
code
stringlengths 501
4.91M
| package
stringlengths 2
88
| path
stringlengths 11
291
| filename
stringlengths 4
197
| parsed_code
stringlengths 0
4.91M
| quality_prob
float64 0
0.99
| learning_prob
float64 0.02
1
|
|---|---|---|---|---|---|---|
# Multiple Factor Analysis (MFA)
```
#changement de dossier
import os
os.chdir("d:/Bureau/PythonProject/packages/scientisttools/data/")
#importation des données
import pandas as pd
url = "http://factominer.free.fr/factomethods/datasets/wine.txt"
wine = pd.read_table(url,sep="\t")
wine.info()
```
Pour réaliser un analyse factorielle multiple avec scientisttools, nous devons effectuer un traitement de notre jeu de données
### MFA
```
wine2 = pd.DataFrame(data=wine.values,
columns = pd.MultiIndex.from_tuples(
[
("others","Label"),
("others","Soil"),
("before shaking","Odor.Intensity"),
("before shaking","Aroma.quality"),
("before shaking","Fruity"),
("before shaking","Flower"),
("before shaking","Spice"),
("vision","Visual.intensity"),
("vision","Nuance"),
("vision","Surface.feeling"),
("after shaking","Odor.intensity"),
("after shaking","Quality.of.odour"),
("after shaking","Fruity"),
("after shaking","Flower"),
("after shaking","Spice"),
("after shaking","Plante"),
("after shaking","Phenolic"),
("after shaking","Aroma.intensity"),
("after shaking","Aroma.persistency"),
("after shaking","Aroma.quality"),
("gustation","Attack.intensity"),
("gustation","Acidity"),
("gustation","Astringency"),
("gustation","Alcohol"),
("gustation","Balance"),
("gustation","Smooth"),
("gustation","Bitterness"),
("gustation","Intensity"),
("gustation","Harmony"),
("overall judgement","Overall.quality"),
("overall judgement","Typical")
]
))
wine2.index= wine.index
groups = wine2.columns.levels[0].drop(["others","overall judgement"]).tolist()
groups
for g in groups:
wine2[g] = wine2[g].astype("float")
wine.info()
from scientisttools.decomposition import MFA
mfa = MFA(n_components=3,
groups=groups,
groups_sup=["others","overall judgement"],
row_labels=wine2.index,
parallelize=True)
mfa.fit(wine2)
# Valeurs propres
from scientisttools.extractfactor import get_eig
eig = get_eig(mfa)
display(eig)
from scientisttools.pyplot import plot_eigenvalues
import matplotlib.pyplot as plt
fig, axe = plt.subplots(figsize=(10,6))
plot_eigenvalues(mfa,choice="eigenvalue",ax=axe)
plt.show()
from scientisttools.pyplot import plotMFA
fig, axe = plt.subplots(figsize=(12,12))
plotMFA(mfa,repel=True,ax=axe)
plt.show()
from scientisttools.extractfactor import summaryMFA
summaryMFA(mfa,to_markdown=True)
```
| scientisttools | /scientisttools-0.0.8.tar.gz/scientisttools-0.0.8/notebooks/mfa_example.ipynb | mfa_example.ipynb | #changement de dossier
import os
os.chdir("d:/Bureau/PythonProject/packages/scientisttools/data/")
#importation des données
import pandas as pd
url = "http://factominer.free.fr/factomethods/datasets/wine.txt"
wine = pd.read_table(url,sep="\t")
wine.info()
wine2 = pd.DataFrame(data=wine.values,
columns = pd.MultiIndex.from_tuples(
[
("others","Label"),
("others","Soil"),
("before shaking","Odor.Intensity"),
("before shaking","Aroma.quality"),
("before shaking","Fruity"),
("before shaking","Flower"),
("before shaking","Spice"),
("vision","Visual.intensity"),
("vision","Nuance"),
("vision","Surface.feeling"),
("after shaking","Odor.intensity"),
("after shaking","Quality.of.odour"),
("after shaking","Fruity"),
("after shaking","Flower"),
("after shaking","Spice"),
("after shaking","Plante"),
("after shaking","Phenolic"),
("after shaking","Aroma.intensity"),
("after shaking","Aroma.persistency"),
("after shaking","Aroma.quality"),
("gustation","Attack.intensity"),
("gustation","Acidity"),
("gustation","Astringency"),
("gustation","Alcohol"),
("gustation","Balance"),
("gustation","Smooth"),
("gustation","Bitterness"),
("gustation","Intensity"),
("gustation","Harmony"),
("overall judgement","Overall.quality"),
("overall judgement","Typical")
]
))
wine2.index= wine.index
groups = wine2.columns.levels[0].drop(["others","overall judgement"]).tolist()
groups
for g in groups:
wine2[g] = wine2[g].astype("float")
wine.info()
from scientisttools.decomposition import MFA
mfa = MFA(n_components=3,
groups=groups,
groups_sup=["others","overall judgement"],
row_labels=wine2.index,
parallelize=True)
mfa.fit(wine2)
# Valeurs propres
from scientisttools.extractfactor import get_eig
eig = get_eig(mfa)
display(eig)
from scientisttools.pyplot import plot_eigenvalues
import matplotlib.pyplot as plt
fig, axe = plt.subplots(figsize=(10,6))
plot_eigenvalues(mfa,choice="eigenvalue",ax=axe)
plt.show()
from scientisttools.pyplot import plotMFA
fig, axe = plt.subplots(figsize=(12,12))
plotMFA(mfa,repel=True,ax=axe)
plt.show()
from scientisttools.extractfactor import summaryMFA
summaryMFA(mfa,to_markdown=True) | 0.308294 | 0.80525 |
# Canonical Discriminant Analysis on Iris dataset
```
from seaborn import load_dataset
import numpy as np
import pandas as pd
iris = load_dataset("iris")
print(iris.head())
# Chargement de la
from scientisttools.discriminant_analysis import CANDISC
candisc = CANDISC(n_components=2,
target=["species"],
row_labels=iris.index,
features_labels=list(iris.columns[:-1]),
parallelize=False)
# Instanciattion
candisc.fit(iris)
```
### Summary Information
```
candisc.summary_information_.T
```
#### Class level Information
```
candisc.class_level_information_
```
### Squared Mahalanobis Distances and Distance statistics
```
candisc.squared_mdist_
# Univariate statistics
candisc.univariate_test_statistis_
candisc.anova_
# Multivariate
# Ne pas oublier la fonction print
print(candisc.manova_)
# Likelihood test
candisc.likelihood_test_
candisc.eig_.T
## Correlation between Canonical and Original Variables
# Total Canonical Structure
from scientisttools.extractfactor import get_candisc_var
pd.concat(get_candisc_var(candisc,choice="correlation"),axis=0)
# Raw Canonical Coefficients
from scientisttools.extractfactor import get_candisc_coef
coef = get_candisc_coef(candisc,choice="absolute")
coef
# Class Means on Canonical Variables
candisc.gmean_coord_
from scientisttools.pyplot import plotCANDISC
import matplotlib.pyplot as plt
fig, axe =plt.subplots(figsize=(16,8))
plotCANDISC(candisc,color=["blue",'#5DC83F','red'],marker=['o',"*",'>'],ax=axe)
plt.show()
score_coef = get_candisc_coef(candisc,choice="score")
score_coef
from scientisttools.extractfactor import summaryCANDISC
summaryCANDISC(candisc,to_markdown=True)
```
## Backward Elimination
```
from scientisttools.discriminant_analysis import STEPDISC
# Backward Elimination
stepdisc = STEPDISC(method="backward",
alpha=0.01,
model_train=True,
verbose=True)
stepdisc.fit(candisc)
stepdisc.train_model_
```
| scientisttools | /scientisttools-0.0.8.tar.gz/scientisttools-0.0.8/notebooks/candisc_iris.ipynb | candisc_iris.ipynb | from seaborn import load_dataset
import numpy as np
import pandas as pd
iris = load_dataset("iris")
print(iris.head())
# Chargement de la
from scientisttools.discriminant_analysis import CANDISC
candisc = CANDISC(n_components=2,
target=["species"],
row_labels=iris.index,
features_labels=list(iris.columns[:-1]),
parallelize=False)
# Instanciattion
candisc.fit(iris)
candisc.summary_information_.T
candisc.class_level_information_
candisc.squared_mdist_
# Univariate statistics
candisc.univariate_test_statistis_
candisc.anova_
# Multivariate
# Ne pas oublier la fonction print
print(candisc.manova_)
# Likelihood test
candisc.likelihood_test_
candisc.eig_.T
## Correlation between Canonical and Original Variables
# Total Canonical Structure
from scientisttools.extractfactor import get_candisc_var
pd.concat(get_candisc_var(candisc,choice="correlation"),axis=0)
# Raw Canonical Coefficients
from scientisttools.extractfactor import get_candisc_coef
coef = get_candisc_coef(candisc,choice="absolute")
coef
# Class Means on Canonical Variables
candisc.gmean_coord_
from scientisttools.pyplot import plotCANDISC
import matplotlib.pyplot as plt
fig, axe =plt.subplots(figsize=(16,8))
plotCANDISC(candisc,color=["blue",'#5DC83F','red'],marker=['o',"*",'>'],ax=axe)
plt.show()
score_coef = get_candisc_coef(candisc,choice="score")
score_coef
from scientisttools.extractfactor import summaryCANDISC
summaryCANDISC(candisc,to_markdown=True)
from scientisttools.discriminant_analysis import STEPDISC
# Backward Elimination
stepdisc = STEPDISC(method="backward",
alpha=0.01,
model_train=True,
verbose=True)
stepdisc.fit(candisc)
stepdisc.train_model_ | 0.492432 | 0.766731 |
# Canonical Discriminant Analysis (CANDISC)
```
# Chargement des librairies
import numpy as np
import pandas as pd
import os
os.chdir("d:/Bureau/PythonProject/packages/scientisttools/data/")
# Chargement de la base
DTrain = pd.read_excel("Data_Illustration_Livre_ADL.xlsx",sheet_name="WINE",header=0)
DTrain.head()
from scientisttools.discriminant_analysis import CANDISC
candisc = CANDISC(n_components=2,
target=["Qualite"],
row_labels=DTrain.index,
features_labels=list(DTrain.columns[:-1]),
priors=None,
parallelize=False)
# Entraînement
candisc.fit(DTrain)
candisc.correlation_ratio_
candisc.anova_
print(candisc.manova_) # ne pas oublier d'utiliser print
```
## Coefficients canoniques bruts
```
from scientisttools.extractfactor import get_candisc_coef
# Coeffcients
coef = get_candisc_coef(candisc)
coef
from scientisttools.pyplot import plotCANDISC
import matplotlib.pyplot as plt
fig, axe =plt.subplots(figsize=(16,8))
plotCANDISC(candisc,color=["blue",'#5DC83F','red'],marker=['o',"*",'>'],ax=axe)
plt.show()
candisc.global_performance_
candisc.likelihood_test_
from scientisttools.extractfactor import get_candisc_var
# Covariance
pd.concat(get_candisc_var(candisc,choice="covariance"),axis=0)
# Correlation avec les axes
pd.concat(get_candisc_var(candisc,choice="correlation"),axis=0)
```
### Individus supplémentaires
```
## Inidvidu supplémentaire
XTest = pd.DataFrame({"Temperature" : 3000, "Soleil" : 1100, "Chaleur" : 20, "Pluie" : 300},index=[1958])
XTest
candisc.transform(XTest)
candisc.decision_function(XTest)
candisc.predict_proba(XTest)
```
## Fonctions de décision
```
score_coef = get_candisc_coef(candisc,choice="score")
score_coef
XTrain = DTrain.drop(columns=["Qualite"])
candisc.decision_function(XTrain).head()
candisc.predict_proba(XTrain).head()
candisc.predict(XTrain).head()
# score
candisc.score(XTrain,DTrain["Qualite"])
from scientisttools.extractfactor import summaryCANDISC
summaryCANDISC(candisc,to_markdown=True)
```
## Backward Elimination
```
from scientisttools.discriminant_analysis import STEPDISC
stepdisc = STEPDISC(method="backward",alpha=0.01,model_train=True,verbose=True)
stepdisc.fit(candisc)
stepdisc.train_model_
fig, axe =plt.subplots(figsize=(16,8))
plotCANDISC(stepdisc.train_model_,color=["blue",'#5DC83F','red'],marker=['o',"*",'>'],ax=axe)
plt.show()
# Summary
summaryCANDISC(stepdisc.train_model_,to_markdown=True)
```
| scientisttools | /scientisttools-0.0.8.tar.gz/scientisttools-0.0.8/notebooks/candisc_wine.ipynb | candisc_wine.ipynb | # Chargement des librairies
import numpy as np
import pandas as pd
import os
os.chdir("d:/Bureau/PythonProject/packages/scientisttools/data/")
# Chargement de la base
DTrain = pd.read_excel("Data_Illustration_Livre_ADL.xlsx",sheet_name="WINE",header=0)
DTrain.head()
from scientisttools.discriminant_analysis import CANDISC
candisc = CANDISC(n_components=2,
target=["Qualite"],
row_labels=DTrain.index,
features_labels=list(DTrain.columns[:-1]),
priors=None,
parallelize=False)
# Entraînement
candisc.fit(DTrain)
candisc.correlation_ratio_
candisc.anova_
print(candisc.manova_) # ne pas oublier d'utiliser print
from scientisttools.extractfactor import get_candisc_coef
# Coeffcients
coef = get_candisc_coef(candisc)
coef
from scientisttools.pyplot import plotCANDISC
import matplotlib.pyplot as plt
fig, axe =plt.subplots(figsize=(16,8))
plotCANDISC(candisc,color=["blue",'#5DC83F','red'],marker=['o',"*",'>'],ax=axe)
plt.show()
candisc.global_performance_
candisc.likelihood_test_
from scientisttools.extractfactor import get_candisc_var
# Covariance
pd.concat(get_candisc_var(candisc,choice="covariance"),axis=0)
# Correlation avec les axes
pd.concat(get_candisc_var(candisc,choice="correlation"),axis=0)
## Inidvidu supplémentaire
XTest = pd.DataFrame({"Temperature" : 3000, "Soleil" : 1100, "Chaleur" : 20, "Pluie" : 300},index=[1958])
XTest
candisc.transform(XTest)
candisc.decision_function(XTest)
candisc.predict_proba(XTest)
score_coef = get_candisc_coef(candisc,choice="score")
score_coef
XTrain = DTrain.drop(columns=["Qualite"])
candisc.decision_function(XTrain).head()
candisc.predict_proba(XTrain).head()
candisc.predict(XTrain).head()
# score
candisc.score(XTrain,DTrain["Qualite"])
from scientisttools.extractfactor import summaryCANDISC
summaryCANDISC(candisc,to_markdown=True)
from scientisttools.discriminant_analysis import STEPDISC
stepdisc = STEPDISC(method="backward",alpha=0.01,model_train=True,verbose=True)
stepdisc.fit(candisc)
stepdisc.train_model_
fig, axe =plt.subplots(figsize=(16,8))
plotCANDISC(stepdisc.train_model_,color=["blue",'#5DC83F','red'],marker=['o',"*",'>'],ax=axe)
plt.show()
# Summary
summaryCANDISC(stepdisc.train_model_,to_markdown=True) | 0.457137 | 0.660172 |
ScientPYfic
---------------
.. image:: https://github.com/monzita/scientpyfic/blob/master/scientpyfic.png
Get the latest news from ScienceDaily.
.. image:: https://github.githubassets.com/images/icons/emoji/unicode/1f4f0.png
Installation
**********************
>>> pip install scientpyfic
Documentation
**********************
Can be seen `here <https://github.com/monzita/scientpyfic/wiki>`_
Example usage
**********************
>>> from scientpyfic.client import ScientPyClient
>>>
>>>
>>> client = ScientPyClient()
>>>
>>> all = client.all.all()
>>>
>>> for news in all:
>>> # news.title
>>> # news.description
>>> # news.pub_date
>>>
>>>
>>> top = client.top.top(body=True, journals=True)
>>>
>>> for news in top:
>>> # news.title
>>> # news.description
>>> # news.pub_date
>>> # news.body
>>> # news.journals
Licence
**********************
`MIT <https://github.com/monzita/scientpyfic/LICENSE>`_ | scientpyfic | /scientpyfic-0.0.3.tar.gz/scientpyfic-0.0.3/README.rst | README.rst | ScientPYfic
---------------
.. image:: https://github.com/monzita/scientpyfic/blob/master/scientpyfic.png
Get the latest news from ScienceDaily.
.. image:: https://github.githubassets.com/images/icons/emoji/unicode/1f4f0.png
Installation
**********************
>>> pip install scientpyfic
Documentation
**********************
Can be seen `here <https://github.com/monzita/scientpyfic/wiki>`_
Example usage
**********************
>>> from scientpyfic.client import ScientPyClient
>>>
>>>
>>> client = ScientPyClient()
>>>
>>> all = client.all.all()
>>>
>>> for news in all:
>>> # news.title
>>> # news.description
>>> # news.pub_date
>>>
>>>
>>> top = client.top.top(body=True, journals=True)
>>>
>>> for news in top:
>>> # news.title
>>> # news.description
>>> # news.pub_date
>>> # news.body
>>> # news.journals
Licence
**********************
`MIT <https://github.com/monzita/scientpyfic/LICENSE>`_ | 0.701713 | 0.562237 |
# Scierra
Scierra [_see-eh-rah_] is a **S**imulated **C**++ **I**nt**er**preter with **R**ecurrent **A**daptation.
In human words, it's a interactive interpreter for C++, which allows you to run and debug your program immediately as you type. Well, basically. But the implementation is slightly trickier.
To get a quick start, simply launch Scierra on the terminal and type `cout << "Hello, World!";`. Yes, that's a complete C++ program in Scierra!
**WARNING:** Scierra is still under development. Even though many vital aspects of C++ (e.g. function definition, templates, classes) are already supported, Scierra does not handle input statements very well. This is unfortunately keeping Scierra in Beta...
## Navigation
* [Example](#Example)
* [Installation](#Installation)
* [Prerequisites](#Prerequisites)
* [Install with PIP](#Install-with-PIP)
* [Usage](#Usage)
* [Quick Start](#Quick-Start)
* [Keywords](#Keywords)
* [Docs](#Docs)
* [Anatomy of a C++ Program in Scierra](#Anatomy-of-a-C-Program-in-Scierra)
* [Unsupported features](#Unsupported-features)
* [LICENSE](#LICENSE)
## Example
***An sample program running on the Scierra interpreter:***
```c++
++> cout << "Hello, World!";
Hello, World!
++> int factorial(int n){
--> if (n==1 || n==0)
--> return 1;
--> else return n * factorial(n-1);
--> }
++> cout << "10 factorial is: " << factorial(10);
10 factorial is: 3628800
```
## Installation
### Prerequisites:
* **Python** must be **installed** and **added to PATH**.
The key ideas of Scierra and it's CLI have been implemented in Python.
* **GCC** (GNU Compiler Collection) must be **installed** and **added to PATH**.
This allows Python to access G++ through the command line. If you're a Linux user, there's a good chance that GCC tools are already included in your distro. Users of other operating systems like Windows or MacOS may need to make additional installations. MinGW has been tested to work with Scierra on Windows.
### Install with PIP
Install Scierra with PIP using:
$ pip install scierra
After installation, run Scierra on your terminal using:
$ scierra
## Usage
### Quick Start
Launch `scierra` in your terminal, and try pasting in the full sample program below.
Note Scierra's ability to automatically categorise whether the block of code you've just typed belongs to the `main` function section, global declarations section, or preprocessors section (refer to the [anatomy of a C++ program in Scierra](#Anatomy-of-a-C-Program-in-Scierra)). The `<esc>` command closes the interpreter.
```c++
cout << "Hello, World!\n";
#define CYAN "\033[36m"
#define GREEN "\033[32m"
#define DEFAULT "\033[0m"
cout << GREEN << "I am SCIERRA" << DEFAULT << endl;
int factorial(int n){
if (n==1 || n==0)
return 1;
else return n * factorial(n-1);
}
cout << CYAN << "10 factorial is: " << factorial(10) << DEFAULT << endl;
<esc>
```
Below is a demo of the above program running in a terminal with Scierra:

### Keywords
Type these special keywords at any stage when writing your code to perform special functions.
* `<print>`: Prints out the code you've written so far.
* `<restart>`: Restarts another interpreter session and forgets all local variables.
* `<esc>`: Terminates Scierra.
#### Code keywords
Put the following keywords at the start of each block of your code for special operations.
* `<`: Using this keyword before a single-lined statement without any semicolons (e.g. `<10+23` or `<"Hey!"`) makes Scierra automatically output the evaluated value of the statement. It works with all data types, variables and classes that supports `cout` statements. You can even join multiple outputs together! E.g.
```c++
++> int x = 132;
++> < x*7
924
++> < x%127 << x%12 << "COOL!"
50COOL!
++>
```
* `<prep>`: Forcefully specifies that the block of code that you type belongs to the 'preprocessor' section of the program. E.g.
```c++
++> <prep>
--> const int Answer_to_Ultimate_Question_of_Life = 42;
++>
```
This puts `const int Answer_to_Ultimate_Question_of_Life = 42;` in the 'preprocessors' section. Without the `<prep>` keyword, this statement would be automatically placed in the `main` function by Scierra.
Refer to: [Anatomy of a C++ Program in Scierra](#Anatomy-of-a-C-Program-in-Scierra).
* `<glob>`: Forcefully specifies that the block of code that you type belongs to the 'globals' section of the program.
Refer to: [Anatomy of a C++ Program in Scierra](#Anatomy-of-a-C-Program-in-Scierra).
* `<main>`: Forcefully specifies that the block of code that you type belongs to the `main` function in the program.
Refer to: [Anatomy of a C++ Program in Scierra](#Anatomy-of-a-C-Program-in-Scierra).
## Docs
### Anatomy of a C++ Program in Scierra
Scierra divides a C++ program into three distinct sections: the 'preprocessor' section, the 'globals' section, and the 'main' section. Please refer to the [keywords and expressions table](#Keywords-and-Expressions-Table) for the full list of keywords and expressions that Scierra uses to categorise a block of code. However, here is a quick overview:
The 'preprocessor' section comes at the top of the program. This is where libraries are imported and namespaces are defined. By default in Scierra, the libraries `iostream`, `sstream`, `fstream`, `vector` and `string` are already imported, and the namespace `std` is under use. The 'globals' section is reserved for global class and function declarations, while the 'main' section goes into the `main` function of your C++ program.
When you enter a block of code in Scierra, it automatically categorises it into one of these three sections based on syntactical keywords and expressions. You can override this automatic behaviour by using one of the [code keywords](#Code-Keywords).
#### Keywords and Expressions Table
Here is a table showing the different keywords and expressions that Scierra uses to categorise your block of code.
| Preprocessor Section | Globals Section | Main Section |
| :---: | :---: | :---: |
| `#include` statement | `class` keyword | _Anything that doesn't fit into the former two sections_ |
| `#define` statement | `struct` keyword | |
| `typedef` keyword | `return` keyword | |
| `using` keyword | `void` keyword | |
| | `template` keyword | |
| | `typename` keyword | |
### Unsupported features
Scierra supports most features that come with your installed version of GCC.
However, unfortunately the following features are not yet supported by Scierra:
* any expression involving inputs
* lambda expressions
* range-based for loops
## LICENSE
[Apache License 2.0](LICENSE)
| scierra | /scierra-0.6.1.tar.gz/scierra-0.6.1/README.md | README.md |
## Installation
### Prerequisites:
* **Python** must be **installed** and **added to PATH**.
The key ideas of Scierra and it's CLI have been implemented in Python.
* **GCC** (GNU Compiler Collection) must be **installed** and **added to PATH**.
This allows Python to access G++ through the command line. If you're a Linux user, there's a good chance that GCC tools are already included in your distro. Users of other operating systems like Windows or MacOS may need to make additional installations. MinGW has been tested to work with Scierra on Windows.
### Install with PIP
Install Scierra with PIP using:
$ pip install scierra
After installation, run Scierra on your terminal using:
$ scierra
## Usage
### Quick Start
Launch `scierra` in your terminal, and try pasting in the full sample program below.
Note Scierra's ability to automatically categorise whether the block of code you've just typed belongs to the `main` function section, global declarations section, or preprocessors section (refer to the [anatomy of a C++ program in Scierra](#Anatomy-of-a-C-Program-in-Scierra)). The `<esc>` command closes the interpreter.
| 0.649023 | 0.851953 |
# SciError
Laboratory report tools in Python.
<i>Lab reports just got a whole lot easier.</i>
A package for automatic measurement error propagation and linear regressions. Stores measurements and their corresponding uncertainties in a Measurement class which can be propagated using the defined methods. CSV files can be read using the DataFile class and sets of data can be linearly regressed using the LinearRegression class. The latex table function is also useful for quickly transferring data into a preformatted latex table which can be copied into a report.
| scierror | /scierror-0.0.3.tar.gz/scierror-0.0.3/README.md | README.md | # SciError
Laboratory report tools in Python.
<i>Lab reports just got a whole lot easier.</i>
A package for automatic measurement error propagation and linear regressions. Stores measurements and their corresponding uncertainties in a Measurement class which can be propagated using the defined methods. CSV files can be read using the DataFile class and sets of data can be linearly regressed using the LinearRegression class. The latex table function is also useful for quickly transferring data into a preformatted latex table which can be copied into a report.
| 0.511717 | 0.418281 |
# sciex
Framework for "scientific" experiments (Result organization; Experiment and Trial setup; Baseline Comparisons)
This tool helps strip out the repetitive parts of setting up and running experiments, and lets you focus on writing the logic of trial running and result types. This reduces the stupid errors one may make when running experiments, and makes results organized and gathering statistics convenient.
## Setup
```
pip install sciex
```
## How it works
#### An Experiment consists of trials
In this framework, an `Experiment` consists of a number of `Trial`s. One trial is independent from another.
```python
class Experiment:
"""One experiment simply groups a set of trials together.
Runs them together, manages results etc."""
def __init__(self, name, trials, outdir,
logging=True, verbose=False):
```
A `Trial` can be initialized by a `name` and a `config`. There is no requirement on the format of `config`; It just needs to be able to be serialized by pickle. Note that we recommend a convention of giving trial names:
```python
class Trial:
def __init__(self, name, config, verbose=False):
"""
Trial name convention: "{trial-global-name}_{seed}_{specific-setting-name}"
Example: gridworld4x4_153_value-iteration-200.
The ``seed'' is optional. If not provided, then there should be only one underscore.
"""
```
**Your job** is to define a child class of `Trial`, implementing its function `run()`, so that it catersx to your experiment design.
#### Parallel trial running
We want to save time and run trials in parallel, if possible. Thus, instead of directly executing the trials, `Experiment` first saves the trials as `pickle` files in **an organized manner**, then generates __shell scripts__, each bundles a subset of all the trials. The shell script contains commands using `trial_runner.py` to conduct trials. More specifically, the **organized manner** means, the pickle files will be saved under, along with `trial_runner.py`, the shell scripts and `gather_results.py`.
```
./{Experiment:outdir}
/{Experiment:name}_{timestamp}
/{Trial:name}
/trial.pkl
gather_results.py
run_{i}.sh
trial_runner.py
```
Inside the shell script `run_{i}` where `i` is the index of the bundle, you will only find commands of the sort:
```
python trial_runner.py {path/to/trial/trial.pkl} {path/to/trial} --logging
```
Thus, you just need to do
```
$ ./run_{i}.sh
```
on a terminal to execute the trials covered by this shell script. You can open multiple terminals and run all shell scripts together in parallel.
##### New
**Divide run scripts by computer.** This is useful
for the case where you have generated a lot of running
scripts (each runs multiple trials) and you want to
add another level of grouping.
```
python -m sciex.divide ./ -c sunny windy rainy cloudy -r 0.3 0.2 0.3 0.2 -n 4 3 4 3
```
where `./` is the path to the experiment root directly (here I am just there),
`sunny windy rainy cloudy` are four computers, and I want to run 30% run scripts
on `sunny`, 20% on `windy`, and so on. On each computer I will start e.g. `4` terminals
for `sunny` and `3` for `windy`, etc.
**Run multiple trials with shared resource.** The trials are contained
in a run script, or a file with a list of paths to trial pickle files.
The trial is expected to implement `provide_shared_resource` and
`could_provide_resource` and the resource should only be read, and not written to
by the trials. (NOTE this doesn't actually work with cuda models because of difficulty sharing CUDA memory)
```
python -m sciex.batch_runner run_script_or_file_with_trial_paths {Experiment:outdir}
```
#### Result types
We know that for different experiments, we may produce results of different type. For example, some times we have a list of values, some times a list of objects, sometimes a particular kind of object, and some times it is a combination of multiple result types. For instance, each trial in a image classification task may produce labels for test images. Yet each trial in image segmentation task may produce arrays of pixel locations. We want you to decide what those result types are and how to process them. Hence the `Result` interface (see `components.py`).
To be more concrete, in `sciex`, each `Trial` can produce multiple `Result`s. Trials with the same `specific_name` (see trial naming convention above) will be **gathered** (to compute a statistic). See the interface below:
```python
class Result:
def save(self, path):
"""Save result to given path to file"""
raise NotImplemented
@classmethod
def collect(cls, path):
"""path can be a str of a list of paths"""
raise NotImplemented
@classmethod
def FILENAME(cls):
"""If this result depends on only one file,
put the filename here"""
raise NotImplemented
@classmethod
def gather(cls, results):
"""`results` is a mapping from specific_name to a dictionary {seed: actual_result}.
Returns a more understandable interpretation of these results"""
return None
@classmethod
def save_gathered_results(cls, results, path):
"""results is a mapping from global_name to the object returned by `gather()`.
Post-processing of results should happen here.
Return "None" if nothing to be saved."""
return None
...
```
Basically, you define how to save this kind of result (`save()`), how to collect it, i.e. read it from a file (`collect()`), how to gather a set of results of this kind (`gather()`), for example, computing mean and standard deviation. As an example, `sciex` provides a `YamlResult` type (see `result_types.py`):
```python
import yaml
import pickle
from sciex.components import Result
class YamlResult(Result):
def __init__(self, things):
self._things = things
def save(self, path):
with open(path, "w") as f:
yaml.dump(self._things, f)
@classmethod
def collect(cls, path):
with open(path) as f:
return yaml.load(f)
```
We didn't define the `gather()` and `save_gathered_results()` functions because these are experiment-specific. For example, in a reinforcement learning experiment, I may want to gather rewards as a type of result. Here's how I may implement that. Notice that since I know I will put these results in a paper, my implementation of `save_gathered_results` will be saving a LaTex table in a `.tex` file.
```python
class RewardsResult(YamlResult):
def __init__(self, rewards):
"""rewards: a list of reward floats"""
super().__init__(rewards)
@classmethod
def FILENAME(cls):
return "rewards.yaml"
@classmethod
def gather(cls, results):
"""`results` is a mapping from specific_name to a dictionary {seed: actual_result}.
Returns a more understandable interpretation of these results"""
# compute cumulative rewards
myresult = {}
for specific_name in results:
all_rewards = []
for seed in results[specific_name]:
cum_reward = sum(list(results[specific_name][seed]))
all_rewards.append(cum_reward)
myresult[specific_name] = {'mean': np.mean(all_rewards),
'std': np.std(all_rewards),
'_size': len(results[specific_name])}
return myresult
@classmethod
def save_gathered_results(cls, gathered_results, path):
def _tex_tab_val(entry, bold=False):
pm = "$\pm$" if not bold else "$\\bm{\pm}$"
return "%.2f %s %.2f" % (entry["mean"], pm, entry["std"])
# Save plain text
with open(os.path.join(path, "rewards.txt"), "w") as f:
pprint(gathered_results, stream=f)
# Save the latex table
with open(os.path.join(path, "rewards_latex.tex"), "w") as f:
tex =\
"\\begin{tabular}{ccccccc}\n%automatically generated table\n"\
" ... "
for global_name in gathered_results:
row = " %s & %s & %s & %s & %s & %s\\\\\n" % (...)
tex += row
tex += "\\end{tabular}"
f.write(tex)
return True
```
Then, after all the results are produced, when you want to gather the results and produce some report of the statistics (or plots), just run
```
$ ./{Experiment:outdir}/{Experiment:name}_{timestamp}/gather_results.py
```
| sciex | /sciex-0.3.tar.gz/sciex-0.3/README.md | README.md | pip install sciex
class Experiment:
"""One experiment simply groups a set of trials together.
Runs them together, manages results etc."""
def __init__(self, name, trials, outdir,
logging=True, verbose=False):
class Trial:
def __init__(self, name, config, verbose=False):
"""
Trial name convention: "{trial-global-name}_{seed}_{specific-setting-name}"
Example: gridworld4x4_153_value-iteration-200.
The ``seed'' is optional. If not provided, then there should be only one underscore.
"""
./{Experiment:outdir}
/{Experiment:name}_{timestamp}
/{Trial:name}
/trial.pkl
gather_results.py
run_{i}.sh
trial_runner.py
python trial_runner.py {path/to/trial/trial.pkl} {path/to/trial} --logging
$ ./run_{i}.sh
python -m sciex.divide ./ -c sunny windy rainy cloudy -r 0.3 0.2 0.3 0.2 -n 4 3 4 3
python -m sciex.batch_runner run_script_or_file_with_trial_paths {Experiment:outdir}
class Result:
def save(self, path):
"""Save result to given path to file"""
raise NotImplemented
@classmethod
def collect(cls, path):
"""path can be a str of a list of paths"""
raise NotImplemented
@classmethod
def FILENAME(cls):
"""If this result depends on only one file,
put the filename here"""
raise NotImplemented
@classmethod
def gather(cls, results):
"""`results` is a mapping from specific_name to a dictionary {seed: actual_result}.
Returns a more understandable interpretation of these results"""
return None
@classmethod
def save_gathered_results(cls, results, path):
"""results is a mapping from global_name to the object returned by `gather()`.
Post-processing of results should happen here.
Return "None" if nothing to be saved."""
return None
...
import yaml
import pickle
from sciex.components import Result
class YamlResult(Result):
def __init__(self, things):
self._things = things
def save(self, path):
with open(path, "w") as f:
yaml.dump(self._things, f)
@classmethod
def collect(cls, path):
with open(path) as f:
return yaml.load(f)
class RewardsResult(YamlResult):
def __init__(self, rewards):
"""rewards: a list of reward floats"""
super().__init__(rewards)
@classmethod
def FILENAME(cls):
return "rewards.yaml"
@classmethod
def gather(cls, results):
"""`results` is a mapping from specific_name to a dictionary {seed: actual_result}.
Returns a more understandable interpretation of these results"""
# compute cumulative rewards
myresult = {}
for specific_name in results:
all_rewards = []
for seed in results[specific_name]:
cum_reward = sum(list(results[specific_name][seed]))
all_rewards.append(cum_reward)
myresult[specific_name] = {'mean': np.mean(all_rewards),
'std': np.std(all_rewards),
'_size': len(results[specific_name])}
return myresult
@classmethod
def save_gathered_results(cls, gathered_results, path):
def _tex_tab_val(entry, bold=False):
pm = "$\pm$" if not bold else "$\\bm{\pm}$"
return "%.2f %s %.2f" % (entry["mean"], pm, entry["std"])
# Save plain text
with open(os.path.join(path, "rewards.txt"), "w") as f:
pprint(gathered_results, stream=f)
# Save the latex table
with open(os.path.join(path, "rewards_latex.tex"), "w") as f:
tex =\
"\\begin{tabular}{ccccccc}\n%automatically generated table\n"\
" ... "
for global_name in gathered_results:
row = " %s & %s & %s & %s & %s & %s\\\\\n" % (...)
tex += row
tex += "\\end{tabular}"
f.write(tex)
return True
$ ./{Experiment:outdir}/{Experiment:name}_{timestamp}/gather_results.py | 0.874533 | 0.897874 |
SciExp²-ExpData
===============
SciExp²-ExpData provides helper functions for easing the workflow of analyzing
the many data output files produced by experiments. The helper functions simply
aggregate the many per-experiment files into a single data structure that
contains all the experiment results with appropriate metadata to identify each
of the experiment results (e.g., using a pandas data frame).
It works best in combination with SciExp²-ExpDef, which can be used to define
many experiments based on parameter permutations.
You can find the documentation in:
https://sciexp2-expdata.readthedocs.io
Copyright
=========
Copyright 2019-2020 Lluís Vilanova <[email protected]>
Sciexp²-ExpData is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
Sciexp²-ExpData is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
| sciexp2-expdata | /sciexp2-expdata-0.1.7.tar.gz/sciexp2-expdata-0.1.7/README.md | README.md | SciExp²-ExpData
===============
SciExp²-ExpData provides helper functions for easing the workflow of analyzing
the many data output files produced by experiments. The helper functions simply
aggregate the many per-experiment files into a single data structure that
contains all the experiment results with appropriate metadata to identify each
of the experiment results (e.g., using a pandas data frame).
It works best in combination with SciExp²-ExpDef, which can be used to define
many experiments based on parameter permutations.
You can find the documentation in:
https://sciexp2-expdata.readthedocs.io
Copyright
=========
Copyright 2019-2020 Lluís Vilanova <[email protected]>
Sciexp²-ExpData is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
Sciexp²-ExpData is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
| 0.752013 | 0.502502 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019, Lluís Vilanova"
__license__ = "GPL version 3 or later"
# pylint: disable=no-name-in-module,import-error
from sciexp2.common import utils
from sciexp2.common.filter import Filter
# pylint: disable=redefined-builtin
def extract(template, function, filter=None, path="_PATH_"):
"""Extract data from all files matching `template` and `filter`.
Parameters
----------
template : str
Template for file paths to extract.
function : callable
Function returning a pandas data frame from a single file.
filter : str or Filter, optional
Filter for the set of path names extracted from `template`. Can
reference any variable name in `template` as well as the one in `path`.
path : str, optional
Variable name used to hold each path name extracted from `template` when
finding the files (see `sciexp2.common.utils.find_files`).
Returns
-------
pandas.DataFrame or None
Pandas data frame with the data from all files matching `template` and
`filter`. Variables in `template` are added as new columns into the
result (with their respective values on each row). If no file is found
matching `template` and `filter`, returns `None`.
Notes
-----
Argument `function` is called with a single argument, corresponding to one
of the file path names matching `template` and `filter`.
"""
filter_ = filter
if filter_ is None:
filter_ = Filter()
else:
filter_ = Filter(filter_)
result = None
files = utils.find_files(template, path=path)
for elem in files:
if not filter_.match(elem):
continue
elem_path = elem.pop(path)
try:
data = function(elem_path)
except:
print(f"ERROR: while extracing data from: {elem_path}")
raise
data = data.assign(**elem)
if result is None:
result = data
else:
result = result.append(data, ignore_index=True)
return result | sciexp2-expdata | /sciexp2-expdata-0.1.7.tar.gz/sciexp2-expdata-0.1.7/sciexp2/expdata/pandas.py | pandas.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019, Lluís Vilanova"
__license__ = "GPL version 3 or later"
# pylint: disable=no-name-in-module,import-error
from sciexp2.common import utils
from sciexp2.common.filter import Filter
# pylint: disable=redefined-builtin
def extract(template, function, filter=None, path="_PATH_"):
"""Extract data from all files matching `template` and `filter`.
Parameters
----------
template : str
Template for file paths to extract.
function : callable
Function returning a pandas data frame from a single file.
filter : str or Filter, optional
Filter for the set of path names extracted from `template`. Can
reference any variable name in `template` as well as the one in `path`.
path : str, optional
Variable name used to hold each path name extracted from `template` when
finding the files (see `sciexp2.common.utils.find_files`).
Returns
-------
pandas.DataFrame or None
Pandas data frame with the data from all files matching `template` and
`filter`. Variables in `template` are added as new columns into the
result (with their respective values on each row). If no file is found
matching `template` and `filter`, returns `None`.
Notes
-----
Argument `function` is called with a single argument, corresponding to one
of the file path names matching `template` and `filter`.
"""
filter_ = filter
if filter_ is None:
filter_ = Filter()
else:
filter_ = Filter(filter_)
result = None
files = utils.find_files(template, path=path)
for elem in files:
if not filter_.match(elem):
continue
elem_path = elem.pop(path)
try:
data = function(elem_path)
except:
print(f"ERROR: while extracing data from: {elem_path}")
raise
data = data.assign(**elem)
if result is None:
result = data
else:
result = result.append(data, ignore_index=True)
return result | 0.785144 | 0.382718 |
SciExp²-ExpDef
==============
SciExp²-ExpDef (aka *Scientific Experiment Exploration - Experiment Definition*)
provides a framework for defining experiments, creating all the files needed for
them and, finally, executing the experiments.
SciExp²-ExpDef puts a special emphasis in simplifying experiment design space
exploration, using a declarative interface for defining permutations of the
different parameters of your experiments, and templated files for the scripts
and configuration files for your experiments. SciExp²-ExpDef supports various
execution platforms like regular local scripts and cluster jobs. It takes care
of tracking their correct execution, and allows selecting which experiments to
run (e.g., those with specific parameter values, or those that were not
successfully run yet).
You can find the documentation in:
https://sciexp2-expdef.readthedocs.io
Copyright
=========
Copyright 2008-2023 Lluís Vilanova <[email protected]>
Sciexp²-ExpDef is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
Sciexp²-ExpDef is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
| sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/README.md | README.md | SciExp²-ExpDef
==============
SciExp²-ExpDef (aka *Scientific Experiment Exploration - Experiment Definition*)
provides a framework for defining experiments, creating all the files needed for
them and, finally, executing the experiments.
SciExp²-ExpDef puts a special emphasis in simplifying experiment design space
exploration, using a declarative interface for defining permutations of the
different parameters of your experiments, and templated files for the scripts
and configuration files for your experiments. SciExp²-ExpDef supports various
execution platforms like regular local scripts and cluster jobs. It takes care
of tracking their correct execution, and allows selecting which experiments to
run (e.g., those with specific parameter values, or those that were not
successfully run yet).
You can find the documentation in:
https://sciexp2-expdef.readthedocs.io
Copyright
=========
Copyright 2008-2023 Lluís Vilanova <[email protected]>
Sciexp²-ExpDef is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
Sciexp²-ExpDef is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
| 0.714927 | 0.407274 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import glob
import os
import six
import pydoc
from sciexp2.common import text
import sciexp2.expdef.system
#: Paths to search for available templates.
#:
#: The order of the list establishes which template will be used in case it
#: exists in more than one directory.
#:
#: Includes the current directory and the `templates` directory shipped with
#: SciExp².
SEARCH_PATH = [
os.curdir,
os.sep.join([os.path.dirname(__file__), "templates"]),
]
def _get_path(name):
"""Get the path to descriptor or template file with given name."""
for path in SEARCH_PATH:
file_path = os.sep.join([path, name])
if os.path.isfile(file_path):
return file_path
return None
_DOC = pydoc.TextDoc()
def _bold(text):
return _DOC.bold(text)
def _indent(text):
return _DOC.indent(text)
class _FakeDict (dict):
def __getitem__(self, key):
if key not in self:
dict.__setitem__(self, key, "")
return dict.__getitem__(self, key)
class TemplateError (Exception):
"""Error retrieving template file."""
def __init__(self, message):
Exception.__init__(self, message)
class Template:
"""A launcher template.
The non-string attributes must be specified in the template descriptor file
as the string identifying the object name.
Attributes
----------
name : str
Template name (taken from the file name of descriptor file).
description : str
Template description.
system : `sciexp2.expdef.system.System`, optional
Name of the execution system this template if for. Can be inherited
from `parent`.
template : str, optional
The template file this descriptor uses. For file ``name.tpl`` you must
use ``name``. Can be inherited from `parent`.
parent : `sciexp2.templates.Template`, optional
Parent template to inherit from.
submit_args : list of str, optional
Extra arguments passed to the job submission program.
overrides : dict, optional
Dictionary mapping variable names in the parent template to their
corresponding values for this template.
defaults : dict, optional
Dictionary mapping variable names in the template to their
corresponding values, in case the user provides none.
Notes
-----
Template descriptor files can use the following variables to refer to the
corresponding attributes set in their parent template:
- `parent_submit_args`
- `parent_overrides`
- `parent_defaults`
Argument `submit_args` can contain variable *LAUNCHER_BASE*, which contains
the absolute path to the base output directory
(`expdef.experiments.Experiments.out`).
"""
_LOADING = []
def __init__(self, name):
"""Create a new template object from its descriptor file."""
if name in Template._LOADING:
raise TemplateError("Circular template dependency: %s"
% " -> ".join(Template._LOADING + [name]))
self.name = name
# load descriptor file
dsc_path = _get_path(self.name + ".dsc")
if dsc_path is None:
raise TemplateError("Cannot find template descriptor file '%s'" %
(self.name + ".dsc"))
dsc = open(dsc_path, "r").read()
# load to know who's the parent
globals_ = dict(
parent_submit_args=[],
parent_overrides=_FakeDict(),
parent_defaults=_FakeDict(),
)
namespace = {}
six.exec_(dsc, globals_, namespace)
self._init_parent(namespace, dsc_path)
# reload with parent-specific information
if self.parent is None:
globals_ = dict(
parent_submit_args=[],
parent_overrides={},
parent_default={},
)
else:
globals_ = dict(
parent_submit_args=list(self.parent.submit_args),
parent_overrides=dict(self.parent.overrides),
parent_default=dict(self.parent.defaults),
)
namespace = {}
six.exec_(dsc, globals_, namespace)
namespace.pop("parent", None)
self._init_description(namespace, dsc_path)
self._init_system(namespace, dsc_path)
self._init_template(namespace, dsc_path)
self._init_submit_args(namespace)
self._init_overrides(namespace)
self._init_defaults(namespace)
# do not accept any other variable in the descriptor
if len(namespace) > 0:
raise TemplateError("Unknown variables in template %s: %s" %
(dsc_path, ", ".join(namespace)))
def _init_parent(self, namespace, dsc_path):
parent_name = namespace.pop("parent", None)
if parent_name is not None:
Template._LOADING.append(self.name)
try:
self.parent = get(parent_name)
except TemplateError as e:
raise TemplateError("When loading parent of %s: %s" %
(dsc_path, e.message))
Template._LOADING.remove(self.name)
else:
self.parent = None
def _init_description(self, namespace, dsc_path):
self.description = namespace.pop("description", None)
if self.description is None:
raise TemplateError("Template descriptor without 'description': "
"%s" % dsc_path)
def _init_system(self, namespace, dsc_path):
self.system = None
if self.parent is not None:
self.system = self.parent.system
system_name = namespace.pop("system", None)
if system_name:
try:
self.system = sciexp2.expdef.system.get(system_name)
except sciexp2.expdef.system.SystemError as e:
raise TemplateError("Error loading 'system' for template "
"%s: %s" % (dsc_path, e.message))
elif self.system is None:
raise TemplateError("Template descriptor without 'system': "
"%s" % dsc_path)
def _init_template(self, namespace, dsc_path):
self.template = None
if self.parent is not None:
self.template = self.parent.template
self.template_path = self.parent.template_path
template_name = namespace.pop("template", None)
if template_name:
self.template = template_name
self.template_path = _get_path(self.template + ".tpl")
if self.template_path is None:
raise TemplateError("Template descriptor with incorrect "
"'template' %r: %s" %
(self.template, dsc_path))
elif self.template is None:
raise TemplateError("Template descriptor without 'template': "
"%s" % dsc_path)
def _init_submit_args(self, namespace):
parent_submit_args = self.parent.submit_args if self.parent else []
self.submit_args = namespace.pop("submit_args", parent_submit_args)
def _init_overrides(self, namespace):
parent_overrides = self.parent.overrides if self.parent else {}
self_overrides = namespace.pop("overrides", {})
self.overrides = dict(self_overrides)
for key, val in parent_overrides.items():
new_val = text.translate(val, self_overrides)
if new_val != val or key not in self_overrides:
self.overrides[key] = new_val
def _init_defaults(self, namespace):
if self.parent:
self.defaults = dict(self.parent.defaults)
else:
self.defaults = {}
self.defaults.update(namespace.pop("defaults", {}))
def get_short_description(self, get_long=False):
"""Get short description."""
res = [_bold(self.name)]
contents = []
contents += [self.description.strip()]
has_parent = self.parent is not None
if has_parent:
contents += [_bold("Parent : ") + self.parent.name]
if get_long or not has_parent:
contents += [_bold("System : ") + self.system.name]
contents += [_bold("Template: ") + self.template]
res.append(_indent("\n".join(contents)))
return "\n".join(res)
def get_description(self):
"""Get a full description."""
res = [self.get_short_description(True)]
contents = []
if len(self.submit_args) > 0:
contents += [_bold("Submit arguments:")]
contents += [_indent(" ".join(self.submit_args))]
if len(self.defaults) > 0:
contents += [_bold("Default values:")]
defaults = ["%-15s :: \"%s\"" % (var, val)
for var, val in sorted(six.iteritems(self.defaults))]
contents += [_indent("\n".join(defaults))]
with open(self.template_path) as contents_file:
mandatory_vars = set(text.get_variables(contents_file.read()))
mandatory_vars |= set([
v
for val in six.itervalues(self.overrides)
for v in text.get_variables(val)])
mandatory_vars -= self.system.assumes()
mandatory_vars -= self.system.defines()
mandatory_vars -= set(self.defaults)
if len(mandatory_vars) > 0:
contents += [_bold("Mandatory variables:")]
mandatory = sorted([str(var) for var in mandatory_vars])
contents += [_indent("\n".join(mandatory))]
with open(self.template_path) as contents_file:
contents += [_bold("Contents:")]
fcontents = "".join(contents_file.readlines())
overrides = dict(self.overrides)
for var in text.get_variables(fcontents):
if var not in overrides:
overrides[var] = "{{%s}}" % var
fcontents = text.translate(fcontents, overrides, recursive=False)
contents += [_indent(fcontents)]
res += [_indent("\n".join(contents))]
return "\n".join(res)
_TEMPLATES = {}
def get(name):
"""Get a Template object by name."""
if name in _TEMPLATES:
res = _TEMPLATES[name]
else:
res = Template(name)
_TEMPLATES[name] = res
return res
def _get_all_templates():
"""Search for all possible template file descriptors."""
for path in SEARCH_PATH:
for file_path in glob.iglob(path + os.sep + "*.dsc"):
name = os.path.basename(file_path)[:-4]
get(name)
def get_description():
"""Get a short description of all available templates."""
_get_all_templates()
return "\n\n".join([tpl.get_short_description()
for tpl in six.itervalues(_TEMPLATES)]) | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/expdef/templates.py | templates.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import glob
import os
import six
import pydoc
from sciexp2.common import text
import sciexp2.expdef.system
#: Paths to search for available templates.
#:
#: The order of the list establishes which template will be used in case it
#: exists in more than one directory.
#:
#: Includes the current directory and the `templates` directory shipped with
#: SciExp².
SEARCH_PATH = [
os.curdir,
os.sep.join([os.path.dirname(__file__), "templates"]),
]
def _get_path(name):
"""Get the path to descriptor or template file with given name."""
for path in SEARCH_PATH:
file_path = os.sep.join([path, name])
if os.path.isfile(file_path):
return file_path
return None
_DOC = pydoc.TextDoc()
def _bold(text):
return _DOC.bold(text)
def _indent(text):
return _DOC.indent(text)
class _FakeDict (dict):
def __getitem__(self, key):
if key not in self:
dict.__setitem__(self, key, "")
return dict.__getitem__(self, key)
class TemplateError (Exception):
"""Error retrieving template file."""
def __init__(self, message):
Exception.__init__(self, message)
class Template:
"""A launcher template.
The non-string attributes must be specified in the template descriptor file
as the string identifying the object name.
Attributes
----------
name : str
Template name (taken from the file name of descriptor file).
description : str
Template description.
system : `sciexp2.expdef.system.System`, optional
Name of the execution system this template if for. Can be inherited
from `parent`.
template : str, optional
The template file this descriptor uses. For file ``name.tpl`` you must
use ``name``. Can be inherited from `parent`.
parent : `sciexp2.templates.Template`, optional
Parent template to inherit from.
submit_args : list of str, optional
Extra arguments passed to the job submission program.
overrides : dict, optional
Dictionary mapping variable names in the parent template to their
corresponding values for this template.
defaults : dict, optional
Dictionary mapping variable names in the template to their
corresponding values, in case the user provides none.
Notes
-----
Template descriptor files can use the following variables to refer to the
corresponding attributes set in their parent template:
- `parent_submit_args`
- `parent_overrides`
- `parent_defaults`
Argument `submit_args` can contain variable *LAUNCHER_BASE*, which contains
the absolute path to the base output directory
(`expdef.experiments.Experiments.out`).
"""
_LOADING = []
def __init__(self, name):
"""Create a new template object from its descriptor file."""
if name in Template._LOADING:
raise TemplateError("Circular template dependency: %s"
% " -> ".join(Template._LOADING + [name]))
self.name = name
# load descriptor file
dsc_path = _get_path(self.name + ".dsc")
if dsc_path is None:
raise TemplateError("Cannot find template descriptor file '%s'" %
(self.name + ".dsc"))
dsc = open(dsc_path, "r").read()
# load to know who's the parent
globals_ = dict(
parent_submit_args=[],
parent_overrides=_FakeDict(),
parent_defaults=_FakeDict(),
)
namespace = {}
six.exec_(dsc, globals_, namespace)
self._init_parent(namespace, dsc_path)
# reload with parent-specific information
if self.parent is None:
globals_ = dict(
parent_submit_args=[],
parent_overrides={},
parent_default={},
)
else:
globals_ = dict(
parent_submit_args=list(self.parent.submit_args),
parent_overrides=dict(self.parent.overrides),
parent_default=dict(self.parent.defaults),
)
namespace = {}
six.exec_(dsc, globals_, namespace)
namespace.pop("parent", None)
self._init_description(namespace, dsc_path)
self._init_system(namespace, dsc_path)
self._init_template(namespace, dsc_path)
self._init_submit_args(namespace)
self._init_overrides(namespace)
self._init_defaults(namespace)
# do not accept any other variable in the descriptor
if len(namespace) > 0:
raise TemplateError("Unknown variables in template %s: %s" %
(dsc_path, ", ".join(namespace)))
def _init_parent(self, namespace, dsc_path):
parent_name = namespace.pop("parent", None)
if parent_name is not None:
Template._LOADING.append(self.name)
try:
self.parent = get(parent_name)
except TemplateError as e:
raise TemplateError("When loading parent of %s: %s" %
(dsc_path, e.message))
Template._LOADING.remove(self.name)
else:
self.parent = None
def _init_description(self, namespace, dsc_path):
self.description = namespace.pop("description", None)
if self.description is None:
raise TemplateError("Template descriptor without 'description': "
"%s" % dsc_path)
def _init_system(self, namespace, dsc_path):
self.system = None
if self.parent is not None:
self.system = self.parent.system
system_name = namespace.pop("system", None)
if system_name:
try:
self.system = sciexp2.expdef.system.get(system_name)
except sciexp2.expdef.system.SystemError as e:
raise TemplateError("Error loading 'system' for template "
"%s: %s" % (dsc_path, e.message))
elif self.system is None:
raise TemplateError("Template descriptor without 'system': "
"%s" % dsc_path)
def _init_template(self, namespace, dsc_path):
self.template = None
if self.parent is not None:
self.template = self.parent.template
self.template_path = self.parent.template_path
template_name = namespace.pop("template", None)
if template_name:
self.template = template_name
self.template_path = _get_path(self.template + ".tpl")
if self.template_path is None:
raise TemplateError("Template descriptor with incorrect "
"'template' %r: %s" %
(self.template, dsc_path))
elif self.template is None:
raise TemplateError("Template descriptor without 'template': "
"%s" % dsc_path)
def _init_submit_args(self, namespace):
parent_submit_args = self.parent.submit_args if self.parent else []
self.submit_args = namespace.pop("submit_args", parent_submit_args)
def _init_overrides(self, namespace):
parent_overrides = self.parent.overrides if self.parent else {}
self_overrides = namespace.pop("overrides", {})
self.overrides = dict(self_overrides)
for key, val in parent_overrides.items():
new_val = text.translate(val, self_overrides)
if new_val != val or key not in self_overrides:
self.overrides[key] = new_val
def _init_defaults(self, namespace):
if self.parent:
self.defaults = dict(self.parent.defaults)
else:
self.defaults = {}
self.defaults.update(namespace.pop("defaults", {}))
def get_short_description(self, get_long=False):
"""Get short description."""
res = [_bold(self.name)]
contents = []
contents += [self.description.strip()]
has_parent = self.parent is not None
if has_parent:
contents += [_bold("Parent : ") + self.parent.name]
if get_long or not has_parent:
contents += [_bold("System : ") + self.system.name]
contents += [_bold("Template: ") + self.template]
res.append(_indent("\n".join(contents)))
return "\n".join(res)
def get_description(self):
"""Get a full description."""
res = [self.get_short_description(True)]
contents = []
if len(self.submit_args) > 0:
contents += [_bold("Submit arguments:")]
contents += [_indent(" ".join(self.submit_args))]
if len(self.defaults) > 0:
contents += [_bold("Default values:")]
defaults = ["%-15s :: \"%s\"" % (var, val)
for var, val in sorted(six.iteritems(self.defaults))]
contents += [_indent("\n".join(defaults))]
with open(self.template_path) as contents_file:
mandatory_vars = set(text.get_variables(contents_file.read()))
mandatory_vars |= set([
v
for val in six.itervalues(self.overrides)
for v in text.get_variables(val)])
mandatory_vars -= self.system.assumes()
mandatory_vars -= self.system.defines()
mandatory_vars -= set(self.defaults)
if len(mandatory_vars) > 0:
contents += [_bold("Mandatory variables:")]
mandatory = sorted([str(var) for var in mandatory_vars])
contents += [_indent("\n".join(mandatory))]
with open(self.template_path) as contents_file:
contents += [_bold("Contents:")]
fcontents = "".join(contents_file.readlines())
overrides = dict(self.overrides)
for var in text.get_variables(fcontents):
if var not in overrides:
overrides[var] = "{{%s}}" % var
fcontents = text.translate(fcontents, overrides, recursive=False)
contents += [_indent(fcontents)]
res += [_indent("\n".join(contents))]
return "\n".join(res)
_TEMPLATES = {}
def get(name):
"""Get a Template object by name."""
if name in _TEMPLATES:
res = _TEMPLATES[name]
else:
res = Template(name)
_TEMPLATES[name] = res
return res
def _get_all_templates():
"""Search for all possible template file descriptors."""
for path in SEARCH_PATH:
for file_path in glob.iglob(path + os.sep + "*.dsc"):
name = os.path.basename(file_path)[:-4]
get(name)
def get_description():
"""Get a short description of all available templates."""
_get_all_templates()
return "\n\n".join([tpl.get_short_description()
for tpl in six.itervalues(_TEMPLATES)]) | 0.645232 | 0.162579 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import hashlib
import os
import stat
import struct
import time
from six.moves import cPickle as pickle
import subprocess
from sciexp2.common.filter import *
from sciexp2.common import instance
from sciexp2.common import progress
from sciexp2.common import text
from sciexp2.common import utils
import sciexp2.expdef.system
class Launcher:
"""Common interface to manage jobs.
The `types` argument to all methods identifies a set of job states to
narrow the selection of jobs.
The `filters` argument to all methods narrows the selection of jobs to
those matching the given filters.
"""
def __init__(self, base_path, system, group, depends, submit_args):
"""
Parameters
----------
base_path : str
Path to the base directory created by
`~sciexp2.expdef.experiments.Experiments.launcher`.
system : str or System subclass
Execution system.
group : `~sciexp2.common.instance.InstanceGroup`
Job descriptors.
depends : sequence of str
Variable names to which jobs depend.
submit_args : sequence of str
Extra arguments to the job-submitting program.
See also
--------
sciexp2.expdef.system.get
"""
if not os.path.isdir(base_path):
raise IOError("Not a directory: " + base_path)
if isinstance(system, str):
name = system
system = sciexp2.expdef.system.get(system)
if system is None:
raise ValueError("Not a launcher system name: " + name)
if not issubclass(system, sciexp2.expdef.system.System):
raise TypeError("Not a System subclass: " +
system.__class__.__name__)
if not isinstance(group, instance.InstanceGroup):
raise TypeError("Not an InstanceGroup")
self._system = system(base_path, group, depends, submit_args)
def parse_filters(self, *filters):
value_filters = []
filters_ = []
for f in filters:
try:
f = Filter(f)
except SyntaxError:
path_abs = os.path.abspath(f)
path = self._system.get_relative_path(
path_abs, self._system._base_abs)
found = None
for var in self.variables():
values = self._system._launchers[var]
if f in values:
found = "%s == %r" % (var, f)
break
if path in values:
found = "%s == %r" % (var, path)
break
if path_abs in values:
found = "%s == %r" % (var, path_abs)
break
if found is None:
raise
value_filters.append(found)
else:
filters_.append(f)
res = and_filters(*filters_)
if len(value_filters) > 0:
res = and_filters(res, or_filters(*value_filters))
res.validate(self.variables())
return res
def variables(self):
"""Return a list with the available variables."""
return list(self._system._launchers.variables())
def values(self, *filters):
"""Return a list with the available variables."""
filter_ = and_filters(*filters)
return list(self._system._launchers.select(filter_))
def summary(self, types, *filters):
"""Print a summary of the state of selected jobs."""
if len(types) == 0:
types = list(sciexp2.expdef.system.Job.STATES)
parts = [(sciexp2.expdef.system.Job.STATE_LONG[t],
len(list(self._system.build([t], *filters))))
for t in types]
max_name = max(len(t) for t, _ in parts)
max_count = max(len(str(n)) for _, n in parts)
fmt = "%%-%ds: %%%dd" % (max_name, max_count)
for t, n in parts:
print(fmt % (t, n))
def state(self, types, *filters, **kwargs):
"""Print the states for the selected jobs."""
expression = kwargs.pop("expression", None)
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
for job in self._system.build(types, *filters):
state, name = job.state()
if expression is not None:
name = text.translate(expression, job)
print("(%s) %s" % (sciexp2.expdef.system.Job.STATE_SHORT[state], name))
def submit(self, types, *filters, **kwargs):
"""Submit selected jobs to execution.
Calls `kill` before submitting a job if it's already running.
"""
submit_args = kwargs.pop("submit_args", [])
keep_going = kwargs.pop("keep_going", False)
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
jobs = list(self._system.build(types, *filters))
exit_code = 0
with progress.progressable_simple(
jobs, None, msg="Submitting jobs...") as pjobs:
for job in pjobs:
if job["_STATE"] == sciexp2.expdef.system.Job.RUNNING:
job.kill()
job_path = self._system.get_relative_path(job["LAUNCHER"])
progress.info("Submitting %s", job_path)
try:
job.submit(*submit_args)
except subprocess.CalledProcessError as e:
exit_code = e.returncode
msg = "ERROR: Exited with code %d" % exit_code
if progress.level() < progress.LVL_INFO:
msg += " (%s)" % self._system.get_relative_path(job["LAUNCHER"])
progress.log(progress.LVL_NONE, msg)
if not keep_going:
break
return exit_code
def kill(self, types, *filters, **kwargs):
"""Kill the execution of selected jobs."""
kill_args = kwargs.pop("kill_args", [])
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
for job in self._system.build(types, *filters):
if job["_STATE"] == sciexp2.expdef.system.Job.RUNNING:
job.kill(*kill_args)
def files(self, types, *filters, **kwargs):
"""List files matching an expression."""
expression = kwargs.pop("expression")
not_expanded = kwargs.pop("not_expanded", False)
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
expr_path = expression
if not os.path.isabs(expr_path):
expr_path = os.path.join(self._system._base_abs, expr_path)
expr_files = list(f["__FILE"]
for f in utils.find_files(expr_path,
path="__FILE"))
job_files = set()
for job in self._system.build(types, *filters):
path = text.translate(expression, job)
abs_path = path
if not os.path.isabs(abs_path):
abs_path = os.path.join(self._system._base_abs, abs_path)
if not os.path.exists(abs_path):
continue
job_files.add(abs_path)
if not_expanded:
res = set(expr_files) - job_files
else:
res = set(expr_files) & job_files
for i in sorted(res, key=expr_files.index):
print(i)
def _header():
return b"#!/usr/bin/env launcher\n"
def _magic():
version = b"launcher"
return hashlib.md5(version).digest()
class LauncherLoadError(Exception):
"""Could not load given file."""
def __init__(self, path):
self.path = path
def __str__(self):
return "Not a job descriptor file: %s" % self.path
def save(file_name, base_to_file, system, group, export, depends, submit_args):
"""Save an InstanceGroup as a job descriptor into a file.
Parameters
----------
file_name : str
Path to destination file.
base_to_file : str
Relative path from some base directory to the directory containing
`file_name`.
system : `~sciexp2.expdef.system.System`
Class of the execution system to use.
group : `~sciexp2.common.instance.InstanceGroup`
Job descriptors.
export : set
Variable names to export into the description file.
depends : sequence of str
Variable names to which jobs depend.
submit_args : sequence of str
Extra arguments to the job-submitting program.
See also
--------
load, sciexp2.expdef.system.get
"""
assert system is not None
if not issubclass(system, sciexp2.expdef.system.System):
system = sciexp2.expdef.system.get(system)
if len(group) > 0:
for assumed in system.assumes():
if assumed not in group:
raise ValueError("'%s' must be defined" % assumed)
file_dir = os.path.dirname(file_name)
if not os.path.exists(file_dir):
os.makedirs(file_dir)
with open(file_name, "wb") as file_obj:
file_obj.write(_header())
version = _magic()
file_obj.write(struct.pack("I", len(version)))
file_obj.write(version)
pickle.dump((base_to_file, system.name, depends, submit_args),
file_obj, -1)
group.dump(file_obj, export)
fmode = stat.S_IRWXU | stat.S_IRWXG | stat.S_IROTH | stat.S_IXOTH
os.chmod(file_name, fmode)
def load(file_name):
"""Load a job description from a file.
Parameters
----------
file_name : str
Path to source file.
Returns
-------
sciexp2.expdef.system.System
Instance of the execution system with the job descriptions.
Raises
------
LauncherLoadError
The given file cannot be loaded as a `Launcher`.
See also
--------
save
"""
with open(file_name, "rb") as file_obj:
header = file_obj.readline()
if header != _header():
raise LauncherLoadError(file_name)
version_size = struct.unpack("I", file_obj.read(struct.calcsize("I")))
version_size = version_size[0]
version = file_obj.read(version_size)
if version != _magic():
raise LauncherLoadError(file_name)
base_to_file, system_name, depends, submit_args = pickle.load(file_obj)
group = instance.InstanceGroup.load(file_obj)
jd_base = os.path.dirname(os.path.abspath(file_name))
if base_to_file != "":
base = jd_base[:-len(base_to_file)]
else:
base = jd_base
base = os.path.relpath(base)
return Launcher(base, system_name, group, depends, submit_args) | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/expdef/launcher.py | launcher.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import hashlib
import os
import stat
import struct
import time
from six.moves import cPickle as pickle
import subprocess
from sciexp2.common.filter import *
from sciexp2.common import instance
from sciexp2.common import progress
from sciexp2.common import text
from sciexp2.common import utils
import sciexp2.expdef.system
class Launcher:
"""Common interface to manage jobs.
The `types` argument to all methods identifies a set of job states to
narrow the selection of jobs.
The `filters` argument to all methods narrows the selection of jobs to
those matching the given filters.
"""
def __init__(self, base_path, system, group, depends, submit_args):
"""
Parameters
----------
base_path : str
Path to the base directory created by
`~sciexp2.expdef.experiments.Experiments.launcher`.
system : str or System subclass
Execution system.
group : `~sciexp2.common.instance.InstanceGroup`
Job descriptors.
depends : sequence of str
Variable names to which jobs depend.
submit_args : sequence of str
Extra arguments to the job-submitting program.
See also
--------
sciexp2.expdef.system.get
"""
if not os.path.isdir(base_path):
raise IOError("Not a directory: " + base_path)
if isinstance(system, str):
name = system
system = sciexp2.expdef.system.get(system)
if system is None:
raise ValueError("Not a launcher system name: " + name)
if not issubclass(system, sciexp2.expdef.system.System):
raise TypeError("Not a System subclass: " +
system.__class__.__name__)
if not isinstance(group, instance.InstanceGroup):
raise TypeError("Not an InstanceGroup")
self._system = system(base_path, group, depends, submit_args)
def parse_filters(self, *filters):
value_filters = []
filters_ = []
for f in filters:
try:
f = Filter(f)
except SyntaxError:
path_abs = os.path.abspath(f)
path = self._system.get_relative_path(
path_abs, self._system._base_abs)
found = None
for var in self.variables():
values = self._system._launchers[var]
if f in values:
found = "%s == %r" % (var, f)
break
if path in values:
found = "%s == %r" % (var, path)
break
if path_abs in values:
found = "%s == %r" % (var, path_abs)
break
if found is None:
raise
value_filters.append(found)
else:
filters_.append(f)
res = and_filters(*filters_)
if len(value_filters) > 0:
res = and_filters(res, or_filters(*value_filters))
res.validate(self.variables())
return res
def variables(self):
"""Return a list with the available variables."""
return list(self._system._launchers.variables())
def values(self, *filters):
"""Return a list with the available variables."""
filter_ = and_filters(*filters)
return list(self._system._launchers.select(filter_))
def summary(self, types, *filters):
"""Print a summary of the state of selected jobs."""
if len(types) == 0:
types = list(sciexp2.expdef.system.Job.STATES)
parts = [(sciexp2.expdef.system.Job.STATE_LONG[t],
len(list(self._system.build([t], *filters))))
for t in types]
max_name = max(len(t) for t, _ in parts)
max_count = max(len(str(n)) for _, n in parts)
fmt = "%%-%ds: %%%dd" % (max_name, max_count)
for t, n in parts:
print(fmt % (t, n))
def state(self, types, *filters, **kwargs):
"""Print the states for the selected jobs."""
expression = kwargs.pop("expression", None)
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
for job in self._system.build(types, *filters):
state, name = job.state()
if expression is not None:
name = text.translate(expression, job)
print("(%s) %s" % (sciexp2.expdef.system.Job.STATE_SHORT[state], name))
def submit(self, types, *filters, **kwargs):
"""Submit selected jobs to execution.
Calls `kill` before submitting a job if it's already running.
"""
submit_args = kwargs.pop("submit_args", [])
keep_going = kwargs.pop("keep_going", False)
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
jobs = list(self._system.build(types, *filters))
exit_code = 0
with progress.progressable_simple(
jobs, None, msg="Submitting jobs...") as pjobs:
for job in pjobs:
if job["_STATE"] == sciexp2.expdef.system.Job.RUNNING:
job.kill()
job_path = self._system.get_relative_path(job["LAUNCHER"])
progress.info("Submitting %s", job_path)
try:
job.submit(*submit_args)
except subprocess.CalledProcessError as e:
exit_code = e.returncode
msg = "ERROR: Exited with code %d" % exit_code
if progress.level() < progress.LVL_INFO:
msg += " (%s)" % self._system.get_relative_path(job["LAUNCHER"])
progress.log(progress.LVL_NONE, msg)
if not keep_going:
break
return exit_code
def kill(self, types, *filters, **kwargs):
"""Kill the execution of selected jobs."""
kill_args = kwargs.pop("kill_args", [])
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
for job in self._system.build(types, *filters):
if job["_STATE"] == sciexp2.expdef.system.Job.RUNNING:
job.kill(*kill_args)
def files(self, types, *filters, **kwargs):
"""List files matching an expression."""
expression = kwargs.pop("expression")
not_expanded = kwargs.pop("not_expanded", False)
if len(kwargs) > 0:
raise ValueError("Unknown arguments: " + " ".join(kwargs.keys()))
expr_path = expression
if not os.path.isabs(expr_path):
expr_path = os.path.join(self._system._base_abs, expr_path)
expr_files = list(f["__FILE"]
for f in utils.find_files(expr_path,
path="__FILE"))
job_files = set()
for job in self._system.build(types, *filters):
path = text.translate(expression, job)
abs_path = path
if not os.path.isabs(abs_path):
abs_path = os.path.join(self._system._base_abs, abs_path)
if not os.path.exists(abs_path):
continue
job_files.add(abs_path)
if not_expanded:
res = set(expr_files) - job_files
else:
res = set(expr_files) & job_files
for i in sorted(res, key=expr_files.index):
print(i)
def _header():
return b"#!/usr/bin/env launcher\n"
def _magic():
version = b"launcher"
return hashlib.md5(version).digest()
class LauncherLoadError(Exception):
"""Could not load given file."""
def __init__(self, path):
self.path = path
def __str__(self):
return "Not a job descriptor file: %s" % self.path
def save(file_name, base_to_file, system, group, export, depends, submit_args):
"""Save an InstanceGroup as a job descriptor into a file.
Parameters
----------
file_name : str
Path to destination file.
base_to_file : str
Relative path from some base directory to the directory containing
`file_name`.
system : `~sciexp2.expdef.system.System`
Class of the execution system to use.
group : `~sciexp2.common.instance.InstanceGroup`
Job descriptors.
export : set
Variable names to export into the description file.
depends : sequence of str
Variable names to which jobs depend.
submit_args : sequence of str
Extra arguments to the job-submitting program.
See also
--------
load, sciexp2.expdef.system.get
"""
assert system is not None
if not issubclass(system, sciexp2.expdef.system.System):
system = sciexp2.expdef.system.get(system)
if len(group) > 0:
for assumed in system.assumes():
if assumed not in group:
raise ValueError("'%s' must be defined" % assumed)
file_dir = os.path.dirname(file_name)
if not os.path.exists(file_dir):
os.makedirs(file_dir)
with open(file_name, "wb") as file_obj:
file_obj.write(_header())
version = _magic()
file_obj.write(struct.pack("I", len(version)))
file_obj.write(version)
pickle.dump((base_to_file, system.name, depends, submit_args),
file_obj, -1)
group.dump(file_obj, export)
fmode = stat.S_IRWXU | stat.S_IRWXG | stat.S_IROTH | stat.S_IXOTH
os.chmod(file_name, fmode)
def load(file_name):
"""Load a job description from a file.
Parameters
----------
file_name : str
Path to source file.
Returns
-------
sciexp2.expdef.system.System
Instance of the execution system with the job descriptions.
Raises
------
LauncherLoadError
The given file cannot be loaded as a `Launcher`.
See also
--------
save
"""
with open(file_name, "rb") as file_obj:
header = file_obj.readline()
if header != _header():
raise LauncherLoadError(file_name)
version_size = struct.unpack("I", file_obj.read(struct.calcsize("I")))
version_size = version_size[0]
version = file_obj.read(version_size)
if version != _magic():
raise LauncherLoadError(file_name)
base_to_file, system_name, depends, submit_args = pickle.load(file_obj)
group = instance.InstanceGroup.load(file_obj)
jd_base = os.path.dirname(os.path.abspath(file_name))
if base_to_file != "":
base = jd_base[:-len(base_to_file)]
else:
base = jd_base
base = os.path.relpath(base)
return Launcher(base, system_name, group, depends, submit_args) | 0.59561 | 0.146392 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import os
import subprocess
import warnings
import sciexp2.expdef.system
import sciexp2.common.instance
from sciexp2.common import progress
class System (sciexp2.expdef.system.System):
"""Manage jobs in a gridengine system."""
STATE_CMD = ["qstat", "-r"]
ASSUMES = ["JOB_NAME", "STDOUT", "STDERR"]
DEFINES = []
def compute_state(self):
# check program exists
try:
subprocess.check_output([self.STATE_CMD[0], "-help"])
exists = True
except OSError as e:
warnings.warn("Could not run %s; assuming no job is running: %s" %
(self.STATE_CMD[0], str(e)))
exists = False
# compute set of running jobs
running = set()
if exists:
pipe = subprocess.Popen(self.STATE_CMD,
stdout=subprocess.PIPE)
for line in pipe.stdout:
line = line.split()
if line[0] == "Full" and line[1] == "jobname:":
running.add(line[2])
if pipe.wait() != 0:
raise Exception("Could not get execution state ('%s'): %s" %
(" ".join(self.STATE_CMD), pipe.returncode))
# build instance group of job states
self._jobs = sciexp2.common.instance.InstanceGroup()
for instance in self._launchers:
if instance["JOB_NAME"] in running:
job = Job(self,
sciexp2.expdef.system.Job.RUNNING,
instance)
else:
job = Job(self,
sciexp2.expdef.system.Job.compute_state(self, instance),
instance)
self._jobs.add(job)
@staticmethod
def post_generate(base, path, instance, xlator):
def ensure_dirs(var):
val = xlator.xlate_rec(instance[var], instance)
if not os.path.isabs(val):
val = os.sep.join([base, val])
val_dir = os.path.dirname(val)
if not os.path.exists(val_dir):
os.makedirs(val_dir)
else:
assert os.path.isdir(val_dir)
ensure_dirs("DONE")
ensure_dirs("FAIL")
class Job (sciexp2.expdef.system.Job):
"""A job in a gridengine system."""
def state(self):
state = self["_STATE"]
if state == sciexp2.expdef.system.Job.RUNNING:
name = self["JOB_NAME"]
elif state == sciexp2.expdef.system.Job.DONE:
name = self._system.get_relative_path(self["DONE"])
elif state == sciexp2.expdef.system.Job.FAILED:
name = self._system.get_relative_path(self["FAIL"])
elif state in [sciexp2.expdef.system.Job.NOTRUN, sciexp2.expdef.system.Job.OUTDATED]:
name = self._system.get_relative_path(self["LAUNCHER"])
else:
raise ValueError("Unknown job state: %r" % state)
return state, name
def submit(self, *args):
launcher = os.sep.join([self._system._base, self["LAUNCHER"]])
assert os.path.isfile(launcher)
cmd = ["qsub"] + self._submit_args(args) + [launcher]
progress.verbose(" %s", " ".join(cmd))
if progress.level() < progress.LVL_DEBUG:
subprocess.check_call(cmd,
stdout=sciexp2.expdef.system._DEVNULL,
stderr=subprocess.STDOUT)
else:
subprocess.call(cmd)
def kill(self, *args):
launcher = os.sep.join([self._system._base, self["LAUNCHER"]])
assert os.path.isfile(launcher)
cmd = ["qdel"] + self._kill_args(args) + [launcher]
progress.verbose(" %s", " ".join(cmd))
if progress.level() < progress.LVL_DEBUG:
subprocess.check_call(cmd,
stdout=sciexp2.expdef.system._DEVNULL,
stderr=subprocess.STDOUT)
else:
subprocess.check_call(cmd, stderr=subprocess.STDOUT) | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/expdef/system/gridengine.py | gridengine.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import os
import subprocess
import warnings
import sciexp2.expdef.system
import sciexp2.common.instance
from sciexp2.common import progress
class System (sciexp2.expdef.system.System):
"""Manage jobs in a gridengine system."""
STATE_CMD = ["qstat", "-r"]
ASSUMES = ["JOB_NAME", "STDOUT", "STDERR"]
DEFINES = []
def compute_state(self):
# check program exists
try:
subprocess.check_output([self.STATE_CMD[0], "-help"])
exists = True
except OSError as e:
warnings.warn("Could not run %s; assuming no job is running: %s" %
(self.STATE_CMD[0], str(e)))
exists = False
# compute set of running jobs
running = set()
if exists:
pipe = subprocess.Popen(self.STATE_CMD,
stdout=subprocess.PIPE)
for line in pipe.stdout:
line = line.split()
if line[0] == "Full" and line[1] == "jobname:":
running.add(line[2])
if pipe.wait() != 0:
raise Exception("Could not get execution state ('%s'): %s" %
(" ".join(self.STATE_CMD), pipe.returncode))
# build instance group of job states
self._jobs = sciexp2.common.instance.InstanceGroup()
for instance in self._launchers:
if instance["JOB_NAME"] in running:
job = Job(self,
sciexp2.expdef.system.Job.RUNNING,
instance)
else:
job = Job(self,
sciexp2.expdef.system.Job.compute_state(self, instance),
instance)
self._jobs.add(job)
@staticmethod
def post_generate(base, path, instance, xlator):
def ensure_dirs(var):
val = xlator.xlate_rec(instance[var], instance)
if not os.path.isabs(val):
val = os.sep.join([base, val])
val_dir = os.path.dirname(val)
if not os.path.exists(val_dir):
os.makedirs(val_dir)
else:
assert os.path.isdir(val_dir)
ensure_dirs("DONE")
ensure_dirs("FAIL")
class Job (sciexp2.expdef.system.Job):
"""A job in a gridengine system."""
def state(self):
state = self["_STATE"]
if state == sciexp2.expdef.system.Job.RUNNING:
name = self["JOB_NAME"]
elif state == sciexp2.expdef.system.Job.DONE:
name = self._system.get_relative_path(self["DONE"])
elif state == sciexp2.expdef.system.Job.FAILED:
name = self._system.get_relative_path(self["FAIL"])
elif state in [sciexp2.expdef.system.Job.NOTRUN, sciexp2.expdef.system.Job.OUTDATED]:
name = self._system.get_relative_path(self["LAUNCHER"])
else:
raise ValueError("Unknown job state: %r" % state)
return state, name
def submit(self, *args):
launcher = os.sep.join([self._system._base, self["LAUNCHER"]])
assert os.path.isfile(launcher)
cmd = ["qsub"] + self._submit_args(args) + [launcher]
progress.verbose(" %s", " ".join(cmd))
if progress.level() < progress.LVL_DEBUG:
subprocess.check_call(cmd,
stdout=sciexp2.expdef.system._DEVNULL,
stderr=subprocess.STDOUT)
else:
subprocess.call(cmd)
def kill(self, *args):
launcher = os.sep.join([self._system._base, self["LAUNCHER"]])
assert os.path.isfile(launcher)
cmd = ["qdel"] + self._kill_args(args) + [launcher]
progress.verbose(" %s", " ".join(cmd))
if progress.level() < progress.LVL_DEBUG:
subprocess.check_call(cmd,
stdout=sciexp2.expdef.system._DEVNULL,
stderr=subprocess.STDOUT)
else:
subprocess.check_call(cmd, stderr=subprocess.STDOUT) | 0.448909 | 0.132739 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import abc
import glob
import imp
import os
import shutil
import six
import weakref
import sciexp2.common.instance
from sciexp2.common.filter import *
from sciexp2.common import text
from sciexp2.common import utils
#: Paths to search for available execution systems.
#:
#: The order of the list establishes which execution system implementation will
#: be used in case it exists in more than one directory.
#:
#: Includes the current directory and the `system` directory shipped with
#: SciExp².
SEARCH_PATH = [
os.curdir,
os.path.dirname(__file__),
]
_DEVNULL = open("/dev/null", "w")
class SystemError (Exception):
"""Error loading system."""
def __init__(self, message):
Exception.__init__(self, message)
class SubmitArgsError (Exception):
"""Error translating job submission arguments."""
def __init__(self, variables):
Exception.__init__(
self,
"Found non-exported variables in job submission arguments: " +
", ".join(variables))
class System (six.with_metaclass(abc.ABCMeta)):
"""Abstract job manager.
Each system must implement the abstract methods defined in this class
and define two class attributes:
========= =======================================================
Name Description
========= =======================================================
`ASSUMES` List of variables that are assumed to be present in the
launchers instance group for the system to work.
`DEFINES` List of variables that the system internally defines and thus
must not be present in the launchers instance group.
========= =======================================================
See also
--------
compute_state
"""
ASSUMES = ["LAUNCHER", "DONE", "FAIL"]
DEFINES = ["_STATE", "LAUNCHER_BASE"]
def __init__(self, base_path, launchers, depends, submit_args):
"""
Parameters
----------
base_path : str
Base directory where launchers are located.
launchers : InstanceGroup
Group describing the launchers.
depends : sequence of str
Variable names to which jobs depend.
submit_args : sequence of str
Extra arguments to the job-submitting program.
"""
self._base = base_path
self._base_abs = os.path.realpath(self._base)
assert os.path.isdir(self._base_abs)
self._launchers = launchers
for assume in self.assumes():
if assume not in self._launchers and len(self._launchers) > 0:
raise ValueError("Variable '%s' must be present" % assume)
for define in self.defines():
if define in self._launchers:
raise ValueError("Variable '%s' must not be present" % define)
self._jobs = None
self._depends = set(depends)
self._submit_args = list(submit_args)
def get_relative_path(self, path, cwd=None):
"""Get path (relative to base) as relative to `cwd`."""
if cwd is None:
cwd = os.getcwd()
if not os.path.isabs(path):
path = os.path.join(self._base_abs, path)
return os.path.relpath(path, cwd)
def build(self, types, *filters):
"""Generate a sequence with the jobs matching the given criteria.
Parameters
----------
types : set
Set of states that the jobs must be on.
filters : list of filters
List of filters that the jobs must match.
See also
--------
Job
"""
self.compute_state()
build_filter = and_filters(*filters)
if len(types) > 0:
state_filter = " or ".join(["_STATE == '%s'" % state
for state in types
if state != "inverse"])
if "inverse" in types:
state_filter = "not (%s)" % state_filter
build_filter = and_filters(build_filter, state_filter)
if len(self._jobs) > 0:
build_filter.validate(set(self._jobs.variables()))
return self._jobs.select(build_filter)
else:
return sciexp2.common.instance.InstanceGroup()
@classmethod
def assumes(cls):
"""The set of variables that must be present on the launchers."""
return set(System.ASSUMES + cls.ASSUMES)
@classmethod
def defines(cls):
"""The set of variables that must not be present on the launchers."""
return set(System.DEFINES + cls.DEFINES)
@abc.abstractmethod
def compute_state(self):
"""Compute the current state of jobs.
The implementation must set the ``_jobs`` attribute with an
InstanceGroup of `Job` instances. This can be computed using the
contents of the ``_launchers`` attribute.
"""
pass
@staticmethod
def post_generate(base, path, instance, xlator):
"""Post-process the generation of file `path`."""
pass
class Job (six.with_metaclass(abc.ABCMeta, sciexp2.common.instance.Instance)):
"""Abstract job descriptor.
Each job must implement the abstract methods defined in this class.
See also
--------
state, submit, kill
"""
# job states
RUNNING = "running"
DONE = "done"
FAILED = "failed"
OUTDATED = "outdated"
NOTRUN = "notrun"
STATES = [
RUNNING,
DONE,
FAILED,
OUTDATED,
NOTRUN,
]
STATE_SHORT = {
RUNNING: u"\u2699",
DONE: u"\u2713",
FAILED: "x",
OUTDATED: "o",
NOTRUN: " ",
}
STATE_LONG = {
RUNNING: "Running",
DONE: "Done",
FAILED: "Failed",
OUTDATED: "Outdated",
NOTRUN: "Not run",
}
def __init__(self, system, state, instance):
"""
Parameters
----------
system : System
System for which this job is.
state : str
Execution state of the job.
instance : str
Launcher instance describing this job.
"""
sciexp2.common.instance.Instance.__init__(self, instance)
self["_STATE"] = state
self._system = weakref.proxy(system)
def __repr__(self):
return repr(sciexp2.common.instance.Instance(self))
@classmethod
def compute_state(cls, system, instance):
"""Generic job state computation.
Parameters
----------
system : System
System for which this job is being checked.
instance
Launcher instance describing a job.
Returns
-------
Generic job state according to the failed/done files; otherwise returns
`NOTRUN`.
"""
fail_path = instance["FAIL"]
if not os.path.isabs(fail_path):
fail_path = os.sep.join([system._base, fail_path])
if os.path.exists(fail_path):
return cls.FAILED
done_path = instance["DONE"]
if not os.path.isabs(done_path):
done_path = os.sep.join([system._base, done_path])
if not os.path.exists(done_path):
return cls.NOTRUN
done_mtime = os.stat(done_path).st_mtime
for dep in system._depends:
path = text.translate(dep, instance)
if path == "":
continue
path = utils.get_path(path)
if not os.path.isabs(path):
path = os.sep.join([system._base, path])
if not os.path.exists(path) or \
done_mtime < os.stat(path).st_mtime:
return cls.OUTDATED
return cls.DONE
@abc.abstractmethod
def state(self):
"""Return a string describing the job and its state."""
pass
@abc.abstractmethod
def submit(self, *args):
"""Submit a job to execution."""
pass
def _submit_args(self, args):
"""Return extra arguments for the job submitting program."""
instance = dict(self)
instance["LAUNCHER_BASE"] = self._system._base_abs
try:
return [text.translate(arg, instance)
for arg in self._system._submit_args + list(args)]
except text.VariableError as e:
raise SubmitArgsError(e.message)
@abc.abstractmethod
def kill(self, *args):
"""Kill a job from execution."""
pass
def _kill_args(self, args):
"""Return extra arguments for the job killing program."""
instance = dict(self)
instance["LAUNCHER_BASE"] = self._system._base_abs
try:
return [text.translate(arg, instance)
for arg in list(args)]
except text.VariableError as e:
raise SubmitArgsError(e.message)
def get(name):
"""Get an execution system implementation by name.
See also
--------
SEARCH_PATH
"""
try:
info = imp.find_module(name, SEARCH_PATH)
system = imp.load_module(name, *info)
except ImportError:
raise SystemError("Unknown system %r" % name)
try:
res = system.System
except AttributeError:
raise AttributeError("Does not look like an execution " +
"system implementation: %s" % name)
res.name = name
return res | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/expdef/system/__init__.py | __init__.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import abc
import glob
import imp
import os
import shutil
import six
import weakref
import sciexp2.common.instance
from sciexp2.common.filter import *
from sciexp2.common import text
from sciexp2.common import utils
#: Paths to search for available execution systems.
#:
#: The order of the list establishes which execution system implementation will
#: be used in case it exists in more than one directory.
#:
#: Includes the current directory and the `system` directory shipped with
#: SciExp².
SEARCH_PATH = [
os.curdir,
os.path.dirname(__file__),
]
_DEVNULL = open("/dev/null", "w")
class SystemError (Exception):
"""Error loading system."""
def __init__(self, message):
Exception.__init__(self, message)
class SubmitArgsError (Exception):
"""Error translating job submission arguments."""
def __init__(self, variables):
Exception.__init__(
self,
"Found non-exported variables in job submission arguments: " +
", ".join(variables))
class System (six.with_metaclass(abc.ABCMeta)):
"""Abstract job manager.
Each system must implement the abstract methods defined in this class
and define two class attributes:
========= =======================================================
Name Description
========= =======================================================
`ASSUMES` List of variables that are assumed to be present in the
launchers instance group for the system to work.
`DEFINES` List of variables that the system internally defines and thus
must not be present in the launchers instance group.
========= =======================================================
See also
--------
compute_state
"""
ASSUMES = ["LAUNCHER", "DONE", "FAIL"]
DEFINES = ["_STATE", "LAUNCHER_BASE"]
def __init__(self, base_path, launchers, depends, submit_args):
"""
Parameters
----------
base_path : str
Base directory where launchers are located.
launchers : InstanceGroup
Group describing the launchers.
depends : sequence of str
Variable names to which jobs depend.
submit_args : sequence of str
Extra arguments to the job-submitting program.
"""
self._base = base_path
self._base_abs = os.path.realpath(self._base)
assert os.path.isdir(self._base_abs)
self._launchers = launchers
for assume in self.assumes():
if assume not in self._launchers and len(self._launchers) > 0:
raise ValueError("Variable '%s' must be present" % assume)
for define in self.defines():
if define in self._launchers:
raise ValueError("Variable '%s' must not be present" % define)
self._jobs = None
self._depends = set(depends)
self._submit_args = list(submit_args)
def get_relative_path(self, path, cwd=None):
"""Get path (relative to base) as relative to `cwd`."""
if cwd is None:
cwd = os.getcwd()
if not os.path.isabs(path):
path = os.path.join(self._base_abs, path)
return os.path.relpath(path, cwd)
def build(self, types, *filters):
"""Generate a sequence with the jobs matching the given criteria.
Parameters
----------
types : set
Set of states that the jobs must be on.
filters : list of filters
List of filters that the jobs must match.
See also
--------
Job
"""
self.compute_state()
build_filter = and_filters(*filters)
if len(types) > 0:
state_filter = " or ".join(["_STATE == '%s'" % state
for state in types
if state != "inverse"])
if "inverse" in types:
state_filter = "not (%s)" % state_filter
build_filter = and_filters(build_filter, state_filter)
if len(self._jobs) > 0:
build_filter.validate(set(self._jobs.variables()))
return self._jobs.select(build_filter)
else:
return sciexp2.common.instance.InstanceGroup()
@classmethod
def assumes(cls):
"""The set of variables that must be present on the launchers."""
return set(System.ASSUMES + cls.ASSUMES)
@classmethod
def defines(cls):
"""The set of variables that must not be present on the launchers."""
return set(System.DEFINES + cls.DEFINES)
@abc.abstractmethod
def compute_state(self):
"""Compute the current state of jobs.
The implementation must set the ``_jobs`` attribute with an
InstanceGroup of `Job` instances. This can be computed using the
contents of the ``_launchers`` attribute.
"""
pass
@staticmethod
def post_generate(base, path, instance, xlator):
"""Post-process the generation of file `path`."""
pass
class Job (six.with_metaclass(abc.ABCMeta, sciexp2.common.instance.Instance)):
"""Abstract job descriptor.
Each job must implement the abstract methods defined in this class.
See also
--------
state, submit, kill
"""
# job states
RUNNING = "running"
DONE = "done"
FAILED = "failed"
OUTDATED = "outdated"
NOTRUN = "notrun"
STATES = [
RUNNING,
DONE,
FAILED,
OUTDATED,
NOTRUN,
]
STATE_SHORT = {
RUNNING: u"\u2699",
DONE: u"\u2713",
FAILED: "x",
OUTDATED: "o",
NOTRUN: " ",
}
STATE_LONG = {
RUNNING: "Running",
DONE: "Done",
FAILED: "Failed",
OUTDATED: "Outdated",
NOTRUN: "Not run",
}
def __init__(self, system, state, instance):
"""
Parameters
----------
system : System
System for which this job is.
state : str
Execution state of the job.
instance : str
Launcher instance describing this job.
"""
sciexp2.common.instance.Instance.__init__(self, instance)
self["_STATE"] = state
self._system = weakref.proxy(system)
def __repr__(self):
return repr(sciexp2.common.instance.Instance(self))
@classmethod
def compute_state(cls, system, instance):
"""Generic job state computation.
Parameters
----------
system : System
System for which this job is being checked.
instance
Launcher instance describing a job.
Returns
-------
Generic job state according to the failed/done files; otherwise returns
`NOTRUN`.
"""
fail_path = instance["FAIL"]
if not os.path.isabs(fail_path):
fail_path = os.sep.join([system._base, fail_path])
if os.path.exists(fail_path):
return cls.FAILED
done_path = instance["DONE"]
if not os.path.isabs(done_path):
done_path = os.sep.join([system._base, done_path])
if not os.path.exists(done_path):
return cls.NOTRUN
done_mtime = os.stat(done_path).st_mtime
for dep in system._depends:
path = text.translate(dep, instance)
if path == "":
continue
path = utils.get_path(path)
if not os.path.isabs(path):
path = os.sep.join([system._base, path])
if not os.path.exists(path) or \
done_mtime < os.stat(path).st_mtime:
return cls.OUTDATED
return cls.DONE
@abc.abstractmethod
def state(self):
"""Return a string describing the job and its state."""
pass
@abc.abstractmethod
def submit(self, *args):
"""Submit a job to execution."""
pass
def _submit_args(self, args):
"""Return extra arguments for the job submitting program."""
instance = dict(self)
instance["LAUNCHER_BASE"] = self._system._base_abs
try:
return [text.translate(arg, instance)
for arg in self._system._submit_args + list(args)]
except text.VariableError as e:
raise SubmitArgsError(e.message)
@abc.abstractmethod
def kill(self, *args):
"""Kill a job from execution."""
pass
def _kill_args(self, args):
"""Return extra arguments for the job killing program."""
instance = dict(self)
instance["LAUNCHER_BASE"] = self._system._base_abs
try:
return [text.translate(arg, instance)
for arg in list(args)]
except text.VariableError as e:
raise SubmitArgsError(e.message)
def get(name):
"""Get an execution system implementation by name.
See also
--------
SEARCH_PATH
"""
try:
info = imp.find_module(name, SEARCH_PATH)
system = imp.load_module(name, *info)
except ImportError:
raise SystemError("Unknown system %r" % name)
try:
res = system.System
except AttributeError:
raise AttributeError("Does not look like an execution " +
"system implementation: %s" % name)
res.name = name
return res | 0.741955 | 0.205416 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import os
import subprocess
import sciexp2.expdef.system
import sciexp2.common.instance
from sciexp2.common import progress
from sciexp2.common.utils import execute_with_sigint
class System (sciexp2.expdef.system.System):
"""Manage local shell jobs."""
STATE_CMD = "ps xwww"
ASSUMES = []
DEFINES = []
def compute_state(self):
# build instance group of job states
self._jobs = sciexp2.common.instance.InstanceGroup()
for instance in self._launchers:
job = Job(self,
sciexp2.expdef.system.Job.compute_state(self, instance),
instance)
self._jobs.add(job)
class Job (sciexp2.expdef.system.Job):
"""A local shell script job."""
def state(self):
state = self["_STATE"]
if state == sciexp2.expdef.system.Job.DONE:
name = self._system.get_relative_path(self["DONE"])
elif state == sciexp2.expdef.system.Job.FAILED:
name = self._system.get_relative_path(self["FAIL"])
elif state in [sciexp2.expdef.system.Job.NOTRUN, sciexp2.expdef.system.Job.OUTDATED]:
name = self._system.get_relative_path(self["LAUNCHER"])
else:
raise ValueError("Unknown job state: %r" % state)
return state, name
def submit(self, *args):
launcher = os.sep.join([self._system._base, self["LAUNCHER"]])
assert os.path.isfile(launcher)
cmd = ["bash"] + self._submit_args(args) + [launcher]
progress.verbose(" %s", " ".join(cmd))
if progress.level() < progress.LVL_DEBUG:
kwargs = dict(stdout=sciexp2.expdef.system._DEVNULL,
stderr=subprocess.STDOUT)
else:
kwargs = dict(stderr=subprocess.STDOUT)
res = execute_with_sigint(cmd, **kwargs)
if res != 0:
raise subprocess.CalledProcessError(res, cmd)
def kill(self, *args):
raise Exception("Cannot kill local shell script jobs") | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/expdef/system/shell.py | shell.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2009-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import os
import subprocess
import sciexp2.expdef.system
import sciexp2.common.instance
from sciexp2.common import progress
from sciexp2.common.utils import execute_with_sigint
class System (sciexp2.expdef.system.System):
"""Manage local shell jobs."""
STATE_CMD = "ps xwww"
ASSUMES = []
DEFINES = []
def compute_state(self):
# build instance group of job states
self._jobs = sciexp2.common.instance.InstanceGroup()
for instance in self._launchers:
job = Job(self,
sciexp2.expdef.system.Job.compute_state(self, instance),
instance)
self._jobs.add(job)
class Job (sciexp2.expdef.system.Job):
"""A local shell script job."""
def state(self):
state = self["_STATE"]
if state == sciexp2.expdef.system.Job.DONE:
name = self._system.get_relative_path(self["DONE"])
elif state == sciexp2.expdef.system.Job.FAILED:
name = self._system.get_relative_path(self["FAIL"])
elif state in [sciexp2.expdef.system.Job.NOTRUN, sciexp2.expdef.system.Job.OUTDATED]:
name = self._system.get_relative_path(self["LAUNCHER"])
else:
raise ValueError("Unknown job state: %r" % state)
return state, name
def submit(self, *args):
launcher = os.sep.join([self._system._base, self["LAUNCHER"]])
assert os.path.isfile(launcher)
cmd = ["bash"] + self._submit_args(args) + [launcher]
progress.verbose(" %s", " ".join(cmd))
if progress.level() < progress.LVL_DEBUG:
kwargs = dict(stdout=sciexp2.expdef.system._DEVNULL,
stderr=subprocess.STDOUT)
else:
kwargs = dict(stderr=subprocess.STDOUT)
res = execute_with_sigint(cmd, **kwargs)
if res != 0:
raise subprocess.CalledProcessError(res, cmd)
def kill(self, *args):
raise Exception("Cannot kill local shell script jobs") | 0.427755 | 0.111 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2013-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections
import contextlib
import multiprocessing
import multiprocessing.pool
from . import utils
#: Default amount of parallelism.
PARALLELISM = True
def get_parallelism(parallelism):
"""Compute the amount of available parallelism according to the system.
Parameters
----------
parallelism
Requested parallelism.
Notes
-----
The returned amount of parallelism depends on the value of `parallelism`:
================ ======================================================
Value Meaning
================ ======================================================
`None` Use `PARALLELISM` instead.
`True` Auto-detect as the number of cores in the system.
positive integer Use the given fixed amount.
negative integer Auto-detect as the number of cores in the system minus
the given value.
================ ======================================================
"""
if parallelism is None:
parallelism = PARALLELISM
if parallelism is True:
parallelism = multiprocessing.cpu_count()
elif isinstance(parallelism, int):
if parallelism == 0:
raise ValueError("Invalid parallelism setting: %s" % parallelism)
if parallelism < 0:
parallelism = multiprocessing.cpu_count() + parallelism
else:
raise TypeError("Invalid parallelism setting: %s" % parallelism)
return parallelism
#: Default amount of blocking.
BLOCKING = 50
#: Amount of blocking to use when the work length is unknown.
BLOCKING_UNKNOWN = 20
#: Maximum amount of blocking.
BLOCKING_MAX = 100
def get_blocking(blocking, work_len, parallelism=None):
"""Compute the amount of necessary blocking according to work length.
Blocking establishes the amount of work items that each worker receives at
a time. When using processes, this will reduce the costs of communication.
Parameters
----------
blocking
Amount of blocking.
work_len : int or None
Work length (unknown if `None`).
parallelism
Argument to `get_parallelism`.
Notes
-----
Argument `blocking` can mean different things depending on its value type:
================ ======================================================
Value Meaning
================ ======================================================
`None` Use `BLOCKING` instead.
`True` Evenly partition block with the amount of parallelism.
positive integer Use the given fixed amount.
positive float Use the given ratio of the given work elements, up to
`BLOCKING_MAX`.
================ ======================================================
If the work size is unknown, `True` or a float argument will revert to
`BLOCKING_UNKNOWN`.
"""
if blocking is None:
blocking = BLOCKING
if blocking is True:
if work_len is None:
blocking = BLOCKING_UNKNOWN
else:
parallelism = get_parallelism(parallelism)
blocking = work_len / parallelism
elif isinstance(blocking, float):
if work_len is None:
blocking = BLOCKING_UNKNOWN
else:
blocking = min(work_len * blocking, BLOCKING_MAX)
elif not isinstance(blocking, int):
raise TypeError("Invalid blocking setting: %s" % blocking)
return blocking
@contextlib.contextmanager
def configuration(**kwargs):
"""Context manager to temporarily override global parameters.
Parameters
----------
kwargs
Temporary values to global parameters.
Examples
--------
Temporarily override the default parallelism to all cores minus one and set
blocking to 100:
>>> def fadd (x) : return x + 1
>>> def fmul (x) : return x * 2
>>> with configuration(PARALLELISM = -1, BLOCKING = 100):
... s = p_imap(range(10000), fadd)
... res = p_imap(s, fmul) # doctest: +SKIP
This is equivalent to:
>>> s = p_imap(range(10000), fadd,
... parallelism = -1, blocking = 100) # doctest: +SKIP
>>> res = p_imap(s, fmul,
... parallelism = -1, blocking = 100) # doctest: +SKIP
"""
variables = ["PARALLELISM", "BLOCKING", "BLOCKING_UNKNOWN", "BLOCKING_MAX"]
backup = {}
new = {}
for var in variables:
backup[var] = globals()[var]
new[var] = kwargs.pop(var, backup[var])
utils.assert_kwargs(kwargs)
globals().update(new)
yield None
globals().update(backup)
def _p_init(work, parallelism, blocking):
if isinstance(work, collections.abc.Sized):
work_len = len(work)
else:
work_len = None
parallelism = get_parallelism(parallelism)
blocking = get_blocking(blocking, work_len, parallelism)
pool = multiprocessing.Pool(processes=parallelism)
return pool, blocking
def p_imap(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses processes.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.Pool, multiprocessing.Pool.imap
"""
pool, blocking = _p_init(work, parallelism, blocking)
res = iter(pool.imap(func, work, chunksize=blocking))
pool.close()
return res
def p_imap_unordered(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses processes.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.Pool, multiprocessing.Pool.imap_unordered
"""
pool, blocking = _p_init(work, parallelism, blocking)
res = iter(pool.imap_unordered(func, work, chunksize=blocking))
pool.close()
return res
def p_map(work, func, parallelism=None, blocking=None):
"""Return a list with the result of mapping `func` to `work` in parallel.
This function uses processes.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.Pool, multiprocessing.Pool.map
"""
pool, blocking = _p_init(work, parallelism, blocking)
res = pool.map(func, work, chunksize=blocking)
pool.close()
return res
def _t_init(work, parallelism, blocking):
if isinstance(work, collections.abc.Sized):
work_len = len(work)
else:
work_len = None
parallelism = get_parallelism(parallelism)
blocking = get_blocking(blocking, work_len, parallelism)
pool = multiprocessing.pool.ThreadPool(processes=parallelism)
return pool, blocking
def t_imap(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses threads.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.pool.ThreadPool, multiprocessing.pool.ThreadPool.imap
"""
pool, blocking = _t_init(work, parallelism, blocking)
res = iter(pool.imap(func, work, chunksize=blocking))
pool.close()
return res
def t_imap_unordered(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses threads.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.pool.ThreadPool, multiprocessing.pool.ThreadPool.imap
"""
pool, blocking = _t_init(work, parallelism, blocking)
res = iter(pool.imap_unordered(func, work, chunksize=blocking))
pool.close()
return res
def t_map(work, func, parallelism=None, blocking=None):
"""Return a list with the result of mapping `func` to `work` in parallel.
This function uses threads.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.pool.ThreadPool, multiprocessing.pool.ThreadPool.map
"""
pool, blocking = _t_init(work, parallelism, blocking)
res = pool.map(func, work, chunksize=blocking)
pool.close()
return res | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/common/parallel.py | parallel.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2013-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections
import contextlib
import multiprocessing
import multiprocessing.pool
from . import utils
#: Default amount of parallelism.
PARALLELISM = True
def get_parallelism(parallelism):
"""Compute the amount of available parallelism according to the system.
Parameters
----------
parallelism
Requested parallelism.
Notes
-----
The returned amount of parallelism depends on the value of `parallelism`:
================ ======================================================
Value Meaning
================ ======================================================
`None` Use `PARALLELISM` instead.
`True` Auto-detect as the number of cores in the system.
positive integer Use the given fixed amount.
negative integer Auto-detect as the number of cores in the system minus
the given value.
================ ======================================================
"""
if parallelism is None:
parallelism = PARALLELISM
if parallelism is True:
parallelism = multiprocessing.cpu_count()
elif isinstance(parallelism, int):
if parallelism == 0:
raise ValueError("Invalid parallelism setting: %s" % parallelism)
if parallelism < 0:
parallelism = multiprocessing.cpu_count() + parallelism
else:
raise TypeError("Invalid parallelism setting: %s" % parallelism)
return parallelism
#: Default amount of blocking.
BLOCKING = 50
#: Amount of blocking to use when the work length is unknown.
BLOCKING_UNKNOWN = 20
#: Maximum amount of blocking.
BLOCKING_MAX = 100
def get_blocking(blocking, work_len, parallelism=None):
"""Compute the amount of necessary blocking according to work length.
Blocking establishes the amount of work items that each worker receives at
a time. When using processes, this will reduce the costs of communication.
Parameters
----------
blocking
Amount of blocking.
work_len : int or None
Work length (unknown if `None`).
parallelism
Argument to `get_parallelism`.
Notes
-----
Argument `blocking` can mean different things depending on its value type:
================ ======================================================
Value Meaning
================ ======================================================
`None` Use `BLOCKING` instead.
`True` Evenly partition block with the amount of parallelism.
positive integer Use the given fixed amount.
positive float Use the given ratio of the given work elements, up to
`BLOCKING_MAX`.
================ ======================================================
If the work size is unknown, `True` or a float argument will revert to
`BLOCKING_UNKNOWN`.
"""
if blocking is None:
blocking = BLOCKING
if blocking is True:
if work_len is None:
blocking = BLOCKING_UNKNOWN
else:
parallelism = get_parallelism(parallelism)
blocking = work_len / parallelism
elif isinstance(blocking, float):
if work_len is None:
blocking = BLOCKING_UNKNOWN
else:
blocking = min(work_len * blocking, BLOCKING_MAX)
elif not isinstance(blocking, int):
raise TypeError("Invalid blocking setting: %s" % blocking)
return blocking
@contextlib.contextmanager
def configuration(**kwargs):
"""Context manager to temporarily override global parameters.
Parameters
----------
kwargs
Temporary values to global parameters.
Examples
--------
Temporarily override the default parallelism to all cores minus one and set
blocking to 100:
>>> def fadd (x) : return x + 1
>>> def fmul (x) : return x * 2
>>> with configuration(PARALLELISM = -1, BLOCKING = 100):
... s = p_imap(range(10000), fadd)
... res = p_imap(s, fmul) # doctest: +SKIP
This is equivalent to:
>>> s = p_imap(range(10000), fadd,
... parallelism = -1, blocking = 100) # doctest: +SKIP
>>> res = p_imap(s, fmul,
... parallelism = -1, blocking = 100) # doctest: +SKIP
"""
variables = ["PARALLELISM", "BLOCKING", "BLOCKING_UNKNOWN", "BLOCKING_MAX"]
backup = {}
new = {}
for var in variables:
backup[var] = globals()[var]
new[var] = kwargs.pop(var, backup[var])
utils.assert_kwargs(kwargs)
globals().update(new)
yield None
globals().update(backup)
def _p_init(work, parallelism, blocking):
if isinstance(work, collections.abc.Sized):
work_len = len(work)
else:
work_len = None
parallelism = get_parallelism(parallelism)
blocking = get_blocking(blocking, work_len, parallelism)
pool = multiprocessing.Pool(processes=parallelism)
return pool, blocking
def p_imap(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses processes.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.Pool, multiprocessing.Pool.imap
"""
pool, blocking = _p_init(work, parallelism, blocking)
res = iter(pool.imap(func, work, chunksize=blocking))
pool.close()
return res
def p_imap_unordered(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses processes.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.Pool, multiprocessing.Pool.imap_unordered
"""
pool, blocking = _p_init(work, parallelism, blocking)
res = iter(pool.imap_unordered(func, work, chunksize=blocking))
pool.close()
return res
def p_map(work, func, parallelism=None, blocking=None):
"""Return a list with the result of mapping `func` to `work` in parallel.
This function uses processes.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.Pool, multiprocessing.Pool.map
"""
pool, blocking = _p_init(work, parallelism, blocking)
res = pool.map(func, work, chunksize=blocking)
pool.close()
return res
def _t_init(work, parallelism, blocking):
if isinstance(work, collections.abc.Sized):
work_len = len(work)
else:
work_len = None
parallelism = get_parallelism(parallelism)
blocking = get_blocking(blocking, work_len, parallelism)
pool = multiprocessing.pool.ThreadPool(processes=parallelism)
return pool, blocking
def t_imap(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses threads.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.pool.ThreadPool, multiprocessing.pool.ThreadPool.imap
"""
pool, blocking = _t_init(work, parallelism, blocking)
res = iter(pool.imap(func, work, chunksize=blocking))
pool.close()
return res
def t_imap_unordered(work, func, parallelism=None, blocking=None):
"""Return a sequence with the result of mapping `func` to `work` in parallel.
This function uses threads.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.pool.ThreadPool, multiprocessing.pool.ThreadPool.imap
"""
pool, blocking = _t_init(work, parallelism, blocking)
res = iter(pool.imap_unordered(func, work, chunksize=blocking))
pool.close()
return res
def t_map(work, func, parallelism=None, blocking=None):
"""Return a list with the result of mapping `func` to `work` in parallel.
This function uses threads.
Parameters
----------
work : sequence
Sequence of items to process in parallel.
func : callable
Function to apply on each element of `work`.
parallelism
Argument to `get_parallelism`.
blocking
Argument to `get_blocking`.
See also
--------
multiprocessing.pool.ThreadPool, multiprocessing.pool.ThreadPool.map
"""
pool, blocking = _t_init(work, parallelism, blocking)
res = pool.map(func, work, chunksize=blocking)
pool.close()
return res | 0.849285 | 0.354266 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2008-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections.abc
import re
import linecache
def _re_match(value, pattern):
cre = re.compile(pattern)
return cre.match(value) is not None
class Filter:
"""Boolean expression to check against a dict-like object.
The filter contains an arbitrary Python expression, where every variable
will be taken from the dict we are matching the filter against.
Parameters
----------
expression : Filter or dict or str, optional
Expression to use in the filter.
Raises
------
SyntaxError
The expression is not valid.
Notes
-----
If `expression` is a dict-like object, it will define an expression that
exactly matches its items.
Every filter will have the following global names defined:
============================ ==========================
``re_match(var, str)`` Check if ``var`` matches the regular
expression ``str``.
============================ ==========================
See also
--------
validate
match
and_filters, or_filters
Examples
--------
Filters can be easily composed together:
>>> f1 = Filter("a < 3")
>>> f2 = Filter("b == 4")
>>> and_filters(f1, f2)
Filter("(a < 3) and (b == 4)")
>>> or_filters(f1, f2)
Filter("(a < 3) or (b == 4)")
Filter objects can be later matched against dict-like objects:
>>> f = Filter("a < 3 and b == 4")
>>> f.match(dict(a=2, b=4))
True
>>> f.match(dict(a=3, b=4))
False
Using a dict as an expression is equivalent to building a perfect match for
the dict's items:
>>> Filter({"VAR1": 1, "VAR2": 2})
Filter("VAR1 == 1 and VAR2 == 2")
"""
_GLOBALS = {"re_match": _re_match}
def __init__(self, expression=None):
if expression is None or expression == "":
expression = "True"
elif isinstance(expression, Filter):
# pylint: disable=protected-access
expression = expression._expression
elif isinstance(expression, collections.abc.Mapping):
keys = sorted(expression.keys())
expression = " and ".join(["%s == %r" % (key, expression[key])
for key in keys])
self._expression = expression
self._code_id = "<dynamic-%d>" % id(self._expression)
self._code = compile(self._expression, self._code_id, "eval")
linecache.cache[self._code_id] = (len(self._expression), None,
self._expression.split("\n"),
self._code_id)
def __del__(self):
if self._code_id in linecache.cache:
del linecache.cache[self._code_id]
def __str__(self):
"""Return a string representation of the filter."""
return self._expression
def __repr__(self):
return "Filter(\"%s\")" % str(self)
def validate(self, allowed):
"""Validate that variables in the filter are present in the given set.
Parameters
----------
allowed : set of variable names
Set of variable names to allow on the filter.
Raises
------
NameError
Filter contains a variable name not present in `allowed`.
"""
present = set(self._code.co_names)
missing = present - (set(allowed) | set(["re_match"]))
if missing:
missing = list(missing)
raise NameError("name %r is not allowed" % missing[0])
def match(self, source):
"""Check if the given `source` matches this filter.
Parameters
----------
source : dict-like
Dictionary to match this filter against.
Returns
-------
bool : Whether the match is positive or not.
Raises
------
NameError
Filter contains a variable name not present in `source`.
See also
--------
validate
"""
# pylint: disable=eval-used
return eval(self._code, dict(source), self._GLOBALS)
def and_filters(*filters):
"""Convenience function to *and* all `filters` together."""
filters = ["(%s)" % Filter(f) for f in filters]
expression = " and ".join(filters)
return Filter(expression)
def or_filters(*filters):
"""Convenience function to *or* all `filters` together."""
filters = ["(%s)" % Filter(f) for f in filters]
expression = " or ".join(filters)
return Filter(expression)
__all__ = [
"Filter", "and_filters", "or_filters",
] | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/common/filter.py | filter.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2008-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections.abc
import re
import linecache
def _re_match(value, pattern):
cre = re.compile(pattern)
return cre.match(value) is not None
class Filter:
"""Boolean expression to check against a dict-like object.
The filter contains an arbitrary Python expression, where every variable
will be taken from the dict we are matching the filter against.
Parameters
----------
expression : Filter or dict or str, optional
Expression to use in the filter.
Raises
------
SyntaxError
The expression is not valid.
Notes
-----
If `expression` is a dict-like object, it will define an expression that
exactly matches its items.
Every filter will have the following global names defined:
============================ ==========================
``re_match(var, str)`` Check if ``var`` matches the regular
expression ``str``.
============================ ==========================
See also
--------
validate
match
and_filters, or_filters
Examples
--------
Filters can be easily composed together:
>>> f1 = Filter("a < 3")
>>> f2 = Filter("b == 4")
>>> and_filters(f1, f2)
Filter("(a < 3) and (b == 4)")
>>> or_filters(f1, f2)
Filter("(a < 3) or (b == 4)")
Filter objects can be later matched against dict-like objects:
>>> f = Filter("a < 3 and b == 4")
>>> f.match(dict(a=2, b=4))
True
>>> f.match(dict(a=3, b=4))
False
Using a dict as an expression is equivalent to building a perfect match for
the dict's items:
>>> Filter({"VAR1": 1, "VAR2": 2})
Filter("VAR1 == 1 and VAR2 == 2")
"""
_GLOBALS = {"re_match": _re_match}
def __init__(self, expression=None):
if expression is None or expression == "":
expression = "True"
elif isinstance(expression, Filter):
# pylint: disable=protected-access
expression = expression._expression
elif isinstance(expression, collections.abc.Mapping):
keys = sorted(expression.keys())
expression = " and ".join(["%s == %r" % (key, expression[key])
for key in keys])
self._expression = expression
self._code_id = "<dynamic-%d>" % id(self._expression)
self._code = compile(self._expression, self._code_id, "eval")
linecache.cache[self._code_id] = (len(self._expression), None,
self._expression.split("\n"),
self._code_id)
def __del__(self):
if self._code_id in linecache.cache:
del linecache.cache[self._code_id]
def __str__(self):
"""Return a string representation of the filter."""
return self._expression
def __repr__(self):
return "Filter(\"%s\")" % str(self)
def validate(self, allowed):
"""Validate that variables in the filter are present in the given set.
Parameters
----------
allowed : set of variable names
Set of variable names to allow on the filter.
Raises
------
NameError
Filter contains a variable name not present in `allowed`.
"""
present = set(self._code.co_names)
missing = present - (set(allowed) | set(["re_match"]))
if missing:
missing = list(missing)
raise NameError("name %r is not allowed" % missing[0])
def match(self, source):
"""Check if the given `source` matches this filter.
Parameters
----------
source : dict-like
Dictionary to match this filter against.
Returns
-------
bool : Whether the match is positive or not.
Raises
------
NameError
Filter contains a variable name not present in `source`.
See also
--------
validate
"""
# pylint: disable=eval-used
return eval(self._code, dict(source), self._GLOBALS)
def and_filters(*filters):
"""Convenience function to *and* all `filters` together."""
filters = ["(%s)" % Filter(f) for f in filters]
expression = " and ".join(filters)
return Filter(expression)
def or_filters(*filters):
"""Convenience function to *or* all `filters` together."""
filters = ["(%s)" % Filter(f) for f in filters]
expression = " or ".join(filters)
return Filter(expression)
__all__ = [
"Filter", "and_filters", "or_filters",
] | 0.811116 | 0.495178 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2008-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import os
import shutil
import signal
import subprocess
import tempfile
import functools
import collections
import weakref
import numpy as np
import six
from . import pp
from . import progress
# -----------------------------
def assert_kwargs(kwargs):
"""Raise an exception if extra keys are present."""
if kwargs:
extra = "s" if len(kwargs) > 1 else ""
raise TypeError("Unexpected argument%s: %s" % (extra,
", ".join(kwargs)))
# -----------------------------
def assert_dir(path):
"""Check that given directory exists, otherwise create it."""
if path != "" and not os.path.exists(path):
os.makedirs(path)
def assert_path(path):
"""Check that given path exists, otherwise create directories."""
if not path.endswith(os.sep):
path = os.path.dirname(path)
assert_dir(path)
def get_path(path):
"""Get path after expanding user and environment variables."""
path = os.path.expanduser(path)
return os.path.expandvars(path)
def get_file(path, mod="w"):
"""Open the given file, creating any intermediate directory."""
dir_path = os.path.dirname(path)
assert_dir(dir_path)
return open(path, mod)
def get_tmp_file(mode="w", delete=True):
"""Get a temporal file."""
return tempfile.NamedTemporaryFile(mode=mode, delete=delete)
with open(os.devnull, "w") as _null:
_HAVE_RSYNC = subprocess.call(["which", "rsync"], stdout=_null)
if _HAVE_RSYNC == 0:
def copy_path_rsync(path_from, path_to, preserve=True, dereference=False):
"""Copy contents using rsync."""
if os.path.isdir(path_from):
path_from = path_from + os.sep
assert_path(path_to)
else:
assert_path(os.path.dirname(path_to) + os.sep)
args = "-rptgoD"
if preserve:
args += "t"
if dereference:
args += "l"
else:
args += "L"
if subprocess.call(["rsync", args, path_from, path_to]) != 0:
raise OSError("Error copying files: %s -> %s" % (
path_from, path_to))
def _copy_path(*args, **kwargs):
copy_path_rsync(*args, **kwargs)
else:
def copy_path_shutil(path_from, path_to, preserve=True, dereference=False):
"""Copy contents using Python's shutil."""
if os.path.isdir(path_from):
# NOTE: will fail if destination already exists
path_from = path_from + os.sep
assert_path(path_to)
shutil.copytree(path_from, path_to, symlinks=not dereference)
else:
assert_path(os.path.dirname(path_to) + os.sep)
if os.path.islink(path_from):
link_to = os.readlink(path_from)
os.symlink(link_to, path_to)
else:
shutil.copy(path_from, path_to)
if preserve:
shutil.copymode(path_from, path_to)
def _copy_path(*args, **kwargs):
copy_path_shutil(*args, **kwargs)
def copy_path(path_from, path_to, preserve=True, dereference=False):
"""Copy files."""
_copy_path(path_from, path_to, preserve=preserve, dereference=dereference)
# -----------------------------
def str2num(arg):
"""Return numeric value of a string, if possible."""
# NOTE: StringConverter barks at non-numeric strings (str/bytes confusion)
try:
return np.lib.npyio.StringConverter().upgrade(arg)
except:
return arg
# -----------------------------
def _wraps(wrapped):
return functools.wraps(wrapped=wrapped,
assigned=['__doc__'])
class ViewError(Exception):
"""Invalid operation in `OrderedSet` view."""
def __init__(self, *args, **kwargs):
Exception.__init__(self, *args, **kwargs)
class OrderedSet(collections.abc.MutableSet, pp.Pretty):
"""A mutable set preserving order of insertion.
.. todo::
All help should come from `~collections.abc.MutableSet` instead of
using `_wraps`.
"""
@_wraps(collections.abc.Container.__init__)
def __init__(self, iterable=None, view_able=False):
self._view_able = view_able
if self._view_able:
self._list = np.array([], dtype=object)
else:
self._list = []
self._set_methods(False)
self._base = None
self._views = {}
self._set = set()
if iterable is not None:
self |= iterable
def set_view_able(self, view_able):
"""Set whether this object can produce "views" from it.
Objects able to produce views have lower performance when adding new
elements to them.
See also
--------
OrderedSet.view
"""
if view_able != self._view_able:
if view_able:
self._list = np.array(self._list, dtype=object)
else:
if self._views:
raise ValueError(
"cannot disable 'view_able' when views already exist")
self._list = list(self._list)
self._view_able = view_able
self._set_methods(False)
def view(self, index):
"""Create a view (sub-set) of this object.
This object also becomes a view. Modifications to the elements of a view
will also take effect on all other views of the same object.
Parameters
----------
index : slice
See also
--------
OrderedSet.set_view_able
"""
if not self._view_able:
raise ValueError("the object is not 'view_able'")
if not isinstance(index, slice):
raise TypeError("view index must be a slice")
self._set_methods(True)
res = OrderedSet([], True)
# pylint: disable=protected-access
res._list = self._list[index]
for elem in res._list:
res._set.add(elem)
res._base = self
res._set_methods(True)
self._views[id(res)] = weakref.ref(res)
return res
def __del__(self):
if self._base is not None:
# pylint: disable=protected-access
del self._base._views[id(self)]
def _set_methods(self, is_view):
if self._view_able:
if is_view:
self._append = self._append_array_view
self._remove = self._remove_array_view
self._pop = self._pop_array_view
else:
self._append = self._append_array
self._remove = self._remove_array
self._pop = self._pop_array
else:
assert not is_view
self._append = self._append_list
self._remove = self._remove_list
self._pop = self._pop_list
def _append_list(self, value):
self._list.append(value)
def _remove_list(self, value):
if self._base is not None:
self._base.remove(value)
else:
self._list.remove(value)
for view in six.itervalues(self._views):
# pylint: disable=protected-access
view()._list.remove(value)
view()._set.remove(value)
def _pop_list(self, index):
self._list.pop(index)
def _append_array(self, value):
self._list = np.append(self._list, value)
def _remove_array(self, value):
self._list = np.delete(self._list, np.where(self._list == value))
def _pop_array(self, index):
self._list = np.delete(self._list, index)
# pylint: disable=no-self-use
def _append_array_view(self, value):
raise ViewError("cannot append to a view")
# pylint: disable=no-self-use
def _remove_array_view(self, value):
raise ViewError("cannot remove from a view")
# pylint: disable=no-self-use
def _pop_array_view(self, index):
raise ViewError("cannot pop from a view")
# pylint: disable=invalid-name
def _repr_pretty_(self, p, cycle):
with self.pformat(p, cycle):
p.pretty(list(self._list))
def __repr__(self):
return pp.Pretty.__repr__(self)
def get_index(self, index):
"""Get item at the 'index'th position."""
return self._list[index]
def copy(self):
"""Make a shallow copy of this `OrderedSet`."""
return OrderedSet(self, self._view_able)
def sorted(self, *args, **kwargs):
"""Same as `sort`, but returns a sorted copy."""
res = self.copy()
res.sort(*args, **kwargs)
return res
def sort(self, key=None, reverse=False):
"""Sort set in-place.
Follows the same semantics of Python's built-in `sorted`.
"""
if self._view_able:
contents = list(self._list)
else:
contents = self._list
contents.sort(key=key, reverse=reverse)
if self._view_able:
self._list[:] = contents
# Container
@_wraps(set.__contains__)
def __contains__(self, key):
return key in self._set
# Sized
@_wraps(set.__len__)
def __len__(self):
return len(self._list)
# Iterable
@_wraps(set.__iter__)
def __iter__(self):
return iter(self._list)
# MutableSet
# pylint: disable=missing-docstring
def add(self, key):
old_length = len(self._list)
self._set.add(key)
if len(self._set) != old_length:
try:
self._append(key)
except ViewError:
self._set.remove(key)
raise
add.__doc__ = collections.abc.MutableSet.add.__doc__
# pylint: disable=missing-docstring
def discard(self, key):
old_length = len(self._list)
self._set.remove(key)
if len(self._set) != old_length:
try:
self._remove(key)
except ViewError:
self._set.add(key)
raise
discard.__doc__ = collections.abc.MutableSet.discard.__doc__
discard.__doc__ += "\n\nThis operation has a cost of O(n)."
# pylint: disable=missing-docstring
@_wraps(collections.abc.MutableSet.pop)
def pop(self, last=True):
if not self:
raise KeyError('set is empty')
key = self._pop(-1) if last else self._pop(0)
self._set.remove(key)
return key
# Pickling
def __getstate__(self):
odict = self.__dict__.copy()
del odict["_append"]
del odict["_remove"]
del odict["_pop"]
del odict["_base"]
del odict["_views"]
return odict
def __setstate__(self, odict):
self.__dict__.update(odict)
self._base = None
self._views = {}
self._set_methods(False)
# -----------------------------
def _template_get_initial_dir(template, template_is_abs):
# pylint: disable=cyclic-import
from . import text
start_dir = ""
for part in template.split(os.sep):
if part == "":
continue
if start_dir == "" and not template_is_abs:
cur_dir = part
else:
cur_dir = os.sep.join([start_dir, part])
try:
text.translate(cur_dir, {})
except text.VariableError:
break
if os.path.isdir(cur_dir):
start_dir = cur_dir
else:
break
return start_dir
def find_files(template, path=None, absolute_path=False, sort=True):
"""Find files matching a given template.
Returns an 'InstanceGroup' with all paths of existing files matching the
given template. Each matching file path is an `Instance` with the extracted
variables in the `template`.
Parameters
----------
template : str
Template of file paths to find.
path : str, optional
On each resulting Instance, add a variable with the given name with the
file path.
absolute_path : bool, optional
Make the value in `path` absolute.
sort : bool, optional
Sort the file paths according to the alphanumeric order of each of the
variables in `template`, in that specific order.
Raises
------
ValueError
The variable in `path` is already present in `template`.
See Also
--------
sciexp2.common.text.extract
Argument `template` is interpreted following the extraction syntax.
Notes
-----
If `template` ends with ``/`` it will search for matching paths, and will
search for matching files otherwise.
Environment variables and user home directories in `template` will be expanded.
"""
# pylint: disable=cyclic-import
from . import text
from .instance import InstanceGroup, Instance
if not isinstance(template, six.string_types):
raise ValueError("Not an expression: " + template)
if path is not None and not isinstance(path, six.string_types):
raise ValueError("path must be either None or a string")
if path in text.get_variables(template):
raise ValueError("path variable is already present in template")
template_is_dir = template[-1] == "/" if template else False
template_is_abs = os.path.isabs(template)
template = get_path(template) + "$"
start_dir = _template_get_initial_dir(template, template_is_abs)
extractor = text.Extractor(template)
res = InstanceGroup()
def add(env, target_path):
# use numbers whenever possible (for later number-aware sorting)
for key, val in six.iteritems(env):
env[key] = str2num(val)
if path is not None:
if absolute_path:
target_path = os.path.abspath(target_path)
env[path] = target_path
res.add(Instance(env))
for dir_path, _, file_list in os.walk(start_dir):
if template_is_dir:
try:
env = extractor.extract(dir_path + os.path.sep)
except text.ExtractError:
pass
else:
add(env, dir_path)
else:
for file_path in file_list:
target_path = os.path.join(dir_path, file_path)
try:
env = extractor.extract(target_path)
except text.ExtractError:
pass
else:
add(env, target_path)
if sort:
# sort result according to file sorting
variables = text.get_variables(template)
res.sort(variables)
return res
# -----------------------------
def execute_with_sigint(cmd, **kwargs):
"""Execute a command and forward SIGINT to it.
Parameters
----------
cmd : list of string
Command to execute
kwargs : dict
Additional arguments to subprocess.Popen.
Returns
-------
Integer with the command's return code.
"""
preexec_fn = kwargs.pop("preexec_fn", None)
def preexec():
os.setpgrp()
if preexec_fn:
preexec_fn()
signals = [
("SIGINT", signal.SIGINT),
("SIGTERM", signal.SIGTERM),
("SIGKILL", signal.SIGKILL),
]
state = dict(proc=None,
error=False,
signal_idx=0)
def run():
if state["proc"] is None:
if not state["error"]:
# pylint: disable=subprocess-popen-preexec-fn
state["proc"] = subprocess.Popen(cmd, preexec_fn=preexec, **kwargs)
else:
return
state["proc"].wait()
def run_with_except(depth=0):
try:
run()
except KeyboardInterrupt:
state["error"] = True
info = signals[state["signal_idx"]]
progress.log(progress.LVL_NONE,
"WARNING: Interrupting child command with %s" % info[0])
state["proc"].send_signal(info[1])
if state["signal_idx"] < len(signals) - 1:
state["signal_idx"] += 1
run_with_except(depth + 1)
if depth == 0:
raise
run_with_except()
return state["proc"].returncode | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/common/utils.py | utils.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2008-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import os
import shutil
import signal
import subprocess
import tempfile
import functools
import collections
import weakref
import numpy as np
import six
from . import pp
from . import progress
# -----------------------------
def assert_kwargs(kwargs):
"""Raise an exception if extra keys are present."""
if kwargs:
extra = "s" if len(kwargs) > 1 else ""
raise TypeError("Unexpected argument%s: %s" % (extra,
", ".join(kwargs)))
# -----------------------------
def assert_dir(path):
"""Check that given directory exists, otherwise create it."""
if path != "" and not os.path.exists(path):
os.makedirs(path)
def assert_path(path):
"""Check that given path exists, otherwise create directories."""
if not path.endswith(os.sep):
path = os.path.dirname(path)
assert_dir(path)
def get_path(path):
"""Get path after expanding user and environment variables."""
path = os.path.expanduser(path)
return os.path.expandvars(path)
def get_file(path, mod="w"):
"""Open the given file, creating any intermediate directory."""
dir_path = os.path.dirname(path)
assert_dir(dir_path)
return open(path, mod)
def get_tmp_file(mode="w", delete=True):
"""Get a temporal file."""
return tempfile.NamedTemporaryFile(mode=mode, delete=delete)
with open(os.devnull, "w") as _null:
_HAVE_RSYNC = subprocess.call(["which", "rsync"], stdout=_null)
if _HAVE_RSYNC == 0:
def copy_path_rsync(path_from, path_to, preserve=True, dereference=False):
"""Copy contents using rsync."""
if os.path.isdir(path_from):
path_from = path_from + os.sep
assert_path(path_to)
else:
assert_path(os.path.dirname(path_to) + os.sep)
args = "-rptgoD"
if preserve:
args += "t"
if dereference:
args += "l"
else:
args += "L"
if subprocess.call(["rsync", args, path_from, path_to]) != 0:
raise OSError("Error copying files: %s -> %s" % (
path_from, path_to))
def _copy_path(*args, **kwargs):
copy_path_rsync(*args, **kwargs)
else:
def copy_path_shutil(path_from, path_to, preserve=True, dereference=False):
"""Copy contents using Python's shutil."""
if os.path.isdir(path_from):
# NOTE: will fail if destination already exists
path_from = path_from + os.sep
assert_path(path_to)
shutil.copytree(path_from, path_to, symlinks=not dereference)
else:
assert_path(os.path.dirname(path_to) + os.sep)
if os.path.islink(path_from):
link_to = os.readlink(path_from)
os.symlink(link_to, path_to)
else:
shutil.copy(path_from, path_to)
if preserve:
shutil.copymode(path_from, path_to)
def _copy_path(*args, **kwargs):
copy_path_shutil(*args, **kwargs)
def copy_path(path_from, path_to, preserve=True, dereference=False):
"""Copy files."""
_copy_path(path_from, path_to, preserve=preserve, dereference=dereference)
# -----------------------------
def str2num(arg):
"""Return numeric value of a string, if possible."""
# NOTE: StringConverter barks at non-numeric strings (str/bytes confusion)
try:
return np.lib.npyio.StringConverter().upgrade(arg)
except:
return arg
# -----------------------------
def _wraps(wrapped):
return functools.wraps(wrapped=wrapped,
assigned=['__doc__'])
class ViewError(Exception):
"""Invalid operation in `OrderedSet` view."""
def __init__(self, *args, **kwargs):
Exception.__init__(self, *args, **kwargs)
class OrderedSet(collections.abc.MutableSet, pp.Pretty):
"""A mutable set preserving order of insertion.
.. todo::
All help should come from `~collections.abc.MutableSet` instead of
using `_wraps`.
"""
@_wraps(collections.abc.Container.__init__)
def __init__(self, iterable=None, view_able=False):
self._view_able = view_able
if self._view_able:
self._list = np.array([], dtype=object)
else:
self._list = []
self._set_methods(False)
self._base = None
self._views = {}
self._set = set()
if iterable is not None:
self |= iterable
def set_view_able(self, view_able):
"""Set whether this object can produce "views" from it.
Objects able to produce views have lower performance when adding new
elements to them.
See also
--------
OrderedSet.view
"""
if view_able != self._view_able:
if view_able:
self._list = np.array(self._list, dtype=object)
else:
if self._views:
raise ValueError(
"cannot disable 'view_able' when views already exist")
self._list = list(self._list)
self._view_able = view_able
self._set_methods(False)
def view(self, index):
"""Create a view (sub-set) of this object.
This object also becomes a view. Modifications to the elements of a view
will also take effect on all other views of the same object.
Parameters
----------
index : slice
See also
--------
OrderedSet.set_view_able
"""
if not self._view_able:
raise ValueError("the object is not 'view_able'")
if not isinstance(index, slice):
raise TypeError("view index must be a slice")
self._set_methods(True)
res = OrderedSet([], True)
# pylint: disable=protected-access
res._list = self._list[index]
for elem in res._list:
res._set.add(elem)
res._base = self
res._set_methods(True)
self._views[id(res)] = weakref.ref(res)
return res
def __del__(self):
if self._base is not None:
# pylint: disable=protected-access
del self._base._views[id(self)]
def _set_methods(self, is_view):
if self._view_able:
if is_view:
self._append = self._append_array_view
self._remove = self._remove_array_view
self._pop = self._pop_array_view
else:
self._append = self._append_array
self._remove = self._remove_array
self._pop = self._pop_array
else:
assert not is_view
self._append = self._append_list
self._remove = self._remove_list
self._pop = self._pop_list
def _append_list(self, value):
self._list.append(value)
def _remove_list(self, value):
if self._base is not None:
self._base.remove(value)
else:
self._list.remove(value)
for view in six.itervalues(self._views):
# pylint: disable=protected-access
view()._list.remove(value)
view()._set.remove(value)
def _pop_list(self, index):
self._list.pop(index)
def _append_array(self, value):
self._list = np.append(self._list, value)
def _remove_array(self, value):
self._list = np.delete(self._list, np.where(self._list == value))
def _pop_array(self, index):
self._list = np.delete(self._list, index)
# pylint: disable=no-self-use
def _append_array_view(self, value):
raise ViewError("cannot append to a view")
# pylint: disable=no-self-use
def _remove_array_view(self, value):
raise ViewError("cannot remove from a view")
# pylint: disable=no-self-use
def _pop_array_view(self, index):
raise ViewError("cannot pop from a view")
# pylint: disable=invalid-name
def _repr_pretty_(self, p, cycle):
with self.pformat(p, cycle):
p.pretty(list(self._list))
def __repr__(self):
return pp.Pretty.__repr__(self)
def get_index(self, index):
"""Get item at the 'index'th position."""
return self._list[index]
def copy(self):
"""Make a shallow copy of this `OrderedSet`."""
return OrderedSet(self, self._view_able)
def sorted(self, *args, **kwargs):
"""Same as `sort`, but returns a sorted copy."""
res = self.copy()
res.sort(*args, **kwargs)
return res
def sort(self, key=None, reverse=False):
"""Sort set in-place.
Follows the same semantics of Python's built-in `sorted`.
"""
if self._view_able:
contents = list(self._list)
else:
contents = self._list
contents.sort(key=key, reverse=reverse)
if self._view_able:
self._list[:] = contents
# Container
@_wraps(set.__contains__)
def __contains__(self, key):
return key in self._set
# Sized
@_wraps(set.__len__)
def __len__(self):
return len(self._list)
# Iterable
@_wraps(set.__iter__)
def __iter__(self):
return iter(self._list)
# MutableSet
# pylint: disable=missing-docstring
def add(self, key):
old_length = len(self._list)
self._set.add(key)
if len(self._set) != old_length:
try:
self._append(key)
except ViewError:
self._set.remove(key)
raise
add.__doc__ = collections.abc.MutableSet.add.__doc__
# pylint: disable=missing-docstring
def discard(self, key):
old_length = len(self._list)
self._set.remove(key)
if len(self._set) != old_length:
try:
self._remove(key)
except ViewError:
self._set.add(key)
raise
discard.__doc__ = collections.abc.MutableSet.discard.__doc__
discard.__doc__ += "\n\nThis operation has a cost of O(n)."
# pylint: disable=missing-docstring
@_wraps(collections.abc.MutableSet.pop)
def pop(self, last=True):
if not self:
raise KeyError('set is empty')
key = self._pop(-1) if last else self._pop(0)
self._set.remove(key)
return key
# Pickling
def __getstate__(self):
odict = self.__dict__.copy()
del odict["_append"]
del odict["_remove"]
del odict["_pop"]
del odict["_base"]
del odict["_views"]
return odict
def __setstate__(self, odict):
self.__dict__.update(odict)
self._base = None
self._views = {}
self._set_methods(False)
# -----------------------------
def _template_get_initial_dir(template, template_is_abs):
# pylint: disable=cyclic-import
from . import text
start_dir = ""
for part in template.split(os.sep):
if part == "":
continue
if start_dir == "" and not template_is_abs:
cur_dir = part
else:
cur_dir = os.sep.join([start_dir, part])
try:
text.translate(cur_dir, {})
except text.VariableError:
break
if os.path.isdir(cur_dir):
start_dir = cur_dir
else:
break
return start_dir
def find_files(template, path=None, absolute_path=False, sort=True):
"""Find files matching a given template.
Returns an 'InstanceGroup' with all paths of existing files matching the
given template. Each matching file path is an `Instance` with the extracted
variables in the `template`.
Parameters
----------
template : str
Template of file paths to find.
path : str, optional
On each resulting Instance, add a variable with the given name with the
file path.
absolute_path : bool, optional
Make the value in `path` absolute.
sort : bool, optional
Sort the file paths according to the alphanumeric order of each of the
variables in `template`, in that specific order.
Raises
------
ValueError
The variable in `path` is already present in `template`.
See Also
--------
sciexp2.common.text.extract
Argument `template` is interpreted following the extraction syntax.
Notes
-----
If `template` ends with ``/`` it will search for matching paths, and will
search for matching files otherwise.
Environment variables and user home directories in `template` will be expanded.
"""
# pylint: disable=cyclic-import
from . import text
from .instance import InstanceGroup, Instance
if not isinstance(template, six.string_types):
raise ValueError("Not an expression: " + template)
if path is not None and not isinstance(path, six.string_types):
raise ValueError("path must be either None or a string")
if path in text.get_variables(template):
raise ValueError("path variable is already present in template")
template_is_dir = template[-1] == "/" if template else False
template_is_abs = os.path.isabs(template)
template = get_path(template) + "$"
start_dir = _template_get_initial_dir(template, template_is_abs)
extractor = text.Extractor(template)
res = InstanceGroup()
def add(env, target_path):
# use numbers whenever possible (for later number-aware sorting)
for key, val in six.iteritems(env):
env[key] = str2num(val)
if path is not None:
if absolute_path:
target_path = os.path.abspath(target_path)
env[path] = target_path
res.add(Instance(env))
for dir_path, _, file_list in os.walk(start_dir):
if template_is_dir:
try:
env = extractor.extract(dir_path + os.path.sep)
except text.ExtractError:
pass
else:
add(env, dir_path)
else:
for file_path in file_list:
target_path = os.path.join(dir_path, file_path)
try:
env = extractor.extract(target_path)
except text.ExtractError:
pass
else:
add(env, target_path)
if sort:
# sort result according to file sorting
variables = text.get_variables(template)
res.sort(variables)
return res
# -----------------------------
def execute_with_sigint(cmd, **kwargs):
"""Execute a command and forward SIGINT to it.
Parameters
----------
cmd : list of string
Command to execute
kwargs : dict
Additional arguments to subprocess.Popen.
Returns
-------
Integer with the command's return code.
"""
preexec_fn = kwargs.pop("preexec_fn", None)
def preexec():
os.setpgrp()
if preexec_fn:
preexec_fn()
signals = [
("SIGINT", signal.SIGINT),
("SIGTERM", signal.SIGTERM),
("SIGKILL", signal.SIGKILL),
]
state = dict(proc=None,
error=False,
signal_idx=0)
def run():
if state["proc"] is None:
if not state["error"]:
# pylint: disable=subprocess-popen-preexec-fn
state["proc"] = subprocess.Popen(cmd, preexec_fn=preexec, **kwargs)
else:
return
state["proc"].wait()
def run_with_except(depth=0):
try:
run()
except KeyboardInterrupt:
state["error"] = True
info = signals[state["signal_idx"]]
progress.log(progress.LVL_NONE,
"WARNING: Interrupting child command with %s" % info[0])
state["proc"].send_signal(info[1])
if state["signal_idx"] < len(signals) - 1:
state["signal_idx"] += 1
run_with_except(depth + 1)
if depth == 0:
raise
run_with_except()
return state["proc"].returncode | 0.624064 | 0.166167 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
from collections import OrderedDict
try:
from collections.abc import Mapping
except:
pass
import pystache
import re
from .utils import OrderedSet
import six
import sys
class ParseError(Exception):
pass
class VariableError(Exception):
pass
class ExtractError(Exception):
pass
def _get_parsed_elems(parsed):
return parsed._parse_tree
def _parse(text, allow_nested=True, allow_inverted=True):
try:
pystache.render(text, {})
except pystache.parser.ParsingError as e:
_, _, exc_traceback = sys.exc_info()
new_e = ParseError(str(e))
six.reraise(new_e.__class__, new_e, exc_traceback)
parsed = pystache.parse(text)
elems = _get_parsed_elems(parsed)
if len(elems) == 0 and len(text) > 0:
raise ParseError("section start tag mismatch")
def traverse(elems, nested):
seen_node = False
for elem in elems:
if not isinstance(elem, six.string_types):
seen_node = True
if isinstance(elem, six.string_types):
pass
elif isinstance(elem, (pystache.parser._EscapeNode,
pystache.parser._ChangeNode)):
pass
elif isinstance(elem, pystache.parser._SectionNode):
nested = traverse(_get_parsed_elems(elem.parsed), True)
if nested and not allow_nested:
raise ParseError(
"nested tags not allowed in section %r" % elem.key)
elif isinstance(elem, pystache.parser._InvertedNode):
if not allow_inverted:
raise ParseError("inverted sections not allowed: %s" % elem.key)
nested = traverse(_get_parsed_elems(elem.parsed_section), True)
if nested and not allow_nested:
raise ParseError(
"nested tags not allowed in inverted section %r" % elem.key)
elif isinstance(elem, pystache.parser._PartialNode):
raise ParseError(
"partial tags not allowed")
else:
raise ParseError("tag not allowed %r" % elem.__class__)
return seen_node
traverse(elems, False)
return parsed
def get_variables(text, nested=False):
"""Get the variables referenced in the given text.
Parameters
----------
text : str
Text to get variables from.
nested : optional
Whether to allow nested variables. Can have values "all" for all the
variables, or "inner" for just the inner variables.
Examples
--------
>>> get_variables("{{a}}")
['a']
>>> get_variables("{{#a}} {{b}} {{/a}}", nested="inner")
['b']
>>> get_variables("{{#a}} {{b}} {{/a}}", nested="all")
['a', 'b']
"""
if nested not in [False, "all", "inner"]:
raise ValueError("invalid nested value:", nested)
parsed = _parse(text, allow_nested=bool(nested))
if not nested: # equivalent due to exception raised above
nested = "all"
def traverse(elems, variables):
added_variables = False
for elem in elems:
if isinstance(elem, pystache.parser._SectionNode):
traversed_variables = traverse(_get_parsed_elems(elem.parsed),
variables)
if nested == "all":
variables.add(elem.key)
added_variables = True
elif nested == "inner" and not traversed_variables:
variables.add(elem.key)
added_variables = True
elif isinstance(elem, pystache.parser._InvertedNode):
traversed_variables = traverse(_get_parsed_elems(elem.parsed_section),
variables)
if nested == "all":
variables.add(elem.key)
added_variables = True
elif nested == "inner" and not traversed_variables:
variables.add(elem.key)
added_variables = True
elif isinstance(elem, (pystache.parser._EscapeNode, pystache.parser._PartialNode)):
variables.add(elem.key)
added_variables = True
else:
assert isinstance(elem, six.string_types), elem
return added_variables
elems = _get_parsed_elems(parsed)
variables = set()
traverse(elems, variables)
return sorted(variables)
class Translator(object):
"""Translate a template text with given variables."""
def __init__(self, template):
"""
Parameters
----------
template : str
Template text to translate.
"""
self._template = template
self._parsed = _parse(self._template, allow_nested=True)
def identity(arg):
return arg
self._renderer = pystache.renderer.Renderer(search_dirs=[], file_extension=False,
partials=None, escape=identity,
missing_tags="strict")
def translate(self, env, recursive=True):
"""Apply translation with given variables.
Parameters
----------
env : dict
Mapping of variable names to their values.
recursive : bool, optional
Whether to apply translations recursively.
Examples
--------
You can perform simple text translations:
>>> t = Translator('Hello {{a}}')
>>> t.translate({'a': 'you'})
'Hello you'
>>> t.translate({'a': [1, 2]})
'Hello [1, 2]'
And also recursive ones:
>>> t.translate({'a': '{{b}}', 'b': 'them'})
'Hello them'
More complex cases like conditionals are also possible:
>>> t = Translator('{{#a}}is true{{/a}}{{^a}}is false{{/a}}')
>>> t.translate({'a': 1})
'is true'
>>> t.translate({'a': 0})
'is false'
Or even calls to functions (arguments are the unexpanded text on the template):
>>> Translator('{{a}}').translate({'a': lambda: 'value'})
'value'
>>> Translator('{{#a}}{{b}}{{/a}}').translate(
... {'a': lambda arg: 2*arg, 'b': 4})
'44'
>>> Translator('{{#a}}{{b}}{{/a}}').translate(
... {'a': lambda arg: " ".join(list(arg))})
'{ { b } }'
And expansion of nested variables with multiple values is also possible:
>>> Translator('{{#a}}A.B=={{b}} {{/a}}').translate({'a': [{'b': 1}, {'b': 2}]})
'A.B==1 A.B==2 '
"""
if not isinstance(env, Mapping):
raise TypeError("not a mapping: %r" % env)
template_new = self._template
parsed_new = self._parsed
while True:
template_old = template_new
parsed_old = parsed_new
try:
template_new = self._renderer.render(parsed_new, env)
except pystache.context.KeyNotFoundError as e:
_, _, exc_traceback = sys.exc_info()
new_e = VariableError("missing variable %s" % e.key)
six.reraise(new_e.__class__, new_e, exc_traceback)
except pystache.common.TemplateNotFoundError as e:
_, _, exc_traceback = sys.exc_info()
new_e = VariableError(str(e))
six.reraise(new_e.__class__, new_e, exc_traceback)
if not recursive:
break
elif template_old == template_new:
break
parsed_new = _parse(template_new, allow_nested=True)
return template_new
def translate_many(self, envs, recursive=True, ignore_variable_error=False,
with_envs=False):
"""Apply translation with given set of variables.
Parameters
----------
envs : sequence of dict
Sequence of variable names to value mappings to apply the
translation for.
recursive : bool, optional
Whether to apply translations recursively.
ignore_variable_error : bool, optional
Ignore translations for variable maps that have missing variables.
with_envs : bool, optional
Get the set of maps that led to each translation.
Returns
-------
list of str
Translations when ``with_envs`` is ``False``.
list of (str, [env])
Translations with their corresponding variable maps when
``with_envs`` is ``True``.
Notes
-----
The result is guaranteed to maintain the order of the elements of
`envs`.
Examples
--------
You can very easily translate a sequence of variable maps:
>>> t = Translator('Hello {{a}}')
>>> t.translate_many([{'a': 'you'}, {'a': 'them'}])
['Hello you', 'Hello them']
Multiple maps can also translate into the same text:
>>> t.translate_many([{'a': 'you'}, {'a': 'them', 'b': 1}, {'a': 'them', 'b': 2}])
['Hello you', 'Hello them']
But you can also get the maps that led to each translation:
>>> t = Translator('Hello {{a}}')
>>> translated = t.translate_many([{'a': 'you'}, {'a': 'them', 'b': 1},
... {'a': 'them', 'b': 2}], with_envs=True)
>>> translated == [('Hello you', [{'a': 'you'}]),
... ('Hello them', [{'a': 'them', 'b': 1},
... {'a': 'them', 'b': 2}])]
True
"""
if with_envs:
result = OrderedDict()
def add(key, val):
if key not in result:
result[key] = []
result[key].append(val)
else:
result_track = OrderedSet()
result = []
def add(key, val):
if key not in result_track:
result_track.add(key)
result.append(key)
for env in envs:
try:
text = self.translate(env)
except VariableError:
if not ignore_variable_error:
raise
else:
add(text, env)
if with_envs:
return list(result.items())
else:
return result
def translate(template, env, **kwargs):
"""Shorthand for ``Translator(template).translate(env, **kwargs)``."""
return Translator(template=template).translate(env=env, **kwargs)
def translate_many(template, envs, **kwargs):
"""Shorthand for ``Translator(template).translate_many(envs, **kwargs)``."""
return Translator(template=template).translate_many(envs=envs, **kwargs)
class Extractor(object):
"""Extract a dict with the variable values that match a given template.
Variables and sections on the template are used to define regular
expressions, following Python's `syntax
<http://docs.python.org/library/re.html#regular-expression-syntax>`_.
"""
def __init__(self, template):
"""
Parameters
----------
template : str
Template text to extract from.
"""
self._template = template
parsed = _parse(template, allow_nested=False, allow_inverted=False)
regex = ""
variables = {}
for elem in _get_parsed_elems(parsed):
if isinstance(elem, six.string_types):
regex += elem
elif isinstance(elem, pystache.parser._SectionNode):
if elem.key in variables:
raise ParseError(
"regex for variable %s has already been set: %s" % (
elem.key, variables[elem.key]))
elem_regex = _get_parsed_elems(elem.parsed)
if len(elem_regex) == 0:
raise ParseError(
"regex for variable %s cannot be empty" % elem.key)
elem_regex = elem_regex[0]
assert len(elem_regex) > 0, template
variables[elem.key] = elem_regex
regex += "(?P<%s>%s)" % (elem.key, elem_regex)
elif isinstance(elem, pystache.parser._EscapeNode):
if elem.key in variables:
regex += "(?P=%s)" % elem.key
else:
elem_regex = ".+"
variables[elem.key] = elem_regex
regex += "(?P<%s>%s)" % (elem.key, elem_regex)
else:
# silently ignore
pass
self._cre = re.compile(regex)
def extract(self, text):
"""Apply extraction to given text.
Parameters
----------
text : str
Text to extract from.
Examples
--------
You can perform simple text extractions, where variables correspond to
the simple regex ``.+``:
>>> e = Extractor('Hello {{a}}')
>>> e.extract('Hello world')
{'a': 'world'}
>>> e.extract('Hello 123!')
{'a': '123!'}
More complex regexes can be specified using section tags:
>>> Extractor('Hello {{#a}}[0-9]+{{/a}}.*').extract('Hello 123!')
{'a': '123'}
And using the same variable on multiple tags ensures they all match the
same contents:
>>> extracted = Extractor('{{#a}}[0-9]+{{/a}}.*{{a}}{{b}}').extract('123-123456')
>>> extracted == {'a': '123', 'b': '456'}
True
"""
match = self._cre.match(text)
if match is None:
raise ExtractError(
"could not extract variables from template %r (regex: %r)" % (
self._template, self._cre.pattern))
return match.groupdict()
def extract(template, text):
"""Shorthand for ``Extractor(template).extract(text)``."""
return Extractor(template).extract(text)
__all__ = [
"ParseError", "VariableError", "ExtractError",
"get_variables",
"Translator", "translate", "translate_many",
"Extractor", "extract",
] | sciexp2-expdef | /sciexp2-expdef-2.0.13.tar.gz/sciexp2-expdef-2.0.13/sciexp2/common/text.py | text.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2023, Lluís Vilanova"
__license__ = "GPL version 3 or later"
from collections import OrderedDict
try:
from collections.abc import Mapping
except:
pass
import pystache
import re
from .utils import OrderedSet
import six
import sys
class ParseError(Exception):
pass
class VariableError(Exception):
pass
class ExtractError(Exception):
pass
def _get_parsed_elems(parsed):
return parsed._parse_tree
def _parse(text, allow_nested=True, allow_inverted=True):
try:
pystache.render(text, {})
except pystache.parser.ParsingError as e:
_, _, exc_traceback = sys.exc_info()
new_e = ParseError(str(e))
six.reraise(new_e.__class__, new_e, exc_traceback)
parsed = pystache.parse(text)
elems = _get_parsed_elems(parsed)
if len(elems) == 0 and len(text) > 0:
raise ParseError("section start tag mismatch")
def traverse(elems, nested):
seen_node = False
for elem in elems:
if not isinstance(elem, six.string_types):
seen_node = True
if isinstance(elem, six.string_types):
pass
elif isinstance(elem, (pystache.parser._EscapeNode,
pystache.parser._ChangeNode)):
pass
elif isinstance(elem, pystache.parser._SectionNode):
nested = traverse(_get_parsed_elems(elem.parsed), True)
if nested and not allow_nested:
raise ParseError(
"nested tags not allowed in section %r" % elem.key)
elif isinstance(elem, pystache.parser._InvertedNode):
if not allow_inverted:
raise ParseError("inverted sections not allowed: %s" % elem.key)
nested = traverse(_get_parsed_elems(elem.parsed_section), True)
if nested and not allow_nested:
raise ParseError(
"nested tags not allowed in inverted section %r" % elem.key)
elif isinstance(elem, pystache.parser._PartialNode):
raise ParseError(
"partial tags not allowed")
else:
raise ParseError("tag not allowed %r" % elem.__class__)
return seen_node
traverse(elems, False)
return parsed
def get_variables(text, nested=False):
"""Get the variables referenced in the given text.
Parameters
----------
text : str
Text to get variables from.
nested : optional
Whether to allow nested variables. Can have values "all" for all the
variables, or "inner" for just the inner variables.
Examples
--------
>>> get_variables("{{a}}")
['a']
>>> get_variables("{{#a}} {{b}} {{/a}}", nested="inner")
['b']
>>> get_variables("{{#a}} {{b}} {{/a}}", nested="all")
['a', 'b']
"""
if nested not in [False, "all", "inner"]:
raise ValueError("invalid nested value:", nested)
parsed = _parse(text, allow_nested=bool(nested))
if not nested: # equivalent due to exception raised above
nested = "all"
def traverse(elems, variables):
added_variables = False
for elem in elems:
if isinstance(elem, pystache.parser._SectionNode):
traversed_variables = traverse(_get_parsed_elems(elem.parsed),
variables)
if nested == "all":
variables.add(elem.key)
added_variables = True
elif nested == "inner" and not traversed_variables:
variables.add(elem.key)
added_variables = True
elif isinstance(elem, pystache.parser._InvertedNode):
traversed_variables = traverse(_get_parsed_elems(elem.parsed_section),
variables)
if nested == "all":
variables.add(elem.key)
added_variables = True
elif nested == "inner" and not traversed_variables:
variables.add(elem.key)
added_variables = True
elif isinstance(elem, (pystache.parser._EscapeNode, pystache.parser._PartialNode)):
variables.add(elem.key)
added_variables = True
else:
assert isinstance(elem, six.string_types), elem
return added_variables
elems = _get_parsed_elems(parsed)
variables = set()
traverse(elems, variables)
return sorted(variables)
class Translator(object):
"""Translate a template text with given variables."""
def __init__(self, template):
"""
Parameters
----------
template : str
Template text to translate.
"""
self._template = template
self._parsed = _parse(self._template, allow_nested=True)
def identity(arg):
return arg
self._renderer = pystache.renderer.Renderer(search_dirs=[], file_extension=False,
partials=None, escape=identity,
missing_tags="strict")
def translate(self, env, recursive=True):
"""Apply translation with given variables.
Parameters
----------
env : dict
Mapping of variable names to their values.
recursive : bool, optional
Whether to apply translations recursively.
Examples
--------
You can perform simple text translations:
>>> t = Translator('Hello {{a}}')
>>> t.translate({'a': 'you'})
'Hello you'
>>> t.translate({'a': [1, 2]})
'Hello [1, 2]'
And also recursive ones:
>>> t.translate({'a': '{{b}}', 'b': 'them'})
'Hello them'
More complex cases like conditionals are also possible:
>>> t = Translator('{{#a}}is true{{/a}}{{^a}}is false{{/a}}')
>>> t.translate({'a': 1})
'is true'
>>> t.translate({'a': 0})
'is false'
Or even calls to functions (arguments are the unexpanded text on the template):
>>> Translator('{{a}}').translate({'a': lambda: 'value'})
'value'
>>> Translator('{{#a}}{{b}}{{/a}}').translate(
... {'a': lambda arg: 2*arg, 'b': 4})
'44'
>>> Translator('{{#a}}{{b}}{{/a}}').translate(
... {'a': lambda arg: " ".join(list(arg))})
'{ { b } }'
And expansion of nested variables with multiple values is also possible:
>>> Translator('{{#a}}A.B=={{b}} {{/a}}').translate({'a': [{'b': 1}, {'b': 2}]})
'A.B==1 A.B==2 '
"""
if not isinstance(env, Mapping):
raise TypeError("not a mapping: %r" % env)
template_new = self._template
parsed_new = self._parsed
while True:
template_old = template_new
parsed_old = parsed_new
try:
template_new = self._renderer.render(parsed_new, env)
except pystache.context.KeyNotFoundError as e:
_, _, exc_traceback = sys.exc_info()
new_e = VariableError("missing variable %s" % e.key)
six.reraise(new_e.__class__, new_e, exc_traceback)
except pystache.common.TemplateNotFoundError as e:
_, _, exc_traceback = sys.exc_info()
new_e = VariableError(str(e))
six.reraise(new_e.__class__, new_e, exc_traceback)
if not recursive:
break
elif template_old == template_new:
break
parsed_new = _parse(template_new, allow_nested=True)
return template_new
def translate_many(self, envs, recursive=True, ignore_variable_error=False,
with_envs=False):
"""Apply translation with given set of variables.
Parameters
----------
envs : sequence of dict
Sequence of variable names to value mappings to apply the
translation for.
recursive : bool, optional
Whether to apply translations recursively.
ignore_variable_error : bool, optional
Ignore translations for variable maps that have missing variables.
with_envs : bool, optional
Get the set of maps that led to each translation.
Returns
-------
list of str
Translations when ``with_envs`` is ``False``.
list of (str, [env])
Translations with their corresponding variable maps when
``with_envs`` is ``True``.
Notes
-----
The result is guaranteed to maintain the order of the elements of
`envs`.
Examples
--------
You can very easily translate a sequence of variable maps:
>>> t = Translator('Hello {{a}}')
>>> t.translate_many([{'a': 'you'}, {'a': 'them'}])
['Hello you', 'Hello them']
Multiple maps can also translate into the same text:
>>> t.translate_many([{'a': 'you'}, {'a': 'them', 'b': 1}, {'a': 'them', 'b': 2}])
['Hello you', 'Hello them']
But you can also get the maps that led to each translation:
>>> t = Translator('Hello {{a}}')
>>> translated = t.translate_many([{'a': 'you'}, {'a': 'them', 'b': 1},
... {'a': 'them', 'b': 2}], with_envs=True)
>>> translated == [('Hello you', [{'a': 'you'}]),
... ('Hello them', [{'a': 'them', 'b': 1},
... {'a': 'them', 'b': 2}])]
True
"""
if with_envs:
result = OrderedDict()
def add(key, val):
if key not in result:
result[key] = []
result[key].append(val)
else:
result_track = OrderedSet()
result = []
def add(key, val):
if key not in result_track:
result_track.add(key)
result.append(key)
for env in envs:
try:
text = self.translate(env)
except VariableError:
if not ignore_variable_error:
raise
else:
add(text, env)
if with_envs:
return list(result.items())
else:
return result
def translate(template, env, **kwargs):
"""Shorthand for ``Translator(template).translate(env, **kwargs)``."""
return Translator(template=template).translate(env=env, **kwargs)
def translate_many(template, envs, **kwargs):
"""Shorthand for ``Translator(template).translate_many(envs, **kwargs)``."""
return Translator(template=template).translate_many(envs=envs, **kwargs)
class Extractor(object):
"""Extract a dict with the variable values that match a given template.
Variables and sections on the template are used to define regular
expressions, following Python's `syntax
<http://docs.python.org/library/re.html#regular-expression-syntax>`_.
"""
def __init__(self, template):
"""
Parameters
----------
template : str
Template text to extract from.
"""
self._template = template
parsed = _parse(template, allow_nested=False, allow_inverted=False)
regex = ""
variables = {}
for elem in _get_parsed_elems(parsed):
if isinstance(elem, six.string_types):
regex += elem
elif isinstance(elem, pystache.parser._SectionNode):
if elem.key in variables:
raise ParseError(
"regex for variable %s has already been set: %s" % (
elem.key, variables[elem.key]))
elem_regex = _get_parsed_elems(elem.parsed)
if len(elem_regex) == 0:
raise ParseError(
"regex for variable %s cannot be empty" % elem.key)
elem_regex = elem_regex[0]
assert len(elem_regex) > 0, template
variables[elem.key] = elem_regex
regex += "(?P<%s>%s)" % (elem.key, elem_regex)
elif isinstance(elem, pystache.parser._EscapeNode):
if elem.key in variables:
regex += "(?P=%s)" % elem.key
else:
elem_regex = ".+"
variables[elem.key] = elem_regex
regex += "(?P<%s>%s)" % (elem.key, elem_regex)
else:
# silently ignore
pass
self._cre = re.compile(regex)
def extract(self, text):
"""Apply extraction to given text.
Parameters
----------
text : str
Text to extract from.
Examples
--------
You can perform simple text extractions, where variables correspond to
the simple regex ``.+``:
>>> e = Extractor('Hello {{a}}')
>>> e.extract('Hello world')
{'a': 'world'}
>>> e.extract('Hello 123!')
{'a': '123!'}
More complex regexes can be specified using section tags:
>>> Extractor('Hello {{#a}}[0-9]+{{/a}}.*').extract('Hello 123!')
{'a': '123'}
And using the same variable on multiple tags ensures they all match the
same contents:
>>> extracted = Extractor('{{#a}}[0-9]+{{/a}}.*{{a}}{{b}}').extract('123-123456')
>>> extracted == {'a': '123', 'b': '456'}
True
"""
match = self._cre.match(text)
if match is None:
raise ExtractError(
"could not extract variables from template %r (regex: %r)" % (
self._template, self._cre.pattern))
return match.groupdict()
def extract(template, text):
"""Shorthand for ``Extractor(template).extract(text)``."""
return Extractor(template).extract(text)
__all__ = [
"ParseError", "VariableError", "ExtractError",
"get_variables",
"Translator", "translate", "translate_many",
"Extractor", "extract",
] | 0.569613 | 0.231788 |
SciExp²-ExpRun
==============
SciExp²-ExpRun (aka *Scientific Experiment Exploration - Experiment Running*)
provides a framework for easing the workflow of executing experiments that
require orchestrating multiple processes in local and/or remote machines.
You can find links to the documentation and all other relevant information in:
https://sciexp2-exprun.readthedocs.io
Copyright
=========
Copyright 2019-2020 Lluís Vilanova <[email protected]>
Sciexp²-ExpRun is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
Sciexp²-ExpRun is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
| sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/README.md | README.md | SciExp²-ExpRun
==============
SciExp²-ExpRun (aka *Scientific Experiment Exploration - Experiment Running*)
provides a framework for easing the workflow of executing experiments that
require orchestrating multiple processes in local and/or remote machines.
You can find links to the documentation and all other relevant information in:
https://sciexp2-exprun.readthedocs.io
Copyright
=========
Copyright 2019-2020 Lluís Vilanova <[email protected]>
Sciexp²-ExpRun is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
Sciexp²-ExpRun is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
| 0.751466 | 0.31384 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections
import re
from . import kernel
def set_freq(shell, path="cpupower", ld_library_path="", freq="max"):
"""Set frequency scaling.
Parameters
----------
shell
Target shell.
path : str, optional
Path to cpupower tool. Default is use the cpupower tool in the PATH.
ld_library_path : str, optional
Library path to run cpupower tool. Default is use the system's library
path.
freq : str, optional
Frequency to set in GHz. Default is use maximum frequency.
Notes
-----
In some systems it might be necessary to boot the Linux kernel with command
line option "intel_pstate=disable" in order to support user frequency
settings.
"""
if freq == "max":
max_freq = shell.run([
"sh", "-c",
f"sudo LD_LIBRARY_PATH={ld_library_path} {path} frequency-info | grep 'hardware limits' | sed -e 's/.* - \\(.*\\) GHz/\\1/'"],
encoding="ascii")
freq = max_freq.output[:-1]
shell.run(["sudo",
f"LD_LIBRARY_PATH={ld_library_path}", path,
"-c", "all", "frequency-set", "--governor", "userspace"])
shell.run(["sudo",
f"LD_LIBRARY_PATH={ld_library_path}", path,
"-c", "all", "frequency-set", "--freq", f"{freq}GHz"])
def _get_mask(cpu_list):
mask = 0
for cpu in cpu_list:
mask += 1 << cpu
return mask
def set_irqs(shell, *irqs, **kwargs):
"""Make irqbalance ignore the given IRQs, and instead set their SMP affinity.
Parameters
----------
shell
Target system.
irqs
IRQ descriptors.
ignore_errors : bool, optional
Ignore errors when manually setting an IRQ's SMP affinity. Implies that
irqbalance will manage that IRQ. Default is False.
irqbalance_banned_cpus : list of int, optional
CPUs that irqbalance should not use for balancing.
irqbalance_args : list of str, optional
Additional arguments to irqbalance.
Each descriptor in `irqs` is a three-element tuple:
* Type: either ``irq`` for the first column in /proc/interrupts, or
``descr`` for the interrupt description after the per-CPU counts.
* Regex: a regular expression to apply to the fields above, or `True` to
apply to all values (a shorthand to the regex ".*"), or an `int` (a
shorthand to the regex "^int_value$").
* SMP affinity: list of cpu numbers to set as the IRQ's affinity; if `True`
is used instead, let irqbalance manage this IRQ.
All matching descriptors are applied in order for each IRQ. If no descriptor
matches, or the last matching descriptor has `True` as its affinity value,
the IRQ will be managed by irqbalance as before.
Returns
-------
The new irqbalance process.
"""
ignore_errors = kwargs.pop("ignore_errors", False)
irqbalance_args = kwargs.pop("irqbalance_args", [])
irqbalance_banned_cpus = kwargs.pop("irqbalance_banned_cpus", [])
irqbalance_banned_cpus_mask = _get_mask(irqbalance_banned_cpus)
if len(kwargs) > 0:
raise Exception("unknown argument: %s" % list(kwargs.keys())[0])
irqs_parsed = []
for arg_irq in irqs:
if len(arg_irq) != 3:
raise ValueError("wrong IRQ descriptor: %s" % repr(arg_irq))
irq_type, irq_re, irq_cpus = arg_irq
if isinstance(irq_re, int):
irq_re = "^%d$" % irq_re
if not isinstance(irq_re, bool) and not isinstance(irq_re, six.string_types):
raise TypeError("wrong IRQ descriptor regex: %s" % str(irq_re))
if not isinstance(irq_re, bool):
irq_re = re.compile(irq_re)
if (not isinstance(irq_cpus, bool) and (isinstance(irq_cpus, six.string_types) or
not isinstance(irq_cpus, collections.Iterable))):
raise TypeError("wrong IRQ descriptor CPU list: %s" % str(irq_cpus))
if irq_type not in ["irq", "descr"]:
raise ValueError("wrong IRQ descriptor type: %s" % str(irq_type))
irqs_parsed.append((irq_type, irq_re, irq_cpus))
irq_manual = []
irqbalance_banned = set()
cre = re.compile(r"(?P<irq>[^:]+):(?:\s+[0-9]+)+\s+(?P<descr>.*)")
with shell.open("/proc/interrupts") as f:
for line in f.read().split("\n"):
match = cre.match(line)
if match is None:
continue
irq = match.groupdict()["irq"].strip()
descr = match.groupdict()["descr"].strip()
cpus = True
for irq_type, irq_cre, irq_cpus in irqs_parsed:
if irq_type == "irq":
if irq_cre == True or irq_cre.match(irq):
cpus = irq_cpus
elif irq_type == "descr":
if irq_cre == True or irq_cre.match(descr):
cpus = irq_cpus
else:
assert False, irq_type
if cpus != True:
irq_manual.append((irq, cpus))
irqbalance_banned.add(irq)
for irq, cpus in irq_manual:
mask = _get_mask(cpus)
try:
shell.run(["sudo", "sh", "-c",
"echo %x > /proc/irq/%s/smp_affinity" % (irq, mask)])
except:
if ignore_errors:
irqbalance_banned.remove(irq)
else:
raise
shell.run(["sudo", "service", "irqbalance", "stop"])
proc = shell.spawn(["sudo", "IRQBALANCE_BANNED_CPUS=%x" % irqbalance_banned_cpus_mask,
"irqbalance"] + irqbalance_args +
["--banirq=%s" % banned
for banned in irqbalance_banned],
encoding="ascii")
return proc
def get_cpus(shell, node=None, package=None, core=None, pu=None, cgroup=None):
"""Get a set of all physical CPU indexes in the system.
It uses the hwloc-calc program to report available CPUs.
Parameters
----------
shell
Target shell.
node : int or str, optional
NUMA nodes to check. Defaults to all.
package : int or str, optional
Core packages to check on selected NUMA nodes. Defaults to all.
core : int or str, optional
Cores to check on selected core packages. Defaults to all.
pu : int or str, optional
PUs to check on selected cores. Defaults to all.
cgroup : str, optional
Cgroup path.
Returns
-------
set of int
Physical CPU indexes (as used by Linux).
Notes
-----
The combination of all the arguments is a flexible way to get all the
information in the system. Each of these arguments can have any of the forms
described under "Hwloc Indexes" in manpage hwloc(7). A few examples.
Second thread of each core:
>>> get_cpus(shell, pu=1)
First thread of each core in first NUMA node:
>>> get_cpus(node=0, pu=0)
Hardware threads in first core of the entire system:
>>> get_cpus(node=0, package=0, core=0)
"""
cmd = ["hwloc-calc", "--intersect", "PU",
"--li", "--po", ""]
def add_level(name, value):
if value is None:
value = "all"
cmd[-1] += ".%s:%s" % (name, str(value))
add_level("node", node)
add_level("package", package)
add_level("core", core)
add_level("pu", pu)
cmd[-1] = cmd[-1][1:]
if cgroup is not None:
cmd = ["sudo", "cgexec", "-g", cgroup] + cmd
res = shell.run(cmd, encoding="ascii")
line = res.output.split("\n")[0]
if line == "":
raise ValueError("hwloc-calc: %r" % res.stderr_output)
return [int(i) for i in res.output.split(",")]
__all__ = [
"set_freq", "set_irqs", "get_cpus",
] | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/cpu.py | cpu.py |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections
import re
from . import kernel
def set_freq(shell, path="cpupower", ld_library_path="", freq="max"):
"""Set frequency scaling.
Parameters
----------
shell
Target shell.
path : str, optional
Path to cpupower tool. Default is use the cpupower tool in the PATH.
ld_library_path : str, optional
Library path to run cpupower tool. Default is use the system's library
path.
freq : str, optional
Frequency to set in GHz. Default is use maximum frequency.
Notes
-----
In some systems it might be necessary to boot the Linux kernel with command
line option "intel_pstate=disable" in order to support user frequency
settings.
"""
if freq == "max":
max_freq = shell.run([
"sh", "-c",
f"sudo LD_LIBRARY_PATH={ld_library_path} {path} frequency-info | grep 'hardware limits' | sed -e 's/.* - \\(.*\\) GHz/\\1/'"],
encoding="ascii")
freq = max_freq.output[:-1]
shell.run(["sudo",
f"LD_LIBRARY_PATH={ld_library_path}", path,
"-c", "all", "frequency-set", "--governor", "userspace"])
shell.run(["sudo",
f"LD_LIBRARY_PATH={ld_library_path}", path,
"-c", "all", "frequency-set", "--freq", f"{freq}GHz"])
def _get_mask(cpu_list):
mask = 0
for cpu in cpu_list:
mask += 1 << cpu
return mask
def set_irqs(shell, *irqs, **kwargs):
"""Make irqbalance ignore the given IRQs, and instead set their SMP affinity.
Parameters
----------
shell
Target system.
irqs
IRQ descriptors.
ignore_errors : bool, optional
Ignore errors when manually setting an IRQ's SMP affinity. Implies that
irqbalance will manage that IRQ. Default is False.
irqbalance_banned_cpus : list of int, optional
CPUs that irqbalance should not use for balancing.
irqbalance_args : list of str, optional
Additional arguments to irqbalance.
Each descriptor in `irqs` is a three-element tuple:
* Type: either ``irq`` for the first column in /proc/interrupts, or
``descr`` for the interrupt description after the per-CPU counts.
* Regex: a regular expression to apply to the fields above, or `True` to
apply to all values (a shorthand to the regex ".*"), or an `int` (a
shorthand to the regex "^int_value$").
* SMP affinity: list of cpu numbers to set as the IRQ's affinity; if `True`
is used instead, let irqbalance manage this IRQ.
All matching descriptors are applied in order for each IRQ. If no descriptor
matches, or the last matching descriptor has `True` as its affinity value,
the IRQ will be managed by irqbalance as before.
Returns
-------
The new irqbalance process.
"""
ignore_errors = kwargs.pop("ignore_errors", False)
irqbalance_args = kwargs.pop("irqbalance_args", [])
irqbalance_banned_cpus = kwargs.pop("irqbalance_banned_cpus", [])
irqbalance_banned_cpus_mask = _get_mask(irqbalance_banned_cpus)
if len(kwargs) > 0:
raise Exception("unknown argument: %s" % list(kwargs.keys())[0])
irqs_parsed = []
for arg_irq in irqs:
if len(arg_irq) != 3:
raise ValueError("wrong IRQ descriptor: %s" % repr(arg_irq))
irq_type, irq_re, irq_cpus = arg_irq
if isinstance(irq_re, int):
irq_re = "^%d$" % irq_re
if not isinstance(irq_re, bool) and not isinstance(irq_re, six.string_types):
raise TypeError("wrong IRQ descriptor regex: %s" % str(irq_re))
if not isinstance(irq_re, bool):
irq_re = re.compile(irq_re)
if (not isinstance(irq_cpus, bool) and (isinstance(irq_cpus, six.string_types) or
not isinstance(irq_cpus, collections.Iterable))):
raise TypeError("wrong IRQ descriptor CPU list: %s" % str(irq_cpus))
if irq_type not in ["irq", "descr"]:
raise ValueError("wrong IRQ descriptor type: %s" % str(irq_type))
irqs_parsed.append((irq_type, irq_re, irq_cpus))
irq_manual = []
irqbalance_banned = set()
cre = re.compile(r"(?P<irq>[^:]+):(?:\s+[0-9]+)+\s+(?P<descr>.*)")
with shell.open("/proc/interrupts") as f:
for line in f.read().split("\n"):
match = cre.match(line)
if match is None:
continue
irq = match.groupdict()["irq"].strip()
descr = match.groupdict()["descr"].strip()
cpus = True
for irq_type, irq_cre, irq_cpus in irqs_parsed:
if irq_type == "irq":
if irq_cre == True or irq_cre.match(irq):
cpus = irq_cpus
elif irq_type == "descr":
if irq_cre == True or irq_cre.match(descr):
cpus = irq_cpus
else:
assert False, irq_type
if cpus != True:
irq_manual.append((irq, cpus))
irqbalance_banned.add(irq)
for irq, cpus in irq_manual:
mask = _get_mask(cpus)
try:
shell.run(["sudo", "sh", "-c",
"echo %x > /proc/irq/%s/smp_affinity" % (irq, mask)])
except:
if ignore_errors:
irqbalance_banned.remove(irq)
else:
raise
shell.run(["sudo", "service", "irqbalance", "stop"])
proc = shell.spawn(["sudo", "IRQBALANCE_BANNED_CPUS=%x" % irqbalance_banned_cpus_mask,
"irqbalance"] + irqbalance_args +
["--banirq=%s" % banned
for banned in irqbalance_banned],
encoding="ascii")
return proc
def get_cpus(shell, node=None, package=None, core=None, pu=None, cgroup=None):
"""Get a set of all physical CPU indexes in the system.
It uses the hwloc-calc program to report available CPUs.
Parameters
----------
shell
Target shell.
node : int or str, optional
NUMA nodes to check. Defaults to all.
package : int or str, optional
Core packages to check on selected NUMA nodes. Defaults to all.
core : int or str, optional
Cores to check on selected core packages. Defaults to all.
pu : int or str, optional
PUs to check on selected cores. Defaults to all.
cgroup : str, optional
Cgroup path.
Returns
-------
set of int
Physical CPU indexes (as used by Linux).
Notes
-----
The combination of all the arguments is a flexible way to get all the
information in the system. Each of these arguments can have any of the forms
described under "Hwloc Indexes" in manpage hwloc(7). A few examples.
Second thread of each core:
>>> get_cpus(shell, pu=1)
First thread of each core in first NUMA node:
>>> get_cpus(node=0, pu=0)
Hardware threads in first core of the entire system:
>>> get_cpus(node=0, package=0, core=0)
"""
cmd = ["hwloc-calc", "--intersect", "PU",
"--li", "--po", ""]
def add_level(name, value):
if value is None:
value = "all"
cmd[-1] += ".%s:%s" % (name, str(value))
add_level("node", node)
add_level("package", package)
add_level("core", core)
add_level("pu", pu)
cmd[-1] = cmd[-1][1:]
if cgroup is not None:
cmd = ["sudo", "cgexec", "-g", cgroup] + cmd
res = shell.run(cmd, encoding="ascii")
line = res.output.split("\n")[0]
if line == "":
raise ValueError("hwloc-calc: %r" % res.stderr_output)
return [int(i) for i in res.output.split(",")]
__all__ = [
"set_freq", "set_irqs", "get_cpus",
] | 0.815416 | 0.357343 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
from contextlib import contextmanager
import joblib
@contextmanager
def step(message, logger=print):
"""Show simple progress messages around a piece of code.
Parameters
----------
message : str
Message to print.
logger : function, optinal
Logging function. Defaults to `print`.
Examples
--------
>>> with step("Doing something")
print("some text")
Doing something...
some text
Doing something... done
"""
logger(message, "...")
yield
logger(message, "... done")
class threaded(object):
"""Context manager to run functions in parallel using threads.
Examples
--------
Run two processes in parallel and wait until both are finished:
>>> with step("Running in parallel"), threaded() as t:
@t.start
def f1():
shell = LocalShell()
shell.run(["sleep", "2"])
print("f1")
@t.start
def f2():
shell = LocalShell()
shell.run(["sleep", "1"])
print("f2")
Running in parallel...
f2
f1
Running in parallel... done
"""
def __init__(self, n_jobs=None):
if n_jobs is None:
n_jobs = -1
self._n_jobs = n_jobs
self._jobs = []
self.result = None
def __enter__(self):
return self
def __exit__(self, *args):
pool = joblib.Parallel(backend="threading", n_jobs=self._n_jobs)
self.result = pool(joblib.delayed(job, check_pickle=False)(*args, **kwargs)
for job, args, kwargs in self._jobs)
def start(self, target):
"""Decorator to start a function on a separate thread."""
self._jobs.append((target, [], {}))
def start_args(self, *args, **kwargs):
"""Callable decorator to start a function on a separate thread.
Examples
--------
>>> with threaded() as t:
@t.start_args(1, b=2)
def f(a, b):
print(a, b)
1, 2
"""
def wrapper(target):
self._jobs.append((target, args, kwargs))
return wrapper
__all__ = [
"step", "threaded",
] | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/util.py | util.py |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
from contextlib import contextmanager
import joblib
@contextmanager
def step(message, logger=print):
"""Show simple progress messages around a piece of code.
Parameters
----------
message : str
Message to print.
logger : function, optinal
Logging function. Defaults to `print`.
Examples
--------
>>> with step("Doing something")
print("some text")
Doing something...
some text
Doing something... done
"""
logger(message, "...")
yield
logger(message, "... done")
class threaded(object):
"""Context manager to run functions in parallel using threads.
Examples
--------
Run two processes in parallel and wait until both are finished:
>>> with step("Running in parallel"), threaded() as t:
@t.start
def f1():
shell = LocalShell()
shell.run(["sleep", "2"])
print("f1")
@t.start
def f2():
shell = LocalShell()
shell.run(["sleep", "1"])
print("f2")
Running in parallel...
f2
f1
Running in parallel... done
"""
def __init__(self, n_jobs=None):
if n_jobs is None:
n_jobs = -1
self._n_jobs = n_jobs
self._jobs = []
self.result = None
def __enter__(self):
return self
def __exit__(self, *args):
pool = joblib.Parallel(backend="threading", n_jobs=self._n_jobs)
self.result = pool(joblib.delayed(job, check_pickle=False)(*args, **kwargs)
for job, args, kwargs in self._jobs)
def start(self, target):
"""Decorator to start a function on a separate thread."""
self._jobs.append((target, [], {}))
def start_args(self, *args, **kwargs):
"""Callable decorator to start a function on a separate thread.
Examples
--------
>>> with threaded() as t:
@t.start_args(1, b=2)
def f(a, b):
print(a, b)
1, 2
"""
def wrapper(target):
self._jobs.append((target, args, kwargs))
return wrapper
__all__ = [
"step", "threaded",
] | 0.775095 | 0.168446 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import logging
from . import wait
logger = logging.getLogger(__name__)
def check_version(shell, version, fail=True):
"""Check that a specific linux kernel version is installed.
Parameters
----------
shell
Target shell.
version : str
Target kernel version.
fail : bool, optional
Whether to raise an exception when a different version is
installed. Default is True.
Returns
-------
bool
Whether the target kernel version is installed.
"""
res = shell.run(["uname", "-r"])
current = res.output.split("\n")[0]
if current == version:
return True
else:
if fail:
raise Exception("Invalid kernel version: target=%s current=%s" % (version, current))
return False
def install_version(shell, version, package_base):
"""Install and reboot into a given linux kernel version if it is not the current.
Parameters
----------
shell
Target shell.
version : str
Target kernel version.
package_base : str
Base directory in target shell where kernel packages can be installed
from.
"""
if check_version(shell, version, fail=False):
return
for name in ["linux-image-%(v)s_%(v)s-*.deb",
"linux-headers-%(v)s_%(v)s-*.deb",
"linux-libc-dev_%(v)s-*.deb"]:
name = os.path.join(package_base, name % {"v": version})
res = shell.run(["sh", "-c", "ls %s" % name])
files = res.output.split("\n")
for path in files:
if path == "":
continue
logger.warn("Installing %s..." % path)
shell.run(["sudo", "dpkg", "-i", path])
res = shell.run(["grep", "-E", "menuentry .* %s" % version, "/boot/grub/grub.cfg"])
grub_ids = res.output.split("\n")
pattern = r" '([a-z0-9.-]+-%s-[a-z0-9.-]+)' {" % re.escape(version)
grub_id = re.search(pattern, grub_ids[0]).group(1)
with step("Updating GRUB %s..." % path, logger=logger.warn):
shell.run(["sudo", "sed", "-i", "-e",
"s/^GRUB_DEFAULT=/GRUB_DEFAULT=\"saved\"/",
"/etc/default/grub"])
shell.run(["sudo", "update-grub"])
shell.run(["sudo", "grub-set-default", grub_id])
with step("Rebooting into new kernel...", logger=logger.warn):
shell.run(["sudo", "reboot"], allow_error=True)
wait.ssh(shell)
check_version(shell, version)
def check_cmdline(shell, arg):
"""Check the linux kernel was booted with the given commandline.
Parameters
----------
shell
Target shell.
arg : str
Command line argument to check.
"""
shell.run(["grep", arg, "/proc/cmdline"])
def check_module_param(shell, module, param, value, fail=True):
"""Check that a linux kernel module was loaded with the given parameter value.
Parameters
----------
shell
Target shell.
module : str
Module name.
param : str
Module name.
value
Module value (will be coverted to str).
fail : bool, optional
Raise an exception if the value is not equal. Default is True.
Returns
-------
bool
Whether the given kernel module was loaded with the given parameter
value.
"""
with shell.open("/sys/module/%s/parameters/%s" % (module, param), "r") as f:
f_val = f.read().split("\n")[0]
if f_val != value:
if fail:
raise Exception("invalid kernel parameter value: target=%s current=%s" % (value, f_val))
return False
else:
return True
__all__ = [
"check_version", "install_version", "check_cmdline",
"check_module_param",
] | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/kernel.py | kernel.py |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import logging
from . import wait
logger = logging.getLogger(__name__)
def check_version(shell, version, fail=True):
"""Check that a specific linux kernel version is installed.
Parameters
----------
shell
Target shell.
version : str
Target kernel version.
fail : bool, optional
Whether to raise an exception when a different version is
installed. Default is True.
Returns
-------
bool
Whether the target kernel version is installed.
"""
res = shell.run(["uname", "-r"])
current = res.output.split("\n")[0]
if current == version:
return True
else:
if fail:
raise Exception("Invalid kernel version: target=%s current=%s" % (version, current))
return False
def install_version(shell, version, package_base):
"""Install and reboot into a given linux kernel version if it is not the current.
Parameters
----------
shell
Target shell.
version : str
Target kernel version.
package_base : str
Base directory in target shell where kernel packages can be installed
from.
"""
if check_version(shell, version, fail=False):
return
for name in ["linux-image-%(v)s_%(v)s-*.deb",
"linux-headers-%(v)s_%(v)s-*.deb",
"linux-libc-dev_%(v)s-*.deb"]:
name = os.path.join(package_base, name % {"v": version})
res = shell.run(["sh", "-c", "ls %s" % name])
files = res.output.split("\n")
for path in files:
if path == "":
continue
logger.warn("Installing %s..." % path)
shell.run(["sudo", "dpkg", "-i", path])
res = shell.run(["grep", "-E", "menuentry .* %s" % version, "/boot/grub/grub.cfg"])
grub_ids = res.output.split("\n")
pattern = r" '([a-z0-9.-]+-%s-[a-z0-9.-]+)' {" % re.escape(version)
grub_id = re.search(pattern, grub_ids[0]).group(1)
with step("Updating GRUB %s..." % path, logger=logger.warn):
shell.run(["sudo", "sed", "-i", "-e",
"s/^GRUB_DEFAULT=/GRUB_DEFAULT=\"saved\"/",
"/etc/default/grub"])
shell.run(["sudo", "update-grub"])
shell.run(["sudo", "grub-set-default", grub_id])
with step("Rebooting into new kernel...", logger=logger.warn):
shell.run(["sudo", "reboot"], allow_error=True)
wait.ssh(shell)
check_version(shell, version)
def check_cmdline(shell, arg):
"""Check the linux kernel was booted with the given commandline.
Parameters
----------
shell
Target shell.
arg : str
Command line argument to check.
"""
shell.run(["grep", arg, "/proc/cmdline"])
def check_module_param(shell, module, param, value, fail=True):
"""Check that a linux kernel module was loaded with the given parameter value.
Parameters
----------
shell
Target shell.
module : str
Module name.
param : str
Module name.
value
Module value (will be coverted to str).
fail : bool, optional
Raise an exception if the value is not equal. Default is True.
Returns
-------
bool
Whether the given kernel module was loaded with the given parameter
value.
"""
with shell.open("/sys/module/%s/parameters/%s" % (module, param), "r") as f:
f_val = f.read().split("\n")[0]
if f_val != value:
if fail:
raise Exception("invalid kernel parameter value: target=%s current=%s" % (value, f_val))
return False
else:
return True
__all__ = [
"check_version", "install_version", "check_cmdline",
"check_module_param",
] | 0.780244 | 0.165593 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
from . import spur
def install(shell, package):
"""Install given `package` using `shell`."""
if spur.is_ssh_shell(shell):
hostname = shell.hostname
else:
hostname = "localhost"
shell.run([
"bash", "-c",
"dpkg -s %s >/dev/null 2>&1 || sudo apt-get install -y %s" % (package,
package),
])
def install_deps(shell):
"""Install all needed system packages.
Must be called on a local shell before using other functions that require a
shell, and before using other functions through the same shell.
Parameters
----------
shell
Target system.
"""
install(shell, "cgroup-tools")
install(shell, "hwloc")
install(shell, "rsync")
install(shell, "netcat-traditional")
install(shell, "psmisc")
install(shell, "util-linux")
def rsync(src_shell, src_path, dst_shell, dst_path, run_shell=None, args=[]):
"""Synchronize two directories using rsync.
Parameters
----------
src_shell
Source shell.
src_path
Source directory.
dst_shell
Destination shell.
dst_path
Destination directory.
run_shell : optional
Shell where to run rsync. Default is local machine.
args : list of str, optional
Additional arguments to rsync. Default is none.
"""
if (not spur.is_local_shell(src_shell) and not spur.is_local_shell(dst_shell) and
run_shell is not src_shell and run_shell is not dst_shell):
raise Exception("rsync cannot work with two remote shells")
if run_shell is None:
run_shell = spur.LocalShell()
ssh_port = 22
cmd_pass = []
if spur.is_local_shell(src_shell) or run_shell is src_shell:
cmd_src = [src_path]
else:
ssh_port = src_shell._port
if src_shell._password is not None:
cmd_pass = ["sshpass", "-p", src_shell._password]
cmd_src = ["%s@%s:%s" % (src_shell.username, src_shell.hostname, src_path)]
if spur.is_local_shell(dst_shell) or run_shell is dst_shell:
cmd_dst = [dst_path]
else:
ssh_port = dst_shell._port
if dst_shell._password is not None:
cmd_pass = ["sshpass", "-p", dst_shell._password]
cmd_dst = ["%s@%s:%s" % (dst_shell.username, dst_shell.hostname, dst_path)]
cmd = []
cmd += cmd_pass
cmd += ["rsync", "-az"]
cmd += ["-e", "ssh -p %d -o StrictHostKeyChecking=no" % ssh_port]
cmd += cmd_src
cmd += cmd_dst
cmd += args
run_shell.run(cmd) | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/files.py | files.py |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
from . import spur
def install(shell, package):
"""Install given `package` using `shell`."""
if spur.is_ssh_shell(shell):
hostname = shell.hostname
else:
hostname = "localhost"
shell.run([
"bash", "-c",
"dpkg -s %s >/dev/null 2>&1 || sudo apt-get install -y %s" % (package,
package),
])
def install_deps(shell):
"""Install all needed system packages.
Must be called on a local shell before using other functions that require a
shell, and before using other functions through the same shell.
Parameters
----------
shell
Target system.
"""
install(shell, "cgroup-tools")
install(shell, "hwloc")
install(shell, "rsync")
install(shell, "netcat-traditional")
install(shell, "psmisc")
install(shell, "util-linux")
def rsync(src_shell, src_path, dst_shell, dst_path, run_shell=None, args=[]):
"""Synchronize two directories using rsync.
Parameters
----------
src_shell
Source shell.
src_path
Source directory.
dst_shell
Destination shell.
dst_path
Destination directory.
run_shell : optional
Shell where to run rsync. Default is local machine.
args : list of str, optional
Additional arguments to rsync. Default is none.
"""
if (not spur.is_local_shell(src_shell) and not spur.is_local_shell(dst_shell) and
run_shell is not src_shell and run_shell is not dst_shell):
raise Exception("rsync cannot work with two remote shells")
if run_shell is None:
run_shell = spur.LocalShell()
ssh_port = 22
cmd_pass = []
if spur.is_local_shell(src_shell) or run_shell is src_shell:
cmd_src = [src_path]
else:
ssh_port = src_shell._port
if src_shell._password is not None:
cmd_pass = ["sshpass", "-p", src_shell._password]
cmd_src = ["%s@%s:%s" % (src_shell.username, src_shell.hostname, src_path)]
if spur.is_local_shell(dst_shell) or run_shell is dst_shell:
cmd_dst = [dst_path]
else:
ssh_port = dst_shell._port
if dst_shell._password is not None:
cmd_pass = ["sshpass", "-p", dst_shell._password]
cmd_dst = ["%s@%s:%s" % (dst_shell.username, dst_shell.hostname, dst_path)]
cmd = []
cmd += cmd_pass
cmd += ["rsync", "-az"]
cmd += ["-e", "ssh -p %d -o StrictHostKeyChecking=no" % ssh_port]
cmd += cmd_src
cmd += cmd_dst
cmd += args
run_shell.run(cmd) | 0.560012 | 0.215846 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import re
import io
import time
from . import spur
def run(shell, *args, **kwargs):
"""Run command with a timeout.
Parameters
----------
shell
Shell used to run given command.
timeout : int, optional
Timeout before erroring out (in seconds). Default is no timeout.
rerun_error : bool, optional
Rerun command every time it fails. Default is False.
args, kwargs
Paramaters to the shell's spawn method.
Returns
-------
spur.ExecutionResult
"""
timeout = kwargs.pop("timeout", 0)
rerun_error = kwargs.pop("rerun_error", False)
allow_error = kwargs.pop("allow_error", False)
proc = None
t_start = time.time()
while True:
t_now = time.time()
if t_now - t_start > timeout > 0:
raise Exception("Wait timed out" + repr((t_now - t_start, timeout)))
if proc is None:
proc = shell.spawn(*args, allow_error=True, **kwargs)
if proc.is_running():
time.sleep(2)
else:
res = proc.wait_for_result()
if res.return_code == 0:
return res
if not allow_error:
if rerun_error:
proc = None
time.sleep(2)
else:
raise res.to_error()
else:
return res
def connection(shell, address, port, timeout=0):
"""Wait until we can connect to given address/port."""
cmd = ["sh", "-c", "echo | nc %s %d" % (address, port)]
run(shell, cmd, timeout=timeout, rerun_error=True)
def ssh(shell, timeout=0):
"""Wait until we can ssh through given shell."""
if spur.is_local_shell(shell):
return
local = spur.LocalShell()
cmd = [
# pylint: disable=protected-access
"sshpass", "-p", shell._password,
"ssh",
"-o", "ConnectTimeout=1",
"-o", "StrictHostKeyChecking=no",
# pylint: disable=protected-access
"-p", str(shell._port), shell.username+"@"+shell.hostname,
"true",
]
run(local, cmd, timeout=timeout, rerun_error=True)
def print_stringio(obj, file=None):
"""Print contents of a StringIO object as they become available.
Useful in combination with `stringio` to print an output while processing
it.
Parameters
----------
obj : StringIO
StringIO object to print.
file : file or function, optional
File or function to print object's contents. Defaults to stdout.
Examples
--------
>>> stdout = StringIO.StringIO()
>>> thread.start_new_thread(print_stringio, (stdout,))
>>> shell.run(["sh", "-c", "sleep 1 ; echo start ; sleep 2; echo end ; sleep 1"],
... stdout=stdout)
start
end
See also
--------
stringio
"""
if not isinstance(obj, io.StringIO):
raise TypeError("expected a StringIO object")
if callable(file):
def flush_file():
pass
print_file = file
else:
def flush_file():
if file is not None:
file.flush()
def print_file(message):
print(message, end="", file=file)
seen = 0
while True:
time.sleep(0.5)
contents = obj.getvalue()
missing = contents[seen:]
if missing:
print_file(missing)
flush_file()
seen += len(missing)
def stringio(obj, pattern, timeout=0):
"""Wait until a StringIO's contents match the given regex.
Useful to trigger operations when a process generates certain output.
Examples
--------
Count time between the "start" and "end" lines printed by a process:
>>> stdout = io.StringIO()
>>> def timer(obj):
stringio(obj, "^start$")
t_start = time.time()
stringio(obj, "^end$")
t_end = time.time()
print("time:", int(t_end - t_start))
>>> thread.start_new_thread(timer, (stdout,))
>>> shell.run(["sh", "-c", "sleep 1 ; echo start ; sleep 2; echo end ; sleep >>> 1"],
... stdout=stdout)
time: 2
See also
--------
print_stringio
"""
if not isinstance(obj, io.StringIO):
raise TypeError("expected a StringIO object")
cre = re.compile(pattern, re.MULTILINE)
t_start = time.time()
while True:
t_now = time.time()
if t_now - t_start > timeout > 0:
raise Exception("Wait timed out" + repr((t_now - t_start, timeout)))
time.sleep(0.5)
contents = obj.getvalue()
match = cre.findall(contents)
if match:
return
__all__ = [
"run", "connection", "ssh", "print_stringio", "stringio",
] | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/wait.py | wait.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import re
import io
import time
from . import spur
def run(shell, *args, **kwargs):
"""Run command with a timeout.
Parameters
----------
shell
Shell used to run given command.
timeout : int, optional
Timeout before erroring out (in seconds). Default is no timeout.
rerun_error : bool, optional
Rerun command every time it fails. Default is False.
args, kwargs
Paramaters to the shell's spawn method.
Returns
-------
spur.ExecutionResult
"""
timeout = kwargs.pop("timeout", 0)
rerun_error = kwargs.pop("rerun_error", False)
allow_error = kwargs.pop("allow_error", False)
proc = None
t_start = time.time()
while True:
t_now = time.time()
if t_now - t_start > timeout > 0:
raise Exception("Wait timed out" + repr((t_now - t_start, timeout)))
if proc is None:
proc = shell.spawn(*args, allow_error=True, **kwargs)
if proc.is_running():
time.sleep(2)
else:
res = proc.wait_for_result()
if res.return_code == 0:
return res
if not allow_error:
if rerun_error:
proc = None
time.sleep(2)
else:
raise res.to_error()
else:
return res
def connection(shell, address, port, timeout=0):
"""Wait until we can connect to given address/port."""
cmd = ["sh", "-c", "echo | nc %s %d" % (address, port)]
run(shell, cmd, timeout=timeout, rerun_error=True)
def ssh(shell, timeout=0):
"""Wait until we can ssh through given shell."""
if spur.is_local_shell(shell):
return
local = spur.LocalShell()
cmd = [
# pylint: disable=protected-access
"sshpass", "-p", shell._password,
"ssh",
"-o", "ConnectTimeout=1",
"-o", "StrictHostKeyChecking=no",
# pylint: disable=protected-access
"-p", str(shell._port), shell.username+"@"+shell.hostname,
"true",
]
run(local, cmd, timeout=timeout, rerun_error=True)
def print_stringio(obj, file=None):
"""Print contents of a StringIO object as they become available.
Useful in combination with `stringio` to print an output while processing
it.
Parameters
----------
obj : StringIO
StringIO object to print.
file : file or function, optional
File or function to print object's contents. Defaults to stdout.
Examples
--------
>>> stdout = StringIO.StringIO()
>>> thread.start_new_thread(print_stringio, (stdout,))
>>> shell.run(["sh", "-c", "sleep 1 ; echo start ; sleep 2; echo end ; sleep 1"],
... stdout=stdout)
start
end
See also
--------
stringio
"""
if not isinstance(obj, io.StringIO):
raise TypeError("expected a StringIO object")
if callable(file):
def flush_file():
pass
print_file = file
else:
def flush_file():
if file is not None:
file.flush()
def print_file(message):
print(message, end="", file=file)
seen = 0
while True:
time.sleep(0.5)
contents = obj.getvalue()
missing = contents[seen:]
if missing:
print_file(missing)
flush_file()
seen += len(missing)
def stringio(obj, pattern, timeout=0):
"""Wait until a StringIO's contents match the given regex.
Useful to trigger operations when a process generates certain output.
Examples
--------
Count time between the "start" and "end" lines printed by a process:
>>> stdout = io.StringIO()
>>> def timer(obj):
stringio(obj, "^start$")
t_start = time.time()
stringio(obj, "^end$")
t_end = time.time()
print("time:", int(t_end - t_start))
>>> thread.start_new_thread(timer, (stdout,))
>>> shell.run(["sh", "-c", "sleep 1 ; echo start ; sleep 2; echo end ; sleep >>> 1"],
... stdout=stdout)
time: 2
See also
--------
print_stringio
"""
if not isinstance(obj, io.StringIO):
raise TypeError("expected a StringIO object")
cre = re.compile(pattern, re.MULTILINE)
t_start = time.time()
while True:
t_now = time.time()
if t_now - t_start > timeout > 0:
raise Exception("Wait timed out" + repr((t_now - t_start, timeout)))
time.sleep(0.5)
contents = obj.getvalue()
match = cre.findall(contents)
if match:
return
__all__ = [
"run", "connection", "ssh", "print_stringio", "stringio",
] | 0.738292 | 0.18352 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections
import os
import re
import six
# pylint: disable=redefined-builtin
def get_tids(shell, pid, filter=None):
"""Get ids of all threads in a given process.
Parameters
----------
shell
Target shell.
pid : int
Target process pid.
filter : str or cre, optional
Return pids that match given filter in process name. Default is all
pids.
Returns
-------
list of int
List of the selected process pids.
Notes
-----
When using a string for `filter` it will simply check it is part of the
process name.
"""
pids = shell.run(["ps", "H", "-o", "tid comm", str(pid)], encoding="utf-8")
lines = pids.output.split("\n")
res = []
for line in lines[1:]:
line = line.strip()
if line == "":
continue
pid, name = line.split(" ", 1)
if filter:
if isinstance(filter, six.string_types):
if filter not in name:
continue
else:
if not filter.match(name):
continue
res.append(int(pid))
return res
def pin(shell, pid, cpus, **shell_kwargs):
"""Pin pid to given physical CPU list.
Parameters
----------
shell
Target shell.
pid : int
Target pid or tid to pin.
cpus : list of int
Physical CPUs to pin the pid to.
shell_kwargs : optional
Arguments to `shell.run`
"""
shell.run(["sudo", "taskset", "-p",
"-c", ",".join(str(c) for c in cpus), str(pid)],
**shell_kwargs)
def cgroup_create(shell, controller, path, **kwargs):
"""Create a cgroup for given subsystem.
Parameters
----------
shell
Target shell.
controller : str
Cgroup controller to configure.
path : str
New cgroup path.
kwargs : dict
Controller parameters to set. Lists are comma-concatenated, all elements
are transformed to str.
"""
shell.run(["sudo", "cgcreate", "-g", controller+":"+path])
for key, val in kwargs.items():
if isinstance(val, six.string_types) or not isinstance(val, collections.Iterable):
val = [val]
val = ",".join(str(v) for v in val)
shell.run(["sudo", "cgset", "-r", "%s.%s=%s" % (controller, key, val), path])
def cgroup_pids(shell, path=None):
"""Get pids in given cgroup path.
Parameters
----------
shell
Target shell.
path : str, optional
Cgroup path to analyze (defaults to entire system).
Returns
-------
list of int
Pids in the given cgroup.
"""
res = set()
base = "/sys/fs/cgroup"
if path is None:
path = ""
cre = re.compile(os.path.join(base, "[^/]*", path))
proc = shell.run(["find", base, "-name", "tasks"], encoding="ascii")
for filepath in proc.output.split("\n"):
if cre.match(os.path.dirname(filepath)):
# pylint: disable=invalid-name
with shell.open(filepath, "r") as f:
pids = (int(pid) for pid in f.read().split("\n")
if pid != "")
res.update(set(pids))
return list(res)
def cgroup_move(shell, controller, path, pids):
"""Move pids to a cgroup.
Parameters
----------
shell
Target shell.
controller : str
Cgroup controller.
path : str
Cgroup path.
pids : pid or list of pid
Pids to move into the cgroup. All elements are transformed to str.
Notes
-----
If you move the process that is serving this shell, you might have to
reconnect the shell to continue using it.
"""
if isinstance(pids, six.string_types) or not isinstance(pids, collections.Iterable):
pids = [pids]
pids_str = " ".join(str(p) for p in pids if str(p) != "")
shell.run([
"sh", "-c",
f"for p in {pids_str}; do sudo cgclassify -g {controller}:{path} $p || true; done"])
__all__ = [
"get_tids", "pin",
"cgroup_create", "cgroup_pids", "cgroup_move",
] | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/process.py | process.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import collections
import os
import re
import six
# pylint: disable=redefined-builtin
def get_tids(shell, pid, filter=None):
"""Get ids of all threads in a given process.
Parameters
----------
shell
Target shell.
pid : int
Target process pid.
filter : str or cre, optional
Return pids that match given filter in process name. Default is all
pids.
Returns
-------
list of int
List of the selected process pids.
Notes
-----
When using a string for `filter` it will simply check it is part of the
process name.
"""
pids = shell.run(["ps", "H", "-o", "tid comm", str(pid)], encoding="utf-8")
lines = pids.output.split("\n")
res = []
for line in lines[1:]:
line = line.strip()
if line == "":
continue
pid, name = line.split(" ", 1)
if filter:
if isinstance(filter, six.string_types):
if filter not in name:
continue
else:
if not filter.match(name):
continue
res.append(int(pid))
return res
def pin(shell, pid, cpus, **shell_kwargs):
"""Pin pid to given physical CPU list.
Parameters
----------
shell
Target shell.
pid : int
Target pid or tid to pin.
cpus : list of int
Physical CPUs to pin the pid to.
shell_kwargs : optional
Arguments to `shell.run`
"""
shell.run(["sudo", "taskset", "-p",
"-c", ",".join(str(c) for c in cpus), str(pid)],
**shell_kwargs)
def cgroup_create(shell, controller, path, **kwargs):
"""Create a cgroup for given subsystem.
Parameters
----------
shell
Target shell.
controller : str
Cgroup controller to configure.
path : str
New cgroup path.
kwargs : dict
Controller parameters to set. Lists are comma-concatenated, all elements
are transformed to str.
"""
shell.run(["sudo", "cgcreate", "-g", controller+":"+path])
for key, val in kwargs.items():
if isinstance(val, six.string_types) or not isinstance(val, collections.Iterable):
val = [val]
val = ",".join(str(v) for v in val)
shell.run(["sudo", "cgset", "-r", "%s.%s=%s" % (controller, key, val), path])
def cgroup_pids(shell, path=None):
"""Get pids in given cgroup path.
Parameters
----------
shell
Target shell.
path : str, optional
Cgroup path to analyze (defaults to entire system).
Returns
-------
list of int
Pids in the given cgroup.
"""
res = set()
base = "/sys/fs/cgroup"
if path is None:
path = ""
cre = re.compile(os.path.join(base, "[^/]*", path))
proc = shell.run(["find", base, "-name", "tasks"], encoding="ascii")
for filepath in proc.output.split("\n"):
if cre.match(os.path.dirname(filepath)):
# pylint: disable=invalid-name
with shell.open(filepath, "r") as f:
pids = (int(pid) for pid in f.read().split("\n")
if pid != "")
res.update(set(pids))
return list(res)
def cgroup_move(shell, controller, path, pids):
"""Move pids to a cgroup.
Parameters
----------
shell
Target shell.
controller : str
Cgroup controller.
path : str
Cgroup path.
pids : pid or list of pid
Pids to move into the cgroup. All elements are transformed to str.
Notes
-----
If you move the process that is serving this shell, you might have to
reconnect the shell to continue using it.
"""
if isinstance(pids, six.string_types) or not isinstance(pids, collections.Iterable):
pids = [pids]
pids_str = " ".join(str(p) for p in pids if str(p) != "")
shell.run([
"sh", "-c",
f"for p in {pids_str}; do sudo cgclassify -g {controller}:{path} $p || true; done"])
__all__ = [
"get_tids", "pin",
"cgroup_create", "cgroup_pids", "cgroup_move",
] | 0.808748 | 0.251947 |
__author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import atexit
import collections
import logging
import os
import signal
import sys
import threading
import time
import traceback
import six
import spur
import spur.ssh
_LOGGER = logging.getLogger(__name__)
def is_local_shell(shell):
"""Whether the given shell is a `spur.LocalShell` or derivative."""
return isinstance(shell, spur.LocalShell)
def is_ssh_shell(shell):
"""Whether the given shell is a `spur.SshShell` or derivative."""
return isinstance(shell, spur.SshShell)
# Patch spur to update the _is_killed attribute when sending signals
def _patch_send_signal(func):
def send_signal_wrapper(self, signum):
if signum in [signal.SIGINT, signal.SIGQUIT, signal.SIGTERM, signal.SIGKILL]:
# pylint: disable=protected-access
self._is_killed = True
shell, kill_args = self._kill
if kill_args:
cmd = []
for arg in kill_args:
if isinstance(arg, with_pid):
cmd.append(arg(self.pid))
elif isinstance(arg, with_signum):
cmd.append(arg(signum))
else:
cmd.append(arg)
shell.run(cmd)
else:
return func(self, signum)
return send_signal_wrapper
spur.local.LocalProcess.send_signal = _patch_send_signal(spur.local.LocalProcess.send_signal)
spur.ssh.SshProcess.send_signal = _patch_send_signal(spur.ssh.SshProcess.send_signal)
# Monitor background processes for failures, so we can error out early
_EXITING = False
_LOCK = threading.RLock()
def _kill_all():
# pylint: disable=global-statement
global _EXITING
_EXITING = True
# pylint: disable=protected-access
LocalShell._atexit_cb()
# pylint: disable=protected-access
SshShell._atexit_cb()
atexit.register(_kill_all)
# pylint: disable=invalid-name,too-few-public-methods
class with_pid:
"""Decorator to define a kill argument that takes the process' pid.
To be used as an element in the `kill` argument to a shell's `run` or
`spawn` method::
shell.run(["sudo", "program"], kill=["sudo", "kill", with_pid()])
Can be used in three ways, depending on the type of `func`:
- `None`: replace with the stringified process pid.
- `str`: format with the process' pid on the ``pid`` key.
- otherwise: call with the pid as an argument.
"""
def __init__(self, func=None):
self._func = func
def __call__(self, pid):
if self._func is None:
return str(pid)
if isinstance(self._func, six.string_types):
return self._func.format(pid=pid)
return self._func(pid)
# pylint: disable=invalid-name,too-few-public-methods
class with_signum:
"""Decorator to define a kill argument that takes the user's signal number.
To be used as an element in the `kill` argument to a shell's `run` or
`spawn` method::
shell.run(["sudo", "program"], kill=["sudo", "kill", with_signum()])
Can be used in three ways, depending on the type of `func`:
- `None`: replace with the stringified signal number.
- `str`: format with the signal number on the ``signum`` key.
- otherwise: call with the signal number as an argument.
"""
def __init__(self, func=None):
self._func = func
def __call__(self, signum):
if self._func is None:
return str(signum)
if isinstance(self._func, six.string_types):
return self._func.format(signum=signum)
return self._func(signum)
def _print_traceback(cmd_msg, stack_info=None):
if stack_info is None:
stack_info = traceback.extract_stack()
stack_idx = 0 if stack_info[0][2] == "<module>" else 6
print("Traceback (most recent call last):")
msg = traceback.format_list(stack_info[stack_idx:-1])
print("".join(msg), end="")
exc_type, exc_value, tb = sys.exc_info()
info = traceback.extract_tb(tb)
msg = traceback.format_list(info)
print("".join(msg), end="")
print("%s.%s: %s" % (exc_type.__module__, exc_type.__name__, exc_value))
print("command:", cmd_msg)
def _watchdog_thread(shell, obj, cmd_msg, exit_on_error):
stack_info = traceback.extract_stack()
def watchdog():
while obj.is_running():
time.sleep(1)
try:
obj.wait_for_result()
# pylint: disable=bare-except
except:
# pylint: disable=protected-access
shell._child_remove(obj)
_LOGGER.info("- %s", cmd_msg)
# pylint: disable=protected-access
if not obj._is_killed and not _EXITING:
_print_traceback(cmd_msg, stack_info)
if exit_on_error:
_kill_all()
os._exit(1)
else:
# pylint: disable=protected-access
shell._child_remove(obj)
_LOGGER.info("- %s", cmd_msg)
thread = threading.Thread(target=watchdog)
thread.daemon = True
thread.start()
# pylint: disable=function-redefined
class LocalShell(spur.LocalShell):
"""An extended version of `spur.LocalShell`.
It will properly kill all created processes when exiting.
The `run` and `spawn` methods have two new arguments:
- ``exit_on_error``: bool, optional
Whether to exit the program when the process fails to execute.
- ``kill``: list of str, optional
Command to execute when killing the process. Useful when process is
run with sudo.
"""
__CHILDREN = collections.OrderedDict()
def _child_add(self, obj):
with _LOCK:
LocalShell.__CHILDREN[obj] = None
@classmethod
def _child_remove(cls, obj):
with _LOCK:
cls.__CHILDREN.pop(obj, None)
# pylint: disable=arguments-differ
def run(self, *args, **kwargs):
process = self.spawn(*args, **kwargs, exit_on_error=False)
result = process.wait_for_result()
return result
def spawn(self, *args, **kwargs):
exit_on_error = kwargs.pop("exit_on_error", True)
kill = kwargs.pop("kill", None)
cmd = args[0]
cmd_msg = " ".join(cmd)
_LOGGER.info("+ %s", cmd_msg)
try:
obj = spur.LocalShell.spawn(self, *args, **kwargs, store_pid=True)
# pylint: disable=bare-except
except:
if exit_on_error:
stack_info = traceback.extract_stack()
_print_traceback(cmd_msg, stack_info)
_kill_all()
# pylint: disable=protected-access
os._exit(1)
else:
raise
else:
obj._is_killed = False # pylint: disable=protected-access
obj._kill = (self, kill) # pylint: disable=protected-access
self._child_add(obj)
_watchdog_thread(self, obj, cmd_msg, exit_on_error)
return obj
@classmethod
def _atexit_cb(cls):
while True:
with _LOCK:
if not cls.__CHILDREN:
return
child = next(iter(cls.__CHILDREN.keys()))
# pylint: disable=protected-access
child._is_killed = True
if child.is_running():
try:
child.send_signal(signal.SIGTERM)
child.wait_for_result()
# pylint: disable=bare-except
except:
pass
# pylint: disable=protected-access
cls._child_remove(child)
class SshShell(spur.SshShell):
"""An extended version of `spur.SshShell`.
It will properly kill all created processes when exiting.
The shell object has two new members:
- ``hostname``: str
Target host name.
- ``username``: str
Target user name.
The `run` and `spawn` methods have two new arguments:
- ``exit_on_error``: bool, optional
Whether to exit the program when the process fails to execute.
- ``kill``: list of str, optional
Command to execute when killing the process. Useful when process is
run with sudo.
"""
__CHILDREN = collections.OrderedDict()
def _child_add(self, obj):
with _LOCK:
SshShell.__CHILDREN[obj] = None
@classmethod
def _child_remove(cls, obj):
with _LOCK:
cls.__CHILDREN.pop(obj, None)
def __init__(self, *args, **kwargs):
spur.SshShell.__init__(self, *args, **kwargs)
self.hostname = self._hostname
self.username = self._username
# pylint: disable=arguments-differ
def run(self, *args, **kwargs):
process = self.spawn(*args, **kwargs, exit_on_error=False)
result = process.wait_for_result()
return result
# pylint: disable=arguments-differ
def spawn(self, *args, **kwargs):
exit_on_error = kwargs.pop("exit_on_error", True)
kill = kwargs.pop("kill", None)
cmd = args[0]
cmd_msg = "ssh -p %d %s@%s %s" % (self._port, self.username, self.hostname, " ".join(cmd))
_LOGGER.info("+ %s", cmd_msg)
try:
obj = spur.SshShell.spawn(self, *args, **kwargs, store_pid=True)
# pylint: disable=bare-except
except:
if exit_on_error:
stack_info = traceback.extract_stack()
_print_traceback(cmd_msg, stack_info)
_kill_all()
# pylint: disable=protected-access
os._exit(1)
else:
raise
else:
obj._is_killed = False # pylint: disable=protected-access
obj._kill = (self, kill) # pylint: disable=protected-access
self._child_add(obj)
_watchdog_thread(self, obj, cmd_msg, exit_on_error)
return obj
@classmethod
def _atexit_cb(cls):
while True:
with _LOCK:
if not cls.__CHILDREN:
return
child = next(iter(cls.__CHILDREN.keys()))
# pylint: disable=protected-access
child._is_killed = True
if child.is_running():
try:
child.send_signal(signal.SIGTERM)
child.wait_for_result()
# pylint: disable=bare-except
except:
pass
# pylint: disable=protected-access
cls._child_remove(child)
def get_shell(server, user=None, password=None, port=22):
"""Get a new shell.
If `server` is a spur shell, return that instead.
Parameters
----------
server : str or object
user : str, optional
password : str, optional
port : int, optional
"""
if is_ssh_shell(server) or is_local_shell(server):
if is_ssh_shell(server):
server = server.hostname
else:
server = "localhost"
if user is None:
user = server.username
if password is None:
password = server._password
return SshShell(hostname=server,
username=user,
password=password,
port=port,
missing_host_key=spur.ssh.MissingHostKey.accept)
__all__ = [
"is_local_shell", "is_ssh_shell", "get_shell",
"with_pid",
]
__all__ += spur.__all__ | sciexp2-exprun | /sciexp2-exprun-0.3.3.tar.gz/sciexp2-exprun-0.3.3/sciexp2/exprun/spur.py | spur.py | __author__ = "Lluís Vilanova"
__copyright__ = "Copyright 2019-2020, Lluís Vilanova"
__license__ = "GPL version 3 or later"
import atexit
import collections
import logging
import os
import signal
import sys
import threading
import time
import traceback
import six
import spur
import spur.ssh
_LOGGER = logging.getLogger(__name__)
def is_local_shell(shell):
"""Whether the given shell is a `spur.LocalShell` or derivative."""
return isinstance(shell, spur.LocalShell)
def is_ssh_shell(shell):
"""Whether the given shell is a `spur.SshShell` or derivative."""
return isinstance(shell, spur.SshShell)
# Patch spur to update the _is_killed attribute when sending signals
def _patch_send_signal(func):
def send_signal_wrapper(self, signum):
if signum in [signal.SIGINT, signal.SIGQUIT, signal.SIGTERM, signal.SIGKILL]:
# pylint: disable=protected-access
self._is_killed = True
shell, kill_args = self._kill
if kill_args:
cmd = []
for arg in kill_args:
if isinstance(arg, with_pid):
cmd.append(arg(self.pid))
elif isinstance(arg, with_signum):
cmd.append(arg(signum))
else:
cmd.append(arg)
shell.run(cmd)
else:
return func(self, signum)
return send_signal_wrapper
spur.local.LocalProcess.send_signal = _patch_send_signal(spur.local.LocalProcess.send_signal)
spur.ssh.SshProcess.send_signal = _patch_send_signal(spur.ssh.SshProcess.send_signal)
# Monitor background processes for failures, so we can error out early
_EXITING = False
_LOCK = threading.RLock()
def _kill_all():
# pylint: disable=global-statement
global _EXITING
_EXITING = True
# pylint: disable=protected-access
LocalShell._atexit_cb()
# pylint: disable=protected-access
SshShell._atexit_cb()
atexit.register(_kill_all)
# pylint: disable=invalid-name,too-few-public-methods
class with_pid:
"""Decorator to define a kill argument that takes the process' pid.
To be used as an element in the `kill` argument to a shell's `run` or
`spawn` method::
shell.run(["sudo", "program"], kill=["sudo", "kill", with_pid()])
Can be used in three ways, depending on the type of `func`:
- `None`: replace with the stringified process pid.
- `str`: format with the process' pid on the ``pid`` key.
- otherwise: call with the pid as an argument.
"""
def __init__(self, func=None):
self._func = func
def __call__(self, pid):
if self._func is None:
return str(pid)
if isinstance(self._func, six.string_types):
return self._func.format(pid=pid)
return self._func(pid)
# pylint: disable=invalid-name,too-few-public-methods
class with_signum:
"""Decorator to define a kill argument that takes the user's signal number.
To be used as an element in the `kill` argument to a shell's `run` or
`spawn` method::
shell.run(["sudo", "program"], kill=["sudo", "kill", with_signum()])
Can be used in three ways, depending on the type of `func`:
- `None`: replace with the stringified signal number.
- `str`: format with the signal number on the ``signum`` key.
- otherwise: call with the signal number as an argument.
"""
def __init__(self, func=None):
self._func = func
def __call__(self, signum):
if self._func is None:
return str(signum)
if isinstance(self._func, six.string_types):
return self._func.format(signum=signum)
return self._func(signum)
def _print_traceback(cmd_msg, stack_info=None):
if stack_info is None:
stack_info = traceback.extract_stack()
stack_idx = 0 if stack_info[0][2] == "<module>" else 6
print("Traceback (most recent call last):")
msg = traceback.format_list(stack_info[stack_idx:-1])
print("".join(msg), end="")
exc_type, exc_value, tb = sys.exc_info()
info = traceback.extract_tb(tb)
msg = traceback.format_list(info)
print("".join(msg), end="")
print("%s.%s: %s" % (exc_type.__module__, exc_type.__name__, exc_value))
print("command:", cmd_msg)
def _watchdog_thread(shell, obj, cmd_msg, exit_on_error):
stack_info = traceback.extract_stack()
def watchdog():
while obj.is_running():
time.sleep(1)
try:
obj.wait_for_result()
# pylint: disable=bare-except
except:
# pylint: disable=protected-access
shell._child_remove(obj)
_LOGGER.info("- %s", cmd_msg)
# pylint: disable=protected-access
if not obj._is_killed and not _EXITING:
_print_traceback(cmd_msg, stack_info)
if exit_on_error:
_kill_all()
os._exit(1)
else:
# pylint: disable=protected-access
shell._child_remove(obj)
_LOGGER.info("- %s", cmd_msg)
thread = threading.Thread(target=watchdog)
thread.daemon = True
thread.start()
# pylint: disable=function-redefined
class LocalShell(spur.LocalShell):
"""An extended version of `spur.LocalShell`.
It will properly kill all created processes when exiting.
The `run` and `spawn` methods have two new arguments:
- ``exit_on_error``: bool, optional
Whether to exit the program when the process fails to execute.
- ``kill``: list of str, optional
Command to execute when killing the process. Useful when process is
run with sudo.
"""
__CHILDREN = collections.OrderedDict()
def _child_add(self, obj):
with _LOCK:
LocalShell.__CHILDREN[obj] = None
@classmethod
def _child_remove(cls, obj):
with _LOCK:
cls.__CHILDREN.pop(obj, None)
# pylint: disable=arguments-differ
def run(self, *args, **kwargs):
process = self.spawn(*args, **kwargs, exit_on_error=False)
result = process.wait_for_result()
return result
def spawn(self, *args, **kwargs):
exit_on_error = kwargs.pop("exit_on_error", True)
kill = kwargs.pop("kill", None)
cmd = args[0]
cmd_msg = " ".join(cmd)
_LOGGER.info("+ %s", cmd_msg)
try:
obj = spur.LocalShell.spawn(self, *args, **kwargs, store_pid=True)
# pylint: disable=bare-except
except:
if exit_on_error:
stack_info = traceback.extract_stack()
_print_traceback(cmd_msg, stack_info)
_kill_all()
# pylint: disable=protected-access
os._exit(1)
else:
raise
else:
obj._is_killed = False # pylint: disable=protected-access
obj._kill = (self, kill) # pylint: disable=protected-access
self._child_add(obj)
_watchdog_thread(self, obj, cmd_msg, exit_on_error)
return obj
@classmethod
def _atexit_cb(cls):
while True:
with _LOCK:
if not cls.__CHILDREN:
return
child = next(iter(cls.__CHILDREN.keys()))
# pylint: disable=protected-access
child._is_killed = True
if child.is_running():
try:
child.send_signal(signal.SIGTERM)
child.wait_for_result()
# pylint: disable=bare-except
except:
pass
# pylint: disable=protected-access
cls._child_remove(child)
class SshShell(spur.SshShell):
"""An extended version of `spur.SshShell`.
It will properly kill all created processes when exiting.
The shell object has two new members:
- ``hostname``: str
Target host name.
- ``username``: str
Target user name.
The `run` and `spawn` methods have two new arguments:
- ``exit_on_error``: bool, optional
Whether to exit the program when the process fails to execute.
- ``kill``: list of str, optional
Command to execute when killing the process. Useful when process is
run with sudo.
"""
__CHILDREN = collections.OrderedDict()
def _child_add(self, obj):
with _LOCK:
SshShell.__CHILDREN[obj] = None
@classmethod
def _child_remove(cls, obj):
with _LOCK:
cls.__CHILDREN.pop(obj, None)
def __init__(self, *args, **kwargs):
spur.SshShell.__init__(self, *args, **kwargs)
self.hostname = self._hostname
self.username = self._username
# pylint: disable=arguments-differ
def run(self, *args, **kwargs):
process = self.spawn(*args, **kwargs, exit_on_error=False)
result = process.wait_for_result()
return result
# pylint: disable=arguments-differ
def spawn(self, *args, **kwargs):
exit_on_error = kwargs.pop("exit_on_error", True)
kill = kwargs.pop("kill", None)
cmd = args[0]
cmd_msg = "ssh -p %d %s@%s %s" % (self._port, self.username, self.hostname, " ".join(cmd))
_LOGGER.info("+ %s", cmd_msg)
try:
obj = spur.SshShell.spawn(self, *args, **kwargs, store_pid=True)
# pylint: disable=bare-except
except:
if exit_on_error:
stack_info = traceback.extract_stack()
_print_traceback(cmd_msg, stack_info)
_kill_all()
# pylint: disable=protected-access
os._exit(1)
else:
raise
else:
obj._is_killed = False # pylint: disable=protected-access
obj._kill = (self, kill) # pylint: disable=protected-access
self._child_add(obj)
_watchdog_thread(self, obj, cmd_msg, exit_on_error)
return obj
@classmethod
def _atexit_cb(cls):
while True:
with _LOCK:
if not cls.__CHILDREN:
return
child = next(iter(cls.__CHILDREN.keys()))
# pylint: disable=protected-access
child._is_killed = True
if child.is_running():
try:
child.send_signal(signal.SIGTERM)
child.wait_for_result()
# pylint: disable=bare-except
except:
pass
# pylint: disable=protected-access
cls._child_remove(child)
def get_shell(server, user=None, password=None, port=22):
"""Get a new shell.
If `server` is a spur shell, return that instead.
Parameters
----------
server : str or object
user : str, optional
password : str, optional
port : int, optional
"""
if is_ssh_shell(server) or is_local_shell(server):
if is_ssh_shell(server):
server = server.hostname
else:
server = "localhost"
if user is None:
user = server.username
if password is None:
password = server._password
return SshShell(hostname=server,
username=user,
password=password,
port=port,
missing_host_key=spur.ssh.MissingHostKey.accept)
__all__ = [
"is_local_shell", "is_ssh_shell", "get_shell",
"with_pid",
]
__all__ += spur.__all__ | 0.561696 | 0.15746 |
=======
SciExp²
=======
SciExp² (aka *SciExp square* or simply *SciExp2*) stands for *Scientific
Experiment Exploration*, which provides a framework for easing the workflow of
creating, executing and evaluating experiments.
The driving idea of SciExp² is that of quick and effortless *design-space
exploration*. It is divided into the following main pieces:
* Launchgen: Aids in defining experiments as a permutation of different
parameters in the design space. It creates the necessary files to run these
experiments (configuration files, scripts, etc.), which you define as
templates that get substituted with the specific parameter values of each
experiment.
* Launcher: Takes the files of launchgen and runs these experiments on different
execution platforms like regular local scripts or cluster jobs. It takes care
of tracking their correct execution, and allows selecting which experiments to
run (e.g., those with specific parameter values, or those that were not
successfully run yet).
* Data: Aids in the process of collecting and analyzing the results of the
experiments. Results are automatically collected into a data structure that
maintains the relationship between each result and the parameters of the
experiment that produced it. With this you can effortlessly perform complex
tasks such as inspecting the results or calculating statistics of experiment
sub-sets, based on their parameter values.
You can find links to the documentation and all other relevant information in:
https://projects.gso.ac.upc.edu/projects/sciexp2
Copyright
=========
Copyright 2008-2018 Lluís Vilanova <[email protected]>
Sciexp² is free software: you can redistribute it and/or modify it under the
terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
SciExp² is distributed in the hope that it will be useful, but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>. | sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/README | README | =======
SciExp²
=======
SciExp² (aka *SciExp square* or simply *SciExp2*) stands for *Scientific
Experiment Exploration*, which provides a framework for easing the workflow of
creating, executing and evaluating experiments.
The driving idea of SciExp² is that of quick and effortless *design-space
exploration*. It is divided into the following main pieces:
* Launchgen: Aids in defining experiments as a permutation of different
parameters in the design space. It creates the necessary files to run these
experiments (configuration files, scripts, etc.), which you define as
templates that get substituted with the specific parameter values of each
experiment.
* Launcher: Takes the files of launchgen and runs these experiments on different
execution platforms like regular local scripts or cluster jobs. It takes care
of tracking their correct execution, and allows selecting which experiments to
run (e.g., those with specific parameter values, or those that were not
successfully run yet).
* Data: Aids in the process of collecting and analyzing the results of the
experiments. Results are automatically collected into a data structure that
maintains the relationship between each result and the parameters of the
experiment that produced it. With this you can effortlessly perform complex
tasks such as inspecting the results or calculating statistics of experiment
sub-sets, based on their parameter values.
You can find links to the documentation and all other relevant information in:
https://projects.gso.ac.upc.edu/projects/sciexp2
Copyright
=========
Copyright 2008-2018 Lluís Vilanova <[email protected]>
Sciexp² is free software: you can redistribute it and/or modify it under the
terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
SciExp² is distributed in the hope that it will be useful, but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>. | 0.696062 | 0.632333 |
.. _news:
Changes in SciExp²
==================
Here's a brief description of changes introduced on each version.
1.1.13
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Allow `sciexp2.common.utils.find_files` (and related) to search for directories (paths ending with "/").
* Fix `sciexp2.data.io.find_files` when using a job descriptor file.
.. rubric:: Documentation
* Fix documentation of `sciexp2.data.io.find_files`.
* Improve documentation of `sciexp2.data.io.extract_txt` and `sciexp2.data.io.extract_regex` regarding variable references and regular expressions.
.. rubric:: Internals
* Properly account progress indication in iterables.
* Fix `sciexp2.common.instance.InstanceGroup.dump` to only have the exported variables. Indirectly affects `sciexp2.data.io.find_files` when used with a job descriptor file.
* Improve Python 3 compatibility.
1.1.12
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Speedup construction of `sciexp2.data.Dim` objects by two orders of magnitude.
* Forward SIGINT and SIGTERM to user-specified commands in job scripts.
* Forward SIGINT to executing jobs with the shell backend (closes :issue:`293`).
* Forward SIGINT to executing commands with `sciexp2.launchgen.Launchgen.execute` (closes :issue:`293`).
.. rubric:: Bug fixes
.. rubric:: Documentation
.. rubric:: Internals
* Properly document `sciexp2.common.utils.OrderedSet.view` and `sciexp2.common.instance.InstanceGroup.view`.
* Add methods `sciexp2.common.utils.OrderedSet.set_view_able` and `sciexp2.common.instance.InstanceGroup.set_view_able`.
* Improve Python 3 compatibility.
1.1.11
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix progress message logging.
* Fix length calculation of progress operations.
* Export relevant variables to user-provided job commands.
.. rubric:: Documentation
.. rubric:: Internals
1.1.10
------
.. rubric:: External compatibility breaks
* Remove ``default_launchgen`` and its methods from module `sciexp2.launchgen.env` (you should explicitly instantiate `sciexp2.launchgen.Launcher` instead).
.. rubric:: New features
.. rubric:: Improvements
* Use package ``tqdm`` to show fancier progress indicators.
* Detect when we're running in a IPython/Jupyter notebook and use proper progress widgets when available.
* Make sure the output of the user's commands in launchgen's default templates is properly seen during interactive execution.
* Add method `sciexp2.data.Data.sort` (closes :issue:`307`).
.. rubric:: Bug fixes
* Fix construction of `~sciexp2.launchgen.Launcher` objects from other objects of the same type.
* Fix handling of argument ``append`` in `sciexp2.launchgen.Launcher.params` when applied to an empty object.
* Support `sciexp2.data.Data` dimensions with missing elements and elements with missing variable values.
.. rubric:: Documentation
* Extend and clarify quickstart, installation and basic concepts.
* Extend and clarify the user guide for `~sciexp2.launchgen`.
* Extend and clarify the installation and execution guide.
.. rubric:: Internals
* Remove unused progress indicator `sciexp2.common.progress.LVL_MARK`.
1.1.9
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix bug in compatibility code handling argument inspection of functions.
* Fix compatibility code to detect unused arguments in older numpy versions.
.. rubric:: Documentation
.. rubric:: Internals
1.1.8
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Do not crash progress reports when running on an IPython notebook.
.. rubric:: Bug fixes
* Fix expression and instance construction in `sciexp2.data.Data.flatten`.
* Fix indexing when using a filter on the last indexed dimension.
* Fix advanced indexing with boolean arrays.
.. rubric:: Documentation
.. rubric:: Internals
1.1.7
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix dimension indexing in `sciexp2.data.DataDims`.
.. rubric:: Documentation
* Improve introduction.
.. rubric:: Internals
1.1.6
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix parsing of the ``keepdims`` argument in `sciexp2.data.wrap_reduce` for newer numpy versions (which affects all reduction operations).
* Fix setuptools dependency on Python (again).
.. rubric:: Documentation
.. rubric:: Internals
1.1.5
-----
.. rubric:: External compatibility breaks
* Changed semantics of callables in `sciexp2.data.meta.Dim.sort` to be compatible with `sort` in Python 3.
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Properly fail ``launcher`` when an experiment errors-out and we're in ``DEBUG`` log level.
* Fix dependency timestamp computation in `sciexp2.data.io.lazy` and friends with Python 3.
.. rubric:: Documentation
.. rubric:: Internals
* Remove ``cmp`` argument on calls to `sort` to be compatible with Python 3.
* Improve compatibility with Python 3.
* Always show a stable element order when pretty-printing instances.
1.1.4
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix setuptools dependency on Python.
.. rubric:: Documentation
.. rubric:: Internals
1.1.3
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
* Add method `sciexp2.data.DataIndexer.as_tuple`.
.. rubric:: Improvements
* Improve output file initialization in the shell template.
* Ignore empty variable values in argument ``DEPENDS`` of `sciexp2.launchgen.Launchgen.launcher` (closes :issue:`298`).
* Do not warn when `sciexp2.data.io.lazy` receives only non-lazy arguments.
.. rubric:: Bug fixes
* Fix boolean negation operator in `~sciexp2.common.filter.Filter`.
* Fix `~sciexp2.data.Data.ravel`.
.. rubric:: Documentation
.. rubric:: Internals
1.1.2
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Allow setting `~sciexp2.data.meta.Dim` ticks to ``None``.
* Remove most limitations of assignments to `sciexp2.data.meta.Dim.expression` and `sciexp2.data.meta.Dim` contents.
* Generalize the following functions to work with any type of arrays: `sciexp2.data.append`, `sciexp2.data.concatenate`, `sciexp2.data.copy`, `sciexp2.data.delete`, `sciexp2.data.drop_fields`, `sciexp2.data.imag`, `numpy.lib.recfunctions.merge_arrays`, `sciexp2.data.ravel`, `sciexp2.data.real`, `numpy.lib.recfunctions.rename_fields`.
* Improve output file initialization in the shell template.
* Ignore empty variable values in argument ``DEPENDS`` of `sciexp2.launchgen.Launchgen.launcher` (closes :issue:`298`).
.. rubric:: Bug fixes
* Properly escape `sciexp2.data.meta.Dim.expression` values to avoid confusing the user's string with parts of a regular expression.
* Fix boolean negation operator in `~sciexp2.common.filter.Filter`.
* Fix `~sciexp2.data.Data.ravel`.
.. rubric:: Documentation
.. rubric:: Internals
* Fix hard resets on `sciexp2.common.instance.InstanceGroup.cache_reset`.
* Fix `sciexp2.data.DataDims` copies.
* Implement consistent named axis selection (``axis`` argument in numpy function) when using multiple array arguments.
* Follow `numpy`'s exception format when using a non-existing field name.
1.1.1
-----
.. rubric:: External compatibility breaks
* Remove argument ``filters`` in `sciexp2.launchgen.Launchgen.expand` in favour of `sciexp2.launchgen.Launchgen.select` (closes :issue:`300`).
* Deprecate argument ``export`` in `sciexp2.launchgen.Launchgen.launcher` in favour of new value ``EXPORTS`` in argument ``values`` (closes :issue:`301`).
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix filter optimization (breaks construction from multiple filters).
* Allow comparing variables in `~sciexp2.common.filter.PFilter` with strings (fixes :issue:`302`, as a refinement of :issue:`278`).
* Do not complain when about empty views when using `sciexp2.launchgen.Launchgen` methods (fixes :issue:`296`).
.. rubric:: Documentation
* Clarify use cases of ``files`` sub-command in :program:`launcher`.
* Clarify how variables are substituted in `sciexp2.launchgen.Launchgen.params`.
.. rubric:: Internals
* Fix representation of strings in `~sciexp2.common.filter.Filter` objects (was breaking escape sequences, used in regular expressions).
1.1
---
.. rubric:: External compatibility breaks
* Remove `sciexp2.data.Data.dim_sort` and ``dim_sort`` argument in `sciexp2.data.Data.reshape` in favour of `sciexp2.data.meta.Dim.sort`.
* Remove unused "filter override" operator.
* Deprecate "add" operation in `~sciexp2.common.filter.Filter` in favour of "and".
* Forbid `~sciexp2.data.Data` indexing with intermediate results from `~sciexp2.data.DataIndexer`.
.. rubric:: New features
* Allow sorting `sciexp2.data.Data` arrays using `sciexp2.data.meta.Dim.sort` (closes :issue:`279`).
* Add filter syntax to check variable existence (``exists(VAR)``; closes :issue:`262`).
* Add ``--inverse`` argument in :program:`launcher` to easily invert the job state selection (closes :issue:`287`).
* Add `sciexp2.data.meta.Dim.values` and `sciexp2.data.meta.Dim.unique_values` to easily retrieve per-variable values (closes :issue:`290`).
* Add `sciexp2.launchgen.Launchgen.translate` and `sciexp2.launchgen.Launchgen.expand` to translate and expand expressions from instances (closes :issue:`276`).
* Add `sciexp2.data.Data.idata` attribute to allow immediate dimension-oblivious indexing (shortcut to `sciexp2.data.Data.indexer`; closes :issue:`282`).
.. rubric:: Improvements
* Auto-optimize filter matching.
* Using `sciexp2.launchgen.LaunchgenView.select_inverse` works properly on nested views (only inverts the last selection).
* Allow `sciexp2.launchgen.Launchgen.pack` to dereference symbolic links (closes :issue:`280`).
* Allow `sciexp2.data.Data.indexer` to accept `~sciexp2.common.filter.PFilter` instances (closes :issue:`284`).
* Allow arbitrary values to be returned by functions used through `sciexp2.data.io.lazy` and similar (closes :issue:`285`).
* Simplify use of variables in the ``files`` sub-command of :program:`launcher` (closes :issue:`281`).
* Allow selecting multiple dimensions in `sciexp2.data.DataDims` and `sciexp2.data.DataIndexer`.
.. rubric:: Bug fixes
* Fix bug in string representation for `sciexp2.common.filter.Filter`.
* Fix indexing in `~sciexp2.data.meta.Dim` when using filters as a start and/or stop slice.
* Fix management of ``DONE`` and ``FAIL`` files in the shell template.
* Fix merging of `~sciexp2.common.filter.PFilter` with strings (closes :issue:`278`).
* Fix result of "or" operation in `~sciexp2.common.filter.Filter`.
* Fix array element-wise comparison (metadata is ignored for now).
* Make indexing logic more robust (closes :issue:`283`).
.. rubric:: Documentation
.. rubric:: Internals
* Add method `sciexp2.common.utils.OrderedSet.copy`.
* Add methods `sciexp2.common.utils.OrderedSet.sorted` and `sciexp2.common.utils.OrderedSet.sort`.
* Add method `sciexp2.common.instance.InstanceGroup.sorted`.
* Implement `sciexp2.common.instance.InstanceGroup.sort` as in-place sorting.
* Auto-optimize simple boolean filter expressions.
* Drop argument ``allowed`` in `~sciexp2.common.filter.Filter` (use `~sciexp2.common.filter.Filter.validate` instead).
* Drop method `sciexp2.common.filter.Filter.constant`.
* Provide exception check callback for missing variable references in `~sciexp2.common.instance.InstanceGroup.select` and `~sciexp2.common.instance.InstanceGroup.expand`.
* Drop argument ``allow_unknown`` from `sciexp2.common.filter.Filter.match`; handle from clients instead.
* Never return an `~numpy.ndarray` in `~sciexp2.data.meta.Data._get_indexes` (work around NumPy bug `#6564 <https://github.com/numpy/numpy/issues/6564>`_).
* Allow variables in `~sciexp2.common.utils.find_files` to span more than one directory (closes :issue:`288`).
1.0.2
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Show progress message when building new dimensions in `sciexp2.data.Data.reshape`.
* Improve performance of `sciexp2.data.Data.reshape`.
.. rubric:: Bug fixes
* Fix spurious ignored `AttributeError` exceptions when using `~sciexp2.common.progress`.
.. rubric:: Documentation
.. rubric:: Internals
1.0.1
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Return ``None`` in `sciexp2.data.meta.Dim.index` when dimension is not associated.
.. rubric:: Bug fixes
* Fix `sciexp2.data.meta.Dim` association when indexing.
.. rubric:: Documentation
.. rubric:: Internals
1.0
---
.. rubric:: External compatibility breaks
* Move dimension-related classes to `sciexp2.data.meta` (with shortened names).
* `sciexp2.data.meta.Dim` constructor no longer performs copies, use `sciexp2.data.meta.Dim.copy` instead.
* Remove argument `copy_dims` from `~sciexp2.data.Data`.
* Remove methods `sciexp2.data.Data.dim` and `sciexp2.data.Data.dim_index` in favour of `sciexp2.data.Data.dims` and `sciexp2.data.meta.Dim.index`, respectively.
* Remove method `sciexp2.data.Data.iteritems`.
* Remove attribute `sciexp2.data.meta.Dim.contents`.
* Remove deprecated (since 0.18) argument `promote` in in data extraction routines (`sciexp2.data.io`).
.. rubric:: New features
* Add `sciexp2.data.meta.Dim.instances` attribute to access the instances of a dimension.
* Add `sciexp2.data.meta.Dim.translate` and `sciexp2.data.meta.Dim.extract`.
* Add `sciexp2.data.DataDims` to query and manipulate collections of dimension metadata objects.
* Allow `~sciexp2.data.meta.Dim` objects with missing ticks or empty expression (closes :issue:`243`).
* Allow `~sciexp2.data.Data` objects with empty dimension metadata (closes :issue:`242`).
* All views of a `~sciexp2.data.Data` object have consistent metadata.
* Allow element and ``expression`` assignments to `~sciexp2.data.meta.Dim` objects (closes :issue:`236`).
* Unhandled `~numpy.ndarray` methods now return a `~sciexp2.data.Data` object without metadata.
* Add `~sciexp2.data.Data.indexer` to facilitate alignment of indexes to dimensions.
.. rubric:: Improvements
* Export `~sciexp2.data.io.lazy_wrap`, `~sciexp2.data.io.lazy_wrap_realize` and `~sciexp2.data.io.lazy_wrap_checkpoint` through `sciexp2.data.env`.
* Return a `~sciexp2.data.Data` when using `~numpy.newaxis` or advanced indexing.
* Allow ``axis`` `numpy.ufunc` argument with multiple values (closes :issue:`274`).
* Let ``keepdims`` `numpy.ufunc` argument return a `~sciexp2.data.Data` object (closes :issue:`275`).
* Return a `~sciexp2.data.Data` object with empty metadata when broadcasting to a `~numpy.ndarray` argument.
.. rubric:: Bug fixes
* Fixed indexing results on `sciexp2.data.meta.Dim.instances`.
.. rubric:: Documentation
* Add a quick example of all modules in the introduction.
* Document array and metadata indexing and manipulation in the user guide.
.. rubric:: Internals
* Move free functions for `~sciexp2.data.Data` objects into `sciexp2.data._funcs`.
* Rename `sciexp2.data.meta.ExpressionError` as `~sciexp2.data.meta.DimExpressionError`.
* Refactor dimension expression logic into `sciexp2.data.meta.DimExpression`.
* Add `~sciexp2.common.progress.progressable_simple` to wrap container iterations with a progress indicator.
* Sanitize `sciexp2.data.meta.Dim` construction.
* Remove the ``EXPRESSION`` internal variable from dimension metadata, making it smaller at the expense of more complex expression lookups (closes :issue:`231`).
* Remove the ``INDEX`` internal variable from dimension metadata, making it smaller at the expense of more costly index lookups.
* Allow constructing views of `sciexp2.data.meta.Dim` objects.
Older versions
--------------
:ref:`news-old`.
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/news.rst | news.rst | .. _news:
Changes in SciExp²
==================
Here's a brief description of changes introduced on each version.
1.1.13
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Allow `sciexp2.common.utils.find_files` (and related) to search for directories (paths ending with "/").
* Fix `sciexp2.data.io.find_files` when using a job descriptor file.
.. rubric:: Documentation
* Fix documentation of `sciexp2.data.io.find_files`.
* Improve documentation of `sciexp2.data.io.extract_txt` and `sciexp2.data.io.extract_regex` regarding variable references and regular expressions.
.. rubric:: Internals
* Properly account progress indication in iterables.
* Fix `sciexp2.common.instance.InstanceGroup.dump` to only have the exported variables. Indirectly affects `sciexp2.data.io.find_files` when used with a job descriptor file.
* Improve Python 3 compatibility.
1.1.12
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Speedup construction of `sciexp2.data.Dim` objects by two orders of magnitude.
* Forward SIGINT and SIGTERM to user-specified commands in job scripts.
* Forward SIGINT to executing jobs with the shell backend (closes :issue:`293`).
* Forward SIGINT to executing commands with `sciexp2.launchgen.Launchgen.execute` (closes :issue:`293`).
.. rubric:: Bug fixes
.. rubric:: Documentation
.. rubric:: Internals
* Properly document `sciexp2.common.utils.OrderedSet.view` and `sciexp2.common.instance.InstanceGroup.view`.
* Add methods `sciexp2.common.utils.OrderedSet.set_view_able` and `sciexp2.common.instance.InstanceGroup.set_view_able`.
* Improve Python 3 compatibility.
1.1.11
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix progress message logging.
* Fix length calculation of progress operations.
* Export relevant variables to user-provided job commands.
.. rubric:: Documentation
.. rubric:: Internals
1.1.10
------
.. rubric:: External compatibility breaks
* Remove ``default_launchgen`` and its methods from module `sciexp2.launchgen.env` (you should explicitly instantiate `sciexp2.launchgen.Launcher` instead).
.. rubric:: New features
.. rubric:: Improvements
* Use package ``tqdm`` to show fancier progress indicators.
* Detect when we're running in a IPython/Jupyter notebook and use proper progress widgets when available.
* Make sure the output of the user's commands in launchgen's default templates is properly seen during interactive execution.
* Add method `sciexp2.data.Data.sort` (closes :issue:`307`).
.. rubric:: Bug fixes
* Fix construction of `~sciexp2.launchgen.Launcher` objects from other objects of the same type.
* Fix handling of argument ``append`` in `sciexp2.launchgen.Launcher.params` when applied to an empty object.
* Support `sciexp2.data.Data` dimensions with missing elements and elements with missing variable values.
.. rubric:: Documentation
* Extend and clarify quickstart, installation and basic concepts.
* Extend and clarify the user guide for `~sciexp2.launchgen`.
* Extend and clarify the installation and execution guide.
.. rubric:: Internals
* Remove unused progress indicator `sciexp2.common.progress.LVL_MARK`.
1.1.9
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix bug in compatibility code handling argument inspection of functions.
* Fix compatibility code to detect unused arguments in older numpy versions.
.. rubric:: Documentation
.. rubric:: Internals
1.1.8
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Do not crash progress reports when running on an IPython notebook.
.. rubric:: Bug fixes
* Fix expression and instance construction in `sciexp2.data.Data.flatten`.
* Fix indexing when using a filter on the last indexed dimension.
* Fix advanced indexing with boolean arrays.
.. rubric:: Documentation
.. rubric:: Internals
1.1.7
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix dimension indexing in `sciexp2.data.DataDims`.
.. rubric:: Documentation
* Improve introduction.
.. rubric:: Internals
1.1.6
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix parsing of the ``keepdims`` argument in `sciexp2.data.wrap_reduce` for newer numpy versions (which affects all reduction operations).
* Fix setuptools dependency on Python (again).
.. rubric:: Documentation
.. rubric:: Internals
1.1.5
-----
.. rubric:: External compatibility breaks
* Changed semantics of callables in `sciexp2.data.meta.Dim.sort` to be compatible with `sort` in Python 3.
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Properly fail ``launcher`` when an experiment errors-out and we're in ``DEBUG`` log level.
* Fix dependency timestamp computation in `sciexp2.data.io.lazy` and friends with Python 3.
.. rubric:: Documentation
.. rubric:: Internals
* Remove ``cmp`` argument on calls to `sort` to be compatible with Python 3.
* Improve compatibility with Python 3.
* Always show a stable element order when pretty-printing instances.
1.1.4
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix setuptools dependency on Python.
.. rubric:: Documentation
.. rubric:: Internals
1.1.3
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
* Add method `sciexp2.data.DataIndexer.as_tuple`.
.. rubric:: Improvements
* Improve output file initialization in the shell template.
* Ignore empty variable values in argument ``DEPENDS`` of `sciexp2.launchgen.Launchgen.launcher` (closes :issue:`298`).
* Do not warn when `sciexp2.data.io.lazy` receives only non-lazy arguments.
.. rubric:: Bug fixes
* Fix boolean negation operator in `~sciexp2.common.filter.Filter`.
* Fix `~sciexp2.data.Data.ravel`.
.. rubric:: Documentation
.. rubric:: Internals
1.1.2
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Allow setting `~sciexp2.data.meta.Dim` ticks to ``None``.
* Remove most limitations of assignments to `sciexp2.data.meta.Dim.expression` and `sciexp2.data.meta.Dim` contents.
* Generalize the following functions to work with any type of arrays: `sciexp2.data.append`, `sciexp2.data.concatenate`, `sciexp2.data.copy`, `sciexp2.data.delete`, `sciexp2.data.drop_fields`, `sciexp2.data.imag`, `numpy.lib.recfunctions.merge_arrays`, `sciexp2.data.ravel`, `sciexp2.data.real`, `numpy.lib.recfunctions.rename_fields`.
* Improve output file initialization in the shell template.
* Ignore empty variable values in argument ``DEPENDS`` of `sciexp2.launchgen.Launchgen.launcher` (closes :issue:`298`).
.. rubric:: Bug fixes
* Properly escape `sciexp2.data.meta.Dim.expression` values to avoid confusing the user's string with parts of a regular expression.
* Fix boolean negation operator in `~sciexp2.common.filter.Filter`.
* Fix `~sciexp2.data.Data.ravel`.
.. rubric:: Documentation
.. rubric:: Internals
* Fix hard resets on `sciexp2.common.instance.InstanceGroup.cache_reset`.
* Fix `sciexp2.data.DataDims` copies.
* Implement consistent named axis selection (``axis`` argument in numpy function) when using multiple array arguments.
* Follow `numpy`'s exception format when using a non-existing field name.
1.1.1
-----
.. rubric:: External compatibility breaks
* Remove argument ``filters`` in `sciexp2.launchgen.Launchgen.expand` in favour of `sciexp2.launchgen.Launchgen.select` (closes :issue:`300`).
* Deprecate argument ``export`` in `sciexp2.launchgen.Launchgen.launcher` in favour of new value ``EXPORTS`` in argument ``values`` (closes :issue:`301`).
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix filter optimization (breaks construction from multiple filters).
* Allow comparing variables in `~sciexp2.common.filter.PFilter` with strings (fixes :issue:`302`, as a refinement of :issue:`278`).
* Do not complain when about empty views when using `sciexp2.launchgen.Launchgen` methods (fixes :issue:`296`).
.. rubric:: Documentation
* Clarify use cases of ``files`` sub-command in :program:`launcher`.
* Clarify how variables are substituted in `sciexp2.launchgen.Launchgen.params`.
.. rubric:: Internals
* Fix representation of strings in `~sciexp2.common.filter.Filter` objects (was breaking escape sequences, used in regular expressions).
1.1
---
.. rubric:: External compatibility breaks
* Remove `sciexp2.data.Data.dim_sort` and ``dim_sort`` argument in `sciexp2.data.Data.reshape` in favour of `sciexp2.data.meta.Dim.sort`.
* Remove unused "filter override" operator.
* Deprecate "add" operation in `~sciexp2.common.filter.Filter` in favour of "and".
* Forbid `~sciexp2.data.Data` indexing with intermediate results from `~sciexp2.data.DataIndexer`.
.. rubric:: New features
* Allow sorting `sciexp2.data.Data` arrays using `sciexp2.data.meta.Dim.sort` (closes :issue:`279`).
* Add filter syntax to check variable existence (``exists(VAR)``; closes :issue:`262`).
* Add ``--inverse`` argument in :program:`launcher` to easily invert the job state selection (closes :issue:`287`).
* Add `sciexp2.data.meta.Dim.values` and `sciexp2.data.meta.Dim.unique_values` to easily retrieve per-variable values (closes :issue:`290`).
* Add `sciexp2.launchgen.Launchgen.translate` and `sciexp2.launchgen.Launchgen.expand` to translate and expand expressions from instances (closes :issue:`276`).
* Add `sciexp2.data.Data.idata` attribute to allow immediate dimension-oblivious indexing (shortcut to `sciexp2.data.Data.indexer`; closes :issue:`282`).
.. rubric:: Improvements
* Auto-optimize filter matching.
* Using `sciexp2.launchgen.LaunchgenView.select_inverse` works properly on nested views (only inverts the last selection).
* Allow `sciexp2.launchgen.Launchgen.pack` to dereference symbolic links (closes :issue:`280`).
* Allow `sciexp2.data.Data.indexer` to accept `~sciexp2.common.filter.PFilter` instances (closes :issue:`284`).
* Allow arbitrary values to be returned by functions used through `sciexp2.data.io.lazy` and similar (closes :issue:`285`).
* Simplify use of variables in the ``files`` sub-command of :program:`launcher` (closes :issue:`281`).
* Allow selecting multiple dimensions in `sciexp2.data.DataDims` and `sciexp2.data.DataIndexer`.
.. rubric:: Bug fixes
* Fix bug in string representation for `sciexp2.common.filter.Filter`.
* Fix indexing in `~sciexp2.data.meta.Dim` when using filters as a start and/or stop slice.
* Fix management of ``DONE`` and ``FAIL`` files in the shell template.
* Fix merging of `~sciexp2.common.filter.PFilter` with strings (closes :issue:`278`).
* Fix result of "or" operation in `~sciexp2.common.filter.Filter`.
* Fix array element-wise comparison (metadata is ignored for now).
* Make indexing logic more robust (closes :issue:`283`).
.. rubric:: Documentation
.. rubric:: Internals
* Add method `sciexp2.common.utils.OrderedSet.copy`.
* Add methods `sciexp2.common.utils.OrderedSet.sorted` and `sciexp2.common.utils.OrderedSet.sort`.
* Add method `sciexp2.common.instance.InstanceGroup.sorted`.
* Implement `sciexp2.common.instance.InstanceGroup.sort` as in-place sorting.
* Auto-optimize simple boolean filter expressions.
* Drop argument ``allowed`` in `~sciexp2.common.filter.Filter` (use `~sciexp2.common.filter.Filter.validate` instead).
* Drop method `sciexp2.common.filter.Filter.constant`.
* Provide exception check callback for missing variable references in `~sciexp2.common.instance.InstanceGroup.select` and `~sciexp2.common.instance.InstanceGroup.expand`.
* Drop argument ``allow_unknown`` from `sciexp2.common.filter.Filter.match`; handle from clients instead.
* Never return an `~numpy.ndarray` in `~sciexp2.data.meta.Data._get_indexes` (work around NumPy bug `#6564 <https://github.com/numpy/numpy/issues/6564>`_).
* Allow variables in `~sciexp2.common.utils.find_files` to span more than one directory (closes :issue:`288`).
1.0.2
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Show progress message when building new dimensions in `sciexp2.data.Data.reshape`.
* Improve performance of `sciexp2.data.Data.reshape`.
.. rubric:: Bug fixes
* Fix spurious ignored `AttributeError` exceptions when using `~sciexp2.common.progress`.
.. rubric:: Documentation
.. rubric:: Internals
1.0.1
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Return ``None`` in `sciexp2.data.meta.Dim.index` when dimension is not associated.
.. rubric:: Bug fixes
* Fix `sciexp2.data.meta.Dim` association when indexing.
.. rubric:: Documentation
.. rubric:: Internals
1.0
---
.. rubric:: External compatibility breaks
* Move dimension-related classes to `sciexp2.data.meta` (with shortened names).
* `sciexp2.data.meta.Dim` constructor no longer performs copies, use `sciexp2.data.meta.Dim.copy` instead.
* Remove argument `copy_dims` from `~sciexp2.data.Data`.
* Remove methods `sciexp2.data.Data.dim` and `sciexp2.data.Data.dim_index` in favour of `sciexp2.data.Data.dims` and `sciexp2.data.meta.Dim.index`, respectively.
* Remove method `sciexp2.data.Data.iteritems`.
* Remove attribute `sciexp2.data.meta.Dim.contents`.
* Remove deprecated (since 0.18) argument `promote` in in data extraction routines (`sciexp2.data.io`).
.. rubric:: New features
* Add `sciexp2.data.meta.Dim.instances` attribute to access the instances of a dimension.
* Add `sciexp2.data.meta.Dim.translate` and `sciexp2.data.meta.Dim.extract`.
* Add `sciexp2.data.DataDims` to query and manipulate collections of dimension metadata objects.
* Allow `~sciexp2.data.meta.Dim` objects with missing ticks or empty expression (closes :issue:`243`).
* Allow `~sciexp2.data.Data` objects with empty dimension metadata (closes :issue:`242`).
* All views of a `~sciexp2.data.Data` object have consistent metadata.
* Allow element and ``expression`` assignments to `~sciexp2.data.meta.Dim` objects (closes :issue:`236`).
* Unhandled `~numpy.ndarray` methods now return a `~sciexp2.data.Data` object without metadata.
* Add `~sciexp2.data.Data.indexer` to facilitate alignment of indexes to dimensions.
.. rubric:: Improvements
* Export `~sciexp2.data.io.lazy_wrap`, `~sciexp2.data.io.lazy_wrap_realize` and `~sciexp2.data.io.lazy_wrap_checkpoint` through `sciexp2.data.env`.
* Return a `~sciexp2.data.Data` when using `~numpy.newaxis` or advanced indexing.
* Allow ``axis`` `numpy.ufunc` argument with multiple values (closes :issue:`274`).
* Let ``keepdims`` `numpy.ufunc` argument return a `~sciexp2.data.Data` object (closes :issue:`275`).
* Return a `~sciexp2.data.Data` object with empty metadata when broadcasting to a `~numpy.ndarray` argument.
.. rubric:: Bug fixes
* Fixed indexing results on `sciexp2.data.meta.Dim.instances`.
.. rubric:: Documentation
* Add a quick example of all modules in the introduction.
* Document array and metadata indexing and manipulation in the user guide.
.. rubric:: Internals
* Move free functions for `~sciexp2.data.Data` objects into `sciexp2.data._funcs`.
* Rename `sciexp2.data.meta.ExpressionError` as `~sciexp2.data.meta.DimExpressionError`.
* Refactor dimension expression logic into `sciexp2.data.meta.DimExpression`.
* Add `~sciexp2.common.progress.progressable_simple` to wrap container iterations with a progress indicator.
* Sanitize `sciexp2.data.meta.Dim` construction.
* Remove the ``EXPRESSION`` internal variable from dimension metadata, making it smaller at the expense of more complex expression lookups (closes :issue:`231`).
* Remove the ``INDEX`` internal variable from dimension metadata, making it smaller at the expense of more costly index lookups.
* Allow constructing views of `sciexp2.data.meta.Dim` objects.
Older versions
--------------
:ref:`news-old`.
| 0.921827 | 0.389779 |
Reference Guide
===============
.. currentmodule:: sciexp2
.. note::
Input files for the examples shown in the documentation are available on the root directory of the source distribution.
.. autosummary::
:toctree: _reference
common.filter
common.instance
common.parallel
common.pp
common.progress
common.utils
common.varref
data
data.env
data.io
data.meta
launcher
launchgen
launchgen.env
system
system.gridengine
system.shell
templates
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/reference.rst | reference.rst | Reference Guide
===============
.. currentmodule:: sciexp2
.. note::
Input files for the examples shown in the documentation are available on the root directory of the source distribution.
.. autosummary::
:toctree: _reference
common.filter
common.instance
common.parallel
common.pp
common.progress
common.utils
common.varref
data
data.env
data.io
data.meta
launcher
launchgen
launchgen.env
system
system.gridengine
system.shell
templates
| 0.648021 | 0.193223 |
.. _news-old:
Older SciExp² versions
======================
0.18.2
------
.. rubric:: External compatibility breaks
.. rubric:: New features
* Lazy result realization also works without a file path (see `~sciexp2.data.io.lazy`).
* Add `~sciexp2.data.io.lazy_wrap`, `~sciexp2.data.io.lazy_wrap_realize` and `~sciexp2.data.io.lazy_wrap_checkpoint` to streamline use of lazily evaluated functions.
* Allow per-variable conversion rules in `~sciexp2.data.io.extract_regex` (closes :issue:`270`).
.. rubric:: Improvements
* Use default value if converter fails in `~sciexp2.data.io.extract_regex`.
* Show an error message (instead of throwing an exception) if job submission fails.
* Add argument ``--keep-going`` to :program:`launcher` to keep submitting jobs even if others fail.
* Provide a crude string representation of lazy results (`~sciexp2.data.io.lazy`).
.. rubric:: Bug fixes
* Make `~sciexp2.data.wrap_reduce` more resilient (closes :issue:`269`).
* Apply converters in `~sciexp2.data.io.extract_txt` for string fields.
* Fix missing value handling in first line for `~sciexp2.data.io.extract_regex`.
* Apply user conversions on missing values for `~sciexp2.data.io.extract_regex` (closes :issue:`268`).
* Fix dtype detection when using ``vars_to_fields`` (data extraction and reshaping).
* Remove output file if there is an error during lazy result realization.
.. rubric:: Documentation
* Document converters and default values in `~sciexp2.data.io.extract_txt`.
.. rubric:: Internals
0.18.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
.. rubric:: Documentation
.. rubric:: Internals
* Switch to Git repository.
0.18
----
.. rubric:: External compatibility breaks
* New argument `fields_to_vars` in data extraction routines (`sciexp2.data.io`; deprecates argument `promote`).
* Rename argument `columns` into `fields` in `~sciexp2.data.io.extract_txt`.
* Rename argument `rows` into `fields` in `~sciexp2.data.io.extract_regex`.
.. rubric:: New features
* Add generic data extraction routine `~sciexp2.data.io.extract_func` (closes :issue:`233`).
* Add support for gzip-compressed source files in data extraction routines for `~sciexp2.data.io` (closes :issue:`232`).
* Add function `~sciexp2.data.data_frombuffer` (closes :issue:`194`).
* Add function `~sciexp2.data.data_memmap`.
* Add argument `fields_to_vars` in `~sciexp2.data.Data.reshape`.
* Add argument `vars_to_fields` in data extraction routines (`sciexp2.data.io`) and `~sciexp2.data.Data.reshape` (closes :issue:`241`).
.. rubric:: Improvements
* Add support for "multi-comparisons" in filters (e.g., ``1 < a < 3``).
* Allow pattern binding operations with any type of arguments in filters.
* Add support for lists in filters (e.g., ``[1, 2, b]``).
* Add support for list membership checks in filters (e.g., ``a in [1, 3, 5]``).
.. rubric:: Bug fixes
* Fix handling of unary minus operator in filters.
* Fix handling of override operator in filters.
.. rubric:: Documentation
* Improve documentation of routines in `sciexp2.data.io`.
* Initial user guide for the `sciexp2.data` package.
.. rubric:: Internals
* Reimplement `~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex` on top of `~sciexp2.data.io.extract_func`.
0.17.1
------
.. rubric:: External compatibility breaks
* Rename `sciexp2.data.Data.sort` as `~sciexp2.data.Data.dim_sort`, since `numpy.sort` already exists (closes :issue:`244`).
* Rename argument `order` in `~sciexp2.data.Data.reshape` as `dim_sort` to keep naming consistent.
.. rubric:: New features
.. rubric:: Improvements
* Lazy evaluation with `sciexp2.data.io.lazy` detects changes to the source code of functions passed as arguments, triggering a re-computation.
.. rubric:: Bug fixes
* Fix command line argument parsing of :program:`launcher` when using a job descriptor file as a binary.
* Fix reductions (`~sciexp2.data.wrap_reduce`) when the result has no dimensions (e.g., a single number).
* Fix indexing of `~sciexp2.data.Data` objects when using the old numeric-compatible basic slicing [#numeric-slicing]_.
.. rubric:: Documentation
.. rubric:: Internals
.. [#numeric-slicing] http://docs.scipy.org/doc/numpy/reference/arrays.indexing.html#basic-slicing
0.17
----
.. rubric:: External compatibility breaks
* Slicing a `~sciexp2.data.Dimension` always returns a new one (or `None`).
.. rubric:: New features
* Added dimension slicing helpers `~sciexp2.data.Dimension.indexes` and `~sciexp2.data.Dimension.ticks`.
* Functions that have an `axis` argument can now identify a dimension by giving the name of one of its variables (closes :issue:`200`).
.. rubric:: Improvements
* Raise exception `~sciexp2.data.io.ConverterError` when the user-provided conversion functions in `~sciexp2.data.io.extract_regex` fail.
* Slicing in `~sciexp2.data.Data` accepts anything that can be converted into a filter (e.g., `dict`; closes :issue:`235`).
* Slicing in `~sciexp2.data.Data` also accepts anything that can be converted into a filter (e.g., `dict`) as long as it selects one element (closes :issue:`230`).
* Fixed dimension metadata when performing binary operations with `~sciexp2.data.Data` objects (closes :issue:`54`).
.. rubric:: Bug fixes
* Raise `~sciexp2.data.io.EmptyFileError` when probing a file without matches during `~sciexp2.data.io.extract_regex`.
* Do not fail when using `~sciexp2.data.io.extract_txt` on files with one single column and row (closes :issue:`238`).
* Properly handle `~numpy.genfromtxt`-specific arguments in `~sciexp2.data.io.extract_txt` (closes :issue:`239`).
.. rubric:: Documentation
.. rubric:: Internals
* Can pretty-print `~sciexp2.data.Dimension` instances.
* Provide copy constructor of `~sciexp2.data.Dimension` instances.
* Provide public `~sciexp2.data.wrap_reduce` and `~sciexp2.data.wrap_accumulate` methods to wrap existing numpy functions.
0.16
----
.. rubric:: External compatibility breaks
* Command :program:`launcher` now has a saner command and option syntax.
* New syntax for template descriptor files.
* Remove commands `monitor` and `reset` from :program:`launcher`.
* Removed variable `sciexp2.common.progress.SHOW` in favour of routine `~sciexp2.common.progress.level`.
* Changed the syntax of `~sciexp2.launchgen.Launchgen.execute` (it's compatible with the common single-string argument).
.. rubric:: New features
* Add commands `summary`, `variables` and `files` to :program:`launcher`.
* Template descriptors can refer to some of the variables defined by their parent.
* Template descriptors, `~sciexp2.launchgen.Launchgen.launcher` and :program:`launcher` can define additional job submission arguments.
* Program :program:`launcher` can define additional job killing arguments.
* Add simple begin/end progress indicator (`sciexp2.common.progress.LVL_MARK`).
* Add `~sciexp2.launchgen.file_contents` to simplify inserting the contents of a file as the value of a variable.
* Add support for parallel command execution in `~sciexp2.launchgen.Launchgen.execute` (closes :issue:`170`).
.. rubric:: Improvements
* Can now run launcher scripts even if the execution system is not installed (assumes no job is currently running).
* Improved error resilience in template scripts.
* All file-generation routines in `~sciexp2.launchgen` will retain the permission bits of their source file.
* Be clever about interactive terminals when showing progress indicators.
* User can set the desired progress reporting level when using :program:`launcher`.
* Program :program:`launcher` now explicitly shows outdated jobs.
.. rubric:: Bug fixes
* Fix error when using `~sciexp2.common.instance.InstanceGroup.select` with a dict-based filter that contains a non-existing value.
* Fix path computation of ``STDOUT`` and ``STDERR`` files in the gridengine template.
* Properly handle operations through a `~sciexp2.launchgen.LaunchgenView`.
* Allow creating a `~sciexp2.launchgen.Launchgen` from a `~sciexp2.launchgen.LaunchgenView` (closes :issue:`228`).
* Fix creation of a `~sciexp2.launchgen.Launchgen` from a `~sciexp2.launchgen.Launchgen` or `~sciexp2.launchgen.LaunchgenView`.
.. rubric:: Documentation
* Point out availability of examples' input files on the source distribution.
.. rubric:: Internals
* Job submission no longer removes results; instead, job scripts do it themselves.
* Do not treat template variables ``DONE`` and ``FAIL`` as glob patterns.
* New module `~sciexp2.common.parallel` providing simple parallelization primitives.
0.15.4
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix data loss bug in `~sciexp2.common.utils.OrderedSet`.
.. rubric:: Documentation
.. rubric:: Internals
0.15.3
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix error during executable file generation in `~sciexp2.launchgen`.
* Fix test number detection in `~sciexp2.launchgen.Launchgen.find_SPEC`.
.. rubric:: Documentation
.. rubric:: Internals
0.15.2
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Add missing package declaration.
.. rubric:: Documentation
.. rubric:: Internals
0.15.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
* Add `sciexp2.data.Data.imag`, `sciexp2.data.imag`, `sciexp2.data.Data.real` and `sciexp2.data.real`.
.. rubric:: Improvements
* Allow building new `~sciexp2.data.Data` instances by copying metadata from others.
* Any unimplemented method in `~sciexp2.data.Data` falls back to a `numpy.ndarray` and (by default) issues a warning (see `~sciexp2.data.WARN_UPCAST`).
* Add `sciexp2.data.Data.copy` and `sciexp2.data.copy`.
* Add `sciexp2.data.Data.ravel`.
.. rubric:: Bug fixes
.. rubric:: Documentation
.. rubric:: Internals
* Provide `sciexp2.data.Dimension.copy`.
0.15
----
.. rubric:: External compatibility breaks
* Remove `sciexp2.data.io.maybe` and `sciexp2.data.io.maybe_other` in favour of `~sciexp2.data.io.lazy`.
* Removed *sort* in `~sciexp2.data.Data.reshape` in favour of *order* using the same semantics as `~sciexp2.data.Data.sort`.
.. rubric:: New features
* Simpler lazy data extraction and management infrastructure with `~sciexp2.data.io.lazy`.
* Allow sorting data dimensions with `~sciexp2.data.Data.sort` (closes :issue:`198`).
* Added `~sciexp2.data.concatenate` (closes :issue:`193`).
* Added `~sciexp2.data.append` (closes :issue:`50`).
* Added `~sciexp2.data.Data.append_fields` (closes :issue:`215`).
* Added `~sciexp2.data.append_fields`, `~sciexp2.data.drop_fields`, `~sciexp2.data.rename_fields` and `~sciexp2.data.merge_arrays` (closes :issue:`215`).
* Added `~sciexp2.data.Data.transpose` (closes :issue:`204`).
* Added `~sciexp2.data.Data.flatten` and `~sciexp2.data.ravel`.
* Added `~sciexp2.data.delete`.
* Added support for multi-line regular expressions in `~sciexp2.data.io.extract_regex` (closes :issue:`206`).
.. rubric:: Improvements
* Detect argument changes in results produced by `~sciexp2.data.io.lazy` to force re-execution.
* Allow lists of filters as arguments to `~sciexp2.data.io.find_files`, and to all the extraction routines by extension (closes :issue:`209`).
* Allow data extraction routines to take a single input file (closes :issue:`210`).
* Properly handle immediate `promote` string in `~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex`.
* Support both `promote` and `count` in `~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex` (closes :issue:`203`).
* Allow passing some arguments in `~sciexp2.data.io.extract_txt` down to `~numpy.genfromtxt` (closes :issue:`211`).
.. rubric:: Bug fixes
* Make scripts generated by `~sciexp2.launchgen.Launchgen.launcher` executable.
* Ensure `~sciexp2.data.data_array` uses the appropriate dtype.
* Fix handling of `Ellipsis` in `~sciexp2.data` (closes :issue:`213`).
* Fix handling of `~sciexp2.data` indexing with multiple filters (closes :issue:`208`).
* Fix data extraction when all fields have the same type (closes :issue:`205` and :issue:`225`).
* Fix descriptor parsing in `~sciexp2.data.io.extract_txt` (closes :issue:`212` and :issue:`223`).
.. rubric:: Documentation
.. rubric:: Internals
0.14.2
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fixed internal error in `~sciexp2.launchgen.Launchgen.execute`.
.. rubric:: Documentation
.. rubric:: Internals
0.14.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fixed internal error in `~sciexp2.launchgen.Launchgen.find_files`.
.. rubric:: Documentation
.. rubric:: Internals
0.14
----
.. rubric:: External compatibility breaks
* Removed prefixed underscore from user-visible variables *LAUNCHER*, *DONE* and *FAIL* generated by `~sciexp2.launchgen.Launchgen` (closes :issue:`216`).
* Removed *done_expr* and *fail_expr* arguments to `~sciexp2.launchgen.Launchgen.launcher` in favour of variables *DONE* and *FAIL*, which have a default value (closes :issue:`217`).
* By default, `~sciexp2.launchgen.Launchgen.launcher` generates the job descriptor in file ``jobs.jd`` (controlled through variable *JD*).
* If specified, argument *export* in `~sciexp2.launchgen.Launchgen.launcher` overrides the variables that are exported by default.
.. rubric:: New features
* Method `~sciexp2.launchgen.Launchgen.execute` can now specify *stdin*, *stdout* and *stderr* (closes :issue:`168`).
* Program :program:`launcher` accepts the values (or the relative path to them, when interpreted as files) of certain variables (e.g., *DONE*) as a short-hand to filters (closes :issue:`182`).
* Method `~sciexp2.launchgen.Launchgen.launcher` accepts a list of variables that `~sciexp2.launchgen.launcher` will use to establish whether a job needs reexecution (closes :issue:`175`).
* Method `~sciexp2.launchgen.Launchgen.params` can also append new contents instead of recombining them with the existing ones (closes :issue:`202`).
* Function `~sciexp2.data.io.find_files` accepts job descriptor files as arguments.
.. rubric:: Improvements
* The user can now easily set when the *gridengine* template should send a mail notification (closes :issue:`126`).
* Properly handle *stdout* and *stderr* redirection in the *gridengine* and *shell* templates (closes :issue:`180`).
* Default templates can have separate values for files holding stdout/stderr (variables *STDOUT* and *STDERR*) and the *DONE* and *FAIL* files.
* Generating or copying files with `~sciexp2.launchgen.Launchgen` will only update these when new contents are available (closes :issue:`174`).
.. rubric:: Bug fixes
* Mark jobs as failed whenever the *_FAIL* file exists (closes :issue:`163`).
* Fix handling of job descriptor files in directories other than the output base.
* Fixed *gridengine* template to establish the base directory (closes :issue:`176`).
.. rubric:: Documentation
.. rubric:: Internals
* Method `~sciexp2.launchgen.Launchgen.launcher` only exports the appropriate variables.
* Method `~sciexp2.launchgen.Launchgen.launcher` makes job launcher scripts executable.
* Added `~sciexp2.common.utils.get_path` to handle path expansions (used in `~sciexp2.launchgen.Launchgen`).
* New implementation of the pretty-printing module `~sciexp2.common.pp` (adds IPython as a dependency).
* Store some metadata in job descriptor files to ensure their formatting.
0.13
----
.. rubric:: External compatibility breaks
* Variable `sciexp2.launchgen.Launchgen.DEFAULT_OUT` has been renamed to `~sciexp2.launchgen.Launchgen.OUTPUT_DIR`.
.. rubric:: New features
* Implemented the *modulus* operation in filters.
* Added *programmatic filters* to streamline the filter writing (see `~sciexp2.common.filter.PFilter`; relates to :issue:`185`).
* Instances of `~sciexp2.launchgen.Launchgen` can be constructed with initial contents (including copies of other instances).
* Method `~sciexp2.launchgen.Launchgen.generate` now accepts filters.
* Added method `~sciexp2.launchgen.Launchgen.select` to return an object that operates on a subset of the contents (closes :issue:`184` and :issue:`186`).
.. rubric:: Improvements
.. rubric:: Bug fixes
* All methods in `~sciexp2.launchgen.Launchgen` performing parameter recombination accept any iterable structure (closes :issue:`164`).
.. rubric:: Documentation
* Rewrote the user guide for launchgen, which is now more concise and tangible, as well as describes the latest features.
.. rubric:: Internals
* Have `~sciexp2.common.filter.Filter` accept a list of arguments.
* Have `~sciexp2.common.filter.Filter.match` silently fail when it contains a variable not present in the source if argument ``allow_unknown`` is set to ``True``.
0.12
----
.. rubric:: External compatibility breaks
* `~sciexp2.data.Dimension` no longer handles named groups if the `expression` argument is a regular expression, as version 0.11.2 removed the feature from the `~sciexp2.data.io` module.
* Removed function `sciexp2.data.build_dimension` and method `sciexp2.data.Dimension.build_instance` in favour of a saner `~sciexp2.data.Dimension` constructor and methods `~sciexp2.data.Dimension.add` and `~sciexp2.data.Dimension.extend`.
.. rubric:: New features
* Progress indicators now try to avoid updating the screen too often. Speed can be controlled through `sciexp2.common.progress.SPEED`.
* Whether to show progress indicators on the screen can be globally controlled through `sciexp2.common.progress.SHOW`.
* Add support for `sciexp2.data.Data.reshape` to sort axes according to their variables.
.. rubric:: Improvements
* Improvement of orders of magnitude on the speed of creation of new `~sciexp2.data.Data` objects (thanks to optimized `~sciexp2.data.Dimension` construction).
* Improvement of orders of magnitude on the speed of `~sciexp2.data.Data.reshape` (thanks to optimized `~sciexp2.data.Dimension` construction and improved algorithm).
* Better progress indication in `~sciexp2.data.Data.reshape` and `~sciexp2.data.Data` slicing.
.. rubric:: Bug fixes
* Fix sorting of results for file-finding routines.
.. rubric:: Documentation
* Reference documentation no longer shows class hierarchies.
.. rubric:: Internals
* Refactored progress indicators into the `~sciexp2.common.progress` module.
* Use context manager protocol with `~sciexp2.common.progress.Counter` and `~sciexp2.common.progress.Spinner`.
* Progress indicator type (counter or spinner) can be automatically selected through `sciexp2.common.progress.get` and `sciexp2.common.progress.get_pickle`.
* Split `~sciexp2.common.instance.InstanceGroup` caching into `~sciexp2.common.instance.InstanceGroup.cache_get` and `~sciexp2.common.instance.InstanceGroup.cache_set`.
* Added proactive and zero-caching instance additions in `~sciexp2.common.instance.InstanceGroup`.
* Small performance improvements on various operations of the `~sciexp2.common.instance` module.
* Move `sciexp2.common.instance.Expander.Result` into `~sciexp2.common.instance.ExpanderResult`.
* Added `~sciexp2.common.progress.progressable` as a means to add progress indication in routines that where oblivious to it (e.g., adding it to an instance group to get progress indication when used with an expander).
* Huge speedup in `~sciexp2.common.instance.InstanceGroup.sort` by using Python's :func:`sorted` routine.
* Add support for progress indicators in `~sciexp2.common.instance.InstanceGroup.sort`.
0.11.2
------
.. rubric:: External compatibility breaks
* Extraction routines in `~sciexp2.data.io` do not retain the complete source expression as the dimension expression (now it just contains the variables).
.. rubric:: New features
.. rubric:: Improvements
* Extraction routines in `~sciexp2.data.io` ignore empty files by default.
* Added `~sciexp2.common.varref.expr_to_regexp` to handle expression-to-regexp conversions in a single place.
* Added `~sciexp2.common.varref.expr_get_vars` and `~sciexp2.common.varref.regexp_get_names` to handle variable/group name extraction in a single place (closes :issue:`195`).
* Failed translations show the offending substitution (closes :issue:`188`).
.. rubric:: Bug fixes
.. rubric:: Documentation
0.11.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
* Added "pattern binding" operators to `~sciexp2.common.filter.Filter`, so that filters can express matches with regular expressions.
.. rubric:: Improvements
* Ensure that `~sciexp2.data.io.maybe` and `~sciexp2.data.io.maybe_other` applied to extraction routines preserve the path used to find files as the dimension expression.
* Properly handle `~numpy.ndarray.argmax` and `~numpy.ndarray.argmin` reductions.
* Properly handle `~numpy.ndarray.cumsum` and `~numpy.ndarray.cumprod` accumulations.
.. rubric:: Bug fixes
* Handle indexing of `~sciexp2.data.Data` objects with boolean arrays.
* Properly handle the `axis` argument in reductions when not explicitly named.
* Properly translate named regular expression groups into variable references in dimension expressions. Integrates with complex path expressions given to extraction routines as an implicit argument to `~sciexp2.data.io.find_files`.
.. rubric:: Documentation
0.11
----
.. rubric:: External compatibility breaks
* Removed top-level scripts ``launchgen`` and ``plotter`` (closes :issue:`119`).
Script ``launcher`` now is able to show the list and contents of templates (instead of the now removed ``launchgen``).
The old functionality of injecting a default instance and its methods is now available (and documented) in the `sciexp2.launchgen.env` module.
* Removed module ``sciexp2.common.cmdline``.
Was used by the top-level scripts, of which only one is present now.
* Removed modules ``sciexp2.common.config`` and ``sciexp2.common.doc`` (closes :issue:`118`).
Was used by the ``--describe`` argument of top-level scripts, which no longer exists.
* Removed ``sciexp2.common.utils.check_module``.
All checks are already performed by the requirements stated in the ``setup.py`` script.
.. rubric:: New features
* Added initial unit-testing framework. Can be run with ``python ./setup test``. See ``python ./setup test --help`` for additional arguments.
* Added module `sciexp2.data.env` to quickly import all relevant functions and classes.
.. rubric:: Improvements
* Depend on Python 2.7 or later (closes :issue:`43`).
This implies that ``sciexp2.common.utils.OrderedDict`` has been removed in favour of Python's `~collections.OrderedDict`, and :program:`launcher` now uses `argparse` instead of `optparse`.
.. rubric:: Bug fixes
.. rubric:: Documentation
* Showing the contents of a template now lists the variables that must be forcefully defined by the user.
* Properly document how to install and run using "virtualenv" and "pip" (closes :issue:`178`).
0.10
----
.. rubric:: External compatibility breaks
* Moved data extraction methods in ``sciexp2.data.io.RawData`` into routines in `sciexp2.data.io` (`~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex`).
* Re-implemented data extraction routines (`~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex`) to provide a saner, simpler and more unified interface (closes :issue:`103`).
* Removed the bit-rotten "valuename" implementation from the `~sciexp2.data.Data` object, which also helps decreasing the number of concepts (closes :issue:`192`).
* Removed ``sciexp2.data.load`` and ``sciexp2.data.io.extract_maybe`` in favour of `~sciexp2.data.io.maybe` and `~sciexp2.data.io.maybe_other`.
* Removed bit-rotten module ``sciexp2.data.save``.
* Remove ``sciexp2.data.io.Source`` in favour of `~sciexp2.data.io.find_files`.
All data extraction utilities in `sciexp2.data.io` can now accept either an `~sciexp2.common.instance.InstanceGroup` (resulting from a call to `~sciexp2.data.io.find_files`), a tuple with the arguments for `~sciexp2.data.io.find_files` or simply the file expression (thus without filters) as the first argument for `~sciexp2.data.io.find_files`.
* Remove ``sciexp2.data.io.RawData`` and ``sciexp2.data.Data.from_rawdata`` in favour of extraction routines that directly return a `~sciexp2.data.Data` object (closes :issue:`122`).
.. rubric:: New features
* Instances of `~sciexp2.data.Data` can be built directly by the user (see `~sciexp2.data.Data` and `~sciexp2.data.data_array`; closes :issue:`51` and :issue:`65`).
* Added `~sciexp2.data.io.maybe` and `~sciexp2.data.io.maybe_other` to simplify the process of caching the initial extraction and transformation of data (closes :issue:`177`).
.. rubric:: Improvements
* Data extraction routines can also work with file-like objects (aside from open existing files).
* Routine `~sciexp2.data.io.extract_regex` can now perform multiple extracts per file.
* Routine `~sciexp2.data.Data.reshape` now lets the user specify per-field filling values for newly-generated entries (closes :issue:`55`).
.. rubric:: Bug fixes
.. rubric:: Documentation
0.9.7
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
* Added the possibility to filter which files to process with `~sciexp2.launchgen.Launchgen.pack`.
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix a strange bug where `~sciexp2.launchgen.Launchgen.find_files` returned no results even though there were files to be found.
.. rubric:: Documentation
0.9.6
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Return a `~sciexp2.data.Data` object when slicing with numpy-derived arrays.
.. rubric:: Bug fixes
* Allow superclasses when specifying indexing methods with `sciexp2.data.with_dim_index` (closes :issue:`92`).
* Allow superclasses when specifying indexing methods with `sciexp2.data.with_new_dim_index`.
* Return a `~sciexp2.data.Data` object with the appropriate metadata when using reduction-like numpy routines; if the result has no meaning as a `~sciexp2.data.Data` object, a :class:`numpy.ndarray` is returned instead.
* Fix import path to ipython's :mod:`IPython.core.ultratb` module.
* Fix a couple of typos in variable names when building `~sciexp2.data.Dimension` objects.
.. rubric:: Documentation
* The :ref:`todo` is temporarily disabled due to a bug in `Sphinx <http://sphinx.pocoo.org>`_.
.. rubric:: Improvements
.. rubric:: Bug fixes
0.9.5
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Move common initialization code to abstract `~sciexp2.system.Job` class.
* Only try to kill jobs in `~sciexp2.launcher.Launcher` if they're in the running state.
.. rubric:: Bug fixes
* Do not use `sciexp2.system.Job.state` to query job state in generic machinery, but use the "_STATE" variable instead.
* Rename abstract `sciexp2.system.Job.status` into `sciexp2.system.Job.state` (closes :issue:`125`).
* Fix cleanup of progress indication stack when (un)pickling contents with progress indication.
.. rubric:: Documentation
0.9.4
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Improve memory usage during `~sciexp2.data.Data.from_rawdata` when using extremely large inputs (closes :issue:`66`).
* Improve speed of `~sciexp2.common.instance.InstaceGroup.select` (closes :issue:`63`). This results in improved speeds during `~sciexp2.data.Data.reshape`.
* Use a plain :class:`dict` during reverse lookup in `~sciexp2.common.instance.InstaceGroup` (closes :issue:`120`). This was unnecessary and a :class:`dict` might yield faster lookups.
* Show a clearer error message when a filter contains unknown variable names during `~sciexp2.common.filter.Filter.match` (closes :issue:`123`).
.. rubric:: Bug fixes
* Allow calls to `sciexp2.launchgen.Launchgen.generate` without any extra values.
* Generate source distribution with description and template data files for launchgen.
.. rubric:: Documentation
* Rewrite the user guide for :ref:`launchgen` and :ref:`launcher` for much more clarity and extensive examples.
0.9.3
-----
.. rubric:: External compatibility breaks
* Deleted variables ``QUEUE_CMD`` and ``STDINDIR`` in launcher's `gridengine` template.
* Job descriptor files for :program:`launcher` use the ``.jd`` suffix instead of ``.dsc``.
.. rubric:: New features
* Added variable ``QSUB_OPTS`` in launcher's `gridengine` template.
* Templates can provide their own default values (see ``launchgen -T templatename``).
.. rubric:: Improvements
* When finding files, the same variable can appear more than once (e.g., ``@v1@-foo-@v2@-bar-@v1@``).
* More robust and faster file finding, including finding files using expressions without variable references.
.. rubric:: Bug fixes
.. rubric:: Documentation
* Add some user-oriented summaries on the launcher template headers.
0.9.2
-----
.. rubric:: External compatibility breaks
* Removed `selector` argument in `sciexp2.launchgen.Launchgen.params`.
.. rubric:: New features
* Let the user tinker with the `~sciexp2.templates.SEARCH_PATH` of launchgen templates.
* Let the user tinker with the `~sciexp2.system.SEARCH_PATH` of execution systems.
.. rubric:: Improvements
.. rubric:: Bug fixes
.. rubric:: Documentation
* User guide for :program:`launchgen`.
* User guide for :program:`launcher`.
* Auto-generated API documentation.
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/news-old.rst | news-old.rst | .. _news-old:
Older SciExp² versions
======================
0.18.2
------
.. rubric:: External compatibility breaks
.. rubric:: New features
* Lazy result realization also works without a file path (see `~sciexp2.data.io.lazy`).
* Add `~sciexp2.data.io.lazy_wrap`, `~sciexp2.data.io.lazy_wrap_realize` and `~sciexp2.data.io.lazy_wrap_checkpoint` to streamline use of lazily evaluated functions.
* Allow per-variable conversion rules in `~sciexp2.data.io.extract_regex` (closes :issue:`270`).
.. rubric:: Improvements
* Use default value if converter fails in `~sciexp2.data.io.extract_regex`.
* Show an error message (instead of throwing an exception) if job submission fails.
* Add argument ``--keep-going`` to :program:`launcher` to keep submitting jobs even if others fail.
* Provide a crude string representation of lazy results (`~sciexp2.data.io.lazy`).
.. rubric:: Bug fixes
* Make `~sciexp2.data.wrap_reduce` more resilient (closes :issue:`269`).
* Apply converters in `~sciexp2.data.io.extract_txt` for string fields.
* Fix missing value handling in first line for `~sciexp2.data.io.extract_regex`.
* Apply user conversions on missing values for `~sciexp2.data.io.extract_regex` (closes :issue:`268`).
* Fix dtype detection when using ``vars_to_fields`` (data extraction and reshaping).
* Remove output file if there is an error during lazy result realization.
.. rubric:: Documentation
* Document converters and default values in `~sciexp2.data.io.extract_txt`.
.. rubric:: Internals
0.18.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
.. rubric:: Documentation
.. rubric:: Internals
* Switch to Git repository.
0.18
----
.. rubric:: External compatibility breaks
* New argument `fields_to_vars` in data extraction routines (`sciexp2.data.io`; deprecates argument `promote`).
* Rename argument `columns` into `fields` in `~sciexp2.data.io.extract_txt`.
* Rename argument `rows` into `fields` in `~sciexp2.data.io.extract_regex`.
.. rubric:: New features
* Add generic data extraction routine `~sciexp2.data.io.extract_func` (closes :issue:`233`).
* Add support for gzip-compressed source files in data extraction routines for `~sciexp2.data.io` (closes :issue:`232`).
* Add function `~sciexp2.data.data_frombuffer` (closes :issue:`194`).
* Add function `~sciexp2.data.data_memmap`.
* Add argument `fields_to_vars` in `~sciexp2.data.Data.reshape`.
* Add argument `vars_to_fields` in data extraction routines (`sciexp2.data.io`) and `~sciexp2.data.Data.reshape` (closes :issue:`241`).
.. rubric:: Improvements
* Add support for "multi-comparisons" in filters (e.g., ``1 < a < 3``).
* Allow pattern binding operations with any type of arguments in filters.
* Add support for lists in filters (e.g., ``[1, 2, b]``).
* Add support for list membership checks in filters (e.g., ``a in [1, 3, 5]``).
.. rubric:: Bug fixes
* Fix handling of unary minus operator in filters.
* Fix handling of override operator in filters.
.. rubric:: Documentation
* Improve documentation of routines in `sciexp2.data.io`.
* Initial user guide for the `sciexp2.data` package.
.. rubric:: Internals
* Reimplement `~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex` on top of `~sciexp2.data.io.extract_func`.
0.17.1
------
.. rubric:: External compatibility breaks
* Rename `sciexp2.data.Data.sort` as `~sciexp2.data.Data.dim_sort`, since `numpy.sort` already exists (closes :issue:`244`).
* Rename argument `order` in `~sciexp2.data.Data.reshape` as `dim_sort` to keep naming consistent.
.. rubric:: New features
.. rubric:: Improvements
* Lazy evaluation with `sciexp2.data.io.lazy` detects changes to the source code of functions passed as arguments, triggering a re-computation.
.. rubric:: Bug fixes
* Fix command line argument parsing of :program:`launcher` when using a job descriptor file as a binary.
* Fix reductions (`~sciexp2.data.wrap_reduce`) when the result has no dimensions (e.g., a single number).
* Fix indexing of `~sciexp2.data.Data` objects when using the old numeric-compatible basic slicing [#numeric-slicing]_.
.. rubric:: Documentation
.. rubric:: Internals
.. [#numeric-slicing] http://docs.scipy.org/doc/numpy/reference/arrays.indexing.html#basic-slicing
0.17
----
.. rubric:: External compatibility breaks
* Slicing a `~sciexp2.data.Dimension` always returns a new one (or `None`).
.. rubric:: New features
* Added dimension slicing helpers `~sciexp2.data.Dimension.indexes` and `~sciexp2.data.Dimension.ticks`.
* Functions that have an `axis` argument can now identify a dimension by giving the name of one of its variables (closes :issue:`200`).
.. rubric:: Improvements
* Raise exception `~sciexp2.data.io.ConverterError` when the user-provided conversion functions in `~sciexp2.data.io.extract_regex` fail.
* Slicing in `~sciexp2.data.Data` accepts anything that can be converted into a filter (e.g., `dict`; closes :issue:`235`).
* Slicing in `~sciexp2.data.Data` also accepts anything that can be converted into a filter (e.g., `dict`) as long as it selects one element (closes :issue:`230`).
* Fixed dimension metadata when performing binary operations with `~sciexp2.data.Data` objects (closes :issue:`54`).
.. rubric:: Bug fixes
* Raise `~sciexp2.data.io.EmptyFileError` when probing a file without matches during `~sciexp2.data.io.extract_regex`.
* Do not fail when using `~sciexp2.data.io.extract_txt` on files with one single column and row (closes :issue:`238`).
* Properly handle `~numpy.genfromtxt`-specific arguments in `~sciexp2.data.io.extract_txt` (closes :issue:`239`).
.. rubric:: Documentation
.. rubric:: Internals
* Can pretty-print `~sciexp2.data.Dimension` instances.
* Provide copy constructor of `~sciexp2.data.Dimension` instances.
* Provide public `~sciexp2.data.wrap_reduce` and `~sciexp2.data.wrap_accumulate` methods to wrap existing numpy functions.
0.16
----
.. rubric:: External compatibility breaks
* Command :program:`launcher` now has a saner command and option syntax.
* New syntax for template descriptor files.
* Remove commands `monitor` and `reset` from :program:`launcher`.
* Removed variable `sciexp2.common.progress.SHOW` in favour of routine `~sciexp2.common.progress.level`.
* Changed the syntax of `~sciexp2.launchgen.Launchgen.execute` (it's compatible with the common single-string argument).
.. rubric:: New features
* Add commands `summary`, `variables` and `files` to :program:`launcher`.
* Template descriptors can refer to some of the variables defined by their parent.
* Template descriptors, `~sciexp2.launchgen.Launchgen.launcher` and :program:`launcher` can define additional job submission arguments.
* Program :program:`launcher` can define additional job killing arguments.
* Add simple begin/end progress indicator (`sciexp2.common.progress.LVL_MARK`).
* Add `~sciexp2.launchgen.file_contents` to simplify inserting the contents of a file as the value of a variable.
* Add support for parallel command execution in `~sciexp2.launchgen.Launchgen.execute` (closes :issue:`170`).
.. rubric:: Improvements
* Can now run launcher scripts even if the execution system is not installed (assumes no job is currently running).
* Improved error resilience in template scripts.
* All file-generation routines in `~sciexp2.launchgen` will retain the permission bits of their source file.
* Be clever about interactive terminals when showing progress indicators.
* User can set the desired progress reporting level when using :program:`launcher`.
* Program :program:`launcher` now explicitly shows outdated jobs.
.. rubric:: Bug fixes
* Fix error when using `~sciexp2.common.instance.InstanceGroup.select` with a dict-based filter that contains a non-existing value.
* Fix path computation of ``STDOUT`` and ``STDERR`` files in the gridengine template.
* Properly handle operations through a `~sciexp2.launchgen.LaunchgenView`.
* Allow creating a `~sciexp2.launchgen.Launchgen` from a `~sciexp2.launchgen.LaunchgenView` (closes :issue:`228`).
* Fix creation of a `~sciexp2.launchgen.Launchgen` from a `~sciexp2.launchgen.Launchgen` or `~sciexp2.launchgen.LaunchgenView`.
.. rubric:: Documentation
* Point out availability of examples' input files on the source distribution.
.. rubric:: Internals
* Job submission no longer removes results; instead, job scripts do it themselves.
* Do not treat template variables ``DONE`` and ``FAIL`` as glob patterns.
* New module `~sciexp2.common.parallel` providing simple parallelization primitives.
0.15.4
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix data loss bug in `~sciexp2.common.utils.OrderedSet`.
.. rubric:: Documentation
.. rubric:: Internals
0.15.3
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix error during executable file generation in `~sciexp2.launchgen`.
* Fix test number detection in `~sciexp2.launchgen.Launchgen.find_SPEC`.
.. rubric:: Documentation
.. rubric:: Internals
0.15.2
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Add missing package declaration.
.. rubric:: Documentation
.. rubric:: Internals
0.15.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
* Add `sciexp2.data.Data.imag`, `sciexp2.data.imag`, `sciexp2.data.Data.real` and `sciexp2.data.real`.
.. rubric:: Improvements
* Allow building new `~sciexp2.data.Data` instances by copying metadata from others.
* Any unimplemented method in `~sciexp2.data.Data` falls back to a `numpy.ndarray` and (by default) issues a warning (see `~sciexp2.data.WARN_UPCAST`).
* Add `sciexp2.data.Data.copy` and `sciexp2.data.copy`.
* Add `sciexp2.data.Data.ravel`.
.. rubric:: Bug fixes
.. rubric:: Documentation
.. rubric:: Internals
* Provide `sciexp2.data.Dimension.copy`.
0.15
----
.. rubric:: External compatibility breaks
* Remove `sciexp2.data.io.maybe` and `sciexp2.data.io.maybe_other` in favour of `~sciexp2.data.io.lazy`.
* Removed *sort* in `~sciexp2.data.Data.reshape` in favour of *order* using the same semantics as `~sciexp2.data.Data.sort`.
.. rubric:: New features
* Simpler lazy data extraction and management infrastructure with `~sciexp2.data.io.lazy`.
* Allow sorting data dimensions with `~sciexp2.data.Data.sort` (closes :issue:`198`).
* Added `~sciexp2.data.concatenate` (closes :issue:`193`).
* Added `~sciexp2.data.append` (closes :issue:`50`).
* Added `~sciexp2.data.Data.append_fields` (closes :issue:`215`).
* Added `~sciexp2.data.append_fields`, `~sciexp2.data.drop_fields`, `~sciexp2.data.rename_fields` and `~sciexp2.data.merge_arrays` (closes :issue:`215`).
* Added `~sciexp2.data.Data.transpose` (closes :issue:`204`).
* Added `~sciexp2.data.Data.flatten` and `~sciexp2.data.ravel`.
* Added `~sciexp2.data.delete`.
* Added support for multi-line regular expressions in `~sciexp2.data.io.extract_regex` (closes :issue:`206`).
.. rubric:: Improvements
* Detect argument changes in results produced by `~sciexp2.data.io.lazy` to force re-execution.
* Allow lists of filters as arguments to `~sciexp2.data.io.find_files`, and to all the extraction routines by extension (closes :issue:`209`).
* Allow data extraction routines to take a single input file (closes :issue:`210`).
* Properly handle immediate `promote` string in `~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex`.
* Support both `promote` and `count` in `~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex` (closes :issue:`203`).
* Allow passing some arguments in `~sciexp2.data.io.extract_txt` down to `~numpy.genfromtxt` (closes :issue:`211`).
.. rubric:: Bug fixes
* Make scripts generated by `~sciexp2.launchgen.Launchgen.launcher` executable.
* Ensure `~sciexp2.data.data_array` uses the appropriate dtype.
* Fix handling of `Ellipsis` in `~sciexp2.data` (closes :issue:`213`).
* Fix handling of `~sciexp2.data` indexing with multiple filters (closes :issue:`208`).
* Fix data extraction when all fields have the same type (closes :issue:`205` and :issue:`225`).
* Fix descriptor parsing in `~sciexp2.data.io.extract_txt` (closes :issue:`212` and :issue:`223`).
.. rubric:: Documentation
.. rubric:: Internals
0.14.2
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fixed internal error in `~sciexp2.launchgen.Launchgen.execute`.
.. rubric:: Documentation
.. rubric:: Internals
0.14.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fixed internal error in `~sciexp2.launchgen.Launchgen.find_files`.
.. rubric:: Documentation
.. rubric:: Internals
0.14
----
.. rubric:: External compatibility breaks
* Removed prefixed underscore from user-visible variables *LAUNCHER*, *DONE* and *FAIL* generated by `~sciexp2.launchgen.Launchgen` (closes :issue:`216`).
* Removed *done_expr* and *fail_expr* arguments to `~sciexp2.launchgen.Launchgen.launcher` in favour of variables *DONE* and *FAIL*, which have a default value (closes :issue:`217`).
* By default, `~sciexp2.launchgen.Launchgen.launcher` generates the job descriptor in file ``jobs.jd`` (controlled through variable *JD*).
* If specified, argument *export* in `~sciexp2.launchgen.Launchgen.launcher` overrides the variables that are exported by default.
.. rubric:: New features
* Method `~sciexp2.launchgen.Launchgen.execute` can now specify *stdin*, *stdout* and *stderr* (closes :issue:`168`).
* Program :program:`launcher` accepts the values (or the relative path to them, when interpreted as files) of certain variables (e.g., *DONE*) as a short-hand to filters (closes :issue:`182`).
* Method `~sciexp2.launchgen.Launchgen.launcher` accepts a list of variables that `~sciexp2.launchgen.launcher` will use to establish whether a job needs reexecution (closes :issue:`175`).
* Method `~sciexp2.launchgen.Launchgen.params` can also append new contents instead of recombining them with the existing ones (closes :issue:`202`).
* Function `~sciexp2.data.io.find_files` accepts job descriptor files as arguments.
.. rubric:: Improvements
* The user can now easily set when the *gridengine* template should send a mail notification (closes :issue:`126`).
* Properly handle *stdout* and *stderr* redirection in the *gridengine* and *shell* templates (closes :issue:`180`).
* Default templates can have separate values for files holding stdout/stderr (variables *STDOUT* and *STDERR*) and the *DONE* and *FAIL* files.
* Generating or copying files with `~sciexp2.launchgen.Launchgen` will only update these when new contents are available (closes :issue:`174`).
.. rubric:: Bug fixes
* Mark jobs as failed whenever the *_FAIL* file exists (closes :issue:`163`).
* Fix handling of job descriptor files in directories other than the output base.
* Fixed *gridengine* template to establish the base directory (closes :issue:`176`).
.. rubric:: Documentation
.. rubric:: Internals
* Method `~sciexp2.launchgen.Launchgen.launcher` only exports the appropriate variables.
* Method `~sciexp2.launchgen.Launchgen.launcher` makes job launcher scripts executable.
* Added `~sciexp2.common.utils.get_path` to handle path expansions (used in `~sciexp2.launchgen.Launchgen`).
* New implementation of the pretty-printing module `~sciexp2.common.pp` (adds IPython as a dependency).
* Store some metadata in job descriptor files to ensure their formatting.
0.13
----
.. rubric:: External compatibility breaks
* Variable `sciexp2.launchgen.Launchgen.DEFAULT_OUT` has been renamed to `~sciexp2.launchgen.Launchgen.OUTPUT_DIR`.
.. rubric:: New features
* Implemented the *modulus* operation in filters.
* Added *programmatic filters* to streamline the filter writing (see `~sciexp2.common.filter.PFilter`; relates to :issue:`185`).
* Instances of `~sciexp2.launchgen.Launchgen` can be constructed with initial contents (including copies of other instances).
* Method `~sciexp2.launchgen.Launchgen.generate` now accepts filters.
* Added method `~sciexp2.launchgen.Launchgen.select` to return an object that operates on a subset of the contents (closes :issue:`184` and :issue:`186`).
.. rubric:: Improvements
.. rubric:: Bug fixes
* All methods in `~sciexp2.launchgen.Launchgen` performing parameter recombination accept any iterable structure (closes :issue:`164`).
.. rubric:: Documentation
* Rewrote the user guide for launchgen, which is now more concise and tangible, as well as describes the latest features.
.. rubric:: Internals
* Have `~sciexp2.common.filter.Filter` accept a list of arguments.
* Have `~sciexp2.common.filter.Filter.match` silently fail when it contains a variable not present in the source if argument ``allow_unknown`` is set to ``True``.
0.12
----
.. rubric:: External compatibility breaks
* `~sciexp2.data.Dimension` no longer handles named groups if the `expression` argument is a regular expression, as version 0.11.2 removed the feature from the `~sciexp2.data.io` module.
* Removed function `sciexp2.data.build_dimension` and method `sciexp2.data.Dimension.build_instance` in favour of a saner `~sciexp2.data.Dimension` constructor and methods `~sciexp2.data.Dimension.add` and `~sciexp2.data.Dimension.extend`.
.. rubric:: New features
* Progress indicators now try to avoid updating the screen too often. Speed can be controlled through `sciexp2.common.progress.SPEED`.
* Whether to show progress indicators on the screen can be globally controlled through `sciexp2.common.progress.SHOW`.
* Add support for `sciexp2.data.Data.reshape` to sort axes according to their variables.
.. rubric:: Improvements
* Improvement of orders of magnitude on the speed of creation of new `~sciexp2.data.Data` objects (thanks to optimized `~sciexp2.data.Dimension` construction).
* Improvement of orders of magnitude on the speed of `~sciexp2.data.Data.reshape` (thanks to optimized `~sciexp2.data.Dimension` construction and improved algorithm).
* Better progress indication in `~sciexp2.data.Data.reshape` and `~sciexp2.data.Data` slicing.
.. rubric:: Bug fixes
* Fix sorting of results for file-finding routines.
.. rubric:: Documentation
* Reference documentation no longer shows class hierarchies.
.. rubric:: Internals
* Refactored progress indicators into the `~sciexp2.common.progress` module.
* Use context manager protocol with `~sciexp2.common.progress.Counter` and `~sciexp2.common.progress.Spinner`.
* Progress indicator type (counter or spinner) can be automatically selected through `sciexp2.common.progress.get` and `sciexp2.common.progress.get_pickle`.
* Split `~sciexp2.common.instance.InstanceGroup` caching into `~sciexp2.common.instance.InstanceGroup.cache_get` and `~sciexp2.common.instance.InstanceGroup.cache_set`.
* Added proactive and zero-caching instance additions in `~sciexp2.common.instance.InstanceGroup`.
* Small performance improvements on various operations of the `~sciexp2.common.instance` module.
* Move `sciexp2.common.instance.Expander.Result` into `~sciexp2.common.instance.ExpanderResult`.
* Added `~sciexp2.common.progress.progressable` as a means to add progress indication in routines that where oblivious to it (e.g., adding it to an instance group to get progress indication when used with an expander).
* Huge speedup in `~sciexp2.common.instance.InstanceGroup.sort` by using Python's :func:`sorted` routine.
* Add support for progress indicators in `~sciexp2.common.instance.InstanceGroup.sort`.
0.11.2
------
.. rubric:: External compatibility breaks
* Extraction routines in `~sciexp2.data.io` do not retain the complete source expression as the dimension expression (now it just contains the variables).
.. rubric:: New features
.. rubric:: Improvements
* Extraction routines in `~sciexp2.data.io` ignore empty files by default.
* Added `~sciexp2.common.varref.expr_to_regexp` to handle expression-to-regexp conversions in a single place.
* Added `~sciexp2.common.varref.expr_get_vars` and `~sciexp2.common.varref.regexp_get_names` to handle variable/group name extraction in a single place (closes :issue:`195`).
* Failed translations show the offending substitution (closes :issue:`188`).
.. rubric:: Bug fixes
.. rubric:: Documentation
0.11.1
------
.. rubric:: External compatibility breaks
.. rubric:: New features
* Added "pattern binding" operators to `~sciexp2.common.filter.Filter`, so that filters can express matches with regular expressions.
.. rubric:: Improvements
* Ensure that `~sciexp2.data.io.maybe` and `~sciexp2.data.io.maybe_other` applied to extraction routines preserve the path used to find files as the dimension expression.
* Properly handle `~numpy.ndarray.argmax` and `~numpy.ndarray.argmin` reductions.
* Properly handle `~numpy.ndarray.cumsum` and `~numpy.ndarray.cumprod` accumulations.
.. rubric:: Bug fixes
* Handle indexing of `~sciexp2.data.Data` objects with boolean arrays.
* Properly handle the `axis` argument in reductions when not explicitly named.
* Properly translate named regular expression groups into variable references in dimension expressions. Integrates with complex path expressions given to extraction routines as an implicit argument to `~sciexp2.data.io.find_files`.
.. rubric:: Documentation
0.11
----
.. rubric:: External compatibility breaks
* Removed top-level scripts ``launchgen`` and ``plotter`` (closes :issue:`119`).
Script ``launcher`` now is able to show the list and contents of templates (instead of the now removed ``launchgen``).
The old functionality of injecting a default instance and its methods is now available (and documented) in the `sciexp2.launchgen.env` module.
* Removed module ``sciexp2.common.cmdline``.
Was used by the top-level scripts, of which only one is present now.
* Removed modules ``sciexp2.common.config`` and ``sciexp2.common.doc`` (closes :issue:`118`).
Was used by the ``--describe`` argument of top-level scripts, which no longer exists.
* Removed ``sciexp2.common.utils.check_module``.
All checks are already performed by the requirements stated in the ``setup.py`` script.
.. rubric:: New features
* Added initial unit-testing framework. Can be run with ``python ./setup test``. See ``python ./setup test --help`` for additional arguments.
* Added module `sciexp2.data.env` to quickly import all relevant functions and classes.
.. rubric:: Improvements
* Depend on Python 2.7 or later (closes :issue:`43`).
This implies that ``sciexp2.common.utils.OrderedDict`` has been removed in favour of Python's `~collections.OrderedDict`, and :program:`launcher` now uses `argparse` instead of `optparse`.
.. rubric:: Bug fixes
.. rubric:: Documentation
* Showing the contents of a template now lists the variables that must be forcefully defined by the user.
* Properly document how to install and run using "virtualenv" and "pip" (closes :issue:`178`).
0.10
----
.. rubric:: External compatibility breaks
* Moved data extraction methods in ``sciexp2.data.io.RawData`` into routines in `sciexp2.data.io` (`~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex`).
* Re-implemented data extraction routines (`~sciexp2.data.io.extract_txt` and `~sciexp2.data.io.extract_regex`) to provide a saner, simpler and more unified interface (closes :issue:`103`).
* Removed the bit-rotten "valuename" implementation from the `~sciexp2.data.Data` object, which also helps decreasing the number of concepts (closes :issue:`192`).
* Removed ``sciexp2.data.load`` and ``sciexp2.data.io.extract_maybe`` in favour of `~sciexp2.data.io.maybe` and `~sciexp2.data.io.maybe_other`.
* Removed bit-rotten module ``sciexp2.data.save``.
* Remove ``sciexp2.data.io.Source`` in favour of `~sciexp2.data.io.find_files`.
All data extraction utilities in `sciexp2.data.io` can now accept either an `~sciexp2.common.instance.InstanceGroup` (resulting from a call to `~sciexp2.data.io.find_files`), a tuple with the arguments for `~sciexp2.data.io.find_files` or simply the file expression (thus without filters) as the first argument for `~sciexp2.data.io.find_files`.
* Remove ``sciexp2.data.io.RawData`` and ``sciexp2.data.Data.from_rawdata`` in favour of extraction routines that directly return a `~sciexp2.data.Data` object (closes :issue:`122`).
.. rubric:: New features
* Instances of `~sciexp2.data.Data` can be built directly by the user (see `~sciexp2.data.Data` and `~sciexp2.data.data_array`; closes :issue:`51` and :issue:`65`).
* Added `~sciexp2.data.io.maybe` and `~sciexp2.data.io.maybe_other` to simplify the process of caching the initial extraction and transformation of data (closes :issue:`177`).
.. rubric:: Improvements
* Data extraction routines can also work with file-like objects (aside from open existing files).
* Routine `~sciexp2.data.io.extract_regex` can now perform multiple extracts per file.
* Routine `~sciexp2.data.Data.reshape` now lets the user specify per-field filling values for newly-generated entries (closes :issue:`55`).
.. rubric:: Bug fixes
.. rubric:: Documentation
0.9.7
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
* Added the possibility to filter which files to process with `~sciexp2.launchgen.Launchgen.pack`.
.. rubric:: Improvements
.. rubric:: Bug fixes
* Fix a strange bug where `~sciexp2.launchgen.Launchgen.find_files` returned no results even though there were files to be found.
.. rubric:: Documentation
0.9.6
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Return a `~sciexp2.data.Data` object when slicing with numpy-derived arrays.
.. rubric:: Bug fixes
* Allow superclasses when specifying indexing methods with `sciexp2.data.with_dim_index` (closes :issue:`92`).
* Allow superclasses when specifying indexing methods with `sciexp2.data.with_new_dim_index`.
* Return a `~sciexp2.data.Data` object with the appropriate metadata when using reduction-like numpy routines; if the result has no meaning as a `~sciexp2.data.Data` object, a :class:`numpy.ndarray` is returned instead.
* Fix import path to ipython's :mod:`IPython.core.ultratb` module.
* Fix a couple of typos in variable names when building `~sciexp2.data.Dimension` objects.
.. rubric:: Documentation
* The :ref:`todo` is temporarily disabled due to a bug in `Sphinx <http://sphinx.pocoo.org>`_.
.. rubric:: Improvements
.. rubric:: Bug fixes
0.9.5
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Move common initialization code to abstract `~sciexp2.system.Job` class.
* Only try to kill jobs in `~sciexp2.launcher.Launcher` if they're in the running state.
.. rubric:: Bug fixes
* Do not use `sciexp2.system.Job.state` to query job state in generic machinery, but use the "_STATE" variable instead.
* Rename abstract `sciexp2.system.Job.status` into `sciexp2.system.Job.state` (closes :issue:`125`).
* Fix cleanup of progress indication stack when (un)pickling contents with progress indication.
.. rubric:: Documentation
0.9.4
-----
.. rubric:: External compatibility breaks
.. rubric:: New features
.. rubric:: Improvements
* Improve memory usage during `~sciexp2.data.Data.from_rawdata` when using extremely large inputs (closes :issue:`66`).
* Improve speed of `~sciexp2.common.instance.InstaceGroup.select` (closes :issue:`63`). This results in improved speeds during `~sciexp2.data.Data.reshape`.
* Use a plain :class:`dict` during reverse lookup in `~sciexp2.common.instance.InstaceGroup` (closes :issue:`120`). This was unnecessary and a :class:`dict` might yield faster lookups.
* Show a clearer error message when a filter contains unknown variable names during `~sciexp2.common.filter.Filter.match` (closes :issue:`123`).
.. rubric:: Bug fixes
* Allow calls to `sciexp2.launchgen.Launchgen.generate` without any extra values.
* Generate source distribution with description and template data files for launchgen.
.. rubric:: Documentation
* Rewrite the user guide for :ref:`launchgen` and :ref:`launcher` for much more clarity and extensive examples.
0.9.3
-----
.. rubric:: External compatibility breaks
* Deleted variables ``QUEUE_CMD`` and ``STDINDIR`` in launcher's `gridengine` template.
* Job descriptor files for :program:`launcher` use the ``.jd`` suffix instead of ``.dsc``.
.. rubric:: New features
* Added variable ``QSUB_OPTS`` in launcher's `gridengine` template.
* Templates can provide their own default values (see ``launchgen -T templatename``).
.. rubric:: Improvements
* When finding files, the same variable can appear more than once (e.g., ``@v1@-foo-@v2@-bar-@v1@``).
* More robust and faster file finding, including finding files using expressions without variable references.
.. rubric:: Bug fixes
.. rubric:: Documentation
* Add some user-oriented summaries on the launcher template headers.
0.9.2
-----
.. rubric:: External compatibility breaks
* Removed `selector` argument in `sciexp2.launchgen.Launchgen.params`.
.. rubric:: New features
* Let the user tinker with the `~sciexp2.templates.SEARCH_PATH` of launchgen templates.
* Let the user tinker with the `~sciexp2.system.SEARCH_PATH` of execution systems.
.. rubric:: Improvements
.. rubric:: Bug fixes
.. rubric:: Documentation
* User guide for :program:`launchgen`.
* User guide for :program:`launcher`.
* Auto-generated API documentation.
| 0.896874 | 0.442516 |
Introduction
============
SciExp² (aka *SciExp square* or simply *SciExp2*) stands for *Scientific Experiment Exploration*, which provides a framework for easing the workflow of creating, executing and evaluating experiments.
The driving idea of SciExp² is that of quick and effortless *design-space exploration*. It is divided into the following main pieces:
* **Launchgen**: Aids in defining experiments as a permutation of different parameters in the design space. It creates the necessary files to run these experiments (configuration files, scripts, etc.), which you define as templates that get substituted with the specific parameter values of each experiment.
* **Launcher**: Takes the files of `~sciexp2.launchgen` and runs these experiments on different execution platforms like regular local scripts or cluster jobs. It takes care of tracking their correct execution, and allows selecting which experiments to run (e.g., those with specific parameter values, or those that were not successfully run yet).
* **Data**: Aids in the process of collecting and analyzing the results of the experiments. Results are automatically collected into a data structure that maintains the relationship between each result and the parameters of the experiment that produced it. With this you can effortlessly perform complex tasks such as inspecting the results or calculating statistics of experiments sub-set, based on their parameter values.
.. _quick_example:
Quick example
-------------
As a quick example, here's how to generate scripts to run an application, run these scripts, and evaluate their results. First, we'll start by generating the per-experiment scripts in the ``experiments`` directory. Each experiment script will execute ``my-program`` with different values of the ``--size`` argument, and we can reference these per-experiment parameters with ``@parameter_name@``::
#!/usr/bin/env python
# -*- python -*-
from sciexp2.launchgen.env import *
l = Launchgen(out="experiments")
# copy program into experiments directory
l.pack("/path/to/my-program", "bin/my-program")
# create one experiment for each value of size
l.params(size=[1, 2, 4, 8])
# generate per-experiment scripts ("scripts/@[email protected]") with the specified command (CMD)
l.launchgen("shell", "scripts/@[email protected]",
CMD="bin/my-program --size=@size@ --out=results/@[email protected]")
The resulting ``experiments`` directory now contains all the files we need::
experiments
|- jobs.jd # auto-generated by l.launchgen()
|- bin
| `- my-program
`- scripts
|- 1.sh
|- 2.sh
|- 4.sh
`- 8.sh
To execute all the experiments, we can simply use the auto-generated ``jobs.jd`` script. It will take care of running each of the per-experiment scripts, controlling if they are finishing correctly::
./experiments/jobs.jd submit
After successfully executing all the scripts, the ``experiments`` directory will also contain the output files we gave on the per-experiment command (``--out=results/@[email protected]``)::
experiments
|- bin
| `- my-program
|- scripts
| |- 1.sh
| |- 2.sh
| |- 4.sh
| `- 8.sh
`- results
|- 1.csv
|- 2.csv
|- 4.csv
`- 8.csv
Now let's assume that ``my-program`` runs the same operation multiple times, and the output file is in CSV format with one line for each run::
run,time
0,3.2
1,2.9
...
We therefore have one result file for each ``size`` parameter value, and each of these results files contains multiple runs of its experiment. A typical step would now be to collect all these results and calculate, for each ``size`` configuration, the mean execution time across all runs::
#!/usr/bin/env python
# -*- python -*-
from sciexp2.data.env import *
# auto-extract all results; the result is a 1-dimensional array with two
# metadata variables: size and run
d = extract_txt('experiments/results/@[email protected]',
fields_to_vars=["run"])
# turn the data into a 2-dimensional array, with experiment size as first
# dimension and run number as second
d = d.reshape(["size"], ["run"])
# get the mean of all runs, so we get a 1-dimensional array with one mean
# per size
d = d.mean(axis="run")
# print CSV-like mean of each size
print("size, time")
for foo in d.dims["size"]:
print("%4d," % size, d[size])
The result could be something like::
size, time
1, 3.05
2, 3.39
4, 4.61
8, 6.37
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/introduction.rst | introduction.rst | Introduction
============
SciExp² (aka *SciExp square* or simply *SciExp2*) stands for *Scientific Experiment Exploration*, which provides a framework for easing the workflow of creating, executing and evaluating experiments.
The driving idea of SciExp² is that of quick and effortless *design-space exploration*. It is divided into the following main pieces:
* **Launchgen**: Aids in defining experiments as a permutation of different parameters in the design space. It creates the necessary files to run these experiments (configuration files, scripts, etc.), which you define as templates that get substituted with the specific parameter values of each experiment.
* **Launcher**: Takes the files of `~sciexp2.launchgen` and runs these experiments on different execution platforms like regular local scripts or cluster jobs. It takes care of tracking their correct execution, and allows selecting which experiments to run (e.g., those with specific parameter values, or those that were not successfully run yet).
* **Data**: Aids in the process of collecting and analyzing the results of the experiments. Results are automatically collected into a data structure that maintains the relationship between each result and the parameters of the experiment that produced it. With this you can effortlessly perform complex tasks such as inspecting the results or calculating statistics of experiments sub-set, based on their parameter values.
.. _quick_example:
Quick example
-------------
As a quick example, here's how to generate scripts to run an application, run these scripts, and evaluate their results. First, we'll start by generating the per-experiment scripts in the ``experiments`` directory. Each experiment script will execute ``my-program`` with different values of the ``--size`` argument, and we can reference these per-experiment parameters with ``@parameter_name@``::
#!/usr/bin/env python
# -*- python -*-
from sciexp2.launchgen.env import *
l = Launchgen(out="experiments")
# copy program into experiments directory
l.pack("/path/to/my-program", "bin/my-program")
# create one experiment for each value of size
l.params(size=[1, 2, 4, 8])
# generate per-experiment scripts ("scripts/@[email protected]") with the specified command (CMD)
l.launchgen("shell", "scripts/@[email protected]",
CMD="bin/my-program --size=@size@ --out=results/@[email protected]")
The resulting ``experiments`` directory now contains all the files we need::
experiments
|- jobs.jd # auto-generated by l.launchgen()
|- bin
| `- my-program
`- scripts
|- 1.sh
|- 2.sh
|- 4.sh
`- 8.sh
To execute all the experiments, we can simply use the auto-generated ``jobs.jd`` script. It will take care of running each of the per-experiment scripts, controlling if they are finishing correctly::
./experiments/jobs.jd submit
After successfully executing all the scripts, the ``experiments`` directory will also contain the output files we gave on the per-experiment command (``--out=results/@[email protected]``)::
experiments
|- bin
| `- my-program
|- scripts
| |- 1.sh
| |- 2.sh
| |- 4.sh
| `- 8.sh
`- results
|- 1.csv
|- 2.csv
|- 4.csv
`- 8.csv
Now let's assume that ``my-program`` runs the same operation multiple times, and the output file is in CSV format with one line for each run::
run,time
0,3.2
1,2.9
...
We therefore have one result file for each ``size`` parameter value, and each of these results files contains multiple runs of its experiment. A typical step would now be to collect all these results and calculate, for each ``size`` configuration, the mean execution time across all runs::
#!/usr/bin/env python
# -*- python -*-
from sciexp2.data.env import *
# auto-extract all results; the result is a 1-dimensional array with two
# metadata variables: size and run
d = extract_txt('experiments/results/@[email protected]',
fields_to_vars=["run"])
# turn the data into a 2-dimensional array, with experiment size as first
# dimension and run number as second
d = d.reshape(["size"], ["run"])
# get the mean of all runs, so we get a 1-dimensional array with one mean
# per size
d = d.mean(axis="run")
# print CSV-like mean of each size
print("size, time")
for foo in d.dims["size"]:
print("%4d," % size, d[size])
The result could be something like::
size, time
1, 3.05
2, 3.39
4, 4.61
8, 6.37
| 0.813683 | 0.736661 |
`{{ fullname }}`
=={{ underline }}
.. currentmodule:: {{ module }}
{% block methods %}
{% if methods %}
.. rubric:: Methods
.. autosummary::
{% for item in methods %}
{% if item != "__init__" %}
~{{ name }}.{{ item }}
{% endif %}
{%- endfor %}
{% endif %}
{% endblock %}
{% block attributes %}
{% if attributes %}
.. rubric:: Attributes
.. autosummary::
{% for item in attributes %}
~{{ name }}.{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
.. autoclass:: {{ objname }}
:members:
:show-inheritance:
:undoc-members:
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/_templates/autosummary/class.rst | class.rst | `{{ fullname }}`
=={{ underline }}
.. currentmodule:: {{ module }}
{% block methods %}
{% if methods %}
.. rubric:: Methods
.. autosummary::
{% for item in methods %}
{% if item != "__init__" %}
~{{ name }}.{{ item }}
{% endif %}
{%- endfor %}
{% endif %}
{% endblock %}
{% block attributes %}
{% if attributes %}
.. rubric:: Attributes
.. autosummary::
{% for item in attributes %}
~{{ name }}.{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
.. autoclass:: {{ objname }}
:members:
:show-inheritance:
:undoc-members:
| 0.664758 | 0.162912 |
`{{ fullname }}`
=={{ underline }}
Source: :code:`{{ fullname.replace(".", "/") }}.py`
.. automodule:: {{ fullname }}
:undoc-members:
{% if name != "env" %}
{% block functions %}
{% if functions %}
.. rubric:: Functions
.. autosummary::
:nosignatures:
{% for item in functions %}
{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% block classes %}
{% if classes %}
.. rubric:: Classes
.. autosummary::
:toctree:
:nosignatures:
{% for item in classes %}
{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% block exceptions %}
{% if exceptions %}
.. rubric:: Exceptions
.. autosummary::
:nosignatures:
{% for item in exceptions %}
{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% block functionlist %}
{% if functions %}
{% for item in functions %}
`{{ item }}`
{{ "-" * (8 + item|length()) }}
.. autofunction:: {{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% endif %}
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/_templates/autosummary/module.rst | module.rst | `{{ fullname }}`
=={{ underline }}
Source: :code:`{{ fullname.replace(".", "/") }}.py`
.. automodule:: {{ fullname }}
:undoc-members:
{% if name != "env" %}
{% block functions %}
{% if functions %}
.. rubric:: Functions
.. autosummary::
:nosignatures:
{% for item in functions %}
{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% block classes %}
{% if classes %}
.. rubric:: Classes
.. autosummary::
:toctree:
:nosignatures:
{% for item in classes %}
{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% block exceptions %}
{% if exceptions %}
.. rubric:: Exceptions
.. autosummary::
:nosignatures:
{% for item in exceptions %}
{{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% block functionlist %}
{% if functions %}
{% for item in functions %}
`{{ item }}`
{{ "-" * (8 + item|length()) }}
.. autofunction:: {{ item }}
{%- endfor %}
{% endif %}
{% endblock %}
{% endif %}
| 0.590307 | 0.231321 |
Basic concepts
==============
The SciExp² framework uses a few concepts across the whole documentation, which are defined here.
Python and Numpy constructs
---------------------------
* `Default argument values <http://docs.python.org/2/tutorial/controlflow.html#default-argument-values>`_
* `Keyword arguments <http://docs.python.org/2/tutorial/controlflow.html#keyword-arguments>`_
* `Argument lists <http://docs.python.org/2/tutorial/controlflow.html#arbitrary-argument-lists>`_
* `Numpy's data arrays <https://docs.scipy.org/doc/numpy-dev/user/quickstart.html>`_
Elements
--------
.. glossary::
variable
Just like in any programming language, a user-specified textual name that holds a value.
value
The specific value of a variable.
instance
A mapping between variables and a specific value for each of these variables (see `~sciexp2.common.instance.Instance`, which is, indeed, a python :class:`dict`), like::
Instance(var1=84, var2="something")
instance group
An ordered container for storing instances (see `~sciexp2.common.instance.InstanceGroup`)::
InstanceGroup([Instance(var1=84, var2="something"),
Instance(var1=48, var2="something"),
Instance(var1=84, var2="else")])
expression
A string with references to an arbitrary number of variables.
The default format for referencing variables is ``@variablename@``::
"sometext-@var1@/@var2@:moretext"
filter
A string to express a set of conditions that the values of an instance must match (see `~sciexp2.common.filter.Filter`)::
"var1 > 30*2 && var2 == 'something'"
You can also use *programmatic filters* to have a more streamlined interface (see `~sciexp2.common.filter.PFilter`)::
(v_.var1 > 30*2) & (v_.var2 == 'something')
Operations
----------
.. glossary::
translation
:term:`Expressions <expression>` can be *translated* into strings.
The most common translation process is a *dictionary-based translation* through an :term:`instance`, which substitutes references to :term:`variables <variable>` in an expression with the values in the given instance.
For example, translating the expression ``"sometext-@var1@/@var2@:moretext"`` with the instance::
Instance(var1=84, var2="something")
yields ``"sometext-84/something:moretext"``.
For the sake of completeness, translators other than dictionary-based are also provided (see the class hierarchy for `~sciexp2.common.varref.Xlator` in the `~sciexp2.common.varref` module).
expansion
:term:`Expressions <expression>` can be *expanded* with a given reference `instance group` (see `~sciexp2.common.instance.Expander`).
The result is (roughly) an ordered dictionary of instance groups, where each group contains all instances that have the same :term:`translation` for the expanded expression, so that expanding ``"foo @var1@ bar"`` with the previous example :term:`instance group` would return::
{"foo 84 bar": InstanceGroup([Instance(var1=84, var2="something"),
Instance(var1=84, var2="else")])),
"foo 48 bar": InstanceGroup([Instance(var1=48, var2="something")])}
extraction
:term:`Instances <instance>` can be *extracted* from a given reference `expression` (see `~sciexp2.common.instance.InstanceExtractor`).
The result is one instance with the variables in the reference expression and the values that appear on the input string. This can be thought of as the inverse of :term:`translation`, so that extracting an instance from the text ``"sometext-100/baz:moretext"`` with the reference expression ``"sometext-@var1@/@var2@:moretext"`` yields::
Instance(var1=100, var2="baz")
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/user_guide/concepts.rst | concepts.rst | Basic concepts
==============
The SciExp² framework uses a few concepts across the whole documentation, which are defined here.
Python and Numpy constructs
---------------------------
* `Default argument values <http://docs.python.org/2/tutorial/controlflow.html#default-argument-values>`_
* `Keyword arguments <http://docs.python.org/2/tutorial/controlflow.html#keyword-arguments>`_
* `Argument lists <http://docs.python.org/2/tutorial/controlflow.html#arbitrary-argument-lists>`_
* `Numpy's data arrays <https://docs.scipy.org/doc/numpy-dev/user/quickstart.html>`_
Elements
--------
.. glossary::
variable
Just like in any programming language, a user-specified textual name that holds a value.
value
The specific value of a variable.
instance
A mapping between variables and a specific value for each of these variables (see `~sciexp2.common.instance.Instance`, which is, indeed, a python :class:`dict`), like::
Instance(var1=84, var2="something")
instance group
An ordered container for storing instances (see `~sciexp2.common.instance.InstanceGroup`)::
InstanceGroup([Instance(var1=84, var2="something"),
Instance(var1=48, var2="something"),
Instance(var1=84, var2="else")])
expression
A string with references to an arbitrary number of variables.
The default format for referencing variables is ``@variablename@``::
"sometext-@var1@/@var2@:moretext"
filter
A string to express a set of conditions that the values of an instance must match (see `~sciexp2.common.filter.Filter`)::
"var1 > 30*2 && var2 == 'something'"
You can also use *programmatic filters* to have a more streamlined interface (see `~sciexp2.common.filter.PFilter`)::
(v_.var1 > 30*2) & (v_.var2 == 'something')
Operations
----------
.. glossary::
translation
:term:`Expressions <expression>` can be *translated* into strings.
The most common translation process is a *dictionary-based translation* through an :term:`instance`, which substitutes references to :term:`variables <variable>` in an expression with the values in the given instance.
For example, translating the expression ``"sometext-@var1@/@var2@:moretext"`` with the instance::
Instance(var1=84, var2="something")
yields ``"sometext-84/something:moretext"``.
For the sake of completeness, translators other than dictionary-based are also provided (see the class hierarchy for `~sciexp2.common.varref.Xlator` in the `~sciexp2.common.varref` module).
expansion
:term:`Expressions <expression>` can be *expanded* with a given reference `instance group` (see `~sciexp2.common.instance.Expander`).
The result is (roughly) an ordered dictionary of instance groups, where each group contains all instances that have the same :term:`translation` for the expanded expression, so that expanding ``"foo @var1@ bar"`` with the previous example :term:`instance group` would return::
{"foo 84 bar": InstanceGroup([Instance(var1=84, var2="something"),
Instance(var1=84, var2="else")])),
"foo 48 bar": InstanceGroup([Instance(var1=48, var2="something")])}
extraction
:term:`Instances <instance>` can be *extracted* from a given reference `expression` (see `~sciexp2.common.instance.InstanceExtractor`).
The result is one instance with the variables in the reference expression and the values that appear on the input string. This can be thought of as the inverse of :term:`translation`, so that extracting an instance from the text ``"sometext-100/baz:moretext"`` with the reference expression ``"sometext-@var1@/@var2@:moretext"`` yields::
Instance(var1=100, var2="baz")
| 0.923868 | 0.699023 |
.. _launchgen:
Experiment creation --- `~sciexp2.launchgen`
============================================
The goal of the `~sciexp2.launchgen` module is to define a set of experiments and create a self-contained directory with all the files necessary for running these experiments. The reason to make it self-contained is that this directory can then be moved into the system(s) where the experiments must be run (e.g., a cluster, or some other machine different from the development one).
For the sake of making the description more tangible, this guide will show how to generate experiments to evaluate all benchmarks on a simple benchmark suite (``mybenchsuite``), where each benchmark is run with different input sets inside a computer simulator program (``mysim``) that uses different configuration parameters (specified in a configuration file). Thus, each experiment will be defined by the tuple comprised of the benchmark name, the benchmark's input set, and the different configuration parameter permutations defined by the user. The initial file organization is the following::
.
|- generate.py # the experiment-generation script described here
|- mysimulator # source code for the simulator
| |- Makefile
| `- mysim.c
|- mysim.cfg.in # template configuration file for the simulator
`- mybenchsuite # benchmark suite
|- 1.foo # source code for a specific benchmark
| |- source.c
| `- Makefile
|- 2.broken
| |- source.c
| `- Makefile
|- 3.baz
| |- source.c
| `- Makefile
|- README # files that can be ignored
`- NEWS
This is the roadmap to create an ``experiments`` directory that will contain all the necessary pieces to run our experiments:
#. Execute external programs to compile the simulator and the benchmarks.
#. Copy files for the simulator and each of the selected benchmarks into the ``experiments`` directory.
#. Define different sets of arguments to run the benchmarks with different inputs.
#. Define different configuration parameter combinations for the simulator.
#. Generate a simulator configuration file for each set of simulation parameters, and generate a script for each combination of simulator parameters, benchmark and benchmark input sets. These files are generated from templates by :term:`translating <translation>` any :term:`variable` they reference in their contents with the values specified by us.
This example also showcases some of the more advanced features of `~sciexp2.launchgen`, but you can first take a look at :ref:`quick_example` for a much shorter and simpler example.
Script preparation
------------------
All the functions typically used in a `~sciexp2.launchgen` script are available in the `sciexp2.launchgen.env` module, so we can import its contents to make them available at the top level::
#!/usr/bin/env python
# -*- python -*-
from sciexp2.launchgen.env import *
# file contents ...
Directory preparation
---------------------
First, we create a `~sciexp2.launchgen.Launchgen` object with its output directory set, where all generated files will be placed::
l = Launchgen(out="./experiments")
This object is initially empty, and only has the output directory set::
>>> l
Launchgen(out='./experiments')
.. note::
It is usually recommended to *not* remove the output directory when re-executing a `~sciexp2.launchgen` script, since methods `~sciexp2.launchgen.Launchgen.pack`, `~sciexp2.launchgen.Launchgen.generate` and `~sciexp2.launchgen.Launchgen.launcher` (see below) already take care of overwriting destination files only if their contents are outdated. Furthermore, the :ref:`launcher <launcher>` program is able to re-run only those experiments whose scripts or configuration files have been updated (e.g., generated with new contents since last run).
Compile and copy the simulator
------------------------------
As there is only one simulator, we can use `~sciexp2.launchgen.Launchgen.execute` right away to execute ``make`` from the current directory, and then use `~sciexp2.launchgen.Launchgen.pack` to copy the resulting binary into the output ``experiments`` directory::
l.execute("make", "-C", "./mysimulator")
# copied into 'experiments/bin/mysim'
l.pack("./mysimulator/mysim", "bin/mysim")
Find, compile and copy benchmarks
---------------------------------
Hard-coding the list of benchmarks is not desirable, so it is much better to dynamically detect them with `~sciexp2.launchgen.Launchgen.find_files` (unsurprisingly, it finds both files and directories)::
l.find_files("./mybenchsuite/[0-9]*\.@benchmark@/",
v_.benchmark != 'broken')
The first argument is an :term:`expression` to find all benchmark directories, which accepts both Python's regular expressions and SciExp²'s expressions with variable references at the same time. The following is an argument list with :term:`filters <filter>` (in this case with a single element) to narrow which of these directories we're interested in. In this case, we want to omit the benchmark directory *2.broken*, since we know it's broken, but we're eager to run all the rest before fixing it. Note that the filter uses the special variable `v_` (provided by `sciexp2.launchgen.env`), but we could have instead used a plain string to specify the same filter: ``"benchmark != 'broken'"``. Note also the trailing slash in the expression, which prevents matching the ``README`` and ``NEWS`` files under the ``mybenchsuite`` directory.
The result is that our `~sciexp2.launchgen.Launchgen` object now contains one element (an :term:`instance`) for each directory that matches the :term:`expression` in `~sciexp2.launchgen.Launchgen.find_files`, and each element contains the :term:`variable <variable>` specified in that expression, plus an additional ``FILE`` variable that contains the full path of what we've found. In the terms used by SciExp², each instance is :term:`extracted <extraction>` from the given :term:`expression` by using the found paths::
>>> l
Launchgen([Instance({'benchmark': 'foo', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'baz', 'FILE': './mybenchsuite/3.baz/'})],
out='./experiments')
Then, we call ``make`` into each of the selected benchmark directories, and copy the resulting binaries into the output directory::
# results in executing the following commands:
# make -C ./mybenchsuite/1.foo/
# make -C ./mybenchsuite/3.baz/
l.execute("make", "-C", "@FILE@")
# results in the following copies:
# ./mybenchsuite/1.foo/foo -> ./experiments/benchmarks/foo
# ./mybenchsuite/3.baz/baz -> ./experiments/benchmarks/baz
l.pack("@FILE@/@benchmark@", "benchmarks/@benchmark@")
Both command execution and file copying use :term:`expressions <expression>`, which are :term:`expanded <expansion>` for each of the :term:`instances <instance>` in the `~sciexp2.launchgen.Launchen` object. This results in executing ``make`` on each of the benchmark directories (since the command only references the ``@FILE@`` variable), and copying each of the per-benchmark binaries we just compiled.
.. note::
Higher level methods based on `~sciexp2.launchgen.Launchgen.find_files` are available for finding and parsing specific contents (e.g., `SPEC <http://www.spec.org>`_ benchmarks or `SimPoint <http://cseweb.ucsd.edu/~calder/simpoint/>`_ results). See `~sciexp2.launchgen.Launchgen` for details.
Define experiment parameters
----------------------------
Defining the experiment parameters is one of the heavy-weight operations, which is encapsulated in `~sciexp2.launchgen.Launchgen.params`. First of all, we want each benchmark to execute with different arguments, which are benchmark specific.
Let's start with the simpler ``foo`` benchmark, which has two possible input values (``small`` or ``big``). For that, we use `~sciexp2.launchgen.Launchgen.select` to get the sub-set of instances for that benchmark, and define their ``inputset`` and ``args`` parameter by applying `~sciexp2.launchgen.Launchgen.params` on that sub-set::
with l.select(v_.benchmark == 'foo') as s:
s.params(inputset="@args@",
args=["small", "big"])
If we look at the `~sciexp2.launchgen.Launchgen` object, it now has the variables defined by `~sciexp2.launchgen.Launchgen.params` only on the sub-set of instances we got from `~sciexp2.launchgen.Launchgen.select`::
>>> l
Launchgen([Instance({'benchmark': 'foo', 'inputset': 'small', 'args': 'small', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'foo', 'inputset': 'big', 'args': 'big', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'baz', 'FILE': './mybenchsuite/3.baz/'})],
out='./experiments')
The ``baz`` benchmark example is a bit more involved, since it has three input arguments (``arg1``, ``arg2`` and ``arg3``). The first two take any value in the 2-element range starting at zero, and the third takes the base-two logarithm of the sum of the first two arguments::
import math
with l.select(v_.benchmark == 'baz') as s:
s.params((v_.arg1 != 0) | (v_.arg2 != 0),
inputset="@arg1@@arg2@",
args="@arg1@ @arg2@ @arg3@",
arg1=range(2),
arg2=range(2),
arg3=defer(math.log, defer("arg1") + defer("arg2"), 2))
In this case, we define the argument list that we will later use to run the benchmark as a string with the benchmark arguments (``args``). Since we must define the value of the third argument as a function of the first two, we have to `~sciexp2.launchgen.defer` its calculation until we know ``arg1`` and ``arg2``. The outer call will `~sciexp2.launchgen.defer` the execution of the `math.log` function until all the values passed as arguments to it are known; in turn, these deferred arguments must be identified with calls to `~sciexp2.launchgen.defer`, passing the deferred variable name as an argument. If we apply any operator or function call on deferred results, the result will in turn be a value deferred until all the variables it depends on are known (i.e., ``defer("arg1") + defer("arg2")``). Note that in this case, `~sciexp2.launchgen.Launchgen.params` also has a filter to avoid having the first two arguments both at zero, since the logarithm is infinite.
Now, the `~sciexp2.launchgen.Launchgen` object would look like this::
>>> l
Launchgen([Instance({'benchmark': 'foo', 'inputset': 'small', 'args': 'small', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'foo', 'inputset': 'big', 'args': 'big', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'baz', 'inputset': '01', 'args': '0 1 0.0', 'arg1': '0', 'arg2': '1', 'arg2': '0.0', 'FILE': './mybenchsuite/3.baz/'}),
Instance({'benchmark': 'baz', 'inputset': '10', 'args': '1 0 0.0', 'arg1': '1', 'arg2': '0', 'arg2': '0.0', 'FILE': './mybenchsuite/3.baz/'}),
Instance({'benchmark': 'baz', 'inputset': '11', 'args': '1 1 1.0', 'arg1': '1', 'arg2': '1', 'arg3': '1.0', 'FILE': './mybenchsuite/3.baz/'})],
out='./experiments')
In both cases, we also generate the ``inputset`` variable, which will help us to uniquely identify each of the benchmark's input sets. Note that in most benchmark suites, the different input sets have a unique name or number assigned to each benchmark, and we could use that instead of building our own unique identifier value.
Finally, we also need to define the parameters we will use with our computer simulator (variables ``cores``, ``l1``, ``l2``, ``l1_assoc`` and ``l2_assoc``), together with filtering-out some configurations that the simulator does not support. Again, this will take each of the benchmark configurations and "extend" each of them with each of the simulator parameter combinations.::
l.params(v_.l1 <= v_.l2,
v_.l1_assoc <= v_.l2_assoc,
cores=range(1, 5),
l1=[2**x for x in range(1, 6)], # size in KB
l2=[2**x for x in range(1, 10)],
l1_assoc=[1, 2, 4],
l2_assoc=[1, 2, 4, 8])
.. note::
Using Python's ``with`` statement with `~sciexp2.launchgen.Launchgen.select` is not mandatory, but can improve code readability in these cases. The canonical way to use it instead would be to treat its result as a regular object::
s = l.select(...)
s.params(...)
.. warning::
The `filter <sciexp2.common.filter.PFilter>` used in the example above is implemented by overloading certain operations. As the logical *and* and logical *or* cannot be overloaded, it uses the bit-wise *and* and bit-wise *or* instead, which have a different operator precedence; thus parentheses must be used to evaluate the expression in the proper order.
More generally, `~sciexp2.launchgen.Launchgen.params` accepts any of the following value type (right-hand-side) for any of the specified variables (left-hand-side):
- *Immediate values*: Can be strings or anything that does not fit the following two categories. In the case of strings, they are treated as :term:`expressions <expression>`, which are :term:`translated <translation>` with the variable values of each :term:`instance`.
- *Value sequences*: Anything that can be iterated and is not a string (e.g., `range`, lists, etc.). If the values in a sequence are strings, they are treated as described above.
- *The* `~sciexp2.launchgen.defer` *function*: An alternative to using strings with variable references when the literal value is necessary for later operating with it.
As a result, the contents of the `~sciexp2.launchgen.Launchgen` object will contain the *cartesian product* of the original contents and the permutations of the newly defined parameters. If this is not desired, you can use different `~sciexp2.launchgen.Launchgen` objects, or can pass the ``append=True`` argument to append new entries instead of recombining them with the existing contents.
Generate simulator configuration files
--------------------------------------
The contents of a `~sciexp2.launchgen.Launchgen` can be used to generate files from an input template, by substituting variable references with the specific values on each instance. In this example, we have a template simulator configuration file in ``mysim.cfg.in`` with the following contents::
cores = @cores@
l1_size = @l1@ # Bytes
l1_assoc = @l1_assoc@
l2_size = @l2@ # Bytes
l2_assoc = @l2_assoc@
With `~sciexp2.launchgen.Launchgen.generate`, we can create a new configuration file from our template (``"conf/@cores@-@l1@-@l1_assoc@-@l2@-@[email protected]"``) for each parameter combination we defined above::
l.generate("mysim.cfg.in", "conf/@cores@-@l1@-@l1_assoc@-@l2@-@[email protected]",
# convert from KB into B
l1=defer("l1") * 1024,
l2=defer("l2") * 1024)
What `~sciexp2.launchgen.Launchgen.generate` does is, for each possible expansion of the second argument (which is an expression), take the file in the first argument (which could also be an expression), and use the instance corresponding to that expansion to :term:`translate <translation>` the file contents (the input file is, in fact, treated as a string whose contents are then translated).
Note that the configuration file expects ``@l1@`` and ``@l2@`` to be defined in Bytes, while we defined our parameters in KBytes. For that, we can use `~sciexp2.launchgen.Launchgen.generate` to also perform parameter recombination like `~sciexp2.launchgen.Launchgen.params`, so that we can "translate" the values for ``l1`` and ``l2`` "in-place". We could acoomplish the same by first invoking `~sciexp2.launchgen.Launchgen.params` and then `~sciexp2.launchgen.Launchgen.generate` (without any parameter arguments); the difference is that the parameter recombinations in `~sciexp2.launchgen.Launchgen.generate` will not modify the contents of our `~sciexp2.launchgen.Launchgen` object. This can be helpful to keep the parameters "clean" of intermediate variables and values by only defining them during the generation of specific files.
.. warning ::
For each possible simulation parameter combination, there exist multiple benchmark/argument combinations. That is, there are multiple instances in the contents that expand to the output file expression. When such things happen, the output file will only be generated once with the first instance expanding to that expression, and subsequent instances will simply show the message "*Skipping already generated file*".
Generate an execution script for each experiment
------------------------------------------------
The final step is to generate some scripts to actually run our experiments with all the selected benchmark, inputs and simulation parameter combinations. We could simply use `~sciexp2.launchgen.Launchgen.generate`, but `~sciexp2.launchgen.Launchgen.launcher` is an extension of it that already has some pre-defined templates, and produces some extra metadata to manage experiment execution with the :program:`launcher` program. We first have to decide which pre-defined template to use; all of them can be seen with :program:`launcher` :option:`--list-templates`. With that, we can now use :program:`launcher` :option:`--show-template` to inspect the template and see what variables we need to define for it to work.
In this example we will use the ``shell`` template. Looking at the output of ``launcher --show-template shell`` we can see that we only need to defined the ``CMD`` variable, which contains the actual command-line that will execute our experiment. Therefore, this will produce our experiment scripts::
l.launcher("shell", "jobs/@[email protected]",
# save some typing by defining these once and for all
ID="@benchmark@-@inputset@-@SIMID@",
SIMID="@cores@-@l1@-@l1_assoc@-@l2@-@l2_assoc@",
DONE="res/@[email protected]",
FAIL="res/@[email protected]",
CMD="""
# Python multi-line strings are handy to write commands in multiple lines
./bin/mysim -config conf/@[email protected] -output @DONE@ -bench ./benchmarks/@benchmark@ @args@
""")
The first two arguments are almost the same as in `~sciexp2.launchgen.Launchgen.generate`; selecting the pre-defined template to use and specifying the output file. The rest either define variables used by the template (``CMD``, ``DONE`` and ``FAIL``) or additional variables used by the former ones (``ID`` and ``SIMID``, which are used to save some typing).
The ``CMD`` variable contains the command-line to run the simulator with the specified configuration file, as well as a specific benchmark along with its arguments. It also instructs the simulator to save its output in the value of the ``DONE`` variable. Note ``DONE`` and ``FAIL`` are used by the shell template, but have default values that we are overriding for clarity.
Finally, this also generates the file ``jobs.jd`` in the output directory. The :program:`launcher` program will use this file to detect the available experiments, and will use the values of the ``DONE`` and ``FAIL`` variables to known which experiments have already been run and, if so, which of these failed.
.. note::
You should also take a look at `~sciexp2.launchgen.Launchgen.launcher`'s ``export`` argument, which will make the variables listed in it available to the :program:`launcher` program, so that you can, for example, run sub-sets of your experiments depending on their configuration parameters.
Argument ``DEPENDS`` is also handy to know when an experiment is outdated and needs re-execution; for example, the compiled simulator or one benchmark binary is newer that the result of its last execution. Coupled with the behaviour of the file-copying and file-generation methods, `~sciexp2.launcher` will always keep track of what experiments get out-of-date.
Writing new templates
---------------------
Sometimes using some of the pre-defined templates is not enough, but the program :program:`launcher` is still very handy to keep track of the state of our experiments. You can override the contents of an existing template by creating a file with the same name as the template (e.g., for the previous example, create ``shell.tpl`` in the same directory where you have ``generate.py``).
For even greater flexibility, you can also extend the set of available templates by creating the appropriate files, which can reside in any of the directories listed in `~sciexp2.templates.SEARCH_PATH`, which by default includes the current directory.
.. seealso:: `sciexp2.templates`
Wrap-up
-------
To wrap things up, here's the contents of the ``generate.py`` file covering the whole example::
#!/usr/bin/env python
# -*- python -*-
import math
from sciexp2.launchgen.env import *
l = Launchgen(out="./experiments")
# compile & copy simulator
l.execute("make", "-C", "./mysimulator")
l.pack("./mysimulator/mysim", "bin/mysim")
# find & compile & copy benchmarks
l.find_files("./mybenchsuite/[0-9]*\.@benchmark@/",
v_.benchmark != 'broken')
l.execute("make", "-C", "@FILE@")
l.pack("@FILE@/@benchmark@", "benchmarks/@benchmark@")
# benchmark arguments
with l.select(v_.benchmark == 'foo') as s:
s.params(inputset="@args@",
args=["small", "big"])
with l.select(v_.benchmark == 'baz') as s:
s.params((v_.arg1 != 0) | (v_.arg2 != 0),
inputset="@arg1@@arg2@",
args="@arg1@ @arg2@ @arg3@",
arg1=range(2),
arg2=range(2),
arg3=defer(math.log, defer("arg1") + defer("arg2"), 2))
# simulation parameters
l.params(v_.l1 <= v_.l2,
v_.l1_assoc <= v_.l2_assoc,
cores=range(1, 5),
l1=[2**x for x in range(1, 6)], # size in KB
l2=[2**x for x in range(1, 10)],
l1_assoc=[1, 2, 4],
l2_assoc=[1, 2, 4, 8])
# simulator config file
l.generate("mysim.cfg.in", "conf/@cores@-@l1@-@l1_assoc@-@l2@-@[email protected]",
# convert from KB into B
l1=defer("l1") * 1024,
l2=defer("l2") * 1024)
# generate execution scripts
l.launcher("shell", "jobs/@[email protected]",
# save some typing by defining these once and for all
ID="@benchmark@-@inputset@-@SIMID@",
SIMID="@cores@-@l1@-@l1_assoc@-@l2@-@l2_assoc@",
DONE="res/@[email protected]",
FAIL="res/@[email protected]",
CMD="""
# Python multi-line strings are handy to write commands in multiple lines
./bin/mysim -config conf/@[email protected] -output @DONE@ -bench ./benchmarks/@benchmark@ @args@
""")
Although this might look unnecessarily long, `~sciexp2.launchgen.Launchgen`'s ability to concisely specify parameter permutations and apply filters on them can keep large parameter explorations under control. If you couple that with the ability to track the execution state of experiments with the :program:`launcher` program, that becomes even more convenient.
| sciexp2 | /sciexp2-1.1.13.tar.gz/sciexp2-1.1.13/doc/user_guide/launchgen.rst | launchgen.rst | .. _launchgen:
Experiment creation --- `~sciexp2.launchgen`
============================================
The goal of the `~sciexp2.launchgen` module is to define a set of experiments and create a self-contained directory with all the files necessary for running these experiments. The reason to make it self-contained is that this directory can then be moved into the system(s) where the experiments must be run (e.g., a cluster, or some other machine different from the development one).
For the sake of making the description more tangible, this guide will show how to generate experiments to evaluate all benchmarks on a simple benchmark suite (``mybenchsuite``), where each benchmark is run with different input sets inside a computer simulator program (``mysim``) that uses different configuration parameters (specified in a configuration file). Thus, each experiment will be defined by the tuple comprised of the benchmark name, the benchmark's input set, and the different configuration parameter permutations defined by the user. The initial file organization is the following::
.
|- generate.py # the experiment-generation script described here
|- mysimulator # source code for the simulator
| |- Makefile
| `- mysim.c
|- mysim.cfg.in # template configuration file for the simulator
`- mybenchsuite # benchmark suite
|- 1.foo # source code for a specific benchmark
| |- source.c
| `- Makefile
|- 2.broken
| |- source.c
| `- Makefile
|- 3.baz
| |- source.c
| `- Makefile
|- README # files that can be ignored
`- NEWS
This is the roadmap to create an ``experiments`` directory that will contain all the necessary pieces to run our experiments:
#. Execute external programs to compile the simulator and the benchmarks.
#. Copy files for the simulator and each of the selected benchmarks into the ``experiments`` directory.
#. Define different sets of arguments to run the benchmarks with different inputs.
#. Define different configuration parameter combinations for the simulator.
#. Generate a simulator configuration file for each set of simulation parameters, and generate a script for each combination of simulator parameters, benchmark and benchmark input sets. These files are generated from templates by :term:`translating <translation>` any :term:`variable` they reference in their contents with the values specified by us.
This example also showcases some of the more advanced features of `~sciexp2.launchgen`, but you can first take a look at :ref:`quick_example` for a much shorter and simpler example.
Script preparation
------------------
All the functions typically used in a `~sciexp2.launchgen` script are available in the `sciexp2.launchgen.env` module, so we can import its contents to make them available at the top level::
#!/usr/bin/env python
# -*- python -*-
from sciexp2.launchgen.env import *
# file contents ...
Directory preparation
---------------------
First, we create a `~sciexp2.launchgen.Launchgen` object with its output directory set, where all generated files will be placed::
l = Launchgen(out="./experiments")
This object is initially empty, and only has the output directory set::
>>> l
Launchgen(out='./experiments')
.. note::
It is usually recommended to *not* remove the output directory when re-executing a `~sciexp2.launchgen` script, since methods `~sciexp2.launchgen.Launchgen.pack`, `~sciexp2.launchgen.Launchgen.generate` and `~sciexp2.launchgen.Launchgen.launcher` (see below) already take care of overwriting destination files only if their contents are outdated. Furthermore, the :ref:`launcher <launcher>` program is able to re-run only those experiments whose scripts or configuration files have been updated (e.g., generated with new contents since last run).
Compile and copy the simulator
------------------------------
As there is only one simulator, we can use `~sciexp2.launchgen.Launchgen.execute` right away to execute ``make`` from the current directory, and then use `~sciexp2.launchgen.Launchgen.pack` to copy the resulting binary into the output ``experiments`` directory::
l.execute("make", "-C", "./mysimulator")
# copied into 'experiments/bin/mysim'
l.pack("./mysimulator/mysim", "bin/mysim")
Find, compile and copy benchmarks
---------------------------------
Hard-coding the list of benchmarks is not desirable, so it is much better to dynamically detect them with `~sciexp2.launchgen.Launchgen.find_files` (unsurprisingly, it finds both files and directories)::
l.find_files("./mybenchsuite/[0-9]*\.@benchmark@/",
v_.benchmark != 'broken')
The first argument is an :term:`expression` to find all benchmark directories, which accepts both Python's regular expressions and SciExp²'s expressions with variable references at the same time. The following is an argument list with :term:`filters <filter>` (in this case with a single element) to narrow which of these directories we're interested in. In this case, we want to omit the benchmark directory *2.broken*, since we know it's broken, but we're eager to run all the rest before fixing it. Note that the filter uses the special variable `v_` (provided by `sciexp2.launchgen.env`), but we could have instead used a plain string to specify the same filter: ``"benchmark != 'broken'"``. Note also the trailing slash in the expression, which prevents matching the ``README`` and ``NEWS`` files under the ``mybenchsuite`` directory.
The result is that our `~sciexp2.launchgen.Launchgen` object now contains one element (an :term:`instance`) for each directory that matches the :term:`expression` in `~sciexp2.launchgen.Launchgen.find_files`, and each element contains the :term:`variable <variable>` specified in that expression, plus an additional ``FILE`` variable that contains the full path of what we've found. In the terms used by SciExp², each instance is :term:`extracted <extraction>` from the given :term:`expression` by using the found paths::
>>> l
Launchgen([Instance({'benchmark': 'foo', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'baz', 'FILE': './mybenchsuite/3.baz/'})],
out='./experiments')
Then, we call ``make`` into each of the selected benchmark directories, and copy the resulting binaries into the output directory::
# results in executing the following commands:
# make -C ./mybenchsuite/1.foo/
# make -C ./mybenchsuite/3.baz/
l.execute("make", "-C", "@FILE@")
# results in the following copies:
# ./mybenchsuite/1.foo/foo -> ./experiments/benchmarks/foo
# ./mybenchsuite/3.baz/baz -> ./experiments/benchmarks/baz
l.pack("@FILE@/@benchmark@", "benchmarks/@benchmark@")
Both command execution and file copying use :term:`expressions <expression>`, which are :term:`expanded <expansion>` for each of the :term:`instances <instance>` in the `~sciexp2.launchgen.Launchen` object. This results in executing ``make`` on each of the benchmark directories (since the command only references the ``@FILE@`` variable), and copying each of the per-benchmark binaries we just compiled.
.. note::
Higher level methods based on `~sciexp2.launchgen.Launchgen.find_files` are available for finding and parsing specific contents (e.g., `SPEC <http://www.spec.org>`_ benchmarks or `SimPoint <http://cseweb.ucsd.edu/~calder/simpoint/>`_ results). See `~sciexp2.launchgen.Launchgen` for details.
Define experiment parameters
----------------------------
Defining the experiment parameters is one of the heavy-weight operations, which is encapsulated in `~sciexp2.launchgen.Launchgen.params`. First of all, we want each benchmark to execute with different arguments, which are benchmark specific.
Let's start with the simpler ``foo`` benchmark, which has two possible input values (``small`` or ``big``). For that, we use `~sciexp2.launchgen.Launchgen.select` to get the sub-set of instances for that benchmark, and define their ``inputset`` and ``args`` parameter by applying `~sciexp2.launchgen.Launchgen.params` on that sub-set::
with l.select(v_.benchmark == 'foo') as s:
s.params(inputset="@args@",
args=["small", "big"])
If we look at the `~sciexp2.launchgen.Launchgen` object, it now has the variables defined by `~sciexp2.launchgen.Launchgen.params` only on the sub-set of instances we got from `~sciexp2.launchgen.Launchgen.select`::
>>> l
Launchgen([Instance({'benchmark': 'foo', 'inputset': 'small', 'args': 'small', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'foo', 'inputset': 'big', 'args': 'big', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'baz', 'FILE': './mybenchsuite/3.baz/'})],
out='./experiments')
The ``baz`` benchmark example is a bit more involved, since it has three input arguments (``arg1``, ``arg2`` and ``arg3``). The first two take any value in the 2-element range starting at zero, and the third takes the base-two logarithm of the sum of the first two arguments::
import math
with l.select(v_.benchmark == 'baz') as s:
s.params((v_.arg1 != 0) | (v_.arg2 != 0),
inputset="@arg1@@arg2@",
args="@arg1@ @arg2@ @arg3@",
arg1=range(2),
arg2=range(2),
arg3=defer(math.log, defer("arg1") + defer("arg2"), 2))
In this case, we define the argument list that we will later use to run the benchmark as a string with the benchmark arguments (``args``). Since we must define the value of the third argument as a function of the first two, we have to `~sciexp2.launchgen.defer` its calculation until we know ``arg1`` and ``arg2``. The outer call will `~sciexp2.launchgen.defer` the execution of the `math.log` function until all the values passed as arguments to it are known; in turn, these deferred arguments must be identified with calls to `~sciexp2.launchgen.defer`, passing the deferred variable name as an argument. If we apply any operator or function call on deferred results, the result will in turn be a value deferred until all the variables it depends on are known (i.e., ``defer("arg1") + defer("arg2")``). Note that in this case, `~sciexp2.launchgen.Launchgen.params` also has a filter to avoid having the first two arguments both at zero, since the logarithm is infinite.
Now, the `~sciexp2.launchgen.Launchgen` object would look like this::
>>> l
Launchgen([Instance({'benchmark': 'foo', 'inputset': 'small', 'args': 'small', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'foo', 'inputset': 'big', 'args': 'big', 'FILE': './mybenchsuite/1.foo/'}),
Instance({'benchmark': 'baz', 'inputset': '01', 'args': '0 1 0.0', 'arg1': '0', 'arg2': '1', 'arg2': '0.0', 'FILE': './mybenchsuite/3.baz/'}),
Instance({'benchmark': 'baz', 'inputset': '10', 'args': '1 0 0.0', 'arg1': '1', 'arg2': '0', 'arg2': '0.0', 'FILE': './mybenchsuite/3.baz/'}),
Instance({'benchmark': 'baz', 'inputset': '11', 'args': '1 1 1.0', 'arg1': '1', 'arg2': '1', 'arg3': '1.0', 'FILE': './mybenchsuite/3.baz/'})],
out='./experiments')
In both cases, we also generate the ``inputset`` variable, which will help us to uniquely identify each of the benchmark's input sets. Note that in most benchmark suites, the different input sets have a unique name or number assigned to each benchmark, and we could use that instead of building our own unique identifier value.
Finally, we also need to define the parameters we will use with our computer simulator (variables ``cores``, ``l1``, ``l2``, ``l1_assoc`` and ``l2_assoc``), together with filtering-out some configurations that the simulator does not support. Again, this will take each of the benchmark configurations and "extend" each of them with each of the simulator parameter combinations.::
l.params(v_.l1 <= v_.l2,
v_.l1_assoc <= v_.l2_assoc,
cores=range(1, 5),
l1=[2**x for x in range(1, 6)], # size in KB
l2=[2**x for x in range(1, 10)],
l1_assoc=[1, 2, 4],
l2_assoc=[1, 2, 4, 8])
.. note::
Using Python's ``with`` statement with `~sciexp2.launchgen.Launchgen.select` is not mandatory, but can improve code readability in these cases. The canonical way to use it instead would be to treat its result as a regular object::
s = l.select(...)
s.params(...)
.. warning::
The `filter <sciexp2.common.filter.PFilter>` used in the example above is implemented by overloading certain operations. As the logical *and* and logical *or* cannot be overloaded, it uses the bit-wise *and* and bit-wise *or* instead, which have a different operator precedence; thus parentheses must be used to evaluate the expression in the proper order.
More generally, `~sciexp2.launchgen.Launchgen.params` accepts any of the following value type (right-hand-side) for any of the specified variables (left-hand-side):
- *Immediate values*: Can be strings or anything that does not fit the following two categories. In the case of strings, they are treated as :term:`expressions <expression>`, which are :term:`translated <translation>` with the variable values of each :term:`instance`.
- *Value sequences*: Anything that can be iterated and is not a string (e.g., `range`, lists, etc.). If the values in a sequence are strings, they are treated as described above.
- *The* `~sciexp2.launchgen.defer` *function*: An alternative to using strings with variable references when the literal value is necessary for later operating with it.
As a result, the contents of the `~sciexp2.launchgen.Launchgen` object will contain the *cartesian product* of the original contents and the permutations of the newly defined parameters. If this is not desired, you can use different `~sciexp2.launchgen.Launchgen` objects, or can pass the ``append=True`` argument to append new entries instead of recombining them with the existing contents.
Generate simulator configuration files
--------------------------------------
The contents of a `~sciexp2.launchgen.Launchgen` can be used to generate files from an input template, by substituting variable references with the specific values on each instance. In this example, we have a template simulator configuration file in ``mysim.cfg.in`` with the following contents::
cores = @cores@
l1_size = @l1@ # Bytes
l1_assoc = @l1_assoc@
l2_size = @l2@ # Bytes
l2_assoc = @l2_assoc@
With `~sciexp2.launchgen.Launchgen.generate`, we can create a new configuration file from our template (``"conf/@cores@-@l1@-@l1_assoc@-@l2@-@[email protected]"``) for each parameter combination we defined above::
l.generate("mysim.cfg.in", "conf/@cores@-@l1@-@l1_assoc@-@l2@-@[email protected]",
# convert from KB into B
l1=defer("l1") * 1024,
l2=defer("l2") * 1024)
What `~sciexp2.launchgen.Launchgen.generate` does is, for each possible expansion of the second argument (which is an expression), take the file in the first argument (which could also be an expression), and use the instance corresponding to that expansion to :term:`translate <translation>` the file contents (the input file is, in fact, treated as a string whose contents are then translated).
Note that the configuration file expects ``@l1@`` and ``@l2@`` to be defined in Bytes, while we defined our parameters in KBytes. For that, we can use `~sciexp2.launchgen.Launchgen.generate` to also perform parameter recombination like `~sciexp2.launchgen.Launchgen.params`, so that we can "translate" the values for ``l1`` and ``l2`` "in-place". We could acoomplish the same by first invoking `~sciexp2.launchgen.Launchgen.params` and then `~sciexp2.launchgen.Launchgen.generate` (without any parameter arguments); the difference is that the parameter recombinations in `~sciexp2.launchgen.Launchgen.generate` will not modify the contents of our `~sciexp2.launchgen.Launchgen` object. This can be helpful to keep the parameters "clean" of intermediate variables and values by only defining them during the generation of specific files.
.. warning ::
For each possible simulation parameter combination, there exist multiple benchmark/argument combinations. That is, there are multiple instances in the contents that expand to the output file expression. When such things happen, the output file will only be generated once with the first instance expanding to that expression, and subsequent instances will simply show the message "*Skipping already generated file*".
Generate an execution script for each experiment
------------------------------------------------
The final step is to generate some scripts to actually run our experiments with all the selected benchmark, inputs and simulation parameter combinations. We could simply use `~sciexp2.launchgen.Launchgen.generate`, but `~sciexp2.launchgen.Launchgen.launcher` is an extension of it that already has some pre-defined templates, and produces some extra metadata to manage experiment execution with the :program:`launcher` program. We first have to decide which pre-defined template to use; all of them can be seen with :program:`launcher` :option:`--list-templates`. With that, we can now use :program:`launcher` :option:`--show-template` to inspect the template and see what variables we need to define for it to work.
In this example we will use the ``shell`` template. Looking at the output of ``launcher --show-template shell`` we can see that we only need to defined the ``CMD`` variable, which contains the actual command-line that will execute our experiment. Therefore, this will produce our experiment scripts::
l.launcher("shell", "jobs/@[email protected]",
# save some typing by defining these once and for all
ID="@benchmark@-@inputset@-@SIMID@",
SIMID="@cores@-@l1@-@l1_assoc@-@l2@-@l2_assoc@",
DONE="res/@[email protected]",
FAIL="res/@[email protected]",
CMD="""
# Python multi-line strings are handy to write commands in multiple lines
./bin/mysim -config conf/@[email protected] -output @DONE@ -bench ./benchmarks/@benchmark@ @args@
""")
The first two arguments are almost the same as in `~sciexp2.launchgen.Launchgen.generate`; selecting the pre-defined template to use and specifying the output file. The rest either define variables used by the template (``CMD``, ``DONE`` and ``FAIL``) or additional variables used by the former ones (``ID`` and ``SIMID``, which are used to save some typing).
The ``CMD`` variable contains the command-line to run the simulator with the specified configuration file, as well as a specific benchmark along with its arguments. It also instructs the simulator to save its output in the value of the ``DONE`` variable. Note ``DONE`` and ``FAIL`` are used by the shell template, but have default values that we are overriding for clarity.
Finally, this also generates the file ``jobs.jd`` in the output directory. The :program:`launcher` program will use this file to detect the available experiments, and will use the values of the ``DONE`` and ``FAIL`` variables to known which experiments have already been run and, if so, which of these failed.
.. note::
You should also take a look at `~sciexp2.launchgen.Launchgen.launcher`'s ``export`` argument, which will make the variables listed in it available to the :program:`launcher` program, so that you can, for example, run sub-sets of your experiments depending on their configuration parameters.
Argument ``DEPENDS`` is also handy to know when an experiment is outdated and needs re-execution; for example, the compiled simulator or one benchmark binary is newer that the result of its last execution. Coupled with the behaviour of the file-copying and file-generation methods, `~sciexp2.launcher` will always keep track of what experiments get out-of-date.
Writing new templates
---------------------
Sometimes using some of the pre-defined templates is not enough, but the program :program:`launcher` is still very handy to keep track of the state of our experiments. You can override the contents of an existing template by creating a file with the same name as the template (e.g., for the previous example, create ``shell.tpl`` in the same directory where you have ``generate.py``).
For even greater flexibility, you can also extend the set of available templates by creating the appropriate files, which can reside in any of the directories listed in `~sciexp2.templates.SEARCH_PATH`, which by default includes the current directory.
.. seealso:: `sciexp2.templates`
Wrap-up
-------
To wrap things up, here's the contents of the ``generate.py`` file covering the whole example::
#!/usr/bin/env python
# -*- python -*-
import math
from sciexp2.launchgen.env import *
l = Launchgen(out="./experiments")
# compile & copy simulator
l.execute("make", "-C", "./mysimulator")
l.pack("./mysimulator/mysim", "bin/mysim")
# find & compile & copy benchmarks
l.find_files("./mybenchsuite/[0-9]*\.@benchmark@/",
v_.benchmark != 'broken')
l.execute("make", "-C", "@FILE@")
l.pack("@FILE@/@benchmark@", "benchmarks/@benchmark@")
# benchmark arguments
with l.select(v_.benchmark == 'foo') as s:
s.params(inputset="@args@",
args=["small", "big"])
with l.select(v_.benchmark == 'baz') as s:
s.params((v_.arg1 != 0) | (v_.arg2 != 0),
inputset="@arg1@@arg2@",
args="@arg1@ @arg2@ @arg3@",
arg1=range(2),
arg2=range(2),
arg3=defer(math.log, defer("arg1") + defer("arg2"), 2))
# simulation parameters
l.params(v_.l1 <= v_.l2,
v_.l1_assoc <= v_.l2_assoc,
cores=range(1, 5),
l1=[2**x for x in range(1, 6)], # size in KB
l2=[2**x for x in range(1, 10)],
l1_assoc=[1, 2, 4],
l2_assoc=[1, 2, 4, 8])
# simulator config file
l.generate("mysim.cfg.in", "conf/@cores@-@l1@-@l1_assoc@-@l2@-@[email protected]",
# convert from KB into B
l1=defer("l1") * 1024,
l2=defer("l2") * 1024)
# generate execution scripts
l.launcher("shell", "jobs/@[email protected]",
# save some typing by defining these once and for all
ID="@benchmark@-@inputset@-@SIMID@",
SIMID="@cores@-@l1@-@l1_assoc@-@l2@-@l2_assoc@",
DONE="res/@[email protected]",
FAIL="res/@[email protected]",
CMD="""
# Python multi-line strings are handy to write commands in multiple lines
./bin/mysim -config conf/@[email protected] -output @DONE@ -bench ./benchmarks/@benchmark@ @args@
""")
Although this might look unnecessarily long, `~sciexp2.launchgen.Launchgen`'s ability to concisely specify parameter permutations and apply filters on them can keep large parameter explorations under control. If you couple that with the ability to track the execution state of experiments with the :program:`launcher` program, that becomes even more convenient.
| 0.913562 | 0.594434 |
# Scientific Filesystem (SCI-F)
[](https://github.com/vsoch/scif/actions?query=branch%3Amaster+workflow%3Aci)
[](https://circleci.com/gh/vsoch/scif)

[](https://asciinema.org/a/156490?speed=2)
The The Scientific Filesystem is an organizational format for scientific software and metadata.
Our goals are centered around **consistency**, **transparency**, **programmatic accessibility**,
and **modularity**. [Read about](https://sci-f.github.io) the format and
please [contribute](https://github.com/vsoch/scif/issues).
**Citation**
> Vanessa Sochat; The Scientific Filesystem, GigaScience, Volume 7, Issue 5, 1 May 2018, giy023, https://doi.org/10.1093/gigascience/giy023
## What is this?
This module will provide tools for generating and interacting with scientific
filesystems, optimized for use on a host or inside a container.
## License
This code is licensed under the Mozilla, version 2.0 or later [LICENSE](LICENSE).
| scif | /scif-0.0.81.tar.gz/scif-0.0.81/README.md | README.md | # Scientific Filesystem (SCI-F)
[](https://github.com/vsoch/scif/actions?query=branch%3Amaster+workflow%3Aci)
[](https://circleci.com/gh/vsoch/scif)

[](https://asciinema.org/a/156490?speed=2)
The The Scientific Filesystem is an organizational format for scientific software and metadata.
Our goals are centered around **consistency**, **transparency**, **programmatic accessibility**,
and **modularity**. [Read about](https://sci-f.github.io) the format and
please [contribute](https://github.com/vsoch/scif/issues).
**Citation**
> Vanessa Sochat; The Scientific Filesystem, GigaScience, Volume 7, Issue 5, 1 May 2018, giy023, https://doi.org/10.1093/gigascience/giy023
## What is this?
This module will provide tools for generating and interacting with scientific
filesystems, optimized for use on a host or inside a container.
## License
This code is licensed under the Mozilla, version 2.0 or later [LICENSE](LICENSE).
| 0.548915 | 0.569673 |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, gender identity and expression, level of experience,
education, socio-economic status, nationality, personal appearance, race,
religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the project team at `[email protected]`. All
complaints will be reviewed and investigated and will result in a response that
is deemed necessary and appropriate to the circumstances. The project team is
obligated to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
[homepage]: https://www.contributor-covenant.org
| scif | /scif-0.0.81.tar.gz/scif-0.0.81/.github/CODE_OF_CONDUCT.md | CODE_OF_CONDUCT.md | # Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, gender identity and expression, level of experience,
education, socio-economic status, nationality, personal appearance, race,
religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the project team at `[email protected]`. All
complaints will be reviewed and investigated and will result in a response that
is deemed necessary and appropriate to the circumstances. The project team is
obligated to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
[homepage]: https://www.contributor-covenant.org
| 0.543348 | 0.667039 |
scifig
======
scifig is a build tool for scientific figures but it could probably be used for non-scientific figures too.
This code basically defines rules to convert sources to final formats such as pdf, eps, svg, etc.
Some rules are defined for gnuplot or tikz figures for examples, but other rules can be defined, it should be easy to do so.
In few words, the idea is to drop your sources in a directory, the tool builds them in various formats and export the ready-to-use files in a directory. Each time you drop a new figure or you make edits, scifig works only on what needs to be rebuild.
It should provide:
* less file manipulations (formats, name...)
* more reproducibility
* source versioning
* automatic translations
This code is a rewritten version of a previous code named SciFigWorkflow. This tool was based on waf. The idea was to use a solid codebase, but it was difficult to maintain and to provide new evolutions to the workflow.
Documentation
=============
To learn more, read https://scifig.readthedocs.io
| scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/README.md | README.md | scifig
======
scifig is a build tool for scientific figures but it could probably be used for non-scientific figures too.
This code basically defines rules to convert sources to final formats such as pdf, eps, svg, etc.
Some rules are defined for gnuplot or tikz figures for examples, but other rules can be defined, it should be easy to do so.
In few words, the idea is to drop your sources in a directory, the tool builds them in various formats and export the ready-to-use files in a directory. Each time you drop a new figure or you make edits, scifig works only on what needs to be rebuild.
It should provide:
* less file manipulations (formats, name...)
* more reproducibility
* source versioning
* automatic translations
This code is a rewritten version of a previous code named SciFigWorkflow. This tool was based on waf. The idea was to use a solid codebase, but it was difficult to maintain and to provide new evolutions to the workflow.
Documentation
=============
To learn more, read https://scifig.readthedocs.io
| 0.559049 | 0.2578 |
How to install?
===============
Requirements
------------
The code is tested with python 3.4.
Po4a is an optional requirement (see below).
Package manager
---------------
* [Archlinux](https://aur.archlinux.org/packages/scifig/)
PyPI
----
`See Pypi <http://pypi.python.org/pypi/scifig/>`_
To install with pip:
.. code-block:: sh
pip install scifig
Manual installation
-------------------
From sources
.. code-block:: sh
python setup.py install
Files for po4a for translations (i18n)
-------------------------------------
Po4a part (optional)
According to your distribution, move pm files
located in po4a/ to
* /usr/share/perl5/vendor_perl/Locale/Po4a
* or /usr/share/perl5/Locale/Po4a (debian)
| scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/doc/source/install.rst | install.rst | How to install?
===============
Requirements
------------
The code is tested with python 3.4.
Po4a is an optional requirement (see below).
Package manager
---------------
* [Archlinux](https://aur.archlinux.org/packages/scifig/)
PyPI
----
`See Pypi <http://pypi.python.org/pypi/scifig/>`_
To install with pip:
.. code-block:: sh
pip install scifig
Manual installation
-------------------
From sources
.. code-block:: sh
python setup.py install
Files for po4a for translations (i18n)
-------------------------------------
Po4a part (optional)
According to your distribution, move pm files
located in po4a/ to
* /usr/share/perl5/vendor_perl/Locale/Po4a
* or /usr/share/perl5/Locale/Po4a (debian)
| 0.666497 | 0.30279 |
.. scifig documentation master file, created by
sphinx-quickstart on Sun Jul 13 21:56:43 2014.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
Welcome to scifig's documentation!
==================================
:Author: François Boulogne
:Devel: `github.com project <https://github.com/sciunto-org/scifig>`_
:Mirror: `git.sciunto.org <https://git.sciunto.org/mirror/scifig>`_
:Bugs: `github.com <https://github.com/sciunto-org/scifig/issues>`_
:Generated: |today|
:License: GPLv3
Contents:
.. toctree::
:maxdepth: 2
what.rst
install.rst
api.rst
tools.rst
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
| scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/doc/source/index.rst | index.rst | .. scifig documentation master file, created by
sphinx-quickstart on Sun Jul 13 21:56:43 2014.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
Welcome to scifig's documentation!
==================================
:Author: François Boulogne
:Devel: `github.com project <https://github.com/sciunto-org/scifig>`_
:Mirror: `git.sciunto.org <https://git.sciunto.org/mirror/scifig>`_
:Bugs: `github.com <https://github.com/sciunto-org/scifig/issues>`_
:Generated: |today|
:License: GPLv3
Contents:
.. toctree::
:maxdepth: 2
what.rst
install.rst
api.rst
tools.rst
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
| 0.497559 | 0.196826 |
What is it?
===========
Introduction
------------
Making figures for presentations, websites or publications usually take
a lot of time. However, the process is usually the same (compile,
convert and export). Thus, automation must be used to focus on the
content and not on managing files. Based on this observation, I
conceived a workflow and I wrote a software that automate this task.
The source code is available here: https://github.com/sciunto-org/scifig
Choices
-------
Languages and softwares for figures
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We need to choose a technology to make figures. I like to write code,
I'm efficient that way, so I choose LaTeX because I already use it for
my documents and my presentations. To draw figures, pstricks or Tikz can
be used. I tried both and Tikz looked to me more efficient (for loops
for instance). To make plots, I'm familiar with
`gnuplot <http://www.gnuplot.info/>`__ for almost a decade now. Gnuplot
has a tikz terminal and this is lucky. It will be very easy to combine
drawings and plots. For rare other needs (chemical formulae), LaTeX
usually have what we need.
`Ktikz <http://kde-apps.org/content/show.php/ktikz?content=63188>`__ and
`gummi <https://github.com/alexandervdm/gummi>`__ are really helpful to
prepare drawings. They refresh the output while you edit the code. It's
almost a live mode.
Output formats
~~~~~~~~~~~~~~
- tex (standalone file)
- eps
- pdf
- svg
Workflow
~~~~~~~~
Now, we need to find a strategy to make our figures.
Drawings
- tikz file: the code you write with Ktiz for instance, between \\begin
and \\end{tikzpicture}
- tex file: we decorate the tikz file with some packages and a document
class (standalone) to have a croped image
- pdf file: the tex file compiled with pdflatex
- eps file: pdf to eps
- svg file: pdf to svg
Plots with gnuplot
- plt file: this is the standard gnuplot script to make a figure, with
tikz terminal
- tikz file: code generated by gnuplot
- plttikz files: optional, inject tikz code before or after the code
generated by gnuplot. It allows to draw in plots!
- tex file: we decorate the plttikz file with some packages and a
document class (standalone) to have a cropped image
- pdf file: the tex file compiled with pdflatex
- eps file: pdf to eps
- svg file: pdf to svg
Others
Any other chain for another tool can be implemented, such as matplotlib
in python, which has a tikz terminal too.
Implementation
--------------
My first implementation (around 2007) was based on shell scripts and
makefile. Quickly coded, but not easy to maintain and the code tend to
become hard to read very rapidly.
The second implementation (around 2011) used
`waf <https://github.com/waf-project/waf>`__, a build to in python. The
idea was to reuse something existing rather than writing from scratch a
workflow. However, in practice, waf is not full adapted for the workflow
I need. I made a working version I used for almost 4-5 years, I found
interesting features (colored output, src and build separated, export
function) but the addition of new workflow would require a lot of
energy.
Then, I arrived to write a third version, from scratch since I know
perfectly what I need:
- a database to record what must be recompiled based on modifications
- a detector to guess the right rule to apply (based on file formats)
- a set of rules to build the figure
- a nice output
| scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/doc/source/what.rst | what.rst | What is it?
===========
Introduction
------------
Making figures for presentations, websites or publications usually take
a lot of time. However, the process is usually the same (compile,
convert and export). Thus, automation must be used to focus on the
content and not on managing files. Based on this observation, I
conceived a workflow and I wrote a software that automate this task.
The source code is available here: https://github.com/sciunto-org/scifig
Choices
-------
Languages and softwares for figures
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We need to choose a technology to make figures. I like to write code,
I'm efficient that way, so I choose LaTeX because I already use it for
my documents and my presentations. To draw figures, pstricks or Tikz can
be used. I tried both and Tikz looked to me more efficient (for loops
for instance). To make plots, I'm familiar with
`gnuplot <http://www.gnuplot.info/>`__ for almost a decade now. Gnuplot
has a tikz terminal and this is lucky. It will be very easy to combine
drawings and plots. For rare other needs (chemical formulae), LaTeX
usually have what we need.
`Ktikz <http://kde-apps.org/content/show.php/ktikz?content=63188>`__ and
`gummi <https://github.com/alexandervdm/gummi>`__ are really helpful to
prepare drawings. They refresh the output while you edit the code. It's
almost a live mode.
Output formats
~~~~~~~~~~~~~~
- tex (standalone file)
- eps
- pdf
- svg
Workflow
~~~~~~~~
Now, we need to find a strategy to make our figures.
Drawings
- tikz file: the code you write with Ktiz for instance, between \\begin
and \\end{tikzpicture}
- tex file: we decorate the tikz file with some packages and a document
class (standalone) to have a croped image
- pdf file: the tex file compiled with pdflatex
- eps file: pdf to eps
- svg file: pdf to svg
Plots with gnuplot
- plt file: this is the standard gnuplot script to make a figure, with
tikz terminal
- tikz file: code generated by gnuplot
- plttikz files: optional, inject tikz code before or after the code
generated by gnuplot. It allows to draw in plots!
- tex file: we decorate the plttikz file with some packages and a
document class (standalone) to have a cropped image
- pdf file: the tex file compiled with pdflatex
- eps file: pdf to eps
- svg file: pdf to svg
Others
Any other chain for another tool can be implemented, such as matplotlib
in python, which has a tikz terminal too.
Implementation
--------------
My first implementation (around 2007) was based on shell scripts and
makefile. Quickly coded, but not easy to maintain and the code tend to
become hard to read very rapidly.
The second implementation (around 2011) used
`waf <https://github.com/waf-project/waf>`__, a build to in python. The
idea was to reuse something existing rather than writing from scratch a
workflow. However, in practice, waf is not full adapted for the workflow
I need. I made a working version I used for almost 4-5 years, I found
interesting features (colored output, src and build separated, export
function) but the addition of new workflow would require a lot of
energy.
Then, I arrived to write a third version, from scratch since I know
perfectly what I need:
- a database to record what must be recompiled based on modifications
- a detector to guess the right rule to apply (based on file formats)
- a set of rules to build the figure
- a nice output
| 0.733261 | 0.528838 |
Search.setIndex({envversion:47,filenames:["api","index","install","what"],objects:{"":{collogging:[0,0,0,"-"],database:[0,0,0,"-"],detector:[0,0,0,"-"],task:[0,0,0,"-"]},"task.GnuplotTask":{"export":[0,1,1,""],check:[0,1,1,""],export_eps:[0,1,1,""],export_pdf:[0,1,1,""],export_png:[0,1,1,""],export_svg:[0,1,1,""],export_tex:[0,1,1,""],get_name:[0,1,1,""],make:[0,1,1,""]},"task.Task":{"export":[0,1,1,""],check:[0,1,1,""],export_eps:[0,1,1,""],export_pdf:[0,1,1,""],export_png:[0,1,1,""],export_svg:[0,1,1,""],export_tex:[0,1,1,""],get_name:[0,1,1,""],make:[0,1,1,""]},"task.TikzTask":{"export":[0,1,1,""],check:[0,1,1,""],export_eps:[0,1,1,""],export_pdf:[0,1,1,""],export_png:[0,1,1,""],export_svg:[0,1,1,""],export_tex:[0,1,1,""],get_name:[0,1,1,""],make:[0,1,1,""]},database:{check_modification:[0,2,1,""],erase_db:[0,2,1,""],store_checksum:[0,2,1,""]},detector:{detect_datafile:[0,2,1,""],detect_task:[0,2,1,""],detect_tikzsnippets:[0,2,1,""]},task:{GnuplotTask:[0,3,1,""],Task:[0,3,1,""],TikzTask:[0,3,1,""]}},objnames:{"0":["py","module","Python module"],"1":["py","method","Python method"],"2":["py","function","Python function"],"3":["py","class","Python class"]},objtypes:{"0":"py:module","1":"py:method","2":"py:function","3":"py:class"},terms:{"_pdf_to_ep":0,"_pdf_to_png":0,"_pdf_to_svg":0,"_pre_mak":0,"_tex_to_pdf":0,"boolean":0,"class":[0,3],"export":[0,3],"function":[0,3],"new":3,"public":3,"return":0,"while":3,accord:2,adapt:3,addit:3,after:3,all:0,allow:3,almost:3,alreadi:3,ani:3,anoth:3,appli:3,archlinux:2,around:3,arriv:3,associ:0,aur:2,autom:3,avail:3,base:[0,3],becaus:3,becom:3,befor:3,begin:3,below:2,between:3,both:3,build:[0,3],built:0,can:[0,3],chain:3,chang:0,check:0,check_modif:0,checksum:0,chemic:3,choic:[],choos:3,code:[2,3],color:3,com:3,combin:3,compil:[0,3],complex:0,compos:0,conceiv:3,content:[1,3],convert:[0,3],could:0,crop:3,crope:3,datafil:0,db_path:0,debian:2,decad:3,decor:3,depend:0,destin:0,detect:0,detect_datafil:0,detect_task:0,detect_tikzsnippet:0,dir:0,directori:0,distribut:2,done:0,draw:3,dst:0,each:0,easi:3,edit:3,effici:3,end:3,energi:3,eras:0,erase_db:0,exist:3,export_ep:0,export_pdf:0,export_png:0,export_svg:0,export_tex:0,extens:0,fals:0,familiar:3,featur:3,figur:[],file:[],filepath:0,find:3,first:3,focu:3,follow:0,format:[],formula:3,found:3,from:[2,3],full:3,gener:3,get_nam:0,github:3,gnuplot:[0,3],gnuplottask:0,guess:3,gummi:3,hard:3,have:3,help:3,here:3,how:[],howev:3,http:[2,3],i18n:[],idea:3,imag:3,implement:[],index:1,initi:0,inject:3,instal:[],instanc:3,interest:3,introduct:[],know:3,ktikz:3,ktiz:3,latex:3,least:0,like:3,list:0,live:3,local:2,locat:2,look:[0,3],loop:3,lot:3,lucki:3,made:3,main:0,maintain:3,make:[0,3],makefil:3,manag:[],manual:[],matplotlib:3,mode:3,modif:3,modul:1,more:3,move:2,must:3,name:0,need:[0,3],nice:3,now:3,object:0,observ:3,option:[2,3],org:[2,3],other:3,our:3,own:0,packag:[],page:1,paramet:0,parent:0,part:2,path:0,pdf:[0,3],pdflatex:3,perfectli:3,perl5:2,pip:2,plot:3,plt:[0,3],plttikz:3,png:0,po4a:[],practic:3,prepar:3,present:3,process:3,pstrick:3,pypi:[],python:[2,3],quickli:3,rapidli:3,rare:3,rather:3,read:3,realli:3,recompil:3,record:3,refresh:3,rel:0,requir:[],reus:3,right:3,role:0,root:0,root_path:0,rule:3,same:3,sciunto:3,scratch:3,script:3,search:1,second:3,see:2,separ:3,set:3,setup:2,sever:0,share:2,shell:3,sinc:3,some:3,someth:3,sourc:[0,2,3],src:3,standalon:3,standard:3,start:0,step:0,store:0,store_checksum:0,strategi:3,sub:0,svg:[0,3],take:3,technolog:3,tend:3,termin:3,test:2,tex:[0,3],than:3,thei:3,them:0,thi:3,third:3,thu:[0,3],tikz:[0,3],tikzpictur:3,tikzsnippet1:0,tikzsnippet2:0,tikzsnippet:0,tikztask:0,time:3,tmp:0,too:3,tool:3,transform:0,translat:[],tri:3,tupl:0,type:0,usr:2,usual:[0,3],vendor_perl:2,veri:3,version:3,waf:3,wai:3,websit:3,what:[],which:3,work:3,would:3,write:3,wrote:3,year:3,you:3,your:2},titles:["libscifig API","Welcome to scifig’s documentation!","How to install?","What is it?"],titleterms:{api:0,choic:3,collog:0,databas:0,detector:0,document:1,figur:3,file:2,format:3,how:2,i18n:2,implement:3,indic:1,instal:2,introduct:3,languag:3,libscifig:0,manag:2,manual:2,output:3,packag:2,po4a:2,pypi:2,requir:2,scifig:1,softwar:3,tabl:1,task:0,translat:2,welcom:1,what:3,workflow:3}}) | scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/doc/build/html/searchindex.js | searchindex.js | Search.setIndex({envversion:47,filenames:["api","index","install","what"],objects:{"":{collogging:[0,0,0,"-"],database:[0,0,0,"-"],detector:[0,0,0,"-"],task:[0,0,0,"-"]},"task.GnuplotTask":{"export":[0,1,1,""],check:[0,1,1,""],export_eps:[0,1,1,""],export_pdf:[0,1,1,""],export_png:[0,1,1,""],export_svg:[0,1,1,""],export_tex:[0,1,1,""],get_name:[0,1,1,""],make:[0,1,1,""]},"task.Task":{"export":[0,1,1,""],check:[0,1,1,""],export_eps:[0,1,1,""],export_pdf:[0,1,1,""],export_png:[0,1,1,""],export_svg:[0,1,1,""],export_tex:[0,1,1,""],get_name:[0,1,1,""],make:[0,1,1,""]},"task.TikzTask":{"export":[0,1,1,""],check:[0,1,1,""],export_eps:[0,1,1,""],export_pdf:[0,1,1,""],export_png:[0,1,1,""],export_svg:[0,1,1,""],export_tex:[0,1,1,""],get_name:[0,1,1,""],make:[0,1,1,""]},database:{check_modification:[0,2,1,""],erase_db:[0,2,1,""],store_checksum:[0,2,1,""]},detector:{detect_datafile:[0,2,1,""],detect_task:[0,2,1,""],detect_tikzsnippets:[0,2,1,""]},task:{GnuplotTask:[0,3,1,""],Task:[0,3,1,""],TikzTask:[0,3,1,""]}},objnames:{"0":["py","module","Python module"],"1":["py","method","Python method"],"2":["py","function","Python function"],"3":["py","class","Python class"]},objtypes:{"0":"py:module","1":"py:method","2":"py:function","3":"py:class"},terms:{"_pdf_to_ep":0,"_pdf_to_png":0,"_pdf_to_svg":0,"_pre_mak":0,"_tex_to_pdf":0,"boolean":0,"class":[0,3],"export":[0,3],"function":[0,3],"new":3,"public":3,"return":0,"while":3,accord:2,adapt:3,addit:3,after:3,all:0,allow:3,almost:3,alreadi:3,ani:3,anoth:3,appli:3,archlinux:2,around:3,arriv:3,associ:0,aur:2,autom:3,avail:3,base:[0,3],becaus:3,becom:3,befor:3,begin:3,below:2,between:3,both:3,build:[0,3],built:0,can:[0,3],chain:3,chang:0,check:0,check_modif:0,checksum:0,chemic:3,choic:[],choos:3,code:[2,3],color:3,com:3,combin:3,compil:[0,3],complex:0,compos:0,conceiv:3,content:[1,3],convert:[0,3],could:0,crop:3,crope:3,datafil:0,db_path:0,debian:2,decad:3,decor:3,depend:0,destin:0,detect:0,detect_datafil:0,detect_task:0,detect_tikzsnippet:0,dir:0,directori:0,distribut:2,done:0,draw:3,dst:0,each:0,easi:3,edit:3,effici:3,end:3,energi:3,eras:0,erase_db:0,exist:3,export_ep:0,export_pdf:0,export_png:0,export_svg:0,export_tex:0,extens:0,fals:0,familiar:3,featur:3,figur:[],file:[],filepath:0,find:3,first:3,focu:3,follow:0,format:[],formula:3,found:3,from:[2,3],full:3,gener:3,get_nam:0,github:3,gnuplot:[0,3],gnuplottask:0,guess:3,gummi:3,hard:3,have:3,help:3,here:3,how:[],howev:3,http:[2,3],i18n:[],idea:3,imag:3,implement:[],index:1,initi:0,inject:3,instal:[],instanc:3,interest:3,introduct:[],know:3,ktikz:3,ktiz:3,latex:3,least:0,like:3,list:0,live:3,local:2,locat:2,look:[0,3],loop:3,lot:3,lucki:3,made:3,main:0,maintain:3,make:[0,3],makefil:3,manag:[],manual:[],matplotlib:3,mode:3,modif:3,modul:1,more:3,move:2,must:3,name:0,need:[0,3],nice:3,now:3,object:0,observ:3,option:[2,3],org:[2,3],other:3,our:3,own:0,packag:[],page:1,paramet:0,parent:0,part:2,path:0,pdf:[0,3],pdflatex:3,perfectli:3,perl5:2,pip:2,plot:3,plt:[0,3],plttikz:3,png:0,po4a:[],practic:3,prepar:3,present:3,process:3,pstrick:3,pypi:[],python:[2,3],quickli:3,rapidli:3,rare:3,rather:3,read:3,realli:3,recompil:3,record:3,refresh:3,rel:0,requir:[],reus:3,right:3,role:0,root:0,root_path:0,rule:3,same:3,sciunto:3,scratch:3,script:3,search:1,second:3,see:2,separ:3,set:3,setup:2,sever:0,share:2,shell:3,sinc:3,some:3,someth:3,sourc:[0,2,3],src:3,standalon:3,standard:3,start:0,step:0,store:0,store_checksum:0,strategi:3,sub:0,svg:[0,3],take:3,technolog:3,tend:3,termin:3,test:2,tex:[0,3],than:3,thei:3,them:0,thi:3,third:3,thu:[0,3],tikz:[0,3],tikzpictur:3,tikzsnippet1:0,tikzsnippet2:0,tikzsnippet:0,tikztask:0,time:3,tmp:0,too:3,tool:3,transform:0,translat:[],tri:3,tupl:0,type:0,usr:2,usual:[0,3],vendor_perl:2,veri:3,version:3,waf:3,wai:3,websit:3,what:[],which:3,work:3,would:3,write:3,wrote:3,year:3,you:3,your:2},titles:["libscifig API","Welcome to scifig’s documentation!","How to install?","What is it?"],titleterms:{api:0,choic:3,collog:0,databas:0,detector:0,document:1,figur:3,file:2,format:3,how:2,i18n:2,implement:3,indic:1,instal:2,introduct:3,languag:3,libscifig:0,manag:2,manual:2,output:3,packag:2,po4a:2,pypi:2,requir:2,scifig:1,softwar:3,tabl:1,task:0,translat:2,welcom:1,what:3,workflow:3}}) | 0.191781 | 0.145722 |
* select a different prefix for underscore
*/
$u = _.noConflict();
/**
* make the code below compatible with browsers without
* an installed firebug like debugger
if (!window.console || !console.firebug) {
var names = ["log", "debug", "info", "warn", "error", "assert", "dir",
"dirxml", "group", "groupEnd", "time", "timeEnd", "count", "trace",
"profile", "profileEnd"];
window.console = {};
for (var i = 0; i < names.length; ++i)
window.console[names[i]] = function() {};
}
*/
/**
* small helper function to urldecode strings
*/
jQuery.urldecode = function(x) {
return decodeURIComponent(x).replace(/\+/g, ' ');
};
/**
* small helper function to urlencode strings
*/
jQuery.urlencode = encodeURIComponent;
/**
* This function returns the parsed url parameters of the
* current request. Multiple values per key are supported,
* it will always return arrays of strings for the value parts.
*/
jQuery.getQueryParameters = function(s) {
if (typeof s == 'undefined')
s = document.location.search;
var parts = s.substr(s.indexOf('?') + 1).split('&');
var result = {};
for (var i = 0; i < parts.length; i++) {
var tmp = parts[i].split('=', 2);
var key = jQuery.urldecode(tmp[0]);
var value = jQuery.urldecode(tmp[1]);
if (key in result)
result[key].push(value);
else
result[key] = [value];
}
return result;
};
/**
* highlight a given string on a jquery object by wrapping it in
* span elements with the given class name.
*/
jQuery.fn.highlightText = function(text, className) {
function highlight(node) {
if (node.nodeType == 3) {
var val = node.nodeValue;
var pos = val.toLowerCase().indexOf(text);
if (pos >= 0 && !jQuery(node.parentNode).hasClass(className)) {
var span = document.createElement("span");
span.className = className;
span.appendChild(document.createTextNode(val.substr(pos, text.length)));
node.parentNode.insertBefore(span, node.parentNode.insertBefore(
document.createTextNode(val.substr(pos + text.length)),
node.nextSibling));
node.nodeValue = val.substr(0, pos);
}
}
else if (!jQuery(node).is("button, select, textarea")) {
jQuery.each(node.childNodes, function() {
highlight(this);
});
}
}
return this.each(function() {
highlight(this);
});
};
/*
* backward compatibility for jQuery.browser
* This will be supported until firefox bug is fixed.
*/
if (!jQuery.browser) {
jQuery.uaMatch = function(ua) {
ua = ua.toLowerCase();
var match = /(chrome)[ \/]([\w.]+)/.exec(ua) ||
/(webkit)[ \/]([\w.]+)/.exec(ua) ||
/(opera)(?:.*version|)[ \/]([\w.]+)/.exec(ua) ||
/(msie) ([\w.]+)/.exec(ua) ||
ua.indexOf("compatible") < 0 && /(mozilla)(?:.*? rv:([\w.]+)|)/.exec(ua) ||
[];
return {
browser: match[ 1 ] || "",
version: match[ 2 ] || "0"
};
};
jQuery.browser = {};
jQuery.browser[jQuery.uaMatch(navigator.userAgent).browser] = true;
}
/**
* Small JavaScript module for the documentation.
*/
var Documentation = {
init : function() {
this.fixFirefoxAnchorBug();
this.highlightSearchWords();
this.initIndexTable();
},
/**
* i18n support
*/
TRANSLATIONS : {},
PLURAL_EXPR : function(n) { return n == 1 ? 0 : 1; },
LOCALE : 'unknown',
// gettext and ngettext don't access this so that the functions
// can safely bound to a different name (_ = Documentation.gettext)
gettext : function(string) {
var translated = Documentation.TRANSLATIONS[string];
if (typeof translated == 'undefined')
return string;
return (typeof translated == 'string') ? translated : translated[0];
},
ngettext : function(singular, plural, n) {
var translated = Documentation.TRANSLATIONS[singular];
if (typeof translated == 'undefined')
return (n == 1) ? singular : plural;
return translated[Documentation.PLURALEXPR(n)];
},
addTranslations : function(catalog) {
for (var key in catalog.messages)
this.TRANSLATIONS[key] = catalog.messages[key];
this.PLURAL_EXPR = new Function('n', 'return +(' + catalog.plural_expr + ')');
this.LOCALE = catalog.locale;
},
/**
* add context elements like header anchor links
*/
addContextElements : function() {
$('div[id] > :header:first').each(function() {
$('<a class="headerlink">\u00B6</a>').
attr('href', '#' + this.id).
attr('title', _('Permalink to this headline')).
appendTo(this);
});
$('dt[id]').each(function() {
$('<a class="headerlink">\u00B6</a>').
attr('href', '#' + this.id).
attr('title', _('Permalink to this definition')).
appendTo(this);
});
},
/**
* workaround a firefox stupidity
* see: https://bugzilla.mozilla.org/show_bug.cgi?id=645075
*/
fixFirefoxAnchorBug : function() {
if (document.location.hash)
window.setTimeout(function() {
document.location.href += '';
}, 10);
},
/**
* highlight the search words provided in the url in the text
*/
highlightSearchWords : function() {
var params = $.getQueryParameters();
var terms = (params.highlight) ? params.highlight[0].split(/\s+/) : [];
if (terms.length) {
var body = $('div.body');
if (!body.length) {
body = $('body');
}
window.setTimeout(function() {
$.each(terms, function() {
body.highlightText(this.toLowerCase(), 'highlighted');
});
}, 10);
$('<p class="highlight-link"><a href="javascript:Documentation.' +
'hideSearchWords()">' + _('Hide Search Matches') + '</a></p>')
.appendTo($('#searchbox'));
}
},
/**
* init the domain index toggle buttons
*/
initIndexTable : function() {
var togglers = $('img.toggler').click(function() {
var src = $(this).attr('src');
var idnum = $(this).attr('id').substr(7);
$('tr.cg-' + idnum).toggle();
if (src.substr(-9) == 'minus.png')
$(this).attr('src', src.substr(0, src.length-9) + 'plus.png');
else
$(this).attr('src', src.substr(0, src.length-8) + 'minus.png');
}).css('display', '');
if (DOCUMENTATION_OPTIONS.COLLAPSE_INDEX) {
togglers.click();
}
},
/**
* helper function to hide the search marks again
*/
hideSearchWords : function() {
$('#searchbox .highlight-link').fadeOut(300);
$('span.highlighted').removeClass('highlighted');
},
/**
* make the url absolute
*/
makeURL : function(relativeURL) {
return DOCUMENTATION_OPTIONS.URL_ROOT + '/' + relativeURL;
},
/**
* get the current relative url
*/
getCurrentURL : function() {
var path = document.location.pathname;
var parts = path.split(/\//);
$.each(DOCUMENTATION_OPTIONS.URL_ROOT.split(/\//), function() {
if (this == '..')
parts.pop();
});
var url = parts.join('/');
return path.substring(url.lastIndexOf('/') + 1, path.length - 1);
}
};
// quick alias for translations
_ = Documentation.gettext;
$(document).ready(function() {
Documentation.init();
}); | scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/doc/build/html/_static/doctools.js | doctools.js | * select a different prefix for underscore
*/
$u = _.noConflict();
/**
* make the code below compatible with browsers without
* an installed firebug like debugger
if (!window.console || !console.firebug) {
var names = ["log", "debug", "info", "warn", "error", "assert", "dir",
"dirxml", "group", "groupEnd", "time", "timeEnd", "count", "trace",
"profile", "profileEnd"];
window.console = {};
for (var i = 0; i < names.length; ++i)
window.console[names[i]] = function() {};
}
*/
/**
* small helper function to urldecode strings
*/
jQuery.urldecode = function(x) {
return decodeURIComponent(x).replace(/\+/g, ' ');
};
/**
* small helper function to urlencode strings
*/
jQuery.urlencode = encodeURIComponent;
/**
* This function returns the parsed url parameters of the
* current request. Multiple values per key are supported,
* it will always return arrays of strings for the value parts.
*/
jQuery.getQueryParameters = function(s) {
if (typeof s == 'undefined')
s = document.location.search;
var parts = s.substr(s.indexOf('?') + 1).split('&');
var result = {};
for (var i = 0; i < parts.length; i++) {
var tmp = parts[i].split('=', 2);
var key = jQuery.urldecode(tmp[0]);
var value = jQuery.urldecode(tmp[1]);
if (key in result)
result[key].push(value);
else
result[key] = [value];
}
return result;
};
/**
* highlight a given string on a jquery object by wrapping it in
* span elements with the given class name.
*/
jQuery.fn.highlightText = function(text, className) {
function highlight(node) {
if (node.nodeType == 3) {
var val = node.nodeValue;
var pos = val.toLowerCase().indexOf(text);
if (pos >= 0 && !jQuery(node.parentNode).hasClass(className)) {
var span = document.createElement("span");
span.className = className;
span.appendChild(document.createTextNode(val.substr(pos, text.length)));
node.parentNode.insertBefore(span, node.parentNode.insertBefore(
document.createTextNode(val.substr(pos + text.length)),
node.nextSibling));
node.nodeValue = val.substr(0, pos);
}
}
else if (!jQuery(node).is("button, select, textarea")) {
jQuery.each(node.childNodes, function() {
highlight(this);
});
}
}
return this.each(function() {
highlight(this);
});
};
/*
* backward compatibility for jQuery.browser
* This will be supported until firefox bug is fixed.
*/
if (!jQuery.browser) {
jQuery.uaMatch = function(ua) {
ua = ua.toLowerCase();
var match = /(chrome)[ \/]([\w.]+)/.exec(ua) ||
/(webkit)[ \/]([\w.]+)/.exec(ua) ||
/(opera)(?:.*version|)[ \/]([\w.]+)/.exec(ua) ||
/(msie) ([\w.]+)/.exec(ua) ||
ua.indexOf("compatible") < 0 && /(mozilla)(?:.*? rv:([\w.]+)|)/.exec(ua) ||
[];
return {
browser: match[ 1 ] || "",
version: match[ 2 ] || "0"
};
};
jQuery.browser = {};
jQuery.browser[jQuery.uaMatch(navigator.userAgent).browser] = true;
}
/**
* Small JavaScript module for the documentation.
*/
var Documentation = {
init : function() {
this.fixFirefoxAnchorBug();
this.highlightSearchWords();
this.initIndexTable();
},
/**
* i18n support
*/
TRANSLATIONS : {},
PLURAL_EXPR : function(n) { return n == 1 ? 0 : 1; },
LOCALE : 'unknown',
// gettext and ngettext don't access this so that the functions
// can safely bound to a different name (_ = Documentation.gettext)
gettext : function(string) {
var translated = Documentation.TRANSLATIONS[string];
if (typeof translated == 'undefined')
return string;
return (typeof translated == 'string') ? translated : translated[0];
},
ngettext : function(singular, plural, n) {
var translated = Documentation.TRANSLATIONS[singular];
if (typeof translated == 'undefined')
return (n == 1) ? singular : plural;
return translated[Documentation.PLURALEXPR(n)];
},
addTranslations : function(catalog) {
for (var key in catalog.messages)
this.TRANSLATIONS[key] = catalog.messages[key];
this.PLURAL_EXPR = new Function('n', 'return +(' + catalog.plural_expr + ')');
this.LOCALE = catalog.locale;
},
/**
* add context elements like header anchor links
*/
addContextElements : function() {
$('div[id] > :header:first').each(function() {
$('<a class="headerlink">\u00B6</a>').
attr('href', '#' + this.id).
attr('title', _('Permalink to this headline')).
appendTo(this);
});
$('dt[id]').each(function() {
$('<a class="headerlink">\u00B6</a>').
attr('href', '#' + this.id).
attr('title', _('Permalink to this definition')).
appendTo(this);
});
},
/**
* workaround a firefox stupidity
* see: https://bugzilla.mozilla.org/show_bug.cgi?id=645075
*/
fixFirefoxAnchorBug : function() {
if (document.location.hash)
window.setTimeout(function() {
document.location.href += '';
}, 10);
},
/**
* highlight the search words provided in the url in the text
*/
highlightSearchWords : function() {
var params = $.getQueryParameters();
var terms = (params.highlight) ? params.highlight[0].split(/\s+/) : [];
if (terms.length) {
var body = $('div.body');
if (!body.length) {
body = $('body');
}
window.setTimeout(function() {
$.each(terms, function() {
body.highlightText(this.toLowerCase(), 'highlighted');
});
}, 10);
$('<p class="highlight-link"><a href="javascript:Documentation.' +
'hideSearchWords()">' + _('Hide Search Matches') + '</a></p>')
.appendTo($('#searchbox'));
}
},
/**
* init the domain index toggle buttons
*/
initIndexTable : function() {
var togglers = $('img.toggler').click(function() {
var src = $(this).attr('src');
var idnum = $(this).attr('id').substr(7);
$('tr.cg-' + idnum).toggle();
if (src.substr(-9) == 'minus.png')
$(this).attr('src', src.substr(0, src.length-9) + 'plus.png');
else
$(this).attr('src', src.substr(0, src.length-8) + 'minus.png');
}).css('display', '');
if (DOCUMENTATION_OPTIONS.COLLAPSE_INDEX) {
togglers.click();
}
},
/**
* helper function to hide the search marks again
*/
hideSearchWords : function() {
$('#searchbox .highlight-link').fadeOut(300);
$('span.highlighted').removeClass('highlighted');
},
/**
* make the url absolute
*/
makeURL : function(relativeURL) {
return DOCUMENTATION_OPTIONS.URL_ROOT + '/' + relativeURL;
},
/**
* get the current relative url
*/
getCurrentURL : function() {
var path = document.location.pathname;
var parts = path.split(/\//);
$.each(DOCUMENTATION_OPTIONS.URL_ROOT.split(/\//), function() {
if (this == '..')
parts.pop();
});
var url = parts.join('/');
return path.substring(url.lastIndexOf('/') + 1, path.length - 1);
}
};
// quick alias for translations
_ = Documentation.gettext;
$(document).ready(function() {
Documentation.init();
}); | 0.387111 | 0.202542 |
(function(){function q(a,c,d){if(a===c)return a!==0||1/a==1/c;if(a==null||c==null)return a===c;if(a._chain)a=a._wrapped;if(c._chain)c=c._wrapped;if(a.isEqual&&b.isFunction(a.isEqual))return a.isEqual(c);if(c.isEqual&&b.isFunction(c.isEqual))return c.isEqual(a);var e=l.call(a);if(e!=l.call(c))return false;switch(e){case "[object String]":return a==String(c);case "[object Number]":return a!=+a?c!=+c:a==0?1/a==1/c:a==+c;case "[object Date]":case "[object Boolean]":return+a==+c;case "[object RegExp]":return a.source==
c.source&&a.global==c.global&&a.multiline==c.multiline&&a.ignoreCase==c.ignoreCase}if(typeof a!="object"||typeof c!="object")return false;for(var f=d.length;f--;)if(d[f]==a)return true;d.push(a);var f=0,g=true;if(e=="[object Array]"){if(f=a.length,g=f==c.length)for(;f--;)if(!(g=f in a==f in c&&q(a[f],c[f],d)))break}else{if("constructor"in a!="constructor"in c||a.constructor!=c.constructor)return false;for(var h in a)if(b.has(a,h)&&(f++,!(g=b.has(c,h)&&q(a[h],c[h],d))))break;if(g){for(h in c)if(b.has(c,
h)&&!f--)break;g=!f}}d.pop();return g}var r=this,G=r._,n={},k=Array.prototype,o=Object.prototype,i=k.slice,H=k.unshift,l=o.toString,I=o.hasOwnProperty,w=k.forEach,x=k.map,y=k.reduce,z=k.reduceRight,A=k.filter,B=k.every,C=k.some,p=k.indexOf,D=k.lastIndexOf,o=Array.isArray,J=Object.keys,s=Function.prototype.bind,b=function(a){return new m(a)};if(typeof exports!=="undefined"){if(typeof module!=="undefined"&&module.exports)exports=module.exports=b;exports._=b}else r._=b;b.VERSION="1.3.1";var j=b.each=
b.forEach=function(a,c,d){if(a!=null)if(w&&a.forEach===w)a.forEach(c,d);else if(a.length===+a.length)for(var e=0,f=a.length;e<f;e++){if(e in a&&c.call(d,a[e],e,a)===n)break}else for(e in a)if(b.has(a,e)&&c.call(d,a[e],e,a)===n)break};b.map=b.collect=function(a,c,b){var e=[];if(a==null)return e;if(x&&a.map===x)return a.map(c,b);j(a,function(a,g,h){e[e.length]=c.call(b,a,g,h)});if(a.length===+a.length)e.length=a.length;return e};b.reduce=b.foldl=b.inject=function(a,c,d,e){var f=arguments.length>2;a==
null&&(a=[]);if(y&&a.reduce===y)return e&&(c=b.bind(c,e)),f?a.reduce(c,d):a.reduce(c);j(a,function(a,b,i){f?d=c.call(e,d,a,b,i):(d=a,f=true)});if(!f)throw new TypeError("Reduce of empty array with no initial value");return d};b.reduceRight=b.foldr=function(a,c,d,e){var f=arguments.length>2;a==null&&(a=[]);if(z&&a.reduceRight===z)return e&&(c=b.bind(c,e)),f?a.reduceRight(c,d):a.reduceRight(c);var g=b.toArray(a).reverse();e&&!f&&(c=b.bind(c,e));return f?b.reduce(g,c,d,e):b.reduce(g,c)};b.find=b.detect=
function(a,c,b){var e;E(a,function(a,g,h){if(c.call(b,a,g,h))return e=a,true});return e};b.filter=b.select=function(a,c,b){var e=[];if(a==null)return e;if(A&&a.filter===A)return a.filter(c,b);j(a,function(a,g,h){c.call(b,a,g,h)&&(e[e.length]=a)});return e};b.reject=function(a,c,b){var e=[];if(a==null)return e;j(a,function(a,g,h){c.call(b,a,g,h)||(e[e.length]=a)});return e};b.every=b.all=function(a,c,b){var e=true;if(a==null)return e;if(B&&a.every===B)return a.every(c,b);j(a,function(a,g,h){if(!(e=
e&&c.call(b,a,g,h)))return n});return e};var E=b.some=b.any=function(a,c,d){c||(c=b.identity);var e=false;if(a==null)return e;if(C&&a.some===C)return a.some(c,d);j(a,function(a,b,h){if(e||(e=c.call(d,a,b,h)))return n});return!!e};b.include=b.contains=function(a,c){var b=false;if(a==null)return b;return p&&a.indexOf===p?a.indexOf(c)!=-1:b=E(a,function(a){return a===c})};b.invoke=function(a,c){var d=i.call(arguments,2);return b.map(a,function(a){return(b.isFunction(c)?c||a:a[c]).apply(a,d)})};b.pluck=
function(a,c){return b.map(a,function(a){return a[c]})};b.max=function(a,c,d){if(!c&&b.isArray(a))return Math.max.apply(Math,a);if(!c&&b.isEmpty(a))return-Infinity;var e={computed:-Infinity};j(a,function(a,b,h){b=c?c.call(d,a,b,h):a;b>=e.computed&&(e={value:a,computed:b})});return e.value};b.min=function(a,c,d){if(!c&&b.isArray(a))return Math.min.apply(Math,a);if(!c&&b.isEmpty(a))return Infinity;var e={computed:Infinity};j(a,function(a,b,h){b=c?c.call(d,a,b,h):a;b<e.computed&&(e={value:a,computed:b})});
return e.value};b.shuffle=function(a){var b=[],d;j(a,function(a,f){f==0?b[0]=a:(d=Math.floor(Math.random()*(f+1)),b[f]=b[d],b[d]=a)});return b};b.sortBy=function(a,c,d){return b.pluck(b.map(a,function(a,b,g){return{value:a,criteria:c.call(d,a,b,g)}}).sort(function(a,b){var c=a.criteria,d=b.criteria;return c<d?-1:c>d?1:0}),"value")};b.groupBy=function(a,c){var d={},e=b.isFunction(c)?c:function(a){return a[c]};j(a,function(a,b){var c=e(a,b);(d[c]||(d[c]=[])).push(a)});return d};b.sortedIndex=function(a,
c,d){d||(d=b.identity);for(var e=0,f=a.length;e<f;){var g=e+f>>1;d(a[g])<d(c)?e=g+1:f=g}return e};b.toArray=function(a){return!a?[]:a.toArray?a.toArray():b.isArray(a)?i.call(a):b.isArguments(a)?i.call(a):b.values(a)};b.size=function(a){return b.toArray(a).length};b.first=b.head=function(a,b,d){return b!=null&&!d?i.call(a,0,b):a[0]};b.initial=function(a,b,d){return i.call(a,0,a.length-(b==null||d?1:b))};b.last=function(a,b,d){return b!=null&&!d?i.call(a,Math.max(a.length-b,0)):a[a.length-1]};b.rest=
b.tail=function(a,b,d){return i.call(a,b==null||d?1:b)};b.compact=function(a){return b.filter(a,function(a){return!!a})};b.flatten=function(a,c){return b.reduce(a,function(a,e){if(b.isArray(e))return a.concat(c?e:b.flatten(e));a[a.length]=e;return a},[])};b.without=function(a){return b.difference(a,i.call(arguments,1))};b.uniq=b.unique=function(a,c,d){var d=d?b.map(a,d):a,e=[];b.reduce(d,function(d,g,h){if(0==h||(c===true?b.last(d)!=g:!b.include(d,g)))d[d.length]=g,e[e.length]=a[h];return d},[]);
return e};b.union=function(){return b.uniq(b.flatten(arguments,true))};b.intersection=b.intersect=function(a){var c=i.call(arguments,1);return b.filter(b.uniq(a),function(a){return b.every(c,function(c){return b.indexOf(c,a)>=0})})};b.difference=function(a){var c=b.flatten(i.call(arguments,1));return b.filter(a,function(a){return!b.include(c,a)})};b.zip=function(){for(var a=i.call(arguments),c=b.max(b.pluck(a,"length")),d=Array(c),e=0;e<c;e++)d[e]=b.pluck(a,""+e);return d};b.indexOf=function(a,c,
d){if(a==null)return-1;var e;if(d)return d=b.sortedIndex(a,c),a[d]===c?d:-1;if(p&&a.indexOf===p)return a.indexOf(c);for(d=0,e=a.length;d<e;d++)if(d in a&&a[d]===c)return d;return-1};b.lastIndexOf=function(a,b){if(a==null)return-1;if(D&&a.lastIndexOf===D)return a.lastIndexOf(b);for(var d=a.length;d--;)if(d in a&&a[d]===b)return d;return-1};b.range=function(a,b,d){arguments.length<=1&&(b=a||0,a=0);for(var d=arguments[2]||1,e=Math.max(Math.ceil((b-a)/d),0),f=0,g=Array(e);f<e;)g[f++]=a,a+=d;return g};
var F=function(){};b.bind=function(a,c){var d,e;if(a.bind===s&&s)return s.apply(a,i.call(arguments,1));if(!b.isFunction(a))throw new TypeError;e=i.call(arguments,2);return d=function(){if(!(this instanceof d))return a.apply(c,e.concat(i.call(arguments)));F.prototype=a.prototype;var b=new F,g=a.apply(b,e.concat(i.call(arguments)));return Object(g)===g?g:b}};b.bindAll=function(a){var c=i.call(arguments,1);c.length==0&&(c=b.functions(a));j(c,function(c){a[c]=b.bind(a[c],a)});return a};b.memoize=function(a,
c){var d={};c||(c=b.identity);return function(){var e=c.apply(this,arguments);return b.has(d,e)?d[e]:d[e]=a.apply(this,arguments)}};b.delay=function(a,b){var d=i.call(arguments,2);return setTimeout(function(){return a.apply(a,d)},b)};b.defer=function(a){return b.delay.apply(b,[a,1].concat(i.call(arguments,1)))};b.throttle=function(a,c){var d,e,f,g,h,i=b.debounce(function(){h=g=false},c);return function(){d=this;e=arguments;var b;f||(f=setTimeout(function(){f=null;h&&a.apply(d,e);i()},c));g?h=true:
a.apply(d,e);i();g=true}};b.debounce=function(a,b){var d;return function(){var e=this,f=arguments;clearTimeout(d);d=setTimeout(function(){d=null;a.apply(e,f)},b)}};b.once=function(a){var b=false,d;return function(){if(b)return d;b=true;return d=a.apply(this,arguments)}};b.wrap=function(a,b){return function(){var d=[a].concat(i.call(arguments,0));return b.apply(this,d)}};b.compose=function(){var a=arguments;return function(){for(var b=arguments,d=a.length-1;d>=0;d--)b=[a[d].apply(this,b)];return b[0]}};
b.after=function(a,b){return a<=0?b():function(){if(--a<1)return b.apply(this,arguments)}};b.keys=J||function(a){if(a!==Object(a))throw new TypeError("Invalid object");var c=[],d;for(d in a)b.has(a,d)&&(c[c.length]=d);return c};b.values=function(a){return b.map(a,b.identity)};b.functions=b.methods=function(a){var c=[],d;for(d in a)b.isFunction(a[d])&&c.push(d);return c.sort()};b.extend=function(a){j(i.call(arguments,1),function(b){for(var d in b)a[d]=b[d]});return a};b.defaults=function(a){j(i.call(arguments,
1),function(b){for(var d in b)a[d]==null&&(a[d]=b[d])});return a};b.clone=function(a){return!b.isObject(a)?a:b.isArray(a)?a.slice():b.extend({},a)};b.tap=function(a,b){b(a);return a};b.isEqual=function(a,b){return q(a,b,[])};b.isEmpty=function(a){if(b.isArray(a)||b.isString(a))return a.length===0;for(var c in a)if(b.has(a,c))return false;return true};b.isElement=function(a){return!!(a&&a.nodeType==1)};b.isArray=o||function(a){return l.call(a)=="[object Array]"};b.isObject=function(a){return a===Object(a)};
b.isArguments=function(a){return l.call(a)=="[object Arguments]"};if(!b.isArguments(arguments))b.isArguments=function(a){return!(!a||!b.has(a,"callee"))};b.isFunction=function(a){return l.call(a)=="[object Function]"};b.isString=function(a){return l.call(a)=="[object String]"};b.isNumber=function(a){return l.call(a)=="[object Number]"};b.isNaN=function(a){return a!==a};b.isBoolean=function(a){return a===true||a===false||l.call(a)=="[object Boolean]"};b.isDate=function(a){return l.call(a)=="[object Date]"};
b.isRegExp=function(a){return l.call(a)=="[object RegExp]"};b.isNull=function(a){return a===null};b.isUndefined=function(a){return a===void 0};b.has=function(a,b){return I.call(a,b)};b.noConflict=function(){r._=G;return this};b.identity=function(a){return a};b.times=function(a,b,d){for(var e=0;e<a;e++)b.call(d,e)};b.escape=function(a){return(""+a).replace(/&/g,"&").replace(/</g,"<").replace(/>/g,">").replace(/"/g,""").replace(/'/g,"'").replace(/\//g,"/")};b.mixin=function(a){j(b.functions(a),
function(c){K(c,b[c]=a[c])})};var L=0;b.uniqueId=function(a){var b=L++;return a?a+b:b};b.templateSettings={evaluate:/<%([\s\S]+?)%>/g,interpolate:/<%=([\s\S]+?)%>/g,escape:/<%-([\s\S]+?)%>/g};var t=/.^/,u=function(a){return a.replace(/\\\\/g,"\\").replace(/\\'/g,"'")};b.template=function(a,c){var d=b.templateSettings,d="var __p=[],print=function(){__p.push.apply(__p,arguments);};with(obj||{}){__p.push('"+a.replace(/\\/g,"\\\\").replace(/'/g,"\\'").replace(d.escape||t,function(a,b){return"',_.escape("+
u(b)+"),'"}).replace(d.interpolate||t,function(a,b){return"',"+u(b)+",'"}).replace(d.evaluate||t,function(a,b){return"');"+u(b).replace(/[\r\n\t]/g," ")+";__p.push('"}).replace(/\r/g,"\\r").replace(/\n/g,"\\n").replace(/\t/g,"\\t")+"');}return __p.join('');",e=new Function("obj","_",d);return c?e(c,b):function(a){return e.call(this,a,b)}};b.chain=function(a){return b(a).chain()};var m=function(a){this._wrapped=a};b.prototype=m.prototype;var v=function(a,c){return c?b(a).chain():a},K=function(a,c){m.prototype[a]=
function(){var a=i.call(arguments);H.call(a,this._wrapped);return v(c.apply(b,a),this._chain)}};b.mixin(b);j("pop,push,reverse,shift,sort,splice,unshift".split(","),function(a){var b=k[a];m.prototype[a]=function(){var d=this._wrapped;b.apply(d,arguments);var e=d.length;(a=="shift"||a=="splice")&&e===0&&delete d[0];return v(d,this._chain)}});j(["concat","join","slice"],function(a){var b=k[a];m.prototype[a]=function(){return v(b.apply(this._wrapped,arguments),this._chain)}});m.prototype.chain=function(){this._chain=
true;return this};m.prototype.value=function(){return this._wrapped}}).call(this); | scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/doc/build/html/_static/underscore.js | underscore.js | (function(){function q(a,c,d){if(a===c)return a!==0||1/a==1/c;if(a==null||c==null)return a===c;if(a._chain)a=a._wrapped;if(c._chain)c=c._wrapped;if(a.isEqual&&b.isFunction(a.isEqual))return a.isEqual(c);if(c.isEqual&&b.isFunction(c.isEqual))return c.isEqual(a);var e=l.call(a);if(e!=l.call(c))return false;switch(e){case "[object String]":return a==String(c);case "[object Number]":return a!=+a?c!=+c:a==0?1/a==1/c:a==+c;case "[object Date]":case "[object Boolean]":return+a==+c;case "[object RegExp]":return a.source==
c.source&&a.global==c.global&&a.multiline==c.multiline&&a.ignoreCase==c.ignoreCase}if(typeof a!="object"||typeof c!="object")return false;for(var f=d.length;f--;)if(d[f]==a)return true;d.push(a);var f=0,g=true;if(e=="[object Array]"){if(f=a.length,g=f==c.length)for(;f--;)if(!(g=f in a==f in c&&q(a[f],c[f],d)))break}else{if("constructor"in a!="constructor"in c||a.constructor!=c.constructor)return false;for(var h in a)if(b.has(a,h)&&(f++,!(g=b.has(c,h)&&q(a[h],c[h],d))))break;if(g){for(h in c)if(b.has(c,
h)&&!f--)break;g=!f}}d.pop();return g}var r=this,G=r._,n={},k=Array.prototype,o=Object.prototype,i=k.slice,H=k.unshift,l=o.toString,I=o.hasOwnProperty,w=k.forEach,x=k.map,y=k.reduce,z=k.reduceRight,A=k.filter,B=k.every,C=k.some,p=k.indexOf,D=k.lastIndexOf,o=Array.isArray,J=Object.keys,s=Function.prototype.bind,b=function(a){return new m(a)};if(typeof exports!=="undefined"){if(typeof module!=="undefined"&&module.exports)exports=module.exports=b;exports._=b}else r._=b;b.VERSION="1.3.1";var j=b.each=
b.forEach=function(a,c,d){if(a!=null)if(w&&a.forEach===w)a.forEach(c,d);else if(a.length===+a.length)for(var e=0,f=a.length;e<f;e++){if(e in a&&c.call(d,a[e],e,a)===n)break}else for(e in a)if(b.has(a,e)&&c.call(d,a[e],e,a)===n)break};b.map=b.collect=function(a,c,b){var e=[];if(a==null)return e;if(x&&a.map===x)return a.map(c,b);j(a,function(a,g,h){e[e.length]=c.call(b,a,g,h)});if(a.length===+a.length)e.length=a.length;return e};b.reduce=b.foldl=b.inject=function(a,c,d,e){var f=arguments.length>2;a==
null&&(a=[]);if(y&&a.reduce===y)return e&&(c=b.bind(c,e)),f?a.reduce(c,d):a.reduce(c);j(a,function(a,b,i){f?d=c.call(e,d,a,b,i):(d=a,f=true)});if(!f)throw new TypeError("Reduce of empty array with no initial value");return d};b.reduceRight=b.foldr=function(a,c,d,e){var f=arguments.length>2;a==null&&(a=[]);if(z&&a.reduceRight===z)return e&&(c=b.bind(c,e)),f?a.reduceRight(c,d):a.reduceRight(c);var g=b.toArray(a).reverse();e&&!f&&(c=b.bind(c,e));return f?b.reduce(g,c,d,e):b.reduce(g,c)};b.find=b.detect=
function(a,c,b){var e;E(a,function(a,g,h){if(c.call(b,a,g,h))return e=a,true});return e};b.filter=b.select=function(a,c,b){var e=[];if(a==null)return e;if(A&&a.filter===A)return a.filter(c,b);j(a,function(a,g,h){c.call(b,a,g,h)&&(e[e.length]=a)});return e};b.reject=function(a,c,b){var e=[];if(a==null)return e;j(a,function(a,g,h){c.call(b,a,g,h)||(e[e.length]=a)});return e};b.every=b.all=function(a,c,b){var e=true;if(a==null)return e;if(B&&a.every===B)return a.every(c,b);j(a,function(a,g,h){if(!(e=
e&&c.call(b,a,g,h)))return n});return e};var E=b.some=b.any=function(a,c,d){c||(c=b.identity);var e=false;if(a==null)return e;if(C&&a.some===C)return a.some(c,d);j(a,function(a,b,h){if(e||(e=c.call(d,a,b,h)))return n});return!!e};b.include=b.contains=function(a,c){var b=false;if(a==null)return b;return p&&a.indexOf===p?a.indexOf(c)!=-1:b=E(a,function(a){return a===c})};b.invoke=function(a,c){var d=i.call(arguments,2);return b.map(a,function(a){return(b.isFunction(c)?c||a:a[c]).apply(a,d)})};b.pluck=
function(a,c){return b.map(a,function(a){return a[c]})};b.max=function(a,c,d){if(!c&&b.isArray(a))return Math.max.apply(Math,a);if(!c&&b.isEmpty(a))return-Infinity;var e={computed:-Infinity};j(a,function(a,b,h){b=c?c.call(d,a,b,h):a;b>=e.computed&&(e={value:a,computed:b})});return e.value};b.min=function(a,c,d){if(!c&&b.isArray(a))return Math.min.apply(Math,a);if(!c&&b.isEmpty(a))return Infinity;var e={computed:Infinity};j(a,function(a,b,h){b=c?c.call(d,a,b,h):a;b<e.computed&&(e={value:a,computed:b})});
return e.value};b.shuffle=function(a){var b=[],d;j(a,function(a,f){f==0?b[0]=a:(d=Math.floor(Math.random()*(f+1)),b[f]=b[d],b[d]=a)});return b};b.sortBy=function(a,c,d){return b.pluck(b.map(a,function(a,b,g){return{value:a,criteria:c.call(d,a,b,g)}}).sort(function(a,b){var c=a.criteria,d=b.criteria;return c<d?-1:c>d?1:0}),"value")};b.groupBy=function(a,c){var d={},e=b.isFunction(c)?c:function(a){return a[c]};j(a,function(a,b){var c=e(a,b);(d[c]||(d[c]=[])).push(a)});return d};b.sortedIndex=function(a,
c,d){d||(d=b.identity);for(var e=0,f=a.length;e<f;){var g=e+f>>1;d(a[g])<d(c)?e=g+1:f=g}return e};b.toArray=function(a){return!a?[]:a.toArray?a.toArray():b.isArray(a)?i.call(a):b.isArguments(a)?i.call(a):b.values(a)};b.size=function(a){return b.toArray(a).length};b.first=b.head=function(a,b,d){return b!=null&&!d?i.call(a,0,b):a[0]};b.initial=function(a,b,d){return i.call(a,0,a.length-(b==null||d?1:b))};b.last=function(a,b,d){return b!=null&&!d?i.call(a,Math.max(a.length-b,0)):a[a.length-1]};b.rest=
b.tail=function(a,b,d){return i.call(a,b==null||d?1:b)};b.compact=function(a){return b.filter(a,function(a){return!!a})};b.flatten=function(a,c){return b.reduce(a,function(a,e){if(b.isArray(e))return a.concat(c?e:b.flatten(e));a[a.length]=e;return a},[])};b.without=function(a){return b.difference(a,i.call(arguments,1))};b.uniq=b.unique=function(a,c,d){var d=d?b.map(a,d):a,e=[];b.reduce(d,function(d,g,h){if(0==h||(c===true?b.last(d)!=g:!b.include(d,g)))d[d.length]=g,e[e.length]=a[h];return d},[]);
return e};b.union=function(){return b.uniq(b.flatten(arguments,true))};b.intersection=b.intersect=function(a){var c=i.call(arguments,1);return b.filter(b.uniq(a),function(a){return b.every(c,function(c){return b.indexOf(c,a)>=0})})};b.difference=function(a){var c=b.flatten(i.call(arguments,1));return b.filter(a,function(a){return!b.include(c,a)})};b.zip=function(){for(var a=i.call(arguments),c=b.max(b.pluck(a,"length")),d=Array(c),e=0;e<c;e++)d[e]=b.pluck(a,""+e);return d};b.indexOf=function(a,c,
d){if(a==null)return-1;var e;if(d)return d=b.sortedIndex(a,c),a[d]===c?d:-1;if(p&&a.indexOf===p)return a.indexOf(c);for(d=0,e=a.length;d<e;d++)if(d in a&&a[d]===c)return d;return-1};b.lastIndexOf=function(a,b){if(a==null)return-1;if(D&&a.lastIndexOf===D)return a.lastIndexOf(b);for(var d=a.length;d--;)if(d in a&&a[d]===b)return d;return-1};b.range=function(a,b,d){arguments.length<=1&&(b=a||0,a=0);for(var d=arguments[2]||1,e=Math.max(Math.ceil((b-a)/d),0),f=0,g=Array(e);f<e;)g[f++]=a,a+=d;return g};
var F=function(){};b.bind=function(a,c){var d,e;if(a.bind===s&&s)return s.apply(a,i.call(arguments,1));if(!b.isFunction(a))throw new TypeError;e=i.call(arguments,2);return d=function(){if(!(this instanceof d))return a.apply(c,e.concat(i.call(arguments)));F.prototype=a.prototype;var b=new F,g=a.apply(b,e.concat(i.call(arguments)));return Object(g)===g?g:b}};b.bindAll=function(a){var c=i.call(arguments,1);c.length==0&&(c=b.functions(a));j(c,function(c){a[c]=b.bind(a[c],a)});return a};b.memoize=function(a,
c){var d={};c||(c=b.identity);return function(){var e=c.apply(this,arguments);return b.has(d,e)?d[e]:d[e]=a.apply(this,arguments)}};b.delay=function(a,b){var d=i.call(arguments,2);return setTimeout(function(){return a.apply(a,d)},b)};b.defer=function(a){return b.delay.apply(b,[a,1].concat(i.call(arguments,1)))};b.throttle=function(a,c){var d,e,f,g,h,i=b.debounce(function(){h=g=false},c);return function(){d=this;e=arguments;var b;f||(f=setTimeout(function(){f=null;h&&a.apply(d,e);i()},c));g?h=true:
a.apply(d,e);i();g=true}};b.debounce=function(a,b){var d;return function(){var e=this,f=arguments;clearTimeout(d);d=setTimeout(function(){d=null;a.apply(e,f)},b)}};b.once=function(a){var b=false,d;return function(){if(b)return d;b=true;return d=a.apply(this,arguments)}};b.wrap=function(a,b){return function(){var d=[a].concat(i.call(arguments,0));return b.apply(this,d)}};b.compose=function(){var a=arguments;return function(){for(var b=arguments,d=a.length-1;d>=0;d--)b=[a[d].apply(this,b)];return b[0]}};
b.after=function(a,b){return a<=0?b():function(){if(--a<1)return b.apply(this,arguments)}};b.keys=J||function(a){if(a!==Object(a))throw new TypeError("Invalid object");var c=[],d;for(d in a)b.has(a,d)&&(c[c.length]=d);return c};b.values=function(a){return b.map(a,b.identity)};b.functions=b.methods=function(a){var c=[],d;for(d in a)b.isFunction(a[d])&&c.push(d);return c.sort()};b.extend=function(a){j(i.call(arguments,1),function(b){for(var d in b)a[d]=b[d]});return a};b.defaults=function(a){j(i.call(arguments,
1),function(b){for(var d in b)a[d]==null&&(a[d]=b[d])});return a};b.clone=function(a){return!b.isObject(a)?a:b.isArray(a)?a.slice():b.extend({},a)};b.tap=function(a,b){b(a);return a};b.isEqual=function(a,b){return q(a,b,[])};b.isEmpty=function(a){if(b.isArray(a)||b.isString(a))return a.length===0;for(var c in a)if(b.has(a,c))return false;return true};b.isElement=function(a){return!!(a&&a.nodeType==1)};b.isArray=o||function(a){return l.call(a)=="[object Array]"};b.isObject=function(a){return a===Object(a)};
b.isArguments=function(a){return l.call(a)=="[object Arguments]"};if(!b.isArguments(arguments))b.isArguments=function(a){return!(!a||!b.has(a,"callee"))};b.isFunction=function(a){return l.call(a)=="[object Function]"};b.isString=function(a){return l.call(a)=="[object String]"};b.isNumber=function(a){return l.call(a)=="[object Number]"};b.isNaN=function(a){return a!==a};b.isBoolean=function(a){return a===true||a===false||l.call(a)=="[object Boolean]"};b.isDate=function(a){return l.call(a)=="[object Date]"};
b.isRegExp=function(a){return l.call(a)=="[object RegExp]"};b.isNull=function(a){return a===null};b.isUndefined=function(a){return a===void 0};b.has=function(a,b){return I.call(a,b)};b.noConflict=function(){r._=G;return this};b.identity=function(a){return a};b.times=function(a,b,d){for(var e=0;e<a;e++)b.call(d,e)};b.escape=function(a){return(""+a).replace(/&/g,"&").replace(/</g,"<").replace(/>/g,">").replace(/"/g,""").replace(/'/g,"'").replace(/\//g,"/")};b.mixin=function(a){j(b.functions(a),
function(c){K(c,b[c]=a[c])})};var L=0;b.uniqueId=function(a){var b=L++;return a?a+b:b};b.templateSettings={evaluate:/<%([\s\S]+?)%>/g,interpolate:/<%=([\s\S]+?)%>/g,escape:/<%-([\s\S]+?)%>/g};var t=/.^/,u=function(a){return a.replace(/\\\\/g,"\\").replace(/\\'/g,"'")};b.template=function(a,c){var d=b.templateSettings,d="var __p=[],print=function(){__p.push.apply(__p,arguments);};with(obj||{}){__p.push('"+a.replace(/\\/g,"\\\\").replace(/'/g,"\\'").replace(d.escape||t,function(a,b){return"',_.escape("+
u(b)+"),'"}).replace(d.interpolate||t,function(a,b){return"',"+u(b)+",'"}).replace(d.evaluate||t,function(a,b){return"');"+u(b).replace(/[\r\n\t]/g," ")+";__p.push('"}).replace(/\r/g,"\\r").replace(/\n/g,"\\n").replace(/\t/g,"\\t")+"');}return __p.join('');",e=new Function("obj","_",d);return c?e(c,b):function(a){return e.call(this,a,b)}};b.chain=function(a){return b(a).chain()};var m=function(a){this._wrapped=a};b.prototype=m.prototype;var v=function(a,c){return c?b(a).chain():a},K=function(a,c){m.prototype[a]=
function(){var a=i.call(arguments);H.call(a,this._wrapped);return v(c.apply(b,a),this._chain)}};b.mixin(b);j("pop,push,reverse,shift,sort,splice,unshift".split(","),function(a){var b=k[a];m.prototype[a]=function(){var d=this._wrapped;b.apply(d,arguments);var e=d.length;(a=="shift"||a=="splice")&&e===0&&delete d[0];return v(d,this._chain)}});j(["concat","join","slice"],function(a){var b=k[a];m.prototype[a]=function(){return v(b.apply(this._wrapped,arguments),this._chain)}});m.prototype.chain=function(){this._chain=
true;return this};m.prototype.value=function(){return this._wrapped}}).call(this); | 0.067803 | 0.252406 |
import glob
import os.path
import logging
from libscifig.task import GnuplotTask, TikzTask
#TODO : recursive glob: https://docs.python.org/3.5/library/glob.html
import os
import fnmatch
def _recursive_glob(base, ext):
"""
Helper function to find files with extention ext
in the path base.
"""
return [os.path.join(dirpath, f)
for dirpath, dirnames, files in os.walk(base)
for f in fnmatch.filter(files, '*' + ext)]
def detect_datafile(plt, root):
"""
Detect datafiles associated with a plt file.
:param plt: plt filepath
:param root: root filepath
:returns: list of filepath starting at root
"""
base = os.path.split(plt)[0]
datafiles = []
for ext in ('csv', '.res', '.dat', '.txt', '.png', '.jpg'):
files = _recursive_glob(base, ext)
files = [os.path.relpath(f, root) for f in files]
datafiles.extend(files)
logging.debug('In %s', base)
logging.debug('Detected datafiles: %s', datafiles)
return datafiles
def detect_tikzsnippets(plt):
"""
Detect tikzsnippets associated with a plt file.
:param plt: plt filepath
:returns: tuple of 2 booleans
"""
base = os.path.splitext(plt)[0] + '.tikzsnippet'
snippets = [os.path.isfile(base),
os.path.isfile(base + '1'),
os.path.isfile(base + '2'),]
logging.debug('In %s', base)
logging.debug('Detected tikzsnippets: %s', snippets)
return snippets
def detect_task(directory, root_path):
"""
Detect the task to do depending on file extensions.
:param directory: directory to look at
:returns: list of tasks
"""
plt_files = glob.glob(os.path.join(directory, '*.plt'))
tikz_files = glob.glob(os.path.join(directory, '*.tikz'))
tasks = []
for plt_file in plt_files:
data = detect_datafile(plt_file, root_path)
snippet, snippet1, snippet2 = detect_tikzsnippets(plt_file)
tasks.append(GnuplotTask(plt_file,
datafiles=data,
tikzsnippet=snippet,
tikzsnippet1=snippet1,
tikzsnippet2=snippet2,
))
for tikz_file in tikz_files:
data = detect_datafile(tikz_file, root_path)
tasks.append(TikzTask(tikz_file,
datafiles=data,
))
return tasks | scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/libscifig/detector.py | detector.py |
import glob
import os.path
import logging
from libscifig.task import GnuplotTask, TikzTask
#TODO : recursive glob: https://docs.python.org/3.5/library/glob.html
import os
import fnmatch
def _recursive_glob(base, ext):
"""
Helper function to find files with extention ext
in the path base.
"""
return [os.path.join(dirpath, f)
for dirpath, dirnames, files in os.walk(base)
for f in fnmatch.filter(files, '*' + ext)]
def detect_datafile(plt, root):
"""
Detect datafiles associated with a plt file.
:param plt: plt filepath
:param root: root filepath
:returns: list of filepath starting at root
"""
base = os.path.split(plt)[0]
datafiles = []
for ext in ('csv', '.res', '.dat', '.txt', '.png', '.jpg'):
files = _recursive_glob(base, ext)
files = [os.path.relpath(f, root) for f in files]
datafiles.extend(files)
logging.debug('In %s', base)
logging.debug('Detected datafiles: %s', datafiles)
return datafiles
def detect_tikzsnippets(plt):
"""
Detect tikzsnippets associated with a plt file.
:param plt: plt filepath
:returns: tuple of 2 booleans
"""
base = os.path.splitext(plt)[0] + '.tikzsnippet'
snippets = [os.path.isfile(base),
os.path.isfile(base + '1'),
os.path.isfile(base + '2'),]
logging.debug('In %s', base)
logging.debug('Detected tikzsnippets: %s', snippets)
return snippets
def detect_task(directory, root_path):
"""
Detect the task to do depending on file extensions.
:param directory: directory to look at
:returns: list of tasks
"""
plt_files = glob.glob(os.path.join(directory, '*.plt'))
tikz_files = glob.glob(os.path.join(directory, '*.tikz'))
tasks = []
for plt_file in plt_files:
data = detect_datafile(plt_file, root_path)
snippet, snippet1, snippet2 = detect_tikzsnippets(plt_file)
tasks.append(GnuplotTask(plt_file,
datafiles=data,
tikzsnippet=snippet,
tikzsnippet1=snippet1,
tikzsnippet2=snippet2,
))
for tikz_file in tikz_files:
data = detect_datafile(tikz_file, root_path)
tasks.append(TikzTask(tikz_file,
datafiles=data,
))
return tasks | 0.353428 | 0.361897 |
import logging
import glob
import os
import os.path
import shutil
import argparse
from libscifig import detector, database
def list_figdirs(src='src'):
"""
Return the list of directories containing figures.
"""
return glob.glob(os.path.join(src, '*'))
def make_build_dir(build='build'):
"""
Make a build directory.
"""
logging.debug('Make build dir: %s' % build)
os.makedirs(build, exist_ok=True)
def clean_up(path):
"""
Clean up all compiled files.
"""
db = os.path.join(path, 'db.json')
logging.debug('Clean up %s' % db)
try:
os.remove(db)
except FileNotFoundError:
pass
build = os.path.join(path, 'build')
logging.debug('Clean up %s' % build)
if os.path.exists(build):
shutil.rmtree(build)
def main(workingdir, dest='/tmp', pdf_only=False):
make_build_dir(os.path.join(workingdir, 'build'))
tasks = []
for directory in list_figdirs(os.path.join(workingdir, 'src')):
tasks.extend(detector.detect_task(directory, workingdir))
db_path = os.path.join(workingdir, 'db.json')
with database.DataBase(db_path) as db:
for task in tasks:
if pdf_only:
task.make_pdf(db)
else:
task.make(db)
task.export(db, dst=dest)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='', epilog='')
parser.add_argument('-c', '--clean', action='store_true',
default=False, help='Clean')
parser.add_argument('--pdf', action='store_true',
default=False, help='PDF only')
parser.add_argument('-d', '--dest', metavar='DEST',
default='/tmp', help='destination')
parser.add_argument('-w', '--workingdir', metavar='WORKINGDIR',
default='.', help='Working directory (where src/ '
'is and build/ will be written)')
parser.add_argument('--debug', action='store_true',
default=False, help='Run in debug mode')
args = parser.parse_args()
from libscifig.collogging import formatter_message, ColoredFormatter
if args.debug:
llevel = logging.DEBUG
else:
llevel = logging.INFO
logger = logging.getLogger()
logger.setLevel(llevel)
if llevel == logging.DEBUG:
FORMAT = "[$BOLD%(name)-10s$RESET][%(levelname)-18s] %(message)s ($BOLD%(filename)s$RESET:%(lineno)d)"
else:
FORMAT = "%(message)s"
COLOR_FORMAT = formatter_message(FORMAT, True)
color_formatter = ColoredFormatter(COLOR_FORMAT)
steam_handler = logging.StreamHandler()
steam_handler.setLevel(llevel)
steam_handler.setFormatter(color_formatter)
logger.addHandler(steam_handler)
if args.clean:
logger.info('Cleaning...')
clean_up(args.workingdir)
elif args.pdf:
main(args.workingdir, args.dest, pdf_only=True)
else:
main(args.workingdir, args.dest, pdf_only=False) | scifig | /scifig-0.1.3.tar.gz/scifig-0.1.3/example/scifig.py | scifig.py |
import logging
import glob
import os
import os.path
import shutil
import argparse
from libscifig import detector, database
def list_figdirs(src='src'):
"""
Return the list of directories containing figures.
"""
return glob.glob(os.path.join(src, '*'))
def make_build_dir(build='build'):
"""
Make a build directory.
"""
logging.debug('Make build dir: %s' % build)
os.makedirs(build, exist_ok=True)
def clean_up(path):
"""
Clean up all compiled files.
"""
db = os.path.join(path, 'db.json')
logging.debug('Clean up %s' % db)
try:
os.remove(db)
except FileNotFoundError:
pass
build = os.path.join(path, 'build')
logging.debug('Clean up %s' % build)
if os.path.exists(build):
shutil.rmtree(build)
def main(workingdir, dest='/tmp', pdf_only=False):
make_build_dir(os.path.join(workingdir, 'build'))
tasks = []
for directory in list_figdirs(os.path.join(workingdir, 'src')):
tasks.extend(detector.detect_task(directory, workingdir))
db_path = os.path.join(workingdir, 'db.json')
with database.DataBase(db_path) as db:
for task in tasks:
if pdf_only:
task.make_pdf(db)
else:
task.make(db)
task.export(db, dst=dest)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='', epilog='')
parser.add_argument('-c', '--clean', action='store_true',
default=False, help='Clean')
parser.add_argument('--pdf', action='store_true',
default=False, help='PDF only')
parser.add_argument('-d', '--dest', metavar='DEST',
default='/tmp', help='destination')
parser.add_argument('-w', '--workingdir', metavar='WORKINGDIR',
default='.', help='Working directory (where src/ '
'is and build/ will be written)')
parser.add_argument('--debug', action='store_true',
default=False, help='Run in debug mode')
args = parser.parse_args()
from libscifig.collogging import formatter_message, ColoredFormatter
if args.debug:
llevel = logging.DEBUG
else:
llevel = logging.INFO
logger = logging.getLogger()
logger.setLevel(llevel)
if llevel == logging.DEBUG:
FORMAT = "[$BOLD%(name)-10s$RESET][%(levelname)-18s] %(message)s ($BOLD%(filename)s$RESET:%(lineno)d)"
else:
FORMAT = "%(message)s"
COLOR_FORMAT = formatter_message(FORMAT, True)
color_formatter = ColoredFormatter(COLOR_FORMAT)
steam_handler = logging.StreamHandler()
steam_handler.setLevel(llevel)
steam_handler.setFormatter(color_formatter)
logger.addHandler(steam_handler)
if args.clean:
logger.info('Cleaning...')
clean_up(args.workingdir)
elif args.pdf:
main(args.workingdir, args.dest, pdf_only=True)
else:
main(args.workingdir, args.dest, pdf_only=False) | 0.30013 | 0.064359 |
<p align="center">
<img src="https://raw.githubusercontent.com/SciFin-Team/SciFin/master/docs/logos/logo_scifin_github.jpg" width=400 title="hover text">
</p>
# SciFin
SciFin is a python package for Science and Finance.
## Summary
The SciFin package is a Python package designed to gather and develop methods for scientific studies and financial services. It originates from the observation that numerous methods developed in scientific fields (such as mathematics, physics, biology and climate sciences) have direct applicability in finance and that, conversely, multiple methods developed in finance can benefit science.
The development goal of this package is to offer a toolbox that can be used both in research and business. Its purpose is not only to bring these fields together, but also to increase interoperability between them, helping science turn into business and finance to get new insights from science. Some functions are thus neutral to any scientific or economical fields, while others are more specialized to precise tasks. The motivation behind this design is to provide tools that perform advanced tasks while remaining simple (not depending on too many parameters).
## Table of Contents
- **[Development Stage](#development-stage)**<br>
- **[Installation](#installation)**<br>
- **[Usage](#usage)**<br>
- **[Contributing](#contributing)**<br>
- **[Credits](#credits)**<br>
- **[License](#license)**<br>
- **[Contacts](#contacts)**<br>
## Development Stage
The current development is focused on the following topics:
| Subpackage | Short Description | Development Stage |
| :-----: | :-----: | :-----: |
| [`classifier`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/classifier) | classification techniques | ■ □ □ □ □ |
| [`fouriertrf`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/fouriertrf) | Fourier transforms | ■ □ □ □ □ |
| [`geneticalg`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/geneticalg) | genetic algorithms | ■ ■ ■ □ □ |
| [`marketdata`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/marketdata) | reading market data | ■ □ □ □ □ |
| [`montecarlo`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/montecarlo) | Monte Carlo simulations | ■ □ □ □ □ |
| [`neuralnets`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/neuralnets) | neural networks | □ □ □ □ □ |
| [`statistics`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/statistics) | basic statistics | ■ □ □ □ □ |
| [`timeseries`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/timeseries) | time series analysis | ■ ■ ■ ■ □ |
The topics already developed are time series analysis, genetic algorithms and statistics.
A lot of development still needs to be done. Other topics will also later follow.
## Installation
Installing SciFin on Linux or Mac is very easy, you can simply run this on a terminal:
`pip install SciFin`
You can also access the last version of the package [on PyPI](https://pypi.org/project/scifin/).
If you encounter problems during installation or after and think you know how the problem can be improved, please share it with me.
Version 0.0.8 may lead to a small problem from pandas. If you get an error message such as:
`ImportError: cannot import name 'urlencode' from 'pandas.io.common'`
it is advised to install pandas version 1.0.3 using e.g. the command line:
`pip install pandas==1.0.3`.
## Usage
The code is growing fast and many classes and function acquire new features. Hence, one version can be significantly different from the previous one at the moment. That's what makes development exciting! But that can also be confusing.
A documentation of the code should help users. Once ready, this documentation will start appearing on [SciFin's Wiki page](https://github.com/SciFin-Team/SciFin/wiki).
If you encounter any problem while using SciFin, please do not hesitate to report it to us by [creating an issue](https://docs.github.com/en/github/managing-your-work-on-github/creating-an-issue).
## Contributing
The package tries to follow the style guide for Python code [PEP8](https://www.python.org/dev/peps/pep-0008/). If you find any part of the code unclear or departing from this style, please let me know. As for docstrings, the format we try to follow here is given by the [numpy doc style](https://numpydoc.readthedocs.io/en/latest/format.html).
It is strongly advised to have a fair knowledge of Python to contribute, at least a strong motivation to learn, and recommanded to read the following [Python3 Tutorial](https://www.python-course.eu/python3_course.php) before joining the project.
To know more about the (evolving) rules that make the project self-consistent and eases interaction between contributors, please refer to details in the [Contributing](https://github.com/SciFin-Team/SciFin/blob/master/CONTRIBUTING.md) file.
## Credits
All the development up to now has been done by Fabien Nugier. New contributors will join soon.
## License
SciFin is currently developed under the MIT license.
Please keep in mind that SciFin and its developers hold no responsibility for any wrong usage or losses related to the package usage.
For more details, please refer to the [license](https://github.com/SciFin-Team/SciFin/blob/master/LICENSE).
## Contacts
If you have comments or suggestions, please reach Fabien Nugier. Thank you very much in advance for your feedback.
| scifin | /SciFin-0.1.0.tar.gz/SciFin-0.1.0/README.md | README.md |
<p align="center">
<img src="https://raw.githubusercontent.com/SciFin-Team/SciFin/master/docs/logos/logo_scifin_github.jpg" width=400 title="hover text">
</p>
# SciFin
SciFin is a python package for Science and Finance.
## Summary
The SciFin package is a Python package designed to gather and develop methods for scientific studies and financial services. It originates from the observation that numerous methods developed in scientific fields (such as mathematics, physics, biology and climate sciences) have direct applicability in finance and that, conversely, multiple methods developed in finance can benefit science.
The development goal of this package is to offer a toolbox that can be used both in research and business. Its purpose is not only to bring these fields together, but also to increase interoperability between them, helping science turn into business and finance to get new insights from science. Some functions are thus neutral to any scientific or economical fields, while others are more specialized to precise tasks. The motivation behind this design is to provide tools that perform advanced tasks while remaining simple (not depending on too many parameters).
## Table of Contents
- **[Development Stage](#development-stage)**<br>
- **[Installation](#installation)**<br>
- **[Usage](#usage)**<br>
- **[Contributing](#contributing)**<br>
- **[Credits](#credits)**<br>
- **[License](#license)**<br>
- **[Contacts](#contacts)**<br>
## Development Stage
The current development is focused on the following topics:
| Subpackage | Short Description | Development Stage |
| :-----: | :-----: | :-----: |
| [`classifier`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/classifier) | classification techniques | ■ □ □ □ □ |
| [`fouriertrf`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/fouriertrf) | Fourier transforms | ■ □ □ □ □ |
| [`geneticalg`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/geneticalg) | genetic algorithms | ■ ■ ■ □ □ |
| [`marketdata`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/marketdata) | reading market data | ■ □ □ □ □ |
| [`montecarlo`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/montecarlo) | Monte Carlo simulations | ■ □ □ □ □ |
| [`neuralnets`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/neuralnets) | neural networks | □ □ □ □ □ |
| [`statistics`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/statistics) | basic statistics | ■ □ □ □ □ |
| [`timeseries`](https://github.com/SciFin-Team/SciFin/tree/master/scifin/timeseries) | time series analysis | ■ ■ ■ ■ □ |
The topics already developed are time series analysis, genetic algorithms and statistics.
A lot of development still needs to be done. Other topics will also later follow.
## Installation
Installing SciFin on Linux or Mac is very easy, you can simply run this on a terminal:
`pip install SciFin`
You can also access the last version of the package [on PyPI](https://pypi.org/project/scifin/).
If you encounter problems during installation or after and think you know how the problem can be improved, please share it with me.
Version 0.0.8 may lead to a small problem from pandas. If you get an error message such as:
`ImportError: cannot import name 'urlencode' from 'pandas.io.common'`
it is advised to install pandas version 1.0.3 using e.g. the command line:
`pip install pandas==1.0.3`.
## Usage
The code is growing fast and many classes and function acquire new features. Hence, one version can be significantly different from the previous one at the moment. That's what makes development exciting! But that can also be confusing.
A documentation of the code should help users. Once ready, this documentation will start appearing on [SciFin's Wiki page](https://github.com/SciFin-Team/SciFin/wiki).
If you encounter any problem while using SciFin, please do not hesitate to report it to us by [creating an issue](https://docs.github.com/en/github/managing-your-work-on-github/creating-an-issue).
## Contributing
The package tries to follow the style guide for Python code [PEP8](https://www.python.org/dev/peps/pep-0008/). If you find any part of the code unclear or departing from this style, please let me know. As for docstrings, the format we try to follow here is given by the [numpy doc style](https://numpydoc.readthedocs.io/en/latest/format.html).
It is strongly advised to have a fair knowledge of Python to contribute, at least a strong motivation to learn, and recommanded to read the following [Python3 Tutorial](https://www.python-course.eu/python3_course.php) before joining the project.
To know more about the (evolving) rules that make the project self-consistent and eases interaction between contributors, please refer to details in the [Contributing](https://github.com/SciFin-Team/SciFin/blob/master/CONTRIBUTING.md) file.
## Credits
All the development up to now has been done by Fabien Nugier. New contributors will join soon.
## License
SciFin is currently developed under the MIT license.
Please keep in mind that SciFin and its developers hold no responsibility for any wrong usage or losses related to the package usage.
For more details, please refer to the [license](https://github.com/SciFin-Team/SciFin/blob/master/LICENSE).
## Contacts
If you have comments or suggestions, please reach Fabien Nugier. Thank you very much in advance for your feedback.
| 0.700383 | 0.895751 |
[](https://github.com/jlandercy/scifit/actions/workflows/pypi.yaml)
[](https://github.com/jlandercy/scifit/actions/workflows/docs.yaml)

# SciFit
> Comprehensive fits for scientists
Welcome to SciFit project the Python package for comprehensive fits for scientists
designed to ease fitting procedure and automatically perform the quality assessment.
The SciFit project aims to support your work by:
- Providing a clean, stable and compliant interface for each solver;
- Perform ad hoc transformations, processing and tests on each stage of a solver procedure;
- Render high quality figures summarizing solver solution and the quality assessment.
## Installation
You can install the SciFit package by issuing:
```commandline
python -m pip install --upgrade scifit
```
Which update you to the latest version of the package.
## Quick start
Let's fit some data:
```python
from scifit.solvers.scientific import *
# Select a specific solver:
solver = HillEquationFitSolver()
# Create some synthetic dataset:
data = solver.synthetic_dataset(
xmin=0.0, xmax=5.0, resolution=50,
parameters=[3.75, 0.21],
sigma=0.1, scale_mode="auto", seed=1234,
)
# Perform regression:
solution = solver.fit(data)
# Render results:
axe = solver.plot_fit()
```

```python
solver.report("hill_report")
```

## Resources
- [Documentations][20]
- [Repository][21]
[20]: https://github.com/jlandercy/scifit/tree/main/docs
[21]: https://github.com/jlandercy/scifit | scifit | /scifit-0.1.12.tar.gz/scifit-0.1.12/README.md | README.md | python -m pip install --upgrade scifit
from scifit.solvers.scientific import *
# Select a specific solver:
solver = HillEquationFitSolver()
# Create some synthetic dataset:
data = solver.synthetic_dataset(
xmin=0.0, xmax=5.0, resolution=50,
parameters=[3.75, 0.21],
sigma=0.1, scale_mode="auto", seed=1234,
)
# Perform regression:
solution = solver.fit(data)
# Render results:
axe = solver.plot_fit()
solver.report("hill_report") | 0.631594 | 0.896115 |
import os
import django
from rest_framework import serializers
from datafiles.models import *
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "sciflow.settings")
django.setup()
class AspectLookupSerializer(serializers.ModelSerializer):
class Meta:
model = AspectLookup
fields = '__all__'
extra_fields = ['aspectfiles_set', 'aspecterrors_set', 'aspectactlog_set']
depth = 1
def get_field_names(self, declared_fields, info):
expanded_fields = super(AspectLookupSerializer, self).get_field_names(declared_fields, info)
if getattr(self.Meta, 'extra_fields', None):
return expanded_fields + self.Meta.extra_fields
else:
return expanded_fields
class FacetLookupSerializer(serializers.ModelSerializer):
class Meta:
model = FacetLookup
fields = '__all__'
extra_fields = ['facetfiles_set', 'faceterrors_set', 'facetactlog_set']
depth = 1
def get_field_names(self, declared_fields, info):
expanded_fields = super(FacetLookupSerializer, self).get_field_names(declared_fields, info)
if getattr(self.Meta, 'extra_fields', None):
return expanded_fields + self.Meta.extra_fields
else:
return expanded_fields
class JsonAspectsSerializer(serializers.ModelSerializer):
aspect_lookup = AspectLookupSerializer()
facet_lookup = FacetLookupSerializer()
class Meta:
model = JsonAspects
fields = '__all__'
# extra_fields = ['']
depth = 1
class JsonFacetsSerializer(serializers.ModelSerializer):
facet_lookup = FacetLookupSerializer()
class Meta:
model = JsonFacets
fields = '__all__'
# extra_fields = ['']
depth = 1
class JsonLookupSerializer(serializers.ModelSerializer):
json_aspects = JsonAspectsSerializer(source="jsonaspects_set", many=True)
json_facets = JsonFacetsSerializer(source="jsonfacets_set", many=True)
class Meta:
model = JsonLookup
fields = '__all__'
extra_fields = ['jsonerrors_set', 'jsonactlog_set']
depth = 2
def get_field_names(self, declared_fields, info):
expanded_fields = super(JsonLookupSerializer, self).get_field_names(declared_fields, info)
if getattr(self.Meta, 'extra_fields', None):
return expanded_fields + self.Meta.extra_fields
else:
return expanded_fields
class JsonFilesSerializer(serializers.ModelSerializer):
json_lookup = JsonLookupSerializer()
class Meta:
model = JsonFiles
fields = '__all__'
depth = 2 | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/datafiles/df_serializers.py | df_serializers.py | import os
import django
from rest_framework import serializers
from datafiles.models import *
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "sciflow.settings")
django.setup()
class AspectLookupSerializer(serializers.ModelSerializer):
class Meta:
model = AspectLookup
fields = '__all__'
extra_fields = ['aspectfiles_set', 'aspecterrors_set', 'aspectactlog_set']
depth = 1
def get_field_names(self, declared_fields, info):
expanded_fields = super(AspectLookupSerializer, self).get_field_names(declared_fields, info)
if getattr(self.Meta, 'extra_fields', None):
return expanded_fields + self.Meta.extra_fields
else:
return expanded_fields
class FacetLookupSerializer(serializers.ModelSerializer):
class Meta:
model = FacetLookup
fields = '__all__'
extra_fields = ['facetfiles_set', 'faceterrors_set', 'facetactlog_set']
depth = 1
def get_field_names(self, declared_fields, info):
expanded_fields = super(FacetLookupSerializer, self).get_field_names(declared_fields, info)
if getattr(self.Meta, 'extra_fields', None):
return expanded_fields + self.Meta.extra_fields
else:
return expanded_fields
class JsonAspectsSerializer(serializers.ModelSerializer):
aspect_lookup = AspectLookupSerializer()
facet_lookup = FacetLookupSerializer()
class Meta:
model = JsonAspects
fields = '__all__'
# extra_fields = ['']
depth = 1
class JsonFacetsSerializer(serializers.ModelSerializer):
facet_lookup = FacetLookupSerializer()
class Meta:
model = JsonFacets
fields = '__all__'
# extra_fields = ['']
depth = 1
class JsonLookupSerializer(serializers.ModelSerializer):
json_aspects = JsonAspectsSerializer(source="jsonaspects_set", many=True)
json_facets = JsonFacetsSerializer(source="jsonfacets_set", many=True)
class Meta:
model = JsonLookup
fields = '__all__'
extra_fields = ['jsonerrors_set', 'jsonactlog_set']
depth = 2
def get_field_names(self, declared_fields, info):
expanded_fields = super(JsonLookupSerializer, self).get_field_names(declared_fields, info)
if getattr(self.Meta, 'extra_fields', None):
return expanded_fields + self.Meta.extra_fields
else:
return expanded_fields
class JsonFilesSerializer(serializers.ModelSerializer):
json_lookup = JsonLookupSerializer()
class Meta:
model = JsonFiles
fields = '__all__'
depth = 2 | 0.422862 | 0.116487 |
from django.db import models
from datasets.models import *
# data tables
class JsonLookup(models.Model):
""" model for the json_lookup DB table """
dataset = models.ForeignKey(Datasets, on_delete=models.PROTECT)
uniqueid = models.CharField(max_length=128, unique=True, default='')
title = models.CharField(max_length=256, default='')
graphname = models.CharField(max_length=256, default='')
currentversion = models.IntegerField(default=0)
auth_user_id = models.IntegerField(default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_lookup'
class JsonFiles(models.Model):
""" model for the json_files DB table """
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
file = models.TextField(default='')
type = models.CharField(max_length=32, default='')
version = models.IntegerField(default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_files'
class JsonErrors(models.Model):
""" model for the json_errors DB table """
session = models.CharField(max_length=24, default=None)
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
json_file = models.ForeignKey(JsonFiles, on_delete=models.PROTECT)
errorcode = models.CharField(max_length=128, default='')
comment = models.CharField(max_length=256, default=None)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_errors'
class JsonActlog(models.Model):
""" model for the json_errors DB table """
session = models.CharField(max_length=24, default=None)
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
json_file = models.ForeignKey(JsonFiles, on_delete=models.PROTECT)
activitylog = models.CharField(max_length=2048, default='')
comment = models.CharField(max_length=256, default=None)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_actlog'
# facet tables
class FacetLookup(models.Model):
""" model for the facet_lookup DB table """
uniqueid = models.CharField(max_length=128)
title = models.CharField(max_length=256)
type = models.CharField(max_length=16)
graphname = models.CharField(max_length=256)
currentversion = models.IntegerField()
auth_user_id = models.PositiveIntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_lookup'
class FacetFiles(models.Model):
""" model for the facet_files DB table """
facet_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
file = models.TextField()
type = models.CharField(max_length=32)
version = models.IntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_files'
class FacetActlog(models.Model):
""" model for the facet_actlog DB table """
facet_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
facet_file = models.ForeignKey(FacetFiles, on_delete=models.PROTECT)
activitycode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_actlog'
class FacetErrors(models.Model):
""" model for the facet_errors DB table """
facet_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
facet_file = models.ForeignKey(FacetFiles, on_delete=models.PROTECT)
errorcode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_errors'
# aspect files
class AspectLookup(models.Model):
""" model for the aspect_lookup DB table """
uniqueid = models.CharField(max_length=128)
title = models.CharField(max_length=256)
type = models.CharField(max_length=16)
graphname = models.CharField(max_length=256)
currentversion = models.IntegerField()
auth_user_id = models.PositiveIntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_lookup'
class AspectFiles(models.Model):
""" model for the aspect_files DB table """
aspect_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
file = models.TextField()
type = models.CharField(max_length=32)
version = models.IntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_files'
class AspectActlog(models.Model):
""" model for the aspect_actlog DB table """
aspect_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
aspect_file = models.ForeignKey(AspectFiles, on_delete=models.PROTECT)
activitycode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_actlog'
class AspectErrors(models.Model):
""" model for the aspect_errors DB table """
aspect_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
aspect_file = models.ForeignKey(AspectFiles, on_delete=models.PROTECT)
errorcode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_errors'
# join tables
class JsonAspects(models.Model):
"""model for the json_aspects join table"""
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
aspects_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_aspects'
class JsonFacets(models.Model):
"""model for the json_facets join table"""
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
facets_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_facets' | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/datafiles/models.py | models.py | from django.db import models
from datasets.models import *
# data tables
class JsonLookup(models.Model):
""" model for the json_lookup DB table """
dataset = models.ForeignKey(Datasets, on_delete=models.PROTECT)
uniqueid = models.CharField(max_length=128, unique=True, default='')
title = models.CharField(max_length=256, default='')
graphname = models.CharField(max_length=256, default='')
currentversion = models.IntegerField(default=0)
auth_user_id = models.IntegerField(default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_lookup'
class JsonFiles(models.Model):
""" model for the json_files DB table """
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
file = models.TextField(default='')
type = models.CharField(max_length=32, default='')
version = models.IntegerField(default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_files'
class JsonErrors(models.Model):
""" model for the json_errors DB table """
session = models.CharField(max_length=24, default=None)
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
json_file = models.ForeignKey(JsonFiles, on_delete=models.PROTECT)
errorcode = models.CharField(max_length=128, default='')
comment = models.CharField(max_length=256, default=None)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_errors'
class JsonActlog(models.Model):
""" model for the json_errors DB table """
session = models.CharField(max_length=24, default=None)
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
json_file = models.ForeignKey(JsonFiles, on_delete=models.PROTECT)
activitylog = models.CharField(max_length=2048, default='')
comment = models.CharField(max_length=256, default=None)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_actlog'
# facet tables
class FacetLookup(models.Model):
""" model for the facet_lookup DB table """
uniqueid = models.CharField(max_length=128)
title = models.CharField(max_length=256)
type = models.CharField(max_length=16)
graphname = models.CharField(max_length=256)
currentversion = models.IntegerField()
auth_user_id = models.PositiveIntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_lookup'
class FacetFiles(models.Model):
""" model for the facet_files DB table """
facet_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
file = models.TextField()
type = models.CharField(max_length=32)
version = models.IntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_files'
class FacetActlog(models.Model):
""" model for the facet_actlog DB table """
facet_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
facet_file = models.ForeignKey(FacetFiles, on_delete=models.PROTECT)
activitycode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_actlog'
class FacetErrors(models.Model):
""" model for the facet_errors DB table """
facet_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
facet_file = models.ForeignKey(FacetFiles, on_delete=models.PROTECT)
errorcode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'facet_errors'
# aspect files
class AspectLookup(models.Model):
""" model for the aspect_lookup DB table """
uniqueid = models.CharField(max_length=128)
title = models.CharField(max_length=256)
type = models.CharField(max_length=16)
graphname = models.CharField(max_length=256)
currentversion = models.IntegerField()
auth_user_id = models.PositiveIntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_lookup'
class AspectFiles(models.Model):
""" model for the aspect_files DB table """
aspect_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
file = models.TextField()
type = models.CharField(max_length=32)
version = models.IntegerField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_files'
class AspectActlog(models.Model):
""" model for the aspect_actlog DB table """
aspect_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
aspect_file = models.ForeignKey(AspectFiles, on_delete=models.PROTECT)
activitycode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_actlog'
class AspectErrors(models.Model):
""" model for the aspect_errors DB table """
aspect_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
aspect_file = models.ForeignKey(AspectFiles, on_delete=models.PROTECT)
errorcode = models.CharField(max_length=16)
comment = models.CharField(max_length=256)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'aspect_errors'
# join tables
class JsonAspects(models.Model):
"""model for the json_aspects join table"""
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
aspects_lookup = models.ForeignKey(AspectLookup, on_delete=models.PROTECT)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_aspects'
class JsonFacets(models.Model):
"""model for the json_facets join table"""
json_lookup = models.ForeignKey(JsonLookup, on_delete=models.PROTECT)
facets_lookup = models.ForeignKey(FacetLookup, on_delete=models.PROTECT)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'json_facets' | 0.632957 | 0.147801 |
from django.db import migrations, models
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='AspectActlog',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('aspects_lookup_id', models.IntegerField()),
('aspects_file_id', models.IntegerField()),
('activitycode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_actlog',
'managed': False,
},
),
migrations.CreateModel(
name='AspectErrors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('aspects_lookup_id', models.IntegerField()),
('aspects_file_id', models.IntegerField()),
('errorcode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_errors',
'managed': False,
},
),
migrations.CreateModel(
name='AspectFiles',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('aspect_lookup_id', models.IntegerField()),
('file', models.TextField()),
('type', models.CharField(max_length=32)),
('version', models.IntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_files',
'managed': False,
},
),
migrations.CreateModel(
name='AspectLookup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('uniqueid', models.CharField(max_length=128)),
('title', models.CharField(max_length=256)),
('type', models.CharField(max_length=16)),
('graphname', models.CharField(max_length=256)),
('currentversion', models.IntegerField()),
('auth_user_id', models.PositiveIntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_lookup',
'managed': False,
},
),
migrations.CreateModel(
name='FacetActlog',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('facets_lookup_id', models.IntegerField()),
('facets_file_id', models.IntegerField()),
('activitycode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_actlog',
'managed': False,
},
),
migrations.CreateModel(
name='FacetErrors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('facets_lookup_id', models.IntegerField()),
('facets_file_id', models.IntegerField()),
('errorcode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_errors',
'managed': False,
},
),
migrations.CreateModel(
name='FacetFiles',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('facet_lookup_id', models.IntegerField()),
('file', models.TextField()),
('type', models.CharField(max_length=32)),
('version', models.IntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_files',
'managed': False,
},
),
migrations.CreateModel(
name='FacetLookup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('uniqueid', models.CharField(max_length=128)),
('title', models.CharField(max_length=256)),
('type', models.CharField(max_length=16)),
('graphname', models.CharField(max_length=256)),
('currentversion', models.IntegerField()),
('auth_user_id', models.PositiveIntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_lookup',
'managed': False,
},
),
migrations.CreateModel(
name='JsonActlog',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('session', models.CharField(max_length=24)),
('json_lookup_id', models.IntegerField()),
('json_file_id', models.IntegerField()),
('activitycode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_actlog',
'managed': False,
},
),
migrations.CreateModel(
name='JsonErrors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('session', models.CharField(max_length=24)),
('json_lookup_id', models.IntegerField()),
('json_file_id', models.IntegerField()),
('errorcode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_errors',
'managed': False,
},
),
migrations.CreateModel(
name='JsonFiles',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('json_lookup_id', models.IntegerField()),
('file', models.TextField()),
('type', models.CharField(max_length=32)),
('version', models.IntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_files',
'managed': False,
},
),
migrations.CreateModel(
name='JsonLookup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('dataset_id', models.IntegerField()),
('uniqueid', models.CharField(max_length=128)),
('title', models.CharField(max_length=256)),
('graphname', models.CharField(max_length=256)),
('currentversion', models.IntegerField()),
('auth_user_id', models.PositiveIntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_lookup',
'managed': False,
},
),
] | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/datafiles/migrations/0001_initial.py | 0001_initial.py |
from django.db import migrations, models
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='AspectActlog',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('aspects_lookup_id', models.IntegerField()),
('aspects_file_id', models.IntegerField()),
('activitycode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_actlog',
'managed': False,
},
),
migrations.CreateModel(
name='AspectErrors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('aspects_lookup_id', models.IntegerField()),
('aspects_file_id', models.IntegerField()),
('errorcode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_errors',
'managed': False,
},
),
migrations.CreateModel(
name='AspectFiles',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('aspect_lookup_id', models.IntegerField()),
('file', models.TextField()),
('type', models.CharField(max_length=32)),
('version', models.IntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_files',
'managed': False,
},
),
migrations.CreateModel(
name='AspectLookup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('uniqueid', models.CharField(max_length=128)),
('title', models.CharField(max_length=256)),
('type', models.CharField(max_length=16)),
('graphname', models.CharField(max_length=256)),
('currentversion', models.IntegerField()),
('auth_user_id', models.PositiveIntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'aspect_lookup',
'managed': False,
},
),
migrations.CreateModel(
name='FacetActlog',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('facets_lookup_id', models.IntegerField()),
('facets_file_id', models.IntegerField()),
('activitycode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_actlog',
'managed': False,
},
),
migrations.CreateModel(
name='FacetErrors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('facets_lookup_id', models.IntegerField()),
('facets_file_id', models.IntegerField()),
('errorcode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_errors',
'managed': False,
},
),
migrations.CreateModel(
name='FacetFiles',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('facet_lookup_id', models.IntegerField()),
('file', models.TextField()),
('type', models.CharField(max_length=32)),
('version', models.IntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_files',
'managed': False,
},
),
migrations.CreateModel(
name='FacetLookup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('uniqueid', models.CharField(max_length=128)),
('title', models.CharField(max_length=256)),
('type', models.CharField(max_length=16)),
('graphname', models.CharField(max_length=256)),
('currentversion', models.IntegerField()),
('auth_user_id', models.PositiveIntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'facet_lookup',
'managed': False,
},
),
migrations.CreateModel(
name='JsonActlog',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('session', models.CharField(max_length=24)),
('json_lookup_id', models.IntegerField()),
('json_file_id', models.IntegerField()),
('activitycode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_actlog',
'managed': False,
},
),
migrations.CreateModel(
name='JsonErrors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('session', models.CharField(max_length=24)),
('json_lookup_id', models.IntegerField()),
('json_file_id', models.IntegerField()),
('errorcode', models.CharField(max_length=16)),
('comment', models.CharField(max_length=256)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_errors',
'managed': False,
},
),
migrations.CreateModel(
name='JsonFiles',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('json_lookup_id', models.IntegerField()),
('file', models.TextField()),
('type', models.CharField(max_length=32)),
('version', models.IntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_files',
'managed': False,
},
),
migrations.CreateModel(
name='JsonLookup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('dataset_id', models.IntegerField()),
('uniqueid', models.CharField(max_length=128)),
('title', models.CharField(max_length=256)),
('graphname', models.CharField(max_length=256)),
('currentversion', models.IntegerField()),
('auth_user_id', models.PositiveIntegerField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'json_lookup',
'managed': False,
},
),
] | 0.589598 | 0.17575 |
import re
from qwikidata.sparql import *
from qwikidata.entity import *
from qwikidata.typedefs import *
from qwikidata.linked_data_interface import *
from chembl_webresource_client.new_client import new_client
def pubchem(identifier, meta, ids, descs, srcs):
"""this function allows retrieval of data from the PugRest API @ PubChem"""
apipath = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/"
srcs.update({"pubchem": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["pubchem"].update({"result": 0, "notes": "Not an InChIKey"})
return
# check to see if compound is in database
other = None
respnse = requests.get(apipath + 'inchikey/' + identifier + '/json')
if respnse.status_code != 200:
other = identifier
uhff = '-UHFFFAOYSA-N'
identifier = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
respnse = requests.get(apipath + 'inchikey/' + identifier + '/json')
if respnse.status_code == 200:
notes = "InChiKey generalized with -UHFFFAOYSA-N"
srcs["pubchem"].update({"result": 0, "notes": notes})
else:
notes = "InChIKey not found, including generic"
srcs["pubchem"].update({"result": 0, "notes": notes})
return
# OK compound has been found go get the data
json = requests.get(apipath + 'inchikey/' + identifier + '/json').json()
full = json["PC_Compounds"][0]
pcid = full["id"]["id"]["cid"]
props = full["props"]
counts = dict(full["count"])
descs["pubchem"] = {}
for k, v in counts.items():
descs["pubchem"][k] = v
ids["pubchem"] = {}
meta["pubchem"] = {}
ids["pubchem"]["pubchem"] = pcid
if other:
ids["pubchem"]["other"] = other # original inchikey if made generic
for prop in props:
if prop['urn']['label'] == "IUPAC Name" and \
prop['urn']['name'] == "Preferred":
ids["pubchem"]["iupacname"] = prop["value"]["sval"]
elif prop['urn']['label'] == "InChI":
ids["pubchem"]["inchi"] = prop["value"]["sval"]
elif prop['urn']['label'] == "InChIKey":
ids["pubchem"]["inchikey"] = prop["value"]["sval"]
elif prop['urn']['label'] == "SMILES" and \
prop['urn']['name'] == "Canonical":
ids["pubchem"]["csmiles"] = prop["value"]["sval"]
elif prop['urn']['label'] == "SMILES" and \
prop['urn']['name'] == "Isomeric":
ids["pubchem"]["ismiles"] = prop["value"]["sval"]
elif prop['urn']['label'] == "Molecular Formula":
meta["pubchem"]["formula"] = prop["value"]["sval"]
elif prop['urn']['label'] == "Molecular Weight":
meta["pubchem"]["mw"] = prop["value"]["fval"]
elif prop['urn']['label'] == "Weight":
meta["pubchem"]["mim"] = prop["value"]["fval"]
elif prop['urn']['label'] == "Count" and \
prop['urn']['name'] == "Hydrogen Bond Acceptor":
descs["pubchem"]["h_bond_acceptor"] = prop["value"]["ival"]
elif prop['urn']['label'] == "Count" and \
prop['urn']['name'] == "Hydrogen Bond Donor":
descs["pubchem"]["h_bond_donor"] = prop["value"]["ival"]
elif prop['urn']['label'] == "Count" and \
prop['urn']['name'] == "Rotatable Bond":
descs["pubchem"]["rotatable_bond"] = prop["value"]["ival"]
# get addition descriptor data if available
search = 'inchikey/' + identifier + '/json?record_type=3d'
response = requests.get(apipath + search)
if response.status_code == 200:
search = 'inchikey/' + identifier + '/json?record_type=3d'
json = requests.get(apipath + search).json()
full = json["PC_Compounds"][0]
coords = full["coords"]
for coord in coords:
for x in coord["conformers"]:
for y in x["data"]:
if y["urn"]["label"] == "Fingerprint" and \
y["urn"]["name"] == "Shape":
descs["pubchem"]["fingerprint"] = \
y["value"]["slist"]
elif y["urn"]["label"] == "Shape" and \
y["urn"]["name"] == "Volume":
descs["pubchem"]["volume3D"] = y["value"]["fval"]
srcs["pubchem"].update({"result": 1})
def classyfire(identifier, descs, srcs):
""" get classyfire classification for a specific compound """
# best to use InChIKey to get the data
apipath = "http://classyfire.wishartlab.com/entities/"
srcs.update({"classyfire": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["classyfire"].update({"result": 0, "notes": "Not an InChIKey"})
return
# check to see if compound is in database
respnse = requests.get(apipath + identifier + '.json')
if respnse.status_code != 200:
# redefine identifier
uhff = '-UHFFFAOYSA-N'
identifier = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
respnse = requests.get(apipath + identifier + '.json')
if respnse.status_code == 200:
notes = "InChiKey generalized by change to block1-UHFFFAOYSA-N"
srcs["classyfire"].update({"result": 0, "notes": notes})
# have we found the compound?
if respnse.status_code != 200:
notes = "InChIKey Not Found, including generic"
srcs["classyfire"].update({"result": 0, "notes": notes})
return
# OK compound has been found go get the data
descs["classyfire"] = {}
respnse = requests.get(apipath + identifier + '.json').json()
descs["classyfire"]["kingdom"] = \
str(respnse['kingdom']["chemont_id"])
descs["classyfire"]["superclass"] = \
str(respnse['superclass']["chemont_id"])
descs["classyfire"]["class"] = str(respnse['class']["chemont_id"])
if respnse["subclass"] is not None:
descs["classyfire"]["subclass"] = \
str(respnse['subclass']["chemont_id"])
if "node" in respnse.keys():
if respnse["node"] is not None:
descs["classyfire"]["node"] = []
for node in respnse['intermediate_nodes']:
descs["classyfire"]["node"].append(node["chemont_id"])
descs["classyfire"]["direct_parent"] = \
str(respnse['direct_parent']["chemont_id"])
descs["classyfire"]["alternative_parent"] = []
for alt in respnse['alternative_parents']:
descs["classyfire"]["alternative_parent"].append(alt["chemont_id"])
srcs["classyfire"].update({"result": 1})
w = "https://www.wikidata.org/w/api.php?action=wbgetclaims&format=json&entity="
def wikidata(identifier, ids, srcs):
""" retreive data from wikidata using the qwikidata python package"""
# find wikidata code for a compound based off its inchikey (wdt:P35)
srcs.update({"wikidata": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["classyfire"].update({"result": 0, "notes": "Not an InChIKey"})
return
# setup SPARQL query
q1 = "SELECT DISTINCT ?compound "
q2 = "WHERE { ?compound wdt:P235 \"" + identifier + "\" ."
q3 = 'SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }}'
query = q1 + q2 + q3
res = return_sparql_query_results(query)
if not res['results']['bindings']:
uhff = '-UHFFFAOYSA-N'
identifier = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
q2 = "WHERE { ?compound wdt:P235 \"" + identifier + "\" ."
query = q1 + q2 + q3
res = return_sparql_query_results(query)
if res['results']['bindings']:
# TODO: why was this here? request.session['originalkey']
notes = "InChiKey generalized by change to block1-UHFFFAOYSA-N"
srcs["wikidata"].update({"result": 0, "notes": notes})
# have we found the compound?
if not res['results']['bindings']:
notes = "InChIKey not found, including generic"
srcs["wikidata"].update({"result": 0, "notes": notes})
return
# OK compound has been found go get the data
eurl = res['results']['bindings'][0]['compound']['value']
wdid = str(eurl).replace("http://www.wikidata.org/entity/", "")
mwurl = w + wdid # 'w' is defined (above) outside of this function
respnse = requests.get(mwurl)
if respnse.status_code == 200:
# response contains many props from which we get specific chemical ones
ids['wikidata'] = {}
json = requests.get(mwurl).json()
claims = json['claims']
propids = {'casrn': 'P231', 'atc': 'P267', 'inchi': 'P234',
'inchikey': 'P235', 'chemspider': 'P661', 'pubchem': 'P662',
'reaxys': 'P1579', 'gmelin': 'P1578', 'chebi': 'P683',
'chembl': 'P592', 'rtecs': 'P657', 'dsstox': 'P3117'}
vals = list(propids.values())
keys = list(propids.keys())
for propid, prop in claims.items():
if propid in vals:
if 'datavalue' in prop[0]['mainsnak']:
value = prop[0]['mainsnak']['datavalue']['value']
key = keys[vals.index(propid)]
ids['wikidata'].update({key: value})
# get aggregated names/tradenames for this compound (and intl names)
cdict = get_entity_dict_from_api(ItemId(wdid))
cmpd = WikidataItem(cdict)
ids['wikidata']['othername'] = []
aliases = cmpd.get_aliases()
aliases = list(set(aliases)) # deduplicate
for alias in aliases:
ids['wikidata']['othername'].append(alias)
ids['wikidata']['othername'] = list(set(ids['wikidata']['othername']))
srcs["wikidata"].update({"result": 1})
else:
notes = "Could not get Wikidata entity '" + wdid + "'"
srcs["wikidata"].update({"result": 0, "notes": notes})
def chembl(identifier, meta, ids, descs, srcs):
""" retrieve data from the ChEMBL repository"""
molecule = new_client.molecule
srcs.update({"chembl": {"result": None, "notes": None}})
print(identifier)
cmpds = molecule.search(identifier)
found = {}
for cmpd in cmpds:
if cmpd['molecule_structures']['standard_inchi_key'] == identifier:
found = cmpd
break
if not found:
uhff = '-UHFFFAOYSA-N'
genericid = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
cmpds = molecule.search(genericid)
found = {}
for cmpd in cmpds:
if cmpd['molecule_structures']['standard_inchi_key'] == identifier:
found = cmpd
break
if found:
notes = "InChiKey generalized by change to block1-UHFFFAOYSA-N"
srcs['chembl'].update({"notes": notes})
if not found:
return
# general metadata
cmpd = found
meta['chembl'] = {}
mprops = ['full_molformula', 'full_mwt', 'mw_freebase', 'mw_monoisotopic']
for k, v in cmpd['molecule_properties'].items():
if k in mprops:
meta['chembl'].update({k: v})
meta['chembl'].update({'prefname': cmpd['pref_name']})
# identifiers
ids['chembl'] = {}
# molecule structures ('canonical smiles' is actually
# 'isomeric canonical smiles')
exclude = ['molfile']
rename = {'canonical_smiles': 'ismiles', 'standard_inchi': 'inchi',
'standard_inchi_key': 'inchikey'}
for k, v in cmpd['molecule_structures'].items():
if k not in exclude:
ids['chembl'].update({rename[k]: v})
# - molecule synonyms
syntypes = []
for syn in cmpd['molecule_synonyms']:
syntype = syn['syn_type'].lower()
syntypes.append(syntype)
if syntype not in ids['chembl'].keys():
ids['chembl'][syntype] = []
ids['chembl'][syntype].append(syn['molecule_synonym'])
# deduplicate entries for synonym types
syntypes = set(list(syntypes))
for syntype in syntypes:
ids['chembl'][syntype] = list(set(ids['chembl'][syntype]))
# descriptors
descs['chembl'] = {}
# - atc
if cmpd['atc_classifications']:
descs['chembl'].update(atclvl1=[], atclvl2=[],
atclvl3=[], atclvl4=[], atclvl5=[])
for c in cmpd['atc_classifications']:
descs['chembl']['atclvl1'].append(c[0:1])
descs['chembl']['atclvl2'].append(c[0:3])
descs['chembl']['atclvl3'].append(c[0:4])
descs['chembl']['atclvl4'].append(c[0:5])
descs['chembl']['atclvl5'].append(c)
descs['chembl']['atclvl1'] = list(set(descs['chembl']['atclvl1']))
descs['chembl']['atclvl2'] = list(set(descs['chembl']['atclvl2']))
descs['chembl']['atclvl3'] = list(set(descs['chembl']['atclvl3']))
descs['chembl']['atclvl4'] = list(set(descs['chembl']['atclvl4']))
descs['chembl']['atclvl5'] = list(set(descs['chembl']['atclvl5']))
# - molecule properties
for k, v in cmpd['molecule_properties'].items():
if k not in mprops:
if v is not None:
descs['chembl'].update({k: v})
# - other fields
dflds = ['chirality', 'dosed_ingredient', 'indication_class',
'inorganic_flag', 'max_phase', 'molecule_type', 'natural_product',
'polymer_flag', 'structure_type', 'therapeutic_flag']
for fld in dflds:
if cmpd[fld] is not None:
descs['chembl'].update({fld: cmpd[fld]})
# sources
srcs.update({"chembl": {"result": 1, "notes": None}})
def comchem(identifier, meta, ids, srcs):
""" retreive data from the commonchemistry API"""
srcs.update({"comchem": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["comchem"].update({"result": 0, "notes": "Not a CAS-RN"})
return
# search for entries and retrieve casrn for compound if present
apipath = "https://commonchemistry.cas.org/"
respnse = requests.get(apipath + 'api/search?q=' + identifier).json()
if respnse['count'] == 0:
srcs["comchem"].update({"result": 0, "notes": "InChIKey not found"})
return False
else:
# even though there may be multiple responses, first is likely correct
casrn = respnse['results'][0]['rn']
res = requests.get(apipath + 'api/detail?cas_rn=' + casrn).json()
# OK now we have data for the specfic compound
ids["comchem"] = {}
ids["comchem"]["casrn"] = casrn
ids["comchem"]["inchi"] = res["inchi"]
ids["comchem"]["inchikey"] = res["inchiKey"]
ids["comchem"]["csmiles"] = res["canonicalSmile"]
ids["comchem"]["othername"] = res["synonyms"]
ids["comchem"]["replacedcasrn"] = res["replacedRns"]
meta["comchem"] = {}
meta["comchem"]["formula"] = res["molecularFormula"]
meta["comchem"]["mw"] = res["molecularMass"]
srcs["comchem"].update({"result": 1})
return True
def pubchemsyns(identifier):
"""this function allows retreival of data from the PugRest API @ PubChem"""
apipath = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/"
# retrieve full record if available based on name
searchpath = 'name/' + identifier + '/synonyms/json'
response = requests.get(apipath + searchpath).json()
syns = response["InformationList"]["Information"][0]["Synonym"]
inchikey = ""
for k in syns:
m = re.search('^[A-Z]{14}-[A-Z]{10}-[A-Z]$', k)
if m:
inchikey = k
return inchikey
def pubchemmol(pcid):
"""
allows retrieval of SDF file from the PugRest API at PubChem
with two entries - atoms and bonds. Each value is a list
atoms list is x, y, z coords and element symbol
bonds list is atom1, atom2, and bond order
:param pcid pubchem id for compound
:return dict dictionary
"""
apipath = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/"
url = apipath + pcid + '/SDF'
response = requests.get(url)
sdf = None
if response.status_code == 200:
sdf = requests.get(url).text
atoms = []
bonds = []
chrgs = []
for ln in sdf.splitlines():
a = re.search(r"([0-9\-.]+)\s+([0-9\-.]+)\s+([0-9\-.]+)\s"
r"([A-Za-z]{1,2})\s+0\s+(\d)\s+0\s+0", ln)
if a:
atoms.append([a[1], a[2], a[3], a[4], a[5]])
continue
b = re.search(r"^\s+(\d{1,2})\s+(\d{1,2})\s+(\d)\s+0\s+0\s+0\s+0$", ln)
if b:
bonds.append([b[1], b[2], b[3]])
continue
c = re.search(r"^M\s+CHG\s+(\d)", ln)
if c:
num = int(c[1])
rest = ln.replace('M CHG ' + str(num), '')
parts = re.split(r"\s{2,3}", rest.strip())
for idx, val in enumerate(parts):
if (idx % 2) != 0:
continue
chrgs.append([val, parts[(idx + 1)]])
return {'atoms': atoms, 'bonds': bonds, 'chrgs': chrgs} | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/substances/external.py | external.py | import re
from qwikidata.sparql import *
from qwikidata.entity import *
from qwikidata.typedefs import *
from qwikidata.linked_data_interface import *
from chembl_webresource_client.new_client import new_client
def pubchem(identifier, meta, ids, descs, srcs):
"""this function allows retrieval of data from the PugRest API @ PubChem"""
apipath = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/"
srcs.update({"pubchem": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["pubchem"].update({"result": 0, "notes": "Not an InChIKey"})
return
# check to see if compound is in database
other = None
respnse = requests.get(apipath + 'inchikey/' + identifier + '/json')
if respnse.status_code != 200:
other = identifier
uhff = '-UHFFFAOYSA-N'
identifier = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
respnse = requests.get(apipath + 'inchikey/' + identifier + '/json')
if respnse.status_code == 200:
notes = "InChiKey generalized with -UHFFFAOYSA-N"
srcs["pubchem"].update({"result": 0, "notes": notes})
else:
notes = "InChIKey not found, including generic"
srcs["pubchem"].update({"result": 0, "notes": notes})
return
# OK compound has been found go get the data
json = requests.get(apipath + 'inchikey/' + identifier + '/json').json()
full = json["PC_Compounds"][0]
pcid = full["id"]["id"]["cid"]
props = full["props"]
counts = dict(full["count"])
descs["pubchem"] = {}
for k, v in counts.items():
descs["pubchem"][k] = v
ids["pubchem"] = {}
meta["pubchem"] = {}
ids["pubchem"]["pubchem"] = pcid
if other:
ids["pubchem"]["other"] = other # original inchikey if made generic
for prop in props:
if prop['urn']['label'] == "IUPAC Name" and \
prop['urn']['name'] == "Preferred":
ids["pubchem"]["iupacname"] = prop["value"]["sval"]
elif prop['urn']['label'] == "InChI":
ids["pubchem"]["inchi"] = prop["value"]["sval"]
elif prop['urn']['label'] == "InChIKey":
ids["pubchem"]["inchikey"] = prop["value"]["sval"]
elif prop['urn']['label'] == "SMILES" and \
prop['urn']['name'] == "Canonical":
ids["pubchem"]["csmiles"] = prop["value"]["sval"]
elif prop['urn']['label'] == "SMILES" and \
prop['urn']['name'] == "Isomeric":
ids["pubchem"]["ismiles"] = prop["value"]["sval"]
elif prop['urn']['label'] == "Molecular Formula":
meta["pubchem"]["formula"] = prop["value"]["sval"]
elif prop['urn']['label'] == "Molecular Weight":
meta["pubchem"]["mw"] = prop["value"]["fval"]
elif prop['urn']['label'] == "Weight":
meta["pubchem"]["mim"] = prop["value"]["fval"]
elif prop['urn']['label'] == "Count" and \
prop['urn']['name'] == "Hydrogen Bond Acceptor":
descs["pubchem"]["h_bond_acceptor"] = prop["value"]["ival"]
elif prop['urn']['label'] == "Count" and \
prop['urn']['name'] == "Hydrogen Bond Donor":
descs["pubchem"]["h_bond_donor"] = prop["value"]["ival"]
elif prop['urn']['label'] == "Count" and \
prop['urn']['name'] == "Rotatable Bond":
descs["pubchem"]["rotatable_bond"] = prop["value"]["ival"]
# get addition descriptor data if available
search = 'inchikey/' + identifier + '/json?record_type=3d'
response = requests.get(apipath + search)
if response.status_code == 200:
search = 'inchikey/' + identifier + '/json?record_type=3d'
json = requests.get(apipath + search).json()
full = json["PC_Compounds"][0]
coords = full["coords"]
for coord in coords:
for x in coord["conformers"]:
for y in x["data"]:
if y["urn"]["label"] == "Fingerprint" and \
y["urn"]["name"] == "Shape":
descs["pubchem"]["fingerprint"] = \
y["value"]["slist"]
elif y["urn"]["label"] == "Shape" and \
y["urn"]["name"] == "Volume":
descs["pubchem"]["volume3D"] = y["value"]["fval"]
srcs["pubchem"].update({"result": 1})
def classyfire(identifier, descs, srcs):
""" get classyfire classification for a specific compound """
# best to use InChIKey to get the data
apipath = "http://classyfire.wishartlab.com/entities/"
srcs.update({"classyfire": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["classyfire"].update({"result": 0, "notes": "Not an InChIKey"})
return
# check to see if compound is in database
respnse = requests.get(apipath + identifier + '.json')
if respnse.status_code != 200:
# redefine identifier
uhff = '-UHFFFAOYSA-N'
identifier = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
respnse = requests.get(apipath + identifier + '.json')
if respnse.status_code == 200:
notes = "InChiKey generalized by change to block1-UHFFFAOYSA-N"
srcs["classyfire"].update({"result": 0, "notes": notes})
# have we found the compound?
if respnse.status_code != 200:
notes = "InChIKey Not Found, including generic"
srcs["classyfire"].update({"result": 0, "notes": notes})
return
# OK compound has been found go get the data
descs["classyfire"] = {}
respnse = requests.get(apipath + identifier + '.json').json()
descs["classyfire"]["kingdom"] = \
str(respnse['kingdom']["chemont_id"])
descs["classyfire"]["superclass"] = \
str(respnse['superclass']["chemont_id"])
descs["classyfire"]["class"] = str(respnse['class']["chemont_id"])
if respnse["subclass"] is not None:
descs["classyfire"]["subclass"] = \
str(respnse['subclass']["chemont_id"])
if "node" in respnse.keys():
if respnse["node"] is not None:
descs["classyfire"]["node"] = []
for node in respnse['intermediate_nodes']:
descs["classyfire"]["node"].append(node["chemont_id"])
descs["classyfire"]["direct_parent"] = \
str(respnse['direct_parent']["chemont_id"])
descs["classyfire"]["alternative_parent"] = []
for alt in respnse['alternative_parents']:
descs["classyfire"]["alternative_parent"].append(alt["chemont_id"])
srcs["classyfire"].update({"result": 1})
w = "https://www.wikidata.org/w/api.php?action=wbgetclaims&format=json&entity="
def wikidata(identifier, ids, srcs):
""" retreive data from wikidata using the qwikidata python package"""
# find wikidata code for a compound based off its inchikey (wdt:P35)
srcs.update({"wikidata": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["classyfire"].update({"result": 0, "notes": "Not an InChIKey"})
return
# setup SPARQL query
q1 = "SELECT DISTINCT ?compound "
q2 = "WHERE { ?compound wdt:P235 \"" + identifier + "\" ."
q3 = 'SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }}'
query = q1 + q2 + q3
res = return_sparql_query_results(query)
if not res['results']['bindings']:
uhff = '-UHFFFAOYSA-N'
identifier = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
q2 = "WHERE { ?compound wdt:P235 \"" + identifier + "\" ."
query = q1 + q2 + q3
res = return_sparql_query_results(query)
if res['results']['bindings']:
# TODO: why was this here? request.session['originalkey']
notes = "InChiKey generalized by change to block1-UHFFFAOYSA-N"
srcs["wikidata"].update({"result": 0, "notes": notes})
# have we found the compound?
if not res['results']['bindings']:
notes = "InChIKey not found, including generic"
srcs["wikidata"].update({"result": 0, "notes": notes})
return
# OK compound has been found go get the data
eurl = res['results']['bindings'][0]['compound']['value']
wdid = str(eurl).replace("http://www.wikidata.org/entity/", "")
mwurl = w + wdid # 'w' is defined (above) outside of this function
respnse = requests.get(mwurl)
if respnse.status_code == 200:
# response contains many props from which we get specific chemical ones
ids['wikidata'] = {}
json = requests.get(mwurl).json()
claims = json['claims']
propids = {'casrn': 'P231', 'atc': 'P267', 'inchi': 'P234',
'inchikey': 'P235', 'chemspider': 'P661', 'pubchem': 'P662',
'reaxys': 'P1579', 'gmelin': 'P1578', 'chebi': 'P683',
'chembl': 'P592', 'rtecs': 'P657', 'dsstox': 'P3117'}
vals = list(propids.values())
keys = list(propids.keys())
for propid, prop in claims.items():
if propid in vals:
if 'datavalue' in prop[0]['mainsnak']:
value = prop[0]['mainsnak']['datavalue']['value']
key = keys[vals.index(propid)]
ids['wikidata'].update({key: value})
# get aggregated names/tradenames for this compound (and intl names)
cdict = get_entity_dict_from_api(ItemId(wdid))
cmpd = WikidataItem(cdict)
ids['wikidata']['othername'] = []
aliases = cmpd.get_aliases()
aliases = list(set(aliases)) # deduplicate
for alias in aliases:
ids['wikidata']['othername'].append(alias)
ids['wikidata']['othername'] = list(set(ids['wikidata']['othername']))
srcs["wikidata"].update({"result": 1})
else:
notes = "Could not get Wikidata entity '" + wdid + "'"
srcs["wikidata"].update({"result": 0, "notes": notes})
def chembl(identifier, meta, ids, descs, srcs):
""" retrieve data from the ChEMBL repository"""
molecule = new_client.molecule
srcs.update({"chembl": {"result": None, "notes": None}})
print(identifier)
cmpds = molecule.search(identifier)
found = {}
for cmpd in cmpds:
if cmpd['molecule_structures']['standard_inchi_key'] == identifier:
found = cmpd
break
if not found:
uhff = '-UHFFFAOYSA-N'
genericid = str(re.search('^[A-Z]{14}', identifier).group(0)) + uhff
cmpds = molecule.search(genericid)
found = {}
for cmpd in cmpds:
if cmpd['molecule_structures']['standard_inchi_key'] == identifier:
found = cmpd
break
if found:
notes = "InChiKey generalized by change to block1-UHFFFAOYSA-N"
srcs['chembl'].update({"notes": notes})
if not found:
return
# general metadata
cmpd = found
meta['chembl'] = {}
mprops = ['full_molformula', 'full_mwt', 'mw_freebase', 'mw_monoisotopic']
for k, v in cmpd['molecule_properties'].items():
if k in mprops:
meta['chembl'].update({k: v})
meta['chembl'].update({'prefname': cmpd['pref_name']})
# identifiers
ids['chembl'] = {}
# molecule structures ('canonical smiles' is actually
# 'isomeric canonical smiles')
exclude = ['molfile']
rename = {'canonical_smiles': 'ismiles', 'standard_inchi': 'inchi',
'standard_inchi_key': 'inchikey'}
for k, v in cmpd['molecule_structures'].items():
if k not in exclude:
ids['chembl'].update({rename[k]: v})
# - molecule synonyms
syntypes = []
for syn in cmpd['molecule_synonyms']:
syntype = syn['syn_type'].lower()
syntypes.append(syntype)
if syntype not in ids['chembl'].keys():
ids['chembl'][syntype] = []
ids['chembl'][syntype].append(syn['molecule_synonym'])
# deduplicate entries for synonym types
syntypes = set(list(syntypes))
for syntype in syntypes:
ids['chembl'][syntype] = list(set(ids['chembl'][syntype]))
# descriptors
descs['chembl'] = {}
# - atc
if cmpd['atc_classifications']:
descs['chembl'].update(atclvl1=[], atclvl2=[],
atclvl3=[], atclvl4=[], atclvl5=[])
for c in cmpd['atc_classifications']:
descs['chembl']['atclvl1'].append(c[0:1])
descs['chembl']['atclvl2'].append(c[0:3])
descs['chembl']['atclvl3'].append(c[0:4])
descs['chembl']['atclvl4'].append(c[0:5])
descs['chembl']['atclvl5'].append(c)
descs['chembl']['atclvl1'] = list(set(descs['chembl']['atclvl1']))
descs['chembl']['atclvl2'] = list(set(descs['chembl']['atclvl2']))
descs['chembl']['atclvl3'] = list(set(descs['chembl']['atclvl3']))
descs['chembl']['atclvl4'] = list(set(descs['chembl']['atclvl4']))
descs['chembl']['atclvl5'] = list(set(descs['chembl']['atclvl5']))
# - molecule properties
for k, v in cmpd['molecule_properties'].items():
if k not in mprops:
if v is not None:
descs['chembl'].update({k: v})
# - other fields
dflds = ['chirality', 'dosed_ingredient', 'indication_class',
'inorganic_flag', 'max_phase', 'molecule_type', 'natural_product',
'polymer_flag', 'structure_type', 'therapeutic_flag']
for fld in dflds:
if cmpd[fld] is not None:
descs['chembl'].update({fld: cmpd[fld]})
# sources
srcs.update({"chembl": {"result": 1, "notes": None}})
def comchem(identifier, meta, ids, srcs):
""" retreive data from the commonchemistry API"""
srcs.update({"comchem": {}})
# check identifier for inchikey pattern
if re.search('[A-Z]{14}-[A-Z]{10}-[A-Z]', identifier) is None:
srcs["comchem"].update({"result": 0, "notes": "Not a CAS-RN"})
return
# search for entries and retrieve casrn for compound if present
apipath = "https://commonchemistry.cas.org/"
respnse = requests.get(apipath + 'api/search?q=' + identifier).json()
if respnse['count'] == 0:
srcs["comchem"].update({"result": 0, "notes": "InChIKey not found"})
return False
else:
# even though there may be multiple responses, first is likely correct
casrn = respnse['results'][0]['rn']
res = requests.get(apipath + 'api/detail?cas_rn=' + casrn).json()
# OK now we have data for the specfic compound
ids["comchem"] = {}
ids["comchem"]["casrn"] = casrn
ids["comchem"]["inchi"] = res["inchi"]
ids["comchem"]["inchikey"] = res["inchiKey"]
ids["comchem"]["csmiles"] = res["canonicalSmile"]
ids["comchem"]["othername"] = res["synonyms"]
ids["comchem"]["replacedcasrn"] = res["replacedRns"]
meta["comchem"] = {}
meta["comchem"]["formula"] = res["molecularFormula"]
meta["comchem"]["mw"] = res["molecularMass"]
srcs["comchem"].update({"result": 1})
return True
def pubchemsyns(identifier):
"""this function allows retreival of data from the PugRest API @ PubChem"""
apipath = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/"
# retrieve full record if available based on name
searchpath = 'name/' + identifier + '/synonyms/json'
response = requests.get(apipath + searchpath).json()
syns = response["InformationList"]["Information"][0]["Synonym"]
inchikey = ""
for k in syns:
m = re.search('^[A-Z]{14}-[A-Z]{10}-[A-Z]$', k)
if m:
inchikey = k
return inchikey
def pubchemmol(pcid):
"""
allows retrieval of SDF file from the PugRest API at PubChem
with two entries - atoms and bonds. Each value is a list
atoms list is x, y, z coords and element symbol
bonds list is atom1, atom2, and bond order
:param pcid pubchem id for compound
:return dict dictionary
"""
apipath = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/"
url = apipath + pcid + '/SDF'
response = requests.get(url)
sdf = None
if response.status_code == 200:
sdf = requests.get(url).text
atoms = []
bonds = []
chrgs = []
for ln in sdf.splitlines():
a = re.search(r"([0-9\-.]+)\s+([0-9\-.]+)\s+([0-9\-.]+)\s"
r"([A-Za-z]{1,2})\s+0\s+(\d)\s+0\s+0", ln)
if a:
atoms.append([a[1], a[2], a[3], a[4], a[5]])
continue
b = re.search(r"^\s+(\d{1,2})\s+(\d{1,2})\s+(\d)\s+0\s+0\s+0\s+0$", ln)
if b:
bonds.append([b[1], b[2], b[3]])
continue
c = re.search(r"^M\s+CHG\s+(\d)", ln)
if c:
num = int(c[1])
rest = ln.replace('M CHG ' + str(num), '')
parts = re.split(r"\s{2,3}", rest.strip())
for idx, val in enumerate(parts):
if (idx % 2) != 0:
continue
chrgs.append([val, parts[(idx + 1)]])
return {'atoms': atoms, 'bonds': bonds, 'chrgs': chrgs} | 0.381104 | 0.158826 |
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "sciflow.settings")
django.setup()
from substances.sub_functions import *
from substances.views import *
from datafiles.df_functions import *
from substances.external import *
from scyjava import config, jimport
# add a new substance to the database
add = None
if add:
key = "AOAOXSUNFXXSGI-UHFFFAOYSA-N"
added = addsubstance(key)
if not added:
print("Substance not added")
exit()
# generate the JSON-LD file for the substance
subid = added.id
jsonld = createsubjld(subid)
# store the JSON-LD in the facet_lookups/facet_files tables
facetid = addfacetfile(jsonld)
# update facet file with the facet_id
jsonld['@id'] = jsonld['@id'].replace('<facetid>', str(facetid))
# save the facet file to the facet_file table
saved = updatefacetfile(jsonld)
if saved:
print("Facet JSON-LD saved to the DB!")
else:
print("Error: something happened on the way to the DB!")
# check output of pubchem request
runpc = None
if runpc:
key = 'VWNMWKSURFWKAL-HXOBKFHXSA-N'
meta, ids, descs, srcs = {}, {}, {}, {}
pubchem(key, meta, ids, descs, srcs)
print(meta, ids, descs)
print(json.dumps(srcs, indent=4))
# check output of chembl request
runcb = None
if runcb:
key = 'REEUVFCVXKWOFE-UHFFFAOYSA-K'
# key = 'aspirin'
meta, ids, descs, srcs = {}, {}, {}, {}
chembl(key, meta, ids, descs, srcs)
print(meta, ids, descs)
print(json.dumps(srcs, indent=4))
# check output of classyfire request
runcf = None
if runcf:
key = 'VWNMWKSURFWKAL-HXOBKFZXSA-N' # (bad inchikey)
descs, srcs = {}, {}
classyfire(key, descs, srcs)
print(descs)
print(json.dumps(srcs, indent=4))
# check output of wikidata request
runwd = None
if runwd:
key = 'BSYNRYMUTXBXSQ-CHALKCHALK-N' # (bad inchikey for aspirin)
ids, srcs = {}, {}
wikidata(key, ids, srcs)
print(ids)
print(json.dumps(srcs, indent=4))
# Get data from commonchemistry using CASRNs
runcc1 = None
if runcc1:
subs = Substances.objects.all().values_list(
'id', 'casrn').filter(
casrn__isnull=False) # produces tuples
for sub in subs:
found = Sources.objects.filter(
substance_id__exact=sub[0],
source__exact='comchem')
if not found:
meta, ids, srcs = {}, {}, {}
comchem(sub[1], meta, ids, srcs)
saveids(sub[0], ids)
savesrcs(sub[0], srcs)
print(sub)
print(json.dumps(srcs, indent=4))
runcc2 = None
if runcc2:
# process compounds with no casrn in substances table
subs = Substances.objects.all().values_list(
'id', flat=True).filter(
casrn__isnull=True)
for sub in subs:
found = Sources.objects.filter(
substance_id__exact=sub,
source__exact='comchem')
if not found:
key = getinchikey(sub)
if key:
meta, ids, srcs = {}, {}, {}
if comchem(key, meta, ids, srcs):
saveids(sub, ids)
# update casrn field in substances
updatesubstance(sub, 'casrn', ids['comchem']['casrn'])
print('CASRN updated')
savesrcs(sub, srcs)
print(sub)
print(json.dumps(srcs, indent=4))
else:
print(sub)
runlm = None
if runlm:
apipath = "https://commonchemistry.cas.org/api/detail?cas_rn="
f = open("reach_ids.txt", "r")
for line in f:
parts = line.replace('\n', '').split(':')
print(parts)
res = requests.get(apipath + parts[1])
if res.status_code == 200:
with open(parts[0] + '.json', 'w') as outfile:
json.dump(res.json(), outfile)
print('Found')
else:
print('Not found')
# check output of getinchikey function
rungi = None
if rungi:
subid = 1
out = getinchikey(subid)
print(out)
# test scyjava
runsj = None
if runsj:
config.add_endpoints('io.github.egonw.bacting:managers-cdk:0.0.16')
workspaceRoot = "."
cdkClass = jimport("net.bioclipse.managers.CDKManager")
cdk = cdkClass(workspaceRoot)
print(cdk.fromSMILES("CCC"))
runls = True
if runls:
subview(None, 5044) | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/substances/example.py | example.py | import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "sciflow.settings")
django.setup()
from substances.sub_functions import *
from substances.views import *
from datafiles.df_functions import *
from substances.external import *
from scyjava import config, jimport
# add a new substance to the database
add = None
if add:
key = "AOAOXSUNFXXSGI-UHFFFAOYSA-N"
added = addsubstance(key)
if not added:
print("Substance not added")
exit()
# generate the JSON-LD file for the substance
subid = added.id
jsonld = createsubjld(subid)
# store the JSON-LD in the facet_lookups/facet_files tables
facetid = addfacetfile(jsonld)
# update facet file with the facet_id
jsonld['@id'] = jsonld['@id'].replace('<facetid>', str(facetid))
# save the facet file to the facet_file table
saved = updatefacetfile(jsonld)
if saved:
print("Facet JSON-LD saved to the DB!")
else:
print("Error: something happened on the way to the DB!")
# check output of pubchem request
runpc = None
if runpc:
key = 'VWNMWKSURFWKAL-HXOBKFHXSA-N'
meta, ids, descs, srcs = {}, {}, {}, {}
pubchem(key, meta, ids, descs, srcs)
print(meta, ids, descs)
print(json.dumps(srcs, indent=4))
# check output of chembl request
runcb = None
if runcb:
key = 'REEUVFCVXKWOFE-UHFFFAOYSA-K'
# key = 'aspirin'
meta, ids, descs, srcs = {}, {}, {}, {}
chembl(key, meta, ids, descs, srcs)
print(meta, ids, descs)
print(json.dumps(srcs, indent=4))
# check output of classyfire request
runcf = None
if runcf:
key = 'VWNMWKSURFWKAL-HXOBKFZXSA-N' # (bad inchikey)
descs, srcs = {}, {}
classyfire(key, descs, srcs)
print(descs)
print(json.dumps(srcs, indent=4))
# check output of wikidata request
runwd = None
if runwd:
key = 'BSYNRYMUTXBXSQ-CHALKCHALK-N' # (bad inchikey for aspirin)
ids, srcs = {}, {}
wikidata(key, ids, srcs)
print(ids)
print(json.dumps(srcs, indent=4))
# Get data from commonchemistry using CASRNs
runcc1 = None
if runcc1:
subs = Substances.objects.all().values_list(
'id', 'casrn').filter(
casrn__isnull=False) # produces tuples
for sub in subs:
found = Sources.objects.filter(
substance_id__exact=sub[0],
source__exact='comchem')
if not found:
meta, ids, srcs = {}, {}, {}
comchem(sub[1], meta, ids, srcs)
saveids(sub[0], ids)
savesrcs(sub[0], srcs)
print(sub)
print(json.dumps(srcs, indent=4))
runcc2 = None
if runcc2:
# process compounds with no casrn in substances table
subs = Substances.objects.all().values_list(
'id', flat=True).filter(
casrn__isnull=True)
for sub in subs:
found = Sources.objects.filter(
substance_id__exact=sub,
source__exact='comchem')
if not found:
key = getinchikey(sub)
if key:
meta, ids, srcs = {}, {}, {}
if comchem(key, meta, ids, srcs):
saveids(sub, ids)
# update casrn field in substances
updatesubstance(sub, 'casrn', ids['comchem']['casrn'])
print('CASRN updated')
savesrcs(sub, srcs)
print(sub)
print(json.dumps(srcs, indent=4))
else:
print(sub)
runlm = None
if runlm:
apipath = "https://commonchemistry.cas.org/api/detail?cas_rn="
f = open("reach_ids.txt", "r")
for line in f:
parts = line.replace('\n', '').split(':')
print(parts)
res = requests.get(apipath + parts[1])
if res.status_code == 200:
with open(parts[0] + '.json', 'w') as outfile:
json.dump(res.json(), outfile)
print('Found')
else:
print('Not found')
# check output of getinchikey function
rungi = None
if rungi:
subid = 1
out = getinchikey(subid)
print(out)
# test scyjava
runsj = None
if runsj:
config.add_endpoints('io.github.egonw.bacting:managers-cdk:0.0.16')
workspaceRoot = "."
cdkClass = jimport("net.bioclipse.managers.CDKManager")
cdk = cdkClass(workspaceRoot)
print(cdk.fromSMILES("CCC"))
runls = True
if runls:
subview(None, 5044) | 0.201971 | 0.100481 |
from django.shortcuts import render
from django.shortcuts import redirect
from django.core.paginator import Paginator
from substances.sub_functions import *
from sciflow.settings import BASE_DIR
from zipfile import ZipFile
def sublist(request):
"""view to generate list of substances on homepage"""
if request.method == "POST":
query = request.POST.get('q')
return redirect('/substances/search/' + str(query))
substances = Substances.objects.all().order_by('name')
return render(request, "substances/list.html", {'substances': substances})
def home(request):
"""present an overview page about the substance in sciflow"""
subcount = Substances.objects.count()
idcount = Identifiers.objects.count()
descount = Descriptors.objects.count()
return render(request, "substances/home.html",
{'subcount': subcount, 'idcount': idcount, 'descount': descount})
def subview(request, subid):
"""present an overview page about the substance in sciflow"""
substance = Substances.objects.get(id=subid)
ids = substance.identifiers_set.values_list('type', 'value', 'source')
descs = substance.descriptors_set.values_list('type', 'value', 'source')
srcs = substance.sources_set.all()
if not descs:
key = ""
for i in ids:
if i.type == 'inchikey':
key = i.value
break
m, i, descs, srcs = getsubdata(key)
savedescs(subid, descs)
idlist = {}
for idtype, value, src in ids:
if idtype not in idlist.keys():
idlist.update({idtype: {}})
if value not in idlist[idtype].keys():
idlist[idtype].update({value: []})
idlist[idtype][value].append(src)
dlist = {}
for desc, value, src in descs:
if desc not in dlist.keys():
dlist.update({desc: {}})
if value not in dlist[desc].keys():
dlist[desc].update({value: []})
dlist[desc][value].append(src)
# print(json.dumps(dlist, indent=4))
# print(descs)
# print(srcs)
# exit()
return render(request, "substances/subview.html",
{'substance': substance, "ids": idlist,
"descs": dlist, "srcs": srcs})
def subids(request, subid):
"""present an overview page about the substance in sciflow"""
substance = Substances.objects.get(id=subid)
ids = substance.identifiers_set.all()
return render(request, "substances/subids.html",
{'substance': substance, "ids": ids})
def subdescs(request, subid):
"""present an overview page about the substance in sciflow"""
substance = Substances.objects.get(id=subid)
ids = substance.identifiers_set.all()
descs = substance.descriptors_set.all()
if not descs:
key = ""
for i in ids:
if i.type == 'inchikey':
key = i.value
break
m, i, descs = getsubdata(key)
savedescs(subid, descs)
return render(request, "substances/subdescs.html",
{'substance': substance, "descs": descs})
def add(request, identifier):
""" check identifier to see if compound already in system and if not add """
# id the compound in the database?
hits = Substances.objects.all().filter(
identifiers__value__exact=identifier).count()
if hits == 0:
meta, ids, descs, srcs = addsubstance(identifier, 'all')
else:
subid = getsubid(identifier)
return redirect("/substances/view/" + str(subid))
return render(request, "substances/add.html",
{"hits": hits, "meta": meta, "ids": ids, "descs": descs})
def ingest(request):
"""ingest a new substance"""
if request.method == "POST":
if 'ingest' in request.POST:
inchikey = request.POST.get('ingest')
matchgroup = re.findall('[A-Z]{14}-[A-Z]{10}-[A-Z]', inchikey)
for match in matchgroup:
hits = Substances.objects.all().filter(identifiers__value__exact=match).count()
if hits == 0:
meta, ids, descs, srcs = addsubstance(match, 'all')
else:
subid = getsubid(match)
elif 'upload' in request.FILES.keys():
file = request.FILES['upload']
fname = file.name
subs = []
if fname.endswith('.json'):
jdict = json.loads(file.read())
for key in jdict['keys']:
subid = getsubid(key)
status = None
if not subid:
status = 'new'
sub = addsubstance(key, 'sub')
subid = sub.id
else:
status = 'present'
meta = getmeta(subid)
subs.append(
{'id': meta['id'], 'name': meta['name'],
'status': status})
request.session['subs'] = subs
return redirect("/substances/list/")
elif fname.endswith('.zip'):
with ZipFile(file) as zfile:
filenames = []
for info in zfile.infolist():
name = info.filename
filenames.append(name)
for file in filenames:
data = zfile.read(file)
m = re.search('^[A-Z]{14}-[A-Z]{10}-[A-Z]$', str(data))
if m:
print(m)
else:
print(':(')
return render(request, "substances/ingest.html",)
def ingestlist(request):
""" add many compounds from a text file list of identifiers """
path = BASE_DIR + "/json/herg_chemblids.txt"
file = open(path)
lines = file.readlines()
# get a list of all chemblids currently in the DB
qset = Identifiers.objects.all().filter(
type__exact='chembl').values_list(
'value', flat=True)
chemblids = sublist(qset)
count = 0
names = []
for identifier in lines:
identifier = identifier.rstrip("\n")
if identifier not in chemblids:
meta, ids, descs, srcs = addsubstance(identifier, 'all')
names.append(ids['pubchem']['iupacname'])
count += 1
if count == 1:
break
return names
def normalize(request, identifier):
"""
create a SciData JSON-LD file for a compound, ingest in the graph
and update data file with graph location
"""
subid = getsubid(identifier)
success = createsubjld(subid)
return render(request, "substances/normalize.html", {"success": success})
def list(request):
"""emtpy view to be accessed via redirect from ingest above"""
if 'subs' in request.session:
subs = request.session['subs']
else:
subs = Substances.objects.all().order_by('name')
paginator = Paginator(subs, 20)
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
return render(request, "substances/list.html", {"page_obj": page_obj, "facet": "Substances"})
def search(request, query):
""" search for a substance """
context = subsearch(query)
if request.method == "POST":
query = request.POST.get('q')
return redirect('/substances/search/' + str(query))
return render(request, "substances/search.html", context) | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/substances/views.py | views.py | from django.shortcuts import render
from django.shortcuts import redirect
from django.core.paginator import Paginator
from substances.sub_functions import *
from sciflow.settings import BASE_DIR
from zipfile import ZipFile
def sublist(request):
"""view to generate list of substances on homepage"""
if request.method == "POST":
query = request.POST.get('q')
return redirect('/substances/search/' + str(query))
substances = Substances.objects.all().order_by('name')
return render(request, "substances/list.html", {'substances': substances})
def home(request):
"""present an overview page about the substance in sciflow"""
subcount = Substances.objects.count()
idcount = Identifiers.objects.count()
descount = Descriptors.objects.count()
return render(request, "substances/home.html",
{'subcount': subcount, 'idcount': idcount, 'descount': descount})
def subview(request, subid):
"""present an overview page about the substance in sciflow"""
substance = Substances.objects.get(id=subid)
ids = substance.identifiers_set.values_list('type', 'value', 'source')
descs = substance.descriptors_set.values_list('type', 'value', 'source')
srcs = substance.sources_set.all()
if not descs:
key = ""
for i in ids:
if i.type == 'inchikey':
key = i.value
break
m, i, descs, srcs = getsubdata(key)
savedescs(subid, descs)
idlist = {}
for idtype, value, src in ids:
if idtype not in idlist.keys():
idlist.update({idtype: {}})
if value not in idlist[idtype].keys():
idlist[idtype].update({value: []})
idlist[idtype][value].append(src)
dlist = {}
for desc, value, src in descs:
if desc not in dlist.keys():
dlist.update({desc: {}})
if value not in dlist[desc].keys():
dlist[desc].update({value: []})
dlist[desc][value].append(src)
# print(json.dumps(dlist, indent=4))
# print(descs)
# print(srcs)
# exit()
return render(request, "substances/subview.html",
{'substance': substance, "ids": idlist,
"descs": dlist, "srcs": srcs})
def subids(request, subid):
"""present an overview page about the substance in sciflow"""
substance = Substances.objects.get(id=subid)
ids = substance.identifiers_set.all()
return render(request, "substances/subids.html",
{'substance': substance, "ids": ids})
def subdescs(request, subid):
"""present an overview page about the substance in sciflow"""
substance = Substances.objects.get(id=subid)
ids = substance.identifiers_set.all()
descs = substance.descriptors_set.all()
if not descs:
key = ""
for i in ids:
if i.type == 'inchikey':
key = i.value
break
m, i, descs = getsubdata(key)
savedescs(subid, descs)
return render(request, "substances/subdescs.html",
{'substance': substance, "descs": descs})
def add(request, identifier):
""" check identifier to see if compound already in system and if not add """
# id the compound in the database?
hits = Substances.objects.all().filter(
identifiers__value__exact=identifier).count()
if hits == 0:
meta, ids, descs, srcs = addsubstance(identifier, 'all')
else:
subid = getsubid(identifier)
return redirect("/substances/view/" + str(subid))
return render(request, "substances/add.html",
{"hits": hits, "meta": meta, "ids": ids, "descs": descs})
def ingest(request):
"""ingest a new substance"""
if request.method == "POST":
if 'ingest' in request.POST:
inchikey = request.POST.get('ingest')
matchgroup = re.findall('[A-Z]{14}-[A-Z]{10}-[A-Z]', inchikey)
for match in matchgroup:
hits = Substances.objects.all().filter(identifiers__value__exact=match).count()
if hits == 0:
meta, ids, descs, srcs = addsubstance(match, 'all')
else:
subid = getsubid(match)
elif 'upload' in request.FILES.keys():
file = request.FILES['upload']
fname = file.name
subs = []
if fname.endswith('.json'):
jdict = json.loads(file.read())
for key in jdict['keys']:
subid = getsubid(key)
status = None
if not subid:
status = 'new'
sub = addsubstance(key, 'sub')
subid = sub.id
else:
status = 'present'
meta = getmeta(subid)
subs.append(
{'id': meta['id'], 'name': meta['name'],
'status': status})
request.session['subs'] = subs
return redirect("/substances/list/")
elif fname.endswith('.zip'):
with ZipFile(file) as zfile:
filenames = []
for info in zfile.infolist():
name = info.filename
filenames.append(name)
for file in filenames:
data = zfile.read(file)
m = re.search('^[A-Z]{14}-[A-Z]{10}-[A-Z]$', str(data))
if m:
print(m)
else:
print(':(')
return render(request, "substances/ingest.html",)
def ingestlist(request):
""" add many compounds from a text file list of identifiers """
path = BASE_DIR + "/json/herg_chemblids.txt"
file = open(path)
lines = file.readlines()
# get a list of all chemblids currently in the DB
qset = Identifiers.objects.all().filter(
type__exact='chembl').values_list(
'value', flat=True)
chemblids = sublist(qset)
count = 0
names = []
for identifier in lines:
identifier = identifier.rstrip("\n")
if identifier not in chemblids:
meta, ids, descs, srcs = addsubstance(identifier, 'all')
names.append(ids['pubchem']['iupacname'])
count += 1
if count == 1:
break
return names
def normalize(request, identifier):
"""
create a SciData JSON-LD file for a compound, ingest in the graph
and update data file with graph location
"""
subid = getsubid(identifier)
success = createsubjld(subid)
return render(request, "substances/normalize.html", {"success": success})
def list(request):
"""emtpy view to be accessed via redirect from ingest above"""
if 'subs' in request.session:
subs = request.session['subs']
else:
subs = Substances.objects.all().order_by('name')
paginator = Paginator(subs, 20)
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
return render(request, "substances/list.html", {"page_obj": page_obj, "facet": "Substances"})
def search(request, query):
""" search for a substance """
context = subsearch(query)
if request.method == "POST":
query = request.POST.get('q')
return redirect('/substances/search/' + str(query))
return render(request, "substances/search.html", context) | 0.358241 | 0.096578 |
from django.db import models
class Substances(models.Model):
""" getting data from the substances DB table"""
id = models.SmallAutoField(primary_key=True)
name = models.CharField(max_length=256, default='')
formula = models.CharField(max_length=256, default='')
monomass = models.FloatField(default=0.00)
molweight = models.FloatField(default=0.00)
casrn = models.CharField(max_length=16, default='')
graphdb = models.CharField(max_length=256, null=True)
facet_lookup_id = models.IntegerField(blank=True, null=True)
comments = models.CharField(max_length=256, null=True)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'substances'
class Identifiers(models.Model):
""" accessing the identifiers DB table"""
CASRN = 'casrn'
INCHI = 'inchi'
INCHIKEY = 'inchikey'
CSMILES = 'csmiles'
ISMILES = 'ismiles'
CSPR = 'chemspider'
PUBCHEM = 'pubchem'
INAME = 'iupacname'
SPRNGR = 'springer'
OTHER = 'othername'
ATC = 'atc'
REAXYS = 'reaxys'
GMELIN = 'gmelin'
CHEBI = 'chebi'
CHEMBL = 'chembl'
RTECS = 'rtecs'
DSSTOX = 'dsstox'
TYPE_CHOICES = [
(CASRN, 'CAS Registry Number'), (INCHI, 'IUPAC InChI String'), (INCHIKEY, 'IUPAC InChI Key'),
(CSMILES, 'Canonical SMILES'), (ISMILES, 'Isomeric SMILES'), (CSPR, 'Chemspider ID'),
(PUBCHEM, 'PubChem Compound ID'), (INAME, 'IUPAC Name'), (SPRNGR, 'Springer ID'),
(OTHER, 'Other Name'), (ATC, 'ATC Code'), (REAXYS, 'Reaxys ID'),
(GMELIN, 'Gmelin ID'), (CHEBI, 'ChEBI ID'), (CHEMBL, 'ChEMBL ID'),
(RTECS, 'RTECS ID'), (DSSTOX, 'DSSTOX ID')
]
substance = models.ForeignKey(Substances, on_delete=models.CASCADE)
type = models.CharField(max_length=10, choices=TYPE_CHOICES, default=CASRN)
value = models.CharField(max_length=768, default='')
iso = models.CharField(max_length=5, default=None)
source = models.CharField(max_length=64, default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'identifiers'
class Sources(models.Model):
""" get data from the sources DB table"""
id = models.AutoField(db_column='Id', primary_key=True) # Field name made lowercase.
substance = models.ForeignKey('Substances', models.DO_NOTHING)
source = models.CharField(max_length=32)
result = models.CharField(max_length=1)
notes = models.CharField(max_length=2000, blank=True, null=True)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'sources'
class Systems(models.Model):
""" getting data from the identifiers DB table"""
class CompTypes(models.TextChoices):
"""list of different composition types"""
PURE = 'PS', 'pure compound'
BINARY = 'BM', 'binary mixture'
TERNARY = 'TM', 'ternary mixture'
QUANARY = 'QM', 'quaternary mixture',
QUINARY = 'NM', 'quinternary mixture'
name = models.CharField(max_length=1024, default='')
composition = models.CharField(max_length=2, choices=CompTypes.choices, default=CompTypes.PURE)
identifier = models.CharField(max_length=128, default='')
substance1 = models.ForeignKey(Substances, null=True, related_name='substance1', on_delete=models.CASCADE)
substance2 = models.ForeignKey(Substances, null=True, related_name='substance2', on_delete=models.CASCADE)
substance3 = models.ForeignKey(Substances, null=True, related_name='substance3', on_delete=models.CASCADE)
substance4 = models.ForeignKey(Substances, null=True, related_name='substance4', on_delete=models.CASCADE)
substance5 = models.ForeignKey(Substances, null=True, related_name='substance5', on_delete=models.CASCADE)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'systems'
class Templates(models.Model):
""" getting data from the template """
type = models.CharField(max_length=16)
json = models.TextField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'templates'
class Descriptors(models.Model):
""" accessing the descriptors DB table"""
substance = models.ForeignKey(Substances, on_delete=models.CASCADE)
type = models.CharField(max_length=128, default='')
value = models.CharField(max_length=768, default='')
source = models.CharField(max_length=64, default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'descriptors'
class SubstancesSystems(models.Model):
""" getting data from the substances_systems join table """
substance = models.ForeignKey(Substances, null=True, related_name='substance_id', on_delete=models.CASCADE)
system = models.ForeignKey(Systems, null=True, related_name='system_id', on_delete=models.CASCADE)
role = models.CharField(max_length=13, blank=True, null=True)
constituent = models.PositiveIntegerField(blank=True, null=True)
mixture_id = models.IntegerField(blank=True, null=True)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'substances_systems' | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/substances/models.py | models.py | from django.db import models
class Substances(models.Model):
""" getting data from the substances DB table"""
id = models.SmallAutoField(primary_key=True)
name = models.CharField(max_length=256, default='')
formula = models.CharField(max_length=256, default='')
monomass = models.FloatField(default=0.00)
molweight = models.FloatField(default=0.00)
casrn = models.CharField(max_length=16, default='')
graphdb = models.CharField(max_length=256, null=True)
facet_lookup_id = models.IntegerField(blank=True, null=True)
comments = models.CharField(max_length=256, null=True)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'substances'
class Identifiers(models.Model):
""" accessing the identifiers DB table"""
CASRN = 'casrn'
INCHI = 'inchi'
INCHIKEY = 'inchikey'
CSMILES = 'csmiles'
ISMILES = 'ismiles'
CSPR = 'chemspider'
PUBCHEM = 'pubchem'
INAME = 'iupacname'
SPRNGR = 'springer'
OTHER = 'othername'
ATC = 'atc'
REAXYS = 'reaxys'
GMELIN = 'gmelin'
CHEBI = 'chebi'
CHEMBL = 'chembl'
RTECS = 'rtecs'
DSSTOX = 'dsstox'
TYPE_CHOICES = [
(CASRN, 'CAS Registry Number'), (INCHI, 'IUPAC InChI String'), (INCHIKEY, 'IUPAC InChI Key'),
(CSMILES, 'Canonical SMILES'), (ISMILES, 'Isomeric SMILES'), (CSPR, 'Chemspider ID'),
(PUBCHEM, 'PubChem Compound ID'), (INAME, 'IUPAC Name'), (SPRNGR, 'Springer ID'),
(OTHER, 'Other Name'), (ATC, 'ATC Code'), (REAXYS, 'Reaxys ID'),
(GMELIN, 'Gmelin ID'), (CHEBI, 'ChEBI ID'), (CHEMBL, 'ChEMBL ID'),
(RTECS, 'RTECS ID'), (DSSTOX, 'DSSTOX ID')
]
substance = models.ForeignKey(Substances, on_delete=models.CASCADE)
type = models.CharField(max_length=10, choices=TYPE_CHOICES, default=CASRN)
value = models.CharField(max_length=768, default='')
iso = models.CharField(max_length=5, default=None)
source = models.CharField(max_length=64, default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'identifiers'
class Sources(models.Model):
""" get data from the sources DB table"""
id = models.AutoField(db_column='Id', primary_key=True) # Field name made lowercase.
substance = models.ForeignKey('Substances', models.DO_NOTHING)
source = models.CharField(max_length=32)
result = models.CharField(max_length=1)
notes = models.CharField(max_length=2000, blank=True, null=True)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'sources'
class Systems(models.Model):
""" getting data from the identifiers DB table"""
class CompTypes(models.TextChoices):
"""list of different composition types"""
PURE = 'PS', 'pure compound'
BINARY = 'BM', 'binary mixture'
TERNARY = 'TM', 'ternary mixture'
QUANARY = 'QM', 'quaternary mixture',
QUINARY = 'NM', 'quinternary mixture'
name = models.CharField(max_length=1024, default='')
composition = models.CharField(max_length=2, choices=CompTypes.choices, default=CompTypes.PURE)
identifier = models.CharField(max_length=128, default='')
substance1 = models.ForeignKey(Substances, null=True, related_name='substance1', on_delete=models.CASCADE)
substance2 = models.ForeignKey(Substances, null=True, related_name='substance2', on_delete=models.CASCADE)
substance3 = models.ForeignKey(Substances, null=True, related_name='substance3', on_delete=models.CASCADE)
substance4 = models.ForeignKey(Substances, null=True, related_name='substance4', on_delete=models.CASCADE)
substance5 = models.ForeignKey(Substances, null=True, related_name='substance5', on_delete=models.CASCADE)
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'systems'
class Templates(models.Model):
""" getting data from the template """
type = models.CharField(max_length=16)
json = models.TextField()
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'templates'
class Descriptors(models.Model):
""" accessing the descriptors DB table"""
substance = models.ForeignKey(Substances, on_delete=models.CASCADE)
type = models.CharField(max_length=128, default='')
value = models.CharField(max_length=768, default='')
source = models.CharField(max_length=64, default='')
updated = models.DateTimeField(auto_now=True)
class Meta:
managed = False
db_table = 'descriptors'
class SubstancesSystems(models.Model):
""" getting data from the substances_systems join table """
substance = models.ForeignKey(Substances, null=True, related_name='substance_id', on_delete=models.CASCADE)
system = models.ForeignKey(Systems, null=True, related_name='system_id', on_delete=models.CASCADE)
role = models.CharField(max_length=13, blank=True, null=True)
constituent = models.PositiveIntegerField(blank=True, null=True)
mixture_id = models.IntegerField(blank=True, null=True)
updated = models.DateTimeField()
class Meta:
managed = False
db_table = 'substances_systems' | 0.646906 | 0.103115 |
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='Descriptors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type', models.CharField(default='', max_length=128)),
('value', models.CharField(default='', max_length=768)),
('source', models.CharField(default='', max_length=64)),
('updated', models.DateTimeField(auto_now=True)),
],
options={
'db_table': 'descriptors',
'managed': False,
},
),
migrations.CreateModel(
name='Identifiers',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type', models.CharField(choices=[('casrn', 'CAS Registry Number'), ('inchi', 'IUPAC InChI String'), ('inchikey', 'IUPAC InChI Key'), ('csmiles', 'Canonical SMILES'), ('ismiles', 'Isomeric SMILES'), ('chemspider', 'Chemspider ID'), ('pubchem', 'PubChem Compound ID'), ('iupacname', 'IUPAC Name'), ('springer', 'Springer ID'), ('othername', 'Other Name'), ('atc', 'ATC Code'), ('reaxys', 'Reaxys ID'), ('gmelin', 'Gmelin ID'), ('chebi', 'ChEBI ID'), ('chembl', 'ChEMBL ID'), ('rtecs', 'RTECS ID'), ('dsstox', 'DSSTOX ID')], default='casrn', max_length=10)),
('value', models.CharField(default='', max_length=768)),
('iso', models.CharField(max_length=5, null=True)),
('source', models.CharField(default='', max_length=64)),
('updated', models.DateTimeField(auto_now=True)),
],
options={
'db_table': 'identifiers',
'managed': False,
},
),
migrations.CreateModel(
name='Sources',
fields=[
('id', models.AutoField(db_column='Id', primary_key=True, serialize=False)),
('source', models.CharField(max_length=32)),
('result', models.CharField(max_length=1)),
('notes', models.CharField(blank=True, max_length=2000, null=True)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'sources',
'managed': False,
},
),
migrations.CreateModel(
name='Substances',
fields=[
('id', models.SmallAutoField(primary_key=True, serialize=False)),
('name', models.CharField(default='', max_length=256)),
('formula', models.CharField(default='', max_length=256)),
('monomass', models.FloatField(default=0.0)),
('molweight', models.FloatField(default=0.0)),
('casrn', models.CharField(default='', max_length=16)),
('graphdb', models.CharField(max_length=256, null=True)),
('comments', models.CharField(max_length=256, null=True)),
('updated', models.DateTimeField(auto_now=True)),
],
options={
'db_table': 'substances',
'managed': False,
},
),
migrations.CreateModel(
name='SubstancesSystems',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('substance_id', models.SmallIntegerField()),
('system_id', models.SmallIntegerField()),
('role', models.CharField(blank=True, max_length=13, null=True)),
('constituent', models.PositiveIntegerField(blank=True, null=True)),
('mixture_id', models.IntegerField(blank=True, null=True)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'substances_systems',
'managed': False,
},
),
migrations.CreateModel(
name='Templates',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type', models.CharField(max_length=16)),
('json', models.TextField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'templates',
'managed': False,
},
),
migrations.CreateModel(
name='Systems',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(default='', max_length=1024)),
('composition', models.CharField(choices=[('PS', 'pure compound'), ('BM', 'binary mixture'), ('TM', 'ternary mixture'), ('QM', 'quaternary mixture'), ('NM', 'quinternary mixture')], default='PS', max_length=2)),
('identifier', models.CharField(default='', max_length=128)),
('updated', models.DateTimeField(auto_now=True)),
('substance1', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance1', to='substances.substances')),
('substance2', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance2', to='substances.substances')),
('substance3', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance3', to='substances.substances')),
('substance4', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance4', to='substances.substances')),
('substance5', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance5', to='substances.substances')),
],
options={
'db_table': 'systems',
'managed': False,
},
),
] | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/substances/migrations/0001_initial.py | 0001_initial.py |
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='Descriptors',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type', models.CharField(default='', max_length=128)),
('value', models.CharField(default='', max_length=768)),
('source', models.CharField(default='', max_length=64)),
('updated', models.DateTimeField(auto_now=True)),
],
options={
'db_table': 'descriptors',
'managed': False,
},
),
migrations.CreateModel(
name='Identifiers',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type', models.CharField(choices=[('casrn', 'CAS Registry Number'), ('inchi', 'IUPAC InChI String'), ('inchikey', 'IUPAC InChI Key'), ('csmiles', 'Canonical SMILES'), ('ismiles', 'Isomeric SMILES'), ('chemspider', 'Chemspider ID'), ('pubchem', 'PubChem Compound ID'), ('iupacname', 'IUPAC Name'), ('springer', 'Springer ID'), ('othername', 'Other Name'), ('atc', 'ATC Code'), ('reaxys', 'Reaxys ID'), ('gmelin', 'Gmelin ID'), ('chebi', 'ChEBI ID'), ('chembl', 'ChEMBL ID'), ('rtecs', 'RTECS ID'), ('dsstox', 'DSSTOX ID')], default='casrn', max_length=10)),
('value', models.CharField(default='', max_length=768)),
('iso', models.CharField(max_length=5, null=True)),
('source', models.CharField(default='', max_length=64)),
('updated', models.DateTimeField(auto_now=True)),
],
options={
'db_table': 'identifiers',
'managed': False,
},
),
migrations.CreateModel(
name='Sources',
fields=[
('id', models.AutoField(db_column='Id', primary_key=True, serialize=False)),
('source', models.CharField(max_length=32)),
('result', models.CharField(max_length=1)),
('notes', models.CharField(blank=True, max_length=2000, null=True)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'sources',
'managed': False,
},
),
migrations.CreateModel(
name='Substances',
fields=[
('id', models.SmallAutoField(primary_key=True, serialize=False)),
('name', models.CharField(default='', max_length=256)),
('formula', models.CharField(default='', max_length=256)),
('monomass', models.FloatField(default=0.0)),
('molweight', models.FloatField(default=0.0)),
('casrn', models.CharField(default='', max_length=16)),
('graphdb', models.CharField(max_length=256, null=True)),
('comments', models.CharField(max_length=256, null=True)),
('updated', models.DateTimeField(auto_now=True)),
],
options={
'db_table': 'substances',
'managed': False,
},
),
migrations.CreateModel(
name='SubstancesSystems',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('substance_id', models.SmallIntegerField()),
('system_id', models.SmallIntegerField()),
('role', models.CharField(blank=True, max_length=13, null=True)),
('constituent', models.PositiveIntegerField(blank=True, null=True)),
('mixture_id', models.IntegerField(blank=True, null=True)),
('updated', models.DateTimeField()),
],
options={
'db_table': 'substances_systems',
'managed': False,
},
),
migrations.CreateModel(
name='Templates',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type', models.CharField(max_length=16)),
('json', models.TextField()),
('updated', models.DateTimeField()),
],
options={
'db_table': 'templates',
'managed': False,
},
),
migrations.CreateModel(
name='Systems',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(default='', max_length=1024)),
('composition', models.CharField(choices=[('PS', 'pure compound'), ('BM', 'binary mixture'), ('TM', 'ternary mixture'), ('QM', 'quaternary mixture'), ('NM', 'quinternary mixture')], default='PS', max_length=2)),
('identifier', models.CharField(default='', max_length=128)),
('updated', models.DateTimeField(auto_now=True)),
('substance1', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance1', to='substances.substances')),
('substance2', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance2', to='substances.substances')),
('substance3', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance3', to='substances.substances')),
('substance4', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance4', to='substances.substances')),
('substance5', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='substance5', to='substances.substances')),
],
options={
'db_table': 'systems',
'managed': False,
},
),
] | 0.573559 | 0.160135 |
from django.shortcuts import render, redirect
# åfrom social_core.exceptions import AuthFailed
from .requests import Request, approverequest, rejectrequest
from django.contrib.auth.decorators import login_required
import json
from django.contrib.auth import logout as log_out
from django.conf import settings
from django.http import HttpResponseRedirect
from urllib.parse import urlencode
def index(request):
"""index page"""
user = request.user
if user.is_authenticated:
return redirect(dashboard)
else:
return render(request, 'users/index.html')
def error(request):
"""error page"""
return render(request, 'users/error.html')
@login_required
def dashboard(request):
"""dashboard page"""
user = request.user
# TODO social_auth unresolved (linked to used import above?)
auth0user = user.social_auth.get(provider='auth0')
userdata = {
'user_id': auth0user.uid,
'name': user.first_name,
'picture': auth0user.extra_data['picture'],
'email': auth0user.extra_data['email'],
}
return render(request, 'users/dashboard.html', {
'auth0User': auth0user, 'userdata': json.dumps(userdata, indent=4)})
def requests(response):
"""requests page"""
request = Request.objects.first()
allrequests = Request.objects.all()
if response.method == "POST":
for k in response.POST:
if 'approve' in k:
rid = k.split("_")[1]
request = request.object.get(id=rid)
approverequest(request)
if 'reject' in k:
rid = k.split("_")[1]
request = request.object.get(id=rid)
rejectrequest(request)
return render(response, 'users/requests.html',
{"request": request, "allrequests": allrequests})
def logout(request):
"""logout processing"""
log_out(request)
return_to = urlencode({'returnTo': request.build_absolute_uri('/')})
logout_url = 'https://%s/v2/logout?client_id=%s&%s' % \
(settings.SOCIAL_AUTH_AUTH0_DOMAIN,
settings.SOCIAL_AUTH_AUTH0_KEY, return_to)
return HttpResponseRedirect(logout_url) | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/users/views.py | views.py | from django.shortcuts import render, redirect
# åfrom social_core.exceptions import AuthFailed
from .requests import Request, approverequest, rejectrequest
from django.contrib.auth.decorators import login_required
import json
from django.contrib.auth import logout as log_out
from django.conf import settings
from django.http import HttpResponseRedirect
from urllib.parse import urlencode
def index(request):
"""index page"""
user = request.user
if user.is_authenticated:
return redirect(dashboard)
else:
return render(request, 'users/index.html')
def error(request):
"""error page"""
return render(request, 'users/error.html')
@login_required
def dashboard(request):
"""dashboard page"""
user = request.user
# TODO social_auth unresolved (linked to used import above?)
auth0user = user.social_auth.get(provider='auth0')
userdata = {
'user_id': auth0user.uid,
'name': user.first_name,
'picture': auth0user.extra_data['picture'],
'email': auth0user.extra_data['email'],
}
return render(request, 'users/dashboard.html', {
'auth0User': auth0user, 'userdata': json.dumps(userdata, indent=4)})
def requests(response):
"""requests page"""
request = Request.objects.first()
allrequests = Request.objects.all()
if response.method == "POST":
for k in response.POST:
if 'approve' in k:
rid = k.split("_")[1]
request = request.object.get(id=rid)
approverequest(request)
if 'reject' in k:
rid = k.split("_")[1]
request = request.object.get(id=rid)
rejectrequest(request)
return render(response, 'users/requests.html',
{"request": request, "allrequests": allrequests})
def logout(request):
"""logout processing"""
log_out(request)
return_to = urlencode({'returnTo': request.build_absolute_uri('/')})
logout_url = 'https://%s/v2/logout?client_id=%s&%s' % \
(settings.SOCIAL_AUTH_AUTH0_DOMAIN,
settings.SOCIAL_AUTH_AUTH0_KEY, return_to)
return HttpResponseRedirect(logout_url) | 0.264643 | 0.07521 |
from datafiles.df_functions import *
from pathlib import Path
from sciflow.settings import *
def testimport():
""" import test data from static/files in the DB"""
folder = Path(BASE_DIR + "/static/files/")
for file in folder.iterdir():
if str(file).endswith('.jsonld'):
filename = str(file).split("\\")[-1]
filetype = None
with open(filename, "r") as f:
data = json.load(f)
if "/aspect/" in data["@id"]:
filetype = "aspect"
elif "/data/" in data["@id"]:
filetype = "data"
elif "/facet/" in data["@id"]:
filetype = "facet"
if adddatafile({"path": filename}, filetype):
print("Imported " + filename)
# ----- MySQL Functions -----
# used in datasets/mysql.py:getcodenames
def getdatasetnames():
""" retrieve the shortnames of all the datasets """
qset = Datasets.objects.all().values_list(
'datasetname', flat=True).order_by('id')
lst = list(qset)
return lst
# used in datasets/mysql.py:getcodenames
def getsourcecodes():
""" retrieve the shortnames of all the datasets """
qset = Datasets.objects.all().values_list(
'sourcecode', flat=True).order_by('id')
lst = list(qset)
return lst
# used in validation.py:validate
def getcodesnames():
""" create unique string to match a file to a dataset """
codes = getsourcecodes()
names = getdatasetnames()
output = {}
for i in range(len(codes)):
output.update({names[i]: codes[i] + ":" + names[i]})
return output
# used to update dataset stats
def updatestats():
"""update the number of files for each different dataset"""
# data
sets = Datasets.objects.exclude(sourcecode='chalklab').\
values_list('id', flat=True)
for setid in sets:
count = JsonLookup.objects.filter(dataset_id=setid).count()
sett = Datasets.objects.get(id=setid)
sett.count = count
sett.save()
# facets
dnames = Datasets.objects.filter(sourcecode='chalklab').\
values_list('id', 'datasetname')
for setid, dname in dnames:
count = FacetLookup.objects.filter(type=dname).count()
sett = Datasets.objects.get(id=setid)
sett.count = count
sett.save()
return | sciflow | /sciflow-0.2.tar.gz/sciflow-0.2/datasets/ds_functions.py | ds_functions.py | from datafiles.df_functions import *
from pathlib import Path
from sciflow.settings import *
def testimport():
""" import test data from static/files in the DB"""
folder = Path(BASE_DIR + "/static/files/")
for file in folder.iterdir():
if str(file).endswith('.jsonld'):
filename = str(file).split("\\")[-1]
filetype = None
with open(filename, "r") as f:
data = json.load(f)
if "/aspect/" in data["@id"]:
filetype = "aspect"
elif "/data/" in data["@id"]:
filetype = "data"
elif "/facet/" in data["@id"]:
filetype = "facet"
if adddatafile({"path": filename}, filetype):
print("Imported " + filename)
# ----- MySQL Functions -----
# used in datasets/mysql.py:getcodenames
def getdatasetnames():
""" retrieve the shortnames of all the datasets """
qset = Datasets.objects.all().values_list(
'datasetname', flat=True).order_by('id')
lst = list(qset)
return lst
# used in datasets/mysql.py:getcodenames
def getsourcecodes():
""" retrieve the shortnames of all the datasets """
qset = Datasets.objects.all().values_list(
'sourcecode', flat=True).order_by('id')
lst = list(qset)
return lst
# used in validation.py:validate
def getcodesnames():
""" create unique string to match a file to a dataset """
codes = getsourcecodes()
names = getdatasetnames()
output = {}
for i in range(len(codes)):
output.update({names[i]: codes[i] + ":" + names[i]})
return output
# used to update dataset stats
def updatestats():
"""update the number of files for each different dataset"""
# data
sets = Datasets.objects.exclude(sourcecode='chalklab').\
values_list('id', flat=True)
for setid in sets:
count = JsonLookup.objects.filter(dataset_id=setid).count()
sett = Datasets.objects.get(id=setid)
sett.count = count
sett.save()
# facets
dnames = Datasets.objects.filter(sourcecode='chalklab').\
values_list('id', 'datasetname')
for setid, dname in dnames:
count = FacetLookup.objects.filter(type=dname).count()
sett = Datasets.objects.get(id=setid)
sett.count = count
sett.save()
return | 0.450359 | 0.306611 |
Unreleased
----------
* No unreleased changes
0.28.2 (2023-08-31)
-------------------
Improved
^^^^^^^^
* General wording and grammar improvements throughout documentation.
* Include more usage examples in the examples documentation in addition
to referring the reader to the test suite.
Fixed
^^^^^
* Fixed a bug when using ``pdg_sig_figs`` with uncertainties larger than
about 1000 by cleaning up ``Decimal`` math.
* Previously, when formatting using the format specification
mini-language, if the prefix exponent format flag was omitted then the
exponent format was forced to ``ExpFormat.STANDARD`` rather than
``None``.
This meant that it was impossible, using the format specification
mini-language combined with global configuration options, to set
``ExpFormat.PARTS_PER``.
Now when the prefix flag is omitted ``exp_format`` is set to ``None``
so that it will be populated by the global default option.
In the future a flag may be added to select "parts-per" formatting
using the format specification mini-language.
0.28.1 (2023-08-28)
-------------------
* Make ``FormatOptions`` inputs ``Optional`` so that ``None`` inputs
pass type checks.
* Write format-specification mini-language documentation to refer to
existing format options documentation to avoid documentation
duplication.
* Setup test coverage analysis automation and upload report to
`codecov <https://codecov.io/gh/jagerber48/sciform>`_.
* Add package status badges to readme.
* Test against Python 3.11.
* List supported Python versions in ``pyproject.toml`` classifiers.
0.28.0 (2023-08-27)
-------------------
* **[BREAKING]** Replace ``prefix_exp`` and ``parts_per_exp`` options
with an ``exp_format`` option which can be configured to
``ExpFormat.STANDARD``, ``ExpFormat.PREFIX`` or
``ExpFormat.PARTS_PER``.
* Previously formating a non-finite number in percent mode would always
display a ``'%'`` symbol, e.g. ``'(nan)%'``.
Now the brackets and ``'%'`` symbol will be omitted unless
``nan_inf_exp=True``.
* In ``latex=True`` mode there is now a space between the number and a
prefix or parts-per translated exponent.
For value/uncertainty formatting the space is still absent.
For ``latex=False`` there is still always a space for number and
value/uncertainty formatting before the translated exponent string.
* In ``latex=True`` mode ``'nan'`` and ``'inf'`` strings are now wrapped
in ``'\text{}'``.
* Refactored code for resolving exponent strings.
* Added more unit tests to reach 100% test coverage. Mostly added test
cases for invalid internal inputs.
* Raise ``NotImplementedError`` when attempting value/uncertainty
formatting with binary exponent modes.
Rounding and truncating are not properly implemented in binary mode
yet.
0.27.4 (2023-08-25)
-------------------
* Setup github action to automatically build and publish on release.
0.27.3 (2023-08-23)
-------------------
* Added ``Unreleased`` section to changelog.
* Removed ``version`` from source code.
Project version is now derived from a git version tag using
``setuptools_scm``.
* Stopped encouraging ``import FormatOptions as Fo``.
0.27.2 (2023-08-20)
-------------------
* Add ``__repr__()`` for ``FormatOptions`` and
``RenderedFormatOptions``.
0.27.1 (2023-08-18)
-------------------
* Add ``examples/`` folder to hold example scripts used in the
documentation as well as the input data for these scripts and their
outputs which appear in the documentation.
* Remove extra ``readthedocs.yaml`` file.
0.27.0 (2023-08-18)
-------------------
* **[BREAKING]** Rename ``AutoRound`` to ``AutoDigits``. This is
because, e.g., ``ndigits=AutoDigits`` sounds more correct than
``ndigits=AutoRound``. Furthermore, ``AutoRound`` could likely be
confused as being an option for ``round_mode``, which it is not.
0.26.2 (2023-08-18)
-------------------
* Fix a bug where illegal options combinations could be realized at
format time when certain global default objects were merged into
certain user specified options.
The bug is fixed by re-checking the options combinations after merging
in the global defaults but before formatting.
0.26.1 (2023-08-18)
-------------------
* Add unit tests, increase test coverage.
0.26.0 (2023-08-15)
-------------------
* **[BREAKING]** Rename some format options to make their usage more
clear.
* ``exp`` to ``exp_val``
* ``precision`` to ``ndigits``
* ``RoundMode.PREC`` to ``RoundMode.DEC_PLACE``
* ``AutoExp`` to ``AutoExpVal``
* ``AutoPrec`` to ``AutoRound``
* Raise more exceptions for incorrect options combinations.
* Raise an exception when using ``pdg_sig_figs`` with a user-supplied
``exp_val``.
* Raise exceptions instead of warnings for invalid user-supplied
``exp_val`` in ``get_mantissa_base_exp()``.
* Minor refactor to ``GlobalDefaultsContext``.
* Documentation:
* Update documentation to reflect name changes above.
* Better centralization of ``float``/``Decimal`` information.
* Better explanations of ``AutoExpVal`` and ``AutoRound`` behavior.
* More accurate descriptions of some invalid options combinations.
0.25.2 (2023-08-11)
-------------------
* Update roadmap
0.25.1 (2023-08-10)
-------------------
* Refactor ``get_pdg_round_digit()`` into a dedicated function.
0.25.0 (2023-08-02)
-------------------
* **[BREAKING]** ``template`` option removed from ``FormatOptions``
constructor.
New ``FormatOptions`` instances can be constructed from two existing
``FormatOptions`` instances using the ``merge()`` method.
* Minor documentation improvements.
0.24.0 (2023-07-30)
-------------------
* **[BREAKING]** percent mode is now accessed via an exponent mode,
``ExpMode.PERCENT``.
There is no longer a ``percent`` keyword argument.
0.23.0 (2023-07-29)
-------------------
* **[BREAKING]** Users now construct ``FormatOptions`` objects which
they pass into ``Formatter`` objects and global configuration
functions.
``Formatter`` and global configuration functions no longer accept bare
keyword arguments to indicate formatting options.
* **[BREAKING]** ``Formatter`` now resolves un-filled format options
from the global defaults at format time instead of initialization
time.
This is consistent with the previous behavior for ``SciNum`` and
``SciNumUnc`` objects.
* Change ``pyproject.toml`` description
0.22.2 (2023-07-27)
-------------------
* Add ``.readthedocs.yaml`` and update documentation
``requirements.txt`` for reproducible documentation builds.
0.22.1 (2023-07-27)
-------------------
* Fix a date typo in the changelog for the entry for version ``0.22.0``.
0.22.0 (2023-07-27)
-------------------
* **[BREAKING]** Rename ``sfloat`` to ``SciNum`` and ``vufloat`` to
``SciNumUnc``
* **[BREAKING]** ``SciNum`` instances do not support arithmetic
operations the same way ``sfloat`` instances did.
This functionality was removed for two reasons.
First, ``SciNum`` uses ``Decimal`` to store its value instead of
``float`` and configuring ``SciNum`` to behave as a subclass of
``Decimal`` would require added complexity.
Second, A decision has been made to keep the ``sciform`` module
focussed solely on formatting individual numbers or pairs of numbers
for early releases.
Convenience functionality outside of this narrow scope will be
considered at a later time.
* Favor ``Decimal`` methods over ``float`` methods in internal
formatting algorithm code.
* Documentation
* Remove ``float``-based language fom documentation.
* Include a discussion in the documentation about ``Decimal`` versus
``float`` considerations that may be important for users.
* Various minor revisions and edits. Notably a typo in the version
``0.21.0`` changelog entry that reversed the meaning of a sentence
was corrected.
* Add "under construction" message to README.
0.21.0 (2023-07-22)
-------------------
* Use ``Decimal`` under the hood for numerical formatting instead of
``float``. ``Decimal`` instances support higher precision than
``float`` and more reliable rounding behavior.
* Update particle data group uncertainty rounding unit tests since edge
cases are now handled property as a result of adopting ``Decimal``.
* Minor cleanup of ``sfloat`` arithemetic functions.
0.20.1 (2023-06-24)
-------------------
* Refactor unit tests to use lists and tuples instead of dicts. Literal
dicts allow the possibility for defining the same key (test case) with
different values, only the latest of which will actually be tested.
The refactoring ensures all elements of the test lists will be tested.
* Refactor ``sfloat`` and ``vufloat`` ``__format__()`` functions to call
``format_float()`` and ``format_val_unc()`` directly instead of
creating a ``Formatter`` object first.
0.20.0 (2023-06-22)
-------------------
* Support passing ``None`` as a value into ``extra_si_prefixes``,
``extra_iec_prefixes``, or ``extra_parts_per_forms`` to prevent
translation of a certain exponent value. This may be useful for
suppressing ``ppb`` or similar local-dependent "parts per"
translations.
* **[BREAKING]** Change the bracket uncertainty flag in the
`FSML <fsml>`_ from ``'S'`` to ``'()'``.
* When an exponent translation mode is used in combination with Latex
mode, the translated exponent will now be wrapped in a Latex text
mode: e.g. ``\text{Mi}``.
* Link to test cases on examples page.
0.19.0 (2023-06-22)
-------------------
* Add python-package.yaml github workflows. Allows automated testing,
doc testing, and flake8 scans during github pull requests.
* Minor flake8 cleanup
0.18.1 (2023-06-21)
-------------------
* Documentation improvements
0.18.0 (2023-06-19)
-------------------
* Add Particle Data Group significant figure auto selection feature,
documentation, and tests.
* **[BREAKING]** Use the larger of value or uncertainty to resolve the
exponent when formatting value/uncertainty pairs. The previous
behavior was to always use the value to resolve the exponent, but this
behavior was not convenient for the important use case of zero value
with non-zero uncertainty.
* Expose ``AutoPrec`` and ``AutoExp`` sentinel classes so that users can
explicitly indicate automatic precision and exponent selection.
0.17.1 (2023-06-19)
-------------------
* Code restructure to make formatting algorithm easier to follow
including more verbose clarifying comments.
* Minor documentation cleanup
0.17.0 (2023-06-19)
-------------------
* Add parts-per notation feature, documentation, and tests.
* **[BREAKING]** Rename ``use_prefix`` option to ``prefix_exp``.
* Fix typos in binary IEC prefixes table.
* Fix some cross links in documentation.
0.16.0 (2023-06-18)
-------------------
* Add ``latex`` option with documentation and tests.
* Refactor exponent string conversion.
* Percent mode for non-finite numbers.
0.15.2 (2023-06-18)
-------------------
* Fix a bug involving space filling and separators.
0.15.1 (2023-06-17)
-------------------
* Changelog formatting typo.
0.15.0 (2023-06-17)
-------------------
* Add ``superscript_exp`` option with documentation and tests.
* Forbid percent mode unless using fixed point exponent mode.
* Add PyPi link to readme.
0.14.0 (2023-06-17)
-------------------
* Add Changelog.
* Add ``unicode_pm`` option with documentation and tests.
| sciform | /sciform-0.28.2.tar.gz/sciform-0.28.2/CHANGELOG.rst | CHANGELOG.rst | Unreleased
----------
* No unreleased changes
0.28.2 (2023-08-31)
-------------------
Improved
^^^^^^^^
* General wording and grammar improvements throughout documentation.
* Include more usage examples in the examples documentation in addition
to referring the reader to the test suite.
Fixed
^^^^^
* Fixed a bug when using ``pdg_sig_figs`` with uncertainties larger than
about 1000 by cleaning up ``Decimal`` math.
* Previously, when formatting using the format specification
mini-language, if the prefix exponent format flag was omitted then the
exponent format was forced to ``ExpFormat.STANDARD`` rather than
``None``.
This meant that it was impossible, using the format specification
mini-language combined with global configuration options, to set
``ExpFormat.PARTS_PER``.
Now when the prefix flag is omitted ``exp_format`` is set to ``None``
so that it will be populated by the global default option.
In the future a flag may be added to select "parts-per" formatting
using the format specification mini-language.
0.28.1 (2023-08-28)
-------------------
* Make ``FormatOptions`` inputs ``Optional`` so that ``None`` inputs
pass type checks.
* Write format-specification mini-language documentation to refer to
existing format options documentation to avoid documentation
duplication.
* Setup test coverage analysis automation and upload report to
`codecov <https://codecov.io/gh/jagerber48/sciform>`_.
* Add package status badges to readme.
* Test against Python 3.11.
* List supported Python versions in ``pyproject.toml`` classifiers.
0.28.0 (2023-08-27)
-------------------
* **[BREAKING]** Replace ``prefix_exp`` and ``parts_per_exp`` options
with an ``exp_format`` option which can be configured to
``ExpFormat.STANDARD``, ``ExpFormat.PREFIX`` or
``ExpFormat.PARTS_PER``.
* Previously formating a non-finite number in percent mode would always
display a ``'%'`` symbol, e.g. ``'(nan)%'``.
Now the brackets and ``'%'`` symbol will be omitted unless
``nan_inf_exp=True``.
* In ``latex=True`` mode there is now a space between the number and a
prefix or parts-per translated exponent.
For value/uncertainty formatting the space is still absent.
For ``latex=False`` there is still always a space for number and
value/uncertainty formatting before the translated exponent string.
* In ``latex=True`` mode ``'nan'`` and ``'inf'`` strings are now wrapped
in ``'\text{}'``.
* Refactored code for resolving exponent strings.
* Added more unit tests to reach 100% test coverage. Mostly added test
cases for invalid internal inputs.
* Raise ``NotImplementedError`` when attempting value/uncertainty
formatting with binary exponent modes.
Rounding and truncating are not properly implemented in binary mode
yet.
0.27.4 (2023-08-25)
-------------------
* Setup github action to automatically build and publish on release.
0.27.3 (2023-08-23)
-------------------
* Added ``Unreleased`` section to changelog.
* Removed ``version`` from source code.
Project version is now derived from a git version tag using
``setuptools_scm``.
* Stopped encouraging ``import FormatOptions as Fo``.
0.27.2 (2023-08-20)
-------------------
* Add ``__repr__()`` for ``FormatOptions`` and
``RenderedFormatOptions``.
0.27.1 (2023-08-18)
-------------------
* Add ``examples/`` folder to hold example scripts used in the
documentation as well as the input data for these scripts and their
outputs which appear in the documentation.
* Remove extra ``readthedocs.yaml`` file.
0.27.0 (2023-08-18)
-------------------
* **[BREAKING]** Rename ``AutoRound`` to ``AutoDigits``. This is
because, e.g., ``ndigits=AutoDigits`` sounds more correct than
``ndigits=AutoRound``. Furthermore, ``AutoRound`` could likely be
confused as being an option for ``round_mode``, which it is not.
0.26.2 (2023-08-18)
-------------------
* Fix a bug where illegal options combinations could be realized at
format time when certain global default objects were merged into
certain user specified options.
The bug is fixed by re-checking the options combinations after merging
in the global defaults but before formatting.
0.26.1 (2023-08-18)
-------------------
* Add unit tests, increase test coverage.
0.26.0 (2023-08-15)
-------------------
* **[BREAKING]** Rename some format options to make their usage more
clear.
* ``exp`` to ``exp_val``
* ``precision`` to ``ndigits``
* ``RoundMode.PREC`` to ``RoundMode.DEC_PLACE``
* ``AutoExp`` to ``AutoExpVal``
* ``AutoPrec`` to ``AutoRound``
* Raise more exceptions for incorrect options combinations.
* Raise an exception when using ``pdg_sig_figs`` with a user-supplied
``exp_val``.
* Raise exceptions instead of warnings for invalid user-supplied
``exp_val`` in ``get_mantissa_base_exp()``.
* Minor refactor to ``GlobalDefaultsContext``.
* Documentation:
* Update documentation to reflect name changes above.
* Better centralization of ``float``/``Decimal`` information.
* Better explanations of ``AutoExpVal`` and ``AutoRound`` behavior.
* More accurate descriptions of some invalid options combinations.
0.25.2 (2023-08-11)
-------------------
* Update roadmap
0.25.1 (2023-08-10)
-------------------
* Refactor ``get_pdg_round_digit()`` into a dedicated function.
0.25.0 (2023-08-02)
-------------------
* **[BREAKING]** ``template`` option removed from ``FormatOptions``
constructor.
New ``FormatOptions`` instances can be constructed from two existing
``FormatOptions`` instances using the ``merge()`` method.
* Minor documentation improvements.
0.24.0 (2023-07-30)
-------------------
* **[BREAKING]** percent mode is now accessed via an exponent mode,
``ExpMode.PERCENT``.
There is no longer a ``percent`` keyword argument.
0.23.0 (2023-07-29)
-------------------
* **[BREAKING]** Users now construct ``FormatOptions`` objects which
they pass into ``Formatter`` objects and global configuration
functions.
``Formatter`` and global configuration functions no longer accept bare
keyword arguments to indicate formatting options.
* **[BREAKING]** ``Formatter`` now resolves un-filled format options
from the global defaults at format time instead of initialization
time.
This is consistent with the previous behavior for ``SciNum`` and
``SciNumUnc`` objects.
* Change ``pyproject.toml`` description
0.22.2 (2023-07-27)
-------------------
* Add ``.readthedocs.yaml`` and update documentation
``requirements.txt`` for reproducible documentation builds.
0.22.1 (2023-07-27)
-------------------
* Fix a date typo in the changelog for the entry for version ``0.22.0``.
0.22.0 (2023-07-27)
-------------------
* **[BREAKING]** Rename ``sfloat`` to ``SciNum`` and ``vufloat`` to
``SciNumUnc``
* **[BREAKING]** ``SciNum`` instances do not support arithmetic
operations the same way ``sfloat`` instances did.
This functionality was removed for two reasons.
First, ``SciNum`` uses ``Decimal`` to store its value instead of
``float`` and configuring ``SciNum`` to behave as a subclass of
``Decimal`` would require added complexity.
Second, A decision has been made to keep the ``sciform`` module
focussed solely on formatting individual numbers or pairs of numbers
for early releases.
Convenience functionality outside of this narrow scope will be
considered at a later time.
* Favor ``Decimal`` methods over ``float`` methods in internal
formatting algorithm code.
* Documentation
* Remove ``float``-based language fom documentation.
* Include a discussion in the documentation about ``Decimal`` versus
``float`` considerations that may be important for users.
* Various minor revisions and edits. Notably a typo in the version
``0.21.0`` changelog entry that reversed the meaning of a sentence
was corrected.
* Add "under construction" message to README.
0.21.0 (2023-07-22)
-------------------
* Use ``Decimal`` under the hood for numerical formatting instead of
``float``. ``Decimal`` instances support higher precision than
``float`` and more reliable rounding behavior.
* Update particle data group uncertainty rounding unit tests since edge
cases are now handled property as a result of adopting ``Decimal``.
* Minor cleanup of ``sfloat`` arithemetic functions.
0.20.1 (2023-06-24)
-------------------
* Refactor unit tests to use lists and tuples instead of dicts. Literal
dicts allow the possibility for defining the same key (test case) with
different values, only the latest of which will actually be tested.
The refactoring ensures all elements of the test lists will be tested.
* Refactor ``sfloat`` and ``vufloat`` ``__format__()`` functions to call
``format_float()`` and ``format_val_unc()`` directly instead of
creating a ``Formatter`` object first.
0.20.0 (2023-06-22)
-------------------
* Support passing ``None`` as a value into ``extra_si_prefixes``,
``extra_iec_prefixes``, or ``extra_parts_per_forms`` to prevent
translation of a certain exponent value. This may be useful for
suppressing ``ppb`` or similar local-dependent "parts per"
translations.
* **[BREAKING]** Change the bracket uncertainty flag in the
`FSML <fsml>`_ from ``'S'`` to ``'()'``.
* When an exponent translation mode is used in combination with Latex
mode, the translated exponent will now be wrapped in a Latex text
mode: e.g. ``\text{Mi}``.
* Link to test cases on examples page.
0.19.0 (2023-06-22)
-------------------
* Add python-package.yaml github workflows. Allows automated testing,
doc testing, and flake8 scans during github pull requests.
* Minor flake8 cleanup
0.18.1 (2023-06-21)
-------------------
* Documentation improvements
0.18.0 (2023-06-19)
-------------------
* Add Particle Data Group significant figure auto selection feature,
documentation, and tests.
* **[BREAKING]** Use the larger of value or uncertainty to resolve the
exponent when formatting value/uncertainty pairs. The previous
behavior was to always use the value to resolve the exponent, but this
behavior was not convenient for the important use case of zero value
with non-zero uncertainty.
* Expose ``AutoPrec`` and ``AutoExp`` sentinel classes so that users can
explicitly indicate automatic precision and exponent selection.
0.17.1 (2023-06-19)
-------------------
* Code restructure to make formatting algorithm easier to follow
including more verbose clarifying comments.
* Minor documentation cleanup
0.17.0 (2023-06-19)
-------------------
* Add parts-per notation feature, documentation, and tests.
* **[BREAKING]** Rename ``use_prefix`` option to ``prefix_exp``.
* Fix typos in binary IEC prefixes table.
* Fix some cross links in documentation.
0.16.0 (2023-06-18)
-------------------
* Add ``latex`` option with documentation and tests.
* Refactor exponent string conversion.
* Percent mode for non-finite numbers.
0.15.2 (2023-06-18)
-------------------
* Fix a bug involving space filling and separators.
0.15.1 (2023-06-17)
-------------------
* Changelog formatting typo.
0.15.0 (2023-06-17)
-------------------
* Add ``superscript_exp`` option with documentation and tests.
* Forbid percent mode unless using fixed point exponent mode.
* Add PyPi link to readme.
0.14.0 (2023-06-17)
-------------------
* Add Changelog.
* Add ``unicode_pm`` option with documentation and tests.
| 0.88173 | 0.590956 |
import json
from typing import Literal
import re
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from tabulate import tabulate
from sciform import Formatter, ExpMode, RoundMode, SignMode, FormatOptions
def get_scale_and_offset_from_offset_str(
ax: plt.Axes, axis: Literal['x', 'y']) -> tuple[float, float]:
"""
Extract the scale and offset for a particular axis from the existing
offset text when the axis is formatted in scientific mode.
"""
plt.draw()
if axis == 'x':
offset_text_obj = ax.xaxis.get_offset_text()
elif axis == 'y':
offset_text_obj = ax.yaxis.get_offset_text()
else:
raise ValueError(f'axis must be \'x\' or \'y\', not '
f'\'{axis}\'.')
ax.ticklabel_format(axis=axis, style='sci')
ax.get_figure().canvas.draw() # Redraw canvas to update offset text
offset_text = offset_text_obj.get_text()
# Replace minus sign with hyphen minus sign
offset_text = offset_text.replace('\u2212', '-')
pattern = re.compile(r'^(?P<scale>1e[+-]?\d+)?(?P<offset>[+-]1e\d+)?$')
match = re.match(pattern, offset_text)
scale = float(match.group('scale') or 1)
offset = float(match.group('offset') or 0)
return scale, offset
def prefix_exp_ticks(ax: plt.Axes, axis: Literal['x', 'y'],
shifted: bool = False) -> None:
"""
Use prefix notation for axis tick labels. Scale the tick labels by
the multiplier that appears in the offset text and format the labels
into SI prefix format. Format any remaining offset value in the
offset text into SI prefix format as well.
"""
if not shifted:
exp_mode = ExpMode.ENGINEERING
else:
exp_mode = ExpMode.ENGINEERING_SHIFTED
tick_formatter = Formatter(FormatOptions(
exp_mode=exp_mode,
prefix_exp=True))
offset_formatter = Formatter(FormatOptions(
sign_mode=SignMode.ALWAYS,
exp_mode=exp_mode,
prefix_exp=True))
ax.ticklabel_format(axis=axis, style='sci')
if axis == 'x':
old_ticklabels = ax.get_xticklabels()
elif axis == 'y':
old_ticklabels = ax.get_yticklabels()
else:
raise ValueError(f'axis must be \'x\' or \'y\', not \'{axis}\'.')
scale, offset = get_scale_and_offset_from_offset_str(ax, axis)
new_tick_locations = list()
new_tick_labels = list()
for old_ticklabel in old_ticklabels:
x, y = old_ticklabel.get_position()
if axis == 'x':
new_tick_locations.append(x)
else:
new_tick_locations.append(y)
# Replace minus sign with hyphen minus sign
old_label_str = old_ticklabel.get_text().replace('\u2212', '-')
val = float(old_label_str) * scale
new_str = tick_formatter(val)
new_tick_labels.append(new_str)
if offset != 0:
offset_str = offset_formatter(offset)
else:
offset_str = ''
if axis == 'x':
ax.set_xticks(new_tick_locations, new_tick_labels)
ax.text(x=1.01, y=0, s=offset_str, transform=ax.transAxes)
else:
ax.set_yticks(new_tick_locations, new_tick_labels)
ax.text(x=0, y=1.01, s=offset_str, transform=ax.transAxes)
def quadratic(x, c, x0, y0):
return (c / 2) * (x - x0) ** 2 + y0
def main():
fit_results_formatter = Formatter(FormatOptions(
exp_mode=ExpMode.ENGINEERING,
round_mode=RoundMode.SIG_FIG,
bracket_unc=True,
ndigits=2))
with open('data/fit_data.json', 'r') as f:
data_dict = json.load(f)
color_list = ['red', 'blue', 'purple']
fit_results_list = list()
fig, ax = plt.subplots(1, 1)
for idx, single_data_dict in enumerate(data_dict.values()):
x = single_data_dict['x']
y = single_data_dict['y']
y_err = single_data_dict['y_err']
fit_results_dict = dict()
color = color_list[idx]
ax.errorbar(x, y, y_err, marker='o', linestyle='none', color=color,
label=color)
popt, pcov = curve_fit(quadratic, x, y, sigma=y_err, p0=(2e13, 0, 1e9))
model_x = np.linspace(min(x), max(x), 100)
model_y = quadratic(model_x, *popt)
ax.plot(model_x, model_y, color=color)
fit_results_dict['color'] = color
fit_results_dict['curvature'] = fit_results_formatter(
popt[0], np.sqrt(pcov[0, 0]))
fit_results_dict['x0'] = fit_results_formatter(
popt[1], np.sqrt(pcov[1, 1]))
fit_results_dict['y0'] = fit_results_formatter(
popt[2], np.sqrt(pcov[2, 2]))
fit_results_list.append(fit_results_dict)
ax.grid(True)
ax.legend()
prefix_exp_ticks(ax, 'x')
prefix_exp_ticks(ax, 'y', shifted=True)
fig.savefig('outputs/fit_plot_with_sciform.png', facecolor='white')
plt.show()
table_str = tabulate(fit_results_list, headers='keys', tablefmt='grid')
with open('outputs/fit_plot_with_sciform_table.txt', 'w') as f:
f.write(table_str)
print(table_str)
if __name__ == "__main__":
main() | sciform | /sciform-0.28.2.tar.gz/sciform-0.28.2/examples/fit_plot_with_sciform.py | fit_plot_with_sciform.py | import json
from typing import Literal
import re
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from tabulate import tabulate
from sciform import Formatter, ExpMode, RoundMode, SignMode, FormatOptions
def get_scale_and_offset_from_offset_str(
ax: plt.Axes, axis: Literal['x', 'y']) -> tuple[float, float]:
"""
Extract the scale and offset for a particular axis from the existing
offset text when the axis is formatted in scientific mode.
"""
plt.draw()
if axis == 'x':
offset_text_obj = ax.xaxis.get_offset_text()
elif axis == 'y':
offset_text_obj = ax.yaxis.get_offset_text()
else:
raise ValueError(f'axis must be \'x\' or \'y\', not '
f'\'{axis}\'.')
ax.ticklabel_format(axis=axis, style='sci')
ax.get_figure().canvas.draw() # Redraw canvas to update offset text
offset_text = offset_text_obj.get_text()
# Replace minus sign with hyphen minus sign
offset_text = offset_text.replace('\u2212', '-')
pattern = re.compile(r'^(?P<scale>1e[+-]?\d+)?(?P<offset>[+-]1e\d+)?$')
match = re.match(pattern, offset_text)
scale = float(match.group('scale') or 1)
offset = float(match.group('offset') or 0)
return scale, offset
def prefix_exp_ticks(ax: plt.Axes, axis: Literal['x', 'y'],
shifted: bool = False) -> None:
"""
Use prefix notation for axis tick labels. Scale the tick labels by
the multiplier that appears in the offset text and format the labels
into SI prefix format. Format any remaining offset value in the
offset text into SI prefix format as well.
"""
if not shifted:
exp_mode = ExpMode.ENGINEERING
else:
exp_mode = ExpMode.ENGINEERING_SHIFTED
tick_formatter = Formatter(FormatOptions(
exp_mode=exp_mode,
prefix_exp=True))
offset_formatter = Formatter(FormatOptions(
sign_mode=SignMode.ALWAYS,
exp_mode=exp_mode,
prefix_exp=True))
ax.ticklabel_format(axis=axis, style='sci')
if axis == 'x':
old_ticklabels = ax.get_xticklabels()
elif axis == 'y':
old_ticklabels = ax.get_yticklabels()
else:
raise ValueError(f'axis must be \'x\' or \'y\', not \'{axis}\'.')
scale, offset = get_scale_and_offset_from_offset_str(ax, axis)
new_tick_locations = list()
new_tick_labels = list()
for old_ticklabel in old_ticklabels:
x, y = old_ticklabel.get_position()
if axis == 'x':
new_tick_locations.append(x)
else:
new_tick_locations.append(y)
# Replace minus sign with hyphen minus sign
old_label_str = old_ticklabel.get_text().replace('\u2212', '-')
val = float(old_label_str) * scale
new_str = tick_formatter(val)
new_tick_labels.append(new_str)
if offset != 0:
offset_str = offset_formatter(offset)
else:
offset_str = ''
if axis == 'x':
ax.set_xticks(new_tick_locations, new_tick_labels)
ax.text(x=1.01, y=0, s=offset_str, transform=ax.transAxes)
else:
ax.set_yticks(new_tick_locations, new_tick_labels)
ax.text(x=0, y=1.01, s=offset_str, transform=ax.transAxes)
def quadratic(x, c, x0, y0):
return (c / 2) * (x - x0) ** 2 + y0
def main():
fit_results_formatter = Formatter(FormatOptions(
exp_mode=ExpMode.ENGINEERING,
round_mode=RoundMode.SIG_FIG,
bracket_unc=True,
ndigits=2))
with open('data/fit_data.json', 'r') as f:
data_dict = json.load(f)
color_list = ['red', 'blue', 'purple']
fit_results_list = list()
fig, ax = plt.subplots(1, 1)
for idx, single_data_dict in enumerate(data_dict.values()):
x = single_data_dict['x']
y = single_data_dict['y']
y_err = single_data_dict['y_err']
fit_results_dict = dict()
color = color_list[idx]
ax.errorbar(x, y, y_err, marker='o', linestyle='none', color=color,
label=color)
popt, pcov = curve_fit(quadratic, x, y, sigma=y_err, p0=(2e13, 0, 1e9))
model_x = np.linspace(min(x), max(x), 100)
model_y = quadratic(model_x, *popt)
ax.plot(model_x, model_y, color=color)
fit_results_dict['color'] = color
fit_results_dict['curvature'] = fit_results_formatter(
popt[0], np.sqrt(pcov[0, 0]))
fit_results_dict['x0'] = fit_results_formatter(
popt[1], np.sqrt(pcov[1, 1]))
fit_results_dict['y0'] = fit_results_formatter(
popt[2], np.sqrt(pcov[2, 2]))
fit_results_list.append(fit_results_dict)
ax.grid(True)
ax.legend()
prefix_exp_ticks(ax, 'x')
prefix_exp_ticks(ax, 'y', shifted=True)
fig.savefig('outputs/fit_plot_with_sciform.png', facecolor='white')
plt.show()
table_str = tabulate(fit_results_list, headers='keys', tablefmt='grid')
with open('outputs/fit_plot_with_sciform_table.txt', 'w') as f:
f.write(table_str)
print(table_str)
if __name__ == "__main__":
main() | 0.718989 | 0.425247 |
# scify-file-reader
The scify-file-reader package provides a convenient class for handling multiple files with the same structure in a directory. It offers functionality to read and process data from various file types, including CSV, XLSX, Parquet, and JSON.
## Installation
You can install scify-file-reader using pip:
```shell
pip install scify-file-reader
```
## Usage
To use scify-file-reader, follow these steps:
1. Import the `FileReader` class:
```python
from scify_file_reader import FileReader
```
2. Create an instance of the FileReader class, providing the content you want to read. The content can be a string representing a `file path`, a `Path` object, or a `zipfile.ZipFile` object:
```python
content = 'path/to/directory'
reader = FileReader(content)
```
3. Read the files using the read_files method:
```python
data = reader.read_files()
```
The `read_files` method returns a dictionary where the keys are the filenames (without the extension) and the values are pandas DataFrames containing the file data.
**For more details on the available methods and parameters, refer to the package documentation.**
## Examples:
Here's an example that demonstrates how to use scify-file-reader:
### Normal Output
```python
from scify_file_reader import FileReader
PATH = '/path/to/directory'
"""
# Supomos que temos estes arquivos dentro do nosso diretório
print(os.listdir(PATH))
# OUT: ['file_1.csv'', 'log_2.csv', 'test_3.csv',
'file_%Y%m%d%H%M%S.csv', 'log_%Y%m%d%H%M%S.csv', 'test_%Y%m%d%H%M%S.csv',
'file_%Y%m%d_%H%M%S.csv', 'log_%Y%m%d_%H%M%S.csv', 'test_%Y%m%d_%H%M%S.csv',
"""
# Example: Reading files from a directory
reader = FileReader('/path/to/directory')
data = reader.read_files() # read_files accept kwargs from pandas read_ methods
"""
OUTPUT: print(data)
{
'file_1.csv': <pd.DataFrame>,
'log_2.csv': <pd.DataFrame>,
'test_3.csv': <pd.DataFrame>,
'file_%Y%m%d%H%M%S.csv': <pd.DataFrame>,
'log_%Y%m%d%H%M%S.csv': <pd.DataFrame>,
'test_%Y%m%d%H%M%S.csv': <pd.DataFrame>,
'file_%Y%m%d_%H%M%S.csv': <pd.DataFrame>,
'log_%Y%m%d_%H%M%S.csv': <pd.DataFrame>,
'test_%Y%m%d_%H%M%S.csv': <pd.DataFrame>
}
"""
```
### Concatenating patterns:
Use this method when you need to concatenate multiple files with similar patterns into a single consolidated file.
**E.g.** In the last example, we demonstrate the use of scify-file-reader with a directory containing 9 files that follow common naming patterns, such as 'file', 'log', and 'test'. By joining these files, we can consolidate and analyze their data more effectively. Let's take a look at the example to understand how they are joined.
```python
from scify_file_reader import FileReader
PATH = '/path/to/directory'
"""
# Let's suppose we have these files inside our directory.
print(os.listdir(PATH))
# OUT: ['file_1.csv'', 'log_2.csv', 'test_3.csv',
'file_%Y%m%d%H%M%S.csv', 'log_%Y%m%d%H%M%S.csv', 'test_%Y%m%d%H%M%S.csv',
'file_%Y%m%d_%H%M%S.csv', 'log_%Y%m%d_%H%M%S.csv', 'test_%Y%m%d_%H%M%S.csv',
"""
# Example: Reading files from a directory
reader = FileReader('/path/to/directory')
data = reader.read_files(join_prefixes=True) #
"""
OUTPUT: print(data)
{
'file': <pd.DataFrame>,
'log': <pd.DataFrame>,
'test': <pd.DataFrame>,
}
"""
```
### Using a specific regular expression
In the example above, all files with common prefixes, such as `file_1.csv`, `file_%Y%m%d%H%M%S.csv`, and `file_%Y%m%d_%H%M%S.csv`, were joined together under the file key in the output.
If you want to use a specific regular expression for filtering your files, you can follow these steps:
```python
from scify_file_reader import FileReader
PATH = '/path/to/directory'
# Example: Reading files from a directory
reader = FileReader('/path/to/directory')
regex = '<some_regex>'
reader.set_prefix_file_pattern_regex(regex)
data = reader.read_files(join_prefixes=True)
```
By default the regular expression is `^([A-Z]+)_\d+`.
### Speficic prefixes instead of regular expressions
If you prefer to use specific prefixes instead of regular expressions, you can utilize the `join_custom_prefixes` argument. This argument accepts a tuple of prefixes that you want to join together.
```python
from scify_file_reader import FileReader
PATH = '/path/to/directory'
"""
# Supomos que temos estes arquivos dentro do nosso diretório
print(os.listdir(PATH))
# OUT: ['file_1.csv'', 'log_2.csv', 'test_3.csv',
'file_%Y%m%d%H%M%S.csv', 'log_%Y%m%d%H%M%S.csv', 'test_%Y%m%d%H%M%S.csv',
'file_%Y%m%d_%H%M%S.csv', 'log_%Y%m%d_%H%M%S.csv', 'test_%Y%m%d_%H%M%S.csv',
"""
# Example: Reading files from a directory
reader = FileReader('/path/to/directory')
specific_prefixes = ('file', 'log', 'test')
data = reader.read_files(join_prefixes=True)
"""
OUTPUT: print(data)
{
'file': <pd.DataFrame>,
'log': <pd.DataFrame>,
'test': <pd.DataFrame>,
}
"""
```
## Contributing
Contributions are welcome! If you have any suggestions, bug reports, or feature requests, please open an issue or submit a pull request on the [scify-file-reader](https://github.com/Jeferson-Peter/scify-file-reader) repository.
| scify-file-reader | /scify-file-reader-0.0.2.tar.gz/scify-file-reader-0.0.2/README.md | README.md | pip install scify-file-reader
from scify_file_reader import FileReader
3. Read the files using the read_files method:
The `read_files` method returns a dictionary where the keys are the filenames (without the extension) and the values are pandas DataFrames containing the file data.
**For more details on the available methods and parameters, refer to the package documentation.**
## Examples:
Here's an example that demonstrates how to use scify-file-reader:
### Normal Output
### Concatenating patterns:
Use this method when you need to concatenate multiple files with similar patterns into a single consolidated file.
**E.g.** In the last example, we demonstrate the use of scify-file-reader with a directory containing 9 files that follow common naming patterns, such as 'file', 'log', and 'test'. By joining these files, we can consolidate and analyze their data more effectively. Let's take a look at the example to understand how they are joined.
### Using a specific regular expression
In the example above, all files with common prefixes, such as `file_1.csv`, `file_%Y%m%d%H%M%S.csv`, and `file_%Y%m%d_%H%M%S.csv`, were joined together under the file key in the output.
If you want to use a specific regular expression for filtering your files, you can follow these steps:
By default the regular expression is `^([A-Z]+)_\d+`.
### Speficic prefixes instead of regular expressions
If you prefer to use specific prefixes instead of regular expressions, you can utilize the `join_custom_prefixes` argument. This argument accepts a tuple of prefixes that you want to join together.
| 0.892829 | 0.888324 |
import os
import re
import zipfile
from io import BytesIO
from pathlib import Path
from typing import Union, IO, Tuple
import pandas as pd
import pyarrow.parquet as pq
class FileReader:
"""
A class to handle and process multiple files with identical structures within a directory or a zip archive.
Args:
content (Union[str, Path, zipfile.ZipFile]): The content to read. It can be a string representing
a file path, a Path object, or a zipfile.ZipFile object.
Attributes:
content (Union[str, Path, zipfile.ZipFile]): The content to read.
is_dir (bool): Indicates if the content is a directory.
is_zipfile (bool): Indicates if the content is a zip archive.
_available_exts (Tuple[str]): Available file extensions to consider when reading files.
_prefix_file_pattern_regex (re.Pattern): Regular expression pattern for file prefixes.
"""
def __init__(self, content: Union[str, Path, zipfile.ZipFile]):
self.content = content
self.is_dir = False
self.is_zipfile = False
self._available_exts = ('.csv', '.xlsx', '.parquet', '.json')
self._prefix_file_pattern_regex = re.compile(r'^([A-Z]+)_\d+')
self._check_content_type()
self._check_extensions()
def set_prefix_file_pattern_regex(self, regex: str):
"""
Set a custom regular expression pattern for file prefixes.
Args:
regex (str): The custom regular expression pattern.
"""
self._prefix_file_pattern_regex = re.compile(regex)
def _check_content_type(self):
"""
Check the type of the content (directory or zip archive) and update the corresponding attributes.
"""
if isinstance(self.content, (str, Path)):
self.content = Path(self.content)
self.is_dir = self.content.is_dir()
if self.content.is_file() and self.content.suffix.lower() == '.zip':
self.is_zipfile = True
self.content = zipfile.ZipFile(self.content)
elif isinstance(self.content, zipfile.ZipFile):
self.is_zipfile, self.is_dir = True, False
def _check_extensions(self):
"""
Check the available file extensions in the content and validate if they are supported.
"""
exts = set()
if self.is_dir:
exts = set([os.path.splitext(x)[1] for x in os.listdir(self.content)
if os.path.splitext(x)[1] != ''])
elif self.is_zipfile:
exts = set([os.path.splitext(x)[1] for x in self.content.namelist()
if os.path.splitext(x)[1] != ''])
if len(exts) <= 0:
raise Exception(f"No data found inside {self.content}")
elif len(exts) > 1:
raise Exception(f"Multiple file types found in content '{self.content}': {exts}")
elif len(exts) == 1:
ext_is_available = list(exts)[0] in self._available_exts
if not ext_is_available:
raise Exception(f"'{list(exts)[0]}' not available. The available file types are {', '.join(self._available_exts)}")
def _get_files_to_read(self):
"""
Get the files to read based on the content type.
Returns:
List[str]: List of file names to read.
"""
if self.is_zipfile:
return self.content.namelist()
elif self.is_dir:
return os.listdir(self.content)
def _zip_file_reader(self, data: dict, file: str, **kwargs):
"""
Read a file from a zip archive and add it to the data dictionary.
Args:
data (dict): Dictionary to store the file data.
file (str): File name to read.
**kwargs: Additional arguments to pass to the pandas read methods.
Returns:
dict: Updated data dictionary.
"""
filename, ext = os.path.splitext(file)
if ext.lower() == '.csv':
with self.content.open(file) as f:
data[filename] = pd.read_csv(f, **kwargs)
elif ext.lower() == '.xlsx':
with self.content.open(file) as f:
data[filename] = pd.read_excel(f, **kwargs)
elif ext.lower() == '.parquet':
with self.content.open(file) as f:
data[filename] = pq.read_table(f, **kwargs).to_pandas()
elif ext.lower() == '.json':
with self.content.open(file) as f:
data[filename] = pd.read_json(f, **kwargs)
return data
def _path_file_reader(self, data: dict, file: str, **kwargs):
"""
Read a file from a directory and add it to the data dictionary.
Args:
data (dict): Dictionary to store the file data.
file (str): File name to read.
**kwargs: Additional arguments to pass to the pandas read methods.
Returns:
dict: Updated data dictionary.
"""
filename, ext = os.path.splitext(file)
path_to_read = os.path.join(self.content, file)
if ext.lower() == '.csv':
data[filename] = pd.read_csv(path_to_read, **kwargs)
elif ext.lower() == '.xlsx':
data[filename] = pd.read_excel(path_to_read, **kwargs)
elif ext.lower() == '.parquet':
data[filename] = pq.read_table(path_to_read, **kwargs).to_pandas()
elif ext.lower() == '.json':
data[filename] = pd.read_json(path_to_read, **kwargs)
return data
def __get_file_pattern(self, filenames: list):
"""
Get the unique file patterns based on the file names.
Args:
filenames (list): List of file names.
Returns:
set: Set of unique file patterns.
"""
prefixes = set([re.match(self._prefix_file_pattern_regex, filename).group(1) for filename in filenames if
re.match(self._prefix_file_pattern_regex, filename)])
return prefixes
def read_files(self,
join_prefixes: bool = False,
regex: bool = True,
join_custom_prefixes: Tuple[str] = None,
**kwargs):
"""
Read and process the files.
Args:
join_prefixes (bool, optional): Whether to join files with the same prefix into a single DataFrame.
Defaults to False.
regex (bool, optional): Whether to use regular expressions to identify file prefixes. Defaults to True.
join_custom_prefixes (Tuple[str], optional): Custom prefixes to join together. Defaults to None.
**kwargs: Additional arguments to pass to the pandas read methods.
Returns:
dict: A dictionary where the keys are the filenames (or prefixes if join_prefixes is True) and
the values are pandas DataFrames containing the file data.
"""
data = {}
files = self._get_files_to_read()
if self.is_zipfile:
for file in files:
data.update(self._zip_file_reader(data, file, **kwargs))
elif self.is_dir:
for file in files:
data.update(self._path_file_reader(data, file, **kwargs))
if join_prefixes:
if not regex and join_custom_prefixes:
unique_file_prefixes = set(join_custom_prefixes)
else:
unique_file_prefixes = self.__get_file_pattern(list(data.keys()))
for prefix in unique_file_prefixes:
file_prefixes = [x for x in data.keys() if prefix in x]
data[prefix] = pd.concat([data[x] for x in file_prefixes], ignore_index=True)
[data.pop(x) for x in file_prefixes]
del file_prefixes
return data
else:
return data | scify-file-reader | /scify-file-reader-0.0.2.tar.gz/scify-file-reader-0.0.2/scify_file_reader/file_reader.py | file_reader.py | import os
import re
import zipfile
from io import BytesIO
from pathlib import Path
from typing import Union, IO, Tuple
import pandas as pd
import pyarrow.parquet as pq
class FileReader:
"""
A class to handle and process multiple files with identical structures within a directory or a zip archive.
Args:
content (Union[str, Path, zipfile.ZipFile]): The content to read. It can be a string representing
a file path, a Path object, or a zipfile.ZipFile object.
Attributes:
content (Union[str, Path, zipfile.ZipFile]): The content to read.
is_dir (bool): Indicates if the content is a directory.
is_zipfile (bool): Indicates if the content is a zip archive.
_available_exts (Tuple[str]): Available file extensions to consider when reading files.
_prefix_file_pattern_regex (re.Pattern): Regular expression pattern for file prefixes.
"""
def __init__(self, content: Union[str, Path, zipfile.ZipFile]):
self.content = content
self.is_dir = False
self.is_zipfile = False
self._available_exts = ('.csv', '.xlsx', '.parquet', '.json')
self._prefix_file_pattern_regex = re.compile(r'^([A-Z]+)_\d+')
self._check_content_type()
self._check_extensions()
def set_prefix_file_pattern_regex(self, regex: str):
"""
Set a custom regular expression pattern for file prefixes.
Args:
regex (str): The custom regular expression pattern.
"""
self._prefix_file_pattern_regex = re.compile(regex)
def _check_content_type(self):
"""
Check the type of the content (directory or zip archive) and update the corresponding attributes.
"""
if isinstance(self.content, (str, Path)):
self.content = Path(self.content)
self.is_dir = self.content.is_dir()
if self.content.is_file() and self.content.suffix.lower() == '.zip':
self.is_zipfile = True
self.content = zipfile.ZipFile(self.content)
elif isinstance(self.content, zipfile.ZipFile):
self.is_zipfile, self.is_dir = True, False
def _check_extensions(self):
"""
Check the available file extensions in the content and validate if they are supported.
"""
exts = set()
if self.is_dir:
exts = set([os.path.splitext(x)[1] for x in os.listdir(self.content)
if os.path.splitext(x)[1] != ''])
elif self.is_zipfile:
exts = set([os.path.splitext(x)[1] for x in self.content.namelist()
if os.path.splitext(x)[1] != ''])
if len(exts) <= 0:
raise Exception(f"No data found inside {self.content}")
elif len(exts) > 1:
raise Exception(f"Multiple file types found in content '{self.content}': {exts}")
elif len(exts) == 1:
ext_is_available = list(exts)[0] in self._available_exts
if not ext_is_available:
raise Exception(f"'{list(exts)[0]}' not available. The available file types are {', '.join(self._available_exts)}")
def _get_files_to_read(self):
"""
Get the files to read based on the content type.
Returns:
List[str]: List of file names to read.
"""
if self.is_zipfile:
return self.content.namelist()
elif self.is_dir:
return os.listdir(self.content)
def _zip_file_reader(self, data: dict, file: str, **kwargs):
"""
Read a file from a zip archive and add it to the data dictionary.
Args:
data (dict): Dictionary to store the file data.
file (str): File name to read.
**kwargs: Additional arguments to pass to the pandas read methods.
Returns:
dict: Updated data dictionary.
"""
filename, ext = os.path.splitext(file)
if ext.lower() == '.csv':
with self.content.open(file) as f:
data[filename] = pd.read_csv(f, **kwargs)
elif ext.lower() == '.xlsx':
with self.content.open(file) as f:
data[filename] = pd.read_excel(f, **kwargs)
elif ext.lower() == '.parquet':
with self.content.open(file) as f:
data[filename] = pq.read_table(f, **kwargs).to_pandas()
elif ext.lower() == '.json':
with self.content.open(file) as f:
data[filename] = pd.read_json(f, **kwargs)
return data
def _path_file_reader(self, data: dict, file: str, **kwargs):
"""
Read a file from a directory and add it to the data dictionary.
Args:
data (dict): Dictionary to store the file data.
file (str): File name to read.
**kwargs: Additional arguments to pass to the pandas read methods.
Returns:
dict: Updated data dictionary.
"""
filename, ext = os.path.splitext(file)
path_to_read = os.path.join(self.content, file)
if ext.lower() == '.csv':
data[filename] = pd.read_csv(path_to_read, **kwargs)
elif ext.lower() == '.xlsx':
data[filename] = pd.read_excel(path_to_read, **kwargs)
elif ext.lower() == '.parquet':
data[filename] = pq.read_table(path_to_read, **kwargs).to_pandas()
elif ext.lower() == '.json':
data[filename] = pd.read_json(path_to_read, **kwargs)
return data
def __get_file_pattern(self, filenames: list):
"""
Get the unique file patterns based on the file names.
Args:
filenames (list): List of file names.
Returns:
set: Set of unique file patterns.
"""
prefixes = set([re.match(self._prefix_file_pattern_regex, filename).group(1) for filename in filenames if
re.match(self._prefix_file_pattern_regex, filename)])
return prefixes
def read_files(self,
join_prefixes: bool = False,
regex: bool = True,
join_custom_prefixes: Tuple[str] = None,
**kwargs):
"""
Read and process the files.
Args:
join_prefixes (bool, optional): Whether to join files with the same prefix into a single DataFrame.
Defaults to False.
regex (bool, optional): Whether to use regular expressions to identify file prefixes. Defaults to True.
join_custom_prefixes (Tuple[str], optional): Custom prefixes to join together. Defaults to None.
**kwargs: Additional arguments to pass to the pandas read methods.
Returns:
dict: A dictionary where the keys are the filenames (or prefixes if join_prefixes is True) and
the values are pandas DataFrames containing the file data.
"""
data = {}
files = self._get_files_to_read()
if self.is_zipfile:
for file in files:
data.update(self._zip_file_reader(data, file, **kwargs))
elif self.is_dir:
for file in files:
data.update(self._path_file_reader(data, file, **kwargs))
if join_prefixes:
if not regex and join_custom_prefixes:
unique_file_prefixes = set(join_custom_prefixes)
else:
unique_file_prefixes = self.__get_file_pattern(list(data.keys()))
for prefix in unique_file_prefixes:
file_prefixes = [x for x in data.keys() if prefix in x]
data[prefix] = pd.concat([data[x] for x in file_prefixes], ignore_index=True)
[data.pop(x) for x in file_prefixes]
del file_prefixes
return data
else:
return data | 0.738858 | 0.297011 |
from scipy.spatial import cKDTree as KDTree
import numpy as np
class IDW(object):
"""
# https://mail.python.org/pipermail/scipy-user/2010-June/025920.html
# https://github.com/soonyenju/pysy/blob/master/pysy/scigeo.py
inverse-distance-weighted interpolation using KDTree:
invdisttree = Invdisttree(X, z)
-- points, values
interpol = invdisttree(q, k=6, eps=0)
-- interpolate z from the 6 points nearest each q;
q may be one point, or a batch of points
"""
def __init__(self, X, z, leafsize = 10):
super()
self.tree = KDTree(X, leafsize=leafsize) # build the tree
self.z = z
def __call__(self, q, k = 8, eps = 0):
# q is coor pairs like [[lon1, lat1], [lon2, lat2], [lon3, lat3]]
# k nearest neighbours of each query point --
# format q if only 1d coor pair passed like [lon1, lat1]
if not isinstance(q, np.ndarray):
q = np.array(q)
if q.ndim == 1:
q = q[np.newaxis, :]
self.distances, self.ix = self.tree.query(q, k = k,eps = eps)
interpol = [] # np.zeros((len(self.distances),) +np.shape(z[0]))
for dist, ix in zip(self.distances, self.ix):
if dist[0] > 1e-10:
w = 1 / dist
wz = np.dot(w, self.z[ix]) / np.sum(w) # weightz s by 1/dist
else:
wz = self.z[ix[0]]
interpol.append(wz)
return interpol
def gen_buffer(lon, lat, step, shape = "rectangle"):
if shape == "rectangle":
# clockwise
coors = [
[lon - step, lat + step], # upper left
[lon + step, lat + step], # upper right
[lon + step, lat - step], # lower right
[lon - step, lat - step], # lower left
]
return coors
def dms2ddm(deg, min_, sec):
# covert Degrees Minutes Seconds (DMS) to Degrees Decimal Minutes (DDM)
min_ = min_ + sec / 60
ddm = deg + min_ / 60
return ddm
def deg2km(lat):
# earth radius: 6371 km
return 6371 * np.cos(lat) * 2* np.pi / 360 | scigeo | /scigeo-0.0.10.tar.gz/scigeo-0.0.10/scigeo-history-versions/scigeo-0.0.2/geobox.py | geobox.py | from scipy.spatial import cKDTree as KDTree
import numpy as np
class IDW(object):
"""
# https://mail.python.org/pipermail/scipy-user/2010-June/025920.html
# https://github.com/soonyenju/pysy/blob/master/pysy/scigeo.py
inverse-distance-weighted interpolation using KDTree:
invdisttree = Invdisttree(X, z)
-- points, values
interpol = invdisttree(q, k=6, eps=0)
-- interpolate z from the 6 points nearest each q;
q may be one point, or a batch of points
"""
def __init__(self, X, z, leafsize = 10):
super()
self.tree = KDTree(X, leafsize=leafsize) # build the tree
self.z = z
def __call__(self, q, k = 8, eps = 0):
# q is coor pairs like [[lon1, lat1], [lon2, lat2], [lon3, lat3]]
# k nearest neighbours of each query point --
# format q if only 1d coor pair passed like [lon1, lat1]
if not isinstance(q, np.ndarray):
q = np.array(q)
if q.ndim == 1:
q = q[np.newaxis, :]
self.distances, self.ix = self.tree.query(q, k = k,eps = eps)
interpol = [] # np.zeros((len(self.distances),) +np.shape(z[0]))
for dist, ix in zip(self.distances, self.ix):
if dist[0] > 1e-10:
w = 1 / dist
wz = np.dot(w, self.z[ix]) / np.sum(w) # weightz s by 1/dist
else:
wz = self.z[ix[0]]
interpol.append(wz)
return interpol
def gen_buffer(lon, lat, step, shape = "rectangle"):
if shape == "rectangle":
# clockwise
coors = [
[lon - step, lat + step], # upper left
[lon + step, lat + step], # upper right
[lon + step, lat - step], # lower right
[lon - step, lat - step], # lower left
]
return coors
def dms2ddm(deg, min_, sec):
# covert Degrees Minutes Seconds (DMS) to Degrees Decimal Minutes (DDM)
min_ = min_ + sec / 60
ddm = deg + min_ / 60
return ddm
def deg2km(lat):
# earth radius: 6371 km
return 6371 * np.cos(lat) * 2* np.pi / 360 | 0.884601 | 0.489503 |
import math
import datetime
class Sunriseset:
def __init__(self, timestamp = None, format = r"%Y-%m-%d"):
if isinstance(timestamp, str):
timestamp = datetime.datetime.strptime(timestamp, format)
self.timestamp = timestamp
def __call__(self, lon, lat):
coords = {'longitude' : lon, 'latitude' : lat}
# Sunrise time UTC (decimal, 24 hour format)
sunrise = self.getSunriseTime(coords)['decimal']
# Sunset time UTC (decimal, 24 hour format)
sunset = self.getSunsetTime(coords)['decimal']
return {
"sunrise": sunrise,
"sunset": sunset
}
def getSunriseTime(self, coords):
return self.calcSunTime(coords, True)
def getSunsetTime(self, coords):
return self.calcSunTime(coords, False)
def getCurrentUTC(self):
now = datetime.datetime.now()
return [now.day, now.month, now.year]
def calcSunTime(self, coords, isRiseTime, zenith = 90.8):
# isRiseTime == False, returns sunsetTime
if self.timestamp:
timestamp = self.timestamp
try:
day, month, year = [timestamp.day, timestamp.month, timestamp.year]
except:
day, month, year = timestamp
# else:
# raise Exception("Wrong input time format...")
else:
print("Use current time...")
day, month, year = self.getCurrentUTC()
longitude = coords['longitude']
latitude = coords['latitude']
TO_RAD = math.pi/180
#1. first calculate the day of the year
N1 = math.floor(275 * month / 9)
N2 = math.floor((month + 9) / 12)
N3 = (1 + math.floor((year - 4 * math.floor(year / 4) + 2) / 3))
N = N1 - (N2 * N3) + day - 30
#2. convert the longitude to hour value and calculate an approximate time
lngHour = longitude / 15
if isRiseTime:
t = N + ((6 - lngHour) / 24)
else: #sunset
t = N + ((18 - lngHour) / 24)
#3. calculate the Sun's mean anomaly
M = (0.9856 * t) - 3.289
#4. calculate the Sun's true longitude
L = M + (1.916 * math.sin(TO_RAD*M)) + (0.020 * math.sin(TO_RAD * 2 * M)) + 282.634
L = self.forceRange( L, 360 ) #NOTE: L adjusted into the range [0,360)
#5a. calculate the Sun's right ascension
RA = (1/TO_RAD) * math.atan(0.91764 * math.tan(TO_RAD*L))
RA = self.forceRange( RA, 360 ) #NOTE: RA adjusted into the range [0,360)
#5b. right ascension value needs to be in the same quadrant as L
Lquadrant = (math.floor( L/90)) * 90
RAquadrant = (math.floor(RA/90)) * 90
RA = RA + (Lquadrant - RAquadrant)
#5c. right ascension value needs to be converted into hours
RA = RA / 15
#6. calculate the Sun's declination
sinDec = 0.39782 * math.sin(TO_RAD*L)
cosDec = math.cos(math.asin(sinDec))
#7a. calculate the Sun's local hour angle
cosH = (math.cos(TO_RAD*zenith) - (sinDec * math.sin(TO_RAD*latitude))) / (cosDec * math.cos(TO_RAD*latitude))
if cosH > 1:
return {'status': False, 'msg': 'the sun never rises on this location (on the specified date)'}
if cosH < -1:
return {'status': False, 'msg': 'the sun never sets on this location (on the specified date)'}
#7b. finish calculating H and convert into hours
if isRiseTime:
H = 360 - (1/TO_RAD) * math.acos(cosH)
else: #setting
H = (1/TO_RAD) * math.acos(cosH)
H = H / 15
#8. calculate local mean time of rising/setting
T = H + RA - (0.06571 * t) - 6.622
#9. adjust back to UTC
UT = T - lngHour
UT = self.forceRange( UT, 24) # UTC time in decimal format (e.g. 23.23)
#10. Return
hr = self.forceRange(int(UT), 24)
min = round((UT - int(UT))*60,0)
return {
'status': True,
'decimal': UT,
'hr': hr,
'min': min
}
def forceRange(self, v, max):
# force v to be >= 0 and < max
if v < 0:
return v + max
elif v >= max:
return v - max
return v
'''
# example:
if __name__ == "__main__":
srs = Sunriseset("2018-01-01")
print(srs(0, 50))
''' | scigeo | /scigeo-0.0.10.tar.gz/scigeo-0.0.10/scigeo-history-versions/scigeo-0.0.2/sun.py | sun.py | import math
import datetime
class Sunriseset:
def __init__(self, timestamp = None, format = r"%Y-%m-%d"):
if isinstance(timestamp, str):
timestamp = datetime.datetime.strptime(timestamp, format)
self.timestamp = timestamp
def __call__(self, lon, lat):
coords = {'longitude' : lon, 'latitude' : lat}
# Sunrise time UTC (decimal, 24 hour format)
sunrise = self.getSunriseTime(coords)['decimal']
# Sunset time UTC (decimal, 24 hour format)
sunset = self.getSunsetTime(coords)['decimal']
return {
"sunrise": sunrise,
"sunset": sunset
}
def getSunriseTime(self, coords):
return self.calcSunTime(coords, True)
def getSunsetTime(self, coords):
return self.calcSunTime(coords, False)
def getCurrentUTC(self):
now = datetime.datetime.now()
return [now.day, now.month, now.year]
def calcSunTime(self, coords, isRiseTime, zenith = 90.8):
# isRiseTime == False, returns sunsetTime
if self.timestamp:
timestamp = self.timestamp
try:
day, month, year = [timestamp.day, timestamp.month, timestamp.year]
except:
day, month, year = timestamp
# else:
# raise Exception("Wrong input time format...")
else:
print("Use current time...")
day, month, year = self.getCurrentUTC()
longitude = coords['longitude']
latitude = coords['latitude']
TO_RAD = math.pi/180
#1. first calculate the day of the year
N1 = math.floor(275 * month / 9)
N2 = math.floor((month + 9) / 12)
N3 = (1 + math.floor((year - 4 * math.floor(year / 4) + 2) / 3))
N = N1 - (N2 * N3) + day - 30
#2. convert the longitude to hour value and calculate an approximate time
lngHour = longitude / 15
if isRiseTime:
t = N + ((6 - lngHour) / 24)
else: #sunset
t = N + ((18 - lngHour) / 24)
#3. calculate the Sun's mean anomaly
M = (0.9856 * t) - 3.289
#4. calculate the Sun's true longitude
L = M + (1.916 * math.sin(TO_RAD*M)) + (0.020 * math.sin(TO_RAD * 2 * M)) + 282.634
L = self.forceRange( L, 360 ) #NOTE: L adjusted into the range [0,360)
#5a. calculate the Sun's right ascension
RA = (1/TO_RAD) * math.atan(0.91764 * math.tan(TO_RAD*L))
RA = self.forceRange( RA, 360 ) #NOTE: RA adjusted into the range [0,360)
#5b. right ascension value needs to be in the same quadrant as L
Lquadrant = (math.floor( L/90)) * 90
RAquadrant = (math.floor(RA/90)) * 90
RA = RA + (Lquadrant - RAquadrant)
#5c. right ascension value needs to be converted into hours
RA = RA / 15
#6. calculate the Sun's declination
sinDec = 0.39782 * math.sin(TO_RAD*L)
cosDec = math.cos(math.asin(sinDec))
#7a. calculate the Sun's local hour angle
cosH = (math.cos(TO_RAD*zenith) - (sinDec * math.sin(TO_RAD*latitude))) / (cosDec * math.cos(TO_RAD*latitude))
if cosH > 1:
return {'status': False, 'msg': 'the sun never rises on this location (on the specified date)'}
if cosH < -1:
return {'status': False, 'msg': 'the sun never sets on this location (on the specified date)'}
#7b. finish calculating H and convert into hours
if isRiseTime:
H = 360 - (1/TO_RAD) * math.acos(cosH)
else: #setting
H = (1/TO_RAD) * math.acos(cosH)
H = H / 15
#8. calculate local mean time of rising/setting
T = H + RA - (0.06571 * t) - 6.622
#9. adjust back to UTC
UT = T - lngHour
UT = self.forceRange( UT, 24) # UTC time in decimal format (e.g. 23.23)
#10. Return
hr = self.forceRange(int(UT), 24)
min = round((UT - int(UT))*60,0)
return {
'status': True,
'decimal': UT,
'hr': hr,
'min': min
}
def forceRange(self, v, max):
# force v to be >= 0 and < max
if v < 0:
return v + max
elif v >= max:
return v - max
return v
'''
# example:
if __name__ == "__main__":
srs = Sunriseset("2018-01-01")
print(srs(0, 50))
''' | 0.596551 | 0.399812 |
from pathlib import Path
from shapely.geometry import Polygon
import rasterio as rio
from rasterio.mask import mask
from rasterio.enums import Resampling
import geopandas as gpd
import warnings
import numpy as np
class Raster(object):
"""
the wrapper of rasterio
"""
def __init__(self, path):
super() # or: super(Raster, self).__init__()
self.path = path
def __del__(self):
if hasattr(self, "src"):
self.src.closed
def read(self):
warnings.filterwarnings("ignore")
with rio.open(self.path) as src:
array = src.read()
profile = src.profile
return {"array": array, "meta": profile}
def fopen(self, src_only = True):
"""
c, a, b, f, d, e = src.transform
gt = rasterio.transform.Affine.from_gdal(c, a, b, f, d, e)
proj = src.crs
count = src.count
name = src.name
mode = src.mode
closed = src.closed
width = src.width
height = src.height
bounds = src.bounds
idtypes = {i: dtype for i, dtype in zip(
src.indexes, src.dtypes)}
meta = src.meta
src = src.affine
"""
self.src = rio.open(self.path)
if not src_only:
self.data = self.src.read()
self.profile = self.src.profile
def write(self, array, fulloutpath, profile, dtype = rio.float64):
count=profile["count"]
# bug fix, can't write a 3D array having a shape like (1, *, *)
if array.ndim == 3 and array.shape[0] == 1:
array = array[0, :, :]
profile.update(dtype = dtype, count = count, compress='lzw')
with rio.open(fulloutpath, 'w', **profile) as dst:
dst.write(array.astype(dtype), count)
def clip(self, polygon):
self.clip_arr, self.clip_transform = mask(self.src, polygon, crop=True)
def resampling(self, new_shape):
"""
new_shape format: height, width, count in order
Resample: default Resampling.bilinear, other choice includes Resampling.average
"""
height, width, count = new_shape
resampled_data = self.src.read(
out_shape = (height, width, count),
resampling = Resampling.bilinear
)
return resampled_data
def get_pntpairs(self, **kwargs):
# compatible with affine format, rather than geotransform
if not kwargs:
# print("Inside data")
affine = self.profile["transform"]
cols = self.profile["width"]
rows = self.profile["height"]
data = self.data.ravel()
else:
# print("Outside data")
# NOTICE: try to transform the geotransform to affine.
affine = kwargs["affine"]
# NOTICE: the first dimension of rasterio array is band.
cols = kwargs["data"].shape[2]
rows = kwargs["data"].shape[1]
data = kwargs["data"].ravel()
# print(affine)
# print(profile)
lats = [idx * affine[4] + affine[5] for idx in range(rows)]
lons = [idx * affine[0] + affine[2] for idx in range(cols)]
lons, lats = np.meshgrid(lons, lats)
pntpairs = np.vstack([lons.ravel(), lats.ravel()]).T
return pntpairs, data
class Vector(object):
"""docstring for Vector"""
def __init__(self, **kwargs):
super(Vector, self).__init__()
if "path" in kwargs.keys():
vector_path = kwargs["path"]
try:
self.path = vector_path.as_posix()
except Exception as e:
print(e)
self.path = vector_path
def __del__(self):
pass
def read(self):
gdf = gpd.read_file(self.path)
return gdf
def write(self, gpd, fulloutpath):
# filetype = fulloutpath.split('.')[-1]
gpd.to_file(fulloutpath)
def create_polygon(self, coors, epsg_code = "4326"):
polygon_geom = Polygon(coors)
crs = {"init": "epsg:" + epsg_code}
poly = gpd.GeoDataFrame(index=[0], crs=crs, geometry=[polygon_geom]) # gdf
# gjs = poly.to_json()
return poly | scigeo | /scigeo-0.0.10.tar.gz/scigeo-0.0.10/scigeo-history-versions/scigeo-0.0.2/geoface.py | geoface.py |
from pathlib import Path
from shapely.geometry import Polygon
import rasterio as rio
from rasterio.mask import mask
from rasterio.enums import Resampling
import geopandas as gpd
import warnings
import numpy as np
class Raster(object):
"""
the wrapper of rasterio
"""
def __init__(self, path):
super() # or: super(Raster, self).__init__()
self.path = path
def __del__(self):
if hasattr(self, "src"):
self.src.closed
def read(self):
warnings.filterwarnings("ignore")
with rio.open(self.path) as src:
array = src.read()
profile = src.profile
return {"array": array, "meta": profile}
def fopen(self, src_only = True):
"""
c, a, b, f, d, e = src.transform
gt = rasterio.transform.Affine.from_gdal(c, a, b, f, d, e)
proj = src.crs
count = src.count
name = src.name
mode = src.mode
closed = src.closed
width = src.width
height = src.height
bounds = src.bounds
idtypes = {i: dtype for i, dtype in zip(
src.indexes, src.dtypes)}
meta = src.meta
src = src.affine
"""
self.src = rio.open(self.path)
if not src_only:
self.data = self.src.read()
self.profile = self.src.profile
def write(self, array, fulloutpath, profile, dtype = rio.float64):
count=profile["count"]
# bug fix, can't write a 3D array having a shape like (1, *, *)
if array.ndim == 3 and array.shape[0] == 1:
array = array[0, :, :]
profile.update(dtype = dtype, count = count, compress='lzw')
with rio.open(fulloutpath, 'w', **profile) as dst:
dst.write(array.astype(dtype), count)
def clip(self, polygon):
self.clip_arr, self.clip_transform = mask(self.src, polygon, crop=True)
def resampling(self, new_shape):
"""
new_shape format: height, width, count in order
Resample: default Resampling.bilinear, other choice includes Resampling.average
"""
height, width, count = new_shape
resampled_data = self.src.read(
out_shape = (height, width, count),
resampling = Resampling.bilinear
)
return resampled_data
def get_pntpairs(self, **kwargs):
# compatible with affine format, rather than geotransform
if not kwargs:
# print("Inside data")
affine = self.profile["transform"]
cols = self.profile["width"]
rows = self.profile["height"]
data = self.data.ravel()
else:
# print("Outside data")
# NOTICE: try to transform the geotransform to affine.
affine = kwargs["affine"]
# NOTICE: the first dimension of rasterio array is band.
cols = kwargs["data"].shape[2]
rows = kwargs["data"].shape[1]
data = kwargs["data"].ravel()
# print(affine)
# print(profile)
lats = [idx * affine[4] + affine[5] for idx in range(rows)]
lons = [idx * affine[0] + affine[2] for idx in range(cols)]
lons, lats = np.meshgrid(lons, lats)
pntpairs = np.vstack([lons.ravel(), lats.ravel()]).T
return pntpairs, data
class Vector(object):
"""docstring for Vector"""
def __init__(self, **kwargs):
super(Vector, self).__init__()
if "path" in kwargs.keys():
vector_path = kwargs["path"]
try:
self.path = vector_path.as_posix()
except Exception as e:
print(e)
self.path = vector_path
def __del__(self):
pass
def read(self):
gdf = gpd.read_file(self.path)
return gdf
def write(self, gpd, fulloutpath):
# filetype = fulloutpath.split('.')[-1]
gpd.to_file(fulloutpath)
def create_polygon(self, coors, epsg_code = "4326"):
polygon_geom = Polygon(coors)
crs = {"init": "epsg:" + epsg_code}
poly = gpd.GeoDataFrame(index=[0], crs=crs, geometry=[polygon_geom]) # gdf
# gjs = poly.to_json()
return poly | 0.643553 | 0.396594 |
**Status:** Development (expect bug fixes, minor updates and new
environments)
<a href="https://unitary.fund/">
<img src="https://img.shields.io/badge/Supported%20By-UNITARY%20FUND-brightgreen.svg?style=for-the-badge"
/>
</a>
# SciGym
<a href="https://www.scigym.net">
<img src="https://raw.githubusercontent.com/HendrikPN/scigym/master/assets/scigym-logo.png" width="120px" align="bottom"
/>
</a>
**SciGym is a curated library for reinforcement learning environments in science.**
This is the `scigym` open-source library which gives you access to a standardized set of science environments.
Visit our webpage at [scigym.ai]. This website serves as a open-source database for science environments: A port where science and reinforcement learning meet.
<a href="https://travis-ci.org/HendrikPN/scigym">
<img src="https://travis-ci.org/HendrikPN/scigym.svg?branch=master" align="bottom"
/>
</a>
[See What's New section below](#whats-new)
## Basics
This project is in line with the policies of the [OpenAI gym]:
There are two basic concepts in reinforcement learning: the environment
(namely, the outside world) and the agent (namely, the algorithm you are
writing). The agent sends `actions` to the environment, and
the environment replies with `observations` and
`rewards` (that is, a score).
The core `gym` interface is [Env], which is the unified
environment interface. There is no interface for agents; that part is
left to you. The following are the `Env` methods you should know:
* `reset(self)`: Reset the environment's state. Returns `observation`.
* `step(self, action)`: Step the environment by one timestep. Returns `observation`, `reward`, `done`, `info`.
* `render(self, mode='human', close=False)`: Render one frame of the environment. The default mode will do something human friendly, such as pop up a window. Passing the `close` flag signals the renderer to close any such windows.
## Installation
There are two main options for the installation of `scigym`:
#### (a) minimal install (recommended)
This method allows you to install the package with no environment specific dependencies, and later add the dependencies for specific environments as you need them.
You can perform a minimal install of `scigym` with:
```sh
pip install scigym
```
or
```sh
git clone https://github.com/hendrikpn/scigym.git
cd scigym
pip install -e .
```
To later add the dependencies for a particular `environment_name`, run the following command:
```sh
pip install scigym[environment_name]
```
or from the folder containing `setup.py`
```sh
pip install -e .[environment_name]
```
#### (b) full install
This method allows you to install the package, along with all dependencies required for all environments. Be careful, scigym is growing, and this method may install a large number of packages. To view all packages that will be installed during a full install, see the `requirements.txt` file in the root directory. If you wish to perform a full installation you can run:
```sh
pip install scigym['all']
```
or
```sh
git clone https://github.com/hendrikpn/scigym.git
cd scigym
pip install -e .['all']
```
## Available Environments
At this point we have the following environments available for you to play with:
- [`teleportation`](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_computing/teleportation)
- [`entangled-ions`](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_information/entangled_ions)
## What's New
- 2021-06-16 Added the [Toric Game](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_computing/toricgame) environment
- 2021-06-09 Added [entangled-ions](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_information/entangled_ions) environment.
- 2021-06-08 This is `scigym` version 0.0.3! Now compatible with gym version 0.18.0
- 2019-10-10 [scigym.ai] is online!
- 2019-08-30 This is `scigym` version 0.0.2!
- 2019-08-30 `scigym` is now available as a package on [PyPI](https://pypi.org/project/scigym/).
- 2019-08-06 Added [Travis-CI](https://travis-ci.org/HendrikPN/scigym).
- 2019-08-06: Added [teleportation](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_computing/teleportation) environment.
- 2019-07-21: Added standardized unit testing for all scigym environments.
- 2019-03-04: Added <a href="https://github.com/R-Sweke/gym-surfacecode">surfacecode</a> environment.
- 2019-02-09: Initial commit. Hello world :)
[image]: https://img.shields.io/badge/Supported%20By-UNITARY%20FUND-brightgreen.svg?style=for-the-badge
[OpenAI gym]: https://github.com/openai/gym
[scigym.ai]: https://www.scigym.net
[Env]: https://github.com/openai/gym/blob/master/gym/core.py
| scigym | /scigym-0.0.3.tar.gz/scigym-0.0.3/README.md | README.md | **Status:** Development (expect bug fixes, minor updates and new
environments)
<a href="https://unitary.fund/">
<img src="https://img.shields.io/badge/Supported%20By-UNITARY%20FUND-brightgreen.svg?style=for-the-badge"
/>
</a>
# SciGym
<a href="https://www.scigym.net">
<img src="https://raw.githubusercontent.com/HendrikPN/scigym/master/assets/scigym-logo.png" width="120px" align="bottom"
/>
</a>
**SciGym is a curated library for reinforcement learning environments in science.**
This is the `scigym` open-source library which gives you access to a standardized set of science environments.
Visit our webpage at [scigym.ai]. This website serves as a open-source database for science environments: A port where science and reinforcement learning meet.
<a href="https://travis-ci.org/HendrikPN/scigym">
<img src="https://travis-ci.org/HendrikPN/scigym.svg?branch=master" align="bottom"
/>
</a>
[See What's New section below](#whats-new)
## Basics
This project is in line with the policies of the [OpenAI gym]:
There are two basic concepts in reinforcement learning: the environment
(namely, the outside world) and the agent (namely, the algorithm you are
writing). The agent sends `actions` to the environment, and
the environment replies with `observations` and
`rewards` (that is, a score).
The core `gym` interface is [Env], which is the unified
environment interface. There is no interface for agents; that part is
left to you. The following are the `Env` methods you should know:
* `reset(self)`: Reset the environment's state. Returns `observation`.
* `step(self, action)`: Step the environment by one timestep. Returns `observation`, `reward`, `done`, `info`.
* `render(self, mode='human', close=False)`: Render one frame of the environment. The default mode will do something human friendly, such as pop up a window. Passing the `close` flag signals the renderer to close any such windows.
## Installation
There are two main options for the installation of `scigym`:
#### (a) minimal install (recommended)
This method allows you to install the package with no environment specific dependencies, and later add the dependencies for specific environments as you need them.
You can perform a minimal install of `scigym` with:
```sh
pip install scigym
```
or
```sh
git clone https://github.com/hendrikpn/scigym.git
cd scigym
pip install -e .
```
To later add the dependencies for a particular `environment_name`, run the following command:
```sh
pip install scigym[environment_name]
```
or from the folder containing `setup.py`
```sh
pip install -e .[environment_name]
```
#### (b) full install
This method allows you to install the package, along with all dependencies required for all environments. Be careful, scigym is growing, and this method may install a large number of packages. To view all packages that will be installed during a full install, see the `requirements.txt` file in the root directory. If you wish to perform a full installation you can run:
```sh
pip install scigym['all']
```
or
```sh
git clone https://github.com/hendrikpn/scigym.git
cd scigym
pip install -e .['all']
```
## Available Environments
At this point we have the following environments available for you to play with:
- [`teleportation`](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_computing/teleportation)
- [`entangled-ions`](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_information/entangled_ions)
## What's New
- 2021-06-16 Added the [Toric Game](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_computing/toricgame) environment
- 2021-06-09 Added [entangled-ions](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_information/entangled_ions) environment.
- 2021-06-08 This is `scigym` version 0.0.3! Now compatible with gym version 0.18.0
- 2019-10-10 [scigym.ai] is online!
- 2019-08-30 This is `scigym` version 0.0.2!
- 2019-08-30 `scigym` is now available as a package on [PyPI](https://pypi.org/project/scigym/).
- 2019-08-06 Added [Travis-CI](https://travis-ci.org/HendrikPN/scigym).
- 2019-08-06: Added [teleportation](https://github.com/HendrikPN/scigym/tree/master/scigym/envs/quantum_physics/quantum_computing/teleportation) environment.
- 2019-07-21: Added standardized unit testing for all scigym environments.
- 2019-03-04: Added <a href="https://github.com/R-Sweke/gym-surfacecode">surfacecode</a> environment.
- 2019-02-09: Initial commit. Hello world :)
[image]: https://img.shields.io/badge/Supported%20By-UNITARY%20FUND-brightgreen.svg?style=for-the-badge
[OpenAI gym]: https://github.com/openai/gym
[scigym.ai]: https://www.scigym.net
[Env]: https://github.com/openai/gym/blob/master/gym/core.py
| 0.88457 | 0.950411 |
SciHub Downloader
----------------------------------------------------
更新日志:
**2020-05-28补充**:已用最新的scihub提取网,目前项目可用,感谢@lisenjor的分享。
**2020-06-25补充**:增加关键词搜索,批量下载论文功能。
**2021-01-07补充**:增加异步下载方式,加快下载速度;加强下载稳定性,不再出现文件损坏的情况。
**2021-04-08补充**:由于sciencedirect增加了机器人检验,现在搜索下载功能需要先在HEADERS中填入Cookie才可爬取,详见第4步。
**2021-04-25补充**:搜索下载增加百度学术、publons渠道。
**2021-12-31补充**:大更新,支持使用命令行下载。感谢@hulei6188的贡献。
**2022-09-22补充**:优化下载方式,适配最新版scihub.
使用doi,论文标题,或者bibtex文件批量下载论文。
支持Python3.6及以上版本。
安装:
```
pip install scihub-cn
```
使用方法如下:
1.给出bibtex文件
```
$scihub-cn -i input.bib --bib
```
2.给出论文doi名称
```
$scihub-cn -d 10.1038/s41524-017-0032-0
```
3.给出论文url
```
$scihub-cn -u https://ieeexplore.ieee.org/document/9429985
```
4.给出论文关键字(关键字之间用_链接,如machine_learning)
```
$scihub-cn -w word1_words2_words3
```
5.给出论文doi的txt文本文件,比如
```
10.1038/s41524-017-0032-0
10.1063/1.3149495
```
```
$scihub-cn -i dois.txt --doi
```
6.给出所有论文名称的txt文本文件
```
Some Title 1
Some Title 2
```
```
$scihub-cn -i titles.txt --title
```
7.给出所有论文url的txt文件
```
url 1
url 2
```
```
$scihub-cn -i urls.txt --url
```
你可以在末尾添加-p(--proxy),-o(--output),-e(--engine),-l(--limit)来指定代理,输出文件夹、搜索引擎以及限制的搜索的条目数
搜索引擎包括 google_scholar、baidu_xueshu、publons、以及science_direct
======================================================================================================================
下面是旧版说明:
文献搜索对于广大学子来说真的是个麻烦事,如果你的学校购买的论文下载权限不够多,或者你不在校园网覆盖的范围内,想必会令你非常头痛。
幸好,我们有Python制作的这个论文搜索工具,简化了我们学习的复杂性
本文完整源代码可在 GitHub 找到:
https://github.com/Ckend/scihub-cn
**1\. 什么是Scihub**
-----------------
首先给大家介绍一下Sci-hub这个线上数据库,这个数据库提供了约8千万篇科学学术论文和文章下载。由一名叫亚历珊卓·艾尔巴金的研究生建立,她过去在哈佛大学从事研究时发现支付所需要的数百篇论文的费用实在是太高了,因此就萌生了创建这个网站,让更多人获得知识的想法

后来,这个网站越来越出名,逐渐地在更多地国家如印度、印度尼西亚、中国、俄罗斯等国家盛行,并成功地和一些组织合作,共同维护和运营这个网站。到了2017年的时候,网站上已有81600000篇学术论文,占到了所有学术论文的69%,基本满足大部分论文的需求,而剩下的31%是研究者不想获取的论文。
**2\. 为什么我们需要用Python工具下载**
--------------------------
在起初,这个网站是所有人都能够访问的,但是随着其知名度的提升,越来越多的出版社盯上了他们,在2015年时被美国法院封禁后其在美国的服务器便无法被继续访问,因此从那个时候开始,他们就跟出版社们打起了游击战
游击战的缺点就是导致scihub的地址需要经常更换,所以我们没办法准确地一直使用某一个地址访问这个数据库。当然也有一些别的方法可让我们长时间访问这个网站,比如说修改DNS,修改hosts文件,不过这些方法不仅麻烦,而且也不是长久之计,还是存在失效的可能的。
**3\. 新姿势:****用Python写好的API工具超方便下载论文**
这是一个来自github的开源非官方API工具,下载地址为:
https://github.com/zaytoun/scihub.py
但由于作者长久不更新,原始的下载工具已经无法使用,Python实用宝典修改了作者的源代码,适配了中文环境的下载器,并添加了异步批量下载等方法:
https://github.com/Ckend/scihub-cn
欢迎给我一个Star,鼓励我继续维护这个仓库。如果你访问不了GitHub,请在 Python实用宝典 公众号后台回复 **scihub**,下载最新可用代码。
解压下载的压缩包后,使用CMD/Terminal进入这个文件夹,输入以下命令(默认你已经安装好了Python)安装依赖:
```
pip install -r requirements.txt
```
然后我们就可以准备开始使用啦!
### 1.ieee文章 ❌
这个工具使用起来非常简单,有两种方式,第一种方式你可以先在 Google 学术(搜索到论文的网址即可)或ieee上找到你需要的论文,复制论文网址如:
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1648853
然后在scihub-cn文件夹里新建一个文件叫 my\_test.py 输入以下代码:
```python
from scihub import SciHub
sh = SciHub()
# 第一个参数输入论文的网站地址
# path: 文件保存路径
result = sh.download('https://ieeexplore.ieee.org/document/26502', path='paper.pdf')
```
进入该文件夹后在cmd/terminal中运行:
```shell script
python my_test.py
```
你就会发现文件成功下载到你的当前目录啦,名字为paper.pdf如果不行,有可能是网络问题,多试几次。实在不行可以在下方留言区询问哦。
上述是第一种下载方式,第二种方式你可以通过在知网或者百度学术上搜索论文拿到DOI号进行下载,比如:
### 2.提供`doi`号填入download函数中✅
```python
from scihub_cn.scihub import SciHub
sh = SciHub()
# 设置is_translate_title可将paper's title进行翻译后下载存储
result = sh.download({"doi": '10.1109/ACC.1999.786344'}, is_translate_title=True)
```
下载完成后就会在文件夹中出现该文献:
### 3.提供`scihub_url`链接填入download函数中✅
```python
from scihub import SciHub
sh = SciHub()
# 设置is_translate_title可将paper's title进行翻译后下载存储
result = sh.download(
info={
'scihub_url': "https://sci-hub.se/10.1016/j.apsb.2021.06.014"
}, is_translate_title=True
)
print(f"论文信息: {result}")
```
注:如果下载比较慢,则可以使用代理,操作如下所示:
1. 使用http代理
```python
from scihub import SciHub
https_proxy = "http://10.10.1.10:1080"
sh = SciHub(proxy=https_proxy)
result = sh.download({"doi": '10.1109/ACC.1999.786344'}, is_translate_title=True)
print(f"论文下载: {result}")
assert type(result) is PaperInfo
```
2. 使用sock代理
> 安装`pip install requests[socks]`
```python
from scihub import SciHub
sock_proxy = "socks5h://127.0.0.1:10808"
sh = SciHub(proxy=sock_proxy)
result = sh.download({"doi": '10.1109/ACC.1999.786344'}, is_translate_title=True)
print(f"论文下载: {result}")
assert type(result) is PaperInfo
```
通过设置`https_proxy`即可使用代理,所用的端口号可以通过代理软件自行设置。
除了这种最简单的方式,我们还提供了 **论文关键词搜索批量下载** 及 **论文关键词批量异步下载** 两种高级的下载方法。
我们在下文将会详细地讲解这两种方法的使用,大家可以看项目内的 **`test.py`** 文件,你可以了解到论文搜索批量下载的方法。
进一步的高级方法在**`download.py`** 中可以找到,它可以实现论文搜索批量异步下载,大大加快下载速度。具体实现请看后文。
**4\. 基于关键词的论文批量下载**
--------------------
支持使用搜索的形式批量下载论文,比如说搜索关键词 端午节(Dragon Boat Festival):
```python
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "Dragon Boat Festival"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")
```
**默认会使用百度学术进行论文搜索,拿到DOI号后再通过scihub下载,运行成功:**
**2021-04-25 更新:**
由于读者们觉得Sciencedirect的搜索实在太难用了,加上Sciencedirect现在必须要使用Cookie才能正常下载,因此我新增了百度学术和publons这2个检索渠道。
由于 Web of Science 有权限限制,很遗憾我们无法直接使用它来检索,不过百度学术作为一个替代方案也是非常不错的。
现在默认的 **`search`** 函数调用了百度学术的接口进行搜索,大家不需要配置任何东西,只需要拉一下最新的代码,使用上述例子中的代码就可以正常搜索下载论文。
其他两个渠道的使用方式如下:
**sciencedirect渠道:**
由于 sciencedirect 加强了他们的爬虫防护能力,增加了机器人校验机制,所以现在必须在HEADER中填入Cookie才能进行爬取。
操作如下:
**1.获取Cookie**
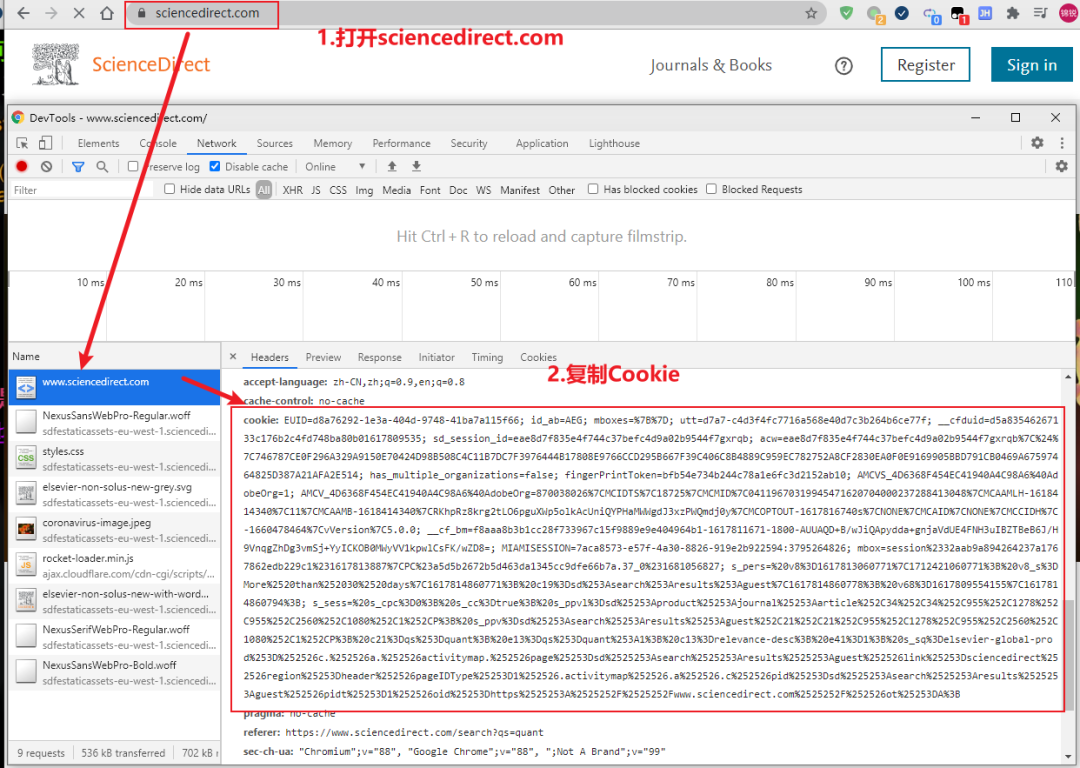
**2.使用sciencedirect搜索时**,需要用 **`search_by_science_direct`** 函数,并将cookie作为参数之一传入:
```python
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "Dragon Boat Festival"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search_by_science_direct(keywords, cookie="你的cookie", limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")
```
这样大概率就能顺利通过sciencedirect搜索并下载文献了。
**publons渠道:**
其实有了百度学术的默认渠道,大部分文献我们都能覆盖到了。但是考虑到publons的特殊性,这里还是给大家一个通过publons渠道搜索下载的选项。
使用publons渠道搜索下载其实很简单,你只需要更改搜索的函数名即可,不需要配置Cookie:
```python
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "Dragon Boat Festival"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search_by_publons(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")
```
**5\. 异步下载优化,增加超时控制**
---------------------
这个开源代码库已经运行了几个月,经常有同学反馈搜索论文后下载论文的速度过慢、下载的文件损坏的问题,这几天刚好有时间一起解决了。
下载速度过慢是因为之前的版本使用了串行的方式去获取数据和保存文件,事实上对于这种IO密集型的操作,最高效的方式是用 asyncio 异步的形式去进行文件的下载。
而下载的文件损坏则是因为下载时间过长,触发了超时限制,导致文件传输过程直接被腰斩了。
因此,我们将在原有代码的基础上添加两个方法:1.异步请求下载链接,2.异步保存文件。
此外增加一个错误提示:如果下载超时了,提示用户下载超时并不保存损坏的文件,用户可自行选择调高超时限制。
首先,新增异步获取scihub直链的方法,改为异步获取相关论文的scihub直链:
```python
async def async_get_direct_url(self, identifier):
"""
异步获取scihub直链
"""
async with aiohttp.ClientSession() as sess:
async with sess.get(self.base_url + identifier) as res:
logger.info(f"Fetching {self.base_url + identifier}...")
# await 等待任务完成
html = await res.text(encoding='utf-8')
s = self._get_soup(html)
iframe = s.find('iframe')
if iframe:
return iframe.get('src') if not iframe.get('src').startswith('//') \
else 'http:' + iframe.get('src')
else:
return None
```
这样,在搜索论文后,调用该接口就能获取所有需要下载的scihub直链,速度很快:
```python
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["doi"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
```
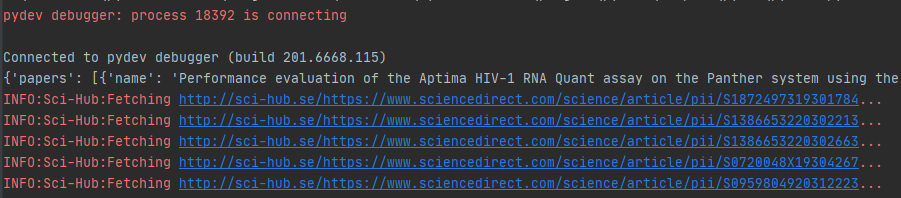
获取直链后,需要下载论文,同样也是IO密集型操作,增加2个异步函数:
```python
async def job(self, session, url, destination='', path=None):
"""
异步下载文件
"""
if not url:
return
file_name = url.split("/")[-1].split("#")[0]
logger.info(f"正在读取并写入 {file_name} 中...")
# 异步读取内容
try:
url_handler = await session.get(url)
content = await url_handler.read()
except Exception as e:
logger.error(f"获取源文件出错: {e},大概率是下载超时,请检查")
return str(url)
with open(os.path.join(destination, path + file_name), 'wb') as f:
# 写入至文件
f.write(content)
return str(url)
async def async_download(self, loop, urls, destination='', path=None):
"""
触发异步下载任务
如果你要增加超时时间,请修改 total=300
"""
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=300)) as session:
# 建立会话session
tasks = [loop.create_task(self.job(session, url, destination, path)) for url in urls]
# 建立所有任务
finished, unfinished = await asyncio.wait(tasks)
# 触发await,等待任务完成
[r.result() for r in finished]
```
最后,在search函数中补充下载操作:
```python
import asyncio
from scihub import SciHub
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["doi"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=f"scihub_cn/files/"))
loop.close()
if __name__ == '__main__':
search("quant", 10)
```
一个完整的下载过程就OK了:
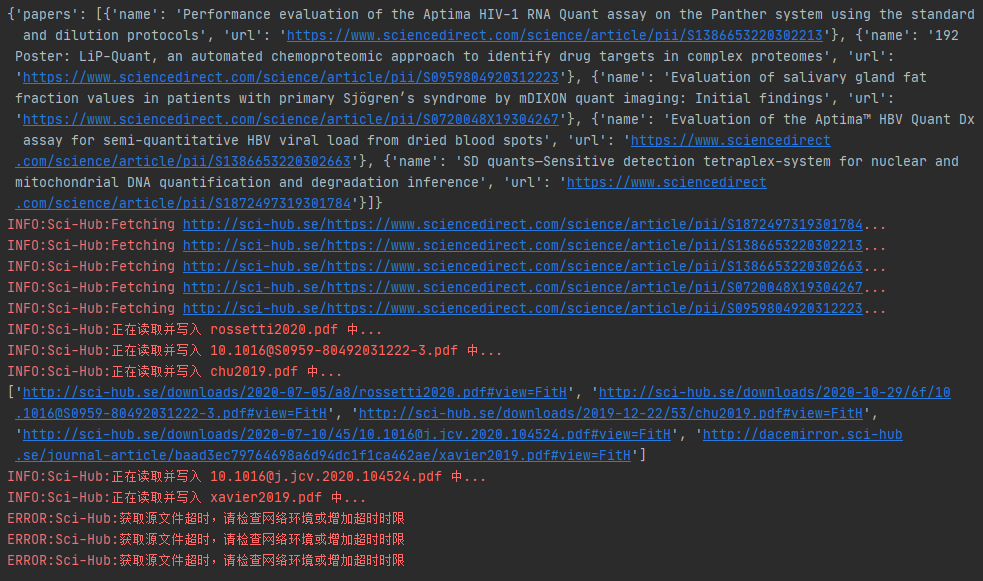
比以前的方式舒服太多太多了... 如果你要增加超时时间,请修改async\_download函数中的 total=300,把这个请求总时间调高即可。
最新代码前往GitHub上下载:
https://github.com/Ckend/scihub-cn
或者从Python实用宝典公众号后台回复 **scihub** 下载。
**6.根据DOI号下载文献**
最近有同学希望直接通过DOI号下载文献,因此补充了这部分内容。
```python
import asyncio
from scihub import SciHub
def fetch_by_doi(dois: list, path: str):
"""
根据 doi 获取文档
Args:
dois: 文献DOI号列表
path: 存储文件夹
"""
sh = SciHub()
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(doi) for doi in dois]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=path))
loop.close()
if __name__ == '__main__':
fetch_by_doi(["10.1088/1751-8113/42/50/504005"], f"files/")
```
默认存储到files文件夹中,你也可以根据自己的需求对代码进行修改。
**7.工作原理**
这个API的源代码其实非常好读懂
**7.1、找到sci-hub目前可用的域名**
首先它会在这个网址里找到sci-hub当前可用的域名,用于下载论文:
https://whereisscihub.now.sh/
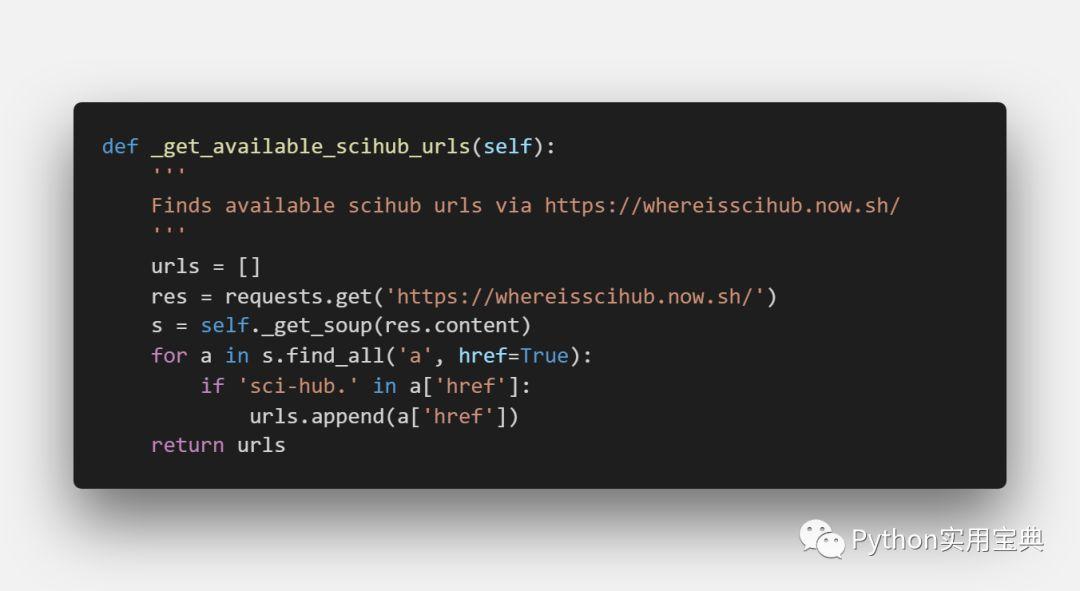
可惜的是,作者常年不维护,该地址已经失效了,我们就是在这里修改了该域名,使得项目得以重新正常运作:
### **7.2、对用户输入的论文地址进行解析,找到相应论文**
1\. 如果用户输入的链接不是直接能下载的,则使用sci-hub进行下载
2\. 如果scihub的网址无法使用则切换另一个网址使用,除非所有网址都无法使用。
3.值得注意的是,如果用户输入的是论文的关键词,我们将调用sciencedirect的接口,拿到论文地址,再使用scihub进行论文的下载。
### **7.3、下载**
1\. 拿到论文后,它保存到data变量中
2\. 然后将data变量存储为文件即可
此外,代码用到了一个retry装饰器,这个装饰器可以用来进行错误重试,作者设定了重试次数为10次,每次重试最大等待时间不超过1秒。
希望大家能妥善使用好此工具,不要批量下载,否则一旦网站被封,学生党们又要哭了。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:**加群**,回答相应**红字验证信息**,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
**点击下方阅读原文可获得更好的阅读体验**
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
 | scihub-cn | /scihub-cn-0.1.1.tar.gz/scihub-cn-0.1.1/README.md | README.md | pip install scihub-cn
$scihub-cn -i input.bib --bib
$scihub-cn -d 10.1038/s41524-017-0032-0
$scihub-cn -u https://ieeexplore.ieee.org/document/9429985
$scihub-cn -w word1_words2_words3
10.1038/s41524-017-0032-0
10.1063/1.3149495
$scihub-cn -i dois.txt --doi
Some Title 1
Some Title 2
$scihub-cn -i titles.txt --title
url 1
url 2
$scihub-cn -i urls.txt --url
pip install -r requirements.txt
from scihub import SciHub
sh = SciHub()
# 第一个参数输入论文的网站地址
# path: 文件保存路径
result = sh.download('https://ieeexplore.ieee.org/document/26502', path='paper.pdf')
你就会发现文件成功下载到你的当前目录啦,名字为paper.pdf如果不行,有可能是网络问题,多试几次。实在不行可以在下方留言区询问哦。
上述是第一种下载方式,第二种方式你可以通过在知网或者百度学术上搜索论文拿到DOI号进行下载,比如:

### 2.提供`doi`号填入download函数中✅
下载完成后就会在文件夹中出现该文献:

### 3.提供`scihub_url`链接填入download函数中✅
```python
from scihub import SciHub
sh = SciHub()
# 设置is_translate_title可将paper's title进行翻译后下载存储
result = sh.download(
info={
'scihub_url': "https://sci-hub.se/10.1016/j.apsb.2021.06.014"
}, is_translate_title=True
)
print(f"论文信息: {result}")
```
注:如果下载比较慢,则可以使用代理,操作如下所示:
1. 使用http代理
2. 使用sock代理
> 安装`pip install requests[socks]`
通过设置`https_proxy`即可使用代理,所用的端口号可以通过代理软件自行设置。
除了这种最简单的方式,我们还提供了 **论文关键词搜索批量下载** 及 **论文关键词批量异步下载** 两种高级的下载方法。
我们在下文将会详细地讲解这两种方法的使用,大家可以看项目内的 **`test.py`** 文件,你可以了解到论文搜索批量下载的方法。
进一步的高级方法在**`download.py`** 中可以找到,它可以实现论文搜索批量异步下载,大大加快下载速度。具体实现请看后文。
**4\. 基于关键词的论文批量下载**
--------------------
支持使用搜索的形式批量下载论文,比如说搜索关键词 端午节(Dragon Boat Festival):
**默认会使用百度学术进行论文搜索,拿到DOI号后再通过scihub下载,运行成功:**

**2021-04-25 更新:**
由于读者们觉得Sciencedirect的搜索实在太难用了,加上Sciencedirect现在必须要使用Cookie才能正常下载,因此我新增了百度学术和publons这2个检索渠道。
由于 Web of Science 有权限限制,很遗憾我们无法直接使用它来检索,不过百度学术作为一个替代方案也是非常不错的。
现在默认的 **`search`** 函数调用了百度学术的接口进行搜索,大家不需要配置任何东西,只需要拉一下最新的代码,使用上述例子中的代码就可以正常搜索下载论文。
其他两个渠道的使用方式如下:
**sciencedirect渠道:**
由于 sciencedirect 加强了他们的爬虫防护能力,增加了机器人校验机制,所以现在必须在HEADER中填入Cookie才能进行爬取。
操作如下:
**1.获取Cookie**

**2.使用sciencedirect搜索时**,需要用 **`search_by_science_direct`** 函数,并将cookie作为参数之一传入:
这样大概率就能顺利通过sciencedirect搜索并下载文献了。
**publons渠道:**
其实有了百度学术的默认渠道,大部分文献我们都能覆盖到了。但是考虑到publons的特殊性,这里还是给大家一个通过publons渠道搜索下载的选项。
使用publons渠道搜索下载其实很简单,你只需要更改搜索的函数名即可,不需要配置Cookie:
**5\. 异步下载优化,增加超时控制**
---------------------
这个开源代码库已经运行了几个月,经常有同学反馈搜索论文后下载论文的速度过慢、下载的文件损坏的问题,这几天刚好有时间一起解决了。
下载速度过慢是因为之前的版本使用了串行的方式去获取数据和保存文件,事实上对于这种IO密集型的操作,最高效的方式是用 asyncio 异步的形式去进行文件的下载。
而下载的文件损坏则是因为下载时间过长,触发了超时限制,导致文件传输过程直接被腰斩了。
因此,我们将在原有代码的基础上添加两个方法:1.异步请求下载链接,2.异步保存文件。
此外增加一个错误提示:如果下载超时了,提示用户下载超时并不保存损坏的文件,用户可自行选择调高超时限制。
首先,新增异步获取scihub直链的方法,改为异步获取相关论文的scihub直链:
这样,在搜索论文后,调用该接口就能获取所有需要下载的scihub直链,速度很快:

获取直链后,需要下载论文,同样也是IO密集型操作,增加2个异步函数:
最后,在search函数中补充下载操作:
一个完整的下载过程就OK了:

比以前的方式舒服太多太多了... 如果你要增加超时时间,请修改async\_download函数中的 total=300,把这个请求总时间调高即可。
最新代码前往GitHub上下载:
https://github.com/Ckend/scihub-cn
或者从Python实用宝典公众号后台回复 **scihub** 下载。
**6.根据DOI号下载文献**
最近有同学希望直接通过DOI号下载文献,因此补充了这部分内容。
| 0.276397 | 0.72054 |
import hashlib
import json
import random
import re
import time
from typing import Optional
import requests
from scihub_cn.models import PaperDetailDescription
def translate(content: str, proxy=None) -> str:
"""对文本content进行翻译"""
lts = str(int(time.time() * 1000))
salt = lts + str(random.randint(0, 9))
sign_str = 'fanyideskweb' + content + salt + 'Ygy_4c=r#e#4EX^NUGUc5'
m = hashlib.md5()
m.update(sign_str.encode())
sign = m.hexdigest()
url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
headers = {
"Referer": "https://fanyi.youdao.com/",
"Cookie": '[email protected]; JSESSIONID=aaamH0NjhkDAeAV9d28-x; OUTFOX_SEARCH_USER_ID_NCOO=1827884489.6445506; fanyi-ad-id=305426; fanyi-ad-closed=1; ___rl__test__cookies=1649216072438',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
data = {
"i": content,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"lts": lts,
"bv": "a0d7903aeead729d96af5ac89c04d48e",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
res = requests.post(url, headers=headers, data=data, proxies=proxy)
response = json.loads(res.text)
value = response['translateResult'][0][0]['tgt']
return value.replace(" ", "").replace("。", "")
def split_description(content: str) -> Optional[PaperDetailDescription]:
"""将抓取的转换成"""
# description: authors, title, publisher, doi
# test case1: {"doi": '10.1109/ACC.1999.786344'}, 无authors
# test case2: {"doi": "10.1016/j.biopha.2019.109317"} authors, title, publisher, doi齐全
pattern = re.compile(
r"^(?P<authors>(?:.*?, )+\w+\. \(\d+\)\. )?(?P<title>[A-Z].*?\. )(?P<publisher>[A-Z].*?\. )(?P<doi>(?:doi:|https:).*?)$")
res = re.search(pattern, content)
if res:
return PaperDetailDescription(
authors=res.group("authors"),
# 去掉末尾的字符
title=res.group("title").strip(". "),
publisher=res.group("publisher"),
doi=res.group("doi")
)
else:
return None
if __name__ == '__main__':
http_proxy = "socks5h://127.0.0.1:10808"
https_proxy = "socks5h://127.0.0.1:10808"
proxies = {
"https": https_proxy,
"http": http_proxy
}
translated_str = translate("你好", proxy=proxies)
print(translated_str) | scihub-cn | /scihub-cn-0.1.1.tar.gz/scihub-cn-0.1.1/scihub_cn/utils.py | utils.py | import hashlib
import json
import random
import re
import time
from typing import Optional
import requests
from scihub_cn.models import PaperDetailDescription
def translate(content: str, proxy=None) -> str:
"""对文本content进行翻译"""
lts = str(int(time.time() * 1000))
salt = lts + str(random.randint(0, 9))
sign_str = 'fanyideskweb' + content + salt + 'Ygy_4c=r#e#4EX^NUGUc5'
m = hashlib.md5()
m.update(sign_str.encode())
sign = m.hexdigest()
url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
headers = {
"Referer": "https://fanyi.youdao.com/",
"Cookie": '[email protected]; JSESSIONID=aaamH0NjhkDAeAV9d28-x; OUTFOX_SEARCH_USER_ID_NCOO=1827884489.6445506; fanyi-ad-id=305426; fanyi-ad-closed=1; ___rl__test__cookies=1649216072438',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
data = {
"i": content,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"lts": lts,
"bv": "a0d7903aeead729d96af5ac89c04d48e",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
res = requests.post(url, headers=headers, data=data, proxies=proxy)
response = json.loads(res.text)
value = response['translateResult'][0][0]['tgt']
return value.replace(" ", "").replace("。", "")
def split_description(content: str) -> Optional[PaperDetailDescription]:
"""将抓取的转换成"""
# description: authors, title, publisher, doi
# test case1: {"doi": '10.1109/ACC.1999.786344'}, 无authors
# test case2: {"doi": "10.1016/j.biopha.2019.109317"} authors, title, publisher, doi齐全
pattern = re.compile(
r"^(?P<authors>(?:.*?, )+\w+\. \(\d+\)\. )?(?P<title>[A-Z].*?\. )(?P<publisher>[A-Z].*?\. )(?P<doi>(?:doi:|https:).*?)$")
res = re.search(pattern, content)
if res:
return PaperDetailDescription(
authors=res.group("authors"),
# 去掉末尾的字符
title=res.group("title").strip(". "),
publisher=res.group("publisher"),
doi=res.group("doi")
)
else:
return None
if __name__ == '__main__':
http_proxy = "socks5h://127.0.0.1:10808"
https_proxy = "socks5h://127.0.0.1:10808"
proxies = {
"https": https_proxy,
"http": http_proxy
}
translated_str = translate("你好", proxy=proxies)
print(translated_str) | 0.545528 | 0.162945 |
from dataclasses import dataclass
from enum import Enum
@dataclass
class PaperInfo:
url: str
title: str
doi: str
publisher: str
authors: str
@dataclass
class PaperDetailDescription:
authors: str
title: str
publisher: str
doi: str
class SearchEngine(Enum):
google_scholar = 1
baidu_xueshu = 2
publons = 3
science_direct = 4
class DownLoadSetting:
def __init__(self) -> None:
super().__init__()
self.__outputPath = "./"
self.__proxy = None
self.__search_engine = SearchEngine.baidu_xueshu
self.__cookie = ''
self.__limit = 10
@property
def limit(self):
return self.__limit
@limit.setter
def limit(self, limit):
self.__limit = limit
@property
def cookie(self):
return self.__cookie
@cookie.setter
def cookie(self, cookie):
self.__cookie = cookie
@property
def search_engine(self):
return self.__search_engine
@search_engine.setter
def search_engine(self, search_engine):
self.__search_engine = search_engine
@property
def outputPath(self):
return self.__outputPath
@outputPath.setter
def outputPath(self, outputPath):
self.__outputPath = outputPath
@property
def proxy(self):
return self.__proxy
@proxy.setter
def proxy(self, proxy):
self.__proxy = proxy
class DownLoadCommandSetting(DownLoadSetting):
def __init__(self) -> None:
super().__init__()
self.__doi = None
self.__url = None
self.__words = None
@property
def doi(self):
return self.__doi
@doi.setter
def doi(self, doi):
self.__doi = doi
@property
def url(self):
return self.__url
@url.setter
def url(self, url):
self.__url = url
@property
def words(self):
return self.__words
@words.setter
def words(self, words):
self.__words = words
class DownLoadCommandFileSetting(DownLoadSetting):
def __init__(self) -> None:
super().__init__()
self.__bibtex_file = None
self.__dois_file = None
self.__urls_file = None
self.__title_file = None
@property
def bibtex_file(self):
return self.__bibtex_file
@bibtex_file.setter
def bibtex_file(self, bibtex_file):
self.__bibtex_file = bibtex_file
@property
def dois_file(self):
return self.__dois_file
@dois_file.setter
def dois_file(self, dois_file):
self.__dois_file = dois_file
@property
def urls_file(self):
return self.__urls_file
@urls_file.setter
def urls_file(self, urls_file):
self.__urls_file = urls_file
@property
def title_file(self):
return self.__title_file
@title_file.setter
def title_file(self, title_file):
self.__title_file = title_file | scihub-cn | /scihub-cn-0.1.1.tar.gz/scihub-cn-0.1.1/scihub_cn/models.py | models.py | from dataclasses import dataclass
from enum import Enum
@dataclass
class PaperInfo:
url: str
title: str
doi: str
publisher: str
authors: str
@dataclass
class PaperDetailDescription:
authors: str
title: str
publisher: str
doi: str
class SearchEngine(Enum):
google_scholar = 1
baidu_xueshu = 2
publons = 3
science_direct = 4
class DownLoadSetting:
def __init__(self) -> None:
super().__init__()
self.__outputPath = "./"
self.__proxy = None
self.__search_engine = SearchEngine.baidu_xueshu
self.__cookie = ''
self.__limit = 10
@property
def limit(self):
return self.__limit
@limit.setter
def limit(self, limit):
self.__limit = limit
@property
def cookie(self):
return self.__cookie
@cookie.setter
def cookie(self, cookie):
self.__cookie = cookie
@property
def search_engine(self):
return self.__search_engine
@search_engine.setter
def search_engine(self, search_engine):
self.__search_engine = search_engine
@property
def outputPath(self):
return self.__outputPath
@outputPath.setter
def outputPath(self, outputPath):
self.__outputPath = outputPath
@property
def proxy(self):
return self.__proxy
@proxy.setter
def proxy(self, proxy):
self.__proxy = proxy
class DownLoadCommandSetting(DownLoadSetting):
def __init__(self) -> None:
super().__init__()
self.__doi = None
self.__url = None
self.__words = None
@property
def doi(self):
return self.__doi
@doi.setter
def doi(self, doi):
self.__doi = doi
@property
def url(self):
return self.__url
@url.setter
def url(self, url):
self.__url = url
@property
def words(self):
return self.__words
@words.setter
def words(self, words):
self.__words = words
class DownLoadCommandFileSetting(DownLoadSetting):
def __init__(self) -> None:
super().__init__()
self.__bibtex_file = None
self.__dois_file = None
self.__urls_file = None
self.__title_file = None
@property
def bibtex_file(self):
return self.__bibtex_file
@bibtex_file.setter
def bibtex_file(self, bibtex_file):
self.__bibtex_file = bibtex_file
@property
def dois_file(self):
return self.__dois_file
@dois_file.setter
def dois_file(self, dois_file):
self.__dois_file = dois_file
@property
def urls_file(self):
return self.__urls_file
@urls_file.setter
def urls_file(self, urls_file):
self.__urls_file = urls_file
@property
def title_file(self):
return self.__title_file
@title_file.setter
def title_file(self, title_file):
self.__title_file = title_file | 0.809012 | 0.165121 |
SciHub |Python| |Build Status| |Pypi|
======
``scihub`` is an unofficial API for sci-hub.cc. scihub.py can download
papers from ``sci-hub``.
If you believe in open access to scientific papers, please donate to
Sci-Hub.
Setup
-----
::
pip install scihub
Usage
-----
fetch
~~~~~
.. code:: python
from scihub import SciHub
sh = SciHub()
# fetch specific article (don't download to disk)
# this will return a dictionary in the form
# {'pdf': PDF_DATA,
# 'url': SOURCE_URL
# }
result = sh.fetch('http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1648853')
with open('output.pdf', 'wb+') as fd:
fd.write(result['pdf'])
License
-------
MIT
.. |Python| image:: https://img.shields.io/badge/Python-3%2B-blue.svg
:target: https://www.python.org
.. |Build Status| image:: https://travis-ci.org/alejandrogallo/python-scihub.svg?branch=master
:target: https://travis-ci.org/alejandrogallo/python-scihub
.. |Pypi| image:: https://badge.fury.io/py/scihub.svg
:target: https://badge.fury.io/py/scihub
| scihub | /scihub-0.0.1.tar.gz/scihub-0.0.1/README.rst | README.rst | SciHub |Python| |Build Status| |Pypi|
======
``scihub`` is an unofficial API for sci-hub.cc. scihub.py can download
papers from ``sci-hub``.
If you believe in open access to scientific papers, please donate to
Sci-Hub.
Setup
-----
::
pip install scihub
Usage
-----
fetch
~~~~~
.. code:: python
from scihub import SciHub
sh = SciHub()
# fetch specific article (don't download to disk)
# this will return a dictionary in the form
# {'pdf': PDF_DATA,
# 'url': SOURCE_URL
# }
result = sh.fetch('http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1648853')
with open('output.pdf', 'wb+') as fd:
fd.write(result['pdf'])
License
-------
MIT
.. |Python| image:: https://img.shields.io/badge/Python-3%2B-blue.svg
:target: https://www.python.org
.. |Build Status| image:: https://travis-ci.org/alejandrogallo/python-scihub.svg?branch=master
:target: https://travis-ci.org/alejandrogallo/python-scihub
.. |Pypi| image:: https://badge.fury.io/py/scihub.svg
:target: https://badge.fury.io/py/scihub
| 0.753467 | 0.363901 |
[](https://badge.fury.io/py/scikick)
[](https://pypistats.org/packages/scikick)
[](https://pypi.python.org/pypi/scikick/)
[](https://pypi.python.org/pypi/scikick/)

### Preface: simple workflow definitions for complex notebooks
A thorough data analysis in
[Rmarkdown](https://rmarkdown.rstudio.com/) or [Jupyter](https://jupyter.org/)
will involve multiple notebooks which must be executed in a specific order.
Consider this two stage data analysis where `QC.Rmd` provides a cleaned dataset
for `model.Rmd` to perform modelling:
```
|-- input/raw_data.csv
|-- code
│ |-- QC.Rmd
│ |-- model.Rmd
|-- output/QC/QC_data.csv
|-- report/out_md
| |-- _site.yml
| |-- QC.md
| |-- model.md
|-- report/out_html
| |-- QC.html
| |-- model.html
```
Each of these notebooks may be internally complex, but the essence of this workflow is:
**`QC.Rmd` must run before `model.Rmd`**
This simple definition can be applied to:
- Reproducibly re-execute the notebook collection.
- Avoid unecessary execution of `QC.Rmd` when `model.Rmd` changes.
- Build a shareable report from the rendered notebooks (*e.g.* using `rmarkdown::render_website()`).
Researchers need to be able to get these benefits from simple workflow definitions
to allow for focus to be on the data analysis.
## **scikick** - your sidekick for managing notebook collections
*scikick* is a command-line-tool for integrating data analyses
with a few simple commands. The `sk run` command will apply dependency definitions to execute steps in the correct order and build a website of results.
Common tasks for *ad hoc* data analysis are managed through scikick:
- Awareness of up-to-date results (via Snakemake)
- Website rendering and layout automation (by project directory structure)
- Collection of page metadata (session info, page runtime, git history)
- Simple dependency tracking of two types:
- notebook1 must execute before notebook2 (external dependency)
- notebook1 uses the file functions.R (internal dependency)
- Automated execution of `.R` as a notebook (with `knitr::spin`)
Commands are inspired by git for configuring the workflow: `sk init`, `sk add`, `sk status`, `sk del`, `sk mv`.
Scikick currently supports `.R` and `.Rmd` for notebook rendering.
[Example Output](https://petronislab.camh.ca/pub/scikick_tests/master/)
### Installation
The following should be installed prior to installing scikick.
|**Requirements** |**Recommended**|
|---|---|
|python3 (>=3.6, [installing with conda](https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-python.html) is recommended) | [git >= 2.0](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) |
|R + packages `install.packages(c("rmarkdown", "knitr", "yaml","git2r"))` | [singularity >= 2.4](http://singularity.lbl.gov/install-linux) |
|[pandoc > 2.0](https://pandoc.org/installing.html) | [conda](https://docs.conda.io/projects/conda/en/latest/user-guide/install/) |
Installation within a virtual environment with [conda](https://docs.conda.io/projects/conda/en/latest/user-guide/install/) is recommended but not required.
Scikick can be installed using pip:
```
pip install scikick
```
Direct conda installation of scikick is still experimental, but may be attempted with:
```
conda install -c tadasbar -c bioconda -c conda-forge scikick
```
To install the latest version of scikick, clone and then:
```
python3 setup.py install
```
## Getting Started
Begin by executing the demo project or reviewing the main commands of scikick below.
### Demo Project
To initiate a walkthrough of scikick commands (using a demo project).
```
mkdir sk_demo
cd sk_demo
sk init --demo
```
### Main Commands
Below are some brief descriptions of the most useful commands. Run `sk <command> --help` for details and available arguments. Run `sk --help` for the full list of commands.
##### sk init
```
sk init
```
Like `git init`, this should be executed at the project root in an existing or an empty project.
It will check for required dependencies and create `scikick.yml` to store the workflow definition which will be configured using other commands.
`sk init` can also be used to create data analysis directories and add to `.gitignore` for the project.
##### sk add
```
sk add hw.Rmd
```
Adds the `hw.Rmd` file to the workflow. Supports wildcards for adding in bulk.
##### sk status
`sk add` added `hw.Rmd` to `scikick.yml` and now `sk status` can be used to inspect the workflow state.
```
sk status
# m-- hw.Rmd
# Scripts to execute: 1
# HTMLs to compile ('---'): 1
```
`sk status` uses a 3 character encoding to show that hw.Rmd requires execution where
the 'm' marking in the first slot indicates the corresponding output file (`report/out_md/hw.md`) is missing.
##### sk run
```
sk run
```
Call on the snakemake backend to generate all out-of-date or missing output files (html pages).
After execution is finished, the directory structure should look like
```
.
├── hw.Rmd
├── report
│ ├── donefile
│ ├── out_html
│ │ ├── hw.html
│ │ └── index.html
│ └── out_md # has many files we can ignore for now
└── scikick.yml
```
The `report/` directory contains all of scikick's output.
Opening `report/out_html/index.html` in a web browser should show the website
homepage with one menu item for hw.html (hw.Rmd's output).
### Tracking out-of-date files
Running `sk status` again will result in no jobs to be run.
```
sk status
# Scripts to execute: 0
# HTMLs to compile ('---'): 0
```
And `sk run` will do nothing.
```
sk run
<...>
sk: Nothing to be done.
<...>
```
scikick tracks files using their timestamp (using snakemake) to determine if the report is up-to-date.
For example, if we make changes to hw.Rmd and run scikick
```
touch hw.Rmd
sk run
```
then scikick re-executes to create `report/out_html/hw.html` from scratch.
### Using dependencies
If the project has dependencies between different files, we can make scikick aware of these.
Let's say we have `greets.Rmd` which sources an R script `hello.R`.
```
# Run this to create the files
mkdir code
# code/hello.R
echo 'greeting_string = "Hello World"' > code/hello.R
# code/greets.Rmd
printf "%s\n%s\n%s\n" '```{r, include = TRUE}' 'source("code/hello.R")
print(greeting_string)' '```' > code/greets.Rmd
# Add the Rmd to the workflow
sk add code/greets.Rmd
```
Be aware that while `code/greets.Rmd` and `code/hello.R` are in the same
directory, all code in scikick is executed from the project root. This means that
`source("hello.R")` will return an error, so instead we need `source("code/hello.R")`.
Let's run `sk run` to create `report/out_html/greets.html`.
Then let's simulate changes to `code/hello.R` to demonstrate what will happen next.
```
touch code/hello.R
sk run
```
Nothing happens since scikick does not know that `code/greets.Rmd` is using `code/hello.R`.
In order to make scikick re-execute `greets.Rmd` when `hello.R` is modified, we have to add it as a dependency with `sk add -d`.
##### sk add -d
```
# add dependency 'code/hello.R' to 'code/greets.Rmd'
sk add code/greets.Rmd -d code/hello.R
```
Now whenever we change `hello.R` and run `sk run`, the file that depends on it (`greets.Rmd`) will be rerun as its results may change.
### Other Useful Commands
##### sk status -v
Use this command to view the full scikick configuration where dependencies for
each file are indented below it.
Out-of-date files are marked with a three symbol code which shows
the reason for their update on the next `sk run`.
##### sk mv
While rearranging files in the project, use `sk mv` so scikick can adjust the workflow definition accordingly.
```
mkdir code
sk mv hw.Rmd code/hw.Rmd
```
If you are using git, use `sk mv -g` to use `git mv`.
Both individual files and directories can be moved with `sk mv`.
##### sk del
We can remove `hw.Rmd` from our analysis with
```
sk del hw.Rmd
```
If the flag '-d' is used (with a dependency specified), only the dependency is removed.
Note that this does not delete the hw.Rmd file.
### Using a Project Template
In order to make our project more tidy, we can create some dedicated directories with
```
sk init --dirs
# creates:
# report/ - output directory for scikick
# output/ - directory for outputs from scripts
# code/ - directory containing scripts (Rmd and others)
# input/ - input data directory
```
If git is in use for the project, directories `report`, `output`, `input` are not
recommended to be tracked.
They can be added to `.gitignore` with
```
sk init --git
```
and git will know to ignore the contents of these directories.
## sk layout
The order of tabs in the website can be configured using `sk layout`.
Running the command without arguments
```
sk layout
```
returns the current ordered list of tab indices and their names:
```
1: hw.Rmd
2: greets.Rmd
3: dummy1.Rmd
4: dummy2.Rmd
```
The order can be changed by specifying the new order of tab indices, e.g.
```
# to reverse the tab order:
sk layout 4 3 2 1
# the list does not have to include all of the indices (1 to 4 in this case):
sk layout 4 # move tab 4 to the front
# the incomplete list '4' is interpreted as '4 1 2 3'
```
Output after running `sk layout 4`:
```
1: dummy2.Rmd
2: hw.Rmd
3: greets.Rmd
4: dummy1.Rmd
```
Also, items within menus can be rearranged similarly with
```
sk layout -s <menu name>
```
## Homepage Modifications
The `index.html` is required for the homepage of the website. scikick will create
this content from a template and will also include any content from an `index.Rmd`
added to the workflow with `sk add code/index.Rmd`.
## Rstudio with scikick
Rstudio, by default, executes code relative to opened Rmd file's location. This
can be changed by going to `Tools > Global Options > Rmarkdown > Evaluate chunks in directory`
and setting to "Current".
## Other scikick files in `report/`
- `donefile` - empty file created during the snakemake workflow that is executed by scikick
- `out_md/`
- `out_md/*.md` - markdown files that were `knit` from Rmarkdown files
- `out_md/_site.yml` - YAML file specifying the structure of the to-be-created website
- `out_md/knitmeta/` - directory of RDS files containing information about javascript libraries that need to be included when rendering markdown files to HTMLs.
- `out_html/` - contains the resulting HTML files
## External vs Internal Dependencies
**Internal dependencies** - code or files the Rmd uses directly during execution
**External dependencies** - code that must be executed prior to the page
scikick assumes that any depedency that is not added as a page (i.e. `sk add <page>`) is an internal dependency.
Currently, only `Rmd` and `R` files are supported as pages. In the future, executables and other file types may be
supported by scikick to allow easy usage of arbitrary scripts as pages.
## Snakemake Backend
Data pipelines benefit from improved workflow execution tools
(Snakemake, Bpipe, Nextflow), however, *ad hoc* data analysis is often left out of
this workflow definition. Using scikick, projects can quickly configure reports
to take advantage of the snakemake backend with:
- Basic depedency management (i.e. GNU Make)
- Distribution of tasks on compute clusters (thanks to snakemake's `--cluster` argument)
- Software virtualization (Singularity, Docker, Conda)
- Other snakemake functionality
Users familiar with snakemake can add trailing snakemake arguments during execution with `sk run -v -s`.
### Singularity
In order to run all Rmds in a singularity image, we have to do two things: specify the singularity image and use the snakemake flag that singularity, as a feature, should be used.
```
# specify a singularity image
sk config --singularity docker://rocker/tidyverse
# run the project within a singularity container
# by passing '--use-singularity' argument to Snakemake
sk run -v -s --use-singularity
```
Only the Rmarkdown files are run in the singularity container, the scikick dependencies are
still required outside of the container with this usage.
### Conda
The same steps are necessary to use conda, except the needed file is a conda environment YAML file.
```
# create an env.yml file from the current conda environment
conda env export > env.yml
# specify that this file is the conda environment file
sk config --conda env.yml
# run
sk run -v -s --use-conda
```
## Incorporating with Other Pipelines
Additional workflows written in [snakemake](http://snakemake.readthedocs.io/en/stable/) should play nicely with the scikick workflow.
These jobs can be added to the begining, middle, or end of scikick related tasks:
- Beginning
- `sk add first_step.rmd -d pipeline_donefile` (where pipeline_donefile is the last file generated by the Snakefile)
- Middle
- Add `report/out_md/first_step.md` as the input to the first job of the Snakefile.
- `sk add second_step.rmd -d pipeline_donefile`
- End
- Add `report/out_md/last_step.md` as the input to the first job of the Snakefile.
| scikick | /scikick-0.1.2.tar.gz/scikick-0.1.2/README.md | README.md | |-- input/raw_data.csv
|-- code
│ |-- QC.Rmd
│ |-- model.Rmd
|-- output/QC/QC_data.csv
|-- report/out_md
| |-- _site.yml
| |-- QC.md
| |-- model.md
|-- report/out_html
| |-- QC.html
| |-- model.html
pip install scikick
conda install -c tadasbar -c bioconda -c conda-forge scikick
python3 setup.py install
mkdir sk_demo
cd sk_demo
sk init --demo
sk init
sk add hw.Rmd
sk status
# m-- hw.Rmd
# Scripts to execute: 1
# HTMLs to compile ('---'): 1
sk run
.
├── hw.Rmd
├── report
│ ├── donefile
│ ├── out_html
│ │ ├── hw.html
│ │ └── index.html
│ └── out_md # has many files we can ignore for now
└── scikick.yml
sk status
# Scripts to execute: 0
# HTMLs to compile ('---'): 0
sk run
<...>
sk: Nothing to be done.
<...>
touch hw.Rmd
sk run
# Run this to create the files
mkdir code
# code/hello.R
echo 'greeting_string = "Hello World"' > code/hello.R
# code/greets.Rmd
printf "%s\n%s\n%s\n" '```{r, include = TRUE}' 'source("code/hello.R")
print(greeting_string)' '```' > code/greets.Rmd
# Add the Rmd to the workflow
sk add code/greets.Rmd
touch code/hello.R
sk run
# add dependency 'code/hello.R' to 'code/greets.Rmd'
sk add code/greets.Rmd -d code/hello.R
mkdir code
sk mv hw.Rmd code/hw.Rmd
sk del hw.Rmd
sk init --dirs
# creates:
# report/ - output directory for scikick
# output/ - directory for outputs from scripts
# code/ - directory containing scripts (Rmd and others)
# input/ - input data directory
sk init --git
sk layout
1: hw.Rmd
2: greets.Rmd
3: dummy1.Rmd
4: dummy2.Rmd
# to reverse the tab order:
sk layout 4 3 2 1
# the list does not have to include all of the indices (1 to 4 in this case):
sk layout 4 # move tab 4 to the front
# the incomplete list '4' is interpreted as '4 1 2 3'
1: dummy2.Rmd
2: hw.Rmd
3: greets.Rmd
4: dummy1.Rmd
sk layout -s <menu name>
# specify a singularity image
sk config --singularity docker://rocker/tidyverse
# run the project within a singularity container
# by passing '--use-singularity' argument to Snakemake
sk run -v -s --use-singularity
# create an env.yml file from the current conda environment
conda env export > env.yml
# specify that this file is the conda environment file
sk config --conda env.yml
# run
sk run -v -s --use-conda | 0.407333 | 0.981185 |
import numpy as np
from random import randint
import matplotlib.pyplot as plt
class Fluid:
def __init__(self, i_size, i_p):
"""
:param i_size: size of the lattice
:param i_p: percolation probability. Must be < 1
"""
self.size = i_size
self.percolation = np.zeros((self.size, self.size))
if i_p > 1:
raise ValueError("Probability cannot be larger than 1.")
else:
self.p = i_p
def percolate(self):
"""
percolate the lattice
:return: the 2D percolation numpy array
"""
for i in range(1, self.size-1):
for j in range(1, self.size-1):
r = randint(0, 100)
if r <= self.p*100:
self.percolation[i][j] = 1
return self.percolation
def recursive_cluster_detector(self, x, y):
"""
:param x: i position in the loop
:param y: j position in the loop
:return: N/A
"""
try:
if self.percolation[x + 1][y] == 1:
self.percolation[x][y] = 5
self.percolation[x+1][y] = 5
self.recursive_cluster_detector(x + 1, y)
except IndexError:
pass
try:
if self.percolation[x - 1][y] == 1:
self.percolation[x][y] = 5
self.percolation[x - 1][y] = 5
self.recursive_cluster_detector(x - 1, y)
except IndexError:
pass
try:
if self.percolation[x][y + 1] == 1:
self.percolation[x][y] = 5
self.percolation[x][y + 1] = 5
self.recursive_cluster_detector(x, y + 1)
except IndexError:
pass
try:
if self.percolation[x][y - 1] == 1:
self.percolation[x][y] = 5
self.percolation[x][y - 1] = 5
self.recursive_cluster_detector(x, y - 1)
except IndexError:
pass
def detect_clusters(self):
"""
detects clusters that resulting from percolation
:return: the 2D percolation numpy array with the clusters highlighted having a value of 5
"""
# Detect clusters loop
for i in range(self.size):
for j in range(self.size):
if self.percolation[i][j] == 1:
self.recursive_cluster_detector(i, j)
else:
continue
def plot(self):
plt.pcolormesh(self.percolation)
plt.grid(True)
plt.show()
"""
# Example use case
example = Fluid(110, 0.6)
example.percolate()
example.detect_clusters()
example.plot()
""" | scikit-CP | /randomSystems/percolation.py | percolation.py | import numpy as np
from random import randint
import matplotlib.pyplot as plt
class Fluid:
def __init__(self, i_size, i_p):
"""
:param i_size: size of the lattice
:param i_p: percolation probability. Must be < 1
"""
self.size = i_size
self.percolation = np.zeros((self.size, self.size))
if i_p > 1:
raise ValueError("Probability cannot be larger than 1.")
else:
self.p = i_p
def percolate(self):
"""
percolate the lattice
:return: the 2D percolation numpy array
"""
for i in range(1, self.size-1):
for j in range(1, self.size-1):
r = randint(0, 100)
if r <= self.p*100:
self.percolation[i][j] = 1
return self.percolation
def recursive_cluster_detector(self, x, y):
"""
:param x: i position in the loop
:param y: j position in the loop
:return: N/A
"""
try:
if self.percolation[x + 1][y] == 1:
self.percolation[x][y] = 5
self.percolation[x+1][y] = 5
self.recursive_cluster_detector(x + 1, y)
except IndexError:
pass
try:
if self.percolation[x - 1][y] == 1:
self.percolation[x][y] = 5
self.percolation[x - 1][y] = 5
self.recursive_cluster_detector(x - 1, y)
except IndexError:
pass
try:
if self.percolation[x][y + 1] == 1:
self.percolation[x][y] = 5
self.percolation[x][y + 1] = 5
self.recursive_cluster_detector(x, y + 1)
except IndexError:
pass
try:
if self.percolation[x][y - 1] == 1:
self.percolation[x][y] = 5
self.percolation[x][y - 1] = 5
self.recursive_cluster_detector(x, y - 1)
except IndexError:
pass
def detect_clusters(self):
"""
detects clusters that resulting from percolation
:return: the 2D percolation numpy array with the clusters highlighted having a value of 5
"""
# Detect clusters loop
for i in range(self.size):
for j in range(self.size):
if self.percolation[i][j] == 1:
self.recursive_cluster_detector(i, j)
else:
continue
def plot(self):
plt.pcolormesh(self.percolation)
plt.grid(True)
plt.show()
"""
# Example use case
example = Fluid(110, 0.6)
example.percolate()
example.detect_clusters()
example.plot()
""" | 0.564579 | 0.49292 |
from randomSystems.walker import Walker
import matplotlib.pyplot as plt
class RWPopulation:
def __init__(self, i_walkers_list=None):
"""
:param i_walkers_list: Initial list of random walkers
"""
if i_walkers_list is not None:
if isinstance(i_walkers_list, list):
self.walkers = i_walkers_list
else:
raise ValueError("Value passed is not a list of Walker types")
def add_walker(self, i_walker):
"""
Adds a walker to the list of walker population
:param i_walker: walker instance
"""
if isinstance(i_walker, Walker):
self.walkers.append(i_walker)
else:
raise TypeError("Value passed is not a Walker type")
def del_walker(self, key):
"""
Deletes a walker instance which is identified within the list using a key
:param key: key used to identify walker instance to be deleted
"""
for i in range(len(self.walkers)):
if self.walkers[i].key == key:
del self.walkers[i]
elif self.walkers[i].key != key and i <= len(self.walkers):
raise ValueError("Key not found")
else:
continue
def detect_intersection_2d(self):
"""
detects when two walkers cross paths in 2d
:return: points of crossing in a list Format: (x, y, step number). False if no intersections occur.
"""
intersect = []
for W_A in self.walkers:
for W_B in self.walkers:
if W_A is W_B:
continue
for i in range(1, len(W_A.x)):
if W_A.x[i] == W_B.x[i] and \
W_A.y[i] == W_B.y[i]:
intersect.append((W_A.x[i], W_A.y[i], i))
if intersect == []:
return False
else:
return intersect
def detect_intersection_3d(self):
"""
detects when two walkers cross paths in 3d
:return: points of crossing in a list Format: (x, y, z, step number). False if no intersections occur.
"""
intersect = []
for W_A in self.walkers:
for W_B in self.walkers:
if W_A is W_B:
continue
for i in range(len(W_A.x)):
if W_A.x[i] == W_B.x[i] and \
W_A.y[i] == W_B.y[i] and \
W_A.z[i] == W_B.z[i]:
intersect.append((W_A.x[i], W_A.y[i], W_A.z[i], i))
if intersect == []:
return False
else:
return intersect
def plot_2d(self):
"""
Plot the paths of walkers in 2d
"""
for i in range(len(self.walkers)):
i_key = self.walkers[i].key
plt.plot(self.walkers[i].x, self.walkers[i].y, label=str(i_key))
plt.legend()
plt.show()
def plot_3d(self):
"""
Plot the paths of walkers in 3d
"""
ax = plt.axes(projection='3d')
for i in range(len(self.walkers)):
i_key = self.walkers[i].key
ax.plot3D(self.walkers[i].x, self.walkers[i].y, self.walkers[i].z, label=str(i_key))
ax.legend()
plt.show()
"""
# use case example
bob = Walker(5, 3, 2)
bob.saw_3d(1000, True)
jon = Walker()
jon.saw_3d(1000, True)
walkers_gang = [bob, jon]
sys = RWPopulation(walkers_gang)
print(sys.detect_intersection_3d())
sys.plot_3d()
""" | scikit-CP | /randomSystems/SIM_RandomWalkers.py | SIM_RandomWalkers.py |
from randomSystems.walker import Walker
import matplotlib.pyplot as plt
class RWPopulation:
def __init__(self, i_walkers_list=None):
"""
:param i_walkers_list: Initial list of random walkers
"""
if i_walkers_list is not None:
if isinstance(i_walkers_list, list):
self.walkers = i_walkers_list
else:
raise ValueError("Value passed is not a list of Walker types")
def add_walker(self, i_walker):
"""
Adds a walker to the list of walker population
:param i_walker: walker instance
"""
if isinstance(i_walker, Walker):
self.walkers.append(i_walker)
else:
raise TypeError("Value passed is not a Walker type")
def del_walker(self, key):
"""
Deletes a walker instance which is identified within the list using a key
:param key: key used to identify walker instance to be deleted
"""
for i in range(len(self.walkers)):
if self.walkers[i].key == key:
del self.walkers[i]
elif self.walkers[i].key != key and i <= len(self.walkers):
raise ValueError("Key not found")
else:
continue
def detect_intersection_2d(self):
"""
detects when two walkers cross paths in 2d
:return: points of crossing in a list Format: (x, y, step number). False if no intersections occur.
"""
intersect = []
for W_A in self.walkers:
for W_B in self.walkers:
if W_A is W_B:
continue
for i in range(1, len(W_A.x)):
if W_A.x[i] == W_B.x[i] and \
W_A.y[i] == W_B.y[i]:
intersect.append((W_A.x[i], W_A.y[i], i))
if intersect == []:
return False
else:
return intersect
def detect_intersection_3d(self):
"""
detects when two walkers cross paths in 3d
:return: points of crossing in a list Format: (x, y, z, step number). False if no intersections occur.
"""
intersect = []
for W_A in self.walkers:
for W_B in self.walkers:
if W_A is W_B:
continue
for i in range(len(W_A.x)):
if W_A.x[i] == W_B.x[i] and \
W_A.y[i] == W_B.y[i] and \
W_A.z[i] == W_B.z[i]:
intersect.append((W_A.x[i], W_A.y[i], W_A.z[i], i))
if intersect == []:
return False
else:
return intersect
def plot_2d(self):
"""
Plot the paths of walkers in 2d
"""
for i in range(len(self.walkers)):
i_key = self.walkers[i].key
plt.plot(self.walkers[i].x, self.walkers[i].y, label=str(i_key))
plt.legend()
plt.show()
def plot_3d(self):
"""
Plot the paths of walkers in 3d
"""
ax = plt.axes(projection='3d')
for i in range(len(self.walkers)):
i_key = self.walkers[i].key
ax.plot3D(self.walkers[i].x, self.walkers[i].y, self.walkers[i].z, label=str(i_key))
ax.legend()
plt.show()
"""
# use case example
bob = Walker(5, 3, 2)
bob.saw_3d(1000, True)
jon = Walker()
jon.saw_3d(1000, True)
walkers_gang = [bob, jon]
sys = RWPopulation(walkers_gang)
print(sys.detect_intersection_3d())
sys.plot_3d()
""" | 0.576423 | 0.342998 |
Master Status: [](https://travis-ci.com/UrbsLab/scikit-ExSTraCS)
# scikit-ExSTraCS
The scikit-ExSTraCS package includes a sklearn-compatible Python implementation of ExSTraCS 2.0. ExSTraCS 2.0, or Extended Supervised Tracking and Classifying System, implements the core components of a Michigan-Style Learning Classifier System (where the system's genetic algorithm operates on a rule level, evolving a population of rules with each their own parameters) in an easy to understand way, while still being highly functional in solving ML problems. It allows the incorporation of expert knowledge in the form of attribute weights, attribute tracking, rule compaction, and a rule specificity limit, that makes it particularly adept at solving highly complex problems.
In general, Learning Classifier Systems (LCSs) are a classification of Rule Based Machine Learning Algorithms that have been shown to perform well on problems involving high amounts of heterogeneity and epistasis. Well designed LCSs are also highly human interpretable. LCS variants have been shown to adeptly handle supervised and reinforced, classification and regression, online and offline learning problems, as well as missing or unbalanced data. These characteristics of versatility and interpretability give LCSs a wide range of potential applications, notably those in biomedicine. This package is **still under active development** and we encourage you to check back on this repository for updates.
This version of scikit-ExSTraCS is suitable for supervised classification problems only. It has not yet been developed for regression problems. Within these bounds however, scikit-ExSTraCS can be applied to almost any supervised classification data set and supports:
<ul>
<li>Feature sets that are discrete/categorical, continuous-valued or a mix of both</li>
<li>Data with missing values</li>
<li>Binary Classification Problems (Binary Endpoints)</li>
<li>Multi-class Classification Problems (Multi-class Endpoints)</li>
</ul>
Built into this code, is a strategy to 'automatically' detect from the loaded data, these relevant above characteristics so that they don't need to be parameterized at initialization.
The core Scikit package only supports numeric data. However, an additional StringEnumerator Class is provided that allows quick data conversion from any type of data into pure numeric data, making it possible for natively string/non-numeric data to be run by scikit-XCS.
In addition, powerful data tracking collection methods are built into the scikit package, that continuously tracks features every iteration such as:
<ul>
<li>Approximate Accuracy</li>
<li>Average Population Generality</li>
<li>Macro & Micropopulation Size</li>
<li>Match Set and Action Set Sizes</li>
<li>Number of classifiers subsumed/deleted/covered</li>
<li>Number of crossover/mutation operations performed</li>
<li>Times for matching, deletion, subsumption, selection, evaluation</li>
</ul>
And many more... These values can then be exported as a csv after training is complete for analysis using the built in "export_iteration_tracking_data" method.
In addition, the package includes functionality that allows the final rule population to be exported as a csv after training.
## Usage
For more information on how to use scikit-ExSTraCS, please refer to the [scikit-ExSTraCS User Guide](https://github.com/UrbsLab/scikit-ExSTraCS/) Jupyter Notebook inside this repository.
## Usage TLDR
```python
#Import Necessary Packages/Modules
from skExSTraCS import ExSTraCS
from skrebate import ReliefF
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score
#Load Data Using Pandas
data = pd.read_csv('myDataFile.csv') #REPLACE with your own dataset .csv filename
dataFeatures = data.drop(classLabel,axis=1).values #DEFINE classLabel variable as the Str at the top of your dataset's action column
dataPhenotypes = data[classLabel].values
#Shuffle Data Before CV
formatted = np.insert(dataFeatures,dataFeatures.shape[1],dataPhenotypes,1)
np.random.shuffle(formatted)
dataFeatures = np.delete(formatted,-1,axis=1)
dataPhenotypes = formatted[:,-1]
#Get Feature Importance Scores to use as Expert Knowledge (see https://github.com/EpistasisLab/scikit-rebate/ for more details on skrebate package)
relieff = ReliefF()
relieff.fit(dataFeatures,dataPhenotypes)
scores = relieff.feature_importances_
#Initialize ExSTraCS Model
model = ExSTraCS(learning_iterations = 5000,expert_knowledge=scores)
#3-fold CV
print(np.mean(cross_val_score(model,dataFeatures,dataPhenotypes,cv=3)))
```
## License
Please see the repository [license](https://github.com/UrbsLab/scikit-ExSTraCS/blob/master/LICENSE) for the licensing and usage information for scikit-ExSTraCS.
Generally, we have licensed scikit-ExSTraCS to make it as widely usable as possible.
## Installation
scikit-ExSTraCS is built on top of the following Python packages:
<ol>
<li> numpy </li>
<li> pandas </li>
<li> scikit-learn </li>
</ol>
Once the prerequisites are installed, you can install scikit-ExSTraCS with a pip command:
```
pip/pip3 install scikit-ExSTraCS
```
We strongly recommend you use Python 3. scikit-ExSTraCS does not support Python 2, given its depreciation in Jan 1 2020. If something goes wrong during installation, make sure that your pip is up to date and try again.
```
pip/pip3 install --upgrade pip
```
## Contributing to scikit-ExSTraCS
scikit-ExSTraCS is an open source project and we'd love if you could suggest changes!
<ol>
<li> Fork the project repository to your personal account and clone this copy to your local disk</li>
<li> Create a branch from master to hold your changes: (e.g. <b>git checkout -b my-contribution-branch</b>) </li>
<li> Commit changes on your branch. Remember to never work on any other branch but your own! </li>
<li> When you are done, push your changes to your forked GitHub repository with <b>git push -u origin my-contribution-branch</b> </li>
<li> Create a pull request to send your changes to the scikit-ExSTraCS maintainers for review. </li>
</ol>
**Before submitting your pull request**
If your contribution changes ExSTraCS in any way, make sure you update the Jupyter Notebook documentation and the README with relevant details. If your contribution involves any code changes, update the project unit tests to test your code changes, and make sure your code is properly commented to explain your rationale behind non-obvious coding practices.
**After submitting your pull request**
After submitting your pull request, Travis CI will run all of the project's unit tests. Check back shortly after submitting to make sure your code passes these checks. If any checks come back failed, do your best to address the errors.
| scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/README.md | README.md | #Import Necessary Packages/Modules
from skExSTraCS import ExSTraCS
from skrebate import ReliefF
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score
#Load Data Using Pandas
data = pd.read_csv('myDataFile.csv') #REPLACE with your own dataset .csv filename
dataFeatures = data.drop(classLabel,axis=1).values #DEFINE classLabel variable as the Str at the top of your dataset's action column
dataPhenotypes = data[classLabel].values
#Shuffle Data Before CV
formatted = np.insert(dataFeatures,dataFeatures.shape[1],dataPhenotypes,1)
np.random.shuffle(formatted)
dataFeatures = np.delete(formatted,-1,axis=1)
dataPhenotypes = formatted[:,-1]
#Get Feature Importance Scores to use as Expert Knowledge (see https://github.com/EpistasisLab/scikit-rebate/ for more details on skrebate package)
relieff = ReliefF()
relieff.fit(dataFeatures,dataPhenotypes)
scores = relieff.feature_importances_
#Initialize ExSTraCS Model
model = ExSTraCS(learning_iterations = 5000,expert_knowledge=scores)
#3-fold CV
print(np.mean(cross_val_score(model,dataFeatures,dataPhenotypes,cv=3)))
pip/pip3 install scikit-ExSTraCS
pip/pip3 install --upgrade pip | 0.355327 | 0.964422 |
import numpy as np
import pandas as pd
from warnings import simplefilter
# ignore all future warnings
simplefilter(action='ignore', category=FutureWarning)
class StringEnumerator:
def __init__(self, inputFile, classLabel):
self.classLabel = classLabel
self.map = {} #Dictionary of header names: Attribute dictionaries
data = pd.read_csv(inputFile, sep=',') # Puts data from csv into indexable np arrays
data = data.fillna("NA")
self.dataFeatures = data.drop(classLabel, axis=1).values #splits into an array of instances
self.dataPhenotypes = data[classLabel].values
self.dataHeaders = data.drop(classLabel, axis=1).columns.values
tempPhenoArray = np.empty(len(self.dataPhenotypes),dtype=object)
for instanceIndex in range(len(self.dataPhenotypes)):
tempPhenoArray[instanceIndex] = str(self.dataPhenotypes[instanceIndex])
self.dataPhenotypes = tempPhenoArray
tempFeatureArray = np.empty((len(self.dataPhenotypes),len(self.dataHeaders)),dtype=object)
for instanceIndex in range(len(self.dataFeatures)):
for attrInst in range(len(self.dataHeaders)):
tempFeatureArray[instanceIndex][attrInst] = str(self.dataFeatures[instanceIndex][attrInst])
self.dataFeatures = tempFeatureArray
self.delete_all_instances_without_phenotype()
def print_invalid_attributes(self):
print("ALL INVALID ATTRIBUTES & THEIR DISTINCT VALUES")
for attr in range(len(self.dataHeaders)):
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataFeatures)):
val = self.dataFeatures[instIndex,attr]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataFeatures[instIndex,attr])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.dataHeaders[attr])+": ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataPhenotypes)):
val = self.dataPhenotypes[instIndex]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataPhenotypes[instIndex])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.classLabel)+" (the phenotype): ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
def change_class_name(self,newName):
if newName in self.dataHeaders:
raise Exception("New Class Name Cannot Be An Already Existing Data Header Name")
if self.classLabel in self.map.keys():
self.map[self.newName] = self.map.pop(self.classLabel)
self.classLabel = newName
def change_header_name(self,currentName,newName):
if newName in self.dataHeaders or newName == self.classLabel:
raise Exception("New Class Name Cannot Be An Already Existing Data Header or Phenotype Name")
if currentName in self.dataHeaders:
headerIndex = np.where(self.dataHeaders == currentName)[0][0]
self.dataHeaders[headerIndex] = newName
if currentName in self.map.keys():
self.map[newName] = self.map.pop(currentName)
else:
raise Exception("Current Header Doesn't Exist")
def add_attribute_converter(self,headerName,array):#map is an array of strings, ordered by how it is to be enumerated enumeration
if headerName in self.dataHeaders and not (headerName in self.map):
newAttributeConverter = {}
for index in range(len(array)):
if str(array[index]) != "NA" and str(array[index]) != "" and str(array[index]) != "NaN":
newAttributeConverter[str(array[index])] = str(index)
self.map[headerName] = newAttributeConverter
def add_attribute_converter_map(self,headerName,map):
if headerName in self.dataHeaders and not (headerName in self.map) and not("" in map) and not("NA" in map) and not("NaN" in map):
self.map[headerName] = map
else:
raise Exception("Invalid Map")
def add_attribute_converter_random(self,headerName):
if headerName in self.dataHeaders and not (headerName in self.map):
headerIndex = np.where(self.dataHeaders == headerName)[0][0]
uniqueItems = []
for instance in self.dataFeatures:
if not(instance[headerIndex] in uniqueItems) and instance[headerIndex] != "NA":
uniqueItems.append(instance[headerIndex])
self.add_attribute_converter(headerName,np.array(uniqueItems))
def add_class_converter(self,array):
if not (self.classLabel in self.map.keys()):
newAttributeConverter = {}
for index in range(len(array)):
newAttributeConverter[str(array[index])] = str(index)
self.map[self.classLabel] = newAttributeConverter
def add_class_converter_random(self):
if not (self.classLabel in self.map.keys()):
uniqueItems = []
for instance in self.dataPhenotypes:
if not (instance in uniqueItems) and instance != "NA":
uniqueItems.append(instance)
self.add_class_converter(np.array(uniqueItems))
def convert_all_attributes(self):
for attribute in self.dataHeaders:
if attribute in self.map.keys():
i = np.where(self.dataHeaders == attribute)[0][0]
for state in self.dataFeatures:#goes through each instance's state
if (state[i] in self.map[attribute].keys()):
state[i] = self.map[attribute][state[i]]
if self.classLabel in self.map.keys():
for state in self.dataPhenotypes:
if (state in self.map[self.classLabel].keys()):
i = np.where(self.dataPhenotypes == state)
self.dataPhenotypes[i] = self.map[self.classLabel][state]
def delete_attribute(self,headerName):
if headerName in self.dataHeaders:
i = np.where(headerName == self.dataHeaders)[0][0]
self.dataHeaders = np.delete(self.dataHeaders,i)
if headerName in self.map.keys():
del self.map[headerName]
newFeatures = []
for instanceIndex in range(len(self.dataFeatures)):
instance = np.delete(self.dataFeatures[instanceIndex],i)
newFeatures.append(instance)
self.dataFeatures = np.array(newFeatures)
else:
raise Exception("Header Doesn't Exist")
def delete_all_instances_without_header_data(self,headerName):
newFeatures = []
newPhenotypes = []
attributeIndex = np.where(self.dataHeaders == headerName)[0][0]
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataFeatures[instanceIndex]
if instance[attributeIndex] != "NA":
newFeatures.append(instance)
newPhenotypes.append(self.dataPhenotypes[instanceIndex])
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def delete_all_instances_without_phenotype(self):
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataPhenotypes[instanceIndex]
if instance != "NA":
newFeatures.append(self.dataFeatures[instanceIndex])
newPhenotypes.append(instance)
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def print(self):
isFullNumber = self.check_is_full_numeric()
print("Converted Data Features and Phenotypes")
for header in self.dataHeaders:
print(header,end="\t")
print()
for instanceIndex in range(len(self.dataFeatures)):
for attribute in self.dataFeatures[instanceIndex]:
if attribute != "NA":
if (isFullNumber):
print(float(attribute), end="\t")
else:
print(attribute, end="\t\t")
else:
print("NA", end = "\t")
if self.dataPhenotypes[instanceIndex] != "NA":
if (isFullNumber):
print(float(self.dataPhenotypes[instanceIndex]))
else:
print(self.dataPhenotypes[instanceIndex])
else:
print("NA")
print()
def print_attribute_conversions(self):
print("Changed Attribute Conversions")
for headerName,conversions in self.map:
print(headerName + " conversions:")
for original,numberVal in conversions:
print("\tOriginal: "+original+" Converted: "+numberVal)
print()
print()
def check_is_full_numeric(self):
try:
for instance in self.dataFeatures:
for value in instance:
if value != "NA":
float(value)
for value in self.dataPhenotypes:
if value != "NA":
float(value)
except:
return False
return True
def get_params(self):
if not(self.check_is_full_numeric()):
raise Exception("Features and Phenotypes must be fully numeric")
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
newInstance = []
for attribute in self.dataFeatures[instanceIndex]:
if attribute == "NA":
newInstance.append(np.nan)
else:
newInstance.append(float(attribute))
newFeatures.append(np.array(newInstance,dtype=float))
if self.dataPhenotypes[instanceIndex] == "NA": #Should never happen. All NaN phenotypes should be removed automatically at init. Just a safety mechanism.
newPhenotypes.append(np.nan)
else:
newPhenotypes.append(float(self.dataPhenotypes[instanceIndex]))
return self.dataHeaders,self.classLabel,np.array(newFeatures,dtype=float),np.array(newPhenotypes,dtype=float) | scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/skExSTraCS/StringEnumerator.py | StringEnumerator.py | import numpy as np
import pandas as pd
from warnings import simplefilter
# ignore all future warnings
simplefilter(action='ignore', category=FutureWarning)
class StringEnumerator:
def __init__(self, inputFile, classLabel):
self.classLabel = classLabel
self.map = {} #Dictionary of header names: Attribute dictionaries
data = pd.read_csv(inputFile, sep=',') # Puts data from csv into indexable np arrays
data = data.fillna("NA")
self.dataFeatures = data.drop(classLabel, axis=1).values #splits into an array of instances
self.dataPhenotypes = data[classLabel].values
self.dataHeaders = data.drop(classLabel, axis=1).columns.values
tempPhenoArray = np.empty(len(self.dataPhenotypes),dtype=object)
for instanceIndex in range(len(self.dataPhenotypes)):
tempPhenoArray[instanceIndex] = str(self.dataPhenotypes[instanceIndex])
self.dataPhenotypes = tempPhenoArray
tempFeatureArray = np.empty((len(self.dataPhenotypes),len(self.dataHeaders)),dtype=object)
for instanceIndex in range(len(self.dataFeatures)):
for attrInst in range(len(self.dataHeaders)):
tempFeatureArray[instanceIndex][attrInst] = str(self.dataFeatures[instanceIndex][attrInst])
self.dataFeatures = tempFeatureArray
self.delete_all_instances_without_phenotype()
def print_invalid_attributes(self):
print("ALL INVALID ATTRIBUTES & THEIR DISTINCT VALUES")
for attr in range(len(self.dataHeaders)):
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataFeatures)):
val = self.dataFeatures[instIndex,attr]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataFeatures[instIndex,attr])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.dataHeaders[attr])+": ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataPhenotypes)):
val = self.dataPhenotypes[instIndex]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataPhenotypes[instIndex])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.classLabel)+" (the phenotype): ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
def change_class_name(self,newName):
if newName in self.dataHeaders:
raise Exception("New Class Name Cannot Be An Already Existing Data Header Name")
if self.classLabel in self.map.keys():
self.map[self.newName] = self.map.pop(self.classLabel)
self.classLabel = newName
def change_header_name(self,currentName,newName):
if newName in self.dataHeaders or newName == self.classLabel:
raise Exception("New Class Name Cannot Be An Already Existing Data Header or Phenotype Name")
if currentName in self.dataHeaders:
headerIndex = np.where(self.dataHeaders == currentName)[0][0]
self.dataHeaders[headerIndex] = newName
if currentName in self.map.keys():
self.map[newName] = self.map.pop(currentName)
else:
raise Exception("Current Header Doesn't Exist")
def add_attribute_converter(self,headerName,array):#map is an array of strings, ordered by how it is to be enumerated enumeration
if headerName in self.dataHeaders and not (headerName in self.map):
newAttributeConverter = {}
for index in range(len(array)):
if str(array[index]) != "NA" and str(array[index]) != "" and str(array[index]) != "NaN":
newAttributeConverter[str(array[index])] = str(index)
self.map[headerName] = newAttributeConverter
def add_attribute_converter_map(self,headerName,map):
if headerName in self.dataHeaders and not (headerName in self.map) and not("" in map) and not("NA" in map) and not("NaN" in map):
self.map[headerName] = map
else:
raise Exception("Invalid Map")
def add_attribute_converter_random(self,headerName):
if headerName in self.dataHeaders and not (headerName in self.map):
headerIndex = np.where(self.dataHeaders == headerName)[0][0]
uniqueItems = []
for instance in self.dataFeatures:
if not(instance[headerIndex] in uniqueItems) and instance[headerIndex] != "NA":
uniqueItems.append(instance[headerIndex])
self.add_attribute_converter(headerName,np.array(uniqueItems))
def add_class_converter(self,array):
if not (self.classLabel in self.map.keys()):
newAttributeConverter = {}
for index in range(len(array)):
newAttributeConverter[str(array[index])] = str(index)
self.map[self.classLabel] = newAttributeConverter
def add_class_converter_random(self):
if not (self.classLabel in self.map.keys()):
uniqueItems = []
for instance in self.dataPhenotypes:
if not (instance in uniqueItems) and instance != "NA":
uniqueItems.append(instance)
self.add_class_converter(np.array(uniqueItems))
def convert_all_attributes(self):
for attribute in self.dataHeaders:
if attribute in self.map.keys():
i = np.where(self.dataHeaders == attribute)[0][0]
for state in self.dataFeatures:#goes through each instance's state
if (state[i] in self.map[attribute].keys()):
state[i] = self.map[attribute][state[i]]
if self.classLabel in self.map.keys():
for state in self.dataPhenotypes:
if (state in self.map[self.classLabel].keys()):
i = np.where(self.dataPhenotypes == state)
self.dataPhenotypes[i] = self.map[self.classLabel][state]
def delete_attribute(self,headerName):
if headerName in self.dataHeaders:
i = np.where(headerName == self.dataHeaders)[0][0]
self.dataHeaders = np.delete(self.dataHeaders,i)
if headerName in self.map.keys():
del self.map[headerName]
newFeatures = []
for instanceIndex in range(len(self.dataFeatures)):
instance = np.delete(self.dataFeatures[instanceIndex],i)
newFeatures.append(instance)
self.dataFeatures = np.array(newFeatures)
else:
raise Exception("Header Doesn't Exist")
def delete_all_instances_without_header_data(self,headerName):
newFeatures = []
newPhenotypes = []
attributeIndex = np.where(self.dataHeaders == headerName)[0][0]
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataFeatures[instanceIndex]
if instance[attributeIndex] != "NA":
newFeatures.append(instance)
newPhenotypes.append(self.dataPhenotypes[instanceIndex])
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def delete_all_instances_without_phenotype(self):
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataPhenotypes[instanceIndex]
if instance != "NA":
newFeatures.append(self.dataFeatures[instanceIndex])
newPhenotypes.append(instance)
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def print(self):
isFullNumber = self.check_is_full_numeric()
print("Converted Data Features and Phenotypes")
for header in self.dataHeaders:
print(header,end="\t")
print()
for instanceIndex in range(len(self.dataFeatures)):
for attribute in self.dataFeatures[instanceIndex]:
if attribute != "NA":
if (isFullNumber):
print(float(attribute), end="\t")
else:
print(attribute, end="\t\t")
else:
print("NA", end = "\t")
if self.dataPhenotypes[instanceIndex] != "NA":
if (isFullNumber):
print(float(self.dataPhenotypes[instanceIndex]))
else:
print(self.dataPhenotypes[instanceIndex])
else:
print("NA")
print()
def print_attribute_conversions(self):
print("Changed Attribute Conversions")
for headerName,conversions in self.map:
print(headerName + " conversions:")
for original,numberVal in conversions:
print("\tOriginal: "+original+" Converted: "+numberVal)
print()
print()
def check_is_full_numeric(self):
try:
for instance in self.dataFeatures:
for value in instance:
if value != "NA":
float(value)
for value in self.dataPhenotypes:
if value != "NA":
float(value)
except:
return False
return True
def get_params(self):
if not(self.check_is_full_numeric()):
raise Exception("Features and Phenotypes must be fully numeric")
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
newInstance = []
for attribute in self.dataFeatures[instanceIndex]:
if attribute == "NA":
newInstance.append(np.nan)
else:
newInstance.append(float(attribute))
newFeatures.append(np.array(newInstance,dtype=float))
if self.dataPhenotypes[instanceIndex] == "NA": #Should never happen. All NaN phenotypes should be removed automatically at init. Just a safety mechanism.
newPhenotypes.append(np.nan)
else:
newPhenotypes.append(float(self.dataPhenotypes[instanceIndex]))
return self.dataHeaders,self.classLabel,np.array(newFeatures,dtype=float),np.array(newPhenotypes,dtype=float) | 0.140602 | 0.305335 |
import random
import copy
class AttributeTracking:
def __init__(self,model):
self.percent = 0
self.probabilityList = []
self.attAccuracySums = [[0]*model.env.formatData.numAttributes for i in range(model.env.formatData.numTrainInstances)]
def updateAttTrack(self,model,pop):
dataRef = model.env.dataRef
if model.attribute_tracking_method == 'add':
for ref in pop.correctSet:
for each in pop.popSet[ref].specifiedAttList:
self.attAccuracySums[dataRef][each] += pop.popSet[ref].accuracy
elif model.attribute_tracking_method == 'wh':
tempAttTrack = [0]*model.env.formatData.numAttributes
for ref in pop.correctSet:
for each in pop.popSet[ref].specifiedAttList:
tempAttTrack[each] += pop.popSet[ref].accuracy
for attribute_index in range(len(tempAttTrack)):
self.attAccuracySums[dataRef][attribute_index] += model.attribute_tracking_beta * (tempAttTrack[attribute_index] - self.attAccuracySums[dataRef][attribute_index])
def updatePercent(self, model):
""" Determines the frequency with which attribute feedback is applied within the GA. """
self.percent = model.iterationCount/model.learning_iterations
def getTrackProb(self):
""" Returns the tracking probability list. """
return self.probabilityList
def genTrackProb(self,model):
""" Calculate and return the attribute probabilities based on the attribute tracking scores. """
#Choose a random data instance attribute tracking scores
currentInstance = random.randint(0,model.env.formatData.numTrainInstances-1)
#Get data set reference.
trackList = copy.deepcopy(self.attAccuracySums[currentInstance])
#----------------------------------------
minVal = min(trackList)
for i in range(len(trackList)):
trackList[i] = trackList[i] - minVal
maxVal = max(trackList)
#----------------------------------------
probList = []
for i in range(model.env.formatData.numAttributes):
if maxVal == 0.0:
probList.append(0.5)
else:
probList.append(trackList[i]/float(maxVal + maxVal*0.01)) #perhaps make this float a constant, or think of better way to do this.
self.probabilityList = probList
def getSumGlobalAttTrack(self,model):
""" For each attribute, sum the attribute tracking scores over all instances. For Reporting and Debugging"""
globalAttTrack = [0.0 for i in range(model.env.formatData.numAttributes)]
for i in range(model.env.formatData.numAttributes):
for j in range(model.env.formatData.numTrainInstances):
globalAttTrack[i] += self.attAccuracySums[j][i]
return globalAttTrack | scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/skExSTraCS/AttributeTracking.py | AttributeTracking.py | import random
import copy
class AttributeTracking:
def __init__(self,model):
self.percent = 0
self.probabilityList = []
self.attAccuracySums = [[0]*model.env.formatData.numAttributes for i in range(model.env.formatData.numTrainInstances)]
def updateAttTrack(self,model,pop):
dataRef = model.env.dataRef
if model.attribute_tracking_method == 'add':
for ref in pop.correctSet:
for each in pop.popSet[ref].specifiedAttList:
self.attAccuracySums[dataRef][each] += pop.popSet[ref].accuracy
elif model.attribute_tracking_method == 'wh':
tempAttTrack = [0]*model.env.formatData.numAttributes
for ref in pop.correctSet:
for each in pop.popSet[ref].specifiedAttList:
tempAttTrack[each] += pop.popSet[ref].accuracy
for attribute_index in range(len(tempAttTrack)):
self.attAccuracySums[dataRef][attribute_index] += model.attribute_tracking_beta * (tempAttTrack[attribute_index] - self.attAccuracySums[dataRef][attribute_index])
def updatePercent(self, model):
""" Determines the frequency with which attribute feedback is applied within the GA. """
self.percent = model.iterationCount/model.learning_iterations
def getTrackProb(self):
""" Returns the tracking probability list. """
return self.probabilityList
def genTrackProb(self,model):
""" Calculate and return the attribute probabilities based on the attribute tracking scores. """
#Choose a random data instance attribute tracking scores
currentInstance = random.randint(0,model.env.formatData.numTrainInstances-1)
#Get data set reference.
trackList = copy.deepcopy(self.attAccuracySums[currentInstance])
#----------------------------------------
minVal = min(trackList)
for i in range(len(trackList)):
trackList[i] = trackList[i] - minVal
maxVal = max(trackList)
#----------------------------------------
probList = []
for i in range(model.env.formatData.numAttributes):
if maxVal == 0.0:
probList.append(0.5)
else:
probList.append(trackList[i]/float(maxVal + maxVal*0.01)) #perhaps make this float a constant, or think of better way to do this.
self.probabilityList = probList
def getSumGlobalAttTrack(self,model):
""" For each attribute, sum the attribute tracking scores over all instances. For Reporting and Debugging"""
globalAttTrack = [0.0 for i in range(model.env.formatData.numAttributes)]
for i in range(model.env.formatData.numAttributes):
for j in range(model.env.formatData.numTrainInstances):
globalAttTrack[i] += self.attAccuracySums[j][i]
return globalAttTrack | 0.428473 | 0.336658 |
import copy
class ExpertKnowledge:
def __init__(self,model):
self.scores = None
if model.doExpertKnowledge:
if not isinstance(model.expert_knowledge,list):
self.scores = model.expert_knowledge.tolist()
else:
self.scores = model.expert_knowledge
else:
raise Exception("EK is invalid. This should never happen")
self.adjustScores(model)
ekRankFlip = sorted(range(len(self.scores)),key=self.scores.__getitem__)
ekRankFlip.reverse()
self.EKRank = ekRankFlip #List of best to worst scores by index
'''
tempEK = copy.deepcopy(self.scores)
for i in range(len(self.scores)):
bestEK = tempEK[0]
bestC = 0
for j in range(1,len(tempEK)):
if tempEK[j] > bestEK:
bestEK = tempEK[j]
bestC = j
self.EKRank.append(bestC)
tempEK[bestC] = 0
'''
'''
self.refList = []
for i in range(len(self.scores)):
self.refList.append(i)
maxVal = max(self.scores)
probList = []
for i in range(model.env.formatData.numAttributes):
if maxVal == 0.0:
probList.append(0.5)
else:
probList.append(self.scores[i] / float(maxVal + maxVal * 0.01))
self.EKprobabilityList = probList
'''
#ADDED: normalizes self.scores
EKSum = sum(self.scores)
for i in range(len(self.scores)):
self.scores[i]/=EKSum
def adjustScores(self,model):
minEK = min(self.scores)
if minEK <= 0: #Changed to <= 0 insteadd of <0
for i in range(len(self.scores)):
self.scores[i] = self.scores[i] - minEK + model.init_fitness #0.76225 training accuracy w/ init_fitness on 20B MP 5k iter vs 0.8022 accuracy w/o.
if sum(self.scores) == 0:
for i in range(len(self.scores)):
self.scores[i] += 1 | scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/skExSTraCS/ExpertKnowledge.py | ExpertKnowledge.py | import copy
class ExpertKnowledge:
def __init__(self,model):
self.scores = None
if model.doExpertKnowledge:
if not isinstance(model.expert_knowledge,list):
self.scores = model.expert_knowledge.tolist()
else:
self.scores = model.expert_knowledge
else:
raise Exception("EK is invalid. This should never happen")
self.adjustScores(model)
ekRankFlip = sorted(range(len(self.scores)),key=self.scores.__getitem__)
ekRankFlip.reverse()
self.EKRank = ekRankFlip #List of best to worst scores by index
'''
tempEK = copy.deepcopy(self.scores)
for i in range(len(self.scores)):
bestEK = tempEK[0]
bestC = 0
for j in range(1,len(tempEK)):
if tempEK[j] > bestEK:
bestEK = tempEK[j]
bestC = j
self.EKRank.append(bestC)
tempEK[bestC] = 0
'''
'''
self.refList = []
for i in range(len(self.scores)):
self.refList.append(i)
maxVal = max(self.scores)
probList = []
for i in range(model.env.formatData.numAttributes):
if maxVal == 0.0:
probList.append(0.5)
else:
probList.append(self.scores[i] / float(maxVal + maxVal * 0.01))
self.EKprobabilityList = probList
'''
#ADDED: normalizes self.scores
EKSum = sum(self.scores)
for i in range(len(self.scores)):
self.scores[i]/=EKSum
def adjustScores(self,model):
minEK = min(self.scores)
if minEK <= 0: #Changed to <= 0 insteadd of <0
for i in range(len(self.scores)):
self.scores[i] = self.scores[i] - minEK + model.init_fitness #0.76225 training accuracy w/ init_fitness on 20B MP 5k iter vs 0.8022 accuracy w/o.
if sum(self.scores) == 0:
for i in range(len(self.scores)):
self.scores[i] += 1 | 0.258139 | 0.169131 |
import copy
class RuleCompaction:
def __init__(self,model):
self.pop = copy.deepcopy(model.population)
self.originalPopLength = len(model.population.popSet)
if model.rule_compaction == 'Fu1':
self.originalTrainAcc = model.get_final_training_accuracy(RC=True)
self.approach_Fu1(model)
elif model.rule_compaction == 'Fu2':
self.originalTrainAcc = model.get_final_training_accuracy(RC=True)
self.approach_Fu2(model)
elif model.rule_compaction == 'CRA2':
self.approach_CRA2(model)
elif model.rule_compaction == 'QRC':
self.approach_QRC(model)
elif model.rule_compaction == 'PDRC':
self.approach_PDRC(model)
elif model.rule_compaction == 'QRF':
self.approach_QRF()
model.trackingObj.RCCount = self.originalPopLength - len(self.pop.popSet)
model.population = self.pop
def approach_Fu1(self,model):
lastGood_popSet = sorted(self.pop.popSet, key=self.numerositySort)
self.pop.popSet = lastGood_popSet[:]
# STAGE 1----------------------------------------------------------------------------------------------------------------------
keepGoing = True
while keepGoing:
del self.pop.popSet[0] # Remove next classifier
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < self.originalTrainAcc:
keepGoing = False
self.pop.popSet = lastGood_popSet[:]
else:
lastGood_popSet = self.pop.popSet[:]
if len(self.pop.popSet) == 0:
keepGoing = False
# STAGE 2----------------------------------------------------------------------------------------------------------------------
retainedClassifiers = []
RefAccuracy = self.originalTrainAcc
for i in range(len(self.pop.popSet)):
heldClassifier = self.pop.popSet[0]
del self.pop.popSet[0]
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < RefAccuracy:
retainedClassifiers.append(heldClassifier)
RefAccuracy = newAccuracy
self.pop.popSet = retainedClassifiers
# STAGE 3----------------------------------------------------------------------------------------------------------------------
finalClassifiers = []
completelyGeneralRuleRef = None
if len(self.pop.popSet) == 0: # Stop Check
keepGoing = False
else:
keepGoing = True
matchCountList = [0.0 for v in range(len(self.pop.popSet))]
for i in range(len(self.pop.popSet)):
model.env.resetDataRef()
for j in range(model.env.formatData.numTrainInstances):
cl = self.pop.popSet[i]
state = model.env.getTrainInstance()[0]
if cl.match(model,state):
matchCountList[i] += 1
model.env.newInstance()
if len(self.pop.popSet[i].condition) == 0:
completelyGeneralRuleRef = i
if completelyGeneralRuleRef != None:
del matchCountList[completelyGeneralRuleRef]
del self.pop.popSet[completelyGeneralRuleRef]
tempEnv = copy.deepcopy(model.env)
trainingData = tempEnv.formatData.trainFormatted
while len(trainingData[0]) > 0 and keepGoing:
bestRef = None
bestValue = None
for i in range(len(matchCountList)):
if bestValue == None or bestValue < matchCountList[i]:
bestRef = i
bestValue = matchCountList[i]
if bestValue == 0.0 or len(self.pop.popSet) < 1:
keepGoing = False
continue
# Update Training Data----------------------------------------------------------------------------------------------------
matchedData = 0
w = 0
cl = self.pop.popSet[bestRef]
for i in range(len(trainingData[0])):
state = trainingData[0][w]
doesMatch = cl.match(model,state)
if doesMatch:
matchedData += 1
del trainingData[0][w]
del trainingData[1][w]
else:
w += 1
if matchedData > 0:
finalClassifiers.append(self.pop.popSet[bestRef]) # Add best classifier to final list - only do this if there are any remaining matching data instances for this rule!
# Update classifier list
del self.pop.popSet[bestRef]
# re-calculate match count list
matchCountList = [0.0 for v in range(len(self.pop.popSet))]
for i in range(len(self.pop.popSet)):
dataRef = 0
for j in range(len(trainingData[0])): # For each instance in training data
cl = self.pop.popSet[i]
state = trainingData[0][dataRef]
doesMatch = cl.match(model,state)
if doesMatch:
matchCountList[i] += 1
dataRef += 1
if len(self.pop.popSet) == 0:
keepGoing = False
self.pop.popSet = finalClassifiers
def approach_Fu2(self,model):
lastGood_popSet = sorted(self.pop.popSet, key=self.numerositySort)
self.pop.popSet = lastGood_popSet[:]
# STAGE 1----------------------------------------------------------------------------------------------------------------------
keepGoing = True
while keepGoing:
del self.pop.popSet[0] # Remove next classifier
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < self.originalTrainAcc:
keepGoing = False
self.pop.popSet = lastGood_popSet[:]
else:
lastGood_popSet = self.pop.popSet[:]
if len(self.pop.popSet) == 0:
keepGoing = False
# STAGE 2----------------------------------------------------------------------------------------------------------------------
retainedClassifiers = []
RefAccuracy = self.originalTrainAcc
for i in range(len(self.pop.popSet)):
heldClassifier = self.pop.popSet[0]
del self.pop.popSet[0]
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < RefAccuracy:
retainedClassifiers.append(heldClassifier)
RefAccuracy = newAccuracy
self.pop.popSet = retainedClassifiers
# STAGE 3----------------------------------------------------------------------------------------------------------------------
Sort_popSet = sorted(self.pop.popSet, key=self.numerositySort, reverse=True)
self.pop.popSet = Sort_popSet[:]
RefAccuracy = model.get_final_training_accuracy(RC=True)
for i in range(len(self.pop.popSet)):
heldClassifier = self.pop.popSet[0]
del self.pop.popSet[0]
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < RefAccuracy:
self.pop.popSet.append(heldClassifier)
else:
RefAccuracy = newAccuracy
def approach_CRA2(self,model):
retainedClassifiers = []
matchSet = []
correctSet = []
model.env.resetDataRef()
for j in range(model.env.formatData.numTrainInstances):
state_phenotype = model.env.getTrainInstance()
state = state_phenotype[0]
phenotype = state_phenotype[1]
# Create MatchSet
for i in range(len(self.pop.popSet)):
cl = self.pop.popSet[i]
if cl.match(model,state):
matchSet.append(i)
# Create CorrectSet
for i in range(len(matchSet)):
ref = matchSet[i]
if self.pop.popSet[ref].phenotype == phenotype:
correctSet.append(ref)
# Find the rule with highest accuracy, generality product
highestValue = 0
highestRef = 0
for i in range(len(correctSet)):
ref = correctSet[i]
product = self.pop.popSet[ref].accuracy * (model.env.formatData.numAttributes - len(self.pop.popSet[ref].condition)) / float(model.env.formatData.numAttributes)
if product > highestValue:
highestValue = product
highestRef = ref
# If the rule is not already in the final ruleset, move it to the final ruleset
if highestValue == 0 or self.pop.popSet[highestRef] in retainedClassifiers:
pass
else:
retainedClassifiers.append(self.pop.popSet[highestRef])
# Move to the next instance
model.env.newInstance()
matchSet = []
correctSet = []
self.pop.popSet = retainedClassifiers
def approach_QRC(self,model):
finalClassifiers = []
if len(self.pop.popSet) == 0: # Stop check
keepGoing = False
else:
keepGoing = True
lastGood_popSet = sorted(self.pop.popSet, key=self.accuracySort, reverse=True)
self.pop.popSet = lastGood_popSet[:]
tempEnv = copy.deepcopy(model.env)
trainingData = tempEnv.formatData.trainFormatted
while len(trainingData[0]) > 0 and keepGoing:
newTrainSet = [[],[]]
matchedData = 0
for w in range(len(trainingData[0])):
cl = self.pop.popSet[0]
state = trainingData[0][w]
doesMatch = cl.match(model,state)
if doesMatch:
matchedData += 1
else:
newTrainSet[0].append(trainingData[0][w])
newTrainSet[1].append(trainingData[1][w])
if matchedData > 0:
finalClassifiers.append(self.pop.popSet[0]) # Add best classifier to final list - only do this if there are any remaining matching data instances for this rule!
# Update classifier list and training set list
trainingData = newTrainSet
del self.pop.popSet[0]
if len(self.pop.popSet) == 0:
keepGoing = False
self.pop.popSet = finalClassifiers
def approach_PDRC(self,model):
retainedClassifiers = []
matchSet = []
correctSet = []
model.env.resetDataRef()
for j in range(model.env.formatData.numTrainInstances):
state_phenotype = model.env.getTrainInstance()
state = state_phenotype[0]
phenotype = state_phenotype[1]
# Create Match Set
for i in range(len(self.pop.popSet)):
cl = self.pop.popSet[i]
if cl.match(model,state):
matchSet.append(i)
# Create Correct Set
for i in range(len(matchSet)):
ref = matchSet[i]
if self.pop.popSet[ref].phenotype == phenotype:
correctSet.append(ref)
# Find the rule with highest accuracy, generality and numerosity product
highestValue = 0
highestRef = 0
for i in range(len(correctSet)):
ref = correctSet[i]
product = self.pop.popSet[ref].accuracy * (model.env.formatData.numAttributes - len(self.pop.popSet[ref].condition)) / float(model.env.formatData.numAttributes) * self.pop.popSet[ref].numerosity
if product > highestValue:
highestValue = product
highestRef = ref
# If the rule is not already in the final ruleset, move it to the final ruleset
if highestValue == 0 or self.pop.popSet[highestRef] in retainedClassifiers:
pass
else:
retainedClassifiers.append(self.pop.popSet[highestRef])
# Move to the next instance
model.env.newInstance()
matchSet = []
correctSet = []
self.pop.popSet = retainedClassifiers
def approach_QRF(self):
retainedClassifiers = []
for i in range(len(self.pop.popSet)):
if self.pop.popSet[i].accuracy <= 0.5 or (self.pop.popSet[i].correctCover == 1 and len(self.pop.popSet[i].specifiedAttList) > 1):
pass
else:
retainedClassifiers.append(self.pop.popSet[i])
self.pop.popSet = retainedClassifiers
def accuracySort(self, cl):
return cl.accuracy
def numerositySort(self, cl):
""" Sorts from smallest numerosity to largest """
return cl.numerosity | scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/skExSTraCS/RuleCompaction.py | RuleCompaction.py | import copy
class RuleCompaction:
def __init__(self,model):
self.pop = copy.deepcopy(model.population)
self.originalPopLength = len(model.population.popSet)
if model.rule_compaction == 'Fu1':
self.originalTrainAcc = model.get_final_training_accuracy(RC=True)
self.approach_Fu1(model)
elif model.rule_compaction == 'Fu2':
self.originalTrainAcc = model.get_final_training_accuracy(RC=True)
self.approach_Fu2(model)
elif model.rule_compaction == 'CRA2':
self.approach_CRA2(model)
elif model.rule_compaction == 'QRC':
self.approach_QRC(model)
elif model.rule_compaction == 'PDRC':
self.approach_PDRC(model)
elif model.rule_compaction == 'QRF':
self.approach_QRF()
model.trackingObj.RCCount = self.originalPopLength - len(self.pop.popSet)
model.population = self.pop
def approach_Fu1(self,model):
lastGood_popSet = sorted(self.pop.popSet, key=self.numerositySort)
self.pop.popSet = lastGood_popSet[:]
# STAGE 1----------------------------------------------------------------------------------------------------------------------
keepGoing = True
while keepGoing:
del self.pop.popSet[0] # Remove next classifier
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < self.originalTrainAcc:
keepGoing = False
self.pop.popSet = lastGood_popSet[:]
else:
lastGood_popSet = self.pop.popSet[:]
if len(self.pop.popSet) == 0:
keepGoing = False
# STAGE 2----------------------------------------------------------------------------------------------------------------------
retainedClassifiers = []
RefAccuracy = self.originalTrainAcc
for i in range(len(self.pop.popSet)):
heldClassifier = self.pop.popSet[0]
del self.pop.popSet[0]
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < RefAccuracy:
retainedClassifiers.append(heldClassifier)
RefAccuracy = newAccuracy
self.pop.popSet = retainedClassifiers
# STAGE 3----------------------------------------------------------------------------------------------------------------------
finalClassifiers = []
completelyGeneralRuleRef = None
if len(self.pop.popSet) == 0: # Stop Check
keepGoing = False
else:
keepGoing = True
matchCountList = [0.0 for v in range(len(self.pop.popSet))]
for i in range(len(self.pop.popSet)):
model.env.resetDataRef()
for j in range(model.env.formatData.numTrainInstances):
cl = self.pop.popSet[i]
state = model.env.getTrainInstance()[0]
if cl.match(model,state):
matchCountList[i] += 1
model.env.newInstance()
if len(self.pop.popSet[i].condition) == 0:
completelyGeneralRuleRef = i
if completelyGeneralRuleRef != None:
del matchCountList[completelyGeneralRuleRef]
del self.pop.popSet[completelyGeneralRuleRef]
tempEnv = copy.deepcopy(model.env)
trainingData = tempEnv.formatData.trainFormatted
while len(trainingData[0]) > 0 and keepGoing:
bestRef = None
bestValue = None
for i in range(len(matchCountList)):
if bestValue == None or bestValue < matchCountList[i]:
bestRef = i
bestValue = matchCountList[i]
if bestValue == 0.0 or len(self.pop.popSet) < 1:
keepGoing = False
continue
# Update Training Data----------------------------------------------------------------------------------------------------
matchedData = 0
w = 0
cl = self.pop.popSet[bestRef]
for i in range(len(trainingData[0])):
state = trainingData[0][w]
doesMatch = cl.match(model,state)
if doesMatch:
matchedData += 1
del trainingData[0][w]
del trainingData[1][w]
else:
w += 1
if matchedData > 0:
finalClassifiers.append(self.pop.popSet[bestRef]) # Add best classifier to final list - only do this if there are any remaining matching data instances for this rule!
# Update classifier list
del self.pop.popSet[bestRef]
# re-calculate match count list
matchCountList = [0.0 for v in range(len(self.pop.popSet))]
for i in range(len(self.pop.popSet)):
dataRef = 0
for j in range(len(trainingData[0])): # For each instance in training data
cl = self.pop.popSet[i]
state = trainingData[0][dataRef]
doesMatch = cl.match(model,state)
if doesMatch:
matchCountList[i] += 1
dataRef += 1
if len(self.pop.popSet) == 0:
keepGoing = False
self.pop.popSet = finalClassifiers
def approach_Fu2(self,model):
lastGood_popSet = sorted(self.pop.popSet, key=self.numerositySort)
self.pop.popSet = lastGood_popSet[:]
# STAGE 1----------------------------------------------------------------------------------------------------------------------
keepGoing = True
while keepGoing:
del self.pop.popSet[0] # Remove next classifier
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < self.originalTrainAcc:
keepGoing = False
self.pop.popSet = lastGood_popSet[:]
else:
lastGood_popSet = self.pop.popSet[:]
if len(self.pop.popSet) == 0:
keepGoing = False
# STAGE 2----------------------------------------------------------------------------------------------------------------------
retainedClassifiers = []
RefAccuracy = self.originalTrainAcc
for i in range(len(self.pop.popSet)):
heldClassifier = self.pop.popSet[0]
del self.pop.popSet[0]
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < RefAccuracy:
retainedClassifiers.append(heldClassifier)
RefAccuracy = newAccuracy
self.pop.popSet = retainedClassifiers
# STAGE 3----------------------------------------------------------------------------------------------------------------------
Sort_popSet = sorted(self.pop.popSet, key=self.numerositySort, reverse=True)
self.pop.popSet = Sort_popSet[:]
RefAccuracy = model.get_final_training_accuracy(RC=True)
for i in range(len(self.pop.popSet)):
heldClassifier = self.pop.popSet[0]
del self.pop.popSet[0]
newAccuracy = model.get_final_training_accuracy(RC=True) # Perform classifier set training accuracy evaluation
if newAccuracy < RefAccuracy:
self.pop.popSet.append(heldClassifier)
else:
RefAccuracy = newAccuracy
def approach_CRA2(self,model):
retainedClassifiers = []
matchSet = []
correctSet = []
model.env.resetDataRef()
for j in range(model.env.formatData.numTrainInstances):
state_phenotype = model.env.getTrainInstance()
state = state_phenotype[0]
phenotype = state_phenotype[1]
# Create MatchSet
for i in range(len(self.pop.popSet)):
cl = self.pop.popSet[i]
if cl.match(model,state):
matchSet.append(i)
# Create CorrectSet
for i in range(len(matchSet)):
ref = matchSet[i]
if self.pop.popSet[ref].phenotype == phenotype:
correctSet.append(ref)
# Find the rule with highest accuracy, generality product
highestValue = 0
highestRef = 0
for i in range(len(correctSet)):
ref = correctSet[i]
product = self.pop.popSet[ref].accuracy * (model.env.formatData.numAttributes - len(self.pop.popSet[ref].condition)) / float(model.env.formatData.numAttributes)
if product > highestValue:
highestValue = product
highestRef = ref
# If the rule is not already in the final ruleset, move it to the final ruleset
if highestValue == 0 or self.pop.popSet[highestRef] in retainedClassifiers:
pass
else:
retainedClassifiers.append(self.pop.popSet[highestRef])
# Move to the next instance
model.env.newInstance()
matchSet = []
correctSet = []
self.pop.popSet = retainedClassifiers
def approach_QRC(self,model):
finalClassifiers = []
if len(self.pop.popSet) == 0: # Stop check
keepGoing = False
else:
keepGoing = True
lastGood_popSet = sorted(self.pop.popSet, key=self.accuracySort, reverse=True)
self.pop.popSet = lastGood_popSet[:]
tempEnv = copy.deepcopy(model.env)
trainingData = tempEnv.formatData.trainFormatted
while len(trainingData[0]) > 0 and keepGoing:
newTrainSet = [[],[]]
matchedData = 0
for w in range(len(trainingData[0])):
cl = self.pop.popSet[0]
state = trainingData[0][w]
doesMatch = cl.match(model,state)
if doesMatch:
matchedData += 1
else:
newTrainSet[0].append(trainingData[0][w])
newTrainSet[1].append(trainingData[1][w])
if matchedData > 0:
finalClassifiers.append(self.pop.popSet[0]) # Add best classifier to final list - only do this if there are any remaining matching data instances for this rule!
# Update classifier list and training set list
trainingData = newTrainSet
del self.pop.popSet[0]
if len(self.pop.popSet) == 0:
keepGoing = False
self.pop.popSet = finalClassifiers
def approach_PDRC(self,model):
retainedClassifiers = []
matchSet = []
correctSet = []
model.env.resetDataRef()
for j in range(model.env.formatData.numTrainInstances):
state_phenotype = model.env.getTrainInstance()
state = state_phenotype[0]
phenotype = state_phenotype[1]
# Create Match Set
for i in range(len(self.pop.popSet)):
cl = self.pop.popSet[i]
if cl.match(model,state):
matchSet.append(i)
# Create Correct Set
for i in range(len(matchSet)):
ref = matchSet[i]
if self.pop.popSet[ref].phenotype == phenotype:
correctSet.append(ref)
# Find the rule with highest accuracy, generality and numerosity product
highestValue = 0
highestRef = 0
for i in range(len(correctSet)):
ref = correctSet[i]
product = self.pop.popSet[ref].accuracy * (model.env.formatData.numAttributes - len(self.pop.popSet[ref].condition)) / float(model.env.formatData.numAttributes) * self.pop.popSet[ref].numerosity
if product > highestValue:
highestValue = product
highestRef = ref
# If the rule is not already in the final ruleset, move it to the final ruleset
if highestValue == 0 or self.pop.popSet[highestRef] in retainedClassifiers:
pass
else:
retainedClassifiers.append(self.pop.popSet[highestRef])
# Move to the next instance
model.env.newInstance()
matchSet = []
correctSet = []
self.pop.popSet = retainedClassifiers
def approach_QRF(self):
retainedClassifiers = []
for i in range(len(self.pop.popSet)):
if self.pop.popSet[i].accuracy <= 0.5 or (self.pop.popSet[i].correctCover == 1 and len(self.pop.popSet[i].specifiedAttList) > 1):
pass
else:
retainedClassifiers.append(self.pop.popSet[i])
self.pop.popSet = retainedClassifiers
def accuracySort(self, cl):
return cl.accuracy
def numerositySort(self, cl):
""" Sorts from smallest numerosity to largest """
return cl.numerosity | 0.395368 | 0.366448 |
import time
class Timer:
def __init__(self):
""" Initializes all Timer values for the algorithm """
# Global Time objects
self.globalStartRef = time.time()
self.globalTime = 0.0
self.addedTime = 0.0
# Match Time Variables
self.startRefMatching = 0.0
self.globalMatching = 0.0
# Covering Time Variables
self.startRefCovering = 0.0
self.globalCovering = 0.0
# Deletion Time Variables
self.startRefDeletion = 0.0
self.globalDeletion = 0.0
# Subsumption Time Variables
self.startRefSubsumption = 0.0
self.globalSubsumption = 0.0
# Selection Time Variables
self.startRefSelection = 0.0
self.globalSelection = 0.0
# Crossover Time Variables
self.startRefCrossover = 0.0
self.globalCrossover = 0.0
# Mutation Time Variables
self.startRefMutation = 0.0
self.globalMutation = 0.0
# Attribute Tracking and Feedback
self.startRefAT = 0.0
self.globalAT = 0.0
# Expert Knowledge (EK)
self.startRefEK = 0.0
self.globalEK = 0.0
# Initialization
self.startRefInit = 0.0
self.globalInit = 0.0
# Add Classifier
self.startRefAdd = 0.0
self.globalAdd = 0.0
# Evaluation Time Variables
self.startRefEvaluation = 0.0
self.globalEvaluation = 0.0
# Rule Compaction
self.startRefRuleCmp = 0.0
self.globalRuleCmp = 0.0
# ************************************************************
def startTimeMatching(self):
""" Tracks MatchSet Time """
self.startRefMatching = time.time()
def stopTimeMatching(self):
""" Tracks MatchSet Time """
diff = time.time() - self.startRefMatching
self.globalMatching += diff
# ************************************************************
def startTimeCovering(self):
""" Tracks MatchSet Time """
self.startRefCovering = time.time()
def stopTimeCovering(self):
""" Tracks MatchSet Time """
diff = time.time() - self.startRefCovering
self.globalCovering += diff
# ************************************************************
def startTimeDeletion(self):
""" Tracks Deletion Time """
self.startRefDeletion = time.time()
def stopTimeDeletion(self):
""" Tracks Deletion Time """
diff = time.time() - self.startRefDeletion
self.globalDeletion += diff
# ************************************************************
def startTimeCrossover(self):
""" Tracks Crossover Time """
self.startRefCrossover = time.time()
def stopTimeCrossover(self):
""" Tracks Crossover Time """
diff = time.time() - self.startRefCrossover
self.globalCrossover += diff
# ************************************************************
def startTimeMutation(self):
""" Tracks Mutation Time """
self.startRefMutation = time.time()
def stopTimeMutation(self):
""" Tracks Mutation Time """
diff = time.time() - self.startRefMutation
self.globalMutation += diff
# ************************************************************
def startTimeSubsumption(self):
"""Tracks Subsumption Time """
self.startRefSubsumption = time.time()
def stopTimeSubsumption(self):
"""Tracks Subsumption Time """
diff = time.time() - self.startRefSubsumption
self.globalSubsumption += diff
# ************************************************************
def startTimeSelection(self):
""" Tracks Selection Time """
self.startRefSelection = time.time()
def stopTimeSelection(self):
""" Tracks Selection Time """
diff = time.time() - self.startRefSelection
self.globalSelection += diff
# ************************************************************
def startTimeEvaluation(self):
""" Tracks Evaluation Time """
self.startRefEvaluation = time.time()
def stopTimeEvaluation(self):
""" Tracks Evaluation Time """
diff = time.time() - self.startRefEvaluation
self.globalEvaluation += diff
# ************************************************************
def startTimeRuleCmp(self):
""" """
self.startRefRuleCmp = time.time()
def stopTimeRuleCmp(self):
""" """
diff = time.time() - self.startRefRuleCmp
self.globalRuleCmp += diff
# ***********************************************************
def startTimeAT(self):
""" """
self.startRefAT = time.time()
def stopTimeAT(self):
""" """
diff = time.time() - self.startRefAT
self.globalAT += diff
# ***********************************************************
def startTimeEK(self):
""" """
self.startRefEK = time.time()
def stopTimeEK(self):
""" """
diff = time.time() - self.startRefEK
self.globalEK += diff
# ***********************************************************
def startTimeInit(self):
""" """
self.startRefInit = time.time()
def stopTimeInit(self):
""" """
diff = time.time() - self.startRefInit
self.globalInit += diff
# ***********************************************************
def startTimeAdd(self):
""" """
self.startRefAdd = time.time()
def stopTimeAdd(self):
""" """
diff = time.time() - self.startRefAdd
self.globalAdd += diff
# ***********************************************************
def updateGlobalTimer(self):
""" Update the global timer """
self.globalTime = (time.time() - self.globalStartRef) + self.addedTime | scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/skExSTraCS/Timer.py | Timer.py | import time
class Timer:
def __init__(self):
""" Initializes all Timer values for the algorithm """
# Global Time objects
self.globalStartRef = time.time()
self.globalTime = 0.0
self.addedTime = 0.0
# Match Time Variables
self.startRefMatching = 0.0
self.globalMatching = 0.0
# Covering Time Variables
self.startRefCovering = 0.0
self.globalCovering = 0.0
# Deletion Time Variables
self.startRefDeletion = 0.0
self.globalDeletion = 0.0
# Subsumption Time Variables
self.startRefSubsumption = 0.0
self.globalSubsumption = 0.0
# Selection Time Variables
self.startRefSelection = 0.0
self.globalSelection = 0.0
# Crossover Time Variables
self.startRefCrossover = 0.0
self.globalCrossover = 0.0
# Mutation Time Variables
self.startRefMutation = 0.0
self.globalMutation = 0.0
# Attribute Tracking and Feedback
self.startRefAT = 0.0
self.globalAT = 0.0
# Expert Knowledge (EK)
self.startRefEK = 0.0
self.globalEK = 0.0
# Initialization
self.startRefInit = 0.0
self.globalInit = 0.0
# Add Classifier
self.startRefAdd = 0.0
self.globalAdd = 0.0
# Evaluation Time Variables
self.startRefEvaluation = 0.0
self.globalEvaluation = 0.0
# Rule Compaction
self.startRefRuleCmp = 0.0
self.globalRuleCmp = 0.0
# ************************************************************
def startTimeMatching(self):
""" Tracks MatchSet Time """
self.startRefMatching = time.time()
def stopTimeMatching(self):
""" Tracks MatchSet Time """
diff = time.time() - self.startRefMatching
self.globalMatching += diff
# ************************************************************
def startTimeCovering(self):
""" Tracks MatchSet Time """
self.startRefCovering = time.time()
def stopTimeCovering(self):
""" Tracks MatchSet Time """
diff = time.time() - self.startRefCovering
self.globalCovering += diff
# ************************************************************
def startTimeDeletion(self):
""" Tracks Deletion Time """
self.startRefDeletion = time.time()
def stopTimeDeletion(self):
""" Tracks Deletion Time """
diff = time.time() - self.startRefDeletion
self.globalDeletion += diff
# ************************************************************
def startTimeCrossover(self):
""" Tracks Crossover Time """
self.startRefCrossover = time.time()
def stopTimeCrossover(self):
""" Tracks Crossover Time """
diff = time.time() - self.startRefCrossover
self.globalCrossover += diff
# ************************************************************
def startTimeMutation(self):
""" Tracks Mutation Time """
self.startRefMutation = time.time()
def stopTimeMutation(self):
""" Tracks Mutation Time """
diff = time.time() - self.startRefMutation
self.globalMutation += diff
# ************************************************************
def startTimeSubsumption(self):
"""Tracks Subsumption Time """
self.startRefSubsumption = time.time()
def stopTimeSubsumption(self):
"""Tracks Subsumption Time """
diff = time.time() - self.startRefSubsumption
self.globalSubsumption += diff
# ************************************************************
def startTimeSelection(self):
""" Tracks Selection Time """
self.startRefSelection = time.time()
def stopTimeSelection(self):
""" Tracks Selection Time """
diff = time.time() - self.startRefSelection
self.globalSelection += diff
# ************************************************************
def startTimeEvaluation(self):
""" Tracks Evaluation Time """
self.startRefEvaluation = time.time()
def stopTimeEvaluation(self):
""" Tracks Evaluation Time """
diff = time.time() - self.startRefEvaluation
self.globalEvaluation += diff
# ************************************************************
def startTimeRuleCmp(self):
""" """
self.startRefRuleCmp = time.time()
def stopTimeRuleCmp(self):
""" """
diff = time.time() - self.startRefRuleCmp
self.globalRuleCmp += diff
# ***********************************************************
def startTimeAT(self):
""" """
self.startRefAT = time.time()
def stopTimeAT(self):
""" """
diff = time.time() - self.startRefAT
self.globalAT += diff
# ***********************************************************
def startTimeEK(self):
""" """
self.startRefEK = time.time()
def stopTimeEK(self):
""" """
diff = time.time() - self.startRefEK
self.globalEK += diff
# ***********************************************************
def startTimeInit(self):
""" """
self.startRefInit = time.time()
def stopTimeInit(self):
""" """
diff = time.time() - self.startRefInit
self.globalInit += diff
# ***********************************************************
def startTimeAdd(self):
""" """
self.startRefAdd = time.time()
def stopTimeAdd(self):
""" """
diff = time.time() - self.startRefAdd
self.globalAdd += diff
# ***********************************************************
def updateGlobalTimer(self):
""" Update the global timer """
self.globalTime = (time.time() - self.globalStartRef) + self.addedTime | 0.565899 | 0.184327 |
from skExSTraCS.Classifier import Classifier
import copy
import random
class ClassifierSet:
def __init__(self):
self.popSet = [] # List of classifiers/rules
self.matchSet = [] # List of references to rules in population that match
self.correctSet = [] # List of references to rules in population that both match and specify correct phenotype
self.microPopSize = 0
def makeMatchSet(self,model,state_phenotype):
state = state_phenotype[0]
phenotype = state_phenotype[1]
doCovering = True
setNumerositySum = 0
model.timer.startTimeMatching()
for i in range(len(self.popSet)):
cl = self.popSet[i]
cl.updateEpochStatus(model)
if cl.match(model,state):
self.matchSet.append(i)
setNumerositySum += cl.numerosity
if cl.phenotype == phenotype:
doCovering = False
model.timer.stopTimeMatching()
model.timer.startTimeCovering()
while doCovering:
newCl = Classifier(model)
newCl.initializeByCovering(model,setNumerositySum+1,state,phenotype)
if len(newCl.specifiedAttList) > 0: #ADDED CHECK TO PREVENT FULLY GENERALIZED RULES
self.addClassifierToPopulation(model,newCl,True)
self.matchSet.append(len(self.popSet)-1)
model.trackingObj.coveringCount += 1
doCovering = False
model.timer.stopTimeCovering()
def addClassifierToPopulation(self,model,cl,covering):
model.timer.startTimeAdd()
oldCl = None
if not covering:
oldCl = self.getIdenticalClassifier(cl)
if oldCl != None:
oldCl.updateNumerosity(1)
self.microPopSize += 1
else:
self.popSet.append(cl)
self.microPopSize += 1
model.timer.stopTimeAdd()
def getIdenticalClassifier(self,newCl):
for cl in self.popSet:
if newCl.equals(cl):
return cl
return None
def makeCorrectSet(self,phenotype):
for i in range(len(self.matchSet)):
ref = self.matchSet[i]
if self.popSet[ref].phenotype == phenotype:
self.correctSet.append(ref)
def updateSets(self,model):
""" Updates all relevant parameters in the current match and correct sets. """
matchSetNumerosity = 0
for ref in self.matchSet:
matchSetNumerosity += self.popSet[ref].numerosity
for ref in self.matchSet:
self.popSet[ref].updateExperience()
self.popSet[ref].updateMatchSetSize(model,matchSetNumerosity) # Moved to match set to be like GHCS
if ref in self.correctSet:
self.popSet[ref].updateCorrect()
self.popSet[ref].updateAccuracy()
self.popSet[ref].updateFitness(model)
def do_correct_set_subsumption(self,model):
subsumer = None
for ref in self.correctSet:
cl = self.popSet[ref]
if cl.isSubsumer(model):
if subsumer == None or cl.isMoreGeneral(model,subsumer):
subsumer = cl
if subsumer != None:
i = 0
while i < len(self.correctSet):
ref = self.correctSet[i]
if subsumer.isMoreGeneral(model,self.popSet[ref]):
model.trackingObj.subsumptionCount += 1
model.trackingObj.subsumptionCount += 1
subsumer.updateNumerosity(self.popSet[ref].numerosity)
self.removeMacroClassifier(ref)
self.deleteFromMatchSet(ref)
self.deleteFromCorrectSet(ref)
i -= 1
i+=1
def removeMacroClassifier(self, ref):
""" Removes the specified (macro-) classifier from the population. """
self.popSet.pop(ref)
def deleteFromMatchSet(self, deleteRef):
""" Delete reference to classifier in population, contained in self.matchSet."""
if deleteRef in self.matchSet:
self.matchSet.remove(deleteRef)
# Update match set reference list--------
for j in range(len(self.matchSet)):
ref = self.matchSet[j]
if ref > deleteRef:
self.matchSet[j] -= 1
def deleteFromCorrectSet(self, deleteRef):
""" Delete reference to classifier in population, contained in self.matchSet."""
if deleteRef in self.correctSet:
self.correctSet.remove(deleteRef)
# Update match set reference list--------
for j in range(len(self.correctSet)):
ref = self.correctSet[j]
if ref > deleteRef:
self.correctSet[j] -= 1
def runGA(self,model,state,phenotype):
if model.iterationCount - self.getIterStampAverage() < model.theta_GA:
return
self.setIterStamps(model.iterationCount)
changed = False
#Select Parents
model.timer.startTimeSelection()
if model.selection_method == "roulette":
selectList = self.selectClassifierRW()
clP1 = selectList[0]
clP2 = selectList[1]
elif model.selection_method == "tournament":
selectList = self.selectClassifierT(model)
clP1 = selectList[0]
clP2 = selectList[1]
model.timer.stopTimeSelection()
#Create Offspring Copies
cl1 = Classifier(model)
cl1.initializeByCopy(clP1,model.iterationCount)
cl2 = Classifier(model)
if clP2 == None:
cl2.initializeByCopy(clP1,model.iterationCount)
else:
cl2.initializeByCopy(clP2,model.iterationCount)
#Crossover
if not cl1.equals(cl2) and random.random() < model.chi:
model.timer.startTimeCrossover()
changed = cl1.uniformCrossover(model,cl2)
model.timer.stopTimeCrossover()
if changed:
cl1.setAccuracy((cl1.accuracy + cl2.accuracy)/2.0)
cl1.setFitness(model.fitness_reduction * (cl1.fitness + cl2.fitness)/2.0)
cl2.setAccuracy(cl1.accuracy)
cl2.setFitness(cl1.fitness)
else:
cl1.setFitness(model.fitness_reduction * cl1.fitness)
cl2.setFitness(model.fitness_reduction * cl2.fitness)
#Mutation
model.timer.startTimeMutation()
nowchanged = cl1.mutation(model,state)
howaboutnow = cl2.mutation(model,state)
model.timer.stopTimeMutation()
if model.env.formatData.continuousCount > 0:
cl1.rangeCheck(model)
cl2.rangeCheck(model)
if changed or nowchanged or howaboutnow:
if nowchanged:
model.trackingObj.mutationCount += 1
if howaboutnow:
model.trackingObj.mutationCount += 1
if changed:
model.trackingObj.crossOverCount += 1
self.insertDiscoveredClassifiers(model,cl1, cl2, clP1, clP2) #Includes subsumption if activated.
def insertDiscoveredClassifiers(self,model,cl1,cl2,clP1,clP2):
if model.do_GA_subsumption:
model.timer.startTimeSubsumption()
if len(cl1.specifiedAttList) > 0:
self.subsumeClassifier(model,cl1, clP1, clP2)
if len(cl2.specifiedAttList) > 0:
self.subsumeClassifier(model,cl2, clP1, clP2)
model.timer.stopTimeSubsumption()
else:
if len(cl1.specifiedAttList) > 0:
self.addClassifierToPopulation(model,cl1,False)
if len(cl2.specifiedAttList) > 0:
self.addClassifierToPopulation(model,cl2,False)
def subsumeClassifier(self, model,cl, cl1P, cl2P):
""" Tries to subsume a classifier in the parents. If no subsumption is possible it tries to subsume it in the current set. """
if cl1P!=None and cl1P.subsumes(model,cl):
self.microPopSize += 1
cl1P.updateNumerosity(1)
model.trackingObj.subsumptionCount+=1
elif cl2P!=None and cl2P.subsumes(model,cl):
self.microPopSize += 1
cl2P.updateNumerosity(1)
model.trackingObj.subsumptionCount += 1
else:
if len(cl.specifiedAttList) > 0:
self.addClassifierToPopulation(model, cl, False)
def selectClassifierRW(self):
setList = copy.deepcopy(self.correctSet)
if len(setList) > 2:
selectList = [None,None]
currentCount = 0
while currentCount < 2:
fitSum = self.getFitnessSum(setList)
choiceP = random.random() * fitSum
i = 0
sumCl = self.popSet[setList[i]].fitness
while choiceP > sumCl:
i = i + 1
sumCl += self.popSet[setList[i]].fitness
selectList[currentCount] = self.popSet[setList[i]]
setList.remove(setList[i])
currentCount += 1
elif len(setList) == 2:
selectList = [self.popSet[setList[0]], self.popSet[setList[1]]]
elif len(setList) == 1:
selectList = [self.popSet[setList[0]], self.popSet[setList[0]]]
return selectList
def getFitnessSum(self, setList):
""" Returns the sum of the fitnesses of all classifiers in the set. """
sumCl = 0.0
for i in range(len(setList)):
ref = setList[i]
sumCl += self.popSet[ref].fitness
return sumCl
def selectClassifierT(self,model):
selectList = [None, None]
currentCount = 0
setList = self.correctSet
while currentCount < 2:
tSize = int(len(setList) * model.theta_sel)
#Select tSize elements from correctSet
posList = random.sample(setList,tSize)
bestF = 0
bestC = self.correctSet[0]
for j in posList:
if self.popSet[j].fitness > bestF:
bestF = self.popSet[j].fitness
bestC = j
selectList[currentCount] = self.popSet[bestC]
currentCount += 1
return selectList
def getIterStampAverage(self):
""" Returns the average of the time stamps in the correct set. """
sumCl=0
numSum=0
for i in range(len(self.correctSet)):
ref = self.correctSet[i]
sumCl += self.popSet[ref].timeStampGA * self.popSet[ref].numerosity
numSum += self.popSet[ref].numerosity #numerosity sum of correct set
if numSum != 0:
return sumCl / float(numSum)
else:
return 0
def getInitStampAverage(self):
sumCl = 0.0
numSum = 0.0
for i in range(len(self.correctSet)):
ref = self.correctSet[i]
sumCl += self.popSet[ref].initTimeStamp * self.popSet[ref].numerosity
numSum += self.popSet[ref].numerosity
if numSum != 0:
return sumCl / float(numSum)
else:
return 0
def setIterStamps(self, iterationCount):
""" Sets the time stamp of all classifiers in the set to the current time. The current time
is the number of exploration steps executed so far. """
for i in range(len(self.correctSet)):
ref = self.correctSet[i]
self.popSet[ref].updateTimeStamp(iterationCount)
def deletion(self,model):
model.timer.startTimeDeletion()
while self.microPopSize > model.N:
self.deleteFromPopulation(model)
model.timer.stopTimeDeletion()
def deleteFromPopulation(self,model):
meanFitness = self.getPopFitnessSum() / float(self.microPopSize)
sumCl = 0.0
voteList = []
for cl in self.popSet:
vote = cl.getDelProp(model,meanFitness)
sumCl += vote
voteList.append(vote)
i = 0
for cl in self.popSet:
cl.deletionProb = voteList[i] / sumCl
i += 1
choicePoint = sumCl * random.random() # Determine the choice point
newSum = 0.0
for i in range(len(voteList)):
cl = self.popSet[i]
newSum = newSum + voteList[i]
if newSum > choicePoint: # Select classifier for deletion
# Delete classifier----------------------------------
cl.updateNumerosity(-1)
self.microPopSize -= 1
if cl.numerosity < 1: # When all micro-classifiers for a given classifier have been depleted.
self.removeMacroClassifier(i)
self.deleteFromMatchSet(i)
self.deleteFromCorrectSet(i)
model.trackingObj.deletionCount += 1
return
def getPopFitnessSum(self):
""" Returns the sum of the fitnesses of all classifiers in the set. """
sumCl=0.0
for cl in self.popSet:
sumCl += cl.fitness *cl.numerosity
return sumCl
def clearSets(self):
""" Clears out references in the match and correct sets for the next learning iteration. """
self.matchSet = []
self.correctSet = []
def getAveGenerality(self,model):
genSum = 0
for cl in self.popSet:
genSum += ((model.env.formatData.numAttributes - len(cl.condition))/float(model.env.formatData.numAttributes))*cl.numerosity
if self.microPopSize == 0:
aveGenerality = 0
else:
aveGenerality = genSum/float(self.microPopSize)
return aveGenerality
def makeEvalMatchSet(self,model,state):
for i in range(len(self.popSet)):
cl = self.popSet[i]
if cl.match(model,state):
self.matchSet.append(i)
def getAttributeSpecificityList(self,model):
attributeSpecList = []
for i in range(model.env.formatData.numAttributes):
attributeSpecList.append(0)
for cl in self.popSet:
for ref in cl.specifiedAttList:
attributeSpecList[ref] += cl.numerosity
return attributeSpecList
def getAttributeAccuracyList(self,model):
attributeAccList = []
for i in range(model.env.formatData.numAttributes):
attributeAccList.append(0.0)
for cl in self.popSet:
for ref in cl.specifiedAttList:
attributeAccList[ref] += cl.numerosity * cl.accuracy
return attributeAccList | scikit-ExSTraCS | /scikit-ExSTraCS-1.1.1.tar.gz/scikit-ExSTraCS-1.1.1/skExSTraCS/ClassifierSet.py | ClassifierSet.py | from skExSTraCS.Classifier import Classifier
import copy
import random
class ClassifierSet:
def __init__(self):
self.popSet = [] # List of classifiers/rules
self.matchSet = [] # List of references to rules in population that match
self.correctSet = [] # List of references to rules in population that both match and specify correct phenotype
self.microPopSize = 0
def makeMatchSet(self,model,state_phenotype):
state = state_phenotype[0]
phenotype = state_phenotype[1]
doCovering = True
setNumerositySum = 0
model.timer.startTimeMatching()
for i in range(len(self.popSet)):
cl = self.popSet[i]
cl.updateEpochStatus(model)
if cl.match(model,state):
self.matchSet.append(i)
setNumerositySum += cl.numerosity
if cl.phenotype == phenotype:
doCovering = False
model.timer.stopTimeMatching()
model.timer.startTimeCovering()
while doCovering:
newCl = Classifier(model)
newCl.initializeByCovering(model,setNumerositySum+1,state,phenotype)
if len(newCl.specifiedAttList) > 0: #ADDED CHECK TO PREVENT FULLY GENERALIZED RULES
self.addClassifierToPopulation(model,newCl,True)
self.matchSet.append(len(self.popSet)-1)
model.trackingObj.coveringCount += 1
doCovering = False
model.timer.stopTimeCovering()
def addClassifierToPopulation(self,model,cl,covering):
model.timer.startTimeAdd()
oldCl = None
if not covering:
oldCl = self.getIdenticalClassifier(cl)
if oldCl != None:
oldCl.updateNumerosity(1)
self.microPopSize += 1
else:
self.popSet.append(cl)
self.microPopSize += 1
model.timer.stopTimeAdd()
def getIdenticalClassifier(self,newCl):
for cl in self.popSet:
if newCl.equals(cl):
return cl
return None
def makeCorrectSet(self,phenotype):
for i in range(len(self.matchSet)):
ref = self.matchSet[i]
if self.popSet[ref].phenotype == phenotype:
self.correctSet.append(ref)
def updateSets(self,model):
""" Updates all relevant parameters in the current match and correct sets. """
matchSetNumerosity = 0
for ref in self.matchSet:
matchSetNumerosity += self.popSet[ref].numerosity
for ref in self.matchSet:
self.popSet[ref].updateExperience()
self.popSet[ref].updateMatchSetSize(model,matchSetNumerosity) # Moved to match set to be like GHCS
if ref in self.correctSet:
self.popSet[ref].updateCorrect()
self.popSet[ref].updateAccuracy()
self.popSet[ref].updateFitness(model)
def do_correct_set_subsumption(self,model):
subsumer = None
for ref in self.correctSet:
cl = self.popSet[ref]
if cl.isSubsumer(model):
if subsumer == None or cl.isMoreGeneral(model,subsumer):
subsumer = cl
if subsumer != None:
i = 0
while i < len(self.correctSet):
ref = self.correctSet[i]
if subsumer.isMoreGeneral(model,self.popSet[ref]):
model.trackingObj.subsumptionCount += 1
model.trackingObj.subsumptionCount += 1
subsumer.updateNumerosity(self.popSet[ref].numerosity)
self.removeMacroClassifier(ref)
self.deleteFromMatchSet(ref)
self.deleteFromCorrectSet(ref)
i -= 1
i+=1
def removeMacroClassifier(self, ref):
""" Removes the specified (macro-) classifier from the population. """
self.popSet.pop(ref)
def deleteFromMatchSet(self, deleteRef):
""" Delete reference to classifier in population, contained in self.matchSet."""
if deleteRef in self.matchSet:
self.matchSet.remove(deleteRef)
# Update match set reference list--------
for j in range(len(self.matchSet)):
ref = self.matchSet[j]
if ref > deleteRef:
self.matchSet[j] -= 1
def deleteFromCorrectSet(self, deleteRef):
""" Delete reference to classifier in population, contained in self.matchSet."""
if deleteRef in self.correctSet:
self.correctSet.remove(deleteRef)
# Update match set reference list--------
for j in range(len(self.correctSet)):
ref = self.correctSet[j]
if ref > deleteRef:
self.correctSet[j] -= 1
def runGA(self,model,state,phenotype):
if model.iterationCount - self.getIterStampAverage() < model.theta_GA:
return
self.setIterStamps(model.iterationCount)
changed = False
#Select Parents
model.timer.startTimeSelection()
if model.selection_method == "roulette":
selectList = self.selectClassifierRW()
clP1 = selectList[0]
clP2 = selectList[1]
elif model.selection_method == "tournament":
selectList = self.selectClassifierT(model)
clP1 = selectList[0]
clP2 = selectList[1]
model.timer.stopTimeSelection()
#Create Offspring Copies
cl1 = Classifier(model)
cl1.initializeByCopy(clP1,model.iterationCount)
cl2 = Classifier(model)
if clP2 == None:
cl2.initializeByCopy(clP1,model.iterationCount)
else:
cl2.initializeByCopy(clP2,model.iterationCount)
#Crossover
if not cl1.equals(cl2) and random.random() < model.chi:
model.timer.startTimeCrossover()
changed = cl1.uniformCrossover(model,cl2)
model.timer.stopTimeCrossover()
if changed:
cl1.setAccuracy((cl1.accuracy + cl2.accuracy)/2.0)
cl1.setFitness(model.fitness_reduction * (cl1.fitness + cl2.fitness)/2.0)
cl2.setAccuracy(cl1.accuracy)
cl2.setFitness(cl1.fitness)
else:
cl1.setFitness(model.fitness_reduction * cl1.fitness)
cl2.setFitness(model.fitness_reduction * cl2.fitness)
#Mutation
model.timer.startTimeMutation()
nowchanged = cl1.mutation(model,state)
howaboutnow = cl2.mutation(model,state)
model.timer.stopTimeMutation()
if model.env.formatData.continuousCount > 0:
cl1.rangeCheck(model)
cl2.rangeCheck(model)
if changed or nowchanged or howaboutnow:
if nowchanged:
model.trackingObj.mutationCount += 1
if howaboutnow:
model.trackingObj.mutationCount += 1
if changed:
model.trackingObj.crossOverCount += 1
self.insertDiscoveredClassifiers(model,cl1, cl2, clP1, clP2) #Includes subsumption if activated.
def insertDiscoveredClassifiers(self,model,cl1,cl2,clP1,clP2):
if model.do_GA_subsumption:
model.timer.startTimeSubsumption()
if len(cl1.specifiedAttList) > 0:
self.subsumeClassifier(model,cl1, clP1, clP2)
if len(cl2.specifiedAttList) > 0:
self.subsumeClassifier(model,cl2, clP1, clP2)
model.timer.stopTimeSubsumption()
else:
if len(cl1.specifiedAttList) > 0:
self.addClassifierToPopulation(model,cl1,False)
if len(cl2.specifiedAttList) > 0:
self.addClassifierToPopulation(model,cl2,False)
def subsumeClassifier(self, model,cl, cl1P, cl2P):
""" Tries to subsume a classifier in the parents. If no subsumption is possible it tries to subsume it in the current set. """
if cl1P!=None and cl1P.subsumes(model,cl):
self.microPopSize += 1
cl1P.updateNumerosity(1)
model.trackingObj.subsumptionCount+=1
elif cl2P!=None and cl2P.subsumes(model,cl):
self.microPopSize += 1
cl2P.updateNumerosity(1)
model.trackingObj.subsumptionCount += 1
else:
if len(cl.specifiedAttList) > 0:
self.addClassifierToPopulation(model, cl, False)
def selectClassifierRW(self):
setList = copy.deepcopy(self.correctSet)
if len(setList) > 2:
selectList = [None,None]
currentCount = 0
while currentCount < 2:
fitSum = self.getFitnessSum(setList)
choiceP = random.random() * fitSum
i = 0
sumCl = self.popSet[setList[i]].fitness
while choiceP > sumCl:
i = i + 1
sumCl += self.popSet[setList[i]].fitness
selectList[currentCount] = self.popSet[setList[i]]
setList.remove(setList[i])
currentCount += 1
elif len(setList) == 2:
selectList = [self.popSet[setList[0]], self.popSet[setList[1]]]
elif len(setList) == 1:
selectList = [self.popSet[setList[0]], self.popSet[setList[0]]]
return selectList
def getFitnessSum(self, setList):
""" Returns the sum of the fitnesses of all classifiers in the set. """
sumCl = 0.0
for i in range(len(setList)):
ref = setList[i]
sumCl += self.popSet[ref].fitness
return sumCl
def selectClassifierT(self,model):
selectList = [None, None]
currentCount = 0
setList = self.correctSet
while currentCount < 2:
tSize = int(len(setList) * model.theta_sel)
#Select tSize elements from correctSet
posList = random.sample(setList,tSize)
bestF = 0
bestC = self.correctSet[0]
for j in posList:
if self.popSet[j].fitness > bestF:
bestF = self.popSet[j].fitness
bestC = j
selectList[currentCount] = self.popSet[bestC]
currentCount += 1
return selectList
def getIterStampAverage(self):
""" Returns the average of the time stamps in the correct set. """
sumCl=0
numSum=0
for i in range(len(self.correctSet)):
ref = self.correctSet[i]
sumCl += self.popSet[ref].timeStampGA * self.popSet[ref].numerosity
numSum += self.popSet[ref].numerosity #numerosity sum of correct set
if numSum != 0:
return sumCl / float(numSum)
else:
return 0
def getInitStampAverage(self):
sumCl = 0.0
numSum = 0.0
for i in range(len(self.correctSet)):
ref = self.correctSet[i]
sumCl += self.popSet[ref].initTimeStamp * self.popSet[ref].numerosity
numSum += self.popSet[ref].numerosity
if numSum != 0:
return sumCl / float(numSum)
else:
return 0
def setIterStamps(self, iterationCount):
""" Sets the time stamp of all classifiers in the set to the current time. The current time
is the number of exploration steps executed so far. """
for i in range(len(self.correctSet)):
ref = self.correctSet[i]
self.popSet[ref].updateTimeStamp(iterationCount)
def deletion(self,model):
model.timer.startTimeDeletion()
while self.microPopSize > model.N:
self.deleteFromPopulation(model)
model.timer.stopTimeDeletion()
def deleteFromPopulation(self,model):
meanFitness = self.getPopFitnessSum() / float(self.microPopSize)
sumCl = 0.0
voteList = []
for cl in self.popSet:
vote = cl.getDelProp(model,meanFitness)
sumCl += vote
voteList.append(vote)
i = 0
for cl in self.popSet:
cl.deletionProb = voteList[i] / sumCl
i += 1
choicePoint = sumCl * random.random() # Determine the choice point
newSum = 0.0
for i in range(len(voteList)):
cl = self.popSet[i]
newSum = newSum + voteList[i]
if newSum > choicePoint: # Select classifier for deletion
# Delete classifier----------------------------------
cl.updateNumerosity(-1)
self.microPopSize -= 1
if cl.numerosity < 1: # When all micro-classifiers for a given classifier have been depleted.
self.removeMacroClassifier(i)
self.deleteFromMatchSet(i)
self.deleteFromCorrectSet(i)
model.trackingObj.deletionCount += 1
return
def getPopFitnessSum(self):
""" Returns the sum of the fitnesses of all classifiers in the set. """
sumCl=0.0
for cl in self.popSet:
sumCl += cl.fitness *cl.numerosity
return sumCl
def clearSets(self):
""" Clears out references in the match and correct sets for the next learning iteration. """
self.matchSet = []
self.correctSet = []
def getAveGenerality(self,model):
genSum = 0
for cl in self.popSet:
genSum += ((model.env.formatData.numAttributes - len(cl.condition))/float(model.env.formatData.numAttributes))*cl.numerosity
if self.microPopSize == 0:
aveGenerality = 0
else:
aveGenerality = genSum/float(self.microPopSize)
return aveGenerality
def makeEvalMatchSet(self,model,state):
for i in range(len(self.popSet)):
cl = self.popSet[i]
if cl.match(model,state):
self.matchSet.append(i)
def getAttributeSpecificityList(self,model):
attributeSpecList = []
for i in range(model.env.formatData.numAttributes):
attributeSpecList.append(0)
for cl in self.popSet:
for ref in cl.specifiedAttList:
attributeSpecList[ref] += cl.numerosity
return attributeSpecList
def getAttributeAccuracyList(self,model):
attributeAccList = []
for i in range(model.env.formatData.numAttributes):
attributeAccList.append(0.0)
for cl in self.popSet:
for ref in cl.specifiedAttList:
attributeAccList[ref] += cl.numerosity * cl.accuracy
return attributeAccList | 0.549882 | 0.196248 |
from __future__ import print_function
from collections import defaultdict
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.ensemble import BaggingClassifier
from sklearn.metrics import accuracy_score
from .mdr import MDR
from ._version import __version__
class MDREnsemble(BaseEstimator, ClassifierMixin):
"""Bagging ensemble of Multifactor Dimensionality Reduction (MDR) models for prediction in machine learning"""
def __init__(self, n_estimators=100, tie_break=1, default_label=0, random_state=None):
"""Sets up the MDR ensemble
Parameters
----------
n_estimators: int (default: 100)
Number of MDR models to include in the ensemble
tie_break: int (default: 1)
Default label in case there's a tie in a set of feature pair values
default_label: int (default: 0)
Default label in case there's no data for a set of feature pair values
random_state: int, RandomState instance or None (default: None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used by np.random.
Returns
-------
None
"""
self.n_estimators = n_estimators
self.tie_break = tie_break
self.default_label = default_label
self.random_state = random_state
self.feature_map = defaultdict(lambda: default_label)
self.ensemble = BaggingClassifier(base_estimator=MDR(tie_break=tie_break, default_label=default_label),
n_estimators=n_estimators, random_state=random_state)
def fit(self, features, classes):
"""Constructs the MDR ensemble from the provided training data
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
classes: array-like {n_samples}
List of class labels for prediction
Returns
-------
None
"""
self.ensemble.fit(features, classes)
# Construct the feature map from the ensemble predictions
unique_rows = list(set([tuple(row) for row in features]))
for row in unique_rows:
self.feature_map[row] = self.ensemble.predict([row])[0]
def predict(self, features):
"""Uses the MDR ensemble to construct a new feature from the provided features
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
return self.ensemble.predict(features)
def fit_predict(self, features, classes):
"""Convenience function that fits the provided data then constructs a new feature from the provided features
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
classes: array-like {n_samples}
List of true class labels
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
self.ensemble.fit(features, classes)
return self.ensemble.predict(features)
def score(self, features, classes, scoring_function=None, **scoring_function_kwargs):
"""Estimates the accuracy of the predictions from the MDR ensemble
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to predict from
classes: array-like {n_samples}
List of true class labels
Returns
-------
accuracy_score: float
The estimated accuracy based on the constructed feature
"""
new_feature = self.ensemble.predict(features)
if scoring_function is None:
return accuracy_score(classes, new_feature)
else:
return scoring_function(classes, new_feature, **scoring_function_kwargs) | scikit-MDR | /scikit_MDR-0.4.5-py3-none-any.whl/mdr/mdr_ensemble.py | mdr_ensemble.py | from __future__ import print_function
from collections import defaultdict
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.ensemble import BaggingClassifier
from sklearn.metrics import accuracy_score
from .mdr import MDR
from ._version import __version__
class MDREnsemble(BaseEstimator, ClassifierMixin):
"""Bagging ensemble of Multifactor Dimensionality Reduction (MDR) models for prediction in machine learning"""
def __init__(self, n_estimators=100, tie_break=1, default_label=0, random_state=None):
"""Sets up the MDR ensemble
Parameters
----------
n_estimators: int (default: 100)
Number of MDR models to include in the ensemble
tie_break: int (default: 1)
Default label in case there's a tie in a set of feature pair values
default_label: int (default: 0)
Default label in case there's no data for a set of feature pair values
random_state: int, RandomState instance or None (default: None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used by np.random.
Returns
-------
None
"""
self.n_estimators = n_estimators
self.tie_break = tie_break
self.default_label = default_label
self.random_state = random_state
self.feature_map = defaultdict(lambda: default_label)
self.ensemble = BaggingClassifier(base_estimator=MDR(tie_break=tie_break, default_label=default_label),
n_estimators=n_estimators, random_state=random_state)
def fit(self, features, classes):
"""Constructs the MDR ensemble from the provided training data
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
classes: array-like {n_samples}
List of class labels for prediction
Returns
-------
None
"""
self.ensemble.fit(features, classes)
# Construct the feature map from the ensemble predictions
unique_rows = list(set([tuple(row) for row in features]))
for row in unique_rows:
self.feature_map[row] = self.ensemble.predict([row])[0]
def predict(self, features):
"""Uses the MDR ensemble to construct a new feature from the provided features
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
return self.ensemble.predict(features)
def fit_predict(self, features, classes):
"""Convenience function that fits the provided data then constructs a new feature from the provided features
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
classes: array-like {n_samples}
List of true class labels
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
self.ensemble.fit(features, classes)
return self.ensemble.predict(features)
def score(self, features, classes, scoring_function=None, **scoring_function_kwargs):
"""Estimates the accuracy of the predictions from the MDR ensemble
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to predict from
classes: array-like {n_samples}
List of true class labels
Returns
-------
accuracy_score: float
The estimated accuracy based on the constructed feature
"""
new_feature = self.ensemble.predict(features)
if scoring_function is None:
return accuracy_score(classes, new_feature)
else:
return scoring_function(classes, new_feature, **scoring_function_kwargs) | 0.924022 | 0.352592 |
from __future__ import print_function
from collections import defaultdict
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin
from scipy.stats import ttest_ind
class ContinuousMDR(BaseEstimator, TransformerMixin):
"""Continuous Multifactor Dimensionality Reduction (CMDR) for feature construction in regression problems.
CMDR can take categorical features and continuous endpoints as input, and outputs a binary constructed feature."""
def __init__(self, tie_break=1, default_label=0):
"""Sets up the Continuous MDR algorithm for feature construction.
Parameters
----------
tie_break: int (default: 1)
Default label in case there's a tie in a set of feature pair values
default_label: int (default: 0)
Default label in case there's no data for a set of feature pair values
Returns
-------
None
"""
self.tie_break = tie_break
self.default_label = default_label
self.overall_mean_trait_value = 0.
self.feature_map = None
def fit(self, features, targets):
"""Constructs the Continuous MDR feature map from the provided training data.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
targets: array-like {n_samples}
List of target values for prediction
Returns
-------
self: A copy of the fitted model
"""
self.feature_map = defaultdict(lambda: self.default_label)
self.overall_mean_trait_value = np.mean(targets)
self.mdr_matrix_values = defaultdict(list)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
self.mdr_matrix_values[feature_instance].append(targets[row_i])
for feature_instance in self.mdr_matrix_values:
grid_mean_trait_value = np.mean(self.mdr_matrix_values[feature_instance])
if grid_mean_trait_value > self.overall_mean_trait_value:
self.feature_map[feature_instance] = 1
elif grid_mean_trait_value == self.overall_mean_trait_value:
self.feature_map[feature_instance] = self.tie_break
else:
self.feature_map[feature_instance] = 0
# Convert defaultdict to dict so CMDR objects can be easily pickled
self.feature_map = dict(self.feature_map)
self.mdr_matrix_values = dict(self.mdr_matrix_values)
return self
def transform(self, features):
"""Uses the Continuous MDR feature map to construct a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples}
Constructed feature from the provided feature matrix
The constructed feature will be a binary variable, taking the values 0 and 1
"""
new_feature = np.zeros(features.shape[0], dtype=np.int)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
if feature_instance in self.feature_map:
new_feature[row_i] = self.feature_map[feature_instance]
else:
new_feature[row_i] = self.default_label
return new_feature.reshape(features.shape[0], 1)
def fit_transform(self, features, targets):
"""Convenience function that fits the provided data then constructs a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
targets: array-like {n_samples}
List of true target values
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
self.fit(features, targets)
return self.transform(features)
def score(self, features, targets):
"""Estimates the quality of the ContinuousMDR model using a t-statistic.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to predict from
targets: array-like {n_samples}
List of true target values
Returns
-------
quality_score: float
The estimated quality of the Continuous MDR model
"""
if self.feature_map is None:
raise ValueError('The Continuous MDR model must be fit before score() can be called.')
group_0_trait_values = []
group_1_trait_values = []
for feature_instance in self.feature_map:
if self.feature_map[feature_instance] == 0:
group_0_trait_values.extend(self.mdr_matrix_values[feature_instance])
else:
group_1_trait_values.extend(self.mdr_matrix_values[feature_instance])
return abs(ttest_ind(group_0_trait_values, group_1_trait_values).statistic) | scikit-MDR | /scikit_MDR-0.4.5-py3-none-any.whl/mdr/continuous_mdr.py | continuous_mdr.py | from __future__ import print_function
from collections import defaultdict
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin
from scipy.stats import ttest_ind
class ContinuousMDR(BaseEstimator, TransformerMixin):
"""Continuous Multifactor Dimensionality Reduction (CMDR) for feature construction in regression problems.
CMDR can take categorical features and continuous endpoints as input, and outputs a binary constructed feature."""
def __init__(self, tie_break=1, default_label=0):
"""Sets up the Continuous MDR algorithm for feature construction.
Parameters
----------
tie_break: int (default: 1)
Default label in case there's a tie in a set of feature pair values
default_label: int (default: 0)
Default label in case there's no data for a set of feature pair values
Returns
-------
None
"""
self.tie_break = tie_break
self.default_label = default_label
self.overall_mean_trait_value = 0.
self.feature_map = None
def fit(self, features, targets):
"""Constructs the Continuous MDR feature map from the provided training data.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
targets: array-like {n_samples}
List of target values for prediction
Returns
-------
self: A copy of the fitted model
"""
self.feature_map = defaultdict(lambda: self.default_label)
self.overall_mean_trait_value = np.mean(targets)
self.mdr_matrix_values = defaultdict(list)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
self.mdr_matrix_values[feature_instance].append(targets[row_i])
for feature_instance in self.mdr_matrix_values:
grid_mean_trait_value = np.mean(self.mdr_matrix_values[feature_instance])
if grid_mean_trait_value > self.overall_mean_trait_value:
self.feature_map[feature_instance] = 1
elif grid_mean_trait_value == self.overall_mean_trait_value:
self.feature_map[feature_instance] = self.tie_break
else:
self.feature_map[feature_instance] = 0
# Convert defaultdict to dict so CMDR objects can be easily pickled
self.feature_map = dict(self.feature_map)
self.mdr_matrix_values = dict(self.mdr_matrix_values)
return self
def transform(self, features):
"""Uses the Continuous MDR feature map to construct a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples}
Constructed feature from the provided feature matrix
The constructed feature will be a binary variable, taking the values 0 and 1
"""
new_feature = np.zeros(features.shape[0], dtype=np.int)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
if feature_instance in self.feature_map:
new_feature[row_i] = self.feature_map[feature_instance]
else:
new_feature[row_i] = self.default_label
return new_feature.reshape(features.shape[0], 1)
def fit_transform(self, features, targets):
"""Convenience function that fits the provided data then constructs a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
targets: array-like {n_samples}
List of true target values
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
self.fit(features, targets)
return self.transform(features)
def score(self, features, targets):
"""Estimates the quality of the ContinuousMDR model using a t-statistic.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to predict from
targets: array-like {n_samples}
List of true target values
Returns
-------
quality_score: float
The estimated quality of the Continuous MDR model
"""
if self.feature_map is None:
raise ValueError('The Continuous MDR model must be fit before score() can be called.')
group_0_trait_values = []
group_1_trait_values = []
for feature_instance in self.feature_map:
if self.feature_map[feature_instance] == 0:
group_0_trait_values.extend(self.mdr_matrix_values[feature_instance])
else:
group_1_trait_values.extend(self.mdr_matrix_values[feature_instance])
return abs(ttest_ind(group_0_trait_values, group_1_trait_values).statistic) | 0.943958 | 0.526951 |
from __future__ import print_function
from collections import defaultdict
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin, ClassifierMixin
from sklearn.metrics import accuracy_score
class MDRBase(BaseEstimator):
"""Base Multifactor Dimensionality Reduction (MDR) functions.
MDR can take categorical features and binary endpoints as input, and outputs a binary constructed feature or prediction."""
def __init__(self, tie_break=1, default_label=0):
"""Sets up the MDR algorithm for feature construction.
Parameters
----------
tie_break: int (default: 1)
Default label in case there's a tie in a set of feature pair values
default_label: int (default: 0)
Default label in case there's no data for a set of feature pair values
Returns
-------
None
"""
self.tie_break = tie_break
self.default_label = default_label
self.class_count_matrix = None
self.feature_map = None
def fit(self, features, class_labels):
"""Constructs the MDR feature map from the provided training data.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
class_labels: array-like {n_samples}
List of true class labels
Returns
-------
self: A copy of the fitted model
"""
unique_labels = sorted(np.unique(class_labels))
if len(unique_labels) != 2:
raise ValueError('MDR only supports binary endpoints.')
# Count the distribution of classes that fall into each MDR grid cell
self.class_count_matrix = defaultdict(lambda: defaultdict(int))
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
self.class_count_matrix[feature_instance][class_labels[row_i]] += 1
self.class_count_matrix = dict(self.class_count_matrix)
# Only applies to binary classification
overall_class_fraction = float(sum(class_labels == unique_labels[0])) / class_labels.size
# If one class is more abundant in a MDR grid cell than it is overall, then assign the cell to that class
self.feature_map = {}
for feature_instance in self.class_count_matrix:
counts = self.class_count_matrix[feature_instance]
fraction = float(counts[unique_labels[0]]) / np.sum(list(counts.values()))
if fraction > overall_class_fraction:
self.feature_map[feature_instance] = unique_labels[0]
elif fraction == overall_class_fraction:
self.feature_map[feature_instance] = self.tie_break
else:
self.feature_map[feature_instance] = unique_labels[1]
return self
class MDR(MDRBase, TransformerMixin):
"""Multifactor Dimensionality Reduction (MDR) for feature construction in binary classification problems.
MDR can take categorical features and binary endpoints as input, and outputs a binary constructed feature."""
def transform(self, features):
"""Uses the MDR feature map to construct a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples, 1}
Constructed features from the provided feature matrix
"""
if self.feature_map is None:
raise ValueError('The MDR model must be fit before transform can be called.')
# new_feature = np.zeros(features.shape[0], dtype=np.int)
new_feature = np.zeros(features.shape[0], dtype=np.int64)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
if feature_instance in self.feature_map:
new_feature[row_i] = self.feature_map[feature_instance]
else:
new_feature[row_i] = self.default_label
return new_feature.reshape(features.shape[0], 1)
def fit_transform(self, features, class_labels):
"""Convenience function that fits the provided data then constructs a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
class_labels: array-like {n_samples}
List of true class labels
Returns
----------
array-like: {n_samples, 1}
Constructed features from the provided feature matrix
"""
self.fit(features, class_labels)
return self.transform(features)
class MDRClassifier(MDRBase, ClassifierMixin):
"""Multifactor Dimensionality Reduction (MDR) for binary classification problems.
MDR can take categorical features and binary endpoints as input, and outputs a binary prediction."""
def predict(self, features):
"""Uses the MDR feature map to construct predictions from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
if self.feature_map is None:
raise ValueError('The MDR model must be fit before predict can be called.')
# new_feature = np.zeros(features.shape[0], dtype=np.int)
new_feature = np.zeros(features.shape[0], dtype=np.int64)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
if feature_instance in self.feature_map:
new_feature[row_i] = self.feature_map[feature_instance]
else:
new_feature[row_i] = self.default_label
return new_feature
def fit_predict(self, features, class_labels):
"""Convenience function that fits the provided data then constructs predictions from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
class_labels: array-like {n_samples}
List of true class labels
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
self.fit(features, class_labels)
return self.predict(features)
def score(self, features, class_labels, scoring_function=None, **scoring_function_kwargs):
"""Estimates the accuracy of the predictions from the constructed feature.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to predict from
class_labels: array-like {n_samples}
List of true class labels
Returns
-------
accuracy_score: float
The estimated accuracy based on the constructed feature
"""
if self.feature_map is None:
raise ValueError('The MDR model must be fit before score can be called.')
new_feature = self.predict(features)
if scoring_function is None:
return accuracy_score(class_labels, new_feature)
else:
return scoring_function(class_labels, new_feature, **scoring_function_kwargs) | scikit-MDR | /scikit_MDR-0.4.5-py3-none-any.whl/mdr/mdr.py | mdr.py | from __future__ import print_function
from collections import defaultdict
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin, ClassifierMixin
from sklearn.metrics import accuracy_score
class MDRBase(BaseEstimator):
"""Base Multifactor Dimensionality Reduction (MDR) functions.
MDR can take categorical features and binary endpoints as input, and outputs a binary constructed feature or prediction."""
def __init__(self, tie_break=1, default_label=0):
"""Sets up the MDR algorithm for feature construction.
Parameters
----------
tie_break: int (default: 1)
Default label in case there's a tie in a set of feature pair values
default_label: int (default: 0)
Default label in case there's no data for a set of feature pair values
Returns
-------
None
"""
self.tie_break = tie_break
self.default_label = default_label
self.class_count_matrix = None
self.feature_map = None
def fit(self, features, class_labels):
"""Constructs the MDR feature map from the provided training data.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
class_labels: array-like {n_samples}
List of true class labels
Returns
-------
self: A copy of the fitted model
"""
unique_labels = sorted(np.unique(class_labels))
if len(unique_labels) != 2:
raise ValueError('MDR only supports binary endpoints.')
# Count the distribution of classes that fall into each MDR grid cell
self.class_count_matrix = defaultdict(lambda: defaultdict(int))
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
self.class_count_matrix[feature_instance][class_labels[row_i]] += 1
self.class_count_matrix = dict(self.class_count_matrix)
# Only applies to binary classification
overall_class_fraction = float(sum(class_labels == unique_labels[0])) / class_labels.size
# If one class is more abundant in a MDR grid cell than it is overall, then assign the cell to that class
self.feature_map = {}
for feature_instance in self.class_count_matrix:
counts = self.class_count_matrix[feature_instance]
fraction = float(counts[unique_labels[0]]) / np.sum(list(counts.values()))
if fraction > overall_class_fraction:
self.feature_map[feature_instance] = unique_labels[0]
elif fraction == overall_class_fraction:
self.feature_map[feature_instance] = self.tie_break
else:
self.feature_map[feature_instance] = unique_labels[1]
return self
class MDR(MDRBase, TransformerMixin):
"""Multifactor Dimensionality Reduction (MDR) for feature construction in binary classification problems.
MDR can take categorical features and binary endpoints as input, and outputs a binary constructed feature."""
def transform(self, features):
"""Uses the MDR feature map to construct a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples, 1}
Constructed features from the provided feature matrix
"""
if self.feature_map is None:
raise ValueError('The MDR model must be fit before transform can be called.')
# new_feature = np.zeros(features.shape[0], dtype=np.int)
new_feature = np.zeros(features.shape[0], dtype=np.int64)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
if feature_instance in self.feature_map:
new_feature[row_i] = self.feature_map[feature_instance]
else:
new_feature[row_i] = self.default_label
return new_feature.reshape(features.shape[0], 1)
def fit_transform(self, features, class_labels):
"""Convenience function that fits the provided data then constructs a new feature from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
class_labels: array-like {n_samples}
List of true class labels
Returns
----------
array-like: {n_samples, 1}
Constructed features from the provided feature matrix
"""
self.fit(features, class_labels)
return self.transform(features)
class MDRClassifier(MDRBase, ClassifierMixin):
"""Multifactor Dimensionality Reduction (MDR) for binary classification problems.
MDR can take categorical features and binary endpoints as input, and outputs a binary prediction."""
def predict(self, features):
"""Uses the MDR feature map to construct predictions from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to transform
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
if self.feature_map is None:
raise ValueError('The MDR model must be fit before predict can be called.')
# new_feature = np.zeros(features.shape[0], dtype=np.int)
new_feature = np.zeros(features.shape[0], dtype=np.int64)
for row_i in range(features.shape[0]):
feature_instance = tuple(features[row_i])
if feature_instance in self.feature_map:
new_feature[row_i] = self.feature_map[feature_instance]
else:
new_feature[row_i] = self.default_label
return new_feature
def fit_predict(self, features, class_labels):
"""Convenience function that fits the provided data then constructs predictions from the provided features.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix
class_labels: array-like {n_samples}
List of true class labels
Returns
----------
array-like: {n_samples}
Constructed features from the provided feature matrix
"""
self.fit(features, class_labels)
return self.predict(features)
def score(self, features, class_labels, scoring_function=None, **scoring_function_kwargs):
"""Estimates the accuracy of the predictions from the constructed feature.
Parameters
----------
features: array-like {n_samples, n_features}
Feature matrix to predict from
class_labels: array-like {n_samples}
List of true class labels
Returns
-------
accuracy_score: float
The estimated accuracy based on the constructed feature
"""
if self.feature_map is None:
raise ValueError('The MDR model must be fit before score can be called.')
new_feature = self.predict(features)
if scoring_function is None:
return accuracy_score(class_labels, new_feature)
else:
return scoring_function(class_labels, new_feature, **scoring_function_kwargs) | 0.942599 | 0.499756 |
from __future__ import print_function
import itertools
from collections import Counter
import scipy
import numpy as np
import copy
import matplotlib.pyplot as plt
from ..mdr import MDR
def entropy(X, base=2):
"""Calculates the entropy, H(X), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the entropy
base: integer (default: 2)
The base in which to calculate entropy
Returns
----------
entropy: float
The entropy calculated according to the equation H(X) = -sum(p_x * log p_x) for all states of X
"""
return scipy.stats.entropy(list(Counter(X).values()), base=base)
def joint_entropy(X, Y, base=2):
"""Calculates the joint entropy, H(X,Y), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the joint entropy
Y: array-like (# samples)
An array of values for which to compute the joint entropy
base: integer (default: 2)
The base in which to calculate joint entropy
Returns
----------
joint_entropy: float
The joint entropy calculated according to the equation H(X,Y) = -sum(p_xy * log p_xy) for all combined states of X and Y
"""
X_Y = ['{}{}'.format(x, y) for x, y in zip(X, Y)]
return entropy(X_Y, base=base)
def conditional_entropy(X, Y, base=2):
"""Calculates the conditional entropy, H(X|Y), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the conditional entropy
Y: array-like (# samples)
An array of values for which to compute the conditional entropy
base: integer (default: 2)
The base in which to calculate conditional entropy
Returns
----------
conditional_entropy: float
The conditional entropy calculated according to the equation H(X|Y) = H(X,Y) - H(Y)
"""
return joint_entropy(X, Y, base=base) - entropy(Y, base=base)
def mutual_information(X, Y, base=2):
"""Calculates the mutual information between two variables, I(X;Y), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the mutual information
Y: array-like (# samples)
An array of values for which to compute the mutual information
base: integer (default: 2)
The base in which to calculate mutual information
Returns
----------
mutual_information: float
The mutual information calculated according to the equation I(X;Y) = H(Y) - H(Y|X)
"""
return entropy(Y, base=base) - conditional_entropy(Y, X, base=base)
def two_way_information_gain(X, Y, Z, base=2):
"""Calculates the two-way information gain between three variables, I(X;Y;Z), in the given base
IG(X;Y;Z) indicates the information gained about variable Z by the joint variable X_Y, after removing
the information that X and Y have about Z individually. Thus, two-way information gain measures the
synergistic predictive value of variables X and Y about variable Z.
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the 2-way information gain
Y: array-like (# samples)
An array of values for which to compute the 2-way information gain
Z: array-like (# samples)
An array of outcome values for which to compute the 2-way information gain
base: integer (default: 2)
The base in which to calculate 2-way information
Returns
----------
mutual_information: float
The information gain calculated according to the equation IG(X;Y;Z) = I(X,Y;Z) - I(X;Z) - I(Y;Z)
"""
X_Y = ['{}{}'.format(x, y) for x, y in zip(X, Y)]
return (mutual_information(X_Y, Z, base=base) -
mutual_information(X, Z, base=base) -
mutual_information(Y, Z, base=base))
def three_way_information_gain(W, X, Y, Z, base=2):
"""Calculates the three-way information gain between three variables, I(W;X;Y;Z), in the given base
IG(W;X;Y;Z) indicates the information gained about variable Z by the joint variable W_X_Y, after removing
the information that W, X, and Y have about Z individually and jointly in pairs. Thus, 3-way information gain
measures the synergistic predictive value of variables W, X, and Y about variable Z.
Parameters
----------
W: array-like (# samples)
An array of values for which to compute the 3-way information gain
X: array-like (# samples)
An array of values for which to compute the 3-way information gain
Y: array-like (# samples)
An array of values for which to compute the 3-way information gain
Z: array-like (# samples)
An array of outcome values for which to compute the 3-way information gain
base: integer (default: 2)
The base in which to calculate 3-way information
Returns
----------
mutual_information: float
The information gain calculated according to the equation:
IG(W;X;Y;Z) = I(W,X,Y;Z) - IG(W;X;Z) - IG(W;Y;Z) - IG(X;Y;Z) - I(W;Z) - I(X;Z) - I(Y;Z)
"""
W_X_Y = ['{}{}{}'.format(w, x, y) for w, x, y in zip(W, X, Y)]
return (mutual_information(W_X_Y, Z, base=base) -
two_way_information_gain(W, X, Z, base=base) -
two_way_information_gain(W, Y, Z, base=base) -
two_way_information_gain(X, Y, Z, base=base) -
mutual_information(W, Z, base=base) -
mutual_information(X, Z, base=base) -
mutual_information(Y, Z, base=base))
def _mdr_predict(X, Y, labels):
"""Fits a MDR model to variables X and Y with the given labels, then returns the resulting predictions
This is a convenience method that should only be used internally.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
Returns
----------
predictions: array-like (# samples)
The predictions from the fitted MDR model
"""
return MDR().fit_predict(np.column_stack((X, Y)), labels)
def mdr_entropy(X, Y, labels, base=2):
"""Calculates the MDR entropy, H(XY), in the given base
MDR entropy is calculated by combining variables X and Y into a single MDR model then calculating
the entropy of the resulting model's predictions.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
base: integer (default: 2)
The base in which to calculate MDR entropy
Returns
----------
mdr_entropy: float
The MDR entropy calculated according to the equation H(XY) = -sum(p_xy * log p_xy) for all output states of the MDR model
"""
return entropy(_mdr_predict(X, Y, labels), base=base)
def mdr_conditional_entropy(X, Y, labels, base=2):
"""Calculates the MDR conditional entropy, H(XY|labels), in the given base
MDR conditional entropy is calculated by combining variables X and Y into a single MDR model then calculating
the entropy of the resulting model's predictions conditional on the provided labels.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
base: integer (default: 2)
The base in which to calculate MDR conditional entropy
Returns
----------
mdr_conditional_entropy: float
The MDR conditional entropy calculated according to the equation H(XY|labels) = H(XY,labels) - H(labels)
"""
return conditional_entropy(_mdr_predict(X, Y, labels), labels, base=base)
def mdr_mutual_information(X, Y, labels, base=2):
"""Calculates the MDR mutual information, I(XY;labels), in the given base
MDR mutual information is calculated by combining variables X and Y into a single MDR model then calculating
the mutual information between the resulting model's predictions and the labels.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
base: integer (default: 2)
The base in which to calculate MDR mutual information
Returns
----------
mdr_mutual_information: float
The MDR mutual information calculated according to the equation I(XY;labels) = H(labels) - H(labels|XY)
"""
return mutual_information(_mdr_predict(X, Y, labels), labels, base=base)
def n_way_models(mdr_instance, X, y, n=[2], feature_names=None):
"""Fits a MDR model to all n-way combinations of the features in X.
Note that this function performs an exhaustive search through all feature combinations and can be computationally expensive.
Parameters
----------
mdr_instance: object
An instance of the MDR type to use.
X: array-like (# rows, # features)
NumPy matrix containing the features
y: array-like (# rows, 1)
NumPy matrix containing the target values
n: list (default: [2])
The maximum size(s) of the MDR model to generate.
e.g., if n == [3], all 3-way models will be generated.
feature_names: list (default: None)
The corresponding names of the features in X.
If None, then the features will be named according to their order.
Returns
----------
(fitted_model, fitted_model_score, fitted_model_features): tuple of (list, list, list)
fitted_model contains the MDR model fitted to the data.
fitted_model_score contains the training scores corresponding to the fitted MDR model.
fitted_model_features contains a list of the names of the features that were used in the corresponding model.
"""
if feature_names is None:
feature_names = list(range(X.shape[1]))
for cur_n in n:
for features in itertools.combinations(range(X.shape[1]), cur_n):
mdr_model = copy.deepcopy(mdr_instance)
mdr_model.fit(X[:, features], y)
mdr_model_score = mdr_model.score(X[:, features], y)
model_features = [feature_names[feature] for feature in features]
yield mdr_model, mdr_model_score, model_features
def plot_mdr_grid(mdr_instance):
"""Visualizes the MDR grid of a given fitted MDR instance. Only works for 2-way MDR models.
This function is currently incomplete.
Parameters
----------
mdr_instance: object
A fitted instance of the MDR type to visualize.
Returns
----------
fig: matplotlib.figure
Figure object for the visualized MDR grid.
"""
var1_levels = list(set([variables[0] for variables in mdr_instance.feature_map]))
var2_levels = list(set([variables[1] for variables in mdr_instance.feature_map]))
max_count = np.array(list(mdr_instance.class_count_matrix.values())).flatten().max()
"""
TODO:
- Add common axis labels
- Make sure this scales for smaller and larger record sizes
- Extend to 3-way+ models, e.g., http://4.bp.blogspot.com/-vgKCjEkWFUc/UPwPuHo6XvI/AAAAAAAAAE0/fORHqDcoikE/s1600/model.jpg
"""
fig, splots = plt.subplots(ncols=len(var1_levels), nrows=len(var2_levels), sharey=True, sharex=True)
fig.set_figwidth(6)
fig.set_figheight(6)
for (var1, var2) in itertools.product(var1_levels, var2_levels):
class_counts = mdr_instance.class_count_matrix[(var1, var2)]
splot = splots[var2_levels.index(var2)][var1_levels.index(var1)]
splot.set_yticks([])
splot.set_xticks([])
splot.set_ylim(0, max_count * 1.5)
splot.set_xlim(-0.5, 1.5)
if var2_levels.index(var2) == 0:
splot.set_title('X1 = {}'.format(var1), fontsize=12)
if var1_levels.index(var1) == 0:
splot.set_ylabel('X2 = {}'.format(var2), fontsize=12)
bars = splot.bar(left=range(class_counts.shape[0]),
height=class_counts, width=0.5,
color='black', align='center')
bgcolor = 'lightgrey' if mdr_instance.feature_map[(var1, var2)] == 0 else 'darkgrey'
splot.set_axis_bgcolor(bgcolor)
for index, bar in enumerate(bars):
splot.text(index, class_counts[index] + (max_count * 0.1), class_counts[index], ha='center')
fig.tight_layout()
return fig | scikit-MDR | /scikit_MDR-0.4.5-py3-none-any.whl/mdr/utils/utils.py | utils.py | from __future__ import print_function
import itertools
from collections import Counter
import scipy
import numpy as np
import copy
import matplotlib.pyplot as plt
from ..mdr import MDR
def entropy(X, base=2):
"""Calculates the entropy, H(X), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the entropy
base: integer (default: 2)
The base in which to calculate entropy
Returns
----------
entropy: float
The entropy calculated according to the equation H(X) = -sum(p_x * log p_x) for all states of X
"""
return scipy.stats.entropy(list(Counter(X).values()), base=base)
def joint_entropy(X, Y, base=2):
"""Calculates the joint entropy, H(X,Y), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the joint entropy
Y: array-like (# samples)
An array of values for which to compute the joint entropy
base: integer (default: 2)
The base in which to calculate joint entropy
Returns
----------
joint_entropy: float
The joint entropy calculated according to the equation H(X,Y) = -sum(p_xy * log p_xy) for all combined states of X and Y
"""
X_Y = ['{}{}'.format(x, y) for x, y in zip(X, Y)]
return entropy(X_Y, base=base)
def conditional_entropy(X, Y, base=2):
"""Calculates the conditional entropy, H(X|Y), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the conditional entropy
Y: array-like (# samples)
An array of values for which to compute the conditional entropy
base: integer (default: 2)
The base in which to calculate conditional entropy
Returns
----------
conditional_entropy: float
The conditional entropy calculated according to the equation H(X|Y) = H(X,Y) - H(Y)
"""
return joint_entropy(X, Y, base=base) - entropy(Y, base=base)
def mutual_information(X, Y, base=2):
"""Calculates the mutual information between two variables, I(X;Y), in the given base
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the mutual information
Y: array-like (# samples)
An array of values for which to compute the mutual information
base: integer (default: 2)
The base in which to calculate mutual information
Returns
----------
mutual_information: float
The mutual information calculated according to the equation I(X;Y) = H(Y) - H(Y|X)
"""
return entropy(Y, base=base) - conditional_entropy(Y, X, base=base)
def two_way_information_gain(X, Y, Z, base=2):
"""Calculates the two-way information gain between three variables, I(X;Y;Z), in the given base
IG(X;Y;Z) indicates the information gained about variable Z by the joint variable X_Y, after removing
the information that X and Y have about Z individually. Thus, two-way information gain measures the
synergistic predictive value of variables X and Y about variable Z.
Parameters
----------
X: array-like (# samples)
An array of values for which to compute the 2-way information gain
Y: array-like (# samples)
An array of values for which to compute the 2-way information gain
Z: array-like (# samples)
An array of outcome values for which to compute the 2-way information gain
base: integer (default: 2)
The base in which to calculate 2-way information
Returns
----------
mutual_information: float
The information gain calculated according to the equation IG(X;Y;Z) = I(X,Y;Z) - I(X;Z) - I(Y;Z)
"""
X_Y = ['{}{}'.format(x, y) for x, y in zip(X, Y)]
return (mutual_information(X_Y, Z, base=base) -
mutual_information(X, Z, base=base) -
mutual_information(Y, Z, base=base))
def three_way_information_gain(W, X, Y, Z, base=2):
"""Calculates the three-way information gain between three variables, I(W;X;Y;Z), in the given base
IG(W;X;Y;Z) indicates the information gained about variable Z by the joint variable W_X_Y, after removing
the information that W, X, and Y have about Z individually and jointly in pairs. Thus, 3-way information gain
measures the synergistic predictive value of variables W, X, and Y about variable Z.
Parameters
----------
W: array-like (# samples)
An array of values for which to compute the 3-way information gain
X: array-like (# samples)
An array of values for which to compute the 3-way information gain
Y: array-like (# samples)
An array of values for which to compute the 3-way information gain
Z: array-like (# samples)
An array of outcome values for which to compute the 3-way information gain
base: integer (default: 2)
The base in which to calculate 3-way information
Returns
----------
mutual_information: float
The information gain calculated according to the equation:
IG(W;X;Y;Z) = I(W,X,Y;Z) - IG(W;X;Z) - IG(W;Y;Z) - IG(X;Y;Z) - I(W;Z) - I(X;Z) - I(Y;Z)
"""
W_X_Y = ['{}{}{}'.format(w, x, y) for w, x, y in zip(W, X, Y)]
return (mutual_information(W_X_Y, Z, base=base) -
two_way_information_gain(W, X, Z, base=base) -
two_way_information_gain(W, Y, Z, base=base) -
two_way_information_gain(X, Y, Z, base=base) -
mutual_information(W, Z, base=base) -
mutual_information(X, Z, base=base) -
mutual_information(Y, Z, base=base))
def _mdr_predict(X, Y, labels):
"""Fits a MDR model to variables X and Y with the given labels, then returns the resulting predictions
This is a convenience method that should only be used internally.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
Returns
----------
predictions: array-like (# samples)
The predictions from the fitted MDR model
"""
return MDR().fit_predict(np.column_stack((X, Y)), labels)
def mdr_entropy(X, Y, labels, base=2):
"""Calculates the MDR entropy, H(XY), in the given base
MDR entropy is calculated by combining variables X and Y into a single MDR model then calculating
the entropy of the resulting model's predictions.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
base: integer (default: 2)
The base in which to calculate MDR entropy
Returns
----------
mdr_entropy: float
The MDR entropy calculated according to the equation H(XY) = -sum(p_xy * log p_xy) for all output states of the MDR model
"""
return entropy(_mdr_predict(X, Y, labels), base=base)
def mdr_conditional_entropy(X, Y, labels, base=2):
"""Calculates the MDR conditional entropy, H(XY|labels), in the given base
MDR conditional entropy is calculated by combining variables X and Y into a single MDR model then calculating
the entropy of the resulting model's predictions conditional on the provided labels.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
base: integer (default: 2)
The base in which to calculate MDR conditional entropy
Returns
----------
mdr_conditional_entropy: float
The MDR conditional entropy calculated according to the equation H(XY|labels) = H(XY,labels) - H(labels)
"""
return conditional_entropy(_mdr_predict(X, Y, labels), labels, base=base)
def mdr_mutual_information(X, Y, labels, base=2):
"""Calculates the MDR mutual information, I(XY;labels), in the given base
MDR mutual information is calculated by combining variables X and Y into a single MDR model then calculating
the mutual information between the resulting model's predictions and the labels.
Parameters
----------
X: array-like (# samples)
An array of values corresponding to one feature in the MDR model
Y: array-like (# samples)
An array of values corresponding to one feature in the MDR model
labels: array-like (# samples)
The class labels corresponding to features X and Y
base: integer (default: 2)
The base in which to calculate MDR mutual information
Returns
----------
mdr_mutual_information: float
The MDR mutual information calculated according to the equation I(XY;labels) = H(labels) - H(labels|XY)
"""
return mutual_information(_mdr_predict(X, Y, labels), labels, base=base)
def n_way_models(mdr_instance, X, y, n=[2], feature_names=None):
"""Fits a MDR model to all n-way combinations of the features in X.
Note that this function performs an exhaustive search through all feature combinations and can be computationally expensive.
Parameters
----------
mdr_instance: object
An instance of the MDR type to use.
X: array-like (# rows, # features)
NumPy matrix containing the features
y: array-like (# rows, 1)
NumPy matrix containing the target values
n: list (default: [2])
The maximum size(s) of the MDR model to generate.
e.g., if n == [3], all 3-way models will be generated.
feature_names: list (default: None)
The corresponding names of the features in X.
If None, then the features will be named according to their order.
Returns
----------
(fitted_model, fitted_model_score, fitted_model_features): tuple of (list, list, list)
fitted_model contains the MDR model fitted to the data.
fitted_model_score contains the training scores corresponding to the fitted MDR model.
fitted_model_features contains a list of the names of the features that were used in the corresponding model.
"""
if feature_names is None:
feature_names = list(range(X.shape[1]))
for cur_n in n:
for features in itertools.combinations(range(X.shape[1]), cur_n):
mdr_model = copy.deepcopy(mdr_instance)
mdr_model.fit(X[:, features], y)
mdr_model_score = mdr_model.score(X[:, features], y)
model_features = [feature_names[feature] for feature in features]
yield mdr_model, mdr_model_score, model_features
def plot_mdr_grid(mdr_instance):
"""Visualizes the MDR grid of a given fitted MDR instance. Only works for 2-way MDR models.
This function is currently incomplete.
Parameters
----------
mdr_instance: object
A fitted instance of the MDR type to visualize.
Returns
----------
fig: matplotlib.figure
Figure object for the visualized MDR grid.
"""
var1_levels = list(set([variables[0] for variables in mdr_instance.feature_map]))
var2_levels = list(set([variables[1] for variables in mdr_instance.feature_map]))
max_count = np.array(list(mdr_instance.class_count_matrix.values())).flatten().max()
"""
TODO:
- Add common axis labels
- Make sure this scales for smaller and larger record sizes
- Extend to 3-way+ models, e.g., http://4.bp.blogspot.com/-vgKCjEkWFUc/UPwPuHo6XvI/AAAAAAAAAE0/fORHqDcoikE/s1600/model.jpg
"""
fig, splots = plt.subplots(ncols=len(var1_levels), nrows=len(var2_levels), sharey=True, sharex=True)
fig.set_figwidth(6)
fig.set_figheight(6)
for (var1, var2) in itertools.product(var1_levels, var2_levels):
class_counts = mdr_instance.class_count_matrix[(var1, var2)]
splot = splots[var2_levels.index(var2)][var1_levels.index(var1)]
splot.set_yticks([])
splot.set_xticks([])
splot.set_ylim(0, max_count * 1.5)
splot.set_xlim(-0.5, 1.5)
if var2_levels.index(var2) == 0:
splot.set_title('X1 = {}'.format(var1), fontsize=12)
if var1_levels.index(var1) == 0:
splot.set_ylabel('X2 = {}'.format(var2), fontsize=12)
bars = splot.bar(left=range(class_counts.shape[0]),
height=class_counts, width=0.5,
color='black', align='center')
bgcolor = 'lightgrey' if mdr_instance.feature_map[(var1, var2)] == 0 else 'darkgrey'
splot.set_axis_bgcolor(bgcolor)
for index, bar in enumerate(bars):
splot.text(index, class_counts[index] + (max_count * 0.1), class_counts[index], ha='center')
fig.tight_layout()
return fig | 0.945514 | 0.773024 |
Master Status: [](https://travis-ci.com/UrbsLab/scikit-XCS)
# scikit-XCS
The scikit-XCS package includes a sklearn-compatible Python implementation of XCS, the most popular and best studied learning classifier system algorithm to date. In general, Learning Classifier Systems (LCSs) are a classification of Rule Based Machine Learning Algorithms that have been shown to perform well on problems involving high amounts of heterogeneity and epistasis. Well designed LCSs are also highly human interpretable. LCS variants have been shown to adeptly handle supervised and reinforced, classification and regression, online and offline learning problems, as well as missing or unbalanced data. These characteristics of versatility and interpretability give LCSs a wide range of potential applications, notably those in biomedicine. This package is **still under active development** and we encourage you to check back on this repository for updates.
This version of scikit-XCS is suitable for single step, classification problems. It has not yet been developed for multi-step reinforcement learning problems nor regression problems. Within these bounds however, scikit-XCS can be applied to almost any supervised classification data set and supports:
<ul>
<li>Feature sets that are discrete/categorical, continuous-valued or a mix of both</li>
<li>Data with missing values</li>
<li>Binary Classification Problems (Binary Endpoints)</li>
<li>Multi-class Classification Problems (Multi-class Endpoints)</li>
</ul>
Built into this code, is a strategy to 'automatically' detect from the loaded data, these relevant above characteristics so that they don't need to be parameterized at initialization.
The core Scikit package only supports numeric data. However, an additional StringEnumerator Class is provided that allows quick data conversion from any type of data into pure numeric data, making it possible for natively string/non-numeric data to be run by scikit-XCS.
In addition, powerful data tracking collection methods are built into the scikit package, that continuously tracks features every iteration such as:
<ul>
<li>Approximate Accuracy</li>
<li>Average Population Generality</li>
<li>Macro & Micropopulation Size</li>
<li>Match Set and Action Set Sizes</li>
<li>Number of classifiers subsumed/deleted/covered</li>
<li>Number of crossover/mutation operations performed</li>
<li>Times for matching, deletion, subsumption, selection, evaluation</li>
</ul>
These values can then be exported as a csv after training is complete for analysis using the built in "export_iteration_tracking_data" method.
In addition, the package includes functionality that allows the final rule population to be exported as a csv after training.
## Usage
For more information on how to use scikit-XCS, please refer to the [scikit-XCS User Guide](https://github.com/UrbsLab/scikit-XCS/blob/master/scikit-XCS%20User%20Guide.ipynb) Jupyter Notebook inside this repository.
## Usage TLDR
```python
#Import Necessary Packages/Modules
from skXCS import XCS
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score
#Load Data Using Pandas
data = pd.read_csv('myDataFile.csv') #REPLACE with your own dataset .csv filename
dataFeatures = data.drop(actionLabel,axis=1).values #DEFINE actionLabel variable as the Str at the top of your dataset's action column
dataActions = data[actionLabel].values
#Shuffle Data Before CV
formatted = np.insert(dataFeatures,dataFeatures.shape[1],dataActions,1)
np.random.shuffle(formatted)
dataFeatures = np.delete(formatted,-1,axis=1)
dataActions = formatted[:,-1]
#Initialize XCS Model
model = XCS(learning_iterations = 5000)
#3-fold CV
print(np.mean(cross_val_score(model,dataFeatures,dataActions,cv=3)))
```
## License
Please see the repository [license](https://github.com/UrbsLab/scikit-XCS/blob/master/LICENSE) for the licensing and usage information for scikit-XCS.
Generally, we have licensed scikit-XCS to make it as widely usable as possible.
## Installation
scikit-XCS is built on top of the following Python packages:
<ol>
<li> numpy </li>
<li> pandas </li>
<li> scikit-learn </li>
</ol>
Once the prerequisites are installed, you can install scikit-XCS with a pip command:
```
pip/pip3 install scikit-XCS
```
We strongly recommend you use Python 3. scikit-XCS does not support Python 2, given its depreciation in Jan 1 2020. If something goes wrong during installation, make sure that your pip is up to date and try again.
```
pip/pip3 install --upgrade pip
```
## Contributing to scikit-XCS
scikit-XCS is an open source project and we'd love if you could suggest changes!
<ol>
<li> Fork the project repository to your personal account and clone this copy to your local disk</li>
<li> Create a branch from master to hold your changes: (e.g. <b>git checkout -b my-contribution-branch</b>) </li>
<li> Commit changes on your branch. Remember to never work on any other branch but your own! </li>
<li> When you are done, push your changes to your forked GitHub repository with <b>git push -u origin my-contribution-branch</b> </li>
<li> Create a pull request to send your changes to the scikit-XCS maintainers for review. </li>
</ol>
**Before submitting your pull request**
If your contribution changes XCS in any way, make sure you update the Jupyter Notebook documentation and the README with relevant details. If your contribution involves any code changes, update the project unit tests to test your code changes, and make sure your code is properly commented to explain your rationale behind non-obvious coding practices.
**After submitting your pull request**
After submitting your pull request, Travis CI will run all of the project's unit tests. Check back shortly after submitting to make sure your code passes these checks. If any checks come back failed, do your best to address the errors.
| scikit-XCS | /scikit-XCS-1.0.8.tar.gz/scikit-XCS-1.0.8/README.md | README.md | #Import Necessary Packages/Modules
from skXCS import XCS
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score
#Load Data Using Pandas
data = pd.read_csv('myDataFile.csv') #REPLACE with your own dataset .csv filename
dataFeatures = data.drop(actionLabel,axis=1).values #DEFINE actionLabel variable as the Str at the top of your dataset's action column
dataActions = data[actionLabel].values
#Shuffle Data Before CV
formatted = np.insert(dataFeatures,dataFeatures.shape[1],dataActions,1)
np.random.shuffle(formatted)
dataFeatures = np.delete(formatted,-1,axis=1)
dataActions = formatted[:,-1]
#Initialize XCS Model
model = XCS(learning_iterations = 5000)
#3-fold CV
print(np.mean(cross_val_score(model,dataFeatures,dataActions,cv=3)))
pip/pip3 install scikit-XCS
pip/pip3 install --upgrade pip | 0.328529 | 0.985677 |
import numpy as np
import pandas as pd
from warnings import simplefilter
# ignore all future warnings
simplefilter(action='ignore', category=FutureWarning)
class StringEnumerator:
def __init__(self, inputFile, classLabel):
self.classLabel = classLabel
self.map = {} #Dictionary of header names: Attribute dictionaries
data = pd.read_csv(inputFile, sep=',') # Puts data from csv into indexable np arrays
data = data.fillna("NA")
self.dataFeatures = data.drop(classLabel, axis=1).values #splits into an array of instances
self.dataPhenotypes = data[classLabel].values
self.dataHeaders = data.drop(classLabel, axis=1).columns.values
tempPhenoArray = np.empty(len(self.dataPhenotypes),dtype=object)
for instanceIndex in range(len(self.dataPhenotypes)):
tempPhenoArray[instanceIndex] = str(self.dataPhenotypes[instanceIndex])
self.dataPhenotypes = tempPhenoArray
tempFeatureArray = np.empty((len(self.dataPhenotypes),len(self.dataHeaders)),dtype=object)
for instanceIndex in range(len(self.dataFeatures)):
for attrInst in range(len(self.dataHeaders)):
tempFeatureArray[instanceIndex][attrInst] = str(self.dataFeatures[instanceIndex][attrInst])
self.dataFeatures = tempFeatureArray
self.delete_all_instances_without_phenotype()
def print_invalid_attributes(self):
print("ALL INVALID ATTRIBUTES & THEIR DISTINCT VALUES")
for attr in range(len(self.dataHeaders)):
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataFeatures)):
val = self.dataFeatures[instIndex,attr]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataFeatures[instIndex,attr])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.dataHeaders[attr])+": ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataPhenotypes)):
val = self.dataPhenotypes[instIndex]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataPhenotypes[instIndex])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.classLabel)+" (the phenotype): ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
def change_class_name(self,newName):
if newName in self.dataHeaders:
raise Exception("New Class Name Cannot Be An Already Existing Data Header Name")
if self.classLabel in self.map.keys():
self.map[self.newName] = self.map.pop(self.classLabel)
self.classLabel = newName
def change_header_name(self,currentName,newName):
if newName in self.dataHeaders or newName == self.classLabel:
raise Exception("New Class Name Cannot Be An Already Existing Data Header or Phenotype Name")
if currentName in self.dataHeaders:
headerIndex = np.where(self.dataHeaders == currentName)[0][0]
self.dataHeaders[headerIndex] = newName
if currentName in self.map.keys():
self.map[newName] = self.map.pop(currentName)
else:
raise Exception("Current Header Doesn't Exist")
def add_attribute_converter(self,headerName,array):#map is an array of strings, ordered by how it is to be enumerated enumeration
if headerName in self.dataHeaders and not (headerName in self.map):
newAttributeConverter = {}
for index in range(len(array)):
if str(array[index]) != "NA" and str(array[index]) != "" and str(array[index]) != "NaN":
newAttributeConverter[str(array[index])] = str(index)
self.map[headerName] = newAttributeConverter
def add_attribute_converter_map(self,headerName,map):
if headerName in self.dataHeaders and not (headerName in self.map) and not("" in map) and not("NA" in map) and not("NaN" in map):
self.map[headerName] = map
else:
raise Exception("Invalid Map")
def add_attribute_converter_random(self,headerName):
if headerName in self.dataHeaders and not (headerName in self.map):
headerIndex = np.where(self.dataHeaders == headerName)[0][0]
uniqueItems = []
for instance in self.dataFeatures:
if not(instance[headerIndex] in uniqueItems) and instance[headerIndex] != "NA":
uniqueItems.append(instance[headerIndex])
self.add_attribute_converter(headerName,np.array(uniqueItems))
def add_class_converter(self,array):
if not (self.classLabel in self.map.keys()):
newAttributeConverter = {}
for index in range(len(array)):
newAttributeConverter[str(array[index])] = str(index)
self.map[self.classLabel] = newAttributeConverter
def add_class_converter_random(self):
if not (self.classLabel in self.map.keys()):
uniqueItems = []
for instance in self.dataPhenotypes:
if not (instance in uniqueItems) and instance != "NA":
uniqueItems.append(instance)
self.add_class_converter(np.array(uniqueItems))
def convert_all_attributes(self):
for attribute in self.dataHeaders:
if attribute in self.map.keys():
i = np.where(self.dataHeaders == attribute)[0][0]
for state in self.dataFeatures:#goes through each instance's state
if (state[i] in self.map[attribute].keys()):
state[i] = self.map[attribute][state[i]]
if self.classLabel in self.map.keys():
for state in self.dataPhenotypes:
if (state in self.map[self.classLabel].keys()):
i = np.where(self.dataPhenotypes == state)
self.dataPhenotypes[i] = self.map[self.classLabel][state]
def delete_attribute(self,headerName):
if headerName in self.dataHeaders:
i = np.where(headerName == self.dataHeaders)[0][0]
self.dataHeaders = np.delete(self.dataHeaders,i)
if headerName in self.map.keys():
del self.map[headerName]
newFeatures = []
for instanceIndex in range(len(self.dataFeatures)):
instance = np.delete(self.dataFeatures[instanceIndex],i)
newFeatures.append(instance)
self.dataFeatures = np.array(newFeatures)
else:
raise Exception("Header Doesn't Exist")
def delete_all_instances_without_header_data(self,headerName):
newFeatures = []
newPhenotypes = []
attributeIndex = np.where(self.dataHeaders == headerName)[0][0]
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataFeatures[instanceIndex]
if instance[attributeIndex] != "NA":
newFeatures.append(instance)
newPhenotypes.append(self.dataPhenotypes[instanceIndex])
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def delete_all_instances_without_phenotype(self):
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataPhenotypes[instanceIndex]
if instance != "NA":
newFeatures.append(self.dataFeatures[instanceIndex])
newPhenotypes.append(instance)
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def print(self):
isFullNumber = self.check_is_full_numeric()
print("Converted Data Features and Phenotypes")
for header in self.dataHeaders:
print(header,end="\t")
print()
for instanceIndex in range(len(self.dataFeatures)):
for attribute in self.dataFeatures[instanceIndex]:
if attribute != "NA":
if (isFullNumber):
print(float(attribute), end="\t")
else:
print(attribute, end="\t\t")
else:
print("NA", end = "\t")
if self.dataPhenotypes[instanceIndex] != "NA":
if (isFullNumber):
print(float(self.dataPhenotypes[instanceIndex]))
else:
print(self.dataPhenotypes[instanceIndex])
else:
print("NA")
print()
def print_attribute_conversions(self):
print("Changed Attribute Conversions")
for headerName,conversions in self.map:
print(headerName + " conversions:")
for original,numberVal in conversions:
print("\tOriginal: "+original+" Converted: "+numberVal)
print()
print()
def check_is_full_numeric(self):
try:
for instance in self.dataFeatures:
for value in instance:
if value != "NA":
float(value)
for value in self.dataPhenotypes:
if value != "NA":
float(value)
except:
return False
return True
def get_params(self):
if not(self.check_is_full_numeric()):
raise Exception("Features and Phenotypes must be fully numeric")
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
newInstance = []
for attribute in self.dataFeatures[instanceIndex]:
if attribute == "NA":
newInstance.append(np.nan)
else:
newInstance.append(float(attribute))
newFeatures.append(np.array(newInstance,dtype=float))
if self.dataPhenotypes[instanceIndex] == "NA": #Should never happen. All NaN phenotypes should be removed automatically at init. Just a safety mechanism.
newPhenotypes.append(np.nan)
else:
newPhenotypes.append(float(self.dataPhenotypes[instanceIndex]))
return self.dataHeaders,self.classLabel,np.array(newFeatures,dtype=float),np.array(newPhenotypes,dtype=float) | scikit-XCS | /scikit-XCS-1.0.8.tar.gz/scikit-XCS-1.0.8/skXCS/StringEnumerator.py | StringEnumerator.py | import numpy as np
import pandas as pd
from warnings import simplefilter
# ignore all future warnings
simplefilter(action='ignore', category=FutureWarning)
class StringEnumerator:
def __init__(self, inputFile, classLabel):
self.classLabel = classLabel
self.map = {} #Dictionary of header names: Attribute dictionaries
data = pd.read_csv(inputFile, sep=',') # Puts data from csv into indexable np arrays
data = data.fillna("NA")
self.dataFeatures = data.drop(classLabel, axis=1).values #splits into an array of instances
self.dataPhenotypes = data[classLabel].values
self.dataHeaders = data.drop(classLabel, axis=1).columns.values
tempPhenoArray = np.empty(len(self.dataPhenotypes),dtype=object)
for instanceIndex in range(len(self.dataPhenotypes)):
tempPhenoArray[instanceIndex] = str(self.dataPhenotypes[instanceIndex])
self.dataPhenotypes = tempPhenoArray
tempFeatureArray = np.empty((len(self.dataPhenotypes),len(self.dataHeaders)),dtype=object)
for instanceIndex in range(len(self.dataFeatures)):
for attrInst in range(len(self.dataHeaders)):
tempFeatureArray[instanceIndex][attrInst] = str(self.dataFeatures[instanceIndex][attrInst])
self.dataFeatures = tempFeatureArray
self.delete_all_instances_without_phenotype()
def print_invalid_attributes(self):
print("ALL INVALID ATTRIBUTES & THEIR DISTINCT VALUES")
for attr in range(len(self.dataHeaders)):
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataFeatures)):
val = self.dataFeatures[instIndex,attr]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataFeatures[instIndex,attr])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.dataHeaders[attr])+": ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
distinctValues = []
isInvalid = False
for instIndex in range(len(self.dataPhenotypes)):
val = self.dataPhenotypes[instIndex]
if not val in distinctValues and val != "NA":
distinctValues.append(self.dataPhenotypes[instIndex])
if val != "NA":
try:
float(val)
except:
isInvalid = True
if isInvalid:
print(str(self.classLabel)+" (the phenotype): ",end="")
for i in distinctValues:
print(str(i)+"\t",end="")
print()
def change_class_name(self,newName):
if newName in self.dataHeaders:
raise Exception("New Class Name Cannot Be An Already Existing Data Header Name")
if self.classLabel in self.map.keys():
self.map[self.newName] = self.map.pop(self.classLabel)
self.classLabel = newName
def change_header_name(self,currentName,newName):
if newName in self.dataHeaders or newName == self.classLabel:
raise Exception("New Class Name Cannot Be An Already Existing Data Header or Phenotype Name")
if currentName in self.dataHeaders:
headerIndex = np.where(self.dataHeaders == currentName)[0][0]
self.dataHeaders[headerIndex] = newName
if currentName in self.map.keys():
self.map[newName] = self.map.pop(currentName)
else:
raise Exception("Current Header Doesn't Exist")
def add_attribute_converter(self,headerName,array):#map is an array of strings, ordered by how it is to be enumerated enumeration
if headerName in self.dataHeaders and not (headerName in self.map):
newAttributeConverter = {}
for index in range(len(array)):
if str(array[index]) != "NA" and str(array[index]) != "" and str(array[index]) != "NaN":
newAttributeConverter[str(array[index])] = str(index)
self.map[headerName] = newAttributeConverter
def add_attribute_converter_map(self,headerName,map):
if headerName in self.dataHeaders and not (headerName in self.map) and not("" in map) and not("NA" in map) and not("NaN" in map):
self.map[headerName] = map
else:
raise Exception("Invalid Map")
def add_attribute_converter_random(self,headerName):
if headerName in self.dataHeaders and not (headerName in self.map):
headerIndex = np.where(self.dataHeaders == headerName)[0][0]
uniqueItems = []
for instance in self.dataFeatures:
if not(instance[headerIndex] in uniqueItems) and instance[headerIndex] != "NA":
uniqueItems.append(instance[headerIndex])
self.add_attribute_converter(headerName,np.array(uniqueItems))
def add_class_converter(self,array):
if not (self.classLabel in self.map.keys()):
newAttributeConverter = {}
for index in range(len(array)):
newAttributeConverter[str(array[index])] = str(index)
self.map[self.classLabel] = newAttributeConverter
def add_class_converter_random(self):
if not (self.classLabel in self.map.keys()):
uniqueItems = []
for instance in self.dataPhenotypes:
if not (instance in uniqueItems) and instance != "NA":
uniqueItems.append(instance)
self.add_class_converter(np.array(uniqueItems))
def convert_all_attributes(self):
for attribute in self.dataHeaders:
if attribute in self.map.keys():
i = np.where(self.dataHeaders == attribute)[0][0]
for state in self.dataFeatures:#goes through each instance's state
if (state[i] in self.map[attribute].keys()):
state[i] = self.map[attribute][state[i]]
if self.classLabel in self.map.keys():
for state in self.dataPhenotypes:
if (state in self.map[self.classLabel].keys()):
i = np.where(self.dataPhenotypes == state)
self.dataPhenotypes[i] = self.map[self.classLabel][state]
def delete_attribute(self,headerName):
if headerName in self.dataHeaders:
i = np.where(headerName == self.dataHeaders)[0][0]
self.dataHeaders = np.delete(self.dataHeaders,i)
if headerName in self.map.keys():
del self.map[headerName]
newFeatures = []
for instanceIndex in range(len(self.dataFeatures)):
instance = np.delete(self.dataFeatures[instanceIndex],i)
newFeatures.append(instance)
self.dataFeatures = np.array(newFeatures)
else:
raise Exception("Header Doesn't Exist")
def delete_all_instances_without_header_data(self,headerName):
newFeatures = []
newPhenotypes = []
attributeIndex = np.where(self.dataHeaders == headerName)[0][0]
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataFeatures[instanceIndex]
if instance[attributeIndex] != "NA":
newFeatures.append(instance)
newPhenotypes.append(self.dataPhenotypes[instanceIndex])
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def delete_all_instances_without_phenotype(self):
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
instance = self.dataPhenotypes[instanceIndex]
if instance != "NA":
newFeatures.append(self.dataFeatures[instanceIndex])
newPhenotypes.append(instance)
self.dataFeatures = np.array(newFeatures)
self.dataPhenotypes = np.array(newPhenotypes)
def print(self):
isFullNumber = self.check_is_full_numeric()
print("Converted Data Features and Phenotypes")
for header in self.dataHeaders:
print(header,end="\t")
print()
for instanceIndex in range(len(self.dataFeatures)):
for attribute in self.dataFeatures[instanceIndex]:
if attribute != "NA":
if (isFullNumber):
print(float(attribute), end="\t")
else:
print(attribute, end="\t\t")
else:
print("NA", end = "\t")
if self.dataPhenotypes[instanceIndex] != "NA":
if (isFullNumber):
print(float(self.dataPhenotypes[instanceIndex]))
else:
print(self.dataPhenotypes[instanceIndex])
else:
print("NA")
print()
def print_attribute_conversions(self):
print("Changed Attribute Conversions")
for headerName,conversions in self.map:
print(headerName + " conversions:")
for original,numberVal in conversions:
print("\tOriginal: "+original+" Converted: "+numberVal)
print()
print()
def check_is_full_numeric(self):
try:
for instance in self.dataFeatures:
for value in instance:
if value != "NA":
float(value)
for value in self.dataPhenotypes:
if value != "NA":
float(value)
except:
return False
return True
def get_params(self):
if not(self.check_is_full_numeric()):
raise Exception("Features and Phenotypes must be fully numeric")
newFeatures = []
newPhenotypes = []
for instanceIndex in range(len(self.dataFeatures)):
newInstance = []
for attribute in self.dataFeatures[instanceIndex]:
if attribute == "NA":
newInstance.append(np.nan)
else:
newInstance.append(float(attribute))
newFeatures.append(np.array(newInstance,dtype=float))
if self.dataPhenotypes[instanceIndex] == "NA": #Should never happen. All NaN phenotypes should be removed automatically at init. Just a safety mechanism.
newPhenotypes.append(np.nan)
else:
newPhenotypes.append(float(self.dataPhenotypes[instanceIndex]))
return self.dataHeaders,self.classLabel,np.array(newFeatures,dtype=float),np.array(newPhenotypes,dtype=float) | 0.140602 | 0.305335 |
import time
# --------------------------------------
class Timer:
def __init__(self):
# Global Time objects
self.globalStartRef = time.time()
self.globalTime = 0.0
self.globalAdd = 0
# Match Time Variables
self.startRefMatching = 0.0
self.globalMatching = 0.0
# Deletion Time Variables
self.startRefDeletion = 0.0
self.globalDeletion = 0.0
# Subsumption Time Variables
self.startRefSubsumption = 0.0
self.globalSubsumption = 0.0
# GA Time Variables
self.startRefGA = 0.0
self.globalGA = 0.0
# Evaluation Time Variables
self.startRefEvaluation = 0.0
self.globalEvaluation = 0.0
# ************************************************************
def startTimeMatching(self):
""" Tracks MatchSet Time """
self.startRefMatching = time.time()
def stopTimeMatching(self):
""" Tracks MatchSet Time """
diff = time.time() - self.startRefMatching
self.globalMatching += diff
# ************************************************************
def startTimeDeletion(self):
""" Tracks Deletion Time """
self.startRefDeletion = time.time()
def stopTimeDeletion(self):
""" Tracks Deletion Time """
diff = time.time() - self.startRefDeletion
self.globalDeletion += diff
# ************************************************************
def startTimeSubsumption(self):
"""Tracks Subsumption Time """
self.startRefSubsumption = time.time()
def stopTimeSubsumption(self):
"""Tracks Subsumption Time """
diff = time.time() - self.startRefSubsumption
self.globalSubsumption += diff
# ************************************************************
def startTimeGA(self):
""" Tracks Selection Time """
self.startRefGA = time.time()
def stopTimeGA(self):
""" Tracks Selection Time """
diff = time.time() - self.startRefGA
self.globalGA += diff
# ************************************************************
def startTimeEvaluation(self):
""" Tracks Evaluation Time """
self.startRefEvaluation = time.time()
def stopTimeEvaluation(self):
""" Tracks Evaluation Time """
diff = time.time() - self.startRefEvaluation
self.globalEvaluation += diff
# ************************************************************
def updateGlobalTimer(self):
""" Set the global end timer, call at very end of algorithm. """
self.globalTime = (time.time() - self.globalStartRef) + self.globalAdd
return self.globalTime | scikit-XCS | /scikit-XCS-1.0.8.tar.gz/scikit-XCS-1.0.8/skXCS/Timer.py | Timer.py | import time
# --------------------------------------
class Timer:
def __init__(self):
# Global Time objects
self.globalStartRef = time.time()
self.globalTime = 0.0
self.globalAdd = 0
# Match Time Variables
self.startRefMatching = 0.0
self.globalMatching = 0.0
# Deletion Time Variables
self.startRefDeletion = 0.0
self.globalDeletion = 0.0
# Subsumption Time Variables
self.startRefSubsumption = 0.0
self.globalSubsumption = 0.0
# GA Time Variables
self.startRefGA = 0.0
self.globalGA = 0.0
# Evaluation Time Variables
self.startRefEvaluation = 0.0
self.globalEvaluation = 0.0
# ************************************************************
def startTimeMatching(self):
""" Tracks MatchSet Time """
self.startRefMatching = time.time()
def stopTimeMatching(self):
""" Tracks MatchSet Time """
diff = time.time() - self.startRefMatching
self.globalMatching += diff
# ************************************************************
def startTimeDeletion(self):
""" Tracks Deletion Time """
self.startRefDeletion = time.time()
def stopTimeDeletion(self):
""" Tracks Deletion Time """
diff = time.time() - self.startRefDeletion
self.globalDeletion += diff
# ************************************************************
def startTimeSubsumption(self):
"""Tracks Subsumption Time """
self.startRefSubsumption = time.time()
def stopTimeSubsumption(self):
"""Tracks Subsumption Time """
diff = time.time() - self.startRefSubsumption
self.globalSubsumption += diff
# ************************************************************
def startTimeGA(self):
""" Tracks Selection Time """
self.startRefGA = time.time()
def stopTimeGA(self):
""" Tracks Selection Time """
diff = time.time() - self.startRefGA
self.globalGA += diff
# ************************************************************
def startTimeEvaluation(self):
""" Tracks Evaluation Time """
self.startRefEvaluation = time.time()
def stopTimeEvaluation(self):
""" Tracks Evaluation Time """
diff = time.time() - self.startRefEvaluation
self.globalEvaluation += diff
# ************************************************************
def updateGlobalTimer(self):
""" Set the global end timer, call at very end of algorithm. """
self.globalTime = (time.time() - self.globalStartRef) + self.globalAdd
return self.globalTime | 0.533397 | 0.171408 |
import csv
import numpy as np
class IterationRecord():
'''
IterationRecord Tracks 1 dictionary:
1) Tracking Dict: Cursory Iteration Evaluation. Frequency determined by trackingFrequency param in eLCS. For each iteration evaluated, it saves:
KEY-iteration number
0-accuracy (approximate from correct array in eLCS)
1-average population generality
2-macropopulation size
3-micropopulation size
4-match set size
5-correct set size
6-average iteration age of action set classifiers
7-number of classifiers subsumed (in iteration)
8-number of crossover operations performed (in iteration)
9-number of mutation operations performed (in iteration)
10-number of covering operations performed (in iteration)
11-number of deleted macroclassifiers performed (in iteration)
12-total global time at end of iteration
13-total matching time at end of iteration
14-total deletion time at end of iteration
15-total subsumption time at end of iteration
16-total selection time at end of iteration
17-total evaluation time at end of iteration
'''
def __init__(self):
self.trackingDict = {}
def addToTracking(self,iterationNumber,accuracy,avgPopGenerality,macroSize,microSize,mSize,aSize,iterAvg,
subsumptionCount,crossoverCount,mutationCount,coveringCount,deletionCount,
globalTime,matchingTime,deletionTime,subsumptionTime,gaTime,evaluationTime):
self.trackingDict[iterationNumber] = [accuracy,avgPopGenerality,macroSize,microSize,mSize,aSize,iterAvg,
subsumptionCount,crossoverCount,mutationCount,coveringCount,deletionCount,
globalTime,matchingTime,deletionTime,subsumptionTime,gaTime,evaluationTime]
def exportTrackingToCSV(self,filename='iterationData.csv'):
#Exports each entry in Tracking Array as a column
with open(filename,mode='w') as file:
writer = csv.writer(file,delimiter=',',quotechar='"',quoting=csv.QUOTE_MINIMAL)
writer.writerow(["Iteration","Accuracy (approx)", "Average Population Generality","Macropopulation Size",
"Micropopulation Size", "Match Set Size", "Action Set Size", "Average Iteration Age of Action Set Classifiers",
"# Classifiers Subsumed in Iteration","# Crossover Operations Performed in Iteration","# Mutation Operations Performed in Iteration",
"# Covering Operations Performed in Iteration","# Deletion Operations Performed in Iteration",
"Total Global Time","Total Matching Time","Total Deletion Time","Total Subsumption Time","Total GA Time","Total Evaluation Time"])
for k,v in sorted(self.trackingDict.items()):
writer.writerow([k,v[0],v[1],v[2],v[3],v[4],v[5],v[6],v[7],v[8],v[9],v[10],v[11],v[12],v[13],v[14],v[15],v[16],v[17]])
file.close() | scikit-XCS | /scikit-XCS-1.0.8.tar.gz/scikit-XCS-1.0.8/skXCS/IterationRecord.py | IterationRecord.py | import csv
import numpy as np
class IterationRecord():
'''
IterationRecord Tracks 1 dictionary:
1) Tracking Dict: Cursory Iteration Evaluation. Frequency determined by trackingFrequency param in eLCS. For each iteration evaluated, it saves:
KEY-iteration number
0-accuracy (approximate from correct array in eLCS)
1-average population generality
2-macropopulation size
3-micropopulation size
4-match set size
5-correct set size
6-average iteration age of action set classifiers
7-number of classifiers subsumed (in iteration)
8-number of crossover operations performed (in iteration)
9-number of mutation operations performed (in iteration)
10-number of covering operations performed (in iteration)
11-number of deleted macroclassifiers performed (in iteration)
12-total global time at end of iteration
13-total matching time at end of iteration
14-total deletion time at end of iteration
15-total subsumption time at end of iteration
16-total selection time at end of iteration
17-total evaluation time at end of iteration
'''
def __init__(self):
self.trackingDict = {}
def addToTracking(self,iterationNumber,accuracy,avgPopGenerality,macroSize,microSize,mSize,aSize,iterAvg,
subsumptionCount,crossoverCount,mutationCount,coveringCount,deletionCount,
globalTime,matchingTime,deletionTime,subsumptionTime,gaTime,evaluationTime):
self.trackingDict[iterationNumber] = [accuracy,avgPopGenerality,macroSize,microSize,mSize,aSize,iterAvg,
subsumptionCount,crossoverCount,mutationCount,coveringCount,deletionCount,
globalTime,matchingTime,deletionTime,subsumptionTime,gaTime,evaluationTime]
def exportTrackingToCSV(self,filename='iterationData.csv'):
#Exports each entry in Tracking Array as a column
with open(filename,mode='w') as file:
writer = csv.writer(file,delimiter=',',quotechar='"',quoting=csv.QUOTE_MINIMAL)
writer.writerow(["Iteration","Accuracy (approx)", "Average Population Generality","Macropopulation Size",
"Micropopulation Size", "Match Set Size", "Action Set Size", "Average Iteration Age of Action Set Classifiers",
"# Classifiers Subsumed in Iteration","# Crossover Operations Performed in Iteration","# Mutation Operations Performed in Iteration",
"# Covering Operations Performed in Iteration","# Deletion Operations Performed in Iteration",
"Total Global Time","Total Matching Time","Total Deletion Time","Total Subsumption Time","Total GA Time","Total Evaluation Time"])
for k,v in sorted(self.trackingDict.items()):
writer.writerow([k,v[0],v[1],v[2],v[3],v[4],v[5],v[6],v[7],v[8],v[9],v[10],v[11],v[12],v[13],v[14],v[15],v[16],v[17]])
file.close() | 0.594904 | 0.479138 |
import random
import copy
class Classifier:
def __init__(self,xcs):
self.specifiedAttList = []
self.condition = []
self.action = None
self.prediction = xcs.init_prediction
self.fitness = xcs.init_fitness
self.predictionError = xcs.init_e
self.numerosity = 1
self.experience = 0 #aka action set count
self.matchCount = 0
self.actionSetSize = None
self.timestampGA = xcs.iterationCount
self.initTimeStamp = xcs.iterationCount
self.deletionProb = None
pass
def initializeWithParentClassifier(self,classifier):
self.specifiedAttList = copy.deepcopy(classifier.specifiedAttList)
self.condition = copy.deepcopy(classifier.condition)
self.action = copy.deepcopy(classifier.action)
self.actionSetSize = classifier.actionSetSize
self.prediction = classifier.prediction
self.predictionError = classifier.predictionError
self.fitness = classifier.fitness/classifier.numerosity
def match(self,state,xcs):
for i in range(len(self.condition)):
specifiedIndex = self.specifiedAttList[i]
attributeInfoType = xcs.env.formatData.attributeInfoType[specifiedIndex]
instanceValue = state[specifiedIndex]
#Continuous
if attributeInfoType:
if instanceValue == None:
return False
elif self.condition[i][0] < instanceValue < self.condition[i][1]:
pass
else:
return False
else:
if instanceValue == self.condition[i]:
pass
elif instanceValue == None:
return False
else:
return False
return True
def initializeWithMatchingStateAndGivenAction(self,setSize,state,action,xcs):
self.action = action
self.actionSetSize = setSize
while len(self.specifiedAttList) < 1:
for attRef in range(len(state)):
if random.random() > xcs.p_general and not(state[attRef] == None):
self.specifiedAttList.append(attRef)
self.createMatchingAttribute(xcs,attRef,state)
def createMatchingAttribute(self,xcs,attRef,state):
attributeInfoType = xcs.env.formatData.attributeInfoType[attRef]
if attributeInfoType:
attributeInfoValue = xcs.env.formatData.attributeInfoContinuous[attRef]
# Continuous attribute
if attributeInfoType:
attRange = attributeInfoValue[1] - attributeInfoValue[0]
rangeRadius = random.randint(25, 75) * 0.01 * attRange / 2.0 # Continuous initialization domain radius.
ar = state[attRef]
Low = ar - rangeRadius
High = ar + rangeRadius
condList = [Low, High]
self.condition.append(condList)
# Discrete attribute
else:
condList = state[attRef]
self.condition.append(condList)
def equals(self,classifier):
if classifier.action == self.action and len(classifier.specifiedAttList) == len(self.specifiedAttList):
clRefs = sorted(classifier.specifiedAttList)
selfRefs = sorted(self.specifiedAttList)
if clRefs == selfRefs:
for i in range(len(classifier.specifiedAttList)):
tempIndex = self.specifiedAttList.index(classifier.specifiedAttList[i])
if not (classifier.condition[i] == self.condition[tempIndex]):
return False
return True
return False
def updateNumerosity(self,num):
self.numerosity += num
def increaseExperience(self):
self.experience += 1
def updatePredictionError(self,P,xcs):
if self.experience < 1.0/xcs.beta:
self.predictionError = self.predictionError + (abs(P - self.prediction) - self.predictionError) / float(self.experience)
else:
self.predictionError = self.predictionError + xcs.beta * (abs(P - self.prediction) - self.predictionError)
def updatePrediction(self,P,xcs):
if self.experience < 1.0 / xcs.beta:
self.prediction = self.prediction + (P-self.prediction) / float(self.experience)
else:
self.prediction = self.prediction + xcs.beta * (P - self.prediction)
def updateActionSetSize(self,numerositySum,xcs):
if self.experience < 1.0/xcs.beta:
self.actionSetSize = self.actionSetSize + (numerositySum - self.actionSetSize) / float(self.experience)
else:
self.actionSetSize = self.actionSetSize + xcs.beta * (numerositySum - self.actionSetSize)
def getAccuracy(self,xcs):
""" Returns the accuracy of the classifier.
The accuracy is determined from the prediction error of the classifier using Wilson's
power function as published in 'Get Real! XCS with continuous-valued inputs' (1999) """
if self.predictionError <= xcs.e_0:
accuracy = 1.0
else:
accuracy = xcs.alpha * ((self.predictionError / xcs.e_0) ** (-xcs.nu))
return accuracy
def updateFitness(self, accSum, accuracy,xcs):
""" Updates the fitness of the classifier according to the relative accuracy.
@param accSum The sum of all the accuracies in the action set
@param accuracy The accuracy of the classifier. """
self.fitness = self.fitness + xcs.beta * ((accuracy * self.numerosity) / float(accSum) - self.fitness)
def isSubsumer(self,xcs):
""" Returns if the classifier is a possible subsumer. It is affirmed if the classifier
has a sufficient experience and if its reward prediction error is sufficiently low. """
if self.experience > xcs.theta_sub and self.predictionError < xcs.e_0:
return True
return False
def isMoreGeneral(self,classifier,xcs):
if len(self.specifiedAttList) >= len(classifier.specifiedAttList):
return False
for i in range(len(self.specifiedAttList)):
if self.specifiedAttList[i] not in classifier.specifiedAttList:
return False
attributeInfoType = xcs.env.formatData.attributeInfoType[self.specifiedAttList[i]]
if attributeInfoType:
otherRef = classifier.specifiedAttList.index(self.specifiedAttList[i])
if self.condition[i][0] < classifier.condition[otherRef][0]:
return False
if self.condition[i][1] > classifier.condition[otherRef][1]:
return False
return True
def subsumes(self,classifier,xcs):
return self.action == classifier.action and self.isSubsumer(xcs) and self.isMoreGeneral(classifier,xcs)
def updateTimestamp(self,timestamp):
self.timestampGA = timestamp
def uniformCrossover(self,classifier,xcs):
p_self_specifiedAttList = copy.deepcopy(self.specifiedAttList)
p_cl_specifiedAttList = copy.deepcopy(classifier.specifiedAttList)
# Make list of attribute references appearing in at least one of the parents.-----------------------------
comboAttList = []
for i in p_self_specifiedAttList:
comboAttList.append(i)
for i in p_cl_specifiedAttList:
if i not in comboAttList:
comboAttList.append(i)
elif not xcs.env.formatData.attributeInfoType[i]:
comboAttList.remove(i)
comboAttList.sort()
changed = False
for attRef in comboAttList:
attributeInfoType = xcs.env.formatData.attributeInfoType[attRef]
probability = 0.5
ref = 0
if attRef in p_self_specifiedAttList:
ref += 1
if attRef in p_cl_specifiedAttList:
ref += 1
if ref == 0:
pass
elif ref == 1:
if attRef in p_self_specifiedAttList and random.random() > probability:
i = self.specifiedAttList.index(attRef)
classifier.condition.append(self.condition.pop(i))
classifier.specifiedAttList.append(attRef)
self.specifiedAttList.remove(attRef)
changed = True
if attRef in p_cl_specifiedAttList and random.random() < probability:
i = classifier.specifiedAttList.index(attRef)
self.condition.append(classifier.condition.pop(i))
self.specifiedAttList.append(attRef)
classifier.specifiedAttList.remove(attRef)
changed = True
else:
# Continuous Attribute
if attributeInfoType:
i_cl1 = self.specifiedAttList.index(attRef)
i_cl2 = classifier.specifiedAttList.index(attRef)
tempKey = random.randint(0, 3)
if tempKey == 0:
temp = self.condition[i_cl1][0]
self.condition[i_cl1][0] = classifier.condition[i_cl2][0]
classifier.condition[i_cl2][0] = temp
elif tempKey == 1:
temp = self.condition[i_cl1][1]
self.condition[i_cl1][1] = classifier.condition[i_cl2][1]
classifier.condition[i_cl2][1] = temp
else:
allList = self.condition[i_cl1] + classifier.condition[i_cl2]
newMin = min(allList)
newMax = max(allList)
if tempKey == 2:
self.condition[i_cl1] = [newMin, newMax]
classifier.condition.pop(i_cl2)
classifier.specifiedAttList.remove(attRef)
else:
classifier.condition[i_cl2] = [newMin, newMax]
self.condition.pop(i_cl1)
self.specifiedAttList.remove(attRef)
# Discrete Attribute
else:
pass
tempList1 = copy.deepcopy(p_self_specifiedAttList)
tempList2 = copy.deepcopy(classifier.specifiedAttList)
tempList1.sort()
tempList2.sort()
if changed and len(set(tempList1) & set(tempList2)) == len(tempList2):
changed = False
return changed
def mutation(self,state,xcs):
changedByConditionMutation = self.mutateCondition(state,xcs)
changedByActionMutation = self.mutateAction(xcs)
return changedByConditionMutation or changedByActionMutation
def mutateCondition(self,state,xcs):
changed = False
for attRef in range(xcs.env.formatData.numAttributes):
attributeInfoType = xcs.env.formatData.attributeInfoType[attRef]
if attributeInfoType:
attributeInfoValue = xcs.env.formatData.attributeInfoContinuous[attRef]
if random.random() < xcs.p_mutation and not(state[attRef] == None):
if not (attRef in self.specifiedAttList):
self.specifiedAttList.append(attRef)
self.createMatchingAttribute(xcs,attRef,state)
changed = True
elif attRef in self.specifiedAttList:
i = self.specifiedAttList.index(attRef)
if not attributeInfoType or random.random() > 0.5:
del self.specifiedAttList[i]
del self.condition[i]
changed = True
else:
attRange = float(attributeInfoValue[1]) - float(attributeInfoValue[0])
mutateRange = random.random() * 0.5 * attRange
if random.random() > 0.5:
if random.random() > 0.5:
self.condition[i][0] += mutateRange
else:
self.condition[i][0] -= mutateRange
else:
if random.random() > 0.5:
self.condition[i][1] += mutateRange
else:
self.condition[i][1] -= mutateRange
self.condition[i] = sorted(self.condition[i])
changed = True
else:
pass
return changed
def mutateAction(self,xcs):
changed = False
if random.random() < xcs.p_mutation:
action = random.choice(xcs.env.formatData.phenotypeList)
while action == self.action:
action = random.choice(xcs.env.formatData.phenotypeList)
self.action = action
changed = True
return changed
def getDelProp(self,meanFitness,xcs):
if self.fitness / self.numerosity >= xcs.delta * meanFitness or self.experience < xcs.theta_del:
deletionVote = self.actionSetSize * self.numerosity
elif self.fitness == 0.0:
deletionVote = self.actionSetSize * self.numerosity * meanFitness / (xcs.init_fit / self.numerosity)
else:
deletionVote = self.actionSetSize * self.numerosity * meanFitness / (self.fitness / self.numerosity)
return deletionVote | scikit-XCS | /scikit-XCS-1.0.8.tar.gz/scikit-XCS-1.0.8/skXCS/Classifier.py | Classifier.py | import random
import copy
class Classifier:
def __init__(self,xcs):
self.specifiedAttList = []
self.condition = []
self.action = None
self.prediction = xcs.init_prediction
self.fitness = xcs.init_fitness
self.predictionError = xcs.init_e
self.numerosity = 1
self.experience = 0 #aka action set count
self.matchCount = 0
self.actionSetSize = None
self.timestampGA = xcs.iterationCount
self.initTimeStamp = xcs.iterationCount
self.deletionProb = None
pass
def initializeWithParentClassifier(self,classifier):
self.specifiedAttList = copy.deepcopy(classifier.specifiedAttList)
self.condition = copy.deepcopy(classifier.condition)
self.action = copy.deepcopy(classifier.action)
self.actionSetSize = classifier.actionSetSize
self.prediction = classifier.prediction
self.predictionError = classifier.predictionError
self.fitness = classifier.fitness/classifier.numerosity
def match(self,state,xcs):
for i in range(len(self.condition)):
specifiedIndex = self.specifiedAttList[i]
attributeInfoType = xcs.env.formatData.attributeInfoType[specifiedIndex]
instanceValue = state[specifiedIndex]
#Continuous
if attributeInfoType:
if instanceValue == None:
return False
elif self.condition[i][0] < instanceValue < self.condition[i][1]:
pass
else:
return False
else:
if instanceValue == self.condition[i]:
pass
elif instanceValue == None:
return False
else:
return False
return True
def initializeWithMatchingStateAndGivenAction(self,setSize,state,action,xcs):
self.action = action
self.actionSetSize = setSize
while len(self.specifiedAttList) < 1:
for attRef in range(len(state)):
if random.random() > xcs.p_general and not(state[attRef] == None):
self.specifiedAttList.append(attRef)
self.createMatchingAttribute(xcs,attRef,state)
def createMatchingAttribute(self,xcs,attRef,state):
attributeInfoType = xcs.env.formatData.attributeInfoType[attRef]
if attributeInfoType:
attributeInfoValue = xcs.env.formatData.attributeInfoContinuous[attRef]
# Continuous attribute
if attributeInfoType:
attRange = attributeInfoValue[1] - attributeInfoValue[0]
rangeRadius = random.randint(25, 75) * 0.01 * attRange / 2.0 # Continuous initialization domain radius.
ar = state[attRef]
Low = ar - rangeRadius
High = ar + rangeRadius
condList = [Low, High]
self.condition.append(condList)
# Discrete attribute
else:
condList = state[attRef]
self.condition.append(condList)
def equals(self,classifier):
if classifier.action == self.action and len(classifier.specifiedAttList) == len(self.specifiedAttList):
clRefs = sorted(classifier.specifiedAttList)
selfRefs = sorted(self.specifiedAttList)
if clRefs == selfRefs:
for i in range(len(classifier.specifiedAttList)):
tempIndex = self.specifiedAttList.index(classifier.specifiedAttList[i])
if not (classifier.condition[i] == self.condition[tempIndex]):
return False
return True
return False
def updateNumerosity(self,num):
self.numerosity += num
def increaseExperience(self):
self.experience += 1
def updatePredictionError(self,P,xcs):
if self.experience < 1.0/xcs.beta:
self.predictionError = self.predictionError + (abs(P - self.prediction) - self.predictionError) / float(self.experience)
else:
self.predictionError = self.predictionError + xcs.beta * (abs(P - self.prediction) - self.predictionError)
def updatePrediction(self,P,xcs):
if self.experience < 1.0 / xcs.beta:
self.prediction = self.prediction + (P-self.prediction) / float(self.experience)
else:
self.prediction = self.prediction + xcs.beta * (P - self.prediction)
def updateActionSetSize(self,numerositySum,xcs):
if self.experience < 1.0/xcs.beta:
self.actionSetSize = self.actionSetSize + (numerositySum - self.actionSetSize) / float(self.experience)
else:
self.actionSetSize = self.actionSetSize + xcs.beta * (numerositySum - self.actionSetSize)
def getAccuracy(self,xcs):
""" Returns the accuracy of the classifier.
The accuracy is determined from the prediction error of the classifier using Wilson's
power function as published in 'Get Real! XCS with continuous-valued inputs' (1999) """
if self.predictionError <= xcs.e_0:
accuracy = 1.0
else:
accuracy = xcs.alpha * ((self.predictionError / xcs.e_0) ** (-xcs.nu))
return accuracy
def updateFitness(self, accSum, accuracy,xcs):
""" Updates the fitness of the classifier according to the relative accuracy.
@param accSum The sum of all the accuracies in the action set
@param accuracy The accuracy of the classifier. """
self.fitness = self.fitness + xcs.beta * ((accuracy * self.numerosity) / float(accSum) - self.fitness)
def isSubsumer(self,xcs):
""" Returns if the classifier is a possible subsumer. It is affirmed if the classifier
has a sufficient experience and if its reward prediction error is sufficiently low. """
if self.experience > xcs.theta_sub and self.predictionError < xcs.e_0:
return True
return False
def isMoreGeneral(self,classifier,xcs):
if len(self.specifiedAttList) >= len(classifier.specifiedAttList):
return False
for i in range(len(self.specifiedAttList)):
if self.specifiedAttList[i] not in classifier.specifiedAttList:
return False
attributeInfoType = xcs.env.formatData.attributeInfoType[self.specifiedAttList[i]]
if attributeInfoType:
otherRef = classifier.specifiedAttList.index(self.specifiedAttList[i])
if self.condition[i][0] < classifier.condition[otherRef][0]:
return False
if self.condition[i][1] > classifier.condition[otherRef][1]:
return False
return True
def subsumes(self,classifier,xcs):
return self.action == classifier.action and self.isSubsumer(xcs) and self.isMoreGeneral(classifier,xcs)
def updateTimestamp(self,timestamp):
self.timestampGA = timestamp
def uniformCrossover(self,classifier,xcs):
p_self_specifiedAttList = copy.deepcopy(self.specifiedAttList)
p_cl_specifiedAttList = copy.deepcopy(classifier.specifiedAttList)
# Make list of attribute references appearing in at least one of the parents.-----------------------------
comboAttList = []
for i in p_self_specifiedAttList:
comboAttList.append(i)
for i in p_cl_specifiedAttList:
if i not in comboAttList:
comboAttList.append(i)
elif not xcs.env.formatData.attributeInfoType[i]:
comboAttList.remove(i)
comboAttList.sort()
changed = False
for attRef in comboAttList:
attributeInfoType = xcs.env.formatData.attributeInfoType[attRef]
probability = 0.5
ref = 0
if attRef in p_self_specifiedAttList:
ref += 1
if attRef in p_cl_specifiedAttList:
ref += 1
if ref == 0:
pass
elif ref == 1:
if attRef in p_self_specifiedAttList and random.random() > probability:
i = self.specifiedAttList.index(attRef)
classifier.condition.append(self.condition.pop(i))
classifier.specifiedAttList.append(attRef)
self.specifiedAttList.remove(attRef)
changed = True
if attRef in p_cl_specifiedAttList and random.random() < probability:
i = classifier.specifiedAttList.index(attRef)
self.condition.append(classifier.condition.pop(i))
self.specifiedAttList.append(attRef)
classifier.specifiedAttList.remove(attRef)
changed = True
else:
# Continuous Attribute
if attributeInfoType:
i_cl1 = self.specifiedAttList.index(attRef)
i_cl2 = classifier.specifiedAttList.index(attRef)
tempKey = random.randint(0, 3)
if tempKey == 0:
temp = self.condition[i_cl1][0]
self.condition[i_cl1][0] = classifier.condition[i_cl2][0]
classifier.condition[i_cl2][0] = temp
elif tempKey == 1:
temp = self.condition[i_cl1][1]
self.condition[i_cl1][1] = classifier.condition[i_cl2][1]
classifier.condition[i_cl2][1] = temp
else:
allList = self.condition[i_cl1] + classifier.condition[i_cl2]
newMin = min(allList)
newMax = max(allList)
if tempKey == 2:
self.condition[i_cl1] = [newMin, newMax]
classifier.condition.pop(i_cl2)
classifier.specifiedAttList.remove(attRef)
else:
classifier.condition[i_cl2] = [newMin, newMax]
self.condition.pop(i_cl1)
self.specifiedAttList.remove(attRef)
# Discrete Attribute
else:
pass
tempList1 = copy.deepcopy(p_self_specifiedAttList)
tempList2 = copy.deepcopy(classifier.specifiedAttList)
tempList1.sort()
tempList2.sort()
if changed and len(set(tempList1) & set(tempList2)) == len(tempList2):
changed = False
return changed
def mutation(self,state,xcs):
changedByConditionMutation = self.mutateCondition(state,xcs)
changedByActionMutation = self.mutateAction(xcs)
return changedByConditionMutation or changedByActionMutation
def mutateCondition(self,state,xcs):
changed = False
for attRef in range(xcs.env.formatData.numAttributes):
attributeInfoType = xcs.env.formatData.attributeInfoType[attRef]
if attributeInfoType:
attributeInfoValue = xcs.env.formatData.attributeInfoContinuous[attRef]
if random.random() < xcs.p_mutation and not(state[attRef] == None):
if not (attRef in self.specifiedAttList):
self.specifiedAttList.append(attRef)
self.createMatchingAttribute(xcs,attRef,state)
changed = True
elif attRef in self.specifiedAttList:
i = self.specifiedAttList.index(attRef)
if not attributeInfoType or random.random() > 0.5:
del self.specifiedAttList[i]
del self.condition[i]
changed = True
else:
attRange = float(attributeInfoValue[1]) - float(attributeInfoValue[0])
mutateRange = random.random() * 0.5 * attRange
if random.random() > 0.5:
if random.random() > 0.5:
self.condition[i][0] += mutateRange
else:
self.condition[i][0] -= mutateRange
else:
if random.random() > 0.5:
self.condition[i][1] += mutateRange
else:
self.condition[i][1] -= mutateRange
self.condition[i] = sorted(self.condition[i])
changed = True
else:
pass
return changed
def mutateAction(self,xcs):
changed = False
if random.random() < xcs.p_mutation:
action = random.choice(xcs.env.formatData.phenotypeList)
while action == self.action:
action = random.choice(xcs.env.formatData.phenotypeList)
self.action = action
changed = True
return changed
def getDelProp(self,meanFitness,xcs):
if self.fitness / self.numerosity >= xcs.delta * meanFitness or self.experience < xcs.theta_del:
deletionVote = self.actionSetSize * self.numerosity
elif self.fitness == 0.0:
deletionVote = self.actionSetSize * self.numerosity * meanFitness / (xcs.init_fit / self.numerosity)
else:
deletionVote = self.actionSetSize * self.numerosity * meanFitness / (self.fitness / self.numerosity)
return deletionVote | 0.542136 | 0.327359 |
import warnings
from abc import ABC, abstractmethod
from copy import deepcopy
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin, RegressorMixin
from sklearn.metrics import accuracy_score
from sklearn.utils.multiclass import check_classification_targets
from sklearn.utils.validation import (
check_array,
check_consistent_length,
column_or_1d,
)
from .exceptions import MappingError
from .utils import (
MISSING_LABEL,
is_labeled,
is_unlabeled,
unlabeled_indices,
ExtLabelEncoder,
rand_argmin,
check_classifier_params,
check_random_state,
check_cost_matrix,
check_scalar,
check_class_prior,
check_missing_label,
check_indices,
)
# '__all__' is necessary to create the sphinx docs.
__all__ = [
"QueryStrategy",
"SingleAnnotatorPoolQueryStrategy",
"MultiAnnotatorPoolQueryStrategy",
"BudgetManager",
"SingleAnnotatorStreamQueryStrategy",
"SkactivemlClassifier",
"ClassFrequencyEstimator",
"AnnotatorModelMixin",
"SkactivemlRegressor",
"ProbabilisticRegressor",
]
class QueryStrategy(ABC, BaseEstimator):
"""Base class for all query strategies in scikit-activeml.
Parameters
----------
random_state : int or RandomState instance, optional (default=None)
Controls the randomness of the estimator.
"""
def __init__(self, random_state=None):
self.random_state = random_state
@abstractmethod
def query(self, *args, **kwargs):
"""
Determines the query for active learning based on input arguments.
"""
raise NotImplementedError
class PoolQueryStrategy(QueryStrategy):
"""Base class for all pool-based active learning query strategies in
scikit-activeml.
Parameters
----------
missing_label : scalar or string or np.nan or None, optional
(default=np.nan)
Value to represent a missing label.
random_state : int or RandomState instance, optional (default=None)
Controls the randomness of the estimator.
"""
def __init__(self, missing_label=MISSING_LABEL, random_state=None):
super().__init__(random_state=random_state)
self.missing_label = missing_label
def _validate_data(
self,
X,
y,
candidates,
batch_size,
return_utilities,
reset=True,
check_X_dict=None,
):
"""Validate input data, all attributes and set or check the
`n_features_in_` attribute.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples, *)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int
The number of samples to be selected in one AL cycle.
return_utilities : bool
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_X_dict : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples, *)
Checked labels of the training data set.
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
batch_size : int
Checked number of samples to be selected in one AL cycle.
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
# Check samples.
if check_X_dict is None:
check_X_dict = {"allow_nd": True}
X = check_array(X, **check_X_dict)
# Check number of features.
self._check_n_features(X, reset=reset)
# Check labels
y = check_array(
y, ensure_2d=False, force_all_finite="allow-nan", dtype=None
)
check_consistent_length(X, y)
# Check missing_label
check_missing_label(self.missing_label, target_type=y.dtype)
self.missing_label_ = self.missing_label
# Check candidates (+1 to avoid zero multiplier).
seed_mult = int(np.sum(is_unlabeled(y, self.missing_label_))) + 1
if candidates is not None:
candidates = np.array(candidates)
if candidates.ndim == 1:
candidates = check_indices(candidates, y, dim=0)
else:
check_candidates_dict = deepcopy(check_X_dict)
check_candidates_dict["ensure_2d"] = False
candidates = check_array(candidates, **check_candidates_dict)
self._check_n_features(candidates, reset=False)
# Check return_utilities.
check_scalar(return_utilities, "return_utilities", bool)
# Check batch size.
check_scalar(batch_size, target_type=int, name="batch_size", min_val=1)
# Check random state.
self.random_state_ = check_random_state(self.random_state, seed_mult)
return X, y, candidates, batch_size, return_utilities
class SingleAnnotatorPoolQueryStrategy(PoolQueryStrategy):
"""Base class for all pool-based active learning query strategies with a
single annotator in scikit-activeml.
"""
@abstractmethod
def query(
self,
X,
y,
*args,
candidates=None,
batch_size=1,
return_utilities=False,
**kwargs,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL).
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
raise NotImplementedError
def _validate_data(
self,
X,
y,
candidates,
batch_size,
return_utilities,
reset=True,
check_X_dict=None,
):
"""Validate input data, all attributes and set or check the
`n_features_in_` attribute.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
candidates : None or array-like of shape (n_candidates,), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates,) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int
The number of samples to be selected in one AL cycle.
return_utilities : bool
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_X_dict : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples)
Checked labels of the training data set.
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
batch_size : int
Checked number of samples to be selected in one AL cycle.
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X, y, candidates, batch_size, return_utilities, reset, check_X_dict
)
y = column_or_1d(y, warn=True)
if candidates is None:
n_candidates = int(
np.sum(is_unlabeled(y, missing_label=self.missing_label_))
)
else:
n_candidates = len(candidates)
if n_candidates < batch_size:
warnings.warn(
f"'batch_size={batch_size}' is larger than number of "
f"candidates. Instead, 'batch_size={n_candidates}' was set."
)
batch_size = n_candidates
return X, y, candidates, batch_size, return_utilities
def _transform_candidates(
self,
candidates,
X,
y,
enforce_mapping=False,
allow_only_unlabeled=False,
):
"""
Transforms the `candidates` parameter into a sample array and the
corresponding index array `mapping` such that
`candidates = X[mapping]`.
Parameters
----------
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples)
Checked labels of the training data set.
enforce_mapping : bool, default=False
If True, an exception is raised when no exact mapping can be
determined (i.e., `mapping` is None).
allow_only_unlabeled : bool, default=False
If True, an exception is raised when indices of candidates contain
labeled samples.
Returns
-------
candidates : np.ndarray of shape (n_candidates, n_features)
Candidate samples from which the strategy can query the label.
mapping : np.ndarray of shape (n_candidates) or None
Index array that maps `candidates` to `X`.
(`candidates = X[mapping]`)
"""
if candidates is None:
ulbd_idx = unlabeled_indices(y, self.missing_label_)
return X[ulbd_idx], ulbd_idx
elif candidates.ndim == 1:
if allow_only_unlabeled:
if is_labeled(y[candidates], self.missing_label_).any():
raise ValueError(
"Candidates must not contain labeled " "samples."
)
return X[candidates], candidates
else:
if enforce_mapping:
raise MappingError(
"Mapping `candidates` to `X` is not "
"possible but `enforce_mapping` is True. "
"Use index array for `candidates` instead."
)
else:
return candidates, None
class MultiAnnotatorPoolQueryStrategy(PoolQueryStrategy):
"""Base class for all pool-based active learning query strategies with
multiple annotators in scikit-activeml.
Parameters
----------
missing_label : scalar or string or np.nan or None, optional
(default=np.nan)
Value to represent a missing label.
random_state : int or RandomState instance, optional (default=None)
Controls the randomness of the estimator.
"""
@abstractmethod
def query(
self,
X,
y,
*args,
candidates=None,
annotators=None,
batch_size=1,
return_utilities=False,
**kwargs,
):
"""Determines which candidate sample is to be annotated by which
annotator.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled
and unlabeled samples.
y : array-like of shape (n_samples, n_annotators)
Labels of the training data set for each annotator (possibly
including unlabeled ones indicated by self.MISSING_LABEL), meaning
that `y[i, j]` contains the label annotated by annotator `i` for
sample `j`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If `candidates` is None, the samples from (X,y), for which an
annotator exists such that the annotator sample pair is
unlabeled are considered as sample candidates.
If `candidates` is of shape (n_candidates,) and of type int,
`candidates` is considered as the indices of the sample candidates
in (X,y).
If `candidates` is of shape (n_candidates, n_features), the
sample candidates are directly given in `candidates` (not
necessarily contained in `X`). This is not supported by all query
strategies.
annotators : array-like of shape (n_candidates, n_annotators), optional
(default=None)
If `annotators` is None, all annotators are considered as available
annotators.
If `annotators` is of shape (n_avl_annotators), and of type int,
`annotators` is considered as the indices of the available
annotators.
If candidate samples and available annotators are specified:
The annotator-sample-pairs, for which the sample is a candidate
sample and the annotator is an available annotator are considered
as candidate annotator-sample-pairs.
If `annotators` is a boolean array of shape (n_candidates,
n_avl_annotators) the annotator-sample-pairs, for which the sample
is a candidate sample and the boolean matrix has entry `True` are
considered as candidate sample pairs.
batch_size : int, optional (default=1)
The number of annotators sample pairs to be selected in one AL
cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : np.ndarray of shape (batchsize, 2)
The query_indices indicate which candidate sample pairs are to be
queried is, i.e., which candidate sample is to be annotated by
which annotator, e.g., `query_indices[:, 0]` indicates the selected
candidate samples and `query_indices[:, 1]` indicates the
respectively selected annotators.
utilities: numpy.ndarray of shape (batch_size, n_samples, n_annotators)
or numpy.ndarray of shape (batch_size, n_candidates, n_annotators)
The utilities of all candidate samples w.r.t. to the available
annotators after each selected sample of the batch, e.g.,
`utilities[0, :, j]` indicates the utilities used for selecting
the first sample-annotator-pair (with indices `query_indices[0]`).
If `candidates is None` or of shape (n_candidates), the indexing
refers to samples in `X`.
If `candidates` is of shape (n_candidates, n_features), the
indexing refers to samples in `candidates`.
"""
raise NotImplementedError
def _validate_data(
self,
X,
y,
candidates,
annotators,
batch_size,
return_utilities,
reset=True,
check_X_dict=None,
):
"""Validate input data, all attributes and set or check the
`n_features_in_` attribute.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled
and unlabeled samples.
y : array-like of shape (n_samples, n_annotators)
Labels of the training data set for each annotator (possibly
including unlabeled ones indicated by self.MISSING_LABEL), meaning
that `y[i, j]` contains the label annotated by annotator `i` for
sample `j`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If `candidates` is None, the samples from (X,y), for which an
annotator exists such that the annotator sample pairs is
unlabeled are considered as sample candidates.
If `candidates` is of shape (n_candidates,) and of type int,
`candidates` is considered as the indices of the sample candidates
in (X,y).
If `candidates` is of shape (n_candidates, n_features), the
sample candidates are directly given in `candidates` (not
necessarily contained in `X`). This is not supported by all query
strategies.
annotators : array-like of shape (n_candidates, n_annotators), optional
(default=None)
If `annotators` is None, all annotators are considered as available
annotators.
If `annotators` is of shape (n_avl_annotators), and of type int,
`annotators` is considered as the indices of the available
annotators.
If candidate samples and available annotators are specified:
The annotator-sample-pairs, for which the sample is a candidate
sample and the annotator is an available annotator are considered
as candidate annotator-sample-pairs.
If `annotators` is a boolean array of shape (n_candidates,
n_avl_annotators) the annotator-sample-pairs, for which the sample
is a candidate sample and the boolean matrix has entry `True` are
considered as candidate sample pairs.
batch_size : int or string, optional (default=1)
The number of annotators sample pairs to be selected in one AL
cycle. If `adaptive = True` `batch_size = 'adaptive'` is allowed.
return_utilities : bool
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_X_dict : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples, n_annotators)
Checked labels of the training data set.
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
annotators : None or np.ndarray of shape (n_avl_annotators), dtype=int
or np.ndarray of shape (n_candidates, n_annotators)
Checked annotator boolean array
batch_size : int
Checked number of samples to be selected in one AL cycle.
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X, y, candidates, batch_size, return_utilities, reset, check_X_dict
)
check_array(y, ensure_2d=True, force_all_finite="allow-nan")
unlabeled_pairs = is_unlabeled(y, missing_label=self.missing_label_)
if annotators is not None:
annotators = check_array(
annotators, ensure_2d=False, allow_nd=True
)
if annotators.ndim == 1:
annotators = check_indices(annotators, y, dim=1)
elif annotators.ndim == 2:
annotators = check_array(annotators, dtype=bool)
if candidates is None or candidates.ndim == 1:
check_consistent_length(X, annotators)
else:
check_consistent_length(candidates, annotators)
check_consistent_length(y.T, annotators.T)
else:
raise ValueError(
"`annotators` must be either None, 1d or 2d " "array-like."
)
if annotators is None:
if candidates is None:
n_candidate_pairs = int(np.sum(unlabeled_pairs))
elif candidates.ndim == 1:
n_candidate_pairs = len(candidates) * len(y.T)
else:
n_candidate_pairs = len(candidates) * len(y.T)
elif annotators.ndim == 1:
if candidates is None:
n_candidate_pairs = int(np.sum(unlabeled_pairs[:, annotators]))
elif candidates.ndim == 1:
n_candidate_pairs = int(
np.sum(unlabeled_pairs[candidates][:, annotators])
)
else:
n_candidate_pairs = len(candidates) * len(annotators)
else:
n_candidate_pairs = int(np.sum(annotators))
if n_candidate_pairs < batch_size:
warnings.warn(
f"'batch_size={batch_size}' is larger than number of "
f"candidates pairs. Instead, 'batch_size={n_candidate_pairs}'"
f" was set."
)
batch_size = n_candidate_pairs
return X, y, candidates, annotators, batch_size, return_utilities
def _transform_cand_annot(
self, candidates, annotators, X, y, enforce_mapping=False
):
"""
Transforms the `candidates` parameter into a sample array and the
corresponding index array `mapping` such that
`candidates = X[mapping]`, and transforms `annotators` into a boolean
array such that `A_cand` represents the available annotator sample
pairs for the samples of candidates.
Parameters
----------
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If `candidates` is None, the samples from (X,y), for which an
annotator exists such that the annotator sample pairs is
unlabeled are considered as sample candidates.
If `candidates` is of shape (n_candidates,) and of type int,
`candidates` is considered as the indices of the sample candidates
in (X,y).
If `candidates` is of shape (n_candidates, n_features), the
sample candidates are directly given in `candidates` (not
necessarily contained in `X`). This is not supported by all query
strategies.
annotators : array-like of shape (n_candidates, n_annotators), optional
(default=None)
If `annotators` is None, all annotators are considered as available
annotators.
If `annotators` is of shape (n_avl_annotators), and of type int,
`annotators` is considered as the indices of the available
annotators.
If candidate samples and available annotators are specified:
The annotator-sample-pairs, for which the sample is a candidate
sample and the annotator is an available annotator are considered
as candidate annotator-sample-pairs.
If `annotators` is a boolean array of shape (n_candidates,
n_avl_annotators) the annotator-sample-pairs, for which the sample
is a candidate sample and the boolean matrix has entry `True` are
considered as candidate sample pairs.
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples,)
Checked labels of the training data set.
enforce_mapping : bool, optional (default=False)
If `True`, an exception is raised when no exact mapping can be
determined (i.e., `mapping` is None).
Returns
-------
candidates : np.ndarray of shape (n_candidates, n_features)
Candidate samples from which the strategy can query the label.
mapping : np.ndarray of shape (n_candidates) or None
Index array that maps `candidates` to `X`
(`candidates = X[mapping]`).
A_cand : np.ndarray of shape(n_candidates, n_annotators)
Available annotator sample pair with respect to `candidates`.
"""
unlbd_pairs = is_unlabeled(y, self.missing_label_)
unlbd_sample_indices = np.argwhere(
np.any(unlbd_pairs, axis=1)
).flatten()
n_annotators = y.shape[1]
if candidates is not None and candidates.ndim == 2:
n_candidates = len(candidates)
if annotators is None:
A_cand = np.full((n_candidates, n_annotators), True)
elif annotators.ndim == 1:
A_cand = np.full((n_candidates, n_annotators), False)
A_cand[:, annotators] = True
else:
A_cand = annotators
if enforce_mapping:
raise ValueError(
"Mapping `candidates` to `X` is not posssible"
"but `enforce_mapping` is True. Use index"
"array for `candidates` instead."
)
else:
return candidates, None, A_cand
if candidates is None:
candidates = unlbd_sample_indices
only_candidates = False
elif annotators is not None:
candidates = np.intersect1d(candidates, unlbd_sample_indices)
only_candidates = False
else:
only_candidates = True
if only_candidates:
A_cand = np.full((len(candidates), n_annotators), True)
elif annotators is None:
A_cand = unlbd_pairs[candidates, :]
elif annotators.ndim == 1:
available_pairs = np.full_like(y, False, dtype=bool)
available_pairs[:, annotators] = True
A_cand = (unlbd_pairs & available_pairs)[candidates, :]
else:
A_cand = annotators
return X[candidates], candidates, A_cand
class BudgetManager(ABC, BaseEstimator):
"""Base class for all budget managers for stream-based active learning
in scikit-activeml to model budgeting constraints.
Parameters
----------
budget : float (default=None)
Specifies the ratio of instances which are allowed to be sampled, with
0 <= budget <= 1. If budget is None, it is replaced with the default
budget 0.1.
"""
def __init__(self, budget=None):
self.budget = budget
@abstractmethod
def query_by_utility(self, utilities, *args, **kwargs):
"""Ask the budget manager which utilities are sufficient to query the
corresponding instance.
Parameters
----------
utilities : ndarray of shape (n_samples,)
The utilities provided by the stream-based active learning
strategy, which are used to determine whether sampling an instance
is worth it given the budgeting constraint.
Returns
-------
queried_indices : ndarray of shape (n_queried_instances,)
The indices of instances represented by utilities which should be
queried, with 0 <= n_queried_instances <= n_samples.
"""
raise NotImplementedError
@abstractmethod
def update(self, candidates, queried_indices, *args, **kwargs):
"""Updates the BudgetManager.
Parameters
----------
candidates : {array-like, sparse matrix} of shape
(n_samples, n_features)
The instances which may be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
queried_indices : array-like
Indicates which instances from candidates have been queried.
Returns
-------
self : BudgetManager
The BudgetManager returns itself, after it is updated.
"""
raise NotImplementedError
def _validate_budget(self):
"""check the assigned budget and set the default value 0.1 if budget is
set to None.
"""
if self.budget is not None:
self.budget_ = self.budget
else:
self.budget_ = 0.1
check_scalar(
self.budget_,
"budget",
float,
min_val=0.0,
max_val=1.0,
min_inclusive=False,
)
def _validate_data(self, utilities, *args, **kwargs):
"""Validate input data.
Parameters
----------
utilities: ndarray of shape (n_samples,)
The utilities provided by the stream-based active learning
strategy.
Returns
-------
utilities: ndarray of shape (n_samples,)
Checked utilities
"""
# Check if utilities is set
if not isinstance(utilities, np.ndarray):
raise TypeError(
"{} is not a valid type for utilities".format(type(utilities))
)
# Check budget
self._validate_budget()
return utilities
class SingleAnnotatorStreamQueryStrategy(QueryStrategy):
"""Base class for all stream-based active learning query strategies in
scikit-activeml.
Parameters
----------
budget : float, default=None
The budget which models the budgeting constraint used in
the stream-based active learning setting.
random_state : int, RandomState instance, default=None
Controls the randomness of the estimator.
"""
def __init__(self, budget, random_state=None):
super().__init__(random_state=random_state)
self.budget = budget
@abstractmethod
def query(self, candidates, *args, return_utilities=False, **kwargs):
"""Ask the query strategy which instances in candidates to acquire.
The query startegy determines the most useful instances in candidates,
which can be acquired within the budgeting constraint specified by the
budgetmanager.
Please note that, this method does not alter the internal state of the
query strategy. To adapt the query strategy to the selected candidates,
use update(...) with the selected candidates.
Parameters
----------
candidates : {array-like, sparse matrix} of shape
(n_samples, n_features)
The instances which may be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
return_utilities : bool, optional
If true, also return the utilities based on the query strategy.
The default is False.
Returns
-------
queried_indices : ndarray of shape (n_sampled_instances,)
The indices of instances in candidates which should be sampled,
with 0 <= n_sampled_instances <= n_samples.
utilities: ndarray of shape (n_samples,), optional
The utilities based on the query strategy. Only provided if
return_utilities is True.
"""
raise NotImplementedError
@abstractmethod
def update(
self,
candidates,
queried_indices,
*args,
budget_manager_param_dict=None,
**kwargs,
):
"""Update the query strategy with the decisions taken.
This function should be used in conjunction with the query function,
when the instances queried from query(...) may differ from the
instances queried in the end. In this case use query(...) with
simulate=true and provide the final decisions via update(...).
This is especially helpful, when developing wrapper query strategies.
Parameters
----------
candidates : {array-like, sparse matrix} of shape
(n_samples, n_features)
The instances which could be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
queried_indices : array-like
Indicates which instances from candidates have been queried.
budget_manager_param_dict : kwargs, optional
Optional kwargs for budgetmanager.
Returns
-------
self : StreamBasedQueryStrategy
The StreamBasedQueryStrategy returns itself, after it is updated.
"""
raise NotImplementedError
def _validate_random_state(self):
"""Creates a copy 'random_state_' if random_state is an instance of
np.random_state. If not create a new random state. See also
:func:`~sklearn.utils.check_random_state`
"""
if not hasattr(self, "random_state_"):
self.random_state_ = deepcopy(self.random_state)
self.random_state_ = check_random_state(self.random_state_)
def _validate_budget(self):
if self.budget is not None:
self.budget_ = self.budget
else:
self.budget_ = 0.1
check_scalar(
self.budget_,
"budget",
float,
min_val=0.0,
max_val=1.0,
min_inclusive=False,
)
def _validate_data(
self,
candidates,
return_utilities,
*args,
reset=True,
**check_candidates_params,
):
"""Validate input data and set or check the `n_features_in_` attribute.
Parameters
----------
candidates: array-like of shape (n_candidates, n_features)
The instances which may be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
return_utilities : bool,
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_candidates_params : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
candidates: np.ndarray, shape (n_candidates, n_features)
Checked candidate samples
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
# Check candidate instances.
candidates = check_array(candidates, **check_candidates_params)
# Check number of features.
self._check_n_features(candidates, reset=reset)
# Check return_utilities.
check_scalar(return_utilities, "return_utilities", bool)
# Check random state.
self._validate_random_state()
# Check budgetmanager.
self._validate_budget()
return candidates, return_utilities
class SkactivemlClassifier(BaseEstimator, ClassifierMixin, ABC):
"""SkactivemlClassifier
Base class for scikit-activeml classifiers such that missing labels,
user-defined classes, and cost-sensitive classification (i.e., cost matrix)
can be handled.
Parameters
----------
classes : array-like of shape (n_classes), default=None
Holds the label for each class. If none, the classes are determined
during the fit.
missing_label : scalar, string, np.nan, or None, default=np.nan
Value to represent a missing label.
cost_matrix : array-like of shape (n_classes, n_classes)
Cost matrix with `cost_matrix[i,j]` indicating cost of predicting class
`classes[j]` for a sample of class `classes[i]`. Can be only set, if
classes is not none.
random_state : int or RandomState instance or None, default=None
Determines random number for `predict` method. Pass an int for
reproducible results across multiple method calls.
Attributes
----------
classes_ : array-like, shape (n_classes)
Holds the label for each class after fitting.
cost_matrix_ : array-like,of shape (classes, classes)
Cost matrix after fitting with `cost_matrix_[i,j]` indicating cost of
predicting class `classes_[j]` for a sample of class `classes_[i]`.
"""
def __init__(
self,
classes=None,
missing_label=MISSING_LABEL,
cost_matrix=None,
random_state=None,
):
self.classes = classes
self.missing_label = missing_label
self.cost_matrix = cost_matrix
self.random_state = random_state
@abstractmethod
def fit(self, X, y, sample_weight=None):
"""Fit the model using X as training data and y as class labels.
Parameters
----------
X : matrix-like, shape (n_samples, n_features)
The sample matrix X is the feature matrix representing the samples.
y : array-like, shape (n_samples) or (n_samples, n_outputs)
It contains the class labels of the training samples.
The number of class labels may be variable for the samples, where
missing labels are represented the attribute 'missing_label'.
sample_weight : array-like, shape (n_samples) or (n_samples, n_outputs)
It contains the weights of the training samples' class labels.
It must have the same shape as y.
Returns
-------
self: skactiveml.base.SkactivemlClassifier,
The `skactiveml.base.SkactivemlClassifier` object fitted on the
training data.
"""
raise NotImplementedError
def predict_proba(self, X):
"""Return probability estimates for the test data X.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Test samples.
Returns
-------
P : numpy.ndarray, shape (n_samples, classes)
The class probabilities of the test samples. Classes are ordered
according to 'classes_'.
"""
raise NotImplementedError
def predict(self, X):
"""Return class label predictions for the test samples `X`.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Input samples.
Returns
-------
y : numpy.ndarray of shape (n_samples)
Predicted class labels of the test samples `X`. Classes are ordered
according to `classes_`.
"""
P = self.predict_proba(X)
costs = np.dot(P, self.cost_matrix_)
y_pred = rand_argmin(costs, random_state=self.random_state_, axis=1)
y_pred = self._le.inverse_transform(y_pred)
y_pred = np.asarray(y_pred, dtype=self.classes_.dtype)
return y_pred
def score(self, X, y, sample_weight=None):
"""Return the mean accuracy on the given test data and labels.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Test samples.
y : array-like of shape (n_samples,)
True labels for `X`.
sample_weight : array-like of shape (n_samples,), default=None
Sample weights.
Returns
-------
score : float
Mean accuracy of `self.predict(X)` regarding `y`.
"""
y = self._le.transform(y)
y_pred = self._le.transform(self.predict(X))
return accuracy_score(y, y_pred, sample_weight=sample_weight)
def _validate_data(
self,
X,
y,
sample_weight=None,
check_X_dict=None,
check_y_dict=None,
y_ensure_1d=True,
):
if check_X_dict is None:
check_X_dict = {"ensure_min_samples": 0, "ensure_min_features": 0}
if check_y_dict is None:
check_y_dict = {
"ensure_min_samples": 0,
"ensure_min_features": 0,
"ensure_2d": False,
"force_all_finite": False,
"dtype": None,
}
# Check common classifier parameters.
check_classifier_params(
self.classes, self.missing_label, self.cost_matrix
)
# Store and check random state.
self.random_state_ = check_random_state(self.random_state)
# Create label encoder.
self._le = ExtLabelEncoder(
classes=self.classes, missing_label=self.missing_label
)
# Check input parameters.
y = check_array(y, **check_y_dict)
if len(y) > 0:
y = column_or_1d(y) if y_ensure_1d else y
y = self._le.fit_transform(y)
is_lbdl = is_labeled(y)
if len(y[is_lbdl]) > 0:
check_classification_targets(y[is_lbdl])
if len(self._le.classes_) == 0:
raise ValueError(
"No class label is known because 'y' contains no actual "
"class labels and 'classes' is not defined. Change at "
"least on of both to overcome this error."
)
else:
self._le.fit_transform(self.classes)
check_X_dict["ensure_2d"] = False
X = check_array(X, **check_X_dict)
check_consistent_length(X, y)
# Update detected classes.
self.classes_ = self._le.classes_
# Check classes.
if sample_weight is not None:
sample_weight = check_array(sample_weight, **check_y_dict)
if not np.array_equal(y.shape, sample_weight.shape):
raise ValueError(
f"`y` has the shape {y.shape} and `sample_weight` has the "
f"shape {sample_weight.shape}. Both need to have "
f"identical shapes."
)
# Update cost matrix.
self.cost_matrix_ = (
1 - np.eye(len(self.classes_))
if self.cost_matrix is None
else self.cost_matrix
)
self.cost_matrix_ = check_cost_matrix(
self.cost_matrix_, len(self.classes_)
)
if self.classes is not None:
class_indices = np.argsort(self.classes)
self.cost_matrix_ = self.cost_matrix_[class_indices]
self.cost_matrix_ = self.cost_matrix_[:, class_indices]
return X, y, sample_weight
def _check_n_features(self, X, reset):
if reset:
self.n_features_in_ = X.shape[1] if len(X) > 0 else None
elif not reset:
if self.n_features_in_ is not None:
super()._check_n_features(X, reset=reset)
class ClassFrequencyEstimator(SkactivemlClassifier):
"""ClassFrequencyEstimator
Extends scikit-activeml classifiers to estimators that are able to estimate
class frequencies for given samples (by calling 'predict_freq').
Parameters
----------
classes : array-like, shape (n_classes), default=None
Holds the label for each class. If none, the classes are determined
during the fit.
missing_label : scalar or str or np.nan or None, default=np.nan
Value to represent a missing label.
cost_matrix : array-like of shape (n_classes, n_classes)
Cost matrix with `cost_matrix[i,j]` indicating cost of predicting class
`classes[j]` for a sample of class `classes[i]`. Can be only set, if
classes is not none.
class_prior : float or array-like, shape (n_classes), default=0
Prior observations of the class frequency estimates. If `class_prior`
is an array, the entry `class_prior[i]` indicates the non-negative
prior number of samples belonging to class `classes_[i]`. If
`class_prior` is a float, `class_prior` indicates the non-negative
prior number of samples per class.
random_state : int or np.RandomState or None, default=None
Determines random number for 'predict' method. Pass an int for
reproducible results across multiple method calls.
Attributes
----------
classes_ : np.ndarray of shape (n_classes)
Holds the label for each class after fitting.
class_prior_ : np.ndarray of shape (n_classes)
Prior observations of the class frequency estimates. The entry
`class_prior_[i]` indicates the non-negative prior number of samples
belonging to class `classes_[i]`.
cost_matrix_ : np.ndarray of shape (classes, classes)
Cost matrix with `cost_matrix_[i,j]` indicating cost of predicting
class `classes_[j]` for a sample of class `classes_[i]`.
"""
def __init__(
self,
class_prior=0,
classes=None,
missing_label=MISSING_LABEL,
cost_matrix=None,
random_state=None,
):
super().__init__(
classes=classes,
missing_label=missing_label,
cost_matrix=cost_matrix,
random_state=random_state,
)
self.class_prior = class_prior
@abstractmethod
def predict_freq(self, X):
"""Return class frequency estimates for the test samples `X`.
Parameters
----------
X: array-like of shape (n_samples, n_features)
Test samples whose class frequencies are to be estimated.
Returns
-------
F: array-like of shape (n_samples, classes)
The class frequency estimates of the test samples 'X'. Classes are
ordered according to attribute 'classes_'.
"""
raise NotImplementedError
def predict_proba(self, X):
"""Return probability estimates for the test data `X`.
Parameters
----------
X : array-like, shape (n_samples, n_features) or
shape (n_samples, m_samples) if metric == 'precomputed'
Input samples.
Returns
-------
P : array-like of shape (n_samples, classes)
The class probabilities of the test samples. Classes are ordered
according to classes_.
"""
# Normalize probabilities of each sample.
P = self.predict_freq(X) + self.class_prior_
normalizer = np.sum(P, axis=1)
P[normalizer > 0] /= normalizer[normalizer > 0, np.newaxis]
P[normalizer == 0, :] = [1 / len(self.classes_)] * len(self.classes_)
return P
def _validate_data(
self,
X,
y,
sample_weight=None,
check_X_dict=None,
check_y_dict=None,
y_ensure_1d=True,
):
X, y, sample_weight = super()._validate_data(
X=X,
y=y,
sample_weight=sample_weight,
check_X_dict=check_X_dict,
check_y_dict=check_y_dict,
y_ensure_1d=y_ensure_1d,
)
# Check class prior.
self.class_prior_ = check_class_prior(
self.class_prior, len(self.classes_)
)
return X, y, sample_weight
class SkactivemlRegressor(BaseEstimator, RegressorMixin, ABC):
"""SkactivemlRegressor
Base class for scikit-activeml regressors.
Parameters
__________
missing_label : scalar, string, np.nan, or None, optional
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int, RandomState or None, optional (default=None)
Determines random number for 'fit' and 'predict' method. Pass an int for
reproducible results across multiple method calls.
"""
def __init__(self, missing_label=MISSING_LABEL, random_state=None):
self.missing_label = missing_label
self.random_state = random_state
@abstractmethod
def fit(self, X, y, sample_weight=None):
"""Fit the model using X as training data and y as numerical labels.
Parameters
----------
X : matrix-like, shape (n_samples, n_features)
The sample matrix X is the feature matrix representing the samples.
y : array-like, shape (n_samples) or (n_samples, n_targets)
It contains the labels of the training samples.
The number of numerical labels may be variable for the samples,
where missing labels are represented the attribute 'missing_label'.
sample_weight : array-like, shape (n_samples)
It contains the weights of the training samples' values.
Returns
-------
self: skactiveml.base.SkactivemlRegressor,
The `skactiveml.base.SkactivemlRegressor` object fitted on the
training data.
"""
raise NotImplementedError
@abstractmethod
def predict(self, X):
"""Return value predictions for the test samples X.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Input samples.
Returns
-------
y : numpy.ndarray, shape (n_samples)
Predicted values of the test samples 'X'.
"""
raise NotImplementedError
def _validate_data(
self,
X,
y,
sample_weight=None,
check_X_dict=None,
check_y_dict=None,
y_ensure_1d=True,
):
if check_X_dict is None:
check_X_dict = {"ensure_min_samples": 0, "ensure_min_features": 0}
if check_y_dict is None:
check_y_dict = {
"ensure_min_samples": 0,
"ensure_min_features": 0,
"ensure_2d": False,
"force_all_finite": False,
"dtype": None,
}
check_missing_label(self.missing_label)
self.missing_label_ = self.missing_label
# Store and check random state.
self.random_state_ = check_random_state(self.random_state)
X = check_array(X, **check_X_dict)
y = check_array(y, **check_y_dict)
if len(y) > 0:
y = column_or_1d(y) if y_ensure_1d else y
if sample_weight is not None:
sample_weight = check_array(sample_weight, **check_y_dict)
if not np.array_equal(y.shape, sample_weight.shape):
raise ValueError(
f"`y` has the shape {y.shape} and `sample_weight` has the "
f"shape {sample_weight.shape}. Both need to have "
f"identical shapes."
)
return X, y, sample_weight
class ProbabilisticRegressor(SkactivemlRegressor):
"""ProbabilisticRegressor
Base class for scikit-activeml probabilistic regressors.
"""
@abstractmethod
def predict_target_distribution(self, X):
"""Returns the predicted target distribution conditioned on the test
samples `X`.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Input samples.
Returns
-------
dist : scipy.stats._distn_infrastructure.rv_frozen
The distribution of the targets at the test samples.
"""
raise NotImplementedError
def predict(self, X, return_std=False, return_entropy=False):
"""Returns the mean, std (optional) and differential entropy (optional)
of the predicted target distribution conditioned on the test samples
`X`.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Input samples.
return_std : bool, optional (default=False)
Whether to return the standard deviation.
return_entropy : bool, optional (default=False)
Whether to return the differential entropy.
Returns
-------
mu : numpy.ndarray, shape (n_samples)
Predicted mean conditioned on `X`.
std : numpy.ndarray, shape (n_samples), optional
Predicted standard deviation conditioned on `X`.
entropy : numpy..ndarray, optional
Predicted differential entropy conditioned on `X`.
"""
rv = self.predict_target_distribution(X)
result = (rv.mean(),)
if return_std:
result += (rv.std(),)
if return_entropy:
result += (rv.entropy(),)
if len(result) == 1:
result = result[0]
return result
def sample_y(self, X, n_samples=1, random_state=None):
"""Returns random samples from the predicted target distribution
conditioned on the test samples `X`.
Parameters
----------
X : array-like, shape (n_samples_X, n_features)
Input samples, where the target values are drawn from.
n_samples: int, optional (default=1)
Number of random samples to be drawn.
random_state : int, RandomState instance or None, optional
(default=None)
Determines random number generation to randomly draw samples. Pass
an int for reproducible results across multiple method calls.
Returns
-------
y_samples : numpy.ndarray, shape (n_samples_X, n_samples)
Drawn random target samples.
"""
rv = self.predict_target_distribution(X)
rv_samples = rv.rvs(
size=(n_samples, len(X)), random_state=random_state
)
return rv_samples.T
class AnnotatorModelMixin(ABC):
"""AnnotatorModelMixin
Base class of all annotator models estimating the performances of
annotators for given samples.
"""
@abstractmethod
def predict_annotator_perf(self, X):
"""Calculates the performance of an annotator to provide the true label
for a given sample.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Test samples.
Returns
-------
P_annot : numpy.ndarray of shape (n_samples, n_annotators)
`P_annot[i,l]` is the performance of annotator `l` regarding the
annotation of sample `X[i]`.
"""
raise NotImplementedError | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/base.py | base.py | import warnings
from abc import ABC, abstractmethod
from copy import deepcopy
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin, RegressorMixin
from sklearn.metrics import accuracy_score
from sklearn.utils.multiclass import check_classification_targets
from sklearn.utils.validation import (
check_array,
check_consistent_length,
column_or_1d,
)
from .exceptions import MappingError
from .utils import (
MISSING_LABEL,
is_labeled,
is_unlabeled,
unlabeled_indices,
ExtLabelEncoder,
rand_argmin,
check_classifier_params,
check_random_state,
check_cost_matrix,
check_scalar,
check_class_prior,
check_missing_label,
check_indices,
)
# '__all__' is necessary to create the sphinx docs.
__all__ = [
"QueryStrategy",
"SingleAnnotatorPoolQueryStrategy",
"MultiAnnotatorPoolQueryStrategy",
"BudgetManager",
"SingleAnnotatorStreamQueryStrategy",
"SkactivemlClassifier",
"ClassFrequencyEstimator",
"AnnotatorModelMixin",
"SkactivemlRegressor",
"ProbabilisticRegressor",
]
class QueryStrategy(ABC, BaseEstimator):
"""Base class for all query strategies in scikit-activeml.
Parameters
----------
random_state : int or RandomState instance, optional (default=None)
Controls the randomness of the estimator.
"""
def __init__(self, random_state=None):
self.random_state = random_state
@abstractmethod
def query(self, *args, **kwargs):
"""
Determines the query for active learning based on input arguments.
"""
raise NotImplementedError
class PoolQueryStrategy(QueryStrategy):
"""Base class for all pool-based active learning query strategies in
scikit-activeml.
Parameters
----------
missing_label : scalar or string or np.nan or None, optional
(default=np.nan)
Value to represent a missing label.
random_state : int or RandomState instance, optional (default=None)
Controls the randomness of the estimator.
"""
def __init__(self, missing_label=MISSING_LABEL, random_state=None):
super().__init__(random_state=random_state)
self.missing_label = missing_label
def _validate_data(
self,
X,
y,
candidates,
batch_size,
return_utilities,
reset=True,
check_X_dict=None,
):
"""Validate input data, all attributes and set or check the
`n_features_in_` attribute.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples, *)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int
The number of samples to be selected in one AL cycle.
return_utilities : bool
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_X_dict : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples, *)
Checked labels of the training data set.
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
batch_size : int
Checked number of samples to be selected in one AL cycle.
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
# Check samples.
if check_X_dict is None:
check_X_dict = {"allow_nd": True}
X = check_array(X, **check_X_dict)
# Check number of features.
self._check_n_features(X, reset=reset)
# Check labels
y = check_array(
y, ensure_2d=False, force_all_finite="allow-nan", dtype=None
)
check_consistent_length(X, y)
# Check missing_label
check_missing_label(self.missing_label, target_type=y.dtype)
self.missing_label_ = self.missing_label
# Check candidates (+1 to avoid zero multiplier).
seed_mult = int(np.sum(is_unlabeled(y, self.missing_label_))) + 1
if candidates is not None:
candidates = np.array(candidates)
if candidates.ndim == 1:
candidates = check_indices(candidates, y, dim=0)
else:
check_candidates_dict = deepcopy(check_X_dict)
check_candidates_dict["ensure_2d"] = False
candidates = check_array(candidates, **check_candidates_dict)
self._check_n_features(candidates, reset=False)
# Check return_utilities.
check_scalar(return_utilities, "return_utilities", bool)
# Check batch size.
check_scalar(batch_size, target_type=int, name="batch_size", min_val=1)
# Check random state.
self.random_state_ = check_random_state(self.random_state, seed_mult)
return X, y, candidates, batch_size, return_utilities
class SingleAnnotatorPoolQueryStrategy(PoolQueryStrategy):
"""Base class for all pool-based active learning query strategies with a
single annotator in scikit-activeml.
"""
@abstractmethod
def query(
self,
X,
y,
*args,
candidates=None,
batch_size=1,
return_utilities=False,
**kwargs,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL).
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
raise NotImplementedError
def _validate_data(
self,
X,
y,
candidates,
batch_size,
return_utilities,
reset=True,
check_X_dict=None,
):
"""Validate input data, all attributes and set or check the
`n_features_in_` attribute.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
candidates : None or array-like of shape (n_candidates,), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates,) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int
The number of samples to be selected in one AL cycle.
return_utilities : bool
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_X_dict : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples)
Checked labels of the training data set.
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
batch_size : int
Checked number of samples to be selected in one AL cycle.
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X, y, candidates, batch_size, return_utilities, reset, check_X_dict
)
y = column_or_1d(y, warn=True)
if candidates is None:
n_candidates = int(
np.sum(is_unlabeled(y, missing_label=self.missing_label_))
)
else:
n_candidates = len(candidates)
if n_candidates < batch_size:
warnings.warn(
f"'batch_size={batch_size}' is larger than number of "
f"candidates. Instead, 'batch_size={n_candidates}' was set."
)
batch_size = n_candidates
return X, y, candidates, batch_size, return_utilities
def _transform_candidates(
self,
candidates,
X,
y,
enforce_mapping=False,
allow_only_unlabeled=False,
):
"""
Transforms the `candidates` parameter into a sample array and the
corresponding index array `mapping` such that
`candidates = X[mapping]`.
Parameters
----------
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples)
Checked labels of the training data set.
enforce_mapping : bool, default=False
If True, an exception is raised when no exact mapping can be
determined (i.e., `mapping` is None).
allow_only_unlabeled : bool, default=False
If True, an exception is raised when indices of candidates contain
labeled samples.
Returns
-------
candidates : np.ndarray of shape (n_candidates, n_features)
Candidate samples from which the strategy can query the label.
mapping : np.ndarray of shape (n_candidates) or None
Index array that maps `candidates` to `X`.
(`candidates = X[mapping]`)
"""
if candidates is None:
ulbd_idx = unlabeled_indices(y, self.missing_label_)
return X[ulbd_idx], ulbd_idx
elif candidates.ndim == 1:
if allow_only_unlabeled:
if is_labeled(y[candidates], self.missing_label_).any():
raise ValueError(
"Candidates must not contain labeled " "samples."
)
return X[candidates], candidates
else:
if enforce_mapping:
raise MappingError(
"Mapping `candidates` to `X` is not "
"possible but `enforce_mapping` is True. "
"Use index array for `candidates` instead."
)
else:
return candidates, None
class MultiAnnotatorPoolQueryStrategy(PoolQueryStrategy):
"""Base class for all pool-based active learning query strategies with
multiple annotators in scikit-activeml.
Parameters
----------
missing_label : scalar or string or np.nan or None, optional
(default=np.nan)
Value to represent a missing label.
random_state : int or RandomState instance, optional (default=None)
Controls the randomness of the estimator.
"""
@abstractmethod
def query(
self,
X,
y,
*args,
candidates=None,
annotators=None,
batch_size=1,
return_utilities=False,
**kwargs,
):
"""Determines which candidate sample is to be annotated by which
annotator.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled
and unlabeled samples.
y : array-like of shape (n_samples, n_annotators)
Labels of the training data set for each annotator (possibly
including unlabeled ones indicated by self.MISSING_LABEL), meaning
that `y[i, j]` contains the label annotated by annotator `i` for
sample `j`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If `candidates` is None, the samples from (X,y), for which an
annotator exists such that the annotator sample pair is
unlabeled are considered as sample candidates.
If `candidates` is of shape (n_candidates,) and of type int,
`candidates` is considered as the indices of the sample candidates
in (X,y).
If `candidates` is of shape (n_candidates, n_features), the
sample candidates are directly given in `candidates` (not
necessarily contained in `X`). This is not supported by all query
strategies.
annotators : array-like of shape (n_candidates, n_annotators), optional
(default=None)
If `annotators` is None, all annotators are considered as available
annotators.
If `annotators` is of shape (n_avl_annotators), and of type int,
`annotators` is considered as the indices of the available
annotators.
If candidate samples and available annotators are specified:
The annotator-sample-pairs, for which the sample is a candidate
sample and the annotator is an available annotator are considered
as candidate annotator-sample-pairs.
If `annotators` is a boolean array of shape (n_candidates,
n_avl_annotators) the annotator-sample-pairs, for which the sample
is a candidate sample and the boolean matrix has entry `True` are
considered as candidate sample pairs.
batch_size : int, optional (default=1)
The number of annotators sample pairs to be selected in one AL
cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : np.ndarray of shape (batchsize, 2)
The query_indices indicate which candidate sample pairs are to be
queried is, i.e., which candidate sample is to be annotated by
which annotator, e.g., `query_indices[:, 0]` indicates the selected
candidate samples and `query_indices[:, 1]` indicates the
respectively selected annotators.
utilities: numpy.ndarray of shape (batch_size, n_samples, n_annotators)
or numpy.ndarray of shape (batch_size, n_candidates, n_annotators)
The utilities of all candidate samples w.r.t. to the available
annotators after each selected sample of the batch, e.g.,
`utilities[0, :, j]` indicates the utilities used for selecting
the first sample-annotator-pair (with indices `query_indices[0]`).
If `candidates is None` or of shape (n_candidates), the indexing
refers to samples in `X`.
If `candidates` is of shape (n_candidates, n_features), the
indexing refers to samples in `candidates`.
"""
raise NotImplementedError
def _validate_data(
self,
X,
y,
candidates,
annotators,
batch_size,
return_utilities,
reset=True,
check_X_dict=None,
):
"""Validate input data, all attributes and set or check the
`n_features_in_` attribute.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled
and unlabeled samples.
y : array-like of shape (n_samples, n_annotators)
Labels of the training data set for each annotator (possibly
including unlabeled ones indicated by self.MISSING_LABEL), meaning
that `y[i, j]` contains the label annotated by annotator `i` for
sample `j`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If `candidates` is None, the samples from (X,y), for which an
annotator exists such that the annotator sample pairs is
unlabeled are considered as sample candidates.
If `candidates` is of shape (n_candidates,) and of type int,
`candidates` is considered as the indices of the sample candidates
in (X,y).
If `candidates` is of shape (n_candidates, n_features), the
sample candidates are directly given in `candidates` (not
necessarily contained in `X`). This is not supported by all query
strategies.
annotators : array-like of shape (n_candidates, n_annotators), optional
(default=None)
If `annotators` is None, all annotators are considered as available
annotators.
If `annotators` is of shape (n_avl_annotators), and of type int,
`annotators` is considered as the indices of the available
annotators.
If candidate samples and available annotators are specified:
The annotator-sample-pairs, for which the sample is a candidate
sample and the annotator is an available annotator are considered
as candidate annotator-sample-pairs.
If `annotators` is a boolean array of shape (n_candidates,
n_avl_annotators) the annotator-sample-pairs, for which the sample
is a candidate sample and the boolean matrix has entry `True` are
considered as candidate sample pairs.
batch_size : int or string, optional (default=1)
The number of annotators sample pairs to be selected in one AL
cycle. If `adaptive = True` `batch_size = 'adaptive'` is allowed.
return_utilities : bool
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_X_dict : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples, n_annotators)
Checked labels of the training data set.
candidates : None or np.ndarray of shape (n_candidates), dtype=int or
np.ndarray of shape (n_candidates, n_features)
Checked candidate samples.
annotators : None or np.ndarray of shape (n_avl_annotators), dtype=int
or np.ndarray of shape (n_candidates, n_annotators)
Checked annotator boolean array
batch_size : int
Checked number of samples to be selected in one AL cycle.
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X, y, candidates, batch_size, return_utilities, reset, check_X_dict
)
check_array(y, ensure_2d=True, force_all_finite="allow-nan")
unlabeled_pairs = is_unlabeled(y, missing_label=self.missing_label_)
if annotators is not None:
annotators = check_array(
annotators, ensure_2d=False, allow_nd=True
)
if annotators.ndim == 1:
annotators = check_indices(annotators, y, dim=1)
elif annotators.ndim == 2:
annotators = check_array(annotators, dtype=bool)
if candidates is None or candidates.ndim == 1:
check_consistent_length(X, annotators)
else:
check_consistent_length(candidates, annotators)
check_consistent_length(y.T, annotators.T)
else:
raise ValueError(
"`annotators` must be either None, 1d or 2d " "array-like."
)
if annotators is None:
if candidates is None:
n_candidate_pairs = int(np.sum(unlabeled_pairs))
elif candidates.ndim == 1:
n_candidate_pairs = len(candidates) * len(y.T)
else:
n_candidate_pairs = len(candidates) * len(y.T)
elif annotators.ndim == 1:
if candidates is None:
n_candidate_pairs = int(np.sum(unlabeled_pairs[:, annotators]))
elif candidates.ndim == 1:
n_candidate_pairs = int(
np.sum(unlabeled_pairs[candidates][:, annotators])
)
else:
n_candidate_pairs = len(candidates) * len(annotators)
else:
n_candidate_pairs = int(np.sum(annotators))
if n_candidate_pairs < batch_size:
warnings.warn(
f"'batch_size={batch_size}' is larger than number of "
f"candidates pairs. Instead, 'batch_size={n_candidate_pairs}'"
f" was set."
)
batch_size = n_candidate_pairs
return X, y, candidates, annotators, batch_size, return_utilities
def _transform_cand_annot(
self, candidates, annotators, X, y, enforce_mapping=False
):
"""
Transforms the `candidates` parameter into a sample array and the
corresponding index array `mapping` such that
`candidates = X[mapping]`, and transforms `annotators` into a boolean
array such that `A_cand` represents the available annotator sample
pairs for the samples of candidates.
Parameters
----------
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If `candidates` is None, the samples from (X,y), for which an
annotator exists such that the annotator sample pairs is
unlabeled are considered as sample candidates.
If `candidates` is of shape (n_candidates,) and of type int,
`candidates` is considered as the indices of the sample candidates
in (X,y).
If `candidates` is of shape (n_candidates, n_features), the
sample candidates are directly given in `candidates` (not
necessarily contained in `X`). This is not supported by all query
strategies.
annotators : array-like of shape (n_candidates, n_annotators), optional
(default=None)
If `annotators` is None, all annotators are considered as available
annotators.
If `annotators` is of shape (n_avl_annotators), and of type int,
`annotators` is considered as the indices of the available
annotators.
If candidate samples and available annotators are specified:
The annotator-sample-pairs, for which the sample is a candidate
sample and the annotator is an available annotator are considered
as candidate annotator-sample-pairs.
If `annotators` is a boolean array of shape (n_candidates,
n_avl_annotators) the annotator-sample-pairs, for which the sample
is a candidate sample and the boolean matrix has entry `True` are
considered as candidate sample pairs.
X : np.ndarray of shape (n_samples, n_features)
Checked training data set.
y : np.ndarray of shape (n_samples,)
Checked labels of the training data set.
enforce_mapping : bool, optional (default=False)
If `True`, an exception is raised when no exact mapping can be
determined (i.e., `mapping` is None).
Returns
-------
candidates : np.ndarray of shape (n_candidates, n_features)
Candidate samples from which the strategy can query the label.
mapping : np.ndarray of shape (n_candidates) or None
Index array that maps `candidates` to `X`
(`candidates = X[mapping]`).
A_cand : np.ndarray of shape(n_candidates, n_annotators)
Available annotator sample pair with respect to `candidates`.
"""
unlbd_pairs = is_unlabeled(y, self.missing_label_)
unlbd_sample_indices = np.argwhere(
np.any(unlbd_pairs, axis=1)
).flatten()
n_annotators = y.shape[1]
if candidates is not None and candidates.ndim == 2:
n_candidates = len(candidates)
if annotators is None:
A_cand = np.full((n_candidates, n_annotators), True)
elif annotators.ndim == 1:
A_cand = np.full((n_candidates, n_annotators), False)
A_cand[:, annotators] = True
else:
A_cand = annotators
if enforce_mapping:
raise ValueError(
"Mapping `candidates` to `X` is not posssible"
"but `enforce_mapping` is True. Use index"
"array for `candidates` instead."
)
else:
return candidates, None, A_cand
if candidates is None:
candidates = unlbd_sample_indices
only_candidates = False
elif annotators is not None:
candidates = np.intersect1d(candidates, unlbd_sample_indices)
only_candidates = False
else:
only_candidates = True
if only_candidates:
A_cand = np.full((len(candidates), n_annotators), True)
elif annotators is None:
A_cand = unlbd_pairs[candidates, :]
elif annotators.ndim == 1:
available_pairs = np.full_like(y, False, dtype=bool)
available_pairs[:, annotators] = True
A_cand = (unlbd_pairs & available_pairs)[candidates, :]
else:
A_cand = annotators
return X[candidates], candidates, A_cand
class BudgetManager(ABC, BaseEstimator):
"""Base class for all budget managers for stream-based active learning
in scikit-activeml to model budgeting constraints.
Parameters
----------
budget : float (default=None)
Specifies the ratio of instances which are allowed to be sampled, with
0 <= budget <= 1. If budget is None, it is replaced with the default
budget 0.1.
"""
def __init__(self, budget=None):
self.budget = budget
@abstractmethod
def query_by_utility(self, utilities, *args, **kwargs):
"""Ask the budget manager which utilities are sufficient to query the
corresponding instance.
Parameters
----------
utilities : ndarray of shape (n_samples,)
The utilities provided by the stream-based active learning
strategy, which are used to determine whether sampling an instance
is worth it given the budgeting constraint.
Returns
-------
queried_indices : ndarray of shape (n_queried_instances,)
The indices of instances represented by utilities which should be
queried, with 0 <= n_queried_instances <= n_samples.
"""
raise NotImplementedError
@abstractmethod
def update(self, candidates, queried_indices, *args, **kwargs):
"""Updates the BudgetManager.
Parameters
----------
candidates : {array-like, sparse matrix} of shape
(n_samples, n_features)
The instances which may be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
queried_indices : array-like
Indicates which instances from candidates have been queried.
Returns
-------
self : BudgetManager
The BudgetManager returns itself, after it is updated.
"""
raise NotImplementedError
def _validate_budget(self):
"""check the assigned budget and set the default value 0.1 if budget is
set to None.
"""
if self.budget is not None:
self.budget_ = self.budget
else:
self.budget_ = 0.1
check_scalar(
self.budget_,
"budget",
float,
min_val=0.0,
max_val=1.0,
min_inclusive=False,
)
def _validate_data(self, utilities, *args, **kwargs):
"""Validate input data.
Parameters
----------
utilities: ndarray of shape (n_samples,)
The utilities provided by the stream-based active learning
strategy.
Returns
-------
utilities: ndarray of shape (n_samples,)
Checked utilities
"""
# Check if utilities is set
if not isinstance(utilities, np.ndarray):
raise TypeError(
"{} is not a valid type for utilities".format(type(utilities))
)
# Check budget
self._validate_budget()
return utilities
class SingleAnnotatorStreamQueryStrategy(QueryStrategy):
"""Base class for all stream-based active learning query strategies in
scikit-activeml.
Parameters
----------
budget : float, default=None
The budget which models the budgeting constraint used in
the stream-based active learning setting.
random_state : int, RandomState instance, default=None
Controls the randomness of the estimator.
"""
def __init__(self, budget, random_state=None):
super().__init__(random_state=random_state)
self.budget = budget
@abstractmethod
def query(self, candidates, *args, return_utilities=False, **kwargs):
"""Ask the query strategy which instances in candidates to acquire.
The query startegy determines the most useful instances in candidates,
which can be acquired within the budgeting constraint specified by the
budgetmanager.
Please note that, this method does not alter the internal state of the
query strategy. To adapt the query strategy to the selected candidates,
use update(...) with the selected candidates.
Parameters
----------
candidates : {array-like, sparse matrix} of shape
(n_samples, n_features)
The instances which may be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
return_utilities : bool, optional
If true, also return the utilities based on the query strategy.
The default is False.
Returns
-------
queried_indices : ndarray of shape (n_sampled_instances,)
The indices of instances in candidates which should be sampled,
with 0 <= n_sampled_instances <= n_samples.
utilities: ndarray of shape (n_samples,), optional
The utilities based on the query strategy. Only provided if
return_utilities is True.
"""
raise NotImplementedError
@abstractmethod
def update(
self,
candidates,
queried_indices,
*args,
budget_manager_param_dict=None,
**kwargs,
):
"""Update the query strategy with the decisions taken.
This function should be used in conjunction with the query function,
when the instances queried from query(...) may differ from the
instances queried in the end. In this case use query(...) with
simulate=true and provide the final decisions via update(...).
This is especially helpful, when developing wrapper query strategies.
Parameters
----------
candidates : {array-like, sparse matrix} of shape
(n_samples, n_features)
The instances which could be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
queried_indices : array-like
Indicates which instances from candidates have been queried.
budget_manager_param_dict : kwargs, optional
Optional kwargs for budgetmanager.
Returns
-------
self : StreamBasedQueryStrategy
The StreamBasedQueryStrategy returns itself, after it is updated.
"""
raise NotImplementedError
def _validate_random_state(self):
"""Creates a copy 'random_state_' if random_state is an instance of
np.random_state. If not create a new random state. See also
:func:`~sklearn.utils.check_random_state`
"""
if not hasattr(self, "random_state_"):
self.random_state_ = deepcopy(self.random_state)
self.random_state_ = check_random_state(self.random_state_)
def _validate_budget(self):
if self.budget is not None:
self.budget_ = self.budget
else:
self.budget_ = 0.1
check_scalar(
self.budget_,
"budget",
float,
min_val=0.0,
max_val=1.0,
min_inclusive=False,
)
def _validate_data(
self,
candidates,
return_utilities,
*args,
reset=True,
**check_candidates_params,
):
"""Validate input data and set or check the `n_features_in_` attribute.
Parameters
----------
candidates: array-like of shape (n_candidates, n_features)
The instances which may be queried. Sparse matrices are accepted
only if they are supported by the base query strategy.
return_utilities : bool,
If true, also return the utilities based on the query strategy.
reset : bool, default=True
Whether to reset the `n_features_in_` attribute.
If False, the input will be checked for consistency with data
provided when reset was last True.
**check_candidates_params : kwargs
Parameters passed to :func:`sklearn.utils.check_array`.
Returns
-------
candidates: np.ndarray, shape (n_candidates, n_features)
Checked candidate samples
return_utilities : bool,
Checked boolean value of `return_utilities`.
"""
# Check candidate instances.
candidates = check_array(candidates, **check_candidates_params)
# Check number of features.
self._check_n_features(candidates, reset=reset)
# Check return_utilities.
check_scalar(return_utilities, "return_utilities", bool)
# Check random state.
self._validate_random_state()
# Check budgetmanager.
self._validate_budget()
return candidates, return_utilities
class SkactivemlClassifier(BaseEstimator, ClassifierMixin, ABC):
"""SkactivemlClassifier
Base class for scikit-activeml classifiers such that missing labels,
user-defined classes, and cost-sensitive classification (i.e., cost matrix)
can be handled.
Parameters
----------
classes : array-like of shape (n_classes), default=None
Holds the label for each class. If none, the classes are determined
during the fit.
missing_label : scalar, string, np.nan, or None, default=np.nan
Value to represent a missing label.
cost_matrix : array-like of shape (n_classes, n_classes)
Cost matrix with `cost_matrix[i,j]` indicating cost of predicting class
`classes[j]` for a sample of class `classes[i]`. Can be only set, if
classes is not none.
random_state : int or RandomState instance or None, default=None
Determines random number for `predict` method. Pass an int for
reproducible results across multiple method calls.
Attributes
----------
classes_ : array-like, shape (n_classes)
Holds the label for each class after fitting.
cost_matrix_ : array-like,of shape (classes, classes)
Cost matrix after fitting with `cost_matrix_[i,j]` indicating cost of
predicting class `classes_[j]` for a sample of class `classes_[i]`.
"""
def __init__(
self,
classes=None,
missing_label=MISSING_LABEL,
cost_matrix=None,
random_state=None,
):
self.classes = classes
self.missing_label = missing_label
self.cost_matrix = cost_matrix
self.random_state = random_state
@abstractmethod
def fit(self, X, y, sample_weight=None):
"""Fit the model using X as training data and y as class labels.
Parameters
----------
X : matrix-like, shape (n_samples, n_features)
The sample matrix X is the feature matrix representing the samples.
y : array-like, shape (n_samples) or (n_samples, n_outputs)
It contains the class labels of the training samples.
The number of class labels may be variable for the samples, where
missing labels are represented the attribute 'missing_label'.
sample_weight : array-like, shape (n_samples) or (n_samples, n_outputs)
It contains the weights of the training samples' class labels.
It must have the same shape as y.
Returns
-------
self: skactiveml.base.SkactivemlClassifier,
The `skactiveml.base.SkactivemlClassifier` object fitted on the
training data.
"""
raise NotImplementedError
def predict_proba(self, X):
"""Return probability estimates for the test data X.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Test samples.
Returns
-------
P : numpy.ndarray, shape (n_samples, classes)
The class probabilities of the test samples. Classes are ordered
according to 'classes_'.
"""
raise NotImplementedError
def predict(self, X):
"""Return class label predictions for the test samples `X`.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Input samples.
Returns
-------
y : numpy.ndarray of shape (n_samples)
Predicted class labels of the test samples `X`. Classes are ordered
according to `classes_`.
"""
P = self.predict_proba(X)
costs = np.dot(P, self.cost_matrix_)
y_pred = rand_argmin(costs, random_state=self.random_state_, axis=1)
y_pred = self._le.inverse_transform(y_pred)
y_pred = np.asarray(y_pred, dtype=self.classes_.dtype)
return y_pred
def score(self, X, y, sample_weight=None):
"""Return the mean accuracy on the given test data and labels.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Test samples.
y : array-like of shape (n_samples,)
True labels for `X`.
sample_weight : array-like of shape (n_samples,), default=None
Sample weights.
Returns
-------
score : float
Mean accuracy of `self.predict(X)` regarding `y`.
"""
y = self._le.transform(y)
y_pred = self._le.transform(self.predict(X))
return accuracy_score(y, y_pred, sample_weight=sample_weight)
def _validate_data(
self,
X,
y,
sample_weight=None,
check_X_dict=None,
check_y_dict=None,
y_ensure_1d=True,
):
if check_X_dict is None:
check_X_dict = {"ensure_min_samples": 0, "ensure_min_features": 0}
if check_y_dict is None:
check_y_dict = {
"ensure_min_samples": 0,
"ensure_min_features": 0,
"ensure_2d": False,
"force_all_finite": False,
"dtype": None,
}
# Check common classifier parameters.
check_classifier_params(
self.classes, self.missing_label, self.cost_matrix
)
# Store and check random state.
self.random_state_ = check_random_state(self.random_state)
# Create label encoder.
self._le = ExtLabelEncoder(
classes=self.classes, missing_label=self.missing_label
)
# Check input parameters.
y = check_array(y, **check_y_dict)
if len(y) > 0:
y = column_or_1d(y) if y_ensure_1d else y
y = self._le.fit_transform(y)
is_lbdl = is_labeled(y)
if len(y[is_lbdl]) > 0:
check_classification_targets(y[is_lbdl])
if len(self._le.classes_) == 0:
raise ValueError(
"No class label is known because 'y' contains no actual "
"class labels and 'classes' is not defined. Change at "
"least on of both to overcome this error."
)
else:
self._le.fit_transform(self.classes)
check_X_dict["ensure_2d"] = False
X = check_array(X, **check_X_dict)
check_consistent_length(X, y)
# Update detected classes.
self.classes_ = self._le.classes_
# Check classes.
if sample_weight is not None:
sample_weight = check_array(sample_weight, **check_y_dict)
if not np.array_equal(y.shape, sample_weight.shape):
raise ValueError(
f"`y` has the shape {y.shape} and `sample_weight` has the "
f"shape {sample_weight.shape}. Both need to have "
f"identical shapes."
)
# Update cost matrix.
self.cost_matrix_ = (
1 - np.eye(len(self.classes_))
if self.cost_matrix is None
else self.cost_matrix
)
self.cost_matrix_ = check_cost_matrix(
self.cost_matrix_, len(self.classes_)
)
if self.classes is not None:
class_indices = np.argsort(self.classes)
self.cost_matrix_ = self.cost_matrix_[class_indices]
self.cost_matrix_ = self.cost_matrix_[:, class_indices]
return X, y, sample_weight
def _check_n_features(self, X, reset):
if reset:
self.n_features_in_ = X.shape[1] if len(X) > 0 else None
elif not reset:
if self.n_features_in_ is not None:
super()._check_n_features(X, reset=reset)
class ClassFrequencyEstimator(SkactivemlClassifier):
"""ClassFrequencyEstimator
Extends scikit-activeml classifiers to estimators that are able to estimate
class frequencies for given samples (by calling 'predict_freq').
Parameters
----------
classes : array-like, shape (n_classes), default=None
Holds the label for each class. If none, the classes are determined
during the fit.
missing_label : scalar or str or np.nan or None, default=np.nan
Value to represent a missing label.
cost_matrix : array-like of shape (n_classes, n_classes)
Cost matrix with `cost_matrix[i,j]` indicating cost of predicting class
`classes[j]` for a sample of class `classes[i]`. Can be only set, if
classes is not none.
class_prior : float or array-like, shape (n_classes), default=0
Prior observations of the class frequency estimates. If `class_prior`
is an array, the entry `class_prior[i]` indicates the non-negative
prior number of samples belonging to class `classes_[i]`. If
`class_prior` is a float, `class_prior` indicates the non-negative
prior number of samples per class.
random_state : int or np.RandomState or None, default=None
Determines random number for 'predict' method. Pass an int for
reproducible results across multiple method calls.
Attributes
----------
classes_ : np.ndarray of shape (n_classes)
Holds the label for each class after fitting.
class_prior_ : np.ndarray of shape (n_classes)
Prior observations of the class frequency estimates. The entry
`class_prior_[i]` indicates the non-negative prior number of samples
belonging to class `classes_[i]`.
cost_matrix_ : np.ndarray of shape (classes, classes)
Cost matrix with `cost_matrix_[i,j]` indicating cost of predicting
class `classes_[j]` for a sample of class `classes_[i]`.
"""
def __init__(
self,
class_prior=0,
classes=None,
missing_label=MISSING_LABEL,
cost_matrix=None,
random_state=None,
):
super().__init__(
classes=classes,
missing_label=missing_label,
cost_matrix=cost_matrix,
random_state=random_state,
)
self.class_prior = class_prior
@abstractmethod
def predict_freq(self, X):
"""Return class frequency estimates for the test samples `X`.
Parameters
----------
X: array-like of shape (n_samples, n_features)
Test samples whose class frequencies are to be estimated.
Returns
-------
F: array-like of shape (n_samples, classes)
The class frequency estimates of the test samples 'X'. Classes are
ordered according to attribute 'classes_'.
"""
raise NotImplementedError
def predict_proba(self, X):
"""Return probability estimates for the test data `X`.
Parameters
----------
X : array-like, shape (n_samples, n_features) or
shape (n_samples, m_samples) if metric == 'precomputed'
Input samples.
Returns
-------
P : array-like of shape (n_samples, classes)
The class probabilities of the test samples. Classes are ordered
according to classes_.
"""
# Normalize probabilities of each sample.
P = self.predict_freq(X) + self.class_prior_
normalizer = np.sum(P, axis=1)
P[normalizer > 0] /= normalizer[normalizer > 0, np.newaxis]
P[normalizer == 0, :] = [1 / len(self.classes_)] * len(self.classes_)
return P
def _validate_data(
self,
X,
y,
sample_weight=None,
check_X_dict=None,
check_y_dict=None,
y_ensure_1d=True,
):
X, y, sample_weight = super()._validate_data(
X=X,
y=y,
sample_weight=sample_weight,
check_X_dict=check_X_dict,
check_y_dict=check_y_dict,
y_ensure_1d=y_ensure_1d,
)
# Check class prior.
self.class_prior_ = check_class_prior(
self.class_prior, len(self.classes_)
)
return X, y, sample_weight
class SkactivemlRegressor(BaseEstimator, RegressorMixin, ABC):
"""SkactivemlRegressor
Base class for scikit-activeml regressors.
Parameters
__________
missing_label : scalar, string, np.nan, or None, optional
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int, RandomState or None, optional (default=None)
Determines random number for 'fit' and 'predict' method. Pass an int for
reproducible results across multiple method calls.
"""
def __init__(self, missing_label=MISSING_LABEL, random_state=None):
self.missing_label = missing_label
self.random_state = random_state
@abstractmethod
def fit(self, X, y, sample_weight=None):
"""Fit the model using X as training data and y as numerical labels.
Parameters
----------
X : matrix-like, shape (n_samples, n_features)
The sample matrix X is the feature matrix representing the samples.
y : array-like, shape (n_samples) or (n_samples, n_targets)
It contains the labels of the training samples.
The number of numerical labels may be variable for the samples,
where missing labels are represented the attribute 'missing_label'.
sample_weight : array-like, shape (n_samples)
It contains the weights of the training samples' values.
Returns
-------
self: skactiveml.base.SkactivemlRegressor,
The `skactiveml.base.SkactivemlRegressor` object fitted on the
training data.
"""
raise NotImplementedError
@abstractmethod
def predict(self, X):
"""Return value predictions for the test samples X.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Input samples.
Returns
-------
y : numpy.ndarray, shape (n_samples)
Predicted values of the test samples 'X'.
"""
raise NotImplementedError
def _validate_data(
self,
X,
y,
sample_weight=None,
check_X_dict=None,
check_y_dict=None,
y_ensure_1d=True,
):
if check_X_dict is None:
check_X_dict = {"ensure_min_samples": 0, "ensure_min_features": 0}
if check_y_dict is None:
check_y_dict = {
"ensure_min_samples": 0,
"ensure_min_features": 0,
"ensure_2d": False,
"force_all_finite": False,
"dtype": None,
}
check_missing_label(self.missing_label)
self.missing_label_ = self.missing_label
# Store and check random state.
self.random_state_ = check_random_state(self.random_state)
X = check_array(X, **check_X_dict)
y = check_array(y, **check_y_dict)
if len(y) > 0:
y = column_or_1d(y) if y_ensure_1d else y
if sample_weight is not None:
sample_weight = check_array(sample_weight, **check_y_dict)
if not np.array_equal(y.shape, sample_weight.shape):
raise ValueError(
f"`y` has the shape {y.shape} and `sample_weight` has the "
f"shape {sample_weight.shape}. Both need to have "
f"identical shapes."
)
return X, y, sample_weight
class ProbabilisticRegressor(SkactivemlRegressor):
"""ProbabilisticRegressor
Base class for scikit-activeml probabilistic regressors.
"""
@abstractmethod
def predict_target_distribution(self, X):
"""Returns the predicted target distribution conditioned on the test
samples `X`.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Input samples.
Returns
-------
dist : scipy.stats._distn_infrastructure.rv_frozen
The distribution of the targets at the test samples.
"""
raise NotImplementedError
def predict(self, X, return_std=False, return_entropy=False):
"""Returns the mean, std (optional) and differential entropy (optional)
of the predicted target distribution conditioned on the test samples
`X`.
Parameters
----------
X : array-like, shape (n_samples, n_features)
Input samples.
return_std : bool, optional (default=False)
Whether to return the standard deviation.
return_entropy : bool, optional (default=False)
Whether to return the differential entropy.
Returns
-------
mu : numpy.ndarray, shape (n_samples)
Predicted mean conditioned on `X`.
std : numpy.ndarray, shape (n_samples), optional
Predicted standard deviation conditioned on `X`.
entropy : numpy..ndarray, optional
Predicted differential entropy conditioned on `X`.
"""
rv = self.predict_target_distribution(X)
result = (rv.mean(),)
if return_std:
result += (rv.std(),)
if return_entropy:
result += (rv.entropy(),)
if len(result) == 1:
result = result[0]
return result
def sample_y(self, X, n_samples=1, random_state=None):
"""Returns random samples from the predicted target distribution
conditioned on the test samples `X`.
Parameters
----------
X : array-like, shape (n_samples_X, n_features)
Input samples, where the target values are drawn from.
n_samples: int, optional (default=1)
Number of random samples to be drawn.
random_state : int, RandomState instance or None, optional
(default=None)
Determines random number generation to randomly draw samples. Pass
an int for reproducible results across multiple method calls.
Returns
-------
y_samples : numpy.ndarray, shape (n_samples_X, n_samples)
Drawn random target samples.
"""
rv = self.predict_target_distribution(X)
rv_samples = rv.rvs(
size=(n_samples, len(X)), random_state=random_state
)
return rv_samples.T
class AnnotatorModelMixin(ABC):
"""AnnotatorModelMixin
Base class of all annotator models estimating the performances of
annotators for given samples.
"""
@abstractmethod
def predict_annotator_perf(self, X):
"""Calculates the performance of an annotator to provide the true label
for a given sample.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Test samples.
Returns
-------
P_annot : numpy.ndarray of shape (n_samples, n_annotators)
`P_annot[i,l]` is the performance of annotator `l` regarding the
annotation of sample `X[i]`.
"""
raise NotImplementedError | 0.908798 | 0.393909 |
from functools import partial
import numpy as np
from sklearn import clone
from sklearn.utils import check_array
from sklearn.metrics import mean_squared_error
from skactiveml.base import (
ProbabilisticRegressor,
SingleAnnotatorPoolQueryStrategy,
)
from skactiveml.pool.utils import _update_reg, _conditional_expect
from skactiveml.utils import (
check_type,
simple_batch,
MISSING_LABEL,
_check_callable,
is_unlabeled,
)
class ExpectedModelOutputChange(SingleAnnotatorPoolQueryStrategy):
"""Regression based Expected Model Output Change.
This class implements an expected model output change based approach for
regression, where samples are queried that change the output of the model
the most.
Parameters
----------
integration_dict : dict, optional (default=None)
Dictionary for integration arguments, i.e. `integration_method` etc.,
used for calculating the expected `y` value for the candidate samples.
For details see method `skactiveml.pool.utils._conditional_expect`.
The default `integration_method` is `assume_linear`.
loss : callable, optional (default=None)
The loss for predicting a target value instead of the true value.
Takes in the predicted values of an evaluation set and the true values
of the evaluation set and returns the error, a scalar value.
The default loss is `sklearn.metrics.mean_squared_error` an alternative
might be `sklearn.metrics.mean_absolute_error`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
----------
[1] Christoph Kaeding, Erik Rodner, Alexander Freytag, Oliver Mothes,
Oliver, Bjoern Barz and Joachim Denzler. Active
Learning for Regression Tasks with Expected Model Output Change, BMVC,
page 1-15, 2018.
"""
def __init__(
self,
integration_dict=None,
loss=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.loss = loss
self.integration_dict = integration_dict
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
X_eval=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg : ProbabilisticRegressor
Predicts the output and the target distribution.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
X_eval : array-like of shape (n_eval_samples, n_features),
optional (default=None)
Evaluation data set that is used for estimating the probability
distribution of the feature space. In the referenced paper it is
proposed to use the unlabeled data, i.e.
`X_eval=X[is_unlabeled(y)]`.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", ProbabilisticRegressor)
if self.integration_dict is None:
self.integration_dict = {"method": "assume_linear"}
check_type(self.integration_dict, "self.integration_dict", dict)
if X_eval is None:
X_eval = X[is_unlabeled(y, missing_label=self.missing_label_)]
if len(X_eval) == 0:
raise ValueError(
"The training data contains no unlabeled "
"data. This can be fixed by setting the "
"evaluation set manually, e.g. set "
"`X_eval=X`."
)
else:
X_eval = check_array(X_eval)
self._check_n_features(X_eval, reset=False)
check_type(fit_reg, "fit_reg", bool)
if self.loss is None:
self.loss = mean_squared_error
_check_callable(self.loss, "self.loss", n_positional_parameters=2)
X_cand, mapping = self._transform_candidates(candidates, X, y)
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
y_pred = reg.predict(X_eval)
def _model_output_change(idx, x_cand, y_pot):
reg_new = _update_reg(
reg,
X,
y,
sample_weight=sample_weight,
y_update=y_pot,
idx_update=idx,
X_update=x_cand,
mapping=mapping,
)
y_pred_new = reg_new.predict(X_eval)
return self.loss(y_pred, y_pred_new)
change = _conditional_expect(
X_cand,
_model_output_change,
reg,
random_state=self.random_state_,
**self.integration_dict,
)
if mapping is None:
utilities = change
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = change
return simple_batch(
utilities,
batch_size=batch_size,
random_state=self.random_state_,
return_utilities=return_utilities,
) | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_expected_model_output_change.py | _expected_model_output_change.py | from functools import partial
import numpy as np
from sklearn import clone
from sklearn.utils import check_array
from sklearn.metrics import mean_squared_error
from skactiveml.base import (
ProbabilisticRegressor,
SingleAnnotatorPoolQueryStrategy,
)
from skactiveml.pool.utils import _update_reg, _conditional_expect
from skactiveml.utils import (
check_type,
simple_batch,
MISSING_LABEL,
_check_callable,
is_unlabeled,
)
class ExpectedModelOutputChange(SingleAnnotatorPoolQueryStrategy):
"""Regression based Expected Model Output Change.
This class implements an expected model output change based approach for
regression, where samples are queried that change the output of the model
the most.
Parameters
----------
integration_dict : dict, optional (default=None)
Dictionary for integration arguments, i.e. `integration_method` etc.,
used for calculating the expected `y` value for the candidate samples.
For details see method `skactiveml.pool.utils._conditional_expect`.
The default `integration_method` is `assume_linear`.
loss : callable, optional (default=None)
The loss for predicting a target value instead of the true value.
Takes in the predicted values of an evaluation set and the true values
of the evaluation set and returns the error, a scalar value.
The default loss is `sklearn.metrics.mean_squared_error` an alternative
might be `sklearn.metrics.mean_absolute_error`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
----------
[1] Christoph Kaeding, Erik Rodner, Alexander Freytag, Oliver Mothes,
Oliver, Bjoern Barz and Joachim Denzler. Active
Learning for Regression Tasks with Expected Model Output Change, BMVC,
page 1-15, 2018.
"""
def __init__(
self,
integration_dict=None,
loss=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.loss = loss
self.integration_dict = integration_dict
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
X_eval=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg : ProbabilisticRegressor
Predicts the output and the target distribution.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
X_eval : array-like of shape (n_eval_samples, n_features),
optional (default=None)
Evaluation data set that is used for estimating the probability
distribution of the feature space. In the referenced paper it is
proposed to use the unlabeled data, i.e.
`X_eval=X[is_unlabeled(y)]`.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", ProbabilisticRegressor)
if self.integration_dict is None:
self.integration_dict = {"method": "assume_linear"}
check_type(self.integration_dict, "self.integration_dict", dict)
if X_eval is None:
X_eval = X[is_unlabeled(y, missing_label=self.missing_label_)]
if len(X_eval) == 0:
raise ValueError(
"The training data contains no unlabeled "
"data. This can be fixed by setting the "
"evaluation set manually, e.g. set "
"`X_eval=X`."
)
else:
X_eval = check_array(X_eval)
self._check_n_features(X_eval, reset=False)
check_type(fit_reg, "fit_reg", bool)
if self.loss is None:
self.loss = mean_squared_error
_check_callable(self.loss, "self.loss", n_positional_parameters=2)
X_cand, mapping = self._transform_candidates(candidates, X, y)
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
y_pred = reg.predict(X_eval)
def _model_output_change(idx, x_cand, y_pot):
reg_new = _update_reg(
reg,
X,
y,
sample_weight=sample_weight,
y_update=y_pot,
idx_update=idx,
X_update=x_cand,
mapping=mapping,
)
y_pred_new = reg_new.predict(X_eval)
return self.loss(y_pred, y_pred_new)
change = _conditional_expect(
X_cand,
_model_output_change,
reg,
random_state=self.random_state_,
**self.integration_dict,
)
if mapping is None:
utilities = change
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = change
return simple_batch(
utilities,
batch_size=batch_size,
random_state=self.random_state_,
return_utilities=return_utilities,
) | 0.957068 | 0.647756 |
import warnings
import numpy as np
from scipy.interpolate import griddata
from scipy.optimize import minimize_scalar, minimize, LinearConstraint
from sklearn import clone
from sklearn.linear_model import LogisticRegression
from sklearn.utils.extmath import safe_sparse_dot, log_logistic
from ..base import SingleAnnotatorPoolQueryStrategy, SkactivemlClassifier
from ..classifier import SklearnClassifier, ParzenWindowClassifier
from ..utils import (
is_labeled,
simple_batch,
check_scalar,
check_type,
MISSING_LABEL,
check_equal_missing_label,
)
class EpistemicUncertaintySampling(SingleAnnotatorPoolQueryStrategy):
"""Epistemic Uncertainty Sampling.
Epistemic uncertainty sampling query strategy for two class problems.
Based on [1]. This strategy is only implemented for skactiveml parzen
window classifier and sklearn logistic regression classifier.
Parameters
----------
precompute : boolean, optional (default=False)
Whether the epistemic uncertainty should be precomputed.
Only for ParzenWindowClassifier significant.
missing_label : scalar or string or np.nan or None, optional
(default=MISSING_LABEL)
Value to represent a missing label.
random_state : int or np.random.RandomState
The random state to use.
References
----------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
def __init__(
self, precompute=False, missing_label=MISSING_LABEL, random_state=None
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.precompute = precompute
def query(
self,
X,
y,
clf,
fit_clf=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
clf : skactiveml.classifier.ParzenWindowClassifier or
sklearn.linear_model.LogisticRegression
Only the skactiveml ParzenWindowClassifier and a wrapped sklearn
logistic regression are supported as classifiers.
fit_clf : bool, default=True
Defines whether the classifier should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), default=None
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
return_utilities : bool, default=False
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Validate input parameters.
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Validate classifier type.
check_type(clf, "clf", SkactivemlClassifier)
check_equal_missing_label(clf.missing_label, self.missing_label_)
# Validate classifier type.
check_type(fit_clf, "fit_clf", bool)
# Fit the classifier.
if fit_clf:
clf = clone(clf).fit(X, y, sample_weight)
# Chose the correct method for the given classifier.
if isinstance(clf, ParzenWindowClassifier):
if not hasattr(self, "precompute_array"):
self._precompute_array = None
# Create precompute_array if necessary.
if not isinstance(self.precompute, bool):
raise TypeError(
"'precompute' should be of type bool but {} "
"were given".format(type(self.precompute))
)
if self.precompute and self._precompute_array is None:
self._precompute_array = np.full((2, 2), np.nan)
freq = clf.predict_freq(X_cand)
(
utilities_cand,
self._precompute_array,
) = _epistemic_uncertainty_pwc(freq, self._precompute_array)
elif isinstance(clf, SklearnClassifier) and isinstance(
clf.estimator_, LogisticRegression
):
mask_labeled = is_labeled(y, self.missing_label_)
if sample_weight is None:
sample_weight_masked = None
else:
sample_weight = np.asarray(sample_weight)
sample_weight_masked = sample_weight[mask_labeled]
utilities_cand = _epistemic_uncertainty_logreg(
X_cand=X_cand,
X=X[mask_labeled],
y=y[mask_labeled],
clf=clf,
sample_weight=sample_weight_masked,
)
else:
raise TypeError(
f"`clf` must be of type `ParzenWindowClassifier` or "
f"a wrapped `LogisticRegression` classifier. "
f"The given is of type {type(clf)}."
)
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
# Epistemic uncertainty scores for pwc.
def _epistemic_uncertainty_pwc(freq, precompute_array=None):
"""
Computes the epistemic uncertainty score for a parzen window classifier
[1]. Only for two class problems.
Parameters
----------
freq : np.ndarray of shape (n_samples, 2)
The class frequency estimates.
precompute_array : np.ndarray of a quadratic shape, default=None
Used to interpolate and speed up the calculation. Will be enlarged if
necessary. All entries that are 'np.nan' will be filled.
Returns
-------
utilities : np.ndarray of shape (n_samples,)
The calculated epistemic uncertainty scores.
precompute_array : np.nparray of quadratic shape with length
int(np.max(freq) + 1)
The enlarged precompute_array. Will be None if the given is None.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
if freq.shape[1] != 2:
raise ValueError(
"Epistemic is only implemented for two-class "
"problems, {} classes were given."
"".format(freq.shape[1])
)
n = freq[:, 0]
p = freq[:, 1]
utilities = np.full((len(freq)), np.nan)
if precompute_array is not None:
# enlarges the precompute_array array if necessary:
if precompute_array.shape[0] < np.max(n) + 1:
new_shape = (
int(np.max(n)) - precompute_array.shape[0] + 2,
precompute_array.shape[1],
)
precompute_array = np.append(
precompute_array, np.full(new_shape, np.nan), axis=0
)
if precompute_array.shape[1] < np.max(p) + 1:
new_shape = (
precompute_array.shape[0],
int(np.max(p)) - precompute_array.shape[1] + 2,
)
precompute_array = np.append(
precompute_array, np.full(new_shape, np.nan), axis=1
)
# precompute the epistemic uncertainty:
for N in range(precompute_array.shape[0]):
for P in range(precompute_array.shape[1]):
if np.isnan(precompute_array[N, P]):
pi1 = -minimize_scalar(
_pwc_ml_1,
method="Bounded",
bounds=(0.0, 1.0),
args=(N, P),
).fun
pi0 = -minimize_scalar(
_pwc_ml_0,
method="Bounded",
bounds=(0.0, 1.0),
args=(N, P),
).fun
pi = np.array([pi0, pi1])
precompute_array[N, P] = np.min(pi, axis=0)
utilities = _interpolate(precompute_array, freq)
else:
for i, f in enumerate(freq):
pi1 = -minimize_scalar(
_pwc_ml_1,
method="Bounded",
bounds=(0.0, 1.0),
args=(f[0], f[1]),
).fun
pi0 = -minimize_scalar(
_pwc_ml_0,
method="Bounded",
bounds=(0.0, 1.0),
args=(f[0], f[1]),
).fun
pi = np.array([pi0, pi1])
utilities[i] = np.min(pi, axis=0)
return utilities, precompute_array
def _interpolate(precompute_array, freq):
"""
Linearly interpolation.
For further informations see scipy.interpolate.griddata.
Parameters
----------
precompute_array : np.ndarray of a quadratic shape
Data values. The length should be greater than int(np.max(freq) + 1).
freq : np.ndarray of shape (n_samples, 2)
Points at which to interpolate data.
Returns
-------
Array of interpolated values.
"""
points = np.zeros(
(precompute_array.shape[0] * precompute_array.shape[1], 2)
)
for n in range(precompute_array.shape[0]):
for p in range(precompute_array.shape[1]):
points[n * precompute_array.shape[1] + p] = n, p
return griddata(points, precompute_array.flatten(), freq, method="linear")
def _pwc_ml_1(theta, n, p):
"""
Calulates the maximum likelihood for class 1 of epistemic for pwc.
Parameters
----------
theta : array-like
The parameter vector.
n : float
frequency estimate for the negative class.
p : float
frequency estimate for the positive class.
Returns
-------
float
The maximum likelihood for class 1 of epistemic for pwc.
"""
if (n == 0.0) and (p == 0.0):
return -1.0
piH = ((theta**p) * ((1 - theta) ** n)) / (
((p / (n + p)) ** p) * ((n / (n + p)) ** n)
)
return -np.minimum(piH, 2 * theta - 1)
def _pwc_ml_0(theta, n, p):
"""
Calulates the maximum likelihood for class 0 of epistemic for pwc.
Parameters
----------
theta : array-like
The parameter vector.
n : float
frequency estimate for the negative class.
p : float
frequency estimate for the positive class.
Returns
-------
float
The maximum likelihood for class 0 of epistemic for pwc.
"""
if (n == 0.0) and (p == 0.0):
return -1.0
piH = ((theta**p) * ((1 - theta) ** n)) / (
((p / (n + p)) ** p) * ((n / (n + p)) ** n)
)
return -np.minimum(piH, 1 - 2 * theta)
# Epistemic uncertainty scores for logistic regression.
def _epistemic_uncertainty_logreg(X_cand, X, y, clf, sample_weight=None):
"""
Calculates the epistemic uncertainty score for logistic regression [1].
Only for two class problems.
Parameters
----------
X_cand : np.ndarray
The unlabeled pool from which to choose.
X : np.ndarray
The labeled pool used to fit the classifier.
y : np.array
The labels of the labeled pool X.
clf : skactiveml.classifier.SklearnClassifier
Only a wrapped logistic regression is supported as classifier.
sample_weight : array-like of shape (n_samples,) (default=None)
Sample weights for X, only used if clf is a logistic regression
classifier.
Returns
-------
utilities : np.ndarray of shape (n_samples_cand,)
The calculated epistemic uncertainty scores.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
if not isinstance(clf, SklearnClassifier) or not isinstance(
clf.estimator, LogisticRegression
):
raise TypeError(
"clf has to be a wrapped LogisticRegression "
"classifier but \n{}\n was given.".format(clf)
)
if len(clf.classes) != 2:
raise ValueError(
"epistemic is only implemented for two-class "
"problems, {} classes were given."
"".format(len(clf.classes))
)
# Get the probability predictions.
probas = clf.predict_proba(X_cand)
# Get the regularization parameter from the clf.
gamma = 1 / clf.C
# Get weights from the classifier.
if clf.is_fitted_:
w_ml = np.append(clf.coef_, clf.intercept_).flatten()
else:
warnings.warn(
"The given classifier is not fitted or was fitted with "
"zero labels. Epistemic uncertainty sampling will fall "
"back to random sampling."
)
w_ml = np.zeros(X.shape[1] + 1)
# Calculate the maximum likelihood of the logistic function.
L_ml = np.exp(
-_loglike_logreg(
w=w_ml, X=X, y=y, gamma=gamma, sample_weight=sample_weight
)
)
# Set the initial guess for minimize function.
x0 = np.zeros((X_cand.shape[1] + 1))
# Set initial epistemic scores.
pi1 = np.maximum(2 * probas[:, 0] - 1, 0)
pi0 = np.maximum(1 - 2 * probas[:, 0], 0)
# Compute pi0, pi1 for every x in candidates.
for i, x in enumerate(X_cand):
Qn = np.linspace(0.01, 0.5, num=50, endpoint=True)
Qp = np.linspace(0.5, 1.0, num=50, endpoint=False)
A = np.append(x, 1) # Used for the LinearConstraint
for q in range(50):
alpha_n, alpha_p = Qn[0], Qp[-1]
if 2 * alpha_p - 1 > pi1[i]:
# Compute theta for alpha_p and x.
theta_p = _theta(
func=_loglike_logreg,
alpha=alpha_p,
x0=x0,
A=A,
args=(X, y, sample_weight, gamma),
)
# Compute the degrees of support for theta_p.
pi1[i] = np.maximum(
pi1[i],
np.minimum(
_pi_h(
theta=theta_p,
L_ml=L_ml,
X=X,
y=y,
sample_weight=sample_weight,
gamma=gamma,
),
2 * alpha_p - 1,
),
)
if 1 - 2 * alpha_n > pi0[i]:
# Compute theta for alpha_n and x.
theta_n = _theta(
func=_loglike_logreg,
alpha=alpha_n,
x0=x0,
A=A,
args=(X, y, sample_weight, gamma),
)
# Compute the degrees of support for theta_n.
pi0[i] = np.maximum(
pi0[i],
np.minimum(
_pi_h(
theta=theta_n,
L_ml=L_ml,
X=X,
y=y,
sample_weight=sample_weight,
gamma=gamma,
),
1 - 2 * alpha_p,
),
)
Qn, Qp = np.delete(Qn, 0), np.delete(Qp, -1)
utilities = np.min(np.array([pi0, pi1]), axis=0)
return utilities
def _pi_h(theta, L_ml, X, y, sample_weight=None, gamma=1):
"""
Computes np.exp(-_loglike_logreg())/L_ml, the normalized likelihood.
Parameters
----------
theta : np.ndarray of shape (n_features + 1,)
Coefficient vector.
L_ml : float
The maximum likelihood estimation on the training data.
Use np.exp(-_loglike_logreg) to compute.
X : np.ndarray
The labeled pool used to fit the classifier.
y : np.array
The labels of the labeled pool X.
sample_weight : np.ndarray of shape (n_samples,) (default=None)
Sample weights for X, only used if clf is a logistic regression
classifier.
gamma : float
The regularization parameter.
Returns
-------
pi_h : float
The normalized likelihood.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
check_scalar(L_ml, name="L_ml", target_type=(float, int))
L_theta = np.exp(
-_loglike_logreg(
w=theta, X=X, y=y, sample_weight=sample_weight, gamma=gamma
)
)
return L_theta / L_ml
def _loglike_logreg(w, X, y, sample_weight=None, gamma=1):
"""Computes the logistic loss.
Parameters
----------
w : np.ndarray of shape (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : np.ndarray of shape (n_samples,)
The labels of the training data X.
gamma : float
Regularization parameter. gamma is equal to 1 / C.
sample_weight : array-like of shape (n_samples,) default=None
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
Returns
-------
out : float
Logistic loss, the negative of the log of the logistic function.
"""
if len(y) == 0:
return np.log(2) * len(X)
return _logistic_loss(
w=w, X=X, y=y, alpha=gamma, sample_weight=sample_weight
)
def _theta(func, alpha, x0, A, args=()):
"""
This function calculates the parameter vector as it is shown in equation 22
in [1].
Parameters
----------
func : callable
The function to be optimized.
alpha : float
ln(alpha/(1-alpha)) will used as bound for the constraint.
x0 : np.ndarray of shape (n,)
Initial guess. Array of real elements of size (n,), where ‘n’ is the
number of independent variables.
A : np.ndarray
Matrix defining the constraint.
args : tuple
Will be pass to func.
Returns
-------
x : np.ndarray
The optimized parameter vector.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
bounds = np.log(alpha / (1 - alpha))
constraints = LinearConstraint(A=A, lb=bounds, ub=bounds)
res = minimize(
func, x0=x0, method="SLSQP", constraints=constraints, args=args
)
return res.x
def _logistic_loss(w, X, y, alpha, sample_weight=None):
"""Computes the logistic loss. This function is a copy taken from
https://github.com/scikit-learn/scikit-learn/blob/1.0.X/sklearn/
linear_model/_logistic.py.
Parameters
----------
w : ndarray of shape (n_features,) or (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : ndarray of shape (n_samples,)
Array of labels.
alpha : float
Regularization parameter. alpha is equal to 1 / C.
sample_weight : array-like of shape (n_samples,) default=None
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
Returns
-------
out : float
Logistic loss.
References
----------
[1] Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B,
Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J.
"Scikit-learn: Machine learning in Python." Journal of Machine
Learning Research. 2011.
"""
w, c, yz = _intercept_dot(w, X, y)
if sample_weight is None:
sample_weight = np.ones(y.shape[0])
# Logistic loss is the negative of the log of the logistic function.
out = -np.sum(sample_weight * log_logistic(yz))
out += 0.5 * alpha * np.dot(w, w)
return out
def _intercept_dot(w, X, y):
"""Computes y * np.dot(X, w). It takes into consideration if the intercept
should be fit or not. This function is a copy taken from
https://github.com/scikit-learn/scikit-learn/blob/1.0.X/sklearn/
linear_model/_logistic.py.
Parameters
----------
w : ndarray of shape (n_features,) or (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : ndarray of shape (n_samples,)
Array of labels.
Returns
-------
w : ndarray of shape (n_features,)
Coefficient vector without the intercept weight (w[-1]) if the
intercept should be fit. Unchanged otherwise.
c : float
The intercept.
yz : float
y * np.dot(X, w).
References
----------
[1] Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B,
Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J.
"Scikit-learn: Machine learning in Python." Journal of Machine
Learning Research. 2011.
"""
c = 0.0
if w.size == X.shape[1] + 1:
c = w[-1]
w = w[:-1]
z = safe_sparse_dot(X, w) + c
yz = y * z
return w, c, yz | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_epistemic_uncertainty_sampling.py | _epistemic_uncertainty_sampling.py | import warnings
import numpy as np
from scipy.interpolate import griddata
from scipy.optimize import minimize_scalar, minimize, LinearConstraint
from sklearn import clone
from sklearn.linear_model import LogisticRegression
from sklearn.utils.extmath import safe_sparse_dot, log_logistic
from ..base import SingleAnnotatorPoolQueryStrategy, SkactivemlClassifier
from ..classifier import SklearnClassifier, ParzenWindowClassifier
from ..utils import (
is_labeled,
simple_batch,
check_scalar,
check_type,
MISSING_LABEL,
check_equal_missing_label,
)
class EpistemicUncertaintySampling(SingleAnnotatorPoolQueryStrategy):
"""Epistemic Uncertainty Sampling.
Epistemic uncertainty sampling query strategy for two class problems.
Based on [1]. This strategy is only implemented for skactiveml parzen
window classifier and sklearn logistic regression classifier.
Parameters
----------
precompute : boolean, optional (default=False)
Whether the epistemic uncertainty should be precomputed.
Only for ParzenWindowClassifier significant.
missing_label : scalar or string or np.nan or None, optional
(default=MISSING_LABEL)
Value to represent a missing label.
random_state : int or np.random.RandomState
The random state to use.
References
----------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
def __init__(
self, precompute=False, missing_label=MISSING_LABEL, random_state=None
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.precompute = precompute
def query(
self,
X,
y,
clf,
fit_clf=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
clf : skactiveml.classifier.ParzenWindowClassifier or
sklearn.linear_model.LogisticRegression
Only the skactiveml ParzenWindowClassifier and a wrapped sklearn
logistic regression are supported as classifiers.
fit_clf : bool, default=True
Defines whether the classifier should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), default=None
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
return_utilities : bool, default=False
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Validate input parameters.
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Validate classifier type.
check_type(clf, "clf", SkactivemlClassifier)
check_equal_missing_label(clf.missing_label, self.missing_label_)
# Validate classifier type.
check_type(fit_clf, "fit_clf", bool)
# Fit the classifier.
if fit_clf:
clf = clone(clf).fit(X, y, sample_weight)
# Chose the correct method for the given classifier.
if isinstance(clf, ParzenWindowClassifier):
if not hasattr(self, "precompute_array"):
self._precompute_array = None
# Create precompute_array if necessary.
if not isinstance(self.precompute, bool):
raise TypeError(
"'precompute' should be of type bool but {} "
"were given".format(type(self.precompute))
)
if self.precompute and self._precompute_array is None:
self._precompute_array = np.full((2, 2), np.nan)
freq = clf.predict_freq(X_cand)
(
utilities_cand,
self._precompute_array,
) = _epistemic_uncertainty_pwc(freq, self._precompute_array)
elif isinstance(clf, SklearnClassifier) and isinstance(
clf.estimator_, LogisticRegression
):
mask_labeled = is_labeled(y, self.missing_label_)
if sample_weight is None:
sample_weight_masked = None
else:
sample_weight = np.asarray(sample_weight)
sample_weight_masked = sample_weight[mask_labeled]
utilities_cand = _epistemic_uncertainty_logreg(
X_cand=X_cand,
X=X[mask_labeled],
y=y[mask_labeled],
clf=clf,
sample_weight=sample_weight_masked,
)
else:
raise TypeError(
f"`clf` must be of type `ParzenWindowClassifier` or "
f"a wrapped `LogisticRegression` classifier. "
f"The given is of type {type(clf)}."
)
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
# Epistemic uncertainty scores for pwc.
def _epistemic_uncertainty_pwc(freq, precompute_array=None):
"""
Computes the epistemic uncertainty score for a parzen window classifier
[1]. Only for two class problems.
Parameters
----------
freq : np.ndarray of shape (n_samples, 2)
The class frequency estimates.
precompute_array : np.ndarray of a quadratic shape, default=None
Used to interpolate and speed up the calculation. Will be enlarged if
necessary. All entries that are 'np.nan' will be filled.
Returns
-------
utilities : np.ndarray of shape (n_samples,)
The calculated epistemic uncertainty scores.
precompute_array : np.nparray of quadratic shape with length
int(np.max(freq) + 1)
The enlarged precompute_array. Will be None if the given is None.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
if freq.shape[1] != 2:
raise ValueError(
"Epistemic is only implemented for two-class "
"problems, {} classes were given."
"".format(freq.shape[1])
)
n = freq[:, 0]
p = freq[:, 1]
utilities = np.full((len(freq)), np.nan)
if precompute_array is not None:
# enlarges the precompute_array array if necessary:
if precompute_array.shape[0] < np.max(n) + 1:
new_shape = (
int(np.max(n)) - precompute_array.shape[0] + 2,
precompute_array.shape[1],
)
precompute_array = np.append(
precompute_array, np.full(new_shape, np.nan), axis=0
)
if precompute_array.shape[1] < np.max(p) + 1:
new_shape = (
precompute_array.shape[0],
int(np.max(p)) - precompute_array.shape[1] + 2,
)
precompute_array = np.append(
precompute_array, np.full(new_shape, np.nan), axis=1
)
# precompute the epistemic uncertainty:
for N in range(precompute_array.shape[0]):
for P in range(precompute_array.shape[1]):
if np.isnan(precompute_array[N, P]):
pi1 = -minimize_scalar(
_pwc_ml_1,
method="Bounded",
bounds=(0.0, 1.0),
args=(N, P),
).fun
pi0 = -minimize_scalar(
_pwc_ml_0,
method="Bounded",
bounds=(0.0, 1.0),
args=(N, P),
).fun
pi = np.array([pi0, pi1])
precompute_array[N, P] = np.min(pi, axis=0)
utilities = _interpolate(precompute_array, freq)
else:
for i, f in enumerate(freq):
pi1 = -minimize_scalar(
_pwc_ml_1,
method="Bounded",
bounds=(0.0, 1.0),
args=(f[0], f[1]),
).fun
pi0 = -minimize_scalar(
_pwc_ml_0,
method="Bounded",
bounds=(0.0, 1.0),
args=(f[0], f[1]),
).fun
pi = np.array([pi0, pi1])
utilities[i] = np.min(pi, axis=0)
return utilities, precompute_array
def _interpolate(precompute_array, freq):
"""
Linearly interpolation.
For further informations see scipy.interpolate.griddata.
Parameters
----------
precompute_array : np.ndarray of a quadratic shape
Data values. The length should be greater than int(np.max(freq) + 1).
freq : np.ndarray of shape (n_samples, 2)
Points at which to interpolate data.
Returns
-------
Array of interpolated values.
"""
points = np.zeros(
(precompute_array.shape[0] * precompute_array.shape[1], 2)
)
for n in range(precompute_array.shape[0]):
for p in range(precompute_array.shape[1]):
points[n * precompute_array.shape[1] + p] = n, p
return griddata(points, precompute_array.flatten(), freq, method="linear")
def _pwc_ml_1(theta, n, p):
"""
Calulates the maximum likelihood for class 1 of epistemic for pwc.
Parameters
----------
theta : array-like
The parameter vector.
n : float
frequency estimate for the negative class.
p : float
frequency estimate for the positive class.
Returns
-------
float
The maximum likelihood for class 1 of epistemic for pwc.
"""
if (n == 0.0) and (p == 0.0):
return -1.0
piH = ((theta**p) * ((1 - theta) ** n)) / (
((p / (n + p)) ** p) * ((n / (n + p)) ** n)
)
return -np.minimum(piH, 2 * theta - 1)
def _pwc_ml_0(theta, n, p):
"""
Calulates the maximum likelihood for class 0 of epistemic for pwc.
Parameters
----------
theta : array-like
The parameter vector.
n : float
frequency estimate for the negative class.
p : float
frequency estimate for the positive class.
Returns
-------
float
The maximum likelihood for class 0 of epistemic for pwc.
"""
if (n == 0.0) and (p == 0.0):
return -1.0
piH = ((theta**p) * ((1 - theta) ** n)) / (
((p / (n + p)) ** p) * ((n / (n + p)) ** n)
)
return -np.minimum(piH, 1 - 2 * theta)
# Epistemic uncertainty scores for logistic regression.
def _epistemic_uncertainty_logreg(X_cand, X, y, clf, sample_weight=None):
"""
Calculates the epistemic uncertainty score for logistic regression [1].
Only for two class problems.
Parameters
----------
X_cand : np.ndarray
The unlabeled pool from which to choose.
X : np.ndarray
The labeled pool used to fit the classifier.
y : np.array
The labels of the labeled pool X.
clf : skactiveml.classifier.SklearnClassifier
Only a wrapped logistic regression is supported as classifier.
sample_weight : array-like of shape (n_samples,) (default=None)
Sample weights for X, only used if clf is a logistic regression
classifier.
Returns
-------
utilities : np.ndarray of shape (n_samples_cand,)
The calculated epistemic uncertainty scores.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
if not isinstance(clf, SklearnClassifier) or not isinstance(
clf.estimator, LogisticRegression
):
raise TypeError(
"clf has to be a wrapped LogisticRegression "
"classifier but \n{}\n was given.".format(clf)
)
if len(clf.classes) != 2:
raise ValueError(
"epistemic is only implemented for two-class "
"problems, {} classes were given."
"".format(len(clf.classes))
)
# Get the probability predictions.
probas = clf.predict_proba(X_cand)
# Get the regularization parameter from the clf.
gamma = 1 / clf.C
# Get weights from the classifier.
if clf.is_fitted_:
w_ml = np.append(clf.coef_, clf.intercept_).flatten()
else:
warnings.warn(
"The given classifier is not fitted or was fitted with "
"zero labels. Epistemic uncertainty sampling will fall "
"back to random sampling."
)
w_ml = np.zeros(X.shape[1] + 1)
# Calculate the maximum likelihood of the logistic function.
L_ml = np.exp(
-_loglike_logreg(
w=w_ml, X=X, y=y, gamma=gamma, sample_weight=sample_weight
)
)
# Set the initial guess for minimize function.
x0 = np.zeros((X_cand.shape[1] + 1))
# Set initial epistemic scores.
pi1 = np.maximum(2 * probas[:, 0] - 1, 0)
pi0 = np.maximum(1 - 2 * probas[:, 0], 0)
# Compute pi0, pi1 for every x in candidates.
for i, x in enumerate(X_cand):
Qn = np.linspace(0.01, 0.5, num=50, endpoint=True)
Qp = np.linspace(0.5, 1.0, num=50, endpoint=False)
A = np.append(x, 1) # Used for the LinearConstraint
for q in range(50):
alpha_n, alpha_p = Qn[0], Qp[-1]
if 2 * alpha_p - 1 > pi1[i]:
# Compute theta for alpha_p and x.
theta_p = _theta(
func=_loglike_logreg,
alpha=alpha_p,
x0=x0,
A=A,
args=(X, y, sample_weight, gamma),
)
# Compute the degrees of support for theta_p.
pi1[i] = np.maximum(
pi1[i],
np.minimum(
_pi_h(
theta=theta_p,
L_ml=L_ml,
X=X,
y=y,
sample_weight=sample_weight,
gamma=gamma,
),
2 * alpha_p - 1,
),
)
if 1 - 2 * alpha_n > pi0[i]:
# Compute theta for alpha_n and x.
theta_n = _theta(
func=_loglike_logreg,
alpha=alpha_n,
x0=x0,
A=A,
args=(X, y, sample_weight, gamma),
)
# Compute the degrees of support for theta_n.
pi0[i] = np.maximum(
pi0[i],
np.minimum(
_pi_h(
theta=theta_n,
L_ml=L_ml,
X=X,
y=y,
sample_weight=sample_weight,
gamma=gamma,
),
1 - 2 * alpha_p,
),
)
Qn, Qp = np.delete(Qn, 0), np.delete(Qp, -1)
utilities = np.min(np.array([pi0, pi1]), axis=0)
return utilities
def _pi_h(theta, L_ml, X, y, sample_weight=None, gamma=1):
"""
Computes np.exp(-_loglike_logreg())/L_ml, the normalized likelihood.
Parameters
----------
theta : np.ndarray of shape (n_features + 1,)
Coefficient vector.
L_ml : float
The maximum likelihood estimation on the training data.
Use np.exp(-_loglike_logreg) to compute.
X : np.ndarray
The labeled pool used to fit the classifier.
y : np.array
The labels of the labeled pool X.
sample_weight : np.ndarray of shape (n_samples,) (default=None)
Sample weights for X, only used if clf is a logistic regression
classifier.
gamma : float
The regularization parameter.
Returns
-------
pi_h : float
The normalized likelihood.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
check_scalar(L_ml, name="L_ml", target_type=(float, int))
L_theta = np.exp(
-_loglike_logreg(
w=theta, X=X, y=y, sample_weight=sample_weight, gamma=gamma
)
)
return L_theta / L_ml
def _loglike_logreg(w, X, y, sample_weight=None, gamma=1):
"""Computes the logistic loss.
Parameters
----------
w : np.ndarray of shape (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : np.ndarray of shape (n_samples,)
The labels of the training data X.
gamma : float
Regularization parameter. gamma is equal to 1 / C.
sample_weight : array-like of shape (n_samples,) default=None
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
Returns
-------
out : float
Logistic loss, the negative of the log of the logistic function.
"""
if len(y) == 0:
return np.log(2) * len(X)
return _logistic_loss(
w=w, X=X, y=y, alpha=gamma, sample_weight=sample_weight
)
def _theta(func, alpha, x0, A, args=()):
"""
This function calculates the parameter vector as it is shown in equation 22
in [1].
Parameters
----------
func : callable
The function to be optimized.
alpha : float
ln(alpha/(1-alpha)) will used as bound for the constraint.
x0 : np.ndarray of shape (n,)
Initial guess. Array of real elements of size (n,), where ‘n’ is the
number of independent variables.
A : np.ndarray
Matrix defining the constraint.
args : tuple
Will be pass to func.
Returns
-------
x : np.ndarray
The optimized parameter vector.
References
---------
[1] Nguyen, Vu-Linh, Sébastien Destercke, and Eyke Hüllermeier.
"Epistemic uncertainty sampling." International Conference on
Discovery Science. Springer, Cham, 2019.
"""
bounds = np.log(alpha / (1 - alpha))
constraints = LinearConstraint(A=A, lb=bounds, ub=bounds)
res = minimize(
func, x0=x0, method="SLSQP", constraints=constraints, args=args
)
return res.x
def _logistic_loss(w, X, y, alpha, sample_weight=None):
"""Computes the logistic loss. This function is a copy taken from
https://github.com/scikit-learn/scikit-learn/blob/1.0.X/sklearn/
linear_model/_logistic.py.
Parameters
----------
w : ndarray of shape (n_features,) or (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : ndarray of shape (n_samples,)
Array of labels.
alpha : float
Regularization parameter. alpha is equal to 1 / C.
sample_weight : array-like of shape (n_samples,) default=None
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
Returns
-------
out : float
Logistic loss.
References
----------
[1] Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B,
Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J.
"Scikit-learn: Machine learning in Python." Journal of Machine
Learning Research. 2011.
"""
w, c, yz = _intercept_dot(w, X, y)
if sample_weight is None:
sample_weight = np.ones(y.shape[0])
# Logistic loss is the negative of the log of the logistic function.
out = -np.sum(sample_weight * log_logistic(yz))
out += 0.5 * alpha * np.dot(w, w)
return out
def _intercept_dot(w, X, y):
"""Computes y * np.dot(X, w). It takes into consideration if the intercept
should be fit or not. This function is a copy taken from
https://github.com/scikit-learn/scikit-learn/blob/1.0.X/sklearn/
linear_model/_logistic.py.
Parameters
----------
w : ndarray of shape (n_features,) or (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : ndarray of shape (n_samples,)
Array of labels.
Returns
-------
w : ndarray of shape (n_features,)
Coefficient vector without the intercept weight (w[-1]) if the
intercept should be fit. Unchanged otherwise.
c : float
The intercept.
yz : float
y * np.dot(X, w).
References
----------
[1] Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B,
Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J.
"Scikit-learn: Machine learning in Python." Journal of Machine
Learning Research. 2011.
"""
c = 0.0
if w.size == X.shape[1] + 1:
c = w[-1]
w = w[:-1]
z = safe_sparse_dot(X, w) + c
yz = y * z
return w, c, yz | 0.892217 | 0.511839 |
import numpy as np
from sklearn.base import clone
from ..base import SingleAnnotatorPoolQueryStrategy
from ..classifier import MixtureModelClassifier
from ..utils import (
rand_argmax,
is_labeled,
check_type,
MISSING_LABEL,
check_equal_missing_label,
check_scalar,
)
class FourDs(SingleAnnotatorPoolQueryStrategy):
"""FourDs
Implementation of the pool-based query strategy 4DS for training a
MixtureModelClassifier [1].
Parameters
----------
lmbda : float between 0 and 1, optional
(default=min((batch_size-1)*0.05, 0.5))
For the selection of more than one sample within each query round, 4DS
uses a diversity measure to avoid the selection of redundant samples
whose influence is regulated by the weighting factor 'lmbda'.
missing_label : scalar or string or np.nan or None, optional
(default=MISSING_LABEL)
Value to represent a missing label.
random_state : int or np.random.RandomState, optional (default=None)
The random state to use.
References
---------
[1] Reitmaier, T., & Sick, B. (2013). Let us know your decision: Pool-based
active training of a generative classifier with the selection strategy
4DS. Information Sciences, 230, 106-131.
"""
def __init__(
self, lmbda=None, missing_label=MISSING_LABEL, random_state=None
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.lmbda = lmbda
def query(
self,
X,
y,
clf,
fit_clf=True,
sample_weight=None,
candidates=None,
return_utilities=False,
batch_size=1,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X: array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y: array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
clf : skactiveml.classifier.MixtureModelClassifier
GMM-based classifier to be trained.
fit_clf : bool, optional (default=True)
Defines whether the classifier should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If True, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Check standard parameters.
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X=X,
y=y,
candidates=candidates,
batch_size=batch_size,
return_utilities=return_utilities,
reset=True,
)
# Check classifier type.
check_type(clf, "clf", MixtureModelClassifier)
check_type(fit_clf, "fit_clf", bool)
check_equal_missing_label(clf.missing_label, self.missing_label_)
# Check lmbda.
lmbda = self.lmbda
if lmbda is None:
lmbda = np.min(((batch_size - 1) * 0.05, 0.5))
check_scalar(
lmbda, target_type=(float, int), name="lmbda", min_val=0, max_val=1
)
# Obtain candidates plus mapping.
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Storage for query indices.
query_indices_cand = np.full(batch_size, fill_value=-1, dtype=int)
# Fit the classifier and get the probabilities.
if fit_clf:
clf = clone(clf).fit(X, y, sample_weight)
P_cand = clf.predict_proba(X_cand)
R_cand = clf.mixture_model_.predict_proba(X_cand)
is_lbld = is_labeled(y, missing_label=clf.missing_label)
if np.sum(is_lbld) >= 1:
R_lbld = clf.mixture_model_.predict_proba(X[is_lbld])
else:
R_lbld = np.array([0])
# Compute distance according to Eq. 9 in [1].
P_cand_sorted = np.sort(P_cand, axis=1)
distance_cand = np.log(
(P_cand_sorted[:, -1] + 1.0e-5) / (P_cand_sorted[:, -2] + 1.0e-5)
)
distance_cand = (distance_cand - np.min(distance_cand) + 1.0e-5) / (
np.max(distance_cand) - np.min(distance_cand) + 1.0e-5
)
# Compute densities according to Eq. 10 in [1].
density_cand = clf.mixture_model_.score_samples(X_cand)
density_cand = (density_cand - np.min(density_cand) + 1.0e-5) / (
np.max(density_cand) - np.min(density_cand) + 1.0e-5
)
# Compute distributions according to Eq. 11 in [1].
R_lbld_sum = np.sum(R_lbld, axis=0, keepdims=True)
R_sum = R_cand + R_lbld_sum
R_mean = R_sum / (len(R_lbld) + 1)
distribution_cand = clf.mixture_model_.weights_ - R_mean
distribution_cand = np.maximum(
np.zeros_like(distribution_cand), distribution_cand
)
distribution_cand = 1 - np.sum(distribution_cand, axis=1)
# Compute rho according to Eq. 15 in [1].
diff = np.sum(
np.abs(clf.mixture_model_.weights_ - np.mean(R_lbld, axis=0))
)
rho = min(1, diff)
# Compute e_dwus according to Eq. 13 in [1].
e_dwus = np.mean((1 - P_cand_sorted[:, -1]) * density_cand)
# Normalization such that alpha, beta, and rho sum up to one.
alpha = (1 - rho) * e_dwus
beta = 1 - rho - alpha
# Compute utilities to select sample.
utilities_cand = np.empty((batch_size, len(X_cand)), dtype=float)
utilities_cand[0] = (
alpha * (1 - distance_cand)
+ beta * density_cand
+ rho * distribution_cand
)
query_indices_cand[0] = rand_argmax(
utilities_cand[0], self.random_state_
)
is_selected = np.zeros(len(X_cand), dtype=bool)
is_selected[query_indices_cand[0]] = True
if batch_size > 1:
# Compute e_us according to Eq. 14 in [1].
e_us = np.mean(1 - P_cand_sorted[:, -1])
# Normalization of the coefficients alpha, beta, and rho such
# that these coefficients plus
# lmbda sum up to one.
rho = min(rho, 1 - lmbda)
alpha = (1 - (rho + lmbda)) * (1 - e_us)
beta = 1 - (rho + lmbda) - alpha
for i in range(1, batch_size):
# Update distributions according to Eq. 11 in [1].
R_sum = (
R_cand
+ np.sum(R_cand[is_selected], axis=0, keepdims=True)
+ R_lbld_sum
)
R_mean = R_sum / (len(R_lbld) + len(query_indices_cand) + 1)
distribution_cand = clf.mixture_model_.weights_ - R_mean
distribution_cand = np.maximum(
np.zeros_like(distribution_cand), distribution_cand
)
distribution_cand = 1 - np.sum(distribution_cand, axis=1)
# Compute diversity according to Eq. 12 in [1].
diversity_cand = -np.log(
density_cand + np.sum(density_cand[is_selected])
) / (len(query_indices_cand) + 1)
diversity_cand = (diversity_cand - np.min(diversity_cand)) / (
np.max(diversity_cand) - np.min(diversity_cand)
)
# Compute utilities to select sample.
utilities_cand[i] = (
alpha * (1 - distance_cand)
+ beta * density_cand
+ lmbda * diversity_cand
+ rho * distribution_cand
)
utilities_cand[i, is_selected] = np.nan
query_indices_cand[i] = rand_argmax(
utilities_cand[i], self.random_state_
)
is_selected[query_indices_cand[i]] = True
# Remapping of utilities and query indices if required.
if mapping is None:
utilities = utilities_cand
query_indices = query_indices_cand
if mapping is not None:
utilities = np.full((batch_size, len(X)), np.nan)
utilities[:, mapping] = utilities_cand
query_indices = mapping[query_indices_cand]
# Check whether utilities are to be returned.
if return_utilities:
return query_indices, utilities
else:
return query_indices | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_four_ds.py | _four_ds.py |
import numpy as np
from sklearn.base import clone
from ..base import SingleAnnotatorPoolQueryStrategy
from ..classifier import MixtureModelClassifier
from ..utils import (
rand_argmax,
is_labeled,
check_type,
MISSING_LABEL,
check_equal_missing_label,
check_scalar,
)
class FourDs(SingleAnnotatorPoolQueryStrategy):
"""FourDs
Implementation of the pool-based query strategy 4DS for training a
MixtureModelClassifier [1].
Parameters
----------
lmbda : float between 0 and 1, optional
(default=min((batch_size-1)*0.05, 0.5))
For the selection of more than one sample within each query round, 4DS
uses a diversity measure to avoid the selection of redundant samples
whose influence is regulated by the weighting factor 'lmbda'.
missing_label : scalar or string or np.nan or None, optional
(default=MISSING_LABEL)
Value to represent a missing label.
random_state : int or np.random.RandomState, optional (default=None)
The random state to use.
References
---------
[1] Reitmaier, T., & Sick, B. (2013). Let us know your decision: Pool-based
active training of a generative classifier with the selection strategy
4DS. Information Sciences, 230, 106-131.
"""
def __init__(
self, lmbda=None, missing_label=MISSING_LABEL, random_state=None
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.lmbda = lmbda
def query(
self,
X,
y,
clf,
fit_clf=True,
sample_weight=None,
candidates=None,
return_utilities=False,
batch_size=1,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X: array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y: array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
clf : skactiveml.classifier.MixtureModelClassifier
GMM-based classifier to be trained.
fit_clf : bool, optional (default=True)
Defines whether the classifier should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If True, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Check standard parameters.
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X=X,
y=y,
candidates=candidates,
batch_size=batch_size,
return_utilities=return_utilities,
reset=True,
)
# Check classifier type.
check_type(clf, "clf", MixtureModelClassifier)
check_type(fit_clf, "fit_clf", bool)
check_equal_missing_label(clf.missing_label, self.missing_label_)
# Check lmbda.
lmbda = self.lmbda
if lmbda is None:
lmbda = np.min(((batch_size - 1) * 0.05, 0.5))
check_scalar(
lmbda, target_type=(float, int), name="lmbda", min_val=0, max_val=1
)
# Obtain candidates plus mapping.
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Storage for query indices.
query_indices_cand = np.full(batch_size, fill_value=-1, dtype=int)
# Fit the classifier and get the probabilities.
if fit_clf:
clf = clone(clf).fit(X, y, sample_weight)
P_cand = clf.predict_proba(X_cand)
R_cand = clf.mixture_model_.predict_proba(X_cand)
is_lbld = is_labeled(y, missing_label=clf.missing_label)
if np.sum(is_lbld) >= 1:
R_lbld = clf.mixture_model_.predict_proba(X[is_lbld])
else:
R_lbld = np.array([0])
# Compute distance according to Eq. 9 in [1].
P_cand_sorted = np.sort(P_cand, axis=1)
distance_cand = np.log(
(P_cand_sorted[:, -1] + 1.0e-5) / (P_cand_sorted[:, -2] + 1.0e-5)
)
distance_cand = (distance_cand - np.min(distance_cand) + 1.0e-5) / (
np.max(distance_cand) - np.min(distance_cand) + 1.0e-5
)
# Compute densities according to Eq. 10 in [1].
density_cand = clf.mixture_model_.score_samples(X_cand)
density_cand = (density_cand - np.min(density_cand) + 1.0e-5) / (
np.max(density_cand) - np.min(density_cand) + 1.0e-5
)
# Compute distributions according to Eq. 11 in [1].
R_lbld_sum = np.sum(R_lbld, axis=0, keepdims=True)
R_sum = R_cand + R_lbld_sum
R_mean = R_sum / (len(R_lbld) + 1)
distribution_cand = clf.mixture_model_.weights_ - R_mean
distribution_cand = np.maximum(
np.zeros_like(distribution_cand), distribution_cand
)
distribution_cand = 1 - np.sum(distribution_cand, axis=1)
# Compute rho according to Eq. 15 in [1].
diff = np.sum(
np.abs(clf.mixture_model_.weights_ - np.mean(R_lbld, axis=0))
)
rho = min(1, diff)
# Compute e_dwus according to Eq. 13 in [1].
e_dwus = np.mean((1 - P_cand_sorted[:, -1]) * density_cand)
# Normalization such that alpha, beta, and rho sum up to one.
alpha = (1 - rho) * e_dwus
beta = 1 - rho - alpha
# Compute utilities to select sample.
utilities_cand = np.empty((batch_size, len(X_cand)), dtype=float)
utilities_cand[0] = (
alpha * (1 - distance_cand)
+ beta * density_cand
+ rho * distribution_cand
)
query_indices_cand[0] = rand_argmax(
utilities_cand[0], self.random_state_
)
is_selected = np.zeros(len(X_cand), dtype=bool)
is_selected[query_indices_cand[0]] = True
if batch_size > 1:
# Compute e_us according to Eq. 14 in [1].
e_us = np.mean(1 - P_cand_sorted[:, -1])
# Normalization of the coefficients alpha, beta, and rho such
# that these coefficients plus
# lmbda sum up to one.
rho = min(rho, 1 - lmbda)
alpha = (1 - (rho + lmbda)) * (1 - e_us)
beta = 1 - (rho + lmbda) - alpha
for i in range(1, batch_size):
# Update distributions according to Eq. 11 in [1].
R_sum = (
R_cand
+ np.sum(R_cand[is_selected], axis=0, keepdims=True)
+ R_lbld_sum
)
R_mean = R_sum / (len(R_lbld) + len(query_indices_cand) + 1)
distribution_cand = clf.mixture_model_.weights_ - R_mean
distribution_cand = np.maximum(
np.zeros_like(distribution_cand), distribution_cand
)
distribution_cand = 1 - np.sum(distribution_cand, axis=1)
# Compute diversity according to Eq. 12 in [1].
diversity_cand = -np.log(
density_cand + np.sum(density_cand[is_selected])
) / (len(query_indices_cand) + 1)
diversity_cand = (diversity_cand - np.min(diversity_cand)) / (
np.max(diversity_cand) - np.min(diversity_cand)
)
# Compute utilities to select sample.
utilities_cand[i] = (
alpha * (1 - distance_cand)
+ beta * density_cand
+ lmbda * diversity_cand
+ rho * distribution_cand
)
utilities_cand[i, is_selected] = np.nan
query_indices_cand[i] = rand_argmax(
utilities_cand[i], self.random_state_
)
is_selected[query_indices_cand[i]] = True
# Remapping of utilities and query indices if required.
if mapping is None:
utilities = utilities_cand
query_indices = query_indices_cand
if mapping is not None:
utilities = np.full((batch_size, len(X)), np.nan)
utilities[:, mapping] = utilities_cand
query_indices = mapping[query_indices_cand]
# Check whether utilities are to be returned.
if return_utilities:
return query_indices, utilities
else:
return query_indices | 0.914823 | 0.534005 |
import numpy as np
from sklearn import clone
from sklearn.metrics import pairwise_distances, pairwise
from skactiveml.base import (
SingleAnnotatorPoolQueryStrategy,
SkactivemlRegressor,
)
from skactiveml.utils import (
rand_argmax,
labeled_indices,
MISSING_LABEL,
is_labeled,
check_type,
check_scalar,
)
class GreedySamplingX(SingleAnnotatorPoolQueryStrategy):
"""Greedy Sampling on the feature space.
This class implements greedy sampling on the feature space. A query strategy
that tries to select those samples that increase the diversity of the
feature space the most.
Parameters
----------
metric : str, optional (default="euclidean")
Metric used for calculating the distances of the samples in the feature
space. It must be a valid argument for
`sklearn.metrics.pairwise_distances` argument `metric`.
metric_dict : dict, optional (default=None)
Any further parameters are passed directly to the pairwise_distances
function.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional
Random state for candidate selection.
References
----------
[1] Wu, Dongrui, Chin-Teng Lin, and Jian Huang. Active learning for
regression using greedy sampling, Information Sciences, pages 90--105, 2019.
"""
def __init__(
self,
metric=None,
metric_dict=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.metric = metric
self.metric_dict = metric_dict
def query(
self, X, y, candidates=None, batch_size=1, return_utilities=False
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL).
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
sample_indices = np.arange(len(X), dtype=int)
selected_indices = labeled_indices(y, missing_label=self.missing_label)
if mapping is None:
X_all = np.append(X, X_cand, axis=0)
candidate_indices = len(X) + np.arange(len(X_cand), dtype=int)
else:
X_all = X
candidate_indices = mapping
query_indices_cand, utilities_cand = _greedy_sampling(
X_cand,
X_all,
sample_indices,
selected_indices,
candidate_indices,
batch_size,
random_state=self.random_state_,
method="x",
metric_x=self.metric,
metric_dict_x=self.metric_dict,
)
if mapping is not None:
utilities = np.full((batch_size, len(X)), np.nan)
utilities[:, mapping] = utilities_cand
query_indices = mapping[query_indices_cand]
else:
utilities, query_indices = utilities_cand, query_indices_cand
if return_utilities:
return query_indices, utilities
else:
return query_indices
class GreedySamplingTarget(SingleAnnotatorPoolQueryStrategy):
"""Greedy Sampling on the target space.
This class implements greedy sampling on the target space. A query strategy
that at first selects samples to maximize the diversity in the
feature space and than selects samples to maximize the diversity in the
feature and the target space (GSi), optionally only the diversity in the
target space can be maximized (GSy).
Parameters
----------
x_metric : str, optional (default=None)
Metric used for calculating the distances of the samples in the feature
space. It must be a valid argument for
`sklearn.metrics.pairwise_distances` argument `metric`.
y_metric : str, optional (default=None)
Metric used for calculating the distances of the samples in the target
space. It must be a valid argument for
`sklearn.metrics.pairwise_distances` argument `metric`.
x_metric_dict : dict, optional (default=None)
Any further parameters for computing the distances of the samples in
the feature space are passed directly to the pairwise_distances
function.
y_metric_dict : dict, optional (default=None)
Any further parameters for computing the distances of the samples in
the target space are passed directly to the pairwise_distances
function.
n_GSx_samples : int, optional (default=1)
Indicates the number of selected samples required till the query
strategy switches from GSx to the strategy specified by `method`.
method : "GSy" or "GSi", optional (default="GSi")
Specifies whether only the diversity in the target space (`GSy`) or the
diversity in the feature and the target space (`GSi`) should be
maximized, when the number of selected samples exceeds `n_GSx_samples`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional
Random state for candidate selection.
References
----------
[1] Wu, Dongrui, Chin-Teng Lin, and Jian Huang. Active learning for
regression using greedy sampling, Information Sciences, pages 90--105, 2019.
"""
def __init__(
self,
x_metric=None,
y_metric=None,
x_metric_dict=None,
y_metric_dict=None,
method=None,
n_GSx_samples=1,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.method = method
self.x_metric = x_metric
self.y_metric = y_metric
self.x_metric_dict = x_metric_dict
self.y_metric_dict = y_metric_dict
self.n_GSx_samples = n_GSx_samples
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg: SkactivemlRegressor
Regressor to predict the data.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", SkactivemlRegressor)
check_type(fit_reg, "fit_reg", bool)
if self.method is None:
self.method = "GSi"
check_type(self.method, "self.method", target_vals=["GSy", "GSi"])
check_scalar(self.n_GSx_samples, "self.k_0", int, min_val=0)
X_cand, mapping = self._transform_candidates(candidates, X, y)
n_labeled = np.sum(is_labeled(y, missing_label=self.missing_label_))
batch_size_x = max(0, min(self.n_GSx_samples - n_labeled, batch_size))
batch_size_y = batch_size - batch_size_x
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
sample_indices = np.arange(len(X), dtype=int)
selected_indices = labeled_indices(y)
y_cand = reg.predict(X_cand)
if mapping is None:
X_all = np.append(X, X_cand, axis=0)
y_all = np.append(y, reg.predict(X_cand))
candidate_indices = len(X) + np.arange(len(X_cand), dtype=int)
else:
X_all = X
y_all = y.copy()
y_all[mapping] = y_cand
candidate_indices = mapping
query_indices = np.zeros(batch_size, dtype=int)
utilities = np.full((batch_size, len(X_cand)), np.nan)
if batch_size_x > 0:
query_indices_x, utilities_x = _greedy_sampling(
X_cand=X_cand,
y_cand=y_cand,
X=X_all,
y=y_all,
sample_indices=sample_indices,
selected_indices=selected_indices,
candidate_indices=candidate_indices,
batch_size=batch_size_x,
random_state=None,
metric_x=self.x_metric,
metric_dict_x=self.x_metric_dict,
method="x",
)
query_indices[0:batch_size_x] = query_indices_x
utilities[0:batch_size_x, :] = utilities_x
else:
query_indices_x = np.array([], dtype=int)
selected_indices = np.append(
selected_indices, candidate_indices[query_indices_x]
)
candidate_indices = np.delete(candidate_indices, query_indices_x)
is_queried = np.full(len(X_cand), False)
is_queried[query_indices_x] = True
unselected_cands = np.argwhere(~is_queried).flatten()
X_cand = np.delete(X_cand, query_indices_x, axis=0)
y_cand = np.delete(y_cand, query_indices_x)
if batch_size_y > 0:
query_indices_y, utilities_y = _greedy_sampling(
X_cand=X_cand,
y_cand=y_cand,
X=X_all,
y=y_all,
sample_indices=sample_indices,
selected_indices=selected_indices,
candidate_indices=candidate_indices,
batch_size=batch_size_y,
random_state=None,
metric_x=self.x_metric,
metric_dict_x=self.x_metric_dict,
metric_y=self.y_metric,
metric_dict_y=self.y_metric_dict,
method="xy" if self.method == "GSi" else "y",
)
query_indices[batch_size_x:] = unselected_cands[query_indices_y]
utilities[batch_size_x:][:, unselected_cands] = utilities_y
if mapping is not None:
utilities_cand, query_indices_cand = utilities, query_indices
utilities = np.full((batch_size, len(X)), np.nan)
utilities[:, mapping] = utilities_cand
query_indices = mapping[query_indices_cand]
if return_utilities:
return query_indices, utilities
else:
return query_indices
def _greedy_sampling(
X_cand,
X,
sample_indices,
selected_indices,
candidate_indices,
batch_size,
y_cand=None,
y=None,
random_state=None,
method=None,
**kwargs,
):
dist_dict = dict(
X_cand=X_cand, y_cand=y_cand, X=X, y=y, method=method, **kwargs
)
query_indices = np.zeros(batch_size, dtype=int)
utilities = np.full((batch_size, len(X_cand)), np.nan)
distances = np.full((len(X_cand), len(X)), np.nan)
if len(selected_indices) == 0:
distances[:, sample_indices] = _measure_distance(
sample_indices, **dist_dict
)
else:
distances[:, selected_indices] = _measure_distance(
selected_indices, **dist_dict
)
not_selected_candidates = np.arange(len(X_cand), dtype=int)
for i in range(batch_size):
if len(selected_indices) == 0:
dist = distances[not_selected_candidates][:, sample_indices]
util = -np.sum(dist, axis=1)
else:
dist = distances[not_selected_candidates][:, selected_indices]
util = np.min(dist, axis=1)
utilities[i, not_selected_candidates] = util
idx = rand_argmax(util, random_state=random_state)
query_indices[i] = not_selected_candidates[idx]
distances[:, candidate_indices[idx]] = _measure_distance(
candidate_indices[idx], **dist_dict
)
selected_indices = np.append(
selected_indices, candidate_indices[idx], axis=0
)
candidate_indices = np.delete(candidate_indices, idx, axis=0)
not_selected_candidates = np.delete(not_selected_candidates, idx)
return query_indices, utilities
def _measure_distance(
indices,
X_cand,
y_cand,
X,
y,
metric_dict_x=None,
metric_x=None,
metric_dict_y=None,
metric_y=None,
method=None,
):
metric_x = metric_x if metric_x is not None else "euclidean"
metric_y = metric_y if metric_y is not None else "euclidean"
for metric, name in zip([metric_x, metric_y], ["metric_x", "metric_y"]):
check_type(
metric,
name,
target_vals=pairwise.PAIRWISE_DISTANCE_FUNCTIONS.keys(),
)
metric_dict_x = metric_dict_x if metric_dict_x is not None else {}
metric_dict_y = metric_dict_y if metric_dict_y is not None else {}
for metric_dict, name in zip(
[metric_dict_x, metric_dict_y], ["metric_dict_x", "metric_dict_y"]
):
check_type(metric_dict, name, dict)
dist = np.ones((len(X_cand), len(indices)))
if "x" in method:
dist *= pairwise_distances(
X_cand, X[indices], metric=metric_x, **metric_dict_x
)
if "y" in method:
dist *= pairwise_distances(
y_cand.reshape(-1, 1),
y[indices].reshape(-1, 1),
metric=metric_y,
**metric_dict_y,
)
return dist | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_greedy_sampling.py | _greedy_sampling.py | import numpy as np
from sklearn import clone
from sklearn.metrics import pairwise_distances, pairwise
from skactiveml.base import (
SingleAnnotatorPoolQueryStrategy,
SkactivemlRegressor,
)
from skactiveml.utils import (
rand_argmax,
labeled_indices,
MISSING_LABEL,
is_labeled,
check_type,
check_scalar,
)
class GreedySamplingX(SingleAnnotatorPoolQueryStrategy):
"""Greedy Sampling on the feature space.
This class implements greedy sampling on the feature space. A query strategy
that tries to select those samples that increase the diversity of the
feature space the most.
Parameters
----------
metric : str, optional (default="euclidean")
Metric used for calculating the distances of the samples in the feature
space. It must be a valid argument for
`sklearn.metrics.pairwise_distances` argument `metric`.
metric_dict : dict, optional (default=None)
Any further parameters are passed directly to the pairwise_distances
function.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional
Random state for candidate selection.
References
----------
[1] Wu, Dongrui, Chin-Teng Lin, and Jian Huang. Active learning for
regression using greedy sampling, Information Sciences, pages 90--105, 2019.
"""
def __init__(
self,
metric=None,
metric_dict=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.metric = metric
self.metric_dict = metric_dict
def query(
self, X, y, candidates=None, batch_size=1, return_utilities=False
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL).
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
sample_indices = np.arange(len(X), dtype=int)
selected_indices = labeled_indices(y, missing_label=self.missing_label)
if mapping is None:
X_all = np.append(X, X_cand, axis=0)
candidate_indices = len(X) + np.arange(len(X_cand), dtype=int)
else:
X_all = X
candidate_indices = mapping
query_indices_cand, utilities_cand = _greedy_sampling(
X_cand,
X_all,
sample_indices,
selected_indices,
candidate_indices,
batch_size,
random_state=self.random_state_,
method="x",
metric_x=self.metric,
metric_dict_x=self.metric_dict,
)
if mapping is not None:
utilities = np.full((batch_size, len(X)), np.nan)
utilities[:, mapping] = utilities_cand
query_indices = mapping[query_indices_cand]
else:
utilities, query_indices = utilities_cand, query_indices_cand
if return_utilities:
return query_indices, utilities
else:
return query_indices
class GreedySamplingTarget(SingleAnnotatorPoolQueryStrategy):
"""Greedy Sampling on the target space.
This class implements greedy sampling on the target space. A query strategy
that at first selects samples to maximize the diversity in the
feature space and than selects samples to maximize the diversity in the
feature and the target space (GSi), optionally only the diversity in the
target space can be maximized (GSy).
Parameters
----------
x_metric : str, optional (default=None)
Metric used for calculating the distances of the samples in the feature
space. It must be a valid argument for
`sklearn.metrics.pairwise_distances` argument `metric`.
y_metric : str, optional (default=None)
Metric used for calculating the distances of the samples in the target
space. It must be a valid argument for
`sklearn.metrics.pairwise_distances` argument `metric`.
x_metric_dict : dict, optional (default=None)
Any further parameters for computing the distances of the samples in
the feature space are passed directly to the pairwise_distances
function.
y_metric_dict : dict, optional (default=None)
Any further parameters for computing the distances of the samples in
the target space are passed directly to the pairwise_distances
function.
n_GSx_samples : int, optional (default=1)
Indicates the number of selected samples required till the query
strategy switches from GSx to the strategy specified by `method`.
method : "GSy" or "GSi", optional (default="GSi")
Specifies whether only the diversity in the target space (`GSy`) or the
diversity in the feature and the target space (`GSi`) should be
maximized, when the number of selected samples exceeds `n_GSx_samples`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional
Random state for candidate selection.
References
----------
[1] Wu, Dongrui, Chin-Teng Lin, and Jian Huang. Active learning for
regression using greedy sampling, Information Sciences, pages 90--105, 2019.
"""
def __init__(
self,
x_metric=None,
y_metric=None,
x_metric_dict=None,
y_metric_dict=None,
method=None,
n_GSx_samples=1,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.method = method
self.x_metric = x_metric
self.y_metric = y_metric
self.x_metric_dict = x_metric_dict
self.y_metric_dict = y_metric_dict
self.n_GSx_samples = n_GSx_samples
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg: SkactivemlRegressor
Regressor to predict the data.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", SkactivemlRegressor)
check_type(fit_reg, "fit_reg", bool)
if self.method is None:
self.method = "GSi"
check_type(self.method, "self.method", target_vals=["GSy", "GSi"])
check_scalar(self.n_GSx_samples, "self.k_0", int, min_val=0)
X_cand, mapping = self._transform_candidates(candidates, X, y)
n_labeled = np.sum(is_labeled(y, missing_label=self.missing_label_))
batch_size_x = max(0, min(self.n_GSx_samples - n_labeled, batch_size))
batch_size_y = batch_size - batch_size_x
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
sample_indices = np.arange(len(X), dtype=int)
selected_indices = labeled_indices(y)
y_cand = reg.predict(X_cand)
if mapping is None:
X_all = np.append(X, X_cand, axis=0)
y_all = np.append(y, reg.predict(X_cand))
candidate_indices = len(X) + np.arange(len(X_cand), dtype=int)
else:
X_all = X
y_all = y.copy()
y_all[mapping] = y_cand
candidate_indices = mapping
query_indices = np.zeros(batch_size, dtype=int)
utilities = np.full((batch_size, len(X_cand)), np.nan)
if batch_size_x > 0:
query_indices_x, utilities_x = _greedy_sampling(
X_cand=X_cand,
y_cand=y_cand,
X=X_all,
y=y_all,
sample_indices=sample_indices,
selected_indices=selected_indices,
candidate_indices=candidate_indices,
batch_size=batch_size_x,
random_state=None,
metric_x=self.x_metric,
metric_dict_x=self.x_metric_dict,
method="x",
)
query_indices[0:batch_size_x] = query_indices_x
utilities[0:batch_size_x, :] = utilities_x
else:
query_indices_x = np.array([], dtype=int)
selected_indices = np.append(
selected_indices, candidate_indices[query_indices_x]
)
candidate_indices = np.delete(candidate_indices, query_indices_x)
is_queried = np.full(len(X_cand), False)
is_queried[query_indices_x] = True
unselected_cands = np.argwhere(~is_queried).flatten()
X_cand = np.delete(X_cand, query_indices_x, axis=0)
y_cand = np.delete(y_cand, query_indices_x)
if batch_size_y > 0:
query_indices_y, utilities_y = _greedy_sampling(
X_cand=X_cand,
y_cand=y_cand,
X=X_all,
y=y_all,
sample_indices=sample_indices,
selected_indices=selected_indices,
candidate_indices=candidate_indices,
batch_size=batch_size_y,
random_state=None,
metric_x=self.x_metric,
metric_dict_x=self.x_metric_dict,
metric_y=self.y_metric,
metric_dict_y=self.y_metric_dict,
method="xy" if self.method == "GSi" else "y",
)
query_indices[batch_size_x:] = unselected_cands[query_indices_y]
utilities[batch_size_x:][:, unselected_cands] = utilities_y
if mapping is not None:
utilities_cand, query_indices_cand = utilities, query_indices
utilities = np.full((batch_size, len(X)), np.nan)
utilities[:, mapping] = utilities_cand
query_indices = mapping[query_indices_cand]
if return_utilities:
return query_indices, utilities
else:
return query_indices
def _greedy_sampling(
X_cand,
X,
sample_indices,
selected_indices,
candidate_indices,
batch_size,
y_cand=None,
y=None,
random_state=None,
method=None,
**kwargs,
):
dist_dict = dict(
X_cand=X_cand, y_cand=y_cand, X=X, y=y, method=method, **kwargs
)
query_indices = np.zeros(batch_size, dtype=int)
utilities = np.full((batch_size, len(X_cand)), np.nan)
distances = np.full((len(X_cand), len(X)), np.nan)
if len(selected_indices) == 0:
distances[:, sample_indices] = _measure_distance(
sample_indices, **dist_dict
)
else:
distances[:, selected_indices] = _measure_distance(
selected_indices, **dist_dict
)
not_selected_candidates = np.arange(len(X_cand), dtype=int)
for i in range(batch_size):
if len(selected_indices) == 0:
dist = distances[not_selected_candidates][:, sample_indices]
util = -np.sum(dist, axis=1)
else:
dist = distances[not_selected_candidates][:, selected_indices]
util = np.min(dist, axis=1)
utilities[i, not_selected_candidates] = util
idx = rand_argmax(util, random_state=random_state)
query_indices[i] = not_selected_candidates[idx]
distances[:, candidate_indices[idx]] = _measure_distance(
candidate_indices[idx], **dist_dict
)
selected_indices = np.append(
selected_indices, candidate_indices[idx], axis=0
)
candidate_indices = np.delete(candidate_indices, idx, axis=0)
not_selected_candidates = np.delete(not_selected_candidates, idx)
return query_indices, utilities
def _measure_distance(
indices,
X_cand,
y_cand,
X,
y,
metric_dict_x=None,
metric_x=None,
metric_dict_y=None,
metric_y=None,
method=None,
):
metric_x = metric_x if metric_x is not None else "euclidean"
metric_y = metric_y if metric_y is not None else "euclidean"
for metric, name in zip([metric_x, metric_y], ["metric_x", "metric_y"]):
check_type(
metric,
name,
target_vals=pairwise.PAIRWISE_DISTANCE_FUNCTIONS.keys(),
)
metric_dict_x = metric_dict_x if metric_dict_x is not None else {}
metric_dict_y = metric_dict_y if metric_dict_y is not None else {}
for metric_dict, name in zip(
[metric_dict_x, metric_dict_y], ["metric_dict_x", "metric_dict_y"]
):
check_type(metric_dict, name, dict)
dist = np.ones((len(X_cand), len(indices)))
if "x" in method:
dist *= pairwise_distances(
X_cand, X[indices], metric=metric_x, **metric_dict_x
)
if "y" in method:
dist *= pairwise_distances(
y_cand.reshape(-1, 1),
y[indices].reshape(-1, 1),
metric=metric_y,
**metric_dict_y,
)
return dist | 0.932645 | 0.633566 |
import numpy as np
from sklearn.utils import check_array
from ..base import SkactivemlClassifier
from ..pool._query_by_committee import _check_ensemble, QueryByCommittee
from ..utils import (
rand_argmax,
MISSING_LABEL,
check_type,
check_scalar,
check_random_state,
)
class BatchBALD(QueryByCommittee):
"""Batch Bayesian Active Learning by Disagreement (BatchBALD)
The Bayesian-Active-Learning-by-Disagreement (BatchBALD) [1] strategy
reduces the number of possible hypotheses maximally fast to minimize the
uncertainty about the parameters using Shannon’s entropy. It seeks the data
point that maximises the decrease in expected posterior entropy. For the
batch case, the advanced strategy BatchBALD [2] is applied.
Parameters
----------
n_MC_samples : int > 0, default=n_estimators
The number of monte carlo samples used for label estimation.
missing_label : scalar or string or np.nan or None, default=np.nan
Value to represent a missing label.
random_state : int or np.random.RandomState, default=None
The random state to use.
References
----------
[1] Houlsby, Neil, et al. Bayesian active learning for classification and
preference learning. arXiv preprint arXiv:1112.5745, 2011.
[2] Kirsch, Andreas; Van Amersfoort, Joost; GAL, Yarin.
Batchbald: Efficient and diverse batch acquisition for deep bayesian
active learning. Advances in neural information processing systems,
2019, 32. Jg.
"""
def __init__(
self,
n_MC_samples=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.n_MC_samples = n_MC_samples
def query(
self,
X,
y,
ensemble,
fit_ensemble=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.)
ensemble : list or tuple of SkactivemlClassifier or
SkactivemlClassifier.
If `ensemble` is a `SkactivemlClassifier`, it must have
`n_estimators` and `estimators_` after fitting as
attribute. Then, its estimators will be used as committee. If
`ensemble` is array-like, each element of this list must be
`SkactivemlClassifier` or a `SkactivemlRegressor` and will be used
as committee member.
fit_ensemble : bool, default=True
Defines whether the ensemble should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), default=None
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features), default=None
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
return_utilities : bool, default=False
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Validate input parameters.
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Validate classifier type.
check_type(fit_ensemble, "fit_ensemble", bool)
ensemble, est_arr, _ = _check_ensemble(
ensemble=ensemble,
X=X,
y=y,
sample_weight=sample_weight,
fit_ensemble=fit_ensemble,
missing_label=self.missing_label_,
estimator_types=[SkactivemlClassifier],
)
probas = np.array([est.predict_proba(X_cand) for est in est_arr])
if self.n_MC_samples is None:
n_MC_samples_ = len(est_arr)
else:
n_MC_samples_ = self.n_MC_samples
check_scalar(n_MC_samples_, "n_MC_samples", int, min_val=1)
batch_utilities_cand = batch_bald(
probas, batch_size, n_MC_samples_, self.random_state_
)
if mapping is None:
batch_utilities = batch_utilities_cand
else:
batch_utilities = np.full((batch_size, len(X)), np.nan)
batch_utilities[:, mapping] = batch_utilities_cand
best_indices = rand_argmax(
batch_utilities, axis=1, random_state=self.random_state_
)
if return_utilities:
return best_indices, batch_utilities
else:
return best_indices
def batch_bald(probas, batch_size, n_MC_samples=None, random_state=None):
"""BatchBALD: Efficient and Diverse Batch Acquisition
for Deep Bayesian Active Learning
BatchBALD [1] is an extension of BALD (Bayesian Active Learning by
Disagreement) [2] whereby points are jointly scored by estimating the
mutual information between a joint of multiple data points and the model
parameters.
Parameters
----------
probas : array-like of shape (n_estimators, n_samples, n_classes)
The probability estimates of all estimators, samples, and classes.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
n_MC_samples : int > 0, default=n_estimators
The number of monte carlo samples used for label estimation.
random_state : int or np.random.RandomState, default=None
The random state to use.
Returns
-------
scores: np.ndarray of shape (n_samples)
The BatchBALD-scores.
References
----------
[1] Kirsch, Andreas, Joost Van Amersfoort, and Yarin Gal. "Batchbald:
Efficient and diverse batch acquisition for deep bayesian active
learning." Advances in neural information processing systems 32 (2019).
[2] Houlsby, Neil, et al. "Bayesian active learning for classification and
preference learning." arXiv preprint arXiv:1112.5745 (2011).
"""
# Validate input parameters.
if probas.ndim != 3:
raise ValueError(
f"'probas' should be of shape 3, but {probas.ndim}" f" were given."
)
probs_K_N_C = check_array(probas, ensure_2d=False, allow_nd=True)
check_scalar(batch_size, "batch_size", int, min_val=1)
if n_MC_samples is None:
n_MC_samples = len(probas)
check_scalar(n_MC_samples, "n_MC_samples", int, min_val=1)
random_state = check_random_state(random_state)
probs_N_K_C = probs_K_N_C.swapaxes(0, 1)
log_probs_N_K_C = np.log(probs_N_K_C)
N, K, C = log_probs_N_K_C.shape
batch_size = min(batch_size, N)
conditional_entropies_N = _compute_conditional_entropy(log_probs_N_K_C)
batch_joint_entropy = _DynamicJointEntropy(
n_MC_samples, batch_size - 1, K, C, random_state
)
utilities = np.zeros((batch_size, N))
query_indices = []
for i in range(batch_size):
if i > 0:
latest_index = query_indices[-1]
batch_joint_entropy.add_variables(
log_probs_N_K_C[latest_index : latest_index + 1]
)
shared_conditinal_entropies = conditional_entropies_N[
query_indices
].sum()
utilities[i] = batch_joint_entropy.compute_batch(
log_probs_N_K_C, output_entropies_B=utilities[i]
)
utilities[i] -= conditional_entropies_N + shared_conditinal_entropies
utilities[i, query_indices] = np.nan
query_idx = rand_argmax(utilities[i], random_state=0)[0]
query_indices.append(query_idx)
return utilities
class _ExactJointEntropy:
def __init__(self, joint_probs_M_K):
self.joint_probs_M_K = joint_probs_M_K
@staticmethod
def empty(K):
return _ExactJointEntropy(np.ones((1, K)))
def add_variables(self, log_probs_N_K_C):
N, K, C = log_probs_N_K_C.shape
joint_probs_K_M_1 = self.joint_probs_M_K.T[:, :, None]
probs_N_K_C = np.exp(log_probs_N_K_C)
# Using lots of memory.
for i in range(N):
probs_i__K_1_C = probs_N_K_C[i][:, None, :]
joint_probs_K_M_C = joint_probs_K_M_1 * probs_i__K_1_C
joint_probs_K_M_1 = joint_probs_K_M_C.reshape((K, -1, 1))
self.joint_probs_M_K = joint_probs_K_M_1.squeeze(2).T
return self
def compute_batch(self, log_probs_B_K_C, output_entropies_B=None):
B, K, C = log_probs_B_K_C.shape
M = self.joint_probs_M_K.shape[0]
probs_b_K_C = np.exp(log_probs_B_K_C)
b = probs_b_K_C.shape[0]
probs_b_M_C = np.empty((b, M, C))
for i in range(b):
np.matmul(
self.joint_probs_M_K,
probs_b_K_C[i],
out=probs_b_M_C[i],
)
probs_b_M_C /= K
output_entropies_B = np.sum(
-np.log(probs_b_M_C) * probs_b_M_C, axis=(1, 2)
)
return output_entropies_B
def _batch_multi_choices(probs_b_C, M, random_state):
"""
probs_b_C: Ni... x C
Returns:
choices: Ni... x M
"""
probs_B_C = probs_b_C.reshape((-1, probs_b_C.shape[-1]))
B = probs_B_C.shape[0]
C = probs_B_C.shape[1]
# samples: Ni... x draw_per_xx
choices = [
random_state.choice(C, size=M, p=probs_B_C[b], replace=True)
for b in range(B)
]
choices = np.array(choices, dtype=int)
choices_b_M = choices.reshape(list(probs_b_C.shape[:-1]) + [M])
return choices_b_M
def _gather_expand(data, axis, index):
max_shape = [max(dr, ir) for dr, ir in zip(data.shape, index.shape)]
new_data_shape = list(max_shape)
new_data_shape[axis] = data.shape[axis]
new_index_shape = list(max_shape)
new_index_shape[axis] = index.shape[axis]
data = np.broadcast_to(data, new_data_shape)
index = np.broadcast_to(index, new_index_shape)
return np.take_along_axis(data, index, axis=axis)
class _SampledJointEntropy:
"""Random variables (all with the same # of categories $C$) can be added via `_SampledJointEntropy.add_variables`.
`_SampledJointEntropy.compute` computes the joint entropy.
`_SampledJointEntropy.compute_batch` computes the joint entropy of the added variables with each of the variables in the provided batch probabilities in turn.
"""
def __init__(self, sampled_joint_probs_M_K, random_state):
self.sampled_joint_probs_M_K = sampled_joint_probs_M_K
@staticmethod
def sample(probs_N_K_C, M, random_state):
K = probs_N_K_C.shape[1]
# S: num of samples per w
S = M // K
choices_N_K_S = _batch_multi_choices(probs_N_K_C, S, random_state)
expanded_choices_N_1_K_S = choices_N_K_S[:, None, :, :]
expanded_probs_N_K_1_C = probs_N_K_C[:, :, None, :]
probs_N_K_K_S = _gather_expand(
expanded_probs_N_K_1_C, axis=-1, index=expanded_choices_N_1_K_S
)
# exp sum log seems necessary to avoid 0s?
probs_K_K_S = np.exp(
np.sum(np.log(probs_N_K_K_S), axis=0, keepdims=False)
)
samples_K_M = probs_K_K_S.reshape((K, -1))
samples_M_K = samples_K_M.T
return _SampledJointEntropy(samples_M_K, random_state)
def compute_batch(self, log_probs_B_K_C, output_entropies_B=None):
B, K, C = log_probs_B_K_C.shape
M = self.sampled_joint_probs_M_K.shape[0]
b = log_probs_B_K_C.shape[0]
probs_b_M_C = np.empty(
(b, M, C),
)
for i in range(b):
np.matmul(
self.sampled_joint_probs_M_K,
np.exp(log_probs_B_K_C[i]),
out=probs_b_M_C[i],
)
probs_b_M_C /= K
q_1_M_1 = self.sampled_joint_probs_M_K.mean(axis=1, keepdims=True)[
None
]
output_entropies_B = (
np.sum(-np.log(probs_b_M_C) * probs_b_M_C / q_1_M_1, axis=(1, 2))
/ M
)
return output_entropies_B
class _DynamicJointEntropy:
def __init__(self, M, max_N, K, C, random_state):
self.M = M
self.N = 0
self.max_N = max_N
self.inner = _ExactJointEntropy.empty(K)
self.log_probs_max_N_K_C = np.empty((max_N, K, C))
self.random_state = random_state
def add_variables(self, log_probs_N_K_C):
C = self.log_probs_max_N_K_C.shape[2]
add_N = log_probs_N_K_C.shape[0]
self.log_probs_max_N_K_C[self.N : self.N + add_N] = log_probs_N_K_C
self.N += add_N
num_exact_samples = C**self.N
if num_exact_samples > self.M:
self.inner = _SampledJointEntropy.sample(
np.exp(self.log_probs_max_N_K_C[: self.N]),
self.M,
self.random_state,
)
else:
self.inner.add_variables(log_probs_N_K_C)
return self
def compute_batch(self, log_probs_B_K_C, output_entropies_B=None):
"""Computes the joint entropy of the added variables together with the batch (one by one)."""
return self.inner.compute_batch(log_probs_B_K_C, output_entropies_B)
def _compute_conditional_entropy(log_probs_N_K_C):
N, K, C = log_probs_N_K_C.shape
nats_N_K_C = log_probs_N_K_C * np.exp(log_probs_N_K_C)
nats_N_K_C[np.isnan(nats_N_K_C)] = 0
entropies_N = -np.sum(nats_N_K_C, axis=(1, 2)) / K
return entropies_N | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_batch_bald.py | _batch_bald.py | import numpy as np
from sklearn.utils import check_array
from ..base import SkactivemlClassifier
from ..pool._query_by_committee import _check_ensemble, QueryByCommittee
from ..utils import (
rand_argmax,
MISSING_LABEL,
check_type,
check_scalar,
check_random_state,
)
class BatchBALD(QueryByCommittee):
"""Batch Bayesian Active Learning by Disagreement (BatchBALD)
The Bayesian-Active-Learning-by-Disagreement (BatchBALD) [1] strategy
reduces the number of possible hypotheses maximally fast to minimize the
uncertainty about the parameters using Shannon’s entropy. It seeks the data
point that maximises the decrease in expected posterior entropy. For the
batch case, the advanced strategy BatchBALD [2] is applied.
Parameters
----------
n_MC_samples : int > 0, default=n_estimators
The number of monte carlo samples used for label estimation.
missing_label : scalar or string or np.nan or None, default=np.nan
Value to represent a missing label.
random_state : int or np.random.RandomState, default=None
The random state to use.
References
----------
[1] Houlsby, Neil, et al. Bayesian active learning for classification and
preference learning. arXiv preprint arXiv:1112.5745, 2011.
[2] Kirsch, Andreas; Van Amersfoort, Joost; GAL, Yarin.
Batchbald: Efficient and diverse batch acquisition for deep bayesian
active learning. Advances in neural information processing systems,
2019, 32. Jg.
"""
def __init__(
self,
n_MC_samples=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.n_MC_samples = n_MC_samples
def query(
self,
X,
y,
ensemble,
fit_ensemble=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.)
ensemble : list or tuple of SkactivemlClassifier or
SkactivemlClassifier.
If `ensemble` is a `SkactivemlClassifier`, it must have
`n_estimators` and `estimators_` after fitting as
attribute. Then, its estimators will be used as committee. If
`ensemble` is array-like, each element of this list must be
`SkactivemlClassifier` or a `SkactivemlRegressor` and will be used
as committee member.
fit_ensemble : bool, default=True
Defines whether the ensemble should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), default=None
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features), default=None
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
return_utilities : bool, default=False
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Validate input parameters.
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Validate classifier type.
check_type(fit_ensemble, "fit_ensemble", bool)
ensemble, est_arr, _ = _check_ensemble(
ensemble=ensemble,
X=X,
y=y,
sample_weight=sample_weight,
fit_ensemble=fit_ensemble,
missing_label=self.missing_label_,
estimator_types=[SkactivemlClassifier],
)
probas = np.array([est.predict_proba(X_cand) for est in est_arr])
if self.n_MC_samples is None:
n_MC_samples_ = len(est_arr)
else:
n_MC_samples_ = self.n_MC_samples
check_scalar(n_MC_samples_, "n_MC_samples", int, min_val=1)
batch_utilities_cand = batch_bald(
probas, batch_size, n_MC_samples_, self.random_state_
)
if mapping is None:
batch_utilities = batch_utilities_cand
else:
batch_utilities = np.full((batch_size, len(X)), np.nan)
batch_utilities[:, mapping] = batch_utilities_cand
best_indices = rand_argmax(
batch_utilities, axis=1, random_state=self.random_state_
)
if return_utilities:
return best_indices, batch_utilities
else:
return best_indices
def batch_bald(probas, batch_size, n_MC_samples=None, random_state=None):
"""BatchBALD: Efficient and Diverse Batch Acquisition
for Deep Bayesian Active Learning
BatchBALD [1] is an extension of BALD (Bayesian Active Learning by
Disagreement) [2] whereby points are jointly scored by estimating the
mutual information between a joint of multiple data points and the model
parameters.
Parameters
----------
probas : array-like of shape (n_estimators, n_samples, n_classes)
The probability estimates of all estimators, samples, and classes.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
n_MC_samples : int > 0, default=n_estimators
The number of monte carlo samples used for label estimation.
random_state : int or np.random.RandomState, default=None
The random state to use.
Returns
-------
scores: np.ndarray of shape (n_samples)
The BatchBALD-scores.
References
----------
[1] Kirsch, Andreas, Joost Van Amersfoort, and Yarin Gal. "Batchbald:
Efficient and diverse batch acquisition for deep bayesian active
learning." Advances in neural information processing systems 32 (2019).
[2] Houlsby, Neil, et al. "Bayesian active learning for classification and
preference learning." arXiv preprint arXiv:1112.5745 (2011).
"""
# Validate input parameters.
if probas.ndim != 3:
raise ValueError(
f"'probas' should be of shape 3, but {probas.ndim}" f" were given."
)
probs_K_N_C = check_array(probas, ensure_2d=False, allow_nd=True)
check_scalar(batch_size, "batch_size", int, min_val=1)
if n_MC_samples is None:
n_MC_samples = len(probas)
check_scalar(n_MC_samples, "n_MC_samples", int, min_val=1)
random_state = check_random_state(random_state)
probs_N_K_C = probs_K_N_C.swapaxes(0, 1)
log_probs_N_K_C = np.log(probs_N_K_C)
N, K, C = log_probs_N_K_C.shape
batch_size = min(batch_size, N)
conditional_entropies_N = _compute_conditional_entropy(log_probs_N_K_C)
batch_joint_entropy = _DynamicJointEntropy(
n_MC_samples, batch_size - 1, K, C, random_state
)
utilities = np.zeros((batch_size, N))
query_indices = []
for i in range(batch_size):
if i > 0:
latest_index = query_indices[-1]
batch_joint_entropy.add_variables(
log_probs_N_K_C[latest_index : latest_index + 1]
)
shared_conditinal_entropies = conditional_entropies_N[
query_indices
].sum()
utilities[i] = batch_joint_entropy.compute_batch(
log_probs_N_K_C, output_entropies_B=utilities[i]
)
utilities[i] -= conditional_entropies_N + shared_conditinal_entropies
utilities[i, query_indices] = np.nan
query_idx = rand_argmax(utilities[i], random_state=0)[0]
query_indices.append(query_idx)
return utilities
class _ExactJointEntropy:
def __init__(self, joint_probs_M_K):
self.joint_probs_M_K = joint_probs_M_K
@staticmethod
def empty(K):
return _ExactJointEntropy(np.ones((1, K)))
def add_variables(self, log_probs_N_K_C):
N, K, C = log_probs_N_K_C.shape
joint_probs_K_M_1 = self.joint_probs_M_K.T[:, :, None]
probs_N_K_C = np.exp(log_probs_N_K_C)
# Using lots of memory.
for i in range(N):
probs_i__K_1_C = probs_N_K_C[i][:, None, :]
joint_probs_K_M_C = joint_probs_K_M_1 * probs_i__K_1_C
joint_probs_K_M_1 = joint_probs_K_M_C.reshape((K, -1, 1))
self.joint_probs_M_K = joint_probs_K_M_1.squeeze(2).T
return self
def compute_batch(self, log_probs_B_K_C, output_entropies_B=None):
B, K, C = log_probs_B_K_C.shape
M = self.joint_probs_M_K.shape[0]
probs_b_K_C = np.exp(log_probs_B_K_C)
b = probs_b_K_C.shape[0]
probs_b_M_C = np.empty((b, M, C))
for i in range(b):
np.matmul(
self.joint_probs_M_K,
probs_b_K_C[i],
out=probs_b_M_C[i],
)
probs_b_M_C /= K
output_entropies_B = np.sum(
-np.log(probs_b_M_C) * probs_b_M_C, axis=(1, 2)
)
return output_entropies_B
def _batch_multi_choices(probs_b_C, M, random_state):
"""
probs_b_C: Ni... x C
Returns:
choices: Ni... x M
"""
probs_B_C = probs_b_C.reshape((-1, probs_b_C.shape[-1]))
B = probs_B_C.shape[0]
C = probs_B_C.shape[1]
# samples: Ni... x draw_per_xx
choices = [
random_state.choice(C, size=M, p=probs_B_C[b], replace=True)
for b in range(B)
]
choices = np.array(choices, dtype=int)
choices_b_M = choices.reshape(list(probs_b_C.shape[:-1]) + [M])
return choices_b_M
def _gather_expand(data, axis, index):
max_shape = [max(dr, ir) for dr, ir in zip(data.shape, index.shape)]
new_data_shape = list(max_shape)
new_data_shape[axis] = data.shape[axis]
new_index_shape = list(max_shape)
new_index_shape[axis] = index.shape[axis]
data = np.broadcast_to(data, new_data_shape)
index = np.broadcast_to(index, new_index_shape)
return np.take_along_axis(data, index, axis=axis)
class _SampledJointEntropy:
"""Random variables (all with the same # of categories $C$) can be added via `_SampledJointEntropy.add_variables`.
`_SampledJointEntropy.compute` computes the joint entropy.
`_SampledJointEntropy.compute_batch` computes the joint entropy of the added variables with each of the variables in the provided batch probabilities in turn.
"""
def __init__(self, sampled_joint_probs_M_K, random_state):
self.sampled_joint_probs_M_K = sampled_joint_probs_M_K
@staticmethod
def sample(probs_N_K_C, M, random_state):
K = probs_N_K_C.shape[1]
# S: num of samples per w
S = M // K
choices_N_K_S = _batch_multi_choices(probs_N_K_C, S, random_state)
expanded_choices_N_1_K_S = choices_N_K_S[:, None, :, :]
expanded_probs_N_K_1_C = probs_N_K_C[:, :, None, :]
probs_N_K_K_S = _gather_expand(
expanded_probs_N_K_1_C, axis=-1, index=expanded_choices_N_1_K_S
)
# exp sum log seems necessary to avoid 0s?
probs_K_K_S = np.exp(
np.sum(np.log(probs_N_K_K_S), axis=0, keepdims=False)
)
samples_K_M = probs_K_K_S.reshape((K, -1))
samples_M_K = samples_K_M.T
return _SampledJointEntropy(samples_M_K, random_state)
def compute_batch(self, log_probs_B_K_C, output_entropies_B=None):
B, K, C = log_probs_B_K_C.shape
M = self.sampled_joint_probs_M_K.shape[0]
b = log_probs_B_K_C.shape[0]
probs_b_M_C = np.empty(
(b, M, C),
)
for i in range(b):
np.matmul(
self.sampled_joint_probs_M_K,
np.exp(log_probs_B_K_C[i]),
out=probs_b_M_C[i],
)
probs_b_M_C /= K
q_1_M_1 = self.sampled_joint_probs_M_K.mean(axis=1, keepdims=True)[
None
]
output_entropies_B = (
np.sum(-np.log(probs_b_M_C) * probs_b_M_C / q_1_M_1, axis=(1, 2))
/ M
)
return output_entropies_B
class _DynamicJointEntropy:
def __init__(self, M, max_N, K, C, random_state):
self.M = M
self.N = 0
self.max_N = max_N
self.inner = _ExactJointEntropy.empty(K)
self.log_probs_max_N_K_C = np.empty((max_N, K, C))
self.random_state = random_state
def add_variables(self, log_probs_N_K_C):
C = self.log_probs_max_N_K_C.shape[2]
add_N = log_probs_N_K_C.shape[0]
self.log_probs_max_N_K_C[self.N : self.N + add_N] = log_probs_N_K_C
self.N += add_N
num_exact_samples = C**self.N
if num_exact_samples > self.M:
self.inner = _SampledJointEntropy.sample(
np.exp(self.log_probs_max_N_K_C[: self.N]),
self.M,
self.random_state,
)
else:
self.inner.add_variables(log_probs_N_K_C)
return self
def compute_batch(self, log_probs_B_K_C, output_entropies_B=None):
"""Computes the joint entropy of the added variables together with the batch (one by one)."""
return self.inner.compute_batch(log_probs_B_K_C, output_entropies_B)
def _compute_conditional_entropy(log_probs_N_K_C):
N, K, C = log_probs_N_K_C.shape
nats_N_K_C = log_probs_N_K_C * np.exp(log_probs_N_K_C)
nats_N_K_C[np.isnan(nats_N_K_C)] = 0
entropies_N = -np.sum(nats_N_K_C, axis=(1, 2)) / K
return entropies_N | 0.893699 | 0.677741 |
import math
import numpy as np
from sklearn import clone
from skactiveml.base import (
SkactivemlRegressor,
SingleAnnotatorPoolQueryStrategy,
SkactivemlClassifier,
)
from skactiveml.utils import (
check_type,
simple_batch,
check_scalar,
MISSING_LABEL,
check_X_y,
check_random_state,
_check_callable,
)
class ExpectedModelChangeMaximization(SingleAnnotatorPoolQueryStrategy):
"""Expected Model Change.
This class implements expected model change, an active learning
query strategy for linear regression.
Parameters
----------
bootstrap_size : int, optional (default=3)
The number of bootstraps used to estimate the true model.
n_train : int or float, optional (default=0.5)
The size of a bootstrap compared to the training data if of type float.
Must lie in the range of (0, 1]. The total size of a bootstrap if of
type int. Must be greater or equal to 1.
ord : int or string, optional (default=2)
The Norm to measure the gradient. Argument will be passed to
`np.linalg.norm`.
feature_map : callable, optional (default=None)
The feature map of the linear regressor. Takes in the feature data. Must
output a np.array of dimension 2. The default value is the identity
function. An example feature map is
`sklearn.preprocessing.PolynomialFeatures().fit_transform`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
----------
[1] Cai, Wenbin, Ya Zhang, and Jun Zhou. Maximizing expected model change
for active learning in regression, 2013 IEEE 13th international conference
on data mining pages 51--60, 2013.
"""
def __init__(
self,
bootstrap_size=3,
n_train=0.5,
ord=2,
feature_map=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.bootstrap_size = bootstrap_size
self.n_train = n_train
self.ord = ord
self.feature_map = feature_map
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg : SkactivemlRegressor
Regressor to predict the data. Assumes a linear regressor with
respect to the parameters.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", SkactivemlRegressor)
check_type(fit_reg, "fit_reg", bool)
if self.feature_map is None:
self.feature_map = lambda x: x
_check_callable(self.feature_map, "self.feature_map")
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
X_cand, mapping = self._transform_candidates(candidates, X, y)
learners = _bootstrap_estimators(
reg,
X,
y,
bootstrap_size=self.bootstrap_size,
n_train=self.n_train,
sample_weight=sample_weight,
random_state=self.random_state_,
)
results_learner = np.array(
[learner.predict(X_cand) for learner in learners]
)
pred = reg.predict(X_cand).reshape(1, -1)
scalars = np.average(np.abs(results_learner - pred), axis=0)
X_cand_mapped_features = self.feature_map(X_cand)
norms = np.linalg.norm(X_cand_mapped_features, ord=self.ord, axis=1)
utilities_cand = scalars * norms
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
def _bootstrap_estimators(
est,
X,
y,
bootstrap_size=5,
n_train=0.5,
sample_weight=None,
random_state=None,
):
"""Train the estimator on bootstraps of `X` and `y`.
Parameters
----------
est : SkactivemlClassifier or SkactivemlRegressor
The estimator to be be trained.
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set.
bootstrap_size : int, optional (default=5)
The number of trained bootstraps.
n_train : int or float, optional (default=0.5)
The size of each bootstrap training data set.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
random_state : int | np.random.RandomState (default=None)
The random state to use. If `random_state is None` random
`random_state` is used.
Returns
-------
bootstrap_est : list of SkactivemlClassifier or list of SkactivemlRegressor
The estimators trained on different bootstraps.
"""
check_X_y(X=X, y=y, sample_weight=sample_weight)
check_scalar(bootstrap_size, "bootstrap_size", int, min_val=1)
check_type(n_train, "n_train", int, float)
if isinstance(n_train, int) and n_train < 1:
raise ValueError(
f"`n_train` has value `{type(n_train)}`, but must have a value "
f"greater or equal to one, if of type `int`."
)
elif isinstance(n_train, float) and n_train <= 0 or n_train > 1:
raise ValueError(
f"`n_train` has value `{type(n_train)}`, but must have a value "
f"between zero and one, excluding zero, if of type `float`."
)
if isinstance(n_train, float):
n_train = math.ceil(n_train * len(X))
check_type(est, "est", SkactivemlClassifier, SkactivemlRegressor)
random_state = check_random_state(random_state)
bootstrap_est = [clone(est) for _ in range(bootstrap_size)]
sample_indices = np.arange(len(X))
subsets_indices = [
random_state.choice(sample_indices, size=int(len(X) * n_train + 1))
for _ in range(bootstrap_size)
]
for est_b, subset_indices in zip(bootstrap_est, subsets_indices):
X_for_learner = X[subset_indices]
y_for_learner = y[subset_indices]
if sample_weight is None:
est_b.fit(X_for_learner, y_for_learner)
else:
weight_for_learner = sample_weight[subset_indices]
est_b.fit(X_for_learner, y_for_learner, weight_for_learner)
return bootstrap_est | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_expected_model_change_maximization.py | _expected_model_change_maximization.py | import math
import numpy as np
from sklearn import clone
from skactiveml.base import (
SkactivemlRegressor,
SingleAnnotatorPoolQueryStrategy,
SkactivemlClassifier,
)
from skactiveml.utils import (
check_type,
simple_batch,
check_scalar,
MISSING_LABEL,
check_X_y,
check_random_state,
_check_callable,
)
class ExpectedModelChangeMaximization(SingleAnnotatorPoolQueryStrategy):
"""Expected Model Change.
This class implements expected model change, an active learning
query strategy for linear regression.
Parameters
----------
bootstrap_size : int, optional (default=3)
The number of bootstraps used to estimate the true model.
n_train : int or float, optional (default=0.5)
The size of a bootstrap compared to the training data if of type float.
Must lie in the range of (0, 1]. The total size of a bootstrap if of
type int. Must be greater or equal to 1.
ord : int or string, optional (default=2)
The Norm to measure the gradient. Argument will be passed to
`np.linalg.norm`.
feature_map : callable, optional (default=None)
The feature map of the linear regressor. Takes in the feature data. Must
output a np.array of dimension 2. The default value is the identity
function. An example feature map is
`sklearn.preprocessing.PolynomialFeatures().fit_transform`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
----------
[1] Cai, Wenbin, Ya Zhang, and Jun Zhou. Maximizing expected model change
for active learning in regression, 2013 IEEE 13th international conference
on data mining pages 51--60, 2013.
"""
def __init__(
self,
bootstrap_size=3,
n_train=0.5,
ord=2,
feature_map=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.bootstrap_size = bootstrap_size
self.n_train = n_train
self.ord = ord
self.feature_map = feature_map
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg : SkactivemlRegressor
Regressor to predict the data. Assumes a linear regressor with
respect to the parameters.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", SkactivemlRegressor)
check_type(fit_reg, "fit_reg", bool)
if self.feature_map is None:
self.feature_map = lambda x: x
_check_callable(self.feature_map, "self.feature_map")
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
X_cand, mapping = self._transform_candidates(candidates, X, y)
learners = _bootstrap_estimators(
reg,
X,
y,
bootstrap_size=self.bootstrap_size,
n_train=self.n_train,
sample_weight=sample_weight,
random_state=self.random_state_,
)
results_learner = np.array(
[learner.predict(X_cand) for learner in learners]
)
pred = reg.predict(X_cand).reshape(1, -1)
scalars = np.average(np.abs(results_learner - pred), axis=0)
X_cand_mapped_features = self.feature_map(X_cand)
norms = np.linalg.norm(X_cand_mapped_features, ord=self.ord, axis=1)
utilities_cand = scalars * norms
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
def _bootstrap_estimators(
est,
X,
y,
bootstrap_size=5,
n_train=0.5,
sample_weight=None,
random_state=None,
):
"""Train the estimator on bootstraps of `X` and `y`.
Parameters
----------
est : SkactivemlClassifier or SkactivemlRegressor
The estimator to be be trained.
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set.
bootstrap_size : int, optional (default=5)
The number of trained bootstraps.
n_train : int or float, optional (default=0.5)
The size of each bootstrap training data set.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
random_state : int | np.random.RandomState (default=None)
The random state to use. If `random_state is None` random
`random_state` is used.
Returns
-------
bootstrap_est : list of SkactivemlClassifier or list of SkactivemlRegressor
The estimators trained on different bootstraps.
"""
check_X_y(X=X, y=y, sample_weight=sample_weight)
check_scalar(bootstrap_size, "bootstrap_size", int, min_val=1)
check_type(n_train, "n_train", int, float)
if isinstance(n_train, int) and n_train < 1:
raise ValueError(
f"`n_train` has value `{type(n_train)}`, but must have a value "
f"greater or equal to one, if of type `int`."
)
elif isinstance(n_train, float) and n_train <= 0 or n_train > 1:
raise ValueError(
f"`n_train` has value `{type(n_train)}`, but must have a value "
f"between zero and one, excluding zero, if of type `float`."
)
if isinstance(n_train, float):
n_train = math.ceil(n_train * len(X))
check_type(est, "est", SkactivemlClassifier, SkactivemlRegressor)
random_state = check_random_state(random_state)
bootstrap_est = [clone(est) for _ in range(bootstrap_size)]
sample_indices = np.arange(len(X))
subsets_indices = [
random_state.choice(sample_indices, size=int(len(X) * n_train + 1))
for _ in range(bootstrap_size)
]
for est_b, subset_indices in zip(bootstrap_est, subsets_indices):
X_for_learner = X[subset_indices]
y_for_learner = y[subset_indices]
if sample_weight is None:
est_b.fit(X_for_learner, y_for_learner)
else:
weight_for_learner = sample_weight[subset_indices]
est_b.fit(X_for_learner, y_for_learner, weight_for_learner)
return bootstrap_est | 0.922591 | 0.682537 |
import numpy as np
from sklearn import clone
from sklearn.utils.validation import check_array
from ..base import SingleAnnotatorPoolQueryStrategy, SkactivemlClassifier
from ..utils import (
MISSING_LABEL,
check_cost_matrix,
simple_batch,
check_classes,
check_type,
check_equal_missing_label,
)
class UncertaintySampling(SingleAnnotatorPoolQueryStrategy):
"""Uncertainty Sampling.
This class implement various uncertainty based query strategies, i.e., the
standard uncertainty measures [1], cost-sensitive ones [2], and one
optimizing expected average precision [3].
Parameters
----------
method : string, default='least_confident'
The method to calculate the uncertainty, entropy, least_confident,
margin_sampling, and expected_average_precision are possible.
cost_matrix : array-like of shape (n_classes, n_classes)
Cost matrix with cost_matrix[i,j] defining the cost of predicting class
j for a sample with the actual class i. Only supported for
`least_confident` and `margin_sampling` variant.
missing_label : scalar or string or np.nan or None, default=np.nan
Value to represent a missing label.
random_state : int or np.random.RandomState
The random state to use.
References
----------
[1] Settles, Burr. Active learning literature survey.
University of Wisconsin-Madison Department of Computer Sciences, 2009.
[2] Chen, Po-Lung, and Hsuan-Tien Lin. "Active learning for multiclass
cost-sensitive classification using probabilistic models." 2013
Conference on Technologies and Applications of Artificial Intelligence.
IEEE, 2013.
[3] Wang, Hanmo, et al. "Uncertainty sampling for action recognition
via maximizing expected average precision."
IJCAI International Joint Conference on Artificial Intelligence. 2018.
"""
def __init__(
self,
method="least_confident",
cost_matrix=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.method = method
self.cost_matrix = cost_matrix
def query(
self,
X,
y,
clf,
fit_clf=True,
sample_weight=None,
utility_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
clf : skactiveml.base.SkactivemlClassifier
Model implementing the methods `fit` and `predict_proba`.
fit_clf : bool, optional (default=True)
Defines whether the classifier should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
utility_weight: array-like, optional (default=None)
Weight for each candidate (multiplied with utilities). Usually,
this is to be the density of a candidate. The length of
`utility_weight` is usually n_samples, except for the case when
candidates contains samples (ndim >= 2). Then the length is
`n_candidates`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
return_utilities : bool, default=False
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Validate input parameters.
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Validate classifier type.
check_type(clf, "clf", SkactivemlClassifier)
check_equal_missing_label(clf.missing_label, self.missing_label_)
# Validate classifier type.
check_type(fit_clf, "fit_clf", bool)
# Check `utility_weight`.
if utility_weight is None:
if mapping is None:
utility_weight = np.ones(len(X_cand))
else:
utility_weight = np.ones(len(X))
utility_weight = check_array(utility_weight, ensure_2d=False)
if mapping is None and not len(X_cand) == len(utility_weight):
raise ValueError(
f"'utility_weight' must have length 'n_candidates' but "
f"{len(X_cand)} != {len(utility_weight)}."
)
if mapping is not None and not len(X) == len(utility_weight):
raise ValueError(
f"'utility_weight' must have length 'n_samples' but "
f"{len(utility_weight)} != {len(X)}."
)
# Validate method.
if not isinstance(self.method, str):
raise TypeError(
"{} is an invalid type for method. Type {} is "
"expected".format(type(self.method), str)
)
# sample_weight is checked by clf when fitted
# Fit the classifier.
if fit_clf:
clf = clone(clf).fit(X, y, sample_weight)
# Predict class-membership probabilities.
probas = clf.predict_proba(X_cand)
# Choose the method and calculate corresponding utilities.
with np.errstate(divide="ignore"):
if self.method in [
"least_confident",
"margin_sampling",
"entropy",
]:
utilities_cand = uncertainty_scores(
probas=probas,
method=self.method,
cost_matrix=self.cost_matrix,
)
elif self.method == "expected_average_precision":
classes = clf.classes_
utilities_cand = expected_average_precision(classes, probas)
else:
raise ValueError(
"The given method {} is not valid. Supported methods are "
"'entropy', 'least_confident', 'margin_sampling' and "
"'expected_average_precision'".format(self.method)
)
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
utilities *= utility_weight
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
def uncertainty_scores(probas, cost_matrix=None, method="least_confident"):
"""Computes uncertainty scores. Three methods are available: least
confident ('least_confident'), margin sampling ('margin_sampling'),
and entropy based uncertainty ('entropy') [1]. For the least confident and
margin sampling methods cost-sensitive variants are implemented in case of
a given cost matrix (see [2] for more information).
Parameters
----------
probas : array-like, shape (n_samples, n_classes)
Class membership probabilities for each sample.
cost_matrix : array-like, shape (n_classes, n_classes)
Cost matrix with C[i,j] defining the cost of predicting class j for a
sample with the actual class i. Only supported for least confident
variant.
method : {'least_confident', 'margin_sampling', 'entropy'},
optional (default='least_confident')
Least confidence (lc) queries the sample whose maximal posterior
probability is minimal. In case of a given cost matrix, the maximial
expected cost variant is used. Smallest margin (sm) queries the sample
whose posterior probability gap between the most and the second most
probable class label is minimal. In case of a given cost matrix, the
cost-weighted minimum margin is used. Entropy ('entropy') queries the
sample whose posterior's have the maximal entropy. There is no
cost-sensitive variant of entropy based uncertainty sampling.
References
----------
[1] Settles, Burr. "Active learning literature survey".
University of Wisconsin-Madison Department of Computer Sciences, 2009.
[2] Chen, Po-Lung, and Hsuan-Tien Lin. "Active learning for multiclass
cost-sensitive classification using probabilistic models." 2013
Conference on Technologies and Applications of Artificial Intelligence.
IEEE, 2013.
"""
# Check probabilities.
probas = check_array(probas)
if not np.allclose(np.sum(probas, axis=1), 1, rtol=0, atol=1.0e-3):
raise ValueError(
"'probas' are invalid. The sum over axis 1 must be one."
)
n_classes = probas.shape[1]
# Check cost matrix.
if cost_matrix is not None:
cost_matrix = check_cost_matrix(cost_matrix, n_classes=n_classes)
# Compute uncertainties.
if method == "least_confident":
if cost_matrix is None:
return 1 - np.max(probas, axis=1)
else:
costs = probas @ cost_matrix
costs = np.partition(costs, 1, axis=1)[:, :2]
return costs[:, 0]
elif method == "margin_sampling":
if cost_matrix is None:
probas = -(np.partition(-probas, 1, axis=1)[:, :2])
return 1 - np.abs(probas[:, 0] - probas[:, 1])
else:
costs = probas @ cost_matrix
costs = np.partition(costs, 1, axis=1)[:, :2]
return -np.abs(costs[:, 0] - costs[:, 1])
elif method == "entropy":
if cost_matrix is None:
with np.errstate(divide="ignore", invalid="ignore"):
return np.nansum(-probas * np.log(probas), axis=1)
else:
raise ValueError(
f"Method `entropy` does not support cost matrices but "
f"`cost_matrix` was not None."
)
else:
raise ValueError(
"Supported methods are ['least_confident', 'margin_sampling', "
"'entropy'], the given one is: {}.".format(method)
)
def expected_average_precision(classes, probas):
"""
Calculate the expected average precision.
Parameters
----------
classes : array-like, shape=(n_classes)
Holds the label for each class.
probas : np.ndarray, shape=(n_X_cand, n_classes)
The probabilistic estimation for each classes and all instance in
candidates.
Returns
-------
score : np.ndarray, shape=(n_X_cand)
The expected average precision score of all instances in candidates.
References
----------
[1] Wang, Hanmo, et al. "Uncertainty sampling for action recognition
via maximizing expected average precision."
IJCAI International Joint Conference on Artificial Intelligence. 2018.
"""
# Check if `probas` is valid.
probas = check_array(
probas,
accept_sparse=False,
accept_large_sparse=True,
dtype="numeric",
order=None,
copy=False,
force_all_finite=True,
ensure_2d=True,
allow_nd=False,
ensure_min_samples=1,
ensure_min_features=1,
estimator=None,
)
if (np.sum(probas, axis=1) - 1).all():
raise ValueError(
"probas are invalid. The sum over axis 1 must be " "one."
)
# Check if `classes` are valid.
check_classes(classes)
if len(classes) < 2:
raise ValueError("`classes` must contain at least 2 entries.")
if len(classes) != probas.shape[1]:
raise ValueError(
"`classes` must have the same length as `probas` has " "columns."
)
score = np.zeros(len(probas))
for i in range(len(classes)):
for j in range(len(probas)):
# The i-th column of p without p[j,i]
p = probas[:, i]
p = np.delete(p, [j])
# Sort p in descending order
p = np.flipud(np.sort(p, axis=0))
# calculate g_arr
g_arr = np.zeros((len(p), len(p)))
for n in range(len(p)):
for h in range(n + 1):
g_arr[n, h] = _g(n, h, p, g_arr)
# calculate f_arr
f_arr = np.zeros((len(p) + 1, len(p) + 1))
for a in range(len(p) + 1):
for b in range(a + 1):
f_arr[a, b] = _f(a, b, p, f_arr, g_arr)
# calculate score
for t in range(len(p)):
score[j] += f_arr[len(p), t + 1] / (t + 1)
return score
# g-function for expected_average_precision
def _g(n, t, p, g_arr):
if t > n or (t == 0 and n > 0):
return 0
if t == 0 and n == 0:
return 1
return p[n - 1] * g_arr[n - 1, t - 1] + (1 - p[n - 1]) * g_arr[n - 1, t]
# f-function for expected_average_precision
def _f(n, t, p, f_arr, g_arr):
if t > n or (t == 0 and n > 0):
return 0
if t == 0 and n == 0:
return 1
return (
p[n - 1] * f_arr[n - 1, t - 1]
+ p[n - 1] * t * g_arr[n - 1, t - 1] / n
+ (1 - p[n - 1]) * f_arr[n - 1, t]
) | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_uncertainty_sampling.py | _uncertainty_sampling.py |
import numpy as np
from sklearn import clone
from sklearn.utils.validation import check_array
from ..base import SingleAnnotatorPoolQueryStrategy, SkactivemlClassifier
from ..utils import (
MISSING_LABEL,
check_cost_matrix,
simple_batch,
check_classes,
check_type,
check_equal_missing_label,
)
class UncertaintySampling(SingleAnnotatorPoolQueryStrategy):
"""Uncertainty Sampling.
This class implement various uncertainty based query strategies, i.e., the
standard uncertainty measures [1], cost-sensitive ones [2], and one
optimizing expected average precision [3].
Parameters
----------
method : string, default='least_confident'
The method to calculate the uncertainty, entropy, least_confident,
margin_sampling, and expected_average_precision are possible.
cost_matrix : array-like of shape (n_classes, n_classes)
Cost matrix with cost_matrix[i,j] defining the cost of predicting class
j for a sample with the actual class i. Only supported for
`least_confident` and `margin_sampling` variant.
missing_label : scalar or string or np.nan or None, default=np.nan
Value to represent a missing label.
random_state : int or np.random.RandomState
The random state to use.
References
----------
[1] Settles, Burr. Active learning literature survey.
University of Wisconsin-Madison Department of Computer Sciences, 2009.
[2] Chen, Po-Lung, and Hsuan-Tien Lin. "Active learning for multiclass
cost-sensitive classification using probabilistic models." 2013
Conference on Technologies and Applications of Artificial Intelligence.
IEEE, 2013.
[3] Wang, Hanmo, et al. "Uncertainty sampling for action recognition
via maximizing expected average precision."
IJCAI International Joint Conference on Artificial Intelligence. 2018.
"""
def __init__(
self,
method="least_confident",
cost_matrix=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.method = method
self.cost_matrix = cost_matrix
def query(
self,
X,
y,
clf,
fit_clf=True,
sample_weight=None,
utility_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL.
clf : skactiveml.base.SkactivemlClassifier
Model implementing the methods `fit` and `predict_proba`.
fit_clf : bool, optional (default=True)
Defines whether the classifier should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight: array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
utility_weight: array-like, optional (default=None)
Weight for each candidate (multiplied with utilities). Usually,
this is to be the density of a candidate. The length of
`utility_weight` is usually n_samples, except for the case when
candidates contains samples (ndim >= 2). Then the length is
`n_candidates`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, default=1
The number of samples to be selected in one AL cycle.
return_utilities : bool, default=False
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Validate input parameters.
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
X_cand, mapping = self._transform_candidates(candidates, X, y)
# Validate classifier type.
check_type(clf, "clf", SkactivemlClassifier)
check_equal_missing_label(clf.missing_label, self.missing_label_)
# Validate classifier type.
check_type(fit_clf, "fit_clf", bool)
# Check `utility_weight`.
if utility_weight is None:
if mapping is None:
utility_weight = np.ones(len(X_cand))
else:
utility_weight = np.ones(len(X))
utility_weight = check_array(utility_weight, ensure_2d=False)
if mapping is None and not len(X_cand) == len(utility_weight):
raise ValueError(
f"'utility_weight' must have length 'n_candidates' but "
f"{len(X_cand)} != {len(utility_weight)}."
)
if mapping is not None and not len(X) == len(utility_weight):
raise ValueError(
f"'utility_weight' must have length 'n_samples' but "
f"{len(utility_weight)} != {len(X)}."
)
# Validate method.
if not isinstance(self.method, str):
raise TypeError(
"{} is an invalid type for method. Type {} is "
"expected".format(type(self.method), str)
)
# sample_weight is checked by clf when fitted
# Fit the classifier.
if fit_clf:
clf = clone(clf).fit(X, y, sample_weight)
# Predict class-membership probabilities.
probas = clf.predict_proba(X_cand)
# Choose the method and calculate corresponding utilities.
with np.errstate(divide="ignore"):
if self.method in [
"least_confident",
"margin_sampling",
"entropy",
]:
utilities_cand = uncertainty_scores(
probas=probas,
method=self.method,
cost_matrix=self.cost_matrix,
)
elif self.method == "expected_average_precision":
classes = clf.classes_
utilities_cand = expected_average_precision(classes, probas)
else:
raise ValueError(
"The given method {} is not valid. Supported methods are "
"'entropy', 'least_confident', 'margin_sampling' and "
"'expected_average_precision'".format(self.method)
)
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
utilities *= utility_weight
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
def uncertainty_scores(probas, cost_matrix=None, method="least_confident"):
"""Computes uncertainty scores. Three methods are available: least
confident ('least_confident'), margin sampling ('margin_sampling'),
and entropy based uncertainty ('entropy') [1]. For the least confident and
margin sampling methods cost-sensitive variants are implemented in case of
a given cost matrix (see [2] for more information).
Parameters
----------
probas : array-like, shape (n_samples, n_classes)
Class membership probabilities for each sample.
cost_matrix : array-like, shape (n_classes, n_classes)
Cost matrix with C[i,j] defining the cost of predicting class j for a
sample with the actual class i. Only supported for least confident
variant.
method : {'least_confident', 'margin_sampling', 'entropy'},
optional (default='least_confident')
Least confidence (lc) queries the sample whose maximal posterior
probability is minimal. In case of a given cost matrix, the maximial
expected cost variant is used. Smallest margin (sm) queries the sample
whose posterior probability gap between the most and the second most
probable class label is minimal. In case of a given cost matrix, the
cost-weighted minimum margin is used. Entropy ('entropy') queries the
sample whose posterior's have the maximal entropy. There is no
cost-sensitive variant of entropy based uncertainty sampling.
References
----------
[1] Settles, Burr. "Active learning literature survey".
University of Wisconsin-Madison Department of Computer Sciences, 2009.
[2] Chen, Po-Lung, and Hsuan-Tien Lin. "Active learning for multiclass
cost-sensitive classification using probabilistic models." 2013
Conference on Technologies and Applications of Artificial Intelligence.
IEEE, 2013.
"""
# Check probabilities.
probas = check_array(probas)
if not np.allclose(np.sum(probas, axis=1), 1, rtol=0, atol=1.0e-3):
raise ValueError(
"'probas' are invalid. The sum over axis 1 must be one."
)
n_classes = probas.shape[1]
# Check cost matrix.
if cost_matrix is not None:
cost_matrix = check_cost_matrix(cost_matrix, n_classes=n_classes)
# Compute uncertainties.
if method == "least_confident":
if cost_matrix is None:
return 1 - np.max(probas, axis=1)
else:
costs = probas @ cost_matrix
costs = np.partition(costs, 1, axis=1)[:, :2]
return costs[:, 0]
elif method == "margin_sampling":
if cost_matrix is None:
probas = -(np.partition(-probas, 1, axis=1)[:, :2])
return 1 - np.abs(probas[:, 0] - probas[:, 1])
else:
costs = probas @ cost_matrix
costs = np.partition(costs, 1, axis=1)[:, :2]
return -np.abs(costs[:, 0] - costs[:, 1])
elif method == "entropy":
if cost_matrix is None:
with np.errstate(divide="ignore", invalid="ignore"):
return np.nansum(-probas * np.log(probas), axis=1)
else:
raise ValueError(
f"Method `entropy` does not support cost matrices but "
f"`cost_matrix` was not None."
)
else:
raise ValueError(
"Supported methods are ['least_confident', 'margin_sampling', "
"'entropy'], the given one is: {}.".format(method)
)
def expected_average_precision(classes, probas):
"""
Calculate the expected average precision.
Parameters
----------
classes : array-like, shape=(n_classes)
Holds the label for each class.
probas : np.ndarray, shape=(n_X_cand, n_classes)
The probabilistic estimation for each classes and all instance in
candidates.
Returns
-------
score : np.ndarray, shape=(n_X_cand)
The expected average precision score of all instances in candidates.
References
----------
[1] Wang, Hanmo, et al. "Uncertainty sampling for action recognition
via maximizing expected average precision."
IJCAI International Joint Conference on Artificial Intelligence. 2018.
"""
# Check if `probas` is valid.
probas = check_array(
probas,
accept_sparse=False,
accept_large_sparse=True,
dtype="numeric",
order=None,
copy=False,
force_all_finite=True,
ensure_2d=True,
allow_nd=False,
ensure_min_samples=1,
ensure_min_features=1,
estimator=None,
)
if (np.sum(probas, axis=1) - 1).all():
raise ValueError(
"probas are invalid. The sum over axis 1 must be " "one."
)
# Check if `classes` are valid.
check_classes(classes)
if len(classes) < 2:
raise ValueError("`classes` must contain at least 2 entries.")
if len(classes) != probas.shape[1]:
raise ValueError(
"`classes` must have the same length as `probas` has " "columns."
)
score = np.zeros(len(probas))
for i in range(len(classes)):
for j in range(len(probas)):
# The i-th column of p without p[j,i]
p = probas[:, i]
p = np.delete(p, [j])
# Sort p in descending order
p = np.flipud(np.sort(p, axis=0))
# calculate g_arr
g_arr = np.zeros((len(p), len(p)))
for n in range(len(p)):
for h in range(n + 1):
g_arr[n, h] = _g(n, h, p, g_arr)
# calculate f_arr
f_arr = np.zeros((len(p) + 1, len(p) + 1))
for a in range(len(p) + 1):
for b in range(a + 1):
f_arr[a, b] = _f(a, b, p, f_arr, g_arr)
# calculate score
for t in range(len(p)):
score[j] += f_arr[len(p), t + 1] / (t + 1)
return score
# g-function for expected_average_precision
def _g(n, t, p, g_arr):
if t > n or (t == 0 and n > 0):
return 0
if t == 0 and n == 0:
return 1
return p[n - 1] * g_arr[n - 1, t - 1] + (1 - p[n - 1]) * g_arr[n - 1, t]
# f-function for expected_average_precision
def _f(n, t, p, f_arr, g_arr):
if t > n or (t == 0 and n > 0):
return 0
if t == 0 and n == 0:
return 1
return (
p[n - 1] * f_arr[n - 1, t - 1]
+ p[n - 1] * t * g_arr[n - 1, t - 1] / n
+ (1 - p[n - 1]) * f_arr[n - 1, t]
) | 0.918366 | 0.697165 |
import warnings
import numpy as np
from joblib import Parallel, delayed
from sklearn import clone
from sklearn.base import BaseEstimator, RegressorMixin
from sklearn.isotonic import IsotonicRegression
from sklearn.metrics import euclidean_distances
from sklearn.neighbors import NearestNeighbors
from sklearn.svm import SVR
from sklearn.utils import check_array, check_symmetric
from ..base import SingleAnnotatorPoolQueryStrategy
from ..utils import (
simple_batch,
check_classifier_params,
MISSING_LABEL,
check_scalar,
check_random_state,
check_X_y,
is_labeled,
ExtLabelEncoder,
)
class CostEmbeddingAL(SingleAnnotatorPoolQueryStrategy):
"""Active Learning with Cost Embedding (ALCE).
Cost sensitive multi-class algorithm.
Assume each class has at least one sample in the labeled pool.
This implementation is based on libact.
Parameters
----------
classes: array-like of shape(n_classes,)
base_regressor : sklearn regressor, optional (default=None)
cost_matrix: array-like of shape (n_classes, n_classes),
optional (default=None)
Cost matrix with `cost_matrix[i,j]` defining the cost of predicting
class j for a sample with the actual class i. Only supported for least
confident variant.
missing_label: str or numeric, optional (default=MISSING_LABEL)
Specifies the symbol that represents a missing label.
random_state : int or np.random.RandomState, optional
(default=None)
Random state for annotator selection.
embed_dim : int, optional (default=None)
If is None, `embed_dim = n_classes`.
mds_params : dict, optional (default=None)
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.manifold.MDS.html
nn_params : dict, optional (default=None)
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html
References
----------
[1] Kuan-Hao, and Hsuan-Tien Lin. "A Novel Uncertainty Sampling Algorithm
for Cost-sensitive Multiclass Active Learning", In Proceedings of the
IEEE International Conference on Data Mining (ICDM), 2016
"""
def __init__(
self,
classes,
base_regressor=None,
cost_matrix=None,
embed_dim=None,
mds_params=None,
nn_params=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.classes = classes
self.base_regressor = base_regressor
self.cost_matrix = cost_matrix
self.embed_dim = embed_dim
self.missing_label = missing_label
self.random_state = random_state
self.mds_params = mds_params
self.nn_params = nn_params
def query(
self,
X,
y,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Query the next instance to be labeled.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled
and unlabeled samples.
y : array-like of shape (n_samples,)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL).
sample_weight: array-like of shape (n_samples,), optional
(default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If True, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size,)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Check standard parameters.
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X=X,
y=y,
candidates=candidates,
batch_size=batch_size,
return_utilities=return_utilities,
reset=True,
)
# Obtain candidates plus mapping.
X_cand, mapping = self._transform_candidates(candidates, X, y)
util_cand = _alce(
X_cand,
X,
y,
self.base_regressor,
self.cost_matrix,
self.classes,
self.embed_dim,
sample_weight,
self.missing_label,
self.random_state_,
self.mds_params,
self.nn_params,
)
if mapping is None:
utilities = util_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = util_cand
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
def _alce(
X_cand,
X,
y,
base_regressor,
cost_matrix,
classes,
embed_dim,
sample_weight,
missing_label,
random_state,
mds_params,
nn_params,
):
"""Compute the alce score for the candidate instances.
Parameters
----------
X_cand: array-like, shape (n_candidates, n_features)
Unlabeled candidate samples.
X: array-like, shape (n_samples, n_features)
Complete data set.
y: array-like, shape (n_samples)
Labels of the data set.
base_regressor: RegressorMixin
Regressor used for the embedding.
cost_matrix: array-like, shape (n_classes, n_classes)
Cost matrix with cost_matrix[i,j] defining the cost of predicting class
j for a sample with the true class i.
classes: array-like, shape (n_classes)
Array of class labels.
embed_dim: int
Dimension of the embedding.
sample_weight : array-like, shape (n_samples)
Weights for uncertain annotators.
missing_label : scalar | string | np.nan | None
Value to represent a missing label.
random_state : int | np.random.RandomState
Random state for annotator selection.
mds_params : dict
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.manifold.MDS.html
nn_params : dict
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html
Returns
-------
utilities: np.ndarray, shape (n_candidates)
The utilities of all candidate instances.
"""
# Check base regressor
if base_regressor is None:
base_regressor = SVR()
if not isinstance(base_regressor, RegressorMixin):
raise TypeError("'base_regressor' must be an sklearn regressor")
check_classifier_params(classes, missing_label, cost_matrix)
if cost_matrix is None:
cost_matrix = 1 - np.eye(len(classes))
if np.count_nonzero(cost_matrix) == 0:
raise ValueError(
"The cost matrix must contain at least one positive " "number."
)
# Check the given data
X, y, X_cand, sample_weight, sample_weight_cand = check_X_y(
X,
y,
X_cand,
sample_weight,
force_all_finite=False,
missing_label=missing_label,
)
labeled = is_labeled(y, missing_label=missing_label)
y = ExtLabelEncoder(classes, missing_label).fit_transform(y)
X = X[labeled]
y = y[labeled].astype(int)
sample_weight = sample_weight[labeled]
# If all samples are unlabeled, the strategy randomly selects an instance
if len(X) == 0:
warnings.warn(
"There are no labeled instances. The strategy selects "
"one random instance."
)
return np.ones(len(X_cand))
# Check embedding dimension
embed_dim = len(classes) if embed_dim is None else embed_dim
check_scalar(embed_dim, "embed_dim", int, min_val=1)
# Update mds parameters
mds_params_default = {
"metric": False,
"n_components": embed_dim,
"n_uq": len(classes),
"max_iter": 300,
"eps": 1e-6,
"dissimilarity": "precomputed",
"n_init": 8,
"n_jobs": 1,
"random_state": random_state,
}
if mds_params is not None:
if type(mds_params) is not dict:
raise TypeError("'mds_params' must be a dictionary or None")
mds_params_default.update(mds_params)
mds_params = mds_params_default
# Update nearest neighbor parameters
nn_params = {} if nn_params is None else nn_params
if type(nn_params) is not dict:
raise TypeError("'nn_params' must be a dictionary or None")
regressors = [clone(base_regressor) for _ in range(embed_dim)]
n_classes = len(classes)
dissimilarities = np.zeros((2 * n_classes, 2 * n_classes))
dissimilarities[:n_classes, n_classes:] = cost_matrix
dissimilarities[n_classes:, :n_classes] = cost_matrix.T
W = np.zeros((2 * n_classes, 2 * n_classes))
W[:n_classes, n_classes:] = 1
W[n_classes:, :n_classes] = 1
mds = MDSP(**mds_params)
embedding = mds.fit(dissimilarities).embedding_
class_embed = embedding[:n_classes, :]
nn = NearestNeighbors(n_neighbors=1, **nn_params)
nn.fit(embedding[n_classes:, :])
pred_embed = np.zeros((len(X_cand), embed_dim))
for i in range(embed_dim):
regressors[i].fit(X, class_embed[y, i], sample_weight)
pred_embed[:, i] = regressors[i].predict(X_cand)
dist, _ = nn.kneighbors(pred_embed)
utilities = dist[:, 0]
return utilities
"""
Multi-dimensional Scaling Partial (MDSP)
This module is modified from
https://github.com/scikit-learn/scikit-learn/blob/14031f6/sklearn/manifold/mds.py
by Kuan-Hao Huang.
"""
# author: Nelle Varoquaux <[email protected]>
# Licence: BSD
def _smacof_single_p(
similarities,
n_uq,
metric=True,
n_components=2,
init=None,
max_iter=300,
verbose=0,
eps=1e-3,
random_state=None,
):
"""
Computes multidimensional scaling using SMACOF algorithm.
Parameters
----------
n_uq
similarities: symmetric ndarray, shape [n * n]
similarities between the points
metric: boolean, optional, default: True
compute metric or nonmetric SMACOF algorithm
n_components: int, optional, default: 2
number of dimension in which to immerse the similarities
overwritten if initial array is provided.
init: {None or ndarray}, optional
if None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array
max_iter: int, optional, default: 300
Maximum number of iterations of the SMACOF algorithm for a single run
verbose: int, optional, default: 0
level of verbosity
eps: float, optional, default: 1e-6
relative tolerance w.r.t stress to declare converge
random_state: integer or numpy.RandomState, optional
The generator used to initialize the centers. If an integer is
given, it fixes the seed. Defaults to the global numpy random
number generator.
Returns
-------
X: ndarray (n_samples, n_components), float
coordinates of the n_samples points in a n_components-space
stress_: float
The final value of the stress (sum of squared distance of the
disparities and the distances for all constrained points)
n_iter : int
Number of iterations run.
"""
similarities = check_symmetric(similarities, raise_exception=True)
n_samples = similarities.shape[0]
random_state = check_random_state(random_state)
W = np.ones((n_samples, n_samples))
W[:n_uq, :n_uq] = 0.0
W[n_uq:, n_uq:] = 0.0
V = -W
V[np.arange(len(V)), np.arange(len(V))] = W.sum(axis=1)
e = np.ones((n_samples, 1))
Vp = (
np.linalg.inv(V + np.dot(e, e.T) / n_samples)
- np.dot(e, e.T) / n_samples
)
sim_flat = similarities.ravel()
sim_flat_w = sim_flat[sim_flat != 0]
if init is None:
# Randomly choose initial configuration
X = random_state.rand(n_samples * n_components)
X = X.reshape((n_samples, n_components))
else:
# overrides the parameter p
n_components = init.shape[1]
if n_samples != init.shape[0]:
raise ValueError(
"init matrix should be of shape (%d, %d)"
% (n_samples, n_components)
)
X = init
old_stress = None
ir = IsotonicRegression()
for it in range(max_iter):
# Compute distance and monotonic regression
dis = euclidean_distances(X)
if metric:
disparities = similarities
else:
dis_flat = dis.ravel()
# similarities with 0 are considered as missing values
dis_flat_w = dis_flat[sim_flat != 0]
# Compute the disparities using a monotonic regression
disparities_flat = ir.fit_transform(sim_flat_w, dis_flat_w)
disparities = dis_flat.copy()
disparities[sim_flat != 0] = disparities_flat
disparities = disparities.reshape((n_samples, n_samples))
disparities *= np.sqrt(
(n_samples * (n_samples - 1) / 2) / (disparities**2).sum()
)
disparities[similarities == 0] = 0
# Compute stress
_stress = (
W.ravel() * ((dis.ravel() - disparities.ravel()) ** 2)
).sum()
_stress /= 2
# Update X using the Guttman transform
dis[dis == 0] = 1e-5
ratio = disparities / dis
_B = -W * ratio
_B[np.arange(len(_B)), np.arange(len(_B))] += (W * ratio).sum(axis=1)
X = np.dot(Vp, np.dot(_B, X))
dis = np.sqrt((X**2).sum(axis=1)).sum()
if verbose >= 2:
print("it: %d, stress %s" % (it, _stress))
if old_stress is not None:
if (old_stress - _stress / dis) < eps:
if verbose:
print(f"breaking at iteration {it} with stress {_stress}")
break
old_stress = _stress / dis
return X, _stress, it + 1
def smacof_p(
similarities,
n_uq,
metric=True,
n_components=2,
init=None,
n_init=8,
n_jobs=1,
max_iter=300,
verbose=0,
eps=1e-3,
random_state=None,
return_n_iter=False,
):
"""
Computes multidimensional scaling using SMACOF (Scaling by Majorizing a
Complicated Function) algorithm
The SMACOF algorithm is a multidimensional scaling algorithm: it minimizes
a objective function, the *stress*, using a majorization technique. The
Stress Majorization, also known as the Guttman Transform, guarantees a
monotone convergence of Stress, and is more powerful than traditional
techniques such as gradient descent.
The SMACOF algorithm for metric MDS can summarized by the following steps:
1. Set an initial start configuration, randomly or not.
2. Compute the stress
3. Compute the Guttman Transform
4. Iterate 2 and 3 until convergence.
The nonmetric algorithm adds a monotonic regression steps before computing
the stress.
Parameters
----------
similarities : symmetric ndarray, shape (n_samples, n_samples)
similarities between the points
metric : boolean, optional, default: True
compute metric or nonmetric SMACOF algorithm
n_components : int, optional, default: 2
number of dimension in which to immerse the similarities
overridden if initial array is provided.
init : {None or ndarray of shape (n_samples, n_components)}, optional
if None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array
n_init : int, optional, default: 8
Number of time the smacof_p algorithm will be run with different
initialisation. The final results will be the best output of the
n_init consecutive runs in terms of stress.
n_jobs : int, optional, default: 1
The number of jobs to use for the computation. This works by breaking
down the pairwise matrix into n_jobs even slices and computing them in
parallel.
If -1 all CPUs are used. If 1 is given, no parallel computing code is
used at all, which is useful for debugging. For n_jobs below -1,
(n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one
are used.
max_iter : int, optional, default: 300
Maximum number of iterations of the SMACOF algorithm for a single run
verbose : int, optional, default: 0
level of verbosity
eps : float, optional, default: 1e-6
relative tolerance w.r.t stress to declare converge
random_state : integer or numpy.RandomState, optional
The generator used to initialize the centers. If an integer is
given, it fixes the seed. Defaults to the global numpy random
number generator.
return_n_iter : bool
Whether or not to return the number of iterations.
Returns
-------
X : ndarray (n_samples,n_components)
Coordinates of the n_samples points in a n_components-space
stress : float
The final value of the stress (sum of squared distance of the
disparities and the distances for all constrained points)
n_iter : int
The number of iterations corresponding to the best stress.
Returned only if `return_n_iter` is set to True.
Notes
-----
"Modern Multidimensional Scaling - Theory and Applications" Borg, I.;
Groenen P. Springer Series in Statistics (1997)
"Nonmetric multidimensional scaling: a numerical method" Kruskal, J.
Psychometrika, 29 (1964)
"Multidimensional scaling by optimizing goodness of fit to a nonmetric
hypothesis" Kruskal, J. Psychometrika, 29, (1964)
"""
similarities = check_array(similarities)
random_state = check_random_state(random_state)
if hasattr(init, "__array__"):
init = np.asarray(init).copy()
if not n_init == 1:
warnings.warn(
"Explicit initial positions passed: "
"performing only one init of the MDS instead of %d" % n_init
)
n_init = 1
best_pos, best_stress = None, None
if n_jobs == 1:
for it in range(n_init):
pos, stress, n_iter_ = _smacof_single_p(
similarities,
n_uq,
metric=metric,
n_components=n_components,
init=init,
max_iter=max_iter,
verbose=verbose,
eps=eps,
random_state=random_state,
)
if best_stress is None or stress < best_stress:
best_stress = stress
best_pos = pos.copy()
best_iter = n_iter_
else:
seeds = random_state.randint(np.iinfo(np.int32).max, size=n_init)
results = Parallel(n_jobs=n_jobs, verbose=max(verbose - 1, 0))(
delayed(_smacof_single_p)(
similarities,
n_uq,
metric=metric,
n_components=n_components,
init=init,
max_iter=max_iter,
verbose=verbose,
eps=eps,
random_state=seed,
)
for seed in seeds
)
positions, stress, n_iters = zip(*results)
best = np.argmin(stress)
best_stress = stress[best]
best_pos = positions[best]
best_iter = n_iters[best]
if return_n_iter:
return best_pos, best_stress, best_iter
else:
return best_pos, best_stress
class MDSP(BaseEstimator):
"""Multidimensional scaling
Parameters
----------
metric : boolean, optional, default: True
compute metric or nonmetric SMACOF (Scaling by Majorizing a
Complicated Function) algorithm
n_components : int, optional, default: 2
number of dimension in which to immerse the similarities
overridden if initial array is provided.
n_init : int, optional, default: 4
Number of time the smacof_p algorithm will be run with different
initialisation. The final results will be the best output of the
n_init consecutive runs in terms of stress.
max_iter : int, optional, default: 300
Maximum number of iterations of the SMACOF algorithm for a single run
verbose : int, optional, default: 0
level of verbosity
eps : float, optional, default: 1e-6
relative tolerance w.r.t stress to declare converge
n_jobs : int, optional, default: 1
The number of jobs to use for the computation. This works by breaking
down the pairwise matrix into n_jobs even slices and computing them in
parallel.
If -1 all CPUs are used. If 1 is given, no parallel computing code is
used at all, which is useful for debugging. For n_jobs below -1,
(n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one
are used.
random_state : integer or numpy.RandomState, optional
The generator used to initialize the centers. If an integer is
given, it fixes the seed. Defaults to the global numpy random
number generator.
dissimilarity : string
Which dissimilarity measure to use.
Supported are 'euclidean' and 'precomputed'.
Attributes
----------
embedding_ : array-like, shape [n_components, n_samples]
Stores the position of the dataset in the embedding space
stress_ : float
The final value of the stress (sum of squared distance of the
disparities and the distances for all constrained points)
References
----------
"Modern Multidimensional Scaling - Theory and Applications" Borg, I.;
Groenen P. Springer Series in Statistics (1997)
"Nonmetric multidimensional scaling: a numerical method" Kruskal, J.
Psychometrika, 29 (1964)
"Multidimensional scaling by optimizing goodness of fit to a nonmetric
hypothesis" Kruskal, J. Psychometrika, 29, (1964)
"""
def __init__(
self,
n_components=2,
n_uq=1,
metric=True,
n_init=4,
max_iter=300,
verbose=0,
eps=1e-3,
n_jobs=1,
random_state=None,
dissimilarity="euclidean",
):
self.n_components = n_components
self.n_uq = n_uq
self.dissimilarity = dissimilarity
self.metric = metric
self.n_init = n_init
self.max_iter = max_iter
self.eps = eps
self.verbose = verbose
self.n_jobs = n_jobs
self.random_state = random_state
def fit(self, X, y=None, init=None):
""" Compute the position of the points in the embedding space.
Parameters
----------
X : array, shape=[n_samples, n_features], or [n_samples, n_samples] \
if dissimilarity='precomputed'
Input data.
init : {None or ndarray, shape (n_samples,)}, optional
If None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array.
"""
self.fit_transform(X, init=init)
return self
def fit_transform(self, X, y=None, init=None):
""" Fit the data from X, and returns the embedded coordinates.
Parameters
----------
X : array, shape=[n_samples, n_features], or [n_samples, n_samples] \
if dissimilarity='precomputed'
Input data.
init : {None or ndarray, shape (n_samples,)}, optional
If None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array.
"""
X = check_array(X)
if X.shape[0] == X.shape[1] and self.dissimilarity != "precomputed":
warnings.warn(
"The MDS API has changed. ``fit`` now constructs an"
" dissimilarity matrix from data. To use a custom "
"dissimilarity matrix, set "
"``dissimilarity=precomputed``."
)
if self.dissimilarity == "precomputed":
self.dissimilarity_matrix_ = X
elif self.dissimilarity == "euclidean":
self.dissimilarity_matrix_ = euclidean_distances(X)
else:
raise ValueError(
"Proximity must be 'precomputed' or 'euclidean'."
" Got %s instead" % str(self.dissimilarity)
)
self.embedding_, self.stress_, self.n_iter_ = smacof_p(
self.dissimilarity_matrix_,
self.n_uq,
metric=self.metric,
n_components=self.n_components,
init=init,
n_init=self.n_init,
n_jobs=self.n_jobs,
max_iter=self.max_iter,
verbose=self.verbose,
eps=self.eps,
random_state=self.random_state,
return_n_iter=True,
)
return self.embedding_ | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_cost_embedding_al.py | _cost_embedding_al.py | import warnings
import numpy as np
from joblib import Parallel, delayed
from sklearn import clone
from sklearn.base import BaseEstimator, RegressorMixin
from sklearn.isotonic import IsotonicRegression
from sklearn.metrics import euclidean_distances
from sklearn.neighbors import NearestNeighbors
from sklearn.svm import SVR
from sklearn.utils import check_array, check_symmetric
from ..base import SingleAnnotatorPoolQueryStrategy
from ..utils import (
simple_batch,
check_classifier_params,
MISSING_LABEL,
check_scalar,
check_random_state,
check_X_y,
is_labeled,
ExtLabelEncoder,
)
class CostEmbeddingAL(SingleAnnotatorPoolQueryStrategy):
"""Active Learning with Cost Embedding (ALCE).
Cost sensitive multi-class algorithm.
Assume each class has at least one sample in the labeled pool.
This implementation is based on libact.
Parameters
----------
classes: array-like of shape(n_classes,)
base_regressor : sklearn regressor, optional (default=None)
cost_matrix: array-like of shape (n_classes, n_classes),
optional (default=None)
Cost matrix with `cost_matrix[i,j]` defining the cost of predicting
class j for a sample with the actual class i. Only supported for least
confident variant.
missing_label: str or numeric, optional (default=MISSING_LABEL)
Specifies the symbol that represents a missing label.
random_state : int or np.random.RandomState, optional
(default=None)
Random state for annotator selection.
embed_dim : int, optional (default=None)
If is None, `embed_dim = n_classes`.
mds_params : dict, optional (default=None)
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.manifold.MDS.html
nn_params : dict, optional (default=None)
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html
References
----------
[1] Kuan-Hao, and Hsuan-Tien Lin. "A Novel Uncertainty Sampling Algorithm
for Cost-sensitive Multiclass Active Learning", In Proceedings of the
IEEE International Conference on Data Mining (ICDM), 2016
"""
def __init__(
self,
classes,
base_regressor=None,
cost_matrix=None,
embed_dim=None,
mds_params=None,
nn_params=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
missing_label=missing_label, random_state=random_state
)
self.classes = classes
self.base_regressor = base_regressor
self.cost_matrix = cost_matrix
self.embed_dim = embed_dim
self.missing_label = missing_label
self.random_state = random_state
self.mds_params = mds_params
self.nn_params = nn_params
def query(
self,
X,
y,
sample_weight=None,
candidates=None,
batch_size=1,
return_utilities=False,
):
"""Query the next instance to be labeled.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled
and unlabeled samples.
y : array-like of shape (n_samples,)
Labels of the training data set (possibly including unlabeled ones
indicated by self.MISSING_LABEL).
sample_weight: array-like of shape (n_samples,), optional
(default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X). This is not supported by all query strategies.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If True, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size,)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
# Check standard parameters.
(
X,
y,
candidates,
batch_size,
return_utilities,
) = super()._validate_data(
X=X,
y=y,
candidates=candidates,
batch_size=batch_size,
return_utilities=return_utilities,
reset=True,
)
# Obtain candidates plus mapping.
X_cand, mapping = self._transform_candidates(candidates, X, y)
util_cand = _alce(
X_cand,
X,
y,
self.base_regressor,
self.cost_matrix,
self.classes,
self.embed_dim,
sample_weight,
self.missing_label,
self.random_state_,
self.mds_params,
self.nn_params,
)
if mapping is None:
utilities = util_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = util_cand
return simple_batch(
utilities,
self.random_state_,
batch_size=batch_size,
return_utilities=return_utilities,
)
def _alce(
X_cand,
X,
y,
base_regressor,
cost_matrix,
classes,
embed_dim,
sample_weight,
missing_label,
random_state,
mds_params,
nn_params,
):
"""Compute the alce score for the candidate instances.
Parameters
----------
X_cand: array-like, shape (n_candidates, n_features)
Unlabeled candidate samples.
X: array-like, shape (n_samples, n_features)
Complete data set.
y: array-like, shape (n_samples)
Labels of the data set.
base_regressor: RegressorMixin
Regressor used for the embedding.
cost_matrix: array-like, shape (n_classes, n_classes)
Cost matrix with cost_matrix[i,j] defining the cost of predicting class
j for a sample with the true class i.
classes: array-like, shape (n_classes)
Array of class labels.
embed_dim: int
Dimension of the embedding.
sample_weight : array-like, shape (n_samples)
Weights for uncertain annotators.
missing_label : scalar | string | np.nan | None
Value to represent a missing label.
random_state : int | np.random.RandomState
Random state for annotator selection.
mds_params : dict
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.manifold.MDS.html
nn_params : dict
For further information, see
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html
Returns
-------
utilities: np.ndarray, shape (n_candidates)
The utilities of all candidate instances.
"""
# Check base regressor
if base_regressor is None:
base_regressor = SVR()
if not isinstance(base_regressor, RegressorMixin):
raise TypeError("'base_regressor' must be an sklearn regressor")
check_classifier_params(classes, missing_label, cost_matrix)
if cost_matrix is None:
cost_matrix = 1 - np.eye(len(classes))
if np.count_nonzero(cost_matrix) == 0:
raise ValueError(
"The cost matrix must contain at least one positive " "number."
)
# Check the given data
X, y, X_cand, sample_weight, sample_weight_cand = check_X_y(
X,
y,
X_cand,
sample_weight,
force_all_finite=False,
missing_label=missing_label,
)
labeled = is_labeled(y, missing_label=missing_label)
y = ExtLabelEncoder(classes, missing_label).fit_transform(y)
X = X[labeled]
y = y[labeled].astype(int)
sample_weight = sample_weight[labeled]
# If all samples are unlabeled, the strategy randomly selects an instance
if len(X) == 0:
warnings.warn(
"There are no labeled instances. The strategy selects "
"one random instance."
)
return np.ones(len(X_cand))
# Check embedding dimension
embed_dim = len(classes) if embed_dim is None else embed_dim
check_scalar(embed_dim, "embed_dim", int, min_val=1)
# Update mds parameters
mds_params_default = {
"metric": False,
"n_components": embed_dim,
"n_uq": len(classes),
"max_iter": 300,
"eps": 1e-6,
"dissimilarity": "precomputed",
"n_init": 8,
"n_jobs": 1,
"random_state": random_state,
}
if mds_params is not None:
if type(mds_params) is not dict:
raise TypeError("'mds_params' must be a dictionary or None")
mds_params_default.update(mds_params)
mds_params = mds_params_default
# Update nearest neighbor parameters
nn_params = {} if nn_params is None else nn_params
if type(nn_params) is not dict:
raise TypeError("'nn_params' must be a dictionary or None")
regressors = [clone(base_regressor) for _ in range(embed_dim)]
n_classes = len(classes)
dissimilarities = np.zeros((2 * n_classes, 2 * n_classes))
dissimilarities[:n_classes, n_classes:] = cost_matrix
dissimilarities[n_classes:, :n_classes] = cost_matrix.T
W = np.zeros((2 * n_classes, 2 * n_classes))
W[:n_classes, n_classes:] = 1
W[n_classes:, :n_classes] = 1
mds = MDSP(**mds_params)
embedding = mds.fit(dissimilarities).embedding_
class_embed = embedding[:n_classes, :]
nn = NearestNeighbors(n_neighbors=1, **nn_params)
nn.fit(embedding[n_classes:, :])
pred_embed = np.zeros((len(X_cand), embed_dim))
for i in range(embed_dim):
regressors[i].fit(X, class_embed[y, i], sample_weight)
pred_embed[:, i] = regressors[i].predict(X_cand)
dist, _ = nn.kneighbors(pred_embed)
utilities = dist[:, 0]
return utilities
"""
Multi-dimensional Scaling Partial (MDSP)
This module is modified from
https://github.com/scikit-learn/scikit-learn/blob/14031f6/sklearn/manifold/mds.py
by Kuan-Hao Huang.
"""
# author: Nelle Varoquaux <[email protected]>
# Licence: BSD
def _smacof_single_p(
similarities,
n_uq,
metric=True,
n_components=2,
init=None,
max_iter=300,
verbose=0,
eps=1e-3,
random_state=None,
):
"""
Computes multidimensional scaling using SMACOF algorithm.
Parameters
----------
n_uq
similarities: symmetric ndarray, shape [n * n]
similarities between the points
metric: boolean, optional, default: True
compute metric or nonmetric SMACOF algorithm
n_components: int, optional, default: 2
number of dimension in which to immerse the similarities
overwritten if initial array is provided.
init: {None or ndarray}, optional
if None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array
max_iter: int, optional, default: 300
Maximum number of iterations of the SMACOF algorithm for a single run
verbose: int, optional, default: 0
level of verbosity
eps: float, optional, default: 1e-6
relative tolerance w.r.t stress to declare converge
random_state: integer or numpy.RandomState, optional
The generator used to initialize the centers. If an integer is
given, it fixes the seed. Defaults to the global numpy random
number generator.
Returns
-------
X: ndarray (n_samples, n_components), float
coordinates of the n_samples points in a n_components-space
stress_: float
The final value of the stress (sum of squared distance of the
disparities and the distances for all constrained points)
n_iter : int
Number of iterations run.
"""
similarities = check_symmetric(similarities, raise_exception=True)
n_samples = similarities.shape[0]
random_state = check_random_state(random_state)
W = np.ones((n_samples, n_samples))
W[:n_uq, :n_uq] = 0.0
W[n_uq:, n_uq:] = 0.0
V = -W
V[np.arange(len(V)), np.arange(len(V))] = W.sum(axis=1)
e = np.ones((n_samples, 1))
Vp = (
np.linalg.inv(V + np.dot(e, e.T) / n_samples)
- np.dot(e, e.T) / n_samples
)
sim_flat = similarities.ravel()
sim_flat_w = sim_flat[sim_flat != 0]
if init is None:
# Randomly choose initial configuration
X = random_state.rand(n_samples * n_components)
X = X.reshape((n_samples, n_components))
else:
# overrides the parameter p
n_components = init.shape[1]
if n_samples != init.shape[0]:
raise ValueError(
"init matrix should be of shape (%d, %d)"
% (n_samples, n_components)
)
X = init
old_stress = None
ir = IsotonicRegression()
for it in range(max_iter):
# Compute distance and monotonic regression
dis = euclidean_distances(X)
if metric:
disparities = similarities
else:
dis_flat = dis.ravel()
# similarities with 0 are considered as missing values
dis_flat_w = dis_flat[sim_flat != 0]
# Compute the disparities using a monotonic regression
disparities_flat = ir.fit_transform(sim_flat_w, dis_flat_w)
disparities = dis_flat.copy()
disparities[sim_flat != 0] = disparities_flat
disparities = disparities.reshape((n_samples, n_samples))
disparities *= np.sqrt(
(n_samples * (n_samples - 1) / 2) / (disparities**2).sum()
)
disparities[similarities == 0] = 0
# Compute stress
_stress = (
W.ravel() * ((dis.ravel() - disparities.ravel()) ** 2)
).sum()
_stress /= 2
# Update X using the Guttman transform
dis[dis == 0] = 1e-5
ratio = disparities / dis
_B = -W * ratio
_B[np.arange(len(_B)), np.arange(len(_B))] += (W * ratio).sum(axis=1)
X = np.dot(Vp, np.dot(_B, X))
dis = np.sqrt((X**2).sum(axis=1)).sum()
if verbose >= 2:
print("it: %d, stress %s" % (it, _stress))
if old_stress is not None:
if (old_stress - _stress / dis) < eps:
if verbose:
print(f"breaking at iteration {it} with stress {_stress}")
break
old_stress = _stress / dis
return X, _stress, it + 1
def smacof_p(
similarities,
n_uq,
metric=True,
n_components=2,
init=None,
n_init=8,
n_jobs=1,
max_iter=300,
verbose=0,
eps=1e-3,
random_state=None,
return_n_iter=False,
):
"""
Computes multidimensional scaling using SMACOF (Scaling by Majorizing a
Complicated Function) algorithm
The SMACOF algorithm is a multidimensional scaling algorithm: it minimizes
a objective function, the *stress*, using a majorization technique. The
Stress Majorization, also known as the Guttman Transform, guarantees a
monotone convergence of Stress, and is more powerful than traditional
techniques such as gradient descent.
The SMACOF algorithm for metric MDS can summarized by the following steps:
1. Set an initial start configuration, randomly or not.
2. Compute the stress
3. Compute the Guttman Transform
4. Iterate 2 and 3 until convergence.
The nonmetric algorithm adds a monotonic regression steps before computing
the stress.
Parameters
----------
similarities : symmetric ndarray, shape (n_samples, n_samples)
similarities between the points
metric : boolean, optional, default: True
compute metric or nonmetric SMACOF algorithm
n_components : int, optional, default: 2
number of dimension in which to immerse the similarities
overridden if initial array is provided.
init : {None or ndarray of shape (n_samples, n_components)}, optional
if None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array
n_init : int, optional, default: 8
Number of time the smacof_p algorithm will be run with different
initialisation. The final results will be the best output of the
n_init consecutive runs in terms of stress.
n_jobs : int, optional, default: 1
The number of jobs to use for the computation. This works by breaking
down the pairwise matrix into n_jobs even slices and computing them in
parallel.
If -1 all CPUs are used. If 1 is given, no parallel computing code is
used at all, which is useful for debugging. For n_jobs below -1,
(n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one
are used.
max_iter : int, optional, default: 300
Maximum number of iterations of the SMACOF algorithm for a single run
verbose : int, optional, default: 0
level of verbosity
eps : float, optional, default: 1e-6
relative tolerance w.r.t stress to declare converge
random_state : integer or numpy.RandomState, optional
The generator used to initialize the centers. If an integer is
given, it fixes the seed. Defaults to the global numpy random
number generator.
return_n_iter : bool
Whether or not to return the number of iterations.
Returns
-------
X : ndarray (n_samples,n_components)
Coordinates of the n_samples points in a n_components-space
stress : float
The final value of the stress (sum of squared distance of the
disparities and the distances for all constrained points)
n_iter : int
The number of iterations corresponding to the best stress.
Returned only if `return_n_iter` is set to True.
Notes
-----
"Modern Multidimensional Scaling - Theory and Applications" Borg, I.;
Groenen P. Springer Series in Statistics (1997)
"Nonmetric multidimensional scaling: a numerical method" Kruskal, J.
Psychometrika, 29 (1964)
"Multidimensional scaling by optimizing goodness of fit to a nonmetric
hypothesis" Kruskal, J. Psychometrika, 29, (1964)
"""
similarities = check_array(similarities)
random_state = check_random_state(random_state)
if hasattr(init, "__array__"):
init = np.asarray(init).copy()
if not n_init == 1:
warnings.warn(
"Explicit initial positions passed: "
"performing only one init of the MDS instead of %d" % n_init
)
n_init = 1
best_pos, best_stress = None, None
if n_jobs == 1:
for it in range(n_init):
pos, stress, n_iter_ = _smacof_single_p(
similarities,
n_uq,
metric=metric,
n_components=n_components,
init=init,
max_iter=max_iter,
verbose=verbose,
eps=eps,
random_state=random_state,
)
if best_stress is None or stress < best_stress:
best_stress = stress
best_pos = pos.copy()
best_iter = n_iter_
else:
seeds = random_state.randint(np.iinfo(np.int32).max, size=n_init)
results = Parallel(n_jobs=n_jobs, verbose=max(verbose - 1, 0))(
delayed(_smacof_single_p)(
similarities,
n_uq,
metric=metric,
n_components=n_components,
init=init,
max_iter=max_iter,
verbose=verbose,
eps=eps,
random_state=seed,
)
for seed in seeds
)
positions, stress, n_iters = zip(*results)
best = np.argmin(stress)
best_stress = stress[best]
best_pos = positions[best]
best_iter = n_iters[best]
if return_n_iter:
return best_pos, best_stress, best_iter
else:
return best_pos, best_stress
class MDSP(BaseEstimator):
"""Multidimensional scaling
Parameters
----------
metric : boolean, optional, default: True
compute metric or nonmetric SMACOF (Scaling by Majorizing a
Complicated Function) algorithm
n_components : int, optional, default: 2
number of dimension in which to immerse the similarities
overridden if initial array is provided.
n_init : int, optional, default: 4
Number of time the smacof_p algorithm will be run with different
initialisation. The final results will be the best output of the
n_init consecutive runs in terms of stress.
max_iter : int, optional, default: 300
Maximum number of iterations of the SMACOF algorithm for a single run
verbose : int, optional, default: 0
level of verbosity
eps : float, optional, default: 1e-6
relative tolerance w.r.t stress to declare converge
n_jobs : int, optional, default: 1
The number of jobs to use for the computation. This works by breaking
down the pairwise matrix into n_jobs even slices and computing them in
parallel.
If -1 all CPUs are used. If 1 is given, no parallel computing code is
used at all, which is useful for debugging. For n_jobs below -1,
(n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one
are used.
random_state : integer or numpy.RandomState, optional
The generator used to initialize the centers. If an integer is
given, it fixes the seed. Defaults to the global numpy random
number generator.
dissimilarity : string
Which dissimilarity measure to use.
Supported are 'euclidean' and 'precomputed'.
Attributes
----------
embedding_ : array-like, shape [n_components, n_samples]
Stores the position of the dataset in the embedding space
stress_ : float
The final value of the stress (sum of squared distance of the
disparities and the distances for all constrained points)
References
----------
"Modern Multidimensional Scaling - Theory and Applications" Borg, I.;
Groenen P. Springer Series in Statistics (1997)
"Nonmetric multidimensional scaling: a numerical method" Kruskal, J.
Psychometrika, 29 (1964)
"Multidimensional scaling by optimizing goodness of fit to a nonmetric
hypothesis" Kruskal, J. Psychometrika, 29, (1964)
"""
def __init__(
self,
n_components=2,
n_uq=1,
metric=True,
n_init=4,
max_iter=300,
verbose=0,
eps=1e-3,
n_jobs=1,
random_state=None,
dissimilarity="euclidean",
):
self.n_components = n_components
self.n_uq = n_uq
self.dissimilarity = dissimilarity
self.metric = metric
self.n_init = n_init
self.max_iter = max_iter
self.eps = eps
self.verbose = verbose
self.n_jobs = n_jobs
self.random_state = random_state
def fit(self, X, y=None, init=None):
""" Compute the position of the points in the embedding space.
Parameters
----------
X : array, shape=[n_samples, n_features], or [n_samples, n_samples] \
if dissimilarity='precomputed'
Input data.
init : {None or ndarray, shape (n_samples,)}, optional
If None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array.
"""
self.fit_transform(X, init=init)
return self
def fit_transform(self, X, y=None, init=None):
""" Fit the data from X, and returns the embedded coordinates.
Parameters
----------
X : array, shape=[n_samples, n_features], or [n_samples, n_samples] \
if dissimilarity='precomputed'
Input data.
init : {None or ndarray, shape (n_samples,)}, optional
If None, randomly chooses the initial configuration
if ndarray, initialize the SMACOF algorithm with this array.
"""
X = check_array(X)
if X.shape[0] == X.shape[1] and self.dissimilarity != "precomputed":
warnings.warn(
"The MDS API has changed. ``fit`` now constructs an"
" dissimilarity matrix from data. To use a custom "
"dissimilarity matrix, set "
"``dissimilarity=precomputed``."
)
if self.dissimilarity == "precomputed":
self.dissimilarity_matrix_ = X
elif self.dissimilarity == "euclidean":
self.dissimilarity_matrix_ = euclidean_distances(X)
else:
raise ValueError(
"Proximity must be 'precomputed' or 'euclidean'."
" Got %s instead" % str(self.dissimilarity)
)
self.embedding_, self.stress_, self.n_iter_ = smacof_p(
self.dissimilarity_matrix_,
self.n_uq,
metric=self.metric,
n_components=self.n_components,
init=init,
n_init=self.n_init,
n_jobs=self.n_jobs,
max_iter=self.max_iter,
verbose=self.verbose,
eps=self.eps,
random_state=self.random_state,
return_n_iter=True,
)
return self.embedding_ | 0.908412 | 0.534612 |
import numpy as np
from sklearn import clone
from sklearn.utils import check_array
from skactiveml.base import (
ProbabilisticRegressor,
SingleAnnotatorPoolQueryStrategy,
)
from skactiveml.utils import check_type, simple_batch, MISSING_LABEL
from skactiveml.pool.utils import _update_reg, _conditional_expect
class ExpectedModelVarianceReduction(SingleAnnotatorPoolQueryStrategy):
"""Expected Model Variance Reduction.
This class implements the active learning strategy expected model variance
minimization, which tries to select the sample that minimizes the expected
model variance.
Parameters
----------
integration_dict : dict, optional (default=None)
Dictionary for integration arguments, i.e. `integration method` etc.,
used for calculating the expected `y` value for the candidate samples.
For details see method `skactiveml.pool.utils._conditional_expect`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
----------
[1] Cohn, David A and Ghahramani, Zoubin and Jordan, Michael I. Active
learning with statistical models, pages 129--145, 1996.
"""
def __init__(
self,
integration_dict=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.integration_dict = integration_dict
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
X_eval=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg : ProbabilisticRegressor
Predicts the output and the conditional distribution.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
X_eval : array-like of shape (n_eval_samples, n_features),
optional (default=None)
Evaluation data set that is used for estimating the probability
distribution of the feature space.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", ProbabilisticRegressor)
check_type(fit_reg, "fit_reg", bool)
if X_eval is None:
X_eval = X
else:
X_eval = check_array(X_eval)
self._check_n_features(X_eval, reset=False)
if self.integration_dict is None:
self.integration_dict = {"method": "assume_linear"}
check_type(self.integration_dict, "self.integration_dict", dict)
X_cand, mapping = self._transform_candidates(candidates, X, y)
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
old_model_variance = np.average(
reg.predict(X_eval, return_std=True)[1] ** 2
)
def new_model_variance(idx, x_cand, y_pot):
reg_new = _update_reg(
reg,
X,
y,
sample_weight=sample_weight,
y_update=y_pot,
idx_update=idx,
X_update=x_cand,
mapping=mapping,
)
_, new_model_std = reg_new.predict(X_eval, return_std=True)
return np.average(new_model_std**2)
ex_model_variance = _conditional_expect(
X_cand,
new_model_variance,
reg,
random_state=self.random_state_,
**self.integration_dict
)
utilities_cand = old_model_variance - ex_model_variance
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
return simple_batch(
utilities,
batch_size=batch_size,
random_state=self.random_state_,
return_utilities=return_utilities,
) | scikit-activeml | /scikit_activeml-0.4.1-py3-none-any.whl/skactiveml/pool/_expected_model_variance.py | _expected_model_variance.py | import numpy as np
from sklearn import clone
from sklearn.utils import check_array
from skactiveml.base import (
ProbabilisticRegressor,
SingleAnnotatorPoolQueryStrategy,
)
from skactiveml.utils import check_type, simple_batch, MISSING_LABEL
from skactiveml.pool.utils import _update_reg, _conditional_expect
class ExpectedModelVarianceReduction(SingleAnnotatorPoolQueryStrategy):
"""Expected Model Variance Reduction.
This class implements the active learning strategy expected model variance
minimization, which tries to select the sample that minimizes the expected
model variance.
Parameters
----------
integration_dict : dict, optional (default=None)
Dictionary for integration arguments, i.e. `integration method` etc.,
used for calculating the expected `y` value for the candidate samples.
For details see method `skactiveml.pool.utils._conditional_expect`.
missing_label : scalar or string or np.nan or None,
(default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
random_state : int | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
----------
[1] Cohn, David A and Ghahramani, Zoubin and Jordan, Michael I. Active
learning with statistical models, pages 129--145, 1996.
"""
def __init__(
self,
integration_dict=None,
missing_label=MISSING_LABEL,
random_state=None,
):
super().__init__(
random_state=random_state, missing_label=missing_label
)
self.integration_dict = integration_dict
def query(
self,
X,
y,
reg,
fit_reg=True,
sample_weight=None,
candidates=None,
X_eval=None,
batch_size=1,
return_utilities=False,
):
"""Determines for which candidate samples labels are to be queried.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and
unlabeled samples.
y : array-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones
indicated by `self.missing_label`).
reg : ProbabilisticRegressor
Predicts the output and the conditional distribution.
fit_reg : bool, optional (default=True)
Defines whether the regressor should be fitted on `X`, `y`, and
`sample_weight`.
sample_weight : array-like of shape (n_samples), optional (default=None)
Weights of training samples in `X`.
candidates : None or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features),
optional (default=None)
If candidates is None, the unlabeled samples from (X,y) are
considered as candidates.
If candidates is of shape (n_candidates) and of type int,
candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, n_features), the
candidates are directly given in candidates (not necessarily
contained in X).
X_eval : array-like of shape (n_eval_samples, n_features),
optional (default=None)
Evaluation data set that is used for estimating the probability
distribution of the feature space.
batch_size : int, optional (default=1)
The number of samples to be selected in one AL cycle.
return_utilities : bool, optional (default=False)
If true, also return the utilities based on the query strategy.
Returns
-------
query_indices : numpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is
to queried, e.g., `query_indices[0]` indicates the first selected
sample.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
utilities : numpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch,
e.g., `utilities[0]` indicates the utilities used for selecting
the first sample (with index `query_indices[0]`) of the batch.
Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates), the indexing
refers to samples in X.
If candidates is of shape (n_candidates, n_features), the indexing
refers to samples in candidates.
"""
X, y, candidates, batch_size, return_utilities = self._validate_data(
X, y, candidates, batch_size, return_utilities, reset=True
)
check_type(reg, "reg", ProbabilisticRegressor)
check_type(fit_reg, "fit_reg", bool)
if X_eval is None:
X_eval = X
else:
X_eval = check_array(X_eval)
self._check_n_features(X_eval, reset=False)
if self.integration_dict is None:
self.integration_dict = {"method": "assume_linear"}
check_type(self.integration_dict, "self.integration_dict", dict)
X_cand, mapping = self._transform_candidates(candidates, X, y)
if fit_reg:
reg = clone(reg).fit(X, y, sample_weight)
old_model_variance = np.average(
reg.predict(X_eval, return_std=True)[1] ** 2
)
def new_model_variance(idx, x_cand, y_pot):
reg_new = _update_reg(
reg,
X,
y,
sample_weight=sample_weight,
y_update=y_pot,
idx_update=idx,
X_update=x_cand,
mapping=mapping,
)
_, new_model_std = reg_new.predict(X_eval, return_std=True)
return np.average(new_model_std**2)
ex_model_variance = _conditional_expect(
X_cand,
new_model_variance,
reg,
random_state=self.random_state_,
**self.integration_dict
)
utilities_cand = old_model_variance - ex_model_variance
if mapping is None:
utilities = utilities_cand
else:
utilities = np.full(len(X), np.nan)
utilities[mapping] = utilities_cand
return simple_batch(
utilities,
batch_size=batch_size,
random_state=self.random_state_,
return_utilities=return_utilities,
) | 0.939345 | 0.689364 |