl"/>
</div>
Pass the image and the candidate object labels to the pipeline. Here we pass the image directly; other suitable options
include a local path to an image or an image url.
The candidate labels can be simple words like in this example, or more descriptive.
```py
>>> predictions = detector(image, candidate_labels=["fox", "bear", "seagull", "owl"])
>>> predictions
[{'score': 0.9996670484542847, 'label': 'owl'},
{'score': 0.000199399160919711, 'label': 'seagull'},
{'score': 7.392891711788252e-05, 'label': 'fox'},
{'score': 5.96074532950297e-05, 'label': 'bear'}]
```
## Zero-shot image classification by hand
Now that you've seen how to use the zero-shot image classification pipeline, let's take a look how you can run zero-shot
image classification manually.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads).
Here we'll use the same checkpoint as before:
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
Let's take a different image to switch things up.
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg" alt="Photo of a car"/>
</div>
Use the processor to prepare the inputs for the model. The processor combines an image processor that prepares the
image for the model by resizing and normalizing it, and a tokenizer that takes care of the text inputs.
```py
>>> candidate_labels = ["tree", "car", "bike", "cat"]
>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
```
Pass the inputs through the model, and post-process the results:
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits = outputs.logits_per_image[0]
>>> probs = logits.softmax(dim=-1).numpy()
>>> scores = probs.tolist()
>>> result = [
... {"score": score, "label": candidate_label}
... for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
... ]
>>> result
[{'score': 0.998572, 'label': 'car'},
{'score': 0.0010570387, 'label': 'bike'},
{'score': 0.0003393686, 'label': 'tree'},
{'score': 3.1572064e-05, 'label': 'cat'}]
``` | huggingface/transformers/blob/main/docs/source/en/tasks/zero_shot_image_classification.md |
Pandas
[Pandas](https://pandas.pydata.org/docs/index.html) is a popular DataFrame library for data analysis.
To read from a single Parquet file, use the [`read_parquet`](https://pandas.pydata.org/docs/reference/api/pandas.read_parquet.html) function to read it into a DataFrame:
```py
import pandas as pd
df = (
pd.read_parquet("https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0000.parquet")
.groupby('horoscope')['text']
.apply(lambda x: x.str.len().mean())
.sort_values(ascending=False)
.head(5)
)
```
To read multiple Parquet files - for example, if the dataset is sharded - you'll need to use the [`concat`](https://pandas.pydata.org/docs/reference/api/pandas.concat.html) function to concatenate the files into a single DataFrame:
```py
df = (
pd.concat([pd.read_parquet(url) for url in urls])
.groupby('horoscope')['text']
.apply(lambda x: x.str.len().mean())
.sort_values(ascending=False)
.head(5)
)
``` | huggingface/datasets-server/blob/main/docs/source/pandas.mdx |
The certification process
The certification process is **completely free**:
- To get a *certificate of completion*: you need **to pass 80% of the assignments**.
- To get a *certificate of excellence*: you need **to pass 100% of the assignments**.
There's **no deadlines, the course is self-paced**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/certification.jpg" alt="Course certification" width="100%"/>
When we say pass, **we mean that your model must be pushed to the Hub and get a result equal or above the minimal requirement**.
To check your progression and which unit you passed/not passed: https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
Now that you're ready for the certification process, you need to:
1. Go here: https://huggingface.co/spaces/huggingface-projects/Deep-RL-Course-Certification/
2. Type your *hugging face username*, your *first name*, *last name*
3. Click on "Generate my certificate".
- If you passed 80% of the assignments, **congratulations** you've just got the certificate of completion.
- If you passed 100% of the assignments, **congratulations** you've just got the excellence certificate.
- If you are below 80%, don't be discouraged! Check which units you need to do again to get your certificate.
4. You can download your certificate in pdf format and png format.
Don't hesitate to share your certificate on Twitter (tag me @ThomasSimonini and @huggingface) and on Linkedin.
| huggingface/deep-rl-class/blob/main/units/en/communication/certification.mdx |
Post-processors
<tokenizerslangcontent>
<python>
## BertProcessing
[[autodoc]] tokenizers.processors.BertProcessing
## ByteLevel
[[autodoc]] tokenizers.processors.ByteLevel
## RobertaProcessing
[[autodoc]] tokenizers.processors.RobertaProcessing
## TemplateProcessing
[[autodoc]] tokenizers.processors.TemplateProcessing
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/post-processors.mdx |
MnasNet
**MnasNet** is a type of convolutional neural network optimized for mobile devices that is discovered through mobile neural architecture search, which explicitly incorporates model latency into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency. The main building block is an [inverted residual block](https://paperswithcode.com/method/inverted-residual-block) (from [MobileNetV2](https://paperswithcode.com/method/mobilenetv2)).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('mnasnet_100', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mnasnet_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('mnasnet_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2019mnasnet,
title={MnasNet: Platform-Aware Neural Architecture Search for Mobile},
author={Mingxing Tan and Bo Chen and Ruoming Pang and Vijay Vasudevan and Mark Sandler and Andrew Howard and Quoc V. Le},
year={2019},
eprint={1807.11626},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: MNASNet
Paper:
Title: 'MnasNet: Platform-Aware Neural Architecture Search for Mobile'
URL: https://paperswithcode.com/paper/mnasnet-platform-aware-neural-architecture
Models:
- Name: mnasnet_100
In Collection: MNASNet
Metadata:
FLOPs: 416415488
Parameters: 4380000
File Size: 17731774
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Inverted Residual Block
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
ID: mnasnet_100
Layers: 100
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4000
Image Size: '224'
Interpolation: bicubic
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L894
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mnasnet_b1-74cb7081.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.67%
Top 5 Accuracy: 92.1%
- Name: semnasnet_100
In Collection: MNASNet
Metadata:
FLOPs: 414570766
Parameters: 3890000
File Size: 15731489
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Inverted Residual Block
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: semnasnet_100
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L928
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mnasnet_a1-d9418771.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.45%
Top 5 Accuracy: 92.61%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/mnasnet.mdx |
atasets and DataFrames equals love. Although the processing functions of Datasets will cover most the cases needed to train a model, there are times when you’ll need to switch to a library like Pandas to access more powerful features or high-level APIs for visualisation. Fortunately, Datasets is designed to be interoperable with libraries like Pandas, as well as NumPy, PyTorch, TensorFlow, and JAX. In this video, we'll take a look at how we can quickly switch our data to Pandas DataFrames and back. As an example, let's suppose we're analysing Supreme Court cases from Switzerland. As usual we download our dataset from the Hub using the load_dataset() function, and you can see that the first element of the training set is an ordinary Python dictionary with various fields of interest. Now suppose that before we train any models, we'd like to explore the data a bit. For example we might be interested in knowing which legal area is most common or we might want to know how the languages are distributed across regions. Answering these questions with the native Arrow format isn't easy, but we can easily switch to Pandas to get our answers! The way this works is by using the set_format() method, which will change the output format of the dataset from Python dictionaries to Pandas DataFrames. As you can see in this example, each row in the dataset is represented as a DataFrame, so we can slice the whole dataset to get a single DataFrame of the dataset. The way this works under the hood is that the Datasets library changes the magic __getitem__() method of the dataset. The __getitem__() method is a special method for Python containers that allows you to specify how indexing works. In this case, the __getitem__() method of the raw dataset starts off by returning Python dictionaries and then after applying set_format() we change __getitem__() to return DataFrames instead. The Datasets library also provides a to_pandas() method if you want to do the format conversion and slicing of the dataset in one go. And once you have a DataFrame, you can find answers to all sorts of complex questions or make plots with your favourite visualisation library and so on. The only thing to remember is that once you are done with your Pandas analysis, you should reset the output format back to Arrow tables. If you don't, you can run into problems if you try to tokenize your text because it is no longer represented as strings in a dictionary. By resetting the output format, we get back Arrow tables and can tokenize without problem! | huggingface/course/blob/main/subtitles/en/raw/chapter5/03b_dataframes.md |
n this video, we'll study the decoder architecture. An example of a popular decoder-only architecture is GPT-2. In order to understand how decoders work, we recommend taking a look at the video regarding encoders: they're extremely similar to decoders. One can use a decoder for most of the same tasks as an encoder, albeit with, generally, a little loss of performance. Let's take the same approach we have taken with the encoder to try and understand the architectural differences between an encoder and a decoder. We'll use a small example, using three words. We pass them through the decoder. We retrieve a numerical representation of each word. Here, for example, the decoder converts the three words “Welcome to NYC” in these three sequences of numbers. The decoder outputs exactly one sequence of numbers per input word. This numerical representation can also be called a "Feature vector", or "Feature tensor". Let's dive in this representation. It contains one vector per word that was passed through the decoder. Each of these vector is a numerical representation of the word in question. The dimension of that vector is defined by the architecture of the model. Where the decoder differs from the encoder is principally with its self-attention mechanism. It's using what is called "masked self-attention". Here for example, if we focus on the word "to", we'll see that its vector is absolutely unmodified by the "NYC" word. That's because all the words on the right (also known as the right context) of the word is masked. Rather than benefitting from all the words on the left and right, I.e., the bidirectional context, decoders only have access to the words on their left. The masked self-attention mechanism differs from the self-attention mechanism by using an additional mask to hide the context on either side of the word: the word's numerical representation will not be affected by the words in the hidden context. So when should one use a decoder? Decoders, like encoders, can be used as standalone models. As they generate a numerical representation, they can also be used in a wide variety of tasks. However, the strength of a decoder lies in the way a word has access to its left context. The decoders, having only access to their left context, are inherently good at text generation: the ability to generate a word, or a sequence of words, given a known sequence of words. In NLP, this is known as Causal Language Modeling. Let's look at an example. Here's an example of how causal language modeling works: we start with an initial word, which is "My". We use this as input for the decoder. The model outputs a vectors of dimension 768. This vector contains information about the sequence, which is here a single word, or word. We apply a small transformation to that vector so that it maps to all the words known by the model (mapping which we'll see later, called a language modeling head). We identify that the model believes the most probable following word is "name". We then take that new word, and add it to the initial sequence. From "My", we are now at "My name". This is where the "autoregressive" aspect comes in. Auto-regressive models re-use their past outputs as inputs in the following steps. Once again, we do that the exact same operation: we cast that sequence through the decoder, and retrieve the most probable following word. In this case, it is the word "is". We repeat the operation until we're satisfied. Starting from a single word, we've now generated a full sentence. We decide to stop there, but we could continue for a while; GPT-2, for example, has a maximum context size of 1024. We could eventually generate up to 1024 words, and the decoder would still have some memory of the first words of the sequence! If we go back several levels higher, back to the full transformer model, we can see what we learned about the decoder part of the full transformer model. It is what we call, auto-regressive: it outputs values that are then used as its input values. We repeat this operations as we like. It is based off of the masked self-attention layer, which allows to have word embeddings which have access to the context on the left side of the word. If you look at the diagram however, you'll see that we haven't seen one of the aspects of the decoder. That is: cross-attention. There is a second aspect we haven't seen, which is it's ability to convert features to words; heavily linked to the cross attention mechanism. However, these only apply in the "encoder-decoder" transformer, or the "sequence-to-sequence" transformer (which can generally be used interchangeably). We recommend you check out the video on encoder-decoders to get an idea of how the decoder can be used as a component of a larger architecture! | huggingface/course/blob/main/subtitles/en/raw/chapter1/06_decoders.md |
--
title: Stable Diffusion with 🧨 Diffusers
thumbnail: /blog/assets/98_stable_diffusion/thumbnail.png
authors:
- user: valhalla
- user: pcuenq
- user: natolambert
- user: patrickvonplaten
---
# Stable Diffusion with 🧨 Diffusers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
# **Stable Diffusion** 🎨
*...using 🧨 Diffusers*
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
It is trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
*LAION-5B* is the largest, freely accessible multi-modal dataset that currently exists.
In this post, we want to show how to use Stable Diffusion with the [🧨 Diffusers library](https://github.com/huggingface/diffusers), explain how the model works and finally dive a bit deeper into how `diffusers` allows
one to customize the image generation pipeline.
**Note**: It is highly recommended to have a basic understanding of how diffusion models work. If diffusion
models are completely new to you, we recommend reading one of the following blog posts:
- [The Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion)
- [Getting started with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
Now, let's get started by generating some images 🎨.
## Running Stable Diffusion
### License
Before using the model, you need to accept the model [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) in order to download and use the weights. **Note: the license does not need to be explicitly accepted through the UI anymore**.
The license is designed to mitigate the potential harmful effects of such a powerful machine learning system.
We request users to **read the license entirely and carefully**. Here we offer a summary:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content,
2. We claim no rights on the outputs you generate, you are free to use them and are accountable for their use which should not go against the provisions set in the license, and
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users.
### Usage
First, you should install `diffusers==0.10.2` to run the following code snippets:
```bash
pip install diffusers==0.10.2 transformers scipy ftfy accelerate
```
In this post we'll use model version [`v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4), but you can also use other versions of the model such as 1.5, 2, and 2.1 with minimal code changes.
The Stable Diffusion model can be run in inference with just a couple of lines using the [`StableDiffusionPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) pipeline. The pipeline sets up everything you need to generate images from text with
a simple `from_pretrained` function call.
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
```
If a GPU is available, let's move it to one!
```python
pipe.to("cuda")
```
**Note**: If you are limited by GPU memory and have less than 10GB of GPU RAM available, please
make sure to load the `StableDiffusionPipeline` in float16 precision instead of the default
float32 precision as done above.
You can do so by loading the weights from the `fp16` branch and by telling `diffusers` to expect the
weights to be in float16 precision:
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
```
To run the pipeline, simply define the prompt and call `pipe`.
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```
The result would look as follows

The previous code will give you a different image every time you run it.
If at some point you get a black image, it may be because the content filter built inside the model might have detected an NSFW result.
If you believe this shouldn't be the case, try tweaking your prompt or using a different seed. In fact, the model predictions include information about whether NSFW was detected for a particular result. Let's see what they look like:
```python
result = pipe(prompt)
print(result)
```
```json
{
'images': [<PIL.Image.Image image mode=RGB size=512x512>],
'nsfw_content_detected': [False]
}
```
If you want deterministic output you can seed a random seed and pass a generator to the pipeline.
Every time you use a generator with the same seed you'll get the same image output.
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```
The result would look as follows

You can change the number of inference steps using the `num_inference_steps` argument.
In general, results are better the more steps you use, however the more steps, the longer the generation takes.
Stable Diffusion works quite well with a relatively small number of steps, so we recommend to use the default number of inference steps of `50`.
If you want faster results you can use a smaller number. If you want potentially higher quality results,
you can use larger numbers.
Let's try out running the pipeline with less denoising steps.
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=15, generator=generator).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```

Note how the structure is the same, but there are problems in the astronauts suit and the general form of the horse.
This shows that using only 15 denoising steps has significantly degraded the quality of the generation result. As stated earlier `50` denoising steps is usually sufficient to generate high-quality images.
Besides `num_inference_steps`, we've been using another function argument, called `guidance_scale` in all
previous examples. `guidance_scale` is a way to increase the adherence to the conditional signal that guides the generation (text, in this case) as well as overall sample quality.
It is also known as [classifier-free guidance](https://arxiv.org/abs/2207.12598), which in simple terms forces the generation to better match the prompt potentially at the cost of image quality or diversity.
Values between `7` and `8.5` are usually good choices for Stable Diffusion. By default the pipeline
uses a `guidance_scale` of 7.5.
If you use a very large value the images might look good, but will be less diverse.
You can learn about the technical details of this parameter in [this section](#writing-your-own-inference-pipeline) of the post.
Next, let's see how you can generate several images of the same prompt at once.
First, we'll create an `image_grid` function to help us visualize them nicely in a grid.
```python
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
```
We can generate multiple images for the same prompt by simply using a list with the same prompt repeated several times. We'll send the list to the pipeline instead of the string we used before.
```python
num_images = 3
prompt = ["a photograph of an astronaut riding a horse"] * num_images
images = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
# you can save the grid with
# grid.save(f"astronaut_rides_horse.png")
```

By default, stable diffusion produces images of `512 × 512` pixels. It's very easy to override the default using the `height` and `width` arguments to create rectangular images in portrait or landscape ratios.
When choosing image sizes, we advise the following:
- Make sure `height` and `width` are both multiples of `8`.
- Going below 512 might result in lower quality images.
- Going over 512 in both directions will repeat image areas (global coherence is lost).
- The best way to create non-square images is to use `512` in one dimension, and a value larger than that in the other one.
Let's run an example:
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```

## How does Stable Diffusion work?
Having seen the high-quality images that stable diffusion can produce, let's try to understand
a bit better how the model functions.
Stable Diffusion is based on a particular type of diffusion model called **Latent Diffusion**, proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752).
Generally speaking, diffusion models are machine learning systems that are trained to *denoise* random Gaussian noise step by step, to get to a sample of interest, such as an *image*. For a more detailed overview of how they work, check [this colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb).
Diffusion models have shown to achieve state-of-the-art results for generating image data. But one downside of diffusion models is that the reverse denoising process is slow because of its repeated, sequential nature. In addition, these models consume a lot of memory because they operate in pixel space, which becomes huge when generating high-resolution images. Therefore, it is challenging to train these models and also use them for inference.
<br>
Latent diffusion can reduce the memory and compute complexity by applying the diffusion process over a lower dimensional _latent_ space, instead of using the actual pixel space. This is the key difference between standard diffusion and latent diffusion models: **in latent diffusion the model is trained to generate latent (compressed) representations of the images.**
There are three main components in latent diffusion.
1. An autoencoder (VAE).
2. A [U-Net](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb#scrollTo=wW8o1Wp0zRkq).
3. A text-encoder, *e.g.* [CLIP's Text Encoder](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel).
**1. The autoencoder (VAE)**
The VAE model has two parts, an encoder and a decoder. The encoder is used to convert the image into a low dimensional latent representation, which will serve as the input to the *U-Net* model.
The decoder, conversely, transforms the latent representation back into an image.
During latent diffusion _training_, the encoder is used to get the latent representations (_latents_) of the images for the forward diffusion process, which applies more and more noise at each step. During _inference_, the denoised latents generated by the reverse diffusion process are converted back into images using the VAE decoder. As we will see during inference we **only need the VAE decoder**.
**2. The U-Net**
The U-Net has an encoder part and a decoder part both comprised of ResNet blocks.
The encoder compresses an image representation into a lower resolution image representation and the decoder decodes the lower resolution image representation back to the original higher resolution image representation that is supposedly less noisy.
More specifically, the U-Net output predicts the noise residual which can be used to compute the predicted denoised image representation.
To prevent the U-Net from losing important information while downsampling, short-cut connections are usually added between the downsampling ResNets of the encoder to the upsampling ResNets of the decoder.
Additionally, the stable diffusion U-Net is able to condition its output on text-embeddings via cross-attention layers. The cross-attention layers are added to both the encoder and decoder part of the U-Net usually between ResNet blocks.
**3. The Text-encoder**
The text-encoder is responsible for transforming the input prompt, *e.g.* "An astronaut riding a horse" into an embedding space that can be understood by the U-Net. It is usually a simple *transformer-based* encoder that maps a sequence of input tokens to a sequence of latent text-embeddings.
Inspired by [Imagen](https://imagen.research.google/), Stable Diffusion does **not** train the text-encoder during training and simply uses an CLIP's already trained text encoder, [CLIPTextModel](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel).
**Why is latent diffusion fast and efficient?**
Since latent diffusion operates on a low dimensional space, it greatly reduces the memory and compute requirements compared to pixel-space diffusion models. For example, the autoencoder used in Stable Diffusion has a reduction factor of 8. This means that an image of shape `(3, 512, 512)` becomes `(3, 64, 64)` in latent space, which requires `8 × 8 = 64` times less memory.
This is why it's possible to generate `512 × 512` images so quickly, even on 16GB Colab GPUs!
**Stable Diffusion during inference**
Putting it all together, let's now take a closer look at how the model works in inference by illustrating the logical flow.
<p align="center">
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/stable_diffusion.png" alt="sd-pipeline" width="500"/>
</p>
The stable diffusion model takes both a latent seed and a text prompt as an input. The latent seed is then used to generate random latent image representations of size \\( 64 \times 64 \\) where as the text prompt is transformed to text embeddings of size \\( 77 \times 768 \\) via CLIP's text encoder.
Next the U-Net iteratively *denoises* the random latent image representations while being conditioned on the text embeddings. The output of the U-Net, being the noise residual, is used to compute a denoised latent image representation via a scheduler algorithm. Many different scheduler algorithms can be used for this computation, each having its pro- and cons. For Stable Diffusion, we recommend using one of:
- [PNDM scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py) (used by default)
- [DDIM scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [K-LMS scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_lms_discrete.py)
Theory on how the scheduler algorithm function is out-of-scope for this notebook, but in short one should remember that they compute the predicted denoised image representation from the previous noise representation and the predicted noise residual.
For more information, we recommend looking into [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364)
The *denoising* process is repeated *ca.* 50 times to step-by-step retrieve better latent image representations.
Once complete, the latent image representation is decoded by the decoder part of the variational auto encoder.
After this brief introduction to Latent and Stable Diffusion, let's see how to make advanced use of 🤗 Hugging Face `diffusers` library!
## Writing your own inference pipeline
Finally, we show how you can create custom diffusion pipelines with `diffusers`.
Writing a custom inference pipeline is an advanced use of the `diffusers` library that can be useful to switch out certain components, such as the VAE or scheduler explained above.
For example, we'll show how to use Stable Diffusion with a different scheduler, namely [Katherine Crowson's](https://github.com/crowsonkb) K-LMS scheduler added in [this PR](https://github.com/huggingface/diffusers/pull/185).
The [pre-trained model](https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main) includes all the components required to setup a complete diffusion pipeline. They are stored in the following folders:
- `text_encoder`: Stable Diffusion uses CLIP, but other diffusion models may use other encoders such as `BERT`.
- `tokenizer`. It must match the one used by the `text_encoder` model.
- `scheduler`: The scheduling algorithm used to progressively add noise to the image during training.
- `unet`: The model used to generate the latent representation of the input.
- `vae`: Autoencoder module that we'll use to decode latent representations into real images.
We can load the components by referring to the folder they were saved, using the `subfolder` argument to `from_pretrained`.
```python
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
```
Now instead of loading the pre-defined scheduler, we load the [K-LMS scheduler](https://github.com/huggingface/diffusers/blob/71ba8aec55b52a7ba5a1ff1db1265ffdd3c65ea2/src/diffusers/schedulers/scheduling_lms_discrete.py#L26) with some fitting parameters.
```python
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
```
Next, let's move the models to GPU.
```python
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
```
We now define the parameters we'll use to generate images.
Note that `guidance_scale` is defined analog to the guidance weight `w` of equation (2) in the [Imagen paper](https://arxiv.org/pdf/2205.11487.pdf). `guidance_scale == 1` corresponds to doing no classifier-free guidance. Here we set it to 7.5 as also done previously.
In contrast to the previous examples, we set `num_inference_steps` to 100 to get an even more defined image.
```python
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
batch_size = len(prompt)
```
First, we get the `text_embeddings` for the passed prompt.
These embeddings will be used to condition the UNet model and guide the image generation towards something that should resemble the input prompt.
```python
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
We'll also get the unconditional text embeddings for classifier-free guidance, which are just the embeddings for the padding token (empty text). They need to have the same shape as the conditional `text_embeddings` (`batch_size` and `seq_length`)
```python
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
```
For classifier-free guidance, we need to do two forward passes: one with the conditioned input (`text_embeddings`), and another with the unconditional embeddings (`uncond_embeddings`). In practice, we can concatenate both into a single batch to avoid doing two forward passes.
```python
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
```
Next, we generate the initial random noise.
```python
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
```
If we examine the `latents` at this stage we'll see their shape is `torch.Size([1, 4, 64, 64])`, much smaller than the image we want to generate. The model will transform this latent representation (pure noise) into a `512 × 512` image later on.
Next, we initialize the scheduler with our chosen `num_inference_steps`.
This will compute the `sigmas` and exact time step values to be used during the denoising process.
```python
scheduler.set_timesteps(num_inference_steps)
```
The K-LMS scheduler needs to multiply the `latents` by its `sigma` values. Let's do this here:
```python
latents = latents * scheduler.init_noise_sigma
```
We are ready to write the denoising loop.
```python
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
```
We now use the `vae` to decode the generated `latents` back into the image.
```python
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
```
And finally, let's convert the image to PIL so we can display or save it.
```python
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]
```

We've gone from the basic use of Stable Diffusion using 🤗 Hugging Face Diffusers to more advanced uses of the library, and we tried to introduce all the pieces in a modern diffusion system. If you liked this topic and want to learn more, we recommend the following resources:
- Our [Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb).
- The [Getting Started with Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) notebook, that gives a broader overview on Diffusion systems.
- The [Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion) blog post.
- Our [code in GitHub](https://github.com/huggingface/diffusers) where we'd be more than happy if you leave a ⭐ if `diffusers` is useful to you!
### Citation:
```
@article{patil2022stable,
author = {Patil, Suraj and Cuenca, Pedro and Lambert, Nathan and von Platen, Patrick},
title = {Stable Diffusion with 🧨 Diffusers},
journal = {Hugging Face Blog},
year = {2022},
note = {[https://huggingface.co/blog/rlhf](https://huggingface.co/blog/stable_diffusion)},
}
```
| huggingface/blog/blob/main/stable_diffusion.md |
# How to release
# Before the release
Simple checklist on how to make releases for `safetensors`.
- Freeze `main` branch.
- Run all tests (Check CI has properly run)
- If any significant work, check benchmarks:
- `cd safetensors && cargo bench` (needs to be run on latest release tag to measure difference if it's your first time)
- Run all `transformers` tests. (`transformers` is a big user of `safetensors` we need
to make sure we don't break it, testing is one way to make sure nothing unforeseen
has been done.)
- Run all fast tests at the VERY least (not just the tokenization tests). (`RUN_PIPELINE_TESTS=1 CUDA_VISIBLE_DEVICES=-1 pytest -sv tests/`)
- When all *fast* tests work, then we can also (it's recommended) run the whole `transformers`
test suite.
- Rebase this [PR](https://github.com/huggingface/transformers/pull/16708).
This will create new docker images ready to run the tests suites with `safetensors` from the main branch.
- Wait for actions to finish
- Rebase this [PR](https://github.com/huggingface/transformers/pull/16712)
This will run the actual full test suite.
- Check the results.
- **If any breaking change has been done**, make sure the version can safely be increased for transformers users (`safetensors` version need to make sure users don't upgrade before `transformers` has). [link](https://github.com/huggingface/transformers/blob/main/setup.py#L154)
For instance `safetensors>=0.10,<0.11` so we can safely upgrade to `0.11` without impacting
current users
- Then start a new PR containing all desired code changes from the following steps.
- You will `Create release` after the code modifications are on `master`.
# Rust
- `safetensors` (rust, python & node) versions don't have to be in sync but it's
very common to release for all versions at once for new features.
- Edit `Cargo.toml` to reflect new version
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (python PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/safetensors/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `crates.io`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/safetensors/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
# Python
- Edit `bindings/python/setup.py` to reflect new version.
- Edit `bindings/python/py_src/safetensors/__init__.py` to reflect new version.
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (node PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/safetensors/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `python-vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `pypi`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/safetensors/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
- This CI/CD has 3 distinct builds, `Pypi`(normal), `conda` and `extra`. `Extra` is REALLY slow (~4h), this is normal since it has to rebuild many things, but enables the wheel to be available for old Linuxes
# Node
- Edit `bindings/node/package.json` to reflect new version.
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (python PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/safetensors/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `node-vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `npm`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/safetensors/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
# Testing the CI/CD for release
If you want to make modifications to the CI/CD of the release GH actions, you need
to :
- **Comment the part that uploads the artifacts** to `crates.io`, `PyPi` or `npm`.
- Change the trigger mechanism so it can trigger every time you push to your branch.
- Keep pushing your changes until the artifacts are properly created.
| huggingface/safetensors/blob/main/RELEASE.md |
Summary [[summary]]
That was a lot of information! Let's summarize:
- Reinforcement Learning is a computational approach of learning from actions. We build an agent that learns from the environment **by interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
- The goal of any RL agent is to maximize its expected cumulative reward (also called expected return) because RL is based on the **reward hypothesis**, which is that **all goals can be described as the maximization of the expected cumulative reward.**
- The RL process is a loop that outputs a sequence of **state, action, reward and next state.**
- To calculate the expected cumulative reward (expected return), we discount the rewards: the rewards that come sooner (at the beginning of the game) **are more probable to happen since they are more predictable than the long term future reward.**
- To solve an RL problem, you want to **find an optimal policy**. The policy is the “brain” of your agent, which will tell us **what action to take given a state.** The optimal policy is the one which **gives you the actions that maximize the expected return.**
- There are two ways to find your optimal policy:
1. By training your policy directly: **policy-based methods.**
2. By training a value function that tells us the expected return the agent will get at each state and use this function to define our policy: **value-based methods.**
- Finally, we speak about Deep RL because we introduce **deep neural networks to estimate the action to take (policy-based) or to estimate the value of a state (value-based)** hence the name “deep”.
| huggingface/deep-rl-class/blob/main/units/en/unit1/summary.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Load different Stable Diffusion formats
[[open-in-colab]]
Stable Diffusion models are available in different formats depending on the framework they're trained and saved with, and where you download them from. Converting these formats for use in 🤗 Diffusers allows you to use all the features supported by the library, such as [using different schedulers](schedulers) for inference, [building your custom pipeline](write_own_pipeline), and a variety of techniques and methods for [optimizing inference speed](../optimization/opt_overview).
<Tip>
We highly recommend using the `.safetensors` format because it is more secure than traditional pickled files which are vulnerable and can be exploited to execute any code on your machine (learn more in the [Load safetensors](using_safetensors) guide).
</Tip>
This guide will show you how to convert other Stable Diffusion formats to be compatible with 🤗 Diffusers.
## PyTorch .ckpt
The checkpoint - or `.ckpt` - format is commonly used to store and save models. The `.ckpt` file contains the entire model and is typically several GBs in size. While you can load and use a `.ckpt` file directly with the [`~StableDiffusionPipeline.from_single_file`] method, it is generally better to convert the `.ckpt` file to 🤗 Diffusers so both formats are available.
There are two options for converting a `.ckpt` file: use a Space to convert the checkpoint or convert the `.ckpt` file with a script.
### Convert with a Space
The easiest and most convenient way to convert a `.ckpt` file is to use the [SD to Diffusers](https://huggingface.co/spaces/diffusers/sd-to-diffusers) Space. You can follow the instructions on the Space to convert the `.ckpt` file.
This approach works well for basic models, but it may struggle with more customized models. You'll know the Space failed if it returns an empty pull request or error. In this case, you can try converting the `.ckpt` file with a script.
### Convert with a script
🤗 Diffusers provides a [conversion script](https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py) for converting `.ckpt` files. This approach is more reliable than the Space above.
Before you start, make sure you have a local clone of 🤗 Diffusers to run the script and log in to your Hugging Face account so you can open pull requests and push your converted model to the Hub.
```bash
huggingface-cli login
```
To use the script:
1. Git clone the repository containing the `.ckpt` file you want to convert. For this example, let's convert this [TemporalNet](https://huggingface.co/CiaraRowles/TemporalNet) `.ckpt` file:
```bash
git lfs install
git clone https://huggingface.co/CiaraRowles/TemporalNet
```
2. Open a pull request on the repository where you're converting the checkpoint from:
```bash
cd TemporalNet && git fetch origin refs/pr/13:pr/13
git checkout pr/13
```
3. There are several input arguments to configure in the conversion script, but the most important ones are:
- `checkpoint_path`: the path to the `.ckpt` file to convert.
- `original_config_file`: a YAML file defining the configuration of the original architecture. If you can't find this file, try searching for the YAML file in the GitHub repository where you found the `.ckpt` file.
- `dump_path`: the path to the converted model.
For example, you can take the `cldm_v15.yaml` file from the [ControlNet](https://github.com/lllyasviel/ControlNet/tree/main/models) repository because the TemporalNet model is a Stable Diffusion v1.5 and ControlNet model.
4. Now you can run the script to convert the `.ckpt` file:
```bash
python ../diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path temporalnetv3.ckpt --original_config_file cldm_v15.yaml --dump_path ./ --controlnet
```
5. Once the conversion is done, upload your converted model and test out the resulting [pull request](https://huggingface.co/CiaraRowles/TemporalNet/discussions/13)!
```bash
git push origin pr/13:refs/pr/13
```
## Keras .pb or .h5
<Tip warning={true}>
🧪 This is an experimental feature. Only Stable Diffusion v1 checkpoints are supported by the Convert KerasCV Space at the moment.
</Tip>
[KerasCV](https://keras.io/keras_cv/) supports training for [Stable Diffusion](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion) v1 and v2. However, it offers limited support for experimenting with Stable Diffusion models for inference and deployment whereas 🤗 Diffusers has a more complete set of features for this purpose, such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
The [Convert KerasCV](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) Space converts `.pb` or `.h5` files to PyTorch, and then wraps them in a [`StableDiffusionPipeline`] so it is ready for inference. The converted checkpoint is stored in a repository on the Hugging Face Hub.
For this example, let's convert the [`sayakpaul/textual-inversion-kerasio`](https://huggingface.co/sayakpaul/textual-inversion-kerasio/tree/main) checkpoint which was trained with Textual Inversion. It uses the special token `<my-funny-cat>` to personalize images with cats.
The Convert KerasCV Space allows you to input the following:
* Your Hugging Face token.
* Paths to download the UNet and text encoder weights from. Depending on how the model was trained, you don't necessarily need to provide the paths to both the UNet and text encoder. For example, Textual Inversion only requires the embeddings from the text encoder and a text-to-image model only requires the UNet weights.
* Placeholder token is only applicable for textual inversion models.
* The `output_repo_prefix` is the name of the repository where the converted model is stored.
Click the **Submit** button to automatically convert the KerasCV checkpoint! Once the checkpoint is successfully converted, you'll see a link to the new repository containing the converted checkpoint. Follow the link to the new repository, and you'll see the Convert KerasCV Space generated a model card with an inference widget to try out the converted model.
If you prefer to run inference with code, click on the **Use in Diffusers** button in the upper right corner of the model card to copy and paste the code snippet:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline", use_safetensors=True
)
```
Then, you can generate an image like:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline", use_safetensors=True
)
pipeline.to("cuda")
placeholder_token = "<my-funny-cat-token>"
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
image = pipeline(prompt, num_inference_steps=50).images[0]
```
## A1111 LoRA files
[Automatic1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) (A1111) is a popular web UI for Stable Diffusion that supports model sharing platforms like [Civitai](https://civitai.com/). Models trained with the Low-Rank Adaptation (LoRA) technique are especially popular because they're fast to train and have a much smaller file size than a fully finetuned model. 🤗 Diffusers supports loading A1111 LoRA checkpoints with [`~loaders.LoraLoaderMixin.load_lora_weights`]:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"Lykon/dreamshaper-xl-1-0", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
```
Download a LoRA checkpoint from Civitai; this example uses the [Blueprintify SD XL 1.0](https://civitai.com/models/150986/blueprintify-sd-xl-10) checkpoint, but feel free to try out any LoRA checkpoint!
```py
# uncomment to download the safetensor weights
#!wget https://civitai.com/api/download/models/168776 -O blueprintify.safetensors
```
Load the LoRA checkpoint into the pipeline with the [`~loaders.LoraLoaderMixin.load_lora_weights`] method:
```py
pipeline.load_lora_weights(".", weight_name="blueprintify.safetensors")
```
Now you can use the pipeline to generate images:
```py
prompt = "bl3uprint, a highly detailed blueprint of the empire state building, explaining how to build all parts, many txt, blueprint grid backdrop"
negative_prompt = "lowres, cropped, worst quality, low quality, normal quality, artifacts, signature, watermark, username, blurry, more than one bridge, bad architecture"
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
generator=torch.manual_seed(0),
).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/blueprint-lora.png"/>
</div>
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/other-formats.md |
--
title: 'Deploy Hugging Face models easily with Amazon SageMaker'
thumbnail: /blog/assets/17_the_partnership_amazon_sagemaker_and_hugging_face/thumbnail.png
---
<img src="/blog/assets/17_the_partnership_amazon_sagemaker_and_hugging_face/cover.png" alt="hugging-face-and-aws-logo" class="w-full">
# **Deploy Hugging Face models easily with Amazon SageMaker 🏎**
Earlier this year[ we announced a strategic collaboration with Amazon](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face) to make it easier for companies to use Hugging Face in Amazon SageMaker, and ship cutting-edge Machine Learning features faster. We introduced new Hugging Face Deep Learning Containers (DLCs) to[ train Hugging Face Transformer models in Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html#getting-started-train-a-transformers-model).
Today, we are excited to share a new inference solution with you that makes it easier than ever to deploy Hugging Face Transformers with Amazon SageMaker! With the new Hugging Face Inference DLCs, you can deploy your trained models for inference with just one more line of code, or select any of the 10,000+ publicly available models from the[ Model Hub](https://huggingface.co/models), and deploy them with Amazon SageMaker.
Deploying models in SageMaker provides you with production-ready endpoints that scale easily within your AWS environment, with built-in monitoring and a ton of enterprise features. It's been an amazing collaboration and we hope you will take advantage of it!
Here's how to use the new[ SageMaker Hugging Face Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit) to deploy Transformers-based models:
```python
from sagemaker.huggingface import HuggingFaceModel
# create Hugging Face Model Class and deploy it as SageMaker Endpoint
huggingface_model = HuggingFaceModel(...).deploy()
```
That's it! 🚀
To learn more about accessing and using the new Hugging Face DLCs with the Amazon SageMaker Python SDK, check out the guides and resources below.
---
# **Resources, Documentation & Samples 📄**
Below you can find all the important resources for deploying your models to Amazon SageMaker.
## **Blog/Video**
- [Video: Deploy a Hugging Face Transformers Model from S3 to Amazon SageMaker](https://youtu.be/pfBGgSGnYLs)
- [Video: Deploy a Hugging Face Transformers Model from the Model Hub to Amazon SageMaker](https://youtu.be/l9QZuazbzWM)
## **Samples/Documentation**
- [Hugging Face documentation for Amazon SageMaker](https://huggingface.co/docs/sagemaker/main)
- [Deploy models to Amazon SageMaker](https://huggingface.co/docs/sagemaker/inference)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
- [Notebook: Deploy one of the 10 000+ Hugging Face Transformers to Amazon SageMaker for Inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb)
- [Notebook: Deploy a Hugging Face Transformer model from S3 to SageMaker for inference](https://github.com/huggingface/notebooks/blob/master/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb)
---
# **SageMaker Hugging Face Inference Toolkit ⚙️**
In addition to the Hugging Face Transformers-optimized Deep Learning Containers for inference, we have created a new[ Inference Toolkit](https://github.com/aws/sagemaker-huggingface-inference-toolkit) for Amazon SageMaker. This new Inference Toolkit leverages the `pipelines` from the `transformers` library to allow zero-code deployments of models without writing any code for pre- or post-processing. In the "Getting Started" section below you find two examples of how to deploy your models to Amazon SageMaker.
In addition to the zero-code deployment, the Inference Toolkit supports "bring your own code" methods, where you can override the default methods. You can learn more about "bring your own code" in the documentation[ here](https://github.com/aws/sagemaker-huggingface-inference-toolkit#-user-defined-codemodules) or you can check out the sample notebook "deploy custom inference code to Amazon SageMaker".
## **API - Inference Toolkit Description**
Using the` transformers pipelines`, we designed an API, which makes it easy for you to benefit from all `pipelines` features. The API has a similar interface than the[ 🤗 Accelerated Inference API](https://api-inference.huggingface.co/docs/python/html/detailed_parameters.html), meaning your inputs need to be defined in the `inputs` key and if you want additional supported `pipelines` parameters you can add them in the `parameters` key. Below you can find examples for requests.
```python
# text-classification request body
{
"inputs": "Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days."
}
# question-answering request body
{
"inputs": {
"question": "What is used for inference?",
"context": "My Name is Philipp and I live in Nuremberg. This model is used with sagemaker for inference."
}
}
# zero-shot classification request body
{
"inputs": "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!",
"parameters": {
"candidate_labels": [
"refund",
"legal",
"faq"
]
}
}
```
# **Getting started 🧭**
In this guide we will use the new Hugging Face Inference DLCs and Amazon SageMaker Python SDK to deploy two transformer models for inference.
In the first example, we deploy for inference a Hugging Face Transformer model trained in Amazon SageMaker.
In the second example, we directly deploy one of the 10,000+ publicly available Hugging Face Transformers models from the[ Model Hub](https://huggingface.co/models) to Amazon SageMaker for Inference.
## **Setting up the environment**
We will use an Amazon SageMaker Notebook Instance for the example. You can learn[ here how to set up a Notebook Instance.](https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html) To get started, jump into your Jupyter Notebook or JupyterLab and create a new Notebook with the `conda_pytorch_p36` kernel.
**_Note: The use of Jupyter is optional: We could also launch SageMaker API calls from anywhere we have an SDK installed, connectivity to the cloud, and appropriate permissions, such as a Laptop, another IDE, or a task scheduler like Airflow or AWS Step Functions._**
After that we can install the required dependencies.
```bash
pip install "sagemaker>=2.48.0" --upgrade
```
To deploy a model on SageMaker, we need to create a `sagemaker` Session and provide an IAM role with the right permission. The `get_execution_role` method is provided by the SageMaker SDK as an optional convenience. You can also specify the role by writing the specific role ARN you want your endpoint to use. This IAM role will be later attached to the Endpoint, e.g. download the model from Amazon S3.
```python
import sagemaker
sess = sagemaker.Session()
role = sagemaker.get_execution_role()
```
---
## **Deploy a trained Hugging Face Transformer model to SageMaker for inference**
There are two ways to deploy your SageMaker trained Hugging Face model. You can either deploy it after your training is finished, or you can deploy it later, using the `model_data` pointing to your saved model on Amazon S3. In addition to the two below-mentioned options, you can also instantiate Hugging Face endpoints with lower-level SDK such as `boto3` and `AWS CLI`, `Terraform` and with CloudFormation templates.
### **Deploy the model directly after training with the Estimator class**
If you deploy your model directly after training, you need to ensure that all required model artifacts are saved in your training script, including the tokenizer and the model. A benefit of deploying directly after training is that SageMaker model container metadata will contain the source training job, providing lineage from training job to deployed model.
```python
from sagemaker.huggingface import HuggingFace
############ pseudo code start ############
# create HuggingFace estimator for running training
huggingface_estimator = HuggingFace(....)
# starting the train job with our uploaded datasets as input
huggingface_estimator.fit(...)
############ pseudo code end ############
# deploy model to SageMaker Inference
predictor = hf_estimator.deploy(initial_instance_count=1, instance_type="ml.m5.xlarge")
# example request, you always need to define "inputs"
data = {
"inputs": "Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days."
}
# request
predictor.predict(data)
```
After we run our request we can delete the endpoint again with.
```python
# delete endpoint
predictor.delete_endpoint()
```
### **Deploy the model from pre-trained checkpoints using the <code>HuggingFaceModel</code> class**
If you've already trained your model and want to deploy it at some later time, you can use the `model_data` argument to specify the location of your tokenizer and model weights.
```python
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data="s3://models/my-bert-model/model.tar.gz", # path to your trained sagemaker model
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.6", # transformers version used
pytorch_version="1.7", # pytorch version used
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge"
)
# example request, you always need to define "inputs"
data = {
"inputs": "Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days."
}
# request
predictor.predict(data)
```
After we run our request, we can delete the endpoint again with:
```python
# delete endpoint
predictor.delete_endpoint()
```
## **Deploy one of the 10,000+ Hugging Face Transformers to Amazon SageMaker for Inference**
To deploy a model directly from the Hugging Face Model Hub to Amazon SageMaker, we need to define two environment variables when creating the `HuggingFaceModel`. We need to define:
* HF_MODEL_ID: defines the model id, which will be automatically loaded from[ huggingface.co/models](http://huggingface.co/models) when creating or SageMaker Endpoint. The 🤗 Hub provides 10,000+ models all available through this environment variable.
* HF_TASK: defines the task for the used 🤗 Transformers pipeline. A full list of tasks can be found[ here](https://huggingface.co/transformers/main_classes/pipelines.html).
```python
from sagemaker.huggingface.model import HuggingFaceModel
# Hub Model configuration. <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'distilbert-base-uncased-distilled-squad', # model_id from hf.co/models
'HF_TASK':'question-answering' # NLP task you want to use for predictions
}
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.6", # transformers version used
pytorch_version="1.7", # pytorch version used
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge"
)
# example request, you always need to define "inputs"
data = {
"inputs": {
"question": "What is used for inference?",
"context": "My Name is Philipp and I live in Nuremberg. This model is used with sagemaker for inference."
}
}
# request
predictor.predict(data)
```
After we run our request we can delete the endpoint again with.
```python
# delete endpoint
predictor.delete_endpoint()
```
---
# **FAQ 🎯**
You can find the complete [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq) in the [documentation](https://huggingface.co/docs/sagemaker/faq).
_Q: Which models can I deploy for Inference?_
A: You can deploy:
* any 🤗 Transformers model trained in Amazon SageMaker, or other compatible platforms and that can accommodate the SageMaker Hosting design
* any of the 10,000+ publicly available Transformer models from the Hugging Face[ Model Hub](https://huggingface.co/models), or
* your private models hosted in your Hugging Face premium account!
_Q: Which pipelines, tasks are supported by the Inference Toolkit?_
A: The Inference Toolkit and DLC support any of the `transformers` `pipelines`. You can find the full list [here](https://huggingface.co/transformers/main_classes/pipelines.html)
_Q: Do I have to use the `transformers pipelines` when hosting SageMaker endpoints?_
A: No, you can also write your custom inference code to serve your own models and logic, documented [here](https://huggingface.co/docs/sagemaker/inference#user-defined-codemodules).
_Q: Do I have to use the SageMaker Python SDK to use the Hugging Face Deep Learning Containers (DLCs)?_
A: You can use the Hugging Face DLC without the SageMaker Python SDK and deploy your models to SageMaker with other SDKs, such as the [AWS CLI](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-training-job.html), [boto3](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_training_job) or [Cloudformation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-sagemaker-endpoint.html). The DLCs are also available through Amazon ECR and can be pulled and used in any environment of choice.
_Q: Why should I use the Hugging Face Deep Learning Containers?_
A: The DLCs are fully tested, maintained, optimized deep learning environments that require no installation, configuration, or maintenance. In particular, our inference DLC comes with a pre-written serving stack, which drastically lowers the technical bar of DL serving.
_Q: How is my data and code secured by Amazon SageMaker?_
A: Amazon SageMaker provides numerous security mechanisms including **[encryption at rest](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-at-rest-nbi.html)** and **[in transit](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-in-transit.html)**, **[Virtual Private Cloud (VPC) connectivity](https://docs.aws.amazon.com/sagemaker/latest/dg/interface-vpc-endpoint.html),** and **[Identity and Access Management (IAM)](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html)**. To learn more about security in the AWS cloud and with Amazon SageMaker, you can visit **[Security in Amazon SageMaker](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html)** and **[AWS Cloud Security](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html)**.
_Q: Is this available in my region?_
A: For a list of the supported regions, please visit the **[AWS region table](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/)** for all AWS global infrastructure.
_Q: Do you offer premium support or support SLAs for this solution?_
A: AWS Technical Support tiers are available from AWS and cover development and production issues for AWS products and services - please refer to AWS Support for specifics and scope.
If you have questions which the Hugging Face community can help answer and/or benefit from, please **[post them in the Hugging Face forum](https://discuss.huggingface.co/c/sagemaker/17)**.
---
If you need premium support from the Hugging Face team to accelerate your NLP roadmap, our[ Expert Acceleration Program](https://huggingface.co/support) offers direct guidance from our open-source, science, and ML Engineering teams.
| huggingface/blog/blob/main/deploy-hugging-face-models-easily-with-amazon-sagemaker.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 🤗 Optimum
🤗 Optimum is an extension of [Transformers](https://huggingface.co/docs/transformers) that provides a set of performance optimization tools to train and run models on targeted hardware with maximum efficiency.
The AI ecosystem evolves quickly, and more and more specialized hardware along with their own optimizations are emerging every day.
As such, Optimum enables developers to efficiently use any of these platforms with the same ease inherent to Transformers.
🤗 Optimum is distributed as a collection of packages - check out the links below for an in-depth look at each one.
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./habana/index"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Habana</div>
<p class="text-gray-700">Maximize training throughput and efficiency with <span class="underline" onclick="event.preventDefault(); window.open('https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html', '_blank');">Habana's Gaudi processor</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./intel/index"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Intel</div>
<p class="text-gray-700">Optimize your model to speedup inference with <span class="underline" onclick="event.preventDefault(); window.open('https://docs.openvino.ai/latest/index.html', '_blank');">OpenVINO</span> and <span class="underline" onclick="event.preventDefault(); window.open('https://www.intel.com/content/www/us/en/developer/tools/oneapi/neural-compressor.html', '_blank');">Neural Compressor</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/docs/optimum-neuron/index"
><div class="w-full text-center bg-gradient-to-br from-orange-400 to-orange-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">AWS Trainium/Inferentia</div>
<p class="text-gray-700">Accelerate your training and inference workflows with <span class="underline" onclick="event.preventDefault(); window.open('https://aws.amazon.com/machine-learning/trainium/', '_blank');">AWS Trainium</span> and <span class="underline" onclick="event.preventDefault(); window.open('https://aws.amazon.com/machine-learning/inferentia/', '_blank');">AWS Inferentia</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://github.com/huggingface/optimum-nvidia"
><div class="w-full text-center bg-gradient-to-br from-green-600 to-green-600 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">NVIDIA</div>
<p class="text-gray-700">Accelerate inference with NVIDIA TensorRT-LLM on the <span class="underline" onclick="event.preventDefault(); window.open('https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/', '_blank');">NVIDIA platform</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./amd/index"
><div class="w-full text-center bg-gradient-to-br from-red-600 to-red-600 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">AMD</div>
<p class="text-gray-700">Enable performance optimizations for <span class="underline" onclick="event.preventDefault(); window.open('https://www.amd.com/en/graphics/instinct-server-accelerators', '_blank');">AMD Instinct GPUs</span> and <span class="underline" onclick="event.preventDefault(); window.open('https://ryzenai.docs.amd.com/en/latest/index.html', '_blank');">AMD Ryzen AI NPUs</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./furiosa/index"
><div class="w-full text-center bg-gradient-to-br from-green-400 to-green-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">FuriosaAI</div>
<p class="text-gray-700">Fast and efficient inference on <span class="underline" onclick="event.preventDefault(); window.open('https://www.furiosa.ai/', '_blank');">FuriosaAI WARBOY</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./onnxruntime/overview"
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">ONNX Runtime</div>
<p class="text-gray-700">Apply quantization and graph optimization to accelerate Transformers models training and inference with <span class="underline" onclick="event.preventDefault(); window.open('https://onnxruntime.ai/', '_blank');">ONNX Runtime</span></p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./bettertransformer/overview"
><div class="w-full text-center bg-gradient-to-br from-yellow-400 to-yellow-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">BetterTransformer</div>
<p class="text-gray-700">A one-liner integration to use <span class="underline" onclick="event.preventDefault(); window.open('https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/', '_blank');">PyTorch's BetterTransformer</span> with Transformers models</p>
</a>
</div>
</div>
| huggingface/optimum/blob/main/docs/source/index.mdx |
--
title: "Introducing Prodigy-HF: a direct integration with Hugging Face"
thumbnail: /blog/assets/171_prodigy_hf/thumbnail.png
authors:
- user: koaning
guest: true
---
# Introducing Prodigy-HF
[Prodigy](https://prodi.gy/) is an annotation tool made by [Explosion](https://explosion.ai/), a company well known as the creators of [spaCy](https://spacy.io/). It's a fully scriptable product with a large community around it. The product has many features, including tight integration with spaCy and active learning capabilities. But the main feature of the product is that it is programmatically customizable with Python.
To foster this customisability, Explosion has started releasing [plugins](https://prodi.gy/docs/plugins). These plugins integrate with third-party tools in an open way that encourages users to work on bespoke annotation workflows. However, one customization specifically deserves to be celebrated explicitly. Last week, Explosion introduced [Prodigy-HF](https://github.com/explosion/prodigy-hf), which offers code recipes that directly integrate with the Hugging Face stack. It's been a much-requested feature on the [Prodigy support forum](https://support.prodi.gy/), so we're super excited to have it out there.
## Features
The first main feature is that this plugin allows you to train and re-use Hugging Face models on your annotated data. That means if you've been annotating data in our interface for named entity recognition, you can directly fine-tune BERT models against it.
<figure>
<div style="background-color: #eee; padding-top: 8px; padding-bottom: 8px;">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/prodigy-hf/interface.png" width="100%">
</div>
<figcaption style="text-color: gray; margin-left: auto; margin-right: auto; text-align:center; padding-top: 8px;"><small>What the Prodigy NER interface looks like.</small></figcaption>
</figure>
After installing the plugin you can call the `hf.train.ner` recipe from the command line to train a transformer model directly on your own data.
```
python -m prodigy hf.train.ner fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
```
This will fine-tune the `distilbert-base-uncased` model for the dataset you've stored in Prodigy and save it to disk. Similarly, this plugin also supports models for text classification via a very similar interface.
```
python -m prodigy hf.train.textcat fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
```
This offers a lot of flexibility because the tool directly integrates with the `AutoTokenizer` and `AutoModel` classes of Hugging Face transformers. Any transformer model on the hub can be fine-tuned on your own dataset with just a single command. These models will be serialised on disk, which means that you can upload them to the Hugging Face Hub, or re-use them to help you annotate data. This can save a lot of time, especially for NER tasks. To re-use a trained NER model you can use the `hf.correct.ner` recipe.
```
python -m prodigy hf.correct.ner fashion-train path/to/model-out examples.jsonl
```
This will give you a similar interface as before, but now the model predictions will be shown in the interface as well.
### Upload
The second feature, which is equally exciting, is that you can now also publish your annotated datasets on the Hugging Face Hub. This is great if you're interested in sharing datasets that others would like to use.
```
python -m prodigy hf.upload <dataset_name> <username>/<repo_name>
```
We're particularly fond of this upload feature because it encourages collaboration. People can annotate their own datasets independently of each other, but still benefit when they share the data with the wider community.
## More to come
We hope that this direct integration with the Hugging Face ecosystem enables many users to experiment more. The Hugging Face Hub offers _many_ [models](https://huggingface.co/models) for a wide array of tasks as well as a wide array of languages. We really hope that this integration makes it easier to get data annotated, even if you've got a more domain specific and experimental use-case.
More features for this library are on their way, and feel free to reach out on the [Prodigy forum](https://support.prodi.gy/) if you have more questions.
We'd also like to thank the team over at Hugging Face for their feedback on this plugin, specifically @davanstrien, who suggested to add the upload feature. Thanks!
| huggingface/blog/blob/main/prodigy-hf.md |
Reference
## Deep Learning Container
Below you can find a version table of currently available Hugging Face DLCs. The table doesn't include the full `image_uri` here are two examples on how to construct those if needed.
**Manually construction the `image_uri`**
`{dlc-aws-account-id}.dkr.ecr.{region}.amazonaws.com/huggingface-{framework}-{(training | inference)}:{framework-version}-transformers{transformers-version}-{device}-{python-version}-{device-tag}`
- `dlc-aws-account-id`: The AWS account ID of the account that owns the ECR repository. You can find them in the [here](https://github.com/aws/sagemaker-python-sdk/blob/e0b9d38e1e3b48647a02af23c4be54980e53dc61/src/sagemaker/image_uri_config/huggingface.json#L21)
- `region`: The AWS region where you want to use it.
- `framework`: The framework you want to use, either `pytorch` or `tensorflow`.
- `(training | inference)`: The training or inference mode.
- `framework-version`: The version of the framework you want to use.
- `transformers-version`: The version of the transformers library you want to use.
- `device`: The device you want to use, either `cpu` or `gpu`.
- `python-version`: The version of the python of the DLC.
- `device-tag`: The device tag you want to use. The device tag can include os version and cuda version
**Example 1: PyTorch Training:**
`763104351884.dkr.ecr.us-west-2.amazonaws.com/huggingface-pytorch-training:1.6.0-transformers4.4.2-gpu-py36-cu110-ubuntu18.04`
**Example 2: Tensorflow Inference:**
`763104351884.dkr.ecr.us-east-1.amazonaws.com/huggingface-tensorflow-inference:2.4.1-transformers4.6.1-cpu-py37-ubuntu18.04`
## Training DLC Overview
The Training DLC overview includes all released and available Hugging Face Training DLCs. It includes PyTorch and TensorFlow flavored
versions for GPU.
| 🤗 Transformers version | 🤗 Datasets version | PyTorch/TensorFlow version | type | device | Python Version |
| ----------------------- | ------------------- | -------------------------- | -------- | ------ | -------------- |
| 4.4.2 | 1.5.0 | PyTorch 1.6.0 | training | GPU | 3.6 |
| 4.4.2 | 1.5.0 | TensorFlow 2.4.1 | training | GPU | 3.7 |
| 4.5.0 | 1.5.0 | PyTorch 1.6.0 | training | GPU | 3.6 |
| 4.5.0 | 1.5.0 | TensorFlow 2.4.1 | training | GPU | 3.7 |
| 4.6.1 | 1.6.2 | PyTorch 1.6.0 | training | GPU | 3.6 |
| 4.6.1 | 1.6.2 | PyTorch 1.7.1 | training | GPU | 3.6 |
| 4.6.1 | 1.6.2 | TensorFlow 2.4.1 | training | GPU | 3.7 |
| 4.10.2 | 1.11.0 | PyTorch 1.8.1 | training | GPU | 3.6 |
| 4.10.2 | 1.11.0 | PyTorch 1.9.0 | training | GPU | 3.8 |
| 4.10.2 | 1.11.0 | TensorFlow 2.4.1 | training | GPU | 3.7 |
| 4.10.2 | 1.11.0 | TensorFlow 2.5.1 | training | GPU | 3.7 |
| 4.11.0 | 1.12.1 | PyTorch 1.9.0 | training | GPU | 3.8 |
| 4.11.0 | 1.12.1 | TensorFlow 2.5.1 | training | GPU | 3.7 |
| 4.12.3 | 1.15.1 | PyTorch 1.9.1 | training | GPU | 3.8 |
| 4.12.3 | 1.15.1 | TensorFlow 2.5.1 | training | GPU | 3.7 |
| 4.17.0 | 1.18.4 | PyTorch 1.10.2 | training | GPU | 3.8 |
| 4.17.0 | 1.18.4 | TensorFlow 2.6.3 | training | GPU | 3.8 |
| 4.26.0 | 2.9.0 | PyTorch 1.13.1 | training | GPU | 3.9 |
## Inference DLC Overview
The Inference DLC overview includes all released and available Hugging Face Inference DLCs. It includes PyTorch and TensorFlow flavored
versions for CPU, GPU & AWS Inferentia.
| 🤗 Transformers version | PyTorch/TensorFlow version | type | device | Python Version |
| ----------------------- | -------------------------- | --------- | ------ | -------------- |
| 4.6.1 | PyTorch 1.7.1 | inference | CPU | 3.6 |
| 4.6.1 | PyTorch 1.7.1 | inference | GPU | 3.6 |
| 4.6.1 | TensorFlow 2.4.1 | inference | CPU | 3.7 |
| 4.6.1 | TensorFlow 2.4.1 | inference | GPU | 3.7 |
| 4.10.2 | PyTorch 1.8.1 | inference | GPU | 3.6 |
| 4.10.2 | PyTorch 1.9.0 | inference | GPU | 3.8 |
| 4.10.2 | TensorFlow 2.4.1 | inference | GPU | 3.7 |
| 4.10.2 | TensorFlow 2.5.1 | inference | GPU | 3.7 |
| 4.10.2 | PyTorch 1.8.1 | inference | CPU | 3.6 |
| 4.10.2 | PyTorch 1.9.0 | inference | CPU | 3.8 |
| 4.10.2 | TensorFlow 2.4.1 | inference | CPU | 3.7 |
| 4.10.2 | TensorFlow 2.5.1 | inference | CPU | 3.7 |
| 4.11.0 | PyTorch 1.9.0 | inference | GPU | 3.8 |
| 4.11.0 | TensorFlow 2.5.1 | inference | GPU | 3.7 |
| 4.11.0 | PyTorch 1.9.0 | inference | CPU | 3.8 |
| 4.11.0 | TensorFlow 2.5.1 | inference | CPU | 3.7 |
| 4.12.3 | PyTorch 1.9.1 | inference | GPU | 3.8 |
| 4.12.3 | TensorFlow 2.5.1 | inference | GPU | 3.7 |
| 4.12.3 | PyTorch 1.9.1 | inference | CPU | 3.8 |
| 4.12.3 | TensorFlow 2.5.1 | inference | CPU | 3.7 |
| 4.12.3 | PyTorch 1.9.1 | inference | Inferentia | 3.7 |
| 4.17.0 | PyTorch 1.10.2 | inference | GPU | 3.8 |
| 4.17.0 | TensorFlow 2.6.3 | inference | GPU | 3.8 |
| 4.17.0 | PyTorch 1.10.2 | inference | CPU | 3.8 |
| 4.17.0 | TensorFlow 2.6.3 | inference | CPU | 3.8 |
| 4.26.0 | PyTorch 1.13.1 | inference | CPU | 3.9 |
| 4.26.0 | PyTorch 1.13.1 | inference | GPU | 3.9 |
## Hugging Face Transformers Amazon SageMaker Examples
Example Jupyter notebooks that demonstrate how to build, train, and deploy [Hugging Face Transformers](https://github.com/huggingface/transformers) using [Amazon SageMaker](https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html) and the [Amazon SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/).
| Notebook | Type | Description |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|----------------------------------------------------------------------------------------------------------------------------------------|
| [01 Getting started with PyTorch](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/sagemaker-notebook.ipynb) | Training | Getting started end-to-end example on how to fine-tune a pre-trained Hugging Face Transformer for Text-Classification using PyTorch |
| [02 getting started with TensorFlow](https://github.com/huggingface/notebooks/blob/main/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb) | Training | Getting started end-to-end example on how to fine-tune a pre-trained Hugging Face Transformer for Text-Classification using TensorFlow |
| [03 Distributed Training: Data Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/03_distributed_training_data_parallelism/sagemaker-notebook.ipynb) | Training | End-to-end example on how to use distributed training with data-parallelism strategy for fine-tuning a pre-trained Hugging Face Transformer for Question-Answering using Amazon SageMaker Data Parallelism |
| [04 Distributed Training: Model Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb) | Training | End-to-end example on how to use distributed training with model-parallelism strategy to pre-trained Hugging Face Transformer using Amazon SageMaker Model Parallelism |
| [05 How to use Spot Instances & Checkpointing](https://github.com/huggingface/notebooks/blob/main/sagemaker/05_spot_instances/sagemaker-notebook.ipynb) | Training | End-to-end example on how to use Spot Instances and Checkpointing to reduce training cost |
| [06 Experiment Tracking with SageMaker Metrics](https://github.com/huggingface/notebooks/blob/main/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb) | Training | End-to-end example on how to use SageMaker metrics to track your experiments and training jobs |
| [07 Distributed Training: Data Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb) | Training | End-to-end example on how to use Amazon SageMaker Data Parallelism with TensorFlow |
| [08 Distributed Training: Summarization with T5/BART](https://github.com/huggingface/notebooks/blob/main/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb) | Training | End-to-end example on how to fine-tune BART/T5 for Summarization using Amazon SageMaker Data Parallelism |
| [09 Vision: Fine-tune ViT](https://github.com/huggingface/notebooks/blob/main/sagemaker/09_image_classification_vision_transformer/sagemaker-notebook.ipynb) | Training | End-to-end example on how to fine-tune Vision Transformer for Image-Classification |
| [10 Deploy HF Transformer from Amazon S3](https://github.com/huggingface/notebooks/blob/main/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb) | Inference | End-to-end example on how to deploy a model from Amazon S3 |
| [11 Deploy HF Transformer from Hugging Face Hub](https://github.com/huggingface/notebooks/blob/main/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb) | Inference | End-to-end example on how to deploy a model from the Hugging Face Hub |
| [12 Batch Processing with Amazon SageMaker Batch Transform](https://github.com/huggingface/notebooks/blob/main/sagemaker/12_batch_transform_inference/sagemaker-notebook.ipynb) | Inference | End-to-end example on how to do batch processing with Amazon SageMaker Batch Transform |
| [13 Autoscaling SageMaker Endpoints](https://github.com/huggingface/notebooks/blob/main/sagemaker/13_deploy_and_autoscaling_transformers/sagemaker-notebook.ipynb) | Inference | End-to-end example on how to do use autoscaling for a HF Endpoint |
| [14 Fine-tune and push to Hub](https://github.com/huggingface/notebooks/blob/main/sagemaker/14_train_and_push_to_hub/sagemaker-notebook.ipynb) | Training | End-to-end example on how to do use the Hugging Face Hub as MLOps backend for saving checkpoints during training |
| [15 Training Compiler](https://github.com/huggingface/notebooks/blob/main/sagemaker/15_training_compiler/sagemaker-notebook.ipynb) | Training | End-to-end example on how to do use Amazon SageMaker Training Compiler to speed up training time |
| [16 Asynchronous Inference](https://github.com/huggingface/notebooks/blob/main/sagemaker/16_async_inference_hf_hub/sagemaker-notebook.ipynb) | Inference | End-to-end example on how to do use Amazon SageMaker Asynchronous Inference endpoints with Hugging Face Transformers |
| [17 Custom inference.py script](https://github.com/huggingface/notebooks/blob/main/sagemaker/17_custom_inference_script/sagemaker-notebook.ipynb) | Inference | End-to-end example on how to create a custom inference.py for Sentence Transformers and sentence embeddings |
| [18 AWS Inferentia](https://github.com/huggingface/notebooks/blob/main/sagemaker/18_inferentia_inference/sagemaker-notebook.ipynb) | Inference | End-to-end example on how to AWS Inferentia to speed up inference time |
## Inference Toolkit API
The Inference Toolkit accepts inputs in the `inputs` key, and supports additional [`pipelines`](https://huggingface.co/docs/transformers/main_classes/pipelines) parameters in the `parameters` key. You can provide any of the supported `kwargs` from `pipelines` as `parameters`.
Tasks supported by the Inference Toolkit API include:
- **`text-classification`**
- **`sentiment-analysis`**
- **`token-classification`**
- **`feature-extraction`**
- **`fill-mask`**
- **`summarization`**
- **`translation_xx_to_yy`**
- **`text2text-generation`**
- **`text-generation`**
- **`audio-classificatin`**
- **`automatic-speech-recognition`**
- **`conversational`**
- **`image-classification`**
- **`image-segmentation`**
- **`object-detection`**
- **`table-question-answering`**
- **`zero-shot-classification`**
- **`zero-shot-image-classification`**
See the following request examples for some of the tasks:
**`text-classification`**
```json
{
"inputs": "This sound track was beautiful! It paints the senery in your mind so well I would recomend it
even to people who hate vid. game music!"
}
```
**`sentiment-analysis`**
```json
{
"inputs": "Don't waste your time. We had two different people come to our house to give us estimates for
a deck (one of them the OWNER). Both times, we never heard from them. Not a call, not the estimate, nothing."
}
```
**`token-classification`**
```json
{
"inputs": "My name is Sylvain and I work at Hugging Face in Brooklyn."
}
```
**`question-answering`**
```json
{
"inputs": {
"question": "What is used for inference?",
"context": "My Name is Philipp and I live in Nuremberg. This model is used with sagemaker for inference."
}
}
```
**`zero-shot-classification`**
```json
{
"inputs": "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!",
"parameters": {
"candidate_labels": ["refund", "legal", "faq"]
}
}
```
**`table-question-answering`**
```json
{
"inputs": {
"query": "How many stars does the transformers repository have?",
"table": {
"Repository": ["Transformers", "Datasets", "Tokenizers"],
"Stars": ["36542", "4512", "3934"],
"Contributors": ["651", "77", "34"],
"Programming language": ["Python", "Python", "Rust, Python and NodeJS"]
}
}
}
```
**`parameterized-request`**
```json
{
"inputs": "Hugging Face, the winner of VentureBeat’s Innovation in Natural Language Process/Understanding Award for 2021, is looking to level the playing field. The team, launched by Clément Delangue and Julien Chaumond in 2016, was recognized for its work in democratizing NLP, the global market value for which is expected to hit $35.1 billion by 2026. This week, Google’s former head of Ethical AI Margaret Mitchell joined the team.",
"parameters": {
"repetition_penalty": 4.0,
"length_penalty": 1.5
}
}
```
## Inference Toolkit environment variables
The Inference Toolkit implements various additional environment variables to simplify deployment. A complete list of Hugging Face specific environment variables is shown below:
**`HF_TASK`**
`HF_TASK` defines the task for the 🤗 Transformers pipeline used . See [here](https://huggingface.co/docs/transformers/main_classes/pipelines) for a complete list of tasks.
```bash
HF_TASK="question-answering"
```
**`HF_MODEL_ID`**
`HF_MODEL_ID` defines the model ID which is automatically loaded from [hf.co/models](https://huggingface.co/models) when creating a SageMaker endpoint. All of the 🤗 Hub's 10,000+ models are available through this environment variable.
```bash
HF_MODEL_ID="distilbert-base-uncased-finetuned-sst-2-english"
```
**`HF_MODEL_REVISION`**
`HF_MODEL_REVISION` is an extension to `HF_MODEL_ID` and allows you to define or pin a model revision to make sure you always load the same model on your SageMaker endpoint.
```bash
HF_MODEL_REVISION="03b4d196c19d0a73c7e0322684e97db1ec397613"
```
**`HF_API_TOKEN`**
`HF_API_TOKEN` defines your Hugging Face authorization token. The `HF_API_TOKEN` is used as a HTTP bearer authorization for remote files like private models. You can find your token under [Settings](https://huggingface.co/settings/tokens) of your Hugging Face account.
```bash
HF_API_TOKEN="api_XXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
```
| huggingface/hub-docs/blob/main/docs/sagemaker/reference.md |
--
title: "How to Install and Use the Hugging Face Unity API"
thumbnail: /blog/assets/124_ml-for-games/unity-api-thumbnail.png
authors:
- user: dylanebert
---
# How to Install and Use the Hugging Face Unity API
<!-- {authors} -->
The [Hugging Face Unity API](https://github.com/huggingface/unity-api) is an easy-to-use integration of the [Hugging Face Inference API](https://huggingface.co/inference-api), allowing developers to access and use Hugging Face AI models in their Unity projects. In this blog post, we'll walk through the steps to install and use the Hugging Face Unity API.
## Installation
1. Open your Unity project
2. Go to `Window` -> `Package Manager`
3. Click `+` and select `Add Package from git URL`
4. Enter `https://github.com/huggingface/unity-api.git`
5. Once installed, the Unity API wizard should pop up. If not, go to `Window` -> `Hugging Face API Wizard`
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/packagemanager.gif">
</figure>
6. Enter your API key. Your API key can be created in your [Hugging Face account settings](https://huggingface.co/settings/tokens).
7. Test the API key by clicking `Test API key` in the API Wizard.
8. Optionally, change the model endpoints to change which model to use. The model endpoint for any model that supports the inference API can be found by going to the model on the Hugging Face website, clicking `Deploy` -> `Inference API`, and copying the url from the `API_URL` field.
9. Configure advanced settings if desired. For up-to-date information, visit the project repository at `https://github.com/huggingface/unity-api`
10. To see examples of how to use the API, click `Install Examples`. You can now close the API Wizard.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/apiwizard.png">
</figure>
Now that the API is set up, you can make calls from your scripts to the API. Let's look at an example of performing a Sentence Similarity task:
```
using HuggingFace.API;
/* other code */
// Make a call to the API
void Query() {
string inputText = "I'm on my way to the forest.";
string[] candidates = {
"The player is going to the city",
"The player is going to the wilderness",
"The player is wandering aimlessly"
};
HuggingFaceAPI.SentenceSimilarity(inputText, OnSuccess, OnError, candidates);
}
// If successful, handle the result
void OnSuccess(float[] result) {
foreach(float value in result) {
Debug.Log(value);
}
}
// Otherwise, handle the error
void OnError(string error) {
Debug.LogError(error);
}
/* other code */
```
## Supported Tasks and Custom Models
The Hugging Face Unity API also currently supports the following tasks:
- [Conversation](https://huggingface.co/tasks/conversational)
- [Text Generation](https://huggingface.co/tasks/text-generation)
- [Text to Image](https://huggingface.co/tasks/text-to-image)
- [Text Classification](https://huggingface.co/tasks/text-classification)
- [Question Answering](https://huggingface.co/tasks/question-answering)
- [Translation](https://huggingface.co/tasks/translation)
- [Summarization](https://huggingface.co/tasks/summarization)
- [Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition)
Use the corresponding methods provided by the `HuggingFaceAPI` class to perform these tasks.
To use your own custom model hosted on Hugging Face, change the model endpoint in the API Wizard.
## Usage Tips
1. Keep in mind that the API makes calls asynchronously, and returns a response or error via callbacks.
2. Address slow response times or performance issues by changing model endpoints to lower resource models.
## Conclusion
The Hugging Face Unity API offers a simple way to integrate AI models into your Unity projects. We hope you found this tutorial helpful. If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)! | huggingface/blog/blob/main/unity-api.md |
InstructPix2Pix SDXL training example
***This is based on the original InstructPix2Pix training example.***
[Stable Diffusion XL](https://huggingface.co/papers/2307.01952) (or SDXL) is the latest image generation model that is tailored towards more photorealistic outputs with more detailed imagery and composition compared to previous SD models. It leverages a three times larger UNet backbone. The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder.
The `train_instruct_pix2pix_sdxl.py` script shows how to implement the training procedure and adapt it for Stable Diffusion XL.
***Disclaimer: Even though `train_instruct_pix2pix_sdxl.py` implements the InstructPix2Pix
training procedure while being faithful to the [original implementation](https://github.com/timothybrooks/instruct-pix2pix) we have only tested it on a [small-scale dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples). This can impact the end results. For better results, we recommend longer training runs with a larger dataset. [Here](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) you can find a large dataset for InstructPix2Pix training.***
## Running locally with PyTorch
### Installing the dependencies
Refer to the original InstructPix2Pix training example for installing the dependencies.
You will also need to get access of SDXL by filling the [form](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
### Toy example
As mentioned before, we'll use a [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) for training. The dataset
is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) used in the InstructPix2Pix paper.
Configure environment variables such as the dataset identifier and the Stable Diffusion
checkpoint:
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export DATASET_ID="fusing/instructpix2pix-1000-samples"
```
Now, we can launch training:
```bash
accelerate launch train_instruct_pix2pix_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--push_to_hub
```
Additionally, we support performing validation inference to monitor training progress
with Weights and Biases. You can enable this feature with `report_to="wandb"`:
```bash
accelerate launch train_instruct_pix2pix_sdxl.py \
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--val_image_url_or_path="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" \
--validation_prompt="make it in japan" \
--report_to=wandb \
--push_to_hub
```
We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
[Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
## Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
accelerate launch --mixed_precision="fp16" --multi_gpu train_instruct_pix2pix_sdxl.py \
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--val_image_url_or_path="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" \
--validation_prompt="make it in japan" \
--report_to=wandb \
--push_to_hub
```
## Inference
Once training is complete, we can perform inference:
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionXLInstructPix2PixPipeline
model_id = "your_model_id" # <- replace this
pipe = StableDiffusionXLInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
url = "https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "make it Japan"
num_inference_steps = 20
image_guidance_scale = 1.5
guidance_scale = 10
edited_image = pipe(prompt,
image=image,
num_inference_steps=num_inference_steps,
image_guidance_scale=image_guidance_scale,
guidance_scale=guidance_scale,
generator=generator,
).images[0]
edited_image.save("edited_image.png")
```
We encourage you to play with the following three parameters to control
speed and quality during performance:
* `num_inference_steps`
* `image_guidance_scale`
* `guidance_scale`
Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
If you're looking for some interesting ways to use the InstructPix2Pix training methodology, we welcome you to check out this blog post: [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd).
## Compare between SD and SDXL
We aim to understand the differences resulting from the use of SD-1.5 and SDXL-0.9 as pretrained models. To achieve this, we trained on the [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) using both of these pretrained models. The training script is as follows:
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5" or "stabilityai/stable-diffusion-xl-base-0.9"
export DATASET_ID="fusing/instructpix2pix-1000-samples"
accelerate launch train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--val_image_url="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" \
--validation_prompt="make it in Japan" \
--report_to=wandb \
--push_to_hub
```
We discovered that compared to training with SD-1.5 as the pretrained model, SDXL-0.9 results in a lower training loss value (SD-1.5 yields 0.0599, SDXL scores 0.0254). Moreover, from a visual perspective, the results obtained using SDXL demonstrated fewer artifacts and a richer detail. Notably, SDXL starts to preserve the structure of the original image earlier on.
The following two GIFs provide intuitive visual results. We observed, for each step, what kind of results could be achieved using the image
<p align="center">
<img src="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" alt="input for make it Japan" width=600/>
</p>
with "make it in Japan” as the prompt. It can be seen that SDXL starts preserving the details of the original image earlier, resulting in higher fidelity outcomes sooner.
* SD-1.5: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sd_ip2p_training_val_img_progress.gif
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sd_ip2p_training_val_img_progress.gif" alt="input for make it Japan" width=600/>
</p>
* SDXL: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl_ip2p_training_val_img_progress.gif
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl_ip2p_training_val_img_progress.gif" alt="input for make it Japan" width=600/>
</p>
| huggingface/diffusers/blob/main/examples/instruct_pix2pix/README_sdxl.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Perceiver
## Overview
The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process
inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example,
Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
The abstract from the paper is the following:
*The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point
clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of
inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without
sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce
outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales
linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves
strong results on tasks with highly structured output spaces, such as natural language and visual understanding,
StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT
baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art
performance on Sintel optical flow estimation.*
Here's a TLDR explaining how Perceiver works:
The main problem with the self-attention mechanism of the Transformer is that the time and memory requirements scale
quadratically with the sequence length. Hence, models like BERT and RoBERTa are limited to a max sequence length of 512
tokens. Perceiver aims to solve this issue by, instead of performing self-attention on the inputs, perform it on a set
of latent variables, and only use the inputs for cross-attention. In this way, the time and memory requirements don't
depend on the length of the inputs anymore, as one uses a fixed amount of latent variables, like 256 or 512. These are
randomly initialized, after which they are trained end-to-end using backpropagation.
Internally, [`PerceiverModel`] will create the latents, which is a tensor of shape `(batch_size, num_latents,
d_latents)`. One must provide `inputs` (which could be text, images, audio, you name it!) to the model, which it will
use to perform cross-attention with the latents. The output of the Perceiver encoder is a tensor of the same shape. One
can then, similar to BERT, convert the last hidden states of the latents to classification logits by averaging along
the sequence dimension, and placing a linear layer on top of that to project the `d_latents` to `num_labels`.
This was the idea of the original Perceiver paper. However, it could only output classification logits. In a follow-up
work, PerceiverIO, they generalized it to let the model also produce outputs of arbitrary size. How, you might ask? The
idea is actually relatively simple: one defines outputs of an arbitrary size, and then applies cross-attention with the
last hidden states of the latents, using the outputs as queries, and the latents as keys and values.
So let's say one wants to perform masked language modeling (BERT-style) with the Perceiver. As the Perceiver's input
length will not have an impact on the computation time of the self-attention layers, one can provide raw bytes,
providing `inputs` of length 2048 to the model. If one now masks out certain of these 2048 tokens, one can define the
`outputs` as being of shape: `(batch_size, 2048, 768)`. Next, one performs cross-attention with the final hidden states
of the latents to update the `outputs` tensor. After cross-attention, one still has a tensor of shape `(batch_size,
2048, 768)`. One can then place a regular language modeling head on top, to project the last dimension to the
vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048, 262)` (as Perceiver uses a vocabulary
size of 262 byte IDs).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg"
alt="drawing" width="600"/>
<small> Perceiver IO architecture. Taken from the <a href="https://arxiv.org/abs/2105.15203">original paper</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
<Tip warning={true}>
Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
</Tip>
## Resources
- The quickest way to get started with the Perceiver is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
audio classification, video classification, etc.
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Image classification task guide](../tasks/image_classification)
## Perceiver specific outputs
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverModelOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverDecoderOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassifierOutput
## PerceiverConfig
[[autodoc]] PerceiverConfig
## PerceiverTokenizer
[[autodoc]] PerceiverTokenizer
- __call__
## PerceiverFeatureExtractor
[[autodoc]] PerceiverFeatureExtractor
- __call__
## PerceiverImageProcessor
[[autodoc]] PerceiverImageProcessor
- preprocess
## PerceiverTextPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
## PerceiverImagePreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
## PerceiverOneHotPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
## PerceiverAudioPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
## PerceiverMultimodalPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
## PerceiverProjectionDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
## PerceiverBasicDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicDecoder
## PerceiverClassificationDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
## PerceiverOpticalFlowDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
## PerceiverBasicVideoAutoencodingDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
## PerceiverMultimodalDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
## PerceiverProjectionPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
## PerceiverAudioPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
## PerceiverClassificationPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
## PerceiverMultimodalPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
## PerceiverModel
[[autodoc]] PerceiverModel
- forward
## PerceiverForMaskedLM
[[autodoc]] PerceiverForMaskedLM
- forward
## PerceiverForSequenceClassification
[[autodoc]] PerceiverForSequenceClassification
- forward
## PerceiverForImageClassificationLearned
[[autodoc]] PerceiverForImageClassificationLearned
- forward
## PerceiverForImageClassificationFourier
[[autodoc]] PerceiverForImageClassificationFourier
- forward
## PerceiverForImageClassificationConvProcessing
[[autodoc]] PerceiverForImageClassificationConvProcessing
- forward
## PerceiverForOpticalFlow
[[autodoc]] PerceiverForOpticalFlow
- forward
## PerceiverForMultimodalAutoencoding
[[autodoc]] PerceiverForMultimodalAutoencoding
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/perceiver.md |
--
title: "Proximal Policy Optimization (PPO)"
thumbnail: /blog/assets/93_deep_rl_ppo/thumbnail.png
authors:
- user: ThomasSimonini
---
# Proximal Policy Optimization (PPO)
<h2>Unit 8, of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit8/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/93_deep_rl_ppo/thumbnail.png" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit8/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
**[In the last Unit](https://huggingface.co/blog/deep-rl-a2c)**, we learned about Advantage Actor Critic (A2C), a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance with:
- *An Actor* that controls **how our agent behaves** (policy-based method).
- *A Critic* that measures **how good the action taken is** (value-based method).
Today we'll learn about Proximal Policy Optimization (PPO), an architecture that improves our agent's training stability by avoiding too large policy updates. To do that, we use a ratio that will indicates the difference between our current and old policy and clip this ratio from a specific range \\( [1 - \epsilon, 1 + \epsilon] \\) .
Doing this will ensure **that our policy update will not be too large and that the training is more stable.**
And then, after the theory, we'll code a PPO architecture from scratch using PyTorch and bulletproof our implementation with CartPole-v1 and LunarLander-v2.
<figure class="image table text-center m-0 w-full">
<video
alt="LunarLander"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/63_deep_rl_intro/lunarlander.mp4" type="video/mp4">
</video>
</figure>
Sounds exciting? Let's get started!
- [The intuition behind PPO](https://huggingface.co/blog/deep-rl-ppo#the-intuition-behind-ppo)
- [Introducing the Clipped Surrogate Objective](https://huggingface.co/blog/deep-rl-ppo#introducing-the-clipped-surrogate-objective)
- [Recap: The Policy Objective Function](https://huggingface.co/blog/deep-rl-ppo#recap-the-policy-objective-function)
- [The Ratio Function](https://huggingface.co/blog/deep-rl-ppo#the-ratio-function)
- [The unclipped part of the Clipped Surrogate Objective function](https://huggingface.co/blog/deep-rl-ppo#the-unclipped-part-of-the-clipped-surrogate-objective-function)
- [The clipped Part of the Clipped Surrogate Objective function](https://huggingface.co/blog/deep-rl-ppo#the-clipped-part-of-the-clipped-surrogate-objective-function)
- [Visualize the Clipped Surrogate Objective](https://huggingface.co/blog/deep-rl-ppo#visualize-the-clipped-surrogate-objective)
- [Case 1 and 2: the ratio is between the range](https://huggingface.co/blog/deep-rl-ppo#case-1-and-2-the-ratio-is-between-the-range)
- [Case 3 and 4: the ratio is below the range](https://huggingface.co/blog/deep-rl-ppo#case-3-and-4-the-ratio-is-below-the-range)
- [Case 5 and 6: the ratio is above the range](https://huggingface.co/blog/deep-rl-ppo#case-5-and-6-the-ratio-is-above-the-range)
- [Let's code our PPO Agent](https://huggingface.co/blog/deep-rl-ppo#lets-code-our-ppo-agent)
## The intuition behind PPO
The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large policy updates.**
For two reasons:
- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
- A too big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and having a long time or even no possibility to recover.**
<figure class="image table text-center m-0 w-full">
<img class="center" src="assets/93_deep_rl_ppo/cliff.jpg" alt="Policy Update cliff"/>
<figcaption>Taking smaller policy updates improve the training stability</figcaption>
<figcaption>Modified version from RL — Proximal Policy Optimization (PPO) Explained by Jonathan Hui: https://jonathan-hui.medium.com/rl-proximal-policy-optimization-ppo-explained-77f014ec3f12</figcaption>
</figure>
**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
## Introducing the Clipped Surrogate Objective
### Recap: The Policy Objective Function
Let’s remember what is the objective to optimize in Reinforce:
<img src="assets/93_deep_rl_ppo/lpg.jpg" alt="Reinforce"/>
The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
However, the problem comes from the step size:
- Too small, **the training process was too slow**
- Too high, **there was too much variability in the training**
Here with PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
This new function **is designed to avoid destructive large weights updates** :
<img src="assets/93_deep_rl_ppo/ppo-surrogate.jpg" alt="PPO surrogate function"/>
Let’s study each part to understand how it works.
### The Ratio Function
<img src="assets/93_deep_rl_ppo/ratio1.jpg" alt="Ratio"/>
This ratio is calculated this way:
<img src="assets/93_deep_rl_ppo/ratio2.jpg" alt="Ratio"/>
It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy divided by the previous one.
As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
### The unclipped part of the Clipped Surrogate Objective function
<img src="assets/93_deep_rl_ppo/unclipped1.jpg" alt="PPO"/>
This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/unclipped2.jpg" alt="PPO"/>
<figcaption><a href="https://arxiv.org/pdf/1707.06347.pdf">Proximal Policy Optimization Algorithms</a></figcaption>
</figure>
However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
### The clipped Part of the Clipped Surrogate Objective function
<img src="assets/93_deep_rl_ppo/clipped.jpg" alt="PPO"/>
Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
To do that, we have two solutions:
- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
<img src="assets/93_deep_rl_ppo/clipped.jpg" alt="PPO"/>
This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
## Visualize the Clipped Surrogate Objective
Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
### Case 1 and 2: the ratio is between the range
In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
### Case 3 and 4: the ratio is below the range
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
### Case 5 and 6: the ratio is above the range
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
So we update our policy only if:
- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
- Being below the ratio but the advantage is > 0
- Being above the ratio but the advantage is < 0
**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
<img src="assets/93_deep_rl_ppo/ppo-objective.jpg" alt="PPO objective"/>
That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
## Let's code our PPO Agent
Now that we studied the theory behind PPO, the best way to understand how it works **is to implement it from scratch.**
Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
So, to be able to code it, we're going to use two resources:
- A tutorial made by [Costa Huang](https://github.com/vwxyzjn). Costa is behind [CleanRL](https://github.com/vwxyzjn/cleanrl), a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: [https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
Then, to test its robustness, we're going to train it in 2 different classical environments:
- [Cartpole-v1](https://www.gymlibrary.ml/environments/classic_control/cart_pole/?highlight=cartpole)
- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
<figure class="image table text-center m-0 w-full">
<video
alt="LunarLander"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/63_deep_rl_intro/lunarlander.mp4" type="video/mp4">
</video>
</figure>
And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. **How incredible is that 🤩.**
<iframe src="https://giphy.com/embed/pynZagVcYxVUk" width="480" height="480" frameBorder="0" class="giphy-embed" allowFullScreen></iframe><p><a href="https://giphy.com/gifs/the-office-michael-heartbreak-pynZagVcYxVUk">via GIPHY</a></p>
Start the tutorial here 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit8/unit8.ipynb
---
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. 🥳, **this was one of the hardest of the course**.
Don't hesitate to train your agent in other environments. The **best way to learn is to try things on your own!**
I want you to think about your progress since the first Unit. **With these eight units, you've built a strong background in Deep Reinforcement Learning. Congratulations!**
But this is not the end, even if the foundations part of the course is finished, this is not the end of the journey. We're working on new elements:
- Adding new environments and tutorials.
- A section about **multi-agents** (self-play, collaboration, competition).
- Another one about **offline RL and Decision Transformers.**
- **Paper explained articles.**
- And more to come.
The best way to keep in touch is to sign up for the course so that we keep you updated 👉 http://eepurl.com/h1pElX
And don't forget to share with your friends who want to learn 🤗!
Finally, with your feedback, we want **to improve and update the course iteratively**. If you have some, please fill this form 👉 **[https://forms.gle/3HgA7bEHwAmmLfwh9](https://forms.gle/3HgA7bEHwAmmLfwh9)**
See you next time!
### **Keep learning, stay awesome 🤗,**
| huggingface/blog/blob/main/deep-rl-ppo.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT-NeoX-Japanese
## Overview
We introduce GPT-NeoX-Japanese, which is an autoregressive language model for Japanese, trained on top of [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
Japanese is a unique language with its large vocabulary and a combination of hiragana, katakana, and kanji writing scripts.
To address this distinct structure of the Japanese language, we use a [special sub-word tokenizer](https://github.com/tanreinama/Japanese-BPEEncoder_V2). We are very grateful to *tanreinama* for open-sourcing this incredibly helpful tokenizer.
Following the recommendations from Google's research on [PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html), we have removed bias parameters from transformer blocks, achieving better model performance. Please refer [this article](https://medium.com/ml-abeja/training-a-better-gpt-2-93b157662ae4) in detail.
Development of the model was led by [Shinya Otani](https://github.com/SO0529), [Takayoshi Makabe](https://github.com/spider-man-tm), [Anuj Arora](https://github.com/Anuj040), and [Kyo Hattori](https://github.com/go5paopao) from [ABEJA, Inc.](https://www.abejainc.com/). For more information on this model-building activity, please refer [here (ja)](https://tech-blog.abeja.asia/entry/abeja-gpt-project-202207).
### Usage example
The `generate()` method can be used to generate text using GPT NeoX Japanese model.
```python
>>> from transformers import GPTNeoXJapaneseForCausalLM, GPTNeoXJapaneseTokenizer
>>> model = GPTNeoXJapaneseForCausalLM.from_pretrained("abeja/gpt-neox-japanese-2.7b")
>>> tokenizer = GPTNeoXJapaneseTokenizer.from_pretrained("abeja/gpt-neox-japanese-2.7b")
>>> prompt = "人とAIが協調するためには、"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens, skip_special_tokens=True)[0]
>>> print(gen_text)
人とAIが協調するためには、AIと人が共存し、AIを正しく理解する必要があります。
```
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoXJapaneseConfig
[[autodoc]] GPTNeoXJapaneseConfig
## GPTNeoXJapaneseTokenizer
[[autodoc]] GPTNeoXJapaneseTokenizer
## GPTNeoXJapaneseModel
[[autodoc]] GPTNeoXJapaneseModel
- forward
## GPTNeoXJapaneseForCausalLM
[[autodoc]] GPTNeoXJapaneseForCausalLM
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/gpt_neox_japanese.md |
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual
identity and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the overall
community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or advances of
any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email address,
without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
[email protected].
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series of
actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or permanent
ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within the
community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.1, available at
[https://www.contributor-covenant.org/version/2/1/code_of_conduct.html][v2.1].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available at
[https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.1]: https://www.contributor-covenant.org/version/2/1/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
| huggingface/transformers/blob/main/CODE_OF_CONDUCT.md |
Gradio Demo: image_component_events
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_img = gr.Image(type="filepath", label="Input Image", sources=["upload", "clipboard"])
with gr.Column():
output_img = gr.Image(type="filepath", label="Output Image", sources=["upload", "clipboard"])
with gr.Column():
num_change = gr.Number(label="# Change Events", value=0)
num_load = gr.Number(label="# Upload Events", value=0)
num_change_o = gr.Number(label="# Change Events Output", value=0)
num_clear = gr.Number(label="# Clear Events", value=0)
input_img.upload(lambda s, n: (s, n + 1), [input_img, num_load], [output_img, num_load])
input_img.change(lambda n: n + 1, num_change, num_change)
input_img.clear(lambda n: n + 1, num_clear, num_clear)
output_img.change(lambda n: n + 1, num_change_o, num_change_o)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/image_component_events/run.ipynb |
Training from memory
In the [Quicktour](quicktour), we saw how to build and train a
tokenizer using text files, but we can actually use any Python Iterator.
In this section we'll see a few different ways of training our
tokenizer.
For all the examples listed below, we'll use the same [`~tokenizers.Tokenizer`] and
[`~tokenizers.trainers.Trainer`], built as
following:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START init_tokenizer_trainer",
"end-before": "END init_tokenizer_trainer",
"dedent": 8}
</literalinclude>
This tokenizer is based on the [`~tokenizers.models.Unigram`] model. It
takes care of normalizing the input using the NFKC Unicode normalization
method, and uses a [`~tokenizers.pre_tokenizers.ByteLevel`] pre-tokenizer with the corresponding decoder.
For more information on the components used here, you can check
[here](components).
## The most basic way
As you probably guessed already, the easiest way to train our tokenizer
is by using a `List`{.interpreted-text role="obj"}:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START train_basic",
"end-before": "END train_basic",
"dedent": 8}
</literalinclude>
Easy, right? You can use anything working as an iterator here, be it a
`List`{.interpreted-text role="obj"}, `Tuple`{.interpreted-text
role="obj"}, or a `np.Array`{.interpreted-text role="obj"}. Anything
works as long as it provides strings.
## Using the 🤗 Datasets library
An awesome way to access one of the many datasets that exist out there
is by using the 🤗 Datasets library. For more information about it, you
should check [the official documentation
here](https://huggingface.co/docs/datasets/).
Let's start by loading our dataset:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START load_dataset",
"end-before": "END load_dataset",
"dedent": 8}
</literalinclude>
The next step is to build an iterator over this dataset. The easiest way
to do this is probably by using a generator:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START def_batch_iterator",
"end-before": "END def_batch_iterator",
"dedent": 8}
</literalinclude>
As you can see here, for improved efficiency we can actually provide a
batch of examples used to train, instead of iterating over them one by
one. By doing so, we can expect performances very similar to those we
got while training directly from files.
With our iterator ready, we just need to launch the training. In order
to improve the look of our progress bars, we can specify the total
length of the dataset:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START train_datasets",
"end-before": "END train_datasets",
"dedent": 8}
</literalinclude>
And that's it!
## Using gzip files
Since gzip files in Python can be used as iterators, it is extremely
simple to train on such files:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START single_gzip",
"end-before": "END single_gzip",
"dedent": 8}
</literalinclude>
Now if we wanted to train from multiple gzip files, it wouldn't be much
harder:
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py",
"language": "python",
"start-after": "START multi_gzip",
"end-before": "END multi_gzip",
"dedent": 8}
</literalinclude>
And voilà!
| huggingface/tokenizers/blob/main/docs/source-doc-builder/training_from_memory.mdx |
Gradio Demo: reverse_audio
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('audio')
!wget -q -O audio/cantina.wav https://github.com/gradio-app/gradio/raw/main/demo/reverse_audio/audio/cantina.wav
!wget -q -O audio/recording1.wav https://github.com/gradio-app/gradio/raw/main/demo/reverse_audio/audio/recording1.wav
```
```
import os
import numpy as np
import gradio as gr
def reverse_audio(audio):
sr, data = audio
return (sr, np.flipud(data))
input_audio = gr.Audio(
sources=["microphone"],
waveform_options=gr.WaveformOptions(
waveform_color="#01C6FF",
waveform_progress_color="#0066B4",
skip_length=2,
show_controls=False,
),
)
demo = gr.Interface(
fn=reverse_audio,
inputs=input_audio,
outputs="audio",
examples=[
"https://samplelib.com/lib/preview/mp3/sample-3s.mp3",
os.path.join(os.path.abspath(''), "audio/recording1.wav"),
],
cache_examples=True,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/reverse_audio/run.ipynb |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
## Summarization
This directory contains examples for finetuning and evaluating transformers on summarization tasks.
Please tag @patil-suraj with any issues/unexpected behaviors, or send a PR!
For deprecated `bertabs` instructions, see [`bertabs/README.md`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/bertabs/README.md).
For the old `finetune_trainer.py` and related utils, see [`examples/legacy/seq2seq`](https://github.com/huggingface/transformers/blob/main/examples/legacy/seq2seq).
### Supported Architectures
- `BartForConditionalGeneration`
- `FSMTForConditionalGeneration` (translation only)
- `MBartForConditionalGeneration`
- `MarianMTModel`
- `PegasusForConditionalGeneration`
- `T5ForConditionalGeneration`
- `MT5ForConditionalGeneration`
`run_summarization.py` is a lightweight example of how to download and preprocess a dataset from the [🤗 Datasets](https://github.com/huggingface/datasets) library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files
and you also will find examples of these below.
## With Trainer
Here is an example on a summarization task:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Only T5 models `t5-small`, `t5-base`, `t5-large`, `t5-3b` and `t5-11b` must use an additional argument: `--source_prefix "summarize: "`.
We used CNN/DailyMail dataset in this example as `t5-small` was trained on it and one can get good scores even when pre-training with a very small sample.
Extreme Summarization (XSum) Dataset is another commonly used dataset for the task of summarization. To use it replace `--dataset_name cnn_dailymail --dataset_config "3.0.0"` with `--dataset_name xsum`.
And here is how you would use it on your own files, after adjusting the values for the arguments
`--train_file`, `--validation_file`, `--text_column` and `--summary_column` to match your setup:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
The task of summarization supports custom CSV and JSONLINES formats.
#### Custom CSV Files
If it's a csv file the training and validation files should have a column for the inputs texts and a column for the summaries.
If the csv file has just two columns as in the following example:
```csv
text,summary
"I'm sitting here in a boring room. It's just another rainy Sunday afternoon. I'm wasting my time I got nothing to do. I'm hanging around I'm waiting for you. But nothing ever happens. And I wonder","I'm sitting in a room where I'm waiting for something to happen"
"I see trees so green, red roses too. I see them bloom for me and you. And I think to myself what a wonderful world. I see skies so blue and clouds so white. The bright blessed day, the dark sacred night. And I think to myself what a wonderful world.","I'm a gardener and I'm a big fan of flowers."
"Christmas time is here. Happiness and cheer. Fun for all that children call. Their favorite time of the year. Snowflakes in the air. Carols everywhere. Olden times and ancient rhymes. Of love and dreams to share","It's that time of year again."
```
The first column is assumed to be for `text` and the second is for summary.
If the csv file has multiple columns, you can then specify the names of the columns to use:
```bash
--text_column text_column_name \
--summary_column summary_column_name \
```
For example if the columns were:
```csv
id,date,text,summary
```
and you wanted to select only `text` and `summary`, then you'd pass these additional arguments:
```bash
--text_column text \
--summary_column summary \
```
#### Custom JSONLINES Files
The second supported format is jsonlines. Here is an example of a jsonlines custom data file.
```json
{"text": "I'm sitting here in a boring room. It's just another rainy Sunday afternoon. I'm wasting my time I got nothing to do. I'm hanging around I'm waiting for you. But nothing ever happens. And I wonder", "summary": "I'm sitting in a room where I'm waiting for something to happen"}
{"text": "I see trees so green, red roses too. I see them bloom for me and you. And I think to myself what a wonderful world. I see skies so blue and clouds so white. The bright blessed day, the dark sacred night. And I think to myself what a wonderful world.", "summary": "I'm a gardener and I'm a big fan of flowers."}
{"text": "Christmas time is here. Happiness and cheer. Fun for all that children call. Their favorite time of the year. Snowflakes in the air. Carols everywhere. Olden times and ancient rhymes. Of love and dreams to share", "summary": "It's that time of year again."}
```
Same as with the CSV files, by default the first value will be used as the text record and the second as the summary record. Therefore you can use any key names for the entries, in this example `text` and `summary` were used.
And as with the CSV files, you can specify which values to select from the file, by explicitly specifying the corresponding key names. In our example this again would be:
```bash
--text_column text \
--summary_column summary \
```
## With Accelerate
Based on the script [`run_summarization_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/summarization/run_summarization_no_trainer.py).
Like `run_summarization.py`, this script allows you to fine-tune any of the models supported on a
summarization task, the main difference is that this
script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then
```bash
python run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| huggingface/transformers/blob/main/examples/pytorch/summarization/README.md |
n our other videos, and as always, there'll be links below if you want to check those out, we showed you how to initialize and fine-tune a transformer model in TensorFlow, so the question now is: What can we do with a model after we train it? The obvious thing to try is to use it to get predictions for new data, so let's see how to do that. Again, if you're familiar with Keras, the good news is that because there are just standard Keras models, we can use the standard Keras predict() method, as shown here. You simply pass in tokenized text to this method, like you'd get from a tokenizer, and you get your results. Our models can output several different things, depending on the options you set, but most of the time the thing you want is the output logits. If you haven’t come across them before, logits are the outputs of the last layer of the network, before a softmax has been applied. So if you want to turn the logits into the model’s probability outputs, you just apply a softmax, like so. What if we want to turn those probabilities into class predictions? Simple, we just pick the biggest probability for each output! The easiest way to do that is with the argmax function. Argmax will return the index of the largest probability in each row, which means in this case that we’ll get a vector of 0 and 1 values. Those are our class predictions! In fact, if class predictions are all you want, you can skip the softmax step entirely, because the largest logit will always be the largest probability too. If probabilities and class predictions are all you want, then you’ve seen everything you need at this point! But if you’re interested in benchmarking your model or using it for research, you might want to delve deeper into the results you get. And one way to do that is to compute some metrics for the model’s predictions. If you're following along with our datasets and fine-tuning videos, we got our data from the MRPC dataset, which is part of the GLUE benchmark. Each of the GLUE datasets, as well as many of our other datasets, has some predefined metrics, and we can load them easily with the datasets load_metric() function. For the MRPC dataset, the built-in metrics are accuracy, which just measures the percentage of the time the model’s prediction was correct, and the F1 score, which is a slightly more complex measure that measures how well the model trades off precision and recall. To compute those metrics to benchmark our model, we just pass them the model’s predictions, and the ground truth labels, and we get our results. If you’re familiar with Keras, though, you’ll notice that this is a weird way to compute metrics - we’re only computing metrics at the end of training, but Keras has the built-in ability to compute a wide range of metrics on the fly while you're training. If you want to use built-in metric computations, it's very straightforward - you just pass a 'metric' argument to compile(). As with things like loss and optimizer, you can specify the metrics you want by string, or you can import the actual metric objects if you want to pass specific arguments to them, but note that unlike loss and accuracy, you have to supply a list of metrics, even if you only have one. Once a model has been compiled with a metric, it will report that metric for training, validation and predictions. You can even write your own Metric classes. Though this is a bit beyond the scope of this course, I'll link to the relevant TF docs below because it can be very handy if you want a metric that isn't supported by default in Keras, such as the F1 score. | huggingface/course/blob/main/subtitles/en/raw/chapter3/03e_keras-metrics.md |
Glossary [[glossary]]
This is a community-created glossary. Contributions are welcomed!
### Strategies to find the optimal policy
- **Policy-based methods.** The policy is usually trained with a neural network to select what action to take given a state. In this case it is the neural network which outputs the action that the agent should take instead of using a value function. Depending on the experience received by the environment, the neural network will be re-adjusted and will provide better actions.
- **Value-based methods.** In this case, a value function is trained to output the value of a state or a state-action pair that will represent our policy. However, this value doesn't define what action the agent should take. In contrast, we need to specify the behavior of the agent given the output of the value function. For example, we could decide to adopt a policy to take the action that always leads to the biggest reward (Greedy Policy). In summary, the policy is a Greedy Policy (or whatever decision the user takes) that uses the values of the value-function to decide the actions to take.
### Among the value-based methods, we can find two main strategies
- **The state-value function.** For each state, the state-value function is the expected return if the agent starts in that state and follows the policy until the end.
- **The action-value function.** In contrast to the state-value function, the action-value calculates for each state and action pair the expected return if the agent starts in that state, takes that action, and then follows the policy forever after.
### Epsilon-greedy strategy:
- Common strategy used in reinforcement learning that involves balancing exploration and exploitation.
- Chooses the action with the highest expected reward with a probability of 1-epsilon.
- Chooses a random action with a probability of epsilon.
- Epsilon is typically decreased over time to shift focus towards exploitation.
### Greedy strategy:
- Involves always choosing the action that is expected to lead to the highest reward, based on the current knowledge of the environment. (Only exploitation)
- Always chooses the action with the highest expected reward.
- Does not include any exploration.
- Can be disadvantageous in environments with uncertainty or unknown optimal actions.
### Off-policy vs on-policy algorithms
- **Off-policy algorithms:** A different policy is used at training time and inference time
- **On-policy algorithms:** The same policy is used during training and inference
### Monte Carlo and Temporal Difference learning strategies
- **Monte Carlo (MC):** Learning at the end of the episode. With Monte Carlo, we wait until the episode ends and then we update the value function (or policy function) from a complete episode.
- **Temporal Difference (TD):** Learning at each step. With Temporal Difference Learning, we update the value function (or policy function) at each step without requiring a complete episode.
If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
This glossary was made possible thanks to:
- [Ramón Rueda](https://github.com/ramon-rd)
- [Hasarindu Perera](https://github.com/hasarinduperera/)
- [Arkady Arkhangorodsky](https://github.com/arkadyark/)
| huggingface/deep-rl-class/blob/main/units/en/unit2/glossary.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Informer
## Overview
The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting ](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
The abstract from the paper is the following:
*Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, including quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse self-attention mechanism, which achieves O(L logL) in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.*
This model was contributed by [elisim](https://huggingface.co/elisim) and [kashif](https://huggingface.co/kashif).
The original code can be found [here](https://github.com/zhouhaoyi/Informer2020).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Check out the Informer blog-post in HuggingFace blog: [Multivariate Probabilistic Time Series Forecasting with Informer](https://huggingface.co/blog/informer)
## InformerConfig
[[autodoc]] InformerConfig
## InformerModel
[[autodoc]] InformerModel
- forward
## InformerForPrediction
[[autodoc]] InformerForPrediction
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/informer.md |
The Reinforcement Learning Framework [[the-reinforcement-learning-framework]]
## The RL Process [[the-rl-process]]
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process.jpg" alt="The RL process" width="100%">
<figcaption>The RL Process: a loop of state, action, reward and next state</figcaption>
<figcaption>Source: <a href="http://incompleteideas.net/book/RLbook2020.pdf">Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto</a></figcaption>
</figure>
To understand the RL process, let’s imagine an agent learning to play a platform game:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process_game.jpg" alt="The RL process" width="100%">
- Our Agent receives **state \\(S_0\\)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state \\(S_0\\),** the Agent takes **action \\(A_0\\)** — our Agent will move to the right.
- The environment goes to a **new** **state \\(S_1\\)** — new frame.
- The environment gives some **reward \\(R_1\\)** to the Agent — we’re not dead *(Positive Reward +1)*.
This RL loop outputs a sequence of **state, action, reward and next state.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/sars.jpg" alt="State, Action, Reward, Next State" width="100%">
The agent's goal is to _maximize_ its cumulative reward, **called the expected return.**
## The reward hypothesis: the central idea of Reinforcement Learning [[reward-hypothesis]]
⇒ Why is the goal of the agent to maximize the expected return?
Because RL is based on the **reward hypothesis**, which is that all goals can be described as the **maximization of the expected return** (expected cumulative reward).
That’s why in Reinforcement Learning, **to have the best behavior,** we aim to learn to take actions that **maximize the expected cumulative reward.**
## Markov Property [[markov-property]]
In papers, you’ll see that the RL process is called a **Markov Decision Process** (MDP).
We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it's this: the Markov Property implies that our agent needs **only the current state to decide** what action to take and **not the history of all the states and actions** they took before.
## Observations/States Space [[obs-space]]
Observations/States are the **information our agent gets from the environment.** In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
There is a differentiation to make between *observation* and *state*, however:
- *State s*: is **a complete description of the state of the world** (there is no hidden information). In a fully observed environment.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/chess.jpg" alt="Chess">
<figcaption>In chess game, we receive a state from the environment since we have access to the whole check board information.</figcaption>
</figure>
In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
- *Observation o*: is a **partial description of the state.** In a partially observed environment.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/mario.jpg" alt="Mario">
<figcaption>In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.</figcaption>
</figure>
In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
In Super Mario Bros, we are in a partially observed environment. We receive an observation **since we only see a part of the level.**
<Tip>
In this course, we use the term "state" to denote both state and observation, but we will make the distinction in implementations.
</Tip>
To recap:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/obs_space_recap.jpg" alt="Obs space recap" width="100%">
## Action Space [[action-space]]
The Action space is the set of **all possible actions in an environment.**
The actions can come from a *discrete* or *continuous space*:
- *Discrete space*: the number of possible actions is **finite**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/mario.jpg" alt="Mario">
<figcaption>In Super Mario Bros, we have only 4 possible actions: left, right, up (jumping) and down (crouching).</figcaption>
</figure>
Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
- *Continuous space*: the number of possible actions is **infinite**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/self_driving_car.jpg" alt="Self Driving Car">
<figcaption>A Self Driving Car agent has an infinite number of possible actions since it can turn left 20°, 21,1°, 21,2°, honk, turn right 20°…
</figcaption>
</figure>
To recap:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/action_space.jpg" alt="Action space recap" width="100%">
Taking this information into consideration is crucial because it will **have importance when choosing the RL algorithm in the future.**
## Rewards and the discounting [[rewards]]
The reward is fundamental in RL because it’s **the only feedback** for the agent. Thanks to it, our agent knows **if the action taken was good or not.**
The cumulative reward at each time step **t** can be written as:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/rewards_1.jpg" alt="Rewards">
<figcaption>The cumulative reward equals the sum of all rewards in the sequence.
</figcaption>
</figure>
Which is equivalent to:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/rewards_2.jpg" alt="Rewards">
<figcaption>The cumulative reward = rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + ...
</figcaption>
</figure>
However, in reality, **we can’t just add them like that.** The rewards that come sooner (at the beginning of the game) **are more likely to happen** since they are more predictable than the long-term future reward.
Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse's goal is **to eat the maximum amount of cheese before being eaten by the cat.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/rewards_3.jpg" alt="Rewards" width="100%">
As we can see in the diagram, **it’s more probable to eat the cheese near us than the cheese close to the cat** (the closer we are to the cat, the more dangerous it is).
Consequently, **the reward near the cat, even if it is bigger (more cheese), will be more discounted** since we’re not really sure we’ll be able to eat it.
To discount the rewards, we proceed like this:
1. We define a discount rate called gamma. **It must be between 0 and 1.** Most of the time between **0.95 and 0.99**.
- The larger the gamma, the smaller the discount. This means our agent **cares more about the long-term reward.**
- On the other hand, the smaller the gamma, the bigger the discount. This means our **agent cares more about the short term reward (the nearest cheese).**
2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, **so the future reward is less and less likely to happen.**
Our discounted expected cumulative reward is:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/rewards_4.jpg" alt="Rewards" width="100%">
| huggingface/deep-rl-class/blob/main/units/en/unit1/rl-framework.mdx |
Gradio Demo: blocks_page_load
```
!pip install -q gradio
```
```
import gradio as gr
def print_message(n):
return "Welcome! This page has loaded for " + n
with gr.Blocks() as demo:
t = gr.Textbox("Frank", label="Name")
t2 = gr.Textbox(label="Output")
demo.load(print_message, t, t2)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_page_load/run.ipynb |
Unigram tokenization[[unigram-tokenization]]
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section7.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section7.ipynb"},
]} />
The Unigram algorithm is often used in SentencePiece, which is the tokenization algorithm used by models like AlBERT, T5, mBART, Big Bird, and XLNet.
<Youtube id="TGZfZVuF9Yc"/>
<Tip>
💡 This section covers Unigram in depth, going as far as showing a full implementation. You can skip to the end if you just want a general overview of the tokenization algorithm.
</Tip>
## Training algorithm[[training-algorithm]]
Compared to BPE and WordPiece, Unigram works in the other direction: it starts from a big vocabulary and removes tokens from it until it reaches the desired vocabulary size. There are several options to use to build that base vocabulary: we can take the most common substrings in pre-tokenized words, for instance, or apply BPE on the initial corpus with a large vocabulary size.
At each step of the training, the Unigram algorithm computes a loss over the corpus given the current vocabulary. Then, for each symbol in the vocabulary, the algorithm computes how much the overall loss would increase if the symbol was removed, and looks for the symbols that would increase it the least. Those symbols have a lower effect on the overall loss over the corpus, so in a sense they are "less needed" and are the best candidates for removal.
This is all a very costly operation, so we don't just remove the single symbol associated with the lowest loss increase, but the \\(p\\) (\\(p\\) being a hyperparameter you can control, usually 10 or 20) percent of the symbols associated with the lowest loss increase. This process is then repeated until the vocabulary has reached the desired size.
Note that we never remove the base characters, to make sure any word can be tokenized.
Now, this is still a bit vague: the main part of the algorithm is to compute a loss over the corpus and see how it changes when we remove some tokens from the vocabulary, but we haven't explained how to do this yet. This step relies on the tokenization algorithm of a Unigram model, so we'll dive into this next.
We'll reuse the corpus from the previous examples:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
and for this example, we will take all strict substrings for the initial vocabulary :
```
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"]
```
## Tokenization algorithm[[tokenization-algorithm]]
A Unigram model is a type of language model that considers each token to be independent of the tokens before it. It's the simplest language model, in the sense that the probability of token X given the previous context is just the probability of token X. So, if we used a Unigram language model to generate text, we would always predict the most common token.
The probability of a given token is its frequency (the number of times we find it) in the original corpus, divided by the sum of all frequencies of all tokens in the vocabulary (to make sure the probabilities sum up to 1). For instance, `"ug"` is present in `"hug"`, `"pug"`, and `"hugs"`, so it has a frequency of 20 in our corpus.
Here are the frequencies of all the possible subwords in the vocabulary:
```
("h", 15) ("u", 36) ("g", 20) ("hu", 15) ("ug", 20) ("p", 17) ("pu", 17) ("n", 16)
("un", 16) ("b", 4) ("bu", 4) ("s", 5) ("hug", 15) ("gs", 5) ("ugs", 5)
```
So, the sum of all frequencies is 210, and the probability of the subword `"ug"` is thus 20/210.
<Tip>
✏️ **Now your turn!** Write the code to compute the frequencies above and double-check that the results shown are correct, as well as the total sum.
</Tip>
Now, to tokenize a given word, we look at all the possible segmentations into tokens and compute the probability of each according to the Unigram model. Since all tokens are considered independent, this probability is just the product of the probability of each token. For instance, the tokenization `["p", "u", "g"]` of `"pug"` has the probability:
$$P([``p", ``u", ``g"]) = P(``p") \times P(``u") \times P(``g") = \frac{5}{210} \times \frac{36}{210} \times \frac{20}{210} = 0.000389$$
Comparatively, the tokenization `["pu", "g"]` has the probability:
$$P([``pu", ``g"]) = P(``pu") \times P(``g") = \frac{5}{210} \times \frac{20}{210} = 0.0022676$$
so that one is way more likely. In general, tokenizations with the least tokens possible will have the highest probability (because of that division by 210 repeated for each token), which corresponds to what we want intuitively: to split a word into the least number of tokens possible.
The tokenization of a word with the Unigram model is then the tokenization with the highest probability. In the example of `"pug"`, here are the probabilities we would get for each possible segmentation:
```
["p", "u", "g"] : 0.000389
["p", "ug"] : 0.0022676
["pu", "g"] : 0.0022676
```
So, `"pug"` would be tokenized as `["p", "ug"]` or `["pu", "g"]`, depending on which of those segmentations is encountered first (note that in a larger corpus, equality cases like this will be rare).
In this case, it was easy to find all the possible segmentations and compute their probabilities, but in general it's going to be a bit harder. There is a classic algorithm used for this, called the *Viterbi algorithm*. Essentially, we can build a graph to detect the possible segmentations of a given word by saying there is a branch from character _a_ to character _b_ if the subword from _a_ to _b_ is in the vocabulary, and attribute to that branch the probability of the subword.
To find the path in that graph that is going to have the best score the Viterbi algorithm determines, for each position in the word, the segmentation with the best score that ends at that position. Since we go from the beginning to the end, that best score can be found by looping through all subwords ending at the current position and then using the best tokenization score from the position this subword begins at. Then, we just have to unroll the path taken to arrive at the end.
Let's take a look at an example using our vocabulary and the word `"unhug"`. For each position, the subwords with the best scores ending there are the following:
```
Character 0 (u): "u" (score 0.171429)
Character 1 (n): "un" (score 0.076191)
Character 2 (h): "un" "h" (score 0.005442)
Character 3 (u): "un" "hu" (score 0.005442)
Character 4 (g): "un" "hug" (score 0.005442)
```
Thus `"unhug"` would be tokenized as `["un", "hug"]`.
<Tip>
✏️ **Now your turn!** Determine the tokenization of the word `"huggun"`, and its score.
</Tip>
## Back to training[[back-to-training]]
Now that we have seen how the tokenization works, we can dive a little more deeply into the loss used during training. At any given stage, this loss is computed by tokenizing every word in the corpus, using the current vocabulary and the Unigram model determined by the frequencies of each token in the corpus (as seen before).
Each word in the corpus has a score, and the loss is the negative log likelihood of those scores -- that is, the sum for all the words in the corpus of all the `-log(P(word))`.
Let's go back to our example with the following corpus:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
The tokenization of each word with their respective scores is:
```
"hug": ["hug"] (score 0.071428)
"pug": ["pu", "g"] (score 0.007710)
"pun": ["pu", "n"] (score 0.006168)
"bun": ["bu", "n"] (score 0.001451)
"hugs": ["hug", "s"] (score 0.001701)
```
So the loss is:
```
10 * (-log(0.071428)) + 5 * (-log(0.007710)) + 12 * (-log(0.006168)) + 4 * (-log(0.001451)) + 5 * (-log(0.001701)) = 169.8
```
Now we need to compute how removing each token affects the loss. This is rather tedious, so we'll just do it for two tokens here and save the whole process for when we have code to help us. In this (very) particular case, we had two equivalent tokenizations of all the words: as we saw earlier, for example, `"pug"` could be tokenized `["p", "ug"]` with the same score. Thus, removing the `"pu"` token from the vocabulary will give the exact same loss.
On the other hand, removing `"hug"` will make the loss worse, because the tokenization of `"hug"` and `"hugs"` will become:
```
"hug": ["hu", "g"] (score 0.006802)
"hugs": ["hu", "gs"] (score 0.001701)
```
These changes will cause the loss to rise by:
```
- 10 * (-log(0.071428)) + 10 * (-log(0.006802)) = 23.5
```
Therefore, the token `"pu"` will probably be removed from the vocabulary, but not `"hug"`.
## Implementing Unigram[[implementing-unigram]]
Now let's implement everything we've seen so far in code. Like with BPE and WordPiece, this is not an efficient implementation of the Unigram algorithm (quite the opposite), but it should help you understand it a bit better.
We will use the same corpus as before as an example:
```python
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
```
This time, we will use `xlnet-base-cased` as our model:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
```
Like for BPE and WordPiece, we begin by counting the number of occurrences of each word in the corpus:
```python
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
word_freqs
```
Then, we need to initialize our vocabulary to something larger than the vocab size we will want at the end. We have to include all the basic characters (otherwise we won't be able to tokenize every word), but for the bigger substrings we'll only keep the most common ones, so we sort them by frequency:
```python
char_freqs = defaultdict(int)
subwords_freqs = defaultdict(int)
for word, freq in word_freqs.items():
for i in range(len(word)):
char_freqs[word[i]] += freq
# Loop through the subwords of length at least 2
for j in range(i + 2, len(word) + 1):
subwords_freqs[word[i:j]] += freq
# Sort subwords by frequency
sorted_subwords = sorted(subwords_freqs.items(), key=lambda x: x[1], reverse=True)
sorted_subwords[:10]
```
```python out
[('▁t', 7), ('is', 5), ('er', 5), ('▁a', 5), ('▁to', 4), ('to', 4), ('en', 4), ('▁T', 3), ('▁Th', 3), ('▁Thi', 3)]
```
We group the characters with the best subwords to arrive at an initial vocabulary of size 300:
```python
token_freqs = list(char_freqs.items()) + sorted_subwords[: 300 - len(char_freqs)]
token_freqs = {token: freq for token, freq in token_freqs}
```
<Tip>
💡 SentencePiece uses a more efficient algorithm called Enhanced Suffix Array (ESA) to create the initial vocabulary.
</Tip>
Next, we compute the sum of all frequencies, to convert the frequencies into probabilities. For our model we will store the logarithms of the probabilities, because it's more numerically stable to add logarithms than to multiply small numbers, and this will simplify the computation of the loss of the model:
```python
from math import log
total_sum = sum([freq for token, freq in token_freqs.items()])
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
```
Now the main function is the one that tokenizes words using the Viterbi algorithm. As we saw before, that algorithm computes the best segmentation of each substring of the word, which we will store in a variable named `best_segmentations`. We will store one dictionary per position in the word (from 0 to its total length), with two keys: the index of the start of the last token in the best segmentation, and the score of the best segmentation. With the index of the start of the last token, we will be able to retrieve the full segmentation once the list is completely populated.
Populating the list is done with just two loops: the main loop goes over each start position, and the second loop tries all substrings beginning at that start position. If the substring is in the vocabulary, we have a new segmentation of the word up until that end position, which we compare to what is in `best_segmentations`.
Once the main loop is finished, we just start from the end and hop from one start position to the next, recording the tokens as we go, until we reach the start of the word:
```python
def encode_word(word, model):
best_segmentations = [{"start": 0, "score": 1}] + [
{"start": None, "score": None} for _ in range(len(word))
]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
# If we have found a better segmentation ending at end_idx, we update
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
score = segmentation["score"]
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, score
```
We can already try our initial model on some words:
```python
print(encode_word("Hopefully", model))
print(encode_word("This", model))
```
```python out
(['H', 'o', 'p', 'e', 'f', 'u', 'll', 'y'], 41.5157494601402)
(['This'], 6.288267030694535)
```
Now it's easy to compute the loss of the model on the corpus!
```python
def compute_loss(model):
loss = 0
for word, freq in word_freqs.items():
_, word_loss = encode_word(word, model)
loss += freq * word_loss
return loss
```
We can check it works on the model we have:
```python
compute_loss(model)
```
```python out
413.10377642940875
```
Computing the scores for each token is not very hard either; we just have to compute the loss for the models obtained by deleting each token:
```python
import copy
def compute_scores(model):
scores = {}
model_loss = compute_loss(model)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = compute_loss(model_without_token) - model_loss
return scores
```
We can try it on a given token:
```python
scores = compute_scores(model)
print(scores["ll"])
print(scores["his"])
```
Since `"ll"` is used in the tokenization of `"Hopefully"`, and removing it will probably make us use the token `"l"` twice instead, we expect it will have a positive loss. `"his"` is only used inside the word `"This"`, which is tokenized as itself, so we expect it to have a zero loss. Here are the results:
```python out
6.376412403623874
0.0
```
<Tip>
💡 This approach is very inefficient, so SentencePiece uses an approximation of the loss of the model without token X: instead of starting from scratch, it just replaces token X by its segmentation in the vocabulary that is left. This way, all the scores can be computed at once at the same time as the model loss.
</Tip>
With all of this in place, the last thing we need to do is add the special tokens used by the model to the vocabulary, then loop until we have pruned enough tokens from the vocabulary to reach our desired size:
```python
percent_to_remove = 0.1
while len(model) > 100:
scores = compute_scores(model)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * percent_to_remove)):
_ = token_freqs.pop(sorted_scores[i][0])
total_sum = sum([freq for token, freq in token_freqs.items()])
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
```
Then, to tokenize some text, we just need to apply the pre-tokenization and then use our `encode_word()` function:
```python
def tokenize(text, model):
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in words_with_offsets]
encoded_words = [encode_word(word, model)[0] for word in pre_tokenized_text]
return sum(encoded_words, [])
tokenize("This is the Hugging Face course.", model)
```
```python out
['▁This', '▁is', '▁the', '▁Hugging', '▁Face', '▁', 'c', 'ou', 'r', 's', 'e', '.']
```
That's it for Unigram! Hopefully by now you're feeling like an expert in all things tokenizer. In the next section, we will delve into the building blocks of the 🤗 Tokenizers library, and show you how you can use them to build your own tokenizer.
| huggingface/course/blob/main/chapters/en/chapter6/7.mdx |
Gradio & LLM Agents 🤝
Large Language Models (LLMs) are very impressive but they can be made even more powerful if we could give them skills to accomplish specialized tasks.
The [gradio_tools](https://github.com/freddyaboulton/gradio-tools) library can turn any [Gradio](https://github.com/gradio-app/gradio) application into a [tool](https://python.langchain.com/en/latest/modules/agents/tools.html) that an [agent](https://docs.langchain.com/docs/components/agents/agent) can use to complete its task. For example, an LLM could use a Gradio tool to transcribe a voice recording it finds online and then summarize it for you. Or it could use a different Gradio tool to apply OCR to a document on your Google Drive and then answer questions about it.
This guide will show how you can use `gradio_tools` to grant your LLM Agent access to the cutting edge Gradio applications hosted in the world. Although `gradio_tools` are compatible with more than one agent framework, we will focus on [Langchain Agents](https://docs.langchain.com/docs/components/agents/) in this guide.
## Some background
### What are agents?
A [LangChain agent](https://docs.langchain.com/docs/components/agents/agent) is a Large Language Model (LLM) that takes user input and reports an output based on using one of many tools at its disposal.
### What is Gradio?
[Gradio](https://github.com/gradio-app/gradio) is the defacto standard framework for building Machine Learning Web Applications and sharing them with the world - all with just python! 🐍
## gradio_tools - An end-to-end example
To get started with `gradio_tools`, all you need to do is import and initialize your tools and pass them to the langchain agent!
In the following example, we import the `StableDiffusionPromptGeneratorTool` to create a good prompt for stable diffusion, the
`StableDiffusionTool` to create an image with our improved prompt, the `ImageCaptioningTool` to caption the generated image, and
the `TextToVideoTool` to create a video from a prompt.
We then tell our agent to create an image of a dog riding a skateboard, but to please improve our prompt ahead of time. We also ask
it to caption the generated image and create a video for it. The agent can decide which tool to use without us explicitly telling it.
```python
import os
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY must be set")
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from gradio_tools import (StableDiffusionTool, ImageCaptioningTool, StableDiffusionPromptGeneratorTool,
TextToVideoTool)
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history")
tools = [StableDiffusionTool().langchain, ImageCaptioningTool().langchain,
StableDiffusionPromptGeneratorTool().langchain, TextToVideoTool().langchain]
agent = initialize_agent(tools, llm, memory=memory, agent="conversational-react-description", verbose=True)
output = agent.run(input=("Please create a photo of a dog riding a skateboard "
"but improve my prompt prior to using an image generator."
"Please caption the generated image and create a video for it using the improved prompt."))
```
You'll note that we are using some pre-built tools that come with `gradio_tools`. Please see this [doc](https://github.com/freddyaboulton/gradio-tools#gradio-tools-gradio--llm-agents) for a complete list of the tools that come with `gradio_tools`.
If you would like to use a tool that's not currently in `gradio_tools`, it is very easy to add your own. That's what the next section will cover.
## gradio_tools - creating your own tool
The core abstraction is the `GradioTool`, which lets you define a new tool for your LLM as long as you implement a standard interface:
```python
class GradioTool(BaseTool):
def __init__(self, name: str, description: str, src: str) -> None:
@abstractmethod
def create_job(self, query: str) -> Job:
pass
@abstractmethod
def postprocess(self, output: Tuple[Any] | Any) -> str:
pass
```
The requirements are:
1. The name for your tool
2. The description for your tool. This is crucial! Agents decide which tool to use based on their description. Be precise and be sure to include example of what the input and the output of the tool should look like.
3. The url or space id, e.g. `freddyaboulton/calculator`, of the Gradio application. Based on this value, `gradio_tool` will create a [gradio client](https://github.com/gradio-app/gradio/blob/main/client/python/README.md) instance to query the upstream application via API. Be sure to click the link and learn more about the gradio client library if you are not familiar with it.
4. create_job - Given a string, this method should parse that string and return a job from the client. Most times, this is as simple as passing the string to the `submit` function of the client. More info on creating jobs [here](https://github.com/gradio-app/gradio/blob/main/client/python/README.md#making-a-prediction)
5. postprocess - Given the result of the job, convert it to a string the LLM can display to the user.
6. _Optional_ - Some libraries, e.g. [MiniChain](https://github.com/srush/MiniChain/tree/main), may need some info about the underlying gradio input and output types used by the tool. By default, this will return gr.Textbox() but
if you'd like to provide more accurate info, implement the `_block_input(self, gr)` and `_block_output(self, gr)` methods of the tool. The `gr` variable is the gradio module (the result of `import gradio as gr`). It will be
automatically imported by the `GradiTool` parent class and passed to the `_block_input` and `_block_output` methods.
And that's it!
Once you have created your tool, open a pull request to the `gradio_tools` repo! We welcome all contributions.
## Example tool - Stable Diffusion
Here is the code for the StableDiffusion tool as an example:
```python
from gradio_tool import GradioTool
import os
class StableDiffusionTool(GradioTool):
"""Tool for calling stable diffusion from llm"""
def __init__(
self,
name="StableDiffusion",
description=(
"An image generator. Use this to generate images based on "
"text input. Input should be a description of what the image should "
"look like. The output will be a path to an image file."
),
src="gradio-client-demos/stable-diffusion",
hf_token=None,
) -> None:
super().__init__(name, description, src, hf_token)
def create_job(self, query: str) -> Job:
return self.client.submit(query, "", 9, fn_index=1)
def postprocess(self, output: str) -> str:
return [os.path.join(output, i) for i in os.listdir(output) if not i.endswith("json")][0]
def _block_input(self, gr) -> "gr.components.Component":
return gr.Textbox()
def _block_output(self, gr) -> "gr.components.Component":
return gr.Image()
```
Some notes on this implementation:
1. All instances of `GradioTool` have an attribute called `client` that is a pointed to the underlying [gradio client](https://github.com/gradio-app/gradio/tree/main/client/python#gradio_client-use-a-gradio-app-as-an-api----in-3-lines-of-python). That is what you should use
in the `create_job` method.
2. `create_job` just passes the query string to the `submit` function of the client with some other parameters hardcoded, i.e. the negative prompt string and the guidance scale. We could modify our tool to also accept these values from the input string in a subsequent version.
3. The `postprocess` method simply returns the first image from the gallery of images created by the stable diffusion space. We use the `os` module to get the full path of the image.
## Conclusion
You now know how to extend the abilities of your LLM with the 1000s of gradio spaces running in the wild!
Again, we welcome any contributions to the [gradio_tools](https://github.com/freddyaboulton/gradio-tools) library.
We're excited to see the tools you all build!
| gradio-app/gradio/blob/main/guides/08_gradio-clients-and-lite/gradio-and-llm-agents.md |
--
title: "Very Large Language Models and How to Evaluate Them"
thumbnail: /blog/assets/106_zero_shot_eval_on_the_hub/thumbnail.png
authors:
- user: mathemakitten
- user: Tristan
- user: abhishek
- user: lewtun
- user: douwekiela
---
# Very Large Language Models and How to Evaluate Them
Large language models can now be evaluated on zero-shot classification tasks with [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator)!
Zero-shot evaluation is a popular way for researchers to measure the performance of large language models, as they have been [shown](https://arxiv.org/abs/2005.14165) to learn capabilities during training without explicitly being shown labeled examples. The [Inverse Scaling Prize](https://github.com/inverse-scaling/prize) is an example of a recent community effort to conduct large-scale zero-shot evaluation across model sizes and families to discover tasks on which larger models may perform worse than their smaller counterparts.

## Enabling zero-shot evaluation of language models on the Hub
[Evaluation on the Hub](https://huggingface.co/blog/eval-on-the-hub) helps you evaluate any model on the Hub without writing code, and is powered by [AutoTrain](https://huggingface.co/autotrain). Now, any causal language model on the Hub can be evaluated in a zero-shot fashion. Zero-shot evaluation measures the likelihood of a trained model producing a given set of tokens and does not require any labelled training data, which allows researchers to skip expensive labelling efforts.
We’ve upgraded the AutoTrain infrastructure for this project so that large models can be evaluated for free 🤯! It’s expensive and time-consuming for users to figure out how to write custom code to evaluate big models on GPUs. For example, a language model with 66 billion parameters may take 35 minutes just to load and compile, making evaluation of large models accessible only to those with expensive infrastructure and extensive technical experience. With these changes, evaluating a model with 66-billion parameters on a zero-shot classification task with 2000 sentence-length examples takes 3.5 hours and can be done by anyone in the community. Evaluation on the Hub currently supports evaluating models up to 66 billion parameters, and support for larger models is to come.
The zero-shot text classification task takes in a dataset containing a set of prompts and possible completions. Under the hood, the completions are concatenated with the prompt and the log-probabilities for each token are summed, then normalized and compared with the correct completion to report accuracy of the task.
In this blog post, we’ll use the zero-shot text classification task to evaluate various [OPT](https://ai.facebook.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/) models on [WinoBias](https://uclanlp.github.io/corefBias/overview), a coreference task measuring gender bias related to occupations. WinoBias measures whether a model is more likely to pick a stereotypical pronoun to fill in a sentence mentioning an occupation, and observe that the results suggest an [inverse scaling](https://github.com/inverse-scaling/prize) trend with respect to model size.
## Case study: Zero-shot evaluation on the WinoBias task
The [WinoBias](https://github.com/uclanlp/corefBias) dataset has been formatted as a zero-shot task where classification options are the completions. Each completion differs by the pronoun, and the target corresponds to the anti-stereotypical completion for the occupation (e.g. "developer" is stereotypically a male-dominated occupation, so "she" would be the anti-stereotypical pronoun). See [here](https://huggingface.co/datasets/mathemakitten/winobias_antistereotype_test) for an example:

Next, we can select this newly-uploaded dataset in the Evaluation on the Hub interface using the `text_zero_shot_classification` task, select the models we’d like to evaluate, and submit our evaluation jobs! When the job has been completed, you’ll be notified by email that the autoevaluator bot has opened a new pull request with the results on the model’s Hub repository.

Plotting the results from the WinoBias task, we find that smaller models are more likely to select the anti-stereotypical pronoun for a sentence, while larger models are more likely to learn stereotypical associations between gender and occupation in text. This corroborates results from other benchmarks (e.g. [BIG-Bench](https://arxiv.org/abs/2206.04615)) which show that larger, more capable models are more likely to be biased with regard to gender, race, ethnicity, and nationality, and [prior work](https://www.deepmind.com/publications/scaling-language-models-methods-analysis-insights-from-training-gopher) which shows that larger models are more likely to generate toxic text.

## Enabling better research tools for everyone
Open science has made great strides with community-driven development of tools like the [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) by EleutherAI and the [BIG-bench](https://github.com/google/BIG-bench) project, which make it straightforward for researchers to understand the behaviour of state-of-the-art models.
Evaluation on the Hub is a low-code tool which makes it simple to compare the zero-shot performance of a set of models along an axis such as FLOPS or model size, and to compare the performance of a set of models trained on a specific corpora against a different set of models. The zero-shot text classification task is extremely flexible—any dataset that can be permuted into a Winograd schema where examples to be compared only differ by a few words can be used with this task and evaluated on many models at once. Our goal is to make it simple to upload a new dataset for evaluation and enable researchers to easily benchmark many models on it.
An example research question which can be addressed with tools like this is the inverse scaling problem: while larger models are generally more capable at the majority of language tasks, there are tasks where larger models perform worse. The [Inverse Scaling Prize](https://github.com/inverse-scaling/prize) is a competition which challenges researchers to construct tasks where larger models perform worse than their smaller counterparts. We encourage you to try zero-shot evaluation on models of all sizes with your own tasks! If you find an interesting trend along model sizes, consider submitting your findings to round 2 of the [Inverse Scaling Prize](https://github.com/inverse-scaling/prize).
## Send us feedback!
At Hugging Face, we’re excited to continue democratizing access to state-of-the-art machine learning models, and that includes developing tools to make it easy for everyone to evaluate and probe their behavior. We’ve previously [written](https://huggingface.co/blog/eval-on-the-hub) about how important it is to standardize model evaluation methods to be consistent and reproducible, and to make tools for evaluation accessible to everyone. Future plans for Evaluation on the Hub include supporting zero-shot evaluation for language tasks which might not lend themselves to the format of concatenating completions to prompts, and adding support for even larger models.
One of the most useful things you can contribute as part of the community is to send us feedback! We’d love to hear from you on top priorities for model evaluation. Let us know your feedback and feature requests by posting on the Evaluation on the Hub [Community](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions) tab, or the [forums](https://discuss.huggingface.co/)!
| huggingface/blog/blob/main/zero-shot-eval-on-the-hub.md |
Models
<tokenizerslangcontent>
<python>
## BPE
[[autodoc]] tokenizers.models.BPE
## Model
[[autodoc]] tokenizers.models.Model
## Unigram
[[autodoc]] tokenizers.models.Unigram
## WordLevel
[[autodoc]] tokenizers.models.WordLevel
## WordPiece
[[autodoc]] tokenizers.models.WordPiece
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/models.mdx |
--
title: TREC Eval
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The TREC Eval metric combines a number of information retrieval metrics such as precision and nDCG. It is used to score rankings of retrieved documents with reference values.
---
# Metric Card for TREC Eval
## Metric Description
The TREC Eval metric combines a number of information retrieval metrics such as precision and normalized Discounted Cumulative Gain (nDCG). It is used to score rankings of retrieved documents with reference values.
## How to Use
```Python
from evaluate import load
trec_eval = load("trec_eval")
results = trec_eval.compute(predictions=[run], references=[qrel])
```
### Inputs
- **predictions** *(dict): a single retrieval run.*
- **query** *(int): Query ID.*
- **q0** *(str): Literal `"q0"`.*
- **docid** *(str): Document ID.*
- **rank** *(int): Rank of document.*
- **score** *(float): Score of document.*
- **system** *(str): Tag for current run.*
- **references** *(dict): a single qrel.*
- **query** *(int): Query ID.*
- **q0** *(str): Literal `"q0"`.*
- **docid** *(str): Document ID.*
- **rel** *(int): Relevance of document.*
### Output Values
- **runid** *(str): Run name.*
- **num_ret** *(int): Number of retrieved documents.*
- **num_rel** *(int): Number of relevant documents.*
- **num_rel_ret** *(int): Number of retrieved relevant documents.*
- **num_q** *(int): Number of queries.*
- **map** *(float): Mean average precision.*
- **gm_map** *(float): geometric mean average precision.*
- **bpref** *(float): binary preference score.*
- **Rprec** *(float): precision@R, where R is number of relevant documents.*
- **recip_rank** *(float): reciprocal rank*
- **P@k** *(float): precision@k (k in [5, 10, 15, 20, 30, 100, 200, 500, 1000]).*
- **NDCG@k** *(float): nDCG@k (k in [5, 10, 15, 20, 30, 100, 200, 500, 1000]).*
### Examples
A minimal example of looks as follows:
```Python
qrel = {
"query": [0],
"q0": ["q0"],
"docid": ["doc_1"],
"rel": [2]
}
run = {
"query": [0, 0],
"q0": ["q0", "q0"],
"docid": ["doc_2", "doc_1"],
"rank": [0, 1],
"score": [1.5, 1.2],
"system": ["test", "test"]
}
trec_eval = evaluate.load("trec_eval")
results = trec_eval.compute(references=[qrel], predictions=[run])
results["P@5"]
0.2
```
A more realistic use case with an examples from [`trectools`](https://github.com/joaopalotti/trectools):
```python
qrel = pd.read_csv("robust03_qrels.txt", sep="\s+", names=["query", "q0", "docid", "rel"])
qrel["q0"] = qrel["q0"].astype(str)
qrel = qrel.to_dict(orient="list")
run = pd.read_csv("input.InexpC2", sep="\s+", names=["query", "q0", "docid", "rank", "score", "system"])
run = run.to_dict(orient="list")
trec_eval = evaluate.load("trec_eval")
result = trec_eval.compute(run=[run], qrel=[qrel])
```
```python
result
{'runid': 'InexpC2',
'num_ret': 100000,
'num_rel': 6074,
'num_rel_ret': 3198,
'num_q': 100,
'map': 0.22485930431817494,
'gm_map': 0.10411523825735523,
'bpref': 0.217511695914079,
'Rprec': 0.2502547201167236,
'recip_rank': 0.6646545943335417,
'P@5': 0.44,
'P@10': 0.37,
'P@15': 0.34600000000000003,
'P@20': 0.30999999999999994,
'P@30': 0.2563333333333333,
'P@100': 0.1428,
'P@200': 0.09510000000000002,
'P@500': 0.05242,
'P@1000': 0.03198,
'NDCG@5': 0.4101480395089769,
'NDCG@10': 0.3806761417784469,
'NDCG@15': 0.37819463408955706,
'NDCG@20': 0.3686080836061317,
'NDCG@30': 0.352474353427451,
'NDCG@100': 0.3778329431025776,
'NDCG@200': 0.4119129817248979,
'NDCG@500': 0.4585354576461375,
'NDCG@1000': 0.49092149290805653}
```
## Limitations and Bias
The `trec_eval` metric requires the inputs to be in the TREC run and qrel formats for predictions and references.
## Citation
```bibtex
@inproceedings{palotti2019,
author = {Palotti, Joao and Scells, Harrisen and Zuccon, Guido},
title = {TrecTools: an open-source Python library for Information Retrieval practitioners involved in TREC-like campaigns},
series = {SIGIR'19},
year = {2019},
location = {Paris, France},
publisher = {ACM}
}
```
## Further References
- Homepage: https://github.com/joaopalotti/trectools | huggingface/evaluate/blob/main/metrics/trec_eval/README.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# TFVisionTextDualEncoder and CLIP model training examples
The following example showcases how to train a CLIP-like vision-text dual encoder model
using a pre-trained vision and text encoder.
Such a model can be used for natural language image search and potentially zero-shot image classification.
The model is inspired by [CLIP](https://openai.com/blog/clip/), introduced by Alec Radford et al.
The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their
captions into the same embedding space, such that the caption embeddings are located near the embeddings
of the images they describe.
### Download COCO dataset (2017)
This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
COCO dataset before training.
```bash
mkdir data
cd data
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip
cd ..
```
Having downloaded COCO dataset manually you should be able to load with the `ydshieh/coc_dataset_script` dataset loading script:
```py
import os
import datasets
COCO_DIR = os.path.join(os.getcwd(), "data")
ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir=COCO_DIR)
```
### Create a model from a vision encoder model and a text encoder model
We can either load a CLIP-like vision-text dual encoder model from an existing dual encoder model, or
by using a pre-trained vision encoder model and a pre-trained text encoder model.
If you wish to load an existing dual encoder model, please use the `--model_name_or_path` argument. If
you want to use separate pre-trained vision and text models, please use the
`--vision_model_name_or_path` and `--text_model_name_or_path` arguments instead.
### Train the model
Finally, we can run the example script to train the model:
```bash
python examples/tensorflow/contrastive-image-text/run_clip.py \
--output_dir ./clip-roberta-finetuned \
--vision_model_name_or_path openai/clip-vit-base-patch32 \
--text_model_name_or_path roberta-base \
--data_dir $PWD/data \
--dataset_name ydshieh/coco_dataset_script \
--dataset_config_name=2017 \
--image_column image_path \
--caption_column caption \
--remove_unused_columns=False \
--do_train --do_eval \
--per_device_train_batch_size="64" \
--per_device_eval_batch_size="64" \
--learning_rate="5e-5" --warmup_steps="0" --weight_decay 0.1 \
--overwrite_output_dir \
--push_to_hub
```
| huggingface/transformers/blob/main/examples/tensorflow/contrastive-image-text/README.md |
his document covers all steps that need to be done in order to do a release of the `huggingface_hub` library.
1. On a clone of the main repo, not your fork, checkout the main branch and pull the latest changes:
```
git checkout main
git pull
```
2. Checkout a new branch with the version that you'd like to release: v<MINOR-VERSION>-release,
for example `v0.5-release`. All patches will be done to that same branch.
3. Update the `__version__` variable in the `src/huggingface_hub/__init__.py` file to point
to the version you're releasing:
```
__version__ = "<VERSION>"
```
4. Make sure that the conda build works correctly by building it locally:
```
conda install -c defaults anaconda-client conda-build
HUB_VERSION=<VERSION> conda-build .github/conda
```
5. Make sure that the pip wheel works correctly by building it locally and installing it:
```
pip install setuptools wheel
python setup.py sdist bdist_wheel
pip install dist/huggingface_hub-<VERSION>-py3-none-any.whl
```
6. Commit, tag, and push the branch:
```
git commit -am "Release: v<VERSION>"
git tag v<VERSION> -m "Adds tag v<VERSION> for pypi and conda"
git push -u --tags origin v<MINOR-VERSION>-release
```
7. Verify that the docs have been built correctly. You can check that on the following link:
https://huggingface.co/docs/huggingface_hub/v<VERSION>
8. Checkout main once again to update the version in the `__init__.py` file:
```
git checkout main
```
9. Update the version to contain the `.dev0` suffix:
```
__version__ = "<VERSION+1>.dev0" # For example, after releasing v0.5.0 or v0.5.1: "0.6.0.dev0".
```
10. Push the changes!
```
git push origin main
```
| huggingface/huggingface_hub/blob/main/docs/dev/release.md |
A quick tour
🤗 Evaluate provides access to a wide range of evaluation tools. It covers a range of modalities such as text, computer vision, audio, etc. as well as tools to evaluate models or datasets. These tools are split into three categories.
## Types of evaluations
There are different aspects of a typical machine learning pipeline that can be evaluated and for each aspect 🤗 Evaluate provides a tool:
- **Metric**: A metric is used to evaluate a model's performance and usually involves the model's predictions as well as some ground truth labels. You can find all integrated metrics at [evaluate-metric](https://huggingface.co/evaluate-metric).
- **Comparison**: A comparison is used to compare two models. This can for example be done by comparing their predictions to ground truth labels and computing their agreement. You can find all integrated comparisons at [evaluate-comparison](https://huggingface.co/evaluate-comparison).
- **Measurement**: The dataset is as important as the model trained on it. With measurements one can investigate a dataset's properties. You can find all integrated measurements at [evaluate-measurement](https://huggingface.co/evaluate-measurement).
Each of these evaluation modules live on Hugging Face Hub as a Space. They come with an interactive widget and a documentation card documenting its use and limitations. For example [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/evaluate/media/resolve/main/metric-widget.png" width="400"/>
</div>
Each metric, comparison, and measurement is a separate Python module, but for using any of them, there is a single entry point: [`evaluate.load`]!
## Load
Any metric, comparison, or measurement is loaded with the `evaluate.load` function:
```py
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
```
If you want to make sure you are loading the right type of evaluation (especially if there are name clashes) you can explicitly pass the type:
```py
>>> word_length = evaluate.load("word_length", module_type="measurement")
```
### Community modules
Besides the modules implemented in 🤗 Evaluate you can also load any community module by specifying the repository ID of the metric implementation:
```py
>>> element_count = evaluate.load("lvwerra/element_count", module_type="measurement")
```
See the [Creating and Sharing Guide](/docs/evaluate/main/en/creating_and_sharing) for information about uploading custom metrics.
### List available modules
With [`list_evaluation_modules`] you can check what modules are available on the hub. You can also filter for a specific modules and skip community metrics if you want. You can also see additional information such as likes:
```python
>>> evaluate.list_evaluation_modules(
... module_type="comparison",
... include_community=False,
... with_details=True)
[{'name': 'mcnemar', 'type': 'comparison', 'community': False, 'likes': 1},
{'name': 'exact_match', 'type': 'comparison', 'community': False, 'likes': 0}]
```
## Module attributes
All evalution modules come with a range of useful attributes that help to use a module stored in a [`EvaluationModuleInfo`] object.
|Attribute|Description|
|---|---|
|`description`|A short description of the evaluation module.|
|`citation`|A BibTex string for citation when available.|
|`features`|A `Features` object defining the input format.|
|`inputs_description`|This is equivalent to the modules docstring.|
|`homepage`|The homepage of the module.|
|`license`|The license of the module.|
|`codebase_urls`|Link to the code behind the module.|
|`reference_urls`|Additional reference URLs.|
Let's have a look at a few examples. First, let's look at the `description` attribute of the accuracy metric:
```py
>>> accuracy = evaluate.load("accuracy")
>>> accuracy.description
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
```
You can see that it describes how the metric works in theory. If you use this metric for your work, especially if it is an academic publication you want to reference it properly. For that you can look at the `citation` attribute:
```py
>>> accuracy.citation
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
Before we can apply a metric or other evaluation module to a use-case, we need to know what the input format of the metric is:
```py
>>> accuracy.features
{
'predictions': Value(dtype='int32', id=None),
'references': Value(dtype='int32', id=None)
}
```
<Tip>
Note that features always describe the type of a single input element. In general we will add lists of elements so you can always think of a list around the types in `features`. Evaluate accepts various input formats (Python lists, NumPy arrays, PyTorch tensors, etc.) and converts them to an appropriate format for storage and computation.
</Tip>
## Compute
Now that we know how the evaluation module works and what should go in there we want to actually use it! When it comes to computing the actual score there are two main ways to do it:
1. All-in-one
2. Incremental
In the incremental approach the necessary inputs are added to the module with [`EvaluationModule.add`] or [`EvaluationModule.add_batch`] and the score is calculated at the end with [`EvaluationModule.compute`]. Alternatively, one can pass all the inputs at once to `compute()`. Let's have a look at the two approaches.
### How to compute
The simplest way to calculate the score of an evaluation module is by calling `compute()` directly with the necessary inputs. Simply pass the inputs as seen in `features` to the `compute()` method.
```py
>>> accuracy.compute(references=[0,1,0,1], predictions=[1,0,0,1])
{'accuracy': 0.5}
```
Evaluation modules return the results in a dictionary. However, in some instances you build up the predictions iteratively or in a distributed fashion in which case `add()` or `add_batch()` are useful.
### Calculate a single metric or a batch of metrics
In many evaluation pipelines you build the predictions iteratively such as in a for-loop. In that case you could store the predictions in a list and at the end pass them to `compute()`. With `add()` and `add_batch()` you can circumvent the step of storing the predictions separately. If you are only creating single predictions at a time you can use `add()`:
```py
>>> for ref, pred in zip([0,1,0,1], [1,0,0,1]):
>>> accuracy.add(references=ref, predictions=pred)
>>> accuracy.compute()
{'accuracy': 0.5}
```
Once you have gathered all predictions you can call `compute()` to compute the score based on all stored values. When getting predictions and references in batches you can use `add_batch()` which adds a list elements for later processing. The rest works as with `add()`:
```py
>>> for refs, preds in zip([[0,1],[0,1]], [[1,0],[0,1]]):
>>> accuracy.add_batch(references=refs, predictions=preds)
>>> accuracy.compute()
{'accuracy': 0.5}
```
This is especially useful when you need to get the predictions from your model in batches:
```py
>>> for model_inputs, gold_standards in evaluation_dataset:
>>> predictions = model(model_inputs)
>>> metric.add_batch(references=gold_standards, predictions=predictions)
>>> metric.compute()
```
### Distributed evaluation
Computing metrics in a distributed environment can be tricky. Metric evaluation is executed in separate Python processes, or nodes, on different subsets of a dataset. Typically, when a metric score is additive (`f(AuB) = f(A) + f(B)`), you can use distributed reduce operations to gather the scores for each subset of the dataset. But when a metric is non-additive (`f(AuB) ≠ f(A) + f(B)`), it's not that simple. For example, you can't take the sum of the [F1](https://huggingface.co/spaces/evaluate-metric/f1) scores of each data subset as your **final metric**.
A common way to overcome this issue is to fallback on single process evaluation. The metrics are evaluated on a single GPU, which becomes inefficient.
🤗 Evaluate solves this issue by only computing the final metric on the first node. The predictions and references are computed and provided to the metric separately for each node. These are temporarily stored in an Apache Arrow table, avoiding cluttering the GPU or CPU memory. When you are ready to `compute()` the final metric, the first node is able to access the predictions and references stored on all the other nodes. Once it has gathered all the predictions and references, `compute()` will perform the final metric evaluation.
This solution allows 🤗 Evaluate to perform distributed predictions, which is important for evaluation speed in distributed settings. At the same time, you can also use complex non-additive metrics without wasting valuable GPU or CPU memory.
## Combining several evaluations
Often one wants to not only evaluate a single metric but a range of different metrics capturing different aspects of a model. E.g. for classification it is usually a good idea to compute F1-score, recall, and precision in addition to accuracy to get a better picture of model performance. Naturally, you can load a bunch of metrics and call them sequentially. However, a more convenient way is to use the [`~evaluate.combine`] function to bundle them together:
```python
>>> clf_metrics = evaluate.combine(["accuracy", "f1", "precision", "recall"])
```
The `combine` function accepts both the list of names of the metrics as well as an instantiated modules. The `compute` call then computes each metric:
```python
>>> clf_metrics.compute(predictions=[0, 1, 0], references=[0, 1, 1])
{
'accuracy': 0.667,
'f1': 0.667,
'precision': 1.0,
'recall': 0.5
}
```
## Save and push to the Hub
Saving and sharing evaluation results is an important step. We provide the [`evaluate.save`] function to easily save metrics results. You can either pass a specific filename or a directory. In the latter case, the results are saved in a file with an automatically created file name. Besides the directory or file name, the function takes any key-value pairs as inputs and stores them in a JSON file.
```py
>>> result = accuracy.compute(references=[0,1,0,1], predictions=[1,0,0,1])
>>> hyperparams = {"model": "bert-base-uncased"}
>>> evaluate.save("./results/", experiment="run 42", **result, **hyperparams)
PosixPath('results/result-2022_05_30-22_09_11.json')
```
The content of the JSON file look like the following:
```json
{
"experiment": "run 42",
"accuracy": 0.5,
"model": "bert-base-uncased",
"_timestamp": "2022-05-30T22:09:11.959469",
"_git_commit_hash": "123456789abcdefghijkl",
"_evaluate_version": "0.1.0",
"_python_version": "3.9.12 (main, Mar 26 2022, 15:51:15) \n[Clang 13.1.6 (clang-1316.0.21.2)]",
"_interpreter_path": "/Users/leandro/git/evaluate/env/bin/python"
}
```
In addition to the specified fields, it also contains useful system information for reproducing the results.
Besides storing the results locally, you should report them on the model's repository on the Hub. With the [`evaluate.push_to_hub`] function, you can easily report evaluation results to the model's repository:
```py
evaluate.push_to_hub(
model_id="huggingface/gpt2-wikitext2", # model repository on hub
metric_value=0.5, # metric value
metric_type="bleu", # metric name, e.g. accuracy.name
metric_name="BLEU", # pretty name which is displayed
dataset_type="wikitext", # dataset name on the hub
dataset_name="WikiText", # pretty name
dataset_split="test", # dataset split used
task_type="text-generation", # task id, see https://github.com/huggingface/evaluate/blob/main/src/evaluate/config.py#L154-L192
task_name="Text Generation" # pretty name for task
)
```
## Evaluator
The [`evaluate.evaluator`] provides automated evaluation and only requires a model, dataset, metric in contrast to the metrics in `EvaluationModule`s that require the model's predictions. As such it is easier to evaluate a model on a dataset with a given metric as the inference is handled internally. To make that possible it uses the [`~transformers.pipeline`] abstraction from `transformers`. However, you can use your own framework as long as it follows the `pipeline` interface.
To make an evaluation with the `evaluator` let's load a `transformers` pipeline (but you can pass your own custom inference class for any framework as long as it follows the pipeline call API) with an model trained on IMDb, the IMDb test split and the accuracy metric.
```python
from transformers import pipeline
from datasets import load_dataset
from evaluate import evaluator
import evaluate
pipe = pipeline("text-classification", model="lvwerra/distilbert-imdb", device=0)
data = load_dataset("imdb", split="test").shuffle().select(range(1000))
metric = evaluate.load("accuracy")
```
Then you can create an evaluator for text classification and pass the three objects to the `compute()` method. With the label mapping `evaluate` provides a method to align the pipeline outputs with the label column in the dataset:
```python
>>> task_evaluator = evaluator("text-classification")
>>> results = task_evaluator.compute(model_or_pipeline=pipe, data=data, metric=metric,
... label_mapping={"NEGATIVE": 0, "POSITIVE": 1},)
>>> print(results)
{'accuracy': 0.934}
```
Calculating the value of the metric alone is often not enough to know if a model performs significantly better than another one. With _bootstrapping_ `evaluate` computes confidence intervals and the standard error which helps estimate how stable a score is:
```python
>>> results = eval.compute(model_or_pipeline=pipe, data=data, metric=metric,
... label_mapping={"NEGATIVE": 0, "POSITIVE": 1},
... strategy="bootstrap", n_resamples=200)
>>> print(results)
{'accuracy':
{
'confidence_interval': (0.906, 0.9406749892841922),
'standard_error': 0.00865213251082787,
'score': 0.923
}
}
```
The evaluator expects a `"text"` and `"label"` column for the data input. If your dataset differs you can provide the columns with the keywords `input_column="text"` and `label_column="label"`. Currently only `"text-classification"` is supported with more tasks being added in the future.
## Visualization
When comparing several models, sometimes it's hard to spot the differences in their performance simply by looking at their scores. Also often there is not a single best model but there are trade-offs between e.g. latency and accuracy as larger models might have better performance but are also slower. We are gradually adding different visualization approaches, such as plots, to make choosing the best model for a use-case easier.
For instance, if you have a list of results from multiple models (as dictionaries), you can feed them into the `radar_plot()` function:
```python
import evaluate
from evaluate.visualization import radar_plot
>>> data = [
{"accuracy": 0.99, "precision": 0.8, "f1": 0.95, "latency_in_seconds": 33.6},
{"accuracy": 0.98, "precision": 0.87, "f1": 0.91, "latency_in_seconds": 11.2},
{"accuracy": 0.98, "precision": 0.78, "f1": 0.88, "latency_in_seconds": 87.6},
{"accuracy": 0.88, "precision": 0.78, "f1": 0.81, "latency_in_seconds": 101.6}
]
>>> model_names = ["Model 1", "Model 2", "Model 3", "Model 4"]
>>> plot = radar_plot(data=data, model_names=model_names)
>>> plot.show()
```
Which lets you visually compare the 4 models and choose the optimal one for you, based on one or several metrics:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/evaluate/media/resolve/main/example_viz.png" width="400"/>
</div>
## Running evaluation on a suite of tasks
It can be useful to evaluate models on a variety of different tasks to understand their downstream performance. The [EvaluationSuite](evaluation_suite) enables evaluation of models on a collection of tasks. Tasks can be constructed as ([evaluator](base_evaluator), dataset, metric) tuples and passed to an [EvaluationSuite](evaluation_suite) stored on the Hugging Face Hub as a Space, or locally as a Python script. See the [evaluator documentation](base_evaluator) for a list of currently supported tasks.
`EvaluationSuite` scripts can be defined as follows, and supports Python code for data preprocessing.
```python
import evaluate
from evaluate.evaluation_suite import SubTask
class Suite(evaluate.EvaluationSuite):
def __init__(self, name):
super().__init__(name)
self.suite = [
SubTask(
task_type="text-classification",
data="imdb",
split="test[:1]",
args_for_task={
"metric": "accuracy",
"input_column": "text",
"label_column": "label",
"label_mapping": {
"LABEL_0": 0.0,
"LABEL_1": 1.0
}
}
),
SubTask(
task_type="text-classification",
data="sst2",
split="test[:1]",
args_for_task={
"metric": "accuracy",
"input_column": "sentence",
"label_column": "label",
"label_mapping": {
"LABEL_0": 0.0,
"LABEL_1": 1.0
}
}
)
]
```
Evaluation can be run by loading the `EvaluationSuite` and calling the `run()` method with a model or pipeline.
```
>>> from evaluate import EvaluationSuite
>>> suite = EvaluationSuite.load('mathemakitten/sentiment-evaluation-suite')
>>> results = suite.run("huggingface/prunebert-base-uncased-6-finepruned-w-distil-mnli")
```
| accuracy | total_time_in_seconds | samples_per_second | latency_in_seconds | task_name |
|------------:|---------------------:|--------------------------:|:----------------|:-----------|
| 0.3 | 4.62804 | 2.16074 | 0.462804 | imdb |
| 0 | 0.686388 | 14.569 | 0.0686388 | sst2 |
| huggingface/evaluate/blob/main/docs/source/a_quick_tour.mdx |
Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
[email protected].
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
[https://www.contributor-covenant.org/version/2/0/code_of_conduct.html][v2.0].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available
at [https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.0]: https://www.contributor-covenant.org/version/2/0/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
| huggingface/datasets/blob/main/CODE_OF_CONDUCT.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Interacting with Discussions and Pull Requests
Check the [`HfApi`] documentation page for the reference of methods enabling
interaction with Pull Requests and Discussions on the Hub.
- [`get_repo_discussions`]
- [`get_discussion_details`]
- [`create_discussion`]
- [`create_pull_request`]
- [`rename_discussion`]
- [`comment_discussion`]
- [`edit_discussion_comment`]
- [`change_discussion_status`]
- [`merge_pull_request`]
## Data structures
[[autodoc]] Discussion
[[autodoc]] DiscussionWithDetails
[[autodoc]] DiscussionEvent
[[autodoc]] DiscussionComment
[[autodoc]] DiscussionStatusChange
[[autodoc]] DiscussionCommit
[[autodoc]] DiscussionTitleChange
| huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/community.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Methods and tools for efficient training on a single GPU
This guide demonstrates practical techniques that you can use to increase the efficiency of your model's training by
optimizing memory utilization, speeding up the training, or both. If you'd like to understand how GPU is utilized during
training, please refer to the [Model training anatomy](model_memory_anatomy) conceptual guide first. This guide
focuses on practical techniques.
<Tip>
If you have access to a machine with multiple GPUs, these approaches are still valid, plus you can leverage additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
</Tip>
When training large models, there are two aspects that should be considered at the same time:
* Data throughput/training time
* Model performance
Maximizing the throughput (samples/second) leads to lower training cost. This is generally achieved by utilizing the GPU
as much as possible and thus filling GPU memory to its limit. If the desired batch size exceeds the limits of the GPU memory,
the memory optimization techniques, such as gradient accumulation, can help.
However, if the preferred batch size fits into memory, there's no reason to apply memory-optimizing techniques because they can
slow down the training. Just because one can use a large batch size, does not necessarily mean they should. As part of
hyperparameter tuning, you should determine which batch size yields the best results and then optimize resources accordingly.
The methods and tools covered in this guide can be classified based on the effect they have on the training process:
| Method/tool | Improves training speed | Optimizes memory utilization |
|:-----------------------------------------------------------|:------------------------|:-----------------------------|
| [Batch size choice](#batch-size-choice) | Yes | Yes |
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
| [Mixed precision training](#mixed-precision-training) | Yes | (No) |
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
| [Data preloading](#data-preloading) | Yes | No |
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
| [torch.compile](#using-torchcompile) | Yes | No |
<Tip>
Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a
large model and a small batch size, the memory use will be larger.
</Tip>
You can combine the above methods to get a cumulative effect. These techniques are available to you whether you are
training your model with [`Trainer`] or writing a pure PyTorch loop, in which case you can [configure these optimizations
with 🤗 Accelerate](#using-accelerate).
If these methods do not result in sufficient gains, you can explore the following options:
* [Look into building your own custom Docker container with efficient softare prebuilds](#efficient-software-prebuilds)
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention)
Finally, if all of the above is still not enough, even after switching to a server-grade GPU like A100, consider moving
to a multi-GPU setup. All these approaches are still valid in a multi-GPU setup, plus you can leverage additional parallelism
techniques outlined in the [multi-GPU section](perf_train_gpu_many).
## Batch size choice
To achieve optimal performance, start by identifying the appropriate batch size. It is recommended to use batch sizes and
input/output neuron counts that are of size 2^N. Often it's a multiple of 8, but it can be
higher depending on the hardware being used and the model's dtype.
For reference, check out NVIDIA's recommendation for [input/output neuron counts](
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and
[batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size) for
fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)
define the multiplier based on the dtype and the hardware. For instance, for fp16 data type a multiple of 8 is recommended, unless
it's an A100 GPU, in which case use multiples of 64.
For parameters that are small, consider also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization).
This is where tiling happens and the right multiplier can have a significant speedup.
## Gradient Accumulation
The **gradient accumulation** method aims to calculate gradients in smaller increments instead of computing them for the
entire batch at once. This approach involves iteratively calculating gradients in smaller batches by performing forward
and backward passes through the model and accumulating the gradients during the process. Once a sufficient number of
gradients have been accumulated, the model's optimization step is executed. By employing gradient accumulation, it
becomes possible to increase the **effective batch size** beyond the limitations imposed by the GPU's memory capacity.
However, it is important to note that the additional forward and backward passes introduced by gradient accumulation can
slow down the training process.
You can enable gradient accumulation by adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
```
In the above example, your effective batch size becomes 4.
Alternatively, use 🤗 Accelerate to gain full control over the training loop. Find the 🤗 Accelerate example
[further down in this guide](#using-accelerate).
While it is advised to max out GPU usage as much as possible, a high number of gradient accumulation steps can
result in a more pronounced training slowdown. Consider the following example. Let's say, the `per_device_train_batch_size=4`
without gradient accumulation hits the GPU's limit. If you would like to train with batches of size 64, do not set the
`per_device_train_batch_size` to 1 and `gradient_accumulation_steps` to 64. Instead, keep `per_device_train_batch_size=4`
and set `gradient_accumulation_steps=16`. This results in the same effective batch size while making better use of
the available GPU resources.
For additional information, please refer to batch size and gradient accumulation benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
## Gradient Checkpointing
Some large models may still face memory issues even when the batch size is set to 1 and gradient accumulation is used.
This is because there are other components that also require memory storage.
Saving all activations from the forward pass in order to compute the gradients during the backward pass can result in
significant memory overhead. The alternative approach of discarding the activations and recalculating them when needed
during the backward pass, would introduce a considerable computational overhead and slow down the training process.
**Gradient checkpointing** offers a compromise between these two approaches and saves strategically selected activations
throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. For
an in-depth explanation of gradient checkpointing, refer to [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9).
To enable gradient checkpointing in the [`Trainer`], pass the corresponding a flag to [`TrainingArguments`]:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
```
Alternatively, use 🤗 Accelerate - find the 🤗 Accelerate example [further in this guide](#using-accelerate).
<Tip>
While gradient checkpointing may improve memory efficiency, it slows training by approximately 20%.
</Tip>
## Mixed precision training
**Mixed precision training** is a technique that aims to optimize the computational efficiency of training models by
utilizing lower-precision numerical formats for certain variables. Traditionally, most models use 32-bit floating point
precision (fp32 or float32) to represent and process variables. However, not all variables require this high precision
level to achieve accurate results. By reducing the precision of certain variables to lower numerical formats like 16-bit
floating point (fp16 or float16), we can speed up the computations. Because in this approach some computations are performed
in half-precision, while some are still in full precision, the approach is called mixed precision training.
Most commonly mixed precision training is achieved by using fp16 (float16) data types, however, some GPU architectures
(such as the Ampere architecture) offer bf16 and tf32 (CUDA internal data type) data types. Check
out the [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) to learn more about
the differences between these data types.
### fp16
The main advantage of mixed precision training comes from saving the activations in half precision (fp16).
Although the gradients are also computed in half precision they are converted back to full precision for the optimization
step so no memory is saved here.
While mixed precision training results in faster computations, it can also lead to more GPU memory being utilized, especially for small batch sizes.
This is because the model is now present on the GPU in both 16-bit and 32-bit precision (1.5x the original model on the GPU).
To enable mixed precision training, set the `fp16` flag to `True`:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
```
If you prefer to use 🤗 Accelerate, find the 🤗 Accelerate example [further in this guide](#using-accelerate).
### BF16
If you have access to an Ampere or newer hardware you can use bf16 for mixed precision training and evaluation. While
bf16 has a worse precision than fp16, it has a much bigger dynamic range. In fp16 the biggest number you can have
is `65535` and any number above that will result in an overflow. A bf16 number can be as large as `3.39e+38` (!) which
is about the same as fp32 - because both have 8-bits used for the numerical range.
You can enable BF16 in the 🤗 Trainer with:
```python
training_args = TrainingArguments(bf16=True, **default_args)
```
### TF32
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead
of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total. It's "magical" in the sense that
you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput
improvement. All you need to do is to add the following to your code:
```
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
```
CUDA will automatically switch to using tf32 instead of fp32 where possible, assuming that the used GPU is from the Ampere series.
According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/), the
majority of machine learning training workloads show the same perplexity and convergence with tf32 training as with fp32.
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
You can enable this mode in the 🤗 Trainer:
```python
TrainingArguments(tf32=True, **default_args)
```
<Tip>
tf32 can't be accessed directly via `tensor.to(dtype=torch.tf32)` because it is an internal CUDA data type. You need `torch>=1.7` to use tf32 data types.
</Tip>
For additional information on tf32 vs other precisions, please refer to the following benchmarks:
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
## Flash Attention 2
You can speedup the training throughput by using Flash Attention 2 integration in transformers. Check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2) to learn more about how to load a model with Flash Attention 2 modules.
## Optimizer choice
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed for NVIDIA GPUs, or [ROCmSoftwarePlatform/apex](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
`adamw_apex_fused`, `adamw_anyprecision`, `adafactor`, or `adamw_bnb_8bit`. More optimizers can be plugged in via a third-party implementation.
Let's take a closer look at two alternatives to AdamW optimizer:
1. `adafactor` which is available in [`Trainer`]
2. `adamw_bnb_8bit` is also available in Trainer, but a third-party integration is provided below for demonstration.
For comparison, for a 3B-parameter model, like “t5-3b”:
* A standard AdamW optimizer will need 24GB of GPU memory because it uses 8 bytes for each parameter (8*3 => 24GB)
* Adafactor optimizer will need more than 12GB. It uses slightly more than 4 bytes for each parameter, so 4*3 and then some extra.
* 8bit BNB quantized optimizer will use only (2*3) 6GB if all optimizer states are quantized.
### Adafactor
Adafactor doesn't store rolling averages for each element in weight matrices. Instead, it keeps aggregated information
(sums of rolling averages row- and column-wise), significantly reducing its footprint. However, compared to Adam,
Adafactor may have slower convergence in certain cases.
You can switch to Adafactor by setting `optim="adafactor"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training)
you can notice up to 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of
Adafactor can be worse than Adam.
### 8-bit Adam
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization
means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the
idea behind mixed precision training.
To use `adamw_bnb_8bit`, you simply need to set `optim="adamw_bnb_8bit"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
```
However, we can also use a third-party implementation of the 8-bit optimizer for demonstration purposes to see how that can be integrated.
First, follow the installation guide in the GitHub [repo](https://github.com/TimDettmers/bitsandbytes) to install the `bitsandbytes` library
that implements the 8-bit Adam optimizer.
Next you need to initialize the optimizer. This involves two steps:
* First, group the model's parameters into two groups - one where weight decay should be applied, and the other one where it should not. Usually, biases and layer norm parameters are not weight decayed.
* Then do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
```py
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
```
Finally, pass the custom optimizer as an argument to the `Trainer`:
```py
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training),
you can expect to get about a 3x memory improvement and even slightly higher throughput as using Adafactor.
### multi_tensor
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations
with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner, take a look at this GitHub [issue](https://github.com/huggingface/transformers/issues/9965).
## Data preloading
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it
can handle. By default, everything happens in the main process, and it might not be able to read the data from disk fast
enough, and thus create a bottleneck, leading to GPU under-utilization. Configure the following arguments to reduce the bottleneck:
- `DataLoader(pin_memory=True, ...)` - ensures the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
- `DataLoader(num_workers=4, ...)` - spawn several workers to preload data faster. During training, watch the GPU utilization stats; if it's far from 100%, experiment with increasing the number of workers. Of course, the problem could be elsewhere, so many workers won't necessarily lead to better performance.
When using [`Trainer`], the corresponding [`TrainingArguments`] are: `dataloader_pin_memory` (`True` by default), and `dataloader_num_workers` (defaults to `0`).
## DeepSpeed ZeRO
DeepSpeed is an open-source deep learning optimization library that is integrated with 🤗 Transformers and 🤗 Accelerate.
It provides a wide range of features and optimizations designed to improve the efficiency and scalability of large-scale
deep learning training.
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don't need to use DeepSpeed
as it'll only slow things down. However, if the model doesn't fit onto a single GPU or you can't fit a small batch, you can
leverage DeepSpeed ZeRO + CPU Offload, or NVMe Offload for much larger models. In this case, you need to separately
[install the library](main_classes/deepspeed#installation), then follow one of the guides to create a configuration file
and launch DeepSpeed:
* For an in-depth guide on DeepSpeed integration with [`Trainer`], review [the corresponding documentation](main_classes/deepspeed), specifically the
[section for a single GPU](main_classes/deepspeed#deployment-with-one-gpu). Some adjustments are required to use DeepSpeed in a notebook; please take a look at the [corresponding guide](main_classes/deepspeed#deployment-in-notebooks).
* If you prefer to use 🤗 Accelerate, refer to [🤗 Accelerate DeepSpeed guide](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed).
## Using torch.compile
PyTorch 2.0 introduced a new compile function that doesn't require any modification to existing PyTorch code but can
optimize your code by adding a single line of code: `model = torch.compile(model)`.
If using [`Trainer`], you only need `to` pass the `torch_compile` option in the [`TrainingArguments`]:
```python
training_args = TrainingArguments(torch_compile=True, **default_args)
```
`torch.compile` uses Python's frame evaluation API to automatically create a graph from existing PyTorch programs. After
capturing the graph, different backends can be deployed to lower the graph to an optimized engine.
You can find more details and benchmarks in [PyTorch documentation](https://pytorch.org/get-started/pytorch-2.0/).
`torch.compile` has a growing list of backends, which can be found in by calling `torchdynamo.list_backends()`, each of which with its optional dependencies.
Choose which backend to use by specifying it via `torch_compile_backend` in the [`TrainingArguments`]. Some of the most commonly used backends are:
**Debugging backends**:
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
**Training & inference backends**:
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
**Inference-only backend**s:
* `dynamo.optimize("ofi")` - Uses Torchscript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
* `dynamo.optimize("fx2trt")` - Uses NVIDIA TensorRT for inference optimizations. [Read more](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
For an example of using `torch.compile` with 🤗 Transformers, check out this [blog post on fine-tuning a BERT model for Text Classification using the newest PyTorch 2.0 features](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)
## Using 🤗 Accelerate
With [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) you can use the above methods while gaining full
control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications.
Suppose you have combined the methods in the [`TrainingArguments`] like so:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
```
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
```py
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
```
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method.
When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)
we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call.
During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)
call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same [8-bit optimizer](#8-bit-adam) from the earlier example.
Finally, we can add the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see
how gradient accumulation works: we normalize the loss, so we get the average at the end of accumulation and once we have
enough steps we run the optimization.
Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the
benefit of more flexibility in the training loop. For a full documentation of all features have a look at the
[Accelerate documentation](https://huggingface.co/docs/accelerate/index).
## Efficient Software Prebuilds
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuilt with the cuda toolkit
which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
At times, additional efforts may be required to pre-build some components. For instance, if you're using libraries like `apex` that
don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated.
To address these scenarios PyTorch and NVIDIA released a new version of NGC docker container which already comes with
everything prebuilt. You just need to install your programs on it, and it will run out of the box.
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
To find the docker image version you want start [with PyTorch release notes](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/),
choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's
components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go
to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
Next follow the instructions to download and deploy the docker image.
## Mixture of Experts
Some recent papers reported a 4-5x training speedup and a faster inference by integrating
Mixture of Experts (MoE) into the Transformer models.
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the
number of parameters by an order of magnitude without increasing training costs.
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function
that trains each expert in a balanced way depending on the input token's position in a sequence.

(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude
larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or
hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the
memory requirements moderately as well.
Most related papers and implementations are built around Tensorflow/TPUs:
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
## Using PyTorch native attention and Flash Attention
PyTorch 2.0 released a native [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA),
that allows using fused GPU kernels such as [memory-efficient attention](https://arxiv.org/abs/2112.05682) and [flash attention](https://arxiv.org/abs/2205.14135).
After installing the [`optimum`](https://github.com/huggingface/optimum) package, the relevant internal modules can be
replaced to use PyTorch's native attention with:
```python
model = model.to_bettertransformer()
```
Once converted, train the model as usual.
<Tip warning={true}>
The PyTorch-native `scaled_dot_product_attention` operator can only dispatch to Flash Attention if no `attention_mask` is provided.
By default, in training mode, the BetterTransformer integration **drops the mask support and can only be used for training that does not require a padding mask for batched training**. This is the case, for example, during masked language modeling or causal language modeling. BetterTransformer is not suited for fine-tuning models on tasks that require a padding mask.
</Tip>
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
| huggingface/transformers/blob/main/docs/source/en/perf_train_gpu_one.md |